|

Ministère de l'enseignement
supérieur
et de la Recherche Scientifique

2019/2021
Département Informatique
Mémoire de Projet de Fin d'Etudes
Présenté pour l'obtention du
Diplôme National de Mastère
professionnel
Mention Cybersécurité
Réalisé par :
Joseph DEMBELE
Intitulé :
Sujet : Mise en place d'un système de gestion
centralisé des logs et des
évènements « SIEM
»
Encadré Par :
Mr Nizar BEN NEJI Université Centrale Encadreur
Universitaire
Mr Bilel ARFAOUI Auditeur Cybersécurité Encadreur
Industriel
|
Dédicaces
Avec l'expression de ma reconnaissance, je dédie ce
modeste travail à la mémoire
de mon père disparu trop
tôt.
A ma chère mère Agathe qui a souffert sans me
laisser souffrir et dont le mérite,
les sacrifices et les
qualités humaines m'ont permis de vivre ce jour.
A mes chers
frères et soeurs pour leur grand amour et leur soutien qu'ils
trouvent
ici l'expression de ma haute gratitude
A tous mes proches et
tous ceux qui, de près ou de loin, m'ont apporté
leurs
sollicitudes pour accomplir ce travail.
|
II
REMERCIEMENTS
Après avoir rendu grâce à Dieu le Tout
Puissant, je tiens à remercier vivement
tous ceux de près ou
de loin ont participé à la rédaction de ce document. Je
tiens
à remercier mes parents, je remercie le personnel de l'Agence
Nationale de la
Sécurité Informatique (ANSI) pour
l'expérience enrichissante et pleine d'intérêt
qu'ils
m'ont fait vivre durant ma période de stage.
Je tiens à
remercier vivement mon maitre de stage, Mr Bilel ARFAOUI,
Auditeur cyber
sécurité au sein de l'ANSI, pour son accueil, le temps
passé
ensemble et le partage de son expertise au
quotidien.
J'exprime mes profonds remerciements au Dr. Nizar Ben NEJI, mon
encadreur
pour son assistance, ses directives, sa formation et ses conseils
précieux.
Je saisi cette occasion pour adresser mes profonds
remerciements aux
responsables et aux personnels de l'Université
Centrale (Ecole Centrale
d'informatique et de
Télécommunications).
Un grand merci à ma famille, pour
leurs conseils ainsi que leur soutien
inconditionnel, à la fois moral
et économique.
III
IV
Table des matières
INTRODUCTION GENERALE 1
CHAPITRE I - ETAT DE L'ART 5
1 Cybersécurité 5
1.1 Définition 5
1.2 Objectifs de la sécurité informatique 6
1.3 Services principaux de la cybersécurité 6
2 Cyberattaques 7
2.1 Différents types de cyberattaques les plus courants
7
2.2 Conséquences d'une cyberattaque 7
3 Security Operations Center (SOC) 9
3.1 Définition 9
3.2 Modèles de SOC 9
3.3 Comment fonctionne un SOC 10
4 Security Information and Event management (SIEM) 11
4.1 Fonctionnement 11
4.2 Solutions disponibles 12
4.3 Etude comparative des solutions 13
4.4 Critères de choix des solutions SIEM 15
4.5 Choix de la solution et justification 15
4.6 Architecture de la solution 15
4.7 Critères techniques de la solution 18
CHAPITRE II : REALISATION 21
1 Environnement de travail 21
1.1 Environnement matériel 21
1.2 Environnement logiciel 22
1.3 Présentation de la topologie 23
2 Installation d'Elastic Stack 24
2.1 Installation de Java 24
2.2 Installation d'Elasticsearch 25
2.3 Installation du tableau de bord Kibana 25
2.4 Installation de Nginx et httpd-tools 26
2.5 Installation de Logstash 26
2.6 Installation de Filebeat 26
3 Configuration de la pile Elastic 27
3.1 Configuration d'Elasticsearch 27
3.2 Configuration de Kibana 29
3.3 Configuration du chiffrement SSL 30
3.4 Configuration de Logstash 31
3.5 Configuration Nginx 33
3.6 Configuration de Filebeat 33
3.7 Installation des outils d'aide à la détection
des attaques 40
CHAPITRE III : TESTS ET EVALUATIONS 48
1 Prise en main et exploration des données sur Kibana
48
2 Visualisation des données 53
2.1 Création d'une visualisation sur Kibana 53
2.2 Création d'un tableau de bord (dashboard) 55
2.3 Exploration des tableaux de bord Kibana fournit par Filebeat
56
3 Scénarios d'attaque et détection des attaques
59
3.1 Attaque par brute force SSH 59
3.2 Attaque par Denis de service(DOS) 64
3.3 Attaques locales de types système 66
3.4 Attaque réseau : Scan des ports Nmap 69
3.5 Attaque de Brute force des répertoires d'un serveur
Web (Fuzzing Web) 72
3.6 Attaque par malwares 74
CONCLUSION ET PERSPECTIVES 78
REFERENCES 80
V
VI
Liste des Figures
Figure 1 : Architecture d'Elastic Stack 16
Figure 2 : Topologie de l'infrastructure
23
Figure 3 : Commande d'affichage de la version
de Java 24
Figure 4 : Variable d'environnement Java
24
Figure 5 : Affichage de la version de Java
25
Figure 6 : Fichier de configuration
Elasticsearch 27
Figure 7 : Fichier de configuration
Elasticsearch (suite) 28
Figure 8 : Réponse http de curl sur le
port Elasticsearch. 29
Figure 9 : Configuration du fichier
kibana.yml 29
Figure 10 : Génération des
clé SSL 30
Figure 11 : Copie du certificat Logstash vers
la machine cliente Ubuntu 31
Figure 12 : Fichier de configuration input de
Logstash 31
Figure 13 : Fichier de configuration filter
de Logstash 32
Figure 14 : Configuration du fichier output
de Logstash 32
Figure 15 : Génération du mot
de passe 33
Figure 16 : Configuration de Nginx pour le
reverse proxy 33
Figure 17 : Configuration du fichier
filebeat.yml sur CentOS 34
Figure 18 : Configuration de l'output vers
Logstash du fichier Filebeat sur CentOS 35
Figure 19 : Installation de Filebeat
côté client 35
Figure 20 : Configuration du fichier
filebeat.yml 36
Figure 21 : Configuration du fichier
filebeat.yml (Partie Kibana) 36
Figure 22 : Configuration du fichier
filebeat.yml (Partie Elasticsearch) 36
Figure 23 : Configuration du fichier
filebeat.yml (Partie Logstash) 37
Figure 24 : Téléchargement de
Winlogbeat sur Windows 37
Figure 25 : Configuration de Winlogbeat
(Partie Kibana) 38
Figure 26 : Configuration de Winlogbeat
(Partie Logstash) 38
Figure 27 : Exécution du fichier
d'installation des services Winlogbeat 39
Figure 28 : Interface de connexion web de
Kibana 39
Figure 29 : Interface des status de Kibana
40
Figure 30 : Configuration de la variable
HOME_NET 42
Figure 31 : Définition de l'interface
réseau dans le fichier suricata.yaml 42
Figure 32 : Définition de la variable
default-rule-path 42
Figure 33 : Vérification du GRO et du
LRO 43
Figure 34 : Test de la configuration de
Suricata 43
Figure 35 : Configuration du fichier de
configuration de Auditbeat output Elasticsearch 45
Figure 36 : Configuration du fichier de
configuration de Auditbeat output vers Logstash 45
Figure 37 : Création des
modèles d'index de Winlogbeat 48
Figure 38 : Page `Discover' de Kibana (index
filebeat) 49
Figure 39 : Page `Discover' de Kibana (index
Filebeat) 49
Figure 40 : Visualisation des logs sous forme
de table 50
Figure 41 : Filtrage des authentifications
réussies du 25/05/2021 51
Figure 42 : Paramétrage du
sélecteur de temps selon le mode "Relative" 51
Figure 43 : Paramétrage du
sélecteur de temps selon le mode "Absolute" 52
Figure 44 : Exemple de filtre de recherche
52
Figure 45 : Types de visualisation
disponibles dans Kibana 53
Figure 46 : Menu de sélection pour les
types de visualisation 54
Figure 47 : Première visualisation
créée 54
Figure 48 : Onglet de création d'une
nouvelle visualisation Kibana 55
Figure 49 : Première Dashboard
crée sur Kibana 55
Figure 50 : Liste des dashboards Filebeat
56
Figure 51 : Première partie du
dashboard de Suricata 57
Figure 52 : Deuxième partie du
Dashboard de Suricata 57
Figure 53 : Troisième partie du
Dashboard de Suricata 58
Figure 54 : Quatrième partie du
Dashboard de Suricata 58
Figure 55 : Manage detection rules 60
Figure 56 : Configuration de la règle
section "Define rule" 61
Figure 57 : Configuration de la règle
section "Define rule" 2 61
Figure 58 : Configuration de la règle
brute force SSH `About rule' 62
Figure 59 : Configuration de la règle
section "Schedule rule" 63
Figure 60 : Configuration de la règle
section "Actions" 63
Figure 61 : Aperçu de la règle
créée 63
Figure 62 : Attaque Brute force avec l'outil
Hydra 64
Figure 63 : Attaque par brute force SSH
détecté avec succès par Kibana 64
Figure 64 : Attaque DoS avec l'outil Hping3
sur Kali Linux 65
Figure 65 : Détection de l'alerte par
le dashboard Suricata 65
Figure 66 : Détails de l'attaque DoS
dans le dashboard 66
Figure 67 : Maps de localisation des IP de
l'attaque 66
Figure 68 : Chargement des règles par
défaut 67
Figure 69 : Activation de la règle
"Sudoers File Modification" 68
Figure 70 : Modification du fichier sudoers
68
Figure 71 : Alerte "Sudoers File
Modification" détecté par Kibana 68
Figure 72 : Activation de la règle
"Attempt to Disable IPTables or Firewall" 69
Figure 73 : Alerte pour la
désactivation du firewall 69
Figure 74 : Création de la
règle pour la détection de scan Nmap section "Define rule " 70
Figure 75 : Création de la
règle pour la détection de scan Nmap section "Schedule rule "
71
Figure 76 : Scan Nmap sur Kali Linux 71
Figure 77 : Alerte "Nmap scan Detected" 72
Figure 78 : Création de la
règle pour la détection du fuzzing web "Define rule" 73
Figure 79 : Création de la
règle pour la détection du fuzzing web "About rule" 73
Figure 80 : Attaque avec dirb sur notre
serveur web 73
Figure 81 : Détection de l'attaque
"Web Fuzzing Attack Detected" par Kibana 74
Figure 82 : Configuration de l'antivirus pour
Winlogbeat 74
Figure 83 : Création de la
règle pour la détection de malware 75
Figure 84 : Création de la
règle pour la détection de malware section "About rule" 75
Figure 85 : Création de la
règle pour la détection de malware section "Schedule rule" 76
Figure 86 : Détection du malware par
l'antivirus Windows 76
Figure 87 : Alerte "Un malware a
été détecté" par Kibana 76
VII
Liste de tableau
Tableau 1 : Comparaison des solutions SIEM 14
VIII
IX
Liste des abréviations et acronymes
Abréviation Signification
ANSI Agence Nationale de la Sécurité
Informatique
DHCP Dynamic Host Configuration Protocol
DNS Domain Name Server
DOS Denial Of Service
ELK Elasticsearch Logstash Kibana
EQL Event Query Language
FTP File Transfert Potocol
GPG GNU Private Guard
GRO Generic Receive Offload
HTTP HyperText Transfert Protocol
HTTPS HyperText Transfert Protocol Secure
IBM International Business Machines
ICMP Internet Control Message Protocol
IDS Intrusion Detection System
IP Internet Protocol
IPS Intrusion Prevention System
JDK Java Development Kit
JSON JavaScript Object Notation
KQL Kibana Query Language
LRO Large Receive Offload
LTS Long Term Support
MSSP Managed Security Service Provider
NAT Network Adress Translation
NFS Network File System
NMAP Network Mapper
NOC Network Operations Center
OSSIM Open Source Security Information Management
PDG Président Directeur Général
PHP Hypertext Preprocessor
REST Representational State Transfert
RSA Rivest-Shamir-Adleman
RSSI Responsable Sécurité des Systèmes
D'information
SEM Security Event Management
SIEM Security Information and Event Management
SIM Security Information Management
SMB Server Message Block
SMS Short Message Service
SOC Security Operations Center
SQL Structured Query Language
SSH Secure Shell
SSL Secure Sockets Layer
SYN Synchronize
TCP Transmission Communication Protocol
TLS Transport Layer Security
UDP User Datagram Protocol
URL Uniform Ressource Locator
XSS Cross-site Scripting
X
YUM Yellowdog Updater, Modified
1
INTRODUCTION GENERALE
Les exigences de la sécurité de l'information au
sein des organisations ont conduit à deux changements majeurs au cours
des dernières décennies. Avant l'usage
généralisé d'équipements informatiques, la
sécurité de l'information était assurée par des
moyens physiques (classeurs fermés par un cadenas) ou administratifs
(examen systématique des candidats au cours de leur recrutement).
Le second changement majeur qui affecte la
sécurité est l'introduction de systèmes distribués
et l'utilisation de réseaux et dispositifs de communication pour
transporter des données entre un terminal utilisateur et un ordinateur,
et entre ordinateurs.
Avec ces avènements, le besoin de protéger les
données a donné vie à la cybersécurité.
La cybersécurité représente l'ensemble
des outils, politiques, concepts de sécurité, mécanismes
de sécurité, consistant à protéger les ordinateurs,
les serveurs, les appareils mobiles, les systèmes électroniques,
les réseaux et les données contre les attaques malveillantes. Les
systèmes d'information sont sensibles aux menaces qui pourront
entraîner la perte d'informations vitales ou même des dommages
physiques aux machines.
Afin de faire face à ces menaces informatiques, les
organisations et entreprises de toutes tailles doivent pouvoir surveiller leurs
réseaux et systèmes d'information, afin d'identifier les actions
malveillantes qui les menacent et de se prémunir de potentielles
attaques avant qu'elles ne causent de graves dommages.
Bien que les dispositifs de sécurité à
point unique puissent facilement détecter les attaques courantes, ils
sont plus susceptibles de passer à côté de vecteurs
d'attaque lents, distribués et ciblés. Au cours des
dernières années, nous avons vu de nombreux incidents au cours
desquels il a fallu des mois aux entreprises pour se rendre compte qu'elles
avaient été violées.
Les données de journal générées
par ces appareils jouent un rôle crucial dans la détection des
activités suspectes sur un réseau. L'exploration manuel de chaque
entrée de journal devient une tâche fastidieuse pour les
équipes de sécurité. Cela diminue considérablement
leur efficacité et entraîne de la fatigue. C'est là que le
SIEM intervient pour aider les équipes de sécurité
à détecter les incidents de sécurité et à
répondre dans des délais négligeables.
De l'anglais Security Information and Event Management, ou
gestion des informations et des événements de
sécurité en français, si la définition de ce terme
peut échapper à certains, il est aujourd'hui dans toutes les
bouches quand il s'agit d'aborder des sujets de cybersécurité.
2
Introduction générale
Le SIEM est une approche du management de la
sécurité, une technologie spécifique qui permet d'analyser
les menaces, il consiste à examiner depuis un guichet unique les
données relatives à la sécurité de l'entreprise qui
sont générées en de nombreux points.
Il combine les fonctions du SIM et le SEM en un seul
système de management de sécurité. Security Information
Management (SIM) fait référence à la collecte de fichiers
journaux et au stockage dans un référentiel central pour une
analyse ultérieure et le SEM (Security Event Management) consiste
à identifier, rassembler, évaluer, corréler et surveiller
les événements et les alertes du système. Dans un sens, le
SEM est une amélioration du SIM, bien que les deux soient
considérés comme des domaines distincts de la gestion de la
sécurité.
Le SIEM permet à travers une seule vitre
d'améliorer les capacités de détection et de
réponse aux menaces de notre organisation en permettant une analyse en
temps réel des journaux et des événements de
sécurité provenant de plusieurs sources.
Ce système aide un administrateur système
à avoir une vue d'oiseau sur l'ensemble de son système à
travers les données collectées auprès des logiciels
antivirus, des pare-feux, des serveurs web ou encore des systèmes
d'exploitation en tout genre.
Il pourra ainsi identifier et détecter toute tentative
d'intrusion dans le système et mener des enquêtes post-erreur.
C'est donc dans cette optique que se situe le sujet de ce
projet de mastère effectué au sein de l'Agence Nationale de la
Sécurité Informatique qui est le coordinateur national de
référence, oeuvrant à développer un climat de
confiance des technologies de l'information pour rassurer les utilisateurs,
l'état, les investisseurs et protéger les biens publics et
privés contre toute menace cybernétique.
L'ANSI oeuvre à renforcer la sécurité du
cyber espace national contre les risques et les menaces cybernétiques et
instaurer une culture cybersécurité de haut niveau.
Ce projet consistera particulièrement à
étudier et à mettre en place un système centralisé
de gestion de logs et d'évènements à travers des outils
open source, une solution qui va permettre de faire face et désamorcer
les menaces pouvant affecter notre système d'information. En bref, SIEM
est synonyme de simplicité.
L'objectif de ce projet consiste à fournir une solution
qui va assurer la gestion, l'intégration, la corrélation,
l'analyse en un seul endroit pour pouvoir détecter des anomalies de
manière précise et les attaques informatiques sur notre
système d'information.
Introduction générale
Le déploiement d'une solution de gestion de logs et
événements de sécurité (SIEM) se heurte à
des difficultés qui sont pas à sous-évaluées :
notamment la gestion du volume des données, l'identification des
comportements anormaux, le filtre et l'intelligence des entrées logs et
notre solution ne devrait pas avoir d'impacts importants sur les performances
réseau et systèmes.
Le présent travail est organisé en trois parties
: la première partie va exposer l'état des connaissances en
cybersécurité, les différentes solutions sur le
marché ainsi que la solution adoptée.
Le deuxième chapitre abordera la réalisation
pratique de notre solution SIEM, la topologie, les prérequis logicielles
et matérielles nécessaires pour assurer l'administration et enfin
dans la troisième partie nous allons nous familiariser avec notre
solution et mener des séries d'attaque sur notre solution.
Finalement, nous terminons par une conclusion qui
résume nos travaux déjà réalisé et qui
présente les perspectives sur l'ensemble des travaux menés au
cours de ce projet.
3

