Epigraphe
La différence entre la théorie et la pratique,
c'est qu'en théorie,
il n'y a pas de différence entre la théorie et
la pratique, mais
qu'en pratique, il y en a une.
Jan van de Sneptscheut
Dédicace
|
|
A mes très chers parents, papa BIRAMBOVOTE
Hubert et maman TOTYA KAVIRA, à qui je dois tout. Je ne cesserai de leur
être redevable pour leur amour témoigné en ma faveur. Et si
le monde était à refaire, je vous choisirai toujours comme
parents.
|
Avant-propos et
remerciements
Au terme de notre cursus académique à
l'université de Kinshasa, nous tenons tout d'abord à rendre
grâce à l'ETERNEL, le Dieu Tout
Puissance, auteur de toute vie sur terre de nous avoir accordé
le souffle de vie combien importante.
Nous tenons à remercier le professeur MBUYI
MUKENDI Eugènequi, en dépit de ses multiples
occupations, a accepté de diriger ce travail. Ses remarques pertinents,
ses conseils et sa disponibilité nous ont profondément
marqué. Qu'il en soit vivement remercié.
Notre reconnaissance s'adresse également au chef
des travaux J.D BATUBENGA MWAMBA de nous avoir
encadré pendant toute la rédaction de ce travail, il a
été la lumière quant il faisait noir dans ce travail.
Encore une fois nous te disons merci.
Nous profitons également de cette occasion pour
remercier nos autorités de la faculté des sciences en
général et en particulier celles du département des
mathématiques et informatique, pour le dévouement qu'elles ont
fait montre durant notre parcours au sein de cette faculté pour nous
encadrer. Chers professeurs, recevez l'expression de notre reconnaissance
affectueuse.
Merci, rien que merci, se veut le seul mot que nous
adressons à l'endroit de : Papa MAZANGA FRANCOIS et son
épouse MUHINDO Valley, Papa KANGUNGU Médard et son épouse
Jeannine, Mon cousin MUHINDO Paul.
Mes remerciements s'adressent aussi aux membres de ma
famille particulièrement à mon grand frère MUHINDO
BIRAMBOVOTE, KAMBALE BIRAMBOVOTE Jacques et mon cousin MOBYSSA NGESERA Fabrice,
Ma cousine KINYOMA NICOLE.
Nous ne pouvons les oubliés, nos compagnons de
lutte et toute la promotion de deuxième licence informatique
2012-2013.
Nous ne pouvons clore nos propos sans toutefois remercier
nos amis : ELONJA MPANDOTE Jordan, MBIYA MUTAMBAYI Simms et ZAGABE SERUTI
Claude, KASEREKA MUSUMBA Bienfait.
Vrai et réel merci à vous tous, qui de loin
ou de près avez contribué à la réalisation de ce
travail. Sincèrement recevez nos remerciements.
Liste des
abréviations
|
BD : Base de données
|
|
CI : Cellule d'infrastructures
|
|
DW : Data Warehouse
|
|
EAI : Enterprise Application Integration
|
|
ED : Entrepôt de Données
|
|
ETL : Extract-Transform-Load
|
|
FTP :File Transfer Protocol
|
|
HTTP : HyperText Transfer Protocol
|
|
IT : Information technology
|
|
ISO : International Organization for Standardization
|
|
MCD : modèle conceptuel des données
|
|
MLD : Modèle Logique des données
|
|
MPD : Modèle Physique des données
|
|
OLAP : Online Analytical Processing
|
|
OLTP : Online Transaction Processing
|
|
SI :Systèmed'Information
|
|
SIG :
Systèmed'InformationGéographique
|
|
SGBD :
Système
de Gestion de Base de Données
|
|
SGBDR :Système de Gestion de Base de
Données Relationnel
|
|
SMTP : Simple Mail Transfer Protocol
|
|
SOA : Service-Oriented Architecture
|
|
SQL :Structured Query Language
|
Tableau des figures et de
tableaux
|
Liste des figures
|
|
Figure 1 Structure du SGBD
|
|
Figure 2 Les deux composants d'un système de bases
de données relationnelles
|
|
Figure 3 Décideur
|
|
Figure 4 Exemple d'un cube de données
|
|
Figure 5 : Composants de base d'un data warehouse
|
|
Figure 6 Approche architecturale de Bill Inmon
|
|
Figure 7 Approche architecturale de Ralph Kimball
|
|
Figure 8 Architecture d'un entrepôt de données
|
|
Figure 9 Schéma d'un modèle en Etoile
|
|
Figure 10 schémas du modèle en flocon
|
|
Figure 11 Exemple d'architecture d'un outil ETL moderne
|
|
Figure 12 Fonctionnement d'un site web statique
|
|
Figure 13 Fonctionnement d'un site web dynamique
|
|
Figure 14 Représentation en mode vectoriel
|
|
Figure 15 Représentation des données
matricielles
|
|
Figure 16 Représentation des différents types de
données SIG
|
|
Figure 17 Organisation et fonctionnement du SIG de la Cellule
d'infrastructure
|
|
Figure 18 Architecture d'un serveur cartographique sur
internet
|
|
Figure 19 Modèle Conceptuel de données
|
|
Figure 20 Modèle Logique de données
|
|
Figure 21 Modèle physique de données
|
|
Figure 22 Interface de mise à jour Axe Routier
|
|
Figure 23 Interface d'enregistrement de données
géographique
|
|
Figure 24 Carte géographique de Kinshasa
|
|
Figure 25 Carte géographique de la ville de
Lubumbashi
|
|
Figure 26 Modèle en étoile de notre
entrepôt de données
|
|
Figure 27 Architecture globale du système
décisionnel.
|
|
Figure 28 Processus de chargement de données
|
|
Figure 29 Schémas de construction de la base de
préparation des données.
|
|
Figure 30 Présentation du cube
|
|
Figure 31 Histogramme de coût de SAFRICAS
|
|
Figure 32 Histogramme de coût par province
|
|
Liste de tableau
|
|
Tableau 1 Tableau comparatif de deux philosophies actuelles
|
|
Tableau 2 : présentation des composantes du
système d'information
|
|
Tableau 3 Représentation des relations
|
|
Tableau 4 Tableau de dictionnaire de données
|
|
Tableau 5 Présentation d'un tableau de bord
|
|
Tableau 6 Tableau de résultat SAFRICAS
|
|
Tableau 7 Tableau croisé sous Analysis Services pour
la présentation des statistiques.
|
TABLE DES MATIERES
Epigraphe
Erreur ! Signet non
défini.
Dedicace
Erreur ! Signet non
défini.
Avant-propos et remerciements
iii
Liste des abréviations
iv
Tableau des figures et de
tableaux
v
INTRODUCTION
1
CHAP I LES NOTIONS FONDAMENTALES SUR LES
BASES DE DONNEES
4
1.1 Description
d'une Base de données
4
1.1.1
Définition d'une base de données
4
1.1.2 Type des
bases de données
4
1.1.3 Architecture
d'un SGBD
4
1.1.4
Typologie
5
1.2 L'approche
SGBD
5
1.3 Système
de gestion de bases de données relationnelle
7
1.3.1
Définition
7
1.3.2 Composants
d'un système bases de données relationnelles
7
1.3.3Caractéristique d'un
système de gestion de bases données relationnelle
8
1.4 Le
modèle Entité-Association
8
1.4.1
Définition d'un modèle
entité-association
8
1.4.2
Entités et associations
8
1.4.3 Les types
d'associations
9
1.4.4 Les phases de
la construction d'un modèle de données
9
1.5 Les principaux
systèmes de gestion de bases de données
10
1.6 Le langage de
base de données
10
CHAP II SYSTEME DECISIONNEL [3] [5] [8] [9]
[10] [16] [20] [21]
11
2.1 Notion sur le
décideur
11
2.2.1
Entreprise
11
2.2.2
Décideur
11
2.2.3 Les facteurs
d'amélioration de la prise de décision
12
2.2 Système
d'Information
13
2.2.1
Définition
13
2.2.2 Enjeux du
système d'information
13
2.3 Concepts de
base des systèmes d'aide à la décision
14
2.3.1
Entrepôt de Données (data warehouse)
14
2.3.2 La fouille de
données (Data mining)
15
2.3.3 Modèle
Multidimensionnel
15
2.4 Les Composantes
d'un Entrepôt de Données
16
2.4.1 Objet d'un
entrepôt de données
16
2.4.2
Composantes
17
2.4.3 Architecture
d'un entrepôt de données
21
2.5 La
Modélisation Dimensionnelle
24
2.5.1
Terminologie
24
2.5.2
Schématisation
26
2.6 Les outils de
chargement
28
2.6.1 Le concept
ETL (Extract-Transform-Load)
28
2.6.2 Les
qualités d'un bon ETL
28
2.6.3 Les
catégories d'outil ETL
29
2.6.4 Architecture
d'un outil ETL
29
CHAP III TECHNOLOGIE WEB
[4] [7]
31
3.1 Introduction
à l'Internet et le Web
31
3.1.1
Définition
31
3.1.2 Quelques
dates importantes au sujet du Web
31
3.2 Les
applications Internet classiques
32
3.2.1 HTTP
(L'HyperText Transfer Protocol)
32
3.2.2 SMTP (Simple
Mail Transfer Protocol)
32
3.2.3 FTP (File
Transfer Protocol)
32
3.2.4
Telnet
32
3.3 Fonctionnement
d'un site web
32
3.3.1 Cas d'un site
statique
33
3.3.2 Cas d'un site
dynamique
33
3.4 Les langages du
Web
34
3.4.1
HTML
34
3.4.2
XHTML
34
3.4.3
CSS
34
3.4.4PHP
34
3.4.5
JavaScript
34
CHAP IV : SYSTEMES D'INFORMATION
GEOGRAPHIQUE
36
4.1
Définition
36
4.2 Utilité
d'un SIG
36
4.3
Capacités d'un SIG
36
4.4 Typologie des
Données SIG
37
4.4.1 Les
données géographiques
37
4.4.2Les données
attributaires
38
4.5
Représentation des Données SIG
38
4.5.1
Représentation en mode vectoriel
38
4.5.2
Représentation en mode matriciel (raster)
39
4.6 Modelés
des systèmes d'informations géographiques
40
4.6.1 Le
modèle métrique ou spaghetti
40
4.6.2Le modèle
topologique
41
4.7
l'échelle d'une carte
41
4.8 Sorte de
carte
41
4.9 Concepts
liés aux Géodatabase
42
4.6.1
Définition d'une Géodatabase
42
4.6.2Types de
géodatabase
42
4.10Avantage de serveur SIG
43
4.11 Les
composantes d'un SIG
44
4.12
Fonctionnalités d'un SIG
44
4.13 Domaines
d'applications
45
4.14Le Webmapping (Cartographie
Dynamique)
45
4.14.1Généralités
45
4.14.2Fonctionnement du
WebMapping
46
4.14.3Architecture d'un système de
Webmapping
47
4.14.4Fonctionnalités
48
CHAP V RESEAUX ROUTIES EN RDC
50
5.1
Présentation du secteur
50
5.1.1 Situation des
infrastructures routières en RDC
50
5.1.2 Cellule
infrastructures
51
5.2 Système
d'information existant
53
5.2.1 Critique de
l'existant
53
5.2.2
Motivation
53
CHAP VI : CONCEPTION ET
IMPLEMENTATION
[10] [18]
3
6.1 Aperçue
des différents outils utilisées
54
6.1.1 Les SGBD
utilisées
54
6.1.2 Le serveur
web
55
6.1.3 Le serveur
Google Maps
55
6.2 Application de
webmapping
56
6.2.1 Conception et
modélisation de la base de donnes
56
6.2.2
Présentation des quelques interfaces
61
6.2.3 Quelque code
de l'application
64
6.3
Implémentation de l'entrepôt de
données
70
6.3.1
Modélisation multidimensionnelle
70
6.3.2 Architecture
type du data warehouse
71
6.3.3
Implémentation de la base de données du data
Warehouse
72
6.3.4Chargement de données dans les
dimensions
73
6.3.5 Construction
de la base de préparation
74
6.3.6Chargement de la table
fait
74
6.3.7
Déploiement du cube et analyse
76
CONCLUSION
80
INTRODUCTION
Avec la révolution et le changement que l'informatique
a apporté dans la plus part des secteurs de la vie, la République
Démocratique du Congo pourrait considérablement profité
de ses atouts. Avec son défi de construction et modernisation des
infrastructures routières, l'utilisation des outils modernes de gestion
est d'une grande nécessité.
De son temps, Stanley avait dit « sans le chemin
de fer le Congo (RDC) ne vaut pas un pénis ». A travers
cette pensée, nous pouvons comprendre l'importance de voies de
communication pour ce pays à la dimension continentale.Elle garde tout
son sens pour ce qui est du domaine routier.
En RDC, un bon réseau routier constituera un facteur
important pour la croissance économique. Tous les secteurs de la vie
bénéficieront de la fluidité des trafics et, de la
mobilité des personnes, des biens et des services. Pour le secteur
agricole par exemple, l'acheminement des semences vers les zones agricoles,
l'évacuation des récoltes jusque dans les centres de
transformation et la redistribution vers les consommateurs.
L'enjeu pour la RDC consiste à parvenir à
conserver en bon état les routes existantes et d'en construire de
nouvelles pour permettre le développement économique et
désenclaver l'ensemble du territoire national.
Malheureusement le pays débourse beaucoup d'argent dans
ce secteur pour un résultat non proportionnel. La Cellule
d'Infrastructures, organe du ministère d'Infrastructure, Travaux Public
et Reconstruction en charge de la gestion de passation de marchés et
d'inspection des travaux routiers ne dispose pas d'un système
informatique approprié permettant une gestion informatisée
d'immense données dont elle dispose pour en extraire des
éléments statistiques nécessaires à
l'amélioration de la prise de décision.
Cette défaillance a conduit à:
Ø Une appréciation estimative lors de passation
de marchés qui n'est guère soutenue par des statistiques,
cachées pourtant dans leurs immenses bases de données ;
Ø Une mauvaise cotation des inspecteurs qui sont
senséssuperviser les travaux et procéder aux
contrôles ;
Ø L'absence de mécanisme pour contrer les actes
de corruption qui caractérisent certains fonctionnaires ;
Ø Un déficit de confiance de la population
à l'égard du Gouvernement, car ce dernier continue à
attribuer des marchés à des entreprises de construction qui sont
dépourvues d'expertise et de compétences
avérées ;
Ø Une sous information au sujet de l'évolution
et la maintenance des infrastructures.
Il est alors nécessaire de bien conserver le flux
d'information du réseau routier. Le réseau routier
génère un volume significatif de données complexes qui
nécessite un système efficace pour le stockage, le traitement et
les analyses.
Les questions qui ont motivé notre travail sont
alors :
Ø Comment mettre en oeuvre un Système
Décisionnel qui permettra d'améliorer la prise de décision
du gouvernement congolais à travers la Cellule d'Infrastructures dans le
domaine des infrastructures routières ?
Ø Comment mettre en oeuvre une application de
webmapping qui permettra à toute la population congolaise selon son
centre d'intérêt, d'obtenir via internet une carte
géographique contenant les routes qui sont en cours de construction ou
de réhabilitation ?
C'est pour cette raison que nous avons été
motivé de travailler autour du thème intitulé
« Mise en place d'un Data Warehouse et d'une application de
Webmapping pour la gestion du réseau routier : Cas De la
République Démocratique du Congo».
Notre objectif est d'avoir un système d'aide à
la prise de décision qui permettra à l'Etat congolais d'avoir un
aperçu clair et à temps utile sur la performance des
différents acteurs intervenant activement dans le secteur des
infrastructures, en vue d'une gestion moderne et efficace du réseau
routier.
Le Webmapping permettra à la population d'être
informée sur les routes en cours de réhabilitation ou de
(re)construction.
Parmi plusieurs techniques existantes pour la collecte des
données servant à alimenter notre système informatique,
nous avons eu recours à la technique documentaire et interview qui nous
a permis à déceler les difficultés qui acculent le
secteur, mais aussi apprécier les avancées qui y sont
réalisées.
Pour réaliser ce présent travail, nous nous
sommes inspiré d'une documentation constituée d'un grand nombre
d'ouvrages, notes de cours et articles.
Notre travail comptera au-delà de l'introduction six
chapitres puis une conclusion offrant des perspectives.
Le premier chapitre portera sur les notions de base sur les
Bases de Données, utiles pour ce travail. Il contient des points
essentiels sur les bases de données, le modèle
entité-association et les systèmes de gestion des bases de
données.
Le deuxième chapitre est consacré au
Système Décisionnel. Nous nous focaliserons plus sur les concepts
de base du système décisionnel, ses avantages et sur la
Modélisation Multidimensionnelle.
Le troisième aborde les notions sur les technologies
web. Nous présenterons de manière simple et concise l'essentiel
des langages de programmation et techniques utilisées dans cet univers
du web.
Le quatrième chapitre sera dédié au
système d'information géographique (SIG). Il développera
quelques points essentiels sur le fonctionnement du SIG, son architecture et
le webmapping.
Le cinquième chapitre portera sur la
présentation de la Cellule d'infrastructures en suite sur l'analyse de
leur état de la gestion actuelle.
Le sixième chapitre sera réservé à
la description de notre démarche méthodologique. Nous terminerons
par la mise au point de la solution ainsi que la présentation des
principales fonctionnalités de celle-ci.
