|
UNIVERSITE DE FIANARANTSOA
ECOLE DE MANAGEMENT ET D'INNOVATION
TECHNOLOGIQUE
MEMOIRE DE FIN D'ETUDES POUR L'OBTENTION DU DIPLOME DE
MASTER RECHERCHE EN INFORMATIQUE
Estimation du temps de parcours aux soins de santé dans
le District d'Ifanadiana
PARCOURS : SYSTEME D'INFORMATION, GEOMATIQUE ET
DECISION
Présenté par : FANJANIRINA
Harimanana Samuëline
Encadreur pédagogique : Monsieur
BAKARI Maecha
Encadreur professionnel : Monsieur
ANDRIANARIJAONA Claude Samuëlson
Présenté par :
RANDRIAMIHAJA Heriniaina Mauricianot
Devant les membres du jury :
|
Président :
|
Professeur RAZAFIMANDIBY Josvah
|
|
Directeur de recherche :
|
Docteur GARCHITORENA Andres
|
|
Co-encadrant :
|
Docteur RAKOTONIRAINY Hasina
Monsieur RALAIVAO Christian
|
|
Examinateur :
|
Docteur HAJALALAINA Aimé Richard
|
|
|
Année Universitaire : 2017-
2018



UNIVERSITE DE FIANARANTSOA
ECOLE DE MANAGEMENT ET D'INNOVATION
TECHNOLOGIQUE
MEMOIRE DE FIN D'ETUDES POUR L'OBTENTION DU DIPLOME DE
MASTER EN INFORMATIQUE
PARCOURS : SYSTEME D'INFORMATION, GEOMATIQUE ET
DECISIONEstimation du temps de parcours aux soins de santé dans
le District d'Ifanadiana
Présenté par : FANJANIRINA
Harimanana Samuëline
Encadreur pédagogique : Monsieur
BAKARI Maecha
Encadreur professionnel : Monsieur
ANDRIANARIJAONA Claude Samuëlson
Présenté par :
RANDRIAMIHAJA Heriniaina Mauricianot
Devant les membres du jury :
|
Président :
|
Professeur RAZAFIMANDIBY Josvah
|
|
Directeur de recherche :
|
Docteur GARCHITORENA Andres
|
|
Co-encadrant :
|
Docteur RAKOTONIRAINY Hasina
Monsieur RALAIVAO Christian
|
|
Examinateur :
|
Docteur HAJALALAINA Aimé Richard
|
|
|
Année Universitaire : 2017-
2018
CURRICULUM VITAE
ETAT CIVIL

RANDRIAMIHAJA Heriniaina Mauricianot
Né le 27 octobre 1994 à Majunga
Situation Familiale : Célibataire
Nationalité : Malagasy
Lot: 202-B /3306 Ambodirano
Contact: +261 34 60 149 81
E-mail:
mauricianothr@gmail.com
LinkedIn:
https://www.linkedin.com/in/mauricianot
ETUDIANT EN DEUXIEME ANNEE MASTER EN SYSTEME
D'INFORMATION GEOMATIQUE ET DECISION
A L'ECOLE DE MANAGEMENT ET D'INNOVATION TECHNOLOGIQUE
(EMIT) DE L'UNIVERSITE DE FIANARANTSOA
DIPLOMES OBTENUS
· 2017 : Obtention du
diplôme de licence professionnelle en Développement d'Application
et Système d'Information
· 2013 : Obtention du
diplôme du baccalauréat Technique TMEL avec Mention : Assez
-Bien
ETUDES ET FORMATIONS
· 2017-2018 :
2ème année de Master en Système d'Information
Géomatique et Décision (SIGD) à l'Ecole de Management et
d'Innovation Technologique(EMIT) de l'Université de Fianarantsoa
(UF).
· 2017 : Formation en
conception de jeux vidéo niveau 1, chez talenta center situé
à Fianarantsoa, outils de réalisation « Unity
5 ».
· 2015-2016 :
3ème année de licence en Développement
d'Application et Système d'Information (DASI) à l'Ecole de
Management et d'Innovation Technologique(EMIT) de l'Université de
Fianarantsoa (UF).
EXPERIENCES PROFESSIONNELLES
· 2019 :Etude d'un projet
MAGIE « Estimation du temps de parcours aux soins de santé
dans le District d'Ifanadiana à partir de mesures prises sur le
terrain »au sein de l'ONG Pivot Médical avec les outils
suivantes : OsmAnd (Enregistrement des parcours sur le terrain), QGIS
(Pré-traitements), R (Analyse) et PostGIS (Base de données
spatiales).
· 2018 :Programmation d'un
projet « conception et réalisation d'une application web pour
la gestion de scolarité EMIT sur les modules (Inscription,
Réinscription, Assiduité)sous langage PHP5 avec Framework PHP
(CodeIgniter 3), PostgreSQL (Base de données), JavaScript, JQuery,
Framework Bootstrap 3 et déployer par Apache Server.
· 2017 : Programmation d'un
projet « Conception et réalisation d'une application
desktop pour la gestion de marchandise » au sein de la
société GALANA Fianarantsoasous langage Visual Basic .NET et MS
Access (Base de données).
· 2016 : Programmation d'un
projet « conception et réalisation d'une application
web pour la gestion des immobilisations dans une grande
société multi-sites » au sein de la société
d'AQUALMA sous langage PHP5 avec framework CodeIgniter v3, base de
données MySQL et déployer par WampServer 2.5.
· 2015 : Programmation d'un
projet « gestion d'état civil » au sein de la
commune urbaine de Fianarantsoa sous langage VB.NET et base de données
Access.
· 2013 : Installation
électrique (Travaux Pratiques) avec certificat de diplôme
BEP(EL).
CONNAISSANCES EN INFORMATIQUE
Systèmes d'exploitation :
Linux/Unix, Windows.
Informatique bureautique : Microsoft
Office, Libre Office, Open Office.
Maintenance : Matérielle,
Logicielle.
Systèmes de gestion des Base de
données : Access, PostgreSQL (PostGIS), MySQL (MyGIS), SQL
Server 2008.
Langages de programmation : Pascal, C,
C++, Java, Visual Basic, Python, R.
Technologies Web : HTML, JavaScript,
Java, PHP, HTML5, CSS3, JSP, AngularJS.
Méthode d'analyse et de
conception : Merise II.
Analyse et conception
orientée-objet : UML, UML Spatial.
Framework web: Framework PHP, Framework JSP
et Framework Bootstrap.
CONNAISSANCES LINGUISTIQUES
|
Langue
|
Compréhension
|
Expression Orale
|
Expression écrite
|
|
Malagasy
|
|
|
|
|
Français
|
B2
|
B2
|
B2
|
|
Anglais
|
A2
|
A2
|
A2
|
Grille d'évaluation :
A2 :Intermédiaire ou usuel,
B2 :niveau avancé ou indépendant et
:Maîtrise.
DIVERS
· Sport: Basket-Ball, Hand-Ball,
Natation, Foot-Ball;
· Loisir : Lire le Journal, Faire
des recherches sur internet, les nouvelles technologies, voyages.
AVANT-PROPOS
Tous les étudiants en passage de cinquième
année dans l'Ecole de Management et d'Innovation Technologique (EMIT)
devront passer un stage de six (06) mois au sein d'une entreprise d'accueil
pour mettre en pratique les connaissances théorique acquis durant les
années universitaires.
Ce stage est nécessaire afin d'approfondir la
valorisation, en tant qu'étudiant chercheur et d'introduire dans le
monde du métier en tant quechercheur.
Ayant déposé ma demande à l'ONG
Médicale Pivot.Cette ONG m'a permis d'avoir plus ample connaissance sur
le fonctionnement du système de santé à Madagascar et m'a
initié à la recherche appliquée à la
santéavec mon thème « Estimation du temps de parcours
aux soins du santé dans le district d'Ifanadiana ».
REMERCIEMENTS
Premièrement, permettez-moi de remercier Dieu qui m'a
accordé quotidiennement sa bénédiction et m'a toujours
donné la force et la santé pour arriver au terme de cet
ouvrage.
Par ailleurs, mes remerciements vont à :
- Professeur RAFAMANTANANTSOA Fontaine, Président de
l'Université de Fianarantsoa ;
- Docteur HAJALALAINA Aimé Richard, Directeur de
l'École de Management et d'Innovation Technologique (EMIT), qui nous a
reconnu comme étudiants dans cette établissement ;
- Docteur RAKOTONIRAINY Hasina, le responsable de la mention
en Informatique, qui a déployé tous ses efforts pour nous
dispenser toutes les formations nécessaires durant les deux ans dans
l'établissement et qui est aussi mon encadreur pédagogique.
- Monsieur RALAIVAO Jean Christian, mon encadreur
pédagogique pour ses conseils et son entière
disponibilité.
- DocteurAndres GARCHITORENA (Directeur du département
recherche et Felana IHANTAMALALA(Ingénieurde recherche), mes
maîtres de stage d'avoir voulu m'accueillir et leurs précieux
aides.
Je tiens également à exprimer toute magratitude
aux membres du jury, à l'ensemble du personnel de l'établissement
et particulièrement à tous les enseignants qui nous ont
partagé leurs connaissances ;
Jeremercie également le responsable de l'équipe
communautaire,du CHRD, de lacommunicationet tous les personnels de Pivot, de
m'avoir fourni les informations nécessaires à la
réalisation de ce stage, ainsi que pour l'ambiance de travail durant ce
stage ;
Et pour finir, j'exprime mes reconnaissances envers tous les
membres de mafamille, qui m'a soutenumoralement et financièrement, tout
au long de mes études et à tous ceux qui de près ou de
loin ont contribué à la réalisation de ce mémoire,
qu'ils trouvent ici, l'expression de mes vifs et sincères
remerciements.
RESUME
Dans ce mémoire, nous avons
réalisé un projet permettant de mieux comprendre l'accès
géographique aux soins de santé dans une zone rurale
située dans le district d'Ifanadiana, au sud-est de Madagascar, avec
l'ONG Médicale Pivot. Le projet consiste à estimer les temps de
parcours aux soins de santé pour chaque village dans le District
d'Ifanadiana à partir des données de terrain en utilisant une
approche en géomatique et statistique.
Pour ce faire, plusieurs étapes ont été
effectuées. La première consiste à collecter les
données sur le terrain en utilisant une application OSMAnd afin
d'enregistrer des temps de parcours en fonction des conditions topographiques
et climatiques. Ensuite, l'utilisation des outils de système
d'information géographique comme : l'ArcGIS, QGIS, R software et
PostGIS pour la gestion de données géographiques en créant
une base de données analysable. D'après cela, on a
développé des analyses sur R software pour comparer le temps de
parcours réel avec des estimations théoriques issues de la
littérature scientifique.
Pour les données à traitées, on a
utilisé 168 parcours à pieds qui sont collecté sur le
terrain et 5048 parcours en véhicules pour les données
prévenant de la société TAG-IP, ainsi que des
données de prédiction météorologie (POWER NASA) et
d'occupation du sol (Image sentinelle 2). Quant à la gestion de
données géographiques, nous avons réalisé des
pré-traitements et des calculs concernant : le temps, la distance,
les pentes, la vitesse, le pourcentage de l'occupation du sol
(intersecté par rapport aux parcours) et l'exportation de données
(en csv). Enfin, l'analyse s'est faite par l'emploi des modèles GAM
(pour l'estimation à pied) /lmer (pour l'estimation en véhicule)
pour la prédiction et l'interpolation des prédictions de temps de
parcours dans le district avec et sans pluie.
Pour cette étude, les résultats d'analyse
d'estimation du temps de parcours à pied sans pluie montrent que 83,22 %
des villageois sont à plus d'une heure à pied pour aller au CSB
plus proche, 38,85 % sont à plus de deux heures et 4,63% sont à
plus de quatre heures. Et pour l'estimation du parcours en véhicule, on
a utilisé des variables explicatives très importants comme le
pont, la zone résidentielle et les réseaux routiers. Pour ces
variables, il existe une forte décélération de la vitesse
avec une médiane de 10 km/h pour le pont, 20km/h pour la zone
résidentielle, 10 km/h pour sur les réseaux routiers a par la
route nationale tandis que sur une route normale, il est de 30 à
40km/h.
La majorité des populations du district d'Ifanadiana
sont à risque pour des urgences de santé, à cause de
l'éloignement des soins de santé primaires. Il nécessaire
de mettre en place des stratégies pour améliorer l'accès
aux soins et rendre les services de soins plus proches des villageois. Une
possibilité pourrait être de renforcer le système
communautaire, ou bien de construire des nouveaux CSB, centrés, entre
plusieurs villages en utilisant le système barycentre en physique.
Mots-Clés : Parcours,
District, Centre de Santé de Base, Temps de déplacement,
Accès aux soins, Barrières Géographiques.
Chapitre 1
ABSTRACT
In this thesis, we carried out a project to better understand
geographical access to health care in a rural area located in the Ifanadiana
district, in the south-east of Madagascar, with the NGO Medical Pivot. The
project involves estimating travel times to health care for each village in
Ifanadiana District from field data using a geomatics and statistical
approach.
To do this, several steps have been performed. The first is to
collect data in the field using an OSMAnd application to record travel times
based on topographic and climatic conditions. Then, the use of geographic
information system tools like: ArcGIS, QGIS, R software and PostGIS for the
management of geographic data by creating an analysable database. Based on
this, we have developed analyzes on R software to compare the actual travel
time with theoretical estimates from the scientific literature.
For the data processed, 168 footpaths were collected in the
field and 5,048 routes in vehicles for the data of TAG-IP, as well as
meteorological prediction data (POWER NASA) and data. land use (Sentinel Image
2). As for the management of geographic data, we carried out pre-treatments and
calculations concerning: time, distance, slopes, speed, the percentage of the
land occupation (intersected with the course) and the data export (in csv).
Finally, the analysis was done using GAM models (for foot estimation) / lmer
(for vehicle estimation) for prediction and interpolation of travel time
predictions in the district. with and without rain.
For this study, the results of the rainless walk time
estimation analysis show that 83.22% of the villagers are more than an hour
walk to the nearest CSB, 38.85% are to more than two hours and 4.63% are more
than four hours. And for the estimation of the route in vehicle, we used very
important explanatory variables like the bridge, the residential zone and the
road networks. For these variables, there is a strong deceleration of the speed
with a median of 10 km / h for the bridge, 20 km / h for the residential zone,
10 km / h for on the road networks has by the national road while on a normal
road, it is 30 to 40 km / h.
The majority of people in Ifanadiana district are at risk for
health emergencies because of the remoteness of primary health care. There is a
need to put in place strategies to improve access to care and make care
services closer to villagers. One possibility might be to strengthen the
community system, or to build new CSBs, centered between several villages using
the barycenter system in physics.
Keywords: Course, District, Basic
Health Center, Travel Time, Access to Care, Geographical Barriers.
LISTE DES FIGURES
Figure 1.1 : La carte de la zone du projet
1
Figure 1.2 : Un exemple de relief dans le Fokontany
d'Ambonihonana situé dans la Commune de Kelilalina
5
Figure 1.3 : La carte des réseaux
hydrographiques du district d'Ifanadiana
6
Figure 1.4: Une carte d'occupation du sol dans le
district d'Ifanadiana
8
Figure 1.5: Une carte des formations sanitaire dans
le district d'Ifanadiana
10
Figure 1.6 : Le contexte d'étude et les
barrières géographiques
11
Figure 4.1: Un exemple de parcours à pied
enregistré à l'aide d'OSMAnd dans la commune de Kelilalina
22
Figure 4.2 : Un exemple des données du
TAG-IP
23
Figure 4.3 : Un exemple des données du POWER
API
23
Figure 4.4 : Les fonctionnalités possible sur
GPS Track Editor
24
Figure 4.5 : Un exemple de données
stockés sur PostGIS
25
Figure 6.1 : Utilisation de l'outil GPS Track
Editor
31
Figure 6.2 : Conversion du fichier GPS sous
shapefile
32
Figure 6.3 : Modification des données
(ajouter deux champs : track et individu)
32
Figure 6.4 : Importation des données des
parcours effectuée sur PostGIS
33
Figure 6.5 : Table "gps_track_pied" sur
PostgreSQL
33
Figure 6.6 : Téléchargement des
données pluviométrie
34
Figure 6.7 : Les données
pluviométrie
34
Figure 6.8 : Importation des données
pluviométrie sur PostGIS
35
Figure 6.9 : Intersection des données
collectées et les paysages
35
Figure 6.10 : Modification des données
(ajouter un champ length_km)
36
Figure 6.11 : Importation des données
d'occupation du sol sur PostGIS
36
Figure 6.12 : Le base de données analysable
pour l'estimation du temps de parcours à pied
37
Figure 6.13 : Le base de données analysable
pour l'estimation du temps de parcours en véhicule motorisé
37
Figure 6.14 : Le résultat de la
prédiction du temps de parcours
42
Figure 6.15 : Les données d'OSRM
43
Figure 6.16 : Les données complètes
pour l'interpolation
43
Figure 6.17 : L'interpolation des données
pour le temps de parcours sans pluie
44
Figure 6.18 : L'interpolation des données
pour le temps de parcours avec pluie
44
Figure 7.1 : Une carte des données
collectées sur le terrain
45
Figure 7.2 : Exploration de données à
pied pour la variable vitesse
46
Figure 7.3 : Exploration de données à
pied pour la variable pente
47
Figure 7.4 : Exploration de données à
pied pour la variable distance
48
Figure 7.5 : Exploration de données à
pied pour la variable pluie
49
Figure 7.6 : Exploration de données à
pied pour la variable individu
50
Figure 7.7 : Exploration de données à
pied pour la variable occupation du sol
50
Figure 7.8 : Les résultats du modèle
multivarié
55
Figure 7.9 : Estimation du temps de parcours
à pied sans pluie
56
Figure 7.10 : Estimation du temps de parcours
à pied avec pluie
56
Figure 8.1 : Une carte des données
collectées par les véhicules
57
Figure 8.2 : Exploration de données des
véhicules motorisés pour la variable vitesse
58
Figure 8.3 : Exploration de données de
véhicule pour la variable vitesse
59
Figure 8.4 : Exploration de données en
véhicule pour la variable distance
60
Figure 8.5 : Exploration de données en
véhicule pour la variable pluie
61
Figure 8.6 : Exploration de données en
véhicule pour la variable pont
61
Figure 8.7 : Exploration de données de
véhicule pour la variable route
62
Figure 8.8 : Exploration de données en
véhicule pour la variable zone résidentielle
63
Figure 8.9 : Exploration de données de
véhicule pour une voiture et une moto
63
Figure 9.1 : Exemple de la maquette complète
du projet
70
LISTE
DES TABLEAUX
Tableau 2.1: Récapitulatif des études
portant sur le calcul du temps de parcours aux soins
1
Tableau 3.1 : La représentation de la
caractéristique de l'image satellitaire
21
Tableau 7.1: La résultat d'analyse des
variables explicatives avec le modèle univariés
51
Tableau 7.2 : La résultat d'analyse avec le
modèle multivariés.
54
Tableau 8.1 : La résultat d'analyse des
variables explicatives avec le modèle univariées
64
Tableau 8.2 : La résultat d'analyse avec le
modèle multivariées.
65
Tableau 8.3 : La résultat d'effets
aléatoire du modèle multivariés.
66
Tableau 9.1 : Le comparatif des
résultats à pied par rapport aux littératures
existantes
68
Tableau 9.2 : Le comparatif des résultats en
véhicule motorisé par rapport aux littératures
existantes
69
LISTE
DES ABREVIATIONS
AC : Agent
Communautaire
ACC : Accompagnateurs des Agents
Communautaires
CHRD :Centre
Hospitalier de Référence de
District
CRENAS : Centre de
Récupération Nutritionnelle
Ambulatoire pour Sévères
CSB I:Centre de Santé
de Base de niveau I
CSB II : Centre de
Santé de Base de niveau
II
EMIT : Ecole de
Management et d'Innovation
Technologique
ET : Ecart Type
GPS : Global
Positioning System
GPX : GPS eXchange
Format
HDR : Habilité à
Diriger des Recherches
INSTAT : Institut
National des Statistiques
MNT :Modèles
Numérique de Terrain
OMS : Organisation
Mondiale de la Santé
ONG : Organisation Non
Gouvernementale
OSRM : Open Source
Routing Machine
PCIMEC : Prise en
Charge Intégrée de la
Maladie de l'Enfants au
Niveau Communautaire
RN :Route Nationale
SC : Site
Communautaire
SOU : Soins
Obstétricaux d'Urgence
SHP : Shapefile
SIG : Système
d'Information Géographique
SRTM:Shuttle Radar
Topography Mission
GLOSSAIRE
Analyse multivariée est une analyse en tenir compte de
l'interaction des critères les uns sur les autres.
Analyse univariée est un critère d'analyse
sans tenir compte des autres.
L'intersection est lieu de rencontre (de deux lignes, de
deux surfaces, ou de deux volumes qui se coupent).
L'itinéraire est un chemin à suivre ou
suivi pour aller d'un lieu à un autre.
La procédure stepwise est une méthode pour
la régression multiple ; on réexamine simultanément
toutes les variables à considérer.
La revue narrative est une revue de littérature de
base, souvent appelée d'ailleurs simplement « revue de
littérature ».
La revue systématique utilise une méthodologie
rigoureuse, qui a été développée depuis plusieurs
décennies, pour recueillir et analyser les articles portant sur un sujet
particulier.
La statistique inférentielle consiste à induire
les caractéristiques inconnues d'une population à partir d'un
échantillon issu de cette population. Les caractéristiques de
l'échantillon, une fois connues, reflètent avec une certaine
marge d'erreur possible celles de la population.
Le Homesteads Act (littéralement « Loi
de propriété fermière ») est une loi des
Etats-Unis d'Amérique. Elle permet à chaque famille pouvant
justifier qu'elle occupe un terrain depuis 5 ans d'en revendiquer la
propriété privée, et ce dans la limite de 160 acres (soit
65 hectares).
Le krigeage est une méthode stochastique
d'interpolation spatiale qui prévoit la valeur d'un
phénomène naturel en des sites non échantillonnés
par une combinaison linéaire sans biais et à variance minimale
des observations du phénomène en des sites voisins.
Le spatio-temporelle est une observation d'un
phénomène météorologique de type
déterminé montre que son étendue au sein de
l'atmosphère reste incluse à maturité dans une certaine
échelle de variation (verticale et surtout horizontale).
Le système de santé correspond à
l'ensemble des éléments qui déterminent l'état de
santé d'une population. Il se conçoit comme un système
organisé d'actions, dont la finalité est d'améliorer la
santé de la population.
Le temps de parcours est la durée d'un chemin pour
relier l'un à l'autre.
Les barrières géographiques sont les
difficultés, l'obstacles d'accès rencontrer sur le terrain.
Les données empiriques est un terme collectif pour
designer la connaissance ou les sources de la connaissance acquise au moyen des
sens, en particulier par l'observation et l'expérimentation.
Les données raster sont composé d'une matrice de
cellules (ou pixels) organisées en lignes et en colonnes (grille) dans
laquelle chaque cellule contient une valeur représentant des
informations ; l'altitude (élévation).
Les données secondaires sontemployées pour
désigner des données externes à l'entreprise
utilisées dans le cadre d'études de marché.
Les données sur le terrain est le fait de se
rendre sur lieu de collectes des données.
Les requêtes spatiales est une interrogation
portant sur la géométrie et la position des entités d'une
ou plusieurs couches et permettant de sélectionner des entités en
fonction des entités d'une autre couche.
Les soins de santé relèvent des sciences
appliquées et du corps en sciences biomédicales. Ils
intéressent santé des humaines et santé animale.
Les soins obstétricaux englobent tous les soins
apportés aux femmes pendant la grossesse, l'accouchement et le
post-partum, ainsi que les soins aux nouveau-nés. Ils visent à
prévenir les problèmes de santé pendant la grossesse,
à détecter des états anormaux, à apporter
l'assistance médicale en cas de besoin et à mettre en place des
mesures d'urgences si celle-ci fait défaut.
