4.2 L'approche "empirique"
L'approche empirique, contrairement à l'approche
systématique, se base sur le document ou l'ensemble de documents qui
doivent être traduits et non sur un ensemble de documents de
référence.
Cette démarche passe tout d'abord par la traduction
"manuelle" de parties du document pour déterminer les règles de
traduction.
On traduit ainsi des parties dont le lexique, la
sémantique et la syntaxe sont différents jusqu'à obtenir
des règles permettant de traiter l'ensemble du document. Une fois ces
règles écrites, il est alors possible de les appliquer au
document afin d'en obtenir une traduction complète.
1Pour les langages naturels, on peut par exemple
citer le français, l'espagnol et l'italien qui sont des langues latines.
Pour l'informatique, on peut citer le C++ et la java qui ont des origines dans
le C ou Sybase et MS-SQL qui sont partis tous les deux d'une ancienne version
de Sybase
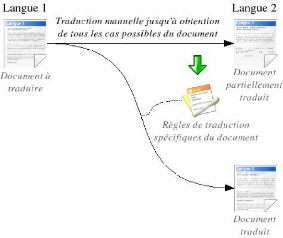
FIG. 4.2 - Utilisation d'une méthode empirique pour la
traduction de textes
Ici, cette approche peut être assimilée à
un approche montante (également appelée 'bottom-up') car on part
de "problèmes spécifiques" à un document jusqu'à
obtenir un traducteur par agrégation de ces problèmes.
Si on possède suffisamment de documents
différents et qu'ils couvrent tous les cas existants, on peut, par
empirisme, obtenir un traducteur aussi complet que celui qu'on obtiendrait par
une approche systématique mais cela nécessiterait une
quantité de travail bien supérieure.
De plus, la complexité non linéaire de cette
approche est un problème car chaque "cas particulier" résolu
risque de rentrer en conflit avec les cas résolus
précédemment ce qui implique que plus le nombre de règles
de traduction augmente, plus le nombre de contradictions possibles augmente.
En fait, cette approche n'est rapide à mettre en place
que si on a un nombre limité de "problèmes" de traduction et que
l'on veut obtenir un traducteur pour un faible nombre de documents (ou si ces
documents utilisent exactement les mêmes règles de traduction).
Cependant, cette démarche est limitée par le
fait que l'écriture des règles passe par une phase de traduction
manuelle. Si on doit traduire des documents très différents ou si
les schémas linguistiques ne se trouvent pas assez souvent
répétés, l'ensemble du travail de traduction sera
finalement réalisé manuellement. Par exemple, si on se trouve
dans le cas d'un document trop court, chaque élément traduit
manuellement créera une nouvelle règle mais celle-ci ne sera
utilisée que pour cet élément.
Comme les approches de type bottom-up ont une relation
très forte avec l'existant, elles sont beaucoup plus adaptées
dans le cas où on ne veut pas faire un outil généraliste
mais spécifique à une situation. L'approche empirique sera donc
réservée à la
résolution de problèmes ponctuels et à une
traduction unidirectionelle (car les problèmes liés à la
traduction ne sont pas forcément bijectifs).
| 

