Mashup sémantique( Télécharger le fichier original )par Abdelhamid MALKI Université Djillali Liabes de Sidi Bel Abbes, Algérie - Master en informatique 2011 |

2.7.3. Architecture des environnements des Mashups entreprise......29
3.4.5. WS-BPEL 46 3.4.6. Sythèse 48 3.4.7. Mashup vs SOA 48 3.5. Les Service Web Sémantique .49 3.5.1. Classification des Approches .51 3.5.1.1. Annotation sémantique ..51 3.5.1.2. Ontologie de service 53 3.5.2. Synthèse .57 3.5.3. Matching des services web 59 3.6. Conclusion .60 4. REST( Representational State Transfer) 61 4.1 Introduction 62 4.2 Architecture orienté ressources ..62 4.3 Les services web REST 63 4.4 Web Application Description Language (WADL) ....66 4.5 Les avantages de l'architecture REST ..67 4.6 Les Services Web REST Sémantique 69 4.6.1 Ontologie de service .....69 4.6.2 Annotation sémantique ..71 4.6.3 Synthèse .75 4.7 Conclusion .76 5. Les approches d'ingénierie des applications Mashup ..77 5.1. introduction 78 5.2. Le modèle de catégorisation des mashup frameworks 78 5.3. Les différentes approches pour la création des MASHUPS .78 5.3.1. L'approche manuelle .78 5.3.2. L'approche semi-automatique 79 5.3.3. L'approche automatique ...80 5.4. Comparaison entre les différentes approches ..81 5.5. Conclusion .82 6. La construction de Mashup Sémantique ..83 6.1. Introduction 84 6.2. SAWADL 85 6.3. Le processus d'ingénierie d'un Mashup Sémantique .87
8. Conclusion Générale 103 Référence biographique .106 Annexe 109 TABLE DE FIGUREFigure 2.1 Progression des technologies de Mashup 15 Figure 2.2 Les catégories de technologies utilisées par les Mashups ..........16 Figure 2.3 la croissance des mashups .20 Figure 2.4 L'architecture d'une application Mashup typiques ...20 Figure 2.5 Utilisation des services de BizTalk comme un service de plate-forme 22 Figure 2.6 Architecture de Mashup: côté-serveur 24 Figure 2.7 Architecture de Mashup: côté client ..25 Figure 2.8 : architecture d'un mashup entreprise en 4 couches 30 Figure 2.9 architecture mashup d'entreprise en 3 couches 31 Figure 3.1 Acteurs et interactions dans l'architecture à services 37 Figure 3.2 Mécanismes nécessaires pour un environnement d'intégration de service 38 Figure 3.3 Composition de services. ....39 Figure 3.4 Chorégraphie de services. ....40 Figure 3.5 Orchestration de services 41 Figure 3.6 Composition structurelle ....42 Figure 3.7 Architecture pour les services Web ....43 Figure 3.8 Le fichier WSDL. .....44 Figure 3.9 Exemple de message SOAP pour interroger un service Web. ....46 Figure 3.10 Exemple d'un processus WS-BPEL. 47 Figure 3.11 L'évolution du WEB 50 Figure 3.12 Exemple d'un WSDL_S ..52 Figure 3.13 Structure générale de l'ontologie OWL-S ..54 Figure 3.14 la structure d'une otologie WSMO ..57 Figure 3.15 Mise en correspondance horizontale 59 Figure 3.16 Mise en correspondance verticale 1:1 ..59 Figure 3.17 Mise en correspondance verticale 1:N .59 Figure 4.1 Description WADL pour un service REST 67 Figure 4.2 Architecture typique d'un outil de mashup ..69 Figure 4.3 Architecture d'un outil de mashup renforcé par une couche sémantique .70 Figure 4.4 Un exemple de l'ontologie SOOWL-S pour un flux RSS 71 Figure 4.5 Service RESTful en SA-REST ..72 Figure 4.6 L'annotation sémantique des services web RESTful avec SWEET .73 Figure 4.7 Un service RESTful décrit en HREST ..74 Figure 4.8 Exemple d'un service REST annoté par MICROWSMO .75 Figure 6.1 Exemple d'un service web REST en SAWADL .85 Figure 6.2 Annotation des méthodes avec SAWADL 86 Figure 6.3 Annotation des entrés et des sorties internement avec SAWADL 86 Figure 6.4 Annotation des entrés et des sorties globalement avec SAWADL 87 Figure 6.5 Cycle de vie d'un Mashup sémantique .88 Figure 7.1 L'architecture du prototype ...92 Figure 7.2 Aperçu de l'outil d'annotation des services web SOAP 94 Figure 7.3 Aperçu de l'outil d'annotation des services web REST 95 Figure 7.4 Aperçu de l'outil de Matching 96 Figure 7.5 Aperçu de l'outil de Matching 96 Figure 7.6 Ontologie global de Maintenance de la société SNTF ..98 Figure 7.7 Exemple de sémantisation d'un API ..99 Figure 7.8 Exemple de Matching entre APIs 100 Figure 7.9 Architecture de Mashup de Maintenance SNTF ..100 Figure 7.10 : Aperçus de Mashup de Maintenance SNTF 101 LISTE DES TABLEAUXTable 2.1 Comparaison entre les mashup entreprise .29 Table 3.1 Récapitulatif de la technologie des services Web. 48 Table 3.2 Comparaison SOA et MASHUP .49 Table 3.3 Comparaison entre les différentes approches des services web sémantique 58 Table 4.1 Correspondance entre les méthodes HTTP et actions CR 66 Table 4.2 Comparaison entre les différentes approches des services REST sémantique 75 Table 5.1 Tableau comparatif entre les différentes approches d'ingénieries de Mashup 82 Table 6.1 Les distances sémantique 90 Chapitre 1 Introduction Générale
8 Chapitre 1INTRODUCTION GENERALEChapitre 1 Introduction Générale
9 1. Problématique:Le processus d'ingénierie des applications d'entreprise à base de web suit généralement le cycle de vie de développement de logiciel impliquant initialement la spécification de besoins des utilisateurs, suivi d'un ensemble d'étapes d'analyse, de conception, de codification et de test. Les fonctionnalités fournis par ces applications sont issues des besoins des utilisateurs. En fait, de nombreux besoins qui changent dynamiquement ne sont pris en considération dans tel processus. En outre, les utilisateurs ont besoin des applications qui répondent exactement à leurs exigences quotidiennes et qui peuvent être développées et adaptées rapidement (ie., dans des jours et non pas dans des mois voir des années). Afin de répondre aux besoins de l'entreprise, il y a des approches basées sur la réutilisation comme par exemple l'architecture orienté service (SOA) qui définit un ensemble de services faiblement couplés dont les interfaces sont publiées, découvertes et invoquées par réseaux (internet, intranet, extranet, ...) ainsi que leurs interactions. SOA vise à améliorer l'efficacité, l'agilité, la flexibilité et la productivité par des services. Malgré ses avantages, très peu d'organisations exposent leurs services à d'autres, en plus l'approche SOA à mois de souplesse pour réagir à l'évolution des besoins des utilisateurs. Pour répondre à la flexibilité organisationnelle et aux besoins des utilisateurs finaux, de nouvelles technologies sont indispensables pour permettre aux personnes non-techniques de créer leurs propres applications sans avoir besoins des connaissances en programmation. En raison de ces carences en matière d'agilité et de flexibilité des systèmes d'information d'entreprise, une nouvelle approche appelée « MASHUP » est née. Les Mashups sont des applications web développées par la combinaison : des données, des logiques métiers, et/ou des interfaces utilisateurs des sources web publiées et réutilisées via des APIs. Ainsi, Les Mashups visent à réduire le coût et le temps de développement des applications web. Malgré ces avantages, l'ingénierie des applications Mashups nécessite forcément l'intervention du développeur qui a besoin non seulement des compétences en programmation mais aussi comprendre la structure et la sémantique des APIs qu'il souhaite les intégrer. Actuellement, plusieurs outils Mashup( IBM-CENTER, Dapper, Convertigo, Serena, Popfly, Yahoo-pipes,...) sont utilisés pour faciliter aux utilisateurs finaux( avec moins de compétences en programmation) la construction des applications Mashup (i.e., combinaison et l'agrégation des APIs) et ignorer l'intervention du développeur professionnel. Mai, cette dernière est nécessaire dans le cas où les données et les APIs sont hétérogènes, chose qui a poussé les chercheurs de trouver des solutions efficaces pour la création des Mashups de manière qu'un utilisateur final peut construire une application Mashup avec un outil lui garantisse la découverte, la sélection, et la superposition automatique ou dynamique des APIs en se basant sur l'approche sémantique, ce qu'on appel « MASHUP SEMANTIQUE ». Chapitre 1 Introduction Générale
10 Les Mashups sémantiques sont des Mashup dont les APIs combinés sont soutenus (ou annotés) par une couche sémantique qui permet de les sélectionner et les composer de manières automatique (non-ambigüe). Le Mashup sémantique est un enjeu majeur pour l'intégration des systèmes d'information. Il se propose d'interconnecter les applications au niveau interface utilisateur ; permettant ainsi de rendre plus flexible le processus de combinaison des applications. A l'origine, la sémantique constitue une branche de la linguistique qui s'occupe de l'étude des sens des termes. Dans ce projet, la sémantique sert à donnée à la machine le droit de réaliser certaines tâches sans l'intervention de l'utilisateur. 2. Objectif :L'objectif visé par notre travail, dans le cadre de projet de Master 2, consiste à réaliser l'intégration des systèmes d'information d'entreprise à base de Mashup Sémantique qui consiste à sémantiser les deux types de services (Soap et Rest) avec plus d'agilité et flexibilité. 3. Contribution :Nous proposons dans ce travail de définir une nouvelle approche pour la sémantisation des services web REST(SAWADL) de manière qu'elle soit plus flexible et adaptative vis-à-vis les autres approches de sémantisation tel que l'approche SAWSDL qui sert à annoter la description WSDL des services web SOAP avec des concepts ontologiques. De manière similaire que celle des services web SOAP, notre langage SAWADL utilise la description WADL afin d'enrichir les APIs de type REST avec une couche sémantique qui permet la découverte et la superposition automatique des APIs afin de construire automatiquement des applications Mashup. SAWADL utilise presque les mêmes techniques utiliser dans l'approche SAWSDL (annotation des méthodes, annotation des entrées/sorties, ...), chose qui les rend plus adaptatives et facile à les mettre en correspondance. La construction automatique des applications Mashup exige non seulement une tâche de sémantisation mais aussi l'implémentation d'un algorithme de Matching qui assure la combinaison automatique des APIs en se basant sur la sémantique de ces derniers. Enfin et pour qu'on puisse valider notre travail, nous proposons le développement d'un prototype réalisant l'intégration, à base de Mashup sémantique, des applications de maintenance de l'atelier de Maintenance Ferroviaire de SNTF de Sidi Bel-abbes. 4. Organisation de rapport :Le reste du rapport regroupe sept chapitres : Chapitre 1 Introduction Générale
11 Le deuxième chapitre présente une étude de l'approche Mashup de manière générale en présentant sa relation avec l'évolution des technologies du web2.0, et l'architecture utilisée dans cette approche ainsi que une classification de différents type de Mashup. Dans le troisième chapitre, nous décrivons les services web sémantique en montrant les éléments caractéristiques de l'approche SOA, plus une étude sur une technologie(web service) particulière qui met en oeuvre une grande partie des principes de l'approche à services ainsi que une comparaison entre l'approche SOA et MASHUP. Après avoir montré les services web nous entament dans une quatrième partie l'aspect sémantique des services web dans laquelle nous proposons une classification des approches de service web sémantique (ontologie de service et annotation sémantique) puis on termine par une comparaison entre ces différentes approches. Le quatrième chapitre est consacré au service web REST sémantique qui représente un concurrent des services web de type soap. Dans cette partie, nous présentons l'architecture orienté ressource, les services web REST ainsi une comparaison avec les services web de type SOAP. . Après avoir montré les services web REST nous entament l'aspect sémantique des services web REST dans laquelle nous proposons une classification des approches de service web REST sémantique (ontologie de service et annotation sémantique) puis nous terminons par une comparaison entre ces différentes approches. Le cinquième chapitre décrit un état de l'art des différentes approches d'ingénieries des applications Mashups telles que les approches manuelles, les approches semi-automatiques, et les approches automatiques ou sémantique. Dans le sixième chapitre, nous décrivons le cycle de vie d'un Mashup sémantique auquel nous montrons l'utilité de la sémantisation des APIs. Puis nous proposons une approche (SAWADL) qui permet de sémantiser les APIs de type REST. Le septième chapitre présente la mise en oeuvre de notre prototype qui permet la création de mashup automatique en implémentant l'approche SAWSDL pour la sémantisation des services web SOAP et notre l'approche SAWADL pour celle des services web REST plus un algorithme de Matching basé sur la similarité sémantique. Enfin nous utilisons notre prototype pour la création d'un mashup pour la gestion de maintenance en niveau de la société SNTF. Chapitre 2 Notion de base sur les Mashups
12 Chapitre 2NOTION DE BASE SUR LES MASHUPChapitre 2 Notion de base sur les Mashups
13 1. IntroductionLe Web2.0 permet de faciliter la création, l'utilisation, la recherche, le partage, et la réutilisation des ressources web. A base de ces concepts plusieurs technologies ont été développées (e.g. les blogs, les réseaux sociaux,..). Dans le web2.0 les fournisseurs de services qui exposent leurs applications soit à travers des API web tels que Googlemap, Amazone.com,.., soit à l'aide de flux de données comme RSS et ATOM. Toutes ces formes d'applications utilisent les services et/ou les fonctionnalités comme composants (ou ingrédients) qui peuvent être réutilisés et combinés pour créer des nouvelles applications. En guise les objectifs du web2.0, le Mashup apparait comme solution incontournable. Il constitue une nouvelle approche de développement et qui permet à l'utilisateur d'agréger plusieurs services pour créer un seul service qui répond à son objectif. Contrairement à la composition des services web dans la quelle on fait la composition seulement avec des services. Le Mashup va plus loin en offrant plus de fonctionnalités qui permettent la combinaison de plusieurs ressources hétérogènes (REST, SOAP, JS, RSS,..). 2. Définitions2.1 Définition 1Mashup ou bien « to mash up » un mot anglais qui signifie : ? Verbe : qui veut dire prendre des éléments depuis deux ou plusieurs pièces préexistantes d'une musique et les combiner pour faire une nouvelle chanson. ? Nom : une chanson composée d'éléments de deux ou plusieurs pièces préexistantes de la musique. 2.2 Définition 2On parle de Mashup dans le cadre d'une superposition de deux images provenant de sources différentes ou bien une superposition de données visuelles et sonores différentes dans le but de créer une nouvelle expérience [Koschmider and al 2009] . 2.3 Définition 3Un Mashup ou application composite désigne un site Web combinant plusieurs applications Web pour créer un nouveau service. Il s'agit ainsi par exemple d'agréger des contenus provenant d'autres sites. Ces applications tierces sont mises à disposition par le biais d'API, interfaces de programmation, autorisant l'extraction et le traitement d'informations. Chapitre 2 Notion de base sur les Mashups
14 De nombreux éditeurs fournissent des APIs libres afin d'inciter les développeurs à concevoir des Mashups exploitant leur contenu (Google, Yahoo, Amazon, eBay ou Microsoft). 3. Facteurs de croissance des Mashups :Comment, dans seulement quelques années, les Mashups ont un tel succès? L'histoire nous mène en arrière ; il y a quelques années déjà passées. Initialement le Web (nommé dans ce contexte le « Web 1.0 ») est caractérisé par des pages Web statiques, rarement (jamais) mises à jour qui a évolué lentement vers un Web dynamique utilisant des systèmes de gestion de contenus. Il est considéré principalement comme un outil de diffusion et de visualisation de données. En septembre 2005, l'édition Tim O'Reilly a écrit un article intitulé 'What is Web 2.0 ?'' Pour déclarer succinctement les traits de site Web 2.0 contre ceux du Web 1.0. Il y avait trois caractéristiques qui étaient des catalyseurs directs pour le développement des Mashups, ces caractéristiques sont : ? L'importance des données. ? La communauté des utilisateurs. ? Les développements récents des technologies de Mashups. 3.1. L'importance des données :L'une des caractéristiques est l'importance des données ; pourquoi des compagnies investissent des millions de dollars pour recueillir leurs données et leurs systèmes de base de données, en revanche elles les donnent gratuitement pour les autres utilisateurs ? La réponse est la suivante: en ouvrant leurs systèmes, les développeurs de Mashups aident à augmenter la portée des propriétaires de données. 3.2. La communauté des utilisateurs :La deuxième caractéristique est le rôle de l'utilisateur dans l'évolution d'un service proposé par un fournisseur. Le site Netflix a toujours permis aux utilisateurs d'estimer un film qu'ils ont déjà regardé. D'autres sites dépendent complètement des données ajoutées par les utilisateurs. YouTube et Flickr fournissent respectivement, l'hébergement gratuit des vidéos et des images. Non seulement l'hébergement, les deux sites fournissent aussi des dispositifs de gestion des réseaux sociaux : comme la possibilité d'estimer et de commenter un item hébergé ainsi l'étiquetage "folksnomic", qui laisse fondamentalement des utilisateurs à décrire le contenu avec leurs propre mots-clés. Les visiteurs peuvent employer ces mots-clés pour la recherche du contenu.
