INTRODUCTION
0.1. MISE EN CONTEXTE
Le dossier médical d'un patient est une mémoire
écrite des informations cliniques, biologiques, diagnostiques et
thérapeutiques, obtenues au cours du parcours hospitalier du malade.
C'est un outil de réflexion, de synthèse, de
planification et de traçabilité des soins, voire de recherche et
d'enseignement. C'est aussi un élément de centralisation des
actions de tous les intervenants dans le domaine de la santé.
Cet outil, à facettes multiples, était toujours,
dans de nombreux pays, sujets d'une grande attention et d'innombrables
interventions d'innovation et de développement tant sur le plan
législatif et réglementaire que sur le plan médical et
scientifique.
En République Démocratique du Congo, ce
processus de modernisation du dossier médical n'a pas encore
commencé et ce secteur voudrait bien franchir actuellement un nouveau
pas par l'effort de l'informatisation de ce dossier.
Le présent travail est
intitulé« Implémentation
et administration d'un système d'information distribué pour le
suivi des dossiers médicaux dans un
hôpital ».Et nous avons comme cadre de travail,
l'Hôpital Général de Référence de Kinkanda.
Ce dernier pourra nous offrir une bonne gestion épris des
quantités importantes des données et facilitera le traitement et
l'analyse des données épidémiologiques, cliniques et
évolutives du patient.
0.2. PROBLEMATIQUE
L'informatisation du dossier médical n'est pas,
seulement, une évolution naturelle des choses, mais elle répond
aussi à un besoin réel de plus en plus évident vu que:
v Le volume du dossier a augmenté :
Pour un malade donné, pour la même maladie, dans
une même structure, la masse d'information recueillie peut
considérablement augmenter. Les raisons en sont multiples : le passage
à la culture de l'écrit, l'effort d'exhaustivité, la
multitude d'examens complémentaires, la difficulté de trier les
informations, la prise en charge des maladies chroniques et du vieillissement,
la pratique généralisée de copies, les contraintes
réglementaires et les inquiétudes médico-légales,
l'apparition des dossiers paramédicaux sont là les
éléments qui fondent notre étude.
En pratique, les dossiers s'accumulent et les renseignements
deviennent difficiles à retrouver et, cependant la recherche d'une
information précise devientd'emblée impossible.
v Le nombre de dossiers semultiplie :
De plus en plus, les informations médicales concernant
une personne sont fragmentées en de multiples sous-dossiers. Le nombre
de professionnels ne cessed'augmenter. A côté du médecin
généraliste, le spécialiste, l'infirmier, le pharmacien
organisent leurs propres dossiers pour le même patient.
De même, le flux de malade vers les services
médicaux s'intensifie.
v L'importance pratique du dossier est devenue
considérable :
La bonne prise en charge d'un patient, en particulier en
situation d'urgence et en milieu hospitalier, dépend fortement des
renseignements contenus dans son dossier initial, lesquels sont,
généralement, inaccessibles. Il ne s'agit pas des informations
générales que le patient connaît, mais des informations
détaillées et ponctuelles.
En effet, au sein del'Hôpital Général de
Référence de Kinkanda, un besoin est exprimé après
une longuepériode d'évaluation et de promotion des pratiques
professionnelles prenant comme base, le dossier du patient.
Ce faisant, fait notre problématique sepenche sur les
questions suivantes :
- Pourquoi informatiser un dossier médical ?
- Comment stocker et partager les informations constituant un
dossier médical entre le corps médical ?
- Comment réduire considérablement le temps
d'accès et de traitement d'un dossier médical ?
Nous répondrons à ces questions dans les lignes
qui suivent.
0.3. HYPOTHESE
Partant de ce qui précède, trois hypothèses
sont retenues, à savoir :
H1 :L'informatisation permettrait
d'améliorer significativement la qualité des dossiers
médicaux, essentiellement, par deux mécanismes. D'une part par la
structuration et l'organisation qu'elle apporte, et d'autre part par les outils
informatiques et les possibilités propres aux technologies de
l'information.
Le bénéfice est palpable d'abord sur la
qualité du contenu du dossier médical. Un dossier médical
informatisé serait à la fois plus lisible, précis et
complet qu'un dossier papier. Il peut être plus exhaustif sans pour
autant être difficile à remplir.
H2 :La mise en place d'une base de
données répartie en plus de stocker les informations d'une
manière persistante et cohérente, pourra permettre aux
médecins se trouvant sur les différents sites d'avoir les
mêmes données, ce qui facilite largement leurs travails.
H3 :Il serait bien de mettre en place
une base de données répartie dont la manipulationsera à
partir d'un SGBD qui mettrait à la portée les instruments
nécessaires pour gérer le personnel médical, que les
patients. Ainsi, concevoir une application permettant au médecin
d'effectuer les différentes opérations à effectuer au sein
de la base de données pourrait, considérablement, réduire
le temps d'accès au dossier médical en microsecondes et non plus
en terme des heures.
0.4. CHOIX ET INTERET DU
SUJET
Notre choix se justifie par la nécessité de
vouloir mettre en place une étude pouvant résoudre un
problème de gestion des patients dans un hôpital.
Alors que l'intérêt n'est plus à
démontrer car l'informatisation permet d'améliorer
significativement la qualité des dossiers médicaux
essentiellement par deux mécanismes : d'une part par la structuration et
l'organisation qu'elle apporte, et d'autre part par les outils informatiques et
les possibilités propres aux technologies de l'information.
Le bénéfice est palpable d'abord sur la
qualité du contenu du dossier médical. Un dossier médical
informatisé est à la fois plus lisible, plus précis et
plus complet qu'un dossier papier. Il peut être plus exhaustif sans pour
autant être difficile à remplir.
0.5. DELIMITATION DU
SUJET
Le présent travail se réalisera à une
période comprise entre 2019 à 2020 ; cette intervalle nous
servira de rassembler toutes les informations relatives à cette oeuvre
scientifique juste pour justifier le temps. En outre
L'environnement que nous allons étudier pour avoir les
informations faisant partie intégrante de ce travail se trouve
être de l'Hôpital Général de Référence
de KINKANDA, dans la ville de Matadi.
0.6. BUT DU
MEMOIRE
Le but de la recherche est l'amélioration de la
qualité, la lisibilité, la fiabilité, la
présentabilité, l'accessibilité et la facilité de
reproduction des données médicales, ainsi que la réduction
des erreurs de saisie, du temps des travaux administratifs et d'archivage, la
rentabilité des médecins et la satisfaction des patients.Et enfin
Une réduction du taux de mortalité.
0.7. METHODES ET TECHNIQUES
UTILISEES
Notre recherche, utilisera tout à tour les
méthodes ci-dessous :
- La méthode historique : elle a
consisté à se référer au passe pour obtenir le
présent et envisager le futur.
- Méthode
structuro-fonctionnelle : elle nous a permis de définir la
structure fonctionnelle de l'hôpital général de
référence de kinkanda Matadi afin de comprendre la
répartition des taches des différents postes de travail.
- Méthode analytique : elle nous
a permis d'analyser le système de gestion en place.
- Méthode PERT : elle nous a
permis de planifier et d'évaluer notre projet.
a) Techniques
- Technique d'interview
Elle nous a aidé à composer des questions pour
avoir les informations relatives à notre travail en passant une
conversation avec les autorités de l'hôpital afin d'enrichir notre
recherche.
- Technique d'observation
Celle-ci nous a permis d'observer directement comment se
déroule la gestion que nous voulons analyser pour les informations
liées à notre travail lors des différentes descentes sur
terrain (hôpital) et les activités y relatifs.
- Technique documentaire
Celle-ci a consisté à consulter des ouvrages
relatifs à notre sujet de recherche et à l'hôpital
général de référence de KINKANDA, des livres
publiés, des notes de cours et des anciens travaux de fin d'étude
élaborés avant nous par nos ainés scientifiques dans
l'intérêt d'enrichir notre travail.
0.8. SUBDIVISION DU
TRAVAIL
Hormis l'introduction et la conclusion, le présent
travail comprend deux parties :
Le premier concerne l'étude préalable et est
subdivisé en trois chapitres. Le premier chapitre est axé sur
l'évaluation de projet ce qui nous a permis d'avoir une idée fixe
sur les délais des différentes taches ayant trait à notre
projet et de pouvoir déterminé le cout du projet. Le chapitre
deuxième est la présentation de l'entreprise.
Le second concerne l'étude du système futur
où nous avons pu faire une modélisation concernant notre nouveau
système d'information en se basant les données
récoltées au sein de l'entreprise en le scindant en trois
section :
- La modélisation statique ;
- La modélisation dynamique
- La confrontation de modèle statique et dynamique.
En dehors de ce trois section, la dernière partie du
présent travail comprend un chapitre qui est l'étude technique,
orienté vers la réalisation et la mise en oeuvre de notre
système d'information.
IIERE PARTIE : ETUDE
PREALABLE
CHAPITRE PREMIER :
EVALUATION DU PROJET
1. PRINCIPES DE REPRESENTATION
EN P.E.R.T
Si dans le vocabulaire de tous les jours, la notion de «
projet » désigne assez globalement « une action future »,
cette notion renvoie par contre à une formulation beaucoup plus
précise pour tous les acteurs impliqués dans le
déroulement opérationnel d'un projet.
Un graphe de dépendances est utilisé. Pour
chaque tâche, sont indiquées une date de début et de fin au
plus tôt et au plus tard. Le diagramme permet de déterminer le
chemin critique qui conditionne la durée minimale du projet1(*).
Le but est de trouver la meilleure organisation possible pour
qu'un projet soit terminé dans les meilleurs délais, et
d'identifier les tâches critiques, c'est-à-dire les tâches
qui ne doivent souffrir d'aucun retard sous peine de retarder l'ensemble du
projet.
1.1. BREF APERÇU SUR LA
METHODE P.E.R.T2(*)
La méthode Technique d'évaluation et de
contrôle de Programme en anglais (Progam Evaluation and Review Technic)
en sigle PERT a pour objet essentiel la mise en évidence des
différentes liaisons qui existent entre les taches. Son but est
d'organiser les tâches sous la forme d'un réseau afin de faciliter
la gestion du projet. Cette représentation graphique permet d'identifier
les connexions entre les différentes tâches, les temps
d'exécution, les interdépendances. L'outil de base est le
graphe.Pour le cas du projet informatique le graphe sera tracé sur base
d'algorigramme du projet.
Un organigramme de programmation (parfois appelé
algorigramme, logigramme ou plus rarement ordinogramme) est une
représentation graphique normalisée de l'enchaînement des
opérations et des décisions effectuées par un programme
d'ordinateur.
1.2. GENERALITES3(*)
Le terme PERT est l'acronyme de « program evaluation and
review technology » ou « program evaluation research task ». Sa
traduction française serait : « technique d'évaluation et
d'examen de programmes » ou « de projets », ou encore «
technique d'élaboration et de mise à jour de programme ».
L'adjectif anglais « pert », signifie « malicieux », «
mutin ».
Le PERT est créé en 1958 à la demande de
la marine américaine, qui veut planifier la durée de son
programme de missiles balistiques nucléaires miniaturisés
Polaris. L'enjeu principal est de rattraper le retard en matière de
balistique par rapport à l'URSS, après le choc de la « crise
de Spoutnik ». L'étude est réalisée par la
société de conseil en stratégie Booz Allen Hamilton3.
Alors que le délai initial de ce programme - qui a fait intervenir 9 000
sous-traitants et 250 fournisseurs - était de 7 ans, l'application de la
technique du PERT a permis de réduire ce délai à 4 ans.
L'attribution du succès du programme Polaris à l'usage du PERT a
néanmoins fait l'objet de critiques documentées, notamment par H.
Sapolsky (The Polaris System Development, Harvard University Press, 1972).
1.3. PRESENTATION DU
P.E.R.T
La méthode Technique d'évaluation et de
contrôle de Programme en anglais (Program Evaluation and Review Technic)
en sigle PERT a pour objet essentiel la mise en évidence des
différentes liaisons qui existent entre les taches. Son but est
d'organiser les tâches sous la forme d'un réseau afin de faciliter
la gestion du projet. Cette représentation graphique permet d'identifier
les connexions entre les différentes tâches, les temps
d'exécution, les interdépendances. L'outil de base est le graphe.
Pour le cas du projet informatique le graphe sera tracé sur base
d'algorigramme du projet.
Un organigramme de programmation (parfois appelé
algorigramme, logigramme ou plus rarement ordinogramme) est une
représentation graphique normalisée de l'enchaînement des
opérations et des décisions effectuées par un programme
d'ordinateur.
1.4. L'IMPORTANCE DE LA
METHODE PERT
Cet outil facilite la maîtrise du projet. En effet, il
permet de :
ï Donner une vue réelle de la livraison
du projet,
ï Anticiper l'affectation des ressources
humaines et financières, des moyens techniques,
ï Identifier les tâches à traiter
plus rapidement si l'on souhaite livrer le projet plus tôt,
ï Repérer les tâches à
traiter simultanément (travail en parallèle) et les
tâches antérieures,
ï Identifier les tâches critiques et le
non-critique pour tenir les délais - permet par exemple de
redéployer des ressources si nécessaires,
ï préparer
la
construction d'un planning Gantt.
ï Affecter des responsabilités
1.5. BUT DE LA METHODE
P.E.R.T
La méthode Pert a pour but de (4(*)):
ü Trouver le meilleur enchainement possible des
tâches pour que l'ensemble du projet soit réalisé dans les
meilleurs délais ;
ü Identifier les marges existantes sur les tâches
(avec une date de début au plus tôt et au plus tard) ;
ü Trouver la meilleure
organisation
possible pour qu'un projet puisse s'exécuter dans les meilleurs
délais, et d'identifier les tâches critiques, c'est-à-dire
les tâches qui ne doivent subir aucun retard sous peine de retarder l'
ensemble
du projet.
ü Identifier les tâches critiques afin de leur
appliquer une gestion rigoureuse ;
ü Faire une meilleure affectation des ressources ;
ü Etudier les coûts de réalisation de chaque
tâche et le coût global du projet ;
ü Optimiser les coûts en rapprochant les
tâches qui nécessitent les mêmes ressources ;
ü Evaluer la durée optimale de l'ensemble du
projet ;
ü Effectuer le suivi du projet afin de détecter le
plus tôt possible tout retard et de réagir en apportant des
solutions adaptées.
1.6. LES CONDITIONS PREALABLES
A LA CONSTRUCTION DU GRAPHE PERT
Par cette méthode PERT, il nous faudra prévoir
une entrée et une sortie et les tâches seront
représentées par des flèches, tandis que le sommet
représente comment les opérations vont se dérouler5(*).
Elle permet :
ü La prise en compte des différentes tâches
à réaliser ;
ü La détermination de la durée globale du
projet et des tâches qui la conditionnent ;
ü La détermination des dates ;
ü Etablissement d'un planning d'exécution.
Activité
Fin (i)
Durée (i)
Début
Sommet
Tâche suivante
Tâche précédente
Figure 1 : Bref aperçu sur le graphique
P.E.R.T
Certaines de ces tâches ne peuvent démarrer avant
