|
République Algérienne Démocratique et
Populaire
Ministère de l'enseignement supérieur et de la
recherche scientifique
Université de Tébessa
Faculté
: Sciences et technologie
Département : Informatique
MEMOIRE DE FIN D'ETUDES
En vue de
l'obtention du diplôme d'ingénieur d'état en
informatique
Option : Systèmes d'Informations
Thème
Planification multi-agents pour la composition
dynamique
de services web
Réalisé par : Encadré par
:
Ilhem BRAKNI M. Rohallah BENABOUD
Ouahiba AOUNALLAH
Promotion 2009-2010
Remerciements
Avant tout, nous tenons à remercier Dieu
tout puissant de nous avoir aider à réaliser ce travail.
Puis, nos remerciements s'adressent :
- À nos parents, nos soeurs et nos frères pour
leurs énormes aides et encouragements.
- À notre encadreur M. R Benaboud pour nous avoir
encadré pendant cette année et de nous avoir fait confiance dans
le parcours de notre projet.
- À tous les membres du jury pour l'honneur qu'ils nous
font en acceptant de juger notre travail. - À tous nos enseignants et
nos camarades de promotion « 2009-2010 ».
- Et à toute personne a participée à
l'élaboration de notre projet de prés ou de loin.
Résumé
Le développement rapide dans le monde informatique a
entraîné le développement de nouveaux paradigmes
d'interaction entre applications. Notamment, l'architecture orienté
service a été mise en avant afin de permettre des interactions
entres applications distantes. Cette architecture est construite autour de la
notion de service web. L'intérêt des services web
est de permettre à une entreprise d'exporter, via le réseau
Internet, ses compétences et son savoir-faire, ou encore d'ouvrir de
nouveaux marchés et de nouveaux supports à la vente.
Afin d'exploiter au maximum les avantages de ce nouveaux types
d'applications, la communauté des services web doit ce doter d'outils
donnant la possibilité de pouvoir assembler différents services
entre eux. C'est la composition de services web.
L'approche actuelle de composition de services web consiste
à définir des processus métiers, i.e., des
enchaînements réutilisables de services. Une autre approche
envisageable est la composition « dynamique ». Les
services web sont composés dynamiquement en fonction de leurs
fonctionnalités, et de leur disponibilité.
L'objectif de ce travail est d'étudier les
mécanismes nécessaires à la mise en oeuvre de la
composition dynamique de services web et plus particulièrement de
proposer un modèle de composition s'appuyant sur l'approche agents. Nous
proposons, ensuite, une étude de cas permettant de montrer
l'efficacité du modèle proposé.
Mots-clés : Services web, Agents,
Composition.
Abstract
The rapid development in computing has involved the
development of new paradigms of interaction between applications. Notably, the
service-oriented architecture has been proposed to allow interactions enter
distant applications. This architecture is built around the concept of
web service. The interest of web services is to enable a
company to export via the Internet, its competences and its know-how, or even
to open new markets and new supports for sale.
In order to maximize the benefits of this new type of
applications, web services community must develop tools that give the
possibility to assemble various services among them. It is the
composition of web services.
The current approach to web service composition is to define
business processes, i.e., reusable sequences of services. Another possible
approach is the "dynamic" composition. Web services are
composed dynamically according to their functionality, and availability.
The objective of this work is to study the mechanisms needed
to implement the dynamic composition of web services and more particularly to
propose a composition model based on the agents approach. We propose, then, a
case study allowing the demonstration of the effectiveness of the proposed
model.
Key-words : Web services, Agents,
Composition.
Introduction générale 1
1. Planification et systèmes multi-agents
3
Introduction .. 3
1. La planification .. 3
1.1. Définition et aspects . 3
1.2. La planification classique . 4
1.2.2. Modèle de base . 4
1.2.2. Représentation et langages 4
1.2.3. Recherche d'une solution (calcul d'un plan) 10
2. Les SMA 12
2.1. Qu'est ce qu'un agent? . 12
2.2. Architectures d'agents .. 13
2.2.1. Agents réactifs .. 13
2.2.2. Agents délibératifs 13
2.2.3. Agents hybrides 13
2.3. Systèmes multi-agents 13
3. La planification multi-agents 15
3.1. Planification et coordination . 16
3.2. Modèles de la planification multi-agents 16
3.2.1. Planification centralisée 16
3.2.2. Planification distribuée . 17
Conclusion 17
2. Des services web aux services web sémantiques
18
Introduction .. 18
1. Services web .. 18
1.1. Qu'est ce qu'un service web ? .. 18
1.2. Architecture, modèle de fonctionnement .. 19
1.3. Principales technologies utilisées . 20
1.4. Problèmes existants dans le domaine des services web
22
2. vers les services web sémantiques . 22
3. Services web sémantiques .. 23
3.1. Le langage OWL-S 23
3.1.1. Le Service Profile . 24
3.1.2. Le Service Process Model 25
3.1.3. Le Service Grounding 26
Conclusion 27
3. Composition de services web : état de l'art et
approche proposée 28
Introduction 28
1. La composition : état de l'art 28
1.1. Un model abstrait pour la composition de SW .. 28
1.2. Approches existantes . 30
1.2.1. Composition statique des services web . 31
1.2.2. Composition dynamique des services web 31
2. La composition : Approche proposée . 33
2.1. Spécification du problème . 34
2.3. Le modèle proposé : Présentation
générale et architecture 35
Conclusion 36
4. Composition par planification multi-agents :
Conception du système 37
Introduction .. 37
1. Analyse du système : vue externe et vue interne 37
2. Méthodologies et langages exploités dans la
conception 38
3. Vue externe du système .. 38
3.1. Description générale du système
38
3.2. Identification et représentation des
fonctionnalités offertes par le système 39
3.2.1. Diagramme de cas d'utilisation . 39
3.2.2. Diagrammes d'activités . 41
4. Vue interne du système ... 42
4.1. Architecture interne du système 42
4.2. Architectures internes et fonctionnement des agents . 43
4.3. Interactions entre les agents du système 58
5. Etude de cas 61
Conclusion 62
5. Composition par planification multi-agents :
Réalisation du système 63
Introduction .. 63
1. Etapes de la réalisation 63
2. Outils exploités 63
3. Création des descriptions OWL-S .. 64
4. Implémentation du traducteur OWL-S vers
opérateurs STRIPS 69
5. Implémentation du planificateur . 70
6. Implémentation des agents du système .. 74
7. Interfaces du système . 79
Conclusion 82
Conclusion générale 83
Bibliographie 85
Annexes A-1
Annexe A : Outils pour la conception du système
A-1
1. UML A-1
2. AUML . A-2
3. Le langage FIPA-ACL A-3
|
Table des matières
|
iii
|
|
Annexe B : Outils pour la réalisation du
système
|
B-1
|
|
1.
|
Eclipse .
|
B-1
|
|
2.
|
OWL-S IDE
|
B-1
|
|
3.
|
JADE
|
B-2
|
|
4.
|
JBuilder IDE
|
B-4
|
|
1.1
|
Exemple du monde de blocs
|
5
|
|
1.2
|
L'exemple du monde de blocs dans l'état S'
|
7
|
|
1.3
|
Exemple d'un problème de planification dans le monde des
blocs
|
8
|
|
1.4
|
Modèles de la planification multi-agents
|
17
|
|
2.1
|
Modèle de fonctionnement de l'architecture service web
|
20
|
|
2.5
|
Eléments d'une description OWL-S
|
24
|
|
2.6
|
Ontologie de processus
26
|
|
|
2.7
|
Relation entre OWL-S et WSDL .
|
27
|
|
3.1
|
Cadre général du système de composition de
services
29
|
|
|
3.2
|
Vue générale de l'orchestration
|
30
|
|
3.3
|
Vue générale de la chorégraphie
|
31
|
|
3.4
|
Différentes phases du modèle proposé
|
35
|
|
4.1
|
Description générale du système ..
|
38
|
|
4.2
|
Description externe du système
|
39
|
|
4.3
|
Diagramme de cas d'utilisation du système .
|
40
|
|
4.4
|
Diagramme d'activités pour << Demander service
>> .
|
41
|
|
4.5
|
Diagramme d'activités pour << Annuler demande
service >> ..
|
41
|
|
4.6
|
Diagramme d'activités pour << Fournir owl-s service
et ensemble de données>> ......
|
41
|
|
4.7
|
Diagramme d'activités pour << Identifier
administrateur >>
|
42
|
|
4.8
|
Architecture générale d'un agent cognitif
|
43
|
|
4.9
|
Mode de fonctionnement d'un agent cognitif ..
|
43
|
|
4.10
|
Diagramme d'activités pour le fonctionnement de l'agent
utilisateur .
|
44
|
|
4.11
|
Diagramme d'activités pour le fonctionnement de l'agent
administrateur ..
|
46
|
|
4.12
|
Architecture interne de << l'agent service >> ..
|
47
|
|
4.13
|
Correspondance processus atomique OWL-S et opérateur
STRIPS
|
49
|
|
4.14
|
Diagramme d'activités pour le fonctionnement de l'agent
service ..
|
51
|
|
4.15
|
Architecture interne de << l'agent médiateur
>> ..
|
52
|
|
4.16
|
Diagramme d'activités pour le fonctionnement de l'agent
médiateur .
|
58
|
|
4.17
|
Diagramme de protocole d'interactions d'AUML << agent
administrateur - agent
|
|
|
utilisateur >> ..
|
59
|
|
4.18
|
Diagramme de protocole d'interactions d'AUML << agent
administrateur - agent
|
|
|
médiateur >> ..
|
60
|
|
4.19
|
Diagramme de protocole d'interactions d'AUML << agent
utilisateur - agent
|
|
|
médiateur >> ..
|
60
|
|
4.20
|
Diagramme de protocole d'interactions d'AUML << agent
médiateur - agent
|
|
|
service >>
|
61
|
|
4.21
|
Architecture générale des services proposés
en terme d'entrées et de sorties
|
62
|
|
4.22
|
Architecture d'un service en terme de préconditions et
effets .
|
62
|
65
65
66
69
70
A-4
5.1 Classe Java implémentant le service de
réservation de vols aériens
5.2 Une partie de la description OWL-S du modèle de
processus générée en mode
graphique ..
5.3 Une partie de la description OWL-S du
modèle de processus générée en mode
textuel .. 5.4 La description OWL-S du process model du
service « Réservation de vols aériens ».. 5.5 Fonction
Java implémentant le traducteur OWLS vers opérateurs STRIPS
A.2 Exemple d'un message ACL
Liste des tableaux
|
2.1
|
Comparaison entre STRIPS et ADL
|
9
|
|
A.1
|
Eléments d'un message FIPA-ACL .
|
A-4
|
|
A.2
|
Actes communicatifs du langage ACL
|
A-6
|
Introduction générale
De nos jours, le web n'est plus simplement un énorme
entrepôt de texte et d'images, son évolution a fait qu'il est
aussi un fournisseur de services. Aujourd'hui, même si toutes les
entreprises n'ont pas fondé l'essentiel de leurs services
économiques sur le net, elles se doivent au moins d'y être
représentées, ne serait-ce que pour donner l'image d'une
entreprise moderne, dynamique et technologiquement à la page. Une
nouvelle technologie leur facilite grandement les choses et permet une
communication facile et à distance entre ces entreprises et leurs
partenaires et clients c'est les services web [2].
La notion de « service web » désigne
essentiellement une application mise à disposition sur Internet par un
fournisseur de services, et accessible par les clients à travers des
protocoles Internet standards.
Actuellement, les services web sont mis en oeuvre au travers
une infrastructure basée sur trois technologies standard : WSDL, UDDI et
SOAP. Ces technologies facilitent la description, la découverte et la
communication entre services. Cette infrastructure est suffisante pour mettre
en place des composants interopérables et intégrables mais
insuffisante pour rendre automatique et efficace plusieurs tâches
liées au cycle de vie des services web.
Pour pouvoir utiliser un service web, il ne faut que le
rechercher dans des annuaires UDDI, de récupérer sa description
WSDL et puis de l'invoquer à travers des messages SOAP. Cependant, ces
étapes sont suffisantes seulement si le service requis peut être
atteint directement par un seul service web. Certaines fois les demandes des
utilisateurs ne peuvent pas être résolues que par
l'intégration de plusieurs services web. Cette intégration est
connue par composition de services web.
La composition des services web se réfère au
processus de création d'un service composite offrant une nouvelle
fonctionnalité, à partir de services web existants plus simples,
par le processus de découverte dynamique, d'intégration et
d'exécution de ces services dans un ordre bien défini afin de
satisfaire un besoin bien déterminé [3].
Dans le départ, la composition est faite manuellement.
Mais rapidement, une automatisation de ce processus devient un domaine de
recherche très actif. Dans ce chemin, la première approche
consiste à définir des processus métier, i.e., des
enchaînements réutilisables de services ; c'est la composition
statique. Une autre approche envisageable est la composition « dynamique
». Les services web sont composés dynamiquement en fonction de
leurs fonctionnalités et de leur disponibilité. La composition
dynamique, peut se justifier par les points suivants [1]:
- du fait de l'évolution permanente de l'offre de
services et de leurs capacités, une description statique de la
composition est difficile à maintenir ;
- elle permet d'adapter la composition aux attentes de
l'utilisateur et donc de ne pas être contraint par une composition a
priori ;
- elle permet de faire d'Internet une zone de compétences
composables et évolutives.
Le besoin d'automatisation du processus de conception et de
mise en oeuvre des services web rejoint les préoccupations à
l'origine du Web sémantique, à savoir comment décrire
formellement les connaissances de manière à les rendre
exploitables par des machines. En conséquence, les technologies et les
outils développés dans le contexte du Web sémantique
peuvent certainement compléter la technologie des services web en vue
d'apporter des réponses crédibles au problème de
l'automatisation. C'est la naissance des services web
sémantiques. Plusieurs langages de description des services web
sémantiques sont apparus. Celui de référence est le
langage OWL-S.
OWL-S respecte une syntaxe XML et une sémantique de OWL
et a pour objectif de fournir une plus grande expressivité en permettant
la description des caractéristiques des services afin de pouvoir
raisonner dessus dans le but de découvrir, invoquer, composer et
gérer les services web de façon la plus automatisée
possible.
L'objectif de notre travail est d'étudier les
mécanismes nécessaires à la mise en oeuvre d'une
composition dynamique de services basée sur l'utilisation de ses
descriptions sémantiques et d'une technique évolutive de
l'intelligence artificielle ; celle de la planification
multi-agents.
La planification et les SMA ont faits deux domaines de
recherche très actifs de l'intelligence artificielle. Le premier vise le
développement d'algorithmes pour produire des plans, typiquement pour
l'exécution par un robot ou tout autre agent. Le deuxième
s'intéresse aux comportements collectifs produits par les interactions
de plusieurs entités autonomes et flexibles appelées
agents.
La planification dans les systèmes multi-agents, ou
planification multi-agents considère alors le problème de
planification dans le contexte des systèmes multi agent. Elle
étend la planification traditionnelle en intelligence artificielle aux
domaines où plusieurs agents sont impliqués dans un plan et ont
besoin d'agir simultanément.
La grande correspondance entre les descriptions OWL-S et les
représentations en planification ainsi que la nature distribuée
des services web et leurs autonomies, expliquent donc l'intérêt
croissant de l'exploitation de la planification et des SMA dans la composition
de services web.
La méthode de composition dynamique que nous proposons
est basée sur le modèle de planification multi-agents
centralisé dont l'existence d'un agent coordinateur est
nécessaire. Chaque service web est représenté dans le
modèle par un agent assurant ses fonctionnalités. Le plan
solution (s'il existe) est construit par l'agent coordinateur en planifiant
(coordonnant) les différentes actions des agents représentants
des services extraites des descriptions OWL-S des services qu'ils
représentent.
Nous essayons tout au long de notre travail d'illustrer
l'efficacité de ce modèle. Pour le faire le rapport est
présenté dans deux parties : la première contient une
étude des différents aspects lié au problème et est
composée de trois chapitres, un pour présenter les concepts
liés à la planification et les systèmes multi-agents, un
autre pour les concepts des services web et des services web sémantiques
incluant une brève présentation du langage OWL-S et en fin un
troisième citant les différentes approches de composition
existantes ainsi que l'approche proposée. La deuxième partie du
rapport élabore au travers deux chapitres la conception et la
réalisation d'un système implémentant le modèle
proposé.
Introduction
Le thème des systèmes
multi-agents, s'il n'est pas récent, est actuellement un champ
de recherche très actif. Cette discipline est à la connexion de
plusieurs domaines en particulier de l'intelligence artificielle, des
systèmes informatiques distribués et du génie logiciel.
C'est une discipline qui s'intéresse aux comportements collectifs
produits par les interactions de plusieurs entités autonomes et
flexibles appelées agents. Ces agents peuvent
être en effet classifiés en deux catégories selon les
techniques qu'ils emploient dans leurs décisions : les agents
réactifs, basent leur décision suivante seulement sur
l'entrée sensorielle courante et les agents planificateur,
prennent en compte une anticipation des développements futures du monde
pour décider sur l'action favorable.
La planification est aussi un autre
thème ayant depuis les années 60 une grande importance dans
plusieurs domaine et surtout celui de la robotique. C'est une discipline de
l'intelligence artificielle qui vise le développement d'algorithmes pour
produire des plans, typiquement pour l'exécution par un robot ou tout
autre agent. Les logiciels de planification qui incorporent ces algorithmes se
nomment planificateurs.
La planification dans les systèmes multi-agents, ou
planification multi-agents considère alors le problème de
planification dans le contexte des systèmes multi agent. Elle
étend la planification traditionnelle en intelligence artificielle aux
domaines où plusieurs agents sont impliqués dans un plan et ont
besoin d'agir simultanément.
Pour parler donc sur la planification multi-agents, il faut
passer premièrement par une description de la planification classique et
des principaux concepts des SMA.
I. La planification
I.1. Définition et
aspects
La planification est une sous-discipline de l'intelligence
artificielle qui se propose [9]:
1- Etant donnée une représentation de
l'état initial du monde.
2- Etant donné un ensemble d'opérateurs de
changement d'état du monde (qui représentent les actions qu'il
est possible d'effectuer dans le monde).
3- Etant donné un but à atteindre (problème
à résoudre).
De donner les moyens à un système informatique de
trouver une suite d'actions (c-à-d
d'opérateurs directement
exécutables) à appliquer sur le monde pour le faire passer de
l'état initial
à un état qui satisfait le but à atteindre.
Un plan est un ensemble structuré d'actions qui mène au but. Le
plan est élaboré par une partie du système appelée
générateur de plan (ou planificateur).
Idéalement, pour résoudre ces problèmes
de planification, il faut un algorithme général au
résonnement des problèmes de planification. Cependant, un tel
algorithme peut être non-existant. Nous commençons alors à
concentrer sur une simplification du problème de planification
général nommé « problème de planification
classique ».
I.2. La planification classique I.2.1. Modèle de
base
Le cadre formel de référence, relativement
auquel on définit généralement la sémantique des
représentations utilisées en planification, est celui des graphes
de transition d'états étiquetés. C'est un quadruplets G =
(S, A, E, ã) où :
· S = {s1, s2, ..., sn} est un ensemble fini et
récursivement énumérable d'états ;
· A = {a1, a2, ..., an} est un ensemble fini et
récursivement énumérable d'actions ;
· E = {e1, e2, ..., en} est un ensemble fini et
récursivement énumérable d'événements ;
· ã: S × A × E ? 2^S est une fonction de
transition entre états. Elle est définie par : si a est une
action et ã(s, a) est non vide alors a est applicable à
l'état s.
Ce système de transition d'états peut être
représenté par un graphe direct dont les noeuds sont les
états de S. Les arcs sont appelés transitions d'états.
Planifier dans ce cadre revient à trouver un chemin
dans G entre un état initial et un but [10]. Ayant un problème
spécifié par G, un état initial s0 E S, et un
sous-ensemble d'états buts Sg ? S, on cherche une séquence
d'actions (a1, a2, ..., an), telle que: an(...a2(a1(s0))..) soit un état
de Sg .
I.2.2. Représentation et langages
Pour travailler, tout algorithme de planification à
besoin d'une description de l'univers (représentation) sous une forme
facilement compréhensible. Le choix d'une représentation
adaptée aux problèmes à résoudre est un des
éléments les plus importants pour la conception d'un
système efficace; de nombreuses approches peuvent être
employés parmi [1, 10]:
La représentation dans la théorie des
ensembles : chaque état du monde est un ensemble de
propositions et chaque action est une expression spécifiant les
propositions qui doivent appartenir à l'état courant pour que
l'action puisse être exécutée, ainsi que celles qui seront
ajoutées et enlevées de l'état suite à
l'exécution de l'action ;
La représentation classique :
contrairement à la représentation
précédente, des prédicats du premier ordre et des
connecteurs logiques sont utilisés à la place des propositions
;
La représentation par variables d'états
: chaque état est représenté par un tuple de n
variables d'états valuées {x1, x2, ..., xn} et chaque action est
représentée par une fonction partielle qui permet de passer d'un
tuple à un autre tuple de variables d'états instanciées
;
Le but est de trouver un langage qui est à la fois
suffisamment expressif pour décrire une grande variété de
problèmes mais assez restrictif pour permettre à des algorithmes
efficaces d'agir. Pour cette raison plusieurs langages sont apparus comme
STRIPS, ADL mais le langage le plus
utilisé est PDDL [11].
I.2.2.1. Représentation avec STRIPS
Dans ce qui suit, nous introduisons dans un premier temps les
principaux concepts du domaine de la planification en utilisant
STRIPS; le langage basique de représentation des
planificateurs classiques.
Pour mieux comprendre les choses, la présentation de
cette représentation sera illustrée à travers l'exemple le
plus fameux des domaines de planification : le monde de blocs.
Il consiste en un ensemble de blocs, de forme cubique posés sur une
table « figure1.1 >> :
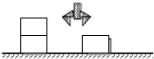
C
A
B
Figure1.1: Exemple du monde de blocs
· Les blocs peuvent s'entasser les uns sur les autres, mais
seulement un bloc peut être mis directement sur un autre bloc ;
· Un bras de robot peut tenir seulement un bloc à la
fois, donc il ne peut pas tenir un bloc qui a un autre bloc sur lui ;
· L'objectif sera toujours de bâtir une ou plusieurs
piles de blocs, spécifiées en termes de quels blocs sont au
dessus d'autres blocs.
· Représentation des états :
Les planificateurs décomposent le monde en conditions logiques
et représentent un état comme une conjonction de
littéraux positifs. Des restrictions sont
permises dans cette représentation :
· On peut considérer des littéraux
propositionnels: BrasVide peut représenter l'état : le bras du
robot est vide ;
· On peut considérer des littéraux du
premier-ordre: Sur(C,B)?Sur(B,A) peuvent représenter
l'état : le bloc C est sur le bloc B et B est sur A ;
· Les littéraux du premier-ordre doivent être
instanciés (ground) et libres de
fonctions; des littéraux comme sur(x,y) ou
habite(père(Paul), Paris) ne sont pas permis ; et
· L'hypothèse du monde-clos est
utilisée; cela signifie que toute condition non mentionnée dans
un état est considérée fausse.
Pour l'exemple de la « figure1.1 >> la
représentation de l'état sera :
S =

