|
JUILLET 2018
UNIVERSITE LIBERTE
FACULTE DES SCIENCES INFORMATIQUES

ETUDE ET CONCEPTION D'UN DATA WAREHOUSE ET
L'IMPACT DU
DEPLOIEMENT D'UN SYSTEME DECISIONNEL
DANS UNE SOCIETE DE VENTE ET DE
PRODUCTION
(CAS DE LA BRASIMBA)
Par MASSAMBA SENDWE Cédric
Travail présenté et défendu en vue
de l'obtention du grade d'Ingénieur en Sciences
Informatiques.
Option : Ingénierie des Systèmes
d'Information
ANNEE ACADEMIQUE 2017-2018
UNIVERSITE LIBERTE
FACULTE DES SCIENCES INFORMATIQUES

ETUDE ET CONCEPTION D'UN DATA WAREHOUSE ET
L'IMPACT DU
DEPLOIEMENT D'UN SYSTEME DECISIONNEL
DANS UNE SOCIETE DE VENTE ET DE
PRODUCTION
(CAS DE LA BRASIMBA)
Par MASSAMBA SENDWE Cédric
Dirigé par Prof. Blaise FYAMA, PhD Codirecteur:
Ass. Ruphin NYAMI
I
EPIGRAPHE
«L'invention scientifique réside dans la
création d'une hypothèse heureuse et féconde ; elle est
donnée par le sentiment ou le génie même du savant qui l'a
créée.»
Claude Bernard
II
DEDICACE
A tout chercheur scientifique, particulièrement
celui du domaine informatique
ayant la passion de bien vouloir
appréhender, améliorer ou approfondir le sujet
traité
dans ce travail [...]
III
AVANT-PROPOS
A toi Dieu source de toute créativité,
créateur de l'univers, Père de notre Seigneur
Jésus-Christ, me voici devant ta face pour exprimer ma gratitude et mes
vifs remerciements suite à la bienveillance et ta grâce
m'accordées depuis mon enfance jusqu'à aujourd'hui, reçois
bien mon obligeance.
Monsieur le Doyen de la Faculté des Sciences
Informatiques, le Professeur Blaise FYAMA, veuillez trouver ici l'expression de
notre reconnaissance pour avoir dirigé ce travail avec amour
malgré ce pain sur la planche qui guette quotidiennement votre
porte.
Nous remercions toutes les autorités de
l'Université Liberté plus particulièrement le
Secrétaire Général Académique ainsi que le Doyen de
la faculté des Sciences Informatiques pour leur encadrement tout au long
de notre parcours académique.
Chers parents, MASSAMBA WA MASSAMBA Ferdinand et BANZE
MOMA Anastasie, voici l'expression de ma parfaite reconnaissance pour le devoir
que vous avez accompli et je vous demande de savourer dès maintenant le
fruit de votre patience.
Nous n'oublierons pas d'expédier nos sentiments de
remerciements à nos chers collègues, amis et compagnons de lutte
de deuxième Grade ISI 2018, à l'Université
Liberté.
A vous tous qui nous avez soutenu de loin ou de
près, veuillez trouver ici l'expression de notre parfaite
reconnaissance.
IV
LISTE DES FIGURES
Figure 1: Architecture globale d'un système
décisionnel 11
Figure 2: Composants du DWH refermant la boucle 15
Figure 3: Architecture d'un Data Warehouse 16
Figure 4: Diagramme du cycle de vie d'un modèle
dimensionnel 22
Figure 5: Modèle logique de données ventes
(sources opérationnelles) 34
Figure 6 : Diagramme de cas d'utilisation du
système décisionnel 39
Figure 7:DSS DU CU « S'authentifier » 40
Figure 8 : DSS DU CU « Alimenter l'entrepôt
» 41
Figure 9: DSS DU CU "Gérer comptes utilisateurs"
43
Figure 10: DSS DU CU « Analyser les données
» 45
Figure 11 : DSS DU CU « Visualiser les cubes des
données » 46
Figure 12:DCP du CU « S'authentifier »
47
Figure 13: DCP du CU « alimenter entrepôt
» 48
Figure 14: DCP du CU « Gérer comptes
utilisateurs » 48
Figure 15: DCP du CU « Analyser les données
» 49
Figure 16: DCP du CU « Visualiser les cubes des
données » 50
Figure 17 : Diagramme de classes de conception 51
Figure 18: Modèle logique des données
51
Figure 19: Modèle dimensionnel en flocon 53
Figure 20 : Modèle dimensionnel en étoile du
fait Vente 59
Figure 21: Représentation des sources Excel
61
Figure 22: Représentation des sources Access
62
Figure 23: Représentation des sources MySQL
62
Figure 24: Architecture technique proposée
67
Figure 25: Importation des fichiers sources 69
Figure 26 : Création de connexion pour les sources
externes 1ère étape 69
Figure 27: Création de connexion pour les sources
externes 2e étape 70
Figure 28 : Récupération du schéma :
1ère étape 70
Figure 29: Récupération du schéma :
2e étape 71
Figure 30: Création des Jobs 71
Figure 31: Extraction et transformation des données
sources 72
Figure 32: Correspondance des champs 72
Figure 33: Chargement des données dans
l'entrepôt 73
Figure 34: Connexion à l'entrepôt 1ère
étape 73
Figure 35: Création des dimensions et des mesures
74
V
Figure 36: Connexion à l'entrepôt 2e
étape 74
Figure 37: Les clients autour de toutes les zones
commerciales de Lubumbashi 75
Figure 38: La liste de clients autour d'une commune
(Commune de Ruashi) 75
Figure 39: Le comportement du produit SIMBA 73CL autours
de toutes les communes de la ville 76
Figure 40: Tableau de bord du comportement de tous les
produits 76
Figure 41: Tableau de bord du comportement de tous les
produits vendus dans la commune de Katuba 77 Figure 42: Statistiques de tous
les produits dans toutes les zones commerciales 77
VI
LISTE DES TABLEAUX
Tableau 1: Comparaison entre les systèmes
transactionnels et systèmes décisionnels 18
Tableau 2: Eléments constitutifs d'un modèle
relationnel 29
Tableau 3 : Liste de tous les produits de la Brasimba
32
Tableau 4: Exemple de la fiche de ventes pour le secteur
Ville-Est 33
Tableau 5: Tableau des acteurs 38
Tableau 6: Liste de propriétés de la
dimension Produit 55
Tableau 7: Liste de propriétés de la
dimension Client 55
Tableau 8 : Liste de propriétés de la
dimension Periode 55
Tableau 9: Liste de propriétés de la
dimension ZoneCommerciale 56
Tableau 10: Liste des propriétés de la table
des faits Vente 56
Tableau 11: Outils du décisionnel utilisés
68
Tableau 12: Environnement d'exécution 68
VII
LISTE DES SIGLES ET ABREVIATIONS
AS400 : Application System/400
BD : Base de données
CRM : Customer Relationship Management
CSV : Comma-separated values
CU : Cas d'utilisation
DBA : Database administrator
DCU : Diagramme de cas d'utilisation
DCP : Diagramme de classes participantes
DM : Data mart
DSS : Diagramme de séquence
système
DWH : Data warehouse
EAI : Echange de données
Inter-Applications
ERP : Entreprise Ressources Planing
ESB : Enterprise Service Bus
ETC : Extraction, transformation et
Chargement
ETL : Extract-Transform-Load
FK : Foreign key
FTP : File Transfert Protocol
GB : Gigabyte
GPL : General Public License
HTML : Hypet Text Markup Language
HTTP : Hypertext Transfer Protocol
KPI : Key Performance Indicator
MLD : Modèle logique de
données
ODBC : Open Database Connectivity
OLAP : OnLine Analytical Processing
OLTP : OnLine Transaction Processing
OS : Operating System
PHP : Hypertext Preprocessor
PK : Primary Key
QBE : Query by Example
SAP : Systems, Applications and Products for
data processing
SGBD : Système de gestion de base de
données
SGBDR : Système de gestion de bases de
données relationnelles
SI : Système d'information
VIII
SID : Système d'information
décisionnel
SQL : Structured Query Language
SSH : Secure Shell
TB : Terabyte
TCD : Tableau croisé dynamique
TOS : Talend Open Studio
TOS DI : Talend Open Studio for Data
Integration
TXT : Text
VBA : Visual Basic for Applications
UML : Unified Modeling Language
UP : Unified Process
URL : Uniform Resource Locator
WWW : World Wide Web
XAMPP : X (cross) apache MariaDB Perl PHP
XML : eXtensible Markup Language
1
INTRODUCTION GENERALE
« L'une des plus grandes richesses d'une entreprise est son
information. » [1]
La conservation et le stockage de celle-ci se base sur la
structuration et la normalisation des données sur un support, c'est
l'objectif premier des bases de données.
Dans une entreprise de grande envergure, l'information est
stockée sous diverses formes et de manière
éparpillée, éparse et hétérogène car
chaque service peut éventuellement utiliser plusieurs applications dont
les données sont structurées et codifiées de
manière différente par rapport aux autres services.
Cette approche ne facilite pas la tâche aux
décideurs qui doivent prendre des décisions stratégiques
et pertinentes dans un temps aussi court que raisonnable car ils ne peuvent
avoir la vision globale de l'entreprise vu que ces données sont
collectées pour un objectif purement transactionnel et non pas
décisionnel.
Or, les dirigeants des entreprises, quel qu'en soit le domaine
d'activités d'ailleurs, doivent être en mesure de mener à
bien les missions qui leur incombent en la matière et doivent prendre
notamment les décisions les plus opportunes.
Ces décisions qui influeront grandement sur la
stratégie de l'entreprise, et donc sur son devenir, ne doivent pas
être prises ni à la légère, ni de manière
trop hâtive, compte tenu de leurs conséquences sur la survie de
l'entreprise. Il s'agira de prendre des décisions fondées,
basées sur des informations claires, fiables et pertinentes.
Pour avoir une vision globale de l'entreprise, il est
nécessaire de réunir toutes ces informations provenant des
sources transactionnelles ou opérationnelles.
Ces données seront alors transformées,
filtrées, croisées et reclassées afin de les
intégrer dans un endroit spécifique pour que les responsables et
analystes des entreprises aient une connaissance de ces données à
un niveau global et ainsi leur permettre la prise des décisions de
façon sûre en se basant sur les faits.
Or, pour avoir une meilleure vue de ces données, sous
plusieurs axes, afin de permettre aussi une meilleure analyse, la solution
consistera à l'utilisation et la réutilisation de ces
données collectées, qui malheureusement ne peuvent plus
être gérées à l'aide des bases de données
classiques en fonction de leur volume et de leur éventuelle
hétérogénéité.
En voulant répondre aux besoins de ses consommateurs,
aux attentes du marché et en observant parallèlement la crise
économique qui frappe l'humanité actuellement,
2
C'est dans ce contexte que les « systèmes
décisionnels » ont vu le jour. Ils offrent aux décideurs des
informations de qualité sur lesquelles ils pourront s'appuyer pour
arrêter leurs choix décisionnels.
Ces systèmes utilisent un large éventail de
technologies et de méthodes, dont les «Entrepôts de
données » ou « Data warehouses » représentent
l'élément principal et incontournable pour la mise en place d'un
bon système décisionnel, permettant ainsi une analyse claire et
pertinente de données de l'entreprise.
La Brasimba est une société de production, de
vente, et de distribution des boissons installée au numéro 1200,
avenue N'Djamena à Lubumbashi en République Démocratique
du Congo.
Filiale du groupe CASTEL, leader dans l'industrie brassicole
sur le marché d'Afrique Francophone, cette société a pour
vision d'être leader en industrie et en distribution des boissons dans le
cadre d'une production moderne, efficace, performante, et citoyenne dans notre
pays.
Elle est une société commerciale qui a aussi
pour mission d'assurer la distribution et la qualité constante des
produits aux meilleurs prix tout en perpétuant son savoir-faire
brassicole, et ne cesse de cultiver sa passion pour l'innovation d'une gamme
variée de boissons d'une extrême qualité pour le goût
des consommateurs.
Cette société s'est inscrite dans la production
et dans la commercialisation de ses marques et de ses gammes entre autres : la
bière, l'alcool mix, les boissons gazeuses, les boissons
énergisantes ainsi que de l'eau minérale. La chaine
Marketing-Vente-Distribution assure l'écoulement de ses produits.
Evoluant dans un environnement fortement complexe et hautement
concurrentiel, ce climat de forte concurrence exige de cette entreprise une
surveillance très étroite du marché afin de ne pas se
laisser distancer par les concurrents et cela en répondant, le plus
rapidement possible, aux attentes du marché, de sa clientèle et
de ses partenaires.
3
l'utilisation du principe de ne privilégier que
l'essentiel doit être de mise pour espérer toujours une croissance
et une stabilité économique.
La question est : Comment arriver à
homogénéiser ces informations naturellement
hétérogènes afin d'effectuer des analyses pour la prise
des décisions ?
Cette question est la préoccupation majeure des
responsables d'entreprise qui ont besoin de :
+ Savoir le comportement d'une marque par rapport aux
critères temporel, géographique, et démographique ;
+ Trouver toutes les marques de produits vendues au cours
d'une certaine période ; + Détailler les ventes totales des
marques par secteur, par commune, ou par région ; + Connaître le
coût et le chiffre d'affaires...
Eu égard à ce qui précède, la
société procédera à se poser les questions
suivantes :
+ Qu'a-t-on vendu ?
+ Quel est le total des ventes d'une marque en une certaine
période ?
+ Quel est le total des ventes d'une marque par secteur, par
commune ?
+ Quelles sont les marques les plus vendues dans un secteur, dans
une commune, dans
une ville, dans une région ?
Voilà quelques-unes des préoccupations qui
retiennent l'esprit du décideur qui désire améliorer ses
performances décisionnelles sur base des données pouvant lui
éclairer et lui faciliter une prise de décision prompte en
connaissance des causes et des faits.
La résolution à ce problème serait donc
de modéliser un système qui requiert la mise en place d'un
entrepôt de données fiable, contenant les informations
nécessaires à l'accomplissement des processus décisionnels
pour permettre aux décideurs de savoir cibler plus
précisément les consommateurs d'une marque dans un secteur et
à une période donnés.
Le présent projet tendra à donner réponse
à toutes ces questions car nous concevrons un système capable de
consolider les données issues des systèmes transactionnels, et
d'offrir aux décideurs des informations fiables.
Etant donné qu'un entrepôt de données est
un type de base orienté sujet, les données collectées
seront orientées `métier' et donc triées par
thème.
4
L'objectif attendu de ce projet est de concevoir un Data
warehouse, l'élément primordial de tout système
décisionnel qui permettra de donner accès aux données
existantes de l'organisation, sous une forme intégrée, de
faciliter leur interrogation croisée et massive pour les fins
d'analyse.
Ce système servira d'interface entre les
systèmes échangeant des données. Des données
contenues dans des fichiers soit Excel, soit Access, ou MySQL seront
chargées dans un entrepôt grâce à un outil
d'extraction, de transformation et de chargement appelé ETL.
Nous rendons hommage à notre prédécesseur
KAHLOULA BOUBAKAR qui a parlé sur le « Chargement de données
XML dans un data warehouse : Approche pour l'automatisation du Schema Matching
» pour l'obtention de son diplôme de Master en Informatique et
Automatique, Université d'Oran en République Algérienne
Démocratique et Populaire.
La différence entre nous est que lui, avait la
tâche de charger dans le data warehouse les données XML
uniquement, contrairement à nous qui irons à charger des
différents formats de données tels que Excel, Access, MySQL,
etc.
« Les sciences informatiques comme toutes les autres
branches des sciences possèdent des méthodes et des techniques
intrinsèques et inhérentes propres à leur nature. Leur
permettant ainsi d'apporter des réponses à leurs diverses
problématiques et d'évoluer en tant que domaine porteur des
nouvelles sciences et technologies.» [2]
En Ingénierie, il existe des méthodes et des
techniques répondant à une problématique
particulière, à la réutilisation des composants logiciels
ou à la construction des systèmes et infrastructures à
base des logiciels.
