|
GÉNÉRATION DYNAMIQUE D'INTERFACES
SPÉCIFIQUES
DANS L'EXPLOITATION DES PROCESSUS D'INGÉNIERIE
LOGICIELLE EN APPRENTISSAGE
(DYNAMIC GENERATION OF SPECIFIC GRAPHICAL USER INTERFACE
FOR
LEARNING IN SOFTWARE ENGINEERING)
Par
Claude Albert MOGHOMAYE
Ingénieur de Conception en Informatique
Master's
Degree in Engineering
POUR L'OBTENTION DU
DEA EN SCIENCES DE L'INGENIEUR OPTION
GENIE LOGICIEL
a
l' ECOLE NATIONALE SUPERIEURE POLYTECHNIQUE
NATIONAL
HIGH POLYTECHNIC SCHOOL
YAOUNDE, CAMEROUN
20 SEPTEMBRE 2004
ECOLE NATIONALE SUPÉRIEURE POLYTECHNIQUE
NATIONAL HIGH POLYTECHNIC SCHOOL
DÉPARTEMENT DE GÉNIE INFORMATIQUE
Ce mémoire a été présenté et
soutenu le 20 Septembre 2004 devant le jury composé des membres
ci-dessous :
Président du Jury : Pr Laure Pauline FOTSO,
Maître de Conférences, UY1
Superviseurs : Dr Claude TANGHA,
Chargé de cours, ENSP
Dr Roland YATCHOU, Assistant, ENSP
Examinateurs : Dr Guillaume KOUM,
Chargé de cours, ENSP
Dr Marcel FOUDA, Chargé de cours, UY1
Dr Georges KOUAMOU, Chargé de cours, ENSP
To GOD, 'my shepherd 'my all
To nobody but to all those who are concerns.
Table des matières
Table des mat ières v
Liste des Figures viii
Résumé ix
Abstract x
Remerciements xi
Sigles & Abréviations 1
1 Introduction 2
1.1 Assistance au déroulement des processus 2
1.2 Elaboration et Exploitation des BCPD 3
1.3 PERSEE 3
1.4 Pourquoi une troisième dimension? 4
1.5 Plan du mémoire 4
2 Problématique 6
2.1 Notions d'Interaction Homme-Machine 6
2.2 D'oii vient le besoin d'un interfacage dynamique ? 7
2.3 Comment cela se résout-il généralement
? 10
2.3.1 Générer du code, le compiler et
l'intégrer 11
2.3.2 Mettre en oeuvre des interfaces génériques
11
2.3.3 Offrir un moyen de décrire une interface 11
2.4 Une appréciation de ces méthodologies 12
3 Méthodes et Concepts 14
3.1 Les objets réutilisables 14
3.2 Le langage XUL 15
3.3 L'approche méthodologique 15
4 Modélisation 18
4.1 Une spécification formelle des interfaces 18
4.1.1 Pourquoi une spécification formelle ? 18
4.1.2 Quelques observations préliminaires 18
4.1.3 Principe de conception des interfaces 19
4.1.4 Typologie de l'interfacage 19
4.2 Une spécification semi-formelle des interfaces 20
4.3 Un modèle de ROSE 21
4.3.1 Le modèle de ROSE du Process State 22
4.3.2 Le modèle de ROSE du Process Engine 24
4.3.3 Le modèle de ROSE du Process GUI 25
4.4 Les besoins en acquisition 26
4.4.1 Les éléments à renseigner 26
4.4.2 Tâches à réaliser 26
4.5 Les besoins en exploitation 27
4.5.1 Les éléments à exploiter 27
4.5.2 Tâches à réaliser 27
5 Réalisation 30
5.1 Outils de réalisation 30
5.2 Description des GUI 31
5.3 Un scénario d'utilisation 31
5.4 Architecture Logicielle 31
5.5 Le déploiement des ROSE 35
5.6 Elaboration de la BC de MERISE 35
5.6.1 Artefacts de MERISE 37
5.6.2 Activités de MERISE 38
5.6.3 Roles de MERISE 38
5.6.4 Règles de validation des artefacts 38
6 Discussions & Conclusion 40
6.1 Rappel des objectifs 40
6.2 Intérêt du Process GUI 40
6.3 Avantages de PERSEE 41
6.4 Limites & Recherches futures 41
Bibliographie 43
A La structure d'un document XML i
A.1 La déclaration du type DOCTYPE i
A.2 La déclaration des notations i
A.3 La déclaration des entités i
A.4 La déclaration des éléments ii
A.5 La déclaration des attributs ii
B XML User interface Language iii
C Software Process Engineering Metamodel vi
C.1 Les éléments du processus vi
C.2 Les dépendances vii
Table des figures
2.1 Paradigme MVC 7
2.2 Description linéaire du processus RUP par IBM 9
2.3 Les trois (03) dimensions d'une base de connaissances 10
3.1 Représentation d'une interface en XUL 16
3.2 Interface XUL de la figure 3.1 générée
par un interpréteur 16
4.1 Trois (03) niveaux de conception d'une interface 21
4.2 Le schéma UML du Process State 22
4.3 Dépendances entre les tâches d'acquisition
28
4.4 La démarche d'acquisition et d'exploitation 29
5.1 Créer un nouveau projet : choisir le processus 32
5.2 Créer un nouveau projet : spécifier
l'emplacement 32
5.3 Création d'une entité dans l'activité
Elaboration de la solution 33
5.4 Création d'un acteur dans l'activité Rechercher
les acteurs et les cu 34
5.5 Architecture logicielle de PERSEE 35
5.6 La répartition physique des ROSE 36
5.7 La codification des ROSE 36
B.1 Code xul de l'interface spécifique B.2 iii
B.2 Interface spécifique de création d'un acteur
iv
B.3 Code xul de l'interface spécifique B.4 iv
B.4 Interface spécifique de création d'une
entité v
C.1 Le package Process Structure de SPEM [OMG 2002] vi
C.2 Le package Dependancies de SPEM [OMG 2002] vii
Résumé
Les systèmes à base de connaissances offrent des
mécanismes permettant d'acquérir et de stocker les connaissances
factuelles et les règles sur les processus de développement. Les
connaissances ainsi acquises peuvent être exploitées pour
l'apprentissage par des utilisateurs en quête du savoir faire sur un
processus donné. On dénombre aujourd'hui plus d'une centaine de
processus d'ingénierie logicielle, d'oii la difficulté de mettre
en oeuvre une stratégie évolutive et adaptative afin d'exploiter
les connaissances (faits et regles) sur celles-ci.
De plus, les utilisateurs d'un système interactif
doivent accomplir certaines tâches structurées. L'Interaction
Homme-Machine (IHM) doit donc avoir la même structure afin d'accomplir
efficacement ces tâches. Découvrir une structuration
adéquate de ces tâches du domaine et la restituer en interface
utilisateur nécessite une expertise que beaucoup d'ingénieurs du
logiciel ne possèdent pas. Nous proposons d'intégrer à
l'acquisition et à l'exploitation des connaissances une troisième
dimension : la dimension GUI (Graphic User Interface). Ainsi, nous pourrions
décrire notre base de connaissances sur les processus de
développement comme un ensemble d'objets réutilisables sur les
connaissances factuelles, les règles, ainsi que les interfaces visuelles
d'exploitation des processus de développement. Notre démarche
s'appuie sur l'abstraction des interfaces; en effet, nous réalisons une
catégorisation des interfaces; elle s'intéresse également
aux attributs, méthodes, et à une abstraction des objets
manipulés par celles-ci. L'apport de cette approche est de permettre une
transparence dans l'exploitation des connaissances à des fins
pédagogiques.
Nous mettons en oeuvre cela avec l'outil PERSEE (PERform
Software Engineering on Education) qui est un outil d'assistance active au
déroulement (enactment) des processus de développement.
Mots dles : base de connaissances, processus de
développement, interface, objets réutilisables
Abstract
The Knowledge Base System offers mechanisms allowing to
acquire and store factual knowledge and rules on the software engineering
process. Knowledge thus acquired can be exploited for the training of learners
who want to gain knowledge on a given process. Today, there are more than one
hundred software process, the difficulty is to implement an evolutionary and
adaptive strategy in order to exploit knowledge (facts and rules) on
process.
In addition, the users of an interactive system has to
accomplish certain structured tasks. The Human-Computer Interaction (HCI) then
should have the same structure in order to achieve these tasks effectively.
Discovering an adequate structuring of the domain tasks and restore it in user
interface need an expertise that most software engineers do not have. We
propose to integrate in the acquisition and the exploitation of knowledge a
third dimension : dimension GUI (Graphic User Interface). Thus, we could
describe our software engineering knowledge base like a whole of reusable
objects on factual knowledge, rules, as well as visual interfaces of
exploitation. Our apprach is based on the abstraction of interfaces; in fact,
we carry out a typology of the dynamic and generic interfaces; we are also
interested in the attributes, methods, and the abstraction of objects handled
by these. The contribution of this approach is to allow transparency in
exploitation of knowledge for teaching matters.
We implement this approch with PERSEE (PERform Software
Engineering on Education) which is a active assistance tool to enactment of
software process.
Keywords : knowledge base, software engineering process,
interface, reusable objects
Remerciement s
Cette partie est probablement la plus difficile à
rédiger dans un manuscrit de mémoire, et cela pour deux raisons :
tout d'abord, c'est la plus personnelle; mais surtout c'est la seule partie qui
va être consciencieusement lue par la famille, les amis ainsi que les
collègues. Tout d'abord, je souhaite remercier Dr Roland YATCHOU, mon
superviseur de recherche, pour sa patience et pour m'avoir soutenu (ou
supporté) durant ces années. Je dois également avouer que
si ce document est lisible, c'est en grande partie grace à ses talents
de relecteur. Je tiens également à remercier Dr Claude TANGHA,
Directeur du LABORIMA et Chef de Département du Génie
Informatique, dont le soutien m'a été précieux,
particulièrement lors des difficiles débuts de rédaction.
D'une salve paternelle, il a su grace à ses conseils avisés et
ses efforts de relecture me donner l'envie !d'amorcer la pompe".
Je remercie également les membres de mon jury. Mme Le
Président du jury : Pr Laure Pauline FOTSO pour l'honneur qu'elle me
fait en présidant ce jury. Parmi les membres du jury, je tiens à
remercier Dr Marcel FOUDA pour la vision transcendante qu'il m'a donné
du Génie Logiciel. Je suis également redevable pour beaucoup au
Dr Guillaume KOUM. Je tiens également à remercier Dr Georges
KOUAMOU pour l'initiation au Génie Logiciel et pour avoir accepté
d'examiner ce travail.
Je mentionnerais ici que mes travaux ont été
subventionnés par le laboratoire de Gestion, Diffusion et Acquisition
des Connaissances (GDAC) de l'UQAM et Le Groupe Infotel (LGI). J'en remercie le
Pr Roger NKAMBOU, Directeur du laboratoire et monsieur Raphael NBOGNI,
Président de LGI dont les soutiens intellectuels et financiers ont
été précieux.
Ces quelques lignes ne suffiront pas à exprimer un
grand merci à tous ceux qui jour et nuit nous ont
imprégnés des disciplines mathématique, physique &
chimie, informatique, langues, ...durant ces six (06) années : nos
enseignants.
Bien évidemment, je suis reconnaissant à toute
ma famille (Charles, Chantal, Julienne, Alexis, Mary, Laëtitia, Joel, ...)
et aux familles (Defo, Fono, Fotso, Kamga, Kaptué, Kengne, Momo, Piam,
Tankeu, ...), ainsi que Michel, Charles, ... pour le soutien
indéfectible qu'ils m'ont toujours accordé.