que certaines autres soient effectuées, tandis qu'il existe des
tâches qui peuvent s'exécuter en parallèle. Le graphe PERT
est composé d'étapes et de tâches. Dans la méthode
PERT, on calcule deux valeurs pour chaque étape :
ü La date au plus
tôt : il s'agit de la date à laquelle la
tâche pourra commencer au plus tôt, en tenant compte du
tempsnécessaire
à l'exécution des tâches précédentes.
ü La date au plus tard :
il s'agit de la date à laquelle une tâche doit commencer à
tout
prix si l'on ne veut pas retarder l'ensemble du projet.
1.7. LA CONSTRUCTION DU GRAPHE
P.E.R.T
Le PERT (Program of Evaluation and Review Technique) est une
méthode consistant à mettre en ordre sous forme de réseau
plusieurs tâches qui, grâce à leur dépendance et
à leur chronologie, concourent toutes à l'obtention d'un produit
fini. La méthode PERT est la plus souvent synonyme de gestion de projets
important à long terme. C'est pourquoi, plusieurs actions sont
nécessaires pour réussir sa mise en oeuvre. Il est une
méthode anglo-saxonne, A on A, c'est-à-dire Activité sur
l'Arc.
- Un arc correspond à une tâche
- La valeur de l'arc représente la durée de la
tâche.
- un sommet est une étape signifiant
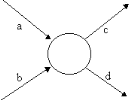
Toutes les tâches qui y arrivent sont terminées
toutes les tâches qui en partent peuvent commencer a et b doivent
être terminées pour que c et d puissent commencer
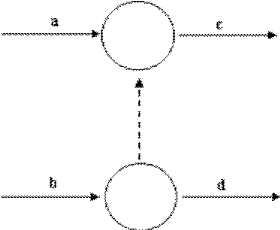
Il est quelque fois nécessaire d'introduire des
tâches fictives de durée nulle. a et b doivent être
terminées pour que c puisse commencer et uniquement b doit être
terminée pour que d commence
Deux arcs ne peuvent avoir à la fois la même
origine et la même extrémité. Il est nécessaire de
rajouter une tâche fictive dans ces conditions :
Sera transformé en
- Chaque sommet est représenté par un cercle
divisé et trois parties
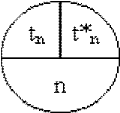
§ Où n = nom ou numéro de
l'étape
§ tn = date de début au plus tôt
de l'étape
§ t*n = date de début au plus tard de
l'étape
- Un sommet terminal et un sommet initial sont rajoutés
au graphe.
a) Contraintes dans un graphe P.E.R.T
Dans ce paragraphe, nous avons des tâches pour des
contraintes de postérité qui signifient simplement on ne peut
démarrer la tâche sans que les tâches (a), (b), et (c)
arrivent à la fin.6(*)
b) Identification des taches
|
Lettre
|
Taches
|
Durées (jours)
|
|
A
|
Etude préalable détaillée
|
28
|
|
B
|
Dossier de paramétrage
|
6
|
|
C
|
Modélisation de la base de données
|
10
|
|
D
|
Modélisation des traitements
|
12
|
|
E
|
Réalisation de la base de données
|
4
|
|
F
|
Réalisation de l'application
|
33
|
|
G
|
Réalisation des tests
|
7
|
|
H
|
Rédaction du manuel
|
10
|
|
I
|
Acquisition des matériels
|
30
|
|
J
|
Formation
|
15
|
|
K
|
Mise en production
|
5
|
Tableau 1 : identification des taches
0.1. 1.8. EVALUATION DES TEMPS
ET COUT TOTAL DU PROJET (CALENDRIER DU PROJET)
|
Lettre
|
Taches
|
Durées
|
Début
|
Fin
|
Cout
|
|
A
|
Etude préalable détaillée
|
28
|
Lundi, 16/12/2019
|
Lundi , 13/01/2020
|
250 $
|
|
B
|
Dossier de paramétrage
|
6
|
Mardi , 14/01/2020
|
Lundi , 20/01/2020
|
110 $
|
|
C
|
Modélisation de la base de données
|
10
|
Mardi , 20/01/2020
|
Jeudi , 30/01/2020
|
1500 $
|
|
D
|
Modélisation des traitements
|
12
|
Vendredi , 31/01/2020
|
Mercredi , 12/02/2020
|
1000 $
|
|
E
|
Réalisation de la base de données
|
4
|
Jeudi , 13/02/2020
|
Lundi , 17/02/2020
|
3500 $
|
|
F
|
Réalisation de l'application
|
33
|
Mardi , 18/02/2020
|
Dimanche, 22/03/2020
|
80000 $
|
|
G
|
Réalisation des tests
|
7
|
Lundi, 23/03/2020
|
Lundi, 30/03/2020
|
200 $
|
|
H
|
Rédaction du manuel
|
10
|
Mardi, 31/03/2020
|
Vendredi, 10/04/2020
|
250 $
|
|
I
|
Acquisition des matériels
|
30
|
Jeudi, 11/04/2020
|
Lundi, 11/05/2020
|
500.000 $
|
|
J
|
Formation
|
15
|
Mardi, 12/05/2020
|
Mercredi, 27/05/2020
|
200 $
|
|
K
|
Mise en production
|
5
|
Jeudi, 28/05/2020
|
Mercredi, 03/06/2020
|
100 $
|
Tableau 2 : calendrier du projet
1.9. 1
2
3
4
5
6
7
8
9
10
11
A (28)
B (6)
C (10)
D (12)
E (4)
F (33)
G (7)
H (10)
I (30)
J (15)
K (5)
Début
GRAPHE P.E.R.T NON ORDONNE
Schéma 1 : Graphe non ordonné
1.10. IDENTIFICATION DU CHEMIN
CRITIQUE (RECHERCHE DES RANGS)
Le chemin critique est celui qui passe par les sommets
où la DTO est égale à la DTA (7(*))
Nous avons identifié un chemin, dont nous
avons :
· Premier Chemin : A-B-C-D-E-F-G-H-I-J-K
· calcul des rangs
Rn-Nombre de sommet S=R0
Rn - 10=R0
N-10=0
n=10
Rn-1=R10-1=R9
Rn-2=R10-2=R8
Rn-3=R10-3=R7
Rn-4=R10-4=R6
Rn-5=R10-5=R5
Rn-6=R10-6=R4
Rn-7=R10-7=R3
Rn-8=R10-8=R2
Rn-9=R10-9=R1
Rn-10=R10-10=R0
1.11. GRAPHE PERT ORDONNE AVEC
DTO ET DTA
Le code de présentation est le suivant :
§ On symbolise une étape par un cercle C le
commencement ou la fin d'une tâche ;
§ Un arc fléché pour signifier la
tâche (au-dessus de la flèche vous inscrivez le code de la
tâche et en dessous sa durée.
Pour représenter un réseau PERT, il existe des
règles :
§ Chaque tâche est représentée par 1
arc et seul C= une étape ne peut être représentée
qu'une fois ;
§ 2 tâches ne peuvent être identifiées
par 2 arcs ayant la même origine et la même
extrémité ;
§ Ainsi si 2 tâches sont simultanées, elles
seront représentées par 2 arcs différents en partant de la
même origine.
1.12. RECHERCHE DES DATES AU
PLUS TOT ET DATES AU PLUS TARD
Ayant estimé les durés des toutes les taches
consécutives du graphe, nous pouvons calcules les dates du début
et la fin de chacune d'elles. Il faut procéder en deux temps :
calcul aller « dates au plus tôt », nous allons
chercher à quelles dates au plus tôt peuvent être
exécuté les différentes taches du projet.
a. Date au plus tôt
Sa formule est : DTO (x) = max [DTO (y) + d
(i)].
DTO (x) est considérée comme la deuxième
étape et DTO (y) comme la première étape et i comme une
tâche.
DTO (Début) = 0+0?DTO (Début)
=0
DTO (1) = 0+28?DTO (1) =28
DTO (2) = 28 + 6?DTO (2) = 34
DTO (3) = 34 + 10?DTO (3) = 44
DTO (4) = 44 + 12?DTO (4) = 56
DTO (5) = 56 + 4?DTO (5) = 60
DTO (6) =60 + 33?DTO (6) = 93
DTO (7) = 93 + 7 ?DTO (7) = 100
DTO (8) = 100 + 10?DTO (8) = 110
DTO (9) = 110 + 30?DTO (9) = 140
DTO (10) = 140 + 15?DTO (10) = 155
DTO (11) =155 + 5?DTO (10) = 160
b. Date au plus tard (DTA)
C'est la date à laquelle il faut impérativement
terminer la tâche X si on veut terminer absolument le projet dans sa
durée minimale. Sa formule est :
DTA (x) = min DTA (y) - d (i)
DTA (11) = 160
DTA (10) = 160 - 5?DTA (10) = 155
DTA (9) = 155 - 15 = 140
DTA (8) = 140 - 30?DTA (8) = 110
DTA (7) = 110 - 10?DTA (7) = 100
DTA (6) = 100 - 7?DTA (6) =93
DTA (5) = 93 - 33?DTA (5) = 60
DTA (4) = 60 - 4?DTA (4) = 56
DTA (3) = 56 - 12?DTA (3) = 44
DTA (2) = 44 - 10?DTA (2) = 34
DTA (1) = 34- 6?DTA (1) = 28
DTA (Début) = 28- 28?DTA (Début) =
0
1.13. MARGES LIBRES ET MARGES
TOTALES
· Marge libre
C'est le retard maximum que l'on peut prendre dans la mise en
route d'une tâche sans remettre en cause les dates au plus tôt des
tâches suivantes (donc sans retarder la fin des travaux).
ML(x) = tm - tn - V(n,m) , si la tâche x
va du sommet n au sommet m
NB: si du sommet d'arrivée m ne
partent que des tâches fictives, on retiendra le minimum sur tous les
premiers sommets suivants d'où partent au moins une tâche
réelle
· Marge totale (MT)
Le retard maximum que l'on peut prendre dans la mise en route
d'une tâche sans remettre en cause les dates au plus tard des
tâches suivantes (donc sans retarder la fin des travaux).
MT(x) = T*x - Tx
NB : En marge totale l'ordre est nul.
L'activité est critique, d'où on ne peut pas y accorder un
délai sans pour autant réduire le temps, on touche sur les
activités critiques.
1.14. TABLEAU DES MARGES
LIBRES ET MARGES TOTALES
|
Tâche
|
MT
|
ML
|
|
1
|
28-28=0
|
(28-0-28)= 0
|
|
2
|
34-34=0
|
(34-6-28)= 0
|
|
3
|
44-44=0
|
(44-10-34)= 0
|
|
4
|
56-56=0
|
(56-12-44)= 0
|
|
5
|
60-60=0
|
(60-4-56)= 0
|
|
6
|
93-93=0
|
(93-33-60)= 0
|
|
7
|
100-100=0
|
(100-7-93)= 0
|
|
8
|
110-110=0
|
(110-10-100)= 0
|
|
9
|
140-140=0
|
(140-30-110)= 0
|
|
10
|
155-155=0
|
(155-15-140)= 0
|
|
11
|
160-160=0
|
(160-5-155)= 0
|
Tableau 3 : Tableau de Marges (libres et
totales)
a) a) Graphe
ordonné
0
0
28
28
34
34
44
44
56
56
93
93
110
110
155
155
60
60
100
100
140
140
160
160
1
2
3
4
5
6
7
8
9
10
11
A(28)
B(6)
C(10)
D(12)
E(4)
F(33)
G(7)
H(10)
I(30)
J(15)
K(5)
Début
Schéma 2 : Graphe ordonné
b) Choix du chemin
critique
Le chemin critique sert de guide pour tout le
déroulement du projet. Les tâches qui le composent vont devoir
être observées, surveillées durant toute la durée du
projet. Le planning déterminé va servir de
référence et toute tâche critique prenant du retard va
entraîner sa mise à jour, ainsi que celle du chemin critique, de
façon à suivre au plus près l'évolution de la date
de fin prévue.
Le chemin critique est : A, B, C, D, E, F, G, H, I, J,
K
c) Durée du
projet
Nous considérons seulement les durées des
activités critiques pour évaluer la durée totale de notre
projet car les activités non critiques sont celle sont celle qui n'ont
pas d'influence sur l'ensemble de projet du point de durée termes.
DTP=d (A) + d(B) + d(C) + d(D) + d(E) + d(F) +
d(G) + d(H) + d(I) + d(J) + d(K)
DTP= 28 + 6 + 10 + 12 + 4 + 33 + 7 + 10 + 30 +
15 + 5 = 160 Jours.
d) Cout total du
projet
U
Le coût total du projet est de donnée par la formule
suivante :
N
Formule : CTE = ? =0 (I) = C (A) + C (B)+ C
(C) + C (D) + C (E) + C (F) + C (G) + C (H) + C (I) + C (J) + C (K)
Soit, CTE =250+ 110 + 1500 + 1000 + 3500 + 80000
+ 200 + 250 + 500000 + 200 +100 = 587.110 $
Conclusion partielle
Il nous a paru naturel de pouvoir insinuer sur ce que
représente le projet que nous avons eu en mettre en marche en y
dégageant une évolution subséquente dans le respect des
priseurs.
CHAPITRE DEUXIEME :
CADRAGE DU PROJET
II.1. PRESENTATION DE
L'ENTREPRISE
Dans cette partie, nous allons présenter l'organigramme
général de l'hôpital Général de
Référence de KINKANDA en général par son
historique, sa situation géographique, son organigramme
général, ses objectifs et ambitions puis terminer par la prise en
connaissance de notre service concerné en particulier.
II.2. HISTORIQUE DE
L'ENTREPRISE
L'hôpital Général de
référence de KINKANDA est construit en 1945 par l'OTRACO (OFFICE
DE TRANSPORT DU CONGO, EX ONATRA), actuellement la SCTP (Société
Commerciale des Transports et Ports) pour assurer les soins de santé de
ses agents. A l'époque, la gestion fut confiée aux
révérendes soeurs qui habitaient à l'actuelle paroisse
sacré coeur de KINKANDA.
La ville prenant de l'extension et la population ayant suivi
le même mouvement, l'hôpital de l'état situé sur le
site actuel nommé INSTITUT LONDE devint incapable de prendre en charge
toute la population. C'est ainsi que l'état congolais de cette
époque réquisitionnera l'hôpital de L'OTRACO, devenu
hôpital général de KINKANDA pour en faire un hôpital
général ouvert à toute la population de la ville de MATADI
et de ses environs ; et toujours sous la gestion des
révérendes soeurs. En 1959, les révérendes soeurs
craignant la deuxième accession qui avait précédé
l'avènement de notre pays à l'indépendance,
préfèrent rentrer dans leurs pays ; abandonnant
l'hôpital entre les mains des anciens assistants médicaux de
l'époque.
C'est enfin en 1961 que le gouvernement de ce temps-là
affectera un premier médecin indigène du nom du Docteur Arthur
KIENDO.
II.3. ORGANIGRAMME
CONSEIL DE GESTION
COMITE DE DIRECTION
SECRETARIAT
Direction de service Administratif
Direction de service de microtechnique
Direction de service médical et
hôpital
Personnel
Radiologie
Médecin interne
Mouvement
Kinésithérapie
Chirurgie général
Sciatique
Pharmacie
Assainissement
Laboratoire
Gynéco obstétrique
Morgue
Nutrition
Pavillon privé
Buanderie
Et ophtamogie
Réception
Comptabilité
Caisse
Facturation
Recouvrement
Banque de sang
Bloc opératoire
Soins intensifs
Schéma 3 : Organigramme général
de l'hôpital général de référence de
Kinkanda
Source : Secrétariat de
l'Hôpital Général de KINKANDA
II.4. DESCRIPTION DE POSTE DE
L'ORGANIGRAMME
Equipe cadre : c'est un organe
décisif de l'entreprise qui a pour objectif de tracer le planning de
l'institution.
L'équipe cadre est constitué du (de
l') :
Médecin directeur :
président et chef de l'institution ;
AG Titulaire :
Secrétaire, il seconde le médecin directeur titulaire dans la
gestion quotidienne de l'institution pour son bon fonctionnement ;
Médecin chef de
staff : Membre au sein de l'équipe cadre, il
assure l'encadrement en ce qui concerne la technicité des
médecins ;
Directeur de Nursing :
représentant du médecin, il encadre et veille à la bonne
administration du traitement des patients en ce qui concerne la
technicité des infirmiers ;
Représentant de
personnel : Il intervient pour défendre les
intérêts des personnels dans l'institution ;
Représentant de
syndicat : Il intervient pour défendre les
intérêts de leurs membres tels-que (médecin, infirmier) les
cadres de santé en outre, et les administrateurs ;
Représentant des autorités
Urbaines : Il s'agit ici de l'autorité Urbaine de la
ville, qui représente les différentes autorités
politico-urbaines (l'ETAT) ;
Comité de direction :
C'est un organe exécutif qui a pour rôle (attribution)
d'exécuter les injonctions et ordres provenant de l'équipe cadre
au sein de l'entreprise qui, pour nous, est l'hôpital. Ce comité
de direction est composé des différents personnages
qualifiés et dotés de talents, il est composé du
(d') :
ü Médecin directeur (MD) ;
ü Administrateur gestionnaire titulaire (AGT) ;
ü Médecin chef de staff (MCS) ;
ü Directeur de nursing (DN) ;
ü Représentant des techniciens (RP).
Administrateur gestionnaire titulaire :
Secrétaire, elle seconde le médecin directeur dans la gestion
quotidienne de l'institution pour son bon fonctionnement.
Chef Nursing : Il veille aux
traitements administrés par les infirmiers auprès des
patients.
Représentant des techniciens :
Il intervient pour défendre les intérêts des techniques de
santé (Dentiste, Nutritionniste,...) ;
Représentant de
syndicat (SYNAMED) (ont
l'intérêt de défendre les médecins et leurs
intérêts).
II.5. SITUATION GEOGRAPHIQUE
L'hôpital général de
référence de KINKANDA/Matadi est situé dans la commune de
Matadi, aire de sante de l'Hygiène, zone de sante Urbano-rurale de
Matadi, ville de Matadi, province du kongo central. En ce qui concerne sa
limitation, l'Hôpital General de Reference de Kinkanda/Matadi est
limité :
Au Nord, par la maternité provinciale (ancienne
clinique KINKANDA) ;
Au sud, par l'actuel garage MVUKI vers la frontière de
L'ANGOLA (ANGO-ANGO) ;
A l'Est, par le FLAT HOTEL LEDYA ;
Et à l'Ouest, par le nouveau lotissement de
KINKANDA.
II.6. OBJECTIFS POURSUIVIS
.
Cet hôpital a plus pour objectif premier de ramener la
guérison au plus vite possible dans le Corps d'un patient en
détails :
Accueillir les patients peu importe l'état de la
santé ;
Administrer des soins médicaux possibles au
patient ;
Aider à la réadaptation de patient ;
Fournir des informations possibles aux chercheurs
scientifiques pour l'amélioration et le progrès de l'entreprise
en ce qui concerne des différentes failles rencontrées au sein de
celle-ci.
II.7. CONNAISSANCE DU PLAN
DIRECTEUR INFORMATIQUE
Nous avons subdivisé la conception du plan directeur
informatique en six étapes (voir le schéma de la page suivante).
