|



ECOLE SUPERIEURE POLYTECHNIQUE
DEPARTEMENT GENIE INFORMATIQUE
Centre de Dakar

Conception et Réalisation d'une plateforme TP
d'investigation digitale.
MÉMOIRE DE FIN DE CYCLE
Pour l'obtention du :
DIPLÔME DE MASTER MSSI
Lieu de stage :ESP- UCAD
Période stage :01/2022 - 04/2022
Présenté et soutenu par Professeur encadreur
Maître de stage
OKANGONDO LOSHIMAJUNIORIDY DIOP
MOHAMED K.KEITA
Année universitaire : 2020 - 2021
REPUBLIQUE DU SENEGAL
***** * * ********
UNIVERSITE CHEIKH ANTA DIOP DE DAKAR


ECOLE SUPERIEURE POLYTECHNIQUE
DEPARTEMENT GENIE INFORMATIQUE
Centre de Dakar


MEMOIRE DE FIN
DE CYCLE
Pour
l'obtention du :
DIPLOME DE
MASTER MSSI
Conception et Réalisation d'une plateforme TP
d'investigation digitale.
Lieu de stage :ESP-UCAD
Période stage :01/2022 - 04/2022
Présenté et soutenu par Professeur
encadreurMaître de stage
OKANGONDO LOSHIMA JUNIORIDY
DIOP MOHAMED K. KEITA

Année universitaire : 2020- 2021

DEDICACES
DEDICACES
Je dédie ce mémoire :
A mon cher Père.
A ma chère Mère.
A ma très chère épouse et mon
fils.

REMERCIEMENTS
REMERCIEMENTS
Mes vifs remerciements sont d'abord adressés à
Monsieur le Professeur Dr. IDY DIOP qui m'a fait l'honneur de diriger ce
travail de recherche. Je tiens à lui exprimer ma gratitude et mon
profond respect.
Je remercie également mon maître de stage
MOHAMEDK. KEITA pour m'avoir accordé son temps, sa disponibilité
et son orientation pendant toute cette période cruciale de ma vie.
Je tiens également à remercier mes amis pour
leurs relectures successives, le temps qu'ils m'ont consacré pour que ce
travail puisse représenter toute l'énergie, le temps investi et
ainsi faire de ce mémoire le chapitre final d'une période de ma
vie.
Je dois également exprimer ma très profonde
gratitude à ma famille pour leur compréhension, leur soutien et
leur compassion tout au long de mes années d'études. Je tiens
également à remercier mon épouse et mon fils pour leurs
soutiens sans faille, leurs patiences et pour leurs nombreux encouragements
pendant cette épreuve.
Finalement, je terminerai par remercier l'ensemble de
Professeurs de l'Ecole Supérieure Polytechnique, plus
précisément au Département de Génie Informatique
pour d'innombrables connaissances nous accordées et orientations pendant
toute cette période de mes études.
AVANT-PROPOS
AVANT-PROPOS
Je voudrais tout d'abord par ces quelques lignes remercier le
Professeur Dr. IDY DIOP, qui m'a offert
l'opportunité de travailler sur un sujet aussi intéressant qu'est
l'investigation digitale. Merci aussi et surtout pour l'aide qu'il m'a fournie,
ses conseils et surtout pour sa disponibilité. Je remercie
également le Professeur Docteur IBRAHIMA NGOM, qui nous a vraiment
aidé et orienté tout au long de l'année académique,
que Dieu lui accorde toute sa bénédiction. Ensuite, je tiens
à remercier mon père, ma mère, ma famille et mes amis pour
leur soutien tout au long de la rédaction de ce mémoire de
recherche.
? RESUME
RESUME
Dans ce projet de recherche, il est question de doter
l'école supérieure polytechnique de l'Université Cheikh
Anta Diop de Dakar, plus précisément dans son Département
de Génie informatique un laboratoire de travaux pratiques
d'investigation digitale enfin de faciliter lesétudiants et apprenants
externes de pouvoirapprendre et de pratiquer l'essentielde l'investigation
digitale. La croissance accrue d'utilisationdes outilsnumériques
(ordinateur et téléphone par exemple) dans cette ère des
nouvelles technologies, font à ce qu'il y est augmentation grandissante
de vol des données et piratages informatiques dans nos systèmes,
et en cela, chaque entreprisse et/ou personne doit se doter des moyens
nécessaires pour s'en prémunir et s'informer. Nos juges et nos
dirigeants ayant appris dans une ère où on ne prenait pas en
compte les nouvelles technologies et leurs impacts dans la
société, doivent faire un effort de se conformer à cette
nouvelle du 21ème siècle grâce aux
enquêteurs forensics formés en milieu universitaire aussi le
temple du savoir. D'où la nécessité de mettre en place une
plateforme digitale d'investigation numérique des travaux pratiques.
Ladite plateforme ne va pas seulement reposer sur les travaux pratiques mais
aussi sur l'apprentissage des modules publiés par son personnel
formé et ayant une expertise pragmatique dans ledit domaine.
La mise en place de cette plateforme aidera les futurs
enquêteurs digitaux à développer des connaissances en
criminalistique informatique au fur et à mesure selon une progression
personnelle voulue par l'apprenant dans des laboratoires et couvrant des sujets
clés de l'informatique judiciaire; y compris la création et
l'examen d'images médico-légales, la réalisation
d'analyses médico-légales de la mémoire pour identifier
l'activité des logiciels malveillants, la gravure de données et
plus encore. Ils s'entraîneront à utiliser des outils
médico-légaux populaires tels que EnCase, FTK imager, Autopsy,
Wireshark, Volatility, etc.
? ABSTRACT
ABSTRACT
In this research project, it is a question of providing the
Polytechnic School of the Cheikh Anta Diop University of Dakar, more precisely
in its Computer Engineering Department, with a laboratory for practical work in
digital investigation, finally, to facilitate students and external learners to
be able to learn and practice the essentials in this field of digital
investigation. The increased growth in the use of digital tools (computer and
telephone for example) in this era of new technologies means that there is a
growing increase in data theft and computer hacking in our systems, and in
this, each company and/or no one must equip themselves with the necessary means
to protect themselves and inform themselves. Our judges and leaders, having
learned in an era where new technologies and their impacts on society were not
taken into account, must make an effort to comply with this news of the 21st
century thanks to forensic investigators trained in academia as well. temple of
knowledge. Hence the need to set up a digital platform for digital
investigation of practical work. The said platform will not only be based on
practical work but also on the learning of the modules published by its trained
staff with pragmatic expertise in the said field.
The implementation of this platform will help future digital
investigators to develop knowledge in computer forensics as they go along
according to a personal progression desired by the learner in laboratories and
covering key topics of computer forensics; including creating and reviewing
forensic images, performing forensic memory scans to identify malware activity,
data burning and more. They will practice using popular forensic tools such as
EnCase, FTK imager, Autopsy, Wireshark, Volatility...
Table des matières
Table des matières
DEDICACES
1
REMERCIEMENTS
II
AVANT-PROPOS
III
RESUME
IV
ABSTRACT
V
Table des matières
VI
Sigles et abréviations
IX
Introduction
1
PRÉSENTATION GÉNÉRALE
3
I.2. Présentation de la structure
d'accueil
3
I.3. Contexte
5
I.4. Problématique
5
I.5. Objectifs
5
Conclusion
6
INVESTIGATION NUMÉRIQUE
7
2.1 Introduction
7
2.2 Concepts et terminologie
8
2.2.1. Légal et la science légale
(forensic and forensic Science)
8
2.2.2. Digital Forensics
8
2.2.3. Digital Forensics Investigation
9
a) Informatique légale (Computer
Forensics)
10
b) Investigation de réseau
légale (Network Forensics)
11
c) Investigation mobile légale
(Mobile Forensics)
12
2.2.4. Preuve numérique (Digital
evidence)
13
2.2.5. Rapport d'investigation (Chain of
evidence)
15
2.2.6. Rapport de garde (Chain of custody)
15
2.3. Support numérique dans un crime
15
2.4. Processus d'investigation légale
16
2.4.1. Collection
16
2.4.2. Examen
17
2.4.3. Analyse
17
2.4.4. Rapport
19
2.5. Catégories d'investigation
numérique
19
2.5.1. L'analyse forensic judiciaire
19
2.5.2. L'analyse forensic en réponse
à un incident
19
2.5.3. L'analyse forensic scientifique
20
2.6. Objectifs de l'investigation
numérique
20
2.7. Cybercriminalité
20
2.7.1. Types d'attaques de
cybercriminalité
21
2.8. Les Objets d'investigation légale
23
2.8.1. Métadonnées
23
2.8.2. Analyse de la scène de crime
24
2.9. Collection de données
25
2.9.1 Création des images
25
2.9.2 Collecte des Dumps
26
2.9.3 Collecte des données du Registre
26
2.10. Récupération des
données
29
2.11. Récupération de fichiers
supprimés de la MFT
30
2.11.1. Sculpture de fichiers
30
2.11.2. Sculpture de fichier avec un éditeur
Hex
31
2.12. Analyse les fichiers de Log
31
2.12.1 Analyse des données non
organisées
32
2.13. Investigation numérique sur la
mémoire
32
2.13.1 La mémoire volatile
32
2.13.2 Acquisition de la RAM
33
2.13.3 Capture de la RAM
33
2.13.4. Analyse de la RAM
33
2.13.5. Identification du profil
33
2.13.6. Lister les processus en cours
34
2.13.7 Analyse des Malware
34
2.13.8. Extraction de mots de passe
35
2.14. Outils d'investigation numérique
légale
37
2.15. Atouts des outils d'investigation
numérique légale
38
2.16. Computer forensique test
39
2.16.1. Fondamentaux FAT32
47
2.16.2. Fondamentaux NTFS (New Technology File
System)
48
2.16.3. Collecte des données
48
2.16.4. Artefacts
49
2.16.5. Analyse des images
52
Conclusion
58
Méthodes d'analyse et de conception
59
3.1. Introduction
59
3.2. Définition des concepts
59
3.4. Classification des méthodes d'analyse
et de conception
61
3.4.1. Méthodes cartésiennes
ou fonctionnels
61
3.4.2. Méthodes objet
61
3.4.3. Méthodes
systémiques
61
3.4.4. Approche orientée aspect
62
3.5. Choix d'une méthode d'analyse et
de conception
62
Conclusion
63
CONCEPTION ET IMPLEMENTATION DU SYSTEME
64
4.1. Introduction
64
4.2. Le langage PHP
65
4.3. Conception générale du
système proposé
67
4.3.1. Architecture fonctionnelle
67
4.3.2. Architecture technique
68
4.4. Conception et modélisation
détaillée avec UML
68
4.4.1. Détermination des acteurs potentiels
du système
68
4.4.2. Description des cas d'utilisation
68
A. Diagramme de séquence créer
un compte
72
B. Diagramme de séquence
s'authentifier
72
C. Diagramme de séquence ajout d'une
formation
73
73
D. Diagramme de séquence rechercher
une formation
74
4.5. Implémentation
75
4.5.1. Introduction
75
4.5.2. Virtualisation
75
4.5.3 Machine virtuelle et Container
78
4.5.4. Virtualisation et Cloud Computing
78
4.6.1. AWS : Une plateforme de solutions Cloud
flexible et sécurisée
79
4.6.2. AWS : Histoire
79
4.6.3. AWS : Les principaux services
80
4.6.4. AWS : Développement logiciel
80
4.6.5. AWS : Développement mobile
81
4.6.6. AWS : Avantages et
inconvénients
81
4.7. Base de données et interfaces
utilisateurs
82
a) Base de données
82
b) Interface d'accueil
82
c) Interface d'authentification
83
d) Création compte
83
e) Ajout des cours
84
f) Le tableau de bord de l'apprenant
84
g) Formulaire de contact
85
4.7.2. Codes sources
85
4.8. Installation des outils dans les ordinateurs
virtuels
85
Conclusion
85
CONCLUSION GENERALE
86
BIBLIOGRAPHIE
87
A. Ouvrages
87
B. Normes
88
Sigles et abréviations
Sigles et abréviations
Nous présentons ici certains sigles et abréviations
que nous utiliserons dans le document.
|
ESP
|
Ecole Supérieure Polytechnique
|
|
UCAD
|
Université Cheikh Anta Diop
|
|
FTK
|
Forensic ToolKit
|
|
IP
|
Institut Polytechnique
|
|
IUT
|
Institut universitaire de Technologie
|
|
TP
|
Travaux pratiques
|
|
POA
|
Programmation Orientée Aspect
|
|
PHP
|
Hypertext Preprocessor
|
|
UML
|
Unified Modeling Language
|
|
FBI
|
Bureau fédéral d'investigation
|
|
DOS
|
Deny Of Service
|
|
U2R
|
User to Root
|
|
R2L
|
Remote to Local
|
|
IDS
|
Système de Détection d'Intrusion
|
|
SMS
|
Short Message Service
|
|
GPS
|
Global Positioning System
|
|
RAM
|
Random Access Memory
|
|
ROM
|
Read Only Memory
|
|
RFC
|
Research Forensics Computer
|
|
NIST
|
National Institute of Standards and Technology
|
|
MAC
|
Modification time of last Access time of Création
|
|
GRC :
|
Gestion de la Relation Client
|
|
DDOS :
|
Distributed Denial of Service Attack
|
|
MitM :
|
Man-in-the-middle attack
|
|
IP
|
Internet Protocol
|
|
HTTP
|
Hypertext Transfer Protocol
|
|
SQL
|
Structured Query Language
|
|
XSS
|
Cross-site scripting
|
|
CD
|
Compact Disc
|
|
SAM
|
Security Account Manager
|
|
HKLM
|
HKey_Local_Machine
|
|
PC
|
Personal Computer
|
|
USB
|
Universal Serial Bus
|
|
MFT
|
Managed-= File Transfer
|
|
NTFS
|
New Technology File System
|
|
RAW
|
Research and Analysis Wing
|
|
OS
|
Operating System
|
|
SIEM
|
Security Information and Event Management
|
|
PID
|
Process Identifier
|
|
FTP
|
File Transfer Protocol
|
|
DVD
|
Digital Versatile Disc
|
|
URL
|
Uniform Resource Locator
|
|
BIOS
|
Basic Input Out System
|
|
VSS
|
Volume Shadow Copy Service
|
|
MiB
|
Mebibyte
|
|
FAT
|
File Allocation Table
|
|
HTML
|
HyperText Markup Language
|
|
CSS
|
Cascading Style Sheets
|
|
KVM
|
Kernel-based Virtual Machine
|
|
SOAP
|
Simple Object Access Protocol
|
|
REST
|
REpresentational State Transfer
|
|
XML
|
Extensible Markup Language
|
|
SQS
|
Simple Queue Service
|
|
EBN
|
European Business and Innovation Center Network
|
|
CDN
|
Content Delivery Network
|
Liste des figures
Figure 2.1 Liens entre la preuve, le suspect, la victime et la
scène du crime
Figure 2.2 Résolution d'un crime numérique
Figure 2.3 Classification des domaines d'investigation
numérique légale
Figure 2.4 Computer Forensics
Figure 2.5. Investigation numérique dans le pare-feu
Tableau 2.1 Comparaison entre l'informatique légale et
l'investigation mobile légale
Figure 2.7 Types de crimes digitaux ou fraudes
Figure 2.8 Processus d'investigation numérique
légale
Figure 2.8 Dump du registre
Figure 2.9. Registre Dumpé
Figure 2.10 RegRipper
Tableau 3.2. Atouts des outils d'investigation numérique
légale
Figure 2.11. Arborescence Os Windows
Figure 2.12. Variable d'environnement
Figure 2.13. Le certificat windows
Figure 2.14. Le VSS
Figure 2.15. Le pare-feu
Figure 2.16. Informations boot système
Figure 2.17. Event logs
Figure 2.18. Les services
Figure 2.19. Les registres
Figure 2.20. Registre Dumpé
Figure 2.21. Informations du Dump
Figure 2.22. Liste de processus Dump mémoire
Figure 2.23. Affichage de processus Dump avec Arborescence
Figure 2.24. Liste de processus Dump cachés
Figure 2.25. Liste de processus ayant ouverts les connexions
à l'ordinateur
Figure 2.26. Liste de processus, leurs ports et protocoles
utilisés
Figure 2.27. Commandes stockées du Dump
Figure 2.28. Exécutable du processus suspect
Figure 2.29. Analyse de l'exécutable obtenu sur virus
total
Figure 4.1. Architecture fonctionnelle
Figure 4.2. Architecture technique de la plateforme
Figure 4.3. Diagramme de séquence créer un
compte
Figure 4.3. Diagramme de séquence d'authentification
Figure 4.4. Diagramme de séquence ajout d'une formation
Figure 4.5. Diagramme de séquence recherche d'une
formation
Figure 4.6 Diagramme de classe
Figure 4.7. La base de données
Figure 4.8. La page d'accueil de la plateforme
Figure 4.9. La page d'authentification utilisateur
Figure 4.10. Formulaire de création de compte
utilisateur
Figure 4.11. Formulaire de création de formation
Figure 4.12. Tableau de l'étudiant
Figure 4.12. Formulaire de contact
? INTRODUCTION
Introduction
La diversité technologique actuelle de l'information et
le développement de la cybercriminalité a conduit à la
création d'une nouvelle branche dans le domaine de l'informatique :
l'investigation numérique.
L'investigation numérique est un sujet
vaste qui nécessite des années d'apprentissage et de
pratique pour comprendre en détail le fonctionnement d'un système
d'exploitation, et en extraire les bonnes informations.
Les techniques et méthodes d'investigation ne font
qu'évoluer et la pluralité des supports de stockage
numériques implique de suivre des règles et des procédures
strictes, nécessaires à la recherche, la conservation et
l'interprétation des données extraites. Cette branche
initialement exercée par des experts judiciaires de la police nationale
ou de la gendarmerie à des fins de perquisition numérique,
s'étend et se développe au secteur privé dans le cadre
d'audit de sécurité et de réponse à incident. En ce
jour, relativement nouvelle au Sénégal et dans plusieurs pays
d'Afrique, l'investigation numérique est de plus en plus demandée
par des sociétés privées telles que les banques et les
multinationales. Aujourd'hui, les criminels sont de plus en plus conscients des
aspects judiciaires et sont maintenant capables de compromettre des ordinateurs
sans accéder au disque dur de l'ordinateur cible. Ainsi de nombreuses
sociétés spécialisées en sécurité
informatique ont développé cette activité pour
répondre à la demande croissante des entreprises.
L'analyse forensique numérique est le travail
mené sur un système d'information pour extraire, conserver et,
parfois interpréter l'ensemble des informations que l'on peut y trouver,
essentiellement sur ses différentes mémoires (vives, mortes,
caches), sur son fonctionnement ou le plus souvent, sur un dysfonctionnement
actuel ou passé.
Elle peut avoir des objectifs différents, selon le
cadre dans lequel elle est conduite : dans un cadre judiciaire, elle vise
à collecter toutes les preuves légales et incontestables
permettant d'identifier et de punir les auteurs d'un délit ou d'un
crime. Dans le cadre de la sécurité des systèmes
d'information, elle vise à collecter toutes les informations permettant
de comprendre l'enchaînement des processus informatiques ayant conduit
à un dysfonctionnement ou au succès d'une attaque et
d'évaluer son impact, afin de prendre les mesures correctrices
nécessaires pour restaurer la sécurité et la
disponibilité du système, de ses processus et de ses
données.
L'objectif de ce projet de recherche est de guider les
étudiants voulant être des experts en charge de l'investigation au
moyen de règles dites de « bonnes pratiques » mais
également de les faire découvrir les méthodes forensiques
et à toutes les personnes désirant développer leurs
compétences dans ce domaine. Nous avons jugé de mettre en place
une plateforme d'investigation numérique des travaux pratiques pour le
Département de Génie Informatique de l'Ecole Supérieure
Polytechnique, enfin de permettre les futurs chercheurs d'avoir la
maîtrise et d'informations suffisantes pour s'en familiariser, s'en
servir et aider les entreprises voir aussi la justice.
Dans le premier chapitre, nous commençons naturellement
par la présentation générale de l'Ecole Supérieure
Polytechnique de l'Université Cheikh Anta Diop de Dakar où nous
avons pu faire notre stage plus précisément dans son
Département de Génie informatique, nous allons également
présenter notre problématique et clôturer avec le contexte
du projet.
Dans le deuxième chapitre, nous allons présenter
le domaine d'investigation numérique légale, ses notions, les
principales sous disciplines. Ensuite, nous présenterons les
différents processus de l'investigation légale, avant de se
focaliser sur la phase d'analyse. Nous détaillerons quelques
méthodes et techniques qui existent dans la littérature pour
l'analyse de preuves. Enfin nous donnons un aperçu des outils
d'investigation les plus couramment déployés.
Dans le troisième chapitre, nous parlerons des
méthodes d'analyse et de conception et dans le quatrième
chapitre, nous procéderons à l'implémentation de la
plateforme tout en proposant l'architecture système ayant un choix sur
les différentes technologies (plus surtout, open source) existantes
pouvant nous servir à bien mener notre implémentation de la
plateforme et enfin, une conclusion générale.
CHAPITRE
1
PRÉSENTATION
GÉNÉRALE
I.1. Introduction
L'école supérieure polytechnique de Dakar, est
le milieu où nous avons effectué notre stage, dans ce chapitre
nous essaierons un aperçu généralisé de
l'établissement dont sa mission principale est l'éducation
professionnelle des jeunes. Ensuite de nous présenterons le contexteet
la problématique de notre sujet de recherche.
o I.2. Présentation de la structure d'accueil
L'école supérieure polytechnique de Dakar, plus
connue sous l'acronyme ESP est une école de formation professionnelle
placée sous la tutelle du ministère de l'enseignement
supérieur du Sénégal. Elle a été
fondée en mai 1964.1(*) Elle est rattachée à l'université
Cheikh-Anta-Diop (UCAD) de Dakar mais est dotée de la
personnalité juridique et d'une autonomie financière. L'ESP de
Dakar est l'une des écoles d'ingénieurs les plus importantes du
Sénégal et de l'Afrique de l'Ouest. Elle forme des techniciens
supérieurs et des ingénieurs dans le domaine de la science, de la
technique et de la gestion.
L'ESP compte six départements (génie
informatique, génie électrique, génie mécanique,
génie civil, génie chimique et biologie appliquée et le
département de gestion) et des laboratoires de recherche.
Depuis sa création, l'École Supérieure
Polytechnique de Dakar a toujours constitué un véritable
pôle d'excellence pour la formation des étudiants du
Sénégal, de la sous-région et d'ailleurs.
L'Institut Polytechnique (IP), fondé sur les fonts
baptismaux en mai 1964 est devenu IUT (Institut universitaire de Technologie)
en novembre 1967. Le 30 avril 1973, la promulgation de la loi 73-17 et le
décret 73-387 permettent à l'Institut Universitaire de
Technologie (IUT) d'être un établissement public doté de la
personnalité juridique et de l'autonomie financière au sein de
l'Université de Dakar.
A la rentrée universitaire de 1973-1974, l'Ecole
Nationale des Travaux Publics et Bâtiments (ENTPB) qui formait des agents
techniques pour le ministère de l'équipement est
intégrée au département de génie civil de l'IUT. La
même année, d'autres réformes ont permis à
l'Institut Universitaire de Technologie de dispenser des enseignements en
commerce et d'administration des entreprises.
C'est ainsi que ces formations complémentaires ont
entrainé la délivrance de Diplôme d'Ingénieur
Technologue (DIT) et le Diplôme d'études Supérieures en
Commerce et Administration des Entreprises (DESCAE). L'IUT devient ENSUT (Ecole
nationale supérieure universitaire de Technologie) en 1974.
Le 24 novembre 1994, la loi N° 94-78 la transforme en
École Supérieure Polytechnique (ESP) avec deux centres : Dakar et
Thiès. Elle regroupe l'ENSUT, l'Ecole Polytechnique de Thiès
(EPT) et la section industrielle de l'Ecole Nationale Supérieure
d'Enseignement Technique Professionnel2(*) (ENSETP). Au même moment, elle se sépare
de sa division tertiaire devenue Institut Supérieur de Gestion (ISG) qui
est rattaché à la Faculté des Sciences Economiques et de
Gestion3(*) (FASEG).
L'ENSETP a été reconstituée en 2005 en
reprenant sa partie industrielle qui était dans l'ESP. L'ex
Département Gestion de l'ex-ENSUT, devenu Institut Supérieur de
Gestion rattaché à la FASEG est revenu dans l'ESP en 2006.
En 2007, l'ex Centre de Thiès de l'École
Supérieure Polytechnique (ex EPT) est redevenu l'Ecole Polytechnique de
Thiès, rattachée à l'Université de Thiès et
ensuite rattachée directement au Ministère chargé de
l'Enseignement Supérieur4(*).
L'Ecole Supérieure Polytechnique de Dakar a pour
domaine d'activités principale la formation professionnelle et
universitaire des étudiants dont elle fait preuve et applaudi à
chaque fois dans la société sénégalaise, car tous
ceux qui y sortent sont des cadres respectés dans les entreprises
publiques et privées. Cette formation est répartie en plusieurs
domaines ou département comme cités ci-haut. D'où elle
regorge actuellement six départements et chaque département peut
avoir plusieurs filières.
o I.3. Contexte
À l'ère actuelle où tout est
numérique, l'enquête numérique est jugée
plutôt bonne pour servir la justice. L'investigation numérique
passe immanquablement par la collecte de preuves disséminées sur
les divers appareils électroniques utilisés par les suspects.
Dans ce projet de recherche, il est question de mettre en
place une plateforme TP d'investigation digitale dans le cadre d'approfondir
leurs connaissances et de servir au mieux la société qui est
remplie d'outils numériques. Mais toutefois, il s'agit bien souvent d'un
terrain miné sur lequel les apprenants doivent respecter des
procédures en constante mutation et sur la vie privée des
concernés réglementé par la loi n° 2008-12 du 25
janvier 2008 portant sur la Protection des données à
caractère personnel.5(*)
o I.4. Problématique
Le but ultime de l'implémentation d'une plateforme
d'investigation digitale au Département de Génie Informatique,
est de former et de permettre aux étudiants de faire des travaux
pratiques et de leurs démontrer comment la preuve numérique
peut-elle, être utilisée pour la reconstruction des
événements qui se sont produits lors d'un incident.
C'est un élément fondamental pour le
Département d'avoir de tels services pour ses étudiants et la
société car d'elle tout le monde vient solliciter le savoir. En
apprenant et en appliquant les différentes méthodologies
d'investigation numérique, les futurs enquêteurs seront en mesure
de faire la reconstruction de la scène du crime en se
référant au processus systématique d'assemblage des
éléments de preuves et des informations recueillies lors de
l'étape de collecte qui conduit à une image plus complète
de l'incident afin de mieux répondre sur les questions quand ?qui ?quoi
?comment ? et pourquoi ?
o I.5. Objectifs
La conception et la mise en place d'une plateforme digitale de
travaux pratiques des étudiants au département de génie
informatique s'avère très important pour les jeunes
écoliers car l'investigation numérique est une branche de
l'informatique qui aide la justice à voir clair sur certains crimes
commis sur l'espace numérique. C'est dans le cadre de former des futurs
enquêteurs numériques qui pourront aider la justice aujourd'hui et
dans le futur.
? Conclusion
La mise en place d'une plateforme numérique
d'investigation digitale dans cet établissement d'enseignement
supérieur, est un fait réel à grande échelle pour
l'avenir, car dans la société actuelle, tout se tourne vers le
numérique, d'où il est important de songer à former des
jeunes chercheurs dans ce domaine d'investigation digitale qui seront capables
de servir au mieux la société malgré cette croissance
accrue. Dans le chapitre suivant, nous parlerons de l'état de l'art de
l'investigation numérique.
CHAPITRE
2
INVESTIGATION
NUMÉRIQUE
? 2.1 Introduction
L'investigation numérique légale est le
processus d'emploi des méthodes scientifiques d'analyse des informations
stockées électroniquement pour déterminer la
séquence des événements qui ont mené à un
incident particulier. Ce processus permet d'analyser la preuve, classer,
comparer et individualiser les interactions entre les suspects et les preuves.
En d'autres termes, cette investigation permet de relier les
éléments de preuves, des suspects, des victimes et de la
scène du crime, comme indiqué dans la figure 3.1.
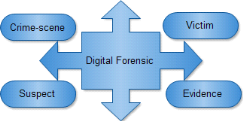
Figure 2.1 Liens entre la preuve, le suspect, la victime et la
scène du crime6(*)
Les enquêteurs numériques n'ont plus à
essayer de lire dans les pensées des gens parce que les
intérêts des gens, les secrets cachés, les informations
financières et même leur vie amoureuse ; sont tous sur leur
ordinateur et plus encore dans leurs téléphones portables.
Les gens ne réalisent généralement pas
les artefacts, ou les secrets, qu'ils laissent derrière eux lorsqu'ils
utilisent et/ou se déconnectent d'un ordinateur. Ces artefacts et
secrets sont appelés « preuves ». Les utilisateurs
d'ordinateurs pensent qu'en supprimant simplement les traces de leurs
activités, tout est parti. Ce qu'ils ne réalisent pas, c'est
qu'en utilisant le bon outil de criminalistique numérique, nous pouvons
localiser, extraire et analyser ce qui s'y trouvait auparavant et les
récupérer. On peut être surpris de voir le nombre
d'artefacts qui peuvent être récupérés et extraits,
même à partir des plus petits appareils.
? 2.2 Concepts et terminologie
Dans cette partie du chapitre, nous allons donner une suite de
définitions pour essayer de clarifier certains concepts liés
à la science de digital forensique, nous n'allons pas introduire toute
la taxonomie des concepts liés à cette science, nous nous
restreindrons uniquement aux concepts que nous allons discuter dans les
chapitres suivants.
? 2.2.1. Légal et la science légale (forensic
and forensic Science)
Définition 2.2.1
Le terme « Forensic » est
dérivé du latin « forensis » ou
« légal », qui signifie « en audience
publique ou public », qui lui-même vient du latin
« du forum », se référant à un
emplacement réel « un marché public carré
utilisé pour les affaires judiciaires et autres ». En
dictionnaires légales, forensics est définie comme le processus
d'utilisation des connaissances scientifiques pour la collecte, l'analyse et la
présentation de la preuve devant les tribunaux7(*). La science de forensics est
« l'application des principes et des techniques scientifiques pour
fournir la preuve aux enquêtes juridiques et aux
déterminations½.8(*)
Définition 2.2.1
L'investigation numérique est l'application de
connaissance scientifique au droit, et principalement, appelée à
l'investigation de crimes.9(*)
? 2.2.2. Digital Forensics
Définition 2.2.2.
C'est une branche de science légale qui permet
l'utilisation des méthodes scientifiquement dérivées et
éprouvées pour la préservation, la collecte, la
validation, l'identification, l'analyse, l'interprétation, la
documentation et la présentation de la preuve numérique
dérivée de sources digitales dans le but de faciliter la
reconstruction des événements en relation avec le crime, ou aider
à anticiper des actions non autorisées.10(*)
? 2.2.3. Digital Forensics Investigation
Définition 2.2.3
L'investigation numérique légale est un
processus qui utilise la science et la technologie pour examiner des objets
numériques et qui se développe et teste des théories, qui
peut être entré dans une cour de justice, et répondre
à des questions sur les événements qui se
produisent.11(*)
L'objectif d'une investigation numérique est d'exposer
et de présenter la vérité, ce qui conduit souvent à
des réponses aux questions suivantes relatives à un crime
numérique (voir la figure 3.2).12(*)
- Le quand : Se réfère à l'intervalle du
temps pendant la scène du crime
- Le quoi : Concerne les activités
exécutées sur le système informatique.
- Le qui : Concerne la personne responsable du crime.
- Le où : Se réfère à l'endroit
où se trouve la preuve.
- Le comment : Traite la manière dont les
activités ont été réalisées.
- Le pourquoi : Chercher à savoir les motivations du
crime.
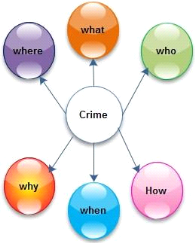
Figure 2.2 Résolution d'un crime numérique
L'investigation numérique légale peut être
classée dans trois domaines clés, à savoir l'informatique
légale, l'investigation de réseau légale, l'investigation
mobile légale tels quels sont illustrés à la figure 3.3
Network Forensics
Digital Forensics
Mobile Forensics
Computer Forensics

