CHAPITRE 4. ANALYSE ET DISCUSSION DES
RÉSULTATS

38
(a) Graphe du Précision-Rappel des résultats. (b)
Graphe du Précision@K des résultats.
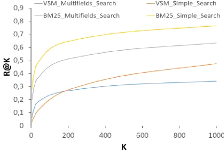
(c) Graphe du Rappel@K des résultats.
FIGURE 4.2: Graphes d'évaluation du Module de Recherche
d'Information.
représente le pourcentage de documents prédits
correctement par rapport au nombre de documents erronés
retournés. Le rappel lui, implique le pourcentage des documents corrects
qui sont donnés sans se préoccuper du nombre de documents
erronés retournés. Afin de remédier à tout
ça, nous avons établi un nouveau graphe présent dans la
Figure 4.2 qui met en valeur la relation précision-rappel à
chaque valeur de K. Encore une fois, la méthode BM25 SimpleSearch
Figure comme étant la meilleure méthode de recherche en
obtenant un rapport précision-rappel toujours au-dessus des autres
méthodes.
À la fin, après avoir comparéles
différentes méthodes de recherche présentées
antérieurement, nous sortons avec une conclusion qui permet de passer
à l'étape suivante qui est le classifieur des documents tout en
lui fournissant 5 documents. Le choix du nombre de documents passés au
classifieur vient suite aux performances affichées par la méthode
de recherche BM25 SimpleSearch, qui en moyenne, permet d'avoir le bon
document parmi les 5 premiers documents retournés par notre moteur de
recherche (MRR = 0.20).
CHAPITRE 4. ANALYSE ET DISCUSSION DES
RÉSULTATS
4.4 Résultats du module de classification
MC
Après la mise en place et obtention des passages
pertinents du moteur de recherche , il est nécessaire
àprésent, de tester le MC et suivre l'évolution
du MRR à l'aide d'un ensemble d'expérimentations sur le
même
dataset »Test Set» utiliséà
l'étape précédente, oùnous vérifions si le
système fonctionne, tout en classifiant correctement les réponses
acquises. L'évaluation du modèle a étéfaite sur la
base de 2 métriques qui sont: Loss (Erreur) et
Accuracy. Ci-dessous les graphes des résultats
obtenus.

(a) Accuracy (b) Loss
FIGURE 4.3: Graphes d'évaluation du Module de
Classification.
D'après la Figure 4.3, nous remarquons que
l'Accuracy augmente avec le nombre d'époques,
jusqu'àl'Epoch (10), avec un pourcentage de 92% durant l'apprentissage
(Training) et 87% sur le Validation dataset. De même,
l'erreur d'apprentissage (Training) et de la Validation
varient avec le nombre d'Epochs, oùle Training Loss
diminue jusqu'àl'atteinte de 0.54 à la fin
de cette étape et le Validation Loss se stabilise au bout de 10
Epochs, dans la valeur 0.57.

39
(a) Training (b) Validation
40
| 

