|

REPUBLIQUE DEMOCRATIQUE DU CONGO
ENSEIGNEMENT SUPERIEUR ET UNIVERSITAIRE INSTITUT
SUPERIEUR PEDAGOGIQUE
BP : 854 BUKAVU
SECTION DES SCIENCES COMMERCIALES
ADMINISTRATIVES ET
INFORMATIQUE
DEPARTEMENT D'INFORMATIQUE DE GESTION
Caractérisation et extraction informatiques de
la
structure d'un tableau par une méthode implémentant
un
réseau de neurones
Par BISIMWA MUGISHO Pacifique
Mémoire présenté et soutenu pour
l'obtention du diplôme de licence en pédagogie appliquée
Option : Informatique de Gestion
Dirigé par : Prof. Blaise MWEPU FYAMA codirecteur
: Ass. Dieudonné KYENDA

EPIGRAPHE
"Tout est pur pour ceux qui sont purs ; mais rien n'est pur
pour ceux qui sont impurs et
incroyants, car leur intelligence et leur
conscience sont marquées par l'impureté. "
(Tite 1: 15)
"La vision est une faculté tellement merveilleuse que,
si l'être humain parvient à discerner le
vrai et le faux par la
perception, alors l'ordinateur y parvient aussi en opérant une
nette
discrimination entre zéro et un. "
"Vous n'avez le droit de critiquer chez les autres que les
faiblesses que vous avez réussi à
vaincre en vous. Chaque fois
que vous portez un jugement négatif sur quelqu'un, vous
êtes
vous-même jugé. Et par qui ? Par votre conscience,
votre tribunal intérieur. Une voix s'élève
alors en vous pour vous demander : « Et toi qui te
prononces ainsi, es-tu si sûr que d'une
manière ou d'une autre tu n'as pas ce
défaut-là ?... »..." (Omraam Mikhaël Aïvanhov)
II
DEDICACE
Ce travail, fruit de notre évolution dans la recherche
scientifique et de sacrifices incommensurables, est dédié :
A mon père,
A ma très chère maman,
A mes frères et soeurs,
A ma future épouse,
A sa majesté, le Mwami Pierre NDATABAYE WEZA III.
BISIMWA MUGISHO Pacifique
III
AVANT PROPOS
Le présent travail, pour lequel nous avons
consacré quelques mois de recherche et cinq années
d'études, porte deux sens emblématiques différents. D'une
part, ce travail concrétise notre volonté, non seulement de
cheminer dans les méandres de la recherche scientifique, mais aussi d'y
évoluer. D'autre part, ce travail témoigne de notre souci
d'apporter une pierre à l'édifice qui devra abriter toute
l'humanité afin de le protéger contre le pire des maux qu'est
l'ignorance. C'est là l'une des tâches les moins faciles, certes,
mais il n'en demeure pas moins vrai que si tous les chercheurs
s'efforçaient de réaliser un travail correct et consciencieux,
nous arriverons un jour à atteindre la perfection et à
éradiquer définitivement ce mal.
En attendant de relever ce grand défi,
l'humanité doit donc continuer à lutter pour corriger ses
erreurs. Et cela n'est possible qu'en ayant un regard critique sur tout ce qui
est considéré comme vérité préétablie
ou, du moins, ce qui en donne l'apparence. Cette critique, loin du simple
doute, s'avère être un véritable questionnement sur le
pourquoi des êtres et des choses. Il est vrai que c'est un
démarche intellectuel trop risqué au regard des structures
conventionnelles préétablies depuis des années, voire
même, des siècles mais c'est là le prix à payer pour
développer la créativité nécessaire à
l'évolution de la science.
Ce travail est donc le fruit, non seulement des connaissances
que nous avons acquises tout au long de notre cursus universitaire, mais aussi
de notre propre créativité. Ainsi, bien qu'imparfait (car
étant une oeuvre humaine), nous lui reconnaissons son caractère
original.
La liberté scientifique étant sous - tendue par
celle de l'esprit, nous abandonnons au lecteur toute sa latitude d'approuver ou
de contredire la démarche proposée. Dans le cas où il
opterait pour la contradiction, loin de nous de lui en vouloir ; nous lui
proposons seulement de soumettre d'abord ses arguments aux règles de
l'expérimentation et de les exposer ensuite à la lumière
de la raison.
Cela dit, nous exprimons notre affection et notre
reconnaissance à tous ceux qui nous ont aidés dans la
réalisation de ce travail, modeste soit - il.
Plus spécialement, nous adressons notre sincère
et profonde gratitude au Professeur Blaise FYAMA pour son dynamisme
scientifique avec lequel il a guidé nos pas depuis le commencement de ce
travail jusqu'à son parachèvement.
IV
Nous remercions également le corps enseignant de
l'Institut Supérieur Pédagogique (ISP/Bukavu) en
général et ceux du département d'Informatique de Gestion
en particulier. Le savoir qui est nôtre aujourd'hui est le fruit de leur
sérieux et précieux encadrement.
Nos remerciements s'adressent encore à toute la famille
BISIMWA RWIZIBUKA pour tous les sacrifices consentis. Leurs bienfaits sont
inoubliables et resteront gravés en nous.
Enfin, nous exprimons notre reconnaissance aux amis,
connaissances et camarades avec qui nous avons partagé et vécu
les peines et jubilations tout au long de notre séjour en milieu
estudiantin.
Que tous ceux dont les noms ne sont pas repris ci-haut ne se
sentent pas isolés car ils ont apporté, chacun en ce qui le
concerne, une pierre à l'édifice.
BISIMWA MUGISHO Pacifique
V
SIGLES ET ABREVIATIONS
ASCII : American Standard Code For Information
Interchange (en français, `' Code standard américain pour
l'échange de l'information»)
HTML : HyperText Markup Language (en
français, `'Langage de balisage hypertexte») ISODATA
: Iterative Self-Organizing Data Analysis Technique yAy! (en
français, Technique d'analyse itérative et auto - organisatrice
des données).
JPEG : Joint Photographic Expert Group (en
français, `'Union des groupes d'experts en photographie»)
KNN : K Nearest Neighbours (en français,
`'K plus proches voisins»)
MS : Microsoft
OCR : Optical Caracter Recognition (en
français, «Réconnaissance optique des
caractères»)
RVB : Rouge Vert Bleu
SVM : Support Vector Machine (en
français, `'Machine à vecteur support»)
XML : eXtensible Markup Langage (en
français, `'Langage de balisage extensible»)
VI
Résumé
La reproduction automatique de la structure des tableaux
contenus sur des documents physiques pose encore un sérieux
problème lors de la réédition de ces documents ; surtout
lorsque ces derniers sont déjà remplis de données. Ce
problème réside dans la détection et la
compréhension de la structure même du tableau
numérisé en vue d'une reproduction de cette structure pour la
réédition du même document.
Le présent travail montre que le problème de
détection et d'extraction de la structure des tableaux peut être
résolu efficacement en utilisant une approche implémentée
avec les réseaux de neurones artificiels, et basée sur les
éléments de structuration d'un tableau. Ces
éléments de structuration sont considérés comme des
exemples d'apprentissage pour le réseau de neurones. Dans le contexte de
ce travail, un tableau est défini comme un ensemble de lignes et de
colonnes et les intersections de ces derniers constituent les cellules du
tableau.
Sachant que la conception de l'architecture d'un réseau
de neurones ne repose sur aucun modèle donné qu'elle est
plutôt heuristique, nous avons donc choisi une architecture qui nous a
semblé convenable et efficace à la résolution de notre
problème de recherche.
Une approche neuronale a été
implémentée et sa performance expérimentée. Les
résultats obtenus nous ont permis de confirmer l'atteinte de nos
objectifs car, la structure du tableau ainsi reproduite (au format MS WORD)
peut être utilisée pour la réédition d'un autre
document tabulaire de même type.
Mots clés : vision par ordinateur,
réseaux de neurones, détection des tableaux, structure des
tableaux.
Abstract
The automatic reproduction of table's structure on physical
documents still remain a serious problem during the repetition of these
documents; especially when these last are already filled of data. This problem
resides in the detection and the understanding of table's structure in digital
picture in view of a reproduction of this structure for the repetition of the
same document.
The present work shows that the problem of detection and
extraction of table's structure can be solved efficiently while using an
implemented approach with the artificial neural networks, and based on
structuring elements of a table. These structuring elements are
VII
considered as examples of training for the neural network. In
the context of this work, a table is defined as a set of lines and columns and
intersections of these last constitute cells of the table.
Knowing that the conception of the architecture of a neural
network doesn't rest on any given model that it is rather heuristic, we chose
an architecture that seemed to us appropriate and efficient to the resolution
of our research problem therefore.
A neural approach has been implemented and its performance
experienced. The gotten results permitted us to confirm the reach of our
objectives because, the structure of the table thus reproduced (to MS WORD
format) can be used in the same way for the repetition of another tabular
document type.
Keywords: computer vision, neural networks,
table detection, table structure

8
0. INTRODUCTION
0.1. Problématique
La reconnaissance de formes figure parmi les champs
d'application les plus intéressantes de l'Intelligence Artificielle dont
la visée principale est de réaliser, par modélisation, une
imitation du fonctionnement de l'Intelligence de l'homme dans le but de
faciliter la tâche de ce dernier.
Or, entre la manière de réfléchir de
l'homme et le fonctionnement quasi - intelligent de la machine, il
s'avère qu'il existe une certaine différence. Cette
dernière est rendue visible par le fossé (non moins profond) qui
existe entre le terrain du raisonnement réflexif humain et la logique
déductive de l'automate programmable qu'est l'ordinateur. A titre
illustratif, pour reconnaître le(s) tableau(x) figurant sur un document,
l'oeil humain n'éprouve aucune difficulté (bien entendu si son
processeur est en bonne santé !). Par contre, pour un ordinateur, cette
reconnaissance ne sera pas possible tant qu'aucune indication sur la marche
à suivre ne lui sera fournie.
Néanmoins, par ses capacités sans cesse
croissantes (à cette époque où la technologie
évolue à une très grande vitesse), l'ordinateur se
comporte mieux par rapport au traitement avec vélocité d'une
grande quantité de données et au stockage de ces
dernières.
C'est ainsi que, toujours dans sa course de gain de temps,
l'être humain fera toujours recours à l'ordinateur pour, par
exemple, extraire des données se trouvant sur un grand nombre de
documents. Dans ce cas, il est évident que l'homme peut utiliser la
reprographie ou la saisie manuelle pour obtenir une copie des données se
trouvant sur les documents originaux. Cependant, lorsqu'il voudra
réutiliser ces données pour divers autres traitements
informatiques (dans le cas d'une analyse ou d'une synthèse de ces
données, par exemple), il sera alors contraint de ressaisir les
données sont il a besoin ; ce qui lui rendra encore la tâche
beaucoup plus fastidieuse lorsqu'il s'agît d'un grand nombre de documents
à saisir. Ce même problème s'observe aussi dans le cas de
la conservation électronique des archives et documents anciens sur
papier.
Dans cette situation, la reconnaissance automatique de ces
documents par l'ordinateur lui serait d'un grand secours en ce sens que
l'ordinateur pourra «reconnaître » les éléments
figurant sur chaque document et les mémoriser en tant que tels dans une
base de données en vue de leur traitement ou leur utilisation
ultérieure.

9

10
Il est vrai qu'une avancée non moins significative a
déjà été réalisée dans le domaine de
la reconnaissance de documents numérisés. C'est à ce titre
que l'on peut trouver actuellement quelques systèmes de reconnaissance
optique de caractères (OCR), de reconnaissance d'écriture
manuscrite, etc. Cependant, il n'en demeure pas moins vrai que, dans la
reconnaissance des tableaux, malgré les travaux qui ont
déjà été effectués, il persiste encore des
zones d'ombre qui empêchent la formalisation et l'objectivation à
la fois théorique et pratique de cet autre sous - domaine de la
reconnaissance de formes.
Ainsi, quoi de plus naturel que d'aborder ce champ
d'application de l'Intelligence Artificiel si intéressant et si utile
qu'est la reconnaissance de tableaux ?
En fait, dans la reconnaissance de tableaux, on bute
d'emblée sur la difficulté à reconnaître la
structure même d'un tableau donné. Cela demeure d'autant plus vrai
que, si pour un être humain c'est facile de dire, du premier coup d'oeil,
que tel tableau possède autant de lignes et autant de colonnes, cela
n'est pas du tout évident pour un ordinateur qui, rappelons - le, n'est
qu'un automate programmable sans capacités réelles de
réflexion propre.
A titre illustratif, prenons le cas d'un secrétaire qui
a la tâche de concevoir et de reproduire des documents administratifs
complexes tels que des documents tabulaires, des formulaires, etc. A supposer
qu'il vient de perdre son ordinateur qui contenait toute sa banque de
données (documents administratifs et autres) et qu'il est dans l'urgence
de concevoir un formulaire administratif vierge qui serait difficile ou presque
impossible à reproduire rapidement parce qu'il se présente sous
forme d'un tableau très complexe. Bien qu'il possède un
exemplaire physique (déjà rempli !) du document, notre
secrétaire se trouvera paralysé devant l'impossibilité de
reproduire ce document dans un bref délai.
Dans une telle situation, le problème de ce
secrétaire consistera donc à savoir :
- Comment reproduire rapidement la structure du tableau sans
avoir à le redessiner manuellement ?
- Comment extraire et conserver cette structure d'un document
physique que l'on possède en vue d'une reproduction diligente et
ultérieure ?
0.2. Hypothèse
En vue d'apporter une réponse aux questions
posées ci - haut, nous nous proposons d'émettre les
considérations hypothétiques suivantes :
- La reproduction rapide de la structure d'un tableau requiert
l'usage d'un système informatique capable de (d') :
o Analyser les caractéristiques structurelles du tableau
à reproduire ;
o Sauvegarder ces caractéristiques en les
transférant dans un format modifiable quelque part en mémoire.
- L'extraction et la conservation de la structure de tableaux
d'un document physique est possible grâce à l'usage d'un
système informatique de reconnaissance de tableaux et qui fonctionne sur
base d'un algorithme implémentant un réseau de neurones
artificiels.
0.3. Objet, choix et Intérêt du
sujet
0.3.1. Objet du sujet
Essentiellement scientifique, notre recherche se penche sur
l'étude d'une méthodologie permettant la caractérisation
et l'extraction informatique de la structure d'un tableau figurant sur l'image
d'un document, et cela, à travers l'implémentation d'un
réseau de neurones. Cela étant, l'objet de notre sujet s'inscrit
dans une recherche purement technologique car il possède comme
soubassement, le développement d'une technique.
0.3.2. Choix et intérêt du sujet
N'étant en aucun cas un fait du hasard, le choix
porté sur notre sujet de recherche est consécutif au constat de
la persistance du problème que posent la réédition et
l'archivage (au format électronique) des documents tabulaires dans les
milieux administratifs. Ainsi avons - nous pensé que notre contribution,
à travers ce travail, apporterait un plus à la modernisation du
traitement et de la conservation des documents administratifs.
En outre, il sied de remarquer que ce sujet de recherche
s'inscrit dans la liste des investigations relatives aux champs d'application
de l'Intelligence Artificielle qui est notre domaine de prédilection,
d'où notre intérêt.
0.4. Etat de la question
A l'heure actuelle, comme l'écrit C. Lukoba
(cité par M. MUKE1), un sujet de recherche est rarement neuf.
D'autres chercheurs l'ont certainement déjà
élaboré, sous certains aspects, dans d'autres milieux. C'est
ainsi qu'il nous a été nécessaire d'effectuer d'abord
une
1 MUKE M., La recherche en science sociales et
humaines : guide pratique, méthodologie et cas concrets,
l'Harmattan, Paris, 2011, p. 147.

11

12

13
recherche exploratoire aux fins de savoir où en est la
question dans le domaine de la reconnaissance des tableaux. C'est dans cette
perspective que nous avons consacré tout le premier chapitre de ce
travail à cette recherche préliminaire.
Par ailleurs, dans le même but de déceler les
aspects qui ont été laissés de côté par les
autres chercheurs afin d'en faire l'objet d'une nouvelle recherche et apporter
ainsi un plus sur la connaissance humaine, nous avons été
amenés à consulter un certain nombre de travaux de fin
d'études réalisés par nos prédécesseurs.
Parmi ces travaux, nous trouvons le mémoire de monsieur
ISHARA2 intitulé «La reconnaissance optique des
données numériques. » En fait, ce travail a attiré
particulièrement notre attention dans la mesure où il traite
aussi de la reconnaissance des tableaux. Et, ainsi que nous l'avons
remarqué, dans son travail, ISHARA s'est limité à
l'extraction des contenus des différentes cellules d'un tableau sans se
préoccuper de la reproduction de la structure de ce tableau.
0.5. Délimitation du sujet
Dans la perspective d'une meilleure perception des
problèmes soulevés et de la traduction des diverses solutions
proposées en actes concrets, nous avons été amenés
à limiter notre champ d'investigation dans le temps et dans l'espace.
Ainsi,
- dans le temps, notre étude s'est effectuée au
courant de l'année académique 2011 - 2012 ;
- dans l'espace, les enceintes de l'Institut Supérieur
Pédagogique ont abrité nos activités de recherche. Cette
institution supérieure se situe en plein milieu de la ville de Bukavu,
à quelques mètres de la grande poste.
Par ailleurs, il convient de signaler que nos recherches se
sont appesanties sur une méthode de caractérisation et
d'extraction de la structure d'un tableau via l'implémentation d'un
réseau de neurones. Au fait, cette méthode pourrait être
intégrée dans des systèmes de reconnaissance des documents
numériques afin d'améliorer leurs performances.
0.6. Démarche de recherche, méthodes et
techniques utilisées
2 Voir la bibliographie à la fin de ce
travail.
Pour la réalisation de ce travail, nous avons
utilisé la démarche hypothético - déductive. En
fait, à la fois empirique, acceptable et
élémentaire3, cette démarche nous a
amené à recourir aux méthodes et techniques suivantes :
s La méthode expérimentale
Usant de cette méthode, nous avons pu émettre
nos hypothèses de recherche avant de les mettre à
l'épreuve par une vérification expérimentale.
s La méthode d'analyse de traces
Faisant appel à la technique d'analyse de contenu,
cette méthode nous a permis de réaliser la revue de la
littérature en reconnaissance des tableaux.
s La méthode comparative
C'est grâce à cette méthode que nous avons
pu comparer les méthodologies utilisées par différents
chercheurs dans le domaine de la reconnaissance des tableaux.
s La méthode d'analyse
systémique
Cette méthode nous a permis de concevoir, de
manière logique et structurée, l'architecture de notre
réseau de neurones, en particulier ainsi que celui de tout le
système de reconnaissance en général.
s La statistique
C'est grâce à cette technique que nous avons pu
analyser et traiter les données quantitatives issues de notre recherche
exploratoire.
0.7. Présentation sommaire du travail
Le présent travail est subdivisé en quatre
chapitres précédés d'une introduction et terminée
par une conclusion générale.
Le premier chapitre présente l'état de la
littérature en reconnaissance de tableaux. Le second chapitre traite du
problème de la reconnaissance des tableaux tel que nous le concevons. Le
troisième chapitre étale la méthodologie adoptée en
présentant, de manière détaillée, l'algorithme du
réseau de neurones ainsi implémenté. Enfin, le
quatrième chapitre
3 MUKE M., La recherche en science sociales et
humaines : guide pratique, méthodologie et cas concrets,
l'Harmattan, Paris, 2011, p. 53.
présente d'abord, de manière
détaillée, l'implémentation de l'algorithme du chapitre
précédent en langage Java et ensuite donne un aperçu des
résultats expérimentaux issus de l'exécution du programme
sur quelques documents tabulaires.
0.8. Difficultés rencontrées
La réalisation de ce travail ne s'est pas
achevée sans connaître quelques embûches, notamment :
- L'instabilité manifeste du courant électrique
qui a considérablement retardé la rédaction de ce travail
;
- La mauvaise foi et la perfidie de certaines personnes qui,
bien que mieux placés à nous aider, ne voulaient pas voir nos
recherches aboutir et ont ainsi refusés de nous rendre certains
services.
- la surcharge de notre horaire qui ne nous a pas
facilité l'élaboration continue et
rapide de ce travail car les recherches se faisaient pendant les
heures de cours.
Pour contrer les difficultés ci - haut citées, nous
avons opté pour les solutions suivantes :
- l'achat d'une batterie neuve pour notre ordinateur portable
avec une autonomie d'au moins 5 heures.
- le recours aux services de personnes de bonne foi et qui
avaient la bonne volonté de nous aider dans l'avancement de notre
travail.
- La réalisation des nos activités de recherche
pendant les heures libres, voire même, tardives, nous privant ainsi du
sommeil.

14
CHAPITRE I. ETAT DE L'ART EN RECONNAISSANCE DES
TABLEAUX
1.1. Objectifs
Dans ce chapitre, nous nous proposons d'étaler les
différents points de vue existant dans le domaine de la reconnaissance
de tableaux. Pour ce faire, nous commencerons d'abord par donner une
idée claire des différents types de reconnaissance de tableaux
déjà réalisés, ensuite, nous identifierons les
méthodes, algorithmes et techniques utilisés par
différents chercheurs en vue d'obtenir les meilleurs résultats.
Enfin, nous jetterons un regard analytique sur les résultats obtenus par
ces chercheurs, les difficultés qu'ils ont rencontrées afin de
relever les zones d'ombre qui persistent encore en reconnaissance de
tableaux.
1.2. Aperçu succinct de la littérature en
reconnaissance des tableaux
Cela fera bientôt plus de deux décennies que la
littérature en reconnaissance de tableau abonde et regorge les travaux
d'éminents chercheurs dans ce domaine. Il est évident que des
progrès considérables ont été
réalisés par bon nombre d'auteurs. Cependant, comme nous allons
le remarquer plus bas, malgré les efforts de conceptualisation
déjà fournis sur le plan théorique, l'aspect pratique de
la reconnaissance de tableaux laisse entrevoir encore beaucoup de zones d'ombre
car ce domaine de l'intelligence artificielle demeure encore un puzzle complexe
à résoudre jusqu'à nos jours. C'est ce qui explique, entre
autres conséquences, l'absence ou la rareté des logiciels
spécialisés dans la reconnaissance de tableaux.
1.2.1. Types de reconnaissance de tableaux
Les nombreuses tentatives de reconnaissance de tableaux
laissent entrevoir différentes considérations du problème
par les chercheurs selon le point de vue de chacun. Au fait, lorsque l'on
considère l'image du document portant le tableau à
reconnaître, on s'aperçoit qu'il peut être constitué,
non seulement des tableaux, mais aussi d'autres objets tels que des images, du
texte, des graphiques, etc. De plus le document devient encore plus complexe
lorsque les objets précités font partie intégrante du
contenu du tableau à détecter.
Ainsi, Laurentini et Viada4 considèrent que
l'identification d'un tableau dans un document complexe contenant du texte,
des dessins, des diagrammes, etc. revient à comprendre le
4 Laurentini A. et Viada P., «Identifying
and Understanding Tabular material in compound Documents» in
IEEE, Torino, 1992, pp 405-409.

