|
MÉMOIRE DE FIN D'ÉTUDES
CONCEPTION D'UN FILTRE D'UN RESEAU D'OBJETS CONNECTES
PAR APPRENTISSAGE PROFOND
Réalisé par :
NYABENG MINEME SANDRA ROCHELLE
Matricule : 15T31081
En vue de l'obtention du
DIPLÔME DE MASTER EN
TELECOMMUNICATIONS
Option
SECURITE DES RESEAUX ET SYSTEMES
Sous la supervision de :
Sous la supervision de :
Dr. SAMEH NAJEH
Maître Assistante, Enseignante à
SUP'COM
Encadreur Académique
Enseignante à Sup'Com
Année académique : 2019-2020
DÉDICACE
A MA MERE NYANDING BLANDINE PASCAL ET MON PERE MINEME AFANA
MVODO
REMERCIEMENTS
Tout d'abord je remercierais Dieu tout puissant pour la
volonté d'entamer et de terminer ce projet de fin d'étude.
Ensuite ma gratitude ira vers mon Encadreur Madame Sameh
Najeh pour sa patience, son suivi, ses remarques et sa confiance. Ses conseils
m'ont énormément aidé.
Je remercie l'Ecole Nationale Supérieure des Postes,
des Télécommunications et des Technologies de l'Information et de
la Communication, SUP'PTIC et les enseignants qui m'ont accompagné
durant ma formation.
Enfin je voulais remercier ma famille et toute les personnes
qui m'ont soutenu et aidés pour ce projet
RÉSUMÉ
L'insécurité des objets connectés est une
menace pour la société connectée vers laquelle nous
évoluons. Les technologies propriétaires et le manque de
sensibilisation chez les utilisateurs n'arrangent pas les choses. C'est chaque
fabricant ou développeur qui conçoit son objet et les solutions
de sécurité. Malheureusement ce qu'ils proposent sont souvent
propres à leurs objets uniquement ou à un protocole de
communication spécifique. Le risque s'accroît encore plus
lorsqu'on sait qu'un virus peut se propager dans un réseau. Des
solutions applicables à l'ensemble des objets sans prendre en compte le
protocole de communication ou les caractéristiques des objets sont
nécessaires. Un réseau d'objet connecté peut
représenter une menace pour les utilisateurs. Avec des données
collectées sur plusieurs types d'objets utilisant des protocoles de
communications et des systèmes différents, quelques solutions
impliquant ou pas des algorithmes d'intelligence artificielle ont
déjà été suggérés. Ceci pour isoler
les objets suspects ou créer des règles de pare-feu après
avoir filtré les paquets. Nous proposons dans ce mémoire une
autre approche qui implique de filtrer les paquets. Nous nous basons sur la
détection des attaques spécifiques aux objets connectés
grâce à l'apprentissage profond et détectons les objets de
notre réseau domotique en se basant sur des empreintes digitales elles
aussi construites par des algorithmes. Tout ceci permettra d'une part de
protéger des objets connectés dans le réseau domotique
mais aussi mais aussi d'alléger la tâche d'un pare-feu. De plus
sans avoir à générer des règles
supplémentaires qui entraînent des anomalies au fil du temps.
Nous avons choisi des algorithmes d'apprentissage profond pour réaliser
nos modèles. Les réseaux de neurones ont montré de bonnes
performances même s'il a fallu beaucoup de modifications de nos
réseaux.
Mots clés : Objets Connectés,
Réseau, Apprentissage Profond, Sécurité
ABSTRACT
The insecurity of connected objects is a threat to the
connected society we are moving towards. Proprietary technologies and a lack of
awareness among users don't help. It is each manufacturer or developer who
designs their purpose and security solutions. Unfortunately what they offer are
often specific to their objects only or to a specific communication protocol.
The risk is further increased when it is known that a virus can spread over a
network. Solutions applicable to all objects without taking into account the
communication protocol or the characteristics of the objects are necessary. A
connected object network can pose a threat to users. With data collected on
several types of objects using different communication protocols and systems, a
few solutions involving or not involving artificial intelligence algorithms
have already been suggested. This is to isolate suspicious objects or create
firewall rules after filtering the packets. We propose in this paper another
approach which involves filtering the packets. We rely on the detection of
attacks specific to connected objects through deep learning and detect the
objects of our home automation network based on fingerprints also built by
algorithms. All this will on the one hand protect connected objects in the home
automation network but also but also lighten the burden of a firewall. Plus
without having to generate additional rules that cause anomalies over time. We
chose deep learning algorithms to build our models. Neural networks have shown
good performance even though it took a lot of modifications to our networks.
