|

EPIGRAPHE
Les détails font la perfection et la
perfection
n'est pas un détail.
Léonard de Vinci.
DEDICACES
A mes très chers et adorables parents Symphorien
MAKENGA et Angélique TSHIKUTA que j'aime énormément ; Pour
tout le soutien et l'amour dont vous m'avez entouré, pour tout ce que
vous avez fait pour moi, que ce modeste travail, soit l'exaucement de vos voeux
tant formulés et de vos prières quotidiennes ;
Que Dieu, le père tout puissant, vous préserve
et vous procure santé et longue vie afin que je puisse à mon tour
vous combler.
A mes frères et soeurs : Robert MAZAMBA, Solange
BAFUAFUA, Grégoire MUTOMBO, Nick NDOMBA, Clémence NKANKOLONGO,
Mike YANDA, Christelle TSHIBUABUA, Evariste NKONGOLO ; Vous occupez une place
particulière dans mon coeur. Je vous dédie ce travail en vous
souhaitant un avenir radieux, plein de bonheur et de succès.
A tous nos amis avec lesquels nous avons partagé nos
moments de joie et de bonheur. Les mots ne sauront résumés notre
reconnaissance et notre amour à votre égard.
II
Symphorien Dieumerci MAKENGA NUNU
III
REMERCIEMENTS
Au Dieu tout puissant, créateur du ciel et de la terre,
source d'intelligence et de sagesse, pour le souffle de vie qu'il nous accorde
tous les jours ainsi que la protection que nous avons
bénéficié tout au long de nos études ;
Notre profonde gratitude s'exprime de façon
particulière au Professeur Docteur Pierre KAFUNDA KATALAY qui, par son
expertise, a bien voulu accepter la direction scientifique de ce travail
malgré ses nombreuses occupations.
Ensuite nous témoignons notre profonde reconnaissance
à l'assistant Joël KABEYA pour avoir accepté la codirection
de ce travail.
A papa Nicaise MUNGA, maman Wivine LOKOSO, Riad YALENGA, Lydia
KAHOLA pour tous le soutien, l'écoute accorder et le sacrifice
consentit
A nos collègues et compagnons de lutte: Roger MUTOTO,
Patrick KATOLO, Béni KAMANDA, Jordan MOSONGO, Glody MBOKO, Jonathan
MBIYE, Gédéon KATAMBAYI, Réné MUAKUILAYI, Samuel
EKOFO, Jonathan MAZINA, Naomi NGAJA, Divine OKAKO, Rachel TULENGEJ, ... pour
votre franche collaboration.
Que tous ceux qui sont omis ici, veillent ne pas nous tenir
rigueur en acceptant sincèrement les mêmes sentiments de
reconnaissances et de remerciements.
Que tous ceux qui ont contribué de près ou de loin
à l'accomplissement de ce travail de fin de cycle, trouvent en ceci
notre sincère gratitude ;
Puisse l'Alpha et l'Omega vous rendre le centuple.
Symphorien Dieumerci MAKENGA NUNU
iv
LISTES DES FIGURES
Figure 1.1. Schéma de fonctionnement d'un
système client/serveur
Figure 1.2. Architectures 2 tiers
Figure 1.3. Architecture 3 tiers
Figure 1.4. Middleware
Figure 1.5a. model hiérarchique
Figure 1.5b. model réseau
Figure 1.6. Modèle Objet
Figure 1.7. Niveaux d'abstraction
Figure 1.8. Etapes de conception d'une base de
donnée
Figure 2.1. Fonctionnement d'une application web
Figure 2.2. Un assistant personnel
Figure 2.3. Les smartphones
Figure 2.4. Les tablettes
Figure 3.1. Organigramme
Figure 4.1. Différents diagrammes de uml
Figure 4.2. Diagramme de cas d'utilisation
Figure 4.3. Diagramme de cas d'utilisation s'authentifier
Figure 4.4. Diagramme de cas d'utilisation gérer les
patients
Figure 4.5. Diagramme du cas d'utilisation consulter un
dossier patient
Figure 4.6. Diagramme de séquence lié au cas
d'utilisation s'authentifié
Figure 4.7. Diagramme de séquence lié au cas
d'utilisation ajouté un patient
Figure 4.8. Diagramme de séquence lié au cas
d'utilisation supprimé un patient
Figure 4.9. Diagramme de séquences lié au cas
d'utilisation consulter données d'un
patient
V
Figure 4.10. Diagramme de classe Figure 4.11. Tables dans
mysql.
Figure 4.12. Table users
Figure 4.13. Table patients
Figure 4.14. Table adresses
Figure 4.15. Table prelevements
Figures 4.16. Interfaces d'authentification
Figures 4.17. Interfaces d'acceuil
Figures 4.18. Page d'accueil
Figures 4.19. Interface d'inscription
Figures 4.20. Interface d'ajout d'un patient
Figures 4.21. Consultation de la liste et autres options
Figures 4.22. Ajout prélèvement
Figures 4.23. Consultation des données
prélevées
Figures 4.24. Edition du profil
LISTES DES TABLEAUX
Tableau 1.1. Model relationnel Tableau 1.2. Modèle
relationnel -objet
Tableau 1.3. Exemple de fichier Tableau 3.1. Moyens logistique
Tableau 3.2. Analyse du flux d'information
Tableau 4.1. Description des classes
vi
INTRODUCTION
Il y a environ trente-ans, l'invention de l'internet a
révolutionné la façon de penser et de vivre dans le monde,
elle a permis aux consommateurs de faire des transactions, et accomplir leurs
tâches sans devoir se déplacer physiquement. Une dizaine
d'années après, cette innovation est suivie par l'apparition de
la technologie mobile qui a pris une place importante dans notre
société, les assistants personnels (PDA),
téléphones cellulaires, smartphones, tablettes, etc., et aussi
les moyens de connexion comme les réseaux sans fil (Wifi, GPRS et
d'autres) ont permis de suivre et accéder aux informations dont on a
besoin par tout ou il y a une couverture réseau.
1. Problématique
En effet ce travail va concerner la gestion des hypertendus
avec comme cadre d'étude l'hôpital général de
référence de Kinshasa, comme d'autre hôpital, il est
butté à un certain nombre de difficulté liées au
traitement manuel des informations des patients.
Le mode de traitement ainsi utilisé par ce dernier
occasionne une perte d'information, Et après une observation
continuelle, nous avons pu observer les insuffisances suivantes :
? Volume important des informations traitées manuellement,
ce qui provoque
parfois des erreurs dans l'établissement des documents des
hypertendus.
? Recherche difficile sur les registres qui engendre une perte de
temps.
? Nombre important des archives qui engendre une
difficulté de stockage.
? Détérioration des archives à force de leur
utilisation trop fréquente.
? Manque d'information précise et rapide sur l'hypertendu
en cas de
déplacement du médecin
Nous constatons que la solution informatique est la plus
adéquate puisqu'elle répond mieux aux anomalies souvent
fréquentes dans la gestion manuelle.
Ainsi nous avons décidé de concevoir une
application web adaptables à la plateforme mobile qui va permettre
d'optimiser la gestion des hypertendus et surtout d'améliorer la
rapidité d'accès à l'information.
VII
2. Hypothèse
Avant l'invention de l'ordinateur, nous enregistrons toutes
les informations manuellement sur des supports en papier. Ce qui engendrait
beaucoup de problèmes tel que la perte de temps considérable dans
la recherche de ces informations ou la dégradation de ces
dernières.
La nouvelle logique de l'organisation du travail dans les
établissements se veut d'utiliser essentiellement l'informatique pour
pouvoir être plus efficace. Ils doivent donc intégrer un
développement du système d'information dans leurs investissements
stratégiques.
Les hôpitaux auquel nous rattacheront d'ailleurs notre
étude, font partie intégrante des établissements où
l'informatique peut se révéler être très
bénéfique. En effet, la croissance de la population
nécessite la mise en place d'une gestion rationnelle et rapide, or et
jusqu' à ce jour, la manière de gérer manuellement est
encore dominante d'où la nécessite d'introduire l'informatique
dans ces milieux.
3. Choix et intérêt du sujet
Nous avons porté notre choix sur ce sujet compte tenu
des difficultés que rencontre les médecins dans la
société congolaise dans leur lutte pour permettre aux hypertendus
de modifier leur style de vie. La solution développée permettra
d'assurer une gestion cohérence, rapide et sécuriser des
informations des patients.
Néanmoins ce travail servira de support de base pour
tout ce qui voudront apprendre dans ce domaine.
4. Délimitation du travail
Tout travail scientifique doit être
délimité dans le temps et dans l'espace, ainsi Le présent
travail couvre temporellement les informations allant de janvier 2016 à
Octobre 2019. Dans l'espace, notre travail restreint le champs d'application
à l'hôpital général de référence de
Kinshasa.
VIII
5. Méthodes et techniques utilisées
5.1. Méthodes
Pour élaborer ce travail nous avons recouru aux
méthodes suivantes :
? La méthode structuro-fonctionnelle : elle nous a
permis d'étudier la structure de l'hôpital et son
fonctionnement.
? La méthode de développement logiciel UP
(Processus Unifié) et UML comme langage de modélisation.
5.2. Techniques
Dans le cadre de ce travail nous avons utilisé les
techniques ci-après :
? La technique documentaire : utilisée à travers
la lecture des ouvrages et autres documents écrits se rapportant
à notre sujet d'étude.
? La technique d'interview : en procédant par
questions-réponses dans nos récoltes de données ;
6. Subdivision du travail
Hormis l'introduction et la conclusion notre travail comprend 4
chapitres entre autres :
Chapitre 1 : Architecture client-serveur et bases de
données Chapitre 2 : Application web-mobile
Chapitre 3 : Etude préalable
Chapitre 4 : Conception et implémentation de
l'application
9
CHAPITRE I. ARCHITECTURE CLIENT SERVEUR
ET BASE DE DONNEES
[1] [2] [3] [4] [5] [7] [8] [10] [11] [14] [15] [23] [29]
[30]
1.1. ARCHITECTURE CLIENT/SERVEUR
Le développement des ordinateurs personnels peu
coûteux ainsi que des réseaux de communication à haut
débit a permis l'élaboration d'une nouvelle architecture misant
sur la capacité de traitement dévolue localement aux postes de
travail des utilisateurs. La capacité de traitement n'est plus
désormais l'apanage de l'ordinateur central. Les utilisateurs disposent
alors de postes de travail qui prennent en charge en tout ou en partie le
traitement des données. Cette architecture est dite à
traitement distribué par opposition à la forme
traditionnelle de traitement centralisé. La forme la plus connue de
traitement distribué est l'architecture client-serveur.
1.1.1. Définition
Spécification d'un système informatique dans
lequel un processus appelé le serveur agit comme
fournisseur de ressources pour d'autres processus qui demandent ces ressources,
soit les processus clients. Le processus client et le
processus serveur s'exécutent le plus souvent sur des machines
différentes reliées au même
réseau.
1.1.2. Notions de base
? Client : Processus demandant l'exécution
d'une opération à un autre processus par envoi d'un message
contenant le descriptif de l'opération à exécuter et
attendant la réponse à cette opération par un message en
retour.
? Serveur : Processus accomplissant une
opération sur demande d'un client et transmettant la réponse
à ce client.
? Requête : Message transmis par un client
à un serveur décrivant l'opération à
exécuter pour le compte du client.
10
? Réponse : Message transmis par un serveur
à un client suite à l'exécution d'une opération
contenant les paramètres de retour de l'opération.
Fonctionnement d'un système client serveur
Le client émet une requête vers le serveur
grâce à son adresse et à son
port, qui désigne un service particulier du serveur ;
Le serveur reçoit la demande et répond à l'aide de
l'adresse de la machine client (et de son port).
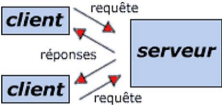
Figure 1.1. Schéma de fonctionnement d'un système
client/serveur
1.1.3. Répartition des taches
Dans l'architecture client-serveur une application est
constituée de trois parties :
? Logique de présentation (L'interface utilisateur) :
est responsable de la gestion de l'interface utilisateur notamment la
présentation des données à l'écran et l'interaction
avec l'utilisateur.
? Logique applicative (logique de traitements) : prend en
charge les traitements propres à l'application, soit les Règles
d'affaires d'un métier la nature des calculs qui doivent être
effectués.
? Logique d'accès (logique de gestion de
données) : est relative à l'exécution des requêtes
par le SGBD pour fournir à la logique applicative les données
dont elle a besoin pour exécuter les processus du métier.
11
1.1.4. Différant modèles de client
serveur
En fait, les différences sont essentiellement
liées aux services qui sont assurées par le serveur. On distingue
couramment :
? Client-serveur de donnée :
dans ce cas, le serveur assure des tâches de gestion, de stockages
et de traitement de données. C'est le cas le plus connu de
client-serveur est qui est utilisé par tous les grands SGBD.
? Client-serveur de présentation :
dans ce cas la présentation des pages affichées par le client est
intégralement prise en charge par le serveur. Cette
organisation présente l'inconvénient de
générer un fort trafic réseau.
? Client-serveur de traitement : dans ce cas,
le serveur effectue des traitements à la demande du client. Il peut
s'agir de traitement particulier sur des données, de vérification
de formulaires de saisie, de traitements d'alarmes ...
Ces traitements peuvent être réalisés par
des programmes installé sur des serveurs mais également
intégrés dans des bases de données (triggers,
procédures stockées), dans ce cas la partie donnée et
traitement sont intégrés.
1.1.5. Différentes architectures
a) Architecture Client Serveur à deux niveaux
Dans l'architecture client-serveur à deux niveaux
(2 tiers), le poste de travail de l'utilisateur, appelé le
poste client, prend en charge tous les traitements liés
à la fois à la logique de présentation et à la
logique applicative. La logique d'accès est dévolue à un
serveur qui agit comme serveur de données exclusivement Le poste client
compose des requêtes, dans le langage SQL par exemple, selon les besoins
en données de l'application qui s'exécute sur le poste. Il
transmet ensuite la requête à travers le réseau au serveur
qui l'exécute à son tour et retourne en réponse au poste
client Le résultat de son exécution
L'expérience a démontré qu'il
était couteux et contraignant de vouloir faire porter l'ensemble des
traitements applicatifs par le poste client. On en arrive aujourd'hui à
ce que l'on appelle le client lourd. L'architecture 2-tiers dispose d'un grand
inconvénient, vu qu'il est au coeur du réseau, si celui-ci tombe
tout tombe.
12
Malgré tout, l'architecture deux tiers présente
de nombreux avantages qui lui permettent d'un bilan globalement positifs :
? Elle permet l'utilisation d'une interface utilisateur riche,
? Elle a permis l'approbation des applications par l'utilisateur,
? Elle a permis la notion d'interopérabilité.
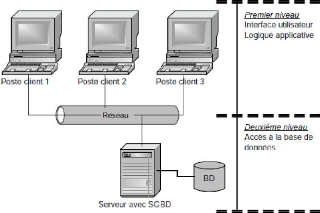
Figure 1.2. Architectures 2 tiers
b) Architecture Trois Niveaux
De manière à simplifier l'entretien et la mise
à jour de la logique applicative, lin autre modèle client-serveur
a été mis au point permettant de délester le poste client
de ce composant. Il s'agit de l'architecture client-serveur à trois
niveaux (three-tier). Dans ce modèle la logique
applicative est prise en charge par un deuxième serveur, ne laissant au
poste client que les tâches liées à la gestion de
l'interface utilisateur .C'est ainsi qu'est né le concept de client
léger, léger dans le sens que le poste client ne
nécessite plus de ressources aussi importantes en matière
d'espace de mémoire principale et de vitesse d'exécution que
demandait le modèle à deux niveaux .Dans certaines applications
client-serveur à trois niveaux, la gestion de l'interface utilisateur se
fait avec un simple navigateur Web avec pour conséquence une
administration considérablement simplifiée des mises à
jour des applications côté client ; L'entretien de la logique
applicative ne concerne désormais qu'une seule machine que l'on appelle
le serveur d'application. La facilité d'administration des
13
mises à jour n'est pas le seul avantage d'un
modèle à trois niveaux. Il est en revanche d'une grande
souplesse. Il permet par exemple d'assurer aux utilisateurs un service sans
interruption en cas de panne. En mettant en oeuvre ce modèle avec
plusieurs serveurs d'application, offrant tous la même logique
applicative, la panne d'un serveur a peu d'impact sur les utilisateurs car les
autres serveurs pourront prendre la relève en tout temps même si
la performance globale s'en trouvera légèrement
dégradée, mais cette architecture possède un grand
inconvénient coût.
