Approche du design et implémentation d'un lan hiérarchique redondant pour la haute disponibilité d'une infrastructure réseau. Cas du réseau de la drkat / Lubumbashi.( Télécharger le fichier original )par Albert Matakano Pasu Université Méthodiste au Katanga / Mulungwishi - Diplôme de Licence dà¢â¬â¢Ingénieur Système et Réseaux 2015 |

10 Ir. Magloire KITUTWE, Personnel IT chargé de la maintenance informatique et de l'exploitation, interviewé lors de l'Inventaire des imprimantes en date du 09 Octobre 2014 à 10h09', Lubumbashi. - 15 -
2. Imprimantes Ce tableau suivant répertorie les différentes imprimantes installées sur le LAN 10:
- 16 -
3. Équipements d'interconnexions Tableau 2: Tableau synoptique des équipements d'interconnexions
- 17 -
- 18 -
4. Autres équipements Les autres équipements installés sur l'infrastructure sont répertoriés dans le tableau suivant :
- 19 -
- 20 -
fr Salle du Bureau Informatique (IT) Modem ADSL
Antenne VSAT RACK de Serveurs 4:7 -rus- Salle Bureaux Salle du Bur. des Imptôts sur les Salle du Bureau Salle Bureau Impôts Fonciers revenus locatives Taxes Récouvrement J~ J\ l \ / Salle contrôle Technique Salle Réunion, Ch. `14101 L l Salle Bur. Suivi Users mobiles Figure 1: Topologie Physique de la Division Urbaine de Lubumbashi - 21 - B. Partie logique1. Logiciels clients, serveurs de la Division DRKAT / Lubumbashi
11 Interview de Ir. Christian BAMBINO, Personnel IT chargé du Réseau et sécurité informatique, Lubumbashi, 24 Septembre 2014, 11h12'. - 22 -
(>) 192.168.1.5 - 75 255.255.255.0 i 1 1 1 1 1 1 1 5. ! ~.. Fi 9 ~ Serveur File Maker (Application de gestion Serveur Annuaire Active Dire
!E2. 1 1 1 1 1 1 1 192.168.1.10 - 13 255.255.255. Work Station situé dans les différentes 1 1 1 Serveur Annuaire Active Directory (serveur de reprise) 1 J 4 LIGNE ROUGE (>) L Figure 2: Topologie Logique du LAN de la Division Urbaine de Lubumbashi - 23 - IV. CRITIQUE DU LAN DE LA DIVISION URBAINE DE LA DRKAT /LUBUMBASHIÀ la lumière de la description détaillée ci-haut faite sur le LAN de la Division Urbaine de la DRKAT - Lubumbashi ; en dépit du fait que son infrastructure réseau répond à quelque pourcentage près à certaines caractéristiques d'un bon réseau, cela n'exclut pas ses défaillances et problèmes. C'est ainsi qu'il a été observé et constaté que cette infrastructure est beaucoup plus vulnérable ou est exposée une indisponibilité des ressources, services, équipements et même médias de communications d'autant plus que ses objectifs se concentrent sur la mobilisation des recettes. Concrètement, c'est qu'en présence de coupure d'un câble vertical interconnectant le répartiteur intermédiaire (du local où sont connectés un nombre d'utilisateur d'un local) au répartiteur central (situé dans la salle serveur ou IT) ; les conséquences seront plus que mauvaises car les utilisateurs de ce local se verront indisponible par rapport au serveur sur lequel est installée l'application de gestion. Du point de vu financier, il n'y aura pas d'entrée des recettes pendant ce période d'indisponibilité ; et donc le bureau concerné sera non opérationnel et moins rentable. Et même en cas de disfonctionnement d'un équipement actif (routeur wifi, Switch, etc.) le groupe d'utilisateur dépendant de lui se verra down à cause de l'indisponibilité de l'équipement fournisseur. En plus de cela, au vue de l'administrateur, le réseau présente une complexité d'administration à cause de sa conception non adaptée à la structuration ou hiérarchisation des postes ; de l'utilisation d'un adressage présentant du gaspillage d'adresses IP ; dans certains cas, il y a redondance des certaines ressources d'un même bureau, etc. Après avoir épluché les différents aspects du cadre de référence de notre étude en l'occurrence de la Division Urbaine de la DRKAT / Lubumbashi, nous passons directement au chapitre consacré à la présentation de la méthode et solution. - 24 - Chapitre deuxièmeCONSIDERATIONS METHODOLOGIQUESDans ce chapitre, nous allons d'une part présenter de manière détaillée la méthode utilisée pour concevoir et déployer notre solution. Elle n'est rien d'autre que l'ensemble des procédés raisonnés utilisés pour la réalisation d'une oeuvre ; d'une chose. Elle sera pour nous comme démarche, un fil conducteur tout au long de la conception et l'implémentation de notre solution informatique ; et de l'autre part nous ferons la mise en des hypothèses, la solution du problème ainsi que ses contraintes expérimentales. I. PRESENTATION DE LA METHODE TOP DOWN NETWORKDESIGNDans la quête d'atteindre nos objectifs et ainsi concevoir et d'implémenter notre solution informatique, nous userons de la méthode « Top Down Network Design ». Elle est une méthode orientée réseaux informatiques et a été élaborée dans le but de donner une démarche descendante dans le cadre de projet de conception, d'implémentation, d'optimisation des réseaux informatiques. A. Description de la méthode Top Down Network DesignLa méthode Top Down Network Design revêt d'une démarche descendante dans le projet de conception, d'implémentation et d'optimisation des réseaux informatiques. Elle consiste en une analyse du plus haut niveau d'abstraction vers le plus bas niveau c'est-à-dire qu'elle part de la couche supérieure vers la couche basse du modèle de référence OSI. Elle se présente selon plusieurs parties ou phases dont voici dans les lignes qui suivent leurs détails. B. Phases de la méthode Top Down Network Design 1. Phase I : Identification des besoins et objectifs de l'entreprise Cette première phase de la méthode Top Down Network Design donne une vue générale sur la démarche entière. - 25 - Elle permet au concepteur des Systèmes Réseaux d'effectuer systématiquement une analyse des contraintes et buts de l'entreprise demandeur, de ses besoins et échanges techniques ; la présentation des éléments caractéristiques du réseau existant ainsi que de ses interconnexions jusqu'à aboutir à l'analyse des trafics réseaux à savoir quelles applications sont-elles utilisées sur le réseau sous étude. 2. Phase II : Conception logique du réseauConcevoir une topologie réseau logique est la première étape dans la phase de conception logique des réseaux selon la méthodologie Top Down Network Design. Parce que par la conception de la topologie logique avant l'implémentation physique nous avons la possibilité d'accroître ou de majorer la chance d'atteindre le but du client par des possibilités telles que la scalabilité ou extensibilité, adaptabilité ainsi que la performance.12 Dans la même optique, cette partie se focalise aussi sur la présentation du modèle d'adressage et de nommage des équipements ; la sélection des protocoles de routages et de commutations ; au développement des stratégies de sécurités ainsi qu'à la gestion de ces dernières. L'adressage doit être adapté aux besoins des clients en termes du nombre d'utilisateurs et des équipements susceptibles d'être identifiés sur le réseau. 3. Phase III : Conception physique du réseauCette troisième phase de la méthodologie Top Down Network Design tournera autour de la conception pièce par pièce de l'architecture physique du futur réseau. Elle est la première étape dans la conception physique du réseau selon la perspective de la méthode Top Down Network Design. L'objectif de cette phase est de doter à l'Ingénieur concepteur les informations nécessaires sur les caractéristiques de scalabilité, manageabilité, de performance des options typiques, d'aider l'Ingénieur à effectuer des bonnes sélections d'équipements selon les besoins de l'entreprise.13 En effet, cette conception physique du réseau s'articulera autour de la sélection des technologies et périphériques réseaux à utiliser dans le futur réseau ; laquelle conception 12 Priscililla Oppenheimer, Top-Down Network Design, CISCO, Third Edition, August 2011, pg. 163. 13 Idem, pg. 283. - 26 - devra déterminer la conception du plan de câblage, la sélection des différents équipements d'interconnexions à utiliser dans le futur réseau. 4. Phase IV : Test, Optimisation et Documentation du réseauCette phase comme vous le constatez dans son intitulé est selon certains auteurs une synthèse de trois étapes à savoir le test, l'optimisation et la documentation du réseau. Cela est un point de vue qui n'est pas partagé par certains autres auteurs qui souhaitent y ressortir trois étapes. Ainsi dans la présente étude, nous avons adopté la synthèse de toutes les trois étapes. C'est parce qu'elle nous a permis d'effectuer au fur et à mesure que nous évoluons la documentation, les essais ainsi que la correction de certaines erreurs pour que le future réseau donne le meilleur de lui-même. Cette partie est plus importante dans le processus de conception de réseau car elle permet à l'Ingénieur concepteur de prouver que la solution qu'il développe et propose. Elle permettra d'atteindre les buts et objectifs techniques de l'entreprise. Par ce test, l'Ingénieur vérifiera si sa solution fournira au demandeur ou client la performance ainsi que la qualité de service (QOS) que ce dernier espère. y' Test du prototype réseau : Réaliser un test dans l'approche de conception des réseaux informatiques revient à utiliser un type de test industriel, à construire et tester un prototype ou premier modèle dans la conception d'une solution, à écrire l'implémentation d'un plan de test pour la conception du futur réseau et enfin à utiliser un des outils de conception de réseau. y' Optimiser le réseau : Dans un réseau performant, pour atteindre les buts de l'entrepris, il est recommandé d'avoir une variété des techniques d'optimisation à savoir le NetFlow Switching, Cisco Express Forwarding (particuliers à CISCO), l'IP Multicast Technologie. C'est une technologie d'optimisation des réseaux ; elle incluse l'adressage multicast, Internet Group Management Protocol (IGMP) pour permettre aux clients de se joindre au groupe multicast, le protocole multicast de routage. - 27 - L'optimisation d'un réseau est l'étape critique dans la conception des réseaux pour les organisations qui utilisent une haute bande passante (high-bandwidth) et un taux de retard moins élevé dans la transmission des données14. L'optimisation permet ainsi de gérer les différentes frousses que peuvent présenter certaines applications. De ce fait, optimiser un réseau revient à utiliser différentes techniques pouvant permettre à ce dernier de fournir les au maximum les meilleurs de lui-même à ses utilisateurs. V' Documentation du réseau : Cette étape consiste en général à archiver par des écrits dans un document toutes les informations relatives à la topologie (physique et logique du réseau), l'adressage et le nommage, la sécurité et ses stratégies, les technologies utilisées sur le réseau ainsi que les protocoles. Dans le cadre d'un projet, ce document doit inclure le plan d'implémentation de ce dernier afin de mesurer son succès par rapport à l'implémentation. Il doit également inclure le budget en termes de coût de différents équipements constituant le réseau. Ce document doit également renseigner les différentes modifications apportées au réseau afin d'évaluer son processus d'évolution. II. MISE EN OEUVRE DES HYPOTHESES ET DESCRIPTION DE LASOLUTIONL'approche descendante ci-haut décrite nous servira d'un fil conducteur au cours de la démarche de conception et implémentation de notre solution informatique. Laquelle solution s'inscrit dans la perspective du design et d'implémentation d'un réseau hiérarchique visant la haute disponibilité de l'infrastructure avec possibilité de gestion de Broadcast Storm et définition de réseau sans boucles. Cependant, pour arriver à l'issue augurée dans cette quête, nous mettrons ensemble les éléments qui suivent pour matérialiser notre solution informatique finale: le premier volet nous permettra de déployer la technologie de redondance des routeurs pour la haute disponibilité, le second se proposera de répartir les charges entres ces routeurs de redondances afin d'optimiser ses performances, le troisième s'articulera autour de la proposition d'une 14 Priscililla Oppenheimer, Top-Down Network Design, CISCO, Third Edition, August 2011, pg. 367. - 28 - technologie d'agrégation des liens physiques et le dernier chutera sur la proposition d'une technologie de définition de réseau sans boucle et la gestion de Broadcast Storm. Toutes ces technologies doivent à priori reposer sur un modèle de conception hiérarchique de réseau informatique que nous concevrons préalablement. III. CONDITIONS EXPERIMENTALESEn ce qui concerne l'épreuve expérimentale de notre solution de haute disponibilité d'une infrastructure réseau, l'environnement technique devra à priori répondre aux principales conditions techniques que voici : y' Un logiciel simulateur / émulateur de la plateforme CISCO sera principalement utilisé pour ainsi nous offrir un bon et bel environnement de travail ; y' Pour les configurations de redondance à l'accès WAN et celles de la répartition de charges des routeurs coeurs, nous userons principalement des routeurs CISCO dont l'Internet Operating System est de la série de 3700 ; y' Ainsi, les configurations liées à
