|
REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET POPULAIRE
MINISTERE D'ENSEIGNEMENT SUPPERIEUR ET DE LA
RECHERCHE
SCIENTIFIQUE
UNIVERSITE SAAD DAHLAB - BLIDA
USDB
FACULTE DES SCIENCES
DEPARTEMENT D'INFORMATIQUE
Mémoire pour l'obtention
du diplôme
d'ingénieur d'état en informatique
Option : Système d'information
Sujet
:
Affectation de circuits d'une bibliothèque a des
unîtes fonctionnelles d'une partie opérative avec des contraintes
de surface, de vitesse et de consommation d'énergie.
Présenté par : LOUACHENI FARIDA.
Promoteur : Mr : MAHDOUM ALI.
KADID NADIA.
Organisme d'accueil : CDTA (laboratoire
de microélectronique).
2010-2011
SOMMAIRE
Résume 2
Introduction générale 3
CHAPITRE1 : Définitions et rappels
1.1 Introduction 7
1.2 Définitions et rappels ..7
1.3 Problématique 8
1.4 Conclusion 10
CHAPITRE2 : Etude technique de la
problématique
2.1 Introduction 13
2.2 Définition technique du problème 13
2.3 Complexité algorithmique du problème 14
2.4 Définition des contraintes du problème 15
2.4.1 Surface 15
2.4.2 Vitesse 16
2.4.3 Consommation de la puissance ..17
2.4.3.1 Consommation due aux courts circuits 17
2.4.3.2 Consommation dynamique 21
2.4.3.3 Consommation due aux fuites de courant 22
2.5 Conclusion 24
CHAPITRE3 : Méthode exhaustive
développée
3.1 Introduction 26
3.2 Présentation générale de notre
méthode 26
3.3 Détails techniques de notre méthode 29
3.3.1 Structure de données 29
3.3.2 Formats des enregistrements des fichiers 30
3.3.3 Algorithmes 31
3.3.4 Exemple d'illustration 48
3.4 Conclusion 50
CHAPITRE4 : Résultats
4.1 Introduction 52
4.2 Présentation des résultats 52
4.3 Conclusion 65
Conclusion générale 67
Bibliographie 69
TABLE DES FIGURES
Figure 2.1 :
Inverseur dans la technologie CMOS 19
Figure 2.2 : Fonction F= A . (B+C) en
technologie CMOS 20
Figure 2.3 : Description structurelle partielle
d'une partie opérative 23
Figure 3.1 : Schéma synoptique de
l'application 28
Figure 3.2 : Schéma pour les
différentes listes chaînées 41
TABLE DES ALGORITHMES
Algorithme 3.3.3.1 : Algorithme pour la fonction
récursive configuration 31
Algorithme 3.3.3.2 : Algorithme pour calculer la
surface, la vitesse et la puissance d'une configuration
33
Algorithme 3.3.3.3 : Algorithme pour mettre à
jour la surface de la configuration en
|
cours, lire la vitesse et la puissance d'une instance
donnée
|
36
|
|
Algorithme 3.3.3.4 : Algorithme pour la fonction
reporter_t_p ()
|
36
|
|
Algorithme 3.3.3.5 : Algorithme pour la fonction
maj2_dp ()
|
37
|
|
Algorithme 3.3.3.6 : Algorithme pour la fonction
maj_dp ()
|
.38
|
|
Algorithme 3.3.3.7 : Algorithme pour
créer les différentes listes
|
38
|
|
Algorithme 3.3.3.8 : Algorithme pour la fonction
récursif t_arrgts ()
|
42
|
|
Algorithme 3.3.3.9 : Algorithme pour la fonction
inserer ()
|
44
|
|
Algorithme 3.3.3.10 : Algorithme pour la
fonction inserer2 ()
|
44
|
|
Algorithme 3.3.3.11 : Algorithme pour la
fonction inserer3()
|
44
|
|
Algorithme 3.3.3.12 : Algorithme pour la
fonction inserer4 ()
|
45
|
|
Algorithme 3.3.3.13 : Algorithme principal
|
45
|
RESUME
Il existe actuellement des applications ayant des
caractéristiques différentes en termes de surface, vitesse et
consommation de puissance. De ce fait, la conception du circuit ou
système implémentant l'application concernée est sujette
à ses spécifications.
Une méthode de conception répondant à ces
critères serait de concevoir le circuit ou système à
partir d'aucun composant (?from scratch?) en veillant à satisfaire les
différentes contraintes au cours de la conception. Néanmoins, la
concurrence et la compétitivité féroces dans le
marché des systèmes électroniques font que cette
démarche présente l'inconvénient majeur de
nécessiter un temps de conception énorme, ou du moins, ne
répondant pas à la demande pressante du marché. Aussi,
cette méthodologie de conception (appelée dans la terminologie
anglo-saxonne ?full custom?) est écartée pour ce genre
d'applications commerciales.
Une autre méthode serait de constituer tout le circuit
(ou système) à partir de composants déjà
conçus, et ce, pour des fins de rapidité de conception.
Toutefois, ces composants de base ont certaines caractéristiques
électriques et pourraient, en les assemblant, ne pas répondre au
cahier des charges de l'application concernée. Alors comment
concevoir rapidement un système tout en veillant
à satisfaire les contraintes imposées ?
L'objet du travail décrit dans ce mémoire est une
contribution à répondre favorablement à la question
précédemment citée.
Mots-clés :
applications différentes, contraintes différentes,
rapidité de conception, satisfaction du cahier des charges.
INTRODUCTION GENERALE
La prolifération importante de systèmes
électroniques sur le marché actuel a engrangé une
concurrence et une compétitivité sans merci. C'est à la
compagnie qui mettra, la première, un produit sur le marché que
reviendra la plus grande part de ce marché. Il est donc tout à
fait primordial que la conception doive être rapide. Comme il a
été souligné dans le résumé, concevoir le
circuit (ou système) à partir de zéro (?from scratch?)
n'est certainement pas la voie indiquée. Il s'agira alors de constituer
le système à partir de composants déjà
conçus. Mais ces composants ont euxmêmes certaines
caractéristiques électriques. En les assemblant, il n'est pas
sûr de satisfaire le cahier des charges de l'application
concernée. Alors comment procéder pour que :
- la conception du système soit rapide,
- les contraintes de l'application concernée soient
satisfaites ?
Le travail décrit dans ce mémoire est une
contribution pour répondre favorablement au dilemme posé. Il
s'articule sur l'utilisation d'une bibliothèque de composants. Cette
bibliothèque se caractérise par le fait que pour tout composant
assurant une ou des fonctions données, plusieurs instances de ce
même composant existent. Ces instances, quoique assurant la même
fonctionnalité, ont toutefois des caractéristiques
électriques différentes. Le système à concevoir
étant composé d'une ou de plusieurs instances d'un certain nombre
ou de tous les composants (assurant des fonctions différentes) de la
bibliothèque, il s'agira a lors de combiner, judicieusement, ces
instances pour répondre au cahier des charges de l'application.
Il est clair qu'une combinaison manuelle de ces instances est
à abandonner, étant donné que le nombre de combinaisons
est extraordinaire: ceci prendrait plusieurs mois, et l'intérêt de
la rapidité de conception serait perdu. Nous verrons dans ce
mémoire, que même avec l'utilisation d'un processeur, le temps CPU
serait considérable si on considérait exhaustivement toutes les
combinaisons, puis de sélectionner celle qui répondrait le mieux
à l'application concernée. Il s'agirait alors de
développer une méthode approchée qui répondra
à la double problématique d'être polynomiale et de produire
une solution optimale ou pré-optimale.
C'est un défi assez important que l'on ne peut relever
qu'avec des méthodes rigoureuses, s'articulant sur des principes connus
(algorithmes génétiques ou évolutionnaires,
séparation et évaluation, recuit simulé, Tabu search,
etc,...). Il est très important d'indiquer que ce n'est pas le principe
choisi (algorithme génétique, ....) qui conduirait à une
solution de qualité, mais plutôt comment procéder à
l'initialisation, comment passer d'une solution à une autre, comment
éviter un traitement redondant (gaspillage inutile de temps CPU), ...
Des réponses à ces questions sont indiquées dans [1].
Toutefois, quoique l'algorithmique développé repose sur une bonne
heuristique ou une bonne méta-heuristique, comment ?mesurer? la
qualité de la solution qu'il a produite ? Ceci peut se faire moyennant
l'utilisation de benchmarks, données dont la
génération a été bien réfléchie (afin
de répondre à des cas réels dans le monde industriel) et
qui sont mises à la disposition (par téléchargement) des
laboratoires de recherche. Ainsi, les chercheurs pourraient comparer leurs
algorithmes sur les mêmes données. Cette
comparaison permettrait éventuellement d'améliorer l'algorithme
si la qualité de la solution qu'il produit est loin de valoir celles
produites par d'autres algorithmes. Néanmoins, de tels benchmarks
n'existent pas pour tout ce qu'on pourrait développer. Alors le seul
moyen de mesurer la qualité de notre solution serait de la comparer
à la solution exacte, c'està-dire celle obtenue après
l'exploration exhaustive dans l'espace des solutions. Evidemment,
l'exécution de la méthode exacte ne peut être envisageable
que pour des cas possibles, ceux engendrant un temps CPU raisonnable. Cette
méthode a surtout pour mérite d'indiquer qu'une méthode
approchée n'est pas bonne. En effet, si les méthodes
approchée et exacte produisent la même solution pour certains cas
(ceux rendant possibles l'exécution de la méthode exacte), qu'en
est-il pour les autres cas ? Toutefois, si la méthode approchée a
été développée en respectant certaines
règles de base [1] et si sa solution est identique ou proche de celle
produite par la méthode exhaustive pour de nombreux jeux d'essais, l'on
peut espérer que pour les cas où la méthode exacte n'est
pas envisageable, la solution obtenue serait fiable.
Du fait de l'indisponibilité de benchmarks, notre
travail a consisté à développer la méthode exacte
qui servira comme un moyen de mesure de la qualité de la solution
obtenue avec une méthode approchée (autre projet potentiel de fin
d'études).
Notre mémoire est organisé comme suit : Dans le
premier chapitre, nous apporterons quelques définitions qui faciliteront
au lecteur la compréhension des autres chapitres. Le deuxième
chapitre sera consacré à l'étude technique du
problème concerné, en particulier sa complexité
algorithmique, suivi par le troisième chapitre qui décrira nos
algorithmes, les structures de données, ainsi que les formats des
enregistrements des différents fichiers utilisés. Nous
présenterons les résultats obtenus au quatrième chapitre,
et terminerons notre mémoire par une conclusion au cinquième
chapitre. Enfin, ce dernier chapitre sera suivi par la citation des
références bibliographiques.
CHAPITRE 1
cD~finitions et rappe(s
1.1. Introduction :
Dans ce chapitre, nous donnerons quelques définitions
et rappels qui sont en rapport avec le problème traité. Nous
espérons qu'ils aideront le lecteur à mieux cerner le contenu de
ce mémoire et la problématique, définie dans ce même
chapitre, qui est posée.
1.2. Définitions et rappels :
Par le passé, la conception d'un circuit
intégré se faisait à partir du tout début (?from
scratch?). Cette méthode de conception appelée dans la
terminologie anglosaxonne ?full custom? a pour avantage de produire un circuit
sur mesure, c'est-à-dire conformément à la demande du
client. Son inconvénient majeur et par ailleurs évident est le
temps de conception.
On opta alors pour une autre méthode appelée
?Gate Arrays? ou réseaux prédiffusés qui consiste à
concevoir un circuit à partir d'un circuit constitué de
composants assurant plusieurs fonctions. Ce circuit est déjà
fabriqué et ne reste que la phase de métallisation qui consiste
à relier les blocs permettant de réaliser le circuit
demandé. Cette méthode est relativement rapide mais l'un de ses
inconvénients est que des blocs peuvent exister dans le circuit sans
pour autant être utilisés. Ceci a pour conséquence
d'augmenter inutilement la surface du circuit et d'induire un coût de
silicium (assez cher) supplémentaire.
Les années passant, on conceva plusieurs circuits
(additionneurs, multiplieurs, comparateurs, ...) et l'idée vint de les
utiliser comme des briques de base pour constituer un circuit plus complexe. On
constitua alors des bibliothèques de cellules (?standard cells?) servant
à cet effet. Ainsi, on gagna l'avantage des réseaux
prédiffusés (?gate arrays?) en matière de rapidité
de conception, tout en évitant de gaspiller inutilement du silicium.
