DEDICACE
A
MES PARENTS
Monsieur et Madame TEGUEU
REMERCIEMENTS
Le présent travail a été
réalisé grâce aux efforts conjugués de plusieurs
personnes à qui je voudrai exprimer ma profonde gratitude.
Merci :
Ø Au Pr FOGUE MEDARD directeur de
l'établissement pour sa disponibilité et la supervision
générale des cours.
Ø Au Pr TCHINDA RENE vice directeur de
l'établissement pour sa rigueur et sa discipline.
Ø A Dr KAPCHE chef de département, pour ses
conseils, sa franchise et surtout les efforts consentis pour la satisfaction
de tous ses étudiants.
Ø A mon encadreur académique M. LIENOU JEAN
PIERRE pour sa disponibilité et ses conseils qui ont permis
d'améliorer d'avantage ce rapport et de remplir le cahier des charges
qui m'était confié.
Ø Aux enseignants du département pour leur
soutien et leur encadrement.
Ø Au personnel des services Support technique et
infrastructure de CREOLINK COMMUNICATIONS DOUALA en particulier à mon
tuteur professionnel M. YARRO, pour les connaissances, la confiance et les
responsabilités qu'ils m'ont confiées.
Ø A mes tantes tata Juliette et tata Solange pour leurs
conseils, leur soutient financier, leur amour et leur confiance.
Ø A tous mes frères et soeurs : GOCHE
Daniel, GOYA Caroline et MOKO Sonia pour leurs sincères
encouragements.
Merci à tous ceux qui de près ou de loin ont
contribué à la réalisation de ce rapport.
GLOSSAIRE
|
VPN
|
Virtual Private Network
|
|
PPTP
|
Point-to-Point Tunneling Protocol
|
|
L2TP
|
Layer2 Tunneling Protocol
|
|
IPSEC
|
Internet Protocol Security
|
|
MPLS
|
Multi-Protocol Label Switching
|
|
NAS
|
Network Access Server
|
|
L2F
|
Layer2 Forwarding
|
|
RADUIS
|
Remote Authentification Dial-In User Service
|
|
MSCHAP
|
Microsoft Challenge Handshake Authenticity
|
|
RAID
|
Redundant Array of Independant Disks
|
|
HA
|
High Avalaibility
|
|
FOS
|
Fail Over Services
|
|
DRDB
|
Distributed Replicated Block Device
|
|
NBD
|
Network Block Device
|
|
STONITH
|
Shot The Other Node In The Heat
|
|
SPOF
|
Single Point Of Failure
|
|
NLB
|
Network Load Balancing
|
|
NFS
|
Network File System
|
|
GFS
|
Global File System
|
|
NAS
|
Network Attach Storage
|
|
SAN
|
Storage Area Network
|
|
EFS
|
Extended File System
|
|
LVS
|
Linux Virtual Server
|
|
DNS
|
Domain Name Server
|
|
IMAP
|
Internet Message Access Protocol
|
|
SSL
|
Secure Socket Layer
|
|
FOS
|
Fail Over Service
|
|
MTBF
|
Mean Time Between Failure
|
|
MTTR
|
Mean Time To Repair
|
|
RSYNC
|
Remote Synchronization
|
AVANT-PROPOS
L'institut Universitaire de Technologie FOTSO Victor de
BANDJOUN en abrégé IUT-FV est l'établissement de
l'Université de Dschang, né de la reforme Universitaire de 1993,
suivant l'arrêté présidentiel N° 008/CAB/PR du 19
Janvier 1993, l'IUT-FV de BANDJOUN a pour vocation principale de dispenser en
formation initiale un enseignement dans les domaines industriels et
commerciaux. A ce titre, il fournit aux entreprises ou administrations des
prestations de recherches appliquées, de services ou de formation
professionnelle correspondant à ses activités.
Ø L'IUT-FV forme en deux ans, les étudiants qui
obtiendront par la suite, sous réussite, un diplôme universitaire
de technologie(DUT) dans les domaines de :
· Génie électrique (option
électronique et électrotechnique)
· Génie des Télécommunications et
Réseaux(GTR)
· Informatique de Gestion(IG)
· Maintenance Industrielle et Productrice(MIP)
· Génie civil(GC)
Ø L'IUT-FV prépare les candidats au Brevet de
Technicien Supérieur(BTS). Pour cela, dispose dans ce cycle les domaines
suivantes :
· Génie électrique (option
électronique et électrotechnique)
· Génie Civil(GC)
· Secrétariat de Direction(SD)
· Action Commercial(AC)
· Comptabilité et Gestion d'Entreprise(CGE)
Ø L'IUT-FV forme également les étudiants
en cycle de licence technologique dans les domaines :
· Ingénierie des Télécommunications
et Réseaux (ITR)
· Génie électrique
· Informatique et Réseaux
· Maintenance Industrielle et Productique
· Génie Civil
Ø L'IUT-FV forme également les étudiants
en cycle de licence professionnelle dans les domaines :
· Gestion Comptable et Financier
· Gestion Administrative et Management des
Organisations
· Marketing Manager Opérationnel
· Banque Gestionnaire des Relations Clientèle
Ø L'IUT-FV forme également les certifiés
réseaux grâce à l'académie CISCO
En somme, l'IUT-FOTSO Victor avec son administration
entreprenante, des enseignants dotés d'une conscience professionnelle et
ses étudiants bénéficiant de son lotissement très
propice à l'enseignement, à un avenir promoteur.
CAHIER DES CHARGES
NOM : SIMO TEGUEU
PRENOM : ARMEL FRANCKLIN
THEME : plate forme d'entreprise
sécurisée et de haute disponibilité


PRESENTATION DU THEME
Assurer la haute disponibilité d'un service et des
données, signifie notamment être capable d'assurer la
continuité du service malgré une panne du serveur sur le lequel
il est situé. Il s'agit donc en général de doubler un
maximum d'éléments matériels du système
(habituellement, on double le serveur) et de prévoir les
mécanismes de basculement d'exploitation du matériel vers celui
de réserve. Nous partons du principe que le service assuré est
critique et que des procédures de basculement automatiques sont
nécessaires : le basculement doit être
déclenchée immédiatement après la détection
de la panne. Le principal défi dans le cas des services réseaux
impliquant la manipulation intensive des données (serveur IMAP, une base
SQL) est donc de s'assurer que les données qui étaient
présentées à l'utilisateur avant la panne soient toujours
disponibles et intègres, lorsque le service sera de nouveau rendu
(normalement quelques secondes plus tard).
Ø Situation contextuelle du projet et
importance pour l'entreprise
La solution couramment utilisée pour assurer les
mécanismes de reprise arrière consiste à placer les
données sur l'équipement SAN accessible depuis deux
serveurs : en cas de panne du serveur actif, le serveur de secours
retrouvera les données à jour sur le SAN. Cependant cette
solution présente plusieurs inconvénients :
· Elle revient relativement chère pour la
structure
· Elle peut représenter un SPOF si elle vient
à tomber en panne. Redonder complètement une baie SAN est
possible, jusqu'à la double connexion au serveur, mais alors les prix
s'envolent de manière astronomique et on a vu des cas où
même avec tout cet équipement, une panne survenait.
D'où le déploiement de notre solution qui est
fiable et qui présente un rapport qualité prix quasi
excellent.
Ø Description du Travail à
Faire
· Déploiement d'un service de noms (DNS) de noms
de domaine creolink.lan
· Déploiement d'un service web
sécurisé SSL (HTTPS) de nom www.
· Haute disponibilité concept et principe
· Haute disponibilité niveau de service : les
logiciels
· Haute disponibilités de données
· Surveillance applicative et systèmes de
fichiers
· Implémentation : Mise en haute
disponibilité des services du domaine creolink.lan.
Ø Résultats escomptés
La configuration matérielle de notre solution est la
suivante : deux serveurs identiques disposant chacun des ressources en
disque suffisantes pour assurer le service. En temps normal, un seul de ces
deux serveurs (HAserver0) rend effectivement le service : il dispose de
l'adresse IP sur laquelle est disponible le service, le système de
fichier contenant les données est monté, et les différents
services réseaux lancés. L'autre machine (HAserver) au contraire
se contente d'attendre. Les deux machines s'informent mutuellement de leur
fonctionnement par un système de « battement de
coeur » implémenté par le logiciel
« heartbeat ». Lorsqu'une panne survient sur HAserver0, la
machine HAserver détecte l'arrêt de battement de coeur et lance
une procédure de bascule : HAserver va acquérir l'adresse IP
du service, monter le système de fichier, et lancer les services
réseaux rendus par le cluster tout ceci grâce à un
système d'IP aliasing. Le système de fichier que l'on monte sur
HAserver doit contenir exactement les mêmes données que celui de
HAserver0 au moment du crash : c'est là que DRDB fonctionne alors
comme une sorte de raid1 sur IP au niveau block device. Ce
raid1 sur IP s'accompagne d'une gestion intelligente des
synchronisations : quand un serveur est temporairement retiré puis
ré-attaché au cluster, seules les données modifiées
entre temps sont synchronisées. Pour ce qui est du troisième
logiciel à savoir Mon, il assure la surveillance active des services.
SOMMAIRE
DEDICACE
Erreur ! Signet non
défini.
REMERCIEMENTS
ii
GLOSSAIRE
iii
AVANT-PROPOS
iv
CAHIER DES CHARGES
vi
SOMMAIRE
viii
INTRODUCTION GENERALE
1
PARTIE I: PRESENTATION DE L'ENTREPRISE ET
DEROULEMENT DU STAGE.
