INTRODUCTION GENERALE
Le réseau informatique est la mise en communication, la
circulation des informations sur des machines (PC) distantes les unes des
autres. Dans le réseau informatique, il existe plusieurs sortes : le MAN
(Metropolitain Area Network), le WAN (World Area Network) et le LAN (Local Area
Network).
Notre travail se basera plus sur le LAN avec une petite
extension sur le WAN. Le LAN qui est un réseau local pouvant pendre en
charge deux à plusieurs machines distantes dans différentes
topologies du réseau. Nous verrons dans les pages qui suivent une
brève esquisse de ces différentes topologies de mise en
réseau et leur fonctionnement.
Nous ne nous arrêtons pas à ce niveau car le
travail consistera en effet à décrire ni les différentes
architectures du réseau ni les différentes topologies du
réseau en informatique mais en fait l'administration d'un système
de réseau LAN avec connexion sur le WAN pour permettre de partager une
connexion sécurisée.
Ce travail consistera en fait à administrer un
réseau ce qui revient à contrôler, gérer et suivre
toutes les informations qui trafiquent sur ce réseau et permettre une
communication Mail intranet par la mise en place d'un serveur de
Messageries.
Pour ce faire, nous aurons le choix entre deux Operating
System (Système d'Exploitation) pour gérer notre réseau.
Un OS payant et graphique qui est le Microsoft Windows et un autre Open Source
et CLI (Command Line) qui est Linux. Nous démontrons leurs avantages et
inconvénients dans les lignes qui suivent et où se portera notre
choix.
De ce choix nous démarrons notre administration, sa
réalisation et sa mise en route pour nous permettre d'avoir un
réseau administré et sécurisé ou il y'aura
fluidité des informations.
I. BREVE ENTREVUE SUR LE RESEAU
La topologie de réseau
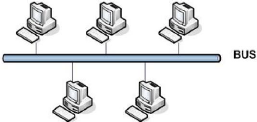
A. Structure BUS :
Un réseau de type BUS se compose d'une longueur
continue du câble qui relie deux dispositifs ou plus ensemble. Un
réseau de type BUS s'appelle également un réseau
Backbone.
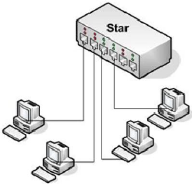
B. Structure STAR (Etoile) :
Une structure de réseau Étoile se compose de
l'ordinateur individuel relié à un point central sur le
réseau. Le réseau Étoile est le type le plus commun de
réseau.
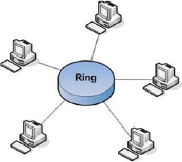
C. Structure RING (Anneau) :
Une structure de réseau Anneau se compose de l'ordinateur
individuel relié à une longueur simple du câble
disposé dans un anneau.
D. Structure Hybride :
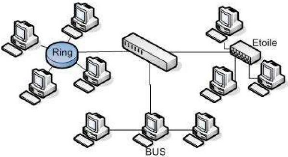
La structure hybride de réseau emploie un mélange
de différents genres de structures de réseau, comme STAR, BUS et
également RING.
TYPE DE RESEAU
Il y a beaucoup de différents types de réseaux
employés par des entreprises et des organisations. Trois types
importants de systèmes répartis sont :
? LAN (Local Area
Network) : est le type le plus commun de réseau
trouvé dans les entreprises. Il relie des ordinateurs et des dispositifs
situés près de l'un l'autre, tel que dedans un même
bâtiment, bureau, etc.
? MAN (Metropolitan Area
Network) : une collection de réseaux locaux. Les MAN
relient des ordinateurs situés dans le même secteur
géographique tel qu'une ville. (LAN + LAN, Village, entreprise
<--> entreprise)
? WAN (Wide Area
Network) : relie des réseaux locaux et
métropolitains ensemble. Les réseaux qui composent d'un
réseau étendu peuvent être situés dans tout un pays
ou même autour du monde. (LAN + LAN + MAN)
E. SERVEUR
Lors de la mise en place d'une infrastructure de type Intranet,
deux directions peuvent être envisagées :
· Soit la confiance est accordée au système
de type Microsoft ;
· Soit la confiance est accordée aux systèmes
ouverts de type Linux.
Même si ces deux environnement peuvent communiquer entre
eux, il y'a un moment ou un choix doit être vraiment
réalisé.
Chaque environnement à ses avantages et peut avoir aussi
ses inconvénients ; parmi ceux-ci nous citons :
> Pour Microsoft
· Intégration global à tous les niveaux,
depuis les postes clients en passant par la gestion du réseau,
l'accès aux applications et aux bases de données. Microsoft
répond à tous les besoins qu'un Intranet peut requérir
;
· Démarrage d'une solution Intranet relativement
aisée ;
· En général les systèmes sont stables
mais il faut appliquer un grand nombre de patch pour corriger les erreurs ;
· Le prix des licences sont relativement
élevé, tant à l'achat que pendant l'exploitation ;
· La maintenance évolutive est trop chère
(humain et matériel) ;
· Le système n'est pas inter opérable ou
difficilement (système propriétaire) quoique certaines portes
sont ouvertes ;
· La sécurité laisse à désirer
bien que la Société Microsoft tente d'améliorer la
situation.
> Pour Linux (Open Source)
· Possibilité de trouver des solutions qui
correspondent à tous les besoins mais comme la plupart des solutions et
outils sont gratuits, la commercialisation, le support peuvent faire
défaut (tout est disponible sur Internet mais tout ne résout pas
le problème adéquat) ;
· De plus de « vendeurs » portent leurs
applications sous Linux, qui deviennent intégrables dans le
réseau Open Source (comme serveur de fichier, gestions du réseau,
serveur de sauvegarde, barrière de sécurité
(pare-feu)....) ;
· Pour des raisons de sécurité et de
réactivité à certaines trous de sécurité,
nous utiliserons des Open Source ;
· Prix de loin inférieur ;
· Les grands producteurs (IBM, HP, COMPAQ, SUN) offrent des
contrats de support à l'année ;
· Peu ou pas de virus, ils ne se lancent pas
automatiquement comme sur Microsoft ;
· Normes standard du marché sont utilisés
;
· Système en constance évolution, stable dans
le temps, qui compte plus en plus de praticien ;
· Possède dans son paquetage beaucoup de
serveur et gratuitement :
· Barriere de sécurité (pare feu)
· Serveur de messagerie (SendMail, PostFix, SquireMail)
;
· Serveur DNS ;
· Serveur NIS ;
· Serveur de fichier (NFS) ;
· Serveur de sauvegarde des données ;
· Serveur LDAP (répertoire électronique,
équivalent à Active Directory de Microsoft) ;
· Serveur de bases de données des grands producteurs
;
· Serveurs d'indexations et de repérages des
données.
II. ADMINISTRATION DU SYSTEME D'EXPLOITATION
A. INSTALLATION DE LINUX RED HAT 9.0
Le choix du Système s'est fait sur un Système
Open Source et nous avons porté sur une distribution Linux (Red Hat
9.0). Pourquoi le choix de cette distribution mais pas d'une autre distribution
Linux. Les causes sont multiples :
· Nous disposons des CD ROM d'installation de cette
distribution et puis de la dernière version la plus stable;
· Les paquetages d'administration tous sont
intégrés dans le CD ROM d'installation et qu'il suffit seulement
de les cochés ;
· Les multiples possibilités d'utilisation du
Système :
> Bureau, pour une utilisation personnelle dans un cadre
privé du système comme Windows XP ou Vista de Microsoft ;
> Poste de travail, plus utilisé par les
développeurs puisque les codes sont libres et donc modifiables à
volonté et à convenance ;
> Serveur, pour administrer un réseau professionnel et
ce sera aussi notre possibilité utilisée ;
> Personnalisé, cette option est la plus
compliquée puisque seuls les professionnels du Linux peuvent l'utiliser
car elle donne la possibilité de développer un autre
Système d'Exploitation à partir de l'ancien et de personnaliser
le Système à ses convenances.
· La stabilité du Système
· L'interopérabilité du Système....
Nous ne citons que ceux.
B. LES ETAPES DE L'INSTALLATION
Les prés requis :
· Le PC doit supporter un affichage de 32 Bits ;
· Le PC doit disposer au moins de 128 Mbits de RAM ;
· Le PC doit avoir un peu de mémoire disponible
sur le Disque (Même 10 Go est largement suffisant pour le bon
fonctionnent d'un Linux contrairement aux dernières versions de Windows)
;
· Apres toutes ces vérifications nous passons
à la première étape de l'installation :
1. Boot
Le PC doit nécessairement booter sur le lecteur DVD/CD
ROM pour permettre l'installation du Système. Là, au
démarrage il faut appuyer sur la touche fonction F2
pour entrer dans le bios pour changer l'ordre de démarrage
(master boot). Dans le bios on met en première position le lecteur
DVD/CD ROM puis on appui sur la fonction F10 pour valider la
nouvelle configuration et sortir du Bios.
2. Démarrage de l'installation
Apres être sortie du Bios, il faut insérer le
premier CD ROM d'installation du Red Hat 9.0 (puisqu'il possède trois CD
ROM d'installation). Apres il faut redémarrer le PC pour qu'il puisse
prendre le CD ROM au démarrage ; si c'est le cas, il ne reste
qu'à appuyer sur la touche Valider
(Entrée) pour valider l'installation.
3. Choix de la Langue
L'étape primordiale de l'installation et la configuration
d'un Système d'Exploitation (Type Serveur) est la langue qui sera
utilisé dans le Système. Nous proposons le
Français.
4. Choix de l'option du Clavier
Ce choix est en fonction du clavier dont dispose le poste qui
doit recevoir ce nouveau Système. Les différents systèmes
du clavier dépendent des langues utilisées.
5. Choix de la Souris
Ce choix est indispensable sinon la souris ne marchera pas.
Quelques descriptions sur les souris :
· Souris à deux boutons, souris possédant
deux touches ;
· Souris à trois boutons, souris possédant
une troisième touche au milieu ou à coté ;
· Souris trois boutons et émulation, souris
possédant à la place du troisième bouton une molette.
6. Choix de la manière de l'Installation
Dans cette partie, il existe deux manière d'installer
Linux si c'est la première installation sinon trois :
· Installer le Système sur tout le disque, formatage
complet du disque ;
· Installer en dual boot pour le permettre de
fonctionner en collaboration avec un Système d'Exploitation (Si c'est
pour faire un dual boot avec un Système Windows, il serait
préférable et conseillé d'installer le Système
Windows avant le Linux quelque soit sa distribution) ;
· Conserver l'ancienne version du Système linux s'il
existe une ancienne version de Linux et faire une mise à niveau.
7. Paramétrage du Grub ou du Lilo
Grub ou le Lilo sont comme pour le Windows le DOS ; nous avons
le choix entre le Grub ou le Lilo au démarrage.
8. Configuration des espaces
La configuration des espaces représentent l'utilisation
des espaces du disque dur. Si la configuration est manuelle :
· Il faut donner le double de la RAM au Swap
L'espace swap dans Linux est utilisé lorsque la mémoire
physique (RAM) est pleine. Si le système a besoin de plus de ressources
de mémoire et que la mémoire physique est pleine, les pages
inactives de la mémoire sont déplacées dans l'espace de
swap. Même si l'espace de swap peut aider les ordinateurs disposant d'une
quantité de RAM limitée, il ne faut pas le considérer
comme un outil remplaçant la RAM. L'espace de swap est situé sur
les disques durs ayant un temps d'accès plus lent que la mémoire
physique.
· L'espace de swap peut être une partition de swap
consacrée (option recommandée), un fichier de swap ou une
combinaison de partitions et de fichiers de swap. La taille de votre espace de
swap devrait être équivalente à deux fois la RAM de votre
ordinateur ou 32 Mo (selon la quantité la plus importante), mais ne doit
pas dépasser 2048 Mo (ou 2 Go). (il représente la mémoire
virtuel du Système)
· Il faut donner au moins 50 Mbits pour le Lilo ou le Grub
selon le choix du Shell de démarrage.
· Si la configuration est automatique, le travail et le
calcul se fait automatiquement par le Système.
9. Choix de l'utilisation du Système
Ce choix détermine la façon de l'utilisation de
Linux Red Hat 9.0 :
· Bureau ;
· Poste de travail ;
· Serveur (le choix s'est imposé à cette
option) ;
· Personnalisé.
10. Choix des paquetages
Arriver à l'avant dernière partie de notre
installation, cette étape permet la configuration du Système
à notre connivence. Comme nous devons utiliser un Système
serveur, nous cochons tous les paquetages disponibles pour éviter que
notre configuration ne puisse pas marcher à cause des problèmes
des dépendances inter paquetages.
11. Adaptation de l'écran
Nous devons à partir d'ici choisir la bonne configuration
qui correspond aux spécificités de notre écran.
12. La manière de l'utilisation
Cette est la partie la plus importante de notre installation
et de l'utilisation prochaine de notre Système. Nous avons le choix
entre :
v' Le mode texte, l'interface ou le bureau (dépend des
prononciations) sera en ligne de commande (CLI, Command Ligne) donc un
écran noir qu'il faudrait entrer des codes pour l'utiliser ;
v' Le mode graphique, l'interface sera conviviale comme Windows
XP avec des images, des graphiques et des animations.
13. Fin de l'installation
Selon le choix de chacun, il y'a le choix :
· Créer un disque de démarrage, il est
obligatoire lors du démarrage d'une nouvelle session du PC à
chaque fois ;
· Ne pas créer un d'amorçage
(démarrage et amorçage c'est la même chose), là Lilo
ou le Grub sera alloué sur un espace du disque dur. Le démarrage
du Système se fera donc automatiquement.
· Maintenant il ne reste plus qu'à retirer le
troisième CD ROM et redémarrer le PC.
III. FIN DE L'INSTALLATION

Lorsque l'installation de Linux est terminée, le
système se réinitialise. Par la suite, chaque fois que l'on
démarre Linux, le système demandera un nom d'utilisateur et le
mot de passe correspondant. Cette requête peut s'effectuer soit en mode
texte, soit en mode graphique; cela dépend de la configuration de la
distribution. Par défaut, sous Linux Red Hat 9.0, c'est un écran
de login en mode graphique qui est proposé. Quoi qu'il en soit, le
principe est le même : on doit se connecter au système avant de
pouvoir l'utiliser.
1) Le démarrage de Linux
Durant le démarrage de Linux, nous verrons bon nombre
d'informations s'afficher à l'écran. Nous ne devrons nous
inquiéter ni du fait que nous n'y comprenons rien, ni que
certains services ne se chargent pas correctement (le mot
« fail » peut, rarement, apparaître en rouge, alors que
généralement il est indiqué « OK »).
Exemple:
Init version 2.84
bootin
Mounting proc filesystem
Init: Entering runlevel: 5
Montage du système de fichier proc (OK)
Configuration des paramètres du noyau (OK)
Chargement de la configuration clavier (OK)
Remontage du système de fichiers en mode
lecture-écriture (OK)
Activation des partitions swap (OK)
2) L'écran de connexion en mode graphique

Figure : L'écran de login en mode
graphique.
Nous voici à présent devant l'écran de
connexion (également appelé « écran de login»)
en mode graphique. Nous avons la possibilité d'y changer la langue
à utiliser par défaut ou le type de session (par exemple, si nous
avons les environnements graphiques Gnome et KDE, tous deux installés,
nous pouvons décider avec lequel nous allons travailler). Le plus
simple, pour commencer, est d'entrer notre nom d'utilisateur (pierre dans notre
exemple) et le mot de passe (nous avons changé le nom d'utilisateur pour
raison de sécurité).
3) Le chargement de la session
Après avoir entré notre nom d'utilisateur et notre
mot de passe commence le chargement de la session. Nous devrons patienter un
peu, le temps que le système effectue
quelques préparatifs (gestionnaire de
périphériques, gestionnaire de fenêtres, tableau de bord,
etc.). Que nous choisissions Gnome ou KDE comme environnement graphique ne
change rien : le système procède aux mêmes initialisations.
A présent, du moment que nous utilisons un compte normal, nous pouvons
essayer absolument tout ce que nous voulons : nous ne risquons pas d'endommager
quoi que ce soit (voir L'utilisation d'un compte normal).

Le chargement d'une session KDE. Ça y est, nous pouvons
enfin travailler sous Linux !
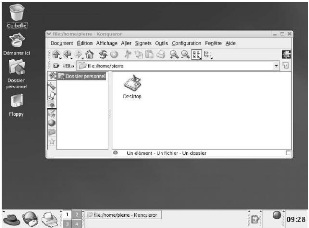
Figure : L'écran de connexion en mode
texte
Lorsque nous nous connecterons à Linux en mode texte
(par exemple parce que notre système est configuré de la sorte ou
parce que nous avons fait appel à un terminal virtuel), nous obtiendrons
les informations suivantes :
Linux Red Hat release 9 (Shrike)
Kernel 2.4.20-8 on an i686
localhost login: root
<ENTRÉE> Password
Last login: Wed Sep 17 19:24:42 on tty1 (
root@enerca.cf)$
Après avoir entré notre nom d'utilisateur,
également appelé nom de login, le système nous demande le
mot de passe correspondant. Comme nous pourrons le constater, le système
ne reflète pas le mot de passe à l'écran (même pas
par des astérisques). Pour ce qui est du reste, ce premier écran
donne déjà un certain nombre de renseignements :
· la version du noyau (2.4 - les deux premiers chiffres
sont les plus importants) ;
· le type de processeur (i686, soit un processeur
compatible Intel et équivalent, au minimum, à un Pentium II) ;
· la date et l'heure de notre dernière connexion
(ou, plus précisément, de la dernière fois que nous nous
étions connectés sur ce compte - pierre dans notre exemple) ;
· le nom d'utilisateur (pierre) ainsi que le nom de la
machine (localhost, ce nom ayant été choisi par défaut
lors de l'installation et qui, pour bien faire, devrait être
changé plus tard) et, sur la même ligne, le nom du
répertoire dans lequel nous nous trouvons (pierre, comme le nom
d'utilisateur dans ce cas-ci).
Lorsque nous nous retrouvons devant l'invite du Shell,
après avoir entré notre mot de passe, nous pouvons lancer
l'interface graphique en entrant la commande startx : (pierre@localhost
pierre)$ startx <ENTRÉE>
Donc, en résumé, démarrer en mode texte
et entrer ensuite startx revient au même que démarrer directement
en mode graphique. L'auteur configure ses différents systèmes de
façon à ce que le login s'effectue toujours en mode texte et il
démarre ensuite manuellement le mode graphique (à l'aide de la
commande startx). Cela peut éviter d'être bloqué si un mode
graphique non supporté par le moniteur est malencontreusement
sélectionné.
4) L'utilisation d'un compte normal
Lorsque l'on découvre pour la première fois
Linux, il est fortement conseillé de ne pas utiliser le compte root
(encore appelé « compte administrateur ») mais bien un compte
normal. La raison en est simple : nous serons soit perdu parmi les centaines de
programmes accessibles depuis l'interface graphique, soit bloqué
à l'invite du mode texte - sans avoir la moindre idée des
commandes à y entrer. Une fausse manoeuvre est alors vite
arrivée, ce qui peut, suivant que l'on soit l'utilisateur root ou un
simple utilisateur, avoir des conséquences désastreuses ou...
aucune importance ! En effet, en tant que simple utilisateur nous ne pourrons
jamais dérégler le système ni effacer de fichiers
importants. Dans le pire des cas, nous pourrions complètement
dérégler nos paramètres de configuration, par exemple
à un point tel qu'il sera impossible de récupérer la
configuration d'origine de ce compte utilisateur en particulier. A ce
moment-là, il n'y aurait qu'à créer un nouveau compte
utilisateur (seul l'utilisateur root a ce droit)....
5) La procédure de reboot
Linux est installé sur notre système et nous
sommes capables de nous y connecter, mais il nous reste encore bien des choses
à apprendre. En effet, même si l'interface graphique de Linux (que
nous utilisions Gnome ou KDE) présente des similitudes avec Windows, il
en va tout autrement du mécanisme intrinsèque du système
d'exploitation. Les différences se situent, entre autres, au niveau du
système de fichiers, du mode multi-utilisateurs, de l'installation de
nouveaux programmes, de l'interface graphique, etc. Avant d'approfondir ces
sujets, voici la démarche à suivre pour quitter Linux. Tout comme
c'est le cas pour Windows, il vaut mieux quitter Linux proprement. Il ne suffit
pas simplement de couper l'ordinateur : cela pourrait endommager le
système de fichiers (voire même, mais c'est très rare,
endommager physiquement le disque dur). Si l'ordinateur n'est pas éteint
correctement, cela se traduira par un prochain démarrage de Linux
ralenti (le système vérifiera si la coupure impromptue n'a pas
entraîné la perte de fichiers). Aucune méthode n'est
meilleure qu'une autre et il n'est pas nécessaire d'apprendre par coeur
des commandes fastidieuses (par exemple shutdown -h 0). Nous en
présentons simplement quelques-unes afin que nous puissions nous faire
une idée de ce qu'il se passe « sous le capot ».
6) L'arrêt depuis l'interface graphique
Si notre système est configuré, comme c'est le
cas par défaut avec la distribution Linux Red Hat 9, pour
démarrer en mode graphique, il suffit de quitter la session en cours
(par exemple en choisissant dans le menu Quitter puis Quitter KDE) : nous nous
retrouvons devant l'écran de connexion en mode graphique et il nous
suffira de cliquer sur Arrêter. Cette technique ne fonctionne pas si
notre ordinateur démarre en mode texte. En effet, lorsque nous quittons
l'interface graphique nous nous retrouvons alors devant l'écran de login
en mode texte, qui ne propose pas de bouton Arrêter. Il est
également possible d'ouvrir un terminal virtuel depuis l'interface
graphique et d'appeler manuellement la commande reboot (ou shutdown).
7) L'appel manuel de la commande reboot
Pour couper ou redémarrer l'ordinateur, il faut lancer
soit la commande shutdown, soit la commande reboot (qui appellera alors
elle-même la commande shutdown avec les paramètres
adéquats). Le système se coupera alors proprement. Lorsque nous
avons accès à un Shell (par exemple si nous avons
démarré en mode texte ou si nous avons lancé un terminal
virtuel dans notre interface graphique), nous pouvons entrer la commande reboot
:
(trinite@localhost trinite)$ reboot
<ENTRÉE> The system is going down for
reboot NOW!!! Init is switching to system level 6
Suivant les distributions de Linux, voire suivant les
différentes versions d'une même distribution de Linux, les droits
d'exécution de cette commande peuvent varier. Par défaut, Linux
Red Hat 9 autorise n'importe quel utilisateur à lancer cette commande
et, donc, à redémarrer l'ordinateur.
8) L'appel de la commande shutdown
Normalement seul l'utilisateur root a le droit d'appeler la
commande shutdown. Dès lors, nous devrons probablement appeler la
commande su avant de lancer la procédure de shutdown. La
commande «shutdown -h 0 » (-h pour halt) permet de couper
l'ordinateur sans qu'il ne redémarre. Exemple:
(trinite@localhost ~/) $ /sbin/shutdown -h 0
shutdown: you must be root to do that!
(pierre@localhost ~/) $ su
Password:
(root@spyda /home/trinite/) # /sbin/shutdown -h 0
The system is going down for reboot NOW!!!
Init is switching to system level 6
Unmounting file system
L'utilisateur trinite essaye d'appeler la commande shutdown
(présente dans le répertoire /sbin/) mais se voit refuser
l'accès (« You must be root to do that »). Il lance alors la
commande su pour devenir l'utilisateur root et il peut ensuite lancer la
procédure de shutdown. Certains utilisateurs gardent leur système
Linux allumé durant des semaines, voire des mois et ceci soit par
nécessité (par exemple parce que le système sert de
serveur) soit par facilité (à quoi bon redémarrer un
système qui ne se bloque jamais ?). La commande uptime permet
de voir depuis combien de temps le système Linux est
démarré. Exemple:
[gospa@enerca ~/] $ uptime
14:46:59 up 15 days, 9:35, 10 users, load average: 0.19,
0.66, 0.57
[gospa@enerca ~/] $
L'utilisateur gospa constate que le système nommé
enerca est allumé depuis plus de 15
jours.
9) La session de secours
Même si nous ne connaissons encore aucune commande
Unix, il peut être bon de préciser que lors du login en mode
graphique nous pouvons lancer une session de secours (dans le menu
Session/Secours). Nous nous retrouvons alors devant un bureau vide (aucun
environnement graphique, ni Gnome ni KDE, n'est lancé) ne contenant
qu'une seule fenêtre : un terminal virtuel. Ce terminal peut alors servir
pour réparer le système (par exemple en créant un nouveau
compte utilisateur).

