|

Sujet : Conception et réalisation d'un
système moteur de recherche des enfants perdus par reconnaissance
faciale
par
Benedict Obed Nyamungu
05116
In accordance with UCBC policies, this thesis is accepted in
partial fulfillment of requirements for the degree of Licencié.
_______________________________
Erick Kalwana, MSc. Génie Logiciel
Directeur
_____________________
Date
_______________________________
Sage Kataliko, MSc. Technology
Encadreur
_____________________
_______________________________
Felix Kathimika, CT,
Doyen de la faculté des Sciences Appliquées
_______________________________
Felix Kathimika, CT,
SGAC chargé des recherches et documentation
_____________________
_____________________
Déclaration d'honnêteté
académique
Par mon honneur, je confirme que ce présent travail
scientifique intitulé :
« Conception et réalisation d'un système
moteur de recherche des enfants perdus par reconnaissance
faciale »
est original et n'a été soumis à aucun
autre collège ou institution universitaire pour le crédit
universitaire. Tout texte ou digramme tiré d'un ouvrage, travail
scientifique, Site Web, et autres ressources ont et utilisés et
cités correctement dans les textes et dans la liste des
références. Je reconnais avoir mentionné toute personne
ayant porté une contribution scientifique à ce travail.
Je suis conscient que toute déclaration fausse annule
ce travail et entraine des pénalités sévères selon
la loi.
Signature : _____________________
Benedict Obed Nyamungu
05116
Date : __________________
EPIGRAPHE
« Recommande à l'Eternel tes oeuvres, Et tes
projets réussiront.»
Proverbes 16 : 3
DEDICACE
A ma très chère mère
A mon très cher père
A ma très chère grand-mère
Au succès de Window of Innovation,
A ma future épouseet mes futurs
enfants.
REMERCIEMENTS
La réalisation de ce travail a été
possible grâce au concours de plusieurs personnes à qui je
voudrais témoigner toute ma reconnaissance.Toutes les lettres ne
sauraient trouver les mots qu'il faut... Tous les mots ne sauraient exprimer la
gratitude, l'amour, le respect, la reconnaissance...
Mes remerciements les plus sincères s'adressent
à Dieu le père qui a toujours combattu pour moi durant les
moments difficiles.
Je tiens à exprimer toute ma reconnaissance à
mon Directeur de mémoire MonsieurERICK KALWANA et à mon Encadreur
Monsieur SAGE KATALIKO. Je remercie ces derniers de m'avoir encadré,
orienté, aidé et conseillé tout au long de ce travail.
J'adresse mes sincères remerciements à tous les
membres de staff de l'UCBC, intervenants et toutes les personnes qui, par leurs
paroles, leurs écrits, leurs conseils et leurs critiques ont
guidé mes réflexions et ont accepté à me rencontrer
et répondre à mes questions durant mes recherches.
Je tiens àremercier ma très chère
mère HELENE KASALI qui m'a comblé avec sa
tendresse et affection tout au long de mon parcours.
D'une façon très singulière, je remercie
mon très cher père OBED MUKANIRWA qui a su
m'inculquer le sens de la responsabilité, de l'optimisme et de la
confiance en soi face aux difficultés de la vie.Que ce travail soit
l'accomplissement de vos voeux tant allégués, et le fruit de
votre soutien infaillible.
Je remercie trop ma chère grand-mère
IVONE KANZANZA, pour les expressions des voeux que vous
qu'elle n'a pas cessé de formuler dans ses prières.
Je remercie mes frères Richy MUKANIRWA, Johnny
MUKANIRWA, Fabrice KAMBALE et mes soeurs Souzan MUKANIRWA, Glorieuse MUKANIRWA,
Grace MUKANIRWA, Joy MUKANIRWA, Esperance SENGEMOJA, pour leur
encouragement.
Je désire aussi remercier le groupe People in Big Union
(PBU, en sigle) qui a toujours prouvé son union envers tout le monde et
m'a particulièrement arraché de stress dès lors que
j'étais en stress et me rendait toujours dans ma bonne humeur.
Mes remerciements les plus sincères s'adressent
à tous mes compagnons de lutte, mes camarades de classe ; les 17
apôtres de la promotion 2020 en faculté des sciences
appliquées : KASEREKA Mathina, POSITE Pochelin, SARAH Fina, ROSINE
Alimasi, Clément WASUKUNDI, SELYABO Bonheur, MASINDA Jonathan, Franck
MULYAMA, Emmanuel KANDUKI, KATSUVA Bienfait, Benjamin OMVUANI, Cherubin
WAMBELE, Gédéon LUBEMBA, Fiston KAMALA, BARAKA Darcy, Dany MUNDUA
pour leur accompagnement.
BENEDICT OBED N.
Enfin, je remercie particulièrement tous mes Ami(e)s
que j'aime tant David Muviri, Farahani Nyembo, Claudine Winya, Rachel Kapinga,
Anuarite Mathe pour leur sincère amitié et confiance, et à
qui je dois ma reconnaissance et mon attachement.
Mes sincères remerciements à la famille SUDA
pour l'hospitalité et de nous avoir octroyé un espace serein de
travail tout le long de notre cursus.
SIGLES ET ABBREVIATIONS
ADN : Acide
Désoxyribonucléique
CSS : Cascading
Style Sheets
DPs : Personnes
Déplacées
HTML :
HyperText Markeup
Language
IA : Intelligence
Artificielle
IDE : Integrated
Development Environment
KNN :
K-Nearest Neighbors
ML : Machine
Learning
OpenCv : OpenComputer
Vision
PC : Personal
Computer
SGBDR : Système
de Gestion de Base de
Données Relationnelles
SQL : Structured
Query Language
UCBC :
Université Chrétienne
Bilingue du Congo
UML : Unified
Modeling Language
URL : Universal
Ressource Locator
VSCode : Visual
Studio Code
LISTE DES FIGURES
Figure
1 : Diagramme de fonctionnement du Machine Learning
2
Figure
2 : Apprentissage non supervisé illustré
10
Figure
3 : Différentes modalités biométriques: (a) Empreintes
digitales, (b) Geste, (c) Iris, (d) Rétine, (e) Visage, (f) Empreinte de
la paume, (g) Oreille, (h) ADN, (i) Voix, (j) Marche, (k) Signature, (l)
Frappes du clavier.
13
Figure
4 : Principaux modules d'un système biométrique ainsi que les
différents modes.
15
Figure
5: Etapes de la reconnaissance de visage.
17
Figure
6: Variation des poses (illustrés)
18
Figure
7 : Variation d'illumination illustrée
19
Figure
8 : Exemple d'une détection des visages
20
Figure
9: Schéma fonctionnel d'identification d'un individu dans un
système de reconnaissace faciale.
21
Figure
10 : Fonctionnement de l'algorithme KNN
23
Figure
11: Ordinogramme de l'algorithme de Serign Modou Bah et Fang Ming
26
Figure
12 : Diagramme cas d'utilisation global
30
Figure
13: Diagramme de cas d'utilisation : Cas
« enrôler »
36
Figure
14: Diagramme d'activité : Cas
« enrôler » l'enfant
37
Figure
15 : Diagramme de séquence pour le cas enrôler l'enfant
38
Figure
16 : Diagramme de classe
39
Figure
17: Diagramme cas d'utilisation pour le cas reconnaitre l'enfant
41
Figure
18: Diagramme d'activité pour la reconnaissance
42
Figure
19 : Diagramme de séquence pour la reconnaissance
44
Figure
20 : Diagramme de déploiement
44
Figure
21 : Architecture du système
46
Figure
22 : Interface d'enrôlement de l'enfant
49
Figure
23 : Interface de reconnaissance de l'enfant
50
LISTE DES TABLEAUX
Tableau 1 : Les cas d'utilisation
expliqués
2
RESUME
La reconnaissance faciale étant une discipline assez
étendu dans le monde actuel, ce présent travail traite sur la
conception et réalisation d'un système moteur de recherche des
enfants perdus par reconnaissance faciale. Il faut en effet constater que les
avancées de la reconnaissance faciale offrent des avantages
inégalement répartis sur la surface de la terre. Ce
système permet une recherche indexée de l'enfant perdu en
analysant les caractéristiques biométriques de son visage.
Un enfant perdu et dépourvu, sera amené dans une
station de police ou vers un service spécialisé et sera
placé devant une caméra pour que certaines informations lui
concernant soient dégagées. Ces informations permettront bien
à l'agent de police de contacter les parents de l'enfant ou de le
ramener directement à son domicilegrâce à un module
intégré pour la géolocalisation du domicile de l'enfant.
Notons ici que toutes ces tâches ne sont possibles qu'après
l'enrôlement en avancede l'enfant
Différentes méthodologies sont utilisées
pour atteindre l'objectif que nous nous sommes assigné dans ce travail,
dont la revue de la littérature, la simulation et bien d'autres. Le
système conçu comporte deux parties, la première
centrée autour de l'enrôlement des enfants de, et la seconde
centrée autour de la reconnaissance de l'enfant.
Mots clés : Reconnaissance
faciale, caméra, enfant, biométrique.
ABSTRACT
Facial recognition being a fairly extensive discipline in
today's world, this work deals with the design and implementation of a search
engine system for lost children through facial recognition. Indeed, it must be
noted that advances in facial recognition offer benefits unevenly distributed
over the surface of the earth. This system allows an indexed search of the lost
child by analyzing the biometric characteristics of his face.
A lost and deprived child will be brought to a police station
or to a specialized service and will be placed in front of a camera to release
certain information about him/her. This information will allow the police
officer to contact the child's parents or to bring the child directly to his or
her home through an integrated module for the geolocation of the child's home.
Note here that all these tasks are only possible after the child has been
enlisted in advance.
Different methodologies are used to achieve the goal we have
set for ourselves in this work, including literature review, simulation and
many others. The system designed has two parts, the first centered around the
enrolment of children, and the second centered around the recognition of the
child.
Keywords: Facial recognition, camera, child,
biometrics.
INTRODUCTION GENERALE
0.1. PREAMBULE
À la fin de la seconde guerre mondiale, des centaines
de milliers d'enfants ont disparu. Sous l'invite « Qui connaît
nos parents et nos origines ? », leurs visages ornent les
affiches de la Croix-Rouge. Que ce soit à cause des bombardements, du
service militaire, de la déportation, du travail forcé, du
nettoyage ethnique ou des meurtres, un nombre sans précédent
d'enfants se retrouve séparé de leurs parents pendant la guerre.
La Croix-Rouge allemande reçoit plus de 300 000 requêtes pour
retrouver la trace d'enfants ou de parents disparus entre 1945 et 1958 alors
que le Service international de recherche (ITS, International Tracing
Service) piste 343 057 enfants perdus entre 1945 et 1956[1].
Le problème de la réunification des familles
après la seconde guerre mondiale s'avère être bien plus
qu'un puzzle logistique dantesque. S'ils ne représentent qu'une faible
partie des millions de personnes déplacées (DPs) dans l'Europe
d'après-guerre, les enfants dits perdus occupent une place toute
particulière dans l'imaginaire de l'époque. Ils se trouvent au
centre de conflits politiques aigus entre les autorités militaires, les
familles d'accueil allemandes, les social workers[2], les agences
juives, les officiels communistes d'Europe de l'Est et les personnes
déplacées elles-mêmes, chacun se pensant le plus à
même de déterminer leur avenir. Ces conflits sont liés,
à tour de rôle, aux idéaux émergents des Droits de
l'homme, aux conceptions de la famille, de la démocratie, de la
protection de l'enfance et de façon plus large au processus de
reconstruction de la civilisation européenne. Vinita A. Lewis, une
représentante de l'Organisation internationale pour les
réfugiés (OIR) en Allemagne, déclare :
« L'identité perdue de ces enfants est aujourd'hui le
problème social numéro un en Europe[3].
Selon RFI, environ 500 enfants Sud-Africains se sont perdus
sur les plages de la ville durant la seule journée du 1er janvier 2015.
La police débordée a passé la journée à
arpenter les plages à l'aide de haut-parleurs pour tenter de retrouver
les parents. Quelques 70 enfants n'avaient toujours pas retrouvé leurs
parents le même jour et ont passé la nuit dans les
différents postes de police de la ville[4].
Comme l'a dit `Alexandre Dumasfils',
« L'enfant n'a pas de meilleure amie que sa mère
»[5], il est cependant très nécessaire de bien fournir
plus d'effort pour le garder à côté de sa mère (de
son père ou de son tuteur) afin qu'il jouisse beaucoup plus d'une
éducation de base pertinente et adéquate. Etant prêt de ses
parents, celui-ci a un avenir tant garanti.
En effet, il est donc pertinent de s'intéresser aux
outils de la technologie de l'information et de la communication pour sauver
les vies des enfants perdus en leurs offrant encore une autre chance de passer
beaucoup plus de temps à côté de leurs parents. Les
informations locales sur les pertes des enfants ont soulevé des
questionnements qui m'ont interpellé et ont piqué mon
intérêt pour la réalisation d'un tel système faisant
usage de la vision par ordinateur et de l'apprentissage machine pour retrouver
facilement les informations nécessaires sur l'enfant et de rapidement le
faire parvenir à ses parents.
0.2. PROBLEMATIQUE
Aujourd'hui, plusieurs enfants disparaissent pour plusieurs
causes ; travail forcé, des meurtres et d'autres se perdent et se
volatilisent dans la nature. Mais, malheureusement, les parents ne peuvent
pas toujours surveiller leurs enfants qui ont constamment envie
d'expérimenter de nouvelles choses et de vivre
de grandes et intrépides aventures.
Chaque jour, les informations locales relatent que les enfants
se perdent et certains d'entre eux partent se retrouver à la police ou
dans les bureaux des chaines des radios locales tout simplement parce qu'ils ne
savent pas s'exprimer correctement et implicitement, ils ignorent leurs
adresses. Les parents des enfants disparus s'inquiètent trop pour leurs
enfants disparus et de fois se questionnent sur l'état dans lequel ils
les retrouveront (vivant, mort, tamponné par une moto, voiture, etc.).
En république tchèque par exemple, plus de 1000 enfants de moins
de 15 ans se perdent et sont trouvés peu après et quelques
enfants disparus sont victimes d'un crime[6], cela prouve donc qu'il est
très nécessaire de bien concentrer beaucoup plus d'efforts pour
la lutte contre ces jours passés hors du toit paternel.