l'agrégation des liens et la définition de réseau Ainsi saisie de la démarche de notre que nous avons opté dans la présente étude, nous pouvons maintenant faire un tour d'horizon dans diverses bibliothèques pour y analyser les ouvrages ayant trait à notre sujet sous étude. - 29 - Chapitre troisièmeREVUE BIBLIOGRAPHIQUEDans cette partie de notre mémoire, nous allons devoir présenter et effectuer une étude comparative de différents travaux scientifiques sinon les différents oeuvres littéraires qui ont traité à la base les mêmes matières et théories que celles abordées dans le présent mémoire. Progressivement, nous exhiberons les divergences qui y existent. I. PRESENTATION DES TRAVAUX ANTERIEURS
Tableau 3: Présentation synoptique des travaux antérieurs II. CRITIQUES ET ETUDE COMPARATIVE DES TRAVAUXANTERIEURSA. Etude comparative du 1er ouvrage scientifiquePrincipalement, l'auteur de cet ouvrage a traité sur l'implémentation en redondance des 2 serveurs (de la plateforme Linux) de résolution des noms c'est-à-dire un serveur primaire et un autre secondaire ; de telle manière à ce que s'il y a une requête de la traduction de nom en adresse IP et que le premier serveur DNS est en panne, que cette requête soit - 30 - répondue positivement par le deuxième serveur DNS. Cette opération se passera de manière inaperçue aux yeux du poste utilisateur. La seule matière ambiante qui nous met ensemble est la redondance générale en réseau informatique. Mais toute fois, sa redondance est plus orientée aux serveurs de traduction de nom de domaine en adresse IP et inversement. Mais la redondance couplée à la répartition des charges que nous traitons dans la présente étude sont plus orientées accès WAN ; en plus elles reposent sur un bon design réseau qui est celui basé sur le réseau hiérarchique. B. Etude comparative du 2ème ouvrage scientifiqueNKONGOLO TSHENDESHA Thierry15 dans son travail s'est engagé à concevoir et implémenter des réseaux locaux et à les interconnecter en redondance par le biais d'un WAN. Il a principalement utilisé la technologie basée sur le protocole HSRP pour interconnecter les deux LANs. En dépit de la redondance matérielle qui paraît une matière partagée entre l'étude de cet auteur et la nôtre, il s'avère opportun de spécifier que la présente prend l'axe qui converge vers la redondance couplée à la répartition des charges sur les routeurs de l'accès WAN. A cela s'est ajoutée une agrégation des liens afin de maximiser la bande passante ; et enfin une possibilité de définition de réseau sans boucle avec la technologie basée sur le protocole STP et cela en adoptant un modèle de conception hiérarchique de réseau informatique. C. Etude comparative du 3ème ouvrage scientifiqueCet ouvrage a traité des aspects réseaux LAN et WAN ainsi que leurs interconnexions jusqu'à déboucher à une proposition d'un modèle type d'architecture, de conception et de réalisation16. Techniquement, il a principalement usé et implémenté les protocoles : VTP pour la construction et la gestion de VLAN ; STP pour la définition de réseau sans boucle. Pour le design du futur réseau, il a opté pour l'architecture modulaire de réseau informatique. 15NKONGOLO TSHENDESHA Thierry, « Etude de conception et mise en oeuvre des réseaux LAN interconnectés par deux WAN » Cas de l'AEMI, Mémoire de Licence, UMK / Mulungwishi, Juillet 2014. 16Khaled TRABELSI & Haythem AMARA, Rapport de stage de perfectionnement, Université Virtuelle de Tunis, 2010 - 2011. - 31 - Au de la présentation synthétique de l'essentiel du 3ème travail, il faut dire que les similitudes sont proches. Nonobstant, la présente étude reposera sur un design hiérarchique et dont sa répartition de charge et sa redondance WAN seront rendu possible principalement par le protocole GLBP et l'agrégation des liens sera concrétisée par le protocole EtherChannel. En plus de cela, nous avons déployé une technologie de définition de réseau sans boucle avec STP ce qui est aussi une matière que nos confrères de l'UVT ont également abordé. D. Etude comparative du 4ème ouvrage scientifiqueL'auteur de cette oeuvre scientifique a pris sa propre orientation visant la haute disponibilité des ressources partagées sur le serveur des fichiers Samba. Il s'est donc focalisé sur l'étude du déploiement des serveurs de partage des fichiers mais qui étaient placés en redondance en vue d'offrir à ses utilisateurs une haute disponibilité de données partagées sur ces derniers. Il a concrétisé sa solution en usant des technologies de redondance de disques de stockages ; technologie dite RAID. La redondance abordée par l'auteur cité ci-haut est orientée serveur de sauvegarde de disque dur mais la nôtre s'axe sur les interconnexions LAN qui donne accès au WAN. A cela se sont ajoutées les technologies d'agrégation des liens pour l'optimisation en bande passante et de définition de réseau sans boucle afin d'atteindre une bonne performance et haute disponibilité de notre infrastructure réseau. III. PERSPECTIVE GENERALE DE LA PRESENTE OEUVRESCIENTIFIQUE Par rapport aux travaux précités, en dépit de la redondance générale qui paraît une matière commune et partagée, le présent s'inscrit dans la conception et l'implémentation d'un réseau hiérarchique qui vise la haute disponibilité de l'infrastructure tout en fournissant un accès redondant au WAN, une répartition de charge entre les équipements actifs fournissant cet accès, une optimisation de la bande passante au niveau d'équipements de la couche intermédiaire et enfin une définition du réseau sans boucle et la gestion de Broadcast Storm. Voilà l'optique et la perspective dans lesquelles s'inscrit la présente oeuvre scientifique. 17 Laurent Lesavre, Théories de la communication et nouvelles technologies de l'information et de la communication, Groupe ESC Grenoble, Paris, Mars 2001, pg. 4. - 32 - Chapitre quatrièmeETAT DE L'ART SUR LA HAUTE DISPONIBILITE D'UNEINFRASTRUCTURE RESEAUCe chapitre se livrera à la présentation théorique de divers éléments qui entrent en jeu dans la conception et l'implémentation de notre solution de haute disponibilité de l'infrastructure réseau. Il présentera également diverses théories attachées aux technologies et applications informatiques que nous userons pour concevoir et mettre en oeuvre la solution. Cela dit, nous avons porté notre choix sur le protocole GLBP pour la haute disponibilité du Gateway, la répartition de charge, la continuité de service ainsi que la tolérance aux pannes à l'accès WAN; l'EtherChannel pour l'agrégation des liens et le protocole STP pour la gestion des Broadcast Storm au niveau de la couche de distribution. Voilà pourquoi nous nous permettons de présenter séquentiellement différentes théories basiques ayant trait à notre thématique. Puis itérativement, nous présenterons pour chacune d'entre elles les technologies permettant de les concrétiser. I. THEORIE DE L'INFORMATION ET DE NTICL'élément central et basique de toute innovation technologique est l'information : son traitement et sa transmission. Elle se traduit par un élément abstrait qui réduit l'ignorance. Elle est l'élément moteur qu'on qualifie de patrimoine de développement d'entreprise où les réseaux de nos jours ont à leurs charges s'assurer de son partage ou de sa transmission. Voilà pourquoi pour s'y prendre, il faut faire usage de Technologie dites NTIC ou TIC. Les Nouvelles Technologies de l'Information et de la Communication (NTIC) regroupent l'ensemble des techniques qui contribuent à numériser ou digitaliser l'information, à la traiter, à la stocker et à la mettre à la disposition d'un ou de plusieurs utilisateurs17. Ces technologies sont dites « nouvelles » car elles concernent l'information et la communication et permettent la création, la diffusion et l'échange « d'hyper informations », c'est à dire pouvant contenir des textes, des images, du son et mises en forme dans un contexte interactif. - 33 - II. CONSIDERATIONS THEORIQUES SUR LA REDONDANCEMATERIELLE A. Présentation générale et objectifs de la redondance matérielleQuelque soit le service rendu par un système, il est essentiel que les utilisateurs aient confiance dans son fonctionnement et de l'utiliser dans les meilleurs conditions. Cela devient une préoccupation majeure des Ir informaticiens de nos jours, dans la gestion de réseaux informatiques qui sont de plus en plus multiple à voir le jour et à subir les conséquences de NTIC à l'instar de la RNIS. A cela, pour arriver à fournir divers services aux utilisateurs, et cela en dépit des défaillances pouvant surgir sur ses infrastructures, la redondance des matérielles s'avère un point prioritaire. Mais qu'est-ce alors ? La redondance matérielle est la multiplication d'un équipement en vue de fournir un sous-service à l'ensemble ou à la partie de l'architecture du service.18 Elle est utile pour augmenter la capacité totale ou les performances d'un système, pour réduire le risque de panne et combiner ces deux effets. L'objectif principal de la redondance est d'abord la disponibilité puis la continuité de service et la tolérance aux pannes. La disponibilité correspond à la quantité de temps durant lequel un équipement ou un service est accessible et exploitable19. Mais la haute disponibilité (High Availability) qui est le résultat escompté dans ce travail se traduit par l'ensemble des dispositions visant à s'assurer de la disponibilité d'un service. L'objectif de la haute disponibilité tend à assurer du bon fonctionnement d'un service de façon continuelle, soit 24 heures sur 24 et 7 jours sur 7 sans aucune interruption. Ainsi le terme disponibilité désigne alors la probabilité qu'un service soit en bon état de fonctionnement à un moment donné. B. Rapport du taux de disponibilité et durée d'indisponibilité d'unsystème
18 Marco CARTA-GULLUNG, Giacomo ROMBAUT, Lucas Jourdes, Redondance matérielle, haute disponibilité et reprise sur panne, POLYTECH, Nice-Sophia, p. 8. 19 Idem. - 34 -
Tableau 4: Rapport taux de disponibilité et durée d'indisponibilité C. Types de redondancesNous distinguons les types de redondances suivants : V' La redondance symétrique repose sur le principe de dupliquer deux systèmes opposés dans l'espace à l'identique. V' La redondance asymétrique permet de basculer d'un type de matériel à un autre, il n'est pas forcément identique mais assure les mêmes fonctionnalités. V' La redondance évolutive fait qu'en cas de panne sur
un système, on isole la V' La redondance modulaire est une technique qui permet de dévier une panne d'un système sur un autre.20 V. CONSIDERATIONS THEORIQUES SUR LE LOAD BALANCINGA. Présentation de la répartition de charge (Load Balancing)Le Load Balancing est une opération qui consiste pour le (s) routeur(s) à répartir le trafic réseau vers une même destination mais en passant par plusieurs chemins21. Dans sa réalisation, nous distinguons deux types de répartition des charges à savoir la répartition de charge à « coût égal » et celle à « coût inégale ». Dans la première, le trafic réseau est réparti sur plusieurs routes de métriques identiques ; mais dans la seconde, le trafic réseau est réparti sur plusieurs routes de métriques différentes. La part de trafic transportée par chacune des routes est inversement proportionnelle à sa métrique (plus la métrique est faible, synonyme de bande passante élevée, plus la part de trafic absorbé est importante). 20 Marco CARTA-GULLUNG, Giacomo ROMBAUT, Lucas Jourdes, Redondance matérielle, haute disponibilité et reprise sur panne, POLYTECH, Nice-Sophia, p. 12. 21 André VAUCAMPS, CISCO : Protocoles et concepts de routage - configurations avancées de routeurs, Edition Eni, France, pg 31. - 35 - B. Mode de répartition de charges
