|
ECOLE SUPÉRIEURE D'INFORMATIQUE SALAMA
République Démocratique du Congo
Province du Haut Katanga
Lubumbashi
www.esisalama.com



Travail présenté et défendu en vue de
l'obtention du grade d'ingénieur technicien en Administration
système et réseau
ETUDE ET MISE EN PLACE D'UNE
PLATEFORME CLOUD COMPUTING SECURISEE AU SEIN D'UNE INSTITUTION PUBLIQUE(Cas de
la DPI)

Par : MBUYI TSHIBANGU Caleb
Option : Administration systèmes et
réseaux
Juillet 2022
ECOLE SUPÉRIEURE D'INFORMATIQUE SALAMA
République Démocratique du Congo
Province du Haut Katanga
Lubumbashi
www.esisalama.com


ETUDE ET MISE EN PLACE D'UNE PLATEFORME CLOUD COMPUTING
SECURISEE AU SEIN D'UNE INSTITUTION PUBLIQUE(Cas de la DPI)
Travail présenté et défendu en vue de
l'obtention du grade d'ingénieur technicien en Administration
système et réseau

Par : MBUYI TSIBANGU Caleb
Option : Administration systèmes et
réseaux
Directeur: Mr MPIANA Fernand
Co-directeur: Mr SHINGALETA Darryl
Juillet 2022
EPIGRAPHE
« Pour réussir, votre désir de
réussite doit être plus grand que votre peur de
l'échec».
Bill COSBY
DEDICACE
Je dédie ce travail
A ma famille, elle qui m'a doté d'une éducation
digne, son amour a fait de moi ce que je suis aujourd'hui :
Particulièrement à mon père Augustin
TSHIBANGU, pour le goût à l'effort qu'il a suscité en moi,
de par sa rigueur. A toi ma mère Christine BEA, ceci est ma profonde
gratitude pour ton éternel amour, que ce travail soit le meilleur cadeau
que je puisse t'offrir.
A vous mes frères et soeursSéraphin NKONGOLO,
Junior MBUYAMBA, Buscapé NGANDU, Ruffin NGOIE, Steve KALOMBO, Vainqueur
LABA, Eugénie META, Micheline LUSAMBA, Carole TSHIBANGU, Florine
TSHIBANGU, Rosie MBIYA, Ruth TSHIBANGU, Dorcas TSHIBANGU et Annie TSHIBANGU qui
m'ont toujours soutenu et encouragé durant ces années
d'études.
A Ketsia NSEYA pour son soutien et ses encouragements.
REMERCIEMENT
Au terme de ces cinq années de formation passées
à l'Ecole Supérieure d'Informatique Salama, il m'est difficile
d'exprimer à leur juste valeur les sentiments que j'éprouve
à l'endroit de ceux qui m'ont soutenu dans l'accomplissement de cette
mission estudiantine. Ainsi donc, il m'est agréable d'exprimer ma
gratitude en adressant mes sincères remerciements à l'endroit
:
De notre Dieu tout puissant créateur du ciel et de la
terre, pour sa grâce dans notre vie et pour avoir rendu possible la
réalisation de ce travail en nous faisant part de sa force, de son
intelligence et de son souffle de vie.
De notre directeur, Monsieur Fernand MPIANA, ainsi que notre
codirecteur, Monsieur Darryl SHINGALETA, qui malgré leurs multiples
occupations, ont toujours su nous orienter comme aînés
scientifiques ainsi que tuteurs académiques.
De notre institution, Ecole Supérieure d'Informatique
Salama en sigle ESIS, par l'entremise de son Directeur général le
professeur Jacky PUNGU, pour la qualité des enseignements reçus
et savoir-faire technique.
De notre coordonnateur de filière, Monsieur
Michée KALONDA, ainsi que à notre secrétaire de
filière monsieur Jonathan BAYONGA.
De tout coeur à l'ingénieur Jacques NTAMBA, Elie
MWAMBAYI, ingénieur Akim ILUNGA, ingénieur Olivier,
ingénieur Thierry, ingénieur Stéphane pour leur
accompagnement et leur assistance dans l'élaboration de ce travail.
Nos remerciements s'adressent également à Lina
DJIMILA, Joëlla KIBELUSHI Paul LUMBALA, Merveille BANGI, Ruth NGALULA,
Laetitia MBAYO, Christian UMBALO, Rebecca TSHIKALA, Joyce MBULA, Isaac NSENGA,
Patricia MANDE, Caroline KALONGA, Lynda NGONGO, Mélanie MANDA,Gloire
LWAMBA, Sephora INANZALA, Ornelly INANZALA, Lauriane KANDAL, Dorcas MBANGU,
Paul MBANGU, Bénita TSHIMANGA, Bénédicte MULANGA, Wini
MUTAIS, Sarah WINY MANDELA, Jessica CHANSA pour toutes les dimensions de
soutiens manifestées en notre faveur.
A Gersy MAZEL, Guedaliah LWIMBI, Jessica META, Esther KALONJI,
Deborah MBUYU, Lazare NSEYA, Chrétien ILUNGA, Larissa NSOMPO, Patiente
NKONGOLO, Laetitia MUBALO, Russel MUKIND, Marc NTAMBWE, Olga TSHAMApour des
moments agréables que nous avons eu à passer.
Pour clore cette page, à tous ceux qui de près
ou de loin ont contribué d'une manière ou d'une autre à
l'élaboration de ce travail et qui n'ont pas vu leurs noms
mentionnés ici, nous vous disons merci.
MBUYI TSHIBANGU Caleb
LISTE DES FIGURES
Figure
1. 1 Figure 1 Vue de dessus du bâtiment DPI/Katanga
7
Figure
1. 2 Organigramme de la DPI/Katanga
8
Figure
1. 3 Architecture physique DPI/Katanga
9
Figure 1. 4 Système de stockage actuel de la
DPI
11
Figure 2. 1 Architecture Cloud privé
17
Figure 2. 2 Architecture Cloud public
18
Figure 2. 3 Architecture cloud privé du
réseau local de la DPI
21
Figure 2. 4 Description des éléments
du cloud
22
Figure 2. 5 Architecture du système
centralisé de la DPI
24
Figure 2. 6 Système de clustering cloud
26
Figure 2. 7 Cluster de basculement
27
Figure 2. 8 Schéma logique de
load-balancing
29
Figure 2. 9 Etude comparative des solutions
cloud
33
Figure 2. 10 Logo CentreStack
34
Figure 2. 11 Déploiement sur le même
réseau
35
Figure 2. 12 Déploiement dans un emplacement
centralisé
36
Figure 2. 13 Diagramme d'activité
38
Figure 3. 1 Installation de l'hyperviseur
VMware
40
Figure 3. 2 Ajout du rôle IIS au Serveur
40
Figure 3. 3 Processus d'installation du client
41
Figure 3. 4 Ouverture de la session client
Windows
41
Figure 3. 5 Choix du type de serveur de base de
données MySQL
42
Figure 3. 6 Vérification des composants
MySQL
42
Figure 3. 7 Installation de MySQL
43
Figure 3. 8 Ajout de l'utilisateur MySQL
43
Figure 3. 9 Utilisateurs ajoutés
44
Figure 3. 10 Choix du mode de
réplication
44
Figure 3. 11 Interface graphique MySQL
45
Figure 3. 12 Test de connexion à MySQL
45
Figure 3. 13 Page de connexion MySQL
46
Figure 3. 14 Initialisation automatique de
MySQL
46
Figure 3. 15 Installation de CentreStack
47
Figure 3. 16 Interface d'authentification de
CentreStack
48
Figure 3. 17 Tableau de bord de CentreStack
48
Figure 3. 18 Interface CentreStack du Client
Windows sur Windows server
49
Figure 3. 19 Interface d'installation
côté Windows client
50
Figure 3. 20 Installation de CentreStack sur
Android
51
Figure 3. 21 Interface d'authentification
CentreStack sur Android
51
Figure 3. 22 Interface du client Android
52
Figure 3. 23 Configuration du compte Administrateur
du cluster
52
Figure 3. 24 Interface d'importation Active
Directory
53
Figure 3. 25 Sélection de l'option
d'importation
54
Figure 3. 26 Création de l'utilisateur
Active Directory
54
Figure 3. 27 Importation de l'utilisateur
créé
55
Figure 3. 28 Vue des utilisateurs
importés
55
Figure 3. 29 Dossier partagé
56
Figure 3. 30 Vue des fichiers partagés
56
Figure 3. 31 Le fichier TFC partagé
57
Figure 3. 32 Le fichier TFC sur le Serveur
Cloud
57
Figure 3. 33 Vue du contenu cloud sur Android
58
Figure 3. 34 Sélection des fichiers
58
Figure 3. 35 Vue des fichiers partagés par
le client Android
59
LISTE DES TABLEAUX
Tableau 1. 1 Recommandation de la norme
ISO27701
11
Tableau 2. 1 La haute disponibilité des
données
25
Tableau 2. 2 La haute disponibilité des
données
33
Tableau 3. 1 Besoin non fonctionnel
59
Tableau 3. 2 Besoins fonctionnels
60
LISTE DES ACRONYMES
AFNOR : Association Française de Normalisation
API: Application Programming Interface
AWS:Amazon Web Services
CD: Compact Disc
CDI : Centre Des Impôts
CIS : Centre d'Impôts Synthétiques
DGE : Direction des Grandes Entreprises
DGI : Direction Générale des Impôts
DPI : Direction Provinciale des Impôts
I.S.P : Internet Service Provider
I.T: Ingénieur Technicien
IaaS :Infrastructure as a Services
IHM : Interfaces Homme-Machine
NLB : Network Load Balancing
NTFS : New Technology File System
PaaS: Platform as a Services
PC: Personal Computer
QoS: Quality of Services
SaaS: Software as a Services
SQL : Structured Query Language
UML: Unified Modeling Language
UPS: Uninterruptible Power Supply
UTP: Unterer Tod Punkt
VLAN: Virtual Local Area Network
VLR: Visitor Location Register
VM: Virtual Machine
WPA: Wi-Fi Protected Access
TABLE DES MATIERES
EPIGRAPHE
I
DEDICACE
II
REMERCIEMENT
III
LISTE DES FIGURES
IV
LISTE DES TABLEAUX
VI
LISTE DES ACRONYMES
VII
TABLE DES MATIERES
VIII
AVANT-PROPOS
XI
CHAPITRE 0 : INTRODUCTION GENERALE
1
0.1 Problématique
1
0.2Hypothèses
1
0.3Choix et intérêt du sujet
2
0.4Méthode et Techniques
3
0.4.1. Méthodes
3
0.4.2. Techniques
3
0.5Etat de l'art
3
0.6Délimitation du travail
4
0.7Subdivision du travail
5
0.8Outils logiciels utilisés
5
CHAPITRE 1 : ETUDE DU SYSTEME EXISTANT
6
1.1. Présentation de la DGI
6
1.1.1. Historique
6
1.1.2. Situation géographique
6
1.1.3 Mission et vision
7
1.1.4 Attribution des divisions
7
1.1.5 Organigramme de la DPI/Katanga
8
1.2 Etude de l'existant
9
1.2.2 Présentation du
réseau
10
1.3 Présentation du système de
stockage de la DPI
10
1.4 Critique de l'existant
11
1.4.1 Points faibles
13
1.4.2 Points forts
14
1.5 Identification des besoins
14
1.5.1 Besoin fonctionnel
14
1.5.2 Besoin non fonctionnel
15
1.6 Conclusion partielle
15
CHAPITRE 2 : CONCEPTION GENERALE DU FUTURE
SYSTEME
16
2.1 Migration vers un système de stockage
cloud computing
16
2.1.1 Cloud privé
16
2.1.2 Cloud public
17
2.1.3 Cloud Hybride
19
2.1.4 Architecture cloud retenue
19
2.1.5 Présentation de l'architecture
retenue
20
2.1.6 Description des éléments
essentiels du cloud computing
22
2.2 Intégration du système de
centralisation des données
23
2.3 Optimisation de la haute disponibilité
du système de stockage
24
2.3.1 La haute disponibilité
24
2.3.2 Stratégie permettant la haute
disponibilité
25
2.4 Choix de la technologie
29
2.4.1 Critère de choix
29
2.4.2 Présentation des solutions
proposées
29
2.5 Présentation de CentreStack
34
2.5.1 Types de déploiement
35
2.6 Identification des acteurs et leurs
interactions dans le système
36
2.6.1 Identification des besoins fonctionnels et
non fonctionnels
37
2.6.2 Diagramme d'activité du future
système
38
2.7 Conclusion partielle
38
CHAPITRE 3 : IMPLEMENTATION DE LA SOLUTION
39
3.1 Procédure et planification
39
3.1.1. Le sommaire
39
· Installation de l'hyperviseur
VMware
39
· Installation du serveur
40
· Installation du client
41
· Installation de MySQL
42
· Installation de CentreStack
46
· Installation utilisateurs
CentreStack
48
· Configuration du compte
administrateur
52
· Création et importation des
utilisateurs Active Directory
53
3.2 Evaluation des besoins
59
3.3.1. Besoins non fonctionnels
59
3.3.2 Les Besoins fonctionnels
60
3.4 Conclusion partielle
60
CONCLUSION GENERALE
61
Perspectives d'avenir
62
BIBLIOGRAPHIE
63
AVANT-PROPOS
L'Ecole Supérieure d'Informatique Salama, régie
par le programme national desinstitutions supérieures techniques,
prévoit des défenses des travaux ou projets à la fin de
notre cursus académiques des ingénieurs techniciens en
informatique.
C'est dans cet ordre d'idée que s'inscrit ce travail de
fin d'études en administration système et réseau
intitulé «étude et mise en place d'une plateforme cloud
computing sécurisée au sein d'une institution publique».
Pour notre cas, après l'observation des
problèmes des gestions des données par les administrateurs
systèmes et réseaux, le temps de la synchronisation des
données ainsi que la haute disponibilité dans la conception du
système réseau a la Direction Provinciale des Impôts
n'existe pas.
La compréhension de ce travail exige la lecture globale
de tous les trois chapitres,étant donné que la fin de chaque
chapitre constitue le début du prochainchapitre.
CHAPITRE 0 :
INTRODUCTION GENERALE
Toute entreprise vise une grande productivité en
mettant en jeu des moyens afin d'aboutir à une bonne
rentabilité. Les données d'une entreprise constituent
l'élément majeur de confidentialité et de
rentabilité de celle-ci. De ce fait, un bon stockage ainsi qu'une
meilleure sécurisation des données constituent un
véritable cheval de bataille des entreprises.
