2.3.2.2 Failover service
Le failover, ou basculement est un mode de fonctionnement de
secours qui consiste à basculer automatiquement sur une base de
données, un serveur ou un réseau placé en attente si le
système principal tombe en panne ou est arrêté le temps
d'une maintenance. Le failover est une fonction extrêmement importante
sur les systèmes critiques qui doivent rester accessibles à
chaque instant. La fonctionnalité de failover redirige de manière
transparente toutes les requêtes au système injoignable vers le
système de secours, lequel imite l'environnement du système
initial.
Le failover peut s'appliquer à n'importe quel aspect
d'un système :
Ø Sur un ordinateur personnel ou un appareil mobile, un
déclencheur matériel ou logiciel peut protéger l'appareil
lorsqu'un composant (par exemple le processeur ou même une cellule de
batterie) tombe en panne.
Ø Au sein d'un réseau, un failover peut
s'appliquer à n'importe quel composant individuel du réseau, ou
bien à un ensemble de composants formant un système, par exemple
un chemin de connexion, un périphérique de stockage ou bien un
serveur Web.
Ø Avec une application Web ou une base de
données hébergée, le failover permet à plusieurs
serveurs en local ou dans le cloud de maintenir une connexion constante et
sécurisée, avec peu ou pas d'interruption de service.
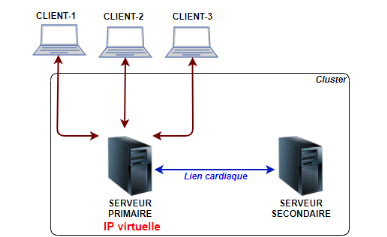
Figure 2. 7 Cluster de
basculement
2.3.2.3 Répartition de charge
Une technique qui permet de à la fois de
répondre à une monté en charge d'un service en distribuant
les requête sur plusieurs serveurs, et de réduire
considérablement l'indisponibilité de ce service que pourrait
provoquer la panne logiciel ou matérielle d'un unique serveur.
Les répartiteurs de charge utilisent différents
algorithmes pour gérer le trafic. Leur but est de repartir
intelligemment la charge et d'optimiser L'utilisation de l'ensemble des
serveurs du cluster.
Voici les algorithmes de répartition de charge :
Ø Round-robin (répartition de charge
équitable) : Le Round-robin permet de repartir la requête à
tour de rôle à chaque Serveur, quels que soient le nombre actuel
de connexions. Cet algorithme est adapté si les serveurs du cluster
disposent des mêmes capacités de traitement ; sinon, certains
serveurs risquent de recevoir plus de requêtes qu'ils ne peuvent en
traiter tandis que d'autres n'utiliseront qu'une partie de leurs ressources.
Ø Weighted Round-robin (répartition de charge
pondérer): Un algorithme Weighted Round-robin prend en compte la
capacité de traitement de chaque serveur. Les administrateurs affectent
manuellement un coefficient de performance à chaque serveur et une
séquence d'ordonnancement est générée
automatiquement en fonction de cette valeur. Les demandes sont ensuite
affectées aux différents serveurs selon une séquence de
répétition alternée.
Ø Least-connection (répartition de charge selon
la moindre connexion) : Envoie des demandes aux serveurs d'un cluster en
fonction de celui qui sert actuellement le moins de connexions
Ø Load-based (répartition basée sur la
charge) : Envoie les demandes aux serveurs d'un cluster en fonction de celui
dont la Charge est actuellement la plus faible.
| 