Cependant, vu l'inquiétude des parents, ceux-ci se
mettent à investir des frais à payer dans plusieurs chaines de
radios locales pour lancer un avis de recherche de leurs enfants. Dans le
contexte local, la population souffrante qu'elle est, se voit peiner à
payer tous ces frais dans toutes ces chaines et peuvent se choisir de ne payer
que les frais dans une des radios mais avec des frais moins chers et
malheureusement la moins captée.
En effet, pour parvenir à la résolution des
problèmes mentionnés ci-haut, nous nous sommes posé
certaines questions qui guideront les idées de notre recherche :
1. Par quel moyen la recherche d'un enfant perdu serait rapide
et facile ?
2. Comment la personne ayant retrouvé l'enfant serait
à mesure de savoir des identitéscomplètes et adresses de
l'enfant ?
0.3. HYPOTHESES
Pour les questions posées ci-haut, voici les
réponses anticipatives que nous proposons :
1. Mettre en place un systèmemoteur de recherche par
reconnaissance faciale serait une solution rapide pour rechercher un enfant
perdu dans la nature.
2. Implémenter un module qui se chargerait de retourner
les informations nécessaires sur l'enfant serait une solution
prometteuse face à ce problème.
0.4. OBJECTIFS DU TRAVAIL
0.4.1 Objectif global
Ce travail a comme objectif d'implémenter un
système capable reconnaitre l'image d'un enfant perdu et de retourner
une pop-up des informations trouvées sur l'enfant enfin de permettre
à la personne qui l'a retrouvé de facilement retrouver son
domicile et/ou de joindre ses parents via la ligne téléphonique.
Juste avec un smartphone, la vie de cet (cette) enfant sera évidemment
sauvée.
0.4.2. Objectifs
spécifiques
Afin d'atteindre l'objectif global de ce travail, nous nous
sommes assigné certaines étapes clés à suivre :
Ø Etudier les quelques systèmes existants de
reconnaissance faciale,
Ø Concevoir et modéliser notre système de
reconnaissance faciale,
Ø Intégrer un module de communication entre la
personne responsable de l'enfant et la personne ayant retrouvé ce
dernier,
Ø Tester le système réalisé par
rapport aux fonctionnalités assignées durant l'extraction des
exigences du système pour ainsi tester les hypothèses.
0.5. CHOIX ET INTERET DU TRAVAIL
La question épineuse de la perte des enfants demeure
jusqu'à présent un problème dans le monde. Ces derniers se
perdent presque tous les jours et sont en difficulté de retrouver leurs
toits quotidiens tout simplement parce qu'ils ne savent pas mieux s'exprimer,
ils ignorent innocemment l'adresse d'où ils vivent. Or, en faisant usage
des TIC, en concevant des systèmes informatiques utilisant une
intelligence artificielle par exemple, ceux-ci seraient innocentés de
passer plusieurs jours hors de leurs maisons et leurs parents seraient moins
inquiets car ils pourront être contactés à l'avance.D'ici,
ce travail intitulé « conception et réalisation
d'un système moteur de recherche des enfants perdus par reconnaissance
faciale », vise donc à effectuer une recherche par
image d'un(des) enfant(s) perdus en renvoyant certaines informations
nécessaires sur l'enfant en vue de permettre à la personne qui
l'a retrouvé de facilement retrouver les identités de l'enfant et
absolument celles des parents de l'enfant.
Notre travail revêt d'abord un intérêt
social, économique, puis scientifique.
Du point de vue sociétal, ce sujet intéresse
toute la société dans laquelle nous vivons car la perte des
enfants est une affaire de tous et nous devons bien mener les luttes pour
diminuer les risques qui découleraient de ces pertes incessantes
d'enfant.
Du point de vue économique, les personnes ayant perdu
leurs enfants se verront soulagées car les frais à payer aux
radios comme cautions de communiquer vont surement diminuer.
Scientifiquement, ce sujet est très important aux
futurs chercheurs car s'inscrivant dans le siècle d'automatisation,
servira d'aide à ceux-ci sur l'utilisation rationnelle de l'intelligence
artificielle avec une kyrielle de ses sous branches comme le machine Learning
et la vision par ordinateur (computer vision). Les futurs chercheurs pourront
donc comprendre l'utilisation rationnelle des branches de l'informatique
dans la recherche par image.
0.6. LIMITATION ET DELIMITATION DU TRAVAIL
A. LIMITATION
Quant au contenu, nous nous limiterons à la
modélisation du système, la reconnaissance faciale de l'enfant
perdu en retournant ses identités et celles de ses parents ainsi que
certaines autres informations conquises lors de l'enregistrement de l'enfant
dans le système. Toutes autres raisons hors de celles citées
ci-haut ne seront pas donc concernées dans ce travail.
B. DELIMITATION
Tout travail scientifique doit avoir toujours des limites
spatiales et temporelles, c'est pourquoi, nous avons pris soin de circonscrire
aussi le nôtre dans le temps et dans l'espace.
a. Délimitation dans le temps
Vu l'importance et la nécessité en ce qui
concerne l'aspect temporel, la présente étude s'étend sur
l'intervalle de temps allant de Décembre 2019 à Novembre 2020.
b. Délimitation dans l'espace
Toutes nos recherches ont
été faites spécifiquement en ville de Beni, mais ce
travail peut être appliqué dans n'importe quel coin du monde.
0.7. AUDIENCE
Etant donné que toute personne peut être
frappée par la perte d'un enfant sous sa tutelle et que toute personne
peut se heurter sur le chemin d'un quelconque enfant perdu, ce travail ne fera
pas distinction entre différentes couches des personnes. Les papas, les
mamans, les tuteurs et toutes personnes majeures sachant au moins manipuler un
smartphone constitueront l'audience de ce présent travail. Les
étudiants et chercheurs s'intéressant à l'usage de
l'apprentissage machine et vision par ordinateur trouveront leur part dans ce
présent travail.
0.8. SUBDIVISION DU TRAVAIL
Hormis l'introduction et la conclusion, ce présent
travail est subdivisé en trois chapitres :
ü CHAPITRE I : GENERALITES ET REVUE DE
LITTERATURE
Dans cette partie nous présentons et définissons
certains concepts clés que regorge notre travail. Aussi, nous cherchons
à comprendre les pensées des autres auteurs sur la recherche par
reconnaissance faciale. Nous allons faire l'étude des travaux existants
pourvu que le présent travail soit conscientiel des anciens. Enfin, nous
présentons les exigences logicielles de notre projet.
ü CHAPITRE II : METHODOLOGIE ET CONCEPTION
DU SYSTEME
Dans ce chapitre nous présentons les différents
schémas et diagrammes qui traduisent directement comment notre
système va fonctionner.
ü CHAPITRE III : IMPLEMENTATION,
PRESENTATION ET TEST
Ce dernier chapitre explique clairement les différentes
manipulations de notre système de recherche d'un enfant perdu par
reconnaissance faciale avec les différents modules qu'offre ce
dernier ; lesquels modules spéculés dans la partie
d'hypothèse. Enfin, cette partie comportera les indications sur le
déroulement des tests et les résultats obtenus après ces
tests.
CHAPITRE I. GENERALITES
Tout travail scientifique revêtant un caractère
innovant a toujours un fondement terminologique approprié. C'est ainsi
que dans ce chapitre nous épinglons, définissons et
détaillons les concepts opérationnels constituant notre travail.
Nous présentons aussi la revue de la littérature qui nous
permettra de relever les démarches méthodologiques qu'ont suivis
les auteurs lus tout en spéculant les préoccupations de
départ de ceux-ci, leurs objectifs, les résultats de leurs
recherches ainsi que leurs recommandations ; ce qui nous permettra donc
tirer certains points différenciant notre travail des leurs. Enfin, nous
présentons la spécification d'exigences logicielles qui
décrira le comportement externe de l'application à concevoir.
I.1. GENERALITES SUR
L'INTELLIGENCE ARTICIFIELLE
1. Définition de l'IA
C'est en 1956 que Marvin Lee Minsky [7], scientifique
américain, définit pour la première fois l'intelligence
artificielle comme étant « la construction de programmes
informatiques qui s'adonnent à des tâches qui sont, pour
l'instant, accomplies de façon plus satisfaisante par des êtres
humains, car elles demandent des processus mentaux de haut niveau tels que :
l'apprentissage perceptuel, l'organisation de la mémoire et le
raisonnement critique ».
En d'autres termes, l'Intelligence
artificielle est un ensemble de théories et de techniques
développant des programmes informatiques complexes capables de simuler
certains traits de l'intelligence humaine (raisonnement, apprentissage...).
2. Types d'intelligence artificielle
Il existe deux grands types de l'intelligence
artificielle : l'Intelligence Artificielle faible et l'Intelligence
Artificielle forte :
A. L'intelligence Artificielle faible
L'IA Faible est utilisé dans des tâches
simples. C'est une intelligence assez limitée par ses fonctions car elle
ne fonctionne qu'avec une succession d'algorithmes programmés par des
humains pour simuler une intelligence.
C'est la forme la plus courante d'IA disponible dans les
industries d'aujourd'hui. L'IA faible ne peut pas fonctionner au-delà de
ce qui est assigné au système. En effet, il est formé pour
effectuer une seule tâche spécifique.
Le Siri d'Apple, par exemple, est un exemple pour l'AI faible.
Siri est formé pour exécuter un ensemble limité de
fonctions prédéfinies. D'autres exemples incluent les voitures
autonomes, les systèmes de reconnaissance d'images et de parole.
B. L'intelligence Artificielle forte
L'IA Forte, qui est encore une idée futuriste,
se base sur l'analyse d'une situation concrète (algorithme
évolutionniste, système de neurone). Elle est à la
recherche d'une réelle autonomie ; pour les chercheurs, le robot
possédant une IA forte serait doté d'une réelle conscience
et éprouverait des sentiments. De plus, son raisonnement doit se
rapprocher de celui de l'être humain, c'est le
rêve ambitieux de beaucoup de chercheurs d'arriver à ce
stade [8].
3. Quelques sous-disciplines de l'IA
L'intelligence artificielle est en soit une discipline trop
vaste. En effet, elle regorge une multitude de sous-disciplines dont en voici
certaines :
· Le
machine Learning
Le Machine Learning (ML) aussi appelé apprentissage
automatique ou « apprentissage statistique », est un sous-ensemble de
l'IA, parmi d'autres sous-disciplines. Ce terme renvoie à un processus
de développement, d'analyse et d'implémentation conduisant
à la mise en place de procédés systématiques [9].
Pour faire simple, il s'agit d'une sorte de programme permettant à un
ordinateur ou à une machine un apprentissage automatisé, de
façon à pouvoir réaliser un certain nombre
d'opérations très complexes. Tout ML est AI, mais toute IA n'est
pas ML. Dans l'apprentissage automatique, la machine exécute quelque
chose qu'on ne lui a pas commandé, elle a ses propres règles. Ce
système permet donc à la machine d'apprendre de ses erreurs.
Concrètement, on nourrit la machine d'une quantité importante des
données pour l'aider à « devenir
intelligente ».
L'objectif visé est de rendre la machine ou
l'ordinateur capable d'apporter des solutions à des problèmes
compliqués, par le traitement d'une quantité astronomique
d'informations. Cela offre ainsi une possibilité d'analyser et de mettre
en évidence les corrélations qui existent entre deux ou plusieurs
situations données, et de prédire leurs différentes
implications.
1. Fonctionnement du Machine Learning
Le diagramme ci-dessous explique comment l'algorithme de
Machine Learning fonctionne :
L'algorithme du Machine Learning
Conception des modèles logiques
Sorties
Entrées
Training
Apprentissage des données
Nouvelle donnée
Figure
0 : Diagramme de fonctionnement du Machine Learning
2. Classification du Machine Learning
Le Machine Learning implique deux principaux systèmes
d'apprentissage qui définissent ses différents modes de
fonctionnement. Il s'agit de :
i. L'apprentissage supervisé ou analyse
discriminatoire
Ici, la machine s'appuie sur des classes
prédéterminées et sur un certain nombre de paradigmes
connus pour mettre en place un système de classement à partir de
modèles déjà catalogués. Dans ce cas, deux
étapes sont nécessaires pour compléter le processus,
à commencer par le stade d'apprentissage qui consiste à la
modélisation des données cataloguées. Ensuite, il s'agira
au second stade de se baser sur les données ainsi définies pour
attribuer des classes aux nouveaux modèles introduits dans le
système, afin de les cataloguer eux aussi [9].
ii. L'apprentissage non-supervisé ou
clustering
Dans ce mode de fonctionnement du machine Learning, il n'est
pas question de s'appuyer sur des éléments
prédéfinis, et la tâche revient à la machine de
procéder toute seule à la catégorisation des
données. Pour ce faire, le système va croiser les informations
qui lui sont soumises, de manière à pouvoir rassembler dans une
même classe les éléments présentant certaines
similitudes. Ainsi, en fonction du but recherché, il reviendra à
l'opérateur ou au chercheur de les analyser afin d'en déduire les
différentes hypothèses [9].
Figure
0 : Apprentissage non supervisé illustré
En effet, en entrée nous avons une catégorie de
fruits mélangées. Notre collection de données ne contient
pas d'exemple qui indique ce que l'on cherche, alors l'apprentissage
non-supervisé permettra de classifier ces fruits selon leurs
ressemblances. On peut ainsi regrouper ces fruits dans des clusters ;
c'est le Clustering. D'où à la sortie, on aura
les fruits regroupés selon leurs ressemblances. Les pommes dans un
cluster, les bananes dans un autre cluster et les tomates dans un autre
cluster.
Ainsi les algorithmes les plus utilisés en clustering
sont : le K-means Clustering et le hierarchical clustering.
· Le
deep learning
Venons-en au concept de deep learning qui est, lui aussi,
lié à l'Intelligence Artificielle. Cette méthode est une
technologie d'apprentissage, basée sur des réseaux de neurones
artificiels. Le deep learning permet à un programme de reconnaître
le contenu d'une image ou de comprendre le langage parlé. Ce
système d'apprentissage et de classification, basé sur des
« réseaux de neurones artificiels »
numériques, est utilisé par Siri, Cortana et Google Now pour
comprendre la voix et être capable d'apprendre à reconnaître
des visages.