CHAP I LES NOTIONS
FONDAMENTALES SUR LES BASES DE DONNEES
[1] [11] [12] [13] [19]
1.1Description d'une Base de
données
1.1.1Définition d'une
base de données
Une base de données permet de stocker et de
récupérer facilement des informations. Ces informations sont
structurées de manière à refléter la
réalité tout en respectant quelques règles (unicité
de l'information, chaque élément doit pouvoir être
identifié de manière unique ...).
1.1.2Type des bases de
données
Il existe de nos jours cinq grands types des bases de
données:
Ø Les bases des données hiérarchiques
Ø Les bases des données réseau
Ø Les bases des données relationnelles
Ø Les bases des données déductives
Ø Les bases des données objets
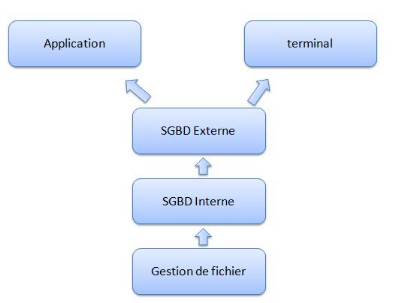
1.1.3Architecture d'un SGBD
251608064
Figure 1 Structure du SGBD
Le SGBD se décomposer en trois sous-systèmes
:
Ø le système de gestion de fichiers :
Il permet le stockage des informations sur un support
physique.
Ø le SGBD interne :
Il s'occupe du placement et de l'assemblage des
données, la gestion des liens et la gestion de l'accès rapide.
Ø le SGBD externe :
Il s'occupe de la présentation et de la manipulation de
données aux concepteurs et utilisateurs. Il s'occupe de la gestion de
langages de requête élabores et des outils de présentation.
1.1.4Typologie
L'usage qui est fait des données diffère d'une
base de données à l'autre. Les bases de données peuvent
être classifiées en fonction du nombre d'usagers, du type de
contenu, notamment s'il est faiblement ou fortement structuré, ainsi que
selon l'usage qui est fait de la base de données, notamment
l'utilisation opérationnelle ou à des fin d'analyse.
La manière la plus populaire de classer les bases de
données est selon l'usage qui en est fait, et l'aspect temporel du
contenu.
Ø Les bases de données
dites opérationnelles ou
OLTP (de
l'anglais Online Transaction Processing) sont destinées à
assister des usagers à tenir l'état d'activités
quotidiennes. Elles permettent en particulier de stocker sur le champ les
informations relatives à chaque opération effectuée dans
le cadre de l'activité. Dans de telles applications l'accent est mis sur
la vitesse de réponse et la capacité de traiter plusieurs
opérations simultanément.
Ø Les bases de données d'analyse dites
aussi
OLAP (de
l'anglais online analyticalprocessing), sont composées
d'informations historiques telles que des mesures sur lesquelles sont
effectuées des opérations massives en vue d'obtenir des
statistiques et des prévisions. Les bases de données sont souvent
des
entrepôts
de données (anglais datawarehouse): des bases de
données utilisées pour collecter des énormes
quantités de données historiques de manière quotidienne
depuis une base de données opérationnelle. Le contenu de la base
de données est utilisé pour effectuer des analyses
d'évolution temporelle et des statistiques telles.
1.2L'approche SGBD
Cette approche est venue résoudre un problème
de gestion de données. A l'époque c'était l'approche
fichier, il s'est avérée que cette solution avec des
imperfections pour palier à ce souci ; on a inventé une
nouvelle approche qu'on a appelé approche SGBD.
Les objectifs de l'approche SGBD sont :
Ø Indépendance physique :
Le SGBD offre une structure canonique permettant la
représentation des données réelles sans se soucier de
l'aspect matériel.
Ø Indépendance logique :
C'est l'une des innovations, car avec cette
indépendance cette indépendance chaque groupe peut se concentrer
sur ce qui les intéresse. D'où chaque utilisateur a son propre
aperçu lorsqu'il travail.
Ø Manipulation par des langages non-procéduraux
et de haut niveau :
Un SGBD doit permettre d'obtenir des données par des
langages non procéduraux ou non. D'où la facilité pour un
informaticien de l'utiliser. Compatible avec des langages des programmations
(java , C++, pascal, vb , delphi , etc .).
Ø Administration facile des données :
Un SGBD doit offrir des outils pour permettre la mise à
jour des données qui est le premier rôle d'un SGBD
Ø Non redondance des données :
Un SGBD doit permettre d'éviter la redondance des
données, car lorsqu'on élabore une base de
données, on doit tenir compte de l'espace mémoire.
Ø Cohérences des données :
Il doit respecter les contraintes d'intégrité.
Une contrainte d'intégrité est une contrainte sur les
données de la base de données, qui doit toujours être
vérifiée pour assurer la cohérence dans cette base de
données.
Ø Souplesse d'accès aux données
Un SGBD doit permettre d'accéder facilement à
n'importe quelle donnée de la base de données.
Ø Sécurité
Un SGBD doit être capable de protéger les
données qu'il gère contre toute sorte d'agressions
extérieures.
Ø Partage des données
L'importance première d'une base de données est
de partager des données entre plusieurs applications.
1.3Systèmede gestion
de bases de données relationnelle
1.3.1Définition
Un système de gestion de bases de données
relationnelle (relationaldatabase management system, en anglais), SGBDR en
abrégé, souvent appelé simplement système de bases
de données relationnelles, est un système intégré
pour la gestion unifiée des bases de données relationnelles. Un
SGBDR dispose de fonctions utilitaires d'une part, et d'un langage descriptif
pour la définition et la manipulation de données d'autre part.
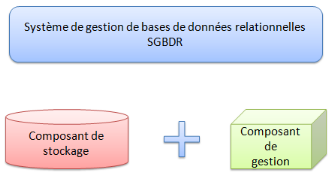
1.3.2Composants d'un
système bases de données relationnelles
Un système de bases de données relationnelles
est constitué d'un composant de stockage et d'un composant de gestion de
données. Le composant de stockage a pour but de réunir dans des
tables l'ensemble des données et tous les liens qui les unissent. On
distingue d'une part les tables qui contiennent des données appartenant
aux applications des utilisateurs, d'autre part les tables systèmes
indispensables au fonctionnement d'une base de données.
Les tables systèmes contiennent les définitions
de données que les utilisateurs peuvent consulter à tout moment
sans être autorisés à les modifier. Le composant de gestion
comporte essentiellement un langage relationnel de définition et de
manipulation des données. Ce composant englobe aussi des fonctions
utilitaires telles que la restauration de la base de données en cas de
panne, la protection et la sécurité des données.
251607040
Figure 2 Les deux composants d'un système de
bases de données relationnelles
1.3.3Caractéristique
d'un système de gestion de bases données relationnelle
Une base de données relationnelle se caractérise
par les éléments suivants :
Ø Un SGBDR permet une organisation structurée
des données, fondée sur une base formelle claire. Toutes les
informations sont stockées dans des tables. Des dépendances entre
les valeurs d'attributs dans une table, ou la présence d'informations
redondantes sont identifiées.
Ø Un SGBDR dispose d'un langage ensembliste pour la
définition et la manipulation de données. C'est un langage
descriptif qui vise à faciliter la formulation des requêtes par
l'utilisateur en le déchargeant des tâches de programmation.
Ø Un SGBDR garantit une grande indépendance des
données, c'est-à-dire la nette séparation entre celles-ci
et les programmes d'application. Cette propriété résulte
du fait que le composant de gestion dissocie les applications du composant de
stockage dans un SGBDR.
Ø Un SGBDR fonctionne dans un environnement
multiutilisateur en permettant à plusieurs personnes d'interroger ou de
traiter simultanément une même base de données.
Ø Un SGBDR dispose de mécanismes garantissant
l'intégrité des données. Ce terme englobe le stockage de
données sans erreur, la protection contre les destructions, les pertes,
les abus et les accès non autorisés.
1.4 Le modèle
Entité-Association
Définition d'un
modèle entité-association
Un modèle de données est une description
formelle et structurée des données et de leurs relations dans un
système d'information.
Entités et
associations
Une entité est un objet spécifique
(c'est-à-dire qui peut être identifié distinctement parmi
d'autres objets) dans le monde réel ou dans notre pensée. Elle
peut désigner une personne, un objet, un concept abstrait ou un
événement. Les entités de même type forment un
ensemble d'entités caractérisées par un certain nombre
d'attributs.
Pour chaque ensemble d'entités, nous définissons
une clé d'identification, formée d'un attribut ou d'une
combinaison d'attributs, qui permet de distinguer chaque entité de
manière unique.
Les associations désignent les liens qui
existent entre différentes entités.
Les types d'associations
Association simple
Dans une association simple (type 1), à chaque
entité dans l'ensemble d'entités EE_1 correspond «une et une
seule» entité dans l'ensemble EE_2.
Association conditionnelle
À chaque entité dans l'ensemble d'entités
EE_1 correspond «zéro ou une entité»,
c'est-à-dire au plus une entité dans l'ensemble EE_2.
Association multiple
Dans une association multiple (type m), à chaque
entité dans l'ensemble d'entités EE_1 correspondent «une ou
plusieurs» entités dans l'ensemble EE_2.
Association multiple conditionnelle
À chaque entité dans l'ensemble d'entités
EE_1 correspondent «aucune, une ou plusieurs» entités dans
l'ensemble EE_2. Le type d'association multiple conditionnelle distingue du
type d'association multiple par le fait que chaque entité dans EE_1
n'est pas forcément reliée aux entités dans EE_2.
Les phases de la construction
d'un modèle de données
Première phase
La première phase, l'analyse de données, vise
à déterminer, en collaboration avec les utilisateurs, les
données nécessaires à un système d'information,
leurs relations ainsi que la structure des ensembles qui en résultent.
C'est ainsi qu'on parvient à délimiter dès le début
les frontières d'un système. À travers une démarche
itérative, les interviews, l'analyse des besoins, les questionnaires,
les formulaires, etc., doivent permettre de produire une documentation
complète.
Deuxième phase
La deuxième phase d'abstraction vise à concevoir
un modèle entité-association où l'on définit les
ensembles d'entités et les ensembles de liens entre ces entités.
Dans ce modèle, les ensembles d'entités sont
représentés graphiquement par des rectangles, et les ensembles de
liens par des losanges. Il convient de souligner ici qu'il n'est pas toujours
facile d'identifier des ensembles d'entités et de liens ainsi que leurs
attributs de manière unique. Bien au contraire, la phase de conception
exige de la compétence et de l'expérience pratique de la part de
l'architecte de données.
Troisième phase
La troisième phase a pour but de convertir le
modèle entité-association en un schéma de base de
données relationnelle. Définir un schéma de base de
données, c'est fournir une description formelle des objets dans la base
de données considérée. Sachant qu'une base de
données relationnelle n'admet que des tables comme objets, on doit donc
exprimer tous les ensembles d'entités et de liens sous forme de
tables.
1.5 Les principaux
systèmes de gestion de bases de données
Les systèmes de bases de données
non-relationnelles ne satisfont que partiellement aux objectifs que nous venons
de présenter. De ce fait, les systèmes de bases de données
relationnelles ont réussi une percée sur le marché ces
dernières années et continuent à gagner du terrain. On
assiste à une amélioration continuelle de leurs performances
malgré le prix à payer qui découle de la conception
ensembliste du traitement. L'expérience pratique des systèmes de
bases de données relationnelles a donné une impulsion aux
nouveaux développements dans le domaine des bases de données
réparties et des bases de connaissances et de méthodes.
Tellement la liste est exhaustifs, on peut que citez qu'une
partie dont les plus connus sont :
Ø Oracle
Ø Mysql
Ø Sql server
Ø PostgreSQL
Ø Paradox
Ø Sybase
Ø Dbase
Ø Visuel Dbase
Ø Access
1.6 Le langage de base de
données
Pour interroger une base de données, on a besoin d'un
langage de base de données, sur ce le plus connu et les plus
utilisé est le langage SQL (StructuredQuery langage).
C'est un langage conçu par le mathématicien
americaincodd en 1970. Il fait appel à des opérations
élémentaires qui manipulent les tables ainsi que leurs
données. Il prépare la conception de requêtes qui seront
traduite en SQL.
Il est composé de deux types
d'opérateurs :
Ø Relationnels : Sélection, Projection,
Jointure et Division.
Ø Ensemblistes : Union, Intersection,
Différence.
Il existe 4 opérations classiques (ou
requêtes) :
Ø La création (ou insertion).
Ø La modification (ou mise-à-jour).
Ø La destruction.
Ø La recherche.
CHAP II SYSTEME
DECISIONNEL
[3] [5] [8] [9] [10] [16] [20] [21]
2.1 Notion sur le
décideur
2.2.1
Entreprise
Une entreprise est une organisation dotée d'une mission
et d'un objectif métier. Elle doit gérer sa raison d'être
et/ou sa pérennité au travers de différents objectifs
(sécurité, développement, rentabilité). Par voie de
conséquence, cette organisation humaine est dotée d'un centre de
décision.
2.2.2
Décideur
Le décideur est une personne dotée d'un pouvoir
de décision, il peut-être le responsable d'une entreprise, le
responsable d'une fonction ou d'un secteur. Il est donc celui qui engage la
pérennité ou la raison d'être de l'entreprise. Pour ces
raisons, il doit être doté de différents moyens lui
permettant une prise de décision la plus pertinente et la plus
appropriée possible. Parmi ces moyens, les data warehouses ont une place
primordiale et privilégié. En effet, ils contiennent les
données de toute l'activité de l'entreprise jugée utile
pour la prise de décision. Le principal problème réside
dans l'exploitation de ces informations. Pour cela, il est primordial de bien
penser le datamining.
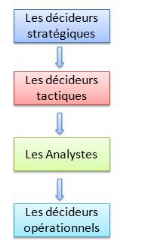
Nous pouvons répartir le décideur sous trois
catégories :
Ø Les décideurs stratégiques
Horizon de travail : Long terme.
Périmètre de travail : Tous les services, tous
les territoires.
Leur rôle : Ces décideurs définissent les
grandes lignes que l'entreprise doit prendre et mobilisent les moyens
nécessaires pour y parvenir. Donc ils orientent la politique et les
valeurs de l'organisation.
Ø Les décideurs tactiques
Horizon de travail : Moyen terme.
Périmètre de travail : un service ou un
territoire.
Leur rôle : les décideurs tactiques sont les
relais des caps stratégiques, fixés par les décideurs
stratégiques.
Ce sont eux qui fixent les objectifs de leur direction ou de
leur territoire, qui élaborent et choisissent la meilleure tactique pour
atteindre ces objectifs.
Ø Les décideurs opérationnels
Horizon de travail : court terme.
Périmètre de travail : un service sur un
territoire.
Leur rôle : faire face à la réalité
du terrain, gérer le quotidien.
À ces trois profils de décideurs s'ajoute celui
des analystes. Le rôle des analystes est de récolter et de
travailler l'information, fiabiliser les données, expliquer les
résultats. Leur rôle est d'aider à la prise de
décision des décideurs. Les analystes varient suivant le type
d'organisation (industrie, négoce, service public...) et le service
auquel ils appartiennent.
251595776
Figure 3 Décideur
Cette classification a de l'importance, car elle va
révéler de grosses différences dans le type d'outils dont
chacun a besoin.
2.2.3 Les facteurs
d'amélioration de la prise de décision
Généralement, on présente les trois
facteurs de prise de décision comme étant :
Ø La connaissance et l'analyse du passé.
Ø La représentation du présent.
Ø L'anticipation du futur.
Les informations permettant d'appréhender ces facteurs
peuvent être de deux natures différentes :
Ø Les informations quantitatives : ce sont toutes les
données chiffrées telles que les montants, quantités,
pourcentages, délais...
Ø Les informations qualitatives : ce sont toutes les
informations non quantifiables telles qu'un commentaire accompagnant un
rapport, des mécontentements, un sentiment, une directive, une nouvelle
procédure...
2.2 Système
d'Information
2.2.1
Définition
Un système d'information (noté SI)
représente l'ensemble des éléments participant à
la gestion, au stockage, au traitement, au transport et à la diffusion
de l'information au sein d'une organisation.
2.2.2 Enjeux du
système d'information
Le système d'information coordonne les activités
de l`entreprise. Il est le véhicule de la communication dans
l'organisation. De plus, le SI représente l'ensemble des ressources et
systèmes (personnes, matériels, logiciels) organisés pour
les objectifs suivants :
Ø Saisie des informations
Ø Stockage des informations
Ø Traitement des informations
Ø Restitution des informations
Ø Transmission des informations
2.2.3 Catégorie
Il existe deux grandes catégories de systèmes
d'information, les systèmes transactionnels et les systèmes
décisionnels. Les premiers servent à gérer le quotidien,
l'opérationnel de l'entreprise. Les seconds sont utilisés pour
prendre du recul, et servir de support aux décisions de l'entreprise et
de ses dirigeants.
2.2.4 Les systèmes transactionnels
(opérationnels)
Ce sont les outils que nous utilisons chaque jour. Ils
assurent le bon fonctionnement de l'ensemble d'organisation.
Toutes ses applications répondent à la
même attente : permettre la saisie d'informations, leur traitement, et la
production en sortie de résultats, sous forme de documents papier, de
consultations à l'écran ou d'autres informations.
Les trois principales caractéristiques d'un
système transactionnel sont donc :
Ø la capacité à gérer de grands
volumes de données,
Ø des temps de réponse très
réduits,
Ø mais des requêtes relativement simples du point
de vue informatique.
2.2.5 Les Systèmes
Décisionnels
Le principe même de la prise de décision est de
s'appuyer sur des informations précises pour en déduire des
comportements et passer à l'action.
