Modèle de fertilisation (npk) durable pour le riz en double culture irriguée dans la vallée du fleuve Sénégal( Télécharger le fichier original )par Oumar THIAM Université Gaston Berger de Saint-Louis Sénégal - Diplôme d'études appliquées de statistiques pour l'Afrique Francophone et application au vivant ( STAFAV ) 2010 |

N : Azote P : Phosphore K : Potassium PM : Phosphate de Matam (28,7 P205) Le 26PM représente une fumure uniforme apportant 26KgPha-1 sous forme de PM et le 52PM correspond à un double dose. CSC : Contre saison chaude HIV: Hivernage II. CONDITION DE L'EXPÉRIMENTATION 7 II.2 structure des donnéesLe facteur principal est traitement (T) avec 12 niveaux présentés par le tableau II.1 et 3 facteurs secondaires dont : - Le site : l'endroit ou l'essai est fait, il est représenté par L avec 2 modalités - Le bloc ou répétition, dispositif dans le site qui regroupe une série de parcelles carrées, il est noté R avec 4 modalités. - La saison, représentée par 4 niveaux (2 Contres saisons chaudes (CSC) et 2 Hivernages (HIV)). Le facteur expliqué est le rendement en grain de riz exprimé en tha-1, il est obtenu aprés avoir éliminé les surfaces de bordure des quatres côtés d'une parcelle. La surface récoltée est 6m2 pour chaque parcelle conformément au norme standard puis les grains sont battus, néttoyés, séchés et pesés séparément. La phase finale correspond à la détermination du pourcentage d'humidité en ajustant le poids des grains à 14% d'humidité selon la formule: Poids des grains ajustés = A × Z où A est le coefficient d'ajustement et Z le poids des grains récoltés. Le coefficient A est donné par la formule : A = 100-M 86 où M est le pourcentage d'humidité des grains. Figure II.1 - comparaison site 8 CHAPITRE II. MATÉRIELS ET MÉTHODES III Analyse descriptiveDans cette partie, nous allons présenter les rendements en fonction des sites et des saisons de cultures. III.1 Rendement en fonction des deux sitesL'analyse du graphique II.1 montre une légère différence du point de vue rendement entre ces deux sites. Par contre la moyenne des rendements est moins élevée à Fanaye qu'à Ndiaye, ce dernier a une étendue plus petite. Cela atteste du fait d'autres facteurs qui diffèrent des traitements appliqués peuvent être source de cette diffèrence. L'ecart moyen favorise le site de Ndiaye, mais le site de Fanaye présente des minima plus petits et des maxima plus grands que ceux de Ndiaye, ceci correspond à des valeures extrêmes qui sont des rendements rarement obtenues. D'où le site de Ndiaye est beacoup plus stable que celui de Fanaye du point de vue rendement.
III. ANALYSE DESCRIPTIVE 9 Figure II.2 - compraison saison III.2 Analyse par saisonLe graphique II.2, montre que les rendements sont beaucoup plus élevés en contre saison chaude qu'en hivernage. Les maxima sont obtenus en contre saison et les minima en hivernage. Cela atteste que la contre saison est beaucoup plus favorable pour le riz au point de vue rendement.
10 CHAPITRE IIIModélisationL A modélisation peut se définir comme une technique qui permet d'établir une représentation explicative d'un phénomène ou comportement en recensant les variables ou facteurs explicatifs et l'importance relative de chacune de ces variables, afin d'en proposer une représentation interprétable, reproductible et simulable. Par ailleurs, un modèle est une théorie orientée vers l'action à laquelle, elle doit servir. En clair, elle permet d'avoir un apperçu théorique d'une idée en vue d'un objectif concret. Dans le cadre de cet étude, elle consiste à établir une relation qui explique pour chaque site, le rendement du riz en fonction du traitement, du bloc et de la saison. En effet, pour cet essai un modèle additif a été proposé dans le mémoire (Dieng, 2009) : Yijk = u + Si + Tj + cijk avec Si niveau du facteur site et Tj niveau du facteur traitement. c'est un modèle qui est fait sur une observation (la contre saison chaude), l'expérimen-tation est poursuivi jusqu'à quatre saisons sur les mêmes parcelles. Cela entraine un probléme de dépendance entre les cultures successives sur les mêmes parcelles. D'où la necessité d'améliorer ce modèle en tenant compte cette dépendance. En effet l'analyse de variance classique (Dagnellie, 2003) nous permet d'idenfier les différents effets significatifs. Cette méthode montre que l'effet site est significatif. Pour mieux approcher les différences entre les traitements, on fera le modèle par site, du fait aussi de la cohésion avec la division géographique (le delta et la moyenne vallée). On est dans les conditions d'une analyse de variance à mesures répétées dans le temps. Cette méthode prend la place de l'analyse de la variance classique