|
Année Académique 2012 / 2013.
|
Université de Maroua
******
Institut
Supérieur du Sahel
************
Département
d'Informatique
et des Télécommunications
******
|
|
The University of Maroua
******
The Higher Institute of the
Sahel
*************
Department of Computer
Science and
Telecommunications
******
|
Informatique et télécommunications
CONCEPTION ET DÉPLOIEMENT DE LA
TECHNOLOGIE
MPLS DANS UN RÉSEAU
MÉTROPOLITAIN
Mémoire présenté et soutenu en vue de
l'obtention du Diplôme
d'Ingénieur de Conception en
Télécommunications.
Par :
TANGUEP Freddy Rolland
Ingénieur des Travaux en Ingénierie des
Télécommunications et Réseaux Mobiles
(ITRM)
Matricule : 11V219S
Sous la Direction de
Dr VIDEME BOSSOU Olivier
Chargé de Cours.
Devant le jury composé de :
Président : Prof. Dr. -Ing. habil.
KOLYANG Examinateur : Dr EMVUDU WONO Yves Sébastien
Rapporteur : Dr VIDEME BOSSOU Olivier
i
Épigraphe
« Un être humain fait partie d'un
tout que nous appelons ' l?univers'' ; il demeure limité dans
l'espace et le temps. Il fait l'expérience de son être, de ses
pensées et de ses sensations comme étant séparés du
reste : une sorte d'illusion d'optique de sa conscience. Cette
illusion est pour nous une prison, nous restreignant à nos désirs
personnels et à une affection réservée à nos
proches. Notre tâche est de nous libérer de cette prison
en élargissant notre compassion afin qu'il embrasse tous les êtres
vivants, et la nature entière, dans sa splendeur, ... »
Albert Einstein
Dédicace
ii
À la Famille NTCHANKWE.
iii
Remerciements
Qu'il me soit permis ici d'exprimer ma profonde gratitude et
mes sincères remerciements à toutes les personnes qui ont
contribué de quelques façons que ce soit à la
réalisation concrète et efficiente de ce mémoire. Plus
précisément, mes pensées s'orientent vers :
> Le président du jury: Prof. Dr. -Ing. habil. KOLYANG
;
> L'examinateur : Dr. EMVUDU WONO Yves Sébastien;
> L'encadreur : Dr. VIDEME BOSSOU Olivier ;
> Le corps enseignant de l'institut supérieur du sahel,
en particulier :
? Le Dr. VIDEME BOSSOU Olivier: pour son encadrement continu
et sa disponibilité incessante en mon endroit ;
? Monsieur TERDAM Valentin : pour ses conseils, le partage de son
expérience; > Les familles : FOTSO à Yaoundé ; FOTSO
à Bafoussam ; FOAKA à Bandjoun ;
> La grande famille des étudiants de l'ISS en
particulier mes promotionnaires ;
> Ma famille d'accueil qui m'a permis de m'épanouir
à Maroua en particulier : Martial KEMAJOU ; KOLYAN et ses frères
; ERIC ; la 'MATER'' ; ABDOU ; MAZOUMOURI ; MVOGO Thierry ; ...
> Mes amies ABBE M. Christine ; KAMNEING Varissa ; NGUEFACK
Jeanne R. ; Gaëlle ; Carine ; ...
> Tous mes amis et connaissances : Aquin DJOMOU ; BOMOKIN
Hugues ; NEGUEM TOGUE Arthur; DJEUGA D. Franck ; AWAOU Samira ; TAYOUMESSIE ;
VAGSSA Pascal; TAYA ; TASSY Ludovic; ESSOMO .B ; MVONDO; Elvira ; ... et tous
ceux dont je n'ai pas cité ici pour des raisons de concision mais qui se
reconnaitrons : sincèrement merci pour toute votre sympathie et votre
convivialité incommensurable.
iv
Table des Matières
Épigraphe i
Dédicace ii
Remerciements iii
Table des Matières iv
Résumé vii
Abstract vii
Liste des tableaux viii
Liste des figures et illustrations ix
Liste des sigles et abréviations x
Introduction générale 1
Chapitre 1 : Contexte et Problématique. 2
1.1-) Introduction 2
1.2-) Présentation du lieu de stage 2
1.3-) Contexte et problématique 3
1.3.1-) Contexte 3
1.3.2-) Problématique 4
1.4-) Objectifs 4
1.5-) Méthodologie 5
1.6-) Conclusion 5
Chapitre 2 : Le MPLS et les coeurs des réseaux. 6
2.1-) Introduction 6
2.2-) Généralités sur la technologie MPLS
6
2.2.1-) Introduction à la technologie MPLS 6
2.2.2-) Historique 6
2.2.3-) Concepts de base et fonctionnement du MPLS 7
2.2.4-) Le routage dans MPLS 14
2. 3-) Les coeurs de réseaux et les techniques qui y sont
utilisées 27
2.3.1-) Les techniques de commutation les plus utilisées
27
V
2.3.2-) Les techniques hybrides et la tendance vers les
techniques NGN 30
2.3.3-) Les techniques de transfert dans les coeurs de
réseaux type NGN 31
2.4-) Une extension du MPLS : le GMPLS 31
2.4-) Conclusion 33
Chapitre 3 : Conception des réseaux MPLS 34
3.1-) Introduction 34
3.2-) Définition et spécification du cahier des
charges 34
3.2.1-) Les besoins fonctionnels 34
3.2.2-) Les besoins non fonctionnels 34
3.3-) La conception des réseaux MPLS 34
3.3.1-) Introduction à la conception réseau 34
3.3.2-) La conception d'un réseau type IP/MPLS 35
3.4-) Méthodologie de mise en oeuvre d'un réseau
MPLS 39
3.4.1-) Les étapes à suivre dans le cas d'une
migration vers le MPLS 39
3.4.2-) Les étapes à suivre dans le cas d'un
nouveau réseau MPLS 42
3.5) Conclusion 43
Chapitre 4: Déploiement du MPLS. 44
4.1-) Introduction 44
4.2-) Définition d'une maquette d'émulation 44
4.2.1-) L'architecture physique de notre maquette
d'émulation 44
4.2.2-) Choix de l'adressage pour notre maquette
d'émulation 45
4.3-) Déploiement et implémentation de la
technologie MPLS 46
4. 3.1-) Configuration basique et activation du MPLS 47
4.3.2-) Déploiement de l'ingénierie de trafic MPLS
48
4.3.3-) Déploiement de la QoS-MPLS 52
4.3.4-) Déploiement de l'ingénierie VPN-MPLS 57
4.4-) Présentation des logiciels et matériels
utilisés 60
4.5-) Conclusion 61
Chapitre 5: Résultats et commentaires. 62
5.1-) Introduction 62
5.2-) Quelques résultats 62
vi
5.2.1-) Résultats concernant l?ingénierie MPLS
62
5.2.2-) Résultats concernant la qualité de service
MPLS 66
5.2.3-) Résultats concernant le VPN VRF du MPLS 67
5.3-) Capture du trafic et analyse sous Wireshark 68
5.5-) Conclusion 72
Conclusion générale 73
BIBLIOGRAPHIE 74
1-) Ouvrages : 74
2-) Articles / Supports de cours : 74
3-) Thèse et mémoire : 74
4-) Articles du web 74
5- ) RFC (Request For Comment) 75
ANNEXES A
Annexe1: Les configurations MPLS-TE A
Pour PE1 on a en résumé: A
Pour PE2 on a en résumé: B
Pour P1 on a en résumé: B
Pour P2 on a en résumé: C
Annexe 2: Les configurations MPLS-QoS. D
Pour les Pi (i=1; 2) routeurs: D
Pour les PEi (i=1; 2) routeurs: E
Annexe 3: Les configurations MPLS-VPN VRF (Sur les routeurs
PEi uniquement) F
Annexe 4: Les commandes de vérification et de
débuggage du MPLS G
Quelques commandes de Vérifications : G
Quelques commandes de débuggage: H
Commandes utilisées dans notre démonstration: I
vii
Résumé
L'objectif de ce mémoire est de concevoir et
déployer la technologie MPLS dans un réseau
métropolitain.
Pour atteindre cet objectif, nous avons commencé par
les généralités sur le MPLS et les coeurs des
réseaux. Ensuite, nous avons présenté l'ingénierie
MPLS et ses applications. Puis, nous somme passé à la conception
et au déploiement du MPLS suivant deux cas à savoir : le cas
d'une migration technologique vers le MPLS et ; le cas de la mise sur pied du
MPLS sur la base d'aucun existant réseau. Enfin nous avons
effectué une simulation du MPLS ; ce qui nous a conduit à
déboucher sur une conclusion et des perspectives.
Brièvement, nous avons proposé une
méthode de mise en oeuvre de la technologie MPLS dans un réseau
métropolitain.
Mots clés : MPLS ; ingénierie de
trafic ; coeur de réseau ou backbone ; qualité de service ; VPN ;
conception et déploiement ; réseaux et
télécommunications.
Abstract
The objective of this memory is to conceive and to open out
the MPLS technology in a metropolitan network.
To reach this objective we started with generalities on the
MPLS and the cores networks. Then, we presented the MPLS engineering and her
applications. Then, add us passes to the conception and the spreading of the
MPLS following two cases known as: the case of a technological migration toward
the MPLS and; the case of the setting up of the MPLS on the basis of none
existing network. At the end point, we did a simulation of the MPLS; what drove
us to the conclusion and the perspectives.
Briefly, we proposed an appropriate method to set up the MPLS
technology in a metropolitan network.
Key words: MPLS; traffic engineering; core
network or backbone; quality of service; VPN; Conception and spreading;
networks and telecommunications.
viii
Liste des tableaux
Tableau II.1 : Tableau très résumé du
vocable MPLS 8
Tableau II.2 : Les neuf types de messages RSVP-TE 18
Tableau II.3 : Comparaison succincte entre CR-LDP et RSVP-TE
[3] 26
Tableau IV.1 : Plan d?adressage pour notre maquette 46
Tableau IV.2 : Les classes de services crées pour notre
émulation 53
Tableau IV.3 : Logiciels utilisés 61
ix
Liste des figures et illustrations
Figure I.1 : Organigramme simplifié de l'Institut
Supérieur du Sahel 3
Figure II.1: La place du MPLS dans le modèle OSI [10]
7
Figure II.2: Architecture simplifiée d'un réseau
MPLS [10] 9
Figure II.3 : Mécanismes basés sur les deux
plans de commutation dans MPLS 11
Figure II.4 : Entête de trame MPLS [5] 12
Figure II.5 : Encapsulation avec une pile composée d'un
seul entête [5] 12
Figure II.6 : Forme générale d'une trame MPLS
contenant un datagramme IP [5] 13
Figure II.7 : Format des messages Path (à gauche) et
Rsev (à droite) 17
Tableau II.2 : Les neuf types de messages RSVP-TE 18
Figure II.8 : Format général des messages
RSVP-TE 18
Figure II.9 : Format des objets RSVP-TE 19
Figure II.10 : Illustration de l'établissement d'un
CR-LDP LSP 25
Figure II.11 : Illustration de la commutation de circuits [2]
27
Figure II.12: Temps de réponse comparés du
transfert de messages/de paquets [3] 28
Figure II.13 : Réseau étendu à transfert
de trame (Frame Relay) [2] 29
Figure II.14 : Architecture résumée GMPLS [3]
32
Figure III.1 : L'architecture EoMPLS de Cisco 37
Figure III.2 : L'architecture 'Enhanced IP VPN'' de
Lucent/Juniper 38
Figure III.3 : L'architecture MPE de Nortel 39
Figure IV.1 : Maquette utilisée pour notre
émulation 45
Figure VI.2 : Exemple de Réseau type VPN-MPLS 57
Figure V.1 : Résultat de la bannière
d'avertissement (Warning message) 62
Figure V.2 : Visualisation des tunnels MPLS-TE sur le ingress
LER 63
Figure V.3 : Visualisation des tunnels MPLS-TE sur le ingress
LER 64
Figure V.4 : Visualisation du labelling dans notre
réseau intégrant MPLS-TE 65
Figure V.5 : Résultats pour la QoS ou CoS MPLS 66
Figure V.6 : Visualisation des paramètres VPN VRF MPLS
67
Figure V.7 : Exemple de capture de trafic sur un lien du coeur
de réseau MPLS 68
Figure V.8 : Code de couleur de Wireshark 69
Figure V.9 : Fenêtre d'observation des dialogues entre
les hôtes du réseau 70
Figure V.10.1 : Conversations sur les entées standards
: type Ethernet 70
Figure V.10.2 : Conversations sur les entées standards
: type IPv4 71
Figure V.10.3 : Conversations sur les entées standards
: type UDP 71
Figure V.11 : Statistique hiérarchisée sur les
protocoles utilisés dans notre réseau 72
Liste des sigles et abréviations
AF (Assured
Forwarding)
AFDP (Adaptive
File Distribution
Protocol)
ARIS (Aggregate
Route-base IP Switching)
AS (Autonome
System)
ATM (Asynchronous
Transfer Mode) AToM
(Any Transport over
MPLS)
BE (Best
Effort)
BGP (Border
Gateway Protocol) BS
(Bit Stack)
CE (Customer
Edge or Equipment)
CEF (Cisco
Express Forwarding)
CLI (Command
Line Interface)
CoS (Class of
Service)
CPU (Central
Processing Unit)
CRC (Cyclic
Redundancy Check)
CR-LDP (Constraint-based
Routing /
Label Distribution
Protocol)
CSPF (Constrained
Shortest Path First)
DCE (Data
Circuit Equipment) DiffServ
(Differentiated Services)
DSCP (DiffServ
Code Points) DWDM
(Dense WDM)
EGP (Exterior
Gateway Protocol) EIGRP
(Extended Interior
Gateway Routing Protocol)
EIPVPN (Enhanced IP
VPN) EoMPLS (Ethernet
over MPLS) ETTD
(Équipement Terminal de
Transmission de Données)
x
FAI (Fournisseur
d?Accès à Internet) FEC
(Forwarding Equivalency
Classes) FF (Fixed
Filter)
FIB (Forwarding Information Base) FIFO
(First In First Out)
FP (File
Prioritaire)
FQ (Fair
Queuing)
FSC (Fiber
Switch Capable)
GMPLS (Generalized
MPLS)
GNS3 (Global
Network Simulator 3)
GPS (Global Positioning
System) GS (Guaranteed
Service)
ID (IDentifier)
IETF (Internet
Engineering Task Force)
IGP (Interior Gateway
Protocol) IntServ
(Integrated Services)
IP (Internet
Protocol)
IPv4 / IPv6 (Internet
Protocol version 4 /
Internet Protocol version
6)
IPX (Internetwork
Packet eXchange) IS-IS
(Intermediate System to
Intermediate System)
ISO (International
Standardization Organization)
L3PID (Layer 3
Protocol Identifier) LDP
(Label Distribution
Protocol) LER (Label
Edge Router)
LFIB (Label
Forwarding Information
Base)
LIB (Label
Information Base) LSC
(Lambda Switching
Capable) LSFT (Label
Switching Forwarding
Table)
LSP (Label
Switched Path)
LSR (Label
Switch Router)
MAC (Medium
Access Controller) MAN
(Metropolitan Area
Network) Mbb (Make
before break)
MP-BGP
(Multi-Protocol
Border Gateway Protocol)
MPE (Multiservice
Provider Edge) MPIBGP
(Multi-Protocol
Internal Border Gateway
Protocol)
MPLS
(Multi-Protocol
Label Switching) MPLS-QoS
(Multi-Protocol
Label Switching / Quality
of Services) MPLS-TE
(Multi-Protocol
Label Switching / Traffic
Engineering) MPLS-VPN
(Multi-Protocol
Label Switching / Virtual
Private Network) MQC
(Modular Quality of
Service)
NGN (Next
Generation Network)
OC-12 (Optical
Carrier-12)
xi
OSI (Open
Systems Interconnection) OSPF
(Open Shortest Path
First)
P (Provider)
PE (Provider
Edge)
PEPS (Premier
Entré Premier Sorti)
PGPS (Deuxième appellation de WFQ)
PHB (Per Hop
Behavior)
PQ (Priority
Queuing)
QdS (Qualité de
Service) QoS (Quality of
Service)
RD (Route
Distinguisher)
RED (Random
Early Detection)
RIB (Routing
Information Base)
RIP (Routing
Information Protocol) RSVP
(ReSource
reserVation Protocol)
RSVP-TE (RSVP-Traffic
Engineering) RT (Route
Target)
RTCP
(Real-Time Control
Protocol)
SE (Shared
Explicit)
SDH (Synchronous
Digital Hierarchy) SONET
(Synchronous Optical
NETwork)
TCP (Transmission
Control Protocol) TDM LSP
(Time Division
Multiplexing Label
Distribution Protocol)
TDP/LDP (Tag
Distribution Protocol /
Label Distribution
Protocol)
xii
ToS (Type of
Service) TTL (Time
To Live)
UDP (User
Datagram Protocol)
VLAN (Virtual
Local Area Network)
VoD (Video on
Demand)
VoIP (Voice
over Internet Protocol)
VPLS (Virtual Private
Local area network Services)
VPN (Virtual
Private Network)
VRF (Virtual
Routing and Forwarding) VVD
(Voix Vidéo Données)
WAN (Wide Area
Network) WDM (Wavelength
Division Multiplexing)
WF (Wildcard
Filter)
WFQ (Weighted
Fair Queuing) WRR
(Weighted Round
Robin)
1
Introduction générale
Avant l'avènement du MPLS, plusieurs technologies de
transports comme ATM et Frame Relay ont longtemps été
utilisés par les opérateurs réseaux dans le monde.
Aujourd'hui, le développement des services VVD
(Voix, Vidéo et Données) ; le
développement fulgurant d'internet ; la
convergence des réseaux (réseaux de
téléphonie fixe et mobile, réseaux informatiques,
réseaux satellitaires,...) vers le réseau IP
et bien d'autres facteurs, font que ces technologies historiques
soient dépassées. Car, la tendance actuelle est celle
impulsée par les NGNs (Next Generation Networks ;
en français réseaux de prochaine génération)
qui se veulent exigeantes en terme de débit (de l'ordre du gigabit) et
de qualité de service plus évoluée. Dès lors, il
faut penser à des technologies de transport offrant du très haut
débit, une très bonne qualité de service et surtout
permettre le transport des flux temps réels. Il revient alors à
se tourner vers une technologie respectant les critères qu'imposent les
NGNs. De ce fait, nous nous posons la question de savoir : quelle technologie
choisir ?
Pour le présent mémoire, nous nous somme
tourné vers la technologie MPLS pour des raisons que nous justifierons
plus loin. D'où le travail à faire : concevoir et
déployer la technologie MPLS dans un réseau
métropolitain.
Le présent mémoire est organisé en cinq
chapitres. Dans le premier chapitre, nous parlerons succinctement du cadre de
travail, de l'environnement du stage ainsi que du sujet traité. Le
second chapitre sera consacré aux généralités sur
le MPLS et les coeurs de réseaux. Le troisième chapitre ira plus
loin que les généralités en ce sens qu'il nous permettra
de présenter l'ingénierie MPLS et ses applications. Le
quatrième chapitre par contre s'intéressera à la
conception et au déploiement du MPLS proprement dit. Enfin, le dernier
chapitre concernera exclusivement la présentation des résultats
obtenus et commentaires.
2
Chapitre 1 : Contexte et Problématique.
1.1-) Introduction
Ce chapitre nous plonge dans le contexte de l'étude de
notre projet. Il met un accent particulier sur les objectifs à atteindre
et la méthodologie utilisée pour y parvenir.
1.2-) Présentation du lieu de stage
Nous avons effectué notre travail de mémoire au
sein de l'Université de Maroua, plus précisément dans le
laboratoire informatique de l'Institut Supérieur du Sahel sous la
direction du Dr. Olivier VIDEME BOSSOU.
En effet, créée par le décret
présidentiel n°2008 / 280 du 09 Août 2008,
l'université de Maroua est un regroupement pour l'instant de deux
grandes écoles à savoir lÉcole Normale
Supérieur et l'Institut Supérieur du
Sahel.
L'Institut Supérieur du Sahel en abrégé
ISS est une école d'ingénierie qui a été
créé en 2008 suite à la demande émise par les
populations du Nord et de l'Extrême Nord d'avoir une Université
dans leurs régions. Cette institution dépend de
l'Université de Maroua. L'ISS a à sa tête le Prof. Dr.
-Ing. habil. KOLYANG.
? Objectifs : L'ISS a été
créé dans le but de former les jeunes camerounais ayant à
leur actif au minimum le Baccalauréat dans divers domaines de la vie et
de ce fait, leur permettre d'intégrer le monde professionnel.
? Les différents départements de l'ISS
sont:
· INFOTEL: Informatique et
Télécommunication;
· HYMAE: Hydraulique et Maitrise des
Eaux;
· ENREN: Énergie Renouvelable;
· AGEPD: Agriculture, Élevage et Produits
Dérivés;
· TRAMARH: Traitement des Matériaux, de
l'Architecture et de l'Habitat;
· GTC: Génie du Textile et Traitement du
Cuir;
· BEASP: Beaux-Arts et Sciences du
Patrimoine;
· SISCOD: Science Sociale pour le
Développement;
· CLIHYPE : Climatologie, hydrologie,
pédologie ;
3
? SCIENV : Science environnementale.