Pour bien comprendre le deep learning, il faut parler de
l'apprentissage supervisé, une technique courante en IA, permettant aux
machines d'apprendre. Par exemple, pour qu'un programme apprenne à
reconnaître une voiture, on le « nourrit » de
dizaines de milliers d'images de voitures. Un
« entrainement », qui peut nécessiter des heures,
voire des jours. Une fois entraîné, le programme peut reconnaitre
des voitures sur base de nouvelles images.
b. Quelques applications de l'IA
Aujourd'hui, l'intelligence artificielle regorge des
nombreuses capacités et beaucoup de taches sont actuellement faciles
à grâce celle-ci. L'IA s'applique :
Ø Dans la conception des systèmes
experts : ici le système va simuler le raisonnement d'un
expert dans un domaine quelconque et ses compétences seront
évaluées à un niveau élevé d'expertise. Le
premier système expert était fait en 1972 par les chercheurs de
Stanford University. Ce système devrait diagnostiquer certaines
infections.
Ø Dans la reconnaissance : l'IA
fait des nombreux progrès dans ce domaine par le fait qu'il possible
actuellement de reconnaitre les écritures, les visages, la parole...
Ø Dans la robotique : les robots
se trouvent actuellement dans nombreuses exploitations comme les industries, la
médecine, l'exploitation spatiale...
c. Les grands géants de l'IA
1. Google
Google, très impliqué dans l'intelligence
artificielle, procède habituellement par rachat. En 2014, Google a
acheté la société anglaise DeepMind, qui avait
développé des réseaux de neurones pour jouer aux jeux
vidéo. Mais l'objectif avoué de DeepMind est actuellement de
« comprendre ce qu'est l'intelligence ». DeepMind est
célèbre pour son programme AlphaGo, qui a battu le champion du
monde de go. En octobre 2017, le programme a franchi une étape
supplémentaire : en jouant contre lui-même, non seulement son
apprentissage a été plus court, mais surtout il est devenu plus
fort que la version précédente. Nous avons ici un premier exemple
d'apprentissage non supervisé, facilité par le fait que le
contexte, à savoir les règles du jeu de go, est parfaitement
mathématisable. Google a aussi son propre moteur de recommandation
nommé Google Home, un haut-parleur et un assistant vocal disponible en
trois versions différentes [7].
2. Amazon
Amazon utilise de l'intelligence artificielle dans son moteur
de recommandation, nommé Echo, et dans ses assistants basés sur
son système de reconnaissance vocale, Alexa, disponible en sept versions
différentes. Via son offre de services dans le cloud, Amazon propose
également des services fondés sur l'intelligence artificielle,
comme la reconnaissance de la parole ou des robots de discussion, les fameux
chatbot [7].
3. Facebook
Facebook est un énorme utilisateur d'intelligence
artificielle. Il choisit les messages qu'il affiche en utilisant un moteur de
type moteur de recommandation. Récemment, Facebook a mis en place un
moteur d'intelligence artificielle pour détecter les tendances
suicidaires 24. Comme le dit Joaquin Candela, directeur du département
d'intelligence artificielle appliquée, « Facebook n'existerait pas
sans intelligence artificielle »[7]
I.2. GENERALITE SUR LA
RECONNAISSANCE FACIALE
I.2.1. APERÇU GLOBAL
Dans notre vie quotidienne, nous identifions différents
visages des gens tout le long de la journée. Cependant, lorsque nous
rencontrons une personne sur notre chemin, notre cerveau cherche dans notre
mémoire si la personne vue est connue ou non. C'est une tâche
facile et aisée pour nous les humains. Pour un ordinateur, le processus
est presque pareil ; le visage d'un individu est localisé sur une
photo ou une vidéo puis les caractéristiques de son
visage sont d'abord extraites puis ensuite converties en
données, et ces données peuvent ensuite être
comparées avec celles de visage entrées dans une base de
données centralisée.
La biométrie est« l'analyse des
caractéristiques physiques strictement propres à une
personne ». Ces caractéristiques sont les
données biométriques. Il peut s'agir par exemple des empreintes
digitales, de l'iris, du visage, de la voix
ou
même de l'ADN d'une personne[10]. Les données
biométriques sont de plus en plus utilisées à des fins
d'authentification et identification. En effet, les données
biométriques de chaque individu sont uniques et immuables. Les appareils
électroniques sont donc en mesure de les mesurer, de les collecter, et
de les comparer
avec une
base de données afin d'identifier instantanément une
personne.
Notons ici, qu'il existe principalement deux catégories
des technologies biométriques : les mesures physiologiques et les
mesures comportementales. Les mesures physiologiques peuvent
être morphologiques ou biologiques. Ce sont surtout les
empreintes
digitales, la forme de la main, du doigt, le réseau veineux, l'oeil
(iris et rétine), ou encore la forme du visage, pour les analyses
morphologiques. En matière d'analyse biométrique, on trouve le
plus souvent l'ADN, la salive ou l'urine utilisés dans le domaine
médical, pour des investigations criminelles ou même dans le
domaine du sport pour des contrôles de dopage. Les
mesures
comportementales? les plus répandues sont la reconnaissance vocale,
la dynamique des signatures (vitesse de déplacement du stylo,
accélérations, pression exercée, inclinaison), la
dynamique de frappe au clavier d'un ordinateur, la façon d'utiliser des
objets, la démarche, le
Figure 0 : Différentes modalités
biométriques: (a) Empreintes digitales, (b) Geste, (c) Iris, (d)
Rétine, (e) Visage, (f) Empreinte de la paume, (g) Oreille, (h) ADN, (i)
Voix, (j) Marche, (k) Signature, (l) Frappes du clavier.

bruit des pas, la gestuelle...[11].
On estime que les mesures physiologiques ont l'avantage
d'être plus stables dans la vie d'un individu. Par exemple, elles ne
subissent pas autant les effets du stress, contrairement à
l'identification par mesure comportementale.
En effet, chaque caractéristique (ou modalité
biométrique) possède ses forces et ses faiblesses, et faire
correspondre un système biométrique à une application
quelconque dépend du mode opérationnel de l'application et des
caractéristiques biométriques choisies.
I.2.2. LES SYSTEMES
BIOMETRIQUES
Un système biométrique est
essentiellement un système de reconnaissance des formes qui utilisent
les données biométriques d'un individu. Selon le contexte de
l'application, un système biométrique d'enrôlement, en mode
de vérification ou bien en mode d'identification :
· Le mode
d'enrôlement : est une phase
d'apprentissage qui a pour but de recueillir des informations
biométriques sur les personnes à identifier. Plusieurs campagnes
d'acquisitions de données peuvent être réalisées
afin d'assurer une certaine robustesse au système de reconnaissance aux
variations temporelles des données. Pendant cette phase, les
caractéristiques biométriques des individus sont saisies par un
capteur biométrique (ou plus généralement une interface
utilisateur), puis représentées sous forme numérique
(signatures), et enfin stockées dans la base de données [12]. En
effet, cette étape peut être supervisée par un expert qui
peut orienter le processus d'acquisition.
· Le mode vérification
ou authentification : c'est une comparaison
« un à un », dans laquelle le système valide les
identités d'une personne en comparant les données
biométriques saisies avec le modèle biométrique de cette
personne stocké dans la base des données du système. Dans
ce mode, le système doit répondre à la question
suivant : « Suis-je vraiment la personne que je suis en
train de proclamer ? »
· Le mode
d'identification : est une comparaison
« 1 à N » dans laquelle le système
reconnait un individu en l'appariant un des modèles de la base des
données. Ce mode consiste donc à attribuer une identité
à une personne. Autrement dit, le système répond à
question « Qui suis-je ? ».
Figure
0 : Principaux modules d'un système biométrique ainsi que les
différents modes.
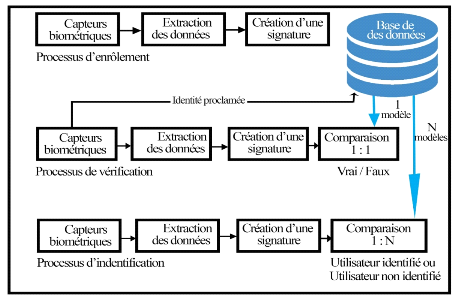
La figure (4) inclut les différents modules
que comporte un système biométrique. Le fonctionnement de ces
modules est résumé dans les lignes suivantes :
§ Module capteur
biométrique : correspond à la lecture de
certaines caractéristiques comportementales, physiologiques ou
biologiques d'une personne en utilisant un appareil de capture
biométrique (ou capteur biométrique) ;
§ Module extraction des
données : extrait les informations nécessaires
et pertinentes à partir des données biométriques brutes,
par exemple des images de visage ou des régions caractéristiques
de visage ;
§ Module création d'une
signature : crée un modèle numérique
afin de représenter la donnée biométrique acquise. Ce
modèle, aussi appelé Signature sera conservé sur un
support portable (puce ou autre) ou dans une base de données ;
§ Module comparaison :
ici, il s'agit de la comparaison entre les données biométriques
d'une personne soumises au contrôle (volontairement ou à son insu)
avec les signatures enregistrées. Ce module fonctionne soit en
mode vérification (pour une identité proclamée), soit en
mode identification (pour une identité recherchée).
§ Module base de
données : c'est dans ce module où l'on stocke
les données biométriques d'un utilisateur enrôlé.
I.2.3. PLACE DE LA
RECONNAISSANCE FACIALE PARMI LES AUTRES TECHNIQUES BIOMETRIQUES
Il est à noter que les empreintes
digitales sont les caractéristiques biométriques les plus
utilisées dans le monde dès 1888 et elles sont utilisées
depuis un siècle pour l'identification criminelle [13]. Le premier
système utilisant les empreintes digitales était
commercialisé vers les annexes soixante. D'une autre part, plusieurs
recherches affirment que l'iris est la caractéristique la plus
extraordinairement fiable car il procure une unicité très
élevées (1 sur 10 puissance 72) et sa stabilité est tendue
jusqu'à la mort d'un individu [14]. Toutes fois ces méthodes
présentent l'inconvénient d'être intrusives, ce qui limite
énormément leurs domaines d'applications. Par ailleurs, cette
méthode de l'identification de l'iris demeure gênante pour
certains utilisateurs qui ne préfèrent pas placer leurs yeux
devant un appareil de capture. La reconnaissance faciale quant à elle,
peut être implémentée indépendamment des autres
modalités biométriques, elle est souvent utilisée pour les
systèmes de surveillance. D'ici, la reconnaissance faciale nous offre la
possibilité de mettre en place les systèmes de capture
(c.à.d. les caméras) qui sont facile à installer et cela
le plus souvent dans des lieux publics ce qui nous permet d'obtenir des
énormes bases des données qui permettraient d'améliorer
même la performance de la reconnaissance.
I.2.4. SYSTEMES BIOMETRIQUES
BASES SUR LA RECONNAISSANCE DE VISAGE
La reconnaissance automatique des visages s'effectue en trois
principales étapes :
v Détection de visage et prétraitement,
v Extraction et normalisation des caractéristiques du
visage,
v Identification et/ou vérification (voir Figure
5).
Certaines techniques de traitement de l'image peuvent
être communes à plusieurs étapes. Comme la reconnaissance
faciale est aussi parmi les mesures biométriques physiologiques,
celles-ci nous permettent alors d'exploiter certaines informations
nécessaires relatives à l'homme ; comme déterminer
son identité par exemple. Le système de reconnaissance faciale
est souvent une approche logicielle visant à reconnaitre une personne
grâce à son visage d'une manière automatique. Cette
reconnaissance peut alors prendre plusieurs aspects : déterminer
à qui appartient le visage (identification), décider si oui ou
non le visage est connu ou non (identification), et dans un autre cas de
vérifier qu'une personne est bien celle qu'elle prétend
être (authentification : dans le cadre d'un contrôle
d'accès).
Figure
0: Etapes de la reconnaissance de visage.

Détecter et reconnaître une personne
nécessite un apprentissage de ses caractéristiques faciales
inhérentes et remarquables. Partant du même principe de la
reconnaissance humaine des visages, la détection et la reconnaissance
automatique nécessite un processus d'apprentissage qui diffère
selon les modèles et les techniques mis en oeuvre.
Cependant, la reconnaissance faciale peut être faite
à l'aide des images fixes (photos) ou à partir des
séquences d'images (vidéos). Dans le présent travail nous
allons bien utiliser la deuxième approche qui est celle de la
reconnaissance faciale à partir des séquences images
(vidéos) pour reconnaitre le visage d'un enfant perdu et tirer certaines
informations nécessaires sur l'enfant qui sont enregistrées lors
du recensement (noms, numéros des parents, adresses...).
Nous détaillerons dans les paragraphes qui suivent
chaque étape de reconnaissance faciale et nous présenterons les
difficultés auxquelles on fait face dans les systèmes de
reconnaissance faciale.
A. Détection de visage
L'efficacité des systèmes biométriques
basés sur l'authentification de visage dépend essentiellement de
la méthode utilisée pour localiser le visage dans l'image. Dans
la littérature scientifique, le problème de localisation de
visages est aussi désigné par la terminologie
« détection de des visages ». Plusieurs travaux de
recherches ont été effectués dans ce domaine [12]. Ils ont
donné lieu au développement d'une multitude de techniques allant
de la simple détection du visage, à la localisation
précise des régions caractéristiques visage, tels que les
yeux, le nez, les narines, les sourcils, la bouche, les lèvres, les
oreilles, etc. Cependant, les solutions proposées jusqu'à
présent sont loin d'être satisfaisantes car elles fonctionnent
uniquement dans des environnements contrôlés, et par
conséquent elles ne gèrent pas la variabilité des
conditions d'acquisition de la vie quotidienne, notamment :
§
Figure 0: Variation des poses (illustrés)

La pose : les images d'un visage
changent en fonction de l'orientation de ce dernier (frontal, 45 degré,
profil). Notons ici que le taux de reconnaissance de visage baisse très
considérablement quand des variations de pose apparaissent dans les
images.La variation de pose est considérée comme un
problème majeur pour les systèmes de reconnaissance faciale.
Quand le visage est de profil dans le plan image (orientation < 30°),
il peut être normalisé en détectant au moins deux traits
faciaux (passant par les yeux). Cependant, lorsque la rotation est
supérieure à 30°, la normalisation géométrique
n'est plus possible (voir figure 9) [12].