Figure : La session de secours permet
d'accéder à un terminal virtuel.
10) Le principe multi-utilisateur
Comme tous les systèmes Unix, Linux supporte et,
surtout, encourage l'utilisation de plusieurs comptes utilisateurs...
même si nous sommes le seul à utiliser le système !
Après avoir installé Linux, au moins deux comptes utilisateurs
seront présents sur la machine : l'un étant le compte de
l'administrateur (root) et l'autre un simple compte utilisateur, que le
programme d'installation nous a invité à créer.
11) Le compte utilisateur
Chaque utilisateur dispose d'un répertoire personnel,
placé, par convention, dans le répertoire /home/. C'est
dans ce répertoire que l'utilisateur pourra organiser, à sa
guise, ses fichiers et répertoires personnels. L'on peut même dire
que c'est le seul répertoire dans lequel l'utilisateur a le droit de
modifier quelque chose ! La session de secours permet d'accéder à
un terminal virtuel. En effet, étant donné le système de
permissions d'accès utilisé par Linux, un utilisateur se voit
dans l'impossibilité d'effacer ou de modifier des fichiers importants.
C'est ce qui explique notamment que les virus ne peuvent pas se reproduire ni
d'un utilisateur à un autre, ni d'une machine à une autre. C'est
ce qui explique également pourquoi Linux est si robuste : il est
impossible qu'une application installée par un utilisateur
dérègle tout le système ! Le répertoire principal
d'un utilisateur contient également ses fichiers de configuration
c'est-à-dire les fichiers de configuration créés par les
différents programmes auxquels l'utilisateur a recours. La capture
d'écran suivante montre le contenu du répertoire principal des
utilisateurs pierre et robin. Nous devons noter qu'il a fallu devenir super
utilisateur, ou root, pour pouvoir lister le contenu du répertoire
/home/robin/ : c'est normal, il n'y a aucune raison que l'utilisateur pierre
puisse avoir accès aux informations personnelles de
l'utilisateur robin ! Le message classique qu'obtient un
utilisateur essayant d'ouvrir un fichier auquel il n'a pas le droit
d'accéder est : « permission non accordée » (ou parfois
« permission denied » puisque les programmes de la Red Hat ne sont
pas tous traduits). Si le terminal n'est pas correctement configuré (ou
si un programme n'est pas correctement configuré), il se peut
également que le message s'affiche en gérant mal les
caractères accentués (par exemple : « permission non
accordée »). Nous verrons plus loin comment configurer le terminal
pour remédier à ce problème. La plupart des fichiers
contenus dans les répertoires de ces deux utilisateurs sont des fichiers
cachés (leurs noms commencent par un point). Le contenu des
répertoires,
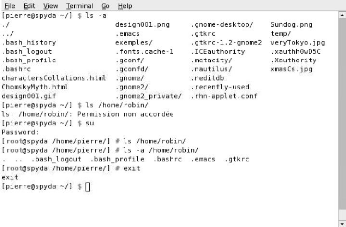
/home/pierre/ et /home/robin/.
fichiers de configuration des programmes utilisés.
L'on peut ainsi constater, par exemple, que l'utilisateur pierre a
déjà utilisé l'environnement Gnome tandis que le
répertoire /home/robin/ ne contient que quelques fichiers cachés
(c'est normal, car il s'agit d'un compte tout fraîchement
créé). Quant aux fichiers personnels, l'utilisateur pierre
dispose de quelques images (.gif, .png et .jpg) et de deux fichiers .html. A
noter également la présence du répertoire .metacity, qui
indique que l'environnement graphique Gnome utilise le gestionnaire de
fenêtre metacity. Rien ne nous force à consulter le contenu de
notre répertoire personnel depuis un terminal, nous pouvons tout aussi
bien recourir à un navigateur de fichiers, tel Nautilus.
Figure : L'ajout d'un nouveau compte
utilisateur
Nous pouvons ajouter un nouveau compte utilisateur en nous
rendant, par exemple, dans le menu Paramètres systèmes /
Groupes et utilisateurs. Le nom d'utilisateur employé pour le
login doit être écrit en minuscules. Le répertoire
utilisé par défaut se trouve dans le répertoire /home/ et
porte le nom de login (par exemple /home/robin/ pour l'utilisateur nommé
robin). Le contenu des répertoires /home/pierre/ et
/home/robin/.
Ajouter un nouvel utilisateur consiste simplement à
créer une nouvelle entrée dans les fichiers de connexion
(notamment dans le fichier /etc/passwd - qui contient tous les utilisateurs)
ainsi qu'un nouveau répertoire dans le répertoire /home/.
12) Le compte root
Le compte root est quelque peu particulier puisqu'il s'agit
du compte de l'administrateur du système. Tout d'abord, il n'est pas
situé dans le répertoire /home/ des utilisateurs normaux mais
bien directement à la racine du disque dur (répertoire /root/).
Ensuite, l'utilisateur root est l'administrateur du système et il a donc
tous les droits.
L'ajout d'un utilisateur nommé robin (par exemple) au
système. Pour effectuer certaines tâches nous serons
obligés d'être, du moins momentanément, l'administrateur du
système. Il en sera ainsi, par exemple, lorsque nous désirons
installer un nouveau programme ou créer un nouveau compte utilisateur.
Etant donné que l'administrateur a tous les droits, il peut modifier ou
effacer n'importe quel fichier. Une seule fausse manoeuvre peut alors suffire
à compromettre tout le système et c'est pourquoi il est
très fortement recommandé de n'utiliser le compte root que
lorsque c'est vraiment nécessaire.
13) Les terminaux virtuels
Quelle que soit la version de Linux que nous utilisons,
plusieurs terminaux virtuels sont disponibles et ce avant même que nous
ne soyons connectés. En effet, étant donné que Linux est
multi-utilisateur et multitâche il est possible de connecter
simultanément plusieurs utilisateurs (ou plusieurs fois le même
utilisateur) au système.
Il est par exemple possible d'ouvrir simultanément
plusieurs consoles en mode texte sous X (l'interface graphique des
systèmes Unix) et de s'y connecter sous différents noms
d'utilisateur. De même, il est possible d'accéder à
différents terminaux virtuels ; ce qui, en plus d'être très
impressionnant, est fort pratique ! Sur la capture d'écran
présente à la page suivante, on peut constater qu'il y a quatre
terminaux X ouverts. Deux appartiennent à l'utilisateur carrera, un
à l'utilisateur pierre et un à l'utilisateur root (le super
utilisateur). On accède à une console en mode texte en combinant
les touches <CTRL>+<ALT> avec la touche de
fonction correspondant au numéro du terminal qu'on désire
obtenir. Par défaut, Linux Red Hat 9 (et beaucoup d'autres distributions
de Linux) permet d'utiliser six terminaux virtuels en mode texte
(numérotés de 1 à 6). Au démarrage, on est
connecté soit au premier terminal en mode texte, soit au premier
terminal en mode graphique. Un exemple valant mieux qu'un long discours, voici
la démarche à suivre :
· démarrons Linux ;
· connectons-nous en entrant notre nom d'utilisateur -
nous nous retrouvons alors face soit à l'invite d'un Shell (en mode
texte), soit à l'écran de login de l'interface graphique (suivant
la façon dont le système est configuré) ;
· appuyez sur les touches
<CTRL>+<ALT>+<F2>...
Autant spécifier que nous venons de faire un reset du
système, mais simplement d'accéder pour la première fois
à un terminal virtuel, en mode texte. Nous pouvons nous en assurer en
« retrouvant » l'interface graphique
(<CTRL>+<ALT>+<F7>) ou notre ancien terminal
(<CTRL>+<ALT>+<F1>) tel que nous l'avons
quitté. Lorsqu'on se connecte pour la première fois à un
autre terminal, on se retrouve devant l'invite login. On peut très bien
se connecter sur le même compte utilisateur depuis différents
terminaux virtuels. Puisque le système propose par défaut six
terminaux virtuels en mode texte (de <F1> à
<F6>), le système permet
d'accéder à l'interface graphique à l'aide de la touche
<F7> (<CTRL>+<ALT>+<F7>). Nous verrons
plus loin qu'il est même possible de lancer plusieurs interfaces
graphiques simultanément et de passer de l'une à l'autre.
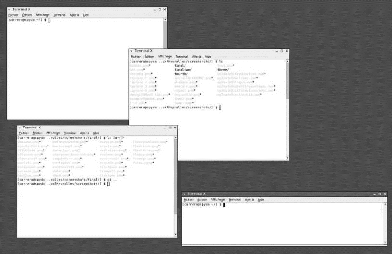
Figure : Quatre terminaux virtuels sont ouverts
simultanément 14) L'utilisation de plusieurs
terminaux
A priori, recourir à différents terminaux ne
nous semble peut-être pas utile. Voici donc quelques exemples
d'utilisation de ces terminaux et, à n'en pas douter, nous en trouverons
bien d'autres...
· Lorsqu'on utilise Linux dans notre entreprise ou chez
soi, il vaut mieux travailler en tant que «simple utilisateur » mais
il est parfois nécessaire de lancer des commandes en tant qu'utilisateur
root et de passer d'un compte à l'autre.
· Si notre Shell ou notre interface graphique plante (ce
qui est très rare) ou que nous sommes bloqués dans un logiciel,
la commande <CTRL>+<ALT>+<F2>, par exemple,
fonctionne généralement encore. Nous pouvons alors
rétablir l'ordre dans notre système (par exemple en tuant les
processus douteux depuis le compte root).
· Si nous effectuons des manipulations depuis le Shell
sur deux répertoires simultanément et que ces deux
répertoires ne se trouvent pas du tout au même endroit dans notre
système de fichiers, il peut être pratique d'avoir un terminal
ouvert sur le premier répertoire et un autre sur le second.
· Certaines tâches mettent du temps à
s'exécuter et peuvent donc monopoliser un terminal ou encore afficher
des informations et donc bloquer le terminal (en utilisant, par exemple, un
terminal pour visualiser en continu un fichier de log). Dans ce cas, il est
fort pratique de pouvoir quitter le terminal en question. Il est
également fort pratique de pouvoir y revenir de temps à autre,
afin de voir où en est l'exécution de la tâche.
La touche <CTRL> n'est
nécessaire que lorsqu'on désire quitter l'interface graphique
pour un terminal virtuel en mode texte (pour passer d'un terminal virtuel
à un autre terminal, ou à
l'interface graphique, la combinaison
<ALT>+<FX> suffit), toutefois, il est plus facile
de ne retenir que la combinaison
<CTRL>+<ALT>+<FX>, qui fonctionne à
tous les coups.
IV. CONFIGURATION RESEAU
nous allons traiter maintenant de la configuration du serveur
Linux Red Hat 9 en tant que passerelle Internet pour un réseau interne
composé de clients Windows. Ce serveur gèrera la connexion
Internet ; il sera serveur DHCP, DNS et firewall.

Donc nous allons nous atteler à installer et
configurer la connexion Internet sur notre serveur Red Hat (dans notre cas la
liaison avec le modem est faite via un câble Ethernet). Il est donc
nécessaire que notre machine possède 2 cartes Ethernet.
L'installation et la configuration se font en 3
étapes:
· 1 - 1 Configuration réseau.
· 1 - 2 Installation et configuration du
modem.
· 1 - 3 Mise en place d'un Firewall
(NAT).
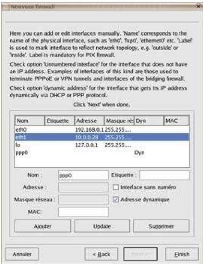
La première des choses à faire est de donner des
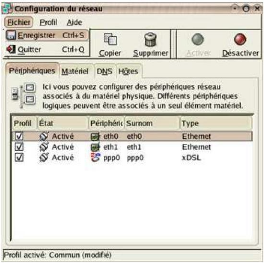
adresses IP fixes à nos 2 cartes réseaux. Nous cliquons sur le
chapeau Redhat ==>Paramètre système
=>Réseau.
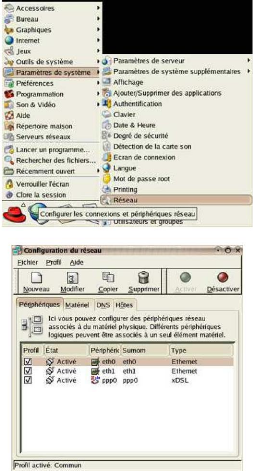
Nous sélectionnons la carte Eth0 et nous lui donnons
une adresse du type ex : 192.168.0.1 et
255.255.255.0 en masque de sous-réseau (adresse de
classe C de type privé, carte reliée à notre réseau
interne).
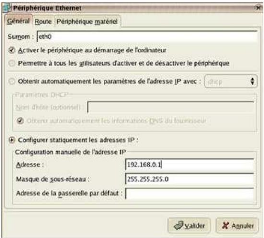
Et nous reproduisons la même opération pour la carte
Eth1 par un double-clic et nous luidonnons une adresse du type
10.0.0.28 et 255.255.255.0 en masque de
sous-réseau ; cette carte sera celle reliée au modem via le
câble Ethernet.
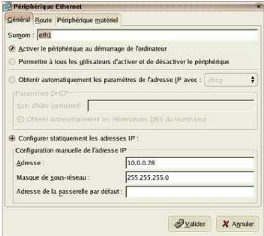
Vu que l'onglet DNS est tout proche, on va ajouter les adresses
Primaire et Secondaire de notre Provider Internet.
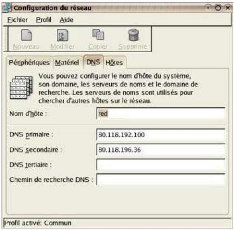
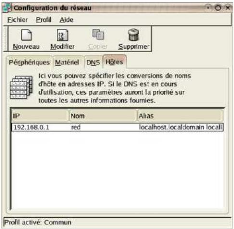
Nous cliquons sur l'onglet Hôtes et indiquer le nom
hostname de notre serveur Redhat.
Puis sauvegarder pour valider la configuration : nous faisons
Fichier ==> Enregistrer.
Pour vérifier les modifications, nous ouvrons un
terminal par un clic-droit sur le bureau et nous nous logons sous
root par su, pour relancer le service network
par la commande /etc/rc.d/init.d/network restart ou service
network restart et faire un ifconfig, nous pouvons observer les
nouvelles IP attribuées aux cartes Eth0 et Eth1.
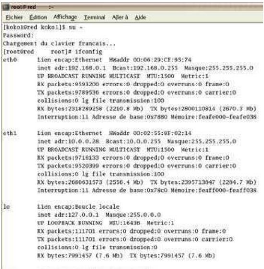
Figure : Installation et configuration modem
V. INSTALLATION DU MODEM
Pour cela, nous allons installer un Package RPM du type
rp-pppoexxx i386.rpm, i386 si lors de l'installation nous l'avons
oublié.
Pour faire l'installation du Package RPM, nous ouvrons à
nouveau un terminal par un clic-
droit sur le bureau et nous nous logons sous
root, nous nous plaçons dans le répertoire
oünotre RPM a été téléchargé
à l'aide de la commande cd /mon_rep, ls pour lister le
répertoire,
puis utiliser la commande rpm -Uvh mon_package.rpm. Une
fois installé, il nous reste plus qu'à configurer la connexion
PPP0 avec la commande adsl-setup
Nous devons remplir tous les éléments
demandés, attention : choisir la bonne carte Ethernet (Eth0 ou Eth1)
identifiant, mot de passe, DNS, nous devons être vigilants à la
dernière option qui traite du firewall, pour bien indiquer la valeur
0, pour non.
La configuration étant effectuée et le modem
branché correctement, nous pouvons lancer une connexion par la commande
adsl-start ou adsl-connect, au bout de quelques secondes le
Shell nous rend la main.
Nous pouvons vérifier que la connexion est bien active
à l'aide de la commande ifconfig, nous devrions voir
apparaître une IP pour l'interface PPP0. Si c'est le cas nous pouvons
lancer un browser Internet (navigateur) et naviguer sur le Web (Internet
Explorer, Google Chrome ou Mozilla Firefox).