Figure I.1 : Organigramme simplifié de
l'Institut Supérieur du Sahel
1.3-) Contexte et problématique
Il sera question pour nous dans ce paragraphe, de situer notre
travail et de ressortir la problématique qui en découle
clairement.
1.3.1-) Contexte
Concernant les réseaux des opérateurs des
télécommunications et des fournisseurs de services
réseaux, la tendance actuelle consiste à une convergence totale
vers le réseau IP.
4
En effet, avec l'évolution d'internet, avec
l'exponentiation des demandes de connexion internet, les exigences en termes de
débit sont devenues une priorité. De plus, le
développement des technologies de communication temps réels sur
IP comme la téléphonie sur IP, la visiophonie, la
vidéoconférence, la télésurveillance via IP, ... ,
ont très vite montré les limites des technologies comme ATM
(dont le débit ne peut pas atteindre le gigabit exigé par les
NGNs ) et Frame Relay. Pourtant, le but de l'industrie des
télécommunications est de faire évoluer les technologies
au fil du temps et de permettre aux entreprises exerçant dans ce domaine
de rester compétitives.
Ainsi il devient une nécessité pour ces
entreprises de s'adapter aux changements technologiques. Pour aider ces
opérateurs, nous avons travaillé sur une des nouvelles
technologies de coeurs des réseaux : la technologie MPLS.
D'où notre thème : « Conception et
déploiement de la technologie MPLS dans un réseau
métropolitain ».
1.3.2-) Problématique
Parlant de la technologie MPLS, il est important de recentrer
notre orientation sur le sujet. Se pencher sur un réseau
métropolitain revient alors pour nous à appesantir sur
l'architecture physique et logique de ce dernier et spécifiquement son
coeur de réseau.
Pour ce qui est du cas d'espèce : conception et
déploiement de la technologie MPLS dans un réseau
métropolitain ; il nous reviendra tout d'abord de chercher à
comprendre ce qu'est effectivement le MPLS et ensuite de comprendre ses
applications ; ceci, dans le but de proposer une solution de
déploiement de la technologie MPLS dans un réseau
métropolitain.
1.4-) Objectifs
Ce travail a pour objectifs de :
? Produire un réseau métropolitain
implémentant le MPLS sur toutes ses formes, à savoir :
? L'ingénierie de trafic (MPLS-TE), ? La
qualité de service (QoS-MPLS),
5
? Les VPN (VPN-MPLS) ;
> Proposer une méthode de déploiement du
MPLS.
1.5-) Méthodologie
Pour pouvoir atteindre les objectifs suscités, nous
adopterons une méthode par étapes à savoir :
> 1ère Étape : Faire une étude
bibliographique sur le MPLS ;
> 2e Étape : Étudier le MPLS et ses
applications ;
> 3e Étape : Proposer un canevas de
déploiement du MPLS :
? Cas d'une migration d'un réseau quelconque vers un
réseau type IP/MPLS,
? Cas d'un déploiement sous la base d'aucun existant
réseau ;
> 4e Étape : Construire une maquette de
réseau métropolitain et simuler le MPLS ;
> 5e Étape : Effectuer des tests et valider
les résultats.
1.6-) Conclusion
Dans ce chapitre nous nous somme attelé à
présenter l'environnement de travail ainsi que le sujet concerné
: conception et déploiement de la technologie dans un réseau
métropolitain. Dans le chapitre suivant, il sera question
premièrement d'aborder les généralités sur le MPLS
; puis deuxièmement nous verrons quelques techniques de commutation
utilisés aux coeurs des réseaux.
6
Chapitre 2 : Le MPLS et les coeurs des réseaux.
2.1-) Introduction
Ce chapitre décrit fidèlement les
généralités liées à notre sujet. À
cet effet, nous commencerons par l'historique sur le MPLS, puis nous
enchainerons avec ses concepts de base et fonctionnement, enfin nous ferons un
flash-back sur quelques technologies des coeurs des réseaux.
2.2-) Généralités sur la technologie
MPLS 2.2.1-) Introduction à la technologie MPLS
La technologie MPLS (Multi Protocol Label Switching)
a été définie par l'IETF comme étant relativement
simple, très souple, multi protocolaire et particulièrement
efficace. MPLS se voit comme une technologie réseau actuellement en
finalisation et dont le rôle principal souhaité est la
combinaison des concepts et techniques de routage de niveau 3 et des
mécanismes efficaces de commutation de niveau 2 et surtout
l'ingérence de plusieurs protocoles tels qu'IP, IPX, AppleTalk,...
2.2.2-) Historique
L'ingénieuse idée du MPLS naît en
1996 au sein d'un groupe d'ingénieurs d'Ipsilon
Network. Par la suite, plusieurs constructeurs se lanceront sur les
traces du MPLS en développant des protocoles propriétaires
basés sur le même principe, il s'agit de :
? ARIS de la maison IBM ;
? IP Navigator de CASCADE, ASCENA
et LUCEN ;
? IP Switching d'Ipsilon
Network et NOKIA ;
? Tag Switching de Cisco Systems
Inc.
Mais, au tout début de l'histoire, il était
prévu que MPLS ne fonctionne que sur ATM, ce qui a
poussé Ipsilon Network à mettre au point son
IP Switching. Cet attachement à ATM
poussera d'ailleurs certains constructeurs comme
Cisco à sortir sa version Tag Switching, qui
par la suite sera renommée en Label Switching pour
standardisation par l'IETF en tant que MPLS
à proprement parler. Cisco en sortira vainqueur à cette
époque parce que son Tag Switching allait au-delà d'ATM.
7
Certains auteurs qualifient le MPLS comme étant un
protocole de niveau 2,5 au sens OSI du terme (ce que nous illustrons par la
figure II.1) :
7-Application
6-Présentation
5-Session
4-Transport
2,5-MPLS

2-Liaison de données
3-Réseau
IPV4
ATM
IPV6
PPP
Ethernet
IPX
Apple Talk
Frame Relay
1-Physique
Figure II.1: La place du MPLS dans le modèle
OSI [10]
2.2.3-) Concepts de base et fonctionnement du
MPLS
2.2.3.1-) Vocabulaire du MPLS
Pour pouvoir comprendre les schémas explicatifs que
nous présenterons par la suite, il convient de prendre tout d?abord
connaissance avec le vocabulaire MPLS que nous avons consigné dans le
tableau ci-dessous :
8
|
Acronymes
|
Explications et détails
|
|
FEC
(Forwarding
Equivalency
Classes)
|
Il représente un groupe de paquets qui ont en commun
les mêmes exigences de transport. Ils reçoivent
ainsi le même traitement lors
de leur acheminement. À l'opposé des
transmissions IP
traditionnelles, ici, à un paquet est assigné
à une FEC, une et une seule fois ; ceci se faisant lors de son
entrée dans le réseau. Les FEC prennent en comptes les besoins en
termes de service pour certains groupes de paquets ou même un certain
préfixe d'adresses. Ainsi, chaque LSR se construit une table pour savoir
comment un paquet doit être transmis : c'est la table dite
Label Information Base
(LIB).
|
|
Label ou Étiquette
|
C'est un entier naturel qui est
associé à un paquet lorsqu'il circule dans un réseau type
MPLS ; il sert à prendre les décisions de routage.
|
|
LER
(Label Edge
Routeur)
|
C'est un LSR qui est situé entre le réseau MPLS
et le monde extérieur. Il est chargé par exemple de
"labelliser" les paquets à leur entrée dans le
réseau MPLS. Il est selon le cas équivalent à un
ingress node ou à un egress node. Il a
au moins une partie qui comprend l'IP et une le MPLS.
|
|
LDP
(Label
Distribution
Protocol)
|
C'est un protocole permettant d'apporter aux LSR les
informations sur l'association des labels
dans un réseau. Il s'utilise pour associer les labels
aux FEC, et créer des LSPs. Il construit la
table de commutation des labels sur chaque routeur et se base
sur le protocole IGP (Internal Gateway Protocol) pour le routage.
|
|
LSR
(Label Switch
Router)
|
C'est un routeur d'un réseau MPLS dont toutes les
interfaces supportent le protocole IP et qui est capable de retransmettre les
paquets au niveau de la couche 3 en se basant seulement sur le mécanisme
des labels.
|
|
LSP
(Label Switch
Path)
|
C'est une séquence de labels à chaque noeud du
chemin allant d'une source à une ou plusieurs destinations. Elle est
établie en fonction du type de transmission de données ou
après détection d'un certain type de données. Ainsi, il
est clair qu'un LSP sera unidirectionnel et le trafic de retour doit donc
prendre un autre LSP.
|
|
MPLS Egress node
Ou
routeur de sortie MPLS
|
C'est un routeur gérant le trafic sortant d'un
réseau MPLS. Il
possède à la fois des interfaces IP
traditionnelles et des interfaces connectées au réseau MPLS.
C'est l'usine du popping ou label disposition car il retire le
label aux paquets sortants sauf si le mode PHP (Penultimate Hop
Popping) est activé.
|
|
MPLS Ingress node
Ou
routeur d'entrée MPLS
|
C'est un routeur gérant le trafic entrant dans un
réseau MPLS. Il possède également des interfaces IP
traditionnelles et des interfaces connectées au réseau MPLS.
C'est l'usine du label pushing ou label
imposition car il impose le label aux paquets
entrants. Il est aussi
appelé LER (Label Edge
Routeur) due au fait qu'il connecte le réseau MPLS au monde
extérieur.
|
Tableau II.1 : Tableau très résumé
du vocable MPLS
Voyons à présent à quoi ressemble le
fonctionnement du MPLS.
9
2.2.3.2-) Le fonctionnement du MPLS
a-) Le principe de fonctionnement du MPLS
Comme nous le présente la figure II.2 ci-dessous,
une architecture MPLS se compose de deux grande parties : les sites
utilisateurs et du domaine MPLS (coeur de
réseau).

Figure II.2: Architecture simplifiée d'un
réseau MPLS [10] Explications :
? À l'entré dans le domaine MPLS, tout paquet ou
trame réseau provenant d'un site utilisateur (Réseau
d?utilisateurs) est examiné (examen prioritairement basé
sur le champ CoS) et classés dans un FEC (voir tableau
II.1) auquel on attribue une étiquette avant de l'envoyer dans le
coeur du domaine MPLS : c'est le label pushing ;
? Une fois au coeur du domaine MPLS, tous les paquets arrivant
sur un routeur sont examinés (examen basé sur les labels
uniquement) et labels enlevés ; par la suite, une autre
étiquette est ajouté à chacun de ces paquets en fonction
du chemin qu'il
10
prendra : c'est le label swapping. Cette
opération sera répétée jusqu'à ce que les
trames arrivent aux frontières du domaine MPLS.
? À la sortie du domaine MPLS, les trames venant du
coeur du domaine MPLS sont examinés et leurs étiquettes
enlevés ; puis ces paquets sont envoyés vers leurs destinations :
c'est le label se popping. Mais, puisque les opérations
de routage sont complexes et coûteuses, il est recommandé pour des
réseaux de grande taille, d'effectuer l'opération de
dépilement sur le dernier LSR (Penultimate
node1) du LSP (avant-dernier
noeud du LSP avant le LER) pour éviter de surcharger le
LER inutilement.
En résumé :
? On a une fonction de routage qui s'effectue à la
première étape et ;
? On a une fonction de commutation simple pour les paquets de
même FEC à travers les chemins découverts.
L'acheminement des paquets dans le domaine MPLS ne se fait
donc pas à base d'adresse IP mais de label (commutation de
label). Il est clair qu'après la découverte de chemin
(par le protocole de routage type IGP), il faut mettre en oeuvre un
protocole qui permet de distribuer les labels entre les LSRs pour que ces
derniers puissent constituer leurs tables de commutation et ainsi
exécuter la commutation de labels adéquate à chaque paquet
entrant. Cette tâche est effectuée par "un protocole de
distribution de label " : LDP
(Label Distribution
Protocol) et RSVP-TE
(ReSerVation
Protocol-Traffic
Engineering).
b-) La structure fonctionnelle du MPLS en
simple
En effet le protocole MPLS est fondé sur deux plans
principaux à savoir : le plan de contrôle et le plan de
données.
? Le plan de contrôle :
Il permet de contrôler les informations de routages de
niveau 3 grâce à des protocoles de routage existant et biens
connus tels qu'OSPF, IS-IS, BGP ; et les labels grâce
à des
1 Penultimate node1 :
c'est le routeur immédiat précédent le routeur LER de
sortie pour un LSP donné au sein d'un réseau MPLS ; simplement il
est l'avant denier saut sur un LSP. Il joue un rôle particulier pour
l'optimisation.
11
protocoles de labelling comme : LDP (Label
Distribution Protocol), BGP (dans sa version utilisée par
MPLS-VPN) ou RSVP (utilisé par MPLS-TE)
échangés entre les périphériques
adjacents.
? Le plan de données :
Il est indépendant des algorithmes de routages et
d'échanges de label et utilise une base de données LFIB
(Label Forwarding Information Base : laquelle base qui se remplie à
l'aide des protocoles d'échange de label) pour transmettre ou faire
suivre les paquets avec les bons labels.

Figure II.3 : Mécanismes basés sur les
deux plans de commutation dans MPLS 2.2.3.3-) L'entête d'une trame
MPLS et la commutation hiérarchique
a-) L'entête d'une trame MPLS
L'entête d'une trame MPLS est constituée de
(Voir figure II.4 ci-dessous):
? Un champ LABEL codé sur 20 bits ;
? Un champ CoS ou Exp (Classe of Service / Experimental) :
codé sur 3 bits, il sert à la classe de service (Class of
Service) ;
12
? Un champ BS pour bit stack : il est codé sur 1 bit et
permet de supporter un label hiérarchique (empilement de
labels) ;
? Un champ TTL pour Time To Live : pareil au TTL de IP, il est
codé sur 8 bits et sert à limiter la durée de vie d'un
paquet dans le réseau.
|
LABEL
|
CoS / Exp
|
BS
|
TTL
|
|
20 bits
|
3 bits
|
1 bit
|
8 bits
|
Figure II.4 : Entête de trame MPLS
[5]
Comme nous venons de le voir, dans la constitution de
l'entête MPLS, il y a la présence d'un bit stack qui permet de
supporter l'empilement des labels encore appelé label
hiérarchique. En quoi consiste cette hiérarchie et à quoi
sert-elle exactement?
b-) La commutation hiérarchique dans
MPLS
Le principe de label hiérarchique est basé sur
l'empilement des labels et permet en particulier d'associer plusieurs contrats
de services à un flux donnée au cours de sa chevauché
à travers le réseau MPLS. Ainsi, il incombe aux LSRs de
frontière la responsabilité de pousser ou de tirer la pile de
labels pour désigner le niveau d'utilisation courant de label
concerné. En effet, on dit que la commutation MPLS est
hiérarchique parce qu'en plus de commuter des étiquettes, elle
permet d'en ajouter ou d'en enlever. L'entête MPLS attaché
à un même paquet IP représente une pile d'étiquette
appelé label stack. De façon pratique, le
protocole MPLS se traduit par l'ajout d'une pile d'entête dans la trame
(Voir figure II.5).
|
Entête de couche
|
Entête de niveau N
|
|
|
Entête de niveau N+1
|
|
|
Entête de niveau N+2
|
Entête de
couche liaison
|
Autres entêtes de
couches et
données
|
Figure II.5 : Encapsulation avec une pile
composée d'un seul entête [5]
Malgré le fait qu'MPLS soit indépendant du niveau
2, le placement de l'entête est différent suivant le protocole
utilisé. Cela signifie que dans le cas d'un protocole de
13
niveau deux utilisant la commutation de cellule, le champ
correspondant au label sera utilisé comme label MPLS. Dans le cas
spécifique d'une trame Ethernet, le
'préambule'' et le 'bit
Start'' sont remplacés par l'entête MPLS (Voir figure
II.6).
|
Entête de couche
|
Entête MPLS
|
|
|
|
Datagramme IP
|
|
|
|
Préambul
|
Star
|
Dest.Add
|
Source.Add
|
Type
|
Données
|
CRC
|
Dest.Add
Source.Add
Type
Données
CRC
Label CoS
|
Entête MPLS
|
|
Trame Ethernet taguée
|
Trame Ethernet avec Tag MPLS
BS
TTL



