|

I
REPUBLIQUE DEMOCRATIQUE DU CONGO
MINISTERE DE
L'ENSEIGNEMENT SUPERIEUR ET UNIVERSITAIRE
UNIVERSITE SAINT LAURENT DE KANANGA
« USLKA »
B.P.70 KANANGA
FACULTE DE SCIENCES INFORMATIQUES
« Modélisation et implémentation
d'un système
décisionnel pour la gestion du personnel à
la Régie
des Voies Aériennes de Kananga ».
Présenté par KABEYA ILUNGA
Paulin
Mémoire présenté et défendu en
vue de l'obtention du Grade de Licencié en Sciences
Informatiques.
Option : Conception de
système d'information et programmation Avancée
Octobre 2021

EPIGRAPHE
« Il faut appeler science que l'ensemble des recettes
qui réussissent
toujours. Tout le reste est littérature, car
la science n'a pas de patrie ».
Paulin KABEYA ILUNGA

IN MEMORIAM

A vous cher père François ILUNGA,
chère mère
Marthe BUKAWU et très chère
grand-mère
Madeleine KABEDI, que la terre de nos
ancêtres
avait arraché si tôt, vos souvenirs
innombrables
marquants ne m'ont pas laissé
indifférent, de
là où vous êtes, sachez que votre
semence a porté
des fruits. Je ne saurai vous
oublier.
Paulin KABEYA ILUNGA
III
DEDICACE
A ma charmante épouse Jeannette
MBOMBO
En témoignage de nos moments de liesse, de
fraternité, d'amour et des épreuves difficiles qu'on a pu
surmonter ensemble et de tout ce qu'on a partagé et qu'on
partagéra toujours ensemble. Ton soutien moral,
matériel
et financier ainsi que ta compréhension ont toujours
été présents aux
moments les plus difficiles.
Aucun mot, aucune dédicace ne saurait exprimer mon
respect, ma
gratitude, pour m'avoir laissé la liberté
du choix, pour avoir eu confiance
en moi.
Je vous rends hommage par ce modeste travail en guise de
ma
reconnaissance éternelle et mon infini amour.
Paulin KABEYA ILUNGA
IV
REMERCIEMENTS
Le développement de tout homme implique des longues
années du dur labeur aux cours desquelles, il recherche par les
expériences vécues avec les autres et dans un silence
antérieur à pénétrer le mystère de son
être pour acquérir certaine maturité et donner un sens
à son existence.
Dans notre pèlerinage et plus
précisément durant l'élaboration de notre mémoire
de fin de cycle, des nombreuses personnes ont jouées des rôles
actifs, certaines par leurs conseils et dévouements, d'autres par leurs
soutiens moraux que matériaux.
Ainsi, au moment où nous publions notre
mémoire, nous nous sentons redevable envers eux. C'est pourquoi nous
voudrons nous acquitter de l'agréable devoir d'exprimer toute notre
reconnaissance à tous ceux qui de loin ou de prêt ont
contribué à donner à cette dissertation sa forme
actuelle.
Nos remerciements à notre Directeur le Professeur
Pierre KAFUNDA KATALAY pour son entière
disponibilité, son aide inestimable et ses conseils, sans lesquels ce
mémoire n'aurait pu aboutir.
Nous remercions de tout coeur le co-directeur de ce
mémoire en la personne de l'Ingénieur Cédrick
MUAMBA Muya pour ses différentes remarques et orientations dans
l'élaboration; qu'il trouve ici l'expression de nos sentiments de
gratitude.
Nous remercions également aussi les membres du
Comité de Gestion de l'Université Saint Laurent de Kananga pour
le suivi, disponibilité, leurs précieux conseils et remarques
constructives tout au long de nos cinq années d'études.
Que tous les enseignants de l'USLKA qui ont
contribué à notre formation, le long de ces cinq années
trouvent ici l'expression de ma gratitude et plus particulièrement
l'Assistant Pierrot MUKENDI ainsi que les Chefs des travaux Anaclet TSHIKUTU et
Nobla TSHILUMBA.
Mes remerciements s'adressent au professeur
Laurent LUMU NGALAMULUME Tu es l'être le plus cher sur terre,
toi qui a pris la place d'un parent et qui a toujours su être à
mon écoute et me réconforter au moment opportun ; à tes
encouragements et tes prières qui m'ont toujours soutenue et
guidé ; ta bonté, ton honnêteté, ta
générosité et tes grandes qualités humaines
demeurent pour moi le meilleur exemple à suivre.
A ma jolie soeur Ivette KABEDI, mes chers frères
Serge KAYEMBE et Jean-Pierre TSHITENGE ; nul mot ne saurait exprimer l'amour,
la tendresse et l'attachement que j'ai pour vous. Je vous dédie ce
travail en témoignage de l'amour et des liens de sang qui nous unissent.
Puissions-nous rester unis dans la tendresse et fidèles à
l'éducation que nous avons reçue.
V
Mes remerciements s'adressent aussi plus
particulièrement à mes Oncles : Martin MADIMBA LUKUSA et Hubert
BEYA pour leur soutien moral, matériel et financier ; que le bon Dieu
vous bénisse.
Mes remerciements à mes meilleurs amis : Emmanuel
KABIENA, Joseph NTUMBA, Jean KAYIMUSUMBA et Michel BITANGALO, je vous dis que
la cohorte est atteinte.
Je remercie également mes compagnons,
collaborateurs et collaboratrices : Josée-Lyska NTUMBA, Christine
TSHILANDA, Angel MBUYI et Christophe KALONGA.
Je ne peux clore cette page sans remercier mes camarades
de lutte : Achille MALUNDU et Judith TSHIBOLA eux qui ont souffert ensemble
avec moi.
Que toute personne qui de loin ou de près à
contribuer à mes études trouve ici l'expression de ma
gratitude.
Paulin KABEYA ILUNGA
VI
SIGLES
CUBE : Schéma Multidimensionnel
DGRKOC : Direction Générale des Recettes du
Kasaï Occidental
DW : Data Warehouse
ECD : Employé de Courte Durée
EFA : Employé de Fonction Auxiliaire
ELD : Employé de Longue Durée
ETL : Extraction Transformation an Loading
GKN : Général Kinshasa Company
HDD : Hard Drive Disk
HOLAP : Hybrid On Line Analytic Processing
MCD : Modèle Conceptuel de Données
MLD : Modèle Logique de Données
MOA : Maîtrise d'Ouvrage
MOE : Maître d'oeuvre informatique
MOLAP : Multidimensinnel On Line Analytic Processing
MPD : Modèle Physique de Données
OLAP : On Line Analytic Processing
OLTP : On Line Transaction Processing
OMG : Object Management Group
OMT : Obect Modeling Technique
OOSE : Object Oriented Software Engineering
PC : Personnal Computer
PV : Procès-Verbal
RAM : Radom Access Memory
ROLAP : Relational On Line Analytic Processing
RVA : Régie des Voies Aériennes
SABENA : Société Anonyme Belge pour
l'Exploitation de la Navigation Aérienne
SARL : Société à
Résponsabilité Limitée
SGBD : Système de Gestion de Base de Données
SID : Système d'Information Décisionnel
UML : Unified Modeling Language
VII
LISTE DE FIGURES
Figure 1 : Architecture
Générale d'un système décisionnel
Figure 2: schéma en étoile
Figure 3: schéma d'un modèle en
flocon
Figure 4: Exemple de schéma
multidimensionnel
Figure 5: Architecture d'un Data
Mart
Figure 6 : Architecture ROLAP
Figure 7: Architecture MOLAP
Figure 8 : Architecture HOLAP
Figure 9: Arbre de décision construit
à partir de l'attribut âge
Figure 10 : Arbre de décision
finale
Figure 11 : graphe connexe
Figure 12 : Arbres
Figure 13 : arborescence
Figure 14 : Diagramme de cas
d'utilisation de la gestion du personnel
Figure 15 : diagramme de
séquence de cas d'utilisation engager
Figure 16 : diagramme
d'activité de cas Engager
Figure 17 : diagramme de
séquence lister personnel
Figure 18 : diagramme
d'activité lister personnel
Figure 19 : diagramme de
séquence modifier_personnel
Figure 20 : diagramme
d'activité modifier personnel
Figure 21 : diagramme de classe de
la gestion du personnel
Figure 22 : SQL Server
Figure 23 : Microsoft SQL Server
Management Studio
Figure 24 : création de la
base de données
Figure 25 : nouvelle base de
données
Figure 26 : table
Figure 27 : Business Intelligence
Figure 28 : Assistant Source de
données
Figure 29 : Gestionnaire de
connexion
Figure 30 : Assistant source de
données
Figure 31 : Sélection des
tables
Figure 32 : création
dimensions
Figure 33 : création de
cube
VIII
LISTE DE TABLEAUX
Tableau 1 : Différence entre SGBD et
entrepôts de données
Tableau 2 : compare les
caractéristiques des systèmes
Tableau 3: le processus du
datamining.
Tableau 4: les taches et technique du
datamining.
Tableau 5: exemples pratiques
Tableau 6: Liste des matériels
existants
Tableau 7: Autres matériels
Tableau 8 : Dictionnaire de
données
Tableau 9 : Identification Engager
personnel
Tableau 10 : identification de
Lister personnel
Tableau 11 : identification de
modifier personnel
1
0. INTRODUCTION GENERALE
C'est lorsque la fumée des annonces se dissipe et
lorsque le tapage médiatique s'apaise que l'on peut voir,
éventuellement, les projets se mettre en place. L'innovation arrive sur
le terrain au moment où elle quitte la scène.
La raison d'être d'un Système d'Information
Décisionnel est l'établissement de ponts entre opérations
et stratégie, entre automatisation et conduite, entre détail et
synthèse, entre situation et évolution. On lui demande, en
quelque sorte, de faire le grand écart entre des notions
indépendantes ou opposées. On peut se demander pourquoi un tel
besoin apparaît aujourd'hui avec une telle ampleur.
En réalité, l'information décisionnelle
est une notion ancienne ; l'idée de Système d'Aide à la
Décision (Decision Support System) est en effet âgée d'un
bon quart de siècle. Elle est donc largement plus ancienne que toutes
les techniques auxquelles on l'associe aujourd'hui. Elle a toutefois
fondamentalement évolué depuis sa naissance. Cette
évolution a été rendue possible, mais non pas
provoquée, par l'innovation technologique.
En particulier, l'expansion actuelle des entrepôts de
données découle presque directement des nouvelles
caractéristiques de l'« écosystème » dans lequel
vivent les organisations. Dans un univers marqué par des
phénomènes de déréglementation et de
mondialisation, même si la portée de ces phénomènes
a été jusqu'à présent largement
exagérée, la compétition et le changement imposent un
nouveau cadre de prise de décisions et une nouvelle conception de la
stratégie. Cette nouvelle donne et affecte en premier lieu les
entreprises intervenant dans les secteurs les plus concurrentiels, pour
lesquelles l'adaptation au changement est une question de survie
immédiate.
Le modèle du commandement central, de l'automatisation
et du contrôle a posteriori, qui correspondait à l'environnement
plus stable des précédentes décennies, n'est pas assez
souple pour ce nouveau contexte.
C'est aujourd'hui la logique de la détection
avancée et de l'adaptation rapide qui tend à prévaloir, de
manière inégale mais réelle. Tout ceci implique
nécessairement une redistribution de la responsabilité
décisionnelle. Il en résulte une gigantesque dissémination
de l'information décisionnelle et un foisonnement de projets aussi
variés dans leur envergure que dans leur contenu.
Un modèle de données sans données ne
serait bien entendu qu'une coquille vide. A la problématique de la
modélisation succède donc naturellement celle de l'alimentation.
Or l'alimentation d'un entrepôt de données décisionnel
n'est pas qu'un problème de connectique et de transfert physique. C'est
même le problème politique, conceptuel et architectural le plus
délicat du système, et le plus susceptible de décider de
la réussite d'un projet.
Le marché met progressivement à notre
disposition un certain nombre d'outils et de composants susceptibles de jouer
un rôle dans la construction des solutions décisionnelles. Nous
croyons utile de résumer ici les grandes alternatives technologiques.
2
Enfin, il nous a semblé indispensable de
présenter le présent travail sur « la
modélisation et l'implémentation d'un système
décisionnel pour la gestion du personnel à la RVA Kananga
».
0.1. Choix et intérêt du sujet 0.1.1.
Choix du sujet
Nous avons choisi ce sujet pour deux raisons :
Aider les décideurs de la Régie des Voies
Aériennes du Kasaï Central d'avoir toutes les données
nécessaires à la prise de décision en un temps
réduit et d'éviter les erreurs dans l'analyse et
l'interprétation de données ;
La seconde réside sur l'obligation qu'à tout
étudiant de présenter et défendre un mémoire
à la fin du deuxième cycle en Informatique afin de faire la
liaison des théories apprises dans notre formation à la
pratique.
0.1.2. Intérêt du
sujet
Ce mémoire présente pour nous un triple
intérêt :
? Il nous permet d'obtenir le grade de Licencié en
Sciences Informatiques dès qu'il est défendu et accepté
;
? Pour la RVA Kasaï Central, cette étude permettra
d'améliorer son système de
gestion du personnel et surtout dans la prise de
décisions par les décideurs ; ? Pour les futurs chercheurs qui
embrasseront le domaine du système décisionnel, c'est
un document de référence.
0.2. Etat de la question
Dans cette partie, il nous convient de signaler que nous
n'avons pas la présentation de faire de ce mémoire une
originalité scientifique personnelle d'autant plus certains de nos
prédécesseurs ont déjà abordé ce sujet d'une
manière ou d'une autre. Parmi eux, voici ceux qui ont retenu notre
attention :
? MANKAMBA YANKUMBA Jean-Luc, UKA 2015-2016 : « Mise
en place d'un système décisionnel basé sur le Data Mart et
l'arbre de décision pour le recrutement du personnel à la DGRKOC
» ; il s'est penché sur les problèmes liés
à la gestion du personnel en général et en particulier sur
la gestion des recrutements.
Quant à nous, nous allons nous basés sur «
la modélisation et l'implémentation d'un système
décisionnel pour la gestion du personnel à la RVA Kananga »,
tout en se focalisant sur la gestion de recrutement, de congé ainsi
que la retraite du personnel de cette Régie des Voies
Aériennes.
3
0.3. Problématique et hypothèses 0.3.1.
Problématique
La problématique se présente dans toute
recherche scientifique comme un ensemble des préoccupations que posent
un chercheur et qui nécessite des réponses dès que l'on
descend sur terrain. Cela étant, elle est définie comme
l'ensemble des questions que l'on se pose devant un constat que soulève
une étude ou une recherche pour arriver à la
vérité.1
Ainsi, notre problématique se résume en ces termes
:
? Le déploiement d'un système décisionnel
pour la gestion du personnel pourra-t-il
aider les décideurs de la RVA Kasaï Central à
prendre des bonnes décisions ? ? La gestion du personnel tenue
manuellement donne-t-elle satisfaction?
? Comment le système décisionnel peut-il
contribué à l'amélioration de la prise de décision
?
0.3.2. Hypothèses
Les hypothèses sont définies comme des
suppositions liées à un phénomène donné dont
on veut se proposer de vérifier si elle est pertinente ou non à
travers la mise en oeuvre de diverses méthodes de
recherche.2
Les hypothèses sont des propositions des réponses
provisoires émises par le chercheur comme fil conducteur qui seront
infirmées ou affirmées.3
Nous pensons que le déploiement d'un système
décisionnel pour la gestion du personnel constituera une solution pour
pallier aux difficultés majeures dans la prise de décisions par
les décideurs; il permettra à la RVA de se doter d'un outil
rentable pour un bon rendement car il consiste au déploiement de Cube
afin de manipuler les données et fouiller ces dernières pour la
prise de décisions en un temps très court.
De ce qui concerne la gestion du personnel tenue manuellement,
elle ne donne pas satisfaction du fait qu'elle présente quelques
erreurs, plus de lourdeur et lenteur dans la prise de décisions.
D'où, le système décisionnel contribuera
à l'amélioration de la prise de décisions par les
décideurs dès qu'il est mis en place, car il mettra les
données nécessaires à la disposition des décideurs
à un temps réduit pour que les bonnes décisions soient
prises.
0.4. Méthodes et techniques 0.4.1.
Méthodes
La méthode est un ensemble des principes, des
règles et d'opérations intellectuelles permettant d'analyser les
données collectées en vue d'atteindre les
résultats.4
1 MALENGA M. ; Notes de cours d'initiation à la
Recherche Scientifique, G1 Informatique, USLKA, 2016-2017,
inédit
2 MUKADI C. ; Notes de Cours de Méthodes de Recherche
Scientifique, G2 Informatique, USLKA, 2017-2018, inédit
3 GRAWITZ M. ; Les méthodes des Sciences Sociales,
Paris, édition Dalloz, 1955, p.10
4 FREYSSINET J. ; Méthode de recherche en Sciences
Sociales, éd.Mont Chrétien, Paris, 1997, p.12
4
En outre, la méthode est un ensemble ordonné des
principes et règles permettant de comprendre la structure fonctionnelles
de l'institution et avoir une idée sur son organisation
interne.5
Pour bien mener notre étude, nous avons recourus aux
méthodes suivantes:
Méthode analytique: qui nous
a permis à faire l'analyse des faits. Cette méthode va de l'effet
aux causes. Hélas! Comme elle ne suffisait pas, nous avons fait appel
à deux autres méthodes;
La méthode historique:
celle-ci nous a permis de connaitre l'origine des événements du
fait qu'elle est une méthode descriptive, sa démarche est parfois
chronologique. Et enfin;
La méthode structurale: qui a
consisté à connaitre les relations que l'élément
entretien avec la structure. Ces principes opératoires consistent
à identifier un phénomène ou une entité sociale
à étudier et ensuite analyse ce phénomène ou
entité dans sa totalité.
0.4.2. Techniques
En vue de récolter les données
nécessaires dans Régie et correspondantes à notre
problématique, nous nous sommes référer aux techniques
ci-dessous:
? Technique d'interview: elle nous a
servi à interviewer les agents de la place avec une série des
questions plus détaillées et face auxquelles des réponses
nous ont été données et ont aidées à
l'élaboration de ce mémoire;
? Technique documentaire: celle-ci
nous a aidés plus dans la récolte de données utiles et
fiables tout en lisant les ouvrages et les archives ayant trait aux faits qui
causent le disfonctionnement dans la gestion du personnel;
? Technique d'observation: cette
dernière nous a permis quant à elle d'observer le
déroulement des activités faisant l'objet de notre
étude.
0.5. Objectif de la recherche
Notre objectif est d'apporter des solutions nouvelles pour la
modélisation et le développement d'entrepôts. Face à
la profusion d'informations hétérogènes, la conception et
le développement de systèmes décisionnels adaptés
s'avèrent primordiaux. Le cadre applicatif de notre mémoire de
fin de cycle se situe dans le domaine décisionnel notamment sur
«Le déploiement d'un système décisionnel pour le
gestion du personnel au sein de la Régie des Voies Aériennes de
Kananga».
Par ailleurs, les applications décisionnelles (et plus
généralement toutes les applications décisionnelles)
utilisent fréquemment des données temporelles. Malgré
l'intérêt que portent les décideurs aux évolutions
des données, les systèmes commerciaux actuels n'intègrent
pas l'historisation des données dans les entrepôts. En outre, peu
de travaux de recherche sur les entrepôts traitent de cet aspect. C'est
ainsi que notre étude est d'une grande importance car les
résultats obtenus à la fin pourraient aider le service du
5 GRAWITZ M. ; Op.cit, p.14
5
personnel de la RVA à adopter des nouvelles
stratégies dans la prise de décisions sur la gestion du
personnel.
Enfin, le présent mémoire apportera une solution
à la modélisation d'un système décisionnel qui
prendra en compte les problèmes difficiles à gérer et
trouver une solution voulue. C'est ainsi que dans le cadre de notre formation
spécifique entant que concepteur
de système d'information, celui-ci facilitera à
la communauté scientifique à pouvoir identifier les
problèmes similaires à celui que nous tentons de résoudre
ici pour y trouver
des solutions dans un court délai.
0.6. Délimitation de la recherche
Vu que le terrain de recherche est trop vaste, il est
impérieux que chaque chercheur limite ses recherché dans le temps
et dans l'espace.
a) Dans le temps: notre
étude va de 2020 à 2021, l'année 2020 est choisie comme
point de départ de nos recherches et 2021 comme l'année de fin de
nos investigations, ou soit une année de recherches.
b) Dans l'espace: elle porte sur la
Régie des Voies Aériennes Central précisément dans
le service Administratif, Financier et Commercial ayant en charge la gestion du
personnel.
La raison majeure qui nous a amené à faire ce
choix sur la gestion du personnel se justifie qu'entend que chercheur,
certaines observations sur la RVA nous ont prouvés qu'elle a les
difficultés dans la gestion à ce qui concerne le personnel.
0.7. Subdivision du travail
Hormis l'introduction et la conclusion générale, ce
mémoire portera sur cinq chapitres à savoir:
? Chapitre premier qui abordera les
Généralités sur le Système Décisionnel (e
Business);
? Chapitre deuxième qui portera sur les entrepôts de
données (Data Warehouse); ? Chapitre troisième qui parlera de
Datamining ;
? Chapitre quatrième qui traitera sur la
présentation du cadre d'étude et spécification de besoins
;
? Chapitre cinquième qui chutera par
l'implémentation de la Solution.
6
CHAPITRE I : GENERALITES SUR LES SYSTEMES
DECISIONNELS
I.0. Introduction
Toute entreprise qui veut atteindre des performances est
censée prendre des décisions rationnelles en se basant sur un
système décisionnel. La faillite de bon nombre d'entreprises est
due au manque d'un personnel qualifié, à une mauvaise gestion et
à une prise de décisions non adéquate.
I.1. Présentation du
décisionnelle
Avant de rentrer dans des considérations techniques,
il est bon de faire un point sur ce qu'est le décisionnel et ce que ce
terme sous-entend. Pour faire très simple, l'informatique
décisionnelle recouvre tous les moyens informatiques destinés
à améliorer la prise de décision des décideurs
d'une organisation. Cette définition pose trois nouvelles questions :
? Qu'est-ce qu'un décideur ?
? Qu'est-ce qui peut permettre d'améliorer la prise de
décision ?
? Quels sont les moyens informatiques disponibles ?
I.2. Définition d'un système
décisionnel
Les systèmes décisionnels sont un ensemble de
technologies destinées à permettre aux collaborateurs d'avoir
accès et de comprendre les données de pilotage plus rapidement,
de telle sorte qu'ils prennent des décisions meilleures et plus rapides
pour enfin atteindre les objectifs de leur organisation. Les systèmes
décisionnels dans leur version la plus complète. 6
1.2.1. La notion de décideur
Sous le modèle du taylorisme et jusque dans les
années 1890, les organisations étaient organisées de
manière pyramidale. Les décisions étaient prises au sommet
de la pyramide et les ordres étaient transmis de manière
descendante et unilatérale à tous les niveaux
opérationnels. Dans ce type d'organisation, les décideurs
étaient seulement les dirigeants de l'organisation.
Ce type d'organisation était efficace tant que le
marché était localisé et qu'il suffisait de produire pour
vendre. Depuis, nous sommes confrontés à une complexité
grandissante du marché liée :
? À la mondialisation : les concurrents sont plus
nombreux, plus innovants, mieux armés.
6 KAFUNDA KATALAYI JP,
Entrepôts des données, L2 informatique option Gestion, cours
inédit, U.K.A 2015-2016.
7
? À une modification des comportements d'achats :
l'organisation se doit d'être centrée client. En effet, les
Produits sont de plus en plus personnalisés (on parle de one-to-one).
