b. La méthodologie proposée par Pereira
13
Utilisant une petite connaissance à priori sur les
tableaux, l'approche proposée consiste en un algorithme s'articulant sur
plusieurs phases de détection et de correction d'erreurs. Ci -
après, les grandes lignes de cet algorithme :
Phase I : Acquisition du formulaire - tableau et seuillage
:
· acquisition de l'image à 300X300 pixels de
résolution ;
· conversion de l'image en niveau de gris ;
· binarisation de l'image et seuillage.
Phase II : Détection et correction de l'angle
d'inclinaison du formulaire - tableau :
· détection de l'angle d'inclinaison par la
transformée de Hough14 ;
· correction d'angle d'inclinaison par rotation unique avec
interpolation bilinéaire.
Phase III : Localisation et identification de l'angle
d'intersection :
13 Op. cit.
14 Voir l'algorithme de la transformation de Hough en
Annexes
·

19
Chaque type de coin est représenté par un
élément de structuration ;
· L'opération d'érosion produit des images
ne contenant que les points des coins correspondant à
l'élément de structuration utilisé. Tous les coins
reconnus sont enregistrés dans un « tableau réel ».
Phase IV : Détection systématique d'erreurs
:
· Analyse du « tableau réel » ;
· Chaque intersection est comparée aux
intersections voisines en utilisant les tables de rejet ;
· Lorsqu'une fausse intersection est localisée
dans le tableau réel, le compteur qui a pour rôle respectif dans
le tableau d'erreurs sera incrémenté de 1.
Phase V : Analyse et correction récursives d'erreurs
:
· La correction est effectuée avec le compteur
d'erreurs le plus élevé dans le tableau d'erreurs ;
· Le voisinage d'erreurs est analysé par
vérification de ses points - finaux dans le tableau d'erreurs ;
· Des tableaux de points - finaux sont
créés pour les directions Nord, Sud, Est et Ouest.
Phase VI : Extraction des cellules du formulaire - tableau
:
· Pour des voisins dont les points finaux sont
dirigés vers une erreur d'intersection, la solution de correction
d'intersections est évaluée.
Phase VII : Identification de la structure
hiérarchique.
c. Le procédé prôné par Zanibbi
15
Après analyse des diverses approches utilisées
jusqu'alors en reconnaissance de tableaux, Zanibbi et ses collaborateurs
remarquent que ces différentes méthodes peuvent se regrouper en
un seul procédé facilement intelligible. Et ce
procédé, ajoutent - ils, s'articule sur trois concepts
essentiels, à savoir : les observations, les
transformations et les inférences. En fait, ces
auteurs nous montrent que ces trois concepts sont indispensables à tout
processus de reconnaissance de tableau. Dans un schéma clair et
précis, ils présentent ainsi les trois concepts comme parties
intégrantes de tout le procédé de reconnaissance,
procédé
15 Op. cit.

20
basé sur une connaissance à priori : le
modèle de tableau à reconnaître. Avant d'expliciter les
différentes étapes de ce procédé, nous
présentons ci-dessous le schéma proposé par ces
chercheurs.
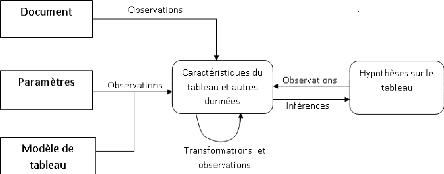
Fig. 1. Le procédé de reconnaissance de
tableaux selon Zanibbi et ses collaborateurs.
> Le Document :
D'après le schéma ci-dessus, un
système de reconnaissance de tableaux possède toujours un
document d'entrée qui fournit les données de base pour la
reconnaissance. Ce document peut représenter soit une image du tableau
à reconnaître (provenant d'un capteur tel qu'un
scanneur), soit des données tabulaires au format texte (un
fichier texte). Dans tous les cas, le document d'entrée contient
toujours des informations à analyser par le système de
reconnaissance.
> Les paramètres :
Afin que la reconnaissance s'exécute
correctement, il est souvent nécessaire de fournir au système un
certain nombre de valeurs pouvant l'aider à réaliser les
différentes opérations de reconnaissance. Ces valeurs portent le
nom de « paramètres » et peuvent être :
· Statiques : lorsqu'elles sont définies
au départ et restent inchangées tout au long du processus de
reconnaissance (c'est le cas des constantes tels que la hauteur et la largeur
de l'image d'entrée);
· Adaptatives : lorsqu'elles varient tout au
long du processus en fonction des différentes
étapes de la reconnaissance (c'est le cas des différents seuils
de niveau de couleur qui peuvent varier au niveau des différentes
étapes de traitement).