CHAPITRE I : ETAT DE L'ART
Plan
Introduction 5
1. Cybersécurité 5
2. Cyberattaques 7
3. Security Operations Center (SOC) 9
4. Security Information and Event management (SIEM) 11
5. Solutions disponibles 12
Conclusion 19
5
CHAPITRE I - ETAT DE L'ART
Introduction
Dans ce chapitre, nous allons introduire les notions
essentielles à la compréhension du contexte de ce projet.
Ensuite, on va présenter les différentes solutions disponibles et
faire une étude comparative de ces solutions ainsi que notre choix et la
justification de ce choix. Puis on va présenter le principe de la
solution proposée ainsi que les technologies adoptées dans ce
projet.
1 Cybersécurité
1.1 Définition
La cybersécurité consiste à
protéger les ordinateurs, les serveurs, les appareils mobiles, les
systèmes électroniques, les réseaux et les données
contre les attaques malveillantes. On l'appelle également
sécurité informatique ou sécurité des
systèmes d'information. On peut la rencontrer dans de nombreux
contextes, de l'informatique d'entreprise aux terminaux mobiles. Elle peut
être divisée en plusieurs catégories :
? La sécurité réseaux :
consiste à protéger le réseau informatique contre
les intrus. ? La sécurité des applications :
vise à protéger les logiciels et les appareils contre
les
menaces. Un système de sécurité fiable se
reconnaît dès l'étape de conception, bien
avant le déploiement d'un programme ou d'un
appareil.
? La sécurité des informations :
veille à garantir l'intégrité et la
confidentialité des données, qu'elles soient stockées ou
en transit.
? La sécurité opérationnelle :
comprend les processus et les décisions liés au
traitement et à la protection des donnée (autorisations des
utilisateurs pour l'accès au réseau, stockage et l'emplacement
des données).
? La reprise après sinistre et la
continuité des opérations : spécifient la
manière dont une entreprise répond à un incident de
cybersécurité ou tout autre événement causant une
perte des opérations ou de données.
6
Chapitre I : Etat de l'art
· La formation des utilisateurs finaux :
porte sur le facteur le plus imprévisible : les personnes.
1.2 Objectifs de la sécurité
informatique
La sécurité informatique à plusieurs
objectifs, liés aux types de menaces ainsi qu'aux types de ressources.
Les principaux points sont les suivants :
- Empêcher la divulgation non-autorisée de
données
- Empêcher la modification non autorisée de
données
- Empêcher l'utilisation non-autorisée de
ressources réseaux ou informatiques de façon
générale.
1.3 Services principaux de la
cybersécurité
Pour remédier aux failles et pour contrer les
attaques, la sécurité informatique se base sur un certain nombre
de services qui permettent de mettre en place une réponse
appropriée à chaque menace. Décrivons les principaux
services de sécurité :
· Confidentialité : (seules les
personnes autorisées peuvent avoir accès aux informations qui
leur sont destinées)
· Authentification : (les utilisateurs
doivent prouver leur identité)
· Intégrité : (les
données doivent être celles que l'on attend, et ne doivent pas
être altérées de façon fortuite, illicite ou
malveillante)
· Autorisation : (contrôle
d'accès)
· Disponibilité : (l'accès
aux ressources du système d'information doit être permanent).
D'autres aspects peuvent aussi être considérés comme des
objectifs de la sécurité des systèmes d'information, tels
que :
· La non-répudiation (assurer que
l'émetteur ne nie la transaction)
· La traçabilité (ou
« preuve ») : garantie que les accès et tentatives
d'accès aux éléments considérés sont
tracés et que ces traces sont conservées et exploitables. Pour
plus d'information voir [12]
7
Chapitre I : Etat de l'art
2 Cyberattaques
Au fil des années, la cybersécurité
s'est transformée, offrant de nouvelles possibilités et
opportunités aux organisations. Cependant, elles doivent se
réorganiser pour faire face aux menaces de plus en plus nombreuses et
sophistiquées.
Une cyberattaque est une tentative d'atteinte à des
systèmes d'information réalisée dans un but malveillant,
et destinée à provoquer un dommage aux informations et aux
systèmes qui les traitent, pouvant ainsi nuire aux activités dont
ils sont le support. L'objectif d'une cyberattaque est de voler des
données (secrets militaires, diplomatiques ou industriels,
données personnelles bancaires, etc.), de détruire, endommager ou
altérer le fonctionnement normal de systèmes d'information (dont
les systèmes industriels).
2.1 Différents types de cyberattaques les plus
courants
Les cyberattaques frappent les entreprises tous les jours.
John Chambers, ancien PDG de Cisco, a déclaré : « Il y a
deux types d'entreprises : celles qui ont été piratées et
celles qui ne savent pas encore qu'elles ont été piratées
».
Nous avons recensé une liste modeste des cyberattaques
les plus fréquents :
· Logiciel malveillant (malware)
· Attaques par déni de service (DoS) et par
déni de service distribué (DDoS)
· Attaque de l'homme au milieu (MitM)
· Ingénierie sociale
· Hameçonnage (phishing) et harponnage (spear
phishing)
· La cyberusurpation d'identité
· Cassage de mot de passe
· Injection SQL
· Cross-site Scripting (XSS)
· Le vol d'informations
· Le défaçage.
2.2 Conséquences d'une cyberattaque
Une cyberattaque peut entraîner une cybercrise, que ce
soit au niveau IT, financier ou de réputation. Les cyberattaques peuvent
avoir les conséquences suivantes :
· Paralysie des systèmes
Chapitre I : Etat de l'art
· Vol d'identité, fraude, extorsion
· Financières
· Matériel volé, comme les ordinateurs
portables ou les appareils mobiles
· Sniffing de mot de passe
· Infiltration du système
· Dégradation du site Web
· Vol de propriété intellectuelle (IP).
Pour plus d'information voir [12]
8
9
Chapitre I : Etat de l'art
3 Security Operations Center (SOC)
3.1 Définition
Le Security Operations Center, ou centre opérationnel
de sécurité, désigne une division de l'entreprise qui
assure la sécurité de l'organisation, et surtout le volet
sécurité de l'information. C'est lui qui gère les points
suivants :
· Services de détection d'incidents (Incident
detection services)
· Services d'intervention en cas d'incident (Incident
response services)
· Services de récupération en cas d'incident
(Incident recovery services)
· Analyse forensique (Forensic analysis)
· Exécution du plan de reprise (Recovery plan
execution).
Le SOC est chargé de superviser 24h/24h les
systèmes d'information au sein des entreprises afin de se
protéger des cyberattaques et de veiller à la
sécurité informatique sur l'ensemble des infrastructures
installées.
Pour se faire, elles s'appuieront sur un SIEM.
3.2 Modèles de SOC
Il existe plusieurs modèles de SOC à savoir :
· SOC virtuel : ce type de SOC n'a pas
d'installation dédiée et les membres de l'équipe sont
« activés » en cas d'alerte ou d'incident critique, un peu
comme des pompiers.
· SOC dédié : comme son
nom l'indique, il nécessite une installation et une équipe
entièrement dédiée en interne.
· SOC distribué ou cogéré :
Lorsqu'il est géré avec un MSSP, le SOC est
cogéré.
· SOC de commande : il coordonne les
autres SOC, fournit les renseignements sur les menaces.
· NOC (Network Operations Center) :
supervision en continu des performances et la santé d'un
réseau.
· Fusion SOC : ce type de modèle
inclus les fonctions SOC traditionnelles et les nouvelles fonctions comme
l'intelligence des menaces, une équipe d'intervention et des fonctions
de technologie opérationnelle. Pour plus d'information voir [9]
Chapitre I : Etat de l'art
3.3 Comment fonctionne un SOC
L'infrastructure typique de SOC comprend des pare-feu, des
IPS/IDS, des solutions de détection des brèches, des sondes et un
système de gestion de l'information et des événements de
sécurité (SIEM). La technologie devrait être en place pour
recueillir les données par le biais des flux de données, de la
métrique, de la capture de paquets, du syslog et d'autres
méthodes afin que l'activité des données puisse être
corrélée et analysée par les équipes SOC. Le centre
des opérations de sécurité surveille également les
réseaux et les points d'extrémité pour détecter les
vulnérabilités afin de protéger les données
sensibles et se conformer aux règlements de l'industrie ou du
gouvernement.
10
11
Chapitre I : Etat de l'art
4 Security Information and Event management
(SIEM)
SIEM = SIM (Security Information Management)
+ SEM (Security Event Management), est une approche du
management de la sécurité, une technologie spécifique qui
permet d'analyser les menaces il consiste à examiner depuis un guichet
unique les données relatives à la sécurité de
l'entreprise qui sont générées en de nombreux points.
Il combine les fonctions du SIM (Security Information
Management) et le SEM (Security Event Management) en un seul système de
management de sécurité. Et l'acronyme SIEM se prononce « sim
» avec un e silencieux.
? SIM (Security Information Management) : Il
s'agit d'un type de logiciel qui automatise la collecte des logs à
partir de dispositifs de sécurité (pare-feu, des serveurs proxy,
IDS, équipements réseaux, logiciels antivirus). Le SIM traduit
les données enregistrées dans des formats corrélés
et simplifiés.
? SEM (Security Event Management) : Il s'agit
des processus permettant l'identification, la surveillance et
l'évaluation des événements liés à la
sécurité. Le SEM aide les administrateurs système à
analyser, ajuster et gérer l'architecture, les politiques et les
procédures de sécurité de l'information.
4.1 Fonctionnement
Les principes sous-jacents de chaque système SIEM est
d'agréger des data pertinentes, de plusieurs sources différentes.
Et d'identifier les écarts possibles par rapport à la moyenne,
afin de prendre les actions appropriées. Par exemple, lorsqu'un
problème potentiel est détecté, le SIEM peut enregistrer
des informations supplémentaires. Puis générer une alerte,
et ordonner à d'autres contrôles de sécurité
d'arrêter la progression de leur activité.
À son niveau le plus basique, un système SIEM peut
être basé sur des règles. Ou utiliser un moteur de
corrélation statistique pour établir des relations entre les
entrées du journal de log. Les fonctions principales du SIEM sont :
? Normalisation : Les traces brutes sont
stockées sans modification pour garder leur valeur juridique. On parle
de valeur probante. La normalisation permet de faire des recherches
multicritères, sur un champ ou sur une date.
? Agrégation : Plusieurs règles
de filtrage peuvent être appliquées. Ils sont ensuite
agrégés selon les solutions, puis envoyés vers le moteur
de corrélation.
12
Chapitre I : Etat de l'art
? Corrélation : Les règles de
corrélation permettent d'identifier un événement qui a
causé la génération de plusieurs autres (un hacker qui
s'est introduit sur le réseau, puis a manipulé tel
équipement...). Elles permettent aussi de remonter une alerte via un
courriel, SMS ou ouvrir un ticket si la solution SIEM est interfacée
avec un outil de gestion de tickets.
? Reporting : Les SIEM permettent
également de créer et générer des tableaux de bord
et des rapports. Ainsi, les différents acteurs du SI, RSSI,
administrateurs, utilisateurs peuvent avoir une visibilité sur le SI
(nombre d'attaques, nombre d'alertes par jour...).
? Archivage : Les solutions SIEM sont
utilisées également pour des raisons juridiques et
réglementaires. Un archivage à valeur probante permet de garantir
l'intégrité des traces.
? Rejeu des événements : La
majorité des solutions permettent également de rejouer les
anciens événements pour mener des enquêtes post-incident.
Il est également possible de modifier une règle et de rejouer les
événements pour voir son comportement.
4.2 Solutions disponibles
Elastic Stack :
Elastic Stack est un groupe de produits open source de Elastic
conçu pour aider les utilisateurs à extraire des données
de tout type de source et dans n'importe quel format et à rechercher,
analyser et visualiser ces données en temps réel. La stack
était anciennement connu sous le nom d'ELK Stack, dans lequel les
lettres du nom représentaient les produits du groupe : Elasticsearch,
Logstash et Kibana. Un quatrième produit, Beats, a ensuite
été ajouté à la pile, rendant l'acronyme potentiel
imprononçable. Pour plus d'information voir [1]
Splunk
Splunk est un moteur de recherche capable d'agréger et
d'indexer les logs de tous les équipements IT de l'entreprise et de
faciliter leur exploration. Elle assure la collecte et analyse d'importants de
volumes de données générées par des machines. Elle
utilise une API standard permettant une connexion directe du service vers les
applications et les appareils. Ce produit répond aux demandes de cadres
et managers non techniques ayant besoin de rapports de données
compréhensibles et facilement actionnables.
Splunk Enterprise Security (ES) est une solution de
sécurité de l'information et de gestion des
événements (SIEM) offrant un aperçu global des
données générées à partir de technologies de
sécurité comme les réseaux, leurs
extrémités, les malwares, les
13
Chapitre I : Etat de l'art
vulnérabilités système et les
renseignements d'identité. C'est une application premium, dont la
licence fonctionne indépendamment du service principal de Splunk.
QRadar
IBM QRadar est un SIEM qui aide les équipes de
sécurité à détecter et hiérarchiser avec
précision les menaces dans toute l'entreprise et fournit des
éclairages intelligents qui permettent de réagir rapidement afin
de réduire l'impact des incidents. QRadar met en corrélation
toutes ces informations et agrège les événements
reliés en des alertes uniques afin d'accélérer l'analyse
et la résolution des incidents. QRadar SIEM peut être
installé sur site ou dans le cloud.
AlienVault OSSIM
AlienVault OSSIM (Open Source SIEM) fournit un SIEM open
source riche en fonctionnalités, complet avec la collecte, la
normalisation et la corrélation d'événements. Lancé
par des ingénieurs en sécurité en raison du manque de
produits open source disponibles, AlienVault OSSIM a été
créé spécifiquement pour répondre à la
réalité à laquelle de nombreux professionnels de la
sécurité sont confronté.
RSA NetWitness Platform
RSA NetWitness Platform est une solution SIEM avancée
et une solution de détection des menaces et de réponse. La
solution est dotée d'une console avancée dédiée aux
analystes, permettant de trier les alertes et les incidents. Elle coordonne les
programmes d'opérations de sécurité de bout en bout.
Security Onion
Security Onion est une distribution Linux
gratuite et open source servant à des fins de SIEM, recherche de
menaces, et la gestion des journaux. Il permet de créer une armée
de capteurs distribués pour une entreprise en quelques minutes.
Security Onion comprend Elasticsearch, Logstash, Kibana,
Suricata, Zeek, Wazuh, Stenographer, TheHive, Cortex, CyberChef, NetworkMiner
et de nombreux autres outils de sécurité.
4.3 Etude comparative des solutions
Ce tableau ci-dessous regroupe une comparaison et résume
les avantages et les inconvénients entre les solutions SIEM
énumérées dans les lignes ci-dessus.
14
Chapitre I : Etat de l'art
Tableau 1 : Comparaison des solutions SIEM
|
Solution SIEM
|
Avantages
|
Inconvénients
|
|
Elastic Stack
|
V' Gratuit et libre
V' Installation facile
V' Notifications par mail
V' Faciliter et accélérer les recherches
V' Efficacité pour générer des graphiques
à plusieurs niveaux de valeurs.
|
- Impossibilité de réaliser
des analyses complexes sur les données (pas
d'écriture d'algorithmes ni de fonctions statistiques
avancées)
- Configuration délicate.
|
|
Splunk
|
- Version d'essai gratuite
- Monitoring en temps réel
- Compatible avec Windows et Linux
- Chiffrement des données
- Puissance du moteur
d'indexation.
|
- Le coût varie selon la
taille des données traitées.
- Mise en place complexe
- Nouveau langage à apprendre
en parallèle de tous les autres.
|
|
QRadar
|
V' Gestion simplifiée de la conformité V'
Élimination des tâches manuelles V' S'intègre directement
à 450 solutions.
|
- La solution est un peu
trop chère.
|
|
Alien Vault OSSIM
|
V' Intégration facile à un tas de plateforme.
|
- Rapport un peu fastidieux à analyser.
|
|
RSA Netwitness Platform
|
V' Investigations rapides V' Automatisation et orchestration
V' Architecture flexible et évolutive
V' Opérations de sécurité de bout en
bout.
|
- La configuration initiale
est très complexe.
|
15
Chapitre I : Etat de l'art
|
Security Onion
|
y' Très évolutif
y' Une communauté en plein essor qui le met à jour
régulièrement
y' Gratuit et libre y' Installation facile.
|
- Nécessite une connaissance élevée - Langue
anglaise seulement disponible.
|
4.4 Critères de choix des solutions
SIEM
Le choix de l'outil SIEM s'articule autour de trois
critères principaux : le budget, l'effectif requis et la pertinence face
aux menaces.
Le budget est un paramètre important car toute
entreprise a besoin d'avoir des perspectives claires en matière d'outils
de gestion de la sécurité informatique. L'idéal est
d'accéder à un outil dont la licence est simple, offrant un
compromis entre l'efficacité et le coût.
Il sera également important d'évaluer le nombre
de personnes nécessaires à exploitation de l'outil choisi.
Cette réponse aux menaces constitue d'ailleurs le
troisième critère de choix d'un SIEM.
Par ailleurs, un SIEM efficace doit posséder un module
de tableau de bord et de rapports complets afin de pouvoir communiquer
facilement auprès de la direction et des auditeurs.
4.5 Choix de la solution et justification
Après avoir effectué une recherche sur les
différentes solutions disponibles bien qu'elles ne soient pas toutes
mentionnées dans le tableau qui précède, et suite à
la comparaison entre ces derniers en termes de coût, compatibilité
et facilité de mise en place, nous avons fait le choix de
procéder dans ce projet avec Elastic Stack/ELK. Ce groupe de produits
est d'autant plus utilisé par une multitude de grandes entreprises comme
LinkedIn, Netflix, Uber et StackOverflow.
4.6 Architecture de la solution
Elastic Stack est un groupe de produits Open Source d'Elastic
conçu pour extraire des données de n'importe quel type de source
dans n'importe quel format, les analyser et les visualiser en temps
réel. Elle utilise Logstash (moteur de collecte de journaux) pour
l'agrégation de journaux, Elasticsearch (base de données) pour le
stockage et la recherche des données, Kibana (outil VI) pour
exploration, la visualisation et l'analyse des données et Beats un
16
Chapitre I : Etat de l'art
expéditeur de données qui collecte les
données chez le client et les expédie à Elasticsearch ou
à Logstash.
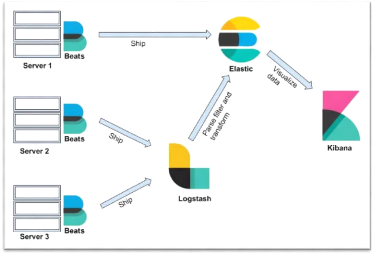
Figure 1 : Architecture d'Elastic Stack
Elasticsearch
Elasticsearch est un moteur de recherche en texte intégral
compatible avec plusieurs locataires
et d'analyse open-source, RESTful et distribué basé
sur Apache Lucene avec une interface Web
HTTP et des documents JSON sans schéma. Elasticsearch est
développé en Java. Les clients
officiels sont disponibles en Java, .NET (C #), PHP, Python,
Apache Groovy, Ruby et de
nombreux autres langages. Selon le classement DB-Engines,
Elasticsearch est le moteur de
recherche d'entreprise le plus populaire suivi d'Apache Solr.
Pour plus d'information voir [1]
? Les fonctionnalités d'Elasticsearch
- Indexation de données
hétérogènes
- Distribué
- Évolutif
- Très disponible
- Recherche en temps quasi réel
- Recherche en texte intégral
- Java, .NET, PHP, Python, Curl, Perl, Ruby
17
Chapitre I : Etat de l'art
- Possède une interface Web de l'API REST avec une sortie
JSON - Recherche en texte intégral
- Prise en charge multilingue et géolocalisation
Logstash
Logstash est l'outil de pipeline de collecte de
données. Il collecte les entrées de données et alimente
Elasticsearch. Il rassemble tous les types de données provenant de
différentes sources et les rend disponibles pour une utilisation
ultérieure.
Logstash peut unifier les données de sources disparates
et normaliser les données dans les destinations souhaitées. Il
permet de nettoyer et de démocratiser toutes nos données pour
l'analyse et la visualisation des cas d'utilisation.
Il se compose de trois éléments :
? Input : passer des journaux pour les traiter
dans une machine en format compréhensible. ? Filter :
il s'agit d'un ensemble de conditions pour effectuer une action ou un
événement particulier.
? Output : Nous pouvons envoyer des
données vers une autre destination.
Kibana
Kibana est un outil de visualisation de données qui
complète la pile ELK. Cet outil est utilisé pour visualiser,
interagir avec la banque de données dans les index Elasticsearch. Le
tableau de bord Kibana propose divers diagrammes interactifs, données
géo spatiales et graphiques pour visualiser des requêtes
complexes.
Nous pouvons facilement effectuer une analyse avancée
des données et visualiser nos données dans une multitude de
graphiques, de tableaux et de cartes, facilitant ainsi la compréhension
des grands volumes de données.
Les fonctionnalités de Kibana :
- Découvrir
- Visualiser
- Tableaux de bord
- Mettez des données géographiques sur n'importe
quelle carte
- Insérez des tableaux de bord dans notre page Web
- Envoyez aux collègues une URL vers un tableau de
bord.
Chapitre I : Etat de l'art
Agents Beats
Beats est un outils Open source qui accueille des agents
réservés au transfert de données. Que ce soit des
centaines ou des milliers de machines et de systèmes, les agents Beats
se chargent de transférer les données vers Logstash et
Elasticsearch.
Les composants de la famille beats sont :
- FileBeat : Utilisé pour
expédier les journaux et la centralisation des données de
journal. Installé en tant qu'agent sur les serveurs, Il surveille les
fichiers journaux ou les emplacements spécifiés, collecte les
événements de journal et les transmet à Elasticsearch ou
Logstash pour indexation.
- Packetbeat : Analyseur de paquets
réseau et de performances en temps réel utilisé avec
Elasticsearch qui expédie les informations sur l'échange de
transactions au sein de notre serveur d'application.
- Il complète la plateforme Beats en offrant une
visibilité entre les serveurs du réseau. Packetbeat renifle le
trafic entre les serveurs, analyse les protocoles au niveau de l'application
à la volée et corrèle les messages en transactions.
Actuellement, Il prend en charge les protocoles suivants : ICMP, DHCP, DNS,
HTTP, Redis, NFS, TLS.
- MetricBeat : Agent de surveillance de
serveur qui collecte les métriques du système d'exploitation et
des services de votre serveur.
- WinlogBeats : Expédiez les
événements du journal Windows.
4.7 Critères techniques de la solution
- Récupération des données provenant de
différentes sources.
- Indexation et analyse du contenu structuré.
- Centralisation des données
hétérogènes.
- Visualisation des données sous forme des graphes,
tableaux . . .
- Observation des résultats et détection des
anomalies.
18
Chapitre I : Etat de l'art
Conclusion
Cette partie nous a tout d'abord permis de développer
notre jargon en sécurité informatique et comprendre les outils
SIEM, leurs fonctionnalités et leurs importances dans la
sécurisation des systèmes d'information. Nous avons
découvert un ensemble d'outils STEM et afin de mener à bien notre
projet nous avons réalisé une étude comparative afin de
choisir les outils qui sont les mieux adaptés à notre projet. Tl
s'agit entre autres du STEM Elastic Stack. Nous l'avons choisi pour diverses
raisons mais principalement pour ses fonctionnalités nombreuses,
ça gratuité et son efficacité à gérer les
dashboards.
19

