Youtaqa : système de questions-réponses intelligent basé sur le deep learning et la recherche d’informationpar Rayane Younes & Asma AGABI & TIDAFI Université d'Alger 1 Benyoucef BENKHEDDA - Master 2020 |

CHAPITRE 3. CONCEPTION ET IMPLÉMENTATION DE YOUTAQA
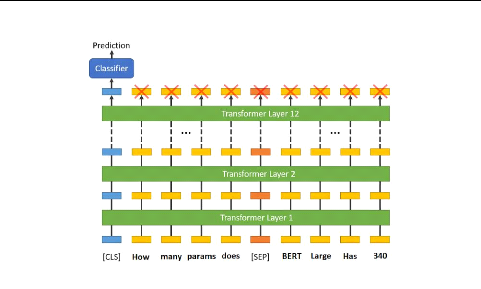
FIGURE 3.6: La classification du texte avec BERT. Le premier token de chaque séquence d'entrée de BERT est toujours un token de classification [CLS] c-à-dire qu'il est utilisépour les tâches de classification NLP de BERT [Devlin et al., 2018]. Le MC prend comme entrée la question et le passage, les passe sur les 12 couches de BERT Base et produit comme sortie une prédiction que le passage contient la réponse recherchée (Figure 3.6). La valeur de sortie est ensuite normalisée avec la fonction Sigmoid6 pour enfin avoir une classification binaire c-à-dire 1 si le passage contient la réponse et 0 sinon. 3.6 Module d'extraction de réponses MER En ce qui concerne le module d'extraction de la réponse, nous avons mis en oeuvre un modèle qui, étant donnéune question et un passage reçu par le MC, BERT doit retourner la partie du texte correspondante à la bonne réponse. En d'autres termes, le modèle prédit le début et la fin de la réponse exacte à partir du passage donnéqui est le plus susceptible de répondre à la question. Pour ce faire, notre modèle doit passer par l'étape d'entraînement en utilisant un ensemble de données destinéà ce cas de figure. Dans ce cas, nous allons utiliser SQuAD. Après avoir sélectionnéle passage le plus pertinent parmi ceux retournés par le MRI, le module d'extraction le prend comme entrée, accompagnépar la question posée. Comme c'était le cas pour le MC, le MER prend comme entrée la paire Question - Passage candidat tokenisée et produit en sortie la réponse jugée exacte à 6. https://fr.wikipedia.org/wiki/Sigmo·ýde (mathématiques) CHAPITRE 3. CONCEPTION ET IMPLÉMENTATION DE YOUTAQAla question donnée et qui est extraite à partir du passage. Le MER proposéa étéentraînéavec BERT Base Uncased.
33 (a) Extraction du début de la réponse (b) Extraction de la fin de la réponse FIGURE 3.7: Extraction du début et fin de la réponse avec BERT. Pour chaque token dans le passage choisi, nous l'introduisons dans le classificateur de token de début/fin. L'extracteur de début/fin passe l'entrée sur les 12 couches de BERT Base et produit un vecteur de sortie (les rectangles oranges produits par la dernière couche dans la Figure 3.7) oùchaque case représente la sortie d'un mot du texte. Ce vecteur est ensuite multipliépar une matrice de début/fin (représentée dans la Figure 3.7 par des rectangles bleus/rouges). La taille de cette matrice est 768*N tel que N représente la taille du passage d'entrée. Le produit est donc un vecteur de taille N sur lequel la fonction Softmax7 est appliquée pour avoir un nouveau vecteur de probabilités (dont la somme est égale à 1). Chaque casei du vecteur représente la probabilitéque le moti tel que i ? N représente le début/la fin de la réponse. BERT englobe les deux modèles d'extraction de début et de fin qui s'entraàýnent séparément. Il comporte une dernière couche qui s'occupe de les fusionner pour délimiter à la fin la réponse à la question posée. Dans l'exemple illustrédans la Figure 3.7, le MER choisi le token 340 comme début de réponse et M comme fin de réponses suivant leurs probabilités. 7. https://fr.wikipedia.org/wiki/Fonction softmax 34 |
|