2
CHAPITRE I : PRESENTATION DE
L'ENTREPRISE
3
I.1 HISTORIQUE, EVOLUTION, MISSIONS ET
ACTIVITES
3
I.1.1 HISTORIQUE
3
I.1.2 EVOLUTION
3
I.1.3 MISSIONS
3
I.1.4 ACTIVITES
4
I.1.5 PLAN DE LOCALISATION
5
I.2 ORGANISATION DE L'ENTREPRISE
5
I.2.1 ORGANIGRAMME
5
I.2.2 FONCTION DE CHAQUE ORGANE
6
I.2.2.1 La Direction
Générale
6
I.2.2.2 La Direction Administrative et
Financière
6
I.2.2.3 La Direction Commerciale
6
I.2.2.4 La Direction Technique
6
I.3 CONCLUSION
7
CHAPITRE II : DEROULEMENT DU STAGE
9
II.1 LE REGLEMENT INTERIEUR, LA HIERACHIE DU
SOUS SYSTEME TECHNIQUE.
9
II.2 FAMILLIARISATION AUX EQUIPEMENTS ET
TACHES ASSIGNEES
9
PARTIE II : PRESENTATION DE LA HAUTE
DISPONIBILITE, ANALYSE COMPARATIVE ET PROPOSITION D'UNE SOLUTION SATISFAISANTE
ET COMPATIBLE AUX SERVICES DE CREOLINK.
12
CHAPITRE I: HAUTE DISPONIBILITE :
CONCEPT ET PRINCIPE
13
I.1 FIABILITE VERSUS DISPONIBILITE
13
I.1.1 CONDITION DE MISE EN PLACE
15
I.2 LINUX ET LA HAUTE DISPONIBILITE
15
I.3 LES COMPOSANTS
16
I.3.1 HAUTE DISPONIBILITE AU NIVEAU
PHYSIQUES : LES COMPOSANTS
16
I.3.1.1 Alimentation redondée
17
I.3.1.2 Utilisation des grappes de
disques
17
I.3.1.3 Multiplication des cartes
réseaux
17
I.3.1.4 Sécuriser l'accès aux
unités de stockages externes
17
CHAPITRE II: SYNTHESE ET FUTUR
22
II.1 TABLEAUX DE COMPARAISON
23
II.2 SYNTHESE
24
II.1 LE FUTUR
25
CHAPITRE III: CAS PRATIQUE :
DEPLOIEMENT DES SERVICES ET MISE EN HAUTE DISPONIBILITE
26
III.1 INSTALLATION ET CONFIGURATION DES
SERVICES
27
III.1.1 LE SERVICE DE NOM (DNS)
27
III.1.2 LE SERVICE WEB SECURISE (HTTPs)
29
III.1.3 LE SERVICE SECURISE DE TRANSFERT DE
FICHIER (FTPs)
30
III.2 MISE EN HAUTE DISPONIBILITE DES
SERVICES CAS :
30
DES SERVICES FTP ET HTTP
30
III.2.1 INSTALLATION ET CONFIGURATION DE LA
PLATE FORME LOGICIELLE
31
III.2.1.1 Hertbeat
31
III.2.1.2 DRBD
35
III.2.1.3 MON (Service Monitoring
Daemon)
36
III.2.2 TEST GENERAL DE BON FONCTIONNEMENT
DE L'INTERACTION HEARTBEAT MON DRBD : CAS PRATIQUE D'UN DOWNLOAD FTP
39
CONCLUSION GENERALE
41
REFERENCES BIBLIOGRAPHIQUES
a
ANNEXES
b
INTRODUCTION GENERALE
Depuis l'avènement relativement récent du
règne informatique, les systèmes matériels et logiciels
ont gagné régulièrement en complexité et en
puissance. Ils ont envahi toute notre vie quotidienne et sont désormais
incontournables dans la majorité des secteurs clefs de l'industrie. Peu
de domaines ont échappé à cette révolution au point
que la cohésion de nos sociétés fortement
industrialisés reposent sur la disponibilité des systèmes
complexes qui rythment notre activité de tous les jours : les
transactions bancaires, les télécommunications, l'audiovisuel,
internet, le transport de personne ou de bien (avion train ou voiture), les
systèmes d'informations des entreprises et les services fournis par les
entreprises etc.
Produire les systèmes stables demande de passer
beaucoup de temps en études et en analyse. Heureusement, il existe des
techniques simples permettant de pallier à la fiabilité des
systèmes complexes, qu'ils soient matériels ou logiciels.
Plutôt que de chercher à rendre ces systèmes stables, on
peut inverser la démarche et intégrer à la source la
notion de panne dans l'étude de ces systèmes : si l'on peut
prévoir la panne d'un composant matériel ou logiciel, on peut
alors l'anticiper et mettre en oeuvre une solution de substitution. On parle
alors de disponibilité du service, voire de Haute Disponibilité
selon la nature de l'architecture mise en place
Aujourd'hui, la trop grande importance que
révèlent les services qu'on offre impose un certain niveau de
sécurité, les solutions de RAID et autres viennent se greffer
à des nouvelles solutions pour assurer une haute disponibilité
des services vitaux, car en effet très souvent d'énormes revenus
sont liés à la disponibilité plus ou moins parfaite de
certains services et ce, en fonction des domaines d'activités.
PARTIE I: PRESENTATION DE L'ENTREPRISE ET DEROULEMENT DU
STAGE.
Chapitre I : PRESENTATION DE L'ENTREPRISE
Chapitre II : DEROULEMENT DU STAGE
CHAPITRE I :
PRESENTATION DE L'ENTREPRISE
I.1 HISTORIQUE,
EVOLUTION, MISSIONS ET ACTIVITES
I.1.1 HISTORIQUE
CREOLINK est une entreprise spécialisée dans la
fourniture des services Télécommunications. Crée en
Janvier 2001 par deux camerounais sous la dénomination de CREOLINK
Cameroun SARL au capital de 10.000.000FCFA divisé en 10.000
actions : 70% pour M.MBOCK JOSEPH (L'initiateur) et 30% pour M.GUY
WASSEU.
En 2005, suite à l'arrivée en force de
concurrents tels que MTN et Orange, la société fusionne avec deux
autres opérateurs du domaine à savoir DOUALA1 et ICCNET pour
devenir MATRIX TELECOM et ce, afin de faire face de façon solide
à la concurrence qui s'annonce rude. L'opérateur de fusion
n'ayant pas atteint son objectif prédéfini, la scission est
réalisée le 26/01/07.
I.1.2 EVOLUTION
Après la scission, CREOLINK Cameroun change de
dénomination pour devenir CREOLINK COMMUNICATIONS. Cette
opération sera suivie d'une augmentation de capital 40.000.000FCFA, du
changement et de la forme sociale et par le rachat des parts de M.GUY WASSEU
par M.JOSEPH MBOCK. CREOLINK est donc une société anonyme
unipersonnelle au capital de 50.000.000FCFA.
I.1.3 MISSIONS
CREOLINK s'est donné un ensemble de mission afin
d'apporter sa modeste contribution à l'effort de développement
technologique du Cameroun, il s'agit de :
Ø Offrir à ses clients, quelle que soit leur
localisation des produits et des services dans le domaine des
télécommunications qui soient de meilleure qualité et
d'une juste mesure en fonction de leurs besoins et leurs moyens financiers.
Ø Etre un fournisseur de services de
télécommunications reconnu comme un leader pour la qualité
de ses produits et de ses services pour le personnalisme de ses ressources.
Ø Réaliser des interventions par des
professionnels hautement motivés offrant une disponibilité totale
envers les clients, tout en démontrant un grand souci de la perfection
et beaucoup de créativité dans les solutions qu'ils proposent.
Ø Refléter une organisation ou les
associés et les employés travaillent dans un climat serein et un
environnement agréable qui leur permettent de s'épanouir et de
jouir de toute l'autonomie souhaitable afin de réussir et de se
dépasser.
Ø Participer à l'économie locale et
régionale en étant un groupe de professionnels présents
dans les activités d'affaires culturelles et sociales.
Ø Etre une société unie et rentable qui
se dispose à offrir à ses partenaires un rendement
supérieur à la moyenne grâce à l'innovation,
à la gestion optimisée, et au positionnement sur le
marché.
I.1.4 ACTIVITES
La société CREOLINK a pour principale
activité la fourniture d'accès internet, mais aujourd'hui, ceci
n'est plus qu'un support des solutions de technologies informatique et
télécommunications qu'elle offre à ses clients. Pour des
besoins de transmission de données, de la vidéo, de la voix,
d'autres services ont été développés :
Ø Services VPN (Réseaux Privés Virtuels)
qui permet de se connecter à un ordinateur ou à un serveur
à distance. Sécurisation des données et connections entre
Bureaux et villes.
Ø VOIP (Voix par IP) permet de faire les appels en se
servant d'internet.
· Appels internationaux
· Numéros Internationaux
· Appels Gratuit entre différents sites
Ø Services Web et applications (construction des sites,
intranet...)
· Développement et Maintenance des sites Web
· Hébergement des sites Web
· Développement des applications Web
Les services de conseils de CREOLINK permettent d'optimiser le
déploiement au quotidien du système de communication en
entreprise.
Ø Réseaux
Ø Sécurité et Restriction d'accès
à l'internet
Ø Réseau Privé Virtuel
Ø Systèmes de messagerie d'Entreprise
Ø Intranet d'entreprise
I.1.5 PLAN DE LOCALISATION

I.2 ORGANISATION DE L'ENTREPRISE
I.2.1 ORGANIGRAMME
DIRECTION GENERALE
DIRECTION
TECHNIQUE
DIRECTION COMMERCIALE
DIRECTION
ADMINISTRATIVE
SERVICE DE DEVELOPPEMENT D'APPLICATIONS
SERVICE INFRASTRUCTUREE
SERVICE SUPPORT TECHNIQUE
I.2.2 FONCTION DE CHAQUE ORGANE
I.2.2.1 La Direction
Générale
Elle a à sa tête le Directeur
Général en sa qualité conjointe d'administrateur et de
fondateur, il est entouré dans sa mission vitale pour l'entreprise par
des collaborateurs qui sont l'attachée de direction et du bureau des
projets spéciaux. Il a pour rôle de :
Ø Fixer les objectifs généraux
Ø Donner son accord sur toutes les décisions
stratégiques de l'entreprise et les dépenses
Ø Signer les chèques, les contrats.