? Au fait que le monde va de plus en plus vite : le
critère de délai de livraison ou de disponibilité de
l'information7 jours sur 7, 24h sur 24 associé à la
mondialisation et la personnalisation du besoin client, démultiplie la
complexité de l'écosystème de l'organisation.
Cette logique, facile à comprendre dans un cadre
commercial, s'applique dans tous les domaines de l'entreprise. La prise de
décision ne peut plus être centrale, celle-ci doit être
déléguée. Du fait, dans une entreprise moderne, tout cadre
devient un décideur de terrain et dispose d'une autonomie relative.
C'est cette explosion du nombre de décideurs qui pose un gros
problème à :
? L'informatique, qui se voit démultiplier le nombre de
demandes de rapports et d'extraction de données.
? La direction, qui a besoin d'outils pour manager ses
décideurs : de la cohérence est nécessaire afin que les
décisions prises à tous les niveaux de l'entreprise, le soient en
accord avec la stratégie d'entreprise.
1.2.1.1. Les facteurs d'amélioration de la
prise de décision
Généralement, on présente les trois facteurs
de prise de décision comme étant :
o La connaissance et l'analyse du passé ;
o La représentation du présent ;
o L'anticipation du futur.
Les informations permettant d'appréhender ces facteurs
peuvent être de deux natures différentes :
a) Les informations quantitatives : ce
sont toutes les données chiffrées telles que les montants,
quantités, pourcentages, délais...
b) Les informations qualitatives :
ce sont toutes les informations non quantifiables telles qu'un
commentaire accompagnant un rapport, des mécontentements, un sentiment,
une directive, une nouvelle procédure...
Ces facteurs n'ont pas le même sens suivant le type de
décideur. Leurs horizons fonctionnels et temporels sont trop
différents pour être traités de manière uniforme.
Les décideurs stratégiques ont besoin d'une vision à
360° de leur organisation. S'ils ont besoin d'une évaluation
régulière de leur politique, ils travaillent surtout sur
l'anticipation de l'avenir. Ils ont besoin de projections chiffrées
internes et externes à l'organisation (données quantitatives),
mais aussi de beaucoup de données qualitatives remontant du terrain :
commentaires, comptes rendus. La conviction repose sur des chiffres, mais aussi
sur
8
l'appréhension et la compréhension d'un contexte
et d'un climat interne ou externe à l'organisation.
Les décideurs tactiques sont souvent les plus grands
demandeurs d'outils décisionnels, car ils sont comprimés entre
des décideurs stratégiques, qui leur demandent des
évaluations de leur politique, et des décideurs de terrain,
parfois très nombreux, qu'il faut cadrer et suivre. Ces décideurs
tactiques ont besoin d'une parfaite compréhension du passé,
travaillent peu avec le présent, mais se doivent de travailler avec des
prévisions pour recadrer leur politique. Les données
chiffrées sont bien évidemment essentielles, encore faut-il que
les différents systèmes s'accordent entre eux. Les
décideurs opérationnels travaillent surtout avec le
présent : il leur faut des données opérationnelles brutes
instantanées. L'analyse du passé relève surtout d'un suivi
opérationnel pour vérifier l'adéquation avec les
objectifs. L'anticipation de l'avenir relève de la fourniture de
données opérationnelles en amont du service.
1.2.1.2. L'informatique
décisionnelle
L'informatique décisionnelle couvre toutes les
solutions informatisées pour améliorer la prise de
décision des décideurs dans l'organisation. Dans ses
débuts, l'informatique décisionnelle s'est contentée tout
d'abord de dupliquer les bases de données des systèmes de
gestion, afin d'isoler les requêtes d'analyse de données des
requêtes opérationnelles. Les requêtes d'analyse
étant souvent très lourdes, l'objectif était surtout de
préserver les performances des systèmes opérationnels.
Ensuite cette base de données dédiée aux requêtes et
à l'analyse a progressivement muté et s'est organisée.
Partant du constat qu'il est difficile de croiser des
données contenues dans des bases de données distinctes, le plus
simple a été de regrouper ces données éparses. Le
concept de la base unique pour centraliser les données de l'entreprise
est plus que jamais d'actualité. Il s'agit du concept d'entrepôt
de données (ou Data Ware house). S'il est plus simple d'analyser ces
données une fois qu'elles sont dans l'entrepôt de données,
il n'en reste pas moins qu'il faut tout de même remplir l'entrepôt
de données l'extraction et le croisement des données des
différents systèmes opérationnels puis le chargement dans
l'entrepôt de données, ont fait émerger des outils
dédiés à cette tâche, avec des concepts
métiers qui leur sont propres : les outils d'ETL (Extract Transform
Load).
Si au début, les requêtes d'analyses portaient
sur une base relationnelle (dites OLTP pour On Line Transaction Processing), le
concept de base multidimensionnelle (dites OLAP pour On Line Analytical
Processing) s'est démocratisé fin des années 90. Ce
concept de bases de données offrait des performances très
largement supérieures aux bases OLTP pour répondre à des
requêtes d'analyse. Ces bases OLAP se sont alors couplées
avantageusement avec l'utilisation de l'entrepôt de données. En
effet, elles offraient à la fois un environnement plus performant, mais
permettaient également aux utilisateurs finaux de
bénéficier d'une interface simplifiée d'accès aux
données, beaucoup plus intuitive qu'une base de données OLTP. On
parle alors de méta-modèle.
9
L'ensemble des moyens informatiques et techniques
destiné à améliorer la prise de décision est
appelé système décisionnel ou encore Système
Informatique d'Aide à la Décision (SIAD).
I.3. Historique des systèmes
décisionnels
La prise de décision est un problème essentiel
qui préoccupe les gestionnaires des entreprises. Cette prise de
décision passe par la modélisation de différents
problèmes qu'ils rencontrent dans la gestion d'où la
nécessité d'un modèle basé sur l'arbre de
décision.
De nos jours pour qu'une entreprise puisse bien marcher, elle
doit avoir besoin d'outils d'aide à la décision. Ces outils
permettront alors aux dirigeants de bien prendre des décisions. Ces
décisions concernent tous les services de cette entreprise. Le
système décisionnel englobe tous les services de l'entreprise
ainsi que leurs informations.
Les systèmes décisionnels travaillent comme des
systèmes opérationnels sur de gros volumes de données.
La décision concerne tous les départements de
l'entreprise : finances, ressources humaines, ventes, et la direction
générale. Les applications utiles dans le processus de prise de
décision sont nombreuses, et déjà présentes dans le
système d'information des entreprises.
I.4. L'informatique décisionnelle
L'informatique décisionnelle désigne les
moyens, les outils et les méthodes qui permettent de collecter,
consolider, modéliser et restituer les données,
matérielles ou immatérielles d'une entreprise, en vue d'offrir
une aide à la décision et de permettre aux dirigeants de prendre
des stratégies pour l'entreprise et d'avoir une vue d'ensemble de
l'activité traitée au sein de l'entreprise7.
En général ce type d'applications utilise un
entrepôt de données pour stocker des données provenant de
plusieurs sources hétérogènes et fait appel à des
traitements par lots pour la collecte de ces informations.
I.5. Définition d'un système
décisionnel (Business intelligence)
Un système est un ensemble de technologies
destinées à permettre aux collaborateurs d'avoir accès et
de comprendre les données de pilotage rapidement, de telle sorte qu'ils
prennent une décision meilleure a temps, résultant d'un processus
comportant le choix conscient entre plusieurs solutions en vue d'atteindre un
objectif précis.
7 P.F. Drucker, « Managing in a Time of Great Change
(The Post-Capitalist Executive) », Penguin 1995.
8 G.A. Gorry et M.S. Scott-Morton, « A framework for
management information systems », Sloane Management Review 1971,
p.15.
10
Un système décisionnel permet de répondre
aux questions suivantes :
y' Que s'est-il passé ? (tableau de bord)
;
y' Pourquoi cela s'est-il passé ?
(analyse) ;
y' Que va-t-il se passé ?
(prédiction) ;
y' Que se passe-t-il en ce moment ? (aide
opérationnelle) ;
y' Que devrait- il se passer ou que faire ?
(prise de décision ou entrepôt actif).
I.5.1 Architecture de systèmes
décisionnels8
L'architecture générale d'un système
décisionnel se décompose en trois processus : extraction et
intégration, organisation et interrogation.
Le processus d'extraction et intégration, situé
les sources de données et l'entrepôt est responsable de
l'identification des données dans les diverses sources internes et
externes dans l'extraction de l'information et de la préparation et de
la transformation (nettoyage, filtrage, etc..) des données à
l'intérieur de l'entrepôt, nous trouvons le processus
d'organisation. Il est responsable de la structuration des données par
rapport à leur niveau de granularité (agrégats).
Différents outils permettent de réaliser
l'analyse des données, pour les différents utilisateurs de
l'entreprise.
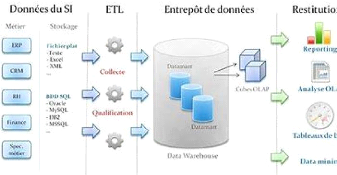
Figure 1 : Architecture Générale
d'un système décisionnel
Les sources de données sont nombreuses, variées,
distribuées et autonomes. Elles peuvent être internes (bases de
production) ou externes (Internet, bases des partenaires) à
l'entreprise.
11
L'entrepôt de données est le lieu de stockage
centralisé des informations utiles pour les décideurs. Il met en
commun les données provenant des différentes sources et conserve
leurs évolutions.
Les magasins de données sont des extraits de
l'entrepôt orientés sujet. Les données sont
organisées de manière adéquate pour permettre des analyses
rapides à des fins de prise de décision.
Les outils d'analyse permettent de manipuler les
données suivant des axes d'analyses. L'information est visualisée
au travers d'interfaces interactives et fonctionnelles dédiées
à des décideurs souvent non informaticiens (directeurs, chefs de
services,...).
I.6. Les différents éléments
constitutifs du système décisionnel I.6.1 Les sources de
données :
Les sources de données sont souvent diverses et
variées et le but est de trouver des outils et en fin de les extraire,
de les nettoyer, de les transformer et de les mettre dans l'entrepôt de
données. Ces sources de données peuvent être de fichiers de
type Excel, des bases de données opérationnelles d'une entreprise
ou fichiers plats.
I.6.2 L'entrepôt de données
:
Il est le coeur du système décisionnel et
demande une analyse profonde de la part de maitre d'ouvrage.
La conception d'un data warehouse diffère de la
conception d'une base de données relationnelles.
En effet, alors que les bases de données relationnelles
tendant le plus souvent à être normalisées, les bases des
données multidimensionnelles, elles sont normalisées en
respectant le modèle en étoile ou en flocon.9
I.6.3. Le service OLAP ou serveur
d'analyse
Le serveur OLAP est opposé à OLTP et a pour but
d'organisé les données à analyser par domaine ou par
thème et d'en ressortir des résultats pertinents pour le
décideur. Les résultats sont obtenus par différents
algorithmes de datamining (fouille de données) du serveur d'analyse. Ces
résultats peuvent amener l'organisation à prendre de très
bonnes décisions en vue d'améliorer le rendement de leurs
entreprises.
9 Bertino E., Ferrari E., Guerrini G., Merlo I., "Extending
the ODMG Object Model with Composite Objects", OOPSLA'98, Vancouver
(Canada), 1998, p.56
12
I.7. Les fonctionnalités d'un système
décisionnel
Les besoins des utilisateurs peuvent être regroupés
en quatre catégories : Simuler, analyser les données,
réduire des états de gestion, suivre et contrôler.
1°) Simuler
? Gestion de modèles de calcul (calculs automatiques
d'ensemble de données complexe en fonction de paramètre par
l'utilisateur et de règles de gestion)
Exemple d'utilisation :
élaboration de business plan ; ? Elaboration collaborative
;
EX : l'élaboration
budgétaire.
2°) Analyse de données
Fonctionnalité OLAP (établissement d'analyse
dynamique multidimensionnelle avec possibilité de trié, filtrer,
zoomer a l'intérieure de données) ;
EX : chiffre d'affaire.
Fonctionnalités avancées de datamining, ensemble
des techniques statistiques sophistiquées permettant de faire apparaitre
des corrélations, des tendances et des prévisions.
3°) Produire des Etat de
gestion
Fonctionnalités de reporting raquetteurs permettant de
produire de façon simple et rapide, des tableaux de données
incorporant des calculs plus ou moins sophistiquées.
4°) 4°) Suivre et contrôler
Elaboration de tableau de bord produit et diffusion
automatiquement à fréquence régulière de tableaux
de bord regroupent des données hétérogènes.
EX : production de tableaux de bord
graphique à destination de responsables opérationnels·
Emission d'alerte génération conditionnelle de
message sur différents supports (email, sms,...) plus ou moins complexes
en fonction de la configuration de données.
Nous avons constaté que l'ensemble de ces
fonctionnalités sont rarement mise en place dans une entreprise.
Les mises en oeuvre sont en outre souvent réalisées
par domaine fonctionnel(les ventes, achats,...). Par ailleurs, il n'existe pas
de produit couvrent l'ensemble de ces fonctionnalités.
13
Chaque progiciel en fonction de son origine et du
positionnement que souhaite lui donner son éditeur est plus au moins
avancé sur l'un ou l'autre thème.
Il est donc crucial de déterminer
précisément ses besoins présent et future, ainsi que les
contraintes liées à son organisation ou à son
activité avant de choisir une solution.
I.8. Les apports des systèmes
décisionnels
Dans beaucoup de nos entreprises ; il est difficile
d'expliquer aux dirigeants que l'on doit parfois dépenser beaucoup
d'argent pour analyser et manipuler des données existant dans le
système d'information de l'entreprise10.
Les apports de systèmes décisionnel sont aussi
défais réels. Ils peuvent être classés en deux
catégories.
? L'amélioration de l'efficacité de la
communication et de la distribution des informations de pilotage ;
? L'amélioration du pilotage des entreprises
résultant de meilleures décisions à prendre plus
rapidement ;
Si le premier point est aisément compréhensible,
présente peu de risque de mise en oeuvre et pose peu de problème
d'évaluation ce n'est clairement pas en revanche une source de gains
significative. Il sera difficile le plus souvent de justifier les couts d'un
projet sur cette seule promesse.
La seconde catégorie a nettement plus de potentiel de
gains. Mais il faut bien reconnaitre que le risque de ne pas atteindre les
objectifs initiaux sont réels sans parler d'énormes
difficultés d'évaluation des bénéfices
escomptés.
Les bénéfices de ce type le plus souvent
cités sont les suivants :
y' Unicité des chiffres, une seule
vérité acceptée par tous ;
y' Meilleure planification ;
y' Amélioration de la prise de
décision ;
y' Amélioration de l'efficacité
des processus ;
y' Amélioration de la satisfaction des
clients et des fournisseurs ;
y' Amélioration de la satisfaction des
employés.
10 S. Kelly, « Data Warehousing - The Route to Mass
Customization », John Wiley & Sons 1996, p.13.
14
I.9. Les Enjeux De L'informatique
Décisionnelle
De nos jours, les données applicatives métier
sont stockées dans une ou plusieurs bases de données
relationnelles ou non relationnelles. Ces données sont extraites,
transformées et chargées par un outil de type ETL.
Un entrepôt de données (data warehouse) peut
prendre la forme d'un data Mart. En règle générale, le
data warehouse globalise toutes les données applicatives de l'entreprise
tandis que les data Marts, généralement alimentés à
partir des données du data warehouse sont des sous-ensembles
d'information concernant un métier particulier de l'entreprise.
I.10. Les fonctions essentielles de l'informatique
décisionnelle
Un système d'information décisionnel assure
quatre fonctions fondamentales, à savoir : la collecte,
l'intégration, la diffusion et la présentation des
données. A ces quatre fonctions s'ajoute une fonction de contrôle
du système d'information décisionnelle lui-même,
l'administration.11
a) Collecte
La collecte est l'ensemble des taches consistant à
détecter, sélectionner, extraire et à filtrer les
données brutes issues des environnements pertinents compte tenu du
périmètre du système d'information décisionnel
(SID).
Les sources de données internes ou externes
étant souvent hétérogène tant sur le plan technique
que sur le plant sémantique, cette fonction est la plus délicate
à mettre en place dans un système décisionnel complexe.
Elle s'appuie notamment sur les outils d'ETL.
Cette alimentation utilise les données sources issues
des systèmes transactionnels de production, le plus souvent sous forme
de compte rendu, d'inventaire ou compte rendu d'opération qui est le
constat au fil du temps des opérations (achats, ventes, écriture,
comptable), le film de l'activité de l'entreprise ; compte rendu
d'inventaire ou compte rendu de stock qui est l'image photo prise a un instant
donné (à une fin de période, mois, trimestre) de
l'ensemble du stock (les clients, les contrats, les commandes). La fonction de
collecte joue également au besoin un rôle de recodage. Une
donnée représentée différemment d'une source
à une autre impose le choix d'une représentation unique pour les
futures analyses.
11 Bret F., Teste O., "Construction Graphique
d'Entrepôts et de Magasins de Données", INFORSID'99, La Garde
(France), Juin 1999.
15
b) Intégration
L'intégration consiste à concentrer les
données collectées dans un espace unifié, dont le socle
informatique essentiel est l'entrepôt.
Élément central du dispositif, il permet aux
applications décisionnelles de bénéficier d'une source
d'information commune, homogène, normalisée et fiable,
susceptible de masquer la diversité de l'origine des données.
Au passage les données sont épurées ou
transformées par un filtrage et une validation des données en vue
du maintien de la cohérence d'ensemble (les valeurs acceptées par
les filtres de la fonction de collecte mais susceptibles d'introduire des
incohérences de référentiel par rapport aux autres
données doivent être soit rejetées, soit
intégrées avec un statut spécial).
Une synchronisation (d'intégrer en même temps ou
à la même date de valeur des événements reçus
ou constatés de manière décalée ou
déphasée).
Une certification (pour rapprocher les données de
l'entrepôt des autres systèmes légaux de l'entreprise comme
la comptabilité ou les déclarations réglementaires).
C'est également dans cette fonction que sont
effectués éventuellement les calculs et les agrégations
(cumuls) communs à l'ensemble du projet. La fonction
d'intégration est généralement assurée par la
gestion de métadonnées, pour l'interopérabilité
entre toutes les ressources informatiques, des données
structurées (bases de données accédées par des
progiciels ou applications), ou des données non structurées.
c) La diffusion ou la distribution
La diffusion met les données à la disposition
des utilisateurs, selon des schémas correspondant au profil ou au
métier de chacun, sachant que l'accès direct à
l'entrepôt ne correspondrait généralement pas aux besoins
d'un décideur ou d'un analyste. L'objectif prioritaire est de segmenter
les données en contextes informationnels fortement cohérents,
simples à utiliser et correspondant à une activité
décisionnelle particulière.
Alors qu'un entrepôt de données peut
héberger de centaines ou de milliers de variables ou indicateurs, un
contexte de diffusion raisonnable n'en présente que quelques dizaines au
maximum.
Chaque contexte peut correspondre à un DataMart, bien
qu'il n'y ait pas de règles générales concernant le
stockage physique.
12 Chaudhuri S., Dayal U., "An Overview of Data
Warehousing and OLAP Technology", ACM SIGMOD Record, 26(1), 1997, p.112
16
Très souvent, un contexte de diffusion est
multidimensionnel, c'est-à-dire modélisable sous la forme d'un
hyper cube, il peut alors être mis à disposition à l'aide
d'un outil OLAP.12
Les différents contextes d'un même système
décisionnel n'ont pas tous besoin du même niveau de
détail.
De nombreux agrégats ou cumuls, n'intéressant que
certaines applications et n'ayant donc pas lieu d'être gères en
tant qu'agrégats communs par la fonction d'intégration,
relèvent donc de la diffusion.
Ces agrégats peuvent être, au choix,
stockés de manière persistante ou calculés dynamiquement
à la demande.
On peut distinguer trois questions à élucider
pour concevoir un système de reporting : À qui s'adresse le
rapport spécialisé ? (choix des indicateurs a présenter,
choix de la mise en page)
? Par quel trajet ? (circuit de diffusion type workflow pour les
personnes, circuits de transmission télécoms pour les moyens)
;
? Selon quel agenda ? (diffusion routinière ou sur
événement prédéfini).
d) Présentation
Cette quatrième fonction, la plus visible pour
l'utilisateur, régit les conditions d'accès de l'utilisateur aux
informations. Elle assure le fonctionnement du poste de travail, le
contrôle d'accès, la prise en charge des requêtes, la
visualisation des résultats sous une forme ou une autre.
Elle utilise toutes les techniques de communication possibles
comme les outils bureautiques, raquetteurs et générateurs
d'états spécialises, infrastructure web,
télécommunications mobiles, etc.
e) Administration
C'est la fonction transversale qui supervise la bonne
exécution de toutes les autres; elle pilote le processus de mise
à jour des données, la documentation sur les données et
sur les métadonnées, la sécurité, les sauvegardes,
la gestion des incidents.
17
I.11. Définition des Modèles de
Données Décisionnels
Un modèle de données s'applique
généralement à une application ou à un ensemble
d'applications dont le périmètre et la définition sont
arrêtés en amont du projet. Ceci est valable pour toute
application informatique. Mais ce principe d'applique d'une manière
particulière dans les projets décisionnels.
Consommateur de données et producteur d'informations,
un SID est nécessairement un dispositif à double face puisque
:
? Il combine des données d'origines diverses,
généralement opérationnelles ;
? Il met des données à disposition selon des
objectifs informationnels.
? Par rapport aux sources de données qui l'alimentent,
le data warehouse est sous-tendu par un modèle fédérateur
ou intégrateur. Mais ce modèle n'est pas directement
représentatif des points de vue informationnels - éventuellement
multiples et changeants des utilisateurs du SID. Or le SID ne vaut que pour les
restitutions informationnelles qu'il offre. Le véritable modèle
de données décisionnel est donc celui qui reflète la mise
à disposition ou encore la diffusion des données, et non leur
concentration.
Cette mise à disposition se conçoit par
domaines, sachant que le périmètre d'un domaine
décisionnel ne coïncide pas avec les frontières d'une
application de production.
Un domaine applicatif concerne un utilisateur ou un ensemble
cohérent d'utilisateurs, et implique un vocabulaire commun et une
manière commune d'appréhender l'information. C'est en quelque
sorte l'univers du discours.
Quelles que soient les modalités de conduite de projet
et les éventuels raccourcis qui seront pris à certaines
étapes, le Modèle Conceptuel des Données (MCD) du domaine
d'application est un passage obligé.
Les modèles dérivés du MCD (MLD et MPD)
sont ensuite élaborés en liaison étroite avec la
technique, selon une démarche fortement tributaire des produits. Quant
au MCD lui-même, rappelons que sa structure ne dépend que de la
sémantique des données et de la vue qu'en ont les utilisateurs.
L'analyste doit par conséquent résister à deux sortes
d'influences pernicieuses qui pèsent, à divers degrés, sur
tous les projets :
? les structures opérationnelles dans lesquelles le SID
puise ses données ;
? les modalités de fonctionnement des outils de gestion
et de présentation.
Les seules bases sur lesquelles il convient de s'appuyer pour
spécifier les objectifs du SID sont les vues externes des utilisateurs.
Ces vues doivent donc être collectées et intégrées
dans le modèle.
18
Un SID comporte donc en réalité au moins deux
Modèles Conceptuels de Données. L'un des deux représente
l'intégration des sources opérationnelles à partir
desquelles s'alimente le système. Il se conçoit et se normalise
selon une démarche traditionnelle de génie logiciel50, qui n'a
pas lieu d'être développée ici. L'autre, celui que nous
examinons dans ce chapitre, correspond à la structure informationnelle
destinée à supporter les requêtes des utilisateurs. C'est
le MCD de diffusion. C'est ce dernier qui représente la structure selon
laquelle l'information doit être mise à disposition ; il constitue
la spécification fonctionnelle du SID13.