§ La présence ou absence des composantes
structurales : les caractéristiques faciales telles que la
barbe, la moustache, les lunettes causent une grande variabilité des
composantes structurales du visage, notamment au niveau de la forme, la couleur
et de la taille.
§ Les occultations : les visages
peuvent être partiellement occultés par d'autres objets. En effet,
dans une image contenant un groupe de personnes par exemple, des visages
peuvent partiellement masquer d'autres visages.
§ Les conditions d'illumination :
des facteurs tels que l'éclairage (distribution de la source de
lumière, son intensité, son spectre) et les
caractéristiques de l'appareil photographique affectent l'aspect d'un
visage dans l'image acquise [12].
Figure
0: Variation d'illumination illustrée

Cependant, cette étape de détection de visage
consiste à localiser la position du visage soit sur une image soit sur
une séquence d'images (sur la vidéo).
La détection de visage dans l'image est un traitement
indispensable et crucial avant la phase de reconnaissance. En effet, le
processus de reconnaissance de visages ne pourra jamais devenir
intégralement automatique s'il n'a pas été
précédé par une étape de détection efficace
[15].
Le traitement consiste à rechercher dans une image la
position des visages et de les extraire sous la forme d'un ensemble d'imagettes
dans le but de faciliter leur traitement ultérieur. Un visage est
considéré correctement détecté si la taille
d'imagette extraite ne dépasse pas 20% de la taille réelle de la
région faciale, et qu'elle contient essentiellement les yeux, le nez et
la bouche [16].
L'image ci-dessous est l'exemple d'une détection
faciale :
Figure
0:Exemple d'une détection des visages

B. Extraction des caractéristiques du visage
L'extraction des caractéristiques telles que les yeux,
le nez, la bouche est étape de prétraitement nécessaire
à la reconnaissance faciale. On peut distinguer deux pratiques
différentes : la première repose sur l'extraction des
régions entières du visage, elle est souvent
implémentée avec une approche globale de reconnaissance de
visage. La deuxième pratique extrait des points particuliers des
différentes régions caractéristiques du visage, tels que
les coins des yeux, la bouche et du nez. Elle est utilisée avec une
méthode locale de reconnaissance et aussi pour l'estimation de la pose
du visage.
Par ailleurs, plusieurs études ont été
menées afin de déterminer les caractéristiques qui
semblent pertinentes pour la perception, la mémorisation et la
reconnaissance d'un visage humain. Certaines études affirment que les
caractéristiques pertinentes rapportées sont : les cheveux,
le contour du visage, les cheveux et la bouche [12].
Cette étape est le coeur du système de
reconnaissance, les données importantes sont extraites de l'image est
sont sauvegardées dans la mémoire pour être
utilisées dans la phase décisionnelle. Le choix de ces
informations utiles revient à ressortir un modèle pour le visage,
elles doivent être non redondantes.
A. La reconnaissance du visage
La module de reconnaissance exploite les
caractéristiques du visage ainsi extraites pour créer une
signature numérique qu'il stocke dans une base de données. Ainsi,
à chaque visage de la base est associée une signature unique qui
caractérise la personne correspondante. La reconnaissance d'un visage
requête est obtenue par l'extraction de la signature requête
correspondante et sa mise en correspondance avec la signature la plus proche
dans la base de données. La reconnaissance dépend du mode de
comparaison utilisé : vérification ou identification.
Figure 0: Schéma fonctionnel d'identification
d'un individu dans un système de reconnaissace faciale.

L'image ci-dessous résume cette partie :
Description de la figure :
A la première étape qui est celle de
l'acquisition de l'image, l'image est capturée soit avec la
caméra d'un dispositif de susceptible d'effectuer cette tâche,
soit tirée d'une base des données d'images (ou gallérie).
Vu que les images peuvent se présenter avec les éclairages et des
ombres différentes ou encore avec des résolutions
différentes. Il est donc important que les données soient
normalisées et que les variations de contraste soient ainsi
représentatives des caractéristiques du visage et non de son
environnement pour que celle soit reconnaissable (détectable) ;
d'où l'apparition des étapes détection et
prétraitement. Ensuite suivra le processus d'extraction de
signatures dans l'image recueillie au processus précèdent. Selon
le mode de fonctionnement, une décision sera dégagée. Si
le système fonctionne en mode enrôlement la signature sera
stockée dans une base de signatures et si on est en mode identification
ou vérification, cela sera associée à une décision
quelconque.
I.2.5. LES ALGORITHMES DE
DETECTION ET RECONNAISSANCE FACIALE
Comme nous l'avons souligné dans les lignes
précédentes, un système automatique de reconnaissance de
visages est composé de trois sous-systèmes : détection de
visage, extraction des caractéristiques et reconnaissance de visages. La
mise en oeuvre d'un système automatique et fiable de reconnaissance
faciale est un verrou technologique qui n'est toujours pas résolu.
Cependant, il existe plusieurs algorithmes, de reconnaissance
faciale. Voici quelques-uns de ces algorithmes :
ü Techniques d'apprentissage supervisé et les
arbres de décisions ;
ü Méthodes d'apprentissage ensemblistes ;
ü Réseaux de neurone (Neural Networks, en
Anglais).
ü K-Nearest Neighbors
Notons ici que nous n'allons détailler que l'algorithme
K-Nearest Neighbors car c'est lui que nous allons utiliser pour la
classification des visages.
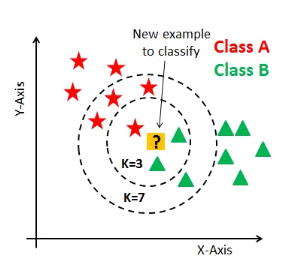
I.2.5.1. L'algorithme K-Nearest Neighbors
K-Nearest Neighbors (les voisins les plus proches) est un
algorithme de l'apprentissage supervisé. Il peut être
utilisé aussi bien pour la classification que pour la régression.
Son fonctionnement peut être assimilé à l'analogie suivante
: «dis-moi qui sont tes voisins, je te dirai qui tu es»
[17].
En effet, cet algorithme est qualifié comme paresseux
(Lazy Learning) car il n'apprend rien pendant la phase d'entraînement.
Pour prédire la classe d'une nouvelle donnée d'entrée, il
va chercher ses K voisins les plus proches (en utilisant la distance
euclidienne, ou autres) et choisira la classe des voisins majoritaires [18].
Figure
0 :Fonctionnement de l'algorithme KNN
Pour appliquer la méthode des voisins les plus proches,
on suit certaines étapes qui sont :
§ On fixe le nombre de voisins k,
§ On détecte k-voisins les plus proches de la
nouvelles données d'entrées qu'on veut classer,
§ On attribue les classes correspondantes par vote
majoritaire.
Pour bien choisir le paramètre k, on prend
arbitrairement un entier et on le fait varier. Ensuite, pour chaque valeur de
cas, on calcule le taux d'erreur de l'ensemble de test et on garde la valeur de
k qui minimise ce taux d'erreur de test. Cet algorithme va nous servir de
classification des visages de ce présent travail. Nous donnerons l'image
d'un enfant en entrée et celui va calculer les voisins les plus proches
des images se situant dans la base de données.
I.2.6. APPLICATIONS D'UN
SYSTEME DE RECONNAISSANCE FACIALE
La reconnaissance faciale est aujourd'hui utilisée dans
des divers domaines et on trouve ses applications dans presque toutes les
activités routinières des hommes bien que plusieurs recherches
sont en cours afin de trouver la bonne approche pour effectuer la
reconnaissance de visages. Nous citons quelques domaines d'application de la
reconnaissance faciale :
v En sécuritéet
authentification : dans ce domaine, le système de
reconnaissance faciale s'assure que l'utilisateur est bien un utilisateur
valide avant de l'autoriser à accéder à un
élément donné. Cela peut être utilisé dans un
lieu public : accès à un avion, par exemple. Signalons la
sécurité est le principal domaine d'application de la
reconnaissance faciale.
v En suivi des présences dans une
organisation : actuellement, le suivi des présents des
agents d'une organisation quelconque est devenue une tâche facile et
précise grâce à la reconnaissance faciale. Le
système capture la face de l'agent juste au moment où celui est
détecté dans la cours de l'organisation et certains autres
détails nécessaires et les sauvegarde dans une base des
données.
v Dans les recherches indexées :
la reconnaissance faciale permet facilement de ressortir l'identité
d'une personne sans même qu'il s'en rendre compte mais cela si et
seulement si celui a un jour suivi la première étape de
reconnaissance de visage (rappel :
l'enrôlement).
I.2. REVUE DE LA
LITTERATURE
En effet, nous ne sommes pas le premier à parler de la
reconnaissance faciale en générale et la reconnaissance faciale
pour les recherches indexées des personnes en particulier. Nombreux en
ont précédemment parlé et ont aboutis à des
résultats finals. Ainsi, voici certains travaux détaillés
brièvement qui ont des traits similaires avec le nôtre :
1. Authentification d'individus par reconnaissance de
caractéristiques biométriques liées aux visages
2D/3D
Dans sa thèse de doctorat, SOUHILA GUERFI ABABSA [12] a
traité deux problématiques majeures et complémentaires
rencontrées en reconnaissance de visage. Il s'agit d'une part de
l'extraction automatique de visage et de ses régions
caractéristiques, et d'autres part de la reconnaissance du visage. Il
signale dans celle-ci que la difficulté de l'extraction de visage et de
ses caractéristiques est due principalement aux variations des
conditions d'éclairage et il a enfin proposé une nouvelle
approche d'extraction qui s'adapte aux changements de l'illumination et de
pose. Propose que dans un premier temps un algorithme de segmentation de
couleur de visage dans l'espace TLS (Teinte, Luminance, Saturation) soit
appliqué sur l'image afin de déterminer les régions
d'intérêt du visage ; c'est pourquoi il a modifié la
méthode de fusion des bassins versants obtenus à partir de
l'algorithme de lignes de partage des eaux (LPE) en ajoutant un critère
basé sur la pertinence de la teinte. Il a défini un domaine de la
peau sur l'espace de la teinte afin d'extraire la région de visage
à partir de l'image segmentée. La méthode qu'il propose
pour l'extraction des zones du visage combine une classification basée
sur la méthode de kmeans avec une approche géométrique
afin d'identifier deux régions caractéristiques du visage en
l'occurrence les yeux et la bouche.
En addition, l'auteur a travaillé sur le
problème de la reconnaissance de visage 2D/3D, dans le contexte de la
vérification. Ill a par ailleurs évalué l'influence de la
détection de régions sur la reconnaissance de visage en extrayant
les régions su visage manuellement puis de manière automatique
son approche d'extraction et il a comparé les résultats de
reconnaissance obtenus sur ces régions en appliqua les méthodes
classiques « EigenFace »
et « EigenFace » modulaire. Les résultats
obtenus ont montré que l'approche modulaire donne les meilleures
performances.
2. Capteur intelligent pour la reconnaissance de
visage
Dans son travail de thèse, Walid Hizem
[19]a mené une étude sur le capteur intelligent pour la
reconnaissance de visage. Etant beaucoup plus intéressé par les
problèmes liés à la lumière dans le domaine de la
reconnaissance faciale, dans son travail, Walid s'est fixé comme
objectif de mettre en place une solution capable d'éliminer le
problème lié à la luminosité. Pour y arriver,
l'auteur à utiliser l'illumination active avec deux méthodes
d'acquisition : la première avec un capteur CMOS
différentiel, la seconde, et qui a présenté son apport
personnel dans son travail, une acquisition avec réduction du temps
d'exposition et un flash synchrone à la période d'acquisition.
Ainsi, comme résultat, il a mis au point une caméra CCD
permettant d'avoir des images de bonne qualité en proche infrarouge et
à moindre cout en éliminant la variation d'illimitation.
3. Détection et identification des personnes
par reconnaissance faciale
BOUDJEL Sofiane [20]a travaillé sur un
système de reconnaissance faciale en utilisant la méthode
EigenFace. Son système a pour objectif de mettre en place un
système de reconnaissance faciale et contrôle d'accès. La
solution qu'il a trouvée était le développement d'une
application qui, malgré des bons résultats que celle-ci a
apporté, l'auteur signale que certains problèmes comme celui de
pose et d'éclairage restent les challenges qui susciteront les
curiosités des futurs chercheurs.
4. Etude et réalisation d'un système de
suivi de présences par reconnaissance faciale dans une salle
d'université (UCBC)
L'auteur de ce travail de mémoire, monsieur Vyakuno
Kathe Joel [21], avait pour objectif de concevoir une application de suivi de
présence dans un auditoire et cela en temps réel. Le constant le
plus amère de l'auteur était que dans beaucoup
d'universités les présences se font toujours manuellement. Il
avait constaté aussi un problème de fatigue, oublie ou
inconscience qui peut ramener les chefs de promotions à cocher tous les
étudiants comme présents même ceux qui ne le sont pas. Pour
remédier à ce problème, cet auteur avait jugé mieux
concevoir un système de reconnaissance faciale en temps réel qui
noterai un étudiant présent que si sa face est
détectée et que celui s'est présenté
personnellement dans l'auteur.
5. An improved face recognition algorithm and its
application in attendance management system
Serign Modou Bah et Fang Ming [22]présentent une
approche efficace et efficiente sur l'utilisation de techniques avancées
de traitement de l'image pour améliorer la reconnaissance des visages
précision basée sur l'algorithme des motifs binaires locaux. Dans
la première partie, ces auteurs utilisent le classificateur en cascade
LBPpour la détection et suivi des visages. En effet, les visages sont
capturés à partir d'une caméra ou d'une image
stockée sur un support et enfin l'algorithme de classification en
cascade sera appliqué pour la détection des faces. Ils sont
parvenus à améliorer le taux de précision de la
détection des visages, qui fait partie intégrante du taux de
précision global de la reconnaissance des visages, tout en
réduisant le nombre de faux positifs et de faux négatifs.
Voici l'ordinogramme du système conçu par Serign
Modou Bah et Fang Ming :
Figure
0: Ordinogramme de l'algorithme de Serign Modou Bah et Fang Ming

La figure montre l'organigramme de l'algorithme. Comme le
montre l'organigramme, les images de visages capturées en entrée
sont traitées à l'aide des techniques de traitement d'images que
ces deux auteurs ont proposés, puis l'algorithme de détection des
visages est appliqué pour détecter les visages. Une fois les
visages détectés, l'algorithme de reconnaissance des visages,
assisté de la méthode proposée, sera appliqué pour
reconnaître les visages. Une fois les visages reconnus, les
métadonnées des visages reconnus seront extraites pour marquer
les présences à l'aide du système de présence.
