|
EPIGRAPHE
Je bénirai, l'Eternel qui me donne conseil durant la
nuit même mes reins m'enseignent ;
Je me suis toujours proposé l'Eternel devant moi parce
qu'il est à ma droite, je ne serai, pas ébranlé ;
C'est pourquoi mon coeur se réjouit, et mon âme
s'égaie ; même ma chair reposera en assurance.
Psaume 16,7-9
DEDICACE
A mes très chères mamans, Sabina NGOMBI et
Régine NGOMA
A mon très cher Père, Victor KALENGA KAMBA.
Qui, des manières constantes, ont accolé leurs
sacrifices pour parfaire l'oeuvre que je suis. Qu'ils en soient
remerciés et trouvent par ici la gratitude de mon coeur.
A tous les miens parents, amis et connaissance ; Que je ne
peux énumérer Je dédie ce travail.
KALENGA SHIMBU Lina
REMERCIEMENTS
A celui qui garde l'âme et protège le corps le
Tout-Puissant Dieu qui renouvelle les forces, nous transmettons nos tout
premiers remerciements ; car après nous avoir gardés tout au long
de notre deuxième cycle en force et bonne santé, a bien voulu que
nous l'achevions avec ce présent travail qui le couronne. Merci Seigneur
Jésus Christ. S'il s'est avéré possible de réaliser
ce présent travail, c'est grâce au Professeur Simon NTUMBA
BADIBANGA qui nous a accepté sous sa direction et son Assistant
Trésor ANONGA MAGUBU qui l'a poursuivi jusqu'à sa perfection ;
qu'ils trouvent à travers ces lignes l'expression de notre profonde
gratitude et de notre respect.
Notre gratitude s'adresse au Professeur Pierre KAFUNDAKATALAY,
Professeur MUSESA LANDU, Professeur Rostin MABELA, Monsieur l'abbé Noel,
Assistant Didier MAMBULU, nous vous sommes très reconnaissantes pour vos
multiples
Conseils et contributions combien substantiels tant pour la
réalisation.
De ce travail que pour la fin de notre parcours dans ce
Département
Des Mathématiques et Informatique. Que l'éternel
Dieu vous bénisse Richement
Nous pensons à la grande famille KALENGA Kathy KALENGA,
Erick KALENGA, Dido KALENGA, Valérie KALENGA, Obel KALENGA, Serge
KABUNDA, Herline NGOMBI, Alexis TSHIMAKA, Marie MANGU Pour leur soutien ainsi
que leur amour fraternel à notre personne.
Que nos amis et connaissances ainsi que nos compagnons de
Lutte trouvent ici notre attention singulière Jean clause LWEMBE Francis
KIMANGA, Vice OKITO, Pamela KAPINGA, Brenda MAUMBA, Chagy KABU, Radine PUNGA,
Lefie NKANDA, Gino LUWIDI, Rodrick MOSHI, Emmanuel MBULU, Richy NGOMBO, Rodrick
MOKUMBA, Jose LILUKA, Nash NKIE, Berty KIFUIDI et Adel NGALULA
LISTE DES ABREVIATIONS
· OLAP : One - line Analytical Processus
· ROLAP : RelationalOlap
· MOLAP : MultidimensionalOlap
·
HOLAP : HybridOlap
·
DW : Data Warehouse
·
SD : Système Décisionnel
· BI : Business Intelligence
· ETL : Extract - Transform -Load
· DM : Data Mart
· SI : système décisionnel
· OLTP : on line transaction processus
· SID : système aide à la
décision
· KDD : knawledje discovery in data bases
· ECD : extraction de connaissances de données
· GRC : gestion de relation de client
· SGBD : système de gestion de base des
données
· ODS : oparational data store
LISTE DES FIGURES
FigureI.1:
Architecture du système
décisionnel..............................page8
FigureI.2:Dissemblance
Décisionnelle..........................................................page10
Figure II.1
:Arbre de
décision construit à partir de l'attribut
Age.........page 31
FigureII.2
Arbre de décision
finale................................................................page33
FigureIII.1 Architecture d'un entrepôt de
données......................................page38
Figure III.2 Architecture d'un Data
Mart.........................................................Page44
Figure III. 1.Exemple de Modélisation en
étoile............................................Page47
Figure III.2. Exemple de modélisation en flocon de
neige..................Page49
Figure III.3. Exemple de Modélisation en
constellation......................Page50
Figure III. 6. Exemplede schéma
multidimensionnel........................Pag51
Figure III.7. Architecture OLAP
Figure III. 8: Architecture MOLAP
Figure III. 4: Architecture HOLAP
LISTE DES TABLEAUX
Tableau II.1. Les taches et techniques du
datamining.............................24
Tableau II.2.Exemple
pratique........................................................31
Tableau III.1Difference entre SGBD et systèmes
Décisionnels...............41
Tableau III.2caracteristique des
systèmes..........................................41
Tableau III.3 Méthodologie a neuf étapes de
kimball............................47
0. INTRODUCTION
La prise de décision est un problème essentiel
qui préoccupe les gestionnaires des entreprises. Cette prise de
décision passe par la modélisation des différents
problèmes qu'ils rencontrent dans la gestion, d'où la
nécessité d'un modèle basé sur l'arbre de
décision.
L'entrepôt de données étant une vision
centralisée et universelle de toutes les informations de l'entreprise,
C'est une structure qui a pour but, contrairement aux bases de données,
de regrouper les données de l'entreprise pour des fins analytiques et
pour aider le manager à la prise de décision
stratégique.
Une décision stratégique est une action
entreprise par les décideurs de l'entreprise qui vise à
améliorer, quantitativement ou qualitativement, la performance de
l'entreprise.
Un problème d'extraction de connaissances consiste
à extraire les connaissances à partir d'un entrepôt de
données ou d'une autre source de données en utilisant les
techniques du Datamining (Arbre de décision, réseaux Bayesien,
réseaux de neurones, etc.).
0.1. PROBLEMATIQUE
Etant
donné que la banque égorge à son sein des agents qui
travaille dans les différentes zones de l'étendu du pays, le
décideur cherche à évaluer la performance de chaque agent
afin de savoir la zone qu'il ne maitrise ou pas pour pouvoir de le permuter.
Sur ce, il a besoin de toutes les données qui lui
permettant d'avoir une décision stratégique. C'est pourquoi nous
avons réalisé notre système d'aide à la prise de
décision qui permettra de réunir toutes les données afin
d'en faire des analyses.
De plus, l'enregistrement de données pour chaque agent
se fait dans un format de fichier Excel, alors le décideur a du mal
à prendre une décision stratégique pour faire
l'évaluation, ce qui justifie la lenteur dans la prise de
décision.
De tout ce qui précède, nous pouvons
résumer notre problématique par des questions suivantes :
Ø Comment mesurer la performance des agents ?
Ø Comment orienter ces agents vers les zones qu'ils
maitrisent ?
0.2. HYPOTHESE
Partant des problèmes soulevés ci-haut
dans la problématique, nous pensons que la mise en place d'un
système décisionnel pour l'analyse de la performance des agents
de la banque FINCA RDC pourrait aider le décideur dans la prise de
décision face à une importante masse de données à
traiter et à gérer.
0.3.
MOTIVATION ET INTERET DU SUJET
Les techniques de l'entrepôt de données sont
d'une grande importance en termes de la prise de décision. Elles jouent
un grand rôle dans les entreprises actuelles avec l'évolution de
budget.
Le choix de ce sujet est motivé par le fait qu'il
aborde un domaine qui est récent et aussi complexe d'informatique
décisionnelle.
Aussi, il permettra à la banque FINCA RDC de
bénéficier d'un outil informatique décisionnel capable
d'aider le décideur à connaitre la performance des agents d'une
manière rationnelle.
En outre, ce travail servira de guide pour les chercheurs qui
voudraient entreprendre des investigations dans le même domaine.
0.4.
METHODES ET TECHNIQUES
0.4.1. Méthodes
utilisées
Une méthode est un ensemble d'opérations
intellectuelles par lesquelles une discipline cherche à atteindre les
vérités qu'elle poursuit, les démontre et les
vérifie. C'est aussi l'ensemble des démarches que suit l'esprit
pour découvrir et démontrer la vérité.
Dans le cadre de notre travail nous avons opté pour
la méthode de Raph Kimball. Elle nous a présenté la faveur
d'aller sur terrain, de récolter les données pour la
construction de notre Data Mart.
0.4.2. Techniques utilisées
Les techniques sont des procédures utilisées
dans la collecte d'informations (chiffre ou nom) qui, grâce aux
méthodes, permettent l'analyse dans une recherche.
Dans le cadre de notre travail, nous avons utilisé
les techniques ci-après :
0.4.2.1. Technique
documentaire
C'est celle qui met en présence d'un coté le
chercheur et d'autre part les documents supposés contenir des
informations ayant trait à l'étude faite par le
chercheur.
Cette technique nous a permis de consulter des ouvrages,
des travaux de fin de cycle, voire l'internet, pour bien rédiger notre
travail.
0.4.2.2. Technique
d'observation
Cette technique nous a permis d'observer des faits qui se
déroulent au sein de la Banque FINCA RDC considère attentivement
les phénomènes ayant trait à notre sujet de
recherche.
0.4.2.3. Technique d'interview
Une interview est une entrevue au cours de laquelle
l'enquêté (interviewer) interroge une personne sur sa vie, ses
projets, ses opinions dans l'intention de publier une relation de
l'entretien.
En d'autres termes, l'interview est la communication
entreprise verbalement entre l'interviewer et l'interviewé dans le but
de récolter les informations qui traduisent fidèlement les
phénomènes sous études visant la solution d'un
problème.
Nous nous sommes servis de cette technique pour
décrire la manière dont se déroule l'évaluation de
la performance des agents auprès des responsables de la Banque FINCA
RDC, d'une part ; et pour recueillir d'autres informations pertinentes en
rapport avec nos investigations, d'autre part.
0.5. DELIMITATION DU TRAVAIL
Pour parler de la délimitation du travail qui
consiste à évoquer sa précision dans le temps et dans
l'espace. Ainsi, nous sommes limités à concevoir un
système décisionnel pour la banque FINCA RDC permettra au
décideur de prendre une décision stratégique.
Ensuite nous avons utilisé l'arbre de
décision comme outil de datamining pour l'extraction de données
dans notre DataMart pour la prise de décision. Notre travail a
été réalisé pour la Banque FINCA RDC avec les
données de 2010 - 2013.
0.6. PLAN DU TRAVAIL
Outre l'introduction et la conclusion, notre travail
comprend quatre chapitres.
Le premier chapitre reprend
les concepts sur les Systèmes Décisionnels, nous
définissons les systèmes décisionnels et ses
enjeux.
Le deuxième chapitre
porte sur le Datamining.
Le troisième chapitre
traite des entrepôts des données où nous expliquons les
différents concepts relatifs aux entrepôts de
données.
Le quatrième chapitre est
consacré à la modélisation et
l'implémentation.
CHAPITRE I. SYSTEME DECISIONNEL [1][2][12][15][16]
I.1. INTRODUCTION
Notons de prime à bord qu'aujourd'hui, le
système d'information (SI) a pour objectif de faciliter
l'établissement et la mise en oeuvre de la stratégie, en
particulier de concrètement supporter la réalisation des
activités : « Produire les informations légales
réclamées par l'environnement, Déclencher les
décisions programmées, Fournir des informations aux
décideurs pour aider à la prise de décisions non
programmées, Coordonner les tâches en assurant les communications
au sein du système organisationnel ».
Il est construit à partir des exigences des
métiers, des processus définis par l'entreprise, et il est
constitué de l'ensemble des moyens (humains, logiciels,
matériels) utilisés pour collecter, stocker, traiter et
communiquer les informations.
Il est d'usage de distinguer trois types différents
de SI, les systèmes supportant la conception des produits (calcul
numérique, ...), les systèmes industriels et les systèmes
de gestion. Ces derniers couvrent toutes les activités de gestion du
fonctionnement de l'entreprise (marketing, vente, achat, production,
logistique, finance, ressources humaines, ...). Pour des raisons techniques,
qui existent toujours en partie aujourd'hui, les SI de gestion ont
été historiquement structurés en deux sous-systèmes
: l'un dit opérationnel qui prend en charge la réalisation des
opérations au jour le jour, et l'autre dit décisionnel, objet de
ce chapitre qui lui, permet de fournir des informations pour définir
des stratégies gagnantes, piloter les opérations et analyser les
résultats.
Disons donc que l'utilisation des informations
contenues dans les bases opérationnelles des entreprises paraissait peu
adaptée pour le support conséquent d'aide à la prise de
décision. Face à cette inadaptabilité, les entreprises ont
mis en place des systèmes spécifiques dédiés
à la prise de décision, lesquels systèmes sont
basés sur l'approche des Entrepôts de Données. Ces
systèmes regroupent un ensemble d'informations et d'outils mis
à la disposition des décideurs pour supporter de manière
efficace la prise de décision.
I.2.
SYSTEME DECISIONNEL
I.2.1. Définition
Un système décisionnel est un ensemble de
moyens, d'outils, et de méthodes permettant de collecter, de
modéliser, de consolider et de restituer les données dans le but
d'apporter une aide dans la prise de décision.
I.2.2. Objectif du système décisionnel
L'objectif du système décisionnel permet
d'améliorer les performances d'une entreprise dans la prise de
décision.
I.2.3. La Décision dans une Entreprise
Notons qu'au regard de la mondialisation et de la
concurrence grandissante des entreprises, la prise de décision est
devenue cruciale pour les dirigeants d'entreprises. L'efficacité de
cette prise de décision repose sur la mise à disposition
d'informations pertinentes et d'outils adaptés. Le problème des
entreprises est d'exploiter efficacement d'importants volumes d'informations,
provenant soit de leurs systèmes opérationnels, soit de leur
environnement extérieur, pour supporter la prise de décision. De
ce fait, il sied de savoir « c'est quoi une décision dans une
entreprise et c'est quoi aussi la prise de
décision ».
La décision consiste à effectuer un choix
lors d'une confrontation à un problème afin de le
résoudre. C'est aussi la solution apportée à un
problème posé.
La prise de décision est un acte essentiel dans la
vie de l'entreprise ; elle constitue une préoccupation constante
que l'on retrouve à tous les moments de la vie de l'entreprise et
à différents niveaux de son organisation.
Les décisions sont nombreuses mais aussi
différentes selon leur nature ou leur portée pour l'entreprise
dans le temps.
La décision est un choix portant soit sur la
détermination des objectifs, soit sur la détermination d'une
position par rapport à un problème posé à
l'entreprise (partenariat, mode d'organisation ou de direction), soit encore
sur la mise en oeuvre de ressources (recherche et acquisition de nouvelles
ressources, modification de leur allocation interne
I.2.4. Rôle du système décisionnel
Le système décisionnel a pour rôle
de :
Ø Exploiter les données structurés et
accumulées dans l'entreprise en les mettant à la disposition de
tous ;
Ø Sauvegarder et gérer les données
dans le Data Warehouse, les raffine avec les outils de datamining, les
informations sont diffusées par le biais du reporting. Dans le Data
warehouse, on stocke le profil de chaque client au cours du temps. Cela permet
à l'entreprise de pratiquer une approche individualisée en
marketing dite : One to one (plus exactement one to few).
I.2.5. Architecture du système décisionnel
L'architecture générale d'un système
décisionnel qui se décompose en trois processus : extraction
et intégration, organisation et interrogation.
Nous trouvons le processus d'extraction et
intégration entre les sources de données et l'entrepôt. Ce
processus est responsable de l'identification des données dans les
divers sources internes et externes ;
De l'extraction de l'information qui nous intéresse
et de la préparation et de la transformation (nettoyage, filtrage, etc)
des données à l'intérieur de l'entrepôt, nous
trouvons le processus d'organisation, il est responsable de structurer les
données par rapport à leur niveau de granularité
(agrégats). Finalement, le troisième processus correspond
à l'interrogation qui se place entre l'entrepôt et les
différents outils pour arriver à l'analyse des données,
pour les différents utilisateurs de l'entreprise.