15
contenu de ce tableau d'abord avant d'identifier ce dernier en
vue de le convertir au format électronique. Plus bas, nous faisons un
bref aperçu de la méthodologie proposée par les deux
auteurs précités pour y parvenir.
Pereira et ses collaborateurs5, quant à eux,
s'intéressent à l'extraction des cellules des formulaires -
tableaux se trouvant dans un état détérioré
(c'est-à-dire dont les lignes ne sont plus toutes visibles et qui
présentent des imperfections liées à l'angle
d'inclinaison). Par la suite, ils estiment que la reconnaissance de tels
tableaux passe par plusieurs phases de correction d'erreurs.
A l'issue de leur enquête sur les recherches
déjà effectuées dans le domaine de la reconnaissance de
tableaux, Zanibbi et ses collaborateurs6 trouvent que le
problème de la reconnaissance de tableaux peut être
envisagé de deux manières différentes, à savoir :
la détermination de leurs structures physiques et la
détermination de leurs structures logiques. C'est ainsi qu'ils
distinguent la reconnaissance de tableau en détection de tableau et en
reconnaissance de la structure du tableau. Afin de concilier les diverses
approches qu'ils avaient rencontrés en reconnaissance de tableaux,
Zanibbi et ses collaborateurs proposent un procédé de
reconnaissance de tableaux faisant la synthèse de tous les autres.
Pour Shin et Guerette7, l'extraction des
informations sur les structures des tableaux dans un document constitue
une étape primordiale dans le processus de reconnaissance de tableaux.
Ces deux auteurs estiment donc que la détection des lignes
verticales et horizontales entre les blocs de texte permettrait
l'identification complète du tableau. Ils proposent ainsi une
méthodologie basée sur la « croissance des régions
» afin de localiser les « boîtes limitatrices » autour du
texte dans le document contenant le tableau à reconnaître.
A leur tour, Kawanaka et ses collaborateurs8
s'intéressent à l'extraction de la structure de tableaux à
l'aide d'un modèle de document. Ils ajoutent aussi la possibilité
d'exporter les informations extraites du document vers le format XML
(génération d'un document XML). Comme nous allons le remarquer
dans la suite, la méthode qu'ils proposent s'avère être
basée sur une connaissance à priori du tableau à
reconnaître.
5 Pereira L. et al., Recognition of deteriorated
Table-form Documents: A New Approach, UFCG, Brazil, 2000, p 1.
6 Zanibbi R. et al., A Survey of Table
Recognition: Models, Observations, Transformations and Inferences, SC,
Queen's University, Ontario, 2003, pp 5-33.
7 Shin J. et Guerette N., «Table Recognition
and Evaluation» in Proceedings of the class of 2005 Senior
Conference, DCSSC, Swarthmore, 2005, pp 8-13.
8 Kawanaka H. et al., Document Recognition and
XML Generation of Tabular Form Discharge summaries for Analogous case Search
System in Methods of Inf med 6, Mie University, Mie, 2007, pp
700-708.

16
Dans une « approche ouverte vers l'analyse comparative
des systèmes de reconnaissance de structure de tableaux »,
Shahab9, Shafait, Kieninger et Dengel, quant à eux, pensent
qu'une analyse comparative des différentes approches jusque là
réalisées en reconnaissance des tableaux est nécessaire
pour résoudre le problème de reconnaissance de la structure des
tableaux ainsi que leur reconstitution.
Chen et Lopresti10 s'intéressent à la
détection des tableaux dans les documents manuscrits non lignés
et contenant beaucoup de bruits. Ainsi posent-ils le problème
d'identification des régions d'un tableau dans un document manuscrit.
Et, pour résoudre ce problème, ils proposent un algorithme
utilisant les classificateurs SVM11 et la programmation
dynamique.
1.2.2. Méthodologies, algorithmes et techniques
utilisés
Dans le domaine de la reconnaissance de tableaux, nombreuses
méthodes ont été proposées par différents
auteurs selon le type de reconnaissance à réaliser. Parmi ces
multiples approches, nous avons retenu quelques unes qui nous ont
semblés plus pertinents et qui ont produit des résultats plus ou
moins fiables.
a. L'approche proposée par Laurentini et Viada12
Cette approche consiste en l'utilisation d'un algorithme
s'articulant sur des procédures de compréhension et
d'identification d'un tableau en vue de la construction d'un « tableau
idéal ». La phase de compréhension de l'algorithme
se résume à détecter les blocs de texte arrangés
dans des modèles réguliers horizontaux et verticaux. La phase
d'identification, elle, consiste à identifier les lignes
horizontales et verticales en comparant leurs positions relatives.
Plus concrètement, les grandes lignes de cet algorithme
s'énoncent dans les étapes suivantes :
· Lire l'image du document scanné ;
· Calculer les composants connectés de l'image ;
9 Shahab A. et al., An open approach towards
the benchmarking of table structure recognition systems, Kaiserslautern,
2010, p.1
10 Chen J. et Lopresti D., «Table
Detection in Noisy Off-Line Handwritten Documents» in IEEE,
University Bethlehem, 2011, pp 399-403.
11 Support Vector Machine ou `'Machine à
Vecteur Support»
12 Op. cit.
·

17
Calculer l'histogramme de taille des boîtes de
contour pour tous les composants noirs de l'image ;
· Trouver la zone la plus peuplée dans
cet histogramme, Amp étant le nombre de composants dans cette
zone ;
· Calculer la moyenne de l'histogramme et
laisser Aavg être le nombre de composants ayant cette taille
moyenne ;
· Fixer un seuil pour la taille des boîtes
de contour (ou boîtes d'encadrement), S1=n X max (Amp, Aavg)
;
· Fixer un seuil pour la longueur maximum des
boîtes de contour, S2 ;
· Filtrer les composants noirs connectés,
en ajoutant à la zone de texte tous ceux ayant
une surface inférieure à S1, un ratio
na gear dans l'intervalle[ , S2], les
autres
largeur
composants étant ajoutés à la zone
de graphiques ;
· Trouver les lignes verticales et horizontales
:
o Fixer un seuil de densité S3=dimension moyenne
des caractères ;
o Initialiser I à 0 ; (avec I : intervalle entre
pixels noirs)
o Parcourir l'image horizontalement et verticalement
tout en tenant compte de
la condition suivante :
Si I<S3 alors
Lire pixels noirs de l'image ;
Calculer I=intervalle entre pixels noirs du parcours
;
FinSi
o Fusionner les parcours suffisamment proches l'un de
l'autre pour obtenir des lignes horizontales et verticales.
· Fusionner en mots
tous les caractères colinéaires satisfaisant des
conditions géométriques adéquates ;
· Fusionner ensuite les mots en
phrases ;
· Identifier une zone rectangulaire contenant
des lignes droites susceptibles d'appartenir à un tableau (au moins une
ligne horizontale et une ligne verticale sont requises) ;
· Fixer le seuil de connexion S4 ;
· Connecter les lignes trouvées en
fonction du seuil S4 ;
·

18
Effectuer quelques ajustements dur les lignes pendantes et celles
dont les bouts sont proches d'autres lignes ;
· Eliminer les zones n'appartenant pas au tableau en
effectuant un test qui consiste en la comparaison des distances entre deux
lignes horizontales adjacents, avec un intervalle de distance interdite
relative à la hauteur du caractère ;
· Comparer l'arrangement de lignes
précédemment déterminé avec celui des blocs de
texte identifiés dans la même zone en vérifiant leur
compatibilité ;
· Vérifier le périmètre du tableau et
de chaque cellule ;
· Considérer les profils de projections horizontales
et verticales des blocs de texte ;
· Si les blocs de texte ne sont pas arrangés suivant
un modèle régulier, alors la construction du tableau
échoue ;
· Sinon, ajouter des lignes droites horizontales et
verticales pour construire le tableau idéal en considérant les
profils de projection et les courtes lignes droites possibles dans les
interstices de profil ;
· Lire et envoyer au programme OCR, les informations
relatives à la dimension et à la position de chaque cellule du
tableau pour la reconnaissance du texte.
b. La méthodologie proposée par Pereira
13
Utilisant une petite connaissance à priori sur les
tableaux, l'approche proposée consiste en un algorithme s'articulant sur
plusieurs phases de détection et de correction d'erreurs. Ci -
après, les grandes lignes de cet algorithme :
Phase I : Acquisition du formulaire - tableau et seuillage
:
· acquisition de l'image à 300X300 pixels de
résolution ;
· conversion de l'image en niveau de gris ;
· binarisation de l'image et seuillage.
Phase II : Détection et correction de l'angle
d'inclinaison du formulaire - tableau :
· détection de l'angle d'inclinaison par la
transformée de Hough14 ;
· correction d'angle d'inclinaison par rotation unique avec
interpolation bilinéaire.
Phase III : Localisation et identification de l'angle
d'intersection :
13 Op. cit.
14 Voir l'algorithme de la transformation de Hough en
Annexes
·

19
Chaque type de coin est représenté par un
élément de structuration ;
· L'opération d'érosion produit des images
ne contenant que les points des coins correspondant à
l'élément de structuration utilisé. Tous les coins
reconnus sont enregistrés dans un « tableau réel ».
Phase IV : Détection systématique d'erreurs
:
· Analyse du « tableau réel » ;
· Chaque intersection est comparée aux
intersections voisines en utilisant les tables de rejet ;
· Lorsqu'une fausse intersection est localisée
dans le tableau réel, le compteur qui a pour rôle respectif dans
le tableau d'erreurs sera incrémenté de 1.
Phase V : Analyse et correction récursives d'erreurs
:
· La correction est effectuée avec le compteur
d'erreurs le plus élevé dans le tableau d'erreurs ;
· Le voisinage d'erreurs est analysé par
vérification de ses points - finaux dans le tableau d'erreurs ;
· Des tableaux de points - finaux sont
créés pour les directions Nord, Sud, Est et Ouest.
Phase VI : Extraction des cellules du formulaire - tableau
:
· Pour des voisins dont les points finaux sont
dirigés vers une erreur d'intersection, la solution de correction
d'intersections est évaluée.
Phase VII : Identification de la structure
hiérarchique.
c. Le procédé prôné par Zanibbi
15
Après analyse des diverses approches utilisées
jusqu'alors en reconnaissance de tableaux, Zanibbi et ses collaborateurs
remarquent que ces différentes méthodes peuvent se regrouper en
un seul procédé facilement intelligible. Et ce
procédé, ajoutent - ils, s'articule sur trois concepts
essentiels, à savoir : les observations, les
transformations et les inférences. En fait, ces
auteurs nous montrent que ces trois concepts sont indispensables à tout
processus de reconnaissance de tableau. Dans un schéma clair et
précis, ils présentent ainsi les trois concepts comme parties
intégrantes de tout le procédé de reconnaissance,
procédé
15 Op. cit.

20
basé sur une connaissance à priori : le
modèle de tableau à reconnaître. Avant d'expliciter les
différentes étapes de ce procédé, nous
présentons ci-dessous le schéma proposé par ces
chercheurs.
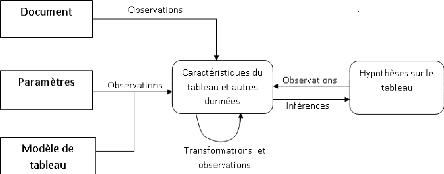
Fig. 1. Le procédé de reconnaissance de
tableaux selon Zanibbi et ses collaborateurs.
> Le Document :
D'après le schéma ci-dessus, un
système de reconnaissance de tableaux possède toujours un
document d'entrée qui fournit les données de base pour la
reconnaissance. Ce document peut représenter soit une image du tableau
à reconnaître (provenant d'un capteur tel qu'un
scanneur), soit des données tabulaires au format texte (un
fichier texte). Dans tous les cas, le document d'entrée contient
toujours des informations à analyser par le système de
reconnaissance.
> Les paramètres :
Afin que la reconnaissance s'exécute
correctement, il est souvent nécessaire de fournir au système un
certain nombre de valeurs pouvant l'aider à réaliser les
différentes opérations de reconnaissance. Ces valeurs portent le
nom de « paramètres » et peuvent être :
· Statiques : lorsqu'elles sont définies
au départ et restent inchangées tout au long du processus de
reconnaissance (c'est le cas des constantes tels que la hauteur et la largeur
de l'image d'entrée);
· Adaptatives : lorsqu'elles varient tout au
long du processus en fonction des différentes
étapes de la reconnaissance (c'est le cas des différents seuils
de niveau de couleur qui peuvent varier au niveau des différentes
étapes de traitement).

21
> Le Modèle de tableau :
Le processus de reconnaissance doit se dérouler
suivant un certain nombre de règles et de faits décrivant les
caractéristiques du tableau à reconnaître. Ces
caractéristiques peuvent provenir d'un modèle de tableau
bien défini ou bien d'un certain nombre de
propriétés communes à tous les tableaux en
général. Par ailleurs, les paramètres fournis au
début du processus peuvent permettre de préciser le modèle
de tableau sur lequel sera basée la reconnaissance.
> Les observations :
Intervenant à chaque étape du
procédé de reconnaissance, les observations permettent la
circulation de l'information au sein de tout le système. En fait, les
observations permettent d'acquérir les données provenant :
- du document d'entrée : mesure des
caractéristiques du tableau à reconnaître, obtention
d'autres informations concernant le document, etc.;
- des paramètres du système :
acquisition des données précises sur base desquelles devra se
dérouler le processus de reconnaissance, telles que le seuillage, les
périodicités, les tolérances, etc. ;
- du modèle de tableau : obtention des
données sur le type de tableau à reconnaître sur base des
paramètres du système (acquisition des caractéristiques -
type en fonction desquelles se déroulera l'analyse du tableau
d'entrée) ;
- d'autres observations : utilisation des
résultats d'observations précédentes sous forme de
données statistiques, des probabilités, des combinaisons
d'observations et des comparaisons.
- des hypothèses sur le tableau :
considération des suppositions ou énoncés de départ
en vue de faciliter la prise de décision concernant le tableau à
reconnaître.
> Les transformations :
Au coeur de tout le processus de reconnaissance de tableau se
trouve toute une série de transformations effectuées par le
système en fonction des observations faites. Ces transformations ne sont
rien d'autre qu'une combinaison de deux ou plusieurs opérations
destinées à modifier les valeurs des résultats d'une
observation ou d'un ensemble d'observations en vue de mettre en évidence
les caractéristiques d'un ensemble de données

22
ou de prendre une décision finale sur le tableau
à reconnaître. Selon le type de données auxquelles elles
s'appliquent, nous pouvons trouver plusieurs types de transformations, à
savoir :
· Pour les données physiques (image d'un tableau ou
fichier texte contenant des données tabulaires) :
o La transformation de Hough : qui est
utilisée pour l'estimation des paramètres des formes
géométriques. Elle est surtout utilisée dans la
détection des lignes et d'angle d'inclinaison dans une image de tableau
;
o Les transformations affines : dont les plus
utilisées sont la rotation, le découpage (ou rognage), la
translation et l'homothétie. Ces transformations sont utilisées
soit pour corriger l'angle d'inclinaison de l'image, soit pour réduire
sa taille (ou ses dimensions) ;
o Les prétraitements : qui incluent la
compression, la binarisation, le prélèvement d'une partie de
l'image, etc.
· Pour les données décrivant la structure
et/ou le contenu du tableau (structure logique) :
o Les transformations par arbres : qui sont
utilisées pour corriger les erreurs de structure, soit pour regrouper
les régions individuelles en une région de tableau ;
o Les transformations par graphes : qui sont
utilisées soit pour regrouper les régions individuelles en une
région de tableau, soit pour corriger les erreurs de structure ;
o Les transformations par filtres : utilisées
soit pour la réduction du bruit dans l'image, soit pour l'extraction des
textures, ou des niveaux de couleurs dans l'image ;
o La reconstruction des formes à partir d'une
liste de points : qui est employée pour relier les intersections de
lignes dans un tableau ;
o L'ordonnancement et l'indexation d'objets :
servant à réarranger les contenus des différentes cellules
d'un tableau ;
o La conversion : qui est utilisée pour
changer les représentations du tableau (par exemple du format HTML vers
le format texte) ;
·

23
Pour les données statistiques :
o Le lissage et le seuillage des histogrammes de
projections : c'est la transformation qui permet, en appliquant le
seuillage, de réduire la variance dans la localisation des lignes de
texte et des séparateurs lors des différentes projections
(horizontales et/ou verticales).
> Les inférences :
Dans un système de reconnaissance de tableau, les
inférences constituent l'aboutissement et le but même du processus
de reconnaissance. En effet, les inférences prennent en compte les
résultats des observations et des transformations effectuées sur
le document d'entrée pour les confronter avec les hypothèses
existants avant d'émettre une décision de reconnaissance ou de
non reconnaissance du tableau. En d'autres termes, les inférences
effectuent une certaine comparaison entre les caractéristiques
prédéfinies du modèle de tableau et les données
issues des observations et des transformations avant de générer
des tests d'hypothèses auxquels seront soumis ensuite les
résultats de cette comparaison.
Après une profonde analyse des différentes
techniques utilisées jusqu'alors, Zanibbi et ses collaborateurs sont
parvenus à synthétiser les techniques d'inférence en trois
grands groupes, notamment : les classificateurs, les segmenteurs et les
parseurs (ou analyseurs).
o Les classificateurs : ce sont des techniques qui
permettent d'affecter les types de structure et les types de relation d'un
modèle de tableau à un ensemble de données. Les
classificateurs utilisés en reconnaissance de tableaux incluent :
· Les arbres de décision : par
exemple, la classification d'un ensemble de caractéristiques en
caractéristiques d'une colonne par seuillage, etc. ;
· Les plus proches voisins : par
exemple, la méthode des k plus proches voisins (kNN) pour
déterminer l'appartenance à une région d'un tableau, etc.
;
· Les réseaux de neurones ;
·

24
Les méthodes syntaxiques : par
exemple, l'affectation des types aux lignes de texte d'un tableau, la
classification des rôles des mots dans des tableaux de contenus, etc.;
· Les méthodes statistiques :
par exemple, les classificateurs bayésiens, les réseaux
bayésiens, etc.
o Les segmenteurs : ce sont des techniques
d'inférence qui permettent de localiser les structures du modèle
de tableau dans une image. Ils utilisent un classificateur binaire et une
fonction de recherche pour localiser les composants du modèle de
tableau. Les régions cibles trouvées par le classificateur et qui
satisfont la fonction objective de la recherche sont regroupés ou
partitionnés à l'intérieur de l'ensemble de
données. Selon que les données sont groupées ou
partitionnées, Zanibbi et ses collaborateurs distinguent deux grandes
familles de segmenteurs :
· Les segmenteurs de regroupement : parmi lesquels nous
retrouvons : le regroupement hiérarchique des régions par
distance, la fermeture transitive, etc. ;
· Les segmenteurs de partitionnement : citons, la
détection de tableau utilisant la programmation
dynamique, l'algorithme du simplex, etc.
o Les parseurs (ou analyseurs) : ce sont des
techniques d'inférence utilisés pour produire des graphes de
structure relatifs à la syntaxe du tableau en fonction de celle
définie dans le modèle de tableau. Ces graphes décrivent
donc la structure logique des composants du modèle de tableau. Selon le
type de grammaire utilisé pour l'encodage de la syntaxe de la structure
logique, Zanibbi et ses collaborateurs distinguent les types de parseurs
suivants :
· Les modèles de Markov cachés
: par exemple, la maximisation des probabilités d'adjacence des
régions dans un tableau, etc. ;
· Les graphes de grammaire : par
exemple, une méthode d'induction de grammaire pour les contenus des
tableaux à partir de données étiquetées, des
méthodes adaptatives pour définir des expressions

25
régulières décrivant les types de
données des contenus de cellules,
etc.
d. La méthodologie de Shin et Guerette16
Focalisant leur attention sur des tableaux au contenu
textuel, Shin et Guerette pensent que la localisation des blocs de texte
contenus dans les cellules, le regroupement de ces blocs dans des colonnes
ainsi que l'examen des relations spatiales entre ces colonnes permettrait la
reconnaissance facile des tableaux. Ils proposent ainsi une approche consistant
en deux étapes successives, à savoir : la recherche des zones (ou
blocs) de texte et l'identification du tableau.
· La recherche des zones de texte :
Pour trouver les boîtes délimitant les textes du
tableau en zones, ces deux auteurs proposent l'utilisation de la méthode
de « croissance de région », dont les grandes lignes de
l'algorithme s'énoncent comme suit :
· Lire l'image d'entrée en niveau de gris ;
· Déterminer un seuil d'intensité en
utilisant une adaptation de l'algorithme de regroupement ISODATA17
;
· Utiliser le seuil ainsi obtenu pour binariser l'image
(une intensité pour le fond et un autre pour le texte) ;
· Créer un histogramme des longueurs de bandes
horizontales de pixels d'arrière-plan entre des pixels de texte ;
· Trouver la longueur la plus commune ;
· Examiner et compter les longueurs de plus en plus
longues de l'histogramme, au-delà de la longueur la plus commune ;
· Si le nombre de la première longueur d'espaces
blancs est inférieure à la moitié du nombre de la longueur
d'espace blanc la plus commune ;
· Alors choisir ce nombre comme montant de dilatation
;
· Dilater horizontalement toutes les lettres afin que
tous les caractères soient connectés dans la plupart de mots ;
c'est à dire, marquer les nombreux pixels à
16 Op. cit.
17 Voir le pseudo code de l'algorithme ISODATA en
Annexe.