Toutes ses applications répondent au même
processus : analyser des données préalablement collectées
par les applications opérationnelles de l'entreprise, les mettre en
forme, aider à distinguer les grandes tendances, et publier des
résultats sous forme de graphiques, de tableaux, ou de rapports.
Les trois principales caractéristiques d'un
système décisionnel sont donc :
Ø la capacité à gérer de grands
volumes de données,
Ø appliquent des requêtes beaucoup plus
complexes,
Ø ils disposent de plus de temps pour les
exécuter.
2.3 Concepts de base des
systèmes d'aide à la décision
2.3.1 Entrepôt de
Données (data warehouse)
Un entrepôt de données (ED) ou data warehouse
(DW) se définit selon W. INMON comme étant un ensemble de
données intégrées, orientées sujet, non volatiles,
gérées dans un environnement de stockage particulier,
historisées, résumées, disponibles pour l'interrogation et
l'analyse et organisées pour le support d'un processus d'aide à
la décision.
De part cette définition nous pouvons relève
plusieurs concept qui caractérise un entrepôt de
données : Intégrées- Orientées sujet - Non
volatiles - Historisées - Résumées
Intégrées
Les données de l'entrepôt proviennent de
différentes sources éventuellement
hétérogènes. L'intégration consiste à
résoudre les problèmes
d'hétérogénéité des systèmes de
stockage, des modèles et de la sémantique de données.
Orientées sujet
Après leur intégration dans une sorte de source
globale, les données sont réorganisées autour de
thèmes tels que : les itinéraire, inspecteur,
matériaux...etc.
Chaque décideur d'une organisation doit disposer d'une
vue sur les informations qui lui sont pertinentes, et qui peuvent influer dans
ses décisions pour une meilleure exploitation de ces données.
Non volatiles
Tout se conserve, rien ne se perd : cette
caractéristique est primordiale dans les ED. En effet, et contrairement
aux bases de données classiques, un ED est accessible en ajout ou en
consultation uniquement. Les modifications ne sont autorisées que pour
des cas particuliers (correction d'erreurs...etc.).
Historisées
La conservation de l'évolution des données dans
le temps, constitue une caractéristique majeure des ED. Elle consiste
à s'appuyer sur les résultats passés pour la prise de
décision et faire des prédictions ; autrement dit, la
conservation des données afin de mieux appréhender le
présent et d'anticiper le futur.
Résumées
Les informations issues des sources de données doivent
être agrégées et réorganisées afin de
faciliter le processus de prise de décision.
Disponibles pour
l'interrogation et l'analyse
Les utilisateurs doivent pouvoir consulter les données
en fonction de leurs droits d'accès. L'ED doit comporter un module de
traitement des requêtes, exprimées dans un langage, doté
d'opérateurs puissants, pour l'exploitation de la richesse du
modèle.
2.3.2 La fouille de
données (Data mining)
Au début des années 60, le data mining
s'appelait l'analyse statique. A la fin des années 80, une
sérié de méthodes éclectiques est venue rejoindre
l'analyse statistique classique : la logique floue, le raisonnement
heuristique et les réseaux neuronaux.
Le data mining fait référence à un
ensemble de techniques d'exploration et d'analyse, par des moyens automatiques
ou semi-automatiques, d'une masse importante de données dans le but de
découvrir des tendances cachées ou des règles
significatives (non triviales, implicites et potentiellement utiles) (Inmon,
1996). Les outils de data mining reposent en général, sur des
techniques basées sur les statistiques, la classification ou
l'extraction de règles associatives.
2.3.2.1 Objectifs du data mining
Les objectifs du Data Mining peuvent être
regroupés dans trois axes importants :
Ø Prédiction (What-if) : consiste à
prédire les conséquences d'un événement (ou d'une
décision), se basant sur le passé.
Ø Découverte de règles cachées :
découvrir des règles associatives, entre différents
événements (Exemple : corrélation entre les ventes de deux
produits).
Ø Confirmation d'hypothèses : confirmer des
hypothèses proposées par les analystes et décideurs, et
les doter d'un degré de confiance.
2.3.3 Modèle
Multidimensionnel
Les modèles basés sur le concept
multidimensionnel, sont les plus appropriés, à capturer les
caractéristiques des DW. Ils permettent en effet, de donner une vision
simple, et facilement interprétable par des non informaticiens, et de
visualiser les données selon différentes dimensions.
Le modèle multidimensionnel contient deux types
d'attributs : les dimensions et les mesures. Les mesures sont les valeurs
numériques que l'on compare, les dimensions sont les points de vue
depuis lesquels les mesures peuvent être observées. La
modélisation multidimensionnelle est illustrée par des cubes de
données ou des hyper cubes.
Mesure
251598848
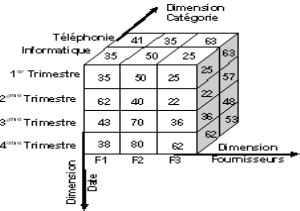
251597824
Figure 4 Exemple d'un cube de données
2.4 Les Composantes d'un Entrepôt de Données
2.4.1 Objectifs d'un
entrepôt de données
Avant de se plonger dans les détails de composantes
constituant un entrepôt de données. Il convient de s'interroger
sur les objectifs fondamentaux de l'entrepôt de données.
L'atout principal d'une entreprise réside dans la
quantité et qualité d'informations qu'elle possède. Ralph
Kimball, l'un des de précurseur du data warehouse, nous parlent des
objectifs fondamentaux d'un data warehouse, il s'agit de:
Ø Rendre accessibles les informations de
l'entreprise
Le contenu de l'entrepôt doit être
compréhensible et l'utilisateur doit pouvoir y naviguer facilement et
avec rapidité. Ces exigences n'ont ni frontières, ni limites.
Ø Rendre cohérente l'information de
l'entreprise
Les informations provenant d'une branche de l'entreprise
peuvent être mises en corrélation avec celles d'une autre branche.
Si deux unités de mesure portent le même nom, elles doivent alors
signifier la même chose. A I' inverse, deux unités ne signifiant
pas la même chose doivent être définies
différemment.Une information cohérente suppose une information de
grande qualité. Cela veut dire que l'Information est prise en compte et
qu'elle est complète.
Ø Constituer une source d'information souple et
adaptable
L'entrepôt de données est conçu dans la
perspective de modifications perpétuelles. L'arrivée de questions
nouvelles ne doit bouleverser ni les données existantes ni les
technologies.
Ø Représenter un bastion sécurisé
qui protège la valeur de l'information
L'entrepôt de données ne contrôle pas
seulement l'accès aux données, mais il offre à ses
gestionnaires une bonne visibilité des Utilisateurs.
Ø Constituer la base décisionnelle de
l'entreprise
L'entrepôt de données recèle en son sein
les Informations propres à faciliter la prise de décisions. Il
n'y a qu'un seul véritable résultat concret à attendre du
data warehouse : les décisions prises grâce aux données
obtenues.
2.4.2
Composantes
Il est d'une importance primordiale de bien comprendre
séparément les éléments constituant l'environnement
d'un entrepôt de données avant de penser les réunir pour
constituer un entrepôt de données. Toute confusion entre ces
différents éléments peut engendrer un échec certain
de l'ensemble.
L'environnement de l'entrepôt de données comporte
quatre parties différentes :
Ø Les applications opérationnelles
sources ;
Ø La préparation des données ;
Ø La présentation des données ;
Ø les outils d'accès aux données.
2.4.2.1 Les applications opérationnelles
sources
La fonction principale des applications opérationnelles
sources est de permettre les captures des transactions au sein de l'entreprise.
Les principales priorités de ces applications sources sont la
performance des traitements et la disponibilité. Nous devons les
considérer comme extérieur à l'entrepôt de
données, car nous n'avons vraisemblablement guère ou pas du tout
de moyens d'influencer le contenu ou le format des données qu'ils
traitent.
Ce sont les différentes origines d'informations de
divers formats, structurées et non structurées. Il peut s'agir de
base de données, de fichiers plats,...Les sources de données sont
nombreuses, variées, distribuées et autonomes.
2.4.2.2 La préparation des données
C'est ensemble de processus permettant la formalisation de
données en vue de leur intégration puis de leur exploitation au
sein du data warehouse. La préparation inclut tout ce qu'il y a entre
les applications opérationnelles source et la présentation des
données.
En résumé c'est une zone ou le processus de
nettoyage, transformation, combinaison, archivage, suppression des doublons
s'effectue avant leur intégration dans l'entrepôt de
données à l'aide des outils ETL que nous présentons au
point 2.6.
2.4.2.3 La présentation des données
Cette zone de présentation de données est
l'emplacement ou les données sont organisées, stockées et
ouvert aux requêtes des utilisateurs, aux logiciels de reporting. La zone
de présentation est l'entrepôt de données, tel qu'il est
perçu par les utilisateurs.
Il est à noter que la majorité d'entrepôt
de données sont implémentés sur des bases de
données relationnelles, ce qui explique le pourquoi, de
l'omniprésence de principe des bases de données relationnelles.
2.4.2.4 Terminologie
Data mart
Sous-ensemble logique d'un data warehouse. Au-delà de
cette définition relativement simple, on considère souvent le
data mart comme la réduction de l'entrepôt de données
à un seul processus ou à un groupe de processus ciblant un groupe
métier spécifique.
OLAP (Online
AnalyticProcessing)
Activité global de requêtage et de
présentation de données textuelles et numériques contenues
dans l'entrepôt de données ; style d'interrogation et de
présentation spécifiquement dimensionnel. La technologie OLAP est
non relationnelle et presque toujours basée sur un cube de
données multidimensionnelles explicites. Les bases de données
OLAP sont également connues sous le terme de bases de données
multidimensionnelles.
ROLAP (relational
OLAP)
Ensemble d'interfaces utilisateur et d'applications qui
donnent une vision dimensionnelle des bases de données
relationnelles.
MOLAP (Multidimensional
OLAP)
Ensemble d'interfaces utilisateur, d'applications et de
technologies de base de données propriétaires dont l'aspect
dimensionnel est prépondérant.
2.4.2.5 Les outils d'accès aux
données
C'est un ensemble de moyens fournis aux utilisateurs pour
exploiter la zone de présentation en vue de prendre des décisions
basées sur des analyses.
Il est constitué :
Ø D'un outil d'accès aux
données ;
Ø D'un tableur ;
Ø D'un logiciel graphique ;
Ø D'un service d'interface utilisateur.
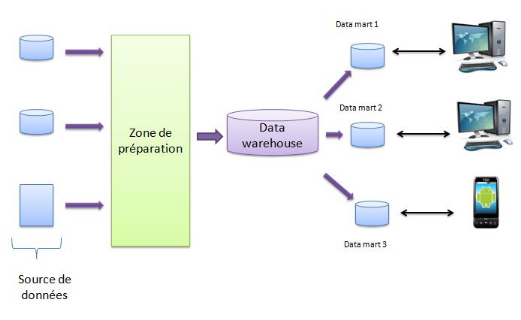
Systèmes sources
Systèmes opérationnls
ZONE DE PREPARATION DES DONNEES
SERVEURS DE PRESENTATION DU DATA WAREHOUSE
Figure 5 : Composants de base d'un data
warehouse
Stockage
Fichiers plats, SGBDR, Autres.
Traitement
Nettoyage, Transformation, Combinaison, Suppression des doublons,
Purge, Standardisation, Mise en conformité des dimensions.
Stockage temporaire.
(Attente de réplication) Archivage, Exportation vers les
data marts.
Pas de service de requêtage utilisateur
DATA MART N°1
Services de requêtage OLAP (ROLAP et/ou MOLAP)
Dimensionnel
Orienté sujet Implanté localement
Dédié à un groupe d'utilisateurs
Peut stocker des données atomiques Peut être
rafraichi régulièrement Conforme au bus du data warehouse
DATA MART N°2
DATA MART N°3
Outils de requêtage ad hoc
Générateurs d'états
Application utilisateur
Application de modélisation
Prévisions Scoring
Affectation budgétaire
Data miningAutres systèmes à flux descendants
Autres paramètres
Interfaces utilisateurs spécifique
Extraire
Peupler
Répliqur
Récupér
Extraire
Extraire
Alimenter
Alimenter
Alimenter
Alimenter
Peupler
Répliquer
Récupérer
Peupler
Répliquer
Récupérer
Bus décisionnel
Bus décisionnel
Dimensions conformes
Faits conformes
Dimensions conformes
Faits conformes
PORTAIL DE RESTITUTION
Chargement des résultats du modèle
Chargement des dimensions nettoyées
2.4.3 Architecture d'un
entrepôt de données
2.4.3.1 Approche théorique
Dans ce domaine d'entrepôt de données deux
auteurs ont défini deux philosophies sur le plan architectural
différente, il s'agit de : Bill Inmon et Ralph Kimball. Deux
philosophies tout à fait différentes mais qui convergent bien.
Ø L'architecture de haut en bas: selon Bill Inmon,
l'entrepôt de données est une base de données au niveau
détail, consistant en un référentiel global et
centralisé de l'entreprise. En cela, il se distingue du DataMart, qui
regroupe, agrège et cible fonctionnellement les données.
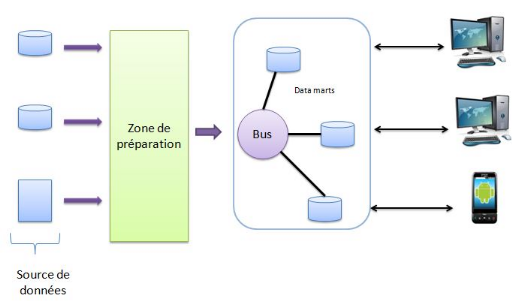
Ø L'architecture de bas en haut: Pour Ralph Kimball,
l'entrepôt de données est constitué peu à peu par
les Data Mart de l'entreprise, regroupant ainsi différents niveaux
d'agrégation et d'historisation de données au sein d'une
même base.
Approche de Bill Inmon
251599872
Figure 6Approche architecturale de Bill Inmon
Approche de Ralph Kimball
251600896
Figure 7 Approche architecturale de Ralph Kimball
|
Ralph Kimball
|
Bill Inmon
|
|
Processus
|
Bottom-Up
|
Top-Down
|
|
Organisation
|
Data Mart
|
Data Warehouse
|
|
schématisation
|
Etoile
|
Flocon
|
Tableau 1 Tableau comparatif de deux philosophies
actuelles
L'architecture d'un ED, représentée dans la
figure 1, s'articule autour de trois phases : l'intégration, la
restructuration, et l'exploitation.
2.4.3.2 Approche pratique
L'architecture d'un entrepôt de données,
représentée dans la figure 7, s'articule autour de trois phases :
l'intégration, la restructuration, et l'exploitation
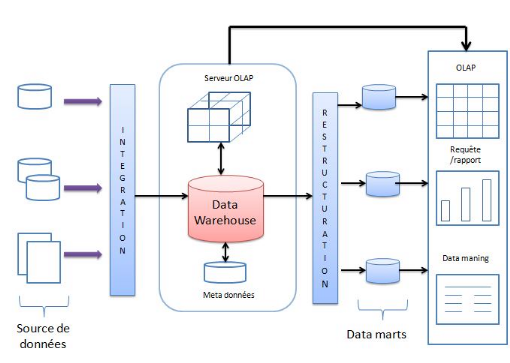
251601920
Figure 8 Architecture d'un entrepôt de
données
Intégration
Cette première étape, est assez délicate,
car elle consiste à extraire et regrouper les données, provenant
de sources multiples, et hétérogènes. Un certain nombre de
problèmes est à résoudre à ce niveau : les
données doivent être filtrées, triées,
homogénéisées et nettoyées.
Structuration
Cette étape consiste à réorganiser les
données, dans des magasins afin de supporter efficacement les processus
d'analyse et d'interrogation, et d'offrir aux différents utilisateurs,
des vues appropriées à leurs besoins.
Interrogation et Analyse
L'exploitation de l'entrepôt, pour l'aide à la
décision peut se faire de différentes façons, dont :
Ø l'interrogation à travers un langage de
requêtes,
Ø La connexion à des composants de report, pour
des représentations graphiques et tabulaires,
Ø L'utilisation des techniques OLAP
(OnLineAnalyticalProcess ),
Ø L'utilisation des techniques de fouille de
données (Data Mining).
2.5 La Modélisation Dimensionnelle
La modélisation dimensionnelle considère les
données comme des points dans un espace à plusieurs dimensions.
Ces points représentent les centres d'intérêts
décisionnels (sujets) analysés en fonction des différents
axes d'analyse.
2.5.1
Terminologie
2.5.1.1 Concept dimension
Une dimension peut être définie comme l'axe sur
lequel on porte les différentes analyses. Lorsqu'on fait un
schéma de Base de données pour un système d'information
classique, on parle en termes de tables et de relations, une table étant
une représentation d'une entité et une relation une technique
pour établir des liens entre ces entités.
2.5.1.2 Concept fait
Un fait est tout ce qu'on voudra analyser. Les faits, en
complément aux dimensions, sont ce sur quoi va porter l'analyse. Ce sont
des tables qui contiennent les mesures de performance qui relatent la vie de
l'entreprise.
2.5.1.3 Processus de modélisation
La construction d'un entrepôt de données
multidimensionnel est itérative et incrémentale. Au fur et
à mesure de sa construction l'entrepôt de données
doit devenir global et transversal via l'intégration de mesures de
processus clés.
Les étapes de construction d'un entrepôt de
données :
Ø Sélection d'un processus clé ;
Ø Choix de la granularité
stockée ;
Ø Choix des axes d'analyse ;
Ø Détermination du Fait.
Sélection d'un processus clé
Le choix du processus clé doit se faire en fonction de
son importance au sein de l'organisation.
