|
EPIGRAPHE
« Savoir écrire n'est pas inné ni
magique. C'est le résultat d'un apprentissage qu'il est
parfaitement possible de
maitriser »
(NTUMBA.N.P)
« L'esprit se nourrit en lisant »
(MENS ALITUS)
« L'homme de la préhistoire a fais le pas
individuel de la réflexion, l'homme d'aujourd'hui fait le pas collectif
de la réflexion. Vision d'une société ou tout se qui monte
converge vers un foyer transcendant, oméga, qui accomplira
l'humanité »
(P. TEILHARD DE CHARDIN)
DEDICACE
A vous mes très chers parents : Symphorien
BANYINGELA MUTEBA et Véronique MALU WA MUEPU, grâce à vos
sage conseils et soutien matériel que financier dès notre
enfance jusqu'à ce jour, que nous sommes devenu homme. Comme il est
toujours impossible de payer tous les bienfaits de ses parents, que ce travail
soit un signe de reconnaissance de ma part et qu'il soit pour vous un fruit de
la personne dont vous avaient voulu que nous devenons.
C'est à vous que je dédie ce volume !
Yannick Nicolas
MUEPU WA BANYINGELA
REMERCIEMENT
Ce travail, fruit de notre formation
dans le milieu académique sanctionne ipso facto l'apocalyptisme de notre
cycle de graduat à l'Université Notre-Dame du Kasayi est le fruit
de la symbiose notamment les encadreurs, la famille, les ami(e)s
également de collègues et toute personne ayant contribué
de loin ou de près à notre formation de façon
matérielle, financier ou de l'oeuvre d'esprit. Ainsi, nos cris de
reconnaissance sont tournes vers le pionnier de ce fruit, à
l'occurrence :
A Dieu tout puissant, pour sa protection dès ma
conception jusqu'à ce jour et par ce qu'il nous a permis à
connaitre sa voie de vérité et de la vie éternelle ;
car sa crainte est le commencement de la sagesse.
Au professeur Rostin MABELA MATENDO, pour sa bonne foi de
pouvoir accepté la direction de ce travail parmi tant d'autre
malgré ses diverses occupations en vue de germer la graine de
connaissance scientifique parfaite.
A l'assistant Patient MUSUBAO, pour l'attention soutenue
à notre égard lors de la rédaction du présent
travail et pour avoir accepté la qualification d'éclaireur des
idées scientifiques jusqu'à terme de travail.
Aux autorités académiques et administratifs,
également faisons allusion aux corps professoral tant local que
visiteurs de la dite université pour les efforts tant soit peu,
conjugués à la réussite de ce premier cycle à
l'égard de tous.
A mes chers parents Symphorien BANYINGELA MUTEBA et
Véronique MALU WA MUEPU pour avoir contribué concrètement
d'une manière financière et morale à notre formation.
A mes chers frères et soeurs : Huguette DIONGA,
Cilvi BITSHILUALUA, Joseph MBUYI, Crispin TSHIMPANGA, Jean TSHISHIKU, Dorcas
MUKAYA.
Aux camarades de promotion : Emery NTUMBA, Anaclet
MUKENGE, Constance BASHINGO, Yannick MULAMBA, Jean Marie KANKU, Freddy
TSHIONDO, et bien d'autres
Amis : Pascal MULUMBA.
Que ceux dont les noms ne sont pas énumérer,
trouvent l'expression de leur encouragement au coeur de ce travail ; fruit
de longue haleine.
Yannick
Nicolas MUEPU WA BANYINGELA
AVANT PROPOS
Un travail de fin d'étude est non seulement un
prolongement de l'immersion de l'étudiant dans le monde professionnel
mais également comme de coutume, permet à celui-ci de couronner
la dernière année d'un cycle universitaire.
Il met en exergue les qualités de réflexion de
l'étudiant et souligne ses aptitudes d'analyse globale à partir
d'une expérience professionnelle.
La réalisation de présent document répond
à l'obligation pour tout étudiant en dernière année
du cycle d'ingéniorat à l'Université Notre-Dame du Kasayi
U.KA en sigle, de présenter un projet de fin d'étude en vu de la
validation de l'année académique.
Il rend compte simultanément de la découverte du
milieu professionnel et de la conduite d'une mission attribuée à
l'étudiant. Le sujet sur lequel s'appui ce travail est :
« LA MISE EN PLACE D'UN SYSTEME D'INFORMATION ARCHITECTURE
CLIENT-SERVEUR POUR LA GESTION DES RETRAITES : Cas de
l'INSS/Kananga »
Nous avons portés notre choix sur ce sujet, vu les
difficultés qu'éprouve les fonctionnaires de l'Institut National
de Sécurité Sociale INSS en sigle dans leurs gestion des
retraités affilier, l'imprécision dans la prise de
décision et principalement le manque d'un outil de gestion et de
traitement automatique des informations par rapport aux retraités et au
système d'information existant.
Yannick Nicolas MUEPU WA BANYINGELA
CHAPITRE 0. INRODUCTION GENERALE
Face à la mondialisation et la concurrence
grandissante, le monde informatique se trouve aujourd'hui dans une
ébullition dont la prise de décision est devenue initiale
à travers les systèmes informatiques pour les dirigeants
d'entreprises.
Depuis 1980, avec l'introduction de la nouvelle technologie
de l'information et de la communication, l'informatique est vivement devenue un
outil indispensable pour le développement économique et
l'optimisation dans la prise de décision par l'entremise
0.1. PROBLEMATQUE
Toute entreprise demeurant non automatisée, se trouve
face à des difficultés nombreuses, entre autre :
- Le non optimisation des intérêts ;
- La porte de temps ;
- L'imprécision dans la prise de décision ;
etc.
Vu les différentes difficultés qu'éprouve
les entreprises particulièrement l'Institut National de
Sécurité Sociale INSS en sigle, dont nous proposerons un projet
d'informatisation de leur système de gestion basé
sur : « La mise en place de l'architecture client-serveur
pour la gestion des retraités » : cas de
l'INSS /KANANGA.
Pour cela, nous métrons à la lumière du
jour les différentes notions de base relative à l'architecture
client-serveur, au système d'information ainsi que des méthodes
de réalisation de présent projet. Par quelle méthode
pouvons-nous traiter une information ou donnée de façon rapide,
pouvant déclencher une prise de décision rationnelle ?
Est là un questionnement global à l'issu de
quel on trouvera des voies et moyens susceptible à traiter
automatiquement une information afin de trouver des pistes de solution beaucoup
plus concrète et cela à un temps réduit.
0.2. CHOIX ET INTERET DU SUJET
Nous avons porté choix sur « la gestion des
retraités » ou les difficultés qu'éprouve
l'INSS. Pour certaine lenteur remarquée dans le traitement dû au
partage manuel de données, notre choix reste focaliser sur un double
rêve à savoir :
- Du point de vue théorique nous allons élaborer
un support de base explicitant brièvement aux lecteurs les notions
essentielles de la conception ou la procédure par laquelle un
système d'entreprise peut être informatisé et du
développement d'une base de données ;
- Du point de vue pratique, nous proposerons à l'INSS
des pistes des solutions pouvant permettre à réorganiser le
système d'information existant et proposerons une solution informatique
avec comme avantage, la réduction de temps d'accès aux
données, la diminution de coût et qui présentera un
traitement beaucoup plus rapide et efficace.
0.3. DELIMITATION DU TRAVAIL
Chronologiquement, nous délimitons notre travail sur
les données des années 2012 - 2013 à l'Institut National
de Sécurité Sociale INSS en sigle plus précisément
dans son service technique gérant les retraités, pour de raison
du temps qui nous est restreint.
C'est en fait pour cela que nous nous sommes assignés
de nous limité aux activités « service
technique ». Ainsi plusieurs méthodologies ou technique de
récolte des données pourront être utilisées,
notamment la technique documentaire, d'interview, d'observation, etc.
0.4. SUBDIVION
Dans le but de présenter au monde scientifique, Un
travail scientifique de qualité, nous sommes parvenus à
subdiviser le présent travail en cinq parties essentielles à
savoir :
- L'introduction générale ;
- L'architecture client - serveur,
- Le système d'information et les bases des
données ;
- La conception et l'implémentation ;
- La conclusion générale.
0.5. HYPOTHESES
Entant que ingénieur informaticien, concepteur et
programmeur, notre imagination sera orientée à la mise en place
de l'architecture client - serveur pour la gestion des retraités de
l'institut national de sécurité social Kananga en proposant un
système informatique dont un logiciel y sera annexé
CHAPITRE I. ARCHITECTURE CLIENT - SERVEUR
Il est évident de clarifier dans ce premier chapitre,
certains concepts de base, de les définir et aussi de démontrer
les origines (et historique) de l'architecture client - serveur tout au long de
ce travail, « une recherche consciente de ses besoins, ne peut passer
qu'en mettant la nécessité de clarifier ses concepts »
dit KING METRON ;
Etant donné que la compréhension d'un texte,
dépend considérablement de la manière dont sont
appréhendés et définis les concepts que l'on y rencontre.
Pour cela, nous allons tenter de définir les concepts de base pour
mettre à la lumière du jour certaines zones d'ombre.
1.1. LES ORIGINES ET HISTORIQUE
Dans une universalité où les nouvelles
idées se bousculent vers les techniques plus évoluées, le
client - serveur s'est taillé une part importante depuis le début
des années 1990. En effet, il faut pouvoir disposer des systèmes
d'informations évolutifs permettant une coopération fructueuse
entre les différentes entités de l'entreprise. Les
systèmes des années 70 et 80 ne répondaient pas à
ces exigences.
Une forme des architectures centralisées au tour des
calculateurs centraux (ordinateur central) avant les années 1980
appelée « mainframe » qui traitait toutes les
tâches, caractérisées par les terminaux passifs à
interface, à la saisie du clavier et l'affichage de l'écran.
Dans cette architecture, les applications étaient
développés souvent en cobol autour des fichiers et ne
satisfaisait qu'à une faible productivité, il est évident
de noter qu'il était difficile de migrer vers des technologies plus
modernes.
Disons que la productivité des développeurs
restait faible et prisonnière de système propriétaire,
l'approche de solution est de remplacer les calculateurs centraux par un ou
plusieurs serveurs départementaux interconnectés à des
stations de travail graphique. La figure ci - dessous présente un grands
système informatique mainframe vers les années 1970 - 1980.
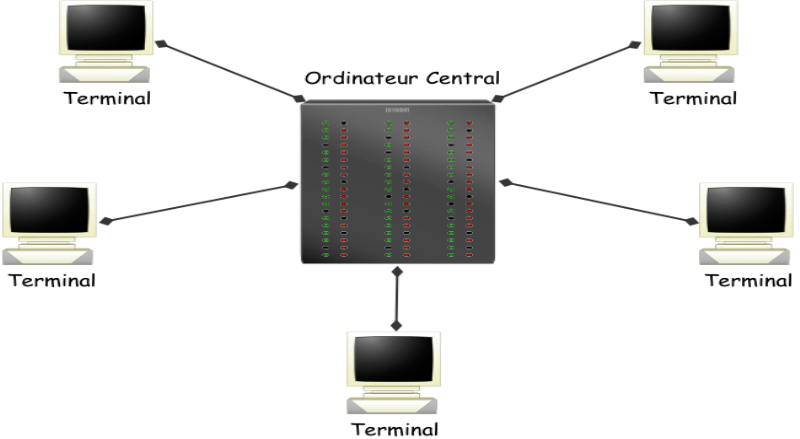
Fig1.1. : Grands systèmes informatiques
(mainframes) vers les années 1970 à 1980
Les systèmes ont commencés à migrer
depuis les systèmes propriétaires vers les systèmes plus
ouverts aux années 1980 ; les bases de données
relationnelles ont vu le jour suivies des langages de développement
structuré autour des données.
C'est alors que SQL s'est imposé comme la norme
d'accès aux données et les réseaux notamment locaux sont
développés. D'un autre coté le micro - ordinateurs se sont
imposés dans les entreprises et ont apportés des interfaces
conviviales ; malgré toutes ces migrations technologiques, le
maintien des mainframes, le développement des systèmes
départementaux, la profusion d'ordinateurs personnels ont rendu les
communications difficiles.
C'est aux années 1990 que les réseaux ont
occupé une place centrale dans l'entreprise, car il y à
eût une concurrence entre les entreprises de manière
exacerbée, la production et la flexibilité de l'informatique
faisait la différence.
Les vitesses de calcul des micros deviennent
impressionnantes, les graphiques figurent partout au niveau des interfaces, le
besoin de partager les données est indispensable aussi bien pour
l'accès transactionnel caractérisé par des mise à
jours rapides en temps réel que pour les accès décisionnel
nettement indiqué par le besoin de requêtes complexes sur de gros
volumes de données.
Pour améliorer la vitesse de développement et
surtout la maintenabilité des applications, on va imposer des
méthodes de conceptions et de développement orientés
objets. La figure ci - dessous présente une architecture client -
serveur moderne des années 1990.
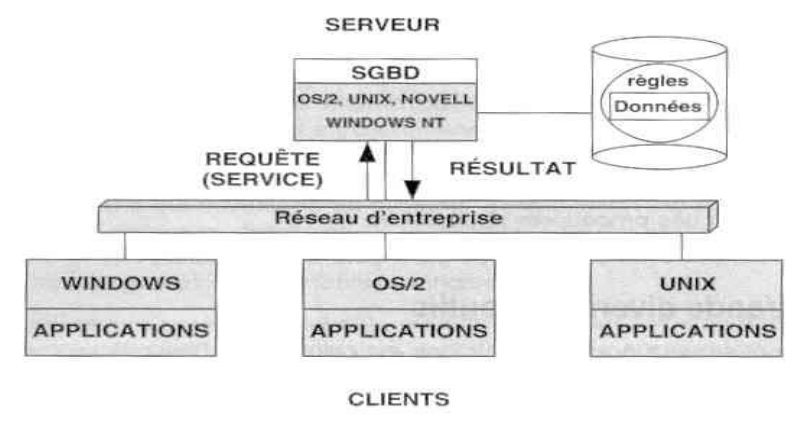
Figure 1.2. Architecture C/S Moderne des années 1990
Grace à la baisse des prix de l'informatique
personnelle et le développement des réseaux ces dernières
années nous avons pu constater une évolution majeure des
systèmes d'information à savoir, le passage d'une architecture
centralisée à travers de grosses machines (mainframe) vers une
architecture distribuée basé sur l'utilisation de serveur et des
postes clients grâce à l'utilisation de PC et des
réseaux.