Stellaria graminea linné est une vivace à
rhizome rampant, d'un vert gai et plus ou moins glauque ; tiges (longueurs
30-60 cm) grêles, étalées-diffuses ; feuilles
(longueur 20-30 mm) linéaires, lancéolées ou oblongues, en
tout cas plus larges vers la base ; fleurs (diamètre 6-10
mm) ; graines rugueuses.
SOMMAIRE
AVANT-PROPOS
i
REMERCIEMENTS
v
RESUME
vi
ABSTRACT
vii
LISTE DES FIGURES
viii
LISTE DES TABLEAUX
x
LISTE DES ABREVIATIONS
xi
GLOSSAIRE
xii
SOMMAIRE
xiv
INTRODUCTION
1
PARTIE
I : CONTEXTE GENERAL
3
Chapitre 1 : Présentation de la zone
d'étude
3
1.1. Localisation géographique
3
1.2. Contexte géographique
5
1.3. Le système de santé dans
le district
9
1.4. Le contexte thématique
10
Chapitre 2 : Etat de l'art
13
2.1. Théorie sur l'estimation du temps
de parcours
13
2.2. Les approches existantes pour
l'estimation du temps de parcours
15
2.3. Estimation du temps de parcours qui
utilise des modèles pour la prédiction
16
2.4. Synthèse
18
PARTIE
II : MATERIELS ET METHODES
19
Chapitre 3 : Présentation des
données
19
3.1. Les données de parcours à
pied
19
3.2. Temps de parcours à moto et
voiture : TAG-IP
19
3.3. Données climatiques
20
3.4. Les données d'occupation du
sol
20
3.5. L'altitude
21
Chapitre 4 : Les outils utilisés
22
4.1. OSMAnd
22
4.2. TAG-IP
22
4.3. Power Api
23
4.4. GPS track editor
24
4.5. QGIS
24
4.6. ArcGIS
24
4.7. PostGIS
25
4.8. R
25
Chapitre 5 : Manipulation des données
26
5.1. Prétraitements
26
5.2. Traitements
27
PARTIE
III : RESULTAT ET DISCUSSION
19
Chapitre 6 : Mise en oeuvre
31
6.1. Prétraitements
31
6.2. Traitements
38
Chapitre 7 : Estimation du temps de parcours
à pied
45
7.1. Les données recueillies
45
7.2. Résultats de la phase
d'exploration des données
46
7.3. Les modèles univariés et
multivariés
51
7.4. Les prédictions du temps de
parcours
55
Chapitre 8 : Estimation du temps de parcours en
véhicule motorisé
57
8.1. Les données recueillies
57
8.2. Exploration des données
utilisées
58
8.3. Les modèles univariés et
multivariés
64
Chapitre 9 : Discussion
67
9.1. Estimation du temps de parcours à
pied
67
9.2. Estimation du temps de parcours en
véhicule motorisé
68
9.3. La plateforme d'affichage des
résultats du projet
69
CONCLUSION ET PERSPECTIVES
xvi
BIBLIOGRAPHIE
xvii
ANNEXES
xix
TABLE DES MATIERES
xx
INTRODUCTION
Le taux de mortalité élevé dans des zones
rurales des pays en voie de développement est devenueune
problématique mondiale pour la santé(Salehi and Ahmadian 2017). A
Madagascar,ce taux est très élevé, en partie à
cause d'unefaible accessibilité aux soins. Les plus vulnérables
sont surtout les femmes enceintes et les enfants. En 2013, 83.6% des femmes ont
déclaré avoir un obstacle pour recevoir un traitement ou un avis
médical(Institut National de la Statistique 2013). Etant un pays en voie
de développement, la pauvreté à Madagascar invoque la
négligence de santé de la population.
Au Sud Est de Madagascar, le district d'Ifanadiana
représente un cas concret sur ces obstacles d'accès aux soins
pour des problèmes de santé publique comme le paludisme, la
tuberculose et l'accouchement.C'est ainsi que l'ONG médical Pivot a mis
en place la gratuité des soins et renforcé le système de
santé dans le district d'Ifanadiana afin de permettre à la
population d'accéder aux soins et contribuer à réduire la
mortalité.
En effet, l'utilisation des soins sanitaires dans une zone
rurale est influencée par des nombreuses barrières
géographiques. Par conséquent, il est important de
connaître réellement le temps de parcours d'un trajet d'un village
vers un centre de santé de basse CSB (à pied)ou d'un Centre de
Santé de Base (CSB)jusqu'à l'hôpital (véhicule)
surtout dans le district d'Ifanadiana vu qu'il existe divers types d'occupation
du sol tels que les zones montagneuses, les rivières, les forêts
(primaires et secondaires), les rizières, ainsi quedifférents
types de routes (goudronnées, pistes, sentiers). Les conditions
climatiques jouent aussi un rôle important dans l'accessibilité
aux soins dans le district avec la détérioration des
réseaux routiers en cas de pluie.
De ce fait, l'ONG Pivot veut mettre en place une base de
données analysable issue du terrain pour mieux comprendre les
barrières géographiques. Ce qui permet d'avoir une estimation du
temps de parcours réel à l'aide de méthodes statistiques
de prédiction. Pour ce travail,deux bases de données ont
été recueillies sur le terrain : le déplacement
à pied et le déplacement en véhiculesmotorisés.
Grace à lagéomatique nous y associons à ces données
de terrain les informations comme : la vitesse, la distance, la pente, la
pluviométrie, l'occupation du sol (rizière, sol nu et zone
habitation, forêts, eau de surface) et lestypes de route.
L'objectif de cette analyse est d'estimer la vitesse
associée pour chaque type d'occupation du sol en considérant
l'influence de pluie afin de prédirele temps réel de trajet pour
les parcours entre chaque village du district et le CSB correspondant. Une fois
développé, on peut appliquer ces mêmes méthodes pour
estimer le temps de trajet entre chaque, village et l'Hôpital de
district, ou encore entre chaque village et site communautaire correspondant.
Pour atteindre l'objectif, on a collecté des traces GPS sur le terrain
pour un ensemble de parcours à pied et en véhicule, etensuite on
a utiliséles plateformes QGIS et R software pour la gestion de ces
données géographiques. Ceci nous a permis de créer des
bases de données analysables, qu'on a ensuite analysées sur R
software pour estimer le temps de parcours réel. Enfin, l'ensemble
desestimations de temps de trajet ont servi à créer des
modèles cartographiques pour l'ensemble du district à traversune
interpolation spatiale pour des scenarios sans pluieet avec pluie.
Le manuscrit sera subdivisé en trois (03) partie, dans
lapremière partieon parlera du contexte général et la
problématique sur la présentation de la zone d'étude et
l'Etat de l'art ensuite des matériels et méthodes en composants
des présentations des données, les outils utilisés et la
manipulation des données. Enfin, nous verrons les résultats
obtenus et les discussions pour l'estimation de temps de parcours
(piétonet véhicule motorisé).
PARTIE I : CONTEXTE GENERAL
Chapitre I: Présentation de la zone d'étude
Le district d'Ifanadiana est un district rural situé
dans la région Vatovavy-Fitovinany au Sud Estde Madagascar.
Cette région a une superficie de 19 605
km2constitué par une altitude moyenne compris entre 0 m et
1200 m. Il compte 1 454 863 habitants en 2014 avec des
différentes ethnies : Tanala, Betsimisaraka,
Sahafatra, Antaimoro, Antsimatra et Antambahoaka.
1.1. Localisation
géographique
Situé entre la latitude 20° 25' et 21° 40' et
la longitude Est de 47° 20' et 47° 50', délimitée par
le district de Nosy Varikaau Nord, Manakara Atsimo au Sud, Mananjaryà
l'Est et la Région Haute Matsiatra à l'Ouest.
Le district a une superficie totale de 3970 km2avec
24,9 millions de la population. Il est constitué par treize communeset
195 Fokontany dont la majorité ne sont accessible qu'à pied
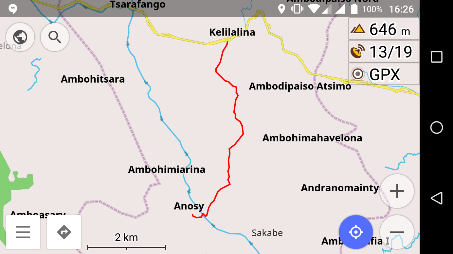
(figure 1.1) : Ranomafana, Kelilaina,
Ifanadiana, Ambiambe,
Antaretra, Tsaratanana, Andrangavola,
Ambohimanga Sud, Ambohimiera, Analampasina, Antsindra, Fasintsara, Maroharatra
et Marotoko.
Dans le district, la ressource économique de la
population est basée sur la fertilité de ses terresen pratiquant
du petit élevage et de l'agriculture.Certain pratique la plantation de
café, la culture du riz, des fécules, la cuture de banane et de
canne à sucre. Cette dernière est destinée à la
fabrication d'alcool local (Toaka Gasy). La population pratique aussi
l'orpaillage et l'extraction minière (pierres précieuses) dans
certaines communes du district.
La figure 1.1 montre la carte du district de la zone
d'étude du projet en tenant compte des communes et de leurs
délimitations.
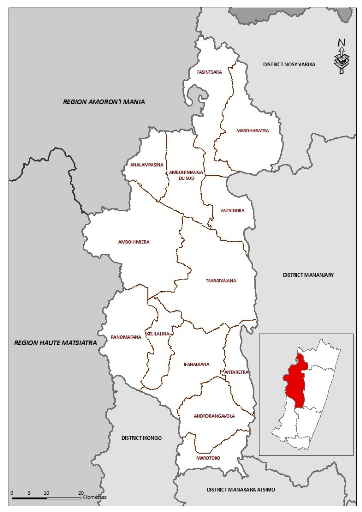
Figure
4.1 : La carte de la zone du projet
Source : Enquête de base de Pivot
1.2. Contexte géographique
Pour cette étude, les caractéristiques
géographiques ont des rôles très importants qui pourraient
constituer une barrière pour accéder aux soins. Ils sont
cités ci-après tels que le relief, les réseaux
hydrologiques, l'occupation du sol, le climat, les réseaux routiers et
les formations sanitaires.
1.2.1. Le relief
Le district est une zone intermédiaire entre les Hautes
Terres centrales et la côte Est, elle est caractérisée par
des montagnes, des falaises et des collines. Une zone
montagneuseaccidentée située sur les hauts plateaux à une
altitude élevée au-delà de 1000 m avec des
vallées profondes. Elle est tranchée par des falaises
d'escarpement de l'Està environ 100 km de la côte,
présentant des dénivellations abruptes de l'ordre de 500 m,
marquée par de fortes pentes, des chutes d'eau et des vallées
très étroites ;

La zone de moyennes collines est peu accidentée, avec
des vallées assez larges, à environ 50 km de la côte suivi
d'une basse colline (Figure 1.2).
Figure 4.2 : Un exemple de relief
dans le Fokontany d'Ambonihonana situé dans la Commune de Kelilalina
1.2.2. Les réseaux
hydrographiques
La zone d'étude est dotée de nombreux cours
d'eaux. Au Nord, elle est longée par Sakaivo, Ampasary et Managnano qui
se déversent dans l'océan indien dans le district de Manakara.
Le plus important cours d'eau du Sud du district est le fleuve
Namorona avec une de longueur de 160 km. Il prend source près
d'Ambalakindresy (à l'Est du district) et il longe le Sud district en
passant par les communes de : Ranomafana, de Kelilalina et d'Ifanadiana.
Et se jette dans l'Océan Indien à 50 km au Sud de Manajary.
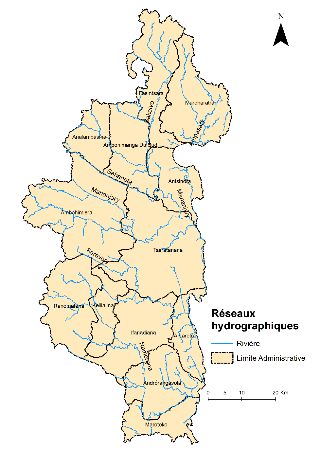
En outre de ces rivières, il existe d'autres
rivières qui alimentent les zones des cultures des habitants du
district. La figure 1.3 ci-dessous montre les réseaux hydrographiques du
district d'Ifanadiana.
Figure 4.3 : La carte des
réseaux hydrographiques du district d'Ifanadiana
1.2.3. L'occupation du sol
L'Ouest de la zone est constitué par une forêt
tropicale (primaire et secondaire), qui est encore conservée grâce
à la création du parc National de Ranomafana.
Dans le district, nous avons considéré cinq
catégories principales d'occupation de sol : la forêt dense
de plus en plus rétrécie (à cause feux de brousse,
charbon, etc..), la savane arborée, la rizière, la zone
d'habitation et l'eau de surface (les rivières).
En 2018, sur les 401071 hectares (ha)de superficie de
district, la forêt humide dispose 85687 ha, la zone de riziculture 1210
ha, le savane arborée 299632ha, la zone d'habitation 13343 ha, et l'eau
de surface 1199,6 ha.
1.2.3.1. La forêt dense
La forêt dense est une formation de
végétation très important (dense).
Elle est située dans la partie, Nord-Ouest et Sud
-Est du district qui représente une grande majoritaires des forêts
du district avec plusieurs centaines de variétés d'arbres et
d'arbustes, ainsi que des milliers d'espèces animales
précieux.
1.2.3.2. La savane arborée
La savane arborée est le couvert herbacé
continu, mélangé avec des arbres. Elle est formée par la
dégradation avancée de la forêt après
défrichage et brulis répétés, ce qui nous donne
lieu à des formations notamment herbeuses.
Principalement, elles sont constituées en
majorité de plantes de la famille des graminea dans le Sud-Est et
s'étendent dans la zone des moyennes collines.Elle représente
également des nombreux types des cultures agricoles mixtes (sauf les
rizières qui forment une catégorie appart), comme le canna
à sucre, le maïs, les haricots et nombreux d'autres.
1.2.3.3. La rizière
La rizière est une mosaïque de culture dont on
applique la riziculture dans laquelle, en générale on inonde avec
de l'eau.
Dans le district, la plupart des habitants pratiquent la
riziculture. Pour cela, ils y forment des autres endroits libres et loin de
leurs villages qu'eux les nommées « Antsaha ».
1.2.3.4. La zone d'habitation
C'est la zone dans laquelle la populationconstruit leurs
maisons ou d'autres infrastructures pour y habiter ou pour certaines
activités économiques ou administratives. Il représente
une ternaire nu qui peut avoir de la boue durant la saison de la pluie ou pas
selon la caractéristique et plan de l'endroit.
Les zones d'habitation constituent des villages ou villes. Il
se peut qu'il aille s'accroitre dans l'année avenir dû à la
croissance de la population fortement jeune.
1.2.3.5. Les eaux de surface
Les eaux de surface sont l'ensemble des eaux qu'on peut
observer par image satellite : masses d'eau, comme des étangs ou zones
inondées, ainsi que des rivières et ruisseaux. Dans le district,
plusieurs d'eaux sont souterraines pour la cultivation des riz ou d'autres
cultures dans les villages, vu qu'il est une zone montagneuse qui permet
d'avoir une source d'eaux.
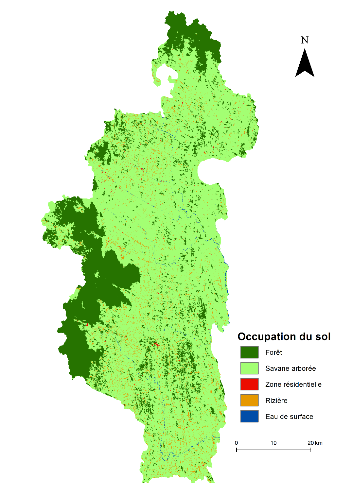
La figure 1.4 montre l'ensemble d'occupation du sol dans le
district d'Ifanadiana obtenue par des méthodes de classification
à partir d'images sentinelle 2.
Figure 4.4: Une carte d'occupation
du sol dans le district d'Ifanadiana
Source : Image sentinelle 2 - Août 2018.
1.2.4. Le climat
Situé à l'Est de Madagascar, le district est
constituépar un climat tropical. La pluie y est très abondante
avec une précipitation annuelle variant entre 0 et1 900mm. La
saison pluvieuse est chaude et humide avec une période de forte pluie
s'étalant entre novembre jusqu'en avril. L'hiver est frais et humide
s'étalant entre mai et août. Pour la pluviométrie, elle est
influencée par l'humidité venant du vent d'alizée de
l'Océan Indien.
1.2.5. Les réseaux
routiers
La plupart des villages sont reliés entre eux par des
chemins non carrossables qui ne sont accessibles qu'à pied. Il est
traversé par une seule route goudronnée, la route nationale
(RN25) d'Ouest en Est en passant à travers la forêt t les communes
de Ranomafana, Kelilalina, Ifanadiana et Antaretra. Une ancienne route
nationale RN 25relie la commune d'Ifanadiana et la partie Nord et une autre RN
7 pour la partie Sud. Mais ces axes Nord et Sud sont des pistes non
goudronnées.
1.3. Le système de santé
dans le district
Le district d'Ifanadiana possèdedessitescommunautaires
(SC),desCSB de niveau I et II et un Centre Hospitalier de
Référence du District (CHRD).
Dans le district, l'ONG Pivot soutienne ces trois niveaux du
système de soins, à la fois en ressources humaines (personnel de
santé), matériels (médicaux, informatiques) et
financières (médicaux, construction, rénovation). Il
soutienne également des nombreux programmes cliniques comme la
malnutrition, les soins d'urgence, et la tuberculose entre autres.
1.3.1. Le site
communautaire
Le site communautaire est le centre desoins le plus proche des
villages, avec des soins minimums exclusivement pour les programmes suivants :
PCIMEC (Prise en Charge Intégrée de la Maladie de l'Enfants au
Niveau Communautaire : les enfants entre 0 à 5 ans), CRENAS (Centre
de Récupération Nutritionnelle Ambulatoire pour
Sévères), Tuberculose, et le Planning Familiale (PF).
Il existe un site communautaire par Fokontany, avec deux ACs
chacun. En total dans tout le district, il y a cent quatre-vingt-quinze (195)
Fokontany. Les communes couvertes par Pivot disposent de 41 sites
communautaires.
Les ACs sont formés par les ACCs (Accompagnateurs des
Agents Communautaires) et le chef CSB. Ettous les deux (02) ans, ils sont
renouvelés par élection ou nomination direct.
Le site est construit par les gens des villages avec l'aide de
l'ONG Pivot en termes de médicaments et de matériels.
1.3.2. Le CSB
Le centre de santé de base exerce un rôle
très importantsur le dispositif du système de santé dans
une zone rurale. Ils offrent les premiers soins d'une dignité capitale
pour les exigences sanitaires de la population.
Le CSB I est gérer par des infirmiers et des
aides-soignantes pour la vaccination et les soins de base. Et le CSB II par des
Médecins, paramédicaux (infirmiers et/ou sage-femme) et offrent
l'ensemble des soins de santé primaire.
Les CSB soutenus par pivot possèdent desinfirmiers, des
médecins supplémentaires employés par Pivot pour renforcer
l'équipe ministériel et améliorer la qualité de
soins.
Figure 4.5: Une carte des
formations sanitaire dans le district d'Ifanadiana
1.3.3. Le CHRD
Il est situé dans la commune d'Ifanadiana. Le centre
hospitalier de référence de district (CHRD) est placé sous
l'autorité du Médecin Inspecteur, le Chef de Service de District
de la Santé Publique et est dirigé par un Médecin chef.
Le CHRD offre les soins obstétricaux essentiels pour la
population.En générale, ils englobent les soins
spécialisés et qui requièrent de l'hospitalisation comme
les soins d'urgence, la chirurgie, les maladies infectieuses, les
soinsintensifs pour la malnutrition aigüe sévère, des
problèmes sévère, d'accouchement et le post-partum, ainsi
que les soins aux nouveau-nées.
1.4. Le contexte thématique
Il représente les parties essentielles de
l'approfondissement qui nous a conduitsà obtenir la problématique
du sujet. Il met en valeur la question de recherche et pourvue d'un ensemble de
méthodes rigoureuses sur laquelle se base l'étude.
1.4.1. Contexte de
l'étude
La majorité des populations dans le district
d'Ifanadiana habite dans des zones rurales enclavées, loin des CSB et de
l'hôpital. Desétudes sur l'accès aux soins
géographiques ont montré que genre de barrières
géographiques présentent dans le district peuvent avoir un grand
impact sur le temps de trajet des gens de chaque village jusqu'au centre de
santé le plus proches, ce qui peut empêcher aux populations
d'aller au CSB pour des problèmes de santé.
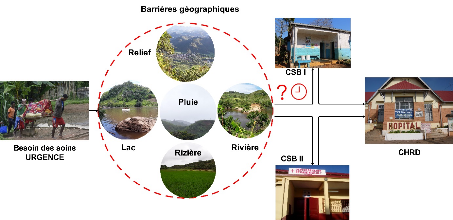
La figure 1.6 montre le contexte d'étude et les
difficultés sur les barrières géographiques durant le
déplacement des gens.
Figure 4.6 : Le contexte
d'étude et les barrières géographiques
En effet, la population des zones enclavés doivent
faire face à des nombreuses barrières géographiques pour
se rendre au CSB comme traversée des montagnes, des
rizières, des eaux de surface, des forêts, etc...) et la pluie.
Dans le cadre de l'étude, il est nécessaire de
connaître de manière très précise le temps de
déplacement en fonction de ces barrières géographiques
citées précédemment. Pour cela, nous allons obtenir de
données sur terrain pour une analyse de temps de trajet.
Dans chaque village, les difficultés d'accès aux
soins diffèrent selon la condition climatique, l'état de la
personne (malade), et les conditions topographiques du parcours. Et il se peut
qu'il y ait un écart sur le temps de déplacement par rapport
à toutes ces caractéristiques.
À l'arrivée au CSB, les patients sont
reçus selon le niveau d'urgence et fonctions des soins dont il a besoin.
Concernant ces soins, il existe une hiérarchie qui était
conçu par l'ONG Pivot pour pouvoir bénéficier des frais
gratuits. Par exemple, un patient qui est maladedoit se faire consulter auCSB.
Et après lediagnostic du médecin, desfois une
référence auprès de l'hôpital s'avère
nécessaire.
1.4.2. La
problématique
La problématique du projet estla difficulté
d'accès aux soinspar rapport à ces barrières
géographique (figure 1.6).Ces barrières ont un grand obstacle
pour les gens concernant l'initiative d'aller au centre de santé pour
soigner. L'impact c'est que les gens n'allaient pas qu'il y a une urgence
à faire et de parcourus ces éloignements avec toutes ces
barrières. Cette mauvaise habitude des gens peut avoir un grand impact
sur l'augmentation des taux de mortalité dans le district.
1.4.3. L'objectif
L'objectif du projet consiste à comprendre les parcours
de soins et le temps requis pour que chaque communauté atteigne
l'établissement de santé le plus proche.
Par rapport à cela, on veut estimer d'une
manière très précise le temps de trajet afin de permettre
à l'ONG Pivot et au ministère de mettre en place des programmes
adaptées. Orpour avoir une estimation la plus précise possible,
il est nécessaire de faire un grand effort en termes de collecte de
données sur le terrain, des données spatiales, d'image
satellitaires, etc.
Dans le district, cette estimation de trajets est liée
à des barrières géographiquescomme la difficulté
par rapport à le relief,la pluviométrie qui cause des boues ou
glissement, l'éloignement d'habitation des gens et les
caractéristiques des paysages durant le trajet.
Pour la santé, un manque de soin peutaugmenter le taux
de mortalité etcela est considéré commeun cas
majeurmondialement sur l'organisation de la santé. Dû à
cela, l'ONG Médicale Pivot s'intéresse àla recherche d'une
solution durablepour aiderla populationà accéder facilement aux
soins.