Ø Veiller à l'exécution des ordres par
les chefs de département
Ø Décider de l'augmentation des salaires du
personnel et des recrutements, c'est lui aussi qui décide du
licenciement, des affectations...
Ø Représente la société partout ou
besoin est.
Il est aidé dans sa mission par un consultant externe
qui le conseille dans les options faire.
I.2.2.2 La Direction
Administrative et Financière
Elle a à sa tête un Directeur administratif et
financier, son but est de traiter et superviser toute opération relative
à la finance et à l'administration. Bref il est
spécialisé dans la transcription chiffrée des informations
de l'entreprise. C'est dans ce département que l'entreprise peut avoir
les informations justifiant si l'activité est rentable ou non. C'est
aussi le centre de rapprochement entre l'entreprise et son environnement
externe.
I.2.2.3 La Direction
Commerciale
Il a à son sommet un directeur commercial et des
représentants à Yaoundé et à Douala. Les
représentations ont à leur tête les chefs de bureaux de
vente qui à leur tour ont sous leurs ordres les commerciaux et une
assistance administrative.
I.2.2.4 La Direction Technique
Comme les autres départements, il a à sa
tête un directeur spécialisé dans le domaine. Il est
aidé dans sa mission par un adjoint. Sur un plan global, il a pour
mission de superviser l'ensemble du personnel se son équipe depuis la
demande d'installation introduite par les commerciaux et les problèmes
techniques que peuvent rencontrer les clients dans la consommation du service.
Ces problèmes sont connus dans le département par le NOC qui sert
de courroie de transmission direct entre les clients plaintifs et
l'entreprise.
I.3 CONCLUSION
Dans ce chapitre, il était question de présenter
l'entreprise où a été effectué notre stage.
Voilà ainsi présentée l'entreprise CREOLINK COMMUNICATIONS
sur son plan externe et interne, et à présent nous pouvons nous
faire une idée de cette entreprise. Le chapitre qui suit résumera
le déroulement du stage.
CHAPITRE II :
DEROULEMENT DU STAGE
Introduction
Ce chapitre présentera la description progressive des
tâches assignées pendant toute la période de notre stage.
Elle consistera donc à établir de toutes les tâches qui
nous ont été allouées et qui régi notre quotidien
en entreprise.
II.1 LE REGLEMENT INTERIEUR, LA
HIERACHIE DU SOUS SYSTEME TECHNIQUE.
Cette phase consiste à embrasser la politique de
fonctionnement interne afin de faciliter notre insertion au sein du
système. Elle s'est étendue sur une semaine
à compter du 09 AOUT 2010 et est très utile pour les futures
interactions avec le personnel de l'entreprise.
Il était question pour l'entreprise de :
Ø Présenter le stagiaire au personnel
(technique, commercial, sécurité...)
Ø Faire visiter les locaux de l'entreprise au
stagiaire.
Ø Lui présenter et éclaircir quelques
points clés du règlement en vigueur.
Ø Insérer le stagiaire dans le système
d'information de l'entreprise.
Cette phase était celle d'initiation dont le but est de
nous acclimater et de respecter le séquencement de l'exécution
des instructions qui nous serons assignées.
II.2 FAMILLIARISATION AUX EQUIPEMENTS ET
TACHES ASSIGNEES
Du 13 AOUT au 18 AOUT 2010. Il était
question d'être capable d'identifier chaque outil. Nous pouvons entre
autre citer
Ø Les types de câbles (RG11, RG6, RJ11...)
Ø Les types de radio (Wimax, Axcelera, VSAT...)
Ø Les équipements de connectiques (splitter,
connecteurs, les dérivateurs, l'injecteurs, les diverses pinces et
pompes...)
Ø Le Modem, Switch, Routeur et Décodeur de
l'entreprise.
Nous avons également pendant cette période
préparé notre bureau de travail qui a été
aménagé d'un pc Desktop dont nous avons assuré sa remise
en marche.
Du 20 AOUT au 30 AOUT 2010 : descente
sur le terrain. Il était question pour nous
d'intervenir chez les clients désirant un service nécessitant un
déploiement ou une extension de la couverture réseau : c'est
le cas des installations des clients sur câble.
Nous devrions intervenir pour un pré dimensionnement et
sur ce, proposer des solutions pour une installation optimale. Ce travail est
généralement connu sous le nom de site survey qui est
sanctionné par un schéma d'installation réalisé
sous visio2003 et qui sera greffé au rapport du technicien
d'installation en charge.
Du 1er SEPTEMBRE au 10 SEPTEMBRE
2010 : intervention au service infrastructure.
Il était question pour nous d'intervenir chez les clients couverts par
la boucle sur fibre et désirant la vidéo. Sous la supervision
d'un technicien, nous accrochions et aménagions la boucle locale du
client et, à l'aide d'un décodeur de préférence
préalablement scanné, nous lui offrons un signal de bonne
qualité.
Du 11 SEPTEMBRE au 20 SEPTEMBRE 2010 :
intervention au service internet. Il était question pour nous
d'intervenir chez les clients plaintifs relativement à un
problème de connexion. Avant de s'y rendre, il est nécessaire que
le client soit plus ou moins explicite, ce qui nous permettra de
démarquer les diagnostics à un niveau de couche bien
précis. Nous pouvons entre autre citer des plaintes telles que :
Ø Lenteur de connexion.
Généralement pour les clients sur câble,
on se connecte directement derrière le modem d'accès pour faire
les tests de bande ou de saturation du réseau.
Généralement la raison de cette lenteur est la
fatigue des équipements de routage et de commutation en local ou encore
la vulnérabilité du réseau sans fils déployé
en local. Et pour les clients sur radio on se rassure que la radio et point
d'accès sont en visibilité direct et si c'est le cas, on se
rassure que la radio est encore fonctionnelle, si c'est cas on se rapproche du
point d'accès et on remonte la panne de proche en proche.
Ø Absence de connexion
Plusieurs raisons peuvent expliquer cette absence de
connexion. Généralement le premier diagnostique consiste à
mesurer la puissance du signal grâce au mesureur. Dans le cas ou le
signal est accès bas ou totalement absent, on signale le problème
au service infrastructure. Dans le cas contraire on signal la situation au NOC
(Network Operating Center) pour une téléassistance.
Notre dernière intervention est celle-là
même qui m'a introduit dans le projet d'extension d'un réseau
VLANisé par déport VPN. Il était question de tenir
compagnie à M. ANTOINE FUN certifié CCNP lors de ses
interventions chez les clients pour interconnexion de site distant par
réseaux VPN ou pour configuration des VLAN et tout autre problème
logique de connexion et de réinitialisation de bouquet vidéo.
C'est durant cette tâche que nous avons eu l'opportunité de
recevoir l'aide de M.FUN (concernant l'intégration des modules 802.1q et
drbd83 sous linux Centos et la configuration du réseau VLANisé)
qui a contribué à la réussite de ce rapport et à la
réalisation d'une prestation assez réussite de la
présentation de ce rapport auprès des dirigeants. C'est
après cette intervention que c'est achevé notre stage
académique le 01 OCTOBRE 2010.
CONCLUSION
Voici présentées en quelques mots, les diverses
occupations principales qui ont régi notre quotidien en entreprise. Il
était donc question de faire valoir nos connaissances académiques
dans un contexte professionnel ou l'enjeu est de se rendre utile et parfois
indispensable.
PARTIE II :
PRESENTATION DE LA HAUTE DISPONIBILITE, ANALYSE COMPARATIVE ET PROPOSITION
D'UNE SOLUTION SATISFAISANTE ET COMPATIBLE AUX SERVICES DE CREOLINK.
Chapitre I: HAUTE DISPONIBILITE : CONCEPT ET
PRINCIPE
Chapitre II: SYNTHESE ET FUTUR
Chapitre III: CAS PRATIQUE : DEPLOIEMENT DES SERVICES ET
MISE EN HAUTE DISPONIBILITE
CHAPITRE I: HAUTE
DISPONIBILITE : CONCEPT ET PRINCIPE
Introduction
Toutes les techniques permettant de venir à bout des
désagréments causés par une indisponibilité
temporaire ou permanente sont regroupées sous différentes
appellations suivant le degré de la réponse qu'elles apportent au
problème posé :
Ø Disponibilité des services
Dans le contexte d'un service critique rendu dans le cadre
d'une entreprise (serveur) ou vis-à-vis d'une clientèle (site
marchand), une panne occasionnant un arrêt du service peut causer un tort
considérable entraînant une perte de productivité, voire de
confiance du client. Dans tous les cas, cela peut coûter à court
ou moyen terme beaucoup d'argent. On base la démarche sur la
disponibilité des données pour ensuite fiabiliser par
différentes techniques la continuité du service ;
Ø Disponibilité des
données
Même si votre système n'est
pas critique et peut supporter un arrêt de service à durée
variable, il est généralement inhabituel de se satisfaire de la
perte de données. Dans ce cas précis, toutes les techniques
utilisées convergent pour garantir l'intégrité des
données ;
Ce document va s'attacher à décrire les
principes fondamentaux qui régissent l'étude et le
développement de systèmes critiques Hautement Disponibles
(résumé sous l'acronyme HA pour High Availability)
Nous verrons d'abord de façon succincte comment nous
pouvons aborder le problème d'un point de vue théorique pour
ensuite élaborer une architecture hautement disponible à partir
de différents composants logiciels choisis dans une liste non
exhaustive. Dans cette partie précise, les briques logicielles que nous
utiliserons sont pour la plupart basées sur les logiciels libres :
la tentation est donc forte de vouloir mettre en oeuvre soi même, et
à peu de frais, des solutions de ce type au sein d'une entreprise.
