Conclusion partielle
Dans ce chapitre, nous avons traité les
généralités sur les systèmes décisionnels
(Business Intelligence) ; avons défini l'informatique
décisionnelle, l'architecture de systèmes décisionnels et
ses différents enjeux avec leurs fonctions ; et avons abordé les
systèmes décisionnels qui sont des systèmes qui permettent
aux décideurs des entreprises de prendre des décisions optimales
et importantes pour une meilleure gestion des leurs entreprises. Le chapitre
suivant abordera les notions de l'entrepôt de données et son
fonctionnement.
14 Jarke M., Lenzerini M., Vassiliou Y., Vassiliadis P.,
"Fundamentals of Data Warehouses", Ed. Springer Verlag, ISBN
3-540-65365-1, 1999, p.187
20
CHAPITRE II: LE DATA WAREHOUSE
II.1. Introduction
Les entrepôts des données intègrent des
informations en provenance de différentes sources, souvent reparties et
hétérogènes ayant pour objectif de fournir une vue globale
de l'information aux analystes et aux décideurs.
La construction et la mise en oeuvre d'un entrepôt de
données représentent une tâche complexe qui se compose de
plusieurs étapes.
La première est l'analyse des sources de
données et l'identification des besoins des utilisateurs, la
deuxième correspond à l'organisation des données à
l'intérieur de l'entrepôt. En fin, la troisième sert
à établir divers outils d'interrogation, d'analyse, et de fouille
de données.
Chaque étape présente des problèmes
spécifiques. Ainsi, par exemple, lors de la première
étape, la difficulté principale consiste en l'intégration
des données, de manière à ce qu'elles soient de
qualité pour leur stockage. Pour l'organisation, il existe plusieurs
problèmes comme la sélection des vues à
matérialiser, le rafraichissement de l'entrepôt, la gestion de
l'ensemble de données courantes et historisées.
En ce qui concerne le processus d'interrogation, nous avons
besoin des outils performants et conviviaux pour l'accès et l'analyse de
l'information.
II.2. Définition d'un data warehouse
(DW)14
Un entrepôt de données est une collection de
données orientées sujet, intégrées, non volatiles
et historisées, organisées pour le support d'un processus d'aide
à la décision. Nous détaillons ces caractéristiques
:
? Orientées sujet : les données
des entrepôts sont organisés par sujet plutôt que par
application, par exemple, une chaine de magasins d'alimentation organise les
données de son entrepôt par rapport aux ventes qui ont
été réalisées par produit et par magasin, au cours
d'un certain temps.
? Intégrées : les
données provenant de différentes sources doivent être
intégrées, avant leur stockage dans l'entrepôt de
données. L'intégration, c'est à dire la mise en
correspondance des formats, permet d'avoir une cohérence
de l'information.
15 Samos J., Saltor F., Sistrac J., Bardés A.,
"Database Architecture for Data Warehousing: An evolutionary
Approach", DEXA'98, Vienna (Austria), 1998, p.72
21
? Non volatiles : à la
différence des données opérationnelles, celles de
l'entrepôt sont permanentes et ne peuvent pas être modifiées
.le rafraichissement de l'entrepôt consiste à ajouter de nouvelles
données, sans modifier ou perdre celles qui existent.
? Historisées :la prise en
compte de l'évolution des données est essentielle pour la prise
de décision qui, par exemple, utilise des techniques de
prédication en s'appuyant sur les évolutions passées pour
prévoir les évolutions futures.
II.2.1. Objectif Du Data Ware house
L'atout principal d'une entreprise réside dans les
informations qu'elle possède. Les informations se présentent
généralement sous deux formes : les systèmes
opérationnels qui enregistrent les données et le Data Ware house.
En bref, les systèmes opérationnels représentent
l'emplacement de saisie des données, et l'entrepôt de
données l'emplacement de restitution15.
Ainsi voici les objectifs fondamentaux du data warehouse :
Rendre accessibles les informations de
l'entreprise : le contenu de l'entrepôt doit être
compréhensible et l'utilisateur doit pouvoir y naviguer facilement et
avec rapidité. Ces exigences n'ont ni frontières, ni limites. Des
données compréhensibles sont pertinentes et clairement
définies. Par données navigables, on n'entend que l'utilisateur
identifie immédiatement à l'écran le but de ses recherches
et accède au résultat en un clic.
Rendre cohérente les informations d'une
l'entreprise : les informations provenant d'une branche de
l'entreprise peuvent être mise en corrélation avec celles d'une
autre branche. Si deux unités de mesure portent le même nom, elles
doivent alors signifier la même chose. A l'inverse, deux unités ne
signifiant pas la même chose doivent être définie
différemment. Une information cohérente suppose une information
de grande qualité. Cela veut dire que l'information est prise en compte
et qu'elle est complète.