21
> Le Modèle de tableau :
Le processus de reconnaissance doit se dérouler
suivant un certain nombre de règles et de faits décrivant les
caractéristiques du tableau à reconnaître. Ces
caractéristiques peuvent provenir d'un modèle de tableau
bien défini ou bien d'un certain nombre de
propriétés communes à tous les tableaux en
général. Par ailleurs, les paramètres fournis au
début du processus peuvent permettre de préciser le modèle
de tableau sur lequel sera basée la reconnaissance.
> Les observations :
Intervenant à chaque étape du
procédé de reconnaissance, les observations permettent la
circulation de l'information au sein de tout le système. En fait, les
observations permettent d'acquérir les données provenant :
- du document d'entrée : mesure des
caractéristiques du tableau à reconnaître, obtention
d'autres informations concernant le document, etc.;
- des paramètres du système :
acquisition des données précises sur base desquelles devra se
dérouler le processus de reconnaissance, telles que le seuillage, les
périodicités, les tolérances, etc. ;
- du modèle de tableau : obtention des
données sur le type de tableau à reconnaître sur base des
paramètres du système (acquisition des caractéristiques -
type en fonction desquelles se déroulera l'analyse du tableau
d'entrée) ;
- d'autres observations : utilisation des
résultats d'observations précédentes sous forme de
données statistiques, des probabilités, des combinaisons
d'observations et des comparaisons.
- des hypothèses sur le tableau :
considération des suppositions ou énoncés de départ
en vue de faciliter la prise de décision concernant le tableau à
reconnaître.
> Les transformations :
Au coeur de tout le processus de reconnaissance de tableau se
trouve toute une série de transformations effectuées par le
système en fonction des observations faites. Ces transformations ne sont
rien d'autre qu'une combinaison de deux ou plusieurs opérations
destinées à modifier les valeurs des résultats d'une
observation ou d'un ensemble d'observations en vue de mettre en évidence
les caractéristiques d'un ensemble de données

22
ou de prendre une décision finale sur le tableau
à reconnaître. Selon le type de données auxquelles elles
s'appliquent, nous pouvons trouver plusieurs types de transformations, à
savoir :
· Pour les données physiques (image d'un tableau ou
fichier texte contenant des données tabulaires) :
o La transformation de Hough : qui est
utilisée pour l'estimation des paramètres des formes
géométriques. Elle est surtout utilisée dans la
détection des lignes et d'angle d'inclinaison dans une image de tableau
;
o Les transformations affines : dont les plus
utilisées sont la rotation, le découpage (ou rognage), la
translation et l'homothétie. Ces transformations sont utilisées
soit pour corriger l'angle d'inclinaison de l'image, soit pour réduire
sa taille (ou ses dimensions) ;
o Les prétraitements : qui incluent la
compression, la binarisation, le prélèvement d'une partie de
l'image, etc.
· Pour les données décrivant la structure
et/ou le contenu du tableau (structure logique) :
o Les transformations par arbres : qui sont
utilisées pour corriger les erreurs de structure, soit pour regrouper
les régions individuelles en une région de tableau ;
o Les transformations par graphes : qui sont
utilisées soit pour regrouper les régions individuelles en une
région de tableau, soit pour corriger les erreurs de structure ;
o Les transformations par filtres : utilisées
soit pour la réduction du bruit dans l'image, soit pour l'extraction des
textures, ou des niveaux de couleurs dans l'image ;
o La reconstruction des formes à partir d'une
liste de points : qui est employée pour relier les intersections de
lignes dans un tableau ;
o L'ordonnancement et l'indexation d'objets :
servant à réarranger les contenus des différentes cellules
d'un tableau ;
o La conversion : qui est utilisée pour
changer les représentations du tableau (par exemple du format HTML vers
le format texte) ;
·