Enfin, j'aimerais remercier : Linda (pour avoir changé
ma vie de pire à mauvais), la grande famille GI2003, mes
collègues du Laborima, mes collègues de DEA, Ghislain,
Hervé, Yves avec qui j'ai longtemps cheminé, ... Je ne saurais
oublier de remercier la communauté anglophone du Centre Catholique
Universitaire et celle des Frères Saint Jean de Vogt.
Sigles & Abréviations
BC : Base de Connaissances
BCPD : Base de Connaissances des Processus de
Développement BD : Base de Données
BF : Base de Faits
BR : Base de Règles
CASE : Computer Aided Software Engineering
CIAO : Conception Intelligement Assistée par Ordinateur
DTD: Document Type Definition GUI : Graphic User Interface
IHM : Interaction Homme-Machine MVC: Modèle
Vue-Contrôleur OCL : Object Constraint Language
PERSEE : Perform Software Engineering on Education
RAS : Reusable Asset Specification
ROSE : Reusable Object for Software Engineering
RUP : Rational Unified Process SMA : Système
Multi-Agents
SPEM : Software Process Engineering Metamodel
UML: Unified Modelling Language
XUL : XML-based User Interface Language XML : eXtensible Markup
Language
Chapitre 1
Introduction
"Birds of a feather flock together"~ Old English adage
1.1 Assistance au déroulement des processus
Les processus de développement : assistance au
déroulement, l'association est peut-être de trop, moins qu'on ne
pourrait le croire. En effet, entre la nécessaire assistance avec des
formations à la demande ou de la documentation et l'assistance fournie
par les outils CASE', le chemin vers l'assistance active au déroulement
des processus d'ingénierie logicielle est encore étroit. On
progressera encore du côté des outils CASE, certes! On augmentera
les formations et l'accès à la documentation, sürement! Pour
autant, il n'y a guère de doute que l'assistance active restera
indispensable et conquèrera un bon nombre d'ingénieurs du
Génie Logiciel. Dans une proportion peut-être moindre il est
vrai.
Déjà une décennie plus tôt, Nacer
Boudjilida2 s'était interessé à ce domaine et
avait élaboré un métamodèle d'assistance au
déroulement des processus d'ingénierie logicielle. Par la suite,
la multiplicité des processus n'a fait qu'apporter beaucoup d'eau
à ce moulin. Car si cet article avait amené beaucoup à
revoir la stratégie d'assistance, elle est demeurée du domaine de
la spécification. Une décennie plus tard, devant
l'intérêt de plus en plus croissant car mobilisant actuellement
l'élite de recherche dans le Génie Logiciel, nous nous y sommes
interessés pour la mettre en oeuvre.
Ainsi, assister était synonyme de guider, fournir des
explications et contrôler les intervenants dans un projet au
déroulement (mise en oeuvre réelle vs description
linéaire). Cette assistance nécessitait d'élaborer les
BCPD3, de les exploiter à l'aide d'un système
d'assistance active. Pour plus de détails sur la nécessité
d'utiliser des système à base de connaissances
'Computer Aided Software Engineering
2Modelling of Software Process Assistance, http ://
www.loria.fr/ nacer/MyPubli.html
3Base de Connaissances des Processus de Développement
pour l'apprentissage, le lecteur se reportera à l'article
de A. Stutt [Stutt 1997]. Nous présentons donc les BCPD4 dans
la suite, ainsi que le système d'assistance.
1.2 Elaboration et Exploitation des BCPD
En se décomposant en Base de Faits (BF) et Base de
Règles (BR), la Base de Connaissances (BC) est devenue
l'élément fondamental du Knowledge Management (gestion des
connaissances) pour la réutilisation des connaissances dans un domaine
quelconque. A tel point que dans nos récents travaux [Konhawa 2003,
Moghomaye 2003, Ngantchaha 2002], nous avons grace au formalisme UML/OCL [OMG
2003] construit les bases de connaissances des processus de
développement MERISE [Nasser 2002] & RUP [Krol et al. 2003]. Ceci
était un travail préalable à la mise en oeuvre d'un outil
d'assistance à la modélisation à l'aide de la technologie
des Multi-Agents. Nous avons ainsi élaboré les connaissances
factuelles sur les éléments d'un processus, les règles sur
les artefacts du processus (validation des artefacts), ainsi que les
règles sur le déroulement du processus (dépen dances). Au
delà de l'acquisition, l'outil a permis l'exploitation de ces
connaissances factuelles, la validation des artefacts par rapport au processus
et l'utilisation des règles sur le déroulement du processus pour
assister (guider, contrOler, expliquer) le développeur dans le How To Do
Knowledge" ou plus simplement la connaissance sur le savoir-faire.
1.3 PERSEE
L'approche avait consisté à fournir un outil
d'assistance active à la modélisation, spécialement pour
les disciplines d'Expression des Besoins, d'Analyse & Conception du
RUP5. Il s'agissait de suivre et assister le développeur
pendant la modélisation en s'assurant qu'il utilise un processus
donné conforme à la spécification SPEM [OMG 2002]. C'est
ainsi que nous avons élaboré un modèle d'assistance et
l'avons mis en oeuvre avec un Système Multi-Agents d'Assistance à
la Modélisation (SM2AM lire SM two AM). Nous partions du fait que la
connaissance utile au développeur pouvait être
représentée sous forme de "best practices" (bonnes pratiques), de
guides, de méthodologies et autres éléments du processus.
SM2AM fournissait cette connaissance et permettait ainsi de combler le
fossé entre la pléiade de documents et les outils CASE UML.
PERform Software Engineering on Education (extension de SM2AM)
est l'outil qui nous permet d'exploiter ces connaissances à des fins
pédagogiques. L'introduction d'une troisième dimension à
la base de connaissances est intéressante à plus d'un titre, on
peut ainsi exploiter la base de connaissances d'un processus de
développement pour l'une quelconque des
4Base de Connaissances des Processus de
Développement 5IBM Rational Software, http : //
www.ibm.com/rup/
phases de celui-ci dams PERSEE. En effet, SM2AM se limitait aux
phases de modélisation, il est né des travaux amorcés dans
le cadre du projet CIAO [Ngantchaha 2002].
1.4 Pourquoi une troisième dimension?
Mais après ceci, nous avons également
élaboré la base de connaissances de MERISE afin de permettre son
exploitation par le même outil. Cela n'a pas été facile,
car il fallait penser et construire toutes les interfaces d'exploitation pour
MERISE, ce qui n'était pas pour participer d'une démarche
scientifique et évolutive.
Aussi avons nous opté pour l'acquisition même des
interfaces d'exploitation et leur utilisation, d'oii la
gémératiom dymamique d'imterfaces spécifiques dams
l'exploitatiom des processus d'imgémierie logicielle em
appremtissage.
Notre apport a déjà été de
bâtir ce SMA, il est maintenant question d'intégrer la
troisième dimension d'une base de connaissances à des fins
pédagogiques. Nos travaux sont menés en parallèle avec
ceux de KOM [Kom 2004] sur l'acquisition des connaissances sur les processus
d'ingénierie. L'importance de cette dimension s'explique par le fait que
la connaissance est accessible par la médiation d'une
représentation comme le souligne Jean Charlet dans [Charlet 2002], que
cette représentation soit un système de symboles ou tout autre
langage. Le support de cette représentation, parcequ'il fournit un
système supplémentaire de signifiants, par exemple l'interface
d'un programme d'ordinateur, est aussi un système de médiation.
Il y a ainsi non séparabilité de la connaissance et de sa
représentation.
1.5 Plan du mémoire
Notre travail se subdivise en six (06) chapitres. Un
aperçu global de celui-ci peut être obtenu en ajoutant à la
lecture de l'introduction et de la conclusion celle des résumés
fournis au début de chaque chapitre. Dans le second (02) chapitre, nous
présentons la problématique de l'interfaçage dynamique.
Cette dernière nous amène à évaluer la
nécessité de celle-ci dans le contexte actuel et à
présenter des projets accompagnés de solutions, existantes ou
envisagées. Nous terminons par une analyse de ces différentes
solutions afin de mieux élaborer la nôtre. Le troisième
(03) chapitre présente la méthodologie adoptée. Il
spécifie la démarche suivie, puis introduit les Objets
Réutilisables et présente le XML User Interface Language. Des
modèles de notre système sont présentés au chapitre
quatre (04). Nous commençons par la typologie d'une interface, ses
attributs et ses méthodes, les objets manipulés, ... Ensuite,
nous proposons une démarche d'élaboration et d'intégration
de celles-ci. Le chapitre cinq (05) s'intéresse davantage à la
mise en oeuvre de la spécification de la solution dans l'environnement
PERSEE.
En conclusion, des discussions et des perspectives au chapitre
six (06) viennent clôre le travail réalisé. Le lecteur
trouvera dans les annexes une brève présentation du langage XML,
du métamodèle SPEM et la mise en oeuvre avec XUL des interfaces
spécifiques.
Chapitre 2
Problématique
La question
Peut-on abstraire la définition des interfaces pour le
déroulement d'un processus de développement à des fins
pédagogiques?
a-t-elle une réponse plausible tenant compte des
attributs, méthodes et objets manipulés par celles-ci?
Dans ce chapitre, nous présentons les motivations ayant
sous-tendu nos travaux pour l'intégration d'une troisième
dimension dans les bases de connaissances des processus de développement
à l'aide des objets réutilisables. Ensuite, nous faisons un tour
d'horizon des approches de résolutions existantes, puis un comparatif de
celles-ci en termes d'avantages et d'inconvénients tenant compte des
attributs de qualité logicielle. Mais avant, nous présentons la
notion d'IHM.
2.1 Notions d'Interaction Homme-Machine
Hans V. Vliet résume l'Interaction Homme-Machine dans
[Vliet 2002] à la résolution du problème suivant : comment
rapprocher le plus possible le modèle mental de l'utilisateur (acquis
par les formations et la documentation) du modèle conceptuel
(modèle technique) d'une application? L'IHM est devenue le leimotiv de
l'ingéniérie du domaine. On a ainsi assisté à
l'émergence de plusieurs modèles d'IHM ayant toutes en commun la
séparation des fonctionnalités du système, des
interactions du système avec l'utilisateur. La décomposition
largement adoptée aujourd'hui est le paradigme
Modèle-Vue-Contrôleur' (MVC). La figure 2.1 présente les
trois concepts du paradigme et les relations entre ces trois concepts et
l'utilisateur. L'utilisateur se sert du contrôleur qui lui-même
manipule le modèle, le modèle met à jour la vue qui est
présentée à l'utilisateur. C'est dans un souci de
séparation du
'MVC, http ://
www.cs.indiana.edu/
cbaray/projects/mvc.html
contenu, du modèle et de la vue que nous vous
présentons la nécessité des interfaces pour l'exploitation
des connaissances sur les processus de développement en
apprentissage.
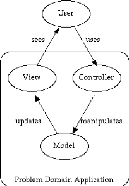
FIG. 2.1 Paradigme MVC
2.2 D'ou vient le besoin d'un interfaçage
dynamique?
Adopter un processus et le mettre en oeuvre c 'est,
logiquement, une démarche qni consiste à instancier les
artefacts, les consulter, les modifier et les supprimer au besoin; par des
rOles précis au conrs d'activités spécifiqnes.