Constituer une source d'information souple et
adaptable : l'entrepôt de données est conçu
dans la perspective de notifications perpétuelle, l'arrivé de
question nouvelles ne doit bouleverser ni les données existantes ni les
technologies. La conception de Data Mart distincts composant un entrepôt
de données doit être répartie et incrémentielle.
16 AHMED T., MIQUEL M., LAURINI R., « Continuous data
warehouse : concepts, challenges and potentials », Proc. of the 12th
International Conference on Geoinformatics, 2004, p.
157-164.
22
Représenter un bastion
sécurisé qui protège la capitale information :
l'entrepôt de données ne contrôle pas
seulement l'accès aux données, mais il offre à ses
gestionnaires une bonne visibilité des utilisations.
Constituer la base décisionnelle de
l'entreprise : l'entrepôt de données recèle
en son sein les informations propres à faciliter la prise de
décisions.
II.2.2. Les Composants de base du Data
Warehouse16
a) Le système source :
système opération d'enregistrement, dont la
fonction consiste à capturer les transactions liées à
l'activité.
b) Zone de préparation des données
: ensemble des processus qui nettoient, transforment, combinent,
archivent, suppriment les doublons, c'est-à-dire prépare les
données sources en vue de leur intégration puis de leur
exploitation au sein du Data Warehouse. La zone de préparation des
données ne doit offrir ni service des requêtes, ni service de
présentation.
c) Serveur de présentation :
machine cible sur laquelle l'entrepôt de données est
stocké et organisé pour répondre en accès direct
aux requêtes émises par des utilisateurs, les
générateurs d'état et les autres applications.
d) Data Mart : sous-ensemble
logique d'un Data Warehouse, il est destiné à quelques
utilisateurs d'un département.
e) Entrepôt de données :
source de données interrogeable de l'entreprise. C'est
tout simplement l'union des Data Marts qui le composent. L'entrepôt de
données est alimenté par la zone de préparation des
données. L'administrateur de l'entrepôt de données est
également responsable de la zone de préparation des
données.
f) OLAP (On Line Analytic Processing) :
Activité globale de requêtage et de
présentation de données textuelles et numériques contenues
dans l'entrepôt de données ; style d'interrogation et de
présentation spécifiquement dimensionnel.
g) ROLAP (Relational OLAP) :
ensemble d'interface utilisateur et d'applications donnant une
vision dimensionnelle des bases de données relationnelles.
h) MOLAP (Multidimensional OLAP) :
ensemble d'interface utilisateur et d'applications dont l'aspect
dimensionnel est prépondérant.
i) Application utilisateur :
ensemble d'outils qui interrogent, analysent et présente
des informations répondant à un besoin spécifique.
L'ensemble des outils minimal se compose d'outil d'accès aux
données, d'un tableur, d'un logiciel graphique et d'un
23
service d'interface utilisateur, qui suscite les
requêtes et simplifie la présentation de l'écran aux yeux
de l'utilisateur.
j) Outil d'accès aux données :
client de l'entrepôt de données.
k) Outil de requête : types
spécifique d'outil d'accès aux données qui invite
l'utilisateur à formuler ses propres requêtes en manipulant
directement les tables et leurs jointures.
l) Application de modélisation :
type de client de base de données sophistiqués
doté de fonctionnalités analytiques qui transforment ou mettent
en forme les résultats obtenus ; on peut avoir :
? les modèles prévisionnels, qui tentent
d'établir des prévisions d'avenir ;
? les modèles de calcul comportemental, qui
catégorisent et classent les comportements d'achat ou d'endettement des
clients ;
? la plupart des outils de Data mining.
m) Métadonnées :
toutes informations de l'environnement du Data Warehouse qui ne
constituent pas les données proprement dites.
II.3. Caractéristiques d'un Data
Warehouse17
Un Data Warehouse est une base de données conçue
pour l'interrogation et l'analyse plutôt que le traitement de
transactions. Il contient généralement des données
historiques dérivées de données transactionnelles, mais il
peut comprendre des données d'autres origines.
Les Data Warehouse séparent la charge d'analyse de la
charge transactionnelle. Ils permettent aux entreprises de consolider des
données de différentes origines.
Au sein d'une même entité fonctionnelle, le Data
Warehouse joue le rôle d'outil analytique.
En complément d'une base de données, un Data
Warehouse inclut une solution d'extraction, de transformation et de chargement
(ETL), des fonctionnalités de traitement analytique en ligne (OLAP) et
de Data mining, des outils d'analyse client et d'autres applications qui
gèrent le processus de collecte et de mise à la disposition de
données.
17 INMON W.-H., Building the data warehouse, QED
Publishing Group, 1992, p.57.
24
II.4 Entrepôts et Bases de
données
Dans l'environnement des entrepôts de données,
les opérations, l'organisation des données, les critères
de performance, la gestion des métadonnées, la gestion des
transactions et le processus de requêtes sont très
différents des systèmes de bases de données
opérationnels.