Maintenant que notre serveur Linux est bien connecté
à Internet, nous allons le configurer afin qu'il puisse faire
bénéficier sa connexion aux clients DHCP. Sous Linux, le principe
de partage est similaire à ce que l'on peut rencontrer sur les
routeurs.
Pour que notre serveur puisse partager sa connexion avec des
clients, il est indispensable qu'il fasse du N. A. T. (Network Address
Translation - Translations de ports). De plus, nous allons nous servir du
service DHCP afin que les clients puissent récupérer les DNS de
notre connexion.
En résumé, pour que la configuration des clients
soit allégée, nous allons laisser le soin à notre Redhat
Linux d'être serveur DHCP pour l'instant et de permettre un rapatriement
des adresses DNS aux clients. Ces derniers n'auront plus qu'à se
connecter au réseau pour accéder à Internet.
Nous commençons à installer notre Red Hat Linux
en serveur DHCP, configuration du NAMED et ensuite la partie N.A.T qui sera
mise en place à l'aide de notre firewall logiciel (Firewall Builder).
La première chose est de nous assurer que le DHCP n'est
pas déjà installé : Soit en cherchant l'existence du RPM,
soit par la présence de l'exécutable dhcpd et named dans
/etc/rc.d/init.t par la commande ls /etc/rc.d/init.d.Pour
voir s'il est installé en RPM, nous devons utiliser la commande rpm
-qa |grep dhcp et rpm -qa |grep named, qui nous listera tous les
packages installés portant les chaînes de caractères dhcp ;
sinon, pas de panique, les RPM sont disponibles ici
dhcp-3.0pl1-23.i386.rpm Pour l'installer, même technique que
précédemment: rpm -Uvh dhcp-3.0pl1-23.i386.rpm
Nous pouvons aussi le charger tout simplement en utilisant le
RPM de base fournit dans le CD d'installation de REDHAT 9. Pour cela, nous
insérons le CD d'installation Linux,
une fenêtre s'ouvre et valider l'ajout d'un nouveau
programme ou package, puis nous sélectionnons le RPM ou le serveur
à ajouter, dans notre cas ici le serveur DHCP. Dans ce cas,
l'installation se fait automatiquement.
Il ne nous reste plus qu'a configurer notre DHCP : Le fichier de
configuration est situé dans /etc/dhcpd.conf, nous
éditons ce fichier par vi /etc/dhcpd.conf et ajoutons les
lignes suivantes:dhcpd.conf
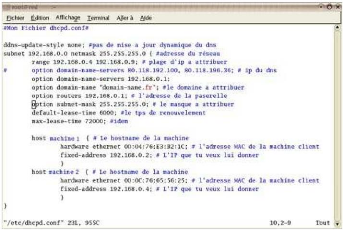
Une fois le DHCP configuré, il nous faut configurer la
partie DNS, par le fichier /etc/named.conf, même
procédures, nous éditons le fichier par vi, vi
/etc/named.conf et nous ajoutons les lignes suivantes :
named.conf

Nous allons adapter
kokoko.dynd.org de
la copie écran par l'URL de notre serveur Apache. Maintenant nous allons
lancer les processus named et dhcpd, par la
commande /etc/rc.d/init.d/named start, /etc/rc.d/init.d/dhcpd
start ou par service named start, service dhcpd start.Le
contrôle des services ou processus en cours d'exécution se fait
par la commande : ps -ef |grep nom_du_service_rechercher, ici named et
dhcpd : ps -ef |grep dhcpd. On voit bien le process en action et la
carte réseau affectée ici eth0.
Nous pouvons donc connecter un poste client au(x)
réseau(x), nous nous logons, puis nous faisons
Démarrer==> Exécuter :
cmd ou command et tapez dans la fenêtre
DOS ipconfig /all, nous voyons apparaître les lignes
suivantes:
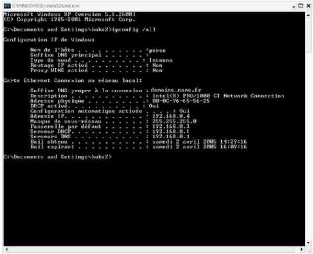
Cela signifie que notre serveur DHCP fonctionne, car l'adresse
de la passerelle (l'adresse de notre serveur DHCP Linux) et le bail dhcp ont
été fournis. Pour finaliser le lancement de ces processus
à chaque reboot de la machine, il nous faut vérifier que le
service sera bien chargé dans le rc5.d (configuration
des services au démarrage), pour cela nous cliquons sur le
chapeau Redhat ==>Paramètre système ==>Service.
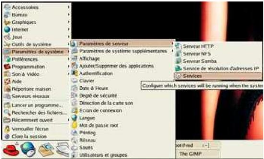
Nous cochons les lignes des services DHCPD et NAMED, nous
pouvons aussi arrêter et redémarrer les services à l'aide
des boutons ici en les sélectionnant. Puis faire
Fichier==> Enregistrer et valider.
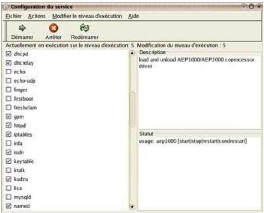
Nous disposons maintenant d'un serveur capable de fournir des
adresses IP à des postes sur le réseau.
VI. MISE EN PLACE D'UN FIREWALL (NAT)
Dernière phase, étape 3 : mise
en place du Firewall (NAT) pour la Passerelle Internet. L'outil utilisé
ici est FIREWALL BUILDER, c'est un programme Graphique qui permet de configurer
et de compiler les règles IPTABLES (firewall), afin de sécuriser
la connexion et faire de la translation de port pour notre partage de connexion
internet (NAT).
FIREWALL BUILDER Release 1:
fwbuilder-1.1.2-1.rh9.i386.rpm
fwbuilder-ipf-1.1.2-1.rh9.i386.rpm fwbuilder-ipfw-1.1.2-1.rh9.i386.rpm
fwbuilder-ipt-1.1.2-1.rh9.i386.rpm fwbuilder-pf-1.1.2-1.rh9.i386.rpm
libfwbuilder-1.0.2-2.rh9.i386.rpm gtkmm-1.2.10-fr3.i386.rpm
libsigc++10-1.0.4-fr3.i386.rpm
FIREWALL BUILDER Release 2:
fwbuilder-2.0.3-1.rh90.i386.rpm
fwbuilder-ipfw-2.0.3-1.rh90.i386.rpm fwbuilder-ipf-2.0.3-1.rh90.i386.rpm
fwbuilder-ipt-2.0.3-1.rh90.i386.rpm fwbuilder-pf-2.0.3-1.rh90.i386.rpm
gtkmm-1.2.10-fr3.i386.rpm
libfwbuilder-2.0.3-1.rh90.i386.rpm
libsigc++10-1.0.4-fr3.i386.rpm
Une fois téléchargée, nous installons les
RPM par la commande :
rpm -Uvh mon_package1.rpm mon_package2.rpm
mon_package3.rpm Une fois le tout installé, deux solutions
s'offrent à nous:
télécharger le fichier fwb (firewall builder) ou
l'installer manuellement.
a. TELECHARGER ET DECOMPRESSER LE
FICHIER fwbuilder dotclear.fwb.tar
Pour décompresser le TAR (fichier compresser), nous
ouvrons un terminal sous root puis nous tapons la commande
tar -xvf fwbuilder_dotclear.fwb.tar ls -la
Pour vérifier si le fichier est exécutable, sinon
nous lui donnons des droits en faisant
chmod 775 fwbuilder_dotclear.fwb chown root:root
fwbuilder_dotclear.fwb (à faire pour des raisons de
sécurité).
Nous ouvrons un terminal sous root et nous
tapons la commande fwbuilder er l'interface graphique
se lance, puis nous ouvrons le fichier et l'adaptons en fonction de notre
système et de notre configuration : Red (hostname de notre linux), eth0,
eth1, nous changeons ou ajoutons les hosts des machines
clientes, plus nos services TCP ou autres.
Puis nous faisons un clic sur le bouton
compiler (ou clic droit sur icône firewall
Red compiler) pour installer les règles, nous ouvrons
un terminal et utilisons les commandes suivantes :
cd /root
ls -la /root/*.fw (liste les fichiers contenant
l'extension fw)
./mon_fichier.fw (ici ./fwbuilder_dotclear.fw) .
Ça y est, le firewall est actif et les règles NAT
sont appliquées, les clients DHCP peuvent surfer en toute
tranquillité. Faire juste, pour les clients DHCP sous Windows dans une
fenêtre DOS, un 'ipconfig /release' puis ipconfig /renew ou pour
un client Linux service network restart
b. INSTALLATION MANUELLE
Nous ouvrons un terminal et tapons la commande fwbuilder
l'interface graphique se lance.
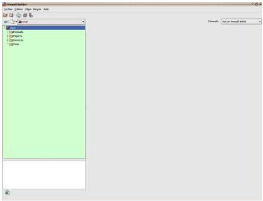
Nous sélectionnons le Firewall, un clic-droit
nouveau Firewall, puis nous indiquons le hostname de notre
serveur et choix du type de firewall logiciel IPTABLES, et
l'OS, puis Next.
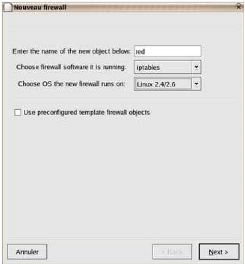
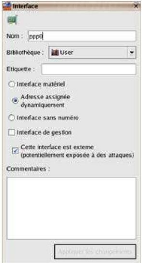
Nous ajoutons notre carte eth0.
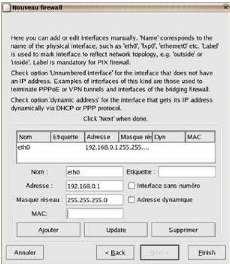
Nous ajoutons notre carte eth1.
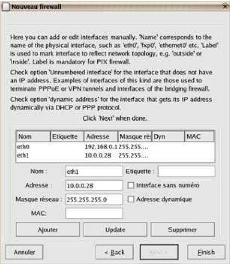
Nous ajoutons notre carte lo.

Nous ajoutons notre interface ppp0 (modem), et
sélectionnons Adresse dynamique, puis nous faisons un
clic sur Finish.
Nous faisons édition ==>
Préférences et indiquer le répertoire de travail
(bien mettre sous root pour raison de sécurité).
Pour vérifier la configuration du firewall, nous faisons
un double-clic sur l'icône firewall Red.

Et configuration firewall. Pour
vérifier et ajouter les options puis nous faisons un clic sur
OK.
Maintenant nous allons configurer, les domaines (WorkGroup
DMZ), nos Hosts clients (Pour des liaisons NAT spécifique: Remote XP,
P2P, etc....), nos services TCP et UDP, la politique générale du
firewall, les règles pour l'interface PPP0, eth0 (reliée au
réseau interne), eth1 (reliée au modem), lo (broadcast) et la
fameuse partie NAT (Network Address Translation : Translation De Ports).
Pour configurer notre domaine : nous faisons un clic droit sur
Network, et nous sélectionnons nouveau réseau.
Ou nous cliquons sur la petite flèche à droite de l'icone suivant
et nous faisons nouveau service TCP :

Nous indiquons de surcroit la classe réseau
(Classe C).
Puis nous rééditons l'opération pour ce que
nous appellerons la DMZ, mini réseau entre notre interface (PPP0) et
notre carte eth0 (reliée à notre modem).
Pour configurer les Hosts, nous faisons pour cela un clic
droit sur hosts, sélectionner nouveau Hosts. Ou nous
faisons un clic sur la petite flèche à droite de l'icone suivant
et faire nouveau service TCP :

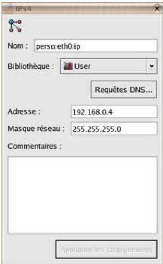
Nous indiquons le host de notre machine
client, nous cliquons sur Next, puis nous
sélectionnons configuration manuelle et un clic sur
Next et nous ajoutons les cartes réseaux :
eth0=192.168.0.4 masque 255.255.255.0 et lo=127.0.0.1 masque idem et
valider.
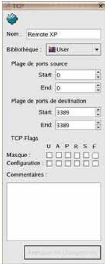
Pour le service TCP, nous faisons un clic sur
SERVICE et clic droit sur service TCP pour ajouter nouveau
service TCP.Ou une autre possibilité nous cliquons sur
la petite flèche à droite de l'icone suivant et faire nouveau
service TCP:

Ajouter les ports de destinations désirés.
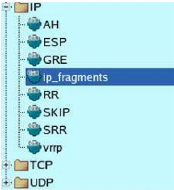
Cliquer sur la partie marquer USER et
sélectionner Standard.

Trouver les services, puis la zone
IP, copier l'icône IP_FRAGMENTS par un
clic droit et retourner dans USER.
Nous cliquons sur l'onglet politique puis
dans le menu, Règle ==> Insérer une règle
et nous collons l'icone IP_FRAGMENTS dans
service, action en
DENY et Source,
Destination, Horaires en
Any.

Nous cliquons sur l'onglet eth0 et dans le menu,
Règle ==> Insérer une règle ensuite
nous glissons nos icones crées (domaine, host, service TCP) dans les
zones adéquates afin de construire nos règles.

Nous cliquons sur l'onglet eth1 et dans le
menu Règle ==> Insérer une règle puis
nous glissons nos icones crées (domaine, host, service TCP) dans les
zones adéquates afin de construire nos règles.

Nous cliquons sur l'onglet lo puis nous
faisons dans le menu, Règle ==> Insérer une
règle et nous glissons nos icones crées (domaine, host,
service TCP) dans les zones adéquates afin de construire nos
règles.