1. 2 TECTHNIQUE DE DIALOGUE CLIENT SERVEUR ET LE
MEDDLEWARE
1.2.1. Technique de dialogue client-serveur
Le client serveur est avant tout une technique de dialogue
entre deux processus, l'un client sous-traitant à l'autre serveur des
fonctions à réaliser. En plus nous allons étudier en
détail le mode de dialogue.
1.2.1.1. Les notions de base
Le modèle de communication client - serveur est
orienté vers la fourniture de services par un processus donc à la
transmission d'une requête à un serveur, ce dernier exécute
l'opération demandé et envoi en retour la réponse. La
communication de ces deux processus s'explique par la compréhension de
certaines notions de base comme l'explique ces différents concepts par
leur approche de définition suivant :
a) Client : c'est un processus
qui demande l'exécution d'une opération à un autre
processus par le transfert d'un message contenant le descriptif de
l'opération à exécuter et attendant la réponse
après exécution.
b) Serveur : c'est
également un processus qui traite ou accomplit une opération sur
demande de processus client et transmet la réponse après
traitement à ce client.
c) Requête : c'est un
message transmis à un serveur par un client décrivant
l'opération à exécuter pour le compte de client ;
d) Réponse (en anglais
Reply) : c'est également un message mais cette fois -
i transmis par un serveur à un client en ou de l'exécution d'une
contenant les paramètres de retour de l'opération.
Il faut savoir que les appels au service de transport mis en
jeu sont au nombre de quatre :
1. Send Request : permet au
client d'émettre le message qui décrit la requête à
une adresse correspondante à la porte d'écoute du
serveur ;
2. Receive Reply : permet aussi
au client de recevoir la réponse en provenance du serveur ;
3. Receive Request : permet au
serveur de recevoir la requête se trouvant sur sa porte
d'écoute ;
4. Send Reply : permet au
serveur enfin, d'envoyer la réponse sur la porte d'écoute de
client selon la requête formulée par ce dernier.
En résumé, la figure ci - dessous illustre les
notions évoquées ci - haut, un client exécute une
application et demande l'exécution d'une opération à un
serveur par le biais d'une requête. Le client reçoit une
réponse, lui indiquant par exemple que l'opération a
été parfaitement exécutée.
Requêtes
CLIENT SERVEUR

Send Request() Reponses
receive Request ()
Receive Reply send Reply ()
Figure 1.3 Dialogue client serveur
1.3. ARCHITECTURE CLIENT - SERVEUR
En effet, l'architecture client - serveur est plus large,
dans la mesure où elle combine les réseaux des ordinateurs au
réseau internet à l'aide des programmes. Un réseau n'est
pas toujours nécessaire, il est possible de le réaliser sur une
même machine (la même machine joue le rôle de client et
serveur). En dégageant deux processus ou deux modes de communication,
l'un, qui envoie des requêtes à l'autre appelé serveur, ce
dernier traite les requêtes et renvoie des réponses.
1.3.1. Définition
L'architecture client - serveur est un modèle de
fonctionnement logiciel qui peut se réaliser sur tout type
d'architectures matérielles interconnectées. On parle de
fonctionnement logiciel dans la mesure où cette architecture est
basée sur l'utilisation de deux types de logiciels, à savoir un
logiciel serveur et un logiciel client s'exécutant notamment sur une ou
deux machines différentes.
1.3.2. Types de serveur
On distingue plusieurs types de serveur repartis selon le
processus de traitement des données. En principe on distingue six
principaux serveurs :
a) Serveur de fichier
Ce type de serveur permet de partager des données
à travers un réseau, dont l'accès aux données
(informations) se fait au moyen des différents protocoles notamment
WEBDAV, SMB, NFS, Appletalk, CIFS,...
Dans ce type de serveur, la machine cliente demande
l'accès à des fichiers c'est - à - dire l'écriture
ou la lecture, d'un fichier en direction de serveur par l'intermédiaire
d'un réseau.
b) Le Serveurs Web
Les internautes utilisent ce serveur tous les jours sans le
savoir. Egalement appelé serveur http, ce serveur désigne soit
l'ordinateur, soit un logiciel.
A titre d'exemple, les navigateurs web tel que :
« INTERNET Explorer », « Mozila
Firefox », jouent le rôle des clients,,,, ils
génèrent l'accès aux données ou informations (les
pages web des sites hébergé et leurs contenus).
Il est nécessaire de noter que les serveurs web les
plus utilisés sont les suivants :
- Apache http serveur d'apache software fondation
- Internet information serveur (IIS) de Microsoft
- Java system web serveur de Sun Microsystems.
c) Serveurs de groupware
C'est un logiciel permettant à un groupe d'utilisateurs
de travailler en collaboration sur un même projet sans être
nécessairement réunis. Il est aussi appelé Groupware
(logiciel de group en français) qui est l'extension de terme
« Hardware et Software ».
Il est ainsi définit par Jean - Claude COURBON, comme
suit : le groupeware est l'ensemble des techniques et des
méthodes de travail associées qui, par l'intermédiaire de
la communication électronique, permettent le partage de l'information
sur un support numérique à un groupe, engagé dans un
travail collaboratif.
Ce type de serveur permet donc :
- De gérer les informations semi - structurées
(texte, images, courrier, messagerie, ordonnancement des
tâches) ;
- De mettre les utilisateurs en contact directe.
Exemple : Microsoft Echange, Lotus Notes, Oracle,
Groupwise, etc.
d) Serveur de base des
données
Signalons que ce type de serveur fera également l'objet
de notre travail. C'est un ordinateur sur lequel l'application de base de
données et la base de données sont installées. Ce type de
serveur, permet la communication entre la machine appelé cliente
à la base de données par l'intermédiaire d'une application
de base de données à travers un réseau (internet). Par
exemple : le logiciel oracle, Microsoft serveur SQL, etc.
e) Serveur d'impression
Ce serveur permet de partager une imprimante entre plusieurs
dizaines ou centaines d'ordinateurs. Etant donné que l'imprimante ne
pouvait pas satisfaire toutes les demandes ou les requêtes des clients en
même temps, ce serveur ou logiciel permettra de mémoriser les
demandes, de gérer les clients (logiciel (serveur) client) en les
mettant dans une file d'attente et de gérer leurs accès à
l'imprimante, etc.
f) Serveur Mail
Ce type de serveur permet de gérer l'ensemble des mails
(messagerie électronique) c'est - à - dire l'envoi, la
réception et le stockage des mails, signalons qu'il est le plus utiliser
pour les courriers électronique.
L'envoi des messages se fait au moyen des certains protocoles
tel que le protocole SIMTP (Simple Mail Transfer Protocol), POP (Post Office
Protocol), IMAP (Internet Message Access Protocol).
On distingue deux catégories des clients pour ce type
de serveur :
- Clients de messagerie : c'est un logiciel qui sert
à lire et envoyer des courriers électroniques. Par exemple :
Microsoft Outlook, Mozila, etc.
- Web mail qui représente des interfaces web. Par
exemple : IMP/orde, Gmail, Yahoo mail, etc.
N.B. on parle souvent d'un service pour
designer la fonctionnalité offerte par un processus serveur. Ainsi, le
serveur est également définit comme un (ordinateur)
spécialisé ou une machine virtuelle ayant pour unique
tâche, l'exécution d'un ou des plusieurs processus serveur.
Prenons l'exemple de deux machines, clients et l'autre
serveur, dont les machines clientes font leurs requêtes à une
autre machine appelée serveur via internet.

Figure1.4 : processus serveur
(exécution des taches)
Il faut notez que les exemples énumérés
dans les deux catégories des clients pour le serveur mail, sont des
outils ou logiciels de gestion des courriers électroniques.
1.3.2.1. La répartition des tâches
Dans l'architecture client - serveur, une application est
constituée de trois parties :
- L'interface utilisateur : qui est une interface
graphique, exécutée par le client.
- La logique des traitements : qui est en
général la requête formulé par le processus client
et le mode de traitement de celle - ci.
- La gestion des données : qui est enfin une
manière de gérer et de manifester de données par le
serveur de bases données.
En effet, la liaison entre le client et le serveur correspond
à tout un ensemble complexe de logiciels appelé middleware qui se
charge de toutes les communications entre les processus.
1.4. DIFFERENTS MODELES DE CLIENT-SERVEUR
En fait, les différences sont essentiellement
liées aux différents services qui sont assurés par le
serveur. On distingue :
1.4.1. Le client serveur des données
Dans ce cas, le serveur assure des tâches de gestion,
stockage et de traitement des données. C'est le cas le plus connu de
client - serveur utilisé par tous les grands systèmes de gestion
de base de données (SGBD), la base de données avec tous ses
outils (maintenance, sauvegarde...) est installée sur un poste serveur
tandis que sur le client, un logiciel d'accès est installé,
permettant d'accéder à la base de données du serveur.
Tous les traitements sur les données sont
effectués sur le serveur qui renvoie les informations demandées
à travers une requête par le client.
1.4.2. Le client serveur de présentation
Dans ce cadre, la présentation des pages (web,...)
affichées par le client est intégralement prise en charge par le
serveur. Ce type d'organisation présente l'inconvénient de
générer un fort trafic réseau.
1.4.3. Le client serveur de traitement
Ici le serveur effectue les traitements à la demande
du client. Il peut s'agir de traitement particulier sur des données, de
vérification de formulaires de saisie, de traitements d'alarmes...
Ces traitements peuvent être réalisés par
des programmes installé sur des serveurs mais également
intégrés dans des bases de données (procédures
stockées), dans ce cas, la partie donnée et traitement sont
intégrés.
1.5. MODE D'ARCHITECTURE
1.5.1. L'architecture a deux - tiers
Ce terme (deux - tiers) désignes la manière de
diviser les traitements de l'application en un traitement de question et
réponse (client - serveur) par le biais de réseau. Dans cette
même otique, une application deux - tiers fournit à plusieurs
forum de travail une couche de présentation uniforme qui communique avec
une couche centralisée de stockage des données. La couche de
présentation correspond en général au client et celle de
stockage des données est le serveur.
Dans une application à deux niveaux, la charge de
traitement est attribuée à l'ordinateur personnel, alors que le
serveur beaucoup plus puissant, se contente de contrôler le trafic entre
l'application et la base de données.
Par conséquent, non seulement les performances de
l'application diminuent du fait de s ces limite l'ordinateur portable (PC),
mais le trafic réseau augmente également. Lorsque la
totalité de l'application est traitée sur le PC, celle - ci doit
ensuite formuler de nombreuses demandes de données avant de pouvoir
afficher quoique ce soit sur l'écran de l'utilisateur. Ces multiples
requêtes soumises à la base de données pénalisent
fortement le trafic de réseau.
L'approche à deux - tiers ou deux - niveaux
éprouve un problème de la maintenance. Vous allez vous en doutez
que la moindre modification apportée à une application implique
une réorganisation complète de la base utilisateur. Quelques
réorganisations après, rendrons difficile la gestion des
différentes versions. Certains utilisateurs peuvent ne pas être
prêts à affronter une réorganisation complète et
ignorer les modifications, tant qu'un autre groupe plaide pour appliquer les
modifications immédiatement.
Cette architecture présente les
propriétés suivantes :
· Un client et un serveur ;
· Développement rapide pour des applications
locales ;
· Efficace pour de petites installations ;
· Très peu adapté à l'internet
(clients très nombreux, distants, impossibles à
gérer) ;
1.5.2. L'architecture a trois - tiers (3 niveaux)
Les limites de l'architecture deux tiers proviennent en
grande partie de la nature du client utilisé :
- Le frontal est complexe et non standard (même pour un
ordinateur personnel sous WINDOWS),
- Le middleware entre client et serveur n'est pas standard
mais dépend de la plate - forme du système de gestion de base des
données (SGBD), etc.
L'architecture à trois - tiers (3 niveau) ajoute au
modèle deux - tiers une nouvelle couche qui place le traitement des
données dans un endroit central et maximise la réutilisation des
objets.
Ainsi la solution résiderait donc à
l'utilisation d'un poste client simple communiquant avec le serveur par le
biais d'un protocole standard. Pour se faire l'architecture trois - tiers
applique les principes suivants :
- Les données (informations) sont toujours
gérées de façon centralisées ;
- La présentation est toujours prise en charge par le
poste client,
- La logique applicative est prise en charge en charge par le
serveur intermédiaire.
Elle est également appelée client - serveur de
deuxième génération ou client - serveur distribué,
sépare l'application en 3 niveaux de services distincts, conformes au
principe précédent :
- Premier niveau : l'affichage et les traitements locaux
(contrôles de saisie, mise en forme de données, etc.) sont pris en
charge par le poste client,
- Deuxième niveau : les traitements applicatifs
globaux sont pris en charge par le service applicatif,
- Troisième niveau : les services de base de
données sont pris en charge par un système de gestion de base des
données (SGBD)
Traitements locaux
251651072
Présentation
251650048
Traitement globaux
251649024
Données
251648000
|
|
|
|
Premier niveau
deuxième niveau troisième niveau
|
Figure 1.5 : présentation d'un
client - serveur distribué.
