Chapitre3
Conception et implémentation de YouTaQA
3.1 Introduction
Dans ce présent chapitre, nous allons présenter
la conception de la solution proposée. Nous décrivons les
différentes opérations de prétraitement effectuées
sur l'ensemble de données de Wikipédia, nous présentons
aussi la structure de notre index. De plus, nous détaillons dans ce
chapitre l'architecture et les paramètres utilisés pour notre
classifieur des passages et de notre module d'extraction des
réponses.
3.2 Architecture globale du système
YouTaQA
Notre système est basésur le Deep Learning et de
la recherche d'information. Son but principal est de permettre aux utilisateurs
d'avoir des réponses exactes à leurs questions uniquement en se
basant sur un moteur de recherche qui dispenserait l'utilisateur de fournir des
documents ou autre chose mis à part la question. Afin d'atteindre
l'objectif de notre système, comme illustrédans la Figure 3.1,
nous avons conçu une architecture composée de trois modules de
base et une interface pour interagir avec l'utilisateur:
(i) Un Moteur de Recherche d'Information (MRI) qui sert
à fournir les 5 passages les plus pertinents à une question
donnée.
(ii) Un module de classification (MC) des passages
basésur le Deep Learning pour choisir et identifier parmi les 5
résultats du moteur de recherche le meilleur passage susceptible de
contenir la bonne réponse à la question.
(iii) Un module d'extraction des réponses (MER)
basésur le Deep Learning qui permet d'extraire la réponse exacte
à partir du passage choisi par le classifieur dans l'étape
précédente.
26
CHAPITRE 3. CONCEPTION ET IMPLÉMENTATION DE
YOUTAQA
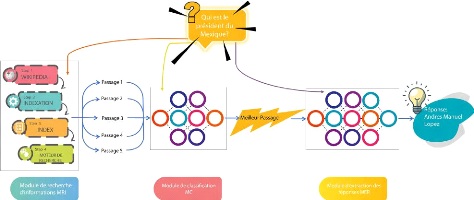
FIGURE 3.1: Schéma global du systeme YouTaQA
3.3 Le choix des jeux de données
Il existe plusieurs jeux de données utilisés
pour l'apprentissage des QAS (Section 1.4). Durant notre projet, pour
l'entraînement du système proposé, nous allons utiliser
SQuAD (Stanford Question Answering Dataset).
3.3.1 SQUAD
SQUAD a étéproposépar
l'universitéde Stanford. Il contient un nombre impressionnant de
questions (100.000 questions posées par des gens sur plus de 500
articles de différents domaines sur Wikipedia). Les passages dans SQuAD
ont étéextraits des articles de Wikipédia et couvrent un
large éventail de sujets dans des domaines variés, allant des
célébrités de la musique aux concepts abstraits. De plus,
les questions sans réponses étaient le talon d'achille des jeux
de données des systèmes questions-réponses,
làencore, SQuAD fournit 50.000 questions sans réponses
posées aléatoirement par la foule qui ont pour but de ressembler
à des questions qui n'ont pas de réponses.
Un passage est un paragraphe d'un article d'une longueur
variable. Chaque passage de SQuAD est accompagnéde plusieurs questions.
Ces questions sont basées sur le contenu du passage et qui peuvent avoir
des réponses en
lisant le passage. Enfin, pour chaque question, il existe une
ou plusieurs réponses. Etant donnéque les réponses sont
des segments des passages, cela permettra au système d'apprendre d'une
manière optimale la façon dont
27
| 