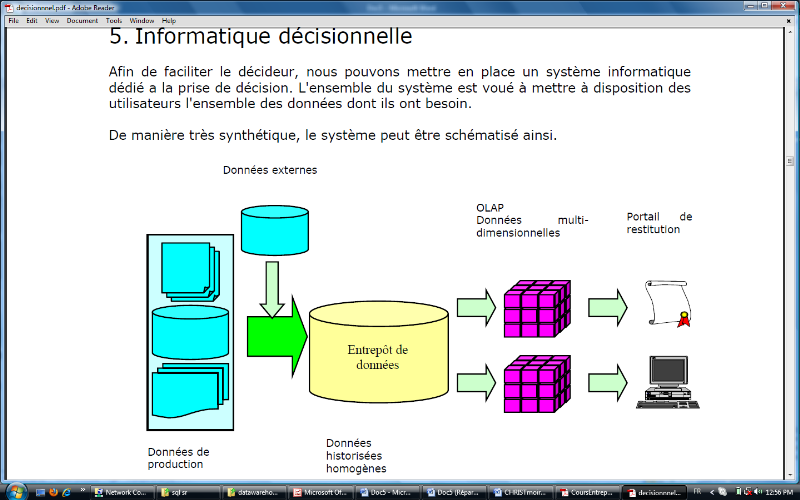
Figure I.1. Architecture du système
décisionnel
I.2.6. Les Systèmes OLTP et OLAP
Le terme OLTP (On Line Transaction processus) regroupe les
concepts mis en place pour un système destiné à
l'autorisation d'un processus de traitement de l'information. On utilise pour
cela les bases de données transactionnelles, les fichiers, dont la
mise à jour est faite en temps réel. Ces bases de données
et fichiers sont utilisés dans les entreprises pour gérer les
importants volumes d'informations contenus dans leurs systèmes
opérationnels (ou transactionnel). Les systèmes transactionnels
se caractérisent de la manière suivante :
Ø Ils sont nombreux au sein d'une
entreprise ;
Ø Ils concernent essentiellement la mise à
jour des données ;
Ø Ils traitent un nombre d'enregistrements
réduit ;
Ø Ils sont définis et exécutés
par de nombreux utilisateurs.
De part leurs caractéristiques, les Processus
Transactionnels en Ligne regorgent une grande masse d'informations cachant une
certaine connaissance dont eux-mêmes sont peu adaptés à
pouvoir déceler. Pour remédier à ceci, il faudrait
torturer cette masse d'informations jusqu'à ce qu'elles vont avouer la
connaissance qu'elles détiennent.
C'est dans cette perspective que plus de 95% d'entreprises
Européennes se sont donc mises à la recherche de
systèmes supportant efficacement les applications d'aide à la
décision à partir de la connaissance extraite dans les
systèmes transactionnels. Ces applications décisionnelles
utilisent des processus d'analyse en ligne de données (OLAP : "On-Line
Analytical Processing". Ces processus OLAP se caractérisent de la
manière suivante :
· Ils sont peu nombreux, mais leurs données et
traitements sont complexes ;
· Il s'agit uniquement de traitements
semi-automatiques visant à interroger, visualiser et synthétiser
les données ;
· Ils concernent un nombre d'enregistrements
importants aux structures hétérogènes ;
· Ils sont définis et mis en oeuvre par un
nombre réduit d'utilisateurs qui sont les décideurs.
Une autre différence que nous pouvons
établir entre les deux systèmes est que les OLTP sont
orientés « Applications », ce qui fait que nous
pouvons parler de la gestion de ressources humaines, des abonnés, de
vente de cartes prépayées, alors que les systèmes OLAP
sont orientés « Sujets ou thèmes ou encore
Activités » et par exemple nous pouvons avoir comme
sujet : la performance des employés, la vente, ... ceci est
illustré par la figure ci-après.
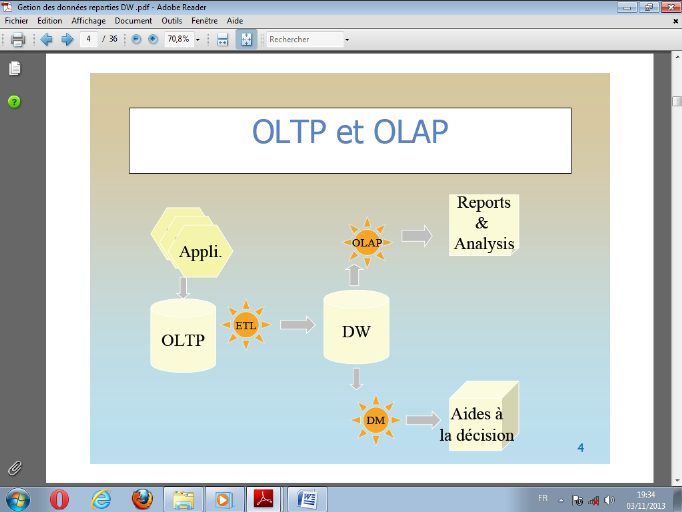
Figure I.2 : Dissemblance entre OLTP
et OLAP
I.2.7. Les Application de L'Informatique
Décisionnelle
Ces applications : la Gestion de la relation client,
la Gestion de commandes, de stocks, les Prévisions de ventes, la
Définition de profil utilisateur, l'Analyse de transactions bancaires
et la Détection de fraudes.
Les nouveaux outils de BI facilitent la mise au point
d'indicateurs fédérant toutes les couches de l'entreprise. La
vision stratégique de la direction générale doit en effet
être diffusée et déclinée dans tous les services de
l'entreprise comme l'illustre la figure 3 : il s'agit de fixer à chacun
des objectifs qui lui « parlent ». Parce qu'un chef d'équipe
sur une chaîne de montage se sentira infiniment plus concerné par
un objectif de réduction des délais de mise en route de la
chaîne ou par un ratio de défauts, que par un objectif
d'accroissement de part de marché au plan mondial.
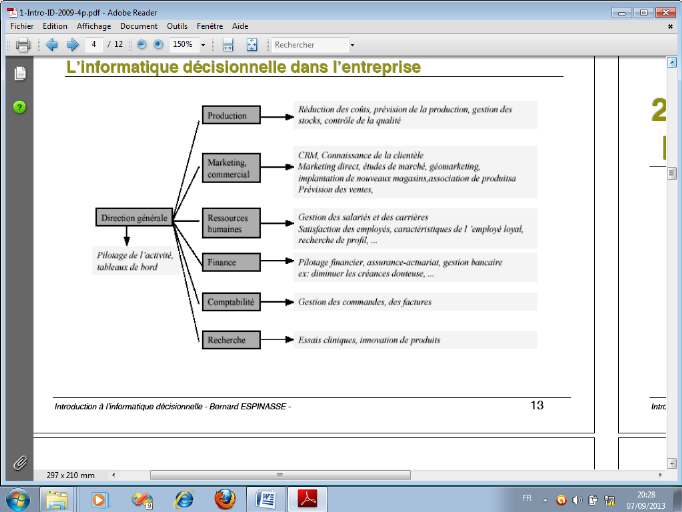
Figure I.3 : L'informatique décisionnelle dans
l'entreprise
I.2.8. Fonctions d'un Système D'aide à la
Décision
Un système d'information décisionnel (SID)
doit être capable d'assurer quatre fonctions fondamentales : la
collecte, l'intégration, la
diffusion et
la présentation des données. À ces quatre fonctions
s'ajoute une fonction d'administration, soit le contrôle du SID
lui-même :
· Fonction de
Collecte : Cette fonction (parfois appelée
datapumping) recouvre l'ensemble des tâches consistant à
détecter, sélectionner, extraire et filtrer les données
brutes issues des environnements pertinents compte tenu du
périmètre couvert par le SID. Comme il est fréquent que
les sources de données internes et/ou externes soient
hétérogènes tant sur le plan technique que sur le plan
sémantique, cette fonction est la plus délicate à mettre
en place dans un système décisionnel complexe. Elle s'appuie
notamment sur des outils d'
ETL
(extract-transform-load pour extraction-transformation-chargement). Les
données sources qui alimentent le SD sont issues des systèmes
transactionnels de production, le plus souvent sous forme :
o D'éléments issus de l'enregistrement de
flux : compte-rendu d'événement ou compte-rendu
d'opération. C'est le constat au fil du temps des opérations
(achats, ventes, écritures comptables, appels
téléphoniques, ...) ; c'est juste le film de
l'activité quotidienne, en tous cas régulière de
l'entreprise.
o D'éléments reflétant une situation
à un moment donné : compte-rendu d'inventaire ou
compte-rendu des services offerts par l'opérateur.
o La fonction de collecte joue également, au
besoin, un rôle de recodage. Une donnée représentée
différemment d'une source à une autre impose le choix d'une
représentation unique et donc d'une mise en équivalence utile
pour les futures analyses.
· Fonction
d'Intégration : Celle-ci consiste à
concentrer les données collectées dans un espace unifié,
dont le socle informatique essentiel est l'entrepôt de données
(concept de central du décisionnel). Celui-ci permet aux applications
décisionnelles de masquer la diversité de l'origine des
données et de bénéficier d'une source d'information
commune, homogène, normalisée et fiable, au sein d'un
système unique et si possible normalisé.
o Au passage les données sont épurées
ou transformées par :
o Un filtrage et une validation des données en vue
du maintien de la cohérence d'ensemble : les valeurs
acceptées par les filtres de la fonction de collecte mais susceptibles
d'introduire des incohérences de référentiel par rapport
aux autres données doivent être soit rejetées, soit
intégrées avec un statut spécial.
o Une synchronisation : s'il y a
nécessité d'intégrer en même temps ou à la
même « date de valeur » des événements
reçus ou constatés de manière décalée ou
déphasée.
o Une certification : pour rapprocher les
données de l'entrepôt des autres systèmes
« légaux » de l'entreprise comme la
comptabilité ou les déclarations réglementaires).
o C'est également dans cette fonction que sont
effectués éventuellement les calculs et les agrégations
(cumuls) communs à l'ensemble du projet. La fonction
d'intégration est généralement assurée par la
gestion de métadonnées, qui assurent
l'interopérabilité entre toutes les ressources informatiques,
qu'il s'agisse de données structurées (bases de données
accédées par des progiciels ou applications), ou des
données non structurées (documents et autres ressources non
structurées, manipulés par les systèmes de gestion de
contenu).
· Fonction de Diffusion (ou
distribution) : La fonction de diffusion met les
données à la disposition des utilisateurs, selon des
schémas correspondant aux profils ou aux métiers de chacun,
sachant que l'accès direct à l'entrepôt de données
ne correspond généralement pas aux besoins spécifiques
d'un décideur ou d'un analyste. L'objectif prioritaire est à ce
titre de segmenter les données en contextes informationnels fortement
cohérents, simples à utiliser et correspondant à une
activité décisionnelle particulière. Alors qu'un
entrepôt de données peut héberger des centaines ou des
milliers de variables ou indicateurs, un contexte de diffusion raisonnable n'en
présente que quelques dizaines au maximum. Chaque contexte peut
correspondre à un Data Mart, bien qu'il n'y ait pas de règles
générales concernant le stockage physique. Très souvent,
un contexte de diffusion est multidimensionnel, c'est-à-dire
modélisable sous la forme d'un hyper cube; il peut alors être mis
à disposition à l'aide d'un outil OLAP.
o À ce stade et lorsqu'il s'agit de concevoir un
système de Reporting, trois niveaux de questionnement doivent être
soulevés :
o À qui s'adresse le rapport
spécialisé ? : Choix des indicateurs à
présenter, choix de la mise en page.
o Par quel trajet ? : Circuit de diffusion type
« workflow » pour les personnes ou circuits de transmission
« télécoms » pour les moyens.
o Selon quel agenda ? : Diffusion
routinière ou déclenchée sur événement
prédéfini
· Fonction
Présentation : Cette quatrième fonction,
la plus visible pour l'utilisateur, régit les conditions d'accès
de l'utilisateur aux informations, dans le cadre d'une interface Homme-machine
déterminée (pour nous il s'agira d'un téléphone
portable mini d'une carte SIM Vodacom). Elle assure le contrôle
d'accès et le fonctionnement du poste de travail, la prise en charge des
requêtes, la visualisation des résultats sous une forme ou une
autre. Elle utilise toutes les techniques de communication possibles :
outils bureautiques, requêteurs et générateurs
d'états spécialisés, infrastructure web,
télécommunications mobiles, etc.
· Fonction
Administration : C'est la fonction transversale qui
supervise la bonne exécution de toutes les autres. Elle pilote le
processus de mise à jour des données, la documentation sur les
données (les métadonnées), la sécurité, les
sauvegardes, et la gestion des incidents.
o Il est évident que ces fonctions du
système décisionnel sont assurées en faisant recours
d'une part aux méthodes et techniques de Data Mining et d'autre part
à l'Entrepôt de données. Bien plus l'entrepôt de
données se trouve au coeur même du système
décisionnel dans une entreprise, ce qui permet à celle-ci de
centraliser ses informations ; alors bien avant de parler de celui-ci,
qu'en est-il des méthodes de Data Mining ?
I.2.9. Les enjeux de l'informatique
décisionnelle
De nos jours, les données applicatives
métier sont stockées dans une ou plusieurs bases de
données relationnelles ou non relationnelles. Ces données
extraites, transformées et chargées dans un entrepôt de
données généralement par un outil du type ETL.
Un entrepôt de données peut prendre la forme
d'un Data Warehouse globalise toutes les données applicatives de
l'entreprise tandis que les Data Marts généralement
alimentés depuis les données du Data warehouse sont des
sous-ensembles d'informations concernant un métier particulier de
l'entreprise assurance, marketing risque, contrôle de gestion,
santé etc.
Les entreprises de données permettent de produire
des rapports qui répondent à la question « que c'est -
il passé ?», mais ils peuvent être également
conçus pour répondre à la question analytique
« pourquoi est-ce que cela c'est passé ? » et
à la question pronostique « que va - t - il se
passer ? ».
Dans un contexte opérationnel, ils répondent
également à la question « que se passe - t- il en ce
moment ? », voire dans le cas d'une solution d'entrepôt de
données actif « que devrait - il se
passer ? ».
I.2.10. Fonctions essentielles de l'informatique
décisionnelle.
Un système d'information décisionnel assure
quatre fonctions fondamentales, à savoir la collecte,
l'intégration, la diffusion et la présentation des données
à ces quatre fonctions s'ajoute une fonction de contrôle du
système d'information décisionnelle lui - même,
l'administration.
· Collecte : La
collecte est l'ensemble des tâches consistant à détecter,
à sélectionner, à extraire et à filtrer les
données brutes issues des environnements pertinentes compte tenu du
périmètre du SI.
· Intégration :
L'intégration consiste à concentrer les données
collectées dans un espace unifié, dont le socle informatique
essentiel est l'entrepôt. Elément centrale du dispositif, il
permet aux applications décisionnelles de bénéficier d'une
source d'information commune, homogène, normalisée et fiable,
susceptible de masquer la diversité de l'origine des
données.
· Diffusion ou la
distribution : La diffusion met les données
à la disposition des utilisateurs, selon des schémas
correspondant au profil ou au métier de chacun, sachant que
l'accès direct à l'entrepôt ne correspondrait
généralement pas aux besoins d'un décideur ou d'une
analyse.