Par conséquent, les SGBD relationnels orientés
vers l'environnement opérationnel, ne peuvent pas être directement
transplantés dans un système d'entrepôt de
données.
Les SGBD ont été créés pour les
applications de gestion de systèmes transactionnels. Par contre, les
entrepôts de données ont été conçus pour
l'aide à la prise de décision. Ils intègrent les
informations qui ont pour objectif de fournir une vue globale de l'information
aux analystes et aux décideurs.
Le tableau suivant résume les différences entre
les systèmes de gestion de bases de données et les
entrepôts de données.
|
SGBD
|
Entrepôts de données
|
|
Objectifs
|
Gestion et production
|
Consultation et analyse
|
|
Utilisateurs
|
Gestionnaire de production
|
Décideurs, analystes
|
|
Taille de base
|
Plusieurs giga-octets
|
Plusieurs téra-octéts
|
|
Organisation de données
|
Par traitement
|
Par métier
|
|
Types de données
|
Données de gestion
(courantes)
|
Données d'analyse
(résumées, historisées)
|
|
Requêtes
|
Simples, prédéterminées,
données détaillées
|
Complexes, spécifiques,
agrégations et group by
|
|
Transactions
|
Courte et nombreuse,
temps réel
|
Longues, peu nombreuses
|
Tableau 1 : Différence entre SGBD et
entrepôts de données II.4.1 Rôle d'un
entrepôt de données
Le rôle primordiale d'un data warehouse apparait ainsi
évident dans une stratégie décisionnelle. L'alimentation
du data warehouse en est la phase la plus critique.
En effet, importer des données inutiles en portera de
nombreux problèmes, cela consommera des ressources système et du
temps. De plus, cela rendra le service d'analyse plus lent. Autre point
à prendre en compte est la périodicité d'extraction des
données ;
25
effectivement, le plus souvent, les opérations de
collecte de données sont couteuses en ressource pour la base
accédée.18
II.4.2 Systèmes transactionnels et
systèmes décisionnels
Les Système de Gestion de Base de Donnée (SGBD)
ont été créés pour gérer de grands volumes
d'information contenus dans les différents systèmes
opérationnels qui appartiennent à l'entreprise.
Ces données sont manipulées en utilisant des
processus transactionnels en ligne, .parallèlement à
l'exploitation de l'information contenue dans ces systèmes
opérationnels, les dirigeants des entreprises ont besoin d'avoir une
vision globale concernant toute cette information pour faire des calculs
prévisionnels, des statistiques ou pour établir des
stratégies de développement et d'analyses des tendances.
|
Système transactionnel
|
Système décisionnel
|
|
Données
|
Exhaustives, courantes,
dynamiques
|
Résumées historiques
statiques
|
|
Orientées applications
|
Orientées sujets (d'analyse)
|
|
Utilisateurs
|
Nombreux
|
Peu nombreux
|
|
Varies (employés,
directeurs)
|
Uniquement les décideurs
|
|
Concurrentes
|
Non concurrentes
|
|
Mises à jour et
interrogations
|
Interrogations
|
|
Requêtes prédéfinies
|
Requêtes imprévisibles et
complexes
|
|
Réponses immédiates
|
Réponses moins rapides
|
|
Accès à peu d'informations
|
Accès à des nombreuses
informations
|
Tableau 2 : compare les
caractéristiques des systèmes
II.4.3 Différence entre le système OLTP
et le Data warehouse
Les Data Warehouse et les Systèmes OLTP (On Line
Transaction Processing) répondent à besoins très
différents. Les Data Warehouse conçu pour prendre en charge des
interrogations ad hoc. La taille du Data Warehouse n'est pas connue à
l'avance. Par conséquent, celui-ci doit être optimisé pour
offrir de bonnes performances dans le cadre d'opérations d'interrogation
très diverses. Les systèmes OLTP prennent
généralement en
18 Dayal U., Blaustein B. T., Buchmann A. P., Chakravarthy U. S.,
Hsu M., Ledin R., McCarthy D. R., Rosenthal A., Sarin S. K., Carey M. J., Livny
M., Jauhari R., "The HiPAC Project: Combining Active Databases and Timing
Constraints", ACM SIGMOD Record, 17(3), Chicago (Illinois, USA), 1988,
p.312-322
26
charge des opérations prédéfinies. Les
applications peuvent être réglées ou conçues
spécifiquement pour ces opérations.
Un Data Warehouse est mise à jour
régulièrement par les processus ETL (Extraction, Transformation
and Loading), un système de chargement de données en masse
soigneusement défini et contrôlé. Il n'est pas mise
à jour directement par les utilisateurs. Dans les systèmes OLTP,
les utilisateurs exécutent régulièrement des instructions
qui modifient les données de la base. La base de données OLTP est
à jour en permanence et elle reflète l'état actuel de
chaque transaction19.