du fait que les observations au sein d'une même unité expérimentale ne sont pas indépendantes d'une saison à l'autre. Pour effectuer cette analyse de variance à mesures répétées on utilise deux approches à savoir : - Les moindres carrés qui est une démarche correspondante à l'approche classique souvent présentée dans les manuels d'introduction à l'analyse de la variance à mesures répétées. - L'analyse par maximum de vraisemblance, conçue pour analyser les modèles à effets mixtes et les modèles linéaires standards. I Approche par les moindres carrésCette approche comprend deux méthodes d'analyses à savoir : - Analyse univariée - Analyse multivariée I. APPROCHE PAR LES MOINDRES CARRÉS 11 L'approche par moindres carrés peut être aborder en six étapes, faisant état de la méthodologie générale, description des analyses univariées et multivariées en décrivant les notations, le modèle et les hypothèses, de la condition de sphéricité de Huynh et Feldt, des ajustements possibles aux degrés de libertés de l'analyse univariée et d'une discussion sur le choix de l'analyse appropriée. I.1 Méthodologie généraleDifférentes étapes à effectuer : - Identifier les sujets; - Identifier les effets fixes et aléatoires en les divisant en facteur intra-sujet et inter sujet. - Choisir une matrice de contraste pour transformer les données. Le choix de la matrice n'a pas d'impact sur le résultat des tests sur les effets fixes comme tels. Pour l'analyse du facteur inter-sujet (traitement), les approches univariée et multivariée conduisent à des résultats simulaires. En ce qui concerne le facteur intra-sujet (bloc) le respect ou non de la condition de sphéricité de la matrice de covariance des données transformées indiquera le type d'analyse appropriée. I.2 Analyse univariéeDans le cadre de cette étude les sujets sont repésentés par des blocs aléatoires à l'in-terieur desquels on randomise l'ordre des traitements. Il en résulte un modèle restreint, i.e. avec une contrainte sur la variance du terme d'interaction entre traitement et le sujet. En effet le traitement reste constant chaque année pour éviter le problème de l'effet du traitement précédent sur le traitement actuel connu sous le nom effet de « carry-over » (Crowder et Hand, 1990). Nous sommes en présence d'un modéle à deux facteurs fixes croisés, soient le facteur S intra-sujet repfesentant la saison (les mesures répétés), le facteur T pour traitement et leur interaction TS. Le facteur aléatoire B (T) représentant les blocs emboités dans le traitement. Ce plan d'expérience peut être vu sous l'angle univariée comme un plan à parcelles divisées (split-plot). Le traitement T constitue la parcelle dans laquelle sont emboités les blocs B (sous-parcelles) et la saison (S), le facteur appliqué à la sous-parcelle. Dans le cas d'un plan équilibré, où on a p mesures sur chaque bloc et n blocs pour chacun des r niveaux du traitement, le modéle est : Yijk = u + Ti + B(i)j + Sk + TSik + ?ijk (III.1) avec
- Yijk repésente la valeur de la variable réponse (rendement du riz) de la saison k pour le jme bloc du groupe de traitement i; - ?ijk est l'erreur aléatoire correspondante, avec une variance ?2 ? - B(i)j qui tient lieu l'erreur parcelle (traitement) et à une variance ?2 B Dans ce modéle on suppose que: - Les variables aléatoires B(i)j r' N(0,?2 B) avec ?2 B la variance inter-bloc. - ?ijk - N (0,?2 ?). 12 CHAPITRE III. MODÉLISATION Y = X13 + (III.2) - B(i)j et ijk sont indépendants. On déduit de ce modèle que: ? corr(Yijk, Yijk?) = ?2 B ? pour des mesures sur le même bloc ?2 B+?2 0 sinon Les statistiques F sont basées sur les espérences des carrés moyens dont on forme le quotient approprié afin d'évaluer l'ampleur de la variabilité due au facteur qui nous intéresse. La table (III.1) résume les tests à effectuer dans cette situation. Tableau III.1 - Tableau d'analyse de la variance
Interaction TS : Au seuil a, on rejette l'hypothèse selon laquelle il n y a pas d'inter-action entre la saison et les traitements si : MSTS> F?,(r_1)(p_1),r(n_1)(p_1) MSE Facteur traitement T : Au seuil a, on rejette l'hypothèse selon laquelle tous les traitements ont le même effet si : MST MSTB > F?,(r_1),r(n_1) Facteur saison S :Au seuil a, on rejette l'hypothèse selon laquelle le rendement est le même pour chaque saison: MSS MSE > F?,(p_1),r(n_1)(p_1) Ainsi, l'analyse univarié montre ses limites si la condition de sphéricité n'est pas satisfait d'où la necessité de recourir à l'analyse multivariée. I.3 Analyse multivariéeDans l'approche multivariée, les p mesures prises sur le mêmes blocs constituent un vecteur d'observations. On construit une matrice Y de dimension rn × p dont chaque ligne représente un bloc. Le modèle mutivariée se conçoit sous forme matricielle de la façon suivante: I. APPROCHE PAR LES MOINDRES CARRÉS 13