Keywords: Connected Objects, Network, Deep Learning,
Security
TABLE DES MATIÈRES
DÉDICACE
i
REMERCIEMENTS
ii
RÉSUMÉ
iii
ABSTRACT
iv
TABLE DES MATIÈRES
v
LISTE DES TABLEAUX
vii
LISTE DES FIGURES
viii
LISTE DES ABREVIATIONS
x
INTRODUCTION GENERALE
1
CHAPITRE 1 : ETAT DE L'ART, CONTEXTE ET
PROBLÉMATIQUE
3
Introduction
3
1. Caractéristiques d'un réseau
d'objet connecté
3
1.1. Acteurs d'un réseau d'objet
connecté
3
1.2. Architecture d'un objet
connecté
5
1.3. Protocoles de communication des objets
connectés
6
2. Problèmes de
sécurités rencontrés sur les objets connectés
8
2.1. Vulnérabilités des objets
connectés
8
2.1.1. Mots de passe faible,
prévisibles ou codés en dur
9
2.1.2. Services réseaux non
sécurisés
9
2.1.3. Interfaces de
l'écosystème non sécurisé
9
2.1.4. Absence de mécanisme de mise
à jour sécurisé
9
2.1.5. Utilisation de composant non
sécurisé ou obsolète
10
2.1.6. Insuffisance dans la protection de la
vie privée
10
2.1.7. Stockage ou transfert de
données sensible non sécurisé
11
2.1.8. Manque de gestion des appareils
11
2.1.9. Configuration par défaut non
sécurisé
11
2.1.10. Manque de protection physique
11
2.2. Attaques sur les objets
connectés
12
3. Quelques solutions de pare-feu des objets
connectés
15
3.1. IoT Sentinel
15
3.2. BPF
17
3.3. Filter.tlk
18
4. Contexte et intérêt du
projet
20
5. Problématique
23
6. Objectif du projet
25
CHAPITRE 2 : MÉTHODOLOGIE
26
Introduction
26
1. Définition de concepts
clés
26
1.1. Algorithme d'apprentissage profond
26
1.2. Empreinte digitale
30
2. Conception de la solution
32
2.1. Architecture de la solution
32
2.2. Les différentes
fonctionnalités
34
3. Outils utilisés
34
4. Conception des modèles
36
4.1. Conception des modèles
d'apprentissage profond
36
4.1.1. Acquisition du jeu de
données
37
4.1.2. Préparation et nettoyage des
données
41
4.1.3. Formation du modèle
d'apprentissage profond
48
4.2. Implémentation du modèle
de détection de trafic malveillant
51
Conclusion
52
CHAPITRE 3 : SIMULATIONS ET
INTERPRÉTATION DES RÉSULTATS
53
Introduction
53
1. Métriques d'évaluation des
modèles
53
2. Tests des modèles et
évaluation
55
2.1. Détection de trafic IoT
malveillant
55
2.2. Identification du type d'objet
59
3. Implémentation du modèle de
détection de trafic malveillant
61
4. Discussions
67
Conclusion
70
CONCLUSION ET PERSPECTIVES
71
ANNEXES 1
73
ANNEXES 2
77
ANNEXES 3
78
RÉFÉRENCES
79
LISTE DES TABLEAUX
Tableau 1 : Les outils utilisés pour
concevoir les modèles
2
Tableau 2 : Ensemble du jeu de donnée
obtenu grâce à des logiciels malveillants sur des objets
connectés
39
Tableau 3 : Ensemble du jeu de donnée du
trafic normal et bénin d'objets connectés
39
Tableau 4 : Attributs utilisés dans
notre jeu de donnée
43
Tableau 5 : Valeurs possibles du champ
conn_state
44
Tableau 6 : Valeurs possibles du champ
history
45
Tableau 7 : Comparaison entre les
résultats des modèles sur le jeu de test
58
Tableau 8 : Configuration des machines du
réseau
63
Tableau 9 : Comparaison des résultats
entre le modèle d'IoT Sentinel et notre modèle
68
LISTE DES FIGURES
Figure 1 : Les acteurs du réseau
d'objets managés
2
Figure 2 : les couches de l'architecture d'un
objet connecté [6]
5
Figure 3 : Liste non exhaustive des protocoles
de communications possibles pour un objet connecté
7
Figure 4 : le top 10
vulnérabilités des objets connectés selon l'OWASP
8
Figure 5 : les cyber-attaques d'une maison
intelligente [8]
12
Figure 6 : l'objet sert de relais de diffusion
d'une attaque.
14
Figure 7 : Design d'un système d'IoT
Sentinel [16]
16
Figure 8 : Architecture de filter.tlk [19]
19
Figure 9 : classement des pays du monde par
détection d'activité de botnet [22]
20
Figure 10 : Classement sur le continent
africain des activités de détection de botnet [22]
21
Figure 11 : Détection d'activité
de botnet au Cameroun du 12 janvier au 18 janvier [22]
21
Figure 12 : Détection d'intrusion au
Cameroun du 11 Janvier au 17 Janvier[22]
21
Figure 13 : Vue en temps réel d'une
infection du botnet Sality su MTN Cameroun [23]
22
Figure 14 : un réseau de neurone avec
trois couches
27
Figure 15 : Connexion des entrées d'une
couche précédente vers un neurone de la couche suivante
27
Figure 16 : Détail de fonctionnement du
réseau LSTM [26]
29
Figure 17 : Architecture du réseau
interne vers le réseau externe
32
Figure 18 : Architecture de la solution
33
Figure 19 : modèle d'apprentissage
profond pour prédire le trafic bénin ou malicieux
33
Figure 20 : Architecture du modèle
d'identification des objets grâce à l'apprentissage profond
33
Figure 21 : Appareil Amazon echo[32]
38
Figure 22 : Dispositif de verrouillage de porte
Somfy[32]
38
Figure 23 : liste des objets connectés
utilisés et de leurs technologies de communications correspondantes
[16]
41
Figure 24 : description des 23 attributs
utilisés pour former le modèle [16]
47
Figure 25 : Architecture réseau LSTM
49
Figure 26 : Architecture réseau MLP
50