I.1 FIABILITE
VERSUS DISPONIBILITE
Pour appréhender la notion de Haute
Disponibilité, il nous faut d'abord aborder les différences qui
existent entre la fiabilité d'un système et sa
disponibilité.
La fiabilité est un attribut permettant de mesurer la
continuité d'un service en l'absence de panne. Les constructeurs
fournissent généralement une estimation statistique de cette
valeur pour leurs équipements : On parle alors de MTBF (pour Mean Time
Between Failure). Un MTBF fort donne une indication précieuse sur la
capacité d'un composant à ne pas tomber en panne trop souvent.
Dans le cas d'un système complexe (que l'on peut décomposer en un
certain nombre de composants matériels ou logiciels), on va alors parler
de MTTF pour Mean Time To Failure, soit le temps moyen passé
jusqu'à l'arrêt de service consécutif à la panne
d'un composant ou d'un logiciel.
La disponibilité en ce qui la concerne, est plus
difficile à calculer car englobant la capacité du système
complexe à réagir correctement en cas de panne pour
redémarrer le service le plus rapidement possible. Il est alors
nécessaire de quantifier l'intervalle moyen de temps ou le service est
indisponible avant son rétablissement : On utilise l'acronyme MTTR (Mean
Time To Repair) pour représenter cette valeur. La formule qui permet de
calculer le taux de disponibilité relative à un système
est la suivante :
Disponibilité =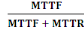

Ainsi, un système qui aspire à une forte
disponibilité se doit d'avoir soit un MTTF fort, soit un MTTR faible.
Une autre approche, plus pratique, consiste à mesurer
la période de temps ou le service n'est plus rendu pour évaluer
le niveau de disponibilité. C'est la méthode la plus souvent
utilisée même si elle ne tient pas compte de la fréquence
des pannes mais plutôt de leur durée. Le calcul se fait le plus
souvent sur une année calendaire. Plus le pourcentage de
disponibilité du service est fort, plus nous pouvons .parler de Haute
Disponibilité. Il est assez facile de qualifier le niveau de Haute
Disponibilité d'un service à partir de la durée
d'arrêt cumulée en utilisant le principe normalisé des "9"
(en dessous de 3 neuf, il n'est plus possible de parle de Haute
Disponibilité mais simplement de disponibilité) :
|
Nombre de 9
|
Arrêt du service sur un an
|
|
3 neufs (99,9%)
|
Environ 9heures
|
|
4 neufs (99,99%)
|
Environ 1heure
|
|
5 neufs (99,999%)
|
Environ 5minutes
|
|
6 neufs (99,9999%)
|
Environ 30secondes
|
I.1.1 CONDITION DE MISE EN PLACE
Une bonne démarche, permettant de mettre une oeuvre
assez rapidement une infrastructure solide capable de garantir la Haute
Disponibilité d'un service critique, consiste à évaluer
les différents objectifs suivants :
Ø Définition des critères
d'indisponibilité du service : Niveau de disponibilité, temps de
rétablissement ou encore temps d'engagement du service ;
Ø Analyse de la volumétrie des données et
des performances nécessaires au bon fonctionnement du service ;
Ø Prise en compte des différents critères
de coûts ;
Ø solution des configurations matérielles et
logicielles (si applicable) ;
Ø Surveillance du service et planification de la
maintenance corrective et préventive (qui, quand, comment).
A ce stade de l'étude, on a une idée bien
précise du type d'architecture qu'il est nécessaire de mettre en
oeuvre pour répondre au besoin posé. L'étape suivante
consiste à évaluer les différentes architectures possibles
et à sélectionnez celle qui semble répondre le mieux aux
différentes contraintes. En effet, identifier les faiblesses d'un
système informatique est la première étape permettant de
fiabiliser son fonctionnement et d'initier une réflexion sur les moyens
qu'il sera possible de mettre en oeuvre pour garantir la continuité du
service, et donc la Haute Disponibilité.
I.2 LINUX ET LA
HAUTE DISPONIBILITE
Les supports de Haute Disponibilité existe depuis
déjà quelques années sous Linux et même si le niveau
de maturité n'est pas encore celui d'autres environnements
propriétaires de type Unix, il est déjà largement
suffisant dans la plupart des cas.
Une bonne part des techniques disponibles reposes sur la
multiplication des ressources critique (physiques ou logicielles) constituant
un serveur. En multipliant les ressources, on supprime du même coup leurs
caractères critiques. Le service pourra donc être assuré
même en cas de panne d'un composant. Cela permet notamment d'utiliser des
composants moins chers puisque la fiabilité du composant ne devient plus
le critère principal.
Une seconde approche considère que l'on peut assez
facilement mettre en place une solution où ce n'est plus la ressource
que l'on va chercher à dupliquer, mais directement le serveur.
L'utilisation de grappes de machines (cluster en anglais) est un bon moyen de
répondre à cette problématique. Si l'on parvient à
disposer d'au moins deux machines sur lesquelles le service est
exécuté de façon unique (sur l'un ou l'autre des noeuds),
la continuité du service sera garantie moyennant le temps de basculement
d'une machine à l'autre (On parle en anglais de FailOver Services, FOS).
La principale difficulté consiste à maintenir
une copie des données entre les noeuds (dans ce type de cluster dit de
Haute Disponibilité, une machine s'appelle un noeud) pour que le service
puisse être indifféremment lancé sur l'un ou l'autre des
serveurs. Pour accomplir cela, il existe différentes techniques
basées soit sur la réplication plus ou moins en temps réel
des données entre les noeuds, soit sur le partage d'une ressource unique
en utilisant notamment un système de fichiers distribués ou
partagés. Dans ce type de configuration, il est important de faire en
sorte que le temps de rétablissement du service soit le plus faible
possible pour réduire le gène occasionné aux utilisateurs.
Le basculement du service dans le cluster ne doit pas être (trop)
perceptible et ne doit surtout pas occasionner une modification du
paramétrage côté client : Afin de rendre transparente cette
étape, on utilise la notion d'alias IP pour associer une adresse IP dite
flottante sur le noeud hébergeant le service. La continuité
apparente du service coté client est donc assurée.
Une dernière technique moins connue permet de
répartir la charge sur un ensemble de noeuds physiques sur lesquels un
service de type réseau est exécuté en parallèle et
en concurrence. Un noeud maître se charge de répartir les
requêtes sur le noeud le moins chargé du cluster. Si un noeud
tombe en panne, il sera détecté par le maître qui pourra
facilement le retirer de sa liste des noeuds actifs.
La plus grande partie des architectures misent en oeuvre pour
garantir la disponibilité d'un service dérivant plus ou moins
directement de ces trois approches.
I.3 LES COMPOSANTS
En premier point, l'on devrait tout d'abord définir
notre champs d'activité tous les composants d'un système
informatique pouvant être d'une manière ou d'une autre mis en
haute disponibilité c'est ainsi que, nous nous limiterons à une
étude relative aux défaillances logiques (logiciels), et
physiques (Terminaux informatique).
I.3.1 HAUTE DISPONIBILITE AU NIVEAU
PHYSIQUES : LES COMPOSANTS
La multiplication des différents composants critiques
présents dans votre système peut vous permettre de survivre
à une panne en considérant que les solutions matérielles
de Haute Disponibilité disponibles sous Linux se rapprochent de plus en
plus de celles proposées sur les serveurs Unix haut de gamme.
Il est assez simple de redonder les alimentations
électriques (transparent pour les systèmes d'exploitation), mais
aussi les disques durs, les contrôleurs disques et les interfaces
réseaux :
I.3.1.1 Alimentation redondée
Certains constructeurs proposent de fournir deux ou trois
alimentations pour prévenir la perte de ce composant. Les alimentations
sont des composants critiques et il n'est pas rare de voir celles-ci faillir
bien avant les autres composants du système. Les alimentations ATX par
exemple ne sont pas réputées pour être des plus fiables
(elles sont notamment très sensibles aux variations de tension).
I.3.1.2 Utilisation des grappes de disques
L'utilisation des technologies RAID est un bon moyen de
sécuriser vos données et prendre en compte notamment la perte
d'un disque. On peut disposer de cette technologie de façon logicielle
sous Linux même car il y est tout à fait envisageable de
l'utiliser par l'intermédiaire de cartes d'interface IDE ou SCSI
à enficher dans votre système (Linux en supporte un grand
nombre).
I.3.1.3 Multiplication des cartes réseaux
Un câble réseau peut être
accidentellement débranché ; Une carte réseau peut
subir les aléas d'une panne et ne plus pouvoir être utilisable. Le
service réseau que vous proposez est donc fortement tributaire de la
disponibilité de ce type de composants. Heureusement pour nous, il
existe une couche logicielle sous Linux permettant de créer une
interface réseau virtuelle regroupant plusieurs cartes : On appelle
cela, le Channel Bonding. Ce procédé est normalisé, vous
pourrez donc l'utiliser en point à point mais aussi en interface avec
des Switchs et mêmes des hubs selon le type d'algorithme
sélectionné. En considérant le prix modeste de certaines
cartes réseaux, il parait incontournable d'utiliser massivement cet
artifice.
I.3.1.4 Sécuriser l'accès aux unités de
stockages externes
Le RAID logiciel sous Linux (driver MD) supporte depuis peu
un nouveau mode dit Multipath qui s'utilise dans le cas ou vous disposez de
deux liens physiques qui pointent vers
une seule et même ressource. Un seul des deux liens sera
effectivement utilisé et, en cas de panne, c'est le second qui prendra
la relève. Cela peut être très utile si vous disposez d'une
baie de stockage externe en SCSI ou en Fibre Channel disposant de deux
interfaces d'entrées/sorties. Il vous faudra prévoir deux
contrôleurs dans votre serveur mais cela reste la solution idéale
pour sécuriser vos écritures disque si votre baie de disque
supporte cette fonctionnalité.