C'est pourquoi nous appréhenderons la démarche
de l'Unified Process (UP), une méthode générique,
incrémentale et itérative qui nous permettra bien-sûr de
mettre en évidence certains diagrammes et compléter la
systématique des modèles UML (Unified Modeling Language) pour la
conception de notre système.
Voilà que nous avons évoqué les mobiles
de notre choix sur ce projet. A présent, nous essayerons dans le
chapitre qui suit, de nous marteler sur le domaine du décisionnel en
5
Notre projet se focalisera au niveau de la vente, qui fera
l'objet ou le soubassement de décider sur la fabrication ou la
production d'un produit, d'une gamme au sein de la Brasimba.
En dehors de l'introduction générale et de la
conclusion générale, la structuration et l'organisation de nos
idées pour aboutir aux résultats, se tourneront autour de quatre
chapitres notamment :
? Chapitre I . Introduction au domaine du
décisionnel
Ce chapitre portera sur les aspects théoriques du domaine
des systèmes d'information d'aide à la décision, en
évoquant les définitions et les concepts relatifs aux
Entrepôts de données ou aux `Data warehouses' et à la
modélisation dimensionnelle.
? Chapitre II . Le stockage de données à la
Brasimba
Cette partie aura pour tâche de mettre en exergue
l'existant, la manière dont l'information est sauvegardée dans
l'entreprise, les types de bases opérationnelles utilisés, pour
en fait recenser les informations nécessaires à intégrer
dans l'entrepôt qui sera construit plus tard.
? Chapitre III . Analyse fonctionnelle
La modélisation du système, la conception d'un
entrepôt de données et l'analyse décisionnelle seront les
éléments-clefs de cette partie du t ravail.
? Chapitre IV . Architecture Logicielle
La description de l'architecture, l'implémentation
d'outils d'exploitation et la présentation des interfaces
hommes-machines de notre solution feront l'objet de ce chapitre.
A ce niveau, nous aurons à présenter et à
démonter l'outil d'intégration de données depuis une base
transactionnelle vers une base décisionnelle, celui de rapports, de
tableaux de bord et/ou de l'analyse décisionnelle.
La précision sur l'impact du déploiement des
systèmes décisionnels dans nos entreprises actuelles sera aussi
de mise dans cette dernière partie de notre travail.
6
passant bien évidemment par la connaissance de termes
et de concepts liés aux systèmes d'aide à la
décision.
7
CHAPITRE I : INTRODUCTION AU DOMAINE DU
DECISIONNEL
I.1. Introduction
Dans ce chapitre, il est question de nous accoutumer aux
systèmes décisionnels. Les concepts qui caractérisent ce
domaine, sa place et son enjeu dans des entreprises, certaines notions sur
l'architecture des data warehouses et l'introduction à la
modélisation dimensionnelle.
I.2. Les systèmes décisionnels I.2.1. Le
décisionnel
L'Informatique décisionnelle (Business Intelligence,
parfois appelée tout simplement le Décisionnel) est un ensemble
de moyens, d'outils et de méthodes permettant de collecter, de
consolider, de modéliser et de restituer les données d'une
entreprise en vue d'offrir une aide à la décision.
Jean-François PILLOU et Pascal CAILLEREZ qualifient
d'Informatique décisionnelle comme: « une exploitation des
données de l'entreprise dans le but de faciliter la prise des
décisions par les décideurs, c'est-à-dire la
compréhension du fonctionnement actuel et l'anticipation des actions
pour un pilotage éclairé de l'entreprise.» [3]
Nous disons donc qu'un système décisionnel est
un ensemble de solutions informatiques, un ensemble d'outils qui permettent une
prise de décisions tactiques ou stratégiques d'une
organisation.
Ce système est issu à la recherche de la nuance
du point de vue fonctionnel entre le système de pilotage et le
système opérationnel. Ces vraies différences seront
clairement définies dans les lignes qui suivent.
I.2.2. La place du décisionnel dans
l'entreprise
Un système de décision ou de pilotage est un
ensemble de personnel constituant le chapeau de l'organisation, car c'est ici
où se passe l'activité décisionnelle la plus importante
dans une organisation. Le décisionnel occupe évidemment une place
à ce niveau car il est certainement dédié au pilotage et
au management de l'entreprise.
Remarque : Les sources de
données internes et/ou externes étant souvent
hétérogènes tant sur le plan technique que sur le plan
sémantique, cette fonction occupe le trois-quarts d'un
8
I.2.3. L'enjeu du décisionnel
La prise de décisions stratégiques dans une
organisation nécessite le recours et le croisement de multiples
informations qui concernent plusieurs départements : Production,
Distribution, Ressources humaines, Achats, Ventes, Marketing, Service
après-vente, Maintenance, ... Or ces données sont
généralement :
? Eparpillées au sein des départements et non
connectées entre elles ;
? Hétérogènes dans leurs formats
techniques et leurs organisations structurelles, voire leurs sémantiques
;
? Implémentées pour l'action (par construction) et
non pour l'analyse.
? Volatiles, au sens où leur mise à jour peut
conduire à oublier des informations obsolètes.
L'enjeu des systèmes décisionnels est de donner
accès à ces données existantes dans l'organisation, sous
une forme intégrée, afin de faciliter leur interrogation massive
et croisée.
I.2.4. Les grandes étapes d'un projet
d'Informatique décisionnelle
Un système d'information décisionnel doit passer
par quatre grandes étapes à savoir : I.2.4.1. La
collecte
La première étape qui est celle de collecte
des données ou le Datapumping consiste à aller
chercher les données où elles se trouvent. Ces données
applicatives métier étant naturellement stockées dans une
ou plusieurs bases de données correspondant à chaque application
utilisée.
La collecte est donc l'ensemble des tâches consistant
à détecter, sélectionner, extraire et filtrer les
données brutes issues des environnements pertinents pour obtenir des
indicateurs utiles dans le cadre d'aide à la décision.
Ces données applicatives sont extraites,
transformées et chargées dans un entrepôt de données
ou Data warehouse par un outil de type ETL (Extract-Tranform-Load) qu'on pourra
expliciter plus tard.
9
projet de type décisionnel et est la plus
délicate à mettre en place dans un système
décisionnel complexe.
I.2.4.2. L'intégration
Cette deuxième étape est l'intégration
des données. Elle consiste à concentrer les données
collectées dans un espace unifié, dont le socle informatique
essentiel est l'entrepôt de données. Ce dernier est
l'élément central du dispositif dans le sens où il permet
aux applications d'aide à la décision de bénéficier
d'une source d'information homogène, commune, normalisée et
fiable. Cette centralisation permet surtout de s'abstraire de la
diversité des sources de données.
Une fois les données centralisées par un outil
d'ETL, celles-ci doivent être structurées au sein de
l'entrepôt de données. Cette étape est toujours faite par
un ETL grâce à un connecteur permettant l'écriture dans le
data warehouse. L'intégration est en fait un prétraitement ayant
pour but de faciliter l'accès aux données centralisées aux
outils d'analyse.
C'est lors de cette étape que les données sont
filtrées, triées, homogénéisées,
nettoyées et transformées en vue du maintien de la
cohérence d'ensemble.
I.2.4.3. La diffusion
Cette fonction appelée autrement Distribution a pour
rôle de mettre les données à disposition des utilisateurs.
L'objectif prioritaire de cette étape est de segmenter les
données en contextes informationnels fortement cohérents, simples
à utiliser et qui correspondent à une activité
particulière.
Ceci est dit dans la mesure où un entrepôt de
données peut héberger des centaines ou des milliers de variables
ou indicateurs, mais un contexte de diffusion ne présente que quelques
dizaines au maximum pour rester dans l'optique d'une simple exploitation.
Généralement un contexte de diffusion est
multidimensionnel, cela veut dire qu'il est modélisable sous forme d'un
hypercube et peut donc être mis à disposition via un outil
OLAP.
10
I.2.4.2. La présentation ou la restitution
Cette dernière étape, également
appelée Reporting, consiste à présenter les
informations à valeur ajoutée de telle sorte qu'elles
apparaissent de la façon la plus lisible possible dans le cadre de
l'aide à la décision. Les données sont principalement
modélisées par des représentations à base de
requêtes afin de constituer des tableaux de bord ou des rapports via des
outils d'analyse décisionnelle.
N.B : IL existe aussi une étape
appelée administration, qui est une fonction transversale
permettant de superviser la bonne exécution de toutes les autres
étapes et ainsi faire le contrôle du système
décisionnel lui-même.
Cette étape pilote le processus de la mise à
jour des données, la documentation sur les données, la
sécurité, les sauvegardes et la gestion des incidents.
I.2.5. Architecture globale d'un système
décisionnel
Avant d'entrer dans le vif du sujet, et passer à
l'étape explicite des éléments constituant l'environnement
d'un Data warehouse, il serait intéressant de connaitre le
positionnement de ces éléments dans une architecture globale d'un
système décisionnel.
Un système décisionnel est architecturé
globalement de la façon suivante :
· En amont un accès au système transactionnel
en lecture seule
· Un DWH fusionnant les données requises
· Un ETL permettant d'alimenter le DWH à partir des
données existantes
· Des applications d'exploitation de reporting, exploration
et/ou de prédiction
· D'éventuels DM permettant de simplifier le DWH en
vue de certaines applications.
11
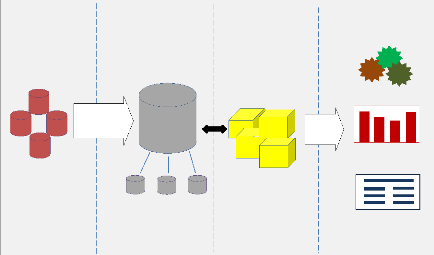
Sources des données Stockage des données
Conception des Restitution des
Extraire Transformer Charger
Data Marts Serveur/Cube OLAP
Data
Warehouse
vues métiers
Servir
Analyse & Statistiques
Requêtes & Rapports
vues métiers
Data Mining
? Intégrées
Les données de l'entrepôt proviennent de
différentes sources éventuellement
hétérogènes.
Figure 1: Architecture globale d'un système
décisionnel
I.3. Le Data warehouse
I.3.1. Définition
Selon Bill INMON : « un Data warehouse est
une collection de données orientées sujet,
intégrées, non volatiles et historiées, organisées
pour le support d'un processus d'aide à la décision. »
[4]
? Orientées sujet
Cela signifie que les données collectées doivent
être orientées « métiers » et donc triées
et
réorganisées par thème.
Donc :
? Les données sont organisées autour de sujets
majeurs de l'entreprise ;
? Données pour l'analyse et la modélisation en vue
de l'aide à la décision, et non pas pour
les opérations et transactions journalières ;
? Vue synthétique des données selon les sujets
intéressant les décideurs ;
12
L'intégration consiste à résoudre les
problèmes d'hétérogénéité des
systèmes de stockage, des modèles de données, de
sémantique de données.
? Non volatiles
Tout se conserve, rien ne se perd : cette
caractéristique est primordiale dans les Data warehouses. En effet, et
contrairement aux bases de données classiques, un Data Warehouse est
accessible en ajout ou en consultation uniquement. Les modifications et les
mises à jour ne sont pas autorisées sauf pour des cas
particuliers (correction d'erreurs par exemple). Une même requête
effectuée à intervalle de temps, en précisant la date
référence de l'information donnera le même
résultat.
? Historiées (données
datées)
La conservation de l'évolution des données dans
le temps, constitue une caractéristique majeure des Data warehouses.
Elle consiste à s'appuyer sur les résultats passés pour la
prise de décision et faire des prédictions ; autrement dit, la
conservation des données afin de mieux appréhender le
présent et d'anticiper le futur.
Eu égard à ce qui précède, nous
disons qu'un data warehouse ou entrepôt de données est une base de
données dédiée au stockage et à l'ensemble des
données utilisées dans le cadre de la prise de décision et
de l'analyse décisionnelle. Il est une vision centralisée et
universelle de toutes les informations de l'entreprise.
Il s'appuie alors non seulement à la
compréhension du fonctionnement actuel de l'entreprise et son pilotage
mais aussi l'anticipation des actions à venir.
I.3.2. Historique des Data warehouses
Dans une entreprise, le volume de données
traitées croît rapidement avec le temps. Ces données
peuvent provenir des fournisseurs, des clients, de la production, de
l'environnement, etc. Cette quantité de données augmente en
fonction du secteur et de l'activité de l'entreprise.
C'est à la suite des nouveaux besoins des entreprises
et aux quantités importantes de données produites par les
systèmes opérationnels, qu'est apparu pour la première
fois, en 1980 bien entendu le concept de « Data warehouse » ou «
Entrepôt de données ».
13
A cette époque, le Data warehouse était
perçu comme étant un simple environnement ou une nouvelle base
dans laquelle on logerait les informations que l'entreprise n'envisage pas
d'usage immédiat, « concept d'infocentre ».
Ce n'est qu'à partir de 1990 pratiquement, que cet
environnement est reconnu non seulement comme un lieu de collection, de
stockage, d'historisation et de journalisation des informations provenant des
bases de données opérationnelles mais aussi un socle
intégré de données conservées de manière
cohérente pour leur exploitation directe et ainsi permettre la prise des
décisions dans des entreprises.
I.3.3. Structure de données d'un Data
warehouse
Le Data Warehouse a une structure bien définie, selon
différents niveaux d'agrégation et de détail des
données. Cette structure est définie par Inmon comme suit :
? Données détaillées :
ce sont les données qui reflètent les
événements les plus récents, fréquemment
consultées, généralement volumineuses car elles sont d'un
niveau détaillé.
? Données détaillées
archivées : anciennes données rarement
sollicitées, généralement stockées dans un disque
de stockage de masse, peu coûteux, à un même niveau de
détail que les données détaillées.
? Données agrégées :
données agrégées à partir des
données détaillées.
? Données fortement agrégées :
données agrégées à partir des
données détaillées, à un niveau d'agrégation
plus élevé que les données agrégées.
? Métadonnées : ce sont les
informations relatives à la structure des données, les
méthodes d'agrégation et le lien entre les données
opérationnelles et celles du Data warehouse. Les
métadonnées doivent renseigner sur :
· Le modèle de données ;
· La structure des données telle qu'elle est vue par
les développeurs ;
· La structure des données telle qu'elle est vue par
les utilisateurs ;
· Les sources des données ;
· Les transformations nécessaires ;
· Suivi des alimentations.
14
I.3.4. Les composantes d'un Data warehouse
L'environnement du Data Warehouse est constitué
essentiellement de quatre éléments : le système
opérationnel source, la zone de préparation des données,
la zone de présentation des données et les outils d'accès
aux données.
? Les applications opérationnelles
sources
Ce sont les applications du système
opérationnel qui capturent les transactions de l'entreprise. Leurs
principales priorités sont la performance des traitements et la
disponibilité. Ces applications sont extérieures au Data
warehouse.
? Préparation des données
La préparation englobe tout ce qu'il y a entre les
applications opérationnelles sources et la présentation des
données. Elle est constituée d'un ensemble de processus
appelé ETL, « Extract, transform and Load », les
données sont extraites et stockées pour subir les transformations
nécessaires avant leur chargement.
Un point très important, dans l'aménagement
d'un entrepôt de données, est d'interdire aux utilisateurs
l'accès à la zone de préparation des données, qui
ne fournit aucun service de requête ou de présentation.
? Présentation des données
C'est le lieu où les données sont
organisées, stockées et offertes aux requêtes directes des
utilisateurs, aux programmes de reporting et autres applications d'analyse. Si
les données de la zone de préparation sont interdites aux
utilisateurs, la zone de présentation est tout ce que l'utilisateur voit
et touche par le biais des outils d'accès.
L'entrepôt de données est constitué d'un
ensemble de Data Mart. Ce dernier est défini comme étant une
miniaturisation d'un Data warehouse, construit autour d'un sujet précis
d'analyse ou consacré à un niveau départemental.
Cette différence de construction, autour d'un sujet ou
au niveau départemental, définit la façon
d'implémentation du Data mart au niveau de l'entrepôt.
