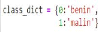Construction d'un modèle prédictif basé sur le réseau de neurones profond pour la détection de cancer de la peaupar Eddy MUTOMBO SHANGA Institut supérieur et pédagogique de Mbanza-Ngungu - Licence 2022 |

Conclusion partielle.Ce chapitre a été consacré essentiellement à la présentation des différentes méthodes existantes dans la littérature relative aux processus de segmentation et de classification des images dermoscopiques. Comme mentionné le long de ce chapitre, la segmentation se présente sous différentes approches et est utilisée sous différentes manières. En premier lieu, nous avons présenté un état de l'art sur les méthodes de segmentation et de classification des images dermoscopiques, en vue de comprendre leurs concepts, leurs principes d'utilisation et leurs applications. Nous avons d'abord présenté une définition du mélanome et des systèmes du diagnostic assisté par ordinateur et ses différents éléments constitutifs pour la détection du mélanome. Ensuite, nous avons dressé un aperçu sur les approches de segmentation utilisées pour les images dermoscopiques. Suivie d'une présentation des méthodes de classification des mélanomes. Etant atteints, les objectifs fixés pour ce chapitre, dans le chapitre suivant, nous allons présenter l'implémentation de l'approche proposée, afin de montrer son efficacité, et d'interpréter les résultats. P a g e | 56 Chapitre quatrième : Implémentation & interprétation desrésultats. 4.1. Introduction. La détection des mélanomes à un stade précoce est la meilleure façon de diminuer le taux de mortalité des personnes atteintes par cette maladie. En effet, ce type de cancer de peau se présente comme des lésions, qui apparaissent sur la peau sous différentes et complexes formes, couleurs et textures. C'est pourquoi les tumeurs malignes peuvent être confondues avec les tumeurs bénignes et rend le diagnostic très difficile pour les dermatologues. D'où l'intérêt d'utiliser des techniques d'apprentissage automatique pour améliorer la précision du diagnostic du mélanome et réduire son incidence élevée. Ce chapitre s`attèlera à la présentation des outils utilisés, la description du simulateur implémenté, la mise en oeuvre d'un cas pratique pour tester notre modèle et une interprétation des résultats de l`approche proposée. Il est divisé en quatre parties principales : V' La première partie décrit les outils utilisés et les détails d'implémentation de l'approche proposée, V' La deuxième partie présente un cas pratique pour tester le modèle. V' La troisième partie représente une exploitation du modèle proposé dans un API11 Flask afin de gérer des nouveaux cas. 4.2. Les outils et les détails d'implémentation. Pour évaluer et tester les performances de l'approche proposée, nous devrons d'abord passer par l'étape de l'implémentation. Dans cette section, nous décrivons les différents outils, et les langages de programmation utilisés. 4.2.1. Environnement de développement. Pour implémenter l'approche PrediCancerPeau, nous avons choisi Jupyter (Voir Figure 31) et spider (Voir Figure 32) comme des environnements de développement, avec utilisation des bibliothèques Flask (Voir Figure 33), TensorFlow et Keras. 11 API : (Application Programme Interface), est une interface logicielle permettant de connecter un logiciel ou service à un autre logiciel ou service afin d'échangé les données. P a g e | 57 4.2.1.1. Jupyter Notebook. Jupyter Notebook est une application Web Open Source permettant de créer et de partager des documents contenant du code (exécutable directement dans le document), des équations, des images et du texte. Avec cette application il est possible de faire du traitement de données, de la modélisation statistique, de la visualisation de données, du Machine Learning, etc. Elle est disponible par défaut dans la distribution Anaconda. Il est développé par « Fernando Pérez » en 2014 et prend en charge plus de 40 langages de programmation, dont Python, R, Julia et Scala.