Pour arriver à la sélection de processus
clé vous devez arriver à répondre à un certain
nombre de question :
Ø Quel est l'objectif que nous voulons atteindre avec
la mise en place d'un entrepôt de données par rapport au but
premier de notre entreprise ?
Ø Quels sont les processus qu'il est nécessaire
d'analyser ?
Ø Quels sont les indicateurs de performance,
d'éclairage ou de risque pertinents aux niveaux stratégique,
analytique et opérationnel ?
Ø Quels gains réels pour l'organisation
apporteraient ces décisions ?
Choix de la granularité
stockée
Au niveau de cette étape nous devons faire le choix du
niveau de détail de l'information que nous souhaitons conserver. Prendre
ce qui peutinfluence la prise de décision.
Choix des axes d'analyse
Le but de cette étape est de choisir quels sont les
axes d'analyse adéquats pour le processus en question.
Pour trouver les dimensions adéquates au processus
mesuré, posez-vous les questions suivantes :
Ø à qui ces données
pourraient-elles être utiles ?
Ø comment les analystes regrouperaient-ils les
données ?
Ø comment les analystes filtreraient-ils les
données ?
Ø quels sont les titres de colonne des rapports
actuellement produits ?
Détermination du Fait
Nous devons définir les mesures sur lesquels les
analyses doivent se base .En effet, le système décisionnel se
limitera toujours à des faits tangibles.
Une question est très importante :
Ø Quelles mesures de performance, d'éclairage ou
de risque serait-il pertinent de rattacher à au processus
clé.
2.5.2
Schématisation
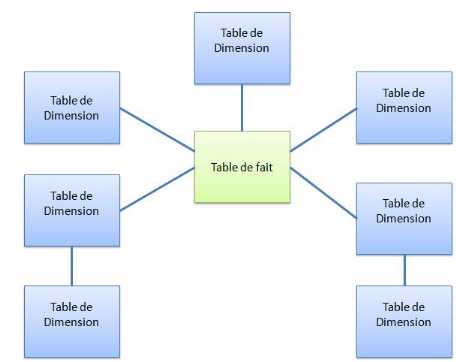
2.5.3.1 Le schéma en étoile
Une étoile est une façon de mettre en relation
les dimensions et les faits dans un entrepôt de données. Le
principe est que les dimensions sont directement reliées à un
fait (schématiquement, ça fait comme une étoile).Ce nom
vient faite qu'il y a la table de fait qui jouer le rôle de
l'élément centralisateur sur laquelle les dimensions sont
reliées
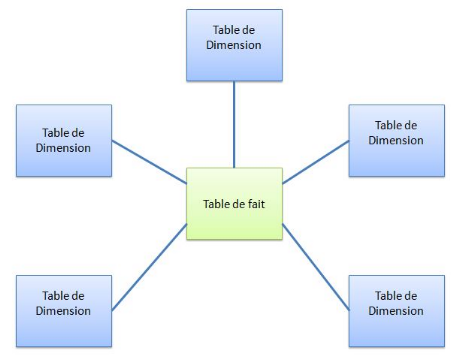
251602944
Figure 9 Schéma d'un modèle en
Etoile
Le schéma en étoile est reconnu comme une
approche de Ralph Kimball. Il se prête mieux à la
modélisation des data mart.
Avantage : Lisibilité et performance des
requêtes.
2.5.3.2 Le schéma en flocon
C'est un autre modèle de mise en relation des
dimensions et des faits dans un entrepôt de données. Le principe
étant qu'il peut exister des hiérarchies de dimensions et
qu'elles sont reliées aux faits, ça fait comme un Flocon.
251603968
Figure 10 schémas du modèle en flocon
Ce modèle s'inscrit dans l'approche de Bill Inmon. Son
principal avantage est la performance des Updates et aussi un atout du
côté de l'espace disque.
2.5.3.3 Le schéma en Constellation
Le schéma en constellation consiste à placer
plusieurs schémas en étoile avec des tables de faits
reliées hiérarchiquement. Les liens entre les différentes
tables de faits permettent de visionner les différents niveaux de
détail.
Donc ce schéma consiste à fusionner plusieurs
modèles en étoile qui utilisent des dimensions Communes.
2.6 Les outils de chargement
2.6.1 Le concept ETL
(Extract-Transform-Load)
Extract-Transform-Load est connu sous le terme ETL. Il
s'agit d'une technologie informatique
intergicielle (
logiciel tiers qui
crée un réseau d'échange d'informations entre
différentes
applications
informatiques) permettant d'effectuer des synchronisations massives
d'information d'une base de données vers une autre. Selon le contexte,
on est amené à exploiter différentes fonctions, souvent
combinées entre elles : « extraction »,
« transformation », « constitution » ou
« conversion », « alimentation ».
Elle repose sur des connecteurs servant à
exporter ou importer les
données dans
les applications (ex : connecteur
Oracle ou
SAP...),
des transformateurs qui manipulent les
données(agrégations,
filtres, conversions...), et des mises en correspondance (mappages).
L'objectif est l'intégration ou la réexploitation de
données d'un
réservoir source dans un réservoir cible.
À l'origine, les solutions d'ETL sont apparues
pour le chargement régulier de
données agrégées
dans les
entrepôts
de données (ou datawarehouse), avant de se diversifier
vers les autres domaines logiciels. Ces solutions sont largement
utilisées dans le monde bancaire et financier, ainsi que dans
l'industrie, au vu de la multiplication des nombreuses interfaces.
Des technologies complémentaires sont apparues par la
suite : l'
Intégration
d'applications d'entreprise (EAI), puis l'
ESB (Enterprise
Service Bus).
2.6.2 Les qualités
d'un bon ETL
Les qualités qui caractérisent un bon ETL
sont:
Ø Qu'il accélère le travail de
développement des flux de données :
Permet le découpage d'un flux d'alimentation en une
multitude de petites tâches de transformation de
données distinctes et ordonnancées. L'amélioration de la
productivité vient du fait qu'il est plus facile de traiter une
multitude de problèmes très simples, plutôt que de traiter
un grand problème très compliqué.
Ø Qu'il offre une vision claire et maintenable des flux
réalisés :
Les règles de transformation pouvant être parfois
très compliquées, il est important qu'elles puissent être
représentées simplement afin que n'importe quel informaticien,
disposant d'une formation ETL, puisse lire et comprendre le déroulement
d'un flux de données.
Ø Qu'il puisse se connecter et travailler avec de
nombreuses sources hétérogènes:
Le propre d'un ETL est d'être ouvert et pouvoir disposer
d'une certaine universalité de connexion.
Ø Qu'il soit performant :
Un ETL dispose souvent de fenêtres de traitement
très courtes pour se connecter à un système source et pour
charger l'entrepôt de données. Il faut alors que l'outil traite de
très gros volumes, très rapidement. Le secret de la performance
des outils d'ETL réside généralement dans leur
capacité à travailler et faire les transformations sur les
données en mémoire vive.
Ø Qu'il dispose de nombreuses fonctionnalités de
transformation de données :
En ce qui concerne la lettre T de ETL, proposer de nombreuses
tâches de transformation : calcul, contrôle, mise en
cohérence des données, conversion, pivotement, union, jointure,
nettoyage, regroupement, échantillonnage...
Ø Qu'il puisse se déployer facilement :
Tout se passe au sein de fichiers de configuration qui peuvent
être de natures diverses (XML, base de données...). Les flux se
lancent et se planifient, soit par le biais de l'agent SQL, soit par le biais
d'une ligne de commande exécutable, si vous disposez de votre propre
ordonnanceur d'entreprise.
2.6.3 Les
catégories d'outil ETL
Actuellement il existe trois catégories d'outils ETL
:
Ø Engine-based : les transformations sont
exécutées sur un serveur ETL, disposant en général
d'un référentiel. Ce genre d'outilsdisposent d'un moteur de
transformation ;
Ø Database-embedded : les transformations sont
intégrées dans la BD ;
Ø Code-generators : les transformations sont
conçues et un code est généré. Ce code est
déployablé indépendamment de la base de données
2.6.4 Architecture d'un
outil ETL
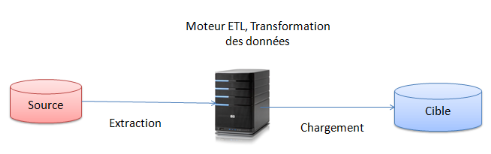
Figure 11 Exemple d'architecture d'un outil ETL
moderne
Extraction
Les données appropriées sont obtenues à
partir des sources dans la phase d'extraction. On peut employer l'extraction
statique quand un entrepôt de données a besoin d'être
chargé pour la première fois. Conceptuellement parlant, ceci
ressemble à un chargement instantané des données
opérationnelles. L'extraction par accroissement, employée pour
mettre à jour des entrepôts de données
régulièrement, saisit les changements appliqués aux
données de base depuis la dernière extraction. L'extraction par
accroissement est souvent basée sur la notation maintenue par le
système de gestion de bases de données opérationnel.
Transformation
A chaque table de la base décisionnelle correspond une
table tampon qui contient :
Ø Les colonnes de la table de dimension ou de faits
correspondantes.
Ø Les clés naturelles et les clés de
substitution.
Ø Une colonne Valide de type oui ou non qui dira si le
membre existe déjà ou non.
Chargement
Comme les données sont chargées dans la base
décisionnelle qui est muni d'un schéma relationnel, il faut
charger ses tables dans cet ordre :
Ø D'abord les tables qui ne contiennent aucune
clé étrangère.
Ø Ensuite les tables qui ne contiennent que des
clés étrangères vers des tables déjà
chargées.
Ø Ensuite, pour chaque table, le chargement se
décompose en deux requêtes:
· Une pour les nouveaux membres ou faits.
· Et un pour les membres ou faits modifiés.
CHAP IIITECHNOLOGIE WEB [4]
[7]
Introduction à
l'Internet et le Web
Définition
Internet
Réseau télématique international, issu du
réseau militaire américain Arpanet (conçu en 1969) et
résultant de l'interconnexion d'ordinateurs du monde entier utilisant un
protocole commun d'échanges de données (IP pour Internet
Protocol).
WWW (wide world web)
Le World Wide Web est un grand très grand
systèmed'information réparti sur un ensemble
desitesconnectés par le réseau Internet. Cesystème est
essentiellement constitué dedocuments hypertextes, ce terme pouvant
êtrepris au sens large : textes, images, sons, vidéos, etc. Chaque
site propose un ensembleimportant de documents, transmis sur le réseau
par l'intermédiaire d'unprogramme serveur.
Site web
Un site ou site web (de l'anglais web
site, qui se traduit littéralement en français par site de
la toile) est un ensemble de
pages web
hyperliens entre
elles et accessible à une
adresse web. On dit
aussi site internet par
métonymie,
le
World Wide
Web reposant sur l'
Internet.
3.1.1 Quelques dates
importantes au sujet du Web
Ø En 1991, Tim-Berners Lee, un chercheur du CERN a
créé le système de Hypertexte afin d'aider la
communauté des physiciens d'énergie de partager les
informations
Ø En 1993, National Center of Supercomputing
Applications lance la 1ère version de Mosaic
Ø En 1996, la guerre des navigateurs (Internet Explorer
gagne en 1999). Ainsi le web ne fait que prendre de l'ampleur.
3.2 Lesapplications
Internet classiques
3.2.1 HTTP (L'HyperText
Transfer Protocol)
L'HyperText Transfer Protocol, plus connu sous l'
abréviation HTTP
littéralement « protocole de transfert
hypertexte »
est un
protocole de
communication
client-serveur développé
pour le
World Wide Web.
HTTPS (avec S
pour secured, soit « sécurisé ») est la
variante du HTTP sécurisée par l'usage des
protocoles
SSL ou
TLS.
3.2.2 SMTP (Simple Mail
Transfer Protocol)
SMTP a été l'une des premières
applications Internet. Il définit une messagerieélectronique
relativement simple, qui se sert des adresses Internet, où la
deuxième partie représente le nom du domaine qui gèrele
serveur de messagerie.
3.2.3 FTP (File Transfer
Protocol)
FTP est un protocole de transfert de fichiers, qui permet de
garantir une qualité de service. Le transfert s'effectue entre deux
adresses extrémité du réseau Internet. L'application FTP
est de type client-serveur, avec un utilisateur, ou client, FTP et un
serveurFTP.
3.2.4 Telnet
Telnet est une application de connexion à distance, qui
permet de connecter un terminal à une machine distante. C'est
l'application de terminal virtuel.
3.3 Fonctionnement d'un
site web
L'Internet est un réseau composé d'ordinateurs.
Ceux-ci peuvent être classés en deux catégories.
Ø Les clients : ce sont les
ordinateurs des internautes. Votre ordinateur fait donc partie de la
catégorie des clients.
Ø Les serveurs web: Il s'agit des
serveurs permettant à des clients web d'accéder à
l'application à partir de tout navigateur (exemple internet explorer).
Installé sur leur poste connecté à internet/intranet
distant du serveur. Un serveur web a donc pour rôle d'interpréter
les requêtes http arrivant sur le port associé par défaut
le port 80 et de fournir une réponse par le même protocole.
3.3.1 Cas d'un site
statique
Avec un site statique. Cela se passe en deux temps :
Ø Le client demande au serveur à voir une page
web ;
Ø Le serveur lui répond en lui envoyant la page
réclamée.
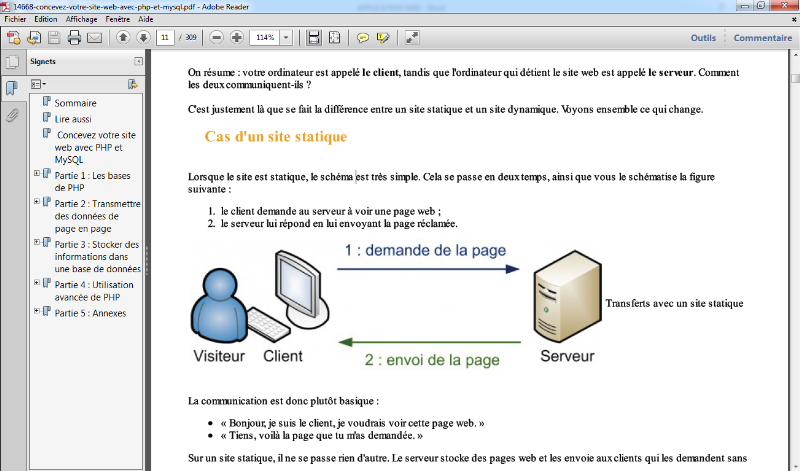
251604992
Figure 12Fonctionnement d'un site web statique
Sur un site statique, il ne se passe rien d'autre. Le serveur
stocke des pages web et les envoie aux clients qui les demandent.
3.3.2 Cas d'un site
dynamique
Lorsque le site est dynamique, il y a une étape
intermédiaire : la page est générée par un serveur
web.
Ø Le client demande au serveur à voir une page
web ;
Ø le serveur prépare la page spécialement
pour le client ;
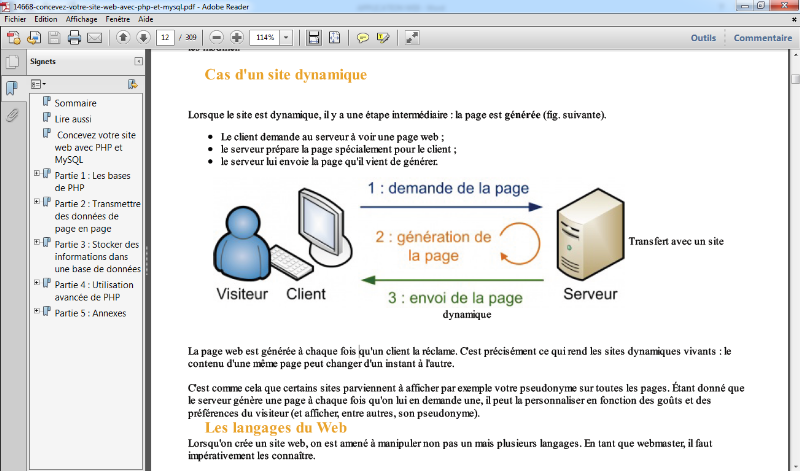
Ø le serveur lui envoie la page qu'il vient de
générer.
Figure 13Fonctionnement d'un site web dynamique
La page web est générée à chaque
fois qu'un client la réclame. C'est précisément ce qui
rend les sites dynamiques vivants : le contenu d'une même page peut
changer d'un instant à l'autre.
3.4 Les langages du Web
3.4.1 HTML
Le langage HTML tire son origine du langage SGML (Standard
GeneralizedMarkupLanguage). Il s'agit d'untype particulier d'annotations
destiné au WWW et qui correspond à une collection de styles
reconnaissables parles navigateurs. Un navigateur (en anglais "browser") est
donc un logiciel qui interprète à l'écran lescommandes
HTML contenues dans un document accessible sur le WWW.
3.4.2 XHTML
Le XHTML est une évolution du HTML, initiales de «
HypertextMarkupLanguage », c'est-à-dire langage de marquage
hypertexte. Cela signifie que la mise en place d'une page web (titres,
paragraphes, images...) utilisera des caractères pour marquer
d'une certaine façon les différentes parties du texte.
Parmi ces caractères de marquage, certains
correspondront à des liens vers d'autres pages web : ce sont des liens
hypertexte. Le « X » de XHTML vient de XML, soit «
eXtensibleMarkupLanguage », langage plus complexe et plus strict que le
HTML. C'est lui qui a inspiré la transition du HTML vers la forme plus
rigoureuse qu'est le XHTML.