Figure 2.3 Classification des domaines d'investigation
numérique légale
a) Informatique légale (Computer
Forensics)
L'informatique légale a été
remontée au 1984, lorsque le gouvernement fédéral du
bureau d'investigation (FBI), ainsi que d'autres organismes d'application de la
loi ont commencé le développement des programmes assistant
à l'examen et l'analyse de preuves numériques. Elle sert à
identifier la preuve qui peut coexister dans des ordinateurs et ses
périphériques qui forment la scène du crime
numérique13(*), un
aperçu général est représenté dans la figure
3.4.
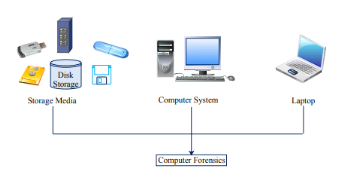
Figure 2.4 Computer Forensics14(*)
b) Investigation de réseau
légale (Network Forensics)
L'investigation de réseau légale a
été introduite dans le début des années 90, elle
sert à la fois comme un moyen de prévention d'attaque dans des
systèmes et la recherche des preuves après une attaque ou un
incident s'est produit. Un aperçu général est
représenté dans la figure 3.5.

Figure 2.5. Investigation numérique dans le pare-feu
Ces attaques incluent le déni de service (Deny of
Service, DOS), utilisateur-à-racine (User to Root, U2R) et
télécommande local (Remote to Local, R2L). L'investigation
légale de réseau consiste à vérifier, capturer,
enregistrer et analyser les pistes de réseau afin de collecter les
évidences. Par exemple, l'analyse des fichiers journaux des
systèmes de détection d'intrusion (IDS), l'analyse du trafic
réseau15(*) [20] et
l'analyse des périphériques réseau. L'informatique
légale et l'investigation de réseau légale ont une chose
en commun. Les deux domaines peuvent contenir des éléments de
preuves quand un incident se produit. Si par exemple, un attaquant attaque un
réseau, le trafic de l'attaque passe en général par un
routeur. A la suite de cela, les éléments de preuves importants
peuvent être collectés en examinant les fichiers journaux de
routeur.
c) Investigation mobile légale
(Mobile Forensics)
La popularité des téléphones mobiles
intelligents(smartphones) continue de croître. Ils changent la
façon du crime au cours des dernières années et les
chercheurs ont été confrontés à la
difficulté d'admissibilité de la preuve numérique sur les
téléphones mobiles. C'est pour ça qu'une science
d'investigation légale a été émergée. Cette
science permet de collecter des preuves numériques depuis un
téléphone mobile dans des conditions juridiquement valides tels
que des détails des appels, des SMS (Short Message Service), des e-mails
et location (Global Positioning System (GPS)), etc., ainsi que des
données supprimées. Un aperçu général est
représenté dans la figure 3.6.
Figure 2.6 - Mobile Forensics
Actuellement, les smartphones ont des fonctionnalités
similaires aux ordinateurs, mais il existe certaines différences entre
l'informatique légale et l'investigation mobile légale qui sont
illustrées dans le tableau 2.1
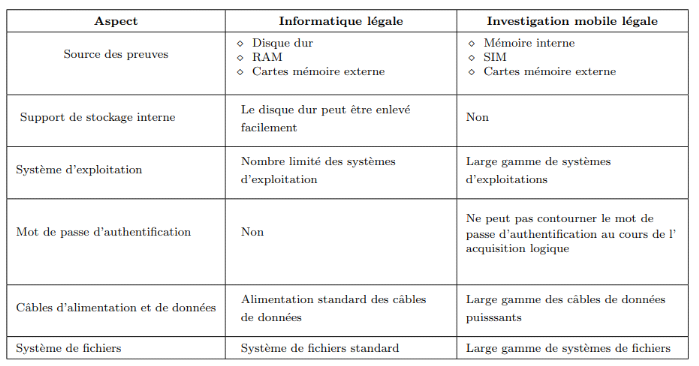
Tableau 2.1 Comparaison entre l'informatique légale et
l'investigation mobile légale
Partant des informations recueillies dans le tableau 3.1, il
est important de dire que l'investigation des smartphones légale est
plus complexe que le l'informatique légale.
? 2.2.4. Preuve numérique (Digital evidence)
Définition 2.2.4.
La preuve numérique est définie comme toute
donnée qui peut établir qu'un crime a eu lieu ou fournit un lien
entre un crime et sa victime ou un crime et son coupable.16(*)
Définition 2.2.4. Est toute information
numérique de valeur probante stockée ou transmise sous forme
numérique. Elle peut être facilement modifiée, reproduite,
restaurée ou détruite.17(*)
La preuve numérique comprend :
- Les données utilisateur
- Les métadonnées associées aux
données de l'utilisateur
- Logs d'activité
- Logs du système
Les données utilisateur se rapportent aux
données directement créées ou modifiées ou
accessibles par un ou plusieurs utilisateurs participant à une
enquête. Les métadonnées se rapportent aux données
qui fournissent le contexte de comment, quand, qui et sous quelle forme les
données des utilisateurs ont été créées ou
modifiées ou accessibles. Les journaux d'activité sont des
enregistrements de l'activité des utilisateurs par un système ou
une application et les actions spécifiques menées par un ou
plusieurs utilisateurs. Les journaux du système se rapportent à
des variations dans le comportement du système fondé sur une ou
plusieurs actions menées par les utilisateurs.
Le 3227 RFC (Research Forensics Computer) décrit les
considérations juridiques liées à la collecte de preuves.
Les règles exigent les preuves numériques d'être :
- Admissible : Se conformer à certaines règles
juridiques avant qu'il puisse être mis devant une cour.
- Authentique : C'est l'intégrité qui permet le
suivi de la chaîne des éléments de preuves qui doivent
être intactes.
- Crédible : Les preuves doivent être claires,
faciles à comprendre et précises. La version de la preuve
présentée au tribunal doit être reliée avec la
preuve binaire d'origine dans le cas contraire il n'y a aucun moyen de savoir
si la preuve a été fabriquée.
- Complète : Toutes les preuves soutenues ou
contredisent une preuve qui incrimine un suspect doivent être
examinées et évaluées. Il est également
nécessaire de recueillir des preuves qui éliminent les autres
suspects.
- Fiable : Les procédures et les outils de la
collection des évidences, l'examen, l'analyse, la préservation et
la présentation doivent être en mesure de reproduire les
mêmes résultats au fil du temps. Les procédures ne doivent
pas douter sur l'authenticité de la preuve ou sur les conclusions
tirées après l'analyse.
Lors de la recherche de preuves sur des supports
numériques, il existe différents types de données à
rechercher, parmi ces types on trouve principalement :
- Les données actives : sont des données qui
résident sur des supports de stockage et qui sont facilement visibles
par le système d'exploitation et accessibles aux utilisateurs.
Ces données comprennent les fichiers de traitement de
texte, les tableurs, les programmes et les fichiers de système
d'exploitation. Celui-ci, y compris les fichiers temporaires, les fichiers
internet temporaires, cookies et les métadonnées du
système de fichiers, etc.18(*)
- Données résiduelles : Ce sont des
données qui semblent avoir été supprimées, mais
peuvent encore être récupérées. Les exemples les
plus courants sont les fichiers d'échange et des fragments de fichiers
récupérés dans l'espace non alloué.19(*)
? 2.2.5. Rapport d'investigation (Chain of evidence)
Le rapport d'investigation est un document qui résume
les étapes d'une investigation afin de valider la preuve
numérique issue d'une information numérique avec les
détails suivants :
? Le format de sauvegarde de l'information originale.
? L'identification de l'empreinte numérique et les
moyens de blocages en écriture
? Identifier les opérations réalisées et
les logiciels mis en oeuvre.
? Les numéros de série des supports
d'informations utilisés pour l'enregistrement.
? L'ensemble des preuves réunies avec des
éventuelles interprétations ainsi que des conclusions.
? 2.2.6. Rapport de garde (Chain of custody)
Le rapport de garde est un procès-verbal qui commence
lors de la réception d'une preuve numérique liée à
la scène du crime. Il est défini :
Définition 3.2.6. La documentation chronologique du
mouvement, localisation et la possession d'éléments de
preuve.20(*)
? 2.3. Support numérique dans un crime
Un crime ou incident est un événement ou
série d'événements qui violent une police et plus
spécifiquement, un crime est un événement ou une
séquence d'événements qui viole la loi.21(*) Un support digital dans un
crime implique le numérique et ça englobe les PCs (Personal
Computers), les ordinateurs portables, les smartphones, les tablettes, les
outils numérique robot... etc., c'est-à-dire tout ce qui est
numérique. Un support numérique peut jouer l'un des trois
rôles dans un crime informatisé. Il peut être la cible du
crime, il peut être l'instrument du crime, ou il peut servir comme un
référentiel de stockage des informations précieuses sur le
crime(évidences).
Lors d'une investigation sur une affaire quelconque, il est
important de savoir quels rôles chaque objet digital a joué dans
le crime et puis adapter le processus d'investigation pour ce
rôle.22(*) Il existe
une variété des crimes tels quels sont représentés
par la figure 3.7