Figure 31. Interface de Jupyter Notebook (source Jupyter) 4.2.1.2. Spyder. Spyder est Créé et il est développé par « Pierre Raybaut » en 2008, c'est est un environnement scientifique puissant écrit en Python, et il est conçu par et pour les scientifiques, les ingénieurs, et les analystes de données (Spyder Website Contributors, 2018). Spyder offre une combinaison unique de la fonctionnalité d'édition avancée, d'analyse, de débogage et de profilage d'un outil de développement complet, avec l'exploration des données, l'exécution interactive, l'inspection approfondie, et de belles capacités de visualisation d'un paquet scientifique (Spyder Website Contributors, 2018). P a g e | 58
Figure 32. Logo de l'IDE Spyder. 4.2.1.3. Flask. Flask est un Framework de développement des applications Web en Python, il garde la souplesse de la programmation en Python à cause de sa légèreté et ne soumet le développeur à aucune restriction, il appartient au développeur de choisir les outils et les bibliothèques qu'il souhaite utiliser (The Pallets Projects, 2010).
Figure 33. Logo de Framework FLASK 4.2.1.4. TensorFlow. TensorFlow est un framework de programmation pour le calcul numérique qui a été rendu Open Source par Google en Novembre 2015. Depuis sa release, TensorFlow n'a cessé de gagner en popularité, pour devenir très rapidement l'un des Frameworks les plus utilisés pour le Deep Learning, comme le montrent les dernières comparaisons suivantes, faites par François Chollet (auteur de la librairie Keras). Nous en entendons beaucoup parler ces derniers temps, et pour cause, TensorFlow est devenu en un temps record l'un des Frameworks de référence pour le Deep Learning, utilisé aussi bien dans la recherche qu'en entreprise pour des applications en production. Au-delà de la hype présente autour de ce Framework et des projets qui émergent grâce à ce dernier, il reste un gap non négligeable à atteindre afin de l'utiliser pleinement et efficacement. P a g e | 59 Voici quelques raisons de sa popularité : V' Multiplateformes (Linux, Mac OS, et même Android et iOS !) ; V' APIs en Python, C++, Java et Go (l'API Python est plus complète cependant, c'est sur celle-ci que nous allons travailler) ; V' Temps de compilation très courts dû au backend en C/C++ ; V' Supporte les calculs sur CPU, GPU et même le calcul distribué sur cluster ; V' Une documentation extrêmement bien fournie avec de nombreux exemples et tutoriels ; V' Last but not least : Le fait que le Framework vienne de Google et que ce dernier ait annoncé avoir migré la quasi-totalité de ses projets liés au Deep Learning en TensorFlow est quelque peu rassurant. Bien qu'il ait initialement été développé pour optimiser les calculs numériques complexes, TensorFlow est aujourd'hui particulièrement utilisé pour le Deep Learning, et donc les réseaux de neurones. Son nom est notamment inspiré du fait que les opérations courantes sur des réseaux de neurones sont principalement faites via des tables de données multidimensionnelles, appelées Tenseurs (Tensor). Un Tensor à deux dimensions est l'équivalent d'une matrice. 4.2.1.5. Keras. Keras est une bibliothèque open source de Deep Learning permettant la génération de réseaux de neurones artificiels. Elle permet une expérimentation efficace de ces derniers de par sa simple utilisation et ses nombreuses possibilités de déploiement grâce à son intégration avec la librairie tensorFlow. Keras est conçu pour être intuitif, modulaire, facile à étendre, et pour fonctionner avec Python. Selon ses créateurs, cette API est » conçue pour les êtres humains, et non pour les machines » et » suit les meilleures pratiques pour réduire la charge cognitive «. Il a été développé dans le cadre de l'effort de recherche du projet ONEIROS (Open-ended Neuro-Electronic Intelligent Robot Operating System), et son principal auteur et mainteneur est François Chollet, un ingénieur Google. Chollet a expliqué que Keras a été conçue comme une interface plutôt que comme un cadre d'apprentissage end to end. Il présente un ensemble d'abstractions de niveau supérieur et plus intuitif qui facilitent la configuration des réseaux neuronaux indépendamment de la bibliothèque informatique de backend. Microsoft travaille également à ajouter un backend CNTK à Keras aussi. P a g e | 60 4.2.1.6. NumPy. Numpy est une bibliothèque python très populaire pour le traitement de matrices et fonctions mathématiques de haut niveau. C'est très utile pour les calculs scientifiques fondamentaux en Machine Learning. Il est particulièrement utile pour l'algèbre linéaire, la transformée de Fourier et les capacités de nombres aléatoires. Les bibliothèques haut de gamme telles que TensorFlow utilisent NumPy en interne pour la manipulation de Tensors. 