26
droite de chaque pixel de texte de l'image original comme
étant aussi des pixels de texte ;
· Appliquer l'algorithme de croissance de
région18 pour placer des boîtes limitatrices autour de
chaque région de pixels de texte liée (le bord le plus à
droite de la boîte limitatrice étant ajustée à
gauche par le montant avec lequel les pixels de texte ont été
dilatés plus tôt, de sorte que les boîtes limitatrices
soient autour du texte original et non le texte dilaté) ;
N.B : Lorsque l'image contient un tableau avec un contour, il
en résulte une zone de délimitation qui entoure le tableau en
plus d'un cadre de délimitation pour chaque mot dans le tableau.
· Détecter cette boîte extérieure en
marquant tous les cadres de délimitation dont la hauteur est
supérieure à la hauteur moyenne de toutes les boîtes
limitatrices, et en les testant afin de déterminer si oui ou non elles
contiennent des petites boîtes limitatrices ;
· Garder une trace de toutes ces "grandes" boîtes
limitatrices et les petites boîtes limitatrices qu'ils contiennent, car
ils sont susceptibles de former un tableau.
· L'identification de tableaux
Après l'avoir implémenté pour
l'identification de tableaux, Shin et Guerette remarquent que l'algorithme de
Kieninger19 présente quelques insuffisances. Ils en proposent
ainsi une version modifiée dont les grandes lignes sont les suivantes
:
· Lire la liste des boîtes limitatrices qui ne sont
pas de « grandes » boîtes limitatrices ;
· Prendre la première boîte de la liste
comme boîte-échantillon et la bouger de haut en bas selon sa
hauteur pour vérifier si aucune boîte de la liste dépasse
la région définie par la boîte - échantillon ;
· Si la hauteur de la boîte - échantillons
est inférieure à la moyenne des hauteurs des boîtes
limitatrices, alors égaliser les deux auteurs ;
18 Voir l'Algorithme de croissance de région
en Annexe
19 Kieninger T. V., «Table Structure
Recognition Based on Robust Block Segmentation» in Proceedings of
Document Recognition, volume V., San Jose, CA, 1998, pp 22-32.
·

27
Si la boîte - échantillon possède au
maximum une boîte limitatrice qui le dépasse en haut et une autre
qui le dépasse en bas, et que les boîtes du dessus et celles d'en
bas ne sont pas alignées horizontalement, alors
· Placer ces boîtes dans le même groupe que
la boîte - échantillon et augmenter la taille verticale de cette
dernière afin de trouver d'autres boîtes susceptibles d'être
liées ;
· Répéter l'étape
précédente jusqu'à ce que le programme ne trouve plus de
boîtes à ajouter au groupe (ici, la boîte -
échantillon dont la taille a été augmentée) ;
· Répéter la procédure ci - dessus
sur d'autres boîtes limitatrices considérées comme non
encore examinées jusqu'à ce que toutes les boîtes
limitatrices soient groupées ou trouvées comme n'appartenant
à aucun groupe ;
N.B : Les groupes ainsi constituées représenteront
les colonnes du tableau.
· Marquer les boîtes ainsi groupées comme
étant de Type1 et les autres comme étant de
Type2.
· Pour chaque boîte limitatrice de Type2, calculer
la distance entre elle et ses voisines horizontales ;
· Calculer le seuil pour la distance horizontale entre
les boîtes limitatrices en utilisant le même algorithme
utilisé plus tôt pour calculer le montant à partir duquel
il fallait dilater les pixels de texte, à la seule exception qu'ici on
examine la distance entre les boîtes limitatrices au lieu des barres
horizontales ;
· Si la distance est inférieure au seuil, la
boîte - échantillon et ses voisines concernées sont
réunies en une seule boîte, et la distance entre la nouvelle
grande boîte et ses voisines concernées est calculée pour
déterminer si d'autres boîtes peuvent être unies à
elle ou non ;
· Répéter la procédure
précédente jusqu'à ce que toutes les boîtes
limitatrices soient examinées réunies si nécessaire ;
· Après avoir terminé la jointure
horizontale, appliquer le même algorithme utilisé pour trouver les
groupes de Type1 sur le nouvel ensemble de boîtes limitatrices.
· Comparer tous les groupes de Type1 finalement
trouvés ;
· Marquer tout groupe contenant des boîtes
limitatrices alignées verticalement comme appartenant à un
tableau.

28
e. Les méthodes proposées par Kawanaka
20
Consacrant leurs recherches à la résolution
d'un cas concret observé à l'hôpital de l'Université
de Mie21, Kawanaka et son équipe se sont posés la
question de savoir « comment automatiser la recherche des cas analogues de
traitement de maladies à partir des fiches des patients ayant
déjà été soignés dans cet hôpital ? ))
La réponse à cette question a amené les auteurs à
décomposer le problème général en trois sous -
problèmes, à savoir :
· La reconnaissance des documents (ici, les fiches -
formulaires des patients ayant déjà subi un traitement
quelconque) ;
· L'extraction des mots-clés et
· La génération automatique des
résultats au format XML
Pour résoudre ces problèmes, Kawanaka et son
équipe proposent ainsi une méthodologie basée sur une
connaissance à priori du document principal que le système
prendra pour « modèle de document à reconnaître)).
L'essentiel de cette méthodologie s'articule sur les étapes
suivantes :
· Obtention des images des documents (les fiches -
formulaires des patients) via un capteur (scanneur) avec une résolution
de 300 dpi ;
· Réduction des bruits et inclinaisons de l'image
par prétraitement ;
· Identification des structures du tableau ;
· Reconnaissance et conversion des caractères du
tableau en données textuelles par le moteur OCR ;
· Génération des documents XML à
partir des résultats obtenus.
Ci-après, la schématisation du système
implémentant la méthodologie proposée :
20 Op. cit.
21 Une ville du Japon.


29
Fig. 2. Schéma du système de
recherche des cas analogues selon Kawanaka
f. L'approche proposée par Chen et Lopresti22
Soulignant l'importance de la détection de tableaux
dans un document manuscrit non ligné et contenant toutes sortes de
bruits, Chen et Lopresti proposent une méthodologie en quatre
étapes permettant de résoudre ce problème. Il s'agit de
:
· L'étape du prétraitement : Cette
étape comprend :
o L'élimination des ombres sur les bordures de la
page : marche à suivre :
· Appliquer la transformation en distance à l'image
d'entrée ;
22 Op. cit.
·

30
Comme dans l'image transformée les régions
ombragées possèdent habituellement des valeurs de distance
très élevées, binariser la page en des demis-noyaux
résiduels en utilisant un seuil ;
· à partir de ces noyaux, mesurer l'augmentation
du nombre de pixels à chaque itération, tout en diminuant le
seuil ;
· à partir d'une augmentation soudaine de ce
nombre, estimer le seuil qui exclura mieux les ombres de bordure.
o La détection de lignes dominantes (se chevauchant
souvent avec l'écriture) : marche à suivre :
· Estimer l'inclinaison de la page en calculant la
moyenne des inclinaisons des lignes horizontales si elles sont présentes
sur la page ;
· A l'aide de la classique transformation de Hough,
projeter chaque point sur un ensemble des points de courbe sinusoïdale
dans le plan (ñ,è) (l'espace de Hough) ;
· Dans chaque itération, sélectionner un
point au hasard du reste de l'ensemble de points, calculer sa courbe
sinusoïdale dans l'espace de Hough et mettre à jour la matrice
d'accumulation ;
· Si le seuil est dépassé alors rechercher
dans chaque direction, à partir de la position courante, les points
d'extrémité du segment de ligne. N.B : comme les lignes
dominantes peuvent être dégradées, les petites lacunes
(jusqu'à 15 pixels) sont tolérées ;
· Dès que la recherche s'arrête, enregistrer
les coordonnées des points d'extrémité du segment de
ligne, exclure les points correspondants de la matrice d'accumulation et
procéder avec l'itération suivante.
· L'étape de classification de texte : Elle comprend
:
o La division de la page en des petits carreaux de même
taille ;
o L'extraction des caractéristiques des carreaux en vue
de leur classification par la Machine à Vecteur Support (SVM) :
· L'extraction des caractéristiques :
· Utiliser les caractéristiques structurelles comme
le Gradient de Concavité Structurel (GSC) pour capturer les
caractéristiques

31
de forme telles que les boucles, les points de
ramification, les
points de terminaison et les points.
N.B : Ces caractéristiques de multi
résolution combinent trois attributs de forme de texte différents
:
- les gradients qui représentent l'orientation
locale des traits ;
- l'information structurelle qui étend le
gradient à des distances plus élevées et qui fournit
l'information à propos des trajectoires de traits ;
- les concavités qui capturent les relations
entre traits à des distances plus élevées.
n La classification des textes : utiliser
l'outil libSVM23 pour classifier les carreaux contenant du texte et
ceux n'en contenant pas.
n L'étape de détection de tableau :
Après avoir identifié les carreaux de texte a travers la
classification SVM, procéder comme suit :
o Utiliser les projections horizontales de profils
afin de repérer les lignes de texte formant probablement les
rangées du tableau.
o Estimer la hauteur H de lignes de texte en
examinant la séquence des pics dans la projection horizontale de
profils.
o Utiliser H pour fixer les limites de chaque ligne
de texte.
o Exclure les lignes candidates insignifiantes
contenant moins de 5 carreaux de texte.
o Appliquer l'algorithme de programmation dynamique
(proposé par Hu24) adapté25 et
décrivant une manière optimale de décomposer une page
entière en un certain nombre de tableaux présentant une
similarité de mesure entre les rangées individuelles. En langage
mathématique, cet algorithme qui permet de détecter les tableaux
du document, présente les grandes lignes (équations) suivantes
:
meritpre(i, [i + 1, j]) = ~x eY(xli_,) X
Incorr(i, k) ; (1)
23 LibSVM désigne un
package contenant l'implémentation des Machines à Vecteur
Support.
24 Hu J. et al., «Medium
Independant Table Detection», in Document Recognition and Retrieval
VIII(IS&T/SPIE Electronic Imaging, 2001, pp. 44 - 55.
25 Au fait, l'algorithme a
été légèrement modifié par Jin Chen et
Daniel Lopresti afin de permettre le calcul correct et sans erreur de la
corrélation entre les rangées d'un tableau.

32
meritapp([i, j - 1], j) = E k-ti er(ili-k)
x Incorr(k,j) ; (2)
meritpre(i, [i + 1,j]) + tab[i + 1,
j]
tab[i, j] = max (3)
tab[i, j - 1] +
meritapp([i, j - 1], j)
avec 1 <_ i < j <_ n ;
tab[i,i] = 0 1 <_ i <_ n ; (4)
tab[i, j]
score[i, j] = max =
(5)
ma5.>,?+@score[i, k] + score[k + 1, j]A
avec 1 <_ i < j <_ n ;
score[i, i] = tab[i, i] 1 <_ i <_ n ;
(6)
Les équations ci-dessus signifient successivement :
(1) : Le mérite de joindre la ligne i au
tableau s'étendant de la ligne i+1 à la ligne j. Ce mérite
se calcule par la sommation de la décroissance des corrélations
internes des espaces entre deux lignes de texte ou deux carreaux de texte
(Incorr(i, k)).
(2) : Le mérite d'ajouter la ligne j au
tableau s'étendant de la ligne i à la ligne j - 1. Ce
mérite se calcule aussi par la sommation de la décroissance des
corrélations internes des espaces entre deux lignes de texte ou deux
carreaux de texte (Incorr(k, j)).
(3) : Le score obtenu en interprétant les
rangées i à j comme faisant partie d'un même tableau. Ce
score est calculé soit en joignant la première rangée
Row[i] commencement de tab [i +1,j], soit en ajoutant la dernière
rangée Row[j] à la fin de tab[i ,j - 1] ;
(4) : La condition de limitation ;
(5) : Le meilleur moyen d'interpréter les
lignes i à j comme constituant un certain nombre de tableaux. En fait,
cette équation exprime la décomposition de la page en un certain
nombre de tableau.
(6) : La condition de limitation.
1.2.3. Analyse et interprétation des
données
Dans cette section, nous présentons et
analysons les données qui ont constitué la toile de fond de nos
recherches avant de donner notre interprétation des résultats. Vu
l'impossibilité

33
d'accéder à tous les documents écrits
traitant sur la reconnaissance de tableaux, nous avons centré nos
investigations sur un échantillon de 8 documents écrits par
d'éminents chercheurs qui ont consacré leurs efforts à
examiner les méthodes et approches susceptibles de rendre les
systèmes de reconnaissance de tableaux beaucoup plus efficaces et plus
performants.
a) Encodage de données
En vue de faciliter leur traitement, nous nous sommes
proposé de coder les données de la manière suivante :
· Les auteurs :
A1 : A. Laurentini et P. Viada
A2 : Luiz Antonio Pereira et al.
A3 : R. Zanibbi et al.
A4 : Jiwon Shin et Nick Guerette
A5 : H. Kawanaka et al.
A6 : Jin Chen et Daniel Lopresti
A7 : Jianying Hu et al.
A8 : Yalin Wang et al.
· Les méthodologies, approches et techniques
utilisées :
M1 : Les approches structurales et statistiques.
M2 : Détection des blocs de texte et identification des
lignes horizontales et verticales
M3 : Détection des coins (ou lignes d'intersection) du
tableau et extraction des cellules du tableau.
M4 : Détection des zones de texte du tableau au moyen de
l'algorithme ISODATA et l'algorithme de croissance de régions.
M5 : Identification de la structure du tableau à partir
d'un modèle et génération des documents XML.
M6 : Détection de tableau en utilisant la
transformation de Hough, les classificateurs SVM et la programmation
dynamique.
M7 : Détection de tableau en utilisant la programmation
dynamique.
M8 : Détection de tableau par optimisation
probabilistique.

34
M9 : L'approche neuronale.
· Le système de pointage
1 : cité ou utilisé par l'auteur
0 : ni cité, ni utilisé par l'auteur
· Les indicateurs
X : La fréquence d'occurrences globales (de toutes les
méthodes)
Xi : La fréquence d'occurrences individuelles (propre
à chaque méthode) n : La taille de l'échantillon (n=8)
? CD
E
DF$
5 : La moyenne des fréquences. 5
= G
s : L'écart - type de l'échantillon
ôJ : L'écart - type de la
distribution d'échantillonnage des moyennes.
x 100
x : L'écart entre un Xi et la moyenne
5
CD
p : la fréquence relative d'un Xi par rapport à n.
p = G
CD
P : la fréquence relative en pourcentage ;
c'est-à-dire P = G
b) Analyse des méthodes et techniques
utilisées
Afin que notre démarche s'analyse soit limpide et claire,
nous présentons d'abord la matière première de notre
analyse dans la grille ci-après :
Auteurs
Méthodologies et techniques
|
A1
|
A2
|
A3
|
A4
|
A5
|
A6
|
A7
|
A8
|
X
|
x=X-5 (avec
5=2,5)
|
x2
|
p
|
P
(%)
|
M1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
8
|
5,5
|
30,25
|
1
|
100
|
M2
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
-1,5
|
2,25
|
0 ,125
|
12,5
|
M3
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
2
|
-0,5
|
0,25
|
0 ,25
|
25
|
M4
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
-1,5
|
2,25
|
0 ,125
|
12,5
|
M5
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
1
|
-1,5
|
2,25
|
0,125
|
12,5
|
M6
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
2
|
-0,5
|
0,25
|
0,25
|
25
|
M7
|
0
|
0
|
1
|
0
|
0
|
1
|
1
|
0
|
3
|
0,5
|
0,25
|
0,375
|
37,5
|
M8
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
1
|
-1,5
|
2,25
|
0,125
|
12,5
|
M9
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
1
|
-1,5
|
2,25
|
0,125
|
12,5
|
Totaux
|
|
|
|
|
|
|
|
|
|
|
42,25
|
|
|
|

35
Tableau 1.1 : Grille présentant la
distribution des fréquences d'occurrence des différentes
approches pour chaque auteur.
D'une manière synthétique, les données
ci-haut présentés peuvent être illustrés par le
graphique suivant :
Fréquences d'occurence (X)
9 8 7 6 5 4 3 2 1 0
|
|
|
|
M1 M2 M3 M4 M5 M6 M7 M8 M9
|
|
Fréquences (X)
Graphique 1.1 : Niveaux des fréquences
d'occurrence pour les différentes approches. De toute évidence,
en observant les données présentées ci-haut, nous
constatons que :
· La majorité de chercheurs en reconnaissance de
tableaux utilisent les approches structurales et statistiques (Cfr. 8/8, soit
100%).
· L'approche neuronale n'est presque pas utilisée
en reconnaissance de tableaux (Cfr. 1/8, soit 12,5%).
Etant donné que nous travaillons sur un
échantillon de 8 chercheurs, nous allons procéder par un test
d'inférence afin de pouvoir généraliser les constats
ci-hauts soulignés à toute la population de chercheurs dans le
domaine de la reconnaissance de tableaux (une population infinie !). Pour ce
faire, les constats précédemment soulevés constituent
d'emblée notre hypothèse de base (H0).
- Hypothèses:
· H0 : Les approches structurales et statistiques sont les
plus souvent utilisées en reconnaissance de tableaux tandis que
l'approche neuronale est quasi absente dans les travaux traitant sur la
reconnaissance de tableaux.
· H1 : Contrairement à l'approche
neuronale, les approches structurales et statistiques
sont très rarement utilisées en
reconnaissance de tableaux.
- Seuil de signification pour le test (Niveau de
confiance): 95%, soit une erreur de 5% (á=0,05) ;
- Distribution à utiliser pour le test : Test t
de Student (car nous nous trouvons dans le cas d'une population infinie et dont
nous ignorons l'écart - type).
- Type de test (ou région de rejet) : Test
bilatéral.
- Calcul des valeurs des indices:
· Moyenne de l'échantillon (5 ) : Cette
moyenne est donnée par
5 = ~ ? N.
M .-~ = ~ O 8+1+2+1+1+2+3+1+1 = 2,5
M
· Ecart - type de l'échantillon (s) : Cet
écart est donné par
< =T? J
M2 = TU~,~V
O2 = W6,0357 = 2,46
· L'écart - type de la distribution
d'échantillonnage des moyennes : Cet écart - type s'obtient par
la formule :
HIJ = =
vM21
[ 2,U]
v^
· Valeurs de t :
= 0,93
o

36
th, = 2,365 ((3r `a = ' - 1 = 8 - 1 = 7 et b =
0,05)
=
=
(1,V^)v^
2,U]
= 1,69
(2,V2h,ij)v^
2,U]
(J2efgf~vM21
o tcalculé = [
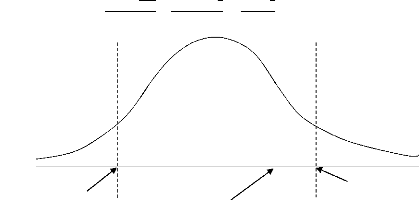
· Représentation de la distribution
:
Région d'acceptation
Région de rejet
Région de rejet
tlu tlu
tcalculé
Graphique 1.2 : Représentation de la
distribution réduite t.

37
- Décision : l'hypothèse de base (H0) est
acceptée
- Conclusion : Avec 5% de risque d'erreur, nous confirmons que
les approches structurales et statistiques sont les plus souvent
utilisées en reconnaissance de tableaux et que l'approche neuronale est
quasi absente dans les travaux traitant sur la reconnaissance de tableaux.
c) Analyse des résultats obtenus par l'utilisation
des différentes méthodes
i. Mesure des performances
L'évaluation des performances et de l'efficacité
des méthodes et algorithmes de reconnaissance de tableau semble
difficile mais non impossible. En fait, comme nous le montre
Shahab26 , les concepteurs des systèmes de reconnaissance de
tableaux ne donnent pas explicitement l'implémentation des algorithmes
qu'ils utilisent, rendant ainsi difficile la reproduction de leurs
système.
Ce problème est d'autant plus préoccupant que
jusqu'à nos jours, il n'existe pas encore de méthodes quasi -
universelles permettant d'évaluer la performance des systèmes de
reconnaissance de tableaux. Afin d'apporter une solution à ce
problème, Shahab pense qu'une analyse comparative et ouverte de
différentes méthodologies appliquées jusqu'alors en
reconnaissance de tableaux s'avère nécessaire. Ainsi propose - il
deux critères de base devant sous - tendre cette comparaison et
permettant d'évaluer la performance des algorithmes de reconnaissance de
tableaux, à savoir : la précision et l'exactitude de
représentation. Ces deux critères, ajoute - t - il, doivent
être examinés à l'aide des mesures basées sur les
« rapports de surface ». Et c'est dans cet ordre d'idée que,
dans leurs travaux, Shafait et Smith (cités par Chen et
Lopresti27) utilisent les boîtes de délimitation pour
décrire les tableaux détectés et les tableaux réels
(ou physiques).
En appellant Gi, la boîte de délimitation pour le
ième tableau physique et Dj, la boîte de
délimitation pour le jème tableau
détecté dans l'image du document, Shafait et Smith
définissent le rapport de chevauchement entre les deux tableaux comme
suit :
~pq#?s1p
AlG1,D+) = ,A E [0,1]
|q#|/ps1p
26 A. Shahab et al., «An open approach towards
the benchmarking of table structure recognition systems», in Proc.
DAS'10, 2010, pp. 9 - 11.
27 Op. cit.

