II.9 Limites de l'étude
- Comme cette étude est explicative, elle ne permet pas
de prédire les
évènements notamment le nombre de malnutris en
fonction du temps.
- De même étant donné que les
données de l'EDS 2013-2014, nous ne sommes
pas permis d'inclure d'autres variables pour cette
étude, notre souci reste celui de mener une étude de survie et
comme dans la base des données, nous n'avons pas la variable temps
jusqu'à la survenue de l'événement qui est la
malnutrition, nous nous sommes limité à l'étude de
déterminants liés à la malnutrition.
II.10Traitement des données
Pour avoir utilisé la base des données de
l'EDS-RDC 2013-2014 et qui comprend des variables en rapport avec la
malnutrition des enfants de moins de cinq ans a été
créée. Ces données étaient corrigées et sur
un échantillon de 18716 enquêtés, nous l'avons
réduit à 8059 individus en rapport avec des informations portant
sur des enfants et analysées à l'aide du logiciel SPSS version
25, R et Stata version 12.
II.11Plan d'analyse des données
II.11.1 Analyse descriptive
Nous avons utilisé le calcul de la proportion
(pourcentage) pour les variables catégorielles par la formule
suivante :
Fr : 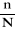
Avec :
Fr : fréquence relative,
n: nombre d'observations,
N : population de l'étude.
- Taux : a été utilisé pour
transformer les fréquences en pourcentage.
T = 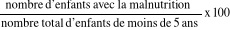
- Pour les variables quantitatives, la moyenne et
l'écart-type ont été calculés par les formules
suivantes :
N
X
X
i
?
=
251674624
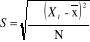 (T. Ancelle, 2006). (T. Ancelle, 2006).
Légende :
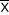 : Moyenne arithmétique ; : Moyenne arithmétique ;
Xi : observations individuelles ;
N : population totale étudiée ;
S : écart-type.
- La médiane sera estimée de la manière
suivante : classer les sujets de l'étude
par ordre de valeur croissante de la variable. Si le nombre de
sujets est impair, la
médiane de la série est la valeur de la variable
observée chez le sujet médian. Si le nombre de sujets est pair,
la médiane est située entre les deux valeurs qui partagent la
série en deux, dans ce cas, en pratique, on prend la moyenne de deux
valeurs centrales.
- Les extrêmes qui sont des valeurs minimum et
maximum.
Si la distribution est normale la moyenne et l'écart-type
seront calculés. Et si la distribution est asymétrique nous
aurons à estimer la médiane et les extrêmes.
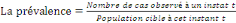 - - 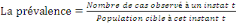 (T. Ancelle, 2006). (T. Ancelle, 2006).
II.11.2 Régression multinomiale
Soient Y la variable réponse catégorielle, à
valeurs dans 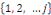 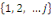 et X le vecteur de variables explicatives. La probabilité de
chaque catégorie j = 1;... ; j-1 (J est parconvention la
catégorie de référence) qui est modélisée
par : et X le vecteur de variables explicatives. La probabilité de
chaque catégorie j = 1;... ; j-1 (J est parconvention la
catégorie de référence) qui est modélisée
par :
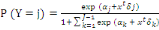 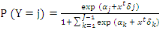 (Jean Peyhardi et al, 2015, (Jean Peyhardi et al, 2015,
Giorgio Russolillo, 2018)
Estimation : On estime généralement ce
modèle grâce à l'algorithme des scores de Fisher, dont
l'itération à l'étape k s'écrit :
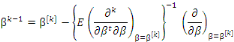
Où 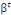 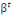 = ( = (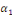 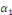 , ..., , ..., 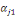 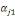 , , 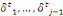 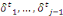 )est le vecteur de paramètres et )est le vecteur de paramètres et   la logarithme de vraisemblance(Abbass, 2015). la logarithme de vraisemblance(Abbass, 2015).
Dans cette étude, nous avons procédé par
l'analyse ajustée par le modèle ascendant jusque à
l'obtention du modèle vraisemblant.
Interprétation
- Si 1 se trouve à l'intérieur de l'intervalle
de confiance de OR, la différence n'est pas significative ;
- Si la limite supérieure de l'intervalle de confiance
de OR est inférieure à 1, la différence est significative
et le facteur étudié est un facteur protecteur ;
- Si la limite inférieure de l'intervalle de confiance
de OR est supérieure à 1, la différence est significative
et le facteur étudié est un facteur risque.
Ce seuil est fixé en intervalle de confiance à
95% '''''(C. Kandala II, 2019; Unicef, 2010)
| 