Avant qu'une nouvelle étape soit entreprise, l'étape
précédente doit être approuvée. Il est normal,
cependant, qu'il y ait certains chevauchements entre les étapes ou que
l'on découvre, à une étape donnée, un
élément important modifiant une étape
précédente. Le chargé de projet devra donc gérer
ces situations et faire approuver toutes modifications par les comités.
Pour chaque étape, on retrouve une section
appelée Activités qui décrit les principales
tâches qui devront être accomplies pour la réalisation de
l'étape. Dans la section Résultats, est décrit le
contenu des rapports qui devront être approuvés par le
comité des SI et le comité de direction au Point de
contrôle avant de passer à l'étape suivante.
II.7.1. PLANIFICATION DU
PROJET
Cette première étape permet d'établir les
bases du plan directeur, tant en ce qui concerne l'orientation qu'en ce qui a
trait aux opérations. Elle nous assure que tous connaissent les aspects
stratégiques de l'entreprise, tels que la mission et les objectifs, et
que le plan directeur sera conforme à ceux-ci. De plus, cette
planification fournit le cadre de référence opérationnel
et technique pour la préparation du rapport relatif au plan directeur.
ACTIVITÉS
ï Examen sommaire du contexte actuel (organisationnel,
législatif, technologique, concurrence, clientèle, etc.).
ï Prise de connaissance du plan stratégique
d'entreprise.
ï Révision des motifs justifiant le plan
directeur.
ï Précision des risques et des contraintes pour
l'entreprise.
ï Évaluation des ressources de l'entreprise en
relation avec le projet.
· Définition et classement par ordre
de priorité des facteurs critiques de succès de l'entreprise.
ï Détermination de la structure du rapport final.
ï Identification des participants au projet.
ï Détermination du calendrier du projet.
ï Établissement des mécanismes de revue du
projet.
II.7.2. CONCEPTION D'UN PLAN
DIRECTEUR INFORMATIQUE
Analyse de la situation actuelle
Analyse des besoins
Planification du projet
Orientation générales et possibilités
d'action
Scénarios possibles
Choix de l'orientation
Mise en oeuvre de plan directeur
Analyse
M
O
D
I
F
I
C
A
T
I
O
N
S
Schéma 4 : Plan directeur informatique
Source : Nous-mêmes
v RÉSULTATS
ï Présentation de la mission, des objectifs, des
priorités, des facteurs critiques de succès, des contraintes et
de l'environnement de l'entreprise.
ï Communication des priorités.
ï Plan de travail et calendrier des rencontres.
ï Structure du rapport final.
v POINTS DE CONTRÔLE
ï Revue de la planification du projet par le comité
de gestion des SI.
ï Validation par un conseiller-expert au besoin.
ï Recommandation au comité de direction pour
approbation.
II.7.3. ANALYSE
D'habitude l'analyse de la situation actuelle et l'analyse des
besoins s'effectuent concurremment. C'est pourquoi nous avons regroupé
ces deux étapes en une seule et l'avons nommée analyse. De plus,
elle comprendra un point de contrôle commun.
II.7.3.1.ANALYSE DE LA SITUATION ACTUELLE
Cette étape permet d'avoir un bilan complet de la
situation actuelle du fonctionnement, de l'information ainsi que des
différentes technologies utilisées. La cueillette de cette
information est essentielle si nous voulons connaître l'impact, pour
l'organisation, des choix qui seront proposés ultérieurement.
v ACTIVITÉS
ï Entrevues avec les gestionnaires pour l'ensemble des
secteurs d'activités.
ï Identification des orientations et des fonctions
actuelles et désirées.
ï Obtention des documents intrants et extrants
(formulaires et rapports).
ï Inventaire des systèmes d'information et des
équipements.
ï Étude des processus et des circuits internes et
externes d'informations.
ï Étude de la relation avec des entités
externes.
ï Description des applications, du système
d'exploitation et des volumes d'information.
ï Étude des processus, des méthodes de
travail, des contrôles et de la sécurité.
ï Identification et documentation des problèmes,
préoccupations et possibilités en relation avec les processus.
ï Identification des processus-clés (actuels et
futurs) pour atteindre les objectifs.
ï Identification des investissements et frais
d'exploitation.
ï Description des points forts et des points faibles.
v RÉSULTATS
ï Bilan organisationnel, informationnel et technologique.
ï Description des processus actuels (en mettant l'accent
sur les réseaux d'information).
II.7.3.2.ANALYSE DES BESOINS
C'est durant cette étape que chacun pourra exprimer ses
besoins en information, tant actuels qu'à court terme (trois à
cinq mois). Il est très important à ce stade-ci d'être
très imaginatif et de ne rejeter aucun besoin a priori même s'il
peut sembler impossible d'y répondre présentement. L'analyse de
ces besoins et le classement de ceux-ci par ordre de priorité en
fonction des orientations et des coûts/bénéfices seront
effectués ultérieurement en se basant sur l'ensemble des besoins.
v ACTIVITÉS
ï Entrevues avec les gestionnaires pour l'ensemble des
secteurs d'activités.
ï Identification des sous-utilisations et surutilisations
des systèmes et logiciels existants.
ï Documentation des besoins par secteur d'activité
selon une typologie permettant de distinguer les uns des autres les besoins de
gestion stratégique, de contrôle et de gestion
opérationnelle.
ï Documentation des besoins dans les domaines :
- Fonctionnels (fonctions requises) ;
- Des échanges d'information entre les fonctions ;
- Quantitatifs (volume, fréquence, etc.).
ï Regroupement des besoins en des ensembles cohérents
pouvant représenter des actions précises et identification des
activités de systématisation requises : formulation de nouvelles
politiques, formation du personnel, révision des rôles et
responsabilités, simplification du travail, élaboration de
systèmes.
v RÉSULTATS
ï Description des besoins par secteur d'activité
(aspects fonctionnel et quantitatif).
ï Description des activités de
systématisation.
v POINTS DE CONTRÔLE - ANALYSE
ï Validation auprès des chefs de service pour
s'assurer de leur compréhension et de leur coopération.
ï Revue de la situation actuelle et des besoins par le
comité de gestion des SI.
ï Validation par un conseiller-expert au besoin.
ï Recommandation au comité de direction pour
approbation.
II.7.4. ORIENTATIONS GENERALES
ET POSSIBILITES D'ACTION
C'est à cette étape que commencera
l'intégration de l'information recueillie et se dessinera l'orientation
informationnelle des années à venir pour chaque secteur
d'activité de l'entreprise. Il est donc crucial, à ce stade-ci,
de s'assurer que l'orientation qui se dégage est en accord avec le plan
stratégique.
v ACTIVITÉS
ï Synthèse des données recueillies pour
dégager :
- Les constatations d'ensemble et les faits saillants de la
situation actuelle :
· Objectifs d'entreprise ;
· Besoins ;
· Contraintes issues du passé.
- Les orientations organisationnelles et technologiques,
fondamentales, envisagées pour les années futures :
· Politiques de fonctionnement (rôles,
responsabilités, philosophie de gestion) ;
· Technologie de production en accord avec la philosophie
de gestion (MRP, JAT, etc.) ;
· Centralisation et/ou décentralisation des
systèmes ;
· Architecture de données et de systèmes
;
· Configurationsinformatiques ;
· Évolution technologique.
v RÉSULTATS
ï Modélisation conceptuelle des systèmes
envisagés.
ï Énoncés d'orientations
générales de systématisation.
ï Estimation sommaire des actions envisagées ainsi
que de leurs exigences, de leurs coûts, de leurs bénéfices
et de leurs impacts.
v POINTS DE CONTRÔLE
ï Validation auprès des chefs de service.
ï Revue de l'orientation générale et des
possibilités d'action par le comité de gestion des SI.
ï Validation par un conseiller-expert au besoin.
ï Recommandation au comité de direction pour
approbation.
II.7.5. SCENARIOS POSSIBLES
Cette étape permettra au comité de direction de
voir les différentes options qui sont offertes et d'orienter le choix
vers une solution en accord avec les objectifs de l'entreprise et selon les
priorités et les ressources disponibles.
v ACTIVITÉS
ï Identification détaillée des principaux
équipements et logiciels.
ï Détermination des objectifs sectoriels de
performance :
- Objectifs de consolidation ;
- Objectifs de développement.
ï Détermination des ressources humaines et
financières requises pour l'acquisition, l'élaboration, la mise
en oeuvre, l'exploitation et la maintenance des systèmes ainsi que pour
la formation du personnel.
ï Prévision des impacts administratifs.
ï Détermination des changements à
apporter aux politiques administratives actuelles.
ï Description sommaire des concepts apportés et
des problèmes résolus.
ï Analyse coûts/bénéfices.
ï Évaluation de l'ensemble et identification des
points critiques de l'environnement informatique futur.
v RÉSULTATS
ï Analyse comparative des scénarios (description,
coûts d'acquisition, d'élaboration, de mise en oeuvre,
d'exploitation et d'impacts administratifs) ; analyse
coûts/bénéfices.
v POINTS DE CONTRÔLE
ï Validation auprès des chefs de service.
ï Revue des scénarios possibles par le
comité de gestion des SI.
ï Validation par un conseiller-expert au besoin.
ï Recommandation au comité de direction pour
approbation.
II.7.6. CHOIX DE
L'ORIENTATION
Cette étape décrira en détail
l'orientation choisie ainsi que le plan de mise en application de la solution
qui sera approuvée par le comité de direction.
v ACTIVITÉS
ï Préparation des recommandations d'orientation
avec un exposé des motifs à l'appui (relevé des
coûts/bénéfices).
ï Revue et discussion des recommandations avec la haute
direction.
ï Description détaillée de l'orientation
retenue.
ï Liste des facteurs critiques de succès.
ï Définition de la stratégie
d'évolution, établissement du plan de développement et du
calendrier de réalisation :
- Impacts et changements organisationnels ;
- Systématisation ;
- Infrastructure technologique ;
- Systèmes d'information ;
- Stratégie d'acquisition et de développement
(projets, méthodologie, budgets).
v RÉSULTATS
ï Recommandation du choix.
ï Plan de réalisation (priorités,
calendrier, engagements, ressources).
v POINTS DE CONTRÔLE
ï Validation auprès des chefs de service.
ï Revue du choix de l'orientation par le comité de
gestion des SI.
ï Validation par un conseiller-expert au besoin.
Recommandation au comité de direction pour
approbation.
II.7.7.MISE EN OEUVRE DU PLAN DIRECTEUR
Cette dernière étape sert à mettre en
place des moyens de contrôle et de suivi permettant de s'assurer que les
développements et acquisitions ultérieurs correspondront à
ce que prévoit le plan directeur.
v ACTIVITÉS
ï Définition de la liste chronologique des actions
à réaliser et des décisions à prendre.
ï Définition de la liste des points de
contrôle (implantation et suivi).
ï Formulation des :
- Processus de mise à jour du plan ;
- Processus d'analyse des bénéfices du plan ;
- Processus d'analyse des impacts du plan ;
- Politiques et programmes d'application ;
- Mécanismes de suivi et de pilotage.
v RÉSULTATS
ï Mécanismes de mise en oeuvre et de suivi du
développement en fonction des budgets et des contraintes.
v POINTS DE CONTRÔLE
ï Revue du plan de mise en oeuvre par le comité de
gestion des SI.
ï Validation par un conseiller-expert au besoin.
ï Recommandation au comité de direction pour
approbation.
II.8. RECENSEMENT ET ROLES DES
INTERVENTIONS
Etant donné que la plupart des informations se trouvant
dans un dossier médical sont soumises au secret médical, le
nombre des intervenants pouvant les manipuler est très restreint. Mais
généralement les personnes intervenantes à la consultation
et aux mises à jour de celui-ci sont :
§ Le médecin : celui-ci est
la personne habilitée à apporter des nouveaux
éléments dans un dossier de l'un de ses patients et peut aussi
consulter le dossier d'un autre patient si celui-ci lui y autorise.
§ Le patient : étant le
propriétaire du dossier, un patient peut ainsi garder une copie à
jour de son dossier pouvant l'aider plus tard.
§ La secrétaire : a
accès aux dossiers des patients du médecin sous son autorisation
et est aussi soumise au secret médical.
§ Ambulancier : celui-ci peut
consulter les dossiers des patients en cas d'urgence, dans la mesure où
il lui est possible d'y avoir accès. Les informations qu'il peut voir
son limités mais avec le dossier en papier il n'y a aucun moyen de le
faire respecter ses limites.
SECTION I :
MODELISATION FONCTIONNELLE
1. ANALYSE
FONCTIONNELLE
1.1. DEFINITION DES BESOINS DU
SYSTEME D'INFORMATION
a) Spécification des besoins des
utilisateurs
Ce système doit permettre la gestion d'un dossier
médical informatisé, de pouvoir permettre la consultation des
dossiers médicaux de manière instantané, d'ajouter des
nouveaux éléments dans les dossiers (Consultation
médicale, hospitalisation, vaccination ou intervention chirurgicale), de
créer un dossier médical s'il est inexistant.
· Pour le secrétaire : Se
connecter au système, consulter un dossier médical et
pouvoir ajouter une activité bien que pour cela il lui faut une
autorisation spéciale du médecin ;
· Ambulancier : Se connecter au
système, Consulter un dossier médical ;
· Patient : Se connecter au
système, Consulter un dossier ;
· Médecin : Ajouter une
activité, créer un dossier et consulter un dossier.
b) Identification des cas d'utilisation
· Créer un dossier : doit se faire par le
Médecin en se connectant au préalable ;
· Ajouter une activité : doit se faire par le
Médecin et parfois le secrétaire. Et cette activité peut
être une hospitalisation, une consultation ou une intervention
chirurgicale ;
· Consulter un dossier : peut se faire avec
n'importe quel utilisateur.
1.2. MODELISATION
METIER
· Présentation des acteurs
Les acteurs d'un système sont les entités
externes à ce système qui interagissent (saisie de
données, réception d'information,) avec lui. Les acteurs sont
donc à l'extérieur du système et dialoguent avec lui. Ces
acteurs permettent de cerner l'interface que le système va devoir offrir
à son environnement. Oublier des acteurs ou en identifier de faux
conduit donc nécessairement à se tromper sur l'interface et donc
la définition du système à produire.
Nous pouvons donc citer nos acteurs qui sont entre autre le
médecin, le patient, le secrétaire ainsi que l'ambulancier.
1.3. DIAGRAMME DE CAS
D'UTILISATION
Un diagramme de cas d'utilisation capture le comportement d'un
système, d'un sous-système, d'une classe ou d'un composant tel
qu'un utilisateur extérieur le voit. Il scinde la fonctionnalité
du système en unités cohérentes, les cas d'utilisation,
ayant un sens pour les acteurs8(*).
v Eléments des diagrammes de cas
d'utilisation
· Acteur : Est
l'idéalisation d'un rôle joué par une personne externe, un
processus ou une chose qui interagit avec un système
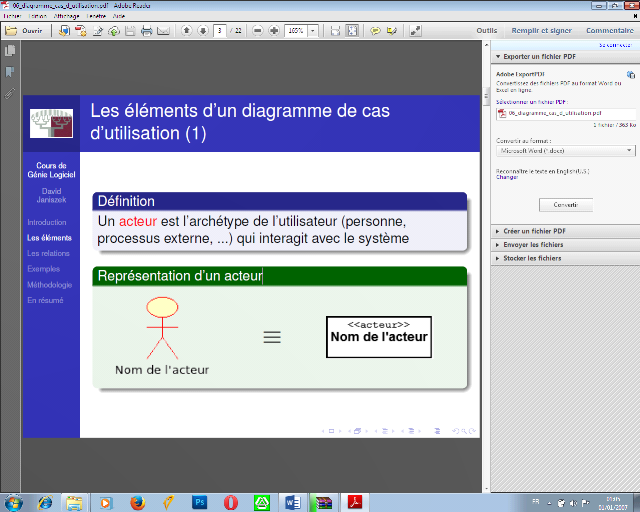
Figure 2 : Représentation d'un acteur
· Cas d'utilisation : Un cas
d'utilisation est une unité cohérente représentant une
fonctionnalité visible de l'extérieur. Il réalise un
service de bout en bout, avec un déclenchement, un déroulement et
une fin, pour l'acteur qui l'initie. Un cas d'utilisation modélise donc
un service rendu par le système, sans imposer le mode de
réalisation de ce service.
Un cas d'utilisation se représente par une ellipse
contenant le nom du cas (un verbe à l'infinitif), et optionnellement,
au-dessus du nom, un stéréotype.