Chapitre 2 : Etat de l'art
Dans ce chapitre, on élaborerales connaissances
existantesdu le sujet de recherchepar rapport à
laproblématique.En générale, des recherches scientifiques
ont utilisé différentes méthodes et approches ainsi que
plusieurs sources de données pour trouver une solution par rapport
à ce problème précis.
2.1. Théorie
sur l'estimation du temps de parcours
Par rapport à notre étude, nombreuses
théories ont été déjà
élaborées par les scientifiques concernant l'estimation du temps
de parcoursaux soins de santéliée aux problématiques
d'accès géographiques.
2.1.1. Estimation par rapport aux situations régionales
Des études dans différentes régions ont
été élaborées concernant l'accès aux
soinscomme l'utilisation des mesures d'accessibilité basé sur le
système d'information géographique (SIG) en utilisant des
méthodes (de la zone de recrutement flottante et basée sur la
gravité) d'analyse de l'accessibilité spatiale aux soins de
santé primaires. Cette approche a été utilisée par
exemple sur l'ensemble des données du recensement de 2000 et des
données du médecin de premier recours dans la région de
Chicago (Luo and Wang 2003).Ces méthodes peuvent être
utilisées pour aider les départements de santé à
améliorer la désignation des zones de pénurie de
professionnels de la santé.D'autresrecherches ont
évaluél'impact des précipitations et des inondations par
rapport à la quantification de l'accès géographique aux
soins(Makanga et al. 2017). Une nouvelle approche est identifiée pour
modéliser l'accès potentiel spatio-temporel en évaluant
les impacts sur l'accès aux soins, les services de santé
maternelle utilisant différents modes de transport. Cela en utilisant de
données tels que les coordonnées GPS des établissements de
santé, les routes, les images satellites à haute
résolution, d'autres données sur la répartition
géographique, les données quotidiennes sur les
précipitations et les inondations pour ces impacts.
2.1.2 Estimation par rapport
aux situations rurales
Pour les études rurales,des nombreuses recherches ont
été élaboréessur l'estimation du temps de
parcours.Certaines comparentle temps de trajet basé sur des
données rétrospectives de Medicare (aux Etats Unis) en utilisant
le trajet par la route entre les populations et les services de
santé(Chan, Hart, and Goodman 2006). D'autres estiment l'accès
physique par rapport aux différents soins cliniques en milieu rural,
urbain et périurbain en interrogeant 23000 ménages concernant
leur usage des cliniqueset leur temps rapporté par rapport à ces
cliniques (Tanser, Gijsbertsen, and Herbst 2006).L'estimation précise du
temps de trajet est très importante carlorsque le temps de trajet
augmente, il a une baisse logistique significative de l'utilisation.Ceci peut
avoir des impacts sur la mortalité, notamment pour des
communautés pauvres et vulnérables, qui résident souvent
dans des zones isolées et rurales avec un accès limité aux
services de soins de santé.Plusieurs données ont
été collectée par le biais d'entretiens approfondis et
discussion de groupes (avec les femmes en âge de procréer et
enceinte), des guérisseurs traditionnels, des matrones et les
fournisseurs de santé primaires afin de les analyser de manière
thématique avec NVivo 10(Munguambe et al. 2016).La faiblesse de
cetteétude repose sur le problème des moyens de transport et les
contraintes financières.Une autre étude a utilisédes
données d'enquête transversale sur les comportements de recherche
de soins liée à lasoins obstétricaux d'urgence (SOU) de 39
grappes urbaines pauvres, ce qui a été liée
géographiquement à un ensemble de données
géo-référencées sur l'emplacement des installations
de SOU(Panciera et al. 2016). Cet étude a montré qu'il est
nécessaire,soit de renforcer les systèmes de
référence et de transport d'urgence, soitde relocaliser les
installations de SOU pour qu'elles soient plus proches des lieux de
résidence de pauvres.Une autre étude identifie trois
retards par rapport à la prise en charge des SOU : décider
de recherche des soins, atteindre un centre de santé et recevoir un
traitement approprié.L'étude est basée sur l'une de ces
dimensions (second retard), et montre que les populations ont un accès
médiocre aux SOU (Hussein, McCaw-Binns, and Webber 2012).Cette
étude définie plusieurs dimensions, notamment la distribution et
la densité des services, la distance et le temps par rapport à
l'accès géographique. Les effets et l'efficacité de bon
nombre de ces interventions sont mal compris et il faut davantage de preuves
pour faciliter la prise de décision, en particulier les pays à
faibles ressources.
2.1.3 Estimation par rapport
aux situations des pays
Des études ont été
élaborées dans plusieurs Pays, surl'approfondissementde
l'accessibilité spatiale par rapport à des soins en
établissement appropriés à la naissance. Cela
nécessite la miseen placed'un ensemble de données spatiales
liées et un modèle géospatial calibré en tenant
comptes les informations tels que les établissements de santé,
les rivières et d'autres caractéristiques du paysagequi influent
sur le parcours`'`'(Gething et al. 2012). Cette approche, avec les
données collectées à l'aide des voyages réels
effectuées par les gens en quête de soins, a permis de mieux
comprendre l'accès géographiques aux soins à la naissance
au Ghana`'`'(Gething et al. 2012).Cette étude suggère que les
références internationales actuelles en matière de
prestation de soins de la santé maternelle ne sont pas adaptées
car elles ne tiennent pas compte de la localisation et de
l'accessibilité des services par rapport aux femmes qu'elles
desservent.D'autres études utilisent la même approche avec
différents données tels que les données du réseau
routier, le modèle numérique d'élévation (DEM),
l'emplacement des hôpitaux et des cliniques, ou des données de
recensementpour comprendre les inégalités géographiques
dans l'accès à des services de soins de santé entre
régions selon le groupe d'âge et groupe de revenus divers se sont
accrus rapidement(Jin et al. 2015).Cetteétude montre qu'il existe une
forte corrélation négative entre le vieillissement de la
population et l'accessibilité aux soins de santé.
2.2. Les approches existantes pour
l'estimation du temps de parcours
La majorité des approches pour estimer le temps de
parcours utilisées sont les modèles géospatiales et
l'utilisation des systèmes d'information géographiques (SIG).
2.2.1. Les approches
méthodologiques
Une étude aremplacé une mesure de distance
traditionnelle (euclidienne) en utilisant des méthodes basées sur
le réseauet surla matrice dans un SIG(Delamater et al. 2012). A partir
de ladistance estimée à partir de ce réseau (en utilisant
la méthodologie d'affectation de la population spécifique
utilisée dans le Michigan), une vitesse de trajet moyen est
appliquée pour obtenir le temps de trajet nécessaire pour
atteindrela structure de santé. Ensuite,l'accessibilité est
calculée en identifiant le nombre de personnes résidant à
plus de 30 minutes d'un hôpital. Cette méthode a été
largement utilisée dans les pays développés où le
réseau routier est très complet et la majorité des trajets
vers un hôpital se font en voiture -(Ouma et al. 2018). La limitation de
ce genre d'étude pour les pays en voie de développement comme
Madagascar est qu'une grande partie des déplacements se font à
pied et que le réseau des sentiers est incomplet,ce qui rend
difficilel'application de ce genre de méthode.
Certains casutilisent la méthode de pondération
surfacique (à partir du SIG)afin d'agrégerles données de
population. L'analyse du chemin le moins coûteux est appliquée
pour calculer le temps de trajet de chaque cellule du bâtiment
résidentiel vers une établissement de santé le plus
proche(Jin et al. 2015).L'accessibilité aux soins de santé entre
la zone urbaine et les zones rurales est examinée en fonction de la
couverture des zones et des populations en comparant trois scénarios
visant à réduire l'intégralité spatiale :la
délocalisation des hôpitaux, la mise à jour des valeurs de
pondération et la combinaison des deux.
Une autre méthode est l'utilisation de la zone de
recrutement flottante (FCA), basée sur la gravité(Delamater et
al. 2012). Elle évalue la variation de l'accessibilité spatiale
aux soins de santé primaire et l'analyse de la sensibilité des
résultats en expérimentant des plages de temps de parcours seuils
par la méthode FCA et des coefficients de modèle de
gravité. Les méthodes élaborées peuvent être
utilisées pour les services sociaux et les départements de
santé pour améliorer la désignation des zones de
pénurie de professionnels de la santé.
2.2.2. Les approches SIG
Il existe une autre approche à partir du système
d'information géographique concernant l'utilisation de l'information
rétrospective. Il compare le temps de trajet, les distances et les
différentes spécialités de médecins à partir
des registres médicaux des patients. Ceci permet de déterminer la
durée du trajet en calculant la distance entre deux centroïde de 1)
les codes du quartierdu patient et 2) la position des prestataires de soins de
santé privés(Hussein et al. 2012).
D'autres utilisedes enquêtes de23000 ménages
concernant l'utilisation des cliniques. Une analyse des coûts pour
estimer le temps de déplacement entre la résidence des
ménages et le clinique le plus proche à partir d'une
enquête avec uneutilisation de modèle statistique est
utilisée(Tanser et al. 2006). La méthodologie a utilisé
constitue un cadre pour la modélisation de l'accèsphysique aux
cliniques dans desnombreux pays en développement.
Un projet mondial concernant l'utilisationdu domaine SIG pour
quantifieren 2015 le temps de trajet vers les villes à une
résolution spatiale d'environ un kilomètre,en intégrant
dix surface globales caractérisant les facteurs affectant les taux de
déplacement humain,et 13840 centres urbaines à haute
densité dans un environnement géospatial établi et pour le
validerà l'aide d'une cartographie (Weiss et al. 2018).La faiblesse de
cette approcheest la non considération des zones à faibles
ressources.
2.3. Estimation du temps de parcours qui
utilise des modèlespour la prédiction
Certainesétudes utilisent de données
spatialement pour estimer le temps de parcours pour les femmes en âge de
procréer jusqu'au centre de santé le plus proche(Hussein et al.
2012)(Delamater et al. 2012). D'autres prennent en compte la proportion de
personnes susceptibles d'utiliser les transports en commun (en fonction du
temps estimé pour se rende à la clinique), la qualité et
la répartition du réseau routier et des barrières
naturelles qui a été calibré en fonction du temps de
déplacement rapporté (Tanser et al. 2006).
Une étude sur la variation saisonnière de
l'accès géographique a été faite pour
déterminer l'accès aux soins maternels. Il propose une nouvelle
approche pour modéliser la variationspatio-temporel de l'accès
aux soins en évaluant l'impact des précipitations et d'inondation
sur l'accès aux services de santé maternelleutilisant plusieurs
modèles de transport (Makanga et al. 2017). En estimant le temps de
trajet à partir du logiciel ArcGIS sur la méthode de centre le
plus proche. Une autre étude visait à évaluer, dans un
contexte rural à forte densité d'installations de santé,
comment une réorganisation du système de santé comportant
moins de sites de prestation de services avec plus de ressources pourrait
impacter en termes d'accès de populations(Fogliati et al. 2015).Il
utilise l'analyse géospatial et des réseaux pour estimer
l'accès aux services obstétricaux (SO)à l'aide d'un
modèle spatiale en utilisant les données sur l'emplacement des
établissements de santé, la dotation en personnel et le nombre de
cas d'accouchements.Cette étude montre que la moitié des
établissements de santé de première ligne ne disposaient
pas d'un personnel suffisant pour des SO à plein temps.D'autres
utilisentséparément endeux niveauxde modèles de soins pour
la santé primaires et soins hospitaliers afin de rendre les
systèmes d'aiguillage essentiels pour l'accès physique. Ces
modèles proposent surmonter les problèmes d'accès physique
incluant les interventions en matière de communications, de transport,
d'éducation, de finance, d'infrastructure et de technologie(Chan et al.
2006).
Des études utilisantles données
géo-référencées sur l'emplacement des installations
deSOU et des techniques géospatiales permettentd'examiner l'impact du
temps de déplacement dans les établissements du SOU sur
l'utilisation des services d'accouchement(Panciera et al. 2016).Ensuite les
données sont appliquées pour quantifier l'impact du temps de
trajet sur un lieu tout en contrôlant les facteurs socio-culturels,
économiques et sociodémographiques.Des analysesont
été aussi réalisées à l'aide de plusieurs
modèles de régression logistique, de régression
linéaire et des tests derapport de vraisemblance(Okwaraji, Webb, and
Edmond 2015).
2.4.
Synthèse
Pour l'estimation du temps de parcours, plusieurs recherches
ont été effectuéesdansdifférents domaines, avec la
majoritéd'étudesse focalisant sur l'accès
géographique, l'utilisation de système d'information
géographique et la mesure de l'accessibilité spatiale.En
générale les données utilisées sont des
données spatiales, des données archivés, des
données d'enquêtes transversaleset des données GPS. Ils
sont pratiqués sur l'analyse spatiale, la modélisation spatiale
et la thématique de « mapping ».
Tableau 5.1: Récapitulatif
des études portant sur le calcul du temps de parcours aux soins
|
Publication
|
|
Localisation
|
Thème
|
Approches utilisée
|
|
(Makanga et al. 2017)
|
Région
|
Mozambique
|
Accès géographique aux soins
|
Modélisation d'accès spatio-temporel
|
|
(Hanson et al. 2017)
|
Rurale
|
Tanzanie
|
Amélioration d'accès aux soins
|
Modélisation d'accès spatiale
|
|
(Makanga et al. 2016)
|
Pays à revenus faibles
|
Exploratoire des SIG en santé
|
Modélisation d'accès spatiale
|
|
(Munguambe et al. 2016)
|
Pays
|
Afrique /Ghana
|
Accès géographique aux soins
|
Modélisation d'accès géospatial
|
|
(Okwaraji et al. 2015)
|
Rurale
|
Ethiopie
|
Obstacles à l'accès physique aux services de
santé
|
Modélisation d'accès spatiale
|
|
(Tanser 2006)
|
Rurale
|
Kwa-Zulu-Natal
|
Optimisation sur l'emplacement des nouveaux établissements
de soins
|
Thématique « mapping »
|
|
(Panciera et al. 2016)
|
Zones urbaines
|
Banglasesh
|
L'influence du temps de déplacement sur le comportement en
matière de recherche de soins
|
Thématique « mapping »
|
|
(Weiss et al. 2018)
|
Nations Unies
|
Carte du temps de trajet des villes pour évaluer les
inégalités d'accessibilité en 2015
|
Thématique « mapping »
|
|
(Salehi and Ahmadian 2017)
|
Echelle mondiale
|
L'application des SIG à l'identification des domaines
prioritaires pour les soins.
|
Thématique « mapping »
|
PARTIE II :MATERIELS ET METHODES
Chapitre 3 :
Présentation des données
Pour cette étude, nous avons créé un
système d'information géographique composé des
éléments suivants : 1) des données de temps de
parcours à pied, collectés sur le terrain (altitude, vitesse,
distance), 2) des données de temps de parcours en véhicule,
collectés à travers la société TAG-IP
(véhicule/moto), 3) des données climatiqueset environnementales,
obtenus par des données satellitaireset4) d'autres données
spatiales téléchargées sur OpenStreetMap.
3.1. Les données de parcours à pied
Il existe plusieurs outils permettant de collecter des
données de parcours comme : OSMAnd, OSMTracker, Sygic, Waze,
etc.... Pour cette étude, OSMAnd a été choisi vu qu'elle
possède un fond de cartesd'OpenStreetMap, libre et ne nécessite
pas de connexion.
3.1.1. Description
Afin d'obtenir différentes données de vitesse de
trajet selon le type d'occupation du sol et d'altitude, des collectes de
données dans cinq communes ont été effectuées. Les
communes concernées étaient : Ranomafana, Kelilalina,
Ifanadiana, Ambianbe et Antaretra.
La collecte des données est effectuée
pardifférents individus (ACCs, villageois et moi-même) ceci dans
le but de voir la variation individuelle de la vitesse.
3.1.2. Structure des
données
Durant chaque parcours, l'OSMAnd enregistretoutes les 10s la
position géographique par GPS, l'heure et l'altitude ce qui permet
d'estimer les vitesses de parcours, le temps de parcours effectué ainsi
que la distance parcourue.
3.2. Temps de
parcours à moto et voiture : TAG-IP
Le TAG-IP est une entreprise travaillant dans le domaine de la
géolocalisation des véhicules motorisés à
Madagascar.Elle a été créée en 2008, en partenariat
avec Telma afin de donner aux entreprises la possibilité de
géolocaliser à tout moment et en tout lieu leur flotte de
véhicules (voitures, moto, et d'autres).L'ONG Pivot utilise sesservices
pour suivre les déplacements de sleurs voitures etmotos.
3.2.1. Description
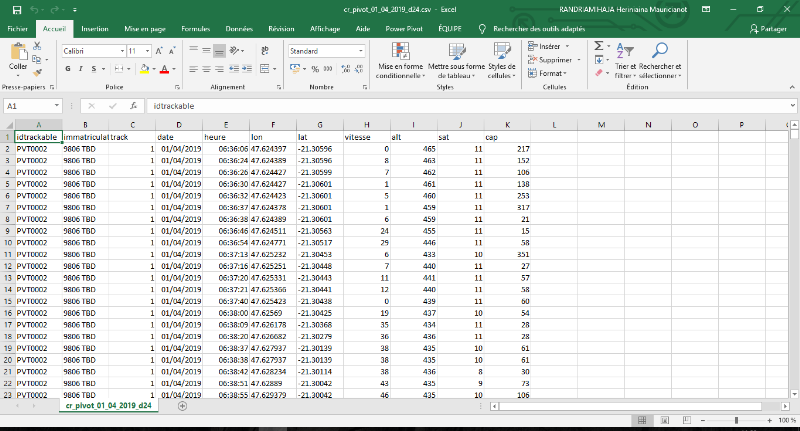
Chaque voiture et moto est dotée d'un GPS. A chaque
déplacement, il enregistre la position de chaque véhicule par
intervalle de temps de 10s (figure 4.2).
Ces données sont enregistrées en temps
réel dans le serveur de la société TAG-IP.
3.2.2. Structure des
données
On dispose de11 variables dont l'identification de
véhicule (idTrackable), le numéro matricule (immatriculation),
l'identification parcours (track), la date et heure du déplacement, les
coordonnées géographiques (lon et lat), la vitesse
d'accélération (vitesse), l'altitude (alt), le numéro
satellite (sat), la capture (cap). Ces informations sontarchivées dans
le serveur du TAG-IP pour une durée limité maximumde trois mois.
3.3. Données
climatiques
Les données de précipitation ont
été utilisés afin de connaitre la variation de la vitesse
de parcours de chaque individu avant, pendant et après le passage de la
pluie.
3.3.1. Description
Dans le district, les précipitions sont
différents pour chaque commune.De ce fait, pendant un parcours on peut
avoir deux valeurs différentes de précipitation pour deux
communes.
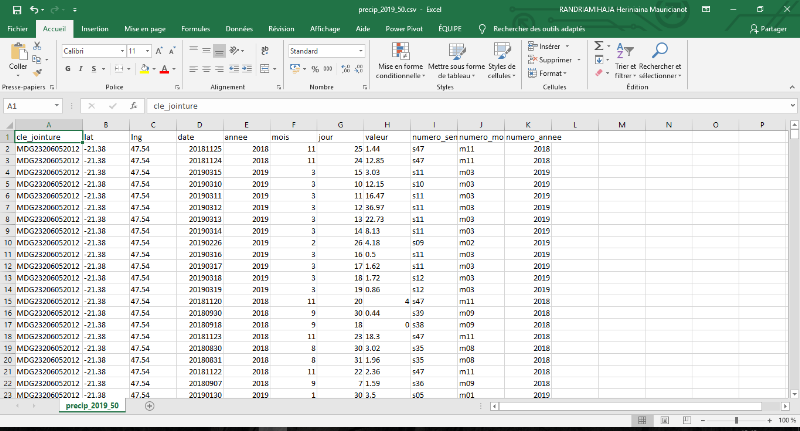
Ces donnéessont disponiblesà partir d'un lien
(POWER API) accessible gratuitementsur le site de NASA « Power Project
Data Set1(*) ».Le
POWER signifie : Prediction Of Wordwide Energy Resource.
3.3.2. Structure des
données
Les données sont constituées parcinq variables
importantestelles que :le code Fokontany (cle_jointure), les coordonnées
géographiques (lng/lat), la date (jour/mois/annee), les valeurs des
précipitations (valeur) et numéro de semaine.
3.4. Les
données d'occupation du sol
Une classification supervisée d'image a
été effectuéeafin d'obtenir une carte d'occupation du sol.
L'image utilisée provient du Sentinel 2 datant du 18 août 2018
avec une résolution de 10m avec un niveau de traitement 2B.
Tableau 6.1 : La
représentation de la caractéristique de l'image satellitaire
|
Metadata
|
IMAGE SENTINEL2 :
- Type :Sentinel SYSTEM SCENE level 2B
- Format : DIMAP
- Raster : GEOTIFF
- 4 bandes : 2- Blue,3- Green, 4- Rouge, 8- Proche
Infrarouge
|
|
SCR :
- Géocodage tables identification : EPSG (5.2)
- Type : PROJECTED
- Horizontal coordination système d'identification :
WGS 84/UTM38S
|
Le traitement a été effectué sur QGIS
à l'aide du plugin « Dzetsaka ». Un plugin qui
effectue un traitement d'image semi-automatique. On crée des zones
d'échantillonnages et après on choisit le pourcentage d'une
partie de ces zones pour la validation (40% pour l'étude).
3.4.1. Description
Pour la création des paysages, la classification
d'image satellitaire semi-automatique. La classification est classée par
cinq (05) catégorie ROI (Region Of Interest) qu'on a
cité précédemment.L'image sentinelle 2 est disponible sur
le site officiel de la sentinelle.
3.4.2. Structure des
données
Après la classification, on obtient un résultat
d'image rasterclassé par catégorie des paysages disponibles dans
le district.Ces paysages sont les suivantes : les rizières, les
forêts, les savanes arborées, l'eaux de surface et les zones
résidentielles.
3.5. L'altitude
Les données d'altitude proviennent de SRTM (Shuttle
Radar Topography Mission). Elles sont utilisées pour obtenir les
valeurs d'élévation du terrain sous la forme d'image en 2D avec
une résolution de 30m. Les données sont disponibles sur le site
de NASA.
Chapitre 4 : Les
outils utilisés
Ce chapitre, représenteles outils utiliséspour
l'acquisition, les pré-traitements et les traitements des
données.Les trois premiers outils sont pour l'acquisition des
données et le reste pour le traitement.
4.1. OSMAnd
OSMAnd est une application cartographique et de navigation qui
exploite les données libres d'OpenStreetMap. Complet, il dispose les
principales fonctionnalités nécessaires pour la collecte des
données sur le terrain telle que le mode hors ligne, enregistrement de
la trace en GPX, localisation de la position par GPS et suivre un parcours
pré-enregistré (figure 4.1).
Il est disponible sur deux plateformes : la version
Android et iOS. On a utilisé la version Android et collecté les
informations à l'aide des tablettes (Samsung Galaxy Tab A6).
Figure 7.1: Un exemple de parcours
à pied enregistré à l'aide d'OSMAnd dans la commune de
Kelilalina
4.2. TAG-IP
Pour la réalisation de la collecte, on a utilisé
les outils suivants : l'API du TAG-IP, un SCRIPT développé
sur Python et les matériels GPS (installés sur les
véhicules).
La figure 4.2 montre un exemple de données
récupérée par le script sous format Excel (.csv).
Figure 7.2 : Un exemple des
données du TAG-IP
4.3. Power Api
Pour obtenir les données des précipitations nous
avons utilisé le service « POWER API » et un SCRIPT
développé enPython.
La figure 4.3 affiche un exemple des données
journalières venant du POWER pour le district d'Ifanadiana par
Fokontany.
Figure 7.3 : Un exemple des
données du POWER API
4.4. GPS track editor
La trace GPS est une séquence ordonnée de points
avec latitude, longitude, date, heure.
Comme les coordonnées obtenues d'un récepteur ne
sont pas toujours très précises, différentes erreurs
pourraient survenir lors de l'acquisition. Par exemple, le récepteur
peut montrer un mouvement en restant immobile.