15 Chapitre 2 Notion de base sur les Mashups3.3. Le développement récent des technologies des Mashups :Comme toutes les technologies, les technologies de Mashups ont évolué avec le temps. La figure 2.1 montre la progression des technologies qui servent comme une fondation pour le développement des Mashups. Figure 2.1 - Progression des technologies de Mashup [GIF 2008] La chose la plus importante à retenir n'est pas quand une technologie particulière a été créée, mais quand elle est devenue pertinente pour la communauté. Un facteur clé est la large adoption des fournisseurs ou les vendeurs [GIF 2008]. Citons l'exemple de Javascript, Javascript ne serait pas aussi important aujourd'hui s'il n'avait pas été adopté par Microsoft et Netscape dans leurs navigateurs. Netscape a créé JavaScript dans son navigateur Netscape Navigator (appelé à l'origine LiveScript) après JavaScript est devenu un standard de facto et tout nouveau venu dans le marché des navigateurs a dû mettre en oeuvre de JavaScript pour être considéré comme un navigateur alternatif viable [GIF 2008]. Avant que chacune de ces technologies ne soit expliquée, il est important de les classer dans les rôles qu'ils jouent dans le développement des Mashups, c'est ce que montre la figure 2.2.
16 Chapitre 2 Notion de base sur les Mashups
Figure 2.2 - Les catégories de technologies utilisées par les Mashups [GIF 2.08] 4. Mashup et l'évolution du WEB :A la question, ce qui est un mashup, plusieurs auteurs ont déjà un pressentiment et souvent une certaine compréhension très propre, mais ne peuvent pas donner une définition nette. Le mashup est un terme encore assez floue et souvent mal compris, s'accorde à reconnaître que le mashup est un nouveau genre d'application Web qui consiste à utiliser les capacités globales de plusieurs ressources Web via des interfaces accessibles au public(API) [Merrill,2006]. Les mashups et leurs fonctionnements sont souvent comparés par analogie avec l'ordinateur. Dans un ordinateur, le système d'exploitation sépare les composants matériels de celles des applications (API) qui encapsulent les interactions de bas niveau, par exemple, affichage, disque dur, et les interfaces réseau. Ces API exposent un ensemble de fonctions de bas niveau et donc, le développement du logiciel sera plus facile et les programmeurs ne vont pas se concentrer sur des fonctionnalités de niveau inférieur, il suffit d'utiliser ces interfaces(API), ce qui permet d'augmenter considérablement l'efficacité du développement. Pour les applications Web, le système d'exploitation de l'ordinateur est échangé par l'Internet, dans le quel les fonctionnalités et les données sont fournies en ligne. Les API Web sont utilisées par les applications Web de la même façon que les applications classiques utilisent les APIs du système. Actuellement plusieurs entreprises exposent leurs services et données avec des APIs Web, par exemple Flickr et Amazon, et nombreuses organisations fournissent des ressources qui sont consommables par les applications Web. Les mashups sont des applications qui utilisent plusieurs de ces services et données agrégées dans des façons nouvelles et novatrices qui n'étaient pas prévus avant. Parfois, les Chapitre 2 Notion de base sur les Mashups
17 fournisseurs de contenu web sont encore inconscients de la réutilisation des ses services. La notion de mashup considère les API Web comme une analogie avec les systèmes d'exploitation aussi elle a inventé le terme "Web comme une plate-forme» ou «Internet Operating System" [O'Reilly, 2005]. 4.1. WEB 1.0 :Le Web (ou World Wide Web) a été développé en 1989 comme un projet au laboratoire de physique du CERN en Suisse. Tim Berners-Lee a imaginé un système hypertexte distribué qui a permis aux scientifiques, même s'ils n'existent pas des ordinateurs experts, capables de générer, partager et garder facilement des traces sur des contenus sans qu'il soit nécessaire de conserver des copies personnelles [Berners-Lee, 1989]. Berners-Lee voit que «le principal objectif du Web était d'être un espace d'information partagé par lequel les humains et les machines pourraient communiquer »[Berners-Lee, 1996]. Il s'est rendu compte qu'un tel système devait être décentralisé (à travers des liens unidirectionnels), plate-forme indépendante, simple, et qui répond aux besoins des humains et des machines. Ce dernier a été établi par le « central context of structured hypertext » qui a défini le Langage (HTML)- qui donne un sens sémantique au texte brut grâce à des balises. En quelques années, l'intérêt scientifique dans le Web a augmenté rapidement et l'univers est sorti de sa présence solitaire. En 1993, plus de 500 serveurs Web étaient en ligne et il était presque impossible de suivre la liste de contenu publié sur le web, chose qui a rendu le Web de plus en plus complexe et qui a exigé d'avoir un moyen qui permet la recherche du contenu sur le web. Les utilisateurs web ont commencé à assembler manuellement les index des pages Web, mais qui a été une solution inefficace et insuffisante. A cette époque, les moteurs de recherche ont apparus. les catalogages des pages web ont été fortement soutenues par l'introduction de la balise META dans langage HTML qui a permis la présentation de la métadonnées des contenus web, comme le titre, description, mots-clés, ou la langue. Actuellement, le Web est devenu un réseau mondial pour tous, pas seulement les scientifiques. Les entreprises ont commencé la communication mondiale et la recherche des moyens pour établir leurs affaires par voie électronique sur le Web même Les gens ont commencé la création des pages, offrant des pages d'accueil personnelles ou les sites qui révèlent des informations sur des sujets précis. Le Web s'est développé pour devenir un réseau. 4.2. WEB 2.0Le terme Web2.0, initialement crédité par Dale Dougherty et Craig Cline, encore populaire par le célèbre article «What is Web 2.0" de Tim O'Reilly [O'Reilly, 2005], ne décrit pas une révolution technologique du Web. Il décrit plutôt une modification de la perception du Web, et une évolution des personnes et des dispositifs qui conduisent le Web. Cette évolution, délimite un changement de paradigme à partir d'un Web de publication vers un Web de la participation. Ceci est devenu visible à travers l'utilisation de nouvelles métaphores, comprenant des balises au lieu des catégories, les wikis au lieu des systèmes de gestion de contenu, et les blogs au lieu des pages personnelles. Chapitre 2 Notion de base sur les Mashups
18 Il identifie trois modèles de base du Web 2.0: service, simplicité, et communauté. Ces modèles décrivent les caractéristiques communes entre les applications Web 2.0. Par rapport à l'article de O'Reilly, cette liste doit être complétée par une autre entité qui est essentiel pour les mashups: les données. Service : De nouveaux dispositifs, tels que les téléphones intelligents, et de nouvelles approches pour les applications Web, comme AJAX, nécessitent de nouvelles interfaces pour les fonctionnalités et les données existantes. L'effort pour servir une telle multitude de nouveaux dispositifs, a conduit à la reconsidération de la conception du système et, éventuellement la décomposition des logiciels existants en un ensemble de services. Les applications ont été démontées ou emballées avec un service adaptateur pour encapsuler les fonctionnalités en éléments très petits. Ce découplage du support et donc, la réutilisation des capacités entre les différents types d'applications et des dispositifs, qui a suggéré le déverrouillage de nouvelles opportunités commerciales. Dans le cadre du Web 2.0, de nombreuses applications ont été adaptées a un tel modèle de service, où les applications sont exécutées dans les agents utilisateurs, c'est à dire les navigateurs Web, et les fonctionnalités de base d'accès en tant que service sur internet. Ces services constituent les API du "Système d'exploitation d'Internet", ce qui rend le Web comme une plate-forme qui permet un développement efficace des applications Web. Données : Les données sont devenues les plus importants blocs de construction des applications Web2.0, Depuis cela, la fonctionnalité ne sert qu'à la combinaison des données. Toutefois, il y a une tâche cruciale pour maintenir et améliorer ces données. Les utilisateurs ont des ressources précieuses pour l'amélioration de données avec des métadonnées. Ils peuvent classer les éléments de données à travers les (tags), d'identifier et d'éliminer les doublons, de compléter les informations manquantes, évaluer la qualité des données par les rétroactions et les commentaires, et d'identifier les informations relatives grâce à des recommandations. Cela n'est possible que si les données sont mises à la disposition des utilisateurs. Avec la participation des usagers dans la production du contenu, les communautés créent et améliorent des magnitudes de données pertinentes et de qualité, plus de données qu'un seul organisme pourrait avoir ou oubien gérer. Des exemples sont les nombreux blogs et les wikis qui ont germé ces dernières années, en tenant Wikipedia comme l'exemple le plus éminent surpassant les encyclopédies commerciales en ligne dans l'actualité, la quantité et la qualité de l'information. La simplicité : Le paradigme Web 2.0 a pris de l'ampleur ces dernières années. Les applications sont devenues plus faciles à utiliser et à développer, elle ont allé au-delà de l'affichage du contenu sur des pages statiques pour récupérer des informations externes. Elles sont maintenant caractérisées par l'expérience de l'utilisateur interactive et visuellement riche, principalement en raison de l'emploi d'AJAX. Web 2.0 est généralement motivé par les Chapitre 2 Notion de base sur les Mashups
19 communautés. Ainsi sont les applications et les services basés sur ce dernier. Cela a conduit à l'évolution des normes ouvertes qui permettent un développement aisé des applications. La syndication est l'un de ces standards ouverts qui permet aux utilisateurs de s'abonner à des flux de contenu uniformément structuré. Ce qui permet une simple consommation machine. En fait, la syndication est devenu le moyen le plus célèbre et appliqué pour consommer données via des API. Le web sémantique désigne la structuration et l'annotation des données significatives avec des métadonnées et il est devenu un sujet académique pertinent. Les concepts du web sémantique soutiennent la consommation machine des données, qui aboutit éventuellement à des systèmes automatiques d'acquisition de connaissances. Un autre exemple important pour l'emploi de la simplicité est le fameux style architecturale Representational State Transfer (REST) [Fielding, 2000] pour les applications Web qui ont simplifié et unifié d'une façon spectaculaire l'accès aux ressources. Communauté. Web2.0 a provoqué un changement dans lequel les utilisateurs participent dans et avec le Web, en affectant la façon d'organisation, d'accès et d'utilisation de l'information des utilisateurs. À venir les applications hébergées sur les coûts des prestataires motivés toute une génération à participer dans la génération de contenu. Le désir de l'homme à communiquer, argumenter les opinions, et partager de nouvelles idées est une force motrice pour aller d'un Web de documents vers un Web de participation. Les effets des communautés qui se résument à la maintenance et à l'amélioration des informations sont connus sous le nom de « wisdom of crowds » (la sagesse des masses) [O'Reilly, 2005]. En plus de l'information, les communautés atteignent les services et la simplicité. Les développeurs des communautés font leur possible pour trouver des solutions simples et fortes en même temps. Parmi un ensemble donné des alternatives, cela est appliqué sous la forme de « la survie du plus fort », entrainant une liste étroite de concepts et technologies prouvés et vaguement adoptés. 4.3. MASHUP :[Clarkin et Holmes, 2007] décrivent le Mashup comme une vue agile composée de services simples qui visent à satisfaire un objectif spécifique. Le Mashup se base sur la réutilisation des ressources existantes, qui facilite le développement rapide des logiciels à la demande et qui permet aussi au développeur de créer des applications qui correspondent à un besoin spécifique dans un contexte particulier. Comme cité précédemment les applications MASHUP permettent de combiner plusieurs ressources web via des API dans le but d'avoir une application qui répond à un ou plusieurs objectifs. Le mashup permet aux différents composants de communiquer les uns avec les autres. Ces APIs web peuvent entre de différent types, soit des services ou des fonctionnalités (e.g moteur de recherche, e-commerce) soit des données ou des flux de données (e.g RSS,ATOM,..), soit des Gadgets (Facebook, méteo,.. ). Les API qui exposent ces ressources utilisent différents techniques (SOA, REST, JAVA SCRIPT, RSS,..).En outre, ces ressources qui sont échangées peuvent être représentées en différents formats (XML, HTML, JSON, RSS/ATOM, ...). Chapitre 2 Notion de base sur les Mashups
20 L'évolution du Web a permis l'émergence et la réutilisation des services et des capacités publiées par les applications et les entreprises du web. Les applications Mashups vont juste combiner un ensemble de ces capacités ou services suivant leurs besoins c-a-d résoudre des besoins spécifiques grâce à l'expertise des autres.
Figure 2.3 : La croissance des Mashups La figure 2.3 montre une croissance régulière des Mashups sur le web. Le diagramme indique l'évolution du nombre de Mashups social enregistré dans le site web PogrammableWeb. En moyenne, 94 nouveaux Mashups sont enregistrés chaque mois alors qu'ils sont encore en croissance, de plus en plus les Mashups gagnent une grande popularité, grâce à les avantages substantiels aux particuliers et aux entreprises. Ces avantages comprennent des coûts réduits et une productivité accrue dans le développement des applications en raison de la composition légère et la réutilisation rapide. 5. Architecture des Mashups :Bien qu'il existe plusieurs types d'interfaces utilisateur et des sources de données utilisés par les différents Mashups, nous pouvons encore tirer des patterns architecturaux communs et partagés par tous les Mashups. Par exemple, tous les Mashups sont de la nature REST (qu'ils soient conformes aux principes de REST-Representational State Transfer) [Larry and al,2008]. La figure2.4 montre une architecture d'un Mashup typique. L'architecture d'une application Mashup est constitue d'un ensemble de composants, à savoir les données, les flux RSS, les services Web, les services plateformes, les applications de Mashups enfin les applications de client. Chapitre 2 Notion de base sur les Mashups
21 Figure 2.4 : L'architecture d'un Mashup typiques [Larry and al,2008] 5.1. Les donnéesL'élément central de tout Mashup est que les données soient agrégées et présentées à l'utilisateur. Bien que le schéma ci-dessus décrive les sources de ces données comme une base de données, le concept de «Mashup» ne nécessite pas une base de données qui sera local pour l'application Mashup ou le client. Les données peuvent provenir strictement à partir des services Web où des données qui sont sérialisées en XML ou JSON . 5.2. Les flux RSSLes flux RSS peuvent être une source de données primaire ou supplémentaire pour les Mashups. Les flux RSS sont faciles à manipuler parce qu'ils sont sous forme XML, et qui sont manipulé par plusieurs bibliothèques dans différents langages. L'idée est donnée la possibilité à un utilisateur de "mixer" plusieurs flux existants pour créer un flux RSS personnalisé, et donc faire en quelques sortes un "best-of" où il aurait tous ses flux favoris rassemblés sur un seul flux. 5.3. Les services Web Il est aussi courant d'inclure au sein des Mashups des appels aux services Web, que ce soit des services Web basés sur WSDL ou sur REST avec même d'autres services qui expose les deux styles (WSDL et REST). Les services Web peuvent être utilisés pour fournir des données supplémentaires. Par exemple : pour un Mashup cartographique, les données Chapitre 2 Notion de base sur les Mashups
22 résultantes peuvent contenir que des adresses mais avec un appel à un service basé sur WSDL ou bien REST, on peut récupérer longitude/latitude de cet adresse. 5.4. Plate-forme de servicesLa figure 2.5 illustre une catégorie spéciale des services qui sont utilisés pour créer les mashups. Nous les appelons plate-forme de services, car ils fournissent des fonctionnalités du modèle requête/réponse comme les services web traditionnels. Nous voyons l'émergence de services de cloud computing bloc de construction qui commencent à créer de la valeur. Par exemple, le service Amazon S3 offre de stockage "dans le nuage », ce qui rend plus facile à exposer les données statiques en le téléchargeant à un fournisseur de stockage hébergé. Microsoft BizTalk Services est un service de plate-forme qui offre une capacité différente - la capacité de relayer les communications Internet à travers un pare-feu En venant de l'entreprise, exposant ainsi des services internes à la consommation par des partenaires commerciaux ou à des tiers la construction de leur propre enterprise mashups. Relayée communication tel que prévu par les Services BizTalk est également utile, même dans une seule entreprise, avec de nombreuses unités d'affaires ou avec de nombreux segments de réseau. Une communication sur Internet relais peut éliminer la topologie du réseau physique comme un obstacle de communication [Larry and al,2008].
