|
N° d'ordre : 24 / STI / TCO Année Universitaire :
2015 / 2016
|
UNIVERSITE D'ANTANANARIVO
|
|
|
ECOLE SUPERIEURE POLYTECHNIQUE
|
|
MENTION TELECOMMUNICATION
|
Directeur de mémoire : M. RAVALIMINOARIMALALASON Toky
Basilide
MEMOIRE
en vue de l'obtention
du DIPLOME de Master
Titre : Ingénieur
Domaine : Sciences de l'ingénieur
Mention: Télécommunication
Parcours : Système de Traitement
d'Information(STI)
par : TAFENO Harimanana Elisa
LOCALISATION PAR EMPREINTE RADIO. APPLICATION SUR LES
RESEAUX MOBILES 2G-3G
Soutenu le 04 Avril 2017 devant la Commission d'Examen
composée de :
Président : M. RANDRIAMITANTSOA Andry Auguste
Examinateurs :
M. RAJAONARISON Roméo
M. RATSIHOARANA Constant
M. RANDRIAMANAMPY Samuel
i
REMERCIEMENTS
Avant tout, je rends grâce à Dieu tout puissant
pour son Amour, sa Bénédiction et pour la Force et le Courage
qu'il m'a donné pour la réalisation de ce Mémoire.
A la mémoire de mon père qui a tant voulu
m'assister en ce moment mais que le destin a empêché. « Paix
à son âme ».
J'exprime toute ma gratitude à Monsieur RAMANOELINA
Panja, Professeur Titulaire, Président de l'Université
d'Antananarivo.
Je souhaite remercier Monsieur ANDRIANAHARISON Yvon,
Professeur Titulaire, Responsable du Domaine Sciences de l'Ingénieur
à l'Ecole Supérieure Polytechnique d'Antananarivo, qui m'a permis
de poursuivre mes études au sein de l'Ecole.
Je suis particulièrement reconnaissant à
Monsieur RAKOTOMALALA Mamy Alain, Maître de Conférences,
Responsable de la Mention Télécommunication.
A terme de ce travail, je tiens à témoigner
toute ma gratitude à tout le personnel du Groupe Telma, de m'avoir
accueilli chaleureusement dans leur Société, plus
particulièrement à Monsieur RAVALIMINOARIMALALASON Toky Basilide,
Docteur de l'Université d'Antananarivo, Ingénieur Radio Planning
et Optimisation Sénior de Telma, Directeur de mémoire et
encadreur professionnel, pour ses recommandations, son soutien et surtout le
temps consacré pour me diriger jusqu'à la finalisation de ce
Mémoire.
J'exprime également toute ma reconnaissance aux membres
du jury présidés par Monsieur RANDRIAMITANTSOA Andry Auguste,
Maître de Conférences, qui ont voulu examiner mon travail :
? Monsieur RAJAONARISON Roméo, Maître de
Conférences,
? Monsieur RATSIHOARANA Constant, Maître de
Conférences,
? Monsieur RANDRIAMANAMPY Samuel, Assistant d'Enseignement
Supérieur et de Recherche.
Je souhaite remercier tous les Membres de ma Famille, qui
n'ont jamais cessé de me soutenir moralement et financièrement
tout au long de mes études et à tous les Enseignants Chercheurs
et Personnels administratifs de l'Ecole Supérieure Polytechnique
d'Antananarivo ainsi qu'à tous mes amis qui de près ou de loin,
ont contribué à l'accomplissement de ce travail.
ii
TABLE DES MATIERES
REMERCIEMENTS i
NOTATIONS ET ABREVIATIONS vi
INTRODUCTION GENERALE 1
CHAPITRE 1 GENERALITE SUR LE RESEAU MOBILE 2
1.1 Introduction 2
1.2 Première génération des
téléphones mobiles 2
1.2.1 AMPS 2
1.2.2 NMT 2
1.2.3 TACS 2
1.2.4 Radiocom 2000 3
1.2.5 Limites du système 1G 3
1.3 Deuxième génération des
téléphones mobiles 3
1.3.1 GSM 3
1.3.2 GPRS 10
1.3.3 HSCSD 12
1.3.4 EDGE 12
1.4 Troisième génération des
téléphones mobiles 13
1.4.1 UMTS 13
1.4.2 Evolution radio de l'UMTS 15
1.5 Quatrième génération des
téléphones mobiles 16
1.5.1 LTE et LTE-Advanced 16
1.6 Mesure des paramètres radio en réseau
mobile 18
1.6.1 Etats de la station mobile 18
1.6.2 Mobilité en mode connecté
18
1.6.3 Mesure des paramètres radio en GSM
22
1.6.4 Niveau de signal et qualité de signal en
UMTS 25
1.6.5 Niveau de signal et qualité de signal en
LTE 26
1.7 Conclusion 27
iii
CHAPITRE 2 TECHNOLOGIES ET TECHNIQUES DE POSITIONNEMENT
28
2.1 Introduction 28
2.2 Technologies de positionnement 28
2.2.1 Systèmes de positionnement radio
28
2.2.2 Systèmes de positionnement non radio
34
2.3 Techniques de positionnement 36
2.3.1 Métriques de positionnement
36
2.3.2 Évaluation de la position
40
2.4 Conclusion 44
CHAPITRE 3 LOCALISATION A BASE D'EMPREINTE RADIO
45
3.1 Introduction 45
3.2 Description d'un système de LFP 45
3.2.1 Phase d'apprentissage 45
3.2.2 Phase de localisation 46
3.3 Terminologie et modélisations
mathématiques 48
3.3.1 Base de données radio et enregistrement
48
3.3.2 Mesure radio 48
3.3.3 Modèle de propagation radio
48
3.4 Méthodes de compression de base de
données radio 49
3.4.1 Technique de clustering 49
3.4.2 PCA 51
3.4.3 KCCA 53
3.5 Méthode de classification 53
3.5.1 KNN 53
3.5.2 SVM 55
3.5.3 ANN 55
3.6 Traitement des données manquantes dans les
systèmes LFP 58
3.6.2 Algorithme de localisation basé sur le
maximum de vraisemblance 59
iv
3.6.3 Algorithme de Multiple Imputation
60
3.7 Positionnement utilisant la méthode de
fingerprinting basé sur OTD 61
3.7.1 Estimation des TDOAs pour un réseau 3G
62
3.7.2 Structure de l'algorithme 63
3.8 Positionnement utilisant le paramètre TA
67
3.9 Conclusion 69
CHAPITRE 4 MISE EN OEUVRE ET SIMULATION DE L'OUTIL DE
TRAITEMENT DE TRACE
ET DE LOCALISATION D'ABONNES 70
4.1 Introduction 70
4.2 Outil de trace 70
4.2.1 Présentation 70
4.2.2 Lecteur et décodeur de trace
72
4.3 Analyse et conception du système informatique
74
4.3.1 Architecture système 74
4.3.2 Analyse des besoins 75
4.3.3 Modélisation UML 77
4.3.4 Diagramme UML de l'application
79
4.3.5 Modèle Conceptuel des Données
82
4.3.6 Langage de programmation 83
4.3.7 Module cartographique 88
4.3.8 Serveur web et serveur d'application
89
4.3.9 Structure du projet 89
4.4 Présentation de l'application web
90
4.4.1 Page d'authentification 90
4.4.2 Création d'utilisateur
91
4.4.3 Localisation d'un abonné
92
4.5 Précision des différents
systèmes de localisation 93
4.6 Conclusion 94
V
CONCLUSION GENERALE 95
ANNEXES 96
BIBLIOGRAPHIE 100
vi
NOTATIONS ET ABREVIATIONS
1. Minuscules latines
c Classe
d Distance entre 02 stations de base
d1 Distance entre mobile et station de base
d2 Distance entre mobile et station de
base
da Rayon du cercle de centre NR.
db Rayon du cercle de centre NR.
dc Rayon du cercle de centre NR.
dE(w) Distance Euclidien pondérée
dl Distance entre une cellule i et un UE
d (xl, xi) Distance entre deux données
f Fonction de transfert du neurone
f Fréquence de transmission
f(x) Fonction sigmoïde
fk(x, y) Système d'équation
hB Hauteur de l'antenne
i Vecteur indicateur
i' Vecteur indicateur d'effacement
m Nombre de cluster
n Nombre d'objets
p Dimension
q Mesures
r Enregistrement
r1 Rayon du cercle centré sur la
station de base
r2 Rayon du cercle centré sur la
station de base
rl Distance obtenue par la valeur de TA
rk,l,i Mesures provenant de k MRM
s Vecteur représentant la mesure radio
s' Mesure effectué par le mobile
vii
sm Centroid
s'(mis) Partie manquante de la mesure
s'(obs) Partie observée de la mesure
u Vecteur représentant linéairement le
nuage de points
umn Représentation de la partition
v Vecteur représentant linéairement le
nuage de points
vl Vecteurs propres
co Vecteur comprenant les poids
{????}??=0,...,n Poids du neurone
x Ensemble des mesures
x Vecteur représentant la partie position
x^ Position estimée pour le terminal
x' Position
xi Vecteur représentant une donnée
xi, yl Coordonnées cartésiennes du
itième NR
x. Vecteur représentant une donnée
(x, y)A,B,C Coordonnées des 03 meilleures
cellules
(x, y)U Position du mobile
y(x) Sortie d'un événement d'apprentissage
2. Majuscules latines
A Région sur lequel le terminal mobile effectue
des mesures
Ak Matrice de rang k
B Station de base
BS Stations de base
Bmax nombre maximum des stations de base mesurable au
niveau du
terminal
C Vitesse de la lumière
Cl Paramètre vérifiant que la
cellule sélectionnée est reçue et ne subit
pas un affaiblissement.
C2 Critère de re-sélection
viii
?????? Paramètre du modèle spécifique pour
une zone urbaine
Cell_Reselect_Offset Valeur de l'offset permanent ajouté
à ??1.
??2(U, R) Fonction d'objective
?????????????? Latitude en valeur décimale de la station
de base
?????????????? Longitude en valeur décimale de la station
de base
?? Matrice carrée symétrique
Max_TXPWR_Max_CCH Paramètre fixant la puissance à
laquelle le mobile doit émettre Max. mobile RF Power Puissance maximale
avec laquelle le mobile est capable d'émettre vers la BTS
N Nombre de ressource block
???? Nombre total des features types
??????(??) Frame offset
????????(??) OTD sur le k-ième MRM, entre l'UE et la
cellule
??1 Point d'intersection recherché
??2 Point d'intersection recherché
PenaltyTime Durée pendant laquelle le TemporaryOffset va
être appliqué
???? Pathloss
?????? Perte moyenne
R Base de données finale
R?? Base de données initiale
R???? Ensemble comprenant ???? éléments
réels.
R???? Ensemble comprenant ???? éléments
réels.
R?????? Niveau de la puissance reçue en 3G
R??R?? Niveau de la puissance reçue en 4G
R??R?? Mesure de qualité de signal
R?????? Puissance totale du signal reçu
R?????? (??, ??) RTD entre 02 cells/sites
Rxlevel Niveau de reception
RX_AccessMin Niveau minimum pour que le mobile puisse
s'accrocher à la BTS
?????? Timing Advance
TemporaryOffset Offset temporaire
ix
Tk(i) Retard de propagation
Tm(i) Chip offset
Tx Puissance de transmission
Uk Matrice des vecteurs ut
Vk Matrice des vecteurs propres
X Ensemble des positions inclues dans la base
X Matrice reconstruite
X1, Y1 Coordonnée géographique connues
d'une station de base
X2, Y2 Coordonnée géographique connues
d'une station de base
XBsK, YBsK Coordonnées d'une station de base
{Xi}i=1,..,n Entrées du système ou peuvent
provenir des autres neurones.
XL, Yi Coordonnées d'un node mobile
XMs, YMs Coordonnées d'une station mobile
Xp1, Yp1 Coordonnée géographique du point
d'intersection recherché
Xp2, Yp2 Coordonnée géographique du point
d'intersection recherché
Xsh Variable aléatoire log-Normal qui
représente l'effet de shadowing
Y1 Variable décrivant un objet
Y2 Variable décrivant un objet
3. Minuscules grecs
oc1 Angle fournie par la station de base et la station
mobile
a12 Angle que fait l'axe horizontal du repère
trigonométrique avec les
stations de base
oc Paramètre de propagation exponentielle
/3 Angle formé par la distance entre les stations
de base et le point
recherché.
SRTD Différence RTD
E(x')
Erreur de la localization
BL Ensemble qui modélise la distribution des
mesures RSS complètes sur
les clusters
BT Inclut les paramètres du
modèle log-Normal
x
A Seuil de sensibilité du terminal
Al Valeurs propres
f Evènement
Ph Sous vecteur correspondant à l'hème
feature type
6 Permutation d'indices des stations de base
(Pk Information fournie par les stations de base
W Ensemble de tous les paramètres qui modélisent le
mécanisme
d'effacement.
4. Majuscules grecs
rm Covariance matrice du m-ème
cluster
Ad Différence entre les distances da et db
ORTD Erreur maximum prédéfinie
? Angle fournie par les deux stations de base
E Matrice diagonal
Ol?? Différence de phase entre deux récepteurs
d'indices i et ]
5. Abréviations
2G Système mobile de seconde génération
3G Système mobile de troisième
génération
3GPP Third Generation Partnership Project
4G Système mobile de quatrième
génération
AAS Adaptive Antenna Systems
AES Advanced Encryption Standard
AGCH Access Grant Channel
AJAX Asynchronous JavaScript and XML
AMPS Advanced Mobile Phone System
AMRF Accès Multiple à Répartition
Fréquentielle
AMRT Accès Multiple à Répartition dans le
Temps
AMS Adaptive Modulation Schemes
ANN Artificial Neural Networks
AOA Angle Of Arrival
API Application Programming Interface
xi
AUC AUthentification Center
BCCH Broadcast Control Channel
BCH Broadcast CHannel
BD Base de Données
BER Bit Error Ratio
BPSK Binary Phase Shift Keying
BSC Base Station Controller
BSS Base Station Subsystem
BTS Base Transceiver Station
BWC Bloc-based Weighted Clustering
CBCH Cell Broadcast Channel
CCCH Common Control Channel
CDF Cumulative Distribution Functions
Cell ID Cell Identification
CN Core Network
CPICH Common PIlot Channel
CRS Cell Reference Signal
CS Coding Scheme
CS Circuit Switched
CSS Cascading StyleSheets
CSV Comma Separated Values
DRNC Drift RNC
EcNo Energy per modulating bit to the noise spectral
density
EDGE Enhanced Data-rates for Global Evolution
EGNOS European Geostationary Navigation Overlay Service
EIR Equipment Identity Register
E-OTD Enhanced Observed Time Difference
eNB evolved Node B
FACCH Fast Associated Control CHannel
FCCH Frequency Correction CHannel
FDD Frequency Division Duplex
FDMA Frequency Division Multiple Access
xii
GGSN Gateway GPRS Support Node
GLONASS GLObal NAvigation Satellite System
GMSC Gateway MSC
GMSK Gaussian Minimum Shift Keying
GPEH General Performance Event Handling
GPRS General Packet Radio Service
GPS Global Positioning System
GSM Global System for Mobile communications
GSN GPRS Service Node
GUI Graphic User Interface
HARQ Hybrid Automatic ReQuest
HLR Home Location Register
HSCSD High Speed Circuit Switched Data
HSDPA High Speed Downlink Packet Access
HSPA Hight Speed Packet Access
HSUPA High Speed Uplink Packet Access
HTML HyperText Mark-Up Language
IEEE Institute of Electrical and Electronics Engineers
IMEI International Mobile Equipment Identity
IMSI International Mobile Subscriber Identifier
IMT2000 International Mobile Telecommunications-2000
J2EE Java 2 Entreprise Edition
JDBC Java Data Base Connectivity
JSP Java Server Page
KCCA Kernel Canonical Correlation Analysis
KNN K-Nearest-Neighbors
LA Location Area
LFP Location Fingerprinting
LP-WPAN Low Power Wireless Personal Area Network
LR-WPAN Low Rate Wireless Personal Area Network
LTE Long Term Evolution
MCC Mobile Country Code
xiii
MCD Modèle Conceptuel des Données
MI Multiple Imputation
MIMO Multiple Input Multiple Output
ML Maximum Likelihood
MME Mobility Management Entity
MNC Mobile Network Code
MRM Mesurement Report Messages
MS Mobile Station
MSC Mobile Switching Center
MSIN Mobile Subscriber Identification Number
MSISDN Mobile Station ISDN
MSRN Mobile Station RoamingNumber
NM Noeud Mobile
NMT Nordic Mobile Telephone
Node B Node for Broadband access
NR Noeud de Reference
NSS Network SubSystem
ODBC Object Data Base Connectivity
OFDM Orthogonal Frequency Division Multiplexing
OFDMA Orthogonal Frequency Division Multiplexing Access
OMC Operation and Maintenance Center
OMG Object Management Group
OSLN One Slop Log-Normal model
OTD Observed Time Differences
PCA Principal Component Analysis
PCH Paging CHannel
PCU Packets Controler Unit
PDN-GW Packet Data Network Gateway
PDOA Phase Difference of Arrival
PMR Performance Management traffic Recording
PN Pseudo Noise
PS Packet Switched
xiv
PSC Primary Scrambling Codes
PSK Phase Shift Keying
QAM Quadrature Amplitude Modulation
QPSK Quadrature Phase Shift keying
RACH Random Access CHannel
RFID Radio-Frequency Identification
RLS Recursive Least Squares
RNC Radio Network Controller
RRM Radio Ressource Management
RS Reference Signal
RSCP Received Signal Code Power
RSRP Reference Signal Received Power
RSRQ Reference Signal Received Quality
RSS Received Signal Strength
RSSI Received Signal Strength Indicator
RTC Réseau Téléphonique Commuté
RTD Relative Time Differences
RXLEV Reception Level
RXQUAL Reception Quality
SACCH Slow Associated Control CHannel
SAE System Architecture Evolution
SCH Synchronisation CHannel
SDCCH Stand-Alone Dedicated Control CHannel
SGBD Système de Gestion de Base de Données
SGBDO Système de Gestion de Base de Données
Objet
SGBDR Système de Gestion de Base de Données
Relationnelles
SGSN Serving GPRS Support Node
S-GW Serving Gateway
SIM Subscriber Identity Module
SMS Short Message Service
SMSC Short Message Service Center
SNR Signal to Noise Ratio
xv
SQL Structured Query Language
SRNC Serving RNC
SVM Support Vector Machines
TA Timing Advance
TACS Total Access Communications System
TCH Traffic CHannel
TCP/IP Transmission Control Protocol/Internet Protocol
TDMA Time Division Multiple Access
TDOA Time Difference Of Arrival
TMSI Temporary Mobile Subscriber Identity
TNT Télédiffusion Numérique Terrestre
TOA Time Of Arrival
TPS TV Positioning System
TRAU Transcoding Rate and Adaptation Unit
UE User Equipment
UETR UE Traffic Recording
UHF Ultra High Frequency
UML Unified Modeling Language
UMTS Universal Mobile Telecommunication System
UTRAN UMTS Terrestrial Radio Access Network
UWB Ultra Wide Band
VBA Visual Basic pour Application
VLR Visitor Location Register
VPP Voisin le Plus Proche
W-CDMA Wideband CDMA
WiFi Wireless Fidelity
WLAN Wireless Local Area Network
WPAN Wireless Personal Area Network
WPS Wi-Fi Positionning System
WWW World Wide Web
XML eXtensible Markup Language
xvi
6. Notations spéciale
eig(M) Valeurs et vecteurs propres d'une matrice M.
Fb (.|m, 8L) CDF de la distribution Gaussien,
correspondant au b-ème
composant radio.
Pb (. |8T) Densité marginale du b
ème composant,
iiX - Ak ii?? . Erreur d'approximation
1
INTRODUCTION GENERALE
Actuellement, le monde des télécommunications
arrive à un carrefour de son évolution. L'importance des
communications sans fils ne cesse de s'accroître très rapidement
à cause de leur accessibilité au grand public. Grâce
à la miniaturisation des technologies, leur performance s'est accrue, et
ne cesse d'augmenter à un rythme effréné.
En vue d'obtenir le Diplôme de Master à
visée professionnelle dans la mention télécommunication,
nous avons eu l'avantage d'effectuer nos travaux de mémoire au sein de
TELMA Analakely, Antananarivo. Ce stage s'est déroulé au sein de
la Direction Technique Groupe, Département Planning - Ingénierie
- Optimisation.
Les systèmes de localisation sont omniprésents.
Ils s'appliquent à différents contexte tels que : la navigation,
la géolocalisation et les réseaux sociaux.
La localisation par empreinte radio (LFP ou Location
Fingerprinting) est une des solutions potentielles pour fournir un
positionnement durable et à un prix abordable. Elle est avant tout un
besoin primordial de l'opérateur téléphonique pour le
suivi (tracking) d'un abonné quelconque. Le GSM ou Global System for
Mobile communications et l'UMTS ou Universal Mobile Telecommunication System
sont les outils de communication les plus demandés à Madagascar.
Pour le cas de TELMA, elle reçoit des plaintes provenant de ses clients.
Il est nécessaire de localiser ces abonnés pour faciliter la
résolution de leur problème.
Notre tâche est de concevoir une application
informatique capable de localiser les abonnés à l'aide de leur
caractéristique radio d'où le détail de ce présent
mémoire intitulé «LOCALISATION PAR EMPREINTE RADIO.
APPLICATION SUR LES RESEAUX MOBILES 2G-3G ».
Les différentes générations de
téléphones mobiles ainsi que la mesure des paramètres
radio en réseau mobile font l'objet du premier chapitre de ce
mémoire.
Ensuite, le second chapitre est consacré aux
présentations des techniques ainsi que les technologies de
positionnements.
Et, nous entamerons au troisième chapitre, la localisation
à base d'empreinte radio.
Enfin, le dernier chapitre concernera la mise en oeuvre et
simulation de l'outil de traitement de trace et de localisation
d'abonnés.
2
CHAPITRE 1
GENERALITE SUR LE RESEAU MOBILE
1.1 Introduction
De nos jours, les réseaux mobiles et sans fil ont connu
un essor sans précédent. La téléphonie mobile est
devenue le moyen de communication le plus dominant et moderne. Elle se
répartit en plusieurs réseaux tels que les réseaux GSM,
l'EDGE, le GPRS, l'UMTS et LTE. Ceux-ci sont regroupés en plusieurs
générations telles, la 2G, la 3G et 4G.
1.2 Première génération des
téléphones mobiles
La première génération des
téléphones mobiles a commencé dès le début
des années 80 en fournissant un service insuffisant et coûteux de
communication mobile. Elle a bénéficié les deux inventions
techniques majeures des années 1970 : le microprocesseur et le transport
numérique des données entre les téléphones mobiles
et la station de base. Les appareils utilisés étaient
particulièrement volumineux. La première génération
de systèmes cellulaires utilisait essentiellement les standards suivants
:
1.2.1 AMPS
AMPS ou Advanced Mobile Phone System, lancé aux
Etats-Unis, est un standard de téléphonie analogique reposant sur
la technologie FDMA ou Frequency Division Multiple Access. Il est basé
sur une technologie de commutation des communications entre cellules.
1.2.2 NMT
NMT ou Nordic Mobile Téléphone a
été lancé en 1981 pour faire face aux limitations de
l'ARP. Il a été surtout conçu dans les pays nordiques
(Danemark, Suède, Norvège, Finlande). Ce standard utilisait la
bande de fréquence UHF 450 à 460MHz avec 180 canaux duplex
espacés de 10MHz et de largeur de 25KHz. Les rayons des cellules
étaient comprises entre 20 et 40 Km (réseaux rurales) et de 0,5Km
(région urbaine). La puissance des stations mobiles variaient de 1,5
à 15W et 50W pour les stations de base.
1.2.3 TACS
TACS ou Total Access Communications System est un standard qui
repose sur la technologie AMPS. Il a été très
utilisé en Grande Bretagne.
3
1.2.4 Radiocom 2000
C'est le réseau de téléphone mobile
français. Il fonctionne sous la bande de fréquence des 400 MHz.
Il se sert de la technologie numérique pour la signalisation et la
modulation analogique pour la voix. Les fréquences sont
attribuées dynamiquement en fonction des besoins.
Ainsi, les premières notions de
téléphonie cellulaire apparaissent avec, peu après son
lancement en 1986, l'apparition du handover et de l'attribution de
fréquences au sein d'une cellule. Le réseau couvre la
quasi-totalité du territoire.
1.2.5 Limites du système 1G
Sa principale anomalie est présentée par ses normes
incompatibles d'une région à une autre, une
transmission analogique non sécurisée (on pouvait
écouter les appels), et l'absence de roaming vers
l'international.
Aussi, le système 1G dispose de quelques limites telles
:
? L'efficacité spectrale assez médiocre
? L'existence de plusieurs normes différentes d'où
absence d'itinérance internationale
? Les infrastructures employées sont volumineuses (taille,
énergie).De ce fait, Le système est
très coûteux d'où l'utilisation restreinte
aux professionnels.
? Le produit du système 1G ne touchait pas le grand
public.
Progressivement, les systèmes numériques remplacent
les systèmes analogiques, tout en conservant
la compatibilité (surtout dans AMPS). [1]
1.3 Deuxième génération des
téléphones mobiles
1.3.1 GSM
Le 2G ou GSM est une norme numérique pour les
téléphones portables. Pratiquement, il s'agit d'un réseau
permettant une communication de type « voix ». Il est apparu dans les
années 90. Son principe, est de passer des appels
téléphoniques, s'appuyant sur les transmissions numériques
permettant une sécurisation des données (avec cryptage). Ainsi,
il contient beaucoup de services tels que l'affichage d'appel, la
conférence, ... Il a connu un succès et a permis de susciter le
besoin de téléphoner en tout lieu avec la possibilité
d'émettre des minimessages (SMS ou Short Message Service, limités
à 80 caractères). Aussi, il autorise le roaming entre pays
exploitants le réseau GSM.
1.3.1.1 Caractéristiques techniques
La bande utilisée en GSM est le 900 Mhz et 1800 Mhz. Sa
vitesse de transmission maximum vaut 23 kbps (théorique) et 9,6 kbps
réel. Cependant, ce débit est insuffisant pour le transfert de
fichiers, d'images, de vidéos, accès à Internet, etc.
Dans un réseau GSM, deux techniques de multiplexage
sont mises en oeuvre : le multiplexage fréquentiel (AMRF ou Accès
Multiple à Répartition Fréquentielle) et le multiplexage
temporel (AMRT ou Accès Multiple à Répartition dans le
Temps).
La modulation définie pour la norme GSM est la
modulation GMSK ou Gaussian Minimum Shift Keying ou modulation à
déplacement minimum gaussien, qui est une modulation de fréquence
à enveloppe constante.
1.3.1.2 Architecture du réseau GSM
La figure 1.01 ci-dessous présente l'architecture du
Réseau GSM.