15
? Outils d'accès aux données
C'est l'ensemble de moyens fournis aux utilisateurs du Data
warehouse pour exploiter la zone de présentation des données en
vue de prendre des décisions basées sur des analyses.
Ces outils varient des simples requêtes ad hoc aux
outils permettant l'application de forage de données plus complexes en
passant par l'évaluation, la prévision, l'application d'analyse
jusqu'à la génération de rapports. Environ quatre-vingt
à nonante pourcent des utilisateurs sont desservis par des applications
d'analyses préfabriquées, consistant essentiellement en
requêtes préétablies.
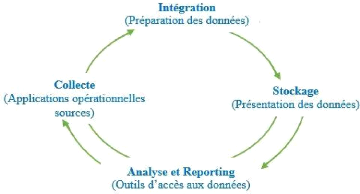
Figure 2: Composants du DWH refermant la boucle
Ce mode de traitement est transactionnel est destiné
aux métiers de l'entreprise pour les assister dans leurs tâches de
gestion.
16
I.3.5. Architecture d'un Data warehouse
La figure suivante nous renseigne de façon globale
l'architecture d'un entrepôt de données, et nous montre la
manière dont les données sont exploitées depuis leur
collecte et intégration jusqu'à leur exploration.
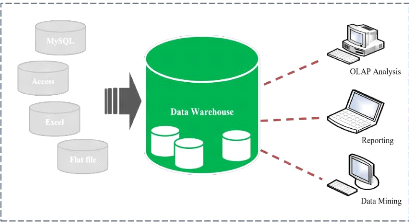
Figure 3: Architecture d'un Data Warehouse
I.4. Comparaison entre les systèmes
transactionnels et systèmes décisionnels
IL serait évident de s'interroger sur le pourquoi de
la réalisation d'une structure informatique décisionnelle alors
qu'il suffirait à l'utilisation d'un simple SGBD.
La réponse est que les objectifs de ces deux
systèmes sont quasiment différents car il y a d'une part un
système dédié aux transactions en temps réel,
à la gestion quotidienne (OLTP) et d'autre part un système
destiné à l'exécution des analyses et des questions
statistiques (OLAP).
I.4.1. OnLine Transaction Processing (OLTP)
Le traitement de transactions en ligne appelé OLTP est
un modèle ou un type d'applications qui s'inscrit dans les
systèmes opérationnels (SGBD).
17
L'objectif d'utilisation d'un tel système est
d'insérer, modifier et interroger rapidement la base de données
en toute sécurité. Ces actions doivent pourvoir être
effectuées en temps réel par des nombreux utilisateurs en
simultané.
I.4.2. OnLine Analytical Processing (OLAP)
Le traitement analytique en ligne appelé OLAP est un
type d'applications couramment utilisé en informatique
décisionnelle, dans le but d'aider la direction à avoir une vue
transversale de l'activité d'une entreprise.
Les applications de type OLAP, utilisées par les
entrepôts de données se fait uniquement en lecture et sont
orientées vers l'analyse sur-le-champ d'informations selon plusieurs
axes, dans le but d'obtenir des rapports de synthèse.
Pour effectuer l'analyse, les programmes consultent une
grande quantité de données. Les principaux objectifs sont de
regrouper et d'organiser des informations à partir de différentes
sources, les intégrer et les stocker afin de donner à l'usager
une vue axée métier, récupérer et analyser
l'information facilement et rapidement.
Le tableau suivant résume de façon non
exhaustive certains éléments de divergence entre les
systèmes transactionnels classiques et les systèmes
décisionnels par rapport à l'usage, aux transactions, au type
d'opérations, à la taille, etc.
Une table de faits est la table centrale d'un modèle
dimensionnel, qui représente un sujet à analyser et où les
mesures de performances sont stockées.
18
Tableau 1: Comparaison entre les systèmes
transactionnels et systèmes décisionnels
Caractéristiques
|
Le système transactionnel
OLTP
|
Le système
décisionnel
OLAP
|
Utilisation
|
-SGBD (Bases de production) -Les opérationnels
(Employés de bureau)
|
-Data Warehouse -Analystes/ décideurs
|
Opération typique
|
· Mise à jour
|
· Analyse
|
Données
|
· Détaillées
|
· Dérivées et agrégées
|
|
· Requêtes complexes et imprévisibles
|
|
· Résumées et globales
|
|
· Orientées sujet
|
|
· Historiques
|
|
· Statiques
|
|
|
Accès aux données
|
-Lecture / Ecriture
|
-Lecture seule
|
|
Transactions
|
-Petites, nombreuses
|
-Grosses, 1 par jour
|
|
Taille BD
|
-Faible (quelques GB)
|
-Importante (pouvant aller jusqu'à plusieurs TB)
|
|
Temps de réponse
|
-Instantané
|
-Réponse moins rapide (seconde à minutes)
|
I.5. Approche générale de la
modélisation dimensionnelle
Lorsqu'on fait un schéma dans la modélisation des
bases de données classiques, on parle de tables et de
relations. Une table étant une représentation
d'entité et une relation une technique pour lier ces entités.
Et bien en Business Intelligence, la modélisation
dimensionnelle parle en termes des Dimensions et des Faits.
Un modèle dimensionnel et/ou multidimensionnel est en fait la
combinaison de dimensions et de faits.
I.5.1. Les faits
C'est un modèle où la table de faits est au
coeur du schéma. Dans ce modèle, toutes les tables de dimension
de la structure sont directement liées à la table principale
(fait) et
19
En complément aux dimensions, les faits sont ce sur
quoi va porter l'analyse. Ce sont des tables qui contiennent des informations
opérationnelles et qui relatent la vie de l'entreprise.
Une ligne d'une table de faits correspond à une ou
plusieurs mesures. Une mesure est un attribut dans une table de faits. Ces
mesures sont généralement des valeurs numériques,
additives ; cependant des mesures textuelles peuvent exister mais sont rares.
Le concepteur doit faire son possible pour faire des mesures textuelles des
dimensions, car elles peuvent êtres corrélées efficacement
avec les autres attributs textuels de dimensions.
Dans les modèles dimensionnels, les tables de faits
expriment des relations de un à plusieurs entre les dimensions. Elles
comportent des clés étrangères, qui ne sont autres que les
clés primaires des tables de dimension.
I.5.2. Les dimensions
Les tables de dimension sont les tables qui permettent
d'interpréter et de raccompagner une table de faits ; elles contiennent
les descriptions textuelles de l'activité.
Le sujet analysé, c'est à dire le fait, est
analysé suivant différentes perspectives. Ces perspectives
correspondent à une catégorie utilisée pour
caractériser les mesures d'activité analysées ; on parle
de dimensions.
Un fait est une table qui contient les données
observables [les faits] que l'on possède sur un sujet et que l'on veut
analyser [les dimensions].
I.5.3. Différents modèles de la
modélisation dimensionnelle
Le concepteur d'un entrepôt de données est
appelé à faire le choix, lequel des modèles dimensionnels
appréhender pour bien représenter sa solution. Avant de faire
notre choix, les lignes qui suivent illustrent consisteront à expliciter
les types de modèles utilisés dans la modélisation
dimensionnelle et/ou multidimensionnelle.
I.5.4. Le modèle en Etoile
20
représente visuellement une étoile. Ce
schéma est le modèle de référence pour la
construction des data marts.
I.5.5. Le modèle en Flocon
C'est une technique de la modélisation dimensionnelle
dérivée du modèle en étoile qui consiste à
éclater ou à décomposer les dimensions. Dans ce
modèle, il y a des dimensions qui sont directement liées à
la table de faits et d'autres passent via d'autres dimensions, on parle de la
hiérarchie.
I.5.5. Le modèle en Constellation
Il s'agit d'une technique qui consiste à fusionner
plusieurs modèles en étoile et où plusieurs tables de
faits peuvent utiliser une table de dimension.
I.5.6. Les Data marts
Littéralement « Magasin de données »,
ce terme désigne un sous-ensemble du Data Warehouse contenant des
données de ce dernier pour un secteur particulier de l'entreprise.
Il doit être un ensemble de tables de données
organisées dans une structure qui favorise la lecture pour du reporting
analytique sur un historique plus important que celui conservé en
production.
Remarques : Un data warehouse et un data mart
se distinguent par le spectre qu'ils recouvrent:
? Le data warehouse recouvre l'ensemble des
données et problématiques d'analyse
visées par
l'entreprise.
? Le data mart recouvre une partie des
données et problématiques liées à un métier
ou
un sujet d'analyse en particulier.
Un data mart est fréquemment un sous-ensemble du data
warehouse de l'entreprise, obtenu par extraction et agrégation des
données de celui-ci.
21
I.5.7. Le cube OLAP
Le principe de la modélisation multidimensionnelle
stipule qu'un sujet à analyser doit être considéré
comme un point à plusieurs dimensions dans un espace. Les données
sont ensuite organisées de manière à mettre en
évidence le sujet analysé et les différentes perspectives
de l'analyse.
Le cube OLAP est donc une catégorie de logiciels
axés sur l'exploration et l'analyse rapide des données selon une
approche multidimensionnelle à plusieurs niveaux
d'agrégation. Il est aussi considéré
comme étant une méthode de stockage de données
sous
forme multidimensionnelle, généralement à des fins des
rapports.
I.5.8. Les attributs
Ce sont les éléments caractéristiques des
tables pour un modèle dimensionnel. Les tables de dimension et de faits
doivent avoir dans le cas échéant des clés techniques, des
clés de substitution, de clés étrangères et bien
d'autres attributs.
I.5.8.1. La clé technique ou de
substitution
Appelée parfois clé artificielle ou encore
clé de remplacement (surrogate key de l'anglais), la clé
technique désigne la clé primaire de la table de dimension car
elle est utilisée pour faire le lien avec la table de faits.
Indépendante du système source, cette clé est du type
entier et est généralement incrémenté
automatiquement à chaque insertion.
I.5.8.2. La clé fonctionnelle ou
opérationnelle
Appelées aussi clés des systèmes source,
les clés fonctionnelles permettent d'identifier de manière unique
un enregistrement de la dimension dans un système source.
I.6. Cycle de vie d'un modèle
dimensionnel
Avant d'étudier de plus près les
spécifications de la conception, du développement et du
déploiement d'un data warehouse, il faudrait exposer une
méthodologie globale tout en présentant le cycle de vie
dimensionnel.
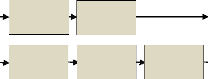
Modélisation dimensionnelle
Définition de
l'architecture technique
Sélection et
installation des
produits
Conception physique
Mise en route
Spécification de
l'application
d'analyse

Plan ning
du projet
Conception/Dév.
de la préparation
de
données
Maintenance et évolution
22
Le schéma suivant représente la succession des
tâches de haut niveau nécessaires à la conception, au
développement et au déploiement d'entrepôt de
données efficaces. Il décrit le cheminement du projet dans son
ensemble ; chaque rectangle sert de poteau d'indicateur ou de borne.
|
Définition des
besoins de
l'entreprise
|
|
Développement des applications
d'analyse
|
Gestion du projet
Figure 4: Digramme du cycle de vie d'un modèle
dimensionnel
I.7. Alimentation du Data warehouse
L'alimentation est une opération qui consiste à
effectuer la migration et la préparation des données provenant
des systèmes opérationnels vers l'entrepôt. Nous pouvons
conclure à notre niveau qu'alimenter un Data warehouse c'est simplement
lui intégrer les données des bases de production.
Cette phase utilise une série d'outils logiciels pour
la découverte, l'extraction, la transformation et le chargement des
données.
I.8. Les outils du décisionnel
La réalisation d'une architecture décisionnelle
exige un certain type d'outils et de logiciels pour sa mise en oeuvre, en voici
les principaux :
I.8.1. Extraction Transformation Loading
L'ETL pour ?Extraction Transformation Loading» ou
Extraction Transformation Chargement en Français, est un processus qui
permet de charger un data warehouse à partir
23
de données externes généralement issues de
bases transactionnelles. Son rôle est de récupérer ces
données et de les traiter pour qu'elles correspondent aux besoins du
modèle dimensionnel.
En général, les données sources doivent
être "nettoyées" et aménagées pour être
exploitables par les outils décisionnels.
Un processus ETL est simplement une copie des données
depuis les tables du système transactionnel vers les tables du
modèle dimensionnel.
Ce processus remplit trois fonctions principales :
I.8.1.1. L'extraction
Elle est la première phase du processus d'apport de
données à l'entrepôt. C'est une opération qui
consiste à cibler et à importer les données depuis une BD
extérieure vers la zone de préparation en vue de subir la
transformation.
I.8.1.2. La transformation
Elle est la deuxième phase du processus qui a
naturellement pour but de rendre les données cibles homogènes
afin qu'elles soient chargées de façon cohérente. Il faut
noter que les données sources qui alimentent le système
d'information décisionnel sont issues des systèmes
transactionnels de production, le plus souvent sous diverses formes.
La transformation est une phase qui effectue les
opérations de filtrage, d'agrégation, de conversion et de mise en
correspondance des données.
I.8.1.3. Le chargement
C'est la troisième et dernière phase du
processus ETL ou de l'alimentation de l'entrepôt. Elle consiste
simplement à charger les données nettoyées et
homogénéisées dans le DWH.
24
I.8.2. Les outils de Reporting
L'ensemble d'outils d'analyse décisionnelle qui
permettent de modéliser des représentations à bases de
requêtes afin de constituer les rapports, les tableaux de bord, s'appelle
le Reporting. Le reporting est l'application la plus utilisée
dans l'informatique décisionnelle, il permet aux décideurs de
:
+ Sélectionner des données par période,
production, secteur de clientèle, etc ;
+ Trier, regrouper ou répartir ces données selon
des critères de choix ;
+ Réaliser des calculs (totaux, moyennes, sommes,
pourcentages, écarts, comparatif, ...) ; + Présenter les
résultats de manière synthétique ou
détaillée, généralement sous forme de
graphiques.
Les programmes utilisés pour le reporting permettent de
faire varier certains critères pour affiner l'analyse. Des instruments
de type tableau de bord équipés de fonctions d'analyses
multidimensionnelles de type OLAP sont aussi utilisés sur cette
dernière partie du SID.
I.8.3. Les outils de data mining
Au sens littéral du terme, le Data mining signifie
« Forage de données ». C'est un ensemble de techniques
d'exploration et d'analyse d'une masse importante de données dans le but
de découvrir des tendances cachées ou des règles
significatives.
Les objectifs du data mining consistent à :
+ Prédire les conséquences d'un
événement ou d'une décision, se basant sur le
passé. + Découvrir de règles cachées : des
règles associatives, entre différents événements. +
Confirmer des hypothèses : des hypothèses proposées par
les analystes et décideurs, et les doter d'un degré de
confiance.
I.8.4. Les outils d'analyse
Comme on peut le voir, ses outils permettent d'effectuer
l'analyse statistique des données en mettant en évidence leurs
tendances ou corrélations entre les données non évidentes
à priori. Cette analyse prend effet après l'utilisation des cubes
dimensionnels ou cubes OLAP.
25
I.9. Conclusion
Voilà que nous avons pris connaissance des concepts
généraux et théoriques de la Business Intelligence, il est
temps pour nous de voler et de prendre une nouvelle allure considérable
pour le data warehousing.
Cependant une étude sur l'existant doit être de
mise, c'est-à-dire une étude perspicace sur la façon dont
les données sont stockées et la manière dont l'information
est manipulée dans l'entreprise ciblée.
C'est pourquoi nous réserverons le chapitre suivant
à cette besogne. A ce niveau, nous essayerons de découvrir une
quantité des données utilisées et en faire les
données conséquentes et importantes qui seront par la suite
intégrées dans la base décisionnelle.
26
CHAPITRE II : LE STOCKAGE DE DONNEES A LA
BRASIMBA
II.1. Introduction
L'analyse préalable est la première
étape dans l'élaboration du projet de type informatique ; elle
est une étude globale relativement grossière du problème
à traiter.