Et aussi nous faisons un clic sur l'onglet
PPP0, nous faisons dans le menu Règle ==>
Insérer une règle et nous faisons glisser nos icones
crées (domaine, host, service TCP) dans les zones adéquates afin
de construire nos règles.
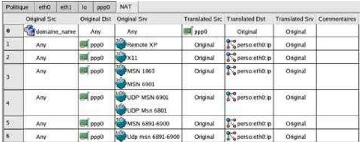
Nous cliquons sur l'onglet NAT dans le menu,
Règle ==> Insérer une
règle et glisser nos icônes crées (domaine, host,
service TCP, UDP ou autre) dans les zones adéquates afin de construire
nos règles.
Pour sauvegarder nous faisons Fichier ==>
Enregistrer. Puis nous faisons un clic sur le bouton
compiler (ou clic droit sur icône firewall
Red compiler). Apres avoir
Installées les règles, nous faisons un clic sur
le bouton Installer (ou clic droit sur icône firewall
Red Installer) soit en ouvrant un terminal sous
root et utiliser les commandes suivantes :
cd /root ls -la /root/*.fw (liste les fichiers
contenant l'extention fw, extension de notre règle firewall). Si le
fichier n'est pas exécutable, nous lui donnons les droits en faisant
chmod 755 mon_fichier.fw./mon_fichier.fw (ici
./fwbuilder_dotclear.fw) ou directement par root/mon_fichier.fw . Nous
pouvons visualiser alors l'application des Règles
Iptables.
Le Firewall et la Passerelle
Internet de notre serveur Red Hat Linux sont activés. Les
clients DHCP peuvent surfer en toute tranquillité pour l'instant avant
de fixer les adresses pour permettre la Messagerie.
VII. CONFIGURATION DE L'AUTHENTIFICATION
Lorsqu'un utilisateur se connecte à un système
Red Hat Linux, la combinaison nom d'utilisateur/mot de passe doit être
vérifiée, ou authentifiée, comme un utilisateur
valide et actif. Dans certaines situations, les informations nécessaires
à la vérification de l'utilisateur se trouvent sur le
système local et dans d'autres situations, le système demande
à une base de données utilisateur se trouvant sur un
système distant d'effectuer l'authentification.
L'Outil de configuration d'authentification
fournit une interface graphique permettant non seulement de configurer NIS,
LDAP et Hesiod de manière à ce qu'ils extraient les informations
d'utilisateur mais permettant également la configuration de LDAP,
Kerberos et SMB en tant que protocoles d'authentification.
Pour démarrer la version graphique de l'Outil
de configuration d'authentification à partir du bureau, nous
sélectionnons le bouton Menu principal (sur le panneau)
=> Paramètres du système =>
Authentification ou par la commande authconfig-gtk
à une invite du Shell (par exemple, dans XTerm GNOME
terminal). Afin de démarrer la version texte, nous tapons la
commande authconfig à une invite du Shell.
a) INFORMATIONS UTILISATEUR
L'onglet Informations utilisateur offre
plusieurs options. Pour activer une option, nous cochons la case de pointage
située à côté d'elle. Pour désactiver une
option, nous faisons un clic sur la case de pointage située à
côté d'elle et tout choix précédent sera
annulé. Nous faisons un clic sur OK afin de sortir du
programme et mettre en oeuvre les modifications apportées.
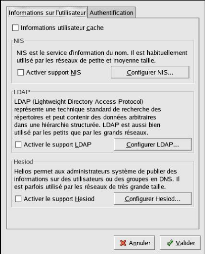
Figure : Informations utilisateur
La liste ci-
dessous explique l'élément que chaque
option configure:
· Cache d'informations utilisateur
: nous sélectionnons cette option
pour
qu'il se lance au démarrage. puisse
fonctionner.
· Activer support NIS
activer le démon de cache de service de noms
(nscd) et le configurer de manière à ce Le
paquetage nscd doit être installé pour que cette option
: cette option permet de configurer le système en tant
que
client NIS qui se connecte à un serveur
NI
S pour l'authentification de l'utilisateur et du
Configurer NIS
mot de passe. Nous cliquons sur le bouton pour
spécifier le domaine
NIS et le serveur NIS. Si le serveur NIS n'est pas
spécifié, le démon essaiera de le trouver
par le biais de la diffusion. Le paquetage ypbind doit être
installé pour que cette option puisse fonctionner. Si
la prise en charge NIS est activée, les services
portmap et ypbind sont non seulement lancés mais sont
également activés de manière à
s'amorcer au démarrage.
· Activer support LDAP : cette option permet de
configurer le système de manière à ce
qu'il extraie les informations utilisateur par le biais de LDAP. Nous
Configurer LDAP pour spécifier le
cliquons sur le bouton DN de la base de
recherche de LDAP et le Serveur
LDAP. En sélectionnant Utiliser TLS pour crypter les
mots de passe , Transport Layer Security deviendra la
méthode de cryptage des mots de passe envoyés au
serveur LDAP. Le paquetage openldap-clients doit être
installé pour que cette option puisse fonctionner.
· Activ er support Hesiod : cette option permet
de configurer le système de manière à ce
qu'il extraie ses informations d'une base de données Hesiod distante,
y compris les informations utilisateurs. Le paquetage hesiod
doit être installé pour que cette option pui
sse fonctionner.
b) AUTHENTIFICATION
L'onglet Authentification
permet la configuration des méthodes
d'authentification réseau. Pour activer une option,
nous devons cliquer sur la case de pointage vierge placée à
côté d'elle. Pour désactiver une option,
nous faisons un clic sur la case de pointage située à
côté d'elle et tout choix précédent
sera annulé.
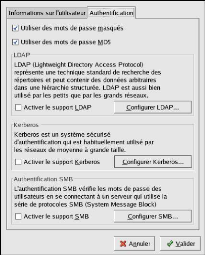
Figure : Authentification
Les informations suivantes expliquent
l'élément que chaque option configure :
· Utiliser des mots de passe
masqués : cette opt
ion permet de conserver les mots de
passe dans un format de mots de passe masqués dans le fichier
/etc/shadow
plutôt que dans le fichier
/etc/passwd
. Les mots de passe masqués
sont activés par défaut lors de l'installation et leur
utilisation est fortement recommandée afin d'augmenter la
sécurité du système. Le paquetage shadowutils doit
être installé pour que cette option puisse
fonctionner.
· Utiliser des mots de passe MD5
: cette option permet d'activer les mots de
passe MD5, qui peuvent avoir une longueur allant jusqu'à 256
caractères au lieu de huit ou moins. Cette option est
sélectionnée par défaut lors de
l'installation et leur utilisation est fortement recommandée
afin d'augmenter la sécurité du
système.
· Activer support LDAP : cette option
permet à
des applications supportant
PAM d'utiliser LDAP pour l'authentification. Nous
cliquons sur le bouton pour spécifier les
éléments suivants :
Configurer LDAP
> Utiliser TLS pour crypter les mots de
passe : cette option permet d'utiliser Transport Layer Security pour
crypter des mots de passe envoyés sur le serveur LDAP.
> DN de la base de recherche LDAP : cette
option permet d'extraire les informations utilisateurs d'après son Nom
Distinct (ou DN de l'anglais 'Distinguished Name').
> Serveur LDAP : cette option permet de
spécifier l'adresse IP du serveur LDAP. Le paquetage openldap-clients
doit être installé pour que cette option puisse fonctionner.
· Activer le support Kerberos : cette
option permet d'activer l'authentification Kerberos. Nous cliquons sur le
bouton Configurer Kerberos pour effectuer la configuration
:
> Zone : cette option permet de
configurer la zone (ou 'Realm') du serveur Kerberos. La zone correspond au
réseau utilisant Kerberos, composée d'un ou plusieurs KDC et
potentiellement, d'un nombre important de clients.
> KDC : cette option permet de
définir le centre de distributeur de tickets (ou KDC, de l'anglais 'Key
Distribution Center'), le serveur émettant les tickets de Kerberos.
> Serveurs Admin : cette option permet de
spécifier les serveurs d'administration exécutant kadmind. Les
paquetages krb5-libs et krb5- workstation doivent être installés
pour que cette option puisse fonctionner.
· Activer support SMB : cette option
permet de configurer les PAM (les modules d'authentification enfichables) de
manière à ce qu'ils utilisent un serveur SMB pour authentifier
les utilisateurs. Cliquez sur le bouton Configurer SMB pour
spécifier les éléments suivants:
> Groupe de travail : cette option permet
de spécifier le groupe de travail SMB à utiliser.
> Contrôleurs de domaine : cette
option permet de spécifier les contrôleurs de domaine SMB à
utiliser.
Pour notre cas, comme nous devons aussi mettre en place un
serveur de messagerie avec le serveur Sendmail nous allons activer LDAP pour
permettre une meilleur authentification des utilisateurs.
VIII. CONFIGURATION DU SERVEUR HTTP APACHE
L'Outil de configuration HTTP nous permet de configurer le
fichier de configuration /etc/httpd/conf/httpd.conf pour le Serveur
HTTP Apache. Il n'utilise pas les anciens fichiers de configuration
srm.conf ou access.conf ; nous pouvons donc les laisser
vides. Il est possible, à partir de l'interface graphique, de configurer
des directives telles que des hôtes virtuels, des attributs de
journalisation ou encore un nombre maximal de connexions. Seuls les modules
livrés avec Red Hat Linux peuvent être configurés avec
l'Outil de configuration
HTTP. Si nous installons des modules supplémentaires,
il ne nous sera pas possible de les configurer à l'aide de cet outil.
Les paquetages rpm httpd et
redhat-config-httpd doivent être préalablement
installés si nous souhaitons utiliser l'Outil de configuration HTTP.
Pour son fonctionnement, il a également besoin du système X
Windows et des privilèges de superutilisateur (ou root). Pour
démarrer l'application, nous nous rendons au bouton Menu
principal => Paramètres de système => Paramètres de
serveur => Serveur HTTP ou nous tapons la commande
redhat-config-httpd à l'invite du Shell (dans un terminal XTerm
ou GNOME).
Attention
Il ne faudrait pas éditer manuellement le fichier de
configuration /etc/httpd/conf/httpd.conf si l'on désire
utiliser cet outil. L'Outil de configuration HTTP génère
automatiquement ce fichier une fois que nous avons enregistré nos
changements et quitté le programme. Si l'on souhaite ajouter des modules
supplémentaires ou des options de configuration qui ne sont pas
disponibles dans l'Outil de configuration HTTP, nous ne pouvons pas utiliser
cet outil.
Ci-dessous figurent les étapes principales de la
configuration du Serveur HTTP Apache à l'aide de l'Outil de
configuration HTTP :
1. Configurer les paramètres de base dans l'onglet
Main (Principal).
2. Cliquer sur l'onglet Virtual Hosts (Hôtes virtuels) et
configurer les paramètres par défaut.
3. Dans l'onglet Virtual Hosts (Hôtes virtuels),
configurer l'hôte virtuel par défaut.
4. Si l'on souhaite servir plusieurs URL ou hôtes
virtuels, on ajoute les hôtes virtuels supplémentaires.
5. Configurer les paramètres du serveur dans l'onglet
Server (serveur).
6. Configurer les paramètres de connexion dans l'onglet
Performance Tuning (Réglage des performances).
7. Copier tous les fichiers nécessaires dans les
répertoires DocumentRoot et cgi-bin.
8. Quitter l'application et choisir d'enregistrer les
paramètres.
a) PARAMETRES DE BASE
Nous utilisons l'onglet Main (Principal) pour
configurer les paramètres de base du serveur.
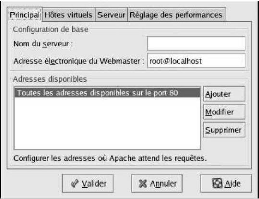
Figure : Paramètres de base
De cette manière nous entrons un nom de domaine
pleinement qualifié pour lequel nous avons des autorisations
d'accès dans la zone de texte Server Name (Nom de
serveur). Cette option correspond à la directive ServerName dans
httpd.conf. Cette directive ServerName définie le nom d'hôte du
serveur Web. Elle est utilisée lors de la création d'URL de
retransmission. Si nous ne définissons pas de nom de serveur, le serveur
Web essaie de le résoudre à partir de l'adresse IP du
système. Le nom de serveur ne doit pas forcément être
identique au nom de domaine résolu à partir de l'adresse IP du
serveur.
Nous entrons alors l'adresse électronique de la
personne qui met à jour le serveur Web dans la zone de texte
Adresse électronique du Webmaster. Cette option
correspond à la directive ServerAdmin dans httpd.conf. Nous configurons
les pages d'erreur du serveur de façon à ce qu'elles contiennent
une adresse électronique, celle-ci sera alors utilisée pour
transmettre tout problème à l'administrateur du serveur. La
valeur par défaut est root@enerca. Nous utilisons la zone
Available Addresses (Adresses disponibles) pour définir
les ports sur lesquels le serveur acceptera les requêtes entrantes. Cette
option correspond à la directive Listen dans httpd.conf. Par
défaut, Red Hat configure le Serveur HTTP Apache de manière
à ce qu'il écoute le port 80 pour des communications Web
non-sécurisées.
Pour cela nous cliquons sur le bouton Add
pour définir des ports supplémentaires pour la réception
de requêtes. Une fenêtre semblable à celle reproduite dans
la Figure ci dessous apparaîtra. Nous pouvons choisir, soit l'option
Listen to all addresses pour écouter toutes les
adresses IP sur le port défini, ou nous pouvons spécifier une
adresse IP spécifique à laquelle le serveur acceptera des
connexions dans le champ d'adresse, Address.
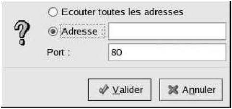
Figure : Adresses disponibles
Après avoir défini un Nom du
serveur, l'adresse électronique du Webmaster
et Adresses disponibles, nous cliquons sur l'onglet
Hôtes virtuels puis sur le bouton Modifier les paramètres par
défaut. La fenêtre reproduite dans la Figure ci dessous s'ouvre
alors. Nous configurons les paramètres par défaut pour le serveur
Web dans cette fenêtre. En ajoutant un hôte virtuel, les
paramètres que nous indiquons ont la priorité pour cet hôte
virtuel. Si une directive n'est pas définie dans les paramètres
de l'hôte virtuel, la valeur par défaut est utilisée. Les
valeurs par défaut de Liste de recherche page répertoire et Page
d'erreur fonctionnent pour la plupart des serveurs.
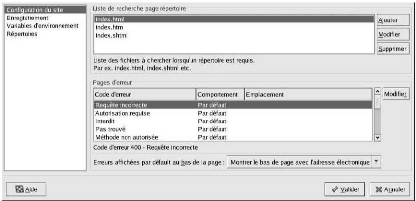
Figure : Configuration du site
Les entrées énumérées dans Liste
de recherche de pages répertoires définissent la directive
DirectoryIndex. DirectoryIndex est la page
par défaut renvoyée par le serveur lorsqu'un utilisateur demande
l'index d'un répertoire en ajoutant une barre oblique (/) à la
fin du nom de ce répertoire.
Par exemple, lorsque des utilisateurs demandent la page
http://www.enerca.cf/hope/,
ils recevront soit la page Hope, si elle existe, soit une liste de
répertoires générée par le serveur. Ce dernier
essaiera de trouver un des fichiers listés dans la directive Hope et
renverra le premier qu'il trouvera. S'il ne trouve aucun de ces fichiers et que
cette Options Indexes à
ce répertoire comme valeur, le serveur
générera une liste des sous-répertoires et fichiers
contenus dans ce répertoire et la renverra, dans un format HTML.
Nous utilisons la section Code d'erreur pour configurer le
Serveur HTTP Apache afin qu'il redirige le client vers une URL locale ou
externe en cas de problème ou d'erreur. Cette option correspond à
la directive ErrorDocument. Si un problème ou une erreur survient
lorsqu'un client essaie de se connecter au Serveur HTTP Apache, le bref message
d'erreur indiqué dans la colonne Code d'erreur s'affiche par
défaut. Pour remplacer cette configuration par défaut, nous
sélectionnons le code d'erreur et cliquons sur le bouton Modifier. Nous
choisissons Défaut afin d'afficher le message d'erreur par
défaut. Nous sélectionnons URL pour rediriger le client vers une
URL externe et entrons une URL complète, y compris
http:// dans le champ Emplacement.
Nous sélectionnons Fichier pour rediriger le client vers une URL interne
et entrons un emplacement de fichier sous le document root du serveur Web.
L'emplacement doit commencer par une barre oblique (/) et être relatif au
document root. Par exemple, pour rediriger un code d'erreur "404 Not Found"
(impossible de trouver la page) vers une page Web que nous avons
créée dans un fichier nommé 404.html, nous copions
404.html dans DocumentRoot/errors/404.html. Dans ce cas, DocumentRoot
correspond au répertoire Document Root que nous avons défini (la
valeur par défaut est /var/www/html). Nous sélectionnons ensuite
Fichier comme comportement pour le code d'erreur 404 - Not Found et entrer
/errors/404.html dans le champ Emplacement.
Nous choisissons l'une des options suivantes dans le menu
Erreurs affichées par défaut au bas de la page :
· Montrer le bas de page avec adresse
électronique .affiche le bas de page par défaut sur chacune des
pages d'erreur ainsi que l'adresse électronique de l'administrateur du
site Web spécifiés par la directive ServerAdmin.
· Montrer le bas de page. n'affiche que le bas de page
par défaut sur les pages d'erreur.
· Aucun bas de page. n'affiche aucun bas de page sur les
pages d'erreur.
b) JOURNALISATION
Par défaut, le serveur enregistre le journal des
transferts dans le fichier /var/log/httpd/access_log et le journal des
erreurs dans le fichier /var/log/httpd/error_log.
Le journal des transferts contient la liste de toutes les
tentatives d'accès au serveur Web. Il enregistre l'adresse IP des
clients qui essaient de se connecter, la date ainsi que l'heure de leurs
tentatives et les fichiers du serveur Web auxquels ils veulent accéder.
Nous entrons le chemin d'accès et le nom du fichier où
enregistrer ces informations. Si le chemin d'accès et le nom de fichier
ne commencent pas par une barre oblique (/), le chemin est alors relatif au
répertoire root du serveur, tel que nous l'avons configuré. Cette
option correspond à la directive TransferLog.
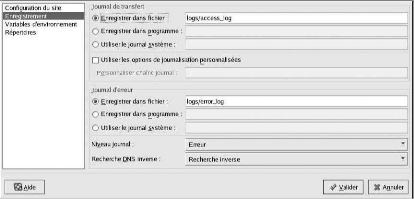
Figure : Journalisation
Nous pouvons configurer un format de journal
personnalisé en cochant l'option Utiliser les options de
journalisation personnalisées et en entrant une chaîne de
journal personnalisée dans le champ Personnaliser chaîne
journal. Cela permet de configurer la directive LogFormat.
Le journal des erreurs contient une liste des erreurs de
serveur. Nous devons entrer le chemin d'accès et le nom du fichier
où enregistrer ces informations. Si le chemin d'accès et le nom
de fichier ne commencent pas par une barre oblique (/), le chemin est alors
relatif au répertoire root du serveur, tel que nous l'avons
configuré. Cette option correspond à la directive ErrorLog. Nous
utilisons le menu Niveau journal afin de définir le degré de
prolixité des messages dans le journal des erreurs. Nous avons le choix
(du moins prolixe au plus prolixe) entre emerg, alert, crit, error, warn,
notice, info et debug. Cette option correspond à la
directive LogLevel.
La valeur choisie dans le menu Recherche DNS
inverse définit la directive HostnameLookups. Ne choisir
Aucune recherche inverse (No Reverse Lookup) configure la
valeur sur "off". Choisir Recherche inverse (Reverse Lookup)
configure la valeur sur "on". Choisir Double recherche inverse
(Double Reverse Lookup) configure la valeur sur "double". Nous
sélectionnons Recherche inverse, le serveur
résout automatiquement l'adresse IP de chaque connexion qui demande un
document au serveur Web. Cela signifie que notre serveur effectue une ou
plusieurs connexions au DNS afin de trouver le nom d'hôte correspondant
à une adresse IP donnée.
Si nous sélectionnons Double recherche
inverse, notre serveur effectue une double recherche DNS. Autrement
dit, après avoir effectué une recherche inverse, le serveur en
effectue une deuxième sur le résultat obtenu. Au moins une des
adresses IP de la seconde recherche doit correspondre à l'une des
adresses de la première. En règle générale, nous
devrions conserver la valeur Aucune recherche inverse pour
cette option car les requêtes
DNS ajoutent une charge à notre serveur et risquent de
le ralentir. Si notre serveur est très occupé, ces recherches,
qu'elles soient simples ou doubles, peuvent avoir un effet assez