Etant donné que les données deviennent de plus
en plus indispensables au sein des entreprises, ces dernières souhaitent
construire les architectures de stockage numérique de données en
leur sein, tout en visant leur sécurité afin de s'assurer d'un
contrôle total ainsi que d'une protection efficace sur ces dites
données.
La gestion et la supervision de l'ensemble des unités
de stockage sont effectués par les administrateurs de base de
données ; ceux-ci doivent garantir le fonctionnement optimal du
réseau de données d'entreprise ainsi que leur
évolutivité, afin d'assurer le bon partage des fichiers ainsi
qu'une meilleure circulation de celles-ci.
0.1 Problématique
Après avoir passé le stage à la Direction
Provinciale des Impôts (DPI), nous avons
constaté que les
données ne cessent de croitre. Et l'entreprise ne sait pas comment
stocker
les nouvelles données et cela est dû au fait que
l'espace de stockage est souvent limité.
Cette observation au coeur de notre étude
soulève les questions suivantes :
Ø Etant donné que les données de
différentes succursales de la DPI sont transportées vers la
direction générale sur des supportsphysiques, quel serait un
moyen optimal d'une transmission automatique et de gestion des
données ?
Ø Quel système mettre en place pour une
sécurisation efficace des données dans leur transmission entre
les différentes succursales de la DPI ?
0.2Hypothèses
Ayant le souci d'apporter satisfaction à la
problématique posée ci-haut ; nous essaierons de donner des
pistes de solution et suggestions de manière suivante :
Ø Nous pourrons mettre en place une solution cloud qui
nous permettra d'offrircette facilité aux utilisateurs des
différentes succursales d'accéder aux données de la DPIet
offrir un accès mobile et unecollaboration en toute
sécurité, répondant à toutes les exigences de
sécurité et deconformité ;
Ø Nous pourrons aussi mettre en place une solution qui
nous permettra d'avoir un fonctionnement qui soit différent de celui
d'un Datacenter classique, ainsi, nous nous priverons de toutes ces
boîtes (Firewall, Load balancer, des serveurs de stockage) et de passer
aux solutions génériques (des éléments logiciels)
dont nous pourrons trouver des solutions open source.
0.3Choix et
intérêt du sujet
Etant au terme de notre cursus académique en
Administration systèmes et réseaux, et ayant acquis des
connaissances dans le domaine qui est le nôtre tout au long de notre
parcourt académique, nous sommes appelés à proposer des
solutions adéquates aux entreprises soit en vue de la résolution
d'un problème précis ou en vue d'apporter une évolution
à ces entreprises. D'où, ce travail entre dans le cadre de
solution éventuelle pour la Direction Provinciale des Impôts du
Katanga, DPI en sigle et toute autre entreprise ou institution qui voudrait
bien héberger ses données sans se soucier de l'infrastructure
matérielle.
L'intérêt par rapport au sujet se situe sur trois
plans :
ï Plan personnel
En tant que futur ingénieur administrateur
systèmes et réseaux, ce travail est d'une importance capitale car
nous serons appelés à faire usage des nouvelles connaissances
dans le secteur de l'informatique dans les nuages, obtenues par
différentes recherches, lectures et expériences que nous aurons
à réaliser.
ï Plan scientifique
Le présent travail est une ressource pour toute
personne désireuse de s'en inspirer à des fins de recherche ou
à des fins purement académiques. Il met en vedette des techniques
d'hébergement d'un Datacenter à l'aide des logiciels
adéquats.
ï Plan pratique et social
Le présent travail permettra aux administrateurs de la
Direction Provinciale des Impôts de mettre sur pied des techniques
d'hébergement plus sûres et efficaces pour la bonne gestion des
données.
0.4Méthode et
Techniques
0.4.1. Méthodes
ï Méthode descriptive : Cette
méthode est utilisée pour décrire lescomposants qui seront
mis en place. Dans notre cas, elle nous a permis dedécrire les
éléments faisant partie de notre système de stockage.
ï Méthode Comparative : Avec
cette méthode, on va étudier plusieurs
solutions pour prendre
celle qui va répondre à nos critères. Dans ce
présenttravail, elle nous a permis de ressortir les avantages et
inconvénients desdifférentes technologies de cloud computing afin
deprendre celle qui va répondre à nos besoins.
ï Méthode expérimentale :
Cette méthode consiste à tester la validité
d'unehypothèse. Dans ce présent travail, elle nous a permis de
mettre en placenotre système en fonction de la technologie choisi du
cloud computing afin de rendre possible l'implémentation de notre
système.
0.4.2. Techniques
Les techniques sont définies comme étant des
voies à utiliser pour atteindre les
objectifs, ce sont des outils
nécessaires qui permettront au chercheur de récolter et
traiterles données nécessaires à l'élaboration de
son travail, ainsi pour notre recherche, nousutiliserons les techniques
ci-après :
ï La documentation : Basée sur
l'ensemble de documents recueillis sur une question, elle nous a permis d'avoir
de données relatives au sujet sur lequel nous
travaillons. Par
ailleurs, des sites internet, des revues, des livres...
ï Interview : Cette technique nous a
facilité la récolte des données auprès
des
personnes mieux informées dans le domaine et nous a aussi permis
de faire des
échanges avec ainés scientifiques qui sont dans
notre domaine d'administration
système et réseau.
0.5Etat de l'art
Comme un chercheur scientifique, nous devons prendre
connaissance des travaux qui entre enrapport avec notre thème pour ne
pas prendre le risque de faire un travail déjà textuellement
faitauparavant qui ne sera pas profitable pour le monde de la science et cela
nous permettra peut-être d'aborder le même thème dans un axe
différent. Nous citons :
Ø L'ingénieur KALOMBO TSHONY
Ephraïmqui a parlé de « la
conteneurisation et le clustering sousproxmox» (2018-2019). Dans son
travail, i a été question de palier à la lenteur
aperçue par les agents de la DRHKAT lorsque ceux-ci émettaient
leurs requêtes à la base de données.
Sur ce, l'ingénieur a mis en place un système
qui garantit la disponibilité des services et qui prend en
chargel'équilibrage des charges des clusters ce qui permettra aux
ressources de plusieurs noeuds d'être rassemblées pour agir comme
un seul ensemble.
Ø L'ingénieur KOKO LEMBI
Léonce qui a parlé sur « mise en place d'une
infrastructure réseau cloud Storageassurant l'enregistrement et
livraison des actes denaissances » (2018-2019).Dans son travail,
l'ingénieur a remarqué l'absence de base de données
comportant l'enregistrement des naissances et la livraison intégrale
des actes de naissance par l'entité administrative. Il a
également fait remarquer que chaque bureau de l'état civil des
différentes communes, effectue l'enregistrement des nouvelles naissances
indépendamment sans tenir compte de la redondance des données. Ce
qui occasionne la détention de plus d'un acte de naissance qu'ilqualifie
de frauduleux. Ce qui entraine une difficulté dans la couverture de
sécurité sociale pour la prise en charge médicale et
nutritionnelle.
C'est ainsi que l'ingénieur a mis en place une
infrastructure Cloud Storage pour l'enregistrement et la livraison des actes de
naissance ce qui permettra de conserver ce document en
sécurité.
Quant à nous, ce présent travail se
démarque de ceux de nos deux prédécesseurs cités
ci-haut, par la muse en place d'un système de centralisation des
données au sein de la Direction Provinciale des Impôts du Katanga.
Ce qui permettra aux différentes succursales de mieux acheminer leurs
données sans recourir au déplacement physique des agents. Et cela
sera fait dans un environnement de libre-échange.
0.6Délimitation du
travail
Dans le temps il sied de noter que ce travail s'étant
au cours de l'année
académique 2020-2021 et est
appliquée particulièrement à la Direction Provinciale des
Impôts du Katanga.
La Direction Provinciale des Impôts du Katanga nous a
permis d'étudier le
fonctionnement de son réseau, d'identifier
le besoin et afin de planifier une éventuelle implémentationde
notre solution dans leur infrastructure existante.
0.7Subdivision du
travail
Notre travail sera reparti précisément en 3
chapitres hormis la partie introductive et la conclusion
générale, réparti comme suit :
Le premier chapitre intitulé « Etude de
l'existant » Dans ce chapitre, nous allons faire une étude
sur le réseau existant de la Direction Provinciale des Impôts du
KATANGA en faisant une analyse générale pour la
spécification des besoins.
Le second chapitre intitulé « Conception
générale du futur système » Nous parlerons
des considérations théoriques ; nous expliquerons les notions qui
cadrent avec notre sujet. Ce chapitre présentera tous les modules du
système ainsi que leurs interactions. Ensuite nous ferons une
étude approfondie des technologies candidates. Celle qui répondra
au mieux aux critères sera sélectionnée.
Le troisième chapitre intitulé «
Mise en place de la solution » nous montrerons les
différentes étapes des installations, des configurations ainsi
que les différents tests qui seront réalisés.
0.8Outils logiciels
utilisés
Dans l'élaboration de notre travail,
nous avons pu recourir à beaucoup d'outils
logiciels qui ont
donné forme à ce dernier, c'est le cas de :
ï Un ordinateur portable
ï Windows 10
ï StarUML
ï Draw.io
ï Windows serveur
ï Microsoft Office Word 2016
ï Microsoft Office Visio 2016
ï CentreStack
CHAPITRE 1 : ETUDE DU
SYSTEME EXISTANT
Dans ce chapitre, il est question de faire une étude
détaillée du système existant, sous différents
aspects. L'analyse des différents aspects et
spécifications des besoins fonctionnels et non fonctionnels nous
aideront à poser les bases de la construction conceptuelle de la
solution.
1.1. Présentation de la
DGI
1.1.1. Historique
La direction générale des impôts, DGI en
sigle est un service public placé sous l'autorité directe du
ministère ayant les finances dans ses attributions. Sur proposition du
commissaire aux finances, d'une administration fiscale et d'une autonomie
administrative et financière créée le 10 mars 1988 par une
ordonnance du chef de l'État. La création de la direction
générale des contributions répondait à un souci
d'accroissement de la mobilisation des recettes fiscales.[1]
Vers les années 1999, l'efficacité de
l'administration fiscale s'est affirmée face aux innovations
législatives qui se poursuivent et aux avancées technologiques
permises par l'informatique. Au prix d'un effort soutenu des services de base,
les grands fichiers informatiques (gestion des ressources humaines
essentiellement) sont désormais constitués. L'informatique
démontre ainsi son aptitude à mettre en place avec
rapidité des mesures conjoncturelles.
1.1.2. Situation
géographique
La Direction Provinciale des Impôts du Katanga, DPI/Kat
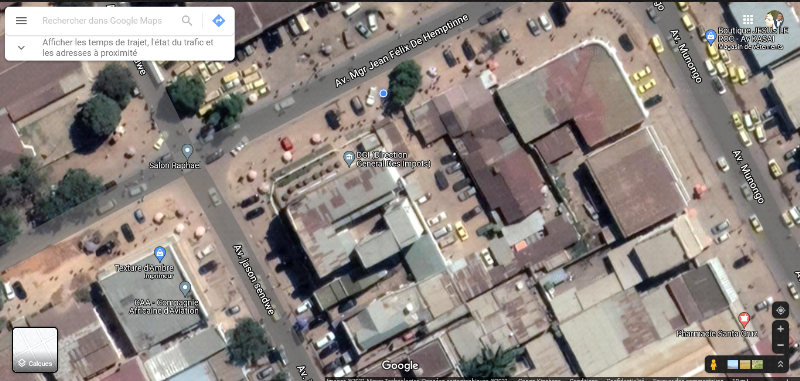
en sigle, se trouve précisément au numéro 198, croisement
des avenues Mgr Jean Félix Hemptinne (ex Tabora) et l'avenue SENDWE dans
la commune de Lubumbashi.
Figure 1. 1 Figure 1 Vue de
dessus du bâtiment DPI/Katanga
1.1.3 Mission et vision
La Direction Générale des Impôts de la
République démocratique du Congo est le service public qui
s'occupe de l'immatriculation des véhicules automoteurs, du recouvrement
des factures émises par l'Etat et de l'attribution des numéros
d'identification fiscale (NIF) ou numéro d'impôts. Elle est
placée sous la tutelle du Ministre ayant les Finances dans ses
attributions. [1]
1.1.4 Attribution des divisions
Le cadre organique actuel reconnait à la direction
provinciale des impôts (DPI)/Katanga, neuf divisions, mais dans cette
partie nous ne parlerons que de la division d'Informatique :
La division de l'informatique :
Cette division s'occupe de :
Ø L'élaboration de la stratégie
d'informatisation du système informatique ;
Ø L'élaboration de cahier de charger de projets
informatiques ;
Ø L'analyse, le développement, l'implantation et la
maintenance des applications et des équipements.
Ø L'assistance technique en la matière de service
tant au niveau de la direction qu'aux niveaux des CIS, de DGE et du CDI
Lubumbashi.
Figure 1. 2 Organigramme de la
DPI/Katanga
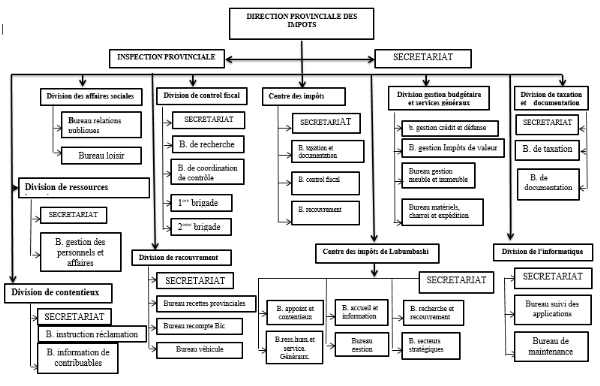
1.1.5 Organigramme de la
DPI/Katanga
La direction provinciale des impôts du Katanga est
chapotée par un directeur de province, suivi d'un corps d'inspecteurs.
Ensuite vient les chefs des divisions, de CIS, du CDI, de CDE et afin de
chefs de bureau et les agents.