La collecte des vues est une affaire de conduite de projet,
dont nous n'ignorons pas la difficulté pratique. La qualité de
cette collecte auprès des utilisateurs est cependant un facteur critique
de succès, et on ne peut pas en faire l'économie sans prendre un
gros risque.
De point de vue de la modélisation proprement dite,
l'intégration des vues n'est pas une simple opération de
juxtaposition. Elle passe par une normalisation.
Les normes d'intégration du MCD, dans un domaine
décisionnel, reposent sur les principes fondamentaux suivants :
Compte tenu de la nature consultative et non transactionnelle
des applications, la structure des vues externes se déduit directement
des requêtes des utilisateurs, et non des connexions
opérationnelles possibles entre les entités ;
A l'intérieur d'un domaine, il existe un ou plusieurs
sous-ensembles de vues liées entre elles par certains critères de
cohérence sémantique et structurelle. C'est sur l'identification
et la validation formelle de ces sous-ensembles, appelés contextes, que
repose toute la démarche de construction du MCD ;
Une requête décisionnelle a pour objet
d'établir un rapprochement non programmé entre des entités
conceptuelles plus ou moins nombreuses. De ce fait, les résultats
attendus sont systématiquement déterminés par des
associations51. La structure des vues reflète celle des associations
possibles. Chaque vue a pour élément central une association
autour de laquelle gravitent deux ou plusieurs entités, et correspond
à une représentation des informations sous forme de tableau
à deux ou plusieurs dimensions ;
La liste exhaustive des requêtes possibles n'est jamais
figée. Celle des vues qui en découlent ne l'est donc pas non
plus. La normalisation du MCD doit permettre d'anticiper et d'intégrer
automatiquement dans chaque contexte le plus grand nombre possible de «
vues probables » d'après la structure des « vues connues
» ; Entre deux entités intervenant dans une même vue, il doit
exister un et un seul chemin de navigation sémantique, et ce chemin doit
être le plus court possible.
13 Groupe EVOLUTION. F. Bret. T. Cruanees. I. Guessarian. E.
Metais. M-C. Rousset. S. Schwer. O. Teste. G. Zurfluh, Ingénerie des
systèmes d'information , édition HERMES, 2001, p.38
19
Conclusion partielle
Dans ce chapitre, nous avons traité les
généralités sur les systèmes décisionnels
(Business Intelligence) ; avons défini l'informatique
décisionnelle, l'architecture de systèmes décisionnels et
ses différents enjeux avec leurs fonctions ; et avons abordé les
systèmes décisionnels qui sont des systèmes qui permettent
aux décideurs des entreprises de prendre des décisions optimales
et importantes pour une meilleure gestion des leurs entreprises. Le chapitre
suivant abordera les notions de l'entrepôt de données et son
fonctionnement.
14 Jarke M., Lenzerini M., Vassiliou Y., Vassiliadis P.,
"Fundamentals of Data Warehouses", Ed. Springer Verlag, ISBN
3-540-65365-1, 1999, p.187
20
CHAPITRE II: LE DATA WAREHOUSE
II.1. Introduction
Les entrepôts des données intègrent des
informations en provenance de différentes sources, souvent reparties et
hétérogènes ayant pour objectif de fournir une vue globale
de l'information aux analystes et aux décideurs.
La construction et la mise en oeuvre d'un entrepôt de
données représentent une tâche complexe qui se compose de
plusieurs étapes.
La première est l'analyse des sources de
données et l'identification des besoins des utilisateurs, la
deuxième correspond à l'organisation des données à
l'intérieur de l'entrepôt. En fin, la troisième sert
à établir divers outils d'interrogation, d'analyse, et de fouille
de données.
Chaque étape présente des problèmes
spécifiques. Ainsi, par exemple, lors de la première
étape, la difficulté principale consiste en l'intégration
des données, de manière à ce qu'elles soient de
qualité pour leur stockage. Pour l'organisation, il existe plusieurs
problèmes comme la sélection des vues à
matérialiser, le rafraichissement de l'entrepôt, la gestion de
l'ensemble de données courantes et historisées.
En ce qui concerne le processus d'interrogation, nous avons
besoin des outils performants et conviviaux pour l'accès et l'analyse de
l'information.
II.2. Définition d'un data warehouse
(DW)14
Un entrepôt de données est une collection de
données orientées sujet, intégrées, non volatiles
et historisées, organisées pour le support d'un processus d'aide
à la décision. Nous détaillons ces caractéristiques
:
? Orientées sujet : les données
des entrepôts sont organisés par sujet plutôt que par
application, par exemple, une chaine de magasins d'alimentation organise les
données de son entrepôt par rapport aux ventes qui ont
été réalisées par produit et par magasin, au cours
d'un certain temps.
? Intégrées : les
données provenant de différentes sources doivent être
intégrées, avant leur stockage dans l'entrepôt de
données. L'intégration, c'est à dire la mise en
correspondance des formats, permet d'avoir une cohérence
de l'information.
15 Samos J., Saltor F., Sistrac J., Bardés A.,
"Database Architecture for Data Warehousing: An evolutionary
Approach", DEXA'98, Vienna (Austria), 1998, p.72
21
? Non volatiles : à la
différence des données opérationnelles, celles de
l'entrepôt sont permanentes et ne peuvent pas être modifiées
.le rafraichissement de l'entrepôt consiste à ajouter de nouvelles
données, sans modifier ou perdre celles qui existent.
? Historisées :la prise en
compte de l'évolution des données est essentielle pour la prise
de décision qui, par exemple, utilise des techniques de
prédication en s'appuyant sur les évolutions passées pour
prévoir les évolutions futures.
II.2.1. Objectif Du Data Ware house
L'atout principal d'une entreprise réside dans les
informations qu'elle possède. Les informations se présentent
généralement sous deux formes : les systèmes
opérationnels qui enregistrent les données et le Data Ware house.
En bref, les systèmes opérationnels représentent
l'emplacement de saisie des données, et l'entrepôt de
données l'emplacement de restitution15.
Ainsi voici les objectifs fondamentaux du data warehouse :
Rendre accessibles les informations de
l'entreprise : le contenu de l'entrepôt doit être
compréhensible et l'utilisateur doit pouvoir y naviguer facilement et
avec rapidité. Ces exigences n'ont ni frontières, ni limites. Des
données compréhensibles sont pertinentes et clairement
définies. Par données navigables, on n'entend que l'utilisateur
identifie immédiatement à l'écran le but de ses recherches
et accède au résultat en un clic.
Rendre cohérente les informations d'une
l'entreprise : les informations provenant d'une branche de
l'entreprise peuvent être mise en corrélation avec celles d'une
autre branche. Si deux unités de mesure portent le même nom, elles
doivent alors signifier la même chose. A l'inverse, deux unités ne
signifiant pas la même chose doivent être définie
différemment. Une information cohérente suppose une information
de grande qualité. Cela veut dire que l'information est prise en compte
et qu'elle est complète.
Constituer une source d'information souple et
adaptable : l'entrepôt de données est conçu
dans la perspective de notifications perpétuelle, l'arrivé de
question nouvelles ne doit bouleverser ni les données existantes ni les
technologies. La conception de Data Mart distincts composant un entrepôt
de données doit être répartie et incrémentielle.
16 AHMED T., MIQUEL M., LAURINI R., « Continuous data
warehouse : concepts, challenges and potentials », Proc. of the 12th
International Conference on Geoinformatics, 2004, p.
157-164.
22
Représenter un bastion
sécurisé qui protège la capitale information :
l'entrepôt de données ne contrôle pas
seulement l'accès aux données, mais il offre à ses
gestionnaires une bonne visibilité des utilisations.
Constituer la base décisionnelle de
l'entreprise : l'entrepôt de données recèle
en son sein les informations propres à faciliter la prise de
décisions.
II.2.2. Les Composants de base du Data
Warehouse16
a) Le système source :
système opération d'enregistrement, dont la
fonction consiste à capturer les transactions liées à
l'activité.
b) Zone de préparation des données
: ensemble des processus qui nettoient, transforment, combinent,
archivent, suppriment les doublons, c'est-à-dire prépare les
données sources en vue de leur intégration puis de leur
exploitation au sein du Data Warehouse. La zone de préparation des
données ne doit offrir ni service des requêtes, ni service de
présentation.
c) Serveur de présentation :
machine cible sur laquelle l'entrepôt de données est
stocké et organisé pour répondre en accès direct
aux requêtes émises par des utilisateurs, les
générateurs d'état et les autres applications.
d) Data Mart : sous-ensemble
logique d'un Data Warehouse, il est destiné à quelques
utilisateurs d'un département.
e) Entrepôt de données :
source de données interrogeable de l'entreprise. C'est
tout simplement l'union des Data Marts qui le composent. L'entrepôt de
données est alimenté par la zone de préparation des
données. L'administrateur de l'entrepôt de données est
également responsable de la zone de préparation des
données.
f) OLAP (On Line Analytic Processing) :
Activité globale de requêtage et de
présentation de données textuelles et numériques contenues
dans l'entrepôt de données ; style d'interrogation et de
présentation spécifiquement dimensionnel.
g) ROLAP (Relational OLAP) :
ensemble d'interface utilisateur et d'applications donnant une
vision dimensionnelle des bases de données relationnelles.
h) MOLAP (Multidimensional OLAP) :
ensemble d'interface utilisateur et d'applications dont l'aspect
dimensionnel est prépondérant.
i) Application utilisateur :
ensemble d'outils qui interrogent, analysent et présente
des informations répondant à un besoin spécifique.
L'ensemble des outils minimal se compose d'outil d'accès aux
données, d'un tableur, d'un logiciel graphique et d'un
23
service d'interface utilisateur, qui suscite les
requêtes et simplifie la présentation de l'écran aux yeux
de l'utilisateur.
j) Outil d'accès aux données :
client de l'entrepôt de données.
k) Outil de requête : types
spécifique d'outil d'accès aux données qui invite
l'utilisateur à formuler ses propres requêtes en manipulant
directement les tables et leurs jointures.
l) Application de modélisation :
type de client de base de données sophistiqués
doté de fonctionnalités analytiques qui transforment ou mettent
en forme les résultats obtenus ; on peut avoir :
? les modèles prévisionnels, qui tentent
d'établir des prévisions d'avenir ;
? les modèles de calcul comportemental, qui
catégorisent et classent les comportements d'achat ou d'endettement des
clients ;
? la plupart des outils de Data mining.
m) Métadonnées :
toutes informations de l'environnement du Data Warehouse qui ne
constituent pas les données proprement dites.
II.3. Caractéristiques d'un Data
Warehouse17
Un Data Warehouse est une base de données conçue
pour l'interrogation et l'analyse plutôt que le traitement de
transactions. Il contient généralement des données
historiques dérivées de données transactionnelles, mais il
peut comprendre des données d'autres origines.
Les Data Warehouse séparent la charge d'analyse de la
charge transactionnelle. Ils permettent aux entreprises de consolider des
données de différentes origines.
Au sein d'une même entité fonctionnelle, le Data
Warehouse joue le rôle d'outil analytique.
En complément d'une base de données, un Data
Warehouse inclut une solution d'extraction, de transformation et de chargement
(ETL), des fonctionnalités de traitement analytique en ligne (OLAP) et
de Data mining, des outils d'analyse client et d'autres applications qui
gèrent le processus de collecte et de mise à la disposition de
données.
17 INMON W.-H., Building the data warehouse, QED
Publishing Group, 1992, p.57.
24
II.4 Entrepôts et Bases de
données
Dans l'environnement des entrepôts de données,
les opérations, l'organisation des données, les critères
de performance, la gestion des métadonnées, la gestion des
transactions et le processus de requêtes sont très
différents des systèmes de bases de données
opérationnels.
Par conséquent, les SGBD relationnels orientés
vers l'environnement opérationnel, ne peuvent pas être directement
transplantés dans un système d'entrepôt de
données.
Les SGBD ont été créés pour les
applications de gestion de systèmes transactionnels. Par contre, les
entrepôts de données ont été conçus pour
l'aide à la prise de décision. Ils intègrent les
informations qui ont pour objectif de fournir une vue globale de l'information
aux analystes et aux décideurs.
Le tableau suivant résume les différences entre
les systèmes de gestion de bases de données et les
entrepôts de données.
|
SGBD
|
Entrepôts de données
|
|
Objectifs
|
Gestion et production
|
Consultation et analyse
|
|
Utilisateurs
|
Gestionnaire de production
|
Décideurs, analystes
|
|
Taille de base
|
Plusieurs giga-octets
|
Plusieurs téra-octéts
|
|
Organisation de données
|
Par traitement
|
Par métier
|
|
Types de données
|
Données de gestion
(courantes)
|
Données d'analyse
(résumées, historisées)
|
|
Requêtes
|
Simples, prédéterminées,
données détaillées
|
Complexes, spécifiques,
agrégations et group by
|
|
Transactions
|
Courte et nombreuse,
temps réel
|
Longues, peu nombreuses
|
Tableau 1 : Différence entre SGBD et
entrepôts de données II.4.1 Rôle d'un
entrepôt de données
Le rôle primordiale d'un data warehouse apparait ainsi
évident dans une stratégie décisionnelle. L'alimentation
du data warehouse en est la phase la plus critique.
En effet, importer des données inutiles en portera de
nombreux problèmes, cela consommera des ressources système et du
temps. De plus, cela rendra le service d'analyse plus lent. Autre point
à prendre en compte est la périodicité d'extraction des
données ;
25
effectivement, le plus souvent, les opérations de
collecte de données sont couteuses en ressource pour la base
accédée.18
II.4.2 Systèmes transactionnels et
systèmes décisionnels
Les Système de Gestion de Base de Donnée (SGBD)
ont été créés pour gérer de grands volumes
d'information contenus dans les différents systèmes
opérationnels qui appartiennent à l'entreprise.
Ces données sont manipulées en utilisant des
processus transactionnels en ligne, .parallèlement à
l'exploitation de l'information contenue dans ces systèmes
opérationnels, les dirigeants des entreprises ont besoin d'avoir une
vision globale concernant toute cette information pour faire des calculs
prévisionnels, des statistiques ou pour établir des
stratégies de développement et d'analyses des tendances.
|
Système transactionnel
|
Système décisionnel
|
|
Données
|
Exhaustives, courantes,
dynamiques
|
Résumées historiques
statiques
|
|
Orientées applications
|
Orientées sujets (d'analyse)
|
|
Utilisateurs
|
Nombreux
|
Peu nombreux
|
|
Varies (employés,
directeurs)
|
Uniquement les décideurs
|
|
Concurrentes
|
Non concurrentes
|
|
Mises à jour et
interrogations
|
Interrogations
|
|
Requêtes prédéfinies
|
Requêtes imprévisibles et
complexes
|
|
Réponses immédiates
|
Réponses moins rapides
|
|
Accès à peu d'informations
|
Accès à des nombreuses
informations
|
Tableau 2 : compare les
caractéristiques des systèmes
II.4.3 Différence entre le système OLTP
et le Data warehouse
Les Data Warehouse et les Systèmes OLTP (On Line
Transaction Processing) répondent à besoins très
différents. Les Data Warehouse conçu pour prendre en charge des
interrogations ad hoc. La taille du Data Warehouse n'est pas connue à
l'avance. Par conséquent, celui-ci doit être optimisé pour
offrir de bonnes performances dans le cadre d'opérations d'interrogation
très diverses. Les systèmes OLTP prennent
généralement en
18 Dayal U., Blaustein B. T., Buchmann A. P., Chakravarthy U. S.,
Hsu M., Ledin R., McCarthy D. R., Rosenthal A., Sarin S. K., Carey M. J., Livny
M., Jauhari R., "The HiPAC Project: Combining Active Databases and Timing
Constraints", ACM SIGMOD Record, 17(3), Chicago (Illinois, USA), 1988,
p.312-322
26
charge des opérations prédéfinies. Les
applications peuvent être réglées ou conçues
spécifiquement pour ces opérations.
Un Data Warehouse est mise à jour
régulièrement par les processus ETL (Extraction, Transformation
and Loading), un système de chargement de données en masse
soigneusement défini et contrôlé. Il n'est pas mise
à jour directement par les utilisateurs. Dans les systèmes OLTP,
les utilisateurs exécutent régulièrement des instructions
qui modifient les données de la base. La base de données OLTP est
à jour en permanence et elle reflète l'état actuel de
chaque transaction19.
Les Data Warehouse utilisent souvent des schémas
dénormalisés ou partiellement dénormalisés (tels
que le schéma en étoile) pour optimiser les performances des
interrogations. A l'inverse, les systèmes OLTP ont souvent recours
à des schémas totalement normalisés pour optimiser les
performances des opérations de mise à jour, d'insertion et de
suppression, et pour garantir la cohérence des données. Il s'agit
là des différences générales, elles ne doivent pas
être considérées comme des distinctions strictes et
absolues.
De manière générale, une interrogation
portant sur un Data Warehouse balaye des milliers voire des millions de lignes.
En revanche, une opération OLTP standard accède à quelque
enregistrement seulement.
Le Data Warehouse contient généralement des
données correspondant à plusieurs mois ou années. Cela
permet d'effectuer des analyses historiques. Les systèmes OLTP
contiennent généralement des données quelque semaine ou
mois. Ils conservent uniquement des données historiques
nécessaires à la transaction en cours.
II.4.4 La problématique de
l'entreprise
L'entreprise construit un système décisionnel
pour améliorer sa performance, elle doit décider et anticiper en
fonction de l'information disponible et capitaliser sur ses
expériences.
Entreprise : est une organisation dotée d'une mission
et d'un objectif métier. Elle doit sa raison d'être et /ou sa
pérennité au travers de différent objectifs
(sécurité, développement, rentabilité ...). Par
voie de conséquence, cette organisation humaine est dotée d'un
centre décision.
? Rôle de décideur : il
peut être le responsable de l'entreprise, le responsable d'une fonction
ou d'un secteur. Il est donc celui qui engage la pérennité ou la
raison d'être de l'entreprise. Pour ces raisons, il doit s'entourer de
différents moyens lui
19 R. Kimball, L. Reeves, M. Ross, W. Thornthwaite, Concevoir
et déployer un data warehouse, Eyrolles, Paris, 2000, page 79
20 Matthias Jarke, Thomas List, Jörg Köller, The
Challenge of Process Data Warehousing, 26th International Conference on
Very Large Databases, Caire, Egypt, 2000, p.112
27
permettant une prise de décision la plus pertinente.
Parmi ces moyens, les Data Warehouse ont une place primordiale.
II.4.5 La Modélisation dimensionnelle et la
Modélisation Entité/Relation
a) Modélisation Entité/Relation :
est une discipline qui permet d'éclairer les relation
microscopique entre les données. Dans sa forme la plus artistique, elle
permet de supprimer toute redondance de données. Ceci apporte de
nombreux avantages au niveau du traitement des transactions, qui deviennent
alors très simples et déterministes.
b) Modélisation dimensionnelle :
est une méthode de conception logique qui vise à
présenter les données sous une forme standardisée
intuitive et qui permet des accès hautement performants. Elle
adhère totalement à la dimensionnalité ainsi qu'à
une discipline qui exploite le modèle relationnel en le limitant
sérieusement. Chaque modèle dimensionnel se compose d'une table
contenant une clé multiple, table des faits, et d'un ensemble de tables
plus petite nommées, tables dimensionnelles.
Chacune de ces dernières possède une clé
primaire unique, qui correspond exactement à l'un des composants de la
clé multiple de la table des faits. Dans la mesure où elle
possède une clé primaire multiple reliée à au moins
deux clés externes, la table des faits exprime toujours une relation n,
n (plusieurs-à-plusieurs).
II.4.6. Relation entre la modélisation
dimensionnelle et la modélisation
entité/relation
Pour mieux appréhender la relation qui existe entre la
modélisation dimensionnelle et la modélisation
entité/relation, il faut comprendre qu'un seul schéma
entité/relation se décompose en plusieurs schémas de table
des faits.
La modélisation dimensionnelle ne se met pas à
son avantage en représentant sur un même schéma plusieurs
processus qui ne coexistent jamais au sein d'une série de données
et à un moment donné. Ce qui le rend indûment complexe.
Ainsi, la conversion d'un schéma entité/relation en une
série de schémas décisionnels consiste à scinder le
premier en autant de sous-schémas qu'il y a de processus métier
puis de les modéliser l'un après l'autre. La deuxième
étape consiste à sélectionner les relations n, n
(plusieurs-à-plusieurs) contenant des faits numériques et
additifs (autres que les clés) et d'en faire autant de table des
faits20.
La troisième étape consiste à
dénormaliser toutes les autres tables en table non séquentielle
dotées de clés uniques qui les relient directement aux tables des
faits. Elles deviennent ainsi des tables dimensionnelles. S'il arrive qu'une
table dimensionnelle soit
Les deux types d'objet les plus courants dans les
schémas de Data Warehouse multidimensionnels sont les tables de faits et
les tables de dimension.
28
reliée à plusieurs tables des faits, nous
représentons cette table dimensionnelle dans les deux schémas et
dirons des tables dimensionnelles qu'elles sont conformes d'un modèle
à l'autre.
II.4.6.1 Avantages de la modélisation
dimensionnelle
Le modèle dimensionnel possède un grand nombre
d'avantages dont le modèle entité/relation est
dépourvu.
Premièrement, le modèle dimensionnel est une
structure prévisible et standardisée. Les
générateurs d'états, outils de requête et interfaces
utilisateurs peuvent reposer fortement sur le modèle dimensionnel pour
faire en sorte que les interfaces utilisateurs soient plus
compréhensibles et que le traitement soit optimisé.
La deuxième force du modèle dimensionnel est que
la structure prévisible du schéma en étoile réside
aux changements de comportement inattendus de l'utilisateur. Toutes les
dimensions sont équivalentes.
La troisième force du modèle dimensionnel
réside dans le fait qu'il est extensible à loisir pour accueillir
des données et des besoins d'analyse non prévus au départ.
Ainsi, il est possible d'accomplir :
o Ajouter des faits nouveaux non prévus initialement ;
o Ajouter des dimensions totalement nouvelles ;
o Ajouter des attributs dimensionnels nouveaux non prévus
initialement ;
o Décomposer les enregistrements d'une dimension
existante en un niveau de détail plus fin à partir d'une date
déterminée.
II.5. Schémas d'un Data Warehouse
Un schéma est un ensemble d'objets de la base de
données tels que les tables, des vues, des vues
matérialisées, des index et des synonymes. La conception du
schéma d'un Data Warehouse est guidée par le modèle des
données source et par les besoins utilisateurs.
L'idée fondamentale de la modélisation
dimensionnelle est que presque tous les types de données peuvent
être représentés dans un cube de données, dont les
cellules contiennent des valeurs mesurées et les angles les dimensions
naturelles de données. Nos conceptions peuvent comporter plus de trois
dimensions. Techniquement, il faudrait parler d'hyper cube, bien que le terme
cube de données ait été adopté par le
métier.
A. Les objets d'un schéma de Data Warehouse
29
? Tables des faits : une table de faits
comprend généralement des colonnes de deux types : celles qui
contiennent des faits numériques (souvent appelés indicateurs) et
celles qui servent de clé étrangère vers les tables de
dimension. Une table de faits peut contenir des faits détaillés
ou agrégées. Les tables contenant des faits agrégés
sont souvent appelées tables agrégées. une table de faits
contient généralement de faits de même niveau
d'agrégation. La plupart des faits sont additifs, mais ils peuvent
être semi-additifs ou non additifs. Les faits additifs peuvent être
agrégés par simple addition arithmétique. C'est par
exemple le cas des ventes. Les faits non additifs ne peuvent pas être
additionnés du tout. C'est le cas des moyennes. Les faits semi-additifs
peuvent être agrégés selon certaines dimensions mais pas
selon d'autres.