Les Data Warehouse utilisent souvent des schémas
dénormalisés ou partiellement dénormalisés (tels
que le schéma en étoile) pour optimiser les performances des
interrogations. A l'inverse, les systèmes OLTP ont souvent recours
à des schémas totalement normalisés pour optimiser les
performances des opérations de mise à jour, d'insertion et de
suppression, et pour garantir la cohérence des données. Il s'agit
là des différences générales, elles ne doivent pas
être considérées comme des distinctions strictes et
absolues.
De manière générale, une interrogation
portant sur un Data Warehouse balaye des milliers voire des millions de lignes.
En revanche, une opération OLTP standard accède à quelque
enregistrement seulement.
Le Data Warehouse contient généralement des
données correspondant à plusieurs mois ou années. Cela
permet d'effectuer des analyses historiques. Les systèmes OLTP
contiennent généralement des données quelque semaine ou
mois. Ils conservent uniquement des données historiques
nécessaires à la transaction en cours.
II.4.4 La problématique de
l'entreprise
L'entreprise construit un système décisionnel
pour améliorer sa performance, elle doit décider et anticiper en
fonction de l'information disponible et capitaliser sur ses
expériences.
Entreprise : est une organisation dotée d'une mission
et d'un objectif métier. Elle doit sa raison d'être et /ou sa
pérennité au travers de différent objectifs
(sécurité, développement, rentabilité ...). Par
voie de conséquence, cette organisation humaine est dotée d'un
centre décision.
? Rôle de décideur : il
peut être le responsable de l'entreprise, le responsable d'une fonction
ou d'un secteur. Il est donc celui qui engage la pérennité ou la
raison d'être de l'entreprise. Pour ces raisons, il doit s'entourer de
différents moyens lui
19 R. Kimball, L. Reeves, M. Ross, W. Thornthwaite, Concevoir
et déployer un data warehouse, Eyrolles, Paris, 2000, page 79
20 Matthias Jarke, Thomas List, Jörg Köller, The
Challenge of Process Data Warehousing, 26th International Conference on
Very Large Databases, Caire, Egypt, 2000, p.112
27
permettant une prise de décision la plus pertinente.
Parmi ces moyens, les Data Warehouse ont une place primordiale.
II.4.5 La Modélisation dimensionnelle et la
Modélisation Entité/Relation
a) Modélisation Entité/Relation :
est une discipline qui permet d'éclairer les relation
microscopique entre les données. Dans sa forme la plus artistique, elle
permet de supprimer toute redondance de données. Ceci apporte de
nombreux avantages au niveau du traitement des transactions, qui deviennent
alors très simples et déterministes.
b) Modélisation dimensionnelle :
est une méthode de conception logique qui vise à
présenter les données sous une forme standardisée
intuitive et qui permet des accès hautement performants. Elle
adhère totalement à la dimensionnalité ainsi qu'à
une discipline qui exploite le modèle relationnel en le limitant
sérieusement. Chaque modèle dimensionnel se compose d'une table
contenant une clé multiple, table des faits, et d'un ensemble de tables
plus petite nommées, tables dimensionnelles.
Chacune de ces dernières possède une clé
primaire unique, qui correspond exactement à l'un des composants de la
clé multiple de la table des faits. Dans la mesure où elle
possède une clé primaire multiple reliée à au moins
deux clés externes, la table des faits exprime toujours une relation n,
n (plusieurs-à-plusieurs).
II.4.6. Relation entre la modélisation
dimensionnelle et la modélisation
entité/relation
Pour mieux appréhender la relation qui existe entre la
modélisation dimensionnelle et la modélisation
entité/relation, il faut comprendre qu'un seul schéma
entité/relation se décompose en plusieurs schémas de table
des faits.
La modélisation dimensionnelle ne se met pas à
son avantage en représentant sur un même schéma plusieurs
processus qui ne coexistent jamais au sein d'une série de données
et à un moment donné. Ce qui le rend indûment complexe.
Ainsi, la conversion d'un schéma entité/relation en une
série de schémas décisionnels consiste à scinder le
premier en autant de sous-schémas qu'il y a de processus métier
puis de les modéliser l'un après l'autre. La deuxième
étape consiste à sélectionner les relations n, n
(plusieurs-à-plusieurs) contenant des faits numériques et
additifs (autres que les clés) et d'en faire autant de table des
faits20.
La troisième étape consiste à
dénormaliser toutes les autres tables en table non séquentielle
dotées de clés uniques qui les relient directement aux tables des
faits. Elles deviennent ainsi des tables dimensionnelles. S'il arrive qu'une
table dimensionnelle soit
Les deux types d'objet les plus courants dans les
schémas de Data Warehouse multidimensionnels sont les tables de faits et
les tables de dimension.
28
reliée à plusieurs tables des faits, nous
représentons cette table dimensionnelle dans les deux schémas et
dirons des tables dimensionnelles qu'elles sont conformes d'un modèle
à l'autre.