1.2 Etude de l'existant
Figure 1. 3 Architecture
physique DPI/Katanga
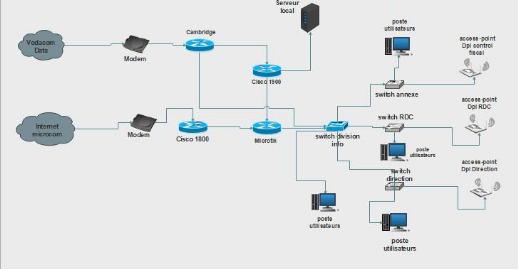
1.2.1 Architecture physique
1.2.2 Présentation du
réseau
1.2.2.1 Description de la topologie physique
L'architecture (physique) réseau de la Division
Provinciale des Impôts est composée des équipements
suivants :
Ø Une antenne VLR : qui
reçoit la connexion venant d'un fournisseur d'accès internet,
Internet Service Provider (I.S.P : MICROCOM)
Ø Des serveursdont :
· Deux (2) Windows server 2008 R2 entreprise Edition est
installé (Serveur d'authentification et serveur
d'application) ;
· Deux (2) Windows server 2003 (Serveur d'impression et
d'antivirus) ;
Ø Un AVR (qui joue le rôle
d'onduleur) ;
Ø Un Rack : qui contient les
différents équipements d'interconnexions notamment : Un Switch
Core qui reçoit le signal de 10MB/100MB/1GB ;
Ø Un rétroprojecteur
Ø Des ordinateurs : Desktop et PC
Ø Des scanners.
1.3 Présentation du
système de stockage de la DPI
Les données constituent les éléments
clés de toute organisation de quelle que nature qu'elle soit. Ainsi,
chaque organisation possède son propre système de stockage lui
permettant de collecter, sauvegarder, partager ou encore stocker les
données.
En effet, la direction provinciale des impôts (DPI)
possède un système de stockage en son sein ; lequel lui
permet de collecter les différentes données en provenance de ses
différentes succursales.
D'après l'illustration du système de stockage de
la DPI ci-dessous, chaque succursale possède en son sein une base des
données Microsoft Access ; celle-ci leur permet de collecter toutes
leurs données reçues en local. Ensuite, ces données sont
gravées sur des CD pour leur acheminement vers la direction provinciale
des impôts (DPI).
Le déplacement de ces CD vers la DPI se fait par voie
routière, et celles-ci sont superposées dans une
étagère dans le bureau de la division d'informatique pour ensuite
être transférées manuellement dans la base de
données centrale da la DPI.
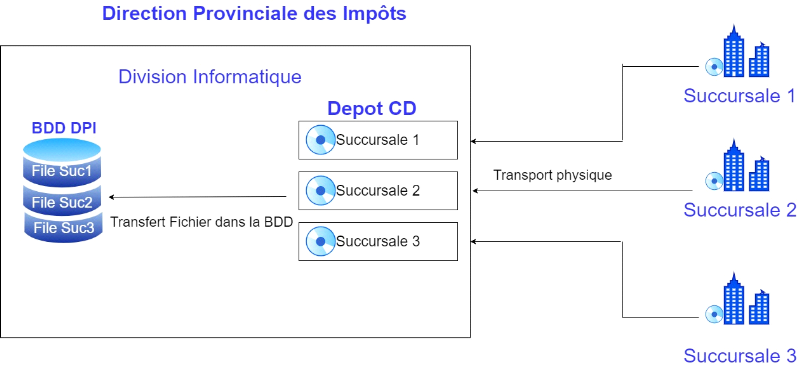
Figure 1. 4 Système de
stockage actuel de la DPI
1.4 Critique de l'existant
Le système de stockage de la DPI permet à
celle-ci de pouvoir collecter et transférer ses données ;
nonobstant cela, son système de stockage ne remplit pas certaines normes
éditées par différents organismes internationaux en terme
de l'évolutivité, la sécurité ainsi que la
protection des données; c'est le cas de la norme ISO27701[2] qui
décrit la bonne gouvernance et les mesures de sécurité des
données, celle-ci recommande une protection assez efficace des supports
amovibles, une gestion des accès et le chiffrement des données.
Cette norme est respectée seulement en partie au sein de la DPI qui
stocke ses données sur des CD transportés par voie
routière, ce qui est un grand risque de perte des données en cas
des chocs des CD, de hausse de température le long du trajet.
Tableau 1. 1 Recommandation de
la norme ISO27701
|
Recommandation de la norme ISO27701
|
Critique par rapport à la DPI
|
|
Définir la stratégie de
sécurité
|
La DPI assure la sécurité aux données par
l'accès aux fichiers conditionné par un mot de passe.
|
|
Gérer les risques de perte des données
|
Aucune mesure n'est mise en place pour gérer les
risques de perte des données au sein de la DPI
|
|
Mettre en place une gestion des incidents et de violation des
données.
|
Cette procédure devra prévoir un système
de signalement en interne permettant aux collaborateurs de lever l'alerte
rapidement sur les violations de données qu'ils pourraient
découvrir ou dont ils pourraient être informés. La DPI fait
passer certaines violations des données puisque les alertes sont quasi
inexistantes.
|
|
Concevoir et rédiger des stratégies de
sécurité
|
Aucune stratégie de sécurité est
conçue ou rédigée.
|
La DPI récolte toutes les informations gravées
sur CD de chaque succursale et les stockent sur sa base de données en
interne, ce qui permet une centralisation de toutes ses données. Mais
qu'à cela ne tienne, avant de centraliser les données, les CD
sont superposés dans la division informatique attendant d'être
transférées dans la base de données. Ce qui rend
l'opération de transfert vers la base centrale très lente
à cause des multiples succursales de la DPI.
La division informatique de la DPI possède une base de
données sous Microsoft Access, ce qui est très important et
très bénéfique pour son stockage des données.
Malgré cela, l'entreprise est butée à quelques
difficultés liées à l'évolutivité de son
infrastructure à cause des limites du logiciel Microsoft Access ;
Nonobstant différentes fonctionnalités qu'offre
Microsoft Access, celui-ci présente également quelques failles
lesquelles rendant son système de stockage non évolutif et moins
performant. Microsoft Access présente quelques limites qui rendent le
système de stockage de la DPI moins performant à savoir :
[3]
Ø Une résistance faible a la montée
en charge (Non évolutif)
La montée en charge désigne une forte augmentation
soudaine du trafic d'un site web ou du volume d'informations demandé
à un ou des serveurs.
Ø Moins puissant que celui d'une base de
serveur
MS Access est plus adapté à la mise en oeuvre de
bases de données légères, ne comprenant pas des centaines
de milliers d'entrées (pour lesquelles il vaut mieux utiliser un serveur
DMBS). Le traitement d'une grande quantité de données est assez
long avec MS Access, notamment au niveau du temps de chargement. C'est
l'inconvénient d'un système reposant sur un seul et unique
fichier, puisqu'à chaque ouverture de la base de données, il faut
charger le fichier entier : plus il est long, plus le temps d'attente est
important. Le programme est également limité en ce qui concerne
l'espace de la base de données, puisque le fichier ne peut pas
dépasser 2 GB. [4]
Ø Peu adapté à des usages
réseaux
Le programme présente des manques par rapport à
des SGBD basés sur SQL. Tout d'abord, le SQL standard fonctionne avec
des concepts d'autorisations très différents de ceux de MS
Access. Par ailleurs, le programme de Microsoft présente quelques
problèmes de lenteur en cas d'utilisation simultanée par
plusieurs personnes : il suffit de quelques utilisateurs seulement pour rendre
le programme significativement plus lent, et il atteint ses limites à
partir de dix utilisateurs simultanés. [4]
Le système de stockage de chaque succursale stocke ses
données sur des CD optiques, lesquelles peuvent être perdues en
une simple erreur de frottement ou par rapport à sa durée de vie
du disque ou encore par la mauvaise conservation de ceux-ci, ce qui le rend ce
dernier moins sécurisé.
D'après le National Institute of Standards and
Technology, l'espérance de vie d'un DVD-R est de 30 ans s'il est
conservé à une température de 25 degrés Celsius et
a une humidité relative de 50 pourcents. [5]
Nous voyons alors que les CD ne sont pas un support
adéquat pour l'archivage a long terme. Les enregistrements successifs
affectent l'espérance de vie de ces disques et peuvent entrainer une
perte ou une altération d'information.
Toutes les données de la DPI sont centralisées
dans la base de données Access mais celles-ci ne peuvent pas être
accessibles à distance par ses succursales.
Les CD contenant les données sont transportés
à partir des succursales jusqu'à la DPI par voie routière,
ce qui coute beaucoup des moyens financiers pour le transport des CD.
La superposition des CD de différents succursales dans
la division informatique constitue une grande prise des risques au cas
où l'administrateur de la base des données de la DPI oublie de
copier les données des certains CD. L'administrateur peut
également fissurer les disques, ce qui perdra complètement les
données.
Le système de stockage de la DPI manque un
système qui permettra l'interconnexion des différentes
succursales et la DPI, ce qui cause le déplacement très
fréquent des CD vers la direction provinciale des impôts (DPI).
Apres analyse assez détaillé du système
existant de la DPI qui nous a permis de définir un nombre de contraintes
pouvant réduire ses performances : et qui peuvent être un obstacle
à la réalisation de la mission du DPI. Et avant d'atterrir avec
ce point, nous pouvons donner quelques points forts et point faibles. Ces
dernières constitueront les points à améliorer lors de la
conception du futur système.
1.4.1 Points faibles
Ø Manques d'une architecture réseaux
reliant la DPI aux autres succursales.
Chaque succursale ainsi que la direction provinciale
possèdent chacune une infrastructure réseau en interne, les
différentes succursales ne sont pas connectées entre elles mais
aussi avec la direction provinciale. La DPI n'a pas une structure reliant les
différentes succursales.
Une architecture centralisée permet d'héberger
une base de données des noms d'utilisateur et mots de passe et, en
même temps, la gestion de niveau d'accès des utilisateurs
individuels et les ordinateurs peuvent avoir des ressources de réseau
spécifiques. [6]
Ø La DPI ainsi que toutes les autres succursales
utilisent un système de stockage non évolutif.
La DPI dispose d'un système de gestion bien
défini du point de vue fonctionnel, chaque site dispose d'une base de
données sur son serveur d'application. Elle utilise Microsoft Access
pour stocker les données.
Notons que chaque fin du mois, les différentes
succursales envoient une sauvegarde sur CD du fichier Access où est
stocker les données. Tous les CD sont entreposés dans le bureau
du chef de division d'informatique.
La base de données Microsoft Access fournit
l'utilisation pour plusieurs utilisateurs simultanés. Toutefois, une
augmentation des utilisateurs simultanés crée une
dégradation des performances. La base de données Access est plus
lente, les utilisateurs connaissent de longues périodes requête
d'attente et le fichier de base de données peuvent expirer au cours des
activités critiques.[4]
1.4.2 Points forts
Ø La sécurité des postes clients est bien
assurer grâce au serveur d'anti-virus ;
Ø Un annuaire permettant de regrouper et gérer les
utilisateurs ainsi que les objets est mis en place.
1.5 Identification des
besoins
La spécification des besoins décrit sans
ambiguïté la solution à développer. Elle est
constituée d'un ensemble de documents et de modèles. Partant de
cette approche, nous allons faire une distinction entre les besoins
fonctionnels et les besoins non fonctionnels de la Direction Provinciale des
Impôts dans le système envisageable.
Ayant le souci d'améliorer la façon de
gérer les données d'une si grande entreprise qui gère le
portefeuille de l'Etat, la division d'informatique a mis sur pied un projet qui
consiste à centraliser les bases de données et d'avoir une vue en
temps réel sur toutes ses bases de données distants.
1.5.1 Besoin fonctionnel
Il s'agit des fonctionnalités du système en
réponse à une demande. Après avoir parcouru le
système existant au sein de la Direction Provinciale des Impôts du
Katanga, voici les besoins fonctionnels aux quels le présent
système répond et qu'il s'agira de mettre en place :
Ø Un système de partage et d'enregistrement de
fichiers (rapport etc..) qui simplifiera
la tache aux agents de la Direction
Provinciale des Impôts du Katanga de ne plus faire usage de leurs pieds
pour déposer leurs rapports ;
Ø Mettre en place un espace de stockage évolutif et
sécurisé ;
1.5.2 Besoin non
fonctionnel
Le besoin non fonctionnel n'est rien d'autre que les exigences
explicites ou obligatoires internes du système. D'où le
système invoqué ci-haut doit être extensible à fin
d'offrir un moyen d'apporter des modifications et des ajouts en termes des
nouvelles fonctionnalités.
Afin d'obtenir un système répondant aux normes,
le système doit avoir :
Ø Sécurité : le
système devra assurer l'authentification, la
confidentialité et l'intégrité des informations
échangées. Et certaines informations ne devront pas
êtreaccessibles à tout le monde
Ø Fiabilité : ici on voit la
probabilité de défaillance moindre pendant le fonctionnement, la
fiabilité devra être accrue par un second système qui
opère en mode redondant et devra être mis en place afin d'assumer
immédiatement les fonctions du système original en cas de
dysfonctionnent de celui-ci
Ø Disponibilité : la
sûreté de fonctionnement et la reconfiguration en cas de panne
doivent caractériser le système, un système d'alimentation
sans coupure (UPS) peut être mise en place pour garantir une
infrastructure fiable et hautement disponible en le préservant de pannes
de courant.
Ø La stabilité : nous voyons par
là un système qui, une fois écarté de sa position
d'équilibre, il tend à y revenir
Ø Le coût : nous voyons une
solution efficace pouvant être implémentée avec un budget
minimum.
1.6 Conclusion partielle
Ce chapitre nous a permis de présenter l'ensemble de
l'infrastructure réseau de la Direction Provinciale des Impôts du
Katanga, nous y avons effectué une étude détaillée
en relevant les problèmes liés à la façon dont sont
stockées les données au sein des différentes succursales
que compose la DPI, à la manière dont sont acheminées ses
dites données vers la direction centrale qui est la DPI. Afin d'y
ressortir le maximum d'idées qui nous permettrons d'atteindre nos
objectifs dans ce présent travail.