38
où 'Gin/D,' est la surface d'intersection
entre les deux tableaux ; 1G11 et 1D11 sont les surfaces individuelles
des deux tableaux
De là, Shafait et Smith arrivent à
distinguer les résultats suivants :
- La détection correcte : lorsque IAD
>_ 0,9 avec une correspondance «un - à - un » entre
les tableaux détectés et les tableaux physiques.
- La détection partiale : lorsque 0,1 <
A < 0,9 avec une
correspondance «un - à - un »
entre les tableaux détectés et les tableaux
physiques.
- La sur-segmentation : lorsque plusieurs tableaux
détectés
correspondent à un seul tableau
physique.
- La sous-segmentation : lorsque plusieurs tableaux
physiques correspondent à un seul tableau
détecté.
- Tableau manquant (ou non trouvé): lorsque
les tableaux réels possèdent des marges de chevauchement avec les
tableaux ; c'est-à-dire A < 0,1 ;
- Fausse détection positive : lorsque les
tableaux détectés possèdent des marges de chevauchement
avec les tableaux réels; c'est-à-dire A <
0,1.
· La précision de surface est
calculée comme suit :
Surface des régions réelles dans les
régions détectées
Surface de toutes les régions
détectées du tableau
· L'exactitude de représentation de surface
est calculée comme suit :
Surface des régions réelles dans les
régions détectées
Surface de toutes les régions réelles
du tableau
ii. Résultats expérimentaux a)
Modalités de tests
D'une manière générale, les
différents algorithmes et méthodes présentés plus
haut ont été testés par leurs auteurs sur des documents
physiques en tenant compte des paramètres suivants :
1) Le type de documents de test

39
Ce paramètre est d'autant plus important qu'il est
déterminé par la méthodologie ou l'algorithme
utilisé(e). Au fait, c'est le concepteur du système de
reconnaissance de tableaux qui précise les documents que son algorithme
est capable de traiter.
Pour la plupart des méthodes qui ont été
soumises à l'expérimentation, le test s'est déroulé
sur des documents suivants :
- des images des documents imprimés et sans bruits (Cfr.
M2 et M8) ;
- des images de tableaux contenant toutes sortes d'objets et
d'écritures manuscrites (Cfr. M3) ;
- des images de tableaux avec ou sans bordures et contenant des
figures, des graphiques, etc. (Cfr. M4) ;
- des images de formulaires - tableaux manuscrits ou
imprimés (Cfr. M5) ;
- des images de documents manuscrits en langue arabe (Cfr. M6)
- des documents texte ASCII et des images de documents
imprimés (Cfr. M7) ;
Par ailleurs, Il sied de signaler que, dans certains cas, parmi
les documents qui ont été choisis pour le test, certains ont
servi pour l'apprentissage du système et d'autres pour évaluer la
performance dudit système.
2) Le nombre de documents de test (images
scannées)
Ainsi que nous l'avons remarqué, ce nombre est
variable d'un auteur à un autre et est choisi uniquement à titre
expérimental. Cependant, il importe de souligner que certaines
méthodes ont été testées sur un nombre
élevé de documents. C'est le cas de la méthode M8 qui a
été testée su 1125 documents et la méthode M3,
testée sur 305 documents. En examinant sérieusement la raison du
choix d'un nombre si élevé pour la base de test, nous constatons
que, pour certaines méthodes, ce nombre améliore l'apprentissage
du système de reconnaissance de tableaux (Cfr. la méthode M8 pour
laquelle 560 documents ont été utilisés rien que pour
l'apprentissage du système !).
3) La taille ou résolution de l'image
d'entrée
Afin de faciliter leur traitement, le degré de
clarté ou de finesse dans les détails des images ou documents
d'entrée doit être prédéfini à
l'entrée du système de reconnaissance de

40
tableaux. Selon les algorithmes ou méthodologies
utilisées, ce nombre total de pixels défini dans chaque image
d'entrée influencera ou n'influencera pas les résultats des
traitements. Ainsi, comme nous l'avons constaté, lors de leurs tests,
certains algorithmes sont restés insensibles à la
résolution de l'image d'entrée (c'est le cas de M2, M4, M7 et
M8). D'autres, par contre, nécessitaient que l'image d'entrée ait
une résolution de 300 X 300 pixels (ou 300 dpi) - c'est le cas de M3, M5
et M6.
b) Les résultats des tests
L'expérimentation des différentes
méthodologies a produit les résultats ci - après (à
l'exception de M1 qui se retrouve dans les autres méthodologies et M9
qui, à notre connaissance, n'a jamais été
expérimentée) :
|
Méthodologie
|
Nombre de documents pour le test
|
Taux de reconnaissance ou détection
correcte
|
|
M2
|
20
|
100%
|
|
M3
|
305
|
85%
|
|
M4
|
20
|
90%
|
|
M5
|
1
|
100%
|
|
M6
|
20
|
84%
|
|
M7
|
50
|
82%
|
|
M8
|
1125
|
95,31%
|
Tableau 1.2 : Grille présentant le
résultat de tests des différentes approches.
1.2.4. Problèmes et difficultés
rencontrés
La reconnaissance de tableaux étant un domaine qui
présente encore des zones d'ombre, nous avons pu relever par - ci, par -
là quelques écueils qui constituent encore des véritables
défis pour le chercheur en Intelligence Artificielle. Ainsi, d'une
manière générale, nos recherches nous ont montré
que des zones d'ombre persistent encore pour :
- la reconnaissance de tableaux contenant des
éléments non textuels (tels que graphismes, dessins, etc.) ;
- la reconnaissance de tableaux dont les bordures ne sont pas
bien définis (cas des tableaux détériorés ou des
tableaux sans bordures explicites.) ;
- la reconnaissance de tableaux présentant des lignes
droites ornementales (c'est-à-dire dont les bordures et le quadrillage
sont constitués de ces sortes de lignes) ;
- la reconnaissance de tableaux manuscrits ;
- la reconnaissance de plusieurs tableaux pouvant figurer sur un
seul document.

41
1.2.5. Conclusion
Au total, comme nos recherches nous l'ont prouvé, le
domaine de la reconnaissance de tableaux demeure encore non exploré
complètement jusqu'à présent. Et c'est un domaine d'autant
plus intéressant que des recherches menées dans ce sens
pourraient faciliter l'éclosion des nouvelles heuristiques en
Intelligence Artificielle. En fait, les algorithmes développés en
reconnaissance de tableaux pourraient ainsi être intégrés
dans les systèmes OCR afin d'améliorer l'efficacité de ces
derniers.
De plus, il est facile de remarquer que, jusque maintenant,
les systèmes de reconnaissance de tableaux autonomes et performants
demeurent encore rares. Ainsi, des recherches menées dans le sens du
développement de tels systèmes ne peuvent que donner un coup de
pouce aux développeurs des systèmes informatiques qui se verront
dotés des meilleurs outils nécessaires à une production
logicielle de qualité.
C'est dans cette optique que, nous avons choisi d'appesantir
nos efforts sur une approche jusqu'alors inexplorée en reconnaissance de
tableaux : l'approche neuronale. Au fait, à travers cette approche, nous
nous proposons d'élaborer un système capable de détecter
des tableaux dans des documents aussi bien manuscrits qu'imprimés et
d'en extraire la structure avant d'exporter cette structure au format html,
facilitant ainsi sa reproduction.
Le chapitre qui suit traite essentiellement du problème
de la reconnaissance des tableaux, tel que nous le concevons et de la
manière dont il peut être résolu par les réseaux de
neurones.

42
CHAPITRE II. LE PROBLEME DE LA RECONNAISSANCE DE
TABLEAUX
2.1. Objectifs
Ce chapitre constitue un exposé succinct de notre
manière d'appréhender le problème de la reconnaissance de
tableaux. En fait, l'objectif étant de donner une lumière sur la
démarche que nous avons adoptée, à travers ce chapitre,
nous nous proposons d'examiner à fond la question de la reconnaissance
de tableaux afin de découvrir les voies et moyens susceptibles
d'apporter une idée sur la solution à adopter en termes de
méthodologie et de technique. Pour ce faire, nous débutons
d'abord par quelques considérations théoriques concernant le
problème de la reconnaissance de tableaux. Ensuite, nous étalons
la solution que nous avons choisie pour résoudre ce problème
avant de donner un aperçu succinct de l'algorithme que nous
implémenterons dans le système de reconnaissance de tableaux.
2.2. Quelques considérations théoriques
du problème
2.2.1. Postulat :
De prime abord, nous considérons qu'un tableau n'est
visible - ou, du moins, détectable à l'oeil humain - qu'à
travers ses traits caractéristiques, notamment : ses lignes droites
horizontales ou verticales le constituant. Nous n'allons donc pas
considérer un tableau «imaginaire» dont les lignes droites
horizontales et verticales sont hypothétiques car non définies ou
invisibles. Ainsi, dans la suite de notre travail, c'est à ces types de
tableaux auxquels nous ferons toujours allusion et sur lesquels nous
travaillerons.
2.2.2. Considérations :
- Soit le tableau de la figure suivante :

Fig. 3. Eléments de structuration d'un
tableau - Soit A, l'ensemble des éléments pouvant constituer un
tableau T. On a :

43
A = {E1,E2,E3,E4,E5,E6, E7,E8,E9,E10,E11}
= {Ei|i E [1,11] C N}
- Les éléments de A sont appelés
«éléments de structuration » de T car ils donnent
l'idée de la structure du tableau T.
- Pour que ces éléments représentent
réellement la structure d'un tableau T, ils doivent être
rangés selon un certain ordre dans un espace à deux dimensions.
Appelons donc M, la matrice d'éléments de structuration de T,
constituée par les indices de ces éléments. Pour le
tableau de la figure précédente, nous aurons donc la matrice :
|
10
|
6
|
10
|
2
|
|
111
|
0
|
11
|
0
|
11
|
|
M = 5
ÉÉÉ
|
10
|
9
|
10
|
7
|
|
11
|
0
|
11
|
0
|
11
|
|
4
|
10
|
8
|
10
|
3
|
- Notons que, dans la matrice ci-dessus, la présence
des 0 (zéro) signifie l'absence d'éléments de
structuration.
- La composition de la matrice M est une expérience
essentiellement aléatoire car, d'une part, il est impossible de
prévoir de quels éléments de structuration le tableau
à détecter sera constitué et, d'autre part, cette matrice
est variable d'un tableau à un autre.
- Notre espace fondamental û sera constitué par
l'ensemble de toutes les possibilités de combinaison
d'éléments de structuration pouvant composer un tableau.
- Une matrice M sera donc un sous - ensemble de l'espace
fondamentale û, c'est - à - dire qu'il est un ensemble de
résultats possibles.
- En considérant la probabilité de
détecter un tableau dans un document (c'est-à-dire, de
créer une matrice M associée à ce tableau), à
chaque occurrence de la matrice M, nous associons un nombre réel P(M).
La valeur de P(M) est une mesure de la chance que la matrice M
représente bel et bien la structure d'un tableau lors du processus de
reconnaissance.
- Le cardinal de M sera donné par sa dimension NM= n X
m (avec n : nombre de lignes et m : nombre de colonnes).
- En postulant que l'ordre des éléments importe
peu (car des faux tableaux seraient ainsi détectés !), le
cardinal de û sera la combinaison avec répétition des 11
éléments de structuration pris 11 à 11,
c'est-à-dire :
21!
- 11)!
?ii
*11= ?ii+ii--i
11 = ?2i
11= = 352 716 = NOE
11! (21

44
- Ainsi la probabilité P(M) sera égale à
:
Nç n x m
= (*)
6
P(M) = N 352 71
- Etant donné que nous devons tout mettre en oeuvre
pour que la matrice M représente bel et bien la configuration
structurelle d'un tableau, sachant aussi que 0 = P(M) = 1 (2
*), la première manche du problème consiste donc
à déterminer les valeurs optimales de n et m qui maximisent
(*) . Et, en langage mathématique, cela se traduit par
:
|
arg max
n,m E [o,352716]?N
|
P(M) =? (3 *)
|
Or, d'après l'inégalité (2
*), nous trouvons que la valeur maximale de (*) est
atteinte lorsque P(M)=1. D'où l'inégalité (*)
devient alors :
n x m
352 716 = 1
? n x m = 352 716 (4 *)
L'équation (4 *) nous donne le produit de
n et m ; ce qui revient à dire que n=m ou
n=m en vertu de(3 *). Les valeurs de n et m
sont donc des éléments de l'ensemble des diviseurs de 353 716.
Pour notre part, nous avons choisi deux valeurs optimum de n et m, à
savoir : 663 et 532 (car 663 x 532 = 352 716).
Ainsi, la valeur de (3 *) devient :
|
arg max
n,m E [o,352716]?N
|
P(M) = @532 ,663A
|
- Soit B, l'ensemble d'éléments présents
sur l'image du tableau. Afin de reconnaître un tableau, notre
système devra déterminer les caractéristiques de l'image
représentant le tableau. Ces caractéristiques ne sont pas
observables directement et peuvent être représentées par un
élément x de l'espace B. De plus, ces caractéristiques
sont observées à partir d'autres caractéristiques
observables de l'image et qui sont représentées par un
élément y de l'espace û. Ici, nous supposerons qu'il
n'existe pas de liens déterministe entre les x et les y -
c'est-à-dire, plusieurs x possibles peuvent correspondre à un y
observé.
Cependant, bien qu'il n'existe aucun lien déterministe
entre les y et les x, l'observation de y doit apporter une certaine information
sur x. Cette information est donnée par une loi de probabilité
sur B, compréhensible grâce à la loi des grands nombres, de
la manière suivante : si la situation de produit un certain nombre de
fois (à y donné), la probabilité p(F|y) (dépendant
de y) d'un ensemble F?B est la proportion des x se trouvant
dans F.

45
Pour calculer l'optimalité, considérons une
fonction L : B2-- R/ qui modélise la gravité des
erreurs ; L(x1,x2) représente le coût de l'erreur « nous
pensons que x est x1 alors que le vrai x est x2 ». Nous appellerons la
fonction L, la « fonction de perte » ou encore « fonction de
coût ». Supposons que nous disposons d'une
règle de décision d : Ù--B, qui associe
à chaque y observé un x inobservable, et que nous souhaitions
évaluer sa qualité. Connaissant la probabilité p(x|y),
nous pouvons donc calculer le risque28 défini par :
R(L,d,y) = J L(d(y),x)p(x|y)dx (5 *)
C
avec y : une caractéristique de tableau pouvant être
observée sur l'image
d : la fonction de décision qui associe un y
observé à un x inobservable
L : la fonction qui évalue la perte lorsqu'on associe un y
observé à un x inobservable La fonction (5 *)
exprime tout simplement le risque global qui est associé
à la perte globale
occasionnée par les erreurs d'observation des x, perte
qui est pondérée par les probabilités d'occurrence de ces
erreurs. 29
Les quantités x et y étant aléatoires,
nous pouvons les considérer comme des variables aléatoires
appartenant respectivement à B et Ù. La loi p(x,y) du couple (B,
Ù) sera donc donnée par la loi p(y) de B et la loi p(x|y) de B
conditionnel à Ù. En considérant que les variables
aléatoires x et y sont discrètes, le risque moyen associé
à L et d sera alors défini par :
R(L, d) = E[L(d(Ù), B)] (6 *)
L'équation (6 *) exprime
l'espérance mathématique de la fonction de perte qui
détermine le risque moyen ; et la décision
Bayésienne30 associée à L sera la
décision qui minimise ce risque moyen :
E[L(d cents(Ù),B)] = arg min
E[L(d(Ù),B)] (7 *)
- Considérons donc le problème de reproduction
d'un tableau comportant deux classes : la classe des pixels appartenant au
tracé du tableau, notée T et la classe des
pixels n'appartenant pas au tracé du tableau, notée Tf
. Lorsque nous souhaitons travailler pixel par pixel, nous observons
sur chaque pixel un niveau de gris y auquel nous devons attribuer un x
de l'ensemble B = [T, Tf }. Nous
nous trouvons dans un contexte probabiliste si un niveau de
28
http://en.wikipedia.org/wiki/Risk
function, lien valide le 08/04/2012 à 20h09'.
29
http://www.cim.mcgill.ca/~friggi/bayes/decision/risk.html
, lien valide le 08/04/2012 à 20h15'.
30
http://www.cim.mcgill.ca/%7Efriggi/bayes/decision/
&usg=ALkJrhiDn1gKh6g9e5FmoLjO6QdzT-EmwQ, , lien valide le 08/04/2012
à 21h15'.
gris donné peut aussi bien correspondre au tracé
d'un tableau qu'au tracé d'un autre objet sur le document (bruits,
images, graphiques, etc.). C'est ce que nous observons fréquemment dans
des images contenant du bruit tels que ceux des documents scannés
comportant, en plus des tableaux, d'autres objets comme des images, des
graphiques, des écritures manuscrites, etc.
La loi p(x,y) du couple (B,û) peut alors être
donnée par la loi p(x) de B, qui est une
probabilité sur B = fT, fT } et
désigne simplement la proportion de deux classes dans le document
concerné, et par les deux lois p(y|T) et
p(y|Tf) de û conditionnel à B. Notons
que ces deux dernières lois modélisent simultanément la
«variabilité naturelle » de deux classes et les diverses
dégradations dues à l'acquisition des données (
cfr. la qualité des capteurs tels que
le scanneur ainsi que les paramètres de capture tels que la
résolution).
Supposons que deux clients souhaitent se porter
acquéreurs de logiciels de reconnaissance de tableaux. Le premier
client, pour lequel la surévaluation de la classe «tracé de
tableau» est plus grave que celle de la classe «pas tracé de
tableau», perd 1 dollar quand un pixel « tracé » est
classé à tort comme « pas tracé », et 10 dollars
quand un pixel « pas tracé » est classé à tort
comme étant « tracé ». Un deuxième client, pour
qui la surévaluation de la classe « pas tracé de tableau
» est plus grave que celle de la classe « tracé de tableau
», perd 1 dollar quand un pixel « pas tracé » est
classé à tort comme étant « tracé », et
20 dollars quand un pixel « tracé » est classé à
tort comme étant « pas tracé ». Nous aurons donc :
L1(T,T) =
L1(Tf,Tf) = 0,
L1(Tf,T) = 10, L1(T,Tf)
= 1, (a *)
L2(T,T) =
L2(Tf,Tf) = 0,
L2(Tf,T) = 1, L2(T,Tf)
= 20 (a **)
Etant donné que nous nous trouvons dans le cas des
variables aléatoires discrètes, à partir de (5 *) nous
pouvons obtenir la fonction de risque encouru par les deux clients. Ainsi cette
fonction sera :
R(L,d1,2,y) = L(d(y),T)p(T|y) +
L(d(y),Tf)p(Tf|y) (8
*)
Ajoutons ici que les probabilités p(T|y) et
p(Tf|y) peuvent être calculées- en
vertu du théorème de Bayes31 - à partir de
p(x), p(y|T) et p(y|Tf) par :
p(T)p(y|T)
p(T)p(y|T) +
p(Tf)p(y|Tf)
p(T|y) =
p(T
p(T)p(y|T)
|y) =
p(T)p(y|T) +
p(Tf)p(y|Tf)

46
31
http://fr.wikipedia.org/wiki/Th%C3%A9or%C3%A8medeBayes,
lien valide le 08/04/2012 à 20h30'.

47
Lorsque nous minimisons la fonction (8 *) par
rapport au premier client, nous observons deux cas :
i) Le cas où ce premier client opte pour la
décision « tracé » (c'est-à-dire d1(y)=
T) :
Dans ce cas, notre client devra minimiser le risque global de sa
décision en excluant le risque de la décision «pas
tracé » du risque de la décision «tracé».
Mathématiquement, cela revient à dire que :
d1(y)= T si L(Tf,T)p(T|y) -
L(T,Tf)p(Tf|y) = 0 len vertu de (a *))
? 10p(T|y) = p(T |y)
ii) Le cas où ce premier client opte pour la
décision « pas tracé » (c'est-à-dire d1(y)=
T)
Dans ce cas, notre client devra minimiser le risque global de
sa décision en excluant le risque de la décision «
tracé » du risque de la décision «pas
tracé». Ce qui se traduit mathématiquement par :
d1(y)= Tf si
L(T,Tf)p(Tf|y) - L(Tf,T)p(T|y) = 0 len
vertu de (a *))
? p(Tf |y) = 10p(T|y)
En appliquant le même raisonnement (ci - dessus) de
minimisation de (8 *) à la situation du second client,
nous obtenons les décisions suivantes :
d2(y)= T si L(Tf,T)p(T|y) -
L(T,Tf)p(Tf|y) = 0 len vertu de (a **))
? p(T|y) = 20p(T |y)
d2(y)= Tf si L(T,
Tf)p(Tf|y) - L(Tf, T)p(T|y) = 0 len vertu de
(a **))
? 20p(Tf |y) = p(T|y)
2.3. Notre démarche de solution
De ce qui précède, nous constatons que le
problème de la reconnaissance de tableaux est essentiellement un
problème de classification bayésienne32 où la
gestion du risque d'erreur joue un rôle capital. Cela est d'autant plus
vrai que, comme nous l'avons remarqué, cette classification s'adapte
parfaitement à la situation générale dans laquelle l'image
d'un document à reconnaître peut contenir, en plus des tableaux,
d'autres objets tels que des graphiques, des bruits, des schémas, des
signatures, etc. Dans une telle situation, le risque d'erreur de classification
est effectivement grand pour le système de reconnaissance de
32 Une classification essentiellement probabiliste.