? y111 y112 ... ... ? ? y1n1 y1n2 ? ? y211 y212 ? ? ... ... yrn1 yrn2 1 1 0... 0 1 1 0... 0 1 0 1... 0 .. .. .. .. 1 0 0... 1 u u .... .... TrS1 TrS2 ???111 ?112 ? ... ... ? ? ? + ?E1n1 E1n2 ? ? ? ??211 ?212 ? ? ? ... ... Ern1 Ern2 ? ? ? ? ? ? ? 1[ ? ????? ? ? ? ? ? ? ? = les rnp erreurs de la matrice e sont indépendantes d'un bloc à l'autre, mais pas entre les p variables d'un même bloc. Soit eij une rangé de la matrice e, i.e. le vecteur des erreurs pour le bloc B(i)j ; on suppose que : ?ij N N(0,E) avec E la matrice pxp des covariances des mesures prises sur un bloc, considéré constante d'un bloc à l'autre, peu importe le traitement subi. Aucune structure n'est imposé à E ; le modèle comprend p(p+1) 2 paramètres de covariance. L'analyse des mesures répétées diffère d'une analyse multivariée ordinaire par l'intérêt porté sur le facteur intra-bloc et à son interaction au facteur traitement, car il s'agit de la même variable mesuré p fois et non p variables différentes n'ayant que peu de liens entre elles. Les hypothèses sur les effets fixes s'expriment de la forme générale : H0 : L3M = 0 où L est la matrice cx(r+1) des contrastes d'intérêt, /3 est la matrice (r+1)xp des effets fixes et M est une matrice p x (p - 1) de transformation des données dont les colonnes forment une base orthogonale au vecteur formé de 1. Interaction TS : Lcx(r+1) est la matrice de contrastes et Mpx(p_1) la matrice de contrastes sélectionnée. Facteur traitement :Lcx(r+1) est la matrice de contrastes et Mpx1 = 1 p(1,1...,1)' Facteur saison S : L1x(r+1) = 1 r+1(1,1...,1) et Mpx(p_1) est la matrice de contrastes sélectionnée. I.4 Condition de sphèricité de Huynh et FeldtCette condition stipule que les différences entre paires d'observations sur un même bloc doivent avoir la même variance. En terme mathématique il faut que : V ar(Yijk - Yijk') = U2Yijk_Yijk, = 2A, Vk =? k',pour un a > 0 Soit Ela matrice des covariances des mesures prises sur un même bloc. Puisque E pxp est homogène pour tous les blocs, nous omettons les indices i et j pour faire référence à 14 CHAPITRE III. MODÉLISATION ses coefficients dans le but d'allèger la notation. Puisque : 2 2 2 ?2 .2 = Uk + ?k, - 2?kk, avec ?2k + ?2k, sont les éléments diagonaux de E et ?kk, la covariance entre les observations Yijk et Yijk, et :
une matrice des covariances d'ordre 2 qui saisfait la condition de spéricité aura la forme générale : ? ? 2 ?i+?z ?1 2 ?i+?2 2 2 ?2 En effet pour que les quotients des carrés moyens utilisés dans l'analyse de la variance univariée suivent une loi exact de Fisher, il faut et il suffit que la matrice des contrastes orthonormés soit sphérique, c'est-à-dire un multiple scalaire de la matrice d'identité d'ordre p - 1 (Crowder et Hand, 1990). Ainsi la condition de spéricité peut être vérifié à l'aide du test de Mauchly. Si cette condition n'est pas vérifié, l'analyse mulivariée s'impose ou bien une analyse univariée avec une statistique de Fisher dont les degrés de libertés seront corrigés par un facteur multiplicatif ?. I.5 Ajustement des degrés de libertés de la statistique de FisherSi la condition de sphéricité est respectée, pour p observations successives, il y'a p - 1 degrés de libertés associés au facteur intra-sujet. Sinon l'information est réduite et le nombre de degrés de libertés devrait par conséquent être diminué. Il reste à savoir l'am-pleur de cette aténuation (Yandell, 1997). Les ajustements proposés se basent sur une mesure de la déviation de la spéricité, ? présenté originellement par Box (1954). Les corrections ont été dévelopées pour des modèles à un seul facteur intra-sujet. Soit S la matrice des covariances échantillonnales pxp des mesures prises sur un même individu et Cp×(p-1) une matrice de contrastes orthonormés. Ainsi, A = C?SC est l'estimation de la variance des contrastes pour laquelle on veut mesurer la sphèricité. Notons aij les éléments de A. Cependant deux ajustements sont proposés : Ajustement de Greenhouse-Heisser (1959) : ?à = (?p-1 i=1 aii)2 (p - 1) x--`Pi ~~=1 aij)2 Ce coefficient devient le multiplicateur des degrés de libertés de la statistique F pour tester l'effet du facteur intra-sujet (saison). Le test pour la comparaison des traitements reste inchangé. Au lieu de comparer la quantité MSA MSE à la distribution F(p-1),r(n-1)(p-1), on le compare avec Fà?(p-1),à?r(n-1)(p-1), sous la condition de sphèricité ?à = 1. Toutefois l'estimateur ?