·
Présentation : Cette quatrième fonction,
la plus visible pour l'utilisateur, régit les conditions d'accès
de l'utilisateur aux informations. Elle assure le fonctionnement du poste de
travail, le contrôle d'accès, la prise en charge des
requêtes, la visualisation des résultats sous une forme ou une
autre. Elle utilise les techniques de communication possibles comme les outils
bureautiques, raquetteurs et générateurs d'états
spécialisés, infrastructure web, télécommunications
mobiles, etc.
· Administration :
c'est la fonction transversale qui supervise la bonne exécution de
toutes les autres, elle pilote le processus de mise à jour des
données, la documentation sur les données et sur les
métadonnées, la sécurité, les sauvegardes, la
gestion des incidents.
I.2.11. Les phases du processus décisionnel
A. Phase de recueil des
exigences
Trois domaines doivent être particulièrement
documentés :
· Le type d'information dont l'utilisateur des
rapports a besoin ;
· Le type de restitution (ergonomie,
fréquence, vitesse de restitution) ;
· Le système technique existant :
technologies utilisées.
B. Phase de conception et de choix technique
En fonction des exigences recueillies, quelles sont les
éléments de la chaine de la valeur décisionnelle qui
doivent être implémentés ?
Doit - on seulement créer un rapport sur un cube
OLAP existant ?
Constituer toute la chaine ?
Quelles sont précisément les données
que l'on doit manipuler ?
Cela conduit au choix de technologies précises et a
un modèle particulier.
I.3.
CONCLUSION
Dans ce chapitre, nous avons parlé le sujet de
système décisionnel, nous avons définit l'informatique
décisionnelle, l'architecture de système décisionnel, ses
différents enjeux avec leurs fonction y compris les phases du processus
dans un système décisionnel.
CHAPITRE II LE DATAMINING
[1][3][4][6][9][10][11[17]
II.1. PRESENTATION
Historiquement, cette approche apparut en 1989 sous un
premier nom de KDD (Knowledge Discovery in Databases, en français ECD
pour Extraction de Connaissances à partir des Données), avant
qu'en 1991 apparaisse pour la première fois le terme de « Data
Mining ».
Ainsi, le développement des moyens informatiques et
de calcul statistique permettent la conservation (bases de données ou
encore Entrepôt de donnés), le traitement et l'analyse d'ensembles
de données très volumineux. Plus récemment, le
perfectionnement des logiciels et de leurs interfaces offrent aux utilisateurs,
statisticiens ou non, des possibilités de mise en oeuvre très
simples de ces méthodes.
Cette évolution, ainsi que la popularisation de
nouvelles techniques algorithmiques (réseaux de neurones, machine
à vecteurs support, Arbres de décision, segmentation, etc.) et
outils graphiques, conduit au développement et à la
commercialisation de logiciels (tels que le SPAD, le WEKA, R) intégrant
un sous-ensemble de méthodes statistiques et algorithmiques
utilisées sous la terminologie de Data Mining
généralement traduit en français par fouille de
données.
Cette approche, dont la présentation est
principalement issue du marketing spécialisé dans la gestion de
la relation client (GRC), trouve également des développements et
applications industrielles en contrôle de qualité ou même
dans certaines disciplines scientifiques dès lors que les
ingénieurs et chercheurs que nous sommes, sont confrontés
à un volume de données important comme celui que nous retrouvons
aujourd'hui dans la téléphonie mobile.
L'accroche publicitaire souvent citée par les
éditeurs de logiciels est :
« Comment trouver un diamant dans un tas de
charbon sans se salir les mains ».
Le terme datamining est souvent employé pour
désigner l'ensemble des outils permettant à l'utilisateur
d'accéder aux données de l'entreprise, de les analyser.
Nous retiendrons ici le terme de data Mining aux outils
ayant pour objet de générer des informations riches à
partir des données de l'entreprise, notamment des données
historiques, de découvrir des modèles implicites dans les
données.
Ces outils peuvent permettre par exemple à un
magasin de dégager des profils de client et des achats types et de
prévoir ainsi les ventes futures. Ils permettent d'augmenter la valeur
des données contenues dans le Data Warehouse.
Les outils d'aides à la décision, qu'ils
soient relationnels ou OLAP, laissent l'initiative à l'utilisateur, de
choisir les éléments qu'il veut observer ou analyser .Au
contraire, dans le cas du datamining ,le système a l'initiative et
découvre lui-même les associations entre données ,sans
que l'utilisateur ait à lui dire de rechercher plutôt dans telle
ou telle direction ou à poser des hypothèses .
Il est alors possible de prédire l'avenir, par le
comportement d'un client, et de détecter, dans le passé, les
données inusuelles, exceptionnelles.
Ces outils ne sont plus destinés aux seuls experts
statisticiens mais doivent pouvoir être employés par des
utilisateurs connaissant leur métier et voulant l'analyser, l'explorer.
Seul un utilisateur connaissant le métier peut
déterminer si les modèles, les règles, les tendances
trouvées par l'outil sont pertinentes, intéressantes et utiles
à l'entreprise.
Ces utilisateurs n'ont donc pas obligatoirement un bagage
statistique important .L'outil doit être soit ergonomique, facile
à utiliser, soit permettre de construire une application clé en
main, pour la transparence de toutes les techniques utilisées par
l'utilisateur.
Nous pourrions définir le data mining comme une
démarche ayant pour objet de découvrir des relations et des
faits, à la fois nouveaux et significatifs, sur de grands ensembles de
données.
Le terme datamining signifie littéralement forage
de données dont le but est de pouvoir extraire un
élément : la connaissance.
Ces concepts s'appuient sur le constat qu'il existe au
sein de chaque entreprise des informations cachées dans le gisement de
données. Nous appellerons datamining l'ensemble des techniques qui
permettent de transformer les données en connaissances.
L'exploration se fait sur l'initiative du système,
par un utilisateur métier, et son but est de remplir l'une des
tâches suivantes : Classification, estimation, prédiction,
regroupement par similitudes, segmentation (cautérisation), description
et, dans une moindre mesure, l'optimisation.
II.2. SATATISTIQUE ET
DATAMINING
Nous pourrions croire que les techniques du datamining
viennent en remplacement des statistiques .En fait, il n'en est rien et
elles sont omniprésentes .On les utilise :
· Pour faire une analyse préalable,
· Pour estimer ou alimenter les valeurs
manquantes,
· Pendant le processus pour évaluer la
qualité des estimations,
· Après le processus pour mesurer les actions
entreprises et faire un bilan.
Ainsi la statistique et datamining sont tout à
fait complémentaires.
II.3. LES TECHNIQUES DE
DATAMINING
Le Data mining met en oeuvre un ensemble de techniques
issues de la statistique, de l'analyse de données et de l'informatique
pour exploiter les données. On distingue deux grandes familles de
techniques à savoir les techniques Descriptives et celles
Prédictives.
Les techniques descriptives permettent évidemment
de « décrire, résumer, synthétiser,
réduire, classer, mettre en oeuvre des informations présentes
mais cachées par le volume de données ». Aussi
appelées techniques non supervisées, elles produisent des
modèles de classement et ne disposent pas de variable cible à
prédire. Elles regroupent entre autre :La Segmentation (clustering
/ Classification Automatique), l'Analyse factorielle des correspondances,
Analyse en composantes principales, la Recherche d'associations (analyse du
ticket de caisse), etc.
Les techniques prédictives visent à
« prédire, extrapoler (anticiper) de nouvelles informations
à partir des informations présentes ». Aussi
appelées techniques supervisées, elles sont plus délicates
à mettre en oeuvre que celles descriptives et leur objectif est de
prévoir une variable cible mais aussi de classer à partir de la
variable cible.
Elles regroupent entre autre :
Ø Classement/discrimination (variable
« cible » qualitative)
Ø Analyse discriminante / Régression
logistique ;
Ø Arbres de décision et Réseaux
de neurones
Ø Prédiction à variable
« cible » quantitative
Ø Régression linéaire (simple et
multiple) ;
Ø Machines de Vecteurs à Supports
(SVM);
II.3.1.La classification ascendante hiérarchique
Elle consiste à obtenir une succession de
partitions (partitionnement horizontal) sur l'ensemble des clients sachant
qu'à chaque partition est associée un seuil de similarité
(de distance) au-delà duquel deux n-uplets sont
considérés comme similaires et appartiennent donc à la
même classe. Ces partitions irons des clients particuliers jusqu'à
une partition globale contenant toute la population. L'algorithme
utilisé fournit une hiérarchie de partitions, se
présentant sous la forme d'arbres appelés
« dendrogrammes » et contenant n-1 partitions.
Il est évident qu'au départ l'ensemble des
individus à segmenter est muni d'une distance, ceci ne suppose donc pas
que les distances soient toutes calculées au départ, d'où
il faudra les calculer ou recalculer à partir des coordonnées des
individus. On construit alors une première matrice de distances entre
tous les individus. .
II.3.2. Régression
La régression est une méthode statistique
qui permet d'étudier la façon dont une variable quantitative
varie en fonction des autres (quantitatives). Aussi appelée
« Modèle Linéaire », elle présente
trois avantages, à savoir : le Description de
phénomènes, le Contrôle et l'estimation (faire des
projections).
Il est évident que nous appliquons la
régression linéaire dans ce travail, pour faire des projections,
(estimation) du nombre d'unités à recharger par un
client  . Ceci étant, il y a lieu d'atteindre cet avantage, que ce
soit avec la régression linéaire simple ou celle
multilinéaire. . Ceci étant, il y a lieu d'atteindre cet avantage, que ce
soit avec la régression linéaire simple ou celle
multilinéaire.
II.3.2.1. La Régression Simple
Il s'agit d'un cas de régression où l'on
considère deux variables dans le but de d'estimer la ou les valeurs de
l'une, dite variable « dépendante », correspondant
à une ou plusieurs valeurs connues de l'autre variable, dite
« indépendante ».
Cependant, la régression linéaire est
conditionnée par les problèmes de corrélation. Ainsi, le
coefficient de corrélation simple, défini dans tous les ouvrages
classiques de statistique que nous avons lus, mesure l'intensité de la
relation linéaire existant entre deux variables. Il peut être
utile notamment, en rapport avec la notion de régression linéaire
simple, dans la prévision ou l'estimation des valeurs d'une variable en
fonction des valeurs d'une autre.
II.3.2.2. La Régression Multiple
Le modèle de régression linéaire
multiple est l'outil statistique le plus habituellement mis en oeuvre pour
l''étude de données multidimensionnelles. Cas particulier de
modèle linéaire, il constitue la généralisation
naturelle de la régression simple que nous venons
d'étudier.
La régression multiple peut être
utilisée chaque fois qu'une variable observe dite variable
dépendante (endogène), doit être exprimée en
fonction de deux ou plusieurs autres variables observées, dites
indépendantes ou explicatives ou mieux exogènes. Le cas le plus
simple est celui où les variables explicatives sont des variables non
aléatoires, leurs valeurs étant toutes choisies à priori
de façon arbitraire.
On suppose alors généralement que la
relation étudiée est linéaire et que les
différentes valeurs de la variable dépendante sont extraites de
distributions normales, indépendantes et de même variance.
II.4. LES TACHES DU DATA MINING
Contrairement aux idées reçues, le Data
Mining n'est pas le remède miracle capable de résoudre toutes les
difficultés ou besoins de l'entreprise .Cependant, une multitude de
problèmes d'ordre intellectuel, médical, économique
peuvent être regroupés, dans leur formalisation, dans l'une des
tâches suivantes :
Ø Classification ;
Ø Estimation ;
Ø Prédiction ;
Ø Discrimination ;
Ø Segmentation.
|
Tâches
|
Technique
|
|
Classification
|
L'arbre de décision
|
|
Le raisonnement par cas
|
|
L'analyse de lien
|
|
Estimation
|
Le réseau de neurones
|
|
Prédiction
|
L'analyse du panier de la ménagère
|
|
Le raisonnement base sur le mémoire
|
|
L'arbre de décision
|
|
Les réseaux de neurones
|
|
Extraction de connaissance
|
L'arbre de décision
|
Tableau II.1. Les tâches
et techniques du datamining.
En outre, hormis ces quelques techniques et tâches
du datamining, nous signalons qu'il existe d'autres que nous n'avons pas
énumérez dans notre travail.
II.5. ARBRE DE DECISION
Un arbre de décision est une structure qui permet
de déduire un résultat à partir de décisions
successives. Pour parcourir un arbre de décision et trouver une
solution, il faut partir de la racine. Chaque noeud est une décision
atomique.
Chaque réponse possible est prise en compte et
permet de se diriger vers un des fils du noeud. De proche en proche, on descend
dans l'arbre jusqu'à tomber sur une feuille. La feuille
représente la réponse qu'apporte l'arbre au cas où l'on
vient de tester.
· Début à la racine de l'arbre
· Descendre dans l'arbre en passant par les noeuds de
test
· La feuille atteinte à la fin permet de
classer l'instance testée.
Très souvent on considère qu'un noeud pose
une question sur une variable, la valeur de cette variable permet de savoir
sur quels fils descendre. Pour les variables énumérées, il
est parfois possible d'avoir un fils par valeurs, on peut aussi décider
que plusieurs variables différentes mènent au même sous
arbre.
Pour les variables continues, il n'est pas imaginable de
créer un noeud qui aurait potentiellement un nombre de fils infini, on
doit discrétiser le domaine continu (arrondis, approximation), donc
décider de segmenter le domaine en sous-ensembles. Plus l'arbre est
simple, et plus il semble techniquement rapide à utiliser.
En fait, il est plus intéressant d'obtenir un arbre
qui est adapté aux probabilités des variables à tester. La
plupart du temps un arbre équilibré sera un bon résultat.
Si un sous arbre ne peut mener qu'à une solution unique, alors toute
cette sous-barbe peut être réduit à sa simple conclusion,
cela simplifie le traitement et ne change rien au résultat
final.
II.5.1. Définition
Un arbre de décision est un outil d'aide à
la décision et à l'exploration de données. Il permet de
modéliser simplement, graphiquement et rapidement un
phénomène mesuré plus ou moins complexe. Sa
lisibilité, sa rapidité d'exécution et le peu
d'hypothèses nécessaires a priori expliquent sa popularité
actuelle.
II.5.2. Caractéristiques et avantages :
Le caractéristique principale est la
lisibilité du modèle de prédiction que l'arbre de
décision fourni, et de faire faire comprendre ses résultats afin
d'emporter l'adhésion des décideurs. Cet arbre de décision
a également la capacité de sélectionner automatiquement
les variables discriminantes dans un fichier de données contenant un
très grand nombre de variables potentiellement intéressantes.
En ce sens, constitue aussi une technique exploratoire
privilégiée pour appréhender de gros fichiers de
données.
II.5.3. Algorithme ID3
L'algorithme ID3 a été
développé à l'origine par ROSS QUINLAN. C'est un
algorithme de classification supervise. C'est-a-dire il se base sur des
échantillons déjà classés dans un ensemble de
classes pour déterminer un modèle de classification. Le
modèle que produit ID3 est un arbre de décision. Cet arbre
servira à classer de nouveaux échantillons
Le modèle que produit ID3 est un arbre de
décision. Cet arbre servira à classer de nouveaux
échantillons. Permet aussi de générer des arbres de
décisions à partir de données. Imaginons que nous ayons
à notre disposition un ensemble d'enregistrements ayant la même
structure, à savoir un certain nombre de paires attribut ou valeur.
L'un de ses attributs représente la
catégorie de l'enregistrement. Le problème consiste à
construire un arbre de décision qui sur la base de réponses
à des questions posées sur des attributs non cible peut
prédire correctement la valeur de l'attribut cible. Souvent l'attribut
cible pend seulement les valeurs vrai, faux ou échec,
succès.