L'algorithme est confondant de simplicité : le premier paquet destiné à ce réseau objet de plusieurs routes emprunte la première route. Le paquet suivant emprunte la route suivante et ainsi de suite pour obtenir un partage de charge à coût égal. Mais le routeur peut aussi changer cette répartition lorsqu'il faut réaliser un partage de charge à coût inégal. Par exemple, un paquet sur la première route, deux paquets sur la seconde, à nouveau un sur la première et ainsi de suite pour réaliser une répartition 1/3 2/3 ou toute autre répartition pour s'ajuster au prorata des métriques de chaque route. CISCO nomme « Process Switching » ce mode de commutation23 . Dans ce mode « Process Switching », pour chacun des paquets, le routeur doit consulter la table de routage, sélectionner une interface de sortie puis retrouver l'adresse physique du correspondant. Ceci entraîne qu'un flux de paquets destiné à une même adresse emprunte plusieurs interfaces de sortie. 22 André VAUCAMPS, CISCO : Protocoles et concepts de routage - configurations avancées de routeurs, Edition Eni, France, pg 31. 23 André VAUCAMPS, CISCO : Protocoles et concepts de routage - configurations avancées de routeurs, Edition Eni, France, pg 31. - 36 - VI. CONSIDERATIONS THEORIQUES DU NETWORK DESIGNA. Présentation du Network DesignLe Network Design décrit le processus de création des solutions pouvant déboucher principalement au partage d'informations24, à la communication, à la prise en charge des applications et services et offre ainsi l'accès aux ressources nécessaires au fonctionnement de l'entreprise. Un réseau viable et de qualité ne se crée pas par accident ; il est le fruit du travail des concepteurs et techniciens réseaux qui identifient les besoins de l'entreprise et choisissent les solutions les mieux adaptées pour y répondre25. Une bonne conception de réseau doit reposer sur une architecture offrant à la fois la disponibilité, la fiabilité, la sécurité et l'extensibilité. C'est ainsi que nous avons choisi pour le cas de la présente étude la conception de réseau selon le modèle hiérarchique car elle permet de regrouper les périphériques à un certain nombre de réseau distinct qui alors est organisé en couches. C. Data Center, Medium et Small Network Design1. Data Center Network Design (Large Campus)Dans l'entreprise, la conception de réseau étendu consiste à centraliser le concentrateur et commutateur de chacun d'emplacements réseau, lequel concentrateur devront interconnecter le petit réseau (Small) et celui du niveau medium (du milieu) afin d'offrir chacun de leurs postes finaux un accès aux ressources partagées du réseau étendu26. Nous pouvons compter jusqu'à plus de 1000 équipements pour les utilisateurs finaux dans ce type de conception. Typiquement, cette conception consiste en la prise en compte de différents emplacements à des tailles variées ainsi que leurs diverses organisations, départements et groupes. L'envergure de ce type de réseau étendu est plus supérieur que celle de type medium 24 Me Dieudonné YAV, Cours inédit Méthodologie de Conception des Réseaux Informatiques, Grade 1, Ingénierie Systèmes Réseaux, Faculté de Sciences de l'Informatique, UMK, 20014-2015. 25 Ass. Ir Erick MPIANA, Cours inédit Réseaux informatiques III, Faculté des Sciences de l'Informatique, UMK, 2012-2013. 26 Rahul Kachalia, Bordeless Campus 1.0 Design Guide, Cisco Systems, 23 Juin 2011, pg. 22. - 37 - et petit et incluant les utilisateurs finaux, les serveurs, équipements de sécurité et divers autres équipements réseaux. 2. Medium Network DesignPar la localisation, la taille et la perspective de la gestion du réseau, la conception de réseau du milieu « medium » n'est pas différente de celle du réseau étendu « large campus »27. Géographiquement, il peut être distant en provenance d'un réseau du type campus étendu et requiert une haute rapidité ou promptitude des circuits WAN pour que les deux campus soient interconnectés. Cette couche offre la possibilité d'obtenir de 200 jusqu'à 1000 équipements pour les utilisateurs finaux. 3. Small Network DesignLa conception de petit réseau ou de Small Campus est typiquement confinée en un seul immeuble qui enjambe ou qui s'étend sur plusieurs étages débouchant sur différentes organisations. Le facteur d'envergure dans cette conception est réduit et comparé à une conception des réseaux de campus étendu et medium. La particularité de cette conception est telle que, dans leur déploiement, le niveau de distribution et coeur peuvent alternativement être comprimé ou mis ensemble sans pour autant compromettre les principes de base de la conception réseau. Et cela peut amener jusqu'à obtenir les équipements inférieur à 200 pour les utilisateurs finaux28. C. Le modèle de conception hiérarchique de réseauLe modèle de réseau hiérarchique préconise l'approche en couches pour leur conception. Chaque couche fournit des fonctions spécifiques. 1. Atouts de la conception hiérarchique de réseauV' Évolutivité : les
réseaux hiérarchiques échellent très bien. La
modularité vous 27 Rahul Kachalia, Bordeless Campus 1.0 Design Guide, Cisco Systems, 23 Juin 2011, pg. 23. 28 Idem, pg. 23 C'est la couche qui a à sa charge la connexion vers des ressources internet. Les dispositifs de cette couche doivent être capables de transmettre rapidement de grandes - 38 - V' Redondance : Tant que le réseau se développe, la disponibilité et la fiabilité deviennent plus importante. Cette caractéristique permettra de résoudre le problème de tolérance aux pannes. V' Performance : C'est un réseau bien conçu pour acquérir une haute vitesse de transmission entre ses périphériques. V' Sécurité : elle garantit
l'intégrité, la confidentialité, la disponibilité
des V' Facilité de gestion : Le changement peut être
répété sur tous les périphériques V' Maintenabilité : En raison de leur modularité
et l'évolutivité, les réseaux 2. Couches du modèle de réseau hiérarchique V' Couche Accès : C'est la couche qui fournit un moyen de dispositifs de connexion au réseau et que l'on contrôle la communication sur le réseau. C'est la couche interface avec le terminal (l'utilisateur). Elle comprend généralement le hub, le commutateur, le pont simple. V' Couche Distribution : Elle se charge d'agréger les données reçues de la couche accès avant de les transmettre à la couche coeur pour le routage. Nous y trouvons des équipements sophistiqués ou raffinés à l'extrême à l'exemple de Switch manageable par rapport à ceux de la couche accès. La présence de tels équipements permettra d'atteindre la haute disponibilité et de redondance pour assurer la fiabilité. V' Couche Coeur : - 39 - quantités de données. Pour les petites entreprises, il est possible de combiner cette à celle de distribution. V. CONSIDERATIONS TECHNOLOGIQUES SUR LA HAUTE DISPONIBILITE D'UNE INFRASTRUCTURE RESEAUA. La haute disponibilité du Gateway et le Load Balancing avec GLBP1. Présentation et fonctionnement du protocole GLBPGLBP est un protocole de redondance implémenté pour obtenir dans un réseau la haute disponibilité de la passerelle par défaut, la continuité de service et la tolérance aux pannes. En plus de sa réputation en matière de redondance, ce protocole permet également la répartition de charges entre différents routeurs participant au groupe GLBP. 2. Composants du protocole GLBPPour opérer sur les routeurs dans un réseau, ce protocole utilise plusieurs de ses composants dont voici leur détail : i. Groupe et VRID Groupe désigne le groupe auquel appartiennent les routeurs qui seront concernés par la configuration du GLBP. Ce groupe est donc identifiable par une clé numérique qui permet d'identifier de manière unique un groupe GLBP. ii. Priorités La priorité (priority) est une valeur numérique qu'on attribue aux routeurs appartement au même groupe et d'être élu ou pas master dans un groupe GLBP. iii. Adresse IP virtuelle L'adresse IP Virtuelle sera l'adresse IP du routeur virtuel par laquelle passeront les paquets LAN vers le WAN ou vis versa. Concrètement, c'est elle-même le Gateway ou passerelle par défaut qui sera configuré sur les périphériques du LAN. Dans un groupe, à cette adresse IP virtuelle sera associée l'adresse MAC virtuelle. - 40 - iv. Préemption C'est une option de permet à un routeur de passer à l'état actif si sa priorité est supérieure à celle du routeur root actuel, même si ce dernier n'est pas tombé down. Sans cette option, il y aura réélection si et seulement si le routeur actif tombe. Ce paramètre permet encore au routeur Master de reprendre son rôle après qu'il ait repris. v. Tracking d'interfaces C'est un paramètre qui permet de surveiller l'activité d'autres interfaces des routeurs du groupe GLBP. Cette surveillance est plus observée à la partie WAN, où si une liaison vers le WAN tombait en panne, que le routeur informe à l'interface LAN ce problème pour que GLBP remède à cela. C. L'AGREGATION DES LIENS AVEC ETHERCHANNEL1. Présentation et fonctionnement du protocole EtherChannelEtherChannel est une technologie d'agrégation permettant de produire une unique liaison réseau, plus performante, en combinant la bande passante de plusieurs cartes Ethernet29. Cet agrégat apparait aux couches supérieures du réseau comme une unique interface Ethernet. Au départ, elle a été conçus et mise au point par la KALPANA au début des années 1990. Puis cette société a ensuite été acquise par Cisco Systems en 1994. Mais c'est en 2000 que l'IEEE a publié le standard 802.3ad, la version ouverte de la technologie de l'EtherChannel.30 Son utilisation est appliquée à tous les médias définis dans le cadre du standard IEEE 802.3.31 Cette technologie nous offre la possibilité de regrouper dans un seul canal logique jusqu'à huit liens physique à partir de leurs ports ; cela produit comme conséquence positive l'obtention d'une bande passante qui sera la somme de débit de chacun des liens. Ainsi, cette technologie est prise en charge par l'ensemble de la gamme de commutateur Cisco Catalyst et 29 Thomas ANCEL, EtherChannel en AIX, Infos Produits, Décembre 2002, pg. 1 30 www.wikipedia.com en date du 21 Février 2015 à 09h 47' 31 www.wikipedia.com en date du 21 Février 2015 à 09h 55' - 41 - tous les autres routeurs sous-systèmes IOS. Son implémentation sur un ordinateur requiert une carte réseau spéciale appelée « photo » ainsi qu'un OS la supportant à l'exemple de FreeBSD. 2. Les composants de l'EtherChannel
Tel que le mot l'indique, il détermine le mode opératoire sur quoi se base cette technologie pour opérer. A l'instar de LACP, cette technologie est utilisée pour forcer l'agrégation des liens, cela est rendu possible grâce au mode « on » qui doit être activé après la réunion des liens physiques. C. La définition de réseau sans boucles et la gestion des Broadcast Stormavec STP1. Presentation du protocole STP«Spanning Tree Protocol is a layer 2 Link management protocol that provides path redundancy while preventing loops in the network.»32 La traduction française n'étant pas sortie, nous nous proposons comme interprétation ce qui suit pour essayer d'appréhender cette terminologie par cette définition. Spanning Tree Protocol est un protocole de gestion de la couche (2) liaison des données, qui fournit un chemin redondant tout en prévenant le boucles dans un réseau. Le protocole Spanning Tree permet de créer un chemin sans boucle dans un environnement commuté et physiquement redondant. STP détecte et désactive ces boucles et 32 Cisco Systems, Configuring STP and RSTP, pg.2 - 42 - fournit un mécanisme de liens de sauvegarde. Le standard a été amélioré en incluant IEEE 802.1w Rapid Spanning Tree (RSTP)33. Nous souhaitons utiliser la version Rapid Spanning Tree grâce à son temps de convergence qui est réduit à 6 secondes max alors que STP opère pendant 50 secondes. C'est avec la commande « spanning-tree mode Rapid-Pvstp 2. FonctionnementSon fonctionnement est tel que dans un réseau local commuté en redondance, toutes les trames doivent toujours passer par un Switch « Root » pour être acheminées à sa destination. Pour cela, une fois tous les Switch up, chacun annoncera par des messages BPDU (Bridge Protocol Data Unit) ses informations ou ses identités à ses voisins. L'identité dont il est question est la combinaison de la priorité (32768 priorité par défaut) plus l'adresse MAC. 3. Etapes d'opérations STPi. Détermination du Root Est considéré comme « Root » le Switch qui a une identité inférieure à celle de ses voisins. ii. Détermination du RootPort Sur les Switch autre que le Root, est RootPort, celui qui a le coût cumulatif (Path Cost) inférieur par rapport à la racine. Cette détermination se fait sur base de chaque Switch. Dans son fonctionnement, STP (RSTP) fait usage de la correspondance entre vitesse de médias et coût, voici ses valeurs :34