Tous ces niveaux étant indépendants, ils
peuvent être implantés sur des machines différentes et a
pour avantage :
- Le poste client ne supporte plus l'ensemble de traitements,
il est moins sollicité et peut être moins évolué,
donc moins coûteux ;
- Les ressources présentes sur le réseau, sont
mieux exploitées, puisque les traitements applicatifs peuvent être
partagés ou regroupés donc le serveur d'application peut
s'exécuter sur la même machine contenant le système de
gestion de base des données (SGBD),
- La fiabilité et les performances de certains
traitements se trouvant améliorées par leur centralisation,
- Il est relativement simple de faire face à une forte
montée en charge, en renforçant le service applicatif.
Dans l'architecture trois - tiers, le poste client est
communément appelé client léger (ou Thin client), par
opposition au client lourd des architectures deux tiers. Il ne prend en charge
que la présentation de l'application avec, éventuellement, une
partie de logique applicative permettant une vérification
immédiate de la saisie et la mise en forme des données.
Le serveur de traitement constitue le coeur de l'architecture
et se trouve souvent fortement sollicité. Dans l'architecture pareille,
il est difficile de répartir la charge entre client et serveur. On se
retrouve face aux problèmes épineux de dimensionnement serveur et
de gestion de la montée en charge comme à l'époque des
mainframes. De plus, les solutions mises en oeuvre sont relativement complexes
à maintenir et la gestion des sessions est problématique, les
contraintes semblent inversées par rapport à celles
rencontrées à l'architecture deux - tiers dont le client
était soulagé, mais le serveur fortement sollicité.
1.4.3. L'architecture n- tiers
On a pensé mettre en place une architecture n - tiers
pour pallier aux limitations des architectures trois tiers pour mettre en place
les applications puissantes et simples à maintenir. Cette architecture
permet de distribuer plus librement la logique applicative pour faciliter la
répartition de la charge entre tous les niveaux.
Ces évolutions des architectures mettent en oeuvre une
approche objet pour offrir une plus grande souplesse d'implémentation et
faciliter la réutilisation des développements.
Théoriquement, l'architecture n - tiers supprime tous
les inconvénients des architectures précédentes :
· Elle permet l'utilisation d'interfaces utilisateurs
riches,
· Elle sépare nettement tous les niveaux de
l'application ;
· Elle offre de grandes capacités d'extension,
· Elle facilite la gestion des sessions.
En effet, l'appellation « n-tiers » met en
oeuvre un nombre indéterminé de niveaux de service, alors que ce
dernier est au maximum trois niveaux d'une application informatique. En fait,
l'architecture n - tiers qualifie la distribution d'application entre de
multiples services et non la multiplication des niveaux de service.
Cette distribution est facilitée par l'utilisation de
composants spécialisés et indépendants, introduits par les
concepts orientés objets (langages de programmation) ; ces
composants rendent un service si possible générique et clairement
identifié. Ils sont capables de communiquer entre eux et peuvent donc
coopérer en étant implantés sur des machines
distinctes.
La distribution des services applicatifs facilite aussi
l'intégration de traitements existants dans les nouvelles applications,
on peut ainsi envisager de connecter un programme de prise de commande
existant sur le site central de l'entreprise à une application
distribuée en utilisant un middleware adapté. Ces nouveaux
concepts sont basés sur la programmation objet ainsi que sur des
communications standards entre application, ainsi est né le concept de
Middleware objet.
1.6. LES PRINCIPES GENERAUX
Il n'y a pas véritablement de définition
exhaustive de la notion de client - serveur, néanmoins des principes
régissent ce que l'on entend par client - serveur :
- Le serveur est le fournisseur de services et que le client
en est le consommateur, on parle de principe de prestation de
« service »,
- C'est toujours le client qui déclenche la demande de
service et le serveur attend passivement les requêtes des clients par le
biais de « protocole »
- Un serveur traite plusieurs requêtes en provenance de
plusieurs clients en même temps et contrôle leur partage aux
ressources, on parle de principe de « partage aux
ressources » ;
- Le logiciel client - serveur marque aux clients la
localisation du serveur, on parle de principe de
« localisation » ;
- Le logiciel client (serveur est indépendant des
plateformes matérielles ainsi que logicielles, on parle de principe
hétérogéniste) ;
- Le redimensionnement des stations clientes
c'est-à-dire qu'il est possible d'ajouter et retirer les stations
clientes de « redimensionnement »,
- Les données du serveur sont gérées sur
le serveur, de façon centralisée et les clients restent
indépendants. Principe d'intégralité ;
- La modification de module serveur sans toucher au module
client vice versa , c'est - à - dire si une station est remplacé
par un modèle plus récent, on modifie le module client par
exemple en améliorant l'interface, sans modifier le module serveur.
Principe de « souplesse et adaptabilité »
1.6.1. Avantage de l'architecture client serveur
Particulièrement, le processus client - serveur est
beaucoup plus recommandé et utilisé actuellement pour des raisons
de fiabilité, ... dont voici les principaux a touts :
1. La redondance ou contradiction : grâce à
la gestion des ressources centralisées, c'est - à - dire qu'en
ayant une seule machine appelé « serveur » et celle
- ci interconnectée à plusieurs utilisateurs appelés
« client » partagent et communique sans aucune interaction
par exemple, une base de données centralisées,
2. Une meilleure sécurité : elle garantit
une triomphante sécurité des données, étant
donné que le monde de points d'entrée permettant l'accès
aux données est moins important ;
3. La mise à jour : l'architecture client -
serveur permet les mises à jour ainsi que l'ajout des autres machines
clientes sans aucune perturbation de fonctionnement de processus et sans une
majeure modification ;
4. L'administration évidente : grâce au
processus client - serveur, les administrateurs ou les gestionnaires des
entreprises ont la faculté de gérer et de prendre des
décisions de la base importantes, grâce à l'interrogation
de la base des données.
1.6.2. Inconvénients majeurs
Les inconvénients majeurs sont notamment :
Un coût élevé : ce
coût est donc dû à la maintenabilité ou
technicité du serveur.
1.6.3. caractéristiques d'un processus serveur
Le processus serveur est caractérisé
par :
1. Il attend une connexion entrante à travers un ou
plusieurs ports réseaux ;
2. A la connexion d'un client sur le port en écoute et
ouvre un stock local au système d'exploitation ;
3. A l'aide de la connexion, le processus serveur communique
avec le client suivant le protocole prévu par la couche application du
modèle OSI.
1.6.4. caractéristiques d'un processus client
La machine (ou processus) cliente est
caractérisée par :
1. Il établit la connexion au serveur à une
destination d'un ou plusieurs ports réseau,
2. Lors de la connexion, elle reçoive une
accusée de réception de la requête envoyée au
serveur et communique comme prévoit la couche applicative du
modèle OSI.
N.B. Le client et le serveur, doivent sans doute utiliser le
même protocole de communication au niveau de la couche transport du
modèle OSI.
1.7. NOTIONS D'ASSEMBLAGES ET DESASSEMBLAGE DES
PARAMETRES
De façon générale, le client et le
serveur s'exécutent sur des machines de différente nature
(hétérogènes) qui communiquent dans un réseau. Il
est donc nécessaire de définir un format d'échange
standard car lors de la communication, les données sont souvent
codées de manière différent sur deux machines distinctes,
afin de convertir les noms de fonctions et de paramètres dans ce format
lors de l'émission, et de la convertir en sens inverse lors de la
réception.
Lors de l'émission d'une requête, les
paramètres doivent être arrangés et codés sous forme
de message, on parle de l'assemblage et à l'arrivé, ils doivent
être remis en format interne de manière symétrique à
partir du message reçu, on parle de désassemblage. Par
définition, on entend par :
1. Assemblage (Marchaling)
Procédé consistant à prendre une
collection de paramètres et les arranger et les coder en format externe
pour constituer un message à émettre.
2. Désassemblage
(Unmarshalling)
C'est un procédé consistant à prendre un
message en format externe à reconstituer la collection des
paramètres qu'ils représentent en format interne.
1.7.1. Dialogue synchrone et asynchrone
Le dialogue entre client et serveur nécessite
l'émission ou l'envoie d'une requête et la réception d'une
réponse. Lors de l'émission d'une requête par une commande
send ressuest (client), celle - ci peut être émise
immédiatement ou mise en file d'attente pour l'émission
ultérieure.
Dans ce deux cas, la commande Send Request n'est
généralement pas bloquante parce que l'utilisateur peut effectuer
une autre tâche avant de venir attendre la réponse par une
commande Receive Request (Serveur). Cette dernière commande peut de
même être bloquante en attente de la réponse, ou non
bloquante avec un code retour signalant que la réponse n'est pas
arrivée, ceci conduit à distinguer les notions de dialogue
synchrone et de dialogue asynchrone.
1. Dialogue synchrone (synchronous
dialog)
C'est un type de dialogue géré sans file
d'attente dans lequel les commandes d'émission et de réception
sont bloquantes. Brièvement dans le cadre de la synchrone, le client
attend le serveur pendant que celui - ci exécute une opération
pour lui rendre compte.
2. Dialogue asynchrone (Asynchronous
dialog)
C'est également un type de dialogue mais
géré avec file d'attente, dans lequel une au moins
d'émission des commandes ou de la réception est non bloquante.
Le dialogue asynchrone permet au client d'effectuer une autre tâche
pendant que le serveur exécute une autre opération pour lui
rendre compte. Il permet aussi de demander plusieurs opérations au
serveur avant de recevoir les réponses par le biais des files
d'attente.
Précisons que, selon la nature des services accomplis
par le serveur pour le client et selon les différents types de client -
serveur explicités dans les paragraphes précédentes,
notons que le client - serveur de données et de procédures
s'avère intéressant pour les échange en réseau.
En ce qui concerne le client - serveur de données
(Data C/S), ajoutons que c'est un programme applicatif contrôlé
par une interface de présentation sur une machine cliente et
accède à des données sur une machines serveur par des
requêtes de recherche et mise à jour, souvent exprimé avec
le langage SQL.
1.7.2. Le middleware ou médiateurs
Fondé sur les techniques de communication client -
serveur vues ci - dessus, le middleware ou médiateurs et les outils de
développement sur les poste clients. Cet ensemble de couches
réseaux et services logiciels (middleware) très spécifique
du client - serveur, cache les réseaux et les mécanismes de
communication associés.
Ces couches assurent une collaboration fluctueuse entre
clients et serveurs, l'approche de la traduction de ce terme anglais
(middleware) a l'avantage de souligner le rôle d'intermédiaire) ou
médiateur généralement souligné par le
middleware.
1.7.2.1. Définition et objectifs de
médiateur
1.7.2.1.1. Définition
Un médiateur (en anglais Middleware) est un
ensemble des services logiciels construis au - dessus d'un protocole de
transport afin de permettre l'échange de requêtes et des
réponses associées entre client et serveur de manière
transparente.
1.7.2.1.2. Objectifs
L'objectif d'un médiateur est donc d'assurer une
liaison transparente, c'est - à - dire de cacher
l'hétérogénéité des composants mis en jeu.
Il s'agit en particulier d'assurer la transparence aux réseaux, aux
systèmes de gestion de base de données (SGBD) et dans une
certaine mesure aux langages d'accès. Cette transparence se fait selon
les niveaux suivants :
1. Transparence Au Réseau
Tous les différents types de réseaux doivent
être supportés qu'ils soient donc LAN, MAN, WAN. C'est pour cette
raison qu'un médiateur doit être construit au-dessus de la couche
transport du modèle OSI, celle - ci sera donc du type TCP/IP, etc. en
fait le médiateur cachera l'hétérogéniste des
réseaux et protocoles (TCP/IP...) de transports utilisés en
offrant une interface standard de dialogue à l'application.
2. Transparence aux serveurs
Toujours dans le même ordre d'idée pour la
transparence au réseau, ici les systèmes de gestion de base de
données (SGBD) mis en oeuvre peuvent être divers, bien que
généralement relationnel (ACCESS, MYSQL, ORACLE, SQL), doivent
offrir cependant des moyen de connexions variés et des syntaxes du
langage CSS souvent différent. Un médiateur se doit alors la
nécessité de cacher la diversité et d'uniformiser le
langage CSS en s'appuyant le plus possible sur les standards.
3. Transparence aux langages
Les différentes syntaxes de langages de
développement sur le réseau possèdent différentes
fonctions de connexions aux serveurs. Le médiateurs permettra donc
l'intégration des fonctions de connexion aux serveurs, l'émission
de requêtes et de réception de réponses dans tout langage
de développement utilisé coté client.
Autrement, le médiateur doit assurer les connexions de
types de données en provenance du serveur dans des types du langage de
développement et réciproquement pour le passage des
paramètres.
1.7.2.1.3. Fonction d'un
médiateur
Lorsqu'un logiciel client veut consulter ou modifier les
données sur le serveur il doit nécessairement se connecter. La
procédure de connexion permet de retrouver le serveur dans le
réseau et si nécessaire ouvrir une session de communication avec
lui.
La connexion c'est donc une opération permettant
d'ouvrir depuis un client vers un serveur désigné par un nom,
avec authentification de l'utilisateur associé par un nom et mot de
passe.
Dans un contexte de serveur de base de données,
après ou pendant la connexion, il est nécessaire d'identifier la
base de données et celui de l'utilisateur mesure la permission qu'a
l'utilisateur dans ce serveur de base de données, si non aucune
procédure d'ouverture spécifique n'est nécessaire.
1.7.3. Les protocoles
Par définition, un protocole est une
méthode facilitant la communication entre processus (client ou serveur)
s'exécutent sur différents ordinateurs c'est - à - dire un
ensemble des règles et des procédures permettant d'acheminer une
information ou une requête d'un processus (client) à un autre
(serveur) ou vers un univers finit.
Certains protocoles ont spécialisés par exemple
à l'échange des fichiers, d'autre serviront à gérer
simplement l'état de transmission sur internet et cela selon le type de
serveur utiliser. Il est donc nécessaire de retenir que les protocoles
utilisés font partie d'une suite de protocoles c'est - à - dire
un ensemble relier entre - eux. Cette suite de protocole s'appelle TCP/IP qui
signifie en français : protocole de contrôle / internet
Protocol/
D'une manière claire, tous périphériques
connecté et capable d'émettre ou recevoir un message tout en
étant sur un réseau, est appelé un noeud. Des
règles purement identiques que nous appelons
« protocoles » doit respecter ou observer ces noeuds pour
la communication entre eux.