1. Principes
Chaque exemple en entrée est constitué d'une
liste d'attributs. Un de ces attributs est l'attribut « cible » et
les autres sont les attributs « non cibles ». On appelle aussi cette
"cible" la "classe". En fait l'arbre de décision va permettre de
prédire la valeur de l'attribut « cible » à partir des
autres valeurs. Bien entendu, la qualité de la prédiction
dépend des exemples : plus ils sont variés et nombreux, plus la
classification de nouveaux cas sera fiable.
Un arbre de décision permet de remplacer un expert
humain dont il modélise le cheminement intellectuel. À chaque
noeud correspond une question sur un attribut non cible. Chaque valeur
différente de cet attribut sera associée à un arc ayant
pour origine ce noeud. Les feuilles de l'arbre, quant à elles, indiquent
la valeur prévue pour l'attribut cible relativement aux enregistrements
contenus par la branche (indiqués par les différents arcs)
reliant la racine à cette feuille.
ID3 construit l'arbre de décision
récursivement. À chaque étape de la récursion, il
calcule parmi les attributs restant pour la branche en cours, celui qui
maximisera le gain d'information. C'est-à-dire l'attribut qui permettra
le plus facilement de classer les exemples à ce niveau de cette branche
de l'arbre. On appelle ce calcul l'entropie de Shannon.
L'entropie est utilisée pour mesurer la
quantité d'information apportée par un noeud. (Cette notion a
été introduite par Claude Shannon lors de ses recherches
concernant la théorie de l'information qui sert de base à
énormément de méthodes du datamining.
2. Algorithme
Entrées : ensemble d'attributs A;
échantillon E; classe c
Début
Initialiser à l'arbre vide;
Si tous les exemples de E ont la même classe
c
Alors étiqueter la racine par c;
Sinon si l'ensemble des attributs A est vide
Alors étiqueter la racine par la classe majoritaire
dans E;
Si non soit au meilleur attribut choisi dans A;
Étiqueter la racine par a;
Pour toute valeur v de a
Construire une branche étiquetée par
v;
Soit Eav l'ensemble des exemples tels que e(a) =
v;
Ajouter l'arbre construit par ID3(A-{a}, Eav,
c);
Fin pour
Fin sinon
Fin sinon
Retourner racine;
Fin
3. Exemple
Pour introduire et exécuter "à la main"
l'algorithme ID3 nous allons tout d'abord considérer l'exemple
ci-dessous: Une entreprise possède les informations suivantes sur ses
clients et souhaite pouvoir prédire à l'avenir si un client
donné effectue des consultations de compte sur Internet.
|
Client
|
Moyenne des montants
|
Age
|
Lieu de Résidence
|
Etudes supérieures
|
Consultation par internet
|
|
1
|
Moyen
|
Moyen
|
Village
|
Oui
|
oui
|
|
2
|
Elevé
|
Moyen
|
Bourg
|
non
|
non
|
|
3
|
Faible
|
Age
|
Bourg
|
non
|
non
|
|
4
|
Faible
|
Moyen
|
Bourg
|
oui
|
oui
|
|
5
|
Moyen
|
Jeune
|
Ville
|
oui
|
Oui
|
|
6
|
Elevé
|
Agé
|
Ville
|
oui
|
non
|
|
7
|
Moyen
|
Agé
|
Ville
|
oui
|
non
|
|
8
|
Faible
|
Moyen
|
Village
|
non
|
non
|
Tableau II.2. Exemples
pratiques
Ici, on voit bien que la procédure de
classification à trouver qui à partir de la description d'un
client, nous indique si le client effectue la consultation de ses comptes par
Internet, c'est-à-dire la classe associée au client.
- Le premier client est décrit par (M : moyen, Age
: moyen, Résidence : village, Etudes : oui) et a pour classe
Oui.
- Le deuxième client est décrit par (M :
élevé, Age : moyen, Résidence : bourg, Etudes : non) et a
pour classe Non.
Pour cela, nous allons construire un arbre de
décision qui classifie les clients. Les arbres sont construits de
façon descendante. Lorsqu'un test est choisi, on divise l'ensemble
d'apprentissage pour chacune des branches et on réapplique
récursivement l'algorithme.
Choix du meilleur attribut : Pour cet algorithme deux
mesures existent pour choisir le meilleur attribut : la mesure d'entropie et la
mesure de fréquence:
L'entropie : Le gain (avec pour
fonction i l'entropie) est également appelé l'entropie de Shannon
et peut se réécrire de la manière suivante :
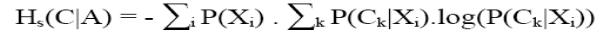
Pour déterminer le premier attribut test (racine de
l'arbre), on recherche l'attribut d'entropie la plus faible. On doit donc
calculer H(C|Solde), H(C|Age), H(C|Lieu), H(C|Etudes), où la classe C
correspond aux personnes qui consultent leurs comptes sur Internet.
H(C|Solde) = -P (faible).(P (C|faible) log(P (C|faible)) +
P (C |faible)log(P (C|faible)))-P (moyen).(P (C|moyen) log(P (C|moyen)) + P
(C|moyen) log(P (C|moyen)))-P (eleve).(P (C|eleve) log(P (C|eleve)) + P
(C|eleve) log(P(C|eleve)))H(C|Solde)
H(C|Solde) = -3/8(1/3.log(1/3) +
2/3.log(2/3)-3/8(2/3.log(2/3) + 1/3.log(1/3)-2/8(0.log(0) + 1.log(1)
H(C|Solde) = 0.20725
H(C|Age) = -P (jeune).(P (C|jeune) log(P (C|jeune)) + P (C
|jeune)log(P (C|jeune)))-P (moyen).(P (C|moyen) log(P (C|moyen)) + P (C |moyen)
log(P (C|moyen)))-P (age).(P (C|age) log(P (C|age)) + P (C|age) log(P
(C|age)))
H(C|Age) = 0.15051
H(C|Lieu) = -P (bourg).(P (C|bourg) log(P (C|bourg)) + P
(C |bourg)log(P (C|bourg)))-P (village).(P (C|village) log(P (C|village)) + P
(C |village) log(P (C|village)))-P (ville).(P (C|ville) log(P (C|ville)) + P
(C|ville)log(P (C|ville)))
H(C|Lieu) = 0.2825
H(C|Etudes) = -P (oui).(P (C|oui) log(P (C|oui)) + P (C
|oui) log(P (C|oui)))-P (non).(P (C|non) log(P (C|non)) + P (C|non) log(P
(C|non)))
H(C|Etudes) = 0.18275
Le premier attribut est donc l'âge (attribut dont
l'entropie est minimale). On obtient l'arbre suivant :
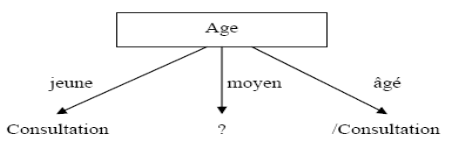
Figure II.1Arbre de
décision construit à partir de l'attribut Age
Pour la branche correspondant à un âge moyen,
on ne peut pas conclure, on doit donc recalculer l'entropie sur la partition
correspondante.
H(C|Solde) = -P (faible).(P (C|faible) log(P (C|faible)) +
P (C |faible) log(P (C|faible)))-P (moyen).(P (C|moyen) log(P (C|moyen)) + P
(C|moyen)log(P (C|moyen)))-P (eleve).(P (C|eleve) log(P (C|eleve)) + P
(C|eleve) log(P (C|eleve)))
H(C|Solde) = -2/4(1/2.log(1/2) + 1/2.log(1/2)-1/4(1.log(1)
+ 0.log(0)-1/4(0.log(0) + 1.log(1)
H(C|Solde) = 0.15051
H(C|Lieu) = -P (bourg).(P (C|bourg) log(P (C|bourg)) + P
(C |bourg) log(P (C|bourg)))-P (village).(P (C|village) log(P (C|village)) + P
(C |village) log(P (C|village)))-P (ville).(P (C|ville) log(P (C|ville)) + P
(C|ville) log(P (C|ville)))
H(C|Lieu) = 0.30103
H(C|Etudes) = -P (oui).(P (C|oui) log(P (C|oui)) + P (C
|oui) log(P (C|oui)))-P (non).(P (C|non) log(P (C|non)) + P (C|non) log(P
(C|non)))
H(C|Etudes) = 0
L'attribut qui a l'entropie la plus faible est «
Etudes ».
L'arbre devient alors :
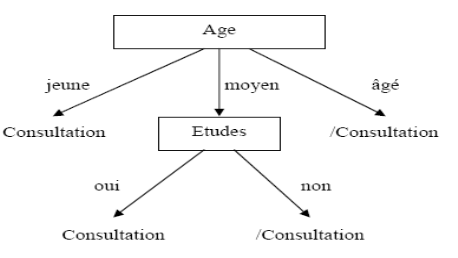
Figure II.2. Arbre de
décision finale
L'ensemble des exemples est classé et on constate
que sur cet ensemble d'apprentissage, seuls deux attributs sur les quatre sont
discriminants.
II.7. CONCLUSION
Dans ce chapitre nous avons présenté le
datamining avec ses différentes méthodes, tâches,
techniques et nous introduit quelque notion relative à la
théorie de graphe avant de parler de l'arbre de décision qui
répond à un problème de discrimination.
Ayant ainsi parlé du Data Mining comme outil
indispensable pour extraire de la connaissance dans les données, il se
pose maintenant un problème de stockage de ces données. Il est
évident que l'Entrepôt de données se trouve au coeur
même du système décisionnel dans une entreprise, ce qui
permet à celle-ci de centraliser ses informations ; alors qu'en
est-il de l'Entrepôt de données.
CHAPITRE III. LES ENTREPOTS DE DONNEES
[1][5][7][8][12][18]
III.1 INTRODUCTION
Les entrepôts des données intègrent
les informations en provenance de différentes sources, souvent reparties
et hétérogènes ayant pour objectif de fournir une vue
globale de l'information aux analystes et aux décideurs.
La construction et la mise en oeuvre d'un entrepôt
de données représentent une tâche complexe qui se compose
de plusieurs étapes.
La première à l'analyse des sources de
données et à l'identification des besoins des utilisateurs, la
deuxième correspond à l'organisation des données à
l'intérieur de l'entrepôt. Finalement, la troisième sert
à établir divers outils d'interrogation, analyse, de fouille de
données.
Chaque étape présente des
problématiques spécifiques. Ainsi, par exemple, lors de la
première étape, la difficulté principale consiste à
l'intégration des données, de manière qu'elles soient de
qualité pour leur stockage .pour l'organisation, il existe
plusieurs problèmes comme : la sélection des vues à
matérialiser, le rafraichissement de l'entrepôt, la gestion de
l'ensemble de données courantes et historiées. En ce qui
concerne le processus d'interrogation, nous avons besoin des outils performants
et conviviaux pour l'accès et l'analyse de l'information.
Notre travail se focalise principalement sur une
étape du processus décisionnel, avec une proposition de la
définition d'un modèle multidimensionnel, pour boucle par une
conclusion.
III.2.
DEFINITION CLASSIQUE D'UN ENTREPOT DES DONNEES
Un entrepôt de données est une collection de
données orientées sujet, intégrées, non volatiles
et historiées, organisées pour le support d'un processus d'aide
à la décision. Nous détaillons ces
caractéristiques :
Orientées sujet : les données des
entrepôts sont organisés par sujet plutôt que par
application : par exemple, une chaine de magasins d'alimentation organise
les données de son entrepôt par rapport aux ventes qui ont
été réalisées par produit et par magasin, au cours
d'un certain temps.
Intégrées :
les données provenant des différentes sources doivent être
intégrées, avant leur stockage dans l'entrepôt de
données. L'intégration c'est à dire la mise en
correspondance des formats, permet d'avoir une cohérence de
l'information.
Non volatiles : à la
différence des données opérationnelles, celles de
l'entrepôt sont permanentes et ne peuvent pas être
modifiées .le rafraichissement de l'entrepôt consiste
à ajouter de nouvelles données, sans modifier ou perdre celles
qui existent.
Historiées : la
prise en compte de l'évolution des données est essentielle pour
la prise de décision qui, par exemple, utilise des techniques de
prédication en s'appuyant sur les évolutions passées pour
prévoir les évolutions futures.
III.3.
ARCHITECTURE D'UN ENTREPOT DE DONNEES
L'architecture des entrepôts de données
repose souvent sur un SGBD séparé du système de production
de l'entreprise qui contient les données de l'entrepôt.
Le processus d'extraction des données permet
d'alimenter périodiquement ce SGBD. Néanmoins avant
d'exécuter ce processus, une phase de transformation est
appliquée aux données opérationnelles.
Celle-ci consiste à les préparer (mise en
correspondance des formats de données), les nettoyer, les filtrer,...,
pour finalement aboutir à leur stockage dans l'entrepôt.
Dans cette figure III.1, nous présentons une
architecture simplifiée d'un entrepôt selon Doucet et Gangarski.
Les différents composants ont été intègres dans
trois parties : les sources de données, l'entrepôt et les outils
existants dans le marché.
Données anciennes
Archivées
O
U
T
I
L
S
Entrepôt de données
Métadonnées
Données fortement résumées
Données légèrement
résumées
Données de détail
Données externes
Données de production
(SGBD ,ODS,système légués)
E
T
L
0
Figure III.1 Architecture
d'un entrepôt de données
a) Les sources : les
données de l'entrepôt sont extraites de diverses sources souvent
reparties et hétérogènes, et qui doivent être
transformées avant leur stockage dans l'entrepôt.
Nous avons deux types de sources des donnes : internes et
externes à l'organisation :
· Internes : la plupart des
données sont saisies à partir des différents
systèmes de production qui rassemblent les divers SGBD
opérationnels, ainsi que des anciens systèmes de production qui
contiennent des données encore exploitées par
l'entreprise.
· Externes : ils
représentent des données externes à l'entreprise et qui
sont souvent achetées.
Magasin des données opérationnel (ODS
operational data store) : c'est un mini annuaire des données
opérationnelles actualisées et intégrées aux
analyses pour un département spécifique au sein de
l'entreprise.
b) Les types de données de
l'entrepôt de données : il existe plusieurs types de
données dans un entrepôt, qui correspondent à diverses
utilisations, comme :
· Données de détail
courantes : ce sont l'ensemble des données
quotidiennes et plus couramment utilisées. Ces données sont
généralement stockées sur le disque pour avoir un
accès rapide. Par exemple, le détail des ventes de l'année
en cours, dans les différents magasins.
· Données de détail
anciennes : ce sont des données quotidiennes
concernant des événements passés, comme par exemple le
détail des ventes des deux dernières années. Nous les
utilisons pour arriver à l'analyse des tendances ou des requêtes
prévisionnelles. Néanmoins ces données sont plus rarement
utilisées que les précédentes, et elles sont souvent
stockes sur des mémoires d'archives.
· Donnes résumées ou
agrégées : ce sont des données moins
détaillées que les deux premières et elles permettent de
réduire le volume des données à stocker. Le type de
données, en fonction de leur niveau de détail, permet de les
classifier commandes données légèrement ou fortement
résumées.
· Les métadonnées
: ce sont des données essentielles pour parvenir
à une exploitation efficace du contenu d'un entrepôt. Elles
représentent des informations nécessaires à l'accès
et l'exploitation des données dans l'entrepôt comme : la
sémantique (leur signification), l'origine (leur provenance), les
règles d'agrégation (leur périmètre), le stockage
(leur format, par exemple : francs, euro,...) et finalement l'utilisation (par
quels programmes sont-elles utilisées).
· Données archives et
sauvegarder : cette partie de l'entrepôt
emmagasine les données détaillées résumées
pour le besoins d'archivage et de sauvegarde. Les données sont
transférées dans des stockages d'archivage tel que des bandes
magnétiques ou disques optiques.
c) Outils : il existe sur le
marché différents outils pour l'aide à la décision,
comme les outils de fouille de données ou datamining (pour
découvrir des liens sémantiques), outils d'analyse en ligne (pour
la synthèse et l'analyse des données multidimensionnelles),
outils d'interrogation (pour faciliter l'accès aux données en
fournissant une interface conviviale au langage de requêtes).