BTS
MS
BTS
BTS
BTS
BTS
MS
BTS
BSC
BSC
MSC
MSC
HLR
VLR
VLR
BSC
BSS NSS RTCP
4
Figure 1.01 : Architecture du Réseau
GSM
5
Le réseau se compose de trois parties
séparées par des interfaces normalisées :
· la station mobile (MS ou Mobile Station)
· le sous-système station de base (BSS ou Base
Station Subsystem)
· le sous-système réseau (NSS ou Network
Subsystem)
1.3.1.3 La station mobile
La station mobile est composée de deux entités
telles que l'équipement mobile ou ME et la carte SIM ou Subscriber
Identity Module qui est une carte à puce avec mémoire non
volatile contenant les informations fixes et variables spécifiques
à l'utilisateur.
a. Identification des stations mobiles
Les réseaux GSM opèrent avec plusieurs
identificateurs :
L'IMSI ou International Mobile Subscriber Identifier n'est
connu qu'à l'intérieur du réseau GSM. Il est d'environ 15
digits (0-9), stocké dans la carte SIM et identifie l'abonné de
manière unique au niveau mondial. L'IMSI est composé de :
· MCC ou Mobile Country Code 3 digits
· MNC ou Mobile Network Code 2 digits
· MSIN ou Mobile Subscriber Identification Number:
longueur variable, contient 3 digits pour l'identificateur de HLR. [2]
Le TMSI ou Temporary Mobile Subscriber Identity est une
identité temporaire utilisée pour identifier le mobile lors des
interactions station mobile/réseau. Il est formé par un mot de 04
octets représenté en hexadécimal.
Le MSISDN ou Mobile Station ISDN est le numéro de
l'abonné, c'est le seul identifiant de l'abonné mobile connu
à l'extérieur du réseau GSM d'où le numéro
de téléphone mobile habituel.
Le MSRN ou Mobile Station Roaming Number est un numéro
attribué lors de l'établissement d'appel. Sa principale fonction
est de permettre l'acheminement des appels par les commutateurs (MSC et
GMSC).
L'IMEI ou International Mobile Equipment Identity identifie
l'équipement mobile (hardware). Le numéro IMEI permet
d'empêcher l'utilisation d'une station volée avec une autre carte
SIM. L'IMEI est composé de 60 bits. [2]
6
b. Fonctions de la station mobile :
Les principales fonctions de la station mobile sont [2] :
· Transmission de la voix et des données
· Synchronisation en fréquence et en temps
· Supervision de la puissance et de la qualité des
cellules voisines
· Egalisation contre les distorsions dues aux chemins de
propagation multiples
La station mobile peut avoir différentes puissances
nominales. La puissance réelle est commandée par la station de
base par pas de 2dB, en fonction du niveau qu'elle reçoit (Minimum:
20mW). Ainsi plus la station mobile s'éloigne de la station de base,
plus sa puissance d'émission augmentera, jusqu'à la valeur
nominale. Le but de la commande de puissance est de réduire le niveau
moyen d'interférences. [2]
1.3.1.4 Le sous-système de station de base
Il est composé de trois parties :
· La station de base (BTS ou Base Transceiver Station)
· Le contrôleur de station de base (BSC ou Base
Station Controller)
· L'unité de transcodage (TRAU ou Transcoding Rate
and Adaptation Unit)
Le BTS assure la réception des appels entrant et
sortant des équipements mobiles. Il est composé des
émetteurs/récepteurs radios.
Le BSC assure le contrôle des stations de bases. Il
gère la ressource radio (allocation de canal, handover).
Le TRAU est utilisée dans les réseaux GSM pour
convertir un signal de 13 kb/s en un signal de 64 Kb/s et vice versa.
1.3.1.5 Le sous-système Réseau
Il est composé d'un ou plusieurs centres de commutation
MSC ou Mobile Switching Center; typiquement un réseau peut compter entre
1 et 10 MSC et des registres (bases de données).
Le MSC ou Centre de commutation de mobile assure la
commutation dans le réseau, il gère les appels départ et
arrivée.
Le GMSC ou Gateway MSC est une passerelle réalisant
l'interface entre le réseau d'un opérateur et le RTC ou
Réseau Téléphonique Commuté.
7
1.3.1.6 Les bases de données
Quand le réseau doit établir un appel avec une
station mobile, il doit savoir où celle-ci se trouve avec une certaine
précision.
Deux cas extrêmes sont imaginables :
D'un côté, le GMSC ne sait pas où est la
station mobile : il faut alors envoyer des messages de paging dans tout le
réseau. Ceci génère un trafic important dans le canal de
paging, canal que chaque station mobile doit "écouter" en permanence.
Et de l'autre, la position est connue à la cellule
près. Dans ce cas, chaque fois qu'une station mobile au repos change de
cellule, elle doit en informer le réseau. Ceci implique aussi un trafic
important et des opérations fréquentes dans la station mobile.
Pour le réseau GSM, on a fait un compromis en
définissant des zones de localisation. Une zone de localisation LA ou
Location Area est la plus petite zone dans laquelle est localisée une
station mobile. Elle recouvre en général plusieurs cellules.
Chaque zone de localisation a un identificateur, qui est diffusé par le
canal BCCH ou Broadcast Control CHannel.
Le HLR ou Home Location Register (Enregistrement de
localisation normale) est une base de données assurant le stockage des
informations sur l'identité et la localisation des abonnés.
Le VLR ou Visitor Location Register (Enregistrement de
localisation pour visiteur) est une base de données assurant le stockage
des informations sur l'identité et la localisation des visiteurs du
réseau. L'AUC ou Authentification Center (centre d'authentification) est
une base de données implémentée avec le HLR. Elle contient
les clés d'authentification et les clés de cryptage des
abonnés au réseau. EIR ou Equipment Identity Register est une
base de données du réseau qui contient tous les numéros
IMEI des mobiles enregistrés. On distingue :
? La liste blanche: numéros des stations normales
? La liste noire: numéros des stations volées
? La liste grise: numéros des stations ayant des
problèmes techniques
1.3.1.7 Le centre d'exploitation et de maintenance
Cette partie du réseau, appelée aussi OMC ou
Operation and Maintenance Center, rassemble trois activités principales
de gestion : la gestion administrative, la gestion commerciale et la gestion
technique. Le réseau de maintenance technique se joint au fonctionnement
des éléments du réseau.
8
Il gère surtout les alarmes, les pannes, la
sécurité, etc. Ce réseau se pose sur un réseau de
transfert de données totalement dissocié du réseau de
communication GSM.
1.3.1.8 Présentation des interfaces
Le tableau 1.01 ci-après présente les interfaces
désignées par des lettres de A à H qui ont
été définies par la norme GSM.
|
Nom de l'interface
|
Localisation
|
Utilisation
|
|
Um
|
MS-BTS
|
Interface radio
|
|
Abis
|
BTS-BSC
|
Divers
|
|
A
|
BSC-MSC
|
Divers
|
|
C
|
GMSC-HLR
|
Interrogation du HLR pour appel entrant
|
|
SM-GMSC-HLR
|
Interrogation du HLR pour message court entrant
|
|
D
|
VLR-HLR
|
Gestion des informations d'abonnés et de
localisation
|
|
VLR-HLR
|
Services supplémentaires
|
|
E
|
MSC-SM-GMSC
|
Transport de messages courts
|
|
MSC-MSC
|
Exécution des handover
|
|
G
|
VLR-VLR
|
Gestion des informations des abonnés
|
|
F
|
MSC-EIR
|
Vérification de l'identité du terminal
|
|
B
|
MSC-VLR
|
Divers
|
|
H
|
HLR-AUC
|
Echange de données d'authentification
|
Tableau 1.01: Les interfaces en GSM
1.3.1.9 Les différents types de signaux
échangés
Les signaux de voix et de contrôle
échangés entre le mobile et la base sont classés en
plusieurs catégories [3]. Mais ils transitent tous sur 2 voies radio
montantes et descendantes :
? La voie balise : FCCH, SCH, BCCH, PCH, RACH ...
? La voie trafic : TCH, SACCH, FACCH...
Le tableau 1.02 nous montre les différentes classes ou
« channels » de signaux échangés.
|
Type
|
Nom
|
Fonction
|
Méthode de
multiplexage
|
|
Voie balise
|
BCH
Broadcast
CHannel
(diffusion)
|
FCCH
|
Frequency
correction
CHannel
|
Calage sur la
porteuse
|
Un burst particulier toutes les 50ms sur le slot 0 de la voie
balise
|
|
SCH
|
Synchronisation CHannel
|
Synchronisation,
identification de la
BTS
|
Un burst sur le slot 0 de la voie balise, une trame après
le burst FCCH
|
|
BCCH
|
Broadcast
Control
CHannel
|
Informations
systèmes
|
04 burst "normaux"
à chaque
multitrame
|
|
CCCH Common Control CHannel (accès partagé)
|
PCH
|
Paging
CHannel
|
Appel des mobiles
|
Sous-blocs
entrelacés sur 04
bursts "normaux"
|
|
RACH
|
Random Access CHannel
|
Accès aléatoire des mobiles
|
Burst court envoyer
sur des slots
particuliers
en
accès aléatoire
|
|
AGCH
|
Access Grant
CHannel
|
Allocation de
ressources
|
08 blocs entrelacés
sur 04 bursts
"normaux"
|
|
CBCH
|
Cell Broadcast
CHannel
|
Message courts
diffusés
(météo,
trafic routier, etc.)
|
Utilise certains
slots de la trame à
51.C
(utilisation
marginale)
|
|
Voie trafic
|
Canaux de
contrôle
dédiés
|
SDCCH
|
Stand-Alone
Dedicated
Control
CHannel
|
Signalisation
|
08 SDCH + 08
SACCH sur un
canal physique
|
|
SACCH
|
Slow
Associated
Control
CHannel
|
Compensation du
délai
de
propagation,
contrôle de
la
puissance
d'émission,
contrôle de la
qualité
de liaison
et mesures sur les
autres stations
|
associé à TCH sur un canal physique ou à 08
SDCH sur un canal physique
|
|
FACCH
|
Fast Associated
Control
CHannel
|
Exécution du
handover
|
vol du TCH lors de
l'exécution du
handover.
|
|
TCH
Traffic
CHannel
|
TCH/FS TCH/HS
|
Traffic
CHannel for
Codes Speech
|
voix plein
débit/démi débit
|
Occupe la majeure
partie d'un canal
physique
|
|
Traffic
CHannel for
data
|
Données utilisateur
9,6 kbit/s,
4,8kbit/s,
<2,4
kbit/s
|
|
9
Tableau 1.02: Les différentes classes
ou « channels » de signaux échangés
1.3.2 GPRS
En 2002, la vitesse de transmission a été remise
à niveau d'où le 2,5G (GPRS ou General Packet Radio Service).
Elle est marquée par l'évolution du coeur IP. Elle permet de
transporter des données utilisateur et des données de
signalisation en optimisant l'utilisation des ressources du sous-système
radio et du sous-système réseau fixe. La norme GPRS
spécifie un nouveau service support de transmission de données
(bearer) en mode paquets sur la technologie GSM.
1.3.2.1 Caractéristiques techniques
GPRS utilise les mêmes fréquences
attribuées au GSM. Sa vitesse de transmission théorique maximum
vaut 170 kbps et varie de 22 à 58 kbps en réel. Le GPRS utilise
aussi le multiplexage fréquentiel mais à la place du multiplexage
temporel, il utilise le multiplexage statistique.
1.3.2.2 Architecture du Réseau GPRS
La figure 1.02 ci-dessous présente l'architecture du
réseau GPRS.

MS
BTS
SGSN
BSC
PCU
GGSN
Gn
Autre PLMN
Gb
Gp
EIR
SGSN
Gf
MSC
Gs
VLR
Ga
Charging Gateway
Function Gr
SMSC
Gd
Gn
Billing
Système
Ga
Gc
Gi
Réseau de
données
HLR
GGSN
10
Figure 1.02 : Architecture du réseau
GPRS
11
Voici un descriptif de quelques entités du réseau
GPRS :
a. PCU
PCU ou Packets Controler Unit est un contrôleur de paquets
intégré dans le BSC.
b. SGSN
SGSN ou Serving GPRS Support Node gère les services
dans le centre de commutation (MSC). C'est une interface logique,
l'abonné GSM et le réseau data externe permettant
établissement de session, la gestion des abonnés actifs et de
leurs mobilités ainsi que la mise à jour permanente des
références d'un abonné et des services utilisés.
c. GGSN
GGSN ou Gateway GPRS Support Node est une passerelle avec les
réseaux data externes. C'est un routeur (au sens IP) qui gère la
taxation des abonnés au service.
d. SMSC et GMSC
Le SMSC ou Short Message Service Center et le GMSC permettent
la communication interne au réseau par l'envoi de messages courts
à destination du terminal GPRS.
1.3.2.3 Les interfaces réseaux internes
En GPRS, les interfaces réseaux internes suivantes ont
été définies [4] :
· Gn : Réseau backbone GSN ou GPRS Service Node.
· Gb : Interface entre BSS et SGSN.
· Gr : Interface entre SGSN et HLR.
· Gp : Interface entre PLMN et PLMN.
· Gs : Interface entre SGSN et MSC.
· Gi : Point de référence entre le
réseau GPRS et un réseau externe (Internet par exemple).
12
1.3.2.4 Modes de codage
La norme prévoit quatre formats de codage (CS ou Coding
Scheme) de trames sur la voie radio : CS1, CS2, CS3 et CS4. Plus un format de
codage est résistant aux interférences plus son débit
instantané est faible. [5]
Le tableau 1.03 ci-dessous nous montre les différents
modes de codage :
Code
|
1 slot
|
8 slots
|
CS1
|
9,05 kb/s
|
72,4 kb/s
|
CS2
|
13,6 kb/s
|
108,8 kb/s
|
CS3
|
15,7 kb/s
|
125,6 kb/s
|
CS4
|
21,4 kb/s
|
171,2 kb/s
|
|
Tableau 1.03: Différents modes de
codage
1.3.3 HSCSD
Cette technologie permet d'avoir des débits de 57,4
kbits/s en concaténant 4 intervalles de temps (time slots) de 14,4
kbit/s au sein d'une cellule GSM TDMA ou Time Division Multiple Access. En
effet, les canaux radio mis en parallèles sont notamment utiles dans des
communications continues, alors que par définition, les communications
TCP/IP ou Transmission Control Protocol/Internet Protocol sont discontinues.
Les services de données HSCSD ou High Speed Circuit
Switched Data sont de très gros consommateurs de ressources radio, et
ils sont mal adaptés au monde Internet.
1.3.4 EDGE
En utilisant toujours la bande 900 et 1800 Mhz,
l'évolution de la nouvelle modulation radio a donnée naissance
à l'EDGE ou Enhanced Data-rates for Global Evolution.
Le réseau EDGE dépasse le débit du GPRS
grâce à l'introduction d'une nouvelle modulation, de nouveaux
schémas de codage et la généralisation du principe de
l'adaptation de lien.
1.3.4.1 Caractéristiques techniques
Théoriquement, son débit maximum vaut 384 kbps
et, réellement, 60 à 280 kbps. En émission, un mobile EDGE
émettra dans une bande qui s'étend de 890 à 915 MHz
(Uplink). En réception, la
13
bande sera 935 à 960 MHz (Downlink). Ainsi, pour une
communication, il y aura 45 MHz de séparation entre le canal
d'émission et le canal de réception.
Ces bandes de fréquences sont divisées en portions
de 200kHz chacune. Ce sont les canaux de transmission. Un canal peut accueillir
jusqu'à 8 transmissions simultanées en temps partagé.
La modulation utilisée pour la technologie EDGE est
appelée 8 PSK ou eight Phase Shift Keying.
1.3.4.2 Inconvénients du réseau EDGE
Le réseau EDGE admet aussi des inconvénients tels
que :
? Son débit est inférieur à l'UMTS.
? Il exige de nouveaux combinés.
? Il représente un risque d'interférence
inter-symbole.
1.4 Troisième génération des
téléphones mobiles
1.4.1 UMTS
Le 3G est un système numérique
évolué de types UMTS. Il suit la recommandation IMT2000 ou
International Mobile Telecommunications-2000. Cette norme européenne est
pour la transmission vocale, texte, vidéo ou multimédia
numérisée. Elle est basée sur une combinaison de services
fixes et radio mobiles. La téléphonie standard, l'accès
à l'Internet, la téléphonie vidéo et des services
spécialement adaptés tels que les actualités et les
informations sur la bourse seront mis incessamment à la disposition des
utilisateurs, où qu'ils soient et lorsqu'ils sont en déplacement.
[6]
1.4.1.1 Caractéristiques techniques
Les spécifications techniques de cette norme sont
développées au sein de l'organisme 3GPP. Les technologies
développées autour de la norme UMTS conduisent à une
amélioration significative des vitesses de transmission pouvant arriver
jusqu'à 2 Mbit/s. Cette amélioration des débits est
obtenue par l'évolution des technologies radio qui admet une meilleure
efficacité spectrale.
En Février 1992, le World Radio Conference avait
alloué pour l'usage de l'UMTS les bandes de 1885-2025 et 2110-2200
MHz.
Sa vitesse théorique maximale varie de 384 kbps
à 2 Mbps et réel varie de 144 à 384 kbps. Elle utilise
comme technique de multiplexage W-CDMA ou Wideband CDMA qui se sert du mode
de
14
duplexage FDD ou Frequency Division Duplex et deux bandes
passantes de 5 Mhz, dont l'une pour le sens montant (uplink) et l'autre pour le
sens descendant (downlink).
Son évolution est exprimée par la commutation de
circuit et des paquets ainsi que la modification totale du réseau. Elle
a besoin de nouveaux équipements mobiles.
De plus, les téléphones mobiles et les
équipements sans fil utilisant le 3G émettent et reçoivent
des données de façon bien plus rapide que les systèmes de
2G. Cela permet de nombreuses caractéristiques et applications
additionnelles.
1.4.1.2 Architecture du réseau UMTS
La figure 1.03 ci-dessous présente l'architecture du
Réseau UMTS.
Equipement
usager
|
|
Réseau
d'accès
|
|
Réseau coeur
|
|
Réseau
externes
|
|

NODE B
NODE B
NODE B
NODE B
Iub
Iub
Iub
Iub
RNC
RNC
Iur
Iu
CS domain
VLR
HLR
GMSC
MSC
Élément commun
AUC
EIR
PS domain
GGSN
SGSN
INTERNET
Figure 1.03 : Architecture du Réseau
UMTS
En général, un réseau UMTS est
constitué de trois domaines :
? L'équipement d'abonné UE ou User Equipment
? Le réseau d'accès UTRAN ou UMTS Terrestrial
Radio Access Network
· 15
Le réseau coeur CN ou Core Network.
L'UTRAN fournit la méthode d'accès sur
l'interface constitué par l'espace libre pour les équipements
d'abonné. Il détermine l'interface radio (méthode
d'accès multiple et de duplexage ainsi que les paramètres
correspondants) utilisée par les UE pour accéder aux services
offerts par le réseau UMTS. La station de base est
dénommée Node B et l'équipement qui contrôle ce
dernier est appelé RNC ou Radio Network Controller.
La principale fonction du coeur du réseau est de
fournir la commutation, le routage et le transit des trafics des usagers. Le
coeur du réseau contient aussi les bases de données sur les
utilisateurs ainsi que les fonctions de gestion du réseau.
L'architecture de base du CN a été fortement inspirée du
réseau GSM avec l'extension GPRS. Cependant tous les équipements
doivent être modifiés et adaptés pour les services et
opérations UMTS.
Le réseau coeur de l'UMTS est composé de trois
parties dont deux domaines :
· Le domaine CS ou Circuit Switched utilisé pour la
téléphonie
· Le domaine PS ou Packet Switched qui permet la
commutation de paquets.
· Les éléments communs aux domaines CS et
PS.
1.4.1.3 Les interfaces de communication
Plusieurs types d'interfaces de communication coexistent au sein
du réseau UMTS :
· Uu : Interface entre un équipement usager et le
réseau d'accès UTRAN. Elle permet la communication avec l'UTRAN
via la technologie CDMA.
· Iu : Interface entre le réseau d'accès
UTRAN et le réseau coeur de l'UMTS. Elle permet au contrôleur
radio RNC de communiquer avec le SGSN.
· Iur : Interface qui permet à deux
contrôleurs radio RNC de communiquer.
· Iub : Interface qui permet la communication entre un
Node B et un contrôleur radio RNC.
· RNCs : interface pour interconnecter un SRNC ou
serving RNC et un DRNC ou drift RNC
1.4.2 Evolution radio de l'UMTS
La technologie HSPA ou Hight Speed Packet Access est une
technologie de téléphonie mobile permettant la transmission de
données à des vitesses allant jusqu'à 21Mbit/s.
Précipitamment, la volonté apparut d'effacer les
limites de la Release 99 en matière de débits. Les
évolutions HSPA, actuellement connues sous le nom de 3G+, furent
introduites :
16
? HSDPA ou High Speed Downlink Packet Access pour la voie
descendante
? HSUPA ou High Speed Uplink Packet Access pour la voie
montante.
Ces évolutions ont été définies
par le 3GPP respectivement en Release 5 (2002) et Release 6 (2005) afin
d'accroître les débits possibles et de réduire la latence
du système.
La modulation 16QAM ou 16 Quadrature Amplitude Modulation est
introduite pour la voie descendante en complément de la modulation QPSK
ou Quadrature Phase Shift Keying en vigueur en Release 99.
De même, la modulation QPSK est introduite pour la voie
montante en complément de la modulation BPSK ou Binary Phase Shift
Keying utilisée en Release 99.
Enfin, un nouveau mécanisme de retransmission rapide
des paquets erronés, appelé HARQ ou Hybrid Automatic ReQuest, est
défini entre l'UE et la station de base, afin de réduire la
latence du système en cas de perte de paquets.
Ces évolutions offrent aux utilisateurs des
débits maximaux de 14,4 Mbit/s en voie descendante et de 5,8 Mbit/s en
voie montante, ainsi qu'une latence réduite. [7]
1.5 Quatrième génération des
téléphones mobiles
1.5.1 LTE et LTE-Advanced
Renouvelant la 3G (l'expérience de ces 20 années
de téléphonie) et aux évolutions de cette norme, le LTE ou
Long Term Evolution apparait avant tout comme une rupture technique avec une
nouvelle Interface radio basée sur un multiplexage d'accès OFDMA
ou Orthogonal Frequency Division Multiplexing et une modification de
l'Architecture réseau existant afin de fournir une connexion tout IP.
LTE est un projet de la 3ème
génération consistant à améliorer la vitesse de
transmission des paquets. LTE-Advanced est le réseau de la
4ème génération. Il permet de faire des
téléchargements plus rapides. Il est intégré au
téléphone en 2008 et apparu sur le réseau en 2010.
D'une manière générale, les technologies
de 4G doivent se différencier aux générations
précédentes par des débits (de 100 Mbit/s à
1Gbit/s, contre moins de 15 Mbit/s pour la 3G) et une qualité de
services augmentés.
1.5.1.1 Architecture du Réseau LTE
Les réseaux 4G présentent la même
architecture générale que les autres types de réseaux
mobiles. On peut distinguer trois parties à savoir les terminaux des
utilisateurs, le réseau d'accès et le réseau coeur. [8]
La figure 1.04 ci-dessous présente l'architecture du
Réseau LTE.