perceptible.
De plus, les recherches inverses et doubles recherches
inverses affectent l'activité Internet en général. Toutes
les connexions individuelles effectuées pour vérifier les noms
d'hôte s'additionnent. Aussi, pour le bien de notre propre serveur Web et
de l'Internet, nous conservons la valeur Aucune recherche inverse. Il est
parfois nécessaire de modifier des variables d'environnement pour les
scripts CGI et les pages à inclure (SSI) au niveau du serveur. Le
Serveur HTTP Apache peut utiliser le module mod_env pour configurer les
variables d'environnement transmises aux scripts CGI et aux pages SSI. Nous
utilisons la page Variables d'environnement pour configurer les directives de
ce module.
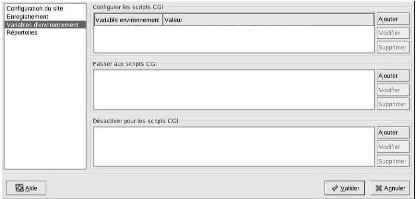
Figure : Variables d'environnement
Nous utilisons la section Configurer les scripts
CGI pour définir une variable d'environnement transmise aux
scripts CGI et aux pages SSI. Exemple, pour donner à la variable
d'environnement MAXNUM la valeur 50, nous cliquons sur le bouton Ajouter dans
la section Configurer les scripts CGI comme le montre la
Figure : Variables d'environnement et tapons MAXNUM
dans le champ de texte Variable d'environnement et 50 dans le
champ de texte Valeur à définir. Nous cliquons
ensuite sur OK pour l'ajouter à la liste. La section
Configurer les scripts CGI sert à configurer la
directive SetEnv. Nous utilisons la section Transmettre aux scripts CGI pour
transmettre la valeur d'une variable d'environnement aux scripts CGI lorsque le
serveur est lancé pour la première fois. Pour visualiser cette
variable d'environnement, nous entrons la commande env à
l'invite du Shell. Nous cliquons sur le bouton Ajouter dans la
section Transmettre aux scripts CGI et entrons le nom de la
variable dans la boîte de dialogue. Puis nous cliquons ensuite sur
OK pour l'ajouter à la liste. La section
Transmettre aux scripts CGI configure la directive PassEnv. Si
nous voulons supprimer une variable d'environnement afin que sa valeur ne soit
pas transmise aux scripts CGI et aux pages SSI, nous utilisons la section
Désélectionner pour les scripts CGI. Nous
cliquons sur Ajouter dans la section
Désélectionner pour les scripts
CGI et entrons le nom de la variable d'environnement à
désélectionner. Puis nous cliquons sur
OK pour l'ajouter à la liste. Cela correspond à
la directive UnsetEnv directive.
Pour modifier une de ces valeurs d'environnement, nous la
sélectionnons parmi la liste et cliquons sur le bouton
Éditer correspondant. Pour supprimer toute
entrée de la liste, nous la sélectionnons puis cliquons sur le
bouton Supprimer correspondant.
c) REPERTOIRES
Nous utilisons la page Répertoires pour configurer des
options de répertoires spécifiques. Cela correspond à la
directive « Répertoires ».
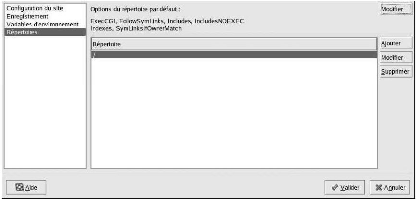
Figure : Répertoires
Nous cliquons sur le bouton Modifier dans le coin
supérieur droit afin de configurer les Options par défaut des
répertoires pour tous les répertoires non spécifiés
dans la liste Répertoire ci-dessous. Les options que vous
sélectionnez sont énumérées en tant que directive
d'options dans la directive « Directory ». Nous pouvons configurer
les options suivantes:
· ExecCGI : permet l'exécution de scripts CGI. Les
scripts CGI ne sont pas exécutés si cette option n'est pas
sélectionnée.
· FollowSymLinks : permet aux liens symboliques
d'être suivis.
· Includes : permet les inclusions sur le serveur.
· IncludesNOEXEC : permet les inclusions sur le serveur,
mais désactive les commandes #exec et #include dans les scripts CGI.
· Indexes : affiche une liste formatée du contenu
d'un répertoire, si aucun DirectoryIndex (tel que index.html) n'existe
dans le répertoire demandé.
· Multiview.prend en charge la multi vue à contenu
variable; cette option est désactivée par défaut.
· SymLinksIfOwnerMatch : suit les liens symboliques
uniquement si le propriétaire du fichier ou du répertoire cible
est le même que celui du lien.
Pour spécifier des options pour des répertoires
particuliers, nous devons cliquer sur le bouton Ajouter
situé près de la zone de liste Répertoire. La
fenêtre présentée dans la Figure :
Paramètres des répertoires s'ouvre alors.
Nous entrons le répertoire à configurer dans le
champ Répertoire situé au bas de la fenêtre. Nous
sélectionnons les options dans la liste située à droite et
configurons la directive Order au moyen des options
situées à gauche. La directive Order
contrôle l'ordre dans lequel les directives d'autorisation et de refus
sont évaluées. Dans les champs de texte Autoriser les
hôtes à partir de et Refuser les hôtes
à partir de, nous pouvons spécifier l'un des
éléments suivants:
· Autoriser tous les hôtes : nous entrons
all pour autoriser l'accès à tous les
hôtes.
· Nom de domaine partiel : autorise tous les hôtes
dont le nom correspond à, ou se termine par, une chaîne
spécifique.
· Adresse IP complète : accorde l'accès
à une adresse IP spécifique.
· Un sous-réseau : par exemple
192.168.1.0/255.255.255.0
· Une spécification CIDR de réseau par
exemple 10.3.0.0/16
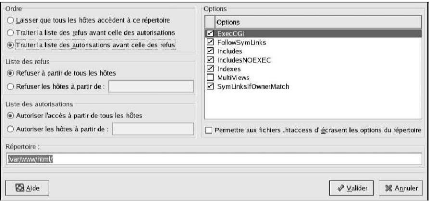
Figure : Paramètres des
répertoires
Nous cochons la case Permettre aux fichiers .htaccess
d'écraser les options du répertoire, les directives de
configuration du fichier .htaccess ont la priorité.
Nous utilisons l'Outil de configuration HTTP pour configurer des
hôtes virtuels. Les hôtes virtuels nous permettent
d'exécuter différents serveurs pour différentes adresses
IP, différents noms d'hôte ou différents ports sur un
même ordinateur. Par exemple, nous pouvons exécuter les sites Web
http://www.enerca.com et
http://www.centrale-energie.com
sur le même serveur Web à l'aide d'hôtes virtuels. Cette
option correspond à la directive « VirtualHost » pour
l'hôte virtuel par défaut ainsi que pour les hôtes virtuels
basés sur l'adresse IP. Cela correspond à la directive «
NameVirtualHost » pour un hôte virtuel basé sur le nom. Les
directives définies pour un hôte virtuel ne s'appliquent
qu'à cet hôte virtuel. Si une directive est définie pour
l'ensemble du serveur au moyen du bouton Modifier
paramètres par défaut et n'est pas définie
dans les paramètres de l'hôte virtuel, le
paramètre par défaut est alors utilisé. Nous pourrions
définir Adresse électronique du Webmaster dans l'onglet Main et
ne pas indiquer d'adresse électronique individuelle pour chacun des
hôtes virtuels. L'Outil de configuration HTTP inclut un hôte
virtuel par défaut.
Figure : Hôtes virtuels
d) AJOUT ET MODIFICATION D'UN HOTE
VIRTUEL
Pour ajouter un hôte virtuel, nous devons cliquer sur
l'onglet Hôtes virtuels puis sur le bouton Ajouter. Nous
pouvons également modifier un hôte virtuel en le
sélectionnant dans la liste, puis en cliquant sur le bouton
Modifier.
e) OPTIONS GENERALES
Les paramètres des Options générales ne
s'appliquent qu'à l'hôte virtuel que nous configurons. Nous
définissons le nom de l'hôte virtuel dans la zone de texte
Nom de l'hôte virtuel. Ce nom est utilisé par
l'Outil de configuration HTTP pour établir une distinction entre les
hôtes virtuels.
Nous définissons la valeur de Répertoire racine
du document en indiquant le répertoire qui contient le document racine
(ou root) (index.html) de l'hôte virtuel. Cette option correspond
à la directive DocumentRoot dans la directive « VirtualHost ».
Toutefois, dans Red Hat Linux 9, le DocumentRoot par défaut est
/var/www/html. L'Adresse électronique du Webmaster correspond à
la directive ServerAdmin dans la directive VirtualHost. Cette adresse
électronique est utilisée dans le bas de page des pages d'erreur
si nous choisissons d'y afficher un bas de page contenant une adresse
électronique. Dans la section Informations sur l'hôte, nous
sélectionnons Hôte virtuel par défaut,
Hôte virtuel basé sur IP ou Hôte
virtuel basé sur le nom :
· Hôte virtuel par
défaut.
Un seul hôte virtuel par défaut
doit être configuré (il n'existe qu'une seule configuration par
défaut). Les paramètres par défaut de l'hôte virtuel
sont utilisés lorsque l'adresse IP demandée n'est pas
explicitement indiquée dans un autre hôte virtuel. Si aucun
hôte virtuel par défaut n'est défini, les paramètres
du serveur principal sont utilisés.
· Hôte virtuel basé sur
IP.
Si nous choisissons Hôte virtuel basé
sur IP, une fenêtre s'ouvre pour configurer la directive «
VirtualHost » en fonction de l'adresse IP du serveur. Nous
spécifions cette adresse IP dans le champ Adresse IP.
Nous pouvons spécifier plusieurs adresses IP en les séparant par
un espace. Pour spécifier un port, nous utilisons la syntaxe
Adresse IP: Port. Nous utilisons : * pour
configurer tous les ports de l'adresse IP. Nous spécifions le nom de
l'hôte virtuel dans le champ Nom d'hôte du
serveur.
· Hôte virtuel basé sur le
nom.
Si nous sélectionnons Hôte virtuel basé
sur le nom, une fenêtre s'ouvre pour configurer la directive
NameVirtualHost en fonction du nom d'hôte du serveur. Nous devons
spécifier l'adresse IP dans le champ Adresse IP. Si
nous spécifions plusieurs adresses IP, nous devons les séparer
par un espace. Pour spécifier un port, nous utilisons la syntaxe
Adresse IP: Port. Nous utilisons : * pour
configurer tous les ports de l'adresse IP. Nous spécifions le nom de
l'hôte virtuel dans le champ Nom d'hôte du
serveur.
Dans la section Alias, nous cliquons sur
Ajouter pour attribuer un surnom à l'hôte.
Ajouter un surnom à cet hôte équivaut à ajouter une
directive ServerAlias dans la directive NameVirtualHost.
f) SSL Remarque :
Nous ne pouvons pas utiliser un hôte virtuel basé
sur un nom avec SSL car l'établissement d'une liaison SSL (lorsque le
navigateur accepte le certificat du serveur Web sécurisé)
s'effectue avant la requête HTTP qui identifie l'hôte virtuel
basé sur le nom approprié. Par conséquent, si nous
souhaitons utiliser un hôte virtuel basé sur un nom, nous devons
utiliser notre serveur Web non-sécurisé.
Figure : Prise en charge SSL
Si le Serveur HTTP Apache n'est pas configuré pour la
prise en charge SSL, les communications entre le Serveur HTTP Apache et ses
clients ne sont pas cryptées. Cela convient aux sites Web ne contenant
aucune information personnelle ou confidentielle. Par exemple, un site Web Open
Source qui distribue de la documentation et des logiciels Open Source n'a
nullement besoin de communications sécurisées. En revanche, un
site Web de commerce électronique qui traite des informations telles que
des numéros de cartes de crédit devrait utiliser la prise en
charge SSL Apache pour crypter ses communications. L'activation de la prise en
charge SSL Apache permet d'utiliser le module de sécurité
mod_ssl. Pour l'activer à partir de l'Outil de configuration HTTP, nous
devons accorder l'accès par le port 443 sous l'onglet Principal
=> Adresses disponibles. Nous sélectionnons ensuite le nom
d'hôte virtuel dans l'onglet Hôtes virtuels et nous cliquons sur le
bouton Modifier puis nous sélectionnons SSL dans le
menu de gauche et cochons l'option Activer support SSL, comme
le montre la Figure prise en charge SSL. La section Configuration SSL est
déjà configurée et contient un certificat numérique
fictif. Ces certificats fournissent l'authentification au serveur Web
sécurisé et identifient ce dernier auprès des navigateurs
Web clients. Nous devons acheter notre propre certificat numérique ce
qui ne sera pas possible pour notre cas.
g) OPTIONS SUPPLEMENTAIRES POUR LES HOTES
VIRTUELS
Les options Configuration du site,
Variables d'environnement et Répertoires pour
les hôtes virtuels correspondent aux mêmes directives que
celles définies à l'aide du bouton Modifier les
paramètres par défaut, à une différence
près que les options définies ici s'appliquent aux hôtes
virtuels individuels que nous configurons.
h) PARAMETRES DU SERVEUR
L'onglet Serveur nous permet de configurer les
paramètres de base du serveur. Les paramètres par défaut
attribués aux différentes options conviennent à la plupart
des situations.
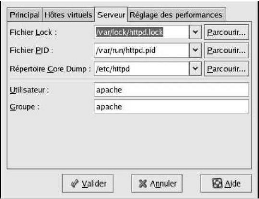
Figure : Configuration du serveur
La valeur Lock File correspond à la
directive LockFile. Cette dernière définit le chemin
d'accès au fichier de verrouillage utilisé lorsque le serveur est
compilé avec USE_FCNTL_SERIALIZED_ACCEPT ou USE_FLOCK_SERIALIZED_ACCEPT.
Il doit être enregistré sur le disque local. La valeur par
défaut sera laissée sauf si le répertoire logs est
situé sur un partage NFS. Dans ce cas, nous devons changer la valeur par
défaut par un emplacement sur le disque local, dans un répertoire
qui ne peut être lu que par l'utilisateur root.
La valeur Fichier PID correspond à la
directive PidFile. Cette directive définit le fichier dans lequel le
serveur enregistre son ID de processus (pid). L'accès en lecture de ce
fichier doit être réservé à l'utilisateur root. Il
est préférable de laisser, dans la plupart des cas, la valeur par
défaut. La valeur Répertoire Core Dump
correspond à la directive CoreDumpDirectory. Le Serveur HTTP Apache
essaie de passer à ce répertoire avant de vider le noyau. La
valeur par défaut est ServerRoot. Toutefois, si l'utilisateur sous
lequel est exécuté le serveur ne peut écrire dans ce
répertoire, le vidage du noyau ne peut être enregistré.
Cette valeur sera modifiée tout en spécifiant un
répertoire pour lequel cette configuration du Serveur HTTP Apache
utilisateur à un droit d'écriture pour pourvoir enregistrer le
vidage du noyau sur le disque à des fins de débogage.
La valeur Utilisateur (User) correspond
à la directive User. Elle définit liD utilisateur utilisé
par le serveur pour répondre aux requêtes. Les paramètres
de cet utilisateur déterminent les droits d'accès au serveur.
Tout chier inaccessible pour cet utilisateur le sera également pour les
visiteurs du site Web. La valeur par défaut d'User est
apache.
L'utilisateur ne doit avoir que les autorisations
nécessaires pour accéder aux fichiers qui doivent être
visibles aux yeux du monde externe. Il sera aussi le propriétaire de
tout processus CGI engendré par le serveur. De plus, il ne devrait pas
être autorisé à exécuter du code si ce n'est pour
répondre à des requêtes HTTP.
i) REGLAGE DES PERFORMANCES
Pour ce fait nous devons cliquer sur l'onglet Réglage
des performances pour configurer le nombre maximal de processus serveur enfants
souhaités ainsi que les options du Serveur HTTP Apache pour les
connexions client. Les paramètres par défaut attribués
à ces options conviennent à la plupart des situations. La
modification de ces paramètres risque d'affecter les performances
générales du serveur Web.
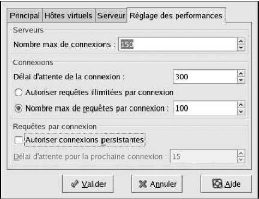
Figure : Réglage des
performances
Nous pouvons configurer l'option Nombre max de
connexions sur le nombre maximal de requêtes client
simultanées que peut gérer le serveur. Pour chaque connexion, un
processus httpd enfant est créé. Une fois que le nombre maximal
de processus est atteint, personne ne peut se connecter au serveur Web tant
qu'un processus enfant n'est pas libéré. Cette option correspond
à la directive MaxClients. Délai d'attente pour la connexion
définit, en secondes, le temps pendant lequel le serveur doit attendre
la réception et la transmission d'informations lors de communications.
Plus spécifiquement, cette option définit le temps pendant lequel
le serveur attend pour recevoir une requête GET, des paquets TCP sur une
requête POST ou PUT et le temps pendant lequel il attend les
accusés de réception en réponse aux paquets TCP. Cette
valeur est par défaut 300 secondes, ce qui convient à la plupart
des situations. Cette option correspond à la directive TimeOut. Nous
configurons Nombre max de requêtes par connexion sur le
nombre maximal de requêtes autorisées par connexion persistante.
La valeur par défaut est 100, ce qui doit convenir à la plupart
des situations. Cette option correspond à la directive
MaxRequestsPerChild. Si nous cochons l'option Autoriser requêtes
illimitées par connexion, la directive MaxKeepAliveRequests
prend la valeur 0 et un nombre illimité de requêtes est alors
autorisé.
Si nous désélectionnons l'option
Autoriser connexions persistantes, la directive KeepAlive
prend la valeur "false" (Faux). Si elle est cochée, la directive
KeepAlive prend la valeur "true" (Vrai) et la directive KeepAliveTimeout prend
alors comme valeur le nombre indiqué dans l'option Délai
d'attente pour la prochaine connexion. Cette directive établit
le
nombre de secondes pendant lequel le serveur attendra une
requête ultérieure, après qu'une requête ait
été servie, avant de fermer la connexion. Cependant, la valeur
Délai d'attente de connexion s'applique une fois qu'une requête a
été reçue.
Au cas où nous indiquons une valeur
élevée pour l'option Connexions persistantes,
cela risque de ralentir le serveur, en fonction du nombre d'utilisateurs qui
essaient de s'y connecter. Plus ils sont nombreux, plus le nombre de processus
serveur qui attendent une autre connexion du dernier client à s'y
être connecté est important.
j) ENREGISTREMENT DES PARAMETRES
Si nous ne souhaitons pas enregistrer les paramètres de
configuration du Serveur HTTP Apache, nous pouvons cliquer sur le bouton
Annuler dans le coin inférieur droit de la
fenêtre de l'Outil de configuration HTTP. Le système demande alors
de confirmer cette décision. Si l'on clique sur Oui
pour confirmer ce choix, les paramètres ne sont pas
enregistrés.
Au cas contraire nous l'enregistrons en faisant un clic sur le
bouton OK dans le coin inférieur droit de la
fenêtre de l'Outil de configuration HTTP. Une
fenêtre de dialogue s'affiche et nous cliquons sur Oui,
les paramètres sont enregistrés dans le fichier
/etc/httpd/conf/httpd.conf. Le fichier de configuration d'origine est
alors écrasé.
Si l'on utilise l'Outil de configuration HTTP pour la
première fois, une boîte de dialogue avertit que le fichier de
configuration a été modifié manuellement. Si l'Outil de
configuration http s'aperçoit que le fichier de configuration httpd.conf
a été modifié manuellement, il enregistre le fichier
modifié sous /etc/httpd/conf/httpd.conf.bak.
IMPORTANT
Après avoir enregistré les paramètres, il
faut redémarrer le démon httpd au moyen de la commande service
httpd restart. Pour ce faire, nous devons être connecté
en tant que super utilisateur (ou root).
IX. CONFIGURATION DES UTILISATEURS ET DES GROUPES
L'outil Gestionnaire d'utilisateurs nous permet d'afficher, de
modifier, d'ajouter et de supprimer des utilisateurs et groupes locaux. Pour
utiliser le Gestionnaire d'utilisateurs, nous devons exécuter le
système X Windows et avoir les privilèges du super-utilisateur.
Le paquetage RPM redhat-config-users doit également
être installé. Pour démarrer le Gestionnaire d'utilisateurs
à partir du bureau, nous allons au bouton Menu principal (sur le
panneau) => Paramètres Système => Utilisateurs et
groupes ou tapons la commande redhat-config-users à
l'invite du Shell (par exemple, dans un terminal X Term ou GNOME).
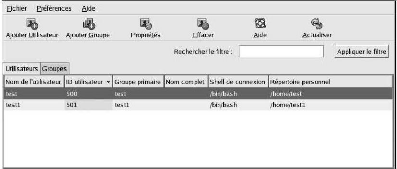
Figure : Gestionnaire d'utilisateurs
Pour afficher une liste de tous les utilisateurs locaux du
système, nous cliquons sur l'onglet Utilisateurs
(Users). Pour afficher une liste de tous les groupes locaux du
système, nous cliquons sur l'onglet Groupes. Si nous
devons trouver un groupe ou un utilisateur spécifique, nous tapons les
premières lettres de son nom dans le champ Filtrer par
(Filter by). Et nous appuyons sur [Entrée] ou nous
cliquons sur Appliquer le filtre (Apply filter). La liste