3.4.3 CSS
CSS, cela signifie « Cascading Style Sheets », ce
qui se traduit en Français par feuilles de style en cascade. La feuille
de style fournit la mise en forme des éléments de la page, qui
auront été écrits en XHTML. Elle s'applique à une
ou plusieurs pages du site.
Le terme « en cascade » indique que la mise en forme
d'une page peut faire appel à plusieurs feuilles de style. Les
différentes propriétés affectées à un
même élément s'ajoutent alors pour lui donner sa mise en
forme finale.
Lorsque deux propriétés se contredisent, des
règles de priorité s'appliquent et c'est
généralement le dernier style défini qui est pris en
compte.
3.4.4 PHP
PHP (PHP HypertextPreProcessor) est un langage de
programmation. PHP est à l'origine un langage de script conçu
spécifiquement pour agir sur les serveurs web. En ajoutant quelques
lignes de PHP à une page HTML, le serveur exécute les
instructions correspondantes pour écrire du code HTML à la place,
code qui est ensuite envoyé au client de la même manière
qu'un site statique.
3.4.5
JavaScript
Le Javascript est un langage de programmation de scripts
orienté objet. Le Javascript est à ce jour utilisé
majoritairement sur Internet, conjointement avec les pages Web (HTML ou XHTML).
Le Javascript s'inclut directement dans la page Web (ou dans un fichier
externe) et permet de dynamiser une page HTML, en ajoutant des interactions
avec l'utilisateur, des animations, de l'aide à la navigation, comme par
exemple :
Ø Afficher/masquer du texte ;
Ø Faire défiler des images ;
Ø Créer un diaporama avec un aperçu
« en grand » des images ;
Ø Créer des infobulles.
Le Javascript est un langage dit client-side,
c'est-à-dire que les scripts sont exécutés par le
navigateur chez l'internaute (le client). Cela diffère des langages de
scripts dits server-side qui sont exécutés par le serveur Web.
C'est le cas des langages comme le PHP.
NB : Cette liste n'est qu'une portion des langages
utilisés dans le web
CHAP IV : SYSTEMES
D'INFORMATION GEOGRAPHIQUE
[2] [6] [14]
4.1 Définition
Un SIG peut être défini comme:
Ø Un système informatique permettant de
gérer, d'analyser et d'afficher des informations géographiques ;
Ø Un système informatique permettant, à
partir de diverses sources, de rassembler et d'organiser, de gérer,
d'analyser et de combiner, d'élaborer et de présenter des
informations localisées géographiquement, contribuant notamment
à la gestion de l'espace ;
Ø Un outil informatique permettant la production de
cartographie à partir d'une base de données spatialisée ;
4.2 Utilité d'un
SIG
La gestion de l'environnement s'effectue au fil de
décisions qui, dans de nombreux cas, reposent sur des critères
géographiques et portent sur des enjeux territoriaux. Il est donc
logique d'avoir recours à l'information géographique, sous
forme de cartes, d'images de la Terre ou de relevés terrain, afin
d'éclairer la prise de décision.
Les applications SIG sont utilisées en raison de leurs
atouts professionnels et leur capacité à exploiter de nombreuses
informations et ressources SIG. Soucieuses de fournir des informations et des
fonctionnalités géo spatiales transversales, la plus part
d'organisations étendent la portée des SIG bureautiques à
l'aide de solutions SIG serveur qui fournissent des contenus et des fonctions
via des services Web.
Ainsi, le rôle du SIG est de proposer une
représentation plus ou moins réaliste de l'environnement spatial
en se basant sur des primitives géographiques telles que des points, des
arcs, des polygones (vecteurs) ou des maillages (raster). A ces primitives
sont associées des informations qualitatives telles que la nature
(route, voie ferrée, forêt, etc.) ou toute autre information
contextuelle.
Bref, l'information géographique peut être
définie comme l'ensemble des descriptions d'un objet et de sa position
géographique à la surface de la Terre.
4.3 Capacités d'un
SIG
Un SIG doit, quel que soit le domaine d'application,
répondre aux 5 questions suivantes:
Ø Où ?
Ø Quoi ?
Ø Comment ?
Ø Quand ?
Ø Et si ?
Où: permet la mise en évidence
de la répartition spatiale des objets.
· Où cet objet, ce phénomène se
trouve-t-il ?
· Où se situe le domaine d'étude et quelle
en est l'étendue
· Où se situe le domaine d'étude et quelle
en est l'étendue géographique?
· Mieux: où se trouvent tous les objets d'un
même type et/ou d'autres types ?
Quoi: permet la mise en évidence des
objets/phénomènes présents sur un territoire
donné.
· Que trouve-t-on à cet endroit ?
· Quels objets peut-on trouver sur l'espace
étudié?
Comment: met en évidence les relations
existant ou non entre les objets et/ou les phénomènes ?
· comment les objets sont répartis dans l'espace
étudié, et quelles sont leurs relations? C'est relatif à
l'analyse spatiale.
Quand:
· Quels sont l'âge et l'évolution de tel
objet/phénomène?
· Quels sont l'âge et l'évolution de tel
objet/phénomène?
· A quel moment des changements sont.C'est relatif
à l'analyse temporelle.
Et si: Quelles conséquences
affecteraient les objets et/ou phénomènes concernés du
fait de leur localisation ?
· Que se passerait-il s'il se produisait tel
événement?
· Que se passerait-il si tel scénario
d'évolution se produisait ?
4.4 Typologie des
Données SIG
Nous pouvons classifier les données SIG en deux grandes
catégories à savoir les données géographiques et
les données attributaire
4.4.1 Les données
géographiques
Une donnée est dite géographique si on peut la
localiser soit directement par ses coordonnées géographiques ou
indirectement par son adresse postale ou par son identifiant cadastral.
Nous pouvons subdiviser les données
géographiques en trois catégories à savoir les
données géométriques, les données graphiques et les
métadonnées.
Ø les données
géométriques : Elles renvoient à la
forme et à la localisation des objets ou phénomènes.Toute
représentation cartographique passe par la traduction des
éléments réels que l'on observe (la voirie, la route) en
objets géométriques qui sont de trois types :
· le point (x, y) : il peut représenter des
arbres, des bornes, des collecteurs d'ordures, ...
· la ligne((x1, y1), ..., (xn, yn)) : elle peut
représenter une route, de ligne de réseaux de
télécommunication, ....
· le polygone ou surfacique : elle peut
matérialiser une entité abstraite comme la surface d'un pays,
d'une forêt, un lac, ...
NB : x et y représentent les
coordonnées géographiques du point. Il s'agit ici des
coordonnées terrestres qui considèrent la terre comme une
sphère, mais une sphère imparfaite soit un ellipsoïde.
L'ellipsoïde est la surface mathématique qui permet de calculer les
coordonnées géographiques d'un lieu en Longitude et en
latitude.
Ø les données
graphiques : Elles caractérisent la présentation
apparente de l'objet.
Ø
les métadonnées : Ce sont les
informations sur l'origine et le propriétaire d'une donnée
géographique.
4.4.2 Les données
attributaires
Elles représentent les caractéristiques ou
propriétés propres à un objet ou à un
phénomène en dehors de sa forme ou de sa localisation. Il peut
s'agir par exemple des informations portant sur l'adresse postale d'un site
géographique.
4.5 Représentation
des Données SIG
Il existe deux modes de représentation des
données géographiques : le mode vecteur et le mode matriciel
(raster).
4.5.1
Représentation en mode vectoriel
La représentation vectorielle consiste à
représenter une entité géographique par un objet
graphique, aussi appelé cartographique. Un bâtiment peut ainsi
devenir un point, une rivière peut devenir une ligne, un lac un
polygone, etc.
En mode vectoriel, le point avec ses coordonnées est le
porteur de l'information géométrique. Les lignes et les surfaces
se comprennent comme une suite définie de points
caractéristiques.
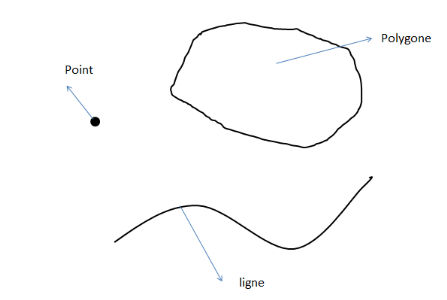
Figure 14 Représentation en mode vectoriel
4.5.2
Représentation en mode matriciel (raster)
Les données raster ont comme élément
essentiel le pixel (Picture élément). Les pixels sont
répartis dans un raster de façon régulière en
lignes et colonnes comme indique la figue 19 ci-dessous. Les lignes et les
surfaces ne peuvent être représentées que par
l'enchaînement de pixel unique. Un objet ne peut donc être
représenté que de façon approximative; c'est ainsi que la
taille du pixel-raster (résolution spatiale) conditionne l'exactitude de
la représentation.
251612160
Figure 15 Représentation des données
matricielles
NB: La donnée raster ou maillée
donne une information en chaque point du territoire.
Les différentes techniques d'acquisitions des
données raster sont :
Photo aérienne
La photo aérienne est la principale source de
nombreuses données géographiques. Elle s'obtient à partir
d'appareils photo ou cameras aéroportés qui fournissent des
détails importants sur la surface de la terre.
La photo aérienne peut être scannée,
corrigée par des méthodes de photogrammétrie des
déformations d'échelles pour en obtenir une ortho
photographie ; elle peut être aussi numérique
c'est-à-dire directement exploitable par un SIG. Dans tous ce cas, la
précision de la photo aérienne dépend de la dimension du
plus petit détail visible on parle alors de la notion de
résolution.
Image satellitaire
C'est une image issue des prises de vue des capteurs
embarqués dans de satellites d'observation placés sur orbites de
la terre. Lorsque l'image est obtenue par le reflet du rayonnement solaire dans
le domaine du visible par les objets situés au sol, on parle d'image
optique (En référence à la
télédétection optique). Il peut s'avérer que
l'image est obtenue par un objet au sol à une onde envoyée par le
satellite, on parlera plutôt d'image radar en référence
à la télédétection RADAR.
Plan scanné ou carte scannée
Un plan scanné est une image issue de la
numérisation d'un plan ou carte sur support papier déjà
traité et exploité.
4.6 Modelés des
systèmes d'informations géographiques
Fondamentalement on dispose de deux types de modèle
à savoir :
Ø Le modèle métrique ou spaghetti
Ø Le modèle topologique
4.6.1 Le modèle
métrique ou spaghetti
Le format dénommé « spaghetti »
désigne habituellement l'absence de structuration topologique. Le
modèle le plus simple consiste à stocker les
éléments graphiques sans aucune structure : les points, les
arcs, les libelles, sont digitalisés comme dessin. Seule l'indication
d'un niveau, ou d'un attribut graphique (comme une couleur ou un type de
symbole), permet de différencier l'appartenance à une
collection.
Ces modèle ne conservent pas la topologie, mais
permettent en général de le reconstituer en utilisant les
références entre les objets.
4.6.2 Le modèle
topologique
Un des avantages des systèmes d'information
géographique est que les relatons entre les objets peuvent être
calculées et donner naissance à des points d'intersection. C'est
la topologie.
Nous avons deux niveaux topologiques :
La topologie de réseau, décrit la relation entre
des ensembles linéaires (polyligne) par leurs extrémités
qui sont les noeuds.
La topologie de voisinage permet à partir des arcs
constituant le polygone de connaître les voisins de chaque surface.
4.7 l'échelle d'une
carte
Échelle numérique : rapport entre la
représentation figurée d'une longueur et sa longueur
réelle correspondante.
Échelle graphique : ligne graduée indiquant le
rapport des dimensions ou distances marquées sur un plan, une carte avec
les dimensions ou distances réelles.
Pour représenter une distance entre deux villes sur une
feuille de papier, il faut utiliser un moyen mathématique qui s'appelle
l'échelle.
L'échelle permet de réduire les distances
réelles relevées sur le terrain pour les représenter sur
une carte.
Le cartographe adopte pour cela une unité de valeur
numérique.Par exemple, si l'échelle choisie est de 1/25 000, 1 cm
sur la carte est égal à 25 000cm (ou 250 m) sur le terrain ;
dans ce cas, pour dessiner une route de 1 km, il faudra dessiner un trait de 4
cm sur la carte.
4.8 Sorte de carte
L'utilisation des données géographiques et des
cartes ne date pas d'hier. Dès les débuts de la colonie, les
explorateurs effectuaient des mesurages sur le territoire pour faire les
subdivisions en seigneuries, gérer les infrastructures portuaires et
militaires ou localiser les routes maritimes et terrestres.
Il existe plusieurs sortes de carte qui se regroupent en deux
grands ensembles :
Ø Les cartes topographiques sont
utilisées pour représenter des régions terrestres avec
leurs caractéristiques naturelles à savoir les montagnes, les
cours d'eau et celles créées par l'homme, les routes, les villes,
ainsi que leurs frontières ;
Ø Les cartes thématiques
donnent de l'information sur des thèmes particuliers comme la carte
routière, la carte d'utilisation du sol, la carte géologique, la
carte forestière, etc.
4.6 Concepts liés
aux Géodatabase
4.6.1 Définition
d'une Géodatabase
Il s'agit d'un ensemble de jeux de données
géographiques de différents types stockés dans un dossier
système de fichiers commun, une base de données Microsoft Access
ou une base de données relationnelles multiutilisateurs (comme Oracle,
Microsoft SQL Server, PostgreSQL ou IBM DB2).
Les géodatabases fonctionnent avec une gamme
étendue d'architectures et de systèmes de fichiers SGBD et
peuvent varier en taille et en nombre d'utilisateurs.
Elles vont des petites bases de données
mono-utilisateurs aux géodatabases d'entreprise, de département
ou de groupe de travail, plus volumineuses, auxquelles ont accès de
nombreux utilisateurs.
251609088
Figure 16 Représentation des différents
types de données SIG
4.6.2 Types de
géodatabase
Il existe trois types de géodatabase :
La géodatabase personnelle
Une géodatabase personnelle utilise le moteur de bases
de données Microsoft Jet, et peut donc être assimilée
à une base de données de type Access pour les données
attributaires.
Ce format concerne des bases de données
géographiques allant jusqu'à 2 Go d'espace-disque.
Une géodatabase personnelle peut être lue par
plusieurs utilisateurs, mais éditée par un seul d'entre eux. De
plus, elle ne supporte pas le versionnement.
Enfin, elle ne permet de gérer que des relations de
topologie simples et temporaires.
Tous les produits ESRI (ArcView, ArcEditor, ArcInfo) peuvent
la lire et l'éditer sans extension.
La géodatabase multiutilisateurs
La géodatabase multiutilisateurs peut fonctionner avec
plusieurs types de modèles de bases de données, comme IBM DB2,
Informix, Microsoft SQL Server, Oracle...
Ce format est destiné à des bases de
données lourdes (au-delà de 2 Go), qui doivent être lues et
éditées par de multiples utilisateurs. D'où la gestion du
versionnement.
Géodatabases fichier
Elles sont stockées sous forme de dossiers dans un
système de fichiers. Aucune limite ne s'applique à la taille des
géodatabases.
4.7 Avantage de serveur
SIG
Les serveurs SIG offrent les avantages suivants :
Ø Des économies d'échelle importantes et
de meilleures performances via le déploiement et l'utilisation du SIG
dans toute l'organisation.
Ø Des ressources informatiques SIG gérées
et partagées de façon centralisée et accessibles à
de nombreux utilisateurs.
Ø Une gamme d'applications et d'outils clients assez
souples pour gérer n'importe quelle tâche ou mission, par exemple,
l'accès au SIG via un navigateur, des périphériques
mobiles, des applications de mise à jour, Arc GIS Explorer, des
applications bureautiques SIG et des applications cartographiques grand public
fournies par Google et Microsoft.
Ø Intégration à d'autres systèmes
de l'entreprise, tels que la gestion des ressources client ou la gestion
globale de l'entreprise à l'aide d'interfaces logicielles et de
méthodes conformes aux normes. Les serveurs SIG permettent de
spatialiser une architecture orientée sur les services (SOA).
Ø Possibilité de créer des applications
personnalisées à l'aide d'environnements de programmation
standard (par exemple, .NET, Java, SOAP, REST, JavaScript, AdobeFlex, etc.).
Ø Un ensemble commun de services de carte et SIG
partagés qui assurent une gestion cohérente des informations et
une vue opérationnelle commune.
Ø Des services de catalogue SIG, un partage de
données et des services de téléchargement des
données pour gérer l'accès aux informations
partagées.
Ø Prise en charge des normes
d'interopérabilité à la fois dans les domaines SIG (par
exemple, OGC et ISO) et plus largement des technologies de l'information (IT)
(par exemple, W3C).
4.8 Les composantes d'un
SIG
Un SIG est constitué de 5 composantes majeures
Ø Logiciel
Ø Matériels
Ø Procédures
Ø Personnel
Ø Réseaux
4.9 Fonctionnalités
d'un SIG
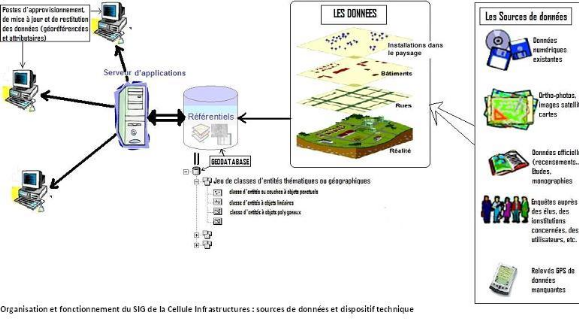
Figure 17 Organisation et fonctionnement du SIG de la
Cellule d'infrastructures
Un SIG a trois volets ci-après :
Ø le volet GEODATABASE
(geographicdatabase) : le SIG est la base de données spatiale contenant
des jeux de données qui représentent des informations
géographiques selon un modèle de données SIG
générique (entités, rasters, topologies, etc.)
