Profil épidémiologique et thérapeutique des infections urogénitales chez les gestantes.par Jérà´me Nsanzimana Université Saint Joseph (USJ) - Graduate en sciences infirmières 2018 |

II.2.3 METHODES STATISTIQUES UTILISEESPour aboutir aux résultats de notre recherche, nous avions utilisées la méthode statistique descriptive et analytique inférentielle et prédictive. La méthode descriptive nous a permet de synthétiser la masse des données à partir des indicateurs tels que la moyenne, la médiane et les mesures de la fréquence (incidence, prévalence et taux de mortalité). La méthode analytique inférentielle
nous a servi de déterminer la relation causale ente les variables
dépendante et indépendante à l'aide de test
d'indépendance dit khi-deux noté ( La méthode analytique prédictive nous a servi de montrer l'intervention d'une variable dite variable explicative dans la variation de l'autre appelée variable expliquée à l'aide du test de corrélation r II.2.4 ALGORYTHMES DES INDICATEURS ET TESTS STATISTIQUES UTILISES48(*)A .La méthode statistique descriptive a utilisé le calcul simple de : * La fréquence des variables considérées en %:
* La moyenne ** Pour les données groupées Pour les données groupées, la moyenne est
donnée par Avec n : Nombre des modalités ni : Effectif absolu des modalités k : Nombre de classe et Xi : Centre de classes (car on va de 1 à k). * L'écart-type à partir de la variance** Pour les données sont groupées en
classe: Pour grouper les données en classe, nous avons utilisé la méthode de LIORZOU qui consiste à: 1. Calculer le nombre de classes par n: Nombre des chiffres de la série ou taille de l'échantillon. 2. Calculer l'étendue du travail par d=Xmax -Xmin Avec d : étendue du travail Xmax : la valeur la plus élevée (le plus grand chiffre) de la série. Xmin : la valeur la plus basse (le plus petit chiffre) de la série. 3. Calculer de l'amplitude de classe par 4. Déterminer la limite inférieure par Avec Li : Limite inférieur de la première classe 5. Déterminer la limite supérieure par Ls= Li + a.k Avec Ls : Limite supérieur de la première classe. 6. Déterminer le centre de classe Xi par B . La méthode statistique
inférentielle et
prédictive a considéré le test
d'indépendance khi-deux ( Pour présenter les résultats de ce travail, nous avons utilisé les tableaux statistiques et graphiques. * 48Zindu Jean-Baptiste : Cours de biostatistique L2 SAPU ISTMAK 2018-2019 |
|


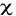 )
)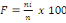
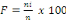 Avec ni = effectifs
observés/partiels et n = effectif total
attendu.
Avec ni = effectifs
observés/partiels et n = effectif total
attendu.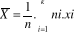
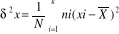 et
et 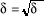

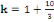 logn ;
logn ; 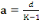
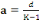
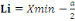
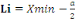
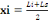
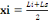
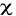 ) et le test de corrélation r dont les calculs ont
été effectués par les logiciels statistiques notamment
SPSS et Excel.
) et le test de corrélation r dont les calculs ont
été effectués par les logiciels statistiques notamment
SPSS et Excel.