2.2.1.2. Présentation
du modèle
De ce qui précède, notre modèle se
présente comme suit :
Y=
a0+a1X1+a2X2+åt
Où : Y = la variable endogène et pour notre
cas il s'agit du taux de chômage ;
X1 et X2 = variables exogènes
a0, a1 et a2= les
paramètres estimés
åt = paramètre
d'erreur.
A. Hypothèses du
modèle
Dans ce sous point nous analyserons les différentes
hypothèses des tests statistiques et économétriques en se
basant sur le relax des hypothèses de modèle des classiques.
Hypothèses de tests
statistiques
Le test statistique tient compte des éléments
ci-après : les paramètres et la validité globale
du modèle.
Test des paramètres
Il permet de tester les paramètres du
modèle par le test t de Student sur lequel s'il
est supérieur à sa valeur théorique, on rejette
l'hypothèse nulle (H0) c'est-à-dire le
paramètre est significatif.
H0 : ai=0 non significatif
Règle de décision
H1 : ai?0 significatif   , on rejette H0 au profit de H1 , on rejette H0 au profit de H1

Où :   = paramètres estimés = paramètres estimés
  = t calculé = t calculé
 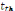 = t théorique = t théorique
a) Test de la validité globale du
modèle
Pour tester la validité globale du modèle on
s'est servi du test F de Fisher qui permet d'interroger sur
les significations globales du modèle de régression.
Ce test peut être formulé de la manière
suivante : « existe-t-il au moins une
variable exogène significative ».
Soit le tes d'hypothèse suivant :
H0 :
ai=ai0=a2=ai le modèle n'est
pas significatif Règle de
décision
H1 : ai?0 le modèle est
globalement significatif Fcal
>Fth, on accepte H0 au profit de
H2
 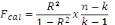 Fth (k-1, n-k) Fth (k-1, n-k) 
Où
Fcal : Fisher calculé
Fth : Fisher théorique
n= nombre d'observation dans la servie
k = nombre des paramètres
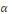  =seuil d'acceptation =seuil d'acceptation
| 