III.4.
ENTREPOTS ET LES BASES DE DONNEES
Dans l'environnement des entrepôts de
données, les opérations, l'organisation des données, les
critères de performance, la gestion des métadonnées, la
gestion des transactions et le processus de requêtes sont très
différents des systèmes de bases de données
opérationnels.
Par conséquent, les SGBD relationnels orientes vers
l'environnement opérationnel, ne peuvent pas être directement
transplantes dans un système d'entrepôt de données.
Les SGBD ont été créés pour
les applications de gestion de systèmes transactionnels. Par contre, les
entrepôts de données ont été conçus pour
l'aide à la prise de décision. Ils intègrent les
informations qui ont pour objectif de fournir une vue globale de l'information
aux analystes et aux décideurs.
Le tableau III.1 résume ces différences
entre les systèmes de gestion de bases de données et les
entrepôts de données.
|
SGBD
|
Entrepôts de données
|
|
Objectifs
|
Gestion et production
|
Consultation et analyse
|
|
Utilisateurs
|
Gestionnaires de production
|
Décideurs, analystes
|
|
Taille de la base
|
Plusieurs giga-octets
|
Plusieurs téraoctets
|
|
Organisation des données
|
Par traitement
|
Par métier
|
|
Type de données
|
Données de gestion (courantes)
|
Données d'analyse (résumées,
historiées)
|
|
Requêtes
|
simples, prédéterminées,
données détaillées
|
Complexes, spécifiques, agrégations et group
by
|
|
Transactions
|
Courtes et nombreuses, temps réel
|
Longues, peu nombreuses
|
Tableau III.1. Différence
entre SGBD et entrepôts de donnée
III.5. SYSTEMES TRANSACTIONNELS ET
SYSTEMES DECISIONNELS :
Les SGBD ont été créés pour
gérer de grands volumes d'information contenus dans les
différents systèmes opérationnels qui appartiennent
à l'entreprise.
Ces données sont manipulées en utilisant des
processus transactionnels en ligne .parallèlement à
l'exploitation de l'information contenue dans ces systèmes
opérationnels, les dirigeants des entreprises ont besoin d'avoir une
vision globale concernant toute cette information pour faire des calculs
prévisionnels, des statistiques ou pour établir des
stratégies de développement et d'analyses des tendances.
|
système transactionnel
|
système décisionnel
|
|
Données
|
Exhaustives
courantes
dynamiques
orientées applications
|
Résumées
historiques
statiques
orientées sujets (d'analyse)
|
|
utilisateurs
|
Nombreux varies (employés, directeurs)
concurrentes
mises à jour et interrogations
requêtes prédéfinies
réponses immédiates
accès a peu d'information
|
peu nombreux
uniquement les décideurs
non concurrents
interrogations
requêtes imprévisibles et complexes
réponses moins rapides
accès à de nombreuses informations
|
Tableau III.2. compare les
caractéristiques des systèmes
III.6. DATAMART
III.6.1 Introduction
Un DataMart(mini entrepôt des données)est un
sous-ensemble d'un
entrepôt
de données; il est généralement exploité dans les
entreprise
pour restituer des informations ciblées sur un métier
spécifique, constituant pour ce dernier un ensemble d'
indicateurs
à vocation de pilotage de l'activité et d'
aide
à la décision. Un DataMart, selon les
définitions, est issu ou fait partie d'un
DataWarehouse,
et en reprend par conséquent la plupart des caractéristique
III.6.2 Définitions
· Le DataMart est un ensemble de
données
ciblées, organisées, regroupées et agrégées
pour répondre à un besoin spécifique à un
métier
ou un domaine donné. Il est donc destine à être
interrogé sur un panel de données restreint à son domaine
fonctionnel, selon des paramètres qui auront été
définis à l'avance lors de sa conception.
· De façon plus technique, le DataMart peut
être considère de deux manières différentes,
attribuées aux deux principaux théoriciens de l'informatique
décisionnelle,
Bill
inmon et
Ralph
Kimball :
· Définition d'inmon : le DataMart est
issu d'un flux de données provenant du DataWarehouse. Contrairement
à ce dernier qui présente le détail des données
pour toute l'entreprise, il a vocation à présenter la
donnée de manière spécialisée,
agrégée et regroupée fonctionnellement.
· Définition de Kimball : le Data Mart
est un sous-ensemble du DataWarehouse, constitue de tables au niveau
détail et à des niveaux plus agrèges, permettant de
restituer tout le spectre d'une activité métier. L'ensemble des
Data Marts de l'entreprise constitue le DataWarehouse.
III.6.3. Structure physique et théorique
Au même titre que les autres parties de la base de
données globale de l'entreprise, les Data Marts sont stockes
physiquement sur
disque dur
par un
système de gestion de
bases de données relationnelle héberge sur un
serveur.
Le DataMart est souvent confondu avec la notion d'hyper
cube ; il peut de fait être représente par un
modèle
en
étoile
ou en flocon dans une
base de
données relationnelle notamment lorsqu'il s'agit de
données élémentaires ou unitaires non
agrégées.
III.7. DATAWAREHOUSE ET
DATAMART
La première étape d'un projet busines
intelligent est de créer un entrepôt central pour avoir une vision
globale des données de chaque service. Cet entrepôt porte le nom
de Data Warehouse. On peut également parler de DataMart, si seulement
une catégorie de services ou métiers est concernée pour
notre travail nous parlerons de DataMart des suivie de traitement
médicale de la consultation jusqu'à la fin.
Par définition, un DataMart peut être contenu
dans un Data Warehouse, ou il peut être seulement issu de
celui-ci.
III.7.1. Architecture d'un Data
Mart
Système transactionnel
Data Mart
Data Mart
Système transactionnel
Système transactionnel
Système transactionnel
Entrepôt
Des données
0
Figure III. 5:Architecture
d'un Data Mart
III.7.2. La place du DataMart dans
l'entreprise
Le DataMart se trouve en toute fin de la chaine de
traitement
de l'information. En règle générale, il se
situe en aval d'un Data Warehouse plus global à partir duquel il est
alimenté, dont il constitue en quelque sorte un extrait.
Un DataMart forme la principale interaction entre les
utilisateurs et les systèmes informatiques qui gèrent la
production de l'entreprise (souvent des
ERP).
Dans un DataMart, l'information est préparée
pour être exploitée brute par les personnes du métier
auquel il se rapporte. Pour ce faire, il est appelé à être
utilise via des logiciels d'interrogation de bases de données (notamment
des outils de
reporting)
afin de renseigner ses utilisateurs sur l'état de l'entreprise à
un moment donné (stock) ou sur son activité (flux).
La préparation de la donnée pour une
utilisation directe, inhérente au DataMart, peut revêtir plusieurs
formes. Il faut noter que toutes représentent une simplification par
rapport au niveau de données inferieur ; on peut citer pour
exemple
L'agrégation de données : le DataMart
ne contient pas le détail de toutes les opérations qui ont eu
lieu, mais seulement des totaux, repartis par groupements. Le retrait de
données inutiles : le DataMart ne contient que les données
qui sont strictement utiles aux utilisateurs.
L'
historisation
des données : le DataMart contient seulement la période de
temps qui intéresse les utilisateurs.
III.8. CONCEPTION D'UN ENTREPOT DE
DONNEES
La conception d'un entrepôt de données se
fait de deux façon, la première consiste à construire
d'abord plusieurs mini-entrepôts selon les directions ou les
départements ensuite les intègres dans un seul entrepôt
pour l'entreprise ; la deuxième consiste à construire un
entrepôt pour l'entreprise ensuite mettre en place un ou plusieurs
mini-entrepôts pour chaque direction ou départements que compte
l'entreprise.
La conception d'un entrepôt de données peut
se faire en utilisant la modélisation relationnelle classique (pour les
bases de données transactionnelles) ou en utilisant la
modélisation dimensionnelle.
Dans un entrepôt de données les
requêtes pour l'interrogation des données utilisent beaucoup des
jointures qui demandent trop de temps ce qui constitue un problème pour
le système transactionnel. C'est pourquoi il est
préférable d'utiliser l'approche multidimensionnelle.
III.8.1
Modélisation Multidimensionnelle
Pour arriver à construire un modèle
approprie pour un entrepôt de données ou un DataMart, nous pouvons
choisir, soit un schéma relationnel (le schéma en étoile,
en flocon de neige ou en constellation) ; soit un schéma
multidimensionnel.
Avant de décrire les différents
schémas, nous commençons par quelques concepts de base. La
modélisation multidimensionnelle consiste à considérer un
sujet analyse comme un point dans un espace a plusieurs dimensions. Les
données sont organisées de manière à mettre en
évidence le sujet (le fait) et les différentes perspectives de
l'analyse(les dimensions). Le fait représente le sujet d'analyse. Il est
compose d'un ensemble de mesures qui représentent les différentes
valeurs de l'activité analysée.
Par exemple, dans le fait ventes, nous pouvons avoir la
mesure "quantité de produits vendus par magasin". Les mesures doivent
être valorisées de manière continue et elles peuvent
être additives (pour résumer une grande quantité
d'enregistrements) ; semi-additives (si elles peuvent seulement être
additionnées pour certaines dimensions) et non additives.
Une dimension modélise une perspective de
l'analyse. Elle se compose de paramètres(ou attributs) qui servent
à enregistrer les descriptions textuelles.
A. Méthodologie de design de la base de
données pour l'entrepôt des données :
Dans cette section nous décrivons une
méthodologie par étapes pour construire la base de données
d'un entrepôt de données cette méthode a été
initialement proposées par Kimball et s'appelle méthodologie a
neuf étape dans la modélisation d'un entrepôt des
données :
|
Etape
|
Activité
|
|
1
|
Choisir la procédure
|
|
2
|
Choisir le grain
|
|
3
|
Identifier les dimensions et s'y conformer
|
|
4
|
Choisir les faits
|
|
5
|
Emmagasiner les calculs préliminaires dans la table
des faits
|
|
6
|
Finaliser les tables de dimensions
|
|
7
|
Choisir la durée de la base de
données
|
|
8
|
Suivre les dimensions a modification lente
|
|
9
|
Les décideurs doits décidé des
priorités de requêtes et des modes de requêtes
|
Tableau III. 3:La méthodologie a neuf
étapes de Kimball
III.8.2. Schémas
relationnels
Dans les schémas relationnels nous trouvons deux
types de schémas. Les premiers sont des schémas qui
répondent fort bien aux processus de type OLTP qui ont été
décrits précédemment, alors que les deuxièmes, que
nous appelons des schémas pour le décisionnel, ont pour but de
proposer des schémas adaptes pour des applications de type OLAP.
Nous décrivons les différents types des
schémas relationnels pour le décisionnel
III.8.3 Le Schéma en
étoile
Il se compose du fait central et de leurs dimensions. Dans
ce schéma il existe une relation pour les faits et plusieurs pour les
différentes dimensions autour de la relation centrale. La relation de
faits contient les différentes mesures et une clé
étrangère pour faire référence à chacune de
leurs dimensions.
La figure 3.3 montre le schéma en étoile en
décrivant les ventes réalisées dans.
Les différents magasins de l'entreprise au cours
d'un jour. Dans ce cas, nous avons une étoile centrale avec une table de
faits appelée ventes et autour leurs diverses dimensions : temps,
produit et magasin
Produits
Cle_P
Description
Type
Catégorie
Temps
Cle_T
Jour
Mois
Année
0
Figure III. 6.Exemple de
Modélisation en étoile
III.8.3 Le schéma en flocon de neige
Il dérivé du schéma
précédent avec une relation centrale et autour d'elle les
différentes dimensions, qui sont éclatées ou
décomposées en sous hiérarchies.
L'avantage du schéma en flocon de neige est de
formaliser une hiérarchie au sein d'une dimension, ce qui peut faciliter
l'analyse. Un autre avantage est représenté par la normalisation
des dimensions, car nous réduisons leur taille.
Néanmoins dans, l'auteur démontre que c'est
une perte de temps de normaliser les relations des dimensions dans le but
d'économiser l'espace disque.
Par contre, cette normalisation rend plus complexe la
lisibilité et la gestion dans ce type de schémas. En effet, ce
type de schéma augmente le nombre de jointures à réaliser
dans l'exécution d'une requête.
Les hiérarchies pour le schéma en flocon de
neige de l'exemple de la figure 3 sont :
Dimension temps = jour mois année
Dimension magasin = commune département
région pays
La figure 4 montre le schéma en flocon de neige
avec les dimensionnes temps et magasin éclatées en sous
hiérarchies.
Temps
Cle_T
Jour
Mois
Ventes
Cle_P
Cle_T
Cle_M
Quantité
T_Mois
Mois
Année
T_Région
Région
Pays
0
Figure
III.7. Exemple de modélisation en flocon de neige
Dans l'exemple ci-dessus, la dimension temps a
été éclatée en deux, temps et T_mois. La
deuxième dimension magasin, a été décomposée
en trois : magasin, m_departement et m_region.
III.8.4 Le schéma en
constellation
Le schéma en constellation représente
plusieurs relations de faits qui partagent des dimensions communes. Ces
différentes relations de faits composent une famille qui partage les
dimensions mais où chaque relation de faits a ses propres dimensions.
La figure 3.4 montre le schéma en
constellation qui est compose de deux relations de faits.
La première s'appelle ventes et enregistre les
quantités de produits qui ont été vendus dans les
différents magasins pendant un certain jour. La deuxième relation
gère les différents produits achètes aux fournisseurs
pendant un certain temps.
T_Fournisseur
Cle_F
Raison_soc
Adresse
Code_postal
Commune
Pays
Achats
Cle_P
Cle_F
Cle_T
Quantité
0
Figure III.8. Exemple de
Modélisation en constellation
La relation de faits ventes partage leurs dimensions temps
et produits avec la table achats. Néanmoins, la dimension magasin
appartient seulement à ventes. Également, la dimension
fournisseur est liée seulement à la relation achats.
III.8.5
Schéma multidimensionnel (cube)
Dans le modèle multidimensionnel, le concept
central est le cube, lequel est constitué des éléments
appelés cellules qui peuvent contenir une ou plusieurs mesures. La
localisation de la cellule est faite à travers les axes, qui
correspondent chacun a une dimension.
La dimension est composée de membres qui
représentent les différentes valeurs. En reprenant une partie du
schéma en étoile, nous pouvons construire le schéma
multidimensionnel suivant.
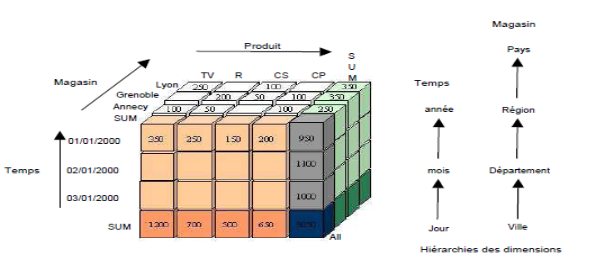
Figure III. 6. Exemple de
schéma multidimensionnel
La figure 3.6, présente un schéma
multidimensionnel pour les ventes qui ont été
réalisées dans les magasins pour les différents produits
au cours d'un temps donne (jour).
III.9. MANIPULATION DES DONNEES MULTIDIMENSIONNELLES
Pour visualise les données multidimensionnelles,
nous pouvons utiliser la représentation sous forme d'une table de
données, qui est la plus courante. Dans une table, nous
représentons les différentes combinaisons des valeurs choisies
pour constituer les noms de lignes et de colonnes.
Néanmoins, quand le nombre de dimensions est
supérieur à deux, l'utilisateur a des problèmes pour
visualiser simultanément l'ensemble de l'information. Pour
résoudre ce problème, nous devons disposer d'opérations
pour manipuler les données et rendre possible la visualisation.
