|
EPIGRAPHE
«Ce qui se conçoit et se programme bien,
s'énonce clairement. »
Jules JUCKA
A Judith MULANGA,mon unique petite
soeur ;
A Daniel NDJIBU, mon seul ami ;
Pour Hortensia Brunel KALONDA G4, mon trésor de vie.
Jules MUSONGIELA
DEDICACE
Je remercie la Famille Léonard MULEMBUE et
Marie-Claude NKONKO pour leurs travaux de soutien et leur existence dans ma
vie : Yvette ESHIBA, Flavie MUIKA, Alain NYOMBO, Erick MUDIMBI ZULU et
Benjamin WENAKONGA ;
Je m'en vais pour remercier mon Père Spirituel :
l'Apôtre Missionnaire Rickson Patrick NGUDIA ;
Mes remerciements les plus distingués à mon
Maître Scientifique pour l'acceptation de la direction de ce projet,
malgré ses multiples occupations, je cite le Professeur Richard
KITONDUA, ainsi qu'à son Assistant Monsieur Deack KINKONKO pour le
rapportage du présent travail.
Mes sincères remerciements au corps académique,
administratif et professoral de l'Ecole Supérieure des Métiers
d'Informatique et de Commerce pour l'organisation des enseignements qui nous
ont ouverts à l'horizon informatique ;
A mes camarades de lutte de la promotion :
Dieudonné MWADIA BILE et Christian DIFUMBA ;
Aux amis et connaissances ;
A ma belle-famille ;
A vous tous qui me lisez sous ces lignes ;
Jules MUSONGIELA
REMERCIEMENTS
AVANT PROPOS
Ce travail est le fruit de ma formation en Administration
Réseau et Gestion de Bases de données, et notamment de la
modélisation des données des systèmes d'information depuis
bientôt cinq ans. Il est l'aboutissement d'une longue réflexion
sur l'approche la plus appropriée pour assurer l'initiation à une
discipline qui de l'avis de plusieurs, surtout dans nos pays
sous-développés, est presqu'un service bureautique.
Dans les tout débuts de l'informatique, le
fonctionnement « intime » des processeurs décidait toujours,
en fin de compte, de la seule manière efficace de programmer un
ordinateur. Alors que l'on acceptait tout programme comme une suite logique
d'instructions et toute base de données comme un ensemble
structuré de données, il était admis que l'organisation de
données et la présentation structurelle même de ces
données ne pouvaient s'éloigner de la façon dont le
processeur les exécutait : pour l'essentiel, des modifications de
données mémorisées, des déplacements ou partage de
ces données d'un emplacement mémoire à un autre, et des
opérations d'arithmétique et de logique élémentaire
ont débouché aux bases de données réparties.
L'hypothèse que sous-tend ce travail est que,
l'implémentation d'une Base de Données
Répartiemènerait la Commission Electorale Nationale
Indépendante à une gestion de haut niveau dans ce cas où
elle permettra non seulement la disponibilité, la confidentialité
et l'intégrité des données en permanence dans
différents sites mais aussi, en surmontant l'exécution manuelle
de certaines tâches par des réplications symétriques
asynchrones, la concurrence aux données et la sécurité de
toutes les opérations y relatives.
Il semble donc préférable de maîtriser des
concepts et une démarche UML plutôt pour la modélisation de
bases de données que de connaître les caractéristiques de
l'outil UML. Cela n'empêchera pas, bien au contraire, d'utiliser l'outil
de manière optimale. C'est pour cela que ce travail détaille
d'une part comment concevoir une base de données avec UML en
général et comment se fait la répartition de
données d'une base avec Oracle 11g R2 en particulier. Et d'autre part,
énonce des règles précises de transformation entre les
différents niveaux d'abstraction qui interviennent dans cette
conception. Cette application pourra ainsi servir de base pratique à
l'utilisation des différents principes étudiés.
Jules MUSONGIELA
IN MEMORIUM
Je l'écris aussi et surtout en mémoire de mon
très cher Grand Père François YAMBA-YAMBA MUANA-KIALU;
Et de mon beau-père Félicien KALONDA
KAFELY ;
Que vos âmes reposent en paix et soient honorées
dans le nom précieux de Notre Seigneur Jésus Christ.
Jules MUSONGIELA
ABBREVIATIONS UTILISÉES
ACID : Atomicité, Cohérence, Isolation,
Durabilité
AFNOR : Association Française de Normalisation
Ang. : Anglais
ANSI : American National Standard Institute
ARGBD : Administration Réseau et Gestion de Base de
données
BD :Base de Données
BDD : Base de Données
BDR : Base de Données Répartie
BLOB : Binary Large Object
BOT : Begin Of Transaction
C++ : Nom de la version du langage C pouvant programmer
les objets
CBO : Cost Based Optimizer
CD RW : Compact Disc ReWritable (ou Read/Write)
CENI : Commission Electorale Nationale
Indépendante
CI : Centre d'Identification
CKPT : Checkpoint
COO : Conception Orientée Objet
CPU : Central Processing Unit
DB : Database
DBWRn : Database Writer
DIFE : Direction de l'informatique et du Fichier
Electorale ;
DTA : Dates au plus tard
DTO : Dates au plus tôt
E/S : Entrées/Sorties
Ed. : Edition
EOT : End Of Transaction
ESMICOM : Ecole Supérieure des Métiers
d'Informatique et de Commerce
Fig. : Figure
Go : Giga Octet
I/O : Input/Output
IBM : International Business Machine
ID : Identifier, Identificateur
INFO : Informatique
ISO : International Standardization Orgaanisation
ISTIA : Institut Supérieur Technique d'Informatique
Appliquée
JQC : Job Queue Coordinator
L2 : Deuxième Licence
LGWR : Log Writer
Max : Maximum
MBM : Mbujimayi
Min : Minimum
ML : Marge Libre
MMAN : Memory Manager
MMON : Memory Monitor
NAMUR :
OMT : Object Modeling Technique
OOSE : Object Oriented Software
p. : Page
P2P : Peer to Peer
PERT : Program Evaluation and Research Task ou Program
Evaluation and Review Technic. En Français : Technique d'Evaluation et
d'Examen de Programme
PGA : Program Global Area
PL/SQL : Procedural Language/Structured Query Language
PMON : Process Monitor
pp. : de la page n à la page x
QQQOCC : Qui, quoi, quand, où, comment,
combien ?
RDC : République Démocratique du Congo
SE : Service de l'Exploitation ;
SED : service des Etudes et
Développement ;
SFE : Service du Fichier électoral.
SGA : System Global Area
SGBD : Système de Gestion de Base de Données
SGBDR : SGBD Répartie
SID : système Identification
SMON : System Monitor
SQL : Structured Query Language
TCP : Transmission Control Protocol
TNS : Transparent Network Substrate
UML : Unified Modeling Language
TABLE DES FIGURES
Fig. I.1. Niveaux d'abstraction.
3
Fig. I.2 : Architecture Client/serveur.
16
Fig. I.3 : Architecture serveur-serveur.
17
Fig. I.4 : Conception ascendante de la BDR
18
Fig. I.5 : Conception descendante de la
BDR
18
Fig. II.1. Organigramme général de la
CENI
31
Fig. II.2. Organigramme spécifique
32
Fig. III.1. Graphe Brut
42
Fig. III.2. Graphe ordonné
44
Fig. III.3. Graphe de la DTO
46
Fig. III.4. Graphe de la DTO
48
Fig. III.5. Réseau PERT avec les dates
« au plus tôt » et « au plus
tard »
49
Fig. IV.1. Evolution d'UML.
55
Fig. IV.2. Diagramme de Cas d'utilisation
60
Fig. IV.3. Diagramme de Séquence -
Candidat
64
Fig. IV.4. Diagramme de séquences - OPS
66
Fig. IV.5. Diagramme de séquence - DBA
67
Fig. IV.6. Diagramme de séquences - BDD
Distante
68
Fig. IV.7. Diagramme de séquences
70
Fig. IV.7. Description des classes de la BD
72
Fig. IV.10. Généralisation et
héritage
74
Fig.IV.11. Diagramme de classe
76
Fig. V.1. Architecture de la BD Oracle
78
Fig. V.2. Segment, Extent et Bloc de
données.
81
Fig. VI.1. Structure générale du
nouveau system réparti.
97
Fig. VI.2. Rôle Utilisateurs
99
Fig. VI.3. Rôle Administrateur CENI.
100
Fig. VI.4. Tablespace
100
Fig.VI.5. Utilisateurs
100
Fig. VI.6. Attribution des Rôles aux
utilisateurs
101
Fig. VI.7. Tables
102
Fig. VI.8. Liens et synonymes
102
Fig. VI.9. Vues matérialisées et
synonymes
103
Fig. VI.10. Connexion Netbeans-Oracle
103
Fig. VI.11. Page d'accueil application
104
Fig. VI.12. Page d'accueil application
104
Fig. VI.13. Interface Utilisateur - Saisie
105
Fig. VI.14. Sous menu d'administration
106
Fig. VI.15. Interface Administrateur
106
TABLE DES TABLEAUX
TABLEAU II.1. TABLEAU DES ANCIENNES ET NOUVELLES
PROVINCES
3
TABLEAU III.1 : AVANCEMENT DES TACHES
39
TABLEAU III.2. LISTE DES TACHES, LEURS DUREES ET
LEURS COUTS
41
TABLEAU III.3. RESULTATS DE LA DTO ET LA DTA
52
TABLEAU III.4. RESULTAT DES MARGES
52
TABLEAU IV.1. FICHE DE DESCRIPTION TEXTUELLE DES
SCENARIOS
61
TABLEAU IV.2. TERMINOLOGIE
73
TABLE DES FORMULES
Formule II.1. Calcul de la (DTO) pour une seule
tâche
3
Formule II.2. Calcul de la (DTO) pour plusieurs
tâches
45
Formule II.3. Calcul de la DTA pour le cas d'une
seule tâche
47
Formule II.4. Calcul de la (DTO) pour le cas de
plusieurs tâches
47
Formule II.5. Marge libre
50
Formule II.6. Marge totale
50
Formule V.1. Jointure des classes
91
Formule V.2. Fragmentation hybride
91
Formule V.3. Allocation du site YAKANYAMA
92
Formule V.4. Allocation du site YAKANYAMA
92
INTRODUCTION GENERALE
L'informatique est une science exacte. Avec but de surmonter
les faiblesses humaines (conscience et sentiments), l'informatique dispose des
méthodes et techniques nécessaires pour l'automatisation de
certaines activités de l'homme. Elle est l'unique science ayant des
moyens fiables et sûrs pour répondre aux besoins de ses
bénéficiaires d'une manière efficace, ce dans tous les
domaines.
A cet effet, la gestion des systèmes d'information
demande l'organisation structurelle de données, qui est l'unité
principale de traitement, pour l'acquisition, l'utilisation (traitement et mis
à jour), le partage et le stockage de ces données. Ces
tâches requièrent la présence des moyens capables de les
prendre en charge pour leur usage effectif : les bases de données
réparties sont la seule solution.
Aujourd'hui, les bases de données ont pris une place
essentielle en informatique, plus particulièrement en gestion. Elles
constituent donc une discipline s'appuyant sur une théorie solide et
offrant de nombreux débouchés pratiques.
C'est ainsi que, la Commission Electorale Nationale
Indépendante, un supra-système, gère une masse importante
de données tant persistantes que volatiles, et éprouve ensuite
d'énormes vulnérabilités qui ne peuvent passer
inaperçues à notre vue et qui nécessitent une
modélisation de son existant pour s'en passer.
1.
PRESENTATION DU PROJET
Le présent travail fait allusion à la
modélisation des activités d'enrôlement des
électeurs dans le processus électoral, au sein de la Commission
Electorale Nationale Indépendante, en République
Démocratique du Congo.
Cette modélisation se fera suivant une approche
conceptuelle dont le but est d'implémenter une Base de Données
Répartie par des démarches UML.
2.
CHOIX ET INTERET DU SUJET
2.1.
CHOIX
Nous avons opté pour ce sujet :
`Modélisation et implémentation d'une base de
données répartie pour la gestion de l'enrôlement dans un
processus électoral. Cas de la Commission Electorale Nationale
Indépendante en République Démocratique du
Congo' ; vue les failles que présente le
système en place à la CENI et les difficultés
observées sur toutes les positions fortes (les finances,
l'administration et la sécurité) dans la gestion des
activités d'enrôlement des électeurs lors de la
révision du fichier électoral.
2.2.
INTERETS
L'intérêt exclusif est pour nous de concilier la
théorie apprise pendant notre parcours estudiantin à la pratique,
en vue de l'obtention du grade de licencié en Administration
Réseau et Gestion de Base de Données.
Ensuite, l'univers scientifique trouve son
intérêt dans ce travail, qui reste une ligne de conduite pour tout
chercheur, de comprendre la modélisation de bases de données
réparties avec UML.
Enfin, ce travail trouve son intérêt
général dans le cas où il permet la disponibilité,
confidentialité et intégrité des données en
permanence dans différents sites afin de permettre à chaque
électeur de voter n'importe quel endroit où il peut se trouver,
et servir en même temps de moyen d'aide à la prise de
décision pour les dirigeants de la CENI.
3.
PROBLEMATIQUE
Est-il qu'il nous soit impérieux de soulever les
éléments ayant motivé notre esprit pour la
modélisation de l'enrôlement dans le système de la
Commission Electorale Nationale Indépendante en République
Démocratique du Congo :
Serait-il possible de modéliser un système
informatique décentralisé capable de prendre en charge toutes les
activités pendant l'enrôlement ?
Ce système, serait-il à même d'assurer la
réplication à temps différé, la
sécurité et l'accélération du traitement de
données pour servir de moyen d'aide à la décision pour la
CENI ?
Si c'est possible, par quelle touche y parvenir ?
Tous ces problèmes techniques préjudicient la
qualité de services rendus par la CENI en suscitant des doutes à
la population congolaise qui est le bénéficiaire direct desdits
services. C'est ainsi que la CENI est taxée de corruptible, non fiable,
non transparente, ce qui a affecté son système de gestion.
4.
HYPOTHESES
Pour anticiper de répondre aux problèmes
sus-soulevés, l'usage des bases de données réparties dans
cette institution (CENI) pour la gestion des opérations
d'enrôlement des électeurs apportera certes, beaucoup d'avantages
non seulement de la disponibilité, la confidentialité et
l'intégrité des données en permanence dans
différents sites mais aussi, en surmontant le problème de
réalisation de certaines tâches manuelles d'une manière
symétrique, de concurrence et de sécurité desdites
opérations, aussi de données en découlant.
5.
METHODOLOGIE
Pour élaborer ce modeste travail, nous avons suivi des
méthodes et utilisé certaines techniques très
efficaces.
5.1.
METHODES
En ce qui concerne les méthodes, nous avons
utilisé :
a) METHODE DESCRIPTIVE
Elle nous a permis, sur base de la description faite sur la
Commission Electorale Nationale Indépendante, de mieux comprendre et
cerner les points nécessaires qui concernent l'organisation
d'activité de l'entreprise.
b) METHODE ANALYTIQUE
Elle nous a permis de bien comprendre et expliquer les
différents problèmes intervenant en matière
d'enrôlement afin d'éclairer les éléments
constitutifs de chaque fonction.
c) METHODE PERT
Elle nous a permis de cadrer de façon
générale le projet et de le planifier après avoir
déterminé sa durée d'exécution, ses tâches et
coûts d'exécution matérialisés par un calendrier
d'élaboration que le projet se base.
Elle nous a aussi permis de maitriser les principales
techniques de planification et de suivi de notre projet.
5.2.
TECHNIQUES
Les techniques de récoltes de données que nous
avons utilisées c'est l'interview, la documentation et l'internet.
a) TECHNIQUE D'INTERVIEW
Elle nous a permis d'entrer en contact avec le personnel de la
CENI et nous échanger avec eux sur notre sujet.
b) TECHNIQUE DOCUMENTAIRE
Elle nous a permis de puiser les différentes
informations nécessaires dans les documents, ouvrages, syllabus
disponible et utile à notre travail. Cette documentation, nous l'avons
recherchée dans notre champ d'investigation (CENI), à
l'école, dans des bibliothèques et sur internet.
6. DELIMITATION SPATIO-TEMPRELLE
Pour bien cerner notre cadre de travail et nous faciliter
l'exécution rapide de la tâche scientifique à notre charge,
nous avons eu à délimiter notre travail dans le temps et dans
l'espace :
? Dans le temps, ce mémoire tient compte de la
période académique allant de 2014 à 2015 ;
? Dans l'espace, nous nous sommes intéressés
à la Commission Electorale Nationale Indépendante, à la
Direction Nationale de Kinshasa en République Démocratique du
Congo.
7.
SUBDIVISION DU TRAVAIL
Ce travail se constitue des points et sous-points, sections et
chapitres dont :
? Chapitre 1. Notions sur les Bases de données et les
Bases de données réparties ;
? Chapitre 2. Analyse préalable ;
? Chapitre 3. Planification et évaluation du
projet ;
? Chapitre 4. Modélisation de la Base de données
répartie ;
? Chapitre 5. La répartition de données avec
Oracle ;
? Chapitre 6. Implémentation.
Chapitre Premier :
NOTIONS
SUR LES BASES DE DONNEES ET LES BASES DE DONNEES REPARTIES
INTRODUCTION
Les bases de données en général servent
d'outils de gestion efficace de l'information dans tous les domaines de
l'administration, comme dans les domaines techniques : elles sont
actuellement au coeur de tout système d'information des
entreprises. Bien gérer une base de données, c'est jouir
d'une très grande charge pour garantir l'intégrité des
données au sein de l'organisation, à savoir le fait que celles-ci
ne seront pas corrompues au moment de leur utilisation. Et ceci demande une
connaissance parfaite en la matière. C'est pourquoi, ce chapitre fera
objet d'analyse sur les notions de bases de données en
général, et en particulier celles des bases de données
réparties (BDR).
SECTION I. NOTIONS SUR LES BASES DE DONNEES
Une base de données constitue la mémoire
permanente de toute application informatique, et plus
généralement du système d'information. C'est à cet
effet que nous avons consacré cette section sur la description
générale des bases de données.
I.1. BASE DE DONNEES (BD)
a)
DEFINITION
Une base de données (en abrégé BD, en
anglais DB : Data Base) est un ensemble de données
modélisant les objets d'une partie du monde réel et servant de
support à une application informatique.1(*) Pour mériter le terme de base de
données, un ensemble de données non indépendantes doit
être interrogeable par le contenu, c'est-à-dire que l'on doit
pouvoir retrouver tous les objets qui satisfont à un certain
critère, comme tous les individus de sexe masculin par exemple. Les
données doivent être interrogeables selon n'importe quel
critère. Il doit être possible aussi de retrouver leur structure,
par exemple le fait qu'un individu possède un nom, un prénom, une
adresse, etc.
A cet effet, nous pouvons définir une BD comme
étant un ensemble structuré d'éléments
d'information, souvent agencés sous forme de tables, dans lesquels les
données sont organisées selon certains critères en vue de
permettre leur exploitation pour répondre aux besoins d'information
d'une organisation (Database).2(*)
Ainsi, pour clarifier cette définition, nous
enchérissons qu' : « Une BD est un ensemble volumineux,
structuré et minimalement redondant de données, reliées
entre elles, stockées sur supports numériques centralisés
ou distribués, servant pour les besoins d'une ou plusieurs applications,
interrogeables et modifiables par un ou plusieurs utilisateurs travaillant
potentiellement en parallèle. »3(*)
b)
LES CRITERES D'UNE BD4(*)
Une Base de Donnéesdoit répondre aux
critères suivants :
L'exhaustivité
Implique la présence dans la base de données, de
tous les renseignements qui ont trait aux applications en question (la
présence dans la base de toutes les informations requises pour le
service que l'on en attend).
La non-redondance
Implique la présence d'un renseignement donné
une fois et une seule. Mais la non-redondance absolue est souvent difficile
à réaliser.
La structure
Implique l'adaptation du mode de stockage des renseignements
aux traitements qui les exploiteront et les mettrons à jour, ainsi qu'au
coût de stockage dans l'ordinateur.
I.2. SYSTEME DE GESTION DE BASES DE DONNEES (SGBD)
a)
DEFINITION
Un SGBD est un logiciel, le plus souvent produit par un
éditeur commercial, qui gère et contrôle l'accès
à une base de données, assurant ainsi une interface
normalisée entre les applications et les bases de données
(Database management system).5(*)
b)
LES OBJECTIFS D'UN SYSTEME DE GESTION DE BASES DE DONNEES
Dans ce cadre les SGBD se fixent les objectifs suivants :
- Indépendance physique des données
- Indépendance logique des données
- Manipulation des données par des
non-informaticiens
- Administration facilitée des données
- Optimisation de l'accès aux données
- Contrôle de cohérence (intégrité
sémantique) des données
- Partageabilité des données
- Sécurité des données
- Sûreté des données
c)
LES CARACTERISTIQUES DES SGBD6(*)
Les Systèmes de Gestion de Bases de Données se
caractérisent par :
- L'indépendance entre les données et les
applications ;
- Le contrôle centralisé des données pour
éviter toute redondance ;
- Le partage des données et accès
concurrents ;
- La gestion de la cohérence et de
l'intégrité des données ;
- La description des données stockées sous forme
de métadonnées.
I.3. NIVEAU D'ABSTRACTION DES DONNEES
Dans un SGBD les programmes qui traitent les données,
les programmes applicatifs implémentant les opérations du SGBD
sont indépendants des données ; cette
propriété importante des bases de données s'appelle
abstraction des données.Le processus de transformation des
requêtes et des résultats qui sortent d'un niveau à un
autre s'appelle correspondance ou mapping.
L'objectif majeur des SGBD est d'assurer une abstraction des
données stockées sur disques pour simplifier la vision des
utilisateurs. Pour cela, trois niveaux d'abstraction ont été
définis en 1974 pour laconception d'une base de données [NAM 74]
(...). Nombre de méthodesde conception ont vu le jour et ont
associé une forme de représentation appelée «
schéma » àchacun de ces niveaux. Un niveau logique est
présent dans certaines de ces méthodes.7(*)
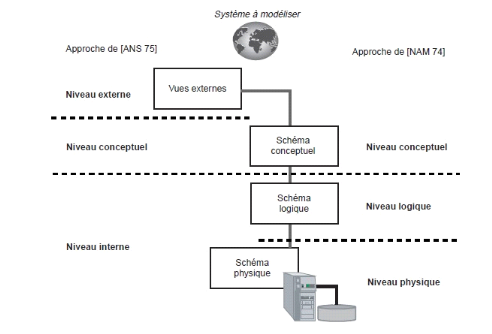
Fig. I.1. Niveaux
d'abstraction.
L'approche du rapport de Namur
Cette approche utilise trois niveaux suivants : niveau
conceptuel, logique et physique.
Le niveau conceptuel spécifie les règles de
gestion en faisant abstraction de toute contrainte de nature organisationnelle
[MOR 92]. Le niveau logique spécifie des choix de type organisationnel
(contraintes liées aux acteurs et types de matériels qui seront
utilisés pour les traitements). Le niveau physique spécifie des
choix techniques (moyens mis en oeuvre pour gérer les données ou
activer les traitements), les optimisations étant également
prises en compte.8(*)
L'approche du rapport de l'ANSI
Pour cette approche, les trois niveaux sont
représentés comme suit : niveau externe, conceptuel et
interne.
Le niveau interne est le niveau relatif à la
mémoire physique. Il s'agit du niveau où les données sont
réellement enregistrées. Le niveau externe est le niveau relatif
aux utilisateurs. Il s'agit du niveau dans lequel les utilisateurs voient les
données. Le niveau conceptuel, aussi appelé « niveau logique
communautaire », est le niveau intermédiaire entre les deux
précédents [DAT 00].9(*)
Notons que même pour les bases de données objet
ou objet-relationnelles, les niveaux de conception sont utiles, car ils
permettent de séparer les spécifications formelles de
l'implémentation et rendent les schémas indépendants des
matériels et des logiciels, dans la mesure du possible.
I.4. STRUCTURATION DE DONNEES
Il existe trois modèles de structuration de
données suivant les types des SGBD. Nous pouvons indiquer que la
structuration de donnée tient compte de l'évolution des SGBD.
Nous les détaillons suivant leur ordre chronologique : le
modèle hiérarchique et réseau, le modèle
relationnel, et enfin le modèle orienté-objet. Aussi, cette
différence de modèles se focalise sur la structure
organisationnelle interne des données.
a)
LES MODELES HIERARCHIQUES ET RESEAUX
Ces SGBD étaient basés surle concept que les
enregistrementsconservésdansdivers fichiers pouvaient être
liés selon une certaine hiérarchie et constituer un assemblage
arborescent.On a appelé structure hiérarchique cette
forme deliaison entre des enregistrements de fichiers distincts. En vertu de ce
modèle d'organisation des données, un enregistrement peut
être le pèredeplusieurs enregistrements qui à leur
tour peuvent avoir des fils.
Dans la même optique, naquit l'idéede
généraliser l'approche des SGBD hiérarchiques en proposant
un modèle d'organisation des données permettant des liens
plusieurs à plusieursentre les fichiers. La hiérarchie
père-fils n'existe pas dans ce modèle, car un enregistrement peut
avoir plusieurs successeurs de même que plusieurs
prédécesseurs. Les fichiers sont liés en
réseau maillé à la manière des
réseaux d'égout (...).Ces SGBD sont dits de type
réseau (ou simplementSGBD réseau) et permettent
dereprésenterdesassociationscomplexesentrelesfichiers.10(*)
b)
LES MODELES RELATIONNELS
Ensuite, viennent au monde les SGBD reposant sur le
modèle relationnel. Le début desannées1970, Edgard
CODD,chercheur au laboratoire de recherche IBM de San Jose en Californie,
s'inspirant de l'algèbrerelationnelle,proposa un mode d'organisation des
données ne nécessitant pasdepointeurspour lier les
enregistrements. Non seulement ce modèle avait ses fondements
théoriquessolidementétablis dans l'algèbre relationnelle,
mais il était aussi d'une grande simplicité.Lastructured'un
fichier est définie comme unerelationentre des données
provenantd'un nombre fini de domaines. Les enregistrements sont des
tuples, et constituent des occurrences de la relation. Les liens sont
assurés entre deux enregistrements sur labased'unchampdemême type,
communauxdeuxenregistrements. Si les champs communs possèdent la
même valeur, lesenregistrements sont logiquement liés.Il n'est
dès lors plus nécessaire de gérer des pointeurs physiques
pour assurer ces liens.Dephysiquesqu'étaient les liens dans les SGBD
hiérarchiques ou réseaux, les liens sont
dorénavantlogiques, basés sur les valeurs des champs, ce
qui rend la navigation entre les enregistrements beaucoup plus souple.
Malgréleursnombreuses qualités, les SGBD
relationnels, constituant la deuxième génération, ont
uncertainnombre de lacunes pour l'expression de modèles de
données àunhautniveaud'abstraction, ce que nous
définissons comme le modèle conceptuel de données. Un
effort considérable de recherche et de réflexion a
étéfaitau cours des vingt dernières annéespour
développer des méthodes et des formalismespermettant d'exprimer
un modèle de données dépouillé des contraintes du
modèle relationnel mais qui puisse se traduire assez directement dansun
SGBD relationnel.11(*)
c)
LES MODELES ORIENTES OBJETS
Le développement de langages orientés objets
(...) a conduit à la mise au point de SGBD devant assurer la
persistance des objets, soit lestockagepermanentsurun support
demémoireauxiliaire des objetscréés à l'aide de ces
langages.CeSGBD dit orienté objet ou simplement SGBD
objet, qui a connu un essor somme toute limité appartient
à latroisième génération.
Le développement des SGBD objets a été
freiné par des SGBD hybrides incorporant le modèle relationnel et
le stockage d'objets.Les objets peuvent être soit de
typestructurécomme ceux créés par un langage
orienté objet ou de type non structurételles que des images, de
la vidéo, des trames sonores, appelé BLOB (Binary Large OBject).
On donne le nomSGBDrelationnel-objet à cette forme hybride car
il combine les propriétés du SGBD relationnel et du
SGBDobjet.12(*)
1.5. LES BASES DE DONNEES AVANCEES
a)
BD PARALLELE
Les données peuvent être distribuées sur
plusieurs disques d'un même site, et l'exécution des
requêtes peut être parallélisée sur les
différentes unités de traitement (CPU) du site.
b)
BD FEDEREE
Plusieurs bases de données
hétérogènes capables d'inter opérer via une vue
commune (modèle commun).13(*)
c)
SYSTEME MULTIBASE
Plusieurs bases de données
(hétérogènes ou non) capables d'inter opérer sans
une vue commune.14(*)
d)
BD REPARTIE
Les données sont distribuées (réparties)
et/ou dupliquées sur différents sites du réseau qui
possèdent un certain degré d'autonomie. Chaque site peut
comporter une BD parallèle.
SECTION II. NOTION SUR LES BASES DE DONNEES REPARTIES
La décentralisation des systèmes informatiques
se heurte aujourd'hui aux problèmes de la répartition de
données. Celle-ci étant un moyen assurant la cohérence, la
sécurité, l'intégrité, la fiabilité des
données géographiquement disséminées sur plusieurs
systèmes, devient de plus en plus complexe.
C'est ainsi que la problématique de bases de
données réparties constitue à cet effet une
préoccupation importante demandant des études très. Cette
section va nous aider à éclairer notre connaissance pour dissiper
toutes confusions caractéristiques aux notions basées sur cette
matière.
II.1. GENERALITES SUR LES BASES DE DONNEES REPARTIES
a)
EVOLUTION DES BDR
La gestion de bases de données centralisées avec
le temps, s'est confrontée à divers problèmes qui sont
:
· L'augmentation du volume de données ;
· L'augmentation du volume de traitements ;
· L'augmentation du volume de transactions ;
· Etc.
Cela a entraîné la lenteur des applications, car
les périphériques de stockage submergés, ne
répondant pas assez vite. Aussi, il est à noter que les
débits des liaisons réseaux évoluaient beaucoup plus vite
que les capacités des périphériques de stockage.
Ainsi, l'idée est venue de multiplier les sources de
données et les faire communiquer par réseau, afin de
bénéficier de traitements parallèles, minimisant ainsi les
temps de réponses. Aujourd'hui, les BDR sont de plus en plus
répandus, et comblent largement les lacunes des bases de données
classiques.
1. SYSTEME REPARTI
Unsystèmerépartiestunensembledesitesreliésparunréseau,comportantchacununeouplusieursmachines.15(*)Dans le système
réparti se passe un partage des ressources matérielles et
logicielles.
2. OBJECTIFS DES BASES DE DONNEES REPARTIES
Les principaux objectifs sont :
- Transparence pour l'utilisateur ;
- Autonomie de chaque site ;
- Absence de site privilégié ;
- Continuité de service (tolérance aux
pannes) ;
- Transparence vis à vis de la localisation des
données ;
- Transparence vis à vis de la fragmentation ;
- Transparence vis à vis de la
réplication ;
- Traitement des requêtes distribuées ;
- Indépendance vis à vis du
matériel ;
- Indépendance vis à vis du système
d'exploitation ;
- Indépendance vis à vis du
réseau ;
- Indépendance vis à vis du SGBD.16(*)
3. INCONVENIENTS DES SYSTEMES REPARTIS
L'inconvénient majeur de la répartition des
données d'une BD entre plusieurs sites est la complexité
résultant de leur coordination. Cette complexité se
répartit de la façon suivante :
- Le coût de mise au point du logiciel;
- Le nombre d'erreurs logicielles plus important;
- Les servitudes du système accrues pour la
coordination :
o Echange de messages ;
o Calcul supplémentaire ;
o Récupération de système plus complexe
après panne (Réintégration des sites ou liaison en
pannes).17(*)
b)
PRINCIPES DES BDR
1. DEFINITION D'UNE BASE DE DONNEES REPARTIE
En soi, une base de données répartie est d'abord
une base de données simple... On appel base de données
répartie une base de données composées de plusieurs base
de données visible comme un système unique, qui échangent
des données avec des messages.18(*)
Une base de données répartie ne contient en
principe pas de redondance, si les données sont copiées d'une BD
à l'autre, on parle de données répliquées.
2. SYSTEME DE GESTION DE BASE DE DONNEES REPARTIE (SGBDR)
Définition
Un système de gestion de bases de données
réparties est donc un ensemble de logiciels systèmes
gérant des données réparties sur un ensemble de sites,
intégrant des modules clients et des modules serveurs. Clients et
serveurs collaborent bien sûr par des médiateurs
spécifiques.19(*)
Il se charge de la création et la maintenance des bases
de données. Il doit rendre la répartition des bases des
données transparentes aux utilisateurs. La base de données
étant répartie, il faut également répartir certaine
fonctionnalités du SGBD.
Fonctions
1. L'accès lointain par un programme d'application
rendu possible grâce à la composante de base de données
répartie.
2. Garantir certains degrés de transparences
réparties.
3. Le support d'administration et de contrôle de base de
données. Le contrôle, l'utilisation des bases de données et
la vue globale des fichiers existants dans les divers sites.
4. Le contrôle de concurrence et la rentabilité
des transactions réparties.
3. CONCEPTS DE BASE
? SCHEMA GLOBAL
Comme toutes les bases de données, une base de
données répartie possède un schéma
appeléschéma global qui permet de définir des types de
données de la base. Il s'agit d'une vision relationnelle de la base. Le
schéma global ignore les concepts d'implémentation. A ce titre,
il est souvent appelé schéma conceptuel.
Dans une base de données répartie, le
schéma global ou conceptuel n'est pas forcément
matérialisé. Chaque base locale implémente une partie. Ces
parties locales sont les seules matérialisées sur des disques.
L'utilisateur d'une base de données répartie se focalise sur sa
vue logique des données et n'a pas besoin de se préoccuper des
fragments physiques.C'est le système de bases de données qui se
charge lui-même d'exécuter les opérations, soit localement,
soit en les distribuant sur plusieurs ordinateurs en cas de besoin.
La définition du schéma global de
répartition est le point de départ pour la modélisation et
surtout qu'il n'existe pas d'autres solutions optimales.
Le concepteur doit donc prendre des décisions dont
l'objectif est de minimiser le nombre de transferts entre sites, les temps de
transfert, le volume de données transférées, les temps
moyens de traitement des requêtes, le nombre de copies de fragments,
etc...
Le schéma global se subdivise en trois schémas
qui sont le schéma interne, le schéma conceptuel et le
schéma externe.
? SCHEMA LOCAL
C'est l'ensemble des segments de tables physiques
alloués aux ordinateurs à travers les sites
géographiquement éloignés.
c)
UTILISATION D'UNE BDR
Le principe fondamental dans l'utilisation des bases de
données répartie est la transparence pour l'utilisateur.
Celle-ci se veut comme le fait de cacher aux utilisateurs
certaines informations. Ce qui lui fait apparaitre la BD comme étant
unique. Cette transparence s'exprime sous trois formes :
1. TRANSPARENCE DE LA LOCALISATION
Les utilisateurs accèdent à la base de
données soit directement par le schéma conceptuel, soit
directement au travers de vues externes. Mais en aucun cas ils n'ont les moyens
d'accéder aux schémas locaux ni de préciser le site.
2. TRANSPARENCE DE PARTITIONNEMENT
De même, les utilisateurs n'ont pas à
connaître les partitionnements de la base de données. Ils ne
doivent pas savoir si telle information est fractionnées, et ne doivent
donc pas se préoccuper de la réunifier. C'est le système
qui gère les partitionnements et les modifier en fonction de ses
besoins, et c'est donc lui qui doit rechercher toutes les partitions et les
intégrer en une seule information logique présentée
à l'utilisateur.
3. TRANSPARENCE DE LA DUPLICATION
Enfin, les utilisateurs n'ont pas à savoir si plusieurs
copies d'une même information sont disponibles. C'est le principe de
transparence de duplication. La conséquence directe est que lors de la
modification d'une information, c'est le système qui doit se
préoccuper de mettre à jours toutes les copies.
d)
LA REPARTITION DES BASES DE DONNEES
1. BUTS
Les bases de données réparties ont une
architecture plus adaptée à l'organisation des entreprises
décentralisées par le fait qu'elles assurent :
§ Plus de fiabilité : les bases de données
réparties ont souvent des données répliquées. La
panne d'un site n'est pas très importante pour l'utilisateur, qui
s'adressera à autre site.
§ Meilleures performances : réduire le trafic sur
le réseau est une possibilité d'accroître les performances.
Le but de la répartition des données est de les rapprocher de
l'endroit où elles sont accédées. Répartir une base
de données sur plusieurs sites permet de répartir la charge sur
les processeurs et sur les entrées/ sorties.
§ Faciliter l'accroissement: l'accroissement se fait par
l'ajout de machines sur le réseau.
2. PROBLEMES A SURMONTER
Les problèmes majeurs à surmonter dans la
répartition des bases de données sont :
Le coût : la distribution entraîne des
coûts supplémentaires en terme de communication, et en gestion des
communications (-hardware et software à installer pour gérer les
communications et la distribution) ;
La concurrence : vis-à-vis à
l'accès aux données de la base par les utilisateurs ;
La sécurité : la sécurité
est un problème plus complexe dans le cas des bases de données
réparties que dans le cas des bases de données
centralisées.
e)
ARCHITECTURE DES BDR
1. AUTONOMIE
Dans une base de données répartie, chaque site
du réseau possède une capacité d'exécution autonome
et peut développer des applications locales. Il peut en outre participer
à l'exécution d'au moins une application globale qui demande de
l'accès aux données de plusieurs sites en utilisant un
système de communication.20(*)
Ce qui en dégage une corrélation logique entre
les données réparties sur différents sites : ces
données possèdent les propriétés qui les tiennent
ensemble malgré la distribution.
2. RELATION ENTRE MACHINES
La relation entre les machines dans un système
réparti est définie suivant deux architectures dont :
? ARCHITECTURE CLIENT/SERVEUR
C'est une architecture dans laquelle les traitements sont
répartis entre les clients qui demandent les informations dont ils ont
besoin au(x) serveurs(x).C'est-à-dire que les serveurs ont pour
rôle de servir les clients. Par servir, on désigne la
réalisation d'une tâche demandée par le client.
Serveur Oracle 11g
BD Oracle



