|
P a g e | i
Épigraphe
C'est bien de travailler dur mais il faut le faire
intelligemment pour ne pas s'épuiser avant d'atteindre
l'objectif.
William Sinclair M.
P a g e | ii
J
e dédie ce modeste travail à mon cher père
SHANGA KAPINGA Denis. Que j'aime plus que tout au monde. A lui je dois toute ma
vie et toutes mes réussites, car sans lui je ne serais pas arrivé
jusqu'ici. J'espère rester toujours fidèle aux valeurs morales
qu'il m'a apprises.
A ma défunte chère mère DIMUKA NGULUBI
Mélanie. Aucun mot ne saurait exprimer mon immense amour, mon estime, ma
profonde affection et ma reconnaissance pour tous les sacrifices qu'elle a
consenti pour mon bonheur et ma réussite.
A toi mon épouse UKOLAMA MUTOMBO Kevine et à mon
fils chéri SHANGA MUTOMBO Ethan pour la force, la motivation, la
patience et l'amour qu'ils me procurent.
Eddy MUTOMBO SHANGA
P a g e | iii
Remerciements
|
N
|
ous remercions le Dieu Tout - Puissant de nous avoir
donné le courage, la volonté, la force et la patience afin de
parvenir à élaborer ce modeste travail.
|
Nous tenons à remercier sincèrement notre
encadreur le Professeur Ruffin-Benoît NGOIE MPOY pour
avoir accepté de diriger ce travail et de nous avoir accompagné
tout au long de sa réalisation avec beaucoup d'intérêt et
de disponibilité ainsi que pour tout le soutien, l'aide, l'orientation,
la guidance et ses encouragements qu'il nous a apportés et d'avoir mis
son expérience à notre profit dans son encadrement.
Nous souhaitons adresser nos remerciements les plus
sincères aux personnes qui nous ont apporté leur aide et qui ont
contribué à l'élaboration de ce mémoire ainsi
qu'à la réussite de cette formidable année
académique.
Nos remerciements s'adressent aussi aux membres du jury qui
ont eu la tâche d'évaluer ce modeste travail pour le raffiner.
Finalement, nous adressons aussi nos remerciements
sincères à nos familles, nos soeurs et frères et à
nos amis.
P a g e | iv
Sigles et abréviations
ABCD : Asymmetry
Border Irregulatity Colour and
Dermoscopic
structure.
API : Application
Programming Interface (Interface de
Programmation d'Application).
BD : Base de
Données.
BIG-DATA : Donnes
très Volumineux.
CASH : Combined
Algorithm Selection and
Hyperparameter.
CNN : Réseaux
Neuronaux Convolutionnels.
CNTK : Microsoft
Cognitive Toolkit.
CPU : Central
Processing Unit.
DAO : Diagnostic
Assisté par Ordinateur.
DATA-SET : Jeu de
Données
DNN : Deep
Neural Network (Réseau de Neurones
Profond).
ELU : Exponential
Linear Unit (Unité Linéaire
Exponentielle).
FCRN : Neonatal Fc
Receptor.
GAC : Contour
Actif Géodesique.
HCA : Analyse de
Classification Hiérarchique.
IA : Intelligence
Artificielle.
ISIC : International
Strandard Industrial
Classification.
ML : Machine
Learning (Apprentissage Automatique).
MLP (PMC) : Multi
Layer Perceptron (Perceptron Multi Couche)
MVS OU SMM : Machine
Vector Support (Machines à Vecteurs
Supports).
OMS : Organisation
Mondiale de la Santé.
P a g e | v
ONEIROS : Open-ended
Neuro-Electronic Intelligent
Robot Operating
System.
PCA : Analyse des
Composants Principaux.
RELU : Rectified
Linear Unit (Unité Linéaire
Rectifiée).
RGB : Red
Green and Blue.
RNN : Réseaux
Neuronaux Récurrents.
ROI : Région
d'Intérêt.
SVM : Support
Vector Machine (Séparateurs à vaste
marge).
TDNN : Time
Delay Neural NetWork (Réseau
de Neurones à Retard
Temporel).
TDS : Total
Dermoscopic Score.
UV :
Ultra-Violets.
XGBOOST : eXtreme
Gradient Boosting.
P a g e | vi
Liste des figures
Figure 1. Apprentissage supervisé. 17
Figure 2. Neurone biologique et neurone artificiel.
18
Figure 3. Apprentissage non supervisé. 19
Figure 4. Apprentissage par renforcement. 20
Figure 5. Les approches et les algorithmes de l'apprentissage
automatique. 21
Figure 6. Le choix de l'algorithme d'apprentissage selon
certains facteurs. 21
Figure 7. Les sous-bronches de l'intelligence artificiel.
27
Figure 8. Un perceptron multicouche. 27
Figure 9. Les différentes aires du cortex visuel.
32
Figure 10. Structure générale d'un CNN.
33
Figure 11. L'architecture des réseaux de neurones
convolutifs. 33
Figure 12. Opération convolutive sur une image.
34
Figure 13. Représentation générale des
cartes de caractéristiques. 35
Figure 14. Convolution sur une histologie. 35
Figure 15. Dimensions d'une image et des cartes de
caractéristiques. 36
Figure 16. Exemple applicatif des différents Pooling.
37
Figure 17. Résultat de différents Pooling sur
une histologie. 38
Figure 18. Stride(ligne,colone). 38
Figure 19. Exemple de dépassement d'une image par un
filtre. 39
Figure 20. Exemple de filtre passant par un pixel. 39
Figure 21. Exemple applicatif d'un Padding-Same. 40
Figure 22. Opération convolutive sans Relu. 41
Figure 23. Opération convolutive avec Relu.
41
Figure 24. Architecture générale d'un CNN.
42
Figure 25. Reconnaissance d'une image avec CNN. 43
Figure 26. Types des mélanomes (a) superficiel
extensif, (b) nodulaire, (c) lentigo
et (d) acral. 45
Figure 27. Dermoscope. 47
Figure 28. Schéma bloc d'un DAO. 47
Figure 29. Segmentation d'une lésion : a) illustration
de ROI, b) masque de la
lésion. 48
Figure 30. Échantillon des
lésions bénignes et malignes de la base des images
dermoscopiques PH2. 52
Figure 31. Interface de Jupyter Notebook (source Jupyter)
57
Figure 32. Logo de l'IDE Spyder. 58
Figure 33. Logo de Framework FLASK 58
Figure 34. Différents types des graines de
beauté de mélanome. 62
Figure 35. Importation bibliothèques. 63
Figure 36. Chargement des données à partir du
Dataset. 64
Figure 37. Chargement des données pour cas exemple.
64
P a g e | vii
Figure 38. Mise à l'échelle des
données. 64
Figure 39. Augmentation des données. 65
Figure 40. Implémentation CNN. 65
Figure 41. Implémentation de la compilation du
modèle. 66
Figure 42. Entraînement de la solution finale.
66
Figure 43. Résultat de l'entrainement du
modèle. 67
Figure 44. Perte et précision de données.
67
Figure 45. Enregistrement du modèle (CNN).
68
Figure 46. Résultats d'un cas testé via le
modèle. 68
Figure 47. Module de prédiction pour l'API.
69
Figure 48. Le logo de l'API. 69
Figure 49. Démarrage de l'API. 70
Figure 50. Interface graphique de prédiction.
70
Figure 51. Exploration des images. 71
Figure 52. Interface de prédiction à
l'état prêt. 71
Figure 53. Résultat du diagnostic via l'API.
72
P a g e | viii
Liste des tableaux
Tableau 1 : Comparaison entre l'apprentissage automatique et
l'apprentissage en
profondeur. 29
P a g e | ix
Table des matières
Épigraphe i
Remerciements iii
Sigles et abréviations iv
Liste des figures vi
Liste des tableaux viii
Table des matières ix
INTRODUCTION GENERALE 12
1. Contexte et Motivation. 12
2. Méthode et Organisation du travail. 14
Chapitre premier : Apprentissage automatique &
Apprentissage profond. 15
1.1. Introduction. 15
1.2. L'apprentissage automatique Machine Learning.
15
1.2.1. Définitions et types d'apprentissage
automatique. 15
1.3. Le choix d'un type d'apprentissage automatique.
21
1.4. Champs industriels d'apprentissage automatique.
22
1.4.1. La reconnaissance de forme. 22
1.4.2. La fouille de données ou datamining. 22
1.4.3. Caractéristique d'apprentissage automatique.
23
1.4.4. Tache d'apprentissage. 24
1.4.5. L'espace des données d'apprentissage.
25
1.5. De l'apprentissage automatique à l'apprentissage
en profondeur. 25
1.6. L'apprentissage en profondeur « Deep Learning
». 26
1.6.1. Définitions et les architectures
d'apprentissage en profondeur. 26
1.7. Comparaison entre l'apprentissage automatique et
l'apprentissage en
profondeur. 29
Conclusion partielle. 30
Chapitre deuxième : Réseau des neurones
à convolution (CNN). 31
2.1. Introduction. 31
2.2. Motivations des réseaux de neurones convolutifs.
31
2.3. Le cortex visuel. 32
2.4. CNN et structure générale. 32
2.5. CNNs et fonctionnement. 33
P a g e | x
2.5.1. Les filtres (Kernel). 34
2.5.2. Cartes de caractéristiques. 34
2.5.3. Profondeur de l'image et des filtres. 35
2.5.4. Le Pooling. 36
2.5.5. Le Stride. 38
2.5.6. Le zero-Padding. 39
2.5.7. Padding-valid, Padding-Same. 40
2.6. Fonction Relu. 40
2.7. Couche de Correction (RELU). 41
2.8. Couche entièrement connectée (FC).
41
2.9. Couche de perte (LOSS). 42
2.10. Deep Neural Network (DNN) final. 42
2.11. Structure générale d'un CNN. 42
2.12. L'application des réseaux neuronaux convolutifs.
42
2.13. Avantages de CNNs. 43
Conclusion partielle. 44
Chapitre troisième : État de l'art sur les
méthodes de segmentation & de
classification d'images. 45
3.1. Introduction. 45
3.2. Le mélanome. 45
3.2.1. Facteurs de risques. 46
3.2.2. Développement du mélanome. 46
3.2.3. Détection et traitement du mélanome.
46
3.2.4. Diagnostic assisté par ordinateur. 47
3.3. Segmentation des lésions cutanées.
48
3.3.1. Segmentation basée clustering. 48
3.3.2. Segmentation basée C-moyennes floues (FCM).
49
3.3.3. Segmentation basée K-means. 49
3.3.4. Segmentation basée sur les réseaux
neuronaux convolutifs. 50
3.4. Classification des lésions cutanées.
52
Conclusion partielle. 55
Chapitre quatrième : Implémentation &
interprétation des résultats. 56
4.1. Introduction. 56
P a i e | xi
4.2. Les outils et les détails
d'implémentation. 56
4.2.1. Environnement de développement. 56
4.2.2. Langage de programmation. 60
4.3. Présentation du problème. 61
4.3.1. Aperçu général sur le cancer
de la peau. 62
4.3.2. Information sur les données. 63
4.3.3. Implémentation du cas en Python. 63
4.4. L'exploitation de modèle (Déploiement).
69
4.4.1. Quelques codes sources de déploiement de
l'API PrediCancerPeau
avec Flask. 72
Conclusion partielle. 74
CONCLUSION GENERALE 75
Bibliographies : 76
Webographie : 79
P a g e | 12
INTRODUCTION GENERALE
1. Contexte et Motivation.
La technologie se développe rapidement et nous la
trouvons dans tous les secteurs dans le monde. Elle permet à l'homme
d'ouvrir de larges horizons dans la recherche et l'exploration. Par exemple ;
elle a été utilisée dans le développement de la
numérisation dans différents domaines, le développement de
l'éducation, la médecine et d'autres domaines (Clayton, 2019).
L'utilisation de l'intelligence artificielle, de la robotique
et des technologies connexes dans le domaine de la santé, annonce une
révolution majeure dans le domaine de la médecine. Ces nouvelles
technologies interviennent dans l'aide au diagnostic « intelligence
artificielle », aux actes techniques « robotique chirurgicale »,
à la consultation « télémédecine », aussi
la révolution des « Micro-Robots » circulants injectés
dans le sang et capables d'atteindre les endroits les plus reculés du
corps humain. Cette évolution indique un brillant avenir pour la
médecine face à diverses maladies incurables (Géron,
2017).
A ce titre, on s'intéresse à un problème
de santé publique majeur : le cancer de la peau de type mélanome.
En effet, depuis quelques années, l'incidence du mélanome ne
cesse d'augmenter dans tous les pays du monde. D'après l'Organisation
Mondiale de la Santé (OMS) 130 000 cas de mélanomes sont
enregistrés dans le monde pour l'année 2020. (Sung et al.,
2021).
Le mélanome est le cancer de la peau le plus dangereux,
il peut se propager rapidement à d'autres parties du corps s'il n'est
pas détecté et traité tôt. Le mélanome
à son état primaire est difficile à détecter. En
effet, à son état précoce, la lésion maligne
présente peu de signes de malignité et peut être,
facilement, confondu à une lésion bénigne.
Vu les difficultés d'identification par les
méthodes manuelles classiques, telles que la règle ABCD
(Asymmetry, Border Irregularity, Colour and Dermoscopic
structure) [Nachbar et al., 1994], CASH (Combined
Algorithm Selection and Hyperparameter) [Henning et al., 2007] et
seven-point checklist [Argenziano et al., 2011] qui sont des examens cliniques
longs et ne constituent pas une solution efficace au vu du nombre important de
cas suspects. Un dermatologue peut prendre beaucoup de temps pour n'examiner
qu'un nombre limité de patients.
P a g e | 13
Il est donc nécessaire de développer un
système automatique, rapide et efficace de discrimination des tumeurs
malignes des tumeurs bénignes à un stade précoce. Un tel
système permet de détecter des caractéristiques peu
discernables à l'oeil nu ce qui augmente les chances de discrimination
et permet un diagnostic sur une large population en un temps réduit.
Avec l'arrivée de machine Learning et du Deep Learning
(les domaines d'étude de l'Intelligence Artificiel), les outils