à serait passablement biaisé : les degrés de libertés sont trop réduits, et le test devient trop conservateur (Crowder et Hand, 1990). II. ANALYSE PAR MAXIMUM DE VRAISEMBLANCE 15 Ajustement de Huynh et Feldt(1976) Huynh et Feldt ont suggéré un nouvel estimateur de , moins biaisé et moins dépendant de la taille de l'echantillon. Leur ajustement ? est une fonction de : ? ? 1, rnà? - 2/(p - 1) ? = min r(n - 1) - (p - 1)à? Ainsi, sans ajustement, on rejettera trop souvent l'hypothèse d'égalité des moyennes. En corrigeant à la baisse les degrés de libertés du test F de l'analyse de variance univariée, la valeur critique augmente, et il devient plus difficile de rejetter l'hypothèse H0. La probabilité de commettre une erreur de type I s'en trouve dimuniée. I.6 Choix de l'analyse appropriéeEn ce qui concerne les tests sur le facteur traitement, l'approche univariée et multivariée donne les mêmes résultats. Ces deux analyses se distinguent sur les tests du facteur intra-sujet. L'avantage de l'analyse multivariée est qu'elle ne suppose aucune structure pour la matrice de covariance des mesures répétées. Le problème est que si la condition de sphèricité est respecté, la puissance des tests multivariés est sensiblement inférieure à celle des tests F univariés. Par ailleur, lorsque la condition de sphèricité de Huynh et Feldt est remplie, on privilégie l'analyse univariée sans corrections des degrés de libertés. II Analyse par maximum de vraisemblanceL'analyse par maximum de vraisemblance comporte plusieurs avantages par rapport aux deux autres méthodes en raison de sa possibilités de tenir en compte les données manquantes sans les estimer et la modèlisation de la structure de la covariance. En effet, cette dernière étape est cruciale dans l'analyse, car les tests sur les effets fixes sont grandement influencés par le choix de la covariance (Stroup et Wolfinger, 1996) et (Verbecke et Molenbergs, 1997). Nous allons traiter les aspects théoriques de cette méthode en précisant d'abord la démarche à suivre, le modèle mixte et l'estimation de ses paramétres, le choix de la structure de la matrice des covariances et les tests sur les effets fixes. II.1 MéthodologieOn identifie d'abord le sujet (bloc) puis on sélectionne les effets fixes à évaluer ainsi que leur interaction. L'étape suivante consiste à choisir les structures de matrices des covariances des facteurs aléatoires et du facteur intra-sujet. Une fois la structure de covariance fixée, on regarde les tests sur les effets fixes afin de déterminer s'il y'a lieu de réduire le modèle proposé. II.2 Le modèle mixte : Notations et hypothèsesLe modèle linéaire mixte est une généralisation du modèle linéaire standard. Il enrichit ce dernier d'une composante aléatoire et permet une structure beaucoup plus souple pour la matrice des covariances des observations. Les dimensions se rapportent à un modèle ayant un facteur fixe inter-bloc à r modalités (le traitement), un facteur fixe intra-bloc à p niveaux (saison) et leur interaction. Les rn blocs constituent un facteur aléatoire, dans le sens où on tient compte de la variabilité dû au bloc sans interesser aux modalités précises 16 CHAPITRE III. MODÉLISATION de ce facteur mais bien à une population plus large d'individus. Ainsi la forme générale du modéle est : Y = X3 + Z'y + (III.3)
Hypothèses du modèle Le modèle mixte retient les hypothèses suivantes : 'y ? J\I w(0, G) 'y et sont indépendants ? J\I rnp(0, R) Il en découle de ces hypothèses que les observations suivent une loi normale multivariée avec une matrice de covariance appelée V : Y J\Irnp(X3,V ) La matrice R des covariances a une forme bloc-diagonale, avec un bloc de covariance [Rij1 pour les p meusues pises sur le jime sujet du groupe i. Les blocs R11 à Rrn ont tous la même structure. En effet la variance des observations V est fonction de Z, G et R : V=Var(Y)=Var(X3 + Z'y + ) = V ar(Z'y + ) = ZGZ' + R II.3 Estimation des paramètresEstimation de 3 : Pour estimer 3 on considère le logarithme de la fonction de vraisemblance : II. ANALYSE PAR MAXIMUM DE VRAISEMBLANCE 17 n 1 l(?,V ) = -2 log(2?) - 2log|V | - 2(Y - X?)?V -1(Y - X?) 1 L'estimateur du maximum de vraisemblance de ? est donc obtenu par moindres carrés généralisés : à?GLS = (X'V -1X)-1X'V -1Y Il reste à remplacer la matrice V = ZGZ' + R par son estimation. En effet on utilise la méthode du maximum de vraisemblance restreint pour les estimations Gà et Rà 1 lR(G,R) = -2log|V | - 2loglX'V -1X| -1 r'V -1r où r = Y - Xà?GLS On obtient ensuite l'estimation finale de ? en remplaçant V par : ?GLS d'où Và = Z àGZ' + Rà dans ?à = (X' Và-1X)-1X' Và-1Y Estimation de ? : Soit ?à cet estimateur de ?