SurTtable(A) , SurTable(B) , Sur(C, A) BrasVide ,
Dégagé(B) , Dégagé(C)
SurTtable(A) , SurTable(B) , Sur(C, B)
BrasVide ,
Dégagé(A)
· Représentation des actions :
Une action est définie par l'application d'un
opérateur de transformation. Le principe de la
représentation d'un opérateur consiste à spécifier
les préconditions qui doivent être valables avant
qu'il puisse être exécutée et les effets
qui s'ensuivent quand il est exécuté. Les
précondition peuvent être positives ou négatives : les
préconditions positives expriment les propriétés qui
doivent être vérifiées, par exemple Sur(C,
A) et les préconditions négatives expriment celles
qui doivent être absentes de l'état pour que l'action soit
appliquée, par exemple not(SurTable(A)).
Un opérateur avec variables est appelé un
schéma d'opérateur. Il ne correspond pas
à une seule action exécutable, mais à une famille d'action
différentes qui peuvent être dérivées en
instanciant les variables à des constantes
différentes.
Plus généralement un schéma
d'opérateur est constitué de trois parties:
Le nom de l'opérateur et une liste de
paramètres : définis par une expression de la forme
n(x1, . . ., xk) où n est le nom de l'opérateur
et x1, . . ., xk représentent les paramètres de
l'opérateur.
Les préconditions : définies
par une conjonction de littéraux (positifs), libres de fonctions,
faisant état de ce qui doit être vrai dans un état avant
que l'opérateur puisse être exécutée. Toute variable
apparaissant dans les préconditions doit aussi apparaître dans la
liste de paramètres de l'opérateur.
Les effets : définis par une
conjonction de littéraux (positifs ou négatifs), libres de
fonctions décrivant les faits à ajouter et les faits à
supprimer de l'état du monde après l'exécution de
l'opérateur : l'effet P?not(Q) signifie ajouter P et
supprimer Q. Les variables dans les effets doivent aussi
apparaître dans la liste de paramètres de l'opérateur.
Certains systèmes de planification divisent les effets en liste
d'addition (add list) pour les littéraux positifs et
en liste de suppression (delete list) pour les
littéraux négatifs.
Pour notre exemple des blocs, on peut définir les deux
opérateurs suivants :
Déplacer(b, x, y) ;;
L'opérateur pour déplacer le bloc b du dessus de x au dessus de y
Precond : Sur(b,
x)?Dégagé(b)?Dégagé(y)
Effet : Sur(b,
y)ADégagé(x)A#172;Sur(b, x)A#172;Dégagé(y)
DéplacerSurTable(b, x) ;;
L'opérateur pour déplacer un bloc b de x à la table
Precond : Sur(b, x)ADégagé(b)
Effet : Sur(b,
Table)ADégagé(x)A#172;Sur(b, x)
Une action est une instance d'un opérateur. Si a est
une action et si un état tel que Precond+(a) appartient à si et
precond-(a) si, alors a est applicable à si, et le résultat de
cette application App est l'état si+1 tel que :
App(si,a) = si+1 = (si - effets-(a)) U effets+(a).
Dans le modèle de l'état « s » de la
figure1.1 décrit précédemment, l'action «
Déplacer(C, A,
B) » peut être appliquée ; le nouveau
état « s' » engendré après son exécution
sera :
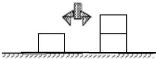
A
C
B
Figure1.2: L'exemple du monde de blocs dans
l'état S'
Le résultat Res de l'application d'une
séquence d'actions ?= <a1, a2, ..., an> sur un état s est
récursivement défini par :
Res(s, < >) = s
Res(s, <a1, a2, ..., an>) =
Res(App(s,a1), <a2, a3, ..., an>)
Remarques :
Il faut noter que si un effet positif est déjà dans
s celui-ci n'est pas ajouté deux fois et si un effet négatif
n'est pas dans s alors cette partie de l'effet est ignorée.
Chaque littéral non mentionné dans l'effet reste
inchangé. De cette façon STRIPS évite le frame
problem (c.a.d. représenter toutes les choses qui restent les
mêmes)
· Représentation des objectifs :
Un objectif est un état partiellement spécifié,
représenté comme une conjonction des littéraux
instanciés positifs comme BrasVide ou Sur(A, C). Un
état propositionnel s satisfait un objectif g si s
contient tous les atomes dans g (et possible d'autres);
l'état Sur(A, C)?Sur(C, B)?Sur(E, D) satisfait l'objectif
Sur(A, C)?Sur(C, B).
· Représentation des domaines : En
planification, un domaine de planification définit l'ensemble des
opérateurs qui peuvent s'appliquer sur le monde.
· Représentation des problèmes :
En planification Un problème P doit spécifier
l'état initial ainsi que le but à atteindre. Il peut être
défini comme un triplet P = (O, s0, g) où :
- s0, l'état initial, est un état quelconque de S
;
- g, le but, définit un ensemble cohérent de
prédicats instanciés, i.e. : les propriétés du
monde devant être atteintes ;
- O, est l'ensemble des opérateurs applicables.
· Représentation des plans : Un
plan solution pour un problème de planification P = (O, s0, g) est une
séquence d'actions ?= <a1, a2, ..., an> décrivant un chemin
d'un état initial s0 à un état final sn tel que le but g
soit inclus dans sn. Autrement dit, le plan ?= <a1, a2, ..., an> est une
solution pour le problème P si Res(s0, ?) satisfait g.
Pour notre exemple une représentation d'un
problème de planification et d'une solution peut être
décrite comme suit :
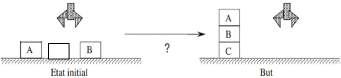
C
Figure1.3 : Exemple d'un problème de
planification dans le monde des blocs
Init (
Sur(A,Table)?Sur(B,Table)?Sur(C,Table)?Bloc(A)?
Bloc(B)?Bloc(C)?Dégagé(A)?Dégagé(B)?Dégagé(C)
) Objectif ( Sur(A, B)?Sur(B, C) )
Action ( Déplacer(b, x,
y)
Precond : Sur(b,
x)?Dégagé(b)?Dégagé(y)
Effet : Sur(b, y)?Dégagé(x)?#172;Sur(b,
x)?#172;Dégagé(y) )
Action (
DéplacerSurTable(b, x)
Precond : Sur(b, x)?Dégagé(b)
Effet : Sur(b, Table)?Dégagé(x)?#172;Sur(b, x)
)
Une solution possible est:
<Déplacer(B, Table, C), Déplacer(A, Table,
B)>
Avec ces aspects, STRIPS impose des restrictions sur la
représentation de la planification ; il est donc assez expressif pour
certains domaines du monde réel. Des extensions sont donc apparues pour
remédier à cette insuffisance de STRIPS. Il s'agit des deux
langages ADL et PDDL.
I.2.2.2. ADL et PDDL
· Le langage ADL
(Action Description language) est une extension significative en
planification classique, permet l'utilisation de quantificateurs et
d'expressions conditionnelles dans la description des opérateurs. Ainsi,
une description plus générale de l'opérateur de
déplacement Déplacer(b, x, y) serait :
Déplacer(b :bloc, x :bloc, y
:bloc)
Precond : Sur(b,
x)?Dégagé(b)?Dégagé(y) ? ~(b, y)
?~(x,y)
Effet : Sur(b, y)?#172;Sur(b, x)?(
~ (x, Table) -* Dégagé(x))?(? (y,
Table) -*Dégagé(y))
Le « tableau1.1 » décrit brièvement le
langage ADL en le comparant avec STRIPS [12]:
Langage STRIPS
|
Langage ADL
|
Seulement des littéraux positifs
dans la description des états :
Sur(b, x)?Dégagé(b)
|
Des littéraux positifs et négatifs
dans la description des états
Sur(b, y)?#172;Sur(b, x)
|
Hypothèse du monde-clos : tout
littéral non mentionné dans un état est
considérée faux.
|
Hypothèse du monde-ouvert : tout
littéral non mentionné dans un état est
considérée faux.
|
|
Effet P?#172;Q signifie : ajouter P et supprimer Q
|
Effet P?#172;Q signifie : ajouter P et #172;Q
et supprimer #172;P et Q
|
Seulement des littéraux instanciés dans les
objectifs :
SurTable(B) ? Sur(C, A)
|
Des variables quantifiées dans les objectifs : Vx
At(P1, x)AAt(P2, x) est l'objectif d'avoir P1 et P2 dans le
même endroit
|
Les objectifs sont des conjonctions:
SurTable(B) ?
Sur(C, A)
|
Les objectifs admettent des
conjonctions et des disjonctions: SurTable(B)?(Sur(C,
B)VSur(A, B))
|
Les effets sont des conjonctions
|
Les effets conditionnels sont admis: when P:
E signifie que E et un effet seulement si P est satisfais
|
Non support de l'égalité
|
Prédicat d'égalité (x = y) admi
|
Non support des types
|
Les variables peuvent avoir des
types : (x :bloc, y :bloc)
|
|
Tableau!.!: comparaison entre STRIPS et
ADL
· Le langage PDDL (Planning Domain
Definition Language) [20] est une tentative pour standardiser
les langages de description des domaines et des problèmes de
planification. C'est un langage créé en 1998 par Drew McDermott
pour la compétition IPC-98 dans le but de développer un seul
langage de description des domaines de planification utilisé par tous
les planificateurs de cette compétition. Il est ensuite devenu comme un
standard utilisé par tous les planificateurs. La
dernière version est PDDL3.1.
En PDDL, les composants nécessaires à la
description de la planification sont :
· Les objets : les choses du monde qui nous
intéresse.
· Les prédicats : propriétés des
objets intéressants pour nous, peuvent être vraies ou fausses.
· L'état initial : l'état du monde de
départ.
· La spécification de l'objectif : les choses que
nous voulons soient vraies dans le monde.
· Actions/Opérateurs : chemins pour changer
l'état du monde.
Ainsi, les problèmes de planification
spécifiés dans ce langage sont séparés dans deux
fichiers :
Fichier du domaine : pour la
spécification des prédicats et des actions. La structure de ce
fichier est la suivante :
(define (domain < nom du domaine >)
< code PDDL pour les prédicats >
< code PDDL pour la première action >
[...]
< code PDDL pour la dernière action >
)
< nom du domaine > : une chaîne de
caractères identifiant le domaine de planification.
Exemple : pour notre exemple des blocs : un
fichier du domaine en PDDL peut être spécifié comme suit
:
(define (domain monde_blocs)
(: predicates (Sur ?x ?y) (Dégagé ?x))
(: action Déplacer
: parameters (?x ?y ?z)
: precondition
(and (Sur ?x ?y)(Dégagé
?x)(Dégagé ?z)
(not (= ?y ?z)) (not (= ?x ?y))
(not (= ?x ?z)) (not (= ?x Table)))
: effect
(and (Sur ?x ?z) (not (Sur ?x ?y))
(when (not (= ?y Table)) (Dégagé
?y))
(when (not (= ?z Table)) (not (Dégagé ?z)))))
Fichier du problème : pour la
spécification des objets, de l'état initial et de l'objectif. La
structure de ce fichier est la suivante :
(define (problem < nom du problème >)
(:domain < nom du domaine >)
< code PDDL pour les objets >
< code PDDL pour l'état initial >
< code PDDL pour la specification de l'objectif
>
)
< nom du problème > : une chaîne de
caractères identifiant le problème de planification.
< nom du domaine > : doit être similaire au
nom du domaine dans le fichier du domaine correspondent.
Exemple : pour notre exemple des blocs : un
fichier du problème de la « figure1.4 » en PDDL peut
être spécifié comme suit :
(define (problem < problème_blocs >)
(:domain < monde_blocs >)
(:objects A B C Table )
(:init (Bloc A) (Bloc B) (Bloc C)
(Dégagé A) (Dégagé B)
(Dégagé C) (Sur A Table) (Sur B Table) (Sur C Table)) (:goal (and
(Sur A B) (Sur B C))
)
I.2.3. Recherche d'une solution (calcul d'un plan)
Pour déterminer la suite d'opérateurs (le plan)
qui permet de passer de la description de l'état initial à un
état qui satisfait le but, le planificateur peut utiliser, selon sa
conception, différentes stratégies (algorithmes) de recherche :
la recherche dans un espace d'états et la recherche dans un espace de
plans.
appliqués pour passer d'un état à un
autre. Le travail effectué par le planificateur pour dresser le plan
peut être représenté par un graphe de recherche qui est un
sous graphe du graphe d'états représentant le problème
à résoudre. Pour parcourir l'espace d'états, le
planificateur peut utiliser différentes méthodes : la recherche
par chaînage avant, par chaînage arrière ou
bidirectionnelle.
La recherche par chaînage avant
(Forward) : Cette approche est
appelée planification progressive puisqu'elle se déplace
vers l'avant. Elle consiste, en partant de l'état initial, à
trouver par essais successifs une suite d'actions qui permette d'arriver
à un état but. Le plan-solution est la suite des
opérateurs étiquetant les arcs du chemin-solution, chemin qui
mène de l'état initial à l'état-but. L'approche
peut être élaboré par l'algorithme ci-dessous [10]. L'appel
Forward(s0, Sg, nil) retourne un chemin de G (graphe d'états)
de s0 à un état de Sg, s'il existe un tel chemin. L'étape
de choix est non-déterministe, elle correspond à un
retour arrière en cas d'échec.
Forward (s, Sg, path)
si sE Sg alors retourner(path)
sinon soit applicables - {a? A| s ??
pré(a)} si applicables = 0 retourner (échec) sinon
Choix a E applicables
retourner (Forward(a(s), Sg, path.a))
|
|
Algorithme1.2: algorithme de planification
par chaînage avant
La recherche par chaînage arrière
(Backward) : Cette approche est
appelée planification régressive puisqu'elle se
déplace vers l'arrière. Elle consiste à parcourir le
graphe de recherche du problème, non pas en partant de l'état
initial, mais en partant du but (qui doit donc être explicitement connu)
et en appliquant l'inverse des opérateurs de planification pour produire
des sous-buts jusqu'à arriver à l'état initial. Si
l'algorithme permet de remonter à cet état initial, alors il
retourne le plan solution trouvé.
L'approche peut être élaborée par
l'algorithme ci-après [10]. L'algorithme choisit une proposition but
particulière << g >> parmi les buts courants
<< y >> et une action pertinente pour ce
but. Une action est dite pertinente pour un objectif conjonctif si
elle accomplit un des conjoints de l'objectif.
La fonction <<
Regression(a, y) >> est définie
comme suit : Ayant un ensemble y de propositions décrivant les
buts, la régression de a relativement à y
cherche un ensemble y' de propositions telles que tout état s
qui les comporte soit dans le domaine de définition de a et
conduise à un état où y est satisfaite :
Regression(a, ?) = y' tel que y' ?=
pré(a) et sE M(y'): a(s) ?? ?
Backward(s0, y , path)
si s0 |= y alors retourner(path)
sinon Choix de g E 7
soit pertinentes -- {a E A | eff(a) |= g}
si pertinentes = 0 alors retourner (échec) sinon
Choix de a E pertinentes
soit y' - Regression(a, ?)
retourner (Backward(s0, y', a.path))
|
|
Algorithme1.3: algorithme de planification
par chaînage arrière
La recherche bidirectionnelle : consiste
à utiliser simultanément les techniques de recherche avant et
arrière jusqu'à rencontrer un état commun aux deux
processus. Le plan-solution est alors la suite des opérateurs qui
permettent de passer de l'état initial à l'état commun
plus l'inverse de la suite des opérateurs qui mènent du but
à l'état commun. Cette méthode nécessite la
connaissance explicite du but.
I.2.3.2. Recherche dans un espace de plans :
Dans l'approche de la planification dans un espace de plans, l'espace
de recherche n'est plus un ensemble d'états du monde mais un espace de
plans partiels dont les noeuds représentent des plans partiellement
spécifiés et les arcs sont des opérations de raffinement
de plans, i.e., qui permettent de réaliser un but ouvert ou d'enlever
une inconsistance potentielle (par exemple lorsque deux actions sont en
conflit) [1]. Cette approche obéit au paradigme de la
décomposition de but, i.e, le problème initial (but à
atteindre) est décomposé en sous-problèmes plus simples
(grâce à l'utilisation de règles de décomposition);
ceux-ci sont à nouveau décomposés, et ainsi de suite
jusqu'à l'obtention de problèmes terminaux (tous solubles par des
actions élémentaires) [9].
II. Les SMA
Le thème des systèmes multi-agents (SMA), s'il
n'est pas récent, est actuellement un champ de recherche très
actif. Cette discipline est à la connexion de plusieurs domaines en
particulier de l'intelligence artificielle, des systèmes informatiques
distribués et du génie logiciel. C'est une discipline qui
s'intéresse aux comportements collectifs produits par les interactions
de plusieurs entités autonomes et flexibles appelées agents, que
ces interactions tournent autour de la coopération, de la concurrence ou
de la coexistence entre ces agents.
C'est un domaine très large ; ce que nous allons
présentées dans cette section ne fait que des points sur les
principaux concepts des SMA ([7], [13], et [15] pour des articles de
référence).
II.1. Qu'est ce qu'un agent?
Dans la littérature, on trouve une multitude de
définitions d'agents. Elles se ressemblent toutes, mais diffèrent
selon le type d'application pour laquelle est conçu l'agent. Nous avons
choisis celle de Jennings, Sycara et Wooldridge [7] :
« Un agent est un système informatique,
situé dans un environnement, et quiagit
d'une façon autonome et flexible pour
atteindre les objectifs pour lesquels il a été conçu
».
Les notions « situé >>, « autonome
>> et « flexible >> sont définies comme suit:
· Situé : l'agent est
capable d'agir sur son environnement à partir des entrées
sensorielles qu'il reçoit de ce même environnement;
· Autonome : l'agent est capable
d'agir sans l'intervention d'un tiers (humain ou agent) et contrôle ses
propres actions ainsi que son état interne;
· Flexible : l'agent dans ce cas
est:
Capable de répondre à temps: il doit
être capable de percevoir son environnement et élaborer une
réponse dans les temps requis;
Proactif: il n'agit pas simplement en réponse
à son environnement, il est également capable d'avoir un
comportement opportuniste, dirigé par ses buts d'utilité, et de
prendre des initiatives au moment approprié.
Social: l'agent doit être capable d'interagir
avec les autres agents (logiciels et humains) quand la situation l'exige afin
de compléter ses tâches ou aider ces agents à accomplir les
leurs.
II.2. Architectures d'agents
Un agent peut toujours être vu comme une fonction liant
ses perceptions à ses actions. Ce qui différencie les
différentes architectures d'agents, c'est la manière dont les
perceptions sont liées aux actions. Les deux grandes familles d'agents
sont : les agents réactifs et les agents
délibératifs (voir [15] pour les détails).
II.2.1. Agents réactifs : Un agent
réactif ne fait que réagir aux changements qui surviennent dans
l'environnement. Autrement dit, un tel agent ne fait ni
délibération ni planification, il se contente simplement
d'acquérir des perceptions et de réagir à celles ci en
appliquant certaines règles prédéfinies tant donné
qu'il n'y a pratiquement pas de raisonnement, ces agents peuvent agir et
réagir très rapidement. Cette catégorie regroupe les deux
types d'architecture suivants :
· les agents à réflexes simples.
· les agents conservant une trace du monde.
II.2.2. Agents délibératifs :
Un agent délibératif est un agent qui effectue une
certaine délibération pour choisir ses actions. Une telle
délibération peut se faire en se basant sur les buts de l'agent
ou sur une certaine fonction d'utilité. Elle peut prendre la forme d'un
plan qui reflète la suite d'actions que l'agent doit effectuer en vue de
réaliser son but. Ainsi, les trois types d'architecture suivants peuvent
être regroupés sous cette catégorie :
· les agents ayant des buts.
· les agents utilisant une fonction d'utilité.
· les agents BDI.
II.2.3. Agents hybrides : Chacune des
architectures précédentes est appropriée à un
certain type de problème. Cependant, pour la majorité des
problèmes, ni une architecture complètement réactive, ni
une architecture complètement délibérative n'est
appropriée. Dans ce cas, une architecture conciliant à la fois
des aspects réactifs et délibératifs est requise. On parle
alors d'architecture hybride.
II.3. Systèmes multi-agents II.3.1.
Définition
Un système multi-agents est un système
distribué composé d'un ensemble d'agents interagissant, le plus
souvent, selon des modes de coopération, de concurrence
ou de coexistence situés dans un environnement commun. Il
possède les caractéristiques principales suivantes [7]:
· chaque agent a des informations ou des capacités
de résolution de problèmes limitées, ainsi chaque agent a
un point de vue partiel ;
· il n'y a aucun contrôle global du système
multi-agents ;
· les donnés sont décentralisées ;
· le calcul est asynchrone.
Pourquoi des SMA ?
· Certains domaines requièrent l'utilisation de
plusieurs entités, par exemple, il y a des systèmes qui sont
géographiquement distribués. Les SMA procurent une façon
facile et efficace de les modéliser.
· Une autre situation, où les sont requis, est
lorsque les différents systèmes et les données qui s'y
rattachent appartiennent à des organisations indépendantes qui
veulent garder leurs informations privées et sécurisées
pour des raisons concurrentielles.
· Les SMA possèdent également les avantages
traditionnels de la résolution distribuée et concurrente de
problèmes [15] :
- La modularité, permet de rendre la
programmation plus simple ;
- La vitesse, due principalement au parallélisme
;
- La fiabilité, qui peut être
également atteinte, dans la mesure où le contrôle et les
responsabilités étant partagés entre les différents
agents, le système peut tolérer la défaillance d'un ou de
plusieurs agents.
· Finalement, les SMA héritent aussi des
bénéfices envisageables du domaine de l'intelligence artificielle
comme par exemple, le traitement symbolique (au niveau des connaissances).
II.3.2. Interaction entre agents : Jacques
Ferber donne la définition suivante de l'interaction : « Une
interaction est la mise en relation dynamique de deux ou plusieurs agents par
le biais d'un ensemble d'actions réciproques... » [13]. Les
interactions entre agents peuvent variées selon les situations dont se
trouve ces agents : coexistence, compétition ou coopération.
· S'ils ne font que coexister, alors
chaque agent ne considère les autres agents que comme des composantes de
l'environnement. Il n'y a aucune communication directe entre les agents
· S'ils sont en compétition,
alors le but de chaque agent est de maximiser sa propre satisfaction. La
compétition entre agents peut avoir plusieurs sources : Les buts des
agents peuvent être incompatibles ou les ressources peuvent être
insuffisantes.
· S'ils sont en coopération,
alors le but des agents n'est plus seulement de maximiser leurs propres
satisfactions mais aussi de contribuer à la réussite du groupe.
Les agents travaillent ensemble à la résolution d'un
problème commun.
II.3.3. Coopération entre agents : La
coopération est nécessaire quand un agent ne peut pas atteindre
ses buts sans l'aide des autres agents. Cette situation est fréquente
même chez des espèces primitives. Les buts nécessitant la
coopération peuvent être.
II.3.4. Coordination entre agents : Il y a
interaction entre les agents soit pace qu'ils coopèrent, soit parce
qu'ils sont en compétition. Dans les deux cas, une coordination peut
être nécessaire pour améliorer le fonctionnement global du
système [13].
Lorsque plusieurs agents travaillent sur le même lieu,
utilisent les mêmes ressources, où résolvent des sous
problèmes qui ne sont pas complètement indépendants
(conception d'un objet
complexe par exemple), ils doivent accomplir, en plus des
tâches liées directement au problème traité, des
tâches de coordination. Ces tâches ne sont pas directement
productives mais elles améliorent les tâches productives.
Les tâches de coordination peuvent être accomplies
directement par les agents concernés quand elles sont relativement rares
et qu'elles n'engagent pas un grand nombre d'agents en même temps. Sinon,
elles sont prises en charge par des agents spécialisés qui
recueillent les demandes et fixent les ordres de priorité ou d'autres
contraintes.
II.3.5. Négociation entre agents :
Comme nous avons vus précédemment, en interagissant dans
un environnement partagé, les agents doivent coordonner leurs actions et
avoir des mécanismes pour la résolution des conflits. Le
mécanisme favori pour la résolution des conflits et
la coordination, inspiré du modèle des humains, est
la négociation.
Dans les systèmes multi-agents, la négociation
est une composante de base de l'interaction surtout parce que les agents sont
autonomes ; il n'y a pas de solution imposée à l'avance et les
agents doivent arriver à trouver des solutions dynamiquement, pendant
qu'ils résolvent les problèmes [14].
II.3.6 Communication entre agents : Les
communications, dans les systèmes multi-agents comme chez les humains,
sont à la base des interactions et de l'organisation sociale. Sans
communication, l'agent n'est qu'un individu isolé, refermé sur sa
boucle perception-délibérationaction. C'est parce que les agents
communiquent qu'ils peuvent coopérer, coordonner leurs actions,
réaliser des taches en commun et devenir ainsi de véritables
êtres sociaux.
Dans les SMA deux stratégies principales ont
été utilisées pour supporter la communication entre
agents:
Communication par transfert de messages :
Dans cette approche, les agents échangent de messages entre eux
directement (pas de mémoire partagée).
Communication par l'utilisation d'un tableau noir :
Un tableau noir est utilisé pour spécifier une
mémoire partagée par divers systèmes. Dans un SMA
utilisant un tableau noir, les agents peuvent écrire des messages,
insérer des résultats partiels de leurs calculs et obtenir de
l'information dans et à partir de ce tableau.
Pour coordonner l'activité d'un ensemble
hétérogène d'agents autonomes, il faut que les agents
communiquent dans un langage compréhensible par tous les autres. Les
deux langages les plus utilisés sont : KQML(1) et
FIPA-ACL(2).
III. La planification multi-agents
La recherche dans la planification multi-agents est
prometteuse pour des problèmes réels : d'une part, les techniques
de planification d'AI fournissent des outils puissants pour résoudre des
problèmes dans le cadre des agents singulier ; et d'une autre part, les
systèmes multi-agents, qui ont fait une grande progression au cours de
ces dernières années, sont identifiés comme technologie
principale pour aborder des problèmes complexes dans des domaines
d'application réalistes.
(1) Knowledge Query and Manipulation Language
(2) Foundations of Intelligent Physical Agents-Agent
Communication Language
En planification multi-agents (référée
aussi par planification distribuée), le domaine de planification est
réparti sur l'ensemble des agents. Chaque agent est capable de
réaliser un certain nombre d'actions: ses compétences. C'est la
mise en commun et l'ordonnancement des compétences de chaque agent, dans
le but de résoudre un problème donné, qui va permettre de
faire émerger un plan solution.
III.1. Planification et coordination
Dans de nombreux cas les dépendances entre les taches
des agents rendent une planification indépendante impossible.
C'est-à-dire, si les agents ne tiennent pas compte des
dépendances entre leurs plans, ils peuvent arrivés à des
conflits quand ils essayent d'exécuter leurs plans.
Pour résoudre leurs dépendances, les agents doivent
coordonner leurs efforts.
Clairement, un problème de planification multi-agents a
deux composants : la planification et la coordination. Le problème de
planification multi-agents peut être donc défini comme suit
[8]:
Le problème de planification multi-agents est le
problème suivant : Etant donné une description de l'état
initial, un ensemble de buts globaux, un ensemble d'agents (au moins de deux),
et pour chaque agent un ensemble de ses capacités et de ses buts
privés, trouver un plan pour chaque agent qui réalise ses buts
privés, tel que ces plans ensemble sont coordonnés et les buts
globaux sont aussi bien atteints.
|
En résumant,
|
Planification multi-agents = Planification + Coordination
|
III.2. Modèles de la planification
multi-agents
Pour distinguer les différents modèles de la
planification multi-agents, on doit référer au problème de
la planification multi-agents en tant que problème de planification
distribuée. Le terme de planification distribuée est toutefois
ambigu car il n'explicite pas ce qui est distribué. En effet, les plans
peuvent être construits de manière centralisée puis
distribués aux agents, ou bien chaque agent peut construire localement
son propre plan puis le coordonner de manière distribuée. Dans le
premier cas, seule l'exécution du plan est distribuée. En
revanche, dans le second, la synthèse de plans, le processus de
coordination ainsi que l'exécution sont réalisés de
manière complètement distribuée [1].
III.2.1. Planification centralisée :
Repose toujours sur l'existence d'un agent coordinateur. Cet agent
centralise l'ensemble des plans des agents du système et résout
les conflits potentiels entre leurs activités en introduisant des
actions de synchronisation. L'agent coordinateur peut:
· soit planifier pour l'ensemble des agents et, dans ce
cas, il doit décomposer le plan global en sous-plans synchronisés
pouvant être exécutés par les agents ;
· soit chaque agent peut planifier localement et, dans ce
cas, le rôle de l'agent coordinateur se limite à la
synchronisation des plans reçus.
III.2.2. Planification distribuée : Le
processus de planification est distribué. Deux modèles sont
envisageables dans cette approche :
Planification distribuée avec plan
centralisé : Dans ce modèle, Le but global des agents
est d'accomplir une tâche T. Cette tâche va être
décomposée en plusieurs sous-tâches non ordonnées
Tj. Après l'assignement de ces sous-tâches aux différents
agents, chaque agent du système élabore un sous-plan pour
résoudre la sous-tâche lui est assignée. En fin, une
synchronisation entre les agents arrive à élaborer un plan global
centralisé permettant de réaliser la tache T.
Décomposition Planification
Synchronisation
Entre agents
T {Ti, Tj, ..., Tk} {PTi, PTj, ..., PTk}
PT
Tàche globale
|
Ensemble de tâches
non ordonnées
|
Plans associés
|
Plan
centralisé
|
|
Planification distribuée avec plan
distribué : Dans ce modèle, le processus de
synthèse et d'exécution d'un plan multi-agents sont les deux
distribués. Deux approches sont envisageables à nouveau dans
cette approche orientée tâches et orienté
agents. La différence réside dans l'existence d'un but
global ou non.
En résumant, les différents modèles de la
planification multi-agents peuvent être résumé dans le
schéma de la figure suivante :
Planification multi-agents
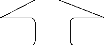
Un planificateur
Plusieurs exécutants
Planification centralisée
Chaque agent
planifie et exécute
Planification distribuée