informatiques s'appliquent régulièrement dans le domaine de
santé comme soulignés ci - haut, mais aussi, dans le souci de
résorber l'incidence de mortalités causé par le cancer de
la peau, soit 8,8 millions de personnes en 2015 selon le rapport de
l'organisation mondiale de santé (Who, 2018) et en tenant compte de la
faible démographique des « dermatologues », tout en sachant
que l'homme est appelé à vieillir puis disparaître et aussi
exposé à l'oubli, pour sauvegarder son expertise dans tel ou tel
domaine, on cherche à construire des modèles capables à
partir d'un bon nombre d'exemples (les données correspondant à
l'expérience passée) d'en assimiler afin d'appliquer ce qu'ils
ont appris aux cas non encore rencontrés lors de son apprentissage. Sur
ce, nous nous posons la question de savoir si ces méthodes permettent de
reconnaître la forme (image de malignité de la personne souffrant
du cancer de la peau de type mélanome à son état primaire)
à partir de la photographie de la peau.
Tenant compte du problème soulevé
précédemment, notre hypothèse consiste
à construire un modèle permettant de reconnaître des
formes, particulièrement les images de la malignité des gens
présentant les symptômes du cancer de la peau en vue d'aider les
corps médicaux de disposer l'arsenal thérapeutique médical
pour la prévenir et l'équilibrer, afin d'éviter les
complications qui en découlent et résorber définitivement
le taux de l'incidence de cas causé par cette maladie dangereuse.
Notre modèle est construit par l'une des
méthodes d'apprentissage supervisé qui est le réseau de
neurones, particulièrement le réseau de neurones à
convolution (CNN) car cette dernière a fait preuve
d'être l'une des méthodes la plus performante dans la
reconnaissance des formes particulièrement aux images vu leurs
résultats par rapport à d'autres méthodes. Notre
choix a été porté sur cette
méthode vue sa haute performance au regard d'autres méthodes de
la même famille, surtout dans le domaine de Deep Learning (ou
apprentissage profond).
En observant la faiblesse des autres méthodes de Deep
Learning, particulièrement le Perceptron Multi Couche
(PMC), il ne prend pas en compte la corrélation entre
les pixels d'une image, il est peu ou pas invariant à des
transformations de l'entrée, le réseau de neurones sont
complètement connectés,
P a g e | 14
c'est-à-dire que la valeur d'un neurone de couche
n va dépendre des valeurs de tous les neurones de la
couche n-1, ce qui augmente le nombre de connexions et le
nombre de paramètres à calculer, bref la complexité dans
le temps et dans l'espace trop importante.
Nous soulignons que ce travail est rédigé au
cours de l'année académique 2021 - 2022, n'a touché que la
reconnaissance des formes, particulièrement des images de
malignité des personnes souffrant du cancer de la peau de type
mélanome à son état primaire en utilisant le réseau
de neurones à convolution, car celui-ci a la capacité de traiter
des problèmes de reconnaissance des formes (images).
2. Méthode et Organisation du travail.
Ce travail s'est appuyé essentiellement sur la
technique documentaire et de simulation.
Ce travail de mémoire porte sur la construction d'un
modèle prédictif basé sur le réseau de neurones
profond pour la détection de Cancer de la peau. Notre travail est
organisé en quatre chapitres, hormis l'introduction et la conclusion
:
? Chapitre 1 :
Apprentissage automatique & Apprentissage profond. Au
début de ce chapitre, nous allons fournir un regard sur le domaine de
l'intelligence artificielle et ses différentes branches «
l'apprentissage automatique et l'apprentissage en profondeur », en
définissant ce domaine, ses branches et ses différentes
caractéristiques.
? Chapitre 2 :
Réseau de neurones à convolution. Ce
chapitre présente le succès du Deep Learning, l'architecture de
réseau de neurones à convolution, les algorithmes
d'apprentissage, etc.
? Chapitre 3 :
État de l'art sur les méthodes de segmentation & de
classification d'images. Ce chapitre fera un état de l'art
des différents algorithmes de segmentation et de classification des
lésions cutanées1.
? Chapitre 4 :
Implémentation & interprétation des
résultats. Ce chapitre présente le problème
à résoudre de ce travail, les différents outils y
intervenant, l'architecture retenue, interprétation des résultats
obtenus, ainsi que le déploiement de notre modèle dans une
application mobile ou web.
1 Lésions cutanées
: est un défaut situé à la surface de la peau
ou sous la peau.
? Le terme « Apprentissage automatique
» a été inventé par l'informaticien
Américain « Arthur Samuel », dans le
début de l'année 1959. Il a créé le
P a g e | 15
Chapitre premier : Apprentissage automatique &
Apprentissage
profond.
1.1. Introduction.
Actuellement l'informatique est presque présente dans
tous les domaines : la santé, l'éducation, l'économie, et
la cosmologie. Cette présence se reflète dans la vie quotidienne
de l'individu et elle a permis des facilités d'utilisation et de
compréhension de plusieurs complexes domaines. Un des domaines les plus
importants qui a été touché par ce terrible
développement de l'informatique est le domaine de la santé. Le
développement de l'informatique et de la technologie continue à
prendre une place de plus en plus importante dans le domaine de santé,
ce qui a permis le développement du matériel médical, les
logiciels de surveillance médicale, et les logiciels d'analyse
médicales qui augmentent la précision des résultats. Ce
dernier a donné une grande attention par les scientifiques, en
particulier les spécialistes dans les domaines : de l'intelligence
artificielle, les systèmes experts, l'apprentissage automatique Machine
Learning, et l'apprentissage en profondeur Deep Learning.
Dans ce chapitre, nous allons d'abord présenter les
techniques d'apprentissage automatique Machine Learning. Ensuite, nous
décrierons comment l'apprentissage automatique a été
déplacé vers l'apprentissage profond pour avoir des architectures
plus prometteuses. Et enfin, nous finirons le chapitre par une conclusion.
1.2. L'apprentissage automatique Machine
Learning.
L'intérêt de l'apprentissage automatique a
augmenté au cours de la dernière décennie, pour tout le
discours sur l'apprentissage automatique, il y a beaucoup de conflits entre ce
que la machine peut faire et ce que nous souhaitons (Patterson et al., 2017).
L'apprentissage automatique est un sous-ensemble de l'intelligence artificielle
« IA », il est axé sur la création des systèmes
qui apprennent et améliorent les performances, en se basant sur des
données qu'ils traitent. Les algorithmes d'apprentissage automatique
entrent en jeu pour optimiser, fluidifier, et sécuriser cette
dernière (Clayton, 2019).
1.2.1. Définitions et types d'apprentissage
automatique. 1.2.1.1. Définitions.
La définition de l'apprentissage automatique a connu
une progression durant plusieurs années, cela est dû qu'à
chaque fois il y avait de nouvelles découvertes dans ce domaine :
2 Est un tableau qui rassemble les
individus qui ont un certain nombre de caractéristiques ou encore c'est
une structure qui contient nos données.
P a g e | 16
premier programme qui permet aux ordinateurs de jouer et
d'apprendre le jeu de dames sans être explicitement programmé
(Géron, 2017).
? En 1997, l'informaticien américain «
Tom Michael Mitchell » introduit une nouvelle
définition de l'apprentissage automatique. Il a considéré
qu'un programme apprend d'une expérience E, par rapport
à une classe de tâches T, et avec une mesure de
performance P (Géron, 2017).
? Avec le temps, la définition de
l'apprentissage automatique a commencé à prendre une dimension
mathématique et statistique. Selon les auteurs dans (Goodfellow et al,
2016), l'apprentissage automatique est essentiellement une forme de
statistiques appliquées, mettant davantage l'accent sur l'utilisation
d'ordinateurs pour estimer statistiquement les fonctions compliquées et
un accent moindre sur la démonstration des intervalles de confiance
autour de ces fonctions.
Ces définitions peuvent varier en fonction de l'angle
étudié, mais elles sont toutes orientées vers une seule
direction, qui est définie comme suit : l'apprentissage automatique est
la science ou l'art de la programmation des ordinateurs afin qu'ils puissent
apprendre à partir des données (Géron, 2017).
1.2.1.2. Types d'apprentissage automatique.
Il existe également de différents types
d'apprentissage automatique. Selon (Géron, 2017), la définition
du type d'apprentissage est basée sur la réponse à ces
deux questions suivantes :
? Est - ce que cet apprentissage compte sur la supervision
humaine dans son entrainement et apprentissage ?
? Est - ce que ce type d'apprentissage utilise une base de
données (dataset2) fournie par l'être humain ?
1-. Si la réponse est oui pour les deux questions,
nous avons un apprentissage supervisé.
2-. Si la réponse est non pour la première
question, et oui pour la deuxième question, nous parlons d'un
apprentissage non supervisé.
3-. Si la réponse est non pour les deux questions, le
type de l'apprentissage est l'apprentissage par renforcement.
Dans ce qui suit, nous définissons chacun de ces types
: apprentissage supervisé, apprentissage non supervisé, et
apprentissage par renforcement.
P a g e | 17
1.2.1.2.1. Apprentissage supervisé.
Dans l'apprentissage supervisé l'être humain aide
l'algorithme pour apprendre, un data scientiste sert de guide et il apprend
à l'algorithme les résultats qu'il doit trouver. Le même
cas lorsqu'on apprend à un enfant d'identifier les fruits, en les
mémorisant dans sa mémoire. Dans l'apprentissage
supervisé, l'algorithme apprend grâce à un jeu de
données déjà étiqueté et dont le
résultat est prédéfini (Goodfellow et al, 2016). (Voir
figure 1).
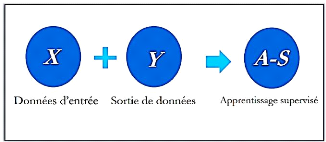
Figure 1. Apprentissage
supervisé.
Les algorithmes de l'apprentissage automatique
supervisé sont les plus couramment utilisés, il y deux types
d'apprentissage supervisé :
? La classification : la classification
consiste à trouver le lien entre une variable
d'entrée (X) et une variable de sortie
discrète (Y), en suivant une loi multinomiale
(Dupré, 2020).
? Régression : la régression
consiste à prédire une valeur continue
pour la variable de sortie (Dave,
2020).
Les algorithmes les plus célèbres
utilisés dans cette approche sont les suivants (GAËL, 2019) :
? SVM (Machines à vecteurs de support)
: est un apprentissage automatique très puissant et polyvalent
modèle, capable d'effectuer la classification linéaire ou non
linéaire, la régression, et même détection des
valeurs aberrantes. C'est l'un des modèles les plus populaires de
l'apprentissage automatique « Machine Learning », et
n'importe qui intéressés par cette approche devraient l'avoir
dans leur boîte à outils. Les SVM sont particulièrement
bien adapté à la classification d'ensembles de données
complexes mais de petite ou moyenne taille. L'algorithme SVM consiste à
chercher à la fois l'hyperplan optimal ainsi que de minimiser les
erreurs de classification.
P a g e | 18
A La méthode des k plus proches voisins
: cet algorithme consiste à essayer différentes valeurs
de K pour obtenir la séparation la plus satisfaisante.
A Naïve Bayes : est un classifieur assez
intuitif à comprendre. Il se base sur le théorème de Bayes
des probabilités conditionnelles, et il suppose que les variables sont
indépendantes entre elles. Cela permet de simplifier le calcul des
probabilités.
A Les arbres de décision : un arbre de
décision sert à classer les futures observations, sachant qu'un
corpus d'observations est déjà étiqueté.
A Les Forêts Aléatoires : cet
algorithme fonde sur les arbres de décision, est un modèle
construit par de multiples arbres de décisions.
A Régression Logistique : l'algorithme
de régression logistique consiste à trouver les meilleurs
coefficients pour minimiser l'erreur entre la prédiction faite pour des
destinations visitées et la vraie étiquette donnée (Ex.
bon, mauvais etc.).
A Les réseaux de neurones : Les
réseaux neuronaux sont un modèle informatique qui partage
certaines propriétés avec le cerveau humain, dans lequel de
nombreuses unités simples travaillent en parallèle sans
centralisation, ils permettent de trouver des patterns complexes dans les
données, il se compose de valeurs d'entrées, poids,
fonction de transfert et une valeur de sortie (Werfelli, 2015)
(Voir figure 2).