CHAPITRE II: SYNTHESE ET
FUTUR
Introduction
Cette partie décrit la méthode
d'évaluation et de comparaison des produits, et la manière dont
les résultats seront présentés. On comparera trois
solutions décrites ci-dessous :
Ø AIX/HACMP ;
Ø Digital Unix/TruClusters ;
Ø Logiciels libres : l'ensemble des produits
décrits dans ce document. Pour chacun des critères fonctionnels,
on rappellera quels sont les produits concernés.
Pour chacune des solutions sont évalués :
Ø Les sous-critères : à chacun d'eux sera
associée une notation qui dépendra du sous-n critère. Elle
pourra être + si la fonctionnalité est présente et
implémentée de façon satisfaisante, - pour indiquer que la
fonctionnalité n'est pas implémentée ou de manière
non satisfaisante. On indiquera n/a si la fonctionnalité ne s'applique
pas, et pas de notation si la fonctionnalité n'a pu être
évaluée. On pourra aussi associer à un sous-critère
une évaluation informelle, par exemple une valeur numérique pour
le sous critère "nombre de noeuds supportés".
Ø Les critères (fonctionnels ou
généraux) : à chacun des critères sera
associée une note,
, selon que l'évaluation du critère
correspondant est mauvaise, moyenne ou bonne. Cette note sera déduite
des évaluations des sous-critères dépendant de ce
critère.
Ces notations seront récapitulées sous la forme
de deux tableaux :
Un tableau d'évaluation présentant l'ensemble
des critères et de leurs sous-critères ;
Un tableau de synthèse ne montrant que les
critères.
Les colonnes de ces tableaux sont les suivantes :
Ø Critères : critères ou
sous-critères évalués ;
Ø HACMP / Trucluster / Logiciel libres : notation du
critère ou sous-critère comme présenté ci-dessus
;
Ø Produits : dans le cas des critères
fonctionnels, cette colonne indique quels sont les produits concernés
par la fonction associée au critère ;
Ø Remarques : Cette rubrique précise la notation
de la solution logicielle libre et peut éventuellement présenter
des éléments de comparaison avec les autres solutions.
II.1 TABLEAUX DE COMPARAISON
Cette partie contient les tableaux d'évaluation et de
synthèse décrits à l'introduction.
Tableau 1 tableau d'évaluation (annexes)
Tableau 2 synthèse d'évaluation
Mise en Cluster
|
Evaluation
|
Logiciels Libres
|
|
|
HACMP
|
Trucluster
|
Log.libres
|
Produits
|
Remarques
|
|
|
Mécanismes de reprise
|
|
|
|
Heartbeat
|
Heartbeat fournit une solution légère de
clustering pour deux serveurs. Ce produit est à compléter par un
outil de détection de pannes logicielles.
|
Disponibilité des données
Détection de panne
|
|
|
|
Heartbeat
Mon
|
Les logiciels libres étudiés permettent de
surveiller la plus part des ressources logicielles et matérielles.
|
|
|
Support RAID
|
|
|
|
Linux
|
RAID logiciel plus complet que les solutions commerciales. Raid
matériels supporte peu de contrôleurs
|
|
Disques partagés
|
|
|
|
GFS
|
Produit complet, mais avec les contraintes importantes sur le
matériel (support d'une extension à la norme SCSI)
|
|
Volumes partagés
|
|
|
|
DRBD
|
DRBD fourni une fonction de réplication au fil de l'eau
et n'a pas d'évanlent dans les solutions commerciales.
|
|
Haute disponibilité des systèmes de fichiers
|
|
|
|
ReiserFS
|
ReiserFS est déjà utilisé en production
par de gros serveurs.
|
II.2 SYNTHESE
On constate que dans l'environnement des logiciels libres on
trouve encore peu de produits fournissant une solution globale de haute
disponibilité, et que pour mettre en place une telle solution il faut
utiliser plusieurs "petits" produits apportant chacun une fonction de la haute
disponibilité (clustering, réplication de disques, RAID, ...).
Les produits doivent ensuite être intégrés.
Les distributions Linux incluent rarement des outils de haute
disponibilité. Il faut donc installer ces produits soi-même et les
intégrer au système d'exploitation. Par exemple, dans le cas de
ReiserFS, cette opération est très lourde: elle nécessite
l'installation d'une distribution, la sauvegarde complète, le
repartitionnement et mise en place des partitions ReiserFS, la restauration
du système, et la mise à jour "à la main" des
fichiers de configuration du système, étant donné que
ReiserFS n'est pas pris en compte par les outils d'administration livré
avec la distribution. Les seules exceptions sont :
Ø Redhat (
www.redhat.com) qui inclut
maintenant le produit piranha ;
Ø Suse 6.4 (
www.suse.com) qui peut s'installer sur
un système de fichier ReiserFS ;
Ø Conectiva Linux qui comprend le
produit Heartbeat.
Faiblesses des produits :
Ø La sécurité a été prise
en compte de manière inégale par les produits
étudiés. En particulier le produit DRBD fait circuler en clair
sur le réseau et sans authentification toutes les mises à jour
apportées au contenu de la partition partagée. La mise en place
d'une solution de haute disponibilité sécurisée passe par
des solutions de type sécurité de périmètre telles
que celles décrite dans la partie 3.3 ;
Ø Les produits ne fournissent pas d'outil
d'administration de haut niveau à part pour les deux solutions
d'équilibrage de charge toutes intégrées (Ultramonkey et
Piranha) ;
Ø Les produits étudiés n'ont pratiquement
pas de références en production actuellement, à part
l'utilisation des fonctions standard de Linux (RAID, Watchdog), et le produit
ReiserFS ;
Ø Les produits étudiés présentent
des limitations très contraignantes (par exemple le nombre de noeuds
supportés par HeartBeat et DRBD), mais les auteurs annoncent que ces
limitations vont être supprimées dans des versions
ultérieures. En particulier, dans le domaine de la mise en cluster : le
produit Heartbeat ne supporte que 2 noeuds, n'a pas de mécanisme de
détection et de reprise dans le cas d'une panne d'une interface
réseau. Aucun produit n'adresse actuellement le problème de
redondance entre sites distants multiples. La vitesse d'évolution
des produits et le nombre d'intervenants participant à
ces projets semblent aller dans ce sens.
Les logiciels libres offrent des solutions de qualité
comparable (à part pour les outils d'administration) avec les produits
commerciaux dans les domaines suivants :
Ø RAID matériel et logiciel
Ø Disques partagés (GFS)
Ø Equilibrage de charge (LVS)
Les logiciels libres permettent la mise en place de solutions
hautement disponibles sur du matériel à faible coût (PC
standard) :
Ø Une solution de réplication de disques
à la volée permet d'assurer la haute disponibilité des
données la ou une solution commerciale équivalente
nécessite la mise en place de disques partagés et donc de
matériel spécifique (Fibre Channel ...) ;
Ø La solution de RAID logiciel fournie par Linux est
plus complète que celles fournies par les solutions commerciales.
Certaines fonctionnalités (RAID 5 par exemple) qu'elle fournit
nécessitent forcément la mise en place d'une solution
matérielle spécifique dans le cas des solutions commerciales.
En conclusion, les solutions de haute disponibilité
dans l'environnement logiciel libre n'ont pas encore atteint le stade de
la maturité. On peut toutefois affirmer que la haute
disponibilité est une réalité satisfaisante pour Linux si
on se limite à des cas simples, et en particulier au cas le plus
couramment utilisé qui est le backup d'un serveur sur un autre avec un
partage de disques.
II.1 LE FUTUR
Les éditeurs de distributions incluent de plus en plus
des produits concernant la haute disponibilité dans leurs distributions
:
Ø Redhat propose le produit Piranha et l'inclut dans sa
distribution;
Ø La distribution Suse peut s'installer sur du ReiserFS
;
Ø Conectiva Linux (www.conectiva.com) est livré
avec Heartbeat.
On voit un nombre croissant d'annonces de
sociétés commerciales qui prennent en compte le problème
de la haute disponibilité et vont proposer (ou proposent
déjà) des solutions complètes, des nouveaux produits, ou
la mise sous licence open source de leurs produits déjà
existants.
CHAPITRE III: CAS
PRATIQUE : DEPLOIEMENT DES SERVICES ET MISE EN HAUTE
DISPONIBILITE
Introduction
Mettre en place un environnement haute disponibilité
est une solution attractive, mais à quel coût ? Les outils que
nous avons utilisés concernant ce sujet, Heartbeat, DRBD et MON sont les
solutions "open source" les plus anciennes et les plus éprouvées.
La plupart des plateformes les acceptent et une large communauté
d'utilisateurs continue de les garder à jour en corrigeant les erreurs
et en proposant de nouvelles améliorations. Leur flexibilité
permet d'administrer des services indépendamment, toujours sous
surveillance.
Assurer la haute disponibilité d'un service et des
données est aujourd'hui devenu le principal souci des DSI dans le monde
de l'entreprise. Actuellement, plusieurs solutions sont disponibles.
Ø L'équipement SAN (Storage area network)
très coûteux et dont la maintenance s'avère très
fastidieuse en cas de panne.
Ø La synchronisation régulière (rsync)
entre les serveurs .L'Inconvénient de cette solution est qu'en cas de
crash les données récupérées dateront de la
dernière synchronisation.
Le projet Linux High Availability a été
développé dans le but de fournir une solution aux
problèmes rencontrés précédemment. Cette solution
répond à plusieurs impératifs: faible coût,
facilité de maintenance et données parfaitement à jour en
cas de bascule serveur.
Dans ce chapitre, nous allons voir pas à pas comment
l'installer et le configurer, le plus simplement possible.