Le développement de logiciels de complexité
croissante s'avère de plus en plus difficile aujourd'hui. Les
développeurs apprennent continuellement les pratiques des nouvelles
méthodologies de développement en les appliquant à leurs
projets. Ces dernières elles mêmes de plus en plus complexes ne
fournissent des résultats qu'après plusieurs années de
mise en oeuvre dans divers autres projets et une adaptation conséquente
au type de projet. Une approche de solution a été proposée
dans [Moghomaye 2003] avec l'élaboration et l'exploitation d'une base de
connaissances qui vient essayer de solutionner ce problème en permettant
de capitaliser des connaissances et les mettre à la disposition du
développeur à des fins pédagogiques
dans le cas du processus RUP2.
Aujourd'hui, l'évolution des methodologies de
developpement a separe celles-ci du langage sous-jacent utilise; il y'a
neanmoins une panoplie de langages ou plutôt de semantiques à
prendre en compte dans l'exploitation des connaissances sur le processus. Pour
illustrer notre propos : avec MERISE, on parle d'entites, associations, flux,
graphe de dependances; avec RUP et les derives qui utilisent UML, on parle de
classes, associations, diagramme de sequence, diagramme d'activite, . . .
Alors, comment derouler un processus en faisant abstraction du langage, mieux,
de la terminologie sous-jacente utilisee?
Alfred AHO dans [Aho et al. 1998] definissait l'informatique
comme la mecanisation de l'abstraction, une science de l'abstraction où
il s'agit de creer le bon modèle pour un problème et d'imaginer
les bonnes techniques automatisables et appropriees pour le resoudre. On se
demande donc comment mettre en oeuvre le processus de moulage des processus
conformes au metamodèle SPEM.
Les systèmes à base de connaissances ont
jusqu'ici abstrait deux (02) dimensions pour l'elaboration des bases de
connaissances les plus complexes. Ce qui est assez singulier c'est qu'on ait
fourni un effort considerable à l'elaboration beaucoup plus qu'à
l'exploitation de celles-ci. En effet, très souvent l'exploitation se
limite à une restitution plus ou moins lineaire (voir figure 2.2 l'outil
RUP de IBM3 Rational Software) à la manière des livres
des connaissances factuelles sur le processus [Nasser 2002, Krol et al. 2003].
Ceci etant très souvent l'agent vecteur d'une surcharge cognitive de
l'apprenant. Pourtant, au-delà de l'interêt que nous avons
toujours voue aux systèmes à base de connaissances sur ces deux
(02) dimensions, nous pensons qu'il faudrait y integrer à des fins
pedagogiques une troisième : la dimension GUI qui consiste à
decrire les interfaces d'apprentissage (voir figure 2.3).
On peut se demander, en faisant une analogie avec les Bases de
Donnees, de l'utilite de munir les Bases de Connaissances de Processus
d'interfaces specifiques pour l'exploitation. En effet, l'approche est assez
deplacee vu le contexte actuel des BD, on ne saurait munir les donnees
d'interfaces specifiques pour les exploiter, ce serait contraindre leur
utilisation. Mais, il faudrait se dire que la BD stocke des donnees tandis que
la BC stocke des connaissances; une connaissance étant une ou plusieurs
donnée(s) et des informations sur celle(s)-ci. D'ohi peut-être la
necessite de gerer des interfaces d'exploitation. On peut egalement se demander
si cette approche couplee aux technologies XUL pour la description des
interfaces, et XSL pour le formatage et la presentation ne serait pas idoine
pour les BD, car il est communement admis que l'on effectue generalement sur
les donnees les operations d'ajout, de consultation, de mise à jour et
de suppression. Et aussi des interfaces permettant d'exploiter les mêmes
donnees ne diffèrent très souvent que par l'Interface Homme
Machine qui concerne beau-
2pational Unified Process
3IBM Rational Software, http
://www.ibm.eom/rational/
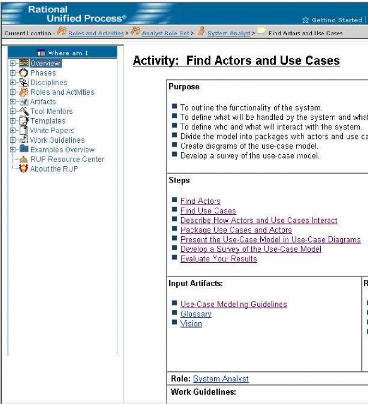
FIG. 2.2 Description linéaire du processus RUP par
IBM
FIG. 2.3 Les trois (03) dimensions d'une base de
connaissances
coup plus les aspects de style. De plus, ce ne serait pas
nouveau, l'approche de Microsoft Access qui permet de monter des projets de
bases de données avec des interfaces prédéfinies et
modelables va dans ce sens. Néanmoins, il sera peut-être difficile
de définir un standard pour les objets (tables) manipulés car ne
les connaissant pas à priori : une base de données pouvant servir
à plusieurs applications dans différents domaines contrairement
à une base de connaissances.
Il s'agit donc pour nous de fournir des préalables
à l'élaboration et l'exploitation des objets réutilisables
des processus de développement afin d'intégrer effectivement ces
trois (03) dimensions.
2.3 Comment cela se résout-il
généralement?
Nous allons dans la suite nous intéresser à la
manière dont les outils d'exploitation font la mise à jour des
connaissances 'visuelles ' impliquant une modification de l'interface
utilisateur. Il existe globalement trois (03) approches, nous ne saurions
donner des exemples exhaustifs d'outils adoptant ces différentes
méthodologies car ce domaine reste, est, et sera toujours en amont du
produit logiciel présenté aux utilisateurs finaux. On peut ainsi
disposer de trois (03) classifications qui consistent à :
- Générer automatiquement du code, le compiler et
l'intégrer manuellement;
- Mettre en oeuvre des interfaces génériques
prenant en compte tous les types de langages ou définir un langage
propre;
- Permettre de décrire les interfaces au niveau de
l'acquisition des connaissances et disposer d'un interpréteur.
2.3.1 Générer du code, le compiler et
l'intégrer
Partant du fait que des processus, ne sont pas
créés tous les jours, on peut se dire que si nous disposons d'un
outil d'exploitation des connaissances à des fins pédagogiques,
on pourrait à chaque nouveau processus, rajouter le code correspondant,
le compiler et l'intégrer ou même produire une nouvelle version.
C'est l'approche classique très utilisée. On y gagne en temps car
il y a réutilisation du code existant. Par contre, on y contraint
l'expertise d'un développeur qui prendra du temps à
s'imprégner s'il ne l'est pas encore. Un exemple parlant est l'outil
WayPointer de Jaczone4. Des outils tels Castor d'Exolab5
et Zeus6 du projet Enhydra permettent même de
générer du code Java à partir d'une DTD (Document Type
Definition).
2.3.2 Mettre en oeuvre des interfaces
génériques
Très souvent, on préfère s'affranchir des
contraintes liées à la codification de nouvelles interfaces en
mettant en oeuvre des interfaces génériques une fois pour toute.
Leur généricité se manifeste par le fait qu'elles
représentent un modèle du domaine et une instance de cellesci est
un couplage interface générique -f paramètres du domaine
en cours. C'est l'approche la plus utilisée, notamment dans les outils
de télé-enseignement et les progiciels.
2.3.3 Offrir un moyen de décrire une interface
Entre l'approche particulière et l'approche
générique, il y'a l'approche descriptive qui consiste à
permettre à l'expert du domaine de décrire une interface, d'un
côté et à l'interpréter au niveau de l'exploitation.
Des outils tels Protégé7 2000 du MIT de Standford
l'ont implémenté. Les éditeurs GLADE8 et
Théodore9 permettent de générer des interfaces
au format XUL.
A titre d'exemple, Avalon'°, la nouvelle couche graphique
du futur système d'exploitation Windows Longhorn de Microsoft sera
piloté par le langage propriétaire XAML (eXtensible Application
Markup Language) dérivé du langage XML et proche de XUL. La
nuance "applicative (au niveau de l'implémentation, car conceptuellement
il est équivalent à XUL) du XAML : c'est en fait un langage pour
réaliser des interfaces visuelles riches et unifiées
dédiées aux applications Windows. C'est un sérieux
concurrent pour XUL qui est largement adopté
4Jaczone, http : //
www.jaczone.com 5Projet
Castor, http :/ /
castor.exolab.org
6Projet Zeus, http ://
zeus.enhydra.org 7MIT,
http ://
www.mit.edu
8GLADE, http : //
glade.gnome.org/
9Théodore, http ://
www.carlsbadcubes.com/theodore/
'°http : //www.laboratoire_microsoft
.org/articles/win/longhorn/
par la communaute du libre. Il existe egalement d'autres
initiatives, notamment Macromedia XML (MXML11) de Macromedia, XML
Data Package (XDP'2) d'Adobe.
2.4 Une appreciation de ces methodologies
Une appreciation de ces methodologies en terme de qualite
logicielle est faite en tenant compte des aspects fonctionnel, fiable,
convivial, performant, maintenable et portable, qui sont les caracteristiques
de qualite selon ISO 9126 (voir /Vliet 2002]). Nous allons situer les attributs
de qualite dans le Genie Logiciel, ainsi que le resultat de la comparaison par
rapport à ceux-ci conformement au tableau presente plus loin.
Fonctionnel La capacite du logiciel à fournir des
fonctions qui satisfont les besoins specifies et implicites lorsque le logiciel
est utilise dans des conditions specifiees. Pour l'aspect fonctionnel, il est
assez explicite qu'une application realisee en tenant compte des besoins de
l'utilisateur est probablement plus fonctionnelle que celle où on a eu
à decrire les interfaces (en effet, la description est contrainte par la
méthodologie adoptée et le dégré d'abstraction
souhaité), encore plus celle qui encapsule tous les besoins de
l'utilisateur en les adaptant à elle.
Fiabilité La capacite du logiciel à maintenir un
niveau de performance du système lorsqu'il est utilise dans les
conditions specifiees. L'impact d'une mise à jour impliquant une
modification du code source est toujours difficile à prevoir sur la
fiabilite du système contrairement à une approche descriptive
où le code source ne subit pas de modification.
Convivialité La capacite du logiciel à
être compris, appris, utilise et accepte par les utilisateurs, lorsqu'il
est utilise dans les conditions specifiees. En effet, il est peut-être
plus facile pour un utilisateur d'apprendre une interface et de s'y adapter que
de s'adapter à de perpetuelles modifications.
Performance La capacite du logiciel à fournir les
performances requises, relative à l'ensemble des ressources utilisees,
sous les conditions de depart. Etant specifiques, les interfaces et programmes
construits avec l'approche de generation du code pourraient être
facilement optimisables en tenant compte des ressources disponibles.
Maintenabilité La capacite du logiciel à
être modifie. Les modifications contiennent les corrections, les
ameliorations ou l'adaptation du logiciel aux changements dans l'environnement,
et dans les besoins et specifications fonctionnelles. L'approche de generation
est peut-être beaucoup moins evolutive que la description qui permet de
tenir
11Macromédia, http ://
www.
macromedia. com/devrnet/flex/articles/paradigm.html '2XML ,
http ://
xml. coverpages.
org/rii2003- 07-15- a. html
compte de tous les aspects nouveaux dans l'environnement.
Portabilité La capacite du logiciel à être
transfere d'un environnement à un autre.