Figure 2.7 Types de crimes digitaux ou fraudes23(*)
? 2.4. Processus d'investigation légale
L'investigation numérique dépend de plusieurs
facteurs techniques tels que le type de l'information ou le dispositif de
communication, en plus le type d'investigation, criminel, civil, commerciale,
militaire ou autre contexte et autres facteurs selon le cas d'investigation.
Malgré cette variation, il existe des phases communes entre les
modèles de processus d'investigation résumé dans le
modèle de NIST qui sont :
? 2.4.1. Collection
Dans cette étape, il s'agit d'identifier,
labéliser, acquérir, stocker, transporter et conserver des
données depuis des différents sources de confiance issues de la
scène du crime. C'est un processus long et complexe puisque les
données doivent être collectées à temps à
cause de la probabilité de perte des données telles que les
connexions réseaux ou bien perte de données dues à la
décharge des batteries de certaines sources (exemple
téléphone portable) ou coupure brusque du courant
électrique (exemple ordinateur de bureau).
? 2.4.2. Examen
Cette étape consiste à faire une recherche
systématique approfondie pour l'évaluation et la localisation des
éléments pertinents à partir de larges volumes de
données recueillies tout en préservant son
intégrité en utilisant une combinaison d'outils automatique, ou
manuel. Les résultats de l'examen sont des objets de données. Ils
peuvent inclure des fichiers journaux, fichiers de données contenant des
phrases spécifiques, des SMS téléphoniques, ...
? 2.4.3. Analyse
C'est la phase la plus importante d'investigation
légale. Elle désigne le processus d'organisation et de
structuration des résultats des examens, en utilisant des
méthodes et des techniques légales et justifiables pour
dériver des connaissances utiles qui adressent les questions qui
résolvent le cas d'investigation.
a) La recherche des preuves
Pendant le processus d'une investigation numérique,
l'étape de recherche des preuves numériques est la tâche la
plus consommatrice du temps. Un des plus grands défis auxquels sont
confrontés les enquêteurs numériques est le volume de
données qui doivent être recherchées lors de la
localisation des preuves numériques, c'est pour ça qu' ils
utilisent des méthodes scientifiques comme le datamining afin de
localiser efficacement la preuve relative au crime. Selon la façon de
rechercher des preuves électroniques, ce processus sera divisé en
deux types de recherches : Statique et dynamique.
? La recherche statique consiste à faire la collecte
des preuves dans un état passif, ce qui signifie que la recherche des
évidences est faite sur des ordinateurs et autres dispositifs
numériques (par exemple téléphone portable) qui ont
quitté la scène du crime.
? La recherche dynamique : C'est la technique de la collecte
des preuves dans le pare-feu, détection d'intrusion et tous les actes
possibles d'acquisition en temps réel.
b) L'analyse de preuves (reconstruction des chaînes des
évidences)
L'enquêteur développe des hypothèses
basées sur des preuves existantes qu'il a collectées à
l'étape précédente et teste ces hypothèses en
cherchant des preuves supplémentaires indiquant si elles sont vraies ou
fausses.24(*) Il existe
trois types d'analyse25(*) :
- L'analyse temporelle : elle répond à la
question quand ? c'est l'ordonnancement dans le temps des preuves
récupérées pour fournir une séquence narrative des
événements pour aider un enquêteur à identifier les
anomalies sur un crime et menant à d'autres sources de données.
De nombreux éléments de données numériques
légales sont naturellement prêtes à cette séquence,
par exemple, fichiers MAC (time of last Modification (M) time of last Access
(A) time of Création (C)), les événements journaux avec
timestamp, e-mails, etc.
- L'analyse fonctionnelle : elle répond des
questions qui ? quoi ? où ? pour montrer les liens entre les
entités dans un crime, par exemple l'existence d'un numéro de
téléphone dans une base de contacts d'un mobile affiche un lien
entre le propriétaire du téléphone et le
propriétaire du numéro de téléphone.
- L'analyse relationnelle : elle répond à
des questions comment ? et pourquoi ? C'est l'acte de déterminer quelles
entités pourraient avoir réalisées l'un des
événements qui sont liés à un cas d'investigation.
Lors de la reconstruction d'un crime, il est souvent utile de se demander
quelles conditions étaient nécessaires pour que certains
scénarios du crime soientpossibles. Par exemple, il est parfois
utile d'effectuer certains gestes fonctionnels sur le matériel
utilisé dans le crime pour s'assurer que le système sous
investigation était capable d'effectuer des actions. L'analyse
fonctionnelle vise à examiner toutes les hypothèses possibles
pour un ensemble des circonstances, par exemple, lorsqu'on lui demande si
l'ordinateur du défendeur peut télécharger un groupe de
fichiers incriminants en une minute, comme il est indiqué par leurs
timestamps, un examinateur légiste peut déterminer que le modem
était trop lent pour télécharger ces fichiers rapidement.
Cependant, l'examinateur ne doit pas être satisfait de cette
réponse et devrait déterminer comment les fichiers ont
été placés sur l'ordinateur. Les analyses temporelles,
fonctionnelles et relationnelles sont nécessaires pour recréer
une image complète d'un crime. Combiner les résultats de ces
analyses peut aider les enquêteurs à comprendre le crime et son
coupable.
? 2.4.4. Rapport
C'est dans cette étape où les conclusions de la
phase d'analyse sont documentées et présentées à
l'autorité sous forme d'un rapport d'investigation, il comprend
l'enregistrement des détails de chaque étape de l'investigation,
telles que les procédures suivies et les méthodes
utilisées pour saisir, recueillir, conserver, restaurer, reconstruire,
organiser et rechercher des éléments de preuves essentiels.
Les étapes du processus d'investigation sont
énumérées dans la figure 3.8 comme suit :
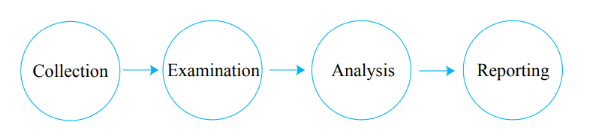
Figure 2.8 Processus d'investigation numérique
légale
Le rapport devra respecter une structure définie qui
détaillera les étapes d'investigation. Voici ci-dessous un
exemple de plan à respecter : page de garde, sommaire,
résumé des investigations, rappel du contexte et des conclusions,
détail des investigations : phase de collecte et hash (copie
d'écran, photos), analyse réalisée et mise en exergue des
découvertes (copie d'écran, photos), hypothèse de
l'analyse, recommandations et la liste des indicateurs de compromission.
? 2.5. Catégories d'investigation numérique
L'investigation numérique peut-être divisée
en trois catégories distinctes :
? 2.5.1. L'analyse forensic judiciaire
Cette catégorie est principalement utilisée dans
le cadre d'enquêtes judiciaires, elle a pour but de rechercher toutes les
preuves numériques (par exemple lors d'une perquisition), afin de
collecter et rassembler un maximum de preuves pouvant incriminer ou innocenter
le suspect d'une enquête.
? 2.5.2. L'analyse forensic en réponse à un
incident
Dans cette catégorie, on vise à identifier les
conditions et les origines d'une attaque informatique, quelles sont les
machines infectées ou encore par quel vecteur l'attaque est survenue.
Dans le cas d'une réponse à une intrusion, elle joue le
rôle de « pompier » et permet d'identifier rapidement les
éléments du système d'information compromis, dans le but
de combler les failles et d'éradiquer le ou les malwares.
? 2.5.3. L'analyse forensic scientifique
Dans cette dernière catégorie, on étudie
les mécanismes et les aspects techniques d'un malware ou autre logiciel
ou matériel malveillant, afin d'identifier les méthodes
utilisées par les attaquants pour pénétrer et compromettre
un réseau informatique. Les analyses sont souvent
réalisées dans un environnement maîtrisé
(appelé sandbox).
? 2.6. Objectifs de l'investigation numérique
L'investigation numérique a pour but de construire une
analyse contenant le lieu, le moment et la raison pour laquelle un acteur
malveillant a pénétré votre système. Cela permet de
comprendre la faille et d'obtenir des conseils sur la façon de contrer
une attaque si elle se reproduit ou de poursuivre ce dernier en justice.
C'est aussi l'opportunité de découvrir les
outils, tactiques et processus que les pirates utilisent pour s'introduire dans
votre SI.
Le suivi de l'empreinte de l'acteur malveillant est l'un des
points de départ de l'investigation numérique. Les cybercriminels
préparent longuement et laborieusement leurs attaques avant de la
lancer. Pour les détecter, il faut remonter à la source, examiner
les schémas de préparation des pirates et établir des
liens entre les différentes relations en jeu.
? 2.7. Cybercriminalité
Selon la GRC, la cybercriminalité renvoie à tout
crime commis principalement à l'aide d'Internet et des technologies de
l'information, comme les ordinateurs, les tablettes ou les
téléphones intelligents.26(*)
Sous le vocable général de
cybercriminalité, la GRC divise les cybercrimes en deux
catégories :
a) Les infractions où la technologie est la cible ;
b) Les infractions où la technologie est l'instrument.
? 2.7.1. Types d'attaques de cybercriminalité
Une cyberattaque est tout type d'action offensive qui vise des
systèmes, des infrastructures ou des réseaux informatiques, ou
encore des ordinateurs personnels, en s'appuyant sur diverses méthodes
pour voler, modifier ou détruire des données ou des
systèmes informatiques.
Il existe plusieurs types d'attaque, mais nous allons citer le
dix types de cyberattaques les plus courants :
1. Attaques par déni de service (DoS) et par
déni de service distribué (DDoS)
Une attaque par déni de service submerge les ressources
d'un système afin que ce dernier ne puisse pas répondre aux
demandes de service.
2. Attaque de l'homme au milieu (MitM)
Une attaque de l'homme du milieu est un pirate qui
s'insère dans les communications entre un client et un serveur. Voici
quelques types courants d'attaques de l'homme du milieu : détournement
de session, usurpation d'IP et la relecture.
3. Hameçonnage (phishing) et harponnage (spear
phishing)
L'hameçonnage consiste à envoyer des e-mails qui
semblent provenir de sources fiables dans le but d'obtenir des informations
personnelles ou d'inciter les utilisateurs à faire quelque chose. Cette
technique combine ingénierie sociale et stratagème technique.
Elle peut impliquer une pièce jointe à un e-mail, qui charge un
logiciel malveillant sur votre ordinateur. Elle peut également utiliser
un lien pointant vers un site Web illégitime qui vous incite à
télécharger des logiciels malveillants ou à transmettre
vos renseignements personnels.
4. Téléchargement furtif (drive-by download)
Les attaques par téléchargement furtif sont une
méthode courante de propagation des logiciels malveillants. Les pirates
recherchent des sites Web non sécurisés et insèrent un
script malveillant dans le code HTTP ou PHP de l'une des pages. Ce script peut
installer des logiciels malveillants directement sur l'ordinateur d'un visiteur
du site, ou rediriger celui-ci vers un site contrôlé par les
pirates.
5. Cassage de mot de passe
Les mots de passe étant le mécanisme le plus
couramment utilisé pour authentifier les utilisateurs d'un
système informatique, l'obtention de mots de passe est une approche
d'attaque courante et efficace. Le mot de passe d'une personne peut être
obtenu en fouillant le bureau physique de la personne, en surveillant la
connexion au réseau pour acquérir des mots de passe non
chiffrés, en ayant recours à l'ingénierie sociale, en
accédant à une base de données de mots de passe ou
simplement en devinant. Cette dernière approche peut s'effectuer de
manière aléatoire ou systématique : force brute ou par
dictionnaire.
6. Injection SQL
L'injection SQL est devenue un problème courant qui
affecte les sites Web exploitant des bases de données. Elle se produit
lorsqu'un malfaiteur exécute une requête SQL sur la base de
données via les données entrantes du client au serveur. Des
commandes SQL sont insérées dans la saisie du plan de
données (par exemple, à la place du nom d'utilisateur ou du mot
de passe) afin d'exécuter des commandes SQL prédéfinies.
Un exploit d'injection SQL réussi peut lire les données sensibles
de la base de données, modifier (insérer, mettre à jour ou
supprimer) les données de la base de données, exécuter des
opérations d'administration de la base de données (par exemple la
fermer), récupérer le contenu d'un fichier spécifique, et,
dans certains cas, envoyer des commandes au système d'exploitation.
7. Cross-site Scripting (XSS)
Les attaques XSS utilisent des ressources Web tierces pour
exécuter des scripts dans le navigateur Web de la victime ou dans une
application pouvant être scriptée. Plus précisément,
l'attaquant injecte un JavaScript malveillant dans la base de données
d'un site Web. Lorsque la victime demande une page du site Web, le site Web
transmet la page à son navigateur avec le script malveillant
intégré au corps HTML. Le navigateur de la victime exécute
ce script, qui envoie par exemple le cookie de la victime au serveur de
l'attaquant, qui l'extrait et l'utilise pour détourner la session. Les
conséquences les plus graves se produisent lorsque XSS sert à
exploiter des vulnérabilités supplémentaires. Ces
vulnérabilités peuvent non seulement permettre à un
attaquant de voler des cookies, mais aussi d'enregistrer les frappes de touches
et des captures d'écran, de découvrir et de collecter des
informations réseau et d'accéder et de contrôler à
distance l'ordinateur de la victime.
8. Écoute clandestine
Les écoutes clandestines sont le résultat d'une
interception du trafic réseau. Elles permettent à un attaquant
d'obtenir des mots de passe, des numéros de carte bancaire et d'autres
informations confidentielles qu'un utilisateur envoie sur le réseau.
9. Attaque des anniversaires
Les attaques des anniversaires sont lancées contre les
algorithmes de hachage qui vérifient l'intégrité d'un
message, d'un logiciel ou d'une signature numérique. Un message
traité par une fonction de hachage produit une synthèse du
message de longueur fixe, indépendante de la longueur du message entrant
; cette synthèse caractérise de façon unique le message.
L'attaque des anniversaires fait référence à la
probabilité de trouver deux messages aléatoires qui
génèrent la même synthèse lorsqu'ils sont
traités par une fonction de hachage. Si un attaquant calcule la
même synthèse pour son message que l'utilisateur, il peut tout
à fait remplacer le message de l'utilisateur par le sien, et le
destinataire ne sera pas en mesure de détecter le remplacement,
même s'il compare les synthèses.
10. Logiciel malveillant (malware)
Un logiciel malveillant peut être décrit comme un
logiciel indésirable installé dans votre système sans
votre consentement. Il peut s'attacher à un code légitime et se
propager, se cacher dans des applications utiles ou se reproduire sur Internet.
? 2.8. Les Objets d'investigation légale
? 2.8.1. Métadonnées
Il existe différents types de métadonnées
qui rendent le système complet et opérationnel. Voici ci-dessous
les trois types de métadonnées les plus courant :
a) Descriptif
Les métadonnées descriptives sont des
informations de base, qui, quoi, quand et où. Considérez-le comme
une description d'un fichier ou d'une oeuvre d'art avec la plaque à
côté. Les métadonnées descriptives sont là
pour aider les individus à savoir ce qu'ils regardent ; par
conséquent, la description change en fonction du contenu de l'objet ou
de l'élément d'information. Par exemple : heure et date de
création, créateur ou auteur des données, taille du
fichier, qualité des données, source des données,
modifications ou programmes utilisés pour modifier le fichier, etc.
b) Structurel
Les métadonnées structurelles définissent
comment les données doivent être catégorisées pour
s'intégrer dans un système plus étendu d'autres objets ou
ensembles d'informations. Par conséquent, les métadonnées
structurelles représentent la signification des champs, de sorte qu'il
peut y avoir une relation établie entre de nombreux fichiers afin qu'ils
puissent être organisés et utilisés en
conséquence.
c) Administratif
Enfin, il y a les métadonnées administratives ;
il s'agit d'informations sur l'historique des données ou de l'objet.
Comme les propriétaires, les droits, les licences et les autorisations,
cela est particulièrement utile pour la gestion des informations. Ainsi,
les fichiers de mots, les chansons, les vidéos et les images, par
exemple, suivent tous une méthode d'information sur les origines, la
création et les utilisations.
? 2.8.2. Analyse de la scène de crime
Le but de l'investigation sur une scène de crime est de
reconstruire le déroulement du crime dans ses détails, ce qu'il
nomme les micro séquences des événements.27(*) Pour procéder à
la reconstruction des événements, les intervenants peuvent
recourir évidemment aux preuves matérielles disponibles, mais
également aux déclarations des témoins ou des victimes et
aux dépositions des suspects.28(*)
L'objectif de l'investigation est parfois exprimé de
manière plus centrée sur la contribution du processus à
l'enquête. Bradbury et Feist identifient par exemple la collecte de
matériel forensique afin de faciliter le processus d'enquête comme
l'objectif principal.29(*)
Selon Olivier Ribaux, « tout se joue sur les lieux
puisque la nature et la qualité de l'information qui y est
collectée vont conditionner l'ensemble du processus judiciaire
».30(*) Une
scène de crime mal gérée peut en effet résulter en
la collecte de preuves de qualité insuffisante, ce qui peut compromettre
l'enquête et même augmenter le risque d'erreur judiciaire.31(*)
? 2.9. Collection de données
? 2.9.1 Création des images
Les images médico -légales sont une technique de
collecte typique pour les PC, quel que soit le système d'exploitation
(Windows, Macintosh, Linux) qu'ils utilisent. Vous pouvez les créer avec
un logiciel ou avec des périphériques matériels
spécialisés, comme par exemple le logiciel FTK imager.
L'utilisation de l'imageur FTK pour créer une image
médico-légale est relativement simple, comme le montrent les
instructions fournies ci-dessous, qui expliquent en quelques étapes
comment acquérir des données à partir d'un support de
stockage.
1. Une fois FTK Imager installé, dans le menu
Démarrer de Windows, sélectionnez Programmes | Accès
Données | Imageur FTK, puis cliquez sur l'élément de menu
Imageur FTK.
2. Lorsque les programmes s'ouvrent, cliquez sur le menu
Fichier, puis cliquez sur l'élément de menu Ajouter un
élément de preuve.
3. Lorsque la boîte de dialogue Sélectionner la
source apparaît, cliquez sur l'option intitulée Lecteur logique.
Cliquez sur le bouton Suivant.
4. Lorsque la boîte de dialogue Sélectionner un
lecteur s'affiche, sélectionnez le lecteur contenant votre disquette ou
votre CD. Cliquez sur Terminer.
5. Lorsque la boîte de dialogue Créer une image
s'affiche, cliquez sur Ajouter.
6. Lorsque la boîte de dialogue Sélectionner la
destination de l'image s'affiche, spécifiez l'emplacement de stockage du
fichier image en saisissant un chemin dans le champ intitulé Dossier de
destination de l'image.
7. Dans le champ intitulé Nom du fichier image,
saisissez le nom que vous souhaitez donner au fichier sans extension. Cliquez
sur Terminer.
8. Lorsque la boîte de dialogue Créer une image
s'affiche à nouveau, cliquez sur Démarrer.
9. Patientez pendant que FTK Imager crée un fichier
d'image médico-légale des données sur le lecteur que vous
avez spécifié. Cela peut prendre plusieurs minutes. Une fois que
le champ Statut indique Image créée avec succès, cliquez
sur le bouton Fermer.
? 2.9.2 Collecte des Dumps
Un "dump" mémoire d'un processus correspond à
une copie du contenu de la mémoire virtuelle (pile, tas managé,
pile d'appels des différents "threads" etc...). Un débogueur peut
écrire le contenu de la mémoire virtuelle dans un fichier sur le
disque de façon à pouvoir le lire plus tard. Avec les sources, on
pourra ensuite lire le "dump" et voir une instance «gelée» du
processus de façon à identifier plus précisément la
ligne de code qui a menée au crash.
Il existe deux sortes de Dumps selon les informations qu'ils
contiennent, Full dump (contiennent tout le contenu de la mémoire
virtuelle, souvent sollicité quand on ne connaît pas l'origine du
problème) et Mini dump (concerne un processus spécifique et est
configurable de façon à choisir les informations qu'il
contiendra).
? 2.9.3 Collecte des données du Registre
Le registre Windows est une base de données
hiérarchique qui stocke les paramètres de bas niveau pour le
système d'exploitation Microsoft Windows et pour les applications qui
choisissent d'utiliser le registre.
Le noyau, les pilotes de périphérique, les
services, le gestionnaire de comptes de sécurité (SAM) et
l'interface utilisateur peuvent tous utiliser le registre.
Le registre contient des informations auxquelles Windows fait
constamment référence pendant son fonctionnement, telles que les
profils de chaque utilisateur, les applications installées sur
l'ordinateur et les types de documents que chacun peut créer, les
propriétés des dossiers et des icônes d'application, le
matériel existant sur le système, et les ports
utilisés.
Les ruches du registre sont stockées dans le
répertoire %SystemRoot%\System32\config.
Une ruche est un groupe logique de clés, de
sous-clés et de valeurs dans le registre, qui contient un ensemble de
fichiers de prise en charge contenant des sauvegardes de ses données.
Chaque fois qu'un nouvel utilisateur ouvre une session sur un
ordinateur, un nouveau répertoire est créé pour cet
utilisateur avec un fichier distinct pour le profil utilisateur. Ceci s'appelle
la ruche de profil d'utilisateur.
La ruche d'un utilisateur contient des informations de
registre spécifiques concernant ses paramètres d'application, son
bureau, son environnement, ses connexions réseau et ses imprimantes. Les
ruches de profil utilisateur se trouvent sous la clé HKEY_USERS. Les
ruches spécifiques à l'utilisateur (NTUSER.DAT) sont
stockées dans le répertoire :
Voici à quoi correspond chaque ruche :
? SAM (gestionnaire de compte de sécurité) :
contient toutes les informations de comptes utilisateurs et de droits
d'accès ;
? Sécurité : le noyau y accédera pour
lire et appliquer la politique de sécurité applicable à
l'utilisateur actuel et à toutes les applications ou opérations
exécutées par cet utilisateur ;
? Défaut : ruche utilisée par le compte
système local. Utilisée par les programmes et services
exécutés en tant que système local ;
? Système : contient des informations sur la
configuration du système Windows, la liste des
périphériques montés contenant un système de
fichiers, ainsi que plusieurs "HKLM \ SYSTEM \ Control Sets"
numérotés, contenant d'autres configurations de pilotes de
système et de services exécutés sur le système
local ;
? Logiciel : contient le logiciel et les paramètres
Windows, principalement modifiés par les installateurs d'applications et
de systèmes ;
? Ntuser.dat : contient les paramètres spécifiques
à chaque utilisateur (les profils itinérants l'utilisent).
Il est possible de dumper les fichiers de registre avec FTK
Imager.
Figure 2.8 Dump du registre
Les fichiers extraits seront ensuite stockés dans votre
répertoire pour analyse.
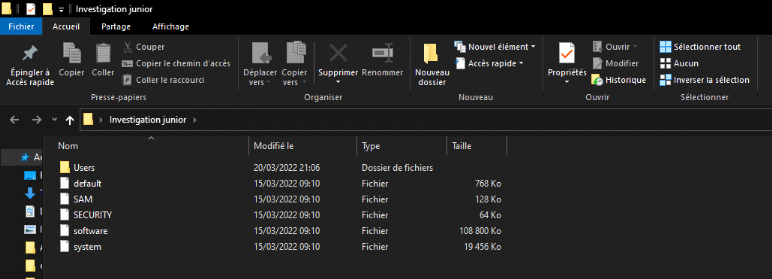
Figure 2.9. Registre Dumpé
Pour explorer ces fichiers, il est possible d'utiliser l'outil
RegRipper. Pour cela, il faudra sélectionner le fichier NTUSER.DAT du
profil de la victime, ici Junio. Puis sélectionnez le nom du rapport
à générer et le profil à utiliser ; ici nous
choisissons le profil "ntuser".
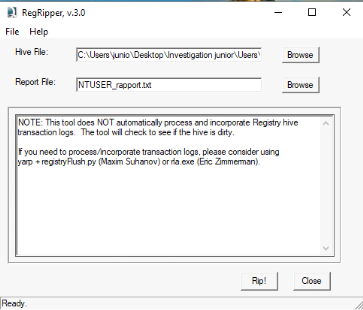
Figure 2.10 RegRipper
Une fois cela terminé, un rapport sera
généré. Si nous recherchons dans les clés RUN avec
Volatility, nous retrouvons rapidement la clé de registre
malveillante.
? 2.10. Récupération des données
Sur un PC, un MAC, une clé USB, un disque dur, une
carte SD, un disque dur externe ou un téléphone portable, la
suppression involontaire des fichiers reste la première cause de la
perte des données ou encore la suppression volontaire pour cacher
certaines informations à la justice en cas de délit
numérique. D'où, il sera nécessaire de pouvoir faire une
récupération de données avec des outils appropriés
enfin d'en avoir clair pendant l'investigation par les enquêteurs
forensiques. Quelle que soit l'origine de la perte des fichiers et le type de
support concerné, découvrez comment récupérer des
données effacées.
Il nous arrive parfois de supprimer certains de nos dossiers
ou fichiers pour pouvoir libérer l'espace dans votre disque dur.
Rassurez-vous, nous pouvons encore les récupérer à partir
de la corbeille. Il se peut encore que vous vidiez cette dernière, cela
devient une suppression permanente mais soyez en sûr et certain, vos
données se trouvent toujours sur votre ordinateur et c'est toujours
possible de les récupérer, c'est juste que vous n'y avez pas
accès.
Si vous avez vidé la corbeille de votre MAC ou PC voire
même un téléphone portable, l'utilisation d'un logiciel de
récupération vous permettra également de
récupérer des données effacées. La méthode
reste la même pour récupérer des données
effacées sur n'importe quel support de stockage ; il suffit
d'utiliser un outil performant, par exemple : Ontrack EasyRecovery,
Recuva, etc.
? 2.11. Récupération de fichiers
supprimés de la MFT
La partition NTFS peut afficher un message d'erreur disant
« la structure du disque est corrompue et illisible » Cela
se produit lorsque votre partition NTFS est devenue RAW ou corrompue. L'outil
de gestion de disque affichera également la partition NTFS au format RAW
et lorsque vous exécutez CHKDSK pour résoudre le problème,
il renverra un message indiquant que le MFT est corrompu.
Quelle que soit la raison de la corruption de la table
MFT ; comme ici, dans le cadre d'investigations numériques, nous
pouvons effectuer une récupération complète des
données de la partition NTFS à l'aide d'un outil de
récupération de données efficace comme Remo Partition
Recovery.
? 2.11.1. Sculpture de fichiers
La sculpture de fichiers se réfère à la
reconstruction de fichiers informatiques qui a lieu sans indicateurs de
métadonnées utiles ou autres conseils spécifiques. En
l'absence de cette information directive, les systèmes logiciels
utilisent des outils d'heuristique et de traitement des probabilités
sophistiqués afin de rassembler avec succès les fichiers.
Certains experts présentent l'idée selon
laquelle les systèmes logiciels doivent collecter avec précision
des informations sur les fichiers à partir d'un ensemble de
données "homogène" plus grand sur un lecteur de disque ou une
autre zone de stockage. Les logiciels de gravure de fichiers peuvent utiliser
des marqueurs tels que des en-têtes et des pieds de page pour essayer
d'identifier des parties d'un fichier. Au-delà de cela, des algorithmes
spécialisés peuvent également aider à
améliorer les résultats de la récupération de
fichiers.
Il est important de noter que d'autres pratiques de
récupération de fichiers reposent sur des informations
système plus disponibles. En revanche, la sculpture de fichiers se fait
en grande partie sur la base de suppositions, c'est pourquoi ces
systèmes logiciels ont besoin de fonctionnalités avancées
qui peuvent plus efficacement mettre de l'ordre dans le chaos.
? 2.11.2. Sculpture de fichier avec un éditeur Hex
L'éditeur Hex est logiciel facile d'utilisation et
soigneusement conçu pour les ordinateurs équipés d'un OS
Windows (jusqu'à la dernière version), il donne un accès
en lecture et en écriture aux disques durs (internes et externes), aux
clés USB, aux CD, aux cartes mémoires, etc. et propose
également une modification de la RAM. Ayant interface ergonomique et
réactive, offrant aussi des fonctionnalités telles que la
recherche et le remplacement, la concaténation et le fractionnement de
fichiers, l'exportation et des statistiques de distribution des bytes
(graphiques de représentation). Grâce à ces outils, HxD Hex
Editor traite efficacement des fichiers volumineux et permet de les comparer
afin d'en vérifier le contenu. Il comporte également un outil de
destruction définitive de fichier.
HxD Hex Editor est un logiciel libre et est destiné aux
utilisateurs expérimentés et aux enquêteurs. Il est
à manier avec précaution puisqu'il permet d'ouvrir et de modifier
des fichiers nécessaires au bon fonctionnement de l'ordinateur.
? 2.12. Analyse les fichiers de Log
L'analyse des fichiers log est l'évaluation d'un ensemble
d'informations enregistrées à partir d'un ou plusieurs
événements intervenus sur un environnement IT. Cette pratique
peut être utilisée pour :
? Analyser le comportement utilisateur et identifier des
modèles de comportement
? Identifier et anticiper des incidents
? Être conforme à la réglementation en
place
? Anticiper et planifier les capacités de l'environnement
IT
L'analyse des fichiers logs est un véritable challenge
et demande un travail fastidieux pour les enquêteurs en raison de la
volumétrie, mais aussi de la diversité des types de logs, ainsi
que les formats propriétaires, les architectures élastiques,
etc.
L'utilisation des logiciels d'analyse des fichiers logs qui
exploitent des algorithmes de Machine Learning réduit
considérablement la charge de travail des enquêteurs qui peuvent
se concentrer sur des tâches à valeur ajoutée. Ce logiciel
d'analyse de logs permet de surveiller, d'agréger, d'indexer et
d'analyser toutes les données des journaux des applications et de
l'infrastructure.
? 2.12.1 Analyse des données non organisées
Les outils d'analyse des données non structurées
ont la capacité d'examiner toutes les données exclusives et
publiques qui peuvent être liées à une fraude pour aider
les enquêteurs à détecter et à régler la
fraude sans autre munition. Possible de procéder par un questionnaire,
par exemple : Junior, a-t-il partagé ses critiques
élogieuses d'une entreprise en ligne, puis a-t-il revendu ses parts de
l'entreprise avant que les actions chutent considérablement ?
L'entreprise paye-t-elle des sinistres d'assurance fortement marqués par
la fraude ? Marie, de la comptabilité, mentionne-t-elle de
manière disproportionnée un certain client ou une certaine
personne dans ses courriels ? Il ne s'agit pas de preuves tangibles, mais les
comportements derrière ces communications influencent tous la
détection de la fraude et l'enquête.
En d'autres mots, les données qui informent un audit de
la culture sont presque toutes qualitatives et non structurées. C'est
là que les outils d'analyse de données non structurées en
audit peuvent être mis en oeuvre pour exécuter un audit de la
culture et justifier ses conclusions
? 2.13. Investigation numérique sur la
mémoire
? 2.13.1 La mémoire volatile
Lorsqu'une application est ouverte sur un appareil, une
certaine quantité de RAM lui est allouée afin qu'elle puisse
s'exécuter. Si plusieurs applications sont ouvertes, l'appareil doit
allouer une plus grande quantité de RAM. C'est pour cette raison que les
appareils dotés d'une RAM plus importante sont plus rapides : ils
peuvent exécuter plus d'applications en même temps.
Pour répondre à un incident de
cybersécurité, cela peut s'avérer complexe. Il arrive que
le serveur compromis n'alimente aucun SIEM en journaux
d'événements, voire même qu'il n'y ait pas de journaux du
tout. Dans ces circonstances, comment pouvons-nous commencer à
enquêter sur l'appareil compromis et à rassembler des preuves en
temps opportun dans le cadre d'un plan de réponse aux incidents ?
Nous devons d'abord confirmer la présence d'un malware
sur l'appareil avant de pouvoir capturer un échantillon et d'entamer la
rétro-ingénierie du malware au moyen d'outils
spécialisés.
La capture d'une image mémoire peut prendre du temps,
et il nous faudra ensuite transférer cette image (dont la taille
pourrait-être gigantesque) vers un emplacement où elle pourra
être analysée. Sans oublier le temps que prendra l'analyse. Face
à ces contraintes, l'analyse de la mémoire peut être un
atout majeur pour l'équipe de réponse. Alors qu'un disque dur
peut dépasser les 150 Go, la RAM de l'appareil est beaucoup plus petite,
généralement entre 8, 16 et 32 Go. La capture d'un vidage de la
RAM d'un appareil sera donc bien plus rapide et moins volumineuse lors du
transfert de la sortie.
? 2.13.2 Acquisition de la RAM
La méthode de capture des données diffère
selon l'appareil, machine physique ou machine virtuelle. Pour notre cas,
ça sera pour une machine physique.
? 2.13.3 Capture de la RAM
La capture de la RAM d'une machine physique peut se faire
à l'aide de plusieurs outils. FTK imager, est un outil parfait et
gratuit, la majorité d'enquêteurs le recommande car il est
très fiable et facile à utiliser.
? 2.13.4. Analyse de la RAM
Lors d'une analyse forensic, l'étude de l'image
mémoire d'un système avec des outils spécifiques peut
s'avérer utile, car elle permettra d'extraire des informations
difficilement exploitables lorsque le système est en fonctionnement.
C'est ce qui nous permettra de comprendre quelles actions ont été
effectuées.
Dans notre situation, nous ne savons pas si l'infection est
survenue ou pas à la suite d'exécution de certains processus. Il
faudra alors faire des recherches pour identifier si un logiciel malveillant a
été exécuté, et de quelle manière.
Pour extraire ces informations sur le dump mémoire que
nous avons réalisé, nous utiliserons le Framework open source
Volatility. Pour cette petite démonstration, nous allons utiliser une
image d'un système d'exploitation Windows XP sp1 ayant
exécuté un logiciel malveillant pendant l'ouverture d'un mail.
? 2.13.5. Identification du profil
Pour commencer, nous devons d'abord définir un profil
pour indiquer à Volatility de quel système d'exploitation
provient l'image de la mémoire. Pour le découvrir nous
utiliserons le plug-in imageinfo. La commande exécutée dans ce
cas est : Python vol.py -f memdump.mem imageinfo. Nous essayerons d'être
beaucoup plus dans le chapitre suivant qui parlera de comment mener une
investigation numérique.
? 2.13.6. Lister les processus en cours
Le système d'exploitation est responsable de la
gestion, de la suspension et de la création de processus,
c'est-à-dire des instances d'un programme.
Lorsqu'un programme s'exécute, un nouveau processus est
créé et associé à son propre ensemble d'attributs,
y compris un ID de processus unique (PID) propre à chacun, et un espace
d'adressage.
L'espace mémoire d'un processus devient un conteneur
pour le code de l'application, les bibliothèques partagées, les
données dynamiques et la pile d'exécution.
Un aspect important de l'analyse de la mémoire consiste
à énumérer les processus qui s'exécutent sur un
système et analyser les données stockées dans leur espace
d'adressage. L'objectif ? Dénicher les processus correspondant à
des programmes potentiellement malveillants, ainsi que comprendre leur
fonctionnement, leur origine, et les analyser en détail. Pour extraire
la liste des processus, il est possible d'utiliser l'option pslist.
Voici la commande : python vol.py -f memdump.mem
--profile=Win7SP1x86 pslist
Il existe une multitude d'options disponibles que nous allons
plus détaillée dans la plateforme. Ces options permettent
d'explorer le contenu de la mémoire et de reconstruire les structures de
données pour en extraire les informations pertinentes.
? 2.13.7 Analyse des Malware
Après identification des logiciels malveillants ayant
conduits avec compromission, Il faudrait procéder à l'analyse
pour comprendre le mode opératoire et comment le contrer.Pour pouvoir
infecter un ordinateur, un attaquant doit faire en sorte d'exécuter du
code malveillant sur la machine cible. Pour ce faire, il doit utiliser un
vecteur d'infection.
Un vecteur d'infection est donc un moyen d'infecter un
ordinateur.32(*) Il
existe plusieurs types de vecteur :
? La navigation internet via le téléchargement
ou via l'exploitation de vulnérabilités.
? L'email contenant une pièce jointe malveillante ou un
lien malveillant. Les pièces jointes peuvent être des fichiers
compromis tels qu'un fichier PDF, ZIP, Office... Cela peut également
être un SMS, ou un message sur les réseaux sociaux.
? Les clefs USB et autres supports externes peuvent aussi
être des vecteurs d'infection.
? Un autre vecteur d'infection est ce qu'on appelle la «
Supply Chain Attack », il s'agit ici de compromettre un tiers de confiance
de l'entreprise cible pour pouvoir la compromettre. Ainsi elle
bénéficiera d'un canal de confiance qui lui permettra de
contourner les protections mis en place. Ce genre de vecteur est beaucoup plus
difficile à détecter et à éviter car il s'agit de
la sécurité des tierces parties avec lequel l'entreprise
travaille.
? 2.13.8. Extraction de mots de passe
Les logiciels de récupération des mots de passe
font aujourd'hui partie des outils informatiques les plus importants. En effet,
ceux-ci permettent de faciliter un grand nombre d'opérations en toute
simplicité. Il peut arriver qu'on se retrouve à devoir formater
un disque dur, refaire un système d'exploitation, ou encore effectuer
toute autre tâche du même genre. C'est ce type de programme qui
permet la récupération des mots de passe potentiellement en
péril, et cachés derrière les logiciels. Mais encore plus
simple, il peut arriver qu'on ait juste oublié votre Password ou dans le
cadre d'investigation numérique. A défaut, que le concerné
ne veut pas donner de plein degré aux enquêteurs, la seule
solution reste un programme de récupération. Il en existe
plusieurs, parmi-lesquels :
1. RecALL
Le programme recALL fait partie aujourd'hui des meilleures
applications de récupération des mots de passe.
Créé par le développeur polonais portant le même
nom, ce logiciel est disponible en téléchargement gratuit et est
compatible avec la majorité des systèmes d'exploitation Windows.
Il permet la récupération des mots de passe à travers plus
de 200 programmes et systèmes confondus. Entre autres : des
navigateurs Web, des clients FTP, des messageries instantanées, des
clients Mails, ou encore des réseaux Wi-Fi.
Il offre aussi la possibilité de
récupérer des clés de licences à travers des
logiciels installés sur un ordinateur. Il est important de
spécifier que c'est l'une des toutes premières applications au
monde à disposer de fonctionnalités avancées. A cet effet,
il est même apte à récupérer les clés de
licence au sein de systèmes d'exploitation endommagés. C'est
l'application la mieuxadaptée pour la récupération de mots
de passe.
2. PasswdFinder
PasswdFinder, est un logiciel gratuit, édité par
Magical Jelly Bean, qui fait également partie des meilleures
applications de récupération des mots de passe. Il est compatible
avec les systèmes d'exploitation Windows 7, 8 et 10.
Il permet de facilement retrouver l'ensemble des mots de passe
enregistrés dans différents navigateurs web. C'est par exemple le
cas pour Safari, Google Chrome, Internet Explorer, ainsi que pour Mozilla
Firefox.
Il prend aussi en charge les clients FTP et Mails à
l'instar de Microsoft Outlook Express, Mozilla Thunderbird, et même les
Messageries instantanées. Ce logiciel est facile à installer, et
dispose également d'une interface simplifiée. Par ailleurs, la
recherche de mots de passe se fait en tenant compte des fichiers d'extensions
*.html, *.xls, *.txt, *.xml, *.csv, *.doc, *.pdf, et enfin *.rtf.
3. KeepPass Password safe
KeepPass Password Safe est un logiciel de gestion et de
protection de mots de passe. C'est un logiciel qui facilite la gestion des
identifiants et mots de passe entre de nombreuses applications. Il s'agit d'un
gestionnaire de mots de passe gratuit et facile à utiliser. Il offre une
meilleure sécurité en matière de gestion et de sauvegarde
de mots de passe. Il est en plus compatible à plusieurs plateformes
telles que Linux, Windows, OS X et Android.
4. IE PassView
IE PassView est un logiciel de récupération des
mots passe, spécialement dédié au navigateur Internet
Explorer. Edité par le studio NirSoft, ce programme est capable de
prendre en charge toutes les versions dudit navigateur. D'autre part, il prend
également en charge le navigateur Microsoft Edge.
Ce logiciel est compatible avec les systèmes
d'exploitation Windows XP, 7, 8, et 10. Le freeware a la particularité
de conférer la visualisation des identifiants et mots de passe
stockés au sein des navigateurs. Par ailleurs, il est possible de
visualiser par la même occasion les adresses Web des sites sur lesquels
vous vous êtes enregistré. La récupération concerne
notamment les stockages protégés, les protections FTP et bien
d'autres encore.
5. Password Cracker
Password Cracker est aussi l'un des meilleurs logiciels de
récupération des mots de passe. Édité par le studio
russe G&G Software, celui-ci permet de récupérer et de
restaurer les mots de passe masqués en astérisque. Ceci dans les
logiciels, et même dans les navigateurs à l'instar d'internet
explorer.
A cet effet, c'est un programme efficace en cas
d'investigation. Il est gratuit et ne nécessite aucune installation
quelconque. Et donc, ce logiciel vous permettra aussi de gagner en temps lors
de son utilisation. En effet, il suffit de faire survoler le curseur au-dessus
des astérisques voilant le mot de passe, pour que ce dernier apparaisse
instantanément dans la fenêtre du logiciel. Par ailleurs, des
tests montrent que ce freeware marche aussi bien en survolant la barre d'URL
des navigateurs.
Pour aller plus loin, prière de visiter la plateforme
forensic TP du Département de Génie informatique de l'Ecole
Supérieur Polytechnique de Dakar qui est même l'objet de ce dit
mémoire.
? 2.14. Outils d'investigation numérique
légale
Une augmentation croissante de crimes numériques a
conduit au développement de toute une série d'outils
d'investigation. Ces outils assurent que la preuve numérique est acquise
et préservée correctement. Ils existent sous forme de logiciels
mis au point pour aider l'enquêteur numérique lors d'une
enquête. Sur cette partie, il est question de développer une
meilleure compréhension de certains des outils d'investigation
légale utilisés plus souvent et qui ont fait une meilleure
réputation grâce à leurs efficacités. Voici une
liste non exhaustive ci-dessous.
a) Forensic ToolKit
La Boîte à outils médico-légale
appelée FTK, est un logiciel de criminalistique informatique
créé par AccessData. Il scanne un disque dur à la
recherche de diverses informations. Il peut, par exemple, localiser les e-mails
supprimés et analyser un disque à la recherche de chaînes
de texte à utiliser comme le dictionnaire de mots de passe pour casser
le cryptage.
De même que pour EnCase Forensic, FTK fonctionne sur la
plateforme windows, cependant, en termes de coût, il est moins cher par
rapport à EnCase Forensic. FTK est constitué de plusieurs
composants, tels que l'imageur FTK, le registre d'affichage(viewer) et le
fichier filtre (filter). Une fois que FTK est lancé, il propose un choix
entre acquérir ou prévisualiser la source de la preuve.
b) Lace Carver
LACE CARVER est un outil autonome, les experts en
cyber-criminalistique sont mesure d'extraire efficacement les fichiers de
preuves et de les importer en utilisant la norme JSON dans tous les
différents outils qu'ils choisissent d'utiliser pour analyser et
examiner les preuves photos, vidéos et documentaires.
c) EnCase
EnCase est traditionnellement utilisé dans
criminalistique pour récupérer des preuves sur les disques durs
saisis. Il permet à l'enquêteur de mener une analyse approfondie
des fichiers utilisateur pour collecter des preuves telles que des documents,
des images, l'historique Internet et des informations du registre Windows.
L'entreprise propose également EnCase formation et certification.
d) Volatility
Volatility est un outil Open Source implémenté
dans le langage Python, et est utilisé très facilement sur les
systèmes Windows, Linux. Elle est composée de plusieurs plugins
qui sont dotés de fonctionnalités spéciales.
e) Magnet et Cellebrite sont deux outils qui permettent de
faire la récupération des données sur des mobiles. Magnet
permet de faire l'acquisition alors que Cellebrite fait l'acquisition et
l'analyse des données.
? 2.15. Atouts des outils d'investigation numérique
légale