Figure 2. Neurone biologique et
neurone artificiel.
Il existe aussi d'autres algorithmes, tels que l'algorithme de
régression linéaire, les Algorithmes Génétiques
(GAËL, 2019). Certains algorithmes de régression peuvent
également être utilisés pour la classification, et la
régression, à titre d'exemple l'algorithme de la
régression logistique (Géron, 2017).
P a g e | 19
1.2.1.2.2. Apprentissage non
supervisé.
Avec l'apprentissage non supervisé la machine n'a pas
besoin de l'aide pour apprendre. L'apprentissage non supervisé est une
approche plus indépendante, dans laquelle un ordinateur apprend à
identifier des processus et des schémas complexes sans aucun guide, Il
implique une formation basée sur des données sans
étiquette, qui ne contiennent aucun résultat spécifique
(Goodfellow et al, 2016). (Voir figure 3).
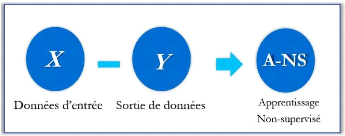
Figure 3. Apprentissage non
supervisé.
Selon (Géron, 2017), il y a deux types d'apprentissage
non supervisé :
A Regroupement (Clustering) : c'est une
méthode d'analyse statistique utilisée pour organiser des
données brutes en silos homogènes, à l'intérieur de
chaque grappe, les données sont regroupées selon une
caractéristique commune.
A Réduction de la dimension :
l'objectif est de simplifier les données sans perdre trop
d'informations, à titre d'exemple, fusionner plusieurs
caractéristiques en un seul caractère.
Les algorithmes les plus célèbres
utilisés dans cette approche sont (Issarane, 2019) :
A K-Moyenne : est un algorithme de
Regroupement (Clustering) il regroupe dans les même Cluster (Groupes) les
données similaires (qui se ressemblent). Il utilise un raffinement
itératif pour produire un résultat final.
A Analyse de classification hiérarchique (HCA)
: la mise dans un cluster hiérarchique est similaire à
la mise dans un cluster normal, sauf que dans ce cas nous souhaitons mettre en
place une hiérarchie des clusters. Cela peut s'avérer très
important surtout quand nous désirons une flexibilité par rapport
au nombre de clusters voulu.
A PCA (Analyse des composants principaux) :
l'algorithme PCA consiste à transformer des variables liées entre
elles, vers de nouvelles variables séparées les uns des autres.
Ces nouvelles variables sont
La figure ci - dessous exprime les différentes branches
et algorithmes de l'apprentissage automatique (Voir figure 5).
P a g e | 20
nommées les composantes principales, elles permettent
au praticien de réduire le nombre de variables et de rendre
l'information moins redondante.
? Apriori : l'algorithme Apriori s'utilise
dans une base de données transactionnelle pour extraire des ensembles
d'éléments fréquents, puis générer des
règles d'association.
1.2.1.2.3. L'apprentissage par renforcement.
Avec l'apprentissage par renforcement la machine n'a pas
besoin de l'aide de l'être humain, ni en termes de supervision, ni en
termes de fourniture de données. L'apprentissage par renforcement est
une branche très différente. Le système d'apprentissage,
appelé un agent dans ce contexte (Voir figure 4), peut observer
l'environnement, sélectionner et effectuer des actions, et enfin obtenir
des récompenses ou des pénalités (des récompenses
négatives). La machine peut apprendre toute seule la meilleure
stratégie à suivre, appelée une politique, pour obtenir
plusieurs récompenses au fil du temps. Une politique définit
l'action que l'agent devrait choisir lorsqu'il est dans une situation
donnée (Géron, 2017).
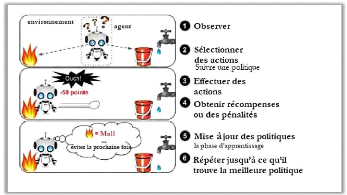
Figure 4. Apprentissage par
renforcement.
Parmi les premiers algorithmes d'apprentissage par
renforcement, c'est l'algorithme « Temporal différence
Learning », proposé par « Richard Sutton »
en 1988 (Sutton, 1988). Aussi l'algorithme « Q-Learning »
mis au point lors d'une thèse soutenue par « Chris Watkins
» en 1989 et publié réellement en 1992 (Watkins et al,
1992).
P a g e | 21
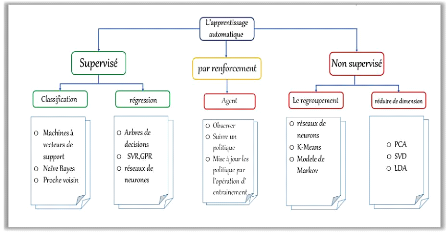
Figure 5. Les approches et les
algorithmes de l'apprentissage automatique. 1.3. Le choix d'un
type d'apprentissage automatique.
Avec la présence de différents types de
classifieurs pour l'apprentissage automatique, l'opération de choix d'un
type est une question typique « Quel algorithme dois-je
utiliser ? ». Selon (Li, 2017), la réponse à
cette question varie les facteurs suivants :
V' La taille, la qualité et la nature des
données. V' Le temps de calcul disponible.
V' L'urgence de la tâche.
V' Le but d'utilisation de ces données.
La figure suivante (Voir figure 6), fournir des indications
sur les algorithmes à essayer en premier selon les facteurs
mentionnés ci-dessus.
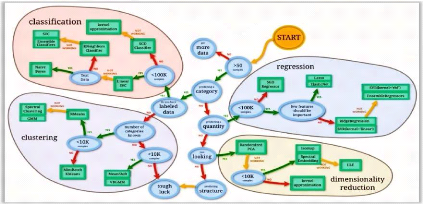
Figure 6. Le choix de
l'algorithme d'apprentissage selon certains facteurs.
P a g e | 22
1.4. Champs industriels d'apprentissage
automatique.
L'apprentissage automatique (l'apprentissage artificiel) a
fourni un grand nombre d'outils aux industriels et aux entrepreneurs. Nous les
regroupons selon deux grands axes: la reconnaissance des formes et la fouille
de données (l'extraction de connaissances des données
(Datamining)) (Chapman et al., 2000).
1.4.1. La reconnaissance de forme.
Elle est un ensemble de technique et méthodes
permettant d'identifier les motifs informatiques à partir des
données brutes pour la prise de décision en
dépendance de la catégorie que l'on attribue à ce motif.
C'est l'un de deux axes sur lesquels l'apprentissage automatique se
développe, elle utilise aussi les statistiques.
Au sens large si on veut bien comprendre la forme, c'est un
motif à nature variée et non pas une simple forme
géométrique.
Il peut s'agir par exemple d'un contenu visuel
(empreinte digitale, code barre, visage, ...) ou
sonore (la parole), d'images
médicales (rayon X, EEG, IRM...) ou
multi spectrales (images satellitaires) et
bien d'autres.
Les méthodes d'apprentissage automatique sont ici à
la base de :
? La reconnaissance des images (écriture manuscrite,
signatures, détection de ressources par satellite, pilotage automatique,
etc...) ; ? La reconnaissance de la parole ;
? Le traitement avancé des signaux biomédicaux ;
Etc.
1.4.2. La fouille de données ou
datamining.
Les problèmes pratiques que peut résoudre en ce
domaine le machine Learning se posent constamment dans la vie industrielle :
comment distinguer un bon client d'un mauvais, comment reconnaître un
mauvais procédé de fabrication et l'améliorer,
voilà deux exemples frappants parmi tant d'autres.
La fouille de données (Datamining, en anglais)
est le processus d'extraction de la connaissance : il consiste à
sélectionner les données à étudier à partir
de bases de données (BD) (hétérogènes ou
homogènes), à épurer ces données et enfin à
les utiliser en apprentissage pour construire un modèle (Gashler et al.,
2008).
Dans le souci de pouvoir corriger certains défauts
qu'avaient connus ses prédécesseurs entre autre (Statistique
descriptive, analyse de données, etc.), qui sont : exigence de
présentation des données sous une forme très rigide et
faiblesse d'intelligibilité constatée sur les
résultats. Dans ce souci est né le datamining.
Depuis, l'évolution de ces domaines, les critiques qui
leur ont été adressés ont changé, et ceci vers les
années 1990. Data ming est effectivement né quadruplet effort.
P a g e | 23
V' Permettre aux utilisateurs de fournir des données
dans l'état où elles sont
(ceci a donné naissance aux techniques de nettoyage
des données);
V' Utiliser les données enregistrées sous
forme de bases de données (en général relationnelles),
ceci a provoqué un large courant de recherche au sein de la
communauté des BD intéressée par la création de
modèles;
V' Fournir aux utilisateurs des outils capables de
travailler sur des données mixtes, numériques et symboliques
;
V' Construire des outils produisant une connaissance
intelligible aux utilisateurs.
C'est ainsi que datamining a pu trouver la large
reconnaissance industrielle dont elle jouit actuellement. Elle a
commencé à résoudre les deux problèmes industriels
principaux de l'analyse des données, ceux qui coûtent le plus cher
(le fait que le client est souvent imprécis dans la dentition du
problème qu'il se pose et le fait que les données dont il dispose
sont souvent de qualité discutable).
1.4.3. Caractéristique d'apprentissage
automatique.
Parmi les principales caractéristiques et
facultés adoptées par les modèles d'apprentissage
automatique, nous citons : l'entraînement, la reconnaissance, la
généralisation, l'adaptation, l'amélioration et
l'intelligibilité (Chapman et al., 2000).
1.4.3.1. Adaptation.
Elle peut être vue comme étant la disposition du
modèle (algorithme ou système) à corriger son
comportement ou à remanier sa réponse (ex.,
prédiction) par rapport à de nouvelles situations.
Pour les tâches de perception, en vision artificielle,
on accumule les bonnes et mauvaises expériences, et à partir
d'elles, on peut faire évoluer les règles pour mieux effectuer la
tâche, c'est le phénomène d'adaptation ou
d'amélioration.
1.4.3.2. Intelligibilité.
C'est améliorer la compréhension des
résultats d'apprentissage, afin que le modèle puisse fournir une
connaissance claire et compréhensible. Au sens interprétable (en
anglais, on parle de comprehensibility ou
understandability).
Exemple, quand un expert extrait de la
connaissance des bases de données (BDs), il apprend une manière
de les résumer ou de les formuler (expliquer, expliciter de
manière simple et précise).
P a g e | 24
D'un point de vue fouille de données, ça revient
purement et simplement à contrôler l'intelligibilité
(clarté) d'un modèle obtenu.
Actuellement, la mesure d'intelligibilité se
réduit à vérifier que la connaissance produite est
intelligible et que les résultats sont exprimés dans le langage
de l'utilisateur et la taille des modèles n'est pas excessive.
1.4.3.3. Généralisation.
D'une autre facette, l'apprentissage est typiquement
caractérisé par une généralisation rationnelle
des règles, c'est-à-dire si d'une expérience
accumulée sur un certain nombre d'exemples, on tire des règles de
comportement, il faudrait que celles-ci soient également applicables
à des situations encore non rencontrées.
1.4.3.4. Reconnaissance.
Avec la reconnaissance de la parole, par exemple, le
programme d'apprentissage n'aura pas besoin d'apprendre tous les sons de ladite
parole. Il va extraire une règle de classification qui lui permettra de
traiter au mieux les sons qu'il aura à décoder.
1.4.3.5. L'amélioration.
Les sciences cognitives définissent l'apprentissage
comme étant une capacité à améliorer les
performances au fur et à mesure de l'exercice d'une
activité. C'est le cas d'un joueur du scrabble au fil des parties,
où l'assimilation de l'expérience et la puissance du raisonnement
se combinent dans sa progression.
1.4.4. Tache d'apprentissage.
Il est possible de parler de l'objectif du processus
d'apprentissage suivant plusieurs points de vue :
? Par rapport à la
connaissance
L'apprentissage peut viser à modifier le contenu de la
connaissance (par l'acquisition de connaissances, soit par révision ou
par oubli), non seulement de modifier mais aussi le rendre plus efficace par
rapport à un certain but ; Par réorganisation, optimisation
ou compilation par exemple. Ce pourrait être le cas d'un joueur
d'échecs ou d'un calculateur mental qui apprend à aller de plus
en plus vite sans pour autant connaître de nouvelles règles de jeu
ou de calcul. On parle dans ce cas d'optimisation de
performance.
P a g e | 25
· Par rapport à
l'environnement
Dans cette optique la tache de l'apprentissage peut
être définie de ce que l'agent apprenant doit réaliser pour
survivre dans son environnement en :
V' Apprenant à reconnaître les
formes ; V' Apprendre à prédire ;
V' Apprendre à être plus
efficace.
· Par rapport à des classes abstraites
de problèmes.
Voyant des problèmes et processus de résolution
qui leur sont assignés, l'apprentissage peut viser à extraire
et à compresser l'information, à décoder ou même
à décrypter un message codé (cryptographie), à
approximer une fonction cachée dans les données
(problème d'analyse), à généraliser une
connaissance déjà apprise (problème d'induction),
à tenter la résolution des problèmes mal posés
(problème issu des mathématiques appliquées).
· Par rapport aux structures de données
ou types d'hypothèses visées.
Dans cette optique, la tâche agent apprenant est
définie sur la détermination de l'algorithme d'apprentissage
à utiliser ainsi que le type de données adéquat à
l'apprentissage. Il consiste parfois à modifier la structure de
données pour en trouver une équivalente mais plus efficace du
point de vue computationnel, c'est encore une fois, sous un autre angle, le
problème de l'optimisation de performance (Mitchell, 1997).
1.4.5. L'espace des données
d'apprentissage.
Le problème de la classification est l'apprentissage
d'une fonction dite de prédiction, de décision etc., au travers
des données. Pour espérer obtenir un classifieur
adapté à la tâche considérée,
quelques points sont à survoler (Wiener et al., 2002).
Ces points se résument autour de deux problèmes
essentiels :
V' Celui de la représentation
adéquate des données ;
V' Et celui de la représentation
des hypothèses faites par le programme d'apprentissage.
1.5. De l'apprentissage automatique à
l'apprentissage en profondeur.
Nous ne pouvons pas différer sur l'efficacité de
l'apprentissage automatique dans la résolution d'une
variété de problèmes, mais il y a beaucoup de
problèmes que ce type fait face, dont les plus importants sont le temps,
la vitesse et l'efficacité, si un algorithme d'apprentissage automatique
renvoie une prédiction inexacte, alors un
P a g e | 26
ingénieur doit intervenir et faire des ajustements,
dans ce cas, il y a un manque d'efficacité qui sera une perte de temps
avec une prévision lente (Grossfeld, 2020).
Les algorithmes simples d'apprentissage automatique
décrits dans ce chapitre fonctionnent très bien sur une grande
variété de problèmes importants. Cependant, ils n'ont pas
réussi à résoudre les problèmes centraux de
l'intelligence artificiel, tels que la reconnaissance de la parole ou la
reconnaissance d'objets. Le développement de l'apprentissage en
profondeur a été motivé en partie par l'échec de
algorithmes traditionnels, lorsque de travaille avec des données de
grande dimension, pour bien généraliser sur de telles
tâches l'intelligence artificiel (Goodfellow et al., 2016).
1.6. L'apprentissage en profondeur « Deep Learning
».
L'apprentissage en profondeur « Deep Learning » a
été un défi à définir pour beaucoup de
spécialiste dans le domaine, car il a changé de forme lentement
au cours de la dernière décennie. Une définition utile
précise que l'apprentissage en profondeur est un réseau neuronal
avec plus de deux couches (Patterson et al., 2017). Le problème avec
cette définition est qu'elle fait écho à l'existence de ce
domaine depuis les années 80 du siècle dernier, formant ainsi une
grande contradiction puisque beaucoup de gens pensent que ce domaine est
relativement nouveau, pour réfuter cette contradiction, il faut
distinguer le moment où le domaine est apparu et celui où il a
été cadré et exploité.
1.6.1. Définitions et les architectures
d'apprentissage en profondeur. 1.6.1.1. Définitions.
Le terme « apprentissage profond » a
été introduit dans le domaine du l'apprentissage automatique par
« Rina Dechter » en 1986, et dans les
réseaux de neurones artificiels par « Igor Aizenberg
» et ses collègues en 2000, dans le contexte des neurones
à seuil booléen (Schmidhuber, 2015), l'apprentissage profond
désigne une technique d'apprentissage d'une machine, c'est une
sous-branche de l'intelligence artificielle qui vise à construire
automatiquement des connaissances à partir de grandes quantités
d'information (Voir figure 7). Les caractéristiques essentielles du
traitement ne seront plus identifiées par un traitement humain dans
algorithme préalable, mais directement par l'algorithme d'apprentissage
profond (Nuageo, 2017).
P a g e | 27
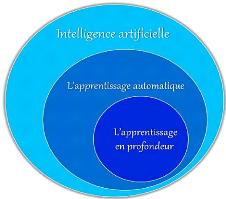
Figure 7. Les sous-bronches de
l'intelligence artificiel.
L'apprentissage en profondeur permet donc implicitement de
répondre à des questions du type « que peut-on
déduire de ces données ? » et décrire
des caractéristiques parfois cachées ou des relations entre des
données souvent impossibles à identifier pour l'homme.
D'après (Patterson & Gibson, 2017)
l'apprentissage profond est un réseau neuronal avec un grand nombre
de paramètres et de couches, l'exemple de base c'est le
perceptron multicouche MLP « multi layer
perceptron » (Voir figure 8).
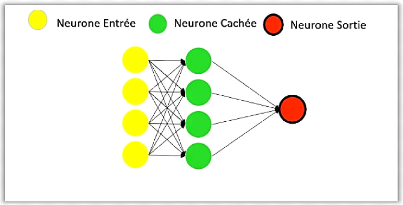
Figure 8. Un perceptron
multicouche.
Perceptrons a été inventé en 1958 au
« Cornell Aviation Laboratory » par « Frank
Rosenblat » financé par le bureau de recherche navale des
États-Unis, Le mot vient de verbe latin « Percipio
» qui signifie en Anglaise understand
; en Français comprendre, qui
montre que le robot ou l'appareil peut apprendre et comprendre le monde
extérieur (Rosenblatt, 1958).
P a g e | 28
Un perceptron multicouche avec plusieurs couches
cachées entre la couche d'entrée et la couche de sortie est un
réseau de neurones profonds (DNN), le DNN est une fonction
mathématique, qui mappe certains ensembles de valeurs d'entrée
aux valeurs de sortie. La fonction est formée par la composition de
nombreuses fonctions plus simples (Goodfellow et al., 2016).
Certaines de ses caractéristiques (Patterson et al., 2017)
:
V' Plus de neurones.
V' Des moyens plus complexes de connecter les couches neurones
dans
les réseaux neuronaux.
V' Puissance de calcul.
V' Extraction automatique des fonctionnalités.
L'apprentissage profond s'applique dans divers domaines
(Goodfellow et al., 2016), tel que :
V' L'intelligence artificielle en général.
V' La reconnaissance visuelle et la comparaison de forme.
V' La robotique.
V' La santé et la bio-informatique.
V' La sécurité.
1.6.1.2. Les architectures d'apprentissage en
profondeur.
Les trois grandes architectures de réseaux profonds
selon (Patterson et al., 2017) :
4. Réseaux de neurones pré-entraînés
non supervisés.
4. Réseaux neuronaux convolutionnels (CNN).
.
4. Réseaux neuronaux récurrents (RNN)
Habituellement, de nombreuses catégories
considèrent les réseaux de neurones supervisés comme
appartenant au domaine d'apprentissage automatique plutôt que
d'apprentissage en profondeur.
P a g e | 29
1.7. Comparaison entre l'apprentissage automatique et
l'apprentissage en profondeur.
|
L'apprentissage
automatique
|
L'apprentissage en
profondeur
|
|
Dépendances des données
|
Une performance excellence
avec des petites bases de
données.
|
Une performance
excellente avec les BIG-DATA3.
|
|
Dépendances du matériel
|
Travail sur une machine
faible.
|
Besoin d'une machine
fort avec un CPU4 fort aussi.
|
|
Les caractéristiques des
données
|
Besoin de comprendre les
caractéristiques des données.
|
Pas besoin de comprendre
les caractéristiques des
données.
|
|
Le temps d'exécution
|
Quelque minute à des heures.
|
Des semaines.
|
|
Interprétable
|
Certains algorithmes sont
faciles (Arber de disions) et
d'autres sont impossibles
(SVM, XGBoost5).
|
Difficile à impossible.
|
Tableau 1 : Comparaison entre
l'apprentissage automatique et l'apprentissage en
profondeur.
3 BIG-DATA : un ensemble
très volumineux de données qu'aucun outil classique de gestion de
base de données ou de gestion de l'information ne peut vraiment
travailler (Bremme, 2015).
4 CPU : Un processeur
« central processing unit »
5 XGBoost : est une
bibliothèque logicielle open source permettant de mettre en oeuvre des
méthodes de Gradient boosting, Le Boosting de Gradient est un algorithme
d'apprentissage supervisé dont le principe et de combiner les
résultats d'un ensemble de modèles plus simple et plus faibles
afin de fournir une meilleure prédiction (Cayla, 2018).
P a g e | 30
Conclusion partielle.
Dans ce chapitre, nous avons présenté
l'apprentissage automatique et l'apprentissage profond. Nous avons d'abord
commencé par la description de l'apprentissage automatique et ses
différentes architectures proposées. Ensuite, nous avons
passé à la description de l'apprentissage profond.
Dans cette démarche, nous avons décelé
les caractéristiques de l'apprentissage artificiel, entre autres :
adaptation, généralisation, reconnaissance, amélioration
et intelligibilité. Ce sont les cinq (5) caractéristiques qu'on
peut trouver dans le modèle de machine Learning.
Etant atteints, les objectifs fixés pour ce chapitre,
nous aborderons dans le second chapitre, l'une de méthodes de
l'apprentissage supervisé qui est le réseau de neurones
artificiels précisément le réseau de neurones
à convolution ( Convolutionnal Neural Network, en anglais)
spécialisé dans le traitement d'images, la reconnaissance de
formes, etc. Il fait partir de Deep Learning (Apprentissage
Profond, en français).
P a g e | 31
Chapitre deuxième : Réseau des neurones
à convolution (CNN).
2.1. Introduction.
Les réseaux neuronaux convolutionnels CNNs «
Convontoinal neurone network » sont un type spécialisé de
réseau neuronal pour le traitement de données qui a une topologie
connue, ils sont des réseaux supervisé et non supervisé,
cela dépend de l'exigence et l'utilisation, cependant, principalement
sont supervisé (Patterson et al., 2017).
L'informaticien japonais « Kunihiko Fukushima
» a jeté les bases du lancement de cette structure par son
travaille sur Neocognitron en 1980 (Vázquez,
2018).
Comme une grille, ils appartiennent aux réseaux de
neurones artificiels acycliques, le nom convolutionnel
indique que le réseau emploie une opération
mathématique appelée convolution, et cela signifie un type
spécialisé d'opération linéaire (Goodfellow et al.,
2016).
Un réseau de neurones convolutif (CNN) s'inspire du
cortex visuel des mammifères afin d'analyser une image en profondeur.
Cette architecture a été introduite par le chercheur "Yann Le
Cun" Dans les années 90.
Dans ce chapitre, nous introduirons le réseau de
neurones convolutif et les différents algorithmes qui le distingue d'un
réseau de neurones classique (DNN6).
2.2. Motivations des réseaux de neurones
convolutifs. Les principales motivations des CNN sont les suivantes
:
A Un Deep Neural Network (DNN) profond pour analyser
une images complexe dégrade rapidement. Il faut trouver une
méthode moins coûteuse et plus intuitive afin de faire du
traitement d'image en général et la détection de forme en
particulier.
A Une image est composée de sous
éléments, il faut donc exploiter cette hiérarchisation
avec une détection de formes plus granulaire.
A Les positions, tailles, couleurs..etc sont
compliqués à extraire pour les réseaux classiques afin
d'avoir une compréhension générale de l'image.
A Réduire la dimensionnalité des
paramètres d'un Deep Neural Network (DNN) classique et celle des
images.
6 DNN : Dense/Deep Neural
Network
P a g e | 32
? S'inspirer de la biologie afin de créer une
intelligence artificielle fut un succès, se tourner une seconde fois
vers elle afin de modéliser une nouvelle IA7 peut être
fructueux.
2.3. Le cortex visuel.
Dans la définition suivante, à chaque
étape, nous citerons entre parenthèses une notion analogue
à celle des CNN.
L'oeil perçoit la lumière
(image en entrée) à travers la
pupille puis véhicule l'information vers le
cortex visuel qui se situe derrière la tête. Cette
information est sous forme de signaux électriques
dont la fréquence correspond
à une information codée (convolution).
Au cours de leurs trajets, les informations passent d'une fibre nerveuse
à une autre grâce aux synapses
(connexion de neurones). Le cortex
visuel est constitué de plusieurs aires spécialisées dans
le traitement des messages nerveux (les
filtres). Selon la fréquence des signaux
électriques émanant de l'information, chaque air
interprète une caractéristique de l'image comme suit
(cartes de caractéristiques) (Maxicours,
2021).

