II.6.3.2 Loi de Zipf
: La loi de Zipf est une observation empirique concernant la
fréquence des mots dans un texte(PETRUSZEWYCZ , 1973)
La fréquence d'occurrence f(n) d'un mot est liée
à son rang n dans l'ordre des fréquences par une loi de la forme
où K est une constante :(MANDELBROT , 1957)
fc = Kn
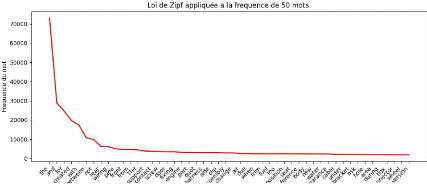
FIG. 9 : Loi zipf appliquée a la frequence des
mots
II.6 Data pre-processing 29
II.6.3.3 Loi normale
Une variable aléatoire continue X suit une
distribution normale si elle a la fonction de densité de
probabilité suivante (JEAN-JACQUES DROESBEKE , 2005)
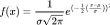
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
FIG. 10 : Loi normale sur les K1/K2
30 CHAPITRE II. LE PROBLÈME
Amassin NACERDDINE Université Paris 8 Vincennes
II.6.4 Sélection des caractéristiques
intéressantes
Il existe des algorithmes d'apprentissage automatique tel que :
ACP,LDA... qui permettent de sélectionner les caractéristiques
les plus représentatives.
Mais aussi utiliser une matrice de corrélation et en
interpréter les résultats.(A.L. , 1901)
Ou encore demander l'avis des experts métier.
voici un aperçu de la matrice de corrélation
appliqué a nos features.(G.U , 1909)
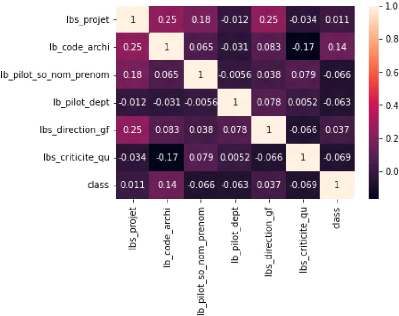
FIG. 11 : Corr matrix
II.6 Data pre-processing 31
PRéVISON DE DATE DE PASSAGE DES JALONS 2022
II.6.5 Transformer les données
La phase de préparation des données consiste
également a manipuler,modifier,voir encore créer de nouvelle
informations a partir d'information disponible.
-Dans mon cas un calcule sur le temps de traitement des tickets
fermés a dû être fait(différence entre deux
dates)Mais aussi dans certain cas et certain ticket le changement du fuseau
horaire.
-Une transformation sur le champ description a dû
être faite.
En effet ce champ représente du texte écrit en
différentes langues (Français,Anglais,Russe
,Allemand,Espagnol...) J'ai dû donc dans un premier temps traduire ce
texte en une langue commune (ici l'anglais).
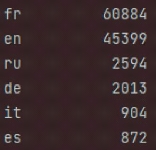
FIG. 12 : Langues dans le dataset
32 CHAPITRE II. LE PROBLÈME
Amassin NACERDDINE Université Paris 8
Vincennes
II.6.5.1 TF-IDF
Après cela une transformation de ce champs de
vecteur,pour ce faire j'ai appliqué la méthode de
pondération TF-IDF (M. J. McGILL , 1983) afin de
déterminer l'importance d'un mot ainsi que sa fréquence dans un
corpus.(JONES , 1972)
II.6.5.2 Word2Vec
Une fois notre vocabulaire déterminer nous pouvons
passer a l'étape de vectorisa-tion Word2Vec.(GOLDBERG et LEvy ,
2014)
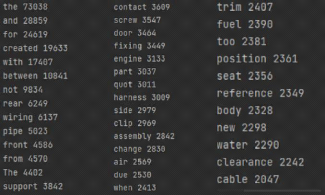
FIG. 13 : Fréquence des mots
II.7 Conclusion 33
II.6.5.3 LabelEncoder
-L'encodage des caractéristiques catégorielles a
aussi été effectué sur certain champs(LabelEncoder).
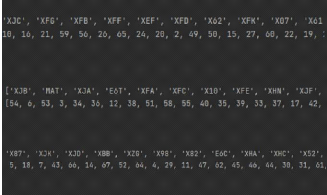
FIG. 14 : LabelEncoder
| 