Tableau 3.2. Atouts des outils d'investigation numérique
légale
? 2.16. Computer forensique test
Nous voici dans le moment crucial de faire preuve de
pragmatisme après avoir fait l'énumérations de plusieurs
outils dans les points précédent ; ici, il est question
d'utiliser ces outils, mais notre choix porte sur les outils open source tels
que FTK, Autopsy et Volatility qui nous permettront d'effectuer les
différents tests dans chaque phase d'une investigation digitale de
façon claire et approfondie. Nous allons pour ce premier test, le faire
sur un ordinateur équipé d'un système d'exploitation
Windows dont il important bien avant de comprendre les fondamentaux de son
environnement, puis procéder aux collectes. Pour ce qui est des autres
environnements, tels que : Mac OS, Mobile et Linux, etc. la même
démarche sera poursuivie et pour être beaucoup plus
compréhensible dans la démarche, voir l'annexe de ce
mémoire.
Le système d'exploitation Windows est de loin le
système d'exploitation le plus populaire sur terre et l'un des nombreux
systèmes d'exploitation utilisés dans le monde, mais la plupart
des nouveaux ordinateurs ou ordinateurs portables utilisent le système
d'exploitation Windows. Cela a donc un impact dans le monde numérique,
la plupart des cybercrimes visent Windows, nous devons donc savoir quels petits
objets seront utilisés comme artefacts, puis effectueront des analyses
médico-légales sur les systèmes Windows.
a) Système de fichiers / Arborescence
Le système d'exploitation Windows est construit sur une
arborescence de fichiers et dossiers qui sont créés et
enregistrés sur le disque dur. Ce dernier est donc organisé en
différents dossiers : dossier Windows, dossiers Programmes et dossier
Utilisateur avec les Bibliothèques.
- Fichier
Un fichier informatique est un ensemble de données
cohérentes réunies33(*), c'est-à-dire une suite de chiffres binaires
dont l'ordre possède une signification pour un ou des programmes
informatiques. Un fichier informatique est enregistré dans une
mémoire de stockage (disque dur local ou réseau, clé USB
ou carte mémoire Flash, CD/DVD, ...) afin de pouvoir lire et/ou modifier
les données qui y sont écrites.
Un fichier informatique est repéré par son nom,
qui possède souvent, mais pas toujours, la structure suivante :
nom.extension où le nom est une suite de caractères quelconque,
et l'extension est une suite de deux, trois ou quatre lettres pouvant donner
une idée du contenu du fichier.
Le système d'exploitation Windows peut être
configuré de manière à sélectionner automatiquement
(c'est-à-dire par double-clique) un programme pour ouvrir un type de
fichier, en fonction de son extension.
Ainsi, généralement, pour les fichiers portant
l'extension .jpg, le système d'exploitation sera configuré de
manière à ouvrir avec un logiciel visionneuse d'image, ou bien un
éditeur d'image.
Non seulement un fichier contient des données brutes,
mais il contient aussi des métadonnées (certaines informations
concernant les informations), telles que, suivant le système de fichier,
la longueur du fichier, son auteur, les personnes autorisées à le
manipuler, ou la date de la dernière modification et ce sont des
informations nécessaires pour les enquêteurs forensic.
- Dossier
Un dossier informatique (ou répertoire, directory en
anglais) est un fichier particulier qui contient les références
à d'autres fichiers.
Dans tous les systèmes de fichier, chaque fichier ou
dossier est référencé par un autre dossier, appelé
parent du fichier ou du dossier correspondant.
Un tel système forme une hiérarchie,
appelée arborescence, dont le point d'entrée est appelé
répertoire racine.
Figure 2.11. Arborescence Os Windows
Donner le chemin absolu d'un fichier ou d'un dossier, c'est
donner l'ensemble des dossiers traversés depuis le répertoire
racine pour atteindre ce fichier ou dossier. Il est possible de donner le
chemin relatif vers un fichier ou un dossier à partir d'un autre dossier
de la même arborescence. Pour cela il est parfois nécessaire de
remonter dans les répertoires parents. Le nom du répertoire
parent n'étant pas connu par le répertoire courant, on utilise la
convention.. (Deux points) pour signifier qu'il faut remonter d'un parent vers
la racine.
b) Séquence de boot Windows
Le boot séquence est l'ordre dans lequel le BIOS
recherche les lecteurs pour démarrer Windows. Lorsqu'on démarre
un ordinateur équipé d'un système d'exploitation Windows,
le BIOS de la carte mère effectue les tests des différents
composants du PC, c'est le POST.
Si le POST se termine correctement, le BIOS cherche un lecteur
(disque-dur, lecteur CD/DVD, lecteur de disquette, etc.) qui contient un
secteur de boot pour lancer le système d'exploitation (OS) qui s'y
trouve.
c) Base de registre
La base de registre Windows ou registre Windows est une base
de données structurées où sont stockées un grand
nombre d'informations. Ces informations sont utilisées par Windows et
ses composants ainsi que les programmes installés par l'utilisateur pour
sauvegarder des informations utiles à leurs fonctionnements. Cette base
de données est invisible à l'utilisateur et est utilisée
en arrière-plan par Windows.
Cependant, il arrive parfois que l'on soit obligé de la
modifier. Cela est utile lorsque l'on rencontre des problèmes techniques
ou pour modifier des paramètres qui ne sont pas accessibles directement
dans Windows.
Pour les enquêteurs ou analystes forensiques, le
Registre ressemble probablement à l'entrée d'une caverne sombre
et inhospitalière dans le système d'exploitation Windows.
D'autres peuvent le voir comme une porte noire à
l'extrémité d'un long couloir sur laquelle est gravé "
Vous qui allez franchir cette porte, abandonnez tout espoir". En
vérité, le Registre est une véritable mine d'informations
pour l'enquêteur forensique. Dans de nombreux cas, le logiciel
utilisé par l'assaillant laisse une empreinte dans le Registre, donnant
alors à l'enquêteur des indices sur l'incident. Si vous savez
où regarder et comment interpréter vos découvertes, vous
disposez d'un formidable moyen de connaître les activités qui ont
eu lieu sur le système.
d) Fichiers logs
1. Le répertoire Prefetch
Le répertoire c:\windows\prefetch contient la liste de
tous les programmes qui ont été exécutés sur un
système Windows 7/8/10. Mais il est important de signaler que cette
fonctionnalité est déjà désactivée sur les
environnements Windows Server 2008/2012/2016. Dans le même ordre
d'idée, le programme Executed Programs List nous permettra de lister
tous les programmes qui ont été exécutés sur notre
machine sans ambigüité.
2. Les ShellBags
Les « ShellBags » permettent de conserver
l'agencement des dossiers que vous avez ouverts. Ils indiquent la date à
laquelle vous y avez accédé. Pour en faire l'objet d'une
investigation, il y a plusieurs outils qui nous permettent d'en obtenir la
liste complète, entre autres :
? ShellBagsView de Nirsoft
? ShellBag Analyzer et Cleaner de Privazer
3. Le MUICache
Dans le même registre, sachez que Windows stocke dans
son registre la liste des dernières applications utilisées au
niveau de la clé HKEY_CLASSES_ROOT\Local
Settings\Software\Microsoft\Windows\Shell\MuiCache. Pour visualiser la liste de
ces applications, vous disposez du logiciel MUICacheView de Nirsoft ce qui est
une mine d'or pour nous les enquêteurs forensic.
Un nouveau programme signé Nirsoft, Execute Programs
List, permet d'obtenir la liste des derniers programmes exécutés
à partir du dossier c:\windows\prefetch comme nous l'avons
signalé précédemment et des clés de registre
suivantes :
- HKEY_CURRENT_USER\Classes\Local
Settings\Software\Microsoft\Windows\Shell\MuiCache
- HKEY_CURRENT_USER\Microsoft\Windows\ShellNoRoam\MUICache
- HKEY_CURRENT_USER\Microsoft\Windows
NT\CurrentVersion\AppCompatFlags\Compatibility Assistant\Persisted
-
HKEY_CURRENT_USER\Microsoft\WindowsNT\CurrentVersion\AppCompatFlags\Compatibility
Assistant\Store
4. Le gestionnaire d'événements
Il permet d'accéder aux journaux Windows
verrouillés par le système, stockés dans le
répertoire C:\windows\system32\config aux côtés des
principaux fichiers qui constituent la base de registre. Vous y accédez
grâce au programme eventvwr.exe ou eventvwr.msc.
5. Les fichiers temporaires
Ils sont accessibles à partir des variables
d'environnement fixées dans les paramètres système
avancés de notre configuration Windows.
Figure 2.12. Variable d'environnement
6. Les caches de navigation et autres traces
Pour Internet Explorer, vous pouvez y accéder à
partir du répertoire
%LOCALAPPDATA%\Microsoft\Windows\TemporaryInternetFiles.
Sous Firefox/Chromium tapez about:cache à partir de la
barre d'adresse ; vous pouvez aussi consulter toutes les adresses
consultées par about:networking.
Sous Chromium encore, pour consulter toutes les informations
disponibles, tapez chrome://chrome-urls.
Pour accéder à ces caches de navigation et aux
autres traces laissées sur notre système, nous pouvons aussi
utiliser la version gratuite des gratuiciels Wise Disk Cleaner et Ccleaner
associé à CCEnhancer. Il existe d'ailleurs de nombreuses
alternatives à Ccleaner comme BleachBit qui est une des rares solutions
Open Source dans ce domaine.
7. Les certificats
De nombreux certificats sont visibles au travers de la console
certmgr.msc.
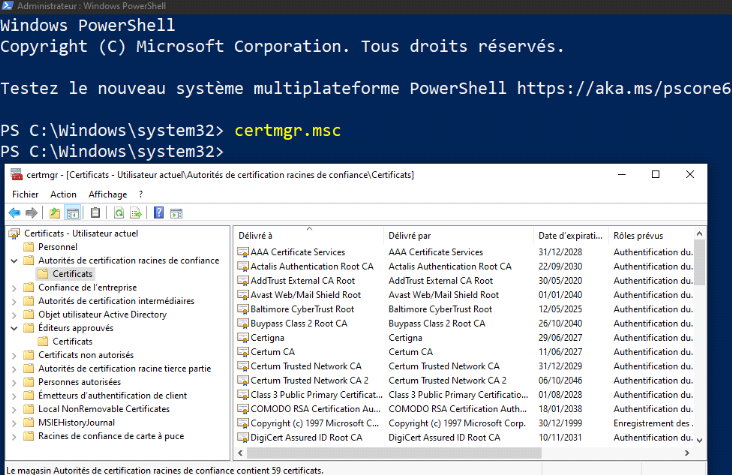
Figure 2.13. Le certificat windows
8. Les clichés instantanés
C'est un mécanisme appelé VSS ou Volume Shadow
copy Service, qui permet de réserver une place pour les versions
antérieures des fichiers qui y sont stockés. Le mécanisme
s'applique aux volumes logiques : vssadmin.exe est l'utilitaire en ligne
de commande pour gérer le VSS.
Figure 2.14. Le VSS
9. Les logs du pare-feu
Grâce au pare-feu (firewall) nous pouvons journaliser
toute l'activité réseau de notre machine. Par défaut, la
taille du fichier de journalisation est de 4 Mo. Cela représente environ
la consignation de 2 jours d'activité. Windows ne permet pas de fixer
une valeur au-delà de 32 Mo. La commande pour accéder au pare-feu
est wf.msc. Dans les propriétés du pare-feu, allez dans chaque
profil et cliquez sur le bouton Personnaliser au niveau de la zone
Enregistrement en bas à droite de la boîte de dialogue.
Figure 2.15. Le pare-feu
10. Les informations liées au boot de votre
système
Avec l'utilitaire msconfig.exe, vous pouvez journaliser les
informations liées au démarrage de votre système. Elle se
trouve consignée dans le fichier c:\windows\ntbtlog.txt.
Figure 2.16. Informations boot système
? 2.16.1. Fondamentaux FAT32
Le système de fichiers FAT32 existe depuis Windows 95.
Il est encore utilisé aujourd'hui car il permet aux clés USB et
aux disques durs mobiles formatés selon ce standard d'être lus sur
différentes plates-formes, par ex. sur des appareils Apple ou des
consoles de jeu.
Le système de fichiers FAT32 est venu compléter
son prédécesseur FAT16 en 1996, c'est-à-dire au moment de
l'introduction du système d'exploitation Windows 95B de Microsoft. Par
conséquent, il n'a pas remplacé complètement la version
précédente et intervenait plutôt comme une extension. Les
bases techniques de FAT32 remontent jusqu'en 1977 lorsque Microsoft a
développé la File Allocation Table (abrégé en :
FAT), qui est aujourd'hui encore le standard industriel par défaut pour
les systèmes de fichiers. En effet, les différents formats FAT
peuvent être utilisés en dehors des limites des différents
systèmes d'exploitation.
FAT32 est le dernier niveau du standard FAT traditionnel et
fait suite à FAT12 et FAT16. exFAT est quant à lui un format
dérivé à partir de FAT. À l'instar de NTFS, un
système de fichiers moins récent, exFAT est un format
propriétaire de Microsoft et n'est donc pas un standard open source.
Avec FAT32, la « largeur des données » est de
32 bits ce qui explique pourquoi les appellations successives intègrent
des chiffres comme 32 et 16. Avec le système de fichiers standard de
Microsoft NTFS, la largeur des données est de 64 bits. Cependant, ces
valeurs sont une simple spécification interne au système de
fichiers et n'ont rien à voir avec la distinction 32/64 bits
opérée pour les systèmes d'exploitation ou dans
l'architecture des processeurs. Le nombre de clusters adressables dans le
système de fichiers FAT32 s'élève à 268 435 456
avec une taille maximale pour chaque cluster d'exactement 32 Ko. Si
l'accès au fichier a lieu via la procédure Logical Block
Addressing (abrégée en LBA), les experts informatiques parlent
plutôt de FAT32X.
Même après l'introduction de FAT16, les
partitions d'une taille inférieure à 512 MiB (mebioctets)
étaient toujours générées en FAT16. À une
époque où les grands volumes de données multimédias
prédominent, les supports de données de petite taille de ce type
n'avaient pratiquement plus d'utilité.
FAT32 est encore utilisé sur des supports de stockage
mobiles tels que les clés USB, les cartes mémoire et les disques
durs externes. Il est parfois indispensable pour permettre un échange de
données entre des appareils anciens et nouveaux. Sur les disques durs
internes Windows modernes, FAT32 n'est en revanche plus utilisé puisque,
depuis Windows Vista, le système de fichiers NTFS est le standard
prévu pour les ordinateurs Windows dans toutes les gammes de prix.
FAT32 vit également ses derniers jours en tant que
standard multi plateformes étant donné que exFAT,
l'amélioration de FAT32, offre davantage de possibilités et une
plus grande capacité de stockage. C'est sur les cartes mémoire et
les clés USB que FAT32 « survivra » le plus longtemps puisque
sur ces supports de stockage, en particulier sur les cartes SD, la faible
taille des partitions (d'env. 32 Go) ne posait aucun problème
jusqu'à il y a quelques années encore puisque la taille des
fichiers et les quantités de données n'atteignent pas ces
limites. FAT32 peut aussi bien être utilisé sur des disques durs
de taille différente (par ex. des HDD 2,5 et 3,5 pouces) que sur des
supports flash modernes comme les disques SSD.
? 2.16.2. Fondamentaux NTFS (New Technology File System)
L'abréviation « NTFS » renvoie à
« New Technology File System » (littéralement : nouveau
système de fichiers technologiques). Du fait de la prédominance
de Microsoft, NTFS est un système de fichiers très répandu
permettant l'organisation des données sur des disques durs et des
supports de données. Depuis l'introduction de Windows XP en 2001, ce
système de fichiers est le standard incontesté pour les
systèmes d'exploitation Windows. Dans les sections suivantes, nous vous
expliquons dans le détail comment il fonctionne, quels sont ses
avantages et en quoi il se démarque des autres systèmes, par
exemple des systèmes FAT.
Dans le système de fichiers NTFS, la taille maximale
d'une partition est d'environ 2 téraoctets. Il n'existe pas de taille
limite pour un fichier individuel. En théorie, il est donc possible
d'enregistrer un fichier de près de 2 téraoctets sur un support
de données formaté en NTFS. Par rapport à des
systèmes de fichiers classiques comme FAT32, la « taille de cluster
» a été nettement étendue dans NTFS et est à
présent d'approximativement 16×10^18. Dans le cas du système
de fichiers FAT32, elle est « seulement » de 4 294 967 296.
D'après le standard NTFS, un nom de fichier peut comporter 255
caractères au maximum.
? 2.16.3. Collecte des données
« On ne peut aller et revenir d'un endroit, entrer et
sortir d'une pièce, sans apporter et déposer quelque chose de
soi, sans emporter et prendre quelque chose qui se trouvait auparavant dans
l'endroit ou la pièce. » C'est le principe de l'échange
formalisé par Locard. Il repose sur l'idée qu'un criminel
à la fois laisse sur les lieux du crime des traces de son passage
(cheveux, fibres de vêtements, empreintes, traces biologiques, etc...
c'est ce même principe qui va aussi nous aider en investigation digitale
pour identifier les éléments sur la machine compromise.
Nous allons procéder au collecte grâce au
logiciel autopsie qui est un outil fiable et rapide voir gratuit qui fait
l'ensemble des phases dans un temps réduit et finit par identifier
l'élément malveillant après avoir effectué à
la loupe les différentes phases d'analyse.
? 2.16.4. Artefacts
Les Artefacts sont les traces de l'attaque et sur windows, ces
traces peuvent se trouver à des multiples endroits, entre autres :
Event logs, les services, le registre, etc.
a) Event logs
Les Event logs Windows sont des journaux qui
répertorient chaque action de chaque application sur le système,
tels que les messages d'erreur, d'information et de warning. Il est possible
d'y accéder en utilisant l'outil natif Event Viewer.
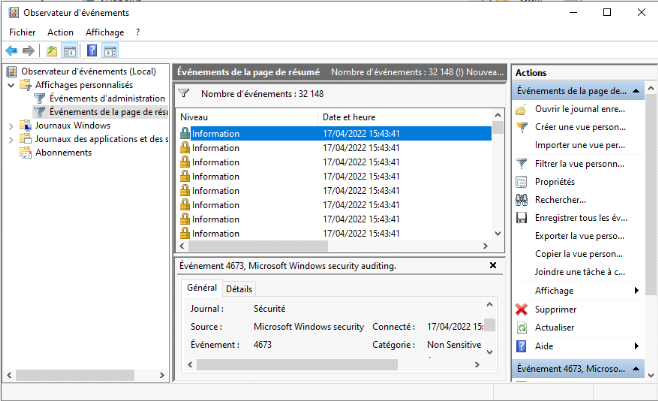
Figure 2.17. Event logs
Les catégories de logs se trouvent sur le panneau de
gauche et vous donnent l'accès aux événements liés
à cette catégorie. Enfin, il sera possible de les analyser sur un
autre système avec le logiciel Event Log Explorer. Il est payant, mais
la démo est utilisable 30 jours.
b) Les services
Les services Windows sont des applications qui
démarrent généralement au démarrage de l'ordinateur
et s'exécutent silencieusement en arrière-plan jusqu'à son
arrêt. À proprement parler, un service est une application Windows
implémentée avec l'API de services et gérant des
tâches de bas niveau, ne requérant que peu ou pas d'interaction de
l'utilisateur. Les malwares peuvent utiliser cette fonctionnalité de
Windows pour rester persistants.
Les techniques de persistance permettent à un malware
de s'exécuter même après que le système ait
été rebooté. Les techniques de persistance
utilisées par les malwares sont nombreuses.
Il est possible d'y accéder avec l'interface native
services.msc.
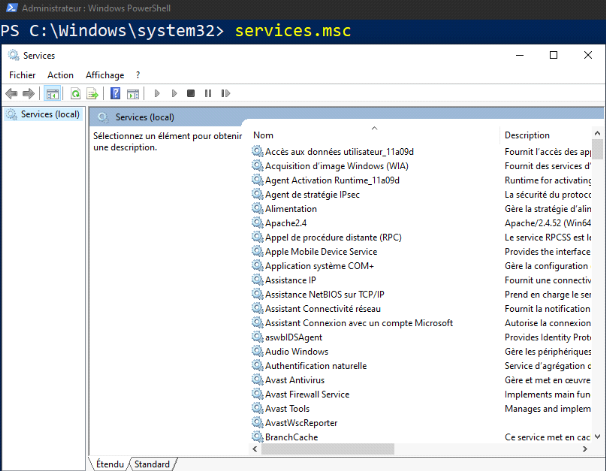
Figure 2.18. Les services
Les Prefetch sont des fichiers créés par le
système lorsqu'une application s'exécute sur le système.
Les fichiers Prefetch sont d'excellents artefacts pour analyser les
applications exécutées sur un système.
Windows crée un fichier Prefetch (.pf) lorsqu'une
application est exécutée pour la première fois à
partir d'un emplacement particulier. Cela permet d'accélérer
le chargement des applications. La fonctionnalité « Prefetch »
??de Windows est généralement activée par
défaut.
Le répertoire Prefetch contiendra un enregistrement
historique des 128 derniers programmes "uniques" exécutés sur le
système. Les Prefetch se trouvent dans le répertoire
C:\Windows\Prefetch. En les classant par ordre chronologique, il sera possible
d'identifier les programmes qui se sont exécutés sur le
système.
c) Le registre
Le registre Windows est une base de données
hiérarchique qui stocke les paramètres de bas niveau pour le
système d'exploitation Microsoft Windows et pour les applications qui
choisissent d'utiliser le registre.
Le noyau, les pilotes de périphérique, les
services, le gestionnaire de comptes de sécurité (SAM) et
l'interface utilisateur peuvent tous utiliser le registre.
Le registre contient des informations auxquelles Windows fait
constamment référence pendant son fonctionnement, telles que les
profils de chaque utilisateur, les applications installées sur
l'ordinateur et les types de documents que chacun peut créer, les
propriétés des dossiers et des icônes d'application, le
matériel existant sur le système, et les ports
utilisés.
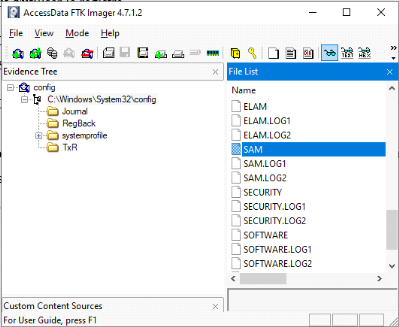
Figure 2.19. Les registres
Le fichier SAM contient toutes les informations de comptes
utilisateurs et de droits d'accès. Il est possible de dumper les
fichiers de registre avec FTK Imager.
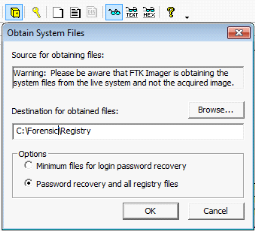
Figure 2.20. Registre Dumpé
? 2.16.5. Analyse des images
a) Obtention des informations du vidage de la mémoire
La toute première commande à exécuter
lors d'une analyse de mémoire volatile est : imageinfo, elle vous aidera
à obtenir plus d'informations sur le vidage mémoire. Avec -f
spécifiant votre fichier de vidage et imageinfo le plugin de
volatilité que vous souhaitez utiliser. Vous devriez obtenir le
résultat suivant :
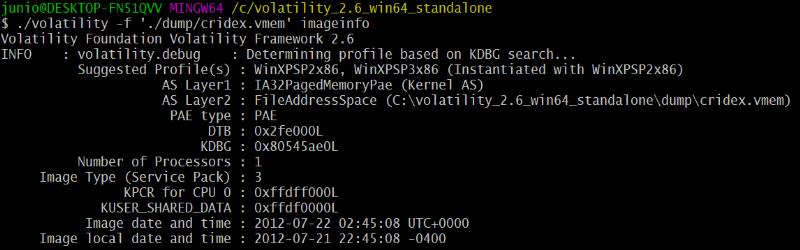
Figure 2.21. Informations du Dump
Nous avons maintenant le système d'exploitation de
l'ordinateur d'où provient ce vidage mémoire (WinXPSP2x86).
L'enquête peut maintenant commencer, nous pouvons spécifier
à volatilité le profil de l'OS (--profile=WinXPSP2x86) et essayer
de trouver ce qui s'est passé sur l'ordinateur de la victime.
b) Liste de processus
Voyons quels étaient les processus en cours
d'exécution utilisant le plugin pslist.
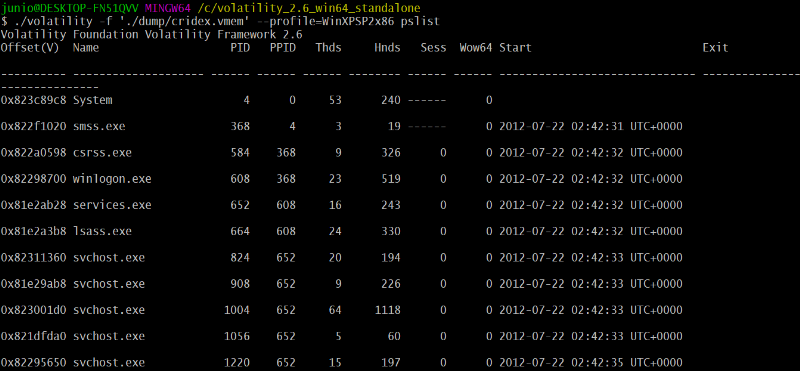