Nous utiliserons trois (03) qualificatifs, +, . et - pour
signifier respectivement le classement; premier, deuxième et
troisième pour l'attribut specifie.
|
Approches
|
Integration
|
Genericite
|
Description
|
|
Fonctionnel
|
+
|
-
|
.
|
|
Fiabilite
|
-
|
.
|
+
|
|
Convivialite
|
-
|
+
|
.
|
|
Performance
|
+
|
-
|
.
|
|
Maintenabilite
|
-
|
.
|
+
|
|
Portabilite
|
-
|
.
|
+
|
Pour nous resumer, disons que l'integration necessite un
investissement (en terme de temps, co2t) initial faible, elle a la
particularite d'être simple au niveau de l'acquisition car on sait
exactement ce qu'on traite. De plus, l'exploitation depend de la mise en oeuvre
realisee. Neanmoins, cette solution n'est pas evolutive et sa fiabilite reste
à demontrer, voir l'exemple du vol 501 de Ariane 5 dans [Vliet 2002].
Pour la genericite, l'investissement est moyen avec une acquisition beaucoup
moins complexe. Neanmoins l'exploitation est contraignante car assez standard.
L'investissement initial est assez eleve pour la description qui fournit une
exploitation aisee car adaptee, bien que l'acquisition soit assez complexe si
on envisage un domaine peu evolutif, mais benefique à long terme pour un
domaine en constante evolution. Nous avons donc opte pour la description des
interfaces compte tenu de la fiabilite, la maintenabilite et la portabilite de
cette approche.
Chapitre 3
Méthodes & Concepts
Au coeur de notre travail, il y'a les objets
réutilisables, le langage XUL' que nous présentons, soutendus par
une approche méthodologique. Il s'agira en fait d'utiliser le langage et
un interpréteur XUL pour l'élaboration et l'exploitation
dynamique des interfaces spécifiques. Ensuite, de les joindre aux objets
de la base de connaissances pour constituer les objets réutilisables des
processus de développement (Reusable Objects for Software Engineering).
Mais avant d'aller présenter la démarche, prenons le soin de
situer quelques concepts nécessaires pour la suite à savoir les
objets réutilisables et le langage XUL.
3.1 Les objets réutilisables
La réutilisation en Génie Logiciel est
correlée à l'architecture logicielle très souvent. Une
architecture logicielle doit donc fournir un contexte pour le
développement de modules réutilisables. Aussi avons nous
opté pour une réutilisabilité dans la dimension substance
utilisée ou contenu avec les objets réutilisables dans la
BCPD.
Les objets réutilisables ne sont pas des objets au sens
d'instance de classe, ce ne sont pas des objets au sens de composants
logiciels, mais c'est des objets au sens de produit permettant de stocker la
connaissance et la manière dont cette connaissance sera utilisée.
C'est ce que nous avons nommé 'Reusable Object' pour le Génie
Logiciel ou plus simplement Reusable Objects for Software Engineering. Sans
pour autant véhiculer des informations, ces objets réutilisables
se rapprochent beaucoup plus des objets d'apprentissages définis par
[Nelson et al. 1997, Nelson 1998, Wiley 2002].
La définition de ces objets dans la BCPD a
été guidée par l'ontologisation du domaine des processus
d'ingénierie logicielle avec le métamodèle SPEM. Leur mise
en oeuvre a été inspirée de l'approche de Falbo qui
propose des démarches pour le passage de l'ontologie du domaine aux
objets réutilisables [Falbo et al. 2002].
'XML-based User Interface Language, prononcé
!zoolU
3.2 Le langage XUL
XUL (XML-based User Interface Language, prononcé
'zool') est un langage de description d'interfaces homme/machine
dérivé de XML2 (eXtensible Markup Language). Il est
né du projet open source de Mozilla3. La norme XUL se propose
de standardiser la manière dont les interfaces sont décrites et
exploitées. Sa puissance de description est telle qu'il per-met de
définir une application aussi complexe qu'un navigateur Web (XUL est au
coeur de Mozilla et de Netscape 6). Certains voient en lui le concurrent de
Java sur le poste client : il existe des interpréteurs pour toutes les
plates-formes, XUL est donc un langage de description d'interface portable.
Certains à l'instar de Frédéric Bordage proposent la
relève des architectures client serveur (client lourd) et du web (client
léger) par ce qu'il qualifie de Client Riche bâti sur XUL et
à mi-chemin entre les deux (02) en corrigeant leurs différents
défauts (voir l'article sur 01net4). De plus, XUL
étant un dérivé de XML, il ne nécessite pas de
compétences informatiques pointues.
Nous illustrons XUL avec un exemple de code XUL (voir la
figure 3.1) et l'interface visuelle correspondante générée
par un interpréteur (voir la figure 3.2).
Ce langage se fait encore discret, pourtant, il est à
l'origine d'une nouvelle vague d'applications: étant écrit en
XML, il est diffusable sur le Web simplement. Aucune documentation de
référence n'est encore disponible, néanmoins on peut
trouver des drafts5, ainsi que des interpréteurs swixml,
luxor, XUI, thinlet, ...
3.3 L'approche methodologique
Ici, nous nous intéressons aux méthodes
adoptées par les outils d'exploitation pour exploiter les connaissances
'visuelles' contenues dans les BC en considérant une exploitation active
vs exploitation passive. Vu ainsi, cela pourrait justifier que nous ayons
adopté la troisième approche celle d'abstraire les interfaces
pour l'exploitation. Mais cela implique également de s'intéresser
à leur acquisition pour les générer dynamiquement. Nous
devons nous assurer qu'on peut acquérir les connaissances sur les
processus de développement et les exploiter. Une partie de ce travail a
déjà été réalisée au cours de nos
précédents travaux [Konhawa 2003, Moghomaye 2003]. Il faudrait
maintenant y intégrer la dimension GUI. Nous allons pour cela
réaliser une typologie des interfaces, ensuite, celle-ci nous servira
à mettre en oeuvre des interfaces d'acquisition de connaissances sur les
processus dans la troisième dimension. Nous nous tournerons aussi vers
l'exploitation de ces connaissances, toujours aidé
2Standards de XML, http ://
www.xml.org
3Site des projets de Mozilla, http ://
sourceforge.net
4Cliemt Riche : La relève du client serveur et
du Web, http ://www.01met.eom
5XUL Planet, http : //
www.xulplanet .org
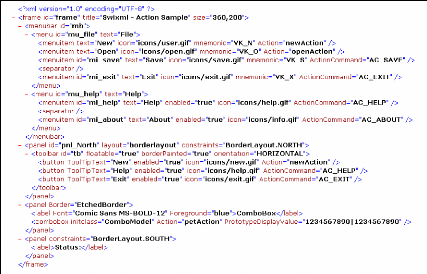
FIG. 3.1 Représentation d'une interface en XUL
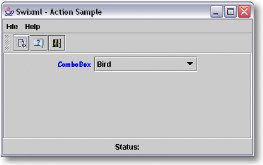
FIG. 3.2 Interface XUL de la figure 3.1
générée par un interpréteur
par la typologie et un interpréteur XUL, afin de rendre
l'outil d'exploitation prêt à acceuillir un quelconque processus.
Le choix de XUL s'est fait en tenant compte que, étant un
dérivé de XML, on pourrait y coller des feuilles de style pour
avoir des interfaces respectant la présentation IHM souhaitée,
d'oii le fait que nous n'ayions pas accordé plus d'importance aux IHM.
Au passage, nous allons construire et exploiter les objets réutilisables
des processus de développement. Nous pourrons ainsi faire de PERSEE un
process engine ou encore un outil permettant de dérouler un quelconque
processus de développement conforme SPEM [OMG 2002].
Chapitre 4
Modélisation
'Useful abstractions are discovered, not invented' R.E. Johnson
& B. Foote in Journal of Object Oriented Programming, 1(1), 1988
Ce chapitre présente une spécification formelle
et semi-formelle du modèle d'interfacage proposé; puis, les
propriétés et méthodes de celles-ci sont analysées,
ainsi que les relations avec les objets manipulés dans la typologie de
l'interfacage. Il définit également un modèle d'objets
réutilisables pour les processus de développement qui
découle de la spécification formelle. Nous définissons
enfin une démarche pour l'acquisition et l'exploitation de ces
objets.
4.1 Une specification formelle des interfaces
4.1.1 Pourquoi une specification formelle?
Nous voulons pouvoir générer dynamiquement des
interfaces spécifiques (en ce sens qu'elles concernent un domaine
précis) dans l'exploitation des processus d'ingénierie
logicielle. Ceci implique de s'intéresser aux objets manipulés
que sont les interfaces et aux processus d'acquisition et d'exploitation de
celles-ci. La spécification formelle des interfaces permet de s'entendre
sur les objets manipulés et d'en extraire des propriétés
intéressantes pour leur manipulation. Ceci guidera l'élaboration
des modèles d'objets réutilisables. Mais avant,
définissons quelques observations empiriques. La spécification
semi-formelle sommaire suivra pour résumer la modélisation des
interfaces.
4.1.2 Quelques observations preliminaires
Les intuitions qui suivent proviennent d'observations
essentiellement empiriques.
Intuition 1. L'ensemble des operations rCalisables sur les
artefacts manipulCes par un processus contient quatre (04) operations :
ajouter, consulter, modifier, supprimer.
Intuition 2. Il existe quatre (04) types d'interfaces dans la
gestion des artefacts : les interfaces d'ajout, de consultation, de
modification et de suppression.
Intuition 3. Toutes les interfaces prennent en entrée un
artefact du processus et produisent en sortie l'artefact modifié. Donc
chaque interface ne manipule qu'un unique artefact.
Illustration 1. Prenons le cas simpliste où nous
voulons établir une association entre deux (02) artefacts, on peut se
dire que l'interface concernée aura à manipuler deux (02)
artefacts, mais on peut également se dire (ce qui nous sied le mieux) qu
'une association est un artefact avec comme attributs des liens logiques vers
les artefacts associés.
Intuition 4. Les champs d'une interface sont un sous-ensemble des
attributs du type d'artefact manipulé par celle-ci.
Trois (03) concepts se dégagent d'une interface : les
attributs de celle-ci, ses méthodes et l'objet manipulé. Ces
éléments vont nous permettre de définir un principe de
conception des interfaces.
4.1.3 Principe de conception des interfaces
Definition 1. Principe de conception des interfaces pour
l'exploitation des connaissances sur les processus
Nous proposons de disposer de trois (03) niveaux pour la
conception des interfaces pour l'exploitation des connaissances sur un
processus : le niveau lexical, le niveau sémantique et le niveau
syntaxique, voir figure 4.1.
1. Le niveau lexical concerne la description des attributs de
l'interface, on parlera de lexique d'une interface,
2. Le niveau sémantique quant à lui permet de
décrire les actions associées à l'interface, on parlera de
sémantique d'une interface,
3. Le niveau syntaxique s 'occupe des objets ou artefacts
manipulés par cette interface, on parlera de syntaxe d'une interface.
Ce principe qui décrit les trois (03) niveaux de
conception d'une interface guide le typage des interfaces que nous
présentons ci-dessous.
4.1.4 Typologie de l'interfacage
Soit I l'ensemble des interfaces associées à un
processus, A l'ensemble des artefacts de ce processus et O l'ensemble des
opérations applicables sur les interfaces,
Definition 2. L'ensemble des opérations sur les interfaces
peut-étre partitionné en quatre (04) sous-ensembles distincts
:
~ Les opérations de création d'un artefact,
~ Les opérations de consultation d'un artefact, ~ Les
opérations de modification d'un artefact,
Les operations de suppression d'un artefact.
