
1
UNIVERSITE DE YAOUNDE I FACULTE DES SCIENCES
UNIVERSITY OF YAOUNDE I FACULTY OF SCIENCES
DEPARTEMENT D'INFORMATIQUE
DEPARTMENT OF COMPUTER SCIENCE
GESTION D'INFORMATIONS : MUTATION
LANGAGE DE PROGRAMMATION SQL
VERS LES BASES DE DONNEES
RELATIONNELLES ET LE
Mémoire présenté en vue de
l'obtention du diplôme de
MASTER II RECHERCHE
Option : S.I &
G.L
Par :
AMINI MUDUMBI Jacques Ingénieur en
Informatique
Sous la direction de :
MARCEL FOUDA NDJODO, Professeur
Année Académique 2017-2018
1
Sommaire
Introduction générale
Chapitre I : L'ordinateur auxiliaire de stockage
Chapitre II: Les bases des données : une nouvelle
considération de stockage et manipulation des données
Chapitre III: Les évidences de mutation vers les bases de
données relationnelles Chapitre IV: Le langage Sql : un manipulateur de
bases de données relationnelles Chapitre V: Le Sql intégré
: un paquetage de Sql Embarqué
Conclusion générale
Bibliographie
2
La mort est certaine mais l'heure de la mort est incertaine.
C'est en sachant que nous sommes poussière et retourneront à la
poussière que notre coeur coule de larmes et de blessures
intérieures surtout que vous n'étiez plus. A notre
regretté Père MUDUMBI Edmond, que vous soyez immortalisée
par ce travail. Vos empreintes restent à jamais marquées dans le
souvenir de nos pensées. C'est aujourd'hui plus que jamais que nous
apprécions la valeur de vos efforts, la justesse de votre
éducation et le caractère précieux de vos conseils.
3
Programmez toujours vos applications comme si la personne qui
doit les maintenir ensuite
était un psychopathe violent qui sait où vous
habitez.
John F. Woods
4
A mes parents et aux êtres qui sont les plus chers au
monde et auxquels je ne saurais jamais exprimer ma gratitude et ma
reconnaissance en quelques lignes.
5
Remerciements
De prime à bord, je remercie Dieu, le Tout Puissant
pour ses faveurs et ses gratitudes, de m'avoir donné le courage et la
patience pour avoir mené à bon escient ce travail durant toutes
ses deux années de recherche.
Mes sincères remerciements s'adressent à
l'ensemble des personnes qui ont eu la gentillesse et la bienveillance de
m'accorder de leur temps et d'eux-mêmes en acceptant de participer
à cette recherche.
Je remercie le Professeur Marcel FOUDA NDJODO
pour m'avoir fait l'honneur de m'encadrer et pour la confiance qu'il
m'a accordée dès le début me permettant ainsi
d'élaborer un travail personnel et propre à mes aspirations. Je
le remercie également pour ses compétences de recherche et son
ouverture d'esprit qui m'ont conduit à tirer le meilleur parti de mes
capacités intellectuelles.
En effet, je lui suis infiniment reconnaissant de m'avoir
encouragé et soutenu durant ce travail, j'ai ainsi pu apprécier
sa rigueur scientifique, ses relectures du manuscrit, ses remarques et
suggestions, son recueil, ses grandes qualités humaines et son oeil
critique qui m'as été très précieux et m'ont
amené à affiner et clarifier toujours plus ma réflexion et
cela m'a permis de structurer mon travail et améliorer sa
qualité. Qu'il soit persuadé de mon plus profonde
considération et plus grand respect.
Un mémoire de recherche ne pourrait être
présenté sans l'évaluation de la qualité et de
l'originalité de la recherche par un jury. Mes seconds remerciements
iront donc, tout naturellement, à ces personnes qui ont jugés ce
travail avec conscience et impartialité. Je remercie tout d'abord mes
deux rapporteurs, le Prof. DONTSI et le Prof. Charles
AWONO ONANA, de m'avoir faire l'honneur d'accepter de lire mon
manuscrit et d'avoir apportés des remarques et des commentaires
constructifs. Je les remercie de leur gentillesse et leur compréhension.
Je remercie mon premier examinateur, Dr. LOUKA Basile, pour sa
sympathie et sa confiance tout au long de mon travail. Je remercie
également le président du jury et mon second examinateur, le
Prof. TCHUENTE Maurice d'avoir pris le temps de m'expliquer le
fonctionnement de sa plate-forme en mathématique-informatique (de
m'avoir à la fois fourni des exemples illustratifs et des explications
théoriques). Je le remercie également d'avoir répondu
rapidement à chacune de mes interrogations et d'avoir su me donner des
conseils pertinents sur la construction de mon modèle.
Je remercie tout particulièrement Armel,
Justine, Blaise, Pascal, Nicolas. Sans eux, je n'aurais sans doute pas
réussi à accéder à certaines données de mes
terrains.
6
Je remercie également mes collègues du Centre
Informatique et Laboratorium (CIL), et en particulier d'autres chercheurs :
Stéphane, Jadel, Sangara, Patient, Pierre, Virginie, Vidal,
Marc-Claudia. Je ne compte plus les séminaires, colloques et
interminables discussions passés ensemble. Au cours de ces deux
années de recherche, ils m'ont été d'une aide inestimable,
que ce soit sur un plan scientifique ou personnel.
Merci aussi à Marie-Anne et Sophie
d'avoir été à mes côtés pour
organiser des moments de réflexion collective autour des
hypothèses que cette mémoire de recherche se propose
d'éprouver. Je remercie à cette occasion toutes les personnes qui
ont contribué à faire vivre ce séminaire.
Je souhaite également faire part de mon attachement et
de ma profonde reconnaissance à Marie-Aziza. Elle m'a
donnée le goût de la recherche et aidé à croire en
moi, et en l'intérêt de mes travaux.
En ce moment si particulier, j'ai bien sûr une
pensée pour mes ami(e)s :
Joseph, Junior, Jonathan, Espoir, Arnold, Louis,
Trésor, Semence. Je pense tout particulièrement à
Ma grande Soeur L'Inf. Justine MUDUMBI, pour tous les
sacrifices consentis jusqu'à l'aboutissement de ce travail, je partage
ma joie avec elle, mais aussi à Francisca et Djemimah,
pour leurs interminables conseils de qualité pour l'accomplissement de
ce travail de recherche. A l'évidence, sans eux, ce mémoire de
recherche ne serait pas ce qu'elle est.
Je remercie également ma famille. Je pense
évidemment à ma mère Marie LUBAO et
à la bienveillance avec laquelle elle s'est attachée à me
mettre dans les meilleures dispositions pour aller au terme de cette recherche.
Je pense aussi à mes frère et soeurs, Prince, Elie,
David, Daniel, Michel, Boniface, Damien, Moise, Inf. Justine, Djemimah,
Francisca, Consolatrice, Lucie, Thèrese, Elysée, Cécile,
Orthance. Il va sans dire qu'un tel projet ne se réalise sans
la compréhension et le soutien moral de ses proches.
Enfin, je ne remercierai jamais assez mon oncle Maternel
Blaise, pour le soutien qu'il m'a apporté, dans les
moments où j'en avais le plus besoin, et la patience dont il a fait
preuve dans la dernière ligne droite de ce travail de recherche.
7
Lexique
ANSI (American National Standard Institute):
Organisme de Normalisation Américain, Constitué des producteurs,
de consommateurs et de groupes d'intérêt général, et
qui est le représentant US à l'ISO.
BD (Base de données) : Est un ensemble
d'informations associées à un sujet particulier. CD
(Compact Disk) : Disque faisant 12centimètres de
diamètre, 1,2 millimètre d'épaisseur, constitué de
polycarbonate recouvert d'une couche d'aluminium, le tout étant vernis
et permettant de stocker environ 650 Mo de données.
CPU (Central Processing Unit) : Unité
de Calcul Centrale, généralement c'est le processeur principal
d'une unité centrale.
DD (Diques et Disquettes)
DVD (Digital Versatil Disk) : Disque Vidéo
Digital, Leur capacité est de 4.7 Giga octets sur une face avec
un taux de transfert de 1.5 Méga octet par seconde. Oui, c'est bien
« Versatil » au milieu, et pas « Vidéà »,
parce qu'on peut mettre toutes sortes de données sur un DVD, pas
seulement de la vdéo...
ISO (International Standard Organisation) :
Organisation internationale de Standardisation, réunissant les
organismes de normalisation de pas mal de pays dans le monde et qui travaille
dans tous les domaines.
GHRZ (Giga Hertz)
LISP (LIST Processing ou de « Lots of Insipid and
Silly Parenthesis») : Langage de programmation basé sur le
traitement de listes et beaucoup utilisé en Intelligence Artificielle.
MCC (Modèle Conceptuel de la Communication):
Elément de la méthode MERISE. MERISE
(Méthode d'Analyse d'un Système d'Information): Elle
vise à remplacer un système manuel d'une organisation par un
système automatisé du traitement de l'information. SI
(Système d'Information) : Ensemble des moyens techniques et
humains permettant à une organisation de traiter son information.
SGBD (Système de Gestion de Base de
Données) : est un ensemble de logiciels prenant en charge la
structuration, le stockage, la mise à jour et la maintenance des
données
SGBDR (Système de Gestion de Base de
Données Relationnel): C'est lorsque les données sont
organisées en fonction de leur utilisation (données fixes dans
une table, données variables dans une autre, etc.). Le «
relationnel » dans SGBDR est au masculin, car c'est le système qui
l'est.
SPARC (Scalar Processor ARChitecture) : RISC
(`Reduced Instruction Set Computer' i.e ordinateur à jeu d'instructions
réduit) qu'on trouve dans les stations Sun et qui fut une
8
référence en matière de calcul scientifique
intensif. De plus, ses spécifications sont dans le domaine public.
USB (Universal Serial Bus) : Interface
destinée à remplacer pas mal de choses dans un PC (Personnel
Computer) (à commencer par le port série et le port
parallèle).
RAM (Random Access Memory) : c'est la
mémoire vive.
ROM (Read Only Memory) : C'est la mémoire
morte.
9
Résume
Ce travail de recherche décrit la définition et
les évidences sur les mutations de la mise en oeuvre d'une base de
données relationnelle et le langage Sql. Dans ce contexte, la gestion
d'informations se déploie massivement dans toutes les fonctions et dans
les secteurs des organisations. Elle devient vite sujet à pinailles et
transforme profondément l'activité des toutes les couches des
organisations. Cependant, cette émergence de gestion d'informations au
service des organisations et de pilotage met en évidence la
nécessaire adéquation entre les services informatiques offerts et
les finalités des organisations.
L'objectif de bases de données, la gestion
d'informations, « le but déterminant des systèmes de gestion
de bases des données relationnelles, c'est la plus-value.
Au demeurant, l'ère des technologies de stockage des
données a conduit à une mutation sensible et pérennes vers
les bases de données relationnelles dans des organisations et de
s'interroger sur la manière de ranger les informations pour que
celles-ci soient retrouvées rapidement. De ce fait, les bases de
données relationnelles constituent des nos jours l'étude
partitionnée si ses données sont gérées sur
plusieurs partitions (également appelées noeuds). Cependant, on
se rend bien compte que les données dans les bases de données
relationnelles sont conservées dans des tables et la table en lignes et
colonnes. D'où, l'approche adoptée est le langage SQL (un
programme informatique chargé de gérer les données) qui
constitue un manipulateur des bases de données relationnelles et un
ensemble d'instructions standard, qui sont exécutées par un
gestionnaire de bases de données.
Dans ce sens, le problème qui se pose toujours c'est de
savoir comment mettre en place un système de gestion informatisé
où des mesures et solutions de gestion d'informations efficacement afin
de réellement protéger les systèmes d'information des
bases des données? La recherche des solutions aux problèmes de
gestion d'informations procède de manière plus ou moins
compromettante car le fait de juxtaposer et de multiplier les solutions de
gestion sans analyser au préalable leur compatibilité et leurs
objectifs respectifs n'a jamais été une solution fiable.
Mots clés: Bases de données,
Mutation, Langages Sql, Base de Données Relationnelles, Gestion
d'informations, Système de Gestion de Base des Données
Relationnelles, Programme informatique.
10
Abstract
This work of research describes the definition and the
evidences on the mutations of the implementation of a relational data base and
the Sql language. In this context, the management of information spreads out
massively in all functions and in the sectors of the organizations. She/it
becomes quickly topic to nitpick and transform the activity of the deeply all
layers of the organizations. However, this emergence of management of
information to the service of the organizations and piloting puts in evidence
the necessary adequacy between the offered computer services and the finalities
of the organizations.
The objective of data bases, the management of information",
the goal determining systems of management of bases of the relational data, it
is the increment.
Moreover, the era of the technologies of storage of the data
drove to a sensitive and perennial mutation toward the relational data bases in
organizations and to wonder about the manner to arrange the information so that
these are recovered quickly. Of this fact, the relational data bases constitute
the our days the survey partition if his/her/its data are managed on several
partitions (also named knots). However, one realizes well that the data in the
relational data bases are kept in tables and the table in lines and columns. Of
where, the adopted approach is the SQL language that (a computer program
assigned to manage the data) constitutes a manipulator of the relational data
bases and a set of standard instructions, that are executed by an administrator
of data bases.
In this sense, the problem who always lands that is to know
how to put a computerized management system in place where measure and
solutions of management of information efficiently in order to protect the
systems of information of the bases of the data really? The research of the
solutions to the problems of management of information proceeds more or less
from manner compromising because makes it to juxtapose and to multiply the
solutions of management without analyzing their compatibility beforehand and
their respective objectives were never a reliable solution.
Key words: Data bases, Mutation, Language
Sql, Data base Relational, Management of information, System of Management of
Basis of the Relational Data, computer Program.
11
Liste des figures
Figure I.1. Mémorisation et traitement d'ordinateur 20
Figure II.1. Cas pratique de type-entité 36
Figure II.2. Cas pratique de modèle
entité-association 37
Figure II.3. Exemple d'occurrences de l'association APPARTENANCE
37
Figure II.4. Représentation graphique et exemples (suppose
qu'un livre ne peut posséder
qu'un auteur) sur les cardinalités .38
Figure II.5. Cas pratique d'associations plurielles entre un
type-entité 39
Figure II.6. Cas pratique d'associations réflexives sur le
type-entité personne 40
Figure II.7. Cas pratique de type-association ternaire
inapproprié 41
Figure II.8. Cas pratique de Type-association ternaire
de la figure précédente corrigé en deux
type-associations binaires 41
Figure II.9. Cas pratique de
type association ternaire entre des type-entités Créneau
horaire,
Salle et Film 42
Figure II.10. Cas pratique de transformation
du type-association ternaire de la figure 2.10 en
un type-entité et trois typeassociations binaires
43
Figure II.11. Cas pratique du Modèle représentant un
type-association ternaire Vol liant trois
type-entités Avion, Trajet et Pilote ..44
Figure II.12.
Cas pratique de transformation du type-association ternaire de la figure 2.12
en
un type-entité et trois typeassociations binaires
44
Figure II.13. Cas pratique du Modèle de la figure 2.13
corrigé au niveau des cardinalités...44
|
Figure III.1 : Erreur de conception du modèle
entité association
|
56
|
|
Figure III.2 : Cas pratique de normalisation de la 2FN
|
..59
|
|
Figure III.3 : Cas pratique de normalisation de la 3FN
|
59
|
|
Figure III.4. Cas pratique de normalisation de la BCFN
|
60
|
|
Figure III.5. Forme non normalisée
|
.61
|
|
Figure III.6. Forme 1NF
|
61
|
|
Figure III.7. Forme 2NF
|
61
|
Figure III.8. Passage en 3NF, en ajoutant la table Code_postal
avec attributs (rue et ville)...61 Figure III.9. Passage en 3NF, après
ajout de la table Code_postal avec attributs (rue et ville)61
|
Figure III.10. Forme 2NF
|
.62
|
|
Figure III.11. Forme 3NF
|
.62
|
|
Figure III.12. Forme BCNF
|
.62
|
|
Figure III.13. Table ELEVE en 2NF
|
63
|
|
Figure III.14. Forme 3NF et intégrité
référentielle
|
63
|
12
Figure IV.1. Les différents types de jointures ..80
13
Liste des tableaux
Tableau II.1. Exemples cardinalités et types 37
Tableau III.1 : Cas pratique d'usage des règles de
passage modèle entité-association du
modèle relationnel 56
Tableau IV.1. Les opérateurs de comparaison d'une
valeur à un ensemble de valeurs 83
Tableau IV.2. Récapitulatif des différentes
clauses 84
14
Introduction générale
Partant de l'approche informatique, cette réflexion
prouve, sur base du système de gestion de base de données, qu'une
gestion d'informations est soumise à une évolution constante. Le
progrès liés à l'augmentation de la finesse de stockage et
de manipulation d'informations en sont la base.
C'est un fait pour toutes les organisations, que la gestion
d'informations a fait ses preuves, à travers différentes
approches de sa capacité à fournir des services de stockage
gigantesque aux organisations en nécessitées. Les
possibilités techniques et les enjeux informatiques actuels incitent la
quasi-totalité des couches sociétales et entrepreneuriales
à réaliser des bases des données de plus en plus
complexes. Comme on peut le constater, l'émergence accrue des
systèmes d'informations impose aux organisations une réaction
rapide et une prise de décisions pertinentes celle de doter leur
Système d'Information d'une interface Web suite à
l'évolution du suivi automatisé des toutes les tâches
entrepreneuriales. Dans ce contexte, il n'est plus possible sans avoir
accès aux informations significatives relatives au problème
traité car l'époque où une faible quantité
d'informations était suffisante pour décrire la situation des
organisations appartient au passé.
Cette motivation de fond, fait que l'accroissement de stockage
et de manipulation de la quantité d'informations requises par les
décideurs a rendu l'identification et l'accès aux informations
des organisations de plus en plus difficiles. C'est dire que l'information est
devenue une des ressources stratégiques des organisations. Cette
dernière s'est développée, faut-il le rappeler, s'est
fortement sur l'organisation de la collecte, du stockage, de la
présentation, de la distribution et de la maintenance des informations
devient un élément ou un facteur prédominant et
conditionnant son fonctionnement efficace.
Au regard du branding réputationnel de l'augmentation
spectaculaire du nombre d'informations manipulées, il n'est plus
possible à concevoir en faisant appel uniquement au bon sens. Le
paradigme sur les évidences des mutations vers des systèmes de
stockage et de manipulation des données a émergé dans ce
contexte comme réponse aux besoins en gestion d'informations. Sans que
cela ait été prémédité, il existe un moyen
simple de se représenter les ressources de la collecte et de la
manipulation de données en considérant chacune d'entre elles
comme un ordinateur physique. Pour ce faire, l'indépendance entre le
niveau physique et le niveau logique de la description des données est
un autre atout de ces SGBD. C'est principalement grâce à ce
fondement théorique que les SGBD relationnel ont des interfaces
d'accès très voisines les unes des autres qui ont convergé
vers le standard qu'est le langage SQL [1] Ce qui est positif reste la
méthode la plus courante pour organiser
15
et accéder à des ensembles de données.
Partant, la situation est essentiellement due à la multiplication des
données en matière d'organisation.
C'est pour cette raison que l'apparition des engins
informatiques qu'éprouvent actuellement la toile mondiale tout et pour
très longtemps d'indiquer la manière dont l'automatisation de la
gestion de l'information a accéléré la réflexion
sur la nature et la structure du "système de pilotage" des organisations
que constituent les circuits d'information.
Une conviction est, à ce sujet, utile : l'ère
des ordinateurs a facilité le stockage et la manipulation de grandes
quantités d'informations. Bien plus, les avantages des ordinateurs ont
permis de comprendre de manière concrète ce que doit être
le système d'information, les composantes qu'il doit posséder et
comment il doit évaluer.
Tout de même, le paradoxe informatique mitigé
entre la compréhension des «services informatiques offerts »
et dès lors, nous pouvons nous poser la question de la nature du lien
entre ces services informatiques et l'«informatique de gestion » nous
pouvons asseoir les termes univoque Informatique qui fournit les moyens du
traitement automatique de l'information et l'informatique de gestion qui
s'appuie sur l'informatique pour automatiser le système d'information et
rendre transparent le traitement de l'information utile et nécessaire
aux activités opérationnelles et de pilotage des organisations.
Cette partie du système d'information automatisé à l'aide
de la technologie des ordinateurs est souvent nommée : Système
d'information informatisé.
Une caractéristique fondamentale liée à
la question du système d'information considérer comme
degré d'existence est la base de données.
De ces quelques réflexions est né le sujet de
cette étude: il nous fait découvrir les services offerts par la
gestion d'informations et les mutations vers le système de gestion de
base de données relationnelles, ce qui permettent de décrire et
d'adapter la structure logique du modèle relationnel de certaines
organisations, la sémantique de pilotage, enfin un contrôle par un
programme qui se fait via une suite d'instructions. Pour y parvenir, il ne nous
serait pas commode d'introduire des instructions et des informations dans
l'ordinateur directement sous forme de signaux électriques.
Cette étude est composée de deux grands temps.
Le premier est une analyse des nombreux concepts introduits pour la gestion des
informations et des bases de données.
Il se base sur une étude informatique comme
mémoire de stockage et propose une approche lié à la
codification d'informations des bases de données et de migrations vers
les SGBDR. Cette partie est couverte par les chapitres 1, 2, et 3.
16
Le deuxième et dernier temps constitue le
dénouement de toute notre démonstration qui contient les
chapitres 4 et 5 ; Ces chapitres décrivent le travail que nous avons
effectué dans le domaine des langages de programmation pour la base de
données. Trois aspects sont principalement traités : notions au
langage Sql, ses catégories d'instructions et le sql
intégré. Le moment où l'ensemble des termes
élaborés tout au long de cette étude de recherche entrent
en cohérence et forment un système pour donner naissance à
la conclusion et aux concepts fondamentaux qui la composent.
17
Chapitre I : L'ordinateur auxiliaire de stockage
I.1. Introduction
Dans ce chapitre, nous présentons l'ordinateur comme un
dispositif auxiliaire de stockage décrivant les différents
outils, langages, méthodes et modèles dont nous avons
réalisés l'étude. Pour cela l'ordinateur comporte des
organes d'entrée et de sortie qui permettent à l'utilisateur de
placer ses informations dans la mémoire et de les y relire lorsque la
machine les a manipulées.
En effet, un ordinateur est une machine à traiter de
l'information; l'information est fournie sous forme de données
traitées par des programmes (exécutés par des ordinateurs)
ce qui ne limite nullement la possibilité de généraliser
notre approche à ceux-ci. Il est donc nécessaire de bien
organiser les données afin d'en ressortir les parties les plus
pertinentes : l'unité logique et arithmétique.
L'information est stockée dans des fichiers (tables).
Ces derniers sont organisés de façon à répondre
efficacement aux attentes de gestion.
I.2. Ordinateur auxiliaire de stockage
La question de l'ordinateur a traversée l'histoire des
différentes lignées et pensées. Au demeurant les
évolutions de son histoire, c'est à coup sûr, et pour cette
raison que ce constat a conduit à la démocratisation d'une
science à travers un outil avec intérêt de savoir manipuler
et stocker très rapidement et sans erreur d'énormes
quantités d'informations.
En termes de remède, l'ordinateur est non sans raison
une affaire de spécialistes, est aujourd'hui devenue l'affaire de tous;
d'où l'importance d'une solide utilisation trousse l'avancement des
toutes les organisations. Par ailleurs cette affaire ayant été
estimée louable, et relativise qu'elle soit pérennisée
tout en améliorant: l'assoupissement de gestion envers les
inconvénients inhérents à tout progrès des
informations.
Ce premier tour d'horizon des problèmes des entreprises
révèle qu'il est un outil qui nous aide à résoudre
certains problèmes. Ces problèmes font généralement
intervenir des symboles ou des signes qui ne nous sont familiers tels que les
lettres de l'alphabet, les chiffres, les signes de ponctuation et quelques
caractères spéciaux comme *,#,+..{[|\^@. Bien entendu, nous
pouvons introduire un ensemble de symboles dans l'ordinateur. Cette
démarche nous rend un autre ensemble de symboles en relation avec ceux
que nous avons introduits.
Pour y parvenir, nous n'examinerons pas en détails la
façon dont l'ordinateur travaille mais nous apprendrons à lui
donner les instructions requises pour qu'il exécute une tâche
18
donnée. Seulement, il est cependant utile de
connaître les différentes parties de sauvegarde et de traitement
d'informations qui constituent un ordinateur.
Cependant, pour ce qui est du rôle joué
actuellement par l'ordinateur, il s'avère que tout
l'intérêt de l'ordinateur réside dans trois de ses
caractéristiques, à savoir: sa capacité d'emmagasiner
une grande quantité d'informations, sa rapidité de traitement, sa
capacité d'assimiler un programme qui contrôle son propre
fonctionnement.
Ainsi, au dire de cette première
caractéristique, il est donc intéressant de pouvoir sauver
certaines informations utiles pour des tâches ultérieures de
façon à les rendre à l'ordinateur autrement qu'en les
tapant au clavier (ce qui s'avérerait vite fastidieux et risquerait
d'introduire des erreurs...).
Au fait, cette mémoire de sauvegarde est
généralement un support magnétique sur lequel on eut
enregistré des informations puis les relire grâce à un
appareil enregistreur/lecteur ad hoc. A ne se limiter qu'à cela, on
laisse bien comprendre que cet appareil peut servir à recevoir les
résultats venant de l'ordinateur (Output) ou à y introduire des
informations (Input).
Outre de ce qui précède, pour les
micro-ordinateurs, il s'agit habituellement des disques durs, de lecteurs de
disquettes souples ("floppy disks") ou de mémoires flash.
Que dire alors de l'information? Mais qu'est-ce qu'une
information pour un ordinateur ? Comment est-elle formée,
stockée, traitée, transmise ? Es-ce-une histoire de 0 et de 1...
Et c'est tout?
Tout d'abord, un ordinateur peut traiter des informations,
c'est-à-dire qui constituent une ressource technique auxiliaire dans le
cadre d'une tâche accomplie par un être humain. Il ne traite pas ce
que cette information signifie, il se contente de manipuler les codes qui la
représentent, la forme de l'information, nous dirons des données,
et non pas le contenu sémantique de l'information.
Cela permet d'en assurer la pérennité et la
disponibilité. En effet, il a été constaté que les
données dans une base de données sont rangées dans des
tables, sortes de grilles où sont rangés les codes
destinés à représenter ces données.
A l'inverse, l'ordinateur est incapable de savoir ce que
représentent ces codes mais cela ne l'empêche pas de savoir les
trier, y chercher un code particulier, les compter, les comparer [W1].
19