? Tables des dimensions et hiérarchies :
une dimension est une structure comprenant une ou plusieurs
hiérarchies qui classe les données en catégories. Les
dimensions sont des étiquettes descriptives fournissant des informations
complémentaires sur les faits, qui sont stockées dans les tables
de dimension. Il s'agit normalement de valeurs textuelles descriptives.
Plusieurs dimensions distinctes combinées avec les faits permettant de
répondre aux questions relatives à l'activité de
l'entreprise. Les données de dimension son généralement
collectées au plus bas niveau de détail, puis
agrégées aux niveaux supérieurs en totaux plus
intéressants pour l'analyse, ces agrégations ou cumuls naturels
au sein d'une table de dimension sont appelés des hiérarchies.
Les hiérarchies sont des structures logiques qui utilisent les niveaux
ordonnées pour organiser les données. Pour une dimension temps,
par exemple, une hiérarchie peut agréger les données selon
le niveau mensuel, le niveau trimestriel, le niveau annuel. Au sein d'une
hiérarchie, chaque niveau est connecté logiquement aux niveaux
supérieurs et inférieurs. Les valeurs des niveaux
inférieurs sont agrégées en valeurs de niveau
supérieur.
a) Le Schéma en Etoile
Le schéma en étoile peut être le type le
plus simple de schéma de Data Warehouse, il est dit en étoile
parce que son diagramme entité/relation ressemble à une
étoile, avec des branches partant d'une table centrale. Un schéma
en étoile est caractérisé par une ou plusieurs tables de
faits, très volumineuses, qui contiennent les informations essentielles
du Data Warehouse et par un certain nombre de tables de dimension, beaucoup
plus petites, qui contiennent chacune des informations sur les entrées
associées à un attribut particulier de la table de faits. Une
interrogation en étoile est une jointure entre une table de faits et un
certain nombre de table de dimensions. Chaque table de dimension est jointe
à la table de faits à l'aide d'une jointure de clé
primaire à clé étrangère, mais les tables de
dimension ne sont pas jointes entre elles.
Les schémas en étoile présentent les
avantages suivants : ils fournissent une correspondance directe et intuitive
entre les entités fonctionnelles analysées par les utilisateurs
et la conception du schéma. Ils sont pris en charge par un grand nombre
d'outils
Le principal avantage du schéma en flocons est une
amélioration des performances des interrogations due à des
besoins réduits en espace de stockage sur disque et la petite
30
décisionnels. La manière la plus naturelle de
modéliser un Data Warehouse est la représenter par un
schéma en étoile dans lequel une jointure unique établit
la relation entre la table de faits et chaque table de dimension. Un
schéma en étoile optimise les performances en contribuant
à simplifier les interrogations et à raccourcir les temps de
réponse.
Les schémas en étoile présentent
néanmoins quelques limites. La table centrale peut devenir très
volumineuse, sa taille maximale étant déterminée par le
produit des nombres de lignes des tables de dimension. En outre, les tables de
dimension ne sont plus normalisées. Elles sont donc plus volumineuses et
plus difficiles à tenir à jour car elles contiennent beaucoup de
données dupliquées.
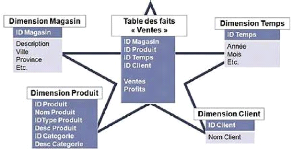
Figure 2: schéma en
étoile
b) Le Schéma en Flocon
Les schémas en flocons normalisent les dimensions pour
éliminer les redondances. Autrement dit, les données de dimension
sont stockées dans plusieurs tables et non dans une seule table de
grande taille. Cette structure de schéma consomme moins d'espace disque,
mais comme elle utilise davantage de tables de dimension, elle nécessite
un plus grand nombre de jointures de clé secondaire. Les interrogations
sont par conséquent plus complexes et moins performantes.
Dans un schéma en flocon, cette même table de
faits, référence les tables de dimensions de premier niveau, au
même titre que le schéma en étoile.
La différence réside dans le fait que les
dimensions sont décrites par une succession de tables (à l'aide
de clés étrangères) représentant la
granularité de l'information. Ce schéma évite les
redondances d'information mais nécessite des jointures lors des
agrégats de ces dimensions.
Cette figure présente un schéma
multidimensionnel pour les ventes qui ont été
réalisées dans les magasins pour les différents produits
au cours d'un temps donné (jour)
31
taille des tables de dimension à joindre. Le principal
inconvénient de ce schéma est le travail de maintenance
supplémentaire imposé par le nombre accru de tables de
dimension.
Figure 3: schéma d'un modèle en
flocon
c) Schéma multi dimensionnel (CUBE)
Dans le modèle multidimensionnel, le concept central
est le cube, lequel est constitué des éléments
appelés cellules qui peuvent contenir une ou plusieurs mesures. La
localisation de la cellule est faite à travers les axes, qui
correspondent chacun a une dimension.
La dimension est composée de membres qui
représentent les différentes valeurs.
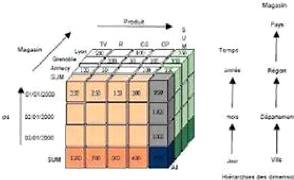
Figure 4: Exemple de schéma
multidimensionnel
32
II.6 Le Data Mart II.6.1
Introduction
Un DataMart est un sous-ensemble d'un entrepôt de
données; il est généralement exploité dans les
entreprises pour restituer des informations ciblées sur un métier
spécifique, constituant pour ce dernier un ensemble d'indicateurs
à vocation de pilotage de l'activité et d'aide à la
décision. Un DataMart, selon les définitions, est issu ou fait
partie d'un Data Warehouse, et en reprend par conséquent la plupart des
caractéristiques.
II.6.2 Les définitions
Le DataMart est un ensemble de données ciblées,
organisées, regroupées et agrégées pour
répondre à un besoin spécifique à un métier
ou un domaine donné. Il est donc destiné à être
interrogé sur un panel de données restreint à son domaine
fonctionnel, selon des paramètres qui auront été
définis à l'avance lors de sa conception.
De façon plus technique, le DataMart peut être
considère de deux manières différentes, attribuées
aux deux principaux théoriciens de l'informatique décisionnelle,
bill inmon et Ralph Kimball :
? Définition d'inmon : le
DataMart est issu d'un flux de données provenant du Data Warehouse.
Contrairement a ce dernier qui présente le détail des
données pour toute l'entreprise, il a vocation à présenter
la donnée de manière spécialisée,
agrégée et regroupée fonctionnellement.
? Définition de Kimball : le
DataMart est un sous-ensemble du Data Warehouse, constitue de tables au niveau
détail et à des niveaux plus agrèges, permettant de
restituer tout le spectre d'une activité métier. L'ensemble des
DataMarts de l'entreprise constitue le Data Warehouse.
II.6.3 La place du datamart dans
l'entreprise
Le DataMart se trouve en toute fin de la chaine de traitement
de l'information. En règle générale, il se situe en aval
d'un Data Warehouse plus global à partir duquel il est alimenté,
dont il constitue en quelque sorte un extrait.
Un DataMart forme la principale interaction entre les
utilisateurs et les systèmes informatiques qui gèrent la
production de l'entreprise (souvent des ERP).
Dans un DataMart, l'information est préparée
pour être exploitée brute par les personnes du métier
auquel il se rapporte. Pour ce faire, il est appelé a être utilise
via des logiciels d'interrogation de bases de données (notamment des
outils de reporting) afin de renseigner ses utilisateurs sur l'état de
l'entreprise à un moment donné (stock) ou sur son activité
(flux).
33
La préparation de la donnée pour une utilisation
directe, inhérente au DataMart, peut revêtir plusieurs formes. Il
faut noter que toutes représentent une simplification par rapport au
niveau de données inferieur ; on peut citer pour exemple :
L'agrégation de données : le DataMart ne contient pas le
détail de toutes les opérations qui ont eu lieu, mais seulement
des totaux, repartis par groupements.
a) Le retrait de données inutiles :
le DataMart ne contient que les données qui sont
strictement utiles aux utilisateurs. L'historisation des données : le
DataMart
contient seulement la période de temps qui
intéresse les utilisateurs.
II.6.4 Datawarehouse Et Datamart
La première étape d'un projet busines
intelligent est de créer un entrepôt central pour avoir une vision
globale des données de chaque service. Cet entrepôt porte le nom
de DataWarehouse.
On peut également parler de DataMart, si seulement une
catégorie de services ou métiers est concernée.
Par définition, un DataMart peut être contenu
dans un DataWarehouse, ou il peut être seulement issu de celui-ci.
II.6.5. Architecture d'un Datamart
Système transactionnel
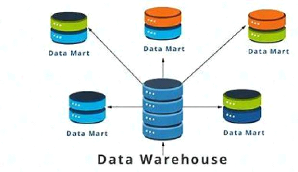
Figure 5: Architecture d'un Data
Mart
II.6.6. Data Warehouse versus Data
Mart
Les Data Marts représentent de toute évidence
une réponse rapide aux besoins des différents départements
de l'entreprise. Leur coût moindre et leur facilité d'emploi
permettent une implémentation rapide et un retour à
l'investissement presque immédiat. Il faut toutefois être prudent
lorsque des Datamarts sont ainsi crées pour plusieurs divisions.
34
Ces dernières utilisent souvent des
représentations différentes de certains concepts de gestion. Par
exemple, les départements finances et marketing peuvent tous deux
effectué un suivi des ventes réalisées par l'entreprise,
mais défini différemment ce concept. Plus tard, si un
employé du marketing a besoin de recueillir certaines informations
à partir du Data Marts des finances, l'entreprise sera confrontée
à un problème. Par conséquent, une vision unifiée
est nécessaire même pour concevoir des Datamarts par
département.
II.7 Les Serveurs OLAP (On-Line Analytical
Processing)
Les données opérationnelles constituent la
source principale d'un système d'information décisionnel. Les
systèmes décisionnels complets reposent sur la technologie OLAP,
conçue pour répondre aux besoins d'analyse des applications de
gestion21.
Nous exposons dans la suite les divers types de stockage des
informations dans les systèmes décisionnels.
II.7.1 Les Serveur ROLAP (Relational Olap)
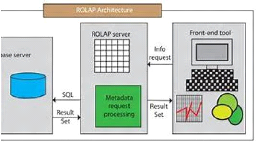
Figure 6 : Architecture ROLAP
Dans les systèmes relationnels OLAP, l'entrepôt
de données utilise une base de données relationnelle. Le stockage
et la gestion de données sont relationnels. Le moteur ROLAP traduit
dynamiquement le modèle logique de données multidimensionnel m en
modèle de stockage relationnel r, la plupart des outils
requièrent que la donnée soit structurée en utilisant un
schéma en étoile ou un schéma en flocon de neige.
La technologie ROLAP a deux avantages principaux :
21 Frank Ravat, Olivier Teste, Gilles Zurfluh :
Modélisation et extraction de données pour un entrepôt
objet, Université Paul Sabatier (Toulouse III), IRIT (Institut de
Recherche en informatique de Toulouse), équipe SIG, Toulouse, France
2001, page 47
35
1) Elle permet la définition de données
complexes et multidimensionnelles en utilisant un modèle relativement
simple.
2) Elle réduit le nombre de jointures à
réaliser dans l'exécution d'une requête.
Le désavantage est que le langage de requêtes tel
qu'il existe, n'est pas assez puisant ou n'est pas assez flexible pour
supporter de vraies capacités d'OLAP.
II.7.2 Le Serveur MOLAP (Multidimensional
OLAP)
Les systèmes multidimensionnels OLAP utilisent une base
de données multidimensionnelle pour stocker les données de
l'entrepôt et les applications analytiques sont construites directement
sur elle. Dans cette architecture, le système de base de données
multidimensionnel sert tant au niveau de stockage qu'au niveau de gestion des
données. Les données des sources sont conformes au modèle
multidimensionnel, et dans toutes les dimensions, les différentes
agrégations sont pour le calculées pour des raisons de
performance.
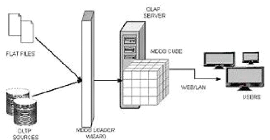
Figure 7: Architecture MOLAP
Les systèmes MOLAP doivent gérer le
problème de données clairsemées, quand seulement un nombre
réduit de cellules d'un cube contiennent une valeur de mesure
associée.
Les avantages des systèmes MOLAP sont bases sur les
désavantages des systèmes ROLAP et elles représentent la
raison de leur création. D'un cote, les requêtes MOLAP sont
très puissantes et flexibles en termes du processus OLAP, tandis que,
d'un autre cote, le modèle physique correspond plus étroitement
au modèle multidimensionnel. Néanmoins, il existe des
désavantages au modèle physique MOLAP. Le plus important, a notre
avis, c'est qu'il n'existe pas de standard du modèle physique.
36
II.7.3 Les Serveur HOLAP (Hybrid
Olap)
Un système HOLAP est un système qui supporte et
intègre un stockage des données multidimensionnel et relationnel
d'une manière équivalente pour profiter des
caractéristiques de correspondance et des techniques d'optimisation donc
c'est l'ensemble des deux serveurs MOLAP et ROLAP.
Dans la figure 7, nous montrons une architecture en utilisant
les types de serveurs ROLAP et MOLAP pour le stockage de données.
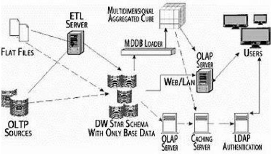
Figure 8 : Architecture HOLAP
Nous traitons une liste des caractéristiques principales
qu'un système HOLAP doit
fournir :
a) La transparence du système :
Pour la localisation et l'accès aux données, sans
connaître si elles sont stockées dans un SGBD relationnel ou
dimensionnel. Pour la transparence de la fragmentation.
b) Un modèle de données
général et un schéma multidimensionnel global
: Pour aboutir à la transparence du premier point, tant le
modèle de données général que le langage de
requête uniforme doivent être fournis. Etant donné qu'il
n'existe pas un modèle standard, cette condition est difficile à
réaliser.
c) Une allocation optimale dans le système
de stockage : Le système HOLAP Doit
bénéficier des stratégies d'allocation qui existent dans
les systèmes distribués tels que : le profil de requêtes,
le temps d'accès, l'équilibrage de chargement.
d) Une réallocation automatique :
Toutes les caractéristiques traitées ci-dessus
changent dans le temps. Ces changements peuvent provoquer la
réorganisation de la distribution des données dans le
système de stockage multidimensionnel et relationnel, pour assurer des
performances optimales.
37
Actuellement, la plupart des systèmes commerciaux
utilisent une approche hybride. Cette approche permet de manipuler des
informations de l'entrepôt de données avec un moteur ROLAP, tandis
que pour la gestion des DataMarts, ils utilisent l'approche
multidimensionnelle.
II.7.4. Les différents outils
OLAP
a) Multidimensionnel OLAP (MOLAP)
Il est plus facile et plus cher à mettre en place, il est
conçu exclusivement pour l'analyse multidimensionnelle avec un mode de
stockage optimisé par rapport aux chemins d'accès
prédéfinis.
MOLAP repose sur un moteur spécialisé, qui stocke
le data dans format tabulaire propriétaire (Cube). Pour accéder
aux données de ce cube, on ne peut pas utiliser le langage de
requête sql, il faut utiliser une API spécifique.
b) Relationnal OLAP (ROLAP)
Il est plus facile et moins cher à mettre en place, il
est moins performant lors des phases de calculs. En effet, il fait appel
à beaucoup de jointure et donc les traitements sont plus
conséquents.
Il superpose au-dessus des SGBD/R bidimensionnels un
modèle qui représente les données dans un format
multidimensionnel.
ROLAP propose souvent un composant serveur, pour optimiser
les performances lors de la navigation dans les données. Il est
déconseillé d'accéder en direct à des bases de
données de production pour faire des analyses tout simplement pour des
raisons des performances.
c) Hybride OLAP (OLAP)
Est une solution hybride entre les deux (MOLAP et ROLAP) qui
recherche un bon compromis au niveau du cout et de la performance.
HOLAP désigne les outils d'analyse multidimensionnelle
qui récupèrent les données dans de bases relationnelles ou
multidimensionnelles, de manière transparente pour l'utilisateur.
Ces trois notions se retrouvent surtout lors du
développement des solutions. Elles dépendent du software et
hardware. Lors de la modélisation, on ne s'intéresse qu'à
concevoir une modélisation orientée décisionnelle,
indépendamment des outils utilisés ultérieurement.
38
Conclusion partielle
Dans ce chapitre, nous avons traité l'entrepôt de
données et le data mart. Nous avons donnés l'architecture d'un
entrepôt de données et celle du data mart. Nous avons
expliqué les différents composants qu'il intègre, les
types de données et les différents outils pour arriver à
la visualisation de l'information ; avons décrit les différents
modèles multidimensionnels pour la construction d'un entrepôt de
données, ainsi que les différentes opérations pour la
manipulation des données multidimensionnelles et le parallélisme
entre le deux, nous avons présenté l'apport de DataMart dans les
entreprises. Le chapitre suivant abordera les notions sur le data mining et
l'arbre de décision.
22 Y. Zhuge, H. Garcia-Molina, J. Hammer, J. Widom, "View
Maintenance in a Warehousing Environment", SIGMOD Record, San Jose (USA),
1995, p.87
39
CHAPITRE III : LE DATA MINING ET ARBRE DE DECISION III.0
Introduction
Le terme datamining est souvent employé pour
désigner l'ensemble des outils permettant à l'utilisateur
d'accéder aux données de l'entreprise, de les analyser. Nous
retiendrons ici le terme de data mining aux outils ayant pour objet de
générer des informations riches à partir des
données de l'entreprise, notamment des données historiques, de
découvrir des modèles implicites dans les
données.22
Ces outils peuvent permettre par exemple à un magasin
de dégager des profils de client et des achats types et de
prévoir ainsi les ventes futures. Ils permettent d'augmenter la valeur
des données contenues dans le DataWarehouse.
Les outils d'aides à la décision, qu'ils soient
relationnels ou OLAP, laissent l'initiative à l'utilisateur, de choisir
les éléments qu'il veut observer ou analyser .Au contraire ,dans
le cas du datamining ,le système a l'initiative et découvre
lui-même les associations entre données ,sans que l'utilisateur
ait à lui dire de rechercher plutôt dans telle ou telle direction
ou à poser des hypothèses .
Il est alors possible de prédire l'avenir, par le
comportement d'un client, et de détecte, dans le passé, les
données inusuelles, exceptionnelles.
Ces outils ne sont plus destinés aux seuls experts
statisticiens mais doivent pouvoir être employés par des
utilisateurs connaissant leur métier et voulant l'analyser,
l'explorer.
Seul un utilisateur connaissant le métier peut
déterminer si les modèles, les règles, les tendances
trouvées par l'outil sont pertinentes, intéressantes et utiles
à l'entreprise. Nous pourrions définir le datamining comme une
démarche ayant pour objet de découvrir des relations et des
faits, à la fois nouveaux et significatifs, sur de grands ensembles de
données.
Le terme datamining signifie littéralement forage de
données dont le but est de pouvoir extraire un élément :
la connaissance.
Ces concepts s'appuient sur le constat qu'il existe au sein de
chaque entreprise des informations cachées dans le gisement de
données. Nous appellerons datamining l'ensemble des techniques qui
permettent de transformer les données en connaissances. L'exploration se
fait sur l'initiative du système, par un utilisateur métier, et
son but est de remplir l'une des tâches suivantes : Classification,
estimation, prédiction, regroupement par similitudes, segmentation
(cautérisation), description et, dans une moindre mesure,
l'optimisation.
40
III.1 Objectifs Du Data Mining23
Les objectifs du Data Mining peuvent être regroupés
dans trois axes importants:
1. Prédiction (What-if) :
consiste à prédire les conséquences d'un
événement (ou d'une décision), se basant sur le
passé.
2. Découverte de règles cachées
: découvrir des règles associatives, entre
différents événements (Exemple : corrélation entre
les ventes de deux produits).
3. Confirmation d'hypothèses :
confirmer des hypothèses proposées par les
analystes et décideurs, et les doter d'un degré de confiance.
En considérant le serveur de base données ou le
serveur d'entrepôt de données, le Data mining est
considéré comme un client riche de ces deux serveurs. Notons que
le client serveur est un mode de dialogue entre deux processus, l'un
appelé client qui sollicite des services auprès de l'autre
appelé serveur, par envoie des requêtes (send request en anglais).
Après avoir lancé une requête par rapport au fait à
analyser, le client data ming applique des méthodes ou procédures
sur les données obtenues, afin d'obtenir les informations
nécessaires pour la prise de décision. Ces procédures ou
méthodes, sont classées en deux catégories :
Apprentissage non supervisé et l'apprentissage
supervisé en dehors de ces deux s'ajoute l'autre qui est
l'apprentissage automatique.
a) Apprentissage non
supervisé
Elle consiste à mettre en évidence les
informations cachées par le grand volume de données, en vue de
détecter dans ces données des tendances cachées. Les
techniques utilisées sont : La segmentation (Clustering en anglais),
L'analyse à composante principale, l'analyse factorielle de
correspondance.
b) Apprentissage supervisé
L'apprentissage supervisé consiste à extrapoler
des nouvelles connaissances à partir de l'échantillon
représentatif issu de l'apprentissage non supervisé. Les
techniques utilisées sont : Les réseaux de neurones, le SVM,
l'arbre de décision, les réseaux de bayes, etc.
c) Apprentissage automatique
L'apprentissage automatique (machine learning en
anglais), un des champs d'étude de l'intelligence artificielle, est la
discipline scientifique concernée par le développement, l'analyse
et l'implémentation de méthodes automatisables qui permettent
à une machine (au sens large) d'évoluer grâce à un
processus d'apprentissage, et ainsi de remplir des tâches
23 ADIBA .M, Entrepôts de données et fouille de
données, Paris 2002, p.19
41
qui sont difficiles ou impossible d'être
réalisées par des moyens algorithmiques plus classiques.
Des systèmes complexes peuvent être
analysés, y compris pour des données associées à
des valeurs symboliques (ex: sur un attribut numérique, non pas
simplement une valeur numérique, juste un nombre, mais une valeur
probabilisée, c'est-à-dire un nombre assorti d'une
probabilité ou associé à un intervalle de confiance) ou un
ensemble de modalités possibles sur un attribut numérique ou
catégoriel.
L'analyse peut même concerner des données
présentées sous forme de graphes ou d'arbres, ou encore de
courbes (par exemple, la courbe d'évolution temporelle d'une mesure ; on
parle alors de données continues, par
opposition aux données discrètes
associées à des attributs-valeurs classiques).
Le premier stade de l'analyse est celui de la
classification, qui vise à « étiqueter »
chaque donnée en l'associant à une classe.
III.1.1. Processus Du Datamining
Le datamining est un processus méthodique : une suite
ordonnée d'opérations aboutissant à un résultat.
Le data ming est décrit comme un processus
itératif complet constitué de quartes divisées en six
phases qui sont représenté dans le tableau suivant :
|
PROCESSUS DU DATAMINING
|
|
Acteur
|
Etapes
|
Phases
|
|
Maitre d'oeuvre
|
Objectifs
|
1. Compréhension du métier :
|
|
2. Compréhension des données
|
|
|
|
Traitements
|
4 .Modélisation
|
|
5.Evaluation de la modélisation
|
|
Maître d'ouvrage
|
Déploiement
|
6. Déploiement des résultats de l'étude
|
Tableau 3: le processus du
datamining.
a) Compréhension du Métier
:
Cette phase consisté à :
? Enoncer clairement les objectifs globaux du
projet et les contraintes de l'entreprise.