Figure 9. Les différentes
aires du cortex visuel. 2.4. CNN et structure
générale.
Construire un CNN revient à superposer plusieurs
couches de manière hiérarchique, chacune d'entre elles calcule
une représentation abstraite de l'image au fur et à mesure
(Nguyên, 2018). L'opération se présente en
général de la manière suivante.
7 IA : Intelligence
Articielle
P a g e | 33
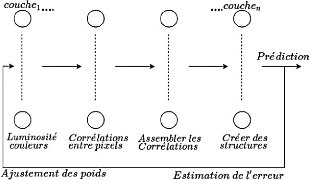
Figure 10. Structure
générale d'un CNN.
2.5. CNNs et fonctionnement.
Le fonctionnement de CNNs est inspiré à partir
du fonctionnement du processus biologique, ils consistent en un empilage
multicouche de perceptrons, dont le but est le prétraitement de petites
quantités d'informations (Patterson et al., 2017).

Figure 11. L'architecture des
réseaux de neurones convolutifs.
Cette architecture des réseaux neuronaux convolutifs
(CNNs) ci - dessus regorge trois couches majeurs, dont :
? Couche d'entrée : la couche
d'entrée accepte généralement l'entrée
tridimensionnelle sous la forme (hauteur x largeur) de l'image et a
une profondeur représentant les canaux de couleur
(généralement trois pour les canaux de couleur RGB).
P a g e | 34
V' Couche d'entrainement : est
construite de :
? Convolution couche.
? Fonction d'activation : Linéaire
rectifiée « Relu ». ? Couche de mise en
commun « pooling ».
V' Couche de classification : la couche
de classification permet de produire des probabilités ou des scores de
classe.
2.5.1. Les filtres (Kernel).
Un filtre est un petit groupe de neurones à partir
desquels la couche suivante est connectée. Comme les filtres
utilisés dans les traitements d'images classiques, ces derniers se
distinguent des filtres ordinaires par leurs auto-apprentissages en effet, on
ne connaît pas d'avance les paramètres qui les constituent, c'est
au réseau de les apprendre (Aston et al., 2020).
Un filtre est une matrice de poids n X n qui
analyse une partie m X m de l'image afin d'en extraire une
valeur pertinente puis répéter le processus sur toute l'image.

Figure 12. Opération
convolutive sur une image. 2.5.2. Cartes de
caractéristiques.
Les cartes de caractéristiques (feature map) sont les
images résultantes de l'opération convolutive.
Dans la pratique, plusieurs filtres sont appliqués
à l'image de départ pour produire plusieurs cartes. Chacune
d'entre elles a pour rôle de détecter une particularité :
contraste, lumière et autres en comparaison avec les régions du
cortex visuel comme suit.
P a g e | 35

Figure 13. Représentation
générale des cartes de caractéristiques.
La figure ci-après est un exemple d'une première
convolution sur une image histologique d'un cancer de la peau invasif. On
remarque suite à une première couche de convolution une
extraction générale des caractéristiques globales :
couleur, contraste, luminosité...etc.
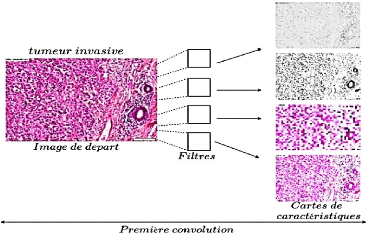
Figure 14. Convolution sur une
histologie. 2.5.3. Profondeur de l'image et des
filtres.
Une image est pour une machine une matrice de
(n X n X k), n représente les
lignes et les colonnes qui constituent ses pixels. Chaque pixel
dispose de 3 valeurs du système de codage RGB
: c'est la dimension k. Par conséquent, un filtre est
en réalité de taille m X m X k.
P a g e | 36
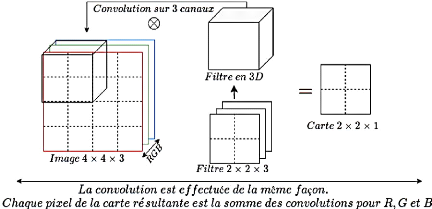
Figure 15. Dimensions d'une image
et des cartes de caractéristiques.
Résultat : le nombre poids est
drastiquement diminué en terme de lignes et colonnes mais
augmenté en profondeur par le rajout de la 3ème
dimension k.
La dimension des images est également augmentée en
profondeur à cause du nombre de cartes générées.
Un des objectifs primaires des CNN
étant de réduire la dimension, celle-ci se voit augmentée
(Aston et al., 2020).
2.5.4. Le Pooling.
Le Pooling (mise en commun) est un algorithme visant
à réduire la dimension d'une image tout en gardant des
sous-parties importantes.
La fenêtre de Pooling est une matrice m x
m, qui parcours l'image afin de produire un seul pixel de
sortie parmi mxm pixels voisins. Plusieurs
méthodes de production de pixels sont mises en place en fonction de
la pertinence de l'information voulue.
Parmi ces méthodes, on compte l'average-Pooling, max et
min-Pooling (Aston et al., 2020).
2.5.4.1. Average-Pooling.
Le principe de l'average-Pooling est de prendre la moyenne des m
X m pixels voisins. Dans le traitement d'image, on parle de "
lissage". La fenêtre de Pooling la plus
utilisée est de 2 X 2.
P a g e | 37
2.5.4.2. Max-Pooling.
Le Max-Pooling permet d'extraire uniquement la plus grande
valeur dans un ensemble de pixels. Ce type de Pooling est avantageux pour
analyser une image dont le fond est noir. Le but est ainsi d'ignorer tous les
pixels de faible valeur (en noir) et d'en extraire l'avant-plan (plus
clair).
2.5.4.3. Min-Pooling.
Le Min-Pooling permet d'extraire le pixel le plus faible parmi
ses m X m pixels voisins. Cette méthode est
adaptée dans les cas où le fond de l'image est clair et l'avant
plan sombre.
La figure suivante illustre les différents
résultats de Pooling et leurs effets réducteurs.

Figure 16. Exemple applicatif des
différents Pooling.
Remarque : théoriquement,
l'Average-Pooling semble être la méthode la plus adéquate
car on ne perd ni trop ni peu d'informations. Cependant, les expériences
ont montré que dans la plupart des problèmes de traitement
d'images, le Max-Pooling semble être la plus adéquate. La figure
suivante représente un test de différents Pooling sur une
histologie.
P a g e | 38

Figure 17. Résultat de
différents Pooling sur une histologie.
Résultat : Le Max-Pooling permet
d'extraire de meilleurs contours afin de détecter les anomalies
(grosseur de cellules) tandis que l'Average-Pooling ne fait que lisser l'image.
Quant au Min-Pooling, il permet que de réduire la luminosité de
l'image, les contours sont donc négligés.
2.5.5. Le Stride.
L'opération de convolution s'effectue en
déplaçant successivement la fenêtre du filtre dans l'image.
Le Stride est donc la taille du pas de déplacement en matière
de ligne et colonne qu'on veut effectuer pour parcourir l'image.
Remarque : Les Strides les plus
utilisées sont de (1; 1) ou (2; 2) afin d'avoir une meilleure
corrélation entre pixels.

Figure 18.
Stride(ligne,colone).
P a g e | 39
2.5.6. Le zero-Padding.
Le Zero-Padding est une technique qui permet d'ajouter des
pixels à valeur nulle à chaque côté des
frontières de l'image. Le but est de compléter celle-ci dans le
cas où le Stride et la taille du filtre ne sont pas compatibles à
celle de l'image.

Figure 19. Exemple de
dépassement d'une image par un filtre.
Les pixels aux extrémités de l'image sont
faiblement traités par rapport aux pixels au centre suite au
déplacement du filtre. La figure suivante illustre ce
phénomène.

Figure 20. Exemple de filtre
passant par un pixel.
P a g e | 40
2.5.7. Padding-valid, Padding-Same.
Le Padding-Valid est caractérisé par l'absence
de Padding. Quand la taille du filtre et de l'image adhère, il n'y a pas
nécessité de rajouter des zéros. Le PaddingSame est
introduit de sorte à avoir la taille de l'image en entrée
égale à celle en sortie. C'est le plus utilisé car
tous les pixels seront traités le même nombre de fois par le
filtre (Aston et al., 2020).

Figure 21. Exemple applicatif
d'un Padding-Same.
2.6. Fonction Relu.
L'opération de convolution sur une image impose de
la linéarité à celle-ci, or les images sont
naturellement non linéaires. Afin d'avoir une meilleure
interprétation, Relu permet de casser
cette linéarité8. Pratiquement, la fonction relu
supprime tous les éléments noirs, en ne gardant que ceux qui
portent une valeur positive (les couleurs grises, blanches et autres).
De plus, quand deux couches de convolution sont
appliquées, les poids des filtres de la 2ème
convolution peuvent prendre soit des valeurs positives ou négatives. Si
la carte de caractéristique de la 1ère convolution est
négative, le produit d'une réponse négative et d'un poids
de filtre négatif produira une valeur positive. Pourtant, le produit
d'une réponse positive et d'un filtre positif produira également
une valeur positive. En conséquence, le système ne peut pas
différencier ces deux cas (Jay Kuo, 2016).
8 C'est - à - dire
remplacés les résultats négatifs par zéro.
P a g e | 41

Figure 22. Opération
convolutive sans Relu.
La figure suivante illustre l'impact de la rectification
linéaire sur les cartes de caractéristiques résultantes en
effet, deux filtres de signes différents produisent deux cartes
différentes.

Figure 23. Opération
convolutive avec Relu. 2.7. Couche de Correction
(RELU).
Après chaque opération de convolution, le
réseau de neurones convolutif applique une transformation ReLU
(unité de rectification linéaire) à la fonction
convoluée, afin d'introduire la non-linéarité dans le
modèle. La fonction ReLU, F(x) = max (0, x), renvoie
x pour toutes les valeurs de x >
0 et renvoie 0 pour toutes les valeurs de
x = 0.
2.8. Couche entièrement connectée
(FC).
Après plusieurs couches de convolution et de
max-pooling, le raisonnement de haut niveau dans le réseau neuronal se
fait via des couches entièrement connectées. Les neurones dans
une couche entièrement connectée ont des connexions vers toutes
les sorties de la couche précédente. Leurs fonctions
d'activations peuvent
P a g e | 42
donc être calculées avec une multiplication
matricielle suivie d'un décalage de polarisation.
2.9. Couche de perte (LOSS).
La couche de perte spécifie comment l'entrainement du
réseau pénalise l'écart entre le signal prévu et
réel. Elle est normalement la dernière couche dans le
réseau. Diverses fonctions de perte adaptées à
différentes tâches peuvent y être utilisées. La
fonction « Softmax » permet de calculer la distribution de
probabilités sur les classes de sortie.
2.10. Deep Neural Network (DNN) final.
Un CNN est une succession de couches convolution/Relu
appliquées aux cartes de caractéristiques résultantes. Ces
opérations s'achèvent par un réseau de neurones
complètement connecté afin d'assembler toutes les informations
apprises et ainsi effectuer les opérations classiques d'un DNN à
savoir : prédiction, estimation de l'erreur, propagation de
gradients puis mise à jour des poids.
2.11. Structure générale d'un
CNN.

Figure 24. Architecture
générale d'un CNN. 2.12. L'application des
réseaux neuronaux convolutifs.
Les réseaux neuronaux convolutifs (CNNs) ont de larges
applications, notamment :
V' La reconnaissance d'image et vidéo.
V' Les systèmes de recommandation.
V' Le traitement du langage naturel.
V' L'efficacité des CNN dans la reconnaissance de
l'image (Voir Figure 25) est l'une des principales raisons pour lesquelles le
monde reconnaît le pouvoir de l'apprentissage profond (Patterson et al.,
2017).
P a g e | 43