Figure 2.5 - Utilisation des services de BizTalk comme un service de plate-forme 5.5. Les applications MashupJusqu'à présent, nous avons identifié de nombreux types de services qui peuvent être utilisés pour créer des Mashup, mais nous n'avons pas abordé l'importance du logiciel qui crée et offre l'expérience du Mashup. Il suffit d'imagine « les applications Mashup » comme Chapitre 2 Notion de base sur les Mashups
23 une combinaison des services et quelques logiciels légers. Pour les Mashups à base de web, le logiciel est souvent écrit en utilisant les technologies Web (comme PHP ou ASP.NET), mais avec l'évolution du temps Larry Clarkin and Josh Holmes voient la ligne entre le serveur et les traitements des demandes du client avec l'émergence du RIA (Application Internet Riches), ce sont des applications qui s'exécutent dans le navigateur avec des fonctionnalités similaires beaucoup à des applications de bureau. Il n'a besoin d'une installation du coté client au-delà de génériques plug-in tels que Adobe Flash ou Microsoft Silverlight. 5.6. Les applications du ClientLe rôle de l'application cliente est de savoir comment le Mashup est livré et présenté à l'utilisateur. Pour les Mashups publics à base de web, l'application la plus courante du côté client est le navigateur Web qui reçoit du code HTML et JavaScript comme livraison à parti d'un serveur Web sur HTTP. A partir d'où sera effectué le mixage de ressources de données, on peut distinguer deux types d'architectures [Sean and al, 2007] ? Architecture côté serveur ; ? Architecture côté client. Architecture côté serveur Dans cette architecture, les données des différentes sources sont intégrées sur un serveur Mashups, qui renvoie la page agrégée au client. Par exemple, des APIs du Facebook sont principalement basées sur l'intégration côté-serveur. Typiquement, le client doit déléguer l'autorisation au serveur d'agir sur son propre compte. La figure suivante montre l'architecture d'un Mashup coté serveur :
Figure 2.6 À Architecture de Mashup: côté-serveur [Sean and al, 2007]
24
25 Chapitre 2 Notion de base sur les MashupsArchitecture côté client : Dans cette architecture (figure 2.7), les données de différentes sources (APIs, flux de données, Serveur Web,...) sont intégrées directement dans le navigateur du client. L'architecture côté client permet aux consommateurs et aux fournisseurs de services de communiquer à travers un navigateur. Cela permet d'éviter le problème de confiance avec un autre tiers d'intégration (Mashup serveur). La figure suivante montre l'architecture de Mashup côté client :
Figure 2.7À Architecture de Mashup: côté client [Sean and al, 2007] 6. Classification des Mashups :Les Mashups peuvent être classifiés sur la base des quatre questions suivantes [Koschmider and al 2009]: ? Quoi ? ? Où ? ? Comment ? ? Pour qui ? Dans les paragraphes suivant, nous allons observer chacun de ces quatre perspectives sur les Mashups. 6.1. Classification selon la question « Quoi ?»Selon le type des éléments qui sont combinés ou intégrés, les Mashups sont assignés à une des trois catégories suivantes : présentation, données et fonctionnalité d'application. ? Mashups de présentation : Un Mashup de présentation se concentre sur la recherche d'information disposé par différentes sources de Web sans considérer l'importance des données ou les fonctionnalités fondamentale de ces applications. Chapitre 2 Notion de base sur les MashupsPour ce type de Mashup préconstruit, les Widgets (Gadgets) sont simplement des glisser-déposer (drags&drops) dans une interface d'utilisateur commune. Habituellement, la création d'un Mashup de présentation exige peu ou pas de connaissances des langages de programmation. ? Mashups de donnée : Un Mashup de données fusionne des données fournies par différentes sources (par exemple, services Web ou page HTML) dans une seule page Web. Cela permet à l'utilisateur de fusionner des données provenant de plusieurs sources et de personnaliser ce flux de données dans une page Web. Ce processus de fusion est complexe parce qu'il fait appel à des procédés d'extraction et d'agrégation de contenu, comme RSS ou Atom. ? Mashups de fonctionnalité : Un Mashup de fonctionnalité combine des données et des fonctionnalités d'applications fournies par différentes sources en obtenant un nouveau service. Les fonctionnalités sont accessibles par l'intermédiaire des APIs. En se basant sur le type des éléments combinés, on peut trouver d'autres classifications des Mashups telles que : ? Cartographie-Mashups : Combinaison d'informations dans des cartes, par exemple, la carte géographique de Google. ? Photo!Vidéo-Mashups : Combinaison d'informations de type photo/vidéo visuels par exemple, le site du Flickr. ? Recherche!Achats-Mashups : Intégration des mécanismes pour la comparaison des prix de produits dans des pages Web. ? Nouvelles-Mashups : intégration des nouvelles dans les pages Web personnelles. 6.2 Classification selon la question « Où ?»Selon l'endroit où ils sont mixés, les Mashups peuvent être classifiés en deux catégories : Mashups coté-serveur et Mashups coté-client. ? Mashups coté-serveur : Les Mashups côté-Serveur intègrent des ressources (par exemple, services et données) sur le serveur. ? Mashups coté-client : Les Mashups côté-client intègrent des ressources sur le client, qui est souvent un navigateur. Chapitre 2 Notion de base sur les Mashups
26 6.3 Classification selon la question « Comment ?»Les Mashups peuvent être encore classifiés par catégories selon la modalité d'intégration ou de combinaison des ressources dans une représentation. À base de cette modalité, on peut distinguer deux catégories : les Mashups d'extraction et les Mashup de flux (flow Mashups). ? Mashups d'extraction : Le Mashup d'extraction peut être considéré comme un récipient de données rassemblant et analysant des ressources de différentes sources et fusionnant ces ressources dans une page Web. ? Mashups de flux : Dans un Mashup de flux (flow Mashup), l'utilisateur adapte le flux d'une page Web combinant des ressources de différentes sources. Ensuite, ces ressources seront transformées et intégrées dans une application du Mashup. Dans ce type des Mashups, l'actualisation du résultat s'effectue d'une manière continue. 6.4 Classification selon la question « Pour qui ?»La question « pour qui ? » concerne les groupes d'utilisateurs intéressés par le Mashup, Dans ce contexte, les Mashups peuvent être classés en deux catégories, Mashups du consommateur et Mashups d'entreprise (business Mashups). ? Mashups du consommateur : Un Mashup du consommateur est prévu pour une utilisation publique. Il permet de combiner des ressources de différentes sources, publiques ou privées, et de les organiser dans une interface simple accessible par le navigateur. ? Mashups d'entreprise : Les Mashups d'entreprise permettent de fusionner de multiples ressources dans un environnement d'entreprise. Ces Mashups combinent des données et des fonctionnalités de différents systèmes par exemple ERP, CRM ou bien des SCM, afin de répondre à leurs objectifs. La création des Mashups d'entreprise exige la considération des politiques de sécurité et de gouvernement d'entreprise (administration, partage, stockage, mise à jours,...). Les Mashups d'entreprise fournissent une solution rapide pour fusionner et représenter les ressources internes et externes de l'entreprise sans intermédiaire. 7. Les Mashups D'entrepriseDans la littérature, la définition exacte d'un Mashup d'entreprise est sujette à débat. Dans ce travail, nous nous référons à la définition suivante: "Un Mashup d'entreprise est une ressource Web qui combine des ressources existantes, que ce soit leur contenues, données ou Chapitre 2 Notion de base sur les Mashups
27 fonctionnalités, à partir de plusieurs sources dans un environnement entreprise en responsabilisant les utilisateurs finaux de créer et adapter leurs informations et applications individuelles [Hoyer and al,2008], en simplifiant le concept de Service-Oriented Architecture (SOA) et en l'améliore avec le Web 2.0". Enterprise Mashups se concentre généralement sur l'intégration du logiciel au niveau interface utilisateur. Contrairement au SOA qui est caractérisés par une haute complexité technique des normes pertinentes, Mashups d'entreprise simplifie aux utilisateurs finaux l'intégration sans compétences en programmation. 7.1. Pourquoi les Mashups en entrepriseIncontournables et reconnues sur le marché, les technologies de Mashup sont aujourd'hui une réalité plébiscitée par les entreprises pour leur capacité, notamment, à rendre plus agile leur architecture informatique. Mais pourquoi un tel engouement pour une approche jusqu'alors regardée comme un concept en devenir ? La logique de réutilisation du patrimoine applicatif existant En effet, plutôt que de réécrire systématiquement des applications, les changer, les intégrer au fur et à mesure des évolutions des standards technologiques, l'approche Mashup permet de capitaliser sur les environnements existants, de les moderniser, les assembler et les intégrer aisément dans le cadre d'un système d'information dynamique. L'optimisation des processus de travail des utilisateurs Les Mashups permettent de concentrer en une application unique une série d'applications, évitant ainsi de passer d'une application à une autre... Ils sont en ce sens générateurs de productivité. Proposer des interfaces sur-mesure aux utilisateurs En réunissant en une interface unique un ensemble d'applications, les Mashups offrent une réponse qualitative et adaptée aux besoins spécifiques des utilisateurs. Ainsi, pour chaque type d'utilisateur, des interfaces sur-mesure proposant un accès à des fonctionnalités spécifiques peuvent être paramétrées (ex. un manager commercial accèdera non pas à l'intégralité des données du CRM mais à une partie au travers d'un Mashup). Permettre aux développeurs de se concentrer sur leur expertise Grâce aux Mashups, les développeurs travaillant par exemple en Cobol ou RPG n'ont pas à étendre leur connaissance en programmation en d'autres languages pour faire fonctionner leurs applications en environnement web dynamique, SOA... En effet, les Chapitre 2 Notion de base sur les Mashups
28 Mashups intègrent aisément les développements des applications historiques dans des architectures modernes. Connecter des applications SaaS au SI En effet, l'une des vertus majeures des technologies dites de Mashup est de pouvoir assembler rapidement des ressources applicatives externes avec des ressources applicatives internes. Les applications Saas en plein boom sont donc totalement intégrées de manière transparente. Faire interagir à la demande ses applications avec le SI des clients et fournisseurs Les Mashups favorisent la création d'un système ouvert et homogène où les applications des clients et fournisseurs viennent aisément interagir et compléter les données provenant des applicatifs d'une entreprise. Publier aisément ses applications dans un environnement mobile En créant des interfaces sur-mesure, les Mashups permettent aux entreprises de décloisonner l'information des murs de l'entreprise pour la publier facilement dans un environnement mobile. Seule une partie des applications est publiée pour répondre aux attentes fondamentales des utilisateurs. Optimisation des coûts d'intégration Une autre force des Mashups tient également à leur simplicité de mise en oeuvre et leur aptitude à réduire significativement les coûts d'intégration. L'approche Mashup se concentre en effet sur une intégration au plus juste des fonctionnalités souhaitées. Cela permet alors de réduire les traditionnels cycles d'intégration orientés approche globale. 7.2 . Classification des entreprises MASHUP:Dans la littérature, des termes comme «EnterpriseMashups »,« BusinessMashups », et « applications composites » sont utilisés de façon interchangeable, mais sont souvent définis à différents niveaux. Sur la base du fonctionnalité des applications existantes, nous avons élaboré une classification de mashups entreprises comme illustré dans le tableau « table 6.1 » .Nous distinguons quatre différents types en fonction de leur complexité. Le classement va de l'intégration simple (niveau présentation) à l'intégration complexes qui fournissent l'orchestration des processus qui permet aux utilisateurs d'entreprises d'automatiser leurs processus de travail (au niveau des processus). 7.2.1 MASHUP d'entreprise de présentation :Le Mashup Entreprise de présentation se concentre sur la récupération des informations et de la mise en page à partir de différentes sources, sans intégrer les données et les Chapitre 2 Notion de base sur les Mashups
29 fonctionnalités [Daniel and al. 2007]. Des Composants préconstruits sont simplement combinés par l'opération drag-drop dans une interface utilisateur graphique. Un exemple d'un tel outil est Dapper. Cet outil permet aux utilisateurs de faire simplement glisser-déposer des composants préconstruits dans une interface utilisateur et qui permet par la suite de réutiliser et partager les résultats obtenues. 7.2.2 MASHUP d'entreprise de données :Les Mashups d'entreprise de Données sont limités à l'intégration des données et les services d'information provenant de différentes sources afin de présenter ces données dans une vue unifiée par exemple, en combinant les données d'une carte géographique avec les données d'un service qui exposent la météo des villes. 7.2.3 MASHUP d'entreprise orientés fonctionnalités :Les Entreprise Mashups orientés fonctionnalités permettre aux utilisateurs de combiner et intégrer tout type de composants (par exemple des informations ou des services d'une application entreprise) via des interfaces génériques(API). [Koschmider and al 2009] 7.2.4 MASHUP d'entreprise orientés processus :Les Mashups orientés processus coordonnent et orchestrent les différents processus. Les Mashups orientés processus permettent à un utilisateur d'automatiser ses tâches. Quand un utilisateur a besoin d'effectuer une tâche cela implique souvent d'obtenir des informations d'un endroit, les agrégées, les filtrées, et les mettre en forme, puis envoyer le résultat obtenu vers un endroit différent, et puis de nouveau jusqu'à ce que le processus terminera. [Vrieze et al 2009]
Table2.1 comparaison entre les mashup entreprise 7.3. Architecture des environnements Mashup entreprise :L'Environnement mashup d'entreprise doit fournir une intégration simple et facile des composants existants ainsi que d'une allocation efficace des composants. Par conséquent, le cycle de vie de développement mashup d'entreprise devrait se concentrer sur la découverte et Chapitre 2 Notion de base sur les Mashups
30 le partage des composants Mashables qui représentent les éléments de base pour un processus de développement en permettant la réutilisation des ressources dans une nouvelle combinaison. Dans la littérature on distingue deux types d'architecture d'un mashup entreprise en 3 couches et en 4 couches . 7.3.1. Architecture en 4 couches :Hoyer et ses collègues [Hoyer and al,2008] ont proposé une architecture de référence pour un environnement mashup entreprise. Cette architecture se compose en un ensemble de couches et un service commun. La figure 2.8 montre l'architecture proposée.
Figure 2.8 : architecture d'un mashup entreprise en 4 couches Les couches représentent les principaux blocs fonctionnels et ils ont un sens traditionnels dans la conception du logiciel. Les services communs représentent les services qui peuvent être utiles pour plusieurs couches(sécurité, collaboration,..) [Hoyer and al,2008]. La couche d'accès aux sources : permet d'accéder aux sources hétérogènes via une interface unifiée. Cette couche fournit un composant spécial s'appel « adaptateur de source » pour chaque type de source, il définit la méta-donnée et le mode d'accès pour chaque source. La couche mashup de donnée : permet de définir une vue sur la combinaison d'un un ou plusieurs sources qui sont accessibles via la couche accès aux sources. Pour plus de détails consulter le chapitre 5. la couche Widget : fournit un composant visuel qui présente une interface graphique pour un mashup de données qui est accessible via la couche mashup de donnée ou Chapitre 2 Notion de base sur les Mashups
31 une interface graphique pour La couche d'accès aux sources. Il existe plusieurs de widgets (widget de requête, widget graphique,...). La couche assemblage des widgets : permet d'assembler plusieurs widgets pour créer une interface graphique unifiée final du mashup. Il assure aussi la coordination entre ces différents widgets. 7.3.2. Architecture en 3 couches :La plupart des architecture proposées d'un mashup entreprise [Wirtsch and al, 2010], [Gurram and al, 2008], [Hoyer and al,2009] sont à base de 3 couches, la figure 2.9 résume ces différents architecture proposé . L'approche en 3 couches représente une extension de l'approche précédente dans laquelle la couche mashup de données et la couche widget de l'approche en 4 couches sont fusionnées en une seule couches qui s'appelle composant pour [Wirtsch and al, 2010] et widgets pour [Hoyer and al,2009], [Gurram and al, 2008].