42
· Traduire ses objectifs et ses contraintes en un
problème de data mining
· Préparer une stratégie initiale pour
atteindre ces objectifs.
b) Compréhension des données Cette phase
consiste à :
Recueillir les données, utiliser l'analyse
exploratoire pour se familiariser avec les données, commencé
à les comprendre et imaginer ce qu'on pourrait en tirer comme
connaissance. Evaluer la qualité des données, Eventuellement,
sélectionner des sous-ensembles intéressants.
c) Préparation des données
Cette phase aide à préparer, à partir des
données brutes, l'ensemble final des données qui va être
utilisé pour toutes les phases suivantes :
· Sélectionner les cas et les variables à
analyser, réaliser si nécessaire les transformations de certaines
données, réaliser si nécessaire la suppression de
certaines données.
d) Modélisation
La phase de la modélisation consiste à :
· Sélectionner les techniques de
modélisation appropriées (pouvant être utilisées
pour le même problème) calibrer les paramètres des
techniques de modélisation choisies pour optimiser les résultats
;
· Eventuellement revoir la préparation des
données pour l'adapter aux techniques utilisées.
e) Evaluation de la modélisation
· Pour chaque technique de modélisation
utilisée, évaluer la qualité (la pertinence) des
résultats obtenus ;
· Déterminer si les résultats obtenus
atteignent les objectifs globaux identifiés pendant la phase de
compréhension du métier ;
· Décider si on passe à la phase suivante
(le déploiement) ou si on souhaite reprendre l'étude en
complétant le jeu de données.
f) Déploiement des résultats obtenus
Cette phase est externe à l'analyse du datamining
.Elle concerne le maître d'ouvrage. Prendre les décisions en
conséquence des résultats de l'étude de data mining.
· Préparer la collecte des informations futures
pour permettre de vérifier la pertinence des décisions
effectivement mis en oeuvre.
43
III.1.2. Les Tâches Du Datamining
Contrairement aux idées reçues, le Data Mining
n'est pas le remède miracle capable de résoudre toutes les
difficultés ou besoins de l'entreprise cependant, une multitude de
problèmes d'ordre intellectuel, médical, économique
peuvent être regroupés, dans leurs formalisations, dans l'une des
tâches suivantes :
1. Classification ;
2. Estimation ;
3. Prédiction ;
4. Discrimination ;
5. Segmentation.
III.I.2.1. Les Tâches Et Technique Du
Datamining
|
TACHES
|
TECHNIQUE
|
|
Classification
|
L'arbre de décision
|
|
Le raisonnement par cas
|
|
L'analyse de lien
|
|
Estimation
|
Le réseau de neurones
|
|
Prédiction
|
L'analyse du panier de la ménagère
|
|
Le raisonnement base sur le mémoire
|
|
L'arbre de décision
|
|
Les réseaux de neurones
|
|
Extraction de connaissance
|
L'arbre de décision
|
Tableau 4: les taches et
technique du datamining.
En outre, hormis ces quelques techniques et tâches du
datamining, nous signalons qu'il existe d'autres que nous n'avons pas
énumérez dans notre travail.
44
III.2. Arbre de décision
III .2.1. Introduction à l'arbre de
décision
Un arbre de décision est une structure qui permet de
déduire un résultat à partir de décisions
successives. Pour parcourir un arbre de décision et trouver une
solution, il faut partir de la racine. Chaque noeud est une décision
atomique.24
Proche en proche, on descend dans l'arbre jusqu'à
tomber sur une feuille. La feuille représente la réponse
qu'apporte l'arbre au cas où l'on vient de tester.
a) Début à la racine de l'arbre
Descendre dans l'arbre en passant par les noeuds de test, la
feuille atteinte à la fin permet de classer l'instance testée.
Très souvent on considère qu'un noeud pose une question sur une
variable, la valeur de cette variable permet de savoir sur quels fils
descendre. Pour les variables énumérées, il est parfois
possible d'avoir un fils par valeurs, on peut aussi décider que
plusieurs variables différentes mènent au même sous
arbre.
Pour les variables continues, il n'est pas imaginable de
créer un noeud qui aurait potentiellement un nombre de fils infini, on
doit discrétiser le domaine continu (arrondis, approximation), donc
décider de segmenter le domaine en sous-ensembles. Plus l'arbre est
simple, et plus il semble techniquement rapide à utiliser.
En fait, il est plus intéressant d'obtenir un arbre qui
est adapté aux probabilités des variables à tester. La
plupart du temps un arbre équilibré sera un bon
résultat.
Si un sous arbre ne peut mener qu'à une solution
unique, alors tout ce sous arbre peut être réduit à sa
simple conclusion, cela simplifie le traitement et ne change rien au
résultat final.
III.2.2. Définition
Un arbre de décision est un outil d'aide à la
décision et à l'exploration de données. Il permet de
modéliser simplement, graphiquement et rapidement un
phénomène mesuré plus ou moins complexe. Sa
lisibilité, sa rapidité d'exécution et le peu
d'hypothèses nécessaires a priori expliquent sa popularité
actuelle.25
III.2.3. Caractéristiques et
Avantages
La caractéristique principale est la lisibilité
du modèle de prédiction que l'arbre de décision fourni, et
de faire comprendre ses résultats afin d'emporter l'adhésion des
décideurs.
24 VINCENT GUIJARRO, Les Arbres de Décisions
L'algorithme ID3, lile, 2006, p.16
25 RAKOTOMALALA. : Graphes d'induction apprentissage et data
mining, hermès, 2000.THESE, p.43
26 KANGIAMA LWANGI Richard : Extraction des connaissances
a partir d'un entrepôt des données à l'aide de l'arbre de
décision application aux données médicales, UNIKIN
2010-2011.
45
Cet arbre de décision a également la
capacité de sélectionner automatiquement les variables
discriminantes dans un fichier de données contenant un très grand
nombre de variables potentiellement intéressantes. En ce sens, constitue
aussi une technique exploratoire privilégiée pour
appréhender de gros fichiers de données.
III.2.4. Algorithme ID3
L'algorithme ID3 a été développé
à l'origine par ROSS QUINLAN. C'est un algorithme de classification
supervisé. C'est-à-dire il se base sur des exemples
déjà classés dans un ensemble de classes pour
déterminer un modèle de classification. Le modèle que
produit ID3 est un arbre de décision. Cet arbre servira à classer
de nouveaux échantillons. Il permet aussi de générer des
arbres de décisions à partir de données. Imaginons que
nous ayons à notre disposition un ensemble d'enregistrements ayant la
même structure, à savoir un certain nombre de paires attribut ou
valeur. L'un de ses attributs représente la catégorie de
l'enregistrement. Le problème consiste à construire un arbre de
décision qui sur la base de réponses à des questions
posées sur des attributs non cible peut prédire correctement la
valeur de l'attribut cible. Souvent l'attribut cible pend seulement les valeurs
vrai, faux ou échec, succès.
III.2.5. Principes
Les principales idées sur lesquels repose ID3 sont les
suivantes :
Dans l'arbre de décision chaque noeud correspond
à un attribut non cible et chaque arc a une valeur possible de cet
attribut. Une feuille de l'arbre donne la valeur escomptée de l'attribut
cible pour l'enregistrement testé décrit par le chemin de la
racine de l'arbre de décision jusqu'à la feuille.
(Définition d'un arbre de décision). Dans l'arbre de
décision, à chaque noeud doit être associé
l'attribut non cible qui apporte le plus d'information par rapport aux autres
attributs non encore utilisés dans le chemin depuis la racine.
(Critère d'un bon arbre de décision). L'entropie est
utilisée pour mesurer la quantité d'information apportée
par un noeud. (Cette notion a été introduite par Claude Shannon
lors de ses recherches concernant la théorie de l'information qui sert
de base à énormément de méthodes du
datamining).26
Algorithme
Entrées : ensemble d'attributs A; échantillon E;
classe c
Début
Initialiser à l'arbre vide;
Si tous les exemples de E ont la même classe c
46
Alors étiqueter la racine par c;
Sinon si l'ensemble des attributs A est vide
Alors étiqueter la racine par la classe majoritaire
dans E;
Si non soit a le meilleur attribut choisi dans A;
Étiqueter la racine par a;
Pour toute valeur v de a
Construire une branche étiquetée par v;
Soit Eav l'ensemble des exemples tels que e(a) = v;
ajouter l'arbre construit par ID3 (A-{a}, Eav, c);
Fin pour Fin sinon
Fin sinon
Retourner racine;
Fin
III.2.6. Exemple Pratique d'un Algorithme
ID3
Pour introduire et exécuter "à la main"
l'algorithme ID3 nous allons tout d'abord considérer l'exemple
ci-dessous: Une entreprise possède les informations suivantes sur ses
clients et souhaite pouvoir prédire à l'avenir si un client
donné effectue des consultations de compte sur Internet.
|
Client
|
Moyenne des
montants
|
Age
|
Lieu de
Résidence
|
Etudes
supérieures
|
Consultation par
internet
|
|
1
|
Moyen
|
Moyen
|
Village
|
Oui
|
Oui
|
|
2
|
Elevé
|
Moyen
|
Bourg
|
Non
|
Non
|
|
3
|
Faible
|
Age
|
Bourg
|
Non
|
Non
|
|
4
|
Faible
|
Moyen
|
Bourg
|
Oui
|
Oui
|
|
5
|
Moyen
|
Jeune
|
Ville
|
Oui
|
Oui
|
|
6
|
Elevé
|
Agé
|
Ville
|
Oui
|
Non
|
|
7
|
Moyen
|
Agé
|
Ville
|
Oui
|
Non
|
|
8
|
Faible
|
Moyen
|
Village
|
Non
|
Non
|
Tableau 5: exemples pratiques
Log (P (C[ville)))
47
Ici, on voit bien que la procédure de classification
à trouver, qui à partir de la description d'un client, nous
indique si le client effectue la consultation de ses comptes par Internet,
c'est-à-dire la classe associée au client.
o Le premier client est décrit par (M : moyen, Age :
moyen, Résidence : village, Etudes : oui) et a pour classe Oui.
o Le deuxième client est décrit par (M :
élevé, Age : moyen, Résidence : bourg, Etudes : non) et a
pour classe Non.
Pour cela, nous allons construire un arbre de décision qui
classifie les clients. Les arbres sont construits de façon descendante.
Lorsqu'un test est choisi, on divise l'ensemble d'apprentissage pour chacune
des branches et on
Réapplique récursivement l'algorithme.
H(C[Lieu) = -P (bourg). (P (C[bourg) log (P (C[bourg)) + P (C
[bourg)
a) Choix du meilleur attribut :
Pour cet algorithme deux mesures existent pour choisir le meilleur
attribut : la mesure d'entropie et la mesure de fréquence:
b) L'entropie : Le gain (avec pour
fonction il'entropie) est également appelé l'entropie de
Shannon et peut se réécrire de la manière suivante :
Pour déterminer le premier attribut test (racine de
l'arbre), on recherche l'attribut d'entropie la plus faible. On doit donc
calculer H(C[Solde), H(C[Age), H(C[Lieu), H(C[Etudes), où la classe C
correspond aux personnes qui consultent leurs comptes sur Internet.
H(C[Solde) = -P (faible).(P (C[faible) log(P (C[faible)) + P (C
[faible) log(P (C[faible)))-P (moyen).(P (Cmoyen) log(P (Cmoyen)) + P (Cmoyen)
log(P (Cmoyen)))-P (eleve).(P (C[eleve) log(P (C[eleve)) + P (C[eleve)
log(P(C[eleve)))H(C[Solde)
H(CSolde) = -3/8(1/3.log(1/3) + 2/3.log(2/3)-3/8(2/3.log(2/3) +
1/3.log(1/3) -2/8(0.log (0) + 1.log(1)
H (C[Solde) = 0.20725
H(C[Age) = -P (jeune).(P (C[jeune) log(P (C[jeune)) + P (C
[jeune) log(P (C[jeune)))-P (moyen).(P (C[moyen) log(P (C[moyen)) + P (C
[moyen) log(P (C[moyen)))-P (age).(P (C[age) log(P (C[age)) + P (C[age) log(P
(C[age)))
H(C[Age) = 0.15051
Log (P (C[bourg)))-P (village).(P (C[village) log(P (C[village))
+ P (C [village) log(P (C[village)))-P (ville).(P (C[ville) log(P (C[ville)) +
P (C[ville)
48
H(C[Lieu) = 0.2825
H(C[Etudes) = -P (oui).(P (C[oui) log(P (C[oui)) + P (C [oui)
log(P (C[oui)))
-P (non).(P (C[non) log(P (C[non)) + P (C[non) log(P (C[non)))
H(C[Etudes) = 0.18275 Le premier attribut est donc l'âge (attribut dont
l'entropie est minimale). On obtient l'arbre suivant :
Age
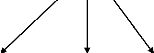
Jeune moyen âgé
Consultation ? Consultation
Figure 9: Arbre de décision construit à partir de
l'attribut âge
Pour la branche correspondant à un âge moyen, on ne
peut pas conclure, on doit donc recalculer l'entropie sur la partition
correspondante.
H(C|Solde) = -P (faible).(P (C|faible) log(P (C|faible)) + P (C
|faible) log(P
(C|faible)))-P (moyen).(P (C|moyen) log(P (C|moyen)) + P
(C|moyen)
Log (P (C|moyen)))-P (eleve). (P (C|eleve) log(P (C|eleve)) + P
(C|eleve) log(P
(C|eleve)))
H(C|Solde) = -2/4(1/2.log(1/2) + 1/2.log(1/2)-1/4(1.log(1) +
0.log(0)
-1/4(0.log (0) + 1.log (1)
H (C|Solde) = 0.15051
H(C|Lieu) = -P (bourg).(P (C|bourg) log(P (C|bourg)) + P (C
|bourg) log(P
(C|bourg)))-P (village).(P (C|village) log(P (C|village)) + P (C
|village) log(P
(C|village)))-P (ville).(P (C|ville) log(P (C|ville)) + P
(C|ville) log(P (C|ville)))
H (C|Lieu) = 0.30103
H (C|Etudes) = -P (oui).(P (C|oui) log(P (C|oui)) + P (C |oui)
log(P (C|oui)))
-P (non). (P (C|non) log(P (C|non)) + P (C|non) log(P (C|non)))
H(C|Etudes) = 0
L'attribut qui a l'entropie la plus faible est « Etudes
».
49
L'arbre devient alors :
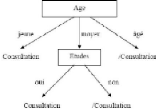
Figure 10 : Arbre de décision
finale
L'ensemble des exemples est classé et on constate que sur
cet ensemble d'apprentissage, seuls deux attributs sur les quatre sont
discriminants.
III.3 Concepts Théoriques Sur Le
Graphe
III.3.1. Définition : Un graphe
G est un couple G=(X, U), X est un ensemble non vide et au plus
dénombrable.
Nota : X est un ensemble fini, les éléments de x X
sont appelés les sommets ou noeuds. U = une famille
d'éléments du produit cartésiens X€X .
Les éléments de U=(x,y) , x,y X, sont
appelés : soit des arcs lorsqu'on tient compte de l'orientation, soit
les arêtes lorsqu'on ne tient pas compte de
l'orientation.27
III.3.2. Graphe connexe a) Définition
:
Un graphe est connexe si l'on peut atteindre n'importe quel
sommet à partir d'un sommet quelconque en parcourant les
différentes arêtes.
Exemple : soit G=(X, U) qui est un
graphe connexe

Figure 11 : graphe connexe
27 MANYA NDJADI, Recherche opérationnelle, G3
informatique option Gestion, cours inédit, U.K.A 2013-2014.
Figure 13 : arborescence
50
U6 U5
U7
U8
EX :
U4
U3
U1 U2
III.3.2. Arbres et arborescence
1. Arbres
a) Définition : Un arbre est un
graphe connexe sans cycle. C'est-à-dire dont on peut atteindre n'importe
quel sommet à partir d'un sommet quel- conque en parcourant
différents arêtes et ses arêtes ne coïncide pas.
EX :
Figure 12 : Arbre
2) Arborescence
a) Définition : une structure
qui permet de déduire un résultat à partir de
décision successive.
Soit G=(X, U) on dit que le sommet rX est une racine de G si V
X, (avec xr) un chemin de r à x .c'est -à -dire un arbre ayant
une racine.
51
Conclusion partielle
Dans ce chapitre nous avons présenté le
datamining avec ses différentes méthodes, tâches,
techniques et nous avons fait un briefing sur la notion relative à la
théorie de graphe. Nous avons aussi construit un arbre de
décision ou nous nous somme basé sur l'attribut âge et
l'étude pour la démonstration. Le chapitre suivant aborder a les
notions sur présentation du cadre d'étude et spécification
de besoins.
52
CHAPITRE IV : PRESENTATION DU CADRE D'ETUDE ET
SPECIFICATION
DE BESOINS
VI.1. La Présentation Cadre d'étude
VI.1.1. Situation géographique
La Régie des Voies Aériennes de Kananga se
trouve dans la ville de Kananga et dans la commune du même nom, plus
précisément à l'Est de la ville. Elle est bornée au
nord par la cité Mulombodi (Fondateur de l'Eglise Christ-Roi), au sud
par la localité Kabanza, à l'Est par la rivière Lungandu
et à l'Ouest par le marché Laurent Désiré KABILA
communément appelé Tshiambandiba
VI.1.2. Historique
En 1928 une circonscription urbaine est érigée
au nord de la Gare. La même année la SABENA «
Société Anonyme Belge pour l'Exploitation de la Navigation
Aérienne » établit une piste d'atterrissage à
l'emplacement actuel de l'institut Kananga I (ex Athénée Royal de
Luluabourg).
Mais le véritable aérodrome comme le premier
pour la ville de Kananga a vu jour en 1940 à l'actuelle Radio
Télé Nationale Congolaise (ancienne la Voix du Congo) sous
gérante de l'aéronautique civile. En 1941, le nouvel
aérodrome fut érigé à l'Oasis par l'OACI sur la
rive droite de la route Kananga-Mbuji-Mayi. La piste de cet endroit demeura
inopérationnelle pendant un temps, l'érosion l'ayant
ravagé.
En 1972 l'entreprise qui s'appelait « aéronautique
civile » a changé de dénomination pour adopter l'appellation
« Régie des Voies Aériennes », R.V.A. en sigle depuis
le 21 février 1972.
Au niveau du siège national de la Régie des
Voies Aériennes, un programme fut mis en place, celui d'assurer la
sécurité des aéronefs qui exploitent ses aéroports
en vue de développer le transport aérien. L'exécution de
programme à Kananga fut confiée aux 3 sociétés de
construction qui sont affectées à ces travaux à partir du
mois de mai 1975 jusqu'au Janvier 1976.
Il s'agissait de la Générale de Kinshasa Company
(GKN) sous le commandement de SIR FREDERIC SNOU de l'International Limited
London (pour les travaux de construction) et la société Plessy
Services LTD wey Bridge (pour les travaux de balisage de la piste).
Ces travaux qui ont duré pratiquement 9 mois, permirent
à l'Aéroport National de Kananga d'être compté parmi
les aéroports capables de pouvoir supporter les poids des gros porteurs
tels que DC-8, Boeing 707, 727, 737 et Iloshin, car sa piste qui fut de 200 m
de longueur sur 30 m de largeur, était passé à 2200m de
longueur et 45 m de largeur, cette piste pouvait désormais recevoir les
aéronefs la nuit ou quand il fait mauvais temps sans inquiétude.
(Les explications du chef du personnel lors de l'entretien)
53
Lors de l'assemblée générale
extraordinaire du septembre 2014, il a été décidé
de la transformation de la forme de la Société par Action
à Responsabilité Limitée (SARL) en nouvelle forme de
Société Anonyme Unipersonnelle, selon que le droit OHADA n'admet
pas la SARL de l'ancienne forme du droit congolais.
C'est une Société Anonyme qui est
l'équivalente de l'ex SARL.
VI.1.3. Statuts juridiques
La Régie des Voies Aériennes a été
initialement créée par Ordonnance-Loi n°72/013 du 21
février 1972 comme entreprise publique à caractère
technique et commercial et dont les statuts ont été fixés
par l'Ordonnance n°78-200 du 05 mai 1978 en application de la loi
n°78-02 du 6 janvier 1978 portant dispositions générales
applicables aux entreprises publiques.
Elle a été transformée en
Société Commerciale de forme « Société par
Actions à Responsabilité Limitée » dont l'Etat est
l'unique actionnaire aux termes des articles 4 et 5 de la Loi n°08/007 du
7 juillet 2008 portant dispositions générales relatives à
la transformation des entreprises publiques du Décret n°09/12 du 24
avril 2009 portant liste des entreprises publiques transformées en
sociétés commerciales, Etablissements publics et services publics
pris en exécution de la Loi n°08/007 du juillet 2008 susdite.
Elle est régie par les statuts dressés,
notariés et publiés au journal officiel de la République
Démocratique du Congo numéro spécial du 29 Décembre
2010, 5ème Année.
Au cours de l'assemblée générale
extraordinaire de la Régie des Voies Aériennes tenue à
Kinshasa le 06 septembre 2014, le président de ladite assemblée a
expliqué aux participants la mise en harmonie des statuts de
l'entreprise publique avec le droit OHADA rend obligatoire la transformation de
la forme actuelle de Société par Actions à
Responsabilité Limitée (SARL) pour remplacer par une des formes
sociales prévues par l'acte uniforme relatif au droit des
sociétés commerciales et du groupement d'intérêt
économique. (PV de l'assemblée générale
extraordinaire de l'actionnaire unique tenue à Kinshasa le 06/09/2014
:4)
VI.1.4. Objet social de la
R.V.A.
La société a pour objet :
? De concevoir, de construire, d'aménager, d'exploiter et
de développer les aéroports ainsi que leurs dépendances en
République Démocratique du Congo ;
? De fournir en République Démocratique du Congo
et à l'étranger, dans ses domaines de compétence tout
service technique, toute prestation de nature industrielle, commerciale ou
intellectuelle relatif aux opérations et à l'exploitation des
aéroports notamment les services d'assistance au sol, de lutte contre
l'incendie et tout autre service spécifié par la
réglementation internationale ;
? D'assurer la conception, la mise en oeuvre, la gestion et le
contrôle de l'espace aérien à travers des installations et
services ayant pour l'objet :
? Les télécommunications aéronautiques ;
? Les aides à la navigation et à l'atterrissage
;
? La surveillance de l'espace et trafic aériens ;
54
? Le contrôle de la circulation aérienne,
l'information en vol et l'alerte ;
? La gestion des flux de trafic aérien, la production
et la fourniture des informations de météorologie
aéronautique, aussi bien pour la circulation en route que pour
l'approche et l'atterrissage sur les aérodromes et aéroports
relevant de sa gestion ; et
? L'information aéronautique.
+ De vendre tous les services et prestations, d'en fixer le
prix, d'en percevoir les montants et, le cas échéant, d'en
modifier les tarifs au titre de redevances aéronautiques et
extra-aéronautiques ; et plus généralement de recouvrer
tous autres revenus par son activité sociale ;
+ De créer, de déposer, d'acquérir, de
vendre, d'échanger, de céder ou d'exploiter, directement ou
indirectement, tous actifs mobiliers et immobiliers, ainsi que tous brevets,
licences, procédés et marques de fabrique, et en concéder
toutes les licences d'exploitation.
VI.1.5. La durée de la R.V.A
La durée de la société est fixée
à quatre-vingt-dix-neuf ans à compter de la date de son
immatriculation au registre de commerce et du crédit mobilier, sauf
dissolution anticipée ou prorogation décidée par
l'Assemblée Générale de l'Etat Actionnaire.
En cas de prorogation de la durée de la
société, un an au moins avant la date de son expiration,
l'Actionnaire Unique devra être consulté par le conseil
d'administration à l'effet de décider si la société
doit être prorogée. A défaut de convocation par l'organe
précité, l'Actionnaire Unique peut demander en justice la
désignation d'un mandataire de justice chargé de provoquer ladite
consultation.