Figure 27 : Evolution de la précision de
l'algorithme LSTM lors de l'entraînement avec le jeu de validation et
d'entraînement lors du premier entrainement avec 04 couches de 128
neurones chacun
55
Figure 28 : Evolution de la perte de
l'algorithme LSTM lors de l'entraînement avec le jeu de validation et
celui d'entraînement lors du premier entraînement avec 04 couches
de 128 neurones chacun
56
Figure 29 : Evolution de la précision de
l'algorithme LSTM lors de l'entraînement avec le jeu de validation et
d'entraînement lors du dernier entraînement avec 02 couches de 100
neurones chacun
56
Figure 30 : Evolution de la perte de
l'algorithme LSTM lors de l'entraînement avec le jeu de validation et
d'entraînement lors du dernier entraînement avec 02 couches de
10101 neurones chacun
57
Figure 31 : Evolution de la perte de
l'algorithme lors de l'entraînement avec le jeu d'entrainement et celui
de validation
57
Figure 32 : Evolution de la précision de
l'algorithme lors de l'entraînement avec le jeu d'entraînement et
le jeu de validation
58
Figure 33 : Rapport de classification de
l'objet connecté Amazon echo
59
Figure 34 : Rapport de classification de
l'ampoule hue bridge
60
Figure 35 : Rapport de classification de la
serrure somfy
60
Figure 36 : Matrice de confusion entre x_test
et les prédictions
60
Figure 37 : Configuration des interfaces du
gateway
62
Figure 38 : Configuration des interfaces d'une
autre machine sur le réseau interne
62
Figure 39 : envoie, réception et
détection des paquets malveillants
63
Figure 40 : Configuration IP des deux machines
de 2 réseaux différents
64
Figure 41 : Ping entre les 2 machines de 2
réseaux différents
65
Figure 42 : Envoi et réception des
paquets de part et d'autre du réseau
65
Figure 43 : Filtrage du trafic
66
Figure 44 : la machine interne renifle les
paquets qu'elle reçoit
66
Figure 45 : Partie 1 résultat du
modèle d'identification des objets
77
Figure 46 : Partie 2 résultat du
modèle d'identification des objets
77
Figure 47 : Résultats des travaux d'IoT
Sentinel
78
LISTE
DES ABREVIATIONS
ARP: Address Resolution Protocol
API: Application Programming Interface
BTT: BPF testing tool
BDAT: BPF design aid tool
BPF: Berkeley Packet Filter
CSV: Comma-Separated Values
C&C: command-and-control
CVE: Common vulnerabilities and Exposures
DDoS: Distributed Denial of Service
DHCP: Dynamic Host Configuration
Protocol
DoS: Denial of Service
DNS: Domain Name System
FAI : Fournisseurs d'accès à
Internet
GSM: Global System for Mobile
Communications
GPRS: General Packet Radio Service
HTTP: HyperText Transfer Protocol
ICMP: Internet Control Message Protocol
IRC: Internet Relay Chat
IPTRB: IPTable rule builder
IP: Internet Protocol
IoT: Internet of Things
LED: light-emitting diode
LTE: Long Term evolution
LSTM: Long Short Term Memory
MLP: multilayer perceptron
MAC: Media Access Control
NF: NetFilter
NFC: Near Field Communication
NBIoT: Narrowband Internet of Things
OWASP: Open Web Application Security Project
OS: Operating System
PCAP: Packet Capture
PC: Personal Computer
SSH: Secure Shell
SSL: secure sockets layer
SD: Secure Digital
TCP: Transmission Control Protocol
UDP: User Datagram Protocol
USB: Universal Serial Bus
UMTS: Universal Mobile Telecommunications
System
6LOWPAN: IPV6 Low-power wireless Personal Area
Network
INTRODUCTION GENERALE
Tous les objets de notre quotidien peuvent devenir
connectés et rendre notre vie plus confortable. Des caméras
intelligentes, des écouteurs sans fil, des télévisions ou
encore des montres connectées. En fait, il suffit d'ajouter un capteur
à un objet et le faire communiquer avec un réseau pour
transmettre et recevoir des données pour en faire un objet
connecté. Les objets connectés représentent une
opportunité immense pour de nombreuses entreprises.
Toutefois, la sécurité des objets
connectés à travers le monde inquiète de plus en
plus. Non seulement on compte environ 26.6 milliards d'appareils
connectés (On compte aussi les téléphones tablettes, etc)
en 2019 [1] mais leur chiffre continue exponentiellement d'augmenter. On ne
cesse de lire dans la presse et les divers sites et blogs liés à
la cyber sécurité tel que celui d'Olivier Ezratty les nombreuses
vulnérabilités dont elle souffre. Dans un des articles de son
site intitulé « peut-on sécuriser l'internet des
objets» [2], il présente les fragilités connues des
objets connectés et leur sécurisation. Nous nous rendons compte
que presque tout est « piratable » si ce n'est tout, que ce
soit des voitures, des caméras, des thermostats, des grille-pain etc.
Tout ceci à partir d'applications facilement trouvables sur internet et
téléchargeables sur son téléphone androïde.
D'ailleurs Kaspersky, l'éditeur de logiciels antivirus avait
déjà estimé en 2019 le nombre de piratages à 105
millions au premier semestre alors qu'il ne s'élevait qu'à 12
millions sur la même période en 2018 - soit neuf fois plus [3].