Figure 3 : Représentation d'un cas
d'utilisation
v Représentation d'un diagramme de cas
d'utilisation
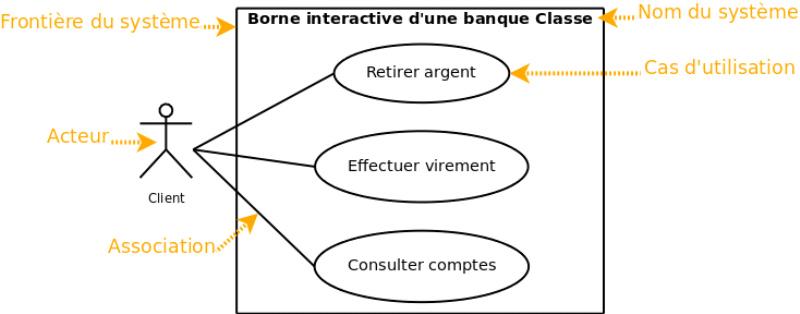
Figure 4 : Représentation d'un diagramme de cas
d'utilisation
v Relations entre acteurs et cas
d'utilisation
Une relation d'association est un lien de communication entre
un acteur et un cas d'utilisation.
· Représentation d'une relation
d'association
Un trait continu
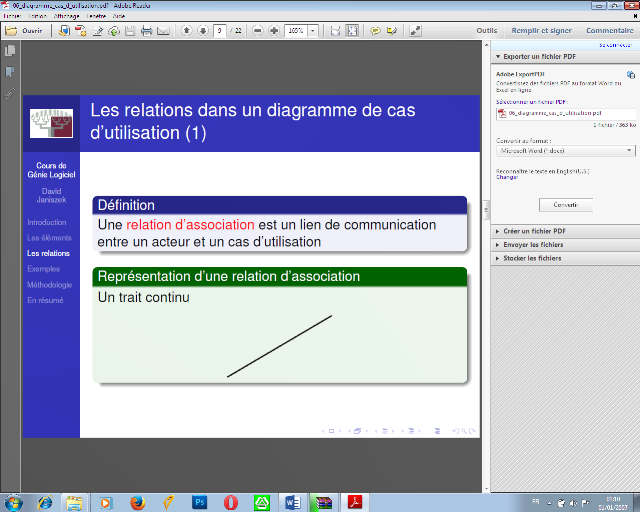
Figure 5 : Représentation d'une relation
d'association
· Relation d'inclusion
La relation d'inclusion spécifie qu'un cas
d'utilisation est nécessairement une partie d'un autre cas
d'utilisation
Représentation d'une relation d'inclusion
Une flèche discontinue stéréotypée
<<inclusion>>
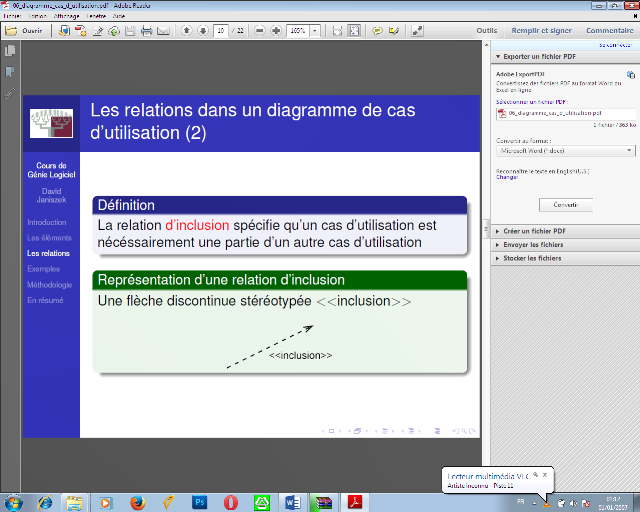
Figure 6.1Représentation d'une relation
d'inclusion
Rôle de la relation d'inclusion
- Décomposer un cas complexe en sous-cas plus
simples
- Factoriser une partie d'un cas d'utilisation commune
à d'autres cas d'utilisation
· Relation d'extension
La relation d'extension spécifie qu'un cas
d'utilisation est éventuellement une partie d'un autre cas
d'utilisation.
Représentation d'une relation d'extension
Une flèche discontinue stéréotypée
<<extension>>
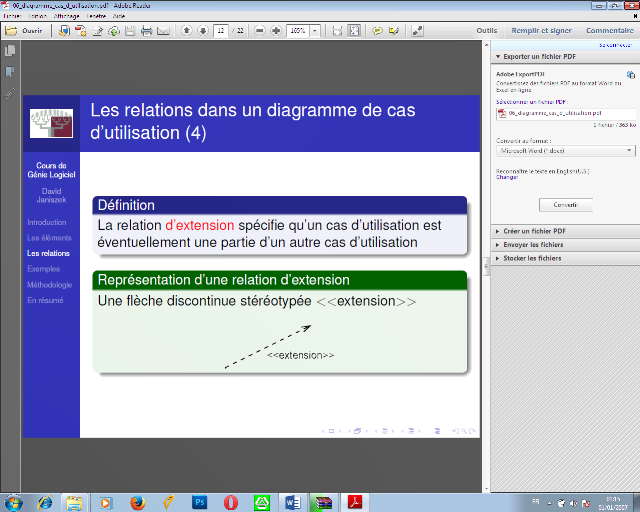
Figure 6.2 Représentation d'une relation
d'extension
v Principe
La relation de
généralisation/spécialisation est la transposition aux cas
d'utilisation de la notion d'héritage dans le paradigme objet.
· Représentation d'une relation de
généralisation/spécialisation
Une flèche dont la pointe (un triangle fermé)
est dirigée vers l'élément le plus
général.
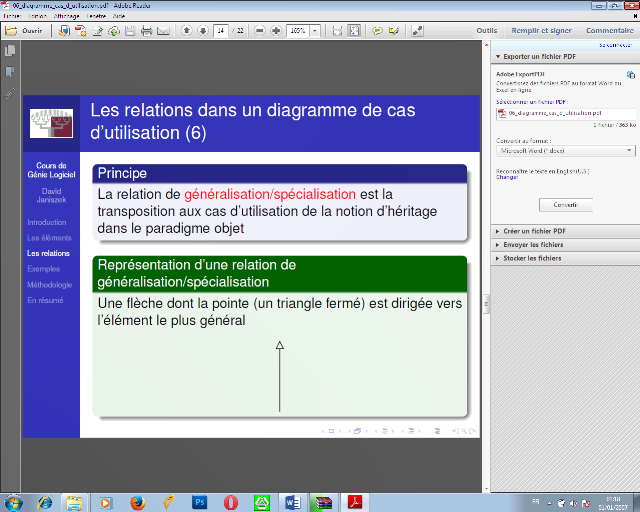
Figure 6.3 : Représentation d'une relation de
généralisation/spécialisation
· Associations
Une relation d'association est chemin de communication entre
un acteur et un cas d'utilisation et est représenté un trait
continu.
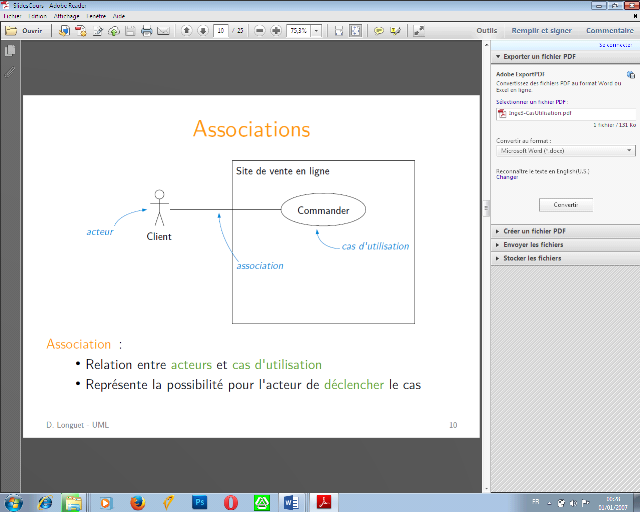
Figure 7 Exemple de relation entre acteur et cas
d'utilisation en ligne
v Association :
· Relation entre acteurs et cas d'utilisation
· Représente la possibilité pour l'acteur
de déclencher le cas
v Multiplicité
Lorsqu'un acteur peut interagir plusieurs fois avec un cas
d'utilisation, il est possible d'ajouter une multiplicité sur
l'association du côté du cas d'utilisation. Le symbole * signifie
plusieurs, exactement n s'écrit tout simplement
n, n..m signifie entre n et m, etc.
Préciser une multiplicité sur une relation n'implique pas
nécessairement que les cas sont utilisés en même temps. La
notion de multiplicité n'est pas propre au diagramme de cas
d'utilisation.
La Multiplicité est le nombre de fois où
l'acteur peut déclencher le cas :
· * : une infinité de fois (pas
représenté en général)
· [n..m] : entre n et m fois
· n : exactement n fois
Acteurs principaux et secondaires
Un acteur est qualifié de principal pour un cas
d'utilisation lorsque ce cas rend service à cet acteur. Les autres
acteurs sont alors qualifiés de secondaires. Un cas
d'utilisation a au plus un acteur principal. Un acteur principal obtient un
résultat observable du système tandis qu'un acteur secondaire est
sollicité pour des informations complémentaires. En
général, l'acteur principal initie le cas d'utilisation par ses
sollicitations. Le stéréotype
« primary » vient orner l'association reliant un
cas d'utilisation à son acteur principal, le stéréotype
« secondary » est utilisé pour les acteurs
secondaires.
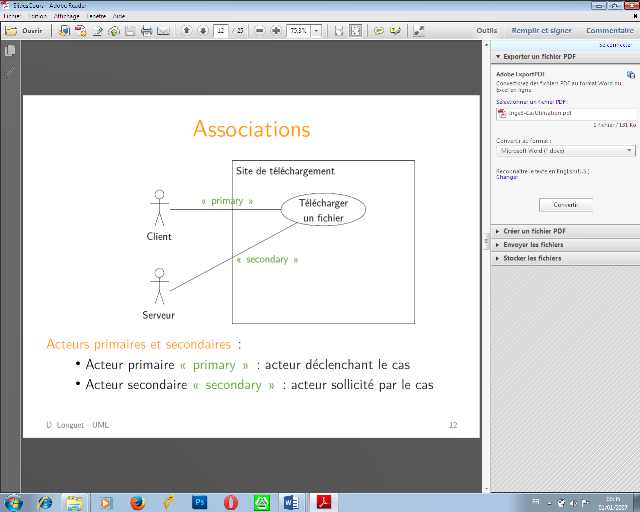
Figure 8 : Acteur primaire et secondaire
v Acteurs primaires et secondaires :
· Acteur primaire « primary » : acteur
déclenchant le cas
· Acteur secondaire « secondary » : acteur
sollicité par le cas
v Cas d'utilisation interne
Quand un cas n'est pas directement relié à un
acteur, il est qualifié de cas d'utilisation interne.
v Relations entre cas d'utilisation
· Inclusion : X « include » Y ?X
implique Y
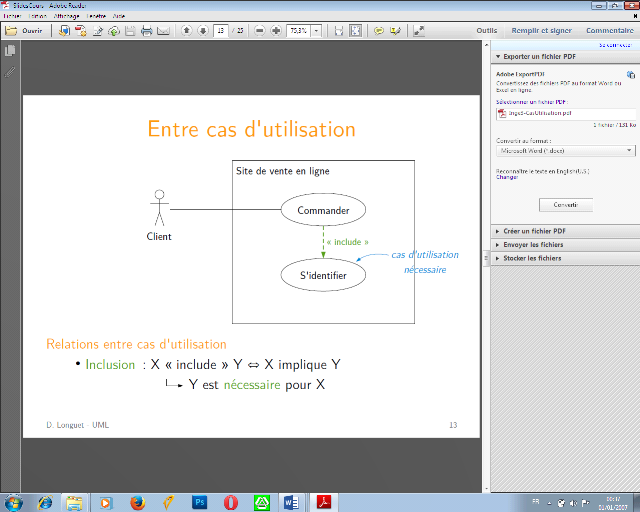
Figure 9.1 : Exemple relation d'inclusion
· Extension : X « extend » Y ?X
peut être provoqué par Y
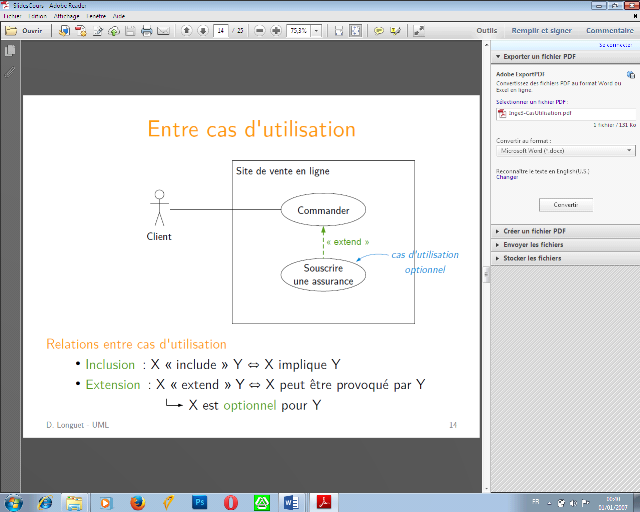
X est optionnel pour Y
Figure 9.2 : Exemple relation d'extension
· Généralisation : X est un
cas particulier de Y
Entre les acteurs
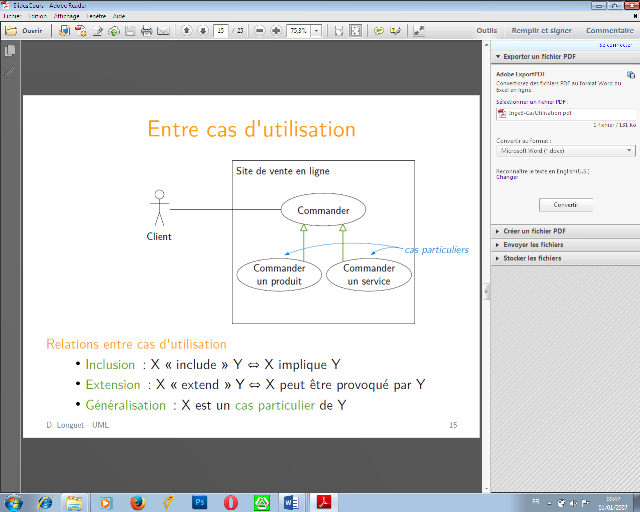
Figure 9.3 : Exemple
généralisation
v Présentation du diagramme de cas
d'utilisation
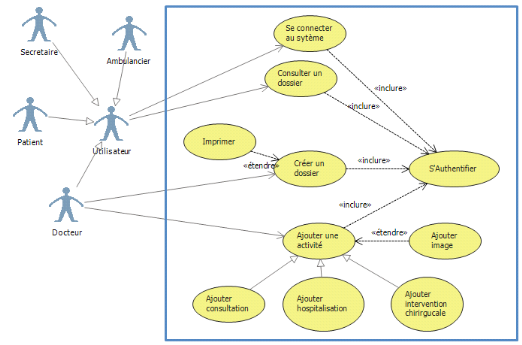
Schéma 5 : Diagramme de cas
d'utilisation
1.4. DESCRIPTION TEXTUELLE DES
CAS D'UTILISATIONS
· Cas d'utilisation créer un
dossier
|
Sommaire d'identification
|
|
Titre : Créer un dossier
But : Permettre au médecin de
créer un dossier pour le compte du patient
Résumé : Prélever les
informations de l'identification du patient ainsi, sa biométrie ainsi
que ses antécédents
Acteur : Médecin
|
|
Description de l'enchainement
|
|
Précondition : validation de
l'authentification dans le système
Post condition : Un nouveau Dossier sera
enregistré
Scénario nominal
1. Le médecin saisie son login et son mot de passe
2. Le système vérifie le login et le mot de
passe
3. Le système affiche un menu du médecin
4. Le médecin choisi Créer un nouveau dossier
5. Le système affiche un formulaire d'enregistrement
6. Le médecin saisi les informations du patient
7. Le système effectue un contrôle sur les champs
obligatoires
8. Le système enregistre les informations
9. Le système affiche un message de confirmation
Scénario alternatif :Erreur
d'authentification
Le scénario reprend au point 1 : Nature des champs
saisie incorrects
Scénario
alternatif :Détection des champs obligatoire vides
Le scénario reprend au point 5 : Champs obligatoires
non remplis
|
Tableau 4.1 : Description textuelle cas d'utilisation
créer dossier
· Cas d'utilisation Consulter un dossier
|
Sommaire d'identification
|
|
Titre : Consulter un dossier
But : Permettre aux utilisateurs de pouvoir
consulter les informations ultérieures du dossier du patient
Résumé : Afficher les
consultations, hospitalisation et toute activité concernant le dossier
du patient
Acteurs : Médecin, ambulancier,
patient, secrétaire
|
|
Description de l'enchainement
|
|
Précondition : validation de
l'authentification dans le système
Post condition : Une fenêtre
d'affichage des données du dossier apparaitra
Scénario nominal
1. L'utilisateur saisie son login et son mot de passe
2. Le système vérifie le login et le mot de
passe
3. Le système affiche un menu du médecin
4. L'utilisateur choisi Consulter un nouveau dossier
5. Le système demande le numéro du dossier ou du
patient
6. L'utilisateur saisi les informations du patient
7. Le système vérifie les informations saisies
8. Le système affiche les données du dossier
Scénario alternatif :Erreur
d'authentification
Le scénario reprend au point 1 : Nature des champs
saisie incorrects
Scénario alternatif :Dossier ou
patient introuvable
Le scénario reprend au point 5 : Champs obligatoires
non remplis
|
Tableau 4.2 : Description textuelle cas d'utilisation
consulter un dossier
· Cas d'utilisation ajouter une
consultation
|
Sommaire d'identification
|
|
Titre : Ajouter une consultation
But : Permettre au médecin d'ajouter
des nouveaux éléments des consultations médicales dans le
dossier du patient
Résumé : Ajouter une
consultation dans le dossier médical du patient tout en ajoutant une
image, une » ordonnance, un examen et la maladie trouvé si
cela est nécessaire
Acteurs : Médecin
|
|
Description de l'enchainement
|
|
Précondition : validation de
l'authentification dans le système
Post condition : Une consultation sera
ajoutée
Scénario nominal
1. Le médecin saisie son login et son mot de passe
2. Le système vérifie le login et le mot de
passe
3. Le système affiche un menu du médecin
4. Le médecin choisi Ajouter une consultation
5. Le système affiche un formulaire d'enregistrement
6. Le médecin saisi les informations de la consultation
7. Le système effectue un contrôle sur les champs
obligatoires
8. Le système enregistre les informations
9. Le système affiche un message de confirmation
Scénario alternatif :Erreur
d'authentification
Le scénario reprend au point 1 : Nature des champs
saisie incorrects
Scénario
alternatif :Détection des champs obligatoire vides
Le scénario reprend au point 5 : Champs obligatoires
non remplis
|
Tableau 4.3 : Description textuelle cas d'utilisation
Ajouter une consultation
· Ajouter une hospitalisation
|
Sommaire d'identification
|
|
Titre : Ajouter une hospitalisation
But : Permettre au médecin d'ajouter
des nouveaux éléments des hospitalisations dans le dossier du
patient
Résumé : Ajouter des une
hospitalisation dans le dossier médical du patient en ajoutant des
images si possibles
Acteurs : Médecin
|
|
Description de l'enchainement
|
|
Précondition : validation de
l'authentification dans le système
Post condition : Une hospitalisation sera
ajoutée
Scénario nominal
1. Le médecin saisie son login et son mot de passe
2. Le système vérifie le login et le mot de
passe
3. Le système affiche un menu du médecin
4. Le médecin choisi Ajouter une hospitalisation
5. Le système affiche un formulaire d'enregistrement
6. Le médecin saisi les informations de
l'hospitalisation
7. Le système effectue un contrôle sur les champs
obligatoires
8. Le système enregistre les informations
9. Le système affiche un message de confirmation
Scénario alternatif :Erreur
d'authentification
Le scénario reprend au point 1 : Nature des champs
saisie incorrects
Scénario
alternatif :Détection des champs obligatoire vides
Le scénario reprend au point 5 : Champs obligatoires
non remplis
|
Tableau 4.4 : Description textuelle cas d'utilisation
Ajouter consultation
· Cas d'utilisation Ajouter une intervention
chirurgicale
|
Sommaire d'identification
|
|
Titre : Ajouter une intervention
chirurgicale
But : Permettre au médecin d'ajouter
des nouveaux éléments des interventions chirurgicales dans le
dossier du patient
Résumé : Ajouter des une
intervention chirurgicale dans le dossier médical du patient en ajoutant
des images si possibles
Acteurs : Médecin
|
|
Description de l'enchainement
|
|
Précondition : validation de
l'authentification dans le système
Post condition : Une intervention
chirurgicale sera ajoutée
Scénario nominal
1. Le médecin saisie son login et son mot de passe
2. Le système vérifie le login et le mot de
passe
3. Le système affiche un menu du médecin
4. Le médecin choisi Ajouter une intervention
chirurgicale
5. Le système affiche un formulaire d'enregistrement
6. Le médecin saisi les informations de la consultation
7. Le système effectue un contrôle sur les champs
obligatoires
8. Le système enregistre les informations
9. Le système affiche un message de confirmation
Scénario alternatif :Erreur
d'authentification
Le scénario reprend au point 1 : Nature des champs
saisie incorrects
Scénario
alternatif :Détection des champs obligatoire vides
Le scénario reprend au point 5 : Champs obligatoires
non remplis
|
Tableau 4.5 : Description textuelle cas d'utilisation
Ajouter une intervention chirurgicale
1.5. IDENTIFICATION DES
CLASSES CANDIDATES
Les classes candidates sont déduites de la description
textuelle des cas d'utilisation. On parle aussi de classes participantes, dans
le sens où elles participent à la description statistique du
domaine.
Dans notre cas nous avons identifié les classes candidates
suivantes :
- Patient
- Antécédent
- Biométrie
- Activité
- Photo
- Consultation
- Médecin
- Intervention
- Consultation
- Examen
- Maladie
- Vaccination
- Ordonnance
- Hospitalisation
2. ANALYSE DES RESSOURCES
UTILISEES
a) Ressources humaines
Généralement la seule personne qui s'occupe du
dossier du patient est le médecin traitant lui-même.
b) Ressources matérielles
|
N°
|
DESIGNATION
|
MARQUE/
TYPE
|
QUANTITE
|
FREQUENCE
|
ANNEE D'ACHAT
|
ETAT
|
|
01
|
Chaise
|
En bois
|
4
|
Journalier
|
2018
|
Bon
|
|
02
|
Table
|
En bois
|
1
|
Journalier
|
2018
|
Bon
|
|
03
|
Lit de consultation
|
Métallique
|
1
|
Journalier
|
2015
|
Bon
|
|
04
|
Armoire
|
En bois
|
1
|
Journalier
|
2013
|
Bon
|
|
05
|
Glucomètre
|
|
1
|
Journalier
|
2013
|
Bon
|
|
06
|
Tension mètre
|
|
1
|
Journalier
|
2020
|
Bon
|
|
07
|
Ventilateur
|
Philips
|
1
|
Journalier
|
2018
|
Bon
|
|
08
|
Corbeil en plastique
|
At.com.Plast
|
1
|
Journalier
|
2020
|
Bon
|
|
09
|
Balance
|
|
1
|
Journalier
|
2019
|
Bon
|
Tableau 5 : Ressourcesmatérielles
c) Ressources financières
L'hôpital Général de la
référence de KINKANDA est sous tutelle de l'état
congolais, en occurrence sous la gestion du ministère de santé
public son premier partenaire auquel il tire ses ressources financières.
Les activités médicales de l'hôpital génèrent
des entrées conséquentes. En dehors de ça il y a aussi les
ressources financières extérieures comme les O.N.G et les
personnes physique et morale de bonne volonté.
3. ETUDE DES DOCUMENTS
CIRCULANT DANS LE DOMAINE
Fiche de consultation
|
Nom Rubrique
|
Nature
|
Taille
|
|
Date consultation
Motif
Observation
Poids
Taille
Pouls
A_T
T_A
Nom du patient
|
AN
AN
AN
N
N
N
N
N
AN
|
10
50
300
5
10
8
8
8
50
|
Tableau 6.1 : Description du document fiche de
consultation
Formulaire d'enregistrement
|
Nom Rubrique
|
Nature
|
Taille
|
|
Numéro patient
Numéro dossier
Nom
Post nom
Prénom
Sexe
Nationalité
Niveau intellectuel
Niveau socio-économique
Adresse
Email
Médecin correspondant
Antécédents
|
N
N
AN
AN
AN
AN
AN
AN
AN
AN
AN
AN
AN
|
10
10
50
50
50
9
30
15
30
100
50
50
300
|
Tableau 6.2 : Description du document formulaire
d'enregistrement
Bon d'analyse labo
|
Nom rubrique
|
Nature
|
Taille
|
|
Nom malade
Age
Sexe
Tension artérielle
Fréquence cardiaque
Fréquence respiratoire
Poids
Taille
Body masse corporelle
Signes vitaux
|
AN
N
AN
AN
AN
AN
N
N
AN
AN
|
20
3
1
10
10
10
3
3
10
50
|
Tableau 6.3 : Description du document bon
d'analyse
Ordonnance médicale
|
Nom rubrique
|
Nature
|
Taille
|
|
Nom
Age
Sexe
Nom du médecin
Catégorie patient
Prescription médicament
Date prescription
|
AN
N
AN
AN
AN
AN
DATE
|
20
10
1
25
5
10
10
|
Tableau 6.4 : Description du document ordonnance
médicale
SECTION II CRITIQUE DE
L'EXISTANT
II.1. POINT FORT
Malgré une gestion manuelle des dossiers
médicaux, l'hôpital général de kinkanda arrive tant
soit peu à organiser les différentes données y
constituant.
II.2. POINT FAIBLE
Nous avons remarqué que les informations relatives aux
patients n'étaient pas placées dans un dossier, certains patients
ne savaient pas à quoi cela servait et les quelques dossier que nous
avons trouvé avez des éléments incomplets.
II.3. PROPOSITION DES
SOLUTIONS
a) Solution manuelle
Une meilleure organisation des dossiers permettrait
d'améliorer le système de santé, tout en accordant une
importance à l'exhaustivité des éléments
médicaux du patient.
- Avantages
- Cout réduit ;
- Faible dépendance technique
- Faible taux de sécurité
- Désavantages
- Risque élevé de perte des données
- Difficultés à garder le dossier à
jour
b) Solution informatique
Un cluster des bases de données composé d'au
moins 3 noeuds permettrait de rendre les données les plus disponibles,
et un logiciel informatique rendrait facile la vérification des
informations en un temps très réduit.
- Avantages
- Temps de réaction réduit
- Faible encombrement d'espace
- Haute disponibilité des données
- Mise à jour facile du dossier
- Pas de perte d'information
- Désavantages
- Coût élevé
Conclusion
Au vu des avantages et désavantages que proposent les
deux solutions, nous croyons que la solution informatique est la plus
adéquate pour améliorer le service du corps médical et
mieux gérer les informations liées aux dossiers
médicaux.
IIième PARTIE :
ETUDE DU SYSTEME FUTUR
CHAPITRE TROISIEME :
MODELISATION STATIQUE ET DYNAMIQUE
SECTION I :
MODELISATION STATIQUE
La modélisation statique d'un système consiste
à décrire les composantes de ce dernier sans tenir compte de leur
évolution dans le temps.
Elle se fait à l'aide de diagrammes suivantes :
- Diagramme de classes
- Diagramme d'objets
- Diagramme de composants
- Diagramme de déploiement
I.1. DIAGRAMME DE CLASSES
Une classe est une représentation abstraite d'un
d'ensemble d'objets, elle contient les informations nécessaires à
la construction de l'objet (c'est-à-dire la définition des
attributs et des méthodes).9(*)
La classe peut donc être considérée comme
le modèle, le moule ou la notice qui va permette la construction d'un
objet. Nous pouvons encore parler de type (comme pour une donnée).
On dit également qu'un objet est l'instance d'une
classe (la concrétisation d'une classe).
a) Classe : une classe est une
description abstraite (condensée) d'un ensemble d'objets du domaine de
l'application : elle définit leur structure, leur comportement et leurs
relations.
Représentation : les classes sont
représentées par des rectangles compartimentés :
· Le 1er compartiment représente le nom de la
classe
· Le 2ème compartiment représente les
attributs de la classe
· Le 3ème compartiment représente les
opérations de la classe