Orienté tâche
Décomposition
Orienté agent Coordination
Figure1.4 : Modèles de la planification
multi-agents
Conclusion
Dans ce chapitre nous avons parlées sur la
planification multi-agents. Mais il nous apparaît clairement que ce
domaine n'est qu'une extension des principes de la planification classiques au
domaine des systèmes multi-agents.
Nous avons donc divisées le chapitre en trois section
: la première section est spécifiée à la
planification classique et à ces principes généraux (de la
représentation des connaissances qu'elle utilise jusqu'à la
recherche de la solution). Dans la deuxième section nous avons
essayées d'aborder brièvement, le domaine des systèmes
multi-agents. En fin et dans la dernière section nous avons
parlées des principes de la planification distribuée (dans un
contexte multi-agents) ainsi que ses différents modèles.
Introduction :
De nos jours, le web n'est plus simplement un énorme
entrepôt de texte et d'images, son évolution a fait qu'il est
aussi un fournisseur de services. Aujourd'hui, même si toutes les
entreprises n'ont pas fondé l'essentiel de leurs services
économiques sur le net, elles se doivent au moins d'y être
représentées, ne serait-ce que pour donner l'image d'une
entreprise moderne, dynamique et technologiquement à la page [2]. Une
nouvelle technologie leur facilite grandement les choses et permet une
communication facile et à distance entre ces entreprises et leurs
partenaires et clients c'est les services web.
La notion de « service web » désigne
essentiellement une application mise à disposition sur Internet par un
fournisseur de services, et accessible par les clients à travers des
protocoles Internet standard.
Actuellement, les services web sont mis en oeuvre au travers
de trois technologies standards : WSDL, UDDI et SOAP. Ces technologies
facilitent la description, la découverte et la communication entre
services. Cependant, cette infrastructure de base ne permet pas encore aux
services web de tenir leur promesse d'une gestion largement automatisée.
Fondamentalement, elle doit s'accommoder d'un moyen pour décrire les
services web d'une manière compréhensible par une machine.
Le web sémantique est une vision du web dans laquelle
toute information possède une sémantique compréhensible
par une machine. Appliqués aux services web, les principes du web
sémantique doivent permettre de décrire la sémantique de
leurs fonctionnalités, ce qui produit par conséquent une
proposition d'automatisation des différentes tâches de leur cycle
de vie.
Plusieurs langages étaient apparus pour faire une
telle description des services web, essentiellement le langage OWL-S.
La suite du chapitre sera présentée
essentiellement en deux parties : une description générale du
concept service web et une autre du concept service web sémantique
contenant une bref présentation du langage OWL-S.
I. Services web
I.1 Qu'est ce qu'un service web ?
Les services web représentent un mécanisme de
communication entre applications distantes à travers le réseau
Internet indépendant de tout langage de programmation et de toute
plate-forme
d'exécution. Pour cette raison les activités de
recherche et développement autour du sujet services web ont un dynamisme
très haut. Le W3C (World Wide Web Consortium) est un groupe qui
travaille sur ce sujet. Nous adoptons donc la définition d'un service
web de ce groupe :
« Un service web est un système logiciel
destiné à supporter l'interaction ordinateur-ordinateur sur le
réseau. Il a une interface décrite en un format traitable par
l'ordinateur (e.g. WSDL). Autres systèmes réagissent
réciproquement avec le service web d'une façon prescrite par sa
description en utilisant des messages SOAP, typiquement transmis avec le
protocole http et une sérialisation XML, en conjonction avec d'autres
standards relatifs au web ».
I.2. Architecture, modèle de fonctionnement
Le modèle des services web repose sur une architecture
orientée service. Celle-ci fait intervenir trois catégories
d'acteurs :
· les fournisseurs de services (i.e. les
entités responsables du service web),
· les clients qui servent
d'intermédiaires aux utilisateurs de services et
· les annuaires qui offrent aux
fournisseurs la capacité de publier leurs services et aux clients le
moyen de localiser leurs besoins en terme de services.
Le fonctionnement des services web repose sur un modèle
en couches, dont les quatre couches fondamentales sont les suivantes :
· la couche publication repose sur le
protocole UDDI, qui assure le regroupement, le stockage et la
diffusion des descriptions de services web.
· la couche description est prise en
charge par le langage WSDL, qui décrit les
fonctionnalités fournies par le service web, les messages reçus
et envoyés pour chaque fonctionnalité, ainsi que le protocole
adopté pour la communication. Les types des données contenues
dans les messages sont décrits à l'aide du langage XML
Schéma.
· la couche message utilise des protocoles
reposant sur le langage XML. Actuellement,
SOAP est le protocole utilisé pour cette couche.
· la couche transport, repose sur le
protocole HTTP. Le protocole le plus utilisé sur Internet pour le
transfert de données et de messages.
La dynamique de l'architecture se décompose ainsi :
· D'abord, on effectue le déploiement du service
web, en fonction de la plateforme.
· Ensuite, on enregistre le service web à l'aide de
WSDL dans l'annuaire UDDI.
· L'étape suivante est la découverte du
service web par le client, par l'intermédiaire d'UDDI qui lui donne
accès à tous les services web inscrits. Pour ce, on utilise
SOAP.
· Enfin, Le client invoque le service web voulu, ce qui
termine le cycle de vie de ce service web.
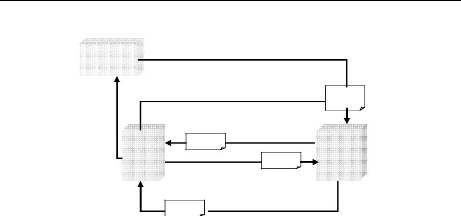
2 : J'ai trouvé ! Voici le serveur
hébergeant ce service
Annuaire
UDDI
1 : je cherche
Un service web
3 : quel est le format d'appel du service que tu
proposes
Contrat SOAP
4 : Voici mon contrat (WSDL)
XML
Client
XML
Serveur
5 : J'ai compris comment invoquer
ton service et je t'envoie un document
représentant ma requête
XML
6 : j'ai exécuté ta requête et je te
retourne le résultat
Figure 2.1 : Modèle de fonctionnement de
l'architecture service web I.3. Principales technologies
utilisées
Un des points forts des services web est l'utilisation des
standards XML, SOAP, WSDL et UDDI augmentant ainsi le niveau d'interaction et
d'interopérabilité entre applications. Dans ce qui suit nous
expliquerons chacun de ces standards en bref.
I.3.1. XML-eXtensible Markup Language :
Recommandation du W3C depuis le 10 février 1998, le langage XML
connait depuis ses débuts un succès indéniable.
Les normes strictes qui gèrent la syntaxe et la
structure de XML rendent le langage et son utilisation plus aisés,
favorisant notamment la factorisation des travaux de développement
d'analyseurs syntaxiques. XML fournit donc un cadre de structuration des
données qui peut être employé pour la définition
rapide et sans ambiguïté syntaxique d'un format de document.
Un document est composé d'une définition de sa
structure et d'un contenu. La structure d'un document XML est souvent
représentée graphiquement comme un arbre. La racine du document
constitue le sujet du document, et les feuilles sont les éléments
de ce sujet. De ce fait, XML est alors flexible et extensible, et est devenu
rapidement le standard d'échange de données sur le web.
L'exemple suivant de document XML permet de décrire une
personne :
<?xml version="1.0" encoding="UTF-8"?>
<personne>
<nom>Dupond</nom>
<prenom>Jean</prenom>
<naissance>
<lieu>
<ville>Paris</ville>
<pays>France</pays> </lieu>
<date>
<jour>14</jour>
<mois>7</mois>
<annee>1789</annee> </date>
</naissance>
</personne>
I.3.2. SOAP-Simple Object Access Protocol :
SOAP est un protocole de communication pour l'échange
d'informations dans un environnement distribué. SOAP encourage le
partage des données entre machines qui seront capables d'analyser
facilement et correctement ces mêmes données [2], grâce
notamment à l'utilisation de XML comme principal format de
données. Il définit la structure des messages XML utilisés
par les applications pour dialoguer entre elles.
SOAP n'est pas lié à aucun système
d'exploitation ni langage de programmation. Il est indépendant du
langage d'implémentation des applications client et serveur. En plus, il
peut potentiellement être utilisé avec une variété
de protocoles (e.g. HTTP, HTTP Extension Framework).
I.3.3. WSDL-Web Services Description Language :
Lorsque vous voulez avoir des informations sur un service web, pour
pouvoir l'utiliser par exemple, vous devez faire une référence au
fichier WSDL.
WSDL est un langage de description de service web sous format
XML et indépendante du modèle de développement. WSDL
propose une double description du service (figure 2.4): Une vue dite
abstraite qui présente les opérations et les messages
des services et une autre dite concrète qui présente les
choix de mise en oeuvre faits par le fournisseur du service. Cette
séparation permet aux composants d'interagir même si l'application
a été modifiée, ce qui est un point important pour assurer
l'interopérabilité des services.
Un document WSDL décrit comment utiliser un service
web. Mais comment trouver ce service web? Comment localiser le document WSDL
qui le décrit? Le registre UDDI est la réponse
à cette question. On le présente dans le paragraphe suivant.
I.3.4. UDDI-Universal Description Discovery and
Integration : L'utilisation d'un service web nécessite sa
publication par son fournisseur aussi que sa découverte par le client
désirant l'invoquer: c'est le rôle d'UDDI.
UDDI est un annuaire de type XML, qui permet de bâtir
des annuaires des entreprises, ainsi que leurs produits et services, leur
permettant de s'enregistrer et de publier les services web qu'elles
désirent offrir au grand public [2].
L'idée derrière UDDI est de normaliser le
format des entrées d'entreprise et de services dans un annuaire pour
faciliter la découverte des services web et encourager les
échanges d'affaires entre elles.
I.4. Problèmes existants dans le domaine des
services web
Les actuels sujets de recherche dans le domaine des services
web sont nombreux. Un nombre considérable d'études tournent
autour de la découverte des services et ses sujets rattachés
comme sont la sélection, la sémantique et la composition.
Problèmes de sélection:
Découvrir un service web qui nous intéresse est une
chose, découvrir le service web le plus adéquat en est une autre.
La qualité de service dans le cas des services web se mesure à
l'aide de plusieurs métriques dont les métriques de performance
et de fiabilité. Une recherche sur UDDI permet certainement de trouver
plusieurs services web qui remplissent ses critères. Mais lequel sera le
meilleur? Il devient ainsi nécessaire de choisir les services
web pertinents parmi ceux trouvés et de se fixer des critères
pour choisir les meilleurs.
Problèmes de sémantique: Tel
que présentés précédemment, les services web sont
décrits syntaxiquement et ne permettent en aucun cas l'interaction entre
services, leur découverte dynamique ou automatique, ou encore leur
composition sans une intervention humaine. Pour le permettre Il paraît
alors nécessaire de se doter d'un mécanisme qui réglerait
ce problème de sémantique.
Problèmes de composition de services web:
Les services web, tels qu'ils sont définis actuellement, sont
limités à des fonctionnalités relativement simples.
Toutefois, pour certains types d'applications, il est nécessaire de
combiner un ensemble de services web simples en un service répondant
à des exigences plus complexes.
Ce qui nous concerne pour notre travail est la
sémantique dans les services web ainsi que la
composition. Deux objet qui seront présentés
dans ce qui suit.
II. Vers les services web sémantiques
Parallèlement aux services web, un autre concept fait
aujourd'hui une grande évolution du web. Celui du web
sémantique.
A sa création par Tim Berners Lee, au début des
années 1990, le web était exclusivement destiné à
partager des informations sous forme de pages html, affichables par un logiciel
« navigateur web », et généralement destinées
à être lues par un utilisateur humain.
Très rapidement, on s'est rendu compte que cette
conception du web était bien trop limitée, et ne permettait pas
un réel partage du savoir : tout au plus cela permettait-il de
présenter des connaissances (de manière syntaxique), mais en
aucun cas de les rendre directement utilisables.
Le web sémantique consiste alors à faire
ajouter à toutes ces ressources une sémantique qui permettrait
aux systèmes informatiques d'en « comprendre » le sens en
accédant à des collections structurées d'informations et
à des règles d'inférence qui peuvent être
utilisé pour conduire des raisonnements automatisés afin de mieux
satisfaire les exigences des utilisateurs.
III. Services web sémantiques
Le besoin d'automatisation du processus de conception et de
mise en oeuvre des services web rejoint les préoccupations à
l'origine du Web sémantique, à savoir comment décrire
formellement les connaissances de manière à les rendre
exploitables par des machines. En conséquence, les technologies et les
outils développés dans le contexte du Web sémantique
peuvent certainement compléter la technologie des Web services en vue
d'apporter des réponses crédibles au problème de
l'automatisation. C'est la naissance des services web sémantiques.
De manière générale, l'objectif
visé par la notion de services web sémantiques est de
créer un web sémantique de services dont les
propriétés, les capacités, les interfaces et les effets
sont décrits de manière non ambiguë et exploitable par des
machines.
La sémantique ainsi exprimée permette
l'automatisation de plusieurs fonctionnalités qui sont
nécessaires pour une collaboration inter-entreprise efficace, dont les
principales sont les suivantes:
Découverte de services web:
Actuellement cette tache doit être réalisée par un
humain qui doit utiliser un moteur de recherche ou un annuaire pour trouver le
service, lire la page Web qui décrit ce service, puis l'exécuter
manuellement pour vérifier que celui-ci correspond bien aux attentes de
l'utilisateur. Cette sémantique doit donc fournir une description
déclarative des propriétés et des capacités du
service web.
Invocation de services web: L'invocation
automatique d'un service signifie l'exécution du service par un
programme informatique ou un agent logiciel. Cet agent doit être capable
d'interpréter cette description sémantique afin de
délivrer les données nécessaires à
l'exécution du service web.
Composition de services web: L'objectif
qu'un utilisateur veut atteindre nécessite souvent l'utilisation de
plusieurs services web. L'agent logiciel chargé d'atteindre cet objectif
doit disposer de suffisamment de données afin de pouvoir
sélectionner, composer et interopérer automatiquement ces
services web. La description sémantique doit donc pouvoir fournir toutes
ces informations.
Surveillance de l'exécution de services web:
un agent logiciel doit pouvoir connaître l'état
d'avancement de sa requête. Cette description sémantique doit
pouvoir fournir les informations nécessaires.
Plusieurs langages de description des services web
sémantiques sont apparus. Celui de référence est le
langage OWL-S.
III.1. Le langage OWL-S
OWL-S est une extension du langage OWL. Il a pour objectif de
fournir une plus grande expressivité en permettant la description des
caractéristiques des services afin de pouvoir raisonner dessus dans le
but de découvrir, invoquer, composer et gérer les services web de
façon la plus automatisée possible.
Ainsi un service dans OWL-S est décrit à travers
les quatre zones conceptuelles suivantes (figure2.5):
Le service profile: contient la réponse à
la question: exige-t-il quoi le service d'un utilisateur ou d'un autre agent,
et lui en fournit quoi ? Ainsi, la classe service présente un
ServiceProfile.
Le Service Process Model: contient la réponse
à la question: Comment fonctionne le service ? Ainsi la classe service
est décrite par un ServiceModel.
Le Service Grounding: contient la réponse
à la question: De quelle façon le service doit-il être
utilisé ? Ainsi, la classe service supporte un
ServiceGrounding.
Service
Présents
(what it does)
Described by
How it works
Supports
How to access it
ServiceProfile
ServiceProcoss
ServiceGrounding
Le Service: il fait seulement attacher les parties
précédentes ensemble dans une seule unité qui peut
être publier et invoquer.
Figure2.5: éléments d'une
description OWL-S
III.1.1. Le Service Profile
Le << profile>> décrit ce que fait le
service, détaille les limitations de son applicabilité et sa
qualité de service et il spécifie également les exigences
que doit l'utilisateur satisfaire pour l'utiliser correctement. Ainsi un
système recherchant un service examinerait la première fois le
<< profile>> pour voir si le service fournit ce qui est
nécessaire.
Un profile OWL-S décrit le service en fonction des
trois types d'information basiques suivants: Quelle est l'organisation
fournissant le service, quelle est la fonction accomplie par le service et un
ensemble de paramètres spécifiant des caractéristiques du
service.
L'information sur le fournisseur consiste en une Contact
Information qui fournit un mécanisme de référence aux
humains ou aux individus responsables du service. Un individu peut être
soit un opérateur de maintenance qui est responsable de
l'exécution du service ou un représentant d'un client qui peut
fournir des informations additionnelles sur le service.
La description fonctionnelle du service est exprimée
selon deux aspects:
· Transformation de d'informations par spécification
des entrées (inputs) requises par le service et des sorties
(outputs) générées.
· Changement d'état produit par
l'exécution du service par spécification des préconditions
(preconditions) requises par le service et des effets
(effects) qui résultent de l'exécution du service.
Finalement, le profile permet la description d'un ensemble de
propriétés pour décrire des caractéristiques du
service. Le premier type d'information donne une classification du service ou
une catégorie (category), le second type spécifie la
qualité du service et le dernier spécifie un ensemble de
paramètres additionnels du service comme par exemple une estimation du
temps de réponse max pour une disponibilité géographique
du service.
Un profile OWL-S est ainsi organisé principalement comme
suit :
· Le nom du service, les contacts et la description du
service qui sont communément appelés propriétés non
fonctionnelles.
· La description de fonctionnalité
"IOPE" (inputs, outputs,
preconditions, effects).
· Une classification selon une taxonomie industrielle
(catégorie) et une description de qualité.
III.1.2. Le Service Process Model
Pour donner une perspective détaillée sur le
fonctionnement d'un service, celui-ci peut être vu comme un
processus. OWL-S fournit une ontologie de processus
(figure2.6) dans laquelle les processus sont vus de deux façons :
· un processus produit une transformation à partir
d'un ensemble de données d'entrée (inputs) vers un
ensemble de données de sortie (outputs).
· un processus produit une transition d'un état du
monde vers un autre. Cette transition est décrite en termes de
preconditions (preconditions) et d'effets (effects).
Dans telle ontologie, un processus peut avoir n'importe quel
nombre d'entrées représentant une information qui est sous
quelques conditions requise pour l'exécution du service. Il peut avoir
n'importe quel nombre de sorties, l'information fournie par le service
conditionnement après son exécution. Il peut être aussi
n'importe quel nombre de préconditions et d'effets. Les sorties et les
effets peuvent avoir des conditions associées à lui. OWL-S ne
permet pas pour le présent l'expression des conditions, les deux
langages principaux sont: SWRL (Semantic Web Rules Language) et DRS.
Le ProcessModel identifie trois types de processus : atomique
(AtomicProcess), simple (SimpleProcess) et composite
(CompositeProcess).
Processus atomique: directement invocable
(par le passage des messages appropriés). Ainsi, il prend un message
d'entrée, exécute et il retourne un message de sortie.
Exécutable dans une seule étape. Il représente le plus
petit processus qui sert à la création des autres processus, et
il ne contient pas de sous processus en interne. L'utilisateur n'a aucune
visibilité sur l'exécution du service.
Processus simple: n'est pas exécutable
(ou invocable) et n'est pas associé d'un grounding. Il fournit une vue
abstraite d'un processus ou d'un ensemble de processus composés.
Processus composite: sont
décomposables en autres (non-composites ou composites) processus. Sa
décomposition peut être spécifié par l'utilisation
des structures de contrôle comme séquence et
if-then-else. OWL-S définit différents types de
structures de contrôle qui régissent l'enchaînement des
composants (atomiques ou composites) d'un processus composite. Parmi nous
citons les suivantes :
Sequence: Une liste de processus
exécutés séquentiellement.
Split: Invoque les éléments d'un
ensemble de processus.
Split+join: Invoque les éléments
d'un ensemble de processus de façon synchronisée.
Unordered: Exécute tous les processus d'un ensemble
sans tenir compte de l'ordre. Choice: Choisit parmi plusieurs
alternatives et exécute l'élément.
If-then-else: Si la condition est
vérifiée alors exécute le <<then >> sinon
exécute le <<else >>. Repeat-Until:
Itère l'exécution d'un ensemble de processus tant que la
condition est vérifiée. Repeat-While:
Itère l'exécution d'un ensemble de processus jusqu'`a ce
que la condition soit vérifiée.
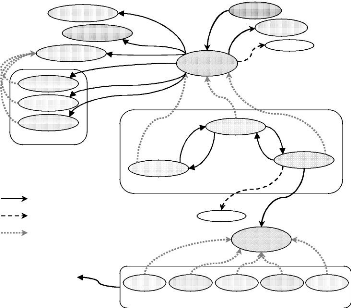
name
ObjectProprety DataTypeProperty
SubClassProperty
ComposedOf
xsd: boolean
Process
&expr;#condition
hasPrecondition
Perform
Result
hasResult
process
hasParticipant
Participant
xsd: boolean
Parameter
hasParameter
Input Output
actor
DisjointWith
hasInput hasOutput
hasLocal
Realizes
Simple Process
CollapsesTo ExpandsTo
RealizedBy
CompositeProcess
Atomic Process
Disjoint With
Invokable
Control Construct
Components
Sequence Split Split-Join Unorder Choice
UnionOf
Figure2.6: Ontologie de processus
III.1.3. Le Service Grounding
Le ServiceProfile et le ServiceProcess sont
considérés comme des représentations abstraites du
service. Le rôle du Grounding est de transformer ces
représentations abstraites en une forme concrète qui peut
être employée pour l'interaction avec le service.
Le Grounding décrit l'accès au service. Il
permet de spécifier les protocoles de transport et les formats des
messages échangés. OWL-S repose sur WSDL pour spécifier
l'interaction avec le service (figure 2.7).
Process Model DL-based types
Atomic Process Inputs/Outputs
Opération Message
Bindings to SOAP, HTTP, etc.
OWL-S
WSDL
Figure2.7: Relation entre OWL-S et WSDL
Conclusion
Les services web fait aujourd'hui une technologie
révolutionnaire. Elle fournie un cadre pour trouver, décrire et
exécuter ces applications à travers le réseau Internet
indépendamment de tout langage de programmation et de toute plate-forme
d'exécution.
Les service web sont basés sur les standards du web: SOAP,
WSDL et UDDI qui permettent à des applications distantes de dialoguer
entre elles.
Mais, l'utilisation de cette technologie a rencontrée
plusieurs limites parmi celle de la composition.
Pour résoudre ce problème plusieurs solutions
ont été proposées. L'une de ces solutions repose sur le
fait qu'une description syntaxique WSDL du service ne suffit pas, elle propose
d'enrichir le service par une description sémantique en utilisant des
langages du web sémantique connaissant lui aussi une grande
évolution de nos jours.
Le langage OWL-S est celui de référence pour faire
une telle description. Nous avons résumées les
éléments de ce langage dans la section précédente
de ce chapitre.
La composition de services web et les principales solutions
existantes en bref font l'objet du chapitre suivant.
Introduction :
Dans le chapitre précédent, nous avons
étudié la description de services web élémentaires.
Mais dans certains cas l'objectif du concepteur d'une application ne peut
être pas atteint par l'invocation d'un simple service web
élémentaire, alors le concepteur doit combiner les
fonctionnalités d'un ensemble de services. Ce processus est
appelé composition de services web. Les services web
invoqués lors d'une composition sont appelés services web
composants [5]. Plusieurs recherches ont été
réalisées sur la composition de services web et la façon
dont cette technique pourrait être utilisée pour arriver à
certains résultats. [2]
Cette composition peut être faite de trois manières
différentes [21]:
Composition manuelle : Suppose que
l'utilisateur génère la composition à la main via un
éditeur de texte et sans l'aide d'outils dédiés.
Composition semi-automatique : Les techniques
de composition semi-automatiques sont une pas en avant en comparaison avec la
composition manuelle, dans le sens qu'ils font des suggestions
sémantiques pour aider à la sélection des services web
dans le processus de composition.
Composition automatique : La composition
totalement automatisée prend en charge tout le processus de composition
et le réalise automatiquement, sans qu'aucune intervention de
l'utilisateur ne soit requise. C'est la catégorie qui nous
intéresse dans la suite.
Dans ce chapitre, nous présenterons en premier temps un
model abstrait et général de la composition, nous expliquerons en
suite brièvement les différentes approches existantes. Une
conclusion sera donnée à la fin.
I. La composition : état de l'art
I.1. Un model abstrait pour la composition de SW :
Ici, nous présentons un cadre général de
la composition automatique de services web. Ce cadre est en haut niveau
d'abstraction, sans considération d'un langage particulier, de la
plate-forme ou de la méthode utilisés dans le processus de
composition [4].
Un cadre général du système de
composition est illustré dans la « figure 3.1 ». Le
système a deux types de participants : le fournisseur de services et le
demandeur de service. Les
fournisseurs proposent des services web. Les demandeurs
consomment des informations ou des services offerts par ces fournisseurs.
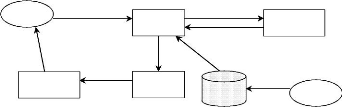
Résultat
Service Spécification
Spécification
Répertoire
de service
Un processus
Fournisseur
Service
Evaluateur
Demandeur
Service
Moteur
D'exécution
Spécification externe
Translateur
Spécification interne
Des processus
Générateur de processus
Des
Processus
Service
Figure 3.1 : Cadre général du
système de composition de services
Le système est composé aussi des composants suivant
: translateur, générateur de processus, évaluateur, moteur
d'exécution et répertoire de services.
Ainsi, dans ce model la composition automatique inclut les phases
suivantes :
Présentation de service individuel :
premièrement, les fournisseurs de service publient leurs
services basiques dans un annuaire global. Les attributs essentiels pour
décrire ces services incluent la signature, les états et des
valeurs non fonctionnelles. La signature est représentée par les
inputs, les outputs et les exceptions du service. Les états sont
spécifiés par les préconditions et les postconditions du
service. Les valeurs non fonctionnelles sont les attributs utilisés dans
l'évaluation du service.
Translation des langages : souvent, les
méthodes de composition de services web distinguent entre les langages
de spécification de services dits externes utilisés par les
participants et permettant à l'utilisateur d'accéder aux services
d'une manière facile et entre les langages dits internes utilisés
par le générateur de processus composites. Le
translateur permet donc la translation entre ces deux langages.
Génération du processus de composition :
dans cette phase, le générateur de processus essaie de
résoudre la requête du demandeur par la composition des services
basiques offerts par les fournisseurs. Le générateur de processus
prend souvent en entrée les fonctionnalités des services et
produit en sortie un model de processus décrivant le service composite.
Le model de processus contient un ensemble de services aussi que les flux de
contrôle et de données entre eux.
Evaluation du service composite : certaines
fois, plusieurs services peuvent fournir des fonctionnalités similaires.
Il est donc possible que le générateur génère plus
qu'un seul service composite pour résoudre la requête du
demandeur. Dans ce cas, les différents services composites sont donc
évalués en utilisant les attributs non fonctionnels fournis par
les descriptions des services.
Exécution du service composite :
après qu'un service composite soit sélectionné,
il sera prêt pour être exécuter. L'exécution du
service composite peut être vue comme la séquence de messages
passés selon les spécifications du model de processus.
I.2. Approches existantes
Il existe principalement deux grandes approches de composition :
l'approche statique et l'approche dynamique. Nous présentons
brièvement chacune de ces approches dans ce qui suit.
I.2.1. Composition statique des services web
Dans cette approche, les services web à composer sont
choisis à l'heure de faire l'architecture et le design. Les composants
sont choisis et reliés ensemble, avant d'être compilés et
déployés [2]. Les techniques de composition statiques sont
définies à l'aide de processus métier :
orchestration et chorégraphie [1].
Orchestration : L'orchestration de services
web exige de définir l'enchaînement des services web selon un
canevas prédéfini, et de les exécuter selon un script
d'orchestration. Ces derniers (le canevas et le script) décrivent les
interactions entre services web en identifiant les messages, et en
spécifiant la logique et les séquences d'invocation. Le module
exécutant le script d'orchestration de services web est appelé un
moteur d'orchestration. Ce moteur d'orchestration est une entité
logicielle qui joue le rôle d'intermédiaire entre les services en
les appelant suivant le script d'orchestration [5]. Ce type de composition
permet de centraliser l'invocation des services web composants.
La « figure 3.2 » illustre l'orchestration [5]. La
requête du client (logiciel ou humain) est transmise au moteur
d'exécution (Moteur). Ce dernier, d'après le processus
préalablement défini, appelle les services Web (ici,
SW1, SW2, SW3 et SW4) selon l'ordre
d'exécution.
SW1 SW2
1 2
Moteur
Client
4
3
Requête Résultat requête
SW3
SW4
Figure 3.2 : vue générale de
l'orchestration
BPML - Business Process Modeling
Language: est un exemple des langages d'orchestration.
Chorégraphie : Contrairement à
l'orchestration, la chorégraphie n'a pas un coordinateur central. Chaque
service web mêlée dans la chorégraphie connaît
exactement quand ses opérations doivent être
exécutées et avec qui l'interaction doit avoir lieu [21]. Elle
est associée à l'échange de messages entre services web
plutôt qu'à un processus métier exécuté par
un seul partenaire.
La « figure 3.3 » permet d'illustrer une vue
générale d'une composition de services web de type
chorégraphie [5]. Le client (logiciel ou humain) établit une
requête qui est satisfaite par l'exécution automatique de quatre
services web (SW1, SW2, SW3 et SW4).
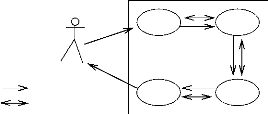
Requête
SW1 SW2
Résultat
Client
Envoi du résultat du SW Echange de messages
SW4 SW3
Figure 3.3 : vue générale de la
chorégraphie
Les principaux langages de chorégraphie de
services web sont : WSCL(1), WSCI(2) et
XLANG(3).
Qu'il s'agisse d'orchestration ou de chorégraphie,
l'agrégation des différents services web se fait de
manière statique avant exécution. L'agrégation obtenue est
rigide et donc difficilement modifiable [1]. Ainsi si les fournisseurs de
services proposent d'autres services ou changent les anciens services, des
incohérences peuvent être causées, ce qui demanderait un
changement de l'architecture du logiciel, voire de la définition du
processus et créerait l'obligation de faire une nouvelle conception du
système [2].
I.2.2. Composition dynamique des services web
On appelle composition dynamique l'agrégation de
services web permettant de résoudre un objectif précis soumis par
un utilisateur en prenant en compte ses préférences. Cette
composition peut se faire avant ou pendant l'exécution des services web.
A l'heur actuelle, il n'existe pas de standard : les recherches sont
principalement académiques [1].
Les différentes approches existantes pour la
composition dynamique de services web peuvent être regroupées en
deux courants : les approches basées sur les workflow et les approches
basées sur les techniques de l'intelligence artificielle.
I.2.2.1. Approches orientées workflow :
L'approche se base sur le fait qu'un service web composite peut
être définit par un ensemble de services atomiques et par la
façon dont ils communiquent entre eux. Cette définition est de
même type que la manière dont est défini un processus
métier. Ce courant propose donc d'adapter les méthodes
d'orchestration et de chorégraphie afin de les rendre dynamiques [1].
Eflow [1], une plateforme pour la spécification, la
création et la gestion de services composites en utilisant les
méthodes de génération de workflows statiques mais
représentés en interne sous la forme d'un graphe qui peut
être modifié dynamiquement lors de l'exécution. Ce graphe
contient, en plus des noeuds représentant les services, des noeuds de
décision et d'événements qui
(1) Web Service Conversation Language
(2) Web Service Choregraphy Interface
(3) XML Business Process Language
permettent une plus grande robustesse du système : en
cas de non disponibilité d'un service web, celui-ci peut être
automatiquement remplacé par un service web équivalent.
Laukkanen et Helin [1] identifient deux solutions possibles
pour composer dynamiquement des processus métier : remplacer un service
web dans un processus métier existant par un autre service ayant des
fonctionnalités similaires, ou définir un nouveau workflow
à partir des services web disponibles. Les auteurs proposent d'utiliser
les descriptions sémantiques des services web pour pouvoir comparer les
fonctionnalités en utilisant les notions de préconditions et
d'effets de OWL-S.
I.2.2.2. Approches orientées intelligence
artificielle : Comme nous avons déjà
présentées dans le chapitre précédent, un service
web dans une description OWL-S peut être spécifié à
l'aide de ses préconditions et ses effets. Ces concepts sont en effet
très proches de ceux de la planification. Un autre domaine a connu ces
dernières années une très grande évolution dans le
domaine de l'intelligence artificielle. Celui des systèmes multi-
agents.
Pour ces raisons et autres, La composition dynamique de
services Web par des techniques d'intelligence artificielle, et plus
particulièrement par des techniques de planification et des
systèmes multi-agents, est la voie qui semble la plus prometteuse
[1].
Dans ce qui suit, nous présentons quelques approches de
composition par planification, par SMA et par d'autres techniques de
l'intelligence artificielle.
Calcul situationnel : dans cette approche, Le
problème de la composition est abordé de la façon suivante
: la requête de l'utilisateur et les contraintes des services sont
représentées en terme de prédicats du premier ordre dans
le langage de calcul situationnel. Les services sont transformés en
actions (primitives ou complexes) dans le même langage. Puis, à
l'aide de règles de déduction et de contraintes, des
modèles sont ainsi générés et sont
instanciés à l'exécution à partir des
préférences utilisateur [1]. Golog fait un exemple de langages de
calcul situationnel.
Preuve de théorèmes : dans
cette approche, les services disponibles et les requêtes utilisateur sont
traduites dans un langage du premier ordre. Puis des preuves sont produites
à partir d'un prouveur de théorèmes [1].
Composition avec SMA : la composition de
services peut être implémentée aussi en utilisant des SMA.
Dans cette approche, chaque agent présente un service et sert à
satisfaire une partie de la requête de l'utilisateur en utilisant ses
propres capacités.
Mùller et Kowalczyk [1] travaillent sur un
système multi-agents pour la composition de services basé sur la
concurrence entre coalitions de services : les agents représentants les
services se contactent les uns les autres pour proposer leurs services en
fonction de leur capacité de raisonnement et ainsi former des coalitions
d'agents capables de résoudre les buts fournis par l'agent utilisateur.
Puis les différentes coalitions vont faire une offre la plus
compétitive possible. Chaque solution reçoit une note de l'agent
utilisateur. C'est donc la solution ayant le plus haut score qui sera
choisie.
Kumar et Mishra dans [6] présentent deux modèles
de composition de services web sémantiques en se basant sur les SMA. Les
deux modèles se différent par l'utilisation d'un
coordinateur dans le processus de composition ou non. Dans le premier
modèle où il n'y a pas de
coordinateur, la requête de l'utilisateur est
décomposée par le système en activités/task
atomiques : task1, task2, ..., taskn. Le système sélectionne en
suite pour chaque activité atomique un agent fournisseur
représentant un service web : AF1, AF2, ..., AFn. L'agent utilisateur
négocie en fin avec chaque agent fournisseur et lui affecte
l'activité associée. Cependant dans le deuxième
modèle un agent coordinateur prend la responsabilité de
contrôler tout le système de composition.
Composition par planification : ordonner des
services web ayant des préconditions et des effets est donc très
similaire à un problème de planification automatique. De
nombreuses études ont été faites pour implémenter
la composition de services web comme une résolution d'un problème
de planification.
Peer [1] propose une approche basée sur le langage PDDL
dans laquelle, après création du domaine de planification
à partir de la description sémantique, un planificateur est
choisi parmi plusieurs en fonction des instructions PDDL utilisées dans
le domaine ou de la complexité du but à atteindre.
Medjahed [1] présente une technique pour
générer des services composites à partir de descriptions
déclaratives de haut niveau. Cette méthode utilise des
règles de composabilité pour déterminer dans quelle mesure
deux services sont composables. L'approche proposée se déroule en
quatre phases : premièrement, une phase de spécification offre
une spécification de haut niveau de la composition désirée
en utilisant le langage CSSL (Composite Service Specification
Langage). En suite, la phase de correspondance utilise des règles
de composabilité pour générer des plans conformes aux
spécifications du service demandé. Si plus d'un plan est
généré, une sélection est effectuée par
rapport à des paramètres de qualité de la composition. La
dernière phase est la phase de génération : Une
description détaillée du service composite est automatiquement
générée et présentée au demandeur. Les
règles de composabilité considèrent les
propriétés syntaxiques et sémantiques des services web.
Wu et al [1] préconisent l'utilisation du planificateur
SHOP2 pour la composition automatique de services web à partir de leur
description sémantique. SHOP2 est un planificateur HTN (Hierachical
Task Network). Dans cette approche, les auteurs considèrent que le
principe de décomposition d'une tache en sous-taches dans la
planification hiérarchique est très similaire au concept de
décomposition de processus composites dans OWL-S.
II. La composition : Approche proposée
Comme nous avons vus, l'automatisation de la composition est
significativement facilitée par le développement du web
sémantique, depuis l'avènement des langages permettant la
description sémantique des services web et notamment le langage OWL-S.
Ce langage permet de décrire les services en terme de flux de
données (inputs et outputs), mais aussi en terme de changement
d'état (préconditions et
effets).
Nous avons vus aussi que la planification a en effet pour
rôle de trouver une séquence d'actions, ou plan, pour, à
partir d'un état initial, arriver à un état but
exprimé par l'utilisateur. Un problème de planification est
résolu dans le cadre d'un domaine, définissant les
différentes actions possibles, leurs
préconditions ainsi que leurs effets
sur l'état du monde.
Cette grande correspondance entre les descriptions OWL-S et
les représentations en planification explique donc
l'intérêt croissant de l'exploitation de la planification dans la
composition de services web.
D'autre part, la nature distribuée des services web
(les services sont généralement géographiquement
distribués), réticence des entreprises à fournir une
description détaillée de leurs services (pour des raisons
concurrentielles) ainsi que l'autonomie des agents peuvent prouver
l'utilité des SMA dans le processus de composition de services web.
Alors, l'utilisation de la planification multi-agents
apparaît très efficace dans la composition automatique et
dynamique des services web. Dans cette partie du chapitre nous
présentons notre modèle de composition exploitant cet
intérêt.
II.1. Spécification du problème
Etant donné un objectif d'un utilisateur et un ensemble
de services web, le rôle de la composition est de trouver une
séquence de requêtes d'appel à des services web. Pour faire
cette composition trois étapes sont distinguées :
1. les services web sont recherchés et
sélectionnés à partir d'un annuaire UDDI en fonction des
besoins à réaliser ;
2. la composition est effectuée en utilisant la
description (syntaxique ou sémantique) des services
sélectionnés ;
3. une description du service composite, i.e.,
l'enchaînement des appels aux services sélectionnés, est
créée.
Dans ce rapport, nous ne traitons que le deuxième point
de l'algorithme de composition, i.e., trouver l'ordre d'exécution des
services web pré-sélectionnés à partir de leur
description sémantique.
Cette étape nécessite en effet deux techniques
critiques : un langage de description compréhensible par la machine et
une approche de composition. Le langage que nous avons choisi est le langage
OWL-S et l'approche est la composition par planification multi-agents.
L'approche proposée consiste alors à transformer
le problème de composition d'un ensemble de services web décrits
par OWL-S à un problème de planification décrit par STRIPS
et de le faire résoudre en utilisant un ensemble d'agents.
Comme précisé ci-dessus, la sélection des
services est considérée comme déjà
effectuée. La première étape consiste à exprimer le
but, l'état initial du système, la base de connaissances ainsi
que la base de compétences pour transformer le problème de
composition en problème et domaine de planification. Le but et
l'état initial sont exprimés par l'utilisateur, tandis que la
base de compétences est extraite des descriptions OWL-S des services
sélectionnées.
Ensuite, ces quatre entrées sont transformées en
problème et domaine de planification. Puisqu'un système
multi-agents est utilisé, où chaque agent a des capacités
précises, le domaine et la base de connaissances doivent être
distribués entre un ensemble d'agents. Nous avons
choisi, de représenter chaque service par un agent,
contenant donc les actions proposées par ce service. Ceci a l'avantage
de permettre à chaque organisation de mettre à jour sa base de
connaissances sans prendre en compte les contraintes de ses partenaires.
En plus des différents agents représentant des
services sélectionnés, deux autres agents sont utilisés
dans le système : l'agent utilisateur et l'agent médiateur. Le
premier initie le processus de composition et le deuxième élabore
coopérativement avec les agents représentant des services un plan
solution satisfaisant la requête de l'utilisateur.
II.3. Le modèle proposé :
Présentation générale et architecture
Notre modèle est basé sur le modèle de
planification multi-agents centralisé dont l'existence d'un agent
coordinateur est nécessaire. Le modèle est constitué de
trois types d'agents :
· d'un agent client qui initie le processus de composition,
en émettant une requête du service composite désiré
par une spécification de son état initial et de son but.
· d'un agent médiateur faisant le lien entre les
agents représentants des services et l'utilisateur. Cet agent joue aussi
le rôle du coordinateur dans le processus de planification et
· de plusieurs agents représentants des services qui
sont chargés de proposer leurs compétences pour résoudre
toute ou partie de la requête soumise par l'utilisateur.
Ce modèle est constitué des trois phases
principales suivantes : création du domaine de planification de chaque
agent représentant d'un service, extraction du problème de
planification d'après la requête de l'utilisateur et en fin
l'élaboration du plan solution. La « figure 3.4 » suivante
représente le déroulement d'une composition en exploitant ces
différentes phases.
Traducteur du domaine