Figure2.9 architecture Mashup d'entreprise en 3 couches 8. Conclusion :Dans cette partie nous avons abordé la notion de mashup et leur relations avec les technologies web. Dans lequel nous avons commencé par un ensemble de définitions pour l'approche mashup, par la suite nous avons présenté la relation et l'évolution du mashup par Chapitre 2 Notion de base sur les Mashups
32 apport au web 2.0 et ses technologies (ajax, json, RSS, soap, rest,..). nous avons aussi monté une première architecture utilisée par la pluparts des applications mashup. Cette architecture implique souvent des composants de type service web données, flux RSS,.. Dans le domaine applicatif nous distingons plusieurs types de mashup pour cette raison on a présenté une classification en se basant plusieurs questions (ou, quoi, comment, pour qui,..), après nous avons présenté lutilisation des applications mashup dans l?environnement entreprise et leurs apports par apport à les applications traditionnelle. Chapitre 3 Les services web sémantique
33 Chapitre 3L'APPROCHE ORIENTÉE SERVICEET SERVICE WEB SEMANTIQUEChapitre 3 Les services web sémantique
34 1. Introduction :Les dernières décennies ont été marquées par le développement rapide des systèmes d'information distribués, et tout particulièrement par la diffusion de l'accès à Internet. Cette évolution du monde informatique a entraîné le développement de nouveaux paradigmes d'interaction entre applications tels que SOA. Cette dernière été mise en avant afin de permettre des interactions entre applications distantes. L'architecture SOA est une architecture de conception basée sur des standards, permettant de créer une infrastructure informatique intégrée capable de répondre rapidement aux nouveaux besoins d'un utilisateur. Elle fournit les principes et directives permettant de transformer un réseau existant de ressources informatiques hétérogènes, distribuées, complexes et rigides en ressources intégrées, simplifiées et particulièrement souples pouvant être modifiées et combinées afin de mieux satisfaire les objectifs de l'utilisateur. Mais un des défis de l'approche SOA est que le standard WSDL utilisé pour la description des services présente des lacunes de précision. Ces lacunes sont liées au niveau d'expressivité faible de la description syntaxique car elle est limitée à l'énumération des opérations et à la description des types des paramètres d'entrée et de sortie associés. Elle ne caractérise pas la sémantique de la fonctionnalité accomplie par le service. Pour pallier le manque de sémantique de WSDL, plusieurs approches proposent de rajouter une couche au dessus de WSDL complétant la description syntaxique par des précisions sémantiques. Par exemple le service web d'Amazon.com, d'écrit en WSDL, a pour objectif la vente de livre. Il permet à un utilisateur de parcourir les catalogues d'Amazon, pour rechercher des livres et les acheter. Cependant, un utilisateur pourra s'en servir pour parcourir les catalogues en guise de recherche d'information, sans acheter. Syntaxiquement, le terme rechercher est différent du terme acheter, cependant sémantiquement ces deux concepts sont liés, le premier étant un pré-requis du second. Une recherche par mots clés d'un service permettant de rechercher un livre ne retournera pas les services décrits comme permettant d'acheter un livre, par suite l'utilisateur ne sera pas informé de tous les services potentiellement pertinents. Une subtilité de ce genre sera contournée si le service fourni une description sémantique plus élaborée qu'un fichier WSDL. 2. Services : définitions et architectureL'approche à services est une approche relativement récente qui présente un certain nombre d'avantages pour la réalisation d'applications. Nous allons, dans un premier temps, définir l'élément-clé de l'approche à services, c'est-à-dire le service. Ensuite, nous présenterons les différents acteurs et leurs interactions pour cette approche. Dans une troisième partie, nous détaillerons l'architecture à services. Nous expliquerons aussi les besoins qui en découlent. Finalement, nous mettrons en évidence les éléments spécifiques qui nous permettront par la suite de caractériser les différentes technologies qui mettent en oeuvre cette approche. Chapitre 3 Les services web sémantique
35 2.1. ServicesLa notion de service reste floue. M.P. Papazoglou a proposé la définition suivante : «Services are self-describing, platform agnostic computational elements.» [Papazoglou,2003] Un service est vu comme une entité logicielle qui peut être utilisée grâce à sa description. Le consommateur du service l'utilise sans avoir connaissance de la technologie sous-jacente pour son implantation ainsi que de sa plate-forme d'exécution. De plus, le service ne connaît pas le contexte dans lequel il va être utilisé par le client. Cette indépendance à double sens est une propriété forte des services qui facilite le faible couplage. Cette définition contient une faiblesse, elle sous-entend qu'un service est exécuté sur une plate-forme distante et qu'il ne peut pas être importé sur une plate-forme locale. Pour le consortium OASIS [OASIS 2006] un service fournit un ensemble de fonctionnalités décrites dans une spécification, appelée interface, ainsi qu'un ensemble de contraintes et de politiques d'accès aux fonctionnalités offertes. L'implantation du service n'est pas visible pour l'utilisateur. Seules les informations qui peuvent permettre de savoir si le service correspond aux besoins de l'utilisateur sont disponibles. Nous pouvons noter qu'il est cependant difficile de discerner une information utile d'une information inutile pour le choix d'un service. Pour rendre plus explicites ces définitions, nous pouvons dire qu'un service est : « une entité logicielle qui fournit un ensemble de fonctionnalités définies dans une description de service. Cette description comporte des informations sur la partie fonctionnelle du service mais aussi sur ses aspects non-fonctionnels. A partir de cette spécification, un consommateur de service peut rechercher un service qui correspond à ses besoins, le sélectionner et l'invoquer en respectant le contrat qui a été accepté par les deux parties. » Nous avons introduit dans cette définition la notion de contrat. Un contrat entre deux parties permet de s'assurer que chacune respectera ce à quoi elle s'est engagée. Un contrat est le résultat d'une négociation entre le fournisseur et le consommateur. Ce contrat représente un accord de niveau de service, en anglais Service Level Agreement (SLA), qui définit les engagements que prend le fournisseur sur la qualité de son service, et les pénalités encourues en cas de manquement. Cette qualité doit être mesurable et mesurée selon des critères objectifs acceptés par les deux parties. Un exemple d'accord de service peut être le temps de rétablissement d'un service en cas d'incident, le fournisseur et le consommateur définissent un délai pour le rétablissement du service. Si le délai est dépassé, le fournisseur doit indemniser le consommateur selon les termes du contrat. La définition de l'accord de niveau de service peut se faire selon plusieurs niveaux, comme défini dans [Antoine,al 1999] :
36 Chapitre 3 Les services web sémantique
2.2. SOC : Service-Oriented Computing :
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
2.3. SOA : Service-Oriented Architecture :
Chapitre 3 Les services web sémantique
3. Composition de services3.1. Définitions :
Chapitre 3 Les services web sémantique
3.2. Composition par procédés :
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
3.3. Composition structurelle :
4. Services Web :
Chapitre 3 Les services web sémantique
4.1. Principes
4.2. WSDL : le langage de description des services Web
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
4.3. UDDI : l'annuaire de services Web
4.4. SOAP: les communications entre services Web
Chapitre 3 Les services web sémantique
4.5. WS-BPEL
Chapitre 3 Les services web sémantique
4.6. Synthèse:
Chapitre 3 Les services web sémantique
4.7. Mashup vs SOA :
Chapitre 3 Les services web sémantique
5. Les service Web Sémantique
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
5.1. Classification et présentation des approches
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
5.1.2. Une ontologie de service
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
5.2. Synthèse :
Chapitre 3 Les services web sémantique
5.3. Matching des services web :
Chapitre 3 Les services web sémantique
Chapitre 3 Les services web sémantique
6. Conclusion :
Chapitre 4 Les services web REST sémantique
Chapitre 4Les Service Web REST SémantiqueChapitre 4 Les services web REST sémantique
1. Introduction
2. Architectures orientées ressource(ROA)
Chapitre 4 Les services web REST sémantique
3. Les services web REST :
Chacune des étapes est expliquée dans ce qui suit Identification des ressources, la conception des URI et des relations : Comme la plate-forme d'intégration REST est mise en oeuvre sur HTTP, les GUID utilisés sont des URL qui sont construits suivant la syntaxe: Chapitre 4 Les services web REST sémantique
64 <scheme name> : <hierarchical part> [ ? <query> ] [ # <fragment>] Scheme name fait référence au protocole utilisé pour interpréter les URL (dans ce cas, HTTP), tandis que la partie hiérarchique contient la plupart des informations essentielles pour identifier ce qui est demandé. Hierarchical part est composé en deux expressions : authority et path. La partie authority stocke les informations liées à l'hôte: nom d'utilisateur et mot de passe de celui qui tente d'accéder à l'hôte, le port utilisé et l'adresse de l'hôte (utilisé pour le routage de la requête). Autority a la syntaxe suivante: [ userinfo "@" ] host [ ":" port ] La partie path (chemin d'accès) contient les informations nécessaires pour localiser la ressource à récupérer dans l'hôte. Un exemple de nom de schéma et la partie hiérarchique: http://johndoe:jd123@www.laboranova.com:8080/people/ Les parties query et fragment sont facultatives et ne doivent pas être utilisés pour identifier les ressources. Toutefois, ils peuvent être utilisés pour filtrer la représentation récupérés. Un exemple d'URL complet : http://www.domain.com:8080/people/?name=John#section2 L'identification des ressources est effectuée de la même manière que celles des objets de paradigme orienté objet. C'est, en divisant la réalité des concepts qui sont importants pour le système et qui vont encapsuler les données nécessaires et les états de l'application. REST oblige l'auteur de définir les URL qui décrivent mieux la ressource qu'il est entrain de créer. Il est très important de choisir des noms représentatifs. Bien qu'il n'existe aucune restriction particulière à la façon dont les URL peuvent être construites. Des exemples de ressources et de leurs identifiants : - Une liste de personnes: http://www.domain.com/persons/ - La quantité des voitures sport rouges: http://www.domain.com/vehicle/red/sports/car/qty/ http://www.domain.com/vehicle/car/sports/red/qty/ - Le commentaire le plus regardé: Chapitre 4 Les services web REST sémantique
65 http://www.domain.com/comments/mostviewed Enfin, il est important de lister les autres ressources qui sont en relation avec celle en cours de conception. Pour chaque relation, il est nécessaire de connaître: ? Son nom et son URI ? La signification de cette relation. ? Définir si elle est une relation plusieurs à plusieurs ou un à plusieurs. Cette liste aide lors des représentations des ressources et des actions qui peuvent être effectuées dans la ressource, il est également nécessaire de fournir cette liste de liens dans la documentation des ressources. Définition de représentation : Une ressource est un mapping conceptuel d'un ensemble d'entités. Ces entités sont ses représentations. Une représentation est une séquence d'octets qui contient des données et des métadonnées pour décrire ces données. Lorsque on utilise REST, le format de données des représentations est le type média ou MIME MIME est un ensemble de conventions créées pour permettre l'échange des fichiers via Internet tout en gardant le processus transparent pour l'utilisateur. Lors d'une demande de ressources de la part du client , le serveur démarre un processus de négociation de contenu. Le client envoie une liste des types MIME qui l'accepte, alors que le serveur choisit la représentation qui correspond le mieux aux exigences du client. Cette liste est envoyée dans la requête HTTP dans l?en-tête. Par conséquent, une fois qu'une ressource a été identifié, il est nécessaire de définir sa représentation. Par exemple, une ressource qui représente une personne pourrait avoir plusieurs représentations: une image JPEG qui stocke une photo de son visage, un document XML qui stocke des informations du contact, une vCard, et ainsi de suite. Description des méthodes : Les ressources sont manipulés par le transfert des représentations à travers une interface uniforme adressée par l'identifiant de ressource. Chaque représentation doit mettre en oeuvre une interface CRUD pour réaliser l'interface uniforme requis par l'architecture REST. Le protocole HTTP/1.1 définit huit méthodes , dont quatre permettent de définir l'interface tels: GET, PUT, POST et DELETE. Le tableau montre la correspondance entre les méthodes HTTP et actions CRUD.
Chapitre 4 Les services web REST sémantique
66 PUT
Table 4.1 : correspondance entre les méthodes HTTP et actions CRUD. Toute représentation doit accepter toutes ces quatre méthodes, bien que cela ne signifie pas qu'ils doivent être mises en oeuvre. 4. Web Application Description Language (WADL) :Le Web Application Description Language (WADL) est un format de fichier basé sur XML qui fournit une description lisible par la machine des applications web. Ces applications sont généralement les services web REST. WADL est un membre du W3C communication. mais «W3C n'a pas l'intention d'accepter un travail basé sur cette approche » . Le but de WADL est de permettre aux services sur Internet (ou tout autre réseau IP) d'être décrit d'une manière compréhensible par la machine, pour rendre plus facile la création des applications Web 2.0 et avoir une façon dynamique pour la création et la configuration des services web. Auparavant, il était nécessaire d'aller à un service Web existant, l'étudier et écrire l'application manuellement. WADL peut être considéré comme l'équivalent REST de Web Services Description Language (WSDL) version 1.1. La version 2.0 de WSDL peut être utilisée pour décrire des services Web REST, ainsi en concurrence avec WADL.La figure 4.1 montre un service REST avec sa description en WADL.
67 Chapitre 4 Les services web REST sémantique
Figure 4.1 description WADL pour un service REST WADL est destiné aux applications qui sont basées sur l'architecture existante du Web. Comme WSDL, il est indépendant du langage et de la plate-forme et vise à assurer la réutilisation des applications au-delà de l'utilisation de base dans un navigateur Web. WADL fournie les modèles des ressources du service, et les relations entre ces dernières. Le service est décrit en utilisant un ensemble d'éléments des ressources. Chacun de ces éléments contient param pour décrire les entrées et les éléments de méthode qui décrivent la requête et la réponse d'une ressource. L'élément de requête précise la façon de représenter l'entrée, les types et les en-têtes HTTP spécifiques qui sont nécessaires. La réponse décrit la représentation de la réponse du service, ainsi que toute information de défaut, pour traiter les erreurs. WADL n'est pas encore largement soutenue. Son avantage sur WSDL le plus compliqué est qu'il n'impose aucun autre niveau d'abstraction sur la description du service, mais comme des outils sont disponibles pour le développement d'applications avec WADL, il est probable qu'ils comprennent des moyens pour générer automatiquement WADL. 5. Les avantages de l'architecture REST5.1 InteropérabilitéNous avons vu que le respect du style d'architecture REST nous permettait d'avoir une interface simple et uniforme pour chacune des ressources. Chapitre 4 Les services web REST sémantique
68 ? ressources identifiées par des URIs ? ensemble de méthodes réduit (GET, PUT, POST, DELETE, ...) ? ressource manipulées par leur représentation Cette interface uniforme nous permet-elle enfin de pouvoir parler d'interopérabilité ? non, le style d'architecture REST ne nous permet pas de nous assurer que notre application sera interopérable. Pourquoi ? Tout simplement parce qu'il paraît aujourd'hui très difficile de développer des systèmes totalement interopérables. Chaque application se place dans un domaine métier précis et possède son vocabulaire. Mais le style d'architecture REST permet de simplifier l'intégration de nouvelles applications à notre système existant. D'une part grâce au modèle d'adressage uniforme des ressources (URI). Tous les composants du système utilisent le même outil pour nommer les choses. Il est plus facile de les manipuler. Le paradigme d'appel de méthode à distance utilise le nom des méthodes métiers pour identifier le service sur le web. L'adressage est donc totalement spécifique au service. Ensuite, l'utilisation d'un nombre réduit de méthodes permet aux clients de savoir, avant même de contacter le service, quelles méthodes sont disponibles. De plus, la sémantique de ces méthodes étant définie clairement. Si le client veut récupérer une ressource, il y a de forte chance que la méthode GET fonctionne. Un client SOAP ne pourra jamais deviner le nom des méthodes avant d'avoir consulter le contrat WSDL. Enfin, le fait de ne pas spécifier le format des messages échangés permet de rendre indépendant l'évolution du langage (format des données) et du support de communication (protocole). Cette indépendance permet d'interconnecter plus facilement des composants qui n'ont à priori rien à voir ensemble. L'exemple le plus connu actuellement est celui de RSS. Un client peut tirer partie de l'information fournie par un flux RSS sans se soucier de la façon dont il a été généré. En standardisant le protocole de communication, le style d'architecture REST permet de se concentrer sur la véritable source de couplage fort : le format de données échangées. Dans son article « SOAP, REST and Interoperability » Paul Prescod cite 4 technologies pouvant aider à la résolution de cette problématique : ? transformations XSLT ? l'héritage de schémas XML ? XML générés par des requêtes XML ? RDF, DAML+OIL et les technologies du web sémantique 5.2 Les aspects non fonctionnelsNous n'avons pas encore parlé des aspects non fonctionnels des web services : sécurité, qualité de services, monitoring, ... Le respect d'une architecture de type REST facilite la mise en place de ces fonctionnalités pour différentes raisons : Chapitre 4 Les services web REST sémantique
69 ? les communications sans état facilitent l'implantation de ces fonctionnalités ? les technologies utilisées étant largement utilisées (HTTP, URI, XML) des outils existent déjà pour gérer ces problématiques L'utilisation de technologies existantes et largement testées sur le web est un avantage majeur de l'approche REST face à une solution SOAP qui redéfinit des protocoles par dessus HTTP (WS-*). 6. Classification Des Approches De Service REST Sémantique :Comme les services web soap La sémantisation des services web REST peuvent être classifié aux deux approches. La première approche consiste à développer une ontologie qui décrit les services Web REST ainsi que leur sémantique d'un seul bloc. La deuxième approche consiste à annoter les langages existants avec de l'information sémantique. L'avantage principal de ce genre de solutions réside dans la facilité pour les fournisseurs de services d'adapter leurs descriptions existantes aux annotations proposées. Nous classifions donc ces approches de la manière suivante : dans un premier temps, nous étudions les ontologies de services REST, puis dans un second temps nous détaillons les annotations de langages existants. 6.1. Une ontologie de service RESTful :6.1.1. SOOWL-S advertisements (a social-oriented version of OWL-S advertisements):Une architecture typique d'un outil mashup est représentée dans la figure4.2 dans laquelle est impliqué le serveur d'outil mashup et une application Web dans laquelle l'outil expose ses fonctionnalités. L'outil fournit un ensemble de modules que les utilisateurs peuvent les sélectionner en vue de développer leurs mashups . En général, ces modules peuvent être classés en deux types, des modules méta-service et modules statiques. Les modules statiques sont liés à des services pré- enregistrés dans l'outil de mashup. Les modules de méta-service sont des modules paramétrés [Meditskos and al, 2011].