Figure I.1. Mémorisation et traitement
d'ordinateur
I.3. Fonctionnalités
Construire des systèmes de gestion d'informations est
une activité informatique fondée sur le raisonnement logique.
Comme on peut le constater, l'accroissement des informations des entreprises a
introduit l'usage de l'ordinateur ce qui revient à dire -de
manière réelle- que cela pour un temps a eu la pleine valeur de
preuve, à la suite il est alors possible que l'outil précieux de
stockage d'informations est l'ordinateur.
Eu égard cette concrétisation, on utilise
presque exclusivement des ordinateurs digitaux (dans lesquels les informations
sont codées sous forme des circuits électriques) et qui
fonctionnent selon les principes d'un calculateur. Bien entendu, ce calculateur
comprend deux parties : une unité logique et
arithmétique.
Dans son sens large, un programme décrit les
opérations logiques à réaliser sur les données.
Considérant les parties du calculateur comme préalable,
l'unité logique est banalisée. La variété
étudiée présente les caractéristiques sur
lesquelles on ne sait pas lors de sa construction à quoi elle va servir,
et si elle sera seulement capable d'exécuter séquentiellement
certaines instructions.
Cela ne signifie certes pas que les programmes et les
données sont placés sur un pied d'égalité dans la
mémoire. Ainsi pour passer à leur exécution, il est
impossible de discerner les programmes des données si ce n'est par
l'effet qu'ils ont sur l'unité logique. Plus précisément,
il importe qu'un ordinateur individuel soit utilisé par une seule
personne à la fois qui décide seule de l'activité de la
machine. C'est à l'issu de celui-ci que sont mis à la disposition
de chacun et connectés en réseau.
De par la nature, lorsque vous saisissez des informations dans
votre ordinateur avec la souris ou clavier, vous envoyez un signal à la
CPU. Ceci suppose que le CPU dispose d'une unité logique qui peut faire
de l'arithmétique de base. Si l'unité de commande ordonne
à l'ordinateur d'exécuter des programmes qui ont
été stockées dans la mémoire, il sera toujours
possible d'effectuer la vitesse à laquelle un ordinateur exécute
des programmes est mesurée en millions d'instructions par seconde, la
vitesse du processeur est mesurée en gigahertz (GHz).
20
De même, lorsque l'information a été
traitée, elle est sortie sous une forme lisible par l'homme à
travers l'écran et haut-parleurs. Dans cette ligne, elle peut
également être stockée à nouveau pour un traitement
ultérieur. En conséquence, les supports de stockage peuvent
être utilisés à la fois données d'entrée et
de sortie [W2].
I.4. Tumulte des couloirs du cosmopolite et trivial
de complexité
I.4.1. Tumulte des couloirs du cosmopolite
Au niveau de la planète terre, divers problèmes
des différentes organisations liés au stockage des données
caractérisent actuellement presque tous les milieux.
Toutes les entreprises sont devenues des grandes chef-d'
accusation, il suffit qu'une erreur se glisse dans la base de données et
la réponse urgente devienne « c'est une erreur de saisi, c'est une
erreur de frappe ».
Dans cette même lancée, nous voyons éclore
de l'ordinateur l'accusation de tous les maux, alors que celui-ci réunit
un correcteur automatique voire des onglets de détection d'erreurs.
I.4.2. Trivial de complexité
En unissant ces trois perspectives de l'analyse du trivial de
complexité, la gestion des données s'affirme, en fait, comme une
dynamique fondamentale de la transformation de toutes les entreprises,
positivement ou négativement. En agissant sur le système de
pilotage et celui opérant, de ce fait, on peut changer l'entreprise et
toute son organisation, dans le bon sens comme dans un sens désastreux
et destructeur.
Cela veut dire qu'il n'est pas un simple réceptacle des
représentations. Cette vision d'ensemble, largement partagée, est
constituée d'un faisceau de vicissitudes, parfois contradictoires, que
nous proposons de classer en trois catégories :
? Trivial de contenus : il laisse
entendre qu'il n'y a pas de contenus spécifiques aux technologies
informatisées à gérer.
? Trivial d'impact : il laisse
penser que les technologies informatisées sont un ensemble d'outils et
de moyens qui changent la gestion des données en place, qu'elles sont
changeables avec les moyens manuelles classiques sans que cela n'ait de
conséquences majeures sur la perte d'une grande quantité des
données.
? Trivial de contexte : il veut
faire croire que les entreprises sont nécessairement mieux avec les
technologies informatisées, quelles que soient les
réalités matérielles.
21
Cela veut dire que les technologies informatisées sont
un ensemble d'objets complexes à intégrer dans des pratiques
complexes. Concrètement, elles ne simplifient ni les contextes, ni les
enjeux, ni les publics entrepreneuriaux.
I.5. Repères pour une question
De par la nature, il importe de remarquer que, dans cette
définition, l'information est le support de la connaissance et non pas
la connaissance elle-même. Il serait donc naïf d'imaginer que les
machines informatiques "comprennent" la signification des informations qu'elles
traitent.
Cela signifie que ces machines ne font que traiter des codes
choisis assez judicieusement par leurs concepteurs pour représenter des
connaissances et de sorte que les manipulations automatisées faites sur
ces codes donnent à leur tour des codes similaires qui
représentent des informations qui ont un sens.
C'est vrai non seulement pour ce qui est de l'informatisation
d'une tâche, lorsqu'elle est possible, consiste à identifier les
informations à traiter, représenter ces informations,
opérer le traitement, produire les informations résultantes du
traitement. La question de preuve des traitements automatisables font appel
à des algorithmes. Ce qui revient à dire que la construction d'un
algorithme suit une démarche créative essentiellement
basée sur l'abstraction appelée analyse [W3].
C'est ce à quoi toute information est
véhiculée par un support, par exemple écrite sur papier,
enregistrée sur cassette audio, Le micro-ordinateur travaille sur une
représentation binaire des informations. Chaque élément
électronique ou magnétique ne sait prendre que deux états
physiques distincts (conducteur ou non conducteur, deux niveaux de tension)
représentés par les chiffres 0 et 1 d'une numérotation
binaire, c'est-à-dire de base 2.
Cela s'applique en particulier avec des bits, d'octets ou de
kilo-octets. Tous ces mots désignent en fait des unités pour
mesurer de capacité de mémorisation d'information par
l'ordinateur.
De même, l'information minimale pour l'ordinateur est le
bit imaginé comme un fil dans l'ordinateur. Deux états le
caractérisent: le courant passe ou ne passe pas. Avec un seul fil, on
peut donc mémoriser une information binaire, c'est-à-dire, deux
valeurs: le courant passe, représenté 1, le courant ne passe pas,
représenté 0. Cette information 0 ou 1 est appelée bit.
A ces raisons s'ajoute la ROM qui sert à stocker le
micro logiciel d'amorçage, les informations que l'ordinateur utilise
pour démarrer.
22
I.6. Des perspectives pour la recherche ?
C'est une évidence : les termes mémoire et
stockage de données sont souvent confondus. Les deux sont des moyens par
lesquels un ordinateur conserve les données utilisées pour
effectuer des tâches.
En tant que tels, les deux sont mesurés en octets.
Cependant, la mémoire et le stockage de données sont deux
entités distinctes et les termes ne doivent pas être
interchangés. Bien que la mémoire est communément
appelée RAM (Random Access Memory), mais comprend également la
mémoire en lecture seule (ROM). Le stockage de données est
également appelé espace sur le disque dur.
Comme le rôle de chacune de partie est défini, la
principale nuance entre la mémoire et le stockage de données est
leur fonction. Le stockage est utilisé pour stocker toutes les
informations de l'ordinateur à l'inverse des données qui sont
stockées sur le disque dur sont permanentes et ne sont pas perdues
lorsque l'ordinateur est éteint.
Lorsqu'un fichier est supprimé, seul l'accès
à ce fichier est supprimé, pas les informations
elles-mêmes. C'est pourquoi les experts en informatique peuvent restaurer
des informations sur un ordinateur même si ces informations ont
été supprimées. Pour supprimer définitivement un
fichier, le disque dur doit être formaté ou remplacé. Il
est même possible que même si un disque a été
formaté, un expert peut toujours visualiser les informations.
Il existe des programmes disponibles qui écrivent des
données sans signification sur les informations du disque, rendant ainsi
les informations illisibles pour quiconque.
C'est pourquoi la mémoire, en revanche, permet à
l'ordinateur d'accéder rapidement aux fichiers du disque dur. Comme la
plu part des fois lorsqu'un ordinateur exécute une application telle
qu'un traitement de texte, l'unité centrale (CPU) récupère
les données du disque dur et les charge dans la RAM, ce qui permet un
accès rapide.
D'où, la quantité de RAM d'un ordinateur limite
le nombre de programmes pouvant être exécutés
simultanément. Etant donné que les informations stockées
dans la RAM sont perdues lors de la mise hors tension de l'ordinateur,
l'enregistrement d'un fichier dans une telle application écrit les
informations sur le disque dur afin qu'elles ne soient pas perdues.
23
Ce qui laisse comprendre que la mémoire et le stockage
de données peuvent cependant fonctionner ensemble et perçues
comme flux de paires que lorsque l'ordinateur ne dispose pas de suffisamment de
RAM pour prendre en charge ses processus, une partie du disque dur est
convertie en mémoire virtuelle alors la mémoire virtuelle agit de
la même manière que la RAM. Cependant, comme il fait partie du
disque dur, l'utilisation de la mémoire virtuelle ralentit l'ordinateur
[W4].
I.7. Bilan du chapitre
A l'issue de ce chapitre nous avons présenté
l'ordinateur et démontrer qu'il est la mémoire précieuse
de stockage. Etant donné que la quantité d'informations des
entreprises fleurit abondamment.
De cette évidence admise, nous avons
démontré de manière permanente que l'ordinateur peut faire
dans un premier temps la gestion des données (mémoriser de
l'information : DD, RAM, ROM, DVD, CD, clé USB, ...) sans lui rajouter
beaucoup d'instructions. Pour bien vérifier ceci il y a
possibilité que cette performance d'informations au sein des entreprises
nécessité des méthodes assez gestionnaire des
données.
24
Chapitre II: Les bases des données : une
nouvelle considération de stockage et manipulation des
données
II.1. Introduction
Depuis peu, avec le développement d'une grande
quantité d'informations, l'ensemble des entreprises ont aspirées
à l'usage des bases de données. Bien attendu, les BD sont
nées à la fin des années 1960 pour combler les lacunes des
systèmes de fichiers et faciliter la gestion qualitative et quantitative
des données informatiques. On peut dire alors que les SGBD comme
étant au carrefour des applications de gestion des données sont
des applications informatiques permettant de créer et de gérer
des BD.
Nous précisons ici, que les BD relationnelles, issues
de la recherche de Codd, sont celles qui ont connu le plus grand essor depuis
l'évolution des différentes années, et qui reste encore
aujourd'hui les plus utilisées.
Cette considération laisse bien comprendre qu'on
utilise des SGBDR pour les implémenter. Un dernier élément
à retenir est que le langage SQL est le langage commun à tous les
SGBDR, ce qui permet de concevoir des BD relativement indépendamment des
systèmes utilisés [5].
Cette appréciation, veut signifier que les usages de BD
se sont aujourd'hui généralisés pour entrer dans tous les
secteurs de l'entreprise, depuis les petites bases utilisées par
quelques personnes dans un service pour des besoins de gestion de
données locales, jusqu'aux bases qui gèrent de façon
centralisée des données partagées par tous les acteurs de
l'entreprise.
Rien n'interdit l'accroissement de l'utilisation du
numérique comme outil de manipulation de toutes données
(bureautique, informatique applicative, etc.) et comme outil d'extension des
moyens de communication (réseaux) ainsi que les évolutions
technologiques (puissance des PC, Internet, etc.). Dans toute la suite sauf
mention du contraire, l'usage numérique a rendu indispensable, mais
aussi complexifié la problématique des BD.
Actuellement, la trajectoire sur les conséquences de
cette généralisation et de cette diversification des usages se
retrouve dans l'émergence de solutions conceptuelles et technologiques
nouvelles, les bases de données du mouvement NoSQL
particulièrement utilisées par les grands acteurs du web.
25
II.2. Base de données
II.2.1. Définition
Que retenir de la définition exacte d'une BD ? Cette
approche par la division de la fonction exercée pour chaque
modélisation reste, de notre point de vue, des quelques
définitions à retenir pour approcher les clivages qui peuvent
exister dans cet ensemble de conception.
Mis à part les définitions modéliser pour
chaque cas, les modélisations s'intéressent aux atouts et
finalités de chaque conception. De cela, retenons quelques
définitions avant d'en tirer une jugée universelle.
§1. Définition d'une BD comme ensemble de
données
a. Est appelé base de données, tout ensemble de
données stocké numériquement et pouvant servir à un
ou plusieurs programme. De leur côté, des fichiers sur un disque
dur, un fichier de tableur, voire un fichier de traitement de texte peuvent
constituer des bases de données.
b. Quel que soit, le support utilisé pour rassembler
et stocker les données (papier, fichiers, etc.), dès lors que des
données sont rassemblées et stockées d'une manière
organisée dans un but spécifique, on parle de base de
données.
§2. Définition d'une BD comme ensemble de
données structuré
a. Une base de données est un ensemble de
données numériques qui possède une structure ; c'est
à dire dont l'organisation répond à une logique
systématique. On parlera de modèle logique de données pour
décrire cette structure.
b. Une base de données est un ensemble
structuré et organisé permettant le stockage de grandes
quantités d'informations afin d'en faciliter l'exploitation (ajout, mise
à jour, la suppression et la recherche de données).
§3. Retenons ces quelques définitions
informatisées
? On appellera base de données un ensemble
structuré de données enregistrées dans un ordinateur et
accessibles de façon sélective par plusieurs utilisateurs [2].
? Est appelle Base de données un gros ensemble
d'informations structurées mémorisées sur un support
permanent [3].
? Une base de données est considérée comme
un recueil d'informations liées à un sujet donné [4].
Certaines mesures visent les bases de données ? Et
comme pour dire que les bases de données de demain devront être
capables de gérer plusieurs dizaines de téraoctets de
données,
26
II.2.2. Domaine problème posé
Tout d'abord, le résultat de la conception d'une base
de données informatisée est d'un premier ordre une description
des données. Compte tenu de la description on entend définir les
propriétés d'ensembles d'objets modélisés dans la
base de données et non pas d'objets particuliers.
Les objets particuliers sont créés par des
programmes d'applications ou des langages de manipulation lors des insertions
et des mises à jour des données. Il faut donc dire, que cette
description des données est réalisée en utilisant un
modèle de données qui du reste est un outil formel utilisé
pour comprendre l'organisation logique des données.
S'agissant de la gestion et l'accès à une base
de données, leurs rapprochements sont assurés par un ensemble de
programmes qui constituent le Système de gestion de base de
données (SGBD). Cela révèle d'un SGBD une
caractéristique par le modèle de description des données
qu'il supporte (hiérarchique, réseau, relationnel, objet).
Ce cadrage rappel que les données sont décrites
sous la forme de ce modèle, grâce à un Langage de
Description des Données (LDD). Cette description est appelée
schéma. D'où, nous consacrons une fois qu'une base de
données spécifiée, on peut y insérer des
données, les récupérer, les modifier et les
détruire. C'est ce qu'on appelle manipuler les données. Ces
données peuvent être manipulées non seulement par un
Langage spécifique de Manipulation des Données (LMD) mais aussi
par des langages de programmation classiques.
Sans prétendre à l'exhaustivité, il
s'agit là d'appréhender la place des bases de données avec
une spécificité importante en informatique, et
généralement dans le domaine de la gestion.
Cette manière de gestion a conduit à une
étude des bases de données qui consacre le développement
de concepts, méthodes et algorithmes spécifiques, notamment pour
gérer les données en mémoire secondaire (i.e. disques
durs).
Il nous faut esquisser ces éléments qui en
effet, dès l'origine de la discipline, les informaticiens ont
observé que la taille de la RAM ne permettait pas de charger l'ensemble
d'une base de données en mémoire. Cette hypothèse est
toujours vérifiée car le volume des données ne cesse de
s'accroître sous la poussée des nouvelles technologies du WEB.
27
géographiquement distribuées à
l'échelle d'Internet, par plusieurs dizaines de milliers d'utilisateurs
dans un contexte d'exploitation changeant (on ne sait pas très bien
maîtriser ou prédire les débits de communication entre
sites) voire sur des noeuds volatiles. En physique des hautes énergies,
on prédit qu'une seule expérience produira de l'ordre du
péta-octets de données par an.
Comme il est peu probable de disposer d'une technologie de
disque permettant de stocker sur un unique disque cette quantité
d'informations, les bases de données se sont orientées vers des
architectures distribuées ce qui permet, par exemple, d'exécuter
potentiellement plusieurs instructions d'entrée/sortie en même
temps sur des disques différents et donc de diviser le temps total
d'exécution par un ordre de grandeur.
II.2.3. Modèle de base de données
1. Modèle hiérarchique
Est appelé base de données hiérarchique
est une forme de système de gestion de base de données qui lie
des enregistrements dans une structure arborescente de façon à ce
que chaque enregistrement n'ait qu'un seul possesseur (par exemple, une paire
de chaussures n'appartient qu'à une seule personne).
De ce fait, les structures de données
hiérarchiques ont été largement utilisées dans les
premiers systèmes de gestion de bases de données conçus
pour la gestion des données du programme Apollo de la NASA.
En effet, à cause de leurs limitations internes, elles
ne peuvent pas souvent être utilisées pour décrire des
structures existantes dans le monde réel. Cependant, les liens
hiérarchiques entre les différents types de données
peuvent rendre très simple la réponse à certaines
questions, mais très difficile la réponse à d'autres
formes de questions.
Si le principe de relation « 1 vers N » n'est pas
respecté (par exemple, un malade peut avoir plusieurs médecins et
un médecin a, a priori, plusieurs patients), alors la hiérarchie
se transforme en un réseau.
2. Modèle réseau
On appelle modèle réseau, modèle qui est
en mesure de lever de nombreuses difficultés du modèle
hiérarchique grâce à la possibilité d'établir
des liaisons de type n-n (relations plusieurs à plusieurs), les liens
entre objets pouvant exister sans restriction.
28
Pour retrouver une donnée dans une telle
modélisation, il faut connaître le chemin d'accès (les
liens) ce qui rend les programmes dépendants de la structure de
données. Ce modèle de bases de données a été
inventé par C.W. Bachman. Pour son modèle, il reçut en
1973 le prix Turing.
3. Modèle relationnel
Une base de données relationnelle est une base de
données structurée suivant les principes de l'algèbre
relationnelle. Le père des bases de données relationnelles est
Edgar Frank Codd. Chercheur chez IBM à la fin des années 1960, il
étudiait alors de nouvelles méthodes pour gérer de grandes
quantités de données car les modèles et les logiciels de
l'époque ne le satisfaisaient pas. Mathématicien de formation, il
était persuadé qu'il pourrait utiliser des branches
spécifiques des mathématiques (la théorie des ensembles et
la logique des prédicats du premier ordre) pour résoudre des
difficultés telles que la redondance des données,
l'intégrité des données ou l'indépendance de la
structure de la base de données avec sa mise en oeuvre physique.
Vers les années 1970, Codd (1970) publia un article
où il proposait de stocker des données
hétérogènes dans des tables, permettant d'établir
des relations entre elles. De nos jours, ce modèle est extrêmement
répandu, mais en 1970, cette idée était
considérée comme une curiosité intellectuelle. On doutait
que les tables puissent être jamais gérées de
manière efficace par un ordinateur.
Ce scepticisme n'a cependant pas empêché Codd de
poursuivre ses recherches. Un premier prototype de Système de gestion de
bases de données relationnelles (SGBDR) a été construit
dans les laboratoires d'IBM. Depuis les années 80, cette technologie a
mûri et a été adoptée par l'industrie. En 1987, le
langage SQL, qui étend l'algèbre relationnelle, a
été standardisé.
4. Modèle objet
La notion de bases de données objet ou
relationnel-objet est plus récente et encore en phase de recherche et de
développement. Elle sera très probablement ajoutée au
modèle relationnel.
29
II.3. Système de gestion de base de
données (SGBD
) II.3.1. Notions et définition
La recherche sur la gestion et l'accès à une
base de données sont assurés par un ensemble de programmes qui
constituent le Système de gestion de base de données (SGBD). Un
SGBD exerce les fonctions comme l'ajout, la modification et la recherche de
données. Il est chargé d'héberge
généralement plusieurs bases de données, qui sont
destinées à des logiciels ou des thématiques
différents.
Cependant du fait de recevoir plusieurs requêtes, la
plupart des SGBD fonctionnent selon un mode client/serveur. Le serveur
(sous-entendu la machine qui stocke les données) reçoit des
requêtes de plusieurs clients et ceci de manière concurrente. Le
serveur analyse la requête, la traite et retourne le résultat au
client. Le modèle client/serveur est assez souvent
implémenté au moyen de l'interface des sockets (voir le cours de
réseau) ; le réseau étant Internet.
Dans ce mouvement, une variante de ce modèle est le
modèle ASP (Application Service Provider). Dans ce modèle, le
client s'adresse à un mandataire (broker) qui le met en relation avec un
SGBD capable de résoudre la requête. La requête est ensuite
directement envoyée au SGBD sélectionné qui résout
et retourne le résultat directement au client.
La déclinaison de ce modèle est qu'un des
problèmes fondamentaux à prendre en compte est la
cohérence des données. Par exemple, dans un environnement
où plusieurs utilisateurs peuvent accéder concurremment à
une colonne d'une table par exemple pour la lire ou pour l'écrire, il
faut s'accorder sur une évidence d'écriture. Cette
évidence peut être : les lectures concurrentes sont
autorisées mais dès qu'il y a une écriture dans une
colonne, l'ensemble de la colonne est envoyée aux autres utilisateurs
l'ayant lue pour qu'elle soit rafraîchie.
Un Système de Gestion de Base de Données est
alors considérer comme un ensemble de logiciels prenant en charge la
structuration, le stockage, la mise à jour et la maintenance des
données. Autrement dit, il permet de décrire, modifier,
interroger et administrer les données. C'est, en fait, l'interface entre
la base de données et les utilisateurs (qui ne sont pas forcément
informaticiens).
30
II.3.2. Objectifs, propriétés, composants et
organisation de la mise en oeuvre d'un SGBD
§1. Objectifs d'un SGBD
Les objectifs et les propriétés principaux ont
été fixés aux SGBD dès l'origine de ceux-ci et ce,
afin de résoudre les problèmes causés par la
démarche classique.
· Indépendance physique
: La façon dont les données sont définies
doit être indépendante des structures de stockage
utilisées.
· Indépendance logique
: Un même ensemble de données peut être vu
différemment par des utilisateurs différents. Toutes ces visions
personnelles des données doivent être intégrées dans
une vision globale.
· Accès aux données
: L'accès aux données se fait par
l'intermédiaire d'un Langage de Manipulation de Données (LMD). Il
est crucial que ce langage permette d'obtenir des réponses aux
requêtes en un temps « raisonnable ». Le LMD doit donc
être optimisé, minimiser le nombre d'accès disques, et tout
cela de façon totalement transparente pour l'utilisateur.
· Administration centralisée des
données (intégration) : Toutes les données
doivent être centralisées dans un réservoir unique commun
à toutes les applications. En effet, des visions différentes des
données (entre autres) se résolvent plus facilement si les
données sont administrées de façon centralisée.
· Non redondance des données
: Afin d'éviter les problèmes lors des mises
à jour, chaque donnée ne doit être présente qu'une
seule fois dans la base.
· Cohérence des données
: Les données sont soumises à un certain nombre de
contraintes d'intégrité qui définissent un état
cohérent de la base. Elles doivent pouvoir être exprimées
simplement et vérifiées automatiquement à chaque
insertion, modification ou suppression des données. Les contraintes
d'intégrité sont décrites dans le Langage de Description
de Données (LDD).
· Partage des données :
Il s'agit de permettre à plusieurs utilisateurs d'accéder aux
mêmes données au même moment de manière transparente.
Si ce problème est simple à résoudre quand il s'agit
uniquement d'interrogations, cela ne l'est plus quand il s'agit de
modifications dans un contexte multi-utilisateurs car il faut : permettre
à deux (ou plus) utilisateurs de modifier la même donnée
« en même temps » et assurer un résultat d'interrogation
cohérent pour un utilisateur consultant une table pendant qu'un autre la
modifie.
31
· Sécurité des données
: Les données doivent pouvoir être
protégées contre les accès non autorisés. Pour
cela, il faut pouvoir associer à chaque utilisateur des droits
d'accès aux données.
· Résistance aux pannes
: Que se passe-t-il si une panne survient au milieu d'une
modification, si certains fichiers contenant les données deviennent
illisibles ? Il faut pouvoir récupérer une base dans un
état « sain ». Ainsi, après une panne intervenant au
milieu d'une modification deux solutions sont possibles : soit
récupérer les données dans l'état dans lequel elles
étaient avant la modification, soit terminer l'opération
interrompue.
§2. Propriétés d'un SGBD
Cette partie retrace les propriétés fondamentales
d'un SGBD à savoir:
· Base formelle reposant sur des
principes parfaitement définis,
· Organisation structurée
des données dans des tables interconnectées
(d'où le qualificatif relationnelles), pour pouvoir détecter les
dépendances et redondances des informations,
· Implémentation d'un langage
relationnel ensembliste permettant à l'utilisateur de
décrire aisément les interrogations et manipulation qu'il
souhaite effectuer sur les données,
· Indépendance des données
vis-à-vis des programmes applicatifs (dissociation entre
la partie "stockage de données" et la partie "gestion" - ou
"manipulation"),
· Gestion des opérations concurrentes
pour permettre un accès multi-utilisateur sans conflit
· Gestion de l'intégrité des
données, de leur protection contre les pannes et les
accès illicites,
§3. Composants des SGBD
La montée en possession d'un certain nombre des
composants logiciels d'un SGBD précise:
· La description des données
au moyen d'un Langage de Définition de
Données(LDD). Le résultat de la compilation est un ensemble de
tables, stockées dans un fichier spécial appelé
dictionnaire (ou répertoire) des données,
· La manipulation des données
au moyen d'un Langage de Manipulation de Données(LMD)
prenant en charge leur consultation et leur modification de façon
optimisée, ainsi que les aspects de sécurité,
32
· La sauvegarde et la
récupération après pannes, ainsi que des
mécanismes permettant de pouvoir revenir à l'état
antérieur de la base tant qu'une modification n'est pas finie (notion de
transaction),
· Les accès concurrents aux
données en minimisant l'attente des utilisateurs et en
garantissant l'obtention de données cohérentes en cas de mises
à jours simultanées,
§4. Organisation de la mise en oeuvre des
SGBD
Les entreprises cherchent à généraliser
les outils d'aide à la décision pour la gestion des
données. Au travers les besoins que concernent cette gestion, c'est sans
conséquence que le souhait des fonctions avec pour objectif de
sécuriser, maintenir et mettre à jour ces informations que le
partage beaucoup plus fin et transparent de l'information via le système
informatique entre les cadres et les agents a des effets sur les modes
d'évaluation du travail des entreprises.
De ce fait, nous décrivons quatre catégories de
fonctions qui consacrent cette gestion de données:
· Les tâches liées à
l'architecture de données consistent à analyser,
classifier et structurer les données au moyen de modèles
confirmés,
· L'administration de données
vise à superviser l'adéquation des
définitions et des formats de données avec les directives de
standardisation et les normes internationales, à conseiller les
développeurs et les utilisateurs, et à s'assurer de la
disponibilité des données à l'ensemble des applications.
L'administrateur assume en outre des responsabilités importantes dans la
maintenance et la gestion des autorisations d'accès,
· Les professionnels en technologie de
données ont en charge l'installation, la supervision, la
réorganisation, la restauration et la protection des bases. Ils en
assurent aussi l'évolution au fur et à mesure des progrès
technologiques dans ce domaine,
· L'exploitation de données
consiste à mettre à disposition des utilisateurs
les fonctions de requête et de reporting (générateurs
d'états), ainsi qu'à assurer une assistance aux différents
services pour qu'ils puissent gérer leur stock propre de données
en autonomie (service infocentre).
Pour atteindre certains de ces objectifs
précités (surtout les deux premiers), trois niveaux de
description des données ont été définis par la
norme ANSI/SPARC.
II.3.3. Affinement de niveaux de description des
ANSI/SPARC
Ce modèle, utilisé pour la phase de conception,
s'inscrit notamment dans le cadre d'une méthode plus
générale et très répandue :
Merise.
33
? Le niveau externe : correspond
à la perception de tout ou partie de la base par un groupe donné
d'utilisateurs, indépendamment des autres. On appelle cette description
le schéma externe ou vue. Il peut exister plusieurs schémas
externes représentant différentes vues sur la base de
données avec des possibilités de recouvrement. Le niveau externe
assure l'analyse et l'interprétation des requêtes en primitives de
plus bas niveau et se charge également de convertir
éventuellement les données brutes, issues de la réponse
à la requête, dans un format souhaité par l'utilisateur.
? Le niveau conceptuel :
décrit la structure de toutes les données de la base, leurs
propriétés (i.e. les relations qui existent entre elles : leur
sémantique inhérente), sans se soucier de l'implémentation
physique ni de la façon dont chaque groupe de travail voudra s'en
servir. Dans le cas des SGBD relationnels, il s'agit d'une vision tabulaire
où la sémantique de l'information est exprimée en
utilisant les concepts de relation, attributs et de contraintes
d'intégrité. On appelle cette description le schéma
conceptuel.
? Le niveau interne ou physique :
s'appuie sur un système de gestion de fichiers pour définir la
politique de stockage ainsi que le placement des données. Le niveau
physique est donc responsable du choix de l'organisation physique des fichiers
ainsi que de l'utilisation de telle ou telle méthode d'accès en
fonction de la requête. On appelle cette description le schéma
interne.
II.4. Modélisation des bases de données
: le modèle entités-associations
II.4.1. Généralités
§1. Pourquoi une modélisation
préalable ?
Ouvrir l'aspect sur la modélisation revient à
dire qu'il est difficile de modéliser un domaine sous une forme
directement utilisable par un SGBD. Cependant, une ou plusieurs
modélisations intermédiaires sont donc utiles, le modèle
entités-associations constitue l'une des premières et des plus
courantes.
Ce modèle, présenté par Chen (1976),
permet une description naturelle du monde réel à partir des
concepts d'entité et d'association. Basé sur la théorie
des ensembles et des relations, ce modèle se veut universel et
répond à l'objectif d'indépendance
données-programmes.
34
§2. Merise
C'est bien ce qui constitue la spécificité de
la méthode MERISE (Méthode d'Étude et de
Réalisation Informatique pour les Systèmes d'Entreprise) qui est
certainement à la disparité comme le langage de
spécification le plus répandu dans la communauté de
l'informatique, des systèmes d'information, et plus
particulièrement dans le domaine des bases de données.
Une représentation Merise permet de valider des choix
par rapport aux objectifs, de quantifier les solutions retenues, de mettre en
oeuvre des techniques d'optimisation et enfin de guider jusqu'à
l'implémentation. Reconnu comme standard, Merise devient un outil de
communication. En effet, Merise réussit le compromis difficile entre le
souci d'une modélisation précise et formelle, et la
capacité d'offrir un outil et un moyen de communication accessible aux
non-informaticiens.
Cela explique que certains des concepts clés de la
méthode Merise est la séparation des données et des
traitements. Cette méthode est donc parfaitement adaptée à
la modélisation des problèmes abordés d'un point de vue
fonctionnel [6].
Si on prend l'exemple méthodologique, on observe que
les données représentent la statique du système
d'information et les traitements sa dynamique. L'expression conceptuelle des
données conduit à une modélisation des données en
entités et en associations.
Merise règne et propose une démarche, dite par
niveaux, dans laquelle il s'agit de hiérarchiser les
préoccupations de modélisation qui sont de trois ordres :
la conception, l'organisation et la technique.
Des nombreuses études ont régulièrement
mis en avant cette méthode, pour aborder la modélisation d'un
système, au fil de temps il convient de l'analyser en premier lieu de
façon globale et de se concentrer sur sa fonction : c'est-à-dire
de s'interroger sur ce qu'il fait avant de définir comment il le fait.
Quelques niveaux de modélisation, sont organisés dans une double
approche données/traitements.
La contrainte est de parler de ces trois niveaux de
représentation des données :
? Niveau conceptuel : le
modèle conceptuel des données (MCD) décrit les
entités du monde réel, en termes d'objets, de
propriétés et de relations, indépendamment de toute
technique d'organisation et d'implantation des données. Ce modèle
se concrétise par
35
un schéma entités-associations
représentant la structure du système d'information, du point de
vue des données.
· Niveau logique : le
modèle logique des données (MLD) précise le modèle
conceptuel par des choix organisationnels. Il s'agit d'une transcription
(également appelée dérivation) du MCD dans un formalisme
adapté à une implémentation ultérieure, au niveau
physique, sous forme de base de données relationnelle ou réseau
d'où les choix techniques d'implémentation (choix d'un SGBD) ne
seront effectués qu'au niveau suivant.
· Niveau physique : le
modèle physique des données (MPD) permet d'établir la
manière concrète dont le système sera mis en place (SGBD
retenu).
II.4.2. Le modèle entités-associations
[W2] II.4.2.1. Définitions
· Une entité est un
objet spécifique, concret ou abstrait, de la réalité
perçue. Ce peut être une personne, un objet inerte, un concept
abstrait, un événement, ...
· Un attribut est une
caractéristique ou une qualité d'une entité ou d'une
association. Il peut être atomique (ex. nom,
prénom) ou composé (ex.
adresse=n°+rue+code_postal+ville)
et peut prendre une ou plusieurs valeur(s) (on parle d'attribut mono- ou
multivalué). Le domaine d'un attribut est
l'ensemble des valeurs que peut prendre celui-ci; il est utile pour
vérifier la validité d'une donnée.
· Un type d'entité est
la classe de toutes les entités de la réalité
perçue qui sont de même nature et qui jouent le même
rôle. Un type d'entité est défini par un nom et un ensemble
d'attributs, qui sont les caractéristiques communes à toutes les
entités de même type; ces dernières forment un ensemble
d'entités (par exemple, un ensemble des travailleurs,
caractérisés par leurs nom et prénom). Par simplification
de la terminologie, on appellera entité un type d'entité, et
occurrence d'une entité un individu
particulier faisant partie d'une entité.
· Le schéma ou intention d'une
entité en est la description ; l'ensemble des occurrences
d'une entité qui existent dans la base à un instant donné
s'appelle l'extension de l'entité. Le schéma d'une entité
ne change pas fréquemment car il en décrit la structure ; son
extension, en revanche, change à chaque insertion ou suppression d'une
occurrence d'entité.
36
? L'attribut clé ou identifiant d'une
entité est un groupe minimal d'attributs permettant de
distinguer sans ambiguïté les occurrences d'entités dans
l'ensemble considéré.
? Un identifiant ou clé d'un
type-entité ou d'un type-association est constitué
par un ou plusieurs de ses attributs qui doivent avoir une valeur unique pour
chaque entité ou association de ce type.
Il est donc impossible que les attributs constituant
l'identifiant d'un type-entité (respectivement type-association)
prennent la même valeur pour deux entités (respectivement deux
associations) distinctes. Prenons un cas pratique : Exemples
d'identifiant: le numéro de sécurité sociale
pour une personne, le numéro d'immatriculation pour une voiture, le code
ISBN d'un livre pour un livre (mais pas pour un exemplaire).