Les protocoles de réseau couvrent trois types de
sévices mis en oeuvre lors des échanges dont les services
d'application qui permettent la communication de même niveau, les
services de transport qui assurent la gestion des adresses et la
fiabilité des données lors de l'échange, et les services
de liaison qui prennent en charge la transmission physique des données
proprement dite.
1.7.4. Réseaux informatique
Le Larousse définit un réseau tout court
comme un ensemble de lignes, de fils entrecroisés, Ensemble de
voies, de lignes téléphoniques, de postes radiophoniques, etc.,
ensemble de personnes en liaison les unes avec les autres pour une action
quelconque. Par exemple réseau de malfaiteur
Du point de vue technique, un réseau désigne un
ensemble des matériels et logiciels interconnectés les uns
aux autres permettant la circulation ou le partage des informations
finies, par exemple, pour la plus part des mathématiciens qui
s'occupent de la « théorie des graphes » un
réseau désigne un « graphe » dont les
arêtes ont des valeurs numériques attribuées et le sens de
ces arêtes va d'un point initial en passent par tous les points nous
retournons qu'a sur lui-même.
Pour cela, un réseau informatique est l'ensemble
d'équipements, matériels et logiciels (appareils
électronique, programme de connectivité internet)
éloignés les uns des autres et interconnectés par les
télécommunications permanente, permettant l'échange des
informations entre - eux. A titre exemplatif, l'internet en est l'illustration
la plus complexe car il regroupe les réseaux régionaux et locaux,
c'est pour cette raison il est appelé réseau de réseau.
En résumé, les termes, client et serveur sont
deux mots qui se complètent l'un à l'autre, dont vous pouvez
rencontrer dans la vie courante. Dans un café par exemple, un client est
une personne qui demande un service ou une chose à un serveur
(étant également une personne) ; le client demande un
café à un serveur et celui - ci lui apporte.
Scientifiquement parlant, le principe est le même en
informatique ; un client demande un service au serveur et celui - ci lui
rend cela en respectant les règles et principes de communication
établit. L'informatisation ou le recours à l'informatique permet
de traiter automatiquement à l'aide des processus client - serveur, une
information nécessaire à une entité donnée. Pour
cela la technique de récolte et de traitement de la dite information, de
sa constitution ou sa mise en place, ferons l'objet de la suite de notre
travail.
CHAPITRE II. SYSTEME D'INFORMATION ET BASE DE
DONNEE
Dans un monde informatique où les nouvelles
innovations se bousculent, le système d'information se doit actuellement
une représentation réelle et complexe à l'origine des
bases de données à traverse les besoins et les intentions
exprimés d'accompagner, de matérialiser et d'automatiser toutes
opérations incluses dans les activités de l'entreprise.
Le présent chapitre explique ainsi de manières
brèves ensembles des notions indispensables à
l'appréhension des concepts du système d'information et de la
base de données.
2.1. Quelques concepts
2.1.1. Système
Dans un premier temps, il est évident de retenir que
tout travaux informatique s'effectue dans un système. Selon plusieurs
auteurs, un système se définit de façon divers ;
Selon Joël de ROSNAYI, un système est un ensemble
d'éléments en innervation dynamique poursuivant un but
commun » (1(*))
Selon Jean Louis Lemoine, Un système se définit
comme suit :
- Quelque chose
- Qui fait quelque chose
- Qui est doté d'une structure
- Qui « voulue dans le temps
- Dans quelques choses
- Pour quelque chose.
Cette dernière définition est plus
spécifique et précise, du fait qu'elle spécifie l'action,
qui est n'importe quoi identifiable (quelque chose), faisant ou effectuant un
mouvement (qui fait quelque chose), structurel et évolutif (qui
évolue dans le temps), tout en étant dans n'importe quoi
identifiable (dans quelque chose), pour un objectif bien précis (pour
quelques chose). Partant de ce qui précède, nous parvenons
à définir le système de l'entreprise comme suit
SYSTEME DE PILOTAGE
251652096
251656192251655168
SYSTEME D'INFORMATION
251653120
251658240251657216
SYSTEME OPERANT
251654144
Figure 1.6 : approche
systématique de l'entreprise.
· Système de pilotage :
définit la politique de développement de l'entreprise, les
stratégies qui peuvent être à court, moyen ou long terme
pour atteindre ses objectifs. Il décide des actions à conduire
sur les systèmes opérant en fonction des objectifs et de la
politique de l'entreprise. Ainsi le système de pilotage a pour
rôle, la prise de décision. Il est composé de membres du
commuté de gestion ou de membre décisionnel ;
· Système d'information :
est donc l'ensemble des moyens pour traiter des informations au sein de
l'entreprise, c'est le trait d'union entre le système de pilotage et le
système opérant, son rôle est de faciliter la prise de
décision ;
Système opérant : il a pour rôle
d'exécuter les tâches, les opérations selon les ordres
provenant du système de pilotage. Il est composé des
exécutants. (2(*))
2.1.2. Information
On sous-entend par information : un signal visuel ou
sonore, une expression écrite ou orale, littérale ou
chiffrée. Plusieurs auteurs définissent l'information à
leurs façons : pour les uns, « l'information est un
élément de connaissance exploitée par
l'entreprise », et pour les autres, « c'est un
renseignement relatif à un fait élémentaire ».
(3(*))
Mais selon J.BERNARD, « tout ce qui peut
s'écrire pour être communiqué entre homme ou machine,
constitue une information : une page d'un livre, un montant de paie,
l'adresse d'un client, etc. sont autant de morceau
d'information ».(4(*))
Par exemple ; le siège administratif de
l'institut nationale de sécurité sociale est avant tout une usine
à information.
Il est évident de classifier l'information selon la
nature et le traitement.
Selon la nature, elle peut être classifiée en
cinq types
· L'information fraiche :
elle est celle dite nouvelle. Celle qui ne pas connu à l'avance mais qui
le sera après un moment. par exemple : la découverte d'un
gisement de pétrole.
· L'information statique :
est celle connu à l'avance, elle n'évolue pas dans le temps mais
peut subir une réactualisation. Par exemple : les dates de
l'indépendance des pays.
· L'information
évolutive : elle diffère de la
première, du fait qu'elle évolue dans le temps ou au cours de
traitement. Par exemple : l'âge d'une personne, la construction des
infrastructures.
· L'information
réexploitable : c'est donc celle utilisée dans
plusieurs traitements
· L'information
édictée : c'est une information connue
après un traitement. Il est destiné au travail d'un
gestionnaire.
Selon le traitement, on distingue :
· L'information
élémentaire : elle est celle brut, susceptible
d'en tirer une ou de nouvelles informations.
· L'information
élaborée : elle est le résultat de
l'information élémentaire après traitement,
· L'information de
transition : c'est donc l'ensemble des opérations de
traitement des données d'entrée et de sortie.(5(*))
2.1.3. système d'information
Un système d'information est un ensemble de sous -
système d'information dans une entreprise. Il peut donc comprendre une
ou plusieurs bases de données, des traitements informatisés ou
pas, des règles de prise de décision,... ou encore, c'est une
opération intellectuelle et technique consistant à
décomposer un dossier, une situation donnée en
éléments représentatifs de leurs contenus informatiques
à partir d'une analyse systématique.
En outre, une analyse et une démarche ou
opération intellectuelle consistant à décomposer un tout
en ses éléments et à en établir les relations.
(6(*))
D'après Dominique DIONSI, le système
d'information est le véhicule de la communication dans l'entreprise,
cette communication possède d'un langage dont les mots sont les
données.(7(*))
Le concept de système d'information recouvre en fait
deux réalités ; L'organisation elle - même qui agit et
évolue à travers l'information, cette notion apparente au
système d'information et mémoriser l'information, et on parle
alors d'objet artificielle dont l'apparition est liée à la
méthode utilisée. (Artefact : terme issu de la biologie
où il désigne un phénomène artificiel dû
à l'observation et non à l'objet)
Il est en liaison d'une part avec un environnement interne et
d'autre part un environnement externe (client, fournisseur, ...), les deux
termes environnementaux constituent l'univers extérieur du
système d'information.(8(*))
2.1.4. Système informatique
Un système informatique est l'ensemble d'objets
(artificiel) composé par les logiciels et les matériels
informatiques indispensable au traitement des données. (9(*)). C'est l'ensemble des moyens
matériels (ordinateurs ou machine et périphériques), des
ressources humaines (moyen intellectuel), des logiciels (algorithmes et
programmes), des procédures (méthodes de conception et d'analyse)
permettant l'automatisation des données (informations).
2.1.5. système informatise
2.1.5.1. Informatiser
Le terme informatiser veut dire exactement : soumettre
aux méthodes, technique de l'informatique. Cette soumission (aux
méthodes et techniques de l'informatique) permet alors un accès
rapide et un traitement rapide de l'information et de la systématique
des résolutions.
Système d'information, système
informatisé, ces deux grandes notions prêtent à confusion.
Elle provient majoritairement de ce que la réflexion existante du
système d'information, indissoluble de toute organisation, est devenue
nécessaire suite à l'apparition, de difficultés
générées par l'information croissante de l'entreprise.
Alors, on dit qu'une partie du système d'information de l'entreprise
peut être informatisée, ainsi nous parlerons du système
informatisé.
2.1.6. la gestion
La gestion des ressources naturelles est
définie en écologie comme étant un ensemble de disposition
visant à protéger et à améliorer les milieux
naturels en vue de leur exploitation rationnelle.
Selon Yves DE RONGE, la gestion des activités vise
l'ensemble des actions qui peuvent être mises en oeuvre par l'entreprise
pour améliorer l'efficience et l'efficacité de ses
activités et processus en se fondant sur l'information relative aux
coûts des activités, processus, produits, clients et autres objets
de coût fourni par un système comptable. (10(*)).
Dans le domaine financier, la gestion est
considérée comme étant l'activité d'une banque ou
d'un agent de change qui gère les valeurs d'un client.
Généralement, la gestion est l'action d'administrer, d'assurer la
rentabilité, c'est la discipline qui étudie l'organisation et le
fonctionnement des unités économiques. (11(*))
Comme nous l'avons dit précédemment qu'un
système d'information est l'ensemble des circuits d'informations dans
une entreprise, et aussi, la partie du système d'information
informatisée forme tout un système informatisé au sein de
l'entreprise. Pour cela, nous constatons que les deux concepts :
système d'information, système informatisé, on a un sens
qu'au sein d'une entreprise. Ainsi il s'avère alors indispensable de
parler de l'entreprise.
2.1.7. l'entreprise
Nous pouvons définir l'entreprise comme étant
toute activité qu'on se propose de faire ou d'entreprendre dans un but
lucratif au travers des objectifs bien définis. Selon KINZONZI,
l'entreprise est une cellule économique autonome organisée
où se combine les facteurs de production afin de créer des biens
et de les vendre sur le marché (12(*)).
D'une façon générale, on appelle
entreprise, l'ensemble de moyens utilisés pour la réalisation
au profit et sous la responsabilité d'une même personne juridique,
d'opérations commerciales ou financières poursuivies pendant une
période plus au moins longue.
2.1.5.2. Diversité d'entreprise
Généralement les entreprises sont
classifiées en fonction des critères, et les plus courantes
portent sur les critères juridiques et économiques.
0. Critères juridiques
Les classifications juridiques instruisent sur la
manière dont est reparti le pouvoir au sein de l'entreprise et sur les
apports des tiers. Pour cela, diverses situations peuvent se
présenter :
- L'entreprise sous forme des coopératives de
consommation ou de production ;
- L'entreprise détenue par une seule personne
propriétaire et responsable de son chiffre d'affaire. Il s'agit de
l'entreprise individuelle, majoritairement représentée dans le
système de production français,
- répandus.
- L'entreprise appartement à l'Etat : ici
plusieurs facette se présentent, et l'on parle d'entreprises
nationalisées où l'Etat procède majoritairement le capital
plus de 50%, et de l'entreprises semi - politiques, où l'Etat
procède minoritairement le capital moins de 50% et l'autre part
étant détenue par des particuliers.
Généralement, toute ces dernière forme
d'entreprises exercent soit une activité jugée sensible soit
stratégique pour l'Etat.
1. Dimensions des entreprises
Selon les critères économiques, on distingue
L'entreprise dont la propriété est repartie entre plusieurs
associés apportant chacun une part de capital, ce sont les cas de
sociétés par action à responsabilité limité
(SARL) et de sociétés anonymes (SA) qui ont des statuts
juridiques assez ceux qui relèvent des dimensions de l'entreprise
à savoir :
· Ceux qui relèvent de l'activité
économique de l'entreprise, comme appartenant à un secteur,
à une branche, citons par exemple ; les entreprises commerciales,
les entreprises industrielles, les entreprises de prestation de services
(vendant les services rendus), les entreprises agricoles et les entreprises
financières ;
· Les critères financiers, notamment le chiffre
d'affaire qui représente le montant des ventes effectuées au
cours d'une année et la valeur ajoutée qui exprime la richesse
créée au cours d'une année d'activité normale de
l'entreprise. Elle se calcul par la différence entre le chiffre
d'affaire de l'entreprise obtenu au cours de l'exercice, les achats et les
charges liées à l'exploitation consommée au cours du
même exercice ;
· Et l'effectif des salariés : ce
critère est utilisé pour opérer des regroupements entre
petites, moyennes et grandes entreprises. Il faut souligner qu'au-delà
d'un certain seuil, des obligations juridiques, fiscales et sociales s'imposent
à l'entreprise. En République Démocratique du Congo (RDC)
le critère de classification des entreprises reste le montant de son
capital.
Disons que l'entreprise constitue l'usine toute entière
de l'information, dans laquelle il y à tout un système
d'information dont cette dernière passe par divers étape de
traitement ou modélisation.