à=àGZ'V -1(Y - Xà?) En effet les résultats dépendent des vraies valeurs des composantes de la variance, ainsi que le modèle ajusté. D'où l'importance de sélectionner la structure de la matrice des covariances pour tirer des bonnes conclusions. II.4 Choix de la structure de covarianceLe choix d'une structure peut se faire de différentes façons. Plusieurs types de structures pouront être utilisés. Le type UN (Unstuctured) qui correspond à la méthode d'analyse univariée, le Compound symmetry plus utilisé dans l'analyse multivariée, les types auto-régressifs, les modèles à coefficients aléatoires et à corrélations spatiales. Aprés le choix des structures, on fait recours aux critèrs d'ajustement basés sur la méthode du maximum de vraisemblance restreint pour ressortir le meilleur modèle. Malgré que la structure de la covariance ne soit pas toujours une question d'intérêt en soi, une modèlisation adéquate est nécessaire afin de porter des inférences valides sur les effets fixes du modèle. La structure choisie devrait donc être flexible, mais économique (Everitt, 1995). Cependant ces structures nous permet d'ajuster le modéle univarié avec ces différents modèles. Yijk = u + Ti + Sk + TSik + ?ijk (III.4) Ce modéle correspond à celui de l'analyse univarié privé du facteur bloc, avec les résidus associés à un même bloc corrélés entre eux selon les structures déjà citées. Avec : ?i.k = [?i1k, ?i2k, ?i3k, ?i4k] L'autre alternative de ce modèle est de supposer que la matrice de corrélation varie d'un groupe de traitement à l'autre. 18 CHAPITRE III. MODÉLISATION II.5 Test sur les effets fixesUne fois la structure de la matrice des covariances déterminée, on peut vérifier le niveau de signification des effets fixes. Cette méthode teste l'hypothèse bilaterale : H0 : L? = 0 à l'aide de la statistique : F0 = ? ?-1 à??L' L(X? Và -1X)-L' L?à ? Frang(L),z, rang(L) Lf×(r+1)(p+1) est une matrice de f contrastes sur les effets fixes (f < (r + 1)(p + 1)). Enfin, les effets fixes non significatifs seront retirés un à un du modèle pour un ajustement plus fin en revérifiant l'adéquation de la structure de covariance pour le modèle final (Wolfinger et Chang, 1995). On peut tester la signification de plusieurs effets fixes simul-tannément au moyen des tests d'hypothèses et d'intervalles de confiance sur les contrastes. II.6 Analyse des contrastesOn dit que une fonction L?+K? est prédictible si la combinaison linéaire des effets fixes L? est estimable, car une combinaison linéaire d'effets aléatores est toujours estimable. Dans ce cas on peut tester l'hypothèse. ? ? ? H0 : [L K] = 0 ? On parle d'espace inférentiel large lorsque K = 0, les conditions s'appliquent alors à toute la population parmi laquelle les effets aléatoires sont echantillonnées. Si tous les éléments de K son nuls, on parle d'inférence étroite et les résultats portent uniquement sur les modalités de sélection des effets aléatoires. Un espace inférentiel intermediaire est généré lorsque la matrice K ne fait appel qu'une portion des effets aléatoires (Tenenhaus, 1999). Avec ce modèle dun maximum de vraisemblance, On utilise l'inférence large. La matrice des covariances echantillonnées de L? à + Kà? est :
où Cà est un estimateur de l'inverse généralisé de la matrice des coefficients des équations du modèle mixte. Alors la statistique est : F0 = ? à?? à??? ? L? ? ? ? L? ??-1 K? K? [L K] C à [L K] rang(L) ? Frang(L),v sous H0 ? ? ? ? Toutefois, ces modèles méritent d'être appliqués sur les données réelles pour distinguer leurs différences et la validation des hypothéses du modèle sélectionné pour faire des estimations de différents traitements. 19 CHAPITRE IVApplicationsD Ans cette partie, nous allons appliquer le modèle d'analyse univariée avec mesures répétées de l'approche par moindres
carrées et le modéle mixte du maximum de I Modèle d'analyse univariéeLe modéle a été bien défini dans la partie modélisation il ne reste que son application dans les données de cette expérimentation. Comme nous l'avons suggéré dans la partie modélisation, l'étude se fait séparément par site à savoir Ndiaye, dans le delta et Fanaye, dans la moyenne vallée. En effet, pour se faire nous allons utiliser la procédure GLM du logiciel SAS (Version 9.00), dont le programme est : proc glm data Ndiaye ; class bloc trait annee ; model rend=trait bloc(trait) annee trait*annee; random bloc(trait) /test; run; Les résultats nous fournissent le table de l'analyse de la variance IV.1 que nous allons analyser. 20 CHAPITRE IV. APPLICATIONS Tableau IV.1 - Tableau d'analyse de la variance univariée