GPS Track Editor sert à nettoyer les traces. Certaines
déviations sont traitées automatiquement mais on peut
contrôler le résultat et éditer une partie de la piste
manuellement.
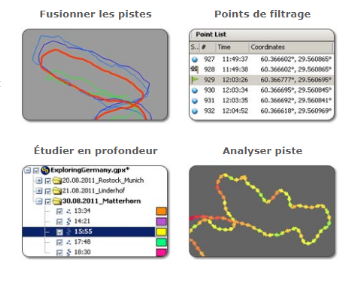
On a utilisé cet outil pour le filtrage des points par
rapport à la données GPX, l'étude en profondeur et
d'autres fonctionnalités qui sont représentés dans la
figure 4.4.
Figure 7.4 : Les
fonctionnalités possible sur GPS Track Editor
4.5. QGIS
L'outil QGIS est un logiciel « open
source », élaboré par une communauté de
développeurs et destiné au traitement des données
géographiques.
Il est utilisé pour la manipulation des données
géographiques, l'importation des données géographiques sur
PostGIS, des requêtes spatiales et la classification d'image satellitaire
à l'aide d'un plugin dzetsaka.
4.6. ArcGIS
L'ArcGIS permet d'analyser des données et publier des
connaissances géographiques pour examiner des relations, tester des
prévisions et prendre des décisions plus avisées.
On a utilisé ArcGIS pour obtenir l'intersection des
données géographiques avec les données de parcours sur le
terrain pourla création des cartes et pour l'interpolation des
résultats spatiales.
4.7. PostGIS
Le PostGIS est un système de gestion de base de
données (SGBD) spatial. Il est utilisé pour stocker les
données collectéescites précédemment avec les
limites administrativesdu district d'Ifanadiana afin deles manipulerà
partir de différentes requêtes.La figure 4.5 suivantes
représente les parties des données.
|
|
|
|
Figure 7.5 : Un exemple de
données stockés sur PostGIS
|
4.8. R
Le logiciel R est un logiciel de statistique. Il sert à
manipuler des données, à afficher des graphiques et à
faire des analyses statistiques.
Pour cette étude, il est utilisé pour
structurerles données, pour effectuer les calculs statistiques,faire
l'exportation des données,faire d'analyse d'exploratoire
pourcréer des modèles et effectuer la prédiction.
Chapitre 5 :
Manipulation des données
Dans ce chapitre, on explique les différentes
procédures effectuées pour le traitement de des données
collectées. Dans un premier temps, on parlera des étapes de
prétraitements, après le traitement et à la fin de la
comparaison entre les résultats théoriques et résultats
sur terrain.
5.1. Prétraitements
Cette phase de prétraitement est nécessaire pour
nettoyer les données collectées afin de faciliter le traitement.
Pour cette étude, on a utilisé différents outils selon
chaque type de données.
5.1.1. Nettoyage des
données prise sur le terrain
LeGPS Track Editor a été utilisé pour
enlever les points erronés prises au début et à la fin
d'un parcours mais aussi pour enlever les points lors des attentes de
transbordement par pirogue. Enfin, ce logiciel nous a aussi servi à
séparer une trace en deux.
5.1.2. Transformation des
données .gpx en .shp sur Qgis
Après le nettoyage, les données ont
été importées sur Qgis pour être transformés
en fichier .shp à l'aide d'un plugin « GPX Segment
Importer ».Après la transformation, on a ajouté deux
variables comme : track pour la spécification des parcours et
l'individu pour la différenciation des vitesses pour chaque parcours. Et
pour finir, on l'importe dans une base de données sur PostGIS.
5.1.3. Intersection des traces
avec l'occupation du sol
L'outil d'intersection d'ArcGIS2(*) a été utilisé afin d'obtenir une
table de toutes les traces avec les différents types d'occupation du sol
qui se coïncide avec. Il est à noter qu'une trace peut se
coïncide avec un ou plusieurs types d'occupation du sol.
5.1.4. Utilisation des
données géographiques sur PostGIS
Toutes les données sont importées dans la base
sur PostGIS. Il représente les informations dans la base de
données nommée « pivot » sur plusieurs tables
avec différents types degéométries.Des requêtes
spatiales avec différentes fonctions ont été
utilisées (st_intersects, st_dump, st_setsrid, st_addmeasure,...) pour
obtenir les caractéristiques du terrain et climatiques pour chaque
segment d'environ 168 parcours. Pour faciliter le traitement, les
requêtes sont structurées sur plusieursvues3(*), c'est-à-dire nous avons
rassemblées sur un vue plusieurs requêtes.
5.1.5. Finalisation de la base
de données
La plus grande étape de la finalisation du
prétraitement a été effectué sous R, après
la récupération des donnés sous PostGIS en utilisant le
plugin « rpostgis ». Tous les paramètres à
étudier étaient fusionnés dans une seule table (gps track,
occupation du sol, ...). Pour chaque segment d'un parcours (distance entre deux
points GPS pris), les variables explicatives associées tels que la pente
(en pourcentage), la vitesse (en km/h), la distance (en km), le temps (en
heure) ont été calculés. On a aussi effectué des
catégorisations pour des variables telles que la
précipitation (0 à 10, 10 à 25 et 25 et plus), la distance
(0 à 13 et 13 et plus), lapente (0 à 30, 30 à 70, 70
à 100 et 100et plus) et l'occupation du sol (0 à 0.1, 0.1
à 50 et 50 à 100). Les valeurs aberrantes ont été
éliminés dans ce traitements et les données ont
été restructurées. Enfin, les données
étaient exportées en fichier .csv.
5.2.
Traitements
Les traitements permettent d'explorer l'ensemble des
données pour savoir des informations sur les donnéeset de
l'analyserafin d'avoir des connaissances pour la création des
modèles.Tous ces traitements sont effectués sur R, à part
l'interpolation postérieur des prédictions des modèles qui
était fait sur ArcGis.
5.2.1. Modélisation
statistique
Il permet d'établir les modèles statistiques
appropriés en fonction de la distributiondes variables explicatives et
réponse ainsi que leur relation, ce qu'on observe durant
l'explorationdes différentes variables. Avec le développent des
modèles, on a effectué deux étapes : 1) l'analyse
exploratoires des données 2) la création des données
statistiques.
5.2.2. Analyses
exploratoires
Cette étape consiste à l'analyse deseffets de
chaque variable explicative par rapport au variable réponse. Les
variables explicatives sont les suivantes :la pente, la distance, la
pluie,l'occupation du sol et la vitesse comme la variable réponse.
Pour chaque variable explicative, on a observéle lien
par rapport à la variable réponse et de les catégoriser en
fonction de l'analyse visuelle pour avoir les comparaisons possibles et
d'interprétations fiables.
Les sous-sectionssuivantesmontrent l'analyse exploratoirede
chaque variable explicative :
- La vitesse
La vitesse est la variable à explique ou
réponse. Il est important de connaitre la distribution de cette variable
pour le choix du modèle (gaussien ou généralisé)
etelle va être comparéeavec toutes les variables explicatives
citées précédemment afin de voir les liaisons entre
eux.
- La pente
La variable pente représente le niveau d'inclinaison du
terrain par rapport aux reliefs, montagnes, ou collines.
Pour le calcul, il existe deux méthodes, tels
que le calcul en dégrée et le calcul du pourcentage (%)
d'une pente. On a opté pour la dernière, celle du pourcentage
suivant la formule4(*) :   . .
Ensuite, les valeurs sont catégorisées pour
avoir des valeurs qualitatives afin de comparer l'exploration des
données obtenues. Ces explorations sont montrées dans la figure
7.2avec les deux valeurs (quantitative / qualitative).
- La distance
La variable distance est utilisée pour identifier
l'effet de la distance depuis le début du parcours sur la vitesse, sous
l'hypothèse que la vitesse réduit après une longue
marche.Elle est représentée sous forme de points en calculantla
distance des deux à l'aide d'une fonction nommée
« spDist », disponible sur R.On a utilisé la formule
suivante pour le calcul : 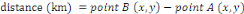 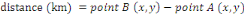 . .
Après le calcul, ces distances partielles sont
regroupéesen une distance de parcourset catégoriséespour
l'analyse d'exploration en qualitative.La valeur de la variable est
catégorisée entre [0 ;13[ et [13 ; 22,9[, selon
l'analyse de la figure 7.3.
- La pluviométrie
La variable pluie (précipitation)est une variable
explicative qui représentel'influence de la pluiejournalière
où le parcours a été effectuéspour tenir en compte
ladétérioration du sol (boue,etc..).L'unité de mesure est
en millimètres (mm).
Durant l'exploration, on a utilisé la
catégorisation des valeurs entre [0,10[, [10, 25] et]25,50]pour
l'analyse qualitative par rapport à la mesurefaite par(Visser and Jones
III 2010) et la valeur originale pour l'analyse quantitative.
- Le pont
Il est utilisé pour l'analyse exploratoire des
véhicules uniquement. La variable explicative pontpermet de voir la
vitesse des véhicules lorsqu'ils passent sur une passerelle. Elle
est catégoriséeendeux valeurs telles que : oui et non.
- La zone résidentielle
Cette variableexplicative est utilisée pour la
détection d'effet sur la vitesse ; lorsque les véhicules
passentparune zone d'habitation. Il est catégorisé en deux
valeurs telles que : oui et non.
- La route
On a utilisé la variable explicative route pour voir
les relations entre les vitesses etles types des routes pour l'analyse
exploratoires des véhicules.Il est catégorisé en quatre
valeurs qui sont les suivantes : la route nationale, la route non
goudronnées, la route non classifiée et le chemin.
- L'individu
Cette variable représente la variation de la vitesse
pour chaque collecte de données durant les parcours effectués. Il
permet de voir la différence des vitesses des individus.
La valeur de la variable est catégorisée telles
que l'ACC (la vitesse des accompagnements des agentscommunautaires), la
vitesse de référence (la vitesse dans mes parcours à moi)
et lesvillageois (la vitesse des villageoisqui ont participé à
l'étude).
- L'occupation du sol
Pour la variable d'occupation du sol,on a utilisé
différents types d'approchespour l'analyse des valeurs tels que :
l'utilisation des valeurs quantitatifs en proportions (séparément
par chaque type), l'utilisation des valeurs en catégorieentre
]0 ;0,1], [0,1 ;50[ et [50,100[pourcent, et l'utilisation du type de
paysage majoritaire sur un parcours.Ces analysespermettent d'observer les
effets d'occupation du solsur la vitesse des individus.
5.2.3. Prédiction de la
vitesse de trajet à pied
Afin d'analyser la variation de la vitesse selon
chaquevariable explicative, des modèles univariés ont
été construits pour identifier les variables qui influencent le
plus la vitesse. Ensuite, un modèle multivarié a
été développé pour inclure toutes les variables qui
ont été significatives lors de l'analyse univarié, afin de
prendre en compte l'effet de tous ces facteurs ensemble.
Suite à l'exploration de données
précédentes, les variables explicatives utilisées dans le
modèle sont les suivantes : la pente (à valeur
quantitative), la pluviométrie (à valeur quantitative), la
distance (à valeur qualitative), l'occupation du sol (à valeur
qualitative) et l'individu (à valeur qualitative pour les
différents types d'individus).
Le modèle univariépermet d'obtenir les
informations sur les coefficientsassociés à chaque variable.Le
modèle est appliqué à l'aide d'une fonction disponible sur
R nommée « lm » avec la formule : 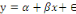 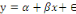 où á est l'intercept (valeur de la variable réponse
quand l'explicative vaut zéro) ; â est le coefficient de
régression (changement dans la variable réponse pour chaque
incrément d'une unité de la variable explicative), et est l'erreur de prédiction (différence
entre valeurs observés et prédits). où á est l'intercept (valeur de la variable réponse
quand l'explicative vaut zéro) ; â est le coefficient de
régression (changement dans la variable réponse pour chaque
incrément d'une unité de la variable explicative), et est l'erreur de prédiction (différence
entre valeurs observés et prédits).
Pour le modèle multivarié, les variables les
plus significatives du modèle précèdent ont
été utilisés. L'AIC (Akaike information
creterion) est calculé pour chaque modèle pour estimer la
qualité du modèle obtenue. Pour le modèle de parcours
à pied, on a utilisé unmodèle additive(GAM) pour prendre
en compte la relation non-linéaire entre la vitesse et la pente (figure
7.3). Pour le modèlede parcours en véhiculemotorisés nous
avons utilisé un modèle gaussien (figure 8.3). Pour les deux
modèles, on a utilisé des modèles mixte, où les
variables explicatives sont les effets fixes et un effet aléatoire a
été rajouté pour chaque parcours individuel (Muller
2018).Les modèlessont disponibles sur R avec les plugins
« mgcv / lmer » et les fonctions nommée
« gam / lmer ».
Après la création des modèles, on a
utilisé des données de parcours entre chaque village et CSB.Ces
parcours représentent les distances minimums de chaque village par
rapport au CSB le plus proche. Pour le structurer, on a effectué les
mêmes étapesque précédemmentpour avoir toutes les
variables explicatives nécessaire à partla
pluviométrie.Ensuite, on fait la prédiction de ces données
à partir du modèle multivarié final pour avoir la valeurde
la vitesse.
5.2.4. Temps de trajet pour
rejoindre les CSB
Pour avoir le temps de trajet de chaque village pour rejoindre
le CSB le plus proche pour tout le district d'Ifanadiana sous forme de carte,
une interpolation est effectuée sur ArcGIS en utilisant la
méthode de « Krigeage »(Sophie 2005).Cette
méthodepermet de générer une surface estimée
à partir d'un ensemble dispersé de points avec des valeurs Z.
Pour cette étudela valeur Z est le temps(en
mn)estimée par la prédictionet présentée sur les
figures 7.9et7.10.
PARTIE III :RESULTAT ET DISCUSSION
Chapitre 6 : Mise
en oeuvre
Dans ce chapitre on élaborela mise en oeuvre du projet
concernant la manipulation des données avec les outils ettous les
traitements pour obtenir les différents résultats. Il est
réalisé selon deux étapes : 1) les prétraitements
qui utilisent les données brutes et les structures afin d'exporter
toutes les variables importantes pour l'étude, et2) les traitements des
données qui permettentleurexploration, la création des
modèles statistiques, la prédiction du temps de parcours et enfin
l'interpolation.
6.1. Prétraitements
Pour les prétraitements, on a utilisé desdivers
outils géomatiques pour manipuler les informationset les
structurées afin d'avoir une base de données analysable.Plusieurs
étapes,ont été utiliséesà commencer par le
nettoyage des données jusqu'à l'importation des
données.
6.1.1 Utilisation des
données avec les outils
a) Données collectées sur le
terrain
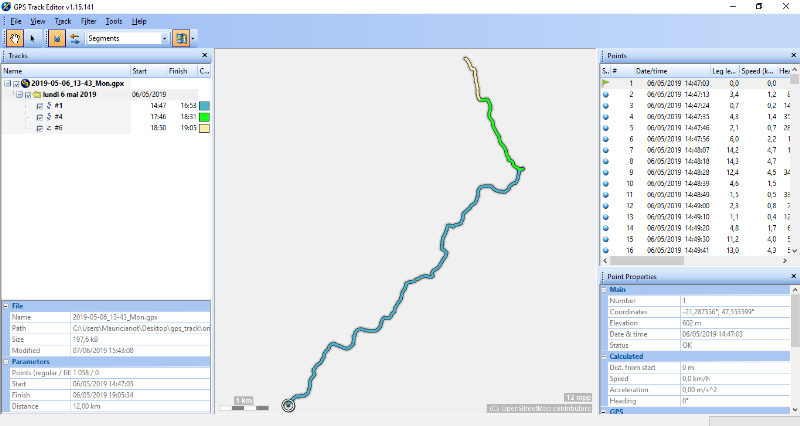
Les données collectées sur le terrain dans la
figure 4.1 sont enregistrées sous format .gpx. Après
l'enregistrement, on l'importedans GPS Track Editor pour lesnettoyeret les
séparer en cas des plusieurs enregistrements detrace
commereprésentédans la figure 6.1.
Figure 9.1 : Utilisation de l'outil
GPS Track Editor
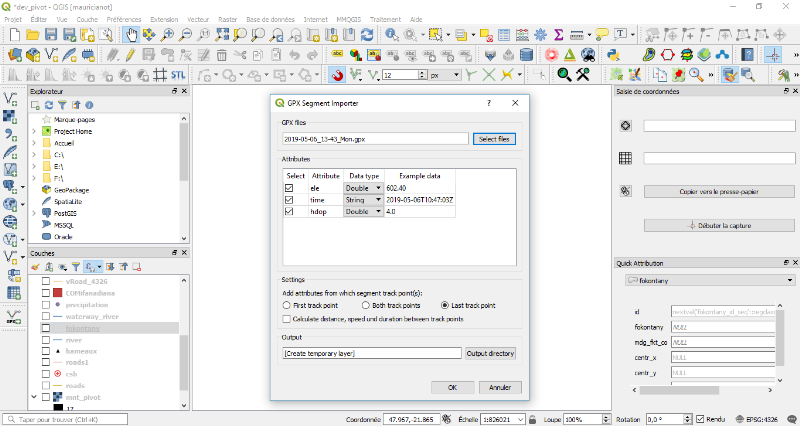
Ensuite, on a faituneconversion du fichier GPS sous fichier
shapefile à l'aide du plugin GPX Segment Importer qui est disponible
dans le dépôt de QGIS. Ce plugin a permisde manipuler les
informations géographiques collectés surQGIS et
représenté par la figure 6.2.
Figure 9.2 : Conversion du fichier
GPS sous shapefile
Après cette conversion, on modifie les données
pour ajouter deux champs : le « track » et l'individu.
Le « track » permet d'identifier chaque parcours
effectué et l'individupermet de reconnaître le type de gens qui
l'a collecté. Le processus est représentépar la figure
6.3.
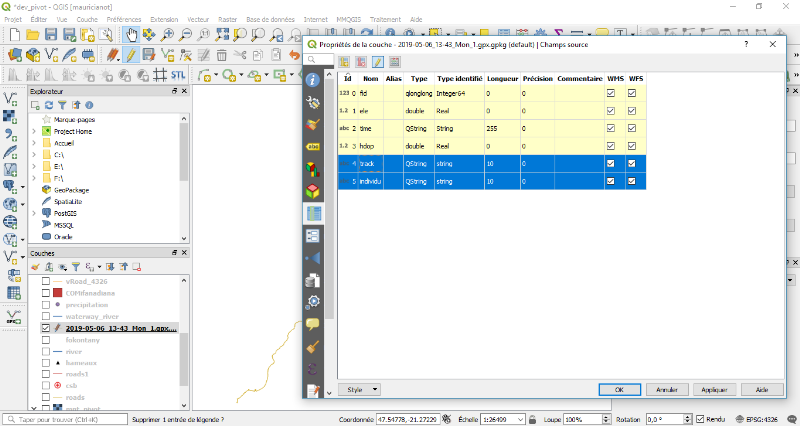
Pour chaque enregistrement, on utilise le même processus
et aprèson les rassembleà l'aide d'un outil de gestion de
données nommé « Fusion des couches vecteurs »
sous QGIS.
Figure 9.3 : Modification des
données(ajouter deux champs : track et individu)
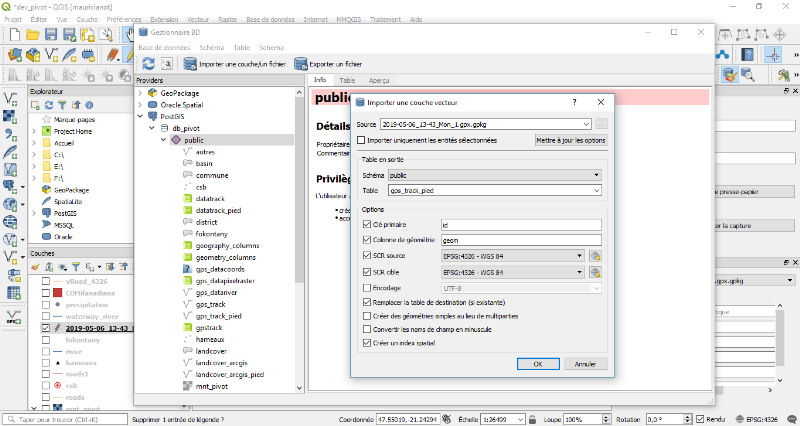
Les données fusionnées sontimportées dans
la base de données PostgreSQL/PostGIS nommée
« pivot » etdansla table
« gps_track_pied ».La figure 6.4 montre l'importation des
données dans la base de données.
Figure 9.4 : Importation des
données des parcours effectuée sur PostGIS
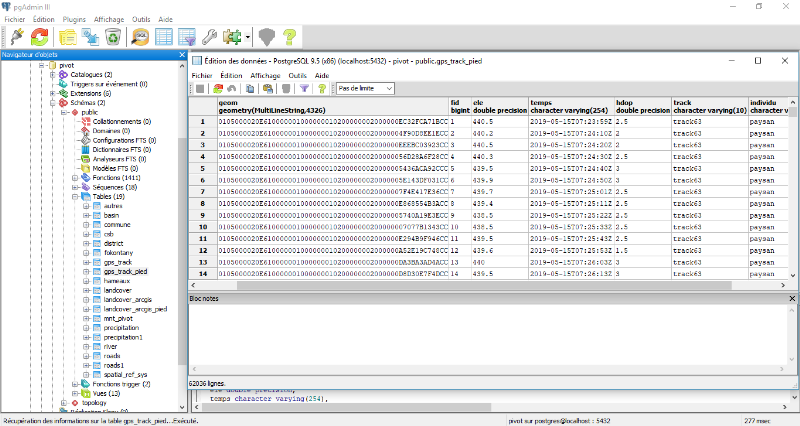
Enfin, La figure 6.5 représente les données
après l'importation concernant les parcours effectués. Celui-ci
est très important afin qu'on puisseutiliser les fonctions spatiales
disponibles sur PostGIS pour les requêtes spatiales.
Figure 9.5 : Table "gps_track_pied"
sur PostgreSQL
b) Données de pluviométrie
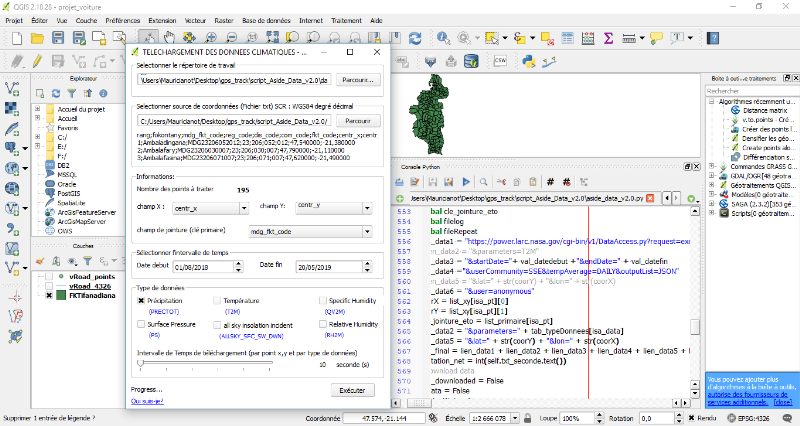
Pour les donnéesde pluviométrie, on a
téléchargé les informations climatiques par Fokontany
à partir d'un outil de téléchargement utilisable sur QGIS
quiest présenté sur la figure 6.6. On a utiliséles
centroïdes des limites administratives, le code de Fokontany pour la
clé de jointure etla durée entre deux dates comme
paramètres.
Figure 9.6 :
Téléchargement des données pluviométrie
Après le téléchargement, les informations
sont retournéesavec la valeur de la pluviométrie par
Fokontanyreprésenté par la figure 6.7. Pour avoir la date, on a
ajouté un champ « datejours » qui est
concaténé à partir des champs tels que :
l'année, mois et jour.