Fig. I.2 :
Architecture Client/serveur.
Dans cette architecture, l'application client se connecte au
serveur de base de données. Ce dernier à son tour, lui renvoie
des réponses en fonction de ses requêtes.
? ARCHITECTURE PEER TO PEER (P2P)
Par ce terme on désigne un type de communication pour
lequel toutes les machines ont une importance équivalente. Il existe en
général plusieurs serveurs de données qui fonctionnent
selon l'architecture suivante :
Mbujimayi
Lubumbashi
Goma
Une base de données logique
Serveur Oracle11g
Serveur Oracle11g
Serveur Oracle11g
Fig. I.3 :
Architecture serveur-serveur.
Chaque machine joue le rôle de serveur et chaque serveur
gère sa base de données et échange les informations avec
les autres. Le tout est vu comme une seule base de données logique.
II.2. TECHNIQUES DE CONCEPTION ET DE GESTION DE BDR
a)
METHODES DE CONCEPTION
La conception d'une base de données répartie
peut être le résultat de deux approches totalement distinctes,
soit d'une part la nécessité de connecter la multitude de bases
de données existantes, ainsi que la disponibilité
nécessaire à la globalisation des systèmes informatiques,
d'autre part. Ce qui permet le rôle de la BDR de rapprocher les
données des sites d'accès malgré leur localisation.
1. CONCEPTION ASCENDANTE (bottom up)
Dans ce cas de figure I.3, il existe plusieurs bases de
données disjointes qu'il faut réunir en une seule base de
données reparties et cohérente avec un schéma de
conception global. C'est la première approche.
Base de Données
BD1
BD2
BDn
...
Fig. I.4 : Conception
ascendante de la BDR
L'approche se base sur le fait que la répartition est
déjà faite, mais il faut réussir à intégrer
les différentes BD existantes en une seule BD globale. En d'autres
termes, les schémas conceptuels locaux existent et il faut
réussir à les unifier dans un schéma conceptuel
global.21(*)
2. CONCEPTION DESCENDANTES (Top down)
La deuxième approche commence par définir un
schéma conceptuel global de la base de données
répartie,puis on le distribue sur les différents sites en des
schémas conceptuels locaux. C'est-à-dire qu'au départ,nous
avons une seule base de données qu'il faut fragmenter et allouer les
fragments aux différents sites.22(*)
Base de Données
BD1
BD2
BDn
...
Fig. I.5 : Conception
descendante de la BDR
La répartition se fait donc en deux étapes, en
première étape la fragmentation, et en fin, l'allocation de ces
fragments aux sites. Cette approche (top down)est intéressante
quand on part du néant. C'est sur elle que nous allons nous appuyer pour
réaliser notre projet.
b)
LA FRAGMENTATION
1. DEFINITION
La fragmentation est le processus de décomposition
d'une base de données logique (telle qu'elle est vue par les
utilisateurs) en un ensemble de "sous" bases de
données. Cette décomposition doit évidemment être
sans perte d'information pour être acceptable.23(*)
Cette décomposition est assurée par une fonction
de définition qui préserve les arguments lors de son
application.
2. OBJECTIF DE LA FRAGMENTATION
L'utilisation de fragments permet de faire tourner plus de
processus simultanément, ce qui entraîne une meilleure utilisation
des capacités du réseau d'ordinateurs.24(*)
Nous devons enchérir que les applications ne
travaillent que sur des sous-ensembles des relations. Une distribution
complète des relations générerait soit beaucoup de trafic,
soit une réplication des données avec tous les problèmes
que cela occasionne : problèmes de mises à jour, problèmes
de stockage. Il est donc préférable de mieux distribuer ces
sous-ensembles.
3. TYPES DE FRAGMENTATIONS
Il existe 2 types de fragmentations :
a. La fragmentation horizontale : la relation
est divisée en plusieurs sous-relations contenant chacune un
sous-ensemble des tuples (lignes) de la relation.25(*)
La fragmentation horizontale a tout son intérêt
pour une société dispersée aux quatre coins du globe et
qui maintient une relation contenant ses employées par exemple. Cette
relation logique peut-être fragmentée horizontalement en plusieurs
groupes contenant chaque fois les employés selon leur localisation.
b. La fragmentation verticale : la relation
est divisée en plusieurs sous-relations contenant chacune un
sous-ensemble des attributs (colonnes) de la relation.26(*)
La fragmentation verticale est plus complexe et moins
intuitive. Les sous-relations ne contiennent pas tous les attributs mais tous
les tuples. Un peu comme une vue permet de cacher les attributs inutiles selon
le contexte, la fragmentation verticale peut-être utile d'un point de vue
hiérarchique.
c. La fragmentation mixte : Elle
résulte de l'application successive d'opérations de fragmentation
horizontale et verticale sur une relation globale.27(*)
La recomposition de la relation initiale se fait par une
succession inverse d'unions (recomposition des fragments horizontaux) et de
jointures (recompositions des fragments verticaux).
4. LES REGLES DE LA FRAGMENTATION
Lacomplétude : pour toute
donnée d'une relation R, il existe un fragment Ri de
la relation R qui possède cette donnée.
Lareconstruction : pour toute relation
décomposée en un ensemble de fragments Ri, il existe une
opération de reconstruction.
La disjonction : une donnée n'est
présente que dans un seul fragment, sauf dans le cas de la fragmentation
verticale pour la clé primaire qui doit être présente dans
l'ensemble des fragments issus d'une relation.
5. L'ALLOCATION DES FRAGMENTS
L'affectation des fragments sur les sites est
décidée en fonction de l'origine prévue des requêtes
qui ont servi à la fragmentation. Le but est de placer les fragments sur
les sites où ils sont les plus utilisés, et ce pour minimiser les
transferts de données entre les sites.
L'allocation peut se faire avec réplication ou sans
réplication. Sachant que la réplication favorise les performances
des requêtes et la disponibilité des données, mais est
coûteuse en considérant les mises à jour des fragments
répliqués.28(*)
c)
TECHNIQUES DE REPARTITION AVANCEES
Dans le cas où la méthode classique de
fragmentation d'allocation ne s'avère pas satisfaisante, des techniques
plus puissantes (mais plus complexes) à mettre en oeuvre doivent
être envisagées : l'allocation avec duplication des fragments,
l'allocation dynamique des fragments ou même la fragmentation
dynamique.
1. ALLOCATION AVEC DUPLICATION
Certains fragments peuvent être dupliqués sur
plusieurs sites (éventuellement sur tous les sites) ce qui procure
l'avantage d'améliorer les performances en termes de temps
d'exécution des requêtes (en évitant certains transferts
des données). Elle permet aussi une meilleure disponibilité des
informations (connues de plusieurs sites) et une meilleure fiabilité
contre les pannes.29(*)
Par contre, l'inconvénient majeur est que les mises
à jour doivent être effectuées sur toutes les copies d'une
même donnée. En conséquences, moins un fragment est sujet
à des modifications et plus il est prédisposé lorsque la
base de données est surjetée à de nombreuse mise à
jours.
2. ALLOCATION DYNAMIQUE
Avec cette technique, l'allocation d'un fragment peut changer
en cours d'utilisation de la base de données réparties... Dans ce
cas, le schéma d'allocation et les schémas locaux doivent
être tenus à jour. Cette technique est une alternative à la
duplication qui se révèle efficace lorsque la base de
données est surjetée à de nombreux sites
d'allocations.30(*)
3. FRAGMENTATION DYNAMIQUE
Dans le cas où le site d'allocation peut changer
dynamiquement, il est possible que deux fragments complémentaires
(verticalement ou horizontalement) se retrouvent sur le même site. Il est
alors normal de les fusionner. A l'inverse, si une partie d'un autre fragment
est appelé sur un autre site, il peut être intéressant de
décomposer ce fragment et de ne faire migrer que la partie
concernée. Ces modifications du schéma de fragmentation se
répercutent sur le schéma d'allocation et sur les schémas
locaux.31(*)
d)
LA REPLICATION
La réplication est une technique de répartition
consistant à gérer des copies sur différents sites, les
copies pouvant être différentes à un instant donné,
mais devant converger vers une même valeur si l'on arrête la
production de transactions de mises à jour.32(*)
Dans le cas où les utilisateurs n'auraient pas besoin
d'accéder aux données les plus récentes, un assortiment
existe pour éviter le trafic qu'engendre l'accès aux
données à jour. Elle consiste en l'utilisation de clichés
(ang. snapshot).
Un cliché représente un état de la base
de données à un instant donné. La pertinence d'un
cliché diminue donc au fur et à mesure que le temps
passe.33(*)
1. PRINCIPE
L'objectif principal de la réplication est de faciliter
l'accès aux données en augmentant leur disponibilité. Soit
parce que les données sont copiées sur différents sites
permettant de répartir les requêtes, soit parce qu'un site peut
prendre la relève lorsque le serveur principal s'écroule.
Le principe de la réplication, qui met en jeu au
minimum deux SGBD, est assez simple et se déroule en trois temps :
o La base « maître » reçoit un ordre de
mise à jour (INSERT, UPDATE ou DELETE).
o Les modifications faites sur les données sont
détectées et stockées (dans une table, un fichier, une
queue) en vue de leur propagation.
o Un processus de réplication prend en charge la
propagation des modifications à faire sur une seconde base dite esclave.
Il peut bien entendu y avoir plus d'une base esclave.
2. AVANTAGES DE REPLICATION
Les avantages de la réplication dépendent du
type de réplication utilisé. Mais généralement, les
avantages sont universels :
- Allégement du trafic réseau en
répartissant la charge sur divers sites. Par conséquent,
rapidité des accès aux données ;
- Amélioration des performances des
requêtes ;
- Résistance aux pannes par l'augmentation de la
disponibilité des données.34(*)
3. TYPE DE REPLICATION
Bien entendu, il est tout à fait possible de faire la
réplication dans les deux sens : de l'esclave vers le maître
et inversement. On parlera dans ce cas-là de réplication
bidirectionnelle ou symétrique.
Dans le cas contraire, c'est-à-dire du maître
vers l'esclave seulement, la réplication est unidirectionnelle et en
lecture seule ou asymétrique.
De plus, la réplication peut être faite de
manière synchrone ou asynchrone. Dans le premier cas, la
résolution des conflits éventuels entre deux sites intervient
avant la validation des transactions (c'est-à-dire à temps
réel). Mais le second cas, la résolution est faite dans des
transactions séparées (à temps différé). Il
est donc possible d'avoir quatre modèles de réplication :
· Réplication asymétrique avec propagation
asynchrone ;
· Réplication asymétrique avec propagation
synchrone ;
· Réplication symétrique avec propagation
asynchrone ;
· Réplication symétrique avec propagation
synchrone.
4. TECHNIQUES DE DIFFUSION DE MISES A JOUR
La diffusion automatique des mises à jour
appliquée d'une copie aux autres copies doit être assurée
par le SGBD réparti. Plusieurs techniques de diffusion sont possibles
parmi lesquelles, nous distinguerons celles basées sur la diffusion de
l'opération de mise à jour, de celles basées sur la
diffusion du résultat de l'opération.
Diffuser le résultat présente l'avantage de ne
pas devoir réexécuter l'opération sur le site de la copie,
mais l'inconvénient de nécessité d'un ordonnancement
identique des mises à jour en tous les sites afin d'éviter les
pertes de mises à jour. Le report d'opération est plus flexible,
notamment dans le cas d'opérations commutatives.
e)
GESTION DES DONNEES REPARTIES
Les règles d'exécution et les méthodes
d'optimisation de requêtes définies pour un contexte
centralisé sont toujours valables, mais il faut prendre en compte d'une
part la fragmentation et la répartition des données sur
différents sites, et d'autre part le problème du coût des
communications entre sites pour transférer les données.
Le problème de la fragmentation avec ou sans
duplication concerne principalement les mises à jours tandis que le
problème des coûts des communications concerne surtout les
requêtes.
1. Mise à jour des données
distantes :
La principale difficulté réside dans le fait
qu'une mise à jour dans une relation du schéma global se traduit
par plusieurs mises à jour dans différents fragments. Il faut
donc identifier les fragments concernés par l'opération de mise
à jour, puis décomposer en conséquence l'opération
en un ensemble d'opération de mise à jour sur ces fragments.
Ø Insertion
Retrouver le fragment horizontal concerné en utilisant
les conditions qui définissent les fragments horizontaux, puis insertion
du tuple dans tous les fragments verticaux correspondants.
Ø Suppression
Rechercher le tuple concerné dans les fragments qui
sont susceptibles de le contenir, et supprimer ses valeurs d'attribut dans tous
les fragments verticaux.
Ø Modification
Rechercher les tuples, les modifier et les déplacer
vers les bons fragments si nécessaire.
f)
LES TRANSACTIONS
1. Définition d'une
transaction
Une transaction est un ensemble d'opérations
menées sur une BD.35(*) Ces opérations peuvent être en lecture
et/ou écriture.
Une opération est atomique, c'est donc une unité
indivisible de traitement.Une transaction est soit validée par un
commit, soit annulée par un rollback, soit interrompue
par un abort.
Une transaction a une marque de début (Begin Of
Transaction BOT), et une marque de fin (End Of Transaction EOT).
2. Propriétés d'une
transaction
La cohérence et la fiabilité d'une transaction
sont garanties par 4 propriétés :
l'Atomicité, la Cohérence,
l'Isolation, la Durabilité qui font
l'ACIDité d'une transaction.
§ Atomicité : cette
propriété signifie qu'une transaction est traitée comme
une seule opération. Toutes les actions sont toutes menées
à bien ou aucune d'entre elles.
§ Cohérence : une transaction est un
programme qui amène la BD d'un état cohérent à un
autre état cohérent, tel que toutes les contraintes
d'intégrité restent vérifiées.
§ Isolation : c'est la propriété
qui impose à chaque transaction de voir la BD cohérente. Une
transaction en exécution ne peut révéler ses
résultats à d'autres transactions concurrentes avant d'effectuer
le commit.
§ Durabilité : c'est la
propriété qui garantit lorsqu'une transaction a effectué
son commit, le résultat sera permanent, et ne pourra être
effacé de la BD quelques soient les pannes du système
rencontrées.
3. Différents niveaux de fragmentation de
la répartition
La transparence est la caractéristique principale d'un
système distribué dans lequel l'utilisateur doit se voir
travailler sur un énorme ordinateur personnel constitué de tous
les ordinateurs connectés.
Nous distinguons plusieurs niveaux de transparence de
répartition qui sont indépendantes du programme d'application de
la répartition :
v Transparence globale
La transparence globale définit toutes les
données contenues dans la base de données réparties comme
si cette base était définie exactement comme dans une base de
données non réparties.
v Transparence de fragmentation
Une relation globale peut être répartie en
plusieurs fragments, une transparence de fragmentation définit une
fonction entre la relation globale et les fragments.
Cette fonction est multivaluée c'est à dire
plusieurs fragments correspondent à une relation globale, mais une seule
relation globale correspond à un seul fragment.
v Transparence d'allocation
Les fragments sont des portions logiques des relations
globales qui sont uniquement situées dans un ou plusieurs sites du
réseau. La transparence d'allocation définit le site dans lequel
est situé un fragment. La relation définit dans la transparence
d'allocation détermine si la base de données répartie est
redondante ou pas.
v Transparence conceptuelle locale
Transparence conceptuelle locale définit une fonction
qui associe chaque image physique aux objets qui sont manipulés par les
systèmes de gestion de base de données locaux. Cette transparence
dépend du type de système de base de données locale.
CONCLUSION PARTIELLE
Nous avons abordé et finalisé en toute
célérité les notions sur les bases de données en
générale et celles réparties en particulier. Dans la suite
nous allons exposer la question sur l'évaluation de notre projet.
Chapitre deuxième :
ETUDE
PREALABLE
INTRODUCTION
L'étude préalable consiste à faire une
analyse minutieuse du système existant pour en dégager les
failles et les forces afin d'arriver à une conclusion qui permettra une
proposition de solutions de la part de l'analyste.
Ce chapitre va nous permettre d'étaler les
activités de la CENI en commençant par : l'historique,
l'organisation, l'analyse de besoins, etc.
SECTION I. PRÉSENTATION ET ANALYSE DE LA STRUCTURE DU
SYSTÈME EXISTANT (CENI)
Dans cette partie nous aurons à analyser les
informations concernant juste l'organisation structurelle de la CENI telles
que : l'historique, la situation géographique, l'objectif,
l'organisation.
I.1. HISTORIQUE
Depuis son indépendance, le 30 juin 1960, la RDC est
confrontée à des crises politiques récurrentes dont l'une
des causes fondamentales est la contestation de la légitimité des
institutions et de leurs animateurs. Cette contestation a pris un relief
particulier avec les guerres qui ont déchiré le pays de 1996
à 2003.
En vue de mettre fin à cette crise chronique de
légitimité et de donner au pays toutes les chances de se
reconstruire, les délégués de la classe politique et de la
société civile, forces vives de la Nation, réunies en
Dialogue inter congolais, ont convenu, dans l'Accord Global et inclusif
signé à Pretoria en Afrique du Sud le 17 décembre 2002, de
mettre en place un nouvel ordre politique, fondé sur une nouvelle
Constitution démocratique sur base de laquelle le peuple congolais
puisse choisir souverainement ses dirigeants, au terme des élections
libres, pluralistes, démocratiques, transparentes et
crédibles.
A l'effet de matérialiser la volonté politique
ainsi exprimée par les participants au Dialogue inter congolais, le
sénat, issu de l'Accord Global et inclusif précité, a
déposé, conformément à l'article 104 de la
Constitution de la transition, un avant-projet de la nouvelle Constitution
à l'Assemblée nationale qui l'a adopté sous forme de
projet de Constitution soumis au référendum populaire.
La Constitution ainsi approuvée s'articule pour
l'essentiel autour des idées forces ci-après :
1.
DE L'ETAT ET DE LA SOUVERAINETE
Dans le but d'une part, de consolider l'unité nationale
mise à mal par des guerres successives et, d'autre part, de créer
des centres d'impulsion et de développement à la base, le
constituant a structuré administrativement l'Etat congolais en 25
provinces plus la ville de Kinshasa dotées de la personnalité
juridique et exerçant des compétences de proximité
énumérées dans la présente Constitution.
En sus de ces compétences, les provinces en exercent
d'autres concurremment avec le pouvoir central et se partagent les recettes
nationales avec ce dernier respectivement à raison de 40 et de 60%.
En cas de conflit de compétence entre le pouvoir
central et les provinces, la cour constitutionnelle est la seule
autorité habilitée à les départager. Au demeurant,
les provinces sont administrées par un Gouvernement provincial et une
Assemblée provinciale. Elles comprennent, chacune, des entités
territoriales décentralisées qui sont la ville, la commune, le
secteur et la chefferie.
Par ailleurs, la présente Constitution réaffirme
le principe démocratique selon lequel tout pouvoir émane du
peuple en tant que souverain primaire.
Ce peuple s'exprime dans le pluralisme politique garanti par
la Constitution qui érige, en infraction de haute trahison,
l'institution d'un parti unique.
En ce qui concerne la nationalité, le constituant
maintient le principe de l'unicité et de l'exclusivité de la
nationalité congolaise.
2.
DES DROITS HUMAINS, DES LIBERTES FONDAMENTALES ET DES DEVOIRS DU CITOYEN ET DE
L'ETAT
Le constituant tient à réaffirmer l'attachement
de la RDC aux Droits humains et aux libertés fondamentales tels que
proclamés par les instruments juridiques internationaux auxquels elle a
adhéré. Aussi, a-t-il intégré ces droits et
libertés dans le corps même de la Constitution? A cet
égard, répondant aux signes du temps, l'actuelle Constitution
introduit une innovation de taille en formalisant la parité
homme-femme.
3.
DE L'ORGANISATION ET DE L'EXERCICE DU POUVOIR
Les nouvelles institutions de la République
Démocratique du Congo sont :
§ Le Président de la République ;
§ Le Parlement ;
§ Le Gouvernement ;
§ Les Cours et Tribunaux ;
Les préoccupations majeures qui président
à l'organisation de ces institutions sont les suivantes :
1. Assurer le fonctionnement harmonieux des institutions de
l'Etat ;
2. Eviter les conflits ;
3. Instaurer un Etat de droit ;
4. Contrer toute tentative de dérive
dictatoriale ;
5. Garantir la bonne gouvernance ;
6. Lutter contre l'impunité ;
7. Assurer l'alternance démocratique ;
C'est pourquoi non seulement le mandat du Président de
la République n'est renouvelable qu'une seule fois, mais aussi, il
exerce ses prérogatives de garantir de la Constitution, de
l'indépendance nationale, de l'intégrité territoriale, de
la souveraineté nationale, du respect des accords et traités
internationaux ainsi que celles de régulateur et d'arbitre du
fonctionnement normal des institutions de la République avec
l'implication du Gouvernement sous le contrôle du Président.
Les actes réglementaires qu'il signe dans les
matières relevant du Gouvernement ou sous gestion ministérielle
sont couverts par le contreseing du Premier ministre qui en endosse la
responsabilité devant l'Assemblée nationale.
Bien plus, les affaires étrangères, la
défense et la sécurité, autrefois domaines
réservés du Chef de l'Etat, sont devenues des domaines de
collaboration.
Cependant, le Gouvernement, sous l'impulsion du Premier
ministre, demeure le maitre de la conduite de la politique de la Nation qu'il
définit en concertation avec le Président de la
République.
Il est comptable de son action devant l'Assemblée
nationale qui peut le sanctionner collectivement par l'adoption d'une motion de
censure.
L'Assemblée nationale peut, en outre, mettre en cause
la responsabilité individuelle des membres du Gouvernement par une
motion de défiance.
Réunis en congrès, l'Assemblée nationale
et le Sénat ont la compétence de déférer le
Président de la République et le Premier ministre devant la cour
constitutionnelle, notamment pour haute trahison et délit
d'initié.
Par ailleurs, tout en jouissant du monopole du pouvoir
législatif et du contrôle du Gouvernement, les parlementaires ne
sont pas au-dessus de la loi ; leurs immunités peuvent être
levées et l'Assemblée nationale peut être dissoute par le
Président de la République en cas de crise persistante avec le
Gouvernement.
La présente Constitution réaffirme
l'indépendance du pouvoir judiciaire dont les membres sont
gérés par le Conseil supérieur de la magistrature
désormais composé des seuls magistrats.
Pour plus d'efficacité, de spécialité et
de célérité dans le traitement des dossiers, les cours et
tribunaux ont été éclatés en trois ordres
juridictionnels :
§ Les juridictions de l'ordre judiciaire placées
sous le contrôle de la cour de cassation ;
§ Celles de l'ordre administratif coiffées par le
Conseil d'Etat ;
§ La cour Constitutionnelle
Des dispositions pertinentes de la Constitution
déterminent la sphère d'action exclusive du pouvoir central et
des provinces ainsi que la zone concurrente entre les deux échelons du
pouvoir d'Etat.
Pour assurer une bonne harmonie entre les provinces
elles-mêmes d'une part, et le pouvoir central d'autre part, il est
institué une conférence des Gouverneurs présidée
par le Chef de l'Etat et dont le rôle est de servir de conseil aux deux
échelons de l'Etat.
De même, le devoir de solidarité entre les
différentes composantes de la Nation exige l'institution de la Caisse
nationale de péréquation placée sous la tutelle du
Gouvernement.
Compte tenu de l'ampleur et de la complexité des
problèmes de développement économique et social aux quels
la République Démocratique du Congo est confrontée, le
constituant crée le conseil économique et social, dont la mission
est de donner des avis consultatifs en la matière au Président de
la République, au Parlement et au Gouvernement.
Pour garantir la démocratie en République
Démocratique du Congo, la présente Constitution retient deux
institutions d'appui à la démocratie, à savoir la
Commission Electorale Nationale et Indépendante chargée de
l'organisation du processus électoral de façon de permanente et
le Conseil supérieur de l'audiovisuel et de la communication dont la
mission est d'assurer la liberté et la protection de la presse ainsi que
tous les moyens de communication des masses dans le respect de la loi.
4.
DE LA REVISION CONSTITUTIONNELLE
Pour préserver les principes démocratiques
contenus dans la présente Constitution contre les aléas de la vie
politique et les révisions intempestives, les dispositions relatives
à la forme républicaine de l'Etat, au principe du suffrage
universel, à la forme représentative du Gouvernement au nombre et
à durée des mandats du Président de la République,
à l'indépendance du pouvoir judiciaire, au pluralisme politique
et syndical ne peuvent faire l'objet d'aucune révision
constitutionnelle. Telles sont les lignes maîtresses qui
caractérisent la présente Constitution.
I.2. SITUATION GEOGRAPHIQUE
La Commission Electorale Nationale et Indépendante est
située dans la ville province de Kinshasa, précisément sur
le boulevard du 30 juin occupe maintenant le bâtiment ex. BCCE en face de
l'ONATRA et à proximité de la gare centrale.
I.3. OBJECTIF
La Commission Electorale Nationale et Indépendante
comme toute autre entreprise a comme objectif de permettre à la
population de s'enrôler pour avoir une carte d'identité principale
appelée « Carte d'électeur » et d'organiser
les élections dans le pays.
I.4. ORGANISATION
1.
LES ORGANIGRAMMES DE LA CENI
a) ORGANIGRAMME GENERAL
Organigramme Spécifique
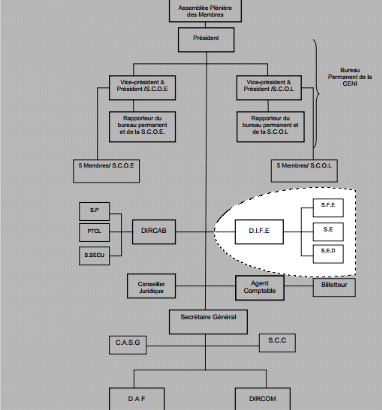
Fig. II.1. Organigramme
général de la CENI
b) ORGANIGRAMME SPECIFIQUE
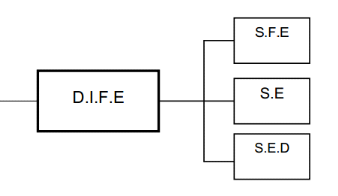
Fig. II.2. Organigramme
spécifique
DIFE : Direction de l'informatique et du Fichier
Electorale ;
SFE : Service du Fichier électoral ;
SE : Service de l'Exploitation.
2. DESCRIPTION DES
ACTIVITÉS
a. STRUCTURE
La Commission Electorale Nationale Indépendante a une
structure hiérarchique organisée par province, circonscription et
centre d'identification.
La province représente l'ensemble de circonscription.
Au niveau provincial, nous trouvons un Bureau Provincial qui gère toutes
les circonscriptions sur son étendue. Sur toute l'étendue de la
République, nous en trouvons 26 selon le nouveau dénombrement de
effectué en 2015. Donc, nous avons 26 Bureaux Provinciaux. Voici la
liste de province recensées après dénombrement :
TABLEAU II.1. TABLEAU DES
ANCIENNES ET NOUVELLES PROVINCES
|
N°
|
ANCIENNES PROVINCES
|
N°
|
NOUVELLES PROVINCES
|
|
1. KINSHASA
|
|
1. KINSHASA
|
|
2. BAS CONGO
|
|
2. KONGO-CENTRAL
|
|
3. BANDUNDU
|
|
3. KWANGO
|
|
4. KWILU
|
|
5. MAI-NDOMBE
|
|
4. EQUATEUR
|
|
6. EQUATEUR
|
|
7. NORD-UBANGI
|
|
8. SUD-UBANGI
|
|
9. MONGALA
|
|
10. TSHUAPA
|
|
5. PROVINCE ORIENTALE
|
|
11. TSHOPO
|
|
12. BAS-UELE
|
|
13. HAUT-UELE
|
|
14. ITURI
|
|
6. NORD-KIVU
|
|
15. NORD-KIVU
|
|
7. SUD-KIVU
|
|
16. SUD-KIVU
|
|
8. KATANGA
|
|
17. HAUT-KATANGA
|
|
18. HAUT-LOMAMI
|
|
19. LUALABA
|
|
20. TANGANIKA
|
|
9. KASAI-ORIENTAL
|
|
21. KASAI-ORIENTAL
|
|
22. SANKURU
|
|
23. LOMAMI
|
|
10. KASAI-OCCIDENTAL
|
|
24. KASAI
|
|
25. KASAI-CENTRAL
|
|
11. MANIEMA
|
|
26. MANIEMA
|
Source : Direction de l'informatique et
du Fichier Electorale
Une circonscription représente un territoire ou une
entité électorale. C'est l'entité la plus importante sur
laquelle se font tous les calculs électoraux. Pour être plus
clair, une circonscription est égale à un Territoire politique,
et est représentée par un Bureau de Liaison (BL) qui
dépend du Bureau Provincial. La circonscription fournit le rapport et
à la direction provinciale, et à la direction centrale
(Kinshasa). Par circonscription, nous avons au total ... circonscriptions
électorales sur toute la RDC.
Le Centre d'Inscription (CI) : c'est le lieu où se
font les enregistrements des électeurs. Il est le centre de
récolte de données. Il est implanté sur une étendue
déterminé dans une circonscription donnée et dépend
directement de celle-ci. Le nombre de Centres par circonscription dépend
de la répartition populaire sur le territoire. Et ils sont beaucoup plus
implantés dans des milieux à grande masse de la population et
dans un lieu accessible par tous. Un centre est obligé d'enrôler
au plus 300 candidats le jour à travers tous ses bureaux. Avec un jour
commençant de 8h à 16h, en semaine anglaise. Un centre est
composé de bureau de vote. Mais lors d'enrôlement, nous trouvons
au plus deux ordinateurs dans un bureau de vote pour l'identification et
l'enregistrement de candidats électeurs.
b. Activité dans l'enceinte du Centre
d'inscription (CI)
Le Président du Centre d'inscription et l'un de ses
opérateurs de saisie établissent des jetons
numérotés à un ordre croissant des nombres qui seront
remis aux différents candidats qui se présenteront pour
s'enrôler.
Le Requérant à son tour dès qu'il arrive
dans le Centre d'inscription, se place sur la file d'attente en attendant qu'on
lui remette le jeton.
Dès qu'il reçoit son jeton
numéroté, il attend qu'on appelle son numéro et dès
que c'est fait, il peut aller s'asseoir dans la salle pour attendre à se
faire enrôler.
c. Activité dans le Centre
d'inscription
Le Requérant entre dans la salle, présente sa
pièce d'identité (ancienne carte d'électeur ou toutes
autres pièces validées par la CENI) à l'opérateur
de saisie. Si c'est une ancienne carte d'électeur prouvant qu'il
était déjà enrôlé alors ça sera pour
lancer directement la recherche des informations à partir du
numéro de la carte ou des autres champs.
Dans le cas contraire, ça sera pour un nouveau
processus d'enrôlement, en enregistrant étape par étape les
informations du requérant empreinte digitale, photo, nom, post-nom,
prénom, etc. jusqu'à sortir la carte.
A la fin de la journée, l'Opérateur de Saisie
(OPS) va graver tous les tuples journaliers sur un CD-RW pour la sauvegarde
(backup), lequel CD sera récolté à la fin de la semaine
par une équipe d'agents. Après le cycle d'enrôlement ou
à la fin de cette période se fait la sauvegarde de toutes les
données de la base sur un disque dure externe.
C'est celui-ci qui sera utilisé lors de la compilation
de résultats pour donner l'effectif sur toute l'étendue du
territoire national. Et faire de statistique d'évaluation de
résultats récoltés.
SECTION II. ETUDE DE L'OPPORTUNITE
II.1. ANALYSE DES BESOINS
La mise à jour de la base de données au niveau
du siège central se fait hebdomadairement à la fin de chaque
semaine (7 jours) par la récolte des CD-RW dûment gravés et
par des agents habilitées à ramener lesdits CDs au BL.
C'est là que se pose les difficultés ayant
suscité notre besoin de faire mieux que l'existant
analysé :
- Un système ou une base de données
centralisée : Tolérant l'utilisation autonome et permettant
des CI fictifs occasionnant l'enrôlement de la population hors de
l'administration de la CENI ;
- Les erreurs de gravure, les conséquences du transport
de supports de stockage (cassure, dommage, perte, vol) surtout avec
l'insécurité qui bat à son plein au Congo ;
- Incohérence de données : de doublons des
personnes qui s'enrôlent plusieurs fois dans des sites différents,
surtout que l'enrôlement dure trois ce qui favorise la fraude ;
- Le coût d'achat des matériels de stockage
(CD-RW) pour chaque point d'enregistrement qui fait encore peser le budget de
la CENI pour l'organisation de l'enrôlement.
II.2. PRESENTATION DES SOLUTIONS
Pour pallier à tout cela, il nous a fallu de penser
à une autre manière de sécuriser l'enrôlement, la
communication entre sites et de récolte de données
recensées.
Il convient aussi de prendre en compte la force et la
gravité d'un incident comme critère à intégrer dans
le processus de haute disponibilité. Il n'est pas toujours possible, de
prendre en compte tous les incidents sans tenir compte du coût ou de la
logistique globale de mise en oeuvre de la solution de dépannage.
Dans notre solution, nous avons proposé de configurer
une répartition de la base effectuant la réplication
symétrique asynchrone du siège central verssites locauxsuite aux
données volumineuses qui seront stockées dans la base de
données lors des opérations d'identification et
d'enrôlement des électeurs.
Au fait, l'idée est de concevoir base de données
répartie, en architecture Client-Serveur, entre le siège central
et les sites locaux (CI), à travers une conception descendante
c'est-à-dire que nous allons partir d'un schéma global à
un schéma local, en passant par le schéma de l'allocation et
celui de duplication.
CONCLUSION PARTIELLE
La réalisation de ce chapitre nous a permis à
déduire, après une analyse préalable de l'organisation et
des activités de l'enrôlement à la CENI, qu'il était
impérieux de remplacer le système en place par un nouveau
système dont le chapitre suivant entamera l'évaluation de sa
durée, son coût et ses risques.
Ce chapitre nous a aidés à développer une
compréhension vis-à-vis du cursus d'enrôlement, du centre
d'inscription au siège central, et nous a donné un aperçu
lointain de ce que nous voulons faire.
Chapitre troisième :
EVALUATION DU PROJET
INTRODUCTION
Un projet est un ensemble d'activités
coordonnées mises en oeuvre pour atteindre des objectifs
spécifiques selon un calendrier, un budget et des paramètres de
performance définis. Les projets visant à atteindre un objectif
commun forment un programme.36(*)
Suivant Fabrice Sincère, un projet est un ensemble des
actions qui concourent à l'obtention d'un résultat défini,
connu et mesurable : le produit ou livrable final.37(*)
Mis à part ces définitions, il existe de
nombreuses tentatives de normalisation de la notion de projet, donnant lieu
à beaucoup de définition relativement proches. Parmi celles-ci,
citons celles proposées par les normes AFNOR X50-115 et ISO
1000638(*) :
Selon ISO 10006, un projet est un processus unique, qui
consiste en un ensemble d'activité coordonnées et
maitrisées ayant un objectif conforme à des exigences
spécifiques telles que des contraintes de délais, de couts et de
ressources.
Selon AFNOR, un projet est un ensemble d'activités
coordonnées et maitrisées comportant des dates de début et
de fins, dans le but d'atteindre un objectif conforme à des
spécifiques.
SECTION I. LA PLANIFICATION
I.1. DEFINITION DE LA PLANIFICATION
La planification c'est l'activité qui consiste à
déterminer et à ordonnancer les tâches du projet, à
estimer leurs charges et à déterminer les profils
nécessaires à leur réalisation.39(*)
Le but de la planification est de définir les
résultats attendus (objectifs) d'une intervention, les apports et les
activités nécessaires pour produire ces résultats, les
indicateurs servant à mesurer leur accomplissement et les
hypothèses clés qui peuvent influer sur l'obtention des
résultats (objectifs).
La planification prend en compte les besoins, les
intérêts, les ressources, les mandats et les capacités de
l'organisation de mise en oeuvre et des diverses parties prenantes. À la
fin de la phase de planification, un plan de projet est élaboré
et prêt à être mis en oeuvre.40(*)
I.2. LE DECOUPAGE DU PROJET
Le découpage repose sur la chronologie ou les phases
(activités) du projet. Desceller les tâches et leurs ressources,
visionner les objectifs à atteindre est primordial à ce niveau.
Ce qui divise notre projet en grandes phases pour mieux
l'exécuter :
§ Etude d'opportunité du projet : Analyse
préalable
§ Elaboration du projet : Etude
détaillée
§ Exécution du projet : Etude technique
(Modélisation du système d'information)
§ Implantation du projet : Réalisation
§ Exploitation du projet : Mise en oeuvre
I.3. L'ORDONNANCEMENT DES TACHES
L'ordonnancement est l'élaboration d'un plan d'action
permettant de déterminer les séquencements ou au contraire les
parallélismes possibles entre l'exécution des tâches
précédemment identifiées.41(*)
La planification d'un projet de système informatique se
concrétise par un plan répondant de façon
détaillée et concrète aux principaux aspects
opérationnel du type QQQOCC : qui, quoi, quand, où, comment,
combien.
I.4. ELABORATION DU TABLEAU D'AVANCEMENT DES TACHES
Nous commençons par construire le tableau de gestion
d'avancement des tâches ; celui-ci reprend, dans un premier temps,
les informations de tâches antérieures / Tâches courantes.
Puis il va nous permettre de définir des niveaux
d'antériorité au sein de l'ensemble des tâches du projet.
Enfin, il nous permet de mettre en place le planning.
TABLEAU III.1 :
AVANCEMENT DES TACHES
|
|
Il faut avoir réalisé la ou les
tâche(s) ...
|
|
|
A
|
B
|
C
|
D
|
E
|
F
|
G
|
H
|
I
|
J
|
K
|
L
|
|
Pour réaliser la tâche ...
|
A
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B
|
X
|
|
|
|
|
|
|
|
|
|
|
|
|
C
|
|
X
|
|
|
|
|
|
|
|
|
|
|
|
D
|
|
|
X
|
|
|
|
|
|
|
|
|
|
|
E
|
|
|
|
X
|
|
|
|
|
|
|
|
|
|
F
|
|
|
|
|
X
|
|
|
|
|
|
|
|
|
G
|
|
|
|
|
|
X
|
|
|
|
|
|
|
|
H
|
|
|
|
|
|
X
|
X
|
|
|
|
|
|
|
I
|
|
|
|
|
|
|
|
X
|
|
|
|
|
|
J
|
X
|
|
|
|
|
|
|
|
|
|
|
|
|
K
|
|
|
|
|
|
|
|
X
|
X
|
X
|
|
|
|
L
|
|
|
|
|
|
|
|
|
|
|
X
|
|
Ici nous précisons les rapports
d'antériorité en renseignant le tableau suivant la règle
Pour réaliser la tâche... Il faut avoir réalisé
la ou les tâche(s)...
SECTION II. CADRAGE DU PROJET
Cette section du cadrage du projet va nous servir de
réponse au formalisme opération QQQOCC.
II.1. CHOIX DE LA METHODE D'ORDONNANCEMENT
Il existe plusieurs méthode d'ordonnancement de projet,
mais notre recherche s'est focalisée sur les plus utilisées
telles que : Le diagramme de gantt, la méthode MPM (Méthode
des patentiels Metra), la méthode PERT (Program Evaluation and Research
Task ou Programm Evaluation and Review Technic).42(*)
En fait, nous avons opté pour la méthode PERT
afin d'élaboration notre planning prévisionnel.
II.2. PRESENTATION DE LA METHODE PERT
PERT (Programm Evaluation and Review Technic = Technique
d'Evaluation et d'Examen de Programme) est une méthode de gestion de
projet visant à prévoir les propriétés d'un projet
en terme de temps, délais et coûts.
L'obtention du planning par la méthode PERT suivie du
graphe de PERT donc de connaître à un moment donné
précis quelles sont les tâches en cours, les tâches à
venir.
Un graphe ou réseau est l'ensemble des tâches et
des étapes formant l'intégralité de la planification du
projet (on parle de diagramme PERT).43(*)
On peut ainsi suivre l'avancement des opérations et
déterminer si un retard a été pris, si celui-ci aura une
répercussion, et quel sera quantitativement cette répercussion.
On utilise aussi les périodes de marge afin de réduire les
coûts.44(*)
Le principe de la méthode PERT est de découper
le projet en un ensemble d'actions appelées tâches et de les
représenter sous forme graphique selon un graphe de
dépendances.
Ainsi, dans un graphe : L'arc représente la
tâche, les sommets représentent les étapes de la
réalisation des tâches, la valeur portée sur l'arc
représente la durée de la tâche.
II.3. CONTRAINTES DE REPRESENTATION GRAPHIQUE
Toute tâche a au moins une étape de début
et au moins une étape de la fin ; une tâche ne peut
démarrer que si la tâche qui la précède est
terminée. On ne peut pas avoir deux tâches différentes qui
ont à la fois même étape de début et même
étape de fin.
Deux étapes qui commencent en même temps et
s'exécutent en même temps sont dites simultanées, et sont
représentées chacune par une flèche dont le pour de
départ est une seule et même étape.
Deux tâches qui s'exécutent en même temps
et s'achèvent en même temps, sont dites convergentes et sont
représentées chacune par une flèche dont le point
d'arrivée est une seule et même étape. Toutefois, ce
principe peut aussi s'appliquer à plus de deux tâches
convergentes.
Lorsque deux tâches convergentes précèdent
une ou plusieurs tâches en commun, et que l'une de ces deux tâches
convergentes précèdes également une tâche (ou
plusieurs) que l'autre tâche convergente ne précède pas, il
est nécessaire d'avoir recours à une tâche fictive.
II.4. EVALUATION PROPREMENT DITE
TABLEAU III.2. LISTE DES
TACHES, LEURS DUREES ET LEURS COUTS
|
CODE
TACHE
|
LIBELLE
|
TACHES ANT.
|
DUREE
(Jours)
|
COÛT
(FC)
|
|
A
|
Analyse de l'existant
|
-
|
7
|
483.700,00 FC
|
|
B
|
Etude de faisabilité et critique
|
A
|
3
|
380.000,00 FC
|
|
C
|
Modélisation du système d'information
|
B
|
56
|
52.080.000,00 FC
|
|
D
|
Implémentation du projet
|
C
|
14
|
6.510.000,00 FC
|
|
E
|
Tests
|
E
|
7
|
3.255.000,00 FC
|
|
F
|
Implantation
- Installation des logiciels dans le serveur
|
E
|
2
|
7.812.000,00 FC
|
|
G
|
Implantation
- Installation des logiciels dans les machines
clientes
|
F
|
19
|
13.020.000,00 FC
|
|
H
|
Implantation
- Configuration des machines
|
F, G
|
7
|
5.208.000,00 FC
|
|
I
|
Test de fonctionnement
|
H
|
7
|
4.650.000,00 FC
|
|
J
|
Formation des utilisateurs
- Planification de la formation
|
A
|
4
|
3.255.000,00 FC
|
|
K
|
Formation des utilisateurs
- Elaboration du matériel didactique
|
H, I, J
|
3
|
1.395.000,00 FC
|
|
L
|
Formation des utilisateurs
- Formation proprement dite
|
K
|
14
|
9.300.000,00 FC
|
II.5. GRAPHE BRUT