Trame Ethernet sans Tag MPLS

Figure II.6 : Forme générale d'une trame
MPLS contenant un datagramme IP [5]
2.2.3.4-) Le labelling ou distribution des labels MPLS
et le protocole LDP
a-) Le labelling ou distribution des labels
MPLS
Les LSRs s'appuient sur l'information de label pour commuter
les paquets dans le coeur de réseau MPLS. Comme nous l'avons vu, quand
tout routeur reçoit un paquet taggué, il utilise le label pour
déterminer l'interface et le label de sortie ; d'où la
nécessité de protéger les informations sur ces labels au
niveau de tous les LSRs. À cet effet, suivant le type d'architecture,
différents protocoles sont employés pour l'échange de
labels entre LSRs ; principalement les plus utilisées sont : TDP/LDP ;
CR-LDP ; RSVP-TE ; MP-BGP.
b-) Le protocole LDP
Comme la plupart des protocoles, le protocole LDP est
un protocole de signalisation et plus précisément de la
distribution de labels. Il fonctionne suivant la notion de chemin le
plus court ; en clair, cette notion stipule que : pour un préfixe
d'adresse, le protocole de routage classique définit un arbre de plus
court chemin avec pour racine le LSR de sortie qui est en effet celui qui a
annoncé le préfixe et, pour feuilles les différents
routeurs d'entrée. Le routeur de sortie annonce le
préfixe (associé au label) à ses voisins et de
proche en proche, les messages de signalisation vont remonter jusqu'aux
routeurs d'entrée, permettant ainsi à chaque LSR
intermédiaire de faire correspondre un label au préfixe. Mais, ce
protocole connait deux inconvénients majeurs à savoir :
? Les contraintes posées par le protocole de routage :
en effet, les LSPs établis par le protocole LDP sont contraints par le
protocole de routage ;
? L'impossibilité de faire une réservation de
ressources : LDP n'a pas la possibilité de spécifier des
paramètres pour l'attribution de trafic à acheminer sur le
LSP.
Bien qu'LDP ait des limitations, il trouve sa compensation par
le complément apporté par d'autres protocoles comme : CR-LDP et
RSVP-TE. Ceci nous conduit aux notions de routage dans MPLS.
2.2.4-) Le routage dans MPLS
Pour ce qui est du routage dans MPLS, nous allons insister sur
les deux protocoles CR-
LDP et RSVP-TE.
2.2.4.1-) Le protocole de réservation de ressources
RSVP-TE
a-) Introduction à RSVP-TE
De façon simple, on peut dire que RSVP-TE est une
extension du protocole RSVP (Ressource ReSerVation Protocol) pour les
réseaux MPLS permettant de prendre en compte la notion de Qualité
de Service et d'ingénierie trafic.
Dans son idée de création, le protocole RSVP est
destiné à être un protocole de signalisation pour
IntServ2. RSVP avec quelques extensions a
été adapté par MPLS pour être un protocole de
signalisation qui supporte MPLS-TE.
L'essentiel est de ne pas quitter des yeux que RSVP-TE est un
protocole de réservation et pas des moindres ; il offre jusqu'à
trois types de réservations à savoir :

2 IntServ2 :
pour Integrated Services ; qui est un modèle de QoS ou un
hôte demande au réseau une QoS donnée pour un flux
spécifique.
14
? Fixed filter (FF) : Cette
méthode propose une réservation de label pour chaque noeud
émetteur ; ainsi les ressources de chaque noeuds ne sont pas
partagées ;
15
? Wildcard Filter (WF) : Cette
méthode propose une seule réservation de label quel que soit le
nombre de noeuds émetteurs ; il permet d'effectuer des connexions point
à multipoints ;
? Shared Explicit (SE) : Cette
méthode permet au récepteur d'inclure explicitement chaque
émetteur dans la réservation ; ainsi chaque émetteur a la
possibilité de spécifier sa route et permettre donc l'existence
de multiples LSPs. La différenciation des types de réservation va
être notamment utilisée dans les mécanismes de
reroutage.
b-) Le Reroutage de RSVP-TE du MPLS
Quand l'on utilise le routage explicite dans les
réseaux MPLS, il peut parfois survenir certaines pannes il est alors
impératif de trouver un moyen de contournement : le reroutage du
trafic.
Le principe du reroutage est de recréer un LSP
transitant par la route désirée et de faire par la suite basculer
le trafic dessus ; enfin de détruire l'ancien LSP en s'appuyant sur le
principe de 'Make befor break3''. Mais
cela n'empêche que parfois peuvent survenir des problèmes dans le
cas où l'ancienne et la nouvelle route ont des liens en communs. Dans ce
cas, durant la création du nouveau lien la bande passante
nécessaire sur ces liens sera double et pourrait alors dépasser
leur capacité ; mais ce problème est résolu par RSVP-TE.
En effet, l'utilisation du même objet SESSION avec comme type de
réservation SE (Shared Explicit) est utilisée et de
plus, afin de différentier l'ancien et le nouveau tunnel un nouvel LSP
ID est inséré ; dès lors, avec ces nouveaux
éléments une nouvelle route est créée suivant la
méthode conventionnelle. Puis, sur les liens en communs les ressources
sont partagées avec l'ancien LSP grâce à la
réservation de type SE. Enfin, dès que le LSP est
créé le trafic est basculé de LSP et l'ancien LSP est
détruit : cette même technique s'utilise pour l'augmentation de la
bande passante.
La fonctionnalité 'd?Explicit
Routing'' du RSVP-TE est très importante en ingénierie de
trafic ; c'est un type de routage permettant de maximiser et d'optimiser
l'utilisation des ressources. Il s'effectue à l'aide de l'objet
EXPLICITE_ROUTE que nous allons bien aborder plus bas. Ce routage se fait
manuellement ou automatiquement à
3 Make befor break3 :
Principe selon lequel ; le reroutage doit être effectué sans
aucune perturbation du trafic courant, car le LSP doit être recrée
sur le tracé considéré avant toute destruction de
l'ancien.
16
l'aide d'un générateur de route. L'objet
EXPLICITE_ROUTE contient la liste des noeuds par lesquels la réservation
du LSP va être effectuée ; laquelle liste peut être une
liste d'adresses IP de sous réseaux IP ou bien des noeuds abstraits
(virtuels). En effet, un noeud abstrait est un groupe de noeuds
adjacents les uns aux autres dont la topologie n'est pas connue pas le noeud
d'entrée : ce sont des systèmes autonomes. Le routage au sein de
ces systèmes s'effectue de manière transparente.
RSVP-TE est un protocole dit `'soft
state», car la liaison n'est établie que pendant la
durée spécifiée par des 'timers»
envoyés dans les messages de demande de réservation ; ce
qui implique le rétablissement régulier de la liaison.
c-) Les messages RSVP-TE
+ L'architecture de communication : Messages /
Objets
Ici, nous présentons les principes de fonctionnement et
les mécanismes entrants dans la mise en oeuvre du RSVP-TE. Partant du
principe que, les noeuds du domaine MPLS doivent pouvoir communiquer entre eux
pour assurer leur fonction de routage ; le protocole RSVP-TE répond
à ce besoin en définissant des types messages et des objets. Un
message est caractérisé par sa propre structure et par les objets
qu'il inclut. À chaque objet on peut attribuer une fonction
particulière. En général, on distingue deux grands types
de messages :
> Les messages destinés à la création des
routes : Path et Resv ;
> Les messages destinés au contrôle
(remontées d?erreurs etc) : PathErr et ResvErr
Comme les messages, il en existe aussi différents objets
parmi lesquels :
> L'objet SESSION : pour identification de session entre un
noeud d'entrée et un noeud de sortie ;
> L'objet SENDER_TEMPLATE et l'objet FILTER_SPEC : tous
deux combinés permettent d'identifier de façon unique un LSP dans
le réseau ;
> L'objet LABEL_REQUEST: il indique une demande de
réservation de labels. Il est transmis à l'intérieur du
message Path (downstream). Cependant, la liaison des labels n'est
effective que lors du passage du message Resv (upstream).
LABEL_REQUEST fournit aussi des renseignements sur le protocole
réseau de couche 3 (L3PID : Layer 3 Protocol Identifier) ;
? L'objet EXPLICITE_ROUTE: son rôle premier est d'imposer
la route à prendre en spécifiant la suite des noeuds à
suivre ;
? L'objet RECORD_ROUTE : il permet d'enregistrer la route
empruntée par le message ;
? L'objet SESSION_ATTRIBUTE : il peut contenir des informations
de contrôle complémentaires, surtout ceux entrant dans le
'trafic engineering'' ;
? L'objet LSP_TUNNEL_IPv4 et l'objet LSP_TUNNEL_IPv6 qui
indiquent si l'adresse du noeud de destination est d'IPV4 ou d'IPV6.
? Les types de Messages RSVP-TE les plus
cités
Il existe deux grand groupes de messages RSVP-TE qui sont
éclatés en neuf types au total.
|
Common header
|
|
[INTEGRITY]
|
|
SESSION
|
|
PHOP
|
|
TIME-VALUES
|
|
[EXPLICIT_ROUTE]
|
|
LABEL_REQUEST
|
|
[SESSION_ATTRIBUTE]
|
|
[POLYCY_DATA]
|
|
SENDER_TEMPLATE
|
|
SENDER_TSPEC
|
|
[ADSPEC]
|
|
[RECORD_ROUTE]
|
|
Common header
|
|
[INTEGRITY]
|
|
SESSION
|
|
NHOP
|
|
TIME-VALUES
|
|
[RESV_CONFIRM]
|
|
[SCOPE]
|
|
[POLYCY_DATA]
|
|
STYLE
|
|
FLOWSPEC
|
|
FILTER_SPEC
|
|
LABEL
|
|
[RECORD_ROUTE]
|
17
Figure II.7 : Format des messages Path (à
gauche) et Rsev (à droite)
Nous voyons que chaque objet contenu dans un message RSVP-TE est
spécifique à une fonction particulière qu'il remplit
pleinement (Voir tableau II.2).
|
Appartenance à un grand groupe
|
Type de
message
|
Commentaire descriptif
|
|
Groupe de messages
Path et Resv : qui
sont des messages
destinés à la création
des routes.
|
Path
|
Utilisé pour établir et maintenir les chemins
tracés.
|
|
PathTear
|
Similaire au message de type Path, mais s'utilise plutôt
pour la suppression des réservations réseau.
|
|
Resv
|
Il est envoyé en réponse au message Path.
|
|
ResvTear
|
Similaire au message de type Resv, mais s'utilise plutôt
pour la suppression des réservations réseau.
|
|
ResvConf
|
S'envoie de façon optionnelle à l'émetteur
d'un
message Resv pour confirmation qu'une
réservation
donnée est bien établie.
|
|
ResvTearConf
|
Similaire au message de type ResvConf, mais est
optionnellement envoyé à l'émetteur d'un
message ResvTear pour confirmer qu'une
réservation
réseau donnée est supprimée.
|
|
Hello
|
C'est un message particulier qui s'envoie entre noeuds voisins
directement connectés entre eux.
|
|
Groupe PathErr et
ResvErr : qui sont
messages
destinés au
contrôle (remontées
d?erreurs etc) :
|
PathErr
|
Il est envoyé par un récepteur d'un message Path
qui détecte une erreur dans ce message.
|
|
ResvErr
|
Il est envoyé aussi par un récepteur d'un
message Resv qui détecte une erreur dans ce message.
|
Tableau II.2 : Les neuf types de messages RSVP-TE
Nous allons maintenant analyser en profondeur le format d'un
message RSVP-TE typique. On voit qu'en général, un message
RSVP-TE est constitué d'un en-tête commun (common header)
et d'un nombre variable d'objets selon le type spécifique de message
(Voir figure II.8 ci-dessous).
En-tête commune
18
0 1 2 3
|
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8
9 0
|
|
Version (4 bits)
|
Flags
(4 bits)
|
Message type
(8 bits)
|
RSVP Checksum
(16 bits)
|
|
Send TTL
(8 bits)
|
Rserved
(8 bits)
|
RSVP length
(16 bits)
|
|
Objets
|
Figure II.8 : Format général des
messages RSVP-TE ? Version (4 bits) : il
renseigne sur la version du protocole RSVP utilisé ; ?
Flags (4 bits) : il n'est pas bien définit pour l'instant ;
19
> Message Type (8 bits):
1 = message Path ; 2 = message Resv ; 3 = message pathErr ; 4 =
message ResvErr ; 5 = message pathTear ; 6 = message ResvTear ; 7 = message
ResvConf ; 10 = message ResvTearConf ; 20 = message Hello ;
> RSVP Checksum (16 bits) : Il est surtout
utilisé pour la détection d'erreur et s'appuie sur les
mêmes principes que le Checksum utilisé dans IP ;
> Send TTL (8 bits) : Il contient la
valeur du TTL (Time To Live), dans le paquet IP, avec lequel ce
message a été envoyé : il impose une durée de vie
du paquet ;
> Reserved (8 bits) : Il est encore non
utilisé pour l'instant ;
> RSVP Length (16 bits) : La longueur de
message RSVP en octets, 'common header'' inclus. La valeur de ce
champ est donc toujours supérieure à 8. Nous venons de
détailler l'intérieur des messages RSVP-TE à
l'intérieur desquels se trouvent des champs objets ; comment se
présente le format des objets RSVP-TE ?
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8
9 0 1
|
Object length (16 bits)
|
Class-num (8 bits)
|
C-type (8 bits)
|
Object contents (variable length)
Figure II.9 : Format des objets RSVP-TE
> Object Length (16 bits) : C'est un
champ dont la valeur est toujours supérieure à
4, il indique la longueur de l'objet RSVP en octets en incluant
l'en-tête de l'objet ;
> Class-Num (8 bits) : Il renseigne
simplement sur la classe de l'objet ;
> C-Type (8 bits) : Il donne le type
auquel correspond la classe de l'objet ;
> Object Contents (longueur
variable) : C'est l'objet lui-même.
On constate que chaque classe a son propre espace de
numéro C-Type. Par exemple :
> La classe SESSION a 4 C-Types : IPv4, IPv6,
LSP_TUNNEL_IPv4, et LSP_TUNNEL_IPv6. Les numéros assignés
à ces C-Types sont 1, 2, 7 et 8.
> LABEL_REQUEST a trois C-Types: Without Label Range, With ATM
Label Range, and With Frame Relay Label Range avec les numéros de
C-Types 1, 2 et 3.
20
De ce fait, pour identifier le contenu d'un message, on doit
prendre en compte les numéros de classe et le numéro de C-Type.
On peut voir les classes et C-Types comme une sorte de la numérotation
hiérarchique. Voir la structure des messages RSVP-TE en
général nous permet dont d'entrer dans le fonctionnement
d'RSVP-TE à proprement parler.
d-) Le fonctionnement global de RSVP-TE
RSVP-TE est un mécanisme de signalisation
utilisé pour réserver des ressources à travers un
réseau : ce n'est pas un protocole de routage car, toute décision
de routage est faite par IGP. RSVP-TE a principalement trois fonctions de base
à savoir :
? L'établissement et le maintien des chemins (Path
setup and maintenance) ;
? La suppression des chemins (Path teardown) ; ? La
signalisation des erreurs (Error signalling).
RSVP-TE est un "soft-state protocol"
: car il a besoin de rafraîchir périodiquement ses
réservations dans le réseau ; ce qui le différentie des
"hard-state protocol", qui par contre signalent leurs
requêtes une seule fois et supposent qu'elles restent maintenues
jusqu'à sa résiliation explicite.
? L'établissement, le maintien, la suppression des
chemins et la signalisation des erreurs :
L'établissement et la maintenance des chemins sont des
concepts très proches utilisant certes les mêmes formats de
messages mais cependant subtilement différents.
1. L'établissement des chemins
:
Lorsque l'ingress LER (appelé aussi MPLS-TE tunnel
headend ou headend tout cour) a terminé sa procédure CSPF
pour un tunnel particulier, il signale alors le chemin trouvé à
travers le réseau ; il réalise ainsi cette opération en
envoyant un message path au prochain noeud dans le chemin calculé vers
la destination désirée. Ce message path contient un objet
EXPLICIT_ROUTE qui lui, contient le chemin calculé par CSPF sous forme
d'une séquence de noeuds. Puis, l'ingress LER ajoute un objet
LABEL_REQUEST pour indiquer qu'une association de label est requise pour ce
chemin et quel type de protocole réseau sera utilisé sur le
chemin qui sera ainsi établit. Enfin, un objet
21
SESSION_ATTRIBUTE est ajouté au message path pour
faciliter l'identification de la session et les diagnostics, et, le message
path est acheminé vers l'Egress LER (appelé aussi MPLS TE
tunnel tail ou tail) en suivant la route spécifiée dans
l'objet EXPLICIT_ROUTE. Lorsque le message path avance dans le réseau,
chaque LSR intermédiaire effectue les deux actions importantes à
savoir :
? La vérification du format du message pour s'assurer
de sa non corruption.
? Le "contrôle d'admission" : qui est la
vérification de la quantité de bande passante demandée par
le message path par utilisation des informations contenues dans les objets
SESSION_ATTRIBUTE, SENDER_TSPEC et POLICY_DATA. Tant que le contrôle
d'admission ne valide pas le message Path, il n'y a aucune réservation
possible ; c'est alors que le LSR intermédiaire crée un nouveau
message path et l'envoie au "next hop" (en se référant
à l'objet EXPLICIT_ROUTE).
Les messages path refont cette procédure avec tous les
routeurs du chemin à établir jusqu'à atteinte du dernier
noeud dans l'EXPICITE_ROUTE. Le 'tunnel tail??
réalise alors le contrôle d'admission du message path,
exactement comme n'importe quel noeud intermédiaire ; s'il
réalise qu'il est la destination du message path, il répond par
un message Resv (qui est une sorte d?acquittement (ACK) pour le saut
précédent (Previous Hop, PHOP) ; en plus, il témoigne la
réussite de la réservation, et contient aussi le
?incoming label?? que le ?Previous Hop?? doit utiliser
pour l'envoie de paquets de données le long du TE-LSP jusqu'au
?tail??. En effet, L'objet LABEL_REQUEST (message path)
réclame aux LSR traversés et au ?tail?? une
association de label pour la session.)
En général, le 'tail'' répond
au LABEL_REQUEST en incluant un objet LABEL dans son message de réponse
Resv. Puis le message Resv est renvoyé vers le headend, en suivant le
chemin inverse à celui spécifié dans l'objet
EXPLICIT_ROUTE. Chaque LSR qui reçoit le message Resv contenant l'objet
LABEL utilisera ce label pour le trafic de donnée sortant. Si le LSR
n'est pas le headend, il alloue un nouveau label qu'il place dans l'objet LABEL
du message Resv, et qu'il fait transiter sur le chemin inverse (grâce
à l'information PHOP qu'il aura mémorisée lors du passage
du message path pendant le processus d'aller).
22
Quand le message Resv arrive au headend, le TE-LSP est
effectivement créé. À l'issue de la création de ce
LSP, des messages de rafraîchissement RSVP-TE devront être
émis périodiquement afin de maintenir le LSP créé
(soft-state protocol).
2. La signalisation des erreurs ; le maintien et
la suppression des chemins :
? Le maintien des chemins : Le maintien des
chemins s'apparente très proche de l'établissement de ceux-ci ;
en effet, environ toute les 30 secondes, le headend envoie un message path par
le tunnel qui a été établit ; si un LSR envoie quatre
messages path successifs et ne reçoit pas de message Resv correspondant,
il considère la réservation supprimée et envoie un message
dans le sens inverse indiquant que la réservation est alors
annulée. Cependant, ne quittons pas des yeux que : les messages Path et
Resv sont tous les deux envoyés d'une façon indépendante
et asynchrone d'un voisin à un autre. Or sachant que les deux messages
ne sont pas connectés (totalement indépendant), il est
clair qu'un message Resv utilisé pour rafraîchir une
réservation existante n'est pas envoyé en réponse à
un message path, comme c'est le cas d'ICMP Echo Reply qui est envoyé en
réponse à un ICMP Echo Request : on n'a donc pas de comportement
Ping/ACK avec les messages Path et Resv.
? La suppression des chemins : La suppression
des chemins peut être vue comme le processus inverse de
l'établissement des chemins. En effet, lorsqu'un noeud du réseau
décide de la fin d'une réservation, immédiatement il se
permet d'envoyer un PathTear le long du même chemin suivi par le message
path et un ResvTear le long du même chemin suivi par le message Resv. Les
messages ResvTear sont envoyés en réponse aux messages PathTear
pour signaler que le tunnel tail a supprimé la réservation du
réseau. Tout comme les messages de rafraîchissement, les messages
PathTear n'ont point besoin de traverser la totalité des noeuds le long
du chemin pour que leur effet se face ressentir.
? La signalisation des erreurs : Tout comme
dans les réseaux purement IP, ici un accent est aussi porté sur
la signalisation des erreurs au sein du réseau
23
(Bande passante non disponible, boucle de routage, routeur
intermédiaire ne prend pas en charge MPLS, message corrompu,
création de label impossible, etc.). Le mécanisme de
signalisation des erreurs dans MPLS est réalisée par le protocole
de signalisation RSVP-TE. Plus précisément, ces erreurs sont
signalées par les messages PathErr ou ResvErr. En effet, une erreur
détectée dans un message path est traitée par un message
PathErr, et une erreur détectée dans un message Resv est
traitée par un message ResvErr ; les messages d'erreurs sont
envoyés ensuite vers la source de l'erreur ; le PathErr est
envoyé vers le headend, et un ResvErr est envoyé vers le tail.
Une fois que les LSP sont établies, les paquets labélisés
peuvent alors être routés ou même reroutés (en
cas de panne) dans le réseau.
2.2.4.2-) Le protocole de routage par contraintes
CR-LDP
a-) Introduction à CR-LDP
Le protocole CR-LDP (Constraint-based Routing over
Label Distribution Protocol) ; est une version étendue du
protocole LDP, où CR correspond à la notion de
« routage basé sur les contraintes imposées par
les LSPs ». Tout comme LDP, CR-LDP utilise des sessions TCP
entre les LSRs, au cours desquelles il envoie les messages de distribution des
étiquettes ; permettant en particulier à CR-LDP d'assurer une
distribution fiable des messages de contrôle. L'idée du protocole
CR-LDP était d'utiliser un protocole de distribution de label
déjà existant et de lui ajouter la capacité de
gérer le Traffic Engineering. C'est ainsi que, CR-LDP ajoute des champs
à ceux déjà définis dans LDP, tel que
"peak data rate4" et
"committed data rate5". La gestion des
réservations dans CR-LDP est très similaire à celle
utilisée dans les réseaux ATM, alors que RSVP-TE utilise
plutôt un modèle basé sur IntServ.
Mais cependant, le problème général
lié au routage par contrainte est de prendre en compte toutes les
contraintes attachées à chacun des LSPs lors de leurs
établissements. Il est dont clair que les contraintes de route et de
bande passante ne sont pas les seules contraintes pouvant être pris en
compte, on trouve également des contraintes du genre:
4 peak data
rate4 : rate
indique le débit maximum avec lequel un trafic peut
être envoyé via le TE-LSP.
5 committed data
rate5 : indique
le débit garanti par le domaine MPLS pour ce trafic.
24
> Affinity : ensemble de contraintes
administratives directement liées aux LSPs ;
> Path Attributes : permet de savoir si le
LSP doit être spécifié manuellement ou s'il doit être
calculé dynamiquement par le 'constraint-based Routing'' ;
> Set-Up Priority : permet de faire un choix
d'un LSP pour attribution des ressources s'il en a plusieurs LSPs candidats
;
> Holding Priority : décide de la
suspension d'un LSP pour la libération des ressources dans le but
d'établir un autre LSP ;
> Adaptability: pour permettre la commutation
d'un LSP sur un chemin optimisé qui pourrait se libérer ;
> Resilience : permet de décider ou
non de rerouter un LSP si le chemin emprunté devenait indisponible
à la suite d'un incident par exemple.
b) Messages CR-LDP et fonctionnement
·
· Les messages CR-LDP :
Il existe quatre catégories de messages CR-LDP pour en
être plus précis:
> Discovery messages : annoncer et maintenir
la présence des LSRs dans le réseau ; > Session
messages : établir, maintenir et libérer des sessions
entre des voisins LDP ; > Advertisement messages :
créer, changer et libérer des associations de FEC et LSP ;
> Notification messages: utilisés
pour véhiculer les informations de supervision (Les notifications
messages sont quant à eux de deux types :
? Error notifications:
utilisés pour signaler les erreurs fatales. Quand ces messages sont
reçus, la session LDP est terminée et toutes les associations de
label correspondantes sont annulées ;
? Advisory notifications: pour
véhiculer des informations sur la session LDP.)
·
· Le fonctionnement de CR-LDP
:
Pour expliquer le fonctionnement de CR-LDP ; nous nous sommes
appuyé sur la figure II.10 ci-dessous. Sur celle-ci, nous avons
entre autres : un Ingress LSR ; un LSR inter2 (qui représente tous
les LSRs du réseau) ; et un Egress LSR. Ces équipements
représentent respectivement l'entrée, le coeur et la sortie du
réseau MPLS.