Ensemble de descriptions OWL-S
des services
sélectionnés

Requête utilisateur
Ensemble de domaines
de planification
Problème de planification

Planificateur
Multi-agents

Plan solution
(ensemble d'actions)
Figure 3.4: Différentes phases du
modèle proposé
Création du domaine de planification des
agents représentants des services : chaque agent de ce type est
initialisé avec la description OWL-S du service qu'il représente
de la quelle il extrait son domaine de planification (l'ensemble
d'opérateurs que peut effectuer) formant son base de
compétences et avec un ensemble de données lui permettant de
résonner (Par exemple, un agent représentant un service de
réservation de transport aérien dispose de la liste des trajets
existants) formant son base de connaissances.
Extraction du problème de planification
d'après la requête de l'utilisateur : de la requête
de l'utilisateur est extraite directement une description de l'état
initial et une description du but à atteindre, qui décrient en
effet un problème de planification à résoudre.
Elaboration du plan solution : l'agent
médiateur, suite à la réception du problème soumis
par l'agent utilisateur, il joue le rôle d'un coordinateur dans le
processus de production du plan solution : il essaye de le produire en
exploitant les compétences des différents agents service.
Conclusion
La composition est l'un des principaux domaines de recherche
autour des services web. Elle peut être manuelle, semi-automatique ou
automatique. Pour faire face à l'automatisation du processus de
composition, un modèle abstrait et général est
présenté dans le début du chapitre.
La génération d'un service composite peut
être statique faite pondant la conception et le design des applications
dont l'orchestration et la chorégraphie sont les techniques
utilisées. Comme elle peut être dynamique faite pendant
l'exécution dont des techniques de l'intelligence artificielle et
surtout celles des SMA et des planification sont utilisées.
Enfin, la proche proposée est basée sur la
planification multi-agents. Le chapitre suivant sert à une conception
d'un système implémentant cette approche.
Introduction
Après avoir abordé dans le chapitre
précédent, les concepts fondamentaux de notre modèle de
composition dynamique de services web basé sur la planification
multi-agents, il apparaît essentiel de réaliser un système
permettant principalement de prouver son efficacité.
Cependant, une réalisation efficace d'un
système informatique, doit être d'abord
précédée par une bonne conception. Cette phase n'est pas
évidente car il faut réfléchir à l'ensemble de
l'organisation que l'on doit mettre en place. Elle nécessite des
méthodes permettant de mettre en place un modèle sur lequel on va
s'appuyer.
Le système peut être vu de deux façons
différentes : son architecture externe, concernant son utilisation et
son architecture interne concernant le déroulement de la composition
proprement dit.
Dans la suite de ce chapitre, nous essayons de
détailler chacune de ces deux vue précédées par une
bref description des méthodologies et des langages utilisées pour
leurs conceptualisation.
I. Analyse du système : vue externe et vue
interne
Le système consiste à une implémentation
du modèle de composition de services web par planification multi-agents
présenté dans le chapitre précédent. Il sert
à satisfaire les demandes de services soumises par les utilisateurs par
la composition des services atomiques existants. Cette composition se faite par
un ensemble d'agents.
Pour un utilisateur final du système, le processus
d'élaboration de la solution ne lui sert à rien. Il cherche
seulement à avoir une réponse à sa requête. Pour
cette raison une distinction entre deux vues du système apparaît
très nécessaire : une vue externe et une vue interne.
La « figure 4.1 » suivante présente une
architecture générale du système, montrant ainsi ces deux
vues.
Vue externe : importante pour les
utilisateurs. Elle permet de spécifier l'ensemble d'acteurs
impliqués dans le système, ses différentes
fonctionnalités et la manière de les utiliser.
Vue interne : permet de spécifier les
différents composants internes du système (les différents
agents), leurs architectures internes et les différents interactions
entre eux dans le but d'élaborer la solution au problème soumis
par l'utilisateur.
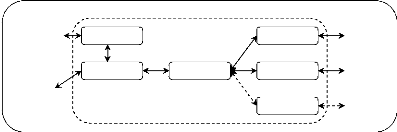
Administrateur
Utilisateur
Vue externe
Agent admin
Vue interne
Agent user
Agent médiat
Agent service1
Agent service2
Agent service..
Fournisseur1
Fournisseur2
Fournisseur..
Figure 4.1 : Description
générale du système
II. Méthodologies et langages exploités
dans la conception
Pour la vue externe le langage UML basé sur une
méthodologie objet est le plus adopté. Mais ce n'est pas le cas
pour la vue interne décrivant le système comme un système
multi-agents.
La programmation orientée agent nécessite
cependant une analyse et une modélisation orientées agent qui
différent assez radicalement d'une méthode d'analyse objet ; les
agents et les objets se différentiant essentiellement au niveau du
comportement et des interactions. Parmi ces différences, on peut citer
:
· l'agent a le contrôle sur son comportement ; un
objet n'a le contrôle que sur son état.
· les objets sont généralement passifs alors
que les agents sont permanemment actifs.
Il y a plusieurs recherches qui s'intéressent à
la méthodologie d'analyse et de conception orientées agent.
Maintenant, il n'y a pas encore une méthode standard car chaque groupe
de recherche propose une méthode différente. Parmi ces
méthodes : MAS CommonKADS, MaSE, Gaia et OMaSE.
Pour faciliter la conception des SMA, une extension du langage
UML prenant en compte les notions agent que ce dernier n'a pas est apparue.
C'est le langage AUML.
III. Vue externe du système
III.1. Description générale du
système
La fonctionnalité principale de notre système
consiste à satisfaire les requêtes des utilisateurs en composant
(s'il est possible) un ensemble de services atomiques existants.
Le système prend une requête d'un utilisateur
demandant un service désiré (exprimée en terme de son
état initial et de son but désiré) en entrée. Et en
exploitant un ensemble descriptions OWL-S de services web
pré-sélectionnés et un ensemble de données fournis
par les fournisseurs des services , il lui rend (si possible) un plan solution
correspondant service composite désiré. Cette description est
illustrée dans la « figure 4.2 » suivante :
Requête
(état initial et but)

OWL-S des services

Système

Réponse de composition Ensemble de données
Client (plan solution) Fournisseur
Administrateur
Figure 4.2 : Description externe du
système
III.2. Identification et représentation des
fonctionnalités offertes par le système
Dans cette section nous aborderons les différentes
fonctionnalités offertes par notre système. C'est en effet, la
chose la plus importante aux ses utilisateurs. Pour le faire les diagrammes
d'UML consistent à l'outil le plus adopté.
Pour bien comprendre les choses, nous commencerons par
élaborer le diagramme de cas d'utilisation après avoir identifier
les différents acteurs du système. Puis nous
représenterons le déroulement de chaque cas d'utilisation
à travers les diagrammes d'activités.
III.2.1. Diagramme de cas d'utilisation
Les cas d'utilisation sont les différents types
d'utilisation du système. Ils définissent
généralement ses fonctionnalités. Ils servent à
structurer les besoins des utilisateurs et les objectifs correspondants du
système.
III.2.1.1. Identification des acteurs et des cas
d'utilisation
Un acteur est une entité externe qui agit sur le
système ; Le terme acteur ne désigne pas seulement les
utilisateurs humains mais également les autres systèmes. Un cas
d'utilisation est un ensemble d'actions réalisées par le
système en réponse à une action d'un acteur.
Pour notre système, voici ses différents acteurs
chacun associé par la liste de ses cas d'utilisation possibles :
1. Utilisateur : c'est l'acteur
principal du système. Il est capable de demander un service ou
d'annuler une demande en cours. Les cas d'utilisation lui sont associés
sont :
· Identifier utilisateur : sert à
identifier chaque utilisateur du système.
· Demander service : sert à
demander le service désiré en émettant sa
requête.
· Annuler demande service : permet
d'annuler une demande effectuée en cours.
· Identifier administrateur : donne
l'autorisation à l'administrateur pour voir le menu du système
lui autorisant d'effectuer des fonctionnalités de gestion de son
système.
· Gérer système : suite
à son identification, l'administrateur à travers ce cas
d'utilisation peut consulter un menu lui permettant de gérer son
système. Ce cas d'utilisation ne sera pas traité dans notre
système ; l'activité de l'administrateur sera terminée
lorsqu'il lui est affiché le menu du système
3. Fournisseur : son rôle consiste
à fournir la description OWL-S de son service. Il lui est associé
le seul cas d'utilisation suivant :
· Fournir owl-s service et ensemble de
données : permet d'entrer la description du service par
son
fournisseur, ainsi qu'un ensemble de données permettant de raisonner sur
ce service.
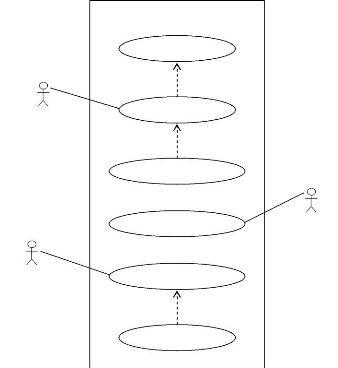
Système de Composition
Identifier utilisateur
<<include>>
Utilisateur
Demander service
<<extend>>
Annuler demande service
Fournir owl-s service
Et ensemble de données
Fournisseur
Administrateur
Identifier administrateur
<<extend>>
Gérer système
III.2.1.2. Diagramme de cas d'utilisation