48
tableau. D'où l'utilisation des probabilités
s'avère d'une importance capitale pour la gestion de ce risque.
Il est évident que ce problème pourrait
être bien résolu par les méthodes bien connues de la
classification bayésienne. Cependant, eu égard à notre
problématique de base - celle de la reproduction de la structure d'un
tableau - nous nous sommes proposés d'adopter une autre approche qui,
quoique différente, se base aussi sur des calculs probabilistes. C'est
l'approche neuronale.
Au fait, bien que très peu ou presque pas
utilisée en reconnaissance de tableau, l'approche par réseaux de
neurones nous semble la mieux adaptée à notre
problématique de base pour les raisons ci - après :
- cette approche concorde avec l'hypothèse forte de
l'intelligence artificielle ; celle de la « reproduction du comportement
d'un être humain dans un domaine spécifique ou non
»33 ;
- comme nous le verrons dans la suite, un réseau de
neurones est une combinaison d'éléments simples : les neurones
;
- cette approche est non linéaire (par «
opposition » aux autres méthodes classiques d'analyse de
données.)34 ;
- cette approche est essentiellement numérique (par
opposition à l'Intelligence Artificielle symbolique - base de
règles, raisonnement par cas, etc.) et donc, mieux adaptée aux
capacités de calcul d'un ordinateur.
- Nous pensons qu'un réseau de neurones est mieux
adapté pour l'extraction des informations structurelles d'un tableau.
Avant d'aborder de manière détaillée la
méthodologie que nous avons adoptée, jetons d'abord un regard
analytique sur les réseaux de neurones.
2.3.1. Généralités sur les
réseaux de neurones.
2.3.1.1. Qu'est ce qu'un réseau de neurones ?
Comme son nom l'indique, un réseau de neurones et un
ensemble de neurones interconnectés. Selon ROBARDET35, c'est
un ensemble de méthodes d'analyses et de traitement de données
issus des considérations biologiques.
33 DJUNGU S. J., Intelligence artificielle et
système expert, DIGITAL-Printer, Kinshasa, 2012, p. 5.
34 ROBARDET C.,
http://prisma.insa-lyon.fr/~crobardet, lien valide le
09/04/2012 à 13h00'.
En fait, un réseau de neurones n'est qu'une
réplique quasi parfaite des neurones biologiques fonctionnant dans le
cerveau humain car, comme nous allons le voir par la suite, il en
possède les caractéristiques essentielles.
2.3.1.2. Structure d'un neurone
|
· Dendrites : Signaux d'entrée
· Axone : Signal de sortie
|

49
Fig. 4. Structure d'un neurone
biologique36.

Fig. 5. Structure d'un neurone artificiel.
A l'instar d'un neurone biologique, un neurone artificiel
présente les caractéristiques suivantes :
- Des connexions entrantes (E1, E2, E3, etc.)
dont les poids (p1, p2, p3, etc.) varient selon l'importance de la connexion.
Au fait, toutes les connexions entrantes d'un neurone (appelées aussi
« synapses ») peuvent être considérées comme une
seule connexion dont la valeur est E=p1*E1+p2*E2+p3*E3+...+pn*En.
- Une fonction d'activation : située
au centre du neurone, cette fonction assure la transformation des
entrées en sorties selon son type. Les fonctions d'activation ne sont
35 Op. cit.
36
http://
www-igm.univ-mlv.fr/dr/XPOSE2002/Neurones/index1a56.html?rubrique=Neuronebiologique,
lien valide le 09/04/2012 à 15h20'.

50
donc pas toujours identiques ou fixées pour tous les
neurones et dépendent de l'application de ces derniers (selon le type
d'implémentation choisi pour le réseau). Néanmoins, dans
la plupart d'implémentations de réseaux de neurones, les
fonctions d'activation suivantes sont utilisées:
o La fonction sigmoïde standard (appelée
encore « courbe en S ») 37 : Cette fonction est
donnée (ou calculée) par :
o La fonction tangente hyperbolique38 :
Cette fonction est définie comme suit :
tanh(x) =
|
sinh(x) cosh(x) =
|
ex - e_X
|
|
|
o La fonction Gaussienne :
Cette fonction s'écrit de la manière suivante :
o La fonction linéaire à seuil39
:
Cette fonction est définie de la manière ci -
après :
f(x) = sign(w1x1 + ? + wGxG -
B)
où =w, ... , w sont les poids des connexions B est
une valeur appelée seuil
- Une ou plusieurs connexions sortantes (S1,
S2, S3, ...) dont la valeur (ou les valeurs) est (sont) le résultat de
la fonction d'activation f(S). Dans un réseau de neurones multicouches
et selon la couche où se trouve le neurone concerné, ces
connexions sortantes peuvent constituer des connexions entrantes pour un autre
neurone du même réseau. Remarquons donc ici que les connexions
entrantes et sortantes assurent la connectivité dans un réseau de
neurones.
2.3.1.3. Types et exemples de réseaux de
neurones
37
http://fr.wikipedia.org/wiki/R%C3%A9seaudeneurones
, lien valide le 09/04/2012 à 19h23'.
38 Ibidem.
39 Koriche F., Cours d'Intelligence Artificielle :
Apprentissage, Université Montpelier II, Montpelier, 2012, p. 6.

51
Notons que les réseaux de neurones sont nombreux et
peuvent être créés selon les contextes d'application.
Cependant, dans la pratique et de manière générale, les
types de réseau suivants sont utilisés :
- Les réseaux de neurones monocouches
Comme leur nom l'indique, ces types de réseaux sont
constitués d'une seule couche. De plus, ces réseaux sont
linéaires et rappellent le système visuel humain. La
première couche (noeuds d'entrée) représente la
rétine. Les connexions entre neurones jouent le rôle de cellules
d'association et les neurones de la couche finale (noeuds de sortie)
représentent les cellules de décision. Ici, les sorties des
neurones ne peuvent prendre que deux états (-1 et 1 ou 0 et 1). Un
exemple plus parlant de ce type de réseau est le perceptron qui fut
conçu en 1958 par Frank Rosenblatt40.
Fig. 6. Un exemple de réseau de neurones
monocouche : Le perceptron - Les réseaux de neurones
multicouches
Ces types de réseaux sont constitués d'une ou
plusieurs couches intermédiaires (appelées noeuds cachés)
entre les noeuds d'entrée et les noeuds de sortie. Dans ces types de
réseaux, chaque neurone n'est relié qu'aux neurones des couches
directement précédentes et suivantes. Comme exemple de
réseau de neurones multicouche, nous trouvons le
40
http://fr.wikipedia.org/wiki/Perceptron,
lien valide le 09/04/2012 à 21h50'.

52
perceptron multicouche (qui est une amélioration du
perceptron de Rosenblatt et qui comprend une ou plusieurs couches
intermédiaires).

Fig. 7. Le perceptron multicouche
2.3.1.4. Modes d'apprentissage d'un réseau de
neurones
Pour être fonctionnel, un réseau de neurones doit
être capable d'apprendre (par exemple : apprendre à
reconnaître un tableau, du texte, des images, etc.) - c'est, d'ailleurs
l'une de ses qualités essentielles. Ainsi, distingue - t - on deux modes
principaux d'apprentissage de réseaux de neurones, à savoir :
l'apprentissage supervisé et l'apprentissage non supervisé. -
L'apprentissage supervisé
Dans ce mode d'apprentissage, on fournit préalablement
au réseau les résultats corrects que l'on souhaite obtenir comme
valeur de sortie du réseau. A l'issue de l'apprentissage, le
réseau est testé en lui fournissant uniquement les valeurs
d'entrée mais non les sorties désirées, et en
vérifiant si le résultat obtenu s'approche du résultat
désiré. Il est à noter que ce mode d'apprentissage est le
plus couramment utilisé en reconnaissance de formes. Cependant, ce mode
d'apprentissage s'avère être moins adaptatif et moins souple car
il

53
demande de fournir au système, à chaque fois,
des exemples pour chaque type de reconnaissance ; ce que nous trouvons
fastidieux.
- L'apprentissage non supervisé
Dans ce mode d'apprentissage, aucun résultat de sortie
attendu n'est fourni au réseau. Ainsi laisse - t - on évoluer le
réseau librement jusqu'à sa stabilisation complète.
Remarque : A côté de ces deux
modes d'apprentissage « classiques », nous ajoutons
l'apprentissage semi - supervisé qui n'est rien d'autre qu'un
apprentissage non supervisé se basant sur une petite connaissance
à priori. Dans la suite de ce travail, c'est précisément
ce type d'apprentissage que nous utiliserons.
2.4. Méthodologie adoptée
Dans le chapitre précédent nous avons
jeté un regard analytique sur quelques algorithmes que nous avons
intentionnellement sélectionnés par leur pertinence
évidente par rapport à nos travaux. Il ressort de nos
observations que, pour la plupart de ces algorithmes, l'étape de
prétraitement était quasi indispensable et influençait
considérablement les résultats. Cela s'expliquerait par le fait
que cette étape permet d'accroître l'efficacité de
l'algorithme qui, de ce fait, n'exécutera que les tâches pour
lesquelles il a été créé sans s'occuper d'autres
tâches superflues tels que la correction d'angles d'inclinaison,
l'élimination des bruits, etc.
De ce qui précède nous trouvons que
l'étape de prétraitement est indispensable à l'algorithme
que nous proposons dans la suite. Cela dit, notre approche étant
essentiellement neuronale, la majorité des étapes de notre
algorithme se trouvent à l'intérieur même (c'est - à
- dire dans la structure) du réseau de neurone à
implémenter. Ces étapes pourront donc être décrites
de manière détaillée dans le chapitre qui suivra (traitant
sur l'implémentation de ce réseau). Cependant, les grandes lignes
de notre méthodologie s'énoncent comme suit :
- Acquisition d'image
- Prétraitement
- Extraction des caractéristiques du tableau
- Génération de la structure du tableau au
format HTML
Schématiquement, le procédé ci - dessus peut
être représenté comme suit :
Acquisition d'image
|
|
Extraction des caractéristiques du tableau
|
|
Prétraitement
|

Réseau
Aire de sortie
Gradient
Rétine
Génération du document
HTML

54
2.5. Conclusion
Au total, le problème de la reconnaissance de tableaux
est celui qui demande la prise en compte du risque d'erreur lors de la
détection même des pixels pouvant appartenir au tracé d'un
tableau. Ainsi, la décision à prendre par le système de
reconnaissance se trouve - t - elle soumise à la gestion de ce risque en
considérant le caractère aléatoire lié à la
manière dont peut se présenter l'image d'un tableau (tableau avec
logos, tableau contenant du texte, etc.).
Ainsi posé, ce problème nous a amené
à proposer, parmi toutes les solutions existantes et envisageables, une
qui nous a semblé non expérimentée jusque maintenant,
à savoir : le réseau de neurones. Une présentation des
généralités sur les réseaux de neurones s'est
avérée nécessaire avant d'étaler les grandes lignes
de la méthodologie que nous proposons pour résoudre ce
problème.

55
CHAPITRE III. APPLICATION D'UN RESEAU DE NEURONE A LA
RECONNAISSANCE
DE TABLEAUX
3.1. Objectifs et but
Dans ce chapitre, nous nous proposons de présenter, de
manière détaillé, l'algorithme utilisant un réseau
de neurones ; algorithme que nous implémenterons par la suite. En fait,
l'objectif de ce chapitre étant de donner une vue globale et
détaillée de la structure de notre réseau de neurones et
de la possibilité d'implémentation de ce dernier, nous nous
proposons d'articuler nos propos sur trois points essentiels ; à savoir
: la composition du réseau, l'organisation structurelle du réseau
et l'algorithmique générale de reconnaissance. Cela étant,
ce chapitre s'attèle à donner une idée claire et
précise sur les différentes étapes à suivre en vue
d'extraire la structure d'un tableau à travers un réseau de
neurones.
3.2. Choix et composition du réseau de
neurones
3.2.1. Choix du réseau de neurones
De prime abord, signalons que le choix d'un réseau de
neurones à implémenter n'est tributaire d'aucune autre
règle à part celle du bon sens du programmeur (ou du chercheur)
faisant face au problème à résoudre. Néanmoins,
certaines contraintes techniques liées à la nature même du
problème à résoudre, comme nous le verrons dans la suite,
imposent une certaine limite dans le choix d'un réseau de neurone pour
l'extraction de la structure du tableau.
3.2.1.1. Le nombre total de neurones
Vu la complexité de l'appareil visuel humain, nous
allons nous baser sur une modélisation assez simpliste du réseau
de neurones à implémenter afin d'avoir une représentation,
non seulement miniaturisée, mais aussi utile du système visuel
humain. En fait, le cerveau humain étant composé de plus de 1000
milliards de neurones interconnectés41, les contraintes
d'espace et de mémoire nous imposent donc de choisir comme nombre total
de neurones composant notre réseau, un nombre inférieur ou
égal à celui calculé dans le chapitre
précédent, c'est-à-dire = NÙ =352 716.
3.2.1.2. Type de réseau de neurones choisi
41
http://
www-igm.univ-mlv.fr/dr/XPOSE2002/Neurones/index1a56.html?rubrique=Neuronebiologique,
lien valide le 10/04/2012 à 16h20'.

56
Afin de mener à bien notre travail et d'atteindre ainsi
les objectifs que nous nous sommes assignés, nous avons opté pour
un réseau de neurones multicouches car, ce dernier représente
plus ou moins bien la structure du réseau de neurones biologiques dans
la réalité. Rappelons ici que dans un réseau de neurones
multicouches, entre la couche d'entrée et la couche de sortie se
trouve(nt) superposée(s) une ou plusieurs autres couches
intermédiaires (appelées couches cachées) permettant la
communication entre les deux couches extrêmes.
3.2.2. Composition du réseau de neurones choisi
Ainsi que nous l'avons signalé
précédemment, la composition de notre réseau de neurones
est calquée sur la structure même d'un réseau de neurones
biologiques moyennant une certaine simplification à des fins
adaptatives.
Donc, à l'instar du système visuel humain, notre
réseau de neurones sera organisé en différentes couches
tels que la rétine, le gradient et l'aire de sortie.
Dans le système visuel humain, lorsque l'oeil
perçoit une image, un signal nerveux est transmis au centre du cerveau.
Et, en suivant l'ordre de propagation de ce signal, on constate qu'il devient
de plus en plus abstrait à mesure qu'il s'éloigne de la
première couche (la rétine). Ainsi, un nombre de neurones
élevé sera nécessaire à la première couche
qui est au contact direct avec les données physiques tandis que ce ne
sera pas le cas pour la dernière couche qui, par voie des faits est
éloignée de la réalité.
Dans l'implémentation de notre réseau, nous
allons donc suivre la même logique en réduisant le nombre de
neurones au fur et à mesure que l'on s'éloigne de la
première couche.
a. Le nombre de neurones composant chaque couche
- Nombre de neurones de la rétine :
La rétine étant la couche qui reçoit
directement les données physiques de l'image d'entrée, nous
allons lui affecter le plus grand nombre de neurones. Ainsi, afin de respecter
la résolution, pour une image de dimension 300X300, nous aurons besoin
de 300 X 300 = 90 000 neurones, à raison d'un neurone par pixel.
- Nombre de neurones du gradient :

57
Considérant que, d'une manière isolé, un
pixel ne donne pas le maximum d'informations sur une image, nous allons chaque
fois regrouper 3X3 pixels afin d'obtenir le minimum d'informations
nécessaires concernant la composition d'une image. Le champ
récepteur d'un neurone du gradient sera donc constitué de 9
neurones de la rétine ; ce qui fait un total de 291 X 291 = 84 681
neurones nécessaires pour constituer la couche du gradient.
- Nombre de neurones de l'aire de sortie :
Cette couche étant la dernière, et suivant
directement celle du gradient, elle aura un champ récepteur
constitué de 84 681 neurones du gradient.
b. L'organisation des neurones dans le réseau
i. L'organisation de neurones de la rétine et du
gradient
Comme nous l'avons signalé précédemment,
chaque neurone du gradient reçoit en entrée la sortie de neuf
neurones de la rétine se trouvant dans son champ récepteur. Et
chacun des neuf neurones est détenteur d'une information sur le pixel
qui se trouvait en face de lui. Cette information est un entier
représentant le niveau de gris du pixel de l'image d'entrée.
ii. L'organisation des neurones du gradient et de l'aire de
sortie
L'aire de sortie étant la dernière couche du
réseau, nous avons un et un seul neurone prenant toutes les sorties des
neurones du gradient en entrée et possédant une et une seule
sortie.
D'une manière synthétique, la configuration
spatiale du réseau se présente comme suit :

Couche de la Rétine
Couche du Gradient
Couche de l'Aire de sortie
Sortie du réseau
(structure du tableau au format *.html ou
*.doc)
Signaux d'entrée provenant de l'image du tableau
(les 3 composantes RVB)

58
Fig. 8. Structure spatiale du réseau de
neurones 3.3. Méthodologie de reconnaissance
Tel que annoncé au point 4 du chapitre 2, notre
méthodologie se repartit en deux grandes étapes qui sont :
- le prétraitement de l'image du document et
- l'extraction des caractéristiques du tableau contenu sur
l'image.
3.3.1. L'étape du prétraitement
Après l'acquisition de l'image via un scanneur, cette
étape est d'une importance capitale dans la mesure où elle
réduit le nombre d'étapes de l'algorithme principal du
système de reconnaissance. Et, dans notre cas, l'algorithme principal
est celui d'extraction des caractéristiques du tableau. Ainsi, selon la
qualité de l'image d'entrée, plusieurs étapes peuvent
être nécessaires avant d'extraire les caractéristiques d'un
tableau dans une image. Parmi ces nombreuses étapes, nous avons retenus
trois qui nous ont semblé plus importantes, à savoir : la
réduction de la taille et la binarisation.
3.3.1.1. Réduction de la taille de l'image:
Cette étape permet de conserver les dimensions de
l'image d'entrée dans des proportions imposées par les neurones
de la première couche, à savoir 300 X 300 (c'est - à -
dire, 300 pixels en hauteur et 300 pixels en largeur).
3.3.1.2. Binarisation de l'image:
Appelé aussi `'seuillage simple», la binarisation
est une étape qui consiste à mettre à zéro tous les
pixels niveau de gris inférieur à une certaine valeur
(appelée seuil, en anglais `'treshold») et à attribuer la
valeur maximale aux pixels ayant une valeur supérieure au seuil. Le
résultat en est une image binaire contenant des pixels noirs et blancs.
Dans le cas des images contenant des tableaux, la binarisation permet
d'accentuer les tracés des lignes et des colonnes ainsi que d'autres
objets sur l'image, rendant ainsi leur identification moins difficile.
Néanmoins, une difficulté demeure au niveau du choix du seuil
à utiliser. Pour palier à cette difficulté, nous nous
sommes proposé de calculer ce seuil en nous appuyant sur les
considérations du chapitre précédent concernant le
problème de la reconnaissance des tableaux.
Calcul du seuil:
Nous savons que le seuil dépend de la qualité
des couleurs de l'image, c'est - à - dire des niveaux de couleurs
contenus dans chaque pixel lu. En outre, le seuil est celui qui nous donne le
niveau de couleur qui maximise la probabilité de détecter les
pixels appartenant au tracé du tableau. Ce seuil sera donc donné
par : S = arg min P(T)
avec P(T) = [0,y]
[0,255] : la probabilité de
détecter les pixels appartenant au tracé du tableau.
y : le niveau de couleur permettant de détecter un pixel
appartenant à au tracé du tableau.
Soit x le niveau de couleur lu sur l'image. En nous
référant à la théorie des 2 clients (cf. Chapitre
II), lorsque nous nous plaçons dans la situation du premier client, nous
observons que la décision `'tracé de tableau» est soumise
à la condition suivante :
p(T|y) = p(T |y)
10
+ p(T) p(y|T)
p(T)p(y|T)
? 10
p(T)p(y|T) + p(T )p(y|T ) p(T)p(y|T)
p(Tf)p(y|Tf)
=
f

59
? 10p(T)p(y|T) = p(Tf) p(y|Tf)
p(T) = p(Tf)p(y|Tf) ?(***)
10p(y|T)
Calculons les termes de (***):
1°) p(T) =
[h,] = /1
[h,2VV] 2V] (a)
2°) p(Tf) = [/1,2VV] = 2VV2 (avec y >
0) (b)
[h,2VV]
V]
|
3°) p(y|Tf) = 1/4(n3/4) =
3/4
|
/1/|À22VV| 2VV2
|
* 256 (c)
|
4°) p(y|T) = 1/4(n3/4) = |À2| * 256
(d)
3/4 /1
Â.Ä
Ainsi, (***) devient : a = ~****~
h
En substituant a,b,c et d par leurs valeurs dans (****),
nous obtenons :
2ÅÅ"Æ *
ÆÈ$È|É"~ÅÅ|
2ÅÇ 2ÅÅ"Æ
* 2V]
/1 = V]
/1 ?=
~
ÆÈ$È|É"2ÅÅ|
$
1h|É"Æ|
ÆÈ$
?10|x - y| - y = 1 + |x - 255| (i *)
Ici, 2 cas peuvent se présenter :
1er cas : x - y > 0 . Dans ce cas, (i *)
devient :
1hÀ2|À22VV|21
10x - 11y = 1 + |x - 255| ?Ê = ~~~ *~
~~2ème cas : x - y < 0 . Dans ce cas, (i
*) devient :
-10x + 9y = 1 + |x - 255| ? Ê =
~hÀ/|À2~VV|/~ ~~~~ *~
i
En tenant compte du fait que nous sommes à la
recherche d'une valeur du seuil S inférieure à y et à ne
pas dépasser, nous rejetons donc (iii *) et nous gardons(ii *). Ainsi,
le seuil sera donné par la valeur de y qui minimise(ii *),
c'est-à-dire :
S = Ê =
10x - |x - 255| - 1
(4i. *)
11

60
3Ëe( x : le niveau de couleur le plus
élevé de tous les pixels de l'image.
3.3.2. L'étape d'extraction des
caractéristiques du tableau.
Toute cette étape est exécutée par
le réseau de neurones et se subdivise en deux phases essentielles,
à savoir : la détection du tableau et la compréhension de
la structure du tableau. De plus, l'essentiel des procédures de cette
étape repose sur le codage du gradient
morphologique des éléments de structuration d'un
tableau tel que schématisé dans la figure suivante :

1 2 3

4 5 6


7 8 9
10 11

61
Fig. 9. Codage des éléments de
structuration d'un tableau sur 3X3 pixels 1ère phase :
Détection du tableau
L'objectif de cette phase est d'arriver à localiser les
éléments de structuration du tableau
contenu sur l'image du document. Pour ce faire, le réseau
de neurones implémente
l'algorithme suivant :
- Au niveau de la rétine (par neurone) :
Initialiser chacun des poids w.
à 1 ;
Fixer le seuil 8 à 0 ;
Recevoir les instances de niveaux de gris
x1 , x2 et
x3 ;