2.1.8. traitement ou modélisation de
l'information
Le rôle de l'administration dans une Entreprise consiste
à :
- Collecter les informations élémentaires
(données) ;
- Procéder à des opérations de
classement, de calcul, de mise à jour et d'enregistrement ;
- Utiliser les informations pour les besoins de l'entreprise
ou des tiers.
L'ensemble de ces opérations constitue ce que l'on
appelle « Traitement de l'information », qui se
définit comme « l'application à des données de
base d'une série d'opérations présentées dans un
ordre logique » (13(*)).
C'est alors que l'information collectée par l'homme ne
peut être soumise à l'ordinateur qu'à son état
brut ; elle doit subir une transformation pour devenir donnée,
c'est - à - dire matière destinée à l'ordinateur.
Cette transformation ou normalisation de l'information s'effectue en plusieurs
étapes :
- Codification des plusieurs étapes
- Codage des données sur des documents
standardisés ;
- Saisie des données sur support informatique.
Pour codifier une information, on conçoit un
système de symbole, permettant de représenter cette information.
La codification implique par conséquent, la mise au
Point de tout un langage de codification. Cette
dernière est définie par trois éléments :
1. Un alphabet c'est - à - dire l'ensemble des signes
ou de symboles retenus pour représenter une information ;
2. La structure syntaxique c'est - à - dire, la
façon dont les caractères sont combinés dans une zone de
codification,
3. Des règles sémantiques, qui
définissent de relation entre les caractères utilisé et
l'information à représenter.
Le codage de données consiste donc à enregistrer
sur supports informatiques (CD, DVD,...), les données peuvent
préalablement être retranscrite sur un document non
standardisé (il se présente sous forme, soit d'un bordereau soit
des questionnaires dont les données sont recueillis de manière
libre sans aucune restriction contraignante), puis sur un document
standardisé (IP s'agit d'un document structuré de manière
à recevoir les informations sous forme codée et qui sont de ce
fait prédestiné à être saisie directement sur un
support informatique en vue d'un traitement future par l'ordinateur.
En outre, on entend par donnée, une suite de
caractères représentant une information et qui se traite par le
machine. Il ressort de cette définition que la donnée est une
information codée, c'est - à - dire, un mot conventionnel
abrégé, forme des caractères alphabétiques,
numériques, alphanumérique ou des symboles et qui sont
attribués à une information. (14(*))
2.1.9. rôle du système d'information
Dans une diversité des rôles d'un système
d'information, avons sélectionné quatre principaux rôles
d'une organisation :
1. Produire les informations légales
réclamées par l'environnement socio - économique ;
2. Déclencher les décisions
programmées ;
3. Aider à la prise de décision en fournissant
au décideur de l'organisation ;
4. Assurer la coordination entre les individus du
système organisationnel. (15(*))
2.1.10. qualité d'un système
d'information
On reconnait la qualité d'un système
d'information à travers quatre paramètres d'importances
égales et qui influencent les uns sur les autres. Il s'agit donc
de :
1. Le temps de réponse : c'est le
délai nécessaire que prend le service de traitement pour
récolter les données, élaborer et diffuser les
résultats, ce temps de réponse ;
2. Le débit : c'est le volume
d'information qui est possible d'être traité pendant une
unité de temps donné. C'est donc la quantité d'information
traitée pendant une unité de temps ; il doit faire face aux
besoins de l'entreprise et doit être facilement augmenter pour
satisfaire le volume d'information
3. La fiabilité : c'est la
confiance que l'on accorde aux données (informations)
récoltées et aux résultats élaborés, elle
vient du verbe édifier qui signifie : donner ou faire
confiance ;
4. Le coût : c'est la demande qui
peut être financière, matérielle ou humaine. Il y à
fiabilité lorsqu'il y a une sorte de suivi et de maintenance, pour
éviter les services biaisés. Un système d'information
doit avoir un débit d'information relatif aux besoins et fiable, qui
évite la confiance et moins chère.
2.1.11. Notions Des Fichiers
a) Définition
Un fichier peut être défini comme l'ensemble
d'enregistrement public ; se rapportant à une population
homogène ou entité, cet enregistrement, étant
organisé sur le support informatique de manière à
permettre à l'ordinateur d'y accéder et de le trouver facilement
à la donnée requise par le traitement à réaliser.
En d'autre terme, le fichier est le regroupement de tous les
enregistrements logiques se rapportant à un même titre
d'entité.
b) Utilité des fichiers
La plupart de donnés que traite l'ordinateur, ne lui
sont pas fournies directement à partir du clavier, mais proviennent d'un
support de stockage. Pour cela, les résultats de traitement ne sont pas
seulement afficher à l'écran ou imprimer sur papier mais sont le
plus souvent stockés sur les supports de stockage, de sorte que ces
données de résultats, peuvent servir des données pour le
traitement ultérieur.
L'accès facile à données stockées
sur un support informatique par l'ordinateur, il est nécessaire qu'elle
soit enregistrée de manière logique et univoque (même
structure), en effet, elles les sont sous forme de fichier. (16(*))
2.1.12. critères généraux de
classification des fichiers
Nous pouvons retenir deux critères de classification
des fichiers informatiques en général :
- Classification selon le mode d'encodage de donnée sur
support informatique ;
- Et la classification selon la nature de donnée
stockée.
D'après le critère de classification selon le
mode d'encodage de données sur support informatique, on distingue deux
types de fichiers d'ordinateur :
- Fichier texte ;
- Fichier binaire
a) Fichier texte
Appelés également fichier ASCII, sont
constitués uniquement d'une suite de caractère standard
imprimable (lettre, chiffre, caractères spéciaux, ...) et de
retour à la ligne.
b) Fichier binaire
Dans les fichiers binaires, les données sont
codées. Automatiquement en binaire (suite de 0 et 1), ils constituent la
plus grande partie de fichier contenant les programmes objet ou compiler, du
son, de l'image, de la vidéo, les fichiers crées par les
tableurs, les logiciels de traitement de texte.
Et d'après la classification selon la nature des
données stockées, il existe plusieurs types des fichiers si l'on
se refaire à leurs contenu, c'est - à - dire à la nature
de donnée qu'ils contiennent :
- Fichier texte simple ;
- Fichier de donnée structurée ;
- Fichier de tableau ;
- Fichier de programmes ;
- Fichier audio ;
- Fichier vidéo ; etc.
C'est ainsi que pour pouvoir spécifier la nature ou le
contenu de différents fichiers, le système de gestion des
fichiers, accorde à la fin de leurs noms des suffixes ou extensions,
former de 3 à 4 lettres minuscule, précéder d'un point,
l'extension rappel donc la nature, le format ou le contenu du fichier.
(17(*))
Par exemple : fichier Etudiant.xlsx, fichier
Info.doc,...
2.1.13. Conception D'un Système D'information Par
L'approche Merise
1. Conception
Qui dérive du verbe concevoir signifiant former,
élaborer dans bon esprit, dans son imagination. Ou encore la
manière d'élaborer quelque chose dans son esprit en s'appuyant
sur une méthode de conception.
En effet, la conception d'un système d'information par
exemple pour la gestion des abonnées, nécessite une analyse et
une conception des bases de données qui constitue une intersection de
toute application mettant en oeuvre un SGBD relationnel.
Ainsi dans le cadre de ce travail ou de ce projet, nous avons
choisis la méthode Merise pour sa simplicité et sa
qualité. Pour ce faire, ce système doit intégrer une base
d'information dans laquelle seront mémorisée la description des
objets, des règles et des contraintes du système
opérant.
a) Brève présentation de la
méthode merise
La Merise (Méthode d'étude et de
réalisation informatique du système d'entreprise) est en fait une
méthode de conception ; modélisation, développement
et de réalisation de projets informatiques.
La conception d'un système d'information n'est pas
évidente, du fait qu'il faut réfléchir par l'ensemble de
l'organisation que l'on doit mettre en place. La phase de conception
nécessite des méthodes permettant de mettre en place un
modèle sur lequel on va s'appuyer, la modélisation consiste donc
à créer une représentation virtuelle d'une
réalité de telle façon à faire ressortir les points
sur lesquels on pourra s'intéresser, ainsi, ce type de méthode,
ou procédure est appelée ANALYSE. La méthode Merise est
basée sur la séparation des données et des traitements
à effectuer en plusieurs modèles conceptuels et physique.
b) Le cycle D'abstraction
L'idéologie du système d'information se fait par
étapes. Afin d'aboutir à un système d'information
fonctionnel reflétant une réalité physique. Il donc
évide de valider une à une chacune des étapes en prenant
en compte les résultats de la phase précédente. D'autre
part, les données étant séparées des traitements,
il faut vérifier que toutes les données nécessaires aux
traitements sont disponibles et qu'il n'y a pas de données
superflues.
Ainsi il existe un consensus sur le découpage d'un
processus de modélisation en trois étapes ou cycle d'abstraction
correspondant à une modélisation de la future base de
données.
1. Niveau conceptuel : c'est
celui qui définit les flux d'informations à prendre en compte. En
terme conceptuel, il représente le contenu de la base de données
indépendamment de toute considération informatique. Ainsi, il est
appelé MCC (Modèle Conceptuel de la Communication)
2. Niveau organisationnel
Permet de définir l'organisation qu'il est souhaitable
de mettre en place dans une entreprise. Il précise le poste de travail,
la chronologie des opérations, le choix d'automatisation tout en
intégrant les contraintes éventuelles. Il consiste à se
poser les questions du point de vue de traitement : qui où ?
Et quand ?, et on envisage les partages des tâches entre les hommes
et les machines. Il se traduit en terme de :
- MLD (Modèle Logique de Donnée)
représentant un choix logiciel pour un S.I et décrit les
règles et les contraintes à prendre en compte.
- MOT, MCT (Modèle Organisationnel ou Conceptuel de
Traitement) décrit les contraintes dues à l'environnement
(organisationnel, spécial, et temporel)18(*)
3. Niveau physique
Il définit ou reflète le choix matériel
pour le système d'information.
2.2. LES BASES DE DONNEES
2.2.1. Définition
C'est en fait un gros ensemble d'informations
structurées mémorisées sur un support permanent. C'est un
ensemble de données modélisant les objets d'une partie du monde
réel et servant de support à une application informatique. C'est
une entité dans laquelle il est possible de stocker des données
de façon structurées et avec le moins de redondance
possible.
Une base de données est un ensemble
structuré de données enregistrées sur des supports
accessible par l'ordinateur pour satisfaire simultanément plusieurs
utilisateurs de manière sélective en un temps opportun.
2.2.2. différents type de base de données
Actuellement, il existe 4 types de bases de données,
qui sont les suivants :
1. Les bases hiérarchiques
Ce sont les premiers SGBD (système de gestion des bases
des données), elles font partie des bases de navigation
constituées d'une gestion de pointeurs entre les enregistrements, dont
le schéma de la base doit être arborescent.
2. Les bases réseaux
Elles ont très vite supplanté les bases
hiérarchiques, elles sont sans doute les bases les plus rapides. C'est
également les bases de navigation gérant les pointeurs entre les
enregistrements. Contrairement aux bases hiérarchique dont leurs
schéma est arborescent, ici le schéma de la base est beaucoup
plus ouvert.
3. Les bases relationnelles
A l'heure actuelle, sont les bases le plus utilisées.
Elles sont basées sur
L'algèbre relationnelle et un langage
déclaratif (généralement SQL). Les données sont ici
représentées en tables.
4. Les bases objets
Les données sont représentées ici en tant
qu'une instance de classes hiérarchisées, dont chaque champ est
un objet. De ce fait, chaque donnée est active et possède ses
propres méthodes d'interrogation et d'affectation. La notion
d'héritage est utilisée comme mécanisme de factorisation
de la connaissance.19(*)
2.2.3. le systeme de gestion de base de données
(sgbd)
Jadis, ont utilisé le système de gestion de
fichiers (SGF) pour manipuler des fichiers (données) de grande taille,
mais ce système présenté plusieurs difficultés qui
n'étaient pas si simple à remonter. Eu égard à
cela ; les informaticiens ont pensé à contourner ces
inconvénients et cela nous ont amené aujourd'hui au SGBD. Un
travail directe sur le fichier présenté plusieurs
inconvénients notamment :
- Le concepteur devrait nécessairement connaitre la
localisation physique des fichiers,
- La structure des enregistrements et le mode d'accès
à ces fichiers,
- La manipulation de données était lourde et
compliquée, il fallait être un grand concepteur pour y
parvenir ;
- Toute modification de la structure de ces enregistrements
(ajout d'un nouveau champ par exemple) entrainait la réécriture
de tous les programmes qui manipulent ces fichiers.
Actuellement, le SGBD est l'intermédiaire entre les
utilisateurs et les fichiers physique, il facilite la gestion de données
avec une représentation simple sous la forme de table et l'on peut
insérer, modifier les données et les structures sans toutefois
modifier les programmes manipulant la base de données.
Actuellement le Modèle relationnel est le plus rependu
au monde suite à sa structuration des données sous la forme de
table pouvant être reliées les uns aux autres. Ainsi le SGBD est
défini comme étant :
Un ensemble de logiciel système permettant aux
utilisateurs d'insérer, modifier et rechercher efficacement des
données spécifique dans une grande masse d'information
partagée par de multiples utilisateurs. Il est donc un logiciel de haute
envergure permettant de manipuler les informations stockées dans une
base de données.
a) Objectifs de SGBD
Nous pouvons énumérer de la manière
suivante, les objectifs d'un système de gestion de base de
données :
- Assurer la facilité de représentation et de
description de données ;
- Mettre des données à la disposition
d'utilisateurs pour des consultation, une saisie soit une mise à
jours ;
- Rendre les données possibles de manière
à pouvoir accédés simultanément par plusieurs
utilisateurs ;
- Faciliter la manipulation en travaillant directement sur le
schéma logique ;
- Permettre l'ajout des contraintes afin d'avoir à tout
instant les données cohérentes ;
b) Fonctions principales d'un
SGBD
Dans une utilisation sauvegarde de grande masse d'information,
on distingue 3 fonctions principales d'un système de gestion de base de
données.