Entrer owl-s service
et ensemble de données
III.2.2. Diagrammes d'activités
Maintenant, après avoir identifier les
différents cas d'utilisation du système, il est important de
détailler chacun d'eux afin de bien les comprendre. UML le permet ;
c'est à travers les diagrammes d'activités.
Les diagrammes d'activités permettent de mettre
l'accent sur les traitements. Ils permettent ainsi de représenter
graphiquement le comportement d'une méthode ou le déroulement
d'un cas d'utilisation. Cette représentation sous forme d'organigrammes
les rend facilement intelligibles.
Dans ce qui suit nous allons détaillées chacun des
cas d'utilisation de notre système identifiés
précédemment par un diagramme d'activités qui lui est
correspond.
1. Demander service
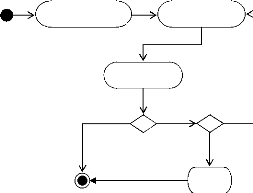
Identifier utilisateur
positif négatif
Afficher résultat
Demander service
Quitter
quitter
autre
Figure 4.4 : Diagramme d'activités pour
« Demander service >>
2. Annuler demande service

Confirmer annulation

Annuler demande
Figure 4.5 : Diagramme d'activités pour
« Annuler demande service >>
3. Fournir owl-s service et ensemble de
données
4. Identifier administrateur
Identifier administrateur Afficher Menu système
Figure 4.7 : Diagramme d'activités pour
« Identifier administrateur »
IV. Vue interne du système
Dans, la section précédente nous avons
présentées une description générale de notre
système, en vue de son utilisation. Mais ce qui est plus important que
cette description pour notre rapport est d'éclaircir la façon
d'exploitation de la planification et des agents pour réaliser la
composition de services. C'est la chose qui nécessite en effet, une
description assez détaillée de l'architecture interne du
système et de son fonctionnement depuis l'émission de la
requête de l'utilisateur jusqu'à l'obtention du plan solution.
Dans cette section, nous présenterons l'architecture
interne du système, nous détaillerons en suite la structure de
chaque agent et son fonctionnement et nous décrirons en fin, les
interactions entre les agents pour permettant de mettre en place le processus
de composition.
IV.1. Architecture interne du système
Le modèle de composition proposé est basé
sur l'utilisation des agents. Les deux acteurs (administrateur et utilisateur)
du système identifié ci-dessus sont représentés
dans le système par un agent assurant ses fonctionnalités. En
plus, chaque service retourné de l'opération de sélection
est représenté aussi par un agent. Et pour faciliter
l'élaboration de la composition un agent médiateur est
ajouté dans le système (figure 4.1).
· Agent utilisateur : c'est
l'entité qui représente l'acteur utilisateur dans le
système. Son rôle consiste à soumettre sa requête
à l'agent médiateur et à recevoir la réponse pour
la visualiser à l'utilisateur.
· Agent administrateur :
représente l'acteur administrateur dans le système.
C'est celui qui lance les autres agents, gère le système (comme
nous avons déjà mentionné, cette fonctionnalité de
gestion n'est pas traitée dans notre système dans ce travail).
· Agents service : ensembles d'agents
représentants les services retournés par la phase de
sélection pré-effectuée (qui nous n'intéresse pas
dans ce travail). Ils servent à recevoir les descriptions OWL-S de ces
services et à les convertissent aux domaines de planification
correspondants (ensemble d'opérateur STRIPS) formant leurs base de
compétances. Ils reçoivent aussi depuis les fournisseurs des
services un ensemble de données lui facilitant la recherche d'actions
à retourner à l'agent médiateur ; ces données
forment leurs bases de connaissances. Ils participent dans le processus de
planification servant à réaliser la composition.
· Agent médiateur : c'est
l'agent faisant le lien entre l'agent utilisateur et les agents services. En
plus de cela, son rôle principal est la réalisation du processus
de planification ; il contient alors un planificateur. C'est donc aussi un
agent coordinateur qui assure la coordination entre les
actions des services participants à la planification afin de
résoudre les conflits qui peuvent se produits. Après qu'il trouve
le plan solution il l'envoie à l'agent utilisateur.
Dans ce qui suit, nous détaillerons l'architecture
interne de chaque agent ainsi que son fonctionnement.
IV.2. Architectures internes et fonctionnement des
agents
Touts les agents du système sont du type cognitif,
sauf les deux agents : utilisateur et administrateur qui sont des agents
réactifs. Ces derniers n'ont aucun raisonnement à effectuer ; ils
ne font qu'agir selon leurs perceptions sur l'environnement.
Cependant, un agent cognitif (délibératif)
dispose d'une base de connaissance comprenant l'ensemble des informations et de
savoir-faire nécessaires à la réalisation de sa
tâche et à la gestion des interactions avec les autres agents et
avec son environnement. Il agit selon un raisonnement
(délibération) effectué. De façon
générale, l'architecture interne de ce type d'agents est la
suivante :
Autres agents

Agent cognitif
Module de communication
Base de connaissances
Base de procédures de raisonnement

Perception
Action

Environnement
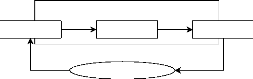
Agent cognitif Perception
Environnement
Délibération
Exécution
Figure 4.8 : architecture
générale d'un agent cognitif
Le module de communication est le même pour l'ensemble
des agent. Il contient des mécanismes assurant l'émission et la
réception des messages entres les agents. La différence entre les
agents est au niveau des deux bases de connaissances et de procédures de
raisonnement.
Ainsi, son fonctionnement peut être modélisé
comme suit :
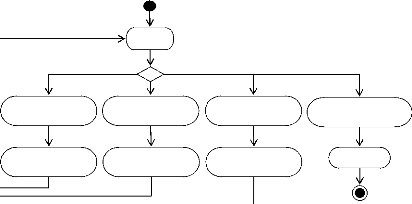
Recevoir
Requête utilisateur
Envoyer requête Au médiateur
Visualiser résultats
A l'utilisateur
Recevoir
Message médiateur
Attente
Recevoir
Demande annulation
Envoyer demande annulation au médiat
Recevoir demande
déconnection utilisateur
Se détruit
Pour décrire les agents il parvient donc utile de
spécifier pour chacun son architecture (en terme de sa base de
connaissances et de sa base de procédures) et son fonctionnement (en
terme de ses perceptions, ses raisonnements et ses actions).
IV.2.1. Agent utilisateur
· Récupère la requête de l'utilisateur
et l'envoie à l'agent médiateur ;
· Récupère la réponse de l'agent
médiateur et la visualise à l'utilisateur.
· Lorsque l'utilisateur veut annuler une demande
déjà effectuée, cet agent envoie sa demande d'annulation
à l'agent médiateur.
· Lorsque l'utilisateur veut se déconnecter, l'agent
se détruit.
1. Architecture interne
Cet agent est un agent réactif son architecture est celle
de base, où il n'existe que les modules de perception, de communication
et d'exécution.
2. Fonctionnement
Perception :
- Réception de la requête de l'utilisateur (depuis
l'interface).
- Réception d'un message du médiateur ou de
l'administrateur.
- Réception d'une demande d'annulation de la requête
par l'utilisateur (depuis l'interface)
Action : il agit selon le diagramme
d'activités suivant :
IV.2.2. Agent administrateur
· visualise l'interface principale du système aux
utilisateurs ;
· lance les agents services pour les services
déjà sélectionnés ;
· lance l'agent médiateur et lui envoie la liste des
identificateurs des agents service ;
· lance un agent utilisateur lorsqu'un utilisateur
s'identifie et se connecte pour
passer une demande de service et lui envoie
l'identificateur de l'agent médiateur;
· vérifie identité administrateur lorsque
celui-ci veut se connecter.
1. Architecture interne
C'est un agent réactif. Selon sa perception, il agit. Il
contient les deux composantes suivantes lui facilitant son fonctionnement :
· Une base de connaissances : elle
contient les identificateurs de l'agent médiateur et des agents services
permettant leurs lancement et l'identificateur de l'administrateur du
système permettant la vérification de l'identité
entrée par l'administrateur (confidentialité).
· Une procédure de vérification :
c'est une procédure permettant de vérifier
l'identité de l'administrateur.
2. Fonctionnement
Perception :
- Réception d'une requête utilisateur ou
administrateur de connexion (depuis l'interface).
- Réception de l'identificateur de l'administrateur.
Raisonnement : son raisonnement consiste
à vérifier l'identificateur de l'administrateur et selon le
résultat de la vérification, il agit.
Action : il agit selon le diagramme
d'activités de la « figure 4.11 » suivante : IV.2.3.
Agent service
· C'est une entité très importante pour
l'élaboration du processus de planification ; il sert à enrichir
le domaine de planification du planificateur se trouvant au niveau de l'agent
médiateur ;
· Récupère la description OWL-S du service
qu'il représente de son fournisseur ;
· Il le convertit vers un ensemble d'opérateurs
PDDL ;
· Suite à la réception du problème
de planification (requête utilisateur) de l'agent médiateur, il
essaye à trouver une action permettant de le résoudre directement
: s'il le trouve, il l'indique à l'agent médiateur ; sinon il
cherche l'ensemble d'actions permettant de le résoudre partiellement et
il les envoie à l'agent médiateur.
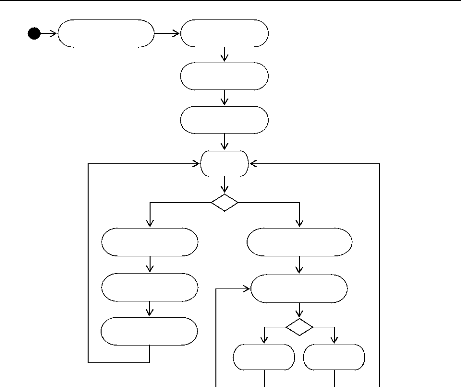
Attente
Valide
Non valide
Afficher erreur
Afficher interface
Principale système
Lui envoyer l'ident
de l'agent médiateur
Recevoir demande connexion utilisateur
Lancer
un agent utilisateur
Lui envoyer les idents des agents service
Lancer
Agent médiateur
Lancer
Agents service
Recevoir demande
connexion administrateur
Recevoir Identificateur
administrateur
Afficher menu
système
Figure 4.11 : Diagramme d'activités pour
le fonctionnement de l'agent administrateur 1. Architecture
interne
Comme déjà indiqué
précédemment, cet agent est de type cognitif. En plus de son
module de communication, il contient : une base de connaissances, une base de
compétences, un traducteur des descriptions OWL-S vers des
opérateurs STRIPS et une procédure de parcours des
opérateurs dans le but de chercher un ensemble d'opérateurs
résolvant tout ou une partie du problème soumis par l'agent
médiateur. Une présentation de l'architecture interne de cet
agent est donnée dans la « figure 4.12 » suivante :
· La base de connaissances : chaque
agent service en plus de la description OWL-S est initialisé avec un
ensemble de données (issue d'une base de données par exemple)
permettant à l'agent de raisonner. Par exemple, un agent
représentant un service de réservation de transport aérien
dispose de la liste des trajets existants. Ces données forment la base
de connaissances de l'agent.
Service
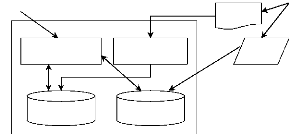
Problème
OWL-S
Agent service
Procédure parcours
des opérateurs
Traducteur
OWL-S vers STRIPS
Ensemble De données
Opérateurs STRIPS
Base de
compétences
Base de
connaissances
Figure 4.12 : Architecture interne de <<
l'agent service >>
· La base de compétences :
À partir de la description sémantique, les agents
service vont créer leur domaine de planification qui regroupe, sous la
forme d'opérateurs STRIPS extraits des processus de la description
OWL-S, les actions réalisables par les agents, i.e., leur base de
compétences.
· Le traducteur OWL-S vers STRIPS :
puisqu'un modèle de composition par planification est
exploité l'une des phases les plus importantes dans le processus de
composition de services est la traduction des descriptions OWL-S des services
sélectionnés à des domaines de planification
(opérateurs STRIPS). C'est ce module de l'agent service que la
permet.
Les étapes de traduction seront détaillées
dans ce paragraphe.
Ce traducteur prend en entrée une description OWL-S du
<< model de processus >> (process model en anglais) du service
représenté par l'agent et produit en sortie un ensemble
d'opérateurs STRIPS (domaine de planification).
OWL-S Process model du service
Traducteur
OWL-S vers PDDL
Ensemble d'opérateurs STRIPS


Dans ce qui suit, nous donnerons premièrement un
ensemble de restriction que nous avons apportées aux descriptions OWL-S
des services, puis nous détaillerons l'algorithme de traduction.
· Restriction sur la sémantique
OWL-S
Le langage OWL-S qui permet d'annoter sémantiquement un
service web est très riche et n'impose que très peu de
contraintes sur la manière d'exprimer cette sémantique. Les
chercheurs dans ce domaine et parmi << J.Guitton >> [1] font
toujours donc un ensemble de restrictions et d'hypothèses. Vu du cadre
et de la période de l'étude, nous avons adoptées de faire
une restriction de la restriction de ce chercheur (l'objectif de notre travail
n'est pas en effet de faire quelque chose qui n'existe pas,
mais de prouver juste l'efficacité de la planification
pour la résolution du problème de composition de services
web).
- Un model de processus d'un service en OWL-S peut contenir
trois types de processus en savoir : les processus atomiques, composites ou
simples, mais seuls les processus atomiques sont pris en compte actuellement
dans notre modèle ;
- Plusieurs formalismes existent pour résoudre les
problèmes de planification, dans notre modèle le formalisme
STRIPS est celui qui a été utilisé, dont un
problème de planification est défini par un ensemble
d'opérateurs, d'un état initial et d'un but à
atteindre.
- nous spécifions les préconditions et les
effets des processus atomiques dans le formalisme STRIPS, comme
représenté dans l'extrait ci-dessous, afin de permettre leur
utilisation directement lors de la création du domaine ;
<process:hasPrecondition>
<expr:KIF-Condition rdf:ID="ExistTrain">
<expr:expressionBody rdf:
datatype="
http://www.w3.org/2001/XMLSchema#string">
(ExistTrain ?From ?To)
</expr:expressionBody>
</expr:KIF-Condition>
</process:hasPrecondition>
? Algorithme de traduction
La traduction de la description sémantique d'un service
vers un domaine de planification consiste à représenter les
processus atomiques OWL-S sous forme d'opérateurs.
L'algorithme « algorithme 4.1 » parcourt le model de
processus du service, chaque fois qu'il rencontre un processus atomique, il le
transforme à un opérateur.
|
Algorithme 4.1 : traduire OWL-S vers STRIPS(P)
Input : model de processus OWL-S « P » Output : ensemble
d'opérateurs STRIPS « OS » OS = Ø ;
Pour chaque processus atomique p
de P faire
Créer nouvel opérateur op ;
op.nom = p.nom ;
op. Paramètres = p.inputs + p.outputs ;
op.préconditions = p.précoditions ; ajouter op à OS
;
Fin pour
Retourner OS ;
Fin
|
En effet, la correspondance ici est directe. Un
opérateur de planification est créé, avec, comme
identifiant, l'identifiant de ce processus, c'est-à-dire le nom de
l'opération du service correspondant. Par exemple, le processus atomique
suivant :
<process:AtomicProcess rdf:ID="AgentTrainReservation">
...
</process:process>
Permet de définir l'opérateur :
(:operator (!AgentTrainReservation ...) ...
)
Puis les préconditions et les effets du processus atomique
sont ajoutés à l'opérateur correspondant.
La « figure 4.13 » suivante présente la
correspondance entre processus atomique OWL-S et un opérateur STRIPS
:
Processus atomique OWL-S
Nom processus atomique
Précondition
Output
Effet
Input
Opérateur STRIPS/PDDL
Nom opérateur
Précondition
Paramètres
Effet
Figure 4.13 : Correspondance processus atomique
OWL-S et opérateur STRIPS
Gestion des préconditions : Les
préconditions d'un processus ont une correspondance directe avec les
préconditions d'un opérateur, du fait de l'hypothèse
formulée sur l'écriture des préconditions et effets dans
la description OWL-S. Soit la précondition OWL-S suivante :
<process:hasPrecondition> <expr:KIF-Condition
rdf:ID="ExistTrain">
<expr:expressionBody rdf: datatype="
http://www.w3.org/2001/XMLSchema#string">
(ExistTrain ?From ?To) </expr:expressionBody>
</expr:KIF-Condition>
</process:hasPrecondition>
De cette précondition est extrait directement le
prédicat suivant :
(ExistTrain ?From ?To)
Gestion des effets : Tout comme les
préconditions, les effets d'un processus atomique sont traduits
directement. Mais ils doivent être distingués en effets positifs
et en effets négatifs au moment de la création de
l'opérateur. Nous choisissons de représenter les effets
négatifs, dans la description OWL-S par des prédicats
commençant par not [1]. Par exemple, la réservation d'un billet
de train a pour effet de déplacer l'utilisateur d'une ville à une
autre :
<expr:KIF-Expression rdf:ID="NotVoyagerAtFrom">
<expr:expressionBody rdf:
datatype="
http://www.w3.org/2001/XMLSchema#string">
(not(at ?User ?From ?Date))
</expr:expressionBody>
</expr:KIF-Expression>
· Le module de parcours : c'est une
procédure permettant de chercher soit une solution directe au
problème de planification envoyé par l'agent médiateur,
sinon de chercher l'ensemble d'opérateurs possibles pouvant servir
à la résolution du problème.
Comme nous avons déjà vu, le problème
à résoudre est représenté a travers un ensemble de
prédicats formant l'état initial (entrés par
l'utilisateur) et un ensemble d'autres prédicats formant le but à
réaliser (entrés aussi par l'utilisateur), ainsi, les
opérateurs STRIPS (extraits de la description OWL-S) sont aussi
représentés par un ensemble de prédicats formant ses
préconditions et un autre formant ses effets.
La recherche est donc faite par parcours des deux bases de
connaissances et de compétences, afin de trouver des correspondances
possibles entre les prédicats de l'état initial et du but avec
ceux des préconditions et des effets des opérateurs STRIPS
respectivement.
Trois cas sont possibles ici :
1. suite à la réception d'un problème de
planification (état initial et but) de l'agent médiateur, si une
correspondance entre l'état initial et l'ensemble des
préconditions d'un opérateur et une correspondance entre
l'état but et les effets de ce même opérateur sont
trouvées ; alors cet opérateur constitue une solution directe du
problème à retourner à l'agent médiateur.
2. Si ce n'est pas le cas, la procédure cherche alors
tous les opérateurs dont leurs effets sont correspondants à
l'état but du problème. La liste des opérateurs
trouvés ainsi que pour chacun la liste de ses préconditions sont
alors retournées à l'agent médiateur.
3. Si aucune des deux solutions précédentes n'est
trouvées, l'agent service retourne alors un message à l'agent
médiateur lui indiquant l'absence d'une solution.
2. Fonctionnement
Perception :
- Réception d'un message contenant le problème
à résoudre d'après l'agent médiateur.
- Réception d'un message de l'agent médiateur
pour arrêter le processus de recherche de la solution (dans le cas
où la solution est déjà trouvée ou l'utilisateur
demande d'annuler la résolution de son problème).
Raisonnement : suite à la
réception du problème à résoudre de l'agent
médiateur, cet agent exécute la procédure de parcours
énoncée précédemment. Le résultat de la
recherche : soit une solution directe, soit une liste d'actions est en suite
envoyé à l'agent médiateur. S'il n'y a pas de
résultats à retourner, l'agent envoie un message à l'agent
médiateur lui indiquant ceci.
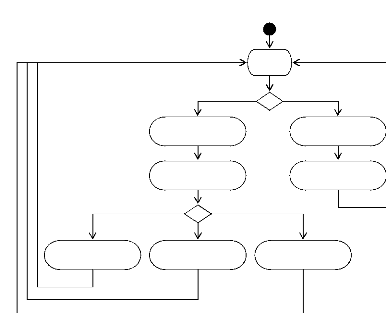
Action : il agit selon le diagramme
d'activités suivant :
Attente
Recevoir problème
du médiateur
Recevoir demande
d'arrêt du médait
Exécuter procédure
de recherche
Arrêter procédure
de recherche
Solution directe trouvée
Non solution trouvée
Non solution directe trouvée
Envoyer solution directe au médiat
Envoyer liste
d'actions au médiat
Envoyer message (non solution)au médiat
Figure 4.14 : Diagramme d'activités pour
le fonctionnement de l'agent service
IV.2.4. Agent médiateur
· Son utilité principale est dans le processus de
planification dont il joue le rôle d'un coordinateur entre les
différents agents services. Il sert à chercher un plan solution
au problème de l'utilisateur en planifiant l'ensemble d'actions
retournées par les agents service et en résolvant les
différents conflits pouvant exister entre eux.
· C'est au niveau du quel donc, qu'un planificateur
existe.
1. Architecture interne
Cet agent est un agent cognitif. Au niveau duquel le
raisonnement principal de notre modèle est réalisé ; c'est
la planification proprement dite.
Afin de bien comprendre son architecture interne, il est
essentiel avant de l'aborder, d'expliquer les grandes lignes du
déroulement de la planification au niveau de cet agent.
En effet, le modèle de planification utilisé
est distribué, le domaine de planification est réparti sur
l'ensemble des agents service. Chaque agent service est capable de
réaliser un certain nombre d'actions : ses compétences. C'est la
mise en commun et l'ordonnancement des compétences de chaque agent, dans
le but de résoudre un problème donné, qui va permettre de
faire émerger un plan solution.
Cette mise en commun et ordonnancement sont assurés
par le module de planification de cet agent médiateur ; le
planificateur.
Le planificateur utilisé dans notre modèle
repose sur la recherche de la solution dans un espace d'états (chapitre
1 § I.2.3.1), exploite le principe du chaînage arrière et
communique avec les différents agents service pour collecter l'ensemble
d'opérateurs lui permettant la poursuite du processus de
planification.
Pour raisonner, ce planificateur a besoin donc d'une
structure de données lui facilitant la construction du graphe
d'états et son parcours et d'un module de communication lui facilitant
l'intégration des compétences des agents service.
Un planificateur, une structure de données
représentant le graphe d'états et un module de communication sont
donc les composants de notre agent médiateur. Ils sont
représentés dans la figure « figure 4.14 » suivante
:
Agent service1
Agent service2
Agent serviceN
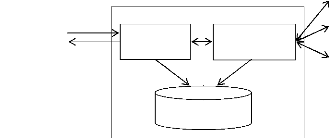
Agent utilisateur
Problème
Plan
Planificateur
Agent médiateur
Graphe
d'états construit
Module de
communication
Figure 4.15 : Architecture interne de «
l'agent médiateur »
· Le graphe d'états construit :
c'est une structure de données qui sert de support au
raisonnement du planificateur. Elle représente un graphe d'états
orienté construit dynamiquement au cours du processus de planification
dont, les noeuds sont les différents états atteints par le
planificateur et les arcs représentent les différents
opérateurs (actions) venants des agents service qui permettent de passer
d'un état à un autre. Le noeud principal du graphe
représente le but de l'utilisateur à atteindre.
But
Sous_but1 Sous_but2 Sous_butn

Sous_sous_but1 Sous_sous_but2
Chaque noeud du graphe représente :
1. les préconditions de l'opérateur venant de l'un
des agents service et permettant de passer de son noeud père à
lui ; et
2. les effets des opérateurs venants des agents service
et permettant de passer de lui à ses noeuds fils.
Lorsque le planificateur arrive à construire un chemin
dans ce graphe permettant d'aller du noeud principal (le but) à un noeud
satisfaisant l'état initial alors, le problème est résolu
et le plan solution sera donc l'inverse de la séquence
d'opérateurs allant du but à l'état initial.
· Le planificateur : l'agent
médiateur lorsqu'il reçoit un problème (état
initial et but) de l'agent utilisateur, il exploite les opérateurs
(compétences) des différents agents service dans un algorithme de
planification pour le résoudre. Ce module de l'agent sert à
implémenter un tel algorithme.
Planificateur

Plan solution
Ensemble d'actions de planification
venants des agents
service
|
|
|
Description de l'état initial
Description du but