Fig. III.1. Graphe Brut
II.8. CALCUL DES RANGS
Rn = 12
Ø Ø Rn - 12 = {1} = R0
Ø Rn - 11 = {2} = R1
Ø Rn - 10 = {3} = R2
Ø Rn - 9 = {4} = R3
Ø Rn - 8 = {5} = R4
Ø Rn - 7 = {6} = R5
Ø Rn - 6 = {7} = R6
Ø Rn - 5 = {8} = R7
Ø Rn - 4 = {9} = R8
Ø Rn - 3 = {10} = R9
Ø Rn - 2 = {11} = R10
Ø Rn - 1 = {12} = R11
II.9. GRAPHE ORDONNE

Fig. III.2. Graphe
ordonné
SECTION III. EXPLOITATION DU PROJET
3.1. CALCUL DES DATES AU PLUS TOT ET DATES AU PLUS TARD
a. DATES AU PLUS TOT (DTO)
Pour une étape donnée, cette information
détermine à quelle date minimum depuis le début du projet
sera atteinte, au plus tôt, l'étape considérée.
Pour ce faire, nous nous basons sur l'estimation de la
durée des tâches. Nous partons de l'étape de début,
pour laquelle la date au plus tôt est initiale à 0, et
nous parcourons le réseau en suivant l'agencement des tâches
déterminé auparavant et un ensemble de règles
définies à cet effet.
Formule :
ü Pour le cas d'une seule tâche :
c'est-à-dire qu'il n'a qu'un seul chemin possible pour atteindre
l'étape :
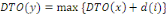
Formule II.1. Calcul de la
(DTO) pour une seule tâche
ü Pour le cas de plusieurs tâches :
c'est-à-dire qu'il y a plusieurs chemins possibles pour atteindre
l'étape :
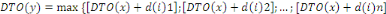
Formule II.2. Calcul de la
(DTO) pour plusieurs tâches
Calculs :
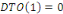
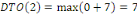
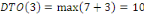
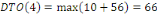
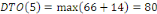
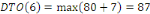
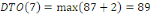
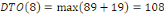
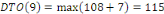
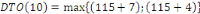
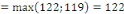
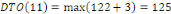
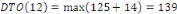
Représentation :

Fig. III.3. Graphe de la
DTO
Nous déterminons donc que notre projet pourra au mieux
être finalisé en l'espace de 139 jours ouvrés.
b. DATES AU PLUS TARD (DTA)
Nous poursuivons avec le calcul des dates au plus
tard. Pour une étape donnée, cette information
détermine à quelle date maximum, depuis le début du
projet, doit être atteinte, au plus tard, l'étape
considérée, afin que le délai de l'ensemble du projet ne
soit pas modifié.
Comme dans le cas précédent, nous nous basons
toujours sur l'estimation de la durée de tâches. Ainsi, nous
partons de l'étape de fin, pour laquelle la date au plus tard
est initialisée à la même valeur que la date au plus
tôt déterminée précédemment, et nous
parcourons le réseau en suivant l'agencement inverse des tâches
tenant toujours compte de règles qui sont régies par les
formules :
ü Pour le cas d'une seule tâche :
c'est-à-dire qu'il n'a qu'un seul chemin possible pour atteindre
l'étape :
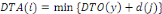
Formule II.3. Calcul de la
DTA pour le cas d'une seule tâche
ü Pour le cas de plusieurs tâches :
c'est-à-dire qu'il y a plusieurs chemins possibles pour atteindre
l'étape :
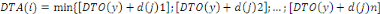
Formule II.4. Calcul de la
(DTO) pour le cas de plusieurs tâches
Calculs :
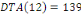
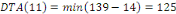
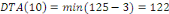
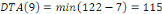
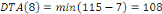
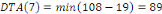
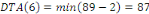
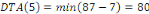
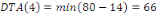
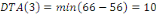
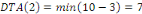
 Représentation : Représentation :

Fig. III.4. Graphe de la
DTO
A titre de vérification, nous devons
nécessairement trouver la valeur de 0 en tant que date au plus
tard de l'étape de début.
Pour terminer, nous regroupons les informations de dates
au plus tôt et au plus tard en un seul
schéma ; le réseau PERT enfin obtenu est donc :