Figure 2.22.Liste de processus Dump mémoire
Une alternative au plugin pslist peut être utilisée
pour afficher les processus et leurs processus parents : pstree
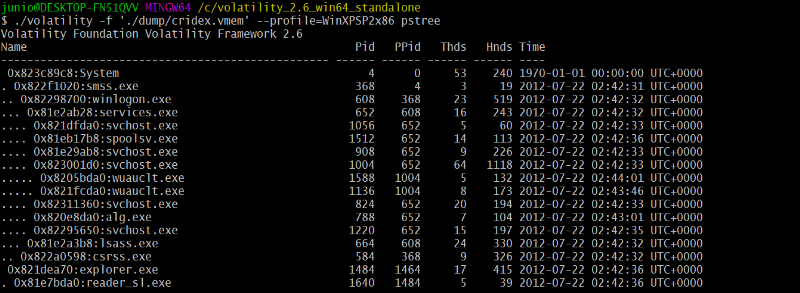
Figure 2.23. Affichage de processus Dump avec Arborescence
À première vue, nous pouvons remarquer un
processus étrange nommé "reader_sl.exe" avec le "explorer.exe"
comme processus parent (PPID) qui était l'un des derniers processus en
cours d'exécution sur la machine.
Exécutions une dernière commande avant
d'approfondir ces deux processus. psxview listera les processus qui essaient de
se cacher lorsqu'ils s'exécutent sur l'ordinateur, ce plugin peut
être très utile.
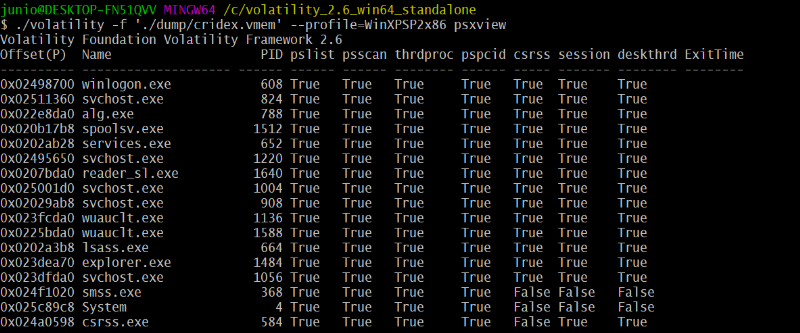
Figure 2.24. Liste de processus Dump cachés
Nous constatons ici qu'aucun processus ne semble être
caché, si c'est le cas, nous aurions vu False dans les deux
premières colonnes (pslist et psscan).
Rentrons à l'enquête car aucun processus ne se
cache. Après avoir vu les processus en cours d'exécution, une
bonne chose à faire est de vérifier les sockets en cours
d'exécution et les connexions ouvertes sur l'ordinateur. Pour ce faire,
nous allons utiliser ces différents plugins : connscan , netscan et
sockets.