CHAPITRE 2 :
CONCEPTION GENERALE DU FUTURE SYSTEME
L'étude du système existant dans le chapitre
précédent a fait une émergence des faiblesses
d'exploitation du système de stockage actuel au sein de la DPI. De
l'approche analytique de ces faiblesses, ce présent chapitre se focalise
sur une étude conceptuelle d'un système de stockage
évolutif en vue de proposer une nouvelle infrastructure utilisant le
Cloud computing pour la sauvegarde des données de la DPI. En sus, il en
étudie le système qui serait efficient et adéquat afin
d'assurer la continuité de services.Eu égard de ce qui
précède ce chapitre se structure en quatre
étapes :
Ø Migration vers un stockage cloud computing ;
Ø Intégration d'un système de
centralisation des données ;
Ø Optimisation de la haute disponibilité du
système de stockage ;
Ø Choix de la technologie cloud computing.
2.1 Migration vers un
système de stockage cloud computing
On peut distinguer trois principaux modèles
de déploiement pour le cloud :
Ø Le cloud privé ;
Ø Le cloud public et
Ø Le cloud hybride
2.1.1 Cloud
privé
2.1.1.1 Principe de fonctionnement
L'infrastructure d'un nuage privé est utilisée
par un seul organisme. Elle peut être gérée parcette
organisation ou par un fournisseur de service et peut être
hébergé dans leslocaux del'entreprise cliente ou externe.
L'utilisation d'un nuage privé permet de garantir que lesressources
matérielles allouées ne seront jamais partagées par deux
clients différents.
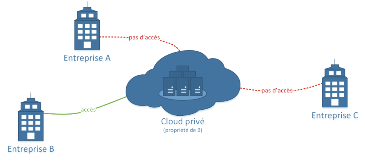
Figure 2. 1 Architecture Cloud
privé
2.1.1.2 Avantages du Cloud privé
Ø L'organisation du Cloud privé est parfaitement
adaptée à une organisation locale. Nous aurons l'occasion
d'organiser des partitions selon le besoin de l'entreprise.
Ø De plus, les experts recommandent ce type de Cloud
car il offre un bon niveau de sécurité, que ce soit au niveau de
son exécution ou de son mode d'accès. En effet, un Cloud
privé n'est accessible que par des liens réseaux privés
sécurisés, et non via l'internet public.
2.1.1.3 Inconvénients du Cloud privé
Ø La mise en place de cette infrastructure
représente un coût plus important qu'une location de partition
dans un Cloud public. De plus, ce mode de Cloud sera moins réactif en
cas de charge « brutale » de données.
2.1.2 Cloud public
2.1.2.1 Principe de fonctionnement
Le Cloud public est ouvert pour tout utilisateur disposant
d'un accès à l'espace Cloud et d'uneconnexion internet. Les
entreprises peuvent aussi utiliser le Cloud public. Elles peuvent lesutiliser,
également, à partir des autres entreprises qui offrent leurs
services aux utilisateursexternes.
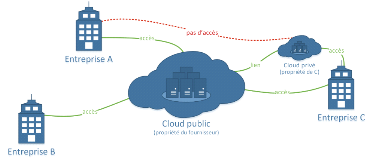
Figure 2. 2 Architecture Cloud
public
2.1.2.2 Avantages du Cloud public
Ø Les délais et coûts de mise en place
sont dérisoires car vous bénéficiez d'une infrastructure
existante. De plus, vous payerez ensuite qu'en fonction de votre utilisation,
selon le modèle « Pay as you use ». Ce mode de sauvegarde est
très flexible et reste très efficace et réactif en cas de
forte augmentation de vos besoins en capacité de stockage.
Ø Les applications Cloud sont personnalisées en
fonction des besoins individuels de l'entreprise.
Ø Les utilisateurs ont un accès exclusif aux
performances et à la bande passante du Cloud. Il ne faut donc pas
s'attendre à des restrictions dues à l'utilisation
simultanée par des tiers.
Ø En outre, comme l'entreprise n'achète ni
matériel ni logiciels, il n'est pas question de maintenance, cette
partie étant assurée par le prestataire de services.
2.1.2.3 Inconvénients du Cloud public
Ø Le Cloud public s'adaptera à vos besoins. Il
se peut donc qu'une augmentation d'abonnement soit nécessaire pour faire
face à la volumétrie stockée. De plus, l'infrastructure
étant existante, il est possible qu'elle ne soit pas parfaitement
adaptée à votre entreprise.
Ø Parmi les limitations, citons la configuration, la
sécurité et la spécificité des accords de niveaux
de service, ce qui en fait une solution peu idéale pour les entreprises
qui utilisent des données sensibles soumises à des règles
de conformité.
2.1.3 Cloud Hybride
2.1.3.1 Principe de fonctionnement
Cette solution Cloud de sauvegarde des données est
souvent utilisée par les grandes entreprises qui ont des organisations
et des besoins complexes. L'idée revient à utiliser des solutions
Cloud privées et publiques, indépendantes les unes des autres,
tout en conservant la possibilité d'une portabilité de ces
données. Opter pour une solution hybride permet notamment de
bénéficier de la puissance des solutions publiques pour des
données non sensibles.
2.1.3.2 Les avantages du Cloud hybride
Ø Il a l'avantage de permettre à une entreprise
de faire des économies car elle ne paie que pour la partie publique de
leur infrastructure seulement quand c'est nécessaire.
Ø En outre, sa charge de travail est contenue dans un
Cloud privé, mais elle conserve la possibilité d'augmenter
spontanément cette dernière et de réaliser des pointes
d'utilisation sur le Cloud public. De plus, le Cloud hybride permet de disposer
à la fois d'une infrastructure centralisée sur site et de
serveurs évolutifs et flexibles.
2.1.4.2 Inconvénients d'un Cloud hybride
Bien que le fait de pouvoir économiser certains
coûts soit un avantage pour une entreprise, il y a quelques points
négatifs à l'utilisation d'un Cloud hybride.
Ø Le premier est que son déploiement
nécessite des experts en informatique pour assurer la
sécurité maximale des données. Pour cette raison,
d'ailleurs, les entreprises optent la plupart du temps pour ce type de solution
pour stocker les données non sensibles.
Ø Il y a également le problème de
compatibilité qui peut se poser car une infrastructure sur site
performante peut ne pas être en mesure de fonctionner correctement avec
une infrastructure publique qui est moins performante, ce qui peut nuire
à l'efficacité du Cloud hybride. Cela étant, avec le
recours aux services d'experts et l'adoption de ressources appropriées,
les inconvénients du Cloud hybride peuvent être
évités.
2.1.4 Architecture cloud
retenue
Notre choix se porte sur l'architecture cloud privé qui
nous offre plus d'avantages. Avec une architecture cloud privé, vous
pouvez organiser, gérer, déployer et exploiter les services
informatiques de manière plus flexible. Les entreprises, en particulier,
peuvent utiliser un Cloud privé pour récupérer et analyser
les informations plus rapidement et ainsi prendre des décisions de
manière plus efficace. Parmi les autres avantages, mentionnons la
capacité de développer et de déployer plus rapidement de
nouvelles fonctions et d'étendre ou de réduire votre
activité en fonction des besoins. Contrairement aux autres solutions de
Cloud computing, vous seul avez accès au Cloud privé, ce qui
permet une meilleure sécurité des données.
Lorsqu'une entreprise conçoit et met en oeuvre
correctement un Cloud privé, elle peut offrir la plupart des avantages
que l'on trouve dans les Cloud publics, tels que le libre-service et
l'évolutivité, ainsi que la possibilité de fournir et de
configurer des machines virtuelles (VM) et de modifier ou d'optimiser les
ressources informatiques à la demande. Une organisation peut
également mettre en place des outils de facturation pour suivre
l'utilisation de l'informatique et s'assurer que les unités commerciales
ne paient que pour les ressources ou les services qu'elles utilisent.
2.1.5 Présentation de
l'architecture retenue
La solution de cloud privé que nous proposons est
construite autour de quatre composants principaux : le système de
stockage, les machines virtuelles (VMs), l'orchestration et le réseau
local de la DPI. Son schéma synoptique se présente comme suit
:
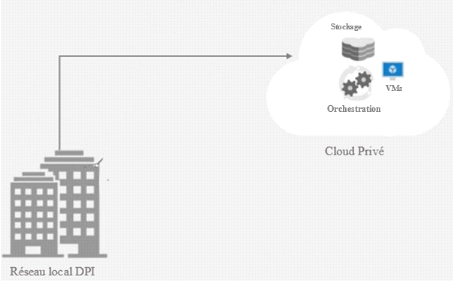
Figure 2. 3 Architecture cloud
privé du réseau local de la DPI
%3CmxGraphModel%3E%3Croot%3E%3CmxCell%20id%3D%220%22%2F%3E%3CmxCell%20id%3D%221%22%20parent%3D%220%22%2F%3E%3CmxCell%20id%3D%222%22%20value%3D%22%26lt%3Bb%26gt%3B%26lt%3Bfont%20style%3D%26quot%3Bfont-size%3A%2016px%26quot%3B%26gt%3BInternet%26lt%3B%2Ffont%26gt%3B%26lt%3B%2Fb%26gt%3B%22%20style%3D%22html%3D1%3BoutlineConnect%3D0%3BgradientDirection%3Dnorth%3BstrokeWidth%3D2%3Bshape%3Dmxgraph.networks.cloud%3BfillColor%3D%23b0e3e6%3BstrokeColor%3D%230e8088%3B%22%20vertex%3D%221%22%20parent%3D%221%22%3E%3CmxGeometry%20x%3D%22440%22%20y%3D%22130.12%22%20width%3D%22130%22%20height%3D%2280%22%20as%3D%22geometry%22%2F%3E%3C%2FmxCell%3E%3C%2Froot%3E%3C%2FmxGraphModel%3E%3CmxGraphModel%3E%3Croot%3E%3CmxCell%20id%3D%220%22%2F%3E%3CmxCell%20id%3D%221%22%20parent%3D%220%22%2F%3E%3CmxCell%20id%3D%222%22%20value%3D%22%26lt%3Bb%26gt%3B%26lt%3Bfont%20style%3D%26quot%3Bfont-size%3A%2016px%26quot%3B%26gt%3BInternet%26lt%3B%2Ffont%26gt%3B%26lt%3B%2Fb%26gt%3B%22%20style%3D%22html%3D1%3BoutlineConnect%3D0%3BgradientDirection%3Dnorth%3BstrokeWidth%3D2%3Bshape%3Dmxgraph.networks.cloud%3BfillColor%3D%23b0e3e6%3BstrokeColor%3D%230e8088%3B%22%20vertex%3D%221%22%20parent%3D%221%22%3E%3CmxGeometry%20x%3D%22440%22%20y%3D%22130.12%22%20width%3D%22130%22%20height%3D%2280%22%20as%3D%22geometry%22%2F%3E%3C%2FmxCell%3E%3C%2Froot%3E%3C%2FmxGraphModel%3E%3CmxGraphModel%3E%3Croot%3E%3CmxCell%20id%3D%220%22%2F%3E%3CmxCell%20id%3D%221%22%20parent%3D%220%22%2F%3E%3CmxCell%20id%3D%222%22%20value%3D%22%26lt%3Bb%26gt%3B%26lt%3Bfont%20style%3D%26quot%3Bfont-size%3A%2016px%26quot%3B%26gt%3BInternet%26lt%3B%2Ffont%26gt%3B%26lt%3B%2Fb%26gt%3B%22%20style%3D%22html%3D1%3BoutlineConnect%3D0%3BgradientDirection%3Dnorth%3BstrokeWidth%3D2%3Bshape%3Dmxgraph.networks.cloud%3BfillColor%3D%23b0e3e6%3BstrokeColor%3D%230e8088%3B%22%20vertex%3D%221%22%20parent%3D%221%22%3E%3CmxGeometry%20x%3D%22440%22%20y%3D%22130.12%22%20width%3D%22130%22%20height%3D%2280%22%20as%3D%22geometry%22%2F%3E%3C%2FmxCell%3E%3C%2Froot%3E%3C%2FmxGraphModel%3E%3CmxGraphModel%3E%3Croot%3E%3CmxCell%20id%3D%220%22%2F%3E%3CmxCell%20id%3D%221%22%20parent%3D%220%22%2F%3E%3CmxCell%20id%3D%222%22%20value%3D%22%26lt%3Bb%26gt%3B%26lt%3Bfont%20style%3D%26quot%3Bfont-size%3A%2016px%26quot%3B%26gt%3BInternet%26lt%3B%2Ffont%26gt%3B%26lt%3B%2Fb%26gt%3B%22%20style%3D%22html%3D1%3BoutlineConnect%3D0%3BgradientDirection%3Dnorth%3BstrokeWidth%3D2%3Bshape%3Dmxgraph.networks.cloud%3BfillColor%3D%23b0e3e6%3BstrokeColor%3D%230e8088%3B%22%20vertex%3D%221%22%20parent%3D%221%22%3E%3CmxGeometry%20x%3D%22440%22%20y%3D%22130.12%22%20width%3D%22130%22%20height%3D%2280%22%20as%3D%22geometry%22%2F%3E%3C%2FmxCell%3E%3C%2Froot%3E%3C%2FmxGraphModel%3E
Comme expliqué précédemment, il existe
troisarchitectures de déploiement du cloud computing.
Notre choix s'est basé sur le « Cloud privé
» pour deux raisons majeurs : puisque d'une part lefait que la DPI
voudrait centraliser leur système de stockage de données sur un
seul site, et d'autre part poursimplifier et réduire sensiblement le
coût de maintenance et gestion de l'infrastructureréseau de la
Direction Provinciale des Impôts du Katanga qui étaient auparavant
obligés d'attendre la fin du mois pour que les données des
différentes succursales soient acheminées vers celle-ci sans
tenir compte de la sécurité des données mais aussi du mode
de transport. Mais grâce à cette architecture, les succursales
peuvent uploader les données sans déplacement mais aussi avec une
sécurité accrue.
2.1.6Description des
éléments essentiels du cloud computing
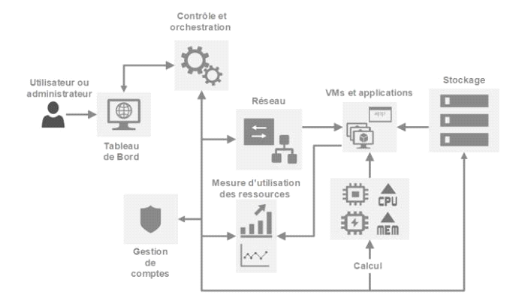
Figure 2. 4 Description des
éléments du cloud
Nous nous intéresserons successivement sur ces deux
points :
Ø La plateforme de Cloud ;
Ø L'hyperviseur ;
2.1.6.1 Les plateformes de gestion de Cloud
Les plateformes de gestion de Cloud sont de véritables
orchestrateurs de centre de données et fournissent les
fonctionnalités suivantes :
Ø Tableau de Bord : Module qui fait
office de portail pour les utilisateurs ou d'APIpour les administrateurs.