I.1 Analyse de l' effet des facteurs fixesEffet traitement Le traitement a un effet significatif sur le rendement, cela signifie que les différents traite-mens appliqués ont une différence trés significative au niveau a = 5 avec une probabilité (Pr > F) < 0.0001. Effet saison La saison a un effet significatif sur le rendement, cela revient à dire que les cultures successives ont une différence significative du point de vue rendement. au seuil a = 5% avec une probabilité (Pr > F) < 0.0001. Interaction traitement et saison L'interaction traitement et saison est significative au seuil de 5%. Ceci indique que la saison a un effet différent pour chacun des traitements appliqués. Cela signifie que le traitement et la saison agissent simultannément sur le rendement du riz Bloc dans traitement La variabilité expliquée par l'unicité des blocs n'est pas significatif, puisque le terme aléatoire bloc dans traitement a un seuil observé de 0.29. Cette non significativité n'implique pas la non variabilité au sein d'un même bloc dans traitement d'où l'ouverture vers le modèle mixte. II. APPROCHE PAR MAXIMUM DE VRAISEMBLANCE 21 II Approche par maximum de vraisemblanceDans cette partie, nous allons essayer d'ajuster ce modéle d'analyse univarié afin de choisir un modéle approprié. Cela revient à utiliser les différentes structures de covariances pour sélectionner le meilleur modéle avec les critères AIC (Akaike Information Criterion) et BIC (Bayesian Information Criterion). II.1 Choix du modèleLe choix du modéle se refère à l'utilisation de l'un des critères suivantes : - AIC AIC = -2 * log(L) + 2 * K où L est la vraisemblance maximisée et k le nombre de paramètres dans le modèle. Avec ce critère la déviance (-2*log(L)) pénalisée par 2 fois le nombre de paramètres. L'application de ce critère est nécessaire que si les modèles à comparer dérivent tous d'un même modèle complet (Burnham et Anderson, 2002). Le meilleur modèle est celui qui a le plus petit AIC. - BIC BIC = -2 * log(L) + K * log(n) où n est le nombre d'individus (bloc) de l'echantillon. le meilleur modèle est celui qui a le plus faible BIC. Cependant dans ce contexte nous choisirons le critère BIC pour déterminer le meilleur modèle. Tableau IV.2 - Comparaison de modèle
22 CHAPITRE IV. APPLICATIONS D'aprés les résultats du tableau IV.2, le modèle 3 AR(1) est le plus faible BIC d'où nous porterons le choix sur ce modèle décrit par : Yijk = u + Ti + Sk + T Sik + ?ijk (IV.1) où : ?i.k = [?i1k, ?i2k, ?i3k, ?i4k] Avec la structure AR(1) de la matrice de corrélation des résidus associés au même bloc qui sera présenté dans l'Annexe 1. Cette structure a pour but de prendre en compte l'effet d'accumulation des cultures successives sur le même bloc. Cependant ce modéle mérite dêtre validé pour pouvoir utiliser les résultats obtenus. II. APPROCHE PAR MAXIMUM DE VRAISEMBLANCE 23 II.2 Validation du modèleLa validation est synonyme du respect des hypothèses déja supposées à savoir : La normalité des résidus, l'indépendance des résidus de deux blocs différents. ? r.,) Nrnp(0, R) Cela revient à utiliser les tests de normalité et appuyer par les graphiques. Le test de shapiro wilks nous montre que les résidus suiivent une distribution normale d'aprés le tableau IV.3 Tableau IV.3 - Tableau de Shapiro Shapiro-Wilk normality test W = 0.9931, p-value = 0.07543 le graphique II.2 (nuage des points) combiné avec la droite de Henry confirme l'hypothèse de normalité anisi que l'histogramme des résidus
24 CHAPITRE IV. APPLICATIONS Indépendance des résidus L'indépendance des résidus entre les blocs est garantie du fait de la disposition des blocs dans chaque site d'aprés le protocole expérimental, les blocs sont bien séparés donc chacun est indépendant des autres d'où les erreurs résiduelles par saison dans deux blocs différents sont bien indépendants. Ainsi ce modèle confirme les hypothèses déjà supposées, sa validation n'est plus à remettre en cause. II.3 Estimation des paramètres du modèleDans cette partie nous allons présenter que les estimations des traitements. L'estima-tion nous permettra de faire un jugement du modèle par rapport à son ajustement des donnèes réelles. D'aprés le modèle IV.1, nous avons les estimations par site : Tableau IV.4 - Tableau d'estimation des traitements à NDIAYE
II. APPROCHE PAR MAXIMUM DE VRAISEMBLANCE 25 ?H0 : uj = uj? H1 : uj =?uj' Tableau IV.5 - Tableau d'estimation des traitements à FANAYE