Figure 2.25. Liste de processus ayant ouverts les connexions
à l'ordinateur
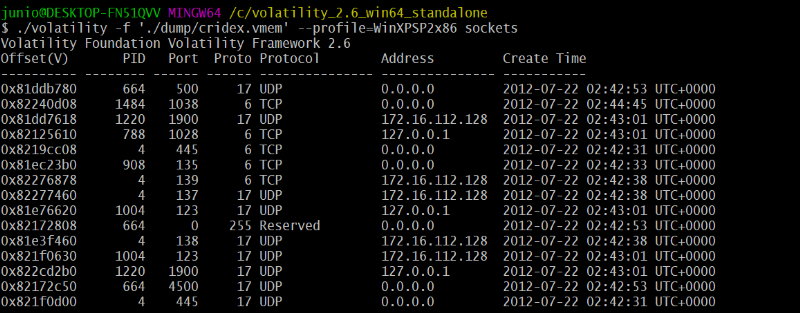
Figure 2.26. Liste de processus, leurs ports et protocoles
utilisés
Le plugin connscan est un scanner pour les connexions TCP,
tandis que les sockets imprimeront une liste des sockets ouverts et enfin
netscan (qui ne peut pas être utilisé dans notre exemple en raison
du profil utilisé) scannera une image Vista (ou ultérieure) pour
les connexions et les sockets.
Dans notre scénario, deux connexions TCP sont
utilisées par le processus avec le PID 1484 (en regardant nos sorties
d'historique de commandes, nous pouvons facilement lier le PID 1484 au
processus explorer.exe). Nous pouvons voir que l'une de ces connexions TCP est
toujours ouverte, celle utilisant le port 1038 et communiquant avec l'adresse
IP de destination 41.168.5.140.
Voyons maintenant les dernières commandes
exécutées, en utilisant cmdscan, les consoles et les plugins
cmdline.
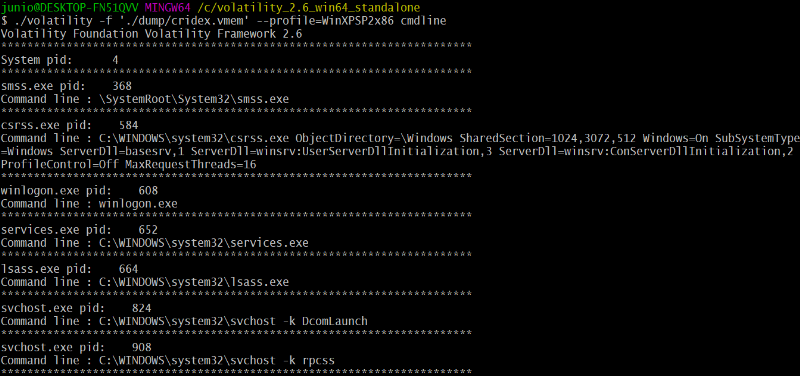
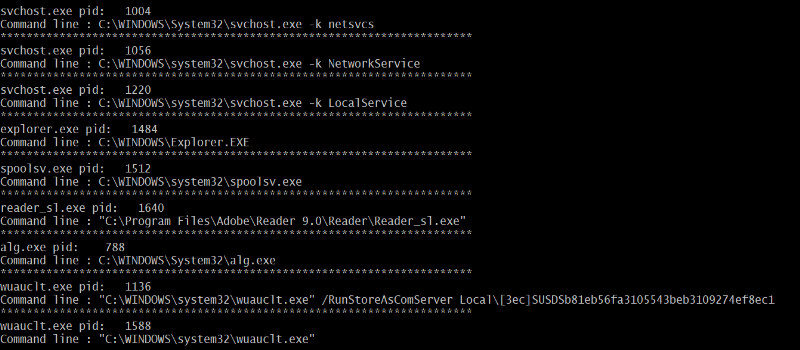
Figure 2.27. Commandes stockées du Dump
Les deux premiers plugins : consoles (qui extrait l'historique
des commandes en recherchant _CONSOLE_INFORMATION) et cmdscan (qui extrait
l'historique des commandes en recherchant _COMMAND_HISTORY) ne contenaient
aucune information dans leurs tampons.
Cependant, le plugin cmdline qui affiche les arguments de
ligne de commande du processus nous a donné des informations
intéressantes. En effet, nous avons maintenant le chemin complet des
processus lancés avec les PID 1484 et 1640. Le processus «
Reader_sl.exe » devient de plus en plus suspect...
Jusqu'alors, nous savons que ce processus a été
lancé par le processus explorateur, censé être une
application Adobe Reader classique, cependant nous avons observé une
connexion en cours d'exécution vers une IP externe utilisée par
ce même processus...
Avant de conclure, intéressons-nous à
l'exécutable concerné et à l'analyse de ce dernier en
utilisant respectivement procdump et memdump en précisant le -p 1640
(son PID) et --dump-dir (le répertoire où l'on veut extraire ces
dumps).


Figure 2.28. Exécutable du processus suspect
Le premier fichier "executable.1640.exe" est une restitution
de l'exécutable "Reader_sl.exe" et le dump extrait "1640.dmp"
représente la mémoire adressable du processus.
Ensuite, une simple analyse de ces fichiers peut se faire en
utilisant la commande linux « strings », soyez patient en
général les dumps contiennent beaucoup d'informations. Dans notre
scénario, nous recherchons une relation entre l'information
déjà récupérée du dump (notamment la
connexion tcp ouverte vers l'IP 41.168.5.140) et ce processus 1640.
Essayons de voir le fichier "executable.1640.exe" sur le site
de Virustotal, pour en savoir plus :
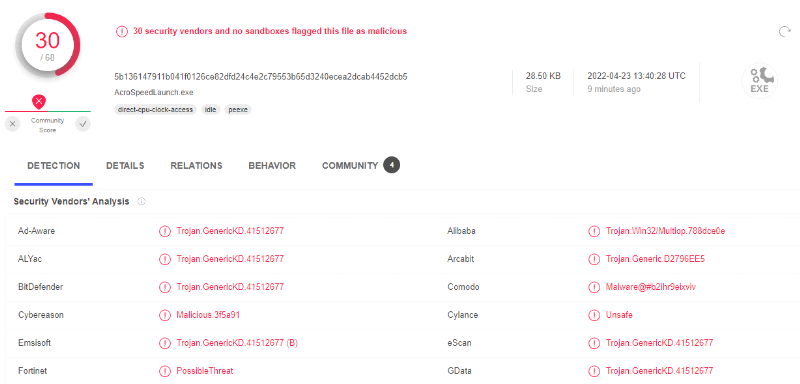
Figure 2.29. Analyse de l'exécutable obtenu sur virus
total
? Conclusion
L'investigation numérique légale est un
processus compliqué qui commence à la scène du crime,
continue aux laboratoires informatiques pour en tirer des
éléments de preuves et se termine dans la cour où se fait
le jugement final. Dans ce chapitre, nous venons de voir plusieurs outils et
utilitaires pour nous permettre d'appréhender les différentes
situations de l'analyse forensique. C'est maintenant à nous de tester et
de choisir nos outils pour réaliser nos investigations. Dans le prochain
chapitre, nous parlerons des méthodes d'analyse et de conception qui
nous permettront d'implémenter la plateforme d'investigation digitale
pour apprendre et réaliser votre analyse forensique à bon
échéant.
CHAPITRE
3
Méthodes d'analyse
et de conception
? 3.1. Introduction
En ingénierie, une méthode d'analyse et de
conception est un procédé qui a pour objectif de permettre de
formaliser les étapes préliminaires du développement d'un
système afin de rendre ce développement plus fidèle aux
besoins du client. Pour ce faire, on part d'un énoncé informel,
ainsi que de l'analyse de l'existant éventuel.
Dans ce chapitre, nous allons aborder les deux phases comme
suit : la phase d'analyse nous permettra de lister les résultats
attendus, en termes de fonctionnalités et la phase de conception nous
permettra de décrire de manière non ambiguë, le plus souvent
en utilisant un langage de modélisation, le fonctionnement futur du
système, afin d'en faciliter la réalisation.
? 3.2. Définition des concepts
Une méthode définit une démarche en vue
de produire des résultats. Par exemple, les cuisiniers utilisent des
recettes de cuisine, les pilotes déroulent des checklists avant de
décoller, les architectes font des plans avant de superviser des
chantiers. Une méthode permet d'assister une ou plusieurs étapes
du cycle de vie du logiciel. Les méthodes d'analyse et de conception
fournissent des notations standards et des conseils pratiques qui permettent
d'aboutir à des conceptions « raisonnables », mais nous ferons
toujours appel à la créativité du concepteur. Sans plus
tarder, nous allons définir les termes qui viennent souvent dont une
méthode, une analyse et la conception.
a) Méthode
Par définition, une méthode est un ensemble de
démarches que suit l'esprit pour découvrir et démontrer la
vérité.34(*)
C'est aussi un ensemble de règles ou de principes sur lesquels reposent
l'enseignement, la pratique (d'une technique, d'un art). Scientifiquement
parlant, une méthode désigne l'ensemble des canons guidant ou
devant guider le processus de production des connaissances scientifiques, qu'il
s'agisse d'observations, d'expériences, de raisonnements, ou de calculs
théoriques. Très souvent, le terme de « méthode
» engage l'idée implicite de son unicité, tant auprès
du grand public que de certains chercheurs, qui de surcroît la confondent
parfois avec la seule méthode hypothético-déductive. Nous
pouvons en déduire qu'une méthode scientifique est une
façon d'accéder à la connaissance
réglementée.
b) Analyse
Une analyse est une opération intellectuelle consistant
à décomposer un tout en ses éléments constituants
et d'en établir les relations.35(*)
c) Conception
La conception technique consiste à rassembler des
renseignements technologiques établis sur un sujet donné,
à choisir les renseignements pertinents et, à partir de ces
derniers, à élaborer une conception pratique, économique
et sécuritaire.36(*)
3.3. Pourquoi utiliser une méthode ?
L'utilisation d'une méthode est de permettre de
formaliser les étapes préliminaires du développement d'un
système afin de rendre ce développement plus fidèle aux
besoins du client. Pour ce faire, on part d'un énoncé informel
(le besoin tel qu'il est exprimé par le client, complété
par des recherches d'informations auprès des experts du domaine
fonctionnel, comme par exemple les futurs utilisateurs d'un logiciel), ainsi
que de l'analyse de l'existant éventuel (c'est-à-dire la
manière dont les processus à traiter par le système se
déroulent actuellement chez le client).
La phase d'analyse permet de lister les résultats
attendus, en termes de fonctionnalités, de performance, de robustesse,
de maintenance, de sécurité, d'extensibilité, etc.
La phase de conception permet de décrire de
manière non ambiguë, le plus souvent en utilisant un langage de
modélisation, le fonctionnement futur du système, afin d'en
faciliter la réalisation.
? 3.4. Classification des méthodes d'analyse et de
conception
Les méthodes d'analyse et de conception sont
réparties en quatre grandes familles :
3.4.1. Méthodes
cartésiennes ou fonctionnels
Les méthodes fonctionnelles ou cartésiennes
consistent à décomposer hiérarchiquement une application
en un ensemble de sous applications. Les fonctions de chacune de ces
dernières sont affinées successivement en sous fonctions simples
à coder dans un langage de programmation donné.
Ces méthodes utilisent intensivement les raffinements
successifs pour produire des spécifications dont l'essentiel est sous
forme de notation graphique en diagrammes de flots de données.
3.4.2. Méthodes
objet
L'approche objet permet d'appréhender un système
en centrant l'analyse sur les données et les traitements à la
fois. Les stratégies orientées objet considèrent que le
système étudié est un ensemble d'objet coopérant
pour réaliser les objectifs des utilisateurs. Les avantages qu'offre une
méthode de modélisation objet par rapport aux autres
méthodes sont la réduction de la « distance » entre le
langage de l'utilisateur et le langage conceptuel, le regroupement de l'analyse
des données et des traitements, la réutilisation des composants
mis en place.
3.4.3. Méthodes
systémiques
Dans les méthodes systémiques37(*), le système est
abordé à travers l'organisation des systèmes constituants
l'entreprise. Elles aident donc à construire un système en
donnant une représentation de tous les faits pertinents qui surviennent
dans l'organisation en s'appuyant sur plusieurs modèles à des
niveaux d'abstraction différents (conceptuel, organisationnel, logique,
physique, etc.).
3.4.4. Approche
orientée aspect
La programmation orientée aspect ou POA est un
paradigme de programmation qui permet de traiter séparément les
préoccupations transversales (en anglais, cross-cutting concerns), qui
relèvent souvent de la technique, des préoccupations
métier, qui constituent le coeur d'une application38(*). Un exemple classique
d'utilisation est la journalisation, mais certains principes architecturaux ou
modèles de conception peuvent être implémentés
à l'aide de ce paradigme de programmation, comme l'inversion de
contrôle39(*).
La programmation orientée aspect est bien une technique
transversale (paradigme) et n'est pas liée à un langage de
programmation en particulier mais peut être mise en oeuvre aussi bien
avec un langage orienté objet comme PHP qu'avec un langage
procédural comme le C, le seul prérequis étant l'existence
d'un tisseur d'aspect pour le langage cible.
3.5. Choix d'une
méthode d'analyse et de conception
Pour procéder à l'implémentation d'une
application web ou desktop, une étude et une conception
normalisée selon la norme de modélisation universellement
reconnue polyvalente et performante, l'utilisation d'UML s'avère
nécessaire. Dans notre démarche, pour la réalisation du
système du projet, nous retenons les étapes suivantes :
? Détermination des acteurs potentiels du
système
? Description des cas d'utilisation fondamentaux
? Les diagrammes de séquence
? Le diagramme de classe de conception
? Le diagramme de déploiement
? Conclusion
Dans chaque projet informatique, il y a toujours un
problème de conception ou de modélisation qui surgit, c'est sur
ce, que dans ce chapitre nous avons parlé des différentes
méthodes de conception qui existent et faire un choix pour faire la
modélisation de notre plateforme avant implémentation. Dans le
chapitre suivant, nous allons faire un choix des outils cités ci-haut et
procéder à l'implémentation de la plateforme
d'investigation digitale.
CHAPITRE
4
CONCEPTION ET
IMPLEMENTATION DU SYSTEME
? 4.1. Introduction
L'application web est le système informatique par
excellence sur le World Wide Web. En effet, c'est un logiciel
hébergé par le moyen d'un serveur et qui ne nécessite pas
d'installation. C'est une manière pratique d'utiliser un service sur son
terminal numérique. C'est par l'utilisation d'un navigateur web que le
client peut utiliser l'application et c'est uniquement en ligne.
C'est par le moyen technique du client-serveur que
l'application fonctionne et s'opère. Dans un premier temps, le
navigateur client achemine au serveur des requêtes vers des pages web.
Puis, ce même serveur tient compte des requêtes acheminées
et soumet des pages web au navigateur. Enfin, le navigateur
génère une page ou des pages pour l'utilisateur.
Il existe un très grand nombre d'applications sur le
web, de toutes sortes et pour différents usages. On peut citer quelques
exemples : les jeux en ligne, les blogs, les e-commerces, etc. Ils sont
très appréciés par tous les internautes. Chacune d'entre
elles a besoin d'une architecture web pour fonctionner : une à 2-tiers
ou 3-tiers pour les plus développées. En fonction de
l'application web, il faut choisir la bonne architecture qui s'adapte à
elle.
L'organisation et la structure d'une application sont les deux
éléments principaux qui définissent son architecture. En
effet, ce sont tous les éléments qui vont permettre de faire
fonctionner l'application et surtout c'est comment ils vont permettre de le
faire. Dans ce type de modèle, on décrit de la manière la
plus détaillée comment on va aboutir à l'application, cela
peut être représenté sous forme de graphique. C'est une
étape de création nécessaire qui prend en compte le
développement du site web et également ses fonctions. C'est avec
l'appui de ce document qu'on peut réaliser les spécifications.
On distingue deux types d'architecture : une architecture dite
fonctionnelle et une autre qui est dite technique.
L'architecture de l'application web dite fonctionnelle, c'est
comment les fonctionnalités vont être organisées sur
l'application web et comment elles vont fonctionner. Le développeur
garde à l'esprit le client car l'application lui est destinée.
Ces fonctionnalités sont conçues pour l'utilisateur afin qu'il
utilise au mieux le ou les services proposés par l'application. On pose
les limites des différentes fonctions dans cette partie-là. Puis,
après qu'elles sont posées, on décrit de la manière
la plus fidèle possible comment les fonctionnalités vont
être appliquées et vont fonctionner. C'est une étape
très importante dans la conception d'une application web.
L'architecture de l'application web dite technique, c'est
comment le développeur va établir le développement et la
gestion du site web. On explicite les différentes parties techniques de
l'application : leurs rôles, leurs interactions, leurs objectifs et leurs
caractéristiques. La personne qui se charge de cette partie a des
compétences avancées en informatique et dispose d'une formation
solide en développement. Il faut maîtriser le code informatique :
HTML, CSS, PHP, Javascript, etc. Puisque dans la partie technique, il faut
expliquer comment on va utiliser le langage de codage pour concevoir
l'application. Dans ce sens, il est intéressant d'utiliser un Framework
pour monter les bases de l'application.
De ce fait, un des langages informatiques les plus
utilisés, pour développer une application web, est le langage
PHP. En effet, pratiquement tous les professionnels de l'informatique savent
l'utiliser, il est universel et libre. C'est un langage très
utilisé dans le domaine de la base de données, il interagit avec
cette dernière à travers un logiciel de type plateforme telle que
WAMP. Il se retrouve dans ce type de logiciel avec MySQL et Apache. Dans ce
cas-là, la programmation du logiciel en ligne se fera essentiellement
avec du PHP.
Ainsi, en matière d'architecture d'application web, le
langage PHP peut être sollicité pour une architecture-type
client-serveur ou une architecture 3-tier (3 niveaux) avec l'intervention d'une
base de données.
? 4.2. Le langage PHP
Le langage PHP ou Hypertext Processor est un langage en code
informatique. Ce type de codage est la plupart du temps exploité afin de
créer des pages web dites dynamiques à travers un serveur HTTP.
C'est son utilité principale mais ce langage n'est pas utilisé
exclusivement pour cela. Le PHP est le langage le plus populaire et vient
ensuite le Java, l'ASP.NET et l'HTML. Il est très apprécié
par le grand public et par les entreprises de toutes tailles. Le PHP est un
type de codage impératif et orienté objet.
Son utilisation a été pensée pour
l'Internet, dans cette optique, son exécution repose sur le principe de
client-serveur. C'est-à-dire que l'utilisateur cherche à visiter
une page web, le navigateur client transmet la requête en question au
serveur web. Dès lors, quand la page web est caractérisée
comme un script PHP alors le serveur communique avec l'interprète PHP
afin qu'il génère le code HTML pour que l'utilisateur voit les
pages HTML.
Le PHP est aussi caractérisé comme un langage
serveur car les serveurs s'interprètent, génèrent des
données et d'autres types de code grâce à lui. Sur le web,
les applications sont principalement utilisées en ligne. Ainsi, les
concepteurs d'application développent un certain dynamisme qui est bien
opéré et exécuté par le PHP. Il est très
flexible, performant et polyvalent. Il est polyvalent puisqu'il peut être
converti en PDF par exemple. Même s'il peut être utilisé
avec un serveur HTTP, il est le plus souvent dans un couplage avec le serveur
Apache, étant donné qu'il permet dans ce cas-là de faire
de la récupération et de la sauvegarde de données à
l'aide d'une base de données.
Le PHP a été souvent renouvelé et
amélioré, de ce fait, il a eu plusieurs versions pour permettre
à ses utilisateurs de profiter des dernières avancées en
matière de code informatique. Sa dernière version est la version
7.4.1.
Ce qui fait aussi son succès, c'est la facilité
de son utilisation, bien que les professionnels ne puissent pas s'en passer,
les débutants peuvent aussi s'en servir et l'utiliser parfaitement. Ce
type de code a été conçu dans le but d'être
accessible par tous. D'autant plus que ce code est totalement gratuit et
facilement installable.
Il s'utilise sur tous les types de systèmes
d'exploitation : Windows, Mac et Linux. Ce qui le rend attractif par l'ensemble
des utilisateurs de code informatique. Il permet à tous de pouvoir
travailler sur le développement web.
L'usage de ce langage va nous permettre ainsi de
générer du contenu affiché sur les pages web de la
plateforme. Ce langage va nous aider aussi à gérer le contenu des
applications de manière efficace. Nous utiliserons une architecture
client-serveur pour concevoir au mieux la plateforme digitale d'investigation
numérique pour le Département de génie informatique.
? 4.3. Conception générale du système
proposé
? 4.3.1. Architecture fonctionnelle