La modification de la durée de la
société, la prorogation de la société comme sa
dissolution anticipée sont décidées par l'Assemblée
Générale de l'Etat Actionnaire Unique.
VI.1.6. Les rôles de la R.V.A
Généralement, aucun pays ne peut manquer un
aéroport ou un aérodrome. Mais cela n'exclut pas à
signaler que malgré l'existence de ceux-ci, ils jouent les
différents rôles selon les diverses provinces.
Il conviendrait de reconnaitre que la Régie des Voies
Aériennes ayant le monopole de tous les aéroports et
aérodromes officiels du pays, son rôle demeure
prépondérant dans la mesure où son fief apporte à
la ville de Kananga beaucoup d'avantages sur plusieurs plans. Elle joue
plusieurs rôles sur la ville de Kananga qui sont :
V' Rôle technique ;
V' Rôle économique ;
V' Rôle social ;
V' Rôle politique ou stratégique ;
V' Rôle humanitaire.
55
VI.1.7. Projet d'avenir de la R.V.A
Dans l'avenir, il y a des prévisions pour le rallongement
et l'agrandissement de l'actuelle piste d'atterrissage pour avoir une nouvelle
piste d'atterrissage de l'aéroport national de Kananga qui sera du type
international.
Cependant, l'aéroport du type international aidera la
communauté Centre-Kasaïenne à leur ravitaillement en
marchandises et autres choses qui viendront directement d'outre-mer ou d'autres
continents.
56
VI.1.8. Organisation Et Fonctionnement VI.1.8.1.
Organigramme de la R.V.A
COMMANDEMENT D'AEROPORT
SECRETARIAT
STAFF COODINATION
SERVICE MOYENS
GENERAUX
SERVICE
TECHNIQUE
SERVICE ADMINISTRATIF,
FINANCIER ET
COMMERCIAL
SERVICE CIRCULATION
AERIENNE
SERVICE SURETE ET
FACILITATION
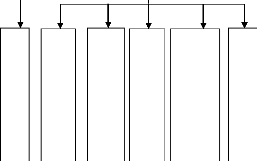
BUREAU FINANCIER
BUREAU
NAVIGATION AERIENNE
BUREAU
CIRCULATION
BUREAU ANTI-INCENDIE
BUREAU STATISTIQUE
BUREAU
TELECOMMUNICATI

BUREAU
COMMERCIAL

BUREAU
ADMINISTRATIF

BUREAU MEDICAL
BUREAU CHARROI AUTOMOBILE
BUREAU
ENTRETIE N
BUREAU
ELECTRICITE ET BALISAGE
BUREAU TELECOMS NAVAIDS
BUREAU POLICE
BUREAU
FACILITATION
Source : R.V.A/Kananga, les documents internes
du secrétariat
57
VI.1.8.2. Fonctionnement de la RVA
1. Commandement d'aéroport
Il est le premier service ayant une préséance
sur tous les autres services au sein de l'aéroport. Tous les autres
services sont obligés à lui faire leurs rapports en vue d'une
harmonisation.
Par commandement d'aéroport, il faut entendre la
direction d'aéroport. Ce changement d'appellation est dû au fait
qu'au début, un aéroport était géré par un
Directeur d'aéroport qui devait être administratif ou
technicien
Depuis un certain temps vers les années nonante, le
terme commandement d'aéroport est resté le seul dont on se sert.
Car, un commandant d'aéroport doit obligatoirement être un
ingénieur en aviation civile pour une mise en application des
règles de la navigation aérienne adoptées par
l'aéronautique civile et l'organisation de l'aviation civile
internationale
2. Staff coordination
C'est un service qui, en absence du commandant
d'aéroport, a le devoir de prise de décision sur n'importe quel
problème survenu à l'aéroport. Il contient 3 coordinateurs
dont un responsable appelé Chef Staff-coordination qui est
secondé par ses deux collègues.
Ce service joue le rôle de maximisation de recettes au
moyen de contrôle sur les accès, l'embarquement, le domanial, le
terrain nu, etc. bref sur les taxes aéronautiques et
extra-aéronautiques pour faire rapport à la hiérarchie. De
ce fait, les coordonnateurs sont toujours au tarmac en vue de veiller sur les
embarquements. Ils restent au bureau dans le souci de surveiller les
entrées pour prendre à l'objectif de leur service.
3. Secrétariat
C'est une cellule qui joue le rôle de communication
entre le service du personnel et le commandement d'aéroport. Il s'occupe
aussi des tâches suivantes : les appels téléphoniques
entrants et sortants, la saisie de courriers, l'organisation de
déplacement et de réunions, l'accueil de visiteurs. Son
rôle d'interface ne se limite pas non seulement au niveau interne de
l'entreprise mais va plus loin au niveau extérieur.
4. Le service administratif, financier et
commercial
Ce service supervise 4 bureaux qui sont : administratif,
financier commercial et médical. Le chef de ce service est appelé
chef de service Administratif, Finances et commercial en abrégé
SAFCO. Nous comprendrons son fonctionnement à travers les bureaux sous
sa dépendance.
58
+ Bureau administratif
Ce bureau est chargé d'harmonisation de différents
rouages et s'occupe essentiellement d'établir le rôle des
congés annuels, circonstanciels, les bons de consultation, le
contrôle des présences et des absences, tenue des dossiers
administratifs du personnel, prépare les sanctions, les dossiers du
pensions, enregistre le décès et naissance. Il traite
généralement tous les problèmes liés aux ressources
humaines.
+ Bureau de financier
C'est un bureau qui s'occupe de la gestion des recettes et des
dépenses. Tout ce qui est produit comme recettes est gardé dans
ce bureau mais à dépenser sur ordre du commandant
d'aéroport suivant le programme établi par lui et le
chargé de finances.
+ Bureau commercial
C'est le bureau générateur des recettes en
dollars et francs congolais. Il tire ses redevances sur l'embarquement, route,
stationnement, etc.
+ Bureau médical
C'est un bureau qui assure le suivi médical de
salariés et conseille l'entreprise. Il est encore là pour la
prévention des risques professionnels. Il veille sur la santé de
salariés et conseille l'employeur sur l'ensemble de
problématiques liées aux conditions de travail.
5. Service de circulation aérienne
Comme l'indique la structure organique, la circulation
aérienne est le service purement technique qui justifie l'importance de
la RVA du fait qu'elle se préoccupe surtout de la sécurité
aérienne, la navigation, l'anti-incendie, sécurité
aéronautique et transmission aéronautique.
+ Bureau circulation aérienne
Ce bureau remplit le rôle de garantir la
sécurité des aéronefs dans l'espace aérien, son
fonctionnement est assuré par les contrôleurs de trafic
aérien dont la plupart sont ressortissants de l'ISTA (Institut
Supérieur de Techniques appliquées). Le lieu de travail des ATC
(mot anglais qui signifie Contrôleurs Transports aériens) est la
tour de contrôle qui est en contact avec tous aéronefs se trouvant
en l'air en vue de leur assurer la sécurité.
+ Bureau navigation
Ce bureau constitue une charnière entre la RVA et les
exploitations. Toutes les informations sur les mouvements des aéronefs
sont transmises par lui. Il reçoit les plans de vol des exploitants
qu'il transmet à la tour de contrôle, tient à jour le
relevé des
Il est chargé de gérer tous les matériels
roulants de l'entreprise ; ce qui expliquerait l'appartenance des chauffeurs
mécaniciens des engins à ce bureau.
59
mouvements aériens, contrôle les documents de
bord (licence, certificat de navigabilité etc.), manifeste des
passagers, les frets, calcule les redevances atterrissages, route,
stationnement à mettre à la disposition de bureau commercial pour
facturation. Les agents de ce bureau sont appelés commis piste. Ils ont
le pouvoir de contrôler les documents de bord.
? Bureau anti-incendie
Ce bureau est chargé de combattre tout incendie
à l'aéroport, il est doté de 2 véhicules
anti-incendie laissés par la MONUSCO; ceux-ci peuvent répondre
à toute ses préoccupations du fait qu'ils sauvegardent les biens
et les vies humaines au sol.
? Bureau télécommunication
aéronautique
Bureau vide, il a le rôle de transmettre les messages
officiels de service, les heures de décollages ou d'atterrissages des
avions d'une entité à une autre à l'intérieur du
pays. De ce fait, il fait aussi partie de la sécurité à la
navigation aérienne dans la mesure où tout aéronef
décollant ou atterrissant à telle ou telle autre entité
vers l'autre est attendu à destination avec précision de l'heure
prévue de son atterrissage. De même que les personnages officiels
dans l'aéronef sont signalés pour une prise de disposition.
? Bureau statistiques
C'est celui qui s'occupe de mouvements des aéronefs y
compris la ventilation des passagers, frets ainsi que les bagages y
afférents ; pour parvenir à dépister le chiffre
réel de passagers, les types d'avions au départ et à
l'arrivée et les frets au bout d'un mois, d'une année, etc.
suivant la demande.
6. Service moyens
généraux
Composé de deux bureaux : celui de l'entretien et celui
du charroi automobile. Ce service s'occupe de l'entretien des infrastructures
de la RVA ; il s'agit précisément de l'entretien de la piste de
l'aéroport, des charrois automobiles, des bâtiments. Il se charge
de tous les approvisionnements à la RVA.
? Bureau entretien
Ce bureau s'occupe de l'entretien de l'infrastructure piste et
bâtiments de l'entreprise. De ce fait, il commande les peintres, les
maçons, les architectes, les nettoyeurs des installations, les
ingénieurs en construction.
? Bureau charroi automobile
60
7. Service technique
Composé de 2 bureaux : celui de télécoms
navaids qui est vacant pour le moment et celui d'électricité et
balisage. Ce service se charge de l'aménagement et réparation des
appareils de télécommunication (Orthophonie, radiophonie etc.)
tout en veillant à la permanence de l'énergie au niveau de
l'aéroport.
? Bureau électricité et
balisage
Ce bureau a comme agents : les RTC (radio techniciens
contrôle) électriciens qui sont les ingénieurs
formés pour la réparation des moteurs et ravitaillement des
installations de la RVA en énergie électrique.
? Bureau télécoms
navaids
Les agents de ce bureau s'appellent R.T.C /
Télécoms. Ils sont également ingénieurs
formés en tant qu'électroniciens. Ce sont ceux qui
préparent les appareils électriques de
télécommunication comme micro, radio etc.
8. Service de sûreté et
facilitation
Il est composé de 2 bureaux : ceux de facilitation et
de la police. Ce service joue le rôle du maintien de l'ordre dans les
installations aéronautiques étant donné que
l'aéroport est un endroit stratégique pour une province. C'est
ainsi qu'on exige l'identification de toute personne qui désire y
accéder.
? Bureau facilitation
C'est un bureau est chargé du protocole de
l'entreprise. C'est ce bureau qui s'occupe de l'organisation de fête de
l'entreprise, accueil des missionnaires, etc.
? Bureau police
Ce bureau a pour rôle la sécurité des
installations aéroportuaires, des biens, des passagers, des visiteurs et
des travailleurs.
Source : R.V.A / Kananga, les
documents internes du bureau personnel
61
IV.1.8.3. Critique de l'existant
Après notre passage à la RVA Kananga pour mener
notre étude, nous avons remarqué les points faibles suivants :
- La gestion du personnel est soumise à une gestion
manuelle ; c'est-à-dire, tout ce qui est fait là est manuel ;
- Il n'y a pas un système de gestion de performance du
personnel. Ce qui cause une prise de décision hasardeuse pour ce qui
concerne leur prise en charge. Avec ce système de performance, la RVA
sera capable de savoir les effectifs des agents salariés et
non-salariés, les agents éligibles au congé et ceux
éligibles à la retraite, ce qui leur sera une source
d'inspiration pour les décisions concernant le personnel.
IV.8.4. Proposition de solution
Pour ainsi pallier aux failles constatées et
soulevées au point ci-haut, nous proposons les solutions suivantes :
- Par rapport au recrutement de personnel, nous souhaitons
mettre en place un système informatique qui va premièrement
pallier la difficulté par rapport au temps de traitement des dossiers
des agents. La façon de gérer manuellement le recrutement retarde
certaines opérations car c'est l'Etre humain qui doit passer au constat
des dossiers reçus.
- Nous mettrons également un système de gestion
du personnel pour permettre aux gestionnaires de bien prendre des
décisions optimales et importantes sur la gestion du personnel.
IV.2. Spécification de besoins
IV.2.1. Source de l'Application
La gestion des agents de la RVA est l'une des tâches
effectuées par le Chef du personnel pour la régularisation de la
situation administrative des personnels en suivant et respectant la
hiérarchie qui existe depuis son recrutement jusqu'à sa
retraite.
En général , les gens pensent que tous les
agents de la RVA sont fonctionnaires, mais il y a des agents non fonctionnaires
; c'est-à-dire agent non encadré par la RVA ou personnel
contractuel tels que l'employé de courte durée (ECD),
employé de longue durée (ELD), et l'employé de fonction
auxiliaire (EFA).
? Concours direct : les concours
directes sont ouverts à tous les agents non fonctionnaires ;
62
a) L'employé de courte
durée
Sa décision d'engagement est renouvelée chaque
6 mois ou 12 mois selon le cas dit dans le contrat. Après 6 ans de
service, le personnel est intégré et après
intégration il effectue un stage pendant 1 an pour devenir
fonctionnaire.
b) L'employé de longue
durée
C'est une attestation de classification ou engagement
directe. Il a une majoration de 10% de son salaire à tous les 2 ans
jusqu'à son intégration. Pour accorder la majoration, il faut
faire une demande et évaluer par un bulletin individuel de note ou
BIN.
c) L'Employé de fonction
auxiliaire
Ce personnel est recruté par décision
d'engagement. Ce contrat est renouvelé tous les 2 ans ; après 6
ans de service le personnel est devenu intégré et effectue un
stage pendant 1 an avant d'être fonctionnaire.
IV.2.2. Gestion de recrutement
Le recrutement est défini comme une action d'embaucher
un nouvel personnel pour travailler dans une entreprise, une
société, etc. l'objectif principal est de trouver l'agent
possédant la compétence et les aptitudes au poste à
pourvoir pour le meilleur rendement et pour assurer la survie de
l'entreprise.
a) Le mode de recrutement
Les candidats sont recrutés soit : ? Par voie de concours
:
- Concours directe ;
- Concours professionnel.
? Par voie d'intégration ; ? Sur titre ;
? Sélection de dossiers.
1. Voie de concours :
63
· Concours professionnels :
les concours professionnels sont fixés à tous les
agents déjà fonctionnaires.
2. Voie d'intégration : le
recrutement par voie d'intégration est réservé aux agents
non encadré.
3. Sur titre : le recrutement sur
titre est ouvert à tous.
4. Sélection des dossiers :
tous personnels aptes physiquement et moralement peuvent
participer à la sélection de dossiers. La sélection de
dossiers dépend du profil exigé par la RVA.
b) Droits et obligations du
fonctionnaire
1. Les droits
Le fonctionnaire a pour droit :
> Les fonctionnaires ont droit conformément aux
règles fixées par la loi
pénale et les lois spéciales, à une
protection contre les menaces, outrages,
injures ou diffamation quel que soit la cause, sans qu'il ait
abus de droit ; > De grever pour la défense de leurs
intérêts professionnels.
2. Les obligations
Les agents de la RVA sont tenus aux obligations :
y' De ponctualité, d'assiduité, de plein emploi,
d'honnêteté et d'efficacité ; y' De l'exécution des
tâches qui lui sont confiées ;
y' D'assurer la marche de son service à l'égard
de ses chefs, de l'autorité qui lui a été
conférée pour cet objet et de l'exécution des ordres qu'il
a donnée.
c) Le poste d'affectation
L'affectation est la désignation du poste de travail
d'un fonctionnaire. Le fonctionnaire est affecté à un poste de
travail vacant régulièrement et normalement prévu dans
l'organigramme par décision règlementaire des supérieurs
hiérarchiques.
1) La prise de décision :
c'est la date d'entrée dans l'administration ou date
d'embauche. Le personnel doit avoir un numéro d'immatriculation et un
certificat administratif. Ces 2 pièces justifient que le personnel est
dès maintenant fonctionnaire.
2) Le stage : le candidat
nommé après concours à un emploi de fonctionnaire est
soumis à un stage dont la durée est fixée
uniformément à 1 an.
64
d) Le contrat de travail
Normalement le contrat de travail ne se termine que par la
mise à la retraite du travailleur ; mais il peut y avoir d'autre
arrêt de contrat qui dépend du travailleur.
1) Renouvellement du contrat : le
renouvellement du contrat est réservé pour les agents non
encadrés de la RVA. A chaque fin du contrat, le renouvellement doit
être systématique. Il est fixé à chaque 6 mois.
2) L'intégration :
l'intégration est tenue pour les personnels contractuels.
Il effectue son service pendant 6 ans consécutifs à compter
à la date d'entrée dans l'administration. Si le personnel est
devenu fonctionnaire, il doit avoir aussi un certificat administratif ;
après 6 ans de prise de service, il fait l'intégration.
Après l'intégration, le personnel
réalise un stage dont la durée est fixée à 6 mois.
Il y a redoublement de stage si le stage si le stage effectué n'est pas
satisfaisant.
3) La titularisation : la
titularisation se fait après l'expiration de ce stage. S'il n'y a pas
redoublement de stage le personnel est directement titularisé.
IV.2.3. Gestion de Formation
a) Le reclassement : tous les
agents de la RVA ayant obtenu des diplômes, titres universitaires ou
qualifications professionnelles reconnus par l'Etat Congolais, avant ou en
cours de la période d'emploi, est reclassé ou assimilé aux
codes des fonctionnaires correspondant à ces diplômes au titre
suivant la réglementation en vigueur.
b) L'avancement : l'avancement a
lieu au profit de tous les agents de la RVA dépend de
l'ancienneté de service.
Il y a deux sortes d'avancement de personnel :
Avancement d'échelon ; Avancement de classe.
1. L'avancement d'échelon :
est un profit des agents de l'Etat. Le personnel jouit d'un
avancement automatique d'échelon au bout de 2 ans d'ancienneté
après la titularisation.
2. L'avancement de classe : il se
fait après la procédure d'échelon. Le corps des
fonctionnaires comprend régulièrement une hiérarchisation
et un échelonnement à 4 classes :
? La première classe a trois échelons ; ? La
deuxième classe a trois échelons ; ? La principale a trois
échelons ;
65
> La classe exceptionnelle a deux échelons.
3. La pension : les fonctionnaires mis
à la retraite bénéficient des différents types de
pension à compter à la date de prise de service jusqu'à la
cessation de service.
IV.2.4. Gestion de congé
Tous les personnels ou agents de la RVA ont un congé
qui dure 30 jours chaque année. Les personnels peuvent prendre un
congé en fonction de ce qu'il veut ou cela (la prise de congé)
dépend de leur choix, c'est-à-dire le nombre de jours de
congé et même le temps du congé. La prise de congé
dépend aussi de l'état de la société ou de
l'entreprise dans laquelle on travaille ; en d'autres termes si l'entreprise ou
la société est en pleine activité, on ne peut pas prendre
du congé de plus si les autres personnels sont en congé. La prise
de congé pour soi est presque impossible. Comme toutes choses, plusieurs
facteurs poussent les personnels à prendre un congé tels que dans
le domaine de santé, familiale ou autre. A noter que lorsque ces 30
jours sont tous pris ; c'est-à-dire qu'il n'y a plus de congé
restant ; le personnel ne peut pas prendre un congé sauf un cas
exceptionnel et lorsqu'il y a un reste cela est additionner avec celui de
l'année suivante.
IV.2.5. Objectif de l'application
L'objectif de cette application est de mettre à la
disposition du Chef de personnel un système permettant :
> D'enregistrer les informations concernant le personnel ;
> De bien suivre les mouvements concernant la retraite du
personnel ;
> De connaitre si ce personnel est vraiment un fonctionnaire
ou non
fonctionnaire déjà intégré ou pas
encore, c'est-à-dire contractuel ;
> De faire les analyses sur la prestation du personnel ;
> De mettre à la disposition des gestionnaires la
situation du personnel en un
temps réduit pour permettre une meilleure prise de
décision ;
> De prendre toutes les décisions nécessaires
pour la meilleure gestion du
personnel.
IV.2.6. Problématique du
projet
Les problèmes qui ont motivé à la
réalisation de ce projet sont :
· L'inexistence d'un système de gestion du
personnel à la RVA : tout est fait manuellement et c'est ce qui entraine
un décalage de la gestion dans le traitement des informations ;
· Le chef du personnel ne sait pas le nombre du
personnel facilement et aussi toutes les informations concernant son personnel
;
66
? La prise de décision sur la gestion du personnel qui
tarde chaque fois qu'on a besoin d'améliorer cette gestion ;
? En cas de décès, le déroulement des
différentes procédures dispensent beaucoup de temps par manque de
système permettant de gérer son personnel.
a) Liste des matériels
existants
|
Type
|
Processeur
|
RAM
|
HDD
|
Nombre
|
|
PC
|
Pentium IV 2,4GHZ
|
512Mb
|
80Gb
|
1
|
|
Pentium IV 2,6GHZ
|
512Mb
|
80Gb
|
1
|
|
Pentium IV 2,8
|
512Mb
|
80Gb
|
2
|
|
1Gb
|
160Gb
|
1
|
|
Pentium IV 3 GHZ
|
1Gb
|
80Gb
|
1
|
|
1 Gb
|
160Gb
|
1
|
|
2Gb
|
120Gb
|
1
|
|
2Gb
|
320Gb
|
1
|
|
Pentium IV 3,2GHZ
|
1Gb
|
120Gb
|
1
|
|
Dual Core 2GHZ
|
1Gb
|
160Gb
|
1
|
|
Dual Core 2,5GHZ
|
4Gb
|
240Gb
|
1
|
|
AMD Athlon 64 2,2GHZ
|
2Gb
|
160Gb
|
1
|
|
TOTAL
|
14
|
|
Portables
|
AMD Turion 64 1,6GHZ
|
768Mb
|
80Gb
|
1
|
|
Core2 Duo 2GHZ
|
4Gb
|
500Gb
|
3
|
|
Total
|
4
|
|
Total Général
|
18
|
Tableau 6: Liste des matériels
existants
b) Répartition autres
matériels
|
Désignation
|
Marque
|
Modèle
|
Nombre
|
|
Onduleur 400VA
|
SENDON
|
UPS-600
|
2
|
|
Onduleur 850VA
|
UPS Technology
|
Upson
|
5
|
|
Onduleur 1500VA
|
UPS Technology
|
Upson
|
2
|
|
Imprimante jet
d'encre
|
HP
|
D1360
|
1
|
|
Imprimante Laser
|
EPSON
|
LQ-2180
|
1
|
|
Imprimante Laser
|
OKI
|
Microline 4410
|
1
|
|
Imprimante Laser
|
LEXMARK
|
120n
|
1
|
|
Scanneur
|
Canon
|
Canoscan lide 100
|
1
|
|
Switch
|
LINKSYS
|
Wireless-G
|
1
|
Tableau 7: Autres matériels
28 KAFUNDA KATALAYI JP, Entrepôts des
données, L2 informatique option Gestion, cours inédit, U.K.A
2015-2016
67
IV.2.7. Les méthodologies des systèmes
d'informations
Plusieurs méthodes existent, mais pour notre projet, nous
allons utiliser la notation
UML.
a) La notation UML
UML (Unified Modeling Language) est une méthode de
modélisation orientée objet développée en
réponse à l'appel à propositions lancé par l'OMG
(Object Management Group) dans le but de définir la notation standard
pour la modélisation des applications construites à l'aide
d'objets. Elle est héritée de plusieurs autres méthodes
telles que OMT (Object Modeling Technique) et OOSE (Object Oriented Software
Engineering) et Booch. Les principaux auteurs de la notation UML sont Grady
Booch, Ivar Jacobson et Jim Rumbaugh.