Ø Contrôle et orchestration :
c'est le module de synchronisation ou coordination du système dans son
ensemble.
Ø Gestion de comptes : module ayant
pour rôle de définir les droits, de vérifier et d'autoriser
par rapport aux informations utilisateurs.
Ø Réseau : module qui
gère certains aspects réseau du système et les ressources
en réseau des machines virtuelles (carte réseau, VLAN, routage, .
. .).
Ø Calcul : c'est le module qui
approvisionne les machines virtuelles en termes deressources de calcul (RAM et
CPU).
Ø Stockage : module qui s'occupe de
l'approvisionnement de stockage aux instances et de la conservation des
fichiers (instances, DaaS, . . .).
Le tout bien évidemment accessible en self-service
depuis un portail internet pourcorrespondre à la philosophie de
l'informatique à la demande.
2.1.6.2 Les hyperviseurs
Un hyperviseur est une couche d'abstraction logicielle. Il
assure les taches de bas niveau, comme l'ordonnancement du CPU et l'isolation
de mémoire utilisé par les machines virtuelles. L'hyperviseur
rend le matériel abstrait pour les VM, il est le seul à avoir la
connaissance du réseau, du stockage ou des ressources graphiques. Les VM
sont ainsi indépendante de la plateforme physique.
2.2 Intégration du
système de centralisation des données
Dans l'organisation d'une entreprise, l'information
représente un élément indispensable, au coeur de toutes
les activités. Sa disponibilité et son exactitude favorisent la
réussite des objectifs des équipes ainsi que la collaboration
entre elles. Toutefois, pour une performance optimale, centraliser les
informations devient aujourd'hui incontournable. Ceci consiste à
regrouper toutes les données sur un serveur central, et les rendre
accessibles à tous, partout et à tout moment.
C'est dans cette optique que la Direction Provinciale des
Impôts du Katanga, ayant le souci d'améliorer la façon de
gérer les données d'une si grande entreprise qui gère le
portefeuille de l'Etat, la division d'informatique a mis sur pied un projet qui
consiste à centraliser les données de ses différentes
succursales et d'avoir une vue en temps réel sur toutes ces
données distants.
En regroupant ces informations sur un cloud, la DPI pourra
mieux les surveiller et garantir leur intégrité. Cela permettra
également à la DPI de minimiser la perte potentielle de
données.
La figure ci-dessous, présente le système
d'interconnexion des succursales à l'architecture centralisée
cloud privé de la DPI.
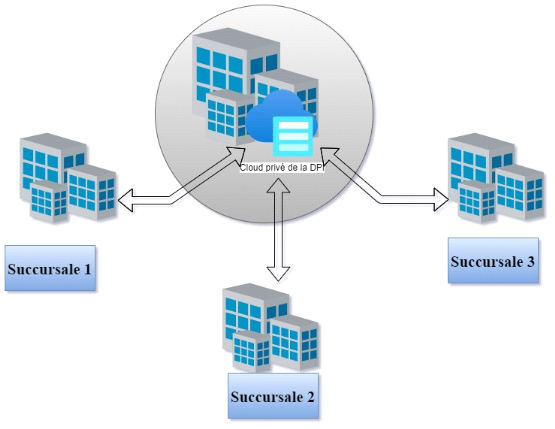
Figure 2. 5 Architecture du
système centralisé de la DPI
2.3 Optimisation de la haute
disponibilité du système de stockage
Dans cette partie du travail, il sera question d'optimiser le
système de stockage cloud computing, en mettant en place un
mécanisme qui garantirait la continuité de service dans
l'architecture cloud de la Direction Provinciale des Impôts du
Katanga.
2.3.1 La haute
disponibilité
La haute disponibilité est l'action d'anticiper les
difficultés que pourrait rencontrer un utilisateur dans le
réseau. Cela permettra de mettre en place des actions et des
paramètres techniques, pour qu'une infrastructure informatique soit
toujours en mesure de répondre à la requête d'un
utilisateur. [7]
Le terme "disponibilité" désigne la
probabilité qu'un service soit en bon état de fonctionnement
à un instant donné.
Le terme « continuité de service », parfois
également utilisé, désigne la probabilité qu'un
système soit en fonctionnement normal sur une période
donnée.
La disponibilité s'exprime la plupart du temps sous la
forme de taux de disponibilité, exprimé en pourcentage, en
ramenant le temps de disponibilité sur le temps total. Le tableau
suivant présente le temps d'indisponibilité sur une base d'une
année (365 jours) en fonction du taux de disponibilité :
Tableau 2. 1 La haute
disponibilité des données
|
Taux de disponibilité
|
Durée d'indisponibilité
|
|
97%
|
11 jours
|
|
98%
|
7 jours
|
|
99%
|
3 jours et 15 heures
|
|
99,9%
|
8 heures et 48 minutes
|
|
99,99%
|
53 minutes
|
|
99,999%
|
5 minutes
|
|
99,9999%
|
32 secondes
|
2.3.2 Stratégie
permettant la haute disponibilité
2.3.2.1 Le clustering
Un cluster est un groupe de ressources, telles que des
serveurs. Ce groupe agit comme un seul et même système. Il affiche
ainsi une disponibilité élevée, voire, dans certains cas,
des fonctions de traitement en parallèle et d'équilibrage de la
charge. On parle ainsi de gestion en cluster (clustering).
Il existe deux types d'utilisation pour le cluster :
Ø Le calcule distribue ici on utilise la puissance de
calcul de toutes les machines afin de réaliser de grandes
opérations arithmétiques.
Ø La haute disponibilité elle a pour but de
favoriser la continuité de service.
Dans ce cas toutes les machines physiques ne forment qu'une
machine logique et le gestionnaire de cluster gère le basculement en cas
de panne d'un noeud.
La figure ci-dessous présente l'architecture type d'un
système cloud computing clustérisé.
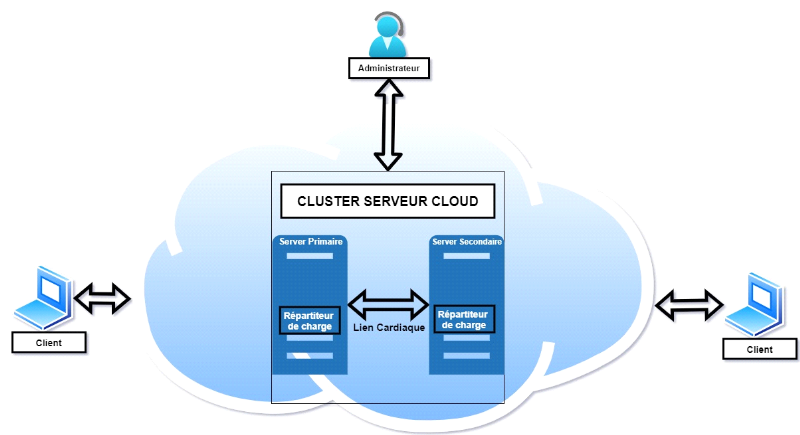
Figure 2. 6 Système de
clustering cloud
Après avoir ressortit l'architecture de notre
système de clustering voici l'ensemble de modules qui le composent :
Ø Cluster serveur Cloud : Permet de
grouper les serveurs cloud pour qu'ils fonctionnent comme un seul et même
système afin de garantir la disponibilité.
Ø Serveur cloud (serveur de stockage)
: Module clé de notre architecture qui Prend avant tout en
charge toutes les données enregistrées sur le réseau.
Grâce à ces serveurs, les utilisateurs présents sur un
réseau n'ont plus besoin de déplacer des données pour
échanger des fichiers.
Ø Client : Est un utilisateur final
ayant de moins de privilège, depuis lequel les demandes sont
envoyées vers le serveur SIP.
Ø Administrateur : Décrit un
utilisateur final connecté au réseau interne ayant un
privilège élevé lui permettant ainsi d'ajouter, de
supprimer un utilisateur et d'accomplir différente configuration sur le
serveur.
Ø Répartiteur de charge : Ce
module permet de repartir les demandes en les distribuant automatiquement aux
serveurs disponibles.
2.3.2.2 Failover service
Le failover, ou basculement est un mode de fonctionnement de
secours qui consiste à basculer automatiquement sur une base de
données, un serveur ou un réseau placé en attente si le
système principal tombe en panne ou est arrêté le temps
d'une maintenance. Le failover est une fonction extrêmement importante
sur les systèmes critiques qui doivent rester accessibles à
chaque instant. La fonctionnalité de failover redirige de manière
transparente toutes les requêtes au système injoignable vers le
système de secours, lequel imite l'environnement du système
initial.
Le failover peut s'appliquer à n'importe quel aspect
d'un système :
Ø Sur un ordinateur personnel ou un appareil mobile, un
déclencheur matériel ou logiciel peut protéger l'appareil
lorsqu'un composant (par exemple le processeur ou même une cellule de
batterie) tombe en panne.
Ø Au sein d'un réseau, un failover peut
s'appliquer à n'importe quel composant individuel du réseau, ou
bien à un ensemble de composants formant un système, par exemple
un chemin de connexion, un périphérique de stockage ou bien un
serveur Web.
Ø Avec une application Web ou une base de
données hébergée, le failover permet à plusieurs
serveurs en local ou dans le cloud de maintenir une connexion constante et
sécurisée, avec peu ou pas d'interruption de service.
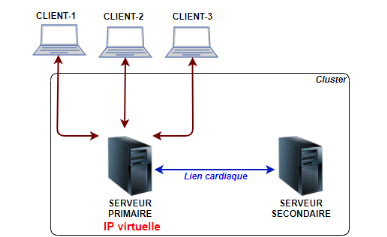
Figure 2. 7 Cluster de
basculement
2.3.2.3 Répartition de charge
Une technique qui permet de à la fois de
répondre à une monté en charge d'un service en distribuant
les requête sur plusieurs serveurs, et de réduire
considérablement l'indisponibilité de ce service que pourrait
provoquer la panne logiciel ou matérielle d'un unique serveur.
Les répartiteurs de charge utilisent différents
algorithmes pour gérer le trafic. Leur but est de repartir
intelligemment la charge et d'optimiser L'utilisation de l'ensemble des
serveurs du cluster.
Voici les algorithmes de répartition de charge :
Ø Round-robin (répartition de charge
équitable) : Le Round-robin permet de repartir la requête à
tour de rôle à chaque Serveur, quels que soient le nombre actuel
de connexions. Cet algorithme est adapté si les serveurs du cluster
disposent des mêmes capacités de traitement ; sinon, certains
serveurs risquent de recevoir plus de requêtes qu'ils ne peuvent en
traiter tandis que d'autres n'utiliseront qu'une partie de leurs ressources.
Ø Weighted Round-robin (répartition de charge
pondérer): Un algorithme Weighted Round-robin prend en compte la
capacité de traitement de chaque serveur. Les administrateurs affectent
manuellement un coefficient de performance à chaque serveur et une
séquence d'ordonnancement est générée
automatiquement en fonction de cette valeur. Les demandes sont ensuite
affectées aux différents serveurs selon une séquence de
répétition alternée.
Ø Least-connection (répartition de charge selon
la moindre connexion) : Envoie des demandes aux serveurs d'un cluster en
fonction de celui qui sert actuellement le moins de connexions
Ø Load-based (répartition basée sur la
charge) : Envoie les demandes aux serveurs d'un cluster en fonction de celui
dont la Charge est actuellement la plus faible.
2.3.2.4 Schéma logique de load-balancing
Ce schéma illustre la façon dont les
mécanismes de l'équilibrage de charge seront appliqués
dans notre solution. Nous allons utiliser l'algorithme de round-robin qui fait
la répartition égale de requêtes et la méthode du
routage direct. Pour simplifier le schéma et sa compréhension,
nous allons utiliser que deux postes clients.
Figure 2. 8 Schéma
logique de load-balancing
2.4 Choix de la technologie
cloud computing
2.4.1 Critère de
choix
Les choix des différentes solutions technologiques ne
seront pas faits de façonarbitraire, nous allons faire recours à
la première partie de notre travail et plus précisémentau
niveau des spécifications des besoins non fonctionnels, ces
dernières vont constituer notre critère de choix pour
différentes solutions technologiques.
Ø Coût (C1) :nous voyons
une solution efficace pouvant être implémentée avec un
budgetminimum.
Ø Fiabilité des services
() :ici on voit la probabilité de défaillance
moindre pendantlefonctionnement ;
Ø Disponibilité des services
(C3) :capacité du système a fonctionné avec
une haute disponibilité ;
Ø Portabilité (C4) :sa
capacité à pouvoir être adapté plus ou moins
facilement en vuede fonctionner dans différents environnements
d'exécution.
Ø Installation (C5) :ici nous
voyons la simplicité d'installation.
Ø Sécurité (C6) :
ici nous voyons l'authentification, la confidentialité et
l'intégrité des informations échangées.
2.4.2 Présentation des
solutions proposées
Le choix de la solution Cloud computing doit également
répondre aux besoins fondamentaux de notre système, ainsi ce
choix se fera parmi les quatre solutions proposé suivantes :
Ø CentreStack
Ø SharePoint
Ø OwnCloud
Ø Hightail
A)SharePoint
Partage et visualisation des applications et des postes de
travail, outils d'annotation, messagerie instantanée, diapositives web
et tableaux blancs.[12]
Les produits SharePoint utilisent le moteur
d'exécution ASP.NET, le serveurweb Internet Information Services (IIS),
et le système de gestion de base dedonnées SQL Server, de
Microsoft. Tout type de document peut y être stocké.
SharePoint est très utile si les employés de
votre entreprise travaillent à distance,s'ils sont
souvent en déplacement. Cet outil est aussi pertinent si les
employés ont besoind'utiliser différents appareils et
d'accéder à du contenu, ou si des documents
doiventrégulièrement être partagés avec les
clients.
La plateforme permet d'accéder à du contenu
à distance, depuis n'importe quelappareil connecté à
internet, même en déplacement, et sans avoir à utiliser de
supportsphysiques tels que les clés USB. De cette façon, les
employés peuvent gagner enproductivité.
v Avantages
§ Offre une accessibilité au cloud.