Elle consiste à inventorier les données et les
traitements actuellement utilisés dans le système en vue de
dégager les besoins et d'envisager l'opportunité d'optimiser
certaines tâches.
C'est en s'inscrivant dans ce même ordre d'idées
que ce chapitre aura l'objectif de s'intéresser sur comment s'effectue
le stockage des informations dans cette société, quels sont les
SGBD utilisés à cette fin, tout en faisant un rappel sur les BD
opérationnelles.
L'analyse des processus qui aboutissent à la vente
sera aussi effectuée dans cette partie de notre travail. Nous nous
intéresserons au processus de vente car c'est elle qui aura une
influence remarquable sur la décision de la production des marchandises
à la Brasimba.
II.2. Aperçu sur les systèmes
transactionnels
Avant de nous lancer sur l'étude pertinente des
éléments qui constituent les processus du système et son
enchainement, nous raflons d'abord sur cette partie qui consistera à
expliciter les éléments et les concepts liés à la
théorie sur les bases de données classiques, lesquelles bases de
données ont donné naissance aux entrepôts de
données.
II.2.1. Qu'est-ce qu'une base de
données
Plusieurs auteurs ont essayé de donner des
définitions plus ou moins parallèles sur les bases de
données, cela nous a conduit à dire qu'il n'existe pas une
définition nette et exacte de ce concept.
Mais la définition générale dit
simplement qu'une base de données pourrait être un ensemble
organisé d'informations ayant un objectif commun.
Peu importe le support utilisé pour rassembler et
stocker les données (papiers, fichiers...), dès lors que des
données sont rassemblées et stockées d'une manière
organisée
27
dans un but spécifique, nous pouvons parler d'une base
de données. Bien entendu, dans le cadre de ce travail, nous nous
intéressons aux bases de données informatisées.
Nous disons donc qu'une base de données
informatisée est un ensemble de données structurées,
organisées, enregistrées dans un support et accessibles par un
ordinateur dans le but de satisfaire une communauté d'utilisateurs
géographiquement repartis.
II.2.2. Problématique de la cohérence des
données
La création d'une base de données répond
aux besoins de rassembler les données qui possèdent un lien entre
elles, dans le but de retrouver l'information en utilisant des critères
de recherche basés sur le contenu de cette information. [5]
La condition sine qua non pour garantir la faisabilité
et la qualité d'une recherche de données par le contenu est la
cohérence des données. Certaines données non
cohérentes souffrent de plusieurs problèmes qui compromettent
leur consultation.
La cohérence des données est la
problématique fondamentale des bases des données. La
première et la plus importante des réponses à ce
problème consiste à limiter au maximum la redondance
d'informations. Il existe évidemment un nombre important de
méthodes qui permettent d'assurer la cohérence des
données.
II.2.3. Système de gestion de base de
données
La gestion et l'accès à une base de
données sont assurés par un ensemble de programmes qui
constituent le Système de Gestion de Base de Données. Un
SGBD héberge généralement plusieurs bases de
données, qui sont destinés à des logiciels ou à des
thématiques différentes.
En définitive, un SGBD est un ensemble coordonné
de logiciels ayant pour tâche de créer, de gérer,
d'interroger une base de données et permettre les opérations
d'insertion, de modification et de suppression des données de
celle-ci.
28
Les principaux objectifs des SGBD pour les données sont
d'assurer leur indépendance physique et logique, l'accès,
l'administration centralisée, la non-redondance, la cohérence, le
partage, la sécurité et la résistance aux pannes.
II.2.4. Enjeux des bases de données
Les bases de données jouent un rôle central et
croissant dans le développement des technologies de l'information depuis
plus d'une trentaine d'années. Les SGBD sont actuellement l'une des
technologies de l'Informatique les plus répandues et matures. Au
début, les bases de données se cantonnaient uniquement aux
systèmes d'information des entreprises.
Actuellement, il y a non seulement les entreprises mais nous
pouvons aussi observer que toute application informatique moderne utilise,
directement ou indirectement une base de données.
II.2.5. Modèle de données
relationnel
Le modèle relationnel représente la base de
données comme un ensemble de tables, sans préjuger de la
façon dont les informations sont stockées dans la machine. Les
tables constituent donc la structure logique du modèle relationnel.
Au niveau physique, le système est libre d'utiliser
n'importe quelle technique de stockage dès lors qu'il est possible de
relier ces structures à des tables au niveau logique. Les tables ne
représentent donc qu'une abstraction de l'enregistrement physique des
données en mémoire. De façon informelle, le modèle
relationnel peut être défini de la manière suivante :
? Les données sont organisées sous forme de tables
à deux dimensions ;
? Les données sont manipulées par des
opérations de l'algèbre relationnelle ;
? L'état cohérent de la base est défini par
un ensemble de contrainte d'intégrité.
29
II.2.6. Eléments constitutifs d'un modèle
relationnel
Tableau 2: Eléments constitutifs d'un modèle
relationnel
|
Eléments
|
Significations
|
|
Attribut
|
Est un identifiant (un nom) décrivant une information
stockée dans une base.
|
|
Domaine
|
Est un ensemble de valeurs qu'un attribut peut prendre.
|
|
Relation
|
|
|
Schéma de relation
|
Précise le nom de la relation ainsi que la liste des
valeurs avec leurs domaines.
|
|
Degré
|
Le degré d'une relation est son nombre d'attributs.
|
|
Occurrence
|
Est un élément de l'ensemble figuré par
une relation. Autrement dit, une occurrence est une ligne de la table qui
représente une relation.
|
|
Cardinalité
|
La cardinalité d'une relation est son nombre
d'occurrences. Cela veut dire le nombre de fois qu'une rela5on participe dans
une relation.
|
|
Clé candidate
|
La clé candidate d'une relation est un ensemble minimal
des attributs de la relation dont les valeurs identifient à coup
sûr une occurrence.
|
|
Clé primaire
|
La clé primaire d'une relation est une de ses
clés candidates.
|
|
Clé étrangère
|
Une clé étrangère dans une relation est
formée d'un ou plusieurs attributs qui constituent une clé
candidate dans une autre relation.
|
|
Schéma relationnel
|
Il est constitué par l'ensemble de schéma de
relation avec mention des clés étrangères.
|
II.3. Description des processus
Dans une entreprise de vente et de production, il existe
plusieurs étapes et processus à exécuter pour enfin avoir
un produit fabriqué qui sera ensuite vendu aux consommateurs. Ces
étapes sont généralement perpétuelles et suivent un
certain enchainement.
Nous éveillons notre intérêt à
expliciter sur les processus par les quels on passe pour que la
société aie un produit fini prêt à vendre ou
à écouler.
30
II.3.1. L'approvisionnement
Avant de fabriquer un produit, toute entreprise de production
a besoin de s'ouvrir sur ses marchés situés en amont, les
fournisseurs, pour pouvoir s'approvisionner en matière
première.
L'approvisionnement est un processus qui a pour but de
répondre aux besoins de l'entreprise en matière de produits ou de
services nécessaires à son fonctionnement.
A la Brasimba, ce service consiste à acheter, au bon
moment et au meilleur prix, les matières premières
(céréales, levure, houblon, arôme, sucre, additifs,...)
pour la fabrication des produits et les quantités nécessaires de
produits de qualité à des fournisseurs qui respectent les
délais de livraison.
Cette fonction est d'autant plus importante pour la
compétitivité de l'entreprise que le rapport qualité
coût des approvisionnements aura une incidence sur le rapport
qualité-coût de la production. Une bonne politique d'achat peut
donc permettre à une entreprise de réduire de manière
significative ses coûts de production et d'améliorer en
conséquence sa marge commerciale. Bien acheter permet à
l'entreprise d'accroître sa rentabilité.
L'approvisionnement concourt deux objectifs :
y' Des objectifs de coûts: qui permettent de
réduire les coûts d'achat et les coûts de stockage ;
y' Des objectifs de qualité pour
privilégier la qualité de l'approvisionnement, donc
réduire les malfaçons, les déchets et donc
améliorer la qualité finale des produits.
L'approvisionnent en matières premières est le
processus initial pour la fabrication d'un produit dans cette
société.
II.3.2. La Fabrication
La Brasimba met à la disposition des consommateurs des
produits. Elle dispose donc d'une unité au minimum, qui réunit
tous les moyens humains et techniques nécessaires à la
fabrication de ses produits. L'objectif du département de production est
la fabrication des gammes variées afin d'améliorer de
façon continue la gestion des flux et stocks inclus dans
Il y a des transporteurs attachés à ce service
qui permettent d'accomplir la tâche de livraison des produits à
des clients.
31
la chaîne de travail qui débute en amont avec les
fournisseurs et se termine en aval chez les clients intermédiaires ou
finaux.
Ce processus, appelée aussi chaine de production, est
un ensemble d'opérations de fabrication nécessaires, à la
réalisation d'un produit manufacturé, des matières
premières jusqu'à la transformation et la mise sur le
marché des produits finis.
Le processus de production ou de fabrication comporte les
étapes nécessaires entre autres le traitement de l'eau, la
réception des matières premières, le mélangeage des
ingrédients, la fabrication des concentrés, la
gazéification des produits, l'embouteillage des concentrés et de
leurs additifs, le soutirage du produit, le conditionnement,
l'expédition des produits finis,...
II.3.3. La Distribution
Le responsable de département de distribution a comme
rôle de coordonner les activités d'un ensemble de rayons (produits
de grande consommation...). Il met en oeuvre et gère la politique
commerciale et d'animation de son département en s'appuyant sur les
managers de rayon.
Ce département a le rôle de :
y' Préparer, diriger et coordonner les opérations
de stockage et de distribution ;
y' Diriger les activités d'organisation qui sont
engagées dans le stockage et dans la
distribution des produits ;
y' Diriger le personnel (Promoteurs) ;
y' Assurer la conformité avec les politiques et
réglementations.
Dans la ville de Lubumbashi, la distribution des produits et
gammes se fait par Zone commerciale (commune) et par secteur. Chaque commune
est gérée par un Manager et chaque secteur est géré
par un Promoteur.
32
II.3.4. La Vente
La Brasimba utilise un système de vente propre à
elle. Un système proposé par la Direction Commercial et
Marketing, qui fait évidemment des études du marché de
façon quotidienne dans la ville de Lubumbashi et ailleurs. Tous les
processus qui ont précédé concourent au même
résultat et au même objectif, celui d'écouler les produits
afin de maximiser les recettes.
Ce système possède des applications
installées sur des tablettes et stocke des informations de vente dans
les bases de données distinctes qui concernent soit un secteur ou
généralement une commune. Ces informations de vente sont
stockées en MySQL, en Microsoft Excel et en Microsoft Access.
Tous les processus utilisés jusqu'ici concourent
à la maximisation des recettes et à la gestion des ventes.
Nous représentons ci-après la liste de tous les
produits fabriqués et distribués par la Brasimba.
Tableau 3 : Liste de tous les produits de la Brasimba
|
Item
|
Désignation
|
Prix
|
Format
|
Vol Alcool
|
Catégorie
|
|
1
|
BOOSTER COLA
|
1300
|
VC33CL
|
7
|
Alcool Mix
|
|
2
|
BOOSTER PINA COLADA
|
1300
|
VC33CL
|
7
|
|
3
|
33EXPORT GM
|
1800
|
VC65CL
|
5
|
Bière
|
|
4
|
33EXPORT PM
|
830
|
VC33CL
|
5
|
|
5
|
BEAUFORT
|
1200
|
VC33CL
|
5
|
|
6
|
Castel GM
|
2400
|
VC65CL
|
5
|
|
7
|
Castel PM
|
1000
|
VC33CL
|
5
|
|
8
|
DOPPEL GM
|
2200
|
VC72CL
|
6
|
|
9
|
DOPPEL MM
|
2200
|
VC65CL
|
6
|
|
10
|
DOPPEL PM
|
1500
|
VC50CL
|
6
|
|
11
|
GUINESS
|
1800
|
VC33CL
|
6
|
|
12
|
SIMBA GM
|
2100
|
VC73CL
|
5
|
|
13
|
SIMBA MM
|
1700
|
VC65CL
|
4
|
|
14
|
SIMBA PM
|
900
|
VC33CL
|
5
|
|
15
|
SKOL GM
|
2000
|
VC72CL
|
5
|
|
16
|
SKOL MM65
|
1800
|
VC65CL
|
5
|
|
17
|
SKOL PM
|
1000
|
VC33CL
|
5
|
|
18
|
SKOL PM50
|
1300
|
VC50CL
|
5
|
|
33
|
|
|
|
|
|
|
19
|
TEMBO GM
|
2000
|
VC65CL
|
5
|
|
20
|
TEMBO MM
|
1700
|
VC60CL
|
6
|
|
21
|
TEMBO PM
|
900
|
VC33CL
|
6
|
|
22
|
XXL PET
|
1200
|
PET33CL
|
0
|
Boissons énergisantes
|
|
23
|
XXL VC
|
1000
|
VC30CL
|
0
|
|
|
|
|
|
|
|
|
24
|
DJINO ANANAS PETGM
|
900
|
PET50CL
|
0
|
Boissons gazeuses
|
|
25
|
DJINO ANANAS PETPM
|
450
|
PET30CL
|
0
|
|
26
|
DJINO ANANAS VCGM
|
800
|
VC60CL
|
0
|
|
27
|
DJINO ANANAS VCPM
|
400
|
VC30CL
|
0
|
|
28
|
DJINO COLA PETGM
|
900
|
PET50CL
|
0
|
|
29
|
DJINO COLA PETPM
|
450
|
PET33CL
|
0
|
|
30
|
DJINO COLA VCGM
|
800
|
VC60CL
|
0
|
|
31
|
DJINO COLA VCPM
|
400
|
VC30CL
|
0
|
|
32
|
DJINO GINGER PETPM
|
450
|
PET33CL
|
0
|
|
33
|
DJINO GRENADINE PETG
|
900
|
PET50CL
|
0
|
|
34
|
DJINO GRENADINE PETP
|
450
|
PET33CL
|
0
|
|
35
|
DJINO GRENADINE VCGM
|
800
|
VC60CL
|
0
|
|
36
|
DJINO GRENADINE VCPM
|
400
|
VC30CL
|
0
|
|
37
|
DJINO ORANGE PETGM
|
900
|
PET50CL
|
0
|
|
38
|
DJINO ORANGE PETPM
|
450
|
PET33CL
|
0
|
|
39
|
DJINO ORANGE VCGM
|
800
|
VC60CL
|
0
|
|
40
|
DJINO ORANGE VCPM
|
400
|
VC30CL
|
0
|
|
41
|
DJINO SODA PETGM
|
900
|
PET50CL
|
0
|
|
42
|
DJINO SODA PETPM
|
450
|
PET33CL
|
0
|
|
43
|
DJINO SODA VCGM
|
800
|
VC60CL
|
0
|
|
44
|
DJINO SODA VCPM
|
400
|
VC30CL
|
0
|
|
45
|
DJINO TONIC PETGM
|
900
|
PET50CL
|
0
|
|
46
|
DJINO TONIC PETPM
|
450
|
PET33CL
|
0
|
|
47
|
DJINO TONIC VCGM
|
800
|
VC60CL
|
0
|
|
48
|
DJINO TONIC VCPM
|
400
|
VC30CL
|
0
|
|
49
|
WORLD COLA GM
|
800
|
VC60CL
|
0
|
|
50
|
WORLD COLA PET
|
450
|
PET33CL
|
0
|
|
51
|
WORLD COLA PM
|
400
|
VC30CL
|
0
|
|
52
|
CRISTAL GM
|
400
|
PET150CL
|
0
|
Eau minérale
|
|
53
|
CRISTAL PM
|
400
|
PET50CL
|
0
|
33
II.3.5. Tableau de présentation de
données de ventes
Tableau 4: Exemple de la fiche de ventes pour le secteur
Ville-Est
|
Fiche des ventes
|
|
N°
|
Produit
|
UOM
|
Qte
|
P.U
|
P.T
|
Format
|
Client
|
|
1
|
CASTEL GM
|
CASIER/12
|
48
|
15.500
|
744.000
|
65CL
|
DEPOT KAS
|
|
2
|
SIMBA GM
|
CASIER/12
|
50
|
17.500
|
875.000
|
73CL
|
DEPOT KAS
|
|
3
|
33 EXPORT
|
CASIER/12
|
32
|
13.500
|
432.000
|
65CL
|
DEPOT KAS
|
|
4
|
TEMBO GM
|
CASIER/12
|
20
|
14.800
|
296.000
|
73CL
|
HEXAGONE
|
|
5
|
SKOL GM
|
CASIER/12
|
35
|
14.800
|
518.000
|
65CL
|
DEPOT KAS
|
|
6
|
GUINESS MM
|
CASIER/24
|
25
|
21.500
|
537.500
|
33CL
|
DEPOT KAS
|
|
7
|
DOPPEL MM
|
CASIER/12
|
25
|
14.800
|
370.000
|
50CL
|
DEPOT KAS
|
|
8
|
BEAUFORT
|
CASIER/24
|
28
|
21.000
|
588.000
|
33CL
|
DEPOT KAS
|
|
9
|
BOOSTER COLA
|
CASIER/24
|
25
|
21.000
|
525.000
|
33CL
|
DEPOT KAS
|
|
10
|
D'JINO
SODA
VCPM
|
FARDE/24
|
100
|
11.000
|
1.100.000
|
30CL
|
DEPOT KAS
|
|
11
|
XXL PET
|
FARDE/24
|
46
|
11.500
|
529.000
|
33CL
|
DEPOT KAS
|
|
12
|
CRISTAL GM
|
FARDE/6
|
120
|
4.500
|
540.000
|
1.5L
|
DEPOT KAS
|
|
|
|
|
|
|
|
|
|
Secteur
ZCom
Date
VILLE-EST
L'SHI
31/12/17
L'SHI
VILLE-EST
L'SHI
VILLE-EST
L'SHI
VILLE-EST
L'SHI
VILLE-EST
L'SHI
VILLE-EST
L'SHI
VILLE-EST
L'SHI
VILLE-EST
L'SHI
VILLE-EST
L'SHI
VILLE-EST
27/12/17
27/12/17
31/12/17
31/12/17
31/12/17
31/12/17
31/12/17
31/12/17
31/12/17
31/12/17
31/12/17
L'SHI
VILLE-EST
L'SHI
VILLE-EST
Source: Promoteur du secteur Ville-Est (Lumumba-30
Juin-Kasaï), Commune de Lubumbashi Date: 12 Mars 2018
Le tableau ci-haut représente la fiche que
détiennent les promoteurs pour établir leur rapport de ventes
hebdomadaires effectué dans le secteur. Ce rapport est
déposé au département Commercial où ces
informations sont enregistrées dans des bases de données.