Rappelons (comme déjà vu dans le chapitre1
§ I.2.3) qu'un nombre important d'algorithmes existe pour faire la
planification. Le planificateur de notre système exploite le
mécanisme de la recherche d'une solution dans un espace d'états
ainsi que le principe du chaînage arrière.
Ce planificateur est considéré
régressif, puisqu'il se déplace vers l'arrière.
Il consiste à construire le graphe de recherche du problème, non
pas en partant de l'état initial, mais en partant du but et en
appliquant l'inverse des opérateurs de planification (venant des agents
service) pour produire des sous-buts jusqu'à arriver à
l'état initial. Si l'algorithme permet de remonter à cet
état initial, alors il retourne le plan solution trouvé.
· L'algorithme de planification :
Avant d'aborder l'algorithme, il convient de montrer
premièrement son principe. Principe :
- L'algorithme est récursif, il exploite le graphe
d'états pour résoudre le problème soumis par
l'utilisateur.
- Il diffuse le but de l'utilisateur avec son état initial
vers tous les agents service comme un premier problème à
résoudre (première itération de l'algorithme).
- Chaque fois que le planificateur reçoit toutes les
réponses des agents service à un nouveau sous-problème, il
dispose d'un mécanisme lui permettant de vérifier l'existence
d'un plan solution au but de l'utilisateur (un chemin dans le graphe
d'états allant du but à l'état initial de
l'utilisateur).
- Si ce n'est pas le cas (l'itération essayée ne
convient pas à résoudre le but de l'utilisateur), et tant qu'il
n'a pas trouvé de solution satisfaisante, le planificateur met
éventuellement à jour le graphe d'états et le parcourt
d'abord pour choisir un nouveau sous-but non résolu encore et il le
diffuse avec l'état initial de l'utilisateur à tous les agents
service comme un nouveau sous-problème à résoudre
(nouvelle itération).
- L'algorithme s'itère alors jusqu'à arriver
à construire dans le graphe d'états, un chemin allant du but de
l'utilisateur à son état initial.
|
Algorithme 4.2 : algorithme de planification
1. mettre le but de l'utilisateur le noeud principal du
graphe d'états ;
2. soit path la séquence
d'opérateurs (actions), permettant de passer du noeud principal du
graphe d'états à un autre noeud du graphe (un sous-but).
3. initialisation :
· path ? ø ;
· nouveau_but ? but_utilisateur ;
· solution_trouvée ? false ;
· non_solution_trouvée ? false ;
4. Tant que
(non(solution_trouvée)et(non(non_solution trouvée)))
faire
· Diffuser (nouveau_but, état initial) aux
différents agents service ;
· Attendre toutes les réponses des agents
service ;
· Si (l'un des agents service
retourne un opérateur « op » dont les effets
correspondent
au « nouveau_but » et les préconditions
correspondent à l'état initial ) alors
solution ? inverse de (path.op) ; solution_trouvée ?
true ;
· Si (toutes les
réponses sont négatives et il n'y a pas encore de noeuds à
visiter dans le graphe d'états) alors
solution ? pas de solution ; non_solution_trouvée ?
true ;
|
|
Algorithme 4.2 : algorithme de planification
(suite)
· Si (toutes les
réponses sont négatives, mais il y'a de noeuds pas encore
traités) alors
nouveau_but ? choisir noeud pas encore traité du
graphe d'états ;
path ? séquence d'opérateurs permettant de
passer du but principal à ce noeud ;
· Si (un ensemble d'agents
service retournent un ensemble d'opérateurs dont les Effets
correspondent à « nouveau_but » mais les préconditions
ne correspondent pas à l'état initial)
alors
Mettre à jour le graphe d'états (ajouter les
préconditions des opérateurs retournés comme des sous-but
fils de « nouveau_but ») ;
nouveau_but ? choisir noeud pas encore traité du
graphe d'états ; path ? séquence d'opérateurs permettant
de passer du but principal à ce noeud ;
5. Fin tant que
6. Retourner (solution) à l'agent utilisateur
;
|
Exemple illustratif :
Afin d'illustrer le fonctionnement de cet algorithme,
introduisons l'exemple suivant :
Notre utilisateur est à Paris le Dimanche et veut se
rendre à New York le Mardi. Il veut organiser son voyage par Internet.
Pour le faire supposons que deux services sont déjà
sélectionnés : un service de réservation de vols
aériens et un autre de réservation de trains.
Dans notre système ces deux services sont
représentés par les deux agents : Agent_S_V et Agent_S_T.
· L'agent Agent_S_V extrait de la description du service
qu'il représente l'opérateur suivant :
Reserver_Vol(Nom_utilisateur Ville_depart Ville_Arrivee
Date_Depart Date_Arrivee) Precond : (À Nom_utilisateur Ville_Depart
Date_Depart)
Effet : (À Nom_utilisateur Ville_Arrivee
Date_Arrivee)
Et a comme base de connaissances :
(Exist_trajet Paris Madrid Dimanche Dimanche)
(Exist_trajet London Moscou Samedi Dimanche) (Exist_trajet London New York
Lundi Mardi)
· L'agent Agent_S_V extrait de la description du service
qu'il représente l'opérateur suivant :
Reserver_Train(Nom_utilisateur Ville_depart Ville_Arrivee
Date_Depart Date_Arrivee) Precond : (À Nom_utilisateur Ville_Depart
Date_Depart)
Effet : (À Nom_utilisateur Ville_Arrivee
Date_Arrivee)
Et a comme base de connaissances :
(Exist_trajet Roma Paris Mercredi Jeudi) (Exist_trajet Alger
Paris Samedi Dimanche) (Exist_trajet Madrid London Dimanche Lundi)
De la requête de l'utilisateur l'agent utilisateur extrait
le problème de planification suivant et l'envoie à l'agent
médiateur :
Etat initial : (A utilisateur Paris Dimanche)
Etat but : (A utilisateur New York Mardi)
Après la réception de ce problème par
l'agent médiateur, l'algorithme se déroule comme suit :
1. Initialisation Le graphe d'état est le suivant :
(A utilisateur New York Mardi)
nouveau_but ? (A utilisateur New York Mardi) path ?
ø
2. L'agent médiateur diffuse le problème
((A utilisateur New York Mardi) , (A utilisateur Paris Dimanche)) aux
deux agents Agent_S_V et Agent_S_T puis, il attend jusqu'à recevoir
leurs réponses.
3. Les deux agents service suite à la réception
de ce problème, cherchent en exploitant leurs bases de connaissances
dans leurs actions celles dont les préconditions correspondent à
l'état initial du problème et les effets correspondent au but.
Agent_S_V ne trouve pas cette correspondance, mais il trouve
une action (Reserver_Vol(utilisateur London New York Lundi Mardi))
dont les effets correspondent au but et dont la précondition ne
correspond pas à l'état initial, cet agent envoie donc cette
précondition ((A utilisateur London Lundi)) comme un nouveau
but à résoudre à l'agent médiateur.
Agent_S_T ne trouve aucune correspondance, il envoie donc une
réponse négative.
4. maintenant, l'agent médiateur dispose des
réponses des deux agents service, il va procéder comme suit :
Il met à jour le graphe d'états, ce dernier sera
donc le suivant :
(A utilisateur New York Mardi)
(A utilisateur London Lundi)
nouveau_but ? (A utilisateur London Lundi)
path ? ( Reserver_Vol(utilisateur London New York Lundi
Mardi))
5. L'agent médiateur diffuse le nouveau
problème ((A utilisateur London Lundi) , (A utilisateur Paris
Dimanche)) aux deux agents Agent_S_V et Agent_S_T puis, il attend
jusqu'à recevoir leurs réponses.
6. Agent_S_V lui renvoie une réponse négative
et Agent_S_T lui renvoie l'opérateur (Reserver_Train(utilisateur
Madrid London Dimanche Lundi)) et comme un nouveau but à
résoudre la précondition de cet opérateur (A
utilisateur Madrid Dimanche).
7. Suite à la réception de ces réponses,
l'agent médiateur : Met à jour le graphe d'états, il sera
le suivant :
(A utilisateur New York Mardi)
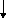
(A utilisateur London Lundi)
(A utilisateur Madrid
Dimanche)
nouveau_but ? (A utilisateur Madrid Dimanche)
path ? ( Reserver_Vol(utilisateur London New York Lundi
Mardi) , Reserver_Train(utilisateur Madrid London Dimanche Lundi) )
8. L'agent médiateur diffuse le nouveau
problème ((A utilisateur Madrid Dimanche) , (A utilisateur Paris
Dimanche)) aux deux agents Agent_S_V et Agent_S_T puis, il attend
jusqu'à recevoir leurs réponses.
9. Agent_S_T lui renvoie une réponse négative
et Agent_S_V lui renvoie l'opérateur (Reserver_Vol(utilisateur Paris
Madrid Dimanche Dimanche)) et un message lui indiquant que cet
opérateur permet de résoudre le nouveau problème
reçu directement.
10. Suite à la réception de ces réponses,
l'agent médiateur va mettre à jour les deux variables : solution
et solution_trouvée comme suit :
solution_trouvee ? true
solution ? ( Reserver_Vol(utilisateur Paris Madrid Dimanche
Dimanche) Reserver_Train(utilisateur Madrid London Dimanche Lundi)
Reserver_Vol(utilisateur London New York Lundi Mardi) )
11. De cette façon, l'algorithme sort de la boucle «
tant que » et retourne à l'agent utilisateur le
plan solution (contenu de la variable « solution »).
2. Fonctionnement
Perception :
- Réception d'un message de l'agent administrateur,
contenant la liste des identificateurs des agents services.
- Réception d'un message de l'agent utilisateur, contenant
la description du problème à résoudre.
- Réception d'un message de l'agent utilisateur,
contenant une demande
d'annulation d'une demande de composition en cours de
résolution.
- Réception d'un message de l'agent service, contenant une
solution directe à un problème.
- Réception d'un message de l'agent service, contenant une
liste d'actions possibles.
- Réception d'un message de l'agent service, indiquant
l'absence d'une solution au niveau de cet agent.
Raisonnement : le raisonnement
effectué par cet agent est au niveau de la planification. Après
que l'agent soit doté de la description du problème (état
initial et but) d'après l'agent utilisateur, il exécute
l'algorithme de planification afin de le résoudre.
Action : selon le diagramme d'activités
suivant :
Attente
Recevoir message (problème) d'un agent utilisateur
Recevoir message (annulation) d'un agent utilisateur
Interroger les agents service
Diffuser message
(annulation) vers
les agents service
Planifier
Autre
Solution trouvée
Non solution trouvée
Envoyer message (solution) à l'agent utilisateur
Envoyer message (pas de solution) à l'agent
utilisateur
Figure 4.16 : Diagramme d'activités pour
le fonctionnement de l'agent médiateur IV.3. interactions entre
les agents du système
Dans la partie précédente, nous avons
présentées l'architecture et le fonctionnement de chaque agent du
système à part. cependant, dans le modèle proposé
aucun des agents ne peut résoudre le problème de l'utilisateur
tout seul. C'est la coopération entre les agents qui le permet.
Cette coopération nécessite en effet, des
différentes interactions entre les agents. Ces dernières sont
directes par envoie de messages.
L'envoie de messages entre les agents nécessite un
langage commun compréhensible par tous les agents du système.
Dans notre travail nous avons choisies le langage FIPA-ACL (il sera
détaillé dans l'annexe).
Pour modéliser les interactions entre les agents, les
concepteurs des systèmes multi-agents peuvent utilisés
différents moyens : les diagrammes de séquence UML peuvent
être utilisés, ils sont simples et intelligibles, mais ils ne
fournissent pas aucun flux de contrôle.
Dans notre travail nous avons exploitées une autre
alternative: l'utilisation des diagrammes de protocole
d'interaction d'AUML utilisés par la FIPA. Ces diagrammes sont
en effet une extension des diagrammes de séquence d'UML, mais qui sont
plus puissants dans leur expressivité. Ils les étendent par
l'ajout d'un nombre d'éléments de flux de contrôles et
utilisent les actes communicatifs d'ACL pour les messages
échangés (voir l'annexe).
Les interactions pouvant existés dans notre système
sont :
· interactions agent administrateur - agent utilisateur
· interactions agent administrateur - agent
médiateur
· interactions agent utilisateur - agent
médiateur
· interactions agent médiateur - agent service
Dans ce qui suit nous détaillerons chaque type
d'interaction à part par une modélisation à travers les
diagrammes de protocole d'interaction AUML.
IV.3.1. Interactions agent administrateur - agent
utilisateur
Lorsqu'un utilisateur se connecte au système à
travers l'interface principale, l'agent administrateur crée un agent
utilisateur lui représentant dans le système. La première
chose que fait l'agent administrateur est l'envoie de l'identificateur de
l'agent médiateur à cet agent utilisateur lui permettant de
communiquer son problème à l'agent médiateur afin de le
résoudre.
Interactions agent administrateur - agent
utilisateur
Agent administrateur
|
|
Agent utilisateur
|
|
inform (identificateur agent médiateur)

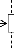
Figure 4.17 : Diagramme de protocole
d'interactions d'AUML « agent administrateur - agent utilisateur »
IV.3.2. Interactions agent administrateur - agent
utilisateur
L'agent administrateur suite à son lancement de
l'agent médiateur, il lui envoie la liste des identificateurs des
différents agents service lui permettant ainsi de les communiquer dans
le but de résoudre de problème soumis par l'utilisateur.


Interactions agent administrateur - agent
médiateur
Agent administrateur
|
|
Agent médiateur
|
|
inform (identificateurs agents service)
Figure 4.18 : Diagramme de protocole
d'interactions d'AUML « agent administrateur - agent médiateur
»
IV.3.3. Interactions agent utilisateur - agent
médiateur
L'agent utilisateur envoie le problème de
l'utilisateur à l'agent médiateur pour le résoudre. Ce
dernier après qu'il accepte de le résoudre, il doit lui renvoyer
un résultat. Ce résultat peut être négatif (pas de
solution) ou positif (plan solution).
Interactions agent utilisateur - agent
médiateur
Agent utilisateur
Agent médiateur
request (résolution problème)
agree
cancel (résolution problème)
inform (résolution interrompue)
[not failed]
failure (résolution non interrompue)
[failed]
failure (pas de solution au problème)
inform (plan solution)
[agreed]
L'agent utilisateur peut demander à l'agent
médiateur d'arrêter la résolution d'un problème
déjà demandée. L'agent médiateur peut refuser
(résolution déjà effectuée) ou accepter. S'il
accepte, alors à la fin de l'arrêt de la résolution il
envoie à l'agent utilisateur un message lui l'indiquant
(résolution arrêtée).
IV.3.4. Interactions agent médiateur - agent
service
L'agent médiateur suite à la réception
d'un problème de l'agent utilisateur, il essaye de le résoudre en
exploitant les compétences des différents agents service. Tant
qu'il n'arrive pas à le résoudre, il parcours le graphe
d'état, choisit un sous-but non encore traité et le diffuse avec
l'état initial de l'utilisateur comme un nouveau problème aux
agents service.
Chaque agent service cherche la solution et lui envoie soit une
solution directe au nouveau problème, soit une liste d'actions pouvant
servir à le résoudre ou encore un message lui d'échec.

Interactions agent médiateur - agent
service
Agent médiateur
|
|
Agent service
|
|
request (résolution nouveau problème)
agree
failure (pas de solution au nouv problème)
inform (solution directe)
inform (liste d'actions)
Figure 4.20 : Diagramme de protocole
d'interactions d'AUML « agent médiateur - agent service »
V. Etude de cas
Dans la partie précédente du chapitre, nous
avons décrits un système misant en place notre modèle de
composition de services web proposé. Mais cette description ne suffit
pas ; il apparaît très nécessaire d'illustrer son
efficacité à travers une étude de cas. Une conception de
l'étude de cas fait l'objet de cette section du chapitre.
Nous choisissons comme étude de cas le domaine de
réservation de voyages. On suppose qu'on a trois services de
réservation qui présentent les mêmes entées et
sorties et les mêmes contraintes d'utilisation
(préconditions/effets). La différence entre eux réside
dans les supports de réservations utilisés et les trajets
existants. Ainsi, les services proposés sont :
· Un service de réservation de voles ;
· Un service de réservation de trains et
· Un service de réservation de bus.
De façon générale, la structure similaire de
touts les services en terme des entrées et des sorties est la suivante
:
Nom_utilisateur Ville_départ Date_départ
Ville_arrivée Date_arrivée
Service de
Réservation