filtrée s'affichera alors à l'écran. Pour trier les
utilisateurs ou les groupes, nous cliquons sur le nom de la colonne. Les
utilisateurs ou groupes seront triés selon la valeur de cette
colonne.
Red Hat Linux réserve les ID utilisateur au-dessous de
500 aux utilisateurs du système. Par défaut, le
Gestionnaire d'utilisateurs n'affiche pas les utilisateurs du
système. Pour afficher tous les utilisateurs, y compris les utilisateurs
du système, nous désélectionnons
Préférences => Filtrer les utilisateurs et groupes du
système (Filter system users and groups) dans le menu
déroulant.
A. AJOUT D'UN NOUVEL UTILISATEUR
Pour ajouter un nouvel utilisateur, nous cliquons sur le
bouton Ajouter utilisateur (Add User). Une fenêtre
apparaît, comme le montre la Figure : Nouvel
utilisateur
Nous Tapons le nom d'utilisateur et le nom complet pour le
nouvel utilisateur dans les champs appropriés. Nous entrons le mot de
passe correspondant dans les champs Mot de passe (Password) et
Confirmer le mot de passe. Le mot de passe doit comporter au moins six
caractères.
NB :
Plus le mot de passe de l'utilisateur sera long, plus il sera
difficile pour quelqu'un d'autre de le deviner et de se connecter sans
permission sous ce compte. Il est aussi recommandé de ne pas baser le
mot de passe sur un nom et de choisir une combinaison de lettres, chiffres et
caractères spéciaux par exemple :
clarisse@123.
Nous sélectionnons un Shell de connexion. Mais autant
nous rappeler que la valeur par défaut est /bin/bash. Le
répertoire d'enregistrement par défaut est /home/nom
d'utilisateur
(Username). Nous pouvons changer le répertoire
d'enregistrement qui est créé pour l'utilisateur, ou choisir de
ne pas créer de répertoire en désélectionnant
Créer un répertoire home (Create home
directory).
En créant un répertoire personnel (home), nous
devons savoir que les fichiers de configuration par défaut seront
copiés du répertoire /etc/skel dans le nouveau
répertoire home.
Red Hat Linux utilise un système dit groupe
privé d'utilisateurs (UPG de l'anglais 'User Private Group').
Le système UPG n'ajoute et ne change rien dans la manière UNIX
standard de traiter les groupes; il offre seulement une nouvelle convention.
Chaque fois que l'on crée un nouvel utilisateur, un groupe unique avec
le même nom que l'utilisateur est aussi créé par
défaut. Si nous ne souhaitons pas créer ce groupe, nous
désélectionnons Créer un groupe privé pour
l'utilisateur (Create a private group for the user).
Pour spécifier un ID utilisateur pour l'utilisateur,
nous sélectionnons Spécifier un ID utilisateur
manuellement (Specify user ID manually). Si l'option n'est pas
sélectionnée, le prochain ID utilisateur libre après le
numéro 500 sera assigné au nouvel utilisateur. Red Hat Linux
réserve les ID utilisateur au dessous de 500 aux utilisateurs du
système.
Nous Cliquons sur OK pour créer l'utilisateur.
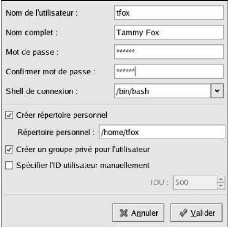
Figure : Nouvel utilisateur
Pour configurer des propriétés d'utilisateur plus
avancées, comme l'expiration des mots de passe, nous modifions les
propriétés de l'utilisateur après l'avoir
ajouté.
Pour ajouter l'utilisateur à des groupes
supplémentaires, nous cliquons sur l'onglet Utilisateur
(User), nous sélectionnons l'utilisateur, puis nous cliquons sur
Propriétés (Properties). Dans la fenêtre
Propriétés de l'utilisateur (User Properties),
nous sélectionnons alors l'onglet Groupes. Nous
sélectionnons aussi les groupes auxquels on veut que l'utilisateur fasse
partie, et nous sélectionnons le groupe principal pour l'utilisateur
puis nous faisons un clic sur OK.
B. MODIFICATION DES PROPRIETES DE L'UTILISATEUR
Pour afficher les propriétés d'un utilisateur
existant, nous devons cliquer sur l'onglet Utilisateurs
(Users), nous sélectionnons âpres l'utilisateur dans la
liste des utilisateurs et on fait un clic sur
Propriétés (Properties) (ou sélectionner
Fichier => Propriétés dans le menu
déroulant). Une fenêtre semblable à celle
reproduite dans la Figure ci dessous apparaîtra alors.
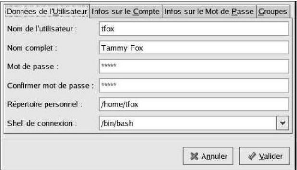
Figure : Propriétés de
l'utilisateur
La fenêtre Propriétés de
l'utilisateur (User Properties) est divisée en pages contenant
des onglets :
· Informations utilisateur
(User Data) : des informations de base sur l'utilisateur sont
configurées lorsque nous ajoutons l'utilisateur. Nous utilisons cet
onglet pour changer le nom complet, le mot de passe, le répertoire
personnel ou le Shell pour la connexion.
· Information du compte
(Account Info) : nous sélectionnons
Activer l'expiration du compte (Enable account
expiration) pour que le compte expire à une certaine date. Nous
entrons la date dans les champs affichés. Alors nous
sélectionnons Compte utilisateur verrouillé
(User account is locked) pour verrouiller le compte
utilisateur afin que l'utilisateur ne puisse plus se connecter au
système.
· Informations mot de passe
(Password Info) : Cet onglet montre la date à laquelle
l'utilisateur a changé son mot de passe pour la dernière fois.
Pour forcer l'utilisateur à changer son mot de passe après un
certain nombre de jours, nous sélectionnons Activer l'expiration
du mot de passe (Enable password expiration). Nous
pouvons aussi sélectionner le nombre de jours avant que l'utilisateur ne
soit autorisé à changer son mot de passe, le nombre de jours
avant que l'utilisateur ne reçoive un message lui demandant de changer
de mot de passe et le nombre de jours avant que le compte ne devienne
inactif.
· Groupes : nous sélectionnons les
groupes auxquels nous souhaitons que l'utilisateur fasse partie ainsi que le
groupe primaire de l'utilisateur.
C. AJOUT D'UN NOUVEAU GROUPE
Pour ajouter un nouveau groupe utilisateur, nous cliquons sur
le bouton Ajouter groupe (Add Group). Une
fenêtre semblable à celle reproduite à la Figure ci dessous
s'affichera à l'écran. Nous entrons le nom du nouveau groupe.
Pour spécifier un ID groupe pour le nouveau groupe, nous
sélectionnons Spécifier l'ID groupe manuellement
(Specify group ID manually) et sélectionnons le GID.
Red Hat Linux réserve les ID groupe inférieurs à 500 aux
groupes du système.
Nous cliquons sur OK pour créer le
groupe. Le nouveau groupe apparaîtra dans la liste des groupes.
Figure : Nouveau groupe
D. MODIFICATION DES PROPRIETES DU GROUPE
Pour afficher les propriétés d'un groupe
existant, nous choisissons le groupe voulu dans la liste et nous cliquons sur
Propriétés (Properties)
à partir du bouton de menu (ou Fichier =>
Propriétés dans le menu déroulant). Une
fenêtre semblable à celle reproduite dans la Figure ci-dessous
apparaîtra.
Figure : Propriétés des
groupes
L'onglet Utilisateurs du groupe (Group
Users) affiche les utilisateurs qui sont membres du groupe. Nous
sélectionnons des utilisateurs supplémentaires pour les ajouter
au groupe et désélectionnons des utilisateurs pour les retirer du
groupe. Nous faisons un Clic sur OK ou
Appliquer (Apply) pour changer les
utilisateurs du groupe.
X. CONFIGURATION DE BIND
Pour bien comprendre cette partie, nous devons
connaître les principes de base de BIND et de DNS car son but n'est pas
d'en expliquer les concepts. Cette partie explique en effet la façon
d'utiliser l'Outil de configuration Bind (redhat-config-bind) pour configurer
des zones de serveur BIND de base.
Cet outil crée le fichier de configuration
/etc/named.conf ainsi que les fichiers de configuration de zones dans
le répertoire /var/named à chaque fois que nous
appliquons nos changements.
IMPORTANT
Ne pas modifier pas le fichier de configuration
/etc/named.conf. L'utilitaire Outil de configuration Bind le
génère une fois que nous avons appliqué nos changements.
Si nous souhaitons configurer des paramètres que l'Outil de
configuration Bind ne permet pas de configurer, il faut les ajouter à
/etc/named.custom.
L'utilitaire Outil de configuration Bind requiert le
système X Window et l'accès superutilisateur (ou root). Pour
lancer l'Outil de configuration Bind, nous cliquons sur le bouton Menu
principal (sur le panneau) => Paramètres de système =>
Paramètres serveur => Service de résolution d'adresse IP
(Domain Name Service) ou nous tapons la commande
redhat-config-bind à l'invite du Shell (dans un terminal XTerm
ou GNOME, par exemple).
Figure : Outil de configuration
Bind
L'utilitaire Outil de configuration Bind configure le
répertoire de zone par défaut sur /var/named. Tous les
fichiers de zone spécifiés sont placés sous ce
répertoire. L'Outil de configuration Bind inclut également un
contrôle de base de la syntaxe lors de la saisie de valeurs. Par exemple,
dans le cadre de la saisie d'une adresse IP valide, nous ne pouvons entrer que
des numéros et des points (.) dans la zone texte.
L'Outil de configuration Bind nous permet d'ajouter une zone
maître de retransmission, une zone maître inverse et une zone
esclave. Une fois les zones ajoutées, nous pouvons les modifier ou les
supprimer de la fenêtre principale comme cela est expliqué dans la
Figure ci dessus.
Après avoir ajouté, modifié ou
supprimé une zone, nous faisons un clic sur le bouton Enregistrer ou
nous sélectionnons Fichier => Enregistrer pour
écrire le fichier de configuration /etc/named.conf et tous les
fichiers de zones individuels dans le répertoire /var/named. En
enregistrant nos changements, le service named procède au rechargement
des fichiers de configuration. Nous pouvons également
sélectionner Fichier => Quitter pour enregistrer les modifications
avant de quitter l'application.
1. AJOUT D'UNE ZONE MAITRE DE RETRANSMISSION
Pour ajouter une zone maître de retransmission
(également appelée maître primaire), nous cliquons sur le
bouton Nouvelle, nous sélectionnons Zone
maître de retransmission et nous entrons le nom de domaine de la
zone maître dans la zone texte, Nom de domaine.
Une nouvelle fenêtre similaire à celle
présentée dans la Figure : Ajout d'une zone
maître de retransmission apparaît avec les options
suivantes:
· Nom : Nom de domaine qui a
été saisi dans la fenêtre précédente.
· Nom de fichier : Nom du fichier de la
base de données DNS, relatif à /var/named. Il est
préétabli au nom de domaine suivi de .zone.
· Contact : Adresse électronique du
contact principal de la zone maître.
· Serveur de noms primaires (SOA) :
Enregistrement SOA ('state of authority'). Cette entrée spécifie
le serveur de noms qui représente la meilleure source d'informations
pour ce domaine.
· Numéro de série :
Numéro de série du fichier de la base de données DNS. Ce
numéro doit être incrémenté chaque fois que nous
modifions le fichier, afin que les serveurs de
noms esclaves de la zone récupèrent les
dernières données. L'Outil de configuration Bind
incrémente ce numéro d'une unité lorsque la configuration
change. Ce numéro peut également être modifié
manuellement en cliquant sur le bouton Établir situé près
de la valeur Numéro de série.
· Paramètres de temps : les
valeurs Rafraîchir, Réessayer, Expirer et Minimum TTL ('Time to
Live', littéralement Temps de vie) qui sont conservées dans le
fichier de base de données DNS. Toutes les valeurs sont exprimées
en secondes.
· Enregistrements : Ajout, modification et
suppression de ressources enregistrées de type Hôte, Alias et
Serveur de noms.
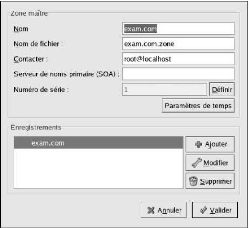
Figure : Ajout d'une zone maître de
retransmission
Un Serveur de noms primaire (SOA) doit être
spécifié ainsi qu'au moins un enregistrement de serveur de noms
en cliquant sur le bouton Ajouter dans la section Enregistrements
section.
Après avoir configuré une zone maître de
retransmission, nous cliquons sur OK pour revenir à la fenêtre
principale, comme le montre la Figure : outil de
configuration. À partir du menu déroulant, nous cliquons
sur Enregistrer pour d'une part, écrire le fichier de configuration
/etc/named.conf et tous les fichiers de zone individuels dans le
répertoire /var/named et d'autre part, demander au démon
de recharger les fichiers de configuration. Suite à la configuration,
une entrée semblable à l'extrait ci-dessous est
enregistrée dans /etc/named.conf:
zone"
forward.eenerca.cf.com"{
typemaster;
file"
forward.enerca.cf.zone";
};
Elle crée également le fichier /var/named/
forward.enerca.cf.zone en y
indiquant les informations ci-dessous :
$TTL86400
@INSOAns.enerca.cf.root.localhost( 2;serial
28800;refresh
7200;retry
604800;expire
86400;ttl
)
INNS192.168.1.1.
2. AJOUT D'UNE ZONE MAITRE INVERSE
Pour ajouter une zone maître inverse, nous cliquons sur
le bouton Ajouter et sélectionnons Zone
maître inverse. Nous entrons les trois premiers octets de la
plage d'adresses IP que nous souhaitons configurer. Par exemple, si nous
configurons la plage d'adresses IP 192.168.10.0/255.255.255.0, nous entrons
192.168.10 dans la zone texte d'Adresse IP (3 premiers Octets).
Une nouvelle fenêtre s'affiche à l'écran,
comme le montre la Figure avec les options ci-dessous:
1. Adresse IP : Les trois premiers octets que
nous avons entrés dans la fenêtre précédente.
2. Adresse IP inverse : Non-modifiable ;
Préconfigurée en fonction de l'adresse IP entrée.
3. Contact : Adresse électronique du
contact principal de la zone maître.
4. Nom de fichier : Nom du fichier de la base
de données DNS dans le répertoire /var/named.
5. Serveur de noms primaire (SOA) :
enregistrement SOA ('state of authority)'. Ceci spécifie le serveur de
noms qui représente la meilleure source d'informations pour ce
domaine.
6. Numéro de série :
Numéro de série du fichier de la base de données DNS. Ce
numéro doit être incrémenté chaque fois que nous
modifions le fichier, afin que les serveurs de noms esclaves de la zone
récupèrent les dernières données. L'Outil de
configuration Bind incrémente ce numéro d'une unité
lorsque la configuration change. Il peut également être
incrémenté manuellement en cliquant sur le bouton Établir
situé près de la valeur Numéro de série.
7. Paramètres de temps : Valeurs
Rafraîchir, Réessayer, Expirer et Minimum TTL (Time to Live,
littéralement Temps de vie) qui sont conservées dans le chier de
la base de données DNS.
8. Serveurs de noms : Ajout, modification et
suppression de serveurs de noms pour la zone maître inverse. Un nom de
serveur est au minimum requis.
9. Table d'adresses inverses : Liste des
adresses IP de la zone maître inverse ainsi que des noms d'hôtes
correspondants. Pour la zone maître inverse 192.168.10, nous pouvons
ajouter 192.168.10.1 dans Table d'adresses inverses avec le nom d'hôte
lumiere.enerca.cf. Le nom
d'hôte doit se terminer par un point (.) pour indiquer
qu'il s'agit d'un nom d'hôte complet.
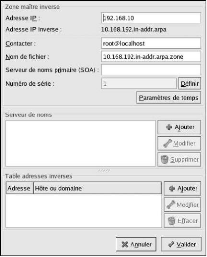
Figure : Ajout d'une zone maître
inverse
Un Serveur de noms primaire (SOA) doit être
spécifié ainsi qu'au moins un enregistrement de serveur de noms
en cliquant sur le bouton Ajouter dans la section
Serveurs de noms.
Après avoir configuré une zone maître
inverse, nous cliquons sur OK pour revenir à la
fenêtre principale. À partir du menu déroulant, nous
cliquons sur Enregistrer pour d'une part, écrire le
fichier de configuration /etc/named.conf et tous les fichiers de zone
individuels dans le répertoire /var/named et d'autre part, demander au
démon de recharger les fichiers de configuration. Suite à la
configuration, une entrée semblable à l'extrait ci-dessous est
enregistrée dans /etc/named.conf :
zone"10.168.192.in-addr.arpa"{
typemaster;
file"10.168.192.in-addr.arpa.zone";
};
Elle crée également le fichier
/var/named/10.168.192.in-addr.arpa.zone, qui contient les informations
suivantes :
$TTL86400
@INSOAns.enerca.cf.root.localhost(
2;serial
28800;refresh
7200;retry
604800;expire
86400;ttk
)
@
INNSns2.enerca.cf.
1INPTRone.enerca.cf.
2INPTRtwo.enerca.cf.
3. AJOUT D'UNE ZONE ESCLAVE
Pour ajouter une zone esclave (également appelée
maître secondaire), nous cliquons sur le bouton Ajouter
et sélectionnons Zone esclave. En ce moment nous
entrons le nom de domaine de la zone esclave dans la zone texte Nom de
domaine.
Une nouvelle fenêtre s'affiche à l'écran,
comme le montre la Figure ci dessous, avec les options ci-dessous :
· Nom : Le nom de domaine qui a
été entré dans la fenêtre
précédente.
· Liste des maîtres : Les serveurs
de noms à partir desquels la zone esclave récupère ses
données.
Chaque valeur doit être une adresse IP valide. La zone de
texte ne peut contenir que des numéros et des points
(.).
· Nom de fichier : Nom du fichier de la
base de données DNS contenu dans /var/named.
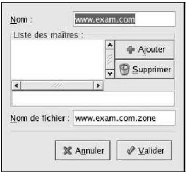
Figure : Ajout d'une zone esclave
Après avoir configuré la zone esclave, nous
cliquons sur OK pour revenir à la fenêtre principale. Alors nous
cliquons sur Enregistrer pour écrire le fichier de configuration
/etc/named.conf et demander au démon de recharger les fichiers de
configuration.
Suite à la configuration, une entrée semblable
à l'extrait ci-dessous est enregistrée dans /etc/named.conf :
zone"
slave.enerca.cf"{
typeslave;
file"
slave.enerca.cf.zone";
masters{
1.2.3.4;
};
};
Le fichier de configuration /var/named/
slave.enerca.cf.zone
est créé par le service named lorsqu'il télécharge
les données de zone du ou des serveurs maîtres.
XI. SYSTEME DE FICHIERS RESEAU (NFS - 'NETWORK FILE
SYSTEM')
Le système de fichiers réseau (ou NFS de
l'anglais 'Network File System') est un moyen de partager des fichiers entre
plusieurs machines sur un même réseau comme si les fichiers se
trouvaient sur le disque dur local. Red Hat Linux peut être à la
fois un serveur NFS et un client NFS, ce qui signifie qu'il peut exporter des
systèmes de fichiers vers d'autres systèmes et monter des
systèmes de fichiers exportés à partir d'autres
machines.
a) POURQUOI UTILISER NFS?
NFS peut être utilisé pour partager des
répertoires de fichiers entre plusieurs utilisateurs sur un même
réseau. Par exemple, un groupe d'utilisateurs qui travaillent sur un
même projet peut accéder aux fichiers de ce projet en utilisant un
répertoire partagé du système de fichiers NFS
(généralement appelée partage NFS) monté dans le
répertoire /myproject. Pour accéder aux fichiers partagés,
l'utilisateur entre dans le répertoire /myproject de son ordinateur sans
taper de mot de passe ni de commande particulière. L'utilisateur
travaille comme si le répertoire se trouvait sur son ordinateur
local.
b) MONTAGE DE SYSTEMES DE FICHIERS
NFS
Il faut utiliser la commande mount pour monter un
système de fichiers NFS partagé d'un autre ordinateur:
mountshadowman.enerca.cf:/misc/export/misc/local
c) AVERTISSEMENT
Le répertoire du point de montage de l'ordinateur
local (/misc/local dans l'exemple cidessus) doit exister. Dans cette
commande,
shadowman.enerca.cf est le nom
d'hôte du serveur de fichiers NFS, /misc/export est le
répertoire que shadowman exporte et /misc/local est
l'emplacement de l'ordinateur local où nous voulons monter le
système de fichiers. Une fois que nous avons exécuté la
commande mount (et si nous avons les autorisations appropriées
du serveur NFS
shadowman.enerca.cf),
l'utilisateur peut exécuter la commande ls /misc/local pour
afficher une liste des fichiers de /misc/export sur
shadowman.enerca.cf.
d) MONTAGE DES SYSTEMES DE FICHIERS NFS AU MOYEN DE
/ETC/FSTAB
Pour monter un partage NFS à partir d'une autre
machine, nous pouvons également ajouter une ligne au fichier
/etc/fstab. La ligne doit contenir le nom d'hôte du serveur NFS,
le répertoire du serveur qui est exporté et le répertoire
de l'ordinateur local où nous désirons monter le partage NFS.