Remarque : Sous R (Version 2.9.2), la paramétrisation par défaut se fait avec une cellule de référence ou niveau « contrôle ». L'ecart du niveau j au niveau 1 est donné par : a = u - u1 où u1 est la moyenne de cellule de référence. On aura donc p - 1 paramètres à estimer. II.4 Test de Comparaison multiple des différents traitementsL'objectif de cet essai est de déterminer le(s) meilleur(s) traitement(s). L'analyse de la variance du modèle nous donne une différence significative entre ces traitements. Une question suscite par rapport à cette différence, quels sont les traitements qui se diffèrent des autres? pour répondre à cette question, on fait recours aux tests de comparaisons de moyennes multiples. Diverses méthodes existent, dont le PPDS (Plus Petite différence si-gnificatve), Duncan, Newmans-Keuls, Tuckey, Dunett, Gupta et Van Der Waerden. Nous utiliserons le PPDS, test paramètrique et le test de Van Der Waerden, test non para-mètrique pour comparer les traitements qui sont significativement diffèrents d'aprés le modéle. PPDS (plus petite différence significative) avec correction de Bonferroni Ce test est plus connu sous le nom LSD (Least Significant Difference), l'un des tests les plus utilisé en agronomie (Gomez and Arturo, 1984), pour une comparaison par paire de traitements dont les hypothéses sont :
26 CHAPITRE IV. APPLICATIONS On utilisera la quantité : t.j = qui fournie la p-value a' à comparer avec le risque de première espèce a si la p-value est plus petite que a, on rejette l'hypothèse nulle. Pour p > 2 traitements, il effectue p(p - 1)/2 tests, cela implique que, plus on multiplie les tests plus on augmente nos chances de conclure à tort. D'òu la necessité de recourir à des corrections telles que Bon-ferroni : - Idèe : même principe (test t), en corrigeant le risque a en fonction du nombre de comparaisons - Pour m comparaisons, on fixe? m, a = 0.05, comme risque de première espèce pour chacun des tests. - Intérêt : rapide et simple à réaliser; donne un apperçu global de l'ensemble des différences de moyennes considérées comme significatives. Test de Van Der Waerden C'est un test non paramètrique qui transforme les rangs en quantile de la loi normale que l'on nomme scores normaux. Cette approche est utilisée lorsque la distribution des observations est proche de la loi normale. Aprés avoir rangé toutes les observations du plus petit au plus grand, calculé la somme des scores intra groupe par :
avec { 1 si k E groupei 8k = 0 sinon où ak = ?-1( Rk N + 1) la statistique est : Rejet de H0 : pas de différence entre les groupes au seuil a si C > X2 ?,t-1 ?t i=1(Ti - àE0[Ti])2/ri C = S2 où : àE0[Ti] = ria
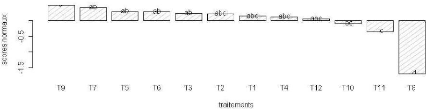
III. RÉSULTATS ET DISCUSSIONS 27 III Résultats et DiscussionsIII.1 Comparaison des traitements par sitePour faire l'analyse, nous avons utilisé le test LSD et celui de Van Der Waerden - NDIAYE LSD avec correction de Bonferroni D'aprés le modéle, il y'a une difference entre les traitements, cette différence n'est pas significative si on prive le traitement sans engrais. D'apres le LSD, il y'a un seul groupe pour les traitements qui diffèrent du témoin absolu. Van Der Waerden C'est le même résultat que le LSD, pour les groupes de traitements d'aprés ce graphique IV.1
Figure IV.1 - Ndiaye LSD et Waerden 28 CHAPITRE IV. APPLICATIONS - FANAYE LSD avec correction de Bonferroni De même que NDIAYE, le modèle montre une différence significative entre les traitements au seuil de 5%. Le LSD prouve cette diffèrence en subdivisant les traitements en 3 groupes par ordre décroissant, privé du groupe témoin sans engrais. Cela atteste que le traitement T9((NPKpm(26)/NPKpm(26)) du phosphate de Matam se distingue bien par rapport aux autres dans ce site. Van Der Waerden Ce test montre une légère différence des résultats avec celui du LSD. On a quatres groupes différents mais pas significative et le groupe témoin qui est significativement diffèrent des autres, le traitement avec phosphate de Matam T9((NPKpm(26)/NPKpm(26)) reste toujours dans les premiers rangs. Par contre les traitements NPK avec phosphate de Ma-tam à double dose ne donnent pas des rendements meilleurs par rapport au traitement NPK complet.
Figure IV.2 - Fanaye LSD et Waerden III. RÉSULTATS ET DISCUSSIONS 29 III.2 Comparaison globale des traitementsDans les deux sites, la fertilisation avec le phosphate de Matam dosé à 26P(200Kg/ha) pour chaque saison reste toujours parmi les meilleurs. Par contre les traitements (NPK/N) et (NK/NPK), ne sont pas trés différents du premier d'aprés le graphique IV.3 du test de Van Der Waerden non paramétrique. Ce test est utilisé pour mieux confirmer les résultats obtenus d'aprés le test LSD utilisant la somme des carrés moyens résiduels issu du modèle. Cela permet d'avoir un apperçu sur l'efficacité du modèle du fait que le test de Van Der Waerden est bien apprécié par rapport aux autres tests non paramètriques. En effet, ces trois traitements pouront bien substituer le traitement NPK complet car leurs rendements sont meilleurs que celui de ce dernier. Pour faire la diffèrence entre ces trois traitements d'autres paramètres tels que la rentabilité économique doivent être prises en compte.