6. Visual observation of Human Emotion
Varun Jan [23] dans son travail de thèse avait comme
objectif de développer des méthodes et des techniques permettant
d'inférer l'état affectif d'une personne à partir des
informations visuelles, c'est-à-dire l'analyse d'expressions du visage.
Dans ses démarches, il avait utilisé l'approche Gaussienne
Multi-Echelle en tant que scripteur d'image pour l'estimation de la pose de la
tête, pour la détection de sourire, puis aussi pour la mesure de
l'affect. En plus de cette approche, il avait tout de même aussi
utilisé l'Analyse en composant principal pour la réduction de la
dimensionnalité et les machines à support des vecteurs pour la
classification et les régressions. Lors de ses expérimentations,
l'auteur a constaté que dans le cas d'un éclairage partiel du
visage, les dérivées Gaussiennes aves des histogrammes locaux de
type LBP (Local Binary Pattern). Avec cette combinaison il avait obtenu des
résultats à la hauteur de l'état de l'art pour la
détection de sourire dans les bases d'images GENKI qui comporte des
images de personnes trouvées dans la nature, sur internet, et avec la
difficile « extended YaleB database ».
7. Authentification et identification de visages
basées sur les ondelettes et réseaux de neurones
Dans son article [24], Mérbaka avait le but de
concevoir un système d'authentification d'identité qui serait
facile et peu couteux dans l'implémentation utilisant le visage humain.
Cette étude menée avec la méthode ACP et la classification
avec le réseau de neurones avait comme objectif de vouloir minimiser le
TEE (Taux d'erreur égale) afin de renforcer les capacités d'une
application de reconnaissance faciale. L'auteur abouti aux résultats
selon lesquels en utilisant la classification d'ACP il a un taux d'erreur
égale (TEE=11,5%) sur une base de données de 40 sujets avec un
TFA (Taux de Fausse Acceptation) égal à 9% et un TFR (Taux de
Faux rejet) égal à 15.32%. En faisant la classification avec le
réseau de neurones, TFA=5%, TFR=57 pour une base de données de 60
sujets et avec la normalisation TFA=12 et un TFR=23 pour la même base de
60 sujets.
8. Génération des modèles
synthétiques de visages à partir d'une image frontale
Francis Charette Migneault [25] avait pour objectif de mettre
en place un système qui implémente un algorithme de
génération synthétique de visages. La solution
développée par l'auteur permet de modéliser l'illumination
ambiante observée dans l'environnement à partir d'un visage
d'individu quelconque pour transférer l'information obtenue vers un
visage d'individu d'intérêt. La personne cible à retrouver
à l'aide d'une reconnaissance de visage dans un système de
surveillance aurait alors plus de chance d'être adéquatement
classifiée grâce aux représentations additionnelles qui
modélisent des variations possibles d'illumination, qui pourraient
être observées sur son visage lors d'une capture par caméra
en environnement non contrôlé.
9. Détection et reconnaissance de
visage
Mohamed Aymen FODDA [26] avait mis en oeuvre une approche
d'identification du visage, et pour aboutir à ce but, il fallait au
préalable aborder un travail de détection du visage. Bien que la
méthode d'amélioration ait montré de bons
résultats, au niveau de l'interpolation de visages non
détectés par la librairie OpenCV, elle élimine parfois de
vrais visages. Après la phase de détection, nous avons pu aborder
la tâche de reconnaissance. Notre apport dans cette tâche
délicate, est d'utiliser la notion des points d'intérêt
pour reconstruire un modèle de visage. L'auteur signale dans son travail
que pour la tâche de détection, et à partir des visages
détectés par la librairie OpenCV, il est intéressant de
trouver d'autres méthodes d'élimination des fausses alarmes et de
détecter en contrepartie les visages oubliés par la
méthode « Viola-Jones ». Nous proposons d'utiliser des
approches heuristiques, pour prévoir si une telle détection
correspond à un visage ou non, en tenant compte des positions des autres
visages. Pour l'identification, il propose d'ajouter ou d'améliorer
d'autres paramètres aux vecteurs qui caractérisent le visage
comme par exemple : la géométrie de la tête et les
distances entre les composantes faciales.
10. Nouvelle approche d'indentification dans les bases
de données biométriques basée sur une classification non
supervisée
Anis Chaari [27], dans sa thèse a mené une
étude sur la localisation du visage dans une image faciale. L'auteur
signale que la détection parfaite du visage était une un objectif
difficile à atteindre lors de la réalisation de son travail. Il
signale ensuite que la localisation de 30 points d'un contour de visage par un
réseau de neurones entrainé par l'une ou l'autre des
méthodes est à l'avantage des moments de Zernike pour
élaborer le vecteur d'entrée du réseau. Le visage une fois
détecté, une procédure classique de normalisation est
appliquée. Enfin il conclut en disant : « meilleur est la
précision de détection du visage, plus grande sont les
performances des systèmes de reconnaissance qui s'ensuivent.
Eu égard aux travaux précédemment
mentionnés, nous tenons à mentionner quelques
éléments constituent les traits de différence entre notre
travail et ceux des autres. Notre système a comme cas d'étude les
enfants perdus. Apres reconnaissance, certaines informations nécessaires
sur l'enfant seront renvoyées. Nous enverrons aussi les
coordonnées GPS préenregistrés qui permettront à
l'utilisateur du système de retrouver d'une facile l'adresse de
l'enfant.
I.3. SPECIFICATION D'EXIGENCES
LOGICIELLES
Dans cette partie de notre travail nous allons décrire
le comportement externe de notre système. Nous allons donner une
idée globale décrivant comment notre système fonctionnera
et nous allons aussi décrire les caractéristiques des
utilisateurs de notre système.
I.3.1 Description globale
a. Perspectives du logiciel
Notre application de recherche des enfants perdus doit
être dotée d'une base des données contenant certaines
informations nécessaires sur l'enfant comme ses noms, ses adresses et
celles de ses parents. En gros, un répertoire sera créé
pour contenir les images des enfants recensés d'avance. L'application
sera en mesure de reconnaitre la face de l'enfant lorsque celui-ci se
positionne devant la caméra et de retourner quelques
éléments qui l'identifient afin de trouver un moyen probant de le
faire revenir sur son toit habituel.
b. Fonctionnalités du logiciel
L'administrateur sera chargé d'enrôler les
enfants en récoltant biens leurs identités et celles des
parents ; il peut supprimer un ou plusieurs enfants du système et
il peut mêmement modifier les informations de ce dernier. Le
système contient aussi la possibilité de localiser la maison de
l'enfant moyennant les coordonnées géographiques fournit d'avance
lors de l'enrôlement. L'enfant va se présenter devant la
caméra connectée directement au système pour
prélever ses identités et créer un ensemble des
données (photos) qui seront entrainées pour permettre une
reconnaissance plus tard. Le système contient la possibilité de
contacter le parent de l'enfant. Notons ici qu'avant d'effectuer n'importe
quelle opération ; le système prévoit une partie
d'authentification pour l'administrateur du système. La figure
ci-dessous décrit très clairement les taches de chacun des
utilisateurs (l'administrateur et l'utilisateur simple):
Figure
0 : Diagramme cas d'utilisation global

c. Caractéristiques des utilisateurs
Cette application sera utilisée dans une station de
police où se retrouvent les enfants qui sont perdus. Donc un agent de
police pouvant utiliser ce système est sensé avoir des notions
basiques sur l'utilisation des outils informatiques.
d. Fonctionnalités reportées à une
version ultérieure
Vu que le système actuel a un statut stationnaire, dans
les versions précédentes ce système changera le statut et
sera bien mobile. Bref, une application mobile grand public sera conçue
pour rendre la tache de la recherche de l'enfant perdue plus facile.
I.3.2. Performance
Ce système supportera l'enregistrement de plusieurs
enfants (utilisateurs) en un même temps vu que la perte d'enfant revient
intempestivement et d'une manière à laquelle on ne s'attend
pas.
I.3.3. Fiabilité
Le système devra être disponible pendant les
heures de service de la station de police. L'administrateur se connecte quand
il veut mais dans la cours de la station de police vu le stationnement du
système. En cas, de panne ou de faille, une équipe est
prête pour le dépannage. Les opérateurs de correction d'une
ou plusieurs erreurs et de la maintenance pourront quelques heures pour
réaliser ladite tache de dépannage.
I.3.4.
Sécurité
Vu la sensibilité des identités
enregistrées dans la base de données, une authentification sera
requise pour l'accéder au système pour que n'importe qui n'aie
pas accès à ces données.
I.3.5. Portabilité
Il a été dit dans les lignes
précédentes que le système sera utilisé dans une
station de police. Que le système ne sera pas trop portable. Signalons
que ça sera plus facile de le déplacer vu que ce sera une
plateforme hébergée sur un serveur distant. Seule
l'administrateur peut y accéder de là où il veut.
Dans ce chapitre nous avons taché lister et
définir certains concepts clés de notre travail, passé en
revue de la littérature et enfin chuté par les exigences
logicielles.
CHAPITRE II. METHODOLOGIES
ET CONCEPTION DU SYSTEME
Après une étude panoramique des concepts de base
de notre système, ce chapitre explique de façon claire et
précise les méthodologies appliquées pour la collecte et
l'analyse des données pour parvenir à la résolution des
problèmes liés à la reconnaissance d'un enfant perdu par
reconnaissance faciale. Etant du domaine des sciences informatiques, dans cette
partie traitant sur les méthodologies de travail, nous nous focaliserons
sur la modélisation, la simulation, et l'expérimentation comme
méthodes et la documentation et le prototypage comme techniques
utilisées pour l'accomplissement de ce présent travail.
II.1 METHODOLOGIES ET
TECHNIQUES
II.1.1 METHODES
La méthode désigne l'ensemble
des canons guidant ou devant guider le processus de production des
connaissances
scientifiques, qu'il s'agisse d'
observations,
d'
expériences,
de
raisonnements,
ou de calculs théoriques [28]. En d'autres termes, le chercheur,
après avoir répertorié un problème à
résoudre dans la société, se plonge dans la confrontation
d'idées pour appréhender au mieux le problème. Pour ce
faire, il n'y va pas aveuglement, mais il se conforme à des principes
établis, lesquels principes sont susceptibles de le conduire à la
compréhension du problème. Elle peut également être
définie comme : « un ensemble d'opérations intellectuelles
permettant d'analyser, de comprendre et d'expliquer la réalité
étudiée [29]». Certaines méthodes scientifiques ont
été suivies lors de l'élaboration de ce travail
scientifique pour pouvoir vérifier et confirmer la
véracité des hypothèses posées dès le
début du travail parmi lesquelles nous citons :
A. Modélisation
La modélisation consiste à créer une
représentation simplifiée d'un problème : le
modèle. Grâce au modèle il est possible de
représenter simplement un problème, un concept et le simuler. La
modélisation comporte deux composantes [30]:
· L'analyse, c'est-à-dire l'étude du
problème dans le but de le comprendre profondément,
· La conception, soit la mise au point d'une solution au
problème. Le modèle constitue ainsi une représentation
possible du système pour un point de vue donné.
Le modèle est alors une représentation abstraite
et simplifiée (i.e. qui exclut certains détails), d'une
entité (phénomène, processus, système, etc.) du
monde réel en vue de le décrire, de l'expliquer ou de le
prévoir. Modèle est synonyme de théorie, mais avec une
connotation pratique : un modèle, c'est une théorie
orientée vers l'action qu'elle doit servir.
Concrètement, un modèle permet de réduire
la complexité d'un phénomène en éliminant les
détails qui n'influencent pas son comportement de manière
significative. Il reflète ce que le concepteur croit important pour la
compréhension et la prédiction du phénomène
modélisé. Les limites du phénomène
modélisé dépendant des objectifs du modèle [31].
Ainsi, plusieurs langages, conventions et notations existent
pour faire la modélisation. Dans ce présent travail nous avons
fait usage d'UML (Unifed Modeling Langage) vu sa popularité dans le
domaine et nous a ouvert à l'implémentation de notre
système.
B. Simulation
Selon futuraTech[32], la simulation informatique, ou
simulation
numérique,
est une série de calculs effectués sur un
ordinateur
et reproduisant un phénomène
physique.
Elle aboutit à la description du résultat de ce
phénomène, comme s'il s'était réellement
déroulé. Cette méthode nous a ainsi permise de simuler la
base des données des enfants considérant que ceux-ci ont
déjà été recensés d'avance. Notons qu'elle
nous a permis de simuler les faces des personnes majeures en considérant
ceux-ci comme des enfants.
C. L'expérimentation
Par expérimentation on sous-entend le fait
d'éprouver, apprendre ou découvrir à partir de
l'expérience, personnelle ou scientifique. Cependant,
cette méthode nous a permis de réaliser certains tests par
rapport aux différentes contraintes de consommation de mémoire,
le nombre d'utilisateur pouvant être connectés
simultanément. Bref, ça nous a permis de tester la performance de
notre système nouvellement implémenté.
II.1.2 TECHNIQUES
Par techniques de recherches, on sous-entend les moyens
indispensables par lesquels un chercheur passe pour récolter les
données nécessaires en vue d'élaborer son travail
scientifique. Pendant l'élaboration de notre travail, nous avons fait
usage de quelques techniques que voici :
A. La technique documentaire
Cette méthode nous a aidé dans l'enrichissement
de notre travail car elle nous a permis de consulter plusieurs archives des
travaux scientifiques qui ont un trait de ressemblance avec le nôtre.
Nous avons ainsi consulté quelques thèses, mémoire,
article et nous y avons tiré certaines informations nécessaires
qui sont d'une façon ou d'une autre intervenues dans la rédaction
comme dans l'implémentation de notre système.
B. La technique d'interview
Nous avons eu à échanger avec quelques parents
des enfants sur la perte de ces derniers et ils ont soulevé un point
commun qui était l'inquiétude de comment sera l'état de
leurs enfants une fois retrouvés.