Parmi tous les domaines d'applications de l'internet des
objets tels que la santé, l'agriculture, les finances, c'est la
domotique qui va nous intéresser. Ceci simplement à cause du fait
que les objets connectés utilisés au sein d'un réseau
domotique sont des proies faciles et parfaites pour des attaquants. Les pirates
utilisent des « maliciels » (logiciels malveillants) pour
infecter ces objets connectés en exploitant des failles connues car peu
de fabricants de ces objets pensent à la sécurité de leurs
objets dès leur conception. Les attaquants les organisent ensuite en
« botnets » (réseau d'automates informatiques
souvent destinés à des usages malveillants) prompts à
déferler sur une cible, bien souvent des serveurs.
De plus, les caractéristiques de ces objets sont
très inférieures à celles d'un équipement de bureau
ce qui rend leur gestion difficile, sans parler de leur nombre et du fait que
certains sont mobiles ou facilement transportables (hors du réseau
domotique). Tout ceci révèle plusieurs difficultés pour
sécuriser les objets connectés : il est difficile
d'être informés d'une attaque en cours, un objet peut être
piraté hors du réseau et s'y reconnecter ensuite, il est
difficile d'avoir une vue des appareils connectés à un certain
temps dans un réseau, il est presque impossible de mettre des agents de
surveillance local sur chaque objet, en bref il est difficile de superviser la
sécurité d'un réseau d'objet connectés.
Cela inquiète et emmène donc à se poser
des questions sur la fiabilité des objets connectés d'une part
pour la confidentialité des données des utilisateurs de ces
objets et d'autre part sur la façon dont les hackers utilisent les
objets dont ils prennent le contrôle.
Nous voulons sécuriser les appareils d'un réseau
domotique au niveau de la passerelle. Un réseau domotique peut
être installé au sein d'une maison comme au sein d'une entreprise.
La domotique est l'ensemble des techniques permettant de centraliser le
contrôle des différents systèmes de la maison et/ou de
l'entreprise. Le plus important est que nous ne concentrons sur la passerelle
qui est l'élément central avec lequel les objets communiquent.
Nous voulons d'une part connaitre quels sont les objets connectés au
réseau et d'autre part bloquer les attaques avant même qu'elles
n'arrivent sur les objets car ceux-ci n'ont presque pas de mécanismes de
défense.
Nous proposons une passerelle qui s'occupe du trafic IoT et de
filtrer les paquets malveillants. Une passerelle permettrait non seulement de
protéger les objets connectés d'attaques auxquels elles sont le
plus exposées mais qui permettrait aussi d'avoir une vue globale des
objets du réseau. Ce travail vise à protéger les appareils
à l'intérieur du réseau interne d'attaques externes.
Notre travail sera présenté en 3
chapitres :
- Chapitre 1 : Nous présenterons ce que c'est
qu'un réseau d'objet connecté, les éléments qui le
composent, les éléments de son environnement, la façon
dont il communique dans le réseau, ses vulnérabilités, les
attaques fréquentes dont il fait face mais aussi des projets
existant.
- Chapitre 2 : Nous parlerons de la méthodologie
c'est-à-dire pour présenter les concepts clés qui nous
ont aidé à proposer une solution, de la façon dont nous
pensons pouvoir protéger le réseau interne et de la conception
des modèles proposés pour nous aidés dans notre
approche.
- Chapitre 3 : Nous présenterons les
résultats obtenus durant l'entraînement et les tests des
modèles suggérés tout en ayant précédemment
expliqués les métriques d'évaluation que nous utiliserons
et l'implémentation du code servant à vérifier le filtrage
sans création de règles de filtrage.
CHAPITRE 1 : ETAT DE
L'ART, CONTEXTE ET PROBLÉMATIQUE
Introduction
Les objets connectés sont un domaine d'étude
très vaste. Il serait facile d'essayer de les limiter à de
simples capteurs capables de communiquer avec une passerelle mais en fait c'est
bien complexe que ça. Leurs composants diffèrent d'un
constructeur à l'autre. Pour mieux cerner le cadre de notre projet, ce
chapitre sera consacré aux réseaux d'objets connectés, ce
qui les caractérisent, les failles et les attaques dont ils sont
victimes, les travaux qui se sont penchés sur les problèmes de
sécurité et présenter notre approche pour une solution.
1. Caractéristiques d'un
réseau d'objet connecté
1.1. Acteurs d'un réseau d'objet connecté
D'après l'article de Pallavi Sethi et Smruti R. Sarangi
qui passe en revue l'internet des objets [4], les objets connectés sont
généralement de petit équipements dotés de
processeurs, de mémoire vive, de stockage de masse et d'interfaces
d'entrées/sorties. Ils ont ajouté que d'un point de vue
logiciel, ces équipements embarquent un système d'exploitation,
plus généralement connu sous le nom de «firmware».
Cependant, afin d'optimiser les coûts par rapport à un ordinateur,
le fabricant intègre généralement «juste ce qu'il
faut» afin d'implémenter les fonctionnalités
nécessaires. Ce qui implique d'après eux des puissances de calcul
réduites, des espaces de stockage limités, des interfaces
d'entrées/sorties correspondant aux fonctionnalités de
l'équipement ainsi qu'un système d'exploitation limité aux
fonctionnalités prévues par le fabricant.