Figure 9.7 : Les données
pluviométrie
Pour terminer, on importe dans la base de données
précédentedans la table
« précipitation ».La figure 6.8 montre cette
importation à partir de la gestion de base de données sur
QGIS.
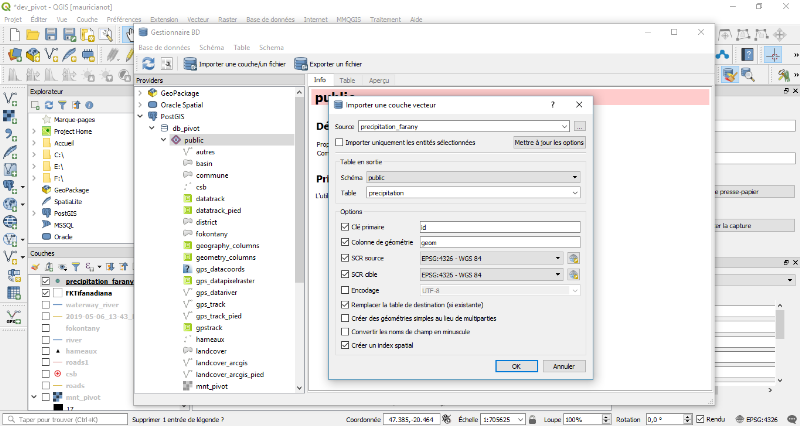
Figure 9.8 : Importation des
données pluviométrie sur PostGIS
c) Données occupation du sol
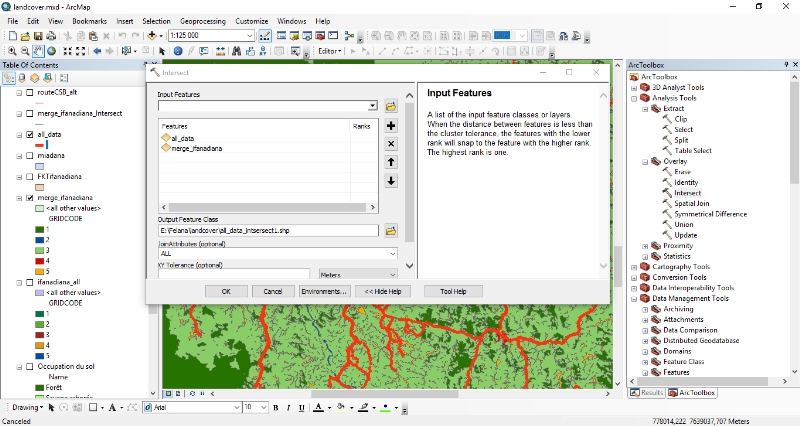
Pour les données d'occupation du sol, on a
effectué uneintersectiondes parcours collectés sur le terrain par
rapport au paysage. L'objectif est derécupérer les informations
d'occupation du sol sur une ligne de parcours.On a utilisé ArcGIS,en
utilisant l'outil intersection sur Arctoolbox
« intersection ».
Figure 9.9 : Intersection des
données collectées et les paysages
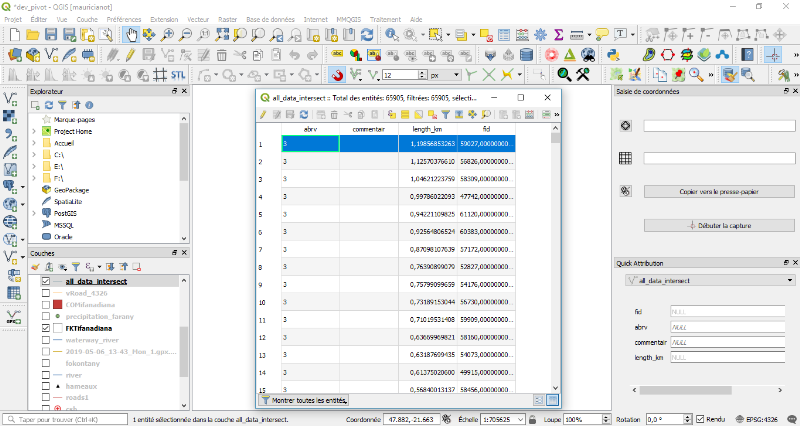
Après cette intersection, on revient sur QGis et on
yajoute un autre champ « length_km » pour la distance de chaque
ligne ($area) commesur la figure 6.10.L'abréviation (abrv) estle type
d'occupation du solcodifié et le commentaire représente
l'étiquette de l'occupation du sol).
Figure 9.10 : Modification des
données (ajouter un champ length_km)
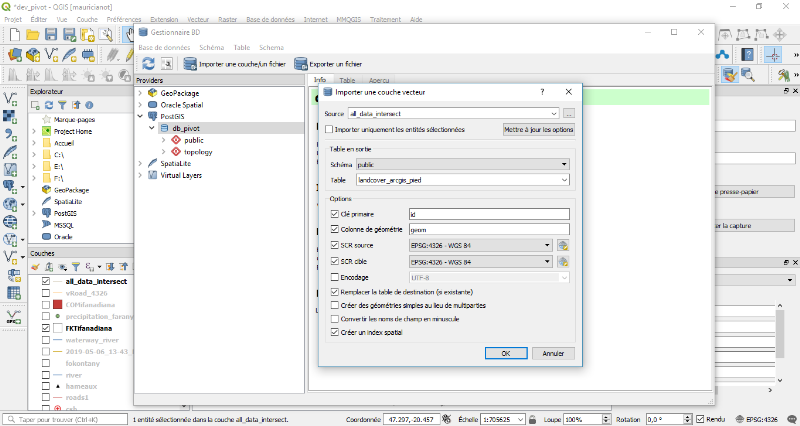
Pour finir, on l'importe dans la base de données dans
une table nommée « landcover_arcgis_pied ». La
figure 6.11 montre cette importation à partir de la gestion de la base
de données sur QGIS.
Figure 9.11 : Importation des
données d'occupation du sol sur PostGIS
6.1.2. Exportation de la base
de données
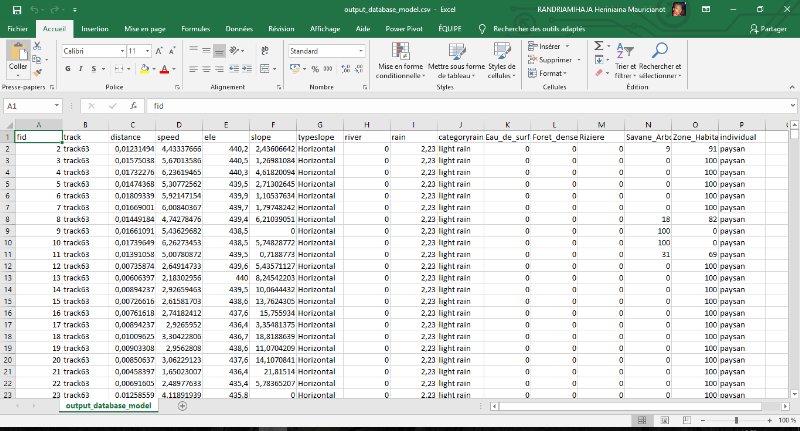
On a utilisé l'outil R software pour les jointures et
les calculs tels que : la distance, la vitesse, la pente et la proportion
des paysages sur des scripts. Enfin, on l'exporte sous format (.csv).La figure
6.12 affiche les informations de base de données analysable pour
l'estimation du temps de parcours à pied.
Figure 9.12 : Le base de
données analysable pour l'estimation du temps de parcours à
pied
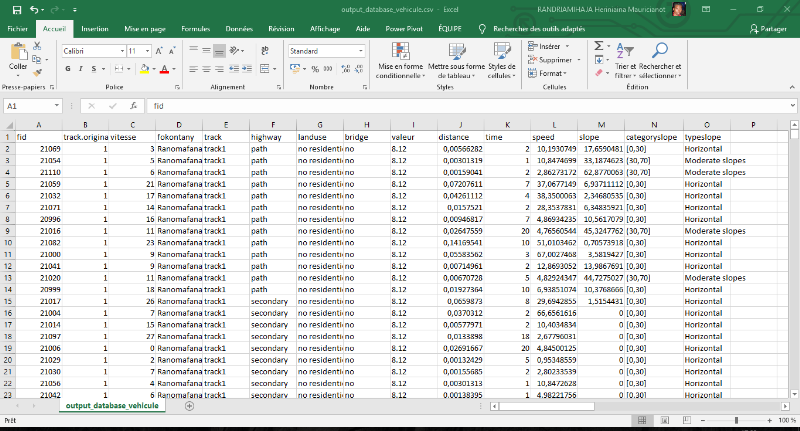
Et la figure 6.13 représente les informations de base
de données analysable pour l'estimation du temps de parcours en
véhicule motorisé.
Figure 9.13 : Le base de
données analysable pour l'estimation du temps de parcours en
véhicule motorisé
6.2.
Traitements
Pour obtenir les résultats, on a élaboré
plusieurs scripts sous R pour les traitementsavec des
méthodesstatistiques afin de résoudre le problème complexe
sur le cas d'étude.Ces scripts sont présentésà
partir du l'extrait des codes dans chaque sous-section.
6.2.1. Exploration des
données
Pour l'exploration, on a utilisé deux modes
exploratoires comme : l'analyse de variables quantitatives et l'analyse de
variables qualitatives.L'analyse de variables qualitatives, pour connaitre le
lien entre la vitesse et des variables catégorielles, se fait à
partirde la boîte à moustache (boxplot) et l'autre à partir
de la fonction plot.
L'extrait du code suivant montre l'analyse exploratoire des
données collectées sur le terrain pour l'estimation du temps de
parcours à pied.Dans ce code, on a crééune variable
« distance originale » (distance cumulée) à
partir de la distance pour avoir l'effet des vitesses par rapport à
l'éloignement depuis le début du parcours afin de le
catégoriser. Ensuite, on catégorise par rapport à leur
type les valeurs de proportion d'occupation du sol en gardant l'une qui a
la valeur la plus élevée. Enfin, on représente
graphiquementles données pour toutes les variables.
|
# Sélectionner chaque track séparément et
obtenir les positions dans la base de données où il se trouve
for (my.track in levels(track.database.model$track)){
position=which(track.database.model$track==my.track)
# Pour chaque track on va calculer la distance depuis le
début du parcours
for (i in 1:length(position)){
if(i==1){track.database.model$distance.origine[position][i]=track.database.model$distance[position][i]}
else{track.database.model$distance.origine[position][i]=track.database.model$distance[position][i]+track.database.model$distance.origine[position][i-1]}
}
}
# Catégorisation de la distance originale des parcours
effectuée durant les trajets
track.database.model$categorydistance <-
cut(track.database.model$distance.origine, c(0, 13 ,
max(track.database.model$distance.origine)), include.lowest = TRUE)
# Catégorisation des valeurs proportion d'occupation du
sol
sum.cat=apply(track.database.model[,c('Savane_Arboree','Foret_dense','Zone_Habitation','Riziere','Eau_de_surface')],1,sum)
hist(sum.cat) ; sum.cat.total=ifelse(sum.cat==100,1,0)
# On utilise cèle qui ont la valeur plus grande pour
l'occupation du sol
main.cat=apply(track.database.model[,c('Savane_Arboree','Foret_dense','Zone_Habitation','Riziere','Eau_de_surface')],
1, function(x){which(x>50)})
ii=which(lapply(main.cat,length)==0) ; main.cat[ii]='Mixte'
track.database.model$occupation=factor(labels(unlist(main.cat)))
; levels(track.database.model$occupation)[1]='Mixte'
# Catégorisation des valeurs proportion d'occupation du
sol
track.database.model$paysages.c <-
cut(as.numeric(track.database.model$paysages), c(0,0.1, 50, 100),
include.lowest = TRUE)
#Diviser par 15 les valeurs des pentes
track.database.model$slope <-
abs(track.database.model$slope)/15
# Frequence du variable reponse
par(mfrow = c(1,3))
hist(track.database.pied$speed, col='grey',
main=NULL,xlab='Vitesse des individus', ylab = "Frequence")
table(track.database.pied$speed)
boxplot(track.database.pied$speed, ylab="Vitesse",
main="Médian des vitesses")
plot(ecdf(track.database.pied$speed), main="Répartition
cumulée")
# variables pente par rapport à la vitesse
par(mfrow = c(1,3))
hist(track.database.pied$slope, col='grey',
main=NULL,xlab='Valeurs des pentes', ylab = "Frequence")
table(track.database.pied$typeslope)
track.database.pied$typeslope=factor(track.database.pied$typeslope,
levels(track.database.pied$typeslope)[c(1,2,4,3)])
boxplot(track.database.pied$speed~track.database.pied$typeslope,
ylab="Vitesse des individus par type des pentes")
plot(track.database.pied$slope,track.database.pied$speed,
ylab='Vitesse des individus / pente de terrain', pch=16, cex=0.5)
abline(lm(speed~slope, data=track.database.pied),
col='lightblue', lwd=2)
lines(smooth.spline(track.database.pied$slope,track.database.pied$speed),col='red',lwd=2)
legend('topright',lty=1, cex = 0.8
,col=c('lightblue','red'),c('Modèle linéaire','Modèle Non
Linéaire'))
cor(track.database.pied$slope, track.database.pied$speed, use
= "complete.obs")
table(track.database.pied$lpaysages.c)
boxplot(track.database.pied$speed ~
track.database.pied$paysages.c, ylab='Vitesse des individus',
xlab="Paysages")
|
|
L'extrait de code suivant montre l'analyse exploratoire des
données des véhicules collectées à l'aide des
outils GPS pour l'estimation du temps de parcours en véhicule
motorisé.
|
|
# variable distance
par(mfrow = c(1,3))
hist(track.database.model.v1$distance.origine, col='grey',
main=NULL,xlab='Distance des parcours effectués', ylab = "Frequence")
track.database.model.v1$categorydistance <-
cut(track.database.model.v1$distance.origine, c(0,2,
max(track.database.model.v1$distance.origine)), include.lowest = TRUE)
table(track.database.model.v1$categorydistance)
boxplot(track.database.model.v1$speed~track.database.model.v1$categorydistance,
ylab='Vitesse des véhicules ', xlab="Distance (km)")
plot(track.database.model.v1$distance.origine,track.database.model.v1$speed,
ylab='Vitesse des véhicules / distance', pch=16, cex=0.5)
abline(lm(speed~distance.origine,
data=track.database.model.v1), col='lightblue', lwd=2)
lines(smooth.spline(track.database.model.v1$distance.origine,track.database.model.v1$speed),col='red',lwd=2)
legend('topright',lty=1, cex = 0.8
,col=c('lightblue','red'),c('Modèle linéaire','Modèle Non
Linéaire'))
cor(track.database.model.v1$distance.origine,
track.database.model.v1$speed, use = "complete.obs")
table(track.database.model.v1$bridge)
boxplot(track.database.model.v1$speed~track.database.model.v1$bridge,
xlab="No - Pas de pond | Yes - Traversant un pond", ylab='Vitesse des
véhicules en traversant un rivière')
# variable résidentielle
#par(mfrow = c(1,2))
table(track.database.model.v1$landuse)
boxplot(track.database.model.v1$speed~track.database.model.v1$landuse,
ylab='Vitesse des véhicules par catégorie')
# variable pont
#par(mfrow = c(1,2))
table(track.database.model.v1$bridge)
boxplot(track.database.model.v1$speed~track.database.model.v1$bridge,
ylab='Vitesse des véhicules par catégorie')
# variable réseaux routiers
#par(mfrow = c(1,2))
table(track.database.model.v1$highway)
track.database.model.v1$highway=factor(track.database.model.v1$highway,
levels(track.database.model.v1$highway)[c(4,3,2,1)])
boxplot(track.database.model.v1$speed~track.database.model.v1$highway,
ylab='Vitesse des véhicules par catégorie')
# variable individu
table(track.database.model.v1$individual)
track.database.model.v1$individual=factor(track.database.model.v1$individual,
levels(track.database.model.v1$individual)[c(2,1)])
boxplot(track.database.model.v1$speed~track.database.model.v1$individual,
ylab='Vitesse des véhicules par catégorie')
|
6.2.2. Mise en place du
modèle statistique
Après les explorations, on élabore un
modèle statistique linéaireunivarié pour toutes les
variables explicatives par rapport à la variable réponse sur
l'interprétation des données. L'extrait du code suivant permet
d'avoir les informations sur les modèles linéaires.
|
#créationtablenulle pour le résultat des
modèles
model.resultat <- data.frame(NULL)
var.name = names(model.test)
for (i in 3:length(var.name)){
variables <- var.name[i]
var.temp <- model.test[, var.name[i]]
rst.model <- lm(model.test$speed ~ var.temp)
modelSummary <- summary(rst.model) # capturer les
informations surles modèles
modelCoeffs <- modelSummary$coefficients # coefficients
des modèles
resultat.categ <- data.frame(NULL)
var.coeffs = names(modelCoeffs[,1])
speed.estimate = modelCoeffs[,1][1]
for (i in 2:length(var.coeffs)){
variable.coeffs <- paste(var.coeffs[i], variables, sep
= " | ", collapse = NULL)
beta.estimate <- modelCoeffs[var.coeffs[i], "Estimate"]
# recup. beta estimate pour var.temp
std.error <- modelCoeffs[var.coeffs[i], "Std. Error"]
# recup. std.error pour var.temp
t_value <- beta.estimate/std.error # calcul t
statistique
p_value <- 2*pt(-abs(t_value),
df=nrow(cars)-ncol(cars)) # calcul p Value
#enlever le préfixe nommé (var.temps)
variable.coeffs <- substring(variable.coeffs, 9)
var.test <- substr(variable.coeffs, 1, 2)
if(var.test == " |"){
variable.coeffs <- substring(variable.coeffs, 3)
}
temp.categ <- data.frame(variable.coeffs,
speed.estimate, beta.estimate, std.error, t_value, p_value, AIC(rst.model))
if(is.data.frame(resultat.categ) &&
nrow(resultat.categ)==0){
resultat.categ <- temp.categ
}else{
resultat.categ <- rbind(resultat.categ,
temp.categ)
}
}
#ajouter à la ligne model.resultat
if(is.data.frame(model.resultat) &&
nrow(model.resultat)==0){
model.resultat <- resultat.categ
}else{
model.resultat <- rbind(model.resultat,
resultat.categ)
}
# effacer les variables temporaires
rm("var.temp","rst.model","modelSummary","modelCoeffs","var.coeffs",
"beta.estimate","speed.estimate","std.error","t_value","p_value","var.coeffs","variables","temp.categ")
}
|
Ci-après le modèle multivarié
utilisé pour l'estimation du temps de parcours à pied avec les
variables explicatives telles que : la pente, la pluie, la distance,
l'occupation du sol et l'individu. Au contraire que pour les modèles
précédents, on utilise un modèle additif (gam) pour
prendre en compte le lien non-linéaire entre la pente et la vitesse.
|
model_pied<-gam(speed~s(slope)+rain+categorydistance+occupation+individual,
data = model.test)
|
Et ci-dessous le modèle multivarié pour
l'estimation du temps de parcours en véhicule motorisé avec les
variables explicatives tels que : la pente, la pluie, la distance, le
pont, la zone résidentielle, les réseaux routières,
l'individu et l'identification des parcours.
|
model_vehicule<-
lmer(speed~slope+rain+categorydistance+bridge+landuse+highway+individual+(1|track),
data = model.vehicule)
|
6 .2.3 Prédiction
du temps de parcours
Pour la prédiction du temps de parcours, on a
utilisé deux valeurs différentes pour la variable pluie tels
que : la valeur sansqui vaut 0 et avec pluie (la valeur maximum de la
pluie par rapport à la base de données analysable). L'extrait du
code suivant permet de faire les prédictions.
|
#prédiction de la vitesse à pied avec et sans
pluie
predict.csb$speed.rain.min <- predict(model, predict.csb,
exclude="s(track)")
predict.csb$speed.rain.max <- predict(model, predict.csb,
exclude="s(track)")
#calcul du temps de parcours en seconde
predict.csb$time.rain.min <-
(predict.csb$distance*1000/predict.csb$speed.rain.min)*3.6
predict.csb$time.rain.max <-
(predict.csb$distance*1000/predict.csb$speed.rain.max)*3.6
|
Après l'exécution du code, on obtient le
résultat montréparla figure 6.14. Il représente les deux
valeursde l'estimation du temps de parcours sans pluie (time.rain.min) et avec
pluie (time.rain.max). Afin de passer à l'étape suivante, il est
nécessaire d'agréger les données par rapport au champ
track pour avoir le temps de trajet de chaque parcours.
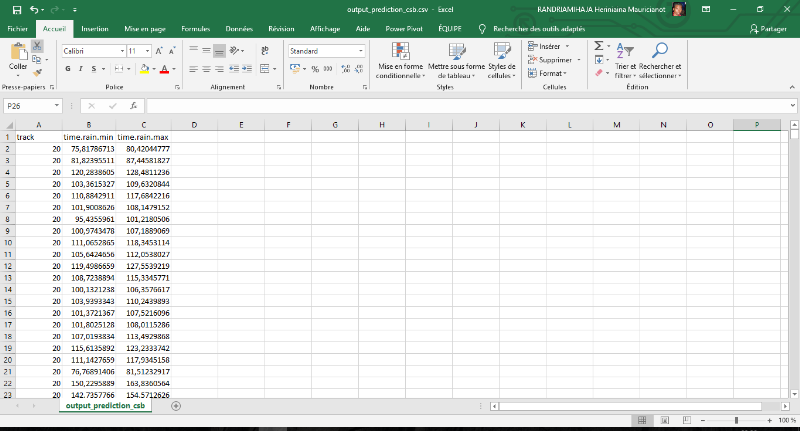
Figure 9.14 : Le résultat de
la prédiction du temps de parcours
6.2.4. Interpolation des
données sur ArcGIS
Pour faire l'interpolation des données, on a
utilisé deux données tels que : les données sur le
temps de parcours dans la figure 6.14 et les données venant d'osrm avec
les informations suivantes : l'Identification (ID), la longitude (X),
latitude (Y), le nom de village (name), la distance minimum entre le village et
le CSB le plus proche (distance_min) et le CSB plus proche (csb_proche). La
figure 6.15 montre les informations des données d'OSRM.
Figure 9.15 : Les données
d'OSRM
Ensuite, on a fusionné les deux données à
partir du track et de l'ID afin d'avoir des données vecteur (points).La
figure 6.16 représente les informationscomplètes pour
l'interpolation de données.
Figure 9.16 : Les données
complètes pour l'interpolation
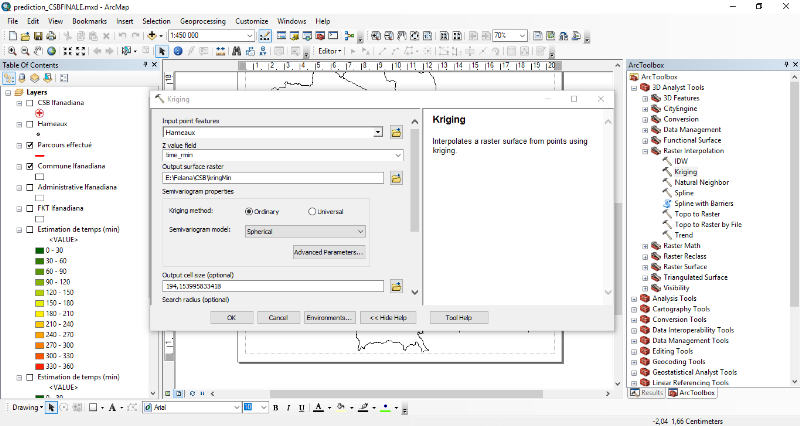
Pour l'interpolation, on a utilisé l'outil ArcGIS avec
l'utilisation de la fonction Krigeage et la couche vecteur
précédent. La figure 6.17montre l'interpolation des
données pour l'estimation du temps de parcours sans pluie.