CHAPITRE II : REALISATION
Plan
Introduction 21
1. Environnement de travail 21
2. Installation d'Elastic Stack 24
3. Configuration de la pile Elastic 27
Conclusion 46
21
CHAPITRE II : REALISATION
Introduction
À la suite d'une étude des spécifications
et des besoins techniques du projet, nous allons exposer dans ce chapitre
l'environnement matériel et logiciel sur lequel on a travaillé,
ainsi que les différentes étapes de mise en place de la
solution.
1 Environnement de travail
Dans cette partie, on va décrire l'environnement
matériel, logiciel et l'architecture pour la réalisation de la
solution.
1.1 Environnement matériel
Pour la réalisation de la solution, on a opté pour
la création de 3 machines virtuelles sur un
ordinateur portable ayant les caractéristiques suivantes
:
? Ordinateur portable
- Constructeur : Asus
- Système d'exploitation : Windows 10 Professional
- Mémoire vive : 16 Go
- Disque dur : 500 Go
- Processeur : Intel Core i7 (8ème
Génération)
- Carte graphique : Nvidia GeForce 820M
Et les trois machines virtuelles :
? Machine virtuelle serveur
- Système d'exploitation : CentOS (version 7.5.1804)
- Mémoire vive allouée : 4 Go
- Espace disque alloué : 40 Go
- Nombre de coeurs de processeur alloués : 2
- 2 cartes réseaux : 1 en NAT et l'autre en configuration
Host Only
22
Chapitre II : Réalisation
? Machine virtuelle cliente Ubuntu
- Système d'exploitation : Ubuntu LTS (version 20.04)
- Mémoire vive allouée : 2 Go
- Espace disque alloué : 25 Go
- Nombre de coeurs de processeur alloués : 1
- 2 cartes réseaux : 1 en NAT et l'autre en configuration
Host Only
? Machine virtuelle cliente Windows
- Système d'exploitation : Windows 10 Professionnel
- Mémoire vive allouée : 2 Go
- Espace disque alloué : 25 Go
- Nombre de coeurs de processeur alloués : 1
- 2 cartes réseaux : 1 en NAT et l'autre en configuration
Host Only
1.2 Environnement logiciel
? VMware Workstation Pro 15 (version 15.5.0)
VMware Workstation est un outil de virtualisation de poste de
travail créé par la société VMware, il peut
être utilisé pour mettre en place un environnement de test pour
développer de nouveaux logiciels, ou pour tester l'architecture complexe
d'un système d'exploitation. L'avantage de VMware dans ce projet c'est
qu'il va nous permettre de mettre en place une architecture composée de
plusieurs machines sur une même machine physique, ce qui va nous
permettre de diminuer le coût financier, et de s'en passer
d'équipement physique pour l'interconnexion de nos machines.
? Java 11.0.10
Java est un langage de programmation orientée objet
créés en 1995. Java 11.0.10 est la dernière version de
Java à ce jour et offre de nouvelles fonctionnalités, des
performances accrues et des corrections de bug pour améliorer
l'efficacité de développement et d'exécution des
programmes Java. Nous installons java pour permettre à Elasticsearch de
fonctionner car celui-ci a été développer en Java.
? NGINX 1.16.1
NGINX est un logiciel libre de serveur Web (ou HTTP) ainsi
qu'un proxy inverse cache HTTP, et load balancer. NGINX est conçu pour
offrir une faible utilisation de la mémoire et une grande
simultanéité. Plutôt que de créer de nouveaux
processus pour chaque requête
Chapitre II : Réalisation
Web, NGINX utilise une approche asynchrone et
événementielle où les requêtes sont traitées
dans un seul thread.
1.3 Présentation de la topologie
L'architecture de l'infrastructure qu'on va implémenter
sera constitué ainsi :
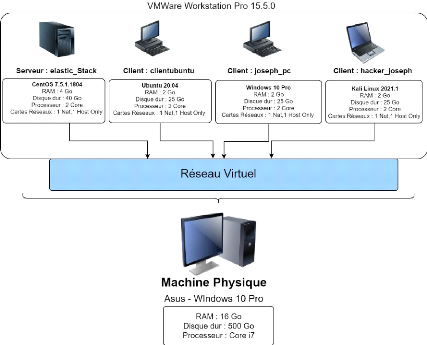
Figure 2 : Topologie de l'infrastructure
23
Chapitre II : Réalisation
2 Installation d'Elastic Stack
Cette partie sera consacrée à l'installation de
la stack, on va installer tous les packages nécessaire pour le
fonctionnement d'Elastic Stack c'est-à-dire Java et Nginx, et ensuite
installer les éléments qui composent la stack, il est très
important que tous les éléments de la stack aient la même
version nous allons utiliser la dernière version du stack disponible
à ce jour qui est la version 7.11.2.
2.1 Installation de Java
Pour que Elastic Stack fonctionne, on commence par installer
openjdk 11 sur le serveur Elastic Stack qui est la dernière version de
Java disponible à ce jour à l'aide du gestionnaire de packages
YUM.
sudo yum install java-11-openjdk-devel
De nombreux programmes tel que Elasticsearch utilisent la
variable d'environnement JAVA_HOME pour déterminer l'emplacement
d'installation de Java.
Pour définir cette variable d'environnement, nous
allons d'abord déterminer où Java est installé avec la
commande sudo update-alternatives --config java
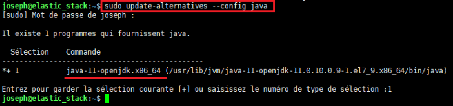
Figure 3 : Commande d'affichage de la version
de Java
Après cela, nous devons éditer le fichier
/etc/environment avec notre éditeur favoris (vim ou
nano) pour ajouter le chemin du fichier exécutable de Java obtenu dans
l'étape précédente. Nous allons définir JAVA_HOME
en tant que variable d'environnement. Nous avons besoin d'être
d'administrateur ou d'avoir les droits sudo pour le modifier.