Figure II.10 : Illustration de
l'établissement d'un CR-LDP LSP
(1) L'Ingress LSR détermine
qu'il a besoin d'établir un nouveau LSP vers l'Egress LSR
en passant par l'LSR Inter2. Pour cela,
l'Ingress LSR envoie à l'LSR
Inter2 un message LABEL_REQUEST avec l'explicit route
(LSR Inter2, Egress LSR) et
le détail des paramètres du trafic nécessaire pour cette
nouvelle route.
(2) L'LSR Inter2 reçoit le
message LABEL_REQUEST, réserve les ressources demandées, modifie
l'explicit route dans le message LABEL_REQUEST et fait suivre le message
à l'Egress LSR. Si nécessaire,
l'LSR Inter2 peut réduire les
réservations demandées dans le cas où les
paramètres correspondant sont marqués négociables dans le
message LABEL_REQUEST.
(3) L'Egress LSR détecte que
c'est effectivement lui l'Egress LSR. Il fait les mêmes activités
de réservation et de négociation que l'LSR
Inter2. Il alloue un label pour le nouveau LSP et l'envoie
à l'LSR Inter2 dans un message LABEL_MAPPING.
Ce message contient aussi les détails des paramètres finaux du
trafic pour ce LSP.
(4) L'LSR Inter2 reçoit le
message LABEL_MAPPING, il finalise la réservation, alloue un label pour
le LSP et met à jour sa table de labels. Ensuite, il envoie le nouveau
label à l'Egress LSR dans un autre message
LABEL_MAPPING.
(5) Le même processus se réalise dans
l'Ingress LSR. Mais vu que l'Ingress LSR
est le headend, il n'aura pas à allouer un label.
25
Ainsi le nouveau LSP est établi et les données
peuvent y transiter sans problèmes.
26
2.2.4.3-) Comparaison entre le RSVP-TE et le
CR-LSP
|
Éléments de
comparaison
|
CR-LDP
|
RSVP-TE
|
|
Support du TE
|
Oui
|
Oui
|
|
Stockage mémoire des LSP
|
Faible
|
500 Octets environ par LSP
|
|
Protocole de Couche 4
|
Utilise TCP pour distribuer
les labels et UDP pour
la
découverte des multiples
LSR
|
Utilise UDP ou IP (Raw IP)
pour distribuer les labels
|
|
Typologie de protocole
|
Protocole type hard-state6
|
Protocole type soft-state7
|
|
Typologie de routage
|
Routage type explicite
|
Routage type explicite
|
|
Notifications
|
Absence de notifications
lorsqu'une panne survient
|
Offre des notifications
lorsqu'une panne survient
|
|
Bande passante entre
éléments du
réseau MPLS
|
Pas spécifié
|
Plus élevée et avec possibilité
de
rafraichissement continu
|
|
Équipementiers favoris
|
Nortel
|
CISCO et JUNIPER
|
|
`'Scaliabilité»
|
Plus 'scaliable''
|
Moins 'scaliable''
|
|
Services proposés
|
Spécification du trafic / Détection des boucles
réseau / Préemption / Message d'erreurs / Partage des
charges / ...
|
Tableau II.3 : Comparaison succincte entre CR-LDP et
RSVP-TE [3]
Nous constatons que cette comparaison ne tranche pas en faveur
d'un des deux protocoles en particulier ; mais on peut dire que CR-LDP est plus
scaliable (c'est-à-dire, résistant à l'augmentation de
la taille du réseau), vu que dans le cas du RSVP-TE, plus le
réseau est étendue plus il sera encombré par des messages
de rafraîchissement. Mais les faits réels sur le terrain disent
plutôt que, malgré ça, RSVP-TE parait être plus
favorable à s'imposer comme protocole supportant le Traffic Engineering
par rapport à CR-LDP.
Nous venons de parler du routage aux coeurs des
réseaux. Mais qu'en est-il exactement des technologies et techniques qui
y sont généralement utilisés.
|
6 Hard-state6 : On dit
d'un protocole qu'il est hard-state dans MPLS lorsqu'une fois un LSR est
établi, il restera maintenu jusqu'à sa libération
explicite.
7 Soft-state7 : Par
contre le soft-state quant à lui, grâce à des messages de
signalisation, permet de rafraichir les LSR qui sont établies
(toutes les 30 seconde environ).
|
27
2. 3-) Les coeurs de réseaux et les techniques qui
y sont utilisées
Vue l'évolution qu'a connue l'ensemble des techniques
employées au coeur des réseaux pour le transport, il
s'avère nécessaire de faire un bref aperçu sur ces
derniers. Ainsi, nous abordons ces techniques dans le sens de faire ressortir
leurs limites et faire un rapprochement au standard MPLS.
2.3.1-) Les techniques de commutation les plus
utilisées
On ne saurait alors parler de coeurs de réseaux sans
faire allusion aux techniques de commutation. Parmi ces techniques de
commutations, les plus connues sont : la commutation de paquets, le transfert
de messages, la commutation de circuits, la commutation de cellules et la
commutation de trames ; pour ne citer que ceux-là.
2.3.1.1-) La commutation de circuits
Dans la commutation de circuits, un circuit
matérialisé est construit entre un émetteur et un
récepteur et, celui-ci n'appartient qu'aux deux équipements qui
communiquent entre eux. L'exemple le plus flagrant de commutation de circuit
est celui implémenté dans les réseaux
téléphoniques RTCP pour permettre à deux abonnés de
communiquer. Retenons ici que la ressource est dédié
jusqu'à la fin de la communication :

c
Récepteur D
Emetteur A
Autocommutateurs
Circuit
Circuit
Récepteur B
tr
Emetteur C
Figure II.11 : Illustration de la commutation de
circuits [2]
t
2.3.1.2-) La commutation ou transfert de messages
Partant de sa définition de base, le message tel que
perçu est une suite d'informations formant un tout logique pour deux ou
plusieurs entités communicantes à savoir
28
expéditeurs et destinataires. Ici, la méthode
utilisé par les noeuds du réseau est du pure `'store
and forward8».
2.3.1.3-) La commutation ou transfert de paquets
Le paquet est une suite d'informations binaires dont la taille
est une valeur fixée d'avance (parfois entre 1000 et 2000
bits). Et le découpage en paquets des messages des utilisateurs
facilite les retransmissions ; il simplifie la reprise sur erreur et
accélère la vitesse de transmission (Voir figure II.12).
La paquétisation permet le multiplexage et augmente les performances.

Figure II.12: Temps de réponse comparés
du transfert de messages/de paquets [3] Deux techniques de
transfert de paquets ont déjà été
explicitées : la commutation de paquets et le routage de paquets.
Internet est un exemple de réseau à transfert de paquets, et plus
précisément à routage de paquets. Ces paquets peuvent
ainsi suivre des routes distinctes et arriver dans le désordre. D'autres
réseaux, comme ATM ou X.25, utilisent la commutation et demandent que
les paquets suivent toujours un même chemin.
2.3.1.4-) Le transfert de trames ou Frame Relay
Le transfert de trames est une extension du transfert de
paquets. Un paquet ne peut être transmis sur une ligne physique car il ne
comporte aucune indication signalant l'arrivée des premiers
éléments binaires qu'il contient. La solution pour transporter un
paquet d'un noeud vers un autre consiste à placer les
éléments binaires dans une trame, dont le début est
reconnu grâce à une zone spécifique, appelée drapeau
(flag) ou préambule. Un
8 Store and forward8 :
Méthode utilisée par les noeuds
réseau (Switch ou tout autre commutateur de niveau 2)
consistant à recevoir au fur et à mesure toute
l'information, le stocker dans sa mémoire tampon et de ne le
retransmettre au noeud suivant que lorsque cette information est correctement
reçu et en intégralité.
29
transfert de trames est donc similaire à un transfert
de paquets, à cette différence près que les noeuds de
transfert sont plus simples. Ainsi, lors de la construction d'un réseau,
quel que soit le mode de transport choisi, deux sites sont toujours
reliés par un minimum de trois composants ou groupes de composants de
base. Chaque site doit avoir son propre équipement (ETTD) pour
accéder au central local (DCE). Le troisième composant
se trouve entre les deux, reliant les deux points d'accès. La
figure II.13, nous présente la partie fournie
par un réseau étendu qui fédère d'autres
réseaux : un réseau fédérateur de transfert de
trames ou Frame Relay.

Terminal
ordinaire
ETTD
Serveur FTP
Serveur Streaming
ETTD
ETTD
DCE
DCE
DCE
Serveur Web
ETTD
DCE
DCE
DCE
Applications
Temps réel
PC de bureau
ETTD
ETTD
Figure II.13 : Réseau étendu à
transfert de trame (Frame Relay) [2]
Le protocole Frame Relay demande moins de temps de traitement
que le X.25, du fait qu'il comporte moins de fonctionnalités.
2.3.1.5-) La commutation de cellules
La commutation de cellules est une commutation de trames
particulière, dans laquelle toutes les trames ont une longueur fixe de
53 octets. Quelle que soit la taille des données à transporter,
la cellule occupe toujours 53 octets. Si les données forment un bloc de
plus de 53 octets, un découpage est effectué. La cellule ATM en
est un exemple typique. La commutation de cellules a pour objectif de remplacer
à la fois la commutation de circuits et la commutation de paquets en
respectant les principes de ces deux techniques.
30
2.3.2-) Les techniques hybrides et la tendance vers les
techniques NGN
Les différentes techniques de transferts
suscités peuvent se combiner pour donner naissance à des
techniques adaptatives en fonction des besoins et permettre de s'arrimer
à la nouvelle donne : celle des NGN9. Ainsi,
plusieurs types de techniques propriétaires hybrides sont mis sur pied ;
c'est le cas du MPLS.
2.3.2.1-) ATM et migration d'IP/ATM vers le MPLS
a-) L'IP/ATM
Dans les années 1994 à 1998, IP sur ATM qui
offre des débits de 155 et de 622 Mbit/s, est le choix par excellence
des opérateurs de télécommunication aux États-Unis.
Le choix de cette technologie se fit sur la base des prévisions de
grandissement exponentiel du trafic téléphonique et les autres
trafics dues aux nouvelles technologies de l'époque. Bien qu'ATM soit
approprié lorsqu'il s'agit du transport de voix, ATM est très mal
adapté au transfert de données ce qui justifiât sa
faiblesse face aux réseaux à nouvelles exigences
multimédias comme internet : d'où la chute progressive d'ATM en
tant que leadeur. Dans le même temps, l'augmentation des
fonctionnalités de commutation réalisables directement de
manière optique conduira à terme IP à être le
protocole unique, soit directement sur fibre optique à 40 Gbit/s et
au-delà, soit sur de multiples sous canaux (WDM) à des
débits binaires de 2,5 et 10 Gbit/s.
b-) La migration ou la convergence de l'IP/ATM vers le
MPLS
L'arrivée du MPLS et des routeurs gigabits, remplacent
progressivement l'ancienne méthode qui consistait à superposer
les réseaux IP aux réseaux ATM dans le but de résoudre les
problèmes de performance réseaux. D'ailleurs même, cette
superposition IP/ATM présentait un inconvénient majeur à
savoir: la nécessité de gérer l'explosion du nombre de
connexions de circuit virtuel ATM nécessaires pour assurer un maillage
complet des liaisons virtuelles entre les paires de routeurs. En effet, le
nombre de circuits virtuels ATM nécessaires augmente comme le
carré du nombre de routeurs connectés au nuage ATM. Mais, la
catastrophe n'apparaitra que lorsque les réseaux IP eurent besoin
d'augmenter leur bande passante ce que les réseaux ATM ne pouvaient leur
fournir ; il
9 NGN9 :
Next Generation Network (tout simplement en français :
Réseaux de prochaine générations)
31
leur fallait des circuits à gigabits, alors que les
circuits ATM étaient limités à des débits
OC-12/STM-4 en raison des équipements. Avec le remplacement progressif
des réseaux IP par les réseaux IP/MPLS, les meilleures techniques
des réseaux de routage et de commutation se trouvent réunies. Les
réseaux IP/MPLS sont capables de s'adapter aux besoins de forte
croissance de l'internet, et de prendre la place de l'ATM en faisant face aux
très grandes exigences du trafic professionnel, surtout avec des
routeurs ultra performant comportant des slots d'extension. De plus, les
réseaux IP/MPLS sont prêts pour la convergence des données,
de la voix et de la vidéo sur IP. Il n'est donc pas surprenant que
l'IP/MPLS soit considéré par la majorité des
opérateurs de réseau comme le réseau cible
à long terme. Le mécanisme de recherche dans la table de
routage est moins consommateur en temps CPU et avec la croissance de la taille
des réseaux ces dernières années, les tables de routage
des routeurs ont constamment augmenté. Il était donc
nécessaire de trouver une méthode plus efficace pour le routage
des paquets, et adoptant bien le concept `'next generation»
: la technologie MPLS au coeur des
réseaux.
2.3.3-) Les techniques de transfert dans les coeurs de
réseaux type NGN
Nous savons que, de par sa définition, les
réseaux de nouvelles générations apparaissent comme des
réseaux englobant toutes sortes de technologies et indépendamment
des appartenances propriétaires quelconques. Ainsi, les solutions de
commutation de nouvelle génération fournissent une gamme
complète de la catégorie de commutation, permettant de
fédérer toute sorte de réseau existant (mobile ou
fixe). Ces solutions s'étendent du plus petits aux plus grands
comme les systèmes optiques de nouvelles générations
rassemblant les deux réseaux optiques existants y compris celui du
multiplexage DWDM et les réseaux optiques SDH. Mais est-ce que MPLS
n'est pas également présent sur les grands réseaux
à fibre optique ?
2.4-) Une extension du MPLS : le GMPLS
Le GMPLS pour
'Generalized Multi Protocol Label Switching''
provient du MPLS et plus précisément des extensions
portées au MPLS pour les réseaux optiques. GMPLS est
destiné à traiter différents types de technologies de
transmission et de transport. Son but est donc d'intégrer les couches de
transmissions au MPLS et d'obtenir une vision
32
globale. Il fournira un plan de contrôle (Voir
figure II.14) consolidé en étendant la connaissance de la
topologie du réseau à toutes les couches et permet de
réaliser le management de la bande passante. Le GMPLS consiste donc
à faire converger le monde de l?optique et celui des données.
Ainsi, le label, en plus de pouvoir être une valeur numérique peut
alors être mappé par une fibre, une longueur d'onde et bien
d'autres paramètres correspondent alors à des valeurs
spécifiques selon les LSPs et les autres paramètres comme la
QoS.