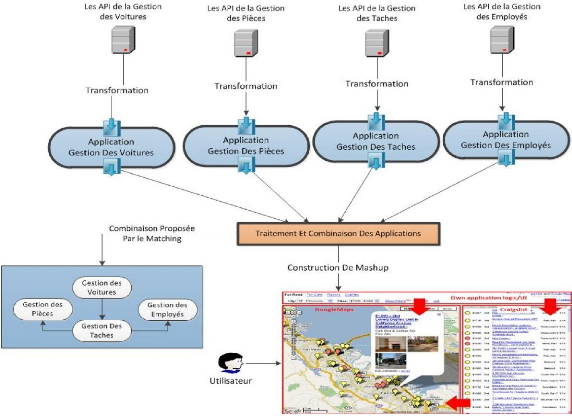
Figure 4.2 Architecture typique d'un outil de mashup Chapitre 4 Les services web REST sémantiqueL'idée de G.Meditskos et sont collègue [Meditskos and al, 2011] est d'ajouter une couche sémantique afin d'automatisé le processus de sélection et découverte des APIs. La figure4.3 montre leur idée.
70 Figure 4.3 Architecture d'un outil de mashup renforcé par une couche sémantique L'outil de mashup est enrichi par une découverte et une publication spéciales et de modules méta-service qui communiquent sémantiquement avec UDDI étendu (MashUDDIs). Ces annuaires stockent des annonces SOOWL-S et ils peuvent être utilisés pour les activités suivantes. Publier des annonces SOOWL-S : l'outil de mashup devrait soutenir un ensemble d'ontologies de domaine jouent le rôle d'un vocabulaire pour le processus d'annotation. L'activité d'annotation suit l'idée que chaque mashup peut être considéré comme une boite noire qui effectue une tâche spécifique, de cette manière nous pouvons annoter sémantiquement ces mashups, comme s'ils s'agissent d'un simple service Web. Rechercher les annonces SOOWL-S : Les utilisateurs devraient être en mesure d'interroger un MashUDDI afin de récupérer des descriptions de service /mashup. Le registre MashUDDI devrait employer un mécanisme permet de récupérer sémantiquement un API suivant les besoins d'un utilisateur. Dans l'ontologie SOOWL-S, en utilisant que le module service-Profile de l'ontologie OWLS qui permet juste d'annoter les paramètres d'entrées /sorties et les propriétés non-fonctionnelles d'un service Web. Chapitre 4 Les services web REST sémantique
71 L'annotation des APIs dans cette approche suit un modèle conceptuel, en utilisant uniquement les entrées, les sorties, et les propriétés non-fonctionnelles d'un API. De cette façon, les services web à base de REST et à base de SOAP peuvent être annotés indépendamment, pour l'API qu'ils suivent. Par exemple, un flux RSS peut être conceptuellement décrit en termes de SOOWL-S
Figure 4.4 Un exemple de l'ontologie SOOWL-S pour un flux RSS 6.2. Annotation sémantique des services web RESTful :6.2.1. SA-REST :Dans cette section, nous présentons l'approche SA-REST [Lathem and al, 2007 ] qui permet d'ajouter la sémantique pour les services Web RESTful. Dans l'approche de [Lathem and al, 2007 ] les éléments annotés dans les services Web RESTful sont les sorties, les entrées et les opérations, ainsi que le type de la requête qui peuvent invoquer le service. Celui-ci n'est pas requis dans SAWSDL car il traite de services traditionnels basés sur SOAP qui transmettent des messages via une requête HTTP POST, tandis que les services Web RESTful, sont beaucoup plus légers, et peuvent utiliser une requête HTTP POST ou une requête HTTP GET. D'après [Lathem and al, 2007 ], la plupart des services web RESTful ont des pages HTML qui décrivent aux utilisateurs ce que le service fait et comment l'invoquer. C'est en quelque sorte l'équivalent d'un WSDL pour les services web RESTful cela serait un endroit idéal pour ajouter les annotations sémantiques. Le problème avec le traitement d'un HTML et que le HTML est conçu pour être lisible par l'homme et non pas par une machine. Afin de résoudre ce problème [Lathem and al, 2007 ] ont utilisé le micro formats RDFa qui permet d'intégrer Chapitre 4 Les services web REST sémantique
72 des triplets RDF afin d'ajouter la sémantique au service REST et le rendre visible et interprétable par la machine. L'idée d'intégrer des triplés RDF à la Page HTML qui décrit le service REST et qui sera à la fois lisible par l'homme et la machine. Le sujet du triplé devrait être l'URL auquel vous souhaitez appeler le service, le prédicat du triplet devrait être soit sarest: input, sarest: output , sarest:operation, sarest:lifting, sarest:lowering, or sarest:fault. L'objet du triple devait être soit un URI ou l'URL d'une ressource en fonction de prédicat du triplet. La figure 4.5 donne un exemple détaillé d'un document SA-REST pour un service Web « rechercher maisons ». <html xmlns:sarest=" http://lsdis.cs.uga.edu/SAREST#"> <p about=" http://craigslist.org/search/"> L'entrée logique de ce service est <span property="sarest:input"> http://lsdis.cs.uga.edu/ont.owl#Location_Query </span> La sortie du service <span property="sarest:output"> http://lsdis.cs.uga.edu/ont.owl#Location </span> objets.Ce service devrait être invoquer en utilisant <span property="sarest:action"> HTTP GET </span> <meta property="sarest:lifting" content= " http://craigslist.org/api/lifting.xsl"/> <meta property="sarest:lowering" content= " http://craigslist.org/api/lowering.xsl"/> a.edu/ont.owl#LocationSearcFigure 4.5 Service RESTful en SA-REST 6.2.2. SWEET (Semantic Web Services E-diting Too):Pour sémantiser les services web REST il faut tout d'abords qu'ils disposent une description permet d'ajouter au-dessus de elles des entités ontologiques comme dans la sémantisation des services web SOAP à l'aide de l'approche SAWSDL. D'après [Maria and al, 2009] la plus par des services web REST sont décrits en html ; par conséquent, l'absence d'une description lisible et interprétable par la machine rende difficile voir impossible
73 Chapitre 4 Les services web REST sémantiqued'ajouter des annotations sémantiques au-dessus des services web REST afin de fournir un certain niveau d'automatisation. Maria et ses collègue [Maria and al, 2009] ont proposé une approche (SWEET) intégrée et léger pour décrire formellement la sémantique des services web RESTful. Ils commencent par la création d'une description pour services web REST qui sera lisible par la machine en utilisant le hRESTS (HTML pour RESTful Services) microformat [Kopecky and al, 2008], puis hRESTS sera complété par le microformat MicroWSMO [Kopecky and al,2009], qui soutient l'annotation sémantique des services web REST, Enfin, les annotations HTML peuvent être sauvegardés et republié, ou il peut être utilisé pour extraire le RDF descriptions MicroWSMO. La figure 4.6 montre les 3-étapes nécessaires pour fournir des annotations sémantiques aux services web RESTful,
Figure 4.6 : L'annotation sémantique des services web RESTful avec SWEET HRESTS : Toutes les interactions possibles avec les services web RESTful, et les services en général, sont imposées dans la description du service, qui donne des informations sur les exigences et hREST [Kopecky and al, 2008] microformat permet la création pour les services web RESTful une descriptions lisible et interprétable par la machine, en ajoutant certains éléments au-dessus du HTML. hREST utilise la « classe » et les attributs « id » de XHTML pour marquer les propriétés du service sans modifier la visualisation de la description au format HTML. hRESTS marquer la description de service dans son ensemble, la méthode utilisée HTTP, l'opération avec ses entrée et ses sortie et le noms de service. Elle permet également le lien entre les différentes pages d'une page principale.la figure 4.7 donne un exemple d'un service web RESTful décrit en hrest. Chapitre 4 Les services web REST sémantique<div class=»service» id=»vol»> <p>Description of the <span class=»label»>billet d'avion</span> service:</p> <div class=»operation» id=»rechercher vol»><p> L'oprération <code class=»label»>getvol</code> est invoqué en utilisant <span class=»method»>GET</span> à<code class=»address»> http://example.com/h/fidg</code>, avec <span class=»input»>le nom de la ville de depart le parameter <code>nom</code></span>. Et retourne <span class=»output»>the les vols en detail <code>ex:volinformation</code> document.</span> </p></div></div>
74 Figure 4.7 Un service RESTful décrit en HREST MicroWSMO : hRESTS marque les principaux propriétés d'un service web RESTful et il fournit une description interprétable par la machine basée sur la documentation disponible (HTML). Le résultat [Maria and al, 2009] utilisent MicroWSMO [Kopecky and al,2009] pour l'annotation sémantique des services web RESTful, et qui permet la création d'un SAWSDL-analogues [Kopecky and al,2007]. Il a trois éléments principaux, qui représentent des liens vers des adresses URI pour des concepts sémantiques et des transformateurs des données. La balise de model indique que l'URI est un lien vers une entité ontologie, tandis que lifting et lowering pointent ver des liens pour lever et descendre des transformations entre le niveau des descriptions techniques (par exemple XML, utilisé comme format d'échange de données) et le niveau de connaissances sémantiques (par exemple RDF, utilisé pour la manipulation fondés sur la sémantique comme le raisonnement). Le microformat MicroWSMO est relativement simple, mais il fournit tous les éléments nécessaires pour attacher des informations sémantiques aux descriptions de services RESTful. Chapitre 4 Les services web REST sémantique<div class=»service» id=»vol»> <a rel="model" href=" http://example.com/events/getEvents"> <p>Description of the <span class=»label»>billet d'avion</span> service:</p> <div class=»operation» id=»rechercher vol»><p> L'oprération <code class=»label»>getvol</code> est invoqué en utilisant <span class=»method»>GET</span> à<code class=»address»> http://example.com/h/fidg </code>, avec <span class=»input»> <h3><a rel="model" href=" http://example.com/data/onto.owl#ville">nom de la ville</a> (<a rel="lowering" href=" http://example.com/data/event.xsparql">lowering</a>)</h3> <p> le nom de la ville de depart.</p>
75 Figure 4.8 Exemple d'un service REST annoté par MICROWSMO 7. Synthèse
Table 4.2 comparaison entre les différentes approches des services REST sémantique Chapitre 4 Les services web REST sémantique
76 8. Conclusion :Dans ce chapitre nous avons pu voir un autre style d'architecture REST, qui est basé sur l'architecture orientée ressources (ROA). Nous avons aussi parlé de la création d'un service web REST et les différentes méthodes utilisées. Ensuite nous avons un peu parlé du langage de description pour les services web REST et à la fin nous avons cité quelques avantages de l'approche REST. Afin de renforcer la découverte et la sélection des services web REST, une tache de sémantisation et nécessaire qui permet non pas une recherche par mot-clé qui est moins efficace mais plutôt une recherche basée sur des concepts ontologiques qui permettent de sélectionner et combiner les différents services de façon automatique et non ambiguë. Pour la sémantisation des services web RSET nous avons présenté un ensemble d'approches (ontologie de service/annotation sémantique) mais la plupart de ces approches n'ont pas donné un grand succès et qu'elles ne sont pas simples à les implémentés. Par exemple, les approches SA-REST [Lathem and al, 2007 ] et SWEET [Maria and al, 2009] nécessitent une page web HTML qui décrive l'API (la documentation) et qui sera transformée par la suite en une description interprétable par la machine afin d'ajouter des annotations sémantique. Chose qui n'est pas toujours vrais et qui rend la tâche plus difficile surtout si l'API REST ne dispose pas une page web qui le décrive. Chapitre 5 L'ingénierie des applications Mashup
77 Chapitre 5L'INGENIERIE DES APPLICATIONSMASHUPChapitre 5 L'ingénierie des applications Mashup
78 1. INTODUCTIONUn Mashup peut être défini comme une application Web qui extrait et combine les données et les fonctionnalités à partir de sources différentes pour répondre aux besoins des utilisateurs[Merrill 2006]. Récemment, un certain nombre de framework ont été proposés pour simplifier le processus de création des mashup afin que les utilisateurs finaux soient en mesure de créer des mashups sans avoir besoins des connaissances en programmation. Dans ce chapitre, nous comparons ces framework à l'égard des besoins en compétences des utilisateurs. L'analyse est basée sur un aperçu représentatif des framework mashup qui ont été proposées par les entreprises et les équipes de recherche. Ensuite, nous donnons un aperçu sur les différents framework de mashup et leurs paradigmes de développement. 2. Le modèle de catégorisation des mashup frameworksLes compétences des utilisateurs peuvent être divisées en catégories développeur, utilisateur, et utilisateur occasionnel. Un développeur doit être familier avec la programmation, les technologies Web, les différents API ainsi que l'utilisation des outils de développement. Un utilisateur n'a pas de compétences en programmation, mais il a une connaissance fonctionnelle détaillée d'un outil spécifique ou un ensemble d'outils. Les utilisateurs occasionnels ont seulement les compétences nécessaires pour utiliser les fonctionnalités d'un navigateur web pour être capables de naviguer dans le Web. Les compétences requises pour les utilisateurs dépendent de l'approche du développement utilisée pour la création du mashup. L'approche du développement des mashup peut être basée sur la création manuelle, semi-automatique ou automatique. La création manuelle signifie que l'intégration des sources de données et des fonctionnalités doit être faite par la programmation ou le Scripting. La Création semi-automatique couvre la création de mashups basée sur les tableurs, des outils de fil et de programmation par démonstration. La création automatique signifie que le mashup est produit sans l'interaction directe de l'utilisateur. Cela signifie que les ressources (par exemple les services de connaissances du web) sont sélectionnées et invoquées automatiquement. En outre, la création des mashup peut être appelées automatique et adaptative, si ce processus génère des mashup adaptés à l'évolution des intérêts des utilisateurs, des tâches et de l'expérience d'un utilisateur, ce qui signifie qu'elle est basée sur un modèle d'utilisateur spécifique [Brusilovsky and al,2007] 3. Les différentes approches pour la création des MASHUPS :3.1. L'approche manuelle :Les frameworks basés sur le paradigme de programmation : Un certain nombre d'outils de création des mashup est basé sur un environnement de développement intégré. IBM WebSphere sMash est un environnement de développement et d'exécution pour les applications web dynamiques. Il permet de réutiliser facilement Chapitre 5 L'ingénierie des applications Mashup
79 et d'intégrer rapidement les différents services web. BungeeConnect est une autre plate-forme qui est offerte comme un service en ligne permettant aux utilisateurs de créer des applications web. Bungee automatise l'importation des services web accessibles au public ainsi que les bases de données traditionnelles et les entrepôts de données. Ce développement manuel des mashup est soutenu par une variété d'environnements de développement et ne peut être fait que par des développeurs expérimentés. Les Framework fondés sur les langages de script : Le développement des mashups est pris en charge par divers outils qui sont basés sur certains langages de script tels que Google Mashup Editor (GME), Web Mashup Scripting Language (WMSL) [Sabbouh and al, 2007], dynamique Fusion of web data , WSO2 Mashup server. En général, il semble être trop compliqué pour un non-développeur de créer de tels scripts dans un temps opportun, car les mashup les plus complexes nécessitent une quantité considérable de code de script assez complexe. 3.2. L'approche semi-automatique :Les Framework basés sur des feuilles de calcul. Les outils de feuille de calcul, tels que StrikeIron SOA,Express pour Excel, Extensio Excel Extender se concentrent sur le mixage des données. Contrairement aux outils wire-oriented, les données sont directement insérées dans une feuille de calcul. Cela signifie que les output d'une source de données sont écrites dans les cellules qui ont été sélectionnés par l'utilisateur. Puis les valeurs des cellules servent d'inputs de requêtes ultérieures des données source. StrikeIron SOA Express et Excel Extensio Extender utilisent les services web SOAPful pour créer des mashups. De plus, Extensio Excel Extender peut donner accès à SAP, plusieurs bases de données ainsi que des fichiers plats. Les framework fondés sur le paradigme de câblage. Outils Wire-orienté de comme Apatar,Damia IBM, Marmite , SABRE ,fils Presto JackBe, Microsoft Popfly, Pipes Yahoo, openkapow, Proto Financial, Anthracite, Mashups Lotus , mixent et fusionnent les données, les fonctionnalités, ou les présentations par un câblage graphique de blocs de construction basics. Cette connexion manuelle est parfois appelé le câblage ou la tuyauterie de différents modules, connecteurs, composants ou blocs. Les éléments disponibles fournissent différents fonctionnalités (par exemple, la récupération de données, transformation de données, la présentation des données, etc) et doivent être connecté pour assurer la coordination souhaitée des mashups. Les outils soutiennent souvent différents types de données, de sources telles que RESTful et / ou SOAPful (par exemple openkapow, Proto Financier, Anthracite) services web, base de données, des tableurs et des fichiers CSV. Chapitre 5 L'ingénierie des applications Mashup