Figure 9.17 : L'interpolation des
données pour le temps de parcours sans pluie
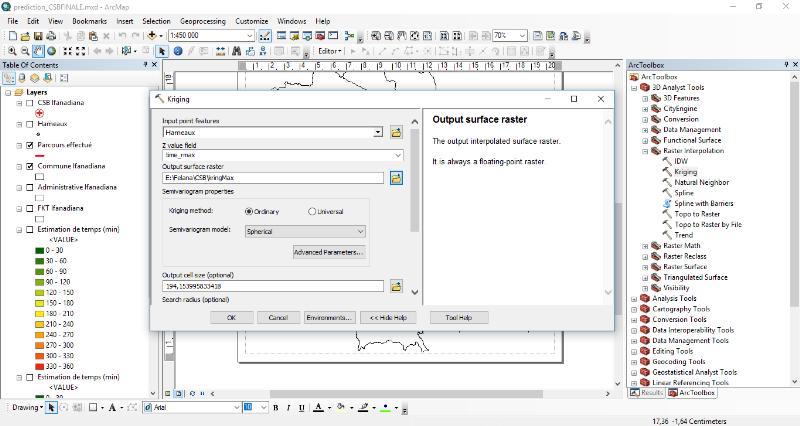
Et la figure 6.18montre l'interpolation des données
pour l'estimation du temps de parcours avec pluie.
Figure 9.18 : L'interpolation des
données pour le temps de parcours avec pluie
Chapitre 7 :
Estimation du temps de parcours à pied
Dans ce chapitre, on présente les résultats
d'étude concernant l'estimation du temps de parcours à pied selon
les données utilisées, l'exploration des données, les
modèlesutilisés et la prédiction du temps de parcours.
7.1. Les données recueillies
On a collecté 168 parcours dans tout le district
d'Ifanadiana.La majorité des données sontsituées dans la
Commune de Kelilalina et d'Ifanadiana.
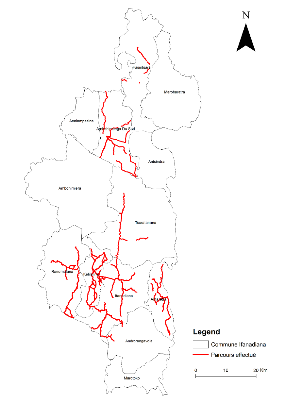
La figure 7.1 montre une carte des données
collectée sur le terrain qui sont utilisées durant cette
étude dans le district d'Ifanadiana.
|
Commune
|
Distance (km)
|
|
Kelilalina
|
286,07
|
|
Ifanadiana
|
266,72
|
|
Ranomafana
|
188,71
|
|
Antaretra
|
121,5
|
|
Ambohimanga Du Sud
|
91,9
|
|
Tsaratanana
|
34,12
|
|
Fasintsara
|
12,75
|
|
Androrangavola
|
12,24
|
|
Antsindra
|
1,66
|
|
Ambohimiera
|
0,15
|
|
Individus
|
Distance (km)
|
|
Paysan
|
593,90
|
|
Mauricianot
|
158,59
|
|
ACC
|
263,33
|
Figure 10.1 : Une carte des
données collectées sur le terrain
7.2. Résultats de la phase d'exploration des
données
Les données exploratoires représentent les
résultats d'analyse exploratoire des différentes variables
explicatives et la variableréponse. Il montretrois types des
résultats pour les variables quantitativestels que :la pente, la
distance, la pluviométrieet un résultatpour les variables
qualitatives.
7.2.1. La vitesse
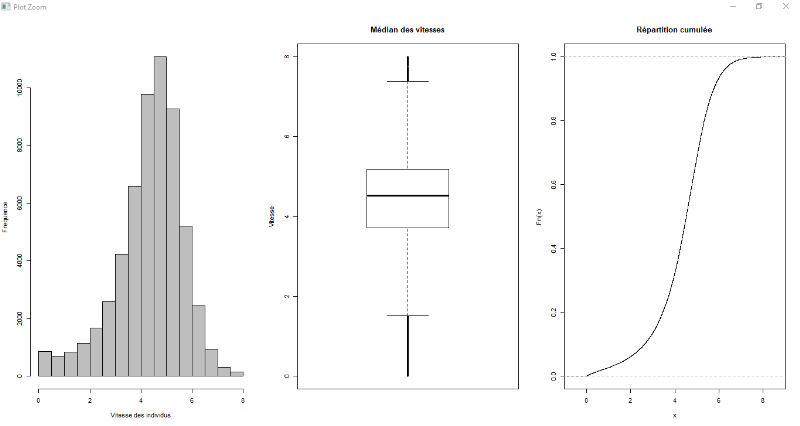
La figure 7.2 représente l'analyse de la variable
réponse avec trois observations différentes : l'histogramme
pour voir la distribution de la vitesse, la boîte à moustache et
la répartition cumuléede la variable vitesse.
Figure 10.2 : Exploration de
données à pied pour la variable vitesse
Par rapport à cette figure, l'histogramme montre une
distribution normale de la variable avec une valeur plus courante entre 4
à 5,5 km/h. Et il se disperse exponentiellement pour les deux
côtés. On observe une vitesse médiane de 4,6 km/h avec une
moyenne de variabilité entre 3,8 à 5,5 km/h. La
répartition cumulée de la vitessemontre une grande augmentation
entre 2 à 6 km/h.
7.2.2. La pente
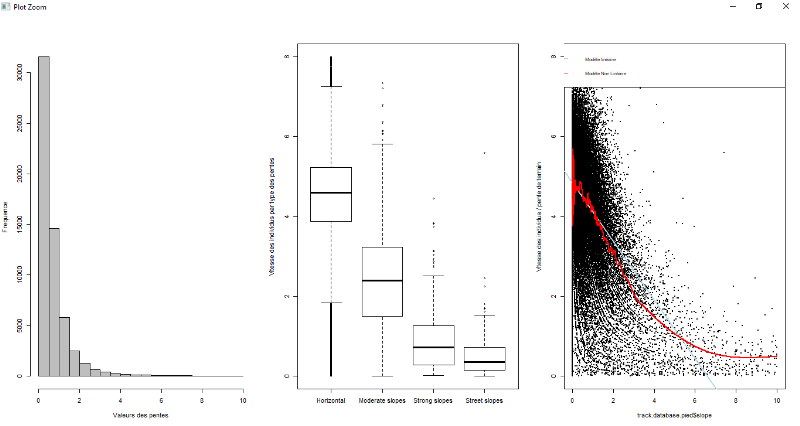
La figure 7.3 montre l'analyse des variables de la pente par
rapport à la vitesse des gens sur l'analyse quantitative et qualitative.
Pour la catégorisation, 94,31% des valeurs ont une pente horizontale,
4,79% pour une pente moyenne, 0,54% pour une pente forte et 0,36% pourune pente
extrême.
Figure 10.3 : Exploration de
données à pied pour la variable pente
D'après la figure de gauche, l'histogramme montre que
la plupart des valeurs se situe entre 0 à 0,5 et la dispersion des
données s'étend de 0,5 à 10.
Pour la boîte à moustache, sur une pente
horizontale, les individus peuvent avoir une vitesse plus rapide pour la pente
modérée,la vitesse est réduite mais avec une grande
variabilité et les deux autres catégories depentes ont une
vitesse encore plus lente avec des pentes très étroite.
La figure de droite représente la relation entre la
variablepente et la variable vitesse par rapport au modèle
linéaire (ligne bleue) et non linéaire (ligne rouge). Selon
l'observation, la variable pente a une relation non linéaire avec la
variable vitesse.
7.2.3. La distance
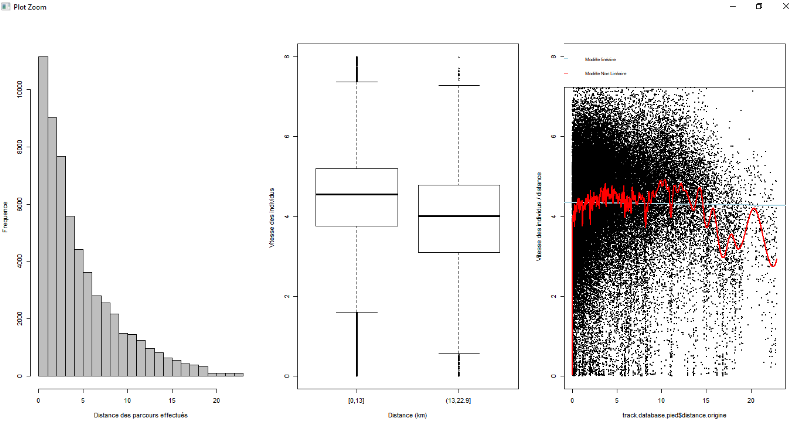
La figure 7.4montre le résultat des données
collectées sur terrain. Pour la valeur qualitative, 93,84% de
données de distance sont àmoins de 13 km et de 6,18% pour le plus
de 13 km.
Figure 10.4 : Exploration de
données à pied pour la variable distance
L'histogrammemontre que la majorité des données
de distance se situent entre 0 à 3km. Et se disperse entre 4 à 19
km, avec une grande diminution pour la valeur de 20 à 23 km.
Pour cette analyse qualitative, la boîte à
moustache montre que la vitesse diminue pour une longue marche deplus de 13 km
qui pourrait être relié à la fatigue.Inversement, lavitesse
estplus rapide pour une distance moins de 13 km.
La dernière analyse permet de voir le lien entre la
donnée terrain et la vitesse. On peut voir que les données
suivent une tendance linéaire entre 0 à 13 km. Par contre, la
tendance diminue rapidement pour la distance plus de 13 km.On distingue doncune
relation non linéaire entreces deux variables, ce qui nous a permis de
faire la catégorisation.
7.2.4. La
pluviométrie
La figure 7.5représente le résultat de l'analyse
exploratoire pour la variable pluie.Pour les données qualitatives,
83,66% des observations étaient de la pluie légère, 14,28%
de pluie modérée et 2,05% de forte pluie.
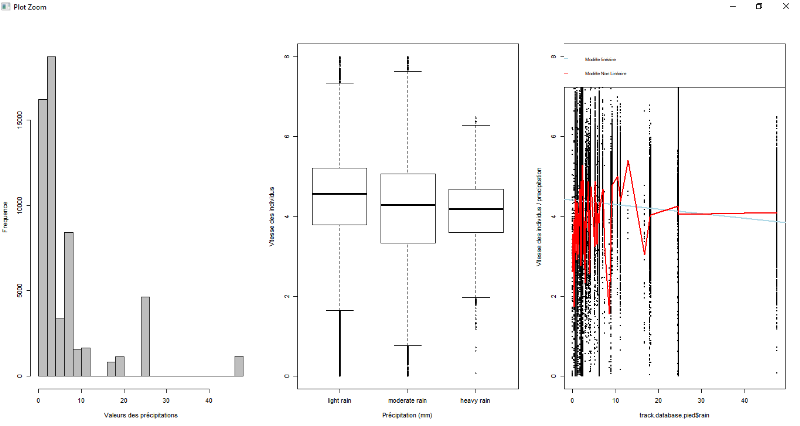
Figure 10.5 : Exploration de
données à pied pour la variable pluie
L'histogrammede gauche nous montre la fréquence de la
pluie. La fréquence la plus élevée se situeentre 0
à 4mm avec une valeur de lafréquence nulle entre 12 à
16mm, 22mm à 24mm et 28 à 46mm. La distribution est dite
positivement asymétrique.
La catégorisation de la pluiemontre le lien entre la
vitesse et l'intensité de pluie. Pour une pluie légère,
les individus marchent à une vitesse entre 3,8 à 5,2 km/h tandis
quepour une pluie modérée on a observé une diminution de
la vitesse de parcourspar rapport à l'influence de la pluie qui
détériore les solset varie entre 3,2 à 4,8 km/h.Et pour la
forte pluie, la vitesse diminue encore plus entre 3,5 à 4,5km/h.
La figure de droite représente, la relation entre la
vitesse et la pluie. On distingue une légère tendance
linéaire négative, mais le modèle non-linéaire
suggère que cette tendance n'est pas très consistante pour
l'étendue des valeurs de pluie.
7.2.5. L'individu
La figure 7.6montre les différentes variations des
vitesses selon la catégorie d'individu.Pour la catégorisation des
données, 83,40% représentent la vitesse des villageois,14,28%
mavitesse et 2,32% pour les ACC.
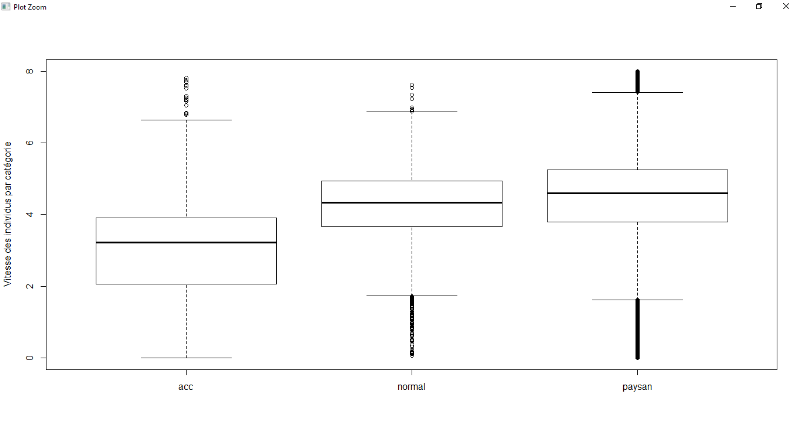
Figure 10.6 : Exploration de
données à pied pour la variable individu
La figure ci-dessus montre une grande différence entre
les vitesses des trois catégories d'individu choisi.
L'ACCreprésente l'individu le moins lent parmi les trois
catégories avec une médiane de 3,5km/h. Un individu normal marche
à peu près avec la même vitesse qu'un villageois avec une
médiane auxalentours de 4km/h.
7.2.6. L'occupation du sol
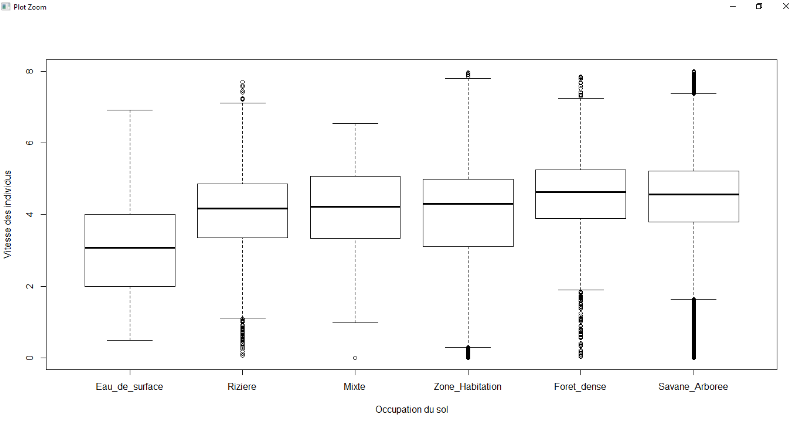
La figure 7.7montre la vitesse des gens pendant le passage sur
chaque type d'occupation du sol.Le pourcentage de chaque classe d'occupation de
sol est comme suit :0,23% d'eau de surface, 5,76 de rizière, 0,08%
depaysage mixte, 9,26% de zone d'habitation, 3,9 % de forêt dense et
80,77% de savane arborée.
Figure 10.7 : Exploration de
données à pied pour la variable occupation du sol
La vitesse la plus faible est identifiée lors du
passage sur une zoned'eau de surface avec une vitesse de 3km/h en moyenne.
Tandis que la plus élevée est pour la forêt dense et la
savane arborée puisque qu'il existe des chemins non carrossables
à travers ces deux classes avec une vitesse moyenne de 5km/h. Pour la
classe rizière, mixte et zone d'habitation la valeur moyenne de la
vitesse et de 4km/k.
7.3. Les
modèles univariés et multivariés
Les résultats des modèles contiennent les
éléments suivants : les variables (la nomination des
variables explicatives), l'estimation (la vitesse estimée ou á),
le beta (l'effet de la variable par rapport à l'estimation), le std.
Erreur (l'erreur d'ajustement), le tvalue (coefficient de probabilité),
le pvalue (vérification de la signification statistique) et l'AIC (les
mesures de la qualité de l'ajustement).
7.3.1. Le modèle
univarié
Le tableau 6.1montre les valeurs de coefficient pour chaque
variable explicative par rapportà lavariable réponse.Un exemple
de la formule suivante a utilisépour le calcul de la pente :  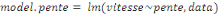 . .
Tableau 10.1: La résultat
d'analyse des variables explicatives avec le modèle univariés
|
8.1.
Variables
|
á
|
â
|
Std Erreur
|
T. Value
|
P. Value
|
AIC
|
|
Pente
|
4,85
|
-0,74
|
0,01
|
-137,70
|
<0,001
|
177719
|
|
Rivière
|
4,34
|
-0,23
|
0,10
|
-2,21
|
0,032
|
194111
|
|
Pluie
|
4,41
|
-0,01
|
0,00
|
-18,87
|
<0,001
|
193761
|
|
Pluie (ctg)
|
Forte pluie (Réf)
|
4,10
|
|
|
|
|
193888
|
|
Légère pluie
|
|
0,28
|
0,04
|
7,29
|
<0,001
|
|
|
Modérée pluie
|
|
0,07
|
0,04
|
1,63
|
0,109
|
|
|
Distance
|
4,35
|
0,00
|
0,00
|
-2,54
|
0,014
|
194109
|
|
Distance (ctg)
|
(0,13] (Réf)
|
4,37
|
|
|
|
|
193560
|
|
(13,22.9]
|
|
-0,53
|
0,02
|
-23,63
|
<0,001
|
|
|
Savane Arborée
|
4,03
|
0,00
|
0,00
|
26,99
|
<0,001
|
193392
|
|
Savane Arborée (ctg)
|
0 (Réf)
|
4,04
|
|
|
|
|
193422
|
|
(0.1,50]
|
|
0,11
|
0,04
|
2,85
|
<0,001
|
|
|
(50,100]
|
|
0,37
|
0,01
|
25,91
|
<0,001
|
|
|
Savane Arborée (bool)
|
4,04
|
0,36
|
0,01
|
25,49
|
<0,001
|
193470
|
|
Forêt dense
|
4,33
|
0,00
|
0,00
|
6,70
|
<0,001
|
194071
|
|
Occupation du sol
|
Mixte (Réf)
|
4,04
|
|
|
|
|
192985
|
|
Eau de surface
|
|
-0,96
|
0,22
|
-4,35
|
<0,001
|
|
|
Forêt dense
|
|
0,47
|
0,19
|
2,43
|
0,019
|
|
|
Rizière
|
|
0,00
|
0,19
|
0,02
|
0,985
|
|
|
Savane Arborée
|
|
0,36
|
0,19
|
1,92
|
0,06
|
|
|
Zone Habitation
|
|
-0,16
|
0,19
|
-0,85
|
0,397
|
|
|
Forêt dense (ctg)
|
0 (Réf)
|
4,33
|
|
|
|
|
194075
|
|
(0.1,50]
|
|
0,15
|
0,09
|
1,71
|
0,092
|
|
|
|
(50,100]
|
|
0,18
|
0,03
|
6,35
|
<0,001
|
|
|
Forêt dense (bool)
|
4,33
|
0,17
|
0,03
|
6,54
|
<0,001
|
194073
|
|
Zone Habitation
|
4,39
|
-0,01
|
0,00
|
-27,58
|
<0,001
|
193360
|
|
Zone Habitation (ctg)
|
0 (Réf)
|
4,39
|
|
|
|
|
193373
|
|
(0.1,50]
|
|
-0,19
|
0,06
|
-3,06
|
>0,001
|
|
|
(50,100]
|
|
-0,51
|
0,02
|
-27,29
|
<0,001
|
|
|
Rizière
|
4,36
|
0,00
|
0,00
|
-14,18
|
<0,001
|
193915
|
|
Rizière (ctg)
|
0 (Réf)
|
4,36
|
|
|
|
|
193882
|
|
(0.1,50]
|
|
-0,29
|
0,04
|
-7,57
|
<0,001
|
|
|
(50,100]
|
|
-0,32
|
0,02
|
-13,63
|
<0,001
|
|
|
Eau de surface
|
4,34
|
-0,01
|
0,00
|
-11,84
|
<0,001
|
193976
|
|
Eau de surface (ctg)
|
0 (Réf)
|
4,34
|
|
|
|
|
193965
|
|
(0.1,50]
|
|
-0,97
|
0,18
|
-5,26
|
<0,001
|
|
|
(50,100]
|
|
-1,26
|
0,11
|
-11,19
|
<0,001
|
|
|
Eau de surface (bool)
|
4,34
|
-1,18
|
0,10
|
-12,28
|
<0,001
|
193965
|
|
Individuel (ctg)
|
Acc (Réf)
|
3,04
|
|
|
|
|
192659
|
|
Normal
|
|
1,22
|
0,04
|
32,21
|
<0,001
|
|
|
Paysan
|
|
1,35
|
0,04
|
37,93
|
<0,001
|
|
L'observation des résultats de chaque variable permet
de distinguer les variables à considérer. Pour les variables qui
ont deux valeurs, on distingue lesquelles des deux sont les meilleurs par
rapport auxrésultats depvalue et l'AIC le plus petit. Par exemple pour
la variable pluie, il est préférable d'utiliser la valeur
quantitative que la catégorie.
D'après le résultat du tableau6.1, par exemple
pour une pente de 0,3la vitesse est donc :   . .
7.3.2. Le modèle
multivarié
Les résultats ci-après montrent les
valeursobtenues après l'utilisation du modèle
multivariépar rapport aux variables explicatives.La formule suivante
permet d'effectuer l'analyse :   . .
Tableau 10.2 : La résultat
d'analyse avec le modèle multivariés.
Pour ce modèle, toutes les variables sont
statistiquement significatives (p < 0,05)avec un R2= 0,314 et un
écart type de 31,4%. Et les autres résultats sont
présentés ci-après.
|
Variables
|
Estimation
|
Std. Erreur
|
T. Value
|
Pr(>|t|)
|
|
Intercept
|
|
1,95
|
0,10
|
20,06
|
< 2e-16 ***
|
|
Pluie
|
|
-0,06
|
0,01
|
-11,02
|
< 2e-16 ***
|
|
Distance (ctg)
|
(0,13] (Réf)
|
|
|
|
|
|
(13,22.9]
|
-0,38
|
0,02
|
-20,08
|
< 2e-16 ***
|
|
Occupation
|
Eau de surface (Réf)
|
|
|
|
|
|
Forêt dense
|
1,33
|
0,10
|
13,92
|
< 2e-16 ***
|
|
Mixte
|
1,32
|
0,18
|
7,16
|
8,36e-13 ***
|
|
Rizière
|
0,87
|
0,09
|
9,21
|
< 2e-16 ***
|
|
Savane Arborée
|
1,27
|
0,09
|
13,61
|
< 2e-16 ***
|
|
Zone Habitation
|
0,80
|
0,09
|
8,44
|
< 2e-16 ***
|
|
Individuel
|
Acc (Réf)
|
|
|
|
|
|
Normal
|
1,20
|
0,03
|
37,16
|
< 2e-16 ***
|
|
Paysan
|
1,29
|
0,03
|
43,09
|
< 2e-16 ***
|
Les résultats montrent que par rapport à ces
valeurs de référence la vitesse est de 1,95 km/h. Les
références sont les valeurs par défaut d'estimation, il
diminue ou augmente selon l'effet des variables explicatives.
Pour la validation du modèle, on
arécupéré les informations du modèle pour les
valeurs des résidus et les valeurs ajustéesou « fitted
values ».Ensuite, on a fait une comparaison entre les deux valeurs et
les résidus du modèle par rapport aux valeurs des pentes pour
voirla concordance entre les deux.La figure 6.8montre ces deux comparaisons,
ainsi quel'effet de la variable pente.