II.4.6.1 Avantages de la modélisation
dimensionnelle
Le modèle dimensionnel possède un grand nombre
d'avantages dont le modèle entité/relation est
dépourvu.
Premièrement, le modèle dimensionnel est une
structure prévisible et standardisée. Les
générateurs d'états, outils de requête et interfaces
utilisateurs peuvent reposer fortement sur le modèle dimensionnel pour
faire en sorte que les interfaces utilisateurs soient plus
compréhensibles et que le traitement soit optimisé.
La deuxième force du modèle dimensionnel est que
la structure prévisible du schéma en étoile réside
aux changements de comportement inattendus de l'utilisateur. Toutes les
dimensions sont équivalentes.
La troisième force du modèle dimensionnel
réside dans le fait qu'il est extensible à loisir pour accueillir
des données et des besoins d'analyse non prévus au départ.
Ainsi, il est possible d'accomplir :
o Ajouter des faits nouveaux non prévus initialement ;
o Ajouter des dimensions totalement nouvelles ;
o Ajouter des attributs dimensionnels nouveaux non prévus
initialement ;
o Décomposer les enregistrements d'une dimension
existante en un niveau de détail plus fin à partir d'une date
déterminée.
II.5. Schémas d'un Data Warehouse
Un schéma est un ensemble d'objets de la base de
données tels que les tables, des vues, des vues
matérialisées, des index et des synonymes. La conception du
schéma d'un Data Warehouse est guidée par le modèle des
données source et par les besoins utilisateurs.
L'idée fondamentale de la modélisation
dimensionnelle est que presque tous les types de données peuvent
être représentés dans un cube de données, dont les
cellules contiennent des valeurs mesurées et les angles les dimensions
naturelles de données. Nos conceptions peuvent comporter plus de trois
dimensions. Techniquement, il faudrait parler d'hyper cube, bien que le terme
cube de données ait été adopté par le
métier.
A. Les objets d'un schéma de Data Warehouse
29
? Tables des faits : une table de faits
comprend généralement des colonnes de deux types : celles qui
contiennent des faits numériques (souvent appelés indicateurs) et
celles qui servent de clé étrangère vers les tables de
dimension. Une table de faits peut contenir des faits détaillés
ou agrégées. Les tables contenant des faits agrégés
sont souvent appelées tables agrégées. une table de faits
contient généralement de faits de même niveau
d'agrégation. La plupart des faits sont additifs, mais ils peuvent
être semi-additifs ou non additifs. Les faits additifs peuvent être
agrégés par simple addition arithmétique. C'est par
exemple le cas des ventes. Les faits non additifs ne peuvent pas être
additionnés du tout. C'est le cas des moyennes. Les faits semi-additifs
peuvent être agrégés selon certaines dimensions mais pas
selon d'autres.
? Tables des dimensions et hiérarchies :
une dimension est une structure comprenant une ou plusieurs
hiérarchies qui classe les données en catégories. Les
dimensions sont des étiquettes descriptives fournissant des informations
complémentaires sur les faits, qui sont stockées dans les tables
de dimension. Il s'agit normalement de valeurs textuelles descriptives.
Plusieurs dimensions distinctes combinées avec les faits permettant de
répondre aux questions relatives à l'activité de
l'entreprise. Les données de dimension son généralement
collectées au plus bas niveau de détail, puis
agrégées aux niveaux supérieurs en totaux plus
intéressants pour l'analyse, ces agrégations ou cumuls naturels
au sein d'une table de dimension sont appelés des hiérarchies.
Les hiérarchies sont des structures logiques qui utilisent les niveaux
ordonnées pour organiser les données. Pour une dimension temps,
par exemple, une hiérarchie peut agréger les données selon
le niveau mensuel, le niveau trimestriel, le niveau annuel. Au sein d'une
hiérarchie, chaque niveau est connecté logiquement aux niveaux
supérieurs et inférieurs. Les valeurs des niveaux
inférieurs sont agrégées en valeurs de niveau
supérieur.
a) Le Schéma en Etoile
Le schéma en étoile peut être le type le
plus simple de schéma de Data Warehouse, il est dit en étoile
parce que son diagramme entité/relation ressemble à une
étoile, avec des branches partant d'une table centrale. Un schéma
en étoile est caractérisé par une ou plusieurs tables de
faits, très volumineuses, qui contiennent les informations essentielles
du Data Warehouse et par un certain nombre de tables de dimension, beaucoup
plus petites, qui contiennent chacune des informations sur les entrées
associées à un attribut particulier de la table de faits. Une
interrogation en étoile est une jointure entre une table de faits et un
certain nombre de table de dimensions. Chaque table de dimension est jointe
à la table de faits à l'aide d'une jointure de clé
primaire à clé étrangère, mais les tables de
dimension ne sont pas jointes entre elles.