S-SW/MME
PDN-GW
eNodeB
eNodeB
eNodeB
Terminaux mobiles
RESEAU PUBLIC
17
Figure 1.04 : Architecture du Réseau
LTE
Le réseau coeur LTE est appelé SAE ou System
Architecture Evolution. Il comprend les passerelles S-GW ou Serving Gateway et
le PDN-GW ou Packet Data Network Gateway. Le S-GW s'occupe de la gestion de la
mobilité à travers le MME ou Mobility Management Entity et du
routage des paquets sortants vers le PDN-GW. Le PDN-GW est responsable de la
tarification ainsi que de l'interfaçage du réseau avec les
réseaux externes. [8]
1.5.1.2 Technologie dans les réseaux mobiles 4G
Les réseaux mobiles 4G utilisent les technologies MIMO
ou Multiple Input Multiple Output, OFDM ou Orthogonal Frequency Division
Multiplexing, AAS ou Adaptive Antenna Systems, AMS ou Adaptive Modulation
Schemes, AES ou Advanced Encryption Standard et IP. Ces technologies
18
leur permettent d'atteindre des débits de plusieurs
dizaines de Mbps et d'introduire les principales fonctionnalités
nécessaires pour permettre la mobilité à de très
grandes vitesses. [8]
1.6 Mesure des paramètres radio en réseau
mobile
1.6.1 Etats de la station mobile
Le réseau reconnaît à la station mobile 3
états: ? Detached
? Idle
? Connected
1.6.1.1 IMSI detached
La station n'est pas alimentée ou est inaccessible;
elle est considérée comme "détachée" du
réseau. [2]
1.6.1.2 Idle
La station mobile est alimentée et "attachée" au
réseau (IMSI attached), mais sans communication. Elle mesure les
puissances des cellules et procède si nécessaire à un
changement de zone de localisation ou Location Update. [2]
1.6.1.3 Dedicated
La station est en communication (téléphone, fax,
data). Elle a au moins deux canaux dédiés dont SACCH. En cas de
changement de cellule, la communication ne doit pas être
perturbée. [2]
1.6.2 Mobilité en mode
connecté
L'usager peut être amené à se
déplacer hors de la cellule sur laquelle l'appel a été
établi pendant un appel sur un réseau mobile. Cette
mobilité ne doit pas mener à la coupure de l'appel. Pour garantir
cette continuité de service, le réseau mobile met en oeuvre des
mécanismes basculant l'UE vers la meilleure cellule qui peut le
recevoir. Ces mécanismes reposent sur des mesures radio
réalisées par l'UE sur la cellule serveuse et les cellules
voisines.
Le réseau choisit alors, essentiellement en fonction de
ces mesures, la cellule cible et la façon de faire basculer l'UE vers
cette cellule. [7]
19
1.6.2.1 La resélection
Elle se repose sur les mêmes principes que ceux
utilisés en mode veille. Par exemple, elle est employée en GPRS
et en UMTS dans des états transitoires ou dormants. L'UE envoie ou
reçoit peu de données (faible activité) et les
périodes d'inactivité lui permettent alors de réaliser des
mesures sur des cellules voisines. Lors d'une resélection, le
réseau n'effectue aucune préparation sur la cellule cible. [7]
1.6.2.2 Redirection
Ce mécanisme consiste à envoyer l'UE vers une
cellule cible, sans dialogue préalable entre la station de base
d'origine et celle de destination. Cette cellule cible peut se trouver sur une
autre fréquence ou appartenir à un autre système. Aucune
ressource radio, logique ou de transmission n'est réservée sur la
cellule ou sur le système cible. Cela réduit donc la
probabilité de succès de l'opération. Par ailleurs, la
procédure de bascule peut être longue et conduit à des
pertes de données, c'est-à-dire, à une dégradation
de la qualité de service perçue par l'usager. En revanche, elle
est simple pour le réseau et n'entraine pas de charge de signalisation
entre les noeuds source et cible. [7]
1.6.2.3 Handover
Le handover est un mécanisme qui permet à une
station mobile active (dans l'état dédié) de changer de
cellule, de changer de LA ou de changer de MSC sans perdre la communication.
[2]
Il se distingue de la redirection par une phase de
préparation de la station de base de destination et bascule du flux de
données plus rapide et souvent plus fiable (car plus proche de
l'interface radio). Il suit le principe de make before break,
c'est-à-dire de préparer l'environnement radio cible avant de
relâcher l'existant. [7]
On peut distinguer trois phases dans la réalisation d'un
handover :
? La phase de mesure sur la cellule serveuse et sur les cellules
voisines ;
? La phase de préparation de la cellule cible, qui met
en jeu des échanges entre les contrôleurs
de stations de base source et destination, ainsi qu'entre ces
contrôleurs et le réseau coeur ; ? La phase d'exécution,
c'est-à-dire la bascule de l'UE et des flux de données, puis la
relâche
des ressources dans la cellule d'origine.
Le schéma suivant (Figure 1.05) montre le
séquencement de ces phases, les noeuds impliqués et les
principales actions réalisées.
la cellule source
1. Phase de mesure
Source
|
la station de base source
|
|
|
ressources
|
|
|
|
|
|
|
|
|
2. Phase de préparation
|
Sécurité
|
|
Source
|
Cible
|
|
à accueillir l'UE
|
|
|
|
|
|
|
|
|
|
Ordre de bascule
|
|
|
|
|
|
|
|
|
|
|
|
Appel en cours sur
3. Phase d'exécution
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Transfert des
données
|
|
|
|
|
Reprise de l'appel
sur la cellule cible
|
|
Source
|
|
|
Cible
|
|
|
|
|
|
|
|
|
20
Choix de la cellule cible par
Cellule cible prête
Allocation des
Figure 1.05 : Les 03 phases de handover
1.6.2.4 Types de Handover en GSM Il existe 04 types de handover
en GSM:
a. Handover Intra-BSC
Le nouveau canal est attribué à la MS dans la
même cellule ou une autre cellule gérée par le
même
BSC.
b. Handover Intra-MSC
Le nouveau canal est attribué à la MS mais dans
une cellule gérée par un autre BSC, lui-même étant
géré par le même MSC.
c. Handover Inter-MSC
Le nouveau canal est attribué dans une cellule qui est
gérée par un autre MSC.
21
d. Handover Inter-System
Un nouveau canal est attribué dans un autre
réseau mobile que celui qui est en charge de la MS (exemple entre un
réseau GSM et UMTS).
1.6.2.5 Handover supporté par l'UMTS
L'UMTS supporte 02 catégories de handovers : soft handover
et hard handover. a. Soft handover
Un soft handover (figure 1.06) survient entre deux cellules ou
deux secteurs qui sont supportés par différents Node B. L'UE
transmet ses données vers différents Node B simultanément
et reçoit des données de ces différents Node B
simultanément. Dans le sens descendant, les données utilisateur
délivrées à l'UE sont émises par chaque Node B
simultanément et sont combinées dans l'UE. Dans le sens montant,
les données utilisateur émises par l'UE sont transmises à
chaque Node B qui les achemine au RNC où les données sont
combinées. [9]

Uu
Uu
Node B
Node B
lub
lu
SRNC
lur
lub
DRNC
Figure 1.06 : Soft handover
Remarque :
Softer handover, dont l'illustration est sur la figure 1.07,
s'agit d'un changement de cellule avec le même RNC, tandis que soft
handover est un changement de cellule avec changement de RNC. Les deux RNC
communiquent entre eux le canal Jur.