Figure II.1. Cas pratique de type-entité
Sémantique de la figure II.1. Comportant quatre
attributs dont un est un identifiant : deux personnes peuvent avoir le
même nom, le même prénom et le même âge, mais
pas le même numéro de sécurité sociale.
? Une association ou relation est
une correspondance entre 2 ou plusieurs occurrences d'entités à
propos de laquelle on veut conserver des informations. On dit que les
occurrences d'entités participent ou jouent un rôle dans
l'association. Un type d'association est défini par un nom et une liste
d'entités avec leur rôle respectif (notation : A (ro1:E1,
ro2 :E2... ron: En)). Eu des termes simples, on appelle
association un type d'association et occurrence d'association toute
correspondance qui existe entre deux ou plusieurs occurrences d'entités.
L'ensemble des occurrences d'une association qui existe dans la base à
un instant donné s'appelle l'extension de l'association.
Exemple d'association: APPARTENANCE (appartient: ELEVE,
inclut: CLASSE) décrit le fait qu'un élève appartient
à une classe et, symétriquement, qu'une classe inclut plusieurs
élève.
37
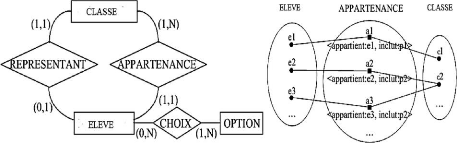
Figure II.2. Cas pratique de modèle
entité-association Figure II.3. Exemple d'occurrences de
l'association APPARTENANCE
? Une association peut aussi
posséder des attributs. Un attribut de l'association APPARTENANCE
pourrait être, par ex., un entier indiquant le(s) semestre(s) scolaire(s)
suivi(s) par l'élève.
? Le degré (ou la dimension) d'une
association est le nombre d'entités y participant. Le cas
le plus fréquent est celui de l'association binaire
II.4.2.2. Cardinalité d'une association
La cardinalité d'une association exprime le nombre
minimum et le nombre maximum de fois où chaque occurrence
d'entité participe à une relation.
Autrement dit, la cardinalité de A(ro1:E1,
ro2:E2,...,ron:En) est définie par un ensemble de
couples (mini, maxi) où mini (resp. maxi) indique le nombre minimum
(resp. maximum) de fois que toute occurrence de Ei doit assumer le rôle
roi.
De ce fait, on distingue 4 cas principaux :

Tableau II.1. Exemples cardinalités et types
38

Figure II.4. Représentation graphique et exemples
(suppose qu'un livre ne peut posséder
qu'un auteur) sur les
cardinalités
La mobilité, en particulier des cardinalités
revêt deux explications à savoir :
? L'expression de la cardinalité est obligatoire pour
chaque patte d'un type-association. ? Une cardinalité minimal est
toujours 0 ou 1 et une cardinalité maximale est toujours 1 ou n.
L'idée de basculer de son fonctionnement revient
à dire que, si une cardinalité maximale est connue et vaut 2, 3
ou plus, alors nous considérons qu'elle est indéterminée
et vaut n.
Cela limitait en effet l'idée : si nous connaissons n
au moment de la conception, il se peut que cette valeur évolue au cours
du temps. Il vaut donc mieux considérer n comme inconnue dès le
départ.
De la même manière, on ne modélise pas des
cardinalités minimales qui valent plus de 1 car ces valeurs sont
également susceptibles d'évoluer. Enfin, une cardinalité
maximale de 0 n'a pas de sens car elle rendrait le type-association inutile.
Les seuls cardinalités admises sont donc :
? 0,1 : une occurrence du
type-entité peut exister tout en étant impliquée dans
aucune association et peut être impliquée dans au maximum une
association.
? 0,n : c'est la cardinalité
la plus ouverte ; une occurrence du type-entité peut exister tout en
étant impliquée dans aucune association et peut être
impliquée, sans limitation, dans plusieurs associations.
? 1,1 : une occurrence du
type-entité ne peut exister que si elle est impliquée dans
exactement (au moins et au plus) une association.
? 1,n : une occurrence du
type-entité ne peut exister que si elle est impliquée dans au
moins une association.
39
Pour pouvoir procèder à des mouvements des
éntités du type-entité, il est tout à fait possible
de preciser qu'une cardinalité minimale de 1 doit se justifier par le
fait que les entités du type-entité en questions ont besoin de
l'association pour exister.
Dans tous les autres cas, la cardinalité minimale vaut
0. Ceci dit, la discussion autour d'une cardinalité minimale de 0 ou de
1 n'est intéressante que lorsque la cardinalité maximale est 1.
Cela explique, que nous verrons cette traduction vers un schéma
relationnel, lorsque la cardinalité maximale est n, nous ne ferons pas
la différence entre une cardinalité minimale de 0 ou de 1.
II.4.3. Notations d'associations
type-entité
II.4.3.1. Associations plurielles
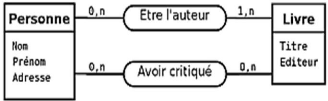
Figure II.5. Cas pratique d'associations plurielles entre un
type-entité
Sémantique de la figure II.5. Cette figure comporte
un type-association qui permet de modéliser que des personnes
écrivent des livres et un autre que des personnes critiquent (au sens de
critique littéraire) des livres.
Il faut aussi noter que deux mêmes entités
peuvent être plusieurs fois en association comme la figure
précédente le démontre.
II.4.3.2. Associations réflexives
Les type-associations réflexifs sont présents
dans la plupart des modèles, il est défini comme un
type-association est qualifié de réflexif quand il
matérialise une relation entre un type-entité et lui-même
comme la fugure suivante.
40
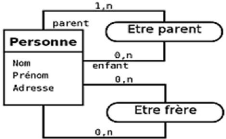
Figure II.6. Cas pratique d'associations réflexives
sur le type-entité personne
Sémantique de la figure II.6. Cette figure comporte
un type-association qui permet de modéliser la relation parent/enfant et
le deuxième type-association la relation de fraternité.
Cette nouvelle règle pose une possession de
légitimité d'une occurrence de ce type-association (i.e. une
association) associe généralement une occurrence du
type-association (i.e. une entité) à une autre entité du
même type. Cette relation peut être symétrique, c'est le cas
du type-association Etre frère la figure II.4.4. le démontre, ou
ne pas l'être, comme le type-association Etre parent sur cette même
figure. Dans le cas où la relation n'est pas symétrique, on peut
préciser les rôles sur les pattes du type-association comme pour
la relation Etre parent de la meme figure. L'ambivalence posée par la
non-symétrie d'un type-association réflexif sera levée
lors du passage au modèle relationnel.
II.4.3.3. Associations n-aire (n>2)
Cette partie introduit la notion de type-association n-aire.
Ce type-association met en relation n type-entités. Même s'il n'y
a, en principe, pas de limite sur l'arité d'un type-association, dans la
pratique on ne va rarement au-delà de trois. Les associations de
degré supérieur à deux sont plus difficiles à
manipuler et à interpréter, notamment au niveau des
cardinalités.
Cas pratique d'association n-aire
inappropriée
41
Figure II.7. Cas pratique de type-association ternaire
inapproprié.
Sémantique de la figure II.7. Cette figure comporte le
type-association ternaire Contient associant les type-entités Facture,
Produit et Client représenté est inapproprié puisqu'une
facture donnée est toujours adressée au même
client.
Le champ d'influence est en effet, cette modélisation
suivante qui implique pour les associations (instances du type association)
Contient une répétition du numéro de client pour chaque
produit d'une même facture.
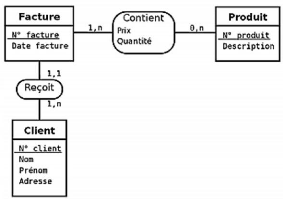
Figure II.8. Cas pratique de Type-association ternaire de la
figure précédente corrigé en deux type-associations
binaires.
Sémantique de la figure II.8. Cette figure comporte
le type-association ternaire Contient associant les type-entités
Facture, Produit et Client représenté est inapproprié
puisqu'une facture donnée est toujours adressée au même
client.
42
Cet constat rélativise une autre solution qui consiste
à éclater le type-association ternaire contient en deux
type-associations binaires.
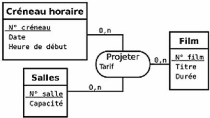
Figure II.9. Cas pratique de type association ternaire entre
des type-entités Créneau horaire,
Salle et Film.
Sémantique de la figure II.9. Cette figure nous
montre un exemple de type-association ternaire entre les type-entités
Créneau horaire, Salle et Film. Il est toujours possible de s'affranchir
d'un type-association n-aire (n > 2) en se ramenant à des
type-associations binaires de la manière suivante :
On remplace le type-association n-aire par un
type-entité et on lui attribut un identifiant.
On crée des type-associations binaire entre le nouveau
type-entité et tous les type-entités de la collection de l'ancien
type-association n-aire.
La cardinalité de chacun des type-associations binaires
créés est 1, 1 du côté du type-entité
créé (celui qui remplace le type-association n-aire), et 0, n ou
1, n du côté des type-entités de la collection de l'ancien
type-association n-aire.
Cette figure suivante illustre le résultat de cette
transformation sur le schéma de la figure II.10. d'où l'avantage
du schéma de la figure suivante est de rendre plus intelligible la
lecture des cardinalités. Il ne faut surtout pas le voir comme un
aboutissement mais comme une étape intermédiaire avant d'aboutir
au schéma de la figure II.10. Ainsi, le mécanisme, que nous
venons de détailler ci-dessus,
43
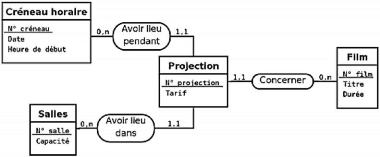
Figure II.10. Cas pratique de transformation du
type-association ternaire de la figure 2.10 en un type-entité et trois
typeassociations binaires.
Sémantique de la figure II.10. Cette figure nous
montre le passage d'un type-association n-aire (n > 2) à un
type-entité et n type-associations binaires est tout à fait
réversible à condition que :
Toutes les pattes des type-associations binaires autour du
type-entité central ont une cardinalitémaximale de 1 au centre et
de n à l'extérieur ;
Les attributs du type-entité central satisfont la
règle de bonne formation des attributs de typeassociation.
Détection d'une erreur de modélisation par
décomposition d'une association n-aire
La détéction d'une erreur pourrait expliquer une
forme de passage en difficulté dans la mesure de diposer d'un plus grand
taux de passage signifié passer par cette étape
intermédiaire ne comportant pas de type-association n-aire (n > 2)
qui peut, dans certains cas, éviter d'introduire un type-association
n-aire inapproprié. Considérons par exemple un type-association
ternaire Vol liant trois type-entités Avion, Trajet et Pilote comme
représenté sur la figure suivante. Cette transformation
consistant à supprimer le type-association ternaire produit le
modèle de la figure II.4.10. Ce modèle fait immédiatement
apparaître une erreur de conception qui était jusque là
difficile à diagnostiquer : généralement, à un vol
donné sont affectés plusieurs pilotes (par exemple le commandant
de bord et un copilote) et non pas un seul. Le modèle correct
modélisant cette situation est celui de la figure II.4.11 où le
type-entité Vol ne peut être transformé en un
type-association ternaire Vol comme sur la figure II.4.10.
44
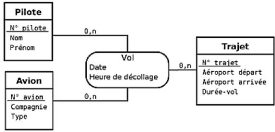
Figure II.11. Cas pratique du Modèle
représentant un type-association ternaire Vol liant
trois
type-entités Avion, Trajet et Pilote.
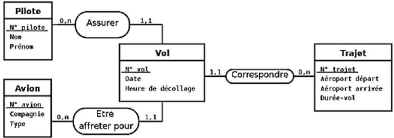
Figure II.12. Cas pratique de transformation du
type-association ternaire de la figure 2.12 en
un type-entité et
trois typeassociations binaires.
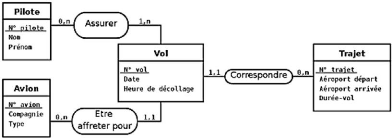
Figure II.13. Cas pratique du Modèle de la figure
2.13 corrigé au niveau des cardinalités.
II.5. Bilan du chapitre
Le panorama bossé sur les évidences des bases
des données, a révélé des éléments
évidents sur les bases des données, ceux décrivant le
système de gestion de base de données et disséminer leurs
intérêt en terme de modélisation et des entités de
types-entités. Plus
45
formellement, une Base des Données est un ensemble
d'informations exhaustives, non redondantes, structurées et
persistantes, concernant un sujet.
De ce fait, introduire le Système de Gestion de Base de
Données peut être le choix de l'organisation, le stockage, la mise
à jour et la maintenance des données. La réponse à
cette question permet de décrire, modifier, interroger et administrer
les données.
46
Chapitre III: Les évidences de mutation vers les
bases de données relationnelles
III.1. Introduction
Avec l'augmentation du rendement de SGBDR, les entreprises ont
adopté le stockage des données dans le SGBDR, qui en fait sont
les logiciels intermédiaires entre les utilisateurs et les bases de
données. Avec ce regard spectaculaire la base de données, est
considérée comme étant un magasin de données
composé de plusieurs fichiers qui sont manipulés exclusivement
par le SGBD. Ce qui permet de cache la complexité de manipulation des
structures de la base de données en mettant à disposition une vue
synthétique du contenu.
La plus part de SGBD et la base de données est
destinée à permettre le stockage de données d'une
manière à offrir beaucoup des aspects relatif par rapport
à un enregistrement conventionnel dans des fichiers. Retenons aussi
qu'il permet d'obtenir et de modifier rapidement des données, de les
partager entre plusieurs usagers. Il garantit l'absence de redondance,
l'intégrité, la confidentialité et la
pérennité des données tout en donnant des moyens
d'éviter les éventuels conflits de modification et en cachant les
détails du format de fichier des bases de données.
Ainsi à la différence des données et le
SGBD, traçons une organisation préalable des indicateurs qui
précise que les données sont enregistrées sous forme de
suites, de bits représentant des lettres, des nombres, des couleurs, des
formes,... alors que le SGBD se compose des mécanismes destinés
à retrouver rapidement les données et de les convertir en vue
d'obtenir des informations qui aient un sens.
Une telle caractéristique, représente une
radicale remise en cause d'enregistrer des données, puis de les
rechercher, de les modifier et de créer automatiquement des comptes
rendus (anglais report) du contenu de la base de données. Il permet de
spécifier les types de données, la structure des données
contenues dans la base de données, ainsi que des règles de
cohérence telles que l'absence de redondance.
Bien qu'il soit indispensable les caractéristiques des
données enregistrées dans la base de données, ainsi que
les relations, les règles de cohérence et les listes de
contrôle d'accès sont enregistrées dans un catalogue qui se
trouve à l'intérieur de la base de données et
manipulé par le SGBD ; il est vrai que les opérations de
recherche et de manipulation des données, ainsi que la définition
de leurs caractéristiques, des règles de cohérence et des
autorisations d'accès peuvent être exprimées sous forme de
requêtes (anglais query) dans un
47
langage informatique reconnu par le SGBD. SQL est le langage
informatique le plus populaire, c'est un langage normalisé de
manipulation des bases de données.
III.2. Généralités sur la notion
de modèle des données
Nombres d'études ayant trait à la notion de
modèle de données mobilisent et insiste sur la portion de
système de types qui est issue des langages de programmation. Il
s'ensuit qu'une des caractéristiques importantes d'un système de
types est sa capacité à modéliser plus ou moins facilement
une situation donnée. Cependant, la notion de type est présente
dans tous les modèles ci-dessus mais elle n'est pas seulement
intentionnelle. Or, dire cela revient à que la notion de modèle
des données est intégrée dans des concepts plus globaux
permettant d'exprimer d'autres notions utiles dans les SGBD. Car, par suite, le
concept décrivant le type d'une entité est notamment
utilisé pour définir le contenant de ces entités.
A ce stade de la réflexion, il apparait donc de
supposer que cette spécificité des activités de service
comme les systèmes de types des langages de programmation
décrivent le modèle de mémoire utilisé par
l'environnement d'exécution du langage, d'où les modèles
de données déterminent le modèle mémoire
implanté par les SGBD. Pour répondre à cette question,
nous mettons en lumière deux niveaux de mémoire (mémoire
centrale / mémoire secondaire), ce qui explique que son système
de types soit moins puissant que ceux des langages de programmation.
Ce faisant, ces derniers travaillent en effet exclusivement en
mémoire centrale. Ainsi, nous pouvons donc dire que, pour ces
différents types de SGBD, le modèle de données
associé est grandement influencé par l'efficacité du
modèle de mémoire qui peut être mis en oeuvre (la
réciproque étant vraie aussi), et surtout celle du modèle
de stockage.
III.3. Structure des modèles des données
à objet
Nous avons vu que la notion des modèles d'objets
constitue la portion de système de types qui est issue des langages de
programmation. Par-là même, dans cette partie nous allons parler
des modèles de données à objet. D'où, il en
résulte que la partie principale qui différencie les
modèles à base de valeurs des modèles objets est la
référence.
En ce sens, elle est utilisée pour dissocier
l'identification d'un objet de sa valeur définissant ainsi des objets
abstraits. Ces choses étant dites, nous reviendrons aussi dans ces
modèles d'identificateur d'objet (oid) et d'état d'un objet.
Sachant cela, nous proposons une étude de ces différentes notions
dans différents modèles de systèmes existants.
Par ailleurs, comme nous ne pouvons pas non plus structurer un
attribut en un autre n-uplet, pour pouvoir définir l'abstraction de
l'adresse dans PERSONNE, nous devons
48
III.3.1. Le modèle de données d'Orion [9]
Le modèle des données dit Orion est un SGBD
orienté objet développé au MCC à Austin (USA). On
peut donc dire de ce modèle qu'il s'agit d'une extension du langage
Lisp, dans lequel sont introduits des concepts objets et base de données
à travers la notion de classe. S'il est pour partie imposée, cela
indique que dans le modèle d'Orion, tout est objet ; à cela nous
n'avons la notion de valeur qu'au niveau des attributs d'un objet.
De plus, la classe apporte aussi des fonctionnalités de
la base de données. Mais cela ne change rien à l'affaire, comme
la relation, la classe définit à la fois un type d'objet et
désigne l'ensemble des instances de cette classe.