Mahmoud Elkhodr, Seyed Shahrestani et Hon Cheung proposent
dans un article une plateforme pour la gestion des objets [5] dans laquelle ils
ont détaillé les caractéristiques d'un objet
connecté et son environnement.
Un objet connecté possède plusieurs attributs
tels que son identifiant, sa localisation, son nom, les données utiles,
etc. Ce sont des données que nous pouvons exploités pour
identifier ces objets.On distingue principalement deux types
d'attributs :
? Attributs de gestion : Ils permettent
de représenter l'objet virtuellement grâce au nom, à l'Id,
le numéro de série, l'adresse Mac, son adresse IP, la version du
firmware, sa localisation si elle fixe, etc. Ces attributs permettent de
décrire l'objet.
? Attributs comportementaux : Ils
représentent les données récupérer par l'objet
comme le son, la température, la pression, la localisation, les
déplacements, détection d'eau ou de feu, etc.
Sur un objet connecté peut être installé
une application «agent » responsable :
? D'établir la communication avec le manageur
? Envoyer des données mises à jour au
manageur
? Récupérer les instructions du manageur et
s'assurer que l'objet les exécute
? Envoyer des notifications au manageur
? Manipuler les requêtes et les réponses
correspondantes depuis ou vers le manageur
Lorsqu'un objet possède un agent, on parle d'objet
managé.
L'objet ne dispose pas des capacités physiques et
logiciels nécessaires pour traiter les informations qu'il récolte
lui-même. Pour ce faire, il aura donc besoin d'un manageur ou d'une
passerelle. La passerelle reçoit et stocke les données qu'il a
reçues de l'objet dans une base de données.

Figure 1 : Les
acteurs du réseau d'objets managés
La figure ci-dessus nous montre que
l'objet connecté constitué d'un agent et de l'objet
lui-même communique avec internet soit à travers une passerelle
appelé ici manageur sur laquelle est téléchargé
une API responsable de la gestion des objets du réseau ou encore les
objets managés communiquent directement vers le Cloud qui possède
la base de donnée et peut être le serveur de l'application afin
que les objets puissent récupérer les résultats des
calculs qu'ils ne peuvent pas faire eux-mêmes et envoyer des
données aux applications qui les gèrent.
Un manageur possède un module d'enregistrement
des objets responsable d'enregistrer les objets dans le
réseau. Un objet rejoint le réseau et devient un objet
managé en se connectant au manageur grâce à son agent. Il
y'a 03 méthodes d'enregistrement d'un objet :
i) Rejoindre directement le
réseau : Dans ce cas l'objet est
préprogrammé avec l'adresse IP du manageur. Cela permet à
l'objet d'envoyer une requête « DIRECT-JOIN ».
ii) Enregistrement via l'association :
l'objet doit faire une requête, optionnellement s'authentifier
auprès du manageur, envoyé une requête d'association et
lorsque celui-ci est approuvé la connexion est établie
iii) Reconnexion au réseau :
l'objet a perdu sa connexion avec le manageur et essaye de se reconnecter.
Cela arrive lorsque l'objet sort de la zone de couverture du manageur ou
lorsque celui-ci pour une raison ou une autre est indisponible. Il utilise
l'une des deux méthodes précédentes à l'exception
que lui n'a pas besoin qu'on l'enregistre une nouvelle fois dans la base de
données ou alors il y aura une mise à jour !
Pour notre projet, connaître les différents
acteurs d'un réseau d'objets connectés et leur
caractéristique physique est important. Un objet connecté est
très simple et restreint en termes de capacité, nous n'allons
donc pas y installer de logiciel mais plutôt surveiller ses
communications avec le manageur. Il n'y aura pas de fonctionnalité en
plus à ajouter à l'agent responsable de l'objet et pas de module
supplémentaire au manageur. Le manageur lui par contre possède
les ressources physiques et logicielles intéressantes pour
installé nos modèles d'apprentissage profond.
1.2. Architecture d'un objet connecté
Il existe plusieurs architectures pour les objets
connectés mais nous allons nous intéresser ici à une
seule architecture à 03 niveaux développés par Pallavi
Sethi et Smruti R. Sarangi [6] dont la figure
ci-dessous est extraite de leur travail:
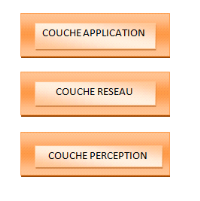
Figure 2 : les couches de l'architecture d'un objet
connecté [6]
i. Couche perception : Elle correspond
à la couche physique. Elle correspond aux capteurs qui collectent les
informations de leur environnement ou identifient d'autres objets intelligents
dans leur environnement. Cette couche comprend ainsi le matériel
nécessaire pour parvenir à la collection de données
contextuelles des objets connectés, à savoir les capteurs, les
étiquettes RFID, caméras, GPS (Global Positioning System) qui
peuvent aussi nous permettre de les identifier.
ii. Couche réseau : Elle est
responsable de la connexion avec les autres objets connectés, les autres
équipements réseaux et les serveurs. Elle est aussi responsable
de transmettre et traiter les données issues des capteurs. Lorsque les
capacités de l'objet ne le permettent pas, ces données sont
envoyées et traitées dans le Cloud.
iii. Couche application : Elle est
responsable de fournir des services applicatifs spécifiques aux
utilisateurs. Il définit les applications variées qu'un objet
connecté est capable de fournir dans différents domaines comme la
domotique, la santé, les villes intelligentes, etc.