§ Il existe des fonctions d'accès mobile.
§ Il existe des options de médias sociaux
disponibles
§ Permet l'intégration de MS Office.
§ Les options de sécurité sont bien
meilleures.
v Inconvénients
§ Il existe des mises en garde contre la
personnalisation.
§ Les options de recherche nécessitent beaucoup de
personnalisation interne.
§ Les réseaux sociaux sont séparés
du reste de l'intranet.
§ Les fonctions des sites Web publics ne sont plus prises
en charge.
§ Les applications disponibles sont difficiles à
utiliser et sont souvent isolées et lourdes.
§ Il ne peut pas être déployé dans un
petit environnement.
B)OwnCloud
OwnCloud offre une solution aux organisations qui doivent
partager des données confidentielles en interne et en externe. La
plateforme ouverte permet d'améliorer la productivité et la
sécurité grâce à la collaboration numérique.
De plus, elle permet aux utilisateurs d'accéder aux données, quel
que soit l'emplacement des données ou l'appareil utilisé.[13]
OwnCloud est avantageux pour les secteurs d'activité
qui traitent des données sensibles ou qui doivent respecter une
réglementation spéciale en matière de
sécurité et de conformité. Parmi ces secteurs figurent les
finances, les soins de santé, etc.
v Avantages
§ Les données sont stockées en interne ou
sur un serveur externe selon le choix de l'entreprise.
§ Les risques de piratage ou de perte de données
se réduisent considérablement.
§ Seules les personnes autorisées auront
accès aux données.
v Inconvénients
§ L'installation d'OwnCloud demande des petites
compétences informatiques, similaires à l'installation d'un CMS,
comme savoir utiliser FileZilla ou une base de données MySQL. En gros,
si vous savez installer WordPress, vous pouvez installer OwnCloud.
§ Vous êtes responsable de la
sécurité de vos données. Le paramétrage de la
sécurité demande certaines compétences et, par
conséquent, la sécurité d'OwnCloud est sous votre
responsabilité, ce qui signifie en général moins bien
cadrée que celle d'un Cloud géré par une
société privée.
C)Hightail
Hightail permet de partager des fichiers, d'obtenir des
commentaires et de mener vos projets de la phase de conception à la
réalisation.[14]
Hightail facilite le partage de gros fichiers et propose des
fonctionnalités de collaboration et de gestion de projet conçues
pour les équipes marketing et leurs partenaires créatifs.
Les utilisateurs du service Hightail
téléchargent un fichier sur les serveurs de Hightail etles
destinataires reçoivent un lien où le fichier peut être
téléchargé. Les utilisateurspeuvent également
gérer des fichiers dans un système de dossiers en ligne, ou
créer desdossiers de bureau qui accèdent au stockage en ligne.
v Avantages
§ Autorisations basée sur les rôles
§ Alertes d'intrusions
§ fonctions d'accès mobile.
v Inconvénients
§ Difficile synchroniser les fichiers stockés dans
le cloud sur le lecteur de l'ordinateur local ;
§ Ne fournis pas d'aperçu du fichier.
D)CentreStack
Outil de partage et de synchronisation de fichiers avec
verrouillage de fichiers, gestion multi-locataires et fonctionnalités de
mappage de lecteur à distance. CentreStack stimule la mobilité de
la main-d'oeuvre avec le partage de fichiers dans le cloud et l'accès
mobile, tout en conservant les autorisations de sécurité et les
expériences utilisateur familières des serveurs de fichiers. Avec
Active Directory et les autorisations héritées, aucune autre
solution ne réunit mieux la sécurité sur site de
l'infrastructure informatique existante avec la mobilité dans le
cloud.[15]
v Avantages
§ Maintenir Active Directory, la sécurité
et les autorisations NTFS sur les fichiers et les dossiers.
§ Fournir une synchronisation et un partage en temps
réel avec des contrôles de version et de révision.
§ Fournir un accès à la demande qui
respecte les autorisations de lecture seule et d'écriture en temps
réel.
§ Mise en miroir des partages réseau locaux pour
Team Collaboration in the Cloud.
§ Fournir une fonctionnalité de mappage de lecteur
et de verrouillage de fichier pour les fichiers dans le Cloud.
§ Fournir un accès consolidé et une gestion
centralisée pour plusieurs bureaux/sites.
v Inconvénients
§ Difficile synchroniser les fichiers stockés dans
le cloud sur le lecteur de l'ordinateur local ;
§ Ne fournis pas d'aperçu du fichier.
Afin de caractériser chaque solution open source et
assurer le choix adéquat pour la construction d'une infrastructure
cloud, un sondage précis et expérimenté via la plateforme
Captera et en nous référant aux différents critères
de classification cités ci-haut, ce tableau nous permettra d'avoir une
image concrète sur la solution que nous utiliserons dans notre
travail.
Tableau 2. 2 La haute
disponibilité des données
|
Solutions
|
Coût
|
Fiabilité
|
Disponibilité
|
Portabilité
|
Sécurité
|
Total /5
|
|
Hightail
|
3
|
4
|
3,5
|
4,4
|
4
|
3,78
|
|
SharePoint
|
3,5
|
4
|
4,5
|
4
|
4
|
4
|
|
OwnCloud
|
4
|
3,2
|
4
|
4,5
|
4
|
3,94
|
|
CentreStack
|
4
|
4,5
|
5
|
4,5
|
5
|
4,6
|
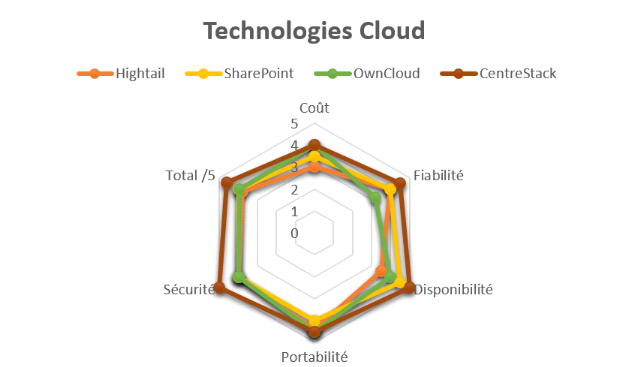
Figure 2. 9 Etude comparative
des solutions cloud
Notre choix est enfin fixé sur CENTRESTACK du fait
qu'il est celui qui
convient le mieux à nos besoins et permet
d'assurer la fonction du cryptage avancé, il est
plus convivial pour
l'utilisateur et il est un système robuste. Les solutions
de
synchronisation et de partage CentreStack offrent de meilleures
performances,
sécurité, contrôle et flexibilité
par rapport à la concurrence. Par exemple, les lecteurs
mappés
sur les clients Mac et Windows offrent une synchronisation à la demande
qui
est très efficace en bande passante, en particulier lorsqu'elle
est associée à des
technologies de mise en cache locales. La
plate-forme offre la flexibilité d'utiliser des
serveurs de fichiers
locaux ou un stockage cloud privé pour un contrôle et une
sécurité
améliorés. Et vous pouvez même
aller jusqu'à héberger vous-même
l'intégralité de lasolution pour un contrôle total. Avec
CentreStack, vous pouvez offrir toute l'utilité des solutions cloud
populaires tout en maintenant les niveaux traditionnels de contrôleet de
sécurité comme nous montre la figure et le tableau de comparaison
ci-dessus.
2.5 Présentation de
CentreStack
CentreStack est une solution d'accès mobile et de
partage de fichiers sécurisé. Il se différencie des autres
File Sync and Share solutions en se concentrant sur la sécurité
des données, les contrôles d'autorisation et les activations cloud
des serveurs de fichiers, y compris la protection des donnéeset la
migration vers le cloud.

Figure 2. 10 Logo
CentreStack
CentreStack est un logiciel pur construit sur la plate-forme
Web Microsoft :
Ø Serveur Windows,
Ø IIS (Internet Information Server) ;
Ø Framework .NET
Ø WCF1(*) (Windows Communication Foundation).
Etant donné que CentreStack est construit sur la
plate-forme Web Microsoft, ils'intègre très bien avec les
composants Microsoft tels que l'autorisation NTFS, ActiveDirectory et les
partages réseau du serveur de fichiers.Il fournit des
fonctionnalités d'accès et de partage de fichiers via des agents
clients pourPC, Mac, serveurs de fichiers, navigateurs Web et appareils
mobiles. Le logiciel de l'agentclient sur Windows et Mac fournit un
véritable mappage de lecteur et une prise en chargedu volume qui
contient de nombreuses façons d'optimiser le transfert de données
WAN(réseau étendu).[15]
2.5.1 Types de
déploiement
Les services peuvent être déployés dans
des combinaisons flexibles pour répondreà différents
besoins. Il existe deux manières principales de déployer la
solutionCentreStack.[15]
1. Déployer la solution CentreStack sur le même
réseau que le serveur de fichiers et le serveur Active Directory, dans
un mode de déploiement d'entreprise unique.
Figure 2. 11
Déploiement sur le même réseau
2. Déployez CentreStack dans un emplacement
centralisé, comme dans un centre de données Amazon ou un centre
de données Windows Azure, ou dans un centre de donnés où
les MSP (Managed Service Provider) ont leur infrastructure.
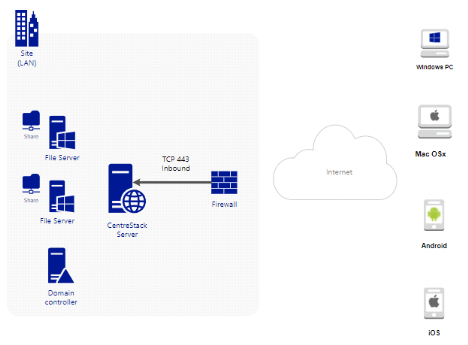
Figure 2. 12
Déploiement dans un emplacement centralisé
Nous prendrons le deuxième mode de déploiement,
il répond au mieux à notre recherche, mettre en place un stockage
centralisé où tous les succursales de la DPI pourront facilement
déposer leur fichiers sans pour autant se déplacer.
2.6Identification des acteurs
et leurs interactions dans le système
Dans cette partie du travail, nous allons définir
différents acteurs agissant sur notre système ainsi que leurs
besoins fonctionnels et non fonctionnels.
Comme nous travaillons sur la mise en place d'un Cloud
privé interne ou les services sonthébergés et
gérés par l'entreprise, les acteurs principaux sont :
v L'administrateur :L'administrateur
réseaux est garant du bon fonctionnement et de la qualité
du réseau de l'entreprise. Il participe à son
évolution et pilote l'accès aux utilisateurs.[16]
v L'agent :Est toute personne physique de
l'entreprise ayant reçu un compted'accès.
2.6.1 Identification des
besoins fonctionnels et non fonctionnels
2.6.1.1 Les besoins fonctionnels
Selon notre système et la nature des acteurs, le
système devra répondre aux besoins
fonctionnels suivants :
v L'administrateur :
§ La gestion des comptes :
création et modification des comptes utilisateursen spécifiant
leurs privilèges.
§ La gestion de partage des fichiers :
envoi, modification et les associer lesfichiers aux groupes.
§ La gestion des groupes :
création, activation/désactivation des droits.
v L'agent :
§ Utilisation du compte : envois,
suppression et modification des messagesou des fichiers
2.6.1.2 Les besoins non fonctionnels
Ces besoins caractérisent le système dont nous
citons :
§ Accès : accès à
la ressource est facile à travers un tableau de bord via unnavigateur
§ Performance : répond aux
différents besoins fonctionnels
§ Disponibilité : application
disponible à l'usage à tout moment
2.6.2 Diagramme
d'activité du future système
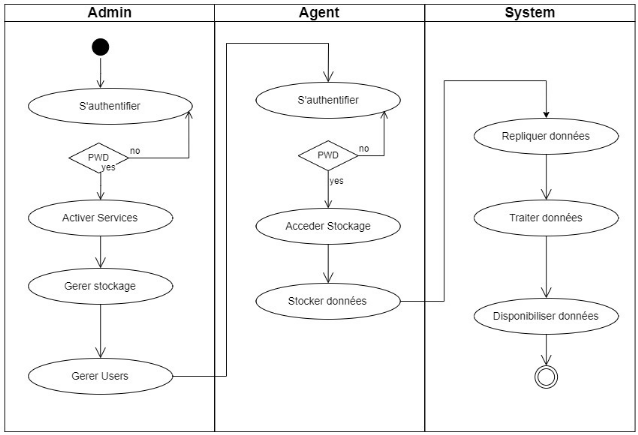
Figure 2. 13 Diagramme
d'activité
2.7 Conclusion partielle
Ce chapitre nous a permis de mettre en évidence les
différents modules qui constituent notre système, de
décrire l'architecture qui permet de déployer notre solution et
également de décrire la solution choisie pour pallier aux
problèmes posés.
Il a été aussi question dans ce chapitre de
passer par une phase d'analyse et de conception. Ainsi, nous avonsconçu
le diagrammed'activité pour comprendre l'interaction des acteurs et le
système.
CHAPITRE 3 :
IMPLEMENTATION DE LA SOLUTION
Après avoir présenté dans les chapitres
précédents le système existant, ce chapitre constituera la
partie pratique de notre solution, ainsi nous décrirons toutes les
étapes de réalisation de notre système.
Nous aurons besoin d'un serveur, d'une base de données,
d'un pare-feu et bien évidemment de notre solution cloud computing.
· Windows Serveur : Il nous aidera
a utilisé les utilisateurs créés dans Active Directory
· MySQL : Il nous servira de base
de données où seront stockées nos données
· Un pare-feu qui servira de
barrière pour empêcher toute tentative d'intrusion dans le
système.
3.1Procédure et
planification
3.1.1. Le sommaire
Ø La procédure d'installation des outils
Ø La procédure de configuration du système
ou de l'application
Ø La procédure de teste de l'application
3.2.1.1. Procédure d'installation des outils
· Installation de l'hyperviseur VMware
Pour ce qui consterne l'outil de virtualisation VMware, son
téléchargement ainsi que son installation sont relativement
simples et n'exigent aucune connaissance supplémentaire pour y
parvenir.