III.1 INSTALLATION ET CONFIGURATION DES
SERVICES
III.1.1 LE SERVICE DE NOM (DNS)
Le programme serveur bind vient nativement avec la
distribution Centos 4.6 qui sera utilisée pour héberger nos
services. Nous allons configurer un serveur de noms pour le domaine
théorique creolink.lan et du réseau 172.16.0.0/16 avec les
hôtes www (pour le web), ftp (pour transfert de fichier), mail pour la
messagerie, haserver0 et haserver1 pour la HA. Pour cela, les fichiers de
configurations sont les suivants :
Ø Fichier de résolution direct que nous noterons
creolink.zone
Ø Fichier de résolution inverse que nous
noterons creolink.rev
Ø Fichier resolv.conf
Ø Fichier named.conf
La configuration respectivement associée à
chaque fichier est la suivante :




Test de bon fonctionnement
Les captures suivantes certifient le bon fonctionnement du
service.

III.1.2 LE SERVICE WEB SECURISE (HTTPs)
C'est le service web s'appuyant sur le protocole SSL,
permettant d'assurer la confidentialité des transactions sur un
réseau public tel qu'internet. Il est généralement
utilisé dans le service de commerce en ligne (e-commerce).
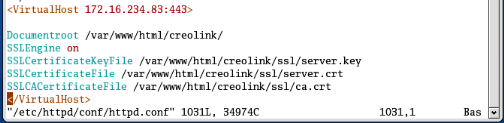
Sa configuration s'effectue dans le fichier http.conf et a
été orientée hôte virtuel et mod-SSL.
Il suffit pour une configuration minimal d'ajouter en fin de page
les lignes comme suit :
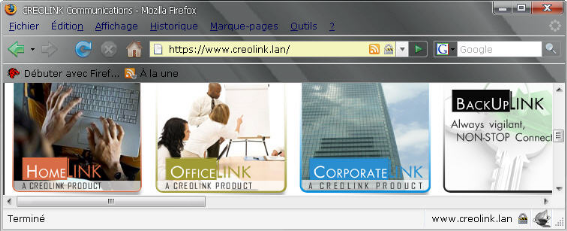
Test de bon fonctionnement
A partir d'un navigateur on se connecte au site
www.creolink.lan
III.1.3 LE SERVICE SECURISE DE TRANSFERT DE FICHIER
(FTPs)
Ce service est généralement utilisé pour
mettre à jour un serveur web ou rendre disponible certains fichiers pour
un téléchargement ftp.
Linux Centos 4.6 intègre le programme VSFTP (Very
Secure File Transfert Protocol). Nous l'avons configuré afin qu'il
accepte les connexions anonymes grâce à l'utilisateur anonymous
donc le répertoire d'accueil est /var/ftp.
Le test de bon fonctionnement sera illustré dans ce
chapitre lors la mise en haute disponibilité de ce service.
III.2 MISE EN HAUTE
DISPONIBILITE DES SERVICES CAS :
DES
SERVICES FTP ET HTTP
Configuration matérielle et logicielle.
Dans le cadre de ce travail notre cluster
FailOver possède deux noeuds distincts : un maître
de nom haserver0.creolink.lan et l'autre de secours de nom
haserver1.creolink.lan ayant presque les mêmes capacités
mémoires et fréquences (pas obligatoire), tournant sous le
système Linux Centos 4.6 de noyau 2.4 qui communiqueront entre eux par
une liaison Ethernet privée point à point via la carte Ethernet0
et avec les autres hôtes du réseau par une liaison, point
à multipoint en conservant la plage d'adresse 172.16.0.0/16. La voie de
communication privée peut utiliser un support de connexion série
qui paraît plus stable.
.
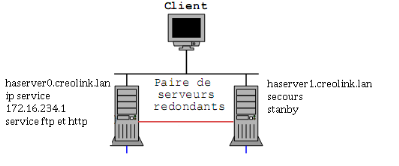
Figure 1 Architecture de test
Les deux noeuds de notre cluster FailOver auront un support
logiciel constitué de: Heartbeat, Mon et drbd pour assurer la haute
disponibilité des données et des services http et ftp
précédemment configurés et actuellement disponibles sur
nos noeuds.
III.2.1 INSTALLATION ET CONFIGURATION DE LA PLATE FORME
LOGICIELLE
Nous avons installé successivement les paquetages
suivants :
a. Heartbeat-pils :
b. Heartbeat-stonith : Il permet d'assure la possession
des ressources par un seul hôte.
c. Heartbeat : Assure la prise de pouls.
d. drbd83 : C'est la bibliothèque des scripts
drbd
e. kmod-drbd83 : C'est le module permettant au noyau de
gérer le périphérique drbd
f. mon : Il permet de surveiller les ressources et
déclenche l'alerte selon leur état.
III.2.1.1
Hertbeat
Heartbeat est situé au coeur du processus de
fonctionnement d'une solution de haute disponibilité. Il constitue le
lien permettant aux deux serveurs de se prendre mutuellement le pouls.
Heartbeat vérifie uniquement la «bonne santé» des
serveurs, sans se préoccuper des applications qui tournent dessus. Pour
ce faire, il faudra le faire interagir avec un outil de monitoring, comme mon.
Nous verrons ci-dessous comment réaliser une synchronisation. On peut
télécharger les paquetages pour la: Centos à cette
adresse :
http://www.ultramonkey.org/download/heartbeat/
III.2.1.1.1 Installation
Nous avons utilisé l'utilitaire d'installation en ligne
yum comme suit:


On peut vérifier son installation comme suit :
III.2.1.1.2 Configuration
Heartbeat a besoin de trois fichiers essentiels pour
fonctionner : ha.cf qui définit le moyen de communication et les
paramètres de base, haresources pour spécifier le noeud
où les services vont être lancés au démarrage et
authkeys pour sécuriser le processus de communication.
NB Au cas où Hearbeat ne les a pas crées
lors de son installation, on les copie depuis /var/lib/hearbeat vers
/etc/ha.d/
Le fichier /etc/ha.d/ha.cf
Ce fichier définit les paramètres
généraux de Heartbeat. Par défaut toutes les lignes sont
marquées avec le symbole "#", nous allons en décommenter
certaines.
# Emplacement des messages de debug
debugfile /var/log/ha-debug
# Autres messages
logfile /var/log/ha-log
# Nombre de secondes entre chaque battement
keepalive 2
# Temps avant qu'un noeud soit déclare mort
deadtime 10
#warntime: intervalle de Temps avant utilisation du dernier
message d'avertissement
warntime 10
# Very first dead time (initdead)
initdead 10
# Port utilise pour la communication en UDP
udpport 694
# Interface utilisée
bcast eth0
# Récupération automatique des ressources par le
serveur maître si celui-ci est à nouveau opérationnel
auto_failback on
# Les noeuds de notre cluster
node hasever0.creolink.lan
node haserver1.creolink.lan
Voilà, il faut maintenant sauver le fichier de
configuration et le copier sur le second serveur grâce à la
commande scp /etc/ha.d/ha.cf root@haserver0.creolink.lan:/etc/ha.d
Tous les autres paramètres sont optionnels pour la
simple redondance que nous cherchons à créer.
Le fichier /etc/ha.d/haresources.s
Le deuxième fichier important est haresources. Son
rôle est de définir quel est le noeud qui deviendra maître
et les services contrôlés par heartbeat. Pour éviter tous
conflits, ce fichier doit être identique de chaque côté de
notre installation. Nous reviendrons plus tard sur ce fichier lors de la
configuration de DRBD. Pour le moment, nous allons tester heartbeat uniquement
avec les services Apache httpd et ftp vsftp bien sûr,
précédemment configurés sur les deux serveurs.
La ligne à modifier pour une utilisation minimale
d'heartbeat est :

haserver0.creolink.lan indique que c'est ce noeud qui est
maître
IPaddr indique le script permettant de récupérer
l'adresse du service sous forme d'alias eth0
Httpd et vsftpd sont respectivement les scripts de
démarrages d'apache (service web) et du service FTP et doivent
être déplacés du répertoire /etc/rc.d/init.d vers
/etc/ha.d/resources afin que heartbeat puisse les trouver et les
exécuter.
Le fichier /etc/ha.d/authekeys
Le troisième fichier à configurer est
utilisé pour sécuriser la communication entre les deux noeuds. Un
échange de clé d'authentification est effectué à
chaque fois que la connexion est établie. Trois modes d'authentification
sont disponibles : crc, md5 and sha1. Les deux derniers nécessitent un
mot de passe qui leur confère une plus grande robustesse.
Considérant les ressources CPU à mettre à
disposition pour le sha1, nous avons préféré utiliser le
chiffrage crc. Le fichier contient deux lignes, comme suit :
Auth 1
1 crc
Nous allons restreindre les permissions d'accès
à ce fichier. En effet L'utilisateur root est le seul à pouvoir
le lire et le modifier.
# chmod 600 /etc/had.d/authkeys
Une fois que tout a été configuré et les
fichiers copiés sur chacun des noeuds, nous pouvons démarrer le
service Heartbeat, d'abord sur la machine haserver0 puis sur
haserver1 :
#/etc/init.d/heartbeat start
Test de bon fonctionnement
La ligne de commande /etc/init.d/heartbeat start permet de
démarrer le serveur heartbeat, pour vérifier que tout se passe
bien nous allons exécuter la commande tail -f /var/log/messages pour
écouter en temps réels la conversation entre les 2 noeuds. Voici
le résultat obtenu sur le noeud de secours haserver1 :

Si nous déconnectons le serveur ou bien stoppons le
service heartbeat, sur le serveur haserver0, nous pouvons observer
ceci :

haserver1 ne détecte plus le pouls de haserver0
à partir d'une durée de 10s (deadtime) indiquée dans le
fichier ha.cf, le déclare comme mort (dead) et récupère
l'IP des services grâces au script IPAddr, acquière les ressources
http et vsftp et envoi une alerte mail warn à l'administrateur d'adresse
simo@creolink.lan via le serveur
de mail lui indiquant comme quoi le noeud haserver0 est mort.