Figure 25. Reconnaissance d'une
image avec CNN. 2.13. Avantages de CNNs.
L'utilisation d'un poids unique associé aux signaux
entrant dans tous les neurones d'un même noyau de convolution est un
avantage majeur des réseaux convolutifs. Par cette méthode, il
y'a réduction de l'empreinte mémoire, amélioration des
performances et permet une invariance du traitement par translation. C'est le
principal avantage du CNN par rapport au MLP, qui lui considère chaque
neurone indépendant et donc affecte un poids différent à
chaque signal entrant. Lorsque le volume d'entrée varie dans le temps
(vidéo ou son), il devient intéressant de rajouter un
paramètre de temporisation (delay) dans le paramétrage des
neurones. On parlera dans ce cas de réseau neuronal à retard
temporel (TDNN).
Comparés à d'autres algorithmes de
classification de l'image, les réseaux de neurones convolutifs utilisent
relativement peu de prétraitement. Cela signifie que le réseau
est responsable de faire évoluer tout seul ses propres filtres
(apprentissage sans supervision), ce qui n'est pas le cas d'autres algorithmes
plus traditionnels. L'absence de paramétrage initial et d'intervention
humaine est un atout majeur des CNN.
P a g e | 44
Conclusion partielle.
Dans ce chapitre, nous avons présenté
l'essentiel sur le réseau de neurones à convolution, nous avons
aussi décrit l'architecture et les avantages que présente ce
dernier par rapport à notre travail. Nous avons également
étudié les fonctionnalités détaillées d'un
réseau de neurones convolutif. Le plus important réside dans la
différence entre un CNN et un DNN classique par la présence de
filtres, de convolutions et les couches de pooling intercalées. Un CNN
effectue grâce à cela une détection de formes plus
granulaire qu'un DNN classique.
Etant atteints, les objectifs fixés pour ce chapitre,
nous aborderons dans le troisième chapitre « l'État
de l'art sur les méthodes de segmentation & de classification
d'images ».
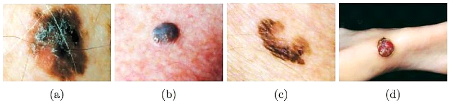
Figure 26. Types des
mélanomes (a) superficiel extensif, (b)
nodulaire, (c) lentigo
et (d) acral.
P a g e | 45
Chapitre troisième : État de l'art sur les
méthodes de segmentation & de classification d'images.
3.1. Introduction.
Ce chapitre est un aperçu de l'état de l'art des
différents algorithmes de segmentation et de classification des
lésions cutanées. La première partie est une étude
des différentes approches de segmentation et leurs limitations
lorsqu'elles sont appliquées avec les images
dermoscopiques. La deuxième partie est consacrée
aux approches de classification.
3.2. Le mélanome.
Le cancer de la peau est une maladie cutanée
caractérisée par la croissance anormale de cellules. Dans un
premier temps, ces cellules se propagent uniquement dans leur environnement
proche, il s'agit d'une tumeur bénigne.
Ensuite, elles continuent à se propager et finissent par envahir
d'autres parties du corps à travers le sang et la lymphe. Ces cellules
tumorales, communément appelées métastases
détériorent alors une ou plusieurs fonctions de l'organisme et
peuvent conduire à la mort. On parle alors d'une tumeur
maligne. Les cancers de la peau les plus fréquents sont :
le carcinome basocellulaire, le carcinome épidermoïde et le
mélanome.
Actuellement, le mélanome est l'un des
cancers les plus dangereux, c'est un problème majeur de
santé publique dans le monde. Une fois que la propagation des
métastases commence, les traitements tels que la
radiothérapie et la chimiothérapie sont inefficaces.
L'immunothérapie, en revanche, augmente la durée de survie sans
récidive du mélanome. Les mélanomes sont
regroupés en plusieurs sous-types dont les quatre principaux
sont le mélanome superficiel extensif, nodulaire, lentigo et acral
(Hartinger, 2012).
P a g e | 46
3.2.1. Facteurs de risques.
Le mélanome provient de la transformation maligne des
mélanocytes. Les mécanismes par lesquels le mélanome se
développe sont encore mal connus, mais trois principaux facteurs de
risque ont été identifiés :
V' L'exposition aux ultraviolets UV,
V' Les prédispositions
génétiques,
V' Les antécédents personnels de
mélanome.
3.2.2. Développement du
mélanome.
Dans la plupart des cas, l'évolution du mélanome
se divise en quatre stades bien définis.
A Premier stade : les cellules
tumorales sont localisées uniquement dans l'épiderme et
progressent horizontalement (mélanome in
situ). A ce stade, une simple excision de la zone affectée
suffit pour éliminer définitivement le cancer et éviter
ainsi toute évolution.
A Deuxième stade : si aucun
traitement n'est effectué, la tumeur se propage en profondeur, traverse
la membrane basale et colonise le derme et l'hypoderme.
A Troisième stade : les
cellules cancéreuses empruntent la circulation lymphatique pour envahir
les ganglions proches de la lésion initiale.
A Quatrième stade : les
métastases continuent de se développer et atteignent les organes
profonds.
3.2.3. Détection et traitement du
mélanome.
La détection précoce du mélanome
constitue une étape importante du traitement des personnes atteintes. En
effet, si la tumeur peut être retirée avant qu'elle n'ait franchi
la jonction dermo-épidermique, l'individu est
en phase de guérison. Généralement, le moyen de
détection consiste en un examen à l'oeil nu par un
dermatologue. Ce dernier utilise couramment des
dermoscopes (Figure 27) pour une meilleure
visualisation. Plusieurs règles ont été
développées afin de caractériser plus efficacement une
lésion suspecte, la plus connue est la règle ABCD
(Nachbar et al., 1994). L'utilisation de cette dernière
présente plusieurs limites. En effet, elle
n'est pas applicable pour des lésions
précoces.
P a g e | 47

Figure 27. Dermoscope.
Lorsque le mélanome n'a pas encore formé de
métastases, le seul traitement curatif est une exérèse
chirurgicale. À ce jour, il n'existe pas de traitement pour le
mélanome métastasé permettant une rémission
complète. Il est donc nécessaire de développer un outil de
détection automatique du mélanome précoce plus
efficace.
3.2.4. Diagnostic assisté par
ordinateur.
Le diagnostic assisté par ordinateur (DAO) pour la
détection du mélanome a été introduit afin
d'améliorer et d'aider les dermatologues et d'autres cliniciens dans la
prévention du cancer de peau. La construction d'un DAO repose
principalement sur quatre étapes essentielles
: le prétraitement de l'image, la segmentation,
l'extraction des attributs et la classification. La figure 28
présente le schéma bloc d'un DAO9.

Figure 28. Schéma bloc d'un
DAO.
9 DAO : Diagnostic
Assisté par Ordinateur
P a g e | 48
1. Prétraitement : regroupe
l'ensemble des processus visant à améliorer la qualité de
l'image acquise.
2. Segmentation : est une
répartition de l'image en régions homogènes selon un
critère déterminé : couleur, texture, niveau de gris,
...etc.
3. Extraction d'attributs
(caractéristiques) : vise à extraire les
informations pertinentes qui caractérisent chaque classe.
4. Sélection des caractéristiques
: est utilisée pour sélectionner les
caractéristiques les plus pertinentes et de réduire la dimension
de l'espace des caractéristiques de manière à
éliminer les caractéristiques redondantes.
5. Classification d'images : est
une identification des classes en utilisant les attributs
sélectionnés.
3.3. Segmentation des lésions
cutanées.
La segmentation des lésions cutanées joue un
rôle crucial dans la détection automatique des mélanomes
en délimitant la région d'intérêt
(ROI) comme montré sur la figure 29, vu que dans cette
région que toutes les caractéristiques sont extraites.
L'étude comparative des performances des différentes techniques
de segmentation présentées dans les articles d'Adeyinka et al.
& d'Oliveira et al., démontrent la contribution de la segmentation
dans l'amélioration de la fiabilité d'un système DAO. Pour
cela, différentes techniques de segmentation automatique ont
été proposées pour la délimitation de ROI.
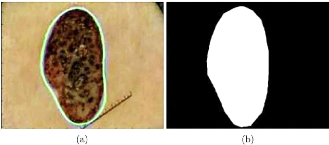
Figure 29. Segmentation d'une
lésion : a) illustration de ROI, b)
masque de la
lésion.
3.3.1. Segmentation basée clustering.
La segmentation par clustering consiste à
affecter à chaque pixel de l'image une classe qui
définit les régions à délimiter sur
l'image. Nous pouvons donc citer des algorithmes de
classification de pixels non-supervisés comme C-moyennes floues (Bezdek,
1980) et les k-means proposés par MAC QUEEN (MacQueen, 1967).
P a g e | 49
3.3.2. Segmentation basée C-moyennes floues
(FCM).
FCM est un algorithme de segmentation basé sur
le regroupement de pixels similaires de manière
itérative, les centres de regroupement étant
ajustés à chaque itération (Bezdek, 1980). En raison de sa
nature itérative, le coût de calcul de l'algorithme
est relativement élevé par rapport aux autres techniques de
segmentation. C'est pourquoi un certain nombre d'approches,
proposées par Cheng et al. & Szilagyi et al., ont été
présentées pour permettre des accélérations
significatives tout en maintenant de bonnes performances de segmentation.
Masood A. et al., ont proposé une nouvelle
méthode de segmentation qui combine FCM, le seuillage et la
méthode level set (LS). Tout d'abord, l'image est
prétraitée pour éliminer les artefacts (poils, bulles
d'air, et les marques de règle) en utilisant un filtre médian
7x7. Ensuite, un seuillage basé sur le FCM est utilisé pour
initialiser l'évolution du LS et réguler les paramètres de
réglage. La méthode proposée a montré une bonne
précision de segmentation des lésions cutanées avec un
taux de détection vrai moyen de 92,6% et une erreur de faux positifs et
de faux négatifs assez réduite, soit 4,66% et 7,34%
respectivement.
Eltayef K. et al., ont présenté une
nouvelle méthode de segmentation des mélanomes à partir
des images dermoscopiques. Pour détecter les poils et
autres bruits dans les images, une étape de prétraitement est
effectuée en appliquant le filtre Gabor. La
région d'intérêt (ROI) de l'image est extraite en combinant
la méthode FCM et Markov Random Field. La
méthode a été évaluée sur un ensemble de
données PH2 de 200 images dermoscopiques. Les résultats de la
méthode proposée ont été comparés aux
masques de la vérité terrain et atteignent une sensibilité
de 93,2%, une spécificité de 98,0% et une précision de
94,0%.
Dans l'article de Jose Luis Garcia et al., l'algorithme
proposé de segmentation des lésions cutanées
dans les images dermoscopiques est basé sur une
classification floue des pixels et un seuillage de l'histogramme.
La méthode a été testée sur deux bases de
données publiques ISIC10 2016 et ISIC 2017 contenant
respectivement 379 et 600 images, et comparée avec les autres travaux de
l'état de l'art, à l'aide des métriques comme
l'exactitude, le coefficient de Dice, l'indice de Jaccard, la
sensibilité et la spécificité : (0.934, 0.869, 0.791,
0.870 et 0.978) et (0.884, 0.760, 0.665, 0.869 et 0.923) respectivement.
3.3.3. Segmentation basée K-means.
L'algorithme des k-means réalise un
partitionnement automatique des pixels de l'image en k classes
homogènes. Divers algorithmes ont été
développés et appliqués pour la segmentation des
lésions cutanées dans le passé. Cette partie
10 ISIC : International
Standard Industrial Classification.
P a g e | 50
présente l'application de certains de ces algorithmes
et leurs performances sur la segmentation des ensembles de
données d'images dermoscopiques.
Alvarez et al., ont développé un algorithme de
segmentation qui se compose des étapes suivantes : une phase du
prétraitement de l'image qui consiste en une opération de
fermeture morphologique réalisée indépendamment sur chacun
des canaux de couleur de l'image RGB, en utilisant comme élément
de sélection un disque de rayon égal à 5 pixels. Ensuite,
un filtre médian 3×3 est appliqué à chaque canal pour
éliminer les poils. Une segmentation de l'image en utilisant
l'algorithme k-means, un calcul d'un ensemble de caractéristiques
décrivant les propriétés de chaque région
segmentée et enfin, un calcul d'un score final pour chaque
région, représentant la probabilité de correspondre
à une segmentation de lésion appropriée. L'algorithme
atteint un indice Jaccard d'environ 0,679.
Dans le travail d'Agarwal et al., une méthode de
segmentation des lésions cutanées basée sur la technique
du clustering est utilisée. D'abord, l'image RGB est convertie en espace
couleur L*a*b*. Une combinaison stratégique est appliquée aux
différents canaux de l'espace L*a*b* pour obtenir une nouvelle image en
niveaux de gris dans laquelle les pixels de la lésion et de la peau sont
plus différenciables. Ensuite, le clustering K-means est mis en oeuvre
pour segmenter la lésion de l'image prétraitée. Enfin, une
étape de post-traitement utilise un filtre moyenneur et un seuillage
basé sur la surface, pour supprimer les pixels bruités (les faux
positifs) de l'image segmentée. La méthode proposée a
été testée sur 50 images de la base de données
public DermIS et DermQuest. Les valeurs du score de chevauchement et du
coefficient de corrélation de la méthode proposée sont
respectivement de 96,75% et 97,66%.
3.3.4. Segmentation basée sur les réseaux
neuronaux convolutifs.
Récemment, les réseaux neuronaux convolutifs ont
été adoptés pour augmenter la précision de la
segmentation des images de lésions cutanées.
Zhang et al., ont développé une structure de
réseau de neurones CNN pour segmenter les lésions
cutanées. L'architecture du réseau comprend plusieurs couches de
convolution, des couches softmax, plusieurs filtres et des
fonctions d'activation. Une fonction d'activation non linéaire
(telle que ReLU et ELU) est utilisée pour
atténuer le problème de disparition du gradient et RMSprop/Adam
sont incorporés pour optimiser l'algorithme de perte. La méthode
a été testée sur l'ensemble de données ISIC 2017,
et elle a atteint une précision de 0.91 qui est plus
élevée que les architectures existantes.
P a g e | 51
Dans le travail de Yu et al., un nouveau réseau
résiduel entièrement convolutif (FCRN) de plus de 50 couches est
proposé, pour la segmentation des images dermoscopiques. Des
expériences sur la base de données ISIC 2016 ont montré
l'efficacité de la méthode proposée. Le FCRN à 50
couches a donné de meilleurs résultats que les architectures
VGG-16, GoogleNet, FCRN-38 et FCRN-100, avec une précision de
segmentation de 94,9%.
Yuan Y. et al., utilisent un réseau convolutif profond
à 19 couches pour la segmentation des lésions cutanées.
L'augmentation des données d'image a été adoptée
pour résoudre le problème des données limitées. De
plus, les performances de segmentation ont été
améliorées par l'utilisation de techniques telles que
la normalisation par lots (Ioffe et al., 2015),
l'optimisation Adam (Kingma et al., 2014) et
la fonction de perte basée sur l'indice Jacquard
(Yang X. et al., 2017). Les résultats expérimentaux
ont montré que la méthode proposée surpasse les autres
algorithmes de l'état de l'art sur la base de données ISIC 2016,
avec un indice de Jaccard de 0,861.
Yang X. et al., ont utilisé l'architecture U-Net pour
segmenter les lésions cutanées. Le modèle d'apprentissage
profond multitâche proposé est entraîné et
évalué sur l'ensemble d'images dermoscopiques ISIC 2017, qui
comprend 2000 échantillons d'entraînement et 150
échantillons d'évaluation. Les résultats
expérimentaux montrent que le modèle d'apprentissage profond
multitâche proposé atteint des performances prometteuses sur la
segmentation des lésions cutanées. La valeur moyenne de l'indice
de Jaccard pour la segmentation des lésions est de 0,724.
Dans l'article de Lin et al., une étude comparative de
deux approches différentes de la segmentation des lésions
cutanées est présentée. La première approche
utilise des U-Nets et introduit une étape de prétraitement
basée sur l'égalisation des histogrammes. La deuxième
approche est une approche basée sur le clustering K-means. Les
expériences ont été testées sur l'ensemble de
données ISIC 2017 pour valider l'étude comparative. En comparant
les deux algorithmes proposés, les U-Nets ont obtenu un indice de
Jaccard significativement plus élevé (0.62) par rapport à
l'approche de clustering (0.44).
P a g e | 52
3.4. Classification des lésions
cutanées.
Différencier les cas malins du
bénins, comme le montre la figure 30 est une tâche
très difficile, même pour des spécialistes
expérimentés. L'utilisation de techniques informatiques et
d'algorithmes peut être d'une grande aide.