Routage:
OSPF-G; IS-IS-G
Signalisation:
RSVP-G ; CR-LDP-G
GMPLS
Gestion
des liens LMP
Figure II.14 : Architecture résumée
GMPLS [3]
Le GMPLS met en place une hiérarchie dans les
différents supports de réseaux optiques et permet ainsi de
transporter les données sur un ensemble de réseaux
hétérogènes en encapsulant les paquets successivement
à chaque entrée dans un nouveau type de réseau. Ceci donne
la possibilité d'avoir plusieurs niveaux d'encapsulations selon le
nombre de réseaux traversés, le label correspondant à ce
réseau étant conservé jusqu'à la sortie du
réseau. GMPLS reprend le plan de contrôle du MPLS en
l'étendant pour prendre en compte les contraintes liées aux
réseaux optiques, car il rajoute une particularité à
l'architecture MPLS : la gestion des liens.
Grâce à GMPLS, on voit apparaître de
nouveaux types de commutation. Les protocoles de signalisation et ceux de
routage seront tout simplement étendus et/ou modifiés pour
pouvoir être adaptés et supporter plusieurs technologies et
surtout pour être adapté à la fibre optique. Il est clair
que de tels réseaux seront plus robustes et plus complets et, surtout
pourront satisfaire les contraintes NGN. Un réseau GMPLS devra donc
comporter des éléments essentiels comme : des routeurs ; des
commutateurs ou Switch ; des ADM, brasseur SDH ou SONET ; des systèmes
DWDM ; des OXC comprenant les OEO et les PXC. On pourra obtenir un
réseau optimisé en utilisant les techniques de protection, de
restauration et de ?Traffic Engineering??
proposé par MPLS. Le MPLS ne faisant que de la commutation de paquets
sur des réseaux constitués
essentiellement de routeurs et de commutateurs et, ne
comprenant également que des interfaces PSC ; le GMPLS, vient en
complément car il permet de supporter d'autres types de commutations et
sera donc constitué des types d'interfaces suivants :
PSC10 ; TDM11 ; LSC12 ;
FSC13.
2.4-) Conclusion
Dans ce chapitre, nous avons passé en revue les
généralités sur la technologie MPLS. Nous en sommes partis
de son historique en passant par ses concepts de base jusqu'aux notions de
réseaux NGN, des coeurs de réseaux NGN et du MPLS
évolué (GMPLS). Dans le chapitre qui va
suivre, nous irons plus loin que des généralités en nous
intéressant aux concepts d'ingénierie MPLS ; ceci dans le but
d'avoir des bases pour comprendre le déploiement.
33
10
PSC10 : Packet Switch Capable ; permet de reconnaître
les limites des paquets et des cellules et prend ses décisions
d'acheminement à partir du contenu de l'en-tête du paquet ou de la
cellule.
11 TDM11
: Time Division Multiplex Capable ; achemine les données des times
slots.
12
LSC12 : Lambda Switch Capable ; permet d'acheminer les
données à partir des longueurs d'onde sur lesquelles les
données sont transportés.
13
FSC13 : Fiber Switch Capable ; permet d'acheminer les
données à partir de la position réelle des données
dans l'espace physique.
34
Chapitre 3 : Conception des réseaux MPLS 3.1-)
Introduction
Dans cette partie nous définissons notre cahier des
charges; puis, nous abordons l'aspect conception d'un réseau MPLS.
Enfin, nous proposons une méthodologie à suivre dans la mise en
oeuvre d'un réseau MPLS.
3.2-) Définition et spécification du cahier
des charges
Nombreuses sont les contraintes (contraintes tant au
niveau physique que logique et/ou technologique) à prendre en
compte lors de la conception des réseaux métropolitains et les
réseaux hyper étendus. Ceci nous conduire à classifier
notre cahier des charges en besoins.
3.2.1-) Les besoins fonctionnels
Un réseau MPLS et plus spécifiquement un coeur
de réseau MPLS doit pouvoir répondre aux fonctionnalités
suivantes :
? Implémenter tous les critères d'ingénierie
de trafic ;
? Implémenter le VPN-MPLS;
? Implémenter les critères de CoS (Class of
Services) et de QoS-MPLS.
3.2.2-) Les besoins non fonctionnels
Un autre besoin indirectement lié aux besoins
fonctionnels est celui de proposer une méthodologie de
conception et de déploiement des réseaux MPLS.
La définition de notre cahier de charge nous conduit
immédiatement à la conception des réseaux type IP/MPLS.
3.3-) La conception des réseaux MPLS 3.3.1-)
Introduction à la conception réseau
Brièvement, la conception d'un réseau passe par la
prise en compte des critères tels que :
? l'architecture physique et ; ? l'architecture logique.
35
Mais cette conception est adaptative et est fonction des
exigences liées à chaque cas spécifiques. En ce qui
concerne les réseaux type MPLS, qu'en est-il exactement ?
3.3.2-) La conception d'un réseau type
IP/MPLS
3.3.2.1-) Les points capitaux dans la conception d'un
réseau MPLS De façon globale, la conception d'un
réseau MPLS passe par :
> La définition d'une architecture physique
(câblage) : Il faut prendre en compte les
paramètres comme:
· La cartographie du site, de la ville ou de la
métropole ;
· Les supports physiques et ou radio à utiliser;
> Les équipements actifs à utiliser
: équipements supportant ou comprenant la technologie MPLS
comme la gamme de routeurs C7200 de CISCO;
> L'architecture logique (technologie)
: ici il faut tabler sur les aspects tels que :
· Les protocoles qui seront utilisés : pour la
signalisation, le transport, ... ;
· Les plans d'adressage : réel et virtuel
(VPN) ;
· Le type de routage : dans la zone MPLS et à
l'extérieur de celle-ci ;
> Les exigences en termes de quantité de
trafic et leurs qualités :
· Quantité de trafic venant des
différents réseaux clients à transporter dans
notre zone MPLS : il faudra bien estimer la quantité probable de trafic
à transporter sur chaque lien, ainsi que leurs exigences
(débit, temps réels,...).
· Estimer aussi les demandes en fonction des
heures creuses et des heures de pointe : ceci permettra
d'éviter des perturbations dans notre futur coeur de réseau.
Ces deux points sont capitaux ; car ils conditionnent
le câblage et le type d'équipements
actifs à choisir pour notre réseau.
> L'administration des équipements, la
maintenance, la surveillance et l'amélioration des performances
;
> Les services réseaux et les applications
particulières, tels quels :
36
? Les multiples VPNs : pour desservir plusieurs clients ayant
chacun plusieurs sites ou pour le transport d'un type de trafic particulier
comme les flux temps réels;
? Les liens loués et dédiés ; ...
? Les outils de sécurité, entre autres
:
? Prendre en compte les connexions avec l'extérieur et
à l'intérieur du réseau ; ... ? Prendre en compte les
équipements ;
? Prendre en compte les besoins des clients.
3.3.2.2-) L'aspect architectural dans la conception d'un
réseau MPLS Ici, nous mettons l'accent sur le point
architecture physique et logique.
En effet, pour réussir son choix architectural, nous
conseillons au concepteur de s'inspirer des architectures MPLS
sécurisés proposés par les constructeurs
d'équipements MPLS les plus célèbres.
Le choix d'une topologie sécurisée
(intégrant les VLANs, les VPNs, ...) est fait pour combiner
l'efficacité, la robustesse, la performance et la sécurité
dans les réseaux MPLS.
a-) L'architecture EoMPLS (Ethernet over
MPLS) de CISCO
Cisco est un des leaders en matériel de réseaux
type MPLS. Dans les VPNs, en général, le tunneling s'effectue au
niveau 3, mais Cisco a mis en place l'EoMPLS pour que le
tunneling puisse désormais s'effectuer au niveau 2 sur un
réseau MPLS. Ainsi, l'EoMPLS utilise
le label pour identifier le client et le VLAN du client. Si
des données sont envoyées d'un des différents sites du
client, elles arriveront obligatoirement au site destinataire de ce même
client.
Alors que MPLS maintient lors de l'encapsulation les
données de niveau 3, EoMPLS garde aussi l'intégralité des
données de niveau 2 (source, adresse MAC) ; effectuant ainsi un
tunneling de niveau 2 et non de niveau 3.

37
Figure III.1 : L'architecture EoMPLS de
Cisco
Le concept EoMPLS est simple (Voir figure
III.1): lorsqu'une trame arrive sur un serveur EoMPLS
(routeur), celui-ci l'encapsule ; puis le numéro de VLAN est
ajouté en tant que label MPLS et ensuite l'étiquette contenant le
numéro de tunnel est ajoutée dans la pile d'entêtes, ce qui
permet d'identifier le client sur le réseau. Une fois les données
délivrées à l'autre extrémité du
réseau (sur le site distant du client) le label du tunnel est
supprimé et le label contenant le numéro de VLAN est
examiné afin de déterminer quel VLAN doit obtenir la trame.
b-) L'architecture `'Enhanced IP VPN» de
Lucent et Juniper
Tout comme Cisco, Lucent et Juniper, ont mis sur pied une
solution architecturale VPN multiservices et multi protocoles : Enhanced IP VPN
qui combine les services ATM et VPN IP. Cette solution est composée
principalement de Switch multiservices Lucent et de routeurs IP Juniper, le
tout géré par un système de gestion de réseaux
baptisé Navis. Il propose ainsi un coeur de réseau MPLS
multiservices qui donne la possibilité de connecter des fournisseurs
d'accès à Internet, des réseaux Extranet, des VPNs et
pleins d'autres. Ceci permet le transport indépendamment du
matériel ou de la technologie.

38
Figure III.2 : L'architecture `'Enhanced IP
VPN» de Lucent/Juniper
Le principe est le suivant: des trames ATM
arrivent sur le réseau MPLS via des LERs basés aux
frontières du réseau. Un LER encapsule les circuits virtuels ATM
dans une pseudo-trame MPLS ; puis la pseudo-trame (pseudo-wire)
traverse alors le tunnel MPLS pour arriver à destination via un autre
LER. Ce modèle a été développé en mode
distribué dans lequel, le routage ATM et le routage MPLS sont
complètement indépendant. Ceci donne la possibilité aux
routeurs ATM d?agréger plusieurs circuits virtuels qui seront par la
suite encapsulés comme un seul circuit par le LER.
c-) L'architecture MPE (Multiservice Provider
Edge) de Nortel
Nortel est actuellement le concurrent numéro un de
Cisco en terme de fourniture de matériel réseau MPLS. Nortel
propose alors différents matériels réseaux comme les
Switch MPE (Multiservice
Provider Edge : qui sont des supers Switchs
multiservices). Les MPEs permettent d'interconnecter des réseaux
d'entreprises sur un backbone MPLS et de gérer simultanément le
routage et la commutation. Un MPE peut être vu comme un routeur physique
qui contient plusieurs routeurs logiques tels que : chaque type de
réseau et/ou service particulier se voit affecter son propre routeur. Il
permet ainsi de multiplexer plusieurs types de trafic différents pour le
faire transiter à travers le réseau MPLS comme étant un
seul. Nortel propose ainsi de placer les MPEs en amont des LERs tout en
intégrant le routage de ces différents réseaux (Voir
figure III.3).

39
Figure III.3 : L'architecture MPE de Nortel
Ainsi, selon le cas, suivant que le concepteur doit :
? Faire migrer un réseau existant vers un réseau
MPLS ou,
? Concevoir depuis la base un nouveau réseau MPLS ; il
devra s'appuyer sur ces différentes architectures pour pouvoir
mettre au point l'architecture physique et logique de son futur
réseau MPLS.
3.4-) Méthodologie de mise en oeuvre d'un
réseau MPLS
Ce que nous proposons dans ce paragraphe, n'est pas une
convention. Le concepteur ou l'ingénieur de déploiement du MPLS
pourra utiliser des approches personnalisées en fonction des
paramètres du moment : il devra faire parler son
ingéniosité.
3.4.1-) Les étapes à suivre dans le cas
d'une migration vers le MPLS
Nous proposons un canevas à suivre pour migrer (en
partant d?un existant) vers un réseau MPLS que nous avons
nommé : 5MPLS-Migrating. Il est constitué de
cinq principales étapes ayant chacune des sous étapes selon les
aspirations du concepteur.
Ainsi, réussir une migration vers la technologie MPLS
revient à suivre le 5MPLS-Mirating à savoir :
1. Optimiser (Upgrade) le réseau IP
vers un réseau parallèle MPLS (construction de la couche
MPLS) en plaçant des noeuds MPLS aux points
stratégiques comme les limites avec les entrées ATM, Frame Relay
et autres (Voir paragraphe 4.2.2.2) :
40
? En effet, le premier pas ici à franchir est
d'améliorer (upgrade) tous les routeurs MAN ou WAN ou du Coeur
de réseau en routeurs supportant la technologie MPLS. Puis, configurer
tout d'abord votre réseau comme un réseau purement IP ; et
vérifier qu'il fonctionne bien (stabilité, performances MAN
ou WAN). Après s'être rassuré que le réseau
purement IP ainsi établit fonctionne correctement ; faire un choix de
routage type EIGRP supportant le MPLS. C'est - à - dire faire un choix
de routage OSPF, ISIS ou tout autre protocole de routage favorable à
prendre en compte MPLS et en même temps permettre le bon fonctionnement
de BGP dans les MAN ou WAN.
? Le deuxième pas consiste à construire une
couche MPLS ou réseau MPLS parallèle au réseau IP
précédemment établit : En fait, lorsque le premier pas a
été bien fait, il faut maintenant activer les découvertes
réseaux MPLS et construire les LSPs pour atteindre toutes les
destinations (sites clients). Si votre intention est créer un
réseau complètement maillé, vous aurez besoin de
construire des LSPs sur chaque ingress LER (ingress Label Edge Router)
vers tous les routeurs du réseau interne MPLS. Ainsi, le choix de votre
protocole de distribution de labels ou d'étiquettes dépendra
essentiellement de vos besoins, des applications qui seront utilisées et
de toutes les exigences imposées à votre réseau.
Pour ceux qui ne souhaitent pas anticiper sur un besoin futur
de l'utilisation du reroutage rapide, et qui désirent simplifier au
maximum l'administration du réseau et la fourniture des services, nous
vous recommandons vivement d'utiliser le protocole LDP pour la gestion des
étiquettes. Mais néanmoins, si vous voulez utiliser le reroutage
rapide il serait préférable de penser à RSVP-MPLS pour la
gestion des labels également. Généralement, si vous avez
affaire aux applications «temps réels» ou
autres exigeantes en une «qualité de service»
particulière ; il faut utiliser RSVP-MPLS tant pour le labelling que
pour l'ingénierie de trafic.
En ce qui concerne les services de couche deux comme le relai
de trames et l'ATM, qui sont des services à qualités de services
intégrées, il faut utiliser RSVP pour implémenter le
DiffServ et supporter toutes les exigences imposées par le transport de
la vidéo, de la voix et d'autres applications temps réels.
41
2. Configurer les paramètres QoS-MPLS
(CoS) et passer ensuite à la configuration du
VPN-MPLS:
Après avoir configuré tous les paramètres
QoS ; on peut passer au VPN. Mais, pour s'attaquer au MPLS-VPN, il faut
s'appesantir sur l'étude au détail prêt, des
différents composants de son futur VPN (qui peut être suivant
les cas très complexe). Ainsi, en fonction de son entreprise ou de
ses clients, selon que l'on soit un opérateur réseau ou non, on
peut par exemple classifier le trafic et par ricochet les VPNs suivant :
> Les directions, départements,
unités d'affaires ou toutes autres fonctions : ici il faut
tenir compte des exigences liées aux différentes fonctions
(qui a accès à quoi ? qui peut faire quoi ? ...) ;
> Les exigences en termes de services : il
permet de ressortir l'aspect des multiples services qui peuvent être
implémentés dans votre réseau ; il permet de mettre sur
pied des VPLS très efficaces ;
> Les exigences en termes de besoins QoS ou CoS :
car certains services ont besoins des exigences particulières
en terme de bande passant, de gigue, et autres ;
> Les exigences en termes de
sécurités : étant donné que les seuls
endroits où les données entrent dans le réseau MPLS coeur
sont les ingress LER, toute l'attention sécuritaire est
prioritairement orientée vers ceux-ci. Ceci en fait d'ailleurs
tout le charme, toute la force et conjointement toute la faiblesse du
MPLS.
> Les exigences en termes de performance :
ici un accent sera porté sur les performances de transport dans
le réseau ;
> Les exigences en termes de services
spéciaux : Quand on parle de services spéciaux, on pense
par exemple à la création d'un VPN spécial pour le trafic
de la voix ; un autre pour la vidéo-conférence ; un autre pour
les services streaming ; un autre pour les applications de commande à
distance ; un autre pour les applications bancaires ...
> Les exigences imposées par le futur:
nous pensons par exemple à la création des VPNs qui
pourront être utilisés par le futur et un VPN spécial de
management qui serait membre de tous les VPNs.
3.
42
En commençant par les sites purement IP, placez
l'un après l'autre les différents réseaux ou
entités ou services dans leurs VPNs respectifs : ici, vous
devez attribuer chaque réseau, chaque service, chaque
éléments du réseau au VPN qui lui est associé.
4. Si l'on veut implémenter les techniques
d'ingénierie de trafic comme le reroutage rapide, il faut le faire ici
en respectant les critères imposés par les contraintes VPN
précédemment définies.
5. Enfin, il faut faire une gestion de trafic
basé sur les utilisateurs, les applications et les heures de pointe.
Modifier alors les paramètres d'ingénierie de trafic si besoin
s'impose, pour rendre efficace le réseau ainsi
constitué.
Ainsi, si ces étapes sont biens suivies ; tout est fait
pour réussir son déploiement MPLS au sein d'un MAN ou d'un WAN ou
de tout hyper-réseau MPLS.
3.4.2-) Les étapes à suivre dans le cas
d'un nouveau réseau MPLS
Si l'on doit déployer un réseau MPLS à
partir du tout début ; c'est à dire sans s'appuyer sur aucun
existant, l'étape différente par rapport au cas
où l'on doit faire une migration est : l'étape
1.
En effet, ici la première étape est de bien
étudier le projet et de proposer une architecture physique qui respecte
les critères comme le trafic maximal et minimal au coeur du
réseau ; les services à implémenter
; l'étendue ; ... et surtout les
paramètres futuristes (planifier en prévoyant
l'évolution et l'avenir) : en bref respecter les critères
que nous avons proposé au paragraphe 4.2.2.1.
Il sera important de faire le choix d'une architecture MPLS
qui assure tant sur le plan trafic, le plan qualité que sur le plan
sécurité. Cela revient à faire des choix portés sur
les équipements supportant le MPLS et sur des topologies
sécurisées.
En dehors de la première étape du
5MPLS-Migrating, les autres étapes restent indemnes pour mettre sur pied
un nouveau réseau MPLS.
43
3.5) Conclusion
Dans ce chapitre, nous avons eu à présenter
notre cahier des charges ; puis nous avons abordé l'aspect conception
des réseaux type IP/MPLS et avons terminé par la proposition
d'une méthodologie générale à suivre pour la mise
en oeuvre d'un réseau MPLS. Ceci nous permet logiquement de poursuivre
avec la partie déploiement du MPLS.
44
Chapitre 4: Déploiement du MPLS.
4.1-) Introduction
Puisque nous travaillons dans un contexte
général ; dans cette partie, nous commencerons par définir
une maquette d'émulation (qui est notre réseau physique sur
lequel nous allons déployer le MPLS). Ensuite, nous allons
implémenter le MPLS sur cette maquette. Et enfin, nous
présenterons les équipements matériels et logiciels ayant
servis pour l'émulation de notre maquette MPLS.
4.2-) Définition d'une maquette
d'émulation
Rappel : La mise sur pied d'un
réseau MPLS passe par le choix des équipements réseaux
(noeuds du réseau ou équipements actifs) comprenant et
implémentant la technologie MPLS. Car tous les routeurs ou commutateurs
de niveau 3, ne permettent pas d'implémenter la technologie MPLS.
Il serait judicieux de porter son choix sur les
équipements des constructeurs d'équipements MPLS les plus en vue
tels que : CISCO, Juniper / Lucent et Nortel. Car, ceux-ci proposent une
assistance en cas de problèmes technique liés aux
équipements et même liés aux configurations.
4.2.1-) L'architecture physique de notre maquette
d'émulation
Dans le cadre de notre déploiement ; nous allons nous
appuyer sur un exemple de topologie relativement simple. Ceci-à cause
des limites de notre ordinateur portable que nous utiliserons pour
l'émulation de ce réseau (réseau virtuel sur un seul
ordinateur demande des ressources énormes). Nous nous
intéresserons uniquement à l'émulation de notre coeur de
réseau (les routeurs) ; car c'est la partie
concernée par le MPLS.