Nous savons faire communiquer nos serveurs, nous devons
maintenant synchroniser le contenu de notre site web et de notre
répertoire ftp. Pour cela, DRBD est un allié efficace.
III.2.1.2 DRBD
DRBD va synchroniser le contenu de nos dossiers en temps
réel afin de garantir une copie conforme du serveur maître si
celui-ci devait tomber. DRBD est disponible pour la plupart des distributions
GNU/Linux mais nécessite quelques modifications du noyau.
III.2.1.2.1 Installation
Nous avons utilisé l'utilitaire d'installation en ligne
yum comme suit:

On peut verifier que drbd est bien installé comme
suit :

III.2.1.2.2 Configuration
La configuration de drbd se fait dans le fichier
/etc/drbd.conf. Le contenu de ce fichier est disponible et doit être
identique sur nos 2 noeuds. Après cette configuration il faut
exécuter un ensemble de ligne de commande comme suit :
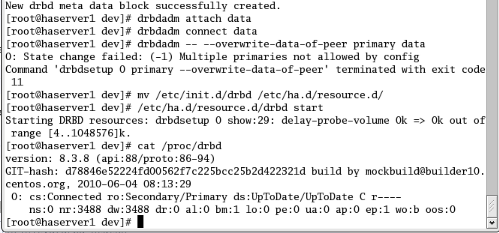
Nous constatons bien que le serveur drbd est bien
démarré sur haserver1 qui est déclaré comme
secondary et haserver0 comme primary.
Test de bon fonctionnement
Pour tester le fonctionnement de drbd, il suffit de
créer un répertoire par exemple /mnt/ test sur le serveur
primaire et monter le périphérique /dev/drbd0 dans /mnt/test,
copier un dossier ou un fichier dans ce répertoire enfin le
démonter et rendre le serveur primaire secondaire. Sur le serveur
secondaire, il faut le rendre primaire puis monter le
périphérique /dev/drbd0 dans un répertoire par exemple
/mnt, vous trouverez dans ce répertoire le contenu du répertoire
/mnt/test du serveur primaire.
III.2.1.3 MON
(Service Monitoring Daemon)
Heartbeat surveille l'état du système mais pas
des services. Mon viendra aiguiser la surveillance jusqu'au niveau service.
III.2.1.3.1 Installation de MON
Mon n'est pas dans l'arbre des paquets Centos. Il nous faudra
donc l'installer manuellement. Les étapes suivantes sont à
effectuer sur les serveurs primaire et secondaire. Récupérez le
package Mon à l'adresse suivante : http://www.kernel.org/software/mon/.
Puis le copier dans /etc/ha.d et enfin exécutez les commandes suivantes
pour l'installer.
# cd /etc/ha.d
# tar xzvf mon-1.2.0.tar.gz
# mv mon-1.2.0.tar.gz mon
De plus, Mon requiert quelques modules Perl externes. Vous
pouvez utiliser votre CPAN
(Compréhensive Perl Archive Network) que l'on peut
récupérer en utilisant les liens ci-dessous:
Ø Period
[http://search.cpan.org/org/CPAN/authors/id/P/PR/PRYAN/Period-1.20.tar.gz]
Ø Time::HiRes
[http://backpan.perl.org/authors/id/J/JH/JHI/Time-HiRes-1.91.tar.gz]
Ø Convert::BER
[http://search.cpan.org/CPAN/authors/id/G/GB/GBARR/Convert-BER-1.3101.tar.gz]
Ø Mon
[http://search.cpan.org/CPAN/authors/id/T/TR/TROCKIJ/Mon-0.11.tar.gz]

Décompressez les archives avec la commande tar xvzf
puis installez les modules en suivant la procédure suivante dans chacun
des dossiers crées.
# perl Makefile.pl
# make && make install
III.2.1.3.2 Configuration
Script démarrage
Nous allons maintenant voir comment configurer la surveillance
des services sur les serveurs avec Mon. Tout d'abord, nous allons avoir besoin
d'un script permettant à Mon de gérer l'état de Heartbeat,
permettant ainsi un passage des ressources en cas de non réponse d'un
service. Le dossier mon.alert contient un ensemble de scripts permettant
à Mon de générer des alertes en cas de défaillance
de services.
Créer le fichier ha-up-down.alert dans
/etc/ha.d/mon/mon.alert.
#!/bin/bash
# arrêt/démarrage du service heartbeat
HEARTBEAT="/etc/rc.d/init.d/heartbeat"
if [ "$9" = "-u" ]; then
$HEARTBEAT start
else
$HEARTBEAT stop
fi
# envoi d'un mail aux administrateurs (argument passé
par mon.cf)
/etc/ha.d/mon/alert.d/mail.alert $*
Le fichier /etc/ha.d/mon/mon.cf
Il est nécessaire de créer le fichier
mon.cf dans /etc/ha.d/mon. Ce fichier contient la liste des services que "mon"
doit surveiller et les actions résultantes de divers
évènements. L'exemple suivant montre comment surveiller
l'état d'un serveur (http, ftp) et basculer les ressources en cas de non
réponse.
# emplacement des fichiers de configuration/d'alerte/logs
cfbasedir = /etc/ha.d/mon/etc
alertdir = /etc/ha.d/mon/alert.d
mondir = /etc/ha.d/mon/mon.d
statedir = /etc/ha.d/mon/state.d
logdir = /var/log/
# type d'authentification
authtype = getpwnam
# le serveur à surveiller
hostgroup server 127.0.0.1
# les services à surveiller sur le serveur
watch servers
service http
interval 30s
monitor http.monitor
period wd {Mon-Sun}
# les actions en cas de panne/retour à la
normale
alert ha-up-down.alert -S "service httpd down !" \
simo@creolink.lan
upalert mail.alert -S "service httpd up !" \
simo@creolink.lan
# délai entre chaque alerte
alertevery 600s
service ftp
interval 30s
monitor ftp.monitor
period wd {Mon-Sun}
# les actions en cas de panne/retour à la
normale
alert ha-up-down.alert -S "service ftps down !" \
simo@creolink.lan
upalert mail.alert -S "service ftp up !" \
simo@creolink.lan
# délai entre chaque alerte
alertevery 600s
On peut alors démarrer mon en faisant
# /etc/ha.d/mon/mon
III.2.2 TEST GENERAL DE BON FONCTIONNEMENT DE L'INTERACTION
HEARTBEAT MON DRBD : CAS PRATIQUE D'UN DOWNLOAD FTP
Notre infrastructure haute disponibilité est maintenant
prête. Pour tester, nous considérons les deux serveurs en
fonctionnement comme suit :
haserver0 maitre/primaire et Mon démarré
haserver1 secours/secondaire et Mon démarré
Lors du transfert de fichier, plusieurs
évènements contraignants peuvent se produire :
Ø Le crash du serveur haserver0.creolink.lan que nous
simulerons par une déconnexion réseau ou même par
l'arrêt de heartbeat. Détection par heartbeat sur haserver1 et
basculement des ressources.
Ø L'arrêt du service (ftp). Détection par
Mon qui arrête hearbeat. Détection de l'arrêt de heartbeat
par heartbeat distant et basculement des ressources.
Cas d'un download
Nous utiliserons le logiciel download manager pour
télécharger un film déposé sur le serveur ftp. Au
cours de ce téléchargement nous avons simulé le
disfonctionnement du serveur principal comme précédemment
présenté. Voici ce que nous obtenons sur le logiciel
utilisateur :

Interprétation
Nous observons bien l'instant de déconnexion (la
connexion avec le serveur a été perdue) à 19h21mn34s et
à 19h21mn52s l'instant de connexion (connexion établie) ce qui
correspond à une durée de 18s (10s le deadtime pour
déclarer le serveur maître comme mort et pour
récupérer les ressources et 5s pour permettre à fake de
mettre à jour les tables ARP, 1s temps moyens des transferts
réseau et 1s temps moyens influencé par la vitesse du processeur
et la mémoire RAM. On peut réduire d'avantage ce temps en
augmentant les capacités des serveurs ou en réduisant le deadtime
dans le fichier /etc/ha.d/ha.cf.
Côté utilisateur, le basculement est totalement
transparent et amorti l'interruption en réduisant la durée
d'indisponibilité de service pour garantir une disponibilité
supérieur à 3 neufs et atteindre la haute disponibilité.
Ce qui pourra permettre à un fournisseur de service internet ou à
un hébergeur de respecter sa part de contrat de niveau de service ou
service agreement.
Conclusion
Le trio DRBD - Heartbeat - Mon est parfait pour assurer la
redondance de deux machines physiquement proches. Assurant à la fois la
surveillance des défaillances des systèmes mais aussi celle des
services, cette solution met un terme au problème de redondance et
d'interruption de service.
Le projet Open source HA est en constante évolution
depuis son lancement en 1999 et la limitation initiale des 2 noeuds est
désormais révolue. Une entreprise aux revenus limités ne
désirant pas investir dans un SAN coûteux et à la
maintenance ardue peut maintenant disposer d'une solution complète,
fiable, facile à administrer et totalement libre. Une bonne idée
est d'associer l'environnement logique que nous venons de traiter à un
environnement physique de disques durs montés en RAID pour des
structures plus larges.
CONCLUSION GENERALE
Au cours de ce stage effectué à CREOLINK
COMMUNICATIONS, force nous a été donnée de remplir non
seulement les tâches quotidiennes qui nous étaient
assignées et le cahier des charges, mais aussi de participer en
parallèle au programme de développement d'une structure
ergonomique de gestion d'un réseau VLANisé étendu par
déport VPN.