Fig. III.5. Réseau
PERT avec les dates « au plus tôt » et « au
plus tard »
3.2. CALCUL DES MARGES
Certaines tâches bénéficient d'une latence
variable dans leur aboutissement sans pour autant remettre en cause la date
d'achèvement du projet ; c'est-à-dire le délai dont
on dispose pour la mise en route de la tâche i sans compromettre la date
au plutôt de l'étape y. Cette période de latence est
appelée « marge ».
L'évaluation quantitative de ces marges permet
d'optimiser la gestion du projet. En effet, l'analyse de ces marges permet
d'aménager le déroulement de certaines tâches selon des
critères autres que temporels : coût, plan de charge de
l'entreprise, goulets d'étranglement, ...
a. MARGE LIBRE (ML(i))
Le délai dont on dispose pour la mise en route de la
tache sans modifier la date au plus tard de l'étape y.
Formule :
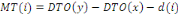
Formule II.5. Marge
libre
Calculs :
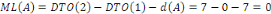
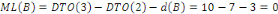
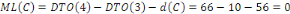
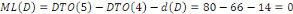
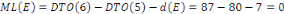
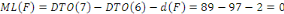
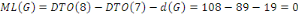
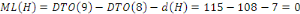
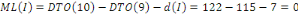
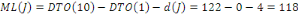
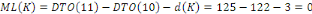
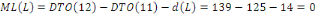
b. MARGE TOTALE (MT(i))
C'est le délai dont on dispose pour la mise en route de
la tache sans modifier la date au plus tard de l'étape y.
Formule :
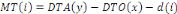
Formule II.6. Marge
totale
Calculs :
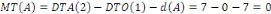
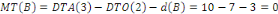
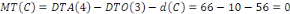
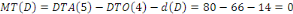
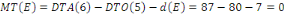
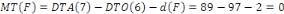
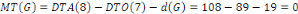
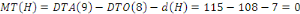
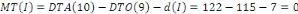
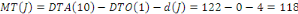
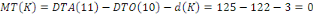
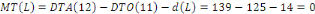
Après calcul et détermination des marges (libre
et totale), nous concluons que les tâches ayant une marge nulle ne
bénéficient donc d'aucune latence dans leur exécution leur
permettant de ne pas retarder le projet. Et c'est leur ensemble qui nous
permettra de déterminer le chemin critique.
c. DETERMINATION DU CHEMIN CRITIQUE
Le chemin critique indique quelles sont les tâches
à successivement observer au cours de la mise en oeuvre du projet afin
de surveiller les éventuels retards. Le but est de détecter les
dérives et d'agir alors rapidement en conséquence afin de
minimiser leur impact sur l durée de l'ensemble du projet.
Nous parlons du « chemin » car il
part de l'étape initiale et mène à l'étape finale
via une suite de différentes tâches.
Il est « critique » car tout
retard pris sur l'une des tâches constituant ce chemin aura une incidence
sur la date d'achèvement du projet ; celui-ci sera retardé
d'autant que la tâche est elle-même retardée. Pour savoir
quel est le chemin critique et donc aussi quelles tâches observer, il
suffit de répertorier toutes les tâches ayant une marge totale
nulle. La mise en avant de ces tâches détermine d'elle-même
le chemin critique :
A - B - C - D - E - F - G - H - I - K - L
d. TABLEAUX DES RESULTATS
TABLEAU III.3. RESULTATS
DE LA DTO ET LA DTA
|
TACHES
|
DUREE (Jrs)
|
|
DTO
|
DTA
|
|
1
|
0
|
139
|
|
2
|
7
|
125
|
|
3
|
10
|
122
|
|
4
|
66
|
115
|
|
5
|
80
|
108
|
|
6
|
87
|
89
|
|
7
|
89
|
87
|
|
8
|
108
|
80
|
|
9
|
115
|
66
|
|
10
|
122
|
10
|
|
11
|
125
|
7
|
|
12
|
139
|
0
|
TABLEAU III.4. RESULTAT
DES MARGES
|
TACHES
|
MARGE
|
OBSERVATION
|
|
ML
|
MT
|
|
A
|
0
|
0
|
Critique
|
|
B
|
0
|
0
|
Critique
|
|
C
|
0
|
0
|
Critique
|
|
D
|
0
|
0
|
Critique
|
|
E
|
0
|
0
|
Critique
|
|
F
|
0
|
0
|
Critique
|
|
G
|
0
|
0
|
Critique
|
|
H
|
0
|
0
|
Critique
|
|
I
|
0
|
0
|
Critique
|
|
J
|
118
|
118
|
Non Critique
|
|
K
|
0
|
0
|
Critique
|
|
L
|
0
|
0
|
Critique
|
e. PRESENTATION DES RESULTATS
Ø Durée globale du projet = 139
jours
Ø Cout total du projet :
CT = 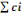  = 483.700,00 FC + 380.000,00 FC + 52.080.000,00 FC +
6.510.000,00 FC + 3.255.000,00 FC + 7.812.000,00 FC + 13.020.000,00 FC +
5.208.000,00 FC + 4.650.000,00 FC + 3.255.000,00 FC + 1.395.000,00 FC = 483.700,00 FC + 380.000,00 FC + 52.080.000,00 FC +
6.510.000,00 FC + 3.255.000,00 FC + 7.812.000,00 FC + 13.020.000,00 FC +
5.208.000,00 FC + 4.650.000,00 FC + 3.255.000,00 FC + 1.395.000,00 FC
= 107 348 700,00 FC
115 428,7097 USD
CONCLUSION PARTIELLE
L'évaluation de notre projet nous a permis de
déchiffrer sa durée et son coût tout en explicitant le
risque à courir au cas où nous ne suivions pas notre
schéma directeur. Ce qui est plus fort en est nous avons
renseigné notre connaissance vis-à-vis de notre cahier de charge
du point de vue recherche et édition du travail et du point de vue
conception et réalisation.
Dans le chapitre qui arrive, nous aurons à nous
étalé sur la modélisation proprement dite.
Chapitre Quatrième :
MODELISATION DE LA BASE DE DONNEES
INTRODUCTION
La modélisation consiste à traduire le besoin en
image fidèle du réel : le modèle. Et
l'implémentation consiste à fabriquer le produit, à partir
du modèle.45(*)
L'étape de modélisation permet d'appropriation
du réel par le maître d'oeuvre que nous sommes ; ce qui nous
pousse à subdiviser ce chapitre en deux sections qui nous faciliteront
à bien transformer l'abstrait au concret : la présentation
d'UML et la conception du nouveau système avec l'outil UML.
SECTION I. PRESENTATION DU LANGAGE UNIFIE DE MODELISATION
(UML)
I.1. LA CONCEPTION ORIENTEE OBJET (COO)
Le vocabulaire des langages orientés objet fait
constamment référence à cinq mots : objet,
classe,message, instance et méthode. Ces différents termes sont
définis en fonction les uns des autres.
Un objet est constitué de deux
parties, la première contient la valeur de l'objet (il s'agit le plus
souvent d'une zone mémoire) et la deuxième est formée par
l'ensemble des opérations que l'on peut appliquer à l'objet
(habituellement des programmes).
Une classe est constituée par les
objets qui ont le même jeu d'opérations mais des valeurs
différentes. On dit que ces objets forment chacun une instance
particulière de la classe.
Un message est envoyé à un
objet pour activer une opération portant sur une valeur. Le message
désigne l'objet, c'est-à-dire qu'il identifie à la fois la
valeur et l'opération demandée. Notons que le message ne
précise jamais la façon de réaliser l'opération
(ceci appartient à l'objet, ou plutôt, à sa classe).
Une méthode décrit la
façon de réaliser une opération. Les méthodes
appartiennent aux objets et ne sont jamais modifiables par les utilisateurs des
objets. L'utilisateur ne connaît la méthode que par son nom et ses
effets sur la valeur de l'objet. Toutes les instances d'une classe
répondent au même ensemble de méthodes.46(*)
La conception orientée objet est la méthode qui
conduit à des architectures logicielles fondées sur les objets du
système, plutôt que sur la fonction qu'il est censé
réaliser. Ainsi, l'architecture du système est dictée par
la structure du problème.47(*) Donc, l'approche objet rapproche les données
et leurs traitements. UML est un outil de modélisation par objets.
I.2. UNIFIED MODELING LANGAGE (UML)
(En français langage de modélisation
unifié) est un langage graphique de modélisation
des données et des traitements. C'est une formalisation très
aboutie et non-propriétaire de la modélisation objet
utilisée en génie logiciel.48(*)
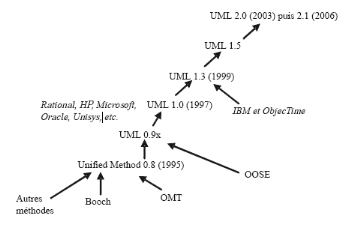
Fig. IV.1. Evolution
d'UML.49(*)
UML 2 est la deuxième version d'UML acceptée et
standardisée fin 2003. Nous allons nous en servir pour concevoir notre
BDR parce qu'il est en effet, depuis quelques années, le standard pour
la représentation graphique de la succession des phases, de l'analyse
à l'installation sur site, que comprend un projet informatique.Il
permet, au moyen de ses 13 diagrammes, de représenter le cahier des
charges du projet, les classes et la manière dont elles s'agencent entre
elles.
La description de la programmation par objets a fait ressortir
l'étendue du travail conceptuel nécessaire :
définition des classes, de leurs relations, des attributs et
méthodes, des interfaces, etc.50(*)
Afin d'accompagner le projet tout au long de sa vie, UML 2
permet finalement, d'organiser les fichiers qui constituent le projet, ainsi
que de penser leur stockage et leur exécution dans les processeurs.
a. LES OBJECTIFS D'UML
v Représenter des systèmes entiers ;
v Etablir un couplage explicite entre les concepts et les
artefacts exécutables ;
v Prendre en compte les facteurs d'échelle ;
v Créer un langage de modélisation utilisable
à la fois par les humains et les machines ;
v Recherche d'un langage commun, utilisable par toutes les
méthodes, adapté à toutes les phases du
développement, compatible avec toutes les techniques de
modélisation.51(*)
b. STRUCTURE D'UN SYSTEME MODELISE EN UML
UML 1.x définit neuf diagrammes : cinq pour les aspects
statiques (classes, objets, cas d'utilisation, composants et
déploiement) et quatre pour les aspects dynamiques (séquence,
collaboration, états-transition, activités), UML 2 ajoute ceux
d'interaction, de structure composite et le timing diagram.
Pour notre cas, nous ne nous intéresserons qu'à
celui (le diagramme) convenant à la conception d'une base de
données, à savoir le diagramme de classes, qui fait partie de
l'aspect statique d'UML.52(*) Il nous aidera à décrire les classes
que le système utilise, ainsi que leurs liens. Et nous le ferons
précéder par le diagramme de cas d'utilisation et celui de
séquence.
Le premier, c'est-à-dire le diagramme de cas
d'utilisation,va nous permettre de recueillir, d'analyser et d'organiser les
besoins, ainsi que recenser les grandes fonctionnalités du
système existant à la CENI. En fin, le second, va nous permettre
de décrire les interactions entre différentes entités
et/ou acteurs du système.
UML est le moyen graphique de garantir que « ce qui se
conçoit et se programme bien s'énonce clairement».53(*)
SECTION II. MODELISATION DE LA BASE DE DONNEE
Une idée centrale des BDD est de séparer la
description des données (effectuée par l'Administrateur) de la
manipulation (effectuée par les programmes d'application).54(*)
La description permet de spécifier les structures et
les types de données ou d'application, alors que la manipulation
consiste à effectuer des interrogations, des insertions et des mises
à jour.
Bien que la notation UML ait été proposée
tout d'abord pour la spécification d'applications, il n'en reste pas
moins que les concepts relatifs au diagramme de classes peuvent s'adapter
à la modélisation d'une base de données relationnelle ou
objet-relationnelle.
UML 2 reprend les concepts du modèle
entité-association et propose en plus des artifices pour
améliorer la sémantique d'un schéma conceptuel
(contraintes, classe-association, stéréotype...). De ce fait,
cette notation est très complète et puissante et peut s'adapter
parfaitement à la description statique d'une base de données.
Une notation étant une convention de
représentation graphique des concepts liés à un
formalisme,proposée par un ou plusieurs auteurs ; un formalisme
alors est l'ensemble de règles de représentation permettant de
formuler un modèle graphiquement. Il comporte un certain nombre de
concepts de base permettant d'exprimer un modèle.55(*)
II.1. DIAGRAMME CAS D'UTILISATION
Le rôle des diagrammes de cas d'utilisation est, comme
nous l'avions souligné, de permettre à recueillir, analyser et
organiser les besoins, et de recenser les grandes fonctionnalités d'un
système. Il s'agit donc de la première étape UML d'analyse
d'un système.
Un diagramme de cas d'utilisation capture le comportement d'un
système, d'un sous-système, d'une classe ou d'un composant tel
qu'un utilisateur extérieur le voit. Il scinde la fonctionnalité
du système en unités cohérentes, les cas d'utilisation,
ayant un sens pour les acteurs. Les cas d'utilisation permettent d'exprimer le
besoin des utilisateurs d'un système, ils sont donc une vision
orientée utilisateur de ce besoin au contraire d'une vision
informatique.
Pour élaborer les cas d'utilisation, il faut se fonder
sur des entretiens avec les utilisateurs.
II.1.1. ELEMENTS DU DIAGRAMME DES CAS D'UTILISATION
a) Acteurs
Dans notre cas, l'acteur principal est le candidat qui vient
se faire enrôler dans le Centre d'Identification (CI) de la CENI. Il est
l'élément déclencheur du processus.
C'est pourquoi nous définissons un acteur comme
étant l'idéalisation d'un rôle joué par une personne
externe, un processus ou une chose qui interagit avec un système.
Il se représente par un petit bonhomme avec son nom
inscrit dessous. Il est également possible de représenter un
acteur sous la forme d'un classeur stéréotypé
<< actor >>.
Pour être plus réaliste, nous avons
recensé pour notre problème les acteurs suivants :
- Candidat ;
- OPS (Opérateur De Saisie) ;
- DBA (DataBase Administrator : Administrateur de la
BD) ;
- BD Distante (Autres sites ou centre d'identification).
b) Cas d'utilisation
Un cas d'utilisation est une unité cohérente
représentant une fonctionnalité visible de l'extérieur. Il
réalise un service de bout en bout, avec un déclenchement, un
déroulement et une fin, pour l'acteur qui l'initie. Un cas d'utilisation
modélise donc un service rendu par le système, sans imposer le
mode de réalisation de ce service.
Un cas d'utilisation se représente par une ellipse
contenant le nom du cas (un verbe à l'infinitif), et optionnellement,
au-dessus du nom, un stéréotype.
II.1.2. RELATIONS DANS LES DIAGRAMMES DE CAS
D'UTILISATION
a) Relations entre Acteurs et Cas d'utilisation :
· Relation d'association ;
· Multiplicité ;
· Relation acteurs principaux et secondaires ;
· Cas d'utilisation interne ;
b) Relation entre les Cas d'utilisation :
· Types et représentations ;
· Relation d'inclusion ;
· Relation d'extension ;
· Relation de généralisation ;
c) Relation entre les Acteurs :
· La généralisation.
II.1.3. PRESENTATION DU DIAGRAMME DE CAS D'UTILISATION
Fig. IV.2. Diagramme de
Cas d'utilisation
II.1.4. DESCRIPTION DE SCENARIO
a) Définition :
Un scénario est une succession particulière
d'enchainement s'exécutant du début à la fin du cas
d'utilisation.
Un cas d'utilisation sera représenté
par :
- Un scénario nominal ;
- Plusieurs scénarios alternatifs (qui se terminent
normalement) ;
- Plusieurs scénarios d'erreurs (qui se terminent par
un échec).
b) Fiche :
La fiche de description textuelle d'un cas d'utilisation n'est
pas normalisée.
TABLEAU IV.1. FICHE DE
DESCRIPTION TEXTUELLE DES SCENARIOS
|
SOMMAIRE
|
Scénario Nominal « Enrôler en
réseau »
|
|
Description
|
1. Le DBA démarre le système
2. Le système affiche l'interface Administrateur
3. Le DBA s'authentifie (Login)
4. Le système vérifie les informations
5. L'OPS se connecte à l'interface Utilisateur
6. Le système affiche l'interface Utilisateur
7. L'OPS s'authentifie (Login)
8. Le système vérifie les informations
9. Le candidat fournit les informations
- Identité
- Empreinte
- Photo
- Adresse
- Origine
10. L'OPS saisit les informations
11. L'OPS lance la sauvegarde les données saisie dans
la BDD
12. Le système vérifie si les informations
existent déjà
13. Le système vérifie si la date de naissance
est éligible
14. L'OPS lance l'impression
15. Le système imprime la carte d'électeur
16. Le candidat retire la carte d'électeur
17. L'OPS vérifie la connectivité réseau
du système
18. Le système exécute la requête de
vérification
19. L'OPS lance la réplication
20. Le système réplique les données
21. Réplication effectuée
22. Le DBA lance le backup
|
|
SOMMAIRE
|
Scénario Alternatif « Démarrer
Système »
|
|
Description
|
S.A.1 : Saisie Login incorrect de 1 à 3 fois
S.A.1 : Démarre au point 4
5. Affichage du message d'erreur et précisant les
informations incorrectes
6. Retour au point 3
|
|
SOMMAIRE
|
Scénario Erreur « Démarrer
Système »
|
|
Description
|
S.E.1 : Saisie Login incorrect à la 4e
fois
S.E.1 : Démarre au point 4
5. Affichage du message d'erreur « Compte
Administrateur invalide »
6. Retour au point 3
|
|
SOMMAIRE
|
Scénario Alternatif « Se connecter au
Système »
|
|
Description
|
S.A.2 : Saisie Login incorrect de 1 à 3 fois
S.A.2 : Démarre au point 8
5. Affichage du message d'erreur et précisant les
informations incorrectes
6. Retour au point 6
|
|
SOMMAIRE
|
Scénario Erreur « Se connecter au
Système »
|
|
Description
|
S.E.2 : Saisie Login incorrect à la 4e
fois
S.E.2 : Démarre au point 8
5. Affichage du message d'erreur « Identifiant et/ou
Mot de passe invalide »
6. Retour au point 6
|
|
SOMMAIRE
|
Scénario Alternatif « Vérifier
informations saisies »
|
|
Description
|
S.A.3 : Lancement de la sauvegarde
S.A.3 : Démarre au point au point 12
13. Affichage du message d'erreur informant l'existence des
informations saisies
14. Retour au point 9
|
|
SOMMAIRE
|
Scénario Erreur « Vérifier
informations saisies »
|
|
Description
|
S.A.3 : Lancement de la sauvegarde
S.A.3 : Démarre au point au point 12
13. Affichage du message d'erreur « Information
existante, candidat déjà enrôlé. Suivant
svp ! »
14. Retour au point 9
|
|
SOMMAIRE
|
Scénario Alternatif « Vérifier
Eligibilité »
|
|
Description
|
S.A.4 : Lancement de la sauvegarde
S.A.4 : Démarre au point au point 13
14. Affichage du message d'erreur précisant l'information
erronée
15. Retour au point 9
|
|
SOMMAIRE
|
Scénario Erreur « Vérifier
Eligibilité »
|
|
Description
|
S.E.4 : Lancement de la sauvegarde
S.E.4 : Démarre au point au point 13
14. Affichage du message d'erreur « Candidat non
éligible, Suivant svp ! »
15. Retour au point 9
|
|
SOMMAIRE
|
Scénario Alternatif « Répliquer
données »
|
|
Description
|
S.A.5 : Lancement requête PING sur tout le
réseau
S.A.5 : Démarre au point 18
19. Echec de la transmission
20. Retour au point 17
|
|
SOMMAIRE
|
Scénario Erreur « Répliquer
données»
|
|
Description
|
S.E.5 : Lancement requête PING sur tout le
réseau
S.E.5 : Démarre au point 18
21. Echec de la transmission et affichage message d'erreur
« Système non connecté ! »
Retour au point 17
|
II.2. DIAGRAMME DE SEQUENCES
Les diagrammes de séquence sont couramment
utilisés par nombre d'acteurs d'un projet, même quelque fois
à leur insu, sans savoir qu'ils utilisent là un des diagrammes
UML.
En effet, le diagramme de séquence est une
représentation intuitive lorsque l'on souhaite concrétiser des
interactions entre deux entités. C'est à dire décrire les
interactions entre différentes entités et/ou acteurs du
système. Ces diagrammes permettent à l'architecte/designer de
créer au fur et à mesure sa solution.
II.2.1. DEFINITION DE CONCEPTS DU DIAGRAMME
Les principales informations contenues dans un diagramme de
séquence sont les messages échangés entre les lignes de
vie, présentés dans un ordre chronologique.
a) Ligne de vie :
Une ligne de vie se représente par un rectangle, auquel
est accrochée une ligne verticale pointillée ayant une
étiquette.
b) Le message :
Un message définie une communication
particulière entre des lignes de vie. Il existe de message d'envoi d'un
signal, d'invocation d'une opération, de création ou de
destruction d'une instance.
Nous distinguons : Les messages asynchrones et les
messages synchrones.
II.2.2. PRESENTATION DES DIAGRAMMES DE SEQUENCE
v Diagramme de séquence -
CANDIDAT :
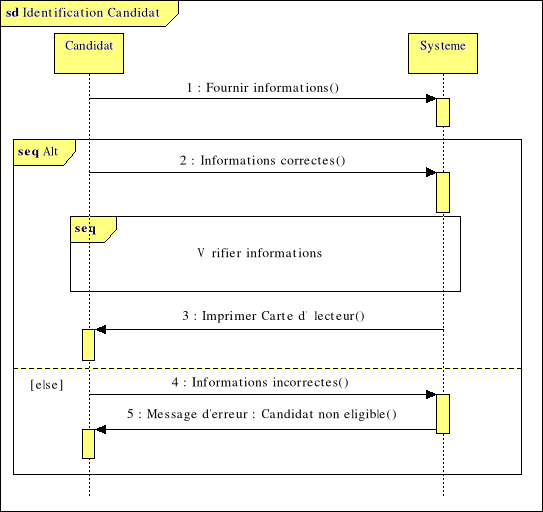
Fig. IV.3. Diagramme de
Séquence - Candidat
v Diagramme de séquences -
OPS :
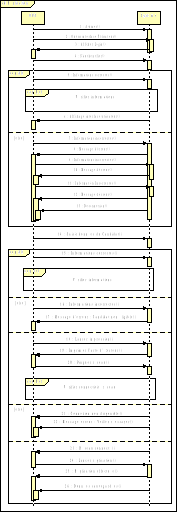
Fig. IV.4. Diagramme de
séquences - OPS
v Diagramme de séquences -
DBA :
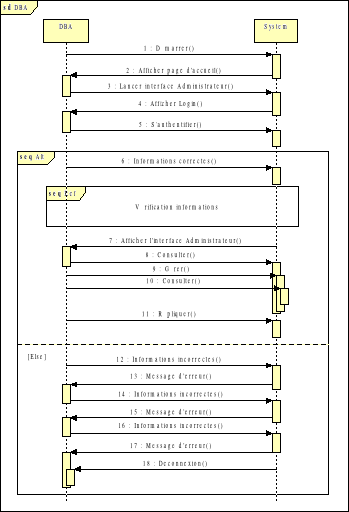
Fig. IV.5. Diagramme de
séquence - DBA
v Diagramme de séquences - BDD
DISTANTE :
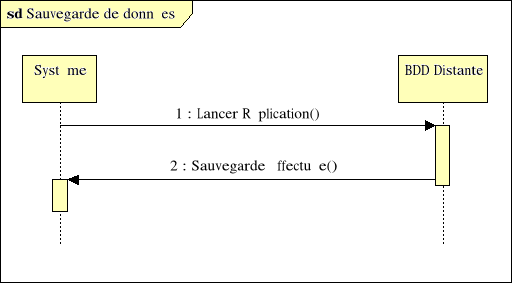
Fig. IV.6. Diagramme de
séquences - BDD Distante
v Diagramme de séquences :
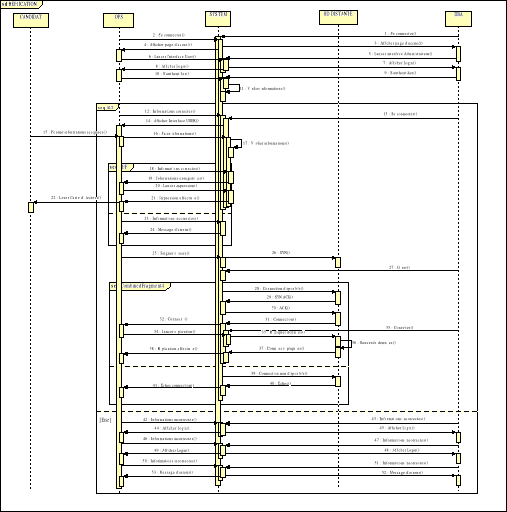
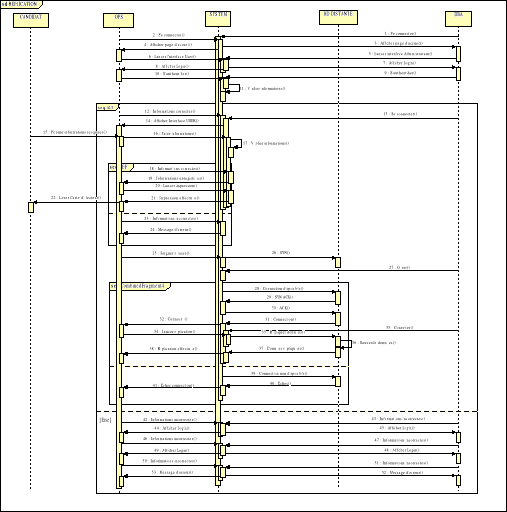
Fig. IV.7. Diagramme de
séquences
II.3. DIAGRAMME DE CLASSES
Le diagramme de classe représente l'architecture
conceptuelle du système : il décrit les classes que le
système utilise, ainsi que leurs liens, que ceux-ci représentent
un emboîtage conceptuel ou une relation organique.
Les opérations décrivent les
éléments individuels d'un comportement que l'on peut invoquer. Ce
sont les fonctions qui peuvent prendre des valeurs en entrée et modifier
les attributs ou produire des résultats. Les attributs, les terminaisons
d'association et les méthodes constituent donc les
caractéristiques d'une classe et de ses instances.
II.3.1. DESCRIPTION
v Définition des classes
Une classe a pour objectif de définir les
propriétés (attributs et opérations) d'un ensemble
d'objets qui pourront être créés et manipulés par
les programmes de l'application : de même, une association a pour
objectif de définir les propriétés d'un ensemble de liens
que l'on pourra établir entre les objets.
La définition des classes UML se divise en trois
compartiments contenant respectivement le nom de la classe, les attributs de la
classe et la signature des méthodes de la classe :
§ Attribut (attribute) : donnée
élémentaire servant à caractériser les classes et
les relations ;
§ Classe (class) : description abstraite d'un
ensemble d'objets de même structure et de même comportement
extraits du monde à modéliser.
§ Méthodes (methods) : opérations
programmées sur les objets d'une classe.56(*)
Bien qu'il n'était pas utile de disposer d'un
identifiant pour chaque classe avec UML, il faudra définir un (ou
plusieurs) attribut(s) assurant ce rôle dans le but de préparer le
passage à SQL. Et il faut disposer l'identifiant en tête des
attributs de la classe.
v Recensement des classes :
Classes recensées pour notre cas sont :
- Chef de Centre : CHEF_CENTRE ;
- Centre d'Identification : CENTRE ;
- Fiche d'Identification : FICHE ;
- Utilisateur : UTILISATEUR ;
- Candidat : CANDIDAT.
v Description des classes :
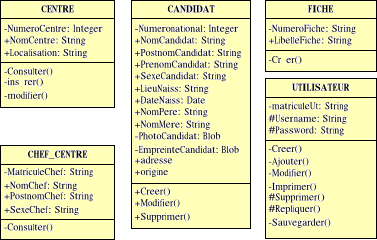
Fig. IV.7. Description des
classes de la BD
II.3.2. ASSOCIATION
A toute association, définie par un nom, correspond un
ensemble de classes, définies dans le diagramme de classes. Tout lien
étant une instance d'une association a pour nom, le nom de l'association
correspondant et relie un objet de chaque classe caractérisant
l'association.
Pour que les classes puissent communiquer entre elles dans un
formalisme au travers de leurs identifiants, il nous faut définir leur
association :
§ Association (Relationship) : l'association
permet de relier une classe à plusieurs autres classes.
§ Multiplicité (multiplicity) : chaque
extrémité d'une association porte une indication de
multiplicité. Elle exprime le nombre minimum et maximum d'objets d'une
classe qui peuvent être reliés à des objets d'une autre
classe.57(*)
La spécification UML 2 (Superstructure - version 2.0 -
formal/05-07-04)58(*)
indique qu'une association est représentée par une ligne
connectant deux classes (dans le contexte d'un diagramme de classes) ou une
classe avec elle-même. Il y est même conseillé de soigner la
présentation des segments de droites quand le lien n'est pas
rectiligne.
« A binary association is normally drawn as a solid
line connecting two classifiers, or a solid line connecting a single classifier
to itself (the two ends are distinct). A line may consist of one or more
connected segments. The individual segments of the line itself have no semantic
significance, but they may be graphically meaningful to a tool in dragging or
resizing an association symbol ».59(*)
Les tableaux IV.2 et IV.3 établissent un
parallèle entre les formalismes du modèle
entité-association de Merise et de la notation UML. Et nous permettent
de dissiper certaines difficultés y afférant.
TABLEAU IV.2.
TERMINOLOGIE
|
ENTITE-ASSOCIATION
|
UML
|
|
Entité
|
Classe
|
|
Association (Relation)
|
Association (Relation)
|
|
Occurrence
|
Objet
|
|
Cardinalité
|
Multiplicité
|
|
Modèle conceptuel de donnés (Merise)
|
Diagramme de classes
|
Associations un-à-un (one-to-one) : 0..1, 1
Associations un-à-plusieurs (one-to-many) : 0..*,
1..*, *
Associations plusieurs-à-plusieurs
(many-to-many) : N..N
II.3.4. GENERALISATION ET HERITAGE
La généralisation décrit une relation
(association) entre une classe générale et une classe
spécialisée. La classe spécialisée est
intégralement cohérente avec la classe de base, mais comporte des
informations supplémentaires (attributs, opérations,
associations).60(*)
Dans une relation de généralisation entre
classes, la super-classe est la classe parentet la sous-classe, la
classe enfant. Partout où une instance du parent est
utilisée, une instance de l'enfant est aussi utilisable (principe de
substitution).61(*)
De toutes les classes que nous utilisons ici, deux cas sont
enregistrés point ce point :
- Dans la classe CENTRE (super-classe) : une sous-classe
LOCALSATION ;
- Dans le classe UTILISATEUR (super-classe) : deux
sous-classes OPS et DBA.
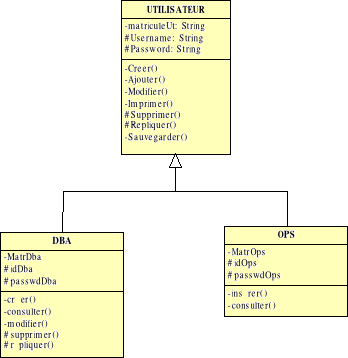
Fig. IV.10.
Généralisation et héritage
II.3.5. ENCAPSULATION
a) Définition :
Concept bien connu des développeurs objet, le principe
de l'encapsulation est d'autoriser l'accèsaux données uniquement
via les méthodes. Une autre édition consiste à
considérer la capacité del'objet à cacher ses
méthodes.62(*)
L'encapsulation permet :
ï D'augmenter le niveau d'abstraction de la classe ;
ï De protéger les objets des classes d'une
manipulation interdite de la part des clients de la classe ;
ï De protéger les clients vis-à-vis des
évolutions de la classe elle-même.
Les méthodes d'une classe représentent les
services de la classe en question. Une classe fournisseur propose des services
aux autres classes clientes. Au niveau d'une base de données, une
méthode peut être programmée par une fonction ou une
procédure cataloguée (pour les bases objet-relationnelles, ces
méthodes sont définies directement au niveau du type de la
table).63(*)
b) Visibilité des attributs et
méthodes :
Les règles de visibilité d'un attribut ou d'une
méthode viennent compléter ou préciser la notion
d'encapsulation. Ainsi, il est possible de préciser le degré de
protection au profit de classes utilisatrices bien particulières,
désignées implicitement dans la spécification de la classe
fournisseur.
UML définit trois niveaux de visibilité
pour les attributs et les méthodes (ces niveaux correspondent
à ce que propose le langage C++) :
ï public (symbole +) :
niveau le moins strict, qui rend l'élément visible à
toutes les autres classes ;
ï protégé (symbole
#) : niveau intermédiaire, qui rend
l'élément visible aux sous-classes de la classe fournisseur (aux
« classes amies », friend classes en C++) ;
ï privé (symbole -) :
niveau le plus strict, qui rend l'élément visible à la
classe fournisseur seule (aux classes amies en C++).64(*)
Ce qui est de notre cas, l'encapsulation et la
visibilité devront être programmées manuellement et
explicitement au niveau de la base (c'est là où se trouve le plus
grand fossé entre classes d'objets et enregistrements de la base). C'est
à dire par l'ajout de méthodes ou des procédures
cataloguées. Il faudra donc prévoir suffisamment de
méthodes d'insertion, de modification et de suppression d'objets de la
base, ainsi que les services à assurer [SOU 04].65(*)
II.3.6. PRESENTATION DU DIAGRAMME DE CLASSE
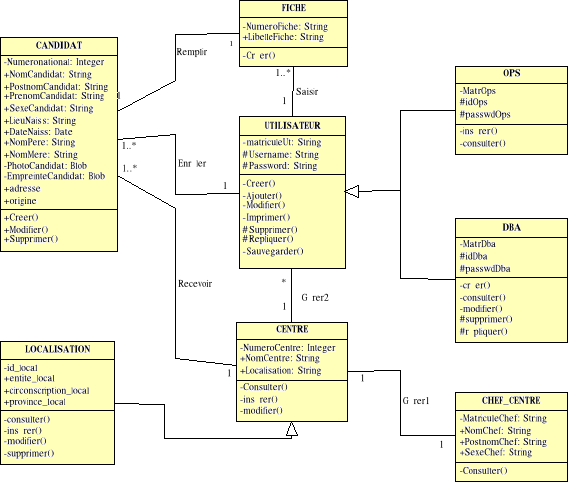
Fig.IV.11. Diagramme de
classe
CONCLUSION PARTIELLE
Ce chapitre nous a permis de concevoir pas à pas notre
projet suivant trois diagrammes dont, les deux premiers détaillent les
interactions relatives à l'application Java, et le dernier concerne la
conception de la base de données en question.
C'est ainsi que nous frayé un chemin nous menant en
profondeur de l'informatique. Les chapitres suivants permettront à
compléter les limites de celui-ci.
Chapitre Cinquième :
LA
REPARTITION DE DONNEES AVEC ORACLE
INTRODUCTION
Oracle, conçue pour les environnements de centres de
données qui évoluent rapidement et changent pour s'adapter aux
besoins de l'entreprise, la version Oracle Database 11g permet aux entreprises
d'adopter rapidement de nouvelles technologies, tout en limitant les risques.
De plus, forte de ses capacités d'autogestion, la version Oracle
Database 11g R2fait bénéficier de ses importantes
améliorations en termes de facilité de gestion et de diagnostic
des pannes.
Trois domaines continuent de poser de réels
problèmes de gestion aux administrateurs de bases de données :
· Les performances : comment faire pour que les
bases de données de production fournissent des performances maximales
afin de respecter les niveaux de service ?
· La gestion des modifications : comment
apporter des modifications (modifications de routine ou introduction
d'innovations technologiques) dans les environnements de bases de
données Oracle à moindre coût, tout en limitant les risques
?
· L'administration en continu : comment
automatiser les tâches quotidiennes répétitives pour que le
personnel en soit libéré et se concentre sur des besoins plus
stratégiques, tels que la sécurité et la haute
disponibilité ?66(*)
Pour résoudre ces problèmes, nous avons
pensé aux bases de données réparties. Surtout qu'Oracle
Database 11g présente d'importantes améliorations en termes de
performances, d'introduction des modifications et d'autogestion, de sorte que
les bases de données Oracle soient encore plus faciles à
gérer.
SECTION I. ORACLE : OBJETS & ARCHITECTURE
L'architecture oracle est constituée d'une instance et
d'une base de données. Une instance, désignée par SID
(Système Identification), est constituée :
§ D'une zone de mémoire partagée
appelée System Global Area (SGA) ;
§ D'un ensemble de processus d'arrière-plan ayant