62
Appliquer la fonction d'activation f(x) =
signOEw.x1
M - 8) ; (fonction linéaire à
seuil)
.-1
Calculer la valeur de sortie du neurone : sort =
sign(w1x1 + w2x2 + w3x3 - 8) ;
- Au niveau du gradient (par neurone) :
Initialiser chacun des poids w.1 à 1 ;
Recevoir la matrice E [][] contenant les sorties de neuf neurones
de la rétine ;
Calculer la valeur de sortie du neurone du gradient selon le cas
:
Si ? E[i][j]wÏÐ == 3 (avec i = 0, 1 ou 2 V
j
~ ) alors sort=10 ;
+-0
Si ? E[i][j]wÏÐ == 3 (avec j = 0, 1 ou 2 V
i
~ ) alors sort=11 ;
.-0
Si ((E[2][1]w21 + E[1][1]w11 + E[1][2]w12 == 3)
et (E[0][0]w00 + E[1][0]w10 +
E[2][0]w20 + E[0][1]w01 +
E[0][2]w02 + E[2][2]w22 == 0)) alors sort=1 ;
Si ((E[0][0]w00 + E[1][0]w10 + E[2][0]w20 + E[0][1]w01 +
E[0][2]w02 == 5) et
(E[2][1]w21 + E[1][1]w11 + E[1][2]w12 +
E[2][2]w22 == 0)) alors sort=1 ;
Si ((E[1][0]w10 + E[1][1]w11 + E[2][1]w21 == 3)
et (E[0][0]w00 + E[2][0]w20 +
E[0][1]w01 + E[0][2]w02 +
E[1][2]w12 + E[2][2]w22 == 0)) alors sort=2 ;
Si ((E[0][0]w00 + E[0][1]w01 + E[0][2]w02 + E[1][2]w12 +
E[2][2]w22 == 5) et
(E[1][0]w10 + E[1][1]w11 + E[2][1]w21 +
E[2][0]w20 == 0)) alors sort=2 ;
Si ((E[1][0]w10 + E[1][1]w11 + E[0][1]w01 == 3)
et (E[0][0]w00 + E[0][2]w02 +
E[1][2]w12 + E[2][0]w20 +
E[2][1]w01 + E[2][2]w22 == 0)) alors sort=3 ;
Si ((E[0][2]w02 + E[1][2]w12 + E[2][0]w20 + E[2][1]w01 +
E[2][2]w02 == 5) et
(E[0][0]w00 + E[1][0]w10 + E[1][1]w11 +
E[0][1]w01 == 0)) alors sort=3 ;
Si ((E[0][1]w01 + E[1][1]w11 + E[1][2]w12 == 3)
et (E[0][0]w00 + E[1][0]w10 +
E[2][0]w20 + E[2][1]w21 +
E[2][2]w22 + E[0][2]w02 == 0)) alors sort=4 ;
Si ((E[0][0]w00 + E[1][0]w10 + E[2][0]w20 + E[2][1]w21 +
E[2][2]w22 == 5) et
(E[0][1]w01 + E[1][1]w11 + E[1][2]w12 +
E[0][2]w02 == 0)) alors sort=4 ;
Si ((E[0][1]w01 + E[1][1]w11 + E[1][2]w12 + E[2][1]w21 ==
4) et (E[0][0]w00 +
E[1][0]w10 + E[2][0]w20 + E[2][2]w22 +
E[0][2]w02 == 0)) alors sort=5 ;
Si ((E[0][0]w00 + E[1][0]w10 + E[2][0]w20 + E[1][1]w11 +
E[1][2]w12 == 5) et
(E[0][1]w01 + E[0][2]w02 + E[2][1]w21 +
E[2][2]w22 == 0)) alors sort=5 ;
Si ((E[1][0]w10 + E[1][1]w11 + E[1][2]w12 + E[2][1]w21 ==
4) et (E[0][0]w00 +
E[0][1]w01 + E[0][2]w02 + E[2][0]w20 +
E[2][2]w22 == 0)) alors sort=6 ;

63
Si ((E[0][0]woo + E[0][1]woi + E[0][2]w02 +
E[1][1]wii + E[2][1]w2i == 5) et
(E[1][0]w10 + E[2][0]w20 +
E[1][2]w12 + E[2][2]w22 == 0)) alors sort=6 ;
Si ((E[0][1]wo1 + E[1][1]w11 +
E[1][0]w10 + E[2][1]w21 == 4) et
(E[0][0]woo +
E[0][2]w02 +
E[1][2]w12 + E[2][2]w22 + E[2][0]w20 == 0))
alors sort=7 ;
Si ((E[1][0]w10 + E[1][1]w11 +
E[1][2]w12 + E[0][2]w02 + E[2][2]w22 == 5)
et
(E[0][0]woo + E[0][1]w01 +
E[2][0]w20 + E[2][1]w21 == 0)) alors sort=7 ;
Si ((E[0][1]wo1 + E[1][0]w10 +
E[1][1]w11 + E[1][2]w12 == 4) et
(E[0][0]woo +
E[0][2]w02 +
E[2][0]w20 + E[2][1]w21 + E[2][2]w22 == 0))
alors sort=8 ;
Si ((E[0][1]wo1 + E[1][1]w11 +
E[2][0]w20 + E[2][1]w21 + E[2][2]w22 == 5)
et
(E[0][0]woo + E[0][2]w02 +
E[1][0]w10 + E[1][2]w12 == 0)) alors sort=8 ;
Si ((E[0][1]wo1 + E[1][1]w11 +
E[1][0]w10 + E[1][2]w12 + E[2][1]w21 == 5)
et
(E[0][0]woo + E[0][2]w02 +
E[2][0]w20 + E[2][2]w22 == 0)) alors sort=9 ;
2ème phase : Compréhension de la
structure du tableau
Cette phase permet de générer automatiquement la
structure du tableau détecté à l'aide de
la phase précédente. Pour y arriver, l'aire de
sortie du réseau implémentera l'algorithme
suivant :
Recevoir la matrice M[][] contenant les sorties de tous les
neurones du gradient ;
Initialiser l, c, nbrcolonnes et nbrlignes à 0 ;
Pour i allant de 0 à 290 faire
Pour j allant de 0 à 290 faire
Si ((M[j][i]==7) ou ((M[j][i]==5)) alors
l=1 ; j=291 ;
sinon l=0 ;
FinSi
FinPour
nbrlignes= nbrlignes+l ;
FinPour
Pour i allant de 0 à 290 faire
Pour j allant de 0 à 290 faire
Si (M[i][j]==6) alors

64
c=1 ; j=291 ;
sinon c=0 ;
FinSi
FinPour
nbrcolonnes = nbrcolonnes +c ;
FinPour
Créer le fichier `'Tableau.html» ;
Ouvrir "Tableau.html" ;
Ajouter la chaîne suivante au contenu de
`'Tableau.html»
"<html> \n <head> <style type=\"text/css\">
<!-- table {border-width: 1px; border-
color:black;} td {border-width: 1px; border-style:solid;
border-color:black;} --> </style> \n
<title> STRUCTURE DU TABLEAU</title>\n</head>
<body><center> <table border
style=\"solid\" cellspacing=\"0\">";
Pour i allant de 0 à nbrlignes faire
Ajouter la chaîne "<tr>" au contenu de "Tableau.html"
;
Pour j allant de 0 à nbrcolonnes faire
Ajouter la chaîne "<td><font
color=\"white\">___</font></td>" au contenu de
"Tableau.html" ;
FinPour
Ajouter la chaîne "</tr>" au contenu de
"Tableau.html" ;
FinPour
Ajouter la chaîne
"</table></center></body></html>" au contenu de
"Tableau.html" ;
Fermer "Tableau.html".
Créer le fichier2 `'Tableau.doc» ;
Ouvrir "Tableau.doc" ;
Ajouter la chaîne suivante au contenu de
`'Tableau.doc»
"<html> \n <head> <style type=\"text/css\">
<!-- table {border-width: 1px; border-
color:black;} td {border-width: 1px; border-style:solid;
border-color:black;} --> </style> \n
<title> STRUCTURE DU TABLEAU</title>\n</head>
<body><center> <table border
style=\"solid\" cellspacing=\"0\">";
Pour i allant de 0 à nbrlignes faire
Ajouter la chaîne "<tr>" au contenu de "Tableau.doc"
;

65
Pour j allant de 0 à nbrcolonnes faire
Ajouter la chaîne "<td><font
color=\"white\">___</font></td>" au contenu de
"Tableau.doc" ;
FinPour
Ajouter la chaîne "</tr>" au contenu de "Tableau.doc"
;
FinPour
Ajouter la chaîne
"</table></center></body></html>" au contenu de
"Tableau.doc" ;
Fermer "Tableau.doc".
3.4. Conclusion
En fin de compte, notre réseau de neurones est
composé de trois couches, à savoir : la rétine, le
gradient et l'aire de sortie. Chaque couche comprend un nombre
déterminé de neurones nécessaires à la fonction qui
est la sienne dans l'algorithme générale de reconnaissance. Par
ailleurs, il importe de remarquer qu'il n'y a pas de connexion entre les
neurones appartenant à une même couche. Par contre, entre les
neurones des différentes couches, il existe bel et bien une ou plusieurs
connexions. Et le nombre de connexions entre une couche et la suivante
dépend du nombre de neurones (de cette couche) dont les sorties sont
reliées à l'entrée d'un neurone de la couche suivante.
C'est à travers cette structure du réseau que,
après un procédé de prétraitement, l'algorithme
parvient à détecter d'abord le tableau en localisant ses
éléments de structuration (Cf. les 11 éléments de
structuration évoqués dans le chapitre précédent)
et à comprendre la structure du tableau détecté en
générant un document html ou un fichier Microsoft Word.

66
CHAPITRE IV. IMPLEMENTATION DU RESEAU ET RESULTATS
4.1. Objectifs et but
Afin de marier la théorie à la pratique, nous
nous proposons de traduire, dans ce chapitre, les algorithmes
précédemment décrites dans un langage
compréhensible par l'ordinateur. Il est évident que plusieurs
langages de programmations se prêtent bien à cette traduction.
Cependant, pour des raisons de souplesse et surtout à cause de sa
rigueur et de sa portabilité, nous avons choisi d'implémenter
notre réseau de neurones en langage Java. Ainsi, ayant la
réalisation de notre système de reconnaissance comme toile de
fond, ce chapitre a pour but de détailler d'une manière beaucoup
plus précise les différents modules qui constituent notre
programme de reconnaissance des tableaux. Pour ce faire, nous étalerons
d'abord l'implémentation du procédé de
prétraitement, ensuite nous implémenterons le réseau de
neurones et enfin, nous analyserons le résultat des tests du programme
sur quelques documents.
4.2. Architecture logiciel de l'application
Avant d'examiner en détail l'implémentation en Java
des algorithmes du chapitre précédent, nous présentons
d'abord l'architecture de notre application dans le diagramme des classes
ci-dessous :
Reseau
quit : Button dem : Batton alp : Button
handleCvent° : boolean main° :void
1
1
1
Aire Sortie
grad : Graillent n : Arad M : irt
lignes : Int colonnes : int
3radient
7G : Ngrad 7eu : Ngrad Ret : Reline 7F-et : Neurone 7s :
Ngrad
etNeurone0(po3N01 : irt,posNO2 : int) : Ngrad
getNeurones(nombreN1 : int,nombreN2 : int) : Ngradpp
Aid
quit : Buffo
handleEvent° : boolean
Refine
nR : Neurone
neuR : Neurone
nR
· Naiirnna
image : Bufferedlmage
irnageTvpee : Bufferedlmacie
trame : WritableRaster
pi:tel : int
y: int
rgb : int
getNeuroneR(posNR1 : int,posNR2 : int) : Neurone
cletNeuronesR(nornbreNR1 : int,nornbreNR2 : int) : Neuronelll
|
1
|
1
|
|
|
Neurone
|
|
|
|
Pretraitement
|
|
entree : in1 sortie : int
|
|
|
Image : Burreredlmage imgRB : Bufferedlmage filename : String
|
|
getEntree(p : intp) : intp setSortie(pix : intp) : int
getSortie(n : Neurone) : int
|
|
|
reduir=Taille(img : Bufferedlmage) : Bufferedlmage
binarisation(irng : void) : Bufferedlmage gotlmagoRB° : BufforolImago
|
Ng ad
entree : Veurone
sortie : int
E:int
vint
:int

68
4.3.Implémentation du prétraitement
Ecrit en code java, le procédé de
prétraitement se présente comme suit :
/**
*
* Classe du Prétraitement
* @author BISIMWA MUGISHO Pacifique
* @version 1.1
* @since 1.0
* @created on 15th June, 2012, 09:19
*
*/
import java.awt.image.*;
import javax.imageio.*;
import java.io.*;
import java.awt.geom.A ffineTrans form;
import java.awt.image.A ffineTrans formOp;
import javax.swing.JFileChooser;
public class Pretraitement{
/**
* Constructeur de la classe Pretraitement
* La méthode reçoit le fichier image au
format jpeg.
* Ensuite la méthode reduit la taille de l'image
avant de le binariser
* L'image réduite et binarisée est
retournée par la méthode @see getImageRB
*/
Bu fferedImage image,imgRB; String filename;
Pretraitement() throws IOException{
JFileChooser choix = new JFileChooser();
choix.setToolTipText("Sélectionnez l'image du
tableau à reconnaître "); i f (choix.showOpenDialog(null) ==
JFileChooser.OPEN_DIALOG){ filename =choix.getSelectedFile().getAbsolutePath();
image=ImageIO.read(new File(filename));}
this.imgRB=binarisation(reduireTaille(image));
}
/**
* Méthode qui réduit la taille de
l'image.
* La méthode prend en entrée une image
temporaire.
* Ensuite la méthode calcule la valeur du ratio
de réduction.
* Après quoi,l'image d'entrée est
reduite.
* @param img l'image temporaire représentant
l'image d'entrée.
* @return imgReduite */
public Bu fferedImage reduireTaille(Bu fferedImage img)
throws IOException{
float ratio,a,b; int e, f;
ratio=(float)1;
e=300; f=300;
a=img.getwidth(); b=img.getHeight();
//Calcul du rapport de taille:
i f ((a*300)>(300*b)){
ratio=300/a;
}else{
ratio=300/b;
}
i f ((b<=300)&&(a<=300)){
e=(int)a;f=(int)b; ratio=(float)1;
}
//Reduction de la taille de l'image:
Bu fferedImage imgReduite=new Bu fferedImage(e,
f,img.getType());
AffineTransform
retailler=A ffineTrans
form.getScaleInstance(ratio,ratio);
int
interpolation=AffineTransformOp.TYPE_BICUBIC;
*
A ffineTrans formOp retaillerimage=new A ffineTrans
formOp(retailler,interpolation);
retaillerimage.filter(img,imgReduite); return
imgReduite;
}
/**
* Méthode qui binarise l'image.
* La méthode prend en entrée une image
temporaire.
* Ensuite la méthode recherche le niveau de
couleur maximal de
l'image.

69
Après quoi,l'image d'entrée est
binarisée.
* @param img l'image temporaire représentant
l'image d'entrée.
* @return imageBinarise
*/
public Bufferedlmage binarisation(Bufferedlmage img)
throws
IOException{
int[][] pixel=new
int[img.getHeight()][img.getwidth()];
int[] rgb=new int[3];
writableRaster trame=img.getRaster();
int seuil=0;
//Recherche du niveau de couleur maximal de
l'image.
for (int i=0;i<img.getHeight();i++){
for (int j=0;j<img.getwidth();j++){
trame.getPixel(j,i,rgb);
pixel[i][j]=rgb[0]+rgb[1]+rgb[2];
i f (pixel[i][j]>seuil){
seuil=pixel[i][j];
}
}
}
//Calcul du seuil de binarisation de
l'image:
seuil=((10*seuil)-1-Math.abs(seuil-765))/11;
//Binarisation de l'image:
Bufferedlmage imageBinarise = new
Bu fferedlmage(img.getwidth(),img.getHeight(),
Bufferedlmage.TYPE_INT_RGB);
writableRaster
trame2=imageBinarise.getRaster();
for (int
i=0;i<imageBinarise.getHeight();i++){
for (int
j=0;j<imageBinarise.getwidth();j++){
i f (pixel[i][j]<seuil){
}else{
}
}
rgb[0]=0;rgb[1]=0;rgb[2]=0;
trame2.setPixel(j,i,rgb);
rgb[0]=255;rgb[1]=255;rgb[2]=255;
trame2.setPixel(j,i,rgb);
}
return imageBinarise;
}
/**
* Méthode qui retourne l'image après tout
le processus de
* prétraitement.
* @return imgRB.
*/
}
Bufferedlmage getlmageRB(){ return
this.imgRB;
}
4.4. Implémentation du réseau de
neurones
4.4.1. Quelques considérations d'ordre
techniques
De prime abord, avouons que l'implémentation
d'un réseau de neurones n'est pas du tout aussi simple qu'on puisse
l'imaginer. Cela est d'autant plus vrai que, dans la réalité,
la

70
configuration spatiale même du réseau
(une configuration en 3D !) n'est pas facile à mettre en oeuvre lorsque
l'on travaille avec des données dans un espace 2D.
Cela étant, afin de matérialiser notre
réseau dans des dimensions acceptables (similaires au 3D), nous avons
recouru à des objets disponibles dans le langage Java, à savoir :
les conteneurs.
En fait, en Java, les conteneurs ne sont rien
d'autres que des objets permettant de stocker soit d'autres objets ou des
scalaires. De plus, il sied de noter que les classes conteneurs ne peuvent
stocker que des références sur des objets. Parmi les conteneurs
les plus utilisés en Java (ou offerts dans les bibliothèques du
langage Java), nous trouvons : les énumérateurs (Enumerator), les
vecteurs (Vector), les itérateurs (Iterator), les listes (ArrayList) ,
les tableaux, etc. De tous ces conteneurs, nous avons choisi d'utiliser les
tableaux pour implémenter notre réseau, et cela, pour les raisons
suivantes :
- Un tableau peut stocker directement des scalaires
aussi bien que des références sur des objets.
- Il est bien plus facile de créer un tableau
et d'accéder à n'importe quel de
ses
éléments.
4.4.2. Implémentation du neurone de la
Rétine
Ecrit en code Java, un neurone de la Rétine se
présente de la manière suivante :
/**
*
* Classe du neurone de la retine
* @author BISIMWA MUGISHO Pacifique
* @version 1.1
* @since 1.0
* @created on 15th June,2012, 09:19
*
*/
public class Neurone{
int[] entree; //variable d'entrée du
neurone
int sortie; //variable de sortie du neurone
/**
* Constructeur de la classe Neurone
* La méthode prend en entrée un tableau de
trois entiers représentant
* les trois couleurs RVB d'un pixel de
l'image.
* Ensuite la méthode fixe la valeur de sortie du
neurone en utilisant
* la valeur retournée par la méthode @see
setSortie
* @param int[]ent le tableau des couleurs RVB
(rouge,vert,bleu) */
Neurone (int[] ent){ this.entree=new int[3]; for (int
i=0;i<3;i++){ this.entree[i]=ent[i]; }
sortie=0;
sortie=setSortie(entree);

71
}
~**
* Méthode qui retourne les valeurs
d'entrée du neurone
* La méthode prend en entrée un tableau
de trois entiers représentant
* les trois couleurs RVB d'un pixel de
l'image.
* Ensuite la méthode fixe la valeur
d'entrée du neurone en lisant
* les trois entiers RVB du pixel
d'entrée.
* @param int[]p le tableau des couleurs RVB
(rouge,vert,bleu) du pixel p
* @return entree
*1
public int[] getEntree(int[] p){ for (int
i=0;i<3;i++){ this.entree[i]=p[i]; }return entree;
}
~**
* Méthode qui calcule la valeur de sortie du
neurone
* La méthode prend en entrée un tableau de
trois entiers représentant
* les trois couleurs RVB d'un pixel de
l'image.
* Ensuite la méthode fixe la valeur
d'entrée du neurone en lisant
* les trois entiers RVB du pixel
d'entrée.
* @param int[]pix le tableau des couleurs RVB
(rouge,vert,bleu) du pixel pix
* @return sortN
*1
public int setSortie(int[] pix){ int[] sort;
int sortN;
sort=new int[3]; sortN=0; sort=getEntree(pix); for (int
i=0;i<3;i++){
sortN+=sort[i];
}
i f (sortN==0){
sortN=1;
}else {
sortN=0;
}
return sortN;
}
~**
* Méthode qui retourne la valeur de sortie du
neurone
* Ensuite la méthode fixe la valeur de sortie en
la calculant à partir
* de la méthode @see setSortie
* les trois entiers RVB du pixel
d'entrée.
* @param n le neurone pour lequel l'on désire
obtenir la valeur de sortie
* @return sortieN
*1
public int getSortie(Neurone n){ int sortieN;
sortieN=setSortie(n.entree); return sortieN;
}
}
4.4.3. Implémentation de la couche
`'Retine»
Ecrite en code Java, la couche de la rétine se
présente comme suit : ~**
*
* Classe de la couche Rétine
* @author BISIMWA MUGISHO Pacifique
* @version 1.1
* @since 1.0
* @created on 15th June,2012, 09:19
*
*/
import java.awt.image.*;
import java.io.*;