Les schémas en étoile présentent les
avantages suivants : ils fournissent une correspondance directe et intuitive
entre les entités fonctionnelles analysées par les utilisateurs
et la conception du schéma. Ils sont pris en charge par un grand nombre
d'outils
Le principal avantage du schéma en flocons est une
amélioration des performances des interrogations due à des
besoins réduits en espace de stockage sur disque et la petite
30
décisionnels. La manière la plus naturelle de
modéliser un Data Warehouse est la représenter par un
schéma en étoile dans lequel une jointure unique établit
la relation entre la table de faits et chaque table de dimension. Un
schéma en étoile optimise les performances en contribuant
à simplifier les interrogations et à raccourcir les temps de
réponse.
Les schémas en étoile présentent
néanmoins quelques limites. La table centrale peut devenir très
volumineuse, sa taille maximale étant déterminée par le
produit des nombres de lignes des tables de dimension. En outre, les tables de
dimension ne sont plus normalisées. Elles sont donc plus volumineuses et
plus difficiles à tenir à jour car elles contiennent beaucoup de
données dupliquées.
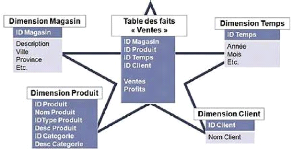
Figure 2: schéma en
étoile
b) Le Schéma en Flocon
Les schémas en flocons normalisent les dimensions pour
éliminer les redondances. Autrement dit, les données de dimension
sont stockées dans plusieurs tables et non dans une seule table de
grande taille. Cette structure de schéma consomme moins d'espace disque,
mais comme elle utilise davantage de tables de dimension, elle nécessite
un plus grand nombre de jointures de clé secondaire. Les interrogations
sont par conséquent plus complexes et moins performantes.
Dans un schéma en flocon, cette même table de
faits, référence les tables de dimensions de premier niveau, au
même titre que le schéma en étoile.
La différence réside dans le fait que les
dimensions sont décrites par une succession de tables (à l'aide
de clés étrangères) représentant la
granularité de l'information. Ce schéma évite les
redondances d'information mais nécessite des jointures lors des
agrégats de ces dimensions.
Cette figure présente un schéma
multidimensionnel pour les ventes qui ont été
réalisées dans les magasins pour les différents produits
au cours d'un temps donné (jour)
31
taille des tables de dimension à joindre. Le principal
inconvénient de ce schéma est le travail de maintenance
supplémentaire imposé par le nombre accru de tables de
dimension.
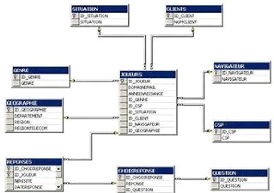
Figure 3: schéma d'un modèle en
flocon
c) Schéma multi dimensionnel (CUBE)
Dans le modèle multidimensionnel, le concept central
est le cube, lequel est constitué des éléments
appelés cellules qui peuvent contenir une ou plusieurs mesures. La
localisation de la cellule est faite à travers les axes, qui
correspondent chacun a une dimension.
La dimension est composée de membres qui
représentent les différentes valeurs.
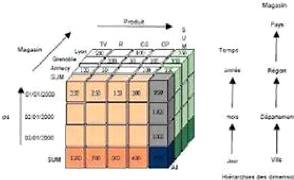
Figure 4: Exemple de schéma
multidimensionnel
32
II.6 Le Data Mart II.6.1
Introduction
Un DataMart est un sous-ensemble d'un entrepôt de
données; il est généralement exploité dans les
entreprises pour restituer des informations ciblées sur un métier
spécifique, constituant pour ce dernier un ensemble d'indicateurs
à vocation de pilotage de l'activité et d'aide à la
décision. Un DataMart, selon les définitions, est issu ou fait
partie d'un Data Warehouse, et en reprend par conséquent la plupart des
caractéristiques.
II.6.2 Les définitions
Le DataMart est un ensemble de données ciblées,
organisées, regroupées et agrégées pour
répondre à un besoin spécifique à un métier
ou un domaine donné. Il est donc destiné à être
interrogé sur un panel de données restreint à son domaine
fonctionnel, selon des paramètres qui auront été
définis à l'avance lors de sa conception.
De façon plus technique, le DataMart peut être
considère de deux manières différentes, attribuées
aux deux principaux théoriciens de l'informatique décisionnelle,
bill inmon et Ralph Kimball :
? Définition d'inmon : le
DataMart est issu d'un flux de données provenant du Data Warehouse.
Contrairement a ce dernier qui présente le détail des
données pour toute l'entreprise, il a vocation à présenter
la donnée de manière spécialisée,
agrégée et regroupée fonctionnellement.
? Définition de Kimball : le
DataMart est un sous-ensemble du Data Warehouse, constitue de tables au niveau
détail et à des niveaux plus agrèges, permettant de
restituer tout le spectre d'une activité métier. L'ensemble des
DataMarts de l'entreprise constitue le Data Warehouse.