Figure 7 : Formalisme d'une classe
b) Attribut :
Un attribut représente la modélisation d'une
information élémentaire représentée par son nom et
son format.
Par commodité de gestion, on choisit parfois de
conserver dans un attribut le résultat d'un calcul effectué
à partir d'autres classes : on parle alors d'attribut
dérivé. Pour repérer un attribut dérivé : on
place un / devant son nom.
UML définit 3 niveaux de visibilité pour les
attributs :
· Public (+) : l'élément
est visible pour tous les clients de la classe
· Protégé (#) :
l'élément est visible pour les sous-classes de la classe
· Privé (-) :
l'élément n'est visible que par les objets de la classe dans
laquelle il est déclaré.
c) Méthode ou opération
L'opération représente un élément
de comportement des objets, défini de manière globale dans la
classe.
Une opération est une fonctionnalité
assurée par une classe. La description des opérations peut
préciser les paramètres d'entrée et de sortie ainsi que
les actions élémentaires à exécuter.
Comme pour les attributs, on retrouve 3 niveaux de
visibilité pour les opérations :
· Public (+) : l'opération est
visible pour tous les clients de la classe
· Protégé (#) :
l'opération est visible pour les sous-classes de la classe
· Privé (-) : l'opération
n'est visible que par les objets de la classe dans laquelle elle est
déclarée.
d) Relation
S'il existe des liens entre objets, cela se traduit
nécessairement par des relations qui existent entre leurs classes
respectives.
Les liens entre les objets doivent être
considérés comme des instances de relations entre classes.
Il existe plusieurs types de relations entre classes :
· L'association
Une association est une relation entre deux classes
(association binaire) ou plus (association n-aire), qui décrit les
connexions structurelles entre leurs instances. Une association indique donc
qu'il peut y avoir des liens entre des instances des classes associées.
L'association existe entre les classes et non entre les instances : elle est
introduite pour montrer une structure et non pour montrer des échanges
de données10(*).
Une association n-aire possède n rôles qui sont
les points terminaux de l'association ou terminaisons.
Chaque classe qui participe à l'association joue un
rôle. Les rôles sont définis par 2 propriétés
:
- La multiplicité : elle
définit le nombre d'instances de l'association pour une instance de la
classe. La multiplicité est définie par un nombre entier ou un
intervalle de valeurs. La multiplicité est notée sur le
rôle (elle est notée à l'envers de la notation
MERISE).11(*)
|
1
|
Un et un seul
|
|
0..1
|
Zéro ou un
|
|
N ou *
|
N (entier naturel)
|
|
M..N
|
De M à N (entiers naturels)
|
|
1..*
|
De un à plusieurs
|
Formalisme
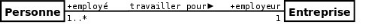
Figure 8 : Exemple multiplicité
- La navigabilité : La
navigabilité n'a rien à voir avec le sens de lecture de
l'association. Une navigabilité placée sur une terminaison cible
indique si ce rôle est accessible à partir de la source.
Par défaut les associations sont navigables dans les 2
sens. Dans certains cas, une seule direction de navigation est utile :
l'extrémité d'association vers laquelle la navigation est
possible porte alors une flèche.