- La description des données : structuration et
codification de données grâce à un langage de description
de données (LDD) ;
- Manipulation et restitution de données (insertion,
mise à jour, interrogation de la base de données,...) Cela
réduit à la mise en oeuvre à l'aide d'un langage de
manipulation de données (MLD) dont SQL (Structured Query Langage) qui
est reconnu standard ;
- En fin, le contrôle en assurant le partage,
l'intégrité, la confidentialité et la
sécurité des données.
Dans la sauvegarde des grandes masses d'informations, le SGBD
permet de :
· Partage de données : accès
simultané de plusieurs utilisateurs. Ici le mécanisme de
contrôle de concurrence basé sur des techniques de verrouillage
des données est inclus par le SGBD ;
· Intégrité de données :
à chaque insertion, suppression, ou modification des données, le
SGBD veille à ce que toutes les contraintes soient
vérifiées grâce à la contrainte sur les
données.
· Confidentialité : plusieurs utilisateurs
utilisant au même moment une base de données, se pose le
problème de la confidentialité données, c'est - à -
dire d'être beaucoup plus discret par rapport aux informations circulant
entre - eux
· Sécurité : une base de
données est souvent vitale dans le fonctionnement d'une organisation, et
il n'est pas tolérable qu'une organisation, et il n'est pas
tolérable qu'une panne puisse remettre en cause son fonctionnement de
manière durable. Les SGBD fournissent donc les mécanismes pour
assurer cette sécurité. (20(*))
CONCLUSION PARTIELLE
Jusque-là nous sommes sûr et certains que tout
lecteur qui lira le présent travail, aura une vision claire et
précise concernant les notions de système d'information et les
bases de données, leurs rôle et fonctionnement et aussi une
brève présentation de l'approche Merise et des notions des
fichiers.
Ensuite, le chapitre suivant pourra nous décrire
l'entreprise cible de notre travail, leur système organisationnel et la
manière dont les informations (données) circulent dans
différents services.
CHAPITRE III. CONCEPTION ET IMPLEMENTATION
3.1. Étude préalable
3.1.1. Présentation de l'inss
1. Les Origines
Par définition, la sécurité sociale est
« l'ensemble des textes légaux et réglementaires ainsi
que de services chargés de leurs applications qui ont pour objet, de
garantir les travailleurs et leurs familles contre certaines risque
sociaux ».
C'était en 1894, qu'on retrouve l'expression
« sécurité sociale » dans la proclamation du
premier congrès national du parti des travailleurs italiens. Le 31
octobre 1918, elle est utilisée dans un degré du conseil des
commissaires du peuple de la République Socialiste Soviétique de
la Russie.
Elle apparait en suite pour la première fois aux Etats
Unis d'Amérique (USA) en 1935 et enfin au lendemain de la
deuxième guerre mondiale, elle est utilisée dans bon nombre de
constitutions avant d'être consacrée solennellement dans la
déclaration universelle des droits de l'homme, Adoptée par
l'Assemblée Générale de l'ONU le 10 décembre
1948.(21(*))
2. La Sécurité Sociale
a) en Afrique
L'Afrique en général s'est dotée d'un
système de sécurité sociale plus d'un demi - siècle
après les pays industrialisés d'Europe.
C'est en fait après 1950 que les principaux
régimes ont vu le jour en Afrique, à l'exception des risques
professionnels pour certains pays. Toutes les institutions de la
sécurité sociale étaient calquées sur le
modèle européen dont la conception juridique, les systèmes
de financement, l'organisation et les méthodes administratives allaient
servir de référence avec quelques efforts d'adaptation aux
circonstances socio - économiques, administratives, propres à
chaque pays africain.
C'est ainsi qu'à quelques exceptions, les
régimes de sécurité sociale en Afrique, à l'image
de ceux de l'Europe, ne s'appliquent qu'aux salariés des secteurs
structurés et ne couvrent qu'une très faible proportion de la
population active. Notre pays n'a pas donc échappé à cette
règle.
b) en RDC (République Démocratique du
Congo
1. période
précoloniale
Jadis, dans le système traditionnel, les risques
sociaux étaient couverts par la famille, le clan, la tribu, le
village,... il existait donc une solidarité clanique entre les membres
de la société. Dans un village, tout le monde s'entraidait de
façon naturelle.
2. période coloniale
Durant cette période, le passage d'une économie
traditionnelle à une économie industrielle a fort diminué
l'efficacité de cette solidarité clanique. En effet,
l'industrialisation a entrainés l'apparition et le développement
des centres urbains et extra coutumiers dans lesquels vivait une classe sociale
qui n'avait comme unique source de revenu que le salaire. Si ce salaire venait
à disparaitre, le travailleur et sa famille se trouvaient inexorablement
plongés dans la misère.
De là, s'était imposé l'impérieux
nécessité de remplacer l'ancienne protection clanique par une
nouvelle protection : celle d'une sécurité sociale efficace
qui a eu pour but de procéder à une certaine redistribution des
revenus de la classe ouvrière, de façon à venir en aide
à ceux d'entre les travailleurs (et aux membres de leurs familles) qui
seraient victimes d'un risque social et qui auraient besoin d'une
assistance.
Il faut noter que le terme « Sécurité
Sociale » a été intégralement adopté en
RD Congo par la promulgation du décret - loi du 19 juin 1961 de l'INSS
comme étant établissement public à caractère
technique et social doté de la personnalité juridique et de
l'autonomie financière. Elle est placée sous la garantie de
l'Etat. (22(*))
1. Situation géographique
Le bureau de l'INSS est implanté sur toute
l'étendue du territoire national de la R D Congo, dont Kinshasa est le
siège Social. Particulièrement dans la province du Kasayi
Occidental, le bureau est implanté dans la ville de Kananga (chef-lieu
de la province), commune de ladite ville, quartier Malandji au numéro
114 de l'avenue Macard ex-Shabunda.
L'INSS/Kananga est borné au Nord par l'Hôtel
Musube, Au Sud par la station Monalux, à l'Est par l'Etat-major de la
Police National Congolaise(PNC), et à l'Ouest par l'institut
Supérieur Pédagogique de Kananga ISP/Kananga en sigle.
2. Mission permanente de l'INSS
Dans le cadre des dispositions légales et
réglementaires en vigueurs, l'INSS est chargé pour l'ensemble du
pays de procéder :
· A l'affiliation et l'immatriculation des employeurs et
des travailleurs ;
· A la liquidation et l'ordonnancement des prestations au
titre familiales
· Allocation familiale ;
· Pension,
· Risques professionnels.
Dont le paiement est confié :
· Aux employeurs ;
· A l'administrateur de territoires,
· Aux établissements bancaires ;
· A certains employeurs y compris des missions.
3. Rôle de l'INSS
Elle a pour rôle principal :
· De repartir les conséquences de
l'invalidité, de la vieillesse, du décès, de l'accident du
travail ainsi que des maladies professionnelles ;
· De faire face aux charges de la famille, en attendant
que d'autres branches de prestation soient instituées.
Mais la question que l'on doit se posée est celle de
savoir : de qui vie l'INSS ?
4. Source de financement
Comparativement à une ONGD basée dans un
domaine, agricole par exemple, cette dernière subsiste grâce
à des financements, les ressourcer de ses récoltes,... ainsi
l'INSS tire ses financé par les produits de placement des fond, par la
majoration de retard soit recourt aux emprunts et par les subventions de
l'Etat.
5. Organigramme général de
l'INSS
L'étude ou l'analyse structurelle des différents
liens existant entre différents services est nécessaire, et elle
est souvent liée à l'organigramme.
ORGANIGRAMME GENERAL DE L'INSS
DIRECTION PROVINCIALE
CORPS DE CONTR KAFUNDA OLE
SECRETARIAT DE SIRECTION
SOUS DIRECTION
SERVICE ADMINISTRATION
SERVICE FINANCE
SERVICE EMPLOYEURS ET SALARIES
SERVICE TECHNIQUE
SERVICES DES ARCHIVES
SECTION DISPENSAIRE
SERVICE COMPTABLE
SECTION INSCRIPTION EMPLOYEURS ET SALARIES
SECTION CONSTITUTION DE DOSSIER
SECTION DISPENSAIRE
SECTION TRESORERIE
SECTION GESTION EMPLOYEURS ET SALAIRIES
SECTION GESTION
SECTION RISQUES PROFESSIONNELS
SECTION PAIEMENT DE PRESTATION SOCIALE
6. Organigramme spécifique
Suite à plusieurs poste de travail constituant
l'organigramme précédent, nous recourons à la voie
hiérarchique de Henry FAYOL qui par l'autorité supérieure
en participant et en ayant l'influence considérée sur tous les
postes et tous les affluents d'un ou de plusieurs services.
Pour cela, voici l'organigramme hiérarchique du
service technique entrant en jeux de notre travail et où sera
fondé notre implémentation.
DIRECTION PROVINCIALE
CORPS DE CONTROLE
SECRETARIAT DE DIRECTION
SOUS DIRCTION PROVINCIAL
SERVICE TECHNIQUE
SECTION CONSTITUTION DE DOSSIERS
SECTION CALCUL DE PRESTATION SOCIALE
SECTION RISQUES PROFESSIONNELS
SECTION PAIEMENT DE PRESTATION SOCIALE
251646976
251645952
3.1.2. Analyse de l'existant
A. présentation des postes de travail
ü Chef de service technique, chargé de :
· Superviser le service ;
· Responsable générale de service ;
· Coordonner les activités des
sections ;
· Discipline de service ;
· Réparer le travail et contrôler
l'avancement des travaux, etc.
ü Section constitution des données :
· Reçu et assurer l'enregistrement des nouvelles
demandes de pension,
· Exploite et étudie les dossiers ;
· Opère les calculs des prestations pour les
dossiers complets et renvoyer aux intéressés par le canal des
entités administratives, etc.
ü Section calcul des prestations sociales :
· Détermine la carrière ;
· Elabore la feuille d'orientation, de décision de
calcul ;
· Effectue le calcul des prorata initiaux à payer
aux bénéficiaires ;
· Etablit les grilles de création et
MODIF ;
· Transmet les dossiers calculés à la
section paiement des prestations sociales.
ü Section paiement des prestations sociales :
· Reçoit les dossiers calculés ;
· Etablit les bordereaux des grilles pour transmission
à la direction technique ;
· Remise de brevet et notifications aux
concernés ;
· Exploite les listings de paie ;
· Litige de réclamations
· Paie les prorata initiaux, etc.
ü Section risques professionnels :
· Reçoit et enregistre le déclaration
d'accident et maladies professionnelles ;
· Etudie les dossiers et examine la
recevabilité ;
· Calcul les rentes et allocation
d'incapacité ;
· Liquidation des indemnités temporaires de
travail ;
· Classement et archives ;
· Dactylographie.
B. prestation des documents
L'INSS utilise les documents suivent :
· La fiche de demande de pension de retraite ;
· Attestation de service rendue ;
· Grille de bénéficiaire ;
· certificat de pension
· Rémunération de 36 derniers mois.
1. FICHE D'ANALYSE DE POSTES DE TRAVAIL
|
N°
|
Nom post de travail
|
Travail Effectue
|
Moyen de traitement
|
Volume prévu
|
Volume réalisé
|
Nbre agent
|
Obs.
|
|
01
|
Direction
|
prise de décision
|
manuel
|
40
|
8
|
1
|
Assez rapide
|
|
02
|
Secrétariat général
|
Enregistre les retraités conforme ;
Correspondance etc.
|
ordinateur
|
50
|
15
|
1
|
rapide
|
|
03
|
Section constitution des dossiers
|
Vérifie les dossiers ;
Renseignes aux guichets, etc.
|
Manuel
|
20
|
10
|
1
|
lent
|
|
04
|
Section calcul des prestations sociales
|
Détermine la carrière,
Calcul des proratas initiaux à payer aux
bénéficiaires,
|
Manuel
|
25
|
10
|
1
|
lent
|
|
05
|
Section paiement des prestations sociales
|
Reçoit les dossiers calculés ;
Etablit les bordereaux ;
Remise de brevet ;
Paiement de prorata
|
manuel
|
35
|
20
|
1
|
Lent
|
|
06
|
Section risques professionnels
|
Reçoit et enregistre les déclarations
d'accident
Calcul les rentes et allocation d'incapacité, etc.
|
Manuel
|
15
|
10
|
1
|
lent
|
Source : (service technique)
2. ANALYSE DE MOYEN DE TRAITEMENT MATERIEL
Afin de réaliser un travail impeccable et rapide,
l'INSS/Kananga a fourni les matériels pouvant faciliter de meilleurs
condition de travails pouvant facilité de meilleurs condition de
travail, spécialement aux travailleurs du service technique. Ainsi, 4
machines à calculée sont mise à leurs disposition, un
ordinateur, une machine à écrire (mécanique), une
imprimante. En fait, ces matériaux ont pour
caractéristiques :
|
NATURE
|
MARQUE
|
CAPACITE CPU
|
MEMOIRE
RAM
|
CAPACITE
HDD
|
S.E
|
|
Machine a calculée
|
SONIC
|
-
|
-
|
-
|
-
|
|
Ordinateur
|
DELL
|
1,5Ghz
|
128Mo
|
250Go
|
WINDOWSP3
|
|
Machine à écrire
|
OLYMPIA
|
-
|
-
|
-
|
-
|
|
Impriment
|
HP
|
-
|
-
|
-
|
-
|
|
|
|
|
|
|
Source : Service technologie
3. ANALYSE DE MOYENS DE TRAITEMENT HUMAIN
L'entreprise étant une entité regroupant des
personnes de toute catégorie et niveau, l'INSS en a parmi ceux qui en
procède particulièrement dans le service technique. Voici
à présent le tableau de classification des différents
titres, qualification et catégorie ou classe des travailleurs.
|
Poste de travail
|
Catégories agents
|
Qualification agent
|
Mois prestés
|
|
Direction général
|
Cadre
|
Licencié
|
10
|
|
Secrétariat général
|
Agent se classe
|
Gradué
|
10
|
|
Chef de service technique
|
Cadre
|
Licencié
|
10
|
|
Section constituions des dossiers
|
Agent 2e classe
|
Gradué
|
10
|
|
Section calcul des prestations sociales
|
Agent 2e classe
|
Gradué
|
10
|
|
Section risques professionnels
|
Agent 2e classe
|
Gradué
|
10
|
Source : service technique
Ainsi, il est évident de présenter l'ensemble
d'informations circulant entre différents postes de travail selon 3
étapes d'analyse, qui nous permettrons de dresser le tableau d'analyse
de flux d'information.