On peut donc dire de manière structurel que le
modèle d'Orion est très proche du modèle relationnel
puisque d'un côté le constructeur ensemble est mis en oeuvre
seulement au niveau de la classe et d'un autre coté l'état d'un
objet a une structure de n-uplet dont les attributs sont soit des valeurs de
base, soit des objets abstraits.
C'est plutôt que, dans la mesure où le seul moyen
de représenter des attributs multi values est alors de gérer
explicitement des structures de listes comme cela est fait pour les champs
"Prenoms" et "Enfants" de la classe Personne.
49
définir un objet de classe ADRESSE. S'il est clairement
établi que nous considérons l'adresse comme propre à
chaque personne, Orion offre la possibilité de définir des liens
dit "composite" entre objet.
Cela signifie que l'objet Adresse ne peut être
partagé par aucun autre objet et qu'il existe une dépendance
existentielle entre les deux objets (si un objet PERSONNE est détruit,
l'objet "composite" ADRESSE l'est aussi). La sémantique de ces deux
types de liens ne peut être mise en oeuvre qu'au niveau de la
référence ou de l'identificateur de l'objet car c'est une
contrainte dynamique associée à l'objet et non à sa
classe.
Autrement dit, toutes les instances d'une classe Orion sont
persistantes. Nous avons donc deux espaces d'instanciation bien
séparés : l'espace temporaire des données Lisp
(essentiellement composé de listes) et l'espace des objets persistants
décrit par les classes.
Mais ce n'est pas tout, nous constatons que le
dysfonctionnement au niveau du système de type n'a pas été
supprimé. Outre, nous avons deux systèmes de types qui partagent
néanmoins leurs domaines de base, ce qui réduit le
dysfonctionnement. Avec les nouveaux concepts objet et la base de
données ne sont donc pas orthogonaux aux autres concepts du langage
initial.
III.3.2. EXTRA : un modèle de données pour
EXODUS
Le modèle de données pour EXODUS [12] est un
SGBD extensible développé à l'université de
Wisconsin (USA). De ce modèle, chacun s'accordera à reconnaitre
qu'il s'agit d'une boite à outils devant permettre d'implanter des SGBD
et ce pour n'importe quel modèle de données. En vue de le
concrétiser, un modèle de données, nommé EXTRA et
un langage de requêtes, nommé EXCESS, sont proposés dans
[13].
C'est un modèle d'objets complexes assez proche de ceux
proposés dans Galileo [10] ou dans Fad [10], dans lequel tous les objets
sont des valeurs. Il est même fréquent que l'introduction d'un
constructeur ref permet de manipuler explicitement les références
aux valeurs de la base. En ce sens, la notion de type permet de définir
structurellement ces valeurs.
50

Il sied de dire que seules les valeurs
générées à partir des types du schéma
peuvent être référencées. Cette diversité des
valeurs générées sont introduites par le constructeur own
dans la définition où leur type intervient. En somme, ces valeurs
sont divisées en deux catégories : les valeurs
référençables et celles qui ne le sont pas. Les valeurs
référençables sont introduites par own ref alors que les
autres le sont par own seulement. Le constructeur own introduit dans tous les
cas une dépendance existentielle pour la valeur ainsi
désignée.
Signalons néanmoins que la manipulation des valeurs de
la base rend transparente la notion de référence. Comme
l'accès à une valeur par un nom qui la désigne directement
ou par un nom qui désigne une référence vers cette valeur
se fait de la même manière pour l'utilisateur. Il est alors
possible de dire que le système infère automatiquement, par
rapport au schéma, le fait qu'il accède à cette valeur par
la fonction í ° ñ ou í ° ñ °
ñ (pour les valeurs référencées). Prenons un cas
pratique, si nous supposons que "pers"est un nom qui désigne une valeur
de type "personne", nous accédons de la même manière
"pers.Nom" et "pers.Epoux.Nom" alors que "pers.Epoux" désigne une
référence vers une valeur de type "personne".
Au final, il s'avère que la différence
étant explicite dans le schéma, car elle est prise en compte lors
de l'opération d'affectation. Seulement tel n'est pas forcément
le cas ; de ce fait nous en distinguons deux types : l'affectation de valeur
(copy to...) et l'affectation d'une référence à une valeur
(insert into...).
En revanche, nous pouvons étendre les domaines de base
avec les ADT (types de données abstraits). Les ADT sont des classes
persistantes définies à partir du langage E [14] (extension de
C++). Un cas pratique de leur utilisation est le champ "DateNais" dans le
type
En cela O2 offre donc un modèle d'objets complexes
faisant intervenir de manière orthogonale les constructeurs n-uplet
(tuple), ensemble (set) et séquence (list). Nous n'avons
51
"personne" dont le type Date est un ADT. Un ADT définit
donc une valeur encapsulée par différentes méthodes qui
lui sont attachées.
Cela revient à dire que toutes les valeurs
créées sont persistantes. Et que nous avons donc un seul espace
d'instanciation dont les données sont manipulées à travers
un langage de requêtes (EXCESS) du même niveau qu'un langage comme
SQL. Ce langage de manipulation n'est pas complet ; nous n'avons pas dans ce
système une intégration entre un langage général et
les aspects base de données.
III.3.3. Le modèle de données de O2
Le modèle de données dit O2 [15] est un SGBD
orienté objet développé par le GIP-Altaïr à
Paris (France). Son objectif est d'offrir un système multi-langages
permettant à ces derniers de manipuler des objets, notamment
persistants, à travers un modèle commun. Le modèle O2 [16]
distingue deux catégories de données : les valeurs et les
objets.
Le nommage des instances (create name...) est
séparé du nommage des types comme dans EXTRA. Cela nous
amène à pointer une autre façon de nommer les types
décrivant des valeurs (create type...) aussi bien que ceux qui
décrivent des objets abstraits (create class...) comme le montre la
représentation O2[17] du cas pratique des personnes.

52
pas explicitement la notion de référence et le
partage de données se fait exclusivement à travers des objets
abstraits.
Or, si celles-ci constituent un support à l'action, le
système permet de créer des objets persistants ainsi que des
objets temporaires. Mais ce n'est pas tout, car il faut alors distinguer deux
types de références suivant le statut de l'objet instancié
qui engendre en fait deux espaces d'instanciation différents.
Alors que, la notion d'objet abstrait impliquant qu'une
référence peut être instanciée dans d'autres objets,
il se pose le problème des références inter-espace. Et
cela n'est pas sans poser problème, qu'une référence dans
l'espace persistant est valide d'une exécution d'un programme à
une autre. Ce n'est pas le cas des références de l'espace
temporaire. Le problème est résolu dans O2 en
déplaçant tout objet abstrait temporaire dans l'espace persistant
si la référence qui l'identifie est instanciée dans
l'espace persistant.
Ces choses étant dites, regardons à
présent en quoi le modèle de O2 est intégré dans un
langage de programmation usuel tel que C, Lisp ou Basic. Pour ce faire, le
système de type défini par le modèle est ajouté au
système de type du langage d'immersion.
Cette intégration n'est pas orthogonale. A cette
caractéristique s'ajoute le fait que le dysfonctionnement au niveau du
système de type n'est donc pas résolu dans les différents
langages associés à O2 tels que O2C. A l'opposé, on a vu
que ce dysfonctionnement est moins sensible car le système de types pour
la définition des données persistantes est au moins aussi
puissant que celui du langage d'immersion même s'il ne partage pas les
domaines de base. Des coopérations sont tout de même possibles
comme un cas pratique qu'une affectation d'une entier C (int) dans un entier O2
(integer).
III.3.4. Le modèle de données de Guide
Le modèle de données de Guide [19] est un
système orienté objet distribué développé
par l'unité mixte Bull-Imag à Grenoble (France). Comme nous
l'avons vu, ce modèle sert de support à un langage orienté
objet portant le même nom dédié à la construction
d'applications réparties. Ici, la réponse d'objets est claire, le
système de type permet essentiellement de définir des objets
abstraits qui sont des instances des classes Guide. En remettant en question
l'explication, la notion de type présente dans Guide correspond à
une interface d'accès aux objets.
53
Nous nous retrouvons donc face à la difficile et
essentielle question de ces objets qui peuvent appartenir à
différentes classes avec une condition si celles-ci sont conformes
à l'interface proposée par le type.
Voilà pourquoi, avec le temps et l'expérience,
l'état associé à un objet Guide est une valeur qui peut
être construite [20]. Bien attendu, il va sans dire que le langage offre
deux constructeurs : le n-uplet (record) et le tableau (array). On voit bien
ici qu'ils peuvent être combinés de manière orthogonale.
Or, nous n'avons pas la puissance d'un modèle d'objets complexes, le
tableau n'offrant pas la dynamicité du constructeur ensemble. Nous avons
pu observer qu'il faut alors comme pour Orion, gérer explicitement des
listes chainées. Une modélisation possible pour le cas pratique
des personnes en Guide est la suivante :

De la même façon que la modélisation, tous
les objets Guide sont persistants. Dit autrement, ils ne persistent
réellement que lorsqu'ils sont accessibles à partir d'un nom.
Tout d'abord, il importe de préciser que, nous avons à faire ici
à un langage de programmation ce qui permet de distinguer deux
partitions dans l'espace de noms : les noms qui désignent des
données de la base, et les noms qui désignent des entités
dans l'environnement d'exécution. Mais ce n'est pas tout.
Nous pouvons par exemple répertorier dans cette
deuxième partition, qui n'existe que dans le cas d'un langage de
programmation, les noms désignant des variables locales d'une
procédure.
Pour résoudre ce problème et en quelque sorte
mettre en claire, cette seconde catégorie de noms peut être
déterminée statiquement par le schéma qui contient dans ce
cas les définitions des traitements (procédures ou
méthodes). Ce faisant d'un côté, ce n'est plus vrai
54
lorsque le langage supporte la récursivité
(empilage potentiellement infini d'environnements). Aussi bien que, comme nous
l'avons vu, l'environnement d'exécution comporte alors une pile
impliquant la création de nouveaux noms à chaque nouvel appel de
procédure. Quoiqu'il en soit, nous avons donc une deuxième racine
de nommage (la première étant la base de données
nommée "BaseDeDonnées") qui est l'environnement
d'exécution que nous nommons "Environ". Dans le cas d'un langage
classique, nous lui attachons généralement deux fils : un nom
désignant un n-uplet dont chaque attribut est une variable globale de
l'application (nous l'appelons "Global"), et le nom désignant la pile
d'exécution (nous l'appelons "Pile").
Seulement, dans Guide, nous pouvons ainsi créer des
objets qui sont désignés par des noms de l'environnement
d'exécution. Ce faisant, ils ont alors la durée de vie de ce nom,
c'est à dire au maximum celle de l'exécution en cours, à
moins qu'un autre nom de la base ne permette de les désigner avant la
fin de cette exécution. La nouveauté réside à
travers ce cas pratique de ce type de nom où
"Environ.Pile.main.Augmenter.this" désigne le paramètre contenant
l'objet sur lequel s'applique la méthode "Augmenter" qui a
été appelée dans la procédure "main" correspondant
au point d'entrée du programme.
Cela dit, tous les objets Guide qui sont créés
sont potentiellement persistants et deviennent réellement persistants
(ils subsistent à l'exécution du programme qui les a
créés) uniquement s'ils sont attachés
(désignés) par un nom de la base. Pour conclure, les
systèmes décrits précédemment, Guide offre un
service de nommage permettant de créer des points d'entrée vers
les objets de la base. Cela étant, ces noms ne font pas partie du
schéma ce qui est une divergence remarquable. Enfin et surtout, ces noms
ne sont pas typés (alors que Guide offre un typage fort) ce qui implique
le besoin de mettre en oeuvre de la vérification de type à
l'exécution lors de l'utilisation de ces noms.
III.4. Passage au modèle relationnel
III.4.1. Généralité de clé
étrangère
La clé étrangère d'une relation R est un
sous-ensemble C des attributs de R tel que :
? Il existe une relation R' (pas nécessairement
distincte de R) possédant une clé candidate C' ;
? Pour chaque valeur différente de C dans R, il existe
une valeur (unique) de C' dans R' identique à C.
55
De même, la clé étrangère dans une
table est un attribut ou une concaténation d'attributs qui forme une
clé d'identification d'une autre table (ou éventuellement de la
même table). Une clé primaire d'une table comportant des
clés étrangères peut être soit une
concaténation de celles-ci, soit une autre clé candidate - par
exemple une clé créée artificiellement.
III.4.2. Règles de passage
Avec les règles de passage, l'opération consiste
à représenter sous forme de tables les entités et les
associations obtenues précédemment. Pour ce faire, on applique
les règles suivantes :
? Chaque entité est traduite en une table distincte,
dont la clé primaire peut être soit celle de l'entité, soit
une autre clé candidate. Les autres attributs de l'entité sont
reportés comme attributs de la nouvelle table.
? La conversion d'une association dépend de sa
cardinalité :
R1. Une association de dimension 2 de type simple-complexe
(par exemple, (1,1)-(1,N)) ne nécessite pas la création d'une
nouvelle table, mais est traduite en définissant une clé
étrangère dans la table qui se situe du côté
"simple" de l'association. Cette clé doit faire référence
à la clé d'identification de la seconde table, et son nom est
judicieusement choisi en conséquence.
R2. Une association de dimension 2 de type simple-simple (par
exemple, (1,1)-(0,1)) se traite de la même façon, en choisissant
en principe d'introduire la clé étrangère dans la table
située du côté (1,1) de l'association.
R3. Chaque association de dimension 2 de type
complexe-complexe (par exemple, (0, N)-(1, N)) est représentée
par une table distincte, contenant les identifiants des deux entités
associées comme clés étrangères. Ces attributs
constituent souvent, à eux deux, la clé primaire de la nouvelle
table.
Si l'association comporte d'autres attributs, ceux-ci sont
également ajoutés à la table.
R4. Une association de dimension supérieure à 2 se
réécrit selon la règle R3.
Figure III.1 : Erreur de conception du modèle
entité association
56
III.4.3. Cas pratique
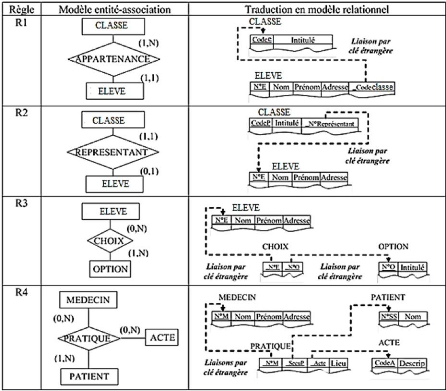
Tableau III.1 : Cas pratique d'usage des règles de
passage modèle entité-association du
modèle
relationnel
III.5. Pertinence de la normalisation dans la
conception d'une Base de données relationnelle
III.5.1. Redondance d'un attribut
Prenons un cas pratique d'un modèle relationnel obtenu
pour représenter les données relatives à l'inscription des
élève dans une classe se soit réduit à une seule
table (suite à une mauvaise conception du modèle
entité-association) :
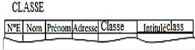
57
Une pareille conception entraîne des difficultés
de redondance des informations. On s'aperçoit en effet que
l'intitulé de la classe est répété pour chaque
élève, et qu'il est identique pour tous les élèves
inscrits dans la même classe. Cet attribut est donc redondant, et il est
préférable de stocker ces informations, relatives à une
classe, dans une table séparée.
III.5.2. Anomalies de mutation
En conséquence, le schéma
précédent n'est pas satisfaisant car il engendre certaines
anomalies lors des opérations de mise à jour, d'insertion et de
suppression des données (anomalies dites de mutation).
? Si par exemple on modifie l'intitulé d'une classe
dans un tuple (ex. de "Etude de la Vie" en "Etude du Vivant"), ce même
intitulé devra être changé pour tous les autres
élèves concernés, sans quoi cette classe possédera
plusieurs intitulés différents (anomalie de mise à
jour).
? Si une nouvelle classe se crée, elle ne pourra pas
être ajoutée dans la table sans y inscrire immédiatement
des élèves, car la clé primaire (N°E) ne peut
être laissée vide. Cette anomalie d'insertion peut être
gênante, par exemple, parce que le stockage d'informations sur la
nouvelle formation (maquette, intervenants, ...) doit pouvoir intervenir avant
toute inscription d'élève.
? Si l'on supprime tous les élèves de la table
(par exemple parce qu'ils ont tous eu leur diplôme !), on perd du
même coup toutes les informations relatives aux promotions (anomalie de
suppression).
Ces termes définis, soulignons qu'à l'instar des
anomalies de mutation, une base de données relationnelle doit stocker un
ensemble de schémas relationnels sans redondance inutile et sans
comportement anormal des relations lors des opérations de mise à
jour. Cependant la théorie de la normalisation des relations a
été associée au modèle relationnel.
III.6. Dépendances fonctionnelles et
normalisations des relations
III.6.1. Dépendance fonctionnelle :
définitions
La notion de dépendance fonctionnelle (DF) a
été introduite par Codd en 1970, elle permet de
caractériser des relations qui peuvent être
décomposée sans perte d'information. Tout d'abord, sa
formalisation mathématique découle de l'observation des
rôles de cardinalité simple (au plus égale à 1). En
intégrant sa pratique, intuitivement, une DF traduit le fait que
58
les valeurs de certains attributs sont nécessairement
déterminées (fixées) lorsque le sont celles d'autres
attributs.
Partant de cela, on dit qu'un attribut ou un ensemble
d'attributs Y est fonctionnellement dépendant d'un autre (ensemble d')
attribut(s) X si, à chaque valeur prise par X correspond une valeur
unique de Y. Autrement dit, des valeurs identiques de X impliquent des valeurs
identiques de Y. Cette dépendance est notée X--Y.
Avec une particularité, qu'une propriété
remarquable des clés d'identification est que, justement, tout attribut
non-clé dépend fonctionnellement de la clé, puisque
celle-ci identifie chaque tuple de manière unique.
Mais avant cela, une des propriétés de la DF est
la transitivité : X--Y et Y--Z X--Z. On dit qu'un attribut Z est
transitivement dépendant d'un attribut X s'il existe un attribut Y tel
que X--Y et Y--Z, et aussi que X ne dépend pas fonctionnellement de
Y.
III.6.2. Normalisation des relations
En pointant la normalisation des relatons que sous-tendent ces
différentes relations, il s'agissait de mettre en exergue les anomalies
de mutation. Pour ce faire, pour éliminer les divers types de
dépendances, et donc éviter les anomalies de mutation, on
applique un processus de normalisation sur les différentes relations de
la base. Les étapes successives de ce processus imposent des
critères de plus en plus restrictifs aux tables normalisées:
? Une relation est en première forme normale
(notée 1NF) si les domaines de tous ses attributs sont des valeurs
atomiques (et non des ensembles, types énumérés ou
listes). De ce fait, tout attribut d'une relation 1NF doit donc être
monovalué. Bien attendu, la 1NF permet d'éliminer les domaines
composés. En sus, pour normaliser une table à la 1NF, il suffit
de créer un tuple distinct pour chaque valeur de l'attribut
multivalué. Cela introduit des redondances, mais la deuxième
forme normale permet d'y remédier.
? Plus précisément, une relation est en
deuxième forme normale (2NF) si elle est 1NF et si, de plus, tout
attribut non-clé dépend fonctionnellement de toute la clé
(et pas seulement d'une partie de celle-ci). Pour qu'une table soit 2NF, il
faut donc, si sa clé est composée (sous-entendu, de plusieurs
attributs), que tout autre attribut soit fonctionnellement dépendant de
la clé entière (on dit parfois qu'il y a dépendance
fonctionnelle totale). La 2NF garantit qu'aucun attribut n'est
déterminé seulement par
59
une partie de la clé. En somme, pour normaliser
à la 2NF une table possédant une clé composée, il
faut décomposer celle-ci en :
? une table formée des attributs dépendants
d'une partie de la clé, et de cette partie même.
? une seconde table formée de la clé
composée et des attributs restants :