72
public class Retine{
Neurone nR; //variable du neurone de la
retine
public Neurone[][] neuR;//variable de la matrice des
neurones de la
retine
Neurone[][] nsR; //variable de la matrice d'un certain
nombre de neurones de la rétine
public static Bufferedzmage image,imageTypee;//variables
de l'image temporaire.
writableRaster trame;//variable de la trame de l'image
d'entrée. int [][]pixel,y; //variable de la matrice
d'entiers.
int [] rgb; //variable du tableau de composantes rvb de
l'image d'entrée.
/**
* Constructeur de la classe Retine
* La méthode crée d'abord une matrice de
300x300 neurones correspondant
* aux pixels de l'image d'entrée.Ensuite,
après avoir lu l'image d'entrée,
* cette dernière est transférée
vers une zone d'image temporaire où elle est
* typée afin de pouvoir en extraire la trame
de pixels qui la composent.
* Après lecture de la trame de pixels, il y a
extraction des composantes rvb
* de chaque pixel et transfert de ces composantes vers
une matrice d'entiers
* qui servira de paramètre à la
méthode du constructeur de la classe @see Neurone.
*
*/
Retine() throws zOException{
neuR=new Neurone[300][300];
Pretraitement p=new Pretraitement();
image=p.getzmageRB();
trame=image.getRaster();
pixel=new int[image.getHeight()][image.getwidth()];
rgb=new
int[4];
int[] RVB=new int[3];
for (int i=0;i<300;i++){
for (int j=0;j<300;j++){
trame.getPixel(i,j,rgb);
RVB[0]=rgb[0];
RVB[1]=rgb[1];
RVB[2]=rgb[2];
neuR[i][j]=new Neurone(RVB);
}
}
}
/**
* Méthode qui retourne un neurone se trouvant
à la position (posNRl,posNR2).
* @param posNRl l'abscisse de la position du neurone
dans la Retine
* @param posNR2 l'ordonnée de la position du
neurone dans la Retine
* @return Neurone
*/
public Neurone getNeuroneR(int posNRl,int
posNR2){
nR=neuR[posNR2][posNRl];
return nR;
}
/**
* Méthode qui retourne une matrice de neurones
nombreNRl x nombreNR2.
* @param nombreNRl le nombre de colonnes de la
matrice de neurones de la Retine
* @param nombreNR2 le nombre de lignes de la matrice de
neurones de la Retine
* @return Neurone[H] []
*/
public Neurone[][] getNeuronesR(int nombreNRl,int
nombreNR2){
nsR=new Neurone[nombreNR2][nombreNR1];
for (int i=0;i<nombreNRl;i++){
for (int j=0;j<nombreNR2;j++){
nsR[i][j]=neuR[i][j];
}
}return nsR; }

73
}
4.4.4. Implémentation du neurone de Gradient
Ecrit en Java, un neurone du Gradient se présente
comme suit :
/**
*
* Classe du neurone du Gradient
* @author BISIMWA MUGISHO Pacifique
* @version 1.1
* @since 1.0
*
*/
import java.io.*;
public class Ngrad{
public Neurone[][] entree;//variable d'entrée du
neurone public int sortie; //variable de sortie du neurone public int[][] E;
int sortN=0;int v=0,w=0;
/**
* Constructeur de la classe Ngrad
* La méthode prend en entrée un tableau de
neuf entiers représentant
* les neuf sorties des neurones de la
Retine.
* Ensuite la méthode fixe la valeur de sortie
du neurone du gradient en utilisant
* la valeur retournée par la méthode
@see getSortie
* @param ret represente la Retine
* @param posx représente l'abscisse du neurone
du Gradient
* @param posY représente l'ordonnée du
neurone du Gradient
*
*/
Ngrad(Retine ret, int posx,int posY) throws
IOException{
entree=new Neurone[3][3];
E=new int[3][3];
v=posx+0; w=posY+0;
entree[0][0]=ret.getNeuroneR(w,v);
v=posx+0; w=posY+1;
entree[0][1]=ret.getNeuroneR(w,v);
v=posx+0; w=posY+2;
entree[0][2]=ret.getNeuroneR(w,v);
v=posx+1; w=posY+0;
entree[1][0]=ret.getNeuroneR(w,v);
v=posx+1; w=posY+1;
entree[1][1]=ret.getNeuroneR(w,v);
v=posx+1; w=posY+2;
entree[1][2]=ret.getNeuroneR(w,v);
v=posx+2; w=posY+0;
entree[2][0]=ret.getNeuroneR(w,v);
v=posx+2; w=posY+1;
entree[2][1]=ret.getNeuroneR(w,v);
v=posx+2; w=posY+2;
entree[2][2]=ret.getNeuroneR(w,v);
|
for (int i=0;i<3;i++){
for (int j=0;j<3; ++){
E[i][j]=entree[i][j].sortie; }
}
i f ((E[0][0]+E[0][1]+E[0][2] ==3) &&
(E[1][0]
|
+ E[1][1]
|
+E[1][2]
|
+E[2][0] +E[2][1] +E[2][2] ==0))
|
sortN=10 ;
|
|
|
i f ((E[1][0]+E[1][1]+E[1][2]
|
==3) && (E[0][0]
|
+ E[0][1]
|
+E[0][2]
|
+E[2][0] +E[2][1] +E[2][2] ==0))
|
sortN=10 ;
|
|
|
i f ((E[2][0]+E[2][1]+E[2][2]
|
==3) && (E[0][0]
|
+ E[0][1]
|
+E[0][2]
|
+E[1][0] +E[1][1] +E[1][2] ==0))
|
sortN=10 ;
|
|
|

74
i f ((E[0][0]+E[1][0]+E[2][0] ==3) && (E[0][1] +
E[1][1]
+E[2][1] +E[0][2] +E[1][2] +E[2][2] ==0)) sortN=11
;
i f ((E[0][1]+E[1][1]+E[2][1] ==3) && (E[0][0] +
E[1][0]
+E[2][0] +E[0][2] +E[1][2] +E[2][2] ==0)) sortN=11 ;
i
f ((E[0][2]+E[1][2]+E[2][2] ==3) && (E[0][0] + E[1][0]
+E[2][0] +E[0][1] +E[1][1] +E[2][1] ==0)) sortN=11
;
i f ((E[2][1]+E[1][1]+E[1][2] ==3) && (E[0][0] +
E[1][0]
+E[2][0] +E[0][1] +E[0][2] +E[2][2] ==0)) sortN=1
;
i f ((E[1][0]+ E[1][1] +E[2][1] ==3) && (E[0][0]
+
E[2][0] +E[0][1] +E[0][2] +E[1][2] +E[2][2] ==0))
sortN=2 ;
i f ((E[1][0]+ E[1][1] +E[0][1] ==3) && (E[0][0]
+E[0][2]
+E[1][2] +E[2][0] +E[2][1] +E[2][2] ==0)) sortN=3
;
i f ((E[0][1] +E[1][1] +E[1][2] ==3) && (E[0][0]
+E[1][0]
+E[2][0] +E[2][1] +E[2][2] +E[0][2] ==0)) sortN=4
;
i f ((E[0][1] +E[1][1] +E[1][2] +E[2][1] ==4) &&
(E[0][0]
+E[1][0] +E[2][0] +E[2][2] +E[0][2] ==0)) sortN=5
;
i f ((E[1][0] +E[1][1] +E[1][2] +E[2][1] ==4) &&
(E[0][0]
+E[0][1] +E[0][2] +E[2][0] +E[2][2] ==0)) sortN=6
;
i f ((E[0][1] +E[1][1] +E[1][0] +E[2][1] ==4) &&
(E[0][0]
+E[0][2] +E[1][2] +E[2][2] +E[2][0] ==0)) sortN=7
;
i f ((E[0][1] +E[1][0] +E[1][1] +E[1][2] ==4) &&
(E[0][0]
+E[0][2] +E[2][0] +E[2][1] +E[2][2] ==0)) sortN=8
;
i f ((E[0][1] +E[1][1] +E[1][0] +E[1][2] +E[2][1] ==5)
&&
(E[0][0] +E[0][2] +E[2][0] +E[2][2] ==0)) sortN=9
;
this.sortie=sortN;
}
}
4.4.5. Implémentation de la couche
`'Gradient»
Ecrite en code Java, la couche du Gradient se
présente comme suit :
/**
*
* Classe du Gradient
* @author BISIMWA MUGISHO Pacifique
* @version 1.1
* @since 1.0
* @created on 15th June,2012, 09:19
*
*/
import java.awt.image.*;
import javax.imageio.*;
import java.io.*;
public class Gradient{
Ngrad nG; //variable du neurone du Gradient
public static Ngrad[][] neuG;//variable de la matrice
des neurones du
Gradient
public Retine Ret;//variable de la couche
"rétine"
Neurone[][] nRet;//variable de la matrice des neurones
de la rétine
Ngrad[][] nsG;//variable de la matrice d'un certain
nombre de
neurones du Gradient
/**
* Constructeur de la classe Gradient
* La méthode crée d'abord une matrice de
291x291 neurones correspondant
* aux sorties des neurones de la Retine.
* Ensuite la méthode récupère les
sorties de 9 neurones de rétine pour chacun de ses neurones.
*
*/
Gradient() throws IOException{
Ret=new Retine();
neuG=new Ngrad[291][291];
Bu fferedImage img=new
Bu fferedImage(291,291,Bu
fferedImage.TYPE_INT_RGB);

75
WritableRaster trameG=img.getRaster();
int[] rgb2=new int[3];
int a ff=0;
}
}
or (int i=0;i<291;i++){
for (int j=0;j<291;j++){
neuG[j][i]=new Ngrad(Ret,j,i);
a ff=neuG[j][i].getSortie(neuG,j,i);
// System.out.print(a ff);
}
// System.out.println("");
or (int i=0;i<291;i++){
for (int j=0;'<291;j++){
a ff=neuG[j][i].getSortie(neuG,j,i);
i f (a ff==0){
rgb2[0]=255;rgb2[1]=255;rgb2[2]=255;
}else{
rgb2[0]=0;rgb2[1]=0;rgb2[2]=0;
}
trameG.setPixel(j,i,rgb2);
}
}
/**
* Méthode qui retourne un neurone se trouvant
à la position (posNG1,posNG2).
* @param posNG1 l'abscisse de la position du neurone
dans le Gradient
* @param posNG2 l'ordonnée de la position du
neurone dans le Gradient
* @return nG
*/
public Ngrad getNeuroneG(int posNG1,int
posNG2){
nG=neuG[posNG2][posNG1];
return nG;
}
/**
* Méthode qui retourne une matrice de neurones
nombreNG1 X nombreNG2.
* @param nombreNG1 le nombre de colonnes de la
matrice de neurones du Gradient
* @param nombreNG2 le nombre de lignes de la matrice de
neurones du Gradient
* @return nsG
*/
public Ngrad[][] getNeuronesG(int nombreNG1,int
nombreNG2){ nsG=new Ngrad [nombreNG2][nombreNG1]; for (int
i=0;i<nombreNG1;i++){
for (int j=0;j<nombreNG2;j++){
nsG[j][i]=neuG[j][i];
}
}
return nsG;
}
}
4.4.6. Implémentation de l'Aire de
sortie
Ecrite en langage Java, l'Aire de sortie se
présente de la manière suivante : /**
*
* Classe de l'Aire de sortie
* @author BISIMWA MUGISHO Pacifique
* @version 1.1
* @since 1.0
* @created on 15th June,2012, 09:19
*
*/
import java.io.*;
public class AireSortie{

76
public Gradient grad; Ngrad [][] nG;
int M[][];
int lignes,colonnes,n,m; /**
* Constructeur de la classe AireSortie
* La méthode crée d'abord une matrice de
291x291 neurones correspondant
* aux sorties des neurones du Gradient.
* Ensuite la méthode récupère les
sorties de tous les neurones du Gradient.
* Après quoi, la méthode compte le
nombre de lignes et de colonnes du tableau
* avant de générer sa structure au
format HTML et au format MS
WORD.
*/
AireSortie() throws zOException{
lignes=0;colonnes=0;n=0;m=0;
grad=new Gradient();
M=new int[291][291];
or (int l=0;l<291;l++){
or (int p=0;p<291;p++){
M[l][p]=grad.getNeuroneG(p,l).sortie;
}
}
//Décompte du nombre de lignes du
tableau:
for (int l=0;l<291;l++){
}
for (int p=0;p<291;p++){
i f ((M[l][p]==7)II(M[l][p]==5)){ m=1;
p=291;
} else{m=0;
}
} lignes=lignes+m;
System.out.println("Nombre de lignes=
"+lignes);
//Décompte du nombre de colonnes du
tableau:
for (int l=0;l<291;l++){
for (int p=0;p<291;p++){
i f (M[p][l]==6) {n=1;
p=291;
}else{n=0;
}
} colonnes=colonnes+n;
}
System.out.println("Nombre de colonnes=
"+colonnes);
//Génération de la structure du tableau au
format HTML :
FileWriter fichier;
StringBuffer contenu=new StringBuffer("");
File nfichier;
nfichier=new File("
C:/Tableau.html");
contenu.append("<html> \n <head> <style
type=\"text/css\"> <!-- table
{border-width: 1px; border-color:black;} td
{border-width: 1px; border-
style:solid; border-color:black;} --> </style>
\n <title> STRUCTURE DU
TABLEAU</title>\n</head>
<body><center> <table border style=\"solid\"
cellspacing=\"0\">");
for (int i=0;i<lignes;i++){
contenu.append("<tr>");
for (int j=0;j<colonnes; ++){
contenu.append("<td><font
color=\"white\">_</font></td>");
}
} contenu.append("</tr>");
contenu.append("</table></center></body></html>");
fichier=new FileWriter(nfichier);
fichier.write(contenu.toString()); fichier.close();
//Génération de la structure du tableau au
format MS WORD : FileWriter fichier2;
StringBuffer contenu2=new StringBuffer("");
File n fichier2;

77
n fichier2=new File("
C:/Tableau.doc");
contenu2.append("<html> \n <head> <style
type=\"text/css\"> <!-- table {border-width: 1px; border-color:black;} td
{border-width: 1px; border-style:solid; border-color:black;} -->
</style> \n <title> STRUCTURE DU
TABLEAU</title>\n</head> <body><center> <table
border style=\"solid\" cellspacing=\"0\">");
for (int i=0;i<lisanes;i++){
contenu2.append( <tr>");
for (int j=0;j<colonnes;j++){
}
contenu2.append("</tr>");
contenu2.append("<td>< font
color=\"white\">_</font></td>");
}
contenu2.append("</table></center></body></html>");
fichier2=new FileWriter(n fichier2);
fichier2.write(contenu.toString()); fichier2.close();
}
}
4.4.7. Implémentation du Réseau (classe
principale)
Ecrite en code Java, la classe principale du
réseau se présente de la manière suivante :
/**
*
* Classe principale du Réseau
* @author BISIMWA MUGISHO Pacifique
* @version 1.1
* @since 1.0
* @created on 15th June,2012, 09:19
*
*/
import java.awt.BorderLayout;
import java.awt.Button;
import java.awt.Color;
import java.awt.Dimension;
import java.awt.Event;
import java.awt.FlowLayout;
import java.awt.Font;
import java.awt.Frame;
import java.awt.GridLayout;
import java.awt.Label;
import java.awt.Panel;
import java.awt.Toolkit;
import java.io.*;
public class Reseau extends Frame{
Button quit = new Button("QUITTER LE
PROGRAMME");
Button dem = new Button("DEMARRER LE
PROGRAMME");
Button alp = new Button("AIDE SUR LE
PROGRAMME");
Aid pa12=new Aid();
Reseau(){
Label nord = new Label();Label nord1 = new
Label();
Panel sud = new Panel();
Label est = new Label();Label est1 = new
Label();
Label ouest = new Label();
Panel centre = new Panel();Panel centre1 = new
Panel();
setTitle("RECONNAISSANCE DES TABLEAUX");
setBackground(new Color(220,220,225));
setLayout(new BorderLayout());
add("North",nord);nord.setBackground(new
Color(210,210,255));
add("East",est);est.setBackground(new
Color(210,210,255));
add("Center",centre);centre.setBackground(new
Color(205,205,255));
add("West",ouest);ouest.setBackground(new
Color(210,210,255));

78
add("South",sud);sud.setBackground(new
Color(210,210,255));
FlowLayout fs_new FlowLayout(FlowLayout.CENTER);
sud.setLayout( fs);
sud.add(quit);quit.setBackground(new Color(100,200,230));
sud.add(dem);dem.setBackground(new Color(100,200,230));
sud.add(alp);alp.setBackground(new Color(100,200,230)); BorderLayout bes_new
BorderLayout();
centre.setLayout(bes);
centre.add("North",nord1); nord1.setBackground(new
Color(150,250,255));
centre.add("East",est1); est1.setBackground(new
Color(150,250,255));
centre.add("Center",centre1);
centre1.setBackground(new Color(150,250,255));
GridLayout gsoe_new GridLayout(16,1);
Label tit1 _ new Label(" BIENVENU
DANS NOTRE PROGRAMME
");
Label tit2 _ new Label("EXTRACTION DE LA STRUCTURE
D'UN TABLEAU PAR UN RESEAU DE NEURONES");
Label tit3 _ new
Label("_________________________________________________________________
");
Label tit4 _ new Label(" ");
Label tit5 _ new Label(" TRAVAIL PRESENTE ET SOUTENU POUR
L'OBTENTION DU DIPLOME DE LICENCE ");
Label tit6 _ new Label(" EN
PEDAGOGIE APPLIQUEE A L'I.S.P./Bukavu ");
Label tit7 _
new Label("
Département d'INFORMATIQUE DE GESTION
");
Label tit8 _ new Label("
Présenté par:");
Label tit9 _ new Label("
BISIMWA MUGISHO Pacifique");
Label tit10 _ new Label("
Travail dirigé par :");
Label tit11 _ new Label("
Professeur Blaise MWEPU FYAMA");
Label tit12 _ new Label(" ");
Label tit13 _ new
Label("____________________________________________________________");
Label tit14 _ new Label(" ");
Label tit15 _ new
Label("
Année académique 2011 - 2012
");
centre1.setLayout(gsoe);
centre1.add(tit1);tit1.setFont(new
Font("ArialBlack",Font.BOLD,20));tit1.setForeground(new
Color(100,200,230));
centre1.add(tit2);tit2.setFont(new
Font("ArialBlack",Font.BOLD,19));tit2.setForeground(Color.BLUE);
centre1.add(tit3);tit3.setFont(new
Font("ArialBlack",Font.BOLD,28));
centre1.add(tit4);tit4.setBackground(new
Color(100,200,220));
centre1.add(tit5);tit5.setFont(new
Font("Helvetica",Font.BOLD,18));tit5.setBackground(new
Color(230,230,255));
centre1.add(tit6);tit6.setFont(new
Font("Helvetica",Font.BOLD,18));tit6.setBackground(new
Color(230,230,255));
centre1.add(tit7);tit7.setFont(new
Font("Helvetica",Font.BOLD,18));tit7.setBackground(new
Color(230,230,255));
centre1.add(tit8);tit8.setFont(new
Font("Helvetica",Font.BOLD+Font.ITALIC,14));tit8.setBackground(new
Color(230,230,255));
centre1.add(tit9);tit9.setFont(new
Font("Helvetica",Font.BOLD,20));tit9.setBackground(new
Color(230,230,255)); centre1.add(tit10);tit10.setFont(new
Font("Helvetica",Font.BOLD+Font.ITALIC,14));tit10.setBackground(new
Color(230,230,255));
centre1.add(tit11);tit11.setFont(new
Font("Helvetica",Font.BOLD,20));tit11.setBackground(new
Color(230,230,255));

79
centrel.add(titl2);titl2.setBackground(new
Color(l00,200,220)); centrel.add(titl3);titl3.setFont(new
Font("ArialBlack",Font.BOLD,30));
centrel.add(titl4);
centrel.add(titl5);titl5.setFont(new
Font("ArialBlack",Font.BOLD+Font.ITALIC,l4));
this.setSize(800,550);
this.setvisible(true);
Dimension screen = Toolkit.getDe
faultToolkit().getScreenSize(); this.setLocation((screen.width -
this.getSize().width)/9,(screen.height -
this.getSize().height)/45);
/**
}
******************************************************************
********************************/
public boolean handleEvent(Event evtl){
/********************************************************************
***************/
i f(evtl.target instanceo f Button){
String strbAc=(String)evtl.arg;
if(strbAc==null)return false;
/********************************************************************
***************/
i f(strbAc.equals("QUITTER LE PROGRAMME")){
System.exit(l);
return true;
}
**********/
if(strbAc.equals("DEMARRER LE PROGRAMME")){
try {
//Détection et extraction de la structure du
tableau :
new AireSortie();
//Affichage de la structure du tableau :
Runtime.getRuntime().exec(new String[]{
"rundll32",
"url.dll,FileProtocolHandler", "
C:/Users/BMP/Desktop/TP2/Tableau.html"});
} catch (IOException e) {
e.printStackTrace();
}
// System.out.println("DEMARRER LE PROGRAMME");
return
true;
}
**********/
i f(strbAc.equals("AIDE SUR LE PROGRAMME")){
pal2.setvisible(true);
return true;
}
}
return true;
}
public static void main(String[]args)throws
IOException{
//Lancement du programme:
new Reseau();
}
}
Le code de la classe Aid se présente comme suit
:
import java.awt.*; import java.io.*;
@SuppressWarnings("serial")
class Aid extends Frame{
Button quit = new Button("retourner");
Aid(){
setTitle("GUIDE DE L'UTILISATEUR");
setBackground(Color.green);
Label nord = new Label();Label nordl = new
Label();
Panel sud = new Panel();
FlowLayout fs=new FlowLayout(FlowLayout.CENTER);
sud.setLayout( fs);
sud.add(quit);quit.setBackground(new Color(l00,l00,225));
Label est = new Label();Label estl = new Label(); Label ouest = new
Label();
Panel centre = new Panel();Panel centrel = new
Panel();
Label nord2 = new Label("
pacifiquemugisho@yahoo.fr
Tél: 099275830l");
Label sud2 = new Label();
Label est2 = new Label();
Label ouest2 = new Label();
TextArea centre2 = new
Textarea();centre2.setBackground(new
Color(200,225,225));
try{
InputStream ips=new FileInputStream("
C:/aidepro.txt");
InputStreamReader ipsr=new InputStreamReader(ips);
BufferedReader br=new BufferedReader(ipsr);
String ligne,chaine;chaine=new String();
while ((ligne=br.readLine())!=null){
System.out.println(ligne);
centre2.setText(chaine+=ligne+"\n");