Figure 4 : Variable d'environnement Java
24
25
Chapitre II : Réalisation
Enfin, nous allons vérifiez la version de java JDK pour
nous assurer qu'elle fonctionne correctement.

Figure 5 : Affichage de la version de Java
2.2 Installation d'Elasticsearch
Dans cette étape, nous installerons Elasticsearch à
partir du package rpm fourni par le site officiel d'Elastic
elastic.co.
Avant d'installer Elasticsearch, nous allons ajouter la
clé GPG publique à partir du site
elastic.co au serveur.
Tous les paquets sont signés avec la clé de
signature Elasticsearch afin de protéger le système contre
l'usurpation de paquets. Nous faisons cela avec la commande :
sudo rpm -import
https://artifacts.elastic.co/GPG-KEY-elasticsearch
Une fois la clé récupérer nous allons
télécharger l'installeur rpm d'Elasticsearch sur le site officiel
d'Elastic avec wget.
wget
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.11.2-
Une fois le téléchargement du fichier
terminé nous allons l'installer avec la commande rpm
-ivh.
L'option i permet d'installer le package
-v verbose (détaille l'avancement de
l'installation) ;
-h hash (permet d'avoir une barre de
progression).
rpm -ivh elasticsearch-7.11.2-x86_64.rpm
2.3 Installation du tableau de bord Kibana
Dans cette étape, nous installerons Kibana puis le
serveur Web Nginx. Nginx agit comme un proxy inverse pour l'application
Kibana.
Téléchargement de Kibana avec wget.
wget
https://artifacts.elastic.co/downloads/kibana/kibana-7.11.2-x86_64.rpm
Chapitre II : Réalisation
Une fois le package récupérer on passe à
l'installation de Kibana avec la commande rpm.
sudo rpm -ivh kibana-7.11.2-x86_64.rpm
2.4 Installation de Nginx et httpd-tools
Nous allons installer Nginx à travers le gestionnaire
de package de CentOS YUM qui va nous permettre de faire notre reverse proxy
puis httpd-tools pour générer un mot de passe de protection pour
l'accès à l'interface web de Kibana.
sudo yum -y install nginx httpd-tools
2.5 Installation de Logstash
Dans cette étape, nous allons télécharger
Logstash puis l'installer.
wget
https://artifacts.elastic.co/downloads/logstash/logstash-7.11.2-x86_64.rpm
Installation de Logstash avec la commande rpm.
rpm -ivh logstash-7.11.2-x86_64.rpm
2.6 Installation de Filebeat
Comme les autres packages nous allons récupérer le
package sur le site officiel d'Elastic avec la commande wget.
wget
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.11.2-x86_64.rpm
Puis l'installer avec le gestionnaire de package rpm.
rpm -ivh filebeat7.11.2-x86_64.rpm
26
27
Chapitre II : Réalisation
3 Configuration de la pile Elastic
Après voir récupérer et installer tous
les composants de notre stack sur notre serveur Elastic Stack, nous allons
configurer les composants pour leurs premières utilisations et leurs
permettre de communiquer entre eux.
3.1 Configuration d'Elasticsearch
Le fichier de configuration d'Elasticsearch est situé
dans
"/etc/elasticsearch/elasticsearch.yml".
Dans ce fichier on va spécifier l'adresse d'association
(bind address) du serveur ELK sur 0.0.0.0, pour permettre un accès
distant depuis n'importe quelle machine et on garde le port d'écoute par
défaut 9200. Pour les besoins d'une configuration à serveur
unique, nous n'ajusterons que les paramètres pour l'hôte du
réseau.
Nous allons utiliser l'éditeur de texte vim pour
modifier le fichier de configuration principal d'Elasticsearch.
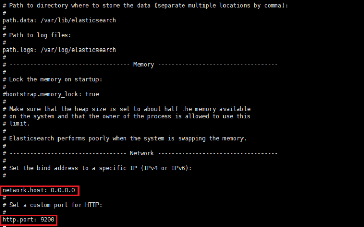
Figure 6 : Fichier de configuration
Elasticsearch
On va spécifier dans l'option "discovery-type" qu'il
s'agit d'un seul noeud.
Chapitre II : Réalisation
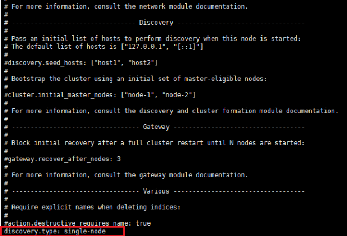
Figure 7 : Fichier de configuration
Elasticsearch (suite)
Après la configuration nous allons démarrer le
service Elasticsearch avec systemctl.
sudo systemctl start elasticsearch
Après le démarrage d'Elasticsearch nous allons
activer l'auto démarrage d'Elasticsearch avec la commande :
sudo systemctl start elasticsearch
Nous pouvons tester si notre service Elasticsearch fonctionne
en envoyant une requête HTTP : Si Elasticsearch à bien
démarrer nous obtiendrons une réponse montrant quelques
informations de base sur notre noeud local, similaire à celle-ci :
28
29
Chapitre II : Réalisation
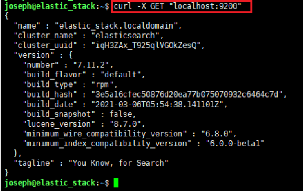
Figure 8 : Réponse http de curl sur le
port Elasticsearch.
3.2 Configuration de Kibana
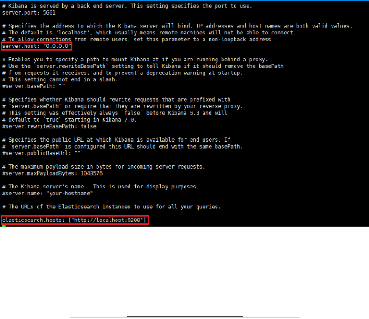
Figure 9 : Configuration du fichier
kibana.yml
Le fichier de configuration de Kibana est situé dans
/etc/kibana/kibana.yml, on spécifie de la même façon la
bind address sur 0.0.0.0 pour donner l'accès à l'interface
à des utilisateurs distants. Puis l'URL de notre instance Elasticsearch
installée sur la même machine. Et le port de communication reste
par défaut (5601).
30
Chapitre II : Réalisation
Après la configuration de Kibana nous allons
démarrer le service Kibana puis activer l'auto démarrage du
service au démarrage du système.
|
sudo systemctl start kibana sudo systemctl enable kibana
|
3.3 Configuration du chiffrement SSL
Les clients vont utiliser Filebeat pour envoyer les logs
à notre serveur Elastick Stack, on va créer un certificat SSL
pour la communication entre Filebeat et Logstash pour que ces derniers puissent
vérifier l'identité de l'un et de l'autre. Cela empêche
qu'une personne malveillante puisse injecter des données dans
Logstash.
Pour cela, on commence par créer les répertoires
pour stocker le certificat et la clef privée avec la commandes "sudo
mkdir -p /etc/pki/tls".
Maintenant, on va associer l'adresse IP du serveur ELK au
certificat SSL. Dans le fichier de configuration "/etc/ssl/openssl.cnf " dans
la section [v3_ca] on ajoute : subjectAltName = IP: 192.168.10.139 .
Finalement, on génère le certificat SSL et la
clef privée avec la commande req qui crée et traite
principalement les demandes de certificats, avec les
spécifications suivantes :
- Fichier de configuration associé :
/etc/ssl/openssl.cnf.
- Fichier contenant la clef privée :
/etc/pki/tls/private/logstash-forwarder.key
- Fichier contenant le certificat :
/etc/pki/tls/certs/logstash-forwarder.crt
- Certificat x509 auto-signé par root comme
autorité de certification.
- Durée de validité : 3650 jours.
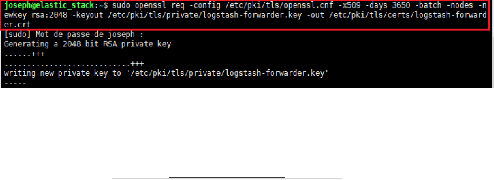
Figure 10 : Génération des
clé SSL
- Chiffrement asymétrique RSA avec clef de taille 2048
bits.
Chapitre II : Réalisation
A l'aide de la commande de copie sécurisée scp, on
copie le certificat généré dans la machine cliente qu'on
va configurer dans les étapes suivantes.

Figure 11 : Copie du certificat Logstash vers
la machine cliente Ubuntu
Une fois la copie effectuer avec succès on recopie ensuite
le certificat dans le répertoire qu'on a créé pour le
stocker c'est-à-dire /etc/pki/tls/certs.
mv /home/joseph/logstash-forwarder.crt /etc/pki/tls/cert
3.4 Configuration de Logstash
La configuration de Logstash comprend trois sections : les
input (entrées), les filter (filtres) et les output (sorties). Ces trois
composantes sont appelées un pipeline. Le fichier de configuration est
au format JSON et stocké dans "/etc/logstash/conf.d".
Nous allons créer un nouveau fichier
'filebeat-input.conf' qui sera notre fichier input, il va contenir les sources
des logs pour Filebeat, puis un fichier 'syslog-filter.conf' qui est le filtre
pour le traitement des fichiers de type syslog et afin un fichier
'output-elasticsearch.conf' pour définir la sortie vers
Elasticsearch.
Toutes les instructions dans ce fichier vont se situer dans la
section input {}
? Beats signifie que nous allons recevoir les fichiers à
travers un agent beat.
? ssl => true indique que nous allons utiliser le chiffrement
ssl.
? ssl_certificate => indique le chemin de notre certificat.
? ssl_key => indique le chemin vers notre clé.
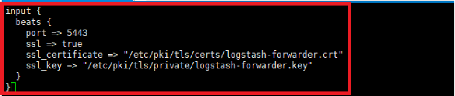
Figure 12 : Fichier de configuration input de
Logstash
31
32
Chapitre II : Réalisation
On va créer un fichier `syslog-filter.conf' contenant la
configuration du fichier du filter. Comme pour le input le contenu du fichier
filter va se situer dans la section filter{}
La fonction grok permet de correspondre des données log
non structurées en entrée à des champs qu'on peut ajouter
pour mieux structurer la sortie du filtre. Les agent beats effectuent un
filtrage par défaut donc cette partie peut être
négliger.
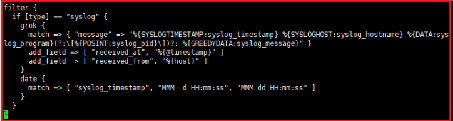
Figure 13 : Fichier de configuration filter de
Logstash
Nous allons maintenant crée le fichier
`output-elasticsearch.conf' et y indiquer des instructions indiquant à
Logstash d'envoyer les log après filtrage à Elasticsearch sur
l'adresse `localhost :9200' puisque celui-ci est installé sur la
même machine que Logstash et nous allons indiquer l'index à
instruire dans Elasticsearch.
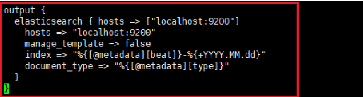
Figure 14 : Configuration du fichier output de
Logstash
Si notre configuration est sans erreur, nous pouvons
démarrer Logstash pour qu'il puisse prendre en compte les changements de
configuration et activer l'auto démarrage.
|
sudo systemctl start logstash sudo systemctl enable logstash
|
33
Chapitre II : Réalisation
3.5 Configuration Nginx
Nginx servira comme proxy inverse HTTPS et offrira un
accès externe à l'aide d'un utilisateur et un mot de passe. On
crée un utilisateur joseph@admin avec un mot de passe à travers
la commande « htpasswd » pour restreindre l'accès à
l'interface Kibana à notre administrateur seulement. Ceci sera
stocké dans le fichier "/etc/nginx/htpasswd.user".