chacun un rôle bien précis ;
§ D'un ensemble de processus serveur chargés de
traiter les requêtes des utilisateurs.
La base de données est l'ensemble des fichiers qui
permettent de gérer les données de la base. Elle est
constituée de :
§ Un fichier de contrôle, contenant les
informations sur tous les autres fichiers de la base (nom, emplacement,
taille) ;
§ Fichiers de Redo Log, contenant l'activité des
sessions connectées à la base. Ce sont des journaux de
transactions de la base. Ils sont organisés en groupe possédant
le même nombre de membres ;
§ D'un ou plusieurs fichiers de données qui
contiennent les données des tables de la base.67(*)
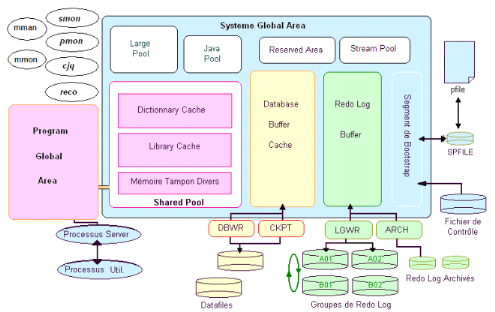
Fig. V.1. Architecture de
la BD Oracle
Chaque fois qu'une BD est lancée sur un serveur (ang.
Instance startup), une partie de la mémoire centrale dite SGA (System
Global Area) est allouée, et plusieurs processus d'arrière-plan
sont lancés. Une instance de BD est un ensemble de structures de
mémoire et de processus d'arrière-plan qui accèdent
à un ensemble de fichiers de données. Dans Parallel Server
plusieurs instances peuvent accéder à la même BD.
Les objets d'une base de données oracle sont :
· Gestion des données : table, index, view,
materialized view, snapshot,etc.;
· Stockage physique: cluster, tablespace, ... ;
· Stockage d'instructions : procedure, trigger,
... ;
· Gestion d'utilisateurs: profile, user, etc.
Nous allons les détailler au fur et à mesure que
nous évoluons, suivant leur utilisation.
I.1. STRUCTURES LOGIQUES DE LA BD
Dans la structure logique d'une base de données, nous
rencontrons quatre objets importants qui caractérisent une base de
donnéees : le tablespace, les segments, l'extent et le bloc de
données :
§ Tablespace
C'est une division logique d'une BD. Chaque BD possède
au moins un tablespace appelé SYSTEM.
Il s'agit donc des espaces de stockage attribué aux
utilisateurs de la base dans lesquels se trouveront leurs objets.68(*)
§ Segments :
Les segments sont des structures logiques de stockage des
données physiques de la base, ils sont assignés à des
tablespace. Il en existe quatre types :
- Les segments de données : Stockage des
données des tables et des clusters utilisateurs et
système ;
- Les segments d'index : Stockage des données
d'index séparément des données ;
- Les segments temporaires : Utilisés pour le
traitement des commandes SQL nécessitant un espace disque temporaire
(order by, group by, distinct, union, instersect ou minus ;
- Les segments de rollback : Enregistrement des actions
effectuées par les transactions.69(*)
§ Extent (extension) :
Unité logique d'allocation d'espace composée
d'un ensemble contiguë de blocs de données alloués
simultanément à un segment. Tout segment est initialement
créé avec au moins une extension appelée extension initial
(Initial Extent)
Lorsque l'espace d'un segment est complétement
utilisé, attribution par Oracle d'une nouvelle extension dite extension
supplémentaire.70(*)
§ Bloc de données:
Appelé également Bloc logique ou Page, un bloc
détermine le niveau de granularité le plus fin où les
données sont sauvées (c'est la plus petite unité logique
d'entrée/sortie utilisée par Oracle). Un bloc de données
correspond à un nombre spécifique d'octets d'espace BD physique
sur disque.
C'est ainsi que toute la gestion de l'espace disque des
fichiers de données d'une base Oracle repose sur ces trois derniers
concepts : de segment, d'extent et de bloc.
Bref, s'il nous faut représenter le lien entre les
trois, nous dirons qu'un ensemble de blocs contigus est nommé un extent
(ou extension). C'est un ensemble logique. Un ensemble d'extents compose un
segment. Le segment est un ensemble logique supérieur à
l'extent.71(*)
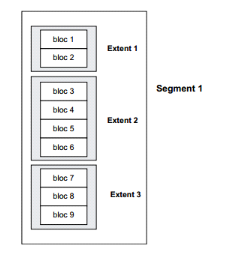
Fig. V.2. Segment, Extent
et Bloc de données.
I.2. STRUCTURES PHYSIQUES DE LA BD
La structure physique est composée d'un ensemble de
fichiers constituant le support physique de stockage des données et
concerne :
v Fichiers de données :
v Fichiers Redo-log:
v Fichiers de contrôle:
v Fichiers trace et journal d'alerte:
I.3. STRUCTURES DE MEMOIRE
Oracle respecte la norme ANSI/X3/SPARC représentant une
base de données en trois niveaux (externe, conceptuel, interne
respectivement les vues et la gestion des utilisateurs et de leurs droits
d'accès, la structure logique, la structure physique)
L'architecture interne d'Oracle est composée de
fichiers, de processus (programmes en cours d'exécution) et de
mémoire. Deux types de mémoire sont distincts :
a) PROGRAM GLOBAL AREA : PGA
Le processus serveur traite les requêtes du processus
utilisateur et retourne le statut et le résultat de cette
requête... Chaque processus serveur utilise une zone de mémoire
appelée la PGA.72(*) Mémoire privée des différents
processus distribuée au moment de la connexion d'un client. Pour un
processus serveur, la PGA contient :
v Une zone de tri (allouée dynamiquement lors d'un
tri) ;
v Des informations sur la session ;
v Des informations sur le traitement des requêtes de la
session ;
v Les variables de session ;
Dans une configuration multithreaded, une partie de la PGA est
en fait stockée dans la SGA (dans la Large Pool ou éventuellement
dans la Shared Pool).
b) SYSTEM GLOBAL AREA : SGA
L'ensemble des structures de mémoire permet
d'améliorer les performances de la BD en limitant le nombre
d'opérations d'E/Ss exécutées sur les fichiers de
données. La zone SGA, regroupe un ensemble de structures de
mémoire partagées qui contiennent les données et les
informations de contrôle concernant une instance Oracle. Lorsque
plusieurs utilisateurs sont connectés à la même instance,
les données de cette zone sont partagées entre eux.
v Le cache de tampons de blocs de données :
v Le tampon du journal de reprise :
v Le cache du dictionnaire :
v Le pool partagé :
I.4. PROCESSUS D'ARRIERE-PLAN
Il est important de distinguer les processus
d'arrière-plan (ang. background processes) des autres processus.
Ils sont indépendants de la connexion des utilisateurs.
Ils sont lancés au démarrage de l'instance et
arrêtés lors de l'arrêt de l'instance. Ils réalisent
des opérations sur l'instance et sur la base de données, comme
l'écriture des fichiers de données, la récupération
de la base de données ou la résolution des erreurs. Certains
processus aident à augmenter les performances globales du
système.
La relation entre les structures physiques et les structures
de mémoire est maintenue, et mise en oeuvre au moyen de processus
d'arrière-plan. Les principaux processus sont :
v Database Writer(DBWRn) ;
v Log Writer (LGWR) ;
v Checkpoint(CKPT) ;
v Process Monitor(PMON) ;
v System Monitor(SMON) ;
v Job Queue Coordinator (CJQ) ;
v Memory Manager(MMAN) ;
v Memory Monitor(MMON) ;
v USER.
I.5. DEROULEMENT DE TRAITEMENT D'UN ORDRE SQL
Lorsqu'un utilisateur lance une requête de mise à
jour sur la table quelconque, et que plusieurs tuples sont affectés par
la requête. La requête est passée au serveur par le
processus USER. Le serveur (exactement le query processor) vérifie si la
requête existe déjà dans le cache de bibliothèques.
Si non trouvée, elle est analysée, pour vérifier au cache
du dictionnaire les privilèges et les attributs etc..,
générer un plan d'exécution. La représentation
analysée et le plan d'exécution sont alors sauvés dans le
cache de bibliothèques.
Pour les objets affectés par ladite table, on
vérifie si les blocs de données sont dans le cache de tampons de
blocs de données (Database Buffer Cache). Si non trouvés, le
processus USER, les met dans le cache de tampons de blocs de données.
Avant que la mise à jour des tuples soit faite,
`l'image avant' des tuples est écrite sur les segments de rollback par
le processus DBWr. Pendant que le tampon redo-log est rempli durant la
modification des blocs de mise à jour, le processus LGWR écrit le
contenu du tampon redo-log dans les fichiers redo log.
Après la fin de mise à jour, l'utilisateur
valide la mise à jour par un commit. Tant qu'un commit n'a pas
été exécuté, les modifications peuvent être
annulées par un rollback. Dans ce cas, les blocs de données mis
à jour dans le tampon BD sont écrasés par les blocs
originaux sauvés dans les segments de rollback. Si l'utilisateur
exécute un commit, l'espace alloué pour les blocs dans les
segments de rollback est désalloué, et peut être
utilisé par d'autres transactions.
SECTION II. LA REPARTITION DE DONNEES
II.1. ORACLE EN RESEAU
a)
ORACLE NET SERVICE
Il fournit des solutions de connectivité dans des
environnements distribués. Il est composé de:
1. Oracle Net :
Initialement appelé SQL*Net, renommé Net8, et
maintenant connu sous le nom d'Oracle Net, est l'ensemble d'outils de
réseau d'Oracle qui peut être utilisé pour se connecter
à des bases de données distribuées.
Oracle Net facilite le partage de données entre
plusieurs bases, même si ces dernières sont
hébergées sur des serveurs différents qui exécutent
des systèmes d'exploitation et des protocoles de communication
différents. Il permet aussi la mise en oeuvre d'application trois tiers
; le serveur gère principalement les E/S de la base de données
tandis que l'application est hébergée sur un serveur
d'application intermédiaire et que les exigences de présentation
des données de l'application sont supportées par les
clients.73(*)
2. Modules d'écoute/listeners :
Le module d'écoute (LISTENER) prend en charge la
demande du client en la transmettant au serveur. Chaque fois qu'un client
demande une session réseau au serveur, un module d'écoute
reçoit la demande. Si les informations du client correspondent à
celles du module d'écoute, ce dernier autorise une connexion au serveur.
Le fichier de configuration LISTENER.ORA contient :
ü son nom, par défaut LISTENER
ü son adresse (HOST et PORT) : (ADDRESS= (PROTOCOL = TCP)
(HOST = localhost) (PORT = 1521)
ü les SIDs (Service ID) des BD guettées ;
3. Oracle Connection Manager ;
4. Outils de configuration et de gestion : Oracle Net
Configuration Assistant, Oracle Net Manager.
b)
TRANSPARENT NETWORK SUBSTRATE(TNS)
Est une sous-couche d'Oracle Net qui reçoit les
requêtes et émet des ouvertures ou fermetures de session, envoie
les requêtes et reçoit des réponses.
c)
COMMUNICATION ENTRE BASES DE DONNEES
Lorsque les hôtes qui supportent les bases de
données Oracle sont connectés via un réseau, les bases
peuvent communiquer via Net8 d'Oracle (précédemment appelé
SQL*Net). Les pilotes de Net8 s'appuient sur le protocole de communication
local pour fournir la connectivité entre deux serveurs.
Afin que Net8 reçoive et traite les communications,
l'hôte doit exécuter un processus appelé listener :
module d'écoute sur un port de communication spécifique.
d)
IDENTIFICATION DES OBJETS
Dans une BD centralisée, la combinaison du nom du
propriétaire d'un objet et du nom de l'objet permet de l'identifier de
façon unique. Dans les BDR deux couches d'identification sont
ajoutées. Le quadruplet [hôte, instance, schéma, objet]
forme un nom d'objet complet ou FQON.
Pour accéder à une table distante son
identifiant FQON doit être connu. La transparence d'emplacement cache
à l'utilisateur le triplet [hôte, instance, schéma].
II.2. LES LIENS DE BASES DE DONNEES
Pour interroger une BD distante, il faut créer un lien
de base de données. Un lien de base de données est un chemin
unidirectionnel d'un serveur à un autre. En effet, un client
connecté à une BD A, peut utiliser un lien stocké dans la
BD A pour accéder à la BD distante B, mais les utilisateurs
connectés à B ne peuvent pas utiliser le même lien pour
accéder aux données sur A.74(*)
Lorsqu'un lien est référencé par une
instruction SQL, Oracle ouvre une session dans la base distante et y
exécute l'instruction. La session demeure ouverte au cas où elle
serait de nouveau nécessaire.
En créant un lien de BD, on doit indiquer le nom du
compte auquel on se connecte, le mot de passe de ce compte, et le nom de
service associé à la base distante. En l'absence d'un nom de
compte, Oracle utilise le nom et le mot de passe du compte local pour la
connexion à la base distante.
II.3. TRANSPARENCE D'EMPLACEMENT
Comme nous l'avions déjà souligné dans le
premier chapitre, pour y arriver, il nous faut ainsi créer les objets
permettant à cacher la distribution des données aux utilisateurs.
C'est la notion de transparence. Mais nous allons d'abord nous focaliser
à la transparence d'emplacement en créant les vues, les synonymes
et les procédures stockées :
II.3.1. VUES
Une vue est une fenêtre sur une table.
Les vues correspondent à ce qu'on appelle le niveau
externe qui reflète la partie visible de la base de données pour
chaque utilisateur.75(*)
Les vues peuvent fournir une transparence par rapport aux tables locales et
distantes. Une vue peut porter sur plusieurs tables, éventuellement
distantes.
La mise à jour d'une vue est en fait la mise à
jour de la table 'A TRAVERS' la vue. Il n'y a pas de duplication de
données.
II.3.2. SYNONYMES
Un synonyme est un alias d'un objet (table, vue,
séquence, procédure, fonction ou paquetage). Les avantages
d'utiliser des synonymes sont les suivants :
- Simplifier l'accès aux objets en abrégeant les
noms de tables, par exemple, ou en regroupant dans un même alias les noms
du schéma et de l'objet, pour les objets qui ne vous appartiennent pas,
mais dont vous avez accès ;
- Masquer le vrai nom des objets ou la localisation des objets
distants (réunis par liens de base de données : database links)
;
- Améliorer la maintenance des applications dans la
mesure où la nature du synonyme peut être modifiée sans
mettre à jour tous les programmes qui l'utilisent (le synonyme garde le
même nom tout en référençant un nouvel
objet).76(*)
Les synonymes sont des noms simples qui permettent
d'identifier de façon unique dans un système distribué les
objets qu'ils nomment. Ils figurent dans le dictionnaire de données.
II.4. MISE AU POINT DES REQUETES DISTRIBUEES
Un serveur BD Oracle génère à partir
d'une requête distribuée, des requêtes distantes, qu'il
envoie aux noeuds distants pour exécution. Les noeuds exécutent
alors les requêtes et retournent les résultats au serveur local.
Un post-traitement est exécuté pour enfin retourner le
résultat à l'utilisateur ou à l'application.
Les stratégies décrites dans ce qui suit, sont
utilisées pour optimiser les requêtes.
I.5.1. COLLOCATED INLINE VIEWS
Le moyen le plus efficace d'optimiser une requête
consiste à réduire au maximum l'accès aux BDs distantes et
de ne rapatrier que les données requises. Pour ce, Oracle utilise des
«Collocated Inline Views», c'est à dire des vues de plusieurs
tables distantes et en ligne, afin de forcer les restrictions sur les sites
distants.
I.6. REPLICATION DES DONNEES
De toutes les étapes précédentes, nous ne
faisions que la préparation de l'environnement pour atterrir sur la
réplication proprement dite.
Afin de réduire la quantité de données
transmises sur le réseau, et améliorer par conséquent les
performances des requêtes, plusieurs options de réplication
peuvent être envisagées : la Commande Copy, le Snapshots et
les vues matérialisées.
I.6.1. COMMANDE COPY
Cette première option consiste à
répliquer régulièrement les données sur le serveur
local au moyen de la commande COPY de SQL*Plus.
I.6.2. SNAPSHOTS
Cette option utilise des snapshots pour répliquer les
données depuis une source maîtresse vers plusieurs cibles. Les
snapshots peuvent être en lecture seule (ang. read-only) ou mis à
jour (ang. Update able). Avant de créer un snapshot, il faut d'abord
créer un lien vers la base de données source.
Deux types de snapshots peuvent être crées :
simples et complexes. Un snapshot simple ne contient pas de clause distinct,
group by, connect by, de jointure multi-tables ou d'opérations set. Mais
l'autre en contient quand même.
I.6.3. VUES MATERIALISEES
Une vue matérialisée peut apporter plusieurs
avantages au niveau performances.
Selon la complexité de la requête, on peut la
remplir avec des changements incrémentiels, à l'aide du journal
de vues matérialisées (MATERIALIZED VIEW
LOG), au lieu de la recréer.
A l'inverse des snapshots, les vues
matérialisées peuvent être utilisées directement par
l'optimiseur, afin de modifier les chemins d'exécution des
requêtes. Pour ce, il faut disposer du privilège QUERY REWRITE
pour pouvoir réécrire la requête.
Une vue matérialisée crée une table
locale pour stocker les données, et une vue qui y accède.
Les vues matérialisées sont le moyen que nous
allons utiliser dans notre cas pour assurer la répartition de notre
base.
SECTION III. ECRITURE RELATIONNELLE DE LA REPARTITION
DESCENDANTE
L'algèbre relationnelle est un ensemble
d'opérateurs qui, à partir d'une ou deux relations existantes,
créent en résultat une nouvelle relation temporaire,
c'est-à-dire qui a une durée de vie limitée
(généralement la relation est détruite à la fin du
programme utilisateur ou de la transaction qui l'a créée). La
relation résultat a exactement les mêmes caractéristiques
qu'une relation de la base de données et peut donc être
manipulée de nouveau par les opérateurs de l'algèbre.
Formellement, l'algèbre comprend cinq opérateurs
(sélection, projection, union, différence et produit) de base et
un opérateur syntaxique (renommer). Ces opérateurs peuvent
être regroupés en deux classes :
§ Les opérateurs provenant de la théorie
mathématique sur les ensembles (applicables car chaque relation est
définie comme un ensemble de tuples) : union, intersection,
différence, produit;
§ Les opérateurs définis
spécialement pour les bases de données relationnelles :
sélection, projection, jointure, division et renommage.
Nous avons utilisé cette notion pour enfin
démontrer comment sommes-nous parti du général au local.
Ce qui étale la technique de conception utilisée qui est
descendante : top down design.
III.1. SCHEMA GLOBAL DE LA BASE DE DONNEES
Le schéma global est
Notre modèle global de la base se présente comme
ça :
- LOCALISATION (id_local, entite_local,
circonscription_local, province_local)
- CENTRE (num_centre, id_local, nom_centre)
- CHEF_CENTRE (matr_chef, num_centre, nom_chef,
postnom_chef, prenom_chef)
- CANDIDAT (NN, nom_cand, postnom_cand, prenom_cand,
sexe_cand, lieu_naiss, date_naiss, père_cand, mere_cand, adresse_cand,
origine_cand, date_enrol, num_centre)
- FICHE (num_fiche, NN, libelle_fiche)
- UTILISATEUR (matr_user, NN, num_centre, num_fiche,
username, password)
La gestion de la base s'appuie sur les hypothèses
suivantes :
· Un candidat remplit une et une seule fiche ;
· Un utilisateur saisit un ou plusieurs fiches par
jour ;
· Un utilisateur enrôle un ou plusieurs
candidat ;
· Le chef de centre gère un et un seul
centre ;
· Un centre gère plusieurs utilisateurs.
III.2. SCHEMA DE REPARTITION OU D'ALLOCATION
Cette opération consiste à fragmenter la base en
sous-bases. Nous allons faire la fragmentation avec trois classes
dont :
Ø Candidat ;
Ø Centre ;
Ø Chef_centre ;
Ø Localisation.
Pour mieux assurer la tâche échéante,
illustrons quelques occurrences pour chaque classe :
CLASSE LOCALISATION :
|
id_local
|
entite_local
|
circonscription_local
|
province_local
|
|
A450/C
|
KALAMU
|
KINSHASA
|
KINSHASA
|
|
A300/C
|
KALAMU
|
KINSHASA
|
KINSHASA
|
|
B601/C
|
LINGWALA
|
KINSHASA
|
KINSHASA
|
|
J005/C
|
LUBUMBASHI
|
LUBUMBASHI
|
KATANGA
|
|
J238/C
|
KISANGA
|
LUBUMBASHI
|
KATANGA
|
|
H992/C
|
KABONDO
|
KABINDA
|
LOMAMI
|
|
O793/C
|
DIULU
|
MBUJIMAYI
|
KASAI-ORIENTAL
|
CLASSE CENTRE :
|
num_centre
|
id_local
|
nom_centre
|
|
1
|
A300/C
|
CS NGEMBA
|
|
2
|
H992/C
|
LYCEE YAKANYAMA
|
|
3
|
J238/C
|
INSTITUT MADINI
|
|
5
|
O793/C
|
INSTITUT MASANKA
|
CLASSE CHEF_CENTRE :
|
matr_chef
|
num_centre
|
nom_chef
|
postnom_chef
|
prenom_chef
|
|
12342
|
3
|
MASIA
|
MANGALA
|
Jhaunel
|
|
32123
|
2
|
MUKONKO
|
LOLO
|
Eric
|
CLASSE CANDIDAT :
|
NN
|
nom_cand
|
postnom_cand
|
prenom_cand
|
sexe_cand
|
lieu_naiss
|
date_naiss
|
père_cand
|
mere_cand
|
adresse_cand
|
origine_cand
|
num_centre
|
|
93
|
MULANGA
|
KAJIJI
|
JUDITH
|
F
|
KABINDA
|
14/10/1996
|
MULIAS
|
NKONKO
|
01 AV. MUD
|
TUMBUE
|
2
|
|
20
|
LUBIKA
|
NTAMBUE
|
MARCEL
|
M
|
FIZI
|
20/08/1989
|
LUBIKA
|
MASOLA
|
991 AV. KAS
|
FIZI
|
3
|
|
21
|
KALONDA
|
KALONDA
|
HORTENSE
|
F
|
KISANGANI
|
24/04/1995
|
KALONDA
|
EBONDO
|
A61 AV. LOM
|
L'SHI
|
3
|
JOINTURE DES CLASSES
Pour arriver à répartir les données, nous
allons nous fier aux données trop utilisables en segmentant les classes
puis le reliant à partir de leur identifiants par une écriture
relationnelle. Nous allons utiliser la jointure relationnelle.
Cette forme est la plus utilisée car elle est la plus
simple à écrire. Un autre avantage de ce type de jointure est
qu'elle laisse le soin au SGBD d'établir la meilleure stratégie
d'accès (choix du premier index à utiliser, puis du
deuxième, etc.) pour optimiser les performances.
Comme nous avons quatre classes, nous aurons 4-1, donc 3
jointures à réaliser. Le type de jointure utilisé dans
notre projet est l'équijointure (equi join). C'est la plus
connue, elle utilise l'opérateur d'égalité dans la clause
de jointure. La jointure naturelle est conditionnée en plus par le nom
des colonnes. La non équijointure utilise l'opérateur
d'inégalité dans la clause de jointure.
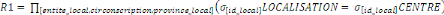
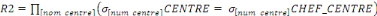
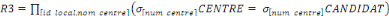
Formule V.1. Jointure des
classes
REPARTITION DES VALEURS AVEC FRAGMENTATION HYBRIDE :
L'algorithme de semi-jointure se présente comme
suit :
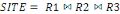
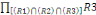
Formule V.2. Fragmentation
hybride
III.3. SCHEMA DE DUPLICATION OU DE REPLICATION
Ce schéma permet de copier sur la base du site les
données de tout le système afin d'assurer la continuité du
travail lorsque la connexion en le site et le serveur ne sera pas
disponible.
III.4. SCHEMA INTERNE LOCAL
Les schémas locaux ne représenteront que les
tables avec ayant trait à la répartition. La vue
extérieure de l'utilisateur sera la table CANDIDAT. Et un candidat du
site YAKANYAMA sera distingué de celui du site MADINI, par le
numéro du centre, ainsi que la localisation de celui-ci. Nous allons
créer 2 sites pour l'instant : le site1 - YAKANYAMA, et le site2 -
MADINI.
v SITE1 - YAKANYAMA
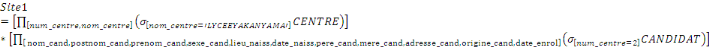
Formule V.3. Allocation du
site YAKANYAMA
v SITE2 - MADINI
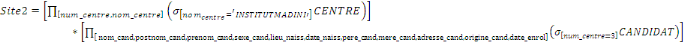
Formule V.4. Allocation du
site MADINI
CONCLUSION PARTIELLE
Ce chapitre nous a permis la répartition du
système de la CENI, par toutes les techniques appropriées. Nous
avons commencé par présenter Oracle, notre SGBD utilisé.
Ensuite, nous avons touché à la répartition de
données avec Oracle. Et en fin, nous avons démontré
comment se déroule la répartition par l'écriture
relationnelle.
Ainsi, nous avons clôt le présent chapitre.
Toutes les théories annoncées ici, vont nous permettre à
comprendre le chapitre qui suit, par la concrétisation du concept.
Chapitre Sixième :
IMPLEMENETATION
INTRODUCTION
Après modélisation et répartition, vient
en fin l'implémentation de notre base de données, qui ne consiste
à rien d'autre que la présentation des étapes de
réalisation de celle-ci et deson application.
Pour y arriver, nous avons subdivisé ce fait en
plusieurs sous points dont, la numérotation va distinguer les uns des
autres.
L'implémentation commence d'abord par le choix du
logiciel (d'outils de développement) et le choix du matériel
(moyens et supports de traitement) :
§ Outils de traitements :
· Système d'exploitation : Microsoft Windows
7 Professional 32 bits ;
· Système de gestion de base de
données : Oracle 11g R2 ;
· Langage de programmation : Java NetBeans ;
· Logiciel de connectivité : JDBC6_g (Java
Database Connectivity).
§ Matériel :
· Ordinateur.
Et effet, le choix du matériel, très
dépendant des caractéristiques et exigences du logiciel, nous
l'avons effectué comme suit :
a. Ordinateur Server :
1. Marque PC : 1 Laptop Toshiba CQ40 Notebook PC et 1
autre Laptop (coordonnées) ;
2. Nom du PC : JUCKA ;
3. Nom Utilisateur : Jules
4. Ecran : 17'' ;
5. Clavier : AZERTY Pavé alphanumérique +
pavé numériquet ;
6. Disque dur : 250 Go ;
7. Ram : 4 Go ;
8. Processeur : Pentium (R) Dual-core PCU T4300 @
2.10Ghz (2PCUs) ~ 2.1Ghz 32bits.
b) Ordinateur Site1 :
1. Marque PC : Laptop HP - Mini 210-2000 ;
2. Nom du PC : MARCELLINE ;
3. Nom Utilisateur : Mymy
4. Ecran : 15'' ;
5. Clavier : AZERTY Pavé alphanumérique
seulement ;
6. Disque dur : 250 Go ;
7. Ram : 2 Go ;
8. Processeur : Intel ® Atom ™ CPU N455 @
1.66Ghz (2CPU), 1.7GHz
c) Ordinateur Site2 :
9. Marque PC : Laptop TOSHIBA ;
10. Nom du PC : JEANBAPTISTE ;
11. Nom Utilisateur : NGOIE
12. Ecran : 17'' ;
13. Clavier : AZERTY Pavé alphanumérique +
pavé numérique ;
14. Disque dur : 1To ;
15. Ram : 8 Go ;
16. Processeur : Intel ® Core ™ i5-3230M CPU @
2.60Ghz (4CPU), 2.6GHz
SECTION I.PRESENTATION DESCRIPTION DES OUTILS DE
DEVELOPPEMENT
I.1. ORACLE
Software
Development Laboratories a été créé en
1977. En
1979, SDL change de nom en
devenant
Relational
Software Inc. (RSI) et introduit son produit Oracle V2 comme
base
de données relationnelle. La version 2 ne supportait pas les
transactions mais
implémentait les fonctionnalités
SQL basiques
de
requête et
jointure. Il n'y a jamais
eu de version 1, pour des raisons de
marketing, la
première version a été la version 2. Celle-ci fonctionnait
uniquement sur les systèmes
Digital
VAX/
VMS.
Oracle 11g R2 est un puissant Système de Gestion de
Bases de Données Relationnelles proposant, en plus du moteur de la base,
de nombreux outils à l'utilisateur, au développeur et à
l'administrateur. Ces outils ont un langage commun : le SQL.
Le SQL est un langage de requêtes descriptif, standard
pour toutes les bases de données qui suivent le modèle
relationnel. Ce langage permet toutes les opérations sur les
données dans tous les cas d'utilisation de la base.
I.2. NETBEANS IDE (Integrated Development Environment)
NetBeans a vu le jour en tant que projet d'étudiant en
République Tchèque (appelé à l'origine Xelfi), en
1996. Le but était d'écrire un EDI Java semblable à
Delphi, mais en Java. Une compagnie fut créée autour de ce
projet, nommé NetBeans. Il y a eu deux versions commerciales de
NetBeans, appelées Developer 2.0 et Developer 2.1. Aux alentours de mai
1999, NetBeans sorti une version béta de ce qui aurait dû
être Developer 3.0. Quelques mois plus tard, en octobre 1999, NetBeans
fut racheté par Sun Microsystems. Après quelques temps de
développement supplémentaires, Sun sortit l'EDI Forté Fro
Java, Edition Communauté - le même EDI qui avait été
en béta comme NetBeans Developer 3.0. En juin 2000, Sun mis l'EDI
NetBeans en open-source.
NetBeans est un projet open source fondé par Sun
Microsystems. L'IDE NetBeans est un environnement de développement
intégré permettant d'écrire, compiler, déboguer et
déployer des programmes. Il propose ou englobe beaucoup d'applications
de programmation, aussi complexes qu'elles soient. Il est écrit en Java,
mais peut supporter n'importe quel langage de programmation. Il y a
également un grand nombre de modules pour étendre l'IDE NetBeans.
L'IDE NetBeans est un produit gratuit, sans aucune restriction quant à
son usage.
La version que nous utiliserons ici c'est la dernière
version Netbeans IDE 8.0.2.
I.3. JAVA
Le langage Java est un
langage de
programmation
informatique
orienté
objet créé par
JAMES
GOSLING et
PATRICK NAUGHTON,
employés de
Sun Microsystems,
avec le soutien de
Bill Joy (cofondateur
de
Sun
Microsystems en
1982), présenté
officiellement le
23
mai
1995 au SunWorld.
La société Sun a été ensuite
rachetée en 2009 par la société
Oracle qui
détient et maintient désormais
Java.
La particularité et l'objectif central de Java est que
les logiciels écrits dans ce langage doivent être très
facilement
portables sur
plusieurs
systèmes
d'exploitation tels qu'
UNIX,
Windows,
Mac OS ou
GNU/Linux, avec peu ou
pas de modifications. Pour cela, divers
plateformes et
frameworks associés
visent à guider, sinon garantir, cette portabilité des
applications développées
en Java.
Le langage java que nous avons utilisé fait partie
intègre de Netbeans : Java Netbeans. Il est un langage Objet
permettant le développement d'applications complètes s'appuyant
sur les structures de données classiques (tableaux, fichier) et
utilisant abondamment l'allocation dynamique de mémoire pour
créer des objets en mémoire. La notion de structure, ensemble de
données décrivant une entité (un objet en Java), est
remplacée par la notion de classe au sens de la programmation Objet. Le
langage Java permet également la définition d'interfaces
graphiques (GUI : Graphical User Interface) facilitant le développement
d'application interactives et permettant à l'utilisateur de piloter son
programme dans un ordre non imposé par le logiciel.
I.4. JDBC (Java DataBase Connectivity)
C'est le middle ware permettant de relier les systèmes
de gestion de base de données à IDE Netbeans.
5.2. CREATION DES BASES DE DONNEES
Au prime abord, nous avons précédé par
installer le SGBD Oracle dans les machines échantillon, trois au
total : une machine Server au site Central de CENI/Gombe, deux machines
représentant deux sites différents (YAKANYAMA et MADINI). Ces
bases, nous les avons créées pendant l'installation du SGBD. Et
nous les avons nommées comme suit : ENROLEMENT pour le Server
Central et ENR pour les sites.
En effet, cette opération nous a valu trois
machines :
1. Création de la Base de données ENROLEMENT
dans la machine Server site/Gombe ;
2. Création de la Base de données ENR dans la
machine cliente du Site1 - YAKANYAMA. Entité : KABONDO, BL :
KABINDA, Province : LOMAMI ;
3. Création de la Base de données ENR dans la
machine cliente du Site2 - MADINI. Entité : KISANGA, BL :
LUBUMBASHI, Province : KATANGA.
SECTION II. IMPLEMENTATION DE LA BASE DE DONNEES REPATIES