Rappelons aussi que pour éviter de constater
l'existence d'erreurs à des bas niveaux de conception et de refaire la
conception (ce qui est une perte de temps et d'argent), on bascula de la
méthodologie de conception ?bottom-up? à la méthodologie
?top-down?. Avec cette dernière, la conception démarre à
partir du niveau de conception le plus abstrait (le moins
détaillé) et le passage d'un niveau à
celui qui est immédiatement inférieur ne se fait
qu'après validation. Ainsi, on augmente la probabilité
d'inexistence d'erreurs aux niveaux d'abstraction les plus bas, ceux où
l'erreur est très coûteuse.
Les méthodologies et méthodes que nous venons de
décrire succinctement concernent les ASICs (?Applied Specific Integrated
Circuits?), ou circuits intégrés à applications
spécifiques. Notons que les différentes phases de conception d'un
ASIC sont menées dans un laboratoire, mais sa fabrication est
exclusivement faite dans une fonderie (appelée aussi salle blanche) qui
est une centrale technologique très coûteuse où sont
menées les différentes phases de fabrication du circuit. Il est
possible d'éviter le recours à une fonderie en utilisant des
circuits déjà fabriqués. Cependant, à la
différence des ?gate arrays?, ceux-ci sont programmables. Il suffit
alors de mener les différentes étapes de conception, puis
à la fin, de générer un code qui va programmer le FPGA.
L'avantage est donc de réaliser toutes les étapes, depuis la
conception jusqu'à la réalisation du circuit, au laboratoire
seulement. L'autre avantage est qu'un FPGA programmé pour une
application donnée peut servir pour une autre application, après
sa reprogrammation. Il existe actuellement plusieurs familles de FPGAs dont le
choix se fait en fonction de la complexité de l'application.
Néanmoins, les FPGAs présentent plusieurs inconvénients
par rapport aux ASICs : moins de performance, plus volumineux et ne peuvent
donc être utilisés pour certaines applications (montre
électronique, carte à puce, puce d'un téléphone,
...). Enfin, leur utilisation à une très grande échelle de
production serait plus coûteuse. On n'utilise donc les FPGAs que pour
réaliser des prototypes.
1.3. Problématique :
Les années passant, les circuits sont devenus de plus
en plus complexes. Alors que dans le passé un additionneur constituait
un composant de base pour concevoir un circuit plus complexe, un circuit ou
système actuel peut avoir pour composant de base un ... processeur !
Autant dire que la complexité des systèmes a
nécessité de nouvelles méthodes de conception (on parle
aujourd'hui de compilation de silicium) associant l'usage intensif de
l'informatique, de la théorie des graphes, de la recherche
opérationnelle, .... La complexité des systèmes est
évidemment liée aux composants que nous utilisons actuellement
dans notre vie quotidienne (téléphones portables, PDAs,
systèmes embarqués - véhicules, satellites, ..-).
Ces systèmes aussi divers que variés ont des
caractéristiques différentes. Certains nécessitent une
faible consommation d'énergie (téléphones portables,
circuits embarqués sur des satellites -l'énergie solaire
emmagasinée le jour doit suffire pour faire fonctionner le circuit la
nuit-, ...). D'autres, par contre, nécessitent un temps de traitement
adéquat (systèmes fonctionnant en temps réel). Ces
nombreuses applications qui nécessitent des caractéristiques
électriques différentes amènent à opter pour des
méthodes de conception adéquates afin de répondre
à leurs contraintes, tout en satisfaisant,
rapidement, la demande du marché. Une solution
partielle est d'opter pour une méthode de conception
conjointe Hardware - Software de circuits. L'idée est
d'implémenter en software toutes les parties qui sont censées
changer d'une application à une autre, et en Hardware (donc une fois
pour toutes) celles qui sont communes aux applications visées par la
compagnie. Ainsi, la circuiterie Hardware déjà prête,
l'écriture rapide de nouveaux codes et leur intégration avec le
Hardware permettraient, en partie, produire rapidement un nouveau
système à partir d'un ancien (?Design reuse?). Toutefois,
produire rapidement un système ne suffit pas. Il faut aussi qu'il
satisfasse les différentes contraintes (principalement la surface, la
vitesse et la consommation d'énergie). De ce fait, cette
méthodologie de conception (conception conjointe) ne suffit pas à
elle seule. Il faut l'accompagner par des techniques supplémentaires de
conception.
Le travail décrit dans ce mémoire est une
contribution pour répondre favorablement à cette
problématique, c'est-à-dire comment concevoir, rapidement, un
système répondant à un certain cahier de charges. Les
méthodes de conception décrites précédemment,
notamment l'utilisation d'une bibliothèque de cellules, ne suffisent pas
à elles-seules et il s'agit alors de les améliorer. Par
définition, les instances d'un circuit donné, sont des circuits
réalisant la même fonction, mais
possédant des caractéristiques électriques
différentes. Afin de répondre à la
problématique donnée, l'idée serait de constituer une
bibliothèque de circuits ayant chacun plusieurs instances
(réalisant la même fonction) mais présentant des
caractéristiques différentes. Ainsi, pour constituer
rapidement le système désiré, il suffit
de puiser de cette bibliothèque les composants qui sont
nécessaires pour l'application. Pour répondre aux
contraintes imposées par cette application, il suffit
de trouver la bonne combinaison. Nous verrons dans la suite de ce
mémoire que la détermination de cette combinaison ne peut se
faire manuellement étant donné le nombre fantastique de
combinaisons.
L'utilisation-même d'un processeur ne peut se faire, sans
l'utilisation d'une méthode adéquate, compte tenu de la taille de
l'espace des solutions.
Nous verrons plus en détails dans le prochain chapitre
que la complexité algorithmique du problème posé n'est pas
polynomiale. De ce fait, une méthode exhaustive est exclue, et il faut
alors recourir à une méthode permettant de générer,
en un temps CPU raisonnable, une solution optimale ou du moins
pré-optimale. Mais comment ?mesurer? la qualité de cette solution
? En général, on a recours à des benchmarks qui
sont des données mises à la disposition des chercheurs et
générées en tenant compte de la réalité (cas
industriel). Ainsi, des méthodes peuvent être comparées sur
les mêmes données. Cette comparaison permettrait
d'opter pour la méthode développée (si elle a
été favorablement comparée, sur plusieurs jeux d'essais,
aux autres méthodes) ou recourir à son amélioration.
Toutefois, ces benchmarks n'existent pas pour toute
problématique, en particulier pour le problème traité dans
ce mémoire. Il ne reste alors qu'une seule alternative, celle de
recourir à la méthode exacte qui consiste à étudier
exhaustivement toutes les combinaisons, puis de sélectionner celle qui
réponde le mieux à l'application concernée. Evidemment,
ceci n'est possible que si l'espace des solutions le permet, et notons que ce
type de comparaison sert beaucoup plus à critiquer la méthode
approchée (repère pour son amélioration) que pour sa
validation. En respectant les règles de base pour développer une
heuristique [5], et en la comparant favorablement à la méthode
exacte, et ce, pour plusieurs jeux d'essais, on pourrait espérer que la
solution obtenue (et incluse dans un espace de solutions très large
interdisant de l'explorer de manière exhaustive) soit fiable.
1.4. Conclusion :
Nous avons décrit dans ce chapitre les
méthodologies et méthodes principales de conception de circuits
intégrés. Nous avons aussi vu que pour produire rapidement un
système satisfaisant certaines contraintes, l'une des méthodes
contribuant à atteindre ce but serait l'utilisation une
bibliothèque contenant un certain nombre d'instances pour chaque type de
composant réalisant une fonctionnalité donnée. Ceci
permettrait de constituer rapidement un système à partir de ces
instances.
La satisfaction des contraintes imposées pour
l'application est achevée grâce à la combinaison
adéquate d'un certain nombre de ces instances.
Ceci ne pouvant se faire manuellement, notre travail a
consisté à développer une méthode exacte qui
servira (dans le futur) de repère pour le développement d'une
méthode approchée qui fera face à n'importe quelle taille
de l'espace de solutions. Afin de montrer plus clairement la motivation de
notre travail en ce sens qu'il est d'un appui incontournable pour le concepteur
de systèmes intégrés, nous aborderons, au prochain
chapitre, les détails techniques du problème posé, en
particulier sa complexité algorithmique. Ceci justifiera que ce travail
ne peut se faire manuellement et que l'utilisation d'un processeur pour
l'exécution d'une méthode adéquate est
nécessaire.
CHAPITRE 2
Etude technique de
la problematique
2.1 Introduction :
Dans ce chapitre, nous montrerons que le travail accompli ne
peut se faire manuellement par un concepteur de systèmes. La
détermination de la complexité algorithmique du problème
posé tranchera sur cette question. Même si la réponse est
d'opter pour une méthode automatisée, cette complexité est
à même de déterminer s'il faut développer une
méthode exacte ou une méthode approchée. Ceci est
très important dans la mesure où si la complexité est
polynomiale, l'utilisation d'une heuristique ne se justifierait pas du fait
qu'elle ne pourra produire, à chaque fois, la solution exacte. De ce
fait, le développement d'une méthode exacte est doublement
bénéfique :
- produire, pour n'importe quel cas, la solution exacte au
problème si sa complexité est polynomiale,
- dans le cas contraire, cette méthode exhaustive
pourrait servir de repère, en absence de benchmarks, pour le
développement d'une méthode approchée fiable
La complexité du problème (consistant à
trouver la combinaison d'instances de circuits qui vont constituer le
système voulu tout en satisfaisant les contraintes qui lui sont
liées) étant déterminée, nous aborderons dans ce
même chapitre quelques aspects sur ces contraintes qui portent en
général sur la surface, la vitesse et la consommation de la
puissance. Ainsi, ce chapitre est entièrement consacré à
une meilleure définition de la fonction objective et aux contraintes
liées à ce problème qui, comme nous le verrons, est
d'optimisation combinatoire.
2.2 Définition technique du problème:
Soit à concevoir un système S à partir
d'une bibliothèque de cellules B={B1,1, B1,2, ...,B1,n1, , Bi,1, Bi,2,
...., Bi,ni, ...,BM,1, ...,BM,nM} en supposant que pour tout type de composant
utilisé par S, il en existe au moins une instance dans la
bibliothèque B.
Notons que Bi,j est la jème
instance du ième composant (1= j = Ni) ; Ni est le nombre
maximal d'instances du composant i réalisant la même
fonctionnalité que ce composant, mais les caractéristiques
électriques de ces instances diffèrent.
Il s'agit alors de trouver la combinaison qui satisfait le
mieux les contraintes imposées. En supposant que la surface, la vitesse
et la consommation de la puissance induites par une combinaison combi
sont respectivement Scomb,i, Vcomb,i et Pcomb,i, cette combinaison ne serait
retenue que si :
Scomb,i = SF ET Vcomb,i = VF ET Pcomb,i = PF
SF, VF et PF sont respectivement les contraintes imposées
sur la surface, la vitesse et la consommation de la puissance du
système.
Ainsi, n'importe quelle combinaison satisfaisant les trois
contraintes peut implémenter le système. Néanmoins, du
fait que notre méthode étudie exhaustivement toutes les
combinaisons, la meilleure parmi les combinaisons retenues sera candidate pour
implémenter le système.
2.3 Complexité algorithmique du problème:
Soit Mi le nombre d`instances du composant i requis pour
concevoir le système. Pour un type de composant donné, Il y'a
alors trois cas possibles:
- il y'a autant d'instances de ce composant dans ce
système que dans la bibliothèque (Mi = Ni)
- le nombre d'instances de ce composant dans le système
est inférieur au
nombre d'instances de ce même composant dans la
bibliothèque (Mi < Ni)
- le nombre d'instances de ce composant dans le système
est supérieur au
nombre d'instances de ce même composant dans la
bibliothèque (Mi > Ni)
Pour les trois cas, et en tenant compte de l'ordre de la position
de chacune des instances dans le système, le nombre de
possibilités est alors :
(2 . 1)
c N Mi
i =
i
En considérant tous les types des
composants implémentant le système, le nombre de
possibilités serait alors :
|
c =
|
Nb Types Systm
_ _
?
i=1
|
N i
M
i
|
(2 .2)
|
Nb_Types_Systm est le nombre de types différents
de composants dans le système à concevoir.
La complexité algorithmique du problème posé
est alors :
CPbm = O( c ) (2 . 3)
L'équation (2.3) montre clairement que la
complexité algorithmique du problème posé n'est pas
polynomiale (noter que Mi n'est pas une constante). De ce fait, une
méthode à base d'une heuristique ou d'une méta-heuristique
est nécessaire afin de faire face à n'importe quelle taille de ce
problème. Néanmoins, et comme il a été dit
auparavant, en absence de benchmarks pour le problème concerné,
une méthode exhaustive est nécessaire pour servir de
référence ou de repère au développement de la
méthode approchée. Les détails techniques de la
méthode exacte que nous avons développée seront
abordés dans le prochain chapitre. Dans ce qui suit, nous allons
décrire quelques aspects de la surface d'un circuit, sa vitesse et sa
consommation de puissance. Ces trois paramètres constituent l'essentiel
des contraintes de notre problème d'optimisation.