Figure 3. 1 Installation de
l'hyperviseur VMware
· Installation du serveur
Nous nous passerons de différentes étapes de
l'installation de Windows server 2016vu que nous savons déjà
comment installer. Pour se faire, nous nousdirigeons dans le
Gestionnaire de serveur/Tableau de bord/Gérer/Ajouter des
rôleset des fonctionnalités puis ajouter le rôle
Web (IIS). Voici la progression de l'installationdu service IIS sur notre
serveur Windows ;
Figure 3. 2 Ajout du
rôle IIS au Serveur
· Installation du client
Pour notre système, nous avons choisi d'installer
Windows 10 pour sa simplicité dansl'installation et sa
facilitédansl'implémentation.
Figure 3. 3 Processus
d'installation du client
Figure 3. 4 Ouverture de la
session client Windows
· Installation de MySQL
Cette étape nous permet de choisir le type de server de
base donnée MySQL qu'onveut installer, son protocole utilisé et
son numéro de port.
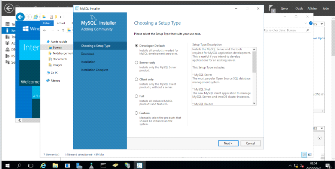
Figure 3. 5 Choix du type de
serveur de base de données MySQL
Après le choix du type de base de données, ici
l'installation et la configuration de la base de données ainsi que ses
composantssont vérifiés afin que le fonctionnement soit
correct.
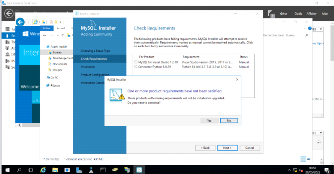
Figure 3. 6
Vérification des composants MySQL
Nous passons à présent à l'installation
de la base de données ainsi que de quelques outils
supplémentaires.
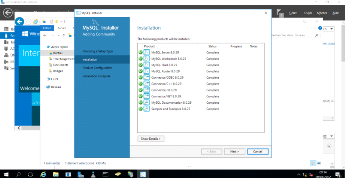
Figure 3. 7 Installation de
MySQL
Après l'installation de la base de données, nous
devons à présent ajouter les utilisateurs de cette
dernière.
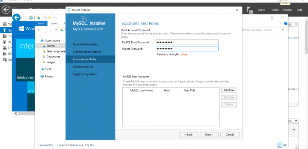
Figure 3. 8 Ajout de
l'utilisateur MySQL
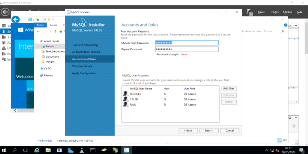
Figure 3. 9 Utilisateurs
ajoutés
Nous allons laisser le modeStandalone MySQL / Classic
MySQL Replication activé et cliquez sur Suivant :
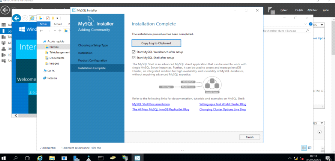
Figure 3. 10 Choix du mode de
réplication
Ensuite on teste la connexion à l'interface graphique
de notre base de données MySQL.
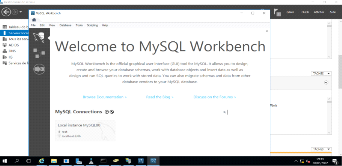
Figure 3. 11 Interface
graphique MySQL
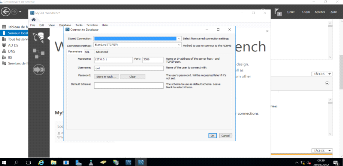
Figure 3. 12 Test de connexion
à MySQL
Figure 3. 13 Page de connexion
MySQL
· Installation de CentreStack
Pour l'implémentation de notre application, notre choix
s'est porté sur l'outil CentreStack dont le téléchargement
ainsi que l'implémentation s'avère très simple et
facile.
En cliquant sur l'exécutable de CentreStack, la base de
données MySQL s'initialiseautomatiquement afin d'avoir un bon
fusionnement entre la base de données et le Cloud.
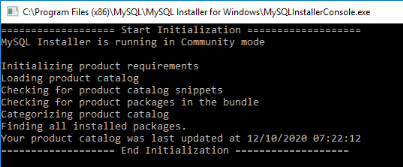
Figure 3. 14 Initialisation
automatique de MySQL
Une fois le processus d'initialisation fini l'interface
d'installation s'affiche et oncontinue en cliquant sur suivant. Nous signalons
que tout installation de la base de donnéeset de notre Cloud CentreStack
doivent se faire en ligne pour des raisons d'installation dequelques packages
ainsi de certaine mise à jour.
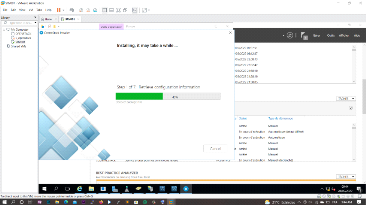
Figure 3. 15 Installation de
CentreStack
Après l'installation de notre application Cloud, nous
devons nous authentifier pour accéder à l'interface webde notre
application et nous verrons aussi quelquesonglets du tableau debord :
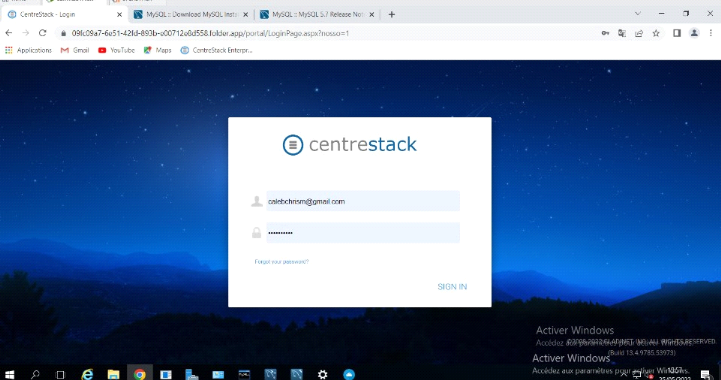
Figure 3. 16 Interface
d'authentification de CentreStack
Figure 3. 17 Tableau de bord
de CentreStack
· Installation utilisateurs CentreStack
Les utilisateurs peuvent accéder aux fichiers cloud de
CentreStack à l'aide de n'importe quel appareil de leur choix, car
CentreStack propose des clients pour Windows, Mac, iPhone, iPad, Android,
Windows 8+, etc.
Dans notre travail, nous nous baserons sur le client Windows
et Android
a. Utilisateur Windows
Normalement, sur une machine de type serveur Windows telle que
2003/2008/2012/2016, utilisez l'agent serveur au lieu de l'agent client.
Cependant, l'agent client peut également
s'exécuter en tant qu'application de bureau sur le système
d'exploitation Windows Server. Par exemple, si vous prévoyez
d'exécuter l'agent de bureau dans un environnement Terminal Server, vous
devez installer l'agent de bureau au lieu de l'agent de serveur.
Figure 3. 18 Interface
CentreStack du Client Windows sur Windows server
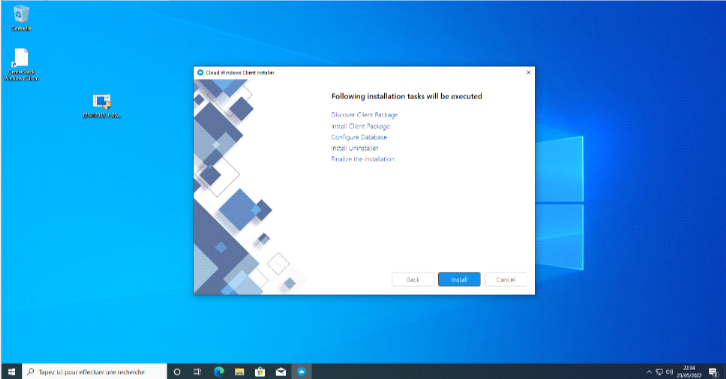
Figure 3. 19 Interface
d'installation côté Windows client
A la fin de l'installation, vous serez invité à
saisir les informations d'identification de votre compte utilisateur. Ces
informations d'identification autoriseront votre client Windows puis le
connectera à votre compte d'utilisateur CentreStack.
b. Utilisateur Android
CentreStack a créé une application Android
native que nouspouvons télécharger depuis le Google Play Store.
Cela permet d'accéder aux fichiers et dossiers de notre compte
CentreStack.
L'application Android CentreStack en marque blanche
appelée "Cloud Android Client"peut être distribuée par les
fournisseurs de services et les entreprises à leurs utilisateurs.

Figure 3. 20 Installation de
CentreStack sur Android

Figure 3. 21 Interface
d'authentification CentreStack sur Android
Figure 3. 22 Interface du
client Android
3.2.1.2. Procédure de configuration du
système ou de l'application
· Configuration du compte administrateur
Après le redémarrage de la machine, la page de
configuration de l'administration par défaut s'affiche.
Tout d'abord, configurez le compte administrateur du
cluster.
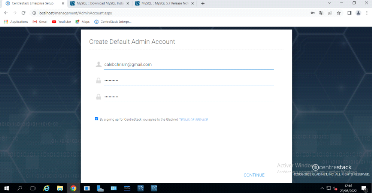
Figure 3. 23 Configuration du
compte Administrateur du cluster
Après avoir configuré le compte de
l'administrateur du cluster, le tableau de bord de l'administrateur du cluster
apparaîtra par défaut.
· Création et importation des utilisateurs Active
Directory
Cette étape consiste à importer les utilisateurs
déjà créés dans l'annuaire dans le but de tout
centraliser, c'est à dire se servir du contrôleur de domaine ainsi
que des services du contrôleur de domaines pour mieux gérer les
utilisateurs. Ici on clique sur le menu tableau de bord du locataire puis
ajouter un nouvel utilisateur en suite cliqué sur le triangle montrant
le domaine.
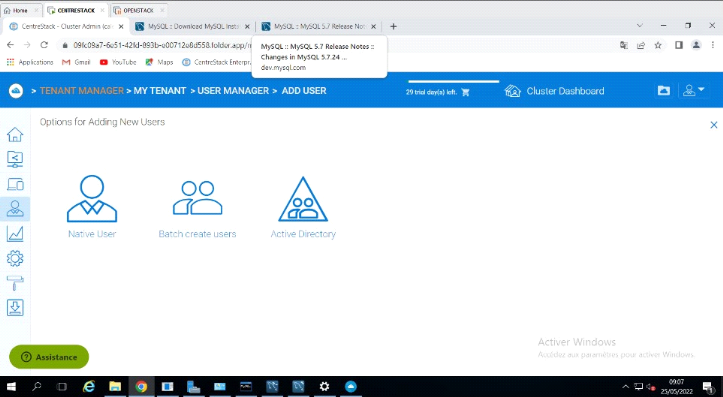
Figure 3. 24 Interface
d'importation Active Directory
Sélectionner l'option « Browse » sur le
deuxième nom complet « Users »
et « CONTAINER »
dans le but de voir les utilisateurs qu'on veut importer dans le
CloudCentreStack.
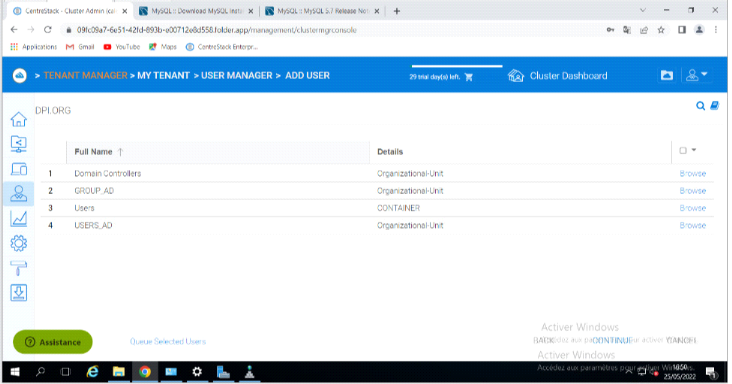
Figure 3. 25 Sélection
de l'option d'importation
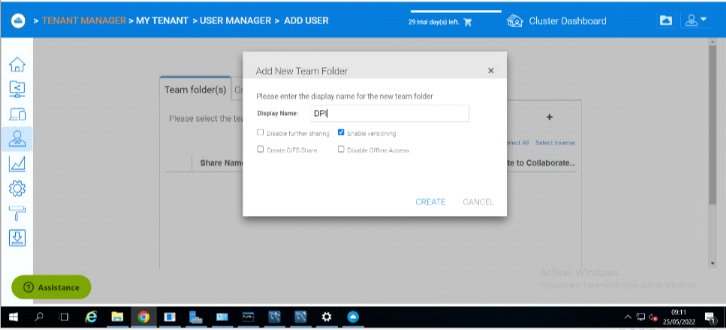
Figure 3. 26 Création
de l'utilisateur Active Directory
La phase suivante donne la possibilité de donner
accès aux utilisateurs importésdans le Cloud à un dossier
particulier. Ces dossiers sont montrés sur la colonne « Nom
departage » et la colonne « invité à collaborer »
sont pour les utilisateurs qui auront accès.
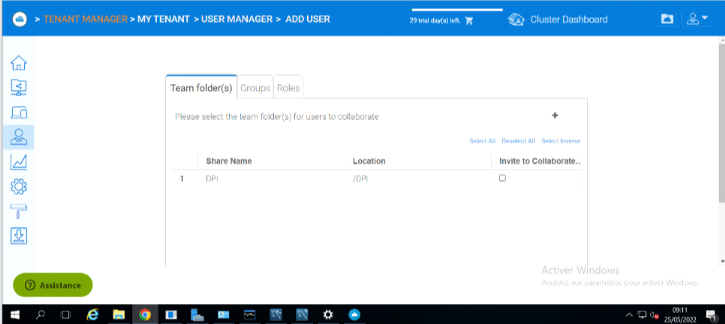
Figure 3. 27 Importation de
l'utilisateur créé
Nous voyons ici, l'utilisateur que nous venons d'importer de
l'annuaire versle Cloud CentreStack et chaque prénom ainsi que le nom du
user est affiché.
Figure 3. 28 Vue des
utilisateurs importés
3.2.1.3 La procédure de teste de l'application
Après avoir fini avec les installations et les
configurations en rapport avec notre système, dans cette section
l'objectif primordial serait de tester l'intégralité des
fonctionnalités afin de déterminer son bon fonctionnement.
Nous allons commencer par importer quelques fichiers du
serveur dans le dossier partagé de notre système dans ...