Figure 4.1. Architecture fonctionnelle
Le concept de partitionner une application en couches et de
garder toute la logique de l'application dans ces couches distinctes et
séparées, a été introduit bien avant l'approche
orientée objet. Ainsi une application est divisée en trois
couches logiques, chacune traitant des fonctions spécifiques :
- Présentation : interface usager et
présentation.
- Logique du logiciel à produire (besoins et services
de la plateforme) : les règlements d'accès et la logique de la
plateforme.
- Logique des données : Base de données et
intégration des services de la plateforme.
Ce concept nous permet de créer des composants
indépendants et de les déployer sur des plates-formes
différentes. En fait, ce concept est très utilisé dans le
développement des applications multi-tier. Plus tard, il fut
adapté au modèle de conception Model-View-Controller (MVC) qui
est un modèle très commun pour développer des applications
distribuées et multi-tier.
? 4.3.2. Architecture technique

Figure 4.2. Architecture technique de la plateforme
? 4.4. Conception et modélisation
détaillée avec UML
? 4.4.1. Détermination des acteurs potentiels du
système
Pour ce qui est des acteurs, il s'agit bien des tous les
étudiants du département de génie informatique de l'ESP
ainsi que son personnel voulant apprendre l'investigation numérique.
? 4.4.2. Description des cas d'utilisation
La description qu'on va élaborer est structurée
comme suit :
A. Cas d'utilisation s'authentifier
a) Pré conditions.
Il s'agit bien d'avoir accès à la plateforme
d'investigation numérique, comme précondition l'utilisateur doit
tout d'abord créer un compte sur la plateforme d'apprentissage pour
avoir un login et un mot de passe puis les informations d'accès
l'ordinateur virtuel pour le test lui seront transmises par l'administrateur
système. Seuls les emails professionnels de l'Ecole Supérieure
Polytechnique seront acceptés.
b) Acteurs
Tous les acteurs seront concernés par
l'authentification.
c) Scénario nominal.
1. Identification
? L'utilisateur saisit ses droits d'accès.
? Le système vérifie si les champs ne sont pas
vides, si erreur alors Exception 1.
? Il vérifie ensuite si les informations sont valides,
si erreur alors Exception 2.
? Le système redirige l'acteur vers son espace selon
son rôle.
2. Inscription
? L'utilisateur introduit les informations demandées
dans le formulaire et valide son inscription.
? Le système vérifie si les champs obligatoires
sont renseignés. Si erreur alors exécuter Exception 3.
? Le système vérifie si les informations sont
valides, si erreur alors Exception 4.
? Il vérifie si le pseudo et l'email existent ou pas,
si oui alors Exception 5.
d) Exceptions :
? Exception 1 : message d'erreur « Un champ est vide
». L'acteur s'authentifie une 2ème fois.
? Exception2 : message d'erreur « login et mot de passe
doivent avoir au moins 6 caractères ». L'utilisateur s'authentifie
une 2ème fois.
? Exception 3 : un message d'erreur contenant : « Un
champ obligatoire est vide ». L'acteur doit remplir les champs
obligatoires.
? Exception 4 : message d'erreur « login et mot de passe
doivent avoir au moins 6 caractères ». L'acteur doit
revérifier les champs.
? Exception 5 : un message d'erreur contenant : ou bien c'est
un champ qui est vide, ou bien le nom existe déjà. L'utilisateur
est invité à corriger son erreur et à la valider.
e) Post conditions.
Après que l'acteur ait rempli toutes les exigences
énumérées ci-dessus, le système va lui rediriger
vers l'espace utilisateur regroupé en deux parties :
- L'espace apprentissage des formations forensic
(Androïd, Mac Os et Windows) et
- L'ordinateur virtuel forensic.
B. CAS D'UTILISATION AJOUT D'UNE FORMATION
a) Acteurs :
Administrateur du système
b) Pré condition :
L'acteur doit s'authentifier.
c) Scénario nominal :
d) Ajouter d'une formation
L'acteur remplit les champs du formulaire.
Le système vérifie si un champ est vide,
invalide, si erreur alors Exception 1. Il valide l'ajout de la nouvelle
formation.
e) Modifier une formation
L'acteur sélectionne la formation.
Il met à jour les informations concernées par la
modification et valide, si erreur alors Exception 1.
f) Lister les différentes formations
Le système affiche la liste de formations
enregistrées au préalable sur la plateforme.
g) Supprimer un produit
L'acteur choisit la formation qu'il veut supprimer.
d) Exceptions :
Exception 1 : un message d'erreur apparaît relatif
à l'erreur rencontrée.
e) Post conditions :
Formation mise à jour.
Mise à jour de la base de données.
C. CAS D'UTILISATION RECHERCHER UNE FORMATION
a) Acteurs :
Administrateur du système et l'apprenant.
b) Pré condition :
Avoir un compte utilisateur au préalable, la recherche
de la formation ne peut se faire que par les acteurs étant
déjà authentifiés.
c) Scénario nominal :
h) Rechercher une formation
L'acteur remplit le champ de recherche et valide.
Le système vérifie si un champ est vide,
invalide, si erreur alors Exception 1.
i) Exceptions :
Exception 1 : un message d'erreur apparaît relatif
à l'erreur rencontrée.
d) Post conditions :
Formation trouvée avec l'affichage des détails
de la formation ou aucun résultat n'a été trouvé si
la formation n'existe pas dans base de données.
5.4.3 Les diagrammes de séquence
A partir du diagramme de cas d'utilisation et de la
description des cas d'utilisation énumérés dans les points
précédents, nous obtenons les diagrammes de séquence
suivants :
A. Diagramme de séquence
créer un compte
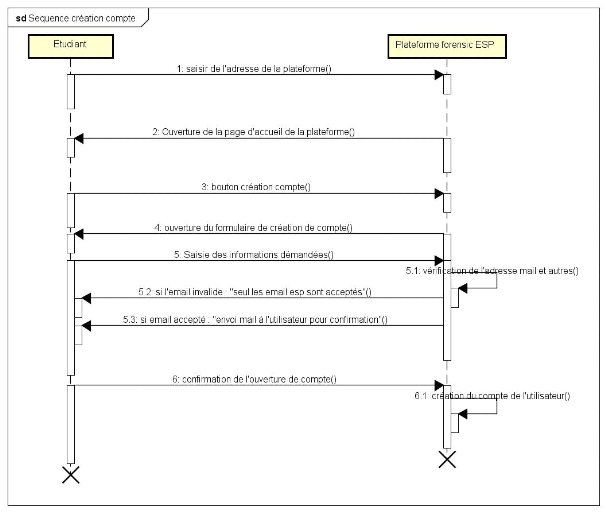
Figure 4.3. Diagramme de séquence créer un
compte
B. Diagramme de séquence
s'authentifier
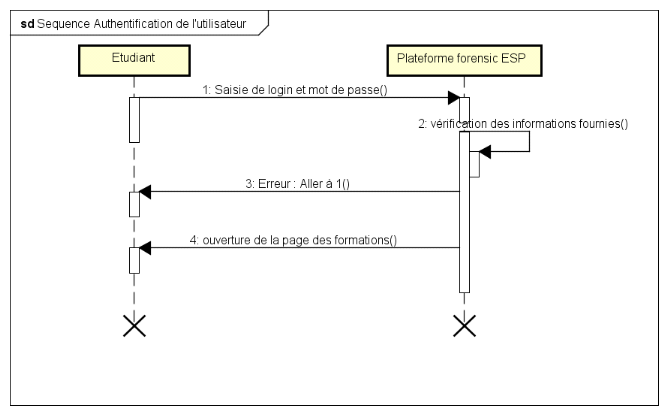
Figure 4.3. Diagramme de séquence d'authentification
C. Diagramme de séquence ajout
d'une formation
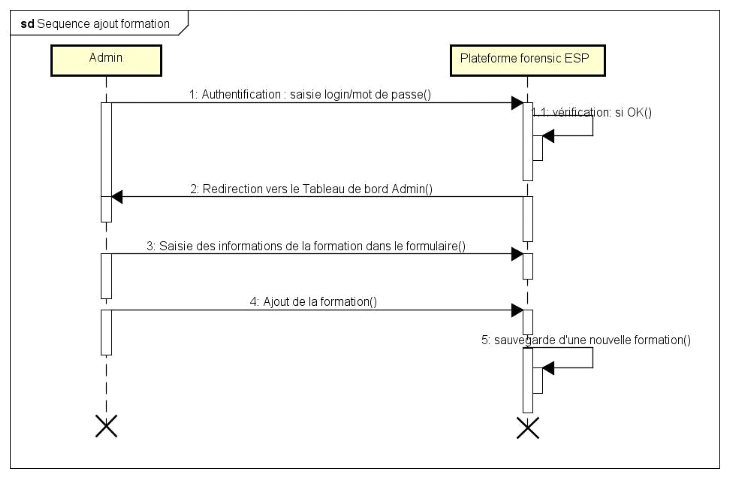
Figure
4.4. Diagramme de séquence ajout d'une formation
D. Diagramme de séquence
rechercher une formation
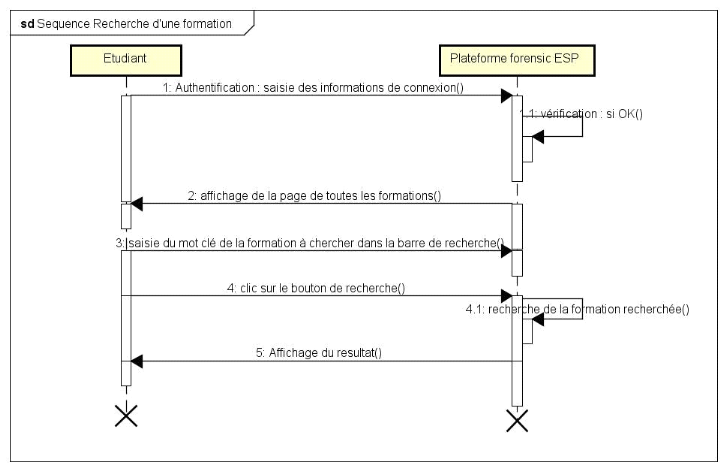
Figure 4.5. Diagramme de séquence recherche d'une
formation
4.4.4 Le diagramme de classe de conception
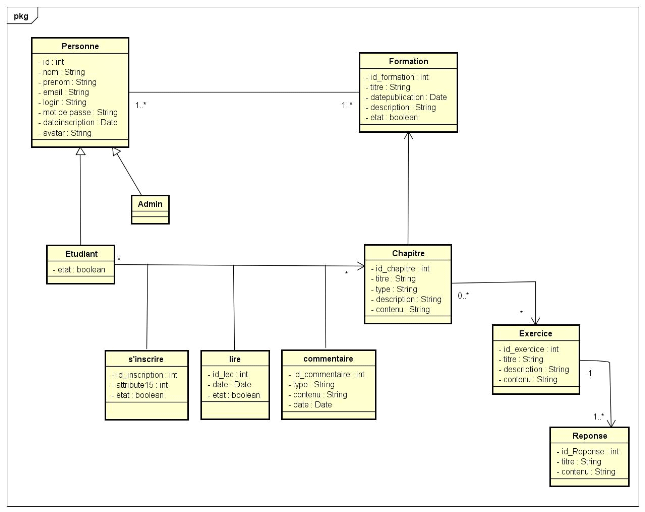
Figure 4.6 Diagramme de classe
? 4.5. Implémentation
? 4.5.1. Introduction
Nous arrivons enfin dans la partie la plus essentielle de
notre recherche. Nous allons présenter les différentes
technologies utilisées pour arriver à la mise en place de la
plateforme ainsi les différentes ressources qui seront placées
sur GitHub en mode private et pour tout celui qui voudra toucher aux codes
sources de cette dernière, les coordonnées de l'Université
y seront bien évidemment pour vous permettre à y avoir
accès.
? 4.5.2. Virtualisation
La virtualisation est une technologie permettant de
créer et d'exécuter une ou plusieurs représentations
virtuelles d'un ordinateur ou de ses différentes ressources sur une
même machine physique.
La virtualisation consiste à créer une
représentation virtuelle, basée logicielle, d'un objet ou d'une
ressource telle qu'un système d'exploitation, un serveur, un
système de stockage ou un réseau. Ces ressources simulées
ou émulées sont en tous points identiques à leur version
physique.
Les machines virtuelles sont exécutées sur une
couche d'abstraction matérielle. Ainsi, les entreprises sont en mesure
d'exécuter plusieurs systèmes d'exploitation et applications
simultanément sur un serveur unique. Les ressources et capacités
du serveur sont réparties entre les différentes instances. Ceci
permet de réaliser d'importantes économies et d'utiliser les
serveurs plus efficacement puisque leurs capacités sont pleinement
exploitées.
De plus, la virtualisation permet d'exécuter des
programmes de façon isolée pour effectuer des tests en toute
sécurité sans risquer de compromettre les autres machines
virtuelles exécutées sur le même serveur hôte. Pour
les particuliers et les utilisateurs de PC, il est aussi possible d'utiliser la
virtualisation pour exécuter des applications nécessitant
différents systèmes d'exploitation sur un seul et même
ordinateur.
a) Comment fonctionne la virtualisation
La technologie de virtualisation repose sur l'abstraction
d'une application, d'un système d'exploitation ou du stockage de
données du véritable logiciel ou du hardware sous-jacent. L'un
des principaux cas d'usage est la virtualisation de serveur, reposant sur une
couche logicielle appelée « hyperviseur » pour
émuler le hardware.
L'hyperviseur permet de créer et d'exécuter des
machines virtuelles. Le logiciel se charge de diviser les ressources entre les
différents environnements virtuels en fonction de leurs besoins.
Par le passé, on distinguait les hyperviseurs natifs,
directement intégrés au hardware du logiciel, et les hyperviseurs
« hébergés » semblables à des
applications logicielles. Cependant, sur les systèmes modernes, cette
distinction a perdu de l'importance. Pour cause, il existe désormais des
systèmes comme le KVM (kernel-based Virtual machine), qui est
intégré au kernel Linux et peut exécuter les machines
virtuelles directement bien qu'il soit possible de continuer à utiliser
le système lui-même comme un ordinateur normal.
Les utilisateurs peuvent ensuite interagir et lancer des
applications ou des calculs au sein de l'environnement virtuel, que l'on
appelle généralement machine virtuelle. La machine virtuelle est
l'équivalent émulé d'un ordinateur, et est
exécutée par-dessus un autre système. Elle peut exploiter
la puissance de calcul du CPU et la mémoire de la machine hôte, un
ou plusieurs disques virtuels pour le stockage, une interface réseau
virtuelle ou réelle, ainsi que les autres composants tels que les cartes
graphiques ou même les clés USB.
La machine virtuelle fonctionne comme un fichier de
données unique. Elle peut donc être transférée d'un
ordinateur à l'autre, et fonctionner de la même manière sur
les deux machines. Si la machine virtuelle est stockée sur un disque
virtuel, on parle souvent d'une image disque.
b) Types de virtualisations
Il existe différents types de virtualisation. On
dénombre six principaux domaines de l'informatique où la
virtualisation est couramment utilisée :
1. La virtualisation de serveur, précédemment
évoquée, permet d'exécuter plusieurs systèmes
d'exploitation sur un seul serveur physique sous forme de machines virtuelles.
Elle permet une efficacité accrue, une réduction des coûts,
un déploiement plus rapide des workloads, une augmentation des
performances d'application, une disponibilité de serveur en hausse, et
l'élimination des complications liées à la gestion de
serveurs.
2. La virtualisation de réseau consiste à
reproduire un réseau physique et ses différents composants :
ports, interrupteurs, routeurs, firewalls, équilibreurs de charges...
ceci permet d'exécuter des applications sur un réseau virtuel
comme sur un réseau physique, tout en profitant de l'indépendance
matérielle inhérente à toute forme de virtualisation.
3. La virtualisation de stockage consiste à assembler
la capacité de stockage de multiples appareils de stockage en
réseau sous forme d'un seul appareil de stockage (virtuel) pouvant
être géré depuis une console centrale.
4. La virtualisation desktop est similaire à la
virtualisation de serveur, mais permet de créer des machines virtuelles
reproduisant des environnements de PC. Ceci permet aux entreprises de
réagir plus rapidement aux changements de besoins et aux nouvelles
opportunités. De plus, les PC virtualisés, tout comme les
applications, peuvent être transférés rapidement à
des sous-traitants ou à des employés travaillant sur des
appareils mobiles comme les tablettes. C'est celle-ci qui va nous servir
à faire le déploiement des machines virtuelles pour tous nos
étudiants qui seront inscrits sur la plateforme en utilisant la
technologie d'amazone Workspace.
5. La virtualisation de données repose sur
l'abstraction des détails techniques traditionnels des données et
du Data Management : localisation, performance, format... Ceci permet d'ouvrir
l'accès aux données et d'accroître la résilience. De
plus, la « Data Virtualization » permet aussi de consolider les
données en une source unique afin de simplifier leur traitement.
6. La virtualisation d'application consiste en l'abstraction
de la couche application du système d'exploitation. Ceci permet
d'exécuter l'application sous une forme encapsulée,
indépendante du système d'exploitation. Ainsi, il est par exemple
possible d'exécuter une application Windows sur Linux et vice-versa.
? 4.5.3 Machine virtuelle et Container
En principe, les containers Linux sont similaires aux machines
virtuelles. Les deux permettent l'exécution d'applications au sein d'un
environnement isolé, et peuvent être accumulés
séparément sur une même machine. Cependant, leur
fonctionnement est différent.
Un container n'est pas une machine indépendante
complète. Il s'agit simplement d'un processus isolé partageant le
même kernel linux que le système d'exploitation hôte, ainsi
que les bibliothèques et autres fichiers nécessaires à
l'exécution du programme contenu dans le container. En
général, les conteneurs sont conçus pour exécuter
un programme unique et non un serveur complet.
? 4.5.4. Virtualisation et Cloud Computing
La virtualisation et le Cloud Computing sont deux technologies
à ne pas confondre. La virtualisation permet de rendre les
environnements informatiques indépendants d'une infrastructure physique,
tandis que le Cloud Computing est un service délivrant les ressources
informatiques partagées à la demande via Internet.
Ces deux technologies sont donc différentes, mais
peuvent aussi être complémentaires. Il est par exemple possible de
virtualiser les serveurs, pour ensuite migrer vers le Cloud en vue d'une
agilité amplifiée et d'un accès self-service.
4.6. Amazon Web Services
Le Cloud AWS est une plateforme de services cloud
développée par le géant américain Amazon. AWS
regroupe plus de 100 services répartis en diverses catégories
telles que le stockage cloud, la puissance de calcul, l'analyse de
données, l'intelligence artificielle ou même le
développement de jeux vidéo. Nous allons devoir apprendre
d'Amazon Web Services, son histoire, ses avantages, son fonctionnement et les
différents services proposés.
Lancé en 2006, Amazon Web Services est la plateforme de
cloud computing qui regroupe les services Cloud d'Amazon. Initialement
conçu comme une ressource interne à partir de l'infrastructure de
Webstore, AWS est ensuite devenu un fournisseur de solutions cloud innovantes
et économiques permettant aux entreprises qui les utilisent de grandir
et de monter en échelle.
C'est grâce à Amazon Web Services que Amazon est
devenu le leader mondial du cloud computing. Les services Amazon Cloud sont
utilisés par des millions d'entreprises dans le monde entier comme
Spotify, Yelp, Shazam ou encore AirBnB. AWS apparaît comme le leader sur
ce marché. Entre 2015 et 2017, ses ventes sont passées de 7,8
millions de dollars à 17,5 millions de dollars en 2017. L'année
dernière son bénéfice net atteignait 4,3 millions de
dollars.
? 4.6.1. AWS : Une plateforme de solutions Cloud flexible et
sécurisée
La plateforme Cloud Amazon Web Services offre une large
variété de solutions de Cloud Computing flexibles, extensibles,
simples d'utilisation et peu coûteuses.
Développée par Amazon, cette plateforme regroupe
des IaaS (infrastructures en tant que service), des PaaS (plateformes en tant
que service), et des SaaS (logiciels en tant que service).
? 4.6.2. AWS : Histoire
L'histoire d'Amazon Web Services débute en 2002, avec
le lancement de la beta « Amazon.com Web Service ». Cette
beta offre aux développeurs des interfaces SOAP et XML pour le catalogue
de produits Amazon. Il s'agit d'un premier pas vers le Cloud que nous
connaissons aujourd'hui.
Peu après, en 2003, Jeff Bezos réunit chez lui
les cadres d'Amazon. Le chef d'entreprise leur demande d'identifier les
principales forces de l'organisation. De cette réunion, il ressort un
constat clair : les services d'infrastructures confèrent à Amazon
un véritable avantage sur la compétition.
Les leaders de la firme de Seattle ont alors l'idée de
combiner des services d'infrastructure et des outils développeurs pour
créer une sorte de système d'exploitation pour internet. Leur
idée serait d'isoler les différentes parties de l'infrastructure,
telles que la puissance de calcul, le stockage et les bases de données
sous forme de composants pour l'OS. Des outils destinés aux
développeurs permettraient de gérer ces composants.
Cette idée sera pour la première fois
dévoilée au public dans un billet de blog, en 2004. Par la suite,
AWS est lancé le 19 mars 2006. A l'époque, la plateforme regroupe
uniquement Simple Storage Service (S3) et Elastic Computer Cloud (E).
Rapidement, Simple Queue Service (SQS) est ajouté.
En 2009, S3 et E sont lancés en Europe. La même
année, Elastic Block Store (EBS) est rendu public au même titre
qu'un puissant CDN (Content Delivery Network) : Amazon Cloudfront. Ces services
attirent de nombreux développeurs et posent les bases de partenariats
avec des entreprises telles que Dropbox, Netflix et Reddit.
Un premier événement est organisé en
2012. Par la suite, AWS file sur la route du succès mondial. La firme
atteint un chiffre d'affaires de 4,6 milliards de dollars en 2015, puis 10
milliards de dollars en 2016.
La même année, Snowball et Snowmobile sont
lancés. En 2019, Amazon Web Services offre près de 100 services
Cloud. Un long chemin a été parcouru depuis les débuts de
la plateforme, et ce n'est en réalité qu'un début...
? 4.6.3. AWS : Les principaux services
Amazone Web Services regroupe actuellement plus d'une centaine
de services, et ne cesse de se développer. Ces services sont
répartis en plusieurs catégories : calcul, stockage, base de
données, migration, mise en réseau et diffusion de contenu,
outils pour développeurs, outils de gestion, sécurité et
identité, analyses, intelligence artificielle, services mobiles,
services applicatifs, messagerie, productivité d'entreprise, streaming
de bureau et d'applications, internet des objets, centres d'appels, et
développement de jeux.
? 4.6.4. AWS : Développement logiciel
Sur AWS, les développeurs logiciels peuvent profiter de
différents outils de lignes de commande et de kits de
développement SDK pour déployer et gérer leurs
applications et services.
La AWS Command Line Interface est l'interface de code
propriétaire d'Amazon. Les outils AWS Tools for PowerShell permettent
quant à eux de gérer des services Cloud à partir
d'environnements Windows.
En outre, le AWS Serverless Application Model permet de
simuler un environnement AWS afin de tester des fonctions Lambda. Les SDK AWS
sont disponibles pour différentes plateformes et langages de
développement comme Java, PHP, Python, Node.js, Ruby, C++, Android et
iOS.
L'Amazon API Gateway permet à une équipe de
développement de créer, de gérer et de surveiller des APIs
permettant aux applications d'accéder aux données ou aux
fonctionnalités de services back-end. Des milliers d'appels APIs
concurrents peuvent être gérés de façon
centralisée.
Le service Amazon Elastic Transcoder est dédié
au transcoding, et le AWS Step Functions permet de visualiser les flux de
travail des applications basées sur les microservices. Par ailleurs, il
est possible de créer des pipelines d'intégration et de livraison
continue grâce à AWS CodePipeline, AWS CodeBuild, AWS CodeDeploy
ou AWS CodeStar.
Enfin, le code informatique peut être stocké dans
des dépôts Git à l'aide de AWS CodeCommit. Les performances
des applications basées sur les microservices peuvent être
évaluées avec AWS X-Ray.
? 4.6.5. AWS : Développement mobile
Les smartphones et tablettes prennent le pas sur les PC. Pour
le développement d'applications mobiles, Amazon propose la suite
d'outils AWS Mobile Hub. On retrouve notamment le AWS Mobile SDK regroupant des
échantillons et des bibliothèques de code.
Le service Amazon Cognito permet de gérer facilement
l'accès des utilisateurs aux applications mobiles. De même, Amazon
Pinpoint permet d'envoyer des notifications push aux utilisateurs finaux et
d'analyser par la suite l'efficacité de ces notifications.
? 4.6.6. AWS : Avantages et inconvénients
La plateforme Amazon Web Services offre de nombreux avantages.
Elle permet aux entreprises d'utiliser des modèles de programmation, des
OS, des bases de données et des architectures déjà
familières.
Toutefois, il s'agit d'une solution économique puisque
les utilisateurs payent uniquement pour les ressources qu'ils utilisent. De
plus, les entreprises qui se tournent vers cette offre n'auront pas besoin de
dépenser d'argent pour exploiter ou maintenir leurs Data Centers. Le
coût total est largement inférieur à celui de serveurs
privés ou dédiés.
Il est possible d'effectuer des déploiements rapides,
dans de nombreuses régions du monde en quelques clics. Les utilisateurs
peuvent ajouter ou supprimer de la capacité en toute simplicité.
L'accès au Cloud est rapide, et la capacité illimitée.
Néanmoins, AWS présente aussi quelques
inconvénients. Tout d'abord, pour profiter d'une assistance
immédiate, il est nécessaire d'opter pour des packages de support
payant.
En outre, Amazon Web Services présente les mêmes
faiblesses que toutes les plateformes Cloud : les utilisateurs perdent un
certain contrôle sur leurs données, et le risque de panne
existe.
Par ailleurs, les limites de ressources (images, volumes,
snapshots...) par défaut varient d'une région à l'autre.
Enfin, en cas de changement au niveau du hardware dans les Data Centers AWS,
les applications peuvent subir des baisses de performances temporaires...
? 4.7. Base de données et interfaces utilisateurs
a) Base de données
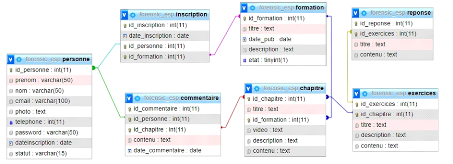
Figure 4.7. La base de données
b) Interface d'accueil