Ø le volet GEOVISUALISATION : le SIG
est un ensemble de cartes intelligentes et de vues qui montrent des
entités et leurs relations à la surface de la terre. Il
élabore différentes vues cartographiques des informations
géographiques utilisables comme des " fenêtres ouvertes sur la
base de données " permettant d'effectuer des requêtes, des
analyses et de modifier les informations.
Ø le volet GEOTRAITEMENT : le SIG
comprend des outils de transformation des informations qui produisent les jeux
de données existants. Les fonctions de géo traitement partent des
informations contenues dans les jeux de données existants, appliquent
des fonctions analytiques et écrivent les résultats dans de
nouveaux jeux de données.
4.10 Domaines
d'applications
Ø Gestion de l'environnement et du territoire;
Ø Cartographie statistique;
Ø Cartographie dynamique
Ø Urbanisation et gestion urbaine, cadastres;
Ø Risques/catastrophes naturels;
Ø Sante;
Ø Télécommunications;
Ø Génie civil;
Ø Gestion côtière;
Ø Océanographie; etc.
4.1 Le Webmapping
(CartographieDynamique)
4.14.1
Généralités
LeWebmapping désigne, au sens
large, tout ce qui relève de la cartographie en ligne sur Internet. Sous
ce terme générique, on englobe différents types
d'applications cartographiques allant du simple visualiseur à l'outil de
cartographie thématique, voire au SIG en ligne. Leur point commun est
d'être accessible à travers un simple navigateur Internet. Le
passage au web dynamique permet de dépasser le
téléchargement de cartes statiques et d'accéder à
des données géographiques contenues sur un serveur cartographique
(bases de données ou fichiers SIG), voire de superposer des couches
d'information aux données en local. Le webmapping est alors synonyme de
cartographie dynamique, l'utilisateur pouvant interagir avec différentes
applications cartographiques via Internet.
On trouve dans cette rubrique des applications cartographiques
concernant des thèmes aussi variés que l'agriculture, l'eau,
l'environnement, les moyens de communication, la politique... Les outils de
cartographie en ligne offrent de plus en plus de possibilités
d'animation et d'interaction pour l'internaute. Les formats sont devenus
interopérables, de sorte que les données peuvent être
partagées, échangées, modifiées par
différents groupes ou organisations.
4.14.2 Fonctionnement du
WebMapping
Comme vous pouvez remarquer sur la figure ci-dessous, un
serveur SIG possède les principales fonctions suivantes : le stockage,
le traitement et la diffusions des cartes et informations géographiques
via le réseau internet.
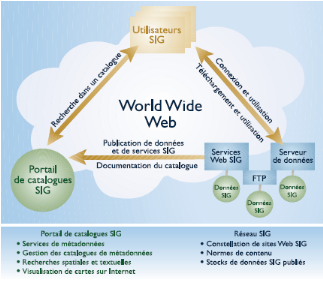
Figure 18Architecture d'un serveur cartographique sur
internet
Le stockage
Pour bien assurer sa fonction de stockage, le serveur SIG
possède deux couches :
· Une couche dédiée aux données
supportées par un SGBD géographique à l'instar de Mysql
avec MyGIS, PostGresql avec son extension Post Gis, ou Oracle avec Oracle
spatial etc....
· Des images géo référencées
comme des cartes géographiques.
Le traitement
Un SIG web est doté s'un serveur web et d'un serveur de
scripts (PHP, JSP, ASP, ...) qui le rendent capable d'assurer le traitement des
requêtes.
SIG, au-delà du stockage des données,
c'est-à-dire la possibilité d'effectuer des requêtes
à composante spéciale :
· Inclusion, juxtaposition, croisement
· Calculs de distance, zone
· Mise à jour des données graphiques et
attributaires
· Assemblage et habillage graphique des couches
d'information pour obtenir une carte
La diffusion
Le serveur SIG va donc ajouter aux fonctions habituelles d'un
serveur internet des fonctions supplémentaires en relation avec la
gestion et le traitement de données graphique de
référencées.
Le serveur SIG doit être capable de fournir
l'information géographique adapte à l'écran de
l'utilisateur.
Le datamining
Le datamining est l'ensemble de techniques d'extraction
d'information d'ordre prévisionnel à partir de grandes bases de
données.
Pour arriver à exploiter ces quantités
importantes de données, le datamining utilise des méthodes
d'apprentissages automatiques.
Ces méthodes sont de deux types :
· les techniques descriptives
· les techniques prédictives
4.14.3 Architecture d'un
système de Webmapping
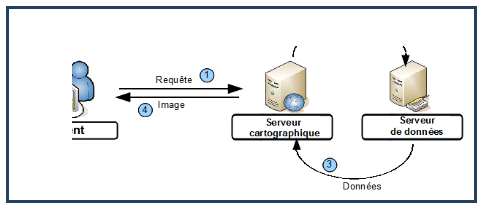
Figure 19 Architecture d'un service de Web Mapping
L'architecture d'un système de Webmapping est
généralement de type client/serveur. Ce système repose
principalement sur les trois composantes suivantes :
Ø Client
Ø Serveur cartographique
Ø Serveur de données
Client
Le client est, dans le cadre du Web Mapping, sous la forme
d'une application web. C'est lui qui permet l'interrogation des serveurs
cartographiques. Les clients utilisent un certain nombre d'outils
développés à base de différentes
bibliothèques (Javascript, Java...), Open Source ou non, tournés
vers la cartographie.
Il existe différents clients qui permettent à
l'utilisateur de visualiser des cartes
géo-référencées depuis une page web tels que Google
maps, Bing Map, OpenLayers...
Serveur cartographique
Un serveur cartographique est un serveur spécifique qui
permet la réalisation de cartes
géo-référencées. Il crée des images de
cartes à l'aide de données spécifiques, stockées
sur les serveurs de base de données mis à leur disposition. Ces
images de cartes sont envoyées aux clients intéressés.
Il existe deux types de serveurs cartographiques :
· Les serveurs cartographiques libres où le code
source est à disposition du grand public, ce qui permet
d'héberger et d'administrer son propre serveur cartographique chez soi
comme GeoServerou MapServer.
· Les serveurs cartographiques semi-libres qui ne
permettent que d'être requêtés comme Google Map Server ou
encore Bing Map Server.
Serveur de données
Les serveurs de données utilisés pour faire de
la cartographie en ligne ne sont autres que des Systèmes de Gestion de
Base de Données Relationnel et Objet (SGBDRO) améliorés
qui introduisent des extensions de données spatiales expriment toutes
les informations concernant la localisation et la forme de
particularités géographiques, ainsi que les rapports.
4.14.4
Fonctionnalités
Le Webmapping permet l'affichage de cartes sur internet mais
pas seulement. Il offre un large panel de fonctionnalités liées
à la cartographie en ligne :
Ø Le Webmapping offre la possibilité de voir
n'importe quelle carte du monde entier en deux dimensions et depuis peu en
trois dimensions.
Ø Les cartes peuvent être de différents
types, plan ou satellite, en y intégrant plusieurs vues possibles
superposables comme le relief, les routes ou encore les noms de villes. A ceci
s'ajoutent des options réalisables en temps réel sur la carte
comme le zoom ou le déplacement.
Ø Il est possible de placer des marqueurs sur une
carte, c'est-à-dire qu'il est possible d'indiquer un emplacement
précis sur une carte, à l'aide de ses coordonnées, comme
un lieu ou un bâtiment.
Ø Il est également possible de calculer et
visualiser un itinéraire sur une carte en ligne.
CHAP V RESEAUX ROUTIES EN
RDC
[15] [17]
5.1 Présentation du
secteur
Le secteur de la voirie implique beaucoup d'organes tant
gouvernementaux qu'internationaux à son sein. Sur ce nous allons
présenter privément la situation des infrastructures
routières et le principal organe dans ce domaine qui est la cellule
infrastructures qui est sous tutelle du Ministère des Infrastructures
Travaux publics et Reconstruction.
Si ce travailler a été réalisé ce
grâce au concours de ces différentes organes que nous avons pu
approcher.
5.1.1 Situation des
infrastructures routières en RDC
Le réseau routier de la RDC comprend au total 153.209
km de routes répartis comme suit :
Ø 58.509 km de routes d'intérêt
général, à charge du Ministère des Infrastructures,
Travaux Publics et Reconstruction, placés sous la gestion de l'Office
des Routes « OR en sigle », dont environ 3.000 km sont
revêtus.
Il comprend les ouvrages de franchissement suivants :
· 3.500 ponts de portée de 4 à 750
mètres pour une longueur totale de 68.000 mètres,
· 175 bacs (à moteur, à traille et à
pirogues)
Ø 7.400 km de voiries urbaines sous la gestion de
l'Office des Voiries et Drainage
« OVD en sigle » ;
Ø 87.300 km de routes d'intérêt local ou
de desserte agricole à charge du Ministère du
Développement Rural, sous la gestion de la Direction des Voies de
Desserte Agricole « DVDA en sigle ».
Répartition du réseau des Routes
d'Intérêt Général
Le réseau des routes d'intérêt
général se réparti en 3 catégories selon leur
importance :
Ø 21.140 km des routes nationales
(RN),
Ø 20.124 km des routes provinciales
prioritaires (RPP),
Ø 17.245 km des routes provinciales secondaires
(RPS).
Réseau prioritaire
Le Ministère des Infrastructures, Travaux Publics et
Reconstruction a défini un réseau prioritaire de 23.140
km, qui présente les caractéristiques principales
suivantes :
Ø il s'articule sur les 3 principaux corridors de
transport - Ouest/Nord-Est, Nord/Sud, Ouest/Sud-Est - qui relient les
chefs-lieux des Provinces et les principaux centres administratifs ;
Ø il draine à lui seul 91% du trafic routier
;
Ø il fait jonction avec le réseau ferré
et fluvial ;
Ø il dessert toutes les zones à fortes
potentialités économiques et densité de population ;
Ø il comprend les principales voies
d'intégration régionale.
De ce réseau prioritaire, il a été
extrait un réseau ultra-prioritaire de 15.836 km à rouvrir
d'urgence pour contribuer à la réunification et à la
relance économique du pays.
5.1.2 Cellule
infrastructures
5.1.1.1 Historique
La Cellule Infrastructures est un organe technique du
Ministère des Infrastructures Travaux publics et Reconstruction,
dotée d'une autonomie administrative et financière.
Elle a été créée en 2004 par
arrêté ministériel n° CAB/TPI/024/MN/FK03/2004 du
07/10/2004 sur initiative du Gouvernement de la RDC, de laCommission
européenne et de la Banque Mondiale.
5.1.1.2 Objectif
L'objectif de la cellule infrastructures est la coordination
sectorielle et l'appui institutionnel au Ministère des
Infrastructures Travaux publics et Reconstruction, principalement
dans son rôle de maîtrise d'ouvrage.
La Cellule Infrastructures fournit donc
un service conseil au MITPR dans la conception, la mise en
oeuvre et le suivi des investissements dans le secteur des
infrastructures. A ce titre, elle intervient principalement en tant que:
Ø Maître d'ouvrage délégué
pour les projets d'infrastructures financés par les partenaires
traditionnels ;
Ø Représentant du maître
d'ouvrage ;
Ø Levier de pilotage et de réintégration
vers les structures publiques pérennes du MITPR de la maîtrise
d'oeuvre des projets d'infrastructures, précédemment
externalisée ;
Ø Interface et coordination avec les partenaires
bilatéraux et multilatéraux.
5.1.1.3 Structure organique
La Cellule Infrastructures est dirigée par un
Coordonnateur et un Coordonnateur adjoint. Elle comprend en son sein:
Cinq sections
opérationnelles :
Ø Routes ;
Ø Voiries;
Ø Bâtiments Publics ;
Ø Appui Institutionnel;
Ø Administration et Finances.
Cinq services
spécialisés :
Ø Passation de Marchés ;
Ø Gestion Financière ;
Ø Audit Interne ;
Ø Gestion Environnementale et Sociale ;
Ø Système d'Information Géographique.
5.1.1.4 Autres organe intervenant dans ce
domaine
Vu le caractère transversal des infrastructures, la
Cellule Infrastructures agit en partenariat avec plusieurs structures et
entités de la République Démocratique du Congo,
notamment :
Ø L'Office des Routes (OR) ;
Ø L'Office de Voirie et Drainage (OVD) ;
Ø Le Bureau d'Etude et d'Aménagement Urbain
(BEAU) ;
Ø Le Bureau Technique de Contrôle (BTC) ;
Ø Le Groupe d'Etude du Transport (GET) ;
Ø Le Groupe d'Etude en Environnement du Congo
(GEEC) ;
Ø Le Comité Technique de Réformes (CTR)
du Ministère des Finances ;
Ø La Direction des Infrastructures du Ministère
du Plan ;
Ø La Direction des Voies de Desserte Agricole
(DVDA) ;
Ø L'Agence Congolaise de Grands Travaux
(ACGT) ;
Ø L'Unité de Coordination des Projets
(UCOP) ;
Ø Le Bureau de Coordination des Marchés des
Infrastructures (BCMI).
5.2 Système
d'information existant
|
Niveau
|
Existant
|
|
Matériels
|
Plusieurs ordinateurs de bureau
|
|
Une machine serveur
|
|
Un réseau LAN
|
|
Logiciels
|
ArcGIS
|
|
La gamme Microsoft
|
|
Traitement
|
Il dispose d'un logiciel leur permettant de produire
automatiquement des cartes géographiques. Sur ce point, il est
informatisé.Mais en ce qui concerne notreproblématique, le
traitement n'est pas encore mise en place.
|
|
Moyen humains
|
Le moyen humain est vraiment important. Les données
viennent de diverse source et ils sont sensés les intègres dans
le Geodatabase.
|
Tableau 2 présentation des composantes du
système d'information.
5.2.1 Critique de
l'existant
A l'issu d'analyses et recherches effectuées dans les
installations de la Cellule d'infrastructures, nous avons constaté des
problèmes majeurs.
Ø La cellule d'infrastructures est incapable de nos
jours de nous dire :
· Une route a été réhabilitée
combien de fois pendant un intervalle des temps.
· Quelles sont les performances des entreprises
intervenant dans la construction du réseau routier congolais ?
· Sur Quellesdonnées empiriquesse base la CI pour
l'attribution de marché des constructions du réseau routier
congolais ?
Ø La population n'est pas informée des blocages,
délabrement ou de la réhabilitation des infrastructures
routières du pays.
5.2.2
Motivation
Au regard des difficultés constatée au sein de
la Cellule d'Infrastructure, nous avons envisagé la mise en place d'un
système décisionnel afin d'améliorer la prise de
décision. Notre pays, étant en pleine reconstruction des
infrastructures, pour un besoin d'efficacité dans la gestion de ce
domaine, mettre en place un Entrepôt des Donnée est vraiment
opportun.
Avec cette infrastructure, la CI sera en mesure de centraliser
toutes les informations concernant le réseau routier enfin d'en
déduire des informations nécessaires pour améliores la
prise de décision.
Un autre atout pour ce projet concerne directement la
population. En effet, par une application de webmapping connectée au
système, elle sera au courant de toute information sur les
infrastructures du pays et des éventuels aménagements.
CHAP VI :CONCEPTION ET
IMPLEMENTATION
[10][18]
6.1 Aperçue des
différents outils utilisées
6.1.1 Les
SGBDutilisées
Pour notre application de webmapping nous avons utilisé
MySQL 5.5.20, le choix s'explique par les avantages que ce SGBD nous offre.
Reconnu comme le
meilleur gestionnaire des données par les ImpactsAwards 2011 de PHP
architect, MySQL reste le SGBD le plus utilisé dans le web.
Parmi les avantages de ce dernier nous pouvons citer :
Ø Coût total d'exploitation faible. Le
déploiement de MySQL pour des applications essentielles permet une
économie de coûts significatifs par rapport à d'autres
SGBD.
Ø Évolutivité et performance.
Satisfaction des contraintes d'évolutivité et de performance des
sites Internet les plus visités et des applications les plus
exigeantes.
Ø Il est open source.
Malheureusement MySQL ne permet pas de faire du Business
Intelligence, sur ce nous avons cherché un notre SGBD pouvant nous
offrir ce service, et notre choix se penche sur SQL Server un produit de
Microsoft. Notre choix a été motivé du faite que SQL
Server est un produit qui a fait déjà ses preuves, départ
sa puissance et sa stabilité dans le décisionnel.
L'offre Microsoft BI est structurée autour des trois
prouesses du décisionnel :
Ø Améliorer l'accès et la qualité
des données : on y retrouve tous les outils destinés à
concevoir un entrepôt de données bien modélisé,
performant et contenant des données fiabilisées.
Ø Gagner en finesse d'analyse et de
compréhension de données : on y retrouve tous les outils qui
permettent aux utilisateurs finaux d'analyser et de naviguer dans leurs
données en toute autonomie, sans avoir à recourir au service
informatique.
Ø Gérer les performances de l'organisation et de
ses politiques : on y retrouve tous les outils destinés
àpartager, à communiquer et à organiser les performances
de l'organisation tels que les outils de tableaux de bord et les outils
d'intranet.
Pour mettre en place un système d'aide à la
décision,Microsoft offre un ensemble d'outils:
Ø SQL Server Integration Services : l'ETL.
Ø SQL Server Master Data Services : le gestionnaire de
données de référence.
Ø SQL Server Analysis Services : la base de
données multidimensionnelle (OLAP) et le méta modèle.