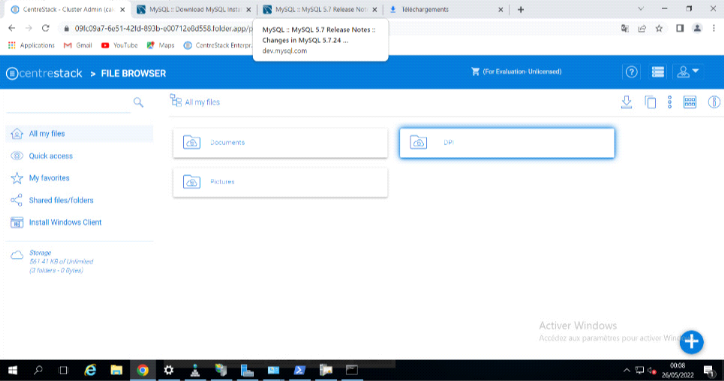
Figure 3. 29 Dossier
partagé
Du côté client Windows nous irons dans la
partition CentreStack, puis aller vérifier dans le dossier partager et y
déposer un fichier qui sera vu en temps réel dans le serveur.
Nous trouverons les fichiers partagés par le serveur.
Nous allons essayer d'uploader un fichier nommé
« TFC » et nous irons sur le serveur pour la
vérification.
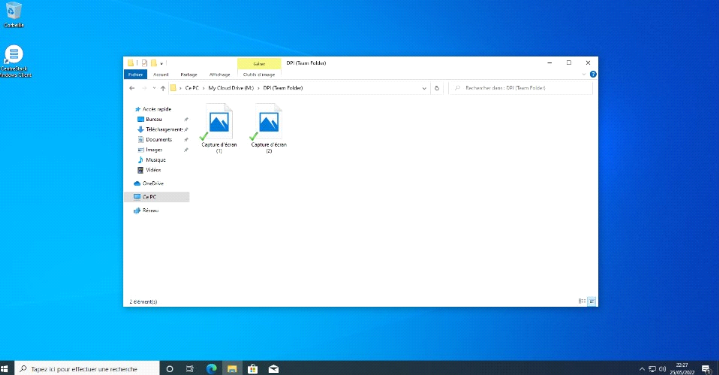
Figure 3. 30 Vue des fichiers
partagés
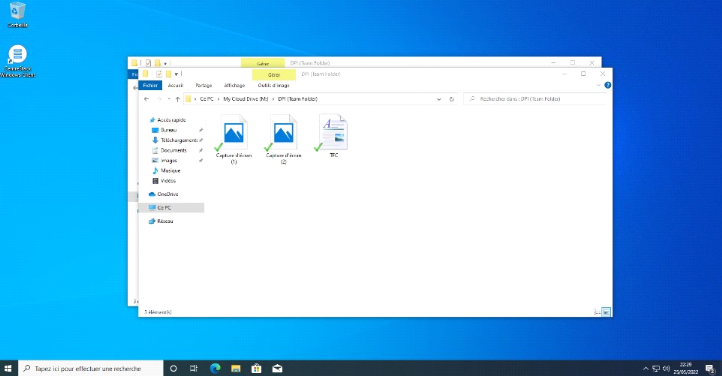
Figure 3. 31 Le fichier TFC
partagé
Nous allons nous diriger vers le serveur pour vérifier
si réellement si le fichier « TFC » est visible dans
notre cloud.
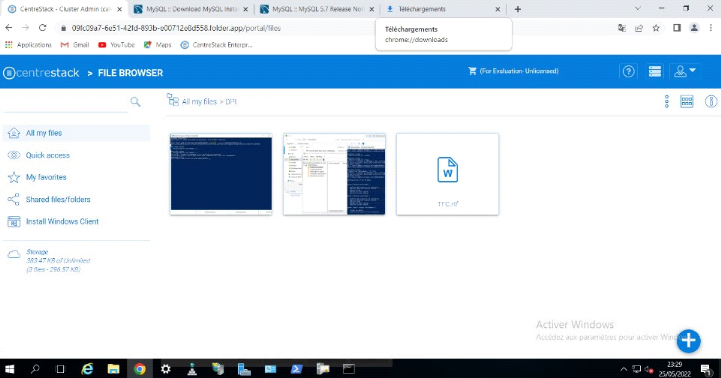
Figure 3. 32 Le fichier TFC
sur le Serveur Cloud
Nous allons cette fois ci essayer avec un utilisateur sur
Android et nous emporterons un fichier pour voir s'il sera
répertorié dans le serveur.
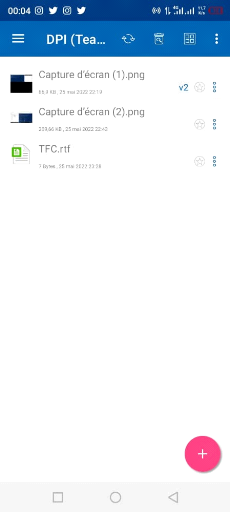
Figure 3. 33 Vue du contenu
cloud sur Android
Figure 3. 34 Sélection
des fichiers
Nous allons vérifier les fichiers emportés de
l'Android sur le serveur pour voir si les fichiers s'y trouvent.
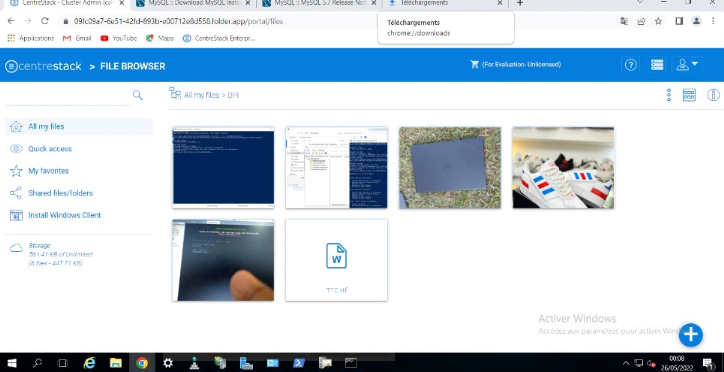
Figure 3. 35 Vue des fichiers
partagés par le client Android
3.2 Evaluation des
besoins
Les besoins fonctionnels tout comme les besoins non
fonctionnels ont été énoncésci-haut dans ce travail
[cf. chap.1]. C'est ainsi qu'en ce point nous allons faire uneévaluation
pour savoir s'ils ont été réalisés comme
énoncés et cela du point de vu desbesoins non fonctionnels et
celui des besoins fonctionnels.
3.3.1. Besoins non
fonctionnels
Tableau 3. 1 Besoin non
fonctionnel
|
Les besoins non fonctionnels
|
Id
|
Evaluation
|
|
Coût
|
C1
|
90 %
|
|
Fiabilité des services
|
|
95 %
|
|
Disponibilité des services
|
C3
|
95 %
|
|
Portabilité
|
C4
|
99 %
|
|
Installation
|
C5
|
97 %
|
|
Sécurité
|
C6
|
90 %
|
|
Moyenne
|
|
98%
|
Après cette évaluation, nous avons
remarqué d'après le tableau ci-haut, que nousn'avions pas atteint
100% de nos besoins non fonctionnels, mais cela pour plusieursraisons par
rapport aux réalités rencontrée durant l'exécution
de ce projet, et n'étant pasparfait, comme nous le disons toujours que
nul n'est parfait, donc la perfection ne serajamais atteinte. Raison pour nous
de se retrouver à la fin avec une moyenne de 87% quidépasse
néanmoins les trois quarts des objectifs fixés aux
préalable ; ce qui est acceptablepour nous comme moyenne par rapport
à nos objectifs fixés dans ce travail.
3.3.2 Les Besoins
fonctionnels
Tableau 3. 2 Besoins
fonctionnels
|
Les besoins fonctionnels
|
ID
|
Evaluation
|
|
Un système de partage et
d'enregistrement
|
Fonct_1
|
98 %
|
|
Une interface de navigation facile à
manipuler
|
Fonct_2
|
96 %
|
|
Un espace de stockage évolutif et
sécurisé
|
Fonct_3
|
97 %
|
En ce qui concerne les besoins fonctionnels, comme cela peut
être constaté dans
le tableau ci-haut, nous avions pu
réaliser au moins tous ce qui devrait être par rapport
aux
grands points du projet, et après l'implémentation de notre
solution, les besoins
fonctionnels ont répondu favorablement à
nos préoccupations.
3.4 Conclusion partielle
Ce chapitre marque la fin de notre travail, il nous a permis
de montrer la réalisation de la solution, nous avons mis en pratique
tous les concepts théoriques et les connaissances nécessaires en
vue de parvenir à la matérialisation de notre conception
technique. Ainsi nous pourrons dire que nous avons réussi à
concrétiser notre idée.
CONCLUSION GENERALE
Nous voici en fin arrivés à terme de notre
travail qui marque la fin de notre cursus académique, qui a parlé
de l'étude et la mise en place d'une plateforme cloud computing
sécurisée au sein d'une institution publique. Nous avons choisi
comme cas d'application la Direction Provinciale des Impôts (DPI). Il a
été question de mettre en place un système de stockage
garantissant une haute disponibilité au sein de la direction Provinciale
des Impôts du Katanga.
Nous avons commencé par faire l'étude du
système existant qui nous a permis de maitriser le système et les
stratégies mises en place en matière de stockage des
données. Al'issu de cette étude, l'étape liée
à la spécification des besoins était faiteafin de
ressortir les différentes fonctionnalités techniques attendues de
notre système,traduites sous forme des besoins fonctionnels et non
fonctionnels à l'utilisation dusystème et ayant servies de
critères de choix des solutions ; ce qui constituent le cahierde charge
fonctionnelle de notre système, qui a même fait l'objet du
chapitrepremier.
Dans le second chapitre, nous avons fait une étude
assez approfondie sur la notion du cloud computing qui constituent même
le pilier de notre système, de décrire l'architecture qui permet
de déployer notre solution et également de décrire la
solution choisie pour pallier aux problèmes posés.
Il a été aussi question dans le chapitre deux de
passer par une phase d'analyse et de conception. Ainsi, nous avonsconçu
le diagrammed'activité pour comprendre l'interaction des acteurs et le
système.
Quant au dernier chapitre, il a été question de
montrer pas à pasl'implémentation de ladite solution du
début jusqu'à la fin. Et parla suite, nous avons effectué
un ensemble des configurations et des testspour cette implémentation du
système qui garantit la disponibilité de données
même en état de mobilité et sécurise l'accès
aux données pour les utilisateurs, ainsi chaque utilisateur a droits
seulement aux données qui lui seront assignées soit dans un
dossier partagé ou encore dans un canal privé.
Perspectives d'avenir
Comme nous le savons tous, toutes oeuvres humaines n'a jamais
de perfection. C'est ainsi qu'après réalisation du travail, nous
devons évaluer notre travail et parler de ses limites pour envisager les
perspectives d'avenir.
Pour notre système nous nous sommes juste
limités sur l'implémentation d'une haute disponibilité de
l'espace de stockage utilisant la technologie CentreStack. Ainsi nous laissons
la possibilité à toute autre personne de continuer les recherches
sur la création des différentes instances d'une manière
automatique avec l'outil d'administration PowerShell etl'intégration
d'autres systèmes de stockage existants.
BIBLIOGRAPHIE
|
[1]
|
[En ligne]. Available:
https://www.dgi.gouv.cd/fr/les-reformes-la-direction-generaledes-impots-brefhistorique#:~:text=Sur%20proposition%20du%20commissaire%20aux,la%20mobilisation.
[Accès le 10 Sepembre 2021].
|
|
[2]
|
I. c. office, Technique de Sécurité - Extension
d'ISO/IEC 27001 et ISO/IEC 27002 - Exigence et lignes directrices, Suisse: iTeh
STANDARD PREVIEW, 2019.
|
|
[3]
|
[En ligne]. Available:
https://stph.scenari-community.org/escom-bd/web/co/acc1c12.html. [Accès
le 23 Avril 2022].
|
|
[4]
|
[En ligne]. Available:
https://www.ionos.fr/digitalguide/serveur/outils/apercu-desalternatives-a-microsoft-access/.
[Accès le 23 Avril 2022].
|
|
[5]
|
[En ligne]. Available:
https://www.pcastuces.com/pratique/windows/fiches/duree_vie_cd_dvd.htm.
[Accès le 23 Mars 2022].
|
|
[6]
|
D. A. Richard Monson, Java Message Service, Paris: O'REILLY,
2002.
|
|
[7]
|
[En ligne]. Available:
https://blog.blaisethirard.com/tag/prive/. [Accès le 14 Mars 2022].
|
|
[8]
|
B. THIRARD. [En ligne]. Available:
https://blog.blaisethirard.com/tag/prive/. [Accès le 14 Juin 2022].
|
|
[9]
|
[En ligne]. Available:
https://www.redhat.com/fr/topics/cloud-computing/public-cloud-vs-private-cloud-and-hybrid-cloud#:~:text=Il%20existe%20quatre%20principaux%20types,as%2Da%2DService)..
[Accès le 13 Juin 2022].
|
|
[10]
|
[En ligne]. Available:
https://cloudcomputing923729653.wordpress.com/2018/07/19/diferencias-entre-servicios-iaas-paas-y-saas/.
[Accès le 11 Juin 2022].
|
|
[11]
|
L. Mathurin, MISE EN PLACE D'UNE PLATEFORME CLOUD DE GESTION
DE, Lubumbashi: ESIS, 2019.
|
|
[12]
|
[En ligne]. Available:
https://support.microsoft.com/fr-fr/office/qu-est-ce-que-sharepoint-c17b6824-cc22-478f-8757-497cc6b57121.
[Accès le 11 Juin 2022].
|
|
[13]
|
C. M. Gavin Kennedy, Accelerating CloudStor Storage
Performance, AARNet Cloud Services.
|
|
[14]
|
[En ligne]. Available:
https://hightail.zendesk.com/hc/en-us/articles/224518527-Introduction-to-Hightail-.
[Accès le 11 Juin 2022].
|
|
[15]
|
Gladinet, CentreStack Administration Guide, Fort Lauderdale,
États-Unis: gladinet, 2021.
|
|
[16]
|
[En ligne]. Available:
https://www.apec.fr/tous-nos-metiers/informatique/administrateur-reseaux.html#:~:text=L'administrateur%20r%C3%A9seaux%20est%20garant,pilote%20l'acc%C3%A8s%20aux%20utilisateurs..
[Accès le 11 Juin 2022].
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
* 1 WCF : est un
sous-système de communication de Windows Vista.
| 