Figure 15 : Génération du mot de
passe
Par la suite, on doit configurer Nginx pour rediriger les
requêtes Kibana vers le HTTP (port 80) en précisant les chemins
vers le certificat SSL et la clef privée du serveur. Nous devons
maintenant créer un nouveau fichier de configuration d'hôte
virtuel dans le répertoire conf.d. Pour ce faire on crée un
fichier 'kibana.conf' avec les configurations suivantes :
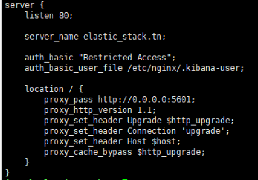
Figure 16 : Configuration de Nginx pour le
reverse proxy
3.6 Configuration de Filebeat
Filebeat prend en charge de nombreuses sorties, mais nous
enverrons généralement les événements que
directement à Elasticsearch ou à Logstash pour un traitement
supplémentaire.
34
Chapitre II : Réalisation
Ici nous utiliserons Logstash pour effectuer des traitements
supplémentaires sur les données collectées par
Filebeat.
Pour configurer Filebeat à envoyer les logs
système, on doit modifier le fichier filebeat.yml qui est l'exemple du
fichier de configuration fourni avec Filebeat situé dans
"/etc/filebeat/filebeat.yml".
On change le paramètre "enabled " en true pour activer
l'envoi des logs de type log.
Dans la section paths, nous allons ajouter les fichiers journaux
qu'on souhaite envoyer à Logstash. Nous ajouterons tous les fichiers
.log situé dans '/var/log/' et les fichiers '/var/log/secure' pour
l'activité ssh et '/var/log/messages' pour le journal du serveur.
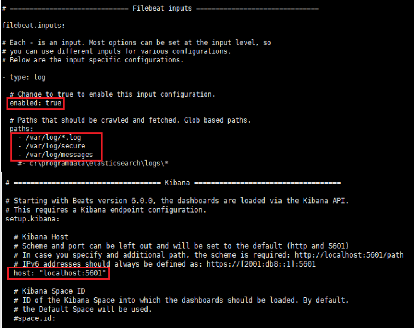
Figure 17 : Configuration du fichier
filebeat.yml sur CentOS
Filebeat n'aura pas besoin d'envoyer de données
directement à Elasticsearch. Nous désactivons donc cette sortie
dans la section "output.elasticsearch" et commentons les lignes suivantes en
les faisant précéder d'un # .
Et on décommente la ligne "output.logstash" en retirant le
# puis on indique localhost comme adresse de notre serveur Logstash puis
après la configuration pour le certificat.
35
Chapitre II : Réalisation
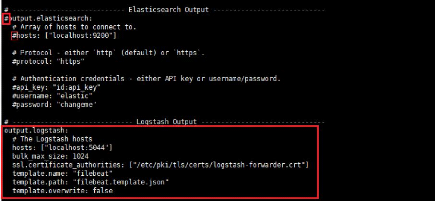
Figure 18 : Configuration de l'output vers
Logstash du fichier Filebeat sur CentOS
On enregistre le fichier puis on démarre le service
Filebeat et on l'active pour qu'il se lance au démarrage de notre
serveur :
|
sudo systemctl start filebeat sudo systemctl enable filebeat
|
Installation et configuration de Filebeat sur les
machines clientes
? Installation sur le client Ubuntu
Pour le client Ubuntu nous allons récupérer sur le
site
elastic.co le fichier d'installation de
Filebeat pour Ubuntu (Debian) :
wget
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.11.2-amd64.deb
Figure 19 : Installation de Filebeat
côté client
Une fois le fichier télécharger nous allons
l'installer avec le gestionnaire de package dpkg et avec la commande dpkg -i
filebeat-7.11.2-amd64.deb.
36
Chapitre II : Réalisation
Une fois Filebeat télécharger nous allons le
configurer tout comme on la fait sur la machine serveur dans le fichier
"/etc/filebeat/filebeat.yml".
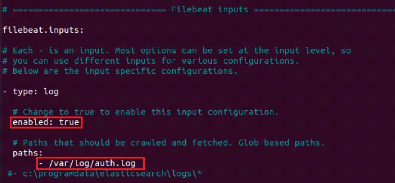
Figure 20 : Configuration du fichier
filebeat.yml
Nous allons ici indiquer l'adresse de notre serveur qui est la
192.168.10.139 dans la partie configuration de Kibana.
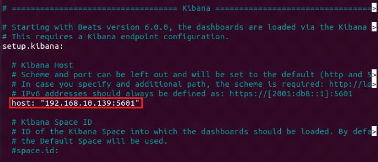
Figure 21 : Configuration du fichier
filebeat.yml (Partie Kibana)
Nous désactivons output vers Elasticsearch.
Figure 22 : Configuration du fichier
filebeat.yml (Partie Elasticsearch)
Chapitre II : Réalisation
Nous enlevons le commentaire de "output.logstash" puis indiquons
l'adresse du serveur et les configurations pour le certificat.
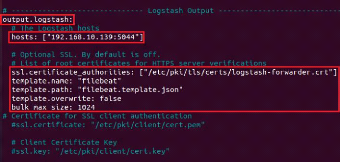
Figure 23 : Configuration du fichier
filebeat.yml (Partie Logstash)
Une fois la configuration terminée nous pouvons lancer
Filebeat et activer le démarrage avec le système.
|
sudo systemctl start filebeat sudo systemctl enable filebeat
|
? Installation sur le client Windows
Pour le client Windows nous allons télécharger la
version zipper x64bit de Winlogbeat.
Figure 24 : Téléchargement de
Winlogbeat sur Windows
37
38
Chapitre II : Réalisation
Puis l'extraire dans
C:\Program Files\ et éditer le fichier
Winlogbeat.
La configuration de Winlogbeat est presque le même que pour
Filebeat nous indiquons l'adresse de la machine serveur dans la section Kibana
qu'on décommette en enlevant le #.
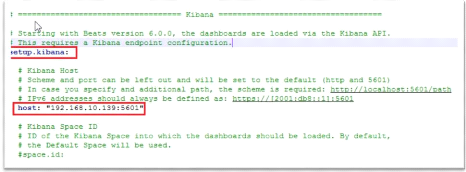
Figure 25 : Configuration de Winlogbeat
(Partie Kibana)
On commente la partie Elasticsearch pour pouvoir envoyer nos logs
à Logstash et configurons l'envoi des logs à travers une
vérification du certificat.
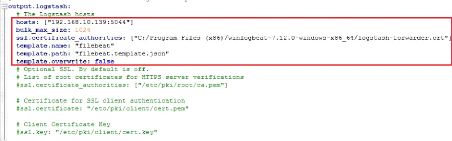
Figure 26 : Configuration de Winlogbeat
(Partie Logstash)
Pour pouvoir lancer le service Winlogbeat nous allons
exécuter PowerShell en mode administrateur et nous placer dans le
répertoire de Winlogbeat puis lancer le service Winlogbeat. Comme
l'exécution du script est désactivée sur notre
système, nous devons définir la politique d'exécution de
la session en cours pour autoriser l'exécution du script avec la
commande :
Chapitre II : Réalisation
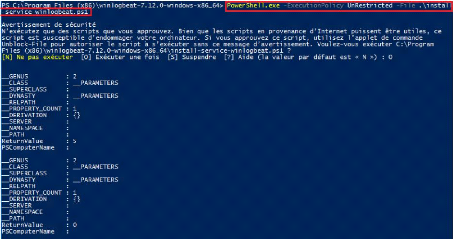
Figure 27 : Exécution du fichier
d'installation des services Winlogbeat
Puis nous allons enfin lancer Winlogbeat avec la commande :
start-service winlogbeat
Après avoir fait toutes les configurations
nécessaires et démarré tous les services sur les
différentes machines, on peut accéder à l'interface de
Kibana à travers l'url
http://192.168.10.139 sur n'importe
qu'elle machine du réseau. On doit s'authentifier avec le nom
d'utilisateur et le mot de passe qu'on a mis lors de la configuration avec
htpasswd pour y accéder.
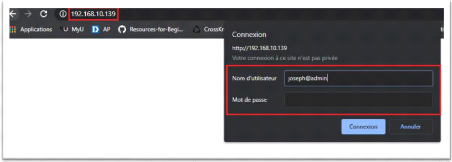
Figure 28 : Interface de connexion web de
Kibana
39
40
Chapitre II : Réalisation
Une fois loguer sur l'interface de Kibana la première
des choses qu'on va faire est de vérifier le statut de Kibana, en
accédant à l'URL 192.168.10.139/status. La page d'état
affiche des informations sur l'utilisation des ressources du serveur et
répertorie les plug-ins installés. Si la page indique que le
statut de Kibana est « green », alors tous les plugins fonctionnent
correctement.

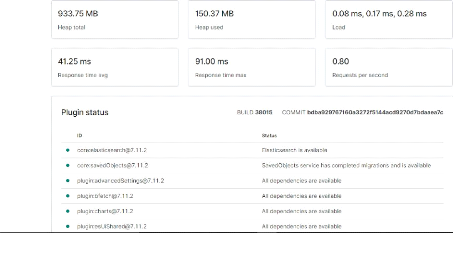
Figure 29 : Interface des status de Kibana
3.7 Installation des outils d'aide à la
détection des attaques
Cette partie sera consacrée à l'installation de
deux outils d'aide à la détection d'attaque c'est-à-dire
Suricata et Auditbeat.
Suricata est un IDS (Intrusion Detection System) /IPS
(Intrusion Prevention Sytem) open source basé sur des signatures, il
permet l'inspection des Paquets en Profondeur et une détection
automatique de protocole (IPv4/6, TCP, UDP, ICMP, HTTP, TLS, FTP, SMB, DNS).
Suricata analyse le trafic sur une ou plusieurs interfaces réseaux en
fonction des règles activés. Il génère, par
défaut, un fichier JSON. Celui-ci sera ensuite utilisé par notre
Stack pour l'analyse et la détection d'attaque.
41
Chapitre II : Réalisation
Auditbeat est un outil de collecte des données du
framework d'audit Linux et qui nous permet de surveiller
l'intégrité de nos fichiers. Auditbeat transfère ces
événements en temps réel vers la suite Elastic en vue
d'une analyse plus poussée.
Installation de Suricata sur le serveur Elastic
Stack
Pour son installation et son fonctionnement Suricata aura besoin
de certain packages qu'on doit installer au préalable. Dans ces packages
nous remarquons les outils gcc, make et beaucoup d'autres librairies.
sudo yum -y install libpcap-devel libcap-ng-devel libnet-devel
prce-devel gcc gcc-c++ automake autoconf libtool make libyaml-devel zlib-devel
libprelude-devel libtool-ltdl-devel file-devel
Une fois l'ensemble des packages installer nous allons
récupérer à travers wget la dernière version de
Suricata sur le site officiel de openinfosecfoundation. A ce jour Suricata est
à sa version 6.0.2.
wget
https://www.openinfosecfoundation.org/download/suricata-6.0.2.tar.gz
Une fois le téléchargement du fichier fini nous le
décompressons avec l'outil tar.
tar -zxvf suricata-6.0.2.tar.gz
Puis on se place dans le répertoire de Suricata en
fessant "cd suricata-6.0.2" et on lance le script de configuration permettant
d'adapter suricata à notre système et verifier si toute les
dépendances sont installées. Cette commande va definir
/usr/bin/suricata comme repertoire de suricata, placer la configuration dans
/etc/suricata et /var/log/suricata comme repertoire de log.
./configure -sysconfdir=/etc --localstatedir=/var --prefix=/usr/
--enable-lua --enable-geoip
Après cette commande nous allons compiler et installer les
règles et les configurations de Suricata avec les commandes :
make
make install-full
Suricata est maintenant installer sur notre serveur Elastic
Stack.
Nous allons maintenant configurer le fichier de configuration de
Suricata qui se trouve dans /etc/suricata/suricata.yaml.
42
Chapitre II : Réalisation
Le fichier de configuration de Suricata contient plusieurs
options. Mais pour une utilisation basique on va seulement configurer le
réseau sur lequel écoute Suricata et l'interface attachée
à ce réseau.
Dans la section `vars' nous allons indiquer dans le variable
HOME_NET l'adresse IP sur lequel Suricata doit écouter et tous les
réseaux locaux qu'il doit protéger. Dans notre cas l'adresse de
notre réseau local est le 192.168.10.0/24.
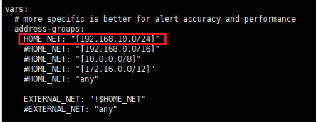
Figure 30 : Configuration de la variable
HOME_NET
Sous la section "af-packet " nous indiquons le nom de notre
interface qui est ens37.

Figure 31 : Définition de l'interface
réseau dans le fichier suricata.yaml
Et dans la variable "default-rule-path" nous indiquons le
répertoire des règles de Suricata.

Figure 32 : Définition de la variable
default-rule-path
Nous sauvegardons le fichier et nous désactivons
l'offloading des paquets Suricata en désactivant l'interface Large
Receive Offload (LRO) / Generic Receive Offload (GRO) avec la commande :
ethtool -K ens37 gro off lro off
43
Chapitre II : Réalisation
Pour vérifier si cela a été bien
désactiver nous lançons la commande ethtool -k ens37 | grep -iE
"generic|large " et nous remarquons que le generic-receive-offload et le
large-receive-offload sont sur off.

Figure 33 : Vérification du GRO et du
LRO
Une fois toute notre configuration finie nous pouvons tester
la configuration avec lacommande suricata -c /etc/suricata/suricata.yml -T -v
et si la sortie de cette commande ne donne pas d'erreur nous pouvons lancer
Suricata.
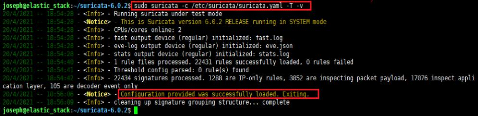
Figure 34 : Test de la configuration de
Suricata
Lançons Suricata avec la commande :
suricata -D -c /etc/suricata/suricata.yml -i ens37
Sachant que ens37 est le nom de notre interface. L'option -D
permet de lancer suricata en arrière-plan et l'option -c permet
d'indiquer le fichier de configuration de Suricata.
Pour que les logs de Suricata puissent être envoyé
à Elasticsearch à travers Filebeat nous activons le module
Suricata de Filebeat avec la commande `filebeat modules enable suricata'. Puis
nous lançons la commande `filebeat setup' pour créer les
dashboards de Filebeat dans Kibana contenant le dashboard de Suricata.
Installation de Suricata sur la machine cliente Ubuntu
L'installation de Suricata sur CentOS et sur Debian reste les
même à quelque millimètre prêt à part les noms
des dépendances qui diffère de Red Hat à Debian les
étapes d'installation reste les mêmes rien ne change des commandes
à la configuration tout reste les mêmes.
Chapitre II : Réalisation
On lance la commande ci-dessous pour installer les
dépendances :
sudo apt-get install rustc cargo make libpcre3 libpcre3-dbg
libpcre3-dev build-essential autoconf automake libtool libpcap-dev libnet1-dev
libyaml-dev zlib1g zlib1g-dev libcap-ng-dev libcap-ng0 libmagic-dev
libjansson-dev libjansson4 pkg-config -y
Une fois les dépendances installés nous suivons
les mêmes étapes d'installation comme sur le serveur Elastic
Stack.
Installation d'Auditbeat sur le serveur Elastic
Stack
L'importance d'Auditbeat est qu'il permet une surveillance
attentive des listes de répertoires, afin de déceler toute
anomalie sous Linux, MacOS et Windows. Si un de ces fichiers est
modifié, il notifie à Elasticsearch en temps réel pour une
analyse approfondie. Ces messages contiennent les métadonnées et
les hachages cryptographiques associés aux contenus des fichiers
concernés.
Pour installer Auditbeat nous aurons besoin de
récupérer la dernière version d'Auditbeat disponible et
compatible à notre système sur le site officiel d'Elastic avec la
commande wget.
wget
https://artifacts.elastic.co/downloads/beats/auditbeat/auditbeat-7.11.2-x86_64.rpm
Une fois Auditbeat télécharger nous allons
l'installer avec la commande `rpm -ivh auditbeat-7.11.2-x86_64.rpm'.
On va configurer le fichier de configuration de Auditbeat
situé dans `/etc/auditbeat/auditbeat.yml'.
Par défaut, le module `file_integrity' est
activé. Ce module surveille les modifications de fichiers telles que
lorsqu'un fichier est créé, mis à jour ou supprimé.
On peut ajouter dans cette section les autres fichiers qu'on veut monitorer
différent de ceux disponibles par défaut.
Dans le fichier de configuration de Auditbeat on
décommente le paramètre d'output vers Elasticsearch car nous
voulons que nos données soient envoyées à Logstash
d'abord.
44
Chapitre II : Réalisation
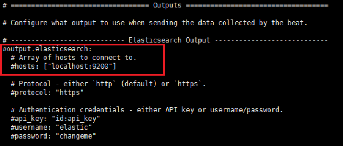
Figure 35 : Configuration du fichier de
configuration de Auditbeat output Elasticsearch
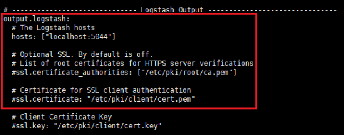
Figure 36 : Configuration du fichier de
configuration de Auditbeat output vers Logstash
Une fois toute les configurations nécessaires
effectuées on peut démarrer Auditbeat et activer le
démarrage automatique.
|
systemctl start auditbeat systemctl enable auditbeat
|
45
Chapitre II : Réalisation
Conclusion
Dans cette partie dédiée au déploiement
et à la configuration de la pile Elastic, nous avons tout d'abord
installer et configurer l'ensemble des programmes qui constitue notre pile
ainsi que configurer le chiffrement SSL pour sécuriser la communication
entre les éléments de notre stack. Ensuite nous avons
installé les agents Beats sur nos machines clientes Windows et Ubuntu
pour nous permettre de recevoir les logs et les évènements sur
notre serveur. Enfin nous avons installé deux outils d'aide à la
détection d'attaque à savoir l'IPS/IDS Suricata et Auditbeat, des
outils qui vont aider notre SIEM à être plus efficace et
efficient.
Notre solution SIEM permettra donc d'une part d'obtenir des
informations liées à la sécurité et l'état
de notre système d'information et d'autre part de gérer les
incidents de sécurité informatique.
La prochaine étape consistera à
expérimenter et tester notre solution afin de présenter de
manière plus explicite ses fonctionnalités.
46