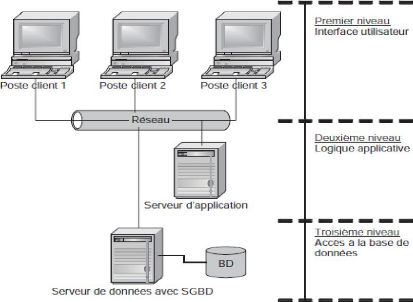
Figure 1.3. Architecture 3 tiers
c) L'architecture N-Tiers
L'architecture n-tiers a été pensée pour
pallier aux limitations des architectures trois tiers et concevoir des
applications puissantes et simples à maintenir. Ce type d'architecture
permet de distribuer plus librement la logique applicative, ce qui facilite la
répartition de la charge entre tous les niveaux.
Cette évolution des architectures trois tiers met en
oeuvre une approche objet pour offrir une plus grande souplesse
d'implémentation et faciliter la réutilisation des
14
développements. Théoriquement, ce type
d'architecture supprime tous les inconvénients des architectures
précédentes :
· Elle permet l'utilisation d'interfaces utilisateurs
riches
· Elle sépare nettement tous les niveaux de
l'application
· Elle offre de grandes capacités d'extension,
· Elle facilite la gestion des sessions.
L'appellation « n-tiers » pourrait faire penser que
cette architecture met en oeuvre un nombre indéterminé de niveaux
de service, alors que ces derniers sont au maximum trois (les trois niveaux
d'une application informatique). En fait, l'architecture n-tiers qualifie la
distribution d'application entre de multiples services et non la multiplication
des niveaux de service.
1.1.7. Les protocoles échanges ou de transferts
Le client et le serveur communiquent par des protocoles plus
ou moins standardisés. Au-delà des interfaces applicatives, les
transporteurs de requêtes mettent en oeuvre des protocoles de niveau
application et session pour expédier des requêtes à des
services distants et récupérer les réponses. Ils
s'appuient sur des protocoles de transports standards. Ils développent
très souvent des protocoles spécifiques qui peuvent être
basés sur l'appel de procédures à distance.
· RDA (Remote Data Access)
· http (Hyper Text Transfert Protocol)
· FTP (File Transfer Protocol)
· TCP/IP (Transmission Control Protocol/Internet
Protocol)
1.1.8. Middleware
1.1.8.1. Définition
C'est un ensemble des services logiciels construits au-dessus
d'un protocole de transport afin de permettre l'échange de
requêtes et des réponses associées entre client et serveur
de manière transparente. Le middleware est ce logiciel du
milieu qui assure les dialogues entre clients et serveurs souvent
hétérogènes. Il est traduit par
médiateur.
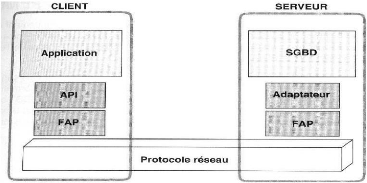
15
Figure 1.4. Middleware
1.1.8.2. Objectifs
Le médiateur ou le middleware a pour objectif :
? Le transport de requêtes et réponses
: le transport depuis le client vers le serveur, c'est la fonction de base
à assurer. Pour cela, un médiateur s'appuiera souvent sur un
protocole permettant de réaliser le Remote Procedure Call
(RPC).
? La simplification de la vision utilisateur : elle
permet de développer des interfaces applicatives (API) transparente,
c'est-à-dire de déporter sur le client les primitives
d'accès que l'on trouve sur le serveur.
? L'harmonisation des types des données :
permet de rendre invisibles les problèmes de conversion de types de
données qui doivent être pris en charge par le médiateur,
de sorte à offrir une intégration uniforme aux langages.
? La performance : un médiateur doit
transmettre les requêtes aussi efficacement que possible. Pour
éviter des transferts inutiles, certains médiateurs proposent la
gestion de caches clients et serveurs, pour les résultats et parfois
pour les requêtes. Les caches de résultats sont
particulièrement nécessaires pour les objets complexes
(ensembles, listes, longues chaînes de bits ou d'octets).
? La fiabilité : la fiabilité des
communications doit être assurée par des techniques de
réémission en cas de non réponse, mais aussi de
détection de double émission à l'aide par exemple d'un
numéro de séquence associé aux requêtes. La
fiabilité des mises à jour nécessite l'intégration
de
16
techniques de gestion de transactions, avec validation
(commit) en cas de succès, et reprise (rollback) en
cas d'échec.
Le médiateur assure aussi le départ des
interfaces des serveurs vers les clients et la sécurité.
1.1.8.3. Types de middleware
Il existe 2 types de middleware :
> Général : il y a les protocoles de
communication, répertoires repartis,
service d'authentification, service de temps, RPC, etc.
> Spécifique :
? De BD : ODBC, IDAPI, EDA/SQL, etc.;
? De Groupware : MAPI, Lotus Notes ;
? D'objets : CORBA, COM/DCOM, .NET.
1.1.8.4. Composantes du middleware
Le middleware est composé de :
> Les canaux : ce sont des services de communications
entre composants et applications : RPC (synchrone), ORB (synchrone), MOM
(Message Oriented Middleware) (asynchrone) ; des services de support de
communication : SSL, annuaires (LDAP).
> Les plates-formes : il s'agit des serveurs
d'applications qui s'exécutent de côté serveur. Ils offrent
les canaux de communication et assurent la répartition,
l'équilibrage de charge, l'intégrité des transactions,
etc.
1.1.8.5. Fonctions
Lorsqu'un logiciel client veut consulter ou modifier des
données sur le serveur, il doit d'abord se connecter et c'est
le middleware qui assure les connexions entre les serveurs de
données et les outils de développement sur les postes clients.
> Procédure de connexion (Connection
procedure) : Opération permettant d'ouvrir un chemin depuis un
client vers un serveur désigné par un nom, avec authentification
de l'utilisateur associé par nom et mot de passe.
> Préparation de requête (Request
preparation) : Opération consistant à envoyer une
requête avec des paramètres non instanciés à un
serveur afin qu'il prépare son exécution.
17
? Exécution de requête (Request
execution) : Opération consistant à envoyer une demande
d'exécution de requête précédemment
préparée à un serveur, en fournissant les valeurs des
paramètres.
? Récupération de résultats (Result
fetching) : Opération permettant de ramener tout ou partie du
résultat d'une requête sur le client.
? Cache de résultats (Result caching) :
Technique permettant de transférer les résultats par blocs et de
les conserver sur le client ou/et sur le serveur afin de les réutiliser
pour répondre à des requêtes.
Au-delà des résultats, les médiateurs
peuvent aussi mémoriser les requêtes avec les plans
d'exécution préparés sur le serveur, ceci afin
d'éviter de les préparer à nouveau lors d'une nouvelle
demande.
? Cache de requêtes (Request caching) :
Technique permettant de conserver des requêtes compilées sur le
serveur afin de les réutiliser pour répondre à des
requêtes similaires.
? Procédure de déconnexion (Deconnection
procedure) : Opération inverse de la connexion, permettant de
fermer le chemin ouvert depuis le client vers le serveur associé.
1.1.8.6. Les services du Middleware
lin middleware est susceptible de rendre les services suivants
:
? Conversion : Service utilisé pour la
communication entre machines mettant en oeuvre des formats de données
différents.
? Adressage : permet d'identifier la machine serveur
sur laquelle est localisé le service demandé afin d'en
déduire le chemin d'accès.
? Sécurité : permet de garantir la
confidentialité et la sécurité des données à
l'aide mécanismes d'authentification et de cryptage des informations.
? Communication : permet la transmission des
messages entre les deux systèmes sans altération. Ce service doit
gérer la connexion au serveur, la préparation de
l'exécution des requêtes, la récupération des
résultats et la déconnexion de l'utilisateur.
Le middleware masque la complexité des échanges
inter-applications et permet ainsi d'élever le niveau des API
utilisées par les programmes. Sans ce mécanisme, la programmation
d'une application client-serveur serait complexe et difficilement
évolutive.
18
1.1.8.7. Serveur Web
lin serveur WEB est une machine sur laquelle le service http
est à l'écoute de requêtes http en provenance du
réseau. L'application cliente d'un serveur http est
généralement un logiciel navigateur qui génère
dynamiquement du contenu HTML. Lorsqu'un utilisateur saisi une liRL dans la
barre d'adresse, il émet une
requête à destination du service http actif sur
un serveur. C'est pourquoi il
est aussi appelé Serveur http par
analogie avec le protocole du même nom. Il gère l'accès aux
données (les pages web des sites hébergés + contenu).
Le serveur WEB ne se contente pas de renvoyer des pages ; il
effectue un traitement, il exécute des programmes codés en
langage PHP, ASP, etc... pour produire des pages. A ce titre il peut être
considéré comme un serveur d'application.
Le serveur WEB peut avoir besoin de données pour
alimenter les pages qu'il construit. A ce titre il est client d'un SGBDR : il
sollicite le service fourni par un SGBDR qui va exécuter les
requêtes transmises par le serveur WEB.
Les serveurs HTTP les plus utilisés sont :
? Apache http Server de Apache Software Fundation, ? Internet
Information Services (IIS) de Microsoft, ? Java System Web Server de Sun
Microsystems...
1.1.8.8. Exemples de Middleware
SQL*Net : Interface propriétaire permettant de faire
dialoguer une application cliente avec une base de données Oracle. Ce
dialogue peut aussi bien être le passage de requêtes SQL que
l'appel de procédures stockées.
ODBC (Object data base Connexion) : Interface
standardisée isolant le client du serveur de données. C'est
l'implémentation par Microsoft d'un standard défini par le SQL
Access Group. Elle se compose d'un gestionnaire de driver standardisé,
d'une API s'interfaçant avec l'application cliente (sous Ms Windows) et
un driver correspondant au SGBD utilisé.
DCE (Distributions Computing Environment) : permet l'appel
à des procédures distantes depuis une application. Il correspond
à RPC (Remote Procedure Call) qui permet d'exécuter des
procédures d'information.
19
1.1.9. Quelques avantages
Le modèle client-serveur est particulièrement
recommandé pour des réseaux nécessitant un grand niveau de
fiabilité, ses principaux atouts sont :
? Des ressources centralisées : étant
donné que le serveur est au centre du réseau, il peut
gérer des ressources communes à tous les utilisateurs, comme par
exemple une base de données centralisée, afin d'éviter les
problèmes de redondance et de contradiction ;
? Une meilleure sécurité : car le nombre de
points d'entrée permettant l'accès aux données est moins
important ;
? Une administration au niveau serveur : le client ayant peu
d'importance dans ce modèle, il a moins besoin d'être
administré. Toute la complexité/puissance peut être
déportée sur le(s) serveur(s), les utilisateurs utilisant
simplement un client léger ;
? Un réseau évolutif : grâce à
cette architecture il est possible de supprimer ou de rajouter des clients sans
perturber le fonctionnement du réseau et sans modification majeure.
20
I.2. BASE DE DONNEES
Le nombre d'informations disponibles et les moyens de les
diffuser sont en constante progression. La croissance du World Wide Web
a encore accru ce développement, en fournissant l'accès
à des bases de données très diverses avec une interface
commune. Celles-ci se situent au coeur de l'activité des entreprises,
des administrations, de la recherche et de bon nombre d'activités
humaines désormais liées à l'informatique.
Dans le domaine purement informatique, elles interviennent
dorénavant à tous les niveaux. Les développeurs
d'applications s'appuient sur des bases de données externes pour
gérer leurs données alors qu'auparavant elles étaient
intégrées dans le programme.
Les bases de données reposent sur des
théories solides et sont à l'origine d'une des plus importantes
disciplines de l'informatique : l'ingénierie des systèmes
d'information. Cette section présente une idée intuitive
de ce qu'est une base de données, de son utilisation puis des
éléments de qualité qui lui sont associés.
1.2.1. Limites du système de gestion de fichier
L'utilisation de fichiers impose d'une part, à
l'utilisateur de connaître l'organisation séquentielle,
indexée, des fichiers qu'il utilise afin de pouvoir accéder aux
informations dont il a besoin et, d'autre part, d'écrire des programmes
pour pouvoir effectivement manipuler ces informations. Pour des applications
nouvelles, l'utilisateur devra obligatoirement écrire de nouveaux
programmes et il pourra être amené à créer de
nouveaux fichiers qui contiendront peut-être des informations
déjà présentes dans d'autres fichiers.
De telles applications sont :
· Rigides,
· Contraignantes,
· Longues et coûteuses à mettre en oeuvre.
Les données associées sont :
· Mal définies et mal désignées,
· Redondantes,
· Peu accessibles de manière ponctuelle,
21
? Peu fiables.
La prise de décision est une part importante de la vie
d'une société. Mais elle nécessite d'être bien
informé sur la situation et donc d'avoir des informations à jour
et disponibles immédiatement.
Les utilisateurs, quant à eux, ne veulent plus de
systèmes d'information constitués d'un ensemble de programmes
inflexibles et de données inaccessibles à tout non
spécialiste ; ils souhaitent des systèmes d'informations globaux,
cohérents, directement accessibles (sans qu'ils aient besoin soit
d'écrire des programmes soit de demander à un programmeur de les
écrire pour eux) et des réponses immédiates aux questions
qu'ils posent. On a donc recherché des solutions tenant compte à
la fois des désirs des utilisateurs et des progrès techniques.
Cette recherche a abouti au concept de base de données.
1.2.2. Notion de base de données et
définition des concepts
Tout le monde a une idée naturelle de ce que peut
être une base de données : elle peut revêtir la forme d'une
liste de CD contenant le nom des artistes et les titres des morceaux ou encore
celle de fiches de recettes de cuisine. On remarque qu'une
caractéristique des données contenues dans une base de
données est qu'elles doivent posséder un lien entre elles. En
effet, des données choisies au hasard ne constituent certainement pas
une base de données. Celle-ci est donc une représentation
partielle et (très) simplifiée du monde réel, que l'on a
obtenu par un processus de modélisation.
Définition Base de donnée (Data Base) :
Une Base de Donnée est un ensemble structuré de
données, enregistrées sur des supports, accessibles par
l'ordinateur, représentant les informations du monde réel et
pouvant être interrogées et mises à jour par une
communauté d'utilisateurs.
Autre définitions
Une Base de Données est un ensemble structuré de
données, enregistrées sur des supports, accessibles par
l'ordinateur, en vue de satisfaire plusieurs personnes de manière
sélective et en temps opportun
Une base de données est un ensemble de données
organisé en vue de son utilisation par des programmes correspondant
à des applications distinctes et
22
de manière à faciliter l'évolution
indépendante des données et des programmes.
Une base de données est une collection de fichiers
(entités) reliés entre eux par des liens logiques et/ou physiques
et organisés de manière à répondre efficacement
à une grande variété de questions ;
Une base de données peut apparaître comme une
collection d'informations modélisant une entreprise du monde
réel, servant de support à une application informatique et dont
les données peuvent être interrogées au moins par leur
contenu ;
1.2.3. Utilisation d'une base de données
La grande différence avec un programme écrit
dans un langage de programmation est qu'une base de données doit pouvoir
répondre à des questions pour lesquelles elle n'a pas
forcément été prévue à la conception.
Une autre différence est que les données sont
susceptibles d'être utilisées par des applications
différentes. Dans un programme classique, la structuration des
données est décrite directement dans le code, ce qui rend leur
utilisation difficile par d'autres programmes, en particulier lorsque l'on
modifie cette structure. Ce que l'on recherche en utilisant une base de
données est d'assurer l'indépendance entre le traitement et les
données. C'est pourquoi, il est nécessaire que l'application
obtienne des informations sur la structure des données (nom, type,
taille, etc.). Pour ce faire, on associe à la base de données une
description que l'on appelle « métadonnée » ou
« catalogue ». Cette dernière décrit la
structure interne de la base de données qui est spécifique au
SGBD employé
L'idée générale est que l'utilisateur ou
l'application utilisatrice des données ne doit pas être
dépendante de leur représentation interne, ce qui constitue une
abstraction des données. C'est la raison pour laquelle on utilise une
description des données sous la forme d'un modèle pour permettre
la restitution la plus efficace possible de l'information.
23
1.2.4. Critères d'une base de données
L'un des objectifs de création d'une base de
données est de pouvoir retrouver les données par leur contenu.
Dans cette optique, il faut s'assurer que les données contenues dans la
base sont de « bonne qualité ». Cependant des nombreux
critères peuvent être pris en compte ; on peut citer parmi les
principaux
? L'exhaustivité implique la
présence dans la base de données, de tous les renseignements qui
ont trait aux applications en question
? La structure implique l'adaptation du mode
de stockage des renseignements aux traitements qui les exploiteront et les
mettront à jour, ainsi qu'au cout de stockage dans l'ordinateur.