Node B
Uu
lub
lu
RNC
Uu
22
Figure 1.07 : Softer handover
b. Hard handover
Le réseau doit procéder à un hard handover
(avec brève interruption du canal) [2]:
· Quand la nouvelle cellule ne travaille pas dans la
même bande de fréquence
· Quand le nouveau contrôleur radio ne peut pas
communiquer avec l'ancien (interface Jur pas disponible)
· Quand la technique de duplexage dans la nouvelle cellule
n'est plus la même
· Quand il faut passer d'un réseau UMTS à un
réseau GSM.
1.6.3 Mesure des paramètres radio en
GSM
Le transfert se fait en fonction de deux mesures faites par la
station mobile:
· La puissance reçue des porteuses BCCH des cellules
voisines (RXLEV).
· La qualité de la réception pendant les
conversations (RXQUAL). On mesure le taux d'erreur par bit (Bit Error Rate).
1.6.3.1 RXLEV
Le Rxlevel, (niveau de réception) est une mesure
quantitative du niveau de champ reçu sur le canal BCCH en veille. Le
BCCH, est toujours émis à puissance constante depuis la BTS et il
n'est pas soumis au saut de fréquence. C'est la mesure certainement la
plus connue des utilisateurs de mobiles, sa visualisation se fait sur un
bargraphe indiquant le niveau de réception du réseau.
23
Le critère C1 est un paramètre vérifiant
que la cellule sélectionnée est toujours parfaitement
reçue et qu'elle ne subit pas un affaiblissement trop fort par rapport
à d'autres cellules avoisinantes. Pour vérifier cette
hypothèse, le critère C1 est composé de 2
parties. Une partie définissant les capacités du mobile et une
autre celles de la BTS. L'équation vérifie la liaison descendante
et montante. Ce critère s'écrit comme suit :
avec:
|
C1 = (RxLev + RX_AccessMin
- ??????(MAX (Max_TXPWR_Max_CCH - Max. mobile RF Power, 0)
|
(1.01)
|
|
? RxLev : Niveau de champs reçu sur le canal BCCH en
veille et en communication sur les canaux TCH, SACCH, SDCCH et FACCH (en
dBm).
? RX_Access_Min : Niveau minimum autorisé par la BTS
pour que le mobile puisse s'accrocher à elle (en dBm).
? Max_TXPWR_Max_CCH : Paramètre fixant la puissance
à laquelle le mobile doit émettre lors de l'accès initial
à une cellule. Si ce paramètre est supérieur à la
classe de puissance du mobile, celui-ci émet à sa puissance
maximale (30 dBm pour un 1W, 33 dBm pour un 2W et 39 dBm pour un 8W).
? Max. mobile RF Power : Puissance maximale avec laquelle le
mobile est capable d'émettre vers la BTS, Ce paramètre est
défini par la classe du mobile (30 dBm pour un 1W, 33 dBm pour un 2W et
39 dBm pour un 8W).
? Max (X,0) signifie que si X > 0 = X et si X<0 = 0
Le critère C2, appelé critère de
re-sélection est implémenté en phase 2. Il a pour fonction
de favoriser ou de défavoriser une cellule candidate à la
re-sélection pendant un temps donné. Lorsqu'il est
présent, le critère C2 remplace le critère C1 pour la
re-sélection de cellule, le critère C1 fait partie de
l'équation du critère C2 :
Si Penalty_Time< 31 (620s), on a:
C2 = C1 + (Cell_Reselect_Offset -
(TemporaryOffset × PenaltyTime)) (1.02)
Si Penalty_Time = 31 (620s), alors:
C2 = C1 - Cell_Reselect_Offset (1.03)
avec:
· Cell_Reselect_Offset : Valeur de l'offset permanent
ajouté à C1.
· Temporary_Offset : Offset temporaire servant à
défavoriser une cellule le temps du Penalty_Time.
· Penalty_Time : Durée pendant laquelle le
Temporary_Offset va être appliqué.
Le BTS paramétrée pour des mobiles 2W avec un
critère C1 de 23 dBm, un offset de 16 dBm et Temporary_Offset de 60 dBm
et un Penalty_Time de 20 secondes.
C2 = C1 + 16 - 60 (1.04)
où 60 dBm pendant 20 secondes.
avec :
C1 : Paramètre vérifiant que la cellule
sélectionnée est reçue et ne subit pas un
affaiblissement.
C2 : Critère de re-sélection
(1.05)
Ainsi, pendant les 20 premières secondes, lorsque la BTS
apparaît parmi la liste des cellules voisines, le critère est
défini ainsi :
C2 = 23 + 16 - 60
C2 = -21 ??????
(1.06)
24
ensuite, on a :
C2 = 23 + 16
C2 = 39 ??????
Le tableau 1.04 récapitule les niveaux de champs.
|
Type de service
|
Niveaux de champ
|
|
Deep Indoor
|
-65 dBm à 0 dBm
|
|
Indoor
|
-75 dBm à -65 dBm
|
|
Incar
|
-85 dBm à -75 dBm
|
|
Outdoor
|
-95 dBm à -85 dBm
|
|
Carkit
|
-110 dBm à -95 dBm
|
Tableau 1.04: Tableau récapitulatif des
niveaux de champs
25
1.6.3.2 RXQUAL
La qualité du signal est évaluée par le
paramètre RxQual. Elle est obtenue en quantifiant le taux d'erreurs
binaires BER ou Bit Error Ratio, sur 08 niveaux. Une valeur spécifique
permet de représenter chaque niveau de RxQual, elle peut être
utilisée pour moyenner diverses mesures du RxQual. Elle correspond
à la moyenne géométrique des bornes de la plage. Le
tableau 1.05 résume le niveau de qualité:
|
RxQual
|
|
|
Bonne qualité
|
0
|
- 4
|
|
Qualité moyenne
|
5
|
- 6
|
|
Mauvais equalité
|
|
7
|
Tableau 1.05: Tableau récapitulatif des
niveaux de qualité. 1.6.4 Niveau de signal et qualité
de signal en UMTS
1.6.4.1 RSCP
Received Signal Code Power ou RSCP représente le niveau
de la puissance reçue de la fréquence pilote d'une station de
base (Noeud B ou nB). Dans le cadre de la 3G, le multiplexage est
réalisé par code, plusieurs nB peuvent transmettre sur la
même fréquence, avec des codes spécifiques. Le RSCP permet
de calculer le niveau de puissance d'une station de base, c'est-à-dire
après démultiplexage du code. [10]
Il interprète notamment l'affaiblissement de la
propagation. A l'intérieur d'un bâtiment, il est surtout sensible
aux matériaux utilisés et l'épaisseur des cloisons. Le
RSCP ne mesure pas directement la puissance du canal utilisé pour le
trafic de données mais permet de fournir une bonne indication de
l'atténuation de ce canal.
1.6.4.2 EcNo
C'est l'énergie reçue par chip (received energy
per chip) du canal pilote divisé par le bruit total. Cela revient
à estimer une image du rapport Signal Sur Bruit, lequel conditionne (Cf.
Shannon) la capacité du canal, autrement dit le débit maximum de
transmission sans erreur. Ec/No (Ratio of energy per modulating bit to the
noise spectral density) est donc égal au RSCP divisé par le RSSI
ou Received Signal Strength Indicator (bruit total).
26
La meilleure valeur de EcNo correspond à la marge de
puissance entre le signal reçue et le bruit sur le signal pilote (et
uniquement sur le signal pilote). C'est pour cette raison que la valeur est
indicative du rapport signal à bruit pour la transmission de
données mais non pas la valeur du SNR ou Signal to Noise Ratio de la
transmission des informations. [10]
1.6.5 Niveau de signal et qualité de signal en
LTE
Le mobile (User Equipment ou UE) et la station de base (eNB)
effectuent périodiquement des mesures radios pour connaître la
qualité du lien radio (canal de propagation). [10]
1.6.5.1 RSRP
Reference Signal Receive Power ou RSRP est la mesure semblable
au RSCP pour la 3G ; Ces deux notions sont donc identiques dans la fonction,
mais s'appliquent à deux technologies différentes. La mesure
s'exprime en Watt ou en dBm. La valeur est comprise entre -140 dBm à -44
dBm par pas de 1dB.
La station de base émet des signaux de
références (RS ou Reference Signal)
permettant d'estimer la qualité du lien du canal radio. Un
signal de référence est un signal émis par
l'émetteur et connu par le récepteur, ce signal ne transmet
aucune information. Cependant, le récepteur compare la séquence
reçue à la séquence émise (donc en clair la
séquence que le récepteur aurait dû recevoir dans
l'idéal) et à partir de la différence entre les deux, le
récepteur estime la déformation apportée par le canal de
transmission (multi-trajets, effets de masque, atténuation,
interférences, etc... [10]
Cette séquence connue est émise sur toute la
cellule. Il s'agit d'un signal broadcasté spécifique par cellule.
Par conséquent il doit être émis avec une puissance
suffisante pour couvrir la cellule et avoir des propriétés
particulières pour différencier le signal reçu d'une
cellule à une autre. Le motif est identique à chaque sous trame,
à un décalage en fréquence près entre les cellules
de manière à limiter l'interférence et améliorer
ainsi la réception du RS. La puissance du CRS ou Cell Reference Signal
peut aussi être augmentée en cas de fort trafic par rapport
à la puissance des données via le Power Boosting pour la voie
descendante. [10]
L'UE quant à lui envoie un signal de
référence de sonde, nommé SRS permettant à l'eNB de
déterminer la qualité du canal montant et de maintenir la
synchronisation. [10]
Les mesures effectuées (signaux de
références aussi appelés pilotes CRS indiquant que le
signal de référence est spécifique à la cellule)
sont relayées aux couches supérieures afin de planifier des
Handovers. [10]
27
L'UE se sert des mesures des signaux de
références afin d'estimer (indicateur) le niveau du signal
reçu (RSRP) permettant ainsi, en mode de veille, de sélectionner
la meilleure cellule. La mesure impacte donc la gestion de la mobilité
de l'UE (RRM ou Radio Ressource Management). [10]
1.6.5.2 RSRQ
Le RSRP ne donne aucune information sur la qualité de
la transmission. Ainsi, le LTE s'appuie alors sur l'indicateur RSRQ ou
Reference Signal Received Quality, qui peut être comparé à
l'indicateur Ec/No réalisé en 3G et défini comme le
rapport entre le RSRP et le RSSI. Le RSSI représente la puissance totale
du signal reçu, cela englobe le signal transmis, le bruit et les
interférences, d'où la formule suivante :
???????? = 10 log(?? × ???????? (1.07)
???????? )
où N étant le nombre de ressource block.
La mesure du RSRQ est intéressante notamment aux
limites des cellules, positions pour lesquelles des décisions doivent
être prises pour accomplir des Handovers et changer de cellule de
références. Le RSRQ mesuré varie entre ?19,5dB à
?3dB par pas de 0.5dB. Il n'est utile que pour des communications,
c'est-à-dire lors de l'état connecté. La précision
absolue (Intra et inter frequentiel) varie de #177;2.5 à #177;4 dB.
L'indicateur RSRQ fournit des informations additionnelles
quand le RSRP n'est pas suffisant pour faire le choix d'un handover ou d'une
re-sélection de cellules.
1.7 Conclusion
Chaque génération de téléphonie
mobile a sa propre caractéristique technique. Elles se
différencient souvent par le débit, l'architecture, la technique
de modulation et de multiplexage, les équipements et surtout par les
mesures de paramètres radio.
28
CHAPITRE 2
TECHNOLOGIES ET TECHNIQUES DE
POSITIONNEMENT
2.1 Introduction
Pour faire référence à un système
permettant de déterminer l'emplacement d'un objet, on emploie le terme
« localisation ».
Un système de positionnement compromet sur une
infrastructure un ensemble de capteurs permettant de prendre les informations
nécessaires. Ces informations sont transmises à une partie
intelligente permettant de traiter les données obtenues et d'extraire
l'information utile pour déterminer la position.
Il faut être capable de placer un objet dans un plan
bidimensionnel (latitude, longitude) ou tridimensionnel (latitude, longitude,
altitude) pour pouvoir le situer dans l'espace.
2.2 Technologies de positionnement
À présent, il existe plusieurs types de
technologies de positionnement qui peuvent être utilisées pour
déterminer la position des utilisateurs, comme les réseaux
cellulaires, en particulier le GSM et l'UMTS, les réseaux WLAN tel que
le Wifi ainsi que les réseaux WPAN, à savoir l'UWB et le
Bluetooth, l'infrarouge, l'ultrason, etc.
2.2.1 Systèmes de positionnement
radio
Un signal radio est une onde électromagnétique
qui se déplace à la vitesse de la lumière. Correctement
codé, ce signal peut transporter de l'information. [11]
Pour établir une liaison radio, il faut un
émetteur et un récepteur. L'émetteur reçoit un
signal électrique qu'il transforme en signal
électromagnétique, lequel est conduit vers l'antenne. Ce dernier
retransmet le signal dans la nature où il peut être capté
par une ou plusieurs antennes. En radio, le signal est propagé partout
et est donc susceptible d'être reçu par tout le monde. L'antenne
réceptrice conduit le signal reçu vers le récepteur.
Les technologies de positionnement les plus courantes sont
celles utilisant les ondes radio (satellitaire et terrestre).
29
2.2.1.1 Systèmes de positionnements basés sur les
satellites
Dans ces systèmes l'objet mobile est localisé
à l'aide de récepteurs des signaux satellitaires. Du fait que les
satellites couvrent d'énormes zones géographiques, le
positionnement par satellites peut déterminer l'emplacement d'une cible
sur un continent tout entier, voire le monde entier. [12] On peut citer le
système américain GPS, le système européen GALILEO
et le système russe GLONASS.
a. Système GPS
Aujourd'hui, le système GPS ou Global Positioning
System domine le monde de la localisation en espace libre. Il a
été développé par le Département de la
Défense des Etats-Unis au début des années 70 pour des
applications militaires. L'objectif étant de permettre aux combattants
de déterminer leur position sur le terrain avec une haute
précision.
Cette technologie comporte trois sous-ensembles:
? le segment spatial comportant les satellites,
? le segment utilisateur composé du système de
réception
? et le segment de contrôle qui assure la synchronisation
entre les satellites.
Le principe de base du positionnement par satellite repose
sur la trilatération spatiale. L'observation des signaux provenant des
satellites permet de mesurer la distance entre le mobile et chacun des
satellites observés. Connaissant la position de chaque satellite dans
l'espace, on peut calculer la position du mobile. [12]
Le système GPS fonctionne avec au moins 24 satellites
et permet ainsi une couverture mondiale. Les satellites sont pourvus d'horloges
très précises leur permettant de maintenir une synchronisation
avec une dérive maximale de 3 ns. Pour obtenir une visibilité, au
moins quatre satellites sont nécessaires dans la méthode de
localisation, à tout moment, partout dans le monde, la constellation
comporte six plans orbitaux, chaque plan contenant quatre satellites. Les
satellites se trouvent sur des trajectoires quasi-circulaires à une
distance d'environ 20200 Km de la surface de la Terre.
b. Système GLONASS
GLONASS ou GLObal NAvigation Satellite System est un
système satellitaire Russe, lancé durant la guerre froide pour
concurrencer les projets américains. Il fut lui aussi
opérationnel en 1995 avec
30
24 satellites en orbite. Le système est fonctionnel
mais, de fait, moins utilisé que le système GPS. [13]
L'intérêt de ce système de navigation demeure
en sa robustesse aux interférences. Chaque satellite retransmet sur sa
propre fréquence. Les satellites dégagent une plus grande
région du globe. La principale imperfection de GLONASS est qu'il est
à peine entretenu. L'entretien des satellites est très
onéreux alors que les autorités russes manquent de moyens
financiers. A présent seulement 07 satellites sur les 24 sont actifs.
c. EGNOS et GALILEO
EGNOS ou European Geostationary Navigation Overlay Service
est un projet complétant les systèmes GPS, et le système
GLONASS en utilisant le système du GPS différentiel.
Financé par l'Europe, ce projet a vu le jour en 1998 et devenu
opérationnel depuis 2009. [13]
GALILEO est un système de positionnement par
satellites, similaire à GPS ou GLONASS. Il a été
lancé en 2001 par un ensemble d'organismes publics et privés
principalement européens. [13]
d. Faiblesses et inconvénients du système de
positionnement par satellite
Néanmoins, un positionnement par satellite connait
quelques faiblesses et inconvénients :
· La visibilité des satellites n'est pas toujours
faisable, au fond d'une vallée ou dans un bâtiment,
· La topologie des satellites n'est pas toujours
parfaite, perte de précision, de position,
· L'ionosphère et le Troposphère
brouillent les signaux radios, Il présente aussi quelques erreurs tels
que :
· Les erreurs d'horloge atomique
· Les erreurs d'orbites,
· Les erreurs intentionnelles, par exemple, en cas de
guerre ou par mesure de représailles sur une zone géographique
donnée.
2.2.1.2 Systèmes de positionnement par la
télévision Numérique terrestre
La télédiffusion numérique terrestre ou
TNT est l'une des meilleures prétendantes pour la localisation. Le
niveau des signaux de télévision numérique est
incomparable à ceux du GPS, d'une quarantaine de décibels dans
les environnements difficiles. Les signaux ne sont pas affectés par
l'effet Doppler de l'émetteur (les stations de base étant fixes
et donc de position connue) et il n'y a
31
plus d'effets dus à la traversée de
l'ionosphère. Ces signaux de synchronisation n'endurent pas autant de
perturbations que les signaux GPS. La propagation des signaux TV connaissant
des fréquences faibles (470-870 MHz) est bien adaptée aux
environnements urbains.
Les avantages de ce moyen de localisation par rapport au GPS
sont [12] :
· Les signaux sont émis à partir d'antennes
de positions connues.
· Les signaux émis sont dimensionnés pour
qu'une antenne TV se trouvant à l'intérieur d'un bâtiment
puisse les recevoir.
· La distance séparant un récepteur d'un
émetteur est comprise entre 25 à 75 km.
· Le positionnement peut être effectué avec
un seul des signaux TV parmi les nombreux signaux disponibles émis par
une station de base.
· La bande des signaux est de 6 à 8 MHz et toute
cette bande est disponible pour faire de la localisation. De ce fait, la
précision temporelle est plus importante que celle du GPS.
· ROSUM exploite les mesures du temps d'arrivée
des signaux (identique à celle du GPS) captés d'au moins trois
émetteurs TV différents.
2.2.1.3 Systèmes de positionnement basés sur les
réseaux cellulaires
L'exploitation des réseaux cellulaires permet aussi
d'avoir une estimation de la position des équipements mobiles.
L'implémentation de méthodes de localisation cellulaire demande
des modifications logicielles ou/et matérielles au niveau de l'objet
mobile ou/et du réseau. Ainsi, on peut classer les technologies [14]:
· Exogènes : modifications au niveau du
réseau cellulaire;
· Endogène : modifications au niveau de l'objet
mobile;
· Hybrides: modifications sur l'ensemble.
Dans le cas de l'approche exogène, une ou plusieurs
stations de base effectuent les mesures nécessaires, appliquent certains
algorithmes pour déterminer la position de l'objet mobile et renvoient
les résultats à l'objet mobile.
Dans celui de l'approche endogène, donne naissance
à deux types d'implémentation :
· Mobile based: l'objet mobile effectue les mesures et
les calculs nécessaires pour déterminer sa position. Un avantage
de cette approche est le positionnement en mode inactif, réalisé
par la mesure de canaux de contrôle qui sont transmis constamment. Cette
méthode requiert des modifications de type matériel et logiciel
au niveau de l'équipement mobile. [14]
32
? Mobile assisted : l'objet mobile effectue les mesures et les
envoie à un centre de gestion qui va effectuer les calculs. Ce type
d'implémentation nécessite plutôt des modifications de type
logiciel. [14]
La méthode la plus simple de localisation cellulaire
est basée sur l'identification de la cellule (figure 2.01) dans laquelle
se trouve l'objet mobile.
Figure 2.01 : Principe de la méthode
Cell ID
Dans cette figure, il y a 03 cellules distinctes et la station
mobile se trouve dans la cellule coloré en rose. Cette méthode
consiste à identifier au niveau du réseau la cellule dans
laquelle l'objet mobile se trouve et lui transmettre la position connue de la
station de base qui desservit la cellule. Un avantage de cette méthode
est représenté par le fait qu'aucun calcul n'est utilisé
pour déterminer la position, la méthode est ainsi très
rapide. L'inconvénient majeur est lié au fait que la
précision de cette technique est directement proportionnelle à la
dimension de chaque cellule qui peut varier entre 2 et 20 km, en fonction de la
densité des obstacles présents dans l'environnement et le nombre
d'utilisateurs desservis.
2.2.1.4 Systèmes de positionnement par les réseaux
locaux WLAN
Le positionnement à l'aide de la technologie Wi-Fi est
nommé WPS pour Wi-Fi Positionning System. Par rapport au GPS, le WPS
modifie l'infrastructure des satellites par les infrastructures radios des
réseaux Wi-Fi et dispose de plusieurs avantages [12]:
? Sa couverture intérieure et extérieure, lui
permet, contrairement au GPS, de continuer à fournir un positionnement
relativement précis en indoor et dans certaines zones urbaines denses
avec des effets de canyon urbain. La technologie fournit toujours les
meilleurs
33
résultats dans un environnement particulièrement
dense, en raison de la multiplication des points d'accès.
? Il n'implique pas de matériel supplémentaire,
l'équipement Wi-Fi étant déjà présent au
sein des différents appareils de communication.
Toutefois, Il présente des inconvénients [12] :
? WPS pose un problème de couverture en environnement
rural ou dans des zones peu équipées en points d'accès
Wi-Fi
? Les points d'accès Wi-Fi sont des récepteurs
plus mobiles que les infrastructures GPS, ce qui peut fausser les calculs si
les bases de données ne sont pas mises à jour
régulièrement.
2.2.1.5 Systèmes de positionnement par les réseaux
personnels WPAN
Les réseaux personnels sans fil WPAN ou Wireless
Personal Area Network sont des réseaux sans fil de faible portée
(courte distance), de l'ordre de quelques mètres. Ces réseaux
peuvent aussi être utilisés pour le positionnement d'un mobile.
a. Bluetooth
Bluetooth est une technologie radio destinée à
simplifier les connexions entre les appareils électroniques et
basé sur le standard IEEE ou Institute of Electrical and Electronics
Engineers 802.15.1.
Dans un système de positionnement par Bluetooth, les
serveurs sont situés dans une zone où la position d'un poste
client doit être estimée. Ces serveurs sont programmés pour
donner les coordonnées de la position d'un client demandeur. Les
périphériques Bluetooth qui ne disposent pas de programmation
particulière pour gérer une demande de positionnement peuvent
également être utilisés.
La méthode de positionnement suppose que si une
connexion est faite, le client demandeur se trouve dans les 10 mètres du
serveur. Une grande précision est obtenue lorsqu'un client
établit une connexion avec deux ou plusieurs serveurs de positionnement.
[12]
b. UWB
L'ultra large bande UWB ou Ultra Wide Band est une technologie
émergente dont les avantages en termes de localisation sont
agréables. Il est basé sur le standard IEEE 802.15.3. Les
techniques de localisation associées sont souvent basées sur les
techniques temporelles.
34
c. Zigbee
Le ZigBee est apparu après les technologies Bluetooth
et WiFi. Il basé sur le standard IEEE 802.15.4 qui est un protocole de
communication employé dans les réseaux sans fil personnels
(LRWPAN pour Low Rate Wireless Personal Area Network ou LP-WPAN pour Low Power
Wireless Personal Area Network) du fait de leur faible consommation, de leur
faible portée et du faible débit de leurs dispositifs.
Un système de positionnement par ZigBee comprend deux
catégories de nodes (noeuds): le node de référence et le
node à positionner (node aveugle, également connu par le node
mobile). Le node de référence qui a une position statique doit
être configurée avec les valeurs X1 et Y1 qui
correspondent à une position physique. La tâche principale du node
de référence est de fournir un paquet d'informations qui contient
les coordonnées X1 et Y1 pour le node mobile. [12]
Le node mobile va communiquer avec les nodes de
référence voisins, pour la collecte des X1, Y1
et les valeurs RSSI de chacun de ces nodes, et calculer sa position X, Y
à base des paramètres d'entrée en utilisant le
matériel de localisation. Ensuite, la position calculée doit
être envoyée à une station de contrôle. Cette station
de contrôle pourrait être un PC ou un autre node dans le
système. [12]
2.2.1.6 Systèmes de positionnement par RFID
La technologie RFID ou Radio-Frequency IDentification a
débuté pendant la seconde guerre mondiale. Il s'agit d'une
méthode destinée à enregistrer et récupérer
des données à distance grâce à des marqueurs
nommés «radio-étiquette» (ou RFID tag). Elles sont
équipées d'une antenne et d'une puce électronique. Ces
puces possèdent un identifiant et doivent être
détectées grâce à un lecteur RFID. L'identifiant est
ensuite assimilé à une zone géographique. Les
étiquettes utilisées sont de petits objets comme des
étiquettes autoadhésives. Elles peuvent aisément
être incorporées à des produits et des organismes
vivants.
2.2.2 Systèmes de positionnement non radio
2.2.2.1 Infrarouge
Comme la lumière visible, le signal infrarouge ne peut
pas franchir des murs ou des obstacles. Il a une portée limitée
dans les environnements indoor. Le système Active Badge,
élaboré entre 1989 et 1992, est l'un des premiers systèmes
de localisation en indoor. Il exploite la technologie infrarouge. Le mobile
à localiser est pourvu d'un tag infrarouge émettant un signal
toutes les 10 secondes. Les
35
récepteurs sont placés au plafond dans chaque
pièce de l'environnement. Ces récepteurs sont reliés entre
eux pour établir un réseau permettant de repérer le tag
actif.
a. Limite de l'infrarouge
La présence de la lumière du jour est un frein
au développement de cette technologie, car cette lumière perturbe
la transmission infrarouge entre l'émetteur et le récepteur. La
faible portée (environ 5 mètres) et le coût
élevé des capteurs ont rapidement dévié les
recherches vers d'autres technologies. [12]
2.2.2.2 Ultrason
Les systèmes à ultrason sont utilisés
pour déterminer la position d'un mobile. Ils sont combinés avec
une autre technologie afin d'obtenir une estimation de la distance
émetteur/récepteur. [15]
L'ultrason fonctionne en basse fréquence (40 kilohertz
typiques). Il possède une bonne précision. Les atouts des
dispositifs ultrason sont leur simplicité et leur faible coût.
L'ultrason ne perce pas les murs mais se réfléchis sur la plupart
des obstacles en indoor. La portée est comprise entre 3m et 10m.
Cependant, l'influence de la température peut affecter les performances
de ce type de système de positionnement.
2.2.2.3 Vidéo/images
La vidéo et les dispositifs recevant des images d'une
scène permettent d'effectuer d'une part une détection de la
présence d'un élément dans une scène, mais aussi de
localiser cet élément dans la scène. La localisation est
effectuée grâce à des transformations entre l'image de la
scène et les angles de vues de la caméra. Une utilisation
possible de cette technique est de détecter les intrusions dans une
zone. Grâce aux techniques de reconnaissance de contours, un objet est
repérable sur une image. Il est possible de suivre le déplacement
de ce contour tant qu'il reste dans le champ de vision de la caméra.
[15]
2.2.2.4 Champ magnétique
L'exploitation d'un réseau de capteurs émettant
un champ magnétique par l'intermédiaire de rails présents
dans le sol a été effectuée. À l'origine, ces
systèmes étaient prévus pour le guidage d'objets dans des
entrepôts, où des robots effectuaient de nombreux parcours pour
aller rechercher des pièces. [12]
36
Un autre domaine d'application est la capture de mouvements
(enregistrement des mouvements effectués par une personne afin de les
réintroduire dans une séance cinématographique). Le
système exige à ce que des émetteurs se trouvent à
des emplacements connus à travers le bâtiment. Chacun de ces
éléments émet un champ magnétique en permanence.
Une séquence PN ou Pseudo Noise rythme les émissions en changeant
la polarité du signal émis. Cette séquence PN distingue
les éléments entre eux. Le mobile qui se déplace dans le
bâtiment capte successivement différents signaux, et donne le
champ magnétique.
À l'aide d'un système basé sur la
corrélation, le récepteur détermine la puissance du signal
en provenance de chacun des émetteurs. Cette information de puissance du
signal est utilisée pour déterminer la position occupée
par le mobile. Le système exploite une estimation de la réponse
impulsionnelle du canal. [12]
2.3 Techniques de positionnement
Avec les systèmes cités
précédemment, les techniques de localisation les plus
étudiées sont les techniques basées sur l'estimation : des
temps d'arrivée TOA ou Time Of Arrival, des différences des temps
d'arrivée TDOA ou Time Difference Of Arrival, des angles
d'arrivée AOA ou Angle Of Arrival, et des puissances des signaux
reçus RSS ou Received Signal Strength. Elles sont classifiées
selon les mesures (métriques) utilisées. Toutes ces
méthodes dépendent de l'émission ou de la réception
des signaux radio pour déterminer la position d'un objet sur lequel un
récepteur radioélectrique ou un transducteur est lié.
2.3.1 Métriques de
positionnement
On distingue quelques métriques de positionnements tels
que l'angle d'arrivée, le temps d'arrivée, la différence
de temps d'arrivée, la puissance reçue et le déphasage
entre les ondes. [15]
2.3.1.1 Méthode basées sur des mesures
temporelles
La distance entre les noeuds peut être
évaluée à partir du temps de propagation d'un signal ou
d'un paquet. 02, approches principales peuvent être définies pour
ces méthodes : l'heure d'arrivée (TOA) et la différence de
temps d'arrivée (TDOA).
37
a. Heure d'arrivée - Time of Arrival
Quand des noeuds sont synchronisés, un seul paquet
allé simple est nécessaire (si l'environnement radio n'est pas
trop perturbé) pour connaître le temps de propagation et estimer
la distance entre les noeuds.
Le système GPS emploie cette méthode pour
fournir des informations de position aux utilisateurs. Toutefois, si des noeuds
ne sont pas synchronisés, deux paquets doivent être
utilisés pour estimer le temps aller-retour du signal entre les noeuds.
Les radars civils et militaires ou encore GPS-free utilisent cette approche.
Les méthodes de localisation basées sur UWB ou Ultra Wide Band
utilisent elles aussi le TOA. [15]
Le TOA possède quelques avantages :
· Paramètres bien estimés ;
· Algorithme de positionnement simple ;
· Précision plus élevée en milieu
confiné. Les principaux inconvénients du TOA sont :
· Synchronisation d'horloge indispensable entre le mobile
et les stations de base;
· Besoin d'avoir le trajet direct ;
· Nécessité d'une résolution
temporelle élevée au récepteur.
b. Différence de Temps d'Arrivée - Time
Difference of Arrival
Une deuxième approche (illustré par la figure
2.02) consiste à évaluer la différence des temps
d'arrivée de deux différents signaux. Ces signaux peuvent
provenir de deux noeuds de référence distincts (a) ou peuvent
être de natures différentes, comme les ultrasons et les signaux
radio qui peuvent être émis par une même source (b).
Plusieurs articles traitent de cette thématique comme dans l'approche
Active Bat. Néanmoins, les ultrasons ne peuvent être
utilisés qu'à l'intérieur d'un bâtiment, une
pièce, un hall. En raison de leurs limitations physiques du fait de la
réduction du rayon de propagation, le faible pouvoir
pénétrateur des obstacles et la faible résistance aux
interférences provenant d'autres sources d'ultrasons, l'utilisation
d'une telle technologie. Tout cela limite grandement le cadre d'utilisation
d'une telle technologie. [15]

??? ???
38
(a) (b)
Figure 2.02 : Temps différentiel
d'arrivée.
Le TDOA possède quelques avantages :
· Paramètres bien estimés ;
· Algorithme de positionnement simple ;
· Précision plus élevée en milieu
confiné ;
· Pas besoin de synchronisation d'horloge entre le mobile
et les stations de base. Les inconvénients du TDOA sont:
· Nécessité d'avoir le trajet direct ;
· Synchronisation d'horloge nécessaire entre les
paires de stations de base ;
· Nécessité d'une résolution
temporelle élevée au récepteur.
2.3.1.2 Phase Difference of Arrival
Pour les systèmes en bande étroite, si on
envisage des techniques interférométriques, cela implique
nécessairement l'exploitation de la différence de phase ?? ????
entre deux récepteurs d'indices j et ??. Au moins deux paires
d'antennes, équipées de récepteurs
hétérodynes, fournissent un déphasage proportionnel au
cosinus des angles d'azimut et d'élévation du front d'onde. Les
antennes de chaque paire sont séparées d'une distance connue sous
le nom de base de l'interféromètre. Le même principe
d'intersection d'hyperboles que dans le cas de la TDOA conduit à
l'estimation de la position de l'objet mobile.
La base de l'interféromètre influence la
précision des mesures, les alternatives étant de disposer d'une
distance importante en basses fréquences (solution adoptée dans
les applications liées à l'astronomie) ou travailler à des
fréquences élevées. Les applications de localisation,
réalisées en hautes fréquences, sont spécifiques
à des courtes et moyennes distances. La solution obtenue n'est pas
unique, des systèmes complémentaires de développement de
phase (unwrapping) sont
39
nécessaires afin de lever l'ambigüité. Ceci
constitue un des principaux inconvénients de cette technique. [14]
2.3.1.3 Méthode basées sur la direction
d'arrivée d'onde
Cette technique est basée sur l'exploitation des
angles d'incidence des signaux émis par l'objet mobile au niveau d'au
moins deux points de réception. Cette technique est illustrée
dans la figure 2.03. L'estimation des angles d'arrivée se fait à
l'aide des antennes directives ou des réseaux d'antennes
utilisées conjointement avec des méthodes à haute
résolution. La position de l'émetteur est donnée par
l'intersection des droites passant par chaque récepteur et d'angle, les
AOA calculés par rapport à une référence
arbitraire. [15]