II.2 CONCEPTION DU SYSTEME DE
RECONNAISSANCE FACIALE
La conception est la phase créative d'un projet
d'ingénierie. Le but premier de la conception est de permettre de
créer un système ou un processus répondant à un
besoin en tenant compte des contraintes. Le système doit être
suffisamment défini pour pouvoir être installé,
fabriqué, construit et être fonctionnel, et pour répondre
aux besoins du client [33].
Notons cependant qu'ici, nous avons fait usage de UML pour la
modélisation dudit système. Par ailleurs, nous nous sommes
basés sur les trois (3) axes de modélisation avec UML pour mieux
modéliser notre système. Ces 3 axes sont : l'axe
fonctionnel, l'axe dynamique et enfin l'axe statique.
1. Axe fonctionnel
Cet axe permet de donner un aperçu global sur le
système à modéliser. Il est à noter que nous nous
sommes servi du diagramme cas d'utilisation pour faire une
illustration de notre système.
2. Axe dynamique
Cet axe va nous permettre de montrerle comportement du
système, les interactions des objets et leur ìévolution
dans le temps. Bref, il met beaucoup d'accent sur la chronologie. Cet axe
comprend plusieurs diagrammes. Nous citions les diagrammes
d''état-transition, de séquence, d'activité, de
collaboration... Cependant, nous avons fait usage des diagrammes
d'activités pour quelques cas seulement et le diagramme de
séquence.
3. Axe statique
Sur cet axe, on modélise les concepts du domaine
d'application, qui est affiché dans les diagrammes de classes, ainsi
nommés, car leur objectif principal est la description des classes. Une
classe est la description d'un concept du domaine d'application ou de la
solution d'application [34]. Cet axe comporte les diagrammes de classe, de
déploiement, d'objet, de composants... Pour modéliser la vue
statique de notre système, nous avons utilisé le diagramme de
classe.
En effet, le système que nous concevons est fait de
deux modules principaux modules : le module
d'enrôlement et module de reconnaissance. Nous
représenterons les diagrammes dépendamment de chacun de ces deux
modules. Pour le module d'enrôlement d'enfant nous allons
démontrer les diagrammes de cas d'utilisation, d'activité, de
séquence, de classe et enfin nous ressortiront le modèle
relationnel pour notre base des données contenant les informations de
l'enfant. En complémentaire, pour le module de reconnaissance, nous
représenterons les diagrammes cas d'utilisation, d'activité et
enfin celui de séquence.
II.2.1. Module
d'enrôlement de l'enfant
Ce module est utilisé au départ pour
l'enregistrement des enfants. A l'issue de cette opération, nous
obtenons une base de données des informations des enfants mais aussi un
model obtenu après entrainement d'un algorithme de machine learning.
Voici quelques diagrammes UML illustrant le fonctionnement de ce
module :
a. Diagramme de cas d'utilisation
Un diagramme de cas d'utilisation capture le comportement d'un
système, d'un sous-système, d'une classe ou d'un composant tel
qu'un utilisateur extérieur le voit. Il scinde la fonctionnalité
du système en unités cohérentes, les cas d'utilisation,
ayant un sens pour les acteurs. Les cas d'utilisation permettent d'exprimer le
besoin des utilisateurs d'un système, ils sont donc une vision
orientée utilisateur de ce besoin au contraire d'une vision informatique
[31]. Ce diagramme sert donc à modéliser à QUOI sert le
système en organisant les interactions possibles avec les acteurs.
Celui-ci se base sur 3 principaux concepts que voici :
acteurs, cas d'utilisation et
liens entre les acteurs et les cas d'utilisation et entre les
acteurs eux-mêmes.
Notre système comporte deux acteurs :
§ L'administrateur : celui-ci est
le maitre du système. Il gère l'enfant (enrôler, supprimer,
modifier), il est primordial qu'il s'authentifie avant d'effectuer toutes
tâches dans le système.
§ Utilisateur simple:c'est un acteur qui
est censé faire les mêmes taches que l'administrateur. Il
hérite tout ce que fait l'administrateur.
Figure
0: Diagramme de cas d'utilisation : Cas
« enrôler »
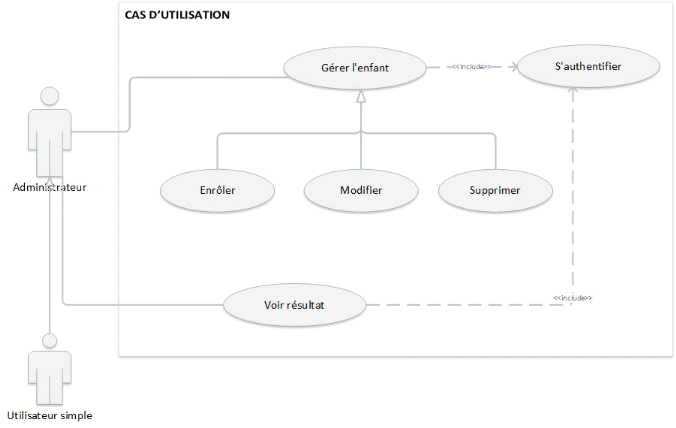
Le diagramme cas d'utilisation illustré dans la
figure 13est brièvement expliqué dans le tableau
ci-dessous :
|
Cas d'utilisation
|
Objectif
|
Précondition
|
Acteurs
|
|
S'authentifier
|
Effectuer une connexion au système
|
Etre agent de la police
|
Administrateur, Utilisateur simple
|
|
Gérer l'enfant
|
Avoir une liste ordonnée des enfants susceptibles
d'être recherchés
|
Etre agent de la police et être connecté au
système
|
Administrateur, Utilisateur simple
|
|
Voir le résultat
|
Visualiser les information sur l'enfant
|
Etre connecté et être un agent de police
|
Administrateur, Utilisateur simple
|
Tableau 1 : Les cas d'utilisation
expliqués
b. Diagramme d'activité
Figure
0:Diagramme d'activité : Cas « enrôler »
l'enfant
Le diagramme d'activité permet de représenter
graphiquement le comportement d'une méthode ou le déroulement
d'un cas d'utilisation [35]. C'est ainsi que nous allons détailler un
cas d'utilisation ; celui de l'enrôlement de l'enfant. Nous
représentons dans la figure suivant le diagramme d'activité du
cas enrôler l'enfant :
Explication de la
figure :l'administrateur (ou l'utilisateur simple) fait une
demande de formulaire à remplir au système via une interface
utilisateur et le système affiche le formulaire toujours via cette
même interface. Ensuite l'utilisateur va remplir le formulaire avec les
informations nécessaires de l'enfant comme ses noms, son adresse... Si
ces données sont bien remplies, il déclenche la capture en
cliquant sur un bouton et la caméra va s'activer et commencera à
sans doute à capturer les images mais cela à condition d'une
quelconque détection de la face devant la caméra. Pendant que la
caméra capture les images, le système attendra quelques secondes
et il appliquera certains prétraitements sur les images
capturéespour finalement enregistrer ces images capturées ainsi
que les informations dans la base de donnée.
c. Diagramme de séquence
Figure
0 : Diagramme de séquence pour le cas enrôler l'enfant

Le diagramme de séquence affiche les
évènements par ordre chronologique ; en d'autres termes, il
nous permet de décrire comment les objets (instances) échangent
les messages dans un ordre particulier.
Explication de la figure : Avant
d'effectuer toute tache, l'administrateur doit se rassurer qu'il s'est bien
authentifié. Après suivra la demande du formulaire comme
expliqué dans les lignes précédentes. Le système
fera une vérification des données entrées par
l'utilisateur si elles sont conformes aux données qui devraient
être saisies dans les champs remplis. Si elles sont correctes alors
l'administrateur pourra déclencher la capture. La camera s'activera
qu'une fois l'administrateur l'a requêter et commencera àcapturer
les images.
d. Diagramme de classe
Le diagramme de classes est considéré comme le
plus important de la modélisation orientée objet, il est le seul
obligatoire lors d'une telle modélisation. Alors que le diagramme de cas
d'utilisation montre un système du point de vue des acteurs, le
diagramme de classe en montre la structure interne. Il permet donc de fournir
une représentation abstraite des objets du système qui vont
interagir entre eux pour réaliser les cas d'utilisation [31]. Le
diagramme de classe permet donc de modéliser les classes du
système et leurs relations indépendamment d'un langage de
programmation particulier.
Figure
0 : Diagramme de classe
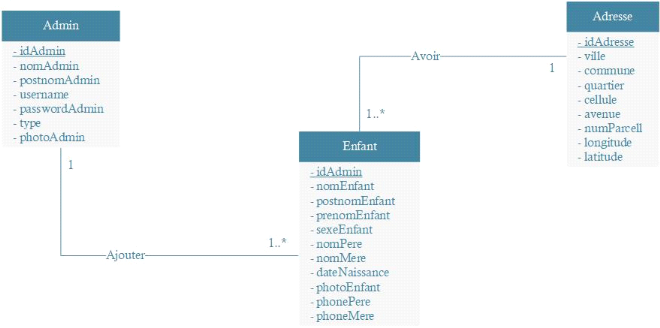
Description de la figure : Notre
diagramme ne comprend que trois (3) classes comme vu dans la figure ci-dessous.
Ainsi nous avons la classe Admin qui contient les attributs
nécessaires correspondants à l'administrateur, la classe
Enfant et enfin la classe Adressequi va nous
permettre stocker les informations nécessaires pour facilement retrouver
le domicile de l'enfant voire les identités de ses parents. Chacune
de ces classes comprend ses attributs bien listés dans la figure. Pour
la classe Admin, on retrouve un attribut nommétype. Celui-ci va
nous permettre d'élargir le nombre d'utilisateurs pouvant venir en aide
à l'administrateur principal une fois son absence est
constatée.
e. Base de données
Une base de données est une collection d'informations
organisées selon différents types et pouvant être
facilement consultables, gérables et mises à jour.Les
données sont organisées donc en colonnes, les lignes et
tableaux.
La création d'une base des données
normalisée se fait suivant trois grands niveaux :
- Niveau conceptuel : ici nous voyons le
diagramme de classe présentée dans la figure 16,
- Niveau relationnel,
- Niveau physique : à ce niveau
on implémente le modèle dans un SGBDR. C'est le traduire dans un
langage de requête ; ici SQL est utilisé.
· Modèle relationnel
Pour passer du diagramme de classe au modèle
relationnel, il faut que le diagramme de classe respecte primordialement les
formes de normalisation d'une base de données. Après suivront les
règles de transformation qui dépendront bien des
multiplicités ou cardinalités maximales des associations entre
les classes. On distingue trois familles d'associations :
- un-à-plusieurs :
ici il faut ajouter un attribut de type clé étrangère
dans la relation fils de l'association. L'attribut portera
donc le nom de la clé primaire de la relation
père de l'association. La relation père est
celle où on trouve une cardinalité égale à
1 et la relation fils est celle où on trouve une
cardinalité plusieurs. Pour se rappeler facilement de
cette règle, on la décrit de la manière suivante :
la clé primaire du père migre dans la relation fils ;
- plusieurs-à-plusieurs et
n-aires : ici l'association (classe-association)
devient une relation dont la clé primaire est composée par la
concaténation des identifiants des entités (classes)
connectés à l'association. Les attributs de l'association (classe
association) doivent être ajoutés à la nouvelle relation et
ne sont ni clé primaire, ni clé étrangère.[36] ;
- un-à-un :si les deux
relations minimales sont égales à un, il est
préférable de fusionner les deux entités
(classes).
Partant des règles cites ci-haut, voici ce que nous
avons produit comme modèle :
ADMIN [idAdmin, nomAdmin,
postnomAdmin, username, password, photoAdmin]
ENFANT [idEnfant, nomEnfant,
postnomEnfant, prenomEnfant, nomPere, nomMere, phonePere, phoneMere,
dateNaissance, photoEnfant, #idAdmin, #idAdresse]
ADRESSE [idAdresse, ville, quartier,
avenue, cellule, numParcelle, longitude, latitude]
II.2.2. Module de
reconnaissance de l'enfant
Dans le chapitre précédent, nous avons
détaillé en large la reconnaissance de visage. En titre de
rappel, le module de reconnaissance se décompose en trois
étapes : la détection de visage et prétraitement,
extraction et normalisation des caractéristiques et enfin
l'identification ou vérification (confer chapitre I). Dans
cette partie nous démontrons les diagrammes y afférents
dont : les diagrammes de cas d'utilisation, d'activité et enfin
celui de séquence.
a. Diagramme de cas d'utilisation
Figure
0: Diagramme cas d'utilisation pour le cas reconnaitre l'enfant

Description du diagramme : Ce diagramme
représente le cas d'utilisation pour la reconnaissance de l'enfant. Tout
doit être commandé par l'utilisateur. Si l'enfant est reconnu
alors le système devra nous afficher les informations lui
correspondant.
b. Diagramme d'activité
Figure
0: Diagramme d'activité pour la reconnaissance

Description de la figure :Au
départ nous avons la caméra qui s'initialise, ensuite suit le
début de la capture de l'image.
- Effectuer les
prétraitements : cette activité nous a permis
de convertir l'image capturée de RVB en niveau niveaux de gris
(grayscale1(*)).
- Détection de la face :
dans cette partie le système va détecter n'importe quel visage
humain présent dans la photo ou dans un flux vidéo. Notons qu'il
existe plusieurs méthodes pour la détection de la face. Dans
notre cas nous avons fait usage de Haar Cascade Classifier qui
est l'une des méthodes les plus connues dans la détection
d'objets. L'entrainement d'un classificateur est une étape trop longue.
Il est nécessaire de réunir et d'annoter un grand nombre d'image
contenant l'objet à détecter. Heureusement, il existe des
classificateurs déjà entrainés disponibles dans les
fichiers2(*) d'OpenCv [37].
Nous pouvons ainsi trouver les détecteurs pour :
- Les yeux : haarcascade_eye.xml
- Les têtes de profil :
haarcascade_profileface.xml
- Les sourires : haarcascade_smile.xml
- Les visages : haarcascade_frontalface_alt.xml
- Les visages : haarcascade_frontalface_defautl.xml
- Etc.
Il nous sied de signaler que nous avons
utiliséhaarcascade_fontalface_default.xml pour
la détection des visages.