1. TABLEAU DE FLUX
Les informations circulant dans le service technique à
l'aide des documents sont représentées de la manière ci -
après :
|
Numéro
|
Nom document
|
Code
|
Information véhicule
|
Origine
|
Destination
|
Observation
|
|
01
|
Carte d'identité
|
ci
|
Nom
Post nom
Prénom
Date nais
adresse
|
Retraité (entreprise)
|
Section constitution dossiers
|
Un exemplaire
|
|
02
|
Certificat de pension
|
SP
|
Nom
Post nom
Age
matricule
|
Retraité (entreprise)
|
Section constitution de dossiers
|
Un exemplaire
|
|
03
|
Fiche de demande de pension
|
FDP
|
Renseigne sur la profession d'un retraité
|
Retraité (entreprise)
|
Direction générale
|
Un exemplaire
|
|
04
|
Attestation de service rendue
|
ASR
|
Signal sur la vie professionnelle d'un retraité
|
Direction générale
|
Service technique
|
Un exemplaire
|
|
05
|
Grille de bénéficiaire
|
GB
|
Renseigne la somme de toute la cotisation durant la vie
professionnelle d'un retraité
|
Section constitution de dossier
|
Section calcul de prestation social
|
Deux exemplaire
|
|
06
|
Rémunération de 36 dernier mois
|
R36
|
Matricule
Nom
Prénom
Age
Date début
Date fin
Nbre de mois
|
Section constitution de dossier
|
Service technique
|
Un exemplaire
|
|
07
|
Dossier complet
|
DC
|
Carte d'identité
Certificat de demande de pension
Attestation de service rendu
Grille de bénéficiaire
Rémunération de 36 dernier mois.
|
Service technique
|
Direction général
|
Un exemplaire
|
2. DICTIONNAIRE DES DONNES
Est un tableau à 2 colonnes et n lignes dont les
numéros ou codes, et les
documents ou désignations.
|
Code documentaire
|
désignations
|
|
01
|
Carte d'identité
|
|
02
|
Attestation de service rendu
|
|
03
|
Fiche de pension de retraite
|
|
04
|
Rémunération de 36 derniers mois
|
|
05
|
Grille de Bénéficiaire
|
|
06
|
Certificat de pension
|
3. LA MATRICE DE FLUX
C'est un tableau des n lignes et n colonnes permettant
d'analyser le flux d'information s'échangeant entre les acteurs.
|
DE
VERS
|
DIRECTION
|
SERVICE TECHNIQUE
|
SECTION. CALCUL DE PRESTATION SOCIAL
|
SECTION CONSTITUTION DES DOSSIERS
|
SECTION CALCUL DE PENSION.
|
|
DIRECTION GENERALE
|
-
|
07
|
-
|
-
|
03
|
|
SERVICE TECHNIQUE
|
04
|
-
|
-
|
06
|
-
|
|
SECTION CALCUL DE PRESTATION SOCIALE
|
-
|
-
|
-
|
-
|
08
|
|
SECTION CONSTITUTION DES DOSSIERS
|
-
|
-
|
-
|
-
|
01
|
|
SECTION CALCUL DE PENSION (RETRAITE)
|
-
|
-
|
-
|
05
|
-
|
Source : analyse de tableau de flux
2. DIAGNOSTICS DU SYSTEME
D'INFORMATION EXISTANT ET PROPOSITIONS
Sur base de ce que nous avons acquis comme connaissance sur le
fonctionnement de l'Institut National de Sécurité Sociale/
Kananga en général et en particulier de la gestion de
retraités, nous avons remarqué que cette aimable institution
néglige le rôle et les avantages de l'information de ses
différents services à l'aide des outils de traitement
automatique.
En amont, la présente remarque est essentiellement
importante dans la façon dont les quelques matériels
informatiques que possède l'INSS. Sont consacrés au traitement
simple de texte vulgairement appelé « saisie ».
En aval, il s'ajoute aussi plusieurs classeurs créer
par le biais de la machine à écrire (mécanique, et aussi
avons remarqué un encombrement total dans la gestion des
retraités.
Eu égard aux remarques précédentes, nous
proposons à l'INSS à son service technique en particulier dans le
but d'optimiser son rendement dans le sens à trouver des solutions en
temps réel à ses problèmes, nous proposons à l'INSS
de :
· Former quelques agents du service technique sur les
notions de l'informatique et sur le fonctionnement du système
informatique ;
· Augmenter le monde d'ordinateurs de grande
capacités dans chaque service ;
· Engager quelques informaticiens pour le maintient des
matériels informatiques et la mise en oeuvre d'une ou de plusieurs
applications informatiques pour l'atteinte de certains objectifs ;
· Installer le signal informatique dans tous les
ordinateurs et dans tous les services ;
Toutes les propositions énumérées ci -
haut pourront aider l'INSS si l'on considère, à atteindre les
objectifs.
3. ETUDE CONCEPTUELLE
3.1. Modèle conceptuelle de données
(MCD)
Pour une gestion automatisée, nous allons mettre en
place les données appropriés et nous y présenterons les
objets manipulés ainsi que les relations les reliant par la
méthode Merise pour la meilleure gestion de retraités.
3.1.3 Schéma du modèle conceptuel des
données
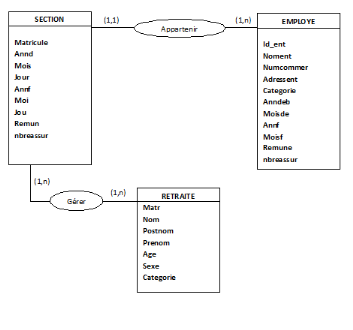
Nous parvenons à retenir les relations suivantes :
appartenir et gérer, ainsi que les cardinalités les
définissant.
Appartenir
Section (1,1) (1,1) Employé
Gérer
Section (1,n) (1,n) Retraité
3.1.4. MODELE LOGIQUE DE DONNEES (MLD)
Vue la grandeur de cette partie, enchainons par un double
objectif, à savoir :
· La description de la logique de traitement des
informations dont la logique de programmation ;
· La détermination des caractéristiques de
la base de données.
D'où deux modèles indissolubles à
savoir :
· Modèle Logique de Données (MLD)
· Modèle physique de données (MPD)
3.1.5. PASSAGE DU MCD au MLD
Les règles suivantes mettent au clair la transformation
d'une structure conceptuelle à une structure logique totalement
algorithmique :
· Toute entité devient une table dans laquelle les
attributs deviennent les colonnes ; et l'identifiant de l'entité
constitue alors la clé primaire de la table ;
· Dans le cas de deux entités reliées par
une association du type 1,n, on ajoute une clé étrangère
dans la table côté 0,1 ou 1,1 vers la clé primaire de la
table côté 0,n ou 1,n ;
· Dans le cas de deux entités reliées par
une clé étrangère vers la clé primaire de l'autre
afin d'assurer la cardinalité maximale de 1 on ajoute une contrainte
d'intégrité sur chacune de ces clés
étrangères ;
· Une association entre deux entités de type 1, n
est traduite par une table supplémentaire (parfois appelée table
de jointure) dont la clé primaire est composée de deux
clés étrangères vers les clés primaires de deux
tables en relation. Les attributs de l'association deviennent les colonnes de
cette table ;
· Une association non binaire est traduite par une table
supplémentaire dont la clé primaire est composée d'autant
des clés primaires étrangères.
3.1.6. PRESENTATION DU MLD
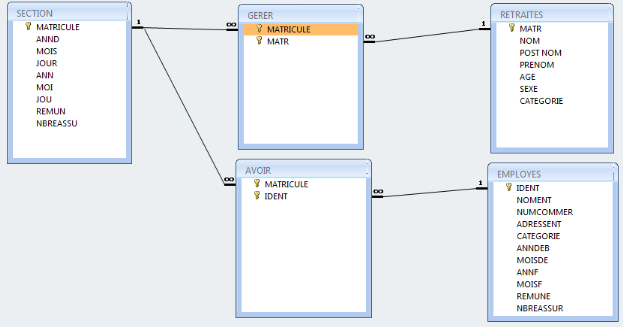
3.1.7. DICTIONNAIRE DES DONNEES
|
N°
|
TABLES
|
PROPRIETES
|
CODES
|
TYPES
|
TAILLE
|
|
01
|
Retraités
|
#matricul
|
matr
|
char
|
8
|
|
Nom
|
nom
|
char
|
15
|
|
Post nom
|
postnom
|
char
|
15
|
|
Prenom
|
prenom
|
char
|
10
|
|
Age
|
age
|
char
|
3
|
|
Sexe
|
sexe
|
char
|
2
|
|
categorie
|
categorie
|
char
|
22
|
|
02
|
Section
|
#matricule
|
Matrec
|
Char
|
8
|
|
Annd
|
Annd
|
Char
|
5
|
|
mois
|
Mois
|
Char
|
3
|
|
jour
|
Jour
|
Char
|
9
|
|
annf
|
Annf
|
Char
|
3
|
|
Moi
|
Moi
|
Char
|
3
|
|
Jou
|
Jou
|
Char
|
9
|
|
Remun
|
Remun
|
Char
|
11
|
|
nbreassu
|
nbreassu
|
char
|
5
|
|
03
|
Employés
|
#Ident
|
ident
|
char
|
25
|
|
noment
|
noment
|
char
|
18
|
|
numcomerc
|
numcomerc
|
char
|
15
|
|
Adressent
|
Adressent
|
char
|
28
|
|
Categorie
|
Categorie
|
char
|
11
|
|
Anndeb
|
Anndeb
|
char
|
4
|
|
Moisde
|
Moisde
|
char
|
9
|
|
Annf
|
Annf
|
char
|
4
|
|
Moidf
|
Moidf
|
char
|
9
|
|
Remune
|
Remune
|
char
|
8
|
|
nbreassur
|
nbreassur
|
char
|
6
|
|
04
|
Gérer
|
#matricul
|
matr
|
char
|
8
|
|
#matricule
|
Matrec
|
Char
|
8
|
|
05
|
Avoir
|
#matricule
|
Matrec
|
Char
|
8
|
|
#Ident
|
ident
|
char
|
25
|
Sources : Analyse du modèle conceptuel de
données(MCD)
3.2. MODELE PHYSIQUE DE DONNEES(MPD)
Cette étape consiste donc a la prise en compte des
contraintes physique liées au matériel de traitement et au
logiciel choisi. Le modèle logique de traitement est le passage du MLD
à la structure de la machine.
Tout système de gestion de basa des données doit
permettre à la créer une base de données à travers
son langage de définition de données (LDD), le chargement de la
base de données, la mise à jour de données et la
structuration de la dite donnée à travers le langage de
manipulation de données (LMD) éventuellement l'interrogation par
les utilisateurs.
3.2.1. REGLES DE PRESENTATION DU MLD AU MPD
Généralement à cette étape, les
tables deviendrons des fichiers et les attributs les champs(ou rubriques). La
structure de cette base de données dépendra du type de
système de gestion de base de données (SGBD) choisi.
a. Présentation du MPD
Au stade présent, signalons qu'il n'existe pas
d'approche normalisée de description et de présentation du niveau
physique de données.por cela, la structure de la base de données
est étroitement liée au SGBD. Ainsi par rapport à notre
cas, la structure physique sera :
ü Création Retraités
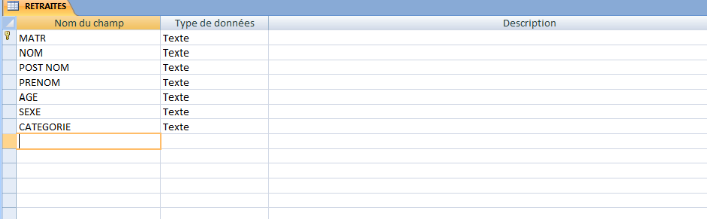
ü Création Section
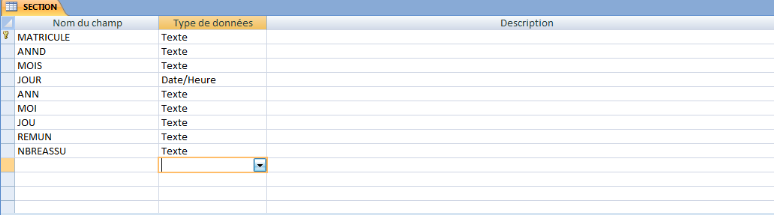
ü Création Employés
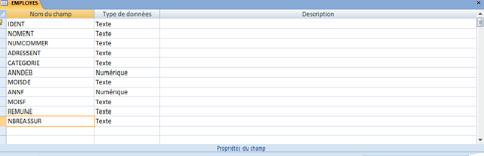
ü Création Gérer
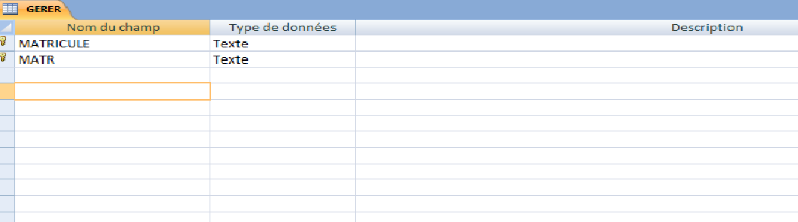
ü Création Avoir
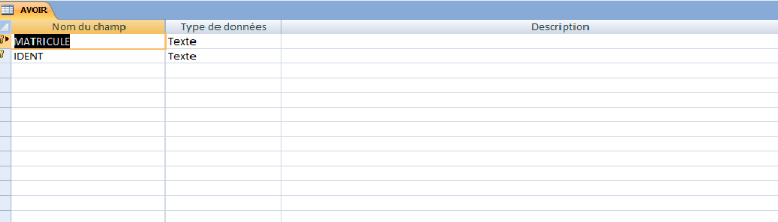
3.3. MISE EN OEUVRE DE LA SOLUTION INFORMATIQUE
RETENUE
3.3.1. l'environnement de développement de
l'application
Il est évident de parler du langage qui nous a permis
à l'implémentation de notre application ; en effet, le
langage de programmation c-Sharp dont nous considérons personnellement
comme un langage classique, Microsoft Visual c-Sharp est un puissant langage
orienté objet construit par la maison Microsoft en vu de surmonter
certaines difficultés ou complexité que présentais
d'autres langages de programmation.