II.6.3 La place du datamart dans
l'entreprise
Le DataMart se trouve en toute fin de la chaine de traitement
de l'information. En règle générale, il se situe en aval
d'un Data Warehouse plus global à partir duquel il est alimenté,
dont il constitue en quelque sorte un extrait.
Un DataMart forme la principale interaction entre les
utilisateurs et les systèmes informatiques qui gèrent la
production de l'entreprise (souvent des ERP).
Dans un DataMart, l'information est préparée
pour être exploitée brute par les personnes du métier
auquel il se rapporte. Pour ce faire, il est appelé a être utilise
via des logiciels d'interrogation de bases de données (notamment des
outils de reporting) afin de renseigner ses utilisateurs sur l'état de
l'entreprise à un moment donné (stock) ou sur son activité
(flux).
33
La préparation de la donnée pour une utilisation
directe, inhérente au DataMart, peut revêtir plusieurs formes. Il
faut noter que toutes représentent une simplification par rapport au
niveau de données inferieur ; on peut citer pour exemple :
L'agrégation de données : le DataMart ne contient pas le
détail de toutes les opérations qui ont eu lieu, mais seulement
des totaux, repartis par groupements.
a) Le retrait de données inutiles :
le DataMart ne contient que les données qui sont
strictement utiles aux utilisateurs. L'historisation des données : le
DataMart
contient seulement la période de temps qui
intéresse les utilisateurs.
II.6.4 Datawarehouse Et Datamart
La première étape d'un projet busines
intelligent est de créer un entrepôt central pour avoir une vision
globale des données de chaque service. Cet entrepôt porte le nom
de DataWarehouse.
On peut également parler de DataMart, si seulement une
catégorie de services ou métiers est concernée.
Par définition, un DataMart peut être contenu
dans un DataWarehouse, ou il peut être seulement issu de celui-ci.
II.6.5. Architecture d'un Datamart
Système transactionnel
Figure 5: Architecture d'un Data
Mart
II.6.6. Data Warehouse versus Data
Mart
Les Data Marts représentent de toute évidence
une réponse rapide aux besoins des différents départements
de l'entreprise. Leur coût moindre et leur facilité d'emploi
permettent une implémentation rapide et un retour à
l'investissement presque immédiat. Il faut toutefois être prudent
lorsque des Datamarts sont ainsi crées pour plusieurs divisions.
34
Ces dernières utilisent souvent des
représentations différentes de certains concepts de gestion. Par
exemple, les départements finances et marketing peuvent tous deux
effectué un suivi des ventes réalisées par l'entreprise,
mais défini différemment ce concept. Plus tard, si un
employé du marketing a besoin de recueillir certaines informations
à partir du Data Marts des finances, l'entreprise sera confrontée
à un problème. Par conséquent, une vision unifiée
est nécessaire même pour concevoir des Datamarts par
département.
II.7 Les Serveurs OLAP (On-Line Analytical
Processing)
Les données opérationnelles constituent la
source principale d'un système d'information décisionnel. Les
systèmes décisionnels complets reposent sur la technologie OLAP,
conçue pour répondre aux besoins d'analyse des applications de
gestion21.
Nous exposons dans la suite les divers types de stockage des
informations dans les systèmes décisionnels.
II.7.1 Les Serveur ROLAP (Relational Olap)
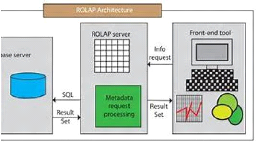
Figure 6 : Architecture ROLAP
Dans les systèmes relationnels OLAP, l'entrepôt
de données utilise une base de données relationnelle. Le stockage
et la gestion de données sont relationnels. Le moteur ROLAP traduit
dynamiquement le modèle logique de données multidimensionnel m en
modèle de stockage relationnel r, la plupart des outils
requièrent que la donnée soit structurée en utilisant un
schéma en étoile ou un schéma en flocon de neige.
La technologie ROLAP a deux avantages principaux :
21 Frank Ravat, Olivier Teste, Gilles Zurfluh :
Modélisation et extraction de données pour un entrepôt
objet, Université Paul Sabatier (Toulouse III), IRIT (Institut de
Recherche en informatique de Toulouse), équipe SIG, Toulouse, France
2001, page 47
35
1) Elle permet la définition de données
complexes et multidimensionnelles en utilisant un modèle relativement
simple.
2) Elle réduit le nombre de jointures à
réaliser dans l'exécution d'une requête.
Le désavantage est que le langage de requêtes tel
qu'il existe, n'est pas assez puisant ou n'est pas assez flexible pour
supporter de vraies capacités d'OLAP.
II.7.2 Le Serveur MOLAP (Multidimensional
OLAP)
Les systèmes multidimensionnels OLAP utilisent une base
de données multidimensionnelle pour stocker les données de
l'entrepôt et les applications analytiques sont construites directement
sur elle. Dans cette architecture, le système de base de données
multidimensionnel sert tant au niveau de stockage qu'au niveau de gestion des
données. Les données des sources sont conformes au modèle
multidimensionnel, et dans toutes les dimensions, les différentes
agrégations sont pour le calculées pour des raisons de
performance.