CHAPITRE III : TESTS ET
EVALUATIONS
Plan
|
Introduction
|
48
|
1. Prise en main et exploration des données sur Kibana
|
48
|
2. Visualisation des données
|
53
|
3. Scénarios d'attaque et détection des attaques
|
|
59
|
|
|
Conclusion
|
.77
|
47
48
CHAPITRE III : TESTS ET EVALUATIONS
Introduction
La dernière partie dans ce projet, consiste à
explorer les différentes données et graphes
générés par Kibana et évaluer le bon fonctionnement
de la solution en effectuant des tests divers et des scénarios
d'attaques.
1 Prise en main et exploration des données sur
Kibana
Avant d'utiliser l'interface de Kibana, il faut commencer par
créer des modèles d'index (index patterns) dans le volet "Stack
management/ Index Patterns/Create index pattern", afin d'indiquer à
Kibana quels sont les indices Elasticsearch qu'on veut explorer. Un index peut
être considéré comme un ensemble de documents, chaque
document est formé par des champs, qui sont des paires clé-valeur
contenant les données.
Comme on à indiquer à Logstash de nommer
winlogbeat-[date] tous les données venant de Winlogbeat et
filebeat-[date] tous les données venant de Filebeat. Dans `index pattern
name' nous indiquons le nom winlogbeat-* pour regrouper tous les index venant
de Winlogbeat.
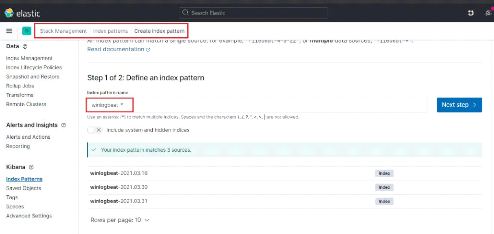
Figure 37 : Création des modèles
d'index de Winlogbeat
Dans `time field' nous indiquons @timestamp qui correspond au
champs d'horodatage des fichiers journal venant de Winlogbeat.
49
Chapitre III : Tests et évaluations
Explorer les données de manière interactive se
fait à partir de la page `Discover'. On peut soumettre des
requêtes de recherche, filtrer les résultats et afficher des
champs spécifiques. La répartition des documents dans le temps
est affichée dans un histogramme en haut de la page et l'index sur
lequel se porte notre recherche se trouve à gauche.
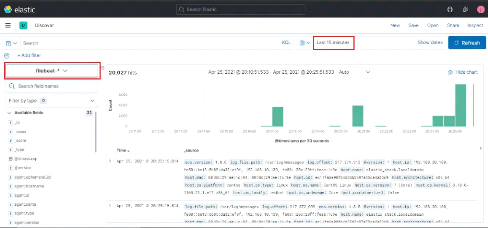
Figure 38 : Page `Discover' de Kibana (index
filebeat)
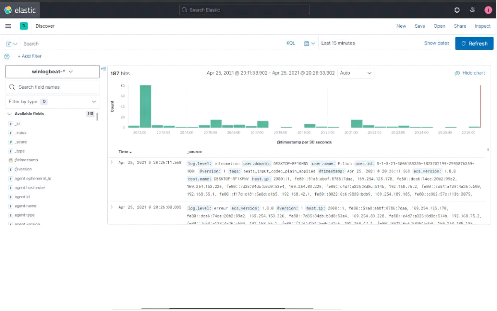
Figure 39 : Page `Discover' de Kibana (index
Filebeat)
Et pour l'index winlogbeat.
Chapitre III : Tests et évaluations
On peut consulter l'intégrité du document sous
forme de table ou sous format JSON en cliquant sur la flèche à
gauche. Le format table particulièrement, permet de mieux visualiser
tous les champs du document.


Figure 40 : Visualisation des logs sous forme de
table
La barre "search" permet de saisir des requêtes selon
des critères de recherche précis. Les conditions sont
exprimées à l'aide du langage d'interrogation de Kibana (KQL)
basé sur les opérateurs mathématiques et logiques. Par
exemple, on peut filtrer les évènements d'authentifications SSH
échouer du 25/04/2021 à travers le filtre message : "sshd" and
message : "Failed password and @timestamp : "2021-04-25" qui indique à
Kibana de chercher tous les évènements dont le contenu du champs
message contient le mot "sshd" et en plus les mots « Failed password
» et dont le timestamp correspond à 2021-04-25.
50
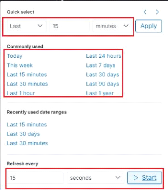
51
Chapitre III : Tests et évaluations
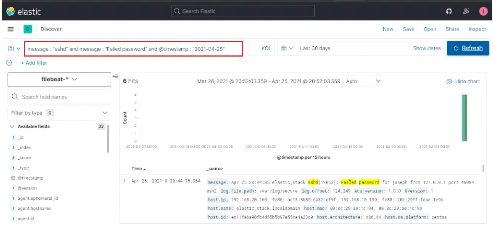
Figure 41 : Filtrage des authentifications
réussies du 25/05/2021
Le sélecteur temporel est défini par
défaut sur les 15 dernières minutes. Toutefois, on peut
définir l'intervalle de temps exact qu'on veut visualiser. Cet
intervalle peut être relatif ou absolu, c'est-à-dire qu'on peut
spécifier l'année, le mois, le jour ainsi que l'heure à la
milliseconde près. Il nous permet aussi de définir le temps de
rechargement de l'index s'il est défini l'index sera rafraîchit
selon le temps indiquer ceci n'est pas obligatoire.
Figure 42 : Paramétrage du
sélecteur de temps selon le mode "Relative"
Chapitre III : Tests et évaluations
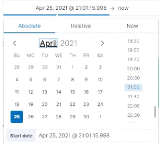
Figure 43 : Paramétrage du
sélecteur de temps selon le mode "Absolute"
On peut créer des filtres de recherche et les
enregistrer à l'aide de l'outil "+add filter" situé en dessous de
la barre de recherche. Le filtre fonctionne directement suite à sa
création et on peut le désactiver à tout moment. Un
exemple de filtre est de rechercher les évènements venant de la
machine serveur Elastic Stack.

Figure 44 : Exemple de filtre de recherche
52
53
Chapitre III : Tests et évaluations
2 Visualisation des données
Une image vaut mieux que 1 000 lignes de log, sur Kibana un
onglet visualisation est prévu pour faire la visualisation de nos
données, on touche ici au coeur de Kibana, il est constitué
d'outils nous permettant d'agréger nos données et d'afficher les
résultats sous formes de graphes, de courbes, de bâtons et de
diagrammes circulaires. Pour plus d'information voir [6]
2.1 Création d'une visualisation sur Kibana
Toute idée de visualisation est réalisable,
ça dépend juste de nos besoins et de notre imagination. Pour
notre première visualisation on va afficher dans un « donut »
(type de graphique circulaire en forme de donut) la machine qui a produit plus
de log pendant la dernière semaine entre notre serveur et notre machine
Ubuntu.
Pour se faire on se rend dans l'onglet "Visualize" qui se
trouve dans "Analytics/Visualize/" puis "Create visualisation". Une fois dans
cet onglet on voit les différents types de visualisation qu'on peut
créer.
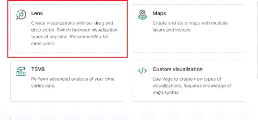
Figure 45 : Types de visualisation disponibles
dans Kibana
Kibana propose des visualisations variées comme les :
heatmaps, diagrammes en bâtons, graphiques en aires et bien d'autres
types de visualisation. Nous pouvons remarquez dans la capture d'écran
ci-dessous les types de visualisation qui existe sur Kibana et nous choisissons
la visualisation Donut qui est la visualisation qui nous intéresse.
Chapitre III : Tests et évaluations
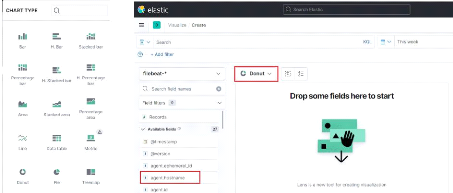
Figure 46 : Menu de sélection pour les
types de visualisation
Une fois qu'on a choisi notre visualisation on peut maintenant
glisser et déposer les champs qui doivent figurer dans notre
visualisation. Pour notre cas l'étude se portera sur le nom des machines
donc on est intéressé par le field "agent.hostname", on le
choisit puis on fait un glissé déposé dans le champs
prévu à droite.

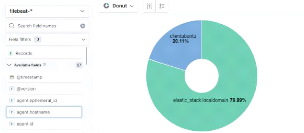
54
Figure 47 : Première visualisation
créée
Une fois notre visualisation créée on peut
l'enregistrer puis l'utiliser après pour nos futurs dashboards.
Chapitre III : Tests et évaluations
2.2 Création d'un tableau de bord (dashboard)
Avec les tableaux de bord, nous pouvons transformer les
données d'un ou plusieurs modèles d'index en un ensemble de
panneaux qui clarifient nos données. On peut comparer les panneaux
côte à côte pour identifier les modèles et les
connexions dans nos données.
Dans cette partie on va créer un dashboard contenant la
visualisation créée précédemment et certaines
visualisations en plus.
Pour créer un dashboard on se rend dans
"Analytics/Dashboard" puis "Create dashboard".
Figure 48 : Onglet de création d'une
nouvelle visualisation Kibana
Et comme on a déjà créé une
visualisation on fait "Add from library" pour ajouter cette visualisation en
d'autre cas on peut directement créer une visualisation dans cet
onglet.
Une visualisation peut être ajouter à
côté de celui ajouté pour avoir un dashboard plus parlant.
Nous allons ajouter la visualisation des top alertes de Suricata, du nombre
d'évènement produit par Suricata, des types de protocole
utilisé et du top des protocoles de transport utilisé.
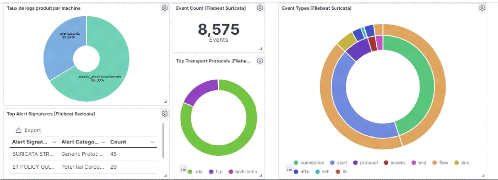
Figure 49 : Première Dashboard
crée sur Kibana
55
Chapitre III : Tests et évaluations
2.3 Exploration des tableaux de bord Kibana fournit par
Filebeat
Filebeat est livré avec des exemples de Dashboard
Kibana, pour visualiser les données Filebeat dans Kibana. Avant de
pouvoir utiliser les tableaux de bord de Filebeat, nous devons avoir un index
filebeat-*, et charger les tableaux de bord dans Kibana avec la commande
filebeat setup -e, ce qu'on a déjà fait quand on a
installé Filebeat.
Une recherche du mot "filebeat" dans l'onglet
"Analytics/Dashboard" nous permet d'afficher la liste de tous les dashboards de
Filebeat.
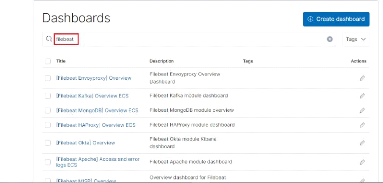
Figure 50 : Liste des dashboards Filebeat
Nous allons explorer plus précisément le
Dashboard prévu pour visualiser les alertes de Suricata nommé
"[Filebeat Suricata] Alert Overview".
La première partie de ce Dashboard comporte un
graphique de comparaison des logs produit par machine et une liste des alertes
Suricata.
56
57
Chapitre III : Tests et évaluations
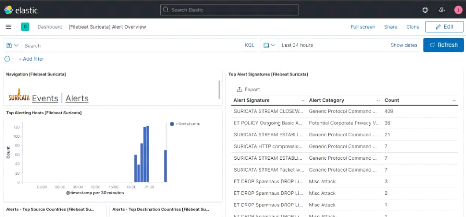
Figure 51 : Première partie du dashboard
de Suricata
La deuxième partie nous renseigne sur le top des pays
d'où proviennent les IP de nos alertes (sources et destinations).
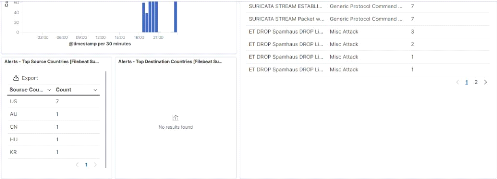
Figure 52 : Deuxième partie du Dashboard
de Suricata
La troisième partie du Dashboard est un maps qui permet de
voir la localisation de nos IP contenu dans les logs (sources et
destinations).
Chapitre III : Tests et évaluations
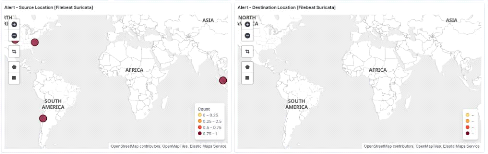
Figure 53 : Troisième partie du Dashboard
de Suricata
La dernière partie du Dashboard est la plus instructive
car elle permet d'avoir une panoplie d'informations sur nos logs (horodatage,
nom de la machine, IP de la machine, les ports, le types d'attaque, le type de
système d'exploitation utilisé, son architecture, et plein
d'autre information).
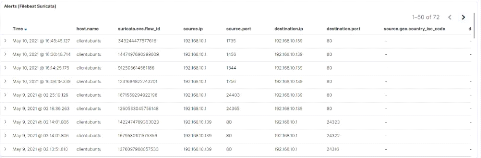
Figure 54 : Quatrième partie du Dashboard
de Suricata
58
59
Chapitre III : Tests et évaluations
3 Scénarios d'attaque et détection des
attaques
Cette partie sera consacré à une série de
scénario d'attaque que peut faire un attaquant sur nos systèmes
et tester le fonctionnement de notre SIEM en détectant ces
différentes attaques. Les attaques suivantes seront
réalisées pour tester le fonctionnement de notre SIEM :
· Attaque par brute force sur le protocole SSH
· Attaque par Denis de service(DOS)
· Attaques locales de type système :
· Elévation de privilège (modification du
fichier sudoers)
· Désactivation du firewall
· Attaque réseau : Scan des ports Nmap
· Attaque de Brute force des répertoires d'un
serveur Web (Fuzzing Web)
· Attaque par malwares
3.1 Attaque par brute force SSH
Une attaque dite « brute force SSH » consiste
à des tentatives de connexions SSH effectuant une succession d'essais
pour découvrir un couple utilisateur/mot de passe valide afin de prendre
le contrôle de la machine. Il s'agit d'une attaque très
répandue et toute machine exposée sur internet se verra attaquer
plusieurs fois par jour. Pour plus d'information voir [7]
Pour chaque tentative d'authentification échoué
le démon SSH génère un journal syslog ressemblant à
celui-ci :
Apr 25 19:55:10 tiger2 sshd[2525]: Failed password for joseph
from 1.2.3.4 port 48459 ssh2
Ce journal permet de récupérer le nom
d'utilisateur, l'adresse IP et le port utilisés pour une tentative de
connexion.
A travers Filebeat les logs SSH sont acheminé vers
Elasticsearch et à travers le moteur de détection de Kibana nous
allons créer une règle de détection qui va nous permettre
de détecter une attaque par brute force SSH.
Pour créer cette règle nous allons nous rendre
dans le moteur de détection de Kibana situé dans la barre
à gauche puis ensuite aller dans "Manage detection rules".
60
Chapitre III : Tests et évaluations
Figure 55 : Manage detection rules
Puis on se rend dans "Create new rule"
Une fenêtre de configuration de la règle
s'affiche nous demandant de choisir le type de règle, Les types de
règle disponible dans Kibana sont les suivantes :
y' Custom query : règle basée
sur une requête, qui recherche les index définis et crée
une alerte lorsqu'un document correspond à la requête de la
règle.
y' Machine learning : règle de machine
learning, qui crée une alerte lorsqu'un travail de machine learning
découvre une anomalie au-dessus du seuil défini.
y' Threshold rules : recherche les index
définis et crée une alerte de détection lorsque le nombre
de fois où la valeur du champ spécifié atteint le seuil au
cours d'une seule exécution.
y' Event correlation : recherche les index
définis et crée une alerte lorsque les résultats
correspondent à une requête EQL (Event Query Language).
y' Indicator match : crée une alerte
lorsque les valeurs de champ d'index Elastic Security correspondent aux valeurs
de champ définies dans les modèles d'index d'indicateur
spécifiés.
Dans notre cas c'est le "Threshold rules" qui nous
intéresse et nous le choisissons puis dans index patterns on indique
l'index qui nous intéresse on peut choisir tous les index mais pour
réduire le temps de recherche on indique de préférence
l'index concerné qui est l'index filebeat-*.
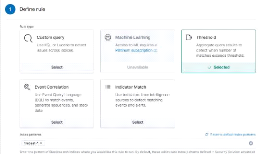
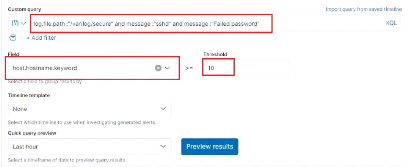
61
Chapitre III : Tests et évaluations