2.4 Définition des contraintes du problème:
2.4.1 Surface
Nous avons auparavant dit que la conception d'un circuit
nécessite plusieurs étapes. Ce n'est qu'à la
dernière étape qui consiste à générer le
fichier des masques (appelé GDS2) et destiné à la fonderie
pour la fabrication du circuit (ou système) où tous les
paramètres électriques sont précis. En d'autres termes,
plus le niveau d'abstraction est élevé, et moins sont
précis les paramètres électriques. Néanmoins, une
estimation de ces paramètres à chaque niveau de conception peut
être faite pour sélectionner, à ce niveau de conception,
une entité parmi d'autres, et ce, sans fausser le choix pour les niveaux
d'abstraction inférieurs.
En ce qui concerne notre problème, les interconnexions
(matérialisées par des lignes de métal - aluminium,
cuivre, ..-) ne sont pas exactement définies à ce niveau de
conception. Quoique ces interconnexions ont un impact non négligeable
sur la surface, la vitesse et la consommation de la puissance, nous
supposerons, sans fausser le problème, que leur impact est sensiblement
le même, quelle que soit la configuration (combinaison des instances des
composants utilisés par le système). De ce fait, afin de
sélectionner une combinaison d'instances parmi d'autres,
l'estimation de la surface requise par les instances
implémentant le système est suffisante. Or, du fait que toute
instance incluse dans la bibliothèque est caractérisée par
sa surface, sa vitesse et sa consommation de puissance, la surface induite par
une combinaison donnée s'obtient simplement par l'équation
suivante :
N
S comb = S I i (2.4)
( )
i = 1
N est le nombre total d'instances utilisées dans le
système ; Ii est une instance puisée de la bibliothèque et
existant dans la combinaison étudiée, S(Ii) est sa surface.
Rappelons que si Scomb > SF, alors cette combinaison serait
écartée.
2.4.2 Vitesse
En supposant que le système S sera
implémenté par un ASIC (Circuit Intégré à
Application Spécifique), la vitesse (ou le temps) d'exécution de
toutes les tâches du système sera estimée selon que des
opérations s'exécutent séquentiellement ou
parallèlement (à la différence d'un processeur classique
à usage général où les opérations sont
exclusivement exécutées séquentiellement). Pour ce
paramètre, il s'agit aussi d'une estimation (la valeur exacte du temps
d'exécution ne sera connue qu'à la toute dernière
étape de conception). Toutefois, en comparant des aspects comparables
(c'est-à-dire que les paramètres qui ne sont pas pris en compte
ont le même impact pour toutes les combinaisons), la conception faite
à ce niveau ne faussera pas les tâches menées aux autres
stades de conception.
Dans le prochain chapitre, des détails seront
donnés sur les fichiers d'entrée (fichiers de données)
nécessaires pour notre travail. Soulignons seulement que notre
présent travail est conduit après deux tâches de
synthèse de circuits appelées ordonnancement d'opérations
et allocation de ressources physiques.
L'ordonnancement d'opérations est défini,
succinctement, comme étant la manière dont sont
exécutées les opérations d'un circuit. En d'autres termes,
quelles sont les opérations qui seront exécutées
séquentiellement ou parallèlement, et à quel moment. Cette
tâche d'ordonnancement est menée de manière à
satisfaire les trois contraintes (surface, vitesse et consommation de
puissance).
L'allocation des ressources physiques, menée
après la tâche d'ordonnancement, consiste à allouer des
registres aux différentes variables utilisées par l'algorithme de
l'application à implémenter par un circuit, ainsi que
l'allocation des interconnexions qui seront utilisées pour les
différents transferts de données entre les registres et les
unités fonctionnelles. Aussi bien pour les registres que pour les
interconnexions, il s'agit d'un problème où il faut optimiser les
nombres de registres et d'interconnexions sans qu'il y'ait pour autant un
conflit quelconque (utilisation simultanée d'un registre par deux ou
plusieurs variables, ou transfert simultané de deux données ou
plus sur la même interconnexion).
Ceci étant dit, l'estimation du temps induit par la
combinaison en cours d'étude se fait en consultant le fichier
d'ordonnancement. Ce temps est défini comme suit :
Nb cycles
_
T = max ; 1
t = =
j Nb
comb j (2.5)
j j,
j=1
Nb_cycles est le nombre total de cycles (pas de
contrôle dans notre contexte) ayant servi pour l'ordonnancement des
différentes opérations ; ti,j est le temps
d'exécution de la jème opération
ordonnancée dans le ième cycle ; Nbi est le
nombre total d'opérations s'exécutant en parallèle dans le
ième cycle.
En notant que chacune des opérations est
exécutée par l'une des instances de la combinaison, le temps
tij est clairement défini (il caractérise le temps
d'exécution de cette instance - incluse dans la bibliothèque
-).
Ainsi, le temps total d'exécution induit par une
combinaison peut être simplement estimé par l'équation
(2.5). Enfin, notons que ce temps T sera une donnée importante pour
fixer la fréquence de fonctionnement du circuit. Théoriquement, F
= 1/T, mais afin de garantir un fonctionnement correct du circuit, F sera
légèrement inférieure à 1/T. Ceci est
évidemment valable si T englobe le temps d'exécution de
toutes les parties (opératives et de contrôle) depuis
l'introduction des signaux d'entrée jusqu'à la
génération totale des signaux de sortie.
2.4.3 Consommation de la puissance
Il existe plusieurs types de consommation de puissance, dont
essentiellement, les types suivants :
2.4.3.1 Consommation due aux courts circuits
Ce type de consommation était pertinent avec
d'anciennes technologies de semi-conducteurs, notamment les technologies NMOS
et pseudo-NMOS. Ce problème a été largement résolu
grâce au développement d'une nouvelle technologie, la technologie
CMOS.
Sans entrer dans les détails, un circuit destiné
aux technologies NMOS et pseudo-NMOS se base sur deux parties : une partie qui
charge la capacité au noeud de sortie de la porte logique (c'est le `1'
logique) et une autre partie qui peut décharger cette capacité
(c'est le `0' logique). Dans ces deux technologies, la charge de la
capacité est assurée par un transistor toujours
conducteur (c'est le transistor de charge). Ainsi, s'il ne peut exister un
chemin par lequel transiterait le courant du noeud de sortie de la porte vers
la masse, cette porte réaliserait le `1' logique. Par contre, s'il est
possible de décharger la capacité (ayant pour noeuds
d'extrémités la sortie de la porte et la masse) à travers
un ou plusieurs chemins vers la masse, on réaliserait alors le `0'
logique. Supposons qu'on injecte au circuit un vecteur de signaux
d'entrée tel qu'il soit possible de décharger la capacité.
Fonctionnellement, le circuit est correct puisqu'il réalise la fonction
désirée. Néanmoins, après la réalisation de
cette fonction (obtenir le `0' logique), il y'aura une dissipation
d'énergie inutile du fait que ce circuit n'est plus utilisé. En
effet, ce dernier vecteur de signaux va assurer au moins un chemin du noeud de
sortie de la porte vers la masse. Comme le transistor de charge est toujours
passant, il y'aura alors le passage d'un courant de l'alimentation vers la
masse. Ce courant est appelé courant de court circuit et rend
ces deux technologies inintéressantes à cause de la forte
dissipation d'énergie qu'elles engendrent.
La technologie CMOS (Complementary Metal Oxide Semi
Conductor) a été une astuce qui repose sur le fait de ne pas
permettre aux deux parties (celles assurant la charge et la décharge de
la capacité de sortie) d'être fonctionnelles en même temps.
Ceci, grâce à la réalisation:
- de la partie ?évaluation? (maintenir la
capacité dans son état ou la décharger) par des
transistors NMOS (transistors MOS à canal N où la conduction est
assurée par des électrons) et
- de la partie ?charge? (charger éventuellement la
capacité) par un ensemble complémentaire
constitué de transistors PMOS (transistors MOS à canal P
où la conduction est assurée par des trous qui sont des charges
positives)
Ainsi, théoriquement, il ne pourra jamais exister un
chemin de l'alimentation vers la masse, d'où l'élimination des
courts circuits (en pratique, un faible courant de court circuit peut se
former, mais durant une très courte durée, puis s'annule : cette
durée concerne la transition d'un ou de plusieurs signaux
d'entrée vers d'autre(s) valeurs()). Afin d'expliquer clairement, et
brièvement, cette technologie encore utilisée actuellement,
considérons deux circuits simples :
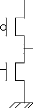
- l'inverseur :
Comme son nom l'indique, sa fonction est d'inverser
l'entrée. Sa table de vérité est la suivante :
|
Entrée (A)
|
Sortie (S)
|
|
0
|
1
|
|
1
|
0
|
Son implémentation en technologie CMOS est comme il est
indiqué dans la figure 2.1.
Rappelons brièvement, sans entrer dans les
détails électriques, que le transistor NMOS est passant
(bloqué) lorsque son entrée est au ?1? (?0?) logique. Par contre,
le transistor PMOS est passant (bloqué) lorsque son entrée est au
?0? (?1?) logique. Ces deux transistors sont donc complémentaires et ne
peuvent être conducteurs en même temps. Ainsi, comme l'indique la
figure 2.1, il ne pourrait exister un chemin de l'alimentation Vdd
vers la masse Vss, d'où l'inexistence d'un courant de court
circuit.
Vdd
Transistor P
A

S
Vss
Figure 2.1. Inverseur dans la technologie CMOS
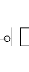
- une fonction quelconque :
Considérons la fonction F= NOT (A and (B or C)). Sa table
de vérité est la suivante :
|
Entrées
|
Sortie
|
|
A
|
B
|
C
|
F
|
|
0
|
0
|
0
|
1
|
|
0
|
0
|
1
|
1
|
|
0
|
1
|
0
|
1
|
|
0
|
1
|
1
|
1
|
|
1
|
0
|
0
|
1
|
|
1
|
0
|
1
|
0
|
|
1
|
1
|
0
|
0
|
|
1
|
1
|
1
|
0
|
Sa réalisation en technologie CMOS est comme il est
indiqué dans la figure 2.2.
B
C
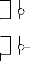

F
A
A
B
C
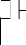
Figure 2.2. Fonction F= A . (B+C) en technologie CMOS
Notons que dans la partie NMOS, le transistor A est en
série avec le groupe qui est constitué des transistors B et C,
qui eux, sont en parallèle. Dans la partie PMOS, il est
impératif, pour que le circuit assure la fonctionnalité
désirée, que les transistors en parallèle (en
série) dans la partie NMOS soient en série (en parallèle)
dans la partie PMOS. Le lecteur vérifiera que le circuit indiqué
dans la figure 2.2 fonctionne conformément à la table de
vérité précédente. En outre, il vérifiera
qu'il ne peut exister un chemin entre Vdd et
Vss, et ce, quelles que soient les valeurs affectées aux signaux
d'entrée A, B et C. Ainsi, cette technologie, combinée avec
d'autres techniques de conception (qui sortent du cadre de ce travail)
permettent de rendre quasi nuls les courants dus aux courts circuits.
2.4.3.2 Consommation dynamique
Une porte logique consomme de la puissance dynamique à
chaque fois que la capacité à son noeud de sortie est
chargée ou déchargée. Un modèle assez
précis, et communément utilisé, de ce type de consommation
est le suivant :
P g 0 . 5 * V dd 2 * f * C g
* N g
= (2.6)
Vdd est la tension d'alimentation de la porte g ; f est la
fréquence de fonctionnement de la porte ; Cg est la capacité au
noeud de sortie de g et Ng est le nombre de transitions (charges et / ou
décharges) de Cg (Ng représente l'activité dynamique de la
porte g).
La consommation de la puissance dynamique d'un circuit
constitué d'un certain nombre de portes logiques est alors :
Nb Portes
P = 0 . 5 * 2 * *
V dd f C i N i
* (2.7)
i = 1
Notons que ce modèle est valide si on suppose que
toutes les portes du circuit sont alimentées par la même tension
d'alimentation. D'autres types de conception (qui sortent du cadre de ce
travail) nécessitent d'autres modèles.
L'équation (2.7) paraît toute simple, mais en
fait elle cache un vrai problème : il est très difficile
d'évaluer la consommation de la puissance dynamique d'un circuit. En
effet, le paramètre Ni est un vrai casse-tête. Rappelons que Ni
représente l'activité dynamique de la porte i du circuit, ou le
nombre de fois que la capacité au noeud de sortie de i a transité
d'un état à l'autre (charge ? décharge ou décharge
? charge).