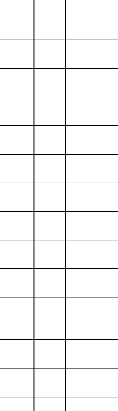
Le modèle logique de données y afférant est
illustré ci-dessous :
Après avoir distribué des produits aux clients,
là commence alors le processus de vente qui est suivi de près par
les promoteurs, et les managers des zones commerciales.
34
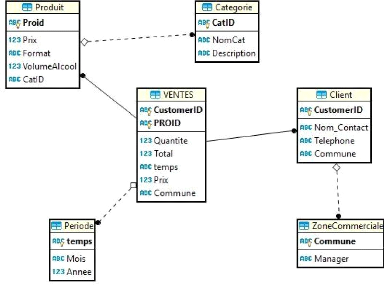
Figure 5: Modèle logique de données ventes
(sources opérationnelles)
II.4. Description textuelle
Nous rappelons ici que le circuit d'information se rapportant aux
processus de fabrication de la bière se déroule de la
manière suivante :
Le département d'approvisionnement se charge d'effectuer
de bons de commande pour l'achat des matières premières, produits
de première nécessité à la fabrication des
boissons.
Une fois l'entreprise approvisionnée en matières
premières, le département de production peut alors commencer son
travail de fabrication en passant par la transformation des matières
premières etc.
La présence des produits fabriqués, finis et
conditionnés génère le début d'un autre processus
qui est celui de la distribution des produits à des clients divers
à travers la ville.
35
Les promoteurs ont un travail quotidien de recueillir les
données de ventes pour chaque secteur et donnent le rapport aux managers
des zones commerciales qui par après enregistrent ces informations de
vente dans des bases de données.
Les données de vente recueillies par les promoteurs
sont déposées et sauvegardées dans des bases de
données par les managers des zones commerciales au niveau de leur
département.
II.5. Evaluation de l'intérêt du changement
II.5.1. Points forts
+ Le département commercial à travers ses
promoteurs éparpillés dans différents secteurs qui
ramènent hebdomadairement le rapport de ventes pour chaque secteur est
toujours présent, opérationnel et remplit bien ses
tâches;
+ Les rapports des ventes établis pour chaque secteur
et/ou chaque commune par les promoteurs et managers sont non seulement
stockés dans des bases de données mais aussi envoyés au
décideur afin de savoir le comportement de chaque produit.
+ Le stockage des données de ventes dans des fichiers
Excel, Access et MySQL sont à applaudir.
II.5.2. Points à améliorer
En ce qui concerne les points à améliorer, nous
remarquons qu'il y a :
+ Manque d'innovation dans la prise de décision dans la
mesure où la société ne peut attendre que quand elle
reçoit les rapports des ventes établis par les promoteurs pour
enfin décider quel produit pourrait-elle privilégier pour la
fabrication ;
+ Un engagement des dépenses remarquables d'argent pour
les salaires de tant de promoteurs que la société dispose alors
qu'il est possible de prendre des décisions sur base des données
déjà préenregistrées ;
+ L'absence d'une source efficace et permanente d'utilisation
et de réutilisation des données existantes qui permettrait
à l'entreprise d'avoir un soubassement d'aide à la
décision après analyse.
36
II.5.3. Améliorations attendues
Partant du diagnostic que nous venons d'effectuer ci-haut,
nous constatons que le département Commercial et Marketing a besoin
d'innover certains de ses traitements et nous proposons de :
? Mettre en place un système d'information
décisionnel capable de réutiliser et prêt à se
servir de données récoltées par le système dit
transactionnel ou opérationnel ;
? Concevoir un entrepôt de données ou Data
warehouse autour de ce système. Cet entrepôt facilitera la
tâche aux décideurs d'effectuer des analyses sur ces
données déjà intégrées ou
agrégées afin de prendre des décisions sur les produits
qu'il faudra privilégier pour la fabrication ;
? Construire des tableaux de bord en passant bien
évidemment par le reporting pour permettre aux décideurs de
savoir le comportement de leurs produits et leurs tendances face aux
clients.
II.6. Conclusion
Il a été question dans ce chapitre, de
présenter notre champ de recherche. Nous nous sommes basés
surtout à identifier les processus qui concourent à la vente des
produits à la Brasimba.
Nous avons mis notre intérêt à partir du
processus d'approvisionnement des matières premières, de
fabrication, de distribution et de l'écoulement de la marchandise
jusqu'au stockage de informations de ventes dans des fichiers
appropriés.
Dans le chapitre qui suit, il sera question d'intégrer
ces données en passant préalablement par la modélisation
du système décisionnel en question.
37
CHAPITRE III : ANALYSE FONCTIONNELLE III.1.
Introduction
Rechercher et caractériser les fonctions offertes par
un produit ou un système pour satisfaire les besoins des utilisateurs,
tel est le rôle de l'analyse fonctionnelle.
Cette partie de notre travail se résume à
effectuer la modélisation de notre système. Pour mener à
bien la démarche de ce projet, nous subdivisons ce chapitre en deux
parties essentielles dont la première consiste à la
modélisation proprement dite du système et la deuxième
consistera à la modélisation dimensionnelle.
III.2. Modélisation du système
III.2.1. Présentation de la méthode UP et
du langage UML
Le Processus Unifié (PU ou UP en anglais pour
Unified Process) est une méthode de développement pour les
logiciels orientés objets. Elle est une méthode
générique, itérative et incrémentale. Cette
méthode nous sert à compléter la systémique des
modèles ou diagrammes UML.
Le langage de modélisation unifié (UML en
anglais pour Unified Modeling process) est un langage de
modélisation graphique à bases des pictogrammes conçu pour
fournir une méthode normalisée pour visualiser la conception d'un
système.
Ce langage nous offre un standard de modélisation,
lequel nous permet de spécifier, visualiser, modifier, construire et
représenter l'architecture logicielle en mettant en évidence des
éléments représentables tels que les acteurs, les
processus, le schéma de bases de données, les composants
logiciels, etc.
III.2.2. Identification des profils
utilisateurs
Le système décisionnel dont nous concevons sera
géré en amont par les administrateurs et manipulé en aval
par les autres utilisateurs ou les analystes. Évidemment qu'il ne
concerne pas tous les utilisateurs de l'entreprise, il est plutôt
dédié aux managers,
38
aux analystes de l'entreprise, les personnes ayant
l'habileté de prendre les décisions dans la
société.
Un acteur est l'idéalisation d'un rôle
joué par une personne externe, un processus ou un objet qui interagit
avec un système. Las acteurs sont donc à l'extérieur du
système et dialoguent avec lui. Le tableau suivant nous montre la liste
des acteurs qui utiliseront le système.
Tableau 5: Tableau des acteurs
|
Acteur
|
Rôle
|
|
1
|
Administrateur
|
Cet acteur a le rôle de collecter les données
externes afin de les charger dans l'entrepôt de données.
|
|
2
|
Analyste
|
Cet acteur est chargé de se connecter à
l'entrepôt et faire des
analyses des données sur les données
intégrées par
l'administrateur.
|
III.2.3. Diagramme de cas d'utilisation
Dans la plupart de cas, la maitrise d'ouvrage et les
utilisateurs des systèmes dans des entreprises ne sont forcément
pas informaticiens. Il leur faut donc un moyen pour exprimer leurs besoins.
C'est précisément le rôle des diagrammes de cas
d'utilisation qui permettent de recueillir, d'analyser et d'organiser les
besoins, et de recenser les grandes fonctionnalités du
système.
Un diagramme de cas d'utilisation (CU) capture le comportement
d'un système, d'un sous-système, d'une classe ou d'un composant
tel qu'un utilisateur extérieur le voit [6]. Il scinde la
fonctionnalité du système en unités cohérentes, les
cas d'utilisation, ayant un sens pour les acteurs.
La représentation d'un cas d'utilisation met en jeu
trois concepts : l'acteur, le cas d'utilisation et l'interaction entre l'acteur
et le cas d'utilisation.
Nous représentons dans ce travail les diagrammes de
séquences qui semblent importants et qui nous exhibent des
fonctionnalités pertinentes de notre système.
39
III.2.4. Cas d'utilisation
Un cas d'utilisation est une entité
cohérente d'une fonctionnalité visible de l'extérieur. Il
réalise un service de bout en bout, avec un déclenchement, un
déroulement et une fin. Un CU modélise donc un service rendu par
le système, sans importer le mode de réalisation de ce
service.
Il représente un ensemble de séquences d'actions
qui sont réalisées par le système et qui produisent un
résultat observable intéressant pour un acteur.
Le diagramme de CU de notre système est
représenté ci-dessous :
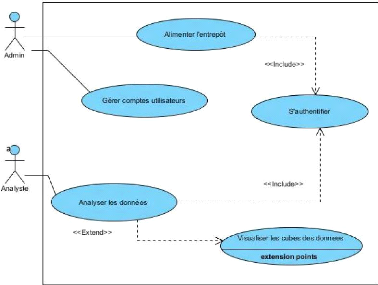
Figure 6 : Diagramme de cas d'utilisation du système
décisionnel
III.2.5. Diagrammes de séquences
Les diagrammes de séquences ont comme objectif de
représenter les interactions entre objets et les messages que ces objets
échangent lors de leur interaction.
40
III.2.5.1. DSS DU CU « S'authentifier
»
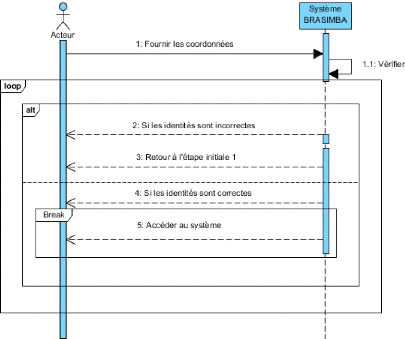
Figure 7:DSS DU CU « S'authentifier »
III.2.5.2. Description textuelle du CU «
S'authentifier »
+ Nom : S'authentifier
+ Résumé : L'utilisateur doit pouvoir introduire
ses coordonnées
d'authentification pour être identifié dans le
système.
+ Acteurs impliqués : Utilisateur
+ Date de création : 23 Juin 2018
+ Date de mise à jour : 28 Août 2018
+ Nom du responsable : Cédric Massamba
+ Numéro de version : 1.0
+ Pré-conditions : L'utilisateur doit
préalablement exister dans le système.
:
+ Scénario nominal
1. Le système affiche le formulaire d'authentification
;
Figure 8 : DSS DU CU « Alimenter l'entrepôt
»
41
2. L'utilisateur introduit son nom d'utilisateur, le mot de
passe et valide ;
3. Accès au système et ouverture de la session.
? Scénario alternatif :
2.a. Si les coordonnées d'authentification sont
incorrectes, le système bloque le processus et ramène
l'utilisateur à l'étape 2.
? Post condition : Ouverture de la session.
III.2.5.3. DSS DU CU « Alimenter l'entrepôt
»
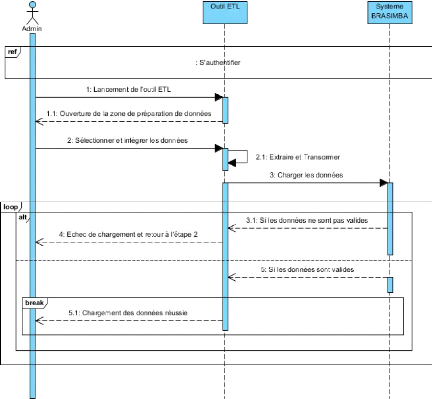
42
III.2.5.4. Description textuelle du CU «
Alimenter l'entrepôt »
+ Nom : Alimenter entrepôt
+ Résumé : L'administrateur sélectionne
les données externes et les
intègre dans le data warehouse.
+ Acteurs impliqués : Administrateur
+ Date de création : 23 Juin 2018
+ Date de mise à jour : 29 Août 2018
+ Nom du responsable : Cédric Massamba
+ Numéro de version : 1.0
+ Pré-conditions : Les sources externes doivent
être disponibles.
:
+ Scénario nominal
1. L'administrateur importe les sources externes vers la zone de
préparation de données ;
2. Le système extrait, transforme et charge les
données dans le data warehouse ;
3. L'administrateur charge les données dans
l'entrepôt.
+ Scénario alternatif :
2.a. Si les données externes sont incohérentes
ou incompatibles avec la table de destination, le système bloque le
processus et ramène l'administrateur à l'étape 1.
+ Post condition : Intégration des données dans le
data warehouse réussie.
43
III.2.4.4. DSS DU CU « Gérer comptes
utilisateurs »
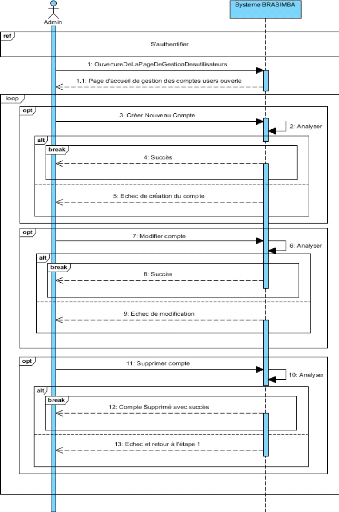
Figure 9: DSS DU CU "Gérer comptes
utilisateurs"
44
III.2.5.5. Description textuelle du CU «
Gérer comptes utilisateurs »
+ Nom : Gérer comptes utilisateurs
+ Résumé : L'administrateur gère les comptes
des utilisateurs et/ou analystes du
système. Il peut ajouter un nouveau compte, le modifier ou
le supprimer.