Figure III.2 : Cas pratique de normalisation de la
2FN
? En suite, une relation est en troisième forme normale
(3NF) si elle est 2NF et si, de plus, tout attribut non-clé ne
dépend pas transitivement de la clé (ou, autrement dit, si tout
attribut non-clé ne dépend pas fonctionnellement d'un attribut
non-clé).
Dans ce cas, la 3NF permet d'éliminer les redondances
dues aux dépendances transitives. C'est-à-dire, pour normaliser
à la 3NF une table possédant une dépendance transitive, il
faut décomposer celle-ci en :
? une table formée de l'attribut redondant et de
l'attribut dont il dépend (nommé ici X); ce dernier devient la
clé de la nouvelle table,
? une seconde table formée de la clé, de
l'attribut X comme clé étrangère, et des autres attributs
:

Figure III.3 : Cas pratique de normalisation de la
3FN
Enfin et surtout, les formes normales 2NF et 3NF assurent
l'élimination des redondances parmi les attributs non-clé, mais
pas les redondances potentielles au sein d'attributs formant une clé
composite. Finalement, Boyce et Codd ont proposé une extension de la
3NF, il s'agit là d'une forme normale dite Boyce-Codd (BCNF).
De ce fait, une relation est en forme normale de Boyce-Codd
(BCNF) si, et seulement si, les seules dépendances fonctionnelles
élémentaires sont celles dans lesquelles une clé
détermine un attribut non-clé.
60
Plus simple que la 3NF, un peu plus restrictive, cette forme
est utile lorsqu'une table possède plusieurs clés candidates.
Plus précisément, lorsque les clés se chevauchent dans une
table, celle-ci risque de transgresser la forme normale de Boyce-Codd,
même si elle est en 3NF. Il faut alors la décomposer
d'après les clés candidates :

Figure III.4. Cas pratique de normalisation de la
BCFN
Cela étant, toute relation admet au moins une
décomposition en BCNF qui est sans perte; cependant, ne telle
décomposition ne préserve généralement pas les
dépendances fonctionnelles.
Retenons alors qu'il existe deux autres formes normales,
encore plus restrictives, mais qui se rencontrent bien moins
fréquemment. La quatrième (4NF), par exemple, est basée
sur les dépendances multivaluées.
III.6.3. Cas pratique
Pour éprouver ces différentes formes normales,
il faut dire que les critères des formes normales sont satisfaits si le
modèle entité-association est bien construit et que si les
règles de passage au modèle relationnel ont été
correctement appliquées. Par-là, la vérification de toutes
les formes normales successives n'a plus alors besoin d'être
systématique [26].
Outre, avec notre part, supposons au contraire que le
modèle entité-association ait fourni la relation suivante (figure
III.5.).
A l'évidence, celle-ci n'est pas en 1NF ; il faut donc
la transformer conformément à la figure III.6. Or, la clé
de la nouvelle table, composée des attributs N°E et Option,
détermine bien de manière unique les attributs non-clé
(c'est-à-dire qu'on a les dépendances fonctionnelles
(N°E,Option)--Nom, (N°E,Option)--Prénom, et
(N°E,Option)--Adresse). Cependant, la transformation a manifestement
créé des redondances et, intuitivement, on sait que l'adresse de
l'élève n'a aucun rapport avec l'option choisie. Cela se traduit
par le fait que les attributs non-clé sont fonctionnellement
dépendants d'une partie de la clé (N°E--Nom,
N°E--Prénom, et N°E--Adresse). La deuxième forme
normale exige donc de créer deux tables séparées (figure
III.7.).
Figure III.9. Passage en 3NF, après ajout de la table
Code_postal avec attributs (rue et ville).
61

Supposons qu'en plus des attributs précédents,
on ait stocké dans la table ELEVE le code postal et la ville, et qu'on
ait séparé le numéro de voie et la rue. La 2NF
correspondante est représentée figure III.8. (la table CHOIX n'a
pas été représentée). Dans cette table, l'attribut
CodePostal dépend fonctionnellement de l'attribut composé (Rue,
Ville) et, par là même, dépend transitivement de la
clé.
Pour passer en 3NF, il faut donc créer une table
CODE_POSTAL distincte, et faire apparaître dans ELEVE l'attribut codant
la rue et la ville sous forme de clé étrangère (figure
III.8.) :

Figure III.8. Passage en 3NF, en ajoutant la table
Code_postal avec attributs (rue et ville).
On trouve seulement, dans la nouvelle table, qu'il y a encore
de la redondance. C'est la raison pour laquelle, si la clé
composée de la rue et de la ville détermine bien le code postal,
la ville est aussi fonctionnellement dépendante du code postal
(c'est-à-dire (Rue,Ville)--CodePostal et CodePostal--Ville). Ceci est
lié au fait que l'attribut (Rue, CodePostal) constitue également
une clé candidate (clé secondaire). Pour obtenir une forme
normale de Boyce-Codd, il faut donc décomposer cette relation en deux
(figure 6-3) :
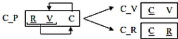
62
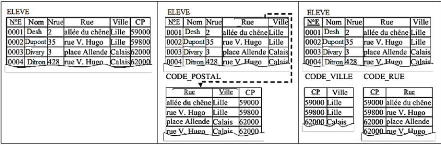
III.6. Intégrité structurelle
III.6.1. Notion et classification
Est appelé contrainte d'intégrité (CI),
une propriété ou une règle que doivent satisfaire les
données de la base pour être considérées comme
correctes (sans ambiguïtés ni incohérences). Une base de
données est dite intègre ou cohérente si ses contraintes
d'intégrité sont satisfaites.
Cela dit, qu'en pratique, ces contraintes ont pour effet de
limiter les occurrences possibles des structures d'informations. La conception
d'une base de données relationnelle se compose du schéma
relationnel même et d'un ensemble de CIs.
De cette présentation faite, il convient de classer les
contraintes selon les valeurs d'attributs à savoir:
? Les contraintes d'intégrité statiques sont des
propriétés qui doivent être vérifiées
à tout moment :
? Les contraintes individuelles imposent un type de
donnée (ex. entier long), un
ensemble de valeurs (par exemple,
AnnéeEmbauche={2010..2017},
AnnéeEmbauche={2001, 2010, 2015},
AnnéeEmbauche>AnnéeNaissance) ou une valeur obligatoire (ex.
"l'attribut pilote doit être obligatoirement renseigné").
? Les contraintes intra-relation portent sur les valeurs des
attributs : unicité devaleur, cardinalité, dépendances
entre les valeurs d'attributs différents (ex. "les espèces e3 et
e6 ne peuvent cohabiter").
? Les contraintes inter-relations sont des dépendances
référentielles ou existentielles (ex. "tout vol doit avoir comme
commandant de bord une personne référencée dans la table
des pilotes").
63
? Les contraintes d'intégrité dynamiques sont
des propriétés que doit respecter tout changement d'état
de la base de données; elles en définissent les séquences
possibles de changement d'état. (ex. "le salaire d'un employé ne
peut qu'augmenter")
Il s'ensuit que trois catégories de contraintes
d'intégrité structurelles sont particulièrement
importantes dans le modèle relationnel : les contraintes
d'unicité (chaque table possède une clé
d'identification qui en identifie les tuples de manière unique),
les contraintes de domaine (les valeurs possibles
d'un attribut sont restreintes à un ensemble de valeurs
prédéfinies) et les contraintes
d'intégrité référentielle (chaque
valeur d'une clé étrangère doit exister comme valeur de la
clé d'identification dans la table référencée).
III.6.2. Intégrité
référentielle
Ces choses étant dites, un avantage demeure, car le
mécanisme d'intégrité référentielle impose
que chaque valeur d'une clé étrangère existe comme valeur
de la clé d'identification dans la table
référencée.
Tout SGBDR digne de ce nom attire et supporte ce concept
fondamental ; prenons un exemple pour l'illustrer. Prenons le cas de la
normalisation en 3NF de la table ELEVE, dans laquelle figure la classe
d'inscription, ait fourni la table de la figure III.14. On remarque qu'aucune
valeur de la clé étrangère _Class ne viole
l'intégrité référentielle. Mais l'insertion d'un
tuple tel que "0005, Mader, DESSDC" serait rejetée si la clé
primaire de la table CLASSE ne contient pas la valeur "DESSDC".
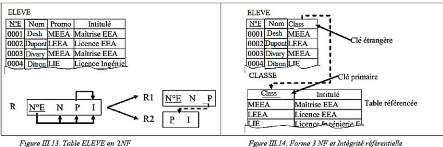
Partant de ces figures, l'on remarque que le respect de
l'intégrité référentielle implique certaines
actions. On a vu que le SGBDR vérifiait l'existence d'une valeur de
clé étrangère lors de l'insertion d'un nouveau tuple ;
mais que se passe-t-il si l'on supprime ou si
64
l'on modifie une valeur de la clé primaire dont
dépendent d'autres valeurs dans une clé étrangère ?
Plusieurs stratégies sont possibles:
Tout d'abord, la suppression (ou la mise à jour)
interdite : l'opération est tout simplement refusée (
ex. la suppression de la ligne "MEEA,
Maîtrise EEA" est impossible car des tuples d'ELEVE y font
référence),
Ensuite, la suppression(ou la mise à jour) en cascade:
dans ce mode, lorsqu'un tuple de la table référencée est
supprimé (ou, respectivement, modifié dans ses attributs
clés), tous les tuples dépendants sont aussi supprimés
(resp. modifiés). Par exemple, la suppression du tuple "MEEA,
Maîtrise EEA" entraîne celle des élèves portant les
numéros 0001 et 0003 ; le changement de clé "MEEA" en "MEA"
affecte de la même façon les valeurs de la clé
étrangère pour ces élèves.
Enfin, la suppression avec initialisation: toutes les
clés étrangères égales à la clé
primaire supprimée sont mises à la valeur nulle (
ex. la suppression du tuple "MEEA,
Maîtrise EEA" entraîne la mise à NULL de l'attribut _Class
des élèves portant les numéros 0001 et 0003).
III.7. Bilan du chapitre
L'objet de ce chapitre était de révéler
ce qui fait la singularité des mutations des entreprises vers l'usage
des SGBD. Pour ce faire, nous avons tout d'abord voulu savoir quelle
était la contribution essentielle de l'usage de SGBD dans des
entreprises. C'est pourquoi nous avons examiné les apports et les
limites des différentes conceptions des modèles des
données. Il en est ressorti qu'en dépit de limites de chacun de
ces différentes conceptions des modèles des données, la
modélisation s'articuler avec la valeur du résultat après
chaque conception.
Ces choses étant dites, restait ensuite à
déterminer ce qui caractérise la valeur des attributs dans
chacune des tables pour chaque choix du modèle des données. Pour
y parvenir, nous nous sommes appuyés sur le passage au modèle
relationnel, sa normalisation des relations dans la conception d'une base de
données relationnelle, sa dépendance fonctionnelle et enfin
chuter par la notion d'intégrité structurelle. Il en est
résulté que la notion d'intégrité structurelle
renferme différentes classifications, d'où
l'intégrité référentielle constitue une
synthèse de ces dernières, car, elle impose que chaque valeur
d'une clé étrangère existe comme valeur de la clé
d'identification dans la table référencée.
65
Chapitre IV: Le langage Sql : un manipulateur de bases
de données relationnelles
IV.1. Introduction
Nombre d'études ayant trait au langage SQL (Structured
Query Language) soutiennent que ce langage d'interrogation des données
est par la plupart supporté par des produits commerciaux que ce soit par
les systèmes de gestion de bases de données micro tel que Access
ou par les produits plus professionnels tels que Oracle. Il s'ensuit que ce
langage a fait l'objet de plusieurs normes ANSI/ISO avec une remontée de
la norme SQL2 qui a été définie en 1992. Cependant, il est
considéré comme le langage d'accès normalisé aux
bases de données.
A ce stade de la réflexion, son succès est
dû essentiellement à sa simplicité et au fait qu'il
s'appuie sur le schéma conceptuel pour énoncer des requêtes
en laissant le SGBD responsable de la stratégie d'exécution. Or,
dire cela revient à expliquer que le langage SQL propose un langage de
requêtes ensembliste et assertionnel. Car, par suite, il ne
possède pas la puissance d'un langage de programmation :
entrées/sorties, instructions conditionnelles, boucles et
affectations.
Pour mieux saisir, avec certains traitements, il est donc
nécessaire de coupler le langage SQL avec un langage de programmation
plus complet. De ce fait, il apparaît donc légitime de dire que
SQL est un langage relationnel, il manipule donc des tables (i.e. des
relations, c'est-à-dire des ensembles) par l'intermédiaire de
requêtes qui produisent également des tables. Par ailleurs, s'il
faut considérer les jalons de son trajectoire, d'un côté
disons que les différents produits phares ont évolué,
entre autre la norme SQL est passée à SQL-2, puis SQL-3. Ainsi
voit-on des files d'évolutions d'attentes en continu, SQL est
désormais un langage incontournable pour tout SGBD moderne.
Dans les faits, la réalité est plus complexe,
bien qu'une norme existe, on assiste à une prolifération de
dialectes propres à chaque produit : soit des sous-ensembles de la norme
(certaines fonctionnalités n'étant pas implantées), soit
des sur-ensembles (ajout de certaines fonctionnalités, propres à
chaque produit). Du reste, Oracle et Informix dominent le marché actuel,
SQL-Server (de Microsoft) tente de s'imposer dans le monde des PC sous NT. Avec
ce lissage d'autres produits très chers, on voit exister heureusement
des systèmes libres et gratuits : MySQL et PostgreSQL qui au final sont
les plus connus.
66
De l'autre côté, bien que ces SGBDR n'aient pas
la puissance des produits commerciaux, certains s'en approchent de plus en
plus. Cela dit, les différences notables concernent principalement les
environnements de développement qui sont de véritables ateliers
logiciels sous Oracle et qui sont réduits à des interfaces de
programmation C, Python, Perl sous PostgreSQL. De même, pour les
interfaces utilisateurs : il en existe pour PostgreSQL, mais ils n'ont
certainement pas la puissance de leurs équivalents commerciaux.
Pour notre cas, nous ne présenterons ici que les
fonctionnalités principales de SQL. Il est ici probant que les langages
utilisés dans les bases de données relationnelles se fondent sur
l'algèbre relationnelle et/ou le calcul relationnel. Une fois de plus,
ce dernier, est basé sur la logique des prédicats (expressions
d'une condition de sélection définie par l'utilisateur). On
distinguer 3 grandes classes de langages :
Les langages algébriques,
basés sur l'algèbre relationnelle de CODD, dans lesquels les
requêtes sont exprimées comme l'application des opérateurs
relationnels sur des relations. Le langage SQL, standard pour l'interrogation
des bases de données, fait partie de cette catégorie.
Les langages basés sur le calcul
relationnel de tuples, construits à partir à partir
de la logique des prédicats, et dans lesquels les variables
manipulées sont des tuples (ex. : QUEL, QUEry Language).
Les langages basés sur le calcul
relationnel de domaines, également construit à
partir de la logique des prédicats, mais en faisant varier les variables
sur les domaines des relations.
Toutefois, le langage SQL, est un langage normalisé
permettant :
La définition des éléments
d'une base de données (tables, colonnes, clefs, index,
contraintes, ...),
La manipulation des données
(insertion, suppression, modification, extraction, . . .),
Le contrôle des données (acquisition et
révocation des droits),
L'interrogation de la base (clause
SELECT)
IV.2. Le langage de définition des
données (LDD) [31]
Le langage de définition de données (LDD, ou
Data Definition Language, soit DDL en anglais) est un langage orienté au
niveau de la structure de la base de données. Le LDD permet de
créer, modifier, supprimer des objets. Il permet également de
définir le domaine des données (nombre, chaîne de
caractères, date, booléen, . . .) et d'ajouter des contraintes
de
67
valeur sur les données. Ces choses étant dit, il
permet enfin d'autoriser ou d'interdire l'accès aux données et
d'activer ou de désactiver l'audit pour un utilisateur donné.
Les instructions du LDD sont : CREATE, ALTER, DROP, AUDIT,
NOAUDIT, ANALYZE, RENAME, TRUNCATE.
IV.2.1. Notion aux contraintes
d'intégrité
Soit le schéma relationnel minimaliste suivant : - Acteur
(Num-Act, Nom, Prénom), - Jouer (Num-Act, Num-Film), -
Film (Num-Film, Titre, Année),
1. Contrainte d'intégrité de
domaine
On ne cesse de parler de cette contrainte
d'intégrité de domaine sans expliquer la cause. Toute comparaison
d'attributs n'est acceptée que si ces attributs sont définis sur
le même domaine. Le SGBD doit donc constamment s'assurer de la
validité des valeurs d'un attribut. C'est pourquoi la commande de
création de table doit préciser, en plus du nom, le type de
chaque colonne.
Par exemple, pour la table Film, on précisera que le
Titre est une chaîne de caractères et l'Année une date.
Lors de l'insertion de n-uplets dans cette table, le système s'assurera
que les différents champs du n-uplet satisfont les contraintes
d'intégrité de domaine des attributs précisées lors
de la création de la base. Si les contraintes ne sont pas satisfaites,
le n-uplet n'est, tout simplement, pas inséré dans la table.
2. Contrainte d'intégrité de relation (ou
d'entité)
Ces choses étant dites, lors de l'insertion de
n-uplets dans une table (i.e. une relation), il arrive qu'un attribut soit
inconnu ou non défini. On introduit alors une valeur conventionnelle
notée NULL et appelée valeur nulle.
Cependant, une clé primaire ne peut avoir une valeur
nulle. De la même manière, une clé primaire doit toujours
être unique dans une table. Cette contrainte forte qui porte sur la
clé primaire est appelée contrainte d'intégrité de
relation.
Il convient de noter que tout SGBD relationnel doit
vérifier l'unicité et le caractère défini (NOT
NULL) des valeurs de la clé primaire.
3. Contrainte d'intégrité de
référence
Dans tout schéma relationnel, il existe deux types de
relation :
? Les relations qui représentent des entités de
l'univers modélisé ; elles sont qualifiées de statiques,
ou d'indépendantes ; les relations Acteur et Film en sont des exemples
;
68
? Les relations dont l'existence des n-uplets dépendent
des valeurs d'attributs situées dans d'autres relations ; il s'agit de
relations dynamiques ou dépendantes ; la relation Jouer en est un
exemple.
--Lors de l'insertion d'un n-uplet dans la relation Jouer, le
SGBD doit vérifier que les valeurs Num-Act et Num-Film correspondent
bien, respectivement, à une valeur de Num-Act existant dans la relation
Acteur et une valeur Num-Film existant dans la relation Film.
--Lors de la suppression d'un n-uplet dans la relation Acteur,
le SGBD doit vérifier qu'aucun n-uplet de la relation Jouer ne fait
référence, par l'intermédiaire de l'attribut Num-Act, au
n-uplet que l'on cherche à supprimer. Le cas échéant,
c'est-à-dire si une, ou plusieurs, valeur correspondante de Num-Act
existe dans Jouer, quatre possibilités sont envisageables :
? interdire la suppression ;
? supprimer également les n-uplets concernés dans
Jouer ;
? avertir l'utilisateur d'une incohérence ;
? mettre les valeurs des attributs concernés à une
valeur nulle dans la table Jouer,
si l'opération est possible (ce qui n'est pas le cas si
ces valeurs interviennent dans une clé primaire) ;
Les types de données
Les types de données peuvent être :
INTEGER : Ce type permet de stocker des entiers signés
codés sur 4 octets.
BIGINT : Ce type permet de stocker des entiers signés
codés sur 8 octets.
REAL : Ce type permet de stocker des réels comportant 6
chiffres significatifs codés sur 4 octets.
DOUBLE PRECISION : Ce type permet de stocker des réels
comportant 15 chiffres significatifs codés sur 8 octets.
NUMERIC[(précision, [longueur])] : Ce type de
données permet de stocker des données numériques à
la fois entières et réelles avec une précision de 1000
chiffres significatifs. longueur précise le nombre maximum de chiffres
significatifs stockés et précision donne le nombre maximum de
chiffres après la virgule.
CHAR(longueur) : Ce type de données permet de stocker des
chaînes de caractères de longueur fixe. longueur doit être
inférieur à 255, sa valeur par défaut est 1.
VARCHAR(longueur) : Ce type de données permet de stocker des
chaînes de caractères de longueur variable. longueur doit
être inférieur à 2000, il n'y a pas de valeur par
défaut. DATE : Ce type de données permet de stocker des
données constituées d'une date.
69
TIMESTAMP : Ce type de données permet de
stocker des données constituées d'une date et
d'une heure.
BOOLEAN : Ce type de données permet de
stocker des valeurs Booléenne.
MONEY : Ce type de données permet de
stocker des valeurs monétaires.
TEXT : Ce type de données permet des
stocker des chaînes de caractères de longueur variable.
IV.2.2. Créer une table : CREATE TABLE
1. Généralités
Une table est un ensemble de lignes et de colonnes. La
création consiste à définir (en fonction de l'analyse) le
nom de ces colonnes, leur format (type), la valeur par défaut à
la création de la ligne (DEFAULT) et les règles de gestion
s'appliquant à la colonne (CONSTRAINT).
2. Création simple
Certes, la commande de création de table la plus simple ne
comportera que le nom et le type de chaque colonne de la table. A la
création, la table sera vide, mais un certain espace lui sera
alloué. La syntaxe est la suivante :
CREATE TABLE nom_table (nom_col1 TYPE1, nom_col2 TYPE2,
...)
La commande CREATE TABLE permet de
définir une table, avec ses colonnes et ses contraintes :
CREATE TABLE nom_table {colonne|contrainte},
{colonne|contrainte_tbl}, ...
Soit, colonne définit à la fois le nom
de la colonne, mais aussi son type, sa valeur par défaut et ses
éventuelles contraintes de colonne (la colonne peut en effet accepter ou
non les valeurs nulles, certaines valeurs de validation, les doublons, ou bien
être une clé primaire ou étrangère) :
colonne:: nom_colonne {type|domaine} [DEFAULT val_default]
[contrainte_col] contrainte_col:: [NOT] NULL | CHECK (prédicat) | UNIQUE
| PRIMARY KEY | FOREIGN KEY [colonne] REFERENCES table(colonne)
spécif_référence
et où les contraintes de table permettent de
définir une clé multi-colonnes ainsi que des contraintes portant
sur plusieurs colonnes (unicité globale, validation multi-attributs ou
intégrité référentielle) :
contrainte_tbl:: CONSTRAINT nom_contrainte
{PRIMARY KEY (liste_cols) | UNIQUE | CHECK (prédicat_tbl)
| FOREIGN KEY (liste_cols) REFERENCES table(liste_cols)
spécif_référence}
70
Il sied de préciser que quand on crée une table, il
faut définir les contraintes d'intégrité que devront
respecter les données que l'on mettra dans la table.
Cas pratique : Si l'on souhaite imposer
les contraintes suivantes à la table Employés :
- les valeurs de département doivent appartenir à
l'intervalle 10..100
- les fonctions sont forcément 'Directeur', 'Analyste',
'Technicien', 'Commercial' ou 'President' - tout employé embauché
après 1986 doit gagner plus de 1000€