Le seul moyen de déterminer Ni est de tracer, à
chaque nouveau vecteur de signaux d'entrée, l'état
précédent de cette capacité (chargée ou
déchargée) et son état actuel avec le nouveau vecteur.
Ceci permettrait alors de savoir si la capacité a changé
d'état (incrémenter Ni) ou pas. Calculer de manière exacte
Ni nous conduirait de considérer chaque ancien vecteur
avec tous les nouveaux vecteurs possibles. Un circuit à
M signaux d'entrée nous amènerait à considérer
2M anciens vecteurs possibles, à combiner avec 2M
nouveaux vecteurs possibles, soit un total de paires de vecteurs à
étudier égal à 2M * 2M =
22*M !!! Pour bien saisir la difficulté du problème,
considérons un simple circuit tel qu'un additionneur à 32 bits.
Cet additionneur aura donc en entrée 64 signaux (32 signaux pour chaque
valeur à additionner). La détermination exacte de
l'activité dynamique pour cet additionneur nécessiterait alors
l'exploration de 22*64=2128 paires de vecteurs, soit des milliards
de possibilités, qu'il est impossible d'explorer toutes, même avec
un processeur de nos jours. Quand il s'agit de déterminer la
consommation de la puissance dynamique de tout un système, autant dire
que le problème posé n'est pas du tout simple et qu'il
nécessite de ce fait des méthodes adéquates et
rigoureuses. Ceci étant, notons que dans le cadre de notre travail, nous
utilisons des instances déjà
caractérisées par leur consommation de puissance.
Néanmoins, à l'inverse de la surface et du temps induits par la
combinaison d'instances, la consommation de la puissance engendrée par
cette combinaison n'est pas simplement la somme des puissances de ces
instances. Nous discuterons ultérieurement de ce point, après
avoir défini la consommation due aux fuites de courant.
2.4.3.3 Consommation due aux fuites de courant
Cette consommation négligeable dans les anciennes
technologies pose de plus en plus de problèmes avec le
développement technologique. Toujours sans entrer dans les
détails électriques, ce type de consommation est en relation
étroite avec la tension de seuil d'un transistor Vth (tension
à partir de laquelle le transistor commence à conduire) et la
différence de potentiel entre la tension de grille du transistor et son
noeud-source Vgs. Le transistor NMOS (un raisonnement similaire peut
être fait pour le transistor PMOS) conduit si Vgs > Vth. Le `0'
logique pour le transistor NMOS correspond à Vgs=0. En pratique, ce
niveau logique n'est pas exactement nul, mais proche de 0. Or avec les
anciennes technologies, la tension de seuil du transistor était assez
élevée (relativement aux tensions actuelles).
Ceci assurait toujours Vgs < Vth et donc il n'y'a aucun
courant dans le canal du transistor quand celui-ci est bloqué. De nos
jours, malheureusement (pour les fuites de courant) et heureusement (pour une
commutation rapide des transistors), la tension de seuil du transistor est
très faible. De ce fait, même si le transistor est censé
être bloqué (`0' logique à sa grille), on peut avoir Vgs
> Vth (puisqu'en pratique Vgs n'est pas parfaitement nul et que de l'autre
côté Vth est très faible). Quoique dans les
nouvelles technologies ce problème n'entrave pas la bonne
fonctionnalité du circuit, il n'en demeure pas moins que cette
dissipation indésirable est estimée à 40% de la
dissipation totale d'énergie, ce qui est loin d'être
négligeable !
Ces types de consommation de puissance étant
définis, nous allons voir dans ce qui suit comment estimer la
consommation de la puissance engendrée par une combinaison d'instances
déjà caractérisées par leurs puissances.
Considérons le pas de contrôle i dans lequel sont
ordonnancées les opérations j, k et l. Si ces opérations
sont soumises à la même condition de contrôle, elles seront
alors parallèlement exécutées. La figure 2.3 indique la
description structurelle de ces trois unités fonctionnelles, des
registres et des interconnexions qu'elles utilisent pour le traitement
simultané des trois opérations.
X X X X X X X X
|
|
X
|
|
X
|
|
|
|
X
|
|
X
|
|
|
|
|
|
|
Rs
|
|
UFj
|
|
Rt
|
|
Ru
|
|
UFk
|
Rv
|
|
Rw
|
UFl
|
Ry
|
X: Interrupteur autorisant ou interdisant un
transfert d'une donnée
Figure 2.3 Description structurelle partielle d'une partie
opérative
Du fait que les trois unités fonctionnelles sont
déconnectées les unes des autres et qu'elles opèrent
uniquement avec leurs propres registres et interconnexions, la dissipation de
l'énergie à un cycle i est alors simplement :
Ni
E i = e ij (2.8)
j 1
Ni est le nombre total d'opérations
exécutées simultanément durant le ième
cycle ; eij est l'énergie dissipée par la jème
opération ordonnancée dans le cycle i. Du fait que ces
opérations sont effectuées grâce aux instances
sélectionnées à partir de la bibliothèque, donc
déjà caractérisées par leurs dissipations
d'énergie, eij est donc totalement définie, et la
dissipation d'énergie en un cycle donné s'obtient simplement en
utilisant l'équation (2.8).
L'obtention de l'énergie totale dissipée par la
combinaison d'instances sélectionnée s'obtiendra, elle aussi,
simplement par l'équation suivante :
Nb cycles
(2.9)
_
Ecomb = E i
i = 1

Enfin, la puissance totale consommée par la combinaison
est :
P = E comb (2.10)
comb Tcomb
Tcomb est tel que défini par l'équation (2.5).
NOTE :
Nous voudrions juste souligner que les équations (2.9)
et (2.10) n'auraient pas été valables si ces unités
fonctionnelles (caractérisées par leurs consommations
d'énergie) étaient conjointement utilisées pour produire
un résultat (c'est-à-dire que le chemin des données depuis
les entrées jusqu'aux sorties traverse ces unités). Il aurait
alors fallu déterminer de nouveau cette dissipation en
tenant compte de l'ensemble de ces unités.
2.5. Conclusion:
Nous avons présenté dans ce chapitre les
détails techniques du problème posé. Ceux-ci ont permis de
montrer que la détermination de la combinaison qui correspond le mieux
aux besoins d'une application donnée ne peut se faire de manière
polynomiale (la complexité algorithmique a été
déterminée à cet effet), et donc même l'utilisation
d'un processeur de nos jours ne pourrait produire la solution en un temps CPU
raisonnable.
Nous avons par la suite défini les trois contraintes
que sont la surface, la vitesse (ou le temps dans notre cas) et la consommation
de la puissance. Ces définitions ont été suivies par la
présentation des méthodes de détermination de ces
contraintes.
Nous rappelons encore que quoique la méthode exhaustive
ne peut faire face à n'importe quel espace de solutions, elle est
néanmoins bénéfique pour servir de repère au
développement d'une méthode approchée à base d'une
heuristique ou d'une méta heuristique. Les détails techniques de
notre méthode exacte feront l'objet du prochain chapitre.
CHAPITRE 3
914itfiode exfiaustive
developpie
3.1 Introduction :
Ce chapitre sera consacré à la
présentation de la méthode exhaustive que nous avons
développée. Encore une fois, nous rappelons que le
développement d'une telle méthode est doublement
bénéfique :
- l'exécuter à des fins d'obtention d'une solution
exacte lorsque le temps CPU le permet,
- l'utiliser comme repère pour le développement
d'une méthode approchée à base d'une heuristique ou d'une
méta heuristique
L'exploration exhaustive dans l'espace des solutions
nécessite aussi bien des procédures algorithmiques
adéquates que des structures de données efficaces. Ceci, du fait
que la taille de la mémoire principale est limitée et qu'il faut
judicieusement l'utiliser afin de ne pas recourir à de nombreux
?swappings? entre cette mémoire et la mémoire secondaire
(ce qui est très néfaste pour le temps d'exécution de
l'application).
Ce sont essentiellement ces aspects qui seront abordés,
de manière technique, dans ce chapitre. Auparavant, nous donnerons une
explication globale de notre méthode en nous appuyant sur un
schéma synoptique. Les détails des structures de données
et des formats des enregistrements des fichiers utilisés par notre
application suivront. Enfin, nos procédures algorithmiques,
commentées, seront décrites, puis nous terminerons ce chapitre
par une conclusion qui sera une synthèse du contenu de ce chapitre.
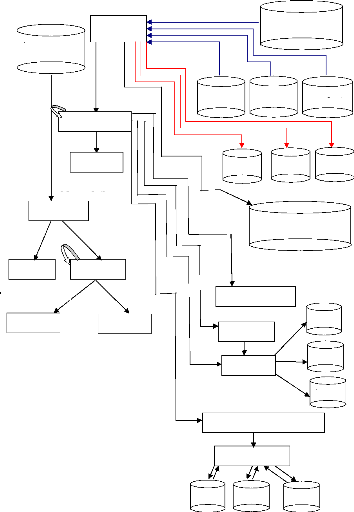
3.2 Présentation générale de notre
méthode:
Notre application, décrite dans la Figure 3.1, se compose
de deux grandes parties: - une partie principale qui contient les fonctions
suivantes :
main (), la fonction récursive configuration (), inserer
(), inserer2 (), inserer3 (),
inserer4 (), calculer_S_T_P (), surface_temps_puissance (),
reporter_t_p (), maj_dp (), maj2_dp ()
- une autre partie qui contient les fonctions suivantes :
create_lists () et la fonction récursive t_arrgts ().
Ces fonctions seront définies et présentées
dans la suite de ce chapitre.
Les fichiers de données utilisés par notre
application sont :
- NB_TRACES : il inclut le nombre de traces dans l'algorithme
à implémenter en Hardware
- DONNEES : il décrit le nombre d'instances dans le
circuit et dans la bibliothèque, et ce, pour chaque type
d'opérateur
- TRACEi : ce fichier décrit pour chaque pas
d'exécution, les opérations qui sont exécutées pour
la trace i (ce fichier est en fait un résultat de la tâche
d'ordonnancement des opérations)
En sortie, les fichiers des résultats obtenus sont :
- DP1, DP2, ..., DPNb_T où Nb_T est le
nombre de traces dans l'algorithme
- T_CPU_AFFECT : indique le temps CPU qui a été
nécessaire pour l'exécution de notre application sur un jeu de
données
Des exemples concrets concernant ces fichiers d'entrée et
de sortie seront ultérieurement donnés afin de rendre plus
compréhensible ce chapitre.
main ()
DONNEES
TRACE1
inserer4 ()
DP2 DPN
DP1
COMBOPS*
create_lists()
inserer ()
t_arrgts ()
OPERATEURS*
DP1
inserer2 ()
inserer3 ()
maj2_dp ()
DP2
INSTANCE*
maj_dp ()
DPN
COMB_TYP_OP*
configuration ()
calculer S_T_P()
TRACE2 TRACEN
T_CPU_AFFECT
NB_TRACES
surface_temps_puissance()
reporter_t_p ()
DP1 DP2
DPN
Figure 3.1 : Schéma synoptique de l'application
3.3 Détails techniques de notre méthode :
3.3.1 Structures de données :
Les structures de données qui ont permis
d'implémenter nos algorithmes sont les suivantes :
INSTANCE :
char nom_fichier [10] : chaîne de caractères qui
indique le nom de l'instance dans la bibliothèque.
INSTANCE *next : pointeur qui pointe sur l'élément
suivant de type INSTANCE. INSTANCE *prev : pointeur qui pointe sur
l'élément précèdent de type INSTANCE.
COMBTYPOP :
INSTANCE *head : pointeur qui pointe sur la tête de la
liste des noeuds de type INSTANCE.
COMB_TYP_OP *next : pointeur qui pointe sur
l'élément suivant de type COMB_TYP_OP.
OPERATEURS :
COMB_TYP_OP *head : pointeur qui pointe sur la tête de la
liste des noeuds de type COMB_TYP_OP.
char operateur [20] : chaîne de caractère qui
indique le nom du composant dans la partie opérative.
OPERATEURS *next : pointeur qui pointe sur
l'élément suivant de type OPERATEURS.
OPERATEURS *prev : pointeur qui pointe sur
l'élément précèdent de type OPERATEURS.
COMBOPS :
char operation [20] : chaîne de caractères qui
indique le nom de l'instance d'une
combinaison pour un type
d'opérateur donné.
float surface : surface d'une combinaison d'un type
d'opérateur donné. float temps : temps d'une combinaison d'un
type d'opérateur donné.
float puissance : puissance d'une combinaison d'un type
d'opérateur donné.
COMB_OPS *next : un pointeur qui pointe sur
l'élément suivant de
type COMB_OPS.
COMB_OPS *prev : un pointeur qui pointe sur
l'élément précédent de
type COMB_OPS .