Coeur de réseau concerné
45
Figure IV.1 : Maquette utilisée pour notre
émulation
Pour notre émulation, nous avons choisi la gamme de
routeurs C7200 avec l'IOS C7200-jk9s-mz.123-22 ; car ils ont les avantages
suivants :
? Les Cisco 7200 sont des routeurs compacts haute performance,
conçu pour un déploiement à la périphérie du
réseau et dans le centre de données, où performances et
services sont essentiels pour faire face aux besoins des entreprises, des
administrations et des fournisseurs de services.
? Les Cisco 7200 sont également capables de gérer
les applications suivantes : ? Accès haut débit à Internet
pour professionnel, spécialistes et particuliers ; ? Messagerie
électronique ; la téléphonie sur IP ; le FAX sur IP ; la
Vidéo MPEG ? Services VPN (Virtual Private Networking) et le
E-business
? Ils sont adaptés aux exigences NGN
4.2.2-) Choix de l'adressage pour notre maquette
d'émulation
Nous avons aléatoirement choisi un plan d'adressage pour
notre maquette que nous avons consigné dans le tableau suivant :
46
Routeurs
|
Interfaces
|
Adresses et Masques
|
|
PE1
|
G1/0
|
10.1.1.2/8
|
|
G2/0
|
11.1.2.3/8
|
|
G3/0
|
12.1.3.4/8
|
|
Loopback
|
102.102.102.101/24
|
|
PE2
|
G1/0
|
15.1.6.11/8
|
|
G2/0
|
14.1.5.9/8
|
|
G3/0
|
16.1.7.12/8
|
|
Loopback
|
102.102.102.102/24
|
|
P1
|
G1/0
|
11.1.2.4/8
|
|
G2/0
|
13.1.4.6/8
|
|
G3/0
|
14.1.5.8/8
|
|
Loopback
|
102.102.102.103/24
|
|
P2
|
G1/0
|
15.1.6.10/8
|
|
G2/0
|
13.1.4.7/8
|
|
G3/0
|
12.1.3.5/8
|
|
Loopback
|
102.102.102.104/24
|
|
CE1
|
G1/0
|
10.1.1.30/8
|
|
F0/0 et F1/0
|
DHCP VMware Workstation
|
|
CE2
|
G1/0
|
16.1.7.13/8
|
|
F0/0 et F1/0
|
DHCP VMware Workstation
|
Tableau IV.1 : Plan d'adressage pour notre maquette
4.3-) Déploiement et implémentation de la
technologie MPLS
Pour déployer la technologie MPLS, il convient de faire
des configurations préliminaires. L'ingénieur réseau peut
alors faire des choix où il pourra configurer des profils de transfert
et tous les autres services de façon manuelle où alors faire un
mix en automatisant certaines tâches ou en automatisant tout le
système (à ses risques).
Rappelons cependant que toutes les indications de
configuration que nous donnons sont typiquement celles de l'académie
CISCO.
47
4. 3.1-) Configuration basique et activation du MPLS
Pour commencer, il faut tout d'abord faire un choix sur les
protocoles de routage supportant le MPLS comme l'IS-IS, OSPF et ensuite activer
le protocole MPLS sur chaque équipement du réseau coeur.
4.3.1.1-) Configuration ou activation du routage
classique
L'activation du routage classique au niveau du backbone,
c'est-à-dire entre les PE-Routeurs et les P-Routeurs doit se
faire ici. Nous avons porté notre choix sur le protocole OSPF à
cause de ses multiples avantages comme :
? le fait qu'il soit un protocole de routage à
états de liens, ? le fait qu'il supporte le trafic engineering,
? le fait qu'il soit rapide en termes de convergence, ...
La configuration d'OSPF doit être effectuée sur
tous les routeurs du réseau MPLS comme suit (exemple pris sur le
routeur PE1 de notre maquette) :
PE1>enable «passage en mode
privilégié»
PE1#configure terminal «passage en mode
configuration du terminal»
PE1(config)#router ospf 110 «activation
du processus OSPF»
PE1(config-router)#network 10.1.1.0 255.0.0.0 area 0
«déclaration des réseaux
participant au
processus OSPF »
Pour notre futur VPN, le protocole de routage classique choisi
est RIPv2 qui se configure comme suit :
PE1>enable «passage en mode
privilégié»
PE1#configure terminal «passage en mode
configuration du terminal»
PE1(config)#router rip «activation de
RIP»
PE1(config-router)#vertion 2 «
activation de la version 2 de RIP »
4. 3.1.2-) Activation du MPLS sur tous les noeuds du
réseau
Pour implémenter la technologie MPLS dans un
réseau, il faut tout d'abord activer le
CEF (Cisco Expresse Forwarding) qui
permet la circulation des trames MPLS.
48
L'activation de MPLS diffère suivant la position du
routeur dans le backbone. Dans les deux routeurs P, nous avons activé
MPLS sur toutes les interfaces ; tandis que, dans les deux autres routeurs PE,
l'activation est seulement faite sur les interfaces les reliant directement aux
routeurs P. Ainsi on aura à faire sur chaque routeur (interfaces
backbone seulement) du réseau coeur les commandes suivantes :
PE1>enable «passage en mode
privilégié»
PE1#configure terminal «passage en mode
configuration du terminal»
PE1(config)#mpls ip «activation
d'MPLS»
PE1(config)#interface G1/0 «activation
d'MPLS sur l'interface S1/1»
Une fois ces configurations de base effectuées ; on
passe aux choses sérieuses. 4.3.2-) Déploiement de
l'ingénierie de trafic MPLS
4.3.2.1-) Pourquoi l'ingénierie de trafic MPLS
?
Dans le cadre du routage classique, s'il existe N
chemins pour pourvoir un paquet de d'une source à une
destination précise, les protocoles de routage classiques (OSPF,
IS-IS, ...) vont principalement se baser sur la notion de plus court
chemin pour le routage; oubliant les notions de coût, de
disponibilité des liens, d'adaptation de trafic par rapport à la
bande passante des liens. Ceci pourra créer des files d'attentes longues
au niveau des équipements présents sur les chemins les plus
courts, entrainant ainsi une lenteur et même des goulots
d'étranglement dans le réseau.
Comment palier à ce problème avec d'autres
solutions que de l'IP classique? C'est alors qu'intervient l'ATM qui permet de
réaliser une telle ingénierie de flux mais en introduisant
parallèlement une grande complexité de gestion due au fait qu'IP
et ATM sont des techniques différentes et avec des contraintes plus
souvent incompatibles.
C'est alors qu'arrive le MPLS-TE qui permet de résoudre
la plupart de ces multiples problèmes soulignés dans le routage
classique et les techniques comme l'ATM.
49
4.3.2.2-) Implémentation de l'ingénierie de
trafic MPLS
Une fois les configurations de base biens effectuées ;
nous pouvons alors suivre de façon méticuleuse les
différentes étapes (générale) suivantes
qui nous permettrons d'implémenter le MPLS-TE au coeur de notre
réseau :
> Étape 1 : Configuration d'une
interface Loopback sur chaque routeur :
1' Router>enable «passage en mode
privilégié»
1' Router#configure terminal «passage en mode
configuration de terminal»
1' Router(config)# interface Loopback
{number} «spécification de l'interface»
1' Router(config-if)# ip address {ip-address}
«spécification de l'adresse de
l'interface»
> Étape 2 : Activation des
interfaces susceptibles d'être utilisées comme chemin TE-LSP :
1' Router>enable «passage en mode
privilégié»
1' Router#configure terminal «passage en mode
configuration de terminal»
1' Router (config) #mpls traffic-eng tunnels
1' Router (config) #interface {type) {number}
1' Router (config-if) # ip address {îp-address} {mask}
1' Router (config-if) # mpls traffic-eng tunnels
> Étape 3 : Configuration des
paramètres de la bande passante des RSVP qui seront
utilisés pour la signalisation et l'allocation des
ressources pour l'ingénierie de trafic:
1' Router>enable «passage en mode
privilégié»
1' Router#configure terminal «passage en mode
configuration de terminal»
1' Router (config) # interface {type} {number}
1' Router {config-if} # ip rsvp bandwidth {reservable bandwidth
1-10000000 kbps}
{maximum reservable bandwidth per flow 1-1000000 kbps}
> Étape 4 : Configuration des
interfaces des tunnels.
Ces configurations consistent principalement à :
? Associer l'adresse IP de l'interface du tunnel à
l'adresse IP de l'interface Loopback
configurée précédemment ;
50
? Configurer le mode de fonctionnement du tunnel, et l'adresse
de destination de son extrémité qui correspond à l'adresse
IP du Loopback du routeur terminal (Tailend).
Si le chemin du LSP n'est pas explicité par
l'utilisateur, son établissement se fait dynamiquement par CSPF. Dans le
cadre de notre émulation nous allons configurer trois LSP explicites
à savoir :
? LSP 1 (LSP spécifique au
transport temps réel comme les flux VoIP, Streaming,
Vidéo à la Demande,... : trafic pour les
applications Temps Réel) : PE1-P1-PE2 ;
? LSP 2 (LSP pour transport des flux
prioritaires par rapport à d?autres comme les
flux http, ftp, ... : trafic pour les applications de Haute
Priorité): PE1-P2-PE2 ;
? LSP 3 (transport de tous les autres flux
sans QoS spécifique : trafic pour tous les
flux sans exigences de QoS (Best Effort)) :
PE1-P1-P2-PE2.
i' Router>enable «passage en mode
privilégié»
i' Router#configure terminal «passage en mode
configuration de terminal»
i' Router(config) # interface Tunnel {number}
i' Router(config-if)# ip unnumbered loopback {number}
i' Router (config-if ) # tunnel mode mpls traffic-eng
i' Router(config-if) # tunnel destination {IP address of remote
loopback}
i' Router(config-if) # tunnel mpls traffic-eng path-option
{priority} [dynamic
[bandwidth {override bandwidth config value} | attributes {lsp
attribute list
name} / lockdown] | explicit { identifier| name name]]
i' Router (config-if) # tunnel mpls traffic-eng bandwidth {number
kbps}
i' Router (config-if) # tunnel mpls traffic-eng priority {setup
priority-value} {hold-
priority value}
> Étape 5 : Configuration du chemin
explicit avec les adresses IP des routeurs next-hop
présents sur un chemin LSP.
i' Router>enable «passage en mode
privilégié»
i' Router#configure terminal
«passage en mode configuration de terminal»
i' Router(config)# ip explicit-path name {name} enable (ou encore
: Router(config) # ip explicit-path identifier {number} enable
51
V' Router (cfg-ip-expl-path)# next-address {ip_address} V'
Router(cfg-ip-expl-path) # next-address {ip_address} V'
Router(cfg-ip-expl-path) # next-address {ip_address} V'
Router(cfg-ip-expl-path)# exit
> Étape 6 : Configuration de l'IGP
première partie.
Puisqu'on sait que, par défaut, l'interface du tunnel
n'est pas annoncée dans la table de routage d'IGP, il faut dont le
configurer sur l'interface concerné pour qu'il puisse être
utilisé comme saut suivant dans la table de routage IGP et ainsi
permettre la continuité du lien :
V' Router>enable «passage en mode
privilégié»
V' Router#configure terminal «passage en mode
configuration de terminal»
V' Router(config)# interface {number/name}
V' Router (config-if ) # interface tunnel {number}
V' Router (config-if) # tunnel mpls traffic-eng autoroute
announce
> Étape 7 : Configuration de l'IGP
deuxième.
Pour terminer, il faut configurer IGP pour qu'il puisse supporter
l'ingénierie de trafic: ? Pour OSPF :
V' Router>enable «passage en mode
privilégié»
V' Router#configure terminal «passage en mode
configuration de terminal»
V' Router(config)#router ospf autonomous system nuber
V' Router(config-router)#net network-entity-title
V' Router(config-router)#mpls traffic-eng router-id interface
number
? Pour IS-IS :
V' Router>enable «passage en mode
privilégié»
V' Router#configure terminal «passage en mode
configuration de terminal»
V' Router(config)#router isis process-id
V' Router(config-router)#net network-entity-title
V' Router(config)# interface type number
V' Router(config-if)# ip router isis process-id
52
( Router(config-router)#mpls traffic-eng level [1 | 2]
( Router(config-router)#mpls traffic-eng router-id interface
number ( Router(config-router)#metric-style wide
En complément; nous ajoutons un Tunnel MPLS traffic-eng
fast-reroute: pour créer en utilisant la méthode normale un
tunnel qui nous servira de backup.
4.3.3-) Déploiement de la QoS-MPLS
Pour implémenter la QoS, nous avons utilisé le
modèle MQC (Modular QoS CLI) qui se subdivise
en réalité en trois grandes étapes à savoir :
> La classification du trafic basée sur les
critères définis par l'utilisateur ;
> La configuration des stratégies de la QoS pour
chacune des catégories définies ;
> L'association des stratégies /ou d'une
stratégie de QoS à une interface.
4.3.3.1-) Implémentation de la QoS-MPLS : la
classification du trafic
La classification du trafic permet de catégoriser les
différentes données ou flux en fonction des critères
imposés par les utilisateurs ou clients MPLS.
En générale, la commande class-map
s'utilise pour créer une classe de trafic correspondant aux
critères donnés par l'utilisateur et même pour
spécifier le nom de la classe.
Quant à la commande match, elle est
utilisée dans le mode de configuration des class-map.
La syntaxe couramment utilisée de class-map est
: class-map [match-any | match-all] nom de la
classe. À côté d'elle, la commande class-map
match-all est cependant utilisée lorsque tous les
critères d'une classe doivent être remplis pour un paquet, pour
faire la correspondance avec la classe du trafic spécifié.
Cependant, la commande class-map match-any est à son
tour utilisée lorsqu'un seul critère d'une classe doit être
rempli pour un paquet, pour faire la correspondance avec la classe du trafic
spécifié. Ainsi, si ni match-all, ni
match-any n'est spécifié alors, la classe du
trafic se comporte par default avec class-map match-all.
En ce qui concerne notre maquette, voici le tableau permettant
d'identifier les classes que nous avons créées pour notre
émulation réseau (maquette) :
53
Classes
|
Identifications
|
|
TempsReel_Out
|
Experimental 0
|
|
TempsReel_In
|
dscp ef
|
|
Important_Out
|
Experimental 1
|
|
Important_In
|
dscp af11
|
|
BestEffort_Out
|
Experimental 2
|
|
BestEffort_In
|
dscp default
|
Tableau IV.2 : Les classes de services crées
pour notre émulation
Pour affecter du trafic aux différentes classes ;
avec class-map, on suit scrupuleusement les étapes
suivantes :
> Étape 1 : Spécification de la
class-map à laquelle les paquets seront identifiés.
1' Router>enable «passage en mode
privilégié»
1' Router#configure terminal «passage
en mode configuration de terminal» 1' Router(config)#
class-map nom de la classe
> Étape 2 : Spécification
des caractéristiques des paquets qui seront identifiés dans la
classe et application des critères associés à chacune
d'elles:
1' Router(config-cmap)# match critère
Avec les différents critères que sont:
? match access-group access-group : pour
configurer les critères pour une classe basée sur un nombre ACL
spécifié ;
? match cos valeur de cos : pour configurer
les critères pour une classe basée sur le marquage cos de la
couche 2 ;
? match destination-address mac adresse :
pour configurer les critères pour une classe basée sur l'adresse
MAC destination ;
? match input-interface nom de l'interface :
permet de configurer les critères pour une classe basée sur une
interface d'entrée spécifiée ;
? match ip dscp valeur de dscp : permet de
configurer les critères pour une classe basée sur la valeur du
champ DSCP, on peut combiner dans une seul déclaration match
jusqu'à huit valeurs DSCP, ces valeurs qui varient entre 0 et 63 ;
54
? match ip precedence valeur de ip precedence
: permet de configurer les critères pour une classe basée sur la
valeur IP precedence, on peut combiner dans une seul déclaration match
jusqu'à quatre valeurs. La valeur d'IP precedence varie entre 0 et 7
;
? match ip rtp starting-port-number
port-range : permet de configurer les critères pour une classe
basée sur le protocole temps réel RTP, la valeur de
starting-port-number varie entre 2000 et 65535, le nombre de ports RTP varie
entre 0 et 16383 ;
? match protocol protocole : permet de
configurer les critères pour une classe basée sur un protocole
spécifié ;
? match qos-group valeur de qos-group: permet
de configurer les critères pour une classe basée sur la valeur du
groupe de la QoS, cette valeur varie entre 0 et 99 et elle n'a pas de
signification mathématique. La valeur du groupe de la QoS est locale sur
le routeur et elle est utilisée pour le marquage. Le traitement de ces
paquets est défini par l'utilisateur à travers la mise en place
des stratégies de la QoS dans le mode configuration de policy map class
;
? match source-address mac adresse : permet
de configurer les critères pour une classe basée sur l'adresse
MAC source.
? Étape 3: Sortie du mode de
configuration class-map :
? Router(config-cmap)# end
Après avoir configuré les classes auxquelles
nous avons associé à chacune des critères
spécifiques ; nous passons aux stratégies (policies en
anglais).
4.3.3.2-) Implémentation de la QoS-MPLS : la
configuration des stratégies La commande
policy-map permet de configurer une stratégie avant de
l'assigner à une classe de trafic particulière avec la
commande class. Sa syntaxe est :
? policy-map nom de la stratégie ; qui
est associé à celle de la classe : ? class nom
de la classe.
55
Ainsi, si l'on configure une classe par défaut, tout le
trafic qui ne parvient pas à satisfaire les critères de la
stratégie, appartient à cette classe par défaut. Pour
configurer les stratégies, il est recommandé de suivre les
étapes suivantes :
> Étape 1 : création
d'une policy-map à rattacher par la suite à une
ou plusieurs interfaces.
ü Router>enable «passage en
mode privilégié»
ü Router#configure terminal
«passage en mode configuration de terminal»
ü Router(config)# policy-map nom de la
stratégie > Étape 2 : Désignation de
la classe.
ü Router(config-pmap)# class nom de la
classe > Étape 3 : Spécification d'une classe
par défaut.
ü Router(config-pmap)# class
class-default
> Étape 4: Indication de la bande
passante minimale à garantir pour une classe de trafic. Ce minimum de
bande passante peut être spécifié en kbps ou en
pourcentage.
ü Router(config-pmap-c)# bandwidth
{bande passante-kbps | percent pourcentage} >
Étape 5 : Précision sur le nombre de files d'attente qui
va être réservées à la classe.
ü Router(config-pmap-c)# fair-queue nombre
de files d'attente. > Étape 6: Indication de la
bande passante maximale.
ü Router(config-pmap-c)# police bps
burst-normal burst-max conform-action action
exceed-action action violate-action action
Les actions suivantes sont appliquées par la commande
police sur les paquets qui arrivent :
· Drop : abandonner le paquet.
· Set-prec-transmitnew-prec :
définir le IP precedence et transmettre le paquet.
· Set-qos-transmitnew-qos : pour
définir le groupe QoS et transmettre le paquet.
· Set-dscp-transmit : pour définir
la valeur DSCP et transmettre le paquet.
· Transmit : transmettre le paquet.
> Étape 7 : Précision sur la
bande passante garantie autorisée pour la priorité du trafic.
ü Router(config-pmap-c)# priority {kbps |
percent pourcentage} [bytes]
> Étape 8 : Précision sur le
nombre maximum de paquets dans la file d'attente (en absence de la
commande random-detect).
56
1' Router(config-pmap-c)# queue-limit nombre de
paquets
> Étape 9 : Activation de l'algorithme
de suppression de paquets WRED pour une
classe de trafic qui a une bande passante garantie.
1' Router(config-pmap-c)# random-detect
> Étape 10: Spécification d'une
valeur ou des valeurs de CoS à associer avec le paquet,
le nombre est entre 0 et 7.
1' Router(config-pmap-c)# set cos valeur de
CoS
1' Étape 11: Spécifications de
l'IP DSCP des paquets dans la classe du trafic.
Router(config-pmap-c)# set ip dscp valeur de
ip-dscp.
De la même façon on définit le bit mpls
experimental et l'IP precedence.
> Étape 12 : Sortie du mode
configuration policy map.
1' Router(config-pmap-c)# end
Après ces étapes ; il faut ensuit attacher ces
stratégies aux différentes interfaces.
4.3.3.3-) Implémentation de la QoS-MPLS :
Assignation des stratégies crées aux différentes
interfaces
Ici, la commande de configuration utilisée est la
commande service-policy. Elle permet ainsi d'attribuer une
stratégie (policy) à une interface et aussi à
spécifier la direction dans laquelle la stratégie devrait
être appliquée. Sa syntaxe est relativement simple :
service-policy {input |
output}
> Étape 1: Choix de l'interface qui
sera concernée par la stratégie à appliquer.
1' Router>enable «passage en mode
privilégié»
1' Router#configure terminal «passage
en mode configuration de terminal»
1' Router(config)# interface nom de
l'interface
> Etape 2 : Attachement de la
stratégie spécifié à l'interface choisie.
1' Router(config-int)# service-policy
input/output nom de la stratégie.
> Etape 3: Sortie du mode configuration
d'interface.
1' Router(config-int)# end
57
Ici, nous pensons qu'on a pu implémenter le minimum des
paramètres de QoS. En plus de la QoS-MPLS ; nous avons aussi vu qu'une
des particularités de MPLS était le VPN-MPLS.
4.3.4-) Déploiement de l'ingénierie
VPN-MPLS
Pour bien intégrer l'implémentation du VPN-MPLS,
nous proposons d'introduire par un exemple de topologie VPN-MPLS.
4.3.4.1-) Introduction à l'implémentation des
VPN-MPLS