Elle est utilisée pour spécifier un logiciel
et/ou pour concevoir un logiciel. Dans la spécification, le
modèle décrit les classes et les cas d'utilisation vus de
l'utilisateur final du logiciel. Le modèle produit par une conception
orientée objet est en général une extension du
modèle issu de la spécification. Il enrichit ce dernier de
classes, dites techniques, qui n'intéressent pas l'utilisateur final du
logiciel mais seulement ses concepteurs. Il comprend les modèles des
classes, des états et d'interaction. UML est également
utilisée dans les phases terminales du développement avec les
modèles de réalisation et de déploiement.
UML est une notation utilisant une représentation
graphique. L'usage d'une représentation graphique est un
complément excellent à celui de représentions textuelles.
En effet, l'une comme l'autre sont ambigus mais leur utilisation
simultanée permet de diminuer les ambigüités de chacune
d'elle. Un dessin permet bien souvent d'exprimer clairement ce qu'un texte
exprime difficilement et un bon commentaire permet d'enrichir une figure.
Il est nécessaire de préciser qu'une notation
telle qu'UML ne suffit pas à produire un développement de
logiciel de qualité à elle seule. En effet, UML n'est qu'un
formalisme, ou plutôt un ensemble de formalismes permettant
d'appréhender un problème ou un domaine et de le
modéliser, ni plus ni moins. Un formalisme n'est qu'un outil. Le
succès du développement du logiciel dépend
évidemment de la bonne utilisation d'une notation comme
UML mais il dépend surtout de la façon dont on
utilise cette méthode à l'intérieur du cycle de
développement du logiciel.28
68
b) Les qualités d'UML
1. Langage standard de fait
UML est reconnu parfois comme un des standards du
marché. Deux facteurs ont permis à UML d'accéder à
ce statut :
? -Il résulte de la fusion de trois outils
préexistant complémentaires qui déjà avaient une
audience non négligeable ;
? -Il a bénéficié de la force
commerciale d'un éditeur particulièrement offensif : Rational,
éditeur de l'outil Rose basé sur UML. Aujourd'hui, Rational est
une entité membre d'IBM (depuis début 2003). Rappelons que
Rational n'est pas le seul éditeur à oeuvrer dans le monde UML et
que certains des outils sont gratuits dans leur version personnelle. Enfin
l'utilisation d'UML est libre de droits.
2. Large spectre d'utilisation
Ce langage peut avoir un domaine d'application très
étendu et les exemples cités par Dominique Vauquier prouvent
qu'UML apporte des bénéfices à toute l'entreprise et pas
uniquement à ceux qui s'occupent de son SI.
3. Capacité à décrire en
emboîtant les niveaux d'abstraction
Les exemples cités ne seraient pas crédibles si
UML ne savait pas gérer les niveaux
d'abstraction habituellement reconnus et hiérarchiser les
représentations.
Ainsi, une entité du modèle (que ce soit un
processus, une instance, un événement,
un flux) pourra être située dans son niveau
hiérarchique :
? Le métier de l'Entreprise (niveau stratégique)
;
? Les blocs fonctionnels, concourant à l'accomplissement
de ce métier (niveau
tactique) ;
? Les fonctions (processus), chargées d'une mission
identifiée (niveau opérationnel I)
;
? Les activités unitaires (niveau opérationnel
II).
4. Méta modèle
accessible
Le langage UML donne accès à son méta
modèle. Dominique Vauquier ne cite pas cette qualité non
négligeable ; je me permets de la signaler. Un méta modèle
est une représentation (une modélisation donc) des concepts
utilisés par le langage lui-même. Cette représentation
permet de théoriser sur l'outil, permet de l'enrichir facilement, permet
de dégager des règles de bonne utilisation.
Par exemple, l'un des principes recommandés pour
assurer la cohérence entre les diagrammes du modèle se formule
ainsi :
y' Toute instance citée dans un diagramme des
séquences doit être membre d'une classe citée dans un
diagramme des classes ;
y' Toute classe doit avoir une entrée dans le
dictionnaire des concepts métier et être citée dans au
moins un Cas d'Utilisation. Dès lors qu'on se préoccupe des
relations
69
entre les éléments constitutifs du langage, on
attaque le méta modèle. Les promoteurs d'UML nous fournissent
beaucoup de descriptions sur ses éléments constitutifs, nous
permettant de formuler quelques critères qualité.
5. Points forts d'UML
UML est un langage formel et normalisé
· Gain de précision
· Gage de stabilité
· Encourage l'utilisation d'outils
UML est un support de communication performant
· Il cadre l'analyse.
· Il facilite la compréhension de
représentations abstraites complexes.
· Son caractère polyvalent et sa souplesse en font
un langage universel.
c) Pourquoi et comment modéliser
?
1. Qu'est-ce qu'un modèle ?
Un modèle est une représentation abstraite et
simplifiée (i.e. qui exclut certains détails), d'une
entité (phénomène, processus, système, etc.) du
monde réel en vue de le décrire, de l'expliquer ou de le
prévoir. Modèle est synonyme de théorie, mais avec une
connotation pratique : un modèle, c'est une théorie
orientée vers l'action qu'elle doit servir.
Concrètement, un modèle permet de
réduire la complexité d'un phénomène en
éliminant les détails qui n'influencent pas son comportement de
manière significative. Il reflète ce que le concepteur croit
important pour la compréhension et la prédiction du
phénomène modélisé, les limites du
phénomène modélisé dépendant des objectifs
du modèle.
Un modèle est avant tout une représentation
abstraite du monde réel. A ce titre, ce n'est pas le monde réel
et donc ce n'est pas, exactement le monde réel. Un modèle offre
donc une vision schématique d'un certain nombre d'éléments
que l'on veut décrire ; un dessin quoi ! On a coutume de dire : «
Un dessin vaut mieux qu'un beau discours » ; et bien écoutons et
tentons de comprendre nos ancêtres, nos parents ou tout ceux qui ont pu
nous répéter cette phrase. Réaliser un modèle c'est
avant tout dessiner ce que l'on a compris d'un problème dans une syntaxe
précise (la syntaxe UML ou Merise).
Un modèle va donc nous servir à communiquer et
échanger des points de vue afin d'avoir une compréhension commune
et précise d'un même problème.
2. Les niveaux d'abstractions :
Lorsque l'on a à traiter un problème complexe,
il est conceptuellement impossible de l'appréhender d'un seul bloc, dans
son ensemble. Notre esprit à besoin de « dégrossir » le
problème afin de pouvoir le comprendre pas à pas, petit à
petit. Une fois le problème découpé en
sous-problèmes de taille plus petite, l'analyse de chacun de ces
sous-problèmes nécessite de commencer à en comprendre les
grandes lignes puis d'affiner sa compréhension pour enfin comprendre
tous les détails.
70
Ce mode de résonnement est à la base même
des niveaux d'abstraction que l'on retrouve dans les méthodes comme
Merise (niveau conceptuel, niveau logique, niveau physique) ou RUP (niveau
fonctionnel, niveau analyse, niveau conception).
Il faut donc bien comprendre la signification de ces niveaux
et le nécessaire enrichissement d'un modèle de niveau N par
l'analyse de niveau N+1.
3. Pourquoi modéliser ?
Modéliser un système avant sa
réalisation permet de mieux comprendre le fonctionnement du
système. C'est également un bon moyen de maîtriser sa
complexité et d'assurer sa cohérence. Un modèle est un
langage commun, précis, qui est connu par tous les membres de
l'équipe et il est donc, à ce titre, un vecteur
privilégié pour communiquer. Cette communication est essentielle
pour aboutir à une compréhension commune aux différentes
parties prenantes (notamment entre la maîtrise d'ouvrage et
maîtrise d'oeuvre informatique) et précise d'un problème
donné.
4. Qui doit modéliser ?
La modélisation est souvent faite par la maîtrise
d'oeuvre informatique (MOE). C'est malencontreux, car les priorités de
la MOE résident dans le fonctionnement de la plate-forme informatique et
non dans les processus de l'entreprise.
Il est préférable que la modélisation
soit réalisée par la maîtrise d'ouvrage (MOA) de sorte que
le métier soit maître de ses propres concepts. La MOE doit
intervenir dans le modèle lorsque, après avoir défini les
concepts du métier, on doit introduire les contraintes propres à
la plate-forme informatique.
d) Les Diagrammes
UML utilise plusieurs diagrammes mais les plus utilisées
sont les suivantes :
1. Diagramme De Cas D'utilisation a.
Généralité
Bien souvent, la maîtrise d'ouvrage et les utilisateurs
ne sont pas des informaticiens. Il leur faut donc un moyen simple d'exprimer
leurs besoins. C'est précisément le rôle des diagrammes de
cas d'utilisation qui permettent de recueillir, d'analyser et d'organiser les
besoins, et de recenser les grandes fonctionnalités d'un système.
Il s'agit donc de la première étape UML d'analyse d'un
système29.
Un diagramme de cas d'utilisation capture le comportement d'un
système, d'un sous-système, d'une classe ou d'un composant tel
qu'un utilisateur extérieur le voit. Il scinde la fonctionnalité
du système en unités cohérentes, les cas d'utilisation,
ayant un sens pour les acteurs. Les cas d'utilisation permettent d'exprimer le
besoin des utilisateurs d'un système, ils sont donc une vision
orientée utilisateur de ce besoin au contraire d'une vision
informatique.
29
https://www.memoireonline.com
71
Il ne faut pas négliger cette première
étape pour produire un logiciel conforme aux attentes des utilisateurs.
Pour élaborer les cas d'utilisation, il faut se fonder sur des
entretiens avec les utilisateurs.
Les diagrammes des cas d'utilisation identifient les
fonctionnalités fournies par le système (cas d'utilisation), les
utilisateurs qui interagissent avec le système (acteurs), et les
interactions entre ces derniers. Les cas d'utilisation sont utilisés
dans la phase d'analyse pour définir les besoins de "haut niveau" du
système. Les objectifs principaux des diagrammes des cas d'utilisation
sont:
? fournir une vue de haut-niveau de ce que fait le
système ;
? Identifier les utilisateurs ("acteurs") du système
;
? Déterminer des secteurs nécessitant des
interfaces homme-machine (IHM).
Les cas d'utilisation se prolongent au-delà des
diagrammes imagés. En fait, des descriptions textuelles des cas
d'utilisation sont souvent employées pour compléter ces derniers
et représentent leurs fonctionnalités plus en détail.
b. Éléments des diagrammes de cas
d'utilisation :
Les composants de base des diagrammes des cas d'utilisation sont
l'acteur, le cas d'utilisation, et l'association.
? Acteur
Un acteur est un utilisateur du système, et est
représenté par une figure filaire. Le rôle de l'utilisateur
est écrit sous l'icône. Les acteurs ne sont pas limités aux
humains. Si le système communique avec une autre application, et
effectue des entrées/sorties avec elle, alors cette application peut
également être considérée comme un acteur.
? Cas d'utilisation
Un cas d'utilisation représente une
fonctionnalité fournie par le système, typiquement décrite
sous la forme Verbe+objet (par exemple
immatriculer voiture, effacer
utilisateur).
Les cas d'utilisation sont représentés par une
ellipse contenant leurs noms.
? Association
Les associations sont utilisées pour lier des acteurs
avec des cas d'utilisation. Elles indiquent qu'un acteur participe au cas
d'utilisation sous une forme quelconque. Les associations sont
représentées par une ligne reliant l'acteur et le cas
d'utilisation.
IV.3. Conception
Nous entrons maintenant dans la phase de conception y compris
les études nécessaires, le dictionnaire de données, les
règles de gestion et ensuite les diagrammes de notre projet.
72
IV.3.1. Quelques études nécessaires
IV.3.1.1. Etude d'opportunité
Cette étape d'avant-projet permet d'étudier la
demande de projet et de décider si le concept est viable. Cette
étape a pour enjeu de valider la demande des utilisateurs par rapport
aux objectifs généraux de l'organisation.
Elle consiste à définir le
périmètre du projet (on parle également du contexte),
notamment à définir les utilisateurs finaux, c'est-à-dire
ceux qui l'ouvrage est destiné (on parle de ciblage ou profilage). A ce
stade du projet il est donc utile d'associer les utilisateurs à la
réflexion globale.
Lors de la phase d'opportunité, les besoins
généraux de la maitrise d'ouvrage doivent être
identifiés. Il est nécessaire de s'assurer que ces besoins
correspondent à une attente de l'ensemble des utilisateurs cibles et
qu'ils prennent en compte les évolutions probables des besoins.
Dans l'étude d'opportunité aussi on parle des
avantages attendus par le projet et ici les avantages attendus par ce projet
sont les suivants :
Facilité au niveau du traitement de l'information,
c'est-à-dire que toute est faite automatiquement, le traitement devient
de plus en plus simple et on a un gain du temps dans le domaine de travail ;
Simplifie le travail du Chef personnel, les mises à jour
et les consultations qui sont faite manuellement au paravent sont tous
traité par cette application ; L'automatisation de la gestion de
personnel permet d'aider le chef personnel ou le service dont elle utilise pour
faciliter la gestion, il suffit de cliquer pour effectuer certains traitements
dans un minimum de temps.
IV.3.1.2. Etude de faisabilité
D'une manière générale, l'étude de
faisabilité occupe une phase importante dans l'étude
préalable de la conception d'un grand projet. Dans ce cas cette
étude se subdivise en trois parties tels que : la faisabilité
organisationnelle et ergonomique, faisabilité technique et
faisabilité de la solution de secours.
1. Faisabilité organisationnelle et
ergonomique
Pour la faisabilité organisationnelle et ergonomique :
la présence de cette application nécessite la
disponibilité des personnels occupant cette responsabilité, le
personnel aussi a besoin de faire ou suivre des formations pour qu'il
deviennent capables de manipuler notre logiciel à créer avec la
conception en supposant que nous sommes les formateurs des personnels dans
cette situation, et aussi pour pouvoir adapter aux nouvelles technologies, la
compréhension des fonctionnements de la Nouvelle Technologie de
l'Information et de la Communication (NTIC) est aussi nécessaire pour
les personnels.
2. Faisabilité technique
La nécessité du matériel et logiciel est
fortement recommandé pour bien exercer le processus du fonctionnement du
logiciel que nous allons développer. Nous recommandons vivement à
la société de se procurer de ses ordinateurs au nombre de
préférence avec des
73
équipements complémentaires afin d'adapter
l'automatisation du système. De ce fait, il suffit alors d'installer les
logiciels nécessaires pour l'exécution de notre programme surtout
notre application qui va répondre principalement les besoins de
l'utilisateur. La mise à jour de notre application à créer
peut être effectuée soit par le personnel que nous aurons
formé, soit par nous-même en parlant donc d'un traitement e
maintenance d'une négociation.
3. Faisabilité de la solution de
secours
Pour bien sécuriser toutes les données
importantes de cette société, il vaut mieux sauvegarder au moins
deux exemplaires dans les supports distincts les informations très
essentielles. Alors l'utilisation des supports physiques est nécessaire
et important car dans ces distincts supports, les données sont alors
bien sécurisées. En outre, il est de préférence de
sauvegarder les informations dans le flash disque ou dans le CD-ROM ou dans un
autre support de sauvegarde autre que le Disque Dur de la machine pour
éviter la disparition des informations essentielles de la
société car la plupart de ces supports que nous avons
cités ci-dessus est très fiable et bien
sécurisé.
L'utilisation du système RAID est évidement
faisable parce qu'il suffit tout simplement d'acheter ce logiciel avec licence
et l'utiliser. Le système RAID est un système avec lequel on
utilise deux disques durs et l'utilisation de ce logiciel permet lorsqu'on fait
une écriture à l'un des disques les informations sont aussi
transmises à l'autre disque. Lorsque l'un des disques est en panne, on
récupère les informations à partir de l'autre disque qui
se sert d'une sauvegarde et cela permet la récupération rapide
des informations au lieu de faire des copies à partir de quelques
supports de sauvegarde.
IV.3.2. Dictionnaire de
données
|
Rubrique
|
Description
|
Type
|
Longueur
|
Etat
|
Remarque
|
|
Im
|
Immatriculation
|
N
|
10
|
E
|
|
|
Nom
|
Nom du personnel
|
A
|
20
|
E
|
|
|
Prenom
|
Prénom du personnel
|
A
|
20
|
E
|
|
|
Sexe
|
Sexe du personnel
|
A
|
6
|
E
|
|
|
Grade
|
Grade du personnel
|
N
|
18
|
E
|
|
|
Tel
|
Téléphone du personnel
|
N
|
10
|
E
|
|
|
Adrs
|
Adresse du personnel
|
A
|
20
|
E
|
|
|
Code_dipl
|
Code du diplôme
|
AN
|
12
|
E
|
A créer
|
|
lib_dipl
|
Libéllé du diplôme
|
A
|
10
|
E
|
A créer
|
|
num_arrt_intgr
|
Numéro de l'arrêté d'intégration
|
N
|
10
|
E
|
A créer
|
|
date_arrt_intgr
|
Date de l'arrêté d'intégration
|
D
|
8
|
E
|
JJ/MM/AA
|
|
num_arrt_titu
|
Numéro arrêté de titularisation
|
N
|
10
|
E
|
A créer
|
74
|
date_arrt_titu
|
Date de l'arrêté de titularisation
|
D
|
10
|
E
|
JJ/MM/AA
|
|
code_cg
|
Code du congé
|
AN
|
6
|
E
|
A créer
|
|
pers_cg
|
Personnel congé
|
A
|
20
|
E
|
A créer
|
|
datedeb_cg
|
Date de début du congé
|
D
|
8
|
E
|
JJ/MM/AA
|
|
durée_cg
|
Durée du congé
|
N
|
2
|
E
|
A créer
|
|
datefin_cg
|
Date de fin congé
|
D
|
8
|
E
|
JJ/MM/AA
|
|
code_aff
|
Code d'affectation
|
AN
|
6
|
E
|
A créer
|
|
pers_aff
|
Personnel affecté
|
A
|
20
|
E
|
A créer
|
|
p_origine
|
Poste d'origine
|
A
|
10
|
E
|
|
|
p_affectation
|
Poste d'affectation
|
A
|
10
|
E
|
A créer
|
|
code_appartenir
|
Code appartenir
|
AN
|
6
|
E
|
A créer
|
|
nom_reg
|
Nom de la région
|
A
|
10
|
E
|
|
|
district
|
district
|
A
|
10
|
E
|
|
|
Lieu
|
Lieu
|
A
|
20
|
E
|
A créer
|
Tableau 8 : Dictionnaire de
données
? Liste des abréviations ? A :
Alphabétique ? AN : Alphanumérique ? N : Numérique
? D : Date
? E : Elémentaire
IV.3.3. Les règles de gestion
Les règles de gestion regroupent les contraintes et les
liens entre les données. Voici les règles qui nous ont permis
:
? RG1 : Le service Personnel gère
toutes les données concernant le personnel de la RVA
? RG2 : Ce service veille sur l'information
sur le poste, et on prépare les dossiers qui se rapportent à tous
les droits et avantages ainsi que les obligations des personnels comme
l'avancement, la distinction honorifique, les congés, l'admission
à la retraite et aussi la neutralité d'appartenance politique.
? RG3 : Chaque personnel doit avoir un
classeur de dossier administratif et sur un support électronique.
? RG4 : Toutes les rubriques proposées
dans cette base doivent être remplies.
75
> RG5 : Chaque personnel doit avoir et
remplir une fiche individuelle de renseignements dans laquelle figure son
état civil, sa situation de famille, son état de service, les
sanctions positives et les sanctions négatives.
> RG6 : La section situation
administrative de la fiche de renseignement figure le grade, son cadre avec le
numéro et la date d'arrêté, sa date d'effet et l'indice
correspondant.
> RG7 : Tout personnel nouvellement
recruté ou nouvellement affecté doit aviser son arrivé en
établissant la lettre de prise de service. De même pour ceux qui
vont partir doivent établir une lettre de cessation de service.
> RG8 : Tout personnel peut faire une
demande d'affectation selon leur choix.
> RG9 : Le grade est identifié par
son code, sa classe et son échelon.
> RG10 : Après la période de
stage, les avancements suivants sont automatiques à chaque deux an.
> RG11 : Les personnels titularisés
commencent par le grade du deuxième classe premier échelon.
> RG12 : Les ELD ou contractuels qui sont
récemment titularisés jouissent des anciennetés
conservées qui sont comptées de la date de son dernier avancement
jusqu'à la date de l'arrêté de titularisation.
> RG13 : Tout personnel a un congé
de 30 jours chaque année.
> RG14 : Les congés qui ne sont pas
prise seront additionnés avec celle de l'année suivante.
> RG15 : Lorsque la retraite approche le
personnel peut prendre toute le reste de son congé
> RG16 : Pour la promotion au grade
supérieur il faut se référer à la date d'effet du
dernier avancement et la date de promotion.
> RG17 : Les contractuels peuvent
être intégrés en corps de fonctionnaires.
> RG18 : Les fonctionnaires doivent
être titularisés après un an de stage.
> RG19 : Un fonctionnaire obtient un grade
et une catégorie conforme à son niveau d'instruction et son
diplôme obtenu.
> RG20 : Une fois intégrée,
le personnel doit avoir un grade.
> RG21 : Après le recrutement, tous
les personnels contractuels doivent passer en ECD et est engagé au
premier contrat.
