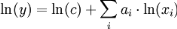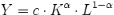Evaluation de l'efficience technique des exploitations riricoles du périmètre irrigué de mission-tové( Télécharger le fichier original )par Agossou GADEDJISSO-TOSSOU Université de Lomé(Togo) - Ingénieur agro-économiste 2009 |

3.3. Le cadre théorique3.3.1. Les fonctions de productionConcernant l'approche déterministe et paramétrique, la fonction de production peut être approximée par la méthode des moindres carrées ordinaires corrigées (MCOC), Cobb-Douglas, Translogarithme, Léontief généralisé etc... (Christensen, Jorgenson, Lau ,1971). Les formes fonctionnelles de type Cobb- Douglas et Translog sont généralement admises pour l'analyse de la fonction de production dans le secteur agricole. 3.3.1.1. La fonction de production de type Cobb- DouglasAfin de caractériser la combinaison productive sans recourir à des hypothèses structurelles particulières, les spécifications courantes de type Cobb-Douglas , doivent être abandonnées au profit de formes flexibles qui n'imposent a priori aucune restriction sur la structure de la production. La forme flexible la plus couramment utilisée, est la fonction Translog définie par Christensen, Jorgenson, Lau (1971). La flexibilité d'une fonction Translog peut être illustrée en comparant les élasticités dérivées de cette formulation à celles issues d'une Cobb-Douglas : les élasticités des facteurs et les rendements d'échelle sont constants pour une fonction Cobb-Douglas, alors qu'ils dépendent du niveau des facteurs pour une Translog. Si une forme flexible présente l'avantage de pouvoir décrire n'importe quelle technologie, elle possède néanmoins certaines limites :
Sa forme linéarisée est la suivante :
En modélisation économique, on utilise fréquemment la fonction particulière suivante :
Dans ce cas particulier (où la somme des coefficients est égale à 1), les rendements d'échelle sont constants (mathématiquement, la fonction est homogène au premier ordre), ce qui signifie que si le niveau des intrants est augmenté d'un certain pourcentage, celui des extrants le sera d'autant. Soit la fonction f(tx,ty) = trf(x,y). Avec : f désignant l'output, x et y les inputs et t la proportion d'augmentation ou de diminution, r étant le degré de la fonction homogène f (MENSAH, 1999) · Si r>1 alors rendements croissants à l'échelle · Si r=1 alors rendements constants à l'échelle · Si r<1 alors rendements décroissants à l'échelle (MENSAH, 1999). Le modèle de la fonction frontière de production se présente comme suit : ln(Yi) = â0 + âiln(Xi) + (Vi-Ui) , où : ln : logarithme népérien Yi : la production Xi : les variables exogènes Vi : la perturbation indépendante, identiquement distribuée et sensé prendre en compte les variables omises et les erreurs de mesure sur les Xi. Elle suit une loi de distribution normale N(o,äv,v2). Ui : perturbation indépendante, non identiquement distribuée, capturant l'inefficience relative à la frontière stochastique et suivant une loi normale tronquée à zéro. La production possible ou observée Yi sera dépassée par la quantité stochastique (quand Ui =0). Les â0, âi désignent les coefficients dont les estimations seront obtenues par le maximum de vraisemblance de l'équation (1) à l'aide du logiciel EVIEWS 3.1. Ces coefficients âi représentent les coefficients d'élasticité de la production par rapport à chacune des variables exogènes considérés dans le modèle. Il est important de mettre en exergue certaines hypothèses du modèle classique de régression linéaire. Le modèle classique de régression linéaire est fondé sur les quatre hypothèses suivantes : H1 : La relation entre la variable endogène et la variable exogène est linéaire et cette linéarité porte sur les coefficients et non les variables (LARE-LANTONE, 2003) ; H2 : Les variables endogènes observées possèdent un élément aléatoire e. Cet élément aléatoire peut provenir par exemple de l'existence d'erreurs non systématiques d'observations ou du fait de la non prise en compte de certaines variables, en particulier de variables dont l'influence sur la variable endogène n'est pas systématique . Dans le modèle classique de régression linéaire l'on suppose de plus que : · l'espérance mathématique des éléments aléatoires est nulle : E (ei ) = 0 quelque soit i. · la variance de l'élément aléatoire est constante (hypothèse d'homoscédasticité) V(ei) = ó2 quelque soit i. · les éléments aléatoires sont statistiquement indépendants soit E (ei . ej ) = 0 ,? quelque soit i et j. · les éléments aléatoires sont distribués suivant une loi normale. H3 : Les variables exogènes sont certaines. Elles ne comportent donc pas d'élément aléatoire. H4 : Les variables exogènes sont non corrélées entre elles (GRELLET, 2003). Ainsi sous les hypothèses H1, H2, H3, H4, l'estimateur des MCO est BLUE (Best Linear Unbiaised Estimator) : théorème de Gauss- Markov (CADORET et al, 2004). Autrement dit, l'estimateur des MCO est : Soit l'équation : y = ao + aixi +ui - non biaisé : l'espérance est égale à la valeur des paramètres de la population E (âi) = ai - efficace : parmi les estimateurs non biaisés des paramètres, il a la variance la plus faible. (IYOHA, 2004). - convergent : si l'on accroît la taille de l'échantillon, la probabilité que les valeurs estimées des paramètres soient différentes des valeurs ai des paramètres est nulle (GRELLET, 2003). |
|