Figure VI.2 : Exemple de Réseau type
VPN-MPLS
Explications:
? La partie coeur (Réseau-P : pour
Réseau Privé ou P-Network) comprend entre autres :
? Les routeurs P (Provider) : ce sont les routeurs placés au
centre de la topologie. Ces routeurs, composent le coeur du backbone MPLS, et
n'ont généralement aucune connaissance des VPNs qui sont
créés. Ils se contentent d'acheminer les données
grâce à la commutation de labels uniquement.
·
58
Les routeurs PE (Provider Edge) : ce sont ceux
placés de part et d'autres des routeurs P. Ils sont des routeurs
situés à la frontière du backbone MPLS et ont par
définition une ou plusieurs interfaces reliées à des
routeurs clients.
> La partie clients
(Réseau-C : pour Réseau Clients ou en anglais
C-Network (Customer Network)) qui comprend entre autres
:
· Les routeurs CE (Customer Edge) qui sont des
routeurs appartenant aux clients et n'ayant aucune connaissance des VPNs ou
même de la notion de label.
· Les équipements derrière les routeurs CE
appartiennent aux clients.
4.3.4.2-) Implémentation des
VPN-MPLS
Dans notre cas ; en se référant à notre
maquette de simulation, nous allons créer un VPN qui supportera le
trafic des applications temps réels (VPN TempsReel). Mieux,
nous avons créé sur les PE1 et PE2 un
VRF14 nommés VRF ClientsTempsReel.
En effet l'idée est la suivante : on suppose par
exemple que nous somme un opérateur de fourniture des services temps
réels comme la VoIP ou la VoD15 et que nous
relions tous les clients sollicitant ce service dans un seul VPN auquel nous
affectons un seul LSP (LSP1).
De façon générale, les configurations des
VPN-MPLS sont articulées autour des étapes suivantes :
> 1ère Étape :
Activer les paramètres MPLS ;
> 2e Étape : Configuration
des paramètres de routage et tous les critères liés
à
l'IGP comme nous avons montré plus haut;
> 3e Étape :
Création et configuration formelle d'autant de VRFs
nécessaires en
fonction de ses besoins (attention à la
complexité du maillage et de la combinaison
entre VRFs : véritables casse-tête).
Nous proposons cette procédure porte plus souvent des
fruits :
14 VRF14 : pour Virtual
Routing and Forwarding instance ; il contient les tables de routage et des
tables d'acheminement des paquets à travers le réseau VPN.
15 VoD15 : pour Video
on Demand (en français Vidéo à la Demande), qui
est un service de demande vidéo fournis par certains opérateurs
permettant aux clients de choisir en temps réel les vidéos
(films) qu'ils veulent regarder.
59
V' Création de VRFs (selon notre maquette nous allons
créer des VRFs sur les routeurs PE1 et PE2) en utilisant les
commandes suivantes :
PE1>enable «passage en mode
privilégié»
PE1#configure terminal «passage en mode
configuration de terminal»
PE1 (config) #ip vrf ClientTR
PE1 (config-vrf) #route-target both 64999:1
PE1 (config-vrf) #rd 999:1
V' Après avoir créé les VRF, nous allons les
assigner aux interfaces :
PE1 (config-vrf) #interface s1/0
PE1 (config-if) #ip vrf forwarding ClientTR
PE1 (config-if) # ip address 192.168.1.10
255.255.255.240
PE1 (config-if)# no shutdown
? 4e Étape : Configuration des
protocoles de routage spécifiques : le MP-BGP.
V' On le fait généralement pour assurer la
communication entre les VRF des
différents PE en utilisant les commandes suivantes :
PE1 (config) #router bgp 1
PE1 (config-router) #no bgp default
ipv4-unicast
PE1 (config-router) #neighbor
192.168.1.101 remote-as 64999
PE1(config-router)# neighbor
192.168.1.101 update-source lo0
PE1 (config-router) #address-family vpnv4
PE1 (config-router-af) #neighbor
192.168.1.101 activate
Après; l?on peut vérifier les configurations avec
la commande :
PE1 #show ip bgp neighbor {interface address}
V' Ensuite, il faut activer le protocole RIP dans chaque VRF:
PE1>enable «passage en mode
privilégié»
PE1#configure terminal «passage en mode
configuration de terminal» PE1 (config) #router
rip
60
PE1 (config-router) #version 2
PE1 (config-router) #address-family ipv4 vrf
ClientTR PE1 (config-router-af) # version 2
PE1 (config-router-af) # network 10.0.0.0
PE1(config-router-af)# no auto-summary
? 5e Étape : Configuration du
protocole RIP entre les CEs et les PEs ; puis on active la redistribution des
routes entre les deux grandes familles de protocoles IGP et BGP et aussi
MP-BGP.
i' Pour y parvenir, il faut utiliser les commandes suivantes :
PE1(config)#router bgp 1
PE1(config-router)#address-family ipv4 vrf
ClientTR PE1(config-router-af)#redistribute rip
metric 1
i' Ensuite nous devons active la distribution des routes BGP de
par RIP PE1(config-router-af)#router rip
PE1(config-router)#version 2
PE1(config-router)#address-family ipv4 vrf
ClientTR PE1(config-router-af)#redistribute bgp
1 metric 1
À la fin, nous pouvons vérifier toutes les
configurations VPNs avec la commande : PE1#show ip bgp vpnv4
all
4.4-) Présentation des logiciels et matériels
utilisés
Pour nos tests, nous n'avons pas eu les moyens d'utiliser les
équipements réels, raison pour laquelle nous avons opté
pour la solution logicielle. En effet nous avons utilisé une pile de
logiciels depuis les dessins et schémas jusqu'à
l'émulation. Nous avons consigné les logiciels les plus utiles
dans le tableau suivant:
61
Dénomination
|
Version
|
Composition et Utilité
|
|
GNS3
|
0.8.3.1_All_in_One (C'est la version tout en un)
|
Cette version incorpore plusieurs autres outils :
? Capture (Qui sert à capture le trafic
au niveau des noeuds réseau. Nous l'avons configuré dans GNS3
pour exécuter de façon automatique Wireshark
(qui est un logiciel libre d'analyse de protocole et de
sniffage réseau utilisé généralement dans le
dépannage et l'analyse des réseaux informatiques, le
développement de protocoles, l'éducation et la
rétro-ingénierie, et aussi le piratage))
? Dynamip (qui est la partie de GNS3
principale pour les simulations)
? Pemu (PIX Firewall Emulation: il permet
d'émuler en toute quietude les pare-feu)
? VirtualBox (il permet l'interfaçage de
GNS3 avec les ordinateurs virtuels installés sur VirtualBox)
|
|
VMware-
Workstation-full
|
7.0.0-203739
|
Qui est un logiciel de virtualisation qui permet d'avoir
plusieurs machines avec des systèmes
d'exploitation différents qui s'exécutent
sur
nombreux ordinateurs. Il est possible de faire
fonctionner plusieurs machines virtuelles en
même temps, la limite correspondant aux
performances
de l'ordinateur hôte. Ces machines peuvent être
interconnectées aux réseaux montés sur GNS3.
|
|
Microsoft Office
Visio
professional
|
2010
|
Qui est un produit microsoft permettant de faire des
illustrations et schémas professionnels dans beaucoup de domaines
d'ingénierie comme : le génie civil, l'électricité,
l'électronique, l'analyse logiciel, les réseaux, ....
|
Tableau IV.3 : Logiciels utilisés
Nous n'oublions pas de citer comme matériel notre
fameux ordinateur portable sur lequel toute cette émulation a
été faite.
4.5-) Conclusion
Dans cette partie, nous avons commencé par
définir une maquette d'émulation de notre solution MPLS ; puis,
nous sommes passés au déploiement du MPLS ; et enfin, avons
présenté les logiciels qui nous ont été utiles.
Dans le chapitre qui va suivre, nous nous intéresserons aux
résultats obtenus.
62
Chapitre 5: Résultats et commentaires.
5.1-) Introduction
Dans cette partie, nous nous permettrons de présenter de
façon sommaire quelques résultats obtenus lors de nos travaux. Il
s'agit principalement des résultats sur :
? L'ingénierie de trafic MPLS; ? Le MPLS-QoS et ;
? Le MPLS-VPN VRF.
Ensuite nous ferons quelques remarques constructives et une
ouverture de débat sur les dispositions futures concernant le MPLS.
5.2-) Quelques résultats
5.2.1-) Résultats concernant l'ingénierie
MPLS
Avant de commencer, nous nous sommes d'abord penchés
sur l'aspect sécurité d'accès à l'administration de
nos routeurs en le protégeant par des mots de passe administrateurs et
surtout en configurant un message de bannière (qui est une sorte de
message qui apparait lorsqu?on réussit à se connecter en mode
console sur un de nos routeurs). Ce message dans notre cas particulier,
est un avertissement pour ceux qui seraient arrivés à ce niveau
administrateur par inadvertance (voir figure V.1) :

Figure V.1 : Résultat de la bannière
d'avertissement (Warning message)
Pour ce qui est de l'ingénierie du trafic; en
résumé, nous avons construit trois LSPs, dont :
63
? le premier LSP pour le transport des flux temps réels
;
? le deuxième LSP pour les applications de seconde
importance (ftp ; http ; ...) et ; ? le dernier LSP pour le reste du trafic
fonctionnant selon le régime « best effort
».
La capture d'écran suivante (voir figure V.2),
nous présente le résumé de ces tunnels MPLS-TE sur un
routeur d'entrée du réseau MPLS que nous avons
émulé.
La commande utilisée pour visualiser ces TE-tunnels est
(cas du routeur PE1) : PE1# show MPLS traffic-eng tunnels
brief

Figure V.2 : Visualisation des tunnels MPLS-TE sur
le ingress LER
La capture d'écran suivante (voir figure V.
3), nous présente les tunnels MPLS-TE de façon
détaillé sur le routeur d'entrée PE1.
La commande utilisée pour visualiser ces TE-tunnels est
(cas du routeur PE1) : PE1# show MPLS traffic-eng
tunnels

64
Figure V.3 : Visualisation des tunnels MPLS-TE sur
le ingress LER
65
Maintenant nous allons voir si les labels sont
distribués dans notre réseau en exécutant la commande
« show MPLS ip binding » sur notre ingress
LER :

Figure V.4 : Visualisation du labelling dans notre
réseau intégrant MPLS-TE
Pour avoir plus de précisions et de certitudes
profondes sur la vérification des résultats ; nous vous renvoyons
à l'annexe 4 où nous donnons un
ensemble de commandes portant sur les commandes de vérification du bon
fonctionnement des paramètres TE, QoS et VPN-MPLS. Nous y avons
également donné quelques commandes de débuggage.
5.2.2-) Résultats concernant la qualité de
service MPLS
Pour poursuivre dans l'optimisation de notre
déploiement de la technologie MPLS, nous avons créé trois
classes de services que nous avons associés à trois types de flux
dont nous avons présenté précédemment. Une fois ces
classes créées avec tous leurs paramètres, nous les avons
associés aux interfaces concernés dans le but d'optimiser le
transport au niveau de notre coeur de réseau. (Voir figure
V.4)

66
Figure V.5 : Résultats pour la QoS ou CoS
MPLS
67
5.2.3-) Résultats concernant le VPN VRF du MPLS
Concernant le VPN; nous avons créé au niveau des
routeurs PEs un VRF nommé VRF ClientsTempsReel qui permet de transporter
uniquement le trafic temps réels à hautes contraintes comme la
VoIP. Ce VRF permet en plus de garantir une qualité de service optimale
pour la VoIP, une sécurité accrue.

Figure V.6 : Visualisation des paramètres VPN
VRF MPLS
68
5.3-) Capture du trafic et analyse sous Wireshark
Nous avons utilisé l'outil d'étude de protocole,
de sniffage et de rétro ingénierie réseau le plus
populaire nommé Wireshark pour capturer les échanges au coeur de
notre réseau (nous avons juste démarré les
équipements du coeur de réseau et avons analysé les
échanges et protocoles liées à l?ingénierie
MPLS). La capture suivante est celle du lien entre le port g1/0 du
routeur PE2 et le port g1/0 du routeur P2 (Voir
figure V.6).

Figure V.7 : Exemple de capture de trafic sur un lien
du coeur de réseau MPLS
Nous pouvons ainsi observer : les sources ; les destinations ;
les adresses (IP ou MAC) concernées par les échanges ;
les protocoles qui interviennent ; les statuts ; ... Pour identifier les
différents protocoles et échanges on doit se servir du code de
couleur qu'offre Wireshark (Voir figure V.7)
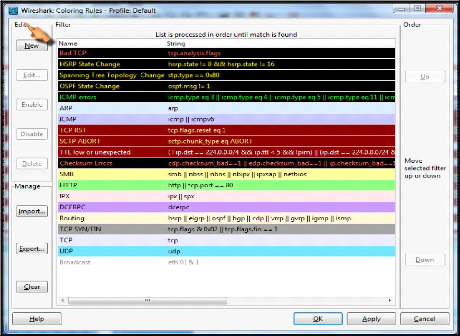
69
Figure V.8 : Code de couleur de Wireshark
En fonction des protocoles et des sources, on peut dire que :
? Nous avons par exemple la communication entre les adresses
102.102.102.102 et 102.102.102.103 via le protocole TCP avec pour information
spécifique Cisc-tdp (Cisco-tag distribution protocol) qui
montre que les tunnels sont biens établies et que le labelling est bien
mise en oeuvre car ces adresses sont celles attribuées aux loopbacks qui
gères les TEs-tunnels MPLS qui ont été
configurés.
? Nous voyons bien qu'entre les hôtes de type 14.1.5.0,
le protocole UDP est bien celui utilisé pour le transport des trames
MPLS dans nos tunnels.
? Nous voyons aussi que le routage utilisé au sein du
coeur de notre réseau est bien le protocole OSPF.
? Nous constatons qu'à travers le protocole LOOP, nos
configurations MPLS sont bien prises en compte dès le démarrage
des routeurs.
Cette interprétation peut se poursuivre et
s'étendre en fonction de nos besoins.
Nous pouvons également consulter le dialogue entre les
hôtes à la milliseconde prêt à partir de l?instant
où la capture a été lancée (Voir figure
V.9) :
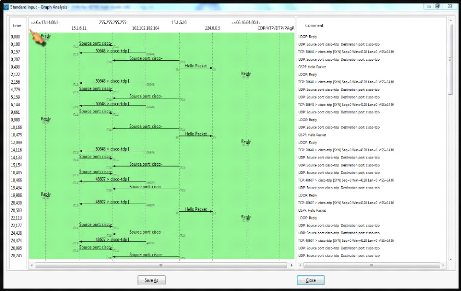
Figure V.9 : Fenêtre d'observation des dialogues
entre les hôtes du réseau Nous pouvons
également voir le résultat donné par la fenêtre des
entrées réseau standard.

70
Figure V.10.1 : Conversations sur les entées
standards : type Ethernet
71
Nous avons également la possibilité de voir les
entrées IPv4 (nombre de paquets, durée du
parcours,...)

Figure V.10.2 : Conversations sur les entées
standards : type IPv4 Sur un autre onglet de cette même
fenêtre, nous pouvons également voir le nombre de paquets qui sont
transportés via tdp de Cisco ainsi que les hôtes
concernés.