Figure 9 : Exemple navigabilité
- Une classe association : Une association
porteuse d'attributs est appelée classe-association.
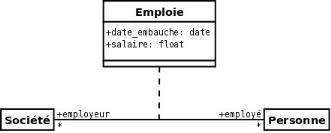
Figure 10 : Exemple classe association
- L'agrégation :Dans UML,
l'agrégation n'est pas un type de relation mais une variante de
l'association.
Une agrégation représente une association non
symétrique dans laquelle une des extrémités joue un
rôle prédominant par rapport à l'autre
extrémité.12(*)
L'agrégation ne peut concerner qu'un seul rôle
d'une association.
L'agrégation se représente toujours avec un
petit losange du côté de l'agrégat.

Figure 11 : Exemple agrégation
- La composition : La composition est un
cas particulier de l'agrégation dans laquelle la vie des composants est
liée à celle des agrégats. Elle fait souvent
référence à une contenance physique. Dans la composition
l'agrégat ne peut être multiple.
La composition implique, en plus de l'agrégation, une
coïncidence des durées de vie des composants : la destruction de
l'agrégat (ou conteneur) implique automatiquement la destruction de tous
les composants liés.

Figure 12 : Exemple composition
ï La généralisation : il
s'agit de prendre des classes existantes déjà mises en
évidences) et de créer de nouvelles classes qui regroupent leurs
parties communes ; il faut aller du plus spécifique au plus
général.
Figure 13 : Exemple
généralisation
ï La spécialisation: il s'agit de
sélectionner des classes existantes (déjà
identifiées) et d'en dériver des nouvelles classes plus
spécialisées, en spécifiant simplement les
différences.
Figure 14 : Exemple spécialisation
1. CONCEPTION DU DIAGRAMME DE
CLASSES CANDIDATES
Le diagramme de classes candidates est la première
construction statique pour le système d'information. C'est une
ébauche de diagramme de classes qui se focalise sur les classes et leurs
associations, sans forcément détailler les attributs et les
opérations.
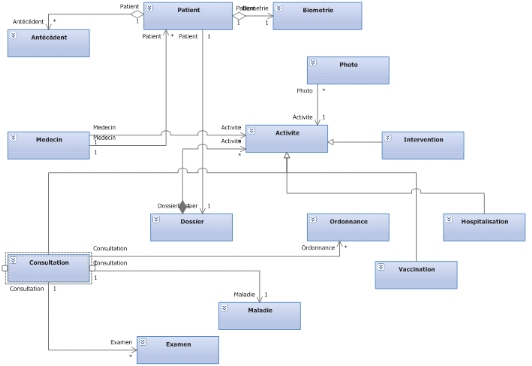
Schéma 6 : Diagramme de classe
candidate
2. CONCEPTION DES DIAGRAMMES
DES CLASSES CANDIDATES COMPLETEES
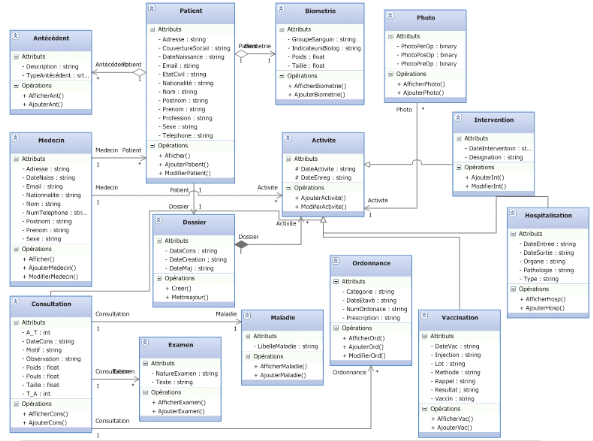
Schéma 7 : Diagramme de classe candidate
complétée
I.2. DIAGRAMME DE COMPOSANT
Diagrammes de composants illustrent les parties du logiciel,
des contrôleurs intégrés, etc., qui feront partie d'un
système. Un diagramme de composants a un niveau d'abstraction plus
élevé qu'un Diagramme de Classes. D'habitude, un composant est
mis en oeuvre par une ou plusieurs classes (ou objets) à
l'exécution. Ils sont des composantes, donc un composant peut
éventuellement englober une grande partie d'un système.
Le diagramme de composants permet de décrire les
composants du système et les relations qui existent entre-eux.13(*)
- Composant :
Les composants sont représentés comme un
classificateur rectangulaire avec le mot-clé "composant".
Éventuellement, le composant peut être affiché comme un
rectangle avec une icône de composant dans le droit coin en haut.
En effet, un composant peut-être :
· Un programme
· Un logiciel regroupant un ensemble de programmes
· Un back office
· Un fichier binaire
· Un code source
· Une API
 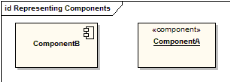
Figure 10.1: Représentation d'un composant
- Dépendances entre les
composants :
Tout en restant à un niveau assez haut d'abstraction, il
est possible de spécifier des relations de dépendance entre
composants.
Figure 10.2 : Dépendance entre les
composants
- Les interfaces
Les composants communiquent généralement entre
en utilisant différentes sortes d'interfaces.
UML permet de représenter simplement ces interfaces,
qui peuvent être :
· Des interfaces
offertes (fournies par le composant)
· Des interfaces
requises (dont le composant a besoin pour fonctionner)

Figure 11 : Représentation des interfaces
Présentation du diagramme des
composants
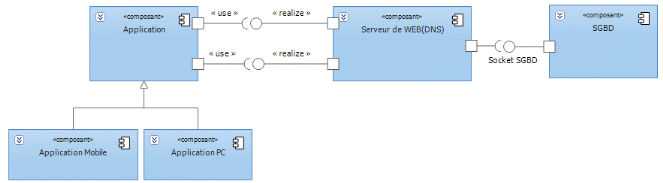
Schéma 8 : Diagramme des composants
I.3. DIAGRAMME DE
DEPLOIEMENT
Le diagramme de déploiement spécifie un ensemble
de constructions qui peuvent être utilisées pour définir
une architecture d'exécution. Celle-ci représente l'affectation
de briques logicielles sur des noeuds. Les noeuds sont reliés entre eux
par des chemins de communication créant ainsi un réseau d'un
niveau de complexité variable selon les applications
déployées.14(*)
Les noeuds sont définis avec d'éventuelles
imbrications et représentent soit des éléments
matériels, soit des environnements d'exécution logiciels. Les
artéfacts représentent des éléments physiques qui
résultent du processus de développement.
Le diagramme de déploiement fournit un modèle
qui est considéré comme suffisant dans la majorité des
applications modernes. Là où des modèles plus
élaborés sont requis, le diagramme peut être étendu
au travers de profiles ou de méta-modèles spécifiques
à certains environnements matériels ou logiciels.
1.3.1. Eléments d'un diagramme de
déploiement15(*)
- Artefact
Un artefact (artifact) est la spécification
d'une partie d'information physique utilisée ou produite lors du
processus de développement d'un logiciel.
Il représente par exemple des fichiers de
modélisation, des fichiers sources, des scripts, etc... C'est un
classificateur. Il peut avoir des instances qui sont déployées
sur un noeud particulier. Il ne faut pas confondre les noeuds présents
dans les diagrammes d'activités et les noeud présents dans les
diagrammes de déploiement
Un artefact défini par l'utilisateur est un
élément concret du monde physique. Il peut avoir des associations
de composition avec d'autres artefacts qu'il contient. Il peut également
avoir des attributs, des associations navigables et des opérations. Les
stéréotypes suivants peuvent être appliqués aux
artifacts: < script >, < document >, <exécutable>,
< file >, < library >, < source >. Voici quelques
artéfacts communs :
- Fichiers exécutables du type .exe ou .jar
- Fichiers de bibliothèque comme les fichiers .dll
- Fichiers sources, par exemple : .java ou .cpp
- Fichiers de configuration utilisés par le
système comme les fichiers .xml, proprerties...
Un artefact se représente en général par
un rectangle avec le stéréotype <<artifact>> et
l'icône document en haut à droire.

Figure 12.1 : Un artefact
- Noeud
Un noeud est une ressource d'exécution sur laquelle des
artefacts peuvent être déployés en vue d'être
exécutés. Les noeuds peuvent être interconnectés via
des chemins de communication (communication path en anglais).
C'est une ressource matérielle ou logicielle qui assure
l'hébergement de logiciels ou de fichiers associés. Un noeud
logiciel peut être vu comme un contexte applicatif. En
général, il ne fit pas partie du logiciel en
développement. C'est souvent un environnement tiers qui offre des
services au logiciel développé.

Figure 12.2 : L'artefact Mon Programme.jar
déployé sur un noeud PC de bureau
Lorsque l'on veut montrer la capacité d'un noeud
à supporter un composant, il est conseillé de le faire en faisant
figurer le mot clé < deploy > sur une relation de
dépendance entre le composant et le noeud. Il est aussi possible de le
faire en imbriquant les symboles des composants dans le symbole du noeud.
Figure 12.3: Autre manière de représenter le
déploiement
On peut noter la liste des artefacts dans un noeud. Cela
permet de synthétiser de façon claire le comportement du
système. Cependant, la liste ne donne pas les relations de
dépendance entre les différents artefacts. Pour cela, une autre
représentation est possible, à l'aide d'une relation de
dépendance.

Figure 13.1: Noeud avec liste des artefacts
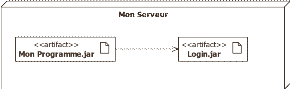
Figure 13.2: Noeud avec des artefacts et leur relation de
dépendance
- Noeuds et instances de
noeuds
Un diagramme inclut parfois deux noeuds du même type. On
peut alors passer de la représentation « noeud » à la
représentation « instance de noeud ». Il s'agit comme c'est
souvent le cas avec les diagrammes UML, de choisir la bonne granularité
de représentation, c'est-à-dire celle qui clarifiera la
représentation pour le client ou le donneur d'ordre.16(*)
Figure 14: Une instance svr1 de Serveur Sun Blade
La figure suivante montre comment modéliser deux
noeuds de même type pour représenter un système
d'équilibrage de charge.
Figure 15: Exemple de deux instances desnoeuds de
même type
- Sortes de noeuds et
artefacts
Ø Support
d'exécution
Un support d'exécution (device) est une sorte
de noeud qui décrit une ressource physique de calcul sur laquelle des
artefacts peuvent être déployés.
Ø Environnement
d'exécution
Un environnement d'exécution (execution
environment) est une sorte de noeud qui décrit un environnement
d'exécution pour un type spécifique de composant. De
manière générale, un environnement d'exécution est
soit contenu par un autre environnement d'exécution soit par un support
d'exécution.
Un environnement d'exécution est noté comme un
noeud auquel on associe le mot clé <ExecutionEnvironment >.
Les environnements d'exécution n'existent pas seuls,
ils s'exécutent sur du matériel. Par exemple, un système
d'exploitation a besoin d'une machine pour fonctionner. On montre cette
relation particulière par un emboîtement.

Figure 16: Imbrication d'un environnement
d'exécution
Ø Cible de
déploiement
Une cible de déploiement est la spécification
d'un endroit où il est possible de déployer des artefacts. Il
existe trois types de cibles de déploiement, les noeuds, les
spécifications d'instances (si celle-ci est l'instance d'un noeud), les
possessions (composite structure diagram), Les spécifications
d'instances peuvent jouer le rôle de cible de déploiement afin de
pouvoir spécifier des déploiements au niveau instance. Les
possessions peuvent jouer le rôle d'une cible de déploiement.
Ø Artefact
déployé
Un artefact déployé (deployed artifact
) est un artefact ou une instance d'artefact qui a été
deployé sur une cible de déploiement.
- Relations
Ø Manifestation
Une manifestation (manifestation) est une relation
qui montre qu'un élément du modèle est incorporé
dans un artefact (qui est la spécification d'un élément
physique). Une relation de manifestation est une spécialisation d'une
dépendance d'abstraction. Lorsque l'on veut lier un artefact à
l'élément empaquetable qu'il manifeste, il faut faire figurer
explicitement le lien de dépendance de l'artifact avec le mot clé
< manifest >
En UML, si un artefact est la représentation physique
d'un composant, il constitue la manifestation de ce composant. La relation se
représente par une flèche de dépendance allant de
l'artefact au composant avec le stéréotype
<<manifest>>. Les artefacts pouvant être affectés
à des noeuds, la relation de dépendance <<manifest>>
fournit le chainon manquant dans la modélisation de l'association entre
les composants logiciels et le matériel.

Figure 17: Exemple de manifestation entre un artefact et un
composant
Ø Chemin de
communication
Un chemin de communication (Communication Path) est
une association entre deux noeuds au travers de laquelle les noeuds peuvent
communiquer par l'échange de messages et de signaux.
Pour effectuer son travail, un noeud peut avoir besoin de
communiquer avec d'autres noeuds. Les chemins de communication servent à
spécifier ces relations. Un chemin de communication est
représenté par une ligne pleine connectant deux noeuds. Le type
de communication est indiqué par un stéréotype sur le
chemin.
Figure 18: Un PC de bureau et un serveur communiquant par
TCP/IP
On peut aussi faire figurer des chemins de communication entre
des noeuds d'environnement d'exécution. On obtient ainsi des
représentations plus précises qu'avec des liens entre noeuds.
Ø Spécification
de déploiement
Une spécification de déploiement
(deployment specification) spécifie un ensemble de
propriétés qui déterminent les paramètres
d'exécution d'un artefact (représentant un composant)
déployé sur un noeud. Une spécification de
déploiement est notée avec le mot clé <deployment
spec>. 17(*)
C'est l'allocation d'un artefact ou d'une instance d'artefact
sur une cible de déploiement. Il est possible de décrire un
déploiement au niveau type et au niveau instance. Il est possible de
décrire les propriétés qui paramètrent le
déploiement et donc l'exécution d'un ou plusieurs artefacts.
En général, l'installation d'un logiciel ne se
réduit pas à la copie d'un fichier sur une machine. Il est
également nécessaire de spécifier un ensemble de
paramètres de configuration qui seront utilisés au moment de
l'exécution. Une spécification de déploiement est un
artefact spécial décrivant le déploiement d'un autre
artefact sur un noeud.
Les spécifications de déploiement sont
représentées par un rectangle avec le stétéotype
<<deployment spec>>.
1.3.2. Présentation du diagramme de
déploiement
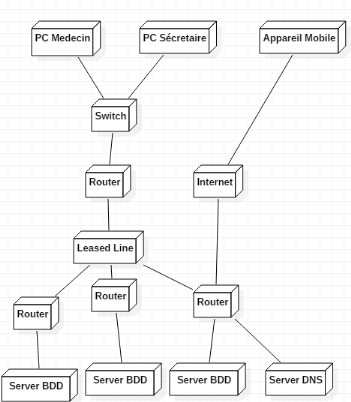
Schéma 9 : Diagramme de
déploiement
SECTION II :
MODELISATION DYNAMIQUE
La modélisation dynamique permet d'examiner le
comportement des objets, les modifications d'états des objets suite aux
réceptions de messages.
En phase d'analyse, les messages échangés entre
objets sont vus comme des événements.
En UML la modélisation dynamique se fait sous la forme
de quatre types diagrammes :
· Diagramme de cas d'utilisation
· Diagrammes de séquences (pour chaque
scénario)
· Diagrammes de collaboration
· Diagrammes d'états (pour chaque classe d'objet
actif)
II.1. DIAGRAMME D'ACTIVITE
Les diagrammes d'activités permettent de mettre
l'accent sur les traitements. Ils sont donc particulièrement
adaptés à la modélisation du cheminement de flots de
contrôle et de flots de données. Ils permettent ainsi de
représenter graphiquement le comportement d'une méthode ou le
déroulement d'un cas d'utilisation.
v Le déroulement séquentiel des
activités
Le diagramme d'états-transitions vu
précédemment présente déjà un
séquencement des activités d'une classe.
Le diagramme d'activités va modifier cette
représentation pour n'en conserver que le séquencement. La notion
d'état disparaît. On obtient ce graphe :
Activité 1
Activité 2

Figure 19 : Exemple diagramme d'activités
Comme dans le diagramme d'états-transitions, la
transaction peut être complétée par une condition
de garde.
Activité 1
Activité 2
[
condition
]

Figure 20 : Exemple diagramme d'activités avec
condition de garde
v La synchronisation
Les flots de contrôle parallèles sont
séparés ou réunis par des barres de synchronisation.
Les activités 2 et 3 seront simultanées.
Activité 1
Activité 2
Activité 3
Figure 21 : Représentation synchronisation
v Activité (activity)
Une activité définit un comportement
décrit par un séquencement organisé d'unités dont
les éléments simples sont les actions. Le flot d'exécution
est modélisé par des noeuds reliés par des arcs
(transitions). Le flot de contrôle reste dans l'activité
jusqu'à ce que les traitements soient terminés. 18(*)
Une activité est un comportement (behavior en
anglais) et à ce titre peut être associée à des
paramètres.
v Noeud d'activité (activity node)

Figure 22 : Représentation graphique des noeuds
d'activité.
De la gauche vers la droite, on trouve : le noeud
représentant une action, qui est une variété de noeud
exécutable, un noeud objet, un noeud de décision ou de fusion, un
noeud de bifurcation ou d'union, un noeud initial, un noeud final et un noeud
final de flot.
Figure 23 : Exemple de diagramme d'activités
modélisant le fonctionnement d'une borne bancaire.
Un noeud d'activité est un type d'élément
abstrait permettant de représenter les étapes le long du flot
d'une activité. Il existe trois familles de noeuds d'activités :
ï Les noeuds d'exécutions (executable
node en anglais) ;
ï Les noeuds objets (object node en anglais) ;
ï Et les noeuds de contrôle (control nodes
en anglais).
v Transition

Figure 24 : Représentation graphique d'une
transition.
Le passage d'une activité vers une autre est
matérialisé par une transition. Graphiquement les transitions
sont représentées par des flèches en traits pleins qui
connectent les activités entre elles. Elles sont
déclenchées dès que l'activité source est
terminée et provoquent automatiquement et immédiatement le
début de la prochaine activité à déclencher
(l'activité cible). Contrairement aux activités, les transitions
sont franchies de manière atomique, en principe sans durée
perceptible.
Les transitions spécifient l'enchaînement des
traitements et définissent le flot de contrôle.
v Noeud exécutable (executable node)
Un noeud exécutable est un noeud d'activité
qu'on peut exécuter (i.e. une activité). Il
possède un gestionnaire d'exceptions qui peut capturer les exceptions
levées par le noeud, ou un de ses noeuds imbriqués.
v Noeud d'action

