INTRODUCTION GÉNÉRALE
Contribution
Nous contribuons par ce projet proposépar
l'universitéde Deakin3 (Située
à Victoria, Australie) à la mise en place d'un système QAS
automatique complet en commençant par un moteur de recherche, en passant
par un classifieur de documents jusqu'àl'extraction des réponses.
Ce pipeline a pour but d'offrir un service de questions-réponses
exhaustif nomméYouTaQA (figure 0.1).
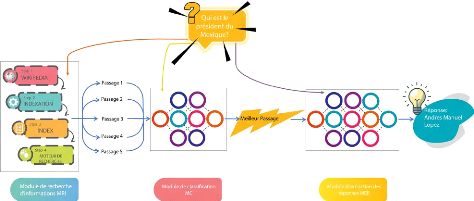
FIGURE 0.1: Schéma global du systeme YouTaQA
Il existe des systèmes questions-réponses qui
ont le même but global, mais qui se contentent d'offrir la partie
extraction des données à leurs utilisateurs en les obligeant
à fournir les documents nécessaires ce qui n'est pas vraiment
pratique, notre système sera donc une version améliorée de
ce qui existe, en permettant aux utilisateurs d'avoir des réponses
exactes à leurs questions uniquement en se basant sur le moteur de
recherche. Ceci épargnera à l'utilisateur de fournir autre chose
que la question, et éventuellement leur facilitera la tâche.
Durant ce travail, nous nous sommes concentrés sur les
interactions entre l'extraction des réponses à l'aide de
l'apprentissage approfondi (Deep Learning ou DL), le traitement du langage
naturel (Natural Language Processing ou NLP) et la recherche d'information
(Information Retrieval ou IR). Plus précisément, notre but est de
mettre en oeuvre une architecture générale d'un QAS en utilisant
des collections et des ensembles de données de référence
sur lesquels nous comptons baser les réponses du système.
3. https://www.deakin.edu.au/
4
INTRODUCTION GÉNÉRALE
Plan du mémoire
Ce présent manuscrit de thèse de Master est
composéde quatre chapitres principaux qui sont:
Chapitre 1 : Ce premier chapitre dresse un
état de l'art des systèmes de questions-réponses
existants. Le chapitre se terminera par une étude bibliographique et une
comparaison de ces systèmes selon plusieurs axes dans un tableau
général.
Chapitre 2 : Ce chapitre est diviséen
deux parties, dans la première nous introduisons la recherche
d'in-formation. Nous décrivons dans la deuxième partie l'aspect
théorique du Deep Learning et du traitement du langage naturel ainsi que
l'architecture du modèle utiliséBERT.
Chapitre 3 : Le troisième chapitre est
consacréà notre contribution et la conception de la solution
proposée. Nous décrivons les différentes opérations
de prétraitements effectuées sur l'ensemble de données de
Wikipédia, nous présentons aussi la structure de notre index. De
plus, nous détaillons dans ce chapitre l'architecture et les
paramètres utilisés pour notre classifieur des passages et de
notre module d'extraction des réponses.
Chapitre 4 : Le dernier chapitre
présente les résultats expérimentaux, leurs
interprétations et enfin une discussion de ces derniers.
Enfin, le manuscrit se termine par nos conclusions sur le
travail effectué. Tout travail de recherche introductif étant
imparfait, cette section présente spécifiquement les
améliorations possibles et offre donc des perspectives de poursuite de
ce travail.
5
| 