Il joue un rôle très considérable dans
l'architecture Microsoft .net Framework et certaines personnes ont
comparé son rôle à celui joué par le langage C dans
le développement De l'UNIX.
3.3.2. Principaux interfaces les graphiques
L'exécution de cette application déclenchera
dans un premier temps par la fenêtre d'accueil, qui prendra pratiquement
cinq seconds en suite, fera appel à la feuille d'authentification
pour des raisons de sécurité.
Comme vous le remarquer, la saisie de nom d'utilisateur et de
mot de passe correct, vous donne l'accès à la page de menu en
cliquant sur le bouton OK :
La fenêtre de menu telle qu'elle, est conçue pour
permettre à l'utilisateur de faire exécuter certaines tache qui
lui sont confiées comme l'enregistrement d'un retraité ;
etc.

Le simple clic sur l'option «
RETRAITE » affichera la fenêtre d'identification d'un
retraité ; c'est-à-dire l'enregistrement des
retraités dans la base de données, leurs suppression et aussi le
retour à la fenêtre de menu.
Une fois que la fenêtre s'est affichée, il suffit
de saisir les renseignements qui lui concerne, sélectionner son sexe, sa
catégorie et cliqué sur le bouton SAVE ;
Pour confirmer l'enregistrement, cliqué sur le bouton
OK se trouvant dans la boitte de dialogue. Cette action
réinitialise les zones de saisie pour permettre la saisie d'un nouvel
pensionné, supprimer ou faire un retour à la fenêtre
d'option.
La fenêtre suivante est celle
générée par l'option
« EMPLOYER » ; elle joue double fonction dont
la soutirassions des informations par rapport à la provenance d'un
retraité et aussi les renseignements susceptible à calculer le
salaire trimestriel d'un retraité.
Après avoir saisi de gauche vers la droite, les
renseignements de la provenance et cèlent considérer comme
données de base susceptible à opéré les calcules
salarial, cliqué sur le bouton SAVE pour enregistrer. Cet
enregistrement génère automatiquement dans la zone
réservée au salaire nommé : « Pension
de retraite » le salaire trimestriel d'un
retraité.
Juste un clic sur SAVE, une boite de dialogue
s'affiche dans laquelle il est inscrit : « Etes-vous
autorisé d'enregistrer ? », alors à vous le
choix.
Si vous cliqués sur « OK »,
on enregistre et réinitialise toutes les zones de saisi et sur
« ANNULER » on ignore toute opération.
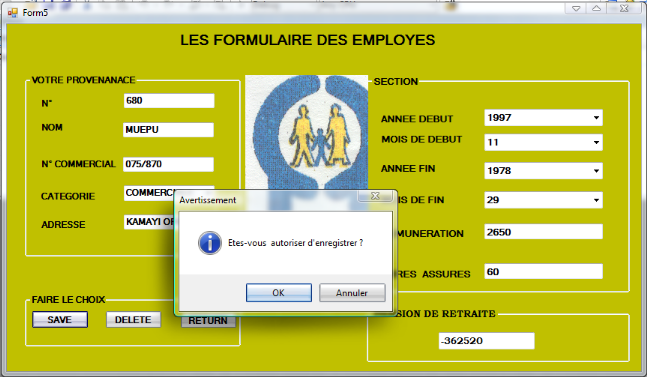
Confirmation de l'enregistrement.
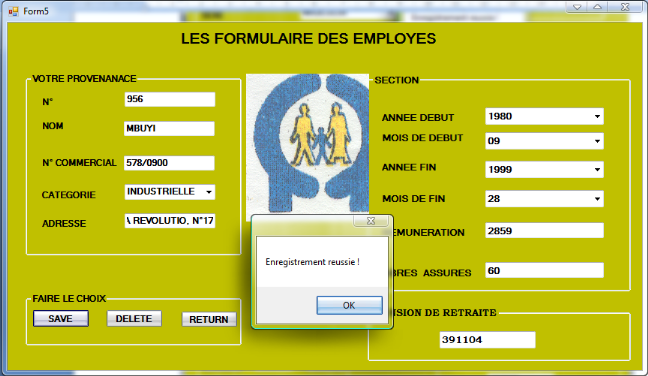
En ce qui concerne la suppression, il suffit de connaitre le
numéro de l'enregistrement d'un retraité dans la base de
données pour qu'elle s'effectue avec succès. Prenons l'exemple de
la fenêtre ici-bas : saisir le numéro d'un retraité
dans la zone « N° » puis cliqué sur le
bouton « DELETE » en suite une boite de
dialogue s'affiche confirmant que « La suppression
réussie »

3 .3.3. LES DIFFERENTS CODES SOURCES
CORRESPONDENT
a. Les codes sources correspondent à la
classe employée
Signalons que les quelque des codes que nous
présenterons, émane de l'ensemble des codes vu dans les cours de
programmation C-Sharp et quelques recherches. Ainsi, voici les quelques des
codes source soutirer dans notre projet informatique
dénommé : « GESTION_DE_RETRAITER ».
namespace GESTION_DE_RETRAITER
{
class Class3_Employe
{
private string ident;
private string noment;
private string numcommer;
private string categorie;
private string aDRESSent;
private int aNNDEB;
private string mOISDE;
private int aNNF;
private string mOISF;
private string rEMUNE;
private string nBREASSUR;
public string IDENT
{
get { return ident; }
set { ident = value; }
}
public string NOMENT
{
get { return noment; }
set { noment = value; }
}
public string NUMCOMMER
{
get { return numcommer; }
set { numcommer = value; }
}
public string CATEGORIE
{
get { return categorie; }
set { categorie = value; }
}
public string ADRESSENT
{
get { return aDRESSent; }
set { aDRESSent = value; }
}
public int ANNDEB
{
get { return aNNDEB; }
set { aNNDEB = value; }
}
public string MOISDE
{
get { return mOISDE; }
set { mOISDE = value; }
}
public int ANNF
{
get { return aNNF; }
set { aNNF = value; }
}
public string MOISF
{
get { return mOISF; }
set { mOISF = value; }
}
public string REMUNE
{
get { return rEMUNE; }
set { rEMUNE = value; }
}
public string NBREASSUR
{
get { return nBREASSUR; }
set { nBREASSUR = value; }
}
}
}
b. Les codes sources correspondent à la
classe retraitée
namespace GESTION_DE_RETRAITER
{
class Class2_retraité
{
private string matr;
private string Nom;
private string postnom;
private string Prenom;
private string age;
private string sexe;
private string categorie;
public string MATR
{
get { return matr; }
set { matr = value; }
}
public string NOM
{
get { return Nom; }
set { Nom = value; }
}
public string POSTNOM
{
get { return postnom; }
set { postnom = value; }
}
public string PRENOM
{
get { return Prenom; }
set { Prenom = value; }
}
public string AGE
{
get { return age; }
set { age = value; }
}
public string SEXE
{
get { return sexe; }
set { sexe = value; }
}
public string CATEGORIE
{
get { return categorie; }
set { categorie = value; }
}
}
}
CONCLUSION GENERALE
A l'issu de ce travail,
nous avons éclairé les différentes notions de
l'architecture client-serveur, du système d'information ainsi que les
divers étapes de la conception pour la réalisation de notre
application : Gestion des Retraités à l'Institut National de
Sécurité Sociale INSS en sigle.
Afin de satisfaire l'utilisateur, nous avons
débutés la conception en usant les formalismes Merise et la mise
en oeuvre de base de données à l'aide de gestionnaire de base de
données Microsoft Access et en suite la concrétisation de
l'application sous l'environnement de langage de programmation C-Sharp.
Cette solution informatique permettra aux fonctionnaires de
l'INSS à :
ü Gérer un retraité ;
ü Diminuer le temps de réponse ;
ü Prendre les décisions rationnelles ;
ü Faire les opérations de pension de retraite ou
d'invalidité avec précision et d'en dégager la somme ou le
salaire trimestriel; etc.
Ce projet a fait le noeud d'une expérience
intéressante qui nous a permis d'améliorer nos connaissances et
compétences du point de vu conception des bases des données et
programmation.
Cependant, les perspectives d'amélioration de notre
application restent envisageable telle que la qualité de renseignement
avec une recherche multicritères.
BIBLIOGRAPHIE
Ouvrage :
1. ALAZARD.C & SEPARES.S, Contrôle de gestion
manuelle et application, Paris, 5è Ed.
Dunod, 2001.
2. ANDREAS VOSS, Dictionnaires de l'informatique et de
l'internet, Paris, Ed. micro application, 2000.
3. BACK.M et ZIMMERMANN.S, Dictionnaires LE ROBERT, Paris,
SEJER, 2005.
4. BERNARD.J, Comprendre et organier le traitement automatique
de l'information, éd. Eyrolles, Paris, 1998.
5. DERONGE.Y, Comptabilité de gestion, Paris,
Bruxelles, Ed.de Boeck & Larcier S.a, 1998.
6. DI SCALA.R-M, Les bases de l'informatique et de la
programmation, éd. Betp d'Alger, 2005.
7. DIONISI.D, L'essentiel sur merise, Paris, 2è Edition
Eyrolles, 1998.
8. GEORGES et Olivier GARDARIN, Le client-serveur, Ed.
Eyrolles, Paris, 1999
9. GARDARIN.G, Bases de données ; objet &
relationnel, Paris, Edition Eyrolles, 1999.
10. GOUPILE.P-A, Technologie des ordinateurs et des
réseaux, Paris, 6è Edition Dunod, 2000.
11. INSS, Guide de l'assuré de la
sécurité sociale, Ed.SP, Kinshasa, 1967.
12. KAZENGU. M ; Informatique
Générale : de la théorie à la pratique,
Kinshasa, Mediaspaul, 2008.
13. KINZONZI.P.V, Comptabilité générale,
gestion et développement, Kin, Ed.CPR, 1995.
14. NTUMBA.N, Guide de rédaction d'un travail de
recherche scientifique, 2è Ed.de l'ISP/Kananga, Kananga, 2011.
15. TARDIEU, ROCHFIELD, COLLETI, La méthode merise,
édition des organisations, Paris, 1989.
Notes de cours :
1. BATUBENGA.J.D, Cours de l'organisation de gestion des
fichiers, Kananga, U.KA, 2013.
2. KAFUNDA.P, Cours de merise, Kananga, U.KA, 2014,
3. KAFUNDA.P, Cours de langage de programmation C-Sharp,
Kananga, U.KA, 2014.
4. KATUMBA.S, Cours de l'informatique générale,
Kananga, U.KA, 2012.
5. MULUMBA.P, Cours de système de gestion de base de
données, Kananga, U.KA, 2013.
Sites consultés :
1. www.Comment ça
marche.net/architecture client-serveur/...
2. http://wikipidia.org
* 1 KAFUNDA. P, Note de
cours de MERISE, Kananga, UKA, 2014.
* 2KAFUNDA. P-Ibidem.
* 3 KAFUNDA. P, Note de
cours de MERISE, Kananga, UKA, 2014.
* 4 BERNARD. J, Comprendre
et Organiser le traitement automatique de l'information, éd
Eryrolles, 1998.
* 5 KATUMBA. S, Note de
cours de l'informatique générale, Kananga, UKA, 2012.
* 6 BACK M. et ZIMMERMANN
S., Dictionnaires LE ROERT, Paris, SEJER, 2005, p. 16
* 7 . DIONSI. D, L'essentiel
sur merise, Paris, 2e édition Eyrolles, 1998, p.11
* 8 TARDIEU, ROCHFIELD,
COLLETI, La méthode merise, paris, édition des
organisations, 1989, p. 123
* 9 ANDREAS VOSS,
Dictionnaire de l'informatique et de l'internet, Paris, Ed. micro
application, 2000, p. 852
* 10 DERONGE. Y,
comptabilité de gestion, Paris, Bruxelles, Ed. de Boeck &
larcier S. a, 1998, p. 408
* 11 ALAZARD. C. & SEPARES
S, contrôle de gestion manuelle et application, Paris,
5e Ed. Dunod, 2001, p.92
* 12 KINZONZI. P.V,
comptabilité Générale, gestion et
développement, Kin, Ed CPR, 1995, p.11
* 13 GOUPILE P-A.,
Technologie des ordinateurs et des réseaux, Paris, 6e
Ed. Dunod, 2000, p. 61 - 71
* 14 BATUBENGA J.D., note de
cours de l'organisation de gestion des fichiers, Kananga, U.KA, 2013
* 15 KAFUNDA P-Ibidem.
* 16
BATUBENGA J.D-Idem
* 17 BATUBENGA. J. D-Ibidem.
* 18 DIONISI.D, L'essentiel
sur merise, Eyrolles, Paris, 1998.
* 19 DIONISI. D-Ibidem.
* S20 MULUMBA P., Note de
cours de système de gestion de base de données, Kananga,
u.ka, 2013.
* 21 INSS, Guide de
l'assuré de la sécurité sociale, Ed. S.P, Kinshasa,
1967.
* 22 INSS-Idem.
| 