IV.2.3. Modifier une table : ALTER TABLE
La commande ALTER TABLE permet de modifier la
définition d'une table en y ajoutant ou en supprimant une colonne ou une
contrainte (mais elle ne permet pas de changer le nom ou le type d'une colonne,
ni d'ajouter une contrainte de ligne [NOT]NULL) :
ALTER TABLE nom_table {
ADD definition_colonne |
ADD CONSTRAINT definition_contrainte |
ALTER nom_colonne {SET DEFAULT valeur_def|DROP DEFAULT} |
DROP nom_colonne [CASCADE|RESTRICT] |
DROP CONSTRAINT nom_contrainte [CASCADE|RESTRICT] };
L'option CASCADE / RESTRICT permet de gérer
l'intégrité référentielle de la colonne ou la
contrainte.
Ajout ou modification de colonnes
ALTER TABLE nom_table {ADD/MODIFY} ([nom_colonne type
[contrainte], ...])
Cas pratique: Modifier la définition de
la table Employés pour que le salaire total dépasse
forcément 1000€ :
ALTER TABLE employes ADD CONSTRAINT ChkSalTot CHECK (salaire+comm
> 1000)
Ajout d'une contrainte de table
ALTER TABLE nom_table ADD [CONSTRAINT nom_contrainte]
contrainte
La syntaxe de déclaration de contrainte est identique
à celle vue lors de la création de table.
71
Si des données sont déjà présentes
dans la table au moment où la contrainte d'intégrité
est
ajoutée, toutes les lignes doivent vérifier la
contrainte. Dans le cas contraire, la contrainte
n'est pas posée sur la table.
Renommer une colonne
ALTER TABLE nom_table RENAME COLUMN ancien_nom TO nouveau_nom
Renommer une table
ALTER TABLE nom_table RENAME TO nouveau_nom
IV.2.4. Supprimer une table : DROP TABLE
La commande DROP TABLE permet de supprimer la
définition d'une table et, dans le même temps, de tout son contenu
et des droits d'accès des utilisateurs à la table (à
utiliser avec précaution, donc !) :
La syntaxe est la suivante :
DROP TABLE nom_table
IV.3. Le langage de manipulation des données
(LMD)
Le langage de manipulation de données (LMD, ou Data
Manipulation Language, soit DML en anglais) est l'ensemble des commandes
concernant la manipulation des données dans une base de données.
Le LMD permet l'ajout, la suppression et la modification de lignes, la
visualisation du contenu des tables et leur verrouillage [30].
Les instructions du LMD sont : INSERT, UPDATE, DELETE, SELECT,
EXPLAIN, PLAN, LOCK TABLE.
Ces éléments doivent être validés par
une transaction pour qu'ils soient pris en compte.
IV.3.1. Insertion de n-uplets : INSERT INTO
La commande INSERT permet d'insérer une ligne dans une
table en spécifiant les valeurs à insérer.
La syntaxe est la suivante :
INSERT INTO nom_table(nom_col_1, nom_col_2, ...) VALUES (val_1,
val_2, ...)
La liste des noms de colonne est optionnelle. Si elle est
omise, la liste des colonnes sera par défaut la liste de l'ensemble des
colonnes de la table dans l'ordre de la création de la table. Si une
liste de colonnes est spécifiée, les colonnes ne figurant pas
dans la liste auront la valeur NULL.
72
Il est possible d'insérer dans une table des lignes
provenant d'une autre table. La syntaxe est
la suivante :
INSERT INTO nom_table(nom_col1, nom_col2, ...)
SELECT ...
L'instruction SELECT sera développer dans les sections
suivantes surtout avec la partie LCD.
IV.3.2. Modification de n-uplets : UPDATE
La commande UPDATE permet de modifier les valeurs d'une ou
plusieurs colonnes, dans une ou plusieurs lignes existantes d'une table. La
syntaxe est la suivante :
UPDATE nom_table
SET nom_col_1 = {expression_1 | ( SELECT ...) }, nom_col_2 =
{expression_2 | ( SELECT ...) },
...
nom_col_n = {expression_n | ( SELECT ...) } WHERE predicat
Les valeurs des colonnes nom_col_1, nom_col_2, ..., nom_col_n
sont modifiées dans toutes les lignes qui satisfont le prédicat.
En l'absence d'une clause WHERE, toutes les lignes sont mises à jour.
Les expressions expression_1, expression_2, ..., expression_n peuvent faire
référence aux anciennes valeurs de la ligne.
IV.3.3. Suppression de n-uplets : DELETE
La commande DELETE permet de supprimer des lignes d'une table. La
syntaxe est la suivante :
DELETE FROM nom_table WHERE predicat
Toutes les lignes pour lesquelles predicat est
évalué à vrai sont supprimées. En l'absence de
clause WHERE, toutes les lignes de la table sont supprimées.
IV.4. Le langage de contrôle des données
(LDC)
Le langage de protections d'accès (ou Data Control
Language, soit DCL en anglais) s'occupe de gérer les droits
d'accès aux tables [25].
Les instructions du DCL sont : GRANT, REVOKE.
La protection des données consiste à identifier
les utilisateurs et gérer les autorisations d'accès. Pour cela,
une mesure fondamentale est de ne fournir aux utilisateurs qu'un accès
aux tables ou aux parties de tables nécessaires à leur travail,
ce que l'on appelle des vues. Grâce à elles, chaque utilisateur
pourra avoir sa vision propre des données. Une vue
73
est définie en SQL grâce à la commande
CREATE VIEW comme résultat d'une requête d'interrogation
SELECT:
CREATE VIEW nom_vue AS SELECT ...
Cas pratique: Créer une vue
constituant une restriction de la table Employés aux noms et salaire des
employés du département 10 :
CREATE VIEW emp10 AS SELECT nom, salaire FROM employes WHERE
_num_dep = 10;
Avec ce cas pratique, il n'y a pas de duplication des
informations, mais le stockage de la définition de la vue. Une fois
créée, la vue peut être interrogée exactement comme
une table. Les utilisateurs pourront consulter la base à travers elle,
c'est-à-dire manipuler la table résultat du SELECT comme s'il
s'agissait d'une table réelle.
En revanche, il existe deux restrictions à la
manipulation d'une vue par un INSERT ou un UPDATE :
Le SELECT définissant la vue ne doit pas comporter de
jointure ;
Les colonnes résultats du SELECT doivent être des
colonnes réelles et non pas des expressions.
Cas pratique: Augmentation de 10% des
salaires du département10 à travers la vue Emp10 :
UPDATE emp10 SET salaire=salaire*1.1;
Une vue peut être supprimée ou renommée par
les commandes :
DROP VIEW nom_vue ouRENAME ancien_nom TO nouveau_nom
Une protection efficace des données nécessite en
outre d'autoriser ou d'interdire certaines opérations, sur les tables ou
les vues, aux différentes catégories d'utilisateurs. Les
commandes correspondantes sont :
GRANT type_privilege1, type_privilege2,... ON {table|vue|*} TO
utilisateur; REVOKE type_privilege1, type_privilege2,... ON {table|vue|*}FROM
utilisateur;
Les types de privilèges correspondent aux commandes SQL
(SELECT pour la possibilité d'interroger, UPDATE pour celle de mise
à jour, etc.) et les utilisateurs concernés sont
désignés par leur identifiant de connexion au serveur, ou par le
mot-clé PUBLIC pour désigner tous les utilisateurs.
Cas pratique: Autoriser la
suppression de la vue Emp10 au seul représentant du personnel
identifié par ID7788:
GRANT DELETE ON emp10 TO ID7788;
Gestion des transactions. Une transaction est un ensemble de
modifications de la base qui forment un tout indivisible, qu'il faut effectuer
entièrement ou pas du tout, sous peine de laisser la base dans un
état incohérent. SQL permet aux utilisateurs de gérer
leurs transactions:
74
la commande COMMIT permet de valider une
transaction. Les modifications deviennent définitives et visibles
à tous les utilisateurs [23];
la commande ROLLBACK permet à tout
moment d'annuler la transaction en cours. Toutes les modifications
effectuées depuis le début de la transaction sont alors
défaites [23].
Enfin, pour assurer ainsi l'intégrité de la base
en cas d'interruption anormale d'une tâche utilisateur, les SGBD dits
transactionnels utilisent un mécanisme de verrouillage qui empêche
deux utilisateurs d'effectuer des transactions incompatibles.
IV.5. Interroger une base de données
IV.5.1. Notion de base
S'il est clairement établi dans certaines des sections
de cette partie, la commande SELECT constitue, à elle
seule, le langage d'interrogation d'une base. A cela, elle permet de:
Sélectionner certaines colonnes d'une table
(opération de projection) ;
Sélectionner certaines lignes d'une table en fonction de
leur contenu (restriction) ; Combiner des informations venant de plusieurs
tables (jointure, union, intersection, différence) ;
Combiner ces différentes opérations ;
Une interrogation, ou requête de sélection, est
une combinaison d'opérations portant sur des tables et dont le
résultat est lui-même une table, mais
éphémère ou dynamique (car elle n'existe que le temps de
la requête).
Dans ce qui suit, nous utiliserons les conventions typographiques
suivantes :
en MAJUCULES les commandes ou opérateurs qu'il faut
recopier tels quels (ex. SELECT)
en italique les paramètres devant être
remplacés par une valeur appropriée (ex. table, alias) en
souligné la valeur par défaut (ex. {ASC|DESC})
des crochets [...] encadrent une valeur optionnelle (ex.
[DISTINCT], [AS alias]) des accolades {...} encadrent des valeurs
(séparées par | ) dont l'une doit être saisie (ex.
{ON|OFF})
des points de suspension ... indiquent que les valeurs
précédentes peuvent être répétées
plusieurs fois (ex. table, ...peut prendre comme valeur table1, table2,
table3)
75
les signes de ponctuation (parenthèses, virgules et
points-virgules) doivent être saisis comme présentés. En
particulier, ne pas oublier le point-virgule obligatoire
à la fin de chaque requête.
Par ailleurs, on désigne par:
alias un synonyme d'un nom de table, de
colonne, ou d'expression calculée
condition une expression prenant la
valeur vrai ou faux
sous-interrogation(ou
sous-requête) une expression de requête (SELECT) figurant
dans une clause WHERE d'une requête principale
expr une colonne ou un attribut
calculé par une expression
num un numéro de colonne
Enfin, dans ce qui suit, nous illustrerons les requêtes sur
une base formée des relations suivantes :
Employes(numemp,nom,fonction,_superieur,date_embauche,salaire,comm,_num_dep)
Departements(num_dep,nom,ville)
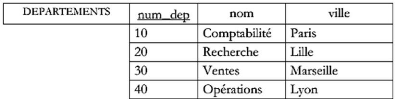
76
IV.5.2. Syntaxe de base
La syntaxe de base de la commande SELECT est la suivante :

Les attributs sont les colonnes que l'on souhaite
voir apparaître dans la réponse. Si l'on souhaite toutes les
colonnes, il faut utiliser le symbole*.
Cas pratique :

Nous avons aussi la possibilité de faire
précéder les noms des attributs de la table où ils
figurent. Cela est obligatoire si l'on extraie les données de plusieurs
tables et que deux attributs sélectionnés portent le même
nom :
SELECT employes.nom, departements.nom FROM employes,
departements;
Il est également possible de renommer une colonne ou
une table par un alias, ce qui est utile lorsqu'on veut donner un nom plus
« parlant » ou plus court pour faciliter sa désignation
ultérieurement dans la requête.
Pour renommer une colonne, on utilise la syntaxe Col1 AS
'Nouveau nom' dans le SELECT (les guillemets ne sont obligatoires que si
l'alias comporte des espaces ou des caractères spéciaux). Pour
renommer une table, il suffit de faire suivre son nom par son alias dans la
clause FROM :
Ceci est particulièrement utile lorsque l'on
définit un attribut calculé à
partir des attributs de tables. Il est en effet possible de faire figurer comme
résultat d'un SELECT une expression composée d'opérateurs,
de fonctions prédéfinies, de variables et de constantes :
La clause WHERE permet de
spécifier quelles sont les lignes à sélectionner. Le
prédicat de sélection, formé d'une expression comportant
des opérandes liés par des opérateurs, sera
évalué pour chaque ligne de la table, et seules les lignes pour
lesquelles il est vrai seront retenues.
77
Les opérandes figurant dans le prédicat peuvent
être des noms de colonnes, ou des constantes de type :
nombres : peuvent inclure un signe, un point décimal et
une puissance de dix (ex. - 1.2E-5)
chaînes : chaînes de caractères entre
apostrophes (Attention : 'Victor' ?'VICTOR') dates : chaînes de
caractères entre apostrophes dans un format spécial. Pour
s'affranchir des problèmes inhérents aux incompatibilités
dans les différentes langues, il est conseillé d'utiliser le
format suivant : 'aaaa-mm-jj' (ex. {d '2001-1031'})
la valeur NULL (valeur non définie), que l'on doit tester
avec l'opérateur IS, et pas = (cf. ci-dessous).
Les opérateurs figurant dans le prédicat peuvent
être :
les opérateurs de comparaison traditionnels (=
(égal), <> (différent de), <, <=, >, >=) les
opérateurs spéciaux
? BETWEEN ... AND (valeur comprise entre 2 bornes) : expr1
BETWEEN expr2
AND expr3
? IN (valeur comprise dans une liste) : expr1 IN (expr2, expr3,
...)
? LIKE (chaîne semblable à une chaîne
générique) : expr1 LIKE chaine
La chaîne générique peut comporter les
caractères jokers `_' (remplace 1 seul caractère quelconque) et
`%' (remplace une chaîne de caractères quelconque, y compris de
longueur nulle)
les opérateurs logiques AND, OR et NOT (inversion logique)
pour combiner plusieurs prédicats.
Des parenthèses peuvent être utilisées
pour impose rune priorité dans l'évaluation du prédicat
(par défaut, l'opérateur AND est prioritaire par rapport à
OR).
Cas pratique :
Employés dont la commission est supérieure au
salaire
SELECT nom, salaire, comm FROM employes WHERE comm >
salaire;
Employés gagnant entre 1700 et 2550€
SELECT nom, salaire FROM employes WHERE salaire BETWEEN 1700 AND
2550;
78
Employés commerciaux ou analystes
SELECT num_emp, nom, fonction FROM employes WHERE fonction IN
('Commercial', 'Analyste');
Employés dont le nom commence par V
SELECT nom FROM employes WHERE nom LIKE 'M%';
Employés du département 30 ayant un salaire
supérieur à 2700 €
SELECT nom FROM employes WHERE _num_dep=30 AND
salaire>2700;
Employés directeurs ou commerciaux travaillant dansle
département 10
SELECT nom, fonction FROM employes
WHERE (fonction='Directeur' OR fonction ='Commercial') AND
_num_dep=10;
Employés percevant une commission
SELECT nom, salaire, comm FROM employes WHERE comm IS NOT
NULL;
IV.5.3. Les jointures
On appelle jointure une opération permettant de
combiner des informations issues de plusieurs tables. Elle se formule
simplement en spécifiant, dans la clause FROM , le nom des tables
concernées et, dans la clause WHERE, les conditions qui vont permettre
de réaliser la jointure (en effet, si l'on ne précise pas de
condition de sélection, on obtient le produit cartésien des
tables présentes derrière le FROM, ce qui n'est en
général pas souhaité).
Or, structurellement, il existe plusieurs types de jointures
(cfr. figure IV.1) :
Equi-jointure (ou jointure naturelle, ou jointure
interne) : permet de relier deux colonnes appartenant à
deux tables différentes mais ayant le même "sens" et venant
vraisemblablement d'une relation 1-N lors de la conception. Les tables sont
reliées par une relation d'égalité entre leur attribut
commun ou, à partir de SQL2, avec la clause INNER JOIN.
Cas pratique : Donner le nom de chaque
employé et la ville où il/elle travaille
SELECT employes.nom, Ville FROM employes, departements WHERE
employes._num_dep=departements.num_dep;
ou
SELECT employes.nom, departements.ville FROM employes
79
INNER JOIN departements ON employes._num_dep =
departements.num_dep;
Auto-jointure: cette jointure d'une
table à elle-même permet derelier des informations venant d'une
ligne d'une table avec des informations venant d'une autre ligne de la
même table. Dans ce cas, il faut renommer au moins l'une des deux
occurrences de la table pour pouvoir préfixer sans ambiguïté
chaque nom de colonne.
Cas pratique : Donner pour chaque
employé le nom de son supérieur hiérarchique
SELECT employes.nom, superieurs.nom FROM employes, employes AS
superieurs WHERE employes._superieur=superieurs.num_emp;
ou
SELECT employes.nom, superieurs.nom FROM employes INNER JOIN
employes AS superieurs
ON employes._superieur=superieurs.num_emp;
O-jointure: si le critère
d'égalité correspond à la jointure la plus naturelle, les
autres opérateurs de comparaison sont également utilisables dans
le prédicat de jointure. Néanmoins, cette possibilité doit
être utilisée avec précaution car elle peut entraîner
une explosion combinatoire (on rappelle qu'une jointure ne constitue qu'une
restriction du produit cartésien de deux relations ou plus).
Cas pratique : Quels sont les
employés gagnant plus que Victor ?
SELECT e1.nom, e1.salaire, e1.fonction FROM employes AS e1,
employes AS e2 WHERE e1.salaire>e2.salaire AND e2.nom='Victor';
Jointure externe: lorsqu'une ligne
d'une table figurant dans une jointure n'a pas de correspondant dans les autres
tables, elle ne satisfait pas au critère d'équi-jointure et ne
figure donc pas dans le résultat de la requête. Une jointure
externe est une jointure qui favorise l'une des tables en affichant toutes ses
lignes, qu'il y ait ou non correspondance avec l'autre table de jointure. Les
colonnes pour lesquelles il n'y a pas de correspondance sont remplies avec la
valeur NULL. Pour définir une telle jointure, on utilise les clauses
LEFT OUTER JOIN (jointure externe gauche) et RIGHT OUTER JOIN (jointure externe
droite).
Cas pratique : Le département
de Cambridge n'apparaissait pas dans l'exemple de l'équi-jointure, mais
figurera ici :
SELECT employes.nom, departements.ville FROM employes
RIGHT JOIN departements ON employes._num_dep =
departements.num_dep;
Cas pratique : Le Président
Patton, sans supérieur hiérarchique, n'apparaissait pas dans
l'exemple de l'autojointure, mais figurera ici (avec NULL comme nom
desupérieur) :
80
SELECT employes.nom, superieurs.nom FROM employes
LEFT JOIN employes AS superieurs ON
employes._superieur=superieurs.num_emp;
Cas pratique : Retrouver les
départements n'ayant aucun employé :
SELECT departements.num_dep, employes.nom FROM employes
RIGHT JOIN departements ON employes._num_dep =
departements.num_dep WHERE employes.nom IS NULL;
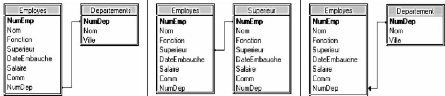
Equi-jointure Auto-jointure Jointure externe
Figure IV.1. Les différents types de
jointures
IV.5.4. Les fonctions de groupes
Ces choses étant dites, dans les exemples
précédents, chaque ligne résultat d'un SELECT était
calculée sur les valeurs d'une seule ligne de la table consultée.
Il existe un autre type de SELECT qui permet d'effectuer des calculs sur
l'ensemble des valeurs d'une colonne, au moyen de l'une des
fonctions de groupe suivantes (toutes portent sur une expression,
qui peut-être un attribut d'une table ou un attribut calculé) :
SUM(expr) Somme des valeurs
AVG(expr) Moyenne des valeurs
COUNT([DISTINCT] expr) Nombre de valeurs (différentes
si
DISTINCT est présent)
COUNT(*) Compte toutes les lignes de la table
MIN(expr) ouMAX(expr) Minimum ou maximum des valeurs
VARIANCE(expr) ouSTDDEV(expr) Variance ou écart-type des
valeurs Cas pratique : Donner le total des salaires
des employés travaillant dans le département 10 :
SELECT SUM(salaire) AS som_salaires FROM employes WHERE
_num_dep=10;
Calcul de résultats sur plusieurs
groupes. Il est possible de subdiviser la table en
groupes, chaque groupe étant l'ensemble des
lignes ayant une valeur commune pour les expressions spécifiées.
C'est la clause GROUP BY qui permet de découper la table en plusieurs
groupes :
81
GROUP BY expr1, expr2, ...
Si l'on en tient compte du regroupement suivant une seule
expression, ceci définit les groupes comme les ensembles de lignes pour
lesquelles cette expression prend la même valeur. Si plusieurs
expressions sont présentes, le groupement va s'effectuer d'abord sur la
première, puis sur la seconde, et ainsi de suite : parmi toutes les
lignes pour lesquelles expr1prend la même valeur, on regroupe celles
ayant expr2identique, etc. Un SELECT de groupe avec une clause GROUP BY donnera
une ligne résultat pour chaque groupe.
Cas pratique : Donner le total des
salaires des employés pour chaque département :
SELECT_num_dep,SUM(salaire)AS som_salaires FROM employes GROUP BY
_num_dep;
Sélection des groupes. De
même que la clause WHERE permet de sélectionner certaines lignes,
il est possible de ne retenir, dans un SELECT comportant une fonction de
groupe, que les lignes répondant à un critère donné
par la clause HAVING. Cette clause se place après la clause GROUP BY et
son prédicat suit les mêmes règles de syntaxe que celui de
la clause WHERE, à la différence près qu'il ne peut porter
que sur des caractéristiques du groupe (fonction de groupe ou expression
figurant dans la clause GROUP BY).
Cas pratique : Donner la liste des
salaires moyens par fonction pour les groupes ayant plus de 2 employés
:
SELECT fonction, COUNT(*) AS nb_employes, AVG(salaire) AS
moy_salaires FROM employes GROUP BY fonction HAVING COUNT(*)>2;
Retenons que :
Dans la liste des colonnes résultat d'un SELECT
comportant une fonction de groupe, ne peuvent figurer que des
caractéristiques de groupe, c'est-à-dire soit des fonctions de
groupe, soit des expressions figurant dans la clause GROUP BY. En effet, de
manière générale, lorsqu'un attribut est
sélectionné dans une clause SELECT, le résultat peut
comporter de zéro à n valeurs ; cela pourrait provoquer des
conflits si l'on utilisait conjointement des fonctions statistiques qui, elles,
ne retournent qu'une seule valeur.
Un SELECT de groupe peut contenir à la fois les clauses
WHERE et HAVING. La première sera d'abord appliquée pour
sélectionner les lignes, puis les fonctions de groupe seront
évaluées, et les groupes ainsi constitués seront
sélectionnés suivant le prédicat de la clause HAVING.
82
Cas pratique : Pour les
départements comportant au moins 2 employés techniciens ou
commerciaux, donner le nombre de ces employés par département
:
SELECT _num_dep, COUNT(*) AS nb_techn_ou_comm FROM employes WHERE
fonction in('Technicien','Commercial')
GROUP BY _num_dep HAVING COUNT(*)>=2;
- Un SELECT de groupe peut être utilisé dans une
sous-interrogation ; inversement, une clause HAVING peut comporter une
sous-interrogation.
IV.5.5. Sous-interrogations
Nous pouvons dire, qu'une caractéristique puissante de
SQL est la possibilité qu'un critère de recherche employé
dans une clause WHERE (expression à droite d'un opérateur de
comparaison) soit lui-même le résultat d'un SELECT ; c'est ce que
l'on appelle une sous-interrogation ou un
SELECT imbriqué. Cela permet de
réaliser des interrogations complexes qui nécessiteraient sinon
plusieurs interrogations avec stockage des résultats
intermédiaires.
Un SELECT peut retourner de zéro
à n lignes comme résultat. On a donc les cas suivants :
Une sous-interrogation ne retournant aucune ligne se termine
avec un code d'erreur, à moins d'utiliser l'opérateur EXISTS qui
retourne faux dans ce cas, vrai si la
sous-interrogation retourne au moins une ligne. Cet opérateur permet
d'empêcher l'exécution de l'interrogation principale si la sous
interrogation ne retourne aucun résultat, mais s'emploie surtout avec
les sous-interrogations synchronisées.
Cas pratique: Donner la liste des
noms et salaires des employés si un des salaires est inférieur
à 1000 :
SELECT nom, salaire FROM employes
WHERE EXISTS(SELECT * FROM employes WHERE salaire<1000);
Si le résultat d'une sous-interrogation ne
comportequ'une seule ligne, il peut être utilisé directement avec
les opérateurs de comparaison classiques.
Cas pratique : Donner le nom des
employés exerçant la même fonction que Victor :
SELECT nom FROM employes
WHERE fonction =(SELECT fonction FROM employes WHERE
nom='Victor');
Une sous-interrogation peut retourner plusieurs lignes
à condition que l'opérateur de comparaison admette à sa
droite un ensemble de valeurs. Les opérateurs permettant de comparer une
valeur à un ensemble de valeurs sont :
83