Nous devons être connecté en tant que super-utilisateur (ou root)
pour
pouvoir modifier le fichier /etc/fstab. La syntaxe
générale de la ligne contenue dans /etc/fstab est la
suivante:
server:/usr/local/pub/pubnfsrsize=8192,wsize=8192,timeo=14,intr
Le point de montage /pub doit exister sur
l'ordinateur client. Après avoir ajouté cette ligne à
/etc/fstab sur le système client, entrez la commande mount
/pub à l'invite de Shell; le point de montage /pub sera
monté à partir du serveur.
e) MONTAGE DE SYSTEMES DE FICHIERS NFS AU MOYEN
D'AUTOFS
La troisième technique de montage d'un partage NFS
concerne l'utilisation d'autofs. Autofs utilise le démon automount pour
gérer les points de montage en ne les montant de façon dynamique
que lorsqu'on y accède. Autofs consulte le fichier de configuration
maître /etc/auto.master pour déterminer quels points de
montage sont définis. Il amorce ensuite un processus de montage
automatique avec les paramètres adéquats pour chaque point de
montage. Chaque ligne du fichier de configuration maître définit
un point de montage et un fichier de configuration séparé qui
définit les systèmes de fichiers devant être montés
sur ce point de montage. Par exemple, si le fichier /etc/auto.misc
définit des points de montage dans le répertoire /misc, cette
relation est définie dans le fichier /etc/auto.master. Chaque
entrée dans auto.master comporte trois champs. Le premier fournit le
point de montage. Le deuxième correspond à l'emplacement du
fichier de configuration et le troisième champ est en option. Ce dernier
peut contenir des informations telles qu'une valeur de dépassement du
délai d'attente. Par exemple, pour monter le répertoire /proj52
de l'ordinateur distant
lumiere.enerca.cf sur le point de
montage /misc/myproject du serveur, nous ajoutons au fichier auto.master la
ligne suivante:
/misc/etc/auto.misc--timeout60
Nous ajoutons la ligne suivante au fichier /etc/auto.misc:
myproject rw,soft,intr,rsize=8192,wsize=
8192lumiere.enerca.cf:/proj52
Le premier champ de /etc/auto.misc affiche le nom du
sous-répertoire /misc. Ce répertoire est créé de
façon dynamique par automount. Il ne devrait en réalité
pas exister sur l'ordinateur client. Le deuxième champ contient les
options de montage, telles que rw pour l'accès en lecture (r: read) et
en écriture (w: write). Le troisième champ indique l'adresse du
serveur NFS d'exportation, comprenant le nom d'hôte et le
répertoire.
Remarque
Le répertoire /misc doit exister sur le système
de fichiers local. Celui-ci ne devrait pas contenir de sous-répertoires
de /misc. Autofs est un service. Pour le démarrer, nous entrons à
l'invite du Shell les commandes suivantes :
/sbin/serviceautofsrestart
Pour afficher les points de montage actifs, nous entrons la
commande suivante à l'invite du Shell :
/sbin/serviceautofsstatus
Si nous modifions le fichier de configuration /etc/auto.master
pendant qu'autofs s'exécute, nous devons dire au démon automount
de recharger le fichier en entrant la commande suivante à l'invite du
Shell :
/sbin/serviceautofsreload
f) EXPORTATION DE SYSTEMES DE FICHIERS
NFS
Le partage de fichiers d'un serveur NFS s'appelle
l'exportation de répertoires. L'Outil de configuration du
serveur NFS peut être utilisé pour configurer un
système en tant que serveur NFS. Pour utiliser l'Outil de
configuration du serveur NFS, le système X Window doit
être en cours d'exécution, nous devons être connecté
en tant que super-utilisateur (ou root) et le paquetage RPM redhat-config-nfs
doit être installé sur le système. Pour lancer
l'application, nous sélectionnons le bouton Menu principal
(sur le tableau de bord) =>
Paramètres de système => Paramètres de serveur
=> Serveur NFS, ou nous pouvons taper la commande
redhat-config-nfs à l'invite du Shell.
Figure : Outil de configuration du serveur
NFS
Pour créer un partage NFS, il faut cliquer sur le
bouton Ajouter. La boîte de dialogue reproduite dans la
Figure ci dessus s'affiche. L'onglet Informations de base
requiert les informations suivantes :
v' Répertoire. Indique le
répertoire à partager, comme par exemple /tmp.
v' Hôte(s). Indique le ou les hôtes
qui partageront le répertoire. Pour une explication relative aux
différents formats possibles
v' Autorisations de base. Indique si le
répertoire doit avoir des autorisations en lectureseule ou en
lecture-écriture.
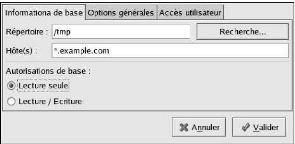
Figure : Ajout d'un partage
L'onglet Options générales permet
de configurer les options suivantes:
· Autoriser les connexions des ports 1024 et
supérieurs. Les services lancés sur les numéros
de ports inférieurs à 1024 doivent être lancés en
tant que super-utilisateur (ou root). Nous sélectionnons cette option
pour permettre au service NFS d'être lancé par un utilisateur
autre qu'un super-utilisateur. Cette option correspond à insecure.
· Activer le verrouillage des fichiers
non-sûrs. Une requête de verrouillage n'est pas
nécessaire. Cette option correspond à insecure_locks.
· Désactiver le contrôle de la
sous-arborescence. Si un sous-répertoire d'un système de
fichiers est exporté, mais pas la totalité de ce système,
le serveur vérifie que le fichier requis se trouve bien dans le
sous-répertoire exporté. Cette vérification s'appelle
vérification de la sous-arborescence.
Nous sélectionnons cette option pour désactiver
la vérification de la sous-arborescence. Si tout le système de
fichiers est exporté et que cette option est sélectionnée,
le taux de transfert sera plus rapide. Cette option correspond à
no_subtree_check :
· Synchroniser les opérations
d'écriture sur demande. Activée par défaut, cette
option ne permet pas au serveur de répondre à des requêtes
avant que les modifications effectuées par la requête ne soient
enregistrées sur le disque. Cette option correspond à
sync. Si elle n'est pas sélectionnée, l'option
async est utilisée.
· Forcer la synchronisation immédiate des
opérations d'écriture. Ne pas retarder l'enregistrement
sur disque. Cette option correspond à no_wdelay. L'onglet
Accès utilisateur permet de configurer les options
suivantes:
? Considérer l'utilisateur root distant comme
root local. Par défaut, les ID d'utilisateur et de groupe de
l'utilisateur root sont tous deux égaux à 0. L'écrasement
de l'utilisateur root lie l'ID d'utilisateur 0 et l'ID de groupe 0 aux ID
d'utilisateur et de groupe d'anonymes afin que le root du client n'ait pas de
privilèges super-utilisateur (ou root) sur le serveur NFS. Si cette
option est sélectionnée, l'utilisateur root n'est pas lié
à l'utilisateur anonyme et le super-utilisateur d'un client dispose de
privilèges root sur les répertoires exportés. Cette option
peut réduire de façon importante le niveau de
sécurité du système. Nous ne la sélectionnons que
si cela s'avère absolument nécessaire. Cette option correspond
à no_root_squash.
? Considérer tous les utilisateurs clients
comme des utilisateurs anonymes. Si cette option est
sélectionnée, tous les ID d'utilisateur et de groupe sont
liés à l'utilisateur anonyme. Cette option correspond à
all_squash.
? Spécifier l'ID de l'utilisateur local pour
les utilisateurs anonymes. Si l'option Considérer tous
les utilisateurs clients comme des utilisateurs anonymes est
sélectionnée, nous pouvons spécifier un ID d'utilisateur
pour l'utilisateur anonyme. Cette option correspond à anonuid.
? Spécifier l'ID de groupe local pour les
utilisateurs anonymes. Si l'option Considérer tous les
utilisateurs clients comme des utilisateurs anonymes est
sélectionnée, nous pouvons spécifier un ID de groupe pour
l'utilisateur anonyme. Cette option correspond à anongid.
Pour modifier un partage NFS existant, nous le
sélectionnons dans la liste et cliquons sur le bouton
Propriétés. Pour supprimer un partage NFS
existant, nous le sélectionnons dans la liste et nous cliquons sur le
bouton Supprimer.
Après avoir cliqué sur OK pour
valider l'ajout, la modification ou la suppression d'un partage NFS de la
liste, les modifications prennent effet immédiatement. Le démon
serveur est relancé et l'ancien fichier de configuration est
enregistré en tant que /etc/exports.bak. Le nouveau fichier de
configuration quant à lui, est enregistré dans
/etc/exports.
L'utilitaire Outil de configuration du serveur NFS
lit et enregistre (ou écrit) directement dans le fichier de
configuration /etc/exports. Le fichier peut donc être
modifié manuellement après avoir utilisé cet outil qui
peut également être utilisé après avoir
modifié manuellement le fichier (si toutefois celui-ci a
été modifié en respectant la syntaxe).
XII. CONFIGURATION DE SAMBA
Samba est un logiciel libre et une mise en
oeuvre du protocole SMB/CIFS sous GNU/Linux, initialement
développée par l'australien Andrew Tridgell. Il est sous licence
GNU GPL 3. Son nom provient du protocole SMB (Server message block), le nom du
protocole standard de Microsoft, auquel ont été ajoutées
les deux voyelles a : « SaMBa ».
À partir de la version 3, Samba fournit des fichiers et
services d'impression pour divers clients Windows et peut s'intégrer
à un domaine Windows Server, soit en tant que contrôleur de
domaine principal (PDC) ou en tant que membre d'un domaine. Il peut
également faire partie d'un domaine Active Directory. Il fonctionne sur
la plupart des systèmes Unix, comme GNU/Linux, Solaris, AIX et les
variantes BSD, y compris Apple, Mac OX X Server (qui a été
ajoutée au client Mac OS X en version 10.2). Samba fait partie
intégrante de presque toutes les distributions GNU/Linux.
SAMBA est un serveur de fichiers pour Linux
compatible avec les réseaux Microsoft Windows. Autrement dit, le Serveur
SAMBA réalise le partage de ressources (fichiers, imprimante) entre
machines fonctionnant avec un système Microsoft Windows et un
système Linux (en licence GNU GPL, donc libre).
Nous allons voir dans cet article, la procédure à
suivre pour pouvoir intégrer une machine Linux dans un domaine NT.
Pour configurer le serveur Samba il faudrait d'abord tester la
présence du paquetage de
Samba
rpm | grep /etc/samba/smb.conf
Cas 1
Si le paquetage existe il reste maintenant à connaitre son
statuts
service smb.conf statuts
Si le service est arrété, il faudrait le
démarrer avec la commande
service smb.conf start
Cas 2
Si le paquetage n'existe pas alors il faudrait l'installer
apt install /etc/samba/smb.conf
Si nous sommes le Super utilisateur qui est root par
défaut
Ou la commande si non
su apt install /etc/samba/smb.conf
Si nous sommes un simple utilisateur, avec la commande su vous
prenez la main sur le super utilisateur qui est root. Apres le test du statut
du service samba, il faut maintenant l'éditer pour pouvoir le
modifier.
vi /etc/samba/smb.conf
a. Configuration de base pour Samba
La configuration générale du serveur samba se passe
dans la section [global] du fichier
/etc/samba/smb.conf, on va donc y ajouter les options
suivantes :
[global]
# Nom du groupe de travail ou du domaine workgroup = WORKGROUP
# nom de la machine (= hostname) netbios name = xblade
# Nom qui apparaît lors du parcours réseau (%h =
hostname) server string = %h
# Activation du cryptage des mots de passe encrypt passwords =
yes
# Mode authentification security = user
# On accepte les inconnus en leurs donnant un droit
d'accès en tant qu'invité map to guest = Bad User
# Liste des utilisateurs non valide ; invalid users = toto
# Pour pouvoir synchroniser l'horloge des clients sur celle du
serveur ; time server = Yes
# Options de connexions
socket options = TCP_NODELAY SO_RCVBUF=8192 SO_SNDBUF=8192 ;
hosts allow = 192.168.0. EXCEPT 192.168.0.35
; hosts deny = ALL
# Configuration des logs du serveur, taille en kb log file =
/var/log/samba/%m.log
max log size = 1000
Ici notre serveur est configuré pour appartenir au
groupe de travail WORKGROUP. Celui-ci fonctionnera
normalement, après redémarrage du service samba avec la commande
/etc/init.d/smb restart. Il ne faudra pas oublier de
créer les comptes utilisateurs, en utilisant la commande
smbpasswd -a trinite.
b. Intégration de Samba dans un domaine
NT
Fichier de configuration pour joindre un domaine NT qui se nomme
ENERCA :
[global]
workgroup = MONDOMAINE security = domain
# Configuration de winbind winbind separator = \
winbind cache time = 10 template shell = /bin/bash template
homedir = /home/%D/%U
idmap uid = 10000-20000 idmap gid = 10000-20000 winbind enum
users = yes winbind enum groups = yes
Une fois samba lancé, nous pouvons joindre notre domaine
avec :
[root@xblade ~]net rpc join -U administrator Password: *****
Joined domain ENERCA .
Apres la configuration, il faut tester le serveur #testparm
smb.conf
Ou
testparm > « nom d'un répertoire
»
S'il n'y a pas de problème, il ne reste qu'à donner
les droits pour la lecture/écriture/exécution pour permettre au
poste Windows de browser le serveur
chmod 764 /etc/samba/smb.conf
Apres l'attribution des droits, il faut maintenant
redémarrer les services de samba
service smb.conf restart supprimer les barrières
de sécurité
#iptables -F
c. Démarrage du service
Lancer le service SAMBA en tapant la commande : service smb
start. L'option restart permet de relancer le serveur et stop
pour l'arrêter.
d. Visualisation du voisinage
réseau
Nous allons voir ici comment se connecter au serveur depuis une
machine Linux ou Windows.
e. Vérification de l'existence d'un serveur
samba
Le client Samba (smbclient) permet de fournir une interface en
ligne de commande pour accéder aux ressources SAMBA á partir
d'une machine de type Unix (Linux).
Pour vérifier l'existence d'un serveur SAMBA sur le
réseau et de lister les ressources qu'il partage nous tapons la commande
suivante :
#smbclient nom_serveur_smb
f) Connexion a partir de Windows
Pour se connecter avec samba, il faut partir sur le voisinage
réseau.
Puis cliquer sur « voir les ordinateurs du groupe de travail
»
XIII. AJOUT D'UNE IMPRIMANTE SAMBA (SMB)
Pour ajouter une imprimante à laquelle on accède
à l'aide du protocole SMB (comme une imprimante reliée à
un système Microsoft Windows), nous cliquons sur le bouton
Nouveau dans la fenêtre principale de l'Outil de
configuration de l'imprimante. La fenêtre reproduite dans la
Figure : Ajout d'une imprimante SMB apparaîtra
alors. Ensuite nous cliquons sur Suivant pour continuer.
Nous sélectionnons Windows (SMB)
réseau dans le menu Sélectionner un type de file
d'attente puis cliquer sur Suivant. Si l'imprimante
est reliée à un système Microsoft Windows, nous
choisissons ce type de file d'attente.
Figure : Ajout d'une imprimante SMB
Comme le montre la Figure : Ajout d'une imprimante
SMB
, les partages SMB sont
détectés automatiquement et listés. Nous faisons
clic sur la flèche à côté de chaque nom de
partage pour obtenir une liste plus détaillée. Dans cette
liste, nous choisissons une imprimante.
Si l'imprimante que nous souhaitons partagée
n'apparaît pas dans la liste, nous cliquons sur le bouton
Spécifier situé à droite. Les
champs de texte relatifs aux options suivantes apparaissent alors :
· Groupe de travail : le nom du groupe de travail
associé à l'imprimante partagée.
· Serveur
: le nom du serveur partageant l'imprimante.
· Partage : le nom de l'imprimante
partagé e au moyen de laquelle nous voulons imprimer.
Ce nom doit être le même que celui défini comme l'imprimante
Samba sur l'ordinateur Windows distant.
· Nom d'utilisateur
: le nom d'utilisateur sous lequel nous devons nous
connecter pour accéder à
l'imprimante.
Cet utilisateur doit exister sur le système
Windows et doit avoir l'autorisation d'accéder à
l'imprimante. Le nom d'utilisateur par défaut est
généralement invité
(Guest)
pour les serveurs Windows, ou personne
(person) pour
les serveurs Samba.
· Mot de passe
: le mot de passe (si nécessaire) de l'utilisateur
spécifié dans le champ Nom
d'utilisateur.
Nous cliquons sur le bouton Suivant pour
continuer. L'
Outil de configuration de l'imprimante essaiera alors
de se connecter à l'imprimante partagée. Si cette
dernière nécessite un nom d'utilisateur et un
mot de passe, une fenêtre de dialogue apparaîtra pour nous
inviter à saisir un nom d'utilisateur et un mot de passe
valides. Dans le cas où un mauvais nom de partage
aurait été spécifié, nous avons la
possibilité le modifier ici également. Si le nom
d'un groupe de travail est nécessaire pour la connexion au
partage, il peut être spécifié dans cette
boîte de dialogue. La fenêtre en question est la même que
celle apparaissant lorsque nous cliquons sur le bouton
Spécifier.
1) SELECTION D'UN MODELE D'IMPRIMANTE ET FIN DU
PROCESSUS Après avoir sélectionné le type de file
d'attente de l'imprimante, l'étape suivante consiste
à sélectionner le modèle de cette imprimante.
Une fenêtre semblable à celle reproduite
dans la Figure : Sélection d'un modèle
d'imprimante
apparaît. Si le modèle n'a pas
été détecté automatiquement, nous le
sélectionnons dans la liste fournie. Les imprimantes sont
réparties par fabricants. Nous
l'imprimante dans le
choisissons le nom du fabricant de menu déroulant.
Les modèles
d'imprimantes sont mis à jour chaque fois qu'un
nouveau fabricant est sélectionné. Nous
choisissons le modèle d'imprimante dans la liste.
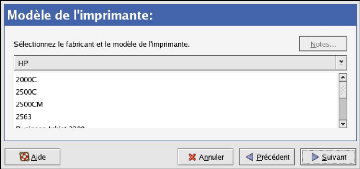
Figure : Sélection d'un modèle
d'imprimante
Le pilote d'impression recommandé est
choi
si en fonction du modèle d'imprimante
retenu. Le pilote d'impression traite les données que nous
souhaitons imprimer dans un format que l'imprimante comprend.
Étant donné qu'une imprimante locale est reliée
directement à un ordinateur, nous avons besoin d'un
pilote d'impression pour traiter les données envoyées
à l'imprimante.
Si nous configurons une imprimante distante (IPP, LPD,
SMB, or NCP), le serveur d'impression distant dispose
généralement de son propre pilote d'impression. Si nous
sélectionnons un
pilote d'impression supplémentaire sur un
ordinateur local, les données
-
seront filtrées plusieurs fois, et converties dans
un format non reconnu par l'imprimante.
Afin de nous assurer que les données ne seront pas
filtrées plusieurs fois, nous allons tout d'abord de
sélectionner Générique pour le fabricant
et
File d'attente d'impression de
base ou Imprimante
Postscript
pour le modèle de l'imprimante. Après
avoir validé les
Si le test
modifications, nous imprimons une page test pour
vérifier la nouvelle configuration.
échoue, il est possible qu'aucun pilote
d'impression ne soit configuré pour le serveur
d'impression distant. Nous sélectionnons maintenant un pilote
d'impression en fonction du fabricant et du modèle de
l'imprimante distante, de valider les modifications et d'imprimer une
page test
2) CONFIRMATION DE LA CONFIGURATION DE
L'IMPRIMANTE
La dernière étape consiste à
confirmer notre configuration d'imprimante. Nous cliquons sur
Appliquer pour ajouter la file d'impression si les paramètres
sont corrects. Nous cliquons alors sur
Précédent
pour modifier la configuration de
l'imprimante.
Nous cliquons sur le bouton Appliquer dans la
fenêtre principale pour enregistrer nos modifications et
redémarrer le daemon d'impression. Après avoir
appliqué les modifications, nous imprimons une page
test pour vérifier que la configuration est bien correcte.
3) MODIFICATION DES IMPRIMANTES
EXISTANTES
Pour supprimer une imprimante existante,
nous sélectionnons l'imprimante et nous
cliquons sur le bouton Supprimer dans la barre d'outils. L
'imprimante est alors retirée de la liste. Nous
cliquons sur Appliquer pour enregistrer les changements et
redémarrer le daemon d'impression.