Ce stage d'une durée de deux mois m'aura donc permis
d'avoir une architecture générale de fonctionnement et
d'exploitation optimale des divers services internet sur un réseau
complexe comme celui de CREOLINK et d'assurer une exploitation optimale du
strict minimum de ressources donc nous disposons.
Au-delà de tout cela, les contacts humains
socioprofessionnels ont beaucoup apporté dans mon savoir vivre en
communauté professionnelle et surtout nous avons appris à
gérer au mieux des cas la pression qui est la conséquence
très souvent d'une obligation de résultat. Je suis donc
très heureux d'avoir effectué une fois de plus ce stage à
CREOLINK, c'est la raison pour laquelle je tiens à remercier une fois de
plus mes tuteurs M. LIENOU J.P et M. Elysée YARRO également tout
le personnel du service « support technique de CREOLINK
DOUALA » pour leur soutient et leur disponibilité.
REFERENCES
BIBLIOGRAPHIQUES
Ouvrages
Ø Nicolas Ferre, Livre blanc Haute disponibilité
sous Linux.
Ø M.Wielsch, J.Prahm, H.G.Esser, LA BIBLE Linux :
Administration-Réseaux TCP/IP Intranet-Programmation.
Ø Jean GABES, Nagios pour la supervision et la
métrologie : Déploiement, configuration et Optimisation.
Liens internet
Ø Article présentant une solution haute
disponibilité dans Linux journal, consulté le 29/08/2010
(http://
www.linuxjournal.com/lj-issues/issue64/3247.html)
Ø Article présentant les différents types
de cluster, consulté le 29/08/2010
(http://www.linuxworld.com/lw-2000-03/lw-03-clustering.html)
Ø HOWTO haute disponibilité consulté le
02/09/2010
(
http://metalab.unc.edu/pub/Linux/ALPHA/linux-ha/High-Availability-HOWTO.html)
Ø Projet mettant en oeuvre diverses configurations de
serveurs en haute disponibilité consulté le 04/09/2010 (
http://ultramonkey.sourceforge.net)
Ø Guide d'installation de RedHat High Avaibility
Server, consulté le 15/09/2010
(
http://www.redhat.com/support/manuals/RHHAS-1.0-Manual/)
Ø Linux Virtual Server (LVF), consulté le
20/09/2010
(
http://www.linuxvirtualserver.org)
Ø Linux High Avaibility, consulté le 01/10/2010
(
http://www.linux-ha.org)
Ø Mon: Service Monitoring Daemon, consulté
10/10/2010 (
http://mon.sourceforge.net)
Ø Fake: Redundant Server Switch, consulté le
15/10/2010 (
http://fake.sourceforge.net)
Ø DRD: Distributed Replicated Block Device,
consulté le 18/10/2010
(
http://www.drbd.org)
ANNEXES
Tableau1 Tableau d'évaluation
Mise en Cluster
|
Evaluation
|
Logiciels Libres
|
|
|
HACMP
|
Trucluster
|
Log.libres
|
Produits
|
Remarques
|
|
|
Mécanismes de reprise
|
|
|
|
Heartbeat
|
Heartbeat fournit une solution légère de
clustering pour deux serveurs. Ce produit est à compléter par un
outil de détection de pannes logicielles.
|
Modules de clusterisation supportés
|
|
|
|
|
Contrairement aux solutions commerciales, Heartbeat qu'un seul
mode de reprise. En particulier, pas de FailOver en cascade, d'instances
multiples de services..., Heartbeat impose un basculement lorsque le noeud est
disponible après une panne
|
|
Nombres de noeuds supportés
|
3
|
8
|
2
|
|
La documentation sur Heartbeat indique que la limitation à
deux noeuds devrait être bientôt supprimée (L'architecture
du produit est prévue pour un plus grand nombre de noeuds)
|
|
Sélection dynamique du noeud de backup
|
|
|
|
|
Cette fonction n'est implémentée dans Heartbeat et
Trucluster.
|
|
Compatibilité avec les produits d'équilibrage de
charge.
|
|
|
|
|
Heartbeat ne supporte pas d'instances multiples de service. Il
n'est donc pas possible d'utiliser Heartbeat pour gérer les serveurs
dans le cadre d'une solution d'équilibrage de charge à l'aide de
ca produit
|
|
Actions correctrices possibles
|
|
|
|
|
Actions possibles :
· Reprise d'adresse IP
· Reprise d'un service via script de démarrage
· Action quelconque (script à fournir)
En cas de panne d'une interface réseau, le produit ne
sait pas basculer sur une autre (sauf à développer cette
fonction).
Les trois produits sont équivalents
|
Mise en Cluster
|
Evaluation
|
Logiciels Libres
|
|
|
HACMP
|
Trucluster
|
Log.libres
|
Produits
|
Remarques
|
|
|
Détection de panne
|
|
|
|
Heartbeat,
|
Les logiciels libres étudiés permettent de
surveiller la plus part des ressources logicielles et matérielles
|
Détection pannes logicielles
|
|
|
|
Mon
|
Mon permet de surveiller un grand nombre de services
réseaux (HTTP, LDAP...)
|
|
Détection pannes matérielles
|
|
|
|
|
Les produits permettent de détecter les pannes
matérielles avec les mécanismes de « Ping »
(pour Mon) ou de dialoguer entre agents présents sur les noeuds. Les
trois produits sont équivalents.
On peut noter que Heartbeat dialogue par plusieurs
méthodes simultanément (réseau et port série), ce
qui lui permet de distinguer les pannes réseau et les pannes
complètes d'un noeud.
Le produit lm-sensors permet de contrôler les sondes de
température, ventilateurs, alimentation présents dans un PC
standard.
|
|
Interfaces API
|
|
|
|
|
Heartbeat ne supporte pas d'instances multiples de service. Il
n'est donc pas possible d'utiliser Heartbeat pour gérer les serveurs
dans le cadre d'une solution d'équilibrage de charge à l'aide de
ca produit
|
|
Actions correctrices possibles
|
|
|
|
|
Actions possibles :
· Reprise d'adresse IP
· Reprise d'un service via script de démarrage
· Action quelconque (script à fournir)
En cas de panne d'une interface réseau, le produit ne
sait pas basculer sur une autre (sauf à développer cette
fonction).
Les trois produits sont équivalents
|
|
Détection de problème de ressources
|
|
|
|
|
Heartbeat : Il est possible de
déclencher le basculement depuis une application par
l'intermédiaire d'outils en ligne de commande. L'API de consultation de
l'état du cluster est en cours de développement et
présente encore de gros problème de stabilité.
Mon : Mon est livré avec un outil
d'administration en ligne de commande que l'on peut exécuter sur le
noeud du serveur Mon ou à distance. Les fonctions de l'outil sont
décrites I.3.1.3. Le produit est livré avec les exemples de
scripts utilisant cet outil.
|
|
Extensibilité
|
|
|
|
|
Heartbeat : On peut ajouter les actions
à déclencher lors du basculement.
Mon : On peut ajouter des scripts de
surveillance de nouvelles ressources ou des scripts à déclencher
en cas d'alerte
|
|
Réglages possibles
|
|
|
|
|
Tous les intervalles de surveillances, le nombre
d'échec avant alerte ou basculement sont paramétrables.
Dans le cas de Mon, on peut définir les
dépendances entre les ressources partagées pour limiter le nombre
d'alarmes.
|
Disponibilité des Données
|
|
Critères
|
Evaluation
|
Logiciels Libres
|
|
HACMP
|
Trucluster
|
Log.libres
|
Produits
|
Remarques
|
|
Support RAID
|
|
|
|
Linux
|
Linus fournit une fonction de RAID logicielle très
complète, mais support très peu de solutions
matérielles.
|
|
RAID matériel
|
|
|
|
|
Un seul produit (contrôleur) supporté par Linux
contrairement aux autres produits
|
|
RAID logiciel
|
|
|
|
|
Très complexe pour Linux
Pas supporté pas HACMP, Support limité par
Digital (pas de RAID 5)
|
|
Disque partagé
|
|
|
|
GFS
|
Solutions commerciales :
· Compaq supporte CFS (Cluster File System)
· IBM supporte la même fonctionnalité mais de
façon non conforme à la norme POSIX
· GFS supporte peu de matériels
|
|
Produits supportés
|
+
|
+
|
-
|
|
GFS impose des limitations au matériel : le disque
ou la baie doivent supporter la spécification Block qui est peu
répandue, et les qui l'ont implémentés ne la supportent
pas.
Support SCSI et Fibre Channel uniquement.
|
|
Accès concurrent possible
|
-
|
+
|
+
|
|
Note : GFS supporte la journalisation dans le cas
d'accès en écriture multiples contrairement à la solution
d'IBM.
|
|
Volumes partagés
|
|
|
|
DRDB
|
Cette fonctionnalité n'est pas
implémentée dans la solution.
|
|
Mécanisme de réplication de volume / utilisation de
volumes distants
|
n/a
|
n/a
|
+
|
|
Le seule mode de fonctionnement de fonctionnement
supporté par DRBD est la réplication à la volée.
|
|
Accès concurrent possible
|
n/a
|
n/a
|
-
|
|
Pas d'accès concurrent possible
|
|
Mécanisme de resynchronisation après
déconnexion.
|
n/a
|
n/a
|
+
|
|
DRDB a 2 mécanismes :
· Resynchronisation partielle déclenchée
automatiquement après une déconnexion temporaire (coupure
réseau panne du secondaire)
· Resynchronisation totale (recopie de l'ensemble du
volume) : son déclenchement se fait manuellement par un outil en
ligne de commande.
Les deux mécanismes fonctionnent en tâches de
fond.
|
|
Nombre de noeuds
supportés
|
n/a
|
n/a
|
2
|
|
La roadmap du produit indique que la limitation à 2
noeuds sera supprimée
|
| 