Fig. VI.1. Structure
générale du nouveau system réparti.
II.1. CONFIGURATION DE LA CONNEXION RESEAU ENTRE LE SERVER ET
LES SITES
Entre deux machines, nous avons configuré un
réseau point à point dont :
· Nom du groupe de travail : JucHor ;
· Adresse IP server : 192.168.10.10
(Statique) ;
· Adresse IP Site1 : 192.168.10.11
(Statique) ;
· Adresse IP Site1 : 192.168.10.12 (Statique).
II.2. CONFIGURATION NET MANAGER
a)
SITES : listener
Editer le fichier :
D:\app\Marcelline\product\11.2.0\dbhome_1\NETWORK\ADMIN\Listener.ora
ECOUTEUR =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = Marcelline-PC)(PORT =
1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.10.11)(PORT =
1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))
)
)
ADR_BASE_ECOUTEUR = D:\app\Marcelline
SID_LIST_ECOUTEUR =
(SID_LIST =
(SID_DESC =
(SID_NAME = CLRExtProc)
(ORACLE_HOME =
D:\app\Marcelline\product\11.2.0\dbhome_1)
(PROGRAM = extproc)
(ENVS =
"EXTPROC_DLLS=ONLY:D:\app\Marcelline\product\11.2.0\dbhome_1\bin\oraclr11.dll")
)
(SID_DESC =
(SID_NAME = ENR)
(ORACLE_HOME =
D:\app\Marcelline\product\11.2.0\dbhome_1)
)
)
b)
SERVER : service_name
Editer le fichier :
C:\app\Jules\product\11.2.0\dbhome_1\NETWORK\ADMIN\tnsname.ora
ENROLEMENT =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT =
1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = enrolement)
)
)
ORACLR_CONNECTION_DATA =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))
)
(CONNECT_DATA =
(SID = CLRExtProc)
(PRESENTATION = RO)
)
)
SITE_YAKANYAMA =
(DESCRIPTION =
(ADRESS = (PROTOCOL = TFC) (HOST = 192.168.10.11) (PORT =
1521))
(CONNECT_DATA =
(SID = orcl)
)
)
II.3. CREATION DES UTILISATEURS ET DE TABLES
a)
CREATION DES ROLES
Nous avons créé deux rôles dont un pour
les utilisateurs OPS, `OPERATEUR' et l'autre pour les Administrateurs de
BL/CENI nommé ADMINISTRATEUR. Nous allons les affecter respectivement
à OPS et DBA_BL pour raisons sécuritaires.
· Rôle pour Utilisateurs :