Figure 2.03 : Localisation exploitant les
AOA
L'AOA possède quelques avantages :
· Nécessite moins de stations de base fixes;
· Algorithme de positionnement simple. Les
inconvénients de l'AOA sont:
· Nécessite un trajet direct ;
· Coût d'implantation élevé ;
· Précision faible ;
· Mauvaise performance dans un canal ayant un profil de
propagation par trajets multiples sévère.
40
2.3.1.4 Exploitation de la puissance du signal reçus
En effet, la caractéristique physique du canal radio
nous renseigne sur la puissance du signal reçu RSS. Celle-ci
dépend de la puissance d'émission et de la distance qui
sépare l'émetteur au récepteur. A partir de
l'atténuation du signal, on peut obtenir la distance qui sépare
l'émetteur du destinataire. Un certain nombre de travaux estiment la
puissance moyenne d'un signal pour une distance donnée aussi bien que la
variabilité du signal. Mais dans un environnement bruité par un
grand nombre d'interférences, il est compliqué d'utiliser une
telle information. [12]
2.3.2 Évaluation de la position
2.3.2.1 Méthodes déterministes
Les méthodes déterministes s'appuient sur des
relations géométriques pour déterminer la position de la
station mobile en utilisant les coordonnées des stations de base qui
sont connues et les distances calculées à partir des
paramètres radio. Souvent, les stations de base, ainsi que le mobile,
sont situés dans un plan bidimensionnel (2D).
a. Angulation
Pour déterminer les coordonnées (XMs,
YMs) d'une station mobile (MS) en appliquant la méthode
d'angulation, au moins deux stations de base BS1 et BS2 sont
nécessaires, et leurs coordonnées (XBsK, YBsK) doivent
être connues, avec k E{1,2}. La seule information fournie par
les stations de base sont les angles tpk. [12]
En général, deux stations de base forment le
système d'équations suivant :
[
tantp1 - 11 ffXMs]l _ ff XBs1tantp1 -
YBs1l (2.01)
tantpp2 - 11
LYMsJ--LXBs2tantp2 - YBs2J avec
· tp1 : information fournie par la
station de base BS1
· tp2 : information fournie par la
station de base BS2
Dans le cas où tantp1 =
tantp2, les stations de base et la station mobile sont
situées sur la même ligne, et le système d'équations
est singulier.
Une station de base supplémentaire est
nécessaire pour déterminer les coordonnées de la station
mobile, mais elle ne doit pas être située sur la même ligne
que les deux autres stations de base utilisées initialement. [12]
b. 41
La triangulation
Une technique identique, généralement
désignée par `triangulation', peut être appliquée.
Elle ne nécessite que deux NR pour une localisation en 2D.
Cette méthode est basée sur la mesure de deux
angles d'un triangle et de l'un des côtés de ce triangle
indiquée dans la figure 2.04. En utilisant les propriétés
géométriques du triangle, on peut montrer que la position de
l'objet peut être obtenue comme suit :
d2 = d1 2 + d2 2 - 2d1d2 cos(8) (2.02)
{ ?? = ??1 + d1 cos(oc1)
Y = Y1 + d1 sin(oc1)
avec :
d : distance entre 02 stations de base
d1: distance entre mobile et station de base
d2 : distance entre mobile et station de base
oc : angle fournie par la station de base et la station mobile 8
: angle fournie par les deux stations de base

d1
è
d2
á1 á2
d
( X 1 , Y 1 ) ( X 2 , Y 2
)
Figure 2.04 : Estimation de position par
triangulation
c. Latération circulaire
La `latération circulaire' est une méthode
fondée sur la distance de la station mobile à partir d'au moins
trois stations de base. Les cordonnées de ces derniers sont
supposées connues.
En effet, la trilatération est un procédé
de localisation relative d'un objet en utilisant les distances entre un minimum
de trois noeuds de référence (NR) pour une localisation en deux
dimensions.
42
Soient (x??, y??) les coordonnées cartésiennes
du ????è???? NR et (x; y). Les coordonnées de l'objet à
localiser un noeud mobile (NM). La position de cet objet est conquise par le
point d'intersection des trois cercles de centre NR1, NR2 et NR3 ayant
respectivement les rayons da, d?? et d??. Cette position
peut être déterminée par la résolution du
système d'équations suivant [16] :
{
(x1 - x)2 + (y1 - y)2 = da 2
(2.03)
(x2 - x)2 + (y2 - y)2 =
d??2 (x3 - x)2 + (y3 - y)2 = d?? 2 avec :
da : Rayon du cercle de centre NR1.
d?? : Rayon du cercle de centre NR2.
d?? : Rayon du cercle de centre NR3.
La figure 2.05 nous montre le principe de la localisation par
trilatération.
(X ,Y )
2 2
db (X 1,Y 1) da
NR
2
dc
(X 3 ,Y 3 )
NR
3
NR
1
Figure 2.05 : Estimation de la position par
trilatération
d. Latération hyperbolique
La `latération hyperbolique' est une méthode
permettant de déterminer l'emplacement de la station mobile à
l'aide des informations sur les différences de distances. Elle utilise
des hyperboles et non pas des cercles. La méthode des hyperboles repose
sur la différence entre les distances de l'objet à localiser aux
deux NR comme nous montre la figure 2.06 suivante :
d1
d2
(0,0)
d
43
Figure 2.06 : Méthode des hyperboles
La différence entre les distances ???? et ???? est
donnée par la formule ci-dessous [15] :
??? = ???? - ???? = v(??+ ??)2 +
??2?v(??? ??)2
+ ??2 (2.04)
Après quelques développements
mathématiques, on obtient l'équation d'une hyperbole à
partir de laquelle la position de l'objet est déterminée [15]:
|
??2
|
|
|
|
??2
|
|
(2.05)
|
|
|
|
|
|
|
|
|
|
?d2
|
|
|
|
4d2? ?d2
|
|
|
|
4
|
|
|
|
4
|
|
|
2.3.2.2 Méthodes probabilistes
Les méthodes probabilistes considèrent les
données disponibles sur l'emplacement de la station mobile comme des
fonctions de densité de probabilité. Cette approche est
adéquate lorsque la précision des données disponibles est
faible, ce qui est souvent le cas dans les problèmes de positionnement
de la station mobile.
Après avoir recueillies toutes les informations
disponibles sur les paramètres reliés à la position, les
fonctions de densité de probabilité correspondantes sont
liées à une seule fonction de densité de
probabilité qui décrit la position de la station mobile. Les
coordonnées de la station mobile sont évaluées comme une
variable aléatoire que possède la fonction de densité de
probabilité résultante. Par rapport aux méthodes
déterministes, les méthodes probabilistes sont de calculs
intensifs.
2.3.2.3 Méthodes par empreinte radio «
Fingerprinting»
À la différence des techniques
précédentes, cette technique requiert une étape de
calibration. Le mot fingerprinting vient du terme `fingerprint' qui signifie
empreinte digitale. Pour fonctionner, cette
44
technique nécessite une base de données qui,
à certaines positions de l'environnement considéré associe
un ensemble d'éléments caractérisant cette position. Ces
éléments doivent permettre de différencier chacune des
positions par rapport aux autres positions de l'environnement. Si cette
condition n'est pas réalisée, les éléments
considérés pour composer cette empreinte ne sont pas
significatifs. [12]
La méthode LFP ou Location Fingerprinting exploite les
réseaux radios existants, comme les réseaux cellulaires, ou les
WLANs. Elle profite des mesures génériques qui sont disponibles
à partir des interfaces radios permettant ainsi une localisation moins
coûteuse.
Le système de LFP comporte deux phases :
Tout d'abord, pendant une "phase d'apprentissage" (training
phase), une base de données radio est constituée sur la
région considérée.
Une fois que la base est construite, les mobiles peuvent
entrer dans la "phase de localisation" (localization phase). Ici, un mobile
fait des mesures de test, et sera localisé en associant ces mesures aux
éléments qui sont déjà enregistrés dans la
base.
Pour le cas des réseaux cellulaires, la méthode
de LFP permet une localisation plus précise que Cell-ID. La
méthode n'exige pas une grande consommation d'énergie, car elle
profite des mesures radios génériques qui se font
régulièrement au sein du terminal. [16]
2.4 Conclusion
Il existe plusieurs types de technologies de positionnement
qui peuvent être utilisés pour déterminer l'emplacement des
utilisateurs.
Ainsi, nous avons pu étudier les différentes
techniques de localisation qui sont classifiées selon les mesures
utilisées et dépendent de l'émission ou de la
réception des signaux radio.
45
CHAPITRE 3
LOCALISATION A BASE D'EMPREINTE RADIO
3.1 Introduction
La technique de fingerprinting ou de pattern matching a
déjà été explorée dans le cadre de la
localisation par réseau GSM. Depuis quelques années, on peut
utiliser des outils de prédiction de couverture radio permettant
d'optimiser les réseaux lors de leur mise en place. Ces outils
prédisent le niveau de champ radioélectrique en tenant compte des
différents phénomènes de propagation auxquels sont
soumises les ondes radio. Ils déterminent le niveau de champ à
chaque position de la zone de couverture.
L'opération de localisation consiste à
rechercher dans la base de données, constituée à l'aide
des outils de prédiction de couverture radio, le n-uplet de puissance le
plus proche du n-uplet des puissances mesurées par le terminal mobile.
Une fois ce n-uplet de la base de données identifiée, la position
du mobile correspond à celle de la mesure
référencée dans la base de données. [17]
Ainsi, la localisation à base d'empreinte radio
exploite les réseaux existantes (réseau cellulaire, le WLAN...)
tout en utilisant les mesures génériques qui sont disponibles
à partir des interfaces radios. Elle permet une localisation plus
précise que Cell-ID. La méthode ne demande pas une grande
consommation d'énergie.
3.2 Description d'un système de LFP
Le système de LFP est divisé en deux phases :
? La phase d'apprentissage (training phase)
? La phase de localisation (localization phase)
3.2.1 Phase d'apprentissage
Une « phase d'apprentissage » ou « training
phase », ou une « phase hors ligne », est constituée par
la création d'une base de données avec les
caractéristiques mesurées par chaque récepteur du
réseau à un ensemble d'emplacements représentatifs pour
les positions possibles de l'objet mobile. Un maillage de la zone
d'intérêt est réalisé. Pour chaque noeud, les
caractéristiques mesurées par chaque récepteur du
réseau sont enregistrées.
46
3.2.2 Phase de localisation
Une fois que la base de données est construite, les
mobiles peuvent entrer dans la « phase de
localisation » ou « localization phase » ou
« phase en ligne ».
Le mobile effectue des mesures de test, et sera
localisé en associant ces mesures aux éléments qui
sont déjà enregistrés dans la base.
Plus précisément, la phase consiste à
trouver, à partir des caractéristiques mesurées de
l'objet
mobile, un correspondant dans la base de données
à l'aide d'un algorithme de positionnement.
Ces algorithmes sont classés en deux catégories
qui sont :
? Déterministes
? Probabilistes
3.2.2.1 Déterministes :
a. VPP
Le VPP ou Voisin le Plus Proche dans la base de données
des puissances (ou plus rarement la TOA) du signal est enregistré durant
la phase hors ligne.
La méthode évalue la distance euclidienne entre
les caractéristiques mesurées dans la phase en ligne et celles
stockées dans la base des données. Le point pour lequel la
distance euclidienne est minimale est considéré comme
représentant la position de l'objet mobile.
b. Moyenne des k voisins les plus proches dans l'espace
puissance du signal reçu
Cette méthode constitue une extension de la
précédente méthode en permettant d'améliorer les
résultats.
Les coordonnées spatiales des k voisins les
plus proches en termes de puissance du signal reçu sont moyennées
pour donner une estimation de la position de l'objet d'intérêt.
[15]
c. Plus petit polygone
Cette méthode consiste à choisir un nombre de
voisins rapprochés et à construire des polygones à partir
de leurs coordonnées spatiales connues. La position de l'objet mobile
est donnée par le centre du polygone d'aire minimale dans l'ensemble de
polygones. [15]
3.2.2.2 Probabilistes:
Ces techniques emploient les distributions de la puissance du
signal reçu au niveau de chaque récepteur du réseau.
Elles essayent d'améliorer les performances des
méthodes déterministes affectées par les problèmes
de stationnarité de l'environnement de mesures. [15]
La figure 3.01 présente une vue d'ensemble
schématique d'un système LFP avec les méthodes
associées.

Phase de localisation
(Classification ,
prédiction)
Mesure effectué par le
mobile.
Phase d'apprentissage
(Construction de la
BD,
étude
supervisé/non
supervisé
Position estimée
Estimation
Position estimée
Classification
Traitement
Traitement (compression de
la BD par PCA, KCCA, etc)
BD initiale
Méthode de
régression
(SVM, ANN)
Méthode de
classification
(KNN, SVM, ANN)
47
Figure 3.01 : Architecture d'un système
LFP
48
3.3 Terminologie et modélisations
mathématiques
Dans cette section, nous allons essayer d'expliquer les
terminologies et les modélisations utilisées dans la
méthode LFP, particulièrement aux systèmes LFP
basés sur les mesures RSS.
3.3.1 Base de données radio et
enregistrement
Une "base de données radio" est un ensemble
"d'enregistrements". Dans ce contexte, chaque enregistrement est
constitué de deux parties: la partie de position (location part), et la
partie radio (radio part). La partie de position décrit la position d'un
point spécifique et la partie radio montre la mesure radio
exécutée à cette position spécifique.
3.3.2 Mesure radio
La mesure radio comprend de nombreux types de
paramètres, disponibles à partir des interfaces radios (par
exemple RSS, Timing Advance ou TA, etc...).
Elle est représentée par un vecteur s E
R???? comprenant ???? éléments
réels.
La partie position est également représentée
par un vecteur x E R????.
De ce fait, un enregistrement est donné par r =
(x, s) E R??, et on a :
?? = ???? + ???? (3.01)
3.3.3
Modèle de propagation radio
Un modèle de propagation radio est nécessaire
pour modéliser les mesures RSS. Le modèle OSLN ou One Slop
Log-Normal model est un modèle classique, qui décrit la perte
radio (pathloss) comme suit:
??????(d) = -k + 10 oc?? log(d) +
????h (3.02)
avec :
? Pla : perte moyenne (en dB),
? k : constant,
? d : distance,
? oc?? : paramètre de propagation
exponentielle (propagation exponent)
? ????h : variable aléatoire log-Normal
qui représente l'effet de shadowing.
Pour l'effet de shadowing, ce modèle ne considère
aucune corrélation géographique.
49
3.4 Méthodes de compression de base de
données radio
L'enrichissement de la base de données n'entraine pas
toujours l'amélioration de la qualité de la localisation. La
taille de la base est un facteur important (surtout dans les approches
mobile-based) parce qu'elle influence la charge de calcule, la charge de
transmission ainsi que l'autonomie énergétique du terminal.
Il y a plusieurs méthodes qui visent à
compresser la base de données radio. La plupart d'entre eux tente de
réduire la dimension de la base, en utilisant des contraintes de
covariance.
Nous allons présenter les 03 méthodes les plus
reconnues :
· La technique de clustering,
· Le PCA ou Principal Component Analysis,
· Le KCCA ou Kernel Canonical Correlation Analysis.
3.4.1 Technique de clustering
Clustering ou regroupement permet de faire une collection
d'objets :
· Similaires au sein d'un même groupe ou,
· Dissimilaires quand ils appartiennent à des
groupes différents.
Ainsi, la technique de clustering réduit le nombre des
enregistrements. Chaque enregistrement est représenté par : ?? =
(??, ??) ? R??
Les positions inclues dans la base sont données par
l'ensemble X tels que : ?? = {??1, ... , ????, ... , ????}
La base radio est données par : ?? = {????}??=1...??
La base de données finale R pourrait être obtenue
en traitant les éléments d'une base de données
« initiale » notée ????; qui est une base radio
constituée selon les mesures terrains brutes.
Un enregistrement de ???? est donné par : ??0
= (??0, ??0)
Les techniques clustering sont très efficaces pour
compresser la base de données initiale ??0 =
{????0}??=1...?? afin d'obtenir une base de données plus
compacte ?? = {????}??=1...??(??<??).
3.4.1.1 Algorithme de clustering
Supposons une base comprenant ?? data-points ??0 =
{????0}dans une espace de
??=1...??
dimension ?? (????0 ? R??). Une
technique de clustering tente de diviser ??0 en ??(?? < ??)
sous-ensemble ou clusters, telle que les points dans chaque cluster soient
similaires dans certain sens.
Pour un système LFP, on considère deux types de
méthode pour réaliser l'étape de clustering :
· L'algorithme de k-means
· La technique hiérarchique agglomérative
a. Algorithme de k-means
Cet algorithme est basé sur le critère de
minimum de la variance intra-cluster (minimum intra-cluster variance). Dans
cette technique, l'algorithme de clustering essaie de chercher une partition
des données qui minimise la somme des variances intra-cluster. Pour
l'ensemble de R° donné, une partition pourrait
être représentée par une matrice ?? x ??, U =
[umn], qui satisfait les critères suivants [16] :
umn ? {0,1}, (3.03)
??
? umn = 1; pour 1 < ??< ??, m=1
|
(3.04)
|
|
??
? umn
|
> 0; pour 1 < ?? < ??,
|
(3.05)
|
|
n=1
Etant donnée la définition ci-dessus,
l'algorithme de k-means essaie de minimiser la fonction d'objective suivante
:
?? ??
j2(U, R) = ? ?umn????(??) 2(rn°
(3.06)
, rm)
50
n=1
avec :
R = {rm}m=1...?? : Ensemble de M vecteur
représentant les centroides des clusters.
????(??) : Distance Euclidien pondérée,
qui a été adopté pour calculer les variances. b.
Technique hiérarchique agglomérative
Cette technique consiste à minimiser la même
fonction d'objective que celle de k-means. Mais, l'optimisation se fait
hiérarchiquement. En supposant que chaque vecteur dans
R°constitue un cluster, on fusionne les deux clusters
qui minimise la variation dans j2 à chaque
étape de la procédure.
51
3.4.1.2 Méthode BWC
La méthode de Bloc-based Weighted Clustering ou BWC
consiste en un algorithme pondéré, adapté à la
structure de la base de données radio. Avant de développer cette
méthode, on formalise le concept de feature type.
a. Principe
Supposons une base de données ?? = {????}??=1...??. On
remarque que tous les éléments dans un
enregistrement ???? n'appartiennent pas à la
même nature. On définit un feature type comme l'ensemble de tous
les paramètres qui appartiennent à la même nature. Dans le
cas le plus simple, il faut au moins deux feature types dans la base : le
feature type « position », et le feature type « RSS ». On
peut envisager des cas plus compliqués, où il existe des feature
types variés (RSS 2G et 3G, TA, etc.). Un enregistrement peut être
représenté aussi comme suit :
?? = ??1, ... , ??h, ...,?????? (3.07)
avec :
???? : Le nombre total des features types
??h : Le sous-vecteur correspondant à
l'hème feature type.
3.4.2 PCA
Un PCA (analyse en composantes principale) permet :
· De représenter des individus
· De représenter des variables
· De compresser des données et d'éliminer du
bruit
Elle peut être appliquée à la compression
d'image. Ainsi, elle est parmi les méthodes permettant de compresser la
base de données radio.
Pour faire une PCA, il faut :
· Réduire et centrer les données
· Calculer la matrice des corrélations
· En extraire les valeurs et les vecteurs propres
· Reconstruire les nouvelles variables
· Choisir k le nombre de facteurs significatifs
3.4.2.1 Valeurs propres :
Soit M une matrice carrée symétrique
définie positive (M = XTX) de dimension p. Il existe
:
· p réels positifs Al, i = 1, p
et
· p vecteurs de RP, vl, i = 1, p tels que :
Mvl = illvl (3.08)
b. Propriétés des valeurs et des vecteurs
propres
· Par convention, on ordonne les valeurs propres Al
<_ .1l_1,i = 2, p
· Par convention, les vecteurs propres sont normés
vlT vl = 1
· Les vecteurs propres sont orthogonaux entre eux :
vlT v' = 0, i * j
· La matrice des vecteurs propres V forme une base
de RP
· La décomposition spectrale : M =
Ep1 yllvlvi
· Le programme([V, D] = eig(M)) permet de calculer
les valeurs et les vecteurs propres.
3.4.2.2 Reconstruction de la matrice
La meilleure représentation linéaire du nuage de
points est donnée par le couple de vecteurs u E Rn et v E
RP permettant au mieux de reconstruire la matrice X. Le couple de
vecteur résout le problème de minimisation suivant :
minJ(u, v) (3.09)
u,v
avec :
n P
J(u, v) = I I(xl' - ulv')2
(3.10)
52
l '
3.4.2.3 Meilleure approximation
Soit X une matrice :
La meilleure approximation de rang k de X, la
matrice Ak minimisant le critère suivant :
minIIX - Ak IIF avec rang(Ak) = k (3.11)
Ak
53
ceci s'obtient à l'aide des ?? vecteurs propres ????, ?? =
1, ?? associées aux ?? plus grandes valeurs propres de la matrice
XTX de la manière suivante :
??k = UkVkT (3.12)
où Vk est la matrice des vecteurs
propres ????; ?? = 1, ??
et Ukest la matrice des vecteurs ???? = X????, ?? = 1, ?? et donc
:
??k = XUkVkT (3.13)
L'erreur
d'approximation est donnée par la somme des valeurs propres restantes
:
|
??
?X - ??k???2 = ? ????
??=k+1
|
(3.14)
|
??k = ?X - UkVkT??? 2 (3.15)
avec : ?? = 1,?? 3.4.3 KCCA
La KCCA présente deux caractéristiques
avantageuses. C'est une analyse qui permet l'intégration de
différents types de données et de faire un apprentissage par
rapport à un jeu de données standard pour lequel les relations
entre objets sont connues. De plus, elle agrée l'inférence de
liens entre tous les objets utilisés.
La KCCA est basée sur l'analyse de corrélation
canonique ou CCA.
Soient deux groupes de variables Y1 et
Y2 décrivant un même objet x. L'analyse de
corrélation canonique consiste à trouver des repères qui
se correspondent pour représenter l'objet dans chacun de ces
repères. Ces derniers sont obtenus en recherchant des combinaisons
linéaires des variables (canoniques) de chaque groupe. [18]
(??))
Le but de la KCCA est de détecter des corrélations
entre deux jeux de données x1 = (x1 (1), ... ,
x1
et x2 = (x2(1), ...
,x2(??)) où ?? est le nombre d'objets et chaque
jeu de données appartient à X1/X2 pour ?? = 1, ... , ??. [18]
3.5 Méthode de classification
3.5.1 KNN
Pendant la phase de localisation, le mobile fait une mesure s'
à la position x'. Afin de localiser le terminal, on utilise
la méthode de classification de KNN ou K Nearest Neighbours.
54
Deux types de métrique sont considérés
pour implémenter la classification KNN : la distance Euclidien, et le
coefficient de corrélation. [16]
Une fois que le mobile est localisé, l'erreur de la
localisation est donnée par :
E(x') = 11x' - x^11 (3.16)
où ^?? est la position estimée pour le terminal.
3.5.1.2 Classification supervisée
En quelques mots, la classification supervisée, dite
aussi discrimination est la tâche qui consiste à spécifier
des données, de façon supervisée (avec l'aide
préalable d'un expert), un ensemble d'objets ou plus largement de
données, de telle manière que les objets d'un même groupe
(appelé classes) sont plus proches (au sens d'un critère de
similarité choisi) les unes aux autres que celles des autres groupes.
Généralement, on passe par une première
étape dite d'apprentissage où il s'agit d'apprendre une
règle de classification à partir de données
annotées (étiquetées) par l'expert et pour lesquelles les
classes sont connues, pour prédire les classes de nouvelles
données, pour lesquelles les données sont inconnues.
La prédiction est une tâche principale
utilisée dans de nombreux domaines, y compris l'apprentissage
automatique, la reconnaissance de formes, le traitement de signal et d'images,
la recherche d'information, etc. [19]
3.5.1.3 Données
Les données traitées en classification peuvent
être des images, signaux, textes, autres types de mesures, etc.
3.5.1.4 Classes
Une classe (ou groupe) est un ensemble de données
formée par des données homogènes qui se ressemblent au
sens d'un critère de similarité (distance, densité de
probabilité, etc). Le nombre de groupes (noté K) en
prédiction est supposé fixe.
3.5.1.5 Algorithme des K-ppv
C'est une approche très simple et directe. Elle ne
nécessite pas d'apprentissage mais simplement le stockage des
données d'apprentissage. En principe, une donnée de classe
inconnue est comparée à
55
toutes les données stockées. On choisit pour la
nouvelle donnée la classe majoritaire parmi ses K plus proches voisins
(Elle peut donc être lourde pour des grandes bases de données) au
sens d'une distance choisie. [19]
Afin de trouver les K plus proches d'une donnée
à classer, on peut choisir la distance euclidienne. Soient deux
données représentées par deux vecteurs x?? et
x??, la distance entre ces deux données est donnée par la
formule suivante :
|
??(x??,x??) =
|
v?? ?(x??k - x??k)2 k=1
|
(3.17)
|
3.5.2 SVM
Les SVM ou Support Vector Machines souvent traduit par
l'appellation de Séparateur à Vaste Marge ou SVM sont une classe
d'algorithmes d'apprentissage initialement définis pour la
discrimination c'est-à-dire la prévision d'une variable
qualitative binaire. Ils ont été ensuite
généralisés à la prévision d'une variable
quantitative. Ils sont basés sur la recherche de l'hyperplan de marge
optimale qui, lorsque c'est possible, classe ou sépare correctement les
données tout en étant le plus éloigné possible de
toutes les observations.
Le principe de base des SVM consiste de ramener le
problème de la discrimination à celui, linéaire, de la
recherche d'un hyperplan optimal.
3.5.2.1 Remarque
Il est parfois utile d'associer des probabilités aux
SVM. Ces derniers peuvent également être mis en oeuvre en
situation de régression.
3.5.3 ANN
3.5.3.1 Définition
Artificial Neural Networks ou Réseaux de Neurones
Artificiels ou RNA sont des réseaux fortement connectés de
processeurs élémentaires fonctionnant en parallèle. Chaque
processeur élémentaire calcule une sortie unique sur la base des
informations qu'il reçoit. Toute structure hiérarchique de
réseaux est évidemment un réseau. [20]
56
Les réseaux de neurones artificiels ont été
développés avec pour objectifs principaux d'une part la
modélisation et compréhension du fonctionnement du cerveau et
d'autre part pour réaliser des architectures ou des algorithmes
d'intelligence artificielle. [21]
3.5.3.2 Principe de fonctionnement
Le principe de fonctionnement d'un neurone artificiel est
montré par le schéma suivant :
Xn
W1
Wi
1
W0
X1
Figure 3.02 : Schéma d'un neurone
artificiel
Wn
Un neurone artificiel est une unité de traitement qui
dispose de ?? entrées {X??}??=1,..,?? qui sont
directement les entrées du système ou peuvent provenir des autres
neurones.
Pour le biais, l'entrée est toujours à 1, ce qui
permet d'ajouter de la flexibilité au réseau en permettant de
varier le seuil de déclenchement du neurone par l'ajustement du poids du
biais lors de l'apprentissage.
La sortie y correspond à la transformation par
une fonction d'une somme pondérée des entrées : y=
f(??) avec ??= w0 + ? w??????
?? (3.18)
??=1
Les quantités {w??}??=0,...,?? sont les poids du
neurone. Ce sont des facteurs multiplicateurs qui affectent l'influence de
chaque entrée sur la sortie du neurone.
La fonction f est appelée fonction d'activation
ou fonction de transfert du neurone. Les fonctions les plus communément
utilisées sont la fonction échelon unité ou Heaviside, la
fonction signe, la fonction linéaire ou semi-linéaire, la
fonction tangente hyperbolique, ou la fonction sigmoïde. [21] La fonction
sigmoïde est définie par :
|
f(??) =
|
1
|
(3.19)
|
|
1 + e-??
|
|
La figure ci-dessous nous présente l'allure d'une fonction
sigmoïde :