4.2.1.7. Pandas. Pandas est une bibliothèque Python populaire pour l'analyse de données. Ce n'est pas directement lié à l'apprentissage automatique. Comme nous savons que le jeu de données doit être préparé avant la formation. Dans ce cas, les pandas sont pratiques car ils ont été développés spécifiquement pour l'extraction et la préparation de données. Il fournit des structures de données de haut niveau et de nombreux outils pour l'analyse des données. Il fournit de nombreuses méthodes intégrées pour tâtonner, combiner et filtrer les données. 4.2.1.8. Matpoltli. Matpoltli est une bibliothèque Python très populaire pour la visualisation de données. Comme les pandas, il n'est pas directement lié à l'apprentissage automatique. Cela s'avère particulièrement utile lorsqu'un programmeur souhaite visualiser les modèles dans les données. C'est une bibliothèque de tracé 2D utilisée pour créer des graphiques et des tracés 2D. Un module appelé pyplot facilite le traçage des programmeurs car il offre des fonctionnalités permettant de contrôler les styles de trait, les propriétés de police, les axes de formatage, etc. Il fournit différents types de graphiques et de tracés pour la visualisation des données, l'affichage, l'histogramme, les graphiques d'erreur, les discussions en barres. , etc. 4.2.2. Langage de programmation. De nos jours, il existe plusieurs langages de programmation et chaque langage possède ses propres caractéristiques. Parmi ses langages, notre choix s'est focalisé sur Python. 4.2.2.1. Python. Il est l'un des langages de programmation les plus intéressants du moment, il est inventé par « Guido van Rossum », la première version de python est sortie en 1991. C'est est un langage de programmation interprété, multi paradigme et P a g e | 61 multiplateformes. Il favorise la programmation impérative structurée, fonctionnelle et orientée objet (python.doctor, 2019). Python est à la fois simple et puissant, il permet d'écrire des scripts très simples, et grâce à ses nombreuses bibliothèques, nous pouvons travailler sur des projets plus ambitieux (python.doctor, 2019). 4.2.2.2. Pourquoi Python ? Python est un langage stable, flexible et il fournit divers outils pour les développeurs. Ce qui permet de le classer en premier choix pour l'apprentissage automatique, à partir du développement, la mise en oeuvre, et la maintenance. Python aide les développeurs de développer des produits confiants (Gupta, 2019). Selon Gupta, Python possède de nombreux avantages: ? Simple et cohérent : la simplicité de Python aide les développeurs à gérer l'algorithme complexe de l'apprentissage automatique. ? La flexibilité : Le facteur de flexibilité réduit la possibilité d'erreurs, il a laissé les programmeurs prendre le contrôle complètement, et de travailler sur elle confortablement. ? Bibliothèques et Framework : Les algorithmes de l'apprentissage automatique sont très complexes, mais Python est le secours avec une large gamme de bibliothèques comme Scikit-learn, Keras et de Framework, à titre d'exemple TensorFlow. ? Lisibilité : Python est facile à lire, de sorte que les développeurs peuvent facilement comprendre le code. ? Indépendance de la plateforme : Python est un langage indépendant de la plate-forme. Il est supporté par de nombreuses plateformes, y compris Windows, LINUX et macOS. 4.3. Présentation du problème. Nous présentons dans cette section, un cas pratique pour tester notre modèle, pour se faire une bonne idée sur l'architecture que nous avons choisie compte tenu de ses avantages dans le chapitre 2 dudit travail, nous essayerons de présenter les résultats en utilisant le CNN avec nos jeux de données. Le domaine d'application choisi à l'issue de ce cas, c'est la santé, où notre travail vise à construire un modèle prédictif basé sur le réseau de neurones profond à partir des images de gens soufrant du « cancer de la peau » de type mélanome. Les corps médicaux trouveront une grande importance à notre système, car ce dernier va leur aider à prendre des décisions relatives avec plus de précision (en tenant compte de la faiblesse démographique des dermatologues), à partir de la photographie des lésions précoce des mélanomes qui apparaissent sur la peau sous P a g e | 62 différentes et complexes formes, couleurs et textures, afin d'améliorer la précision du diagnostic de ladite maladie et réduire son incidence élevée. 4.3.1. Aperçu général sur le cancer de la peau. La peau est considérée comme l'organe humain le plus important en terme de surface. Elle protège le corps des infections et des rayonnements ultraviolets (UV). Elle facilite le contrôle de la température corporelle et l'élimination des déchets organiques par la transpiration. Elle sert également à synthétiser la vitamine D et à stocker les réserves d'eau et de graisse. Elle peut aussi être atteint par un cancer. Il en existe deux grands types dont : les carcinomes et les mélanomes. Le nombre de nouveau cas de cancer de la peau a d'ailleurs plus que triple entre 1980 et 2012. Ceci peut s'expliquer par l'évolution des habitudes d'exposition aux rayonnements UV solaires et artificiels au cours de 40 dernières années, ces expositions constituent le facteur de risque le plus important de développer ce type de cancer.