80 Les framework basés sur la programmation par démonstration. La programmation par démonstration permet aux utilisateurs d'avoir un système en fournissant des exemples. Le internet Scrapbook Système[Sugiura and al, 1998]permet aux utilisateurs ayant des compétences en programmation d'automatiser la tache de navigation peu récurrentes. L'utilisateur est en mesure d'indiquer les fragments de différentes pages Web qui sont intéressant pour lui et les regrouper dans une page personnalisée mashup. L'extraction des données est basée sur la structure HTML de la page web spécifique. Dapper est un service en ligne qui est capable de créer une API pour n'importe quel site web Le site web source est initialement spécifié, Puis l'utilisateur peut sélectionner graphiquement à partir de quelques exemples de sorties les champs qui doivent être extraits. Karma [Tuchinda and al,2008] utilise la programmation par démonstration pour extraire des listes de données à partir des pages web par un simple drag-and-drop des éléments d'une page web. Le système
exploite les informations de 3.3. L'approche automatique(sémantique) :Les Mashups sont des applications web développées par la combinaison des données, de la logique métier, et/ou interface utilisateur des sources web publiées et réutilisées via des APIs. Les Mashup visent à réduire le coût et le temps de développement des applications web, mais malgré ces avantages le mashup ne peut être fait que par un développeur qui a besoins non seulement des compétences en programmation mais aussi comprendre la structure et la sémantique des APIs qu'il souhaite intégrés. Pour résoudre ce problème et données aux utilisateurs finaux la possibilité de créer des applications Mashup avec moi de compétence en informatique il y avait un ensemble d'outils Mashup( IBM-CENTER, Dapper, Convertigo, Serena, Popfly, Yahoo-pipes,...) qui ont permet de résoudre plus moins le problème de combinaison et d'agrégation des APIs et ignorer l'intervention du développeur mais cette dernier est nécessaire dans le cas ou les données et les APIs sont hétérogènes chose qui as poussé les chercheurs de trouver une solution efficace pour la création des mashups de manière qu'un utilisateur final peut développer une application Mashup sous un outil lui garantisse la découverte, la sélection , et la superposition automatique ou dynamique en se basant sur l'approche sémantique c'est qu'on appel « MASHUP SEMANTIQUE » Les Mashups sémantique sont des Mashup dont les APIs combinés sont soutenus par une couche sémantique qui permet de les sélectionnés et les composés de manières automatique ( non-ambigüe). Comme cité précédemment (chapitre 2) il existe plusieurs types d'APIs (SOAP, REST, JS, RSS/ATOM, ...) qui représentent les ingrédients d'une application
81 Chapitre 5 L'ingénierie des applications MashupMashup. Afin d'assurer un Mashup automatique (sémantique) il faut que ces différents APIs soient sémantisés en utilisant différentes approches de sémantisation. La sémantisation des APIs est similaire à celle des services web classiques (vois chapitre 3) dans laquelle les services web sont renforcés par une couches sémantique qui permet de les sélectionner et les composer de manières automatiques. Dans le cas des Mashups le même problème est posé, une sélection et une combinaison automatique qui ont permet d'ajouter une couche sémantique au-dessus des APIs (REST, SOAP, JS, RSS,...). Mais le problème majeur dans les Mashup est que ces APIs ne sont pas de même nature par exemple (les services web soap sont orientés services par contre les services web RESTful sont orientés ressources) et qui ont une description différentes. Par exemple dans un même Mashup on peut trouver deux APIs un à base de SOAP avec une description WSDL et l'autre à base de REST avec la description WADL. La génération automatique des Mashups nécessitera non seulement La sémantisation des APIs mais aussi un algorithme de Matching qui permet de trouver automatiquement les différents APIs qui peuvent être combiner avec un service donnée. Dans le cas des Mashups la combinaison des APIs se fait en niveau des entrées et des sorties des méthodes publiées par ces APIs, par exemple on suppose qu'on va créer un Mashup qui permet de donner des informations météorologiques des villes; dans un premier temps on cherche manuellement l'API qui peut nous donner des informations météorologiques, mais cet API lui seul ne suffit pas car il ne donne pas la possibilité de sélectionner et choisir les villes qu' on veut découvrir , chose qui rend la tache difficile pour un utilisateur final. Pour résoudre ce problème on va chercher un API qui complète l'API météorique de manière que l'input LOCATION de l'API météorique correspond au l'output de l'API qu'on cherche (par exemple GoogleMap). 4. Comparaison entre les différentes approches :
Table 5.1 Tableau comparatif entre les différentes approches d'ingénieries de Mashup Chapitre 5 L'ingénierie des applications Mashup
82 5. ConclusionDans ce chapitre nous avons monté les différentes approches pour la génération des mashups , pour cela nous avons distingué trois types d'approches ; l'approche manuelle , semi-automatique et l'approche automatique. En particulier les outils semi-automatiques qui fournissent souvent une interface utilisateur graphique ont acquis une grande popularité dans ces dernières années. Cependant, comme expliqué dans la section précédente, les approches existantes présentent plusieurs limites. Elles n'ont pas un mécanisme pour sélectionner les sources de données (par exemple, les services web) de manière efficace. En outre, la composition des différents composants doit se faire manuellement, ce qui prend beaucoup de temps, et si le nombre de composants disponibles augmente les mashups deviennent plus complexes. Par conséquent, il y avait l'approche sémantique qui permet la génération automatique des mashup. Le framework sélectionne et combine automatiquement les APIs fournis pour créer les applications mashups. Chapitre 6 Construction de Mashup sémantique
83 Chapitre 6 : Construction de MashupSémantiqueChapitre 6 Construction de Mashup sémantique
84 1. Introduction:Les applications MASHUP permettent de combiner un ensemble de ressources et de fonctionnalités existantes fournis via des APIs (WSDL, REST, JS, RSS,..) afin de rependre aux besoins d'un utilisateur. Ainsi, nous pouvons considérer que le processus d'ingénierie d'une application MASHUP suive les étapes suivantes : ? La spécification des besoins, ? La découverte et la sélection des APIs qui repend aux besoins, ? La combinaison des APIs (créer des correspondances entre l'ensemble d'APIs). Généralement ces différents étapes se font manuellement (par le développeur) ou semi-automatiquement (l'utilisation d'un outil MASHUP). Mais dans les deux cas, la découverte, la sélection, et la combinaison restent des tâches difficiles et complexes grâce à la diversité d'APIs. Une des solutions qui permet de réduire le coût du développement des MASHUP est l'approche sémantique qui vise à automatiser le processus de développement. Cette approche sémantique définit deux étapes qui vont servir à l'automatisation des MASHUP : La sémantisation des APIs, La combinaison à base de Matching des APIs. Notre approche proposée se base beaucoup plus sur la sémantisation des APIs de type REST qui sont les plus utilisés dans les applications Mashup grâce à leur simplicité et qui sont capables de créer des applications interopérables. La plupart des approches de service web REST sémantique n'ont pas donné un grand succès et qu'elles ne sont pas simples à les implémentés. Par exemple, les approches SA-REST [Lathem and al, 2007 ] et SWEET [Maria and al, 2009] nécessitent une page web HTML qui décrive l'API (la documentation) et qui sera transformée par la suite en une description interprétable par la machine afin d'ajouter des annotations sémantique. Une chose qui n'est pas toujours vrais et qui rend la tâche plus difficile surtout si l'API REST ne dispose pas une page web qui le décrive ou cette page ne contient pas les informations qui décrivent les entrés/sorties de cet API. Dans le reste de ce chapitre nous présentons notre approche qui permet de sémantiser les services REST au-dessus de la description WADL (web application description language) qui est plus structurée et adaptative aux exigences des application Mashup sémantique Notre travail est motivé par le fait que jusqu'à maintenant les outils Mashup existants ne répandent pas aux besoins de l'approche Mashup qui permet non seulement aux développeurs de créer des applications mais aussi bien aux utilisateurs finaux sans avoir besoins des connaissances à la programmation. Chapitre 6 Construction de Mashup sémantique2. SAWADL(Semantic Annotation for Web Application description Language) :Afin de créer un Mashup automatique il faut passer tout d'abord par une tache de sémantisation des APIs. Dans cette partie nous proposons une approche qui permet de sémantiser les services WEB RESTful(les plus utilisé dans les applications Mashups) afin de renforcer la sélection et la superposition de ces services dans les applications Mashups. Les approches des services web REST sémantique regroupent deux parties (ontologies de service, annotation sémantique). L'extension du langage WADL que nous propose (SAWADL) fait partie des celles qui permettent d'ajouter des annotations sémantique au-dessus de la description du service. Mais la plupart des approches sont basées sur une annotation sémantique au-dessus d'une description fondée sur HTML qui donne moins d'homogénéité entre les services web REST. Dans notre approche la description WADL présenté précédemment est utilisée pour décrire les services web REST. SAWADL ne spécifie pas un langage pour la représentation des modèles sémantiques. Il fournie des mécanismes pour référencer des concepts de modèles définis à l'extérieure du document WADL. Ces méthodes d'annotation se résument en un seul mécanisme : Model Reference. Cela se fait grâce à l'attribut « sawadl » suivi de l'extension appropriée. Voici un exemple d'annotation SAWADL :
<resources base=" http://ec2.amazonaws.com"> <method id="describeImages" name="GET"> <request> <param name="Action" type="xsd:string" sawadl: model reference =« http://localhost/otologie/teste.owl#Class_8" /> <param name="ImageType" type="xsd:string" sawadl: model reference =" http://localhost/otologie/teste.owl#lo" />
85 Figure 6.1 Exemple d'un service web REST en SAWADL 2.1. Annotation de documents WADL :Pour annoter les documents WADL, nous utilisons Model Reference. Cela permet la catégorisation des méthodes et il leur fournit une description de haut niveau. En ce qui concerne l'annotation des entrées (Input) et des sorties (Output), cela offre une description de bas niveau. Ceci est un exemple d'annotation d'une méthode qui présente une description de haut niveau :
<resources base=" http://ec2.amazonaws.com"> hapitre 6 Construction de Mashup séman <method id=" acheterBilletOp " name="GET" sawadl:modelRefernce ="VoyageOnto:buyTicket"> ....
86 Figure 6.2 Annotation des méthodes avec SAWADL 2.1.1. Annotation des MéthodesDans cette section, nous montrons comment s'effectue l'annotation des méthodes dans un document WADL. Nous allons annoter l'opération acheterBilletOp, en l'associant par le biais de l'attribut modelRefernce avec un concept dans l'ontologie VoyageOnto. Cette opération représente le service d'achat de billet de vol ; elle prend en entrée une carte bancaire et retourne un reçu comme résultat. Bien que, traditionnellement les entrées et les sorties fournissent d'une manière intuitive la sémantique d'une opération, une annotation sémantique simple peut s'avérer utile. 2.1.2. Annotation des entrées et des sortiesCette section se focalise sur la façon dont est faite l'annotation des entrées et des sorties dans SAWADL. En effet, l'annotation d'une entrée ou une sortie peut se faire de façons différentes : l'annotation des niveaux internes : Cette annotation consiste à associer chaque paramètre (input) « <param...> » et sortie (output) d'une méthode à un concept dans une ontologie. Cela suppose que pour chaque paramètre d'entrée, sortie d'une méthode il existe un concept correspondant dans l'ontologie. Par exemple, l'entrée de l'opération achaterBilletOp est une carte bancaire. Une carte bancaire est identifiée par le nom et prénom du propriétaire et le numéro, le type et la date d'expiration de la carte. Nous supposons que pour chaque attribut de la carte bancaire, il existe un concept qui lui correspond dans l'ontologie des cartes bancaire (CarteDeCreditOnto).Dans le cas où il n'y a pas de correspondance, la sémantique des paramètres d'entrées sorties restent non spécifiée.
Figure 6.3 Annotation des entrés et des sorties internement avec SAWADL
87 Chapitre 6 Construction de Mashup sémantiquel'annotation des niveaux externes: Dans ce cas, les entrées d'une méthode sont annotées globalement via la balise « <request> »mais il faut créer des schémas de Maping qui permet de spécifier les schémas de transformation nécessaires entre les paramètres en entrés et les concepts d'une ontologie une chose qui n'est pas traité dans notre travail. A titre d'illustration, nous prenons l'exemple de la carte CarteBancaire définit en WADL (voir figure6.4) et l'ontologie OWL des carte bancaire (voir figure 6.4). Dans cette ontologie il n'y a pas de correspondance individuelle pour les deux attributs Nom et Prénom du type CarteBancaire. Cependant, le concept Propriétaire de l'ontologie correspond à la fusion de ces deux attributs. Afin d'établir la correspondance entre CarteBancaire et CarteDeCredit il faut, premièrement, les associer en utilisant modleRefernce et ensuite définir un schéma de transformation à l'aide d'une feuille de style XSL par exemple.
Figure 6.4 annotation des entrés et des sorties globalement avec SAWADL 3. Le Processus D'ingénierie D'un Mashup Sémantique:La création des applications Mashup automatique nécessitera forcement une couche sémantique au-dessus des APIs (service web) qu'ils les composent. Comme la composition dynamique des services web classiques, les Mashup
sémantique permettent un
88 Chapitre 6 Construction de Mashup sémantiqueLa figure 6.5 montre une architecture de référence pour un mashup sémantique. Cette architecture se compose en un ensemble de couche et une ontologie de domaine. Les couches représentent les principaux blocs fonctionnels pour la génération automatique des Mashup. L'ontologie de domaine vise à enrichir le processus d'ingénierie par une couche sémantique lui permet une sélection et une combinaison automatique des APIs inclus dans l'application Mashup.