57
Figure 3.03 : Sigmoïde
b. Remarque
Dans un neurone artificiel, on appelle « noyau » tous
ce qui intègre toutes les entrées et le biais et calcule la
sortie du neurone selon une fonction d'activation qui est souvent
non-linéaire pour donner une plus grande flexibilité
d'apprentissage.
3.5.3.3 Classification à l'aide d'un neurone
Considérons des événements
caractérisés par un ensemble de ?? mesures (nombres et
types de particules, impulsions, énergies, etc.) que nous notons
{??1}1=1,..,??. Nous souhaitons classer ces événements
entre deux classes.
Supposons que nous avons un échantillon d'apprentissage
de n événements dont nous connaissons la classe d'appartenance
ainsi que les mesures. Pour chaque événement d'apprentissage nous
notons x l'ensemble de ses mesures et c sa classe (0 ou
1).
Le principe de l'apprentissage peut être décrit par
l'algorithme suivant :
1. Choix aléatoire des poids
2. Présentation d'un événement
d'apprentissage en entrée et calcul de la sortie y(x)
3.
(3.20)
Modification des poids :
w'1 = w1 + [c - ??(x)]x1 w'0 = w0 +
[c - ??(x)]
4. Retour à l'étape 2
58
3.6 Traitement des données manquantes dans les
systèmes LFP
Dans les systèmes LFP, la problématique des
données manquantes est très importante.
Pour le cas des systèmes basés sur les mesures de
RSS; ces mesures sont normalement obtenues par
une procédure nommée scanning process qui est
indispensable dans les réseaux radios mobiles, où
chaque terminal mesure le niveau de RSS des cellules en
voisinage.
Cependant, certaines stations de base ne peuvent pas être
détectées au cours de cette procédure, à
cause de différentes raisons :
? Le signal reçu pourrait être plus faible que le
seuil de la sensibilité du terminal,
? Le signal reçu pourrait être perdu dans la forte
interférence,
? Le nombre des stations de base mesurable pourrait être
limité au niveau du terminal,
? Certaines stations de base pourraient être
éteintes.
Tous les signaux non mesurés sont considéré
comme des données manquantes.
Les méthodes statistiques pour le traitement des
données manquantes ont considérablement évolué
depuis les dernières années. [16]
Prenons comme exemple les mesures RSS effectuées par le
terminal mobile, sur une région A où se
trouve B la station de base.
Une mesure complète à la position ?? peut
être représentée par le vecteur s = (s1,
..., s??, ..., s?? ) ?
R??.
La modélisation du mécanisme d'effacement
s'effectue à l'aide de deux paramètres : l'un, X qui
représente le seuil de sensibilité du terminal, et l'autre
notée B?????? qui est le nombre maximum des stations de base
mesurable au niveau du terminal (B?????? = B). Ensuite, pour
formaliser le concept d'effacement, on définit le vecteur indicateur
j ?? {0,1}??correspondant à chaque mesure
s, comme suit :
Supposons que a = ( a(1), a(2), ..., a(B)) est une
permutation d'indices des stations de base, tel
que s??(1) = s??(2) = ? = s??(??) ; le vecteur j
correspondant à s est alors défini comme :
???, 1 = ?? = B, j?? = {1 sj ?? ? {a(1), a(2), ...,
a(B??????)}, et s?? = A, (3.21)
0 ??utre??ent
On définit l'ensemble ø comme l'ensemble de tous
les paramètres qui modélisent le mécanisme d'effacement
(ø = {A, B??????}).
Finalement, pour une position donnée ??, B
(??) = {??: j?? = 1} représente l'ensemble des stations de base
observées à la position ??.
59
Dans les systèmes de LFP, les données manquantes
pourront arriver pendant les deux phases d'apprentissage et localisation.
Dans ce travail, nous traitons le problème en deux
étapes :
· Etape 1 :
On suppose que le mécanisme d'effacement est
présent exclusivement pendant la phase de localisation ; autrement dit,
on suppose que l'on a une base de données complète, mais les
mesures du terminal incomplètes. [16]
· Etape 2 :
Pendant la deuxième étape, on enlève
l'hypothèse d'une base de données complète ; le
mécanisme d'effacement est censé être présent
pendant les deux phases d'apprentissage et localisation. [16]
3.6.2 Algorithme de localisation basé sur le
maximum de vraisemblance
Les algorithmes de localisation basés sur le maximum de
vraisemblance (Maximum Likelihood ou ML) sont déjà
proposés dans le contexte des systèmes de LFP. La méthode
de ML que nous proposons dans ce travail est différente dans le sens
qu'elle prend en compte l'effet d'effacement et les données manquantes.
[16]
La mesure du terminal durant la phase de localisation ??' peut
être décomposée en une partie observée ??'(??????)
et une partie manquante ??'(??????), ayant pour résultat un vecteur
indicateur d'effacement ??'. [16]
Notre algorithme de ML estime la position du terminal comme
suit :
??^ = ????^, ??^ = ?????????????? ?? (??'(??????), ??'|??, ????,
??) (3.22)
avec :
??^ : La position estimée du terminal
???? : Ensemble qui modélise la distribution des mesures
RSS complètes sur les clusters Etant donné le mécanisme
d'effacement, on obtient :
|
??(??'(??????), ??'|??, ????, ??) = ? ??(??'(??????),
??'(??????) |??, ????)????'(??????)
??
|
(3.23)
|
où ?? est un évènement définit par
:
?? = {??': ??? ? ?? (??'), ??'?? = ??'(??')} (3.24)
avec:
(3.25)
??'(??')} = { ?? ????|??(??')| < ??????????????{??'(??????)}
????|??(??')| = ????????
60
Supposant une distribution Gaussienne pour les mesures autours
des centroids. On peut écrire:
p(S'|m, 8L)"'N(Sm, rm) (3.26)
avec :
8L = [(Sm, rm)}??=1,...,?? (3.27)
Sm et r,.,,, : ce sont respectivement le
centroid et la covariance matrice du m-ème cluster.
En prenant une hypothèse d'indépendance parmi les
signaux des différentes stations de base, on obtient:
|
p(S'(obs),iF|m,8L,ip) = pb(S'b |m,8L)
Fb(
Y'bEB(x')
beB(x')
|
(3.28)
??'(??')|??, 8L)
|
où Fb (. |m, 8L) représente
le CDF ou Cumulative Distribution Functions de la distribution Gaussien,
correspondant au b-ème composant radio.
3.6.3 Algorithme de Multiple
Imputation
Ce niveau du problème suppose la présence du
mécanisme d'effacement pendant toutes les deux phases d'apprentissage et
localisation. Afin de traiter les données manquantes au niveau de la
phase d'apprentissage, on propose une méthode de "Multiple Imputation"
ou MI, qui essaie de remplir les valeurs manquantes dans la base. Une fois que
la base radio est complémentée, le traitement des données
manquantes pendant la phase de localisation revient à la même
problématique étudiée dans l'étape
précédente. [16]
La figure 3.04 ci-dessous illustre la méthodologie
proposée.
Phase d'apprentissage Phase de localisation
Imputation
Clustering

Base de
données
initiale

Base de données
complémentées
Classification
Mesure effectué par le
mobile.
Figure 3.04 : Architecture proposée
comprenant l'étape d'imputation
3.6.3.2 Le modèle des données complètes
Le modèle des données complètes, à
cette étape, modélise la base de données radio
complète ??0. Prenant un modèle classique log-Normal,
chaque mesures de RSS pourrait être modélisée comme suivant
:
??(???? 0|????)~??([????,1, ... , ????,??], ?)
(3.29)
oÙ ???? inclut les paramètres du modèle
log-Normal, qui permettent de calculer ????,1, ... , ????,?? et ?. Prenant une
hypothèse d'indépendance parmi les différentes stations de
base, on obtiendra:
|
??
??(???? 0|????) = ? ????(
|
???? 0|????)
|
(3.30)
|
61
??=1
oÙ ????(.|????) est la densité marginale du b
ème composant, pour 1 = ?? = ??.
3.7 Positionnement utilisant la méthode de
fingerprinting basé sur OTD
OTD ou Observed Time Differences est un procédé
de positionnement couramment utilisé parce qu'il a la capacité de
recueillir l'héritage des terminaux. Cette méthode est
spécifique aux réseaux UMTS et nécessite la
réception au niveau de l'objet mobile des signaux provenant d'au moins
trois stations de base. La position de l'objet mobile est donnée par
l'intersection d'au moins deux hyperboles résultant de la
différence des retards des signaux, encodés dans les trames UMTS,
provenant des stations de base prises par deux. [15]
La méthode des différences de temps
d'arrivées observées ou OTDOA est basée sur les mesures
des différences des temps d'arrivée des signaux de liaison
descendante reçus par le mobile. Dans cette méthode, c'est le
mobile qui s'engage à prendre les mesures nécessaires.
L'équipement utilisateur calcule les temps d'arrivée des signaux
reçus simultanément des Node Bs voisins. Le signal mesuré
est le CPICH ou Common Pilot Channel. Le terminal calcule le temps de
propagation du signal à partir de la corrélation entre le signal
reçu et le signal pilot du Node B considéré. Le pic
résultant de la corrélation représente le temps de
propagation du signal observé.
L'estimation des différences des temps d'arrivée
peut s'effectuer soit sur les signaux de la liaison montante soit sur ceux de
la liaison descendante. [22]
On peut calculer les TDOAs par deux méthodes
différentes :
? Soit directement par
l'inter-corrélation des signaux reçus de deux BTSs
62
? Soit indirectement par la soustraction des temps
d'arrivées de deux BTSs, ce qui requiert le calcul des TOAs.
3.7.1 Estimation des TDOAs pour un réseau
3G
L'estimation des TDOAs est obtenue à partir de
plusieurs estimations robustes du profile du canal de transmission. Le canal
CPICH est composé d'une séquence prédéfinie de bits
dits pilotes, qui sont transmis en permanence sur la cellule. Il peut
être considéré comme un canal balise dont les terminaux
mobiles se servent pour faire des mesures de puissance et pour estimer la
réponse impulsionnelle du canal de propagation. [22]
Considérons le cas où un mobile reçoit
trois canaux CPICH issus de trois Node B (station de base) différents,
à partir de la sortie du corrélateur on peut accéder
facilement aux TDOAS comme suit :
1. On réalise des corrélations avec les CPICH
de chaque Node B sur une fenêtre de durée maximale égale au
temps nécessaire de transit du signal à partir du Node B le plus
éloigné.
2. On localise le premier pic de chaque CPICH qui correspond,
soit au trajet direct Node B mobile, soit au plus court trajet indirect,
c'est-à-dire celui produisant le moins d'erreurs.
3. Les TDOAs sont égales à la différence
temporelle entre les premiers pics relatifs aux différents Node Bs comme
nous montre la figure 3.05.
A l'émission:

NodeB_1
NodeB_2
NodeB_3
CPICH
CPICH
CPICH
CPICH
CPICH
CPICH
A la réception:
T3 -
T1

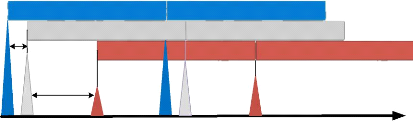
T2 -
T1
ô2 ô3
T3 -T2
CPICH
CPICH
CPICH
CPICH
CPICH
Sortie du corrélateur
CPICH
Figure 3.05 : Calcul des TDOAs
3.7.2 Structure de l'algorithme
Quand un utilisateur passe en mode active, il doit rester
connecter et les rapports de mesures par l'UE vers le réseau doit
être effectué sans interruption. De ce fait, le réseau doit
aider l'UE.
Les rapports de mesures contiennent les informations concernant
la cellule active et la cellule serveuse avec les spécifications
données ci-dessous. [23] [24]
3.7.2.1 Chargement à l'entrée
Les informations concernant le Node B et le MRMs ou Mesurement
Report Messages (figure 3.06) sont des données d'entrée
nécessaires pour calculer, dans une marge d'erreur tolérable,
l'estimation de la position physique de l'UE. On distingue :
a. Données de MRMs
Les données de MRMs sont :
· Rapport d'évènement
réalisé
· Cell IDs de l'Active Set
· Primary Scrambling Codes ou PSCs de l'Active and
Monitored sets Pour chaque liaison radio :
· Ec/N0 en dB
· RSCP en dBm
· Paramètres de synchronisation frame offset (OFF)
et chip offset (Tm)
OFF [1] Tm [1]
PSC [1] Ec/No [1] RSCP [1]
OFF [3] Tm [3]
PSC [3] Ec/No [3] RSCP [3]
OFF [4] Tm [4]
PSC [4] Ec/No [4] RSCP [4]
OFF [2] Tm [2]
PSC [2] Ec/No [2] RSCP [2]
63
Figure 3.06 : Données MRMs sur chaque
liaison radio
???? = 10
|
P?? - 69.55 - 26.16 log10 f + 13.82 log10
hB + ??????
|
(3.32)
|
|
|
|
64
b. Données du Node B
Les données du Node B sont :
· Nom de la cellule
· Cell IDs
· PSCs
· Primary CPICH power measurements
· Coordonnées géographique
· Hauteur de l'antenne
3.7.2.2 Calcul initial
a. Identification de la cellule
Pour la cellule de la station mobile, l'identification à
l'aide d'un PSC n'est pas suffisante. Ainsi, la valeur de l'Ec/N0 de la cellule
active est utilisée comme référence.
b. Elimination de mesures redondantes et identification du
site
Les mesures des cellules localisées dans un même
site génèrent une redondance de données. Les valeurs du
RSCP est un critère de décision.
c. Première estimation de la position
L'algorithme de position utilisé a besoin d'une estimation
initiale, l'exactitude est important pour la convergence. La méthode
consiste à utiliser les trois meilleures cellules :
Calcul de la pathloss
La perte radio est donnée par la formule suivante
où Tx est la puissance de transmission et RSCP le niveau de la puissance
reçue:
P??[??B] = ????[??B??] - ??????P[??B??] (3.31)
Calcul de la distance ????
La distance ???? entre une cellule i et un UE est obtenue par
:
65
où f est fréquence de transmission, hB
est la hauteur de l'antenne et CLc est un paramètre du
modèle spécifique pour une zone urbaine.
A l'aide des coordonnées des 03 meilleures cellules
(x, Y)A,B,c et les distances calculées dA,B,C, les
coordonnées de la première estimation de la position du mobile
(x, Y)UE est obtenue en utilisant la trilatération
géométrique suivante :
{
(xUE - xA)2 + (YUE -
YA)2 - d = 0 (3.33)
(xUE -
xB)2 + (YUE - YB)2 -
dB2 = 0 (xUE - xC)2 + (YUE - YC)2 -
dC = 0 Les coordonnées sont obtenues après avoir
résolu ce système d'équation en appliquant la
méthode
de Cramer.
d. Calcul de l'OTD
L'OTD sur le k-ième MRM, entre l'UE et la cellule i est
donnée par :
OTDK(i) = 38400 X OFF(i) + Tm(i)
(3.34)
(Calculé pour chaque liaison radio non redondante)
avec :
OFF(i) : Frame offset Tm(i) : Chip offset
Remarque :
Le paramètre OFF peut prendre une valeur de 0 à 255
tandis que celle du Tm varie de 0 à 38399. 3.7.2.3 Cycle de
positionnement
a. Estimation du retard de propagation :
Sur le k-ième MRM, le retard de propagation T entre l'UE
et la cellule i est donnée par :
|
Tk(i) =
|
1 2 (3.35)
C X (xc(i) - xue)2 + (Yc(i) - Yue)
|
avec :
C : Vitesse de la lumière
(x, Y)UE : Position du mobile
(X, y)?? : coordonnées du cell i
b. Calcul de la RTD ou Relative Time Differences Le
modèle de RTD entre 02 cells/sites i et j peut être obtenu par:
????(??, ??) (3.36)
????????(??, ??) = (????????(??, ??) - 0.26 ×
10-6)??????(256 × 38400)
L'échantillon calculé est sauvegardé dans
une matrice tridimensionnelle, de position (i,j,end). La valeur utilisée
est une valeur absurde de la médiane atténuée du tableau
(i,j) de la matrice, RTD'(i,j).
c. Méthode RLS ou Recursive Least Squares non
linéaire
Il s'agit d'une multilatération utilisant la
méthode de moindre carrée récursive non linéaire.
Le système d'équation est généré par :
f??(X,y) =
[
f??,1,2(X, y)
f??,1,3(X, y)
?
f??,1,??(X,
y)
(3.37)
A chaque itération, une correction de la valeur est
appliquée, afin de réduire la somme des résidus au
carré :
|
min
??,??
|
IIf (X, y)II2 2 = min
??,??
|
(f1(X,y)2 + f2 (X,y)2
+ ? + f??(X,y)2) (3.38)
|
66
Chaque équation utilise des mesures provenant de k MRM
d'une paire de cell/site (i,j) :
f??,??,?? (X, y) = ????,??,?? - ????,??,?? (X, y)
(3.39)
où
????,??,?? = C × 78 × (??????(??) - ??????(??) -
??????'??(??, ??))
et
????,??,??(X,y) = (X??(??) - X????)2 + (y??(?) -
y????)2 - (X??(??) - X????)2 + (y??(??) -
y????)2
3.7.2.4 Critère de validité
L'estimation de la position n'est pas valide si :
? Le nombre du cycle d'itération k est atteint.
? La méthode a échoué : flag de sortie RLS
négative.
·
67
Un ou plusieurs échantillons est excessivement
dévié de la valeur absurde de la médiane
atténuée.
· Les valeurs des MRMs peuvent être
contaminées d'erreur.
La vérification de la validité finale est
déterminée par le nombre de k-ième échantillon de
MRM RTD divergent des valeurs de RTD'.
La différence
8RTD est
donnée par :
8RTD = |RTDk(i,
j) - RTD'k(i, j)| (3.40)
La position d'UE donnée par cette MRM est
considérée invalide si l'inégalité suivante est
vraie, pour la valeur tolérée d'erreur maximum
prédéfini ORTD tel que :
8RTD ~ ORTD
(3.41)
3.7.2.5 Génération de sortie
La génération de sortie est la phase finale de
l'algorithme. Les sorties générées sont :
· Le text logs de chaque opération
effectuée,
· Les données brutes des MRMs, contenant toutes
les valeurs et structures utilisées pour l'estimation de positions,
· Un fichier tableur CSV ou Comma Separated Values dans
lequel chaque ligne correspond à une mesure et contient les
coordonnées (latitude et longitude) de la position de l'UE, la taille de
l'Active Set, et les mesures RSCP et Ec/N0.
· 02 Fichiers Google Earth KML ou Keyhole Markup
Language (taille de l'active Set et valeurs de l'Ec/N0), pour visualiser les
données contenant tous les points obtenus par l'algorithme.
3.8 Positionnement utilisant le paramètre
TA
Le paramètre Timing Advance ou TA représente le
temps de propagation aller et retour des ondes radioélectriques entre le
mobile et la station de base avec laquelle il est en communication. Ce
paramètre est codé sur six bits et prend des valeurs
entières allant de 0 à 63. Une unité de TA correspond
à la durée d'un bit, soit 3,7 us. Les valeurs de TA correspondent
donc à des valeurs de temps de propagation comprises entre 0 et 233 us.
[25]
68
Un TA de valeur 1 correspond à une distance
aller/retour de deux fois 550 m. Le TA est transmis dans les messages de
signalisation du protocole GSM associé au canal dédié. Sa
valeur est rafraîchie toutes les 480 ms. Le paramètre TA
évolue si le mobile s'éloigne ou se rapproche de la cellule
courante ou si en cours de communication, il y a un changement de station de
base. [25]
On peut calculer les coordonnées du mobile à
partir du paramètre TA, comme nous montre la figure 3.07 ci-après
où il s'agit d'un exemple de calcul des points d'intersection de deux
cercles :