+ Acteurs primaire : Administrateur
+ Acteur secondaire : Analyste
+ Date de création : 24 Juin 2018
+ Date de mise à jour : 30 Août 2018
+ Nom du responsable : Cédric Massamba
+ Numéro de version : 1.0
+ Pré-conditions : S'authentifier, être
administrateur et avoir des comptes utilisateurs
disponibles dans le
système.
+ Scénario nominal :
1. L'administrateur demande l'ouverture du formulaire de
gestion des comptes utilisateurs ;
2. Le système lui demande de s'authentifier ;
3. L'administrateur saisit ses coordonnées
d'authentification ;
4. Le système affiche la page de gestion de comptes
des utilisateurs
5. L'administrateur choisit une opération à
effectuer (Ajouter, Modifier ou supprimer un compte utilisateur) ;
6. Le système affiche la page d'ajout, de modification
ou de suppression de compte utilisateur ;
7. L'administrateur remplit les coordonnées, valide et
envoie le formulaire au système ;
8. Le système met à jour les coordonnées
de l'utilisateur;
+ Scénario alternatif :
3.a. Les informations d'authentification erronées : le
système bloque le processus et retour à l'étape 2 du
scénario nominal.
7.b. Formulaire mal rempli : le système affiche le message
d'erreur et retourne à l'étape 6.
+ Post condition : Intégration des données dans le
data warehouse
réussie.
45
III.2.5.6. DSS DU CU « Analyser les données
»
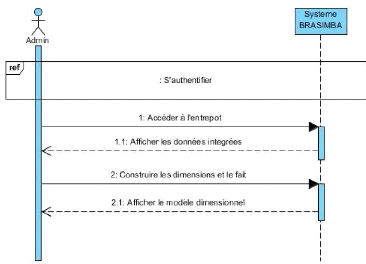
Figure 10: DSS DU CU « Analyser les données
»
III.2.5.7. Description textuelle du CU « Analyser
les données »
+ Nom : Analyser les données
+ Résumé : L'analyste fait des analyses et
l'exploration des données du DWH.
+ Acteurs primaire : Analyste
+ Acteur secondaire : ---
+ Date de création : 24 Juin 2018
+ Date de mise à jour : 01 Septembre 2018 + Nom du
responsable : Cédric Massamba + Numéro de version : 1.1
+ Pré-conditions : S'authentifier, accéder à
l'entrepôt.
+ Scénario nominal :
1. Le système affiche à l'analyste le formulaire
d'authentification ;
2. L'analyste insère des coordonnées pour
s'authentifier au système ;
3. Le système ouvre la session ;
4. L'analyste accède au data warehouse ;
5. Le système affiche la structure complète du
modèle de BD ;
46
6. L'analyste construit le modèle dimensionnel logique
comprenant les mesures et les dimensions, axes d'analyse.
+ Scénario alternatif :
2.a. Les informations d'authentification insérées
non valides : le système
bloque le processus et retour à l'étape 1 du
scénario nominal.
5.b. Absence de connexion à la source de données
(Dwh) : le système affiche le message d'erreur et retourne à
l'étape 4.
+ Post condition : Modèle dimensionnel construit.
III.2.5.8. DSS DU CU « Visualiser les cubes des
données »
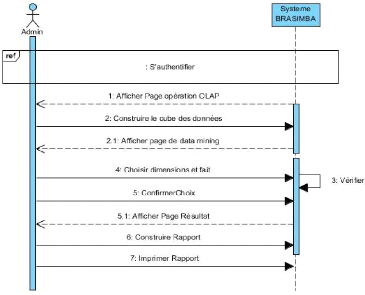
Figure 11 : DSS DU CU « Visualiser les cubes des
données »
III.2.5.9. Description textuelle du CU « Visualiser
les cubes des données »
+ Nom : Visualiser les cubes des données
+ Résumé : L'analyste se connecte à
l'entrepôt pour faire des analyses les
données intégrées.
+ Acteurs primaire : Analyste + Acteur secondaire : ---
47
+ Date de création : 24 Juin 2018
+ Date de mise à jour : 01 Septembre 2018 + Nom du
responsable : Cédric Massamba + Numéro de version : 1.1
+ Pré-conditions : Accéder à
l'entrepôt, modèle dimensionnel disponible.
+ Scénario nominal :
1. Le système affiche la page de création des
cubes OLAP;
2. L'analyste construit le cube sur base des dimensions, faits
et mesures ;
3. Le système valide et affiche le cube;
4. L'analyste conçoit le rapport et/ou le tableau de bord
;
5. L'analyste affiche et publie le résultat.
+ Scénario alternatif :
4.a. Si le cube n'est pas construit le système bloque le
processus et ramène l'utilisateur à l'étape 1.
+ Post condition : Production du rapport.
III.2.6. Diagramme de classes de
participantes
III.2.6.1. DCP du CU « S'authentifier
»

Figure 12:DCP du CU « S'authentifier »

48
III.2.6.2. DCP du CU « alimenter entrepôt
»
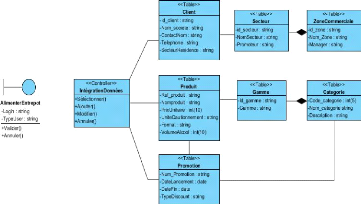
Figure 13: DCP du CU « alimenter entrepôt
»
III.2.6.3. DCP du CU « Gérer comptes
utilisateurs »

Figure 14: DCP du CU « Gérer comptes utilisateurs
»
49
III.2.6.4. DCP du CU « Analyser les données
»
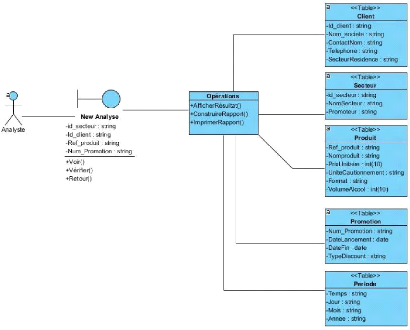
Figure 15: DCP du CU « Analyser les données
»
50
III.2.6.5. DCP du CU « Visualiser les cubes des
données »
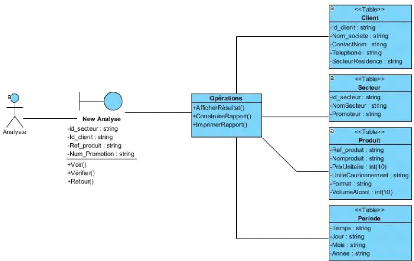
Figure 16: DCP du CU « Visualiser les cubes des
données »
51
III.2.7. Diagramme de classes de conception
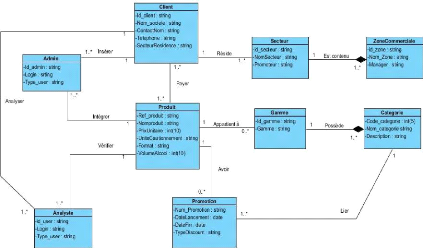
Figure 17 : Diagramme de classes de conception
III.2.8. Modèle logique des
données
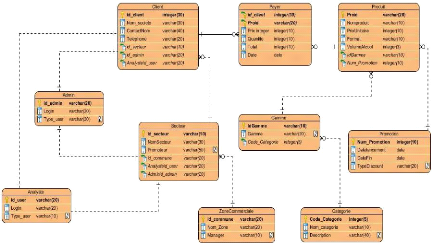
Figure 18: Modèle logique des données
52
III.3. Modélisation dimensionnelle
III.3.1. Principes de la modélisation
dimensionnelle
« La modélisation dimensionnelle est le
résultat d'une analyse des besoins, ce que je souhaite
étudier et d'une analyse des données disponibles, ce que
je peux étudier » [7].
La méthodologie générale de la
modélisation dimensionnelle exige à ce que tout concepteur des
entrepôts de données effectue une analyse perspicace des
données. Cette analyse permet d'effectuer :
? Une étude sur les données (quantification,
analyse générales);
? Une qualification des données (qualité et
intérêt) ;
? Une intégration logique des données (simulation
d'un schéma relationnel virtuel).
III.3.2. Présentation des modèles
dimensionnels III.3.2.1. Modèle en flocon
Le modèle en flocon est un modèle pour lequel
chaque dimension est représentée avec plusieurs tables. Ce
modèle consiste à décomposer les dimensions du
modèle en étoile en sous-hiérarchies.
53
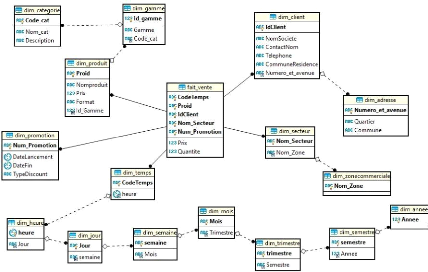
Figure 19: Modèle dimensionnel en flocon
Nous remarquons sur la figure ci-dessus que l'avantage de la
modélisation en flocon ou du modèle en flocon est de formaliser
une hiérarchie entre deux dimensions.
Par contre son inconvénient est que ce modèle
induit une normalisation des dimensions générant une plus grande
complexité en termes de lisibilité et de gestion aux
utilisateurs.
« Les représentations en flocon sont
déconseillées en général en raison de sa
complexité et de son appréhension difficile par l'utilisateur.
» [8]
Afin de vouloir rendre le modèle moins complexe et
faciliter la prise en main aisée des utilisateurs, il est
conseillé d'utiliser le modèle en étoile.
III.3.2.2. Modèle en Etoile
Le modèle en étoile centre la table des faits et la
relie à chaque table de dimension ou axe d'analyse. Ce modèle
permet une économie de jointure à l'interrogation, ce qui le rend
optimisé pour les requêtes d'analyse.
54
III.3.3. Choix du sujet d'analyse : le Fait
Vente
Tous les traitements d'informations et opérations
effectués à la Brasimba en général et au
département commercial en particulier convergent écouler les
produits, maximiser les ventes.
Raison pour laquelle la vente est choisie comme
étant notre point focal dans notre analyse. Elle est une table de fait
dans notre modèle dimensionnel et c'est sur celle-ci que porteront
toutes les analyses pour enfin produire des statistiques de consommation des
produits à travers les sept communes de la ville de Lubumbashi et
à une période donnée.
III.3.4. Les mesures
Appelées autrement métriques ou faits, les
mesures sont des éléments indicateurs de performance, les valeurs
numériques qui accompagnent une table des faits et qui sont
généralement calculées. [9]
Dans notre cas, les mesures sont entre autres :
? La quantité totale de tous les produits vendus au
cours d'une certaine période pour toute la ville de Lubumbashi;
? La quantité totale de tous les produits vendus au
cours d'une certaine période dans une entité géographique
;
? Le montant de toutes les ventes effectuées dans une zone
commerciale ;
? Le montant de toutes les ventes récoltées pour un
produit, etc.
III.3.5. Choix d'axes d'analyse : les
dimensions
Une dimension permet de modéliser une perspective de
l'analyse. Elle est l'axe sur lequel une analyse peut être faite. Notre
modèle en étoile que nous avons schématisé contient
les dimensions suivantes :
? La dimension Produit
Elle contient les attributs propres aux produits
fabriqués. C'est une table qui reprend la liste de tous les produits
fabriqués au sein de la brasserie. Le tableau suivant liste les
propriétés qui y affèrent.
55
Tableau 6: Liste de propriétés de la dimension
Produit
|
N°
|
Désignation
|
Détails
|
|
1
|
Proid
|
PROduct IDentifier, la clé artificielle de la dimension
Produit.
|
|
2
|
Prix
|
Le prix unitaire de chaque produit.
|
|
3
|
Format
|
Le format des bouteilles de chaque produit.
|
|
4
|
VolumeAlcool
|
Le volume d'alcool de tout produit.
|
|
5
|
Categorie
|
La catégorie dans laquelle un produit est
identifié.
|
? La dimension Client
Elle fait référence à tous les clients
enregistrés dans les systèmes de la Brasimba. Elle permettra de
classer les clients par catégorie selon leur chiffre mouvement d'achat ;
cette table renseigne aussi les préférences des gouts des
clients. Un client ici représente le nom de la société
cliente.
Tableau 7: Liste de propriétés de la dimension
Client
|
N°
|
Désignation
|
Détails
|
|
1
|
Customer_ID
|
Cette propriété permet d'identifier de
façon unique un client.
|
|
2
|
Telephone
|
Le numéro de téléphone pour la
société.
|
|
3
|
Commune
|
L'entité géographique de résidence d'un
client.
|
|
4
|
Nom_contact
|
Le nom de la personne responsable.
|
? La dimension Période
Dans l'avènement de prise des décisions, il est
important de savoir quelle est la période est associée la vente
d'un ou d'un tel produit. Dans notre travail, une période est
caractérisée par les sept jours d'une semaine. Et comme l'analyse
de notre projet se portera sur dix-sept mois, soit de Janvier 2018 à mai
2018, nous aurons soixante-huit périodes.
Tableau 8 : Liste de propriétés de la dimension
Periode
|
N°
|
Désignation
|
Détails
|
|
1
|
temps
|
La clé artificielle qui identifie de façon
unique une période
|
|
2
|
Mois
|
Le mois
|
|
3
|
Annee
|
Année à laquelle peut s'effectuer une analyse.
|
56
? La dimension ZoneCommerciale
La zone commerciale représente l'entité dans
laquelle une vente est effectuée, elle nous donne aussi la liste de tous
les clients appartenant à une commune. Dans cette dimension, l'analyse
portera sur le fait de savoir le produit le plus vendu dans une entité
commerciale.