Figure 30. Échantillon des
lésions bénignes et malignes de la base des
images
dermoscopiques PH2.
Kasmi et al., ont proposé d'automatiser la règle
ABCD afin de discriminer les tumeurs malignes des tumeurs bénignes. Une
étape de prétraitement est utilisée pour éliminer
les artefacts (bulles et poils fins) à l'aide d'un filtre médian.
Les poils épais sont détectés en utilisant des filtres de
Gabor avec différentes fréquences et orientations. Ensuite, les
lésions sont segmentées par la méthode des contours actifs
géodésiques (GAC). Enfin, les valeurs de A, B, C et D sont
estimées par différents algorithmes et le Total Dermoscopic Score
(TDS) est calculé. Testé sur 200 images dermoscopiques,
l'algorithme atteint un taux de sensibilité de 91,25%, une
précision de 95,83% et une exactitude de 94,0%.
Jaworek et al., ont utilisé la forme et la texture de
la lésion pour détecter le mélanome à son stade
précoce avec un classificateur SVM. La méthode proposée
contient les étapes suivantes : l'étape du prétraitement
qui comprend l'élimination du cadre noir, le lissage des bulles d'air et
la suppression des poils noirs en utilisant un filtre gaussien et les
opérations morphologiques. Ensuite, une segmentation des lésions
basée sur l'algorithme de croissance de régions est
utilisée. L'extraction des caractéristiques est basée sur
les deux techniques, la règle ABCD pour la forme et 7-points checklist
pour la texture. Ils ont utilisé un ensemble de 200 images et ont obtenu
une sensibilité de 90%, une spécificité de 96% et une aire
sous la courbe de 93,24%.
Dans l'article de Barata et al., un ensemble de
caractéristiques est utilisé. L'étude compare le poids des
descripteurs de couleur (moments et histogrammes) et de texture (Gabor et Laws)
pour le mélanome. Les résultats montrent que les
P a g e | 53
descripteurs de couleur fonctionnent mieux que les
descripteurs de texture et que de bons résultats de classification
peuvent être obtenus en utilisant SVM, avec une sensibilité de 93%
et une spécificité de 88% sur un ensemble de données de
176 images dermoscopiques. La fusion des descripteurs de couleur et de texture
a également obtenu de bons résultats, avec une sensibilité
de 96%, spécificité de 82% pour la combinaison des moments avec
les descripteurs de texture Gabor et Laws.
Alfed et al., combinent la texture (histogramme des gradients,
histogramme des lignes) avec les angles des vecteurs de couleur et les moments
de Zernike comme caractéristiques pour classer les mélanomes des
lésions bénignes de l'ensemble de données PH2. En
utilisant trois classificateurs : SVM, Adaboost et ANN, la méthode
atteint une sensibilité de 99,41%, une spécificité de
98,18% et une précision de 98,79%.
Majumder et al., ont utilisé un réseau neuronal
à rétropropagation (BNN) basé sur les
caractéristiques de la règle ABCD pour classer les
mélanomes et les tumeurs bénignes dans l'ensemble de
données PH2. Ils ont développé cinq
caractéristiques pour classer les mélanomes malins et
bénins. Ces caractéristiques sont le score d'asymétrie
(AS), l'irrégularité des bords (B), la variation des couleurs
(C), le diamètre (D1) et la différence entre les diamètres
de Feret maximum et minimum de l'ellipse la mieux adaptée à la
lésion (D2). La technique proposée atteint une précision
de 98%, une sensibilité de 95% et une spécificité de
98,8%.
Hagerty et al., mélangent les caractéristiques
classiques et d'apprentissage profond après les avoir
évaluées individuellement. D'une part, les trois
caractéristiques classiques sont d'inspiration biologique et
d'information clinique : réseau de pigments atypiques, distribution des
couleurs et vaisseaux sanguins. Les informations cliniques comprennent les
informations soumises au pathologiste - âge du patient, sexe, emplacement
de la lésion, taille et antécédents du patient. Les
caractéristiques d'apprentissage profond utilisent le transfert de
connaissances par l'intermédiaire d'un réseau ResNet-50 qui est
reconverti pour prédire la probabilité de classification du
mélanome. Les scores de classification de chaque caractéristique
individuelle, classique et d'apprentissage profond, sont ensuite
assemblés à l'aide de la régression logistique pour
prédire une probabilité globale des mélanomes. Les
résultats de classification des mélanomes effectuée sur un
ensemble de données HAM10000 comprenant 9174 lésions,
mesurés par l'aire sous la courbe (AUC), montrent l'efficacité
des caractéristiques de fusion en obtenant une précision de
classification de 0,94.
Moura et al., utilisent la règle ABCD et des
caractéristiques de réseaux neuronaux convolutionnels
pré-entraînés CNN : Vgg-m, Vgg-f, Vgg-verydeep-19 et
CaffeNet. A partir du masque binaire, fourni par la base de données
utilisée, la lésion cutanée est segmentée. Les
images originales RGB sont converties dans l'espace couleur HSV. Ensuite, les
caractéristiques sont extraites par les descripteurs de la
P a g e | 54
composante générée par la somme des plans
S et V, puis les descripteurs les plus pertinents sont choisis. Enfin, un
classificateur Perceptron multicouche est utilisé pour distinguer le
mélanome des lésions bénignes. La méthode
proposée a été testée sur les deux bases de
données PH2 et DermIS. La méthode a présenté de
bons résultats avec un taux de précision de 94,9% et un indice de
Kappa de 89,2%.
Hirano et al., ont développé un système
de diagnostic automatisé pour l'identification du mélanome en
utilisant des données hyperspectrales (HSD) et GoogLeNet. Le GoogLeNet
préformé, est utilisé pour alimenter le HSD, ils ont
ajouté un nouveau réseau, appelé "Mini Network", qui
effectue une réduction de taille juste avant la couche d'entrée
de GoogLeNet. Les travaux ont utilisé 619 lésions pour
l'entraînement et les tests. L'évaluation sur 5 validations
croisées indique que sans augmentation des données, la
sensibilité, la spécificité et la précision sont
respectivement de 69.1%, 75.7% et 72.7%. Et avec l'augmentation des
données, la sensibilité, la spécificité et la
précision sont respectivement de 72.3%, 81.2% et 77.2%.
La méthode de classification du mélanome
proposée par Jojoa Acosta et al., se compose de deux étapes :
tout d'abord, la région d'intérêt est
délimitée à l'aide de la technique du masque et du
réseau neuronal convolutif basé sur la région, puis un
classificateur basé sur la structure ResNet152 est utilisé pour
distinguer les lésions malignes. La méthode est
évaluée sur l'ensemble de données ISIC 2017 et atteint une
précision de 90,4%, une sensibilité de 82% et une
spécificité de 92,5%.
Fekrache et al., ont proposé un système
automatisé qui utilise un algorithme de segmentation basé sur les
colonies de fourmis, puis trois types de caractéristiques sont extraits,
basées sur les propriétés géométriques de la
lésion telles que décrites par la règle ABCD, les
caractéristiques de textures calculant des caractéristiques
basées sur l'histogramme du premier ordre, et la couleur relative. 112
caractéristiques sont extraites et 12 attributs pertinents sont
sélectionnés à l'aide de l'algorithme Relief. Deux
classificateurs sont utilisés, le KNN et ANN. Le système
proposé est testé sur 172 images dermoscopiques et atteint une
précision de 85.22% et 93.60% avec KNN et ANN respectivement.
P a g e | 55
Conclusion partielle.
Ce chapitre a été consacré
essentiellement à la présentation des différentes
méthodes existantes dans la littérature relative aux processus de
segmentation et de classification des images dermoscopiques. Comme
mentionné le long de ce chapitre, la segmentation se présente
sous différentes approches et est utilisée sous
différentes manières.
En premier lieu, nous avons présenté un
état de l'art sur les méthodes de segmentation et de
classification des images dermoscopiques, en vue de comprendre leurs concepts,
leurs principes d'utilisation et leurs applications. Nous avons d'abord
présenté une définition du mélanome et des
systèmes du diagnostic assisté par ordinateur et ses
différents éléments constitutifs pour la détection
du mélanome. Ensuite, nous avons dressé un aperçu sur les
approches de segmentation utilisées pour les images dermoscopiques.
Suivie d'une présentation des méthodes de classification des
mélanomes.
Etant atteints, les objectifs fixés pour ce chapitre,
dans le chapitre suivant, nous allons présenter
l'implémentation de l'approche
proposée, afin de montrer son efficacité, et
d'interpréter les résultats.
P a g e | 56
Chapitre quatrième : Implémentation &
interprétation des
résultats.
4.1. Introduction.
La détection des mélanomes à un stade
précoce est la meilleure façon de diminuer le taux de
mortalité des personnes atteintes par cette maladie. En effet, ce type
de cancer de peau se présente comme des lésions, qui apparaissent
sur la peau sous différentes et complexes formes, couleurs et textures.
C'est pourquoi les tumeurs malignes peuvent être confondues avec les
tumeurs bénignes et rend le diagnostic très difficile pour les
dermatologues. D'où l'intérêt d'utiliser des techniques
d'apprentissage automatique pour améliorer la précision du
diagnostic du mélanome et réduire son incidence
élevée.
Ce chapitre s`attèlera à la présentation
des outils utilisés, la description du simulateur
implémenté, la mise en oeuvre d'un cas pratique pour tester notre
modèle et une interprétation des résultats de l`approche
proposée. Il est divisé en quatre parties principales :
V' La première partie décrit les outils
utilisés et les détails d'implémentation de l'approche
proposée,
V' La deuxième partie présente un cas pratique
pour tester le
modèle.
V' La troisième partie représente une
exploitation du modèle proposé dans un API11 Flask
afin de gérer des nouveaux cas.
4.2. Les outils et les détails
d'implémentation.
Pour évaluer et tester les performances de l'approche
proposée, nous devrons d'abord passer par l'étape de
l'implémentation. Dans cette section, nous décrivons les
différents outils, et les langages de programmation utilisés.
4.2.1. Environnement de développement.
Pour implémenter l'approche
PrediCancerPeau, nous avons choisi Jupyter (Voir Figure 31) et
spider (Voir Figure 32) comme des environnements de développement, avec
utilisation des bibliothèques Flask (Voir Figure 33), TensorFlow et
Keras.
11 API : (Application
Programme Interface), est une interface logicielle permettant de connecter un
logiciel ou service à un autre logiciel ou service afin
d'échangé les données.
P a g e | 57
4.2.1.1. Jupyter Notebook.
Jupyter Notebook est une application Web Open Source
permettant de créer et de partager des documents contenant du code
(exécutable directement dans le document), des équations, des
images et du texte. Avec cette application il est possible de faire du
traitement de données, de la modélisation statistique, de la
visualisation de données, du Machine Learning, etc. Elle est disponible
par défaut dans la distribution Anaconda. Il est développé
par « Fernando Pérez » en 2014 et prend en charge plus de 40
langages de programmation, dont Python, R, Julia et Scala.
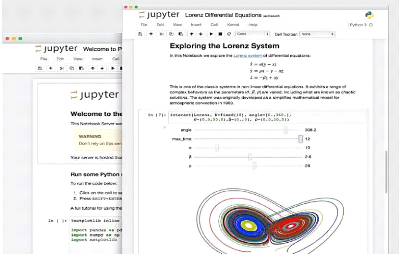
Figure 31. Interface de Jupyter
Notebook (source Jupyter) 4.2.1.2.
Spyder.
Spyder est Créé et il est
développé par « Pierre Raybaut » en 2008,
c'est est un environnement scientifique puissant écrit en Python, et il
est conçu par et pour les scientifiques, les ingénieurs, et les
analystes de données (Spyder Website Contributors, 2018).
Spyder offre une combinaison unique de la
fonctionnalité d'édition avancée, d'analyse, de
débogage et de profilage d'un outil de développement complet,
avec l'exploration des données, l'exécution interactive,
l'inspection approfondie, et de belles capacités de visualisation d'un
paquet scientifique (Spyder Website Contributors, 2018).
P a g e | 58

Figure 32. Logo de l'IDE Spyder.
4.2.1.3. Flask.
Flask est un Framework de développement des
applications Web en Python, il garde la souplesse de la programmation en Python
à cause de sa légèreté et ne soumet le
développeur à aucune restriction, il appartient au
développeur de choisir les outils et les bibliothèques qu'il
souhaite utiliser (The Pallets Projects, 2010).

Figure 33. Logo de Framework FLASK
4.2.1.4. TensorFlow.
TensorFlow est un framework de programmation pour le calcul
numérique qui a été rendu Open Source par Google en
Novembre 2015. Depuis sa release, TensorFlow n'a cessé de gagner en
popularité, pour devenir très rapidement l'un des Frameworks les
plus utilisés pour le Deep Learning, comme le montrent les
dernières comparaisons suivantes, faites par François Chollet
(auteur de la librairie Keras). Nous en entendons beaucoup parler ces derniers
temps, et pour cause, TensorFlow est devenu en un temps record l'un des
Frameworks de référence pour le Deep Learning, utilisé
aussi bien dans la recherche qu'en entreprise pour des applications en
production. Au-delà de la hype présente autour de ce Framework et
des projets qui émergent grâce à ce dernier, il reste un
gap non négligeable à atteindre afin de l'utiliser pleinement et
efficacement.
P a g e | 59
Voici quelques raisons de sa popularité :
V' Multiplateformes (Linux, Mac OS, et même Android et iOS
!) ;
V' APIs en Python, C++, Java et Go (l'API Python est plus
complète cependant, c'est sur celle-ci que nous allons travailler) ;
V' Temps de compilation très courts dû au backend en
C/C++ ;
V' Supporte les calculs sur CPU, GPU et même le calcul
distribué sur cluster ; V' Une documentation extrêmement bien
fournie avec de nombreux exemples et tutoriels ;
V' Last but not least : Le fait que le Framework vienne de
Google et que ce dernier ait annoncé avoir migré la
quasi-totalité de ses projets liés au Deep Learning en TensorFlow
est quelque peu rassurant.
Bien qu'il ait initialement été
développé pour optimiser les calculs numériques complexes,
TensorFlow est aujourd'hui particulièrement utilisé
pour le Deep Learning, et donc les réseaux de neurones.
Son nom est notamment inspiré du fait que les opérations
courantes sur des réseaux de neurones sont principalement faites via des
tables de données multidimensionnelles, appelées Tenseurs
(Tensor). Un Tensor à deux dimensions est l'équivalent d'une
matrice.
4.2.1.5. Keras.
Keras est une bibliothèque open source de Deep Learning
permettant la génération de réseaux de neurones
artificiels. Elle permet une expérimentation efficace de ces derniers de
par sa simple utilisation et ses nombreuses possibilités de
déploiement grâce à son intégration avec la
librairie tensorFlow.
Keras est conçu pour être intuitif, modulaire,
facile à étendre, et pour fonctionner avec Python. Selon ses
créateurs, cette API est » conçue pour les êtres
humains, et non pour les machines » et » suit les meilleures
pratiques pour réduire la charge cognitive «. Il a
été développé dans le cadre de l'effort de
recherche du projet ONEIROS (Open-ended Neuro-Electronic Intelligent Robot
Operating System), et son principal auteur et mainteneur est François
Chollet, un ingénieur Google.
Chollet a expliqué que Keras a été
conçue comme une interface plutôt que comme un cadre
d'apprentissage end to end. Il présente un ensemble d'abstractions de
niveau supérieur et plus intuitif qui facilitent la configuration des
réseaux neuronaux indépendamment de la bibliothèque
informatique de backend. Microsoft travaille également à ajouter
un backend CNTK à Keras aussi.
P a g e | 60
4.2.1.6. NumPy.
Numpy est une bibliothèque python très populaire
pour le traitement de matrices et fonctions mathématiques de haut
niveau. C'est très utile pour les calculs scientifiques fondamentaux en
Machine Learning. Il est particulièrement utile pour l'algèbre
linéaire, la transformée de Fourier et les capacités de
nombres aléatoires. Les bibliothèques haut de gamme telles que
TensorFlow utilisent NumPy en interne pour la manipulation de Tensors.
4.2.1.7. Pandas.
Pandas est une bibliothèque Python populaire pour
l'analyse de données. Ce n'est pas directement lié à
l'apprentissage automatique. Comme nous savons que le jeu de données
doit être préparé avant la formation. Dans ce cas, les
pandas sont pratiques car ils ont été développés
spécifiquement pour l'extraction et la préparation de
données. Il fournit des structures de données de haut niveau et
de nombreux outils pour l'analyse des données. Il fournit de nombreuses
méthodes intégrées pour tâtonner, combiner et
filtrer les données.
4.2.1.8. Matpoltli.
Matpoltli est une bibliothèque Python très
populaire pour la visualisation de données. Comme les pandas, il n'est
pas directement lié à l'apprentissage automatique. Cela
s'avère particulièrement utile lorsqu'un programmeur souhaite
visualiser les modèles dans les données. C'est une
bibliothèque de tracé 2D utilisée pour créer des
graphiques et des tracés 2D. Un module appelé pyplot facilite le
traçage des programmeurs car il offre des fonctionnalités
permettant de contrôler les styles de trait, les propriétés
de police, les axes de formatage, etc. Il fournit différents types de
graphiques et de tracés pour la visualisation des données,
l'affichage, l'histogramme, les graphiques d'erreur, les discussions en barres.
, etc.
4.2.2. Langage de programmation.
De nos jours, il existe plusieurs langages de programmation et
chaque langage possède ses propres caractéristiques. Parmi ses
langages, notre choix s'est focalisé sur Python.
4.2.2.1. Python.
Il est l'un des langages de programmation les plus
intéressants du moment, il est inventé par « Guido van
Rossum », la première version de python est sortie en 1991.
C'est est un langage de programmation interprété, multi paradigme
et
P a g e | 61
multiplateformes. Il favorise la programmation
impérative structurée, fonctionnelle et orientée objet
(python.doctor, 2019). Python est à la fois simple et puissant, il
permet d'écrire des scripts très simples, et grâce à
ses nombreuses bibliothèques, nous pouvons travailler sur des projets
plus ambitieux (python.doctor, 2019).
4.2.2.2. Pourquoi Python ?
Python est un langage stable, flexible et il fournit divers
outils pour les développeurs. Ce qui permet de le classer en premier
choix pour l'apprentissage automatique, à partir du
développement, la mise en oeuvre, et la maintenance. Python aide les
développeurs de développer des produits confiants (Gupta, 2019).
Selon Gupta, Python possède de nombreux avantages:
? Simple et cohérent : la
simplicité de Python aide les développeurs à gérer
l'algorithme complexe de l'apprentissage automatique.
? La flexibilité : Le facteur de
flexibilité réduit la possibilité d'erreurs, il a
laissé les programmeurs prendre le contrôle complètement,
et de travailler sur elle confortablement.
? Bibliothèques et Framework : Les
algorithmes de l'apprentissage automatique sont très complexes, mais
Python est le secours avec une large gamme de bibliothèques comme
Scikit-learn, Keras et de Framework, à titre d'exemple TensorFlow.
? Lisibilité : Python est facile
à lire, de sorte que les développeurs peuvent facilement
comprendre le code.
? Indépendance de la plateforme :
Python est un langage indépendant de la plate-forme. Il est
supporté par de nombreuses plateformes, y compris Windows, LINUX et
macOS.
4.3. Présentation du problème.
Nous présentons dans cette section, un cas pratique
pour tester notre modèle, pour se faire une bonne idée sur
l'architecture que nous avons choisie compte tenu de ses avantages dans le
chapitre 2 dudit travail, nous essayerons de présenter les
résultats en utilisant le CNN avec nos jeux de données. Le
domaine d'application choisi à l'issue de ce cas, c'est la santé,
où notre travail vise à construire un modèle
prédictif basé sur le réseau de neurones profond
à partir des images de gens soufrant du «
cancer de la peau » de type mélanome.
Les corps médicaux trouveront une grande importance
à notre système, car ce dernier va leur aider à prendre
des décisions relatives avec plus de précision (en tenant compte
de la faiblesse démographique des dermatologues), à partir de la
photographie des lésions précoce des mélanomes qui
apparaissent sur la peau sous
P a g e | 62
différentes et complexes formes, couleurs et textures,
afin d'améliorer la précision du diagnostic de ladite maladie et
réduire son incidence élevée.
4.3.1. Aperçu général sur le cancer
de la peau.
La peau est considérée comme l'organe humain le
plus important en terme de surface. Elle protège le corps des infections
et des rayonnements ultraviolets (UV). Elle facilite le contrôle de la
température corporelle et l'élimination des déchets
organiques par la transpiration. Elle sert également à
synthétiser la vitamine D et à stocker les réserves d'eau
et de graisse.
Elle peut aussi être atteint par un cancer. Il en existe
deux grands types dont : les carcinomes et les
mélanomes. Le nombre de nouveau cas de cancer de la peau a
d'ailleurs plus que triple entre 1980 et 2012. Ceci
peut s'expliquer par l'évolution des habitudes d'exposition aux
rayonnements UV solaires et artificiels au cours de 40 dernières
années, ces expositions constituent le facteur de risque le plus
important de développer ce type de cancer.