? L'absence de redondance : implique la
présence dans la base de données d'un renseignement donnée
une fois et une seule.
Nota : La non-redondance absolue est souvent difficile
à réaliser
1.2.5. Évolution des bases de données
Modèles De Bases De Données
Les modèles de données
correspondent à la manière de structurer l'information
dans une base de données. Ils reposent sur les principes et les
théories issus du domaine de la recherche en informatique et permettent
de traduire la réalité de l'information vers une
représentation utilisable en informatique.
a) Modèle hiérarchique et modèle
réseau
Le modèle « hiérarchique » propose une
représentation sous forme d'une structure arborescente
d'enregistrements. Cette structure est conçue avec des pointeurs et
détermine le chemin d'accès aux données.
Chaque noeud de l'arbre correspond à une classe
d'entité du monde réel et les chemins entre les noeuds
représentent les liens existant entre les objets. De nombreuses
situations peuvent ainsi être représentées, mais la nature
arborescente du graphe des objets devient limitative lorsque l'on veut
modéliser le partage de certaines données.
Le modèle « réseau » est une extension
du modèle hiérarchique dans lequel le graphe des objets n'est pas
limité. Il permet, en d'autre terme, de représenter le partage
d'objets ainsi que les liens cycliques entre des objets. Il est le
modèle utilisé par le système CODASYL. lin schéma
conceptuel dans le modèle réseau est composé de
définition d'enregistrement définissant et les liens unissant ces
entités, et l'ensemble exprimant des liens multi-values entre les
enregistrements.
Figure 1.5a. model hiérarchique
24
Figure 1.5b. model réseau
b) 25
Modèle relationnel
En 1970, E. F. Codd propose un nouveau modèle «
relationnel », Il est fondé sur la théorie
mathématique des
relations.il conduit à une
très simple des données sous forme de table constituées de
lignes et de colonnes. Il n'y a plus de pointeurs qui figeait la structure de
la
base.la souplesse apporté par cette
représentation et les études théoriques appuyée sur
la théorie mathématique des relations ont permis le
développement des langages puissant non-procéduraux.
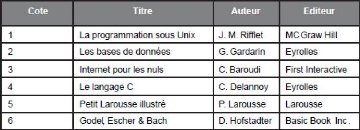
Tableau 1.1. Model relationnel
c) Modèle objet
Dans le sillage du développement des langages
orientés objet (C++, Java...) dans les années 1980, le
concept objet a été adapté aux bases de
données. Plusieurs raisons, en dehors des qualités reconnues de
l'approche objet, ont conduit à définir une extension objet pour
les bases de données.
La première est que le modèle relationnel, dans
sa simplicité, ne permet pas de modéliser facilement toutes les
réalités. La deuxième est qu'un objet permet de
représenter directement un élément du monde réel.
Les structures d'éléments complexes se retrouvent souvent
dispersées entre plusieurs tables dans l'approche relationnelle
classique. De plus, le concept objet est mieux adapté pour
modéliser des volumes de texte importants ou d'autres types de
données multimédias. Enfin, il est beaucoup plus commode de
manipuler directement des objets lorsque l'on développe avec un langage
objet. Les bases de données, on le rappelle, sont dorénavant des
briques constitutives des applications. Les bases de données
« orientées objet » apportent ainsi
aux applications développées en langage objet la
26
persistance des objets manipulés : ces
derniers peuvent ainsi directement être réutilisés par
l'application d'origine ou par d'autres sans redéfinition. Ces concepts
ont été intégrés à partir de la version 2 de
la norme SQL. Les données modélisées sous forme d'objets
sont aussi plus complexes à représenter du point de vue du SGBD
et l'on rencontre encore très souvent des problèmes de
performance.
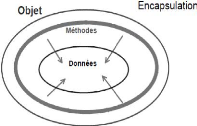
Figure 1.6. Modèle Objet
d) Modèle relationnel-objet
Une demande d'évolution du strict modèle
relationnel existe toutefois. En effet, la gestion des données autres
que du texte et des nombres - comme des images, du son et des vidéos -
implique l'évolution du modèle relationnel. De même, les
champs dits « multivalués », disposant de plusieurs valeurs
telles qu'une liste de prénoms ou des coordonnées
géographiques, ne peuvent pas être modélisés
efficacement en utilisant ce type d'approche. L'idée est alors
d'intégrer de l'objet au modèle relationnel existant plutôt
que d'utiliser l'approche objet pure.
Cette extension, adoptée par la plupart des SGBD, se
nomme « relationnel-objet » et permet aux
concepteurs des bases de données de disposer de types
évolués « abstraits » plus simples à concevoir
et surtout plus commodes à faire évoluer.
27
Tableau 1.2. Modèle relationnel -objet
1.2.6. Systèmes de gestion de bases de
données
lin SGBD est un logiciel complexe qui permet de gérer
et d'utiliser les données que l'on stocke en utilisant les
modèles cités précédemment.
1.2.6.1. Evolution des systèmes de gestion de
base de données
L'évolution des systèmes de gestion de base de
données est très liée au différent modèles
de données
a) Les SGBD hiérarchiques et réseaux
Les SGBD hiérarchiques et réseau constituent la
première génération de SGBD. Malheureusement ils
comportaient certaines lacunes notamment au plan des fondements
théoriques. De plus ils ne permettaient pas en pratique d'assurer
l'indépendance tant souhaitée entre les applications et les
données.
En effet, comme le lien entre deux enregistrements
était implanté à l'aide d'un pointeur, soit une sorte
d'adresse permettant de repérer un enregistrement associé, cela
donnait lieu à des programmes complexes même pour des
requêtes simples.
b) Les SGBD relationnels
De physiques qu'étaient les liens dans les
SGBD hiérarchiques ou réseau, les liens sont dorénavant
logiques, basés sur les valeurs des champs, ce qui rend la
navigation entre les enregistrements beaucoup plus souples. Les SGBD
relationnels
28
sont de deuxième génération et ils ont
tous en commun intrinsèquement un langage appelé SQL (Structured
Query Language) SQL agissant à la fois comme langage de
définition et langage de manipulation de données.
c) Les SGBD orientés objet
Le développement de langages orientés objets a
conduit à la mise au point de SGBD devant assurer la persistance des
objets, soit le stockage permanent sur un support de mémoire
auxiliaire des objets créés à l'aide de tels langages Ce
SGBD dit orienté objet ou simplement SGBD objet
appartient à la troisième
génération
d) Autres SGBD
À l'aube du xxie siècle on parle d'une
quatrième génération de SGBD. Il s'agit d'une
catégorie hétérogène de SGBD conçus avant
tout pour des applications spécialisées, comme par exemple les
SGBD OLAP (On Line Analytical Processing) largement utilisés
pour l'entreposage des données et l'exploration des données, les
SGBD XML pour les applications Web, ou enfin les SGBD de contraintes pour les
applications d'optimisation
1.2.6.2. Fonctionnalités d'un SGBD
De même que l'ISO a déterminé un
modèle théorique en sept couches pour distinguer les applications
réseaux et leurs interactions, il existe désormais un
modèle théorique en trois couches (trois niveaux d'abstraction)
afin de concevoir et d'organiser les fonctionnalités des SGBD.
Cette dernière s'inscrit dans les concepts et
théories de la première génération des bases de
données, dont l'objectif est d'avoir une indépendance
entre les données et les traitements :
i' Niveau interne ou physique. C'est le
niveau le plus « bas ». On décrit les structures de stockage
de l'information, ce qui le rend très dépendant du SGBD
employé. Il se fonde sur un modèle de données
physique.
i' Niveau conceptuel. Il correspond à
l'implémentation du schéma conceptuel de la base de
données, que l'on réalise lors de la phase d'analyse. Il
est utilisé pour décrire les éléments constitutifs
de la base de données et les contraintes qui leur sont
associées.
29
? Niveau externe. Le niveau externe sert
à décrire les vues des utilisateurs,
c'est-à-dire le schéma de visualisation des
données qui est différent pour chaque catégorie
d'utilisateurs. lin schéma externe permet de masquer la
complexité de la base de données complète en fonction des
droits ou des besoins des utilisateurs. Cela facilite la lecture et la
sécurité de l'information.
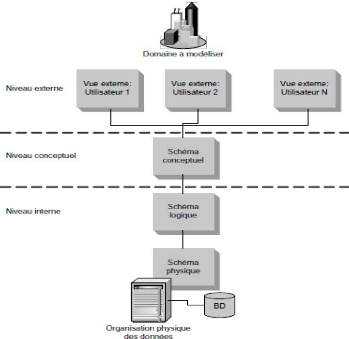
Figure 1.7. Niveaux d'abstraction
Les SGBD ne respectent pas à la lettre le
découpage proposé. Ils se doivent cependant de posséder
les principales caractéristiques qui découlent de ce
modèle en couches :
30
Indépendance physique des données.
Masquer la représentation interne des données ainsi que
les méthodes système d'accès aux utilisateurs.
Indépendance logique des données.
Permettre la modification du schéma conceptuel des
données sans remettre en cause les mécanismes de stockage et de
manipulation internes des données.
Intégrité des données.
Faire en sorte que l'information résultant des liens entre
les données soit cohérente.
Un SGBD doit permettre également la manipulation de la
structure de la base de données, comme l'ajout et la modification de
champs, de manière transparente. Il conserve à cet effet une
description de la structure de la base de données que l'on appelle le
« dictionnaire de données ». Pour réaliser ces
opérations avec l'indépendance souhaitée par rapport
à la représentation, le SGBD offre deux langages de haut niveau
:
? Un Langage de Description de Données (LDD)
qui permet d'agir sur la
structure de la base de données (ajout, suppression et
modification des tables) ? Un Langage de Manipulation de Données
(LMD) qui permet d'interroger et
de mettre à jour le contenu de la base de
données.
Ces langages sont de type « non procédural »,
c'est-à-dire que l'on s'intéresse à l'effet de
l'opération (le quoi) et non pas à la manière dont elle
est réalisée (le comment).
Le SGBD doit également assurer la protection des
données en cas de problèmes. Ceux-ci peuvent être la
conséquence d'une manipulation malheureuse, mais également d'une
panne du système qui survient par exemple à la suite d'une
coupure de courant. Dans tous les cas, le SGBD doit permettre de restaurer les
données. Ces opérations sont généralement
réalisées en utilisant des « journaux » qui
enregistrent au fur et à mesure les opérations faites sur la base
: c'est le mécanisme de la journalisation. Ce journal
est utilisé pour refaire, ou défaire le cas
échéant, ces opérations.
En ce qui concerne les opérations de modification
effectuées sur la base de données, que l'on appelle des
transactions, des propriétés de mesure de la
qualité de ces transactions sont proposées sous le terme ACID
:
· Atomicité. Une transaction est
« atomique » ; elle est exécutée entièrement ou
abandonnée.
· Cohérence. La transaction doit
se faire d'un état cohérent de la base vers un autre état
cohérent.
·
31
Isolement. Des transactions simultanées ne doivent pas
interférer entre elles.
· Durabilité. La transaction a des effets permanents
même en cas de panne.
À noter que tous les SGBD ne réalisent pas
cette propriété ACID pour les transactions.
L'accès concurrentiel implique des opérations
algorithmiques complexes à réaliser, puisqu'il faut par exemple
empêcher la modification d'une valeur par un utilisateur alors qu'elle
est en lecture par un autre. Cela nécessite la gestion d»une
structure de description des utilisateurs comprenant les droits qui leur sont
associés pour chaque élément (lecture, modification...) :
les droits d'accès aux données. Les
mécanismes sont les mêmes que ceux qui sont mis en oeuvre dans les
systèmes d'exploitation multiutilisateurs.
1.2.7. Etapes de la conception des bases d'une
donné
On peut décomposer le processus de conception d'une base
de données en plusieurs étapes :
· l'analyse du système du monde réel à
modéliser ;
· la mise en forme du modèle pour l'intégrer
dans un SGBD ;
· la création effective dans le SGBD des structures
et leur remplissage
1.2.7.1. Analyse du monde réel
La première étape de la démarche de
modélisation des données consiste à effectuer l'analyse de
la situation du monde réel à considérer. C'est une
approche « humaine » qui se fonde en partie sur des entretiens avec
les personnels concernés et ressemble plutôt à une analyse
du discours et de l'organisation de l'entreprise. C'est lors de cette phase
d'analyse que l'on détermine les objectifs du système
d'information à concevoir et que l'on identifie tous les
éléments à prendre en compte dans le système ; ce
sont les champs qui contiendront les données. lin ensemble de champs
peut constituer un objet du monde réel. Par exemple les champs «
nom », « prénom » et « adresse » que l'on
regroupe constituent une « personne ».
Cette modélisation du réel permet de proposer un
schéma conceptuel qui servira à la description
générale du système d'information. Ce schéma est
souvent réalisé à
l'aide de la symbolique du modèle « entité
association » ou, plus couramment aujourd'hui, exprimé avec le
langage UML (Unified Modeling Language).
1.2.7.2. Passage au SGBD
La représentation précédente doit
être transformée pour la rendre acceptable par le SGBD, qu'il soit
relationnel, objet ou relationnel-objet. Souvent, cette étape modifie
considérablement les objets du monde réel ainsi que les liens
définis dans le schéma précédent. C'est lors de
cette phase que l'on vérifie la qualité de la base de
données en utilisant les critères vus précédemment,
comme l'élimination de la redondance.
1.2.7.3. Création et utilisation de la base de
données
Une fois le schéma précédent
défini, on utilise le SGBD pour passer à la création des
tables qui constituent la base de données. Puis, on insère
évidemment les valeurs dans les tables.
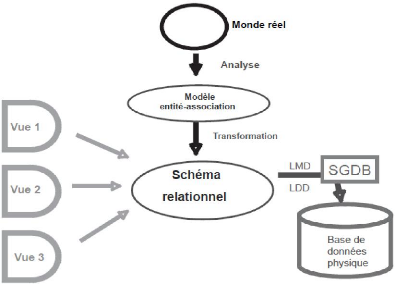
32
Figure 1.8. Etapes de conception d'une base de donnée
33
1.2.8. Langage SQL
Créé en 1974, normalisé depuis 1986, le
langage est reconnu par la grande majorité des systèmes de
gestion de bases de données relationnelles.
SQL (sigle de Structured Query
Language, en français langage de requête
structurée) est un langage informatique normalisé
servant à exploiter des bases de données relationnelles.
La partie langage de manipulation des données
de SQL permet de rechercher, d'ajouter, de modifier ou de supprimer des
données dans les bases de données relationnelles.
Outre le langage de manipulation des données, la partie
langage de définition des données permet de créer
et de modifier l'organisation des données dans la base de
données, la partie langage de contrôle de transaction
permet de commencer et de terminer des transactions, et la partie
langage de contrôle des données permet d'autoriser ou
d'interdire l'accès à certaines données à certaines
personnes.
1.2.8.1. Utilisation
Le langage SQL s'utilise principalement de trois manières
:
? un programme écrit dans un langage de programmation
donné utilise l'interface de programmation du SGBD pour lui transmettre
des instructions en langage SQL. Ces programmes utilisent des composants
logiciels tels que ODBC ou JDBC. Cette technique est utilisée par
l'invite de commande qui permet à un administrateur d'effectuer des
opérations sur les bases de données, opérations qu'il
décrit en SQL ;
? technique dite embedded SQL : des instructions en
langage SQL sont incorporées dans le code source d'un programme
écrit dans un autre langage ;
? technique des procédures stockées : des
fonctions écrites en langage SQL sont enregistrées dans la base
de données en vue d'être exécutées par le SGBD.
Cette
technique est utilisée pour les triggers -
procédures déclenchées
automatiquement sur modification
du contenu de la base de données.
34
1.2.8.2. Syntaxe générale
Les instructions SQL s'écrivent d'une manière
qui ressemble à celle de phrases ordinaires en anglais. Cette
ressemblance voulue vise à faciliter l'apprentissage et la lecture.
C'est un langage déclaratif, c'est-à-dire qu'il
permet de décrire le résultat escompté, sans
décrire la manière de l'obtenir. Les SGBD sont
équipés d'optimiseurs de
requêtes - des mécanismes qui déterminent
automatiquement la
manière optimale d'effectuer les
opérations, notamment par une estimation de la complexité
algorithmique. Celle-ci est fondée sur des statistiques
récoltées à partir des données contenues dans la
base de données (nombre d'enregistrements, nombre de valeurs distinctes
dans une colonne, etc.).