Figure 3.07 : Intersection de deux cercles
D'après la figure ci-dessus :
· XZ, YZ et X2,
Y2 sont respectivement les coordonnées géographiques
connues des stations de base BTSZ et BTS2.
· Latdecl et Londecl représentent respectivement
la latitude et la longitude en valeurs décimales de ces stations de base
(i =1,2)
· rZ et r2 sont les rayons des cercles centrés
sur les stations BTSZ et BTS2.
69
? ??12 est l'angle que fait l'axe horizontal du
repère trigonométrique avec les stations ??????1 et
??????2.
? âest l'angle que fait un des points communs des
deux cercles avec les stations ??????1 et ??????2. ?
P1 et P2 sont les points
d'intersections recherchés de coordonnées respectives
????1, Y??1 et ????2,
Y??2
Il convient de convertir au préalable les valeurs de
longitude et de latitude en valeurs métriques, ce qui donne les
relations suivantes:
??1 = 60 X 1180 X ??????d????1 ??2 = 60 X 1180 X ??????d????2
(3.42)
Y1 = 60 X 1852 X ??????d????1 Y2
= 60 X 1852 X ??????d????2 (3.43)
La valeur de ?????? reçue de la station i
(i=1,2) est convertie en distance r; correspondant au rayon du cercle qui
s'exprime alors sous la forme :
???? = (3,69 X ?????? X 300)/2 (3.44)
L'angle
â est donné par la relation suivante :
??22 - ??12 -
d2 (3.45)
/3 = arccos (-2??1d )
L'angle ??12 est calculé en prenant en compte les
quatre cas de figures rencontrés correspondant aux 4 cadrans du
repère trigonométrique.
Enfin, les coordonnées des points d'intersection sont
données par les relations :
|
????1 = ??1 + ??1 cos(??12 + /3)
|
????2
|
= ??1 + ??1 cos(??12 -
|
/3)
|
(3.46)
|
|
Y??1 = Y1 + ??1sin(
??12 + /3)
|
Y??2
|
= Y1 + ??1 sin( ??12 -
|
/3)
|
(3.47)
|
3.9 Conclusion
Le développement de la localisation à base
d'empreinte radio nous a permis de présenter des modèles
mathématiques et des algorithmes associés. Ainsi, il existe
plusieurs méthodes de compression de base de données radio et de
classification. Et, afin de réaliser notre application de traitement de
traces et localisation d'abonnés, nous avons étudié la
méthode basée sur l'OTD pour le 3G et, le TA pour le 2G, qui sont
des procédés dérivés du système LFP.
70
CHAPITRE 4
MISE EN OEUVRE ET SIMULATION DE L'OUTIL DE TRAITEMENT
DE TRACE ET
DE LOCALISATION D'ABONNES
4.1 Introduction
La société TELMA dispose d'un outil de trace
permettant de recueillir les caractéristiques radios de ses
abonnés. Dans le but de solutionner les différentes plaintes
provenant de ses clients, nous allons voir dans ce chapitre la conception et la
réalisation d'une application informatique capable de traiter les traces
obtenues et de localiser les mobiles du réseau 2G et 3G à partir
de ses caractéristiques radios.
Pour ce faire, nous avons utilisé UML comme langage de
modélisation, Java comme langage de programmation, Eclipse comme
environnement de développement, MySQL/XML comme SGBD, JavaScript et AJAX
comme technologie de développement Web et certaines
bibliothèques, Jquery pour la gestion cartographique.
4.2 Outil de trace 4.2.1
Présentation
L'outil de trace permet de lancer des traces UETR ou UE
Traffic Recording ou 3G, PMR ou Performance management Traffic Recording ou 2G
et GPEH ou General Performance Event Handling. C'est un logiciel
propriétaire d'ERICSSON.
Les traces d'abonnés sont lancées à
partir de leur numéro IMSI tandis que les traces Cell/Site sont
lancées à partir de leur code. Voici quelques captures de l'outil
de trace (figure 4.01, figure 4.02 et figure 4.03).
Figure 4.01 : Interface du PMR
Figure 4.02 : Onglet UE profils
71
72
Figure 4.03 : Onglet GPEH
4.2.2 Lecteur et décodeur de
trace
4.2.2.1 Lecteur de trace
TELMA dispose de quelques outils permettant de faire la lecture
des traces obtenues (UETR, PMR et GPEH). Ces lecteurs (figure 4.04) permettent
de spécifier un nom au fichier à décoder et de
sélectionner les traces récupérés en parcourant
vers le répertoire qui les contient.
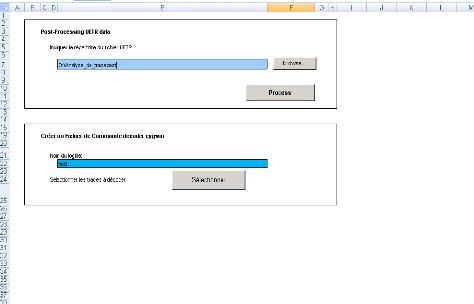
73
Figure 4.04 : Outil lecteur de trace UETR.
4.2.2.2 Décodeur de trace
Un outil nommé Cygwin permet de décrypter le
contenu de chaque trace sélectionnée, comme nous montre la figure
4.05 ci-dessous :
Figure 4.05 : Cygwin
74
4.3 Analyse et conception du système informatique
4.3.1 Architecture système
La figure 4.06 suivante nous montre l'architecture
système avec la répartition des tâches entre le client et
le serveur.
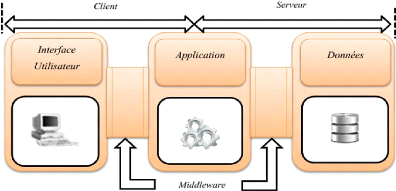
Figure 4.06 : Modèle
général d'architecture système
4.3.1.2 Client
Le client envoie une demande pour solliciter un service ou une
ressource particulière du serveur. 4.3.1.3 Serveur
Le serveur détient les ressources à partager. C'est
lui qui reçoit la requête du client et lui fournit les ressources
demandées (données, services, matériels) moyennant
l'authentification et les privilèges nécessaires.
4.3.1.4 Application
C'est le siège de la partie traitement. Si un client
effectue un traitement important, on parle de Client lourd, dans le cas
contraire, on l'appelle Client léger.
Dans le cas où les applications sont bien
séparées du serveur de données on doit mettre en classe un
autre serveur appelé serveur d'application.
75
4.3.1.5 Les données
On accède aux données via des systèmes de
gestion de base de données qui peut être un réseau, un
SGBDR ou Système de Gestion de Base de Données Relationnelles ou
un SGBDO ou Système de Gestion de Base de Données Objet en se
servant de middleware tel que JDBC ou Java Data Base Connectivity pour la
plate-forme Java, ODBC ou Object Data Base Connectivity pour la plate-forme
Microsoft ou en natif.
4.3.1.6 Interface utilisateur
L'interface utilisateur est le dispositif qui permet à un
usager de machine de se communiquer. Elle
peut être :
? Une GUI ou Graphic User Interface si l'utilisateur est un
être humain
? Une interface web
? Une interface en ligne de commande
? Une autre forme bien établie et suivant une règle
bien déterminée
4.3.1.7 Middleware :
Un middleware est un logiciel tiers qui est le lieu
d'échange d'informations entre différentes applications
informatiques. Pour cela, on utilise une même technique d'échange
d'informations dans toutes les applications impliquées à l'aide
de composants logiciels.
Ces composants logiciels effectuent la communication entre les
applications et ne dépendent ni des ordinateurs impliqués, ni des
caractéristiques matérielles et logicielles des réseaux
informatiques, des protocoles réseau, des systèmes d'exploitation
impliqués.
4.3.2 Analyse des besoins
4.3.2.1 Problèmes liés aux plaintes clients
Ce sont surtout les problèmes rencontrés sur
l'interface radio. Ils sont de plusieurs ordres [26] :
a. 76
Problème de qualité
Le terme « qualité » employé ici est
abordé du point de vue de l'opérateur et désigne
globalement les zones où le RxQual est élevé tandis que le
RxLev est acceptable. Les symptômes de ce problème sont
décrits dans le tableau 4.01. [26]
Plaintes
|
Indicateurs
|
Communications brouillée
|
Fort taux de handover sur qualité et de handover sur
interférence
|
Communication métallique
|
Forts taux d'échec de handover
|
Communications avec silences périodiques
|
Forts taux de coupures TCH
|
|
Tableau 4.01: Symptômes des
problèmes de qualité
b. Problèmes de couverture
Ce sont les problèmes dus à la faiblesse des
signaux perçus par l'abonné (faible RxLev). Ses symptômes
sont donnés dans le tableau 4.02. [26]
Plaintes
|
Indicateurs
|
Un manque de barres de niveau
|
Fort taux de handover sur niveau
|
Communication à sens unique
|
Forts taux de coupures TCH
|
|
Tableau 4.02: Symptômes des
problèmes de couverture
c. Problèmes d'accès
Les problèmes d'accès sont dus à une
saturation des canaux de trafic TCH ou de signalisation SDCCH. [26]
|
Plaintes
|
Indicateurs
|
|
Message « Appel échoué »
|
Fort taux de coupures TCH ou SDCCH
|
|
Communications avec silences périodiques
|
Forts taux d'échec d'allocation de canal SDCCH.
|
|
Message « Busy Network »
|
Congestion des canaux TCH ou SDCCH
|
Tableau 4.03: Symptômes des
problèmes de trafic
77
4.3.2.2 Problème de localisation
Depuis une dizaine d'années environ, surtout avec la
naissance du système de positionnement GPS ou Global Positioning System,
on remarque une demande croissante des systèmes de positionnement. Cette
forte demande est stimulée par plusieurs facteurs dont, entre autres,
l'insécurité croissante, la recherche d'une efficacité
plus grande dans la conduite des affaires commerciales, etc. [13]
Les principaux inconvénients de ce système sont
l'affaiblissement de la performance dans les zones urbaines denses où il
n'y a pas de vue directe vers le ciel et demande une consommation
d'énergie au niveau du mobile, ce qui diminue l'autonomie du terminal.
De plus, l'accès au GPS est très-onéreux
4.3.2.3 Expression des besoins
Les méthodes de localisation basées sur les
réseaux cellulaires, qui est à la portée de tous, ont
été développées. Cependant, l'implémentation
de la combinaison de plusieurs techniques (GPS - Cell ID - UTDOA) est
élevée et beaucoup d'opérateurs n'ont pas adopté
cette méthode.
Notre solution est destinée aux besoins de TELMA.
Ainsi, pour résoudre les problèmes de plaintes clients, nous
avons utilisé la localisation à base d'empreinte radio (OTD et
TA) qui est une méthode durable et abordable.
4.3.2.4 Identification des acteurs
Un acteur représente un rôle joué par une
personne, une chose interagissant avec le système. Pour notre cas, on
distingue :
? L'administrateur
? L'utilisateur
4.3.3 Modélisation UML 4.3.3.1
Définition :
UML, c'est l'acronyme anglais pour « Unified Modeling
Language » qui a été normalisé par l'OMG ou Object
Management Group. On le traduit par « Langage de modélisation
unifié ». La notation UML est un langage visuel formé d'un
ensemble de schémas, appelés des diagrammes, qui donnent
78
chacun une vision différente du projet à traiter.
UML nous fournit des diagrammes pour représenter le logiciel à
développer.
4.3.3.2 Caractéristique :
UML est indépendant du processus de conception et de
développement. Elle ne décrit pas comment il fonctionne. Ce n'est
pas une méthode ou un processus. Elle propose un ensemble de notations
pour que chacun ait à sa disposition les éléments
nécessaires à la conception d'une application. Elle fournit une
notation/syntaxe pour les diagrammes et modèles définis pendant
tout le cycle de développement. [27]
UML permet de définir des modèles de niveaux
différents :
· Analyse
· Conception
· Spécification d'implémentation
4.3.3.3 Diagrammes standardisés
UML comporte plus de 13 diagrammes standardisés qui se
répartissent en 2 catégories :
06 diagrammes structuraux :
· Diagramme de classe
· Diagramme d'objets
· Diagramme de packages
· Diagramme de structure composite
· Diagramme de composants
· Diagramme de déploiement
07 diagrammes comportementaux:
· Diagramme de cas d'utilisation
· Diagramme global des interactions
· Diagramme de séquence
· Diagramme de communication
· Diagramme de temps
· Diagramme d'activités
· Diagramme d'états
79
Ces diagrammes sont réalisés à partir du
besoin des utilisateurs et peuvent être regroupés selon les deux
aspects suivants :
a. Les aspects fonctionnels :
? Qui utilisera le logiciel et pour quoi faire ?
? Comment les actions devront-elles se dérouler ? ?
Quelles informations seront utilisées pour cela ?
b. Les aspects liés à l'architecture :
? Quels seront les différents composants logiciels
à utiliser (base de données, librairies, interfaces, etc...) ?
? Sur quel matériel chacun des composants sera
installé ?
UML modélise donc le système logiciel suivant ces
deux modes de représentation. 4.3.4 Diagramme UML de
l'application
Nous avons réalisé les diagrammes suivant durant
notre avec Visual Paradigm for UML 8.0 Enterprise Edition.

Figure 4.07 : Aperçu de Visual
Paradigm
80
4.3.4.2 Diagramme de cas d'utilisation
Le diagramme de cas d'utilisation (figure 4.08)
représente les fonctionnalités (ou dit cas d'utilisation)
essentielles aux utilisateurs.
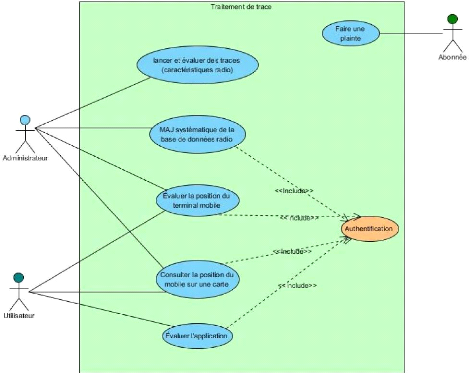
Figure 4.08 : Diagramme de cas d'utilisation
4.3.4.3 Diagramme de classe
Les diagrammes de classes montrent les classes (figure 4.09)
et les relations statiques entre ces classes : classe, attribut,
opération, visibilité, interface, association, agrégation,
héritage, dépendance...
niveau recap cellserveose float -rnreau recep_os3Nosme : float
· guslité_signal_cellserveuse : float
· guadté_signal_celivoisine : float
· o l_id_ootsorverse: string
· rall_id_rativoisine : string
· état_mobie : sting -rnsisdn : int int
-abonne : string
· Id_MAesure : in
-OFF : int -Td: int -TA :it
· Temps'. string
«MeoeoMobie()
getNrveov onopCel Servsuse():float
*setNiveauRecepCeltServeuse(oiveac teoep_celserlase : float) :
void .getNiveau ReccpCcilVaiv ne(} : float .getQualitéSig na !Col
ISoprem.() : float
« setaualitétnig nal
CoIlScrveuse(quoité_signal_cetlsrireuse: float) void
« setNiveau Sig naI CelIVeisine(nivesu_sgnal_ce!Weisine
: float)! void *getqualitdSig nalCelfVoisine(): Boat
*seta ualiténig
noiCelVoisne(quagté_mgnal_colivoslne : float) : void getCCIII.CeIlScrvv
o): string
setCcl IIdCCI ISorveur{cei id ca]lserveuse : string) : void
getCcllid CoIIVoisine{}: string
setCol lid Col IVon ite(raAidcellvoisine : string) void
getEtatMobile(): string
« setEtatMohiie(état_mobie : sting)'. void
*gctMsisdnO int
*setMssdn(mdsdn it): void
*getirnsi(): int
«setlmsl(mii : in) : void
.gotlnà() : int
setlmei{inei : inn)'. void
* getAtiornée() : string
« setAbornée(abonnée : string)! void
*getldMesure)) : int
*setldMesure(Id Massie: m)'. void
+getOFF(): int
«setOFF(OFF'. int): void .getT1A{}:int
setTM(1M : int) : void
* getTA{}'. int
« setTA{TA int): void *getTemps() : string *setTe.rps(Temps
: string) : void
Masure Mob lie
Abonnée
-Id_abornée : int -Num_abnnée string -Type_mobie :
string
«Abonnée()
«getldAbonnie(): Int
«setNunilbnrrsre(Nun aboméa: string) : void
*setldAborutée( id sbonnés: int): void
«getNnnbbonréel]: string getTyp doble() : smog
«setTypeMobie(Type_mmie : string). void
Stalk rnleBase
-Id_®I string -oode_site string -latitude :stag -iongitodo :
string -altitude : string x : string
-y : string
-HSA: string -pissance_Tx it -PSC : int
g etldCel()'. strip
« setldCell{ Id_cel : string}'. void setldSis(id btn
:int)'. void +getCodeite(): string .setCodvSito(nnde_lte : string) : void
. getLatitude(): string «setLatitude(iatitude : string} :
void .getLoiv dodo() string nsetLongilude(Imgltude : string) : void
g etAttdude() : snag setpiti[ude(sltitude : string) : void
*getx0'. string
setX(x : string)'. void .ger{!. string
.setY{x : strng}'. void getHba(): string
« setHba(HtA : string) : void
g etPtissance() : string
.se tPuissaoce(pussance_To fit) : void getPsc((: int
setPsn(PSC: int). void
Positionnement
désignation_Algo : string
· Men rnMobilo : string -Position Estimûe : string
«Position semant()
.getDésignationkgruitMne() : string
« setDésignaticnAtgorithma(désignation
Algo: string): void tgetMesureMohile{) : string
«setMesureMobile( Mes u ieMobie : string) : void
« getPositionEstiméo)) string
setPosi k tettiméa(Positim0Estinée : string ):
void
Pasltla nF stlrroi .
-Id_posilion ::r t -InloPosttion : string
*operation() *getldPosition(): int
« aelldPooitim(Id_pootion string) : void
g etlnfoPosdion() : string
«sellnfoPogtion(Info Position : song) : void
|
OntopeUee
Id_groupe : int description : string
*GropeUsen{}
n getldGrorpe{} : int
«setldGnoup«(ld_grupe : int) : void
g etDescriptiong : string
.setDescription(desuption : string) : void
|
UtëhsMee.
du:int -norn_uo string
· pre nom_ut string -lrxpn_ut : string -pwd_ut : sting -Q
nngoellser : sting
+getout{): int
«setldUt(Id_ot : id) : void getNoenllt{}: string
setNomllt(norn_ut: string): void .getPrénomllt{} : string
«setPrénomUt{pnenrxn_ut : string) : void getLoginllt() : sting
. setLoginLlt{iogin ut : string) : void «getPwdUt() string
n-setPwdut(pwd_ut: strng): void
intopoeeltiotr
-Id nfoP: jot -longitude : sing -latitude : string -altitude :
string -temps : string
«InfoPasition()
. getidnfoP{}: int
.setloinfoP{Itl infoP: nt)'. void *gettwtgitudiri}'. string
setLnrgior lo)!ry iode : sting} : void
g etLatiude(): string .setLatituda{fatitude : strong) : void
«getA titode() : string .setAtitude(altitude : string) : void .getTenps{ }
: string .setTemps(tenps : string) : void
81
Figure 4.09 : Diagramme de classe
82
4.3.4.4 Diagramme de séquence
Le diagramme de séquence permet de décrire tous les
scénarios d'utilisation du système. 4.3.5
Modèle Conceptuel des Données
Le Modèle Conceptuel des Données introduit la
notion d'entités, de relations et de propriétés. Il
décrit de façon formelle les données utilisées par
le système d'information. La représentation graphique, simple et
accessible, permet à un non -informaticien de participer à son
élaboration. Les éléments de base constituant un
modèle conceptuel des données sont :
? les propriétés ;
? les entités ;
? les relations.
La figure 4.10 ci-dessous nous montre le MCD de notre
système informatique, conçu sous Visual Paradigm for UML
Entreprise Edition Version 8.0
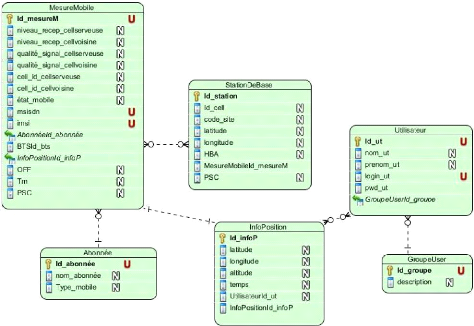
Figure 4.10 : Modèle conceptuel de
données
83
4.3.6 Langage de programmation
4.3.6.1 Visual basic :
EXCEL VBA ou Visual Basic pour Application est un langage de
programmation permettant d'utiliser du code Visual Basic pour exécuter
les nombreuses fonctionnalités de l'Application EXCEL. [28]
Une macro est un programme écrit en VBA. Elle permet
d'automatiser des tâches répétitives
réalisées sous EXCEL. Elle peut aussi être utilisée
pour créer des boîtes de dialogue afin de rendre une application
développée sous EXCEL plus conviviale.
Nous avons utilisé VBA pour récupérer les
données utiles dans la trace sous forme de fichier Excel afin de
construire une base de données.
4.3.6.2 Java et la plateforme JEE
Java est un langage de programmation moderne
développé par Sun Microsystems. Il n'a rien à voir avec
Javascript. Il a une excellente portabilité d'où il fonctionne
sous Windows, Mac, Linux, etc. On peut faire de nombreuses sortes de programmes
avec Java tels que :
· des applications, sous forme de fenêtre ou de
console ;
· des applets, qui sont des programmes Java
incorporés à des pages web ;
· des applications pour appareils mobiles,
· des applications pour la 3D.
La plateforme Java EE ou Java 2 Entreprise Edition s'appuie
totalement sur le langage Java. Java EE est une norme qui nous permet
développer notre propre application qui adapte en totalité ou
partiellement les spécifications de SUN. Il est possible de
représenter Java EE comme un ensemble de spécifications d'API,
une architecture, une méthode de packaging et de déploiement
d'applications et la gestion d'applications déployées sur un
serveur compatible Java.
a. Java EE
Actuellement, il existe plusieurs plates-formes de
développement qui sont basées sur d'autres langages.
Les principaux avantages d'utiliser Java EE sont :
· la portabilité,
· l'indépendance,
84
? la sécurité
? et la multitude de librairies proposées.
Le développement d'applications d'entreprise
nécessite la mise en oeuvre d'une infrastructure importante. Beaucoup de
fonctionnalités sont employés et développées, dans
le but de produire des applications sûres, robustes et faciles à
maintenir.
Certains services sont récursifs comme : l'accès
aux bases de données, l'envoi de mails, les transactions, la gestion de
fichiers, la gestion d'images, le téléchargement, le chargement
ou upload, la supervision du système etc.
C'est pour cette raison que l'architecture Java EE est
très intéressante vu que tous les éléments
fondamentaux sont déjà en place.
Nous n'avons plus besoin de concevoir une architecture, des
librairies et des outils spécialement adaptés. Cela demanderait
un temps et un grand investissement.
b. Environnement de développement :
Eclipse est un environnement de développement
intégré ou Integrated Development Environment dont le but est de
fournir une plate-forme modulaire pour permettre de réaliser des
développements informatiques. Il possède de nombreux points forts
qui sont à l'origine de son énorme succès. [29] Pour
développer notre application web, nous avons choisi Eclipse Mars.1.