Il est tout à fait possible de retrouver des
architectures à 05 ou 04 couches. Par exemple, nous pourrions ajouter la
couche middleware qui sert pour une interface entre la couche
matérielle et les applications. Elle permet la dissimulation de la
complexité des mécanismes de fonctionnement du réseau et
rend plus facile le développement des applications par les concepteurs.
Cette architecture très simple nous a simplifié
la tâche dans notre projet car au final pour nous il existait juste trois
grands objectifs pour un réseau d'objets connectés :
collectés des informations, les transmettre, recevoir des ordres et
fournir des applications.
1.3. Protocoles de communication des objets
connectés
Dans le domaine des réseaux sans-fil et filaire, un
protocole de communication définit les règles et les
procédures de communication des couches physiques et de liaison du
modèle OSI sur un support/canal physique. Il permet ainsi de
connecter un objet à un réseau filaire ou sans-fil. En outre, si
ce réseau comporte une passerelle, c'est-à-dire un appareil
connecté à la fois au réseau et à Internet, alors
cet objet peut transmettre et recevoir des données depuis Internet.
Pour pouvoir choisir quel protocole de communication est
adapté à notre situation, il faut prendre en compte plusieurs
critère tels que :
? Topologie : elle peut être
maillé (un noeud est connecté à un ou plusieurs noeuds du
réseau), en étoile (les objets sont connectés à un
concentrateur ou un routeur), en cellule (Il y'a des zones appelés
cellules et dans chaque cellule, une antenne assure la liaison radio entre les
objets et internet), à diffusion(les messages sont transmis sans que le
ou les destinataire(s) ne soit précisé. Le message sera
analysé par tous les objets du réseau).
? Portée : la distance maximale
à laquelle un récepteur est capable de décoder le signal.
Elle peut être courte (une centaine de mètres au plus), moyenne
(au plus quelques kilomètres), longue (On parle de dizaines de
kilomètres). La portée d'un signal dépend à la fois
de la valeur de la puissance maximale d'émission prévue par le
protocole et le milieu physique.
? Débit :
Le débit est principalement limité par la
modulation du signal et la largeur de la bande
de fréquences : plus celle-ci est large et plus le
débit est important. Bas débit : jusqu'à plusieurs
dizaines de bit/s. Moyen débit : jusqu'à plusieurs centaines de
Kbit/s. Haut débit : Plusieurs centaines de Kbit/s et jusqu'à
plusieurs dizaines de Mbit/s. Très haut débit: Plusieurs
centaines de Mbit/s voire plusieurs Gbit/s.
? Synchrone/Asynchrone : On parle de
synchronisation au niveau de la couche de liaison lorsqu'un objet
est à l'écoute continue ou périodique
des trames émises par la passerelle. En outre, l'objet est
susceptible de répondre à certaines trames pour notifier de sa
présence et fournir une indication sur la qualité du signal
en réception. Il s'agit du principe de Keep Alive.
Il existe des dizaines de protocoles de communication.

Figure 3 :
Liste non exhaustive des protocoles de communications possibles pour un objet
connecté
On distingue les protocoles de
communication cellulaire tels que le GSM/GPRS/3G/4G/LTE-M, d'autres
protocoles à longues portées tels que Sigfox, LoraWAN et
NBIoT et des protocoles à courte porté comme le
Wifi, ZigBee, Z-wave, NFC, Bluetooth Low Energy, Lifi et 6LowPAN
(IPv6 Low-power wireless Personal Area Network). Un tableau avec des
détails est donné en annexe.
Il existe tellement de protocoles que nous avons
décidé de concevoir une solution sans prendre en compte les
détails de chaque protocole. Plusieurs protocoles de communications ont
été utilisés pour la collecte des données. Nous ne
dépendons pas d'un protocole en particulier.
Ensuite pour la topologie, elle serait plutôt en
étoile puisque les objets sont connectés à la passerelle.
La portée n'est pas très grande dans une maison de quelques
dizaines de mètres, ce qui permet à des protocoles simples comme
le wifi ou le Bluetooth d'être facilement utilisés. Le
débit n'a pas non plus été déterminant pendant
notre travail.
2. Problèmes de
sécurités rencontrés sur les objets connectés
2.1. Vulnérabilités des objets
connectés
Pour pouvoir exposer plus facilement les
vulnérabilités des objets connectés, nous avons
adopté le rapport OWASP. Le projet OWASP [7] internet des objets explore
et publie les risques de sécurité liés à l'Internet
des objets, afin d'aider les développeurs, les fabricants et les
consommateurs à mieux les comprendre pour améliorer la
conception de leurs applications pour objets connectés.

Figure 4 : le
top 10 vulnérabilités des objets connectés selon
l'OWASP
2.1.1. Mots de passe faible,
prévisibles ou codés en dur
|
La plupart des objets, surtout ceux qui possèdent des
interfaces web ne sont pas configurés pour permettre aux utilisateurs de
changer facilement les mots de passe par défaut ou pire ce genre de
modification est impossible. Ce qui rend ces objets vulnérables aux
attaques qui se basent sur cette faiblesse. Leur système d'autorisation
est donc faillible.
De plus ces informations d'identifications peuvent être
facilement forcés, sont parfois accessibles via des sites de hackers,
le dark web ou juste des sites de développeurs.