Les instructions SQL couvrent 4 domaines : Langage de
définition de données, Langage de manipulation de données,
Langage de contrôle de données, Langage de contrôle des
transactions.
a) Langage de manipulation de données
Les instructions de manipulation du contenu de la base de
données commencent par les mots clés SELECT, UPDATE, INSERT ou
DELETE qui correspondent respectivement aux opérations de recherche de
contenu, modification, ajout et suppression. Divers mots-clés tels que
FROM, JOIN et GROUP BY permettent d'indiquer les opérations
d'algèbre relationnelle à effectuer en vue d'obtenir le contenu
à manipuler.
b) Langage de définition de données
Les instructions de manipulation des
métadonnées - description de la structure, l'organisation et les
caractéristiques de la base de données - commencent avec les
mots-clés CREATE, ALTER, DROP, RENAME, COMMENT ou TRUNCATE qui
correspondent aux opérations d'ajouter, modifier,
supprimer, renommer, commenter ou vider une métadonnée. Ces mots
clés sont immédiatement suivis du type de
métadonnée à manipuler - TABLE, VIEW, INDEX...
c) Langage de contrôle de données et langage de
contrôle des transactions
Les mots clés GRANT et REVOKE permettent d'autoriser
des opérations à certaines personnes, d'ajouter ou de supprimer
des autorisations. Tandis que les mots clés COMMIT et ROLLBACK
permettent de confirmer ou annuler l'exécution de transactions.
La syntaxe de SQL fait l'objet de la norme ISO 9075. Cette
norme laisse la possibilité aux producteurs de SGBD d'y ajouter des
instructions spécifiques et non normalisées.
35
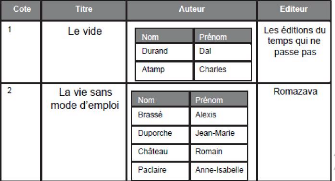
La norme a évolué au cours des années en
vue de s'adapter aux demandes, et les éditeurs de SGBD ont souvent
ajouté des possibilités à leurs produits avant que
celles-ci fassent objet de normes, ce qui provoque des variations dans la
compréhension et l'interprétation qui est faite d'un code source
en SQL par les différents logiciels de SGBD. Ces différences font
qu'un code source écrit sans précautions pour un SGBD
donné ne fonctionnera pas forcément avec un autre SGBD.
1.2.8.3. Exemple de code
·
INSERT insère des n-uplets (informellement
appelés lignes et appelés tuples en anglais) dans
une table existante, exemple :
|
INSERT INTO a_table (field1, field2, field3) VALUES
('test', 'N', NULL);
|
· UPDATE Modifie un ensemble de n-uplets existant dans
une table, exemple :
UPDATE a_table
SET field1 = 'updated value' WHERE field2 =
'N';
|
|
· DELETE Supprime un ensemble de n-uplets existant
dans une table, exemple :
DELETE FROM a_table WHERE field2 = 'N';
|
|
1.2.8.4. Langages apparentés
· Créé par extension de SQL, Transact-SQL
est un langage de programmation des SGBD SQL Adaptive Server Anywhere (ASA),
SQL Adaptive Server Enterprise (ASE), Sybase IQ de Sybase ainsi que SQL Server
de Microsoft.
· PL/SQL est un langage de programmation du SGBD Oracle
Database de Oracle Corporation. PL/pgSQL est un langage de programmation du
SGBD PostgreSQL. Ce sont des langages de programmation procédurale dans
lesquels peuvent être ajoutées des instructions en langage SQL. Le
code source écrit dans ce type de langage est compilé par le
SGBD, puis enregistré dans la base de données et
exécuté au besoin.
· OQL est un langage similaire à SQL, pour
demander des opérations aux bases de données orientées
objet et obtenir les résultats sous forme d'objets. Le langage
36
est normalisé par le Object Data Management Group - un
consortium d'industriels informatiques qui a cessé toute activité
en 2001.
1.2.8.5. Langages concurrents
Parmi les autres langages de requêtes, citons les
ancêtres de SQL comme QUEL (QUery English Language) ou SEQUEL (Structured
English QUEry Language) ou encore le langage QBE (Query By Example). Cependant
le langage QBE, très différent de SQL, est encore en vigueur dans
les SGBDR de type « fichier » tel que sont Paradox (Ansa
Software/Borland/Corel) ou Microsoft Access (base de données) de
Microsoft.
37
CHAPITRE 2 : APPLICATION WEBMOBILE
[6] [14] [15] [18] [19] [24] [25] [31]
Une application web désigne un logiciel applicatif
hébergé sur un serveur et accessible via un navigateur web et Une
application mobile est un logiciel applicatif développé pour
être installé sur un appareil mobile, généralement
un téléphone mobile, un téléphone intelligent ou
une tablette numérique et de la conjoncture de ces deux concepts sont
née les applications web-mobiles.
2.1. Naissance du web-mobile
Le Web mobile est né avec le WAP (Wireless
Application Protocol), langage de description dérivé du
HTML, qui permettait d'adapter les formats d'Internet aux contraintes des
téléphones portables. C'est à la fin des années
1990, alors que l'utilisation du Web sur les ordinateurs était en pleine
explosion, les fabricants de téléphones portables et
opérateurs mobiles décidèrent de mettre en place des
protocoles similaires à ceux utilisés sur le Web, mais
néanmoins incompatibles avec ces derniers. Cet ensemble de technologies
fut dénommé par l'acronyme WAP et standardisé via une
organisation créée pour l'occasion, le WAP Forum. Les raisons de
ce choix stratégique d'imiter sans adopter les technologies du Web
étaient multiples : il s'agissait d'abord de faire face aux
capacités des téléphones portables de l'époque,
immensément plus limitées que celles des téléphones
disponibles aujourd'hui ; le WAP fut aussi désigné pour
être indépendant du protocole de transmission au niveau
réseau, et donc en particulier indépendant de TCP/IP, du fait de
sa difficulté à être déployé sur les
réseaux mobiles de l'époque ; et enfin, de manière plus
subjective, il y avait sans doute une volonté du monde de la
téléphonie de protéger une source de revenus
contrôlée, face à la déferlante anarchique du
Web.
Les technologies WAP furent déployées sur la
majorité des téléphones distribués pendant la
première moitié de la décennie 2000. Le WAP était
incompatible avec le Web, dans la mesure où il utilisait un langage de
balises différent de HTML, WML (Wireless Markup Language), et
un protocole (WTP, Wireless Transaction Protocol) distinct du
protocole du Web, HTTP (Hypertext Transfer Protocol).
Cette incompatibilité de formats et de protocoles
signifiait qu'il n'était pas possible d'accéder au contenu des
pages web existantes depuis un téléphone et, de manière
similaire, un navigateur web classique n'était pas en mesure de lire un
site WAP (à l'exception du navigateur Opera). Pis encore, un grand
nombre d'opérateurs décidèrent de mettre en place une
chasse gardée (walled garden) et de permettre l'accès
uniquement aux sites WAP référencés sur leur portail,
obligeant du même coup les auteurs de sites WAP à négocier
le référencement de leur site avec chacun d'eux.
Au final, et malgré des attentes placées
très haut (vos serviteurs ayant eux-mêmes eu la joie de
créer des sites en WML), l'utilisation du WAP ne décolla jamais
réellement. En 2002, le WAP Forum fut intégré dans une
nouvelle organisation de standardisation d'Internet pour les portables, l'OMA
(Open Mobile Alliance), et les technologies WAP migrèrent vers
les technologies web traditionnelles : le WAP 2.0 tel que défini par
l'OMA fit désormais référence à XHTML (dans une
version optimisée pour les mobiles, XHTML MP, ou XHTML Mobile
Profile, mais compatible avec XHTML 1.0), CSS, HTTP, etc.
2.2. Fonctionnement d'une application web
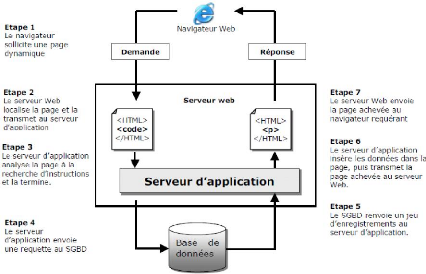
38
Figure 2.1. Fonctionnement d'une application web
39
2.3. Le web mobile
Le terme de Web mobile que nous utilisons désigne le
fait d'utiliser le Web depuis un terminal mobile s'inscrit donc avant
tout dans une continuité du Web (étendu au domaine du mobile), en
opposition au WAP, et non comme un Web séparé ou distinct. La
possibilité d'accéder au contenu optimisé pour les
terminaux mobiles depuis un ordinateur, de la même manière qu'on
peut accéder au contenu conçu pour les ordinateurs depuis un
terminal mobile, est constitutive de la notion d'un seul Web, et non de deux
domaines entièrement disjoints. Cette unicité technologique du
Web d'un type de terminal à l'autre n'implique pas qu'il ne faille
développer qu'un seul site web qui fonctionnerait de manière
identique sur tous les terminaux : bien que cette approche soit
également valide, il y a bien des cas où proposer à
l'utilisateur une version mieux adaptée à son contexte
d'utilisation se révélera la plus intéressante, tant pour
l'utilisateur que pour le fournisseur de services.
Par ailleurs, il convient de noter que l'utilisation de
technologies communes à la base (HTML et HTTP, pour résumer)
n'implique pas que toutes les technologies utilisées aujourd'hui sur un
site web initialement destiné aux ordinateurs fonctionneront sur
téléphone portable, et vice versa. Flash est un exemple classique
en la matière, puisque seul un nombre toujours très réduit
de téléphones est capable de l'interpréter utilement.
2.4. Terminaux mobiles
lin terminal mobile est un petit appareil informatique ou de
communication qu'on peut transporter avec soi dans ses déplacements et
utiliser comme terminal donnant accès sans fil à un ou plusieurs
réseaux. Parmi les terminaux mobiles, on trouve des assistants
numériques personnels (PDA), téléphones intelligents
(Smartphone), des tablettes, etc.
40
? Les assistants personnels (PDA)
Figure 2.2. Assistant personnel
lin assistant personnel est un périphérique
portable qui fonctionne comme un gestionnaire d'informations personnelles. Les
PDA sont utilisés pour la navigation sur le Web, les applications
bureautiques, les vidéos, les photos ou les téléphones
mobiles.
Les caractéristiques du modèle PDA varient,
mais les fonctionnalités communes courantes incluent les écrans
tactiles, la connectivité Bluetooth et Wifi, etc. Les PDA contiennent
des logiciels pour synchroniser les informations.
? Les smartphones

Figure 2.3. Les smartphones
lin smartphone (téléphone intelligent) est un
téléphone portable doté de fonctionnalités
très avancées. lin smartphone typique dispose d'un écran
tactile
41
haute résolution, de la connectivité WIFI, des
capacités de navigation Web et de la capacité d'accepter des
applications sophistiquées. La plupart de ces appareils fonctionnent sur
l'un de ces systèmes d'exploitation mobiles populaire : Android,
Symbian, IOS, BlackBerry OS et Windows.
? Les tablettes

Figure 2.4. Les tablettes
Une tablette PC est un ordinateur portable hybride entre un
assistant numérique personnel(PDA) et un ordinateur portable.
Équipé d'une interface à écran tactile,
possède généralement une application logicielle
utilisée pour exécuter un clavier virtuel. Cependant, de
nombreuses tablettes PC prennent en charge les claviers externes. Elles ont des
fonctions de navigation Web intégrées, des options de
connectivité multiples, des écrans tactiles capacitifs et
multimédia, y compris un support haut définition (HD).
2.5. Les écueils spécifiques au monde
mobile
Quiconque commence à s'intéresser à la
production de contenus Web sur les terminaux mobiles se heurtera très
rapidement à nombre de difficultés et défis qu'il convient
de bien identifier et comprendre pour pouvoir mieux les surmonter.
42
2.5.1. Contraintes matérielles
La première différence que la plupart d'entre
nous noterons au sujet de l'utilisation du Web sur les terminaux mobiles
concerne l'écran : celui-ci, pour être utilisable de
manière portable, est nécessairement réduit en taille, et
cette dimension différente peut avoir un impact important sur la
lisibilité et l'utilisabilité de nombreuses pages web.
À cela s'ajoute le fait que, de manière
générale, ces appareils s'utilisent avec un écran plus
haut que large (orientation portrait), alors que la plupart des ordinateurs
sont utilisés avec un écran plus large que haut (orientation
paysage) ; ils sont aussi fréquemment soumis à des
éclairages nettement moins confortables que ceux d'un écran
d'ordinateur, en particulier en cas d'utilisation à la lumière du
soleil. Mais d'autres considérations matérielles aussi
importantes, et parfois plus, peuvent échapper à une analyse trop
superficielle :
? Du fait de leur taille physique réduite, la
majorité (sinon la totalité) des terminaux mobiles proposent un
système d'entrée de texte au mieux malaisé,
souvent pénible, et de manière générale nettement
plus lent et limité que ceux disponibles sur un clavier d'ordinateur.
? De même, les systèmes de pointage
(curseur, mini-joystick ou système tactile) n'offrent que
très rarement le niveau de précision qu'un utilisateur
expérimenté peut obtenir via une souris (voire une tablette
graphique) sur un ordinateur.
? Une caractéristique trop souvent oubliée des
développeurs (mais rarement des utilisateurs), la durée de vie
limitée de la batterie - ou plus précisément, sa
propension à être vide au moment où l'utilisateur a besoin
de son téléphone et qu'il ne dispose pas de moyen de la recharger
- devra être un souci constant du développeur consciencieux.
? Le processeur, dont l'usage intensif a un effet
délétère rapide sur la durée de vie de la batterie,
est également moins puissant que ceux disponibles sur les
ordinateurs.
? Les capacités limitées en stockage
et surtout en mémoire vive (RAM) peuvent elles aussi avoir
un impact négatif sur l'expérience utilisateur, voire sur la
capacité à charger un site web existant et non
optimisé.
43
2.5.2. Contexte différent
Au-delà des difficultés auxquelles un
utilisateur pourra être confronté lors de la navigation sur le Web
depuis un terminal mobile, le contexte d'utilisation sera lui aussi en
général très différent du contexte traditionnel de
consultation sur un ordinateur.
En premier lieu, ce contexte sera nettement moins uniforme :
pressé ou à la recherche d'un passe-temps, focalisé ou
distrait, l'état d'esprit de l'utilisateur de mobile, clé de la
réalisation d'une expérience utilisateur réussie, sera
nettement plus variable que celui qu'on peut assumer d'un utilisateur assis
face à un ordinateur. Plus spécifiquement, un certain nombre
d'utilisateurs du Web mobile se trouveront effectivement en situation de
mobilité, et auront de ce fait des attentes qui, si elles ne sont
pas satisfaites, impliqueront probablement l'abandon pur et simple de la
session de navigation en cours. Parmi elles, on trouve :
? L'accès rapide à une information
contextuelle - par exemple, pour faciliter leur transit ;
? La possibilité de trouver et d'utiliser ladite
information sans être fortement concentré sur le site web
;
? L'utilisation du site web avec un minimum d'interaction
manuelle, et idéalement via l'emploi d'une seule main, voire d'un
seul doigt.
lin autre contexte d'utilisation du Web mobile de plus en
plus fréquent s'inscrit dans un usage social. Derrière
cela, nous faisons bien sûr référence aux relations
sociales virtuelles que facilitent les réseaux sociaux (type Facebook ou
Twitter), qui sont intégrés de manière de plus en plus
poussée au sein des téléphones de dernière
génération ; les réseaux sociaux restant l'un des types
d'usage les plus importants du Web mobile. De ce fait, l'utilisateur sera
probablement encore plus demandeur d'intégration de
fonctionnalités de partage et de communication sur le Web mobile qu'il
ne le serait sur son ordinateur.
Mais au-delà de ces relations sociales
virtualisées, soulignons aussi, de manière plus concrète,
l'utilisation du Web mobile en famille ou avec des amis, pour chercher la
réponse aux nombreuses questions et interrogations que font naître
les discussions autour d'un repas, d'un verre ou d'un jeu. Dans ce dernier cas,
la nécessité d'un accès rapide via une utilisation
distraite sera à nouveau un élément clé de
l'utilisation effective d'un site web.
44
2.6. Les opportunités offertes par la
plateforme
mobile
Si la création de contenus pour les terminaux mobiles
impose de se confronter à des problématiques nouvelles par
rapport aux contenus web pour ordinateur, en bien des aspects, elle est aussi
une source d'opportunités pour ceux qui savent les saisir.
2.6.1. Disponibilité
lin des plus grands atouts des terminaux mobiles, et en
particulier des téléphones portables, réside dans leur
très grande disponibilité.