Figure 34. Différents types
des graines de beauté de mélanome.
Il existe par ailleurs, des mélanomes dits
achromiques, c'est-à-dire sans couleur. Ces
petites boules de la couleur de votre peau peuvent apparaitre sur les plantes
de main ou de pied, ils sont plus difficiles à détecter car ils
sont ton sur ton12 (semi - permanente) , mais restent heureusement
relativement rares.
12 Ton sur Ton : est une
couleur qui contient des agents oxydants, mais pas d'ammoniaque.
13 Data set (ou jeux de
données) : est un ensemble de données
cohérents qui peuvent se présenter sous différents formats
(textes, chiffres, images, vidéos, etc...).
P a g e | 63
4.3.2. Information sur les données.
Pour construire un modèle de machine Learning, il
faudrait disponibiliser les données dans le
dataset13. Nos données proviennent
de kaggle (Kaggle, 2022).
4.3.2.1. Description du Data-set.
Notre Data-set est constitué de 2 dossiers : Data-set
d'entraînement et de test et contient au total 3297 photos (224x244) du
cancer de la peau de type mélanome.
4.3.2.1.1. Data-set d'entraînement.
Le Data-set d'entraînement comporte deux sous dossiers
intitulés bénin et malin. Chacun d'eux correspond à une
classe de cancer de la peau du type mélanome et contient 2637 images de
grains de beauté par classe. Le Data-set d'entraînement constitue
la base sur laquelle le modèle doit être entrainé afin de
généraliser la solution et détecter le type de cancer de
la peau sur de futures images dérmatoscopie.
4.3.2.1.2. Data-set de test.
Pour vérifier la solution finale des
compétiteurs, un Data-set de test a été fourni par
l'organisation. Ce dossier contient 660 images de grains de beauté
appartenant aux différentes classes de cancer de la peau du type
mélanome, elles respectent la même définition et le
même format que les images du data-set d'entraînement.
4.3.3. Implémentation du cas en
Python.
4.3.3.1. Importation de bibliothèques
essentielles.

Figure 35. Importation
bibliothèques.
P a g e | 64
4.3.3.2. Chargement des données.


Figure 36. Chargement des
données à partir du Dataset. 4.3.3.3. Tracer
quelques exemples d'images.
Figure 37. Chargement des
données pour cas exemple. 4.3.3.4. Mise à
l'échelle des données.


Figure 38. Mise à
l'échelle des données.
P a g e | 65
4.3.3.5. Augmentation des données.
Info: Parce que notre train a un nombre
relativement faible d'images, nous pouvons appliquer l'augmentation des
données qui reproduit les images en appliquant certains changements tels
que la rotation aléatoire, le retournement aléatoire,
le zoom aléatoire et le contraste aléatoire. Cela
peut éventuellement augmenter le score de précision
du modèle. Puisque nous appliquerons l'augmentation de
données au début de l'architecture du réseau neuronal,
nous devrions passer la forme d'entrée.
L'augmentation des données sera inactive lors du test
des données. Les images d'entrée seront augmentées lors
des appels à model.fit (pas model.assess ou model.predict).
Figure 39. Augmentation des
données.
4.3.3.6. Création d'un modèle
d'apprentissage profond. 4.3.3.6.1. Définition d'un réseau de
neurones convolutif CNN

Figure 40. Implémentation
CNN.

P a g e | 66
Dans la figure n°40, nous avons
conçu un réseau de neurones convolutif avec 3 couches à
convolution suivie chacune par un max-pooling, d'une couche complétement
connectée de 128 neurones et d'une dernière couche de
classification d'un neurone.
4.3.3.7. Compilation du modèle.
Figure 41. Implémentation de
la compilation du modèle. 4.3.3.8. Entraînement du
modèle.

Figure 42. Entraînement de la
solution finale. 4.3.3.9. Résultats

P a i e | 67

Figure 43. Résultat de
l'entrainement du modèle.
4.3.3.10. Affichage de perte de données et de la
précision
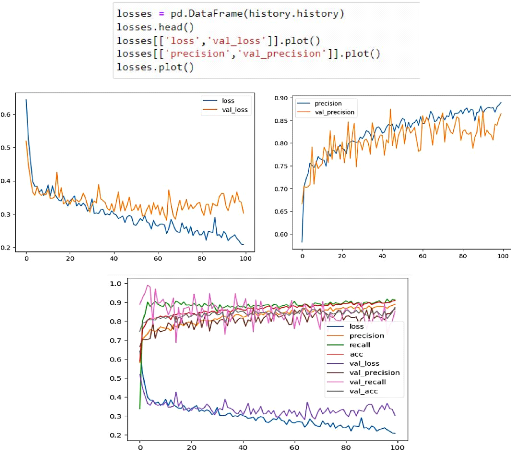
Figure 44. Perte et
précision de données.

P a i e | 68
4.3.3.11. Enregistrement de notre modèle CNN pour
son utilisation dans l'API
Figure 45. Enregistrement du
modèle (CNN). 4.3.3.12. Tests manuels
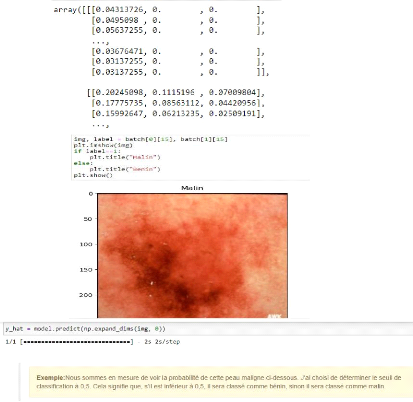


Figure 46. Résultats d'un
cas testé via le modèle.
P a g e | 69
4.3.3.13. Construction du module de prédiction
à partir de données test pour l'API.

Figure 47. Module de
prédiction pour l'API. 4.4. L'exploitation de modèle
(Déploiement).
Cette partie représente une exploitation du
modèle extrait de l'approche PrediCancerPeau. Nous avons
créé un API (Application Programme Interface) Voir Figure 41 afin
de gérer les inférances14 pour notre cas. Cette API
effectue des prédictions basées sur l'utilisation du
modèle d'apprentissage en profondeur extrait de notre approche
soulignée ci - haut afin de réaliser une prédiction
meilleure et moins chère du cancer de la peau de type mélanome
qu'un dermatologue.

Figure 48. Le logo de
l'API.
14 Terme utilisé en Machine
Learning pour désigner les nouvelles données qui n'ont pas servi
d'entrainé le modèle.
P a i e | 70
Figure 49. Démarrage de
l'API.
Figure 50. Interface graphique de
prédiction.
P a g e | 71
Le bouton "choisir une image" sert
à parcourir et visualiser le contenu des bases d'images d'apprentissage
et de test comme le montre la figure 4.4.
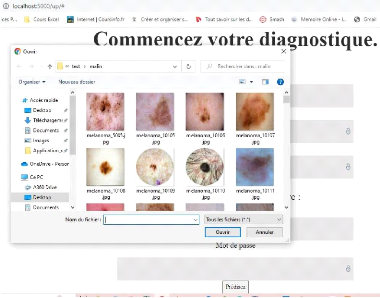
Figure 51. Exploration des
images.
Pour lancer l'apprentissage et la validation du modèle
sur la base d'apprentissage en profondeur pour les 2 classes de cancer de peau
du type mélanome (Bénin/Malin) en se basant sur le réseau
de neurone convolutif, il suffit de cliquer sur le bouton
"Prédisez".