2.1.2. Services réseaux non
sécurisés
L'attaquant utilise des services réseau
vulnérables tels que Telnet ou HTTP pour attaquer l'appareil
lui-même ou faire rebondir les attaques sur l'appareil.
Les services réseau non sécurisé peuvent
être sujets à des attaques par débordement de tampon ou
à des attaques qui créent une condition de déni de service
laissant le périphérique inaccessible à l'utilisateur. Les
attaques par déni de service contre d'autres utilisateurs peuvent
également être facilitées lorsque les services
réseau non sécurisés sont disponibles. Les services
réseau non sécurisés peuvent être
détectés par des outils automatisés tel qu'un scanner de
ports.
Les services réseau non sécurisés
peuvent entraîner la perte ou la corruption de données, le
déni de service ou la facilitation d'attaque sur d'autres appareils.
2.1.3. Interfaces de
l'écosystème non sécurisé
Les interfaces comme le web, le cloud, le mobile ou des API
qui permettent à l'utilisateur d'interagir avec des équipements
intelligent peuvent avoir des vulnérabilités dans
l'implémentation de l'authentification/l'autorisation ou une absence
totale de ceux-ci, des faiblesses dans le chiffrement des données
(faible ou absent), le filtrage des données, etc.
Les interfaces non sécurisées peuvent conduire
à une prise de contrôle complète de l'appareil.
2.1.4. Absence de mécanisme de mise
à jour sécurisé
Certains objets connectés n'offrent pas de mise
à jour sécurisée. Les mises à jour proposent
souvent des réparations de bugs et des nouvelles fonctionnalités,
mais leur intérêt principal réside dans la correction de
failles de sécurité Ces mises à jour doivent être
proposées par les fabricants des objets. Il y'a un véritable
manque de capacité à mettre à jour l'appareil en toute
sécurité. Cela inclut :
? Manque de validation du firmware sur
l'appareil : La validation d'un micrologiciel est une exigence
de qualité afin d'ajouter de la crédibilité aux
performances de celui-ci. Elle est réalisée par des tiers
indépendants qui s'appuient sur les caractéristiques du logiciel.
? Absence de livraison sécurisée (non
chiffrée en transit) : La transmission et le
téléchargement des mises à jour doit être
chiffrée.
? Absence de mécanismes anti-retour en
arrière ou anti-rollback : Le mécanisme de retour
en arrière permet d'annuler les dernières mises à jour.
Mais ce mécanisme permet aussi à des personnes malveillantes
d'installer des versions antérieures de firmware qui contiennent des
failles ultérieures. Il est donc important d'installer d'autres
mécanismes qui bloquent le retour en arrière du micro
logiciel.
? Absence de notifications de modifications de
sécurité en raison de mises à jour : Les
notifications de modifications de sécurité permettent d'afficher
des informations critiques sur la santé et
la sécurité d'un appareil à l'utilisateur.
Notifier ou informer sur les changements de sécurité dus aux
mises à jour est donc un mécanisme de mise à jour
sécurisé surtout lorsqu'elles doivent être faites
manuellement avec l'utilisateur de l'appareil.
2.1.5. Utilisation de composant non
sécurisé ou obsolète
On parle de l'utilisation de composants / bibliothèques
logiciels obsolètes ou non sécurisés qui pourraient
permettre à l'appareil d'être compromis. Cela inclut la
personnalisation non sécurisée des plates-formes du
système d'exploitation et l'utilisation de logiciels ou de composants
matériels tiers issus d'une chaîne d'approvisionnement
compromise.
2.1.6. Insuffisance dans la protection de
la vie privée
Il s'agit ici du stockage non sécurisé de
données personnelles, de leur traitement ou de leur utilisation sans la
permission de l'utilisateur. Les informations personnelles de l'utilisateur
stockées sur l'appareil ou dans l'écosystème qui sont
utilisées de manière non sécurisée, de
manière inappropriée ou sans autorisation.
Les données personnelles d'un utilisateur peuvent
être utilisées de plusieurs manières, que ce soit pour les
espionner, voler leur identités, les vendre, etc.
C'est un problème de confidentialité des
données.
2.1.7. Stockage ou transfert de
données sensible non sécurisé
Les données stockées, transférées,
traitées doivent être chiffrées. Si le chiffrement n'est
pas strictement implémenté, les données sont
vulnérables et deviennent un problème de sécurité
majeur.
Un attaquant peut récupérer et visualiser les
données transmises sur le réseau si celles-ci ne sont pas
chiffrées. Le manque de cryptage lors du transport des données
est répandu sur les réseaux locaux car il est facile de supposer
que le trafic du réseau local ne sera pas largement visible, cependant
dans le cas d'un réseau sans fil local, une mauvaise configuration de ce
réseau sans fil peut rendre le trafic visible à toute personne
à portée de celui-ci.
2.1.8. Manque de gestion des appareils
Il est très important de connaître des
équipements qui constituent le réseau mais également de
gérer ceux-ci de manière efficiente.
Il faut une prise en charge de la sécurité sur
les appareils déployés en production, y compris la gestion des
actifs, la gestion des mises à jour, sécurité mise hors
service, surveillance des systèmes et intervention.
Manager un objet qui a accès au réseau est d'une
importance primordial. Un objet mal géré est une
vulnérabilité pour le réseau entier.
2.1.9.
