5.2.3. Prédiction de la
vitesse de trajet à pied
Afin d'analyser la variation de la vitesse selon
chaquevariable explicative, des modèles univariés ont
été construits pour identifier les variables qui influencent le
plus la vitesse. Ensuite, un modèle multivarié a
été développé pour inclure toutes les variables qui
ont été significatives lors de l'analyse univarié, afin de
prendre en compte l'effet de tous ces facteurs ensemble.
Suite à l'exploration de données
précédentes, les variables explicatives utilisées dans le
modèle sont les suivantes : la pente (à valeur
quantitative), la pluviométrie (à valeur quantitative), la
distance (à valeur qualitative), l'occupation du sol (à valeur
qualitative) et l'individu (à valeur qualitative pour les
différents types d'individus).
Le modèle univariépermet d'obtenir les
informations sur les coefficientsassociés à chaque variable.Le
modèle est appliqué à l'aide d'une fonction disponible sur
R nommée « lm » avec la formule : 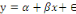 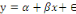 où á est l'intercept (valeur de la variable réponse
quand l'explicative vaut zéro) ; â est le coefficient de
régression (changement dans la variable réponse pour chaque
incrément d'une unité de la variable explicative), et est l'erreur de prédiction (différence
entre valeurs observés et prédits). où á est l'intercept (valeur de la variable réponse
quand l'explicative vaut zéro) ; â est le coefficient de
régression (changement dans la variable réponse pour chaque
incrément d'une unité de la variable explicative), et est l'erreur de prédiction (différence
entre valeurs observés et prédits).
Pour le modèle multivarié, les variables les
plus significatives du modèle précèdent ont
été utilisés. L'AIC (Akaike information
creterion) est calculé pour chaque modèle pour estimer la
qualité du modèle obtenue. Pour le modèle de parcours
à pied, on a utilisé unmodèle additive(GAM) pour prendre
en compte la relation non-linéaire entre la vitesse et la pente (figure
7.3). Pour le modèlede parcours en véhiculemotorisés nous
avons utilisé un modèle gaussien (figure 8.3). Pour les deux
modèles, on a utilisé des modèles mixte, où les
variables explicatives sont les effets fixes et un effet aléatoire a
été rajouté pour chaque parcours individuel (Muller
2018).Les modèlessont disponibles sur R avec les plugins
« mgcv / lmer » et les fonctions nommée
« gam / lmer ».
Après la création des modèles, on a
utilisé des données de parcours entre chaque village et CSB.Ces
parcours représentent les distances minimums de chaque village par
rapport au CSB le plus proche. Pour le structurer, on a effectué les
mêmes étapesque précédemmentpour avoir toutes les
variables explicatives nécessaire à partla
pluviométrie.Ensuite, on fait la prédiction de ces données
à partir du modèle multivarié final pour avoir la valeurde
la vitesse.
| 