La sCmantique d'une interface ne peut donc prendre que l'une des
valeurs : creation, consultation, modification ou suppression.
Definition 3. Soit f : A x O ? I, la fonction
de correspondance d'un couple (artefact,operation) à une interface,
alors :
ViEI, ? ! (a,o)EAxO telque
i=f(a,o)
f est bijective. On peut ainsi associer une unique interface
à tout couple (artefact,methode).
Illustration 2. Une interface ne manipule qu'un unique
artefact (voir Intuition 3), nous avons distinguC quatre (04) types
d'opCrations rCalisables sur un artefact (voir Intuition 1) et Cgalement quatre
(04) types d'interface (voir Intuition 2), la correspondance et l'unicitC sont
vite Ctablies.
Definition 4. Soit f de la definition 3,
Vo E O,
Va=a1,a2,--- ,am E A, m E N,
| {z }
m attributs
Vi = i1, i2, - - - , in E I, n E N,
| {z }
n attributs
{
{i1,i2,...,in} c {a1,a2,...,am}
i = f(a,o) =o =
semantique(i).
Le lexique d'une interface est un sous-ensemble des attributs
de la syntaxe de celle-ci. De méme, la sCmantique d'une interface est
l'opCration que celle-ci realise sur la syntaxe. Plus simplement, l'ensemble
des attributs manipulCs par une interface i en correspondance avec l'artefact a
est un sous-ensemble des attributs de celui-ci.
Il ressort de la typologie que le nombre d'interfaces
nécessaires à un processus donné comportant n types
d'artefacts est au pire des cas égal à 4 *n. La
spécification formelle nous permettra de définir des
modèles de ROSE pour les interfaces. De celle-ci découle une
spécification semi-formelle beaucoup plus proche d'un modèle
'informatique de la représentation des interfaces.
4.2 Une specification semi-formelle des interfaces
La spécification semi-formelle se résume au
modèle présenté à la figure 4.1. Ce modèle
présente les trois (03) niveaux de conception d'une interface. Une
interface munie de son lexique est en relation avec une opération qui
constitue sa sCmantique ; également en relation
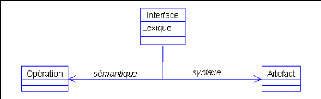
FIG. 4.1 Trois (03) niveaux de conception d'une interface
avec un artefact qui constitue sa syntaxe. Les attributs des
classes présentées sont les mêmes que ceux des
entités correspondantes dans le modèle de ROSE. Ces
différentes spécifications vont nous permettre d'élaborer
le modèle de ROSE du paragraphe suivant en complément du
modèle semi-formel.
4.3 Un modèle de ROSE
modelrose Le triplet (a, o, i) ? A × O × I
tel que i = f(a, o) sera qualifié
d'objet réutilisable sur les processus de développement dans la
dimension GUI constituant ici le Process GUI. Les éléments du
processus selon le métamodèle SPEM' seront dénommés
objets réutilisables sur les processus dans la dimension BF dont
l'ensemble constitue le Process State. Enfin, les règles sur les
artefacts du processus se verront attribuer le qualificatif objet
réutilisable sur les processus dans la dimension BR dont l'ensemble
constitue le Process Engine. Les dénominations Process GUI, Process
State et Process Engine ont été empruntées à Bob
Balzer qui s'était intéressé aux perspectives futures de
la technologie du Génie Logiciel en 1999 dans [Balzer 1999].
Nous définissons la base de connaissances d'un processus
de développement (BCPD) comme un entrepôt d'objets
réutilisables (Object Repository for Software Engineering). Dans la
suite, nous allons tour à tour présenter le modèle de ROSE
sous forme de DTD essentiellement (ce choix est justiflé par le fait que
nos connaissances factuelles, les règles et les interfaces sont
stocicées sous forme de fichier XML) que nous définissons suivant
chacune des dimensions d'une base de connaissances.
'Object Management Group, http ://
www.omg.org
4.3.1 Le modèle de ROSE du Process State
Le modèle de ROSE du Process State s'appuie sur une
spécialisation de la structure du processus suivant le
métamodèle SPEM [OMG 2002]. En effet, nous avons utilisé
la spécification SPEM et y avons ajouté des
éléments afin de faciliter l'exploitation, conformément
à nos objectifs pour constituer le modèle de ROSE. Nous avons
donc obtenu après une étude,
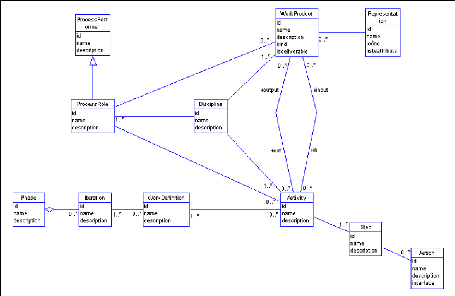
FIG. 4.2 - Le schéma UML du Process State
le schéma de la figure 4.2, et la DTD qui suit a
été obtenue en transformant ce modèle UML et en faisant
les hypothèses et choix suivants :
Pendant la transformation, pour une association père fils,
le père contient des identifiants vers l'ensemble de ses fils et chaque
fils a une référence sur son père.
~ Bien qu'un WorkProduct puisse avoir plusieurs
représentations, pour simplifier, nous
supposerons qu'à un
moment donné, il ne peut avoir qu'une seule représentation.
- Pendant la transformation, pour une association
many-to-many, il faut : soit faire un choix et privilégier un sens de
l'association, soit créer un ensemble de références de
chaque côté de l'association sur le côté
opposé.
- On privilégie l'association de Iteration vers
WorkDefinition; pour obtenir l'autre sens,
on pourra parcourir la liste des itérations.
-- On privilégie l'association de WorkDefinition vers
Activity; pour obtenir l'autre sens, on pourra parcourir la liste des
WorkDefinition.
-- On crée deux (02) nouveaux éléments
Entree et Sortie au niveau de Activity qui représentent les WorkProducts
en entrée et en sortie d'une activité. On crée
également deux (02) nouveaux éléments Entrant et Sortant
au niveau de WorkProduct qui représentent les activités qui
prennent en entrée (resp. en sortie) ce WorkProduct pour des besoins de
navigation.
Description devrait normalement se transformer en attribut de
chacun des éléments, mais nous avons choisi de le garder comme un
élément par souci d'ergonomie de nos fichiers résultants.
En effet, compte tenu du fait que ce champ peut avoir une longueur de
caractères assez importante, le prendre comme attribut rendrait le
document touffu.
-- ProcessPerformer est implémenté comme un
attribut de ProcessRole. En effet, on peut retrouver la description de
ProcessPerformer à partir de celle des ProcessRole correspondants. De
plus, sur le schéma, le ProcessPerformer n'est en relation qu'avec le
ProcessRole, d'oii ce choix.
<!D O CTYPE ProcessState PUBLIC "*. dtd"> <!--
Description -->
<!ELEMENT Description (#PCDATA)>
<!-- Phase -->
<!ELEMENT Phase (Description,Iteration *)> <!ATTLIST
Phase id NMTOKEN #REQUIRED> <!ATTLIST Phase name CDATA #REQUIRED>
<!ATTLIST Phase visibility NMTOKEN #REQUIRED> <!-- Iteration -->
<!ELEMENT Iteration (Description, WorkDefinition*)>
<!ATTLIST Iteration id NMTOKEN #REQUIRED> <!ATTLIST Iteration name
CDATA #REQUIRED> <!ATTLIST Iteration visibility NMTOKEN #REQUIRED>
<!-- WorkDefinition -->
<!ELEMENT WorkDefinition (decription,Activity*)>
<!ATTLIST WorkDefinition id NMTOKEN #REQUIRED> <!ATTLIST
WorkDefinition name CDATA #REQUIRED> <!ATTLIST WorkDefinition visibility
NMTOKEN #REQUIRED>
<!-- Activity -->
<!ELEMENT Activity (Description,ProcessRole,Entree,Sortie,Step
-i-)>
<!ATTLIST Activity id NMTOKEN #REQUIRED> <!ATTLIST
Activity name CDATA #REQUIRED> <!ATTLIST Activity visibility NMTOKEN
#REQUIRED> <!ProcessRole>
<!ELEMENT ProcessRole (Description,Activity *, WorkProdtct
*)> <!ATTLIST ProcessRole id NMTOKEN #REQUIRED> <!ATTLIST
ProcessRole name CDATA #REQUIRED> <!ATTLIST ProcessRole visibility
NMTOKEN #REQUIRED> <!ATTLIST ProcessRole processPerformer CDATA
#REQUIRED>
<!WorkProdtct>
<!ELEMENT WorkProdtct
(Description,Representation,ProcessRole,Entrant,Sortant)>
<!ATTLIST WorkProd'uct id NMTOKEN #REQUIRED>
<!ATTLIST WorkProd'uct name CDATA #REQUIRED>
<!ATTLIST WorkProdnct visibility NMTOKEN #REQUIRED>
<!ATTLIST WorkProdnct kind (report/model/gaide)> <!A
TTLIST WorkProd'uct isDeliverable #PCDATA> <!-- Entrant
-->
<!ELEMENT Entrant (Description,Activity*)>
<!Sortant>
<!ELEMENT Sortant (Description,Activity*)> <!-- Entree
-->
<!ELEMENT Entree (Description, WorkProdtct*)> <!--
Sortie -->
<!ELEMENT Sortie (Description, WorkProdtct*)>
<!Step>
<!ELEMENT Step (Action *)>
<!ATTLIST Step id NMTOKEN #REQUIRED> <!ATTLIST Step name
CDATA #REQUIRED> <!ATTLIST Step visibility NMTOKEN #REQUIRED> <!--
Action -->
<!ELEMENT Action (#PCDA TA)>
<!ATTLIST Action id NMTOKEN #REQUIRED> <!ATTLIST Action
name CDATA #REQUIRED> <!ATTLIST Action visibility NMTOKEN #REQUIRED>
<!ATTLIST Action interface #PCDATA> <!-- Discipline -->
<!ELEMENT Discipline (Description,ProcessRole -/-,Activity-/-,
WorkProdtct-/-)>
<!ATTLIST Discipline id NMTOKEN #REQUIRED> <!ATTLIST
Discipline name CDATA #REQUIRED> <!ATTLIST Discipline visibility NMTOKEN
#REQUIRED>
La notion d'artefact en génie logiciel fait
référence à trois types de production : le rapport, le
modèle (on élément de modèle) et le guide. Nous
supposerons dans la suite que nous ne traitons que de ceux-là. En effet,
il s'avère compliqué de définir jusqu'à la
typologie des rapports, cela pourrait contraindre l'utilisateur et
nécessiterait un travail assez ennuyeux pour l'expert du domaine. Pour
ce qui est des guides, il suffit au moment de renseigner les connaissances sur
les processus de les fournir préalablement élaborés sous
des formats html, pdf ou doc.
4.3.2 Le modèle de ROSE du Process Engine
Nous ne nous étendrons pas sur le modèle de ROSE
du Process Engine, nous donnerons d'abord une explication sur l'importance des
règles.
Si on se refère aux outils CASE qui ont
également des règles de validation, on peut se demander à
quoi bon refaire tout ceci; mais en y regardant de plus près on verra
que les outils CASE s'intéressent à la vérification des
artefacts par rapport au langage sous-jacent utilisé. Tandis que la
validation des artefacts par rapport au processus consiste à s'assurer
que ceux-ci sont conformes au déroulement du processus.