· Il y a nettement plus de possesseurs de
téléphones portables que d'ordinateurs
· La plupart des utilisateurs de
téléphones portables ne s'en séparent que très
rarement.
· Ils sont, sauf exception, toujours allumés et
prêts à l'emploi, et ne requièrent que peu de
maintenance.
· Ils peuvent en général être
connectés partout et quasi immédiatement, avec un minimum
d'intervention de leurs utilisateurs.
De ce fait, le Web mobile permet de toucher un nombre
d'utilisateurs a priori plus important, et en davantage d'occasions que ce
que ne permet l'accès via un ordinateur. Ce dernier point recèle
un large jeu d'opportunités, puisqu'il est en effet désormais
possible d'atteindre, via le Web, des utilisateurs dans des situations qui
n'étaient jusqu'alors que très peu réalistes :
· Dans les transports ;
· Dans les lieux et situations d'attente ;
· Entre amis ou en famille, dans un contexte social ;
Cette liste est bien entendu non exhaustive : il ne s'agit
pour nous que de donner quelques-unes des pistes qui peuvent inspirer la
création de services et de contenus que le Web mobile rend possible,
mais c'est à chacun d'explorer, voire de créer, ces nouveaux
usages. Adaptée au contexte spécifique de leur emploi - par
exemple, en fonction de la localisation géographique de
l'utilisateur.
La combinaison de ces facteurs fait du Web mobile un moyen de
communication très riche pour la création d'une
expérience utilisateur personnalisée, permettant de
45
ce fait de créer des services correspondant mieux aux
attentes et besoins de leurs utilisateurs.
2.6.2. Innovations
Les opportunités qu'offrent les terminaux mobiles et
que nous venons d'évoquer, combinées avec la montée en
puissance des différents composants matériels qui les
constituent, font du domaine mobile l'un des principaux moteurs d'innovation en
matière d'informatique à l'heure actuelle. Ainsi, la très
grande majorité des grandes sociétés d'informatique
investissent très fortement dans ce domaine, et ont commencé
à faire émerger de nouvelles formes d'interactions qui
enrichissent considérablement les possibilités ouvertes au
Web.
2.6.2.1 Interactions tactiles
L'apparition et la popularisation des écrans tactiles
sur les terminaux mobiles créent de nouveaux modes d'interactions qui
commencent tout juste à être explorés. Pour des raisons
ergonomiques (en particulier de positionnement des bras face à un
ordinateur), il est loin d'être évident que ces écrans
tactiles deviennent disponibles sur la plupart des ordinateurs. Le
succès des interactions tactiles et multi tactiles (multitouch)
tient sans doute au fait qu'elles permettent à l'utilisateur
d'établir, de manière beaucoup plus simple qu'avec une souris ou
un curseur, un lien entre ses gestes et les réactions de l'appareil. Ce
lien direct peut être fertile en innovations, et verra sans nul doute
naître de nouvelles métaphores pour les interfaces graphiques
disponibles sur le Web.
2.6.2.2. Mouvements et déplacements
En raison de leur portabilité, les terminaux mobiles
peuvent être facilement déplacés, mais aussi
secoués, retournés, voire utilisés comme sabre laser Jedi.
Ces différents mouvements et gestes peuvent être
détectés par les appareils (via l'emploi
d'accéléromètres et de gyroscopes) et, de ce fait,
employés pour permettre à l'utilisateur d'envoyer des commandes
de manière plus intuitive (par exemple, secouer pour choisir un
élément aléatoire), à des fins ludiques ou pour
capturer des informations de nouveaux genres. Les premières interfaces
de programmation pour
46
accéder à ces informations depuis une page web
commencent à voir le jour et devraient se répandre rapidement sur
les terminaux les plus récents.
2.6.2.4. Interactions vocales
Sur les ordinateurs, l'accès à un microphone
reste le plus souvent optionnel, parfois peu pratique et, dans de nombreux
contextes, socialement difficile : il peut être par exemple
délicat de parler à son ordinateur dans des bureaux sans cloisons
! Les téléphones portables, eux, ont pour fonction
première la communication vocale : l'accès au microphone fait
donc partie des caractéristiques essentielles du design de ces
appareils, et les normes sociales en matière d'usage de la voix avec ces
appareils sont nettement mieux établies.
Par conséquent, la possibilité d'utiliser la
voix pour interagir avec le Web mobile est prometteuse. Bien que la
reconnaissance vocale embarquée au sein même des
téléphones soit encore limitée en raison de leurs faibles
capacités, la possibilité d'effectuer cette reconnaissance sur
des serveurs plutôt que sur l'appareil permet de contourner l'un des
obstacles classiques des outils basés sur la voix.
L'intégration de la voix au Web tel que nous le
connaissons en est encore à ses premiers balbutiements, mais il n'y a
que peu de doutes que c'est là aussi un domaine sur lequel de toutes
nouvelles formes d'interactions vont rapidement devenir possibles.
2.6.2.4. OEil sur le monde
On ne compte plus le nombre d'événements
journalistiques ou médiatiques dont les principaux témoignages
photographiques et vidéo ont été capturés via des
téléphones portables. Là encore, la
quasi-généralisation des appareils photo et caméras sur le
marché des téléphones rend très attractive la
possibilité de faire appel à ceux-ci pour permettre à
l'utilisateur de contribuer du contenu sur un site web. Mais au-delà du
partage de photos et de vidéos, ces capteurs peuvent aussi être
utilisés pour faciliter l'identification des besoins de l'utilisateur :
identification d'un produit par un code-barres, repérage précis
d'un lieu via une photo, voire expérience de réalité
augmentée en superposant des informations à la vue vidéo.
Tout n'est pas encore possible en la matière, mais tout porte à
croire que de nombreuses expériences et innovations verront le jour dans
les années qui viennent.
47
2.6.2.5. Géolocalisation
Les terminaux mobiles sont utilisables presque partout : cela
signifie aussi qu'ils sont utilisés dans des endroits nettement plus
variés que ne le serait un ordinateur, et que la localisation de cet
usage peut fournir des informations sur le contexte riche en enseignements. Les
téléphones peuvent, qui plus est, identifier leur localisation
par plusieurs méthodes : via le repérage des antennes de
communication installées par l'opérateur, via le repérage
de points d'accès Wi-Fi et via l'emploi d'un récepteur GPS
embarqué. Il existe d'ores et déjà une interface de
programmation (API) qui permet d'accéder à ces informations de
géolocalisation depuis une page web, et qui est disponible sur la
dernière génération de smartphones. Les
possibilités de personnalisation qu'offre ce pont entre le monde
réel et le monde virtuel sont encore entièrement à
bâtir.
2.7. Intérêt des applications web mobiles
dans le
secteur médical
Les téléphones mobiles sont devenus un
élément important de ménages et d'une partie invariable de
l'éducation, des affaires, de la profession et de l'industrie des
services. L'informatisation favorise la croissance rapide, réduit les
erreurs et procure ainsi un meilleur service dans chaque domaine de la vie ;
l'intérêt de ces applications dans le secteur de la santé
est expliqué ci-dessous :
? Disponibilité de l'information : obtenir et envoyer
facilement des rapports médicaux.
? Gestion de données : le stockage des données
dans un appareil mobile est un moyen écologique de stocker des
informations et garder facilement les trace d'un patient
Ainsi étant donné que le personnel
médical est appelé à être la majorité de son
temps de service en mouvement dans les hôpitaux ou dans les cabinets
médicaux, les applications mobiles implémentant un système
qui répond aux besoins des professionnels de santé
représente le meilleur moyen pour faciliter leurs tâches.
Ainsi cela permet aux personnels médicaux d'optimiser
leur temps de service et d'améliorer leur rendement.
48
CHAPITRE 3 : ETUDE PREALABLE
[17] [20] [21]
3.1. PRESENTATION DE L'ENTREPRISE
3.1.1. Historique
Le but de l'actuel hôpital provincial de
référence de Kinshasa, en sigle H.P.G.R.K. remonte vers les
années 1912 époque où ce ne fut qu'un simple dispensaire
recevant la population indigène en soins ambulatoires.
A la longue, l'accroissement de la population de la ville de
Kinshasa, l'expansion des industries chanic, itexaf et huileries du Congo-Belge
ainsi que la construction de chemin de fer Matatdi-Leopoldville
entrainèrent une forte migration et une fréquentation
importante.
En 1925, ce dispensaire général fut
transformé en un centre hospitalier avec 4 services de base :
médecine interne, chirurgie, maternité et soins communautaires.
La capacité d'accueil de ce centre fut de 80 lits réserves aux
indigènes.
En 1930, il y eut la construction de nouveaux pavillons (5, 6
et 9) ce qui porta la capacité de l'hôpital a 150 lits.
En 1941, la capacité d'accueil ayant été
dépassée, les autorités congolaises résolurent
d'accroitre le nombre de pavillons pour les services suivants :
· Hospitalisation des malades opérés
· Hospitalisation des fractures et accidentes divers
· Hospitalisation des évolués
· Médecine générale
· Pédiatrie
· Maternité
· Logement du personnel religieux
En 1949, malgré divers bouleversements causes par la
deuxième guerre mondiale et l'enrôlement dans les services
militaires de nombreux Congolais, la population de Léopoldville
s'accroissait du jour au jour.
49
Cette situation incita les responsables de l'hôpital
à renforcer ses services par la construction de quatre pavillons (8, 10,
12 et 14).
En 1953, sur la demande du docteur PERIN, furent construits
deux nouveaux pavillons (16 et 17) et l'hôpital comptait 1250 lits avec
quatre disciplines différentes : médecine interne, chirurgie,
gynéco obstétricale, pédiatrie ainsi que plusieurs
services spécialisés (ophtalmoscopie, stomatologue, dermatologie
et ORL).
En 1958, le médecin provincial supprima l'appellation
de « l'hôpital des Congolais » par sa lettre n° 700/A/6834
du 06 Novembre 1958 pour adopter celui de « l'hôpital de
Léopoldville Est ».
En 1960, les évènements de l'indépendance
provoquèrent beaucoup de départ massif des médecins
expatries. Ce fait entraina un mauvais fonctionnement de l'hôpital et une
dépréciation de la qualité de soins accordes aux
malades.
C'est ainsi que les organismes internationaux comme CMOS vont
assurer rapidement la relevé en fournissant un personnel
qualifié.
En 1970, l'hôpital de Léopoldville Est pris le
nom de « l'hôpital général de Léopoldville
» et sa gestion est confiée à une A.S.B.L
dénommée « Fonds médical de coordination »
FOMECO en sigle.
L'hôpital connaitra une grande expansion avec la
construction des pavillons : Pavillon 10 : Soins respiratoires
Pavillon 21 : Garage
Pavillon 24 : Médecine interne
Pavillon 30 : Service de pharmacie, achat et atelier Pavillon 31
: Radiologie
En 1972, suite à la politique de recours à
l'authenticité et suppression de noms chrétiens l'hôpital
s'appellera « Hôpital Mama YEMO ».
En 1977, les activités de FOMECO connurent un coup dur
à la suite de la crise monétaire qui a affecté notre pays
: il y eut un nouveau départ au sein de cet organisme.
Malgré ces innombrables difficultés,
l'hôpital Mama YEMO resta la plus grande formation médicale du
pays.
50
En 1987, par sa décision n°BUR/CE/29874/S/87 du 26
Novembre 1987, le commissaire d'Etat à la sante publique retira la
gestion de l'hôpital Mama YEMO du FOMECO qui devient « Hôpital
général Mama Yemo ».
En 1989, par ordonnance présidentielle n°89/169 du
07 Août 1989, il fut créé en lieu et place de
l'hôpital Mama YEMO une entreprise publique a caractère social
dénommée « Hôpital Mama YEMO » et sa
capacité a atteint plus de 2000 lits.
En 1992, par sa lettre n°CAB/M1N/SP/0284/92 du
19/02/1992, le ministère de sante décide d'instituer à
l'hôpital un mode de gestion base décentralisé.
En 1996, par décret du premier ministre n°054 du
27/12/1996, l'entreprise publique dotée d'une personnalité
juridique fut remplacée par un établissement public dote d'une
autonomie administrative et financière dénommée
Hôpital Mama YEMO.
En 1997, dans le contexte du nouveau régime issu des
mouvements insurrectionnels de l'A.F.D. L et établi depuis le 17 mai
1997 l'hôpital Mama YEMO a repris le nom de « Hôpital
général de Kinshasa », H.G.K en sigle.
En 2000, par décrets présidentielles n°082
et 083 du 13 juin 2000 portant respectivement nomination des membres du
comité de gestion et de conseil d'administration de l'H.G. K, il est
devenu une entreprise publique à caractère social.
En 2002, le statut d'entreprise publique à
caractère social est dissout par le décret n°075/2002 du 27
juin 2002. Par ce décret, le personnel et le patrimoine de
l'hôpital sont affectés au ministère de la sante publique
pour le service dénommé « Hôpital Provincial
Général de Référence pour la ville de Kinshasa
», H.P.G.R.K en sigle.
En 2005 par arrêté ministériel
n°1250/CAB/M1N/S/BYY/043/MC/2005 du 31 octobre, nomination de
l'équipe du comité de gestion de H.P.G.R.K. Cet
arrêté met ainsi fin au comité de gestion provisoire
installé depuis Novembre 2001.
3.1.2. Mission et objectifs
L'H.G. K a pour mission et objectifs :
? D'assurer les examens de diagnostics et des soins curatifs,
préventifs, promotionnels et des réadaptations aux malades,
blessées dans les niveaux périphérique et
intermédiaire ;
? De participer à la recherche médicale et
pharmaceutique et à l'éducation sanitaire ;
? D'assurer la formation et recherche ;
? De créer un esprit d'émulation entre les
entités décentralisées afin d'améliorer le
rendement.
? De maintenir les équipements nécessaires au
fonctionnement de l'entité ;
? D'accélérer le traitement des dossiers
administratifs ;
? De stimuler l'esprit de créativité et
d'initiative ;
? D'accroitre la production ;
? D'assurer l'encadrement des jeunes professionnels
diplômés et des stagiaires
en cours de formation dans les universités, les instituts
supérieurs des
techniques médicales.
3.2. SITUATION GEOGRAPHIQUE DE L'ENTREPRISE
L'hôpital Provincial General de Reference de Kinshasa
(ex hôpital Mama Yemo) est la plus grande formation hospitalière
du capital et du Congo eu égard de sa capacité d'accueil.
Il est implanté au centre-ville dans la commune de la
Gombe, il est délimité :
Au Nord par l'avenue Wangata ; Au Sud par l'avenue de
l'hôpital ;
A l'Est par le couvent des soeurs sur avenue Tombal baye ;
A l'Ouest par le jardin zoologique de Kinshasa.
51
Sa superficie est 94.345,31 m2 dont 80.565 m2 par les
pavillons.
Division secrétariat
S/Dir Planification
S/Dir form et rech
52
|
Comité de gestion
|
3.3. ORGANIGRAMME
|
Conseil de gestion
|
Direction général


Direction
administrative et
financière
Direction
médicale
S. kinésithérapie
Direction
Nursing
S/Dir Adm
Figure 3.1. Organigramme
Division personnel
Division sociale
Division de réha
Division mouvement
Division appro
D.comptabilité
D.budget & contr
D. tresorerie
D. Facturation
D. recouvrement
D.inventaire
S. Anesthésie
S. chirurgie
S. Med. Int
S. Gyneco & Obst
S. pédiatrie
S. med. légale
S. stérilisation
S. soins com.
S. spécialité ch
S. form & rech
S. Biologie clinique
S. imagerie
Direction de
pharmacie
D. gestion de stock
D. Appro
D. Analyse et contr qualit
D. Préparation
medic
D.Distribution
Corps d'audit interne
Division des relations
publiques
Division sécurité et
contentieux
Grande salles et
conférences
53
3.4. ANALYSE DE L'EXISTANT
3.4.1. Analyse des postes de travail
Dans cette phase d'étude de poste nous parlerons
surtout des activités ou taches de chaque poste, il faut noter qu'une
tache est un ensemble d'opération dont la réalisation se fait de
façon non interrompue dans un poste, il va s'en dire que nous
étudierons le département de la médecine interne car il
est celui assurant le suivi des hypertendus
? Service : Médecine interne Activité : Gestion des
Patients Poste : Infirmier exécutant Qualification : Infirmier(e)
Tâches :
1. Suivre les instructions dictées par le chef de
pavillon
2. Administrer des soins appropriés aux patients en
respectant les normes thérapeutiques établis par le
médecin
? Service: Médecine interne
Activité: Gestion des Patients
Poste: Coordination Nursing
Qualification : Infirmier(e) chef / Médecin chef
Tâches :
1. Contrôler et coordonner les activités infirmiers
(es) et les médecins
2. Veiller à une bonne administration des soins au
niveau de chaque pavillon.