Figure 34. Différents types des graines de beauté de mélanome. Il existe par ailleurs, des mélanomes dits achromiques, c'est-à-dire sans couleur. Ces petites boules de la couleur de votre peau peuvent apparaitre sur les plantes de main ou de pied, ils sont plus difficiles à détecter car ils sont ton sur ton12 (semi - permanente) , mais restent heureusement relativement rares. 12 Ton sur Ton : est une couleur qui contient des agents oxydants, mais pas d'ammoniaque. 13 Data set (ou jeux de données) : est un ensemble de données cohérents qui peuvent se présenter sous différents formats (textes, chiffres, images, vidéos, etc...). P a g e | 63 4.3.2. Information sur les données. Pour construire un modèle de machine Learning, il faudrait disponibiliser les données dans le dataset13. Nos données proviennent de kaggle (Kaggle, 2022). 4.3.2.1. Description du Data-set. Notre Data-set est constitué de 2 dossiers : Data-set d'entraînement et de test et contient au total 3297 photos (224x244) du cancer de la peau de type mélanome. 4.3.2.1.1. Data-set d'entraînement. Le Data-set d'entraînement comporte deux sous dossiers intitulés bénin et malin. Chacun d'eux correspond à une classe de cancer de la peau du type mélanome et contient 2637 images de grains de beauté par classe. Le Data-set d'entraînement constitue la base sur laquelle le modèle doit être entrainé afin de généraliser la solution et détecter le type de cancer de la peau sur de futures images dérmatoscopie. 4.3.2.1.2. Data-set de test. Pour vérifier la solution finale des compétiteurs, un Data-set de test a été fourni par l'organisation. Ce dossier contient 660 images de grains de beauté appartenant aux différentes classes de cancer de la peau du type mélanome, elles respectent la même définition et le même format que les images du data-set d'entraînement. 4.3.3. Implémentation du cas en Python. 4.3.3.1. Importation de bibliothèques essentielles.
Figure 35. Importation bibliothèques. P a g e | 64 4.3.3.2. Chargement des données.
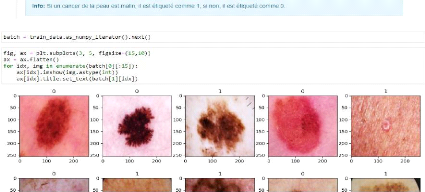
Figure 36. Chargement des données à partir du Dataset. 4.3.3.3. Tracer quelques exemples d'images.
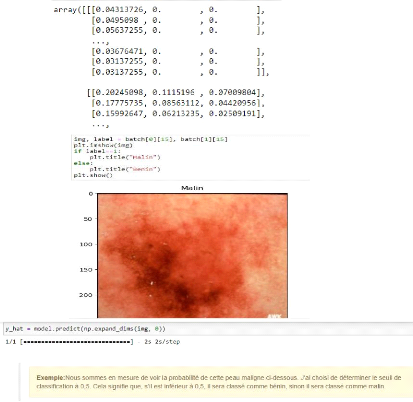
Figure 37. Chargement des données pour cas exemple. 4.3.3.4. Mise à l'échelle des données.