Fig. VI.2. Rôle
Utilisateurs
· Rôle pour Administrateurs CENI :



Fig. VI.3. Rôle
Administrateur CENI.
b)
CREATION DES UTILISATEURS
Pour assurer une grande sécurité de notre
système, nous avons à utiliser deux types d'Utilisateurs. Ces
utilisateurs se limitent au niveau de notre application de base de
données. Ils sont identifiés par un username et un
password. Ils ont les droits et permissions pour gère
l'utilisation de la base et limiter les dégâts.
· Création de l'espace de travail de la Base de
données sur le server :

Fig. VI.4. Tablespace
· Création des utilisateurs :

L'utilisateur OPS n'a le droit que d'insérer et de
sélectionner les données dans la vue
matérialisée
Fig.VI.5. Utilisateurs
· Attribution des rôles :
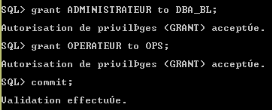
Fig. VI.6. Attribution des
Rôles aux utilisateurs
c)
CREATION DES TABLES
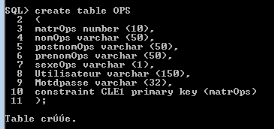
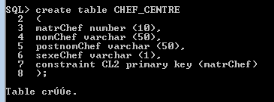
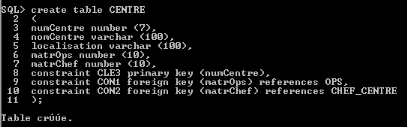
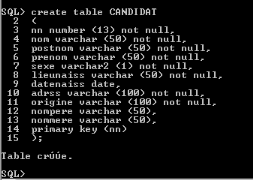
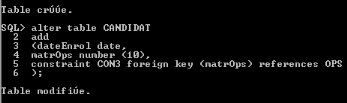
Fig. VI.7. Tables
II.4. CREATION DES LIENS ET SYNONYMES SUR SITES


Fig. VI.8. Liens et
synonymes
II.5. CREATION DES VUES MATERIALISEES SUR SERVER





Fig. VI.9. Vues
matérialisées et synonymes
SECTION III. DEVELOPPEMENT DE L'APPLICATION ET PRESENTATION
DE L'APPLICATION
III.1. DEVELOPPEMENT DE L'APPLICATION
a)
METHODES DE CONNEXION DE NETBEANS VERS ORACLE 11g R2
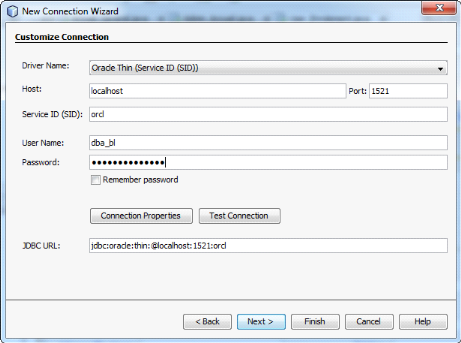
Fig. VI.10. Connexion
Netbeans-Oracle
III.2. PRESENTATION DE L'APPLICATION
a)
STRUCTURE GENERALE
Quand l'utilisateur lance l'application, la page d'accueil
s'affiche lui présentant trois boutons menus :
§ Centre d'identification : pour l'OPS qui effectue
l'enrôlement ;
§ Administration : menu concernant l'administrateur
de la CENI ;
§ Quitter : pour fermer l'application.

Fig. VI.11. Page d'accueil
application
Après avoir choisi son menu, une boite de dialogue
s'affichera lui demandant de s'authentifier. C'est là qu'il va utiliser
son identifiant et son mot de passe :
Fig. VI.12. Page d'accueil
application
b) LES INTERFACES UTILISATEURS : OPS
Si les coordonnées de l'utilisateur ne sont pas vraies,
un message d'erreur s'affiche lui notifiant de l'erreur ; ce, à
trois reprises. A la troisième fois, le programme se ferme. Dès
que les informations introduites sont correctes, la fenêtre
d'enrôlement s'affiche comme suit :
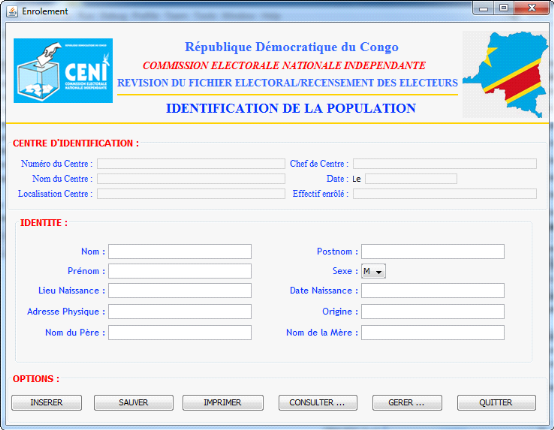
Fig. VI.13. Interface
Utilisateur - Saisie
c) LES INTERFACES ADMINISTRATEURS CENI : DBA_BL
A la page d'accueil, dès que c'est le deuxième
menu choisi : « Administration », et que
l'utilisateur s'authentifie, la page d'accueil-administrateur s'affiche avec
trois sous-menus :
§ Gestion de la base de données : pour
gérer les données recensées dans des centres
d'inscription ;
§ Gestion centre d'inscription : consiste à
gérer les données par centre ;
§ Gestions des utilisateurs : pour créer,
modifier ou supprimer un utilisateur, définir ses droits et permissions
sur les données et sur les objets.
C'est ainsi que la page en question se présente comme
suit :