Figure 4.11 : Eclipse
4.3.6.3 Javascript :
Le Javascript est un langage de script incorporé dans
un document HTML ou HyperText Mark-Up Language. Il est le premier langage de
script pour le Web. C'est un langage de programmation qui permet d'apporter des
améliorations au langage HTML en permettant d'exécuter des
commandes du côté client, c'est-à-dire au niveau du
navigateur et non du serveur web.
Javascript est fortement dépendant du navigateur
appelant la page web dans laquelle le script est incorporé, mais en
contrepartie il ne nécessite pas de compilateur, contrairement au
langage Java, avec lequel il a été longtemps confondu.
L'algorithme de positionnement de notre application a
été élaboré en Javascript.
4.3.6.4 Base de données :
a. MySQL
MySQL est le dérivé direct de SQL ou Structured
Query Language qui est un langage de requête vers les bases de
données profitant le modèle relationnel. Il en reprend la syntaxe
mais n'en conserve pas toute la puissance car de nombreuses
fonctionnalités de SQL n'apparaissent pas dans MySQL (sélections
imbriquées, clés étrangères...). Il peut aussi
jouer le rôle de serveur de base de données SQL multi -
utilisateurs et multi - tâches.
Nous avons utilisé MySQL Version 5.6.17 et pour
l'interface de la gestion d'utilisateur nous avons utilisé phpMyAdmin
dans WAMPSERVER Version 2.5, comme nous montre la figure 4.12.
Figure 4.12 : Interface de phpMyAdmin
85
86
b. XML
Les bases de données contenant les traces
d'abonnés ont été élaborées avec XML. C'est
un langage de balisage conçu spécifiquement pour délivrer
des informations sur WWW ou World Wide Web. Ses principaux avantages sont:
? Extensible, on peut créer des formats.
? Largement utilisé et reconnu par tous les langages de
programmation.
? Plus facile à lire.
Nous avons utilisé le mappage XML pour exporter les
données Excel vers XML comme nous montre la figure 4.13.
Figure 4.13 : Mappage XML
4.3.6.5 AJAX
AJAX ou Asynchronous JavaScript and XML est une technique
utilisant des technologies comme le javascript et le XML pour charger des
données dans une page web sans rechargement de la page. L'utilisation de
la classe XmlHttpRequest a rendu possible l'émergence d'un nouveau type
d'applications pour le Web. Celles-ci sont fluides et rapides et ne
nécessitent pas le rechargement complet de la page web sur laquelle
l'internaute navigue lorsqu'il sollicite des ressources provenant du
serveur.
87
4.3.6.6 JQUERY
Le WWW est aujourd'hui un environnement dynamique et ses
utilisateurs ont des exigences élevées quant à l'aspect et
aux fonctions des sites. Pour construire des sites interactifs
intéressants, les développeurs se tournent vers des
bibliothèques JavaScript, comme jQuery, qui leur permettent
d'automatiser les tâches courantes et de simplifier les plus complexes.
La popularité de jQuery vient de sa capacité à simplifier
un grand nombre de tâches. [30]
Les fonctionnalités de jQuery étant nombreuses.
Sa bibliothèque fournit une couche d'abstraction générique
pour les scripts web classiques. Toutefois, les fonctionnalités standard
permettent de répondre aux besoins suivants :
· Accéder aux éléments d'un
document.
· Modifier l'aspect d'une page web
· Altérer le contenu d'un document
· Répondre aux actions de l'utilisateur
· Animer les modifications d'un document
· Récupérer des informations à partir
d'un serveur sans actualiser la page
· Simplifier les tâches JavaScript courantes
a. Efficacité de jQuery :
Avec l'intérêt récent porté au
HTML dynamique, les frameworks JavaScript ont proliféré. Certains
sont spécialisés et se focalisent sur une ou deux des
tâches précédentes. D'autres tentent de réunir au
sein d'un même paquetage tous les comportements et toutes les animations
imaginables. Pour offrir les diverses fonctionnalités décrites
précédemment, tout en restant compact, jQuery emploie plusieurs
stratégies [30] :
· Exploiter CSS
· Accepter les extensions
· Masquer les excentricités du navigateur
· Manipuler des ensembles
· Autoriser plusieurs actions sur une ligne
88
4.3.7 Module cartographique
4.3.7.1 Cartographie dynamique sur Le Web
La forme de cartographie récente dans l'histoire de la
géographie étant la cartographie dynamique sur le Web. Il s'agit
d'une cartographie où l'utilisateur est acteur de sa découverte
d'informations: il zoome, il change de fond de carte, il ajoute ou modifie des
informations.
La cartographie dynamique sur le Web permet, en fonction d'une
requête d'un client envoyée au serveur cartographique, de
retourner les données désirées sous la forme d'une carte
comme nous montre la figure 4.14 [31]:
Figure 4.14 : Organisation d'une application
de cartographie numérique
4.3.7.2 Google Maps
Comme module cartographique, nous avons choisi Google Maps.
L'API ou Application Programming Interface de ce dernier est l'interface de
programmation pour Internet la plus utilisée à travers le
monde.
a. Remarque
Une API est une interface de programmation. Dans le cas de
Google Maps, il s'agit d'un ensemble de fonctions et classes JavaScript qui
permet de manipuler une carte dynamiquement au sein d'un site web. Le
développement avec l'API de Google Maps nécessite des
connaissances en HTML et en JavaScript. [31]
4.3.8 Serveur web et serveur
d'application
Nous avons utilisé comme serveurs web et serveur
d'applications Apache Tomcat v7.0 qui supporte J2EE 1.2, 1.3, 1.4 et Java EE5
et 6 web modules. Son interface de configuration est illustrée par la
figure 4.15 :
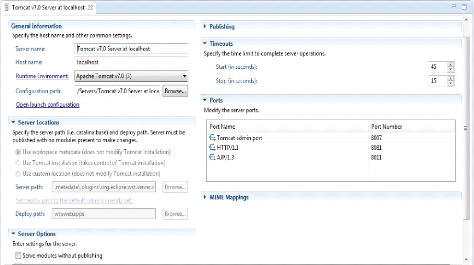
Figure 4.15 : Interface de configuration
d'Apache Tomcat
4.3.9 Structure du projet
La figure 4.16 nous montre la structure de notre projet :
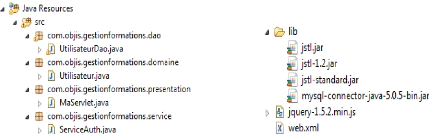
89
Figure 4.16 : Architecture du projet
90
Sur la partie gauche, on peut voir les différentes
classes de notre projet. UtilisateurDao.java est la classe gérant le
stockage des données, logiquement nommée couche de données
appelé DAO. Les autres servlets permettent de gérer les
requêtes.
A droite, nous avons les fichiers jar que nous avons
employés.
Dans la figure 4.17, nous avons toutes les pages JSP ou Java
Server Page et HTML pour la partie vue et les bases de données en XML.
Les scripts JavaScript permettant de gérer le module cartographique
Google maps sont inclus dans les pages HTML. Nous avons utilisé un
framework Jquery-1.5.2.min.js.
Figure 4.17 : Architecture du projet (suite)
4.4 Présentation de l'application web
4.4.1 Page d'authentification
La figure 4.18 présente la page de connexion de notre
application, un utilisateur est identifié par son nom et son mot de
passe.
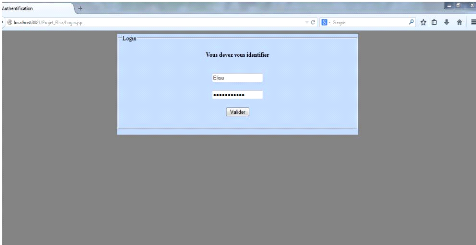
91
Figure 4.18 : Page d'authentification
4.4.2 Création d'utilisateur
La figure 4.19 nous montre la page de création
d'utilisateur de notre application. Les données sont enregistrées
dans une base de données MySQL.
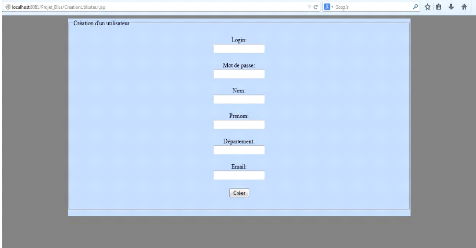
Figure 4.19 : Création d'utilisateur
92
4.4.3 Localisation d'un
abonné
4.4.3.1 Positionnement d'un mobile 2G
La figure 4.20 nous montre le positionnement d'un abonné
2G à l'aide d'une trace PMR.
Figure 4.20 : Positionnement d'un mobile 2G
4.4.3.2 Positionnement d'un mobile 3G
La figure 4.21 nous montre le positionnement d'un abonné
3G à l'aide d'une trace UETR.
Figure 4.21 : Positionnement d'un mobile
3G
4.5 Précision des différents
systèmes de localisation
4.5.1.1 Précision de la localisation basé sur le
TA
Le tableau 4.04 nous montre la précision de la
localisation possible en fonction du nombre de BTS :
|
Nombre de BTS considéré
|
Plage d'erreur de mesures
|
|
1
|
0 à 550 m
|
|
2
|
0 à 380 m
|
|
3
|
0 à 275 m
|
|
4
|
0 à 190 m
|
|
5
|
0 à 75 m
|
Tableau 4.04: Précision de la
localisation en fonction du nombre de BTS
Pour notre cas, puisque nous avons utilisé 02 BTS
(Target cell et Serving cell) alors nous avons une plage d'erreur de mesures de
0 à 380 m.
4.5.1.2 Précision de la localisation en 2G et 3G
93
Dans le tableau 4.05, on peut voir les différentes
précisions de la localisation en 2 G et 3 G.
94
Méthode
|
Réseau
|
Précision
|
Contrôle
par
l'abonné
|
Temps de
localisation
en seconde
|
Coût des
équipements
au sein
du
réseau
|
Coût
supplémentaire
au niveau
du
terminal
|
|
Cell-ID
|
GSM
|
300m à 10 km
|
Non
|
3
|
Aucun
|
Aucun
|
|
Cell- ID++
|
GSM
|
100m à
500m
|
Non
|
4
|
Aucun
|
Aucun
|
|
E OTD
|
GSM
|
150m à
500m
|
Oui
|
5
|
Intermédiaire
|
Intermédiaire
|
|
OTDOA
|
3G
|
30m
|
Non
|
10
|
Elevé
|
Aucun
|
|
GPS
|
GSM
|
30m
|
Oui
|
Jusqu'à 60
|
Nul
|
Elevé
|
Tableau 4.05: Précision des
différents systèmes
Pour notre cas, vu que nous avons utilisé l'OTD pour
localiser les abonnés 3G, la précision doit être aux
alentours de 30 m.
4.6 Conclusion
L'utilisation de l'outil de trace nous a permis non seulement
de recueillir les caractéristiques radios de l'abonné mais aussi
d'identifier les causes de coupure d'appel, échec d'établissement
d'appel, communication brouillé, etc.
Les traces d'abonnés obtenues nous ont aidés
à concevoir, de mettre en oeuvre et de simuler notre outil de
localisation. Plusieurs langages de programmation ont été
employés. Aussi, nous avons utilisé plusieurs outils tels que
WampServer, Eclipse, Visual Paradigm, et Apache Tomcat.
95
CONCLUSION GENERALE
Pour conclure, afin de mieux satisfaire ses clients, les
opérateurs téléphoniques doivent diversifier leurs
services. Ainsi, pour TELMA qui opère en Fixe, en Mobile et Internet, en
plus des services inclus dans la téléphonie (appel, sms,) elle
offre des services de transfert d'argent et payement de facture à l'aide
de Mvola.
La combinaison du chapitre deux avec le chapitre trois nous a
permis d'évaluer les techniques adéquates, pour réaliser
notre application de traitement de traces et localisation d'abonnés.
Ainsi, nous avons employé la méthode basée sur l'OTD pour
le 3G et, le TA pour le 2G.
L'outil de trace nous a facilité le
prélèvement de toutes les mesures radio nécessaires
à la création de notre base de données.
Nous avons élaboré notre algorithme de
positionnement en utilisant les mesures obtenues dans les traces PMR pour
localiser la station mobile de l'abonné dans un réseau GSM et les
traces UETR pour ceux de l'UMTS.
La conception et la réalisation de ce système
informatique nous a permis d'approfondir le langage de modélisation UML,
de maitriser des langages de programmation et l'environnement de
développement, ce dernier qui nous a servi d'élaborer les outils
de localisation, objet de ce travail. Ce mémoire nous a permis
d'appliquer les technologies de l'information et de la
télécommunication au système de géolocalisation,
dans le but de proposer une localisation d'abonné précise et
durable avec un coût moins élevé à
l'opérateur TELMA. Cette procédée pourra, entre autres,
être exploitée pour la sécurisation de clients.
Cependant, en localisation, il y a toujours une marge d'erreur
à respecter. Pour atteindre cet objectif, il est nécessaire de
faire une optimisation de couverture radio dans toutes les provinces surtout
dans les grandes villes.
Finalement, étant donné que TELMA a
commencé à utiliser la technologie 4G, et que nous n'avons pas pu
développer l'application de localisation pour cette technologie, elle
doit prévoir un outil pour le post processing du 4G, dont les
utilisateurs ne cessent d'augmenter.
96
ANNEXES
ANNEXE 1
EXTRAIT DE TRACE PMR
Voici un extrait de trace (figure A1.01) d'abonné mobile
2G du 25/01/2017 à 15h43 au 26/01/2017
à 20h22 :

Figure A1.01 : trace PMR
97
ANNEXE 2
EXTRAIT DE TRACE UETR
Voici un extrait de trace d'abonné mobile 3G (figure
A2.01) du 22/03/2017 de 16h à 16h45 :

Figure A2.01 : trace UETR
98
ANNEXE 3
EXTRAIT DU CODE SOURCE DE L'ALGORITHME DE POSITIONNEMENT
2G
...
$(xml).find('record').each( function(){
var Time =$(this).find('Time').text();
var ServingCellName
=$(this).find('ServingCellName').text();
var TargetCellName
=$(this).find('TargetCellName').text();
var ATA_1 =
parseInt($(this).find('ATA_1').text());
var ATA_2 =
parseInt($(this).find('ATA_2').text());
var Long_T =
parseFloat($(this).find('Long_T').text());
var Lat_T =
parseFloat($(this).find('Lat_T').text());
var Long_S =
parseFloat($(this).find('Long_S').text());
var Lat_S =
parseFloat($(this).find('Lat_S').text());
var D = parseFloat($(this).find('D').text());
var k=i + 1;
//calcul de la distance
var Xi = 60*1180*(Long_S);
var Yi = 60*1852*Lat_S;
var Xj = 60*1180*Long_T;
var Yj = 60*1852*Lat_T;
var r1 = (3.69*ATA_1*300)/2;
var r2 = (3.69*ATA_2*300)/2;
//arccosinus
var num = Math.pow(r2,2) - Math.pow(r1,2) -
Math.pow(D,2);
var den = -2*(r1*D);
var o = num/den;
var beta = Math.acos(o);
var c = (Xj - Xi)/D;
var p = Math.sqrt(1 -
Math.pow(c,2))/Math.sqrt(Math.pow(c,2));
var teta = Math.atan(p);
var alfa = Math.PI + teta;
...
99
ANNEXE 4
EXTRAIT DU CODE SOURCE DE L'ALGORITHME DE POSITIONNEMENT
3G
...
var TM_1 =
parseFloat($(this).find('TM_1').text());
var RSCP_2 =
parseFloat($(this).find('RSCP_2').text());
var OFF_2 =
parseFloat($(this).find('OFF_2').text());.........
var PL_A = txCodePwrVal - RSCP_1;
//calcul de la distance
var num1 = 10*PL_A + 69.55 - 26.16*Math.log10(1922.4)
+
13.82*Math.log10(HB_A);
var den1 = 44.9 - 6.55*Math.log10(HB_A);
var DA= num1/den1;
//d?rmination des coordonn? (x,y)UE
var x_UTM_A = 60*1180*Lon_1;
var y_UTM_A = 60*1852*Lat_1 ;.........
//xUE
var A = Math.pow(x_UTM_A,2) + Math.pow(y_UTM_A,2) -
Math.pow(DA,2);.........
var num4 = A*(y_UTM_C - y_UTM_B) + B*(y_UTM_A - y_UTM_C) +
C*(y_UTM_B
- y_UTM_A);
var den4= 2*(x_UTM_A*(y_UTM_C - y_UTM_B) +
x_UTM_B*(y_UTM_A -
y_UTM_C) + x_UTM_C*(y_UTM_B - y_UTM_A));
var num5 = A*(x_UTM_C - x_UTM_B)+B*(x_UTM_A -
x_UTM_C)+C*(x_UTM_B -
x_UTM_A);
var den5=2*(y_UTM_A*(x_UTM_C - x_UTM_B) + y_UTM_B*(x_UTM_A
-
x_UTM_C) + y_UTM_C*(x_UTM_B - x_UTM_A));.........
// operation OTD = OFF*38400 + TM
var OTD_A = OFF_1*38400 + TM_1;............
//delai de propagation ou diff?nce de temps de mesure (on
va prendre cell A et B)
var Cp = 300000000;
var Tk_A = 1/Cp * Math.sqrt(Math.pow(x_UTM_A - xUE,2) +
Math.pow(y_UTM_A -
yUE,2));.........
//calcul de RTD (entre cell A et B)
var RTD = OTD_A - OTD_B - (Tk_A - Tk_B);.........
100
BIBLIOGRAPHIE
[1] P. Parrend, «Aspects physiques et architecturaux
des réseaux de télécommunication, notamment de
téléphonie» Introduction aux
Télécommunications, 2005.
[2] C. Brielmann, «Réseaux de communication
Mobile », Mobile-F-2006v22.doc, Haute école technique et
informatique, 2006.
[3] J.P Muller, «Le réseau GSM et le
mobile», support de cours, Juillet 2002.
[4] A. Deseine, « GPRS », support de cours,
1999.
[5] H. Badis, «Les réseaux mobiles et sans fil -
Réseaux Cellulaires», support de cours, GM, Université
de Paris-Est Marne-la-Vallée, 2007/2008.
[6] E. Meurisse, « L'UMTS et le haut-débit
mobile », Livre, Février 2007.
[7] Y. Bouguen - Ehardouin - F.X. Wolff, « LTE et les
réseaux 4G », Groupe Eyrolles, ISBN : 978-2-212-12990-8,
2012.
[8] E.A. Lemamou, «Planification globale des
réseaux mobiles de la quatrième génération
(4G)», Thèse de Doctorat, Université de
Montréal, Ecole polytechnique de Montréal, Avril 2014.
[9] Efort, «Réseau d'Accès UMTS -
Architecture et Interfaces», Etude et FORmations en
Télécommunication disponible sur
http://www.efort.com, consulté
le 09 Janvier 2017.
[10] F. Launay «4G - LTE», disponible sur
http://blogs.univ-poitiers.fr/f-launay/2013/08/27/rsrp-et-rsrq-2emedefinition/,
consulté le 25 Janvier 2017.
[11] M. Germain, «Les bases de la radio», Un
livre blanc de Forum ATENA, 2013.
[12] N.E.H. Seghier, «Localisation d'un mobile dans un
réseau UMTS», Mémoire de fin d'études en vue de
l'obtention du diplôme de Magister, Universités des Sciences et de
la Technologie d'Oran. AU : 2012-2013.
[13] N. Dewaele, «État de l'art des
systèmes de localisation», Mémoire d'examen probatoire
en informatique, Le Cnam Centre de Marne-la-Vallée, Mai 2011.
[14] P. Stefanut, «Application des algorithmes de haute
résolution à la localisation de
101
mobiles en milieu confiné», Thèse
de Doctorat, Université des Sciences et Technologies de Lille, Juin
2010.
[15] F. Bouziane, « HTL : Une approche pour
l'hybridation des techniques de localisation», Mémoire de fin
d'étude pour l'obtention du diplôme de Magister en Informatique,
Université El-Hadj Lakhdar-Batna, 2014.
[16] A. Arya, « Localisation à base
d'Empreintes Radios: Méthodes Robustes de Positionnement pour les
Terminaux Cellulaires », Thèse de Doctorat, TELECOM ParisTech,
Ecole de l'Institut Télécom - membre de ParisTech, Septembre
2011.
[17] F. Evennou, «Techniques et technologies de
localisation avancées pour terminaux mobiles dans les environnements
indoor», Thèse de Doctorat, Université Joseph Fourier,
Janvier 2007.
[18] L.L. Kleine, «Détermination du
rôle des certaines peptidases bactériennes par inférence
à partir de données hétérogènes et
incomplètes», Thèse de Doctorat, Institut des Sciences
et Industries du Vivant et de l'Environnement (Agro Paris Tech), Octobre
2008.
[19] F. Chamroukhi, «Projet 1 : Classification
supervisée : Les K -plus proches voisins», Licence 2 Sciences
Pour l'Ingénieur, Université du Sud Toulon, A.U : 2012-2013.
[20] A. Doncescu, «Les réseaux de neurones
artificiels», 2004.
[21] S. Tisserant, «Eléments de
Statistique», article, 2009.
[22] D. Gundlegard, A. Akram, S. Fowler and H. Ahmad,
«Cellular Positioning Using
Fingerprinting Based on Observed Time
Differences». Mobile Telecommunications Department of Science and
Technology - Linkoping University Norrkoping, Sweden, 2011.
[23] T. Pereirinha, «Geolocation based on
Measurements Reports for deployed UMTS
Wireless Networks»7th
Congress of the Portuguese Committee of URSI Lisbon, Portugal, 22 Novembre
2013.
[24] T. Pereirinha, A. Rodrigues, P. Vieira,
«Geolocation based on Measurements
Reports for deployed UMTS
Wireless Networks», Article, 2013.
[25]
102
C. Tatkeu, «Faisabilité de la localisation de
mobiles terrestres par
radiogoniométrie et à l'aide d'un
réseau de radiotéléphonie GSM», 2008.
[26] H. Bamby, «Etude de la qualité de
service dans les réseaux mobiles GSM »,
Institut
supérieur d'informatique - Licence professionnelle 2012.
[27] E. Cariou, «Introduction à
UML2» Université de Pau et des Pays de l'Adour UFR
Sciences
Pau - Département Informatique, 2010.
[28] J. Dibie, «Le Tableur EXCEL. La Programmation
en VBA», AgroParisTech,
U.F.R. d'informatique, 2011.
[29] J.M Doudoux, «Développons en Java avec
Eclipse», document disponible sur
www.fsf.org, 26 Juin 2005.
[30] J. Chaffer et K. Swedberg, «Simplifiez et
enrichissez vos développements
JavaScript», disponible sur
http ://
www.free-livres.com/, Pearson
Education France, 2009, consulté le 02 Février 2017.
[31] F. Goblet, M. Dirix, L. Goblet, J. P. Moreux, «
Développer avec les API GOOGLE
MAPS», DUNOD : Paris,
2010.
FICHE DE RENSEIGNEMENTS

Nom : TAFENO
Prénoms : Harimanana Elisa
Adresse : Lot 2110/1bis cité des 67HA
Nord Est
harimelisa@gmail.com
+261 34 93 188 56
Titre du mémoire :
103
« LOCALISATION PAR EMPREINTE RADIO. APPLICATION
SUR LES RESEAUX
MOBILES 2G-3G.»
Nombres de pages : 104
Nombres de tableaux : 10
Nombre de figures : 43
Directeur de mémoire :
Nom : RAVALIMINOARIMALALASON
Prénoms : Toky Basilide
Grade : Docteur de l'Université d'Antananarivo
Tél : +261 34 00 164 33
RESUME
Ce présent ouvrage développe la conception et la
réalisation d'un système de traitement de trace et de
localisation d'abonné par empreinte radio, dans les réseaux
mobiles 2G et 3G de l'opérateur TELMA. La conception de l'application
web servant pour la localisation a été réalisée
sous la plateforme Java EE. Les coordonnées géographiques de
l'emplacement du mobile ont été obtenues grâce à un
algorithme de positionnement basé sur le TA pour le GSM et sur l'OTD
pour l'UMTS. Le système informatique pour la gestion de l'application
est composé d'un serveur de base de données et d'un serveur Web.
A partir de l'outil de TELMA, la trace de l'abonné est isolée et
l'exécution de l'application permet à son utilisateur de
visualiser les positions de l'équipement mobile selon les
caractéristiques radios obtenues via une carte Google maps.
Mots clés: Fingerprinting, Timing
Advance, Observed Time Differences, Java 2 Entreprise Edition,
positionnement.
ABSTRACT
This present work describes the design and realization of a
system of trace treatment and localization of subscriber, by fingerprinting, in
2G and 3G mobile networks of operator TELMA. The geographical coordinates of
the site of the mobile were obtained thanks to an algorithm of positioning
based on TA for the GSM and the OTD for the UMTS. The computer system of
application management consists of a database server and a Web server. The
design of the Web application was carried out under the platform Java EE. From
TELMA device, the trace of subscribed is isolated and launching the application
allow the user to visualize the positions of the mobile equipment according to
radios characteristics obtained via a Google maps.
Keywords: Fingerprinting, Timing Advance,
Observed Time Differences, Java 2 Entreprise Edition, positioning
| 