Figure V.10.3 : Conversations sur les entées
standards : type UDP
En plus, nous pouvons voir un tableau statistique
hiérarchisé de tous les protocoles qui sont utilisés au
sein de notre réseau (Voir figure V.11)

72
Figure V.11 : Statistique hiérarchisée
sur les protocoles utilisés dans notre réseau
5.5-) Conclusion
Ce chapitre assez particulier, nous a permis de montrer
quelques résultats obtenus lors de notre investigation
scientifico-technologique sur le thème : conception et le
déploiement de la technologie MPLS dans un réseau
métropolitain.
73
Conclusion générale
Il a été question pour nous au cours de ce
travail, de concevoir et déployer la technologie MPLS dans un
réseau métropolitain. Pour y parvenir, nous avons au
premier chapitre situé notre sujet dans l'espace et le temps ; puis au
second chapitre, nous avons abordé les généralités
sur le MPLS. Ensuite, nous nous sommes attaqués à l'aspect
conception des réseaux type IP/MPLS, ce qui nous a conduits au chapitre
concernant le déploiement de la technologie MPLS. Enfin, au
cinquième chapitre, nous avons présenté quelques
résultats obtenus. Concrètement, nous avons proposé une
solution trois en un (3 in 1) : l'ingénierie de
trafic MPLS couplé à une qualité
de service et à un VPN MPLS que
nous avons testé et émulé dans un laboratoire virtuel
(GNS3, VMware Workstation, Wireshark, ...).
Nous pouvons dont affirmer sans prétention aucune, que,
toute conception et déploiement d'un réseau type MPLS
devrait suivre l'enchainement que nous avons proposé dans notre
travail. Bien plus, il faudra également s'inspirer de notre
5MPLS-Migrating.
Puisqu'en science, 'il y a pas de
vérité première mais plutôt d'erreur première
'; nous pensons que, pour approfondir les tests de déploiement de la
technologie MPLS, il faudrait, en plus de tout ce dont nous avons fait
jusqu'ici, se tourner vers la solution de tests avec les équipements
matériels réels. Ce travail, loin d'être complet, pourra
être amélioré dans tous les sens du terme, par qui conque
s'y intéresserait.
De plus, le MPLS généralisé nommé
GMPLS ; qui est l'évolution du MPLS
s'implémentant sur fibre optique, est en revanche une
aventure qu'il faudrait tenter dans un futur proche.
74
BIBLIOGRAPHIE
1-) Ouvrages :
[1] Andew S. Tanenbaum, Computer Networks 4/e, from
Prentice Hall PTR.
[2] Claude Servin , Réseaux &
Télécoms, 2ème édition,
Éditions DUNOD,Paris,France,2003.
[3] Guy Pujolle, Les Réseaux,
6ème édition, Éditions EYROLLES, Paris, France,
2008.
[4] Ivan Pepelnjak, Jim Guichard, Architectures MPLS et
VPN, Éditions Cisco Systems.
2-) Articles / Supports de cours :
[5] AUFFRAY Guillaume, SERRE Samuel, THEVENON Julien,
Multi Protocol Label Switching, [NE520], 2004.
[6] NOVÁK, V.; SLAVÍÈEK, K, Design
and Deployment of Phase 4 of the CESNET2 DWDM Optical Transport Core Network.
In LHOTKA, L, SATRAPA, P. (Ed.) NETWORKING STUDIES. PRAHA: CESNET, 2007,
p. 15-25.
[7] NOVÁK, V.; Josef Vojtìch, Deployment of
a DWDM System with CLA Optical Amplifiers in the CESNET2 Network. In LHOTKA, L,
SATRAPA, P.(Ed) NETWORKING STUDIES. PRAHA: CESNET, 2007, p. 27-37
[8] MRHA, P.; VERICH, J. QoS Design and Implementation in
the CESNET2 MPLS-based Backbone, TECHNICAL REPORT, 17/20083, Praha:
CESNET, 2008.
3-) Thèse et mémoire :
[9] Antoine MAHUL : Apprentissage de la qualité de
service dans les réseaux multiservices : Application au routage optimal
sous contraintes, Doctorat, Université Blaise
Pascal-Clermont-Ferrand II, 2005.
[10] Khodor ABBOUD : Conception et évaluation d?un
modèle adaptatif pour la qualité de service dans les
réseaux MPLS, Doctorat, École centrale de Lille, 2010.
4-) Articles du web
[11]
http://www.afnic.fr/noncvs/formations/routage_long/ospf.html,
06/05/2013, 10h43.
[12]
http://www.cesnet.cz/doc/2007/networking-studies/,
09/06/2013, 16h03.
75
[13]
http://www.cesnet.cz/doc/techzpravy/2008/qos-in-cesnet2-mpls-backbone/,
06/05/2013, 11h43.
[14]
http://www.cisco.com/en/US/tech/tk365/tk480/tsd_technology_support_sub-protocol_home.html
: présentation d?OSPF par Cisco, 09/06/2013,
23h43.
[15]
http://www.cisco.com/warp/public/105/mpls_te_ospf.pdf,
20/06/2013, 00h05.
[16]
http://www.cisco.com/warp/public/105/mplsospf.pdf,
16/06/2013, 12h08.
[17]
http://www.frameip.com/mpls
: concepts généraux sur MPLS, 18/06/2013,
08h43.
[18]
http://www.renater.fr/Video/MPLS/Bidaud/P/Introduction/Slides/htmlimg1.html
: introduction et application de MPLS, 26/05/2013,
11h20.
[19]
http://www.cisco.com/en/US/docs/ios/mpls/command/reference/mp_book.html
: commande MPLS sur IOS Cisco, 19/06/2013, 22h50.
[20]
http://www.GNS3.com/,
16/05/2013, 03h20.
[21] http://www.wireshar.com/ , 26/05/2013,
02h11.
5- ) RFC (Request For Comment)
[22] IS-IS [RFC1195];
[23] IS-IS-TE [RFC5305]
[24] MPLS [RFC3031];
[25] MPLS-TE [RF702]
[26] LDP [RFC5036]
[27] L3VPN MPLS [RF547]
[28] CR-LDP [RFC3468]
[29] OSPF-TE [RFC3630]
[30] RSVP-TE [RFC3209]
ANNEXES
Annexe1:
Les configurations MPLS-TE
Pour PE1 on a en résumé:
hostname PE
!
ip cef
mpls traffic-eng tunnels
!
!
interface Loopback0
ip address 102.102.102.101
255.255.255.0
!
interface Tunnel0
ip unnumbered Loopback0
tunnel destination 102.102.102.102
tunnel mode mpls traffic-eng
tunnel mpls traffic-eng autoroute
announce
tunnel mpls traffic-eng priority 1 1
tunnel mpls traffic-eng bandwidth 100
tunnel mpls traffic-eng path-option 1
explicit name LSP1
!
interface Tunnel1
ip unnumbered Loopback0
tunnel destination 102.102.102.102
tunnel mode mpls traffic-eng
tunnel mpls traffic-eng autoroute
announce
tunnel mpls traffic-eng priority 2 1
tunnel mpls traffic-eng bandwidth 100
tunnel mpls traffic-eng path-option 1
explicit name LSP2
!
interface Tunnel2
ip unnumbered Loopback0
tunnel destination 102.102.102.102
A
tunnel mode mpls traffic-eng
tunnel mpls traffic-eng autoroute
announce
tunnel mpls traffic-eng priority 3 1
tunnel mpls traffic-eng bandwidth 100
tunnel mpls traffic-eng path-option 1
explicit name LSP3
!
interface GigabitEthernet1/0
ip address 10.1.1.2 255.0.0.0
negotiation auto
!
interface GigabitEthernet2/0
ip address 11.1.2.3 255.0.0.0
negotiation auto
mpls traffic-eng tunnels
tag-switching ip
ip rsvp bandwidth 1000
!
interface GigabitEthernet3/0
ip address 12.1.3.4 255.0.0.0
negotiation auto
mpls traffic-eng tunnels
tag-switching ip
ip rsvp bandwidth 1000
!
router ospf 1
log-adjacency-changes
redistribute rip metric 2
network 10.0.0.0 0.255.255.255 area 0
network 11.0.0.0 0.255.255.255 area 0
network 12.0.0.0 0.255.255.255 area 0
network 102.0.0.0 0.255.255.255 area 0
!
router rip
version 2
redistribute ospf 1 metric 2
network 10.0.0.0
neighbor 10.1.1.30
!
ip classless
banner motd ^COTD#TANGUEP Administrator WARNING:Going out of here
if you are not a network administrator# BANNER ^C !
!
end
Pour PE2 on a en résumé:
hostname PE2
!
ip cef
mpls traffic-eng tunnels
!
interface Loopback0
ip address 102.102.102.102
255.255.255.0
!
interface GigabitEthernet1/0
ip address 15.1.6.11 255.0.0.0
negotiation auto
mpls traffic-eng tunnels
tag-switching ip
ip rsvp bandwidth 1000
!
interface GigabitEthernet2/0
ip address 14.1.5.9 255.0.0.0
negotiation auto
mpls traffic-eng tunnels
tag-switching ip
ip rsvp bandwidth 1000
!
interface GigabitEthernet3/0
ip address 16.1.7.12 255.0.0.0
negotiation auto
!
B
router ospf 1
log-adjacency-changes
redistribute rip metric 2
network 14.0.0.0 0.255.255.255 area 0
network 15.0.0.0 0.255.255.255 area 0
network 16.0.0.0 0.255.255.255 area 0
network 102.102.102.0 0.0.0.255 area 0
!
router rip
version 2
redistribute ospf 1 metric 2
network 16.0.0.0
neighbor 16.1.7.12
!
ip classless
!
banner motd ^COTD#TANGUEP
Administrator WARNING:Going out of
here if you are not a network
administrator#
BANNER ^C
!
!
end
Pour P1 on a en résumé:
hostname P1
!
!
ip cef
mpls traffic-eng tunnels
!
!
interface Loopback0
ip address 102.102.102.103
255.255.255.0
!
interface GigabitEthernet1/0
ip address 11.1.2.4 255.0.0.0
negotiation auto
mpls traffic-eng tunnels
tag-switching ip
ip rsvp bandwidth 1000
!
interface GigabitEthernet2/0
ip address 13.1.4.6 255.0.0.0
negotiation auto
mpls traffic-eng tunnels
tag-switching ip
ip rsvp bandwidth 1000
!
interface GigabitEthernet3/0
ip address 14.1.5.8 255.0.0.0
negotiation auto
mpls traffic-eng tunnels
tag-switching ip
ip rsvp bandwidth 1000
!
router ospf 1
log-adjacency-changes
network 11.0.0.0 0.255.255.255 area 0
network 13.0.0.0 0.255.255.255 area 0
network 14.0.0.0 0.255.255.255 area 0
network 102.102.102.0 0.0.0.255 area 0
!
ip classless
!
banner motd ^COTD#TANGUEP
Administrator WARNING:Going out of
here if you are not a network
administrator#
BANNER ^C
!
!
!
end
Pour P2 on a en résumé:
C
hostname P2
!
!
ip cef
!
interface Loopback0
ip address 102.102.102.104
255.255.255.0
!
interface Tunnel200
ip unnumbered Loopback0
tunnel destination 102.102.102.102
tunnel mode mpls traffic-eng tunnel
mpls traffic-eng autoroute announce
tunnel mpls traffic-eng priority 4 2
tunnel mpls traffic-eng bandwidth 100
tunnel mpls traffic-eng path-option 1
explicit name BACKUP !
interface GigabitEthernet1/0
ip address 15.1.6.10 255.0.0.0
negotiation auto
tag-switching ip
ip rsvp bandwidth 1000
!
interface GigabitEthernet2/0
ip address 13.1.4.7 255.0.0.0
negotiation auto
tag-switching ip
ip rsvp bandwidth 1000
!
interface GigabitEthernet3/0
ip address 12.1.3.5 255.0.0.0 negotiation
auto
tag-switching ip
ip rsvp bandwidth 1000
!
router ospf 1
log-adjacency-changes
network 12.0.0.0 0.255.255.255 area 0 network 13.0.0.0
0.255.255.255 area 0 network 15.0.0.0 0.255.255.255 area 0 network
102.102.102.0 0.0.0.255 area 0 !
ip classless
!
!
end
Annexe 2:
Les configurations MPLS-QoS.
Pour les Pi (i=1; 2) routeurs:
hostname P1
!
ip cef
mpls traffic-eng tunnels
!
class-map match-all class2
match mpls experimental topmost 1
class-map match-all class3
match mpls experimental topmost 2
class-map match-all class1
match mpls experimental topmost 0
!
policy-map class_PHB1_policy
class class1
bandwidth 250000
class class2
bandwidth 200000
class class3
D
bandwidth 200000 class class-default fair-queue 32
queue-limit 100
policy-map class_PHB2_policy
class class1
bandwidth 250000
class class2
bandwidth 200000
class class3
bandwidth 200000
class class-default
fair-queue 32
queue-limit 100
!
!
interface Loopback0
ip address 102.102.102.103
255.255.255.0
!
interface GigabitEthernet1/0
ip address 11.1.2.4 255.0.0.0
service-policy output class_PHB1_policy
ip rsvp bandwidth 1000
!
interface GigabitEthernet2/0
ip address 13.1.4.6 255.0.0.0
service-policy output class_PHB1_policy
ip rsvp bandwidth 1000
!
interface GigabitEthernet3/0
ip address 14.1.5.8 255.0.0.0
service-policy output class_PHB1_policy
ip rsvp bandwidth 1000
!
!
end
Pour les PEi (i=1; 2) routeurs: hostname PE1
!
!
class-map match-all TempsReel_In match ip dscp ef
class-map match-all BestEffort_Out match mpls experimental
topmost 2 class-map match-all Important_In match ip dscp af11
class-map match-all Important_Out match mpls experimental topmost
1 class-map match-all TempsReel_Out match mpls experimental topmost 0 class-map
match-all BestEffort_In match ip dscp default
!
!
policy-map input policy
class TempsReel_In
set mpls experimental 0
class Important_In
set mpls experimental 1
class BestEffort_In
set mpls experimental 2
policy-map output_policy
E
class TempsReel_Out
bandwidth 250000
queue-limit 100
class Important_Out
bandwidth 200000
random-detect
random-detect exponential-weighting-
constant 5
class BestEffort_Out
bandwidth 200000
random-detect
random-detect exponential-weighting-
constant 5
class class-default
fair-queue 32
queue-limit 100
!
!
interface GigabitEthernet1/0
ip address 10.1.1.2 255.0.0.0
negotiation auto
service-policy input input_policy
service-policy output output_policy
!
interface GigabitEthernet2/0
ip address 11.1.2.3 255.0.0.0
service-policy input input_policy
service-policy output output_policy
ip rsvp bandwidth 1000
!
!
router rip
version 2
redistribute ospf 1 metric 2
network 10.0.0.0
neighbor 10.1.1.30
!
!
end
F
interface GigabitEthernet3/0 ip address 12.1.3.4 255.0.0.0
service-policy input input_policy service-policy output output_policy ip rsvp
bandwidth 1000
!
end
Annexe 3:
Les configurations MPLS-VPN VRF
(Sur les routeurs PEi uniquement)
hostname PE1
!
!
ip vrf ClientTempsReel
rd 999:1
route-target export 64999:1
route-target import 64999:1
!
ip cef
!
router ospf 1
log-adjacency-changes
redistribute rip metric 2
network 10.0.0.0 0.255.255.255 area 0
network 11.0.0.0 0.255.255.255 area 0
network 12.0.0.0 0.255.255.255 area 0
network 102.0.0.0 0.255.255.255 area 0
G
Annexe 4: Les commandes de vérification et de
débuggage du MPLS
Quelques commandes de Vérifications :
Spécialement, nous avons choisi de ne pas traduire en
français car cela dénature un peu le sens exact de ce que font
exactement ces commandes et options.
|
Commandes Principales
|
Options et sous options
|
Rôles
et Commentaires
|
|
Show mpls
|
Atm-ldp
|
Sous options
|
Rôles
|
ATM LDP Protocol information
|
|
Bindings
|
Dynamic ATM MPLS
information
|
|
Bindwait
|
Label VC in bindwait state
|
|
Capability
|
Dynamic ATM interface
capability information
|
|
Summary
|
Dynamic ATM accounting
information
|
|
cos-map
|
Show MPLS CoS
ATM Multi-VC CoS Map
|
|
forwarding- table
|
Sous options
|
Rôles
|
Show the Label
Forwarding
Information Base
(LFIB)
|
|
A.B.C.D
|
Destination prefix
|
|
Detail
|
Detailed information
|
|
interface
|
Match outgoing
interface
|
|
labels
|
Match label values
|
|
lsp-tunnel
|
LSP Tunnel id
|
|
next-hop
|
Match next hop neighbor
|
|
vrf
|
Show entries for a VPN
Routing/Forwarding instance
|
|
Interfaces
|
Sous options
|
Rôles
|
Per-interface MPLS
forwarding information
|
|
Async
|
Async interface
|
|
BVI
|
Bridge-Group Virtual
Interface
|
|
CTunnel
|
CTunnel interface
|
|
Dialer
|
Dialer interface
|
|
FastEthernet
|
FastEthernet IEEE 802.3
|
|
GigabitEthernet
|
GigabitEthernet IEEE 802.3z
|
|
Loopback
|
Loopback interface
|
|
MFR
|
Multilink Frame Relay bundle interface
|
|
Multilink
|
Multilink-group interface
|
|
Null
|
Null interface
|
|
Port-channel
|
Ethernet Channel of interfaces
|
H
|
|
Tunnel
|
Tunnel interface
|
|
|
Vif
|
PGM Multicast Host interface
|
|
Virtual
|
Virtual interface
|
|
Virtual- Template
|
Virtual Template interface
|
|
Virtual- TokenRing
|
Virtual TokenRing
|
|
XTagATM
|
Extended Tag ATM interface
|
|
all
|
Display all interfaces
|
|
detail
|
Show detailed information
|
|
vrf
|
VPN Routing / Forwarding instance interfaces;
|
|
ip
|
MPLS IP information
|
|
l2transport
|
MPLS circuit transport info
|
|
label
|
Label information
|
|
ldp
|
Label Distribution
Protocol information
|
|
prefix-map
|
Show MPLS CoS
Prefix Map
|
|
traffic-eng
|
Traffic engineering
information
|
|
Show ip
|
Bgp vpnv4 all
|
Pour voir tous les VPN
|
Quelques commandes de débuggage:
|
Commandes
|
Rôles et commentaires
|
|
Debug mpls
|
Permet de résoudre les problèmes de bug
empêchant le bon fonctionnement du MPLS de façon
générale.
|
|
Debug qos
|
Permet de venir à bout des bugs liés à la
QoS de façon générale.
|
|
Debug tag-switching
|
Sert à résoudre les bugs liés à la
commutation par étiquette dans MPLS.
|
|
Debug backup
|
Il permet de débugger les paramètres backup en cas
de trouble.
|
|
Debug vpn
|
Permet de résoudre les problèmes de bugs
liés aux VPN.
|
|
Debug bgp (is- is;rip;ospf;...)
|
Permet de résoudre tous les bugs lies à ces
différents protocoles de routage.
|
I
Commandes utilisées dans notre
démonstration:
1. Show mpls traffic-eng tunnels
2. Show mpls traffic-eng tunnels bref
3. Show mpls ip binding
4. Show mpls forwarding-table
5. Show mpls ldp parameters
6. Show mpls ldp neighbor
7. Show mpls interfaces
8. Show running-config
| 