3. Elaborer un rapport adressé au chef de
département
? Service: Médecine interne
Activité: Gestion des Patients Poste: Chef de Pavillon
Qualification: Chef de Pavillon Tâches:
1. Organiser et contrôler les activités de la
médecine interne au sein de son pavillon
2. Distribuer les tâches que doivent
exécutées les infirmiers (ères)
3. Elaborer un rapport des activités qui sera
adressé à la coordination nursing
4. Hospitaliser les patients et enregistrer dans un ca
hier
54
? Service: Médecine interne
Activité: Gestion des Patients
Poste: Facturation
Qualification : Chef de pool facturation
Tâches :
1. Prélèvement des actes
2. Tarification des actes
3. Etablissement de la fiche des frais
? Service : Médecine interne
Activité : Gestion des Patients Poste : Médecin
interniste Qualification : Médecin
Tâches:
1. S'occuper de la consultation de tous les patients qui se
présente A la médecine interne
2. Etablir les bons provisoires des patients, ainsi que billet
de sortie, attestation de décès et billet de transfert
3. Faire des tours de salles avec les infirmiers pour se rendre
compte de l'état des patients
3.4.2. Analyse des moyens humains, matériels et
logistiques
3.4.2.1. Moyens humains
Le département de la médecine interne compte
deux catégories d'agent oeuvrant en son sein et répartis comme
suit :
1° Professionnel de sante : Médecins, infirmiers, ...
2° Personnel administratif : Comptables, ...
Ils sont repartis par effectif, par poste suivant la
description des postes de travail et taches repris dans le paragraphe
précèdent.
3.4.2.2. Moyens matériels
Les moyens matériels peuvent être
catégorisées en deux nous avons :
? Les fournitures et accessoires de bureau
? Et les différents matériels spéciaux pour
les professionnels de santé
1. Fournitures et accessoires de bureau
Dans cette catégorie, les agents du département de
médecine interne emploient comme fourniture :
· Papiers
· Stylo
· Agrafeuses
· Machine à calculer
2. Matériels spéciaux
· Stéthoscope
· Tensiomètre
· Thermomètre
· Otoscope
3.4.2.3. Moyens logistiques
Ici nous avons recensé les différents documents
qui sont nécessaire à la gestion des patients
NOM DU BUT DU DOCUMENT
DOCUMENT
01 Fiche d'accueil Permet d'identifier le patient qui vient
d'arriver et à
recueillir sa pathologie
02 Fiche de
consultation
|
Permet aux médecins de poser les diagnostics sur le
malade
|
|
03 Registre des Permet d'identifier les malades
hospitalisés en
malades hospitalisés médecine interne
04 Bon labo Permet aux médecins de concilier les
diagnostic
provisoire émis et les réponses du laboratoire
afin d'orienter un schéma thérapeutique
05 Prescription Permet aux médecins de prescrire les
différents
médicale médicaments que doit prendre le
patient
06 Bon radio Permet aux médecins de pouvoir exploiter les
organes
internes sur base des plaintes du patient
55
07 Billet de transfert Permet un transfert du patient dans le
cas des
problèmes qui dépasse le service
08 Attestation de décès Permet de
transférer le corps du patient a la morgue
09 Fiche de suivi et de Permet aux infirmiers d'assurer la
suivie du patient
traitement pour sa meilleure prise en charge
10 Balance de liquidité Permet aux infirmiers de perfuser
ou de transfuser un malade
11 Fiche de Permet aux infirmiers de suivre l'évolution
de la
température température du patient
12 Billet de sortie Permet au médecin traitant de faire
le point sur la fin
des traitements pour autoriser la sortie
13 Fiche des frais (F.F) Permet de faire le calcul pour la
totalité de montant
des actes reçus à l' hôpital
14 Registre de fiche des Permet à enregistrer tous les
fiches des frais établites
frais au cours de la journée
15 Quittance Permet de montrer que le patient s'est
acquitté de ses
dettes vis-a-vis des actes recus a l' ho:pital
16 Rapport de service (R.S)
|
C'est un document présenté sous forme de lettre, a
l'intention du chef de la coordination de nursing et dans lequel le chef de
pavillon et son adjoint font l'exposé de l'état d'avancement et
besoin de leur pavillon
|
|
Tableau 3.1. Moyens logistique
3.4.2.4. Analyse du flux d'information
LIBELLE POSTE TRAITEMENT
ACCUE1L Elaboration de la fiche d'accueil
CHEF DE PAVILLON
|
Réception de la fiche d'accueil
|
|
|
|
Verification des traitements
|
|
|
|
Enrgistrement de transfert
Enregistrement de l'attestation de décès
Prélèvement des actes
56
57
Réception de la fiche de consultation
Réception de la fiche des frais
Vérification de la preuve de paiement
Remise de billet de sortie
Etablissement du rapport de service
INFIRMIER EXERCUTANT Elaboration de la fiche de surveillance et
de
traitement
Elaboration de la balance de liquidite
Elaboration de la fiche des températures
MEDECIN INTERNISTE Réception de la fiche de
consultation
Elaboration du bon d'analyse (labo)
Elaboration de la prescription médicale
Elaboration du bon radio et échographie
Elaboration du billet de transfert
Elaboration de l'attestation de décès
Réception de la fiche de traitement
Transfert de la fiche de consultation
Elaboration du billet de sortie
PATIENT Reception des medicaments préscrits
Reception du bon radio
Réception du billet de transfert
Réception de la fiche des frais
Reception de la quittance
Réception de la quittance après
vérification
Réception du billet de sortie
FACTURATION Réception de la fiche de consultation et
tarification
des actes
Etablissement de la fiche des frais
Enregistrement de la fiche des frais
CAISSE Achat de la fiche de consultation
Paiement de la fiche des frais
Etablissement de la quittance
LABORATOIRE Prescription du résultat labo
RAD1OLOGIE Prescription du résultat radio
PHARMACIE Fourniture des medicaments
SECURITE Verification du document
COORDINAT1ON NURSING
|
Validation et transmission de la copie
|
|
Reception du rapport
58
CHEF DE
DEPARTEMENT
Tableau 3.2. Analyse du flux d'information
3.5. CRITIQUE DE L'EXISTANT
Points forts
· Le climat de collaboration entre les agents est parfait
;
· Chaque service (poste) exécute parfaitement son
rôle et la distribution des taches est bien respectée.
Points faibles
· Nous avons remarqué que les documents sont
conservés dans des papiers fardes qui peuvent être détruit
facilement ;
· Insuffisance des matériels de travail ;
· Difficulté de retrouver avec rapidité la
fiche d'un patient ;
· Manque de moyen de communication qui peut faciliter la
communication entre agents pendant le service ;
3.6. NARRATION ET PROPOSITION D'UNE
SOLUTION
Après cette étude du système nous
comptons mettre en place une application qui permettra aux professionnel de
santé travaillant aux services de médecine interne de mieux
accomplir leur travail en ce qui concerne la prise en charge des hypertendus ;
cette application devra leur permettre de gérer un registre des patients
et de disposer d'un recueil des valeurs de tensions systolique et diastolique
pour chacun des patients. Vue que cette prise en charge peut parfois
nécessiter que le professionnel de santé se rendent au domicile
des patients il donc vrai qu'ils auront besoin des informations n'importe
où et à n'importe qu'elle moment d'où il sera mis en place
une application web-mobile afin de répondre à ces attentes.
59
CHAPITRE 4 : CONCEPTION ET REALISATION
[9] [12] [13] [14] [18] [19] [26] [27] [28]
4.1. CONCEPTION
4.1.1. Méthodologie de conception
Le choix du processus de développement à
utiliser se fait selon plusieurs critères tels que la complexité
et le type de projet, le délai de livraison, le coût de
développement et les compétences de l'équipe.
4.1.1.1. Processus de développement
Un processus définit une séquence d'étapes,
en partie ordonnées, qui concourent à l'obtention d'un
système ou à l'évaluation d'un système existant.
L'objet d'un processus de développement est de produire des logiciels de
qualité qui répondent aux besoins de leurs utilisateurs dans des
temps et des coûts prévisibles.
Il existe plusieurs processus de développement
d'applications, après avoir parcouru ces processus et leurs
caractéristiques, et en ayant connaissance de notre projet et ses
besoins, nous avons opté pour le processus UP (Unified Process) qui
semble adéquat pour ce genre d'application.
4.1.1.2. Processus UP (Unified Process)
Le processus Unifié est un processus de
réalisation ou d'évolution de logiciel entièrement
basé sur UML.
4.1.2. Langage de modélisation UML
4.1.2.1. Définition du l'UML
Langage de modélisation unifié « Unified
Modeling Language » est un langage de modélisation graphique
à base de pictogrammes. Il est apparu dans le monde du génie
logiciel, dans le cadre de la « conception orientée objet ».
Couramment utilisé dans les projets logiciels, il peut être
appliqué à toutes sortes de systèmes ne se limitant pas au
domaine informatique.
UML est l'accomplissement de la fusion de
précédents langages de modélisation objet : Booch, OMT,
OOSE. UML est à présent un standard défini par l'Object
Management Group (OMG).
4.1.2.2. Utilité d'UML
UML est utilisé pour spécifier, visualiser,
modifier et construire les documents nécessaires au bon
développement d'un logiciel orienté objet. UML offre un standard
de modélisation, pour représenter l'architecture de logicielle.
Les différents éléments représentables sont «
Activité d'un objet/logiciel, Acteurs, Processus, Schéma de base
de données, Composants logiciels et Réutilisation de composants
». Grâce aux outils de modélisation UML, il est
également possible de générer automatiquement une partie
de code, par exemple en langage Java, à partir des divers documents
réalisés
4.1.2.3. Différents types de diagrammes
d'UML
UML s'articule maintenant autour de 13 diagrammes
différents, dont quatre nouveaux diagrammes introduits par UML 2.0.
Chacun d'eux est dédié à la représentation d'un
système logiciel suivant un point de vue particulier. Par ailleurs, UML
modélise le système suivant deux modes de représentation :
l'un concerne la structure du système pris « au repos»,
l'autre concerne sa dynamique de fonctionnement. Les deux
représentations sont nécessaires et complémentaires pour
schématiser la façon dont est composé le système et
comment ses composants fonctionnent entre elles.
La figure suivant présente les différents types de
diagramme de l'UML
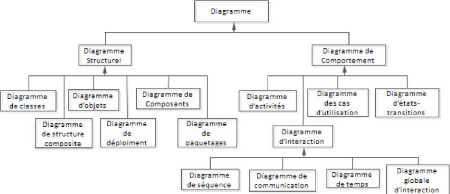
60
Figure 4.1. Différents diagrammes de uml
61
Dans notre travail nous allons utiliser seulement les diagrammes
suivants :
? Diagramme de cas d'utilisation :
représente la structure des fonctionnalités
nécessaires aux utilisateurs du système. Il est utilisé
dans les deux étapes de capture des besoins fonctionnels et
techniques
? Diagramme de séquence : est un
diagramme d'interaction, il représente les échanges de messages
entre objets, dans le cadre d'un fonctionnement particulier du système.
Ils servent ensuite à développer en analyse les scénarios
d'utilisation du système.
? Diagramme de classe : a toujours
été le plus important dans toutes les méthodes
orientés objet. C'est également celui qui contient la plus grande
gamme de notations et de variantes centralise l'organisation des classes de
conception, c'est lui qui se transforme le plus aisément en code.
4.1.3. Spécifications des besoins
4.1.3.1. Les besoins fonctionnels
1. Avoir une base de données pour le stockage des
patients.
2. Manipulation et mise à jour de la base de
données.
3. L'application conçue devra fonctionner en mode 3 -
tiers (client, serveur de données, serveur d'application).
4. Chaque utilisateur possède un login et un mot de
passe unique pour accéder à cette application.
5. Le médecin peut ajouter, supprimer, modifier ses
données.
6. Avoir un historique des prélèvements.
4.1.3.2. Les besoins non-fonctionnels
1. L'application devra être sécurisée car
les informations ne devront pas être accessibles à tout le
monde.
2. L'application doit offrir une interface conviviale,
explicite et simple à utiliser.
3. L'application doit avoir un contrôleur des champs de
saisis, pour éviter l'introduction des informations qui ne correspondent
pas aux types des champs
62
4.1.4. Analyse des besoins
4.1.4.1. Identification des acteurs
Médecin/Infirmier : est l'acteur principale de
l'application celui qui reçoit et entre les renseignements et
gère les patients.
Administrateur : est le responsable de la gestion depuis la
création jusqu'à la maintenance de l'application web.
Note : L'acteur utilisateur (user) c'est l'ensemble des
acteurs (Médecin et infirmier). 4.1.4.2. Diagramme de cas
d'utilisation
Définition
Le diagramme de cas d'utilisations identifie les
fonctionnalités fournies par le système, les utilisateurs qui
interagissent avec le système (acteurs), et les interactions entre ces
derniers
lin cas d'utilisation représente un ensemble de
séquences d'actions qui sont réalisées par le
système et qui produisent un résultat observable
intéressant pour un acteur particulier.
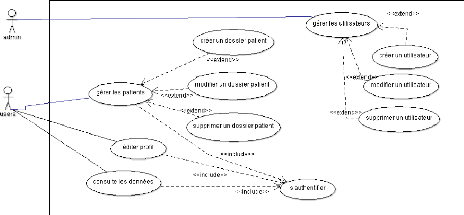
Figure 4.2. Diagramme de cas d'utilisation
63
En s'appuyant sur la figure (), nous avons distingué les
cas d'utilisation suivants :
1. Gérer les utilisateurs qui comprend la
création, la modification et la suppression d'un users.
2. S'authentifier : l'application doit vérifier que
l'utilisateur bien celui qu'il prétend être afin de lui autoriser
l'accès à l'application.
3. Gérer les patients qui comprend : la
création, la modification et la suppression d'un patient.
4. Consulter les données : obtenir des informations
sur un patient.
4.1.4.3. Détails de quelques cas d'utilisation
a) Cas d'utilisations s'authentifier
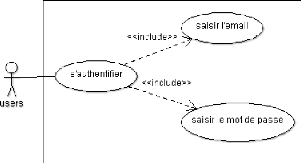
Figure 4.3. Diagramme de cas d'utilisation s'authentifier
Acteur principal : users
Objectif : S'assurer que l'utilisateur est bien celui qu'il
prétend être.
Scenario nominal :
1. L'utilisateur saisit son nom d'utilisateur et son mot de
passe
2. Le système vérifie le nom d'utilisateur et le
mot de passe.
3. Le système affiche l'espace approprié pour
chaque utilisateur.
Scenario alternatif :
Email et mot de passe sont incorrects, un retour vers la page
d'authentification sera effectué avec un message d'erreur.
64
b) Cas d'utilisation gérer les patients
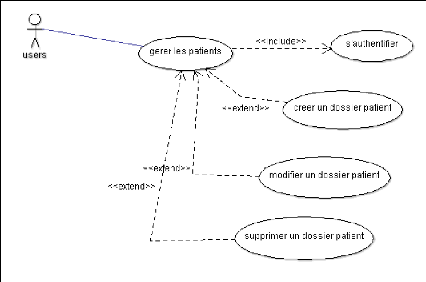
Figure 4.4. Diagramme de cas d'utilisation gérer les
patients
Acteur principal : users
Objectif : ajouter, modifier, supprimer un dossier patient.
Scenario nominal :
Cas 1. Ajouter un dossier patient
1. L'utilisateur choisit d'ajouter un dossier patient
2. Le système affiche le formulaire à remplir
3. L'utilisateur rempli et valide le formulaire
4. Le système ajoute les informations dans la base
5. Le système actualise la liste des étudiants
Cas 2. Modifier un dossier étudiant
1. L'utilisateur choisit le patient à modifier
2. Le système affiche le formulaire de modification
3. Il modifie les champs voulus.
4. Le système met à jour les informations dans
la base
5. Le système actualise la liste des patients
Cas 3. Supprimer un dossier patient
1. L'utilisateur choisit le patient à supprimer
2. Le système demande une confirmation
3. L'utilisateur confirme ou annule la suppression
4. Le système supprime le patient de la base
5. Le système actualise la liste des patients
Scenario alternatif
Cas 1. Patient existe déjà ou champs non conforme
aux types, formulaire vide : un message d'erreur sera affiché
Cas 2. Modification avec des champs vides, champs non conforme
aux types : un message d'erreur sera affiché
c) Cas d'utilisations consulter
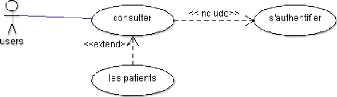
65
Figure 4.5. Diagramme du cas d'utilisation consulter un dossier
patient.