Tableau 5: Correspondance Vitesse de média & coût 33 www.ciscogoffinet.org consulté en date du 15 Décembre 2014 à 14h 42 minutes. 34 Vidéo sur www.netprof.fr/spanningtree Il n'y a que 3 états pour le protocole RSTP à savoir Discarding (au lieu de Disabled, Blocking et Listening), Learning et Forwarding (ayant la même fonction). - 43 - iii. Détermination de DesignatedPort La détermination du DesignatedPort se fait sur base de chaque segment (liaison entre deux Switch). Est DesignatedPort le port qui a le moindre coût vers la racine. Il y ressort deux remarques importantes : premièrement, tous les ports du Root sont des DesignatedPort et deuxièmement, tous les DesignatedPort sont en mode Forwarding. Ce mode permet au port d'accepter et de retransmettre les trames entrantes ; d'accepter et retransmettre les BPDUs; d'incorporer les nouvelles adresses MAC dans sa table. iv. Blocage de tous les autres ports du cascade Seront bloqués tous les autres ports de la cascade. Ils ne sont ni en forwarding, ni DesignatedPort. Ainsi bloqué, cela permet retenir la diffusion ou circulation inutile des trames pour lesquelles le destinataire est déconnecté. Ces ports jettent les trames entrantes, et acceptent les BPDUs mais ne les retransmettent pas ; et enfin, ils ne complètent pas la table d'adresses MAC. 20 secondes pour cette opération. 4. Etats d'opération Spanning TreeSTP opère pendant environ 50 secondes reparties selon les états ; l'état d'initialisation permet l'activation des ports, 20 sec à l'état Blocking, 15 sec à l'état Listening où le port jette les trames entrantes ; accepte et les BPDUs et les retransmets et il complète sa table d'adresse MAC ; 15 Sec pour l'état Learning où le port accepte les trames entrantes mais ne les retransmet pas, il accepte les BPDUs et les retransmets et enfin incorpore les nouvelles adresses MAC dans sa table. Pour de raison temporelle, il souhaitable d'utiliser la version Rapid Spanning Tree Protocol car celui-ci opère dans un temps record que STP. 5. Spanning Tree VS Rapid Spanning TreeRSTP fonctionne de la même manière que Spanning Tree, toute fois, il y a quelques différences : i. Différences d'états de ports - 44 - A l'instar de STP, RSTP présente le même fonctionnement. A la différence que RSTP opère en passant par 3 états à savoir : V' Les Ports RSTP passe par 3 états seulement à savoir : Discarding (au lieu de Disabled, Blocking et Listening sur STP), Learning et Forwarding (ayant la même fonction) V' Les rôles du port Root et port Designated subsitent
ou tiennent toujours. Les Les ports connectant des périphériques terminaux s'appellent des ports Edge qui remplissent la même fonction que la fonction Portfast en PVST+. Cela dit, ce chapitre constitue une ébauche sur l'étude comparative des différentes solutions ayant trait à notre solution informatique. Matière prévue dans le chapitre qui vient juste après. - 45 - Chapitre cinquièmeETUDE COMPARATIVE DES SOLUTIONSTECHNOLOGIQUESCe chapitre est consacré à l'étude comparative et à la présentation des différentes solutions technologiques pouvant conduire à résoudre tant soit peu le problème ayant fait le mobile du présent travail. Cela dit, nous allons commencer par présenter progressivement les solutions technologiques qui offrent une redondance à l'accès WAN, un équilibrage des charges, l'agrégation des liaisons physiques, une gestion des boucles réseaux ou une définition de réseau sans boucle. Cela dans l'objectif d'atteindre l'objectif poursuivi dans la présente étude ; en l'occurrence de la haute disponibilité de l'infrastructure réseau. I. TECHNOLOGIES DE REDONDANCES DES ROUTEURS ETD'EQUILIBRAGE DE CHARGES A. HSRP (Hot Standby Router Protocol)
Dans son fonctionnement, il est définit un groupe de routeurs dans chaque réseau local ou sous réseau où HSRP est actif, il s'agit donc d'un identifiant numérique. Le numéro 35 Cisco, Chapter 9: Configuring HSRP, page 2. - 46 - du groupe varie de 0 à 255, il peut donc exister jusqu'à 256 groupes HSRP dans un même sous-réseau. Chaque groupe est associé à une adresse IP virtuelle distincte. Cependant, dans un groupe, un routeur actif sera élu : c'est lui qui aura la priorité la plus élevée. Les autres routeurs sont en standby et écoutent les messages émis par le routeur actif. Périodiquement, les routeurs du groupe échangent des messages « Hello » pour s'assurer que les routeurs du groupe sont encore joignables. Par défaut, les messages « Hello » sont envoyés toutes les 3 secondes, et un délai de 10 secondes sans message Hello de la part du routeur actif entraîne la promotion du routeur Standby en actif. 3. Avantages et inconvénients du protocole HSRP Le protocole HSRP permet de réaliser la redondance des équipements, offre une tolérance aux pannes, la continuité de service, offre une disponibilité de la passerelle par défaut du réseau local. En dépit de ses atouts, le protocole Hot Standby Router Protocole présente quelques failles: V' Il présente une ouverture intempestive du port relatif à l'HSRP (port 1985). A ce sujet, il a été constaté dans certaines circonstances que sur certaines versions de Cisco IOS (11.2.x, 12.1.x), le port 1985 relatif au protocole HSRP était ouvert même si HSRP n'était pas configuré36. Ce phénomène peut être propice à l'inondation de ce port jusqu'à la saturation des ressources de l'équipement. V' Exposition en claire de mot de passe :
HSRP utilise pour authentifier les B. VRRP (Virtual Ruter Redundancing Protocol) 1. Présentation et fonctionnement du protocole VRRPVirtual Router Redundancing Protocol est aussi le protocole qui permet de concrétiser la théorie de redondance des routeurs en implémentant virtuellement un routeur 36 Couderc, Geniez, Delmon, Lacroix, Mission HSRP, Janvier 2014 - 47 - avec ses adresses IP et MAC. Cela dans le but d'assurer la continuité des services, la tolérance aux pannes, la haute disponibilité de la passerelle par défaut du réseau local. Son fonctionnement est vraiment rapproché et est similaire à celui du protocole HSRP. Il permet d'obtenir dans un réseau la haute disponibilité de la passerelle par défaut grâce une réplication en redondance des divers routeurs C. GLBP (Gateway Load Balancing Protocol)
Le protocole GLBP a dans son fonctionnement les mêmes concepts de bases que HSRP et VRRP. Plus concrètement, à l'intérieur du groupe GLBP, le routeur ayant la plus haute priorité ou la plus haute adresse IP du groupe prendra le statut de « AVG » (Active Virtual Gateway). Ce routeur va intercepter toutes les requêtes ARP effectuées par les clients pour avoir l'adresse MAC de la passerelle par défaut, et grâce à l'algorithme d'équilibrage de charge préalablement configuré, il va renvoyer l'adresse MAC virtuelle d'un des routeurs du groupe GLBP. C'est d'ailleurs le Routeur AVG qui va assigner les adresses MAC virtuelles aux routeurs du groupe, Ainsi ils ont le statut « AVF » (Active Virtual Forwarder). Un maximum de 4 adresses MAC virtuelle est défini par groupe, les autres routeurs ayant des rôles de backup en cas de défaillance des AVF. Toutefois, en dépit du fait que ce protocole reprend les concepts de base de HSRP et VRRP, il convient de noter que contrairement à ces deux protocoles, dans le fonctionnement 37 Redondance des routeurs avec GLBP, Extrait du Idum : http://idum.fr/spip.php?article230 - 48 - du GBLP, tous les routeurs du groupe GLBP participent activement au routage ce qui n'est pas le cas de VRRP ou HSRP, il n'y en a qu'un qui est en mode actif, tandis que les autres sont en attentes (standby). Au-delà des possibilités de redondances, tolérance aux pannes ainsi que la continuité des services que nous offre le protocole GBLP, sa particularité est qu'il est capable d'effectuer l'équilibrage des charges entre routeurs qu'on désigne par « Load Balancing ». voilà pourquoi nous opérons notre choix sur lui. II. TECHNOLOGIES D'AGREGATION DES LIAISONS PHYSIQUESAvant d'éplucher les différentes techniques permettant de concrétiser la théorie de d'agrégations des liens, nous nous permettons de tirer au nette et au claire qu'il en existe deux. Il s'agit d'une part de la technique qui permet de forcer l'agrégation en usant de l'Etherchannel et de l'autre part celle qui permet d'en négocier en faisant recours à l'un des protocoles : PAgP ou LACP. A. PAgP (Port Agregation Protocol)
PAgP présente principalement deux modes de fonctionnement à savoir « auto » et « desirable ». Le premier mode donne la possibilité au port d'un côté d'attendre une requête au port voisin (négociation passive). Et le deuxième mode permet au port d'un côté d'entrer en négociation avec le port voisin (négociation active). - 49 - 3. Avantages et Inconvénients Hormis mis ses capacités lui reconnues en matière de la combinaison de plusieurs liens physiques en un seul logique, ce protocole est reproché d'être propriétaire c'est-à-dire qu'il ne peut être implémenté que sur les équipements Cisco. B. LACP (Link Agregation Control Protocol)
Pour permettre à ce qu'il y est redondance entre les liens physiques agrégés, tous les ports publient leurs capacités d'agrégation et leur état sur une base régulière sur tous les liens agrégables. Les partenaires sur un lien agrégé comparent leurs propres informations/état et décident quelles actions prendre en fonction de ces derniers. LACP émet une information de l'état du lien sur chaque lien agrégé. Même au sein d'une agrégation, des messages indépendants sont envoyés par LACP sur chaque lien pour fournir des informations spécifiques liées au système de partenaires.39 38 F. Nolot, EtherChannel, Université de Reims Champagne Ardenne Cisco Académie, Faculté des Sciences 2008, pg. 5. 39 Dunkerque, Etherchannel, TRSIT, 2010, pg. 5 40 F. Nolot, EtherChannel, Université de Reims Champagne Ardenne Cisco Académie, Faculté des Sciences 2008, pg. 3. - 50 -
Au-delà de ses qualités en matière de la combinaison des liens physiques en un seul logique, ce protocole présente les défauts suivants : V' Il n'y a pas de synchronisation des messages LACP; les partenaires sur un lien agrégeable envoient des messages LACP de manière autonome ; V' Les messages LACP ne sont jamais transmis par un dispositif d'interconnexion de réseaux (Switch ou routeur) ; V' LACP peut être modifié par commandes manuelles si désiré. C. EtherChannel1. Présentation de l'EtherChannel EtherChannel est une technique qui est utilisée pour allouer plusieurs liens physiques en un seul canal virtuel ; cela dans l'objectif d'acquérir une bande passante maximum ainsi que la prévention des pannes. C'est aussi une technique d'interconnexion LAN entre Switch pour offrir sur un seul lien logique, plusieurs ports Fats ou Gigabit Ethernet.40 Nous userons de cette technique pour concrétiser notre implémentation surtout en matière d'agrégation des liens physiques. Voilà pourquoi nous nous réservons des détails et nous nous référerons au chapitre qui parlera de l'Etat d'art ; chapitre destiné à présenter la (les) solution(s) à déployer. - 51 - III. TECHNOLOGIE DE DEFINITION DE RESEAU SANS BOUCLEC. STP (Spanning Tree Protocol)1. Présentation et fonctionnement du protocole STPLe protocole STP (Spanning Tree Protocol) est un protocole de couche 2 qui fonctionne sur des ponts et des commutateurs. La spécification du protocole STP est IEEE 802.1D. L'objectif principal du protocole STP est de vérifier que vous ne créez pas de boucles lorsque vous avez des chemins redondants dans votre réseau. Les boucles sont fatales pour un réseau. Avec le protocole STP, il est essentiel que tous les commutateurs du réseau choisissent un pont racine qui deviendra le point central du réseau. Toutes les autres décisions du réseau, telles que le port à bloquer ou celui à passer en mode transfert, sont prises par rapport à ce pont racine. Un environnement commuté diffère d'un environnement de pontage, gère plutôt plusieurs VLAN. Lorsque vous mettez en oeuvre un pont racine dans un réseau de commutation, il fait généralement office de commutateur racine. Chaque VLAN doit avoir son propre pont racine car chacun d'entre eux est un domaine de diffusion distinct. Les racines des différents VLAN peuvent toutes résider dans un seul ou plusieurs commutateur(s).41 B. RSTP (Rapid Spanning Tree Protocol)Rapid Spanning Tree Protocol est une version avancée du protocole STP. Il reprend les mêmes fonctions que STP mais sa particularité est qu'il opère dans une durée d'environ 6 secondes. Il est basé sous la norme IEEE 802.1w. Cette version améliorée du protocole STP présente principalement un grand par rapport à ce dernier. Il opère ainsi sur une durée estimée à environ 6 secondes alors que STP en présente 50 secondes. Ayant fait état des aspects théoriques ayant trait à notre sujet d'étude, nous nous proposons maintenant de présenter la partie expérimentale de notre solution retenue. 41 www.moncisco.com en date du 19 Novembre 2014 à 11h 51 minutes. - 52 - Deuxième partie
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
N° |
Equipements |
Quantités |
PU |
PT |
|
1 |
Routeur Cisco Série 3700 |
3 |
1800 USD |
5400 USD |
|
2 |
Switch Cisco (Niveau 3) Série 3700 |
3 |
1400 USD |
4200 USD |
|
3 |
Switch Cisco (Niveau 2) Série 2900 |
4 |
700 USD |
700 USD |
|
4 |
Câbles UTP Catégorie 6 |
1000m |
1 USD / m |
1000 USD |
|
5 |
Connecteurs RJ45 |
100 |
0.5 USD |
50 USD |
|
Total Général |
11350 USD |
|||
Tableau 6: Estimation budgétaire des équipements
Hors mis ces précisions budgétaires d'équipements, nous estimons que l'Ir Informaticien des Systèmes & Réseaux sera payé à 6$ / heure. Il y aura un total de 48 $ / jour (8 heures de travail *6) et donc 1248 $ / mois en l'occurrence de 26 heures de travail le jour.
Ce présent mémoire, étant réalisé dans le cadre de la fin de nos études universitaires tiendra a tenue sur une échéance couvrant l'année académique 2014 -2015. C'est pour cela que nous nous proposons de manière synthétique les différentes tâches que nous avons réalisées au cours de cette échéance.
B. Diagramme synoptique du planning de réalisation 1. Définition des tâches à réaliser