Pour définir l'imprimante par défaut,
nous sélectionnons l'imprimante dans la liste
et nous cliquons sur le bouton Défaut dans la
ba rre d'outils. L'icône d'imprimante par défaut
apparaît alors dans la colonne Défaut de l'imprimante par
défaut présente dans la liste.
Après avoir ajouté n otre ou
nos imprimante(s), nous modifions les paramètres en
sélectionnant l'imprimante dans la liste et en cliquant
sur le bouton Éditer. La fenêtre à onglets
reproduite dans la Figure : Modification d'une imprimante
apparaît alors. Elle affiche les valeurs actuelles pour
l'imprimante que nous avons
sélectionnée. Nous apportons tous les
changements souha ités et nous faisons un clic sur
OK. Nous Cliquons ensuite sur
Appliquer dans la fenêtre principale de l' Outil de configuration
de l'imprimante pour e nregistrer les changements et
redémarrer le daemon d'impression.
Figure : Modification d'une
imprimante
4) NOM DE LA FILE D'ATTENTE
Si on décide de renommer une imprimante ou de
changer sa courte description, nous Nom de la file
d'attente
modifions la valeur dans l'onglet . Nous cliquons sur
OK pour
retourner à la fenêtre principale. Le
nouveau nom de l'imprimante devrait alors apparaître
Appliquer
dans la liste des imprimantes. Nous faisons un Clic sur
pour enregistrer la
modification et redémarrer le daemon
d'impression.
5) TYPE DE FILE D'ATTENTE
L'onglet Type de file d'attente montre le
type de file d'attente que nous avons sélectionné lorsque nous
avons ajouté l'imprimante ainsi que ses paramètres. Il est
possible de changer le type de file d'attente ou simplement les
paramètres de l'imprimante. Après avoir effectué les
modifications en cliquant sur OK pour retourner à la
fenêtre principale. Et cliquer ensuite sur Appliquer
pour enregistrer la modification et redémarrer le daemon
d'impression.
Selon le type de file d'attente choisi, différentes
options s'afficheront. Voici la section appropriée traitant de l'ajout
d'une imprimante afin d'obtenir une description des options.
a) PILOTE D'IMPRIMANTE
L'onglet Pilote d'imprimante montre le
pilote d'imprimante actuellement utilisé. Si nous voulons le changer,
nous devons faire clic sur OK pour retourner à la
fenêtre principale. Nous cliquons ensuite sur Appliquer
pour enregistrer les changements et redémarrer le daemon
d'impression.
b) OPTIONS DE PILOTE
L'onglet Options de pilote affiche les options
avancées de l'imprimante. Celles-ci varient selon le pilote. Parmi les
options courantes figurent :
· Sélectionner Envoyer saut de page
(FF) (de l'anglais 'Form-Feed') si la dernière page du travail
d'impression n'est pas éjectée de l'imprimante (par exemple si la
lumière d'alimentation clignote). Si cela ne fonctionne pas, il faut
essayer de sélectionner Envoyer Fin-de-transmission
(EOT) (de l'anglais 'End Of Transmission'). Certaines imprimantes
nécessitent à la fois Envoyer saut de page (FF)
et Envoyer Fin-detransmission (EOT) pour éjecter la
dernière page. Cette option n'est disponible qu'avec le système
d'impression LPRng.
· L'option Envoyer Fin-de-transmission
(EOT) devrait être utilisée lorsque l'envoi d'un saut de
page (FF) ne fonctionne pas. Cette option n'est disponible qu'avec un
système d'impression LPRng.
· L'option Supposer que les données
inconnues font partie d'un texte devrait être
sélectionnée si le pilote d'imprimante ne reconnaît pas
certaines données qui lui sont envoyées. Ne pas
sélectionner cette option que s'il y'a des problèmes
d'impression. Lorsque cette option est sélectionnée, le pilote
d'imprimante suppose que toute donnée non-reconnue est du texte et il
essaie donc de l'imprimer en tant que tel. Si cette option est
sélectionnée en même temps que l'option Convertir
le texte en Postscript, le pilote d'imprimante suppose que les
données inconnues sont du texte et les convertit en PostScript. Cette
option n'est disponible qu'avec un système d'impression LPRng.
· L'option Préparer Postscript
devrait être sélectionnée si l'on veut imprimer des
caractères dépassant le jeu ASCII de base et que leur sortie
n'est pas correcte (comme pour les caractères japonais). Cette option va
retraduire les polices PostScript nonstandard afin qu'elles puissent être
correctement imprimées.
Si l'imprimante ne prend pas en charge les polices qui sont
entrain d'être imprimer, il faut alors essayer de sélectionner
cette option. Par exemple on la choisit pour imprimer des polices japonaises
sur une imprimante non-japonaise.
Un temps supplémentaire est nécessaire pour
accomplir cette action. Cette option est à choisir lorsque l'on
rencontre des problèmes pour imprimer correctement les polices.
· L'option Pré-filtrage
GhostScript, permet de sélectionner Pas de
pré-filtrage, Convertir en PS niveau 1, ou
Convertir en PS niveau 2 dans le cas où l'imprimante
rencontrerait des problèmes lors du traitement de certains niveaux de
PostScript. Cette option est seulement disponible si le pilote PostScript est
utilisé avec le système d'impression CUPS.
· L'option Convertir le texte en
Postscript est sélectionnée par défaut. Si
l'imprimante peut imprimer du texte en clair, il est conseillé de
désélectionner cette option afin de réduire le temps
d'impression. Cette option n'est pas disponible avec le système
d'impression CUPS car le texte est toujours converti en PostScript.
· L'option Format de la page permet de
sélectionner le format papier pour l'imprimante, comme par exemple A4,
A3, US légal et US lettre.
· L'option Filtre effectif de locale est
configurée par défaut sur C.
· L'option Source de support adopte par
défaut la valeur Valeur par défaut de
l'imprimante. On peut Modifier cette option pour utiliser du papier
d'un endroit différent.
Lorsque la modification des options de pilote est
terminée, nous cliquons sur OK pour retourner à
la fenêtre principale. Et nous faisons un clic sur
Appliquer pour enregistrer les changements puis
redémarrer le daemon d'impression.
XIV. CONFIGURATION DE L'AGENT DE TRANSPORT DE
COURRIER
(ATC)
Il est essentiel d'avoir un Agent de Transport de Courrier
(ATC ou MTA de l'anglais 'Mail Transport Agent') pour pouvoir envoyer des
courriers électroniques depuis un système Red Hat Linux. Un Agent
de Gestion de Courrier (AGC ou MUA de l'anglais 'Mail User Agent') comme
Evolution, Mozilla Mail et Mutt, est utilisé pour lire et composer des
courriers électroniques. Lorsqu'un utilisateur envoie un courrier depuis
un agent de gestion du courrier, le message est transmis à l'ATC qui le
fait suivre à une série d'ATC, jusqu'à ce qu'il arrive
à destination.
Même si un utilisateur n'a pas l'intention d'envoyer de
courrier depuis le système, des tâches automatiques ou des
programmes systèmes peuvent utiliser la commande /bin/mail pour envoyer
un courrier électronique contenant les messages de journal à
l'utilisateur root du système local.
Red Hat Linux 9 fournit deux ATC: Sendmail et Postfix. S'ils
sont tous les deux installés, SendMail est l'ATC par défaut. Le
programme Commutateur d'agent de transport de courrier permet à un
utilisateur de choisir SendMail ou postfix comme MTA par défaut pour
le système. Le paquetage RPM redhat-switch-mail doit
être installé de manière à utiliser la version texte
du programme Commutateur d'agent de transport de courrier. Si nous souhaitons
utiliser la version graphique, le paquetage redhat-switch-mail-gnome doit
également être installé.
Pour lancer le programme Commutateur d'agent de transport de
courrier, nous devons sélectionner le bouton Menu
principal (sur le panneau) => Extras => Outils de
système => Commutateur d'agent de transport de courrier, ou
nous tapons la commande redhatswitch-mail à l'invite du
Shell (dans un terminal XTerm ou GNOME, par exemple).
Le programme détecte automatiquement si X Window est en
cours d'exécution. Si c'est le cas, le programme démarre en mode
graphique. Si X Window n'est pas détecté, il démarre en
mode texte. Nous pouvons forcer le Commutateur d'agent de transport de courrier
à fonctionner en mode texte en utilisant la commande
redhat-switch-mail-nox.
Figure : Commutateur d'agent de transport de
courrier
Si nous sélectionnons OK pour changer
le MTA, le daemon mail sera activé de manière à être
lancé lors du démarrage alors que le daemon mail
désélectionné sera lui désactivé afin de ne
par être lancé lors du démarrage. Comme le daemon mail
sélectionné est lancé alors que l'autre daemon est
arrêté, les changements prennent effet immédiatement.
XV. CONFIGURATION DU SERVEUR DE MESSAGERIE
A. MESSAGERIE SendMail
Agent de gestion de courrier Mail User Agent - MUA
C`est le client de messagerie. Il permet de lire et de composer
des messageries électroniques. Autre fonction :
récupération des messages via les protocoles POP et IMAP
Agent de transfert de courrier
Mail Transfert Agent - MTA. Il permet de transférer les
mails d`un serveur de messagerie a un autre via le protocole SMTP.
Agent de distribution du courrier
Mail Delivery Agent - MDA. Il est le composant de routage des
messages dans les différentes boites aux lettres. Utilise par le MTA
auquel il est souvent intègre.
B. PROTOCOLES
1) Protocole IMAP
Internet Message Acces Protocol. C'est l'accès
à distance à des messages stockés par le client de
messagerie. Les messages électroniques sont stockés sur le
serveur ou les utilisateurs les consultent ou les suppriment. Il utilise le
Port 143.
2) Protocole POP
Post Office Protocol
Il permet à des clients de messagerie de retirer du
courrier depuis des serveurs distants et de l'enregistrer sur un serveur local.
Il utilise le Port 110.
Protocole SMTP
Simple Mail Transfert Protocol
C'est le protocole d'envoi du courrier. Il utilise le Port 25.
C. INSTALLATION ET CONFIGURATION DE SENDMAIL
Vérification de l'existence # rpm - qa | grep
SendMail
1. Installation
Normalement SendMail est installé dans le CD ROM
d'installation de Red Hat 9.0 ; il faut le cocher lors de l'installation du CD
ROM.
2. Lutte contre les spams
Editer le fichier /etc/mail/
sendmail.mc
Il faut alors décommenter la ligne ci-dessous pour
interdire les commandes vrfy, expn, etc, sur le serveur mail :
Define (`confPRIVACY_FLAGS', `authwarnings, novrfy, noexpn,
restricqrun'). Il permet de lutter contre les spams.
3. Ouverture du port 25
Nous devons modifier la ligne ci-dessous pour permettre
l'ouverture des connexions Telnet sur le Port 25. Par défaut, cette
ligne est dé-commentée. Ce qui explique que seules les
utilisateurs locales á une machine puissent s'envoyer des mails.
Dnl DAEMON OPTION (`port = SMTP, Addr = 127.0.0.1 Name =
MTA')
4. Activation des macros
Pour cela nous générons la macro m4
# m4 /etc/mail/
sendmail.mc > /etc/
sendmail.cf
5. Redémarrage du service
Pour permettre la mise en marche du SendMail, nous faisons la
commande : # service SendMail restart
6. Barriere de sécurité
Les barrières de sécurité interdisent
l'utilisation efficace de la messagerie; # iptables -F
Vérification de l'ouverture du Port 25 # telnet
127.0.0.1 25
7. Test de fonctionnement
Apres toute configuration, il faut tester le fonctionnement du
serveur. Avec cette commande nous pouvons tester le serveur SendMail :
# /usr/sbin/SendMail -d0.1 -bt, /dev/null
Si le résultat suivant apparait :
(short domain name) $w = <nom de la machine>
(canonical domain name) $j = <nom de la machine. Nom
de
domaine.domaine)
(subdomain name) $m = <nom de domaine. Domaine)
(mode name) $k = (nom de la machine. Nom de
domaine.domaine)
Le serveur sendMail fonctionne correctement.
8. Vérification de l'envoi
Au préalable, pour être certain que l'envoi des
messages sera effectif nous faisons la commande telnet sur le port smtp
# telnet adresse IP (une adresse d'un
PC du réseau) 25 (port SMTP)
9. Envoi d'un mail
#mail
admin@enerca.cf
10. Consultation des mails
Pour consulter les mails dans la file d'attente: #vi
/var/spool/mail/nom_user
11. Problème a éviter
Dans la configuration de SendMail, le nom donné
á la machine (hostname) doit être identique á celui
renseigné au niveau du DNS (fichier /etc/hosts). Autrement dit, il doit
y voir une adéquation entre le hostname du DNS (local) et le hostname de
SendMail.
12. Masque du nom de machine
Il faut éditer le fichier de configuration de SendMail
#vi /etc/mail/
sendmail.mc
Nous ajoutons la ligne suivante :
MASQUERADE_AS (nom_de_machine)
Sauvegarder et quitter Echap (ou Esc) : x!
Apres générer la macro m4
# m4 /etc/mail/
sendmail.mc > /etc/
sendmail.cf
Redémarrer le service SendMail #service SendMail
restart
NB : MASQUERADE_AS (nom de domaine.domaine) masque le nom de
machine du domaine
enerca.cf dans l'Email de
l'expéditeur.
D. CONFIGURATION DES SERVEURS POP/ IMAP
1) Différences entre pop et imap
On se connecte toujours pour la synchronisation entre client et
le serveur avec IMAP.
2) Fonctionnalité du pop 3
Envoi de message via le protocole SMTP et
récupère de message via le protocole
POP.
3) Installation du pop 3
#tar -xvzf imap-xxx.tar.gz -C /usr/local
4) Configuration du serveur pop
Il faudrait d'abord éditer le fichier xinetd
vi /etc/xinetd.d/ipop3
Mettre disable á no
Sauvegarder et quitter
Echap : x!
Puis redémarrer le daemon xinetd restart
#service xinetd restart
NB : le serveur POP3 permet de recevoir les messages. Même
chose pour le serveur IMAP.
5) Test de fonctionnement
La commande suivante permet de tester le fonctionnement du
serveur SendMail #/usr/sbin/sendmail -d0.1 -bt < /dev/null.
Au préalable, pour être certain que la
réception des messages sera effective il faut faire un Telnet sur le
port POP
#telnet adresse IP (port POP)
Et aussi faire un Telnet sur le port IMAP
#telnet adresse IP (port IMAP)
6) Vérification des messages en attente
Pour vérifier les messages en attente et qui doivent
être envoyés. #mailq
7) Configuration client
Dans notre cas de messagerie tous les clients sont sur Microsoft
Windows (et plus précisément sur Windows XP).
> Lancer le client de messagerie Outlook
> Dans l'interface, cliquer sur démarrer
> Ouverture de configuration de Comptes de Messagerie
> Cliquer sur configurer manuellement les paramètres du
serveur ou les types de serveurs supplémentaires
> Ouverture de l'assistant de Connexion Choix du service de
messagerie
> Renseigner le champ nom complet
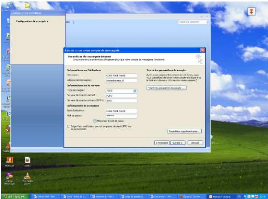
> Dans la boite de dialogue d'E-mail par le
biais de laquelle la réception de courrier se fera.
> Dans la boite de dialogue Noms de courrier
électronique, renseigner les champs : > Mon serveur
de courrier entrant : pour le type de serveur POP ou IMAP
> Serveur de courrier entrant : pour le nom
du serveur entrant
> Serveur de courrier sortant : pour le nom
du serveur sortant
> Dans la boite de dialogue Connexion á la
messagerie, fournir le mot de passe su compte
> Cocher la case relative au type de connexion dont on dispose
et cliquer sur Suivant > La boite de dialogue
Félicitation indique que la connexion a
été réussie.
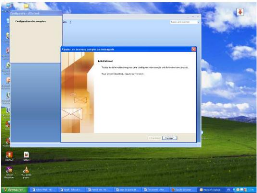
> Cliquer sur nouveau
> Test de l'envoi et de la réception avec Outlook.
CONCLUSION
En effet, l'administration d'un réseau informatique
permet la fluidité, le contrôle des informations dans ce
réseau. Notre choix s'est porté sur un Système Open Source
pour sa sécurité croissante et la stabilité de son
système.
Notre travail de mémoire testé avec
succès au sein de l'entreprise Enerca sera nous l'espérons un
outil de travail pour une prochaine administration dans ce domaine. En somme,
nous pouvons conclure cette administration a été un succès
dans sa mise en oeuvre et nous espérons toujours d'approfondir nos
connaissances dans ce domaine.
BIBLIOGRAPHIE ET WEBOGRAPHIE
Cours de Système d'Exploitation, 3eme Année
Génie Informatique
Jargon informatique
www.redhat.com
www.fedora.com
www.ubuntu.fr
www.wikipedia.fr
www.linuxfrance.fr
Dictionnaire du linux Forum de Fedora Forum d'Ubuntu
Livre « le réseau », édition Eyrolle,
Jacques FOUQUET
LEXIQUE
Apache : serveur http non seulement libre
mais aussi parmi les meilleurs et les plus répandus. Basé sur le
code et les idées du serveur NCSSA httpd avec beaucoup de pactchs au
départ d'où son nom « A PAtCHy sErver ».
Authentification : (cryptographie)
opération par laquelle le destinataire et/ou l'émetteur d'un
message s'assure(nt) de l'identité de son (leur) interlocuteur. C'est
utilisé entre les utilisateurs des sytèmes aussi bien qu'entre
des processus.
BIND : Berkeley Internet Name Domain,
implantation d'un Domain Name Server réalisée par
l'Université de Berkeley. Bind est un logiciel libre en position de
monopole dans son domaine.
Boot : c'est l'abréviation de
bootstrap ; programme lancé à l'allumage d'un ordinateur et
destiné à installer le SE en mémoire et à
l'initialiser. Le « secteur de boot » ou « boot sector »
est le tout premier secteur d'un disque qui peut contenir un bootstrap.
CLI : Command Line Interpreter ;
interpréteur de Ligne de Commande de programme servant d'interface,
recevant et interprétant les commandes envoyées en mode texte par
l'utilisateur (i.e sous la forme de frappes au clavier). Une autre
manière de faire est d'utiliser une Interface Graphique. Sous Ms DOS par
exemple, c'est COMMAND COM.
Client-serveur : architecture de
réseau dans laquelle les traitements sont repartis entre les clients qui
demandent les informations dont ils ont besoin au(x) serveurs(s).
DHCP : Dynamic Host Configuration
Protocol, protocole d'attribution dynamique des adresses sur un réseau
IP basé sur le bootP de façon à pouvoir avoir plus de
terminaux que d'adresse. Il permet d'une façon générale
d'administrer à distance toute la configuration IP d'une machine.
DNS : Domain Name Server ou Domain Nam
System ; service essentiel de l'Internet assurant la conversion des noms de
domaine en adresse IP. L'intérêt essentiel est de disposer de noms
de machines plus faciles à mémoriser.
File d'attente : ensemble d'objets
dans lequel le premier disponible est le premier à y avoir
été placé. Avec un système de priorité, le
premier entré n'est en fait pas toujours le premier servi, mais il est
sur d'être servi.
Firewall : police de l'informatique ;
barriere permettant d'isoler un ordinateur du réseau (tout en ne le
débranchant pas complètement) pour éviter tout
piratage.
FTP : File Transfer Protocol, protocole
de transfert de fichier. Le FTP peut fonctionner en mode actif ou passif ; dans
le premier cas, le client contacte le serveur sur le port 21 et celui-ci
rappelle sur le port 20. Dans le mode passif, c'est le client qui initie toutes
les connexions et seul le port 21 du serveur est utilisé.
Gnome : GNU Network Object Environment
Desktop ; c'est-à-dire environement de bureau, tournant sous X.
GNU : GNU is not Unit (la
définition est récursive), SE cousin d'Unix mis dans le domaine
public par la FSF assez difficile à maitriser car très puissant
et au service d'assistance technique assuré par les utilisateurs
même ainsi que par des sociétés commerciales.
GPL : General Public License, le statut
juridique des logiciels distribués « librement » à
l'origine a commencé comme ça : « Everyone is permitted to
copy and distribute verbatim copies of this license document but changing it is
not allowed. »
Groupe : ensemble d'utilisateurs d'un
système qui ont les mêmes droits sur certaines ressources.
GRUB : Grand Unified Bootloader ;
chargeur de système d'exploitation du projet GNU. Il est très
doué dans son domaine et sait lancer des systèmes très
différents sur une même machine (mais pas en même temps) y
compris Hurd.
Html : Hyper Text Markup Language est le
format de données conçu pour représenter les pages web.
C'est un langage de balisage qui permet d'écrire de l'hypertexte,
d'où son nom. HTML permet également de structurer
sémantiquement et de mettre en forme le contenu des pages, d'inclure des
ressources multimédias dont des images, des formulaires de saisie, et
des éléments programmables tels que des applets. Il permet de
créer des documents interopérables avec des équipements
très variés de manière conforme aux exigences de
l'accessibilité du web. Il est souvent utilisé conjointement avec
des langages de programmation (JavaScript) et des formats de
présentation feuilles de style en cascade). HTML est initialement
dérivé du Standard Generalize Markup Language (SGML).
http : Hyper Text Transfer Protocol.
Protocol de transmission dédié aux clients et aux serveurs du
Web. Facile à implanter car un transfert de données est
associé une connexion, il devient lourd car il multiplie les
connexions.
https : Hyper Text Transfer Protocol
Secure. Protocol de transmission issu de Nescape lié à une
connexion par Socket sécurisée, autrement dit http avec une
pincée de SSL.
IMAP : Internet Message Acces Protocol.
Protocole, dans sa version 4, de gestion de messagerie, destiné à
remplacer POP 3, qui est nettement moins performant. IMAP sait ainsi stocker le
courrier sur le serveur et pas sur le client et gérer toute la chose de
façon correctement sécurisée.
Iptables : est un logiciel libre de
l'espace utilisateur Linux grâce auquel l'administrateur système
peut configurer les chaînes et règles dans le pare-feu en espace
noyau (et qui est composé par des modules Netfilter).
KDE : Desktop intégré
fonctionnant sous X, basé sur la bibliothèque Qt, et copiant
l'interface de MS-Windows. Son grand concurrent est Gnome.
Kerberos : système de
sécurité et d'authentification des utilisateurs, mis au point par
le projet Athena au MIT. Le principe est de s'adresser à un serveur
d'authentification qui vous remet un « ticket » (certificat) avec
lequel vous pouvez accéder à la ressource que vous demandez.
LDAP : Lightweight Directory Access
Protocol ; protocole de gestion d'annuaires de réseau conçu
à l'Université du Michigan et reconnu par la plupart des grosses
sociétés du secteur. C'est aussi le nom des annuaires
gérés par l'intermédiaire de ce protocole.
LILO : LInux Loader, programme qui
s'installe dans le MBR, afin de pouvoir utiliser plusieurs systèmes
d'exploitation sur la même machine, dont bien évidemment Linux.
Linux : l'une des plus connues des
versions d'Unix libres (plus exactement distribue sous GPL)
développée à partir de 1991 par étudiant
finlandais, Linux Torvalds, tout seul à l'origine, qui trouvait d'une
part les limitations de Minix insupportables et d'autres part les versions
commerciales d'Unix trop chères. Il a su convaincre la communauté
mondiale des utilisateurs de l'Internet de l'aider dans sa tache. Maintenant
Linux est devenu un SE à part entière.
Login : procédure de connexion sur
un système, un hote, en général protégé par
un mot de passe.
Macro : macro-commande ou macrocommande ;
commande formée par une succession d'autres commandes
répétitives et pas forcément structurées. Les
commandes macro sont de plus en plus complet de sortent qu'une macro va du
simple double-clic automatisé à la petite application.
MBR : Master Boot Record ; le premier
secteur absolu sur un disque dur de PC.
Modem : abréviation de MODulateur
DEMotulateur. Périphérique permettant de convertir des signaux
analogiques en numériques et inversement et de les transférer par
une ligne téléphonique.
NAT : Network Address Translation.
Méthode de traduction d'adresse IP non routables en adresses routables
et réciproquement, et qui permet de connecter de nombreuses machines au
réseau en n'utilisant qu'un minimum d'adresses officielles.
NFS : Network File System ; c'est un SGF
(Système de Gestion de Fichiers) de réseau défini par un
protocole sans connexion présenté par Sun en 1995 pour des
stations sans disque.
NIS : Network Information Service ;
service d'information sur le réseau. Service donnant accés
à des bases de réseau fournissant par exemple des adresses IP,
Ethernet, des mots de passe ou des noms de serveur. Aussi connu sous le nom de
« Yellow Pages ».
Nom de domaine : chaîne de
caractère identifiant un ensemble d'adresse IP. Exemple de nom de
domaine :
enerca.cf.
Paquetage : archive rassemblant les
fichiers, informations, et procédures nécessaires à
l'installation d'un logiciel sur une plateforme donnée (package en
anglais).
Partage : le fait de mettre des
ressources à la disposition de plusieurs utilisateurs (qui peuvent
être programmés) et par extension la ou les ressource(s=
concernée(s).
Passerelle : Système logiciel
et/ou matériel gérant le passage d'un environnement à un
autre, en assurant la conversion des informations d'un format à
l'autre.
Pilote : logiciel permettant de
gérer un périphérique de le piloter c'est-à-dire de
lui envoyer les bonnes commandes au bon moment (driver en anglais).
POP : Protocol Office Protocol ;
protocole de transfert de courrier électronique, prévu pour
synchroniser les messages et reconnu par l'ISOC.
Port :
· Prise permettant de connecter un ordinateur à ses
périphériques. Il existe deux types de ports séries et les
ports parallèles
· Canal de communication.
PostScript : langage de description de
page proposé en 1984 par la firme Adobe très utilisé
(souvent en émulation) par les imprimantes laser. Les caractères
sont décrits par les courbes de bézier.
Processus : programme en cours
d'exécution avec son environnement.
Proxy : serveur recevant des
requêtes qui ne lui sont pas destinées et qui les transmet aux
autres. Cela permet à quelqu'un qui se trouve derrière un
firewall d'avoir accès à des ressources sans prendre de risques.
Le Proxy sait aussi être intelligent : quand il reçoit une
requête, il stocke le résultat. Si la même requête lui
est à nouveau envoyée, il vérifie que le résultat
n'a pas modifié et renvoie le résultat qu'il a «
déjà sous la main » à celui qui a fait la
requête (fonctionnant ainsi comme un cache).
Red Hat : l'une des distributions de
Linux en vogue, éditée par la société du même
nom. Elle est considérée comme l'une des plus simples, devant la
Debian et la Slackware, mais est surtout utilisée pour les serveurs, et
est très concurrencée par Mandrake sur les clients. En 2003, la
version grand public de la distribution a été abandonnée
au point du projet Fedora.
Root : nom du compte administrateur sous
certains systèmes Unix en particulier les distributions Linux.
Routeur : dispositif matériel ou
logiciel permettant de diriger les messages vers le bon destinataire, dans un
réseau.
Samba : est un logiciel libre et une mise
en oeuvre du protocole SMB/CIFS sous GNU/Linux, initialement
développée par l'australien Andrew Tridgell. Il est sous licence
GNU GPL 3. Son nom provient du protocole SMB (Server message block), le nom du
protocole standard de Microsoft, auquel ont été ajoutées
les deux voyelles a : « SaMBa ». À partir de la
version 3, Samba fournit des fichiers et services d'impression pour divers
clients Windows et peut s'intégrer à un domaine Windows Server,
soit en tant que contrôleur de domaine principal (PDC) ou en tant que
membre d'un domaine. Il peut également faire partie d'un domaine Active
Directory.
Sendmail : c'est un serveur de messagerie
électronique dont le code source est ouvert. Il se charge de la
livraison et de l'envoi de courriers électroniques (courriels).
Serveurs : ordinateur détenant des
ressources particulière et qu'il met à la disposition d'autres
ordinateurs par l'intermédiaire d'un réseau. On parle
d'architecture client-serveur.
Site : ensemble (plus ou moins)
cohérent de documents Web.
SMTP : Simple Mail Transfer Protocol,
protocole de la famille TCP/IP utilisé pour le transfert de courrier
éléctronique. Utilisé evidemment sur Internet et reconnu
par ISOC.
SOA : Start Of Authority, enregistrement
indiquant qu'un serveur DNS contient les informations « autorisées
» sur un domaine particulier. En gros c'est qui sait et personne
d'autre.
Socket : norme de mode de communication
sur réseau, mis au point à Berkeley, qui permet à une
application de dialoguer avec un protocole.
SSH : Secure Shell. Shell permettant de
se connecter de façon sécurisée sur une machine distante
et d'y exécuter des programmes, toujours de façon
sécurisée de chiffrement et destiné à
destiné à remplacer Telnet, rsh ou rlogin.
SSL : Secure Socket Layer. Sockets
sécurisée utilisées principalement par Nescape à
l'origine, puis reconnues ISOC (Internet SOCiety).
Swap : le fait d'utiliser une partie d'un
disque dur comme de la mémoire vive (mémoire
électronique).
TCP/IP : Transmission Control
Protocol/Internet Protocol. Les deux protocoles de communication qui forment
les fondements de l'internet, spécifiés dans la RFC 793.
TLS : Transport Layer Security, protocole
de sécurisation de la couche transport défini par la RFC 2246. La
version 1.0 de TLS est en fait SSL.
Topologie : organisation physique,
cartographie d'un réseau, qui n'a rien à voir avec la disposition
des systèmes qui y sont reliés. C'est la description du
câblage du réseau.
TTL : Time To Live, durée de vie
d'un paquet dans un réseau, sorte de date de péremption. Chaque
fois que le paquet entre dans un routeur, son TTL est
décrémenté et quand il tombe à zéro le
paquet est détruit même s'il n'est pas encore parvenu à
destination (de cette manière, par exemple, des paquets ayant un
destinataire inexistant ne peuvent pas encombrer indéfinitivement le
réseau en tournant en rond).
URL : Uniform Ressource Locator ; sur le
Web, c'est la méthode d'accès à un document distant
créant ainsi par exemple un lien hypertexte avec la syntaxe
<type_connexion>://<serveur> / <ressource>/ ...
Utilisateur : une personne qui travaille
pour de vrai sur un ordinateur, le considérant comme un moyen et pas
comme une fin.
WEB : methode d'exploitation de
l'Internet par l'usage de l'hypertexte et mis au point par un chercheur du
CERN, Tim BERNER-LEE. On parle « du Web » même s'il s'agit en
réalité du « World Wide Wed » ou du « W3
».
X Window System : interface graphique de
l'environnement Unix, mise au point et dans le domaine public par le MT.
Basé sur le protocole X, il permet l'exportation de display sur des
machines distantes. D'une lenteur et d'une lourdeur incomparable
compos d'une multitude de surcouches.
| 