Nous présentons les opérations pour la
manipulation des données multidimensionnelles, en les divisant selon
leur impact sur la façon de présenter les différentes vues des données analysées
III.9.1 Opérations
Classiques
Ces opérations correspondent aux opérations
relationnelles de manipulation des données :
· La sélection : résulte en un
sous-ensemble de données qui respecte certaines conditions
d'appartenance.
· La projection : résulte en un sous-ensemble
des attributs d'une relation, qui sont soit des dimensions, soit des niveaux de
granularité. Dans les systèmes décisionnels, les
opérations de sélection et de projection sont appelées
souvent "slice-and-dice".
· La jointure : permet d'associer les données
de relations différentes.
o Les opérations ensemblistes :
· D'union, d'intersection et de différence
sont des opérations qui agissent sur des relations qui ont le même
schéma. Par exemple, les opérations agissant sur la structure
visent à présenter une vue (face du cube) différente en
fonction de leur analyse, citons :
· La rotation (rotate) : consiste à pivoter ou
à effectuer une rotation du cube, de manière à
présenter une vue différente des données à
analyser.
· La permutation (switch) : consiste à
inverser des membres d'une dimension, de manière à permuter deux
tranches du cube.
· La division (split) : consiste à
présenter chaque tranche du cube en passant d'une représentation
tridimensionnelle à une présentation tabulaire.
· L'emboitement (nest) : permet d'imbriquer les
membres d'une dimension. En utilisant cette opération, nous
représentons dans une table bidimensionnelle toutes les données
d'un cube quel que soit le nombre de dimensions.
· L'enfoncement (push) : consiste à combiner
les membres d'une dimension aux mesures du cube et donc de représenter
un membre comme une mesure.
· L'opération inverse de retrait (pull) :
permet de changer le statut de certaines mesures, pour transformer une mesure
en membre d'une dimension.
· La factualisation (fold) : consiste à
transformer une dimension en mesure(s) ; cette opération permet de
transformer en mesure l'ensemble des paramètres d'une dimension.
· Le para métrisation (unfold) : permet de
transformer une mesure en paramètre dans une nouvelle dimension.
· L'opération cube : permet de calculer des
sous-totaux et un total final.
III.9.2. Opérations
agissant sur la granularité :
Les opérations agissant sur la granularité
des données analysées, permettent de hiérarchiser la
navigation entre les différents niveaux de détail d'une
dimension. Dans la suite nous traitons les deux opérations de ce type
:
· Le forage vers le haut (drill-up ou roll-up) :
permet de représenter les données du cube à un niveau plus
haut de granularité en respectant la hiérarchie de la dimension.
Nous utilisons une fonction d'agrégation (somme, moyenne,...), qui est
paramétrée, pour indiquer la façon de calculer les
données du niveau supérieur à partir de celles du niveau
inférieur.
· Le forage vers le bas (drill-down ou roll-down ou
scale-down) : consiste à représenter les données du cube
à un niveau de granularité inferieur, donc sous une forme plus
détaillée. Ces types d'opérations ont besoin
d'informations non représentées dans un cube, pour augmenter ou
affiner des données, à partir d'une représentation
initiale vers une représentation de granularité
différente. Le forage vers le haut à besoin de connaitre la
fonction d'agrégation utilisée tandis que le forage vers le bas
nécessite de connaitre les données au niveau
inférieur.
III.10.
LES SERVEURS OLAP (ON-LINE ANALYTICAL PROCESSING)
Les données opérationnelles constituent la
source principale d'un système d'information décisionnel. Les
systèmes décisionnels complets reposent sur la technologie OLAP,
conçue pour répondre aux besoins d'analyse des applications de
gestion.
Nous exposons dans la suite les divers types de stockage
des informations dans les systèmes décisionnels.
III.10.1. Les serveur ROLAP (RELATIONAL OLAP)
Dans les systèmes relationnels OLAP,
l'entrepôt de données utilise une base de données
relationnelle. Le stockage et la gestion de données sont relationnels.
Le moteur ROLAP traduit dynamiquement le modèle logique de
données multidimensionnel m en modèle de stockage relationnel,
la plupart des outils requièrent que la donnée soit
structurée en utilisant un schéma en étoile ou un
schéma en flocon de neige.
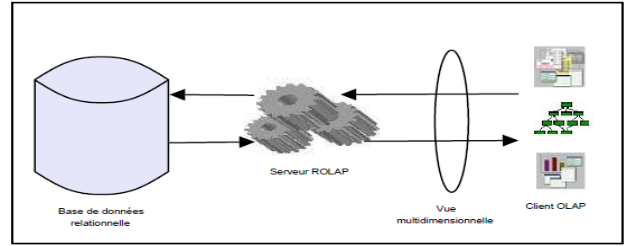
Figure III.9: Architecture
ROLAP
La technologie ROLAP a deux avantages principaux :
(1) Elle permet la définition de données
complexes et multidimensionnelles en utilisant un modèle relativement
simple.
(2) Elle réduit le nombre de jointures à
réaliser dans l'exécution d'une requête.
Le désavantage est que le langage de
requêtes tel qu'il existe, n'est pas assez puisant ou n'est pas assez
flexible pour supporter de vraies capacités d'OLAP.
III.10.2 Les serveur MOLAP (MULTIDIMENSIONAL OLAP)
Les systèmes multidimensionnels OLAP utilisent une
base de données multidimensionnelle pour stocker les données de
l'entrepôt et les applications analytiques sont construites directement
sur elle. Dans cette architecture, le système de base de données
multidimensionnel sert tant au niveau de stockage qu'au niveau de gestion des
données. Les données des sources sont conformes au modèle
multidimensionnel, et dans toutes les dimensions, les différentes
agrégations sont pour le calculées pour des raisons de
performance.
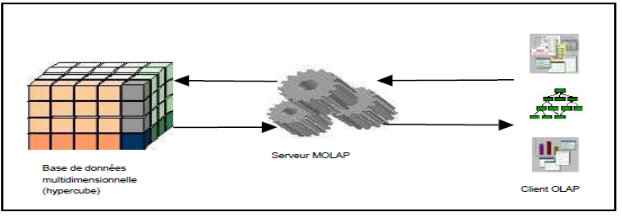
Figure III. 10. Architecture
MOLAP
Les systèmes MOLAP doivent gérer le
problème de données clairsemées, quand seulement un nombre
réduit de cellules d'un cube contiennent une valeur de mesure
associée.
Les avantages des systèmes MOLAP sont bases sur les
désavantages des systèmes ROLAP et elles représentent la
raison de leur création. D'un cote, les requêtes MOLAP sont
très puissantes et flexibles en termes du processus OLAP, tandis que,
d'un autre cote, le modèle physique correspond plus étroitement
au modèle multidimensionnel. Néanmoins, il existe des
désavantages au modèle physique MOLAP. Le plus important, a notre
avis, c'est qu'il n'existe pas de standard du modèle physique.
III.10.3 Les serveur HOLAP (HYBRID OLAP)
Un système HOLAP est un système qui supporte
et intègre un stockage des données multidimensionnel et
relationnel d'une manière équivalente pour profiter des
caractéristiques de correspondance et des techniques d'optimisation donc
c'est l'ensemble des deux serveurs MOLAP et ROLAP.
Dans la figure 9, nous montrons une architecture en
utilisant les types de serveurs ROLAP et MOLAP pour le stockage de
données.
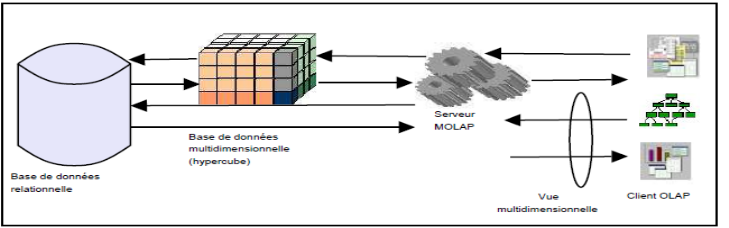
Figure III. 11:Architecture
HOLAP
Ci-dessous, nous traitons une liste des
caractéristiques principales qu'un système HOLAP doit fournir
:
· La transparence du système : Pour la
localisation et l'accès aux données, sans connaître si
elles sont stockées dans un SGBD relationnel ou dimensionnel. Pour la
transparence de la fragmentation.
· Un modèle de données
général et un schéma multidimensionnel global : Pour
aboutir à la transparence du premier point, tant le modèle de
données général que le langage de requête uniforme
doivent être fournis. Etant donné qu'il n'existe pas un
modèle standard, cette condition est difficile à
réaliser.
· Une allocation optimale dans le système de
stockage : Le système HOLAP
· Doit bénéficier des stratégies
d'allocation qui existent dans les systèmes distribués tels que :
le profil de requêtes, le temps d'accès, l'équilibrage de
chargement.
· Une réallocation automatique : Toutes les
caractéristiques traitées ci-dessus
Changent dans le temps. Ces changements peuvent provoquer
la réorganisation de la distribution des données dans le
système de stockage multidimensionnel et relationnel, pour assurer des
performances optimales.
Actuellement, la plupart des systèmes commerciaux
utilisent une approche hybride. Cette approche permet de manipuler des
informations de l'entrepôt de données avec un moteur ROLAP, tandis
que pour la gestion des Data Marts, ils utilisent l'approche
multidimensionnelle.
III.11. CONCLUSION
Dans ce chapitre, nous avons traité le sujet des
entrepôts de données, nous avons données l'architecture
d'un entrepôt de données, nous avons expliqué les
différents composants qu'il intègre, comme les diverses sources,
les types de données et les différents outils pour arriver
à la visualisation de l'information.
Nous avons décrit les différents
modèles multidimensionnels pour la construction d'un entrepôt de
données, ainsi que les différentes opérations pour la
manipulation des données multidimensionnelles et une aperçu sur
le DataMart, le parallélisme entre le deux et présenter l'apport
de DataMart dans les entreprise.
La dernière partie a été
consacrée aux types de serveurs décisionnels.
Dans un premier temps, nous avons décrit le serveur
ROLAP qui utilise une base de données relationnelle, tant au niveau du
stockage qu'au niveau de la gestion de données.
Le serveur MOLAP a été la deuxième
architecture que nous avons traitée.
Ces types de systèmes utilisent une base de
données multidimensionnelle pour le stockage des données. Les
systèmes MOLAP doivent gérer le problème de données
clairsemées, quand seulement un nombre réduit des cellules d'un
cube et aspects temporels une valeur de mesure associée.
La troisième architecture que nous avons
décrite est le serveur HOLAP et quelque caractéristique de ce
types serveur.
CHAPITRE IV. MODELISATION ET
IMPLEMENTION
IV.0. INTRODUCTION
Ce chapitre est consacré à la
réalisation de notre système décisionnel ainsi que
à l'interprétation des résultats obtenue après
construction de notre arbre de décision. Ces applications sont
réalisées pour le département des ressources humaines de
la banque FINCA qui constitue le champ d'application de notre travail.
Ainsi, nous parlerons de l'aperçu historique, la
situation géographique, suivie de la structure organisationnelle pour
terminer par une conception de notre système décisionnel.
Par ailleurs, nous tenons à signaler que notre
étude porte sur la réalisation d'un système
décisionnel qui permettra de faire des analyses sur la performance des
agents de la banque FINCA.
IV.1. ANALYSE DE L'EXISTANT
1. Historique de FINCA R.D.Congo
FINCA RDC est une institution de micro finance appartenant
au groupe FINCA International, présent dans 21 pays du monde. Elle a
demandé ses activités en 2003, grâce à une
subvention de l'USAID consacrée à l'introduction de la technique
« banque villageoise » à Kinshasa. L'IMF, qui
dispose aujourd'hui d'un réseau de 11 agences, concentré dans les
régions de Kinshasa, du bas Congo et du Katanga, a sollicité
l'agence Française de Développement de son portefeuille de
prêts.
L'Agence a répondu favorablement à cette
demande et les deux institutions ont signé le 11 septembre 2009 une
convention de crédit de 2,8 millions de dollars. Le projet vise a
soutenir FINCA RDC, d'une part dans le développement de ses
activités en dehors de Kinshasa, notamment la zone de Lubumbashi et
d'autre part le développement de son portefeuille de crédits aux
TPE (très petites entreprises) au profit de diverses activités
comme le petit commerce, l'artisanat ou les services.
2. Vision, Mission et Stratégies
2.1. La vision
La vision de FINCA s'énonce comme suit :
« tisser un réseau globale au service de micro entrepreneurs
comme jamais au paravent tout en fonctionnant sur base des principes
commerciaux de performance et de stabilité ».
Cette déclaration de vision traduit clairement
d'une part la volonté de FINCA d'être le leader mondial en
matière de services financiers fournis aux micro entrepreneur et d'autre
part la nécessité de travailler de manière rentable et
professionnelle, afin d'assurer la pérennité de ses
opérations.
2.2. La Mission
Toute organisation a une mission précise qui lui
permet d'atteindre le but de son existence et sa vision.
La mission de la FINCA consiste
à « fournir des services financiers aux entrepreneurs de
faibles revenus du monde permettant ainsi de créer des emplois,
générer des capitaux, et améliorer leur niveau de
vie »Aujourd'hui la mission de FINCA est d'atteindre plus de
1.000.000 des clients dans le monde.
L'objectif de cette mission est d'avoir un impact
systématique et générationnel sur la pauvreté, en
rendant accessible le prêts aux femmes pauvres et c'est à grande
échelle.
Dans le secteur du micro crédit, FINCA est
réputée pour atteindre les segments les plus pauvres du
marché
2.3. La stratégie
La stratégie étant un ensemble
cohérent ou conséquent d'actions qu'une organisation entreprend
pour aller vers sa vision.
L'essentiel, en matière de stratégie,
consiste de choisir d'exécuter les opérations de manière
différente par rapport à la concurrence, afin de fournir une
proposition de valeur unique.
3. Situation Géographique
La direction générale de FINCA RDC se situe
dans le district de Lukunga plus précisément dans la commune de
Gombe, au croisement des avenues Colonel Ebeya et de l'hôpital
général de Kinshasa (ex maman yemo), au sein de l'ex immeuble
SODIMCA.
4. Nature Juridique
FINCA RDC est une société par action de
société anonyme (SA), avec comme numéro du registre
commercial KG/4096/M et de l'identification nationale 01-61O-N53321U,
agrée par la Banque Centrale du Congo.
5. Evolution de FINCA/RDC
La FINCA/RDC a débuté ses activités
en Mai 2003 dans un contexte marqué par une situation politique
très instable (la fin de la guerre n'étant pas encore effective
et formelle), ainsi qu'une extrême méfiance du public envers les
institutions financières. En dépit de cela, la FINCA/RDC
dotée alors du statut d'ONG parvint à récolter un
succès impressionnant avec son produit « Village
banking »
En 2005, FINCA/RDC obtint aux termes de l'instruction
n°001 de la banque centrale du Congo, le statut d'institution de micro
finance.
En 2006, un nouveau produit est introduit par
l'institution à savoir « crédit individuel »
lequel a permis à FINCA/RDC de doubler son portefeuille de crédit
en l'espace de quelques mois seulement.
C'est dans ce contexte que FINCA/RDC décida de
passer de la phase d'expansion de ses activités, ce qui impliqua
d'importants investissements dans les infrastructures : il fut
décidé la création de deux branches à Kinshasa, la
branche de Gombe et celle de Masina dotées de bureaux ultramodernes, et
qui devinrent pleinement opérationnelles en Décembre 2006. Au
cours de l'année 2006, le personnel de FINCA/RDC passa de 50 à
plus de 120 employés.