13/01/2015
07/02/2015
05/03/2015
08/02/2015
Etat de l'art sur la haute disponibilité de réseau
Etude comparative de différentes solutions
26/03/2015
06/03/2015
Présentation de la gestion du projet informatique
06/04/2015
Modélisation de la solution
27/03/2015
Conception de la solution
07/05/2015
07/04/2015
- 56 -
TACHES A REALISEES DEBUT DE LA TACHE FIN DE TACHE DUREE REEL / JOUR
Rédaction de l'introduction 15/11/2014 25/11/2014
Présentation du cadre de référence 26/11/2014 21/12/2014
Revue bibliographique 22/12/2014 01/01/2015
Méthode et solution 02/01/2015 12/01/2015
Implémentation, test, optimisation
08/05/2015
25/06/2015
Travaux de compilation et impressions du mémoire 26/06/2015 02/07/2015
Dépôt du mémoire 03/07/2015 04/07/2015
Tableau 7: Tableau synoptique des tâches à réaliser
2. Vue graphique du planning du projet
Tableau 8 : Diagramme synoptique du planning de réalisation
10
25
10
10
25
25
20
10
30
48
6
1
- 57 -
Ce chapitre sera consacré à la modélisation du système ; laquelle modélisation sera précédée par une présentation brève de la théorie des systèmes ; puis itérativement, il fera également état de la conception proprement dite de la solution informatique retenue tout en fournissant le prototype de départ ainsi que les deux topologies.
Il nous est difficile sinon impossible de passer inaperçue sur une théorie aussi basique qu'importante usée dans divers domaines d'études à l'instar de l'Ingénierie Informatique, précisément en Ingénierie Systèmes & Réseaux. Elle permet au chercheur de conceptualiser l'objet étudié comme étant un système ; et de cette manière, ce dernier sera appelé à être décomposé en ses éléments divers en vue d'en avoir une compréhension claire sinon limpide. Voilà pourquoi, nous procédons de manière esquisse à sa description.
La systémique est une théorie issue initialement des recherches menées par Franck LUDWIG dans le domaine de la biologie ; particulièrement dans l'étude cellulaire. Puis par la suite, elle a été abordée par le mathématicien et informaticien Norbert WEINER43.
L'importance de la théorie systémique repose sur sa spécificité à pouvoir conceptualisé comme système tout objet faisant cause ou motif d'une recherche ou d'une étude ; et cela dans plusieurs domaines. Il peut s'agir des recherches dans les sciences de la nature : l'écologie ; des recherches en ingénierie : l'informatique, la robotique, les réseaux de communications, l'intelligence artificielle ; des recherches sur le comportement humain : les sciences de la psychologie, les thérapies de groupe, la cognitive, la pédagogie ; etc.44
Elle se base sur un principe selon lequel tout est système, ou tout peut être conceptualisé selon une logique de système45. En termes d'analyse, il s'agit d'un réseau, plus
43 Me Dieudonné YAV, Cours inédit Méthodologie de Conception des Réseaux Informatiques, Grade 1, Ingénierie Systèmes Réseaux, Faculté de Sciences de l'Informatique, UMK, 20014-2015.
44 Dr. Guy TURCHANY, Théorie des systèmes et systémiques: Vue d'ensemble et définitions, Agir ensemble pour éduquer au développement durable, Ed Petöfi S.u.7, France, pg. 27.
45 Dr. Guy TURCHANY, Théorie des systèmes et systémiques: Vue d'ensemble et définitions, Agir ensemble pour éduquer au développement durable, Ed Petöfi S.u.7, France, pg. 11.
- 58 -
ou moins important et autonome, dont les éléments présentent la particularité de répondre en tout ou en partie à un même objectif46. Le système étant appelé à être décomposé, les échanges entre ses éléments peuvent se faire alors sur base de l'énergie, de la matière ou de l'information. Cela nous ramène à éplucher les éléments d'un système.
Un système est un ensemble d'éléments organisés, qui sont en interrelation et interagissant pour atteindre un objectif commun. Elle est vu dans l'analyse comme une boite noire. Nous y dégageons les caractéristiques suivantes : l'interrelation, l'organisation, la totalité et la complexité.
y' L'interaction ou l'interrelation d'un système renvoie à la compréhension de la coévolution et la symbiose en biologie. La forme particulière de l'interrelation est la rétroaction (ou feed-back) dont l'étude est au centre de la cybernétique47.
y' La totalité ou la globalité d'un système stipule qu'un système est d'abord un ensemble d'éléments, il ne s'y réduit pas48. Cela se traduit par le fait qu'il faut considérer un système par son ensemble.
y' L'organisation est l'agencement d'une totalité en fonction de la répartition de ses éléments en niveaux hiérarchiques. C'est également un processus par lequel de la matière, de l'énergie ou de l'information s'assemblent et se forment une totalité ou une structure.
La complexité d'un système se traduit par le degré élevé d'organisation ; l'incertitude de son environnement ; et la difficulté, sinon l'impossibilité d'identifier tous les éléments et toutes les relations en jeu49.
Pour comprendre le système sous étude, nous allons le représenter artificiellement. Pour cela, nous userons du langage de modélisation unifié UML en faisant appel à quelque de ses diagrammes afin d'en avoir une meilleure appréhension.
46 Idem, pg. 12.
47 Idem, pg. 4.
48 Idem
49 Idem, pg. 5.
- 59 -
Les cas d'utilisation décrivent sous la forme d'actions et de réactions, le comportement du système étudié du point de vue des utilisateurs. Ils définissent les limites du système et ses relations avec son environnement.50 Tandis que le diagramme de CU montre les cas d'utilisation représentés sous la forme d'ovales et les acteurs sous la forme de personnages. Il indique également les relations de communication qui les relient.51