Ø SQL Server Reporting Services : l'outil de reporting
opérationnel et de reporting de masse.
6.1.2 Le serveur
web
Trois arguments nous poussent de choisir le serveur
apache :
Ø C'est le serveur le plus utilisé.
Ø un serveur en OpenSource, gratuit,
évolutif.
Ø le meilleur choix pour l'instant pour
développer en multiplateforme.
Le succès des logiciels libres ne s'explique pas par
leur prix mais par leur qualité, plus d'un million de sites Web
fonctionne avec Apache Selon une enquête "récente" menée
en 2013, le serveur gratuit Apache a dépassé un million de sites
administrés, soit 48% des sites Web devant Microsoft IIS (21,7%) et
Netscape Enterprise (9,6%).
6.1.3 Le serveur Google
Maps
Google Maps est un serveur gratuit de cartographie en
ligne. Le service a été créé par
Google. Lancé en
2004 aux
États-Unis et
au
Canada et en 2005
en
Grande-Bretagne (sous
le nom de Google Local), Google Maps a été lancé jeudi 27
avril 2006, simultanément en
France,
Allemagne,
Espagne et
Italie.
Google Mapsutilise des images satellites et des photographies
aériennes de haute altitude pour une meilleure précision couvrant
la totalité de la surface terrestre. Google Maps par ailleurs propose
une API qui permet aux développeurs web par une bibliothèque de
fonctions JavaScript et au format de fichier KML d'intégrer des cartes
et de pouvoir créer des cartes personnalisées pour leurs
applications. C'est cette opportunité que nous avons saisie pour
intégrer à notre plateforme la cartographie basée sur
Google Maps. La contrainte c'est que notre plateforme doit être
connectée à Internet pour bénéficier de ses
avantages.
6.2 Application
dewebmapping
6.2.1 Conception et
modélisation de la base de donnes
6.1.1.1 Le modèle conceptuel des
données
6.1.1.1.1 Identification des objets
Après des analyses approfondies, nous avons
identifié les entités ci-après:
Ø Axe routier
Ø Entreprise
Ø Inspecteur
Ø Route
Ø Paramètre géographique
Ø Province
6.1.1.1.2 Identification et description des
relations
Les relations trouvent entre les différentes
entités sont les suivantes :
Ø Avoir
Ø Localiser
Ø Réhabiliter
Ø Observer
Ø Peut avoir
|
N°
|
Relation
|
Objets associes
|
|
1
|
avoir
|
Routes-Axe Routier
|
|
2
|
Localiser
|
Province-Axe Routier
|
|
4
|
Réhabiliter
|
Entreprise-Axe Routier
|
|
5
|
Observer
|
Inspecteur-Axe Routier
|
|
6
|
Peut avoir
|
Paramètre géo-Axe Routier
|
Tableau 3 Représentation des relations
6.1.1.1.3 Définition des contraintes des
cardinalités et d'intégrité fonctionnelle
En informatique, les contraintes ce sont les nombres
d'occurrences minimales et maximales d'objet qui participent à une
relation.
|
N°
|
Objet1
|
Cardinalité1
|
Relation
|
Cardinalité2
|
Objet2
|
|
1
|
Route
|
1,n
|
avoir
|
1,1
|
Axe Routier
|
|
2
|
Province
|
1,n
|
Localiser
|
1,n
|
Axe Routier
|
|
4
|
Entreprise
|
1,n
|
Réhabiliter
|
1,1
|
Axe Routier
|
|
5
|
Inspecteur
|
1,n
|
Observer
|
1,n
|
Axe Routier
|
|
6
|
Paramètre géo
|
1,1
|
Peut avoir
|
1,n
|
Axe Routier
|
Tableau 3 Présentation des contraintes de
cardinalités et d'intégrité fonctionnelle
1,n
251641856
Figure 19modèle conceptuel de données
2516500486.1.1.1.1 Présentation du
modèle conceptuel de données
1,n
Province
Idpro
nompro
251616256251631616251621376251622400
Parametregeo
Idpar
Comm_par
Longitude
latitude
251613184
1,n
251649024251619328
Axeroutier
idaxe
Nomaxe
Comm_axe
Taille_axe
Cout
Duree
Date_debut
Date_fin
251614208251635712
Localiser
251628544251636736
Réhabiliter
251629568
1,n
251676672
1,n
251644928
1,1
251642880
1,n
251645952
1,n
251646976
1,1
251643904
1,1
251640832251639808251638784
Peut avoir
251625472251637760251632640251634688251633664251630592
Observer
251627520
Avoir
251626496251623424
Inspecteur
idins
Matricule
Nomobs
Postnom
E-mail
251617280
Routes
idroute
Nomroute
Comm_route
Type_route
Nbredekm
251615232251624448251620352
Entreprise
identre
Nomentre
Numphone
Adresse
Siteweb
E-mail
2516183046.1.1.2 Modèle logique de
données
Province
idpro
nompro
251654144251659264251661312
Inspecteur
#idins
Matricule
Nomobs
Postnom
E-mail
251655168
Routes
#idroute
Nomroute
Comm_route
Type_route
Taille_route
251653120251662336251658240
Entreprise
#identre
Nomentre
Numphone
Adresse
Siteweb
E-mail
251656192
Parametregeo
Idpar
Comm_par
Longitude
Latitude
#idaxe
251651072251667456251665408
Figure 20modèle logique de données
251674624251660288251668480
Axeroutier
idaxe
Nomaxe
Comm_axe
Taille_axe
Coût
Duree
Date_debut
Date_fin
#idroute
#identre
251652096251664384251672576
Observer
idlocalise
#idins
#idaxe
251671552251663360251670528
Localiser
idlocalise
#idpro
#idaxe
251669504251666432251657216251673600
6.1.1.1 6.1.1.3 Le modèle physique de
données
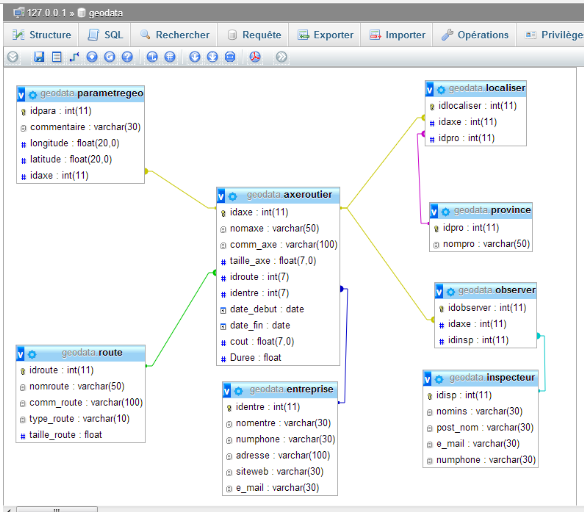
Figure 21 Modèle physique de données
Fig.18 modèle physique de données
6.2.2 Présentation
des quelques interfaces
6.2.2.1 Interface Administrateur
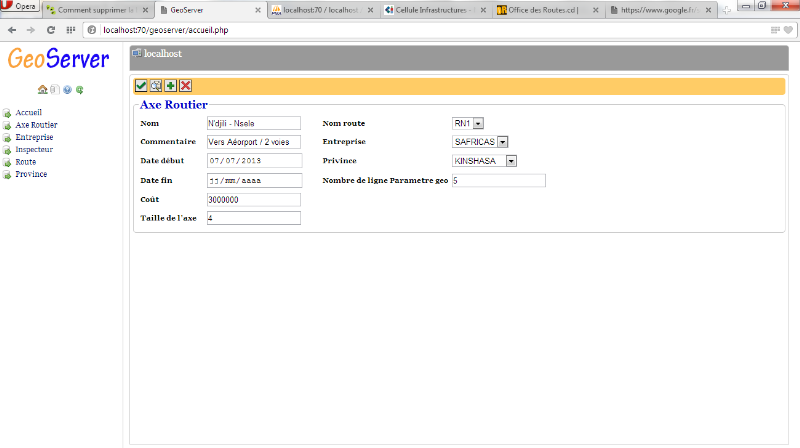
Interface d'enregistrement Axe routier
Figure 22 Interface de mise à jour Axe
Routier
Après s'être loguer, l'administrateur aura une
interface d'accueil pour naviguer dans l'application en vue de mettre à
jour les données.
Comme nous pouvons l'apercevoir sur cette interfaceà
gauche,nous avons notre menu principal qui nous permettra de passer d'une
interface à une autre. La partie droite représente notre
formulaire qui permettra de saisir les données relatives à l'axe
routier.
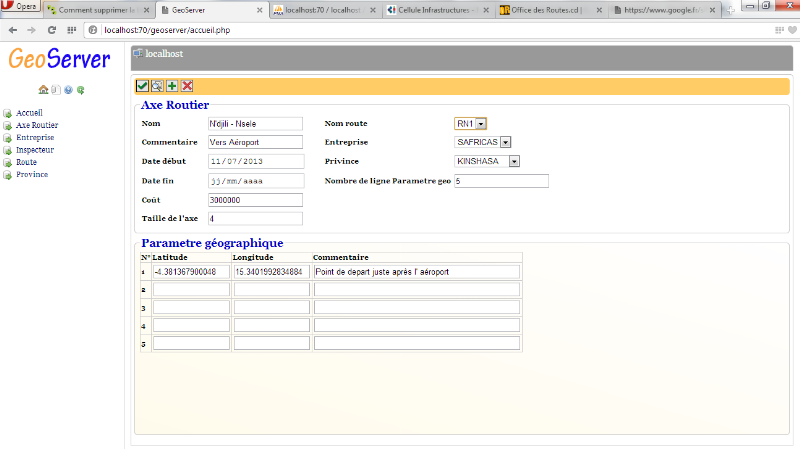
Interface d'enregistrement de paramètre
géographique
Figure 23 Interface d'enregistrement de données
géographique
Sur cette interface nous aurons la possibilité
d'insérer les cordonnées géographique d'une
itinérairedans notre base de données MySQLqui correspondra
à un axe qui est en cours de réhabilitation.
Comment vous pouvez le remarquer, le nombre de ligne
Paramètre géo correspond au nombre de ligne de notre tableau dans
lequel on effectue la saisie.
6.2.2.2 Interface internaute
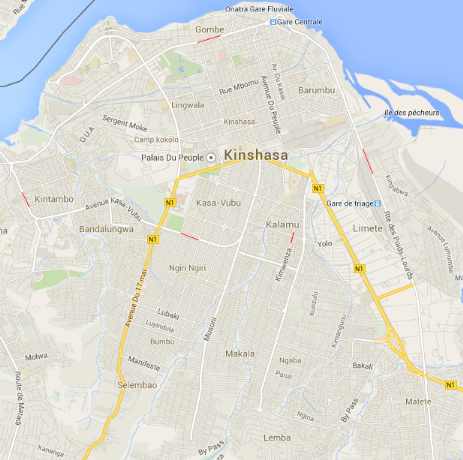
251679744
Figure 24 Carte géographique de Kinshasa
La carte sur la figure suivante représente la vie de
Kinshasa, nous pouvons nous apercevoir des traits rouges qui
représentent les itinéraires qui sont en cours de
réhabilitation dans la ville de Kinshasa.
NB : On a eu à utiliser de données test
pour donner l'aperçu.
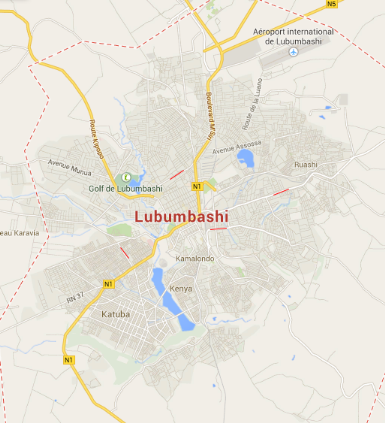
251680768
Figure 25 Carte géographique de la ville de
Lubumbashi
6.2.3 Quelque code de
l'application
Classe connexion à la base de
données
<?php
ClassgoogleConnexion{
static function Connexion(){
try{
$bkas = new PDO('mysql:host=localhost;dbname=geodata', 'root',
'');
return$bkas;
}
catch (Exception $e)
{
echo 'Impossible de se connecter au serveur';
die('Erreur : ' . $e->getMessage());
}
}// Fin de la fonction
}// Fin de la class
?>
Code JavaScript permettant de créer la carte et
dessiner le parcours
varlatlng = new google.maps.LatLng(-4.323303, 15.308161);
var options = {
center: latlng,
zoom: 20,
mapTypeId: google.maps.MapTypeId.ROADMAP
};
var carte = new
google.maps.Map(document.getElementById("carte"),
options);
Dans Google Maps les coordonnées sont sous formes de
latitude et de longitude. La librairie Google Maps met àdisposition un
constructeur permettant de créer un objet de classe
google.maps.LatLng(lat:number,lng:number) qui prend en paramètre des
nombres représentant, respectivement, la latitude et la longitude.
var traceParcours = new google.maps.Polyline({
path: parcours,//chemin du tracé
strokeColor: "#FF0000",//couleur du tracé
strokeOpacity: 1.0,//opacité du tracé
strokeWeight: 2//grosseur du tracé});
Code html de l'Interface d'accueil
<?php
include("connexion/connexion.php");
$conn =new googleConnexion();
$rep = $conn->Connexion();
/*$rep ;*/
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0
Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1" />
<link rel="stylesheet" media="screen" type="text/css"
title="Design" href="css_jsp/design.css" />
<script language="JavaScript" src="css_jsp/jquery.js"
type="text/javascript"></script>
<script language="JavaScript" src="css_jsp/j_scode.js"
type="text/javascript"></script>
<title>GeoServer</title>
</head>
<body>
<div id="gauche">
<div id="logo"><imgsrc="images/logo.png" width="200"
height="50" /></div>
<p></p>
<center>
<table>
<tr>
<td><a
href="accueil.php?nav=1"><imgsrc="images/b_home.png" width="16"
height="16" /></a></td>
<td><a
href="accueil.php?nav=2"><imgsrc="images/b_sqlhelp.png" width="16"
height="16" /></a></td>
<td><a
href="accueil.php?nav=3"><imgsrc="images/b_docs.png" width="16"
height="16" /></a></td>
<td><a
href="accueil.php?nav=4"><imgsrc="images/s_reload.png" width="16"
height="16" /></a></td>
</tr>
</table>
</center>
<p></p>
<div class="menu">
<table>
<tr>
<td><imgsrc="images/b_selboard.png" width="16"
height="16" /></td><td> <a
href="accueil.php?nav=1">Accueil</a></td>
</tr>
<tr>
<td><imgsrc="images/b_selboard.png" width="16"
height="16" /></td><td> <a
href="accueil.php?nav=5">Axe Routier</a></td>
</tr>
<tr>
<td><imgsrc="images/b_selboard.png" width="16"
height="16" /></td><td> <a
href="accueil.php?nav=6">Entreprise</a></td>
</tr>
<tr>
<td><imgsrc="images/b_selboard.png" width="16"
height="16" /></td><td> <a
href="accueil.php?nav=7">Inspecteur</a></td>
</tr>
<tr>
<td><imgsrc="images/b_selboard.png" width="16"
height="16" /></td><td> <a
href="accueil.php?nav=8">Route</a></td>
</tr>
<tr>
<td><imgsrc="images/b_selboard.png" width="16"
height="16" /></td><td> <a
href="accueil.php?nav=9">Province</a></td>
</tr>
</table>
</div>
</div>
<div id="droit">
<div class="entete">
<table>
<tr>
<td><imgsrc="images/s_host.png" width="16"
height="16" /></td>
<td>localhost</td>
</tr>
</table>
</div>
<div class="corpss">
<div class="menuAj">
<table>
<tr>
<td><a href="#"><imgsrc="images/OK.gif"
width="20" height="20" /></a></td>
<td><a href="#"><imgsrc="images/RECHERCHE.gif"
width="20" height="20" /></a></td>
<td><a href="#"><imgsrc="images/AJOUTE.gif"
width="20" height="20" /></a></td>
<td><a href="#"><imgsrc="images/FERMER.gif"
width="20" height="20" /></a></td>
</tr>
</table>
</div>
<fieldset>
<legend>Axe Routier</legend>
<table>
<tr>
<td>Nom</td><td><input name="nomaxe"
type="text"/></td>
<td>Nom route</td><td>
<?php
include("comboR/nomroute.php");
?>
</td>
</tr>
<tr>
<td>Commentaire;</td><td><input
name="commtaxe" type="text"/></td>
<td>Entreprise</td><td>
<?php
include("comboR/entreprise.php");
?>
</td>
</tr>
<tr>
<td>Date début</td><td><input
name="date_debut" type="date"/></td>
<td>Privince</td><td>
<?php
include("comboR/province.php");
?>
</td>
</tr>
<tr>
<td>Date fin</td><td><input name="nom"
type="date_fin" /></td>
<td> Nombre
de ligneParametre geo</td><td><input name="nbrligne"
type="text"/></td>
</tr>
<tr>
<td>Coût</td><td><input name="cout"
type="text" placeholder="En Dollars"/></td>
<td></td><td></td>
</tr>
<tr>
<td>Taille de l'axe</td><td><input
name="taille" type="text" placeholder="Km"/></td>
<td></td><td></td>
</tr>
</table>
</fieldset>
<div class="tabl">
</div>
</div>
</div>
</body>
</html>
Classe de mise à jour axe routier
<?php
Class miseajouraxe{
public function supprimerAxe($idaxe){
$bkas->exec('DELETE FROM axeroutier WHERE
idaxe=\''.$idaxe.'\'');
echo 'Suppression effectuer';
}
public functionenregistrerAxe($nomaxe, $commtaxe,
$date_debut, $date_fin, $cout, $taille, $duree, $idroute, $identre, $pro){
$bkas->exec('INSERT INTO
axeroutier(idaxe,nomaxe,comm_axe,taille_axe,idroute,identre,date_debut,date_fin,cout,Duree)
VALUES(NULL, \''.$nomaxe.'\', \''.$commtaxe.'\', \''.$taille.'\',
\''.$idroute.'\', \''.$identre.'\', \''.$date_debut.'\', \''.$date_fin.'\',
\''.$cout.'\', \''.$duree.'\')');
echo 'enregistrement effectuer';
}
public functionmodifierAxe($idaxe,$nomaxe, $commtaxe,
$date_debut, $date_fin, $cout, $taille, $duree, $idroute, $identre, $pro){
$bkas->exec('UPDATE axeroutier SET
nomaxe=\''.$nomaxe.'\',comm_axe=\''.$commtaxe.'\',date_debut=\''.$date_debut.'\',date_debut=\''.$date_fin.'\',cout=\''.$cout.'\',duree=\''.$duree.'\',taille=\''.$taille.'\'
WHERE idaxe=\''.$idaxe.'\'');
echo 'Modification effectuer';
}
}
?>
6.3 Implémentation
de l'entrepôt de données
6.3.1 Modélisation
multidimensionnelle
6.3.1.1 Les dimensions
Les données du réseau routier seront analysables
par les utilisateurs suivant cinq dimensions, il s'agit :
Ø Dimension Route
Ø Dimension Province
Ø Dimension Inspecteur
Ø Dimension Entreprise
Ø Dimension Temps
6.3.1.2 Les faits
Selon les problématiques posent nous sommes abouti au
choix des mesures suivantes sur lesquelles seront portés les analyses.