Figure 6.5 : Cycle de vie d'un Mashup sémantique 3.1 La sémantisation des APIs :Notre travail consiste à créer un prototype qui permet de faire une combinaison automatique entre deux types D'APIs (SOAP, RESTful) qui sont les plus utilisés dans l'ingénierie des applications MASHUPs. Différentes approches de services web sémantique sont implémentées dans notre outil, tel que l'approche SAWSDL qui est utilisée pour sémantiser les services web SOAP. SAWSDL permet d'annoter les entrées et les sorties d'un fichier WSDL avec des concepts ontologique, cela va servir dans la création automatique des mashups en sélectionnant de manière non-ambigu les Inputs (respectivement Chapitre 6 Construction de Mashup sémantique
89 Outputs) qui peuvent être réutilisées et combinés avec l'Output (respectivement Input) d'un autre API. Pour les services web REST notre approche SAWADL que nous avons proposé est choisie afin d'annoter les entrées et les sorties des APIs de type REST. Les approches SAWADL et SAWSDL font parties de celles d'annotation sémantique, chose qui nous facilite le processus d'annotation et de Matching. 3.2 La combinaison (Matching) des APIs :La composition des APIs web se réfère au processus de création d'un Mashup offrant une nouvelle fonctionnalité, à partir de services web existants plus simples, par le processus de découverte dynamique(automatique), et d'intégration de ces APIs dans un ordre bien défini afin de satisfaire un besoin bien déterminé. Malgré les efforts de recherche et de développement autour de la problématique de Mashup automatique, elle reste une tâche hautement complexe et pose un certain nombre de défis. Sa complexité provient généralement des sources suivantes : L'augmentation dramatique du nombre des APIs sur le web rend très difficile la recherche et la sélection des APIs pouvant répondre à un besoin donné. Les APIs sont crées et mis à jour de façon hautement dynamique. Les APIs web sont d'habitude développés par différentes organisations qui utilisent différents types (REST, SOAP, JS, RSS/ATOM,..) et modèles conceptuels pour décrire les caractéristiques des APIs. La modularité constitue une caractéristique importante des APIs Web, par conséquent, les applications MASHUP doivent garder récursivement les mêmes caractéristiques que les APIs basiques à savoir auto-descriptifs, interopérables, et facilement intégrables. Dans notre cas le Matching horizontale décrit dans le chapitre 3 est utilisé dans le but de trouver des correspondances entre les entrées/sorties de différents APIs (REST, SOAP) qui utilisent respectivement les approches SAWADL et SAWSDL afin d'assurer une certaine automatisation dans le processus d'ingénierie des applications Mashup. Les correspondances entre les APIs sont établies en se basant sur la similarité sémantique qui permet de calculer une distance entre les concepts ontologiques des entrés/sorties et qui sera par la suite comparée avec un seuil prédéfinit pour qu'on puisse savoir si un API pourrai être combiné avec un autre ou non. Le tableau 6.1 définit Les différentes distances sémantiques entre les concepts ontologiques. Chapitre 6 Construction de Mashup sémantique
90
Table 6.1 les distances sémantique [Anne and al,2010] Ces distances sont définies par des ontologistes dans le but de calculer une valeur de Matching qui permet d'estimer le taux de sucée de la combinaison de deux services. Par exemple soit quatre concepts ontologiques Personne, Etudiant, Student, et Nom. En se basant sur le tableau ci-dessus les distances sémantiques entre ces concepts ontologiques sont calculées comme suit : Le concept Etudiant et plus spécifique que le concept Personne, ceci implique que la relation qui existe entre ces deux concepts et bien la relation « SubClassOf » et la distance entre Etudiant et Personne=0.7. Les concepts Etudiant et Student sont équivalents, ceci implique que la relation qui existe entre ces deux concepts et bien la relation « EquivalentClass » et la distance entre Etudiant et Student=0.0. Le concept Nom présente une propriété de concept Personne qui implique que la relation qui existe entre ces deux concepts et bien la relation « HasPropertyClass » et la distance entre Nom et Personne=0.3. La valeur de Matching entre deux services peut être calculée en utilisant la formule suivante : [Anne and al,2010] Où est le nombre des paramètres d'entrés de service ainsi et le nombre des paramètres de sorties de service . Enfin est la distance ontologique entre les paramètres d'entrés et sorties des services . L'hétérogénéité entre les fichiers décrites par l'approche SAWSDL et l'approche SAWADL est résolue en suivant les étapes suivantes : ? Une méthode décrite par la balise «<method>» d'une ressource ou une sous-ressource Chapitre 6 Construction de Mashup sémantique
91 « < resource> » d'un fichier SAWADL correspond à une opération décrite par la balise « <operation> » d'un fichier SAWSDL. ? Un input décrit par la balise « < param> » de l'ensemble entrées « <request>» d'une méthode d'un fichier SAWADL correspond à une entrée décrite dans le XML schéma d'un service web par la balise « <element> » d'un « <complexType> » d'un Input d'une opération décrite dans fichier SAWSDL. ? Un Output décrit par la balise « <response> » d'une méthode d'un fichier SAWADL correspond à une sortie décrite dans le XML schéma d'un service web par la balise « <element> » d'un « <complexType> » d'un output d'une opération décrite dans fichier SAWSDL. ? L'attribut « sawadl: model reference » d'un SAWADL qui exprime la sémantique correspond à l'attribut « sawsdl: model reference » d'un fichier SAWSDL. Remarque : dans notre travail les schémas de Mapping définit dans les deux approches SAWADL et SAWSDL ne sont pas traités. 4. Conclusion :L'automatisation des Mashups à des apports pour le développement rapide des applications et la réduction de coût de ce dernier tout ça grâce à l'utilisation de la sémantique qui donne à la machine certaine autonomie dans la sélection et la combinaison des APIs(services) qui convient. Dans cette partie nous avons montré les principales étapes de cycle de vie d'un Mashup sémantique dans lequel la sémantisation des APIs joue un grand rôle dans le processus d'ingénierie d'un Mashup automatique car elle associé à chaque APIs un ensemble de concepts ontologiques permet d'ajouter une couche sémantique au-dessus des ces APIs, puis en appliquant le processus de Matching pour qu'on puisse récupérer l'ensemble de combinaison qui peuvent existées entre les APIs. Dans cette partie nous avons aussi proposé une approche de sémantisation des services web REST basée sur l'annotation sémantique au-dessus de la description WADL. Chapitre 7 Mise en oeuvre
92 Chapitre 7 : LA MISE EN OEUVRE DUPROTOTYPE
93 Chapitre 7 Mise en oeuvre1. IntroductionDans cette partie, nous présentons un prototype qui permet la sémantisation des applications Mashup et qui regroupe trois composants qui sont les suivants: V' un outil d'annotation de services Web SOAP accessible via une interface graphique, V' un outil d'annotation de services Web REST accessible via une interface graphique, V' un outil de Matching entre les services web REST et SOAP. Ces trois composants ont été développés sous l'environnement de développement Java. Dans ce chapitre, nous détaillons le fonctionnement de chaque composant, ainsi que les détails concrets de leur implantation. Les types de services (API) utilisés pour créer les Mashup dans ce prototype sont les services RESTful et SOAP et qui sont sémantiser respectivement par le langage proposé SAWADL et l'approche SAWSDL afin d'avoir une couche sémantique qui permet la sélection, et la superposition automatique des services web. La figure 7.1 montre l'architecture de notre prototype. 2. L'architecture Du prototype :
Figure 7.1:L'architecture du prototype 2.1. L'outil d'annotation des services web SOAP :
94 Chapitre 7 Mise en oeuvreNotre outil de lecture/écriture de fichiers WSDL permet l'ajout, et la modification des annotations sémantique en se basant sur l'approche SAWSDL décrite dans la section 4.1.2 du chapitre 3 .Il permet aux fournisseurs de services Web d'annoter des fichiers WSDL avec concepts sémantique nécessaire pour réaliser des Mashup automatique. Notre outil fonctionne de la manière suivante : l'utilisateur sélectionne un fichier WSDL qu'il souhaite l'annoté, puis il choisit l'ontologie auquel il va trouver les concepts ontologique qui seront utilisés pour annoter le service web. Une fois le service et l'ontologie sont sélectionnés l'outil affiche à l'utilisateur les différentes méthodes et leurs paramètres décrits par le service ainsi que sons schéma ces derniers seront annotés par l'utilisateur soit en mode externe ou interne.
Figure 7.2 Aperçu de l'outil d'annotation des services web SOAP 2.2. L'outil d'annotation des services web REST :Notre outil de lecture/écriture de fichiers WADL permet l'ajout, et la modification des annotations sémantique en se basant sur notre approche SAWADL décrite dans la deuxième section .Il permet aux fournisseurs de services Web d'annoter des fichiers WADL avec l'information sémantique nécessaire pour réaliser des Mashup automatique.
95 Chapitre 7 Mise en oeuvreNotre outil fonctionne de la manière suivante : l'utilisateur sélectionne un fichier WADL qu'il souhaite l'annoté, puis il choisit l'ontologie auquel il va trouver les concepts ontologique qui seront utilisés pour annoter le service web REST. Une fois le service et l'ontologie sont sélectionnés l'outil affiche à l'utilisateur les différentes ressources, méthodes et leurs paramètres qui sont décrits par le service ces derniers seront annotés par l'utilisateur soit en mode externe ou interne.
Figure 7.3 Aperçu de l'outil d'annotation des services web REST 2.3. L'outil de Matching :Dans ce composant de notre prototype la partie la plus intéressante dans le cycle de vie d'un Mashup automatique et implémenté dans laquelle des correspondances entre les concepts ontologiques des services web REST et SOAP sont établies en utilisant la similarité sémantique. Notre outil fonctionne de la manière suivante : l'utilisateur sélectionne un service (REST ou SOAP) qu'il souhaite le combiner avec d'autre service, puis il sélectionne les l'emplacement des autres services. Une fois les services sont sélectionnés l'outil affiche toutes les correspondances qui peuvent être existées entre tous les services sélectionnés. Chapitre 7 Mise en oeuvre
Figure 7.4 Aperçu de l'outil de Matching
Figure 7.5 Aperçu de l'outil de Matching 96 Le composant de Matching peut aussi donner l'ensemble de services qui peuvent être combiné avec le service en entré en appliquant la formule présentée précédemment et qui estime la valeur de Matching. La figure ci-dessous montre un exemple de services qui peuvent être combiné avec un autre. Chapitre 7 Mise en oeuvre
97 3. Etude De Cas :Tout au long de la partie précédente, nous avons parlé de la notion des Mashups comme étant une technologie de composition des services et des données ensuite nous avons présenté un état de l'art sur les services Web, et les service web REST sémantique, enfin nous avons terminé par l'étude d'un type spécifique de Mashups qui est le "Mashup Sémantique" dans lequel on a montré le cycle de vie d'un Mashup Sémantique et on a aussi proposé une approche (SAWADL) qui permet d'ajouter des annotations sémantiques au-dessus des service Web REST décris par la description WADL . Dans le but de valider notre approche nous proposons la création d'une application Mashup qui intègre les différentes applications et activités de la société nationale des transports ferroviaires(SNTF), en suivant l'approche d'ingénierie sémantique présenté précédemment. Dans cette partie, nous allons commencer par faire une petite étude sur les applications existantes au niveau de la société SNTF et qu'on les souhaite intégrés dans notre Mashup, mais avant cela nous définissons l'ontologie qui sera utilisé pour l'annotation sémantique des APIs. 3.1. Ontologie :Afin de créer un Mashup Sémantique il faut qu'on dispose une ontologie qui sera utilisé pour enrichir les différents APIs avec des concepts ontologiques. Dans cette partie nous proposons la création d'une ontologie OWL DL pour la société SNTF et qui sera utilisée pour la sémantisation, la sélection et le Matching des APIs, tout ceci à travers les APIs Jena (manipulation de L'ontologie), et Pellet(pour raisonnement sur l'ontologie OWL DL). La figure 7.6 montre l'ontologie de Maintenance de la société SNTF. Chapitre 7 Mise en oeuvre
98 Figure 7.6 : ontologie global de Maintenance de la société SNTF 3.2. Architecture de Mashup :Afin de valider notre travail présenté précédemment nous proposons la création d'une application Mashup pour la maintenance des voitures en se basant sur L'approche
99 Chapitre 7 Mise en oeuvresémantique. Dans un premier temps nous identifions l'ensemble des APIs utilisés dans La gestion globale de maintenance de la société SNTF, puis nous utilisons notre prototype pour sémantiser ces APIs en appliquant l'approche SAWSDL pour les APIs de type SOAP et notre approche proposée SAWADL pour ceux de type REST. Pour la couche sémantique l'ontologie définit précédemment est utilisée pour l'annotation sémantique des APIs. Une fois sémantisé les APIs en utilisant le module de Matching (de notre prototype) qui nous propose un ensemble de combinaison entre les différents Service existants. Les principaux APIs (service) utilisés dans La gestion de maintenance se regroupent en quatre modules principaux : la gestion des voitures, la gestion des taches, la gestion des pièces, et la gestion des employés. Pour qu'on puisse créer une application Mashup de manière automatique en se basant sur ces APIs existés, en commençant par l'annotation sémantique. Par exemple l'opération « GetVoiture » du L'API « GestionVoiture » sera annoté comme suis :
Figure 7.7 : exemple de sémantisation d'un API Après la sémantisation des APIs, on passe à l'étape de Matching dans laquelle un ensemble de combinaison seront proposé en se basant sur la similarité sémantique entre les APIs. Par exemple l'API REST de la gestion des taches peut être combiné avec l'API SOAP de la gestion d'employés. La figure ci-après montre les combinaisons proposées par le module de Matching de notre prototype.
100 Chapitre 7 Mise en oeuvre
Figure 7.8 Exemple de Matching entre APIs Après le processus de Matching, nous serons devant le choix d'un ensemble de combinaison entre les différents APIs. La figure 7.9 montre notre architecture de l'application Mashup en se basant sur les combinaisons proposées par notre prototype.
Figure 7.9 Architecture de Mashup de Maintenance SNTF
101 Chapitre 7 Mise en oeuvreAprès avoir appliqué le processus décrit au-dessus nous obtenons l'application Mashup de maintenance et qui intègre quatre applications (Gestion Voiture, Gestion Tâche, Gestion Employer, Gestion Pièce).