Message de confirmation/infirmation

Figure 4.21 : Architecture
générale des services proposés en terme d'entrées
et de sorties
Cependant, en terme des contraintes (préconditions/effets)
chaque service de réservation peut être décrit comme suit
:
(À Nom_utilisateur Ville_départ
Date_départ)
(Existe_trajet Ville_départ Date_départ
Ville_arrivée Date_arrivée)
Service de
Réservation
(À Nom_utilisateur Ville_arrivée
Date_arrivée)
Figure 4.22 : Architecture d'un service en terme
de préconditions et effets
L'utilisateur du système va donc entrer sa
requête (Nom_utilisateur, Ville_départ, Date_départ,
Ville_arrivée, Date_arrivée) ; Ville_départ et
Date_départ construit son état initial et Ville_arrivée et
Date_arrivée son but à atteindre. Le système après
l'élaboration du processus de composition lui renvoie un plan solution
(s'il existe) résolvant son problème.
Conclusion
Dans ce chapitre nous avons présentées une
conception d'un système implémentant notre approche de
composition. Cette conception est abordée selon deux vue
différentes : une vue externe décrivant les acteurs
impliqués dans le système et les fonctionnalités offertes
et une vue interne décrivant l'architecture interne du système
dont le système est vu comme un SMA. Cette partie contient une
description des différents agents, leurs architectures, leurs
fonctionnements et les différentes interactions entre eux dans le but de
réaliser la composition. Le chapitre est terminé par une
description d'une étude de cas choisie.
Après avoir conçu notre système, la
prochaine étape consiste à concrétiser cette conception
i.e, à réaliser ce système. C'est l'objet du chapitre
suivant.
Introduction
Après avoir faire une conception de notre
système dans le chapitre précédent, il reste maintenant
d'essayer à le réaliser en se basant sur cette conception. Ainsi
dans ce chapitre nous présenterons les différentes étapes
de sa réalisation, les différents outils exploités et les
différentes interfaces de sa mise en oeuvre.
I. Etapes de la réalisation
De façon plus générale, notre
système est vu comme un SMA ; sa réalisation consiste à
implémenter ces différents agents. Mais, nous avons vus que
certains agents contiennent des composants pouvant être
implémentés à part pour faciliter les taches, qui sont le
traducteur OWLS vers opérateurs STRIPS existant au niveau des agents
service et le planificateur existant au niveau de l'agent médiateur. En
plus les descriptions OWL-S des services supposés déjà
sélectionnés doivent être aussi
générées dans cette réalisation.
Alors, la réalisation du système peut être
faite à travers les étapes suivantes :
1. Création des descriptions OWL-S des modèles de
processus des services proposés ;
2. Implémentation du traducteur OWL-S vers
opérateurs STRIPS ;
3. Implémentation du planificateur ;
4. Implémentation des différents agents du
système ;
5. Création des différentes interfaces du
système.
II. Outils exploités
Afin de bien réaliser les étapes
précédentes, plusieurs outils de développement peuvent
nous aider.
· L'IDE (Environnement de Développement
Intégré), Eclipse ;
· Le plug-in OWL-S IDE pour Eclipse ;
· L'IDE, JBuilder ;
· La plateforme JADE.
III. Création des descriptions OWL-S
Cette étape consiste à créer les
différentes descriptions OWL-S des Modèles de processus des
services proposés dans le chapitre précédent. Cette
description sert à décrire chaque service comme un processus
atomique. Chaque processus atomique est décrit en terme de son flux de
données (inputs et outputs) ainsi qu'en terme de ses contraintes
d'utilisation (préconditions et effets).
Cette création peut être faite manuellement,
mais plusieurs outils sont apparus pour faciliter la tache. Pour notre travail
nous avons choisis d'utiliser l'éditeur OWL-S IDE utilisé comme
un plug-in Eclipse (voir l'annexe).
Cet éditeur fournit deux modes pour l'édition des
descriptions OWL-S :
· Le mode graphique et
· Le mode textuel
Il permet de créer ces descriptions de différentes
manières :
· Depuis un code Java implémentant le service web
;
· Depuis un fichier WSDL décrivant le service web ;
ou bien
· De les créer directement vides puis de les
compléter à travers l'éditeur.
Comme nous avons vus, les services proposés on presque
la même description OWL-S de leurs modèles de processus. Il suffit
donc dans cette section de présenter le procédé suivi pour
la génération de l'une de ces descriptions ; celle du service de
réservation de vols aériens. En plus, ce qui nous concerne dans
notre travail est seulement la description du modèle de processus du
service. Ainsi, le procédé suivi est le suivant :
1. Génération d'une classe Java
implémentant le service web ;
2. Génération de la description OWL-S du service
à l'aide du support Java2OWL-S fournit par l'éditeur ;
3. Utilisation de l'éditeur des modèles de
processus (process models) pour compléter la description OWL-S du
modèle de processus du service générée.
III.1. Génération de la classe Java
implémentant le service web
Notre service contient une seule opération ; lorsqu'il
reçoit une demande de réservation d'un utilisateur, il renvoie
soit une confirmation (réservation possible) ou une infirmation
(réservation impossible).
La classe Java pouvant l'implémenter peut donc contenir
une seule fonction « Réserver_Vol() », ayant comme
entrées : le nom de l'utilisateur, sa ville de départ, sa date de
départ, sa ville d'arrivée et sa date d'arrivée et ayant
comme une seule sortie une expression exprimant l'existence ou non de la
réservation demandée. Ce que fait le service ne nous concerne pas
; ce qui nous concerne est seulement la signature de la fonction. Cette
génération est faite par l'Eclipse IDE.
Notre classe Java sera donc la suivante :
|
public class Reservation_Vol {
public boolean Reserver_Vol(String
Nom_Utilisateur, String Ville_Depart,
String Date_Depart, String Ville_Arrivee, String Date_Arrivee)
{
}
}
|
Figure 5.1 : classe Java implémentant le
service de réservation de vols aériens III.2.
Génération de la description OWL-S du service
Une fois la génération du code Java
implémentant le service soit terminée, l'éditeur fournit
un support « Java2OWL-S » permettant de générer la
description OWL-S du service à partir de ce code Java. La conversion
Java2OWL-S est faite en deux phases : dans la première le code Java est
converti à un fichier WSDL et dans la deuxième ce dernier est
converti à des fichiers OWL-S. Le résultat de ce processus est
des descriptions WSDL et grounding OWL-S complètes et des
descriptions du profile et du modèle de processus
incomplètes.
Puisque la description du modèle de processus est la seule
description qui nous concerne dans notre travail, nous ne présenterons
dans ce qui suit que ce fichier généré dans cette
étape.
Dans ce qui suit nous présentons la description OWL-S du
modèle de processus dans le mode graphique de l'éditeur puis dans
le mode textuel (format XML) :
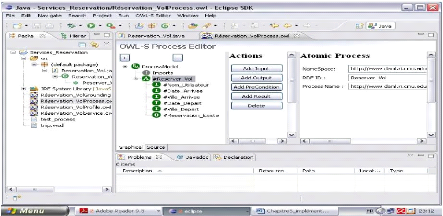
Figure 5.2 : Une partie de la description OWL-S
du modèle de processus générée en mode graphique
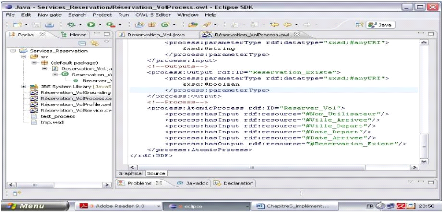
Figure 5.3 : Une partie de la description OWL-S
du modèle de processus générée en mode textuel
III.3. Compléter la description OWL-S
générée
La description OWL-S du modèle de processus du service
générée dans l'étape précédente
décrit le service en terme de son flux de données seulement, mais
pas en terme de ses contraintes d'utilisation (préconditions et effets).
Pour faire la compléter nous allons exploités l'éditeur
des modèles de processus fournit par l'outil OWL-S IDE.
Notre processus atomique a deux préconditions et un seul
effet.
Préconditions :
- (À Nom_Utilisateur Ville_Départ Date_Depart)
- (Existe_Trajet Ville_Depart Date_Depart Ville_Arrivee
Date_Arrivee)
Effet :
- (À Nom_utilisateur Ville_arrivée
Date_arrivée)
Après avoir la compléter et l'organiser (afin de
faciliter sa manipulation en suite), la description OWL-S du modèle de
processus pour notre service de réservation de voles aériens sera
donc la suivante :
<rdf:RDF
xmlns:rdf= "&rdf;#"
xmlns:rdfs= "&rdfs;#"
xmlns:owl= "&owl;#"
xmlns:xsd= "&xsd;"
xmlns:service= "&service;#"
xmlns:process= "&process;#"
xmlns:profile= "&profile;#"
xml:base= "
http://www.daml.ri.cmu.edu/bravoair/Réservation_VolProcess.owl"
>
<owl:Ontology about="">
<owl:versionInfo>
$Id: OWLSProcessModelEmitter.java,v 1.1 naveen
</owl:versionInfo>
<rdfs:comment>
Add Comment
</rdfs:comment>
<owl:imports rdf:resource="&service;" />
<owl:imports rdf:resource="&process;" /> <owl:imports
rdf:resource="&profile;" /> <!-- WSDL2OWL-S :: Add More Imports If
needed -->
</owl:Ontology>
<!-- WSDL2DAML-S_was_here -->
<!-- WSDL2OWL-S :: Add composite processes if needed-->
<!--WSDL 2 OWL-S Generated code--> <!--**List of Atomic
Processes**--> <!--ProcessName :Reserver_Vol-->
<!--*****************************-->
<!--Definitions for Atomic Process : Reserver_Vol-->
<process:AtomicProcess rdf:ID="Reserver_Vol"> <!--Inputs-->
<process:hasInput>
<process:Input rdf:ID="Nom_Utilisateur">
<process:parameterType rdf:datatype="&xsd;#anyURI">
&xsd;#string
</process:parameterType>
</process:Input>
</process:hasInput>
<process:hasInput>
<process:Input rdf:ID="Ville_Arrivee">
<process:parameterType rdf:datatype="&xsd;#anyURI">
&xsd;#string
</process:parameterType>
</process:Input>
</process:hasInput>
<process:hasInput>
<process:Input rdf:ID="Ville_Depart">
<process:parameterType rdf:datatype="&xsd;#anyURI">
&xsd;#string
</process:parameterType>
</process:Input>
</process:hasInput>
<process:hasInput>
<process:Input rdf:ID="Date_Depart">
<process:parameterType rdf:datatype="&xsd;#anyURI">
&xsd;#string
</process:parameterType>
</process:Input>
</process:hasInput>
<process:hasInput>
<process:Input rdf:ID="Date_Arrivee">
<process:parameterType rdf:datatype="&xsd;#anyURI">
&xsd;#string
</process:parameterType>
</process:Input>
</process:hasInput>
<!--Outputs-->
<process:hasOutput>
<process:Output rdf:ID="Reservation_Existe">
<process:parameterType rdf:datatype="&xsd;#anyURI">
&xsd;#boolean
</process:parameterType>
</process:Output>
</process:hasOutput>
<!--Preconditions-->
<process:hasPreConditon>
<process:PreCondition rdf:about="#Etat_Utilisateur">
<process:expressionLanguage rdf:resource="#DRS"/>
<process:expressionBody>
(A Nom_Utilisateur Ville_Depart Date_Depart)
</process:expressionBody>
</process:PreCondition> </process:hasPreConditon>
<process:hasPreConditon>
<process:PreCondition rdf:about="#Existe_Trajet">
<process:expressionLanguage rdf:resource="#DRS"/>
<process:expressionBody>
(Existe_Trajet Ville_Depart Date_Depart Ville_Arrivee
Date_Arrivee)
</process:expressionBody>
</process:PreCondition> </process:hasPreConditon>
|
<!--Effects-->
<process:hasEffect>
<process:Effect rdf:about="#Existe_Trajet">
<process:expressionLanguage rdf:resource="#DRS"/>
<process:expressionBody>
(A Nom_Utilisateur Ville_Arrivee Date_Arrivee)
</process:expressionBody>
</process:Effect>
</process:hasEffect>
</process:AtomicProcess> </rdf:RDF>
|
Figure 5.3 : La description OWL-S du process
model du service « Réservation de vols aériens »
Les descriptions des modèles de processus des deux autres
services sont faites en suivant le même procédé
précédent.
IV. Implémentation du traducteur OWL-S vers
opérateurs STRIPS
Ce traducteur fait un composant dans les agents service.
Ainsi, chaque agent service après son initialisation avec la description
OWL-S du service qu'il représente, il exploite ce composant pour la
transformer à un ensemble d'opérateurs correspondants.
Nous avons implémentées ce traducteur par une
fonction Java (traducteur()), prenant en entrée sous
forme d'un texte la description OWL-S et retournant en sortie la liste
d'opérateurs pouvant être extraits de cette description.
Le principe est le suivant : la fonction parcourt le texte de
la description OWL-S. Chaque fois qu'il rencontre un processus atomique (un
bloc entre les deux balises <process:AtomicProcess et
</process:AtomicProcess>), il le traduit à un opérateur
STRIPS : le nom de ce dernier sera le nom du processus. Puis entre ces balises
chaque fois qu'un input (<process:Input), un output (<process:Output),
une précondition (<process:hasPreCondition>) ou un effet
(<process:hasEffect>) est rencontré, il sera transformé
à un paramètre, une précondition ou un effet pour
l'opérateur créé.
|
//SDD est une structure de données pouvant contenir les
éléments //descriptifs d'un opérateur STRIPS (le nom, les
inputs, les outputs, //les préconditions et les effets)
class SDD{
String nom_operateur;
ArrayList<String> L_parametres=new
ArrayList<String>(); ArrayList<String>
L_preconditions=new ArrayList<String>();
ArrayList<String> L_effets=new
ArrayList<String>();
}
public Vector<SDD> traducteur(String
fichier_owls){
//operateurs est un vecteur qui peut contenir les
éléments // descriptifs des différents opérateurs
extraits de la
// descripton OWL-S
|
|
while((!(str2.equals("</process:atomicprocess")))
&&(tompon.hasMoreTokens())){
if(str2.equals("<process:input")){
//c-à-d: on a trouvé un input => on // l'ajoute à liste
des parametres de // l'operateur op
}
if(str2.equals("<process:output")){
//c-à-d: on a trouvé un output => on //l'ajoute à liste
des parametres de // l'operateur op
}
if(str2.equals("<process:hasprecondition")){
//c-à-d: on a trouvé une précondition
//=> on l'ajoute à liste des
// préconditions de l'operateur op
}
if(str2.equals("<process:haseffect")){
//c-à-d: on a trouvé un effet => on //l'ajoute à liste
des préconditions //de l'operateur op
}
}
//l'ajout de l'opérateur créé à la
liste des // opérateurs extraits de la description OWL-S
operateurs.add(op);
}
}
//retourner la liste d'opérateurs extraits
return operateurs;
}
|
Figure 5.4 : fonction Java implémentant
le traducteur OWLS vers opérateurs STRIPS
V. Implémentation du planificateur
Le planificateur est utilisé au niveau de l'agent
médiateur lui permettant de réaliser le but soumis par
l'utilisateur. Or ce qui est abordé dans cette section n'est pas le
planificateur dans sa globalité mais une partie de lui. Cette partie
consiste au un module pour le traitement des différentes réponses
venantes des agents service en réponse à un sous problème
(état initial de l'utilisateur et un sous but) y envoyé par
l'agent médiateur. Le module est implémenté par une
fonction « traiter_réponses_AS() ».
Le principe est le suivant : l'agent médiateur
après qu'il reçoit toutes les réponses des agents service
à un sous problème déjà envoyé, il les met
dans un vecteur pouvant contenir pour chaque agent la réponse
renvoyée ainsi que son type. Il utilise puis ce vecteur comme
entrée à la fonction << traiter_réponses_AS()
». Cette dernière après qu'elle traite les réponses,
renvoie un autre vecteur contenant le résultat du traitement ainsi que
son type.
Le vecteur d'entrée de la fonction est de dimension 3
(nombre des agents service). Pour chaque agent service ce vecteur contient sa
réponse ainsi que le type de cette réponse. Le type de la
réponse peut être :
- Pas_solution_trouvée : si l'agent service ne trouve pas
une solution au sous problème lui est envoyé.
- Solution_trouvée : si l'agent service a trouvé
une solution directe au sous problème lui est envoyé.
- Nouveaux_sousbut : si l'agent service ne trouve pas une
solution directe au sous problème mais il trouve un ou plusieurs
nouveaux sous but pouvant participer à son résolution. Dans ce
cas ces nouveaux sous but son mets dans le vecteur en plus du type de la
réponse.
Le vecteur de sortie de la fonction peut contenir le
résultat retourné par la fonction ainsi que le type de ce
résultat. Ce type de résultat peut être :
- Pas_solution_trouvée_pb_utilisateur : si toutes les
réponses des agents service sont de
type << pas_solution_trouvée » et le graphe
d'états ne contient pas de sous but à traiter.
- Nouveau_sous_but : si toutes les réponses des agents
service sont de type << pas_solution_trouvée » et le graphe
d'états contient encore de sous but à traiter ou dans le cas
où l'une au moins des réponses est de type <<
Nouveaux_sousbut ». Dans ce dernier cas, le graphe d'états doit
être à jour et un nouveau sous but est retourné par la
fonction.
- Solution_trouvée_pb_utilisateur : dans le cas où
l'une au moins des réponses est de type << solution_trouvée
». Dans ce cas un plan solution est retourné par la fonction
En fin, l'agent médiateur suite à la
réception de ces résultat de traitement de la fonction, il va
résonner : soit il renvoie << pas de solution au problème
de l'utilisateur à l'agent utilisateur, soit envoie un nouveau sous
problème aux agents service ou bien, il retourne à l'agent
utilisateur un plan solution au problème de l'utilisateur.
Premièrement, dans son implémentation, l'agent
médiateur doit se doter d'une variable globale représentant le
graphe d'états. Ce dernier est implémenté par une
structure de pile de vecteur. Chaque vecteur est de type <<
structure_graph » défini ci-après. Chaque vecteur doit
contenir dans son premier champ un sous but ainsi que l'opérateur
permettant d'y parvenir et dans les autres champs les différents sous
but permettant d'aller du but de l'utilisateur (noeud principal du graphe)
à ce sous but.
class Structure_graphe{
String sous_but;
String operateur;
}
//Déclaration du graphe d'états
Stack<Vector<Structure_graphe>>
Graphe_Etats=new
Stack<Vector<Structure_graphe>>();
//Initialisation du graphe d'états
Structure_graphe premier_s_b=new
Structure_graphe(); Vector<Structure_graphe> etat=new
Vector<Structure_graphe>(); premier_s_b.sous_but=But_Utilisateur;
premier_s_b.operateur="";
etat.add(premier_s_b);
Graphe_Etats.push(etat);
Notre fonction « traiter_reponses_AS() » correspond
donc à ce qui suit :
Nous définissons encore une autre variable globale
« Dernier_sousbut_choisi » qui peut contenir le dernier sous but
choisi et traité pour l'utiliser en suite dans la fonction de
traitement. C'est une variable de type « Vector<Structure_graphe>
» :
|
Vector<Structure_graphe>
Dernier_sousbut_choisi=new
Vector<Structure_graphe>();
|
Définissons maintenant la structure des deux vecteurs
d'entrée et de sortie de la fonction « traiter_reponses_AS() »
:
|
class Structure_entree_sortie{
String type_reponse;
ArrayList<String> objet_reponse=new
ArrayList<String>();
}
//Reponses_AS est un vecteur pour contenir les réponses
des agents // service et sera utilisé comme entrée à la
fonction de traitement Vector<Structure_entree_sortie>
Reponses_AS=new
Vector<Structure_entree_sortie>();
//Reponse_AM est un vecteur utilisé pour récuperer
le résultat de la //fonction de traitement
Vector<Structure_entree_sortie>
Reponse_AM=new
Vector<Structure_entree_sortie>();
|
Maintenant, il nous reste à présenter notre
fonction de traitement « traiter_reponses_AS() » :
/****************************************************/
/*
Définition de la fonction "traiter_reponses_AS()
*/
/****************************************************/
public Vector<Structure_entree_sortie>
Traiter_reponses_AS(Vector<Structure_entree_sortie> Reponses_AS)
{
//Déclaration des variables locales
// parcours le vecteur de réponses pour compter le nombre
des // différents types de réponses
ListIterator<Structure_entree_sortie>
iter=Reponses_AS.listIterator();
while(iter.hasNext()){
if((iter.next().type_reponse).equalsIgnoreCase("pas_solution"))
nbre_pas_solution++;
if((iter.next().type_reponse).equalsIgnoreCase("soluion_trouvee"))
nbre_soluion_trouvee++;
if((iter.next().type_reponse).equalsIgnoreCase("nouveaux_sousbut"))
nbre_nouveaux_sousbut++;
}
// Maintenant, le type du traitement à effectuer
dépend de ces // nombres comptés :
// 1. Si toutes les réponses des agents service sont de
type
// "pas_solution"(nbre_pas_solution=3),un test sur l'état
du
// graphe d'états est effectué :
// 1.1. Si il est vide, le résultat à retourner
sera
// "pas_solution_pb_utilisateur"
// 1.2. Si il n'est pas vide, le résultat à
retourner sera un
// nouveau sous but à résoudre
// 2. Si nbre_solutiontrouvee>=1, alors le résultat
à retourner sera // un plan solution
// 3. Si les deux cas précédent ne sont pas
trouvés (nbre_nouveaux
// _sousbut>=1), alors le graphe d'états sera met
à jour et le
// résultat à retourner sera un nouveau sous but
à résoudre
if(nbre_pas_solution==3){
if(Graphe_Etats.isEmpty()){
type_reponse_retour="pas_solution_pb_utilisateu";
objet_reponse_retour.clear();
} else {
type_reponse_retour="nouveau_sous_but";
objet_reponse_retour.add(nouv_sousbut);
}
}
else //pas toutes les réponses sont de
type"pas_solution" {
if(nbre_soluion_trouvee>=1) {
type_reponse_retour="solution_trouvee_pb_utilisateur";
objet_reponse_retour.add(iter3 .next().operateur);
}
else // aucune "solution_trouvee" n'est trouvee
// => il existe au moins une réponse de type { //
"nouveaux_sousbut"
type_reponse_retour="nouveau_sousbut";
objet_reponse_retour.add(nouv_sousbut);
}
}
//************************************************************
// mettre les valeurs des deux variables "type_reponse_retour" // et
"objet_reponse_retour" associés dans le traitement
// précédent au vecteur "Resultat_a_retourner"
à retourner par // la fonction
//************************************************************
Resultat_a_retourner.firstElement().type_reponse
=type_reponse_retour;
Resultat_a_retourner.firstElement().objet_reponse
=objet_reponse_retour;
return(Resultat_a_retourner);
}
/****************************************************/
/* Fin de la fonction "traiter_reponses_AS() */
/****************************************************/
VI. Implémentation des agents du
système
Comme nous avons vus, notre système est composé
d'un ensemble d'agents en interaction pour résoudre le problème
soumis par l'utilisateur. La meilleure façon d'implémenter un
système multi-agents est l'utilisation d'une plateforme multi-agents.
Celle utilisée dans notre travail est JADE. (Voir annexe B).
VI.1. implémentation de l'agent
administrateur
Les principales méthodes utilisées par cet agent
sont :
Setup() : c'est la méthode principale de
chaque agent de JADE. Elle contient toutes les actions exécutées
par cet agent.
public class Agent_Administrateur
extends GuiAgent{
ArrayList<String> Idents_AS=new
ArrayList<String>();
public void setup() {
Idents_AS.add("Agent_S_Vol"); Idents_AS.add("Agent_S_Train");
Idents_AS.add("Agent_S_Bus");
// Lancement de l'agent médiateur et des agents service
// envoie des idents des agents services à l'agent
médiateur ACLMessage msg = new
ACLMessage(ACLMessage.INFORM) ; msg.addReceiver(new
AID("Agent_Mediateur",AID.ISLOCALNAME)) ; msg.setContent(Idents_AS);
send(msg) ;
}
// L'agent médiateur réagit selon le type de
l'événement(ev) // récupéré de l'interface
graphique
protected void onGuiEvent(GuiEvent ev)
{
switch(ev.getType()) {
case conect_client:
// Création et lancement d'une instance de l'agent
//client
// Lui envoyer l'identificateur de l'agent médiateur
ACLMessage msg = new ACLMessage(ACLMessage.INFORM) ;
msg.addReceiver(new
AID("Agent_Client",AID.ISLOCALNAME));
msg.setContent("Agent_Mediateur");
send(msg) ;
break;
case connect_admin:
while(non_valide_mp){
// récupération mot de passe administrateur, //
vérification mot de passe
}
// Afficher Menu système break;
OnGuiEvent() : permettant l'agent administrateur
de réagir aux différents événement capturés
depuis l'interface graphique.
VI.2. Implémentation de l'agent client
public class Agent_Client
extends GuiAgent{
public class Structure_entree_sortie{
String type_reponse;
ArrayList<String> objet_reponse;
}
if(msg_recu.getSender().equals("Agent_Mediateur")) {
}
String Ident_AM; //pour contenir l'ident de l'agent
médiateur
public void setup() {
addBehaviour(new
CyclicBehaviour(this){
public void action(){
ACLMessage msg_recu=receive();
// l'agent client agit selon le distinataire du massage
récu
if(msg_recu.getSender().equals("Agent_Administrateur"))
{
// Récuperation de l'ident de l'agent médiateur
Ident_AM=msg_recu.getContent();
Structure_entree_sortie reponse_AM=
(Structure_entree_sortie) msg_recu.getContentObject(); // Selon
le type de la réponse récupéré //(solution_trouvee
ou bien non_solution_trouvee)
// l'agent affiche les résultat à l'utilisateur
}
// L'agent médiateur réagit selon le type de
l'événement(ev) // récupéré de l'interface
graphique
protected void onGuiEvent(GuiEvent ev)
{
switch(ev.getType()) {
case Demande:
// Récuperer problème utilisateur et l'envoyer
à // l'agent médiateur
break;
case Annulation:
// Envoyer demande d'annulation à l'agent
médiateur
break;
}
}
}
L'agent client est implémenté par la classe
« Agent_Client ». Il hérite comme l'agent administrateur la
classe « jade.gui.GuiAgent » et utilise principalement les deux
méthodes suivantes : Setup() et
OnGuiEvent().
VI.3. Implémentation de l'agent
médiateur
public class Agent_Mediateur
extends Agent{ ArrayList<String> Idents_AS;
public class Structure_entree_sortie{
String type_reponse;
ArrayList<String> objet_reponse;
} else {
}
public void setup() {
addBehaviour(new
CyclicBehaviour(this){
public void action(){
ACLMessage msg_recu=receive();
// l'agent client agit selon le destinataire du massage
reçu
if(msg_recu.getSender().equals("Agent_Administrateur")) {
// récuperer les identificateurs des agents service //
depuis le message envoyé par l'agent dministrateur
ArrayList<String> liste=(ArrayList<String>)
msg_recu.getContentObject(); ListIterator<String> iter =
liste.listIterator(); while(iter.hasNext())
{
Idents_AS.add(iter.next());
}
if(msg_recu.getSender().equals("Agent_Client")))
{
if(// le performatif du msg_recu== Cancel) {
// Diffusion du message "Annuler" aux // agents service
ACLMessage msg = new
ACLMessage(ACLMessage.CANCEL); ListIterator<String>
iter=
Idents_AS.listIterator();
while(iter.hasNext())
{
msg.addReceiver(new
AID(iter.next(),AID.ISLOCALNAME));
}
send(msg) ;
Cet agent est implémenté par la classe «
Agent_Mediateur » qui hérite la classe jade.core.Agent. Ces
différents actions sont regroupées au niveau de la methode
setup(). Il exploite dans cette methode la fonction «
Traiter_reponses_AS() » présentée ci-avant pour
l'élaboration d'un plan solution au problème de l'utilisateur.
else
{
// Appliquer l'algorithme de planification
}
}
else // Message venant de l'un des agents
service {
// Recuperer les réponses des agents service // dans le
vecteur "Reponses_AS" Vector<Structure_entree_sortie> Reponses_AS=
(Vector<Structure_entree_sortie>)
msg_recu.getContentObject();
// Appeler la fonction "Traiter_reponses_AS"
Vector<Structure_entree_sortie> retour_fonction=Traiter_reponses_AS
(Reponses_AS);
}
}
}
VI.4. Implémentation de l'agent service
public class Agent_Service
extends Agent{
public class Structure_entree_sortie{
String type_reponse;
ArrayList<String> objet_reponse;
}
public void setup() {
// récuperer description OWL-S du service
représenté
// appeler Traducteur OWL-S vers operateurs STRIPS
addBehaviour(new
CyclicBehaviour(this){
public void action(){
// Recevoir message de l'agent médiateur ACLMessage
msg_recu=receive();
if(// le performatif du message est CANCEL) {
// Arreter traitement en cours
Cet agent est implémenté par la classe «
Agent_Service » qui hérite la classe jade.core.Agent.
else
{
// Appliquer algorithme de recherche de // solution
// Renvoyer résultats trouvées à l'agent //
médiateur
// (solution_trouvée, solution_non_trouvée ou //
bien nouveau_sousbut)
}
}
VII. Interfaces du système
Afin de mieux exploiter notre système, nous avons
l'enrichir par un une interface graphique facilitant l'utilisation de ses
différentes fonctionnalités.
Premièrement, le lancement du système mène
à afficher son interface d'accueil suivante, permettant à un
utilisateur de se connecter comme un client ou un administrateur.
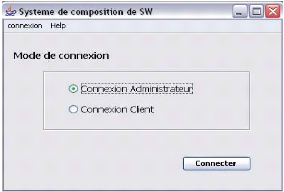
VII.1. Mode client
L'utilisateur suite à sa connexion comme client, le
système lui affiche une autre fenêtre lui permettant d'entrer sa
requête :
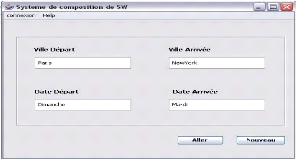
Pendant la recherche de la solution, le système lui
affiche la barre de progression suivante. Cette fenêtre lui permet aussi
d'annuler la demande déjà effectuée :
S'il décide d'annuler la demande, le système
après l'annulation lui affiche un message pour l'informer :
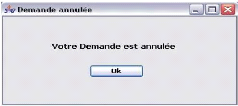
Si la recherche de la solution termine avec un plan solution
trouvée, le système lui affiche le résultat sous forme
d'un plan :
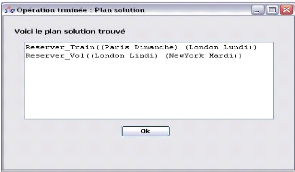
Si la recherche de la solution termine avec un échec, le
système lui affiche un message lui informent :
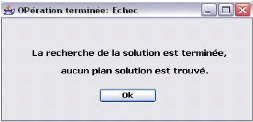
VII.2. Mode administrateur
Lorsque l'utilisateur se connecte comme administrateur, le
système lui affiche une fenêtre pour entrer son mot de passe :
Si le mot de passe ne convient pas, le système lui demande
de le réentrer. S'il convient, il lui affiche le menu du système.
Depuis ce point la suite nous n'intéresse pas.
Conclusion
Ce chapitre sert à réaliser notre système
conçu dans le chapitre précédent, permettant d'illustrer
l'efficacité de la planification multi-agents dans la résolution
du problème de composition de service web.
Nous avons présentées dans le début du
chapitre la façon de création des descriptions OWL-S choisis.
Cette étape est effectuée en utilisant un éditeur
spécifique appelé OWL-S Editor. Dans la deuxième et la
troisième étapes, nous avons implémentées en
utilisant le langage Java et l'IDE Eclipse, notre traducteur OWL-S vers
opérateurs STRIPS respectivement puis nous avons
implémentées les agents de notre système dans la
plateforme JADE. Des interfaces graphiques facilitant l'exploitation de notre
système sont décrites à la fin du chapitre.
Ces dernières années, le concept de service web a
connu un intérêt croissant dans le monde. Il permet
d'échanger des données et des services à distance via le
net.
Dans certains cas, un seul service peut ne pas suffire pour
répondre aux besoins des clients. Une solution à ce
problème consiste à faire composer un nombre de services
existants. Le résultat de cette composition est un enchaînement de
services satisfaisant le besoin du client.
La composition de services web fait aujourd'hui un domaine de
recherche très actif. Les approches que les chercheurs ont prises pour
composer des services web varient particulièrement selon deux courants
de recherche principaux : la composition dite « statique », dont les
composants sont organisés à priori dans des
procédés réutilisables et la composition dite «
dynamique » dont les services web à composer sont choisis au moment
de l'exécution, et en tenant en compte les préférences des
clients.
Des études de comparaisons entre les techniques des
services web et celles du domaine de l'intelligence artificielle ont
montées l'efficacité de l'exploitation de ces dernières et
surtout de la planification et des systèmes multi-agents dans le
processus de composition dynamique.
Dans ce travail, après que nous avons
présentées les différents aspects liés aux ces deux
domaines : de services web d'une part et de la planification multi-agents
d'autre part, nous avons proposées une approche s'appuyant sur
l'utilisation de la planification multi-agents pour élaborer le
processus de composition. Dans notre modèle le problème de
composition est transformé à un problème de planification.
Le domaine de planification est répartit entre un ensemble d'agents
représentants des services ; chacun construit sa partie du domaine
depuis la description sémantique en OWL-S du service qu'il
représente. Puis ces services participent tous dans un processus de
planification suivi par un agent médiateur constituant la plus
importante entité dans le système. En plus de ces agents un agent
utilisateur est employé dans le système permettant ainsi de
récupérer la requête du client et de l'envoyer à
l'agent médiateur.
Le modèle de la composition dynamique de services web par
la planification multi-agents présente un nombre de points forts, citons
parmi :
- Le premier de ces avantages est que la composition est
dynamique ; le système n'est pas contraint par une composition
définie à priori pour répondre à la requête
du client, il essaye à la résoudre en exploitant au maximum les
compétences des services existants.
- Le deuxième point est l'utilisation des agents, ces
derniers permettent de respecter la nature distribuée des services
web.
- Un autre point fort est l'exploitation des descriptions
sémantiques des services, qui permettent de les décrire de
façon plus riche et plus adaptable à l'exploitation dans la
composition.
En fin, le modèle proposé ne présente pas
un modèle complet ou optimal, il ne sert qu'à illustrer
l'efficacité de la planification et des systèmes multi-agents
dans l'élaboration de la composition de services web. Vu la
complexité de la composition, la richesse du langage OWL-S et des
concepts de la planification et des SMA, plusieurs extensions peuvent
être envisagées à ce travail et notamment de prendre en
compte dans les descriptions OWL-S des modèle de processus des services
les notions de processus composites et abstraits ainsi que d'utiliser des
techniques de planifications plus efficace que celle utilisée.
Bibliographie
[1] GUITTON Julien. Planification multi-agent pour la
composition dynamique de services Web,Juin2006,Source<
http://www.cert.fr/dcsd/THESES/jguitton/papers/guitton-master06.pdf>.
[2] ALKAMARI aniss. Composition de services web par
appariement de signatures, Janvier 2008, Source <
http://www.archipel.uqam.ca/998/1/M10209.pdf>.
[3] N. TEMGLIT, H. ALIANE, M.AHMED NACER. Un
modèle de composition des services web sémantiques, Source
<
http://www-direction.inria.fr/international/arima/011/pdf/
version%20definitive-mod+%%BFle%20de%20composition-arima.pdf>
[4] JINGHAI Rao. Semantic Web Service Composition via
Logic-based Program Synthesis, 2004, Source <
http://www.cs.cmu.edu/~jinghai/papers/thesis.pdf>.
[5] LOPEZ-VELASCO Céline. Sélection et
composition de services Web pour la génération d'applications
adaptées au contexte d'utilisation, novembre 2008, Source<
http://tel.archives-ouvertes.fr/docs/00/38/89/91/PDF/These_CLopez-Velasco.pdf
>.
[6] SANDEEP KUMAR, R. B.MISHRA. Multi-Agent Based Semantic
Web Service Composition Models, 2008.
[7] JARRAS Imed, CHAIB-DRAA Brahim. Aperçu sur les
systèmes multiagents, Juillet 2002, Source <
http://www.cirano.qc.ca/pdf/publication/2002s-67.pdf
>.
[8] Mathijs de Weerdt, Adriaan ter Mors, Cees Witteveen.
Multi-agent Planning An introduction to planning and
coordination,Source<
http://www.st.ewi.tudelft.nl/~mathijs/
publications/easss05.pdf >.
[9] REGNIER Pierre. Planification: historique, principes,
problèmes et méthodes (de GPS à ABTWEAK),Source
<
http://www.irit.fr/PERSONNEL/RPDMP/regnier/regnier_old/PLA
NIF
/pdf/Rapport90-22.pdf >.
[10] Malik Ghallab. Planification et
décision,2001, Source <
ftp://ftp.laas.fr/pub/ria/malik/arti
cles /hermes01.pdf >.
[11] LOUKIL Zied et al. Les ressources et la planification
temporelle.
[12] PLANNING, Source <
http://aima.cs.berkeley.edu/newchap11.pdf
>.
[13] Anne Nicolle, Les systèmes multi-agents,
2002, Source < http://users.info.unicaen.fr/ ~anne/HTML/sma.pdf
>.
[14] Agents intelligents cour WEB interactif, 2002,
Source <
http://turing.cs.pub.ro/auf2
/html /chapters/chapters.html >.
[15] Agents et systèmes multiagents, Source <
http://www.damas.ift.ulaval.ca/~coursMAS
/ComplementsH10/Agents-SMA.pdf >.
[16] José Ghislain Quenum, Une synthèse
d'AUML, Sep. 2003, Source <
http://wwwpoleia.lip6.fr/~elfallah/liens/AUML.pdf
>.
[17] Bernhard Bauer, Jörg P. Müller, James Odell.
Agent UML: A Formalism for Specifying Multiagent Interaction.
[18] ZERFAOUI Asma, SALMI Rabia. PlanificationMulti Agents
d'un Emploi du Temps Universitaire, juin 2009.
[19] DJAAFAR lakhdar, MENACEUR saddek. Réalisation
d'une application répartie basée sur l'intégration des
services web et des agents intelligents, juin 2009.
[20] Malik Ghallab et al. PDDL - The Planning Domain
Definition Language.Version 1.2, October1998,Source<
http://homepages.inf.ed.ac.uk/mfourman/tools/propplan
/pddl.pdf >
[21] Nerea Arenaza. Composition semi-automatique de Services
Web, Février 2006, Source <
http://lawww.epfl.ch/webdav/site/la/users/139973/public/repports/Rapport-Arenaza.pdf>.
Annexes
Annexe A : Outils pour la conception du
système
Dans cette annexe nous présentons brièvement les
différents outils exploités dans la conception de notre
système, ce sont trois langages UML, AUML et FIPA-ACL :
1. UML - Unified Modeling Language
UML est une notation permettant de modéliser un
problème de façon standard. Ce langage est né de la fusion
de plusieurs méthodes existant auparavant, et est devenu
désormais la référence en terme de modélisation
objet. Le grand succès de UML peut s'expliquer par plusieurs raisons.
Ces sont, par exemple, la simplicité, l'expressivité, une large
applicabilité et l'adaptabilité. Une autre raison très
pratique est l'existence d'une large variété d'outils, soutenant
la conception et la construction des modèles.
Afin de construire ces modèles, UML 2.0 fournit ainsi
treize types de diagrammes qui se répartissent en deux grands groupes
:
Diagrammes structurels ou diagrammes statiques (UML
Structure)
- diagramme de classes (Class diagram)
- diagramme d'objets (Object diagram)
- diagramme de composants (Component diagram)
- diagramme de déploiement (Deployment
diagram)
- diagramme de paquetages (Package diagram)
- diagramme de structures composites (Composite structure
diagram)
Diagrammes comportementaux ou diagrammes dynamiques
(UML Behavior) - diagramme de cas d'utilisation (Use case
diagram)
- diagramme d'activités (Activity diagram)
- diagramme d'états-transitions (State machine
diagram)
- Diagrammes d'interaction (Interaction diagram)
- diagramme de séquence (Sequence diagram)
- diagramme de communication (Communication diagram)
- diagramme global d'interaction (Interaction overview
diagram) - diagramme de temps (Timing diagram)
Ces diagrammes, d'une utilité variable selon les cas,
ne sont pas nécessairement tous produits à l'occasion d'une
modélisation. Les plus utiles pour la maîtrise d'ouvrage sont les
diagrammes d'activités, de cas d'utilisation, de classes, d'objets, de
séquence et d'états-transitions.
2. AUML - Agents Unified Modeling Language
UML ne fournit pas une base suffisante pour la
modélisation des agents et des systèmes multi-agent [17].
Fondamentalement, cela est dû à deux raisons: premièrement,
par rapport aux objets, les agents sont actifs parce qu'ils peuvent prendre
l'initiative et avoir le contrôle de son savoir et comment traiter des
demandes externes. Deuxièmement, les agents n'agissent pas
isolément, mais par une coopération ou coordination avec d'autres
agents.
Cependant, même s'il y a des différences
fondamentales entre les agents et les objet, un agent peut se définir
comme un objet qui peut dire "allez" (autonomie flexible comme la
capacité d'engager une action sans demande externe) et
<<non>> (autonomie flexible comme la possibilité de refuser
ou de modifier une demande externe). C'est dans cette vue que la FIPA
(Foundations of Intelligent Physical Agents) et le AWG (Agent Work
Group) de l'OMG (Object Management Group) ont recommandés
et explorés l'utilisation d'un ensemble d'extensions à UML pour
permettre la modélisation des systèmes multi-agents. C'est
l'AUML.
AUML fournit des mécanismes pour modéliser
principalement : les classes d'agent, les interactions entre agents et les
traitements internes des agents :
2.1. Les diagrammes de classes d'agent :
<< Une classe d'agent représente un agent
ou un groupe d'agents pouvant jouer un rôle ou
avoir un comportement déterminé >> [16].
Une classe d'agent comporte :
Description de la classe d'agent et des rôles :
un rôle d'agent est un ensemble d'agents ayant certaines
propriétés, interfaces et services ou des comportements
précis.
Description de l'état interne :
définition de variables d'instances qui reflètent
l'état de l'agent (types utilisés dans les objets + types pour
décrire les expressions logiques, ex: les intentions, les buts,
...etc.).
Description des actions, des méthodes et des
services fournis : une action est décrite par
son type (réactive ou pro-active), par sa signature (visibilité
(public, private, ...) + nom + liste de paramètres) et par une
sémantique (pré + post conditions + effets + invariants). Une
méthode est définie comme en UML avec
éventuellement des pré, post conditions et effet. Cette partie
comporte aussi une description informelle des services
fournis.
Messages échangés : description
des messages émis et reçus par l'agent.
2.2. Modélisation des interactions entre agents
Les échanges entre agents peuvent être
modélisés par des diagrammes de séquences, de
collaboration, d'activités ou d'états-transitions.
Diagrammes de séquences : ce sont une
extension des diagrammes de séquences d'UML. Connus aussi par diagrammes
de protocoles d'interactions.
Les messages échangés ne sont plus des noms de
méthodes mais des actes de communication. Ils sont
caractérisés aussi par l'utilisation des threads
d'interaction concurrents suivants :
- Emissions concurrentes : connecteur AND (a);
- 0 ou plusieurs émissions à la fois : connecteur
OR (b);
- 1 seule émission parmi plusieurs candidates : connecteur
XOR (c).