Tableau IV.1. Les opérateurs de comparaison d'une
valeur à un ensemble de valeurs Cas pratique:
Donner la liste des employés gagnant plus que tous ceux du
département 30 :
SELECT nom, salaire FROM employes
WHERE salaire > ALL(SELECT salaire FROM employes WHERE
_num_dep=30);
Sous-interrogation synchronisée avec l'interrogation
principale. Dans les exemples précédents, la sous-interrogation
était évaluée d'abord, puis son résultat
était utilisé pour exécuter l'interrogation principale.
SQL sait également traiter une sous-interrogation faisant
référence à une colonne de la table de l'interrogation
principale. Dans ce cas, le traitement est plus complexe car il faut
évaluer la sous interrogation pour chaque ligne de l'interrogation
principale.
Cas pratique: Donner la liste des
employés ne travaillant pas dans le même département que
leur supérieur :
SELECT nom FROM employes e
WHERE _num_dep<>(SELECT _num_dep FROM employes WHERE
e._superieur=num_emp)
AND _superieur IS NOT NULL;
Il a fallu ici renommer la table Employes de l'interrogation
principale pour pouvoir la référencer sans ambiguïté
dans la sous-interrogation. La dernière ligne est utile car le
président ne possède pas de supérieur (valeur NULL) et la
sous-interrogation ne retourne alors aucune valeur.
Cas pratique: Donner les
employés des départements qui n'ont pas embauché depuis le
début de l'année 1982 :
SELECT * FROM employes e
WHERE NOT EXISTS(SELECT * FROM employes WHERE
date_embauche>=to_date('01/01/1982','DD-MM-YYYY') AND
_num_dep=e._num_dep);
IV.5.6. Bilan de l'instruction SELECT : syntaxe
étendue
La syntaxe étendue de l'instruction SELECT est la suivante
:
SELECT (DISTINCT] {* | expr (AS alias],
... } FROM table (alias], ...
(WHERE { conditions | sous
conditions} ] (GROUP BY expr, ...] (HAVING
conditions]
84
[ORDER BY {expr | num}{ASC |
DESC}, ...];
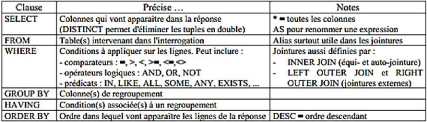
Tableau IV.2. Récapitulatif des différentes
clauses
IV.6. Bilan du chapitre
Au cours de ce chapitre, nous avons présenté les
fonctionnalités principales de SQL au sein d'un SGBD. En effet, il en
est résulté que le langage SQL est un langage normalisé
d'interrogation de bases de données très répandu qui
permet de manipuler assez facilement les bases des données
relationnelles. Il vient d'être montré que le Structured Query
Language est très variable bien qu'il ait été
normalisé deux fois. Sur le plan pratique, il permet d'ajouter des
données, de les supprimer, parfois par tables entières, de les
sélectionner dans des tables, selon toutes sortes de critères
(Order by, Group by, Where...) par-delà grâce à ses
instructions.
Néanmoins avant cela, il nous a été du
reste à examiner la commande SELECT avec ses différentes clauses
qui implique une interrogation et une standardisation des différents
langages, bien qu'ils soient (d'interrogation, de manipulation, de
définition et de contrôle).
85
Chapitre V: Le Sql intégré : un paquetage
de Sql Embarqué
V.1. Introduction
Cet aparté étant terminé, revenons
à présent sur le SQL intégré. Rappelons que SQL
intégré permet d'utiliser SQL dans un langage de troisième
génération (C, Java, Cobol, etc.) avec un(e) :
déclaration d'objets ou d'instructions ;
exécution d'instructions ;
gestion des variables et des curseurs ; traitement
des erreurs.
Bien qu'essentielle, les sections de ce chapitre décrit
le pacquage SQL embarqué pour PostgreSQL ECPG. Il est compatible avec
les langages C et C++ et a été développé par Linus
Tolke et Michael Meskes.
En approfondissant cette idée, un programme SQL
embarqué est en fait un programme ordinaire, dans notre cas un programme
en langage C, dans lequel nous insérons des commandes SQL incluses dans
des sections spécialement marquées. La description des
instructions Embedded SQL commencent par les mots EXEC SQL et se terminent par
un point-virgule (« ; »). Pour générer
l'exécutable, le code source est d'abord traduit par le
préprocesseur SQL qui convertit les sections SQL en code source C ou
C++, après quoi il peut être compilé de manière
classique.
Nous pouvons noter que le SQL embarqué présente
des avantages par rapport à d'autres méthodes pour prendre en
compte des commandes SQL dans du code C. comme par exemple, le passage des
informations de et vers les variables du programme C est entièrement
pris en charge. Ensuite, le code SQL du programme est vérifié
syntaxiquement au moment de la précompilation. Enfin, le SQL
embarqué en C est spécifié dans le standard SQL et
supporté par de nombreux systèmes de bases de données SQL.
L'implémentation PostgreSQL est conçue pour correspondre à
ce standard autant que possible, afin de rendre le code facilement portable
vers des SGBD autre que PostgreSQL.
Comme situation alternative au SQL intégré, on
peut citer l'utilisation d'une API (Application Programming Interface)
permettant au programme de communiquer directement avec le SGBD via des
fonctions fournies par l'API. Dans ce cas de figure, il n'y a pas de
précompilation à effectuer [32].
86
V.2. Connexion au serveur de bases de
données
Il en est de même pour le langage utilisé (C, Java,
PHP, etc.), pour pouvoir effectuer un traitement sur une base de
données, il faut respecter les étapes suivantes :
1. établir une connexion avec la base de
données ;
2. récupérer les informations
relatives à la connexion ;
3. effectuer les traitements désirés
(requêtes ou autres commandes SQL) ;
4. fermer la connexion avec la base de
données.
Mais ce qui va nous intéresser tout
particulièrement ici, c'est comment ouvrir et fermer une connexion, et
nous verrons dans les sections suivantes comment effectuer des traitements.
A. Ouverture de connexion
La connexion à une base de données se fait en
utilisant l'instruction suivante :
La cible peut être spécifiée de l'une des
façons suivantes :
- nom_base[@nom_hôte ][:port] ;
- tcp:postgresql://nom_hôte [:port ] [/nom_base][? options]
;
- unix:postgresql://nom_hôte[: port][/nom_base ][? options]
;
- une chaîne SQL littérale contenant une des formes
ci-dessus ;
- une référence à une variable contenant une
des formes ci-dessus ;
- DEFAULT.
D'une manière réelle, utiliser une chaîne
littérale (entre guillemets simples) ou une variable
de référence génère moins d'erreurs.
La cible de connexion DEFAULT initie une connexion
sur la base de données par défaut avec
l'utilisateur par défaut. Aucun nom d'utilisateur ou
nom de connexion ne pourrait être spécifié
isolément dans ce cas.
Il existe également différentes façons de
préciser l'utilisateur utilisateur :
- nom_utilisateur
- nom_utilisateur/ mot_de_passe
- nom_utilisateur IDENTIFIED BY mot_de_passe
- nom_utilisateur USING mot_de_passe
nom_utilisateur et mot_de_passe peuvent être un
identificateur SQL, une chaîne SQL
littérale ou une référence à une
variable de type caractère.
nom_connexion est utilisé pour gérer plusieurs
connexions dans un même programme.
Il peut être omis si un programme n'utilise qu'une seule
connexion. La dernière connexion
87
ouverte devient la connexion courante, utilisée par
défaut lorsqu'une instruction SQL est à exécuter.
B. Fermeture de connexion
On utilisera l'instruction suivante pour fermer une connexion:
EXEC SQL DISCONNECT [connexion];
Le paramètre connexion peut prendre l'une des valeurs
suivantes :
Si aucun nom de connexion n'est spécifié, c'est
la connexion courante qui est fermée. Il est préférable de
toujours fermer explicitement chaque connexion ouverte.
V.3. Exécuter des commandes SQL
Dans une même perspective, toute commande SQL, incluse
dans des sections spécialement marquées, peut être
exécutée à l'intérieur d'une application SQL
embarqué. Ces sections se présentent toujours de la
manière suivante :
EXEC SQL instructions_SQL ;
En ce qui concerne le mode par défaut, les instructions
ne sont validées que lorsque EXEC SQL COMMIT est
exécuté.
De même, l'interface SQL embarqué supporte aussi
la validation automatique des transactions via l'instruction EXEC SQL SET
AUTOCOMMIT TO ON.
Dans ce cas, chaque commande est automatiquement
validée. Ce mode peut être explicitement désactivé
en utilisant EXEC SQL SET AUTOCOMMIT TO OFF.
Voici un exemple permettant de créer une table :

V.4. Les variables hôtes
A. Notion aux variables hôtes
Aujourd'hui, la transmission de données entre le
programme C et le serveur de base de données est particulièrement
simple en SQL embarqué. C'est dans ce sens qu'il est possible d'utiliser
une variable C, dans une instruction SQL, simplement en la préfixant par
le caractère deux-points (« : »). Comme on peut le constater,
pour insérer une ligne dans la table individu on peut écrire :
EXEC SQL INSERT INTO individu VALUES (:var_num, 'Poustopol',
:var_prenom);
88
Pour pouvoir mettre en oeuvre un exploit, cette instruction
fait référence à deux variables C nommées var_num
et var_prenom et utilise aussi une chaîne littérale SQL
('Poustopol') pour illustrer que vous n'êtes pas restreint à
utiliser un type de données plutôt qu'un autre.
L'obtention d'informations dans l'environnement SQL, fait que
nous appelons les références à des variables C des
variables hôtes.
B. Déclaration des variables hôtes
En connaissant cela, il est dit que les variables hôtes
sont des variables de langage C identifiées auprès du
préprocesseur SQL. Pour cela, et pour être définies, les
variables hôtes doivent être placées dans une section de
déclaration, comme suit :
EXEC SQL BEGIN DECLARE SECTION; declarations_des_variables_C
EXEC SQL END DECLARE SECTION;
Pour pouvoir s'introduire, vous pouvez avoir autant de
sections de déclaration dans un programme que vous le souhaitez.
Grâce aux étapes précédentes, les
variables hôtes peuvent remplacer les constantes dans n'importe quelle
instruction SQL. Un premier accès est lorsque le serveur de base de
données exécute la commande, il utilise la valeur de la variable
hôte. Il en va de même lorsqu'une variable hôte ne peut pas
remplacer un nom de table ou de colonne. Ces choses étant
déjà dites, dans une instruction SQL, le nom de la variable est
précédé du signe deux-points (« : ») pour le
distinguer d'autres identificateurs admis dans l'instruction.
Plus loin, les initialisations sur les variables sont admises
dans une section de déclaration. Il s'agit surtout des sections de
déclarations qui sont traitées comme des variables C normales
dans le fichier de sortie du précompilateur. De ce fait, il ne faut donc
pas les redéfinir en dehors des sections de déclaration. C'est ne
pas tout, les variables qui n'ont pas pour but d'être utilisées
dans des commandes SQL peuvent être normalement déclarées
en dehors des sections de déclaration.
La puissance des variables en langage C ont leur portée
normale au sein du bloc dans lequel elles sont définies. Une fois de
plus, le préprocesseur SQL n'analyse pas le code en langage C. Par
contre, il ne respecte pas les blocs C. outre, pour le préprocesseur
SQL, les variables hôtes sont globales : il n'est pas possible que deux
de ces variables portent le même nom.
89
C. Types des variables hôtes
De leur côté, seul un nombre limité de
types de données du langage C est supporté pour les variables
hôtes. Aussi, certains types de variable hôte n'ont pas de type
correspondant en langage C. Dans ce sens, des macros prédéfinies
peuvent être utilisées pour déclarer les variables
hôtes. Comme, le type prédéfini VARCHAR est la structure
adéquate pour interfacer des données SQL de type varchar. Avec
une déclaration comme
VARCHAR var[31];
Est en fait convertie par le préprocesseur en une
structure :
struct varchar_var { int len; char arr[180]; } var;
D . Utilisation d'une variable hôte : clause
INTO
En ce qui concerne le cas d'une requête de ligne unique,
c'est à dire qui n'extrait pas plus d'une ligne de la base de
données, les valeurs renvoyées peuvent être stockées
directement dans des variables hôtes. Cependant, contrairement au langage
C ou C++, le SQL est un langage ensembliste : une requête peut
très bien retourner plus d'une ligne. Dans ce cas, il faut faire appel
à la notion de curseur.
Il en est également pour le cas d'une requête de
ligne unique, une nouvelle clause INTO est intercalée entre la clause
SELECT et la clause FROM. La clause INTO contient une liste de
variables hôtes destinée à recevoir la valeur de chacune
des colonnes mentionnées dans la clause SELECT. Le
nombre de variables hôtes doit être identique au nombre de colonnes
de la clause SELECT. A la suite, les variables hôtes
peuvent être accompagnées de variables indicateur afin de prendre
en compte les résultats NULL.
C'est peut être, d'ailleurs, le même lors de
l'exécution de l'instruction SELECT, le serveur de base de
données récupère les résultats et les place dans
les variables hôtes. A chaque palier, si le résultat de la
requête contient plusieurs lignes, le serveur renvoie une erreur. De
plus, si la requête n'aboutit pas à la sélection d'une
ligne, un avertissement est renvoyé.
Ainsi, les erreurs et les avertissements sont renvoyés
dans la structure SQLCA.
Il a par exemple, en reprenant la base de données de la
séance de travaux pratiques précédentes et une
requête que nous avons déjà rencontrée: «
nombre de fois que chacun des films a été projeté ».
Mis en avant, nous pouvons récupérer les résultats de
cette requête de ligne unique dans des variables hôtes de la
manière suivante :
90
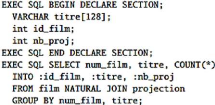
V.5. Variables indicateurs
Aperçu
Etant donné l'augmentation, les variables indicateurs
sont des variables en langage C qui fournissent des informations
complémentaires pour les opérations de lecture ou d'insertion de
données. Après une analyse approfondie, il existe plusieurs types
d'utilisation pour ces variables :
Valeurs NULL : Pour permettre aux
applications de gérer les valeurs NULL.
Troncature de chaînes : Pour
permettre aux applications de gérer les cas où les valeurs lues
doivent être tronquées pour tenir dans les variables
hôtes.
Erreurs de conversion : Pour stocker
les informations relatives aux erreurs.
En analysant ces types d'utilisations, une variable indicateur
est une variable hôte de type int suivant immédiatement une
variable hôte normale dans une instruction SQL. Utilisation de variables
indicateur
La meilleure manière d'apprécier les
données SQL, est que la valeur NULL représente un attribut
inconnu ou une information non applicable. Cela est dû, il ne faut pas
confondre la valeur NULL de SQL avec la constante du langage C qui porte le
même nom (NULL). Cette dernière représente un pointeur non
initialisé, incorrect ou ne pointant pas vers un contenu valide de zone
mémoire.
La valeur NULL n'équivaut à aucune autre valeur
du type défini pour les colonnes. Ainsi, si une valeur NULL est lue dans
la base de données et qu'aucune variable indicateur n'est fournie, une
erreur est générée (SQLE_NO_INDICATOR). Pour transmettre
des valeurs NULL à la base de données ou en recevoir des
résultats NULL, des variables hôtes d'un type particulier sont
requises : les variables indicateurs.
Comme dans l'exemple précédent, une erreur est
générée si, pour une raison quelconque, le titre du film
n'existe pas et que sa valeur est NULL. Pour s'affranchir de ce
problème, on utilise une variable indicateur de la manière
suivante :
91
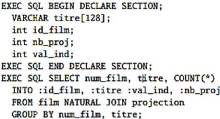
Dans cet exemple, la variable indicateur val_ind vaudra
zéro si la valeur retournée n'est pas NULL et elle sera
négative si la valeur est NULL. Cette approche vaut, si la valeur de
l'indicateur est positive, cela signifie que la valeur retournée n'est
pas NULL mais que la chaîne a été tronquée pour
tenir dans la variable hôte.
V.6. Gestion des erreurs
A. Configurer des rappels : instruction WHENEVER
Nous devons noter, que l'instruction WHENEVER est une
méthode simple pour intercepter les erreurs, les avertissements et les
conditions exceptionnelles rencontrés par la base de données lors
du traitement d'instructions SQL.
Par ailleurs, elle consiste à configurer une action
spécifique à exécuter à chaque fois qu'une
condition particulière survient. Cette opération s'effectue de la
manière suivante :
EXEC SQL WHENEVER condition action;
Le paramètre condition peut prendre une des valeurs
suivantes :
SQLERROR : L'action spécifiée
est appelée lorsqu'une erreur survient pendant l'exécution d'une
instruction SQL.
SQLWARNING : L'action spécifiée est
appelée lorsqu'un avertissement survient pendant l'exécution
d'une instruction SQL.
NOT FOUND : L'action spécifiée est
appelée lorsqu'une instruction ne récupère ou n'affecte
aucune ligne.
Le paramètre action peut avoir une des valeurs suivantes
:
CONTINUE : Signifie effectivement que la condition est
ignorée. C'est l'action par défaut. SQLPRINT :
Affiche un message sur la sortie standard. Ceci est utile pour des programmes
simples ou lors d'un prototypage. Les détails du message ne peuvent pas
être configurés. STOP : Appel de exit(1), ce qui terminera le
programme.
BREAK : Exécute l'instruction C break. Cette action est
utile dans des boucles ou dans des instructions switch.
GOTO label et GO TO label : Saute au label
spécifié (en utilisant une instruction C goto).
92
CALL nom (args) et DO nom (args) : Appelle
les fonctions C spécifiées avec les arguments
spécifiés.
Le standard SQL ne définit que les actions
CONTINUE et GOTO ou GO TO.
De plus, l'instruction WHENEVER peut
être insérée en un endroit quelconque d'un programme SQL
embarqué.
En raison du caractère évolutif d'interrompre
les erreurs, cette instruction indique au préprocesseur de
générer du code après chaque instruction SQL. En
conséquence, cette instruction reste active pour toutes les instructions
en SQL embarqué situées entre la ligne de l'instruction
WHENEVER et l'instruction WHENEVER suivante contenant
la même condition d'erreur, ou jusqu'à la fin du fichier
source.
Ce sont là tous les conditions d'erreur qui sont
fonction du positionnement dans le fichier source de langage C et non du moment
où l'instruction est exécutée.
Seule, cette instruction est fournie pour vous faciliter le
développement de programmes simples. Il est plus rigoureux de
contrôler les conditions d'erreur en vérifiant directement le
champ sql code de la zone SQLCA. A l'issue de cette réflexion,
l'instruction WHENEVER est inutile. Pourquoi parce que en fait,
l'instruction WHENEVER se contente de demander au
préprocesseur de générer un test if (SQLCODE )
après chaque instruction SQL.
B. Zone de communication SQl (SQLCA)
Que faut-il finalement retenir de la zone de communication SQL
(SQLCA), elle est une zone de mémoire qui permet, pour chaque demande
adressée à la base de données, de communiquer des
statistiques et de signaler des erreurs. Il est intéressant, en
consultant la zone SQLCA, vous pouvez tester un code d'erreur
spécifique. Comme un code d'erreur s'affiche dans les champs sqlcode et
sqlstate lorsqu'une requête adressée à la base de
données provoque une erreur.
C'est en nous fondant sur cette observation, qu'une variable
SQLCA globale (sqlca) est définie dans la bibliothèque
d'interface, elle a la structure suivante :