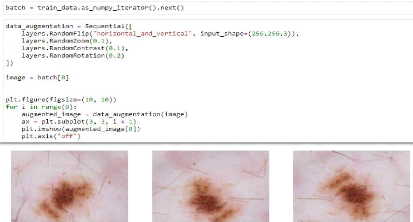
Figure 38. Mise à l'échelle des données. P a g e | 65 4.3.3.5. Augmentation des données. Info: Parce que notre train a un nombre relativement faible d'images, nous pouvons appliquer l'augmentation des données qui reproduit les images en appliquant certains changements tels que la rotation aléatoire, le retournement aléatoire, le zoom aléatoire et le contraste aléatoire. Cela peut éventuellement augmenter le score de précision du modèle. Puisque nous appliquerons l'augmentation de données au début de l'architecture du réseau neuronal, nous devrions passer la forme d'entrée. L'augmentation des données sera inactive lors du test des données. Les images d'entrée seront augmentées lors des appels à model.fit (pas model.assess ou model.predict).
Figure 39. Augmentation des données. 4.3.3.6. Création d'un modèle d'apprentissage profond. 4.3.3.6.1. Définition d'un réseau de neurones convolutif CNN
Figure 40. Implémentation CNN.
P a g e | 66 Dans la figure n°40, nous avons conçu un réseau de neurones convolutif avec 3 couches à convolution suivie chacune par un max-pooling, d'une couche complétement connectée de 128 neurones et d'une dernière couche de classification d'un neurone. 4.3.3.7. Compilation du modèle. Figure 41. Implémentation de la compilation du modèle. 4.3.3.8. Entraînement du modèle.
Figure 42. Entraînement de la solution finale. 4.3.3.9. Résultats
P a i e | 67
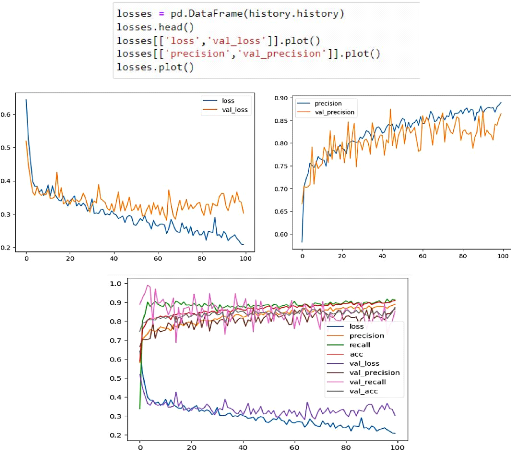
Figure 43. Résultat de l'entrainement du modèle. 4.3.3.10. Affichage de perte de données et de la précision
Figure 44. Perte et précision de données.
P a i e | 68 4.3.3.11. Enregistrement de notre modèle CNN pour son utilisation dans l'API Figure 45. Enregistrement du modèle (CNN). 4.3.3.12. Tests manuels
Figure 46. Résultats d'un cas testé via le modèle. P a g e | 69 4.3.3.13. Construction du module de prédiction à partir de données test pour l'API.
Figure 47. Module de prédiction pour l'API. 4.4. L'exploitation de modèle (Déploiement). Cette partie représente une exploitation du modèle extrait de l'approche PrediCancerPeau. Nous avons créé un API (Application Programme Interface) Voir Figure 41 afin de gérer les inférances14 pour notre cas. Cette API effectue des prédictions basées sur l'utilisation du modèle d'apprentissage en profondeur extrait de notre approche soulignée ci - haut afin de réaliser une prédiction meilleure et moins chère du cancer de la peau de type mélanome qu'un dermatologue.
Figure 48. Le logo de l'API. 14 Terme utilisé en Machine Learning pour désigner les nouvelles données qui n'ont pas servi d'entrainé le modèle. P a i e | 70
Figure 49. Démarrage de l'API.