Figure 25 : Représentation graphique d'un noeud
d'action.
Un noeud d'action est un noeud d'activité
exécutable qui constitue l'unité fondamentale de
fonctionnalité exécutable dans une activité.
L'exécution d'une action représente une transformation ou un
calcul quelconque dans le système modélisé. Les actions
sont généralement liées à des opérations qui
sont directement invoquées. Un noeud d'action doit avoir au moins un arc
entrant.
Figure 26 : Représentation particulière des
noeuds d'action de communication.
v Noeud d'activité structurée (structured
activity node)
Un noeud d'activité structurée est un noeud
d'activité exécutable qui représente une portion
structurée d'une activité donnée qui n'est partagée
avec aucun autre noeud structuré, à l'exception d'une imbrication
éventuelle.
Les transitions d'une activité structurée
doivent avoir leurs noeuds source et cible dans le même noeud
d'activité structurée. Les noeuds et les arcs contenus par noeud
d'activité structuré ne peuvent pas être contenus dans un
autre noeud d'activité structuré.
v Noeud de contrôle (control node)
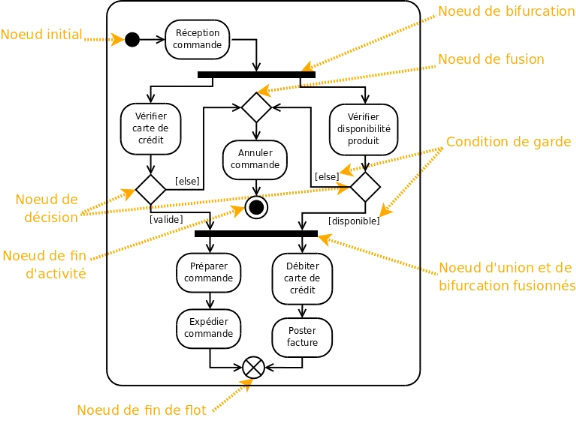
Figure 27 : Exemple de diagramme d'activité illustrant
l'utilisation de noeuds de contrôle.
Ce diagramme décrit la prise en compte d'une
commande.
Un noeud de contrôle est un noeud d'activité
abstrait utilisé pour coordonner les flots entre les noeuds d'une
activité.
Il existe plusieurs types de noeuds de contrôle :
ï Noeud initial (initial node en anglais) ;
ï Noeud de fin d'activité (final node en
anglais) ;
ï Noeud de fin de flot (flow final en anglais) ;
ï Noeud de décision (decision node en
anglais) ;
ï Noeud de fusion (merge node en anglais) ; ?
noeud de bifurcation (fork node en anglais) ; ? noeud d'union
(join node en anglais).
v Noeud initial
Un noeud initial est un noeud de contrôle à partir
duquel le flot débute lorsque l'activité enveloppante est
invoquée. Une activité peut avoir plusieurs noeuds initiaux. Un
noeud initial possède un arc sortant et pas d'arc entrant.
v Noeud final
Un noeud final est un noeud de contrôle possédant un
ou plusieurs arcs entrants et aucun arc sortant.
v Noeud de décision et de fusion
· Noeud de décision (decision node)
Un noeud de décision est un noeud de contrôle qui
permet de faire un choix entre plusieurs flots sortants. Il possède un
arc entrant et plusieurs arcs sortants. Ces derniers sont
généralement accompagnés de conditions de garde pour
conditionner le choix. Si, quand le noeud de décision est atteint, aucun
arc en aval n'est franchissable (i.e. aucune condition de garde n'est
vraie), c'est que le modèle est mal formé
· Noeud de fusion (merge node)
Un noeud de fusion est un noeud de contrôle qui rassemble
plusieurs flots alternatifs entrants en un seul flot sortant. Il n'est pas
utilisé pour synchroniser des flots concurrents (c'est le rôle du
noeud d'union), mais pour accepter un flot parmi plusieurs.
I.4. Présentation des diagrammes
d'activités
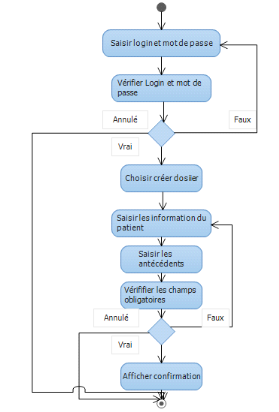
Schéma 10.1 : Diagramme de cas
d'activités créer dossier
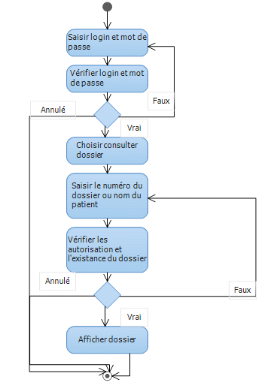
Schéma 10.2 : Diagramme d'activités
consulter dossier
Schéma 10.3 : Diagramme d'activités
ajouter activité
II.. DIAGRAMME DE SEQUENCE
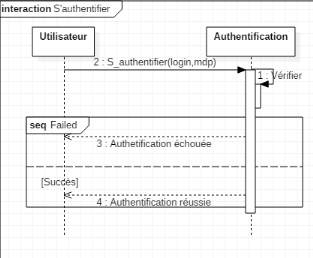
Schéma 11.1 : Diagramme de séquence
s'authentifier
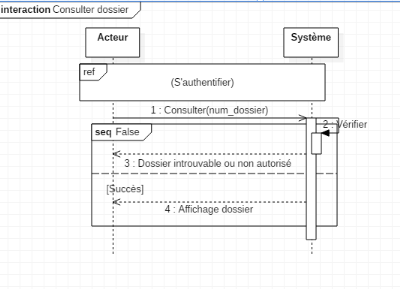
Schéma 11.2 : Diagramme de séquence
consulter dossier
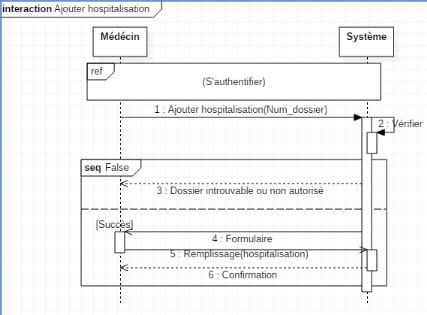
Schéma 11.3 : Diagramme de séquence
ajouter hospitalisation
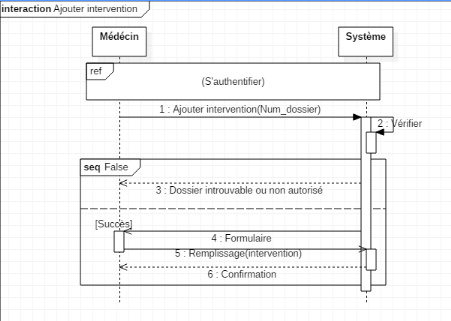
Schéma 11.4 : Diagramme de séquence
ajouter intervention
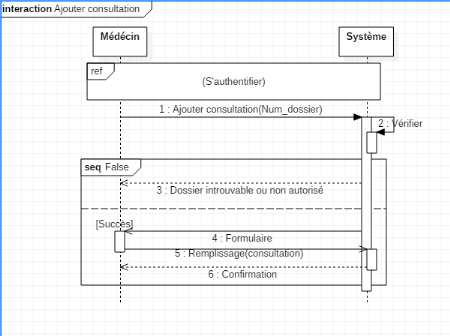
Schéma 11.5 : Diagramme de séquence
ajouter consultation
SECTION III :
CONFRONTATION DE MODELE STATIQUE ET DYNAMIQUE
v Développement du modèle
relationnel
Le modèle relationnel est une manière de
modéliser les relations existantes entre plusieurs informations, et de
les ordonner entre elles. Cette modélisation qui repose sur des
principes mathématiques mis en avant par Edgar Frank Codd est souvent
retranscrite physiquement (implémentée) dans une base de
données.
a) Règle de passage du modèle de classe
UML au modèle relationnel
Règle1: présence de la cardinalité
(?..1) d'un côté de l'association
· Chaque classe se transforme en une table
· Chaque attribut de classe se transforme en un champ de
table
· L'identifiant de la classe qui est associée
à la cardinalité (?..1) (ex: Livre) devient le clé
étrangère de l'autre classe
Contrainte d'intégrité
référentielle :
CléEtrangère ?CléPrimaire
Ex : Exemplaire.Code-Livre ?Livre.Code-Livre
Règle2: présence de (?..N) des deux
côtés de
· Chaque classe se transforme en une table
· Chaque attribut de classe se transforme en un champs de
table
· L'association se transforme en une table. Cette table a
comme champs l'identifiant de chacune des deux classes, plus d'éventuels
autres attributs.
Contraintes d'intégrité
référentielle :
Ex :
Emprunte.Code-Personne ?Personne.Code-Personne
Emprunte.Code-Livre ?Livre.Code-Livre
Règle3: présence d'une
généralisation
- Méthode 1 :
· Créer une table avec tous les attributs des
classes
· Ajouter un attribut pour distinguer les types des
objets
- Méthode 2 :
Créer une table pour chaque sous type, chaque table se
compose des attributs génériques et d'attributs
spécifiques.
- Méthode 3 :
Créer une table par classe et des associations.
a) b) Présentation du modèle
relationnel
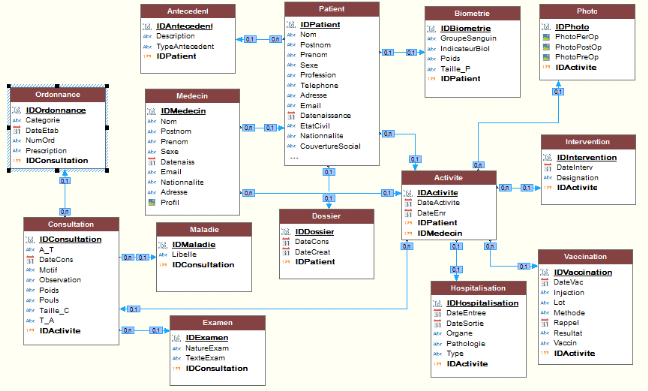
Schéma 12 : modèle relationnel
c) Enumération des interfaces
utilisateurs
Fenêtre d'authentification
Figure 28.1 : Fenêtre d'authentification.
Menu Principal

Figure 28.2 : Menu Principal.
Liste des dossiers
Figure 28.3 : Fenêtre d'authentification.
Création dossier
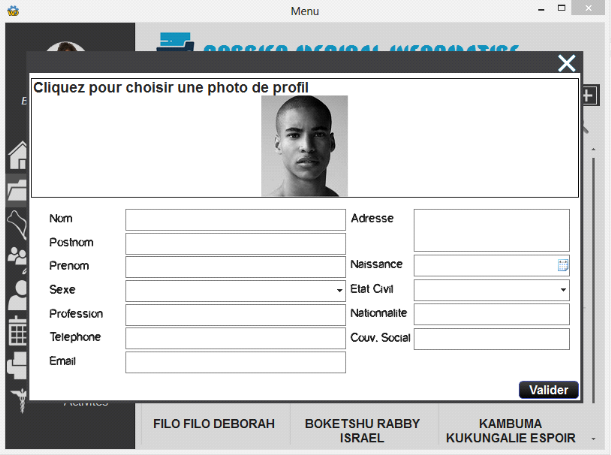
Figure 28.4 : Fenêtre de création du dossier.
Liste des autorisations
Figure 28.5 : Liste des autorisations.
Liste des Rendez-vous
Figure 28.6 : Liste des rendez-vous.
Choix de l'activité

Figure 28.7 : Choix de l'activité.
Saisie des Rendez-vous
Figure 28.8 : Saisie des rendez-vous.
Liste des interventions
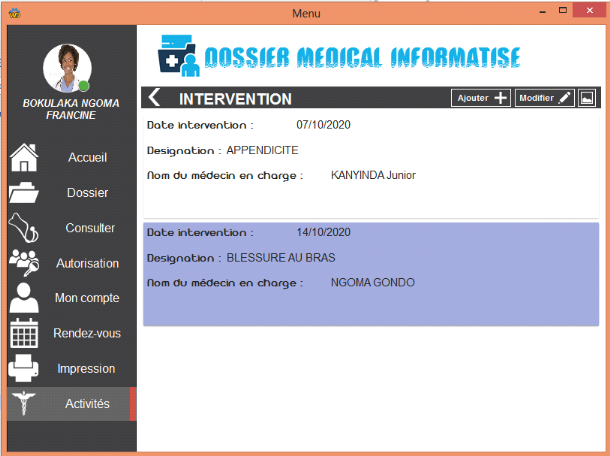
Figure 28.9 : Liste des interventions.
Saisie des interventions
Figure 28.10 : Saisie des interventions.
Ajout des images
Figure 28.11 : Ajout des images.
a) d) Enumération des états en
sortie
Détails sur le patient
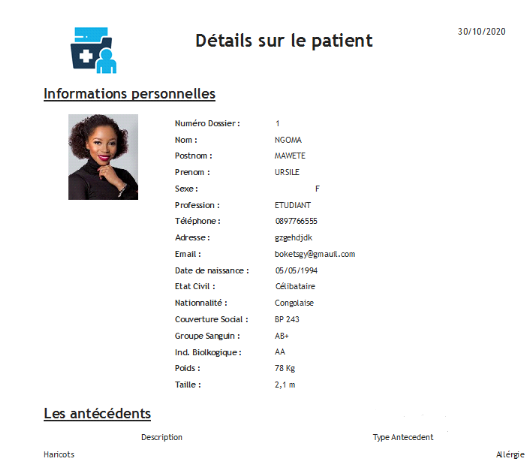
Schéma 13.1 : Etat détails sur le
patient
Liste des consultations du patient

Schéma 13.2 : Etat liste des consultations du
patient
Liste des vaccinations du patient

Schéma 13.3 : Etat liste des vaccinations du
patient
Liste des hospitalisations du patient

