1.2.3. Analyse et interprétation des
données
Dans cette section, nous présentons et
analysons les données qui ont constitué la toile de fond de nos
recherches avant de donner notre interprétation des résultats. Vu
l'impossibilité

33
d'accéder à tous les documents écrits
traitant sur la reconnaissance de tableaux, nous avons centré nos
investigations sur un échantillon de 8 documents écrits par
d'éminents chercheurs qui ont consacré leurs efforts à
examiner les méthodes et approches susceptibles de rendre les
systèmes de reconnaissance de tableaux beaucoup plus efficaces et plus
performants.
a) Encodage de données
En vue de faciliter leur traitement, nous nous sommes
proposé de coder les données de la manière suivante :
· Les auteurs :
A1 : A. Laurentini et P. Viada
A2 : Luiz Antonio Pereira et al.
A3 : R. Zanibbi et al.
A4 : Jiwon Shin et Nick Guerette
A5 : H. Kawanaka et al.
A6 : Jin Chen et Daniel Lopresti
A7 : Jianying Hu et al.
A8 : Yalin Wang et al.
· Les méthodologies, approches et techniques
utilisées :
M1 : Les approches structurales et statistiques.
M2 : Détection des blocs de texte et identification des
lignes horizontales et verticales
M3 : Détection des coins (ou lignes d'intersection) du
tableau et extraction des cellules du tableau.
M4 : Détection des zones de texte du tableau au moyen de
l'algorithme ISODATA et l'algorithme de croissance de régions.
M5 : Identification de la structure du tableau à partir
d'un modèle et génération des documents XML.
M6 : Détection de tableau en utilisant la
transformation de Hough, les classificateurs SVM et la programmation
dynamique.
M7 : Détection de tableau en utilisant la programmation
dynamique.
M8 : Détection de tableau par optimisation
probabilistique.

34
M9 : L'approche neuronale.
· Le système de pointage
1 : cité ou utilisé par l'auteur
0 : ni cité, ni utilisé par l'auteur
· Les indicateurs
X : La fréquence d'occurrences globales (de toutes les
méthodes)
Xi : La fréquence d'occurrences individuelles (propre
à chaque méthode) n : La taille de l'échantillon (n=8)
? CD
E
DF$
5 : La moyenne des fréquences. 5
= G
s : L'écart - type de l'échantillon
ôJ : L'écart - type de la
distribution d'échantillonnage des moyennes.
x 100
x : L'écart entre un Xi et la moyenne
5
CD
p : la fréquence relative d'un Xi par rapport à n.
p = G
CD
P : la fréquence relative en pourcentage ;
c'est-à-dire P = G
b) Analyse des méthodes et techniques
utilisées
Afin que notre démarche s'analyse soit limpide et claire,
nous présentons d'abord la matière première de notre
analyse dans la grille ci-après :
Auteurs
Méthodologies et techniques
|
A1
|
A2
|
A3
|
A4
|
A5
|
A6
|
A7
|
A8
|
X
|
x=X-5 (avec
5=2,5)
|
x2
|
p
|
P
(%)
|
M1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
8
|
5,5
|
30,25
|
1
|
100
|
M2
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
-1,5
|
2,25
|
0 ,125
|
12,5
|
M3
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
2
|
-0,5
|
0,25
|
0 ,25
|
25
|
M4
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
-1,5
|
2,25
|
0 ,125
|
12,5
|
M5
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
1
|
-1,5
|
2,25
|
0,125
|
12,5
|
M6
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
2
|
-0,5
|
0,25
|
0,25
|
25
|
M7
|
0
|
0
|
1
|
0
|
0
|
1
|
1
|
0
|
3
|
0,5
|
0,25
|
0,375
|
37,5
|
M8
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
1
|
-1,5
|
2,25
|
0,125
|
12,5
|
M9
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
1
|
-1,5
|
2,25
|
0,125
|
12,5
|
Totaux
|
|
|
|
|
|
|
|
|
|
|
42,25
|
|
|
|

35
Tableau 1.1 : Grille présentant la
distribution des fréquences d'occurrence des différentes
approches pour chaque auteur.
D'une manière synthétique, les données
ci-haut présentés peuvent être illustrés par le
graphique suivant :
Fréquences d'occurence (X)
9 8 7 6 5 4 3 2 1 0
|
|
|
|
M1 M2 M3 M4 M5 M6 M7 M8 M9
|
|
Fréquences (X)
Graphique 1.1 : Niveaux des fréquences
d'occurrence pour les différentes approches. De toute évidence,
en observant les données présentées ci-haut, nous
constatons que :
· La majorité de chercheurs en reconnaissance de
tableaux utilisent les approches structurales et statistiques (Cfr. 8/8, soit
100%).
· L'approche neuronale n'est presque pas utilisée
en reconnaissance de tableaux (Cfr. 1/8, soit 12,5%).
Etant donné que nous travaillons sur un
échantillon de 8 chercheurs, nous allons procéder par un test
d'inférence afin de pouvoir généraliser les constats
ci-hauts soulignés à toute la population de chercheurs dans le
domaine de la reconnaissance de tableaux (une population infinie !). Pour ce
faire, les constats précédemment soulevés constituent
d'emblée notre hypothèse de base (H0).
- Hypothèses:
· H0 : Les approches structurales et statistiques sont les
plus souvent utilisées en reconnaissance de tableaux tandis que
l'approche neuronale est quasi absente dans les travaux traitant sur la
reconnaissance de tableaux.
· H1 : Contrairement à l'approche
neuronale, les approches structurales et statistiques
sont très rarement utilisées en
reconnaissance de tableaux.
- Seuil de signification pour le test (Niveau de
confiance): 95%, soit une erreur de 5% (á=0,05) ;
- Distribution à utiliser pour le test : Test t
de Student (car nous nous trouvons dans le cas d'une population infinie et dont
nous ignorons l'écart - type).
- Type de test (ou région de rejet) : Test
bilatéral.
- Calcul des valeurs des indices:
· Moyenne de l'échantillon (5 ) : Cette
moyenne est donnée par
5 = ~ ? N.
M .-~ = ~ O 8+1+2+1+1+2+3+1+1 = 2,5
M
· Ecart - type de l'échantillon (s) : Cet
écart est donné par
< =T? J
M2 = TU~,~V
O2 = W6,0357 = 2,46
· L'écart - type de la distribution
d'échantillonnage des moyennes : Cet écart - type s'obtient par
la formule :
HIJ = =
vM21
[ 2,U]
v^
· Valeurs de t :
= 0,93
o

36
th, = 2,365 ((3r `a = ' - 1 = 8 - 1 = 7 et b =
0,05)
=
=
(1,V^)v^
2,U]
= 1,69
(2,V2h,ij)v^
2,U]
(J2efgf~vM21
o tcalculé = [
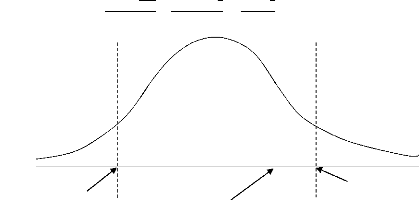
· Représentation de la distribution
:
Région d'acceptation
Région de rejet
Région de rejet
tlu tlu
tcalculé
Graphique 1.2 : Représentation de la
distribution réduite t.

37
- Décision : l'hypothèse de base (H0) est
acceptée
- Conclusion : Avec 5% de risque d'erreur, nous confirmons que
les approches structurales et statistiques sont les plus souvent
utilisées en reconnaissance de tableaux et que l'approche neuronale est
quasi absente dans les travaux traitant sur la reconnaissance de tableaux.
| 