23
Pour les données statistiques :
o Le lissage et le seuillage des histogrammes de
projections : c'est la transformation qui permet, en appliquant le
seuillage, de réduire la variance dans la localisation des lignes de
texte et des séparateurs lors des différentes projections
(horizontales et/ou verticales).
> Les inférences :
Dans un système de reconnaissance de tableau, les
inférences constituent l'aboutissement et le but même du processus
de reconnaissance. En effet, les inférences prennent en compte les
résultats des observations et des transformations effectuées sur
le document d'entrée pour les confronter avec les hypothèses
existants avant d'émettre une décision de reconnaissance ou de
non reconnaissance du tableau. En d'autres termes, les inférences
effectuent une certaine comparaison entre les caractéristiques
prédéfinies du modèle de tableau et les données
issues des observations et des transformations avant de générer
des tests d'hypothèses auxquels seront soumis ensuite les
résultats de cette comparaison.
Après une profonde analyse des différentes
techniques utilisées jusqu'alors, Zanibbi et ses collaborateurs sont
parvenus à synthétiser les techniques d'inférence en trois
grands groupes, notamment : les classificateurs, les segmenteurs et les
parseurs (ou analyseurs).
o Les classificateurs : ce sont des techniques qui
permettent d'affecter les types de structure et les types de relation d'un
modèle de tableau à un ensemble de données. Les
classificateurs utilisés en reconnaissance de tableaux incluent :
· Les arbres de décision : par
exemple, la classification d'un ensemble de caractéristiques en
caractéristiques d'une colonne par seuillage, etc. ;
· Les plus proches voisins : par
exemple, la méthode des k plus proches voisins (kNN) pour
déterminer l'appartenance à une région d'un tableau, etc.
;
· Les réseaux de neurones ;
·

24
Les méthodes syntaxiques : par
exemple, l'affectation des types aux lignes de texte d'un tableau, la
classification des rôles des mots dans des tableaux de contenus, etc.;
· Les méthodes statistiques :
par exemple, les classificateurs bayésiens, les réseaux
bayésiens, etc.
o Les segmenteurs : ce sont des techniques
d'inférence qui permettent de localiser les structures du modèle
de tableau dans une image. Ils utilisent un classificateur binaire et une
fonction de recherche pour localiser les composants du modèle de
tableau. Les régions cibles trouvées par le classificateur et qui
satisfont la fonction objective de la recherche sont regroupés ou
partitionnés à l'intérieur de l'ensemble de
données. Selon que les données sont groupées ou
partitionnées, Zanibbi et ses collaborateurs distinguent deux grandes
familles de segmenteurs :
· Les segmenteurs de regroupement : parmi lesquels nous
retrouvons : le regroupement hiérarchique des régions par
distance, la fermeture transitive, etc. ;
· Les segmenteurs de partitionnement : citons, la
détection de tableau utilisant la programmation
dynamique, l'algorithme du simplex, etc.
o Les parseurs (ou analyseurs) : ce sont des
techniques d'inférence utilisés pour produire des graphes de
structure relatifs à la syntaxe du tableau en fonction de celle
définie dans le modèle de tableau. Ces graphes décrivent
donc la structure logique des composants du modèle de tableau. Selon le
type de grammaire utilisé pour l'encodage de la syntaxe de la structure
logique, Zanibbi et ses collaborateurs distinguent les types de parseurs
suivants :
· Les modèles de Markov cachés
: par exemple, la maximisation des probabilités d'adjacence des
régions dans un tableau, etc. ;
· Les graphes de grammaire : par
exemple, une méthode d'induction de grammaire pour les contenus des
tableaux à partir de données étiquetées, des
méthodes adaptatives pour définir des expressions

25
régulières décrivant les types de
données des contenus de cellules,
etc.
| 