Figure 3: Diagramme de cas d'utilisation
Le diagramme de séquence décrit la dynamique du système. À moins de modéliser un très petit système, il est difficile de représenter toute la dynamique d'un système sur un seul diagramme. Il décrit également les interactions entre un groupe d'objets en montrant, de façon séquentielle, les envois de message qui interviennent entre les objets. Il peut également montrer les flux de données échangées lors des envois de message.52
Un scénario est une instance d'un cas d'utilisation dans laquelle toutes les conditions relatives aux différents événements ont été fixées. Il n'y donc pas d'alternatives du déroulement. Un enchaînement est l'unité de description des séquences d'actions. Un scénario représente une succession particulière d'enchaînement s'exécutant du début à la fin de CU.
50 Laurent DEBRAUWER et Fien VAN DER HEYDE, UML 2 Initiation, exemples et exercices corrigés, Seconde Edition, Ed. Eni, France, Pg. 2.
51 Idem, Pg. 33.
52Laurent DEBRAUWER et Fien VAN DER HEYDE, UML 2 Initiation, exemples et exercices corrigés, Seconde Edition, Ed. Eni, France, Pg. 46.
- 60 -
3. Diagramme de séquence du cas d'utilisation « accéder aux services du WAN »

Figure 4: Diagramme de séquence
- 61 -
4. Diagramme de séquence du CU « maintenir le système en état fonctionnement »