80
}
br.close();
}catch(IOException
ioe){System.out.println();}
setLayout(new BorderLayout());
add("North",nord);nord.setBackground(new
Color(l50,250,255)); add("East",est);est.setBackground(new Color(l50,250,255));
add("Center",centre);centre.setBackground(new Color(l50,250,255));
add("west",ouest);ouest.setBackground(new
Color(l50,250,255)); add("South",sud);sud.setBackground(new
Color(l50,250,255)); BorderLayout bes=new BorderLayout();
centre.setLayout(bes);
centre.add("North",nordl); nordl.setBackground(new
Color(l50,250,255));
centre.add("East",estl); estl.setBackground(new
Color(l50,250,255));
centre.add("Center",centrel); centrel.setBackground(new
Color(l50,250,255));
BorderLayout besl=new BorderLayout();
centrel.setLayout(besl);
centrel.add("North",nord2);nord2.setBackground(new
Color(l50,250,255));
centrel.add("East",est2);est2.setBackground(new
Color(l50,250,255));
centrel.add("Center",centre2);
centrel.add("west",ouest2);ouest2.setBackground(new
Color(l50,250,255));
centrel.add("South",sud2);sud2.setBackground(new
Color(l50,250,255));
this.setSize(500,400);
Dimension screen =
Toolkit.getDefaultToolkit().getScreenSize();
this.setLocation((screen.width -
this.getSize().width)/9,(screen.height -
this.getSize().height)/45);
}
/**************************************************************************
**************************/
public boolean handleEvent(Event evtl){
/********************************************************************
***************/
i f(evtl.target instanceo f Button){
String strbai=(String)evtl.arg;
if(strbAi==null)return false;
/********************************************************************
***************/
if(strbai.equals("retourner")){
// p.setvisible(true);
this.setvisible(false);

81
//System.exit(1);
//system.out.println("retourner");
return true;
}
}
return true;
}
~~~~~~~~~~~~~~~~~~~~~~~~~~~/
}
4.5. Expérimentation
Dans une perspective de vérification du
fonctionnement de notre système de
reconnaissance et de validation de la méthodologie
utilisée, nous l'avons expérimenté sur quelques documents
tabulaires.
a. Préparation des données de test
· Résolution et dimension de l'image
d'entrée
Comme nous l'avons signalé
précédemment, notre système est capable de recevoir des
images ayant une dimension de 300X300 pixels ou plus. La résolution
retenue et convenable au système pour l'image d'entrée est 75pp
(ou 75dpi).
· Type ou nature de documents
d'entrée
L'acquisition des images d'entrée s'est faite
via un scanneur à plat (de marque CanonScan LiDE 100). Comme nous
l'avons signalé précédemment toujours, les documents
traités par notre système sont des documents imprimés
contenant un tableau simple vide ou rempli de texte. Le format retenu pour ces
images de tableau est le format JPEG (*.jpg). Nous l'avons retenu parce que
c'est un format convenable pour des images de petite taille (cf. les
caractéristiques de compression de ce format).
· Nombre de documents
utilisés
Aux fins de mesurer l'efficacité de la
méthodologie utilisée, nous avons testé notre programme
sur quatre documents tabulaires présentant des caractéristiques
différentes :
- un document avec tableau et texte aux dimensions 300 X
300 (sans inclinaison) ;
- un document avec tableau sans texte aux dimensions 300
X 300 (avec inclinaison) ;
- un document avec tableau et texte aux dimensions 637 X
876 (sans inclinaison) ;
- un document avec tableau sans texte aux dimensions 637
X 876 (avec inclinaison).

82
b. Mesure des performances
Signalons que plusieurs mesures de performance ont
été proposées pour évaluer les algorithmes de
détection de tableaux. Et, d'après Zannibi et ses
collaborateurs42, les mesures les plus simples comprennent : la
précision et l'exactitude de représentation. Les mesures les plus
sophistiquées comprennent le calcul de la similarité de 2
documents en considérant la structure de leurs tableaux. Zannibi et ses
collaborateurs ajoutent aussi que pour évaluer un système de
reconnaissance de tableaux, la structure physique et / ou logique des tableaux
dans les documents doit être codé ; et ce codage doit s'appuyer
sur une vérité de base.
Ainsi, pour évaluer notre système de
reconnaissance de tableaux, nous avons choisi de coder la structure des
tableaux en nombre de lignes et nombre de colonnes. Dans la suite, nous
utiliserons donc les mesures basées sur les rapports (ou ratios) entre
le nombre de lignes et de colonnes du tableau détecté et le
nombre de lignes et de colonnes du tableau physique. Ces ratios sont
calculés de la manière suivante :
- Ratio de détection correcte de lignes
:
RL =
nombre de lignes
détectées
nombre de lignes du tableau
physique
- Ratio de détection correcte des colonnes
:
Rc =
nombre de colonnes
détectées nombre de
colonnes du tableau physique
- Ratio de détection correcte du tableau
:
|
c. Résultats
expérimentaux
|
RT =
|
RL Rc
|
Le tableau ci - dessous donne un aperçu des
résultats obtenus à l'issue du test de notre système de
reconnaissance sur 4 images de tableau présentant des
caractéristiques différentes :
42 Zannibi R. et al.,Op.
cit.

83
|
Image
|
Tableau détecté
( RT en %
)
|
Ligne(s) détectée(s) ( RL en
% )
|
Colonne(s)
détectée(s)
( Rc en
% )
|
Observation
|
|
Tableau avec texte aux dimensions 300 X 300
|
65,21
|
65,21
|
100
|
Image sans inclinaison
|
|
Tableau sans texte aux dimensions 300 X 300
|
21,73
|
21,73
|
100
|
Image avec légère inclinaison
|
|
Tableau avec texte aux dimensions 637 X 876
|
70
|
86,95
|
66,66
|
Image sans inclinaison
|
|
Tableau sans texte aux dimensions 637 X 876
|
17,39
|
17,39
|
100
|
Image avec légère inclinaison
|
De visu, les résultats ci-hauts montrent que la
performance de notre système de reconnaissance est liée aussi
bien à la dimension qu'à la rectitude de l'image d'entrée.
Plus l'image d'entrée est de grande dimension et inclinée, moins
elle sera détectée (cf. 17,39%). Plus l'image d'entrée est
de grande dimension et non inclinée, plus bonne sera sa détection
(cf. 70%).
4.6. Conclusion
Dans ce chapitre, nous avons étalé, de
manière précise, notre démarche d'implémentation du
réseau de neurones en langage Java. Pour ce faire, il s'est
avéré nécessaire de souligner la possibilité
d'utilisation des objets très intéressants et disponibles dans le
langage Java, à savoir : les conteneurs. C'est donc à travers ces
derniers que nous avons implémenté l'algorithme d'extraction de
la structure d'un tableau en utilisant un réseau de neurones. Dans le
but de vérifier le fonctionnement du réseau
implémenté, nous l'avons expérimenté sur quelques
tableaux de test.
A l'issue de cette expérimentation, nous avons
constaté que la méthodologie proposée donne des
résultats qui, bien qu'imparfaits, sont néanmoins encourageants
car, comme nous l'avons remarqué, seuls la taille et la position
inclinée de l'image avaient un impact négatif sur les
résultats de la détection.

84
CONCLUSION GENERALE
Notre recherche est partie du constat que le problème
de la réédition automatique des documents imprimés est
encore loin d'être complètement résolu surtout lorsqu'il
s'agit des documents tabulaires. Ce constat nous a amené à
considérer le cas de l'extraction de la structure d'un tableau figurant
sur un document imprimé. De là, nous avons avancé
l'hypothèse selon laquelle un réseau de neurones permettrait
d'extraire la structure d'un tableau à partir de l'image de ce
dernier.
L'hypothèse étant fixée, nous nous sommes
penchés sur la revue de la littérature dans le domaine de la
reconnaissance de tableaux.
A l'issue de cette exploration, nous avons constaté
qu'en dépit du nombre élevé des travaux déjà
réalisés dans le domaine de la reconnaissance des tableaux,
très peu, sinon aucun n'a déjà abordé le
problème d'extraction de la structure des tableaux en utilisant les
réseaux des neurones.
Par la suite, nous avons donc examiné ce
problème en fondant notre approche sur l'implémentation d'un
réseau de neurones utilisant comme seule connaissance à - priori
: les éléments structurels d'un tableau.
Nous avons montré comment calculer le seuil de
binarisation qui permet une bonne détection du tableau par le
réseau de neurones. Et nous avons présenté l'algorithme
d'extraction de la structure d'un tableau par le réseau de neurones
avant de détailler l'implémentation de cet algorithme en langage
Java.
Les résultats expérimentaux préliminaires
nous ont semblé prometteurs mais aussi, ont laissé entrevoir des
zones où des améliorations doivent être faites. Ainsi, des
recherches futurs pourraient examiner comment améliorer l'algorithme du
réseau afin qu'il soit capable de :
- Corriger automatiquement l'angle d'inclinaison d'une image
de tableau,
- Détecter plusieurs tableaux dans un document ;
- Détecter des tableaux présentant une structure
complexe (lignes fusionnées, colonnes fusionnées, etc.),
- Détecter des tableaux ornementaux (c'est - à -
dire des tableaux dont les bordures ne sont pas constitués de lignes
droites).

85
Tels ont été l'objet, la méthode et les
résultats de nos efforts. Certes, ils sont sujets à plus d'une
objection. Néanmoins, nous pouvons compter sur leur mérite dans
la mesure où ils concrétisent notre volonté d'apporter une
pierre à l'édifice de la science.

86
BIBLIOGRAPHIE
I. OUVRAGES ET ARTICLES
· DJUNGU S. J., Intelligence artificielle et
système expert, DIGITAL-Printer, Kinshasa, 2012.
· MUKE M. Z., La recherche en sciences sociales et
humaines : méthodologie et cas concrets, L'Harmattan, Paris,
2011.
· Chen J. et Lopresti D., «Table Detection in Noisy
Off-Line Handwritten Documents» in IEEE, University
Bethlehem, 2011, pp 399-403.
· Shahab A. et al., An open approach towards the
benchmarking of table structure recognition systems, Kaiserslautern,
2010.
· Kawanaka H. et al., Document Recognition and XML
Generation of Tabular Form Discharge summaries for Analogous case Search
System in Methods of Inf med 6, Mie University, Mie, 2007, pp
700-708.
· Shin J. et Guerette N., «Table Recognition and
Evaluation» in Proceedings of the class of 2005 Senior Conference,
DCSSC, Swarthmore, 2005, pp 8-13.
· Zanibbi R.et al., A Survey of Table Recognition:
Models, Observations, Transformations and Inferences, SC, Queen's
University, Ontario, 2003.
· Hu J. et al., «Medium Independant Table
Detection», in Document Recognition and Retrieval VIII
(IS&T/SPIE Electronic Imaging, 2001, pp. 44 - 55.
· Pereira L. A. et al., Recognition of deteriorated
Table-form Documents: A New Approach, UFCG, Brazil, 2000, p 1.
· Kieninger T. V., «Table Structure Recognition
Based on Robust Block Segmentation» in Proceedings of Document
Recognition, volume V., San Jose, CA, 1998, pp 22-32.
· Laurentini A. et Viada P., «Identifying and
Understanding Tabular material in compound Documents» in
IEEE, Torino, 1992, pp 405-409.
II. TFC, MEMOIRES ET THESES
· ISHARA K. R., La reconnaissance optique de
données numériques, mémoire de fin d'études,
IG/ISP-Bukavu, 2010.
· RANGONI Y., Réseau de neurones dynamique :
application à la reconnaissance de structures logiques des
documents, Thèse, Univ. Nancy2, Nancy, 2007.
· KAMPEMPE K. D., La séparation de l'image et
du fond, TFC, IG/ISP-Bukavu, 2006.
· 
87
MONMARCHE N., Algorithmes de fourmis artificielles :
application à la classification et à l'optimisation,
Thèse, UFR, Tours, 2000.
III. COURS
· Koriche F., Cours d'Intelligence Artificielle :
Apprentissage, Université Montpellier II, Montpellier, 2012.
· ZIULU C.T., Cours de statistique inférentielle,
inédit, G2 IG/ISP Bukavu, 2008-2009
· TOUZET C., les réseaux de neurones artificiels
: introduction au connexionnisme, USTL, Montpellier, 1992.
IV. SITES
·
http://en.wikipedia.org/wiki/Riskfunction,
valide le 08/04/2012 à 20h09'
·
http://www.cim.mcgill.ca/~friggi/bayes/decision/risk.html,
valide le 08/04/2012 à 20h15'
·
http://www.cim.mcgill.ca/%7Efriggi/bayes/decision/
?&usg=ALkJrhiDn1gKh6g9e5FmoLjO6QdzT-EmwQ , valide le
08/04/2012 à 21h15'
·
http://fr.wikipedia.org/wiki/Th%C3%A9or%C3%A8medeBayes,
valide le 08/04/2012 à 20h30'
· http://prisma.insa-lyon.fr/~crobardet
, valide le 09/04/2012 à 13h00'
·
http:// www-igm.univ-
mlv.fr/dr/XPOSE2002/Neurones/index1a56.html?rubrique=Neuronebiologique,
valide le 09/04/2012 à 15h20'.
·
http://fr.wikipedia.org/wiki/R%C3%A9seaudeneurones
, valide le 09/04/2012 à 19h23'
·
http://fr.wikipedia.org/wiki/Perceptron
, valide le 09/04/2012 à 21h50'

88
TABLE DE MATIERES
0. INTRODUCTION 1
0.1. Problématique 8
0.2. Hypothèse 9
0.3. Objet, choix et Intérêt du sujet 10
0.4. Etat de la question 10
0.5. Délimitation du sujet 11
0.6. Démarche de recherche, méthodes et techniques
utilisées 11
0.7. Présentation sommaire du travail 12
0.8. Difficultés rencontrées 13
CHAPITRE I. ETAT DE L'ART EN RECONNAISSANCE DES TABLEAUX 14
1.1. Objectifs 14
1.2. Aperçu succinct de la littérature en
reconnaissance des tableaux 14
1.2.1. Types de reconnaissance de tableaux 14
1.2.2. Méthodologies, algorithmes et techniques
utilisés 16
L'approche proposée par Laurentini et Viada 16
La méthodologie proposée par Pereira 18
Le procédé prôné par Zanibbi 19
La méthodologie de Shin et Guerette 25
Les méthodes proposées par Kawanaka 28
L'approche proposée par Chen et Lopresti 29
1.2.3. Analyse et interprétation des données 32
Encodage de données 33
Analyse des méthodes et techniques utilisées 34
Analyse des résultats obtenus par l'utilisation des
différentes méthodes 37
1.2.4. Problèmes et difficultés rencontrés
40
1.2.5. Conclusion 41
CHAPITRE II. LE PROBLEME DE LA RECONNAISSANCE DE TABLEAUX 42
2.1. Objectifs 42

89
2.2. Quelques considérations théoriques du
problème 42
2.2.1. Postulat 42
2.2.2. Considérations 42
2.3. Notre démarche de solution 47
2.3.1. Généralités sur les réseaux
de neurones 48
2.3.1.1. Qu'est ce qu'un réseau de neurones ? 48
2.3.1.2. Structure d'un neurone 49
2.3.1.3. Types et exemples de réseaux de neurones 50
2.3.1.4. Modes d'apprentissage d'un réseau de neurones
52
2.4. Méthodologie adoptée 53
2.5. Conclusion 54
CHAPITRE III. APPLICATION D'UN RESEAU DE NEURONE A LA
RECONNAISSANCE DE
TABLEAUX 55
3.1. Objectifs et but 55
3.2. Choix et composition du réseau de neurones 55
3.2.1. Choix du réseau de neurones 55
3.2.1.1. Le nombre total de neurones 55
3.2.1.2. Type de réseau de neurones choisi 55
3.2.2. Composition du réseau de neurones choisi 56
Le nombre de neurones composant chaque couche 56
L'organisation des neurones dans le réseau 57
3.3. Méthodologie de reconnaissance 58
3.3.1. L'étape du prétraitement 58
3.3.1.1. Réduction de la taille de l'image: 58
3.3.1.2. Binarisation de l'image: 59
3.3.2. L'étape d'extraction des caractéristiques
du tableau 60
1ère phase : Détection du tableau 61
2ème phase : Compréhension de la structure du
tableau 63
3.4. Conclusion 65

90
CHAPITRE IV. IMPLEMENTATION DU RESEAU ET RESULTATS 66
4.1. Objectifs et but 66
4.2. Architecture logiciel de l'application 66
4.3. Implémentation du prétraitement 68
4.4. Implémentation du réseau de neurones 69
4.4.1. Quelques considérations d'ordre techniques 69
4.4.2. Implémentation du neurone de la Rétine 70
4.4.3. Implémentation de la couche `'Retine» 71
4.4.4. Implémentation du neurone de Gradient 73
4.4.5. Implémentation de la couche `'Gradient» 74
4.4.6. Implémentation de l'Aire de sortie 75
4.4.7. Implémentation du Réseau (classe principale)
77
4.5. Expérimentation 81
Préparation des données de test 81
Mesure des performances 82
Résultats expérimentaux 82
4.6. Conclusion 83
CONCLUSION GENERALE 84
BIBLIOGRAPHIE 86
TABLE DE MATIERES 88

91
ANNEXES
I. ALGORITHME DE LA TRANSFORMATION DE HOUGH
Entrée : Image originale sous forme de tableau :
Image1[xMax][yMax]
Sortie : Nouvel image : Image2[xMax][yMax] contenant les
lignes droites détectées.
Structure intermédiaire des données :
Hough[tMax][rMax] pour déterminer les lignes
correspondantes.
Algorithme :
/*Remplissage du Tableau Hough*/
Pour (x=0 ; x<xMax ; x++){
Pour (x=0 ; x<xMax ; x++){
Si (Image1[x][y]>ISeuil){
Pour (t=0 ; t<tMax ; t++){
r=(x-xMax/2)*cos(t)+(y-yMax/2)*sin(t) ;
Si (r>0) { Hough[][]++;}
}
/*Traitement du tableau Hough pour trouver la valeur
maximale*/
Pour (t=0 ; t<tMax ; t++){
Pour (r=0 ; r<rMax ; r++){
Si (Hough[t][r]>HSeuil) {
/*Vérifier le voisinage 5x5 pour trouver le
maximum*/
max=VRAI ;
Pour (dt=(t-2) ;dt<=(t+2) ;dt++)
Pour (dr=(r-2) ;dr<=(r+2) ;dr++)
Si ((dr>=0) et (dr<rMax) et (dt>=0) et (dt<tMax)
et (Hough[dt][dr]>Hough[t][r])) {
max=FAUX ;
arret ;
}
/*Traitement du tableau Hough pour créer l'image de
sortie */
Si (max==VRAI) {
tracerLigne (r,t) ;

92
} }
Procédure tracerLigne(r,t) {
Pour (x=0 ; x<xMax ;x++)
/* calculer y=r/sin(t)-x*cotg(t) et remplir le tableau Image2
*/
}
II. ALGORITHME ISODATA, TEL QUE MODIFIE PAR JIWON SHIN
ET NICK GUERETTE
seuil = rangée / 2;
Tantque (1) {
moyenne_noir = moyenne_blanc = 0;
compteur_noir = compteur_blanc = 0;
pour toutes les zones i inférieur au seuil
dans l'histogramme {
moyenne_noir + = i * compteur_zone [i];
compteur_noir + = compteur_zone [i];
}
pour toutes les zones i pas inférieur au seuil
dans l'histogramme {
moyenne_blanc + = i * compteur_zone [i];
compteur_blanc + = compteur_zone [i];
}
moyenne_noir = moyenne_noir / compteur_noir;
moyenne_blanc = moyenne_blanc / compteur_blanc;
moyenne_pondérée = ((moyenne_noir * biaisblanc
+
moyenne_blanc * biaisnoir)/
(biaisblanc + biaisnoir));
si moyenne_pondérée == seuil, alors
arreter;
sinon
seuil = moyenne_pondérée;
}
retourner seuil;
III. ALGORITHME DE CROISSANCE DE REGION (`'REGION -
GROWING»)

93
Créer la liste « [S] » des points de
départs (triée pour avoir le centre des plus gros blocs
d'abord)
Pour chaque pixel « P » dans la liste « [S]
»
Si le pixel « P » est déjà associé
à une région, alors prendre le pixel « P » suivant
dans
la liste « [S] »
Créer une nouvelle région « [R] »
Ajouter le pixel « P » dans la région « [R]
»
Calculer la valeur/couleur moyenne de « [R] »
Créer la liste « [N] » des pixels voisins du
pixel « P »
Pour chaque pixel « Pn » dans la liste « [N]
»
Si (« Pn » n'est pas associé à une
région ET « R + Pn » est homogène) Alors
Ajouter le pixel « Pn » dans la région «
[R] »
Ajouter les pixels voisins de « Pn » dans la liste
« [N] »
Recalculer la valeur/couleur moyenne de « [R] »
Fin Si Fin Pour
Fin Pour
IV. DOCUMENTS TABULAIRES UTILISES LORS DES TESTS DU
PROGRAMME
(voir pages suivantes)
|
A rid el) Organisatïan
|
€ffectEfs
|
Pourcentzge
|
|
A-.ii.ui;
|
6
|
20
|
|
Etai :un Ol;lis
|
1
|
3,33
|
|
Earreau de Bukavu
|
3
|
3,33
|
|
ADSSE
|
3
|
3,33
|
|
Presse
|
]
|
3r33
|
|
fill et Save The Ciilcirer;
LW
|
1
|
3,3:3
|
|
F.r!s ignCCr'nent
|
1
|
3,33
|
|
Nativris Unies
|
1
|
3,33
|
|
NRC et fv1zCREVU
|
1
|
3,33
|
|
I
·es ASai
|
1
|
3,3.3
|
|
5000ODEFI, CARITAS -DV'PT
|
1
|
3,33
|
|
HOPITALDE PANZI
|
I
|
3:33
|
|
ACTEO
|
4
|
13,33
|
|
PFLARMAKENA
|
1,
|
3,33
|
|
I RAUJMA
|
1
|
3,33'
|
|
OtHA
|
7
|
331
|
|
C0 1Pv1ERCE
|
2
|
e,66
|
|
HCR
|
1
|
3,33
|
|
PNIJ0
|
1
|
3,33
|
|
HERITIER5 DE EA JUSTICE
|
1
|
3,33
|
|
AD CIF
|
j
|
:3, :3
|
|
Total
|
M.3
|
1(30 --
|

I
| 