3.3.2 Formats des enregistrements des fichiers :
Structure d'enregistrement du fichier NBTRACES :
nb traces
nb_traces : entier qui indique le nombre de traces.
Structure d'enregistrement du fichier DONNEES :
|
typ_op
|
|
nb_instances_bibl
|
|
|
|
|
nb_instances_systm
|
|
|
|
|
typ_op : chaîne de caractères qui indique le nom de
l'opération dans la partie opérative.
nb_instances_bibl : entier qui indique le nombres d'instances de
cette
opération dans la bibliothèque.
nb_instances_systm : entier qui indique le nombres d'instances
de cette
opération dans la partie opérative.
Structure d'enregistrement du fichier relatif à
une instance donnée:
Chaque instance d'un opérateur donné se trouvant en
bibliothèque est caractérisée par sa surface, son temps
d'exécution et sa consommation d'énergie.
s : Réel qui indique la surface de cette instance.
t : Réel qui indique le temps de cette instance. e :
Réel qui indique l'énergie de cette instance.
Structure des enregistrements du fichier TRACE T:
num_cycle : Entier qui indique un numéro de cycle pour la
TRACE T.
mot* : Ensemble de chaînes de caractères
qui indique les opérations à exécuter au cycle
num_cycle de la TRACE T.
NOTE : Pour chaque opérateur se
trouvant dans la partie opérative, il existe au moins une trace
où cette opération est exécutée N fois dans un
cycle donné, N étant le nombre d'instances de cet
opérateur dans la partie opérative.
Du fait que N est le nombre d'instances de cet opérateur
dans la partie opérative, alors:
- il ne peut exister de trace où cette opération
est exécutée M fois (M>N) dans un même cycle
donné.
- il peut exister un cycle dans une trace donnée où
cette opération est exécutée K fois (0 = K = N).

Structure des enregistrements des fichiers
DPi:
num_cycle : Entier qui indique le numéro de cycle pour une
trace donnée. mot* : Ensemble de chaînes de
caractères indiquant les instances à utiliser durant le cycle
num_cycle de la trace i.
3.3.3 Algorithmes :
3.3.3.1 Algorithme pour la fonction récursive
configuration() :
Cet algorithme détermine la surface, le temps et la
consommation d'énergie d'une configuration donnée. Ces
configurations sont déterminées de manière
récursive où chacune d'elles est composée de Ni instances
de chaque opérateur i utilisé dans le circuit. Un groupe de Ni
instances est constitué en considérant tous les cas possibles et
en se basant sur les nombres d'instances de cet opérateur en
bibliothèque et dans le circuit à concevoir.
Variable : ptr1 : pointeur de type COMB_TYP_OP ; Ptr11 : pointeur
de type INSTANCE ; surface_partielle : réel ;
DEBUT
surface_partielle :=surface ;
Si (ptr==0)
Alors {
// Faire appel à la fonction calculer_S_T_P() qui permet
de calculer la surface, le // temps et la puissance d'une configuration
calculer_S_T_P (head_comb_ops) ;
flag :=1 ;
surface :=0 ;
return ;
}
Fsi
Afficher (`' configuration : ptr = `', ptr-)operateur),
Si (flag ? 0)
Alors
ptr_svg :=ptr_svg-)prev ;
Fsi
pour (ptr1:=ptr1-)head ; ptr1? 0 ; surface=surface_partielle,
maj_dp(ptr,ptr1),
maj2_dp(ptr->next), ptr1=ptr1->next)
Faire {
ptr11:=ptr1-)head ;
//appel de fonction surface_temp_puissance
surface_temp_puissance (ptr11,ptr-)operateur) ;
Si (flag==0)
Alors {
Allocate (ptr_svg) ; // Allocation de l'espace mémoire
pour le pointeur ptr_svg ptr_svg-)operation := ptr-)operateur ;
ptr_svg-)next := 0 ;
ptr_svg-)next := 0 ;
//Faire appel a la fonction inserer4
inserer4 (ptr_svg) ;
}
Fsi
configuration (ptr-)next) ;// appel récursif
}
Ffaire
ptr_svg := ptr_svg-)next ;
ptr := ptr-)prev ;
FIN
3.3.3.2 Algorithme qui calcule la surface, la vitesse et la
puissance d'une configuration :
La détermination de la surface, du temps et de la
consommation d'énergie d'une configuration donnée sera
ultérieurement expliquée de manière simple et claire
à travers un exemple.
calculer_S_T_P (variable : head_comb_ops : pointeur tête
sur la structure 7 COMB_OPS) :
Variables : ptr2 : pointeur sur la structure COMB_OPS ;
max_delai, max_puissance, delai_moyen, puissance_moyenne :
réel ;
fp, fp1 : Fichier ;
i, num_cycle : entier ;
ch_temp [4], fich_dp [20], mot [20] : chaîne de
caractère ;
c : caractère ;
t_max, energie, e : réel ;
DEBUT max_delai := -1 ;
max_puissance := -1 ;
delai_moyen := 0 ;
puissance_moyenne := 0 ;
pour (i:=1 ; i = nb_traces ; i++)
Faire {
Ecrire la valeur de i dans la chaine ch_temp ;
Ecrire `' DP `' dans la chaine fich_dp;
Concaténer fich_dp et ch_temp ; // concaténation
dans la chaine fich_dp
//ouvrir le fichier fp en lecture
fp :=ouvrir (fich_dp, en lecture) ;
temps := 0 ;
energie := 0 ;
Tant que non fin de fichier pointé par fp
Faire {
t_max := -1 ;
Lecture (fp, num_cycle, mot) ;
Tant que (mot ? `' FIN `')
Faire {
Si (mot ? `' # `')
Alors {
ouvrir le fichier mot en lecture ; // ce fichier est
pointé par fp1
lire à partir de ce fichier s, t et e // s, t et e sont la
surface, le temps et la
// consommation d'énergie d'une instance donnée
Fermer ce fichier;
Si (t > t_max)
Alors
t_max :=t ;
Fsi
energie :=energie+e ;
}
Fsi
lire à partir du fichier pointé par fp la
chaîne de caractères suivante
// cette chaîne indique le nom d'une instance
}
Ffaire
Faire un saut de ligne dans le fichier ponté par fp ;
temps := temps + t_max ;
}
Ffaire
puissance :=energie / temps ;
Si (max_delai < temps)
Alors
max_delai :=temps ;
Fsi
Si (max_puissance < puissance) Alors
max_puissance :=puissance ;
Fsi
delai _moyen :=delai_moyen + max_delai ;
puissance_moyenne := puissance_moyenne + max_puissance ;
fermer le fichier pointé par fp ;
}
Ffaire
delai_moyen :=delai_moyen / nb_traces ;
puissance_moyenne := puissance_moyenne / nb_traces ;
Si (surface <= Sf ET max_delai <= Tf ET max_ puissance
<= Pf)
Alors {
Afficher (`'SUCCES : surface:= , max_delai:= , max_ puissance:=
`',surface, max_delai, max_puissance) ;
Afficher (`' delai_moyen:= , puissance_moyenne:= `', delai_moyen,
puissance_moyenne) ;
Afficher (`' Utiliser les instances d'operateurs se trouvant dans
les fichiers DP `') ; Invoquer Linux pour déterminer le temps CPU de
cette exécution et le sauvegarder dans le fichier T_CPU_AFFECT ;
exit() ;
}
Sinon
Afficher (`'Echec : Contrainte(s) non satisfaite(s) avec cette
combinaison `') ;
Fsi
FIN
3.3.3.3 Algorithme pour mettre à jour la surface de
la configuration en cours,
lire la vitesse et la puissance d'une instance
donnée: surface_vitesse_puissance ( variable : ptr11 :
pointeur sur la structure INSTANCE ;
type_operation : chaine de caractères)
Variable : fp : Fichier ;
s, t, p : réel ;
DEBUT
pour ( ; ptr11 ? 0 ; ptr11:= ptr11-)next)
Faire {
ouvrir en mode de lecture le fichier ptr11-)nom_fichier et
pointé par fp ; lire à partir de ce fichier s, t et p ;
surface := surface + s ;
//Faire appel a la fonction reporter_t_p()
reporter_t_p ( type_operation, ptr11-)nom_fichier) ;
fermer le fichier pointé par fp ;
}
Ffaire
FIN
3.3.3.4 Algorithme pour la fonction reportertp () :
Cet algorithme consiste à remplacer dans un fichier
DPi le type d'opération (exemple ADD) par l'instance en
cours (exemple ADD6). Une fois que DPi est totalement
constitué, l'affectation des instances d'une bibliothèque aux
unités fonctionnelles du circuit sera totalement définie.
DPi servira aussi de déterminer pour la trace i, les
caractéristiques (surface, temps et puissance) de la configuration
obtenue.
reporter_t_p (variable : type_operation : chaine de
caractère,
nom_fichier : chaine de caractère)
Variable : fp : Fichier ;
i, num_cycle : entier ;
fich_dp[20], ch_temp[4], mot[20] : chaine de caractère ; c
: caractère ;
position : long ;
DEBUT
Afficher (`'DEBUT REPORTER NOM FICHIER: `', nom_fichier) ;
Pour( i:=1 jusqu'à nb_traces)
Faire {
Ouvrir en mode de lecture le fichier DPi // ce fichier sera
pointé par fp Tant que non fin de ce fichier
Faire {
Lire enregistrement par enregistrement toutes les chaines de
caractères. Dès qu'une chaîne de caractères
correspond au type d'opération indiqué par la variable
type_operation, remplacer cette chaîne par le contenu de la chaîne
de caractères indiquée par nom_fichier, et passer à
l'enregistrement suivant ;
}
Ffaire
}
Ffaire
FIN
3.3.3.5 Algorithme pour la fonction maj2dp () :
Cette fonction qui fait appel à la fonction maj_dp ()
consiste à reconstituer les fichiers DPi à leur
état initial (types d'opérations au lieu des instances)
après avoir étudié les caractéristiques d'une
configuration donnée. Par exemple, il s'agira de remplacer l'instance
ADD7 par le type d'opération ADD. Ceci permettra ultérieurement
d'explorer d'autres configurations en remplaçant ADD par ADD4, MULT par
MULT2, ...etc.
maj2_dp (variable : ptr : pointeur sur la structure OPERATEURS)
;
Variable : ptr1 : pointeur sur la structure COMB_TYP_OP ;
DEBUT
Si (ptr ? 0)
alors pour ( ; ptr ; ptr=ptr->next)
faire pour (ptr1=ptr->head; ptr1; ptr1=ptr1->next)
faire maj_dp(ptr, ptr1);
ffaire
ffaire
fsi
FIN
3.3.3.6 Algorithme pour la fonction majdp () :
maj_dp (variable : ptr : pointeur sur la structure OPERATEURS
,
ptr1 : pointeur sur la structure COMB_TYP_OP) ;
Variables : ptr11 : pointeur sur la structure INSTANCE ;
fp : Fichier ;
type_operation [10], nom_fichier [10] : chaine de
caractère ;
i, num_cycle : entier ;
fich_dp [20], mot [20], ch_temp [4] : chaine de caractère
;
c : caractère ; position : long ;
DEBUT
Tant que non fin de fichier DPi
Faire remplacer dans ce fichier une instance d'un
opérateur par le nom de l'opérateur
// Exemple Remplacer ADD6 par ADD, MULT7 par MULT, etc....
/* Le nom de l'instance est déterminé grâce
à ptr11 et le type d'opération grâce à ptr1*/
Ffaire
FIN
3.3.3.7 Algorithme pour créer les différentes
listes :
Cet algorithme, avec l'appel d'autres procédures,
permet de créer les différentes listes nécessaires pour le
traitement. Ces listes sont déterminées en considérant,
pour chaque type d'opérateur utilisé dans le circuit, toutes les
combinaisons possibles en se basant sur le nombre d'instances de cet
opérateur qui sont présentes en bibliothèque ainsi que sur
le nombre d'instances utilisées. Dans tous nos algorithmes, nous avons
utilisé les variables suivantes :
- la variable ptr permet de parcourir la liste de tous les
opérateurs utilisés dans le circuit.
- la variable ptr1 permet de parcourir la liste des combinaisons
possibles pour un type d'opérateurs donné.
- la variable ptr11 permet d'accéder aux fichiers
contenant les caractéristiques des instances qui constituent une
combinaison donnée d'instances de même type.