Fig. VI.14. Sous menu
d'administration
Enfin, au premier sous menu, gestion de la base de
données donc, nous aurons une fenêtre semblable à
ceci :
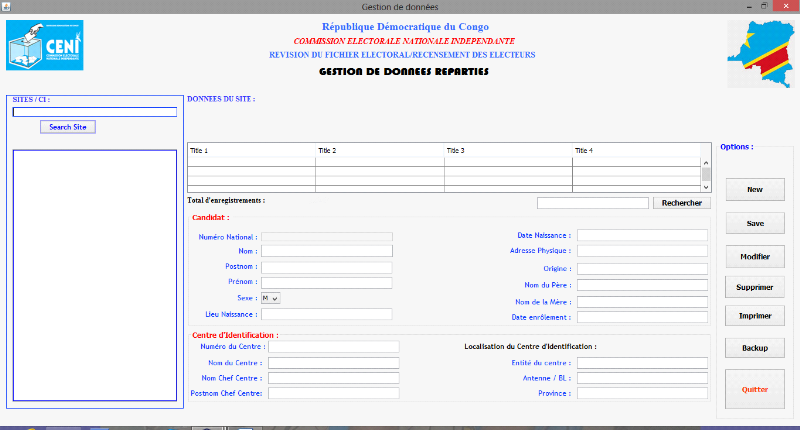
Fig. VI.15. Interface
Administrateur
CONCLUSION PARTIELLE
Nous avons en fin réalisé, notre projet,
après toutes les démarches scientifiques nous imposées. Ce
chapitre referme toutes les étapes parcourues pour la mise en place de
notre travail. Il nous a permis d'exhiber les preuves de la fin dudit travail
par la présentation des interfaces de toutes les étapes de
réalisation de la base de données répartie.
CONCLUSION GENERALE
Notre projet se résume par la confirmation de notre
hypothèse selon laquelle, la faisabilité était de
réaliser une base de données répartie pour ésoudre
les problèmes de cohérence, intégrité,
sécurité de données, de coût de l'enrôlement
et de la centralisation de données par la réplication
symétrique asynchrone et la répartition de l'ensemble de
données à travers le territoire national en République
Démocratique du Congo.
Il nous a été absolu de rappeler les notions de
bases de données et de bases de données réparties pour
booster notre mémoire. L'étude du système existant
à la CENI nous a permis de comprendre le déroulement de
l'activité d'identification des électeurs, et à conclure
pour une réorganisation du processus cible. L'évaluation de notre
projet a descellé toutes les tâches à accomplir pour sa
réalisation pendant une durée de 139 jours, à
approximativement 107 348 700,00 FC, à peu près de
115 428,7097 USD. Ensuite, la conception de la base de données a
valu l'intervention des techniques UML : le diagramme de séquence,
cas d'utilisation et le diagramme de classes. En ce qui concernait la
répartition de la base, nous avons utilisé la méthode de
conception descendante, qui consiste à aller d'un schéma global
vers plusieurs schémas internes locaux, en passant par le schéma
d'allocation et celui de duplication.La fin a justifié le moyen.
L'informatique reste et restera toujours une solution pour
fiabiliser et dynamiser l'activité de l'homme.
Ce travail a été pour nous à la fois, un
sujet de recherche dans le domaine universitaire, et d'affirmation dans le
monde professionnel. En effet cette expérience nous a permis de joindre
l'utile à l'agréable en évaluant aussi bien les
profondeurs théoriques que pratiques de ce vaste et passionnant domaine
qu'est celui des bases de données réparties. D'un
côté, ce projet nous a permis de nous familiariser avec le SGBD
Oracle 11g R2, et d'un autre côté de comprendre la conception des
bases de données avec UML.
Ainsi, tout étant une oeuvre humaine, les remarques et
suggestions seront les bienvenues de notre part.
BIBLIOGRAPHIE
I. OUVRAGE :
1. Aurélien GILLET; Vladimir SVOBODA, Les
bases de données réparties,Edition ENI, Paris,
2012.
2. Christian SOUTOU, SQL pour Oracle, applications
avec Java, PHP et XML, Ed. EYROLLES, 3e
édition, Paris, 2008.
3. Christian SOUTOU, UML2 pour les bases de
données, Edition EYROLLES, Paris, 2002.
4. Clotilde ATTOUCHE, Oracle 11g -
Exploitation, Société TELLORA, V1.2.
5. Fédération internationale des
sociétés de la Croix-Rouge et du Croissant-Rouge,
Planification du projet/programme, Manuel d'oriente,
Ed. Stratégie2020, Genève, 2010.
6. Georges GARDARIN, Bases de données objet
& relationnel, Edition EYROLLES, Paris, 2000.
7. Georges GARDARIN, Bases de
données : les systèmes et leurs langages,
Edition EYROLLES, Paris, 1996.
8. Georges GARDARIN, Bases de
données, Edition EYROLLES, Paris 2001.
9. Gérard BUENO, BS, Conception
méthodique des bases de données, Ed. Ellipses,
Paris, 2008.
10. Gilles BRIARD, Oracle 10g sous
Windows, Ed. EYROLLES, Paris 2006.
11. Gilles ROY, Conception de bases de
données avec UML, Edition Presse de l'Université
Québec, Québec, 2009.
12. H.P. Garnir et F. Monjoie, Introduction
à l'informatique, - (c)U.Lg. New-York, 2006.
13. Hugues BERSINI, L'Orienté Objet, Cours
et exercices UML2, Ed. EYROLLES, 3e édition,
Paris, 2007.
14. Livre blanc Oracle, Oracle Database 11g
Release 2 : Facilité de gestion et présentation de Real
Application Testing, Inédit, California, 2009.
15. Razvan BIZOÏ, Oracle 10g -
Administration, Ed. Tsoft EYROLLES,1ère édition,
Paris, 2005.
16. Sincère F., Gestion des projets :
Techniques de planification des projets, Ed QLIO, Bruxelles,
2011.
17. Stéphane CROZAT S., Conception de base
de données, Edition SCENARI, Compiègne,2005.
II. COURS :
1. Cédric BUCHE, Cours de Programmation
Orientée Objet (UML), Ecole Nationale d'Ingénierie
de Breste Novembre 2013, Inédit.
2. Simon NTUMBA, Cours de base de données
réparties, ESMICOM 2013-2014, L1 Info, Inédit.
3. Richard KITONDUA, Cours de Conception de
système d'information II, ESMICOM 2014-2015, L2 Info,
Inédit.
4. Eddy MEYLAN, Cours de Base de données
II : Base de données répartie, Haute Ecole
Supérieure de Suisse Occidentale 2013-2014, Informatique de gestion,
Inédit.
5. Madame Sonia Rosaire MULUMBA, Cours d'Oracle
11g, ESMICOM 2014-2015, L2 INFO/ARGBD, Inédit.
6. Marcel MPOY Wa MPOY, Cours de méthodes
d'analyse informatique, ISTIA/MBM 2011-2012, G3 Informatique de
gestion, inédit.
7. Mr. MehrezBoulares, Mr.Nour Ben Yahia, Cours de
système réparti, ISI KEF 2013-2014,
Inédit.
8. RENE J. CHEVANCHE, Cours de bases de
données distribuées et
fédérées, CNAM - Mars 2003,
Inédit.
9. Rim MOUSSA, Cours de système de gestion
de base de données répartie et mécanisme de
répartition avec Oracle, Ecole Supérieur de
Technologie et Informatique/Carthage, Année Académique 2005-2006,
Inédit.
III. WEBOGRAPHIE :
1.
http://tice.univ-nc.nc/~taladoire/Pedagogie/RessourcesBD/EPFL/poly3_fichiers/15/15.html
2.
http://www.google.net/projetinformatoque.html
3.
http://www.memoireonline.com/02/11/4278/m_Conception-et-realisation-dune-base-de-donnees-repartie-sous-oracle--cas-de-lhebergement-d0.html.
4.
http://www.peignotc-arqendra.net/gestiondeprojet/methodePERT/cours.pdf
5. http://www.uml.org
6.
http://www-limbio.smbh.univ-paris13.fr/membres/hamon/BDA-20112012
TABLE DES MATIERES
EPIGRAPHE
i
DEDICACE
ii
REMERCIEMENTS
iii
AVANT PROPOS
iv
IN MEMORIUM
v
ABBREVIATIONS UTILISÉES
vi
TABLE DES FIGURES
viii
TABLE DES TABLEAUX
x
TABLE DES FORMULES
xi
INTRODUCTION GENERALE
1
1. PRESENTATION DU PROJET
1
2. CHOIX ET INTERET DU SUJET
1
2.1. CHOIX
1
2.2. INTERETS
2
3. PROBLEMATIQUE
2
4. HYPOTHESES
2
5. METHODOLOGIE
3
5.1. METHODES
3
5.2. TECHNIQUES
3
7. SUBDIVISION DU TRAVAIL
4
Chapitre Premier :
5
NOTIONS SUR LES BASES DE DONNEES ET LES BASES DE
DONNEES REPARTIES
5
INTRODUCTION
5
SECTION I. NOTIONS SUR LES BASES DE DONNEES
5
I.1. BASE DE DONNEES (BD)
5
a) DEFINITION
5
b) LES CRITERES D'UNE BD
6
I.2. SYSTEME DE GESTION DE BASES DE DONNEES
(SGBD)
6
a) DEFINITION
6
b) LES OBJECTIFS D'UN SYSTEME DE GESTION DE BASES
DE DONNEES
7
c) LES CARACTERISTIQUES DES SGBD
7
I.3. NIVEAU D'ABSTRACTION DES DONNEES
7
L'approche du rapport de Namur
8
L'approche du rapport de l'ANSI
8
I.4. STRUCTURATION DE DONNEES
9
a) LES MODELES HIERARCHIQUES ET RESEAUX
9
b) LES MODELES RELATIONNELS
9
c) LES MODELES ORIENTES OBJETS
10
1.5. LES BASES DE DONNEES AVANCEES
10
a) BD PARALLELE
10
b) BD FEDEREE
11
c) SYSTEME MULTIBASE
11
d) BD REPARTIE
11
SECTION II. NOTION SUR LES BASES DE DONNEES
REPARTIES
11
II.1. GENERALITES SUR LES BASES DE DONNEES
REPARTIES
11
a) EVOLUTION DES BDR
11
b) PRINCIPES DES BDR
13
c) UTILISATION D'UNE BDR
14
d) LA REPARTITION DES BASES DE DONNEES
15
e) ARCHITECTURE DES BDR
16
II.2. TECHNIQUES DE CONCEPTION ET DE GESTION DE
BDR
17
a) METHODES DE CONCEPTION
17
b) LA FRAGMENTATION
19
c) TECHNIQUES DE REPARTITION AVANCEES
20
d) LA REPLICATION
21
e) GESTION DES DONNEES REPARTIES
23
f) LES TRANSACTIONS
24
CONCLUSION PARTIELLE
25
Chapitre deuxième :
26
ETUDE PREALABLE
26
INTRODUCTION
26
SECTION I. PRÉSENTATION ET ANALYSE DE LA
STRUCTURE DU SYSTÈME EXISTANT (CENI)
26
I.1. HISTORIQUE
26
1. DE L'ETAT ET DE LA SOUVERAINETE
27
2. DES DROITS HUMAINS, DES LIBERTES FONDAMENTALES
ET DES DEVOIRS DU CITOYEN ET DE L'ETAT
27
3. DE L'ORGANISATION ET DE L'EXERCICE DU
POUVOIR
27
4. DE LA REVISION CONSTITUTIONNELLE
29
I.2. SITUATION GEOGRAPHIQUE
30
I.3. OBJECTIF
30
I.4. ORGANISATION
31
1. LES ORGANIGRAMMES DE LA CENI
31
2. DESCRIPTION DES ACTIVITÉS
32
SECTION II. ETUDE DE L'OPPORTUNITE
35
II.1. ANALYSE DES BESOINS
35
II.2. PRESENTATION DES SOLUTIONS
35
CONCLUSION
EPIGRAPHE
i
DEDICACE
ii
REMERCIEMENTS
iii
AVANT PROPOS
iv
IN MEMORIUM
v
ABBREVIATIONS UTILISÉES
vi
TABLE DES FIGURES
viii
TABLE DES TABLEAUX
x
TABLE DES FORMULES
xi
INTRODUCTION GENERALE
1
1. PRESENTATION DU PROJET
1
2. CHOIX ET INTERET DU SUJET
1
2.1. CHOIX
1
2.2. INTERETS
2
3. PROBLEMATIQUE
2
4. HYPOTHESES
2
5. METHODOLOGIE
3
5.1. METHODES
3
5.2. TECHNIQUES
3
7. SUBDIVISION DU TRAVAIL
4
Chapitre Premier :
5
NOTIONS SUR LES BASES DE DONNEES ET LES BASES DE
DONNEES REPARTIES
5
INTRODUCTION
5
SECTION I. NOTIONS SUR LES BASES DE DONNEES
5
I.1. BASE DE DONNEES (BD)
5
a) DEFINITION
5
b) LES CRITERES D'UNE BD
6
I.2. SYSTEME DE GESTION DE BASES DE DONNEES
(SGBD)
6
a) DEFINITION
6
b) LES OBJECTIFS D'UN SYSTEME DE GESTION DE BASES
DE DONNEES
7
c) LES CARACTERISTIQUES DES SGBD
7
I.3. NIVEAU D'ABSTRACTION DES DONNEES
7
L'approche du rapport de Namur
8
L'approche du rapport de l'ANSI
8
I.4. STRUCTURATION DE DONNEES
9
a) LES MODELES HIERARCHIQUES ET RESEAUX
9
b) LES MODELES RELATIONNELS
9
c) LES MODELES ORIENTES OBJETS
10
1.5. LES BASES DE DONNEES AVANCEES
10
a) BD PARALLELE
10
b) BD FEDEREE
11
c) SYSTEME MULTIBASE
11
d) BD REPARTIE
11
SECTION II. NOTION SUR LES BASES DE DONNEES
REPARTIES
11
II.1. GENERALITES SUR LES BASES DE DONNEES
REPARTIES
11
a) EVOLUTION DES BDR
11
b) PRINCIPES DES BDR
13
c) UTILISATION D'UNE BDR
14
d) LA REPARTITION DES BASES DE DONNEES
15
e) ARCHITECTURE DES BDR
16
II.2. TECHNIQUES DE CONCEPTION ET DE GESTION DE
BDR
17
a) METHODES DE CONCEPTION
17
b) LA FRAGMENTATION
19
c) TECHNIQUES DE REPARTITION AVANCEES
20
d) LA REPLICATION
21
e) GESTION DES DONNEES REPARTIES
23
f) LES TRANSACTIONS
24
CONCLUSION PARTIELLE
25
Chapitre deuxième :
26
ETUDE PREALABLE
26
INTRODUCTION
26
SECTION I. PRÉSENTATION ET ANALYSE DE LA
STRUCTURE DU SYSTÈME EXISTANT (CENI)
26
I.1. HISTORIQUE
26
1. DE L'ETAT ET DE LA SOUVERAINETE
27
2. DES DROITS HUMAINS, DES LIBERTES FONDAMENTALES
ET DES DEVOIRS DU CITOYEN ET DE L'ETAT
27
3. DE L'ORGANISATION ET DE L'EXERCICE DU
POUVOIR
27
4. DE LA REVISION CONSTITUTIONNELLE
29
I.2. SITUATION GEOGRAPHIQUE
30
I.3. OBJECTIF
30
I.4. ORGANISATION
31
1. LES ORGANIGRAMMES DE LA CENI
31
2. DESCRIPTION DES ACTIVITÉS
32
SECTION II. ETUDE DE L'OPPORTUNITE
35
II.1. ANALYSE DES BESOINS
35
II.2. PRESENTATION DES SOLUTIONS
35
CONCLUSION PARTIELLE
36
Chapitre troisième :
37
EVALUATION DU PROJET
37
INTRODUCTION
37
SECTION I. LA PLANIFICATION
38
I.1. DEFINITION DE LA PLANIFICATION
38
I.2. LE DECOUPAGE DU PROJET
38
I.3. L'ORDONNANCEMENT DES TACHES
38
I.4. ELABORATION DU TABLEAU D'AVANCEMENT DES
TACHES
39
SECTION II. CADRAGE DU PROJET
39
II.1. CHOIX DE LA METHODE D'ORDONNANCEMENT
39
II.2. PRESENTATION DE LA METHODE PERT
40
II.3. CONTRAINTES DE REPRESENTATION GRAPHIQUE
40
II.4. EVALUATION PROPREMENT DITE
41
II.5. GRAPHE BRUT
42
II.8. CALCUL DES RANGS
43
II.9. GRAPHE ORDONNE
44
SECTION III. EXPLOITATION DU PROJET
45
3.1. CALCUL DES DATES AU PLUS TOT ET DATES AU PLUS
TARD
45
a. DATES AU PLUS TOT (DTO)
45
b. DATES AU PLUS TARD (DTA)
47
3.2. CALCUL DES MARGES
50
a. MARGE LIBRE (ML(i))
50
b. MARGE TOTALE (MT(i))
50
c. DETERMINATION DU CHEMIN CRITIQUE
51
d. TABLEAUX DES RESULTATS
52
e. PRESENTATION DES RESULTATS
53
CONCLUSION PARTIELLE
53
Chapitre Quatrième :
54
MODELISATION DE LA BASE DE DONNEES
54
INTRODUCTION
54
SECTION I. PRESENTATION DU LANGAGE UNIFIE DE
MODELISATION (UML)
54
I.1. LA CONCEPTION ORIENTEE OBJET (COO)
54
I.2. UNIFIED MODELING LANGAGE (UML)
55
a. LES OBJECTIFS D'UML
56
b. STRUCTURE D'UN SYSTEME MODELISE EN UML
56
SECTION II. MODELISATION DE LA BASE DE DONNEE
57
II.1. DIAGRAMME CAS D'UTILISATION
57
II.1.1. ELEMENTS DU DIAGRAMME DES CAS
D'UTILISATION
58
II.1.2. RELATIONS DANS LES DIAGRAMMES DE CAS
D'UTILISATION
58
II.1.3. PRESENTATION DU DIAGRAMME DE CAS
D'UTILISATION
60
II.1.4. DESCRIPTION DE SCENARIO
61
II.2. DIAGRAMME DE SEQUENCES
63
II.2.1. DEFINITION DE CONCEPTS DU DIAGRAMME
63
II.2.2. PRESENTATION DES DIAGRAMMES DE SEQUENCE
64
II.3. DIAGRAMME DE CLASSES
71
II.3.1. DESCRIPTION
71
II.3.2. ASSOCIATION
72
II.3.4. GENERALISATION ET HERITAGE
73
II.3.5. ENCAPSULATION
75
II.3.6. PRESENTATION DU DIAGRAMME DE CLASSE
76
CONCLUSION PARTIELLE
76
Chapitre Cinquième :
77
LA REPARTITION DE DONNEES AVEC ORACLE
77
INTRODUCTION
77
SECTION I. ORACLE : OBJETS &
ARCHITECTURE
78
I.1. STRUCTURES LOGIQUES DE LA BD
79
I.2. STRUCTURES PHYSIQUES DE LA BD
81
I.3. STRUCTURES DE MEMOIRE
81
I.4. PROCESSUS D'ARRIERE-PLAN
82
I.5. DEROULEMENT DE TRAITEMENT D'UN ORDRE SQL
83
SECTION II. LA REPARTITION DE DONNEES
84
II.1. ORACLE EN RESEAU
84
a) ORACLE NET SERVICE
84
b) TRANSPARENT NETWORK SUBSTRATE (TNS)
84
c) COMMUNICATION ENTRE BASES DE DONNEES
85
d) IDENTIFICATION DES OBJETS
85
II.2. LES LIENS DE BASES DE DONNEES
85
II.3. TRANSPARENCE D'EMPLACEMENT
85
II.3.1. VUES
86
II.3.2. SYNONYMES
86
II.4. MISE AU POINT DES REQUETES DISTRIBUEES
86
I.5.1. COLLOCATED INLINE VIEWS
87
I.6. REPLICATION DES DONNEES
87
I.6.1. COMMANDE COPY
87
I.6.2. SNAPSHOTS
87
I.6.3. VUES MATERIALISEES
87
SECTION III. ECRITURE RELATIONNELLE DE LA
REPARTITION DESCENDANTE
88
III.1. SCHEMA GLOBAL DE LA BASE DE DONNEES
88
III.2. SCHEMA DE REPARTITION OU D'ALLOCATION
89
JOINTURE DES CLASSES
91
III.3. SCHEMA DE DUPLICATION OU DE REPLICATION
91
III.4. SCHEMA INTERNE LOCAL
91
CONCLUSION PARTIELLE
92
Chapitre Sixième :
93
IMPLEMENETATION
93
INTRODUCTION
93
SECTION I. PRESENTATION DESCRIPTION DES OUTILS DE
DEVELOPPEMENT
94
I.1. ORACLE
94
I.2. NETBEANS IDE (Integrated Development
Environment)
95
I.3. JAVA
95
I.4. JDBC (Java DataBase Connectivity)
96
5.2. CREATION DES BASES DE DONNEES
96
SECTION II. IMPLEMENTATION DE LA BASE DE DONNEES
REPATIES
97
II.1. CONFIGURATION DE LA CONNEXION RESEAU ENTRE LE
SERVER ET LES SITES
98
II.2. CONFIGURATION NET MANAGER
98
a) SITES : listener
98
b) SERVER : service_name
98
II.3. CREATION DES UTILISATEURS ET DE TABLES
99
a) CREATION DES ROLES
99
b) CREATION DES UTILISATEURS
100
c) CREATION DES TABLES
101
II.4. CREATION DES LIENS ET SYNONYMES SUR SITES
102
II.5. CREATION DES VUES MATERIALISEES SUR
SERVER
102
SECTION III. DEVELOPPEMENT DE L'APPLICATION ET
PRESENTATION DE L'APPLICATION
103
III.1. DEVELOPPEMENT DE L'APPLICATION
103
a) METHODES DE CONNEXION DE NETBEANS VERS ORACLE
11g R2
103
III.2. PRESENTATION DE L'APPLICATION
104
a) STRUCTURE GENERALE
104
b) LES INTERFACES UTILISATEURS : OPS
105
c) LES INTERFACES ADMINISTRATEURS CENI :
DBA_BL
105
CONCLUSION PARTIELLE
106
CONCLUSION GENERALE
107
BIBLIOGRAPHIE
108
TABLE DES MATIERES
110
PARTIELLE
36
Chapitre troisième :
37
EVALUATION DU PROJET
37
INTRODUCTION
37
SECTION I. LA PLANIFICATION
38
I.1. DEFINITION DE LA PLANIFICATION
38
I.2. LE DECOUPAGE DU PROJET
38
I.3. L'ORDONNANCEMENT DES TACHES
38
I.4. ELABORATION DU TABLEAU D'AVANCEMENT DES
TACHES
39
SECTION II. CADRAGE DU PROJET
39
II.1. CHOIX DE LA METHODE D'ORDONNANCEMENT
39
II.2. PRESENTATION DE LA METHODE PERT
40
II.3. CONTRAINTES DE REPRESENTATION GRAPHIQUE
40
II.4. EVALUATION PROPREMENT DITE
41
II.5. GRAPHE BRUT
42
II.8. CALCUL DES RANGS
43
II.9. GRAPHE ORDONNE
44
SECTION III. EXPLOITATION DU PROJET
45
3.1. CALCUL DES DATES AU PLUS TOT ET DATES AU PLUS
TARD
45
a. DATES AU PLUS TOT (DTO)
45
b. DATES AU PLUS TARD (DTA)
47
3.2. CALCUL DES MARGES
50
a. MARGE LIBRE (ML(i))
50
b. MARGE TOTALE (MT(i))
50
c. DETERMINATION DU CHEMIN CRITIQUE
51
d. TABLEAUX DES RESULTATS
52
e. PRESENTATION DES RESULTATS
53
CONCLUSION PARTIELLE
53
Chapitre Quatrième :
54
MODELISATION DE LA BASE DE DONNEES
54
INTRODUCTION
54
SECTION I. PRESENTATION DU LANGAGE UNIFIE DE
MODELISATION (UML)
54
I.1. LA CONCEPTION ORIENTEE OBJET (COO)
54
I.2. UNIFIED MODELING LANGAGE (UML)
55
a. LES OBJECTIFS D'UML
56
b. STRUCTURE D'UN SYSTEME MODELISE EN UML
56
SECTION II. MODELISATION DE LA BASE DE DONNEE
57
II.1. DIAGRAMME CAS D'UTILISATION
57
II.1.1. ELEMENTS DU DIAGRAMME DES CAS
D'UTILISATION
58
II.1.2. RELATIONS DANS LES DIAGRAMMES DE CAS
D'UTILISATION
58
II.1.3. PRESENTATION DU DIAGRAMME DE CAS
D'UTILISATION
60
II.1.4. DESCRIPTION DE SCENARIO
61
II.2. DIAGRAMME DE SEQUENCES
63
II.2.1. DEFINITION DE CONCEPTS DU DIAGRAMME
63
II.2.2. PRESENTATION DES DIAGRAMMES DE SEQUENCE
64
II.3. DIAGRAMME DE CLASSES
71
II.3.1. DESCRIPTION
71
II.3.2. ASSOCIATION
72
II.3.4. GENERALISATION ET HERITAGE
73
II.3.5. ENCAPSULATION
75
II.3.6. PRESENTATION DU DIAGRAMME DE CLASSE
76
CONCLUSION PARTIELLE
76
Chapitre Cinquième :
77
LA REPARTITION DE DONNEES AVEC ORACLE
77
INTRODUCTION
77
SECTION I. ORACLE : OBJETS &
ARCHITECTURE
78
I.1. STRUCTURES LOGIQUES DE LA BD
79
I.2. STRUCTURES PHYSIQUES DE LA BD
81
I.3. STRUCTURES DE MEMOIRE
81
I.4. PROCESSUS D'ARRIERE-PLAN
82
I.5. DEROULEMENT DE TRAITEMENT D'UN ORDRE SQL
83
SECTION II. LA REPARTITION DE DONNEES
84
II.1. ORACLE EN RESEAU
84
a) ORACLE NET SERVICE
84
b) TRANSPARENT NETWORK SUBSTRATE (TNS)
84
c) COMMUNICATION ENTRE BASES DE DONNEES
85
d) IDENTIFICATION DES OBJETS
85
II.2. LES LIENS DE BASES DE DONNEES
85
II.3. TRANSPARENCE D'EMPLACEMENT
85
II.3.1. VUES
86
II.3.2. SYNONYMES
86
II.4. MISE AU POINT DES REQUETES DISTRIBUEES
86
I.5.1. COLLOCATED INLINE VIEWS
87
I.6. REPLICATION DES DONNEES
87
I.6.1. COMMANDE COPY
87
I.6.2. SNAPSHOTS
87
I.6.3. VUES MATERIALISEES
87
SECTION III. ECRITURE RELATIONNELLE DE LA
REPARTITION DESCENDANTE
88
III.1. SCHEMA GLOBAL DE LA BASE DE DONNEES
88
III.2. SCHEMA DE REPARTITION OU D'ALLOCATION
89
JOINTURE DES CLASSES
91
III.3. SCHEMA DE DUPLICATION OU DE REPLICATION
91
III.4. SCHEMA INTERNE LOCAL
91
CONCLUSION PARTIELLE
92
Chapitre Sixième :
93
IMPLEMENETATION
93
INTRODUCTION
93
SECTION I. PRESENTATION DESCRIPTION DES OUTILS DE
DEVELOPPEMENT
94
I.1. ORACLE
94
I.2. NETBEANS IDE (Integrated Development
Environment)
95
I.3. JAVA
95
I.4. JDBC (Java DataBase Connectivity)
96
5.2. CREATION DES BASES DE DONNEES
96
SECTION II. IMPLEMENTATION DE LA BASE DE DONNEES
REPATIES
97
II.1. CONFIGURATION DE LA CONNEXION RESEAU ENTRE LE
SERVER ET LES SITES
98
II.2. CONFIGURATION NET MANAGER
98
a) SITES : listener
98
b) SERVER : service_name
98
II.3. CREATION DES UTILISATEURS ET DE TABLES
99
a) CREATION DES ROLES
99
b) CREATION DES UTILISATEURS
100
c) CREATION DES TABLES
101
II.4. CREATION DES LIENS ET SYNONYMES SUR SITES
102
II.5. CREATION DES VUES MATERIALISEES SUR
SERVER
102
SECTION III. DEVELOPPEMENT DE L'APPLICATION ET
PRESENTATION DE L'APPLICATION
103
III.1. DEVELOPPEMENT DE L'APPLICATION
103
a) METHODES DE CONNEXION DE NETBEANS VERS ORACLE
11g R2
103
III.2. PRESENTATION DE L'APPLICATION
104
a) STRUCTURE GENERALE
104
b) LES INTERFACES UTILISATEURS : OPS
105
c) LES INTERFACES ADMINISTRATEURS CENI :
DBA_BL
105
CONCLUSION PARTIELLE
106
CONCLUSION GENERALE
107
BIBLIOGRAPHIE
108
TABLE DES MATIERES
110

* 1 GARDARIN G.,
Bases de données objet & relationnel,
Edition EYROLLES, Paris, 2000, page 3-4
* 2 ROY G.,
Conception de bases de données avec UML,
Edition Presse de l'Université Québec, Québec, 2009,
p.2
* 3 CROZAT S.,
Conception de base de données, Edition
SCENARI, Compiègne, 2005, p.21
* 4 MPOY WA MPY M.,
Cours de Méthode d'analyse informatique II,
ISTIA/MBM 2011-2012, G3 Informatique de gestion, Inédit, p.7.
* 5 ROY G., Op.
cit., p.2
* 6 ROY G., Bases
de données, Edition Eyrolles, Paris, 2001, pp. 8-12
* 7 SOUTOU C.,
UML2 pour les Bases de données, Ed. Eyrolles,
Paris, 2002, p.08.
* 8 SOUTOU C.,
Op. cit., p.08.
* 9Idem, p.09.
* 10 ROY G., Op.
cit., pp. 14-15.
* 11ROY G., Op.
cit., pp. 15-16
* 12Idem, pp. 16-17
* 13 CHEVANCHE J. R.,
Cours de bases de données distribuées et
fédérées, CNAM - Mars 2003, Inédit,
p. 29.
* 14 Idem, p. 30.
* 15 Mr. Mehrez Boulares,
Mr. Nour Ben Yahia, Cours de système
réparti, ISI KEF 2013-2014, Inédit., p. 14
* 16 MOUSSA R.,
Cours de système de gestion de base de données
répartie et mécanisme de répartition avec
Oracle, Ecole Supérieur de Technologie et
Informatique/Carthage, Année Académique 2005-2006, Inédit,
p. 12.
* 17 Idem, p. 14.
* 18MEYLAN E.,
Cours de Base de données II : Base de données
répartie, Haute Ecole Supérieure de Suisse
Occidentale 2013-2014, Informatique de gestion, Inédit, p. 33
* 19NTUMBA S.,
Cours de base de données répartie,
ESMICOM 2013-2014, L1 Info, Inédit, p. 56.
* 20NTUMBA S.,
Op. cit, p. 60.
* 21 MOUSSA R.,
Op. cit., p. 25.
* 22 Idem.
* 23
http://tice.univnc.nc/~taladoire/Pedagogie/RessourcesBD/EPFL/poly3_fichiers/15/15.html.
20 février 2015.
* 24
http://www.memoireonline.com/02/11/4278/m_Conception-et-realisation-dune-base-de-donnees-repartie-sous-oracle--cas-de-lhebergement-d0.html.
22 février 2015.
* 25Aurélien G. &
Vladimir S., Les bases de données
réparties, Edition ENI, Paris, 2010, p. 144.
* 26 Idem.
* 27 Ibidem.
* 28 MOUSSA R.,
Op.cit, p. 31.
* 29NTUMBA S.,
Op.cit, pp. 61-62.
* 30 Idem.
* 31NTUMBA S.,
Op.cit., p. 62.
* 32 Idem.
* 33 MOUSSA R.,
Op.cit., p. 34.
* 34
www.memoireonline.com/02/11/4278/m_Conception-et-realisation-dune-base-de-donnees-repartie-sous-oracle--cas-de-lhebergement-d0.html.
Le 02 mars 2015.
* 35 MOUSSA R.,
Op.cit., p. 40.
* 36
Fédération internationale des sociétés de la
Croix-Rouge et du Croissant-Rouge, Planification du
projet/programme, Manuel d'oriente, Ed. STRATEGIE2020, GENEVE,
2010, p.13
* 37 Sincère F.,
Gestion des projets : Techniques de planification des
projets, Ed QLIO, Bruxelles, 2011, p. 31.
* 38
http://www.google.net/projetinformatique.html.
Le08 avril 2015
* 39 BASOSILA B.,
Cours de Méthodes de conduite de projets
informatiques, ESMICOM 2015, L2 INFO, Inédit, p. 56.
* 40
Fédération internationale des sociétés de la
Croix-Rouge et du Croissant-Rouge, Op. cit., p.17.
* 41BASOSILA B.,
Op. cit., p. 60.
* 42MVUMBI PUATI Z.V., Cours
d'Elément de recherche opérationnelle, L1 info, ULK/KIN,
2010-2011, Inédit.
* 43
http://www.peignotc-arqendra.net/gestiondeprojet/methodePERT/cours.pdf
Le 04 avril 2015.
* 44 Idem.
* 45 BUENO G.,
BS, Conception méthodique des bases de
données, Ed. ELLIPSES, Paris, 2008, p.10
* 46 H.P. Garnir et F.
Monjoie, Introduction à l'informatique, -
(c)U.Lg., Paris, 2006, pp. 24-26
* 47KITONDUA R.,
Cours de Conception de système d'information
II, L2 ARGBD, ESMICOM 2014-2015, Inédit, p. 7.
* 48 BUCHE C.,
Cours de Programmation Orientée Objet (UML),
Ecole Nationale d'Ingénierie de Breste Novembre 2013, Inédit, pp.
24-25.
* 49
http://www.uml.org/Le 29 avril 2015.
* 50
http://www.uml.org/Le 29 avril 2015.
* 51 Idem.
* 52SOUTOU C.,
UML 2 pour les bases de données, Ed. EYROLLES,
Paris, 2002, p.15.
* 53 BERSINI H.,
L'Orienté Objet, Cours et exercices UML2, Ed.
EYROLLES, 3e édition, Paris, 2007, p.162
* 54 GARDARIN G.,
Bases de données, Ed. EYROLLES, Paris, 2001,
p.15.
* 55 ROY G.,
Conception de bases de données avec UML,
Edition Presse de l'Université Québec, Québec, 2009,
p.26
* 56 SOUTOU C.,
Op.cit., p.26
* 57 SOUTOU C.,
Op.cit., p.27
* 58
http://www.uml.org/ Le 30 avril 2015.
* 59 SOUTOU C.,
Op.cit., p.28
* 60KITONDUA R.,
Op.cit., p.12.
* 61 BUCHE C.,
Op.cit., p.32.
* 62 SOUTOU C.,
Op.cit., p. 83.
* 63 Idem, p. 84
* 64 Ibidem.
* 65 SOUTOU C.,
Op.cit., p. 84.
* 66 Livre blanc Oracle,
Oracle Database 11g Release 2 : Facilité de gestion et
présentation de Real Application Testing, Inédit,
California, Août 2009, p. 122.
* 67 ATTOUCHE C.,
Oracle 11g - Exploitation, Société
TELLORA, Berlin, 2010, p.28.
* 68 SOUTOU C.,
SQL pour Oracle, applications avec Java, PHP et XML,
Ed. EYROLLES, 3e édition, Paris 2008, p. 193.
* 69
http://www-limbio.smbh.univ-paris13.fr/membres/hamon/BDA-20112012.
Le 02 mai 2015.
* 70 Idem.
* 71 BRIARD G.,
Oracle 10g sous Windows, Ed. EYROLLES, Paris 2006,
pp. 611-612
* 72 Madame MULUMBA R. S.,
Cours d'Oracle 11g, ESMICOM 2014-2015, L2 INFO/ARGBD,
Inédit.
* 73 BIZOÏ R.,
Oracle 10g - Administration, Ed. Tsoft Eyrolles,
1ère édition, Paris 2005. p. 74
* 74 MOUSSA R.,
Op.cit., p. 45.
* 75 SOUTOU C.,
Op.cit., p.221
* 76 Idem, p.237
| 