Figure IV.3 - Comparaison global 30 CHAPITRE IV. APPLICATIONS IV DiscussionLe modèle du maximum de vraisemblance avec srtucture de covariance de type auto-régréssive permet de bien ajuster les données par site. La comparaison des résultats du test LSD construit à partir des sommes des carrés résiduelles du modéle et ceux du test non paramètrique de Van Der Waerden montre une légère différence surtout à Fanaye, par contre à Ndiaye ce sont les mêmes résultats. Ce modèle comparé avec celui de l'analyse de la variance classique donne les meilleurs estimations du fait de l'effet d'accumulation pour chaque saison sur les mêmes blocs qui ne sont pas prise en compte dans le modèle classique. Cependant, lorsqu'on s'intéresse à la golabilité en tenant compte de l'effet site, d'autres alternatives seront proposées pour améliorer le modèle. Au lieu d'analyser en terme de split-plot, on pourait voir le split-split plot, ce qui change c'est le facteur site qui constitue la (Grande parcelle) et les autres restent intactes. 31 ConclusionL'étude sur la conception d'un modèle de fertilisation durable en double culture irriguée dans la vallée du fleuve Sénégal prouve que la combinaison avec le phosphate de Matam (NPKpm (26)) donne des rendements meilleurs par rapport aux autres traitements. Par ailleurs la méthode avec alternance de N et de K (T2(NPK/N) et T7(NK/NPK)) une saison sur deux donne des rendements meilleurs par rapport au traitement complet T1 (NPK ). Ce résultat est le fruit de deux tests souvent utilisés dans la recherche en agriculture, le LSD et le Van Der Waerden. En effet, selon l'objectif fixé qui consiste à réduire les coûts de poduction, cette combinaison (NPKpm (26)) permet de faire une économie grâce à son coût moins èlevè par rapport aux autres. Par ailleurs, il serait intéressant de : - tester l'effet du phosphate de MATAM granulé; - faire l'évaluation économique de ces trois traitements - essayer d'alterner le NPmK (pm = 200Kgha-1) une saison sur deux - faire un essai long terme pour etudier la stabilité de ces trois traitements . Annexe 1Structure de covariance Autoregressive d'ordre 1 avec 2 paramètres : ? ? AR(1) = 0-2 ? ? 1 p p2 p3 p 1 p p2 I p2 p 1 p p3 p p2 1
32 Compound Symetrie avec 2 paramètres :
Sans structure avec P(P+1) 2 33 Annexe 2Ordre R #Importation des données donnees=read.table("rendement.txt",header=T) #Analyse descriptive boxplot(Rdtsite,dimnames=list(levels(site)), xlab="Sites",ylab="Rendement ( t/ha )",notch=T) boxplot(Rdtsaison,dimnames=list(levels(saison)), ylab="Rendement (t/ha)",type="l",lty=1,xlab="saison") #Extracton des deux sites ndiaye=donnees[site=="ndiaye",] ndiaye=donnees[site=="fanaye",] #Modéle library(nlme) model=lme(RdtTrait-i-saison-i-Trait*saison,data=ndiaye, random=1|Rep,correlation=corAR1()) #Test de normalité shapiro.test(model$residuals) #Graphe de normalité f=function(t) dnorm(t,mean=mean(model$residuals),sd=sd(model$residuals)) par(mfrow=c(1,2)) qqnorm(model$residuals) qqline(model$residuals) hist(model$residuals,proba=TRUE,col="lightblue",xlab="Résidus",main="Histogramme des résidus") curve(f,add=T,lwd=3) #Test LSD library(agricolae) compar=LSD.test(ndiaye$Rdt,ndiaye$Trait,df,Mserr, p.adj="bonferroni",group=TRUE) bar.group(compar,density=20,ylab="rendements(t/ha)",xlab="traitements",ylim=c(0,12) #Test de Vander Waerden comparw<-waerden.test(ndiaye$Rdt,ndiaye$Trait,group=TRUE) bar.group(comparw,density=20,ylab="scores normaux",xlab="traitements") 34 CHAPITRE IV. APPLICATIONS Ordres SAS proc mixed data =ndiaye; title'model 1' ; class bloc trait saison; model Rdt=trait saison trait*saison; random bloc(trait) ; proc mixed data =ndiaye; title 'model AR(1)' ; class bloc trait saison; model=Rdt=trait saison trait*saison; repeated saison /subject= bloc(trait) type=AR(1) on change le type (CS ou UN) pour les modèles avec ces types proc mixed data =ndiaye; title'model3 AR(1)' ; class bloc trait saison; model=Rdt=trait saison trait*saison; repeated saison /subject= bloc(trait) type=AR(1) group=trait; on change le type (CS ou UN) pour les modèles avec ces types; 35 BIBLIOGRAPHIE
| 
Changeons ce systeme injuste, Soyez votre propre syndic 
"I don't believe we shall ever have a good money again before we take the thing out of the hand of governments. We can't take it violently, out of the hands of governments, all we can do is by some sly roundabout way introduce something that they can't stop ..." | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||