Variables : chaine [20], svg_chaine [20], typ_op[20] :
chaîne de caractères; num : entier;
ch_tmp[2] : chaîne de caractères;
/* Variables externes :
Début
head_operateurs variable qui pointe sur un élément
de type OPERATEURS ; head_comb_typ_op variable qui pointe sur un
élément de type COMB_TYP_OP;
head_instance variable qui pointe sur un élément de
type INSTANCE; head_comb_ops variable qui pointe sur un élément
de type COMB_OPS; Fin Déclaration des variables externes */
void inserer(OPERATEURS *);
void inserer2(COMB_TYP_OP *);
void inserer3(INSTANCE *);
create_lists ():
Variables : ptr : variable qui pointe sur un
élément de type OPERATEURS ; ptr1 : variable qui pointe un
élément de type COMB_TYP_OP ; ptr11 : variable qui pointe sur un
élément de type INSTANCE ; fp : Pointeur de Fichier ;
ch : pointeur sur une chaîne de caractères;
temp [2] : chaîne de caractères ;
c : caractère ;
i : entier ;
nb_instances_bibl, nb_instances_systm : entier ;
DEBUT
Si ( Erreur d'ouverture du fichier DONNEES)
Alors Afficher (`'Erreur d'ouverture du fichier DONNEES») ;
exit ;
Fsi
Tant que non fin du fichier DONNEES
Faire {
Lire le type d'opération ; // typ_op
Lire le nombre d'instances dans la bibliothèque ; Lire le
nombre d'instances dans le système
Si (nb_instances_systm ? 0)
Alors {
Allocate (ptr) ;// Allocation de l'espace mémoire pour le
pointeur ptr head_comb_typ:=0 ;
ptr-)operateur := contenu de la chaîne typ_op ; ptr-)next
:= 0 ;
ptr-)prev := 0 ;
ch :=adresse de chaine[0] ;
Pour (i :=1 jusqu'à nb_instances_bibl)
Faire {
temp := i ;
*ch++ := temp[0] ;
}
Ffaire
*ch := `\0' ;
ch:= adresse chaine[0] ;
num :=0 ;
//Faire appel a la fonction récursive t_arrgts () t_arrgts
(ch, nb_instances_systm, 0, ptr1, ptr11) ; ptr-)head := head_comb_typ_op ;
inserer (ptr) ;
Fsi
}
FIN
Ffaire
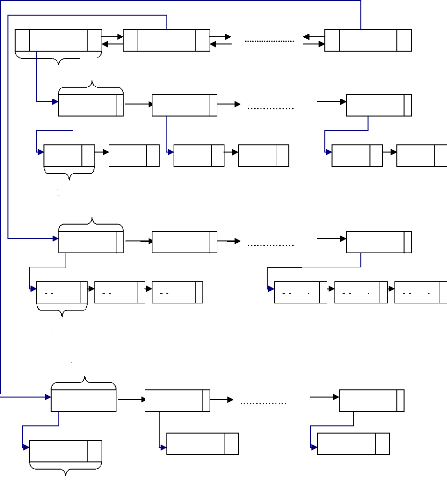
LSHIFT
COMP
ADD
COMP6
COMP6
COMP6
ptr11
COMP1
COMP1
COMP1
ptr1
LSHIFT1
LSHIFT2
ptr11
LSHIFT7
ptr1
...
ptr
ADD1
ADD1
ptr11
ptr1
ADD4
ADD4
ADD1
ADD2
Figure 3.1 : Schéma des différentes listes
chaînées.
3.3.3.8 Algorithme pour la fonction recursive tarrgts ():
Cet algorithme crée, pour chaque type
d'opérateurs, toutes les combinaisons d'instances en tenant compte des
nombres de cet opérateur dans le circuit et en bibliothèque.
t_arrgts ( Variables :ch :pointeur sur caractère ;
p, pos : entier ;
ptr1 : variable qui pointe sur un élément de
type
COMB_ TYP_OP ;
ptr11 : variable qui pointe sur un élément de type
INSTANCE ;) : Variables : c, c1 : caractère ;
ch11, ch12 : variables qui pointent sur des chaîne de
caractères;
ch1 [5] : chaîne de caractères;
j, k, l : entier ;
DEBUT
Si (p==0)
Alors {
num := num+1 ;
Allocate (ptr1) ;// Allocation de l'espace mémoire pour le
pointeur ptr1 ; head_instance := 0 ;
ptr1-)next := 0 ;
//Faire appel a la fonction inserer2 ()
inserer2 (ptr1) ;
Pour (l:=0 ; svg_chaine [l] ? `\0' ; l++)
Faire {
Allocate (ptr11) ; /*Allocation de l'espace mémoire pour
le pointeur ptr11*/
ptr11-)next :=0 ;
ptr11-)nom_fichier := contenu de typ_op ;
ch_tmp [0] := svg_chaine [l] ;
ch_tmp [1] := `\0' ;
ptr11-)nom_fichier = contenu de ch_tmp ;
inserer3 (ptr11); }
Ffaire
ptr1-)head := head_instance ;
return ;
}
Fsi
ch11:=ch ;
Tant que non fin de la chaine de caractères ch11
Faire {Lire de cette chaîne un caractère et le
mettre dans c ;
Pour (j:=p ; j>0 ; j:=j-1)
Faire {
Pour (k :=j, l :=pos ; k>0, k :=k-1)
Faire svg_chaine [l++] := c ;
Ffaire
svg_chaine [l] := `\0' ;
l :=0 ;
ch12 := adresse de chaine [0] ;
Tant que non fin de la chaîne de caractères ch12
Faire {
Lire de cette chaîne un caractère et le mettre dans
c1 ; Si (c1 ? c)
Alors ch1[l++] := c1 ;
Fsi
Ffaire
ch1[l] := '\0' ;
// Faire appel a la fonction récursive t_arrgts ()
t_arrgts ( ch1, p-j, pos+j, ptr1, ptr11) ;
}
Ffaire
}
Ffaire
}
FIN
Ffaire
3.3.3.9 Algorithme pour la fonction inserer () :
Cette fonction permet d'insérer dans une liste un type
d'opérateur utilisé dans le circuit.
DEBUT
Si (head_operateurs ? 0)
Alors {
ptr-)next := head_operateurs ; head_operateurs-)prev := ptr ;
}
Fsi
head _operateurs := ptr ;
FIN
3.3.3.10 Algorithme pour la focntion inserer2 () :
Cette fonction permet d'insérer dans une liste un
élément qui correspond à une combinaison d'instances.
DEBUT
Si (head_comb_typ_op ? 0)
Alors {
ptr1-)next := head_comb_typ_op ;
}
Fsi
head _comb_typ_op := ptr1 ;
FIN
3.3.3.11 Algorithme pour la focntion inserer3 () :
Cette fonction permet d'insérer une combinaison
d'instances d'un type d'opérateur donné.
DEBUT
Si (head_instance ? 0) Alors {
ptr11-)next := head_instance ;
}
Fsi
head _instance := ptr11 ;
FIN
3.3.3.12 Algorithme pour la fonction inserer4 () :
Cette fonction permet d'insérer dans une liste une
configuration (combinaison de combinaisons d'instances.
DEBUT
Si (head_comb_ops ? 0)
Alors {
ptr_svg-)next := head_comb_ops ; head_comb_ops-)prev := ptr_svg ;
}
Fsi
head _comb_ops := ptr_svg ;
FIN
3.3.3.13 Algorithme principal :
L'algorithme principal fait appel aux fonctions décrites
précédemment. Variables globales :
Sf, surface, Tf, temps, Pf, puissance : réel ;
head_operateurs :=0 : variable qui pointe sur un
élément de type OPERATEURS;
head_comb_typ_op :=0 : variable qui pointe sur un
élément de type COMB_TYP_OP ;
head_instance :=0 : variable qui pointe sur un
élément de type
INSTANCE ;
head_comb_ops :=0 : variable qui pointe sur un
élément de type COMB_OPS ;
nb_traces : entier ;
flag :=0 : entier ;
ptr_svg :=0 : variable qui pointe sur un élément
de type COMB_OPS ;
s, t, p : float ;
Variables locales :
i, j, k ,l, m, num_cycle :entier ;
ptr : variable qui pointe sur un élément de type
OPERATEURS ;
ptr1 : variable qui pointe sur un élément de type
COMB_TYP_OP ; ptr11 : variable qui pointe sur un élément de type
INSTANCE ; chaine[16], chaine1[4] : chaînes de caractères ;
fich_trace[20], fich_dp[20], ch_temp[4],mot[20] : chaînes
de caractères ;
fp, fp_dp : pointeurs de Fichiers ;
DEBUT
si (argc ? 4) // argc est le nbre d'arguments dans la commande
alors {
Afficher (`' Erreur de commande- -taper : affect val(Sf) val(Tf)
val(Pf) `');
exit ;
}
fsi
//entrer les valeurs des contraintes imposées par le
concepteur
Lire (Sf) ;
Lire (Tf) ;
Lire (Pf) ;
// Faire appel a la fonction create_lists () qui permet de
créer les différentes listes create_lists () ;
ptr :=head_operateurs ;
//ouvrir le fichier NB_TRACES en lecture ;
fp :=ouvrir (`' NB_TRACES `', en lecture) ;
Lecture (fp, nb_traces) ;
Fermer le fichier (fp) ;
Pour( i :=1 jusqu'à nb_traces)
Faire {
fich_trace := `' TRACE `' ;
ch_temp :=i ;
concatener les contenus de fich_trace avec ch_temp ;
fp :=ouvrir (fich_trace, en lecture) ;
fich_dp := `' DP `' ;
concatener les contenus de fich_dp avec ch_temp
fp_dp :=ouvrir (fich_dp, en écriture) ;
Tant que non fin du fichier pointé par fp
Faire {
//lire à partir du fichier fp num_cycle et mot ;
Lecture (fp, num_cycle, mot) ;
Ecriture (fp_dp, num_cycle) ; // Ecriture dans le fichier
pointé par fp_dp Tant que (mot ? `'FIN `')
Faire {
Ecriture (fp_dp, `' # `', mot) ;
Lecture (fp, mot) ;
}
Ffaire
Ecriture (fp_dp, `' FIN `') ;
Lecture (fp, `' \n `') ;
}
Fsi
Ffaire
Fermer le fichier (fp) ;
Fermer le fichier (fp_dp) ;
}
Ffaire
surface :=0 ;
// Faire appel a la fonction récursive configuration ()
configuration (ptr) ;
Afficher (`' \n Echec total: Aucune combinaison ne satisfait
toutes les contraintes `') ; /* NOTE : En cas de
succès, les résultats sont affichés au niveau de la
procédure calculer_S_T_P() et le programme s'arrête : Le message
d'échec ci-dessus ne s'affichera donc pas*/.
FIN
Fichier Makefile :
Le fichier Makefile qui a nous a servi lors du
développement de notre application est le suivant :
affect: trouve_combinaison.o principal.o
cc -o affect trouve_combinaison.o principal.o
trouve_combinaison.o: trouve_combinaison.c decl.h cc -c -g
trouve_combinaison.c
principal.o: principal.c decl.h
cc -c -g principal.c
> L'option -c permet une compilation séparée et
génère le fichier objet correspondant au fichier source
considéré.
> L'option -g permet d'utiliser le débogueur en cas de
besoin.
> L'option -o permet de générer
l'exécutable (édition des liens à partir des fichiers
objet).
3.3.4 Exemple d'illustration :
Pour faciliter aux lecteurs de ce mémoire la
compréhension des fichiers utilisés par notre application, nous
donnons ci-après un exemple:
Fichier NBTRACES : on suppose que dans
son contenu il y'a la valeur 2, c'est-àdire que l'algorithme à
implémenter en Hardware inclut deux traces:
Fichier TRACE1 :
1 ADD ADD MULT RSHIFT FIN
2 MULT MULT MULT LSHIFT FIN
3 MULT MULT MULT MULT MULT FIN
4 ADD COMP COMP COMP FIN
Ceci veut dire que lors de l'exécution de la trace 1 de
l'algorithme, 2 additions, une multiplication et un décalage à
droite seront initialement exécutés en parallèle, au
1er ?cycle?. Noter que dans notre contexte, le mot cycle signifie
juste un groupe d'opérations à exécuter en
parallèle.
Fichier TRACE2 :
1 ADD ADD MULT RSHIFT FIN
2 MULT MULT MULT MULT MULT MULT MULT MULT LSHIFT FIN
3 MULT MULT RSHIFT RSHIFT MULT FIN
4 ADD COMP COMP MULT FIN
5 MULT ADD RSHIFT LSHIFT COMP FIN
Fichier DONNEES :
ADD 4 2 >Nombre de combinaisons= 42=16.
MULT 5 8 >Nombre de combinaisons=
58=390625.
COMP 6 3 >Nombre de combinaisons= 63=216.
AND 3 0 >Nombre de combinaisons= 3°=1.
RSHIFT 7 2 >Nombre de combinaisons= 72=49.
LSHIFT 7 1 >Nombre de combinaisons= 71=7.