Figure 7.10 : Aperçus de Mashup de Maintenance SNTF. 4. Conclusion :L'utilisation des Mashups aide les entreprises dans la réduction de temps et de coût pour le développement l'intégration des applications. Les Mashups sémantique joue un grand rôle Chapitre 7 Mise en oeuvre
102 en matière d'agilité et de flexibilité en ce qui concerne l'intégration et l'interopérabilité entre les applications internes et externes. Nous avons réalisé un prototype qui aide à l'ingénierie des applications Mashups de façon automatique en se basant sur l'approche sémantique. Notre prototype permet l'annotation sémantique des services web SOAP et REST en utilisant respectivement les langages SAWSDL et SAWADL. Ce prototype permet aussi la découverte et la combinaison entre les différents APIs en appliquant un algorithme de Matching. Notre travail a été validé par la création d'une application Mashup de la gestion de maintenance en niveau de la société SNTF. Nous avons commencé par la création de l'ontologie de maintenance qui est utilisée pour l'annotation sémantique des services web, par la suite nous avons utilisé notre prototype pour l'annotation de service existants (voiture, personnel, pièce, tache) puis nous avons utilisé le composant de Matching afin de générer les différentes interactions qui peuvent être existées entre les services en se basant sur la similarité sémantique. Chapitre 8 Conclusion générale
103 Chapitre 8CONCLUSION GENERALEChapitre 8 Conclusion générale
104 1. Conclusion :Avec le développement rapide des technologies de l'information, l'intégration et l'interopérabilité est de nos jours une problématique centrale des systèmes d'information distribués. Ce domaine de recherche est favorisé par l'adoption de l'architecture orientée service puis par le Mashup comme modèle de développement. Les Mashups ont permis une avancée significative dans l'automatisation des interactions entre les applications et ressources Web. Notamment, la combinaison des APIs Web (REST, SOAP, RSS, JS,. .) est considérée comme un point fort, qui permet de répondre à des besoins complexes en combinant les fonctionnalités et les données de plusieurs services au sein d'une seule application Mashup. Cependant, afin de remédier le manque des langages et protocoles actuels mis en place par la communauté informatique, nous avons vu que les travaux liés `l'ingénierie des applications Mashups sont particulièrement orientés vers le niveau sémantique. L'objectif recherché à travers l'utilisation de la sémantique est de permettre aux machines d'interpréter les données traitées et de saisir leur signification de manière automatique afin d'automatiser la sélection et la combinaison des APIs utilisés pour créer l'application Mashup. Cet objectif est concrètement atteint par le déploiement d'ontologies de domaine, qui sont des descriptions explicites et partagées de la sémantique associée aux données. De nombreux langages et annotations ont été proposés pour la description sémantique des APIs web, par exemple pour les APIs de type SOAP il existe plusieurs approches de sémantisation tel que OWLS, WSMO(ontologie de service) et WSDL-S, SAWSDL(annotation sémantique) ; de la même manière pour les APIs de type REST, plusieurs travaux visent à ajouter une couche sémantique en citant par exemple l'approche SOOWL-S(ontologie de service) et les approches SA-REST [Lathem and al, 2007 ] et SWEET[Maria and al, 2009] (annotation sémantique). Mais ces derniers n'ont pas donné un grand succès et ne sont pas simples à les implémentés. Par exemple, les approches SA-REST et SWEET nécessitent une page web HTML qui décrive l'API (la documentation) et qui sera transformée par la suite en une description interprétable par la machine afin d'ajouter des annotations sémantique. Une chose qui n'est pas toujours vrais et qui rend la tâche plus difficile surtout si l'API REST ne dispose pas une page web qui le décrive. C'est dans le but de répondre à ces problématiques que nous avons mené nos recherches. Nos travaux sont orientés vers la sémantique, et plus particulièrement vers une proposition d'un langage d'annotation sémantique pour les services Web REST. Nous avons étudié les travaux existants relatifs à la description sémantique de services Web REST, afin d'établir notre proposition SAWADL (semantic annotation for web application description language) . Notre approche SAWADL fait partie des approches qui permettent d'ajouter des annotations sémantique au-dessus de la description du service. Contrairement aux approches qui annotent au-dessus d'une description HTML nous utilisons la description WADL( web application description language) qui est utilisée pour décrire syntaxiquement les services web REST. Chapitre 8 Conclusion générale
105 La sémantisation des APIs ne suffit pas pour concevoir et mettre en oeuvre un Mashup automatique, ainsi un processus de Matching est nécessaire pour trouver des correspondances entre les différents APIs, afin de découvrir de manière automatique les composants mashables suivie les besoins d'utilisateur. Nous avons réalisé un prototype qui aide à l'ingénierie des applications Mashups de façon automatique en se basant sur l'approche sémantique. Notre prototype permet l'annotation sémantique des services web SOAP et REST en utilisant respectivement les langages SAWSDL et SAWADL. Ce prototype permet aussi la découverte et la combinaison entre les différents APIs en appliquant un algorithme de Matching. Notre travail a été validé par la création d'une application Mashup de la gestion de maintenance en niveau de la société SNTF de Sidi bel-abbes. Enfin, plusieurs perspectives peuvent être envisagées afin de contribuer beaucoup plus à la l'agilité et la flexibilité de l'approche MASHUP Sémantique, nous citons à titre d'exemple : La sémantisation des autres APIs web tel que les APIs de type javascript, RSS/ATOM,.., qui représentent des composants mashables très utilisés dans le développement des Mashups publics ou consommateur ; mais l'absence d'une description structurelle et modulaire rendre la sémantisation des ces APIs un défi à résoudre. L'utilisation de l'approche sémantique dans la création des Mashups d'entreprise orienté processus qui permettent à un utilisateur d'automatiser ses tâches comme s'il les a effectué manuellement. Cette approche est différente de la gestion des Workflow car les Mashups sont orientés vers un seul utilisateur/rôle. Les Mashups d'entreprise peuvent être considérés comme un complément d'un système workflow. En raison de l'agilité, et la capacité de réagir aux changements des besoins des utilisateurs, et des ressources lies au processus.
106 REFERENCES+ [Antoine,al 1999] Antoine Beugnard, Jean-Marc Jézéquel, Noël Plouzeau, and DamienWatkins. Making Components Contract Aware. Computer, 32(7) :38À45, 1999. + [Anne and al,2010] Anne H.H. Ngu, Michael P. Carlson, Quan Z. Sheng Semantic-based Mashup of Composite Applications,2010. + [Arroyo and al, 2004 ]S. Arroyo and M. Stollberg. WSMO Primer. WSMO Deliverable D3.1, DERIWorking Draft. Technical report, WSMO, 2004. http://www.wsmo.org/2004/d3/d3.1/. + [Athman and al,2010] Athman Bouguettaya, Paul de Vrieze,Lai Xu, Jian Yang,and Jinjun Chen Building enterprise mashups 2010. + [Bruijn and al,2007] Jos de Bruijn, John Domingue, Dieter Fensel, Holger Lausen, Axel Polleres, Dumitru Roman, et Michael Stollberg, Enabling Semantic Web Services : The Web Service Modeling Ontology, édition Springer, 2007. + [Brusilovsky and al, 2007]P. Brusilovsky, A. Kobsa, and W. Nejdl, editors. The Adaptive Web, Methods and Strategies of Web Personalization, 2007. + [Cardoso 2007] Jorge Cardoso, Semantic Web Services : Theory, Tools, and Applications, University of Madeira, Portugal, Information Science reference, édition Dunod, 2007. + [Carlson, and al, 2008 ]M. P. Carlson, A. H.H. Ngu, R. Podorozhny, and L. Zeng. Automatic Mash Up of Composite Applications 2008. + [Chris 2003] Chris Peltz. Web Services Orchestration and Choreography. 2003. + [Curbera , 2007]F. Curbera, M. Duftler, R. Khalaf, D. Lovell, Bite: workflow composition for the web 2007. + [Daconta and al,2003] Michael Daconta, Leo Obrst, et Kevin Smith, Developing the Semantic Web : a Guide to the Future of XML, Web Services, and Knowledge Management, edition Wiley, 2003. + [Daniel and al. 2007]Daniel F, Yu J, Benatallah B, Casati F, Matera M, Saint-Paul R Understanding UI integration.2007. + [Daniel and al,2004] Daniel Austin, Abbie Barbir, Ed Peters, and Steve Ross-Talbot. Web Services Choreography Requirements 1.0. 2004.[Fast,2008] Fast and Advanced Storyboard Tools (FAST) Project,2008 http://fast.morfeo-project.eu/. + [Falquet and al,2001] G. Falquet, et C.L. Mottaz-Jiang, Navigation hypertexte dans une ontologie multi-points de vue, Nîmes TIC, 2001. + [Farrell and al, 2007]Joel Farrell and Holger Lausen. Semantic annotations for wsdl and xml schema, August 2007. + [Fischer and al , 2008] T. Fischer, F. Bakalov, and A. Nauerz. Towards an Automatic Service Composition for Generation of User-Sensitive Mashups 2008. + [Gauzy et al. 2009] Gauzy Di Lorenzo, Hakim Hacid, , Hye-young Paik,Boualem Benatallah , Data integration in mashup , 2009. + [Gurram and al, 2008]Gurram R, Mo B, Gueldemeister R A web based mashup platform for enterprise . 2008. + [GIF 2008] Foundations of Popfly (Rapid Mashup Development) APRESS, Eric Griffin, 2008. 204 pages. + [Hoyer and al,2008] Hoyer, V., Stanoevska-Slabeva, K., Janner, T., and Schroth, Enterprise Mashups: Design Principles towards the Long Tail of User Needs 2006.
107
108 + [Philip and al,2001] Philip A. BernsteinDOI Erhard Rahm. A survey of approaches to automatic schema matching. 2001 + [Sabbouh and al, 2007]M. Sabbouh, J. Higginson, S. Semy, and D. Gagne. Web Mashup Scripting Language., 2007. + [Sean and al, 2007] Ed Ort, Sean Brydon, and Mark Basler Mashup Styles,2007. + [Sugiura and al, 1998] A. Sugiura and Y. Koseki. Internet Scrapbook: Automating Web Browsing Tasks by Demonstration 1998. + [TEMGLIT and al,2008] N. TEMGLIT, H.ALIANE, M.AHMED NACER Un modèle de composition des services web Sémantiques, 2008. + [Tuchinda and al,2008]R. Tuchinda, P. A. Szekely, and C. A. Knoblock. Building Mashups by example,2008 + [Un,2006] UN/CEFACT, ebxml business process specification schema, version 2.0.4, 2006. + [Vrieze et al 2009] Paul de Vrieze, Lai Xu, Athman Bouguettayay, Jian Yangz and Jinjun Chen Process-oriented Enterprise Mashups2009 + [w3c,2005]W3C, web services choreography description language version 1.0, 2005. + [Wirtsch and al, 2010] Wirtsch ,and Roman Beck Enterprise Mashup Systems as Platform for Situational Applications 2010 . + [Xuanzhe,al_07 ]Towards Service Composition Based on Mashup Xuanzhe Liu1, Yi Hui2 , Wei Sun2, Haiqi Liang2, 2007.
109 Annexe A : Ontologie OWL DL de domaine de Maintenance (société SNTF)<?xml version="1.0"?> <rdf:RDF xmlns=" http://localhost:8888/tp_php/sntf/mashup_sntf/ontologie/sntf.owl#" xmlns:rdf=" http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:protege=" http://protege.stanford.edu/plugins/owl/protege#" xmlns:xsp=" http://www.owl-ontologies.com/2005/08/07/xsp.owl#" xmlns:owl=" http://www.w3.org/2002/07/owl#" xmlns:xsd=" http://www.w3.org/2001/XMLSchema#" xmlns:swrl=" http://www.w3.org/2003/11/swrl#" xmlns:swrlb=" http://www.w3.org/2003/11/swrlb#" xmlns:rdfs=" http://www.w3.org/2000/01/rdf-schema#" xml:base=" http://localhost:8888/tp_php/sntf/mashup_sntf/ontologie/sntf.owl"> <owl:Ontology rdf:about=""/> <owl:Class rdf:ID="Vehicule"/> <owl:Class rdf:ID="NumeroEmploye"> <rdfs:subClassOf> <owl:Class rdf:ID="ProprieteEmploye"/> </rdfs:subClassOf> </owl:Class> <owl:Class rdf:ID="NumeroTache"> <rdfs:subClassOf> <owl:Class rdf:ID="ProprieteTache"/> </rdfs:subClassOf> </owl:Class> <owl:Class rdf:ID="ParcourVoiture"> <rdfs:subClassOf> <owl:Class rdf:ID="ProprieteVoiture"/> </rdfs:subClassOf>
110 </owl:Class> <owl:Class rdf:ID="Personne"/> <owl:Class rdf:ID="NumeroGroupeTravail"> <owl:equivalentClass> <owl:Class rdf:ID="NumeroEquipe"/> </owl:equivalentClass> <rdfs:subClassOf rdf:resource="#ProprieteTache"/> </owl:Class> <owl:Class rdf:ID="VoitureVoyageur"> <rdfs:subClassOf rdf:resource="#Vehicule"/> </owl:Class> <owl:Class rdf:ID="PrenomEmploye"> <rdfs:subClassOf rdf:resource="#ProprieteEmploye"/> </owl:Class> <owl:Class rdf:ID="NomEmploye"> <rdfs:subClassOf rdf:resource="#ProprieteEmploye"/> </owl:Class> <owl:Class rdf:ID="NiveauEmploye"> <rdfs:subClassOf rdf:resource="#ProprieteEmploye"/> </owl:Class> <owl:Class rdf:ID="ProprieteEquipe"/> <owl:Class rdf:about="#NumeroEquipe"> <owl:equivalentClass rdf:resource="#NumeroGroupeTravail"/> <rdfs:subClassOf rdf:resource="#ProprieteEquipe"/> </owl:Class> <owl:Class rdf:ID="CategorieVoiture"> <rdfs:subClassOf rdf:resource="#ProprieteVoiture"/> </owl:Class> <owl:Class rdf:ID="Tache"> <rdfs:subClassOf> <owl:Class rdf:ID="Maintenance"/>
111 </rdfs:subClassOf> </owl:Class> <owl:Class rdf:ID="Train"/> <owl:Class rdf:ID="GradeEmploye"> <rdfs:subClassOf rdf:resource="#ProprieteEmploye"/> </owl:Class> <owl:Class rdf:ID="Operation"> <rdfs:subClassOf rdf:resource="#Maintenance"/> </owl:Class> <owl:Class rdf:ID="Locomotive"> <rdfs:subClassOf rdf:resource="#Vehicule"/> </owl:Class> <owl:Class rdf:ID="Piece"/> <owl:Class rdf:ID="NumeroVoiture"> <rdfs:subClassOf rdf:resource="#ProprieteVoiture"/> </owl:Class> <owl:Class rdf:ID="WagonMarchandise"> <rdfs:subClassOf rdf:resource="#Vehicule"/> </owl:Class> <owl:Class rdf:ID="Organe"/> <owl:Class rdf:ID="Equipe"/> <owl:Class rdf:ID="ApplicationTache"> <rdfs:subClassOf rdf:resource="#ProprieteTache"/> </owl:Class> <owl:Class rdf:ID="TypeVoiture"> <rdfs:subClassOf rdf:resource="#ProprieteVoiture"/> </owl:Class> <owl:Class rdf:ID="Employe"> <rdfs:subClassOf rdf:resource="#Personne"/> </owl:Class> <owl:Class rdf:ID="ClasseVoiture">
112 <rdfs:subClassOf rdf:resource="#ProprieteVoiture"/> </owl:Class> <owl:ObjectProperty rdf:ID="HasPropertyTache"> <rdfs:subPropertyOf> <owl:ObjectProperty rdf:ID="HasProperty"/> </rdfs:subPropertyOf> <rdfs:domain rdf:resource="#Tache"/> <rdfs:range rdf:resource="#ProprieteTache"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="HasPropertyVoiture"> <rdfs:domain rdf:resource="#VoitureVoyageur"/> <rdfs:subPropertyOf rdf:resource="#HasProperty"/> <rdfs:range rdf:resource="#ProprieteVoiture"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="HasPropertyEquipe"> <rdfs:subPropertyOf rdf:resource="#HasProperty"/> <rdfs:domain rdf:resource="#Equipe"/> <rdfs:range rdf:resource="#ProprieteEquipe"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="HasPartOperation"> <rdfs:domain rdf:resource="#Operation"/> <rdfs:subPropertyOf> <owl:ObjectProperty rdf:ID="HasPart"/> </rdfs:subPropertyOf> <rdfs:range rdf:resource="#Tache"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="HasPartTrain"> <rdfs:domain rdf:resource="#Train"/> <rdfs:subPropertyOf rdf:resource="#HasPart"/> <rdfs:range rdf:resource="#Vehicule"/> </owl:ObjectProperty>
113 <owl:ObjectProperty rdf:ID="HasPartEquipe"> <rdfs:domain rdf:resource="#Equipe"/> <rdfs:range rdf:resource="#Employe"/> <rdf:type rdf:resource=" http://www.w3.org/2002/07/owl#TransitiveProperty"/> <rdfs:subPropertyOf rdf:resource="#HasPart"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="HasPropertyEmploye"> <rdfs:range rdf:resource="#ProprieteEmploye"/> <rdfs:domain rdf:resource="#Employe"/> <rdfs:subPropertyOf rdf:resource="#HasProperty"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="HasPartVehicule"> <rdfs:subPropertyOf rdf:resource="#HasPart"/> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Organe"/> <owl:Class rdf:about="#Piece"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:domain rdf:resource="#Vehicule"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="OperationAppliquer"> <rdfs:range rdf:resource="#Operation"/> <rdfs:domain rdf:resource="#Vehicule"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="PieceUtiliser"> <rdfs:domain rdf:resource="#Tache"/> <rdfs:range> <owl:Class>
114 <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Piece"/> <owl:Class rdf:about="#Organe"/> </owl:unionOf> </owl:Class> </rdfs:range> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="HasPartOrgane"> <rdfs:subPropertyOf rdf:resource="#HasPart"/> <rdfs:range rdf:resource="#Piece"/> <rdfs:domain rdf:resource="#Organe"/> </owl:ObjectProperty> </rdf:RDF> <!-- Created with Protege (with OWL Plugin 3.4.5, Build 608) http://protege.stanford.edu -->
| 
Changeons ce systeme injuste, Soyez votre propre syndic 
"Il faut répondre au mal par la rectitude, au bien par le bien." | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||