76
IV.4. La conception de diagrammes
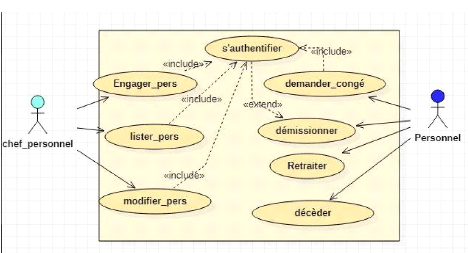
IV.4.1. Diagramme de cas
d'utilisation
Figure 14 : Diagramme de cas d'utilisation de la
gestion du personnel
1°) Cas d'utilisation «
Engager »
Ce cas d'utilisation sert à un engagement;
c'est-à-dire le chef du personnel donne les informations du personnel
à recruter.
a) Description textuelle
|
Identification de cas d'utilisation
|
|
Nom
|
Engager
|
|
Objectif
|
Pour pouvoir être parmi les agents de la RVA
|
|
Acteur principal
|
Chef du personnel
|
|
Date de création : 29/09/2021
|
Date de modification : 06/10/2021
|
|
Auteur
|
Paulinsoft
|
|
Version
|
1.0
|
|
Description des scénarios
|
|
Les préconditions
|
Pas encore inscrit
|
|
Des scénarios nominaux
|
1.1 Authentification
|
|
1.2 Vérification code
|
|
1.3 Affichage menu
|
|
1.4 Saisie information du personnel
|
|
1.5 Enregistrement
|
|
1.6 Enregistrement accepté
|
77
|
Des scénarios alternatifs
|
Au point 1.3
|
|
2.1 : personnel déjà engagé
|
|
2.2 : engagement annulé
|
|
Des scénarios d'exceptions
|
Au point 1.4
|
|
3.1. Erreur de saisie
|
|
3.2. Formulaire de saisie
|
|
Des post conditions
|
Personnel enregistré dans la base de données
|
Tableau 9 : Identification de
engager
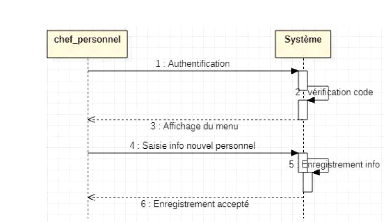
b) Description graphique
1. Diagramme de séquence
correspondante
Figure 15 : diagramme de
séquence de cas d'utilisation engager
78
2. Diagramme d'activité correspondante
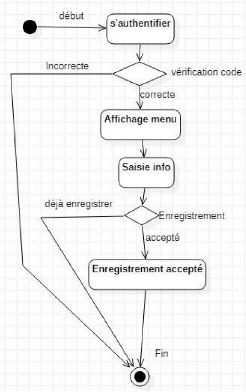
Figure 16 : diagramme d'activité engager
2°) Cas d'utilisation « Modifier personnel
»
Ce cas d'utilisation sert pour la modification ;
c'est-à-dire faire adapter ce qui est dans le système à la
réalité.
a) Description textuelle
|
Identification de cas d'utilisation
|
|
Nom
|
|
Modifier personnel
|
|
Objectif
|
|
Permet de mettre à jour l'information
|
|
Acteur principal
|
|
Chef du personnel
|
|
Date de création :
|
29/09/2021
|
Date de modification : 06/10/2021
|
|
Auteur
|
|
Paulinsoft
|
|
Version
|
|
1.0
|
|
Description des scénarios
|
79
|
Les préconditions
|
Pas encore modifié
|
|
Des scénarios nominaux
|
1.1 Nouvelle modification
|
|
1.2 Modification de l'information
|
|
1.3 Validation information
|
|
1.4 Modification terminée
|
|
Des scénarios alternatifs
|
Au point 1.3
|
|
2.1 : personnel déjà modifié
|
|
2.2 : modification annulée
|
|
Des scénarios d'exceptions
|
Au point 1.4
|
|
1.1. Erreur de saisie
|
|
1.2. Formulaire de modification
|
|
Des post conditions
|
Personnel modifié et enregistrement dans la base de
données
|
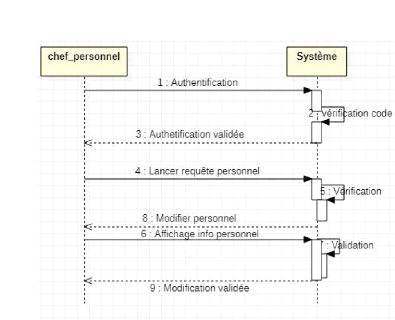
Tableau 10 : identification de
modifier personnel b) Description graphique
1. Diagramme de séquence
correspondante
Figure 17 : diagramme de
séquence modifier personnel
80
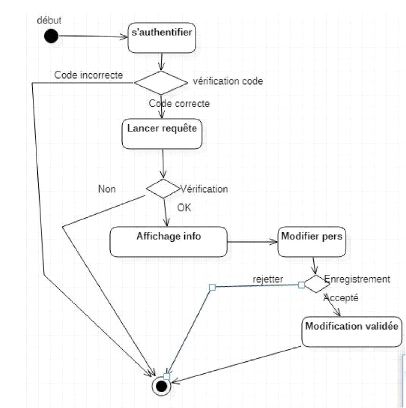
2. Diagramme d'activité
correspondante
Figure 18 : diagramme d'activité modification
personnel
3°) Cas d'utilisation «
Lister_personnel »
Ce cas d'utilisation sert pour lister le personnel ;
c'est-à-dire afficher la liste du personnel recherché.
c) Description textuelle
|
Identification de cas d'utilisation
|
|
Nom
|
|
Lister personnel
|
|
Objectif
|
|
Permet d'afficher la liste de personnel
|
|
Acteur principal
|
|
Chef du personnel
|
|
Date de création :
|
29/09/2021
|
Date de modification : 06/10/2021
|
|
Auteur
|
|
Paulinsoft
|
|
Version
|
|
1.0
|
|
Description des scénarios
|
81
|
Les préconditions
|
Pas encore lister
|
|
Des scénarios nominaux
|
1.1. Nouveau listage
|
|
1.2. listage de l'information
|
|
1.3. Validation information
|
|
1.4. Listage terminé
|
|
Des scénarios alternatifs
|
Au point 1.3
|
|
2.1 : personnel déjà listé
|
|
2.2 : listage annulé
|
|
Des scénarios d'exceptions
|
Au point 1.4
|
|
1.3. Erreur de saisie
|
|
1.4. Formulaire de modification
|
|
Des post conditions
|
Personnel listé et enregistrement dans la base de
données
|
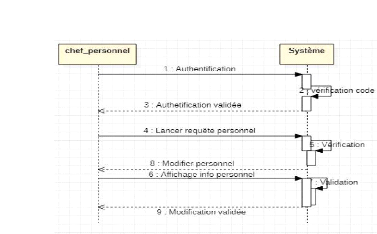
Tableau 11 : identification de
lister personnel d) Description graphique
3. Diagramme de séquence
correspondante
Figure 19 : diagramme de
séquence modifier personnel
82
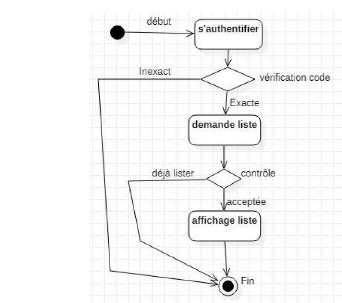
4. Diagramme d'activité
correspondante
Figure 20 : diagramme d'activité
modification personnel
83
IV.4.2. Diagramme de classe
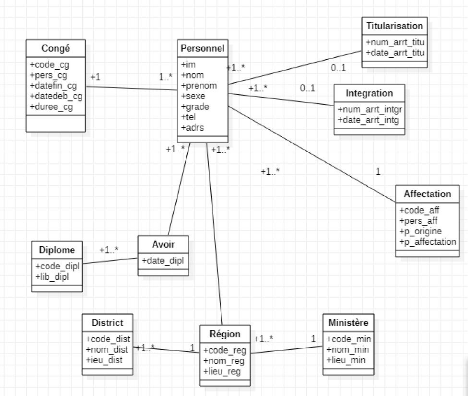
Figure 21 : diagramme de classe de la
gestion du personnel
84
Conclusion partielle
Ce chapitre comporter deux parties dont : l'analyse de
l'existant et la conception, quant à l'analyse de l'existant nous avons
présenté notre cadre de recherche qui est la RVA Kananga et son
fonctionnement. Quant à la deuxième partie nous a eu à
faire la modélisation à l'aide de Start UML qui nous a faciliter
la tâche de concevoir le diagramme de cas d'utilisation, de
séquence, d'activité et enfin celui de classe. Le chapitre
suivant présentera l'implémentation de notre solution.
85
CHAPITRE V : IMPLEMENTATION DE LA SOLUTION
V.1. Présentation De L'outil
C'est la phase finale de la conception de système
d'information. Elle consiste à concevoir un entrepôt de
données pour arriver aux traitements souhaités pour les besoins
de l'entreprise.
Pour notre mémoire, nous avons choisi SQL Server 2008
comme SGBD afin de stocker nos données qui concernent les personnels de
la RVA. Ce choix est justifié par le fait que le modèle
relationnel offre la possibilité de manipuler facilement les
données rapidement.
V.2. Table de faits
Voici notre table de faits pour l'analyse :
Analyse de la situation du personnel
- Nombre de personnel - Salaires
- Date d'integration
- Date de titularisation
|
|
V.3. Première partie : Système
transactionnel (OLTP)
1. Création d'une base de
données
Voici comment nous avons procéder pour créer
notre base de données :
? Démarrer/SQL Server 2008/SQL Server Management
Studio
? Préciser le mode d'accès à votre server
(Authentification Windows ou
Authentification SQL server)
? Le nom de votre serveur
? Pour l'authentification SQL server vous devez préciser
la connexion (par
exemple sa si on accède au serveur comme
administrateur) et votre mot de
passe. Voir la figure suivante :
? Cliquer sur le bouton se conn
86
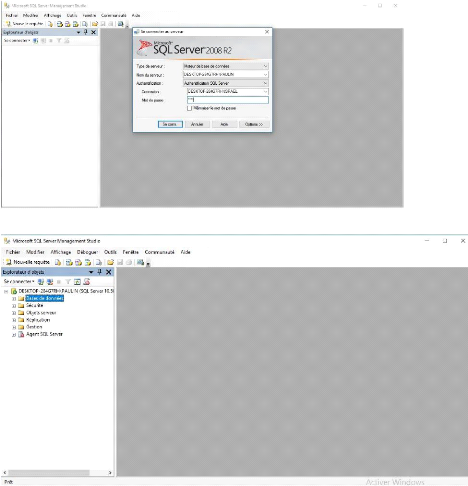
Figure 22 : SQL Server
On obtient ensuite la figure suivante :
Figure 23 : Microsoft SQL Server
Management Studio Création d'une nouvelle base de données :
V' Se positionner le noeud racine de l'arbre.
C'est-à-dire sur le noeud base de données
V' Clic droit sur ce noeud base de données
V' Clic sur nouvelle base de données
V' Donner un nom à votre base de
données
V' Clic sur le bouton ok
Voici l'acheminement de ces étapes sur les figures
suivantes :
87
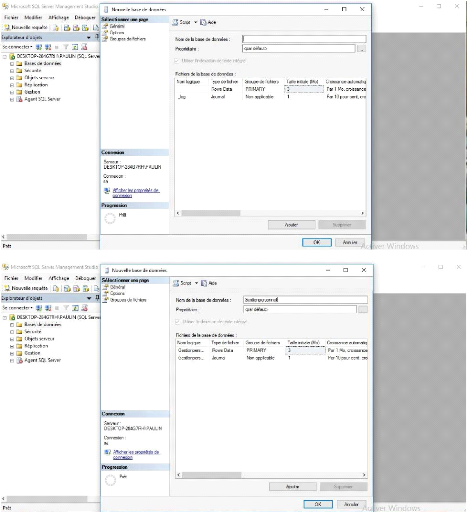
Figure 24 : création de la base
de données
Figure 25 : nouvelle base de
données Notre base de données est nommée Gestion_personnel
Clic sur le bouton ok
Pour la création des tables on procède de la
manière suivante :
? Cliquer sur le symbole + à
côté du noeud base de données pour voir tous ses noeuds
fils,
? Se positionner sur la base de données
Gestion_personnel
88
? Cliquer sur le symbole + à
côté de Gestion_personnel ? Clic droit sur le noeud table
? Clic sur nouvelle table
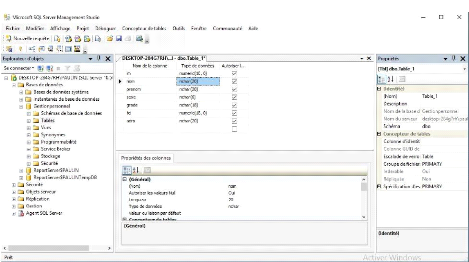
Voir la figure suivante :
Figure 26 : table
V.4. Deuxième partie : Système
Décisionnel (OLAP)
Lancer le Business Intelligence Management Studio
Cliquer sur Démarrer/Programme/Sql server 2008/ server
Business Intelligence Development Studio
89
Figure 27 : Business Intelligence
Cliquer sur créer projet ou Fichier/Nouveau projet
Sélectionner, projet business intelligence
Sélectionner, projet analysis service
Donner un nom à votre projet
V.5. Création Source de données
Clic droit sur source de données/clic sur nouvelle source
de données
L'assistant source de données s'affiche
Cliquer sur le bouton suivant
Cliquer sur le bouton nouveau
Cliquer sur ok
90
Figure 28 : Assistant Source de
données
Définir le provider (fournisseur)
Prendre Microsoft OLEDB Provider for SQL SERVER
Sélectionner votre base de données
Cliquer sur le bouton suivant
Clic sur nouvelle source de données
91
Figure 29 : Gestionnaire de
connexion
Cliquer sur le bouton suivant
92


Figure 30 : Assistant source de
données
V.6. Création Vue de données
> Clic droit sur vue des sources de données
> Clic droit sur nouvelle source de données
> Clic sur suivant, suivant
> Désactiver la case créer des relations logique
en faisant correspondre les colonnes
> Clic sur suivant
> Sélectionner les tables en cliquant sur le bouton
à deux flèches »
> Clic sur suivant
> Clic sur terminer
93
Voir les figures suivantes :
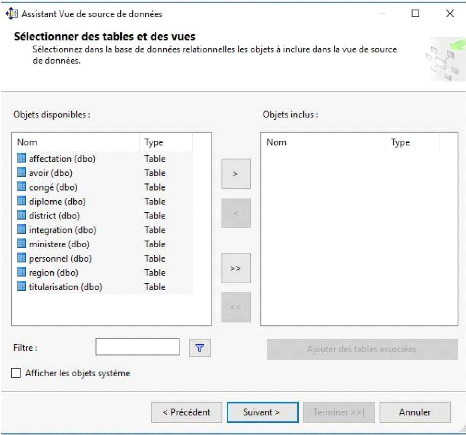
Figure 31 : Sélection des
tables
Créer votre vue en glissant à partir de table de
fait chaque clé étrangère vers la table de dimension
correspondante
Création d'une nouvelle dimension
? Clic droit sur Dimension/nouvelle Dimension
? Clic sur suivant ? Clic sur suivant
? Choisir Temps comme table principale
94
> Définir la hiérarchie (ex :
Année/Trimestre/Mois/Date)
Figure 32 : création
dimensions
V.7. Création du Cube
> Clic sur droit sur Cubes
> Clic sur nouveau cube
> Clic sur suivant
> Clic sur suivant
> Cocher la case de table de fait
> Clic sur suivant, suivant, suivant, suivant, Terminer
95
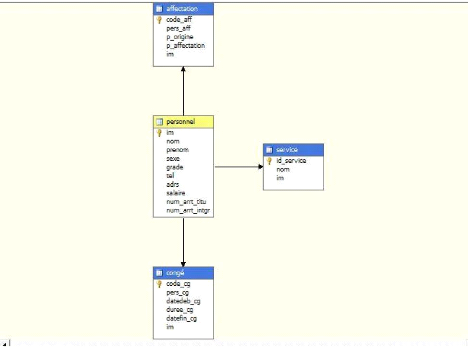
Figure 33 : création de
cube
Double cliquer sur chacune de dimension et glisser les attributs
vers la gauche Exécuter en démarrant le débogage (clic sur
le bouton verts ou touche F5) Double clic sur le cube / Clic sur l'onglet
navigateur
96
Conclusion partielle
Mieux vaut la fin d'une chose que son commencement dit-on,
dans ce chapitre nous avons présenté notre solution informatique
qui est l'entrepôt de données dont nous avons abordé le
système OLTP et le système OLAP qui nous ont conduit au
déploiement du cube afin de matérialiser ce qu'a
été notre rêve et notre désir d'aider la RVA afin
d'appliquer l'informatique décisionnel pour une meilleure prise de
décision.
97
CONCLUSION GENERALE
Nous voici arrivé au terme de notre réflexion
scientifique, fruit de nos recherches rendues visibles par ce travail de fin de
notre deuxième cycle qui sanctionne la fin de nos études
universitaires à l'université Saint Laurent de Kananga (USLKA),
dans la faculté de Sciences Informatiques, Option Conception de
système d'information et programmation avancée ; travail qui a
porté sur la modélisation et l'implémentation d'un
système décisionnel pour la gestion du personnel à la
Régie des Voies Aériennes de Kananga.
Dans notre travail, nous avons parlé d'abord du
système décisionnel qui présente l'ensemble des processus
qui permettent de collecter, d'intégrer, de modéliser et de
présenter les données.
Nous avons également parlé des entrepôts
de données qui constituent le coeur du système décisionnel
jouant un rôle référentiel pour l'entreprise puisqu'il
permet de fédérer des données souvent
éparpillées dans les différentes base de données et
nous avons déployé notre entrepôt de données avec le
SQL Server 2012.
Quant à la conception, nous avons utilisé le
langage de modélisation UML afin de dresser les différents
diagrammes nécessaires à notre travail.
De ce qui précède, nous sommes convaincus que
l'ensemble des préoccupations soulevées à la
problématique de notre travail ont été résolues.
Le but de ce modeste travail est de mettre de mettre en place
un système décisionnel afin d'aider le gestionnaire des
ressources humaines en particulier le Chef du personnel de la Régie des
Voies Aériennes de Kananga d'avoir une vue d'ensemble sur les
informations concernant la gestion du personnel.
Notre contribution dans cette étude était de
réaliser un entrepôt de données pour la gestion du
personnel afin que le Chef du personnel établisse au moment opportun son
rapport et prenne des meilleures décisions dans un très bref
délai.
Enfin, nous disons à nos chers lecteurs que ce travail
étant une oeuvre scientifique et humaine peut avoir des imperfections,
ainsi, vos remarques, critiques et suggestions seront les bienvenues pour sa
perfection car il reste ouvert.
98
BIBLIOGRAPHIE
A. Ouvrages
1. ADIBA .M, Entrepôts de données et fouille
de données, Paris 2002
2. AHMED T., MIQUEL M., LAURINI R., « Continuous data
warehouse : concepts, challenges and potentials », Proc. of the 12th
International Conference on Geoinformatics, 2004
3. Bertino E., Ferrari E., Guerrini G., Merlo I., "Extending
the ODMG Object Model with Composite Objects", OOPSLA'98, Vancouver (Canada),
1998
4. Bret F., Teste O., "Construction Graphique
d'Entrepôts et de Magasins de Données", INFORSID'99, La Garde
(France), Juin 1999.
5. Chaudhuri S., Dayal U., "An Overview of Data Warehousing
and OLAP Technology", ACM SIGMOD Record, 26(1), 1997
6. Dayal U., Blaustein B. T., Buchmann A. P., Chakravarthy U.
S., Hsu M., Ledin R., McCarthy
D. R., Rosenthal A., Sarin S. K., Carey M. J., Livny M.,
Jauhari R., "The HiPAC Project: Combining Active Databases and Timing
Constraints", ACM SIGMOD Record, 17(3), Chicago (Illinois, USA), 1988
7. FREYSSINET J. ; Méthode de recherche en Sciences
Sociales, éd.Mont Chrétien, Paris, 1997
8. G.A. Gorry et M.S. Scott-Morton, « A framework for
management information systems », Sloane Management Review 1971
9. GRAWITZ M. ; Les méthodes des Sciences Sociales,
Paris, édition Dalloz, 1955
10. Groupe EVOLUTION. F. Bret. T. Cruanees. I. Guessarian. E.
Metais. M-C. Rousset. S. Schwer. O. Teste. G. Zurfluh, Ingénerie des
systèmes d'information , édition HERMES, 2001
11. INMON W.-H., Building the data warehouse, QED
Publishing Group, 1992
12. Jarke M., Lenzerini M., Vassiliou Y., Vassiliadis P.,
"Fundamentals of Data Warehouses", Ed. Springer Verlag, ISBN 3-540-65365-1,
1999
13. Matthias Jarke, Thomas List, Jörg Köller, The
Challenge of Process Data Warehousing, 26th International Conference on Very
Large Databases, Caire, Egypt, 2000
14. P.F. Drucker, « Managing in a Time of Great Change
(The Post-Capitalist Executive) », Penguin 1995.
15. R. Kimball, L. Reeves, M. Ross, W. Thornthwaite,
Concevoir et déployer un data warehouse, Eyrolles, Paris, 2000
16. S. Kelly, « Data Warehousing - The Route to Mass
Customization », John Wiley & Sons 1996
17. Samos J., Saltor F., Sistrac J., Bardés A.,
"Database Architecture for Data Warehousing: An evolutionary Approach",
DEXA'98, Vienna (Austria), 1998
18. VINCENT GUIJARRO, Les Arbres de Décisions
L'algorithme ID3, lile, 2006
19. Y. Zhuge, H. Garcia-Molina, J. Hammer, J. Widom, "View
Maintenance in a Warehousing Environment", SIGMOD Record, San Jose (USA),
1995
B. Notes de cours et
thèses
1. KAFUNDA KATALAYI JP, Entrepôts des
données, L2 informatique option Gestion, cours inédit, U.K.A
2015-2016.
2. KANGIAMA LWANGI Richard : Extraction des connaissances a
partir d'un entrepôt des données à l'aide de l'arbre de
décision application aux données médicales, UNIKIN
20102011.
99
3. MALENGA M. ; Notes de cours d'initiation à la
Recherche Scientifique, G1 Informatique, USLKA, 2016-2017, inédit
4. MUKADI C. ; Notes de Cours de Méthodes de Recherche
Scientifique, G2 Informatique, USLKA, 2017-2018, inédit
5. RAKOTOMALALA. : Graphes d'induction apprentissage et data
mining, hermès, 2000.THESE
C. Webographie
1.
https://www.wikipédia.com/système
decisionnel/
2.
https://www.memoireonline.com
3.
https://www.cyberzoide.developpez.com
100
Table des matières
EPIGRAPHE I
IN MEMORIAM II
DEDICACE III
REMERCIEMENTS IV
SIGLES VI
LISTE DE FIGURES VII
LISTE DE TABLEAUX VIII
0. INTRODUCTION GENERALE 1
0.1. Choix et intérêt du sujet 2
0.2. Etat de la question 2
0.3. Problématique et hypothèses 3
0.4. Méthodes et techniques 3
0.5. Objectif de la recherche 4
0.6. Délimitation de la recherche 5
0.7. Subdivision du travail 5
CHAPITRE I : GENERALITES SUR LES SYSTEMES DECISIONNELS 6
I.0. Introduction 6
I.1. Présentation du décisionnelle 6
I.2. Définition d'un système décisionnel
6
I.3. Historique des systèmes décisionnels 9
I.4. L'informatique décisionnelle 9
I.5. Définition d'un système décisionnel
(Business intelligence) 9
I.6. Les différents éléments constitutifs
du système décisionnel 11
I.7. Les fonctionnalités d'un système
décisionnel 12
I.8. Les apports des systèmes décisionnels 13
I.9. Les Enjeux De L'informatique Décisionnelle 14
I.10. Les fonctions essentielles de l'informatique
décisionnelle 14
I.11. Définition des Modèles de Données
Décisionnels 17
Conclusion partielle 19
CHAPITRE II: DATA WAREHOUSE 20
II.1. Introduction 20
II.2. Définition d'un data warehouse (DW) 20
II.3. Caractéristiques d'un Data Warehouse 23
II.4 Entrepôts et Bases de données 24
II.5. Schémas d'un Data Warehouse 28
II.6 Le Data Mart 32
II.7 Les Serveurs OLAP (On-Line Analytical Processing) 34
Conclusion partielle 38
CHAPITRE III : LE DATA MINING ET ARBRE DE DECISION 39
III.0 Introduction 39
III.1 Objectifs Du Data Mining 40
III.1.1. Processus Du Datamining 41
III.1.2. Les Tâches Du Datamining 43
III.I.2.1. Les Tâches Et Technique Du Datamining
43
101
III.2. Arbre de décision 44
III .2.1. Introduction à l'arbre de décision
44
III.2.2. Définition 44
III.2.3. Caractéristiques et Avantages 44
III.2.4. Algorithme ID3 45
III.2.5. Principes 45
III.2.6. Exemple Pratique d'un Algorithme ID3 46
III.3 Concepts Théoriques Sur Le Graphe 49
Conclusion partielle 51
CHAPITRE IV : PRESENTATION DU CADRE D'ETUDE ET SPECIFICATION
DE BESOINS 52
VI.1. La Présentation Cadre d'étude 52
IV.2. Spécification de besoins 61
IV.3. Conception 71
IV.4. La conception de diagrammes 76
Conclusion partielle 84
CHAPITRE V : IMPLEMENTATION DE LA SOLUTION 85
V.1. Présentation De L'outil 85
V.2. SQL SERVER 2008 85
V.3. Première partie : Système transactionnel
(OLTP) 85
V.4. Deuxième partie : Système
Décisionnel (OLAP) 88
V.5. Création Source de données 89
V.6. Création Vue de données 92
Création d'une nouvelle dimension 93
V.7. Création du Cube 94
Conclusion partielle 96
CONCLUSION GENERALE 97
BIBLIOGRAPHIE 98
| 