Figure 5: Diagramme de séquence
Le diagramme de déploiement décrit l'architecture physique du système. Celui-ci est composé de noeuds. Un noeud est une unité matérielle capable de recevoir et d'exécuter du logiciel. La plupart des noeuds sont des ordinateurs. Les liaisons physiques entre noeuds peuvent également être décrites dans le diagramme de déploiement. Elles correspondent aux branches du réseau. Les composants qui constituent l'architecture logicielle du système sont représentés dans le diagramme de déploiement par un artefact qui est souvent un exécutable ou une bibliothèque partagée.53
53 Laurent DEBRAUWER et Fien VAN DER HEYDE, UML 2 Initiation, exemples et exercices corrigés, Seconde Edition, Ed. Eni, France, Pg. 152.
- 62 -

Figure 6: Diagramme de déploiement

Figure 7: Prototype du futur réseau
- 63 -
1. Présentation du modèle d'adressage du futur réseau
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|||||
|
|
|
|
|
|||
|
|
|
|
||||
|
|
|
|
||||
|
|
||||||
|
|
|
|
|
|||
|
|
|
|||||
2. Sélection et présentation des protocoles et services supplémentaires du futur réseau
|
Services |
Protocoles |
Fonctionnalités |
Type de services |
Applications fournisseur du service |
|
Voix sur IP |
H320 |
Permet la transmission de la voix à partir des noeuds réseaux identifiable par l'adresse IP |
Réseau |
Skype |
|
Messagerie électronique |
SMTP, IMAP, POP |
Permet de communiquer par l'envoi et réception des e-mails |
Réseau |
Yahoo mail, Gmail |
|
FTP |
FTP |
Permet le partage d'informations (fichiers) |
Réseau |
Client FTP |
- 64 -
3. Présentation du diagramme de la topologie logique du futur réseau
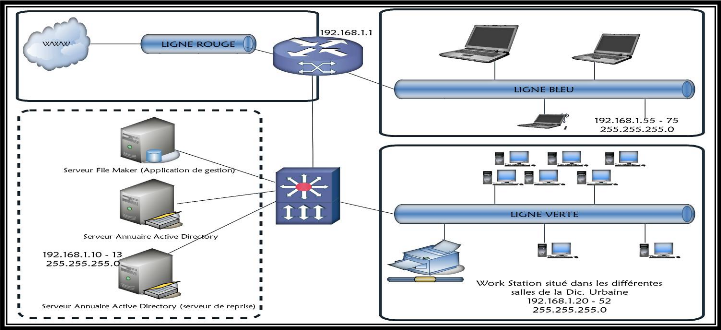
Figure 8: Diagramme de la topologie logique du futur réseau
- 65 -
1. Sélection des équipements du futur réseau
|
Couches |
Equipements |
Caractéristiques techniques |
Nombre |
Localisation |
|
( Plateforme 3700 |
2 |
Salle IT |
||
|
Routeur Cisco |
( 6 ports Fast Ethernet |
|||
|
Couche Coeur |
manageable |
( 2 ports Séries |
||
|
( Plateforme 3700 |
3 |
Salle IT |
||
|
Couche de |
Switch Catalyst Cisco |
( 16 ports Fast Ethernet |
||
|
( Plateforme 2900 |
1 |
Bloc 1 : |
||
|
( 16 ports Fast Ethernet |
( Bureau CD, ( Sec CD, ( B. Vignette. |
|||
|
( Plateforme 2900 |
1 |
Bloc 2 : |
||
|
( 16 ports Fast Ethernet |
( Bureau Division de Suivi |
|||
|
Couche Accès |
Switch Catalyst cisco |
( BDS, ( Bureau Administratif et de Comptabilité. |
||
|
( Plateforme 2900 |
1 |
Bloc 3 : |
||
|
( 16 ports Fast Ethernet |
- Bureau impôt, - Bureau IFRL. |
|||
|
( Plateforme 2900 |
1 |
Bloc 4 : |
||
|
( 16 ports Fast Ethernet |
( Bureau Recouvrement, ( Bureau Taxe, ( Bureau Contrôle Technique. |
Tableau 9: Tableau de la sélection des équipements du futur réseau
- 66 -
2. Présentation du diagramme de la topologie physique

Figure 9: Diagramme de la topologie physique du futur résea
- 67 -
Ce chapitre final de notre mémoire de Fin d'Etudes Universitaires sera essentiellement consacré à la mise en oeuvre ou la réalisation des résultats de la conception. Il s'agira donc de concrétiser ou réaliser par une démonstration via un émulateur / simulateur notre solution informatique.
C'est ainsi que pour concrétiser notre solution, nous ferons appel au protocole GLBP qui se charger d'effectuer l'équilibrage de charges et la redondance à l'accès WAN, EtherChannel pour l'agrégation des liens physiques et STP pour la gestion des Broadcast Strorm sur le réseau.
Pour démontrer le fonctionnement de notre solution informatique afin d'illustrer ses scénarios de configurations, nous avons usés de l'émulateur GNS3. Principalement parce qu'il nous fournit la possibilité d'utiliser le Système d'Exploitation des routeurs et cela nous a ainsi permit d'avoir une vue très rapprochée de la réalité en ce qui concerne les différentes configurations. Voilà pourquoi le monde du Networking lui confère le titre de Simulateur et Emulateur.
Pour acquérir la haute disponibilité du Gateway, l'accès sans arrêt au WAN, la répartition des charges qui fourniront cet accès WAN, la tolérance aux pannes ainsi que la continuité de service, notre choix a été porté sur le protocole GLBP (Gateway Load Balancing Protocol). Car, au-delà de sa réputation en matière de redondance comparativement aux autres technologies précitées (VRRP, HSRP, etc.), GLBP présente un grand avantage qui nous a plus motivé ; c'est celui de la répartition des charges entre routeurs participant au groupe GLBP ;
- 68 -
ce qui offre une bonne gestion de requêtes ARP issues des postes utilisateurs, il permet également d'effectuer une authentification.
Pour sa démonstration dans l'émulateur GNS3, nous l'avons déployé sur des routeurs de la plateforme 3700, modèle 3725, avec IOS de la version 12.4, 120 Mb de la RAM et 55 Kb de NVRAM.
Pour la mise en oeuvre de l'agrégation des liens, notre choix a été porté sur la technologie EtherChannel. Elle nous nous a permis à réunir en un seul canal logique différents liens physiques ; d'optimiser la bande passante et surtout car elle est aussi pris en charge par différents équipements de diverses firmes de fabrications. Etant donné que la présence des liens redondants dans un réseau est à la base de la naissance des boucles réseaux et tempêtes de diffusion. C'est ainsi que pour la gestion de ces dernières, nous avons usés de la technologie STP (Spanning Tree Protocol).
Mais alors, pour démontrer l'implémentation de ces deux technologies, nous nous servis de Switch GNS3 de type Etherswitch Router. C'est ce type de Switch manageable qui peuvent supporter les configurations diverses de technologies précitées.
Nous avons utilisé cet émulateur en sa version 0.8.4 qui est disponible à l'adresse htt:// www.gns3.net. Disons que son installation n'est pas tout à fait exigeante, mais son utilisation l'est. Car il émule les routeurs et il devient ainsi de plus en plus gourmand en termes de mémoire RAM, processeur.
Une fois téléchargée son exécutable, vous devez l'installer en suivant les différentes étapes d'installation jusqu'à leur fin. Aussitôt que l'installation se terminait, pour émuler le routeur vous devez commencer par télécharger les IOS selon les plateformes, puis les importer et les sauver telle que nous montre les figures suivantes.

- 69 -
Figure 10: Lancement de GNS3 / Enregistrement du projet
Figure 11: Importation de l'IOS
Figure 12: Importation de l'IOS vers GNS3
Pour la haute disponibilité du Gateway, l'accès redondant au WAN, la continuité de service et la tolérance aux pannes, nous avons implémenté le protocole GLBP sur 2 routeurs redondants et fonctionnant en mode actif - actif. Ces routeurs doivent se retrouver dans un même groupe identifié et partageront la même adresse IP virtuelle mais plusieurs adresses virtuelles.
- 70 -
3. Configuration réseau sur les routeurs
i. Routeur Master V' Nommage et configurations LAN du routeur Master
Figure 13: Configuration LAN sur le routeur Master
V' Configuration WAN du routeur Master
Figure 14: Configuration WAN sur le routeur Master
ii. Routeur Slave 1 V' Nommage et configuration LAN du routeur Slave 1

Figure 15: Configuration LAN du routeur Slave 1
- 71 -
V' Configuration WAN du routeur Slave 1

Figure 16: Configuration WAN du routeur Slave1
4. Configuration proprement dite du GLBP
|
NOM DU ROUTEUR |
GROUPE GLBP |
ADRESSE IP VIRTUELLE |
PRIORITES |
|
R1_Master_DRAKAT_DUL |
1 |
192.168.1.1 |
200 |
|
R2_Slave1_DRKAT_DUL |
1 |
192.168.1.1 |
150 |
Figure 17: Tableau des paramètres de configurations du GLBP
i. Routeur Master
Figure 18: Configuration du GLBP sur le routeur Master
ii. Routeur Slave 1

Figure 19: Configuration du GLBP sur le routeur Slave 1
5. Configuration du Load Balancing
Pour la configuration de la répartition des charges, parmi les trois modes de configurations, nous avons opté pour la configuration « round robin » car nous voudrons faire en sorte qu'à chaque requête ARP, que le routeur réponde en envoyant l'adresse MAC virtuelle immédiatement disponible.
- 72 -
i. Routeur Master
Figure 20: Configuration du Load Balancing sur le routeur Master
ii. Routeur Slave 1

Figure 21: Configuration du Load Balancing sur le routeur Slave 1
6. Surveillance des interfaces WAN (Tracking)
i. Tracking des interfaces WAN du routeur Master
ii.

Figure 22: Tracking des interfaces WAN du routeur Master
Figure 23: Prise en charge du tracking côté LAN plus décrémentation
Tracking des interfaces WAN du routeur Slave 1

Figure 24: Tracking des interfaces WAN du routeur Slave 1
- 73 -

Figure 25: Prise en charge du Tracking côté LAN plus décrémentation en cas de perte de connexion
7. Authentification GLBP
En matière de sécurité, nous avons opté pour l'authentification par mot de passe afin de vérifier la véracité des utilisateurs qui voudront se connecter au groupe GLBP.
i. Authentification sur le routeur Master
Figure 26: Authentification sur le routeur Master
ii. Authentification sur le routeur Slave 1

Figure 27: Authentification sur le routeur Slave 1
Etant donné que nous avons opté pour une conception hiérarchique du futur réseau, et que ce sont les équipements d'interconnexions et les médias de communications de la couche de distribution qui sont beaucoup plus sollicités dans le trafic, l'agrégation des liens ne concernera alors que cette couche.
- 74 -
C'est pourquoi, l'agrégation des liens sera donc configurée sur tous les Switch de la couche de distribution. Vu le nombre excessif de Switch et liens à configurer tel que représenté dans le prototype, la représentation par des captures sur chacun d'eux devient ainsi longue, voilà pourquoi nous allons à partir des figures qui suivent présenté de manière synthétique et générale comment l'avons-nous configurée.
Pour s'y prendre, nous devons effectuer sur tous les Switch, d'un côté à l'autre un regroupement de deux liens physiques (interfaces) en un seul canal virtuel. Pour cela, nous devons créer un groupe virtuel (avec l'ID : 1) où doivent appartenir les Switch concernés par l'agrégation, regrouper les liens physiques et ainsi activer le mode de l'EtherChannel.
|
NOM DU SWITCH |
INTERFACES |
GROUPE |
Port-Channel |
|
SW1_Main_DRKAT_DUL |
FastEthernet 1/3 - 4 |
1 |
1 |
|
SW2_Slave1_DRKAT_DUL |
FastEthernet 1/3 - 4 |
1 |
1 |
|
SW1_Main_DRKAT_DUL |
FastEthernet 1/5 - 6 |
2 |
2 |
|
SW3_Slave2_DRKAT_DUL |
FastEthernet 1/5 - 6 |
2 |
2 |
|
SW2_Slave1_DRKAT_DUL |
FastEthernet 1/7 - 8 |
3 |
3 |
|
SW3_Slave2_DRKAT_DUL |
FastEthernet 1/7 - 8 |
3 |
3 |
Figure 28: Tableau des paramètres de configuration du protocole EtherChannel