66
Acteur principal : users
Objectif : prendre connaissance des données sur le
patient
Scenario nominal :
1. L'utilisateur saisit son email et son mot de passe.
2. Le système affiche la page d'accueil.
3. L'utilisateur sélectionne l'option consulter.
4. Le système affiche la liste des patients.
5. L'utilisateur consulte les informations qu'il juge
pertinentes.
4.1.5. Diagramme des séquences
Les diagrammes de séquences sont la
représentation graphique des interactions entre les acteurs et le
système selon un ordre chronologique dans la formulation UML.
Ces communications entre les objets sont reconnues comme des
messages. Le diagramme des séquences énumère des objets
horizontalement, et le temps verticalement. Il modélise
l'exécution des différents messages en fonction du temps. Pour
réaliser les diagrammes des séquences nous avons utilisé
des opérateurs d'interactions. Un opérateur d'interaction
définit le type d'un fragment composé. Les opérateurs
d'interaction que nous avant utilisés dans les diagrammes de
séquences sont :
1. Référence (ref) : cet opérateur
désigne que le fragment fait référence à un cas vue
précédemment.
2. Alternative(Alt) : cet opérateur désigne que
le fragment composé représente un choix de comportement. Une
opérande d'interaction au maximum sera choisie.
3. Loop : cet opérateur désigne que le fragment
composé représente une boucle. L'opérande "loop" sera
répétée plusieurs fois.
a) Diagramme de séquence s'authentifier
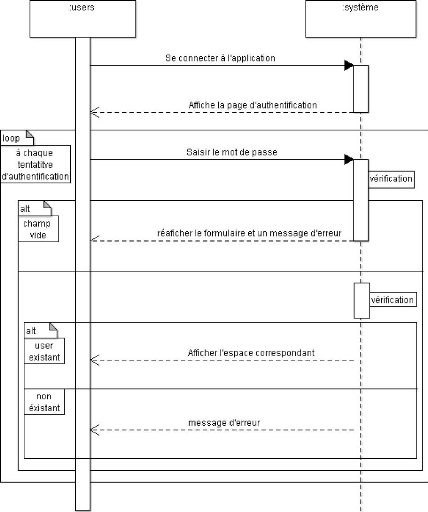
67
Figure 4.6. Diagramme de séquence lié au cas
d'utilisation s'authentifié
b) Diagramme de séquence ajout d'un patient
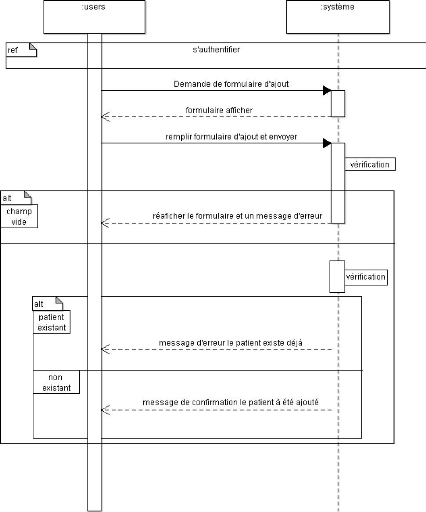
68
Figure 4.7. Diagramme de séquence lié au cas
d'utilisation ajouté un patient
c) Diagramme de séquence modifier les donner d'un
patient
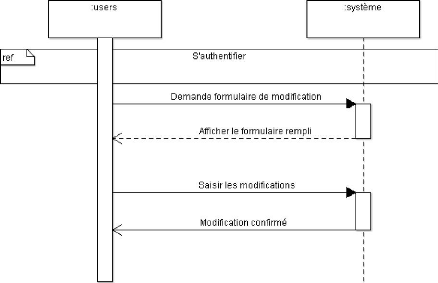
69
Figure 4.7. Diagramme de séquence lié au cas
d'utilisation modifier un dossier patient
d) Diagramme de séquence supprimer un patient
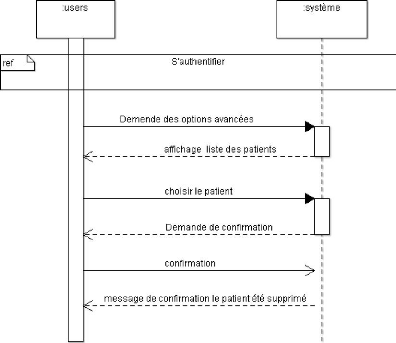
70
Figure 4.8. Diagramme de séquence lié au cas
d'utilisation supprimé un patient
71
e) Diagramme de séquence consulter les données
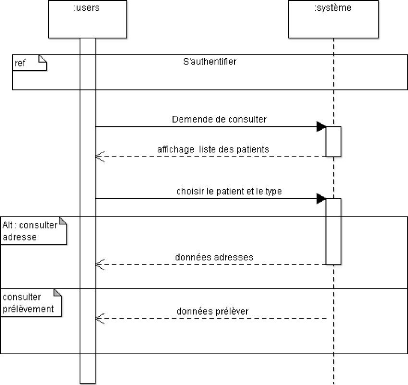
Figure 4.9. Diagramme de séquences lié au cas
d'utilisation consulter un dossier
patient
4.1.6. Diagramme de classes
Un diagramme des classes décrit le type des objets ou
données du système ainsi que les différentes formes de
relations statiques qui relient entre eux.
4.1.6.1. Description des classes
Patient : elle regroupe les informations de base sur le
patient
User : elle regroupe les informations sur les utilisateurs de
l'application
Prélèvement : elle enregistre les valeurs de
tensions systolique et diastolique recueilli lors des séances entre le
patient et le médecin.
Adresse : regroupe les informations relatives à la
localisation du patient
|
Classes
|
Attributs
|
Méthodes
|
|
Patient
|
idPatient, nom, postnom, prenom, nationalité,
dateNaissance, sexe
|
Ajouter(), Modifier(), Supprimer(), Consulter().
|
|
User
|
Id-user, email, password
|
Ajouter(), Modifier() Supprimer()
|
|
Prélèvement
|
IdPrelev,
tensionSystolique, tensionDiastolique
|
Ajouté()
|
|
Adresse
|
idAdresse, numTel, email, résidence
|
Ajouté()
|
72
Tableau 4.1. Description des classes
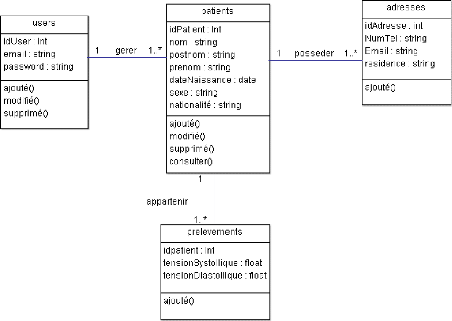
73
Figure 4.10. Diagramme de classe
4.1.7. Passage au model relationnel
Le modèle relationnel est le modèle logique de
donnée qui correspond à l'organisation des données dans
les bases de données relationnelles. Un modèle relationnel est
composé de relations, encore appelée table. Ces tables sont
décrites par des attributs ou champs. Pour décrire une relation,
on indique tout simplement son nom, suivi du nom de ses attributs entre
parenthèses. L'identifiant d'une relation est composé d'un ou
plusieurs attributs qui forment la clé primaire. Une relation peut faire
référence à une autre en utilisant une clé
étrangère, qui correspond à la clé primaire de la
relation référencée.
74
4.1.7.1. Règles de passage du diagramme de
classe au modèle relationnel
Cette section présente les règles permettant de
décrire un schéma logique dans les modèles relationnel et
objet-relationnel à partir d'un diagramme de classe UML. Nous donnons
ci-après quatre règles (de R1 à R4) pour traduire un
schéma UML en un schéma relationnel équivalent. Il existe
d'autres solutions de transformation, mais ces règles sont les plus
simples et les plus opérationnelles.
Transformation des classes (R1)
Chaque classe du diagramme UML devient une relation. Il faut
choisir un attribut de la classe pouvant jouer le rôle d'identifiant. Si
aucun attribut ne convient en tant qu'identifiant, il faut en ajouter un de
telle sorte que la relation dispose d'une clé primaire.
Transformation des associations
Les règles de transformation que nous allons voire
dépendent des cardinalités/multiplicités maximales des
associations. Nous distinguons trois familles d'associations.
? Association un à plusieurs (R2) : Il
faut ajouter un attribut de type clé étrangère dans la
relation fils de l'association. L'attribut porte le nom de la clé
primaire de la relation père de l'association. La clé de la
relation père migre dans la relation fils.
? Association plusieurs à plusieurs (R3) :
L'association (classe-association) devient une relation dont la
clé primaire est composée par la concaténation des
identifiants des classes connectées à l'association. Chaque
attribut devient clé étrangère si classe connectée
dont il provient devient une relation en vertu de la règle R1. Les
attributs de l'association (classe-association) doivent être
ajoutés à la nouvelle relation. Ces attributs ne sont ni
clé primaire, ni clé étrangère.
? Association un à un (R4) : Il faut
ajouter un attribut clé étrangère dans la relation
dérivée de l'entité ayant la cardinalité minimale
égale à zéro. Dans le cas de UML, il faut ajouter un
attribut clé étrangère dans la relation
dérivée de la classe ayant la multiplicité minimale
égale à un. L'attribut porte le nom de la clé primaire de
la relation dérivée de l'entité (classe) connectée
à l'association. Si les deux cardinalités (multiplicités)
minimales sont à zéro, le choix est donné entre les deux
relations dérivées de la règle R1. Si les deux
cardinalités minimales sont à un, il est sans doute
préférable de fusionner les deux entités (classes) en une
seule.
75
Transformation de l'héritage
Trois décompositions sont possibles pour traduire une
association d'héritage en fonction des contraintes existantes dont la
décomposition par distinction, décomposition descendante,
décomposition.
Mais ce cette sous-section ne sera pas développé
vue que notre modèle ne contient pas de relation d'héritage.
4.1.7.2. Modèle logique de données
users (Id-user, email, password)
patients (idPatient, Id-user, nom, postnom, prenom,
nationalité, dateNaissance, sexe)
prelevements (IdPrelev, idPatient, tensionSystolique,
tensionDiastolique)
adresses (idAdresse, idPatient, numTel, email,
résidence)
76
4.2. REALISATION
4.2.1. Environnement de développement
4.2.1.1. Xampp
|
|
|
Xampp est une plate-forme de développement Web pour des
applications
Web dynamiques à l'aide du serveur Apache2, du langage
de scripts PHP et Perl d'une base de données MySQL et MariaDB.
|
4.2.1.2. PhpMyAdmin

PhpMyAdmin est un outil logiciel gratuit écrit en PHP,
destiné à gérer l'administration de MySQL sur le Web.
Prend en charge une large gamme d'opérations sur MySQL tel que la
gestion des bases de données, des tableaux, des colonnes, des relations,
des index, des utilisateurs, des autorisations, etc. ses opérations
peuvent être effectuées via l'interface utilisateur, alors il
offre aussi la possibilité d'exécuter directement une instruction
SQL.
4.2.1.3. Sublime text 3
|
Sublime text est ub éditeur de texte
générique codé en C++ et python, disponible sur Windows,
Mac et Linux. Il prend en charge 44 langages de programmation.
|
4.2.2. Bibliothèques utilisées
4.2.2.1.Twitter bootstrap

Twitter Bootsrap : est une collection
d'outils utile à la création de sites et d'applications web.
C'est un ensemble qui contient des codes HTML et CSS, des formulaires, boutons,
outils de navigation et autres éléments interactifs, ainsi que
des extensions JavaScript en option.
77
4.2.2.2. JQuery
|
jQUERY : est une bibliothèque JavaScript libre qui
porte sur l'interaction entre JavaScript (comprenant Ajax) et HTML, et a pour
but de simplifier des commandes communes de JavaScript.
|
|
4.2.3. Langages de développement
4.2.3.1. Html & css
|
HTML : est un langage dit de « marquage » ou de
« balisage » dont le rôle est de formaliser l'écriture
d'un document avec des balises de formatage.
CSS : feuille de style c'est un langage qui permet de
gérer l'apparence de la page web
|
78
4.2.3.2. Php
|
|
|
PHP : est un langage de programmation libre utilisé
pour produire des pages Web dynamique via un serveur http. Il peut être
intégré facilement au HTML.
|
4.2.3.3.SQL
|
|
|
SQL (Structured Query Language) est un langage informatique
permettant de communiquer avec une base de données.
|
4.2.3.4. JavaScript
|
|
|
C'est un langage de programmation qui offre la
possibilité d'implémenter des traitements élaborés
dans des pages web, et permet d'apporter des améliorations au langage
HTML en permettant d'exécuter des commandes de la cote client
(c'est-à-dire au niveau du navigateur et non du serveur web).
Ainsi le langage JavaScript est fortement dépendant du
navigateur appelant la page web laquelle le script est incorpore, mais en
contrepartie il ne nécessite pas de compilateur.
|
79
4.2.4. Système de gestion de base de
données
|
MySQL est un système de gestion de base de
données relationnelles (SGBDR). Il est distribué sous licence GPL
et propriétaire.
|
4.2.5. Implémentation de la base de donne
? Les tables de la base données

Figure 4.11. Tables dans mysql.
? La table users cette table contient les informations sur les
utilisateurs de l'application
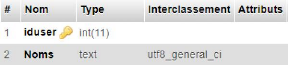

Figure 4.12. Table users
? La table patients cette contient les identifiants des
patients
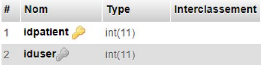



Figure 4.13. Table patients
? La table adresses contient les informations
complémentaires sur le patient
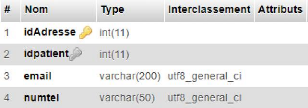
80
Figure 4.14. Table adresses
81
? La table prélèvement contient les informations
sur les prélèvements effectués sur les patients
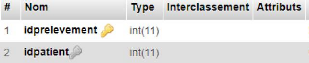


Figure 4.15. Table prelevements
4.2.6. Présentation de l'application
Dans ce qui suit nous allons présenter les interfaces
de notre application à travers les différentes captures
suivantes.
4.2.6.1. Interface d'authentification
Cette interface offre aux utilisateurs un service de
d'authentification où ils doivent remplir les champs en saisissant les
coordonnées et le mot de passe.
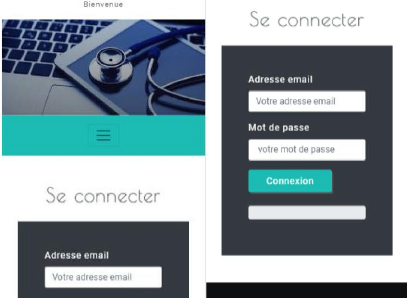
82
(a) (b)
Figures 4.16. Interfaces d'authentification
83
4.2.6.2. Interface d'accueil
Ces interfaces illustrent la page d'accueil de l'application
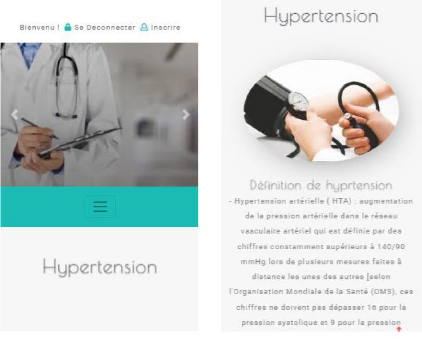
(a) (b)
Figures 4.17. Interfaces d'acceuil
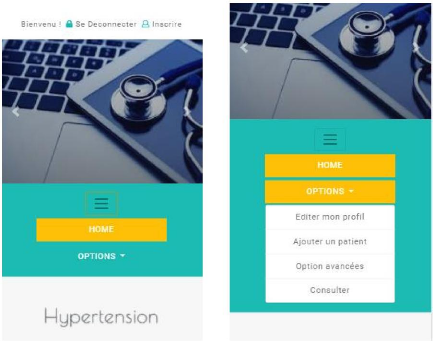
(a) (b)
84
Figures 4.18. Page d'accueil
4.2.6.3. Interface d'inscription
Sur ces interfaces l'utilisateurs doit remplir le formulaire afin
d'inscrire un nouvel utilisateur.