Nombre d'instances de cet opérateur dans la partie
opérative
Nombre d'instances de cet opérateur dans la
bibliothèque
Le nombre total de combinaisons est alors :
16 * 390625 * 216 * 1 * 49 * 7=
463.05*109, c'est à dire 463
milliards et 50 millions de combinaisons à explorer pour ce simple
exemple.
Pour un cas réel, le nombre de combinaisons serait
énorme et rendrait impossible une affectation manuelle d'instances aux
opérateurs du système à concevoir. D'où
l'intérêt de développer un outil d'aide à rendre
possible cette affectation de sorte à satisfaire les contraintes
fixées. Néanmoins, nous rappelons que même avec un
calculateur, la complexité algorithmique de ce problème n'est pas
polynomiale et nécessite une méthode à base d'une
heuristique ou d'une méta heuristique.
Nous rappelons aussi que dans le cadre de ce mémoire,
nous développons la méthode exhaustive dans un double but de
l'utiliser quand le temps CPU le permet (la solution obtenue est alors exacte)
ou pour servir de repère durant le développement de la
méthode approchée.
3.4 Conclusion
Ce chapitre a permis de montrer les détails techniques
de notre méthode (algorithmes, structures de données et formats
des enregistrements des fichiers utilisés). Nous avons notamment
utilisé la récursivité pour des fins d'efficacité.
Néanmoins, ceci nous a demandé de prendre un certain nombre de
précautions afin d'éviter que l'exécution ne boucle
indéfiniment, ou qu'elle se déroule autrement que le demande la
logique de l'application. Ces précautions ont notamment porté sur
les tests d'arrêt et sur la distinction des variables globales de celles
qui sont locales. Nos algorithmes ont été testés avec
succès sur des jeux de données assujettis à des
contraintes différentes comme le montre le chapitre qui suit.
CHAPITRE 4
RJsu(tats
4.1 Introduction :
Les résultats qui vont être
présentés dans ce chapitre ont été obtenus sur une
machine dotée d'une mémoire principale de capacité de 2 Go
et d'un processeur fonctionnant à 2 GHz s'exécutant sous le
système d'exploitation Linux.
Le code source de notre application a été
développé en utilisant le langage C. Dans un souci de conception
modulaire, notre application a été décomposée en
plusieurs modules dont la compilation a été rendue efficace et
aisée grâce à l'utilisation du Makefile, fichier
indiquant les dépendances entre les différents fichiers ainsi que
la (les) commande(s) de compilation (ou d'édition de liens) à
exécuter en cas de modification d'un fichier source ou objet.
4.2 Présentation des résultats :
Nos résultats sont représentés dans le
tableau suivant :
|
SF
um2
|
TF
ns
|
PF
uw
|
surface
um2
|
max_delai
ns
|
max_puissance
uw
|
delai_moy
ns
|
puissance_moy
uw
|
Tps
CPU (s)
|
|
1
|
155.
|
51.
|
2.5
|
155.
|
49.20
|
1.70
|
41.45
|
1.68
|
04
|
|
2
|
155.
|
55.
|
2.0
|
155.
|
49.20
|
1.70
|
41.45
|
1.68
|
04
|
|
3
|
150.
|
52.
|
2.5
|
150.
|
50.50
|
1.67
|
43.75
|
1.57
|
04
|
|
4
|
150.
|
50.
|
2.0
|
149.5
|
50.00
|
1.52
|
43.50
|
1.42
|
05
|
|
5
|
150.
|
50.
|
1.5
|
149.
|
50.00
|
1.49
|
43.50
|
1.38
|
09
|
|
6
|
160.
|
49.0
|
1.8
|
156.
|
48.70
|
1.76
|
41.20
|
1.74
|
03
|
|
7
|
156.
|
48.7
|
1.75
|
153.
|
48.70
|
1.70
|
41.95
|
1.64
|
03
|
|
8
|
160.
|
48.7
|
1.68
|
153.5
|
48.70
|
1.64
|
41.95
|
1.57
|
04
|
|
9
|
150.
|
50.
|
1.40
|
150.
|
50.00
|
1.39
|
43.00
|
1.31
|
14
|
|
10
|
149.
|
49 .5
|
1.49
|
149.
|
49.50
|
1.47
|
43.00
|
1.36
|
46
|
Tableau 4.1 Résultats obtenus pour
différentes contraintes
SF, TF et PF
dénotent respectivement les contraintes de surface, de temps et
de consommation de puissance fixées.
Les 3 colonnes qui suivent indiquent respectivement la
surface, le temps et la consommation de puissance obtenus avec les contraintes
fixées et les fichiers de données suivants :
- Fichier DONNEES :
ADD 4 2 MULT 5 8 COMP 6 3 AND 3 0 RSHIFT 7 2
LSHIFT 7 1
- Fichiers des instances des opérateurs
utilisés dans le circuit :
Pour chacun de ces fichiers, les 3 valeurs représentent
respectivement la surface, le temps et l'énergie qui
caractérisent l'instance considérée.
- Fichier ADD1 :
10. 5. 2.
- Fichier ADD2 :
8. 6. 2.
- Fichier ADD3
11. 4. 3.
- Fichier ADD4
9. 5. 3.
- Fichier MULT1 :
14. 9. 4.
- Fichier MULT2 :
13. 10. 3.
- Fichier MULT3 :
12. 10.5 3.
- Fichier MULT4 :
13. 9.5 3.5
- Fichier MULT5 :
13.5 9.5 5.5 - Fichier COMP1
9. 5. 2.5
- Fichier COMP2 :
8. 6. 2.
- Fichier COMP3 :
6. 7. 1.
- Fichier COMP4 :
7. 5. 2.
- Fichier COMP5 :
8. 3.5 2.5
- Fichier COMP6 :
8.5 4.5 3.
- Fichier RSHIFT1 :
7. 5. 1.5
- Fichier RSHIFT2 :
6.5 5.5 1.
- Fichier RSHIFT3 :
4. 8. 1.
- Fichier RSHIFT4 :
4.5 7.5 1.
- Fichier RSHIFT5 :
2. 9.5 0.8
- Fichier RSHIFT6 :
1. 10. 0.6
- Fichier RSHIFT7 :
1.5 9.7 0.7
- Fichier LSHIFT1 :
7. 5. 1.5
- Fichier LSHIFT2 :
6.5 5.5 1.
- Fichier LSHIFT3 :
4. 8. 1.
- Fichier LSHIFT4 :
4.5 7.5 1.
- Fichier LSHIFT5
2. 9.5 0.8
- Fichier LSHIFT6 :
1. 10. 0.6
- Fichier LSHIFT7 :
1.5 9.7 0.7
Le tableau 4.1 montre que pour les 10 tests, les contraintes
fixées sont bien sûr satisfaites. Il suffit de comparer les
colonnes indiquées par surface, max_delai et
max_puissance à celles correspondant à
SF, TF et
PF, respectivement. Nous donnerons par la suite des
explications détaillées sur l'obtention des résultats
correspondant au 1er jeu d'essais.
Notons que :
- max_delai et max_puissance sont
respectivement le temps et la consommation de puissance obtenus en
considérant toutes les traces et d'en déduire le maximum pour ces
2 paramètres
- delai_moy et puissance_moy sont
déterminés en considérant respectivement la moyenne des
délais de toutes les traces et la moyenne des consommations de puissance
de toutes les traces.
Les temps CPU restent raisonnables (ne dépassant pas 38
secondes) pour déterminer la configuration qui satisfait les contraintes
fixées et montrent que nos algorithmes développés sont
efficaces pour trouver, dans la mesure du possible, la configuration
satisfaisant les contraintes parmi un très grand nombre de
possibilités.
Les résultats indiqués dans le
précédent tableau ne suffisent pas. En effet, il faut indiquer au
concepteur du circuit, la configuration à utiliser. Ceci est
généré dans les fichiers
DPi1 et DPi2
ci-après.
- DPi1 (DPi2)
correspond au fichier décrivant les instances qui seront
utilisées dans le circuit pour exécuter la trace 1 (ou 2) de
l'algorithme à implémenter en Hardware
- 1 = i = 10 correspond à l'un des 10 tests qui figurent
dans le tableau 4.1
Fichiers DP :
155 51 2.5 :
DP11 :
1 ADD3 # ADD4 # MULT4 # RSHIFT6 # FIN
2 MULT4 # MULT5 # MULT4 # LSHIFT7 # FIN
3 MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # FIN
4 ADD3 # COMP6 # COMP5 # COMP6 # FIN
DP12 :
1 ADD3 # ADD4 # MULT4 # RSHIFT6 # FIN
2 MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5
# MULT4 # MULT5 # LSHIFT7 # FIN
3 MULT4 # MULT5 # RSHIFT6 # RSHIFT7 # MULT4 # FIN
4 ADD3 # COMP6 # COMP5 # MULT4 # FIN
5 MULT4 # ADD3 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées pour le 1er
test sont :
ADD3, ADD4 (car il y a 2 additionneurs dans la partie
opérative ou circuit). MULT4, MULT5, MULT4, MULT5, MULT4, MULT5, MULT4,
MULT5 (car il y a 8 multiplieurs dans la partie opérative).
COMP6, COMP5, COMP6 (car il y a 3 comparateurs dans la partie
opérative). RSHIFT6, RSHIFT7 (car il y a 2 décaleurs à
droite dans la partie opérative). LSHIFT7 (car il y a 1 décaleur
à gauche dans la partie opérative).
155 55 2.0:
DP21:
1 ADD3 # ADD4 # MULT4 # RSHIFT6 # FIN
2 MULT4 # MULT5 # MULT4 # LSHIFT7 # FIN
3 MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # FIN
4 ADD3 # COMP6 # COMP5 # COMP6 # FIN
DP22 :
1 ADD3 # ADD4 # MULT4 # RSHIFT6 # FIN
2 MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT4 # MULT5 # RSHIFT6 # RSHIFT7 # MULT4 # FIN
4 ADD3 # COMP6 # COMP5 # MULT4 # FIN
5 MULT4 # ADD3 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD3, ADD4.
MULT4, MULT5, MULT4, MULT5, MULT4, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT6, RSHIFT7.
LSHIFT7.
150 52 2.5 :
DP31 :
1 ADD2 # ADD2 # MULT5 # RSHIFT6 # FIN
2 MULT5 # MULT3 # MULT4 # LSHIFT7 # FIN
3 MULT5 # MULT3 # MULT4 # MULT5 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # COMP6 # FIN
DP32 :
1 ADD2 # ADD2 # MULT5 # RSHIFT6 # FIN
2 MULT5 # MULT3 # MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT5 # MULT3 # RSHIFT6 # RSHIFT7 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # MULT5 # FIN
5 MULT5 # ADD2 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD2, ADD2.
MULT5, MULT3, MULT4, MULT5, MULT4, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT6, RSHIFT7.
LSHIFT7.
150 50 2.0 :
DP41 :
1 ADD2 # ADD2 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT3 # MULT3 # LSHIFT7 # FIN
3 MULT1 # MULT3 # MULT3 # MULT5 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # COMP6 # FIN
DP42 :
1 ADD2 # ADD2 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT3 # MULT3 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT1 # MULT3 # RSHIFT6 # RSHIFT7 # MULT3 # FIN
4 ADD2 # COMP6 # COMP5 # MULT1 # FIN
5 MULT1 # ADD2 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD2, ADD2.
MULT1, MULT3, MULT3, MULT5, MULT4, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT6, RSHIFT7.
LSHIFT7.
150 50 1.5 :
DP51 :
1 ADD2 # ADD2 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT3 # MULT4 # LSHIFT7 # FIN
3 MULT1 # MULT3 # MULT4 # MULT3 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # COMP6 # FIN
DP52 :
1 ADD2 # ADD2 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT3 # MULT4 # MULT3 # MULT4 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT1 # MULT3 # RSHIFT6 # RSHIFT7 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # MULT1 # FIN
5 MULT1 # ADD2 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD2, ADD2.
MULT1, MULT3, MULT4, MULT3, MULT4, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT6, RSHIFT7.
LSHIFT7.
160 49.0 1.8 :
DP61 :
1 ADD3 # ADD4 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT5 # MULT4 # LSHIFT7 # FIN
3 MULT1 # MULT5 # MULT4 # MULT5 # MULT4 # FIN
4 ADD3 # COMP6 # COMP5 # COMP6 # FIN
DP62 :
1 ADD3 # ADD4 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT1 # MULT5 # RSHIFT6 # RSHIFT7 # MULT4 # FIN
4 ADD3 # COMP6 # COMP5 # MULT1 # FIN
5 MULT1 # ADD3 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD3, ADD4.
MULT1, MULT5, MULT4, MULT5, MULT4, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT6, RSHIFT7.