Figure 10.8 : Les résultats
du modèle multivarié
Les deux figures ci-dessus montrent deux valeurs : la
première à gauche est la valeur résiduelle par rapport
à l'estimation et la deuxième à droite est par rapport
à la valeur de la pente.La ligne droite est un modèle
linéaire pour vérifier si les résidus montrent une
tendance, car le modèle a une moyenne de zéro et une pente de
zéro également.
La dernière figure ci-dessusmontre la relation
non-linéaire que le modèle a estimé entre la variable
pente et la vitesse.Etant donné que ce n'est pas une ligne droite et on
ne peut pas estimer une seule valeur de coefficient, la représentation
graphique est la meilleure façon de montrer l'effet de la pente.
7.4. Les
prédictions du temps de parcours
Avec les coefficients du modèle multivarié, deux
estimations ont été effectués pour le temps de parcours
à pied sur l'ensemble des 471 parcours entre chaque village et le CSB le
plus proche en fonction dela base de données analysable. On a fait des
estimations pour deux scénarios : avec de la pluie (0mm minimum,
47,5mm valeur maximum observée). Les figures suivantesmontrent le
résultat de l'interpolation du temps de trajet à partir des
prédictions sur les 689 villages.
|
|
|
Figure 10.9 : Estimation du temps de
parcours à pied sans pluie
|
Figure 10.10 : Estimation du temps
de parcours à pied avec pluie
|
D'après ces deux figures, on constate que la
majorité des villageois(60 %)vivent à plus d'une heure à
piedpar rapport au CSB le plus prochepours un scénario sans pluie. Plus
de 23,14% des villageois sont à plus de deux heures à piedet
2,76% sont à plus de quatre heures à pied. Pour le
scénario avec pluie, 63,3 % des villageois sont à plus d'une
heure à pied par rapport au CSB le plus proche. Plus de 26,75% des
villageois sont à plus deux heures à pied et 3,82% sont à
plus de quatre heures à pied.
Chapitre 8 :
Estimation du temps de parcours envéhicule motorisé
Pour ce chapitre, on présente les résultats
d'étude concernant l'estimation du temps de parcours en véhicule
motorisé, le résultat de l'analyse exploratoire ainsi que les
modèles utilisés.
8.1. Les données recueillies
Les données de TAG-IPreprésententau totale 5048
parcours dont 3327 pour14 voitures et 1721 pour les 10 motos de l'ONG PIVOT.
La figure 8.1 montre la cartographie des données
collectées auprès de TAG-IP pendant une période de 2mois
(17 mars -17 mai 2019).
|
CommunePourcentage
(%)Ifanadiana43,7Ranomafana29,75Kelilalina15,33Antaretra3,54Tsaratanana3,37Androrangavola2,77Ambohimanga
Du
Sud1,04Marotoko0,22Fasintsara0,16Ambohimiera0,07Maroharatra0,05
IndividusPourcentage
(%)Voitures72,75Motos27,25
|
Figure 11.1 : Une carte des
données collectées par les véhicules
8.2. Exploration des données utilisées
Comme pour l'analyse du temps de trajet à pied, les
variables utilisées sont la vitesse, la pente, la distance, la
pluviométrie, l'individu (type de véhicules dans ce cas-ci) mais
on y a ajouté d'autres variables tels que la zone résidentielle
et l'existence de pont ou pas.
8.2.1. La vitesse
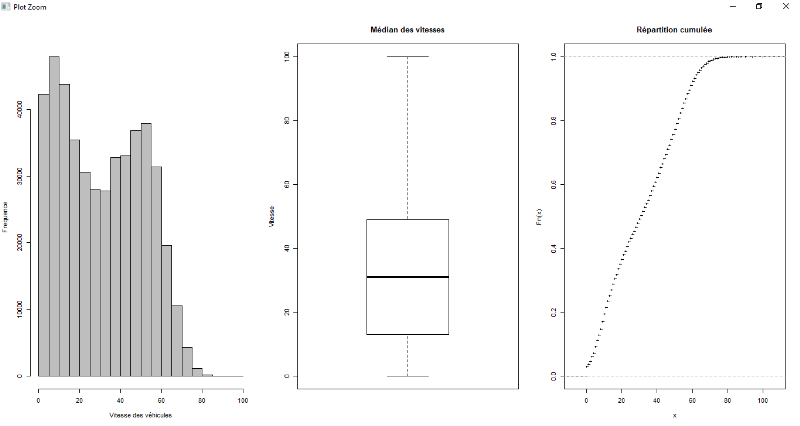
La figure 8.2 représente l'analyse de la variable
vitesse :l'histogramme pour voir la distribution de la vitesse, la
boîte à moustaches pour voir la médiane de la vitesse ainsi
que le rang interquartile, et la répartition cumulée de la
variable pour distinguer le seuil de la vitesse.
Figure 11.2 : Exploration de
données des véhicules motorisés pour la variable
vitesse
L'histogramme ci-dessus nous montre la fréquence de la
vitesse. La majorité des vitesses s'étalent entre 0 à
60km/h. Mais des véhicules dépassent quand même les 60km/h
jusqu'à 100 km/h mais ne sont pas très nombreux.
La boîte à moustache montre le résultat de
l'analyse quantitative.On observe une vitesse médiane de 30 km/h dont
50% des vitesses sont comprises entre12et48 km/h.
Et la répartition cumulée de la vitesse nous
montre le seuil de la vitesse maximale qui est de70 km/h.
8.2.2. La pente
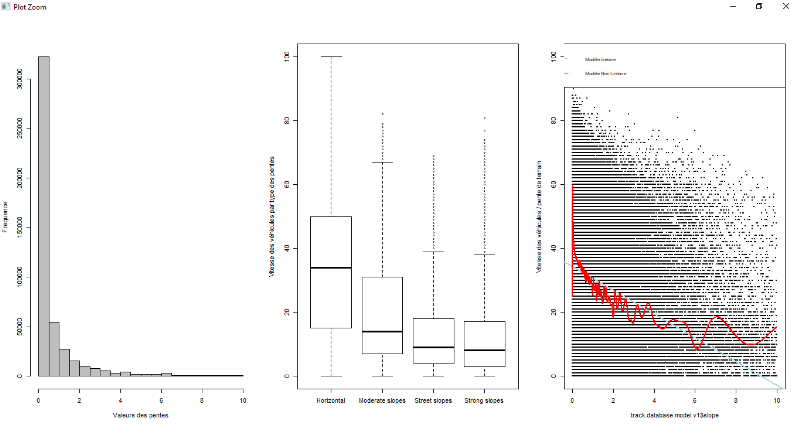
La pente a été catégorisée en 3
classes,90,88% de la zone d'étude ont une pente horizontale, 6,33% une
pente moyenne (entre 30 et 70), 1,82% une forte pente (entre 70, 100)et 0,96%
une pente extrême (entre 100, 150).
Figure 11.3 : Exploration de
données de véhicule pour la variable vitesse
La plupart des pentes est à 0,5 %.
Pour chaque catégorie de pente, lavitesse la plus
élevée est pour la pente horizontale avec une médiane de
35km/h. Après la médiane est de 15km/h pour une pente
modérée et pour une forte pente et une pente abrute la
médiane de la vitesse est à peu près la même avec
une valeur de 10km/h.
La figure de droite nous montre la relation entre la pente et
la vitesse pour les véhicules motorisés. Le résultat
indique qu'il y a une corrélation entre les deux variables car la
vitesse diminue en fonction du degré de la pente avec une relation qui
semble être linéaire.
8.2.3. La distance
Pour la distance depuis l'origine du parcours, 68,21% des
données sont à moins 2 km et 31,79% à plus de 2 km.
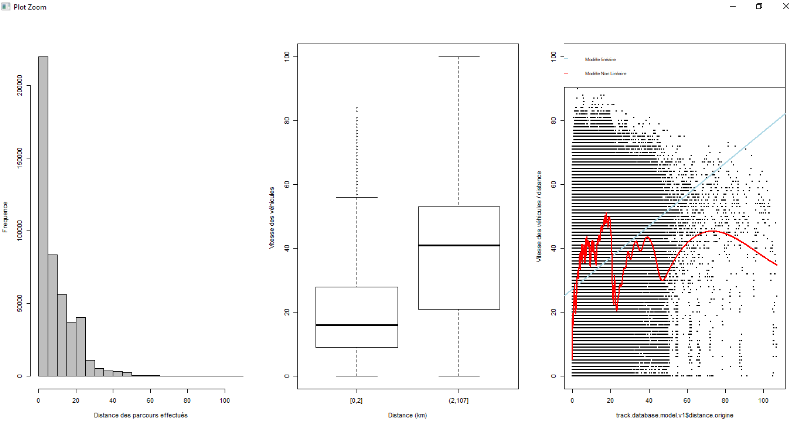
Figure 11.4 : Exploration de
données en véhicule pour la variable distance
L'histogramme montre que la majorité des données
de distance se situe entre 0 à 5km et la dispersion des données
s'étend de 10 à 107 km.
Pour l'analyse qualitative dont le résultat est
représenté par la boîte à moustache
révèle que la vitesse est moins lente pour une distance à
moins de 2km, c'est-à-dire, au début duparcours qui a pour
médiane 18km/h tandis que pour les plus de 2km elle est de 45km/h.
Pour la relation entre la distance et la vitesse, la figure de
droite montre qu'elle n'est pas linéaire car la vitesse n'augmente pas
en fonction de la distance.
8.2.4. La
pluviométrie
La figure 8.5 représente le résultat d'analyse
exploratoire de la variable pluie.La valeur de la précipitationest
comprise entre 0 à 133mm pour une durée deux mois allant du 17
mars au 17 mai 2019.
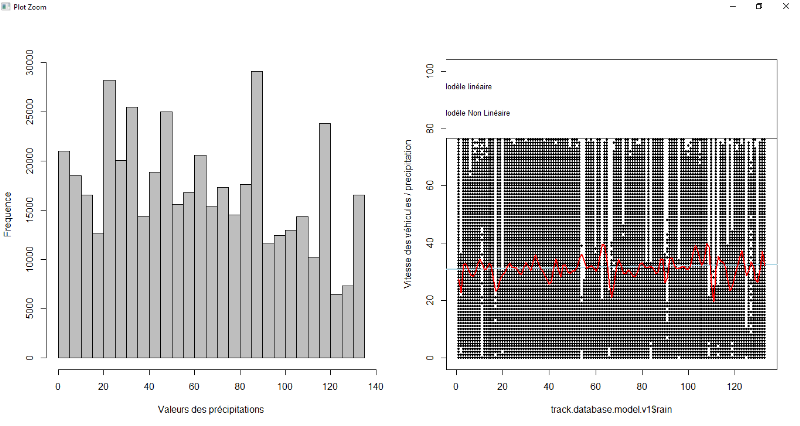
Figure 11.5 : Exploration de
données en véhicule pour la variable pluie
La figure de droite représente l'histogramme de la
variable pluies'étalant entre0 à 135mm. La fréquence la
plus élevé est entre 85 à 90mm et la plus faible entre 120
à 125mm.
L'analyse de la relation avec la vitesse est
représentée par la figure de droite et montre que la vitesse et
la pluie ne sont pas fortement liées.
8.2.5. Le pont
Le passage sur un pont a été
considéré car on suppose que la vitesse change à chaque
fois qu'on traverse un pont.Le pourcentage de passage sur un pont pour les
voitures et moto est de4,44%.
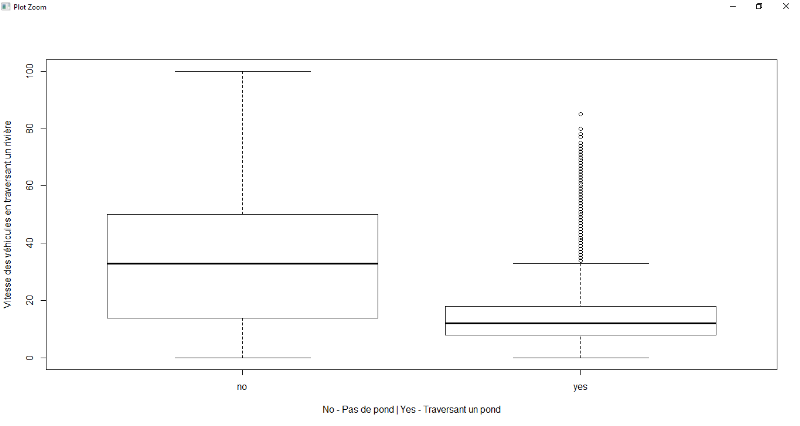
Figure 11.6 : Exploration de
données en véhicule pour la variable pont
Le résultat de l'analyse est représenté
par les boîtes à moustaches ci-dessus. Il indique qu'il y a une
forte décélération des véhicules à chaque
fois qu'ils passent sur un pont avec une médiane de 10km/h tandis que
sur une route normale il est de 30km/h.
8.2.6. Les réseaux
routiers
Les réseaux routiers sont classifiés selon 4
catégories. 74,25% des véhicules passent sur la route nationale,
10,05% sur une route secondaire, 4,58% sur une piste et 9,11% sur un chemin.
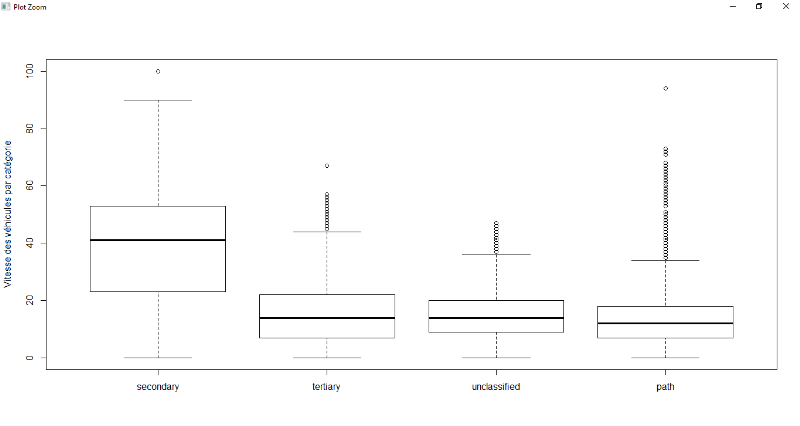
Figure 11.7 : Exploration de
données de véhicule pour la variable route
D'après cette figure, la médiane de la vitesse
est la plus élevée sur la route nationale avec une valeur de
40km/h. Pour les trois autres catégories la vitesse est à peu
près les mêmes avec une valeur de 10km/h.
8.2.7. La zone
résidentielle
Cette analyse consiste à étudier la variation de
la vitesse lors de son passage dans une zone résidentielle. Les
données ont montré que seulement 0,04% des véhicules ont
passé dansune zone résidentielle.
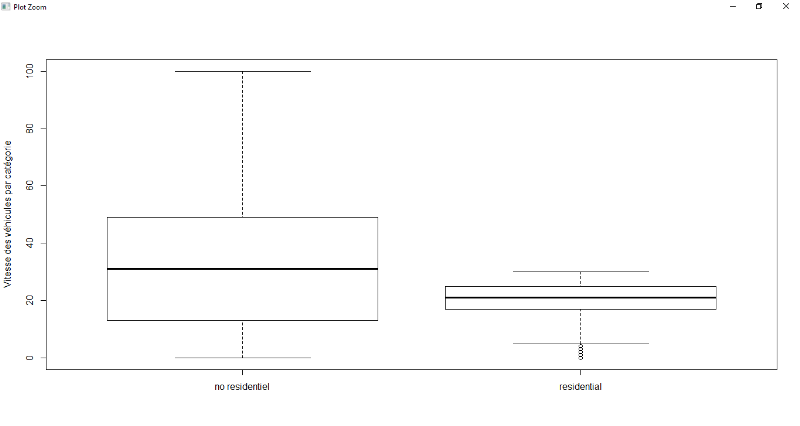
Figure 11.8 : Exploration de
données en véhicule pour la variable zone résidentielle
Le passage dans une zone résidentielle indique une
diminution de la vitesse d'après la figure ci-dessus. Sa médiane
est de 20km/h tandis que pour une zone où il n'y a pas d'habitation la
vitesseest de 30km/h.
8.2.8. Variation de la vitesse
selon le type de véhicule motorisé
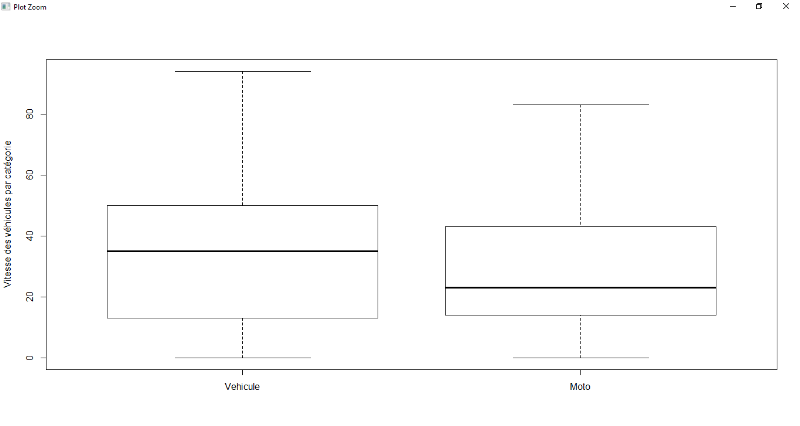
Les deux types de véhicules motorisés sont la
voiture et la moto. Les données collectées montrent que 74,60%
sont des données de voiture et 25,40% des données de moto.
Figure 11.9 : Exploration de
données de véhicule pour une voiture et une moto
D'après la figure ci-dessous, la vitesse des voitures
est plus élevée que celle des motos. Elle a une médiane de
35km/h dont la majorité varie entre 15 à 45km/h. Pour les motos,
la majorité des vitesses varie entre 10 à 40km/h avec une
médiane de 20km/h.
8.3. Les modèles univariés et
multivariés
Les résultats des modèles contiennent les
éléments suivants : les variables explicatives,
l'estimationde la vitesse estimée,l'effet de la variable par rapport
à l'estimation, l'erreur d'ajustement, le coefficient de
probabilité, la significativité statistique et l'AIC qui est la
mesure de la qualité de l'ajustement.
8.3.1. Le modèle
univarié
Les résultats suivants représentent les valeurs
des coefficients pour chaque résultat des variables explicatives par
rapport au variable expliquée. Comme pour le déplacement à
pied, prenons la variable pente comme exemple où la relation entre la
pente et la vitesse est calculé à partir de la formule
ci-après : 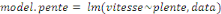  . .
Tableau 11.1 : La résultat
d'analyse des variables explicatives avec le modèle univariées
|
Variables
|
á
|
â
|
Std erreur
|
T. Value
|
P. Value
|
AIC
|
|
Pente
|
34,32
|
-3,73
|
0,02
|
-171,43
|
<0,001
|
4064837
|
|
Pente (ctg)
|
Légère pente (Ref)
|
33,20
|
|
|
|
|
4068862
|
|
Pente modérée
|
|
-13,19
|
0,12
|
-113,96
|
<0,001
|
|
|
Forte pente
|
|
-19,63
|
0,29
|
-68,21
|
<0,001
|
|
|
Extrême pente
|
|
-19,77
|
0,21
|
-93,96
|
<0,001
|
|
|
Distance
|
27,32
|
0,49
|
0,00
|
171,85
|
<0,001
|
4064702
|
|
Distance (ctg)
|
(0,2] (Ref)
|
19,58
|
|
|
|
|
4005513
|
|
(2,107]
|
|
17,86
|
0,06
|
310,95
|
<0,001
|
|
|
Pluie
|
30,90
|
0,01
|
0,00
|
17,63
|
<0,001
|
4093020
|
|
Pont (ctg)
|
Non (Ref)
|
32,55
|
|
|
|
|
4077503
|
|
Oui
|
|
-17,80
|
0,14
|
-126,89
|
<0,001
|
|
|
Zone résidentielle (ctg)
|
Non résidentielle (Ref)
|
31,76
|
|
|
|
|
4093260
|
|
Résidentielle
|
|
-12,28
|
1,46
|
-8,41
|
<0,001
|
|
|
Type de route
|
Route nationale (Ref)
|
37,86
|
|
|
|
|
3948423
|
|
Terrain
|
|
-22,81
|
0,08
|
-292,09
|
<0,001
|
|
|
Non classifier
|
|
-22,95
|
0,12
|
-189,52
|
<0,001
|
|
|
Chemin
|
|
-25,21
|
0,09
|
-285,68
|
<0,001
|
|
|
Individuel
|
Véhicule (Ref)
|
33,10
|
|
|
|
|
3123897
|
|
Moto
|
|
-4,79
|
0,07
|
-67,91
|
<0,001
|
|
L'observation des résultats de chaque variable permet
de distinguer les variables à considérer. Pour les variables qui
ont deux valeurs, on distingue lesquelles des deux sont les meilleurs par
rapport aux résultats de pvalue et l'AIC le plus petit. Par exemple pour
la variable distance, il est préférable d'utiliser la valeur
qualitative que la quantitative.
D'après le résultat du tableau ci-dessus, par
exemple pour une pente de 0,6 la vitesse est donc :  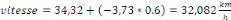 . .
8.3.2. Le modèle
multivarié
Les résultats ci-après montrent les valeurs
obtenues après l'utilisation du modèle multivarié par
rapport aux variables explicatives. Comme on doit tenir en compte toutes les
variables, la formule ci-après permet d'effectuer l'analyse : 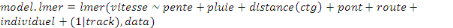  . .
Tableau 11.2 : La résultat
d'analyse avec le modèle multivariées.
Pour ce modèle, on a utiliséla méthode
Residual Maximum Likelihood (REML)avec 463.512 observations. Le
R2= 0,522avec une valeur d'AIC de 3.747.613. Et les autres
résultats sont présentées ci-après.
|
Variables
|
Estimation
|
Std. Erreur
|
T. value
|
|
Intercept
|
29,74
|
0,22
|
134,76
|
|
Pente
|
-1,75
|
0,02
|
-110,82
|
|
Pluie
|
-0,13
|
0,03
|
-5,18
|
|
Distance (ctg)
|
(0,2] (Réf)
|
|
|
|
|
(2,107]
|
9,17
|
0,06
|
149,08
|
|
Pont
|
Non (Réf)
|
|
|
|
|
Oui
|
-17,53
|
0,10
|
-173,63
|
|
Zone résidentielle
|
Non (Réf)
|
|
|
|
|
Oui
|
2,35
|
1,35
|
1,75
|
|
Route
|
Route nationale (Réf)
|
|
|
|
|
Terrain
|
-20,67
|
0,11
|
-191,38
|
|
Non classifier
|
-22,62
|
0,20
|
-113,58
|
|
Chemin
|
-20,61
|
0,10
|
-216,54
|
|
Individuel
|
Voiture (Réf)
|
|
|
|
|
Moto
|
4,27
|
0,25
|
16,96
|
Les résultats montrent que par rapport à ces
valeurs références la vitesse est de 29,74km/h. Les
références sont les valeurs par défaut d'estimation, il
diminue ou augmente selon l'effet des variables explicatives.
Tableau 11.3 : La résultat
d'effets aléatoire du modèle multivariés.
La variable track est utilisée pour la valeur
aléatoire avec 5048 parcours. Il est spécifié à
l'aide d'unidentifiant pour chaque itinéraire effectué.
|
Effets aléatoires :
|
|
Groupes
|
Variable
|
Variance
|
Ecart type
|
|
Track
|
Intercept
|
65,22
|
8,076
|
|
Résiduel
|
|
183,88
|
13,56
|
Chapitre 9 :
Discussion
Dans ce chapitre, on discuterades résultats de
l'estimation du temps de parcours à pied et en véhicule
motorisé. Ensuite, on comparera ces résultats par rapportà
la littérature scientifique existante.
9.1. Estimation du temps de parcours à pied
L'estimation du temps reflète la réalité
sur le terrain.Pour la variable pente, si on monte un pente extrême la
vitesse pourrait diminuer jusqu'à 0,5km/h et elle est de 5,5 km/h
lorsqu' on descend.Pour la variable distance, à partir de 13km de
parcours, la vitesse desindividus diminue entre3,5 à 4,5 km/h cequi
pourrait être liée à la difficulté du terrain et
à la fatigue d'une longue marche. Pour la distance inferieur de 13
km ; la vitesse augmente entre 3,8 à 5,5 km/h.