Schéma 13.4 : Etat liste des hospitalisations
du patient
SECTION IV ETUDE SUR LA BASE
DE DONNEES
1. Conception du stockage des données
Une base de données est définie comme une
collection de données opérationnelles enregistrées et
utilisées par des systèmes d'application d'une organisation
particulière.19(*)
Outre la collection de données, la base est
structurée indépendamment d'une application particulière.
Elle est cohérente, non redondante et accessible simultanément
à plusieurs utilisateurs.
Cette définition fait ressortir des besoins de
structuration, de mise en commun, de non redondance des donnés d'une
base. Certains de ces besoins sont du ressort de l'utilisateur alors que
d'autres sont de celui du logiciel chargé de gérer la base de
données. Ainsi la conception de base de données veillera à
la satisfaction des besoins en structuration, en non redondance et à la
mise en commun de l'information. Le système de gestion de bases de
données devra, quant à lui, veiller à la qualité et
à la disponibilité de l'information.
Le choix du système de gestion de bases de
données doit tenir compte de la dimension temporelle des données
et de la complexité des objets médicaux : texte en langage clair
(clinique, synthèse), données codées (diagnostics,
médicaments...), données multimédia (radiographie...) et
de la nécessité d'intégrer les données et les
connaissances médicales.
Ainsi pour garantir la une haute disponibilité entre
les différents utilisateurs, nous avons choisi de mettre en place un
cluster des bases de données.
Un cluster de base de données comprend au minimum 2
serveurs de bases de données, mais il est conseillé d'avoir au
moins 3 serveurs de base de données. Ainsi, les serveurs de bases de
données sont actifs et les utilisateurs peuvent écrire sur
n'importe quel serveur, les données sont alors répliquées
entre les serveurs restant. Si un serveur devient injoignable, les autres
serveurs sont toujours disponibles afin d'assurer la disponibilité des
services.
2. Choix du système de gestion de base de
données
HFSQL est un puissant SGBDR (Système de Gestion de Base
de Données Relationnelle).
HFSQL est décliné en 5 versions :
- Version locale (monoposte ou réseau)
- Version mobile (embarquée)
- VersionClient/Serveur
- Version Cloud
- Version cluster.
Grâce à la fonctionnalité de cluster de
HFSQL, un ensemble de serveurs physiques apparaît comme un serveur unique
aux clients. La défaillance éventuelle d'un serveur physique ne
provoque pas de défaillance des accès à la base de
données (haute disponibilité, tolérance aux pannes). Les
serveurs se répliquent automatiquement les uns les autres en temps
réel.
La charge d'accès lecture est répartie sur
l'ensemble des serveurs. On peut ajouter et supprimer des serveurs à
chaud. En cas de crash d'un serveur, il se resynchronisera automatiquement au
démarrage. Lorsqu'un utilisateur est connecté à un serveur
qui défaille, l'application sera automatiquement reconnectée
à un serveur valide (basculement automatique).
CHAPITRE IV : ETUDE
TECHNIQUE (REALISATION ET MISE EN OEUVRE)
IV.1 MISE EN RESEAU DE LA BASE
DE DONNEES ET DE L'APPLICATION
a) Outils logique
|
N°
|
Outils
|
Choix
|
|
1
|
Type de réseau (LAN, MAN ou WAN)
|
WAN
|
|
2
|
Topologie physique adoptée
|
Etoile
|
|
3
|
Topologie logique
|
Ethernet
|
|
4
|
architecture
|
Client/serveur
|
|
5
|
Système d'exploitation serveur
|
Windows 2016 server
|
|
6
|
Système d'exploitation client
|
Windows 10
|
|
7
|
Protocole
|
TCP/IP
|
|
8
|
Antivirus
|
Bitdefender Total Security
|
Tableau 7 : Outils logique
b) Outils physique
|
N°
|
Matériel
|
Performance
|
|
Processeur
|
Capacité HDD
|
Capacité RAM
|
|
1
|
Ordinateur server
|
3.6 GHz
|
50 Tb ou plus
|
60 Gb ou plus ;
|
|
2
|
Ordinateur client
|
2 GHz
|
180 Gb ou plus
|
4 Gb ou plus ;
|
|
3
|
Switch
|
16ports
|
|
4
|
Routeur
|
|
|
|
|
5
|
Support de transmission
|
|
|
6
|
Connecteur
|
|
7
|
Goulottes
|
|
8
|
Onduleur serveur
|
|
9
|
Ondulaire client
|
|
10
|
Imprimante
|
à Laser HP ou Autre
|
Tableau 8 : Outils physique
a) c) Paramétrage du réseau
|
Poste
|
Domaine
|
Adresse IP
|
Masque sous réseau
|
Passerelle
|
|
Noeud 1
|
dmi.com
|
128.168.1.5
|
255.255.0.0
|
192.168.0.25
|
|
Noeud 2
|
128.168.1.6
|
255.255.0.0
|
192.168.0.25
|
|
Noeud 3
|
128.168.1.7
|
255.255.0.0
|
192.168.0.25
|
|
Serveur DNS et DHCP
|
128.168.1.8
|
255.255.0.0
|
192.168.0.25
|
Tableau 9 : Paramétrage du
réseau
IV.2 ADMINISTRATION ET SECURITE DE LA BASE DE DONNEES EN
RESEAU
1. Evaluation du coût
|
N°
|
MATERIELS
|
QUANTITE NECESSAIRE
|
QUANTITE EXISTANTE
|
QUANTITE A ACHETER
|
PU
|
PT
|
|
Serveur
Ordinateur
Câble torsadé(Rouleau)
Connecteur RJ45
Goulottes
Pinces à sertir
Switch (8 Ports)
Onduleur (Serveur)
Onduleur (Client)
Imprimante 3Fct
Les vis (6pouces)
Les vis chevilles
Les attaches
Disjoncteur J3
Extincteur
Stabilisateur
Tester de câble
|
4
12
3000m
20 boites
10 Cartons
40
10
10
4
8
4
10 boites
10 boites
10 boites
20
8
8
10
|
0
0
0
20 boites
0 Cartons
0
0
0
0
0
0
0
0
0
0
0
0
0
|
4
12
3000m
20 boites
10 Cartons
40
10
10
4
8
4
10 boites
10 boites
10 boites
20
8
8
10
|
40000$400$
10$
8$
10$
0.7$
5 $
400$
200$
100$
250$
150 $
10 $
6 $
85$
150$
200$
20 $
|
160000$
1800$
30000$
160$
100$
28$
25$
4000$
1000$
800$
1000$
1500$
100$
60$
1700$
1200$
1800$
200$
|
|
FRAIS FORMATION UTILISATEUR
|
1000 $
|
|
FRAIS INFORMATICIEN (LOGICIEL)
|
100000 $
|
|
FRAIS INSTALLATION RESEAU
|
8000 $
|
|
SOUS - TOTAL
|
224573 $
|
|
IMPREVUE (10% DU SOUS -TOTAL)
|
22457,3 $
|
|
TOTAL GENERAL
|
247030,3 $
|
Tableau 10 : Evaluation du cout
CONCLUSION
Le dossier médical est un pilier principal dans le
processus de prise en charge et de surveillance d'un patient. Il est
considéré comme un indicateur de la qualité de soins.
Cependant, il présente, dans sa forme papier, d'innombrables
inconvénients qui nuisent à cette fonction. De ce fait,
l'informatisation de ce dossier peut pallier à ces défauts par
une meilleure structuration grâce aux outils modernes de la technologie
de l'information.
C'est dans ce cadre général que notre
mémoire vient s'inscrire, ayant comme but essentiel
l'implémentation et l'administration d'un système d'information
répartie pour la gestion des dossiers médicauxs'appuyant sur les
données de l'hôpital général de Kinkanda.
Le résultat de ce présent travail est la
conception d'un modèle de dossier médical informatisé qui
explique l'activité globale du service. Cette activité
habituellement sectorisée en hospitalisation, consultation, intervention
chirurgicale, et vaccinationest articulée au niveau de notre application
autour de quatreacteurs : le patient et le médecin, l'ambulancier et le
secrétaire avec tous les avantages de l'ergonomie informatique ainsi que
celui de l'accessibilité via un poste informatique aux accès
(Windows ou Android) se connectant à un des bases de données du
cluster. Ce nouveau système d'information permettra ainsi de satisfaire
les besoins de structuration, en non redondance et à la mise en commun
de l'information et facilitera l'analyse des données cliniques et
évolutives y afférants.
BIBLIOGRAPHIE
I. Ouvrages et notes de cours inédit
KINANGA Masala, Méthodes de recherche
scientifique, ISIPA/Matadi, G2 Info, 2016-2017 ;
BINDUNGWA Ibanda, Comment élaborer un travail de
fin de cycle ?, Kinshasa, Mediaspual, 2008 ;
TIANSENGA Zanzi « Evaluation des
projets », L2 Sciences informatiques ISIPA/MATADI,
2019-2020 ;
VUMA Vuma, Recherche opérationnelle, L1-Info,
ISPA/Matadi, 2013-2014 ;
SULA Bertin, Evaluation des projets,Kinshasa, Nzoi,
2015 ;
ROQUES Pascal, UML 2 : Modéliser une
application web, Paris, 2006,ENI;
MADIBA Luntadila, «'UML », L1 base de
données, ISIPA/MATADI, 2018-2019 ;
SOUTOU Christian, UML 2 pour les bases de
données, Paris, Eyrolles, 2010 ;
BERSINI, Hugues, La programmation orientée
objet, Bruxelles, Bruylant 2011 ;
GABAY, Joseph et GABAY, David, UML 2 : Analyse et
conception, Paris, ENI, 2013 ;
BELLEIL, Claude, Le langage UML 2.0 : Diagramme de
déploiement, Université de Nantes, 2011 ;
CONAN Denis, Introduction au langage de
modélisation UML, Paris, TELECOM Sud, 2015, p.112.
HAINAUT, Jean-Luc, Bases de données :
Concepts, utilisation et développement, Paris, Dunod, 2011.
II. Webographie
http://www.journaldunet.com/Construire-un-rétroplanning-efficace ;
https://fr.wikipedia.org/wiki/PERT
;
http://www.doc-etudiant.fr/Commerce/Logistique/Autre-Les-buts-de-la-methode-pert-37276.html
;
https://laurent-audibert.developpez.com/CoursUML/?page=diagramme-cas-utilisation.
TABLE DES MATIERES
SOMMAIRE................................................................................................I
EPIGRAPHE................................................................................................II
DEDICACE................................................................................................III
FIGURES, SCHEMAS ET
TABLEAUX.................................................................V
RESUME..................................................................................................VIII
ABSTRACT................................................................................................IX
0. INTRODUCTION
1
0.1. MISE EN CONTEXTE
1
0.2. PROBLEMATIQUE
2
0.3. HYPOTHESE
3
0.4. DELIMITATION DU SUJET
4
0.5. CHOIX ET INTERET DU SUJET
4
0.6. BUT DU MEMOIRE
4
0.7. METHODES ET TECHNIQUES UTILISEES
4
0.8. SUBDIVISION DU TRAVAIL
5
IERE PARTIE : ETUDE PREALABLE
6
CHAPITRE PREMIER : EVALUATION DU PROJET
7
1. PRINCIPES DE REPRESENTATION EN P.E.R.T
7
1.1. BREF APERÇU SUR LA METHODE
P.E.R.T
7
1.2. GENERALITES
8
1.3. PRESENTATION DU P.E.R.T
8
1.4. L'IMPORTANCE DE LA METHODE PERT
9
1.5. BUT DE LA METHODE P.E.R.T
9
1.6. LES CONDITIONS PREALABLES A LA
CONSTRUCTION DU GRAPHE PERT
10
1.7. LA CONSTRUCTION DU GRAPHE P.E.R.T
11
1.8. EVALUATION DES TEMPS ET COUT TOTAL DU
PROJET (CALENDRIER DU PROJET)
13
1.9. GRAPHE P.E.R.T NON ORDONNE
14
1.10. IDENTIFICATION DU CHEMIN CRITIQUE
(RECHERCHE DES RANGS)
15
1.11. GRAPHE PERT ORDONNE AVEC DTO ET DTA
15
1.12. RECHERCHE DES DATES AU PLUS TOT ET
DATES AU PLUS TARD
16
1.13. MARGES LIBRES ET MARGES TOTALES
17
1.14. TABLEAU DES MARGES LIBRES ET MARGES
TOTALES
18
a) Graphe ordonné
19
b) Choix du chemin critique
20
c) Durée du projet
20
d) Cout total du projet
20
CHAPITRE DEUXIEME : CADRAGE DU PROJET
21
II.1. PRESENTATION DE L'ENTREPRISE
21
II.2. HISTORIQUE DE L'ENTREPRISE
21
II.3. ORGANIGRAMME
22
II.4. DESCRIPTION DE POSTE DE L'ORGANIGRAMME
23
II.5. SITUATION GEOGRAPHIQUE
24
II.6. OBJECTIFS POURSUIVIS
24
II.7. CONNAISSANCE DU PLAN DIRECTEUR
INFORMATIQUE
25
II.7.1. PLANIFICATION DU PROJET
25
II.7.2. CONCEPTION D'UN PLAN DIRECTEUR
INFORMATIQUE
26
II.7.3. ANALYSE
27
II.7.4. ORIENTATIONS GENERALES ET POSSIBILITES
D'ACTION
29
II.7.5. SCENARIOS POSSIBLES
30
II.7.6. CHOIX DE L'ORIENTATION
32
II.8. RECENSEMENT ET ROLES DES INTERVENTIONS
33
SECTION I : MODELISATION FONCTIONNELLE
35
1. ANALYSE FONCTIONNELLE
35
1.1. DEFINITION DES BESOINS DU SYSTEME
D'INFORMATION
35
1.2. MODELISATION METIER
35
1.3. DIAGRAMME DE CAS D'UTILISATION
36
1.4. DESCRIPTION TEXTUELLE DES CAS
D'UTILISATIONS
43
1.5. IDENTIFICATION DES CLASSES
CANDIDATES
48
2. ANALYSE DES RESSOURCES UTILISEES
48
3. ETUDE DES DOCUMENTS CIRCULANT DANS LE
DOMAINE
49
SECTION II CRITIQUE DE L'EXISTANT
51
II.1. POINT FORT
51
II.2. POINT FAIBLE
51
II.3. PROPOSITION DES SOLUTIONS
51
IIème PARTIE : ETUDE DU
SYSTEME FUTUR
53
CHAPITRE TROISIEME : MODELISATION STATIQUE ET
DYNAMIQUE
54
SECTION I : MODELISATION STATIQUE
54
I.1. DIAGRAMME DE CLASSES
54
1. CONCEPTION DU DIAGRAMME DE CLASSES
CANDIDATES
59
2. CONCEPTION DES DIAGRAMMES DES CLASSES
CANDIDATES COMPLETEES
60
I.2. DIAGRAMME DE COMPOSANT
61
I.3. DIAGRAMME DE DEPLOIEMENT
63
SECTION II : MODELISATION DYNAMIQUE
71
II.1. DIAGRAMME D'ACTIVITE
72
II.. DIAGRAMME DE SEQUENCE
81
SECTION III : CONFRONTATION DE MODELE STATIQUE
ET DYNAMIQUE
84
SECTION IV ETUDE SUR LA BASE DE DONNEES
95
CHAPITRE IV : ETUDE TECHNIQUE (REALISATION ET
MISE EN OEUVRE)
97
IV.1 MISE EN RESEAU DE LA BASE DE DONNEES ET DE
L'APPLICATION
97
CONCLUSION
100
BIBLIOGRAPHIE
101
TABLE DES MATIERES
103

* 1
« Construire
un rétroplanning efficace » , sur
www.journaldunet.com (consulté le 20 février 2020).
* 2Jean-Dévêt
TIANSENGA ZANZI, « Evaluation des projets »,L2
Sciences informatiques, ISIPA/MATADI, 2019-2020, cours inédit.
*
3https://fr.wikipedia.org/wiki/PERT consulté le
13/03/2020à 23h31'.
* 4.
http://www.doc-etudiant.fr/Commerce/Logistique/Autre-Les-buts-de-la-methode-pert-37276.html,
consulté, le 06/06/2020 à 22:31.
* 5VUMA Vuma, Recherche
opérationnelle, L1-Info, ISPA/Matadi, 2013-2014, cours
inédit.
* 6Bertin SULA, Evaluation
des projets, Kinshasa,Nzoi, 2015, p.46.
* 7VUMA Vuma,
Op.cit.
* 8
https://laurent-audibert.developpez.com/CoursUML/?page=diagramme-cas-utilisation,
consulté le 14/06/2020 à 22h41'.
* 9Pascal ROQUES, UML
2 : Modéliser une application web, Paris, ENI, 2006, p.103.
* 10MADIBA Luntadila,
« UML », L1 base de données, ISIPA/MATADI,
2018-2019, cours inédit.
* 11Christian SOUTOU, UML 2
pour les bases de données, Paris, Eyrolles, 2010, p.73.
* 12Laurent AUDIBERT,
UML2 : de l'apprentissage à la pratique, Paris, ENI, 2009,
p.36.
*
13http://www.formation-uml.fr/langage/diagrammes-structurels/diagramme-de-composants/,
consulté le 22/02/2020 à 10h17'.
* 14Hugues BERSINI, La
programmation orientée objet, Bruxelles, Bruylant, 2011, p.79.
* 15
http://www.omg.org/technology/documents/formal/uml.htm,
consulté le 23/02/2020 à 11h42'.
* 16Joseph GABAY et David
GABAY, UML 2 : Analyse et conception, Paris, ENI, 2013, p.94.
* 17Claude BELLEIL, Le
langage UML 2.0 : Diagramme de déploiement, Université de
Nantes, 2011,cours Inédit.
* 18Denis CONAN,
Introduction au langage de modélisation UML, Paris, TELECOM
SudParis, 2015, p.112.
* 19Jean-Luc HAINAUT, Bases
de données : Concepts, utilisation et développement,
Paris, Dunod, 2011, p.31.
| 


{kind=link}
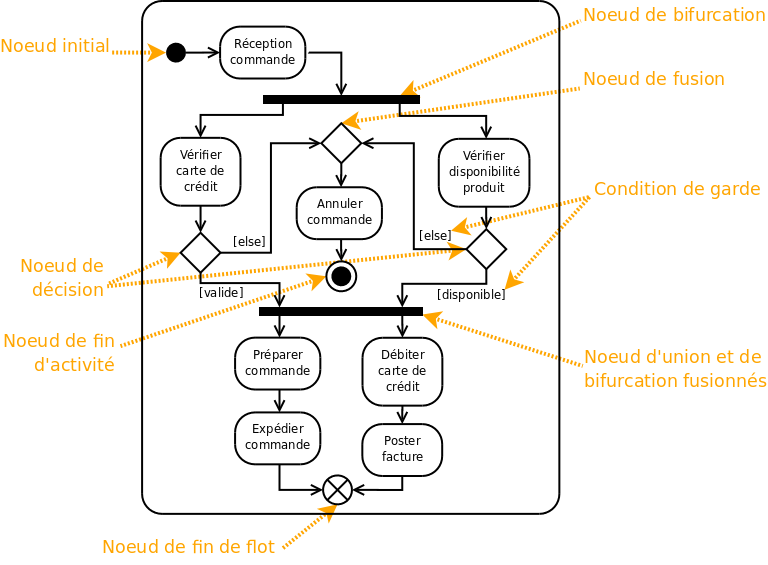{kind=link}