En septembre 2007, FINCA/RDC entama son déploiement
à l'intérieur du pays lequel ne permettait pas d'offrir au public
de nouveaux produits tels que les transferts d'argent et les paiements
électroniques : de par la législation congolaise en effet,
seules les banques sont habilitées à gérer les moyens de
paiement, dont font partie les transferts et le paiement
électronique.
Cet obstacle est désormais levé, car depuis
Mai 2008, FINCA/RDC est devenu une société par action à
responsabilité limité (SARL), disposant du tout nouveau statut
juridique de « société de micro
finance ».
6. Structure Organique
La direction générale de FINCA/RDC est
dirigée par un Directeur nationale assisté d'un adjoint suivie
d'un management Team (une équipe de direction). Il est composé de
9 départements.une attention particulière sera accordé au
département de l'Information Service(IS) dans lequel nous avions
effectué notre stage.
Les 9 départements de la direction
générale de FINCA/RDC sont :
· HR (Ressources humains) ;
· Finance ;
· Légal Counsel ;
· Information Services ;
· Operating département ;
· Audit département ;
· Marketing département;
· Banking Service
· Internal Control
7. Organigramme de la direction générale de
FINCA
Régional IT Manager
Board of Directors
Audit commitine
CEO
MM
ITM
ADC§SS
Saving
Specialists
CFO
cfoO
Management
Accountant
Treasury
ManagerVentes
Cle_P
Cle_T
Cle_M
Quantité
Portolio MangerMagasin
Cle_M
Raison_soc
Adresse
Commune
Département
Région
Pays
Admin Manager
Administrative
officer
ODP 35Produits
Cle_P
Description
Type
Catégorie
Treasury ASS.Magasin
Cle_M
Raison_soc
Adresse
Commune
Département
IT specialists
Procurent & logstic officer vacant
Driver
Chief AccountantT_Département
Département
Région
Financial
Accountant
Branch
Accountant §§
ASS Accountant
HRM
Audit Team
COO
Deputy
&COO
Branch manager
Reg.Man.Kin
Branch managerProduits
Cle_P
Description
Type
Catégorie
Reg.Man.congo.CTemps
Cle_T
Jour
Mois
Année
Branch manager
Ventes
Cle_P
Cle_T
Cle_M
Quantité
Reg.Man.KantanMagasin
Cle_M
Raison_soc
Adresse
Commune
Département
Branch manager
Marketing. Man
Chief Accountant
Chief Accountant
Chief Accountant
F/I légal conseil
Légal conseil vacant
IV.2. OUTIL UITILISE
Nous présentons succinctement les outils ainsi que
les nouvelles méthodes de développement de processus
décisionnels qui en découlent :
· Microsoft Access 2007
· Microsoft Visual Studio team system
· SQL serveur 2008 (business intelligence)
Ici nous allons énumérer les modules et
composantes de SQL serveur 2008 R2.
Répartition des modules SQL serveur 2008 R2 par
composantes.
|
Composant
|
Module SQL Serveur 2008
|
Destination dans l'entreprise
|
|
Workflow+Flux de données (ETL)
|
Intégration de services (SSIS)
|
Administrateur de base des données
|
|
Entrepôt de données relationnel et
multidimensionnel
|
Base de données relationnelle SQL serveur
2005
|
Administrateur et développeurs
|
|
Base de données multidimensionnelle
analytique
|
Analysis services
|
Développeur et utilisateur ayant des connaissances
métier
|
|
Exploration des données
|
Data mining intégré à Analysis
services designer
|
Statistien ou développeur utilisateur
|
|
Création de rapports et de modèle
sémantique métier
|
Reporting services designer
|
Développeurs
|
|
Requêtes et analyses spécifiques
|
Report builder 1 .0 Excel,proclarity
|
Analystes métier
|
|
Développement d'application BI
|
SQL serveur Business
Intelligence Devellopment Studio(BIDS)=Visual
Studio
|
Développeur
|
|
Outils de gestion de base de données
|
SQl Server Management
Studio
|
Administrateur et développeurs
|
|
Services de notification
|
SQL serveur Notification services
|
Alertes envoyées aux managers sur des
événements métier
|
Tableau IV1. Répartition de module de SQL
serveur 2008 par composante.
Parmi ces composantes de SQL serveur 2008 nous avons
utilisé l'intégration des services (SSIS) pour transformer notre
source de données en Excel que nous avons d'abord transforme en Access,
nous avons aussi et utiliser l'analysis service (SSAS) pour réaliser
notre entrepôt des données ainsi pour bien faire le
datamining.
IV.3. MODELISATION
MULTIDIMENSIONNELLE DE DATAMART
Pour construire un entrepôt global d'une entreprise
il ya des méthodes :
· Top down : c'est la
méthode la plus lourde, la plus contraignante et la plus complète
en même temps elle consiste en la conception de tout l'entrepôt,
puis la réalisation de ce dernier.
· Bottom-up : c'est
l'approche inverse, elle consiste à créer les étoiles,
puis les regrouper par des niveaux intermédiaires jusqu'à
l'obtention d'un véritable entrepôt pyramidal avec une vision
d'entreprise.
· Middle-Out : c'est
l'approche hybride, et conseillée par les professionnels du business
intelligence. Cette méthodes consiste en la conception totale de
l'entrepôt des données c-à-dire concevoir toutes
dimensions, tous les faits, toutes les relations, puis créer des
divisions plus petites et plus gérables et les mettre en oeuvre.
Pour notre étude nous avons construit un DataMart
représentant une étoile pour la banque FINCA qui est un DataMart
sur la performance du personnel au département des ressources
humaines.
IV.4. IMPLEMENTATION
IV.4.1. Conception d'un Data Mart
Etape 1 : Définir le processus
à analyser
La procédure ou fonction fait
référence au sujet de notre mini entrepôt des
données. Nous déterminons le processus métier de la
banque FINCA concernant notre étude « la performance des
agents » dont voici la modélisation de la base de
données de l'entrepôt de données
Etape 2 : Déterminer le niveau de
granularité des données
Choisir le grain signifie décider exactement de ce
que représente un enregistrement d'une table de faits par exemple
l'entité performance représente les faits relatifs à
chaque performance et devient la table de faits du schéma en
étoile de la performance du personnel.
Par conséquent, le grain de la table de faits
performance est une performance réalisé au département des
ressources humaines.
A prés avoir choisi le grain de la table de faits
nous allons commencer à identifier les dimensions de la tables de
faits.
A titre d'illustration, l'entité personnel servira
de références aux données concernant la performance et
deviendra la table de dimension du schéma en étoile de la
performance.
Nous ajoutons aussi le Temps comme dimension principale,
car il est toujours présent dans le schéma en
étoile.
Etape 3 : choisir les
dimensions
Les dimensions déterminent le contexte dans lequel
nous pourrons poser des questions à propos des faits établis dans
la table de faits .Un ensemble de dimensions de dimensions bien
constitué rend le mini entrepôt de données
compréhensible et en simplifie l'utilisation.
Nous identifions les dimensions avec suffisance de
détails, pour décrire des choses telles que les clients et les
propriétés avec granularité correcte.
Etape 4 : identifier les métriques
(faits)
Pour notre cas le fait est la performance. Les
métriques sont les données numériques nombre de
familiarisation des clients par des agents, nombre des agents qui sont faible
en marketing, nombre des clients perdus, nombre des agents qui sont
démissionnés et nombre de zone perdu par les agents.
Notons que les autres étapes qui suivent
exclusivement pour la construction d'un entrepôt des données mais
pour notre travail nous construisons un DataMart donc un sous ensemble d'un
entrepôt des données donc nous estimons que nous pouvons nous
arrêter a ce point.
Ø Mesures
Dans l'exemple présenté ci-haut, les mesures
sont définies par la table performance et sont les
suivantes :
Nombre des agents qui sont faible en
marketing ;
Nombre des clients perdus ;
Nombre des agents qui sont démissionnés et
Nombre de zone perdu par les agents
Ø Dimensions
Nous allons effectuer des analyses selon divers axes
d'observation suivantes :
· Axe temps
Idtemps
Année
Mois
Jours
· Axe personnel
Idpersonnel ;
Matricule ;
Nomperson
NiveauEtude ;
Direction ;
Fonction ;
Province ;
Sexe ;
Catégorie.
IV.4.2. Schéma en
étoile de l'entrepôt de données sous SQL serveur2008R2
a. Vue de la source de données
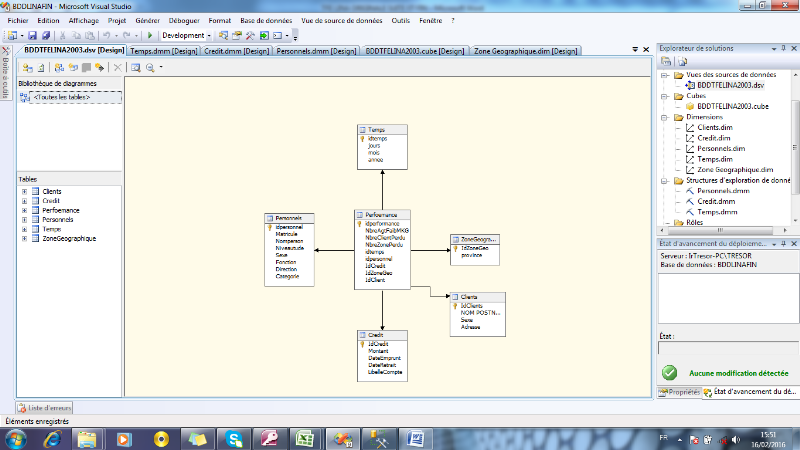
Figure IV.1. Schéma en
étoile de performance du personnel
b. Les dimensions
1. Dimension Personnel
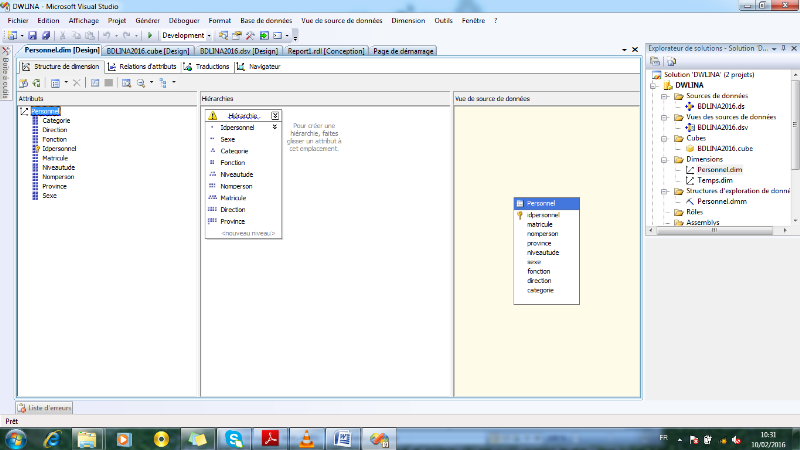
Figure IV.2. Dimension personnel
2. Dimension Temps
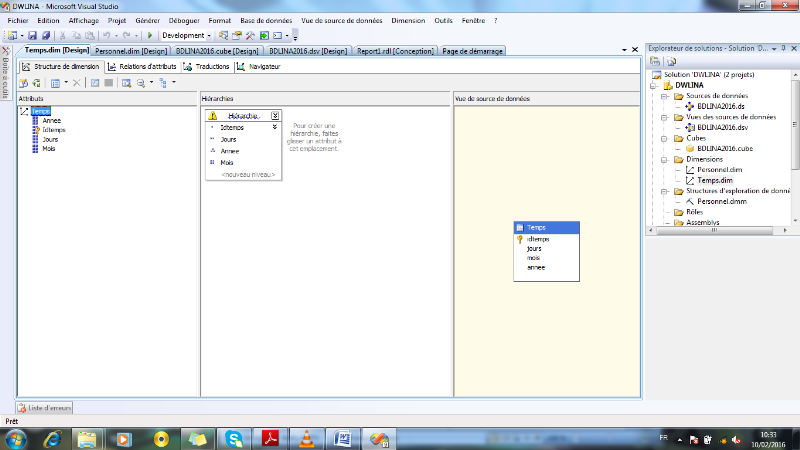
Figure IV.3.Dimension Temps
3. Dimension Clients
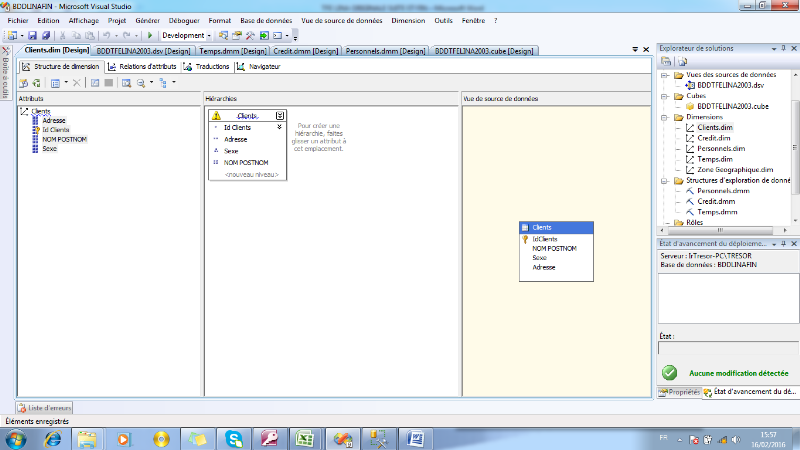
Figure IV.4. Dimension Clients
4. Dimension Crédit
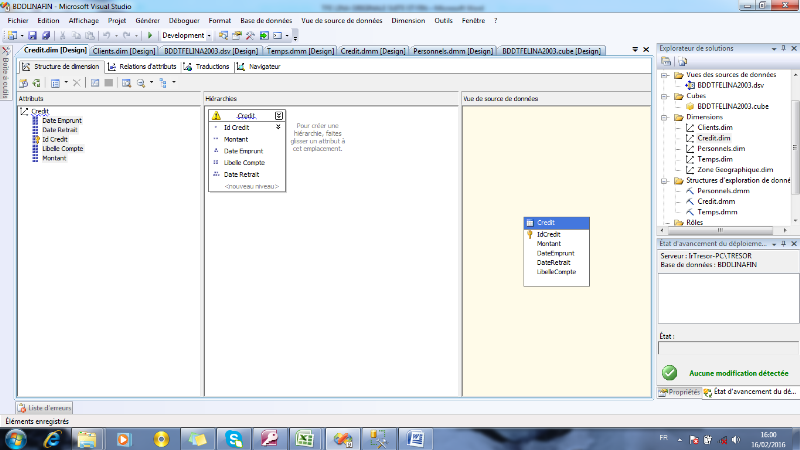
Figure IV.5. Dimension Crédit
5. Dimension Zone Géographique
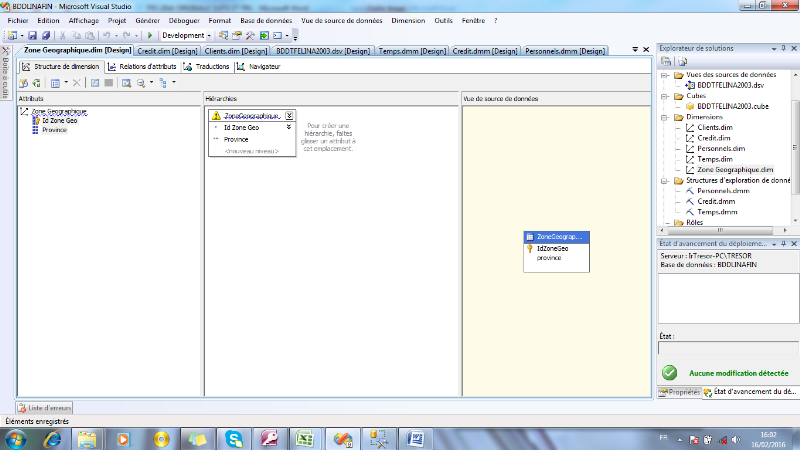
Figure IV.5. Dimension Zone Géographique
c. Modèle en étoile de DataMart
Nous présenterons le modèle en étoile
de notre DataMart
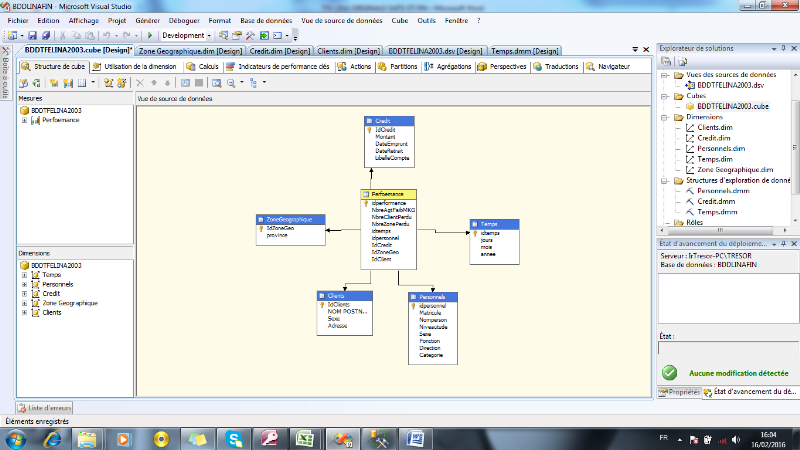
Figure IV.6. Modèle en étoile de Data
Mart
d. Déploiement du Cube
OLAP
Figure IV.7. Déploiement du Cube OLAP
e. Analyse Olap
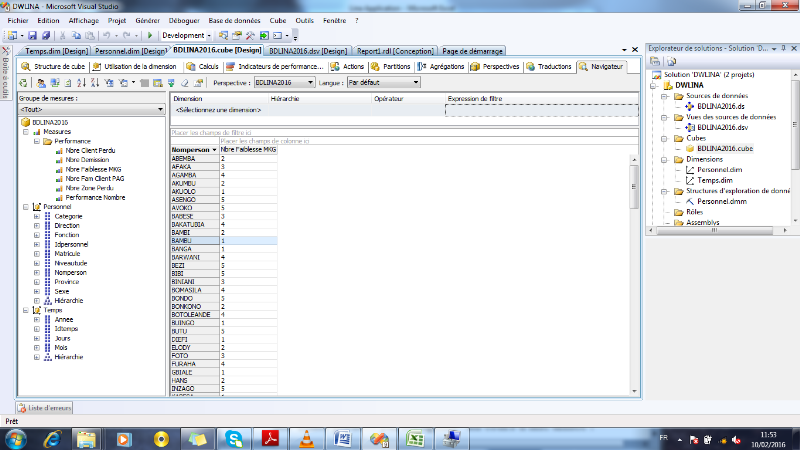
1. Détermination de nombre des agents qui
sont faibles en marketing.