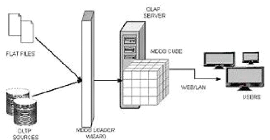
Figure 7: Architecture MOLAP
Les systèmes MOLAP doivent gérer le
problème de données clairsemées, quand seulement un nombre
réduit de cellules d'un cube contiennent une valeur de mesure
associée.
Les avantages des systèmes MOLAP sont bases sur les
désavantages des systèmes ROLAP et elles représentent la
raison de leur création. D'un cote, les requêtes MOLAP sont
très puissantes et flexibles en termes du processus OLAP, tandis que,
d'un autre cote, le modèle physique correspond plus étroitement
au modèle multidimensionnel. Néanmoins, il existe des
désavantages au modèle physique MOLAP. Le plus important, a notre
avis, c'est qu'il n'existe pas de standard du modèle physique.
36
II.7.3 Les Serveur HOLAP (Hybrid
Olap)
Un système HOLAP est un système qui supporte et
intègre un stockage des données multidimensionnel et relationnel
d'une manière équivalente pour profiter des
caractéristiques de correspondance et des techniques d'optimisation donc
c'est l'ensemble des deux serveurs MOLAP et ROLAP.
Dans la figure 7, nous montrons une architecture en utilisant
les types de serveurs ROLAP et MOLAP pour le stockage de données.
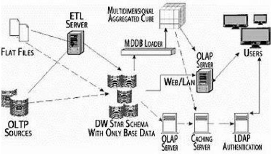
Figure 8 : Architecture HOLAP
Nous traitons une liste des caractéristiques principales
qu'un système HOLAP doit
fournir :
a) La transparence du système :
Pour la localisation et l'accès aux données, sans
connaître si elles sont stockées dans un SGBD relationnel ou
dimensionnel. Pour la transparence de la fragmentation.
b) Un modèle de données
général et un schéma multidimensionnel global
: Pour aboutir à la transparence du premier point, tant le
modèle de données général que le langage de
requête uniforme doivent être fournis. Etant donné qu'il
n'existe pas un modèle standard, cette condition est difficile à
réaliser.
c) Une allocation optimale dans le système
de stockage : Le système HOLAP Doit
bénéficier des stratégies d'allocation qui existent dans
les systèmes distribués tels que : le profil de requêtes,
le temps d'accès, l'équilibrage de chargement.
d) Une réallocation automatique :
Toutes les caractéristiques traitées ci-dessus
changent dans le temps. Ces changements peuvent provoquer la
réorganisation de la distribution des données dans le
système de stockage multidimensionnel et relationnel, pour assurer des
performances optimales.
37
Actuellement, la plupart des systèmes commerciaux
utilisent une approche hybride. Cette approche permet de manipuler des
informations de l'entrepôt de données avec un moteur ROLAP, tandis
que pour la gestion des DataMarts, ils utilisent l'approche
multidimensionnelle.
II.7.4. Les différents outils
OLAP
a) Multidimensionnel OLAP (MOLAP)
Il est plus facile et plus cher à mettre en place, il est
conçu exclusivement pour l'analyse multidimensionnelle avec un mode de
stockage optimisé par rapport aux chemins d'accès
prédéfinis.
MOLAP repose sur un moteur spécialisé, qui stocke
le data dans format tabulaire propriétaire (Cube). Pour accéder
aux données de ce cube, on ne peut pas utiliser le langage de
requête sql, il faut utiliser une API spécifique.
b) Relationnal OLAP (ROLAP)
Il est plus facile et moins cher à mettre en place, il
est moins performant lors des phases de calculs. En effet, il fait appel
à beaucoup de jointure et donc les traitements sont plus
conséquents.
Il superpose au-dessus des SGBD/R bidimensionnels un
modèle qui représente les données dans un format
multidimensionnel.
ROLAP propose souvent un composant serveur, pour optimiser
les performances lors de la navigation dans les données. Il est
déconseillé d'accéder en direct à des bases de
données de production pour faire des analyses tout simplement pour des
raisons des performances.
c) Hybride OLAP (OLAP)
Est une solution hybride entre les deux (MOLAP et ROLAP) qui
recherche un bon compromis au niveau du cout et de la performance.
HOLAP désigne les outils d'analyse multidimensionnelle
qui récupèrent les données dans de bases relationnelles ou
multidimensionnelles, de manière transparente pour l'utilisateur.
Ces trois notions se retrouvent surtout lors du
développement des solutions. Elles dépendent du software et
hardware. Lors de la modélisation, on ne s'intéresse qu'à
concevoir une modélisation orientée décisionnelle,
indépendamment des outils utilisés ultérieurement.
38
| 