Figure 29: Configuration type de l'EtherChannel (Côté 1)

Figure 30: Configuration type de l'EtherChannel (Côté 2)
Dans le simulateur / émulateur de notre solution informatique, ce sont principalement les équipements de la firme Cisco qui y sont utilisés. Cependant, par défaut, le protocole STP
- 75 -
s'active quand il remarque la présence des boucles dans la topologie. Mais alors, nous montrerons les configurations avancées que nous ferons pour adapter ce protocole à notre architecture ci-haut présentée.
1. Configurations avancées du protocole de gestion des boucles
i. Configuration de l'élection du Switch Root
Pour des raisons des contraintes techniques, nous utiliserons et adapterons à notre guise la topologie de notre solution ; pour cela, nous passerons outre le mode de configuration globale traditionnel, mais nous allons néanmoins forcer l'élection du Switch Root qui aura une priorité inférieure, autre que celle qui est fournie par défaut sur tous les autres Switch. Nous avons choisi pour notre cas, en visualisant notre architecture le premier commutateur de la couche de distribution car il est au centre et gère tous les trafics réseau, il permet d'interfacer et lier la couche Coeur et la couche de distribution, et enfin, il occupe la position stratégique. Nous lui avons donné comme priorité 8192 pour qu'il soit véritablement le Switch Root par rapport à ses voisins.

Figure 31: Configuration du Switch Root
ii. Configuration du max-age, forward-time et des messages Hello
Nous allons adapter certains paramètres pour diminuer le délai d'opération du protocole STP. Nous devons paramétrer de telle manière que le message Hello soit lancé après chaque 1» au lieu de 2» ; le basculement vers le temps de basculement l'état de fonctionnement doit prendre 10» au lieu de 15 et le paramètre de délais à 15» au lieu de 20.

Figure 32: Configuration du max-age, forward-time et messages Hello
- 76 -
i. Visualisation des adresses MAC et IP de chacun des routeurs
L'adresse 192.168.1.2 correspond à l'IP de l'interface LAN du premier routeur (le routeur Master), 192.168.1.3 correspond à celle du deuxième routeur et 192.168.1.4 correspond à celle du dernier routeur.
Figure 33: Visualisation des correspondances entre adresses MAC et IP des routeurs
ii. Visualisation esquisse des configurations du protocole GLBP

Figure 34: Visualisation sommaire des configurations du protocole GLBP
- 77 -

Figure 35: Visualisation des configurations d'EtherChannel

Figure 36: Visualisation des configurations du Spanning Tree Protocol
Pour tester la connectivité afin de tenter d'atteindre la passerelle, nous allons en premier lieu à partir d'un poste connecté au Switch de la couche d'accès, effectuer un ping vers le Gateway (côté LAN) et en deuxième lieu un autre ping vers l'interface WAN.
- 78 -

Figure 37: Test de connectivité vers le Gateway (Accès LAN) et vers l'accès WAN

Figure 38: Test de connectivité à la passerelle et traçage de la route
Dans ce scénario normal, c'est le premier Router qui est Master à cause de sa priorité qui est élevée par rapport à l'autre du groupe GLBP. Face à une requête, c'est lui qui se charge d'y répondre.

Figure 39: Capture des trames avec Wireshark / Scénario normal
- 79 -
Master

Figure 40: Continuité de service en cas de panne du routeur Master
Figure 41: Capture avec l'analyse des paquets Wireshark (Reprise de service après panne)
Comme vous le constatez avec nous, en cas d'arrêt de fonctionnement ou de panne du routeur Master, le second prendra le relais afin de répondre aux requêtes des hosts clients. Si nous traçons la route par laquelle le paquet est passé, vous observez avec nous que le paquet est passé par l'interface LAN du routeur Slave1 pour atteindre la passerelle.
- 80 -
Au terme de notre mémoire qui a porté sur une thématique titrée comme suit : « Approche du Design et d'Implémentation d'un LAN hiérarchique redondant pour la haute disponibilité d'une infrastructure » Cas du LAN de la Division Urbaine de la DRKAT / Lubumbashi.
En effet, le mobile de la présente étude a tourné autour de la problématique de l'indisponibilité observé sur l'infrastructure réseau de la Divion Urbaine de la DRKAT / Lubumbashi. Pour y remédier, nous avons proposé par cette étude une solution issue de la combinaison d'un bon processus, d'un bon Design et d'une gamme de Technologie.
Etant une oeuvre scientifique, la présente a été subdivisé principalement en deux parties dont la première s'est livrée à la présentation théorique des éléments littéraires et théoriques ayant trait à notre sujet d'étude et la seconde a fait état de la démonstration sinon l'expérimentation de la solution informatique retenue.
Cependant, la conception de notre solution a suivi une démarche basée principalement sur la méthode Top Down Network Design. Pour répondre à la problématique posée, nous avons usés des Technologies de Load Balancing basée sur GLBP, EtherChannel pour l'agrégation des liens physiques et STP pour la définition de réseau sans boucle. Toute cette gamme a reposé sur une architecture qui répond au modèle de conception hiérarchique de réseau.
Enfin, cette étude ne suffit pas par elle-même pour faire jouir aux utilisateurs de l'infrastructure réseau de la DU / DRKAT Lubumbashi aux vraies bénéfices de NTIC. Elle est loin d'être parfaite ; elle ne constitue qu'une ébauche pour les futurs chercheurs qui voudront bien la perfectionner. Ainsi les futurs chercheurs peuvent partir sur des pistes telles que l'étude et la mise en place du multihoming pour avoir un accès WAN redondant en partant de l'utilisation des deux ou plusieurs FAI.
- 81 -
V' André VAUCAMPS, CISCO : Protocoles et concepts de routage - configurations avancées de routeurs, Edition Eni, France.
V' Dr. Guy TURCHANY, Théorie des systèmes et systémiques: Vue d'ensemble et définitions, Agir ensemble pour éduquer au Développement durable, Ed Petöfi S.u.7, France.
V' Laurent Lesavre, Théories de la communication et nouvelles technologies de l'information et de la communication, Groupe ESC Grenoble, Paris, Mars 2001.
V' Marco CARTA-GULLUNG, Giacomo ROMBAUT, Lucas Jourdes, Redondance matérielle, haute disponibilité et reprise sur panne, POLYTECH, Nice-Sophia.
V' Priscililla Oppenheimer, Top-Down Network Design, CISCO, Third Edition, August 2011.
V' Prof. Rachad ANTONIUS, Ce que doit inclure un projet de mémoire ou de thèse, Département de sociologie, UQAM (Québec), Canada, Juillet 2007.
V' Rahul Kachalia, Bordeless Campus 1.0 Design Guide, Cisco Systems, 23 Juin
2011.
V' Thomas ANCEL, EtherChannel en AIX, Infos Produits, Décembre 2002.
V' Cisco Systems, Configuring STP and RSTP.
V' Cisco, Chapter 9: Configuring HSRP.
V' Couderc, Geniez, Delmon, Lacroix, Mission HSRP, Janvier 2014.
V' Redondance des routeurs avec GLBP, Extrait du Idum :
http://idum.fr/spip.php?article230.
V' Dunkerque, Etherchannel, TRSIT, 2010, pg. 5
V' F. Nolot, EtherChannel, Université de Reims Champagne Ardenne Cisco
Académie, Faculté des Sciences 2008.
V' Laurent DEBRAUWER et Fien VAN DER HEYDE, UML 2 Initiation,
exemples et exercices corrigés, Seconde Edition, Ed. Eni, France.
- 82 -
II. COURS
V' Me Dieudonné YAV, Cours inédit Méthodologie de Conception des Réseaux Informatiques, Grade 1, Ingénierie Systèmes Réseaux, Faculté de Sciences de l'Informatique, UMK, 20014-2015.
V' Ass. Ir Patient KABAMBA, Cours inédit Conception des Architectures Réseaux, Grade II, Sciences de l'Informatique, ISR, UMK / Mulungwishi, 2013-2014.
V' Ass. Ir Erick MPIANA, Cours inédit Réseaux informatiques III, G2, Faculté des Sciences de l'Informatique, UMK, 2012-2013.
III. MEMOIRE
V' NKONGOLO TSHENDESHA Thierry, Etude de conception et mise en oeuvre des réseaux LAN interconnectés par deux WAN, Cas de l'AEMI, Mémoire de Licence, UMK / Mulungwishi, Juillet 2014.
V' Khaled TRABELSI & Haythem AMARA, Rapport de stage de perfectionnement, Université Virtuelle de Tunis, 2010 - 2011.
V' Prince PITSHI, Déploiement d'un système DNS redondant chez un FAI. Cas de Vodanet / Lubumbashi, Mémoire de Licence, UMK, 2013 - 2014.
V' Prince RUMEJ, Etude et implémentation d'un système à haute disponibilité de gestion et de partage des ressources dans un environnement hétérogène Cas de l'INSS / Katanga 3, Mémoire de Licence, UMK, 2013 - 2014.
IV. BROCHURES
V' DRKAT, Présentation de la Direction des Recettes du Katanga, Lubumbashi, Octobre 2009.
V. SITES WEB