Ø Coût
Ø La taille
Ø La durée
6.3.1.3 Modèle
Dim_Province
Id_DW_province
Id_nat_province
nomprovince
Dim_Inspecteur
Id_DW_Inspecteur
Id_nat_Inspecteur
Nominspecteur
Numphone
Dim_Route
Id_DW_Route
Id_nat_Route
Nomroute
Nomaxeroutier
Comm_route
Comm_axe
Type_route
Entreprise
Id_DW_Entreprise
Id_nat_Entreprise
Nomentreprise
Fait
Id_DW
Id_DW_Province
Id_DW_Temps
Id_DW_Entreprise
Id_DW_Inspecteur
Id_DW_Route
Cout
Duree
Taille
Dim_Temps
Id_DW_temps
Id_nat_temps
Année
Mois
Trimestre
Semestre
Figure 26Modèle en étoile de notre
entrepôt de données
6.3.1 6.3.2 Architecture
type du data warehouse
Tableau croisé dynamique de Excel
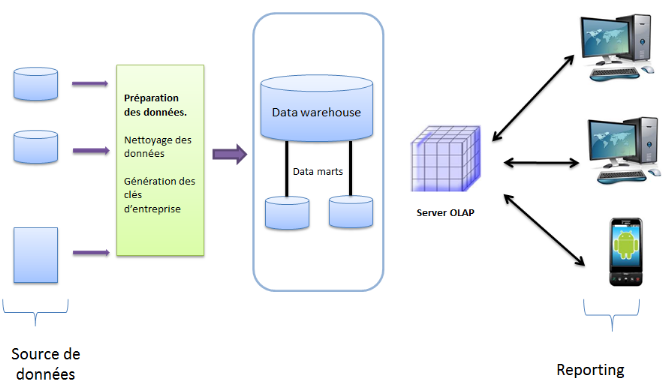
Figure 27 Architecture globale du système
décisionnel.
6.3.3
Implémentation de la base de données du data
Warehouse
Outils utilisé : Microsoft SQL Server 2008
Ø SQL Server Management Studio
Dictionnaire des données
|
Tables
|
Attributs
|
Type de données
|
Rôle
|
|
Dim_Route
|
Id_DW_Route
Id_nat_Route
Nomroute
Nomaxeroutier
Type_route
Date_debut
Date_fin_fin
|
bigint
float
nvarchar(50)
nvarchar(50)
nvarchar(10)
smalldatetime
smalldatetime
|
Clé de l'entrepôt
Clé d'entreprise
Date pour l'historisation
Date pour l'historisation
|
|
Dim_Inspecteur
|
Id_DW_Inspecteur
Id_nat_Inspecteur
Nominspecteur
Post_nom
Numphone
Date_debut
Date_fin
|
bigint
float
nvarchar(30)
nvarchar(30)
nvarchar(30)
smalldatetime
smalldatetime
|
Clé de l'entrepôt
Clé d'entreprise
Date pour l'historisation
Date pour l'historisation
|
|
Dim_Entreprise
|
Id_DW_Entreprise
Id_nat_Entreprise
Nomentreprise
Date_debut
Date_fin
|
bigint
float
nvarchar(30)
smalldatetime
smalldatetime
|
Clé de l'entrepôt
Clé d'entreprise
Date pour l'historisation
Date pour l'historisation
|
|
Dim_Temps
|
Id_DW_temps
Id_nat_temps
Date
Année
Trimestre
Mois
|
bigint
float
smalldatetime
nvarchar(4)
nvarchar(4)
nvarchar(12)
|
Clé de l'entrepôt
Clé d'entreprise
|
|
Dim_Province
|
Id_DW_province
Id_nat_province
nomprovince
Date_debut
Date_fin
|
bigint
float
nvarchar(50)
smalldatetime
smalldatetime
|
Clé de l'entrepôt
Clé d'entreprise
Date pour l'historisation
Date pour l'historisation
|
Tableau 4 Tableau de dictionnaire de
données
6.3.4 Chargement de
données dans les dimensions
Outils utilisé :
Ø Microsoft SQL Server 2008
· SQL Server Integration Services
Ø Microsoft Office
· Microsoft Office Excel 2007
Procédure
Toutes les dimensions, excepté la dimension temps, sont
des dimensions à variation lente. Les sources de données sont des
fichiers Excel que nous avons exportés de notre base de données
MySQL. Nous avons utilisé le processus d'intégration des ETL tel
qu'implémenté dans SQL Server Intégration Services.
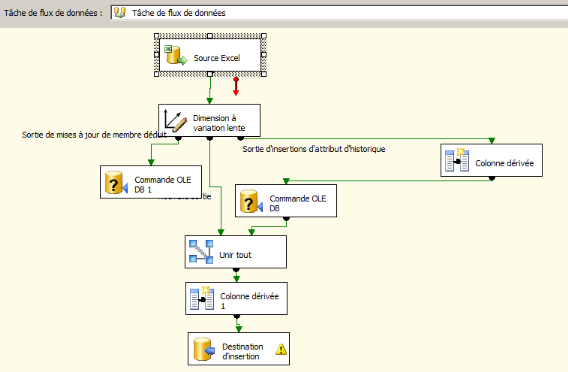
Exemple d'un processus de chargement pour la dimension
route :
Figure 28 Processus de chargement de
données
Chargement de la dimension Temps
Une particularité pour cette dimension, nous l'avons
généré automatiquement en fixant notre plage
d'étude entre 2007 et 2013. Car nos données test correspondent
à cette plage.
6.3.5 Construction de la
base de préparation
Ø Outils: MySQL, Microsoft Office Excel 2007, SQL
Server Integration Services
- Création de la vue de préparation pour
extraire les données qui correspondant aux clés d'entreprise et
les mesures.
MySQL
- Nettoyage de données
- Requête SQL pour l'ajout des champs
- Vérification de la cohérence
Excel
Chargement des données dans la table T_Préparation
de la base de données du Data warehouse avec le processus de copie de
colonne après mappage.
SQL Server Integration Services
Figure 29: Schémas de construction de la base
de préparation des données.
6.3.6 Chargement de la
table fait
La tâche, à ce niveau est facilitée par la
base de préparation déjà chargée de données.
La source de donnée est le résultat d'une requête SQL. Ce
dernier est alors copié dans la table des faits après mappage des
colonnes.
SELECT DISTINCT
dbo.Dim_Inspecteur.id_DW_inspecteur,
dbo.Dim_Route.id_DW_route, dbo.Dim_Temps.id_DW_temps,
dbo.Dim_Province.id_DW_province,
dbo.Dim_entreprise.id_DW_entreprise, dbo.T_Preparation.cout,
dbo.T_Preparation.duree, dbo.T_Preparation.taille_axe
FROM dbo.Dim_InspecteurINNER JOIN
dbo.T_Preparation ON dbo.Dim_Inspecteur.id_nat_inspecteur =
dbo.T_Preparation.id_nat_inspecteurINNER JOIN
dbo.Dim_Province ON dbo.T_Preparation.id_nat_province =
dbo.Dim_Province.id_nat_provinceINNER JOIN
dbo.Dim_entreprise ON dbo.T_Preparation.id_nat_entreprise =
dbo.Dim_entreprise.id_nat_entrepriseINNER JOIN
dbo.Dim_Temps ON dbo.T_Preparation.id_nat_temps =
dbo.Dim_Temps.id_nat_tempsINNER JOIN
dbo.Dim_Route ON dbo.T_Preparation.id_nat_route =
dbo.Dim_Route.id_nat_route
Ce script SQL nous a permis de charger la table de fait en
faisant le mappage entre les clés d'entrepôts.
6.3.7 Déploiement
du cube et analyse
Nous avons procédé à quelques analyses
test pour évaluer les performances de notre système
décisionnel, après le déploiement du cube avec Microsoft
SQL Server Analysis Services.
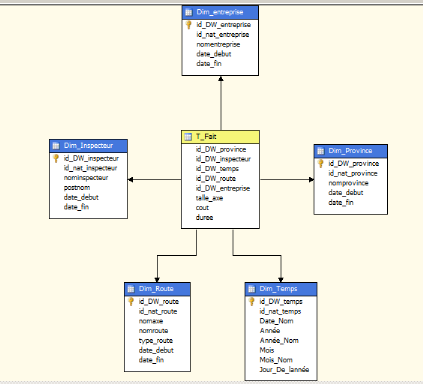
Figure 25 : Présentation du cube
Figure 30 Présentation du cube
6.3.7.1 Analyse de performance
Le cube ainsi déployé constitue un
véritable tableau de bord. En effet, il permet de présenter une
vue claire et synthétique de l'ensemble des activités sur les
infrastructures. Comme illustration simple, en un moindre instant, nous
obtenons dans un rapport l'ensemble des entreprises de construction
croisées avec les provinces où elles ont effectué des
travaux, avec la possibilité de creuser d'avantage et obtenir les divers
axes routiers. A cette présentation s'adjoint le nombre de
kilomètres pour les axes, la durée des travaux et le cout
détaillé et global.
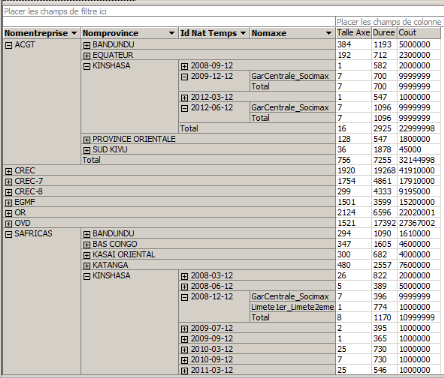
Tableau 18: Extrait de la navigation du
cube
Tableau 5 Présentation d'un tableau de bord
Départ notre tableau de bord, nous pouvons constater
qu'au niveau de l'axe Gare Central et Socimaxdeux entreprises ont eu à
intervenir.Nous pouvons alors prendre une décision en fonction de
différentesmesures.
Présentation de résultat sur
l'entreprise SAFRICAS
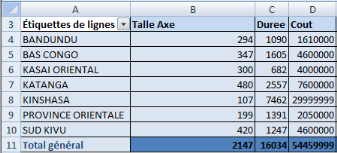
Ø tableau de synthétique
Tableau 6 Tableau de résultat SAFRICAS
Ce tableau nous représente la synthèse statique
de SAFRICAS par rapport à nos trois mesures.
Ø Histogramme
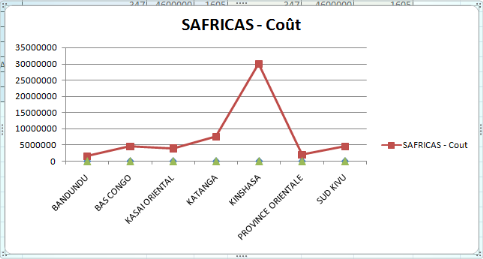
Figure 31Histogramme de coût de SAFRICAS
Sur cette figure nous pouvons constater que la grande partie
de l'argent attribue à SAFRICAS pour les infrastructures
routières fut utilisé à KINSHASA.
6.3.7.2 Représentation des quelques
statistiques

Tableau 7 Tableau croisé sous Analysis Services
pour la présentation des statistiques.
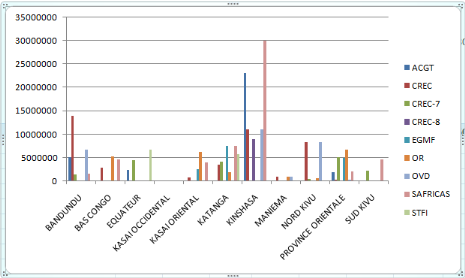
Figure 32 Histogramme de coût par province
CONCLUSION
Le présent travail a fait l'objet de la mise en place
d'un data Warehouse et d'une application de webmapping pour la gestion du
réseau routier de la République Démocratique du Congo.
Si sa mise en oeuvre s'est appuyée sur de bases
théoriques développées dans les premier, deuxième,
troisième, quatrième et cinquième chapitres. Le dernier
chapitre a été entièrement consacré à
l'implémentation de l'application couplée au Système
Décisionnel.
Au cours de la phase théorique, nous avons
débuté par les notions fondamentales sur les bases de
données pour ensuite aborder le Système Décisionnel. Au
troisième chapitre, nous avons passé en revue les
différents langages de programmation et techniques utilisées
dans le web. Au quatrième chapitre, nous avons abordé les
théories sur les Systèmes d'Information Géographique avec
une attention particulière sur le Webmapping. Au cinquième
chapitre nous avons présenté le secteur des infrastructures
routières de la RDC et analyse leur état de la gestion actuelle.
Nous pouvons nous estimer heureux d'être arrivé
aux termes de ce travail qui a proposé une double mise en place, soit:
Ø Un nouveau système d'aide à la
décision qui permettra à la cellule d'infrastructures d'avoir une
vision concrète sur les performances des différents acteurs qui
interviennent dans les systèmes.
Ø Une application de webmapping en vue d'informer la
population en temps réel sur l'état des routes
aménagées qu'elles soient en cours de (re)construction ou
réhabilitation.
Au-delà de tout, nous ne prétendons pas avoir
épuisé le sujet. C'est pourquoi nous sommes ouvert aux critiques
ou remarques allant dans le sens d'améliorer notre travail.
BIBLIOGRAPHIE
A. Ouvrages
[1] ANDREAS MEIER, Introduction pratique aux bases de
données relationnelles, Springer ,2006
[2] BARRE Michèle et ROGER Christophe, les bases de
données spéciales, IRD Paris,2005
[3] BERTRANDBourquier, Business intelligence avec SQL
Server 2008, Dunod, Paris, 2009
[4] Francis Draillard : Premiers pas en CSS et XHTM 2
ème Edition,ÉDITIONS EYROLLES, bd Saint-Germain 75240 Paris
[5] Golfarelli&Rizzi : Data Warehouse Design:
Modern Principles and Methodologies, Indd, 2009
[6] LAURY Quentin et SAYSANASY Jessy, Webmapping, UFR,2011
[7] Philippe RIGAUX : Pratique de MySQL et PHP Conception
et réalisation, Dunod, Paris, 2009
[8] Ralph Kimball, L. Reeves, M. Rose, et W. Thornthwaite, Le
Data warehouse: Guide de conduit de projet, Eyrolles Paris 2011.
[9] Ralph Kimball, M. Ross, Entrepôt de
données ; Guide pratique de modélisation
dimensionnelle, Wiley, 2e édition
[10] Sébastien FANTINI : Business
Intelligence avec SQL Server 2008 R2,ENI Editions 2010
B. Notes de cours
[11] DI GALLO Frédéric :
Méthodologie des systèmes d'information MERISE, note de cours,
Cours du cycle B du Cnam.doc 2000.
[12] Cyril GRUAU : Conception d'une base de
données, note de cours, 2007.
[13] MBUYI MUKENDI Eugène, Système
d'information et base de données, 3ème Graduat
informatique, Faculté de sciences, UNIKIN, 2007-2008.
[14] NGOMBA Marcelline: Introduction aux Systèmes
d'Information Géographique, Faculté de sciences, UNIKIN,
2006-2007.
C. Article
[15] Cellule d'infrastructures, les infrastructures
routières en RDC, Kinshasa, janvier 2009
D. Mémoire
[16] KASEREKA MUSUMBA : Construction d'un Data Warehouse
pour l'aide à la prise de décision en matière de gestion
de l'exploitation industrielle de Bois en République Démocratique
du Congo, Université de Kinshasa 2011-2012.
E. Webographies
[17] http://www.celluleinfra.org, le
01 janvier 2014
[18] http://
www.classroom.fr, le 02 janvier 2014
[19]
http://cyril-gruau.developpez.com/merise, le 01 novembre 2013
[20]
http://freesoftwarestutorials.blogspot.com/search/label/Webmapping, le 11
novembre 2013
[21]
http://www.dwfacile.com/Choix_outils.htm, le 23 décembre
| 