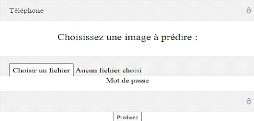
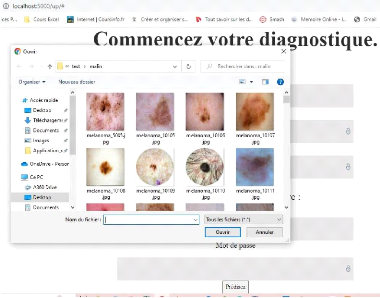
Figure 50. Interface graphique de prédiction. P a g e | 71 Le bouton "choisir une image" sert à parcourir et visualiser le contenu des bases d'images d'apprentissage et de test comme le montre la figure 4.4.
Figure 51. Exploration des images. Pour lancer l'apprentissage et la validation du modèle sur la base d'apprentissage en profondeur pour les 2 classes de cancer de peau du type mélanome (Bénin/Malin) en se basant sur le réseau de neurone convolutif, il suffit de cliquer sur le bouton "Prédisez".
Figure 52. Interface de prédiction à l'état prêt. P a g e | 72
Figure 53. Résultat du diagnostic via l'API. 4.4.1. Quelques codes sources de déploiement de l'API PrediCancerPeau avec Flask. from flask import Flask, request, flash, redirect, url_for,render_template from flask import send_file import os import cv2 import numpy as np from skimage.transform import resize from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow import keras from keras.models import Sequential, Model,load_model from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D from keras.layers import Activation, Dropout, Flatten, Dense,MaxPool2D from PIL import Image from matplotlib.image import imread app = Flask(import_name=__name__, template_folder='templates') app.secret_key = '1234' DOSSIER_UPS = ' C:/Users/hp/Desktop/L2 INFO ALL/MEMOIRE/MEMOIRE ET APP OK SNR/APP CANCER RESEAUX DE NEURONE/Application_web_Shanga/uploads/' chemin_predict=' C:/Users/hp/Desktop/L2 INFO ALL/MEMOIRE/MEMOIRE ET APP OK SNR/APP CANCER RESEAUX DE NEURONE/' def extension_ok(nomfic): """ Renvoie True si le fichier possède une extension d'image valide. """ return '.' in nomfic and nomfic.rsplit('.', 1)[1] in ('png','jpg', 'jpeg', 'gif', 'bmp','PNG') P a i e | 73 @app.route('/up/', methods=['GET', 'POST']) def upload(): image="" if request.method == 'POST': if request.form.get("pw","") == "1234": # on vérifie que le mot depasse est bon f = request.files['fic'] if f: # on vérifie qu'un fichier a bien été envoyé if extension_ok(f.filename): # on vérifie que son extension est valide nom = f.filename i="'"+nom+"'" image=DOSSIER_UPS + nom f.save(image) flash(u'Résultat de la prediction !'.format(lien=url_for('upped',nom=nom)),'succes') flash(u'<img src="{lien}">.'.format(lien=url_for('upped',nom=nom)),'succes') #debut de la prediction flash(prediction(image),'succes') return render_template('up_up.html',image=i) else: flash(u'Ce fichier ne porte pas une extension autorisée !', 'error') else: flash(u'Vous avez oublié le fichier !', 'error') else: flash(u'Mot de passe incorrect', 'error') return render_template('up_up.html',image=image) @app.route('/up/view/') def liste_upped(): images = [img for img in os.listdir(DOSSIER_UPS) if extension_ok(img)] # la liste des images dans le dossier return render_template('up_liste.html', images=images) @app.route('/up/view/<nom>') def upped(nom): nom = nom if os.path.isfile(DOSSIER_UPS + nom): # si le fichier existe return send_file(DOSSIER_UPS + nom, as_attachment=True) #on l'envoie else: flash(u'Fichier {nom} inexistant.'.format(nom=nom),'error') return redirect(url_for('liste_upped')) # sinon on redirige vers la liste des images, avec un message d'erreur def prediction(image): class_dict = {0:'benin',1:'malin'} test_image=Image.open(image) P a g e | 74 test_image=test_image.resize((256,256)) 'chargement du model' model=load_model(chemin_predict+"CancerPeau1_model.h5") test_image = np.expand_dims(test_image, 0) probs = model.predict(test_image) pred_class = np.argmax(probs) pred_class = class_dict[pred_class] return pred_class @app.route('/up/liste/') def liste(): return render_template('up_cancer.html') if__name__ == '__main__': app.run(debug=True) |
|