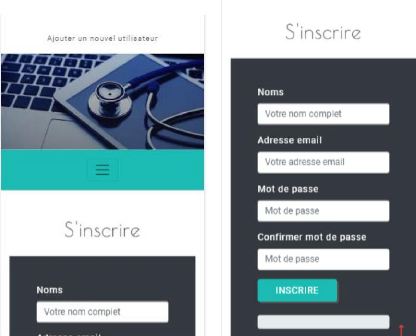
85
(a) (b)
Figures 4.19. Interface d'inscription
4.2.6.4. Interface d'ajout d'un patient
Si l'utilisateur veut ajouter un patient il doit remplir champs
et ensuite valider
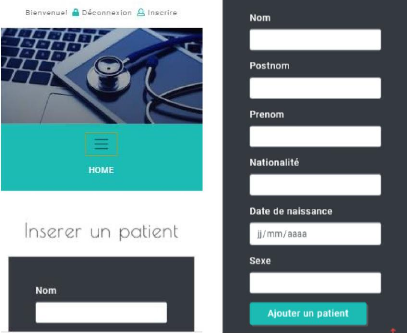
86
(a) (b)
Figures 4.20. Interface d'ajout d'un patient
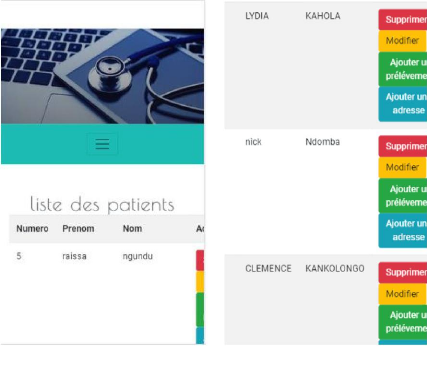
(a) (b)
87
4.2.6.5. Interface de consultation de la liste des
patients et options avancées
88
(c)
Figures 4.21. Consultation de la liste et autres options
4.2.6.6. Interface d'ajout
prélèvement
Ces figures présentent insertion d'un
prélèvement sur un patient
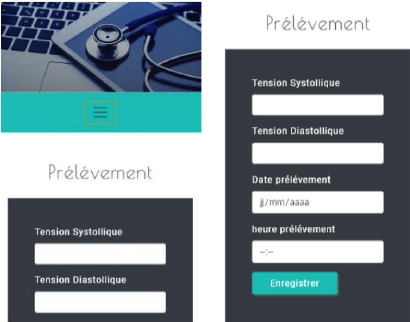
89
(a) (b)
Figures 4.22. Ajout prélèvement
4.2.6.7. Interface de consultation de données
prélevé Ces figures présentent les données
prélevées sur un patient
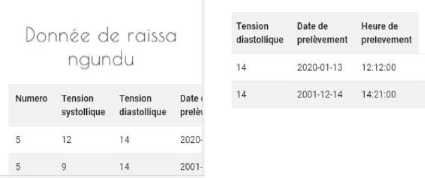
90
(a) (b)
Figures 4.23. Consultation des données
prélevées
4.2.6.8. Interface d'édition du profil
Dans cette l'utilisateur peut mettre à jours ces
informations personnels
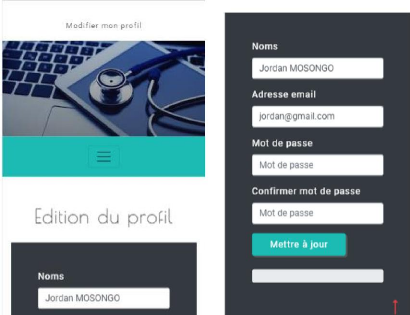
91
(a) (b)
Figures 4.24. Edition du profil
92
CONCLUSION
Face à l'importance de la gestion des hypertendus, nous
avons étudié, conçu et réalisé à
travers de ce travail un système (application web) adaptable au mobile
qui permet aux médecins d'améliorer la qualité de leurs
services en leur permettant de travailler n'importe où et en assurant la
protection de leurs données.
Nous avons dans un premier temps présenté une
étude sur l'architecture client-serveur qui est le modèle de
fonctionnement logiciel qui a été utilisé et sur les bases
données. Nous avons présenté dans la deuxième
partie les applications web mobile, en partant de leur naissance pour terminer
avec leurs intérêts pour le domaine médical. Nous avons
présenté dans la troisième partie une étude de
l'organisme d'accueil qui est l'hôpital général de
référence de Kinshasa. Ensuite dans la quatrième nous
avons entamé les différentes étapes de la conception et de
la réalisation de notre solution en débutant par le
développement des diagramme UML et finissant par la réalisation
de l'application en utilisant MySql comme système de gestion de base
données, les langages tels que le HTML, le JavaScript et le PHP comme
langage de programmation.
Le but de l'application était de montrer
l'intérêt de l'informatisation du secteur de la santé, en
réalisant un prototype de gestion des hypertendus, en assurant plusieurs
avantages par rapport à la gestion manuelle. Ce travail qui a fait
l'objet d'une expérience très enrichissante, nous a permis de
réaliser qu'un projet de réalisation d'une application web mobile
est un ensemble de plusieurs actions planifiées et dépendantes
les unes des autres. Toutes les étapes de ce projet nous ont permis
d'enrichir notre expérience notamment dans les différents outils
et langages dédiés à la programmation.
Au final étant donné que nul ne peut se
prétendre aborder un domaine dans son ensemble nous souhaiterons venir
Améliorer les interfaces pour qu'elles répondent aux
critères ergonomique et Héberger l'application sur un serveur.
Enfin, ce travail étant une oeuvre humaine, n'est donc
pas un modèle unique et parfait, c'est pourquoi nous restons ouverts
à toutes les critiques et nous sommes prêts à recevoir
toutes les suggestions et remarques tendant à améliorer davantage
cette initiative
1.
BIBLIOGRAPHIE
A. Ouvrages
93
Christian SOUTOU, UML 2 pour les bases de
données, Editions Eyrolles.
2. Gilles ROY, Conception des bases
données avec UML, presses de l'université du
Québec,2009.
3. Joseph GABAY & David GABAY, UML 2
analyse et conception, DUNOD, Paris, 2008.
4. Nicolas LARROUSSE, Création de base
de données, collection Synthex Pearson Education France.
5. Stéphane CROZAT, Conception de base
de données, UTC 2005.
B. Brochure
6. François DAOUST & Dominique
HAZAEL-MASSIEUX, Relever le défi du web mobile. Bonnes
pratiques de conception et de développement, Eyrolles.
C. Notes de cours
7. DIGALLO Frédéric,
Intégration des systèmes client-serveur, CNAM Aix provence
2002.
8. KAFUNDA KATALAY Pierre, Cours de base de
données, Centre de recherche en data mining et machine learning,
2017.
9. KASORO MULENDA Nathanaël, Cours de
programmation orientées objet 3ème graduat sciences
informatiques, Université de Kinshasa,2018.
10. MBUYI MUKENDI Eugène, Cours de bases
de données 3ème graduat sciences informatiques,
Université de Kinshasa, 2018.
11. RIGAUX Philippe, Cours de bases de
données, 2001.
94
D. Mémoire et travail de fin de cycle
12. AKOU Hamza & HARKOUK Said,
Conception et réalisation d'une application web de gestion d'hôtel
sous java cas hôtel royal, Mémoire de fin de cycle,
Université Abderrahame mira-Béjaia, informatique, 2015.
13. BARKA Anis, Conception et
réalisation d'une application mobile pour le suivi d'un cabinet
médical, Université A. Mira de Béjaia, informatique,
2016.
14. FASLA Ouassini & BENTOUMI Zouheir
Belhadj, Conception et réalisation d'une application mobile
web, mémoire de fin d'etudes, Université Abou Bakr
Belkaid-Tlemcen, Informatique 2015.
15. KALONZO Sarah, Développement et
mise en place d'une application pour la gestion en ligne d'une
bibliothèque, Travail de Fin de cycle, ULK, Informatique, 2014
16. KATULUMBA MBIYA NGANDU Marcel, Mise en
place d'une application client-serveur pour la gestion des ventes de produits
brassicoles cas de la Brasimba/Mbujimayi, Travail de fin de cycle,
Université de Mbujimayi, informatique.
17. LANDU YONGO Benjamin, Mise en place
d'une application pour la gestion des sinistrés en assurance automobile
cas de la sonas, Travail de fin de cycle, UNIKIN, informatique 2015.
18. MOUSSOUNI ZOBIR & RAMDANI
MASSINISSA, Conception et réalisation d'une application mobile
pour le service de tourisme, cas de WILAYA DE BEJAIA, Mémoire de master,
Université de Béjaia, informatique,2017
19. SAICHE Cylia & OUYOUGOUTE Abdelatif,
Conception et réalisation d'une application web pour la gestion des
étudiants d'une école privée. Cas d'étude : "ISA
School", Mémoire de fin d'étude, Université A/Mira de
Béjaîa, Informatique 2015.
20. SION ISRAEL Sion, travail de fin de
cycle, Mise en place d'une application de Gestion des locaux à la
Faculté des Sciences de l'Université de Kinshasa, informatique
2016.
21. WANGI NGOY Eric, Conception et
réalisation d'un système pour la gestion des patients,
Mémoire de fin de cycle, Université Protestante du Congo,
2007.
22.
E. Site web
95
https://www.doctissimo.fr/sante/dictionnaire-medical/hypertendu
23.
https://fr.wikipedia.org/wiki/StructuredQueryLanguage
24.
https://fr.wikipedia.org/wiki/Web
mobile
25.
https://fr.wikipedia.org/wiki/Application
web
26.
https://fr.wikipedia.org/wiki/sublime
text
27.
https://fr.wikipedia.org/wiki/PhpMyadmin
28.
https://fr.wikipedia.org/wiki/MySQL
29.
https://www.susinfo.com/articles/single/574-architecture-2-tiers-vs-architecture-3-tiers
30.
Polymorphe.free.fr/cours/bd/sql/poly_2.html
31.
Imageordinateur.blogspot.com/2012/11/importance-de-l-dans-le-secteur-de-la.html?m=1
96
TABLES DES MATIERES
EPIGRAPHE i
DEDICACES ii
REMERCIEMENTS iii
LISTES DES FIGURES iv
LISTES DES TABLEAUX v
INTRODUCTION vi
1. Problématique vi
2. Hypothèse vii
3. Choix et intérêt du sujet
vii
4. Délimitation du travail vii
5. Méthodes et techniques utilisées
viii
5.1. Méthodes viii
5.2. Techniques viii
6. Subdivision du travail viii
CHAPITRE I. ARCHITECTURE CLIENT SERVEUR ET BASE DE
DONNEES 9
1.1. ARCHITECTURE CLIENT/SERVEUR 9
1.1.1. Définition 9
1.1.2. Notions de base 9
Fonctionnement d'un système client serveur
10
1.1.3. Répartition des taches 10
1.1.4. Différant modèles de client serveur
11
1.1.5. Différentes architectures 11
a) Architecture Client Serveur à deux niveaux
11
b) Architecture Trois Niveaux 12
c) L'architecture N-Tiers 13
97
1.1.7. Les protocoles échanges ou de transferts 14
1.1.8. Middleware 14
1.1.8.1. Définition 14
1.1.8.2. Objectifs 15
1.1.8.3. Types de middleware 16
1.1.8.4. Composantes du middleware 16
1.1.7.5. Fonctions 16
1.1.8.6. Les services du Middleware 17
1.1.7.7. Serveur Web 18
1.1.8.8. Exemples de Middleware 18
1.1.9. Quelques avantages 19
I.2. BASE DE DONNEES 20
1.2.1. Limites à l'utilisation des fichiers 20
1.2.2. Notion de base de données et définition des
concepts 21
Définition Base de donnée (Data Base) : 21
1.2.3. Utilisation d'une base de données 22
1.2.4. Critères d'une base de données 23
1.2.5. Évolution des bases de données 23
Modèles De Bases De Données 23
a) Modèle hiérarchique et modèle
réseau 23
b) Modèle relationnel 25
c) Modèle objet 25
d) Modèle relationnel-objet 26
1.2.6. Systèmes de gestion de bases de données
27
1.2.6.1. Origine des SGBD
1.2.6.2. Evolution des systèmes de gestion de base de
données 27
a) Les SGBD hiérarchiques et réseaux 27
b) Les SGBD relationnels 27
c)
98
Les SGBD orientés objet 28
d) Autres SGBD 28
1.2.6.3. Fonctionnalités d'un SGBD 28
1.2.7. Etapes de la conception des bases d'une donné 31
1.2.7.1. Analyse du monde réel 31
1.2.7.2. Passage au SGBD 32
1.2.7.3. Création et utilisation de la base de
données 32
1.2.8. Langage SQL 33
1.2.8.1. Utilisation 33
1.2.8.2. Syntaxe générale 34
a) Langage de manipulation de données 34
b) Langage de définition de données 34
c) Langage de contrôle de données et langage de
contrôle des
transactions 34
1.2.8.3. Exemple de code 35
1.2.8.4. Langages apparentés 35
1.2.8.5. Langages concurrents 36
CHAPITRE 2 : APPLICATION WEBMOBILE 37
2.1. Naissance du web-mobile 37
2.2. Fonctionnement d'une application web 38
2.3. Le web mobile 39
2.4. Terminaux mobiles 39
2.5. Les écueils spécifiques au monde mobile 41
2.5.1. Contraintes matérielles 42
2.5.2. Contexte différent 43
2.6. Les opportunités offertes par la plateforme mobile
44
2.6.1. Disponibilité 44
2.6.2. Innovations 45
99
2.6.2.1 Interactions tactiles 45
2.6.2.2. Mouvements et déplacements 45
2.6.2.4. Interactions vocales 46
2.6.2.4. OEil sur le monde 46
2.6.2.5. Géolocalisation 47
2.7. Intérêt des applications web mobiles
dans le secteur médical
................................................................................................
47
CHAPITRE 3 : ETUDE PREALABLE 48
3.1. PRESENTATION DE L'ENTREPRISE 48
3.1.1. Historique 48
3.1.2. Mission et objectifs 50
3.2. SITUATION GEOGRAPHIQUE DE L'ENTREPRISE
51
3.3. ORGANIGRAMME 52
3.4. ANALYSE DE L'EXISTANT 53
3.4.1. Analyse des postes de travail 53
3.4.2. Analyse des moyens humains, matériels et
logistiques 54
3.4.2.1. Moyens humains 54
3.4.2.2. Moyens matériels 54
3.4.2.3. Moyens logistiques 55
3.4.2.4. Analyse du flux d'information 56
3.5. CRITIQUE DE L'EXISTANT 58
3.6. NARRATION ET PROPOSITION D'UNE SOLUTION
58
CHAPITRE 4 : CONCEPTION ET REALISATION 59
4.1. CONCEPTION 59
4.1.1. Méthodologie de conception 59
4.1.1.1. Processus de développement 59
4.1.1.2. Processus UP (Unified Process) 59
100
4.1.2. Langage de modélisation UML 59
4.1.2.1. Définition du l'UML 59
4.1.2.2. Utilité d'UML 60
4.1.2.3. Différents types de diagrammes d'UML 60
4.1.3. Spécifications des besoins 61
4.1.3.1. Les besoins fonctionnels 61
4.1.3.2. Les besoins non-fonctionnels 61
4.1.4. Analyse des besoins 62
4.1.4.1. Identification des acteurs 62
4.1.4.2. Diagramme de cas d'utilisation 62
4.1.4.3. Détails de quelques cas d'utilisation 63
4.1.5. Diagramme des séquences 66
4.1.6. Diagramme de classes 72
4.1.6.1. Description des classes 72
4.1.7. Passage au model relationnel 73
4.1.7.1. Règles de passage du diagramme de classe au
modèle relationnel 74
4.1.7.2. Modèle logique de données 75
4.2. REALISATION 76
4.2.1. Environnement de développement 76
4.2.1.1. Xampp 76
4.2.1.2. PhpMyAdmin 76
4.2.1.3. Sublime text 3 76
4.2.2. Bibliothèques utilisées 77
4.2.2.1.Twitter bootstrap 77
4.2.2.2. JQuery 77
4.2.3. Langages de développement 77
4.2.3.1. Html & css 77
4.2.3.2. Php 78
4.2.3.3.SQL 78
101
4.2.3.4. JavaScript 78
4.2.4. Système de gestion de base de
données 79
4.2.5. Implémentation de la base de donne
79
4.2.6. Présentation de l'application
81
4.2.6.1. Interface d'authentification 81
4.2.6.2. Interface d'accueil 83
4.2.6.3. Interface d'inscription 85
4.2.6.4. Interface d'ajout d'un client 86
4.2.6.5. Interface de consultation de la liste des
patients et options avancées
87
4.2.6.6. Interface d'ajout prélèvement
89
4.2.6.7. Interface de consultation de données
prélevé 90
4.2.6.8. Interface d'édition du profil
91
CONCLUSION 92
BIBLIOGRAPHIE 93
TABLES DES MATIERES 96
| 

