4.1.3. Formation du
modèle d'apprentissage profond
Nous avons créé deux réseaux de neurones
différents pour la détection du trafic malveillant. Un
réseau multicouche profond et un réseau récurrent plus
spécifiquement un Long Short Term Memory (LSTM). Ils sont écrits
sur jupyter.
Nous avons ajouté des couches du réseau avec un
certain nombre de paramètres qui vont permettre de l'entraîner et
de créer un modèle.
D'abord nous instancions la classe
Sequential() grâce à laquelle nous créons
le modèle et nous ajoutons les couches LSTM, Dense et Dropout. Nous nous
servons de la méthode add() pour LSTM et
tf.keras.layers pour MLP pour ajouter de nouvelles couches.
Nous y ajoutons des paramètres comme le nombre de neurones de la couche,
Nous spécifions qu'on ajoutera plus de couches au modèle avec le
paramètre return_sequences (dans le cas du LSTM), la
fonction d'activation relu et sur la première couche
Nous ajoutons le nombre de pas de temps.
Après chaque nouvelle couche, nous ajoutons une couche
de suppression, au modèle LSTM. C'est une couche d'abandon qui permet
d'éviter le sur-ajustement qui est un phénomène dans
lequel un modèle d'apprentissage automatique fonctionne mieux sur les
données d'entraînement que sur les données de test. Nous
nous sommes servis de la méthode Dropout().
Pour rendre notre modèle plus robuste, nous ajoutons
une couche Dense() à la fin du modèle. Le
nombre de neurones dans la couche dense sera fixé à 6 car nous
voulons prédire 6 classes dans la sortie. Nous ajouterons aussi la
fonction d'activation softmax pour obtenir les sorties sous
formes de probabilités, c'est-à-dire que la somme des
résultats en sortie doit donner 1.
Le travail suivant consiste à compiler le réseau
de couches que nous venons de créer avant de pouvoir l'entraîner
sur les données d'entraînement. Nous utilisons l'erreur
quadratique moyenne comme fonction de perte afin de
réduire la perte et pour optimiser l'algorithme, nous utilisons
l'optimiseur adam et sgd. Nous ajoutons aussi la
précision comme métrique, la perte étant ajoutée
par défaut.
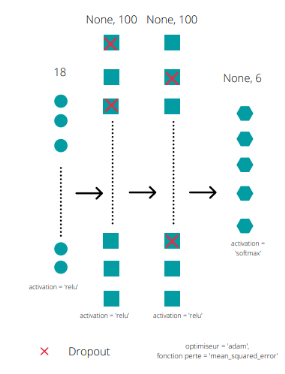
Figure 25 : Architecture
réseau LSTM
Notre réseau de neurones LSTM est
donc constitué de deux couches intermédiaires, de 18 neurones
à l'entrée et à 5 neurones à la couche de sortie.
Nous avons aussi ajouté deux couches dropout pour la
régularisation.
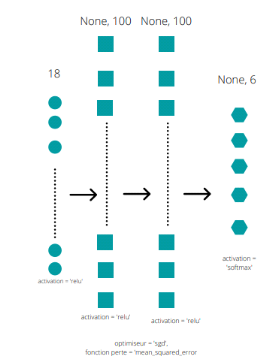
Figure 26 : Architecture
réseau MLP
Le réseau MLP est similaire mais sans couches de
régularisation.
Nous pouvons maintenant former le modèle que nous avons
défini. Nous utilisons la méthode fit() sur le modèle en
transmettant les données d'entraînement, le nombre
d' « epoch » et la taille de chaque batch. Nous
ajoutons aussi les données de validation qui nous permettra ainsi
d'obtenir la précision de validation et la perte de validation.
En ce qui concerne le second modèle, il s'agit
plutôt d'un algorithme écrit en python (sans jupyter). A chaque
objet type nous avons un classifieur. Donc une empreinte doit être
traitée par les différents classifieurs de type d'objets pour
trouver celui auquel il correspond. Donc à chaque fois qu'une nouvelle
empreinte d'un nouvel appareil est capturée, un nouveau classifieur est
entraîné sans modification aucune aux classifieurs existants. Ceci
évite un coût de réapprentissage. Cette approche permet la
découverte de nouveaux appareils et ne force aucune empreinte à
correspondre à une classe donnée.
NB : On parle de nouvelle empreinte lorsque celle-ci ne
correspond à aucun classifieur.
Toutefois une même empreinte peut correspondre à
différents types d'objets d'après les résultats du
classifieur. Une seconde étape consiste donc à calculer la
distance entre les différents types d'objets trouvés. Mais dans
notre travail nous n'avons pas pris en compte cette seconde étape et
nous avons plutôt pris la probabilité la plus
élevé !
| 