- La reconnaissance sera faite par l'algorithme des
voisins les plus proches (confer section I.2.5.1) qui va
comparer la nouvelle face détectée avec celles qui sont dans la
base et enfin afficher les informations correspondantes à la face ;
si celle-ci existe bien. Si elle n'existe pas elle sera enregistrée par
la suite avec les informations qui y correspondent ; il y aura donc un
enrôlement déclenché.
c. Diagramme de séquence
Figure
0 : Diagramme de séquence pour la reconnaissance
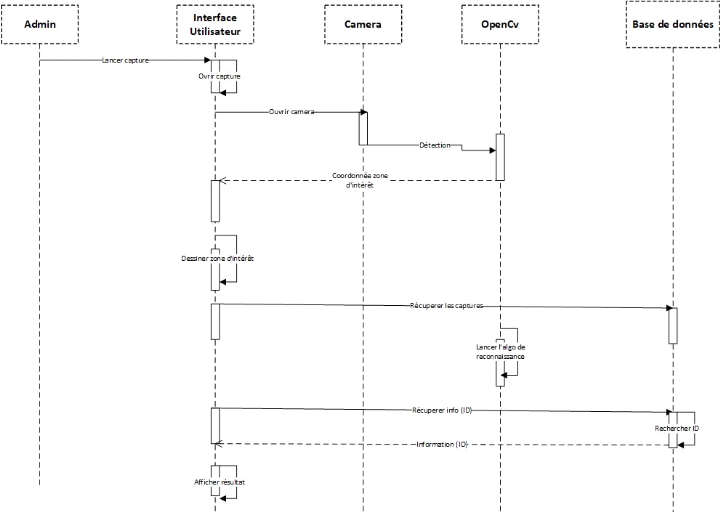
II.2.3. Le diagramme de
déploiement
Figure
0 : Diagramme de déploiement
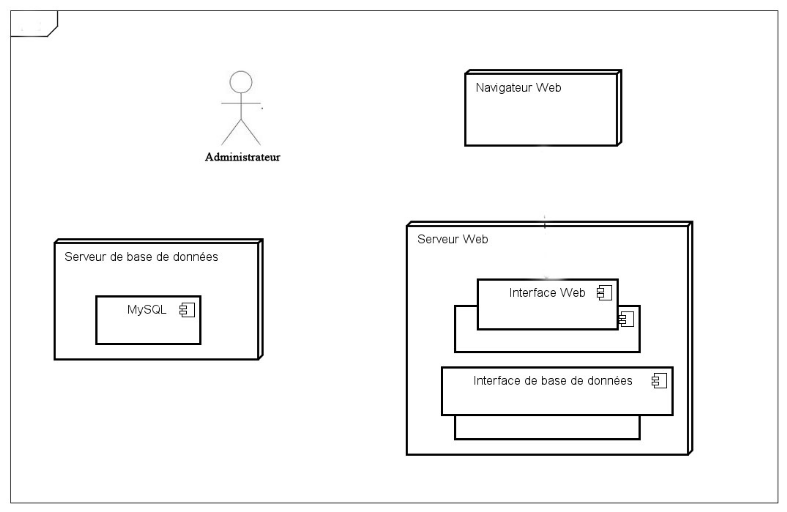
Le diagramme de déploiement permet de spécifier
la projection des artefacts logiciels exécutables sur le
matériel, ainsi que les liens logiques et physiques via le réseau
utilisé [38].
Ce chapitre a traité sur les méthodologies et la
conception du système. Nous avons premièrement
présenté les méthodes et techniques que nous avons
utilisées pour la réalisation de ce présent travail. En
définitif, nous avons présenté les différents
diagrammes qui, d'une manière abstraite, on décrit notre
système. En effet, nous avons fait usage du langage de
modélisation UML pour concevoir les quelques diagrammes
présentés récemment. Citons donc : le diagramme de
cas d'utilisation, le diagramme d'activité, le diagramme de
séquence, le diagramme de classe et enfin le diagramme de
déploiement.
CHAPITRE III.
IMPLEMENTATION ET PRESENTATION DU SYSTEME
Le chapitre précédent a traité sur la
conception du système qui est une partie indispensable dans la
réalisation d'un produit informatique. Ce chapitre, par contre, est
consacréà la présentation de l'architecture du
système, les technologies et outils utilisés lors de
l'implémentation de celui-ci, la présentation des
résultats, l'analyse de performance et enfin nous présentons
quelques vues de notre application web capturées lors des
différents tests issus du fonctionnement de ce dernier.
III.1. ARCHITECTURE DU
SYSTEME
Eu égard à ce qui précède, notre
système n'a qu'un seul type d'utilisateur actif; il s'agit bien d'un ou
plusieurs administrateurs des différentes bases. En outre,
l'administrateur peut accéder au système via son ordinateur
portable en effectuant une requête des données sur le serveur de
bases de données. Cependant, le PC de l'administrateur sera
considéré comme une entité de présentation ou
d'interaction avec ce dernier.
Figure
0 : Architecture du système
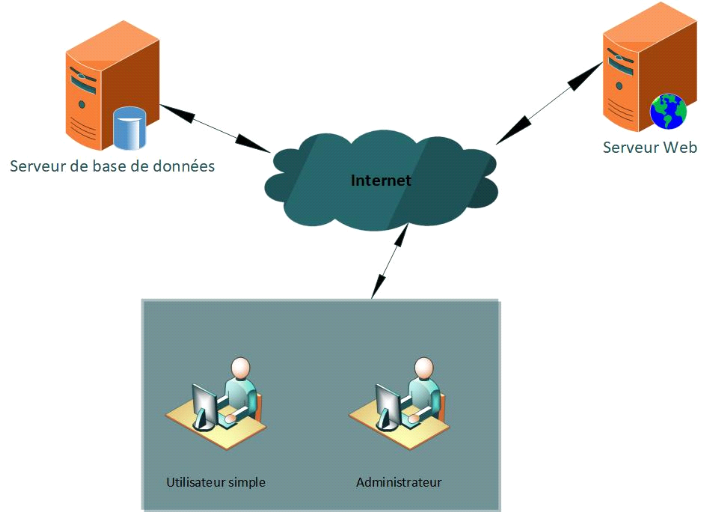
Commentaire : comme vu dans cette
architecture, notre système contient trois grande entités. La
première est constituée d'une interface utilisateur qui va
permettre l'interaction entre le système de l'utilisateur (ici l'admin
et utilisateur simple). Le serveur web ou serveur d'application effectue les
traitements applicatifs et celui-ci sert d'intermédiaire entre
l'interface et les données. Ensuite, le serveur de base de
données stocke les données de l'application.
III.2. TECHNOLOGIES ET OUTILS
UTILISES
Pour parvenir au bout de l'implémentation du
présent système, nous nous sommes servis des technologies
logicielles, matérielles que voici :
1. Technologies utilisées
§ Python : est un langage de script
interprété, actuellement utilisé pour programmer les
applications coté serveur, les applications mobiles. Sa force
réside dans la production du code compréhensible, son
intégration des composants écrits dans d'autres langages comme le
C, C++. Notons que dans notre cas, nous avons utilisé la version
3.7.3 qui nous a permis de coder la partie logique ou back-end
de notre système.
§ SQL : celui-ci n'est pas un
langage de programmation au vrai sens du terme. Il est destinéà
la manipulation de la base de données dans un SGBD et plus
précisément dans un SGBR. Il nous a permis de requêter
notre base de données pour récupérer les informations sur
l'enfant (comme son nom par exemple), sur l'administrateur.
§ Html et Css : respectivement
langages de balisage et de style, ces deux langages ne se classent pas trop
souvent parmi les langages de programmation. Ils nous ont respectivement permis
de créer les structures de nos pages web et y applique un certain style.
En d'autres termes ils nous permettent de coder le font-end de notre
système.
Pour parvenir à la détection et reconnaissance
visage, nous avons utilisé les librairies, bibliothèques et
modules, suivants :
Ø OpenCv3(*) : est une librairie
spécialisée dans le traitement d'images ou des vidéos.
Elle s'utilise dans la vision assistée par ordinateur, qui, est une sous
branche de l'IA. En effet, elle peut s'utiliser sur plusieurs système
d'exploitation et existe pour les langages : Python, Java, C++. Ici elle
nous a permis d'effectuer certains prétraitements sur les images
à traiter; à reconnaitre.
2. Outils logiciels
§ Visual Studio Code : est
un éditeur de code open-source, gratuit et multiplateforme (Windows, Mac
et Linux), développé par Microsoft, à ne pas confondre
avec Visual Studio4(*), qui
nous a permis d'écrire et éditer nos différentes lignes de
code. En effet, quelques raisons nous ont motivé de choisir cet IDE: son
intégration native avec Git5(*), la ligne de commande intégrée, son
intégration avec IntelliSense6(*),
§ Microsoft Visio 2016 :
cet outil nous a permis de faire une conception architecturale de notre
système et les différents diagrammes UML présentés
dans les sections précédentes,
§ Adobe Photoshop CC
2019 : pour l'édition des différentes images
utilisées dans le dans le travail et pendant de l'implémentation
du système,
§ WampServer : nous a
permis d'avoir un serveur web local pour le déploiement de notre
système.
§ Windows 10 Pro 64-bit :
comme système d'exploitation
3. Outilsmatériels
§ Un ordinateur
- Marque : HP Probook 6470b
- Disque dur : 500 GB
- Processeur Intel Core i5-3320M CPU @ 2.60GHz
- RAM 6 GB
III.3. PRESENTATION DES
RESULTATS
Nonobstant les difficultés rencontrées, nous
sommes parvenus à la réalisation du premier modèle de
notre logiciel.Visant les réponses aux problèmes soulevés
dans la partie de la problématique, ce premier modèle
réalisé devra y porter gage autant qu'il le peut. Eu égard
à ce qui précède, notre système comporte 2
principales fonctionnalités ; celle de l'enrôlement de
l'enfant et celle de reconnaissance. Nous illustrons dans cette partie ces deux
fonctionnalitésen capture d'écran.
a. Enrôlement
Cette partie en tout trop importante car sans elle les autres
fonctionnalités du système seraient en difficulté de
fonctionner. C'est pendant cette étape que l'administrateur :
- remplit le formulaire susceptible de remplir la table enfant
dans la base de données ;
- lance la capture les images nous permettant d'entrainer le
modèle pour la classification.
Figure
0 : Interface d'enrôlement de l'enfant
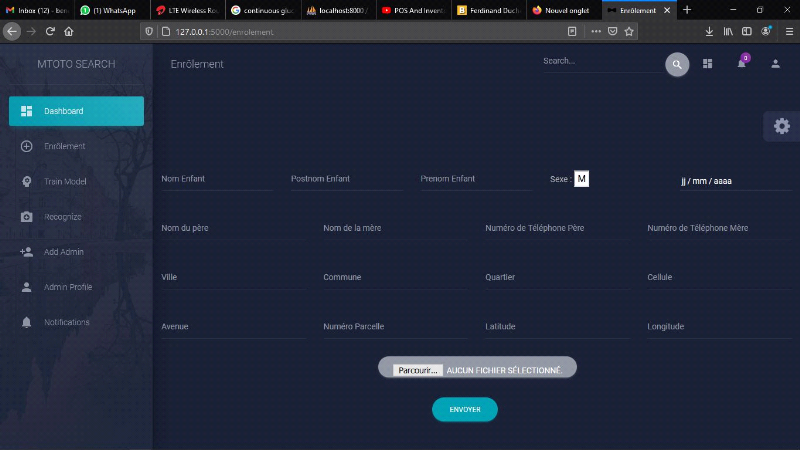
Description de la figure : la figure
ci-dessus décrit l'étape d'enrôlement de l'enfant au sein
du système. Après avoir accédé à son tableau
de bord, sur le volet gauche du tableau de bord, l'administrateur doit cliquer
sur l'option enrôlement pour faire une demande du formulaire à
compléter. Il est clairement vu que l'administrateur doit remplir tous
les champs possibles pour que l'enregistrement réussisse. Notons que le
bouton enregistrer nous sert de double fonctionnalité ; celle
d'enregistrer les éléments complétés dans le
formulaire ainsi que celle de lancer la capture des images de l'enfant,
lesquellesimages seront utilisées pour la comparaison de la nouvelle
image qui sera à chaque fois entrée pour la reconnaissance.
b. Reconnaissance
Ici l'enfant va se présenter devant la caméra
(la webcam intégrée). Après la détection de son
visage, la reconnaissance s'en suivra et son nom, post nom, prénom,
âge, sexe, noms des parents et autres informations serons afficher par la
suite.
Figure
0 : Interface de reconnaissance de l'enfant

Description de la figure :cette figure
est celle qui décrit le module de la reconnaissance de l'enfant. Nous
voyons les faces qui sont détectées et reconnues. La
méthode de simulation décrit dans le chapitre II nous permis
d'utiliser les faces des personnes majeures pour faire des tests de notre
système. Nous voyons alors deux personnes détectées
simuler aux enfants.
Ce chapitre a présenté notre système dans
la partialité. Avant de montrer les résultats auxquels nous
avions aboutis, nous avons commencé par présenter l'architecture
du système qui s'inspire de l'architecture 3-Tiers. Enfin, nous avons
présenté les technologies et outils utilisés pour parvenir
à cette réalisation. Nous avons aussi montré quelques
captures issues des tests préliminaires du système.
CONCLUSION GENERALE
La reconnaissance faciale a rendu des multiples services dans
la recherche d'images par contenu. Par ailleurs, plusieurs organisations
utilisent celle-ci pour faire des recherches indexées basées sur
le visage ; ce qui les permet de rendre cette tâche de recherche
simple etd'une manière souple. De surcroît, nous nous sommes aussi
basés sur la reconnaissance faciale pour résoudre le
problème fréquemment constaté dans la vie quotidienne;
celui des pertes des enfants.
En effet, nous nous sommes fixes comme objectifs de concevoir
un moteur de recherche des enfants perdus par reconnaissance faciale.Les
problèmes énoncés dans la partie introductive ont
motivé la réalisation de ce présent travail. Ainsi donc,
plusieurs méthodes et techniques, parmi lesquelles la documentation,
l'interview, l'expérimentation, la modélisation, le prototypage,
la simulation ont été mises en oeuvre pour son
accomplissement.
Dans le but de détecter le visage l'enfant, nous avons
été contraints d'utiliser le classificateur en Cascade de Haar.
Par contre, pour la reconnaissance de l'enfant, nous avons utilisé la
librairie face_détection. Notons que tout ceci à
été possible grâce à la célèbre
librairie utilisé dans la vision par ordinateur; Opencv. Elle nous a
permis de faire certains prétraitements sur les images de l'enfant,
d'appliquer certaines méthodes pour que la tache de reconnaissance soit
adéquate.