Les règles de validation proviennent essentiellement du
package Dependancies de SPEM [OMG 2002]. Celui-ci propose cinq (05) types de
dépendances pour un processus :
Precedes Spécifie qu'une Activity (ou un WorkProduct)
précède une (ou un) autre.
Import Permet de spécifier qu'un élément du
processus est importé pour appartenir à l'élément
qui l'importe.
RefersTo Pour spécifier qu'un élément du
processus réfère à un autre et s'assurer ainsi qu'ils sont
inclus dans le même composant du processus.
Impact Relation entre deux WorkProduct du processus pour
spécifier que la modification du premier peut avoir un impact sur le
second.
Categorizes Permet de regrouper les éléments du
processus de manière statique dans des packages.
Nous préconisons d'utiliser un moteur de règles
à l'instar de QuickRules2 offrant une interface visuelle pour
renseigner les règles sur les artefacts du processus et une interface
d'exploitation de ces règles au format XML avec un programme Java. Nous
nous réfèrerons donc à la DTD de Quickrules : QRML
disponible en Open Source. On pourrait bien évidemment envisager de
définir un modèle pour les ROSE du Process Engine et ainsi, ne
pas dépendre d'un éditeur quelconque, mais il faudrait
égalemment implémenter un moteur de règles
conséquent. D'oii l'adoption de la DTD de QuickRules.
4.3.3 Le modèle de ROSE du Process GUI
Le modèle de ROSE du Process GUI dérive un peu
de la spécification semi-formelle des interfaces (voir le paragraphe 4.2
et la figure 4.1), nous y avons rajouté des attributs afin de mieux
l'étoffer.
<!D O CTYPE Process GUI PUBLIC "processstate. dtd ">
<!-- Type Operation -->
<!ENTITY %TOperation (create/read/write/delete)> <!--
Lien Interface XUL -->
<!ENTITY %TView #PCDATA>
<!-- Liste des ElEments du lexique -->
<!-- avec pour chacun les contraintes sur les valeurs -->
<!ENTITY %LProp #PCDATA>
<!Interface>
<!ELEMENT Interface (Description, WorkProduct, Operation)>
<!ATTLIST Interface id NMTOKEN #REQUIRED> <!ATTLIST Interface name
CDATA #REQUIRED> <!ATTLIST Interface visibility NMTOKEN #REQUIRED>
<!ATTLIST Interface view %TView #REQUIRED> <!ATTLIST Interface
propertylist %LProp #REQUIRED> <!-- Operation -->
<!ELEMENT Operation (Description)>
<!ATTLIST Operation id NMTOKEN #REQUIRED> <!ATTLIST
Operation name CDATA #REQUIRED>
2QuickRules , http : //
www.quickrules.com
<!ATTLIST Operation visibility NMTOKEN #REQUIRED>
<!ATTLIST Operation type %TOperation #REQUIRED>
Ces différents modèles nous ont permis de
définir les besoins en acquisition et en exploitation des ROSE dans la
suite. Cette démarche est générale et s'intéresse
aux éléments à renseigner et exploiter, ainsi qu'aux
tâches à réaliser.
4.4 Les besoins en acquisition
4.4.1 Les éléments à renseigner
L'acquisition consistera à renseigner les
éléments du Process State, à savoir : - Discipline
WorkDefinition
- ProcessRole
- Activity
- Iteration
- Phase
Representation
- WorkProduct
Une seconde étape consistera à renseigner pour
chaque interface :
- La méthode associée à cette interface
(créer,modifier,consulter,supprimer), elle permet de différencier
les interfaces associées à un WorkProduct,
~ Le WorkProduct concerné choisi dans l'ensemble des
WorkProduct préalablement renseignés,
- La description sommaire de l'interface.
Et pour chacun des champs ou attributs d'une interface, on
renseignera :
- Le nom du champ,
- Le libellé du champ correspondant au label qui sera
affiché,
~ Le type du champ (numérique, texte, image, ...),
- Le renseignement du champ qui représente ici la plage de
valeurs (source) par exemple un champ peut être une liste de choix entre
les différents WorkProduct.
4.4.2 Tâches à réaliser
Il s'agira donc de :
1. Fournir des interfaces permettant de renseigner les
éléments ci-dessus cités dans un ordre efficient,
2. Proposer quatre (04) modèles d'interface adaptable
(ajout, consultation, modification et suppression),
3. Spécifier les différentes
représentations dans un fichier. Nom, description de la
représentation et nom de l'icône associée (au format PNG
16x16) qui doit être copié dans un répertoire
précis. Par défaut, on proposera les représentations UML
pour les work-Product et RUP pour les autres éléments du
processus, et on laissera l'utilisateur choisir,
4. Enregistrer les interfaces dans des fichiers XUL
codifiés,
5. Renseigner les dépendances
~ Précédence : gérée par la
définition des WorkDefinition,
- Import : gérée par une Activity qui importe des
WorkProduct en entrée/sortie, Refers To : gérée par la
définition des Discipline,
~ Impact : gérée dans la définition des
WorkProduct de regroupement,
- Catégorizes : gérée par la
définition des Discipline, WorkProduct, ProcessRole et Activity.
6. Pour chacun des WorkProduct, permettre de spécifier
les règles de validation en proposant un modèle de projet
adaptable sous QuickRules.
7. Bien évidemment, s'assurer que les fichiers .xul
produits sont valides pour l'interpréteur utilisé au niveau de
l'exploitation. Idem pour les règles de validation sous QuickRules.
Les dépendances en terme de précédence entre
les différentes tâches spécifiques à l'acquisition
sont présentées à la figure 4.3.
4.5 Les besoins en exploitation
Les éléments des BCPD étant
élaborés après le processus d'acquisition, l'exploitation
dépend essentiellement de l'orientation qu'on voudrait en faire. Nous
décrivons ici des besoins orientés vers la mise en oeuvre d'un
environnement de formation aux processus d'ingénierie logicielle.
4.5.1 Les éléments à exploiter
Les éléments à exploiter sont
essentiellement ceux du processus, les interfaces d'exploitation, ainsi que les
règles de validation sur les artefacts.
4.5.2 Tâches à réaliser
Il s'agira ici de :
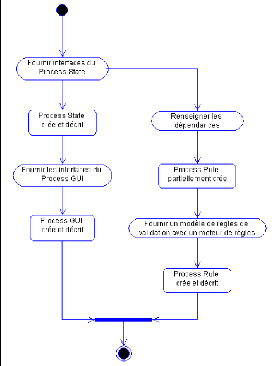
FIG. 4.3 Dépendances entre les tâches
d'acquisition
1. Permettre de choisir un processus et de le
dérouler.
2. Permettre de valider les artefacts sur le processus en cours
en utilisant le moteur de règles de QuickRules.
3. Définir un modèle d'assistance pour prendre en
compte le déroulement d'un processus quelconque.
4. Utiliser un interpréteur pour construire dynamiquement
l'interface spécifique représentée par le fichier xul.
5. Prendre en compte le déroulement de plusieurs
processus par la mise en oeuvre de menus dynamiques adaptés à
chaque processus.
6. Mettre en oeuvre l'importation et l'exportation des projets
vers des outils CASE.
Un résumé de cette démarches est fournie
par la figure 4.4. L'interface est spécifiée par l'expert au
niveau de l'acquisition. A l'exploitation, elle est interprétée
et présentée à un utilisateur qui la renseigne à
des fins d'assistance. Dans la réalisation, nous nous sommes
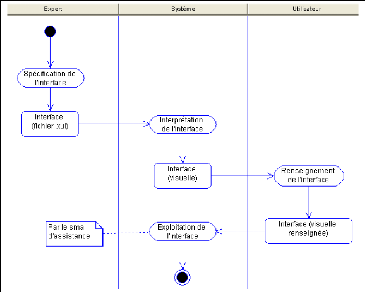
FIG. 4.4 - La démarche d'acquisition et d'exploitation
focalisés sur les besoins en exploitation.
Chapitre 5
Réalisation
"A Good Process Uses Tools to Do More by Doing Less" ~ ...
La réalisation présente la mise en oeuvre de
l'interfacage dynamique dans l'application PERSEE. Il commence par
présenter les outils, puis un scénario d'utilisation. Ensuite,
l'architecture logicielle et le diagramme de déploiement viennent
compléter la compréhension de l'outil. Nous terminons par
quelques éléments sur l'élaboration de la Base de
Connaissances de MERISE.
5.1 Outils de réalisation
Pour aboutir à ce travail, nous avons utilisé les
outils suivants :
XPath Langage d'expression des chemins utilisé pour
sélectionner des éléments dans un document XML.
dom4j Middleware de lecture/écriture/consultation des
fichiers XML. Nous l'avons préféré à jdom car il
est bâti sur jdom, de plus il integre XPath. La recherche d'un
élément dont on ne connaIt pas la position dans l'arborescence
nécessite d'écrire un bout de code sous jdom pour parcourir tout
le document, alors qu'avec dom4j, une seule ligne avec XPath suffit.
NetBeans est un éditeur libre Java : celui de SUN
Microsystems. Cooktop est un éditeur XML libre intégrant XPath,
XSL et XLink.
Protégé 2000 est l'outil qui nous a permis
d'implémenter les différentes bases de connaissances.
Q uickRules est un moteur de regles qui s'integre parfaitement
aux applications Java.
5.2 Description des GUI
L'interface utilisateur (GUI) est beaucoup plus que ce qui est
représenté à l'écran. La différence entre
notre approche et les autres est assez significative. Nous combinons dans notre
approche un interfacage qui prend en compte une exploitation complète
des éléments de la BCPD. Ceci peut se matérialiser dans
l'environnement qui a été réalisé et dont les menus
qui sont dynamiques tirent leur contenu du Process State, le déroulement
d'une activité spécifique exploite le Process GUI et le Process
Rule intervient au niveau du déroulement d'une activité pour la
validation des artefacts.
C'est dire que l'application devant permettre d'exploiter les
BCPD doit être conforme au modèle de ROSE. PERSEE est conforme et
nous présentons un scénario d'utilisation.
5.3 Un scenario d'utilisation
Le scénario d'utilisation consistera à
créer un nouveau projet en spécifiant le processus MERISE (resp.
RUP) (voir figures 5.1 et 5.2). Ensuite, suivant le processus choisi, les menus
Roles, Activités et Artefacts sont générés
dynamiquement. L'utilisateur spécifie l'activité à
réaliser dans le menu Activités; dans la vue en haut et à
droite les éléments de l'activité sont affichés. Il
décide de créer une entité (resp. acteur)
Géographe. L'interface spécifique (voir figures B.4 et B.2 en
Annexes) représentée par le fichier .xul est
interprétée, puis affichée. L'utilisateur renseigne le
lexique (voir figures 5.3 et 5.4) de l'interface puis valide, une
vérification est faite au niveau de la syntaxe de l'interface et la
sémantique est utilisée pour valider la création de
l'acteur Géographe. Ensuite, l'acteur est inséré dans la
vue déroulement du projet. Celle-ci présente un regroupement
spatial des éléments du processus instantiés par le projet
en cours. Le lecteur voudra bien se reporter à l'annexe B pour un
complément d'informations sur la mise en oeuvre de la
génération dynamique d'interfaces spécifiques.
5.4 Architecture Logicielle
Le développement a été fait sous forme de
composants et indépendemment de l'interface. On pourra donc
accéder au système d'assistance et l'utiliser. Nous ne
présentons ici que la distribution pour l'exploitation qui a
été prise en compte au cours du développement. Ces
composants sont :
- processstate contient les classes permettant de gérer
les éléments du processus.