Figure IV.8. Détermination de nombre des agents qui
sont faibles en marketing
L'analyse nous montre sur 148 personnels, il y a 58 soit
39,18919 % personnels qui sont faible en marketing.
2. Détermination de nombre des zones perdues par
les agents au cours d'une année ?
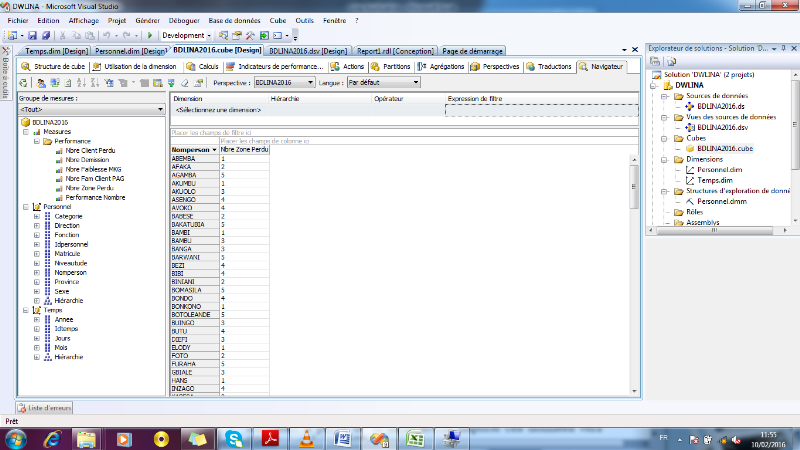
Figure IV.9. Détermination de nombre des zones
perdues au cours d'une année
L'analyse nous montre sur 148 personnels, il y a 30 soit
20,27027 % personnels qui ont perdu une zone, 29 soit 19,59459 % personnels
qui ont perdu deux zones, 30 soit 20,27027 % personnels qui ont perdu trois
zones, 30 soit 20,27027 % personnels qui ont perdu quatre zones et 29 soit
19,59459 % personnels qui ont perdu cinq zones.
IV.4.3. Module de Datamining
Dans ce module de datamining,
nous nous servir de l'arbre de décision en utilisant le logiciel SQL
server 2008 R2 pour nous faciliter d'interpréter les résultats
obtenus. Nous avons importé vers un fichier Excel le résultat
d'une requête sur notre DataMart à partir de là, nous avons
réalisé l'arbre de décision. Dans cet arbre les noeuds
colorés montre qu'il y a beaucoup plus de cas possibles ou d'individus
et les noeuds non colorés montrent il n'y a pas de cas possibles.
D'où, l'interprétation va se basé sur les noeuds
colorés.
1. Prédiction
par rapport à la direction
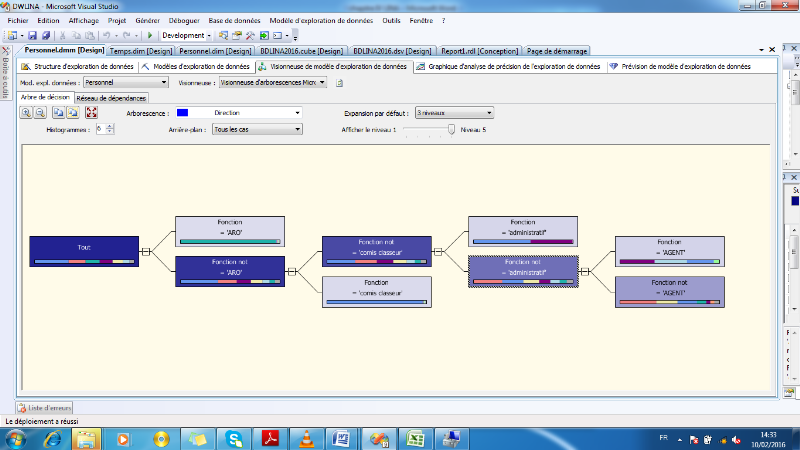
Figure IV.10. Prédiction par rapport à la
direction
Dans cet arbre, nous montre dans la direction de finance
il y a 19,31 % des personnels sont performant et 35,93 % des personnels dans la
direction des ressources humaines ne sont pas performant dans leur zone de
service.
2. Prédiction par rapport à la
fonction
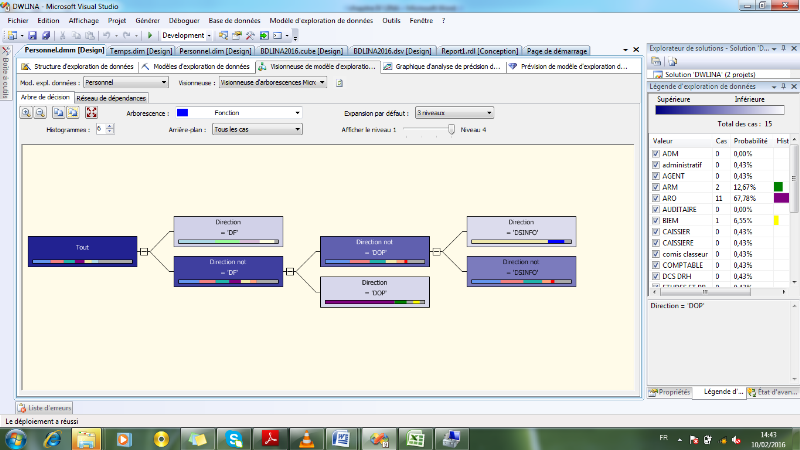
Figure IV.11. Prédiction par rapport à la
fonction
Dans cet arbre, nous montre dans les personnels qui assume
la fonction d'administration ne sont pas compétant soit 16 (16,83 %)
cas sur 85.
3. Prédiction par rapport au
sexe
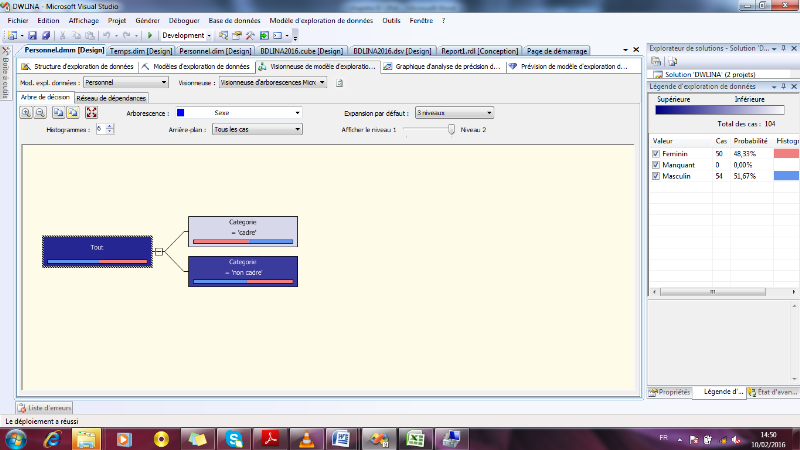
Figure IV.12. Prédiction par rapport au sexe
Dans cet arbre, nous montre dans le sexe dont la
catégorie est non cadre sur 90 cas enregistré il y a 42 soit
46,85% des personnels de sexe féminin sont performant et 48 soit 53,15%
des personnels de sexe masculin ne sont pas performant dans leur zone de
service.
4. Réseau de dépendance de la
direction
Figure IV.13. Réseau de dépendance de la
direction
Le réseau de dépendance représente
comment les variables sont liées entre eux et les variables à
discriminer selon notre modèle de prédiction. Donc, les variables
discriminantes sont le sexe et la fonction.
5. Rapport sur la liste des personnels qui seront
permutés
|
République Démocratique du Congo
==FINCA==
-------------------------------------------
|
|
|
|
|
Nom_PersonnelProvinceNiveau
EtudeSexeGradeABEMBAKinshasaDESMasculinDCSAKUOLOBas
CongoDESFémininDCSASENGOBandunduDEAMasculinDCSBABESEKasai
orientaleDEAMasculinDCSBAKATUBIAKasai
occidentaleL2MasculinDCSBAMBIKatangaL2MasculinDCSBAMBUManiemaG3FemininDCSBIBINord
KivuG3FémininDCSBINIANISud
KivuD6FémininDCSBOMASILAEquateurD6MasculinDCSBONKONOProvince
orientaleD4MasculinDIRBUINGOKinshasaD4FémininDIRBUTUBas
CongoDESFémininDIRFOTOBandunduDESMasculinDIR
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figure IV.14. Rapport sur la liste des agents qui seront
permutés
IV.7. CONCLUSION
Dans ce chapitre nous avons commencé par
présenter l'entreprise bancaire FINCA qui est notre champs
d'application, en suite nous avons cité les outils utilises pour la
réalisation de ce travail.
Et enfin nous avons présenté les interfaces
graphiques de notre DataMart ainsi que l'arbre de décision obtenue pour
boucler par une interprétation de ces résultats.
CONCLUSION GENERALE
Nous voici arrivés au terme de notre travail de fin
d'études qui a porté sur la mise en place d'un entrepôt de
données pour l'analyse de la performance du personnel au sein d'une
entreprise bancaire cas de la banque FINCA.
Dans notre travail, nous avons parlé d'abord du
système décisionnel qui présente l'ensemble des processus
qui permet de collecter, d'intégrer, de modéliser et de
présenter les données.
Nous avons traité du Data mining qui permet de
faire des recherches approfondies sur les données de l'entrepôt,
avec un arbre de décision pour faire la l'extraction de
connaissances.
Ensuite Nous avons également parlé des
entrepôts des données qui constituent le coeur du système
décisionnel jouant un rôle référentiel pour
l'entreprise puisqu'il permet de fédérer des données
souvent éparpillées dans les différentes bases de
données.
Nous avons réalisé le DataMart avec SQL
serveur 2008 R2 avec un modèle de l'arbre de décisions pour nous
permettre de prendre une décision sur nos données.
De ce qui précède, nous sommes
persuadé que l'ensemble des préoccupations répond à
la problématique de notre travail.
Notre contribution dans notre étude de cas
était de réaliser un Data Mart sur la performance du personnel et
à partir de ce DataMart nous avons pu construire un arbre de
décision que nous avons interprété à la fin et pour
finir cet outil permettant au décideur d'avoir une vision centrale sur
tous les personnels et qui lui permettant de prendre une décision
stratégique.
BIBLIOGRAPHIE
A. OUVRAGES
[1]. ADIBA .M, Entrepôts de données et
fouille de données, Paris 2002.
[2]. Bertrand Burquier, Business intelligence avec 2008,
Mise en oeuvre d'un projet décisionnel, Dunod, 2009.
[3]. DANIEL T. LAROSE, Des données à la
connaissance une introduction au Datamining, Vuibert, 2005.
[4]. GUIJARRO Vincent, Les Arbres de Décisions
L'algorithme ID3, Lile ,2006.
[5]. KIMBALL .R and m. ross, Entrepôts de
données, guide pratique de Modélisation dimensionnelle, vuibert,
paris, 2003.
[6].RAKOTOMALALA.R: Graphes d'induction apprentissage et
data mining, hermès, 2000.
B.THESE
[7]. SERNA ENCINAS MARIA, Entrepôts de
données pour l'aide à la prise de décision
médicale, conception et expérimentation, UNIVERSITE JOSEPH
FOURRIER, France 2005
C. NOTES DE COURS
[8]. KAFUNDA KATALAY Pierre, gestion d'infocentre, L2
Informatique option Gestion, cours inédit, UNIKIN 2014-2015.
[9]. KASORO, Analyse des données, L2 Informatique
option Gestion, cours inédit, UNIKIN 2014-2015.
[10] .MANYA NDJADI, statistique II, G2 informatique,
cours inédit, UNIKIN 2014-2015.
[11]. MANYA NDJADI, Recherche opérationnelle, G3
Informatique, cours inédit, UNIKIN 2014-2015.
[12]. NTUMBA BADIBANGA Simon, Informatique de gestion, G3
Informatique, cours inédit, UNIKIN 2014-2015.
D. MEMOIRES et TFC
[13]. ANONGA MAGUBU Trésor, Mise en place d'un Data
Mart au sein d'une entreprise de télécommunication pour la
gestion de vente des Modems, UNIKIN 2012-2013
[14]. KANGIAMA LWANGI Richard, Conception et
réalisation d'une base de données pour la consultation
médicale au sein d'une institution médicale, « Cas de
service de consultation du personnel de l'hôpital saint joseph de
Kinshasa Limete », UNIKIN 2007-2008.
[15]. KALULAMBI KABASELE Didier, Extraction des
connaissances a partir d'un entrepôt des données à l'aide
de l'arbre de décision application a la fouille des données
bancaires, UNIKIN 2008-2009.
E. INTERNET
[16]. www.creatis.insa-lyon.fr, consulté, le 3
janvier 2015.
[17].
www.wilkipedia.org ,
consulté, le 23 Avril 2015.
[18].
www.devellopez.com ,
consulté, le12 Septembre 2015.
Table des Matières
| 