Nombreux sont les études d'estimation de temps de
parcours`'`'(Gething et al. 2012; Makanga et al. 2017) mais elles
diffèrent surl'ensemble des données spatiales et les
approchesutilisées.Le point fort de cette étudeest
l'utilisationdes parcours réels, avec des données de vitesse
spécifiques au contexte géographique et populations du district
d'Ifanadiana qui ont été collectées sur le terrain.Nous
considérons également plusieurs variables qui peuvent avoir une
influence sur la vitesse telles que la pente, la distance parcourue(osrm), la
pluviométrie et d'autres.En autre, la plupart d'études dans les
pays en voie de développement utilisent des méthodes de calcul de
distance par surface de cout car les réseaux de sentiers à pied
sont rarement disponibles. Dans le cadre du projet d'Ifanadiana, plus de
20 000 km de réseaux de sentiers ont été
cartographiés, ce qui nous a permis d'obtenir des itinéraires
fiables et d'extrapoler le temps de parcours avec une précision sans
précédents pour ce genre d'étude.
Les résultats des prédictions du temps de
parcours à pied ont montré que la majorité des
villagesont une faible accessibilité géographique aux soins,
comme ça a été montre dans des études
précédentes (Arsyad and Sodiq 2014). Seulement 36,7 % sont
à moins d'une heure de marche pour atteindre le CSB le plus proche.
D'après les normes internationales de la santé, un soin primaire
doit être effectuer à moins d'une heure au maximumen cas
d'urgence(Qazi 2011). Cela implique quela plupart des villages du district
d'Ifanadiana ne suit pas encore les normes en matière d'accès
physique aux soins surtout en cas d'urgence.
Il est donc nécessaire de mettre en place des nouvelles
structures de soins plus proche des villages afin d'améliorer les
conditions de santé de la population.
Tableau 12.1 : Le comparatif
des résultats à pied par rapport aux littératures
existantes
|
Réel
|
Littérature
|
Opération
|
Source des données
|
|
Oui
|
(Makanga et al. 2017)
|
- 87% (àmoins 1H de marche ou transport en commun) avec
diminution 9 et 5% (plus fort saison de pluie) et 64% (à moins 2H).
|
Enquête sur le terrain et l'utilisation de l'impact des
phénomènes météorologiques violents pour la
modélisation.
|
|
Oui
|
(Fogliati et al. 2015)
|
- A Iringa, 54% (à 1 H de marche) et 87,8% (à
2H)
- A Ludewa, 39,9% (à 1 H de marche) et 82,3% (à
2H).
|
Enquête sur le terrain dans les districts de Ludewa et
Iringa.
|
9.2. Estimation du
temps de parcours en véhicule motorisé
Durant les différentes étapes de l'estimation du
temps de parcours en véhicule motorisé, on a constaté que
l'analyse d'exploratoire des variables explicatives reflète la
réalité du déplacement sur la route.Par exemple, lorsque
les véhicules motorisés traversent un pont, la vitesse varie
entre 5 à 15km/h à cause de la prudence et un véhicule
à la fois.Etlorsque les véhicules motorisés passent surdes
zones résidentielles, la vitesse est réduite entre 18 à 25
km/h pour éviter l'accident, assurer la protection de la population qui
habite sur la route et à cause de la limite de la vitesse sur des zones
résidentielles ;au lieu de15 à 50 km/h sur une route
goudronnée sans obstacles. Quant à la route, les véhicules
motorisésaccélèrent jusqu'à 55 km/h sur la route
nationale et de 20 km/h pour les autres routes (pas goudronnée).
Des études sur l'estimation du temps de parcours en
véhiculeont été réalisées sur les
soinsd'urgence `'`'(Gething et al. 2012; Panciera et al. 2016), sur les
transports en commun(Tanser 2006),et sur les références
(Munguambe et al. 2016)mais elles diffèrent sur l'ensemble des
données spatiales et les approches utilisées. L'avantage de cette
étude, encore une fois, est l'utilisation des données
réelles de voiture et moto avec la considération de diverses
barrières locales à Ifanadiana tels que le pont, la zone
résidentielle, les réseaux routières, la
pluviométrie et d'autres qui pourraient influencer la vitesse. Prendre
en compte ces facteurs est très importantpour estimer l'accès
vers une établissement de santé deréférence.
Avec la réalisation du modèle multivarié
à partir de ces impacts nous avons obtenu un résultat de R2
= 0,522 ce qui suggère qu'on arrive à expliquer la vitesse
des véhicules avec une précision assez bonne. Les
résultats dans le tableau 7.2serviront dans l'avenir à fairela
prédiction du temps de parcours et l'interpolation pour les
véhicules motorisés.
Tableau 12.2 : Le comparatif des
résultats en véhicule motorisé par rapport aux
littératures existantes
|
Réel
|
Littérature
|
Opération
|
Source des données
|
|
Oui
|
(Makanga et al. 2017)
|
- 87 % (à moins 1 H de marche ou transport en commun)
avec diminution 9 et 5 % (plus fort saison de pluie) et 64 % (à moins 2
H).
|
Enquête sur le terrain et l'utilisation de l'impact des
phénomènes météorologiques violents pour la
modélisation.
|
|
Non
|
(Panciera et al. 2016)
|
-Accouchement à la maison 30% (augmentation 5mn
jusqu'à l'installation de COE)
- Accouchement dans l'établissement privé
diminue à 32,9%
-A l'ONG (28,8%) et diminue de 28,6%
|
Enquête transversale avec SOU de 39 grappes et des
données géo-référencées par rapport à
l'installation de SOU
|
9.3. La plateforme
d'affichagedes résultatsdu projet
Il est possible d'afficher les résultats et
prédictions de nos modèlessurune plateforme de
géolocalisation pour permettre aux équipes programmatiques de
Pivot et du Ministère de la Santé de prendre
desdécisionsen prenant compte de la distanceet le temps de trajet entre
les villages et les CSB le plus proche.
9.3.1. Description du
projet
Le projet consiste à mettre en place une plateforme de
géolocalisation pour une estimation du temps de parcours à pied
puis en véhicule motoriséentre un village et un
établissement de santé le plus proche (CSB) en tenant compte de
l'effet topologique du terrain dans le district d'Ifanadiana.
Pour cela, on a besoin des fonctionnalités basiques (la
position actuelle, le point de départ, le point d'arrivé, etc...)
d'une plateforme de géolocalisation et le mode édition du trajet,
la multiple destination, le fond de cartes,l'outil de changement delangue,
l'exportation d'information sous format .gpx, le mapillary et la fusion des
données concernant le temps de parcours réel.
Les outils technologies à utiliser pour la
réalisation sont les suivantes : l'OSRM (pour avoir la distance
minimum),l'API Leaflet (Framework), l'API OpenStreetMap (pour les
données géographiques),Le JavaScript (Les scripts) et le CSS.
9.3.2. Exemple de la maquette
complètedu projet
Il existe déjà une interface complètepour
la réalisation qui est disponible ici5(*) et open source. La figure 9.1 présente
l'exemple de cette interface concernant les outils citez
précédemment avec les fonctionnalités à part la
fusion du temps de parcours réel.
Figure 12.1 : Exemple de la maquette
complète du projet
Chapitre 10 CONCLUSION ET PERSPECTIVES
L'élaboration de ce projet nous a permis d'avoir plus
ample connaissance sur l'effet des différentes barrières
géographiques à l'accessibilité aux soins dans le district
d'Ifanadiana. Il nous a permis aussid'approfondir sue la mise en place d'une
base de données analysable en santé, et à réaliser
desmodèles spatio-temporels.
Dû à cela, on a obtenu les résultats tels
que les résultats exploratoires des variables explicatives (la
pente, la distance, la pluie, l'individu et l'occupation du sol), les
modèles univariés, le modèle multivarié, la
prédiction du temps de parcours et l'interpolation ; par contre, en
ce qui concerne le véhicule motorisé on s'est arrêté
sur la réalisation du modèle multivarié avec plus des
variables explicatives tels que le pont, les réseaux routiers et la zone
résidentiel. Ces résultats ont permis d'obtenir l'estimation du
temps de parcours à pied avec et sans pluie entre les villages et le CSB
plus proche dans le district d'Ifanadiana et une modèle
multivarié prête pour l'estimation du temps de parcours en
véhicule motorisé.
La faiblesse de cette étude est la non
considérationdu poids des patients, le niveau d'état d'urgencedu
patient, le moyen de transport, la maladie des patients, les traitements
médicamenteuxet d'achever jusqu'à l'interpolation pour
l'estimation du temps de parcours en véhicule motorisé.Une
considération pareille, même si elle serait très
pertinente, n'a jamais été appliquée a des études
d'accès aux soins en raison des considérations éthiques
liées à engager des sujets malades dans des recherches qui ne
vont pas les apporter un bénéfice direct.
Cette étude pourrait s'étendre sur la
continuité du projet et d'approfondir encore plus sur les détails
citésprécédemment en essayant d'ajouter,d'analyser, de
vérifier si c'est possible d'améliorer encore plus les
résultats des modèles.
Ce stage a été ma première
expérience, plus relative au monde des chercheursscientifiques pour
mettre en pratique toutes les connaissances théoriques. Il m'a permis
aussi d'augmenter les acquis en matière de compétences techniques
et théoriques mais surtout de me familiariser avec le monde de l'action
humanitaire des ONG Médicales ainsi que de me soutenir à avoir un
aperçu de ce qu'est vraiment le métier des chercheurs dans le
milieu scientifique. Cela nous a inspiré aussi d'acquérir une
expérience presque complète au sein de l'ONG Médicale
Pivot qui a sa grande responsabilité envers la population
d'Ifanadiana.
BIBLIOGRAPHIE
Arsyad, Lincolin and Amirus Sodiq. 2014. OMS |
Statistiques Sanitaires Mondiales 2012 [Internet]. WHO. [Cité 15
Déc 2017]. Vol. 3.
Chan, Leighton, L. Gary Hart, and David C. Goodman. 2006.
«Geographic Access to Health Care for Rural Medicare Beneficiaries.»
Journal of Rural Health 22(2):140-46.
Delamater, Paul L., Joseph P. Messina, Ashton M. Shortridge,
and Sue C. Grady. 2012. «Measuring Geographic Access to Health Care:
Raster and Network-Based Methods.» International Journal of Health
Geographics 11.
Fogliati, Piera, Manuela Straneo, Cosimo Brogi, Pier Lorenzo
Fantozzi, Robert Mahimbo Salim, Hamis Mwendo Msengi, Gaetano Azzimonti,
Giovanni Putoto, and Julie Gutman. 2015. «How Can Childbirth Care for the
Rural Poor Be Improved? A Contribution from Spatial Modelling in Rural
Tanzania.» PLoS ONE 10(9).
Gething, Peter W., Fiifi Amoako Johnson, Faustina
Frempong-Ainguah, Philomena Nyarko, Angela Baschieri, Patrick Aboagye, Jane
Falkingham, Zoe Matthews, and Peter M. Atkinson. 2012. «Geographical
Access to Care at Birth in Ghana: A Barrier to Safe Motherhood.» BMC
Public Health 12(1).
Hanson, Claudia, Sabine Gabrysch, Godfrey Mbaruku, Jonathan
Cox, Elibariki Mkumbo, Fatuma Manzi, Joanna Schellenberg, and Carine Ronsmans.
2017. «Access to Maternal Health Services: Geographical Inequalities,
United Republic of Tanzania.» Bulletin of the World Health
Organization 95(12):810-20.
Hussein, J., A. McCaw-Binns, and R. Webber. 2012.
«Geographical Access, Transport and Referral Systems.» Pp. 139-54 in
Maternal and perinatal health in developing countries. CABI.
Institut National de la Statistique. 2013. «Objectif 05:
Améliorer La Santé Maternelle.» Enquête Nationale
Sur Le Suivi Des Objectifs Du Millénaire Pour Le Développement
à Madagascar 63.
Jin, Cheng, Jianquan Cheng, Yuqi Lu, Zhenfang Huang, and
Fangdong Cao. 2015. «Spatial Inequity in Access to Healthcare Facilities
at a County Level in a Developing Country: A Case Study of Deqing County,
Zhejiang, China.» International Journal for Equity in Health
14(1).
Luo, Wei and Fahui Wang. 2003. «Measures of Spatial
Accessibility to Health Care in a GIS Environment: Synthesis and a Case Study
in the Chicago Region.» Environment and Planning B: Planning and
Design 30(6):865-84.
Makanga, Prestige T., Nadine Schuurman, Peter Von Dadelszen,
and Tabassum Firoz. 2016. «A Scoping Review of Geographic Information
Systems in Maternal Health.» International Journal of Gynecology and
Obstetrics 134(1):13-17.
Makanga, Prestige Tatenda, Nadine Schuurman, Charfudin Sacoor,
Helena Edith Boene, Faustino Vilanculo, Marianne Vidler, Laura Magee, Peter von
Dadelszen, Esperança Sevene, Khátia Munguambe, and Tabassum
Firoz. 2017. «Seasonal Variation in Geographical Access to Maternal Health
Services in Regions of Southern Mozambique.» International Journal of
Health Geographics 16(1):1.
Muller, Dominique. 2018. «Modèles à Effets
Mixtes.»
Munguambe, Khátia, Helena Boene, Marianne Vidler,
Cassimo Bique, Diane Sawchuck, Tabassum Firoz, Prestige Tatenda Makanga, Rahat
Qureshi, Eusébio Macete, Clara Menéndez, Peter Von Dadelszen, and
Esperança Sevene. 2016. «Barriers and Facilitators to Health Care
Seeking Behaviours in Pregnancy in Rural Communities of Southern
Mozambique.» Reproductive Health 13(1).
Okwaraji, Yemisrach B., Emily L. Webb, and Karen M. Edmond.
2015. «Barriers in Physical Access to Maternal Health Services in Rural
Ethiopia.» BMC Health Services Research 15(1):1-8.
Ouma, Paul O., Joseph Maina, Pamela N. Thuranira, Peter M.
Macharia, Victor A. Alegana, Mike English, Emelda A. Okiro, and Robert W. Snow.
2018. «Access to Emergency Hospital Care Provided by the Public Sector in
Sub-Saharan Africa in 2015: A Geocoded Inventory and Spatial Analysis.»
The Lancet Global Health 6(3):e342-50.
Panciera, Rocco, Akib Khan, Syed Jafar Raza Rizvi, Shakil
Ahmed, Tanvir Ahmed, Rubana Islam, and Alayne M. Adam. 2016. «The
Influence of Travel Time on Emergency Obstetric Care Seeking Behavior in the
Urban Poor of Bangladesh: A GIS Study.» BMC Pregnancy and
Childbirth 16(1).
Qazi, Zaitoon. 2011. «Neonatal Care ( EmONC ) Needs
Assessment in Selected Health Facilities in NEZ , Puntland - September
2011.»
Salehi, Fatemeh and Leila Ahmadian. 2017. «The
Application of Geographic Information Systems (GIS) in Identifying the Priority
Areas for Maternal Care and Services.» BMC Health Services
Research 17(1).
Sophie, B. 2005. «Le Krigeage?: Revue de La
Théorie et Application à l'interpolation Spatiale de
Données de Précipitations.» Facultés Des Sciences
et de Génie M.Sc.:137.
Tanser, Frank. 2006. «Methodology for Optimising Location
of New Primary Health Care Facilities in Rural Communities: A Case Study in
KwaZulu-Natal, South Africa.» Journal of Epidemiology and Community
Health 60(10):846-50.
Tanser, Frank, Brice Gijsbertsen, and Kobus Herbst. 2006.
«Modelling and Understanding Primary Health Care Accessibility and
Utilization in Rural South Africa: An Exploration Using a Geographical
Information System.» Social Science and Medicine
63(3):691-705.
Visser, Sent and John Paul Jones III. 2010. «Measurement
and Interpretation.» Pp. 41-59 in Research Methods in
Geography.
Weiss, D. J., A. Nelson, H. S. Gibson, W. Temperley, S.
Peedell, A. Lieber, M. Hancher, E. Poyart, S. Belchior, N. Fullman, B. Mappin,
U. Dalrymple, J. Rozier, T. C. D. Lucas, R. E. Howes, L. S. Tusting, S. Y.
Kang, E. Cameron, D. Bisanzio, K. E. Battle, S. Bhatt, and P. W. Gething. 2018.
«A Global Map of Travel Time to Cities to Assess Inequalities in
Accessibility in 2015.» Nature 553(7688):333-36.
ANNEXES
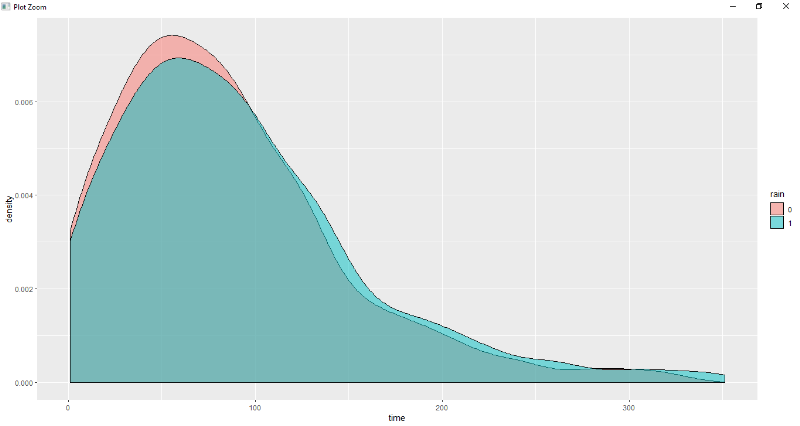
Après la prédiction du modèle
multivarié (sous-section 7.3.2) et le calcul du temps de parcours
(sous-section 6.2.3) ; on a obtenu le résultat suivant pour la
représentation graphique de données par rapport à la
prédiction du temps avec et sans pluie. La figure suivante affiche
l'écart entre les deux valeurs (0- sans pluie et 1- avec pluie).
Par rapport à cette figure, on observe un grand
écart de temps entre 0 à 100 mn. Cela implique qu'il y a certain
temps augment à cause de l'impact de la pluie par rapport à la
situation géographique. Et ces valeurs sont dispersés entre 100
à 360 mn.
TABLE DES MATIERES
AVANT-PROPOS
i
REMERCIEMENTS
v
RESUME
vi
ABSTRACT
vii
LISTE DES FIGURES
viii
LISTE DES TABLEAUX
x
LISTE DES ABREVIATIONS
xi
GLOSSAIRE
xii
SOMMAIRE
xiv
INTRODUCTION
1
PARTIE
I : CONTEXTE GENERAL
3
Chapitre 1 : Présentation de la zone
d'étude
3
1.1. Localisation géographique
3
1.2. Contexte géographique
5
1.2.1. Le relief
5
1.2.2. Les réseaux hydrographiques
6
1.2.3. L'occupation du sol
7
1.2.4. Le climat
9
1.2.5. Les réseaux routiers
9
1.3. Le système de santé dans
le district
9
1.3.1. Le site communautaire
9
1.3.2. Le CSB
10
1.3.3. Le CHRD
10
1.4. Le contexte thématique
10
1.4.1. Contexte de l'étude
10
1.4.2. La problématique
12
1.4.3. L'objectif
12
Chapitre 2 : Etat de l'art
13
2.1. Théorie sur l'estimation du temps
de parcours
13
2.1.1. Estimation par rapport aux situations
régionales
13
2.1.2 Estimation par rapport aux situations
rurales
13
2.1.3 Estimation par rapport aux situations des
pays
14
2.2. Les approches existantes pour
l'estimation du temps de parcours
15
2.2.1. Les approches
méthodologiques
15
2.2.2. Les approches SIG
16
2.3. Estimation du temps de parcours qui
utilise des modèles pour la prédiction
16
2.4. Synthèse
18
PARTIE
II : MATERIELS ET METHODES
19
Chapitre 3 : Présentation des
données
19
3.1. Les données de parcours à
pied
19
3.1.1. Description
19
3.1.2. Structure des données
19
3.2. Temps de parcours à moto et
voiture : TAG-IP
19
3.2.1. Description
19
3.2.2. Structure des données
20
3.3. Données climatiques
20
3.3.1. Description
20
3.3.2. Structure des données
20
3.4. Les données d'occupation du
sol
20
3.4.1. Description
21
3.4.2. Structure des données
21
3.5. L'altitude
21
Chapitre 4 : Les outils utilisés
22
4.1. OSMAnd
22
4.2. TAG-IP
22
4.3. Power Api
23
4.4. GPS track editor
24
4.5. QGIS
24
4.6. ArcGIS
24
4.7. PostGIS
25
4.8. R
25
Chapitre 5 : Manipulation des données
26
5.1. Prétraitements
26
5.1.1. Nettoyage des données prise sur
le terrain
26
5.1.2. Transformation des données .gpx
en .shp sur Qgis
26
5.1.3. Intersection des traces avec
l'occupation du sol
26
5.1.4. Utilisation des données
géographiques sur PostGIS
26
5.1.5. Finalisation de la base de
données
27
5.2. Traitements
27
5.2.1. Modélisation statistique
27
5.2.2. Analyses exploratoires
27
5.2.3. Prédiction de la vitesse de
trajet à pied
29
5.2.4. Temps de trajet pour rejoindre les
CSB
30
PARTIE
III : RESULTAT ET DISCUSSION
19
Chapitre 6 : Mise en oeuvre
31
6.1. Prétraitements
31
6.1.1. Utilisation des données avec
les outils
31
6.1.2. Exportation de la base de
données
37
6.2. Traitements
38
6.2.1. Exploration des données
38
6.2.2. Mise en place du modèle
statistique
40
6.2.3. Prédiction du temps de
parcours
41
6.2.4. Interpolation des données sur
ArcGIS
42
Chapitre 7 : Estimation du temps de parcours
à pied
45
7.1. Les données recueillies
45
7.2. Résultats de la phase
d'exploration des données
46
7.2.1. La vitesse
46
7.2.2. La pente
47
7.2.3. La distance
48
7.2.4. La pluviométrie
48
7.2.5. L'individu
49
7.2.6. L'occupation du sol
50
7.3. Les modèles univariés et
multivariés
51
7.3.1. Le modèle univarié
51
7.3.2. Le modèle multivarié
54
7.4. Les prédictions du temps de
parcours
55
Chapitre 8 : Estimation du temps de parcours en
véhicule motorisé
57
8.1. Les données recueillies
57
8.2. Exploration des données
utilisées
58
8.2.1. La vitesse
58
8.2.2. La pente
59
8.2.3. La distance
59
8.2.4. La pluviométrie
60
8.2.5. Le pont
61
8.2.6. Les réseaux routiers
62
8.2.7. La zone résidentielle
62
8.2.8. Variation de la vitesse selon le type de
véhicule motorisé
63
8.3. Les modèles univariés et
multivariés
64
8.3.1. Le modèle univarié
64
8.3.2. Le modèle multivarié
65
Chapitre 9 : Discussion
67
9.1. Estimation du temps de parcours à
pied
67
9.2. Estimation du temps de parcours en
véhicule motorisé
68
9.3. La plateforme d'affichage des
résultats du projet
69
9.3.1. Description du projet
69
9.3.2. Exemple de la maquette complète du
projet
70
CONCLUSION ET PERSPECTIVES
xvi
BIBLIOGRAPHIE
xvii
ANNEXES
xix
TABLE DES MATIERES
xx
*
1https://power.larc.nasa.gov/
*
2http://desktop.arcgis.com/fr/arcmap/10.3/tools/analysis-toolbox/how-intersect-analysis-works.htm
*
3https://docs.postgresql.fr/8.1/rules-views.html
*
4http://www.toujourspret.com/techniques/orientation/topographie/calcul_du_pourcentage_d%27une_pente.php
*
5https://map.project-osrm.org
| 