- processengine contient les classes permettant de gérer
la validation des artefacts. - processgui contient les classes de manipulation
des interfaces dynamiques. - bind contient les classes de liaison avec les
fichiers XML.
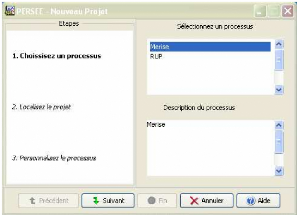
FIG. 5.1 - Créer un nouveau projet : choisir le
processus
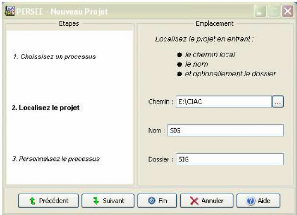
FIG. 5.2 Créer un nouveau projet : spécifier
l'emplacement
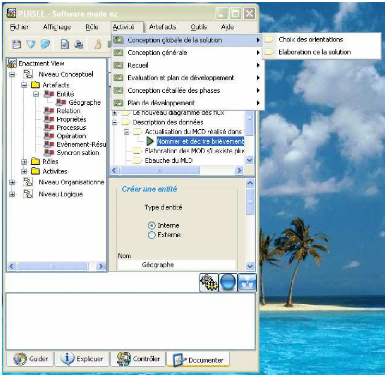
FIG. 5.3 Création d'une entité dans
l'activité Elaboration de la solution
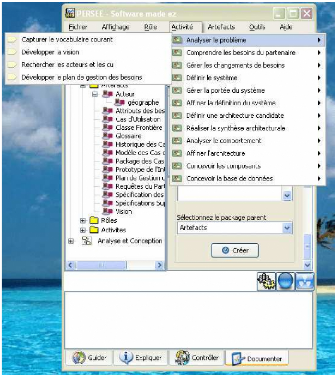
FIG. 5.4 - Création d'un acteur dans l'activité
Rechercher les acteurs et les cu
projet contient les classes de gestion de projet.
- sma contient tous les agents qui s'occupent de l'assistance.
- gui contient les classes pour l'interface utilisateur.
- none contient tous les autres éléments.
Le package projet utilise sma pour l'assistance pendant le
déroulement du processus, il utilise également processgui pour
les interfaces spécifiques, ainsi que none. sma utilise gui pour fournir
ses résultats à l'utilisateur, processstate et processengine pour
les éléments d'assistance, ainsi que none.
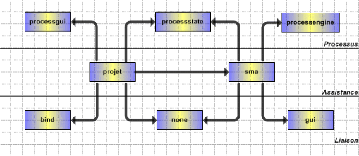
FIG. 5.5 Architecture logicielle de PERSEE
5.5 Le déploiement des ROSE
Nous avons prévu pour le stockage physique une
arborescence (voir figure 5.6) avec les répertoires correspondants
respectivement aux dimensions Fait, Regle et GUI, ceci afin de nous conformer
à la representation de SPEM. La codification qui y est
présentée est détaillée à la figure 5.7.
Cette codification comporte trois (03) champ : le premier représente le
numéro de la discipline, le second peut prendre les valeurs 0,1,2 ou 3
suivant que l'on ait respectivement des WorkDefinition, des Activity, des
WorkProduct ou des ProcessRole, le dernier numéro indique la position de
l'élément du processus correspondant dans sa classe.
5.6 Elaboration de la BC de MERISE
Pour élaborer la base de connaissances de MERISE, nous
avons été guidé par les méthodologies
définies par Joseph Gabay [Gabay 2001] et Jean-Patrick Matheron
[Matheron 2000]. En effet, il est assez difficile de trouver une
démarche standard de MERISE à l'instar de RUP.

FIG. 5.6 - La répartition physique des ROSE
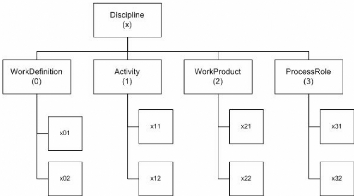
FIG. 5.7 - La codification des ROSE
Nous présentons ici une énumération
sommaire, accompagnée de codifications, des éléments
constituant la BC de MERISE : les artefacts, les activités et les roles.
Les relations entre les éléments du processus ne sont pas
présentés. Nous présenterons également des
règles sur les artefacts de MERISE. Tout ceci concerne les disciplines
d'étude préalable, de conception générale et de
conception détaillée de MERISE.
5.6.1 Artefacts de MERISE
Nous présentons donc les artefacts de MERISE ainsi que
leur codification :
121 Entité
122 Relation
123 Propriété
124 Processus
125 Opération
126 Evènement-Résulat
127 Syncronisation
221 Entité
222 Relation
223 Propriété
224 Procédure
225 Phase
226 Tâche
321 Table
322 Attribut
323 Procédure
324 Phase
325 Tâche
326 Fonction-Module-DLT
Le lecteur attentionné et connaissant un peu MERISE se
demandera où sont le MCD (Modèle Conceptuel de Données),
le MLD (Modèle Logique de Données), ..., en effet, nous ne les
avons pas rescensés comme des artefacts. Nous nous intéressons
essentiellement aux éléments de modèle et un MCD peut
être vue comme un regroupement d'éléments de
modèles, donc beaucoup plus comme un artefact de type rapport. De plus,
les diagrammes qui sont des regroupements de modèles ne sont pas pris en
compte dans notre démarche, autrement, on aurait déporté
l'attention vers la mise en oeuvre d'un AGL à l'instar de IBM Rational
Rose. Nous préférons rester un frontal avec les AGL. Certains
artefacts (WorkProduct) ont été repétés, c'est
intentionnel et nécessaire d'un point de vue structurel, en effet, un
élément du
processus doit toujours appartenir à une discipline.
Nous utilisons l'artifice de duplication pour gérer les
éléments qui se retrouvent dans plusieurs disciplines, ceci
n'empêche pas que ceci soit géré comme un unique artefact,
ce que nous avons fait.
5.6.2 Activités de MERISE
MERISE dispose des six (06) groupes d'activité
(WorkDefinition) suivant :
101 Conception globale de la solution
102 Conception générale
201 Recueil
202 Evaluation et plan de développement
301 Conception détaillée des phases
302 Plan de développement
Ces six (06) groupes d'activités sont un regroupement
logique des dix (10) activités (Activity) suivantes :
111 Choix des orientations
112 Elaboration de la solution 113 Conception
générale
211 Recueil préliminaire
212 Etude de la situation actuelle
213 Synthèse et bilan de la situation actuelle
214 Evaluation de la nouvelle solution
215 Plan de développement
311 Conception détaillée des phases
312 Plan de réalisation
5.6.3 Roles de MERISE
La définition des roles (ProcessRole) sous MERISE est
assez imprécise, néanmoins, nous avons identifié les trois
(03) roles suivant avec pour chacun le groupe de role (ProcessPerformer) auquel
il appartient :
131 Spécificateur des besoins, processPerformer=
Analyste
231 Analyste Système, processPerformer= Analyste
331 Analyste des données et des traitements,
processPerformer= Concepteur
5.6.4 Regles de validation des artefacts
Nous distinguons deux (02) catégories de règles,
celle concernant un unique artefact et celle mettant en relation plusieurs
artefacts.
Regle N 01 (Tous)
Définir les propriétés par exemple identifiant, ...
Regle N02 (Entité) Toutes les
propriétés autres que l'identifiant doivent être en
dépendance fonctionnelle et complète de l'identifiant. Par
conséquent, pour chaque occurrence d'une entité, chaque
propriété doit prendre une et une seule valeur (il ne peut donc y
avoir ni valeurs répétitives, ni absence de valeur pour une
méme propriété).
Regle N 03 (Relation)
Toutes les propriétés d'une relation doivent dépendre
complètement de l'identifiant de la relation; de plus, chaque
propriété doit dépendre de tout l'identifiant et non d'une
partie de cet identifiant. Ainsi, pour chaque occurrence d'une relation, chaque
propriété doit être en dépendance fonctionnelle de
l'identifiant de la relation et doit donc prendre une et une seule valeur.
Regle N 04
(Opération) A l'intérieur d'une opération, il
ne doit pas apparaItre de résultat pouvant conditionner la suite du
déroulement des opérations du processus étudié, si
tel est le cas, il faudrait découper l'opération.
Regle N 05
(Opération) Une opération est une suite ininterrompue
de traitements; toute intervention d'un acteur externe qui entraInerait une
interruption provoque un découpage de l'opération.
Chapitre 6
Discussions & Conclusion
6.1 Rappel des objectifs
A l'origine de ce travail, les objectifs étaient assez
simples, en effet, il fallait élaborer et intégrer la base de
connaissances de MERISE à nos précédents travaux. Nous
nous sommes rendus compte que l'intégration pouvait se faire de
plusieurs façons.
On pouvait envisager de développer de nouvelles
interfaces pour le processus MERISE, ce qui ne devait pas permettre
l'évolutivité future. Il y avait également la
possibilité de mettre en oeuvre des interfaces génériques,
mais une question se posait, seraient-elles assez génériques et
adaptables à tous les types de processus qui pourraient se
présenter? Nous avons finalement opté pour la dernière
solution qui consiste à réaliser une typologie de
l'interfaçage visuel et permettre ainsi de décrire une
interface.
Cette solution impliquait la redéfinition d'une Base de
Connaissances de Processus de Développement comme un entrepôt
d'objets réutilisables dans trois (03) dimensions à savoir :
Process State, Process Engine et Process GUI. La typologie d'une interface nous
a conduit à définir le lexique (attributs renseignés
à partir de l'interface), la syntaxe (artefact manipulé par
l'interface) et la sémantique (operation que l'on realise sur
l'interface) d'une interface. L'innovation dans ces dimensions est le Process
GUI.
6.2 Intérêt du Process GUI
La dimension Process GUI est intéressante à plus
d'un titre. Elle consiste à faire renseigner par l'expert de la base de
connaissances et de manière guidée, les propriétés
des interfaces qui permettront d'exploiter ces connaissances. Puis, à
stocker celles-ci au format d'échange standard des interfaces (XUL) et
utiliser un interpréteur dans l'exploitation pour construire
dynamiquement les interfaces visuelles.
Tout d'abord, les interfaces étant construites
dynamiquement, on s'affranchit de leur dé-
pendance. Ensuite, on adapte l'interface à chaque
processus. On peut également réutiliser dans plusieurs
environnements d'exploitation des connaissances sur les processus,
l'entrepôt d' obj ets réutilisables, améliorant ainsi le
processus d' apprentissage. L 'apprentissage étant intimement lié
au domaine d'application, ainsi qu'au niveau des apprenants; le process GUI
avec la génération dynamique des interfaces spécifiques
permet de prendre en compte le niveau des apprenants en plus du processus. Le
Process GUI a été mis en oeuvre avec l'outil PERSEE dont nous
présentons les avantages.
6.3 Avantages de PERSEE
PERSEE est l'environnement obtenu, mettant en oeuvre
l'exploitation d'un entrepôt d'objets réutilisables. Avec ces
modifications, PERSEE permet donc de dérouler une quelconque phase d'un
processus de développement, c'est donc un système intelligent
d'assistance (sous-tendu par un système multi-agents d'agents cognitifs)
au déroulement (enactment) des processus de développement. Cet
apport participe à un processus d'amélioration de la
qualité. Il peut donc intégrer toutes les phases d'un processus
de développement sous réserve élaborée qu'une
ontologie correspondante ait été intégrée à
la base de connaissances.