Figure 52. Interface de
prédiction à l'état prêt.
P a g e | 72

Figure 53.
Résultat du diagnostic via l'API.
4.4.1. Quelques codes sources de déploiement de
l'API PrediCancerPeau avec Flask.
from flask import Flask, request, flash, redirect,
url_for,render_template
from flask import send_file
import os
import cv2
import numpy as np
from skimage.transform import resize
from tensorflow.keras.preprocessing.image import
ImageDataGenerator
from tensorflow import keras
from keras.models import Sequential, Model,load_model
from keras.layers import Conv2D, MaxPooling2D,
AveragePooling2D
from keras.layers import Activation, Dropout, Flatten,
Dense,MaxPool2D
from PIL import Image
from matplotlib.image import imread
app = Flask(import_name=__name__, template_folder='templates')
app.secret_key = '1234'
DOSSIER_UPS = '
C:/Users/hp/Desktop/L2 INFO
ALL/MEMOIRE/MEMOIRE ET APP OK SNR/APP CANCER RESEAUX DE
NEURONE/Application_web_Shanga/uploads/' chemin_predict='
C:/Users/hp/Desktop/L2 INFO
ALL/MEMOIRE/MEMOIRE ET APP OK SNR/APP CANCER RESEAUX DE NEURONE/'
def extension_ok(nomfic):
""" Renvoie True si le fichier possède une extension
d'image valide. """
return '.' in nomfic and nomfic.rsplit('.', 1)[1] in
('png','jpg', 'jpeg', 'gif', 'bmp','PNG')
P a i e | 73
@app.route('/up/', methods=['GET', 'POST'])
def upload():
image=""
if request.method == 'POST':
if request.form.get("pw","") == "1234": # on vérifie que
le
mot depasse est bon
f = request.files['fic']
if f: # on vérifie qu'un fichier a bien été
envoyé
if extension_ok(f.filename): # on vérifie que son
extension est valide
nom = f.filename
i="'"+nom+"'"
image=DOSSIER_UPS + nom
f.save(image)
flash(u'Résultat de la prediction
!'.format(lien=url_for('upped',nom=nom)),'succes')
flash(u'<img
src="{lien}">.'.format(lien=url_for('upped',nom=nom)),'succes')
#debut de la prediction
flash(prediction(image),'succes')
return render_template('up_up.html',image=i)
else:
flash(u'Ce fichier ne porte pas une extension
autorisée !', 'error')
else:
flash(u'Vous avez oublié le fichier !', 'error')
else:
flash(u'Mot de passe incorrect', 'error')
return render_template('up_up.html',image=image)
@app.route('/up/view/')
def liste_upped():
images = [img for img in os.listdir(DOSSIER_UPS) if
extension_ok(img)] # la liste des images dans le dossier return
render_template('up_liste.html', images=images)
@app.route('/up/view/<nom>')
def upped(nom):
nom = nom
if os.path.isfile(DOSSIER_UPS + nom): # si le fichier existe
return send_file(DOSSIER_UPS + nom, as_attachment=True) #on l'envoie
else:
flash(u'Fichier {nom} inexistant.'.format(nom=nom),'error')
return redirect(url_for('liste_upped')) # sinon on redirige vers la liste des
images, avec un message d'erreur
def prediction(image):
class_dict = {0:'benin',1:'malin'}
test_image=Image.open(image)
P a g e | 74
test_image=test_image.resize((256,256))
'chargement du model'
model=load_model(chemin_predict+"CancerPeau1_model.h5")
test_image = np.expand_dims(test_image, 0)
probs = model.predict(test_image)
pred_class = np.argmax(probs)
pred_class = class_dict[pred_class]
return pred_class
@app.route('/up/liste/') def liste():
return render_template('up_cancer.html')
if__name__ == '__main__': app.run(debug=True)
Conclusion partielle.
Dans ce chapitre, nous avons présenté le
problème que nous avons résolu, les différents outils et
techniques qui nous ont permis à sa réalisation. Et avons aussi,
présenté en détail les ressources matérielles et
logiciels utilisées dans le cadre du développement de notre
solution, nommée PrédiCancerPeau.
Nous avons clôturé le chapitre par le
déploiement de notre modèle de Deep Learning dans un API Flask,
en présentant succinctement les différentes étapes
d'exécution et le résultat obtenu par chacune étape. Nous
avons essayé de simplifier le processus d'exécution par
l'utilisation des imprimés d'écran.
Etant atteints, les objectifs fixés pour ce chapitre,
nous aborderons dans le point suivant la conclusion générale de
notre travail.
P a g e | 75
CONCLUSION GENERALE
Dans ce mémoire, nous nous sommes
intéressés à la construction d'un modèle de deep
learning basé sur le réseau de neurones à convolution pour
la détection précoce du cancer de la peau à partir des
images d'une tumeur bénigne des gens qui souffrent du mélanome.
Ce modèle a pour but d'aider les corps médicaux, de diagnostiquer
avec un taux d'erreur minimal possible les patients à partir de la
photographie de ladite maladie et ce diagnostic peut se faire via l'API ou en
batch pour une prise en charge rapide et à moindre coût ; bien
qu'il y a carence criante des experts dans ce domaine. D'après les
statistiques de l'OMS, près d'un décès sur 6 dans le monde
est dû au cancer de la peau, c'est ce qui fais de lui la deuxième
cause de décès. Cependant, le diagnostiquer à temps, enfin
de disposer l'arsenal médical pour le prévenir et
l'équilibré a une grande importance pour sauver des vies.
D'où l'intérêt d'utiliser des techniques d'apprentissage
automatique pour améliorer la précision du diagnostic du
mélanome et réduire son incidence élevée.
En tenant compte de la faiblesse démographique des
spécialistes dans ce domaine, c'est - à - dire les dermatologues
et les chirurgiens et aussi vu l'accroissement de nombre de cas de patients qui
pourrons atteindre 22 millions au cours de deux prochains décennies
(WHON, 2018), notre système tentera de diagnostiquer sur l'état
d'un patient juste à partir des images d'une tumeur bénigne.
Vue l'ampleur de réseau de neurones artificiels,
particulièrement réseau de neurones à convolution à
traiter une quantité importante des données, surtout l'effet de
prendre en compte la corrélation entre les pixels d'une image et aussi
d'être invariant à des transformations de l'entrée, ces
derniers permettent d'augmenter aussi la précision.
Comme nous, les humains pour avoir la facilité de
reconnaitre une image, nous avons également besoin de voir beaucoup plus
d'images et surtout la variété des images, enfin
d'appréhender ce qui différencie telle chose à l'autre.
C'est de la même manière avec les modèles, sur ce, nous
avons utilisé l'apprentissage supervisé, c'est-à-dire,
nous avons fortement entrainé notre modèle avec 2.637 images de
grains de beauté bénins et malins, ce qui nous a permis
d'atteindre le score de 86,4 % en terme de précision notre
modèle.
Enfin, ce travail présente un aperçu
général sur le machine Learning et en particulier sur le deep
Learning, qui est un domaine de recherche très actif et
intéressant dont les entreprises publiques et privées, ne font
que mettre les moyens pour trouver des solutions aux problèmes de la
société, toutes les remarques et suggestions sont les
bienvenues.
P a g e | 76
Bibliographies :
[1]. Adeyinka A. A. and Viriri S., "Skin lesion images
segmentation: A survey of the stateof-the-art," in International conference on
mining intelligence and knowledge exploration, 2018, pp. 321-330.
[2]. Agarwal A., Issac A., Dutta M. K., Riha K., and Uher V.,
"Automated skin lesion segmentation using K-means clustering from digital
dermoscopic images," in 2017 40th International Conference on
Telecommunications and Signal Processing (TSP), 2017, pp. 743-748.
[3]. Alfed N. and Khelifi, F. "Bagged textural and color
features for melanoma skin cancer detection in dermoscopic and standard
images," Expert Systems with Applications, vol. 90, pp. 101-110, 2017.
[4]. Alvarez D. and Iglesias M., "k-Means clustering and
ensemble of regressions: an algorithm for the ISIC 2017 skin lesion
segmentation challenge," arXiv preprint arXiv : 1702.07333, 2017.
[5]. Argenziano G., Catricalà C., Ardigo M., Buccini
P., De Simone P., Eibenschutz L., Ferrari A., Mariani G., Silipo V., and
Sperduti I. "Seven-point checklist of dermoscopy revisited," British Journal of
Dermatology, vol. 164, pp. 785-790, 2011.
[6]. Aston Zhang, Zachary C. Lipton, Mu Li, and Alexander J.
Smola. Dive into Deep Learning. Aug 11, 2020 Release 0.14.3.
[7]. Barata C., Ruela M., Mendonça T., and Marques, J.
S. "A bag-of-features approach for the classification of melanomas in
dermoscopy images: The role of color and texture descriptors," in Computer
vision techniques for the diagnosis of skin cancer, ed: Springer, 2014, pp.
49-69.
[8]. Bezdek J. C., "A convergence theorem for the fuzzy
ISODATA clustering algorithms," IEEE transactions on pattern analysis and
machine intelligence, pp. 1-8, 1980.
[9]. Chapman, P., Clinton, J., Kerber, R., Reinartz, T.,
Shaerer, C., & Wirth, R. (2000). CRISP-DM 1.0 Step by-step data mining
guide. The CRISP-DM consortium.
[10]. Cheng T. W., Goldgof D. B., and Hall L. O., "Fast fuzzy
clustering," Fuzzy sets and systems, vol. 93, pp. 49-56, 1998.
[11]. Dalila F., Zohra A., Reda K., and Hocine, C.
"Segmentation and classification of melanoma and benign skin lesions," Optik,
vol. 140, pp. 749-761, 2017
[12]. Eltayef K., Li Y., and Liu X., "Detection of melanoma
skin cancer in dermoscopy images," in Journal of Physics: Conference Series,
2017, p. 012034.
[13]. Garcia-Arroyo J. L. and Garcia-Zapirain B.,
"Segmentation of skin lesions in dermoscopy images using fuzzy classification
of pixels and histogram thresholding," Computer methods and programs in
biomedicine, vol. 168, pp. 11-19, 2019.
[14]. Gashler, M., Giraud-Carrier, C., & Martinez, T.
(2008). Decision tree ensemble: Small heterogeneous is better than large
homogeneous. Seventh
P a g e | 77
International Conference on Machine Learning and Applications
(pp. 900-905). IEEE.
[15]. Géron A., (2017).
Hands-On_Machine_Learning_with_Scikit-learn and trensflow. USA: O'Reilly
Media.
[16]. Goodfellow, I., Bengio, Y., & Courville, A. (2016).
Deep Learning. MIT Press.
[17]. Hagerty J. R., Stanley R. J., Almubarak H. A., Lama N.,
Kasmi R., Guo P., Drugge R. J., Rabinovitz H. S., Oliviero M., and Stoecker, W.
V. "Deep learning and handcrafted method fusion: higher diagnostic accuracy for
melanoma dermoscopy images," IEEE journal of biomedical and health informatics,
vol. 23, pp. 1385-1391, 2019.
[18]. Hartinger, A. "Détection du cancer de la peau
par tomographie d'impédance électrique,"École
Polytechnique de Montréal, 2012.
[19]. Henning J. S., Dusza S. W., Wang S. Q., Marghoob A. A.,
Rabinovitz H. S., Polsky D., and Kopf A. W. "The CASH (color, architecture,
symmetry, and homogeneity) algorithm for dermoscopy," Journal of the American
Academy of Dermatology, vol. 56, pp. 45-52, 2007.
[20]. Hirano G., Nemoto M., Kimura Y., Kiyohara Y., Koga H.,
Yamazaki N., Christensen G., Ingvar C., Nielsen K., and Nakamura, A. "Automatic
diagnosis of melanoma using hyperspectral data and GoogLeNet," Skin Research
and Technology, vol. 26, pp. 891-897, 2020.
[21]. Ioffe S. and Szegedy, C. "Batch normalization:
Accelerating deep network training by reducing internal covariate shift," in
International conference on machine learning, 2015, pp. 448-456.
[22]. Jaisakthi S. M., Mirunalini P., and Aravindan C.,
"Automated skin lesion segmentation of dermoscopic images using GrabCut and
k-means algorithms," IET Computer Vision, vol. 12, pp. 1088-1095, 2018.
[23]. Jaworek-Korjakowska J., "Computer-aided diagnosis of
micro-malignant melanoma lesions applying support vector machines," BioMed
research international, vol. 2016, 2016.
[24]. Jay Kuo, C.-C. University of Southern California, Los
Angeles Understanding Convolutional Neural Networks with A Mathematical Model.
02/09/2016.
[25]. Jojoa Acosta M. F., Caballero Tovar L. Y.,
Garcia-Zapirain M. B., and Percybrooks, W. S. "Melanoma diagnosis using deep
learning techniques on dermatoscopic images," BMC Medical Imaging, vol. 21, pp.
1-11, 2021.
[26]. Kasmi R. and Mokrani, K. "Classification of malignant
melanoma and benign skin lesions: implementation of automatic ABCD rule," IET
Image Processing, vol. 10, pp. 448-455, 2016.
[27]. Kingma D. P. and Ba, J. "Adam: A method for stochastic
optimization," arXiv preprint arXiv : 1412.6980, 2014.
[28]. Lin B. S., Michael K., Kalra S., and Tizhoosh, H. R.
"Skin lesion segmentation: U-nets versus clustering," in 2017 IEEE Symposium
Series on Computational Intelligence (SSCI), 2017, pp. 1-7.
[29]. MacQueen J., "Some methods for classification and
analysis of multivariate observations," in Proceedings of the fifth Berkeley
symposium on mathematical statistics and probability, 1967, pp. 281-297.
P a g e | 78
[30]. Majumder S. and Ullah, M. A. "Feature extraction from
dermoscopy images for an effective diagnosis of melanoma skin cancer," in 2018
10th International Conference on Electrical and Computer Engineering (ICECE),
2018, pp. 185188.
[31]. Masood A. and Al-Jumaily A. A., "Fuzzy C mean
thresholding based level set for automated segmentation of skin lesions,"
Journal of signal and information processing, vol. 4, p. 66, 2013.
[32]. Mitchell, T. M. (1997). Machine Learning.
McGraw-Hil.
[33]. Moura N., Veras R., Aires K., Machado V., Silva R.,
Araújo F., and Claro, M. "ABCD rule and pre-trained CNNs for melanoma
diagnosis," Multimedia Tools and Applications, vol. 78, pp. 6869-6888, 2019.
[34]. Nachbar F., Stolz W., Merkle T., Cognetta A. B., Vogt
T., Landthaler M., Bilek P., Braun-Falco O., and Plewig G., "The ABCD rule of
dermatoscopy: high prospective value in the diagnosis of doubtful melanocytic
skin lesions," Journal of the American Academy of Dermatology, vol. 30, pp.
551-559, 1994.
[35]. Nachbar F., Stolz W., Merkle T., Cognetta A. B., Vogt,
M. Landthaler T., Bilek P., Braun-Falco O., and Plewig G. "The ABCD rule of
dermatoscopy: high prospective value in the diagnosis of doubtful melanocytic
skin lesions," Journal of the American Academy of Dermatology, vol. 30, pp.
551-559, 1994.
[36]. Nguyên HOANG, La formule du savoir, juin 2018.
[37]. Oliveira R. B., Mercedes Filho E., Ma Z., Papa J. P.,
Pereira A. S., and Tavares J. M. R., "Computational methods for the image
segmentation of pigmented skin lesions: a review," Computer methods and
programs in biomedicine, vol. 131, pp. 127-141, 2016.
[38]. Patterson J., & Gibson A. (2017). Deep Learning: A
Practitioner's Approach. Beijing: OReilly Media.
[39]. Rosenblatt, F. (1958). THE PERCEPTRON: A PROBABILISTIC
MODEL FOR. Psychological Review, 65.
[40]. Rother C., Kolmogorov V., and Blake A., "" GrabCut"
interactive foreground extraction using iterated graph cuts," ACM transactions
on graphics (TOG), vol. 23, pp. 309-314, 2004.
[41]. Schmidhuber, J. (2015). Deep Learning. Scholarpedia,
10, 32832.
[42]. Sung H., Ferlay J., Siegel R. L., Laversanne M.,
Soerjomataram I., Jemal A., and Bray F. "Global cancer statistics 2020:
GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185
countries," CA: a cancer journal for clinicians, vol.71, pp. 209-249, 2021.
[43]. Sutton, R. S. (1988). Learning to predict by the method
of temporal differences. Machine Learning.
[44]. Szilagyi L., Benyo Z., Szilágyi S. M., and Adam
H., "MR brain image segmentation using an enhanced fuzzy c-means algorithm," in
Proceedings of the 25th annual international conference of the IEEE engineering
in medicine and biology society (IEEE Cat. No. 03CH37439), 2003, pp.
724-726.
[45]. Watkins, C. J., & Dayan, P. (1992). Q-learning.
Machine Learning.
P a g e | 79
[46]. Yang X., Zeng Z., Yeo S. Y., Tan C., Tey H. L., and Su,
Y. "A novel multi-task deep learning model for skin lesion segmentation and
classification," arXiv preprint arXiv : 1703.01025, 2017.
[47]. Yu L., Chen H., Dou Q., Qin J., and Heng, P.-A.
"Automated melanoma recognition in dermoscopy images via very deep residual
networks," IEEE transactions on medicalimaging, vol. 36, pp. 994-1004, 2016.
[48]. Yuan Y., Chao M., and Lo, Y.-C. "Automatic skin lesion
segmentation using deep fully convolutional networks with jaccard distance,"
IEEE transactions on medical imaging,vol. 36, pp. 1876-1886, 2017.
[49]. Zhang X., "Melanoma segmentation based on deep
learning," Computer assisted surgery, vol. 22, pp. 267-277, 2017.
Webographie :
[1]. Bremme, L. (2015). Définition : Qu'est-ce que le
Big Data. Retrieved Mai 18, 2020, from lebigdata:
https://www.lebigdata.fr/definition-big-data
[2]. Cayla, B. (2018). La star des algorithmes de ML :
XGBoost. Retrieved 05 18, 2021, from datacorner:
https://www.datacorner.fr/xgboost/
[3]. Claw, S. (2020). Python. Retrieved 07 19, 2021, from
TkInter:
https://wiki.python.org/moin/TkInter
[4]. Clayton R., (2019). Qu'est-ce que le machine learning ?
Retrieved Novembre 08, 2022, from Oracle Algeria:
https://www.oracle.com/dz/artificial-intelligence/what-is-machine
learning.html
[5]. Dave, A. (2020). Regression in Machine Learning.
Retrieved 19 10,2021,
from Medium:
https://medium.com/datadriveninvestor/regression-in-
machine-learning-296caae933ec
[6]. Dupré, X. (2020). La classification. Retrieved 19
10,2021 from Xavierdupre:
http://www.xavierdupre.fr/app/mlstatpy/helpsphinx/c_ml/rn/rn_
3_clas.html
[7]. GAËL. (2019). Machine Learning. Retrieved 04 05, 2022,
from Datakeen:
https://datakeen.co/8-machine-learning-algorithms-explained-in-human-language/
[8]. Grossfeld, B. (2020). Deep learning vs machine learning:
a simple way to understand the difference. Retrieved from zendesk blog:
https://www.zendesk.com/blog/machine-learning-anddeep-learning/
[9]. Grossfeld, B. (2020). Le programme du Master en
intelligence artificielle.
Retrieved 08 04, 2021, from Unidistance:
https://unidistance.ch/intelligenceartificielle/master/modules/?gclid=Cj0KC
Qjwj7v0BRDOARIsAGh37io1ERDQK4Wb
[10]. Gupta, N. (2019). Why is Python Used for Machine Learning?
from Hacker
Noon:
https://hackernoon.com/why-python-used-for-machine-
learningu13f922ug
[11].
https://www.kaggle.com/code/manoprathabans/skin-cancer-classification-using-cnn/data.
Consulté le 30/10/2022.
P a g e | 80
[12].
https://www.maxicours.com/se/cours/aires-visuelles-et-
perception/tolerance%209999/emergencystretch%203em/hfuzz%20.5/p@%
20/vfuzz%20/hfuzz%20-visuelle/. Consulté le 30/10/2021.
[13]. Issarane, H. (2019). Apprentissage Non
Supervisé. Retrieved 04 05, 2021, from Le DataScientist:
https://le-datascientist.fr/apprentissage-non-supervise
[14]. Li, H. (2017). Which ML Algorithms to Use? Retrieved
from The Eponymous Pickle:
http://eponymouspickle.blogspot.com/2017/04/which-ml-algorithms-touse.html
[15]. Nuageo. (2017). Deep Learning : définition,
concept et usages potentiels. Retrieved 03 21, 2021, from eurocloud:
https://www.eurocloud.fr/deep-learning-definition-concept-usagespotentiels/
[16]. python.doctor. (2019). Apprendre le langage de
programmation python. Retrieved 04 29, 2022, from python.doctor:
https://python.doctor/
[17]. Spyder Website Contributors. (2018). Overview.
Retrieved 04 29, 2021, from pyder-ide:
https://www.spyder-ide.org
[18]. The Pallets Projects. (2010). Flask. Retrieved 07 19,
2021, from Flask palletsprojects:
https://flask.palletsprojects.com/en/1.1.x/
[19]. Vázquez, F. (2018). A «weird»
Introduction to Deep Learning. Retrieved from
bbvadata&analytics:
https://www.bbvadata.com/a-weird-introduction-to-
deep-learning/
[20]. Werfelli, O. (2015). Présentation
générale des réseaux de neurones artificiels.
Cours. Retrieved 04 05, 2021, from
https://fr.slideshare.net/OussamaWerfelli/rseaux-de-neurones-artificiels
[21]. WIENER M. & LIAW A. (2002),
http://www.bios.unc.edu/ Classification and Regression by random Forest.R News,
consulté le 14 novembre 2021.
| 