93
Dans la majorité, SQLCA couvre à la fois les
avertissements et les erreurs. Si plusieurs avertissements ou erreurs
surviennent lors de l'exécution d'une instruction, alors sqlca ne
contient que les informations relatives à la dernière. Si aucune
erreur ne survient dans la dernière instruction SQL,
sqlca.sqlcode vaut 0 et sqlca.sqlstate vaut
"00000". Si un avertissement ou une erreur a eu lieu, alors
sqlca.sqlcode sera négatif et sqlca.sqlstate
sera différent de "00000".
Il est aussi possible que les champs sqlca.sqlstate
et sqlca.sqlcode soient deux schémas
différents fournissant des codes d'erreur. Cette différence
stipule que les deux sont spécifiés dans le standard SQL mais
sqlcode est indiqué comme obsolète dans
l'édition de 1992 du standard et a été supprimé
dans celle de 1999. Du coup, les nouvelles applications sont fortement
encouragées à utiliser sqlstate.
V.7. Curseurs pour résultats à lignes
multiples
Notion
Il est déjà possible, lorsque vous
exécutez une requête dans une application, le jeu de
résultats est constitué d'un certain nombre de lignes. Nous nous
proposons en général, lorsque vous ne connaissez pas le nombre de
lignes que l'application recevra avant d'exécuter la requête, il
est de lors possible que les curseurs constituent un moyen de gérer les
jeux de résultats d'une requête à lignes multiples.
Ces choses étant dites, les curseurs vous permettent de
naviguer dans les résultats d'une requête et d'effectuer des
insertions, des mises à jour et des suppressions de données
sous-jacentes en tout point d'un jeu de résultats.
A cela s'ajoute que, pour gérer un curseur vous devez
respecter les étapes suivantes :
1. Déclarer un curseur pour une instruction SELECT
donnée à l'aide de l'instruction
DECLARE :
EXEC SQL DECLARE nom_curseur CURSOR FOR
requête_select ;
2. Ouvrir le curseur à l'aide de l'instruction OPEN :
EXEC SQL OPEN nom_curseur ;
3. Récupérer une par une les lignes du curseur
à l'aide de l'instruction FETCH : FETCH [ [
NEXT | PRIOR | FIRST | LAST | { ABSOLUTE | RELATIVE } nombre ]
{ FROM | IN } ] nom_curseur
INTO liste_variables
NEXT : Récupère la ligne suivante. Ceci est la
valeur par défaut.
PRIOR : Récupère la ligne
précédente.
FIRST : Récupère la
première ligne de la requête (identique à ABSOLUTE 1). LAST
: Récupère la dernière ligne de la requête
(identique à ABSOLUTE -1).
94
ABSOLUTE nombre : Récupère la
nombre e ligne de la requête ou la abs
(nombre)e ligne à partir de la fin si nombre
est négatif. La position avant la première ligne ou après
la dernière si nombre est en-dehors de l'échelle ; en
particulier, ABSOLUTE 0 se positionne avant la première ligne.
RELATIVE nombre : Récupère la
nombre e ligne ou la abs
(nombre)e ligne avant si nombre est négatif.
RELATIVE 0 récupère de nouveau la ligne
actuelle si elle existe.
nom_curseur : Le nom d'un curseur ouvert.
liste_variables : La liste des variables
hôtes destinées à recevoir la valeur de chacun des
attributs de la ligne courante. Le nombre de variables hôtes doit
être identique au nombre de colonnes de la table résultat.
4. Continuez l'extraction des lignes tant qu'il y en a.
5. Fermer le curseur à l'aide de l'instruction CLOSE :
CLOSE nom_curseur
Cette étape est que lors de son ouverture, un curseur est
placé avant la première ligne. Par
défaut, les curseurs sont automatiquement refermés
à la fin d'une transaction.
Voici un exemple utilisant la commande FETCH
:
V.8. Précompilation et compilation
A. Inclusion de fichiers
Dans sa description, pour inclure un fichier externe SQL
embarqué dans votre programme, utilisez la commande :
EXEC SQL INCLUDE nom_fichier;
Cette commande indique au préprocesseur du SQL
embarqué de chercher un fichier nommé nom_fichier.h, de traiter
et de l'inclure dans le fichier C généré. Du coup, les
instructions SQL embarqué du fichier inclus sont gérées
correctement.
En utilisant la directive classique
#include <nom_fichier.h>
95
De par sa sémantique, le fichier nom_fichier.h ne
serait pas sujet au pré-traitement des commandes SQL. A noter que cela,
vous permet de continuer à utiliser la directive #include
pour inclure d'autres fichiers d'en-tête.
B. Précompilation et compilation
Tout d'abord, il importe de préciser que, la
première étape consiste à traduire les sections SQL
embarqué en code source C, c'est-à-dire en appels de fonctions de
la librairie libecpg. En remettant cette étape en
cause, il s'avère qu'elle est assurée par le préprocesseur
appelé ecpg qui est inclus dans une installation standard de
PostgreSQL.
Face à cette étape, les programmes SQL
embarqué sont nommés typiquement avec une extension
.pgc. et que si vous avez un fichier programme nommé
prog.pgc, vous pouvez le passer au préprocesseur par la
simple commande [33] :
ecpg prog1.pgc
S'agissant ce fichier programme, cette étape permet de
créer le fichier prog.c. Si vos fichiers en
entrée ne suivent pas le modèle de nommage suggéré,
vous pouvez spécifier le fichier de sortie explicitement en utilisant
l'option -o.
Une fois ce fichier traité par le préprocesseur,
il peut alors être compilé de façon classique, comme le
démontre l'exemple suivant:
cc -c prog.c
En remettant en pratique ce fichier programme, il en est de
même que cette étape permet de créer le fichier
prog.o. Les fichiers sources en C générés
incluent les fichiers d'entête provenant de l'installation de
PostgreSQL. Si vous avez installé PostgreSQL
à un emplacement qui n'est pas parcouru par défaut, vous
devez ajouter une option comme - I/usr/local/pgsql/include sur la ligne de
commande de la compilation.
Cette mise à l'épreuve permet enfin de lier le
programme avec la bibliothèque libecpg qui contient les
fonctions nécessaires. Ces fonctions récupèrent
l'information provenant des arguments, exécutent la commande SQL en
utilisant l'interface libpq et placent le résultat dans
les arguments spécifiés pour la sortie. Pour lier un programme
SQL embarqué, vous devez donc inclure la bibliothèque
libecpg :
cc -o monprog prog.o -lecpg
Dit autrement, on peut avoir besoin d'ajouter une option comme
- L/usr/local/pgsql/lib sur la ligne de commande.
V.9. Cas pratique complet
Admettre ce cas pratique, cela revient à accepter la
concrétisation des opérations suivantes : La
connexion à la base ;

96
La vérification de la réussite de la
connexion ;
L'affichage du contenu de la table individu en
utilisant un curseur ; La fermeture de la connexion.
En tenant compte que ce programme est enregistré dans
un fichier nommé prog.pgc, l'exécutable est obtenu de la
manière suivante :
V.10. Bilan du chapitre
Dans ce chapitre, nous avons tout d'abord fait une
régression relativement en détail sur les commandes de SQL vu
précédemment. Nous avons vu que ces principales commandes nous
ont principalement servis de base. Ensuite, nous avons abordé le
thème des instructions Embedded SQL qui constituent la voie pour
commencer et terminer l'exécution du programme. Nous avons
constaté que, pour générer l'exécutable, le code
source est d'abord
97
traduit par le préprocesseur SQL qui convertit les
sections SQL en code source C ou C++, après quoi il peut être
compilé de manière classique. Ces choses étant dites, nous
avons remarqué que le SQL embarqué comme il a été
démontré dans nombreux de cas pratique construit des avantages
vis-à-vis des autres pour prendre en compte les commandes SQL. Il reste
que l'intérêt de SQL embarqué en C est
spécifié dans le standard SQL et supporté par de nombreux
systèmes de bases de données SQL.
Finalement, un des aspects prépondérant avec
l'apport des fonctionnalités du PostgreSQL est d'un côté,
utile que ces fonctionnalités placent toujours le PostgreSQL dans la
catégorie des bases de données relationnel-objet. Cela revient
à dire qu'il ne faut pas confondre cette catégorie avec celle des
serveurs d'objets qui ne tolère pas aussi bien les langages
traditionnels d'accès aux SGBDR. Ainsi, bien que PostgreSQL
possède certaines fonctionnalités orientées objet, il
appartient avant tout au monde des SGBDR. C'est essentiellement l'aspect SGBDR
de PostgreSQL que nous avons abordé dans cette partie. De l'autre,
PostgreSQL apporte une puissance additionnelle substantielle en incorporant les
quatre concepts de base suivants afin que les utilisateurs puissent facilement
étendre le système : classes, héritage, types,
fonctions. Or, d'autres fonctionnalités accroissent la
puissance et la souplesse comme: contraintes, déclencheurs,
règles, intégrité des transactions. Au
final, si ces concepts influent sur les qualités du PostgreSQL,
d'être un logiciel libre, cela c'est à cause de sa gratuité
et que donc les sources sont disponibles, d'où il est alors possible de
l'installer sur les systèmes Unix/Linux et Win32.
98
Conclusion générale
Notre étude a permis d'appréhender la gestion
d'informations-mutations vers les bases des données
relationnelles-langage SQL. L'objectif de cette recherche était de
mettre en évidences les définitions et les enjeux de ces
pratiques dans des organisations enfin de bannir toutes les déperditions
des données.
Nous revenons sur les principaux justificatifs d'usage des
BDR, les défauts qui occasionnent la décadence des données
dans des organisations, et les avantages de valorisation de l'usage du langage
de manipulation de bases des données SQL, ceux qui motiveraient une
mutation des premières envergures.
C'est pourquoi, nous exposons une considération sur les
mutations des BDR ainsi que ses instructions pour servir valablement les
évidences proposées selon les bilans suivants.
Bilan des travaux
S'agissant des gains et avantages qui attraient à la
gestion des informations dans des entreprises, il a été
démontré et déceler que l'ordinateur renferme la
mémoire précieuse de stockage. Notamment au vu de la
quantité d'informations fournies dans des entreprises, l'ensemble des
évidences admises ont démontré de manière
permanente que l'ordinateur peut faire dans un premier temps la gestion des
données (mémoriser de l'information : DD, RAM, ROM, DVD, CD,
clé USB, ...) sans lui rajouter beaucoup d'instructions. Comme il est
clair, il y a la possibilité que cette performance d'informations au
sein des entreprises nécessité des méthodes assez
gestionnaire des données.
Toutefois, même si une certaine maturité de
gestion des données semble venir épauler l'ordinateur dans sa
quête gestionnaire, les évidences des bases des données,
ont décrit le système de gestion de base de données et
disséminer leurs intérêt en terme de modélisation
à travers les entités de types-entités. Dans ce contexte,
une Base des Données est un ensemble d'informations exhaustives, non
redondantes, structurées et persistantes, concernant un sujet. Dans
cette claire définition, introduire le Système de Gestion de Base
de Données peut être le choix de l'organisation, le stockage, la
mise à jour et la maintenance des données. Certes, la
stratégie à cette évidence permet de décrire,
modifier, interroger et administrer les données.
En traversant le tableau que nous peint les différents
modèles d'objets d'une base de données, la singularité des
mutations des entreprises vers l'usage des SGBD est quasi-total capital. C'est
pourquoi, nous avons tout d'abord voulu savoir quelle était la
contribution essentielle de l'usage de SGBD dans des entreprises. Voilà
que nous avons examiné les apports et les limites des différentes
conceptions des modèles des données. Naturellement, Il
99
en est ressorti qu'en dépit de limites de chacun de ces
différentes conceptions des modèles des données, la
modélisation s'articuler avec la valeur du résultat après
chaque conception.
Ces choses étant dites, restait ensuite à
déterminer ce qui caractérise la valeur des attributs dans
chacune des tables pour chaque choix du modèle des données. Pour
y parvenir, nous nous sommes appuyés sur le passage au modèle
relationnel, sa normalisation des relations dans la conception d'une base de
données relationnelle, sa dépendance fonctionnelle et enfin
chuter par la notion d'intégrité structurelle. En effet, nous
avons vu que la notion d'intégrité structurelle renferme
différentes classifications, d'où l'intégrité
référentielle constitue une synthèse de ces
dernières, car, elle impose que chaque valeur d'une clé
étrangère existe comme valeur de la clé d'identification
dans la table référencée.
Tout compte fait, avec des manipulations des bases de
données relationnelles, nous avons présenté les
fonctionnalités principales de SQL au sein d'un SGBD. Ce qui a pour gain
d'engendrer une dimension assez pratique. Qui plus est, un langage
normalisé d'interrogation de bases de données très
répandu qui permet de manipuler assez facilement les bases des
données relationnelles. Nous serions face à un langage
très variable bien qu'il ait été normalisé deux
fois. Avec son développement, il s'est avéré qu'il permet
d'ajouter des données, de les supprimer, parfois par tables
entières, de les sélectionner dans des tables, selon toutes
sortes de critères (Order by, Group by, Where...) par-delà
grâce à ses instructions. De la sorte, cette accessibilité
des instructions a permis d'examiner la commande SELECT avec ses
différentes clauses, ce qui impliquerait une interrogation et une
standardisation des différents langages, bien qu'ils soient
(d'interrogation, de manipulation, de définition et de
contrôle).
En définitive, nous avons fait une régression
détaillant les commandes de SQL vu précédemment. De
ceux-là, les principales commandes nous ont principalement servis de
base. Le principal choix a été celui des instructions Embedded
SQL qui constituent la voie pour commencer et terminer l'exécution du
programme. Cette cible, nous a amené à dévoiler que pour
générer l'exécutable, le code source est d'abord traduit
par le préprocesseur SQL qui convertit les sections SQL en code source C
ou C++, après quoi il peut être compilé de manière
classique. Une constatation que nous avons remarqué, le SQL
embarqué comme il a été démontré dans
nombreux de cas pratique construit des avantages vis-à-vis des autres
pour prendre en compte les commandes SQL. C'est pour pouvoir envisager la
solution que nous avons expliqué le SQL embarqué qui en C est
spécifié dans le standard SQL et supporté par de nombreux
systèmes de bases de données SQL.
Outre, nous nous sommes principalement concentrés sur
l'apport des fonctionnalités du PostgreSQL qui d'un côté,
reste utile, pour cela, elles placent toujours le PostgreSQL dans
100
la catégorie des bases de données
relationnel-objet. Il y a là essentiellement le
déréférence à ne pas confondre cette
catégorie avec celle des serveurs d'objets qui ne tolère pas
aussi bien les langages traditionnels d'accès aux SGBDR. C'est à
un dire que le PostgreSQL possède certaines fonctionnalités
orientées objet, il appartient avant tout au monde des SGBDR. C'est
essentiellement l'aspect SGBDR de PostgreSQL que nous avons abordé. Ce
relais du PostgreSQL apporte une puissance additionnelle substantielle en
incorporant les quatre concepts de base suivants afin que les utilisateurs
puissent facilement étendre le système : classes,
héritage, types, fonctions. Or, d'autres
fonctionnalités accroissent la puissance et la souplesse comme:
contraintes, déclencheurs, règles,
intégrité des transactions. Ces
fonctionnalités nous ont notamment montré que ces aspects
influent sur les qualités du PostgreSQL, d'être un logiciel libre,
à partir de là a été expliqué sa
gratuité et la disponibilité de ses sources.
Les perspectives
Le travail dans lequel nous nous sommes engagés est un
travail de grande ampleur car il couvre tous les niveaux de stockage des
données dans les SGBD et l'usage d'un langage des manipulations des
données. Les premières perspectives concernent la prise en compte
dans la gestion, de toutes les données des organisations. C'est
notamment le cas pour les informations amples qui nous amènent à
envisager leur traitement avec par exemple une approche de gestion
relationnelle. Cela nous conduit alors aussi vers l'étude des
modèles des données liées à la modélisation
et son langage de manipulation des données.
Les autres perspectives concernent d'une part les
considérations des SGBDR vers de nouvelles fonctionnalités et,
d'autre part, à l'étude plus approfondie de l'architecture du
langage qui soutient les pages Web. Cet axe est en train de prendre beaucoup
d'importance dans la communauté des bases de données : on parle
alors de SGBDR (Système de Gestion de Bases des Données
Relationnelles). Il s'agira là, d'un élément
fédérateur qui facilitera la gestion des toutes les
données des organisations. Un des défis pour la recherche dans
les années à venir pourrait bien être la gestion de la
complexité de tels environnements intégrés.
101
Bibliographie
[1] ANSI, (ISO/ANSI working draft) Database
Language SQL2, (X3H2-90-398), Octobre 1990.
[2] R.Grin. Introduction aux bases de
données. Université de Nice Sophia-Antipolis Version 2.1,
decembre 2000.
[3] P.Rigaux. Cours de bases de données.
cours, page 9, juin 2001.
[4] JP.Antoni et Y.Flety. Introduction aux
bases de données. cours.
[5] Codd, E. F. (1970, June). A Relational
Model of Data for Large Shared Data Banks. Communications of the ACM,
377-387.
[6] Dionisi, D. (1993). L'essentiel sur merise. Eyrolles.
[7] S. CLUET, Langages et Optimisation de
Requêtes pour Systèmes de Gestion de Base de Données
Orientés-Objet, Thèse de doctorat de 3ième cycle,
Université de Paris-Sud - Centre d'Orsay, Juin 1991.
[8] S. ABITEBOUL et C. BEERI, On the Power
of Languages for the Manipulation of Complex Objects, (INRIA Research Report
#846), INRIA, Mai 1988.
[9] W. KIM et al., « Integrating an
Object-Oriented Programming System with a Database System», Proc. OOPSLA
88 Conference, Septembre 1988.
[10] A. ALBANO, L. CARDELLI et R. ORSINI,
«Galileo: A Strongly-Typed,Interactive Conceptual Language», Readings
in Object-Oriented Database Systems , édité par S. Zdonik, D.
Maier, Morgan-Kaufman, 1985.
[11] F. BANCILHON, T. BRIGGS, S. KHOSHAFIAN et P.
VALDURIEZ, «FAD, a Powerful and Simple Database Language»,
Proc. VLDB 87 Conference , Brighton, 1987.
[12] M. CAREY et al., The Architecture of
the EXODUS Extensible DBMS: A Preliminary Report , (644), University of
Wisconsin - Madison, Mai 1986.
[13] M. CAREY, D. DE WITT et S. VANDENBERG,
«A Data Model and a Query Language for EXODUS», Proc. ACM SIGMOD 88
Conference, Chicago, Juin 1988.
[14] J.E. RICHARDSON et M.J. CAREY,
«Implementing Persistence in the E Language», International Workshop
on Persistent Object System, 1989.
102
[15] O DEUX et al., «The Story of
O2», IEEE Transactions on Knowledge and Data Engineering, 12(1), Mars
1990.
[16] C. LECLUSE, P. RICHARD et F. VELEZ,
«O2, an Object-Oriented Data Model», Proc. ACM SIGMOD 88 Conference,
Chicago, Juin 1988.
[17] O2 Technology, The O2 User's Manual , 7,
rue du Parc de Clagny 78000 Versailles (France), Décembre 1991.
[18] S. KRAKOWIAK, M. MEYSEMBOURG, H. NGUYEN VAN, M.
RIVEILL et C.ROISIN, «Design and implementation of an
object-oriented, strongly typed language for disributed applications»,
Journal of Object-Oriented Programming, 3(3), Septembre 1990.
[19] C. BEERI et Y. KORNATZKY, «Algebraic
Optimization of Object-Oriented Query Languages », Proc. ICDT 90
Conference , Paris, Décembre 1990.
[20] H. Nguyen Van, M. Riveill et C. Roisin,
Manuel du langage Guide (V1.5), (3-90), Unité mixte Bull-Imag
(Grenoble), Décembre 1990.
[21] Akoka, J. & Comyn-Wattiau, I.
(2001). Conception des bases de données relationnelles. Vuibert
informatique.
[22] Banos, D. & Mouyssinat, M. (1990).
De merise aux bases de données. Eyrolles.
[23] Bourda, Y. (2005a). Le langage SQL.
(http :// wwwlsi.supelec.fr/ www/ yb/ poly_bd/ sql/ tdm_sql.html).
[24] Bourda, Y. (2005b). Systèmes de
Gestion de Bases de Données Relationnelles. (http :// wwwlsi.supelec.fr/
www/ yb/ poly_bd/ poly.html).
[25] Gabillaud, J. (2004). SQL et
algèbre relationnelle - Notions de base. ENI.
[26] Godin, R. (2000a). Systèmes de
gestion de bases de données (Vol. 2). Loze-Dion.
[27] Godin, R. (2000b). Systèmes de
gestion de bases de données (Vol. 1). Loze-Dion.
[28] Gruau, C. (2006). Conception d'une base
de données. (http :// cyril-gruau.developpez.com/ uml/ tutoriel/
ConceptionBD/).
[29] Guézélou, P. (2006).
ModÉlisation des donnÉes : Approche pour la conception des bases
des données. (http ://
philippe.guezelou.free.fr
/mcd /mcd.htm).
[30] Hernandez, M. J. & Viescas, J. L.
(2001). Introduction aux requêtes SQL. Eyrolles.
103
[31] Kauffman, J., Matsik, B. & Spencer, K.
(2001). Maîtrisez SQL (Wrox Press, Ed.). CampusPress.
[32] PostgreSQL (The PostgreSQL Global
Development Group, 2005)
[33] The PostgreSQL Global Development Group.
(2005). Documentation PostgreSQL 7.4.7. (http :// traduc.postgresqlfr.org/
pgsql-fr/ index.html).
104
Références Web
[W1]Encyclopédie Wikipédia.
(2005). Articles en ligne sur Wikipédia. (http ://
fr.wikipedia.org). Mai 2017
[W2]Introduction aux modèles EA et
relationnel:
www.iutc3.unicaen.fr/~moranb/cours/acsi/menu.htm
Janvier 2018
[W3]Bases de données, SGBD: www-
lsr.imag.fr/Les.Personnes/Herve.Martin/HTML/FenetrePrincipale.htm,
Février 2018
[W4] SGBD et SQL :
wwwdi.supelec.fr/~yb/poly_bd/node1.html,
Juin 2017
[W5] Articles en ligne sur
Developpez.com. (2005a). LE
SQL de A à Z : Le simple ( ?) SELECT et les fonctions SQL.
(http :// sql.developpez.com/ sqlaz/ select). Juillet 2017
[W6] Articles en ligne sur
Developpez.com. (2005b). LE
SQL de A à Z : Les jointures, ou comment interroger plusieurs
tables. (http :// sql.developpez.com/ sqlaz/ jointures). Novembre 2017
@mj
§1. Objectifs d'un SGBD 30
105
Tables des matières
Sommaire 1
Remerciements 5
Lexique 7
Résume 9
Abstract 10
Liste des figures 11
Liste des tableaux 13
Introduction générale 14
Chapitre I : L'ordinateur auxiliaire de stockage
17
I.1. Introduction 17
I.2. Ordinateur auxiliaire de stockage 17
I.3. Fonctionnalités 19
I.4. Tumulte des couloirs du cosmopolite et trivial de
complexité 20
I.4.1. Tumulte des couloirs du cosmopolite
20
I.4.2. Trivial de complexité 20
I.5. Repères pour une question 21
I.6. Des perspectives pour la recherche ? 22
I.7. Bilan du chapitre 23
Chapitre II: Les bases des
données : une nouvelle considération de stockage et
manipulation des données 24
II.1. Introduction 24
II.2. Base de données 25
II.2.1. Définition 25
§1. Définition d'une BD comme ensemble de
données 25
§2. Définition d'une BD comme ensemble de
données structuré 25
§3. Retenons ces quelques définitions
informatisées 25
II.2.2. Domaine problème posé
26
II.2.3. Modèle de base de données
27
II.3. Système de gestion de base de données
(SGBD) 29
II.3.1. Notions et définition 29
II.3.2. Objectifs, propriétés, composants et
organisation de la mise en oeuvre d'un
SGBD 30
§2.
106
Propriétés d'un SGBD 31
§3. Composants des SGBD 31
§4. Organisation de la mise en oeuvre des SGBD
32
II.3.3. Affinement de niveaux de description des
ANSI/SPARC 32
II.4. Modélisation des bases de données :
le modèle entités-associations 33
II.4.1. Généralités 33
§1. Pourquoi une modélisation
préalable ? 33
§2. Merise 34
II.4.2. Le modèle entités-associations
35
II.4.3. Notations d'associations type-entité
39
II.5. Bilan du chapitre 44
Chapitre III: Les évidences de mutation vers les
bases de données relationnelles 46
III.1. Introduction 46
III.2. Généralités sur la notion de
modèle des données 47
III.3. Structure des modèles des données
à objet 47
III.3.1. Le modèle de données d'Orion
48
III.3.2. EXTRA : un modèle de données pour
EXODUS 49
III.3.3. Le modèle de données de O2
51
III.3.4. Le modèle de données de Guide
52
III.4. Passage au modèle relationnel
54
III.4.1. Généralité de clé
étrangère 54
III.4.2. Règles de passage 55
III.4.3. Cas pratique 56
III.5. Pertinence de la normalisation dans la conception
d'une Base de données
relationnelle 56
III.5.1. Redondance d'un attribut 56
III.5.2. Anomalies de mutation 57
III.6. Dépendances fonctionnelles et
normalisations des relations 57
III.6.1. Dépendance fonctionnelle :
définitions 57
III.6.2. Normalisation des relations 58
III.6.3. Cas pratique 60
III.6. Intégrité structurelle
62
III.6.1. Notion et classification 62
III.6.2. Intégrité
référentielle 63
III.7. Bilan du chapitre 64
107
Chapitre IV: Le langage Sql : un manipulateur de bases de
données relationnelles 65
IV.1. Introduction 65
IV.2. Le langage de définition des données
(LDD) 66
IV.2.1. Notion aux contraintes d'intégrité
67
IV.2.2. Créer une table : CREATE TABLE
69
IV.2.3. Modifier une table : ALTER TABLE 70
IV.2.4. Supprimer une table : DROP TABLE 71
IV.3. Le langage de manipulation des données
(LMD) 71
IV.3.1. Insertion de n-uplets : INSERT INTO
71
IV.3.2. Modification de n-uplets : UPDATE 72
IV.3.3. Suppression de n-uplets : DELETE 72
IV.4. Le langage de contrôle des données
(LDC) 72
IV.5. Interroger une base de données
74
IV.5.1. Notion de base 74
IV.5.2. Syntaxe de base 76
IV.5.3. Les jointures 78
IV.5.4. Les fonctions de groupes 80
IV.5.5. Sous-interrogations 82
IV.5.6. Bilan de l'instruction SELECT : syntaxe
étendue 83
IV.6. Bilan du chapitre 84
Chapitre V: Le Sql intégré : un paquetage
de Sql Embarqué 85
V.1. Introduction 85
V.2. Connexion au serveur de bases de données
86
V.3. Exécuter des commandes SQL 87
V.4. Les variables hôtes 87
V.5. Variables indicateurs 90
V.6. Gestion des erreurs 91
V.7. Curseurs pour résultats à lignes
multiples 93
V.8. Précompilation et compilation 94
V.9. Cas pratique complet 95
V.10. Bilan du chapitre 96
Conclusion générale 98
Bilan des travaux 98
Les perspectives 100
Bibliographie 101
108
Références Web 104
Tables des matières 105