Diagrammes de collaboration : se construisent
comme dans les modèles objets, ce sont similaires aux diagrammes de
séquences.
Diagrammes d'activités : décrivent
les opérations entre agents et les événements qui les
déclenchent.
Diagramme d'états-transitions :
décrit les changements d'état lors des échanges
entre agents. 2.3. Modélisation des traitements internes des
agents
Les traitements internes des agents et leurs comportements
peuvent être modélisés par des diagrammes
d'activités ou d'états-transitions.
3. Le langage FIPA-ACL 3.1. Introduction
Dans des systèmes multi-agents, les interactions entre
agents font un concept fondamental. Pour assurer ces interactions les agents
ont besoin de communiquer dans un langage compréhensible par tous les
autres.
La compréhension du sens des symboles, ou à quoi
les symboles font référence, demande un standard rigoureux de la
sémantique et de la pragmatique. De plus il est nécessaire que
les agents sachent bien utiliser le vocabulaire pour atteindre leurs buts,
éviter les conflits, coopérer pour exécuter leurs
tâches et modifier l'état mental d'un autre agent [19].
- Notion d'actes de langage : les philosophes
du langage ont développé au cours des 25 dernières
années la théorie des actes de discours qui considère que
« dire quelque chose c'est en quelque sorte agir » [7]. Les paroles
sont interprétées comme des actions appelées actes de
discours. Cette théorie fournit un cadre qui identifie des types d'actes
de discours primitifs et permet de dériver de ces types primitifs
l'interprétation sous forme logique de n'importe quel verbe du langage
qui exprime un acte de discours quelconque. En effet, Les types de messages des
langages de communication entre agents sont appelés des actes de
langage.
3.2. Le langage ACL
Le langage ACL de la FIPA est plus récent et fondé
sur la théorie des actes de langage. Il a bénéficié
grandement des résultats de recherche de KQML.
3.2.1. La syntaxe du message ACL : la syntaxe du
message est assez similaire à celle de KQML. La figure ci-après
résume sur un exemple les éléments principaux du message
ACL.
Message ACL
|
Type d'acte
|
(request
:sender (agent-identifier :name i)
:receiver (set (agent-identifier
:name j)) :content
((action (agent-identifier :name j) (deliver box017 (loc 12
19)))) :protocol fipa-request
:language FIPA-SL
:reply-with order567)
|
|
Paramètres
du message
|
Figure A.2 : Exemple d'un message ACL
Essayons maintenant à définir en bref chaque
élément du message dans le tableau suivant :
|
Elément du message
|
Définition
|
|
Performatif(request)
|
Type d'acte de communication : représente la valeur
illocutoire d'un acte de langage.
|
|
sender
|
l'émetteur du message
|
|
receiver
|
le destinataire du message
|
|
content
|
le contenu du message
(l'information transportée par la performative)
|
|
protocol
|
contrôle la conversation
|
|
language
|
le langage dans lequel le contenu est représenté
|
|
reply-with
|
identificateur unique du message, en vue d'une
référence ultérieure
|
Tableau A.1 : Eléments d'un message
FIPA-ACL.
· Le langage utilisé dans le contenu du
message : le langage de contenu se réfère à la
valeur locutoire d'un message envoyé d'un agent à un autre,
c'est-à-dire au contenu "exprimé" de ce message, et à la
façon de présenter ce contenu. Un message FIPA-ACL supporte par
défaut les langages FIPA-SL, KIF (Knowledge Interchange
Format), XML et RDF ; FIPA-SL ayant été
spécifiquement défini par la FIPA [19].
· Le protocole utilisé : un
modèle structurant uniquement le format d'un message ne suffit pas en
lui même pour pouvoir structurer des conversations entre agents, ce qui
est nécessaire pour conserver la cohérence des échanges
successifs. Nous avons donc besoin de la notion de protocole pour supporter des
conversations valides, ce qui permet aux actes de langage de prendre tout leur
sens. Un tel protocole permet d'inclure le comportement d'un agent dans un
contexte particulier, auquel il doit se conformer en envoyant des messages
cohérents grâce à l'utilisation d'actes de langage
adaptés au discours.
· Actes communicatifs (performatifs) du langage
ACL : FIPA-ACL possède 21 actes communicatifs, exprimés
par des performative, qui peuvent être groupés selon leur
fonctionnalité de la façon suivante [19]:
- Passage d'informations: inform*, inform-if(macro act),
inform-ref(macro act), confirm*, disconfirm* ;
- Réquisition d'information : query-if, query-ref,
subscribe ;
- Négociation : accept-proposal, cfp, propose,
reject-proposal ;
- Distribution de tâches : request*, request-when,
request-whenever, agree, cancel, refuse ; - Manipulation des erreurs : failure,
not-understood.
Ces actes communicatifs peuvent être primitifs
ou composés [19]. Les actes communicatifs primitifs sont
définis de façon atomique, c'est-à-dire qu'ils ne sont pas
définis à partir d'autres actes (dans la classification ci-dessus
ils sont suivis d'une étoile "*"). En revanche, les actes communicatifs
composés sont définis à partir d'autres actes. Le tableau
suivant représente ces différents actes ainsi que leurs
sémantiques :
|
Performatif
|
Syntaxe
|
Sens
|
|
Accept Proposal
|
accept-proposal
|
L'émetteur accepte la proposition d'exécuter
certaines actions présentées à l'avance
|
|
Agree
|
agree
|
L'émetteur accepte d'exécuter certaines actions
|
|
Cancel
|
cancel
|
L'action de l'annulation d'une certaine action
déjà demandée qui a portée dans le temps
(c-à-d: n'est pas instantanée).
|
|
Call for Proposal
|
cfp
|
L'action de l'appel de propositions pour exécuter une
action donnée
|
|
Confirm
|
confirm
|
L'émetteur informe le destinataire qu'une
proposition donnée est vraie
|
|
Disconfirm
|
disconfirm
|
L'émetteur informe le destinataire qu'une
proposition donnée est fausse
|
|
Failure
|
failure
|
L'action de raconter un autre agent que l'action a
été essayée, mais a échouée
|
|
Inform
|
inform
|
L'émetteur informe le récepteur des informations de
l'émetteur connaît.
|
|
Inform If
|
inform-if
|
L'émetteur demande au destinataire une
confirmation ou une non-confirmation d'une certaine
proposition
|
|
Inform Ref
|
inform-ref
|
L'émetteur demande au destinataire un objet qui correspond
à une description envoyée.
|
|
Not Understood
|
not-understood
|
L'émetteur informe le destinataire d'un non
compréhension d'une action effectuée par le destinataire
|
|
Propose
|
propose
|
L'émetteur propose d'exécuter certaines actions
conditionnées à certaines préconditions données
|
|
Proxy
|
proxy
|
L'émetteur demande une transmission d'un
message à des agents dont la description est
donnée
|
|
Query If
|
query-if
|
L'action de demander à un autre agent si une proposition
donnée est vraie ou non
|
|
Query Ref
|
query-ref
|
l'émetteur demande du destinataire un objet
référencé par une expression
|
|
Refuse
|
refuse
|
L'émetteur refuse d'exécuter certaines actions
parce qu'il ne peut pas les exécuter
|
|
Reject Proposal
|
reject-proposal
|
L'action de rejet d'une proposition d'effectuer une action lors
d'une négociation
|
|
Request
|
request
|
L'émetteur demande du destinataire d'exécuter une
certaine action
|
|
Request When
|
request-when
|
L'émetteur veut que le destinataire effectue une action
lorsque certaine proposition donnée soit vraie
|
|
Request Whenever
|
request-whenever
|
L'émetteur veut que le destinataire effectue une action
dès que quelque proposition devient vraie et ensuite, chaque fois que la
proposition devient vraie à nouveau
|
|
Subscribe
|
subscribe
|
L'acte de demander une intention persistante d'informer
l'émetteur de la valeur d'une référence, et de le notifier
à chaque fois que l'objet référencé se change
|
Tableau A.2 : Actes communicatifs du langage
ACL
Annexe B : Outils pour la réalisation du
système
Dans cette annexe nous présentons brièvement les
différents outils exploités dans la réalisation de notre
système : l'EDI Eclipse, l'éditeur OWL-S, la plateforme JADE et
l'EDI Jbuilder :
1. Eclipse
Eclipse est un environnement de développement
intégré (IDE(1)) libre extensible, universel et
polyvalent, dont le but est de fournir une plate-forme modulaire pour permettre
de réaliser des développements informatiques.
Eclipse IDE est principalement écrit en
Java (à l'aide de la bibliothèque graphique SWT,
d'IBM), et ce langage, grâce à des bibliothèques
spécifiques, est également utilisé pour écrire des
extensions.
La spécificité d'Eclipse IDE vient du fait de
son architecture totalement développée autour de la notion de
plugin(2) : d'ailleurs, hormis le noyau de la
plate-forme nommé « Runtime », tout le reste de la plate-forme
est développé sous la forme de plug-ins. Ce concept permet de
fournir un mécanisme pour l'extension de la plate-forme et ainsi fournir
la possibilité à des tiers de développer des
fonctionnalités qui ne sont pas fournies en standard par Eclipse.
Eclipse a passé depuis son développement par
plusieurs versions depuis la première version 1.0 en 2001 et
jusqu'aujourd'hui. Dans notre travail nous avons utilisées la version
3.5.2.
2. OWL-S IDE
La génération des services web sémantiques
est un processus complexe et sujet aux erreurs. Peu d'outils qui la permet.
Dans cette section nous présentons en bref OWL-S IDE.
OWL-S IDE est un environnement de développement
intégré implémenté comme un Eclipse
plugin permettant de soutenir le développeur dans le processus
entier de génération des services web sémantique depuis la
génération du code Java, à la compilation des descriptions
OWL-S au déploiement et à l'enregistrement avec UDDI.
2.1. OWL-S Editor
L'éditeur permet de créer de nouveaux fichiers
OWL-S, soit à partir de zéro, soit à partir d'un WSDL
existant ou d'un code Java.
L'éditeur OWL-S fournit deux modes pour éditer
des description OWL-S : l'édition basée sur le graphique et
l'édition basée sur le texte (format XML). L'onglet au bas de
l'éditeur peut être utilisé pour basculer entre ces deux
modes.
(1) IDE : un programme regroupant un ensemble
d'outils pour le développement de logiciels. En règle
générale, un EDI regroupe un éditeur de
texte, un compilateur, des outils automatiques de fabrication,
et souvent un débogueur.
(2) plugin : un logiciel qui complète un
logiciel hôte pour lui apporter de nouvelles fonctionnalités.
Generation des descriptions OWL-S
OWL-S IDE permet de générer des descriptions OWL-S
:
· à partir d'un fichier WSDL existant ;
· à partir d'un code Java ;
· à partir de zéro (nouvelles
descriptions). 2.1.2. Edition des descriptions OWL-S
générées
Les descriptions OWL-S générées par
l'une des manières précédentes peuvent être
complétées en utilisant l'OWL-S Editor d'une manière
graphique ou textuelle grâce au Profile Editor,
au Process Editor, au Grounding Editor et
au Service Editor.
3. JADE - Java Agent DEvelopment Framework
La description de la plateforme JADE présentée
dans cette section est extraite de [19] et [18]. 3.1.
Présentation générale
JADE est une plate-forme multi-agents(1) crée par le
laboratoire TILAB. Entièrement implémentée en JAVA et
permet le développement et l'exécution de systèmes
multi-agents conformes aux normes de la FIPA.
Un agent selon JADE est conforme au standard FIPA,
possède un cycle de vie, possède un ou plusieurs comportements
(Behaviours), communique avec des messages de type Agent Communication
Language (ACL) et rend des services. Un agent est identifié de
manière globale par un nom unique (l'AgentIdentifier ou
AID).
JADE contient ainsi :
Un environnement d'exécution :
l'environnement ou les agents peuvent vivre. Il doit être
activé pour pouvoir lancer les agents ;
Une librairie de classes : que les
développeurs utilisent pour écrire leurs agents ;
Une suite d'outils graphiques : qui facilitent
la gestion et la supervision de la plateforme des agents.
3.2. Les agents de base de JADE
Pour supporter la tâche difficile du débogage des
applications multi-agents, la plateforme possède l'ensemble d'agents
prédéfinis suivant :
Remote Managment Agent « RMA » : le
RMA permet de contrôler le cycle de vie de la plate-forme
et tous les
agents la composant. Avec son interface, il est possible de créer,
supprimer et de migrer
des agents. L'agent RMA permet également la
création et la suppression des conteneurs et la fermeture de la
plateforme. Il peut être lancé à partir de la ligne de
commande Java jade.Boot -gui.
Agent Management System « AMS >> :
est un agent chargé de la supervision et le contrôle de
l'accès et l'usage de la plateforme. Chaque agent doit s'inscrire
auprès de l'AMS pour obtenir un AID valide.
Agent Communication Canal « ACC >> :
c'est le composant logiciel qui contrôle tous les
échanges de messages dans la plateforme, incluant également les
messages de/vers des plateformes distantes.
Directory Facilitor « DF >> :
enregistre les descriptions et les services des agents et maintient
des pages jaunes de services. Grâce à ce service, un agent peut
connaître les agents capables de lui fournir les services qu'il requiert
pour atteindre son but. L'interface du DF peut être lancée
à partir du menu du RMA.
Dummy Agent « DA >> : l'outil
DummyAgent permet aux utilisateurs d'interagir avec les agents JADE
d'une façon particulière. L'interface permet la composition et
l'envoi de messages ACL et maintient une liste de messages ACL envoyés
et reçus. Cette liste peut être examinée par l'utilisateur
et chaque message peut être vu en détail ou même
édité. Plus encore, le message peut être sauvegardé
sur le disque et renvoyé plus tard.
Sniffer Agent « SA >> : quand un
utilisateur décide d'épier un agent ou un groupe d'agents, il
utilise un agent Sniffer. Chaque message partant ou allant vers ce groupe est
capté et affiché sur l'interface du sniffer. L'utilisateur peut
voir et enregistrer tous les messages, pour éventuellement les analyser
plus tard. L'agent peut être lancé du menu du RMA ou de la ligne
de commande suivant Java jade.Boot sniffer :
jade.tools.sniffer.sniffer.
Introspector Agent : Cet agent permet de
gérer et de contrôler le cycle de vie d'un agent
s'exécutant et de la file de ses messages envoyés et
reçus.
3.3. La bibliothèque du JADE
JADE est composé des principaux packages suivants :
Jade.core : implante le noyau du
système. Il possède la classe << Agent >>
qui doit être étendue par les applications des programmeurs et une
classe << behaviour >>.
Jade.lang : contient un sous-package pour
chaque langage de communication utilisé par JADE et en particulier
jade.lang.acl.
Jade.content : contient un ensemble de classes
qui permettent de définir des ontologies.
Jade.domain : contient toutes les classes Java
qui représentent les entités Agent Management définies par
FIPA en particulier AMS et DF.
Jade.gui : contient un ensemble
générique de classes utiles pour la création de GUIs
pour
l'affichage, l'édition des messages ACL, et de la description
des agents.
Jade.proto : contient des classes qui
modélisent les protocoles standards d'interaction. Les classes
permettent aussi aux programmeurs d'ajouter d'autres protocoles.
Jade.tools : contient certains outils qui
facilitent l'administration de la plate forme et le développement
d'applications.
3.5. Communication entre agents JADE
Pour que plusieurs agents JADE arrivent à collaborer,
ils doivent s'échanger des messages. Chaque agent JADE possède
une sorte de boite aux lettres qui contient les messages qui lui sont
envoyés par les autres agents. Ces boites aux lettres sont sous forme
d'une liste qui contient les messages selon l'ordre chronologique de leur
arrivée.
Les agents JADE utilisent des messages conformes aux
spécifications de la FIPA (FIPAACL). Les messages JADE
sont des instances de la classe ACLMessage du package jade.lang.acl. Ces
messages sont composés en général de :
· L'émetteur du message : un champ rempli
automatiquement lors de l'envoi d'un message.
· L'ensemble des récepteurs du message : un message
peut être envoyé à plusieurs agents
simultanément.
· L'acte de communication : qui représente le but de
l'envoi du message en cours (informer l'agent récepteur, appel d'offre,
réponse à une requête, ...).
· Le contenu du message.
· Un ensemble de champs facultatifs, comme la langue
utilisée, l'ontologie, le timeOut, l'adresse de réponse, ...
Un agent JADE peut ainsi envoyer, recevoir, attendre un message
d'un autre agent ou encore choisir un message dans sa boite aux lettres.
4. JBuilder IDE
JBuilder est un environnement de
développement intégré pour Java, édité par
Borland. L'application est elle-même développée en grande
partie en Java.
JBuilder apporte certaines fonctionnalités
spécifiques, disposant notamment d'une JVM propre, permettant notamment
l'exécution de code Java pas à pas.
Il est très visuel et permet de développer
rapidement tous types d'applications Java, il permet le développement
d'application EJB (Enterprise Java Beans), XML, service web et bases de
données.
| 