PERSEE sera d'un apport appréciable pour l'enseignement
des cours de Génie Logiciel, il permettra notamment aux étudiants
d'y réaliser des travaux pratiques et de bénéficier de
l'assistance active du système. Il pourrait également servir
à la formation ou au recyclage des professionnels du logiciel en
entreprise.
6.4 Limites & Recherches futures
Nous suggérons que les recherches futures s'orientent
vers :
- L'élaboration et l'intégration des
éléments de connaissances sur les autres phases (autres que
Specification des besoins, Analyse & Conception) des processus RUP et
MERISE dans les différentes bases de connaissances;
Nous nous sommes focalisés dans le développement
sur l'exploitation d'une BCPD en supposant celle-ci préalablement
construite, mais en fait il faudrait également faire une étude
pour l'intégration de la dimension Process GUI à l'acquisition
dans nos BCPD. On pourrait pour cela avantageusement partir de GLADE ou
Théodore, deux (02) éditeurs d'interface graphique
générant le code XUL et l'adapter afin d'y intégrer la
syntaxe d'une interface. En effet, ils permettent de définir le lexique
et la sémantique d'une interface visuelle, mais pas la syntaxe.
~ Nous avons souligné plus haut que nous avions pris en
compte les artefacts de type modèle et guide du fait de la
complexité de ceci. On pourrait également étendre nos
travaux par l'utilisation de la récente
spécification RAS de l'OMG [OMG 2004], c'est un standard pour la
réutilisation des groupes d'artefacts d'évaluation à
l'instar des rapp orts.
- Notre travail s'est appuyé sur le
métamodèle des processus d'ingénierie logicielle SPEM,
mais imaginons qu'on veuille appliquer toute cette démarche à un
quelconque processus d'ingénierie (construction mécanique,
aviation, construction navale, aéronautique, chimique,
biomédicale, génie civil, ...), ne pourrait-on pas à juste
titre penser à un méta-modèle des processus
d'ingénierie?
Bibliographie
[Aho et al. 1998] A. AHO & J. ULMANN, Concepts fondamentaux
de l'informatique, 2nd ed., DUNOD, Paris, 1998.
[Balzer 1999] B. BALZER, Current state and future perspectives
of software process technology, Présentation, Information Sciences
Institute, Décembre 1999.
[Charlet 2002] J. CHARLET, L'ingénierie des
connaissances : Développements, résultats et perspectives pour la
gestion des connaissances médicales, Ph.D. thesis, Université
Pierre et Marie Curie, Département d'Informatique, 2002.
[Falbo et al. 2002] R. A. FALBO, GIANCARLO GUIZZARDI, K. C.
DUARTE & A. C. C. NATALI, Developing Software for and with Reuse : An
Ontological Approach, Computer Science Department, Federal University of
Espirito Santo,2002.
[Gabay 2001] J. GABAY, Merise et uml pour la
modélisation des systèmes d'information, un guide complet avec
les études de cas, 4th ed., DUNOD, Paris, 2001.
[Kom 2004] G. KOM MBOUMI, Extraction et exploitation
d'éléments d'ontologies existantes dans un contexte
spécifique : Le cas du projet CIA O-SI, Master's Degree in Engineering,
Université de Yaoundé I, Ecole Nationale Supérieure
Polytechnique, Département de Génie Informatique,
Yaoundé-Cameroun, Juin 2004.
[Konhawa 2003] F. M. KONHAWA, Spécifi cation et
réalisation d'un système d'aide à la production
d'artefacts consistants : Application au RUP, Master's Degree in Engineering,
Université de Yaoundé I, Ecole Nationale Supérieure
Polytechnique, Département de Génie Informatique, Yaoundé-
Cameroun, Juin 2003.
[Krol et al. 2003] P. KROLL & P. KRUCHTEN, The rational
unified process made easy, a practitionner's guide to rup, 1st ed., Object
Technology Series, Addison Wesley, Pearson Education Inc., Boston, April
2003.
[Matheron 2000] J.-P. MATHERON, Comprendre merise, outils
conceptuels et organisationnels, 7th ed., Eyrolles, Paris, 2001.
[Moghomaye 2003] C. A. MOGHOMAYE, Un système multi-agents
d'assistance à la modélisation, Master's Degree in Engineering,
Université de Yaoundé I, Ecole Nationale
Sup érieure Polytechnique, Département de
Génie Informatique, Yaoundé-Cameroun, Juin 2003.
[Nasser 2002] K. NASSER & al., De merise à uml, 1st
ed., Eyrolles, Paris, 2002.
[Nelson et al. 1997] L. M. NELSON & C. M. REIGELUTH, A new
paradigm of isd, vol. 22, pp. 24-35, CO : Libraries Unlimited, Englewood, 1997,
Educational media and technology yearbook.
[Nelson 1998] L.M. NELSON, Collaborative problem solving : An
instructional theory for
learning through small group interaction,
Unpublished doctoral dissertation, 1998.
[Ngantchaha 2002] G. NGANTCHAHA NGOUGUE, Raisonnement à
base de cas appliqué à la conception assistée des
systèmes d'information : Indexation et gestion de cas, Master's Degree
in Engineering, Université de Yaoundé I, Ecole Nationale
Supérieure Polytechnique, Département de Génie
Informatique, Yaoundé-Cameroun, Juin 2002.
[OMG 2002] SPEM, Software process engineering metamodel
specification, Object Management Group, 2002.
[OMG 2003] UML, Unified modeling language specification, vol.
1.5, Object Management Group, March 2003.
[OMG 2004] RAS, Reusable Asset specification, Object Management
Group, June 2004.
[Stutt 1997] A. STUTT, Knowledge Engineering Ontologies,
Constructivist Epistemology, Computer Rhetoric : A Trivium for the Knowledge
Age, edmedia, 1997.
[Vliet 2002] H. V. VLIET, Software engineering : Principles and
practice, 2nd ed., John Wiley & Sons, New York, August 2002.
[Wiley 2002] D. A. WILEY, Connecting learning objects to
instructional design theory : A definition, a metaphor, and a taxonomy,
2002.
La structure d'un document XML
A.1 La declaration du type DOCTYPE
- Référence un fichier contenant la DTD
privée
<!DOCTYPE ProcessGUI PUBLIC !processstate.dtd !>
Référence un fichier contenant la DTD publique
<!DOCTYPE ProcessGUI SYSTEM !processstate.dtd !>
publique - Inclusion de la DTD
<!DOCTYPE ProcessGUI [
<!ELEMENT Interface (Description,WorkProduct ,Operation)>
...]>
A.2 La declaration des notations
- Identifie une information non-XML (donc non parsee)
<!NOTATION boundary SYSTEM !boundary.gif !>
A.3 La declaration des entités
- Entité générale interne : uniquement
utilisée dans un document sous la forme &titre; <!ENTITY
TOperation (create read write delete)>
- Entité paramètre interne : uniquement dans la
DTD
<!ENTITY %TOperation (create read write delete)>
- Entité paramètre externe : uniquement dans la
DTD
<!ENTITY %TOperation SYSTEM !operation.txt !>
Entité générale externe : uniquement dans la
DTD
<!ENTITY TOperation PUBLIC !operation.txt ! NDATA
boundary>
A.4 La declaration des éléments
~ Contenu vide
<!ELEMENT ProcessRole EMPTY>
~ Contenu quelconque
<!ELEMENT ProcessRole ANY>
- Contenu éléments fils : contient des
éléments régis par une expression régulière
(, séquence; alternative; multiplicateur * O-N; + 1-N;? 0-1)
<!ELEMENT ProcessRole(Description,Activity*
,WorkProduct*)>
Contenu mixte
<!ELEMENT ProcessRole (#PCDATA Activity*)>
A.5 La declaration des attributs
- Type chaInes de caractères CDATA
Type prédéfini ID : identifiant unique dans un
document
- Type prédéfini IDREF, IDREFS :
référence ou liste de références d'identifiants ID
du document
- Type prédéfini ENTITY, ENTITIES : nom ou liste de
noms d'entités non-XML, précédemment
déclarées
- Type prédéfini NMTOKEN, NMTOKENS : nom ou liste
de noms de mots clé - Valeurs énumérées
XML User interface Language
Ce paragraphe ne présente pas le langage XUL, mais
plutôt deux (02) exemples de description d'interface avec les interfaces
graphiques générées. Elles ont été
utilisées dans la réalisation.

FIG. B.1 Code xul de l'interface spécifique B.2
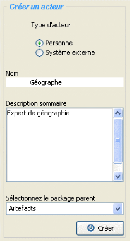
FIG. B.2 Interface specifique de creation d'un acteur

FIG. B.3 - Code xul de l'interface specifique B.4
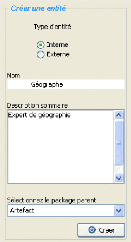
FIG. B.4 - Interface specifique de creation d'une
entité
Annexe C
Software Process Engineering
Met amodel
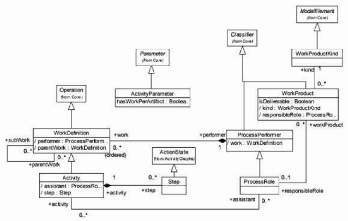
FIG. C.1 Le package Process Structure de SPEM [OMG 2002]
C.1 Les éléments du processus
Un WorkProduct ou Artefact est un élément
produit, consommé ou modiflé par le processus. Un WorkProduct
décrit une classe de produits de travail résultant d'un
processus. Un WorkProductKind décrit une catégorie de produits de
travail, tels les documents textes, les modèles UML, les
exécutables, le code,... WorkDefinition est une Operation qui
décrit le travail réalisé dans le processus. Ses sous
classes sont Activity, Phase, Iteration et Lifecycle
(dams le package Process Lifecycle). Il dispose
d'entrées et de sorties explicites référencées par
ActivityParameter. Activity est la sous-classe principale de WorkDefinition.
Elle décrit un travail réalisé par un unique ProcessRole :
les tâches, les opérations et les actions qui sont
réalisées ou assistées par un role. Un Activity
peut-être décomposé en éléments atomiques
appelés Step. Un ProcessPerformer définit un role pour un
ensemble de WorkDefinitions dans le processus. ProcessPerformer dispose d'une
sous-classe ProcessRole qui définit les responsabilités pour des
WorkProduct spécifiques, et définit les roles qui
réalisent et assistent des activités sp écifiques.
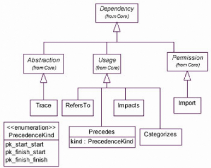
FIG. C.2Le package Dependancies de SPEM [OMG 2002]
C.2 Les dépendances
Une dépendance Categorizes agit d'un package à
un élément individuel du processus dans un autre package. Il
permet d'associer les éléments du processus à plusieurs
catégories. Une dépendance Impacts concerne les WorkProduct, elle
indique que la modification d'un WorkProduct peut en invalider un autre. Une
dépendance Import indique que le contenu du package cible est
ajouté à la visibilité du package source. Une
dépendance Precedes concerne des Activity ou des WorkDefinition pour
indiquer le type de précédence. Start_start : synchronisation au
début; finish_start : séquencement strict; finish_finish :
synchronisation à la fin. Une dépendance Refers To indique qu'un
élément du processus réfère à un autre. Une
dépendance Trace agit sur les WorkDefinition pour montrer pour tracer
les besoins et les changements à travers les modèles.
| 