Configuration par défaut non sécurisé
Les configurations et les autorisations par défaut du
système de fichiers peuvent être non sécurisées.
Cela peut être de la négligence de la part de l'utilisateur qui ne
change pas la configuration par défaut de l'objet et d'autre fois, ce
n'est juste pas possible d'altérer les configurations du système
comme les mots de passe codés en dur ou encore des services
exposés qui fonctionnent avec des privilèges
d'administrateurs.
Les appareils ou systèmes peuvent être
livrés avec des paramètres par défaut non
sécurisés ou n'ont pas la capacité de rendre le
système plus sûr en empêchant les opérateurs de
modifier les configurations.
2.1.10. Manque de protection physique
Les attaques physiques visent à rendre l'objet
indisponible, à extraire des données sensibles pour de futures
attaques ou tout simplement prendre le contrôle de l'objet.
L'attaquant utilise des vecteurs tels que des ports USB, des
cartes SD ou d'autres moyens de stockage pour accéder au système
d'exploitation et potentiellement à toutes les données
stockées sur l'appareil, des informations privées ou des mots de
passe. L'attaquant peut aussi utiliser des fonctionnalités
destinées à la configuration ou à la maintenance.
Notre projet ne vise pas à résoudre tous ces
problèmes mais plutôt protéger les objets d'attaques qui
utilisent ces failles.
2.2. Attaques sur les objets connectés
Les objets connectés peuvent être la cible de
plusieurs attaques différentes. Toutefois nous nous sommes
concentrés ici sur les attaques majeures sur les réseaux
domotiques. Le réseau étant privé, les attaques visent
à prendre le contrôle des objets appartenant à ce
réseau ou à voler des informations.
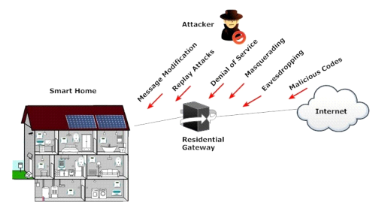
Figure 5 : les cyber-attaques
d'une maison intelligente [8]
Les principales menaces des
réseaux de maison intelligentes d'après le travail sur les
maisons intelligentes et les menaces auxquels ils font face de Shafiq Ul
Rehman et Selvakumar Manickam [8] représenté sur la
figure 5 sont :
? Écoute clandestine: Un
attaquant peut surveiller le trafic de données entrant et sortant des
réseaux domestiques intelligents sans en informer les utilisateurs
autorisés. L'écoute électronique est la menace de
sécurité reconnue la plus courante dans les systèmes
ouverts et est une attaque contre la confidentialité des environnements
de maison intelligente.
? Masquerading : Un attaquant peut
récupérer certains avantages non autorisés en devenant un
autre utilisateur légal. L'attaquant peut imiter un utilisateur
domestique non autorisé et accéder à distance au
système de réseau interne de la maison intelligente en gardant
à l'esprit que l'objectif final est d'obtenir des données
secrètes ou d'acquérir des services. Cette attaque est
fréquemment effectuée avec d'autres attaques, par exemple, une
attaque de relecture.
? Replay attack : Lors d'une attaque par
relecture, un intrus reçoit d'abord les messages qui sont
échangés entre deux parties légales et les retransmet plus
tard en tant qu'élément autorisé. L'attaquant peut
capturer une copie d'une demande de service légitime envoyée
à partir d'un appareil du réseau domestique intelligent et la
stocker. Ensuite, rejouer pour obtenir le service pour lequel l'utilisateur
à domicile a accès.
? Modification des messages : La
modification du message peut se produire lorsqu'un intrus vise à
détourner la communication entre deux parties légitimes, une
certaine modification du logiciel dans l'intention qu'il exécute de
manière malveillante ou modifie les valeurs d'une information. Ce type
d'attaque s'applique à l'intégrité des données.
? Dénis de service : L'attaque
par déni de service est utilisée dans le cadre des cas où
un intrus vise à rendre un réseau indisponible pour les
utilisateurs légitimes ou à réduire l'accessibilité
du service réseau. L'attaquant peut envoyer une énorme
quantité de messages sans fin au système de réseau
domestique intelligent afin de surcharger ses services. De cette
manière, les utilisateurs légitimes ne sont pas en mesure
d'obtenir le service du réseau domestique.
? Codes malveillants : Les codes
malveillants sont des menaces programmées par logiciel qui causent des
problèmes aux systèmes de réseau interne de la maison
intelligente exploitant ses vulnérabilités. Des codes
malveillants sont appliqués pour modifier, démolir ou obtenir des
informations et en plus pour permettre un accès non autorisé.
Pour mieux comprendre en quoi ces menaces sont dangereuses,
nous pouvons donner quelques exemples d'attaques concrets sur les objets
connectés qui utilisent plusieurs de ces failles ou plusieurs de ces
menaces et qui ont déjà causés beaucoup de
dégâts :
- Mirai : C'est un logiciel
malveillant qui transforme des ordinateurs exécutant des versions
obsolètes du noyau Linux et avec des mots de passe faible par
défaut en bots contrôlés à distance,
formant alors une armée de botnets utilisé notamment
pour réaliser des attaques à grande échelle sur les
réseaux. Une attaque en déni de service distribué
(DDoS) le 20 septembre 2016 sur le site de sécurité
informatique du journaliste Brian Krebs, une attaque sur
l'hébergeur français OVH et la cyber attaque
d'octobre 