Après l'expérimentationdes différents
tests et essais, nos hypothèses émises dans l'introduction de ce
travail sont confirmées à ce sens où la biométrie
faciale a été utilisée et intégrée dans la
recherche indexée des enfants perdus et résout le problème
d'inquiétude des parents de ces derniers tout en permettant à
l'administrateur du système qui est dans notre cas un agent de police de
notifier ceux-ci au cas où l'enfant est retrouvé.
Tout compte fait, notre travail n'est ni le premier, ni le
dernier dans le domaine de la reconnaissance faciale. Il en existe toute une
kyrielle. Cependant, la différence réside au niveau des
technologies utilisées et le domaine d'intervention qui est la recherche
indexée des enfants. Par ailleurs, notre système présente
encore certaines failles comme la lenteur lors de la détection et cela
est dû à notre équipement qui nous a servi à faire
les tests (Hp Probook 6470b, core i5). Aux futurs chercheurs, ensemble nous
pouvons concevoir et implémenter un système de reconnaissance
faciale trop consistant.Nous restons donc ouverts à tout chercheur
voulant se lancer dans ce domaine de vision artificielle dans la recherche
indexée.
TABLE DES MATIERES
EPIGRAPHE
ii
DEDICACE
iv
REMERCIEMENTS
v
SIGLES ET ABBREVIATIONS
vi
LISTE DES FIGURES
vii
LISTE DES TABLEAUX
viii
RESUME
ix
ABSTRACT
x
0. INTRODUCTION GENERALE
1
0.1. PREAMBULE
1
0.2. PROBLEMATIQUE
2
0.3. HYPOTHESES
3
0.4. OBJECTIFS DU TRAVAIL
3
0.4.1 Objectif global
3
0.4.2. Objectifs spécifiques
3
0.5. CHOIX ET INTERET DU TRAVAIL
4
0.6. LIMITATION ET DELIMITATION DU
TRAVAIL
5
A. LIMITATION
5
B. DELIMITATION
5
0.7. AUDIENCE
5
0.8. SUBDIVISION DU TRAVAIL
6
CHAPITRE I. GENERALITES
7
I.1. GENERALITES SUR L'INTELLIGENCE ARTICIFIELLE
7
1. Définition de l'IA
7
2. Types d'intelligence artificielle
7
3. Quelques sous-disciplines de l'IA
8
I.2. GENERALITE SUR LA RECONNAISSANCE FACIALE
12
I.2.1. APERÇU GLOBAL
12
I.2.2. LES SYSTEMES BIOMETRIQUES
14
I.2.3. PLACE DE LA RECONNAISSANCE FACIALE PARMI LES
AUTRES TECHNIQUES BIOMETRIQUES
16
I.2.4. SYSTEMES BIOMETRIQUES BASES SUR LA
RECONNAISSANCE DE VISAGE
16
I.2.5. LES ALGORITHMES DE DETECTION ET
RECONNAISSANCE FACIALE
22
I.2.6. APPLICATIONS D'UN SYSTEME DE RECONNAISSANCE
FACIALE
23
I.2. REVUE DE LA LITTERATURE
24
I.3. SPECIFICATION D'EXIGENCES LOGICIELLES
29
I.3.1 Description globale
29
I.3.2. Performance
31
I.3.3. Fiabilité
31
I.3.4. Sécurité
31
I.3.5. Portabilité
31
CHAPITRE II. METHODOLOGIES ET CONCEPTION DU
SYSTEME
32
II.1 METHODOLOGIES ET TECHNIQUES
32
II.1.1 METHODES
32
II.1.2 TECHNIQUES
33
II.2 CONCEPTION DU SYSTEME DE RECONNAISSANCE
FACIALE
34
II.2.1. Module d'enrôlement de l'enfant
35
II.2.2. Module de reconnaissance de l'enfant
41
II.2.3. Le diagramme de déploiement
44
CHAPITRE III. IMPLEMENTATION ET PRESENTATION DU
SYSTEME
46
III.1. ARCHITECTURE DU SYSTEME
46
III.2. TECHNOLOGIES ET OUTILS UTILISES
47
1. Technologies utilisées
47
2. Outils logiciels
48
3. Outils matériels
48
III.3. PRESENTATION DES RESULTATS
49
a. Enrôlement
49
b. Reconnaissance
50
CONCLUSION GENERALE
52
Références
56
ANNEXE
60
Références
|
[1]
|
L. W. Holborn, The International Refugee Organization: A
Specialized Agency of the United Nations: Its History and Work, , 1946-1952,
New York: American Political Science Review, 1956, p. 502.
|
|
[2]
|
T. Zahra, «Les enfants « perdus »,»
Revue d'histoire de l'enfance « irrégulière »,
pp. 23-74, 2013.
|
|
[3]
|
M. p. M. A. Dunn, Politique de l'enfance non
accompagnée, Paris, 1949.
|
|
[4]
|
RFI, «rfi,» 02 Janvier 2015. [En ligne]. Available:
https://www.rfi.fr/fr/afrique/20150102-afrique-sud-record-enfants-perdus-plages-cap.
[Accès le 01 Novembre 2020].
|
|
[5]
|
A. D. fils, La vie à vingt ans, Paris: Michel
Lévis Frère, Libraire-Editeurs, 1850.
|
|
[6]
|
J. Gissübelová, «Des enfants qui se
perdent,» Radio Prague International, 22 06 2001. [En ligne]. Available:
https://francais.radio.cz/des-enfants-qui-se-perdent-8047260. [Accès le
19 10 2020].
|
|
[7]
|
S. SOUDOPLATOFF, L'Iintelligence Artificielle :L'expertise
partout accessible à tous, Fondation pour l'innovation politique, 2018.
|
|
[8]
|
[En ligne]. Available:
https://sites.google.com/site/iatpe2011/1ere-partie-fonctionnement-et-caracteristiques-de-l/deux-types-d-ia.
[Accès le 09 Mars 2020].
|
|
[9]
|
[En ligne]. Available:
https://digitalinsiders.feelandclic.com/construire/definition-quest-machine-learning.
[Accès le 09 Mars 2020].
|
|
[10]
|
B. L., Magazine IA, Cloud et Big Data, 22 Mars 2019. [En
ligne]. Available:
https://www.lebigdata.fr/donnees-biometriques-definition-securite.
[Accès le 29 Octobre 2020].
|
|
[11]
|
«thalesgroupe,» [En ligne]. Available:
https://www.thalesgroup.com/fr/europe/france/dis/gouvernement/inspiration/biometrie.
[Accès le 10 Mai 2020].
|
|
[12]
|
S. G. ABABSA, «Authentification d'individus par
reconnaissance de caractéristiques biométriques liées aux
visages 2D/3D,» Université Evry Val d'Essonne, Paris, 2008.
|
|
[13]
|
J. L. L. J. P. L. C. G. Bernadette DORIZZI, «Technique de
l'ingénieur,» 10 Avril 2004. [En ligne]. Available:
https://www.techniques-ingenieur.fr/base-documentaire/technologies-de-l-information-th9/cryptographie-authentification-protocoles-de-securite-vpn-42314210/la-biometrie-h5530/les-differentes-modalites-h5530niv10002.html.
[Accès le 01 Novembre 2020].
|
|
[14]
|
M. C. ESME-Sudria, «Biométrie online,»
Biometrie online, [En ligne]. Available:
https://www.biometrie-online.net/technologies/iris. [Accès le 01
Novembre 2020].
|
|
[15]
|
K. Bouchra, «Mise au point d'une application de
reconnaissance faciale,» Université Abou Bakr Belkaid - Tlemcen,
Algérie, 2013.
|
|
[16]
|
B. S., «Détection et identification de personne
par méthode biomé-trique.,» Tizi-ouzou : Uni-versité
Mouloud Mammeri.
|
|
[17]
|
Y. Benzak, Octobre 2 2018. [En ligne]. Available:
https://mrmint.fr/introduction-k-nearest-neighbors. [Accès le 15
Novembre 2020].
|
|
[18]
|
K. Harifi, «Medium,» 8 Juin 2020. [En ligne].
Available:
https://medium.com/@kenzaharifi/bien-comprendre-les-m%C3%A9thodes-semi-supervis%C3%A9es-pour-la-d%C3%A9tection-danomalies-fonctionnement-et-a6a993a478cf.
[Accès le 15 Novembre 2020].
|
|
[19]
|
W. Hizem, «Capteur intelligent pour la reconnaissace de
visage,» Evry, Institut national des télécommunications,
Paris, 2009.
|
|
[20]
|
B. Sofiane, «Détection et identification de
personne par méthode biométrique,» Université Mouloud
MAMMERI de TIZI-OUZOU (UMMTO) , Algérie.
|
|
[21]
|
V. K. Joel, «Etude et réalisation d'un
système de suivi de présences par reconnaissance faciale dans une
salle d'université (UCBC),» Université Chrétienne
Bilingue du Congo, Beni, 2017.
|
|
[22]
|
F. M. Serign Modou Bah, «An improved face recognition
algorithm and its application in attendance,» 2019.
|
|
[23]
|
V. Jain, «Visual Observation of Human Emotions,»
Université Grenoble Alpes, Grenoble, 2015.
|
|
[24]
|
M.-B. Mébarka, «Authentification et Identification
de Visagesbaséessur les Ondelettes et les Réseaux de
Neurones.,» Revue science des matériaux, pp. 01-08, 2014.
|
|
[25]
|
F. C. Migneault, «Génération de
modèles synthétiques de visages à partir d'une image
frontale,» 2016.
|
|
[26]
|
M. A. FODDA, «Détéction et Reconnaissance
de visage,» 2010.
|
|
[27]
|
A. Chaari, «Nouvelle approche d'identification dans les
bases de données biométriques basée sur une classification
non supervisée,» Université d'Evry-Val d'Essonne, 2009.
|
|
[28]
|
L. parisien, «Methode Scientifiques,» [En ligne].
Available:
http://dictionnaire.sensagent.leparisien.fr/M%C3%A9thode%20scientifique/fr-fr/.
[Accès le 4 Septembre 2020].
|
|
[29]
|
LAUBET (DB) Jean Louis, Initiation aux méthodes de
recherches en sciences sociales, Paris: Le Harmattan, 2000.
|
|
[30]
|
«modelisation-avec-uml,» [En ligne]. Available:
https://www.commentcamarche.net/contents/1142-modelisation-avec-uml.
[Accès le 04 Septembre 2020].
|
|
[31]
|
L. AUDIBERT, UML 2.0, Paris: Institut Universitaire de
Technologie de Villetaneuse, 2008.
|
|
[32]
|
F. TECH. [En ligne]. Available: En ligne sur :
https://www.futura-sciences.com/tech/definitions/informatique-simulation-informatique-11319/.
[Accès le 13 10 2020].
|
|
[33]
|
[En ligne]. Available: Consulté sur :
http://gpp.oiq.qc.ca/conception.htm. [Accès le 14 Novembre 2020].
|
|
[34]
|
[En ligne]. Available: Consulté sur :
https://www.archimetric.com/faq-items/uml-state-view-uml/. [Accès le 14
Novembre 2020].
|
|
[35]
|
L. Audibert. [En ligne]. Available: Consulté sur :
https://laurent-audibert.developpez.com/Cours-UML/?page=diagramme-activites.
[Accès le 14 Novembre 2020].
|
|
[36]
|
C. Soutou, UML 2 pour les bases de données, EYROLLES.
|
|
[37]
|
Florent, «Pymotion,» 12 Février 2019. [En
ligne]. Available: https://pymotion.com/detection-objet-cascade-haar/.
[Accès le 17 Novembre 2020].
|
|
[38]
|
[En ligne]. Available: Consulté sur :
http://www-inf.it-sudparis.eu/COURS/CSC4002/EnLigne/Cours/CoursUML/8.47.html.
[Accès le 14 November 2020].
|
ANNEXE
Code source Flask pour l'enrôlement de l'enfant
1.
@app.route('/enrolement', methods=['POST', 'GET'])
2. def enrolement_page():
3.
if request.method == 'POST':
4.
adminDetail = request.form
5.
nom = adminDetail['nomE']
6.
postnom = adminDetail['postnomE']
7.
prenom = adminDetail['prenomE']
8.
sexe= adminDetail['sexe']
9.
date = adminDetail['dateNaissance']
10.
nomPere = adminDetail['nomPere']
11.
nomMere = adminDetail['nomMere']
12.
phonePere = adminDetail['numPere']
13.
phoneMere = adminDetail['numMere']
14.
ville = adminDetail['ville']
15.
commune = adminDetail['commune']
16.
quartier = adminDetail['quartier']
17.
cellule = adminDetail['cellule']
18.
avenue = adminDetail['avenue']
19.
numParcelle = adminDetail['numParcelle']
20.
longitude = adminDetail['longitude']
21.
latitude = adminDetail['latitude']
22. 23.
cur = mysql.connection.cursor()
24.
cur.execute("INSERT INTO enfant (nomEnfant, postnomEnfant, prenomEnfant, sexe, nomPere, nomMere, dateNaissance, phonePere, phoneMere, ville, commune, quartier, cellule, avenue, numParcelle, longitude, latitude, idAdmin) VALUES(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)", (nom, postnom, prenom, sexe, nomPere, nomMere, date, phonePere, phoneMere, ville, commune, quartier, cellule, avenue, numParcelle, longitude, latitude, 1))
25. 26.
mysql.connection.commit()
27.
cur.close()
28.
return "<h1>reussi</h1>"
29.
30.
return render_template("enrolement.html", result=output)

* 1Est simplement une image dans
laquelle les seules couleurs sont des nuances de gris.
* 2 Ces fichiers se retrouvent
sur l'URL :
https://github.com/opencv/opencv/tree/master/data/haarcascades.
* 3 Celle-ci peut s'installer en
utilisant la commande pip install opencv-python.
* 4 Visual Studio est l'IDE
propriétaire de Microsoft.
* 5 Git est un système de
contrôle de versions distribué. Ça permet aux
développeurs de disposer d'une copie de travail du code et garde toutes
les historiques de changement.
* 6Une technologie
avancée qui propose, outre à la mise en évidence de la
syntaxe et la complétion automatique du code
| 