Tableau 9: Liste de propriétés de la dimension
ZoneCommerciale
|
N°
|
Désignation
|
Détails
|
|
1
|
Commune
|
Cette propriété permet d'identifier de
façon unique un client. Un client ici représente le nom de la
société cliente.
|
|
2
|
Manager
|
Le numéro de téléphone pour la
société.
|
Le tableau suivant nous montre les propriétés et
les mesures de notre table des faits Vente :
Tableau 10: Liste des propriétés de la table
des faits Vente
|
N°
|
Désignation
|
Détails
|
|
1
|
Proid
|
La clé étrangère qui
référencie la dimension Produit, faisant aussi partie de
la clé artificielle de la table des faits Vente.
|
|
2
|
Customer_ID
|
La clé étrangère de la dimension
Client, qui fait partie de la clé artificielle de la table des
faits Vente.
|
|
3
|
Temps
|
La clé étrangère de la dimension
Periode, qui fait partie de la clé artificielle de la table des
faits Vente.
|
|
4
|
Prix
|
Le prix du produit. C'est l'une de mesures de la table des
faits Vente.
|
|
5
|
Quantité
|
La quantité vendue d'un produit. C'est l'une des
mesures de la table des faits Vente.
|
|
6
|
Total
|
Le montant total des ventes. Cette propriété est
l'une des mesures de la table des faits Vente.
|
57
III.4. Exportation du MLD en SQL III.4.1. Structures des
tables
CREATE TABLE `categorie` (
`CatID` varchar(10) NOT NULL,
`NomCat` varchar(40) NOT NULL,
`Description` varchar(60) DEFAULT NULL, PRIMARY KEY
ÇCatID`));
CREATE TABLE `client` (
`CustomerID` varchar(40) NOT NULL, `Nom_Contact` varchar(60) NOT
NULL, `Telephone` varchar(15) DEFAULT NULL, `Commune` varchar(20) DEFAULT
NULL);
CREATE TABLE `periode` (
`Temps` varchar(20) NOT NULL, `Mois` varchar(15) NOT NULL,
`Annee` int(11) NOT NULL);
CREATE TABLE `produit` (
`Proid` varchar(20) NOT NULL, `Prix` int(11) NOT NULL,
`Format` varchar(20) DEFAULT NULL, `VolumeAlcool` int(11) DEFAULT
NULL,
`CatID` varchar(20) NOT NULL);
CREATE TABLE `ventes` (
`CustomerID` varchar(40) NOT NULL, `Proid` varchar(20) NOT NULL,
`Prix` int(11) NOT NULL,
`Quantite` int(11) NOT NULL, `Total` int(11) NOT NULL, `temps`
varchar(20) NOT NULL );
CREATE TABLE `zonecommerciale` ( `Commune` varchar(20) NOT
NULL,
`Manager` varchar(30) DEFAULT NULL);
58
III.4.2. Index pour les tables
déchargées
ALTER TABLE `categorie`
ADD PRIMARY KEY (`CatID`);
ALTER TABLE `client`
ADD PRIMARY KEY (`CustomerID`),
ADD KEY `FK_Client_zonecommerciale_Commune` (`Commune`);
ALTER TABLE `periode`
ADD PRIMARY KEY (`Temps`);
ALTER TABLE `produit`
ADD PRIMARY KEY (`Proid`),
ADD KEY `FK_Produit_categorie_CatID` (`CatID`);
ALTER TABLE `ventes`
ADD PRIMARY KEY (`CustomerID`,`Proid`),
ADD KEY `FK_Ventes_produit_Proid` (`Proid`), ADD KEY
`FK_Ventes_periode_Temps` (`temps`);
ALTER TABLE `zonecommerciale` ADD PRIMARY KEY (`Commune`);
ALTER TABLE `client`
ADD CONSTRAINT `FK_Client_zonecommerciale_Commune` FOREIGN KEY
(`Commune`) REFERENCES `zonecommerciale` (`Commune`) ON DELETE CASCADE ON
UPDATE CASCADE;
ALTER TABLE `produit`
ADD CONSTRAINT `FK_Produit_categorie_CatID` FOREIGN KEY
(`CatID`) REFERENCES `categorie` (`CatID`) ON DELETE CASCADE ON UPDATE
CASCADE;
ALTER TABLE `ventes`
ADD CONSTRAINT `FK_Ventes_client_CustomerID` FOREIGN KEY
(`CustomerID`) REFERENCES `client` (`CustomerID`) ON DELETE CASCADE ON UPDATE
CASCADE,
ADD CONSTRAINT `FK_Ventes_periode_Temps` FOREIGN KEY (`temps`)
REFERENCES `periode` (`Temps`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `FK_Ventes_produit_Proid` FOREIGN KEY (`Proid`)
REFERENCES `produit` (`Proid`) ON DELETE CASCADE ON UPDATE CASCADE;
COMMIT;
Le schéma en étoile fini et simplifié de
notre entrepôt contiendra quatre dimensions illustrées ci-haut
entourant la table des faits et qui forment une étoile.
III.4.3. Présentation du modèle
dimensionnel en étoile
59
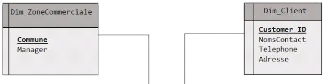
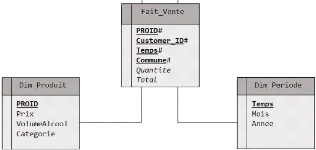
Figure 20 : Modèle dimensionnel en étoile du
fait Vente
III.5. Conclusion
Lorsqu'on veut mettre en place une nouvelle solution, dans notre
domaine, on doit préalablement étudier ou faire une analyse
judicieuse de la situation existante et des besoins.
Cette étape est suivie par celle de la création
d'une série des modèles permettant de représenter tous les
aspects importants, et à partir de ces modèles, on obtient alors
la route de passer à l'implémentation de la nouvelle solution
retenue.
Ayant fini à comprendre le fonctionnement du
système et à faire de l'analyse fonctionnelle de ce projet, le
chapitre qui suit sera consacré au déploiement de la solution
retenue qui est la mise place d'un système d'information
décisionnel.
60
CHAPITRE IV : ARCHITECTURE LOGICIELLE
IV.1. Introduction
L'implémentation est une étape qui consiste
à réaliser la phase finale d'élaboration d'un
système qui permet au matériel, aux logiciels et aux
procédures d'entrer en fonction.
Le déploiement d'un système décisionnel
nécessite l'usage et fait appels à un certain nombre d'outils
nécessaires à sa mise en oeuvre.
Ce chapitre se base sur premièrement sur la mise en place
et présentation de l'architecture technique en passant évidemment
par les outils utilisés dans le nouveau système d'aide à
la prise des décisions.
En deuxième lieu, c'est dans cette partie de notre
travail que nous mettrons un accent sur le pourquoi et l'impact même du
déploiement d'un système décisionnel dans une
société de vente et de production comme Brasimba.
IV.2. Sources de données
opérationnelles
Le Datapumping est une étape qui consiste à
collecter et à identifier les informations sources qui seront par la
suite alimentées dans le data warehouse.
Cette partie consiste donc à identifier le format de
données collectées depuis les sources opérationnelles,
lesquelles données sont considérées comme matières
premières de notre entrepôt.
Comme notre étude se porte sur l'analyse des ventes
à travers la ville de Lubumbashi qui compte sept communes faisant office
sept zones commerciales, nous présentons ici les types de sources de
données utilisés pour le stockage de ces informations.
Microsoft Excel est un logiciel tableur de la suite
bureautique Microsoft Office développé et distribué par
l'éditeur Microsoft.
IV.2.1. Microsoft Office Excel
61
Ce logiciel fonctionne sur les plates-formes Microsoft
Windows, Mac OS X, Android ou Linux. Le logiciel Excel intègre des
fonctions de calcul numérique, de représentation graphique,
d'analyse de données et de programmation, laquelle utilise les macros
écrites dans le langage VBA qui est commun aux autres logiciels de
Microsoft Office.
Le département commercial de la Brasimba utilise la
version la plus récente d'Excel 2016 pour stocker les informations pour
les communes de la Ruashi et de Kampemba.

RUASHI KAMPEMBA
Figure 21: Représentation des sources Excel
IV.2.2. Microsoft Office Access
Microsoft Office Access est une base de données
relationnelle éditée par Microsoft, faisant partie de la suite
Microsoft Office.
Il est composé de plusieurs programmes : le moteur de
base de données Microsoft Jet, un éditeur graphique, une
interface de type QBE pour interroger les bases de données, et le
langage de programmation Visual Basic for Applications.
Depuis les premières versions, l'interface de Microsoft
Access permet de gérer graphiquement des collections de données
dans des tables, d'établir des relations entre ces tables selon les
règles habituelles des bases de données relationnelles, de
créer des requêtes avec le QBE ou directement en langage SQL, de
créer des interfaces homme/machine et des états d'impression.
Le département commercial de la Brasimba utilise la
version la plus récente d'Excel 2016 pour stocker les informations pour
les communes de la Kenya, Kamalondo et Annexe.
62

KENYA KAMALONDO ANNEXE
:
Figure 22: Représentation des sources Access
IV.2.3. MySQL
MySQL est un système de gestion de bases de
données relationnelles. Il est distribué sous une double licence
GPL et propriétaire. Il fait partie des logiciels de gestion de base de
données les plus utilisés au monde, autant par le grand public
(applications web principalement) que par des professionnels, en concurrence
avec Oracle, PostgreSQL et Microsoft SQL Server. [10]
La Brasimba à travers son service commercial utilise
MySQL pour stocker les informations relatives aux ventes pour les communes de
Lubumbashi et celle de Katuba.

LUBUMBASHI KATUBA
Figure 23: Représentation des sources MySQL
Les formats des fichiers sources et de nos bases
opérationnelles déjà identifiées, nous passerons
à justifier sur le choix de nos outils et du serveur de base de
données utilisé pour construire notre data warehouse.
IV.3. Spécification des outils
d'exploitation
IV.3.1. Outil d'ETL : Talend Open Studio for Data
Integration IV.3.1.1. Présentation
ETL est un système de chargement de données
depuis les différentes sources d'information de l'entreprise
(hétérogènes) jusqu'à l'entrepôt de
données (modèles multidimensionnels). [11]
63
Dans le cadre de notre travail, ce processus d'extraction, de
transformation et de chargement de données éparses et
hétérogènes est assuré par le logiciel Talend Open
Studio for Data Integration en sa version 7.0.1. cet outil est
téléchargeable gratuitement sur
https://sourceforge.net/projects/talend-studio/files/latest/download.
TOS est une plate-forme d'intégration de données
Open Source, basée sur le langage Java, permettant de répondre
à toutes les problématiques liées au traitement des
données dans la chaîne décisionnelle, en assurant l'ETC,
l'EIA et la synchronisation des données.
IV.3.1.2. Caractéristiques [11]
L'une des grandes forces de Talend réside dans le fait
de pouvoir se connecter à quasiment toutes les sources de
données, applications métier et types de fichiers existants. Et,
c'est grâce, à plus de 250 composants Talend utilisables par les
développeurs. Parmi ses composants, on trouve différentes
familles :
· Applications Métier (Mode Ecriture, Lecture) :
Microsoft CRM, SAP, Sage CRM, Salesforce, SugarCRM, ...
· Base de données (Mode Ecriture, Lecture) :
AS400, MS SQL, Oracle, DB2, MySQL, PostgreSQL, Access, ODBC, ...
· Fichier (Mode Ecriture, Lecture) : Excel, CSV, TXT,
...
· Internet : FTP, WebServices, HTTP, SSH, ...
· Orchestration. : Fusion des flux, Réplication
des flux, mise en attente de l'exécution, itération sur
l'ensemble du contenu d'un répertoire, ...
· Qualité de données : Unicité des
données, remplacement de caractère dans une chaîne,
changement de l'encodage d'un fichier, ...
· Transformation : Agrégation, Conversion de
type, Filtre, Tri, Mappage.
· XML.
IV.3.1.3. Avantages de Talend Open Studio
· Portabilité de l'espace de travail optimisé
grâce au référentiel sous forme de fichier ;
· Talend tire parti des avantages de Java :
portabilité, puissance,...
· Interface intuitive basée sur Eclipse ;
· Vue graphique des jobs grâce aux interfaces
graphiques élaborées des composants ;
· Possibilité de créer de nouveaux composants
;
64
· Communauté active ;
· Talend est compatible quel que soit l'OS car le
résultat des développements est en fait un compilé JAVA
;
· Talend Open Studio est gratuit pour un utilisateur sur
le référentiel.
IV.3.1.4.Les composants Talend utilisés
Ci-dessous est reprise la liste des composants de Talend Open
Studio for data Integration que nous avons utilisés :
+ Job : Ce composant constitue la couche
d'exécution ou l'implémentation technique
d'un Business Model. Il est la représentation graphique
d'un ou plusieurs composants connectés, permettant de définir et
d'exécuter les processus de gestion de flux de données. Il
traduit les besoins métier en code, en routines ou en programmes, puis
se charge d'exécuter ces derniers.
En bref, le Job permet de mettre en place le flux de
données.
+ TMap : est un composant avancé qui
s'intègre au Studio Talend comme un plug-in,
qui transforme et qui dirige les données à
partir d'une ou plusieurs source (s) et vers une ou plusieurs destination(s).
[12]
Le Mapper est l'éditeur du tMap qui permet de
définir les propriétés d'aiguillage et de transformation
des données.
+ TFileInputExcel : Ce composant lit les
fichiers Excel ou un flux de données ligne
par ligne pour le scinder en champs et envoie les champs tels
que définis dans le schéma au composant suivant du Job via une
connexion Row.
+ TDBAccessInput/ TDBInput(MySQL) : est un
composant qui exécute une requête
en base de données selon un ordre strict et qui doit
correspondre à celui défini dans le schéma. La liste des
champs récupérée est ensuite transmise au composant
suivant une connexion de flux (Main row).
+ TDBOutput(MySQL) : Ce composant écrit,
met à jour, modifie ou supprime les
données d'une base de données. Son objectif est
d'exécuter l'action définie sur les ordres d'une table, en
fonction du flux entrant provenant du composant précédent.
L'étape d'extraction, de nettoyage et de transformation
de données se termine par le chargement de ces données
homogénéisées dans un environnement de stockage. [13]
65
IV.3.2. Outil de navigation dans les données :
OlapCube Writer
La construction des cubes sur les données de notre base
est assurée par OlapCube. OlapCube est un outil conçu pour
concevoir des modèles dimensionnels ou multidimensionnels, basés
essentiellement sur la création des dimensions, et des faits et ainsi
naviguer dans les données d'une base décisionnelle.
Les raisons qui ont motivé notre choix sur l'utilisation
de cet outil sont les suivantes :
? A l'aide de OlapCube Writer, la création (design) et
la construction (build) des cubes sont aisées car cet outil se connecte
directement à plusieurs sources de données comme Oracle,
PostgreSQL, MySQL, Access, MariaDB, etc ;
? permet de lire ou de naviguer un cube grâce à
certaines
opérations OLAP incorporées sous forme de boutons
;
? Il est facile à utiliser même pour tout
utilisateur légèrement averti.
La version utilisée dans le cadre de notre travail est
3.0.3.0 et est téléchargeable sur
https://www.softpedia.com/get/Internet/Servers/Database-Utils/OlapCube.
IV.3.3. Outil de reporting : OlapCube
Dashboard
OlapCube Dashboard est un module intégré dans
OlapCube Writer qui permet de générer une synthèse et de
grouper des données selon les axes ou plusieurs de ses propres
catégories.
Nous utilisons cet outil dans ce travail pour la
synthèse, l'analyse, exploration et la présentation de
données de l'entrepôt.
Nous avons mis notre choix sur outil pour son utilisation
facile par les analystes, la production de tableaux de bord et le rapport.
IV.4. Serveur des données du Data
warehouse
66
Le lieu de stockage utilisé pour notre entrepôt
est le MariaDB, le type de serveur de bases de données inclu dans le
logiciel XAMPP.
XAMPP est un ensemble de logiciels permettant de mettre
facilement en place un serveur Web local, un serveur FTP et un serveur de
messagerie électronique. Il s'agit d'une distribution de logiciels
libres offrant une bonne souplesse d'utilisation, réputée pour
son installation simple et rapide.
Notre choix est porté sur ce logiciel parce qu'il
héberge en son sein MariaDB, un serveur de bases de données
libre.
MariaDB est un système de gestion de base de
données édité sous licence GPL. Il s'agit d'un projet
s'inscrivant dans la démarche visant à remplacer MySQL à
la suite du rachat de ce dernier par Oracle Corporation.
Nous avons porté notre choix sur ce serveur non
seulement parce qu'il est libre mais aussi facile et simple à utiliser
sur tous les systèmes d'exploitation.
La version 10.1.31 de MariaDB est celle que nous avons
utilisée pour le stockage de données de notre Data warehouse dans
le cadre de ce travail.