LSHIFT7.
156 48.7 1.75 :
DP71 :
1 ADD2 # ADD4 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT5 # MULT4 # LSHIFT7 # FIN
3 MULT1 # MULT5 # MULT4 # MULT5 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # COMP6 # FIN
DP72 :
1 ADD2 # ADD4 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT1 # MULT5 # RSHIFT6 # RSHIFT7 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # MULT1 # FIN
5 MULT1 # ADD2 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD2, ADD4.
MULT1, MULT5, MULT4, MULT5, MULT4, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT6, RSHIFT7.
LSHIFT7
160 48.7 1.68 :
DP81 :
1 ADD2 # ADD4 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT1 # MULT4 # LSHIFT7 # FIN
3 MULT1 # MULT1 # MULT4 # MULT5 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # COMP6 # FIN
DP82 :
1 ADD2 # ADD4 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT1 # MULT4 # MULT5 # MULT4 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT1 # MULT1 # RSHIFT6 # RSHIFT7 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # MULT1 # FIN
5 MULT1 # ADD2 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD2, ADD4.
MULT1, MULT1, MULT4, MULT5, MULT4, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT6, RSHIFT7.
LSHIFT7.
150 50 1.40 :
DP91 :
1 ADD2 # ADD2 # MULT2 # RSHIFT6 # FIN
2 MULT2 # MULT2 # MULT4 # LSHIFT7 # FIN
3 MULT2 # MULT2 # MULT4 # MULT2 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # COMP6 # FIN
DP92 :
1 ADD2 # ADD2 # MULT2 # RSHIFT6 # FIN
2 MULT2 # MULT2 # MULT4 # MULT2 # MULT4 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT2 # MULT2 # RSHIFT6 # RSHIFT7 # MULT4 # FIN
4 ADD2 # COMP6 # COMP5 # MULT2 # FIN
5 MULT2 # ADD2 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD2, ADD2.
MULT2, MULT2, MULT4, MULT2, MULT4, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT7, RSHIFT7.
LSHIFT7.
149 49.5 1.49 :
DP101 :
1 ADD2 # ADD2 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT2 # MULT2 # LSHIFT7 # FIN
3 MULT1 # MULT2 # MULT2 # MULT3 # MULT3 # FIN
4 ADD2 # COMP6 # COMP5 # COMP6 # FIN
DP102 :
1 ADD2 # ADD2 # MULT1 # RSHIFT6 # FIN
2 MULT1 # MULT2 # MULT2 # MULT3 # MULT3 # MULT5 # MULT4 # MULT5 #
LSHIFT7 # FIN
3 MULT1 # MULT2 # RSHIFT6 # RSHIFT7 # MULT2 # FIN
4 ADD2 # COMP6 # COMP5 # MULT1 # FIN
5 MULT1 # ADD2 # RSHIFT6 # LSHIFT7 # COMP6 # FIN
Les instances utilisées sont :
ADD2, ADD2.
MULT1, MULT3, MULT3, MULT2, MULT3, MULT5, MULT4, MULT5. COMP6,
COMP5, COMP6.
RSHIFT7, RSHIFT7.
LSHIFT7.
Nous donnons ci-après quelques détails
concernant les résultats obtenus pour le 1er test. En
considérant les fichiers DP11
et DP12 et en tenant compte des valeurs de
surface, temps et énergie de chacune des instances indiquées dans
ces fichiers, on obtient ce qui suit:
i) surface :
Instances utilisées : ADD3, ADD4, MULT4, MULT5, MULT4,
MULT5, MULT4, MULT5, MULT4, MULT5, COMP6, COMP5, COMP6, RSHIFT6,
RSHIFT7, RSHIFT6, LSHIFT7 utilisant ainsi une
surface égale à :
11 + 9 +4*(13 + 13.5) + 8.5 + 8 + 8.5 + 1 + 1.5 + 1 + 1.5 =
155
(Voir la colonne surface dans le tableau 4.1)
ii) temps :
DP11 :
|
1 :
2 :
3 :
4 :
|
4 ; 5 ; 9.5 ; 10
9.5 ; 9.5 ; 9.5 ; 9.7
9.5 ; 9.5 ; 9.5 ; 9.5 ;
4 ; 4.5 ; 3.5 ; 4.5
|
9.5
|
> max = 10 > max = 9.7
> max = 9.5 > max= 4.5
|
T1= Somme des max = 33.7
DP12 :
|
1 :
2 :
3 :
4 :
5 :
|
4 ; 9.5 9.5 4 ; 9.5
|
5 ; 9.5 ; 10
; 9.5 ; 9.5 ; 9.5 ; 9.5 ;
; 9.5 ; 10 ; 9.7 ; 9.5
4.5 ; 3.5 ; 9.5
; 4 ; 10 ; 9.7 ; 4.5
|
9.5 ;
|
9.5 ;
|
9.5 ;
|
9.7
|
> max = 10 > max = 9.7
> max = 10 > max = 9.5
> max = 10
|
T2= Somme des max = 49.2
T = MAX(T1, T2) = 49.20 ns
(Voir la colonne max_delai dans le tableau 4.1)
Tmoyen= (T1 + T2) / 2 = 41.45 ns
(Voir la colonne delai_moy dans le tableau 4.1)
iii) puissance :
DP1 :

Energie1= 3 + 3 + 3.5 +0.6 + 3.5 + 5.5 + 3.5 +
0.7 + 3.5 + 5.5 + 3.5 + 5.5 +
3.5 + 3 + 3 + 2.5 + 3 = 56.3 fJ
Puissance=Energie * Fréquence= Energie1 /
T1= 56.3 / 33.7= 1.67 uW

|
+0.6
|
+ 4*(3.5 + 5.5)
|
+ 0.7
|
+ 3.5
|
+ 5.5 + 0.6 + 0.7 +
|
|
+ 2.5
|
+ 3.5 + 3.5 + 3
|
+ 0.6
|
+ 0.7
|
+ 3 = 83.4 fJ
|
DP2 :
Energie2= 3 + 3 + 3.5
3.5 + 3 + 3
Puissance=Energie * Fréquence= Energie2 /
T2= 83.4 / 49.2= 1.70 uW
Puissance = MAX (1.67 , 1.70) = 1.70
uW
(Voir la colonne max_puissance dans le tableau 4.1)
Puissance moyenne = (1.67 + 1.70) / 2 = 1.69 uW
(sVoir la colonnes Puissance_moy dans le tableau 4.1)
Note : Dans le tableau 4.1 on trouve
1.68 uW du fait que ce résultat a été calculé par
le processeur en utilisant un certain nombre de chiffres significatifs pour les
puissances correspondant à DP1 et
DP2.
Ici, nous avons arrondi ces 2 valeurs à 1.67 et 1.70, ce
qui justifie la petite différence entre 1.69 et 1.68.
4.3 Conclusion :
Dans ce chapitre, nous avons présenté les
résultats que nous avons obtenus. Les résultats obtenus par cette
méthode exhaustive seront importants pour servir de repère au
développement d'une méthode approchée. Il a
été aussi montré que quoique la complexité
algorithmique de la méthode exacte n'est pas polynomiale, nos
résultats ont été tout de même obtenus en des temps
CPU intéressants, et ce, grâce à l'utilisation de
structures de données et de méthodes adéquates. Enfin, le
nombre considérable de combinaisons à explorer pour satisfaire
les contraintes fixées ne permet pas au concepteur de circuits un calcul
manuel. D'où l'importance de ce travail pour une aide efficace à
la conception de circuits intégrés.
Concfusion generaf~
CONCLUSION GENERALE
Nous avons présenté dans ce mémoire notre
affectation d'instances d'une bibliothèque à des composants d'un
système intégré. Nous avions montré que ce
problème n'est pas polynomial, et pour y faire face, le
développement d'une méthode approchée à base d'une
heuristique ou d'une méta-heuristique est nécessaire. Toutefois,
en absence de benchmarks (jeux de test) pour valider la méthode en la
confrontant à d'autres travaux en utilisant les mêmes benchmarks,
nous avons dû développer une méthode exacte. Celle-ci sera
doublement bénéfique dans la mesure où elle produira des
résultats exacts pour des cas où le temps CPU serait raisonnable,
tout comme elle servira de balise pour le développement d'une
méthode approchée.
Nous avons vu que les résultats obtenus sont
intéressants grâce à notre utilisation de structures de
données et de procédures adéquates. Ce travail nous a
permis de mettre en pratique certains aspects informatiques
étudiés durant notre cursus universitaire, tout en ayant un
complément de connaissances en matière de conception de circuits
intégrés et de systèmes Hardware.
Enfin, nous avons aussi remarqué que le nombre
considérable de configurations à explorer pour trouver la
configuration satisfaisant les contraintes fixées interdit à un
concepteur de circuits toute tentative manuelle, ce qui rend notre travail un
outil d'aide efficace à la conception de circuits
intégrés.
cBibliograpfiie
[1] M.R. Garey, D.S. Johnson ?Computers and Intractability: A
Guide to the Theory of NP-Completeness? Freeman, San Francisco, 1979
[2] B. W. Kernighan, D. M. Ritchie ?Le Langage C? Editions
MASSON, 1984
[3] A. V. Aho, J. E. Hopcroft, J. D. Ullman ?Data Structures and
Algorithms? Addison-Wesley Publishing Company, 1983
[4] M. Sakarovitch ?Optimisation Combinatoire, Méthodes
Mathématiques et Algorithmiques : Programmation Discrète?
HERMANN, 1984
[5] A. Mahdoum ?Critique du livre Representations for
Genetic and Evolutionary Algorithms, écrit par Franz Rothlauf,
édité par SPRINGER-VERLAG Editions? critique du livre
publiée dans The Computer Journal, Vol.49, N°5, Sept. 2006, Oxford
Journals, p 629, ISSN: 0010-4620
[6] Weste & Eshraghian «Principles of CMOS VLSI Design:
A systems perspective» Addison Wesley, 1993
[7] A. Bellaouar and M. I. Elmasry ?Low-Power Digital VLSI
Design? Norwell, Kluwer Academic Publishers, 1995
[8] A. Mahdoum ?SPOT: An Estimation of the Switching Power
Dissipation in CMOS Circuits and Data Paths Tool? SASIMI'97, 1-2 Dec.97, Osaka,
Japan
[9] A. Mahdoum ?Démonstrations sur l'Outil de CAO
SPOT? Forum de la conférence DATE, 4-8 Mars 2002, Palais des
Congrès, Paris, France (résumé de l'outil publié
dans DESIGNER'S FORUM PROCEEDINGS DATE'02, 4-8 March 2002, Paris, France), p
260
[10] A. Mahdoum, A. Boutammine, D. Touahri, N. Toubaline
?FREEZER1: Un Outil d'Aide à la Conception de Circuits Digitaux à
Faible Consommation de Puissance? IEEE/FTFC'05, 18-20 Mai 2005, Paris, France,
pp.69-74
[11] A. Mahdoum, N. Badache, H. Bessalah ?A Low-Power Scheduling
Tool for SOC Designs? IEEE/IWSSIP'05, 22-24 Sept. 2005, Chalkida, Greece, pp.
367-372
[12] A. Mahdoum, N. Badache, H. Bessalah ?An Efficient
Assignment of Voltages and Optional Cycles for Maximizing Rewards in Real-Time
Systems with Energy Constraints? Journal Of Low Power Electronics (JOLPE),
Vol.2, N°2, August 2006, American Scientific Publishers, pp. 189-200,
ISSN: 1546-1998
[13] A. Mahdoum, M. L. Berrandjia ?FREEZER2: Un Outil
à Base d'un Algorithme Génétique pour une Aide à la
Conception de Circuits Digitaux à Faible Consommation de Puissance?
IEEE/FTFC'07, 21-23 Mai 2007, Paris, France, pp. 143-148
[14] A. Mahdoum, O. Dahmri, M. Zair ?A New Memory Access
Optimizer Using Array Binding, Memory Allocation, and Combined Code in Embedded
System Design? IEEE/NORCHIP'07, 19-20 Nov. 2007, Aalborg, Denmark
[15] A. Mahdoum ?Synthèse de Systèmes Monopuce
à Faible Consommation d'Energie? FTFC'09, 3-5 Juin 2009, Centre Suisse
d'Electronique et de Microtechnique, Neuchâtel, Suisse
[16] M. Bougherara ?Contribution à l'Ordonnancement
d'Opérations dans une Partie Opérative? Mémoire
d'Ingénieur d'Etat en Informatique, USDBlida, 2002 (encadré par
A. Mahdoum, CDTA)
[17] A. Mahdoum, F. Louiz ?ALLOCATE : Outil d'Allocation de
Registres et d'Interconnexions dans une Partie Opérative? CDTA, 2000
| 