Figure 56 : Configuration de la règle
section "Define rule"
Dans Custom query on met notre requête KQL :
log.file.path : "/var/log/secure" and message : "sshd " and
message : " Failed password "
Cette requête permet d'aller chercher dans le fichier
"/var/log/secure" qui est le fichier dans lequel se situe les logs SSH dans
CentOS puis récupérer tous les logs contenant les mot "sshd" et
"Failed password".
Dans Field on met host.hostname.keyword pour que l'alerte soit
générée pour chaque machine qui apparaît (on peut y
mettre aussi adresse IP) et dans "Threshold" nous indiquons le nombre de fois
d'apparition d'une réponse de la requête. Ici on a choisi 10
puisqu'on trouve qu'une personne légitime connaissant bien son mot de
passe ne va pas faire plus de 10 tentatives de connexion échouée
chaque minute. Ceci dépend de l'analyse qu'on a faite mais on peut y
indiquer le nombre de fois qu'on veut.
Figure 57 : Configuration de la règle
section "Define rule" 2
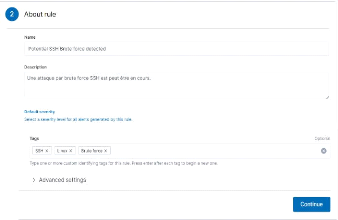
62
Chapitre III : Tests et évaluations
Dans "About rule" on met le nom de notre règle par ex :
"Potential SSH Brute force detected", puis on met une description et un tag qui
classera l'attaque.
L'option default severity contient ces différentes options
:
? Low : alertes qui présentent un
intérêt mais qui ne sont généralement pas
considérées comme des incidents de sécurité.
Parfois, une combinaison d'événements de faible gravité
peut indiquer une activité suspecte.
? Medium : alertes qui nécessitent une
enquête.
? High : alertes qui nécessitent une
enquête immédiate.
? Critical : alertes indiquant qu'il est
très probable qu'un incident de sécurité s'est produit.
Pour cette attaque nous allons définir le niveau de
sévérité à Medium puisque ça
nécessite une enquête.
Figure 58 : Configuration de la règle
brute force SSH `About rule'
Et enfin nous mettons le temps dans lequel nous voulons que
notre règle soit vérifiée soit 1 minutes (ce temps est
flexible selon notre règle).
Ce qui fait en conclusions qu'on aura une alerte à
chaque fois que notre requête est répéter plus de 10 fois
en 1 minutes.
63
Chapitre III : Tests et évaluations
Figure 59 : Configuration de la règle
section "Schedule rule"
La dernière configuration concerne l'action à
effectuer une fois l'alerte détecté. On peut décider
d'envoyer une notification par (mail, sur PaperDuty, Slack, Slack, Webhook,)
pour nous avertir de l'attaque mais cette option n'est pas disponible sur la
licence qu'on utilise donc on pourra pas configurer cette partie.
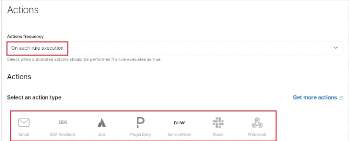
Figure 60 : Configuration de la règle
section "Actions"
Après toute la configuration nous recevrons un message
montrant que notre règle a été créer Et dans la
liste des règles de détection nous avons notre règle qui
apparait dans la liste

Figure 61 : Aperçu de la règle
créée
Une fois notre règle créer nous allons enfin
lancer une attaque par brute force SSH à travers notre machine Kali
Linux avec l'outils Hydra.
On lance la commande :
hydra -l nomdutilisateur -P dictionnaire.txt
ssh://@IPdelamachine
64
Chapitre III : Tests et évaluations

Figure 62 : Attaque Brute force avec l'outil
Hydra
Après avoir lancer l'attaque et une minute après
dans le moteur de détection nous remarquons que notre SIEM à bien
détecter l'attaque et à créer une alerte.
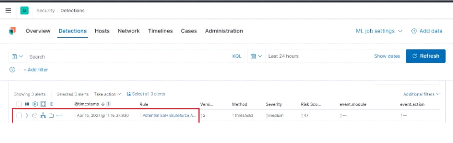
Figure 63 : Attaque par brute force SSH
détecté avec succès par Kibana
3.2 Attaque par Denis de service(DOS)
Le déni de service (ou DoS : Denial of Service) est une
attaque qui vise à rendre indisponible un service le rendant incapable
de répondre aux requêtes de ses utilisateurs légitimes.
Lors d'une attaque DoS, l'attaquant déclenche ce «
déni de service » de façon délibérée en
bombardant la connexion réseau responsable de l'échange de
données externe dans un système informatique avec un flot de
requêtes afin de le surcharger. Lorsque le nombre de requêtes
dépasse la limite de capacité, le système ralentit ou
s'effondre complètement.
On peut comparer une attaque DoS à une boutique
physique dans laquelle des centaines de personnes se présente afin de
distraire le personnel avec des questions déroutantes sans rien
acheté bloquant ainsi les clients intéressés. Le personnel
est surchargé jusqu'à épuisement et les clients effectifs
ne peuvent plus accéder à la boutique et ne sont donc pas
servis.
Ce type d'attaque est très simples à effectuer
parce qu'elles ne nécessitent pas de pénétrer dans des
systèmes informatiques sécurisés. Il n'est pas
nécessaire de disposer de connaissances techniques ou d'un budget
important pour effectuer ce type d'attaques. Pour plus d'information voir
[14]
Chapitre III : Tests et évaluations
Pour détecter une attaque DoS avec notre SIEM nous
allons nous servir de l'IDS/IPS Suricata puisqu'il a une règle
détectant ce type d'attaque. Pour l'alerte on va aussi se servir du
Dashboard suricata de Filebeat déjà disponible dans Kibana.
On pouvait aussi créer une alerte dans le moteur de
détection de Kibana mais cette fois ci on va utiliser le dashboard de
suricata pour pouvoir découvrir celui-ci.
Le dashboard de suricata pour les alertes se trouve dans
"Analytics/Dashboard/[Filebeat Suricata] Alert Overview"
Le dashboard de suricata nous offre une vue
détaillée sur les attaques et les menaces présente sur
notre réseau en temps réel et une cartographie sur la
localisation des IP de l'attaque (source et destinateur).
Le dashboard à la base est déjà
prête et nous pouvons lancer notre attaque DoS avec l'outil hping3 sur la
machine Kali Linux.

Figure 64 : Attaque DoS avec l'outil Hping3 sur
Kali Linux
Après quelques minutes on peut arrêter l'attaque et
remarquer qu'il y a une nouvelle alerte présente dans le dashboard de
Suricata.
Le nom de l'alerte est "LOCAL DOS SYN packet flood inbound,
Potential DOS" (nom personnalisable dans le fichier des règles de
Suricata).
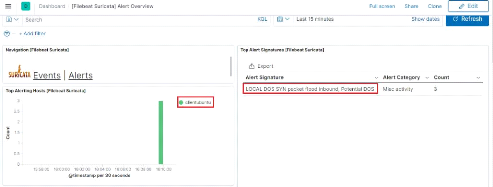
Figure 65 : Détection de l'alerte par le
dashboard Suricata
65
66
Chapitre III : Tests et évaluations
Une fois l'alerte créer et que nous voulions faire une
investigation sur l'alerte on peut cliquer sur l'icône + situé
à la fin du nom de l'alerte.
Ce bouton permet de créer un filtre nous montrant des
détails sur l'attaque dans ces détails on peut retrouver :
l'adresse IP source de l'attaque, le port source, la destination qui est notre
machine Ubuntu, le port destinateur qui nous permet de voir sur quel protocole
a été lancer l'attaque. Ces informations peuvent nous permettre
de bloquer ces adresses ou arrêter le service du protocole servant
à faire l'attaque.
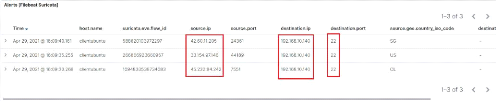
Figure 66 : Détails de l'attaque DoS dans
le dashboard
Le dashboard va même loin en nous montrant sur un maps la
localisation de IP de l'attaquant et du destinateur.
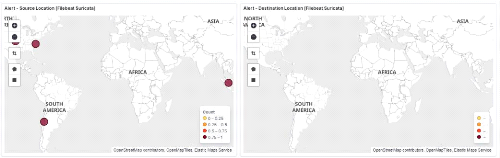
Figure 67 : Maps de localisation des IP de
l'attaque
3.3 Attaques locales de types système
Ici nous allons réaliser deux types d'attaque qu'un
attaquant peut effectuer une fois qu'il a accès à notre
système, pour ces deux types d'attaque système il existe
déjà des règles par défaut sur Kibana qui nous
permettra de détecter ces types d'attaque. Donc on va seulement les
chargées sur Kibana et les activés dans
"Security/Detections/Detection rules/Load Elastic prebuilt rules and timeline
templates".
Chapitre III : Tests et évaluations


67
Figure 68 : Chargement des règles par
défaut
Une fois ces règles chargées on aura une liste
constituée de plus de 400 règles fourni par Kibana.
Elévation de privilège (modification du
fichier sudoers)
sudo (abréviation de substitute user do) est une
commande permettant à l'administrateur système d'accorder
à certains utilisateurs (ou groupes d'utilisateurs) la
possibilité de lancer une commande en tant qu'administrateur.
Les droits d'administrateur peuvent être attribuer
à un utilisateur ou un groupe à travers le fichier
"/etc/sudoers". L'ajout d'une ligne avec les bonnes instructions peut permettre
à un utilisateur d'être administrateur dans notre système.
Un attaquant peut modifier ce fichier une fois qu'il a accès à
notre système sans que l'administrateur du système ne se rende
compte. Détecter cette attaque avec Kibana est très facile puis
ce qu'une règle y est déjà réservée au
préalable il nous suffira juste de l'activer.
Pour se faire on va dans "Security/Detections/Detections
rules" puis on met dans la barre de recherche le mot sudoers puis ce que le nom
de notre règle est "Sudoers File Modification", une fois la règle
apparut on l'active avec le bouton se trouvant dans la colonne "Activated".
Chapitre III : Tests et évaluations

Figure 69 : Activation de la règle
"Sudoers File Modification"
68
La règle activée on peut maintenant se mettre dans
la peau d'un hacker et modifier le fichier "/etc/sudoers" sur notre machine
serveur Elastic Stack, toutes modifications sera détecté.
Figure 70 : Modification du fichier sudoers
Après la modification du fichier sudoers, 5 minutes
après (le temps définit par cette règle) on reçoit
une alerte disant que le fichier sudoers a été modifier.

Figure 71 : Alerte "Sudoers File Modification"
détecté par Kibana
Désactivation du firewall
Le firewall est essentiellement un dispositif de protection
qui constitue un filtre entre un réseau local et un autre réseau
non sûr tel que l'Internet ou un autre réseau local.
Donc il constitue un outil très important pour notre
système car il permet une protection contre : les hôtes du
réseau local et de l'extérieur et contre les logiciels
malveillants.