67
IV.5. Architecture technique proposée
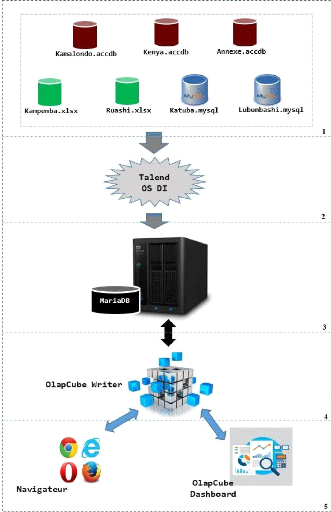
Figure 24: Architecture technique proposée
68
IV.5.1. Interprétation de
l'architecture
Tableau 11: Outils du décisionnel
utilisés
|
N°
|
Désignation
|
Produit
|
Version
|
|
1
|
Sources externes
|
- MS Excel
- MS Access
- MySQL
|
- MS Office 2016
- MS office 2016
|
|
2
|
ETL
|
Talend Open Studio for Data Integration
|
- 7.0.1
|
|
3
|
Serveur de BD
|
MariaDB
|
- 10.1.31
|
|
4
|
Outil d'analyse
|
OlapCube Writer
|
- 3.0.3.0
|
|
5
|
Outil de reporting
|
OlapCube Dashboard
|
- 3.0.3.0
|
IV.5.2. Machine d'exécution
Tableau 12: Environnement d'exécution
|
N°
|
Produit
|
Caractéristiques
|
|
1
|
Fabricant
|
Dell Inc.
|
|
2
|
Système d'exploitation
|
Windows 10 Professionnel, 64Bits,
Version 10.0.17134.285
|
|
3
|
RAM
|
4 GB
|
|
4
|
CPU
|
Intel ® CoreTM i5-3210M@2.50 Ghz
|
|
69
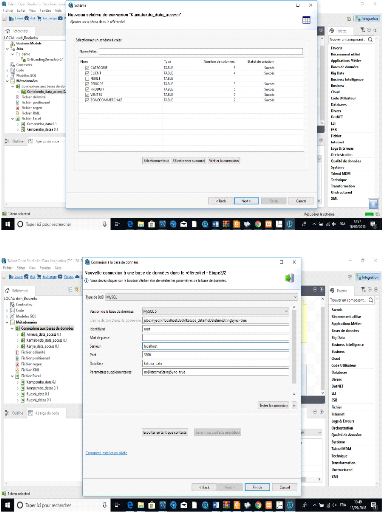
Figure 25: Importation des fichiers sources
Figure 26 : Création de connexion pour les sources
externes 1ère étape
IV.6. Interfaces associées
IV.6.1. Data warehousing
70
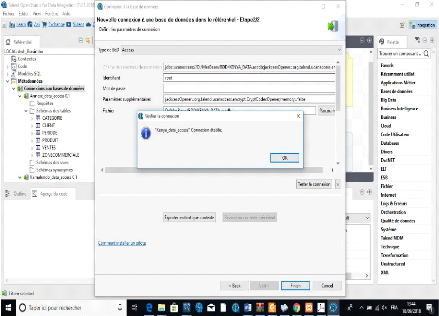
Figure 27: Création de connexion pour les sources
externes 2e étape
Figure 28 : Récupération du schéma :
1ère étape
71
Figure 29: Récupération du schéma : 2e
étape
Figure 30: Création des Jobs
Figure 32: Correspondance des champs
72
Figure 31: Extraction et transformation des données
sources
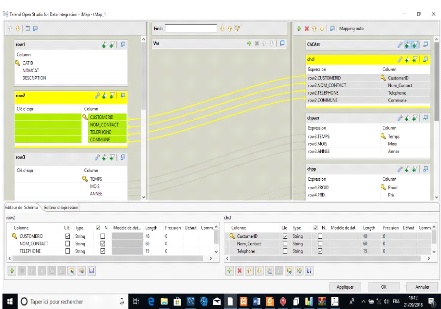
73
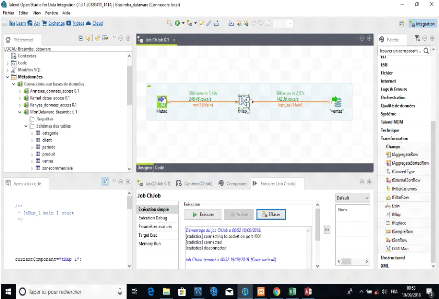
Figure 33: Chargement des données dans
l'entrepôt
IV.6.2. Navigation dans le cube des
données
Figure 34: Connexion à l'entrepôt 1ère
étape
74
Figure 35: Création des dimensions et des
mesures
Figure 36: Connexion à l'entrepôt 2e
étape
75
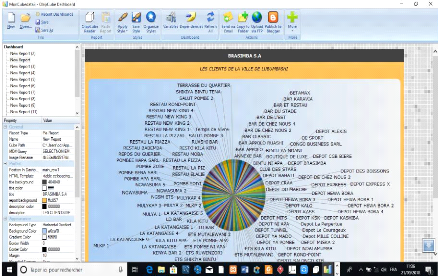
Figure 37: Les clients autour de toutes les zones
commerciales de Lubumbashi
Interprétation : la figure ci-dessus
donne la liste de tous les clients de la Brasimba à travers la ville de
Lubumbashi, enregistrés dans l'entrepôt de données.
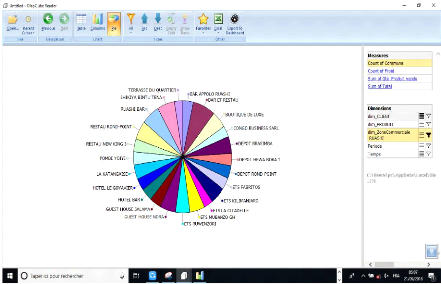
Figure 38: La liste de clients autour d'une commune
(Commune de Ruashi)
76
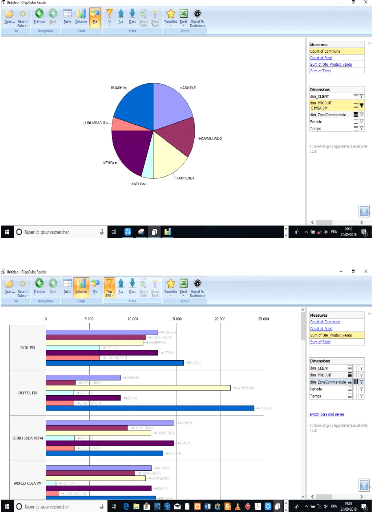
Figure 39: Le comportement du produit SIMBA 73CL autours de
toutes les communes de la ville
Figure 40: Tableau de bord du comportement de tous les
produits
77
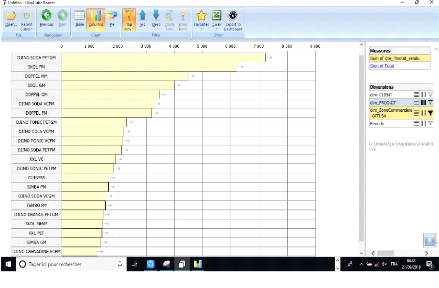
Figure 41: Tableau de bord du comportement de tous les
produits vendus dans la commune de Katuba
Figure 42: Statistiques de tous les produits dans toutes
les zones commerciales
78
IV.7. Conclusion
Ce chapitre a consisté à démontrer les
interfaces hommes-machines sur le comment s'est effectué le
déploiement de notre système décisionnel.
Il s'est basé premièrement sur la mise en place et
présentation de l'architecture technique en passant évidemment
par les outils utilisés dans le nouveau système d'aide à
la décision.
Et cela a permis à comprendre l'importance et l'impact du
déploiement d'un système d'information décisionnel dans
une société de vente et de production comme Brasimba.
79
CONCLUSION GENARALE ET PERSPECTIVES
Avoir la vision globale de son entreprise est une approche qui
préoccupe la plupart des entrepreneurs souhaitant bien piloter leurs
entreprises.
Cette approche consiste à ce que certains responsables
veulent avoir une connaissance des données à niveau global, afin
de se rendre compte de l'évolution de leurs entreprises et ainsi
faciliter la prise des décisions.
L'analyse de données depuis différentes
perspectives et le fait de transformer ces données en informations
utiles, en établissant des relations entre elles ou en repérant
des patterns est le souci majeur des entrepreneurs.
La Brasimba en ce jour, à travers ses services
associés aux ventes accumulent de montagnes d'information sous plusieurs
formats, dans différentes quantités de données pour les
zones commerciales qui entourent la ville de Lubumbashi.
Parmi ces données enregistrées au
département commercial évidemment, on distingue des
données opérationnelles ou transactionnelles, qui sont
stockées sous Excel, Access et MySQL.
Cette hétérogénéité de
sources est un problème qu'il a fallu résoudre dans le cadre de
ce projet. C'est pourquoi nous avons conçu un système
décisionnel capable de collecter ces informations naturellement
hétérogènes et les homogénéiser afin de
rendre facile les tâches des décideurs pour le prise de
décisions.
Ce système a été
matérialisé par la construction d'un Data warehouse et l'usage
des outils nécessaires et des éléments indispensable pour
la mise en place des systèmes décisionnels.
L'alimentation en données a été
effectuée grâce à un outil approprié qui nous a
permis de concevoir un environnement d'extraction, de transformation et de
chargement de sources de données hétérogènes dans
notre entrepôt.
80
A travers ces données externes collectées et
intégrées dans l'entrepôt, nous avons effectué des
analyses sur ces données homogénéisées afin de
découvrir leurs tendances pour chaque commune de la ville de Lubumbashi
et à une certaine période donnée.
Cette analyse a permis ce que la Brasimba sache le
comportement précédant et présent d'un produit, afin de
faire des prédictions et surtout savoir quel produit faudra-t-il
privilégier pour sa production.
La matérialisation des entrepôts de
données consiste à intégrer les sources externes qui
existent déjà, octroyées par la société
elle-même, ce qui a été une tâche difficile pour
nous.
Soucieux de bien approfondir ces notions, nous avons
simulé les données en créant par nous-mêmes les
différentes sources de données externes utilisées à
la Brasimba pour le stockage avant de passer à l'étape
d'intégration.
Ce projet a commencé par l'étape de collecte et
d'identification des sources externes (data pumping). Cette étape est
suivie de l'intégration de ces sources dans l'entrepôt (data
warehousing), et chuter par la production des rapports et/ou des tableaux de
bord (reporting) qui est de toute évidence le résultat de
l'analyse sur les données globales.
Toutefois, ce projet ouvre certaines perspectives entre autres
l'intégration du service web, le dimensionnement et l'administration de
l'entrepôt lui-même.
C'est à ce titre que nous sollicitons l'implication non
modérée d'autres scientifiques non seulement pour la
continuité et l'amélioration de ce projet mais aussi à
nous faire parvenir toutes remarques et suggestions à notre adresse
mail
masscedrick@gmail.com.
81
BIBLIOGRAPHIE
[1] R. K. &. M. Ross, Entrepôt des données:
Guide pratique de modélisation dimensionnelle, 2è éd.,
2002, p. 25.
[2] B. FYAMA, Traité des méthodes et techniques en
Sciences Informatiques, Lubumbashi: UL, 2018, p. 1.
[3] J.-F. P. &. P. CAILLEREZ, Tout sur les sytèmes
d'information, Paris, 2011, p. 119.
[4] B. Inmon, Building the data warehouse, wiley publishing ,
3rd edition, 2002.
[5] l. AUDIBERT, Bases de données : De la
modélisation au SQL, Paris, 2009.
[6] s.-J. A. Djungu, Génie logiciel, Kinshasa:
Médiaspaul, 2017.
[7] S. Crozat, Introduction à la modélisation
dimensionnelle, Compiègne: utc, 2016.
[8] E. d. données, Ralph Kimball & Margy Ross, Paris,
2008.
[9] S. Crozat, Data warehouse et outils décisionnels,
Compreigne, 2016.
[10] L. Welling, PHP et MYSQL, France: Laura, 2009.
[11] «Talend,» 2018. [En ligne]. Available:
Https://fr.talend.com/products/talend-open-studio.
[Accès le 25 Juin 2018].
[12] «Talend,» [En ligne]. Available:
https://help.talend.com/reader.
[Accès le 28 Juillet 2018].
82
[13] T. GAUCHET, SQL Server 2012: Implémentation dune
solution de Business Intelligence, eni, 2013.
TABLES DES MATIERES
EPIGRAPHE I
DEDICACE II
AVANT-PROPOS III
LISTE DES FIGURES IV
LISTE DES TABLEAUX VI
LISTE DES SIGLES ET ABREVIATIONS VII
INTRODUCTION GENERALE 1
CHAPITRE I : INTRODUCTION AU DOMAINE DU DECISIONNEL
7
I.1. Introduction 7
I.2. Les systèmes décisionnels 7
I.2.1. Le décisionnel 7
I.2.2. La place du décisionnel dans l'entreprise 7
I.2.3. L'enjeu du décisionnel 8
I.2.4. Les grandes étapes d'un projet d'Informatique
décisionnelle 8
I.2.5. Architecture globale d'un système
décisionnel 10
I.3. Le Data warehouse 11
I.3.1. Définition 11
I.3.2. Historique des Data warehouses 12
I.3.3. Structure de données d'un Data warehouse 13
I.3.4. Les composantes d'un Data warehouse 14
I.3.5. Architecture d'un Data warehouse 16
83
I.4. Comparaison entre les systèmes transactionnels et
systèmes décisionnels 16
I.4.1. OnLine Transaction Processing (OLTP) 16
I.4.2. OnLine Analytical Processing (OLAP) 17
I.5. Approche générale de la modélisation
dimensionnelle 18
I.5.1. Les faits 18
I.5.2. Les dimensions 19
I.5.3. Différents modèles de la modélisation
dimensionnelle 19
I.5.4. Le modèle en Etoile 19
I.5.5. Le modèle en Flocon 20
I.5.5. Le modèle en Constellation 20
I.5.6. Les Data marts 20
I.5.7. Le cube OLAP 21
I.5.8. Les attributs 21
I.6. Cycle de vie d'un modèle dimensionnel 21
I.7. Alimentation du Data warehouse 22
I.8. Les outils du décisionnel 22
I.8.1. Extraction Transformation Loading 22
I.8.2. Les outils de Reporting 24
I.8.3. Les outils de data mining 24
I.8.4. Les outils d'analyse 24
I.9. Conclusion 25
CHAPITRE II : LE STOCKAGE DE DONNEES A LA BRASIMBA
26
II.1. Introduction 26
II.2. Aperçu sur les systèmes transactionnels
26
II.2.1. Qu'est-ce qu'une base de données 26
II.2.2. Problématique de la cohérence des
données 27
II.2.3. Système de gestion de base de données 27
II.2.4. Enjeux des bases de données 28
84
II.2.5. Modèle de données relationnel 28
II.2.6. Eléments constitutifs d'un modèle
relationnel 29
II.3. Description des processus 29
II.3.1. L'approvisionnement 30
II.3.2. La Fabrication 30
II.3.3. La Distribution 31
II.3.4. La Vente 32
II.4. Description textuelle 34
II.5. Evaluation de l'intérêt du changement 35
II.5.1. Points forts 35
II.5.2. Points à améliorer 35
II.5.3. Améliorations attendues 36
II.6. Conclusion 36
CHAPITRE III : ANALYSE FONCTIONNELLE 37
III.1. Introduction 37
III.2. Modélisation du système 37
III.2.1. Présentation de la méthode UP et du
langage UML 37
III.2.2. Identification des profils utilisateurs 37
III.2.3. Diagramme de cas d'utilisation 38
III.2.4. Cas d'utilisation 39
III.2.5. Diagrammes de séquences 39
III.2.6. Diagramme de classes de participantes 47
III.2.7. Diagramme de classes de conception 51
III.2.8. Modèle logique des données 51
III.3. Modélisation dimensionnelle 52
III.3.1. Principes de la modélisation dimensionnelle
52
III.3.2. Présentation des modèles dimensionnels
52
III.3.3. Choix du sujet d'analyse : le Fait Vente 54
85
III.3.4. Les mesures 54
III.3.5. Choix d'axes d'analyse : les dimensions 54
III.4. Exportation du MLD en SQL 57
III.4.1. Structures des tables 57
III.4.2. Index pour les tables déchargées 58
III.4.3. Présentation du modèle dimensionnel en
étoile 58
III.5. Conclusion 59
CHAPITRE IV : ARCHITECTURE LOGICIELLE 60
IV.1. Introduction 60
IV.2. Sources de données opérationnelles 60
IV.2.1. Microsoft Office Excel 60
IV.2.2. Microsoft Office Access 61
IV.2.3. MySQL 62
IV.3. Spécification des outils d'exploitation 62
IV.3.1. Outil d'ETL : Talend Open Studio for Data Integration
62
IV.3.2. Outil de navigation dans les données : OlapCube
Writer 65
IV.3.3. Outil de reporting : OlapCube Dashboard 65
IV.4. Serveur des données du Data warehouse 65
IV.5. Architecture technique proposée 67
IV.5.1. Interprétation de l'architecture 68
IV.5.2. Machine d'exécution 68
IV.6. Interfaces associées 69
IV.6.1. Data warehousing 69
IV.6.2. Navigation dans le cube des données 73
IV.7. Conclusion 78
CONCLUSION GENARALE ET PERSPECTIVES 79
TABLES DES MATIERES 82
| 