Figure 4.8. La page d'accueil de la plateforme
c) Interface d'authentification
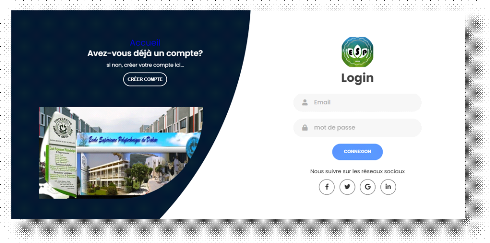
Figure 4.9. La page d'authentification utilisateur
d) Création compte
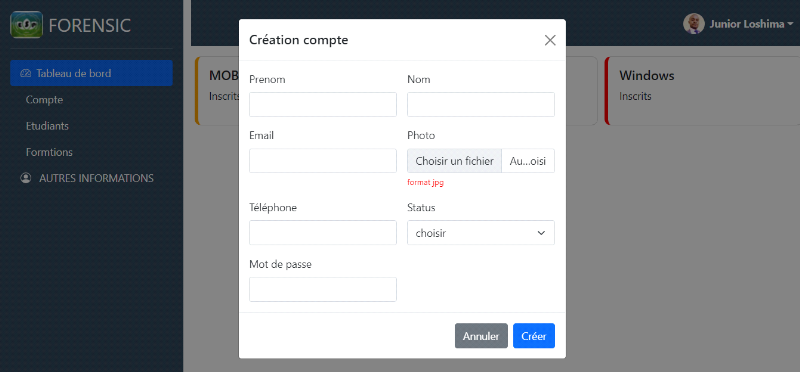
Figure 4.10. Formulaire de création de compte
utilisateur
e) Ajout des cours
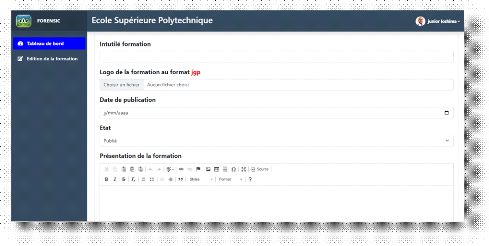
Figure 4.11. Formulaire de création de formation
f) Le tableau de bord de l'apprenant
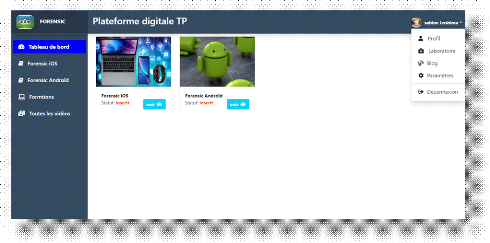
Figure 4.12. Tableau de l'étudiant
g) Formulaire de contact
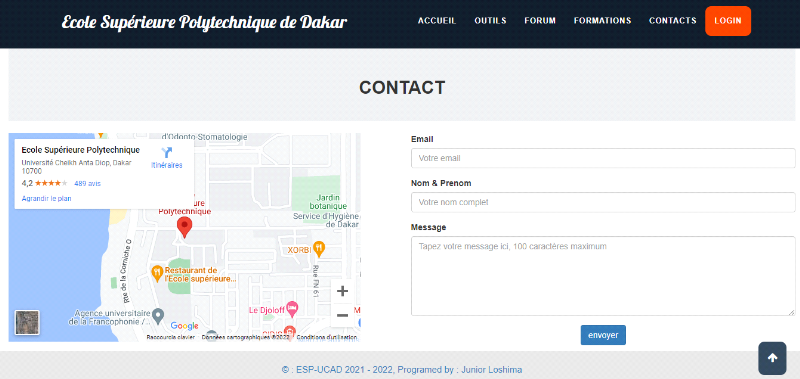
Figure 4.12. Formulaire de contact
? 4.7.2. Codes sources
Les codes sources de la plateforme seront sous la direction du
Département de Génie informatique de l'Ecole Supérieure
Polytechnique de Dakar.
? 4.8. Installation des outils dans les ordinateurs
virtuels
Les différents outils que nous allons installer sur les
machines virtuelles de sont les suivants : Kit FTK, FTK Manager, The Sleuth
Kit Autopsy, Volatility et Rekall.
? Conclusion
En guise de conclusion, ce chapitre est le pilier de nos
recherches car c'est ici où nous avons utilisé toutes les
technologies présentées dans les différents chapitres
précédents. La plateforme a été
implémentée dans un serveur local xampp jusqu'à sa
finition. Le processus d'hébergement sera sous la responsabilité
du Département de Génie informatique.
? CONCLUSION GENERALE
Le domaine de technologie de l'information connaît une
croissance rapide et permet de retracer un crime à l'aide de
médias numériques liés à des crimes assistés
par ordinateur. A travers ce projet de recherche nous avons souhaité
mettre en place une plateforme de travaux pratiques d'investigation digitale
pour les étudiants du Département de Génie Informatique de
l'Ecole Supérieure Polytechnique de Dakar en apportant une
méthodologie d'investigation qui leurs permettra de suivre des
formations très bien structurées et de façon pragmatique
au laboratoire proposé par ladite plateforme pour être
précis et concis lors d'une enquête. Cette dernière
consistera à accompagner les étudiants d'avoir des connaissances
nécessaires, comme par exemple : connaître si des attaquants
se sont introduits sur l'un des serveurs de votre infrastructure ; sile site
Web a subi une altération suite à une attaque d'activistes ;si la
base de données a été exfiltrée et l'organisation
subit un chantage ;si un rançongiciel a infecté une grande partie
du parc informatique ;si une levée de doute est nécessaire sur le
poste de travail d'un employé, etc.
L'apprentissage dans ladite plateforme permettra à
l'étudiant d'être en mesure de qualifier un
événement de sécurité (confirmer qu'il s'agit d'un
incident) ; de mesurer l'impact immédiat, afin de vous conseiller sur la
meilleure réaction à adopter ; de comprendre la
vulnérabilité exploitée, avec comme objectif de vous
proposer un plan de traitement ; d'identifier la source de menace : humaine ou
automatique, motivations, niveau de préparation.
Selon le rapport de Microsoft Security Intelligence, tout le
monde est la cible de cyber attaques, parmi ces attaques, le piratage
informatique. Le Sénégal doit élaborer une bonne
stratégie dans le domaine relativement à travers le temple du
savoir que l'Ecole Supérieure Polytechnique de Dakar, pour faire face
aux cybermenaces il faut passer d'abord, par une prise de conscience,
l'éducation, la formation et le soutien des internautes, le renforcement
du partenariat public-privé, et renforcement des moyens juridique que
des ressources humaines.
Le développement des systèmes embarqués,
l'arrivée des robots dans nos domiciles mais aussi la bio-informatique
sont autant de domaines qui intéressent les cybercriminels de demain.
Ainsi, dans un futur proche, il pourra être possible de pirater une
voiture pour en prendre le contrôle, de s'introduire dans une maison par
le biais d'un robot compromis, ou encore d'arrêter les battements d'un
coeur artificiel à distance ou de contrôler un membre
robotisé. C'est dans ces environnements vulnérables que
l'investigation numérique peut contribuer à la protection de nos
données mais également de l'individu.
? BIBLIOGRAPHIE
A. Ouvrages
1. Beebe N.L., Clark J.G.A., Hierarchical, Objectives-Based
Framework for the Digital Investigations Process. Digit. Invest. 2005.
2. Casey E., Rose C.W., «Forensic Analysis» and
«Handbook of Digital Forensics and Investigation», 2010.
3. Frederick B.Cohen «Fundamentals of Digital Forensic
Evidence, Chapter in Handbook of Information and Communication Security»,
2010.
4. Garfinkel S., Farrell PA., Roussev V., Dinolt G., Bringing
science to digital forensics with standardized forensic corpora. Digit. Invest.
2009.
5. ILAC-G19, Guidelines for forensic science laboratories.
6. Kevin M., Chris P., Matt P., «Incident Response &
Computer Forensics» (2e éd.), McGraw-Hill/Osborne, Emeryville,
2003.
7. Leigland R., Krings A., «A Formalization of Digital
Forensics», International Journal of Digital Evidence, automne 2004,
Volume 3, Édition 2.
8. Palmer G., «A Road Map for Digital Forensic
Research» Rapport technique DTR-T001-01, DFRWS, Report From the First
Digital Forensic Research Workshop (DFRWS), 2001.
9. Pollitt M., «Applying Traditional Forensic Taxonomy to
Digital Forensics», Advances in Digital Forensics IV, actes de la
conférence du TC11.9 de l'IFIP, 2009
10. Valjarevic A., Venter H.S., «Analyses of the
State-of-the-art Digital Forensic Investigation Process Models», The
Southern Africa Telecommunication Networks and Applications Conference
(SATNAC), Afrique du Sud, 2012.
11. Valjarevic A., Venter H.S., «Harmonized Digital
Forensic Investigation Process Model», International workshop on Digital
Forensics in the Cloud (IWDFC), South Africa, 2012.
12. Valjarevic A., Venter H.S., « Towards a Harmonized
Digital Forensic Investigation Readiness Process Modell », neuvième
conférence internationale du WG 11.9 de l'IFIP sur les sciences
forensiques numériques, Orlando. Floride, USA, 2013
B. Normes
1. ISO/IEC
27035 (toutes les parties), Technologies de l'information -- Techniques
de sécurité -- Gestion des incidents de sécurité de
l'information 1 (disponible uniquement en anglais).
2. ISO/IEC
27037 : 2012, Technologies de l'information -- Techniques de
sécurité -- Lignes directrices pour l'identification, la
collecte, l'acquisition et la préservation de preuves
numériques.
3. ISO/IEC
27038, Technologies de l'information -- Techniques de
sécurité -- Spécifications concernant l'expurgation
numérique.
4. ISO/IEC 27041 :
--, Technologies de l'information -- Techniques de sécurité --
Préconisations concernant la garantie d'aptitude à l'emploi et
d'adéquation des méthodes d'investigation sur incident.
5. ISO/IEC
27042 : --, Technologies de l'information -- Techniques de
sécurité -- Lignes directrices pour l'analyse et
l'interprétation des preuves numériques 3
6. ISO/IEC 30121, Technologies de l'information -- Gouvernance
du cadre de risque forensique numérique.
* 1
www.esp.sn [consulté le, 28
février 2022]
* 2
www.ensetp.ucad.sn
[consulté le 28 février 2022]
* 3
www.faseg.ucad.sn
[consulté le 28 février 2022]
* 4 Ministère de
l'Enseignement supérieur, de la Recherche et de l'Innovation- MESRI (
http://www.mesr.gouv.sn), «
Ministère de l'Enseignement supérieur, de la Recherche et de
l'Innovation - Gouvernement du Sénégal » [consulté le
28 février 2022]
* 5
http://www.jo.gouv.sn/spip.php?article6663
[consulté le 01 Mars 2022]
* 6 K. Hung-Jui, W.
Shiuh-Jeng, L. Jonathan, and G. Dushyant. Hash-algorithms output for digital
evidence in computer forensics. In bwcca'11, Proceedings of 2011 International
Conference on Broadband and Wireless Computing, Communication and Applications,
pp. 399-404, Barcelona, (2011).
* 7 M. Clugston and J. Ed. The
New Penguin Dictionary of Science. (1998).
* 8 G. Hong, J. Bo, and H.
Hang. Forensics in Telecommunications, Information, and Multimedia. Second
Edition, Springer Berlin Heidelberg, China, (2011).
* 9 WGDE Scientificc Working
Group on Digital Evidence. Swgde and swgit digital multimedia evidence
glossary. Scientificc Working Group on Digital Evidence, Technical Report,
(2011).
* 10 G. Palmer. A Road Map for
Digital Forensic Research. DFRWS Technical Report n° DTR /T001-2001,
Utica, New York, (2001).
* 11 D. Carrier and E.H.
Spafford. An event-based digital forensic investigation framework. In
CERIAS'04, Center for Education and Research in Information Assurance and
Security Proceedings of the fourth Digital Forensic Research Workshop, pp.
11-13, Baltimore, Maryland, (2004).
* 12 KL. Fei. Data
Vizualisation in Digital Forensics, Magister Scientia in computer science.
Department of Computer Science, University of Pretoria, South Africa,
(2007).
* 13 M. Reith, C. Caar, and
G. Gunsch. An examination of digital forensic models. In IJDE'02, International
Journal of Digital Evidence, Vol. 1, No. 3, (2002).
* 14 KL. Fei. Data
Vizualisation in Digital Forensics, Magister Scientia in computer science.
Department of Computer Science, University of Pretoria, South Africa,
(2007).
* 15 E. Casey. Network
traffic as a source of evidence: Tool strengths, weaknesses, and future needs.
Digital Investigation, Vol. 1, No. 1, pp. 28-43, USA, (2004).
* 16 E. Casey. Digital
Evidence and Computer Crime: Forensic Science, Computers, and the Internet.
Second Edition, Elseiver Academic Press, Great Britain, (2004).
* 17 KL. Fei. Data
Vizualisation in Digital Forensics, Magister Scientia in computer science.
Department of Computer Science, University of Pretoria, South Africa,
(2007).
* 18 P. Motion. Hidden
evidence. In JLSS'05, The Journal of the Law Society of Scotland, Vol. 50, No.
2, pp.32-34, Scotland, (2005).
* 19 Idem
* 20 WGDE Scientificc
Working Group on Digital Evidence. Swgde and swgit digital multimedia evidence
glossary. Scientificc Working Group on Digital Evidence, Technical Report,
(2011).
* 21 Carrier and E.H.
Spafford. An event-based digital forensic investigation framework. In
CERIAS'04, Center for Education and Research in Information Assurance and
Security Proceedings of the fourth Digital Forensic Research Workshop, pp.
11-13, Baltimore, Maryland, (2004).
* 22 J.R. Vacca. Computer
Forensics: Computer Crime Scene Investigation. Second Edition, Charles River
Media, USA, (2005).
* 23 Seema. Analysis of
digital forensic and investigation. In VSRD-IJCSIT'11, International Journal of
Computer Science and Information Technology, Vol. 1, No. 3, pp. 171-178, India,
(2011).
* 24 Valjarevic A., Venter H.S., «
Towards a Harmonized Digital Forensic Investigation Readiness Process Modell
», neuvième conférence internationale du WG 11.9 de l'IFIP
sur les sciences forensiques numériques, Orlando. Floride, USA, 2013.
* 25 Idem
* 26Casey E., Rose C.W., «Forensic Analysis»
and «Handbook of Digital Forensics and Investigation», 2010.
* 27 Barclay, D. (2009). Using
forensic science in major crime inquiries. Dans J. Fraser et R. Williams
(dir.), Handbook of Forensic Science (p. 337-358). Cullompton, UK : Willian
Publishing.
* 28 Chisum, W.J. et Turvey,
B.E. (2011a). Forensic Science. Dans W. J. Chisum et B.E. Turvey (dir.), Crime
Reconstruction (2e éd., p. 3-18). London, UK : Academic Press.
* 29 Bradbury, S.-A. et
Feist, A. (2005). The use of forensic science in volume crime investigations: a
review of the research literature, Home Office Online Report.
Repéré à :
https://www.gov.uk/government/publications/the-use-of-forensic-science-in-volume-crime-investigations-a-review-of-the-research-literature
* 30 Ribaux, O. (2014).
Police scientifique : Le renseignement par la trace. Lausanne, Suisse : Presses
polytechniques et universitaires romandes, p.64
* 31 Julian, R., Kelty, S.
et Robertson, J. (2012). "Get it right the first time": Critical issues at the
crime scene. Current Issues in Criminal Justice, 24(1), 25-38.
* 32
https://www.mailinblack.com/ressources/blog/quels-sont-les-differents-vecteurs-dattaques-informatiques/
* 33
https://www.larousse.fr/dictionnaires/francais/fichier/33578
* 34 Le petit Robert
* 35 Idem
* 36
http://www.innoviscop.com/definitions/conception#
:~:text=La%20conception%20technique%20consiste%20%C3%A0,conception%20pratique%2C%20%C3%A9conomique%20et%20s%C3%A9curitaire.
[Consulté le 23 Février 2022]
* 37Dominique
NANCI, Bernard ESPINASSE, Bernard Cohen, Jean-Claude Asselborn et Henri
Heckenroth, ingénierie des systèmes d'information : Merise
deuxième génération 4°édition-2001
* 38 Maxime Borin, Ramnivas
Laddad, AspectJ in Action: Practical Aspect-Oriented Programming, Manning
Publications, 2003, 512 p.
* 39 Russell Miles, AspectJ
Cookbook, O'Reilly, 2004, 360 p.
| 