69
Chapitre III : Tests et évaluations
Un attaquant une fois sur notre système peut le
désactiver exposant notre système à un grand danger, pour
que ceci n'arrive pas sans qu'on ne se rende compte on va créer une
règle permettant d'être alerter à chaque fois que notre
firewall est désactivé.
Comme pour l'attaque précédente une règle
est déjà réservé pour cette attaque dans les
règles par défaut de Kibana on a juste à le chercher et
à l'activer.
Dans "Security/Detections/Detections rules" on recherche le mot
"Firewall" car le nom de la règle est "Attempt to Disable IPTables or
Firewall" puis on l'active.
Figure 72 : Activation de la règle
"Attempt to Disable IPTables or Firewall"
On désactive le firewall avec la commande "systemctl stop
firewall" pour CentOS et "sudo ufw disable" pour Ubuntu.
5 minutes après la désactivation du firewall on
reçoit une alerte pour cette violation de règle.
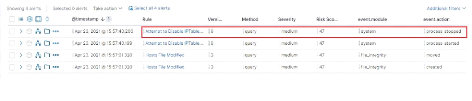
Figure 73 : Alerte pour la désactivation
du firewall
3.4 Attaque réseau : Scan des ports Nmap
Le scanning est une méthode pour découvrir des
voies de communications exploitables sur un système c'est une technique
d'attaque qui existe depuis longtemps. L'idée est de sonder autant de
voies que possibles et de garder celles qui sont réceptives ou
particulièrement utiles. Avec le scanning de port on peut
déterminer les ports ouvert et fermé sur un système on
peut alors déterminer si un port est ouvert et alors voir les
différentes failles existantes sur ce protocole ou sur la version du
logiciel installé.
Ici nous allons utiliser NMAP qui est un des logiciels les
plus répandu, open source, et surtout disponible sur Windows, macOS et
Linux.
Chapitre III : Tests et évaluations
Pour détecter cette attaque nous allons nous servir de
Suricata qui détecte les scan Nmap et créer un log à
chaque 40 port scanner et le log crée contient le champs rule name : "ET
SCAN Possible Nmap User-Agent Observed"
Une fois qu'on lance un scan nmap il scan les 1000 ports les
plus fréquent et pour un scan nmap on aura au minimum 25 log venant de
suricata.
Pour créer cette nouvelle règle on fait Security
? Detections ? Manage detection rules ? Create new rules, on choisit Threshold
ce qui correspond au type de règle qu'on veut créer puis on met
index filebeat-* et on met la requête :
Rule.name : "ET SCAN Possible Nmap User-Agent Observed"
Cette requête va chercher dans l'index filebeat-*
tous les logs qui dans rule.name contient la phrase :
"ET SCAN Possible Nmap User-Agent Observed"
Et dans "Threshold" on met 25 qui correspond exactement à
un scan normal de port Nmap

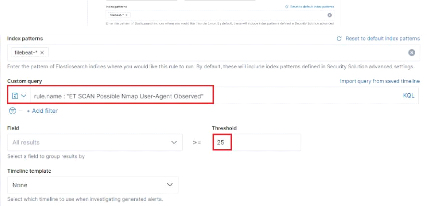
Figure 74 : Création de la règle
pour la détection de scan Nmap section "Define rule "
70
Chapitre III : Tests et évaluations
On indique "Nmap scan Detected" comme nom de la règle, une
petite description, un tag pour notre alerte et 2 minutes comme temps de
vérification de l'alerte.

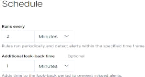
Figure 75 : Création de la règle
pour la détection de scan Nmap section "Schedule rule "
On enregistre notre règle de détection puis
à travers notre machine Kali Linux nous lançons le scan Nmap pour
tester notre règle.
On lance la commande "nmap -A 192.168.10.140" pour scanner les
ports et ainsi afficher les ports ouverts.
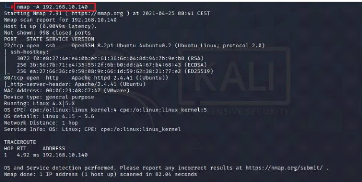
Figure 76 : Scan Nmap sur Kali Linux
71
72
Chapitre III : Tests et évaluations
Une fois notre scan nmap terminé et 2 minutes (selon le
temps défini) on voit une alerte qui apparait.

Figure 77 : Alerte "Nmap scan Detected"
3.5 Attaque de Brute force des répertoires d'un
serveur Web (Fuzzing Web)
Brute forcer les répertoires d'un serveur Web peut
être utile pour trouver des informations confidentielles, qui n'auraient
pas dû être disponibles à un utilisateur lambda. Cela permet
aussi de comprendre un peu mieux l'architecture du site Web (l'utilisation par
exemple d'applications ou de frameworks open source vulnérables), ce qui
permet à un attaquant d'arriver assez rapidement à une
exploitation possible pour prendre le contrôle, ou infecter le
système de programmes malveillants. Pour plus d'information voir [13]
L'attaque consiste à travers un fuzzer exécuter
des requêtes http contenant dans l'URL des noms de répertoire et
des noms de fichier et à travers le résultat il va
déterminer si ces répertoires et fichier existe ou pas. Pour
cette attaque un tas de log avec le code d'erreur 404 va se créer
puisque à chaque répertoire non trouver un 404 apparait. Donc on
va se servir de log de notre serveur web dans notre cas apache pour
détecter cette attaque.
Pour ce test un site web a été héberger sur
la machine Ubuntu.
Comme les autres règle d'alerte on crée une
règle pour cette attaque avec les caractéristiques suivantes :
Index patterns : filebeat-*
Custom query : log.file.path :
"/var/log/apache2/access.log" and http.response.status_code : "404"
Cette requête permet d'aller chercher dans le fichier
/var/log/apache2/access.log toute les requête http dont le code d'erreur
correspond au 404.
Threshold : 200
Field : user_agent.os.name
Name : Web Fuzzing Attack Detected
DescrIPtion : (Personnalisable)
Default Severity : Medium
Chapitre III : Tests et évaluations
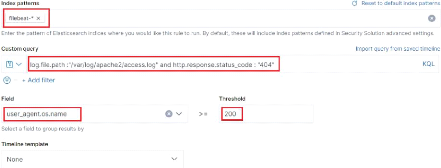
Figure 78 : Création de la règle
pour la détection du fuzzing web "Define rule"


Figure 79 : Création de la règle
pour la détection du fuzzing web "About rule"
Une fois la règle crée on lance l'attaque
à travers l'outil "dirb" sur la machine Kali Linux qui va nous permettre
de faire le brute force des répertoires de notre serveur web
situé sur la machine Ubuntu.
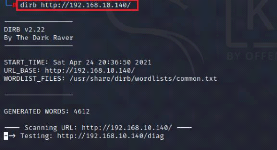
Figure 80 : Attaque avec dirb sur notre
serveur web
73
74
Chapitre III : Tests et évaluations
A la fin de l'attaque une alerte est créer
déclarant qu'une attaque de type Web Fuzzing a été
détecter.
Figure 81 : Détection de l'attaque "Web
Fuzzing Attack Detected" par Kibana
3.6 Attaque par malwares
Une attaque de malware se produit lorsqu'un logiciel
malveillant pénètre sur un système. Ce type d'attaque a
pour but l'accès aux données personnelles de la victime ou
endommager l'appareil, le plus souvent pour leur soutirer de l'argent. Les
virus, spywares, ransomwares et chevaux de Troie sont des types de malwares
différents.
La détection de cette attaque va se faire avec l'aide
de Winlogbeat qui est l'outil qu'on à installer
précédemment pour pouvoir envoyer les logs de Windows vers
Elasticsearch.
Winlogbeat par défaut n'envoie pas les logs de
l'antivirus à Elasticsearch pour qu'il puisse l'envoyer on ajoute une
configuration au fichier winlogbeat.yaml dans la section
"winlogbeat.event.logs" comme sur la capture. Pour plus d'information voir
[15]
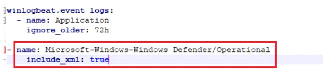
Figure 82 : Configuration de l'antivirus pour
Winlogbeat
On va maintenant créer la règle de
détection pour le Malware avec les caractéristiques suivantes
:
Index patterns : winlogbeat-*
Custom query : event.provider :
"Microsoft-Windows-Windows" and message : "Antivirus Microsoft Defender a
détecté un logiciel malveillant"
Une fois un malware détecter Windows créer un
log qui sera découper et qui contient en event.provider :
"Microsof-Windows-Windows Defender" et dans message le message spécifier
ci-dessus, à travers notre règle nous allons
récupérer ce log une fois qu'il y a un malware.
Thresold : 1
Chapitre III : Tests et évaluations
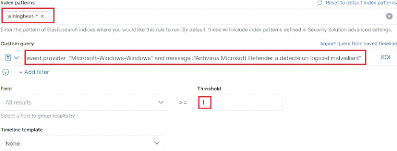
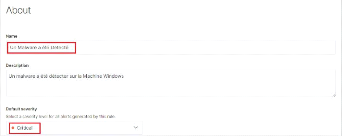
Figure 83 : Création de la règle
pour la détection de malware
75
Name : "Un Malware a été
détecté "
Description : (Description personnalisable
sur l'attaque)
Default severity : Critical
On met le "default severity" à critical puisqu'une
attaque par malware est très dangereux et le
niveau de sévérité est très
élevé.
Figure 84 : Création de la règle
pour la détection de malware section "About rule"
Runs every : 1 minutes
Le temps de vérification de l'alerte doit être
courte car il s'agit d'une attaque très dangereuse et une intervention
doit se faire rapidement en cas d'attaque de ce genre.
76
Chapitre III : Tests et évaluations
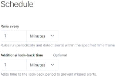
Figure 85 : Création de la règle
pour la détection de malware section "Schedule rule"
Pour tester notre règle on a
téléchargé un rasomware(WannaCry) compresser dans un
fichier rar.
Une fois qu'on extrait le ransomware l'antivirus va
détecter le malware.
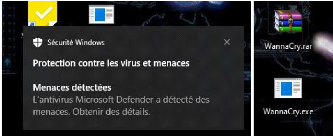
Figure 86 : Détection du malware par
l'antivirus Windows
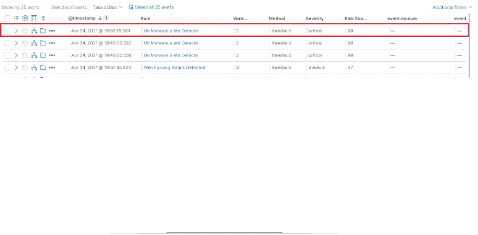
Figure 87 : Alerte "Un malware a
été détecté" par Kibana
Et directement on recoit une alerte nous disant qu'un Malware a
été detecté. Ceci montre que notre regle de detection
fonctionne correctement.
Chapitre III : Tests et évaluations
Conclusion
Au cours de ce chapitre, nous nous somme familiarisé
avec Elastic Stack, puis l'expérimenter en créant des
visualisations et des dashboards mettant ainsi en évidence ses
fonctionnalités, ces dashboards nous ont permis de superviser notre
système et d'avoir une vue globale et plus détaillée des
informations de sécurité et de l'état de santé de
notre système, après la prise en main de Kibana nous avons pu
effectuer des séries d'attaque sur notre solution STEM. Grace au moteur
de détection d'intrusion, nous avons pu détecter ces attaques, ce
qui nous permit donc de réagir afin d'arrêter ou éviter ces
attaques.
77
78
CONCLUSION ET PERSPECTIVES
La cybersécurité est une discipline de
première importance car le système d'information est pour toute
entreprise un élément absolument vital.
Les technologies de l'information deviennent de plus en plus
intégrées dans la société, les incitations à
compromettre la sécurité des systèmes informatiques
déployés augmentent. Ces cyberattaques peuvent
déstabiliser une institution et engendrer une perte économique
colossale.
Les dangers des cyberattaques actuelles font que la question
pertinente des entreprises n'est pas de se demander s'ils seront
attaqués ou pas mais se demander quand cela va arriver, ce qui fait
qu'une protection en amont est primordiale. Avec un tat de solution de
sécurité open source les entreprises n'ont plus d'excuse face aux
cyberattaques.
L'objectif principal de ce travail effectué au sein de
l'Agence Nationale de la Sécurité informatique était de
mettre en place une solution de gestion centralisé de logs et des
évènements.
Dans ce projet on a mis en place la plateforme Elastic Stack
permettant la collecte, le traitement, le stockage et enfin la visualisation
des fichiers logs. Ceci nous a permis d'exploiter les visualisations et les
tableaux de bords de l'interface Kibana pour surveiller l'état du
réseau ainsi que l'activité des équipements et des
machines afin d'éviter les pannes et les attaques d'une part, et de
gagner du temps et de l'argents d'autre part.
À la fin de notre projet, nous avons pu atteindre nos
objectifs c'est-à-dire mettre en place une solution open source
permettant le management de la sécurité de notre système,
notre système a répondu à nos attentes puisque aucun
impact sur les performances réseau et système n'a
été remarqué.
Ce stage, nous a été d'une grande importance et
il a servi d'une arcade qui nous a initié au monde professionnel.
D'autant plus qu'il était une opportunité pour mettre en oeuvre
nos connaissances techniques apprises au cours de nos études.
Il nous a appris sur le plan technique d'être mieux en
mesure de protéger nos ordinateurs et de recommander des mesures de
sécurité aux autres.
Conclusion et perspectives
Du point de vue général, ce projet nous a permis
d'acquérir un savoir non négligeable et d'améliorer notre
aptitude à communiquer, collaborer et s'adapter avec l'environnement
professionnel.
En termes de perspectives, des améliorations sont
possibles pour augmenter la performance de cette solution à savoir :
? L'ajout d'autres modules permettant d'assurer la
sécurité des systèmes d'information. ? Un système
d'analyse basé sur l'intelligence artificielle pour améliorer la
détection des attaques.
? Un système d'envoi d'alerte par sms
téléphonique lors de détection d'attaque sera d'un grand
avantage.
Nous espérons que ce projet soit le début d'une
insertion professionnelle et un guide pour tous ceux qui sont
intéressés par le monde de la cybersécurité.
79
80
REFERENCES
[1]
https://www.elastic.co/fr/elastic-stack
- 10/02/2021
[2]
https://logz.io/learn/complete-guide-elk-stack/
- 14/02/2021
[3]
https://medium.com/@lakinisenanayaka/what-is-elastic-stack-which-everyone-is-talking-about-6c5d94d83983
- 20/02/2021
[4]
https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/
- 27/02/2021
[5]
https://kifarunix.com/install-and-setup-suricata-on-centos-8/
- 05/03/2021
[6]
https://openclassrooms.com/fr/courses/4462426-maitrisez-les-bases-de-donnees-nosql/4686486-visualisez-et-prototypez-avec-kibana
- 10/03/2021
[7]
https://connect.ed-diamond.com/MISC/MISC-076/Une-etude-des-bruteforce-SSH
- 15/03/2021
[8]
https://www.securiteinfo.com/conseils/introsecu.shtml
- 18/03/2021
[9]
https://www.pandasecurity.com/fr/mediacenter/securite/soc-role-cybersecurite/
- 18/03/2021
[10]
https://www.kaspersky.fr/resource-center/definitions/what-is-cyber-security
- 18/03/2021
[11]
https://www.cisco.com/c/fr_ca/products/security/common-cyberattacks.html
- 19/03/2021
[12]
https://www.oracle.com/fr/cloud/cyberattaque-securite-reseau-informatique.html
- 20/03/2021
[13]
https://www.n0secure.org/2008/11/dirbuster-comment-brute-forcer-les-repertoires-dun-site-web.html
- 25/03/2021
[14]
https://github.com/arvindpj007/Suricata-Detect-DoS-Attack
- 21/04/2021
[15]
https://fr.norton.com/internetsecurity-malware-malware-101-how-do-i-get-malware-complex-attacks.html]
- 04/04/2021
[16]
https://lipn.univ-paris13.fr/~poinsot/save/INFO%203/Cours/Cours%201.pdf
-
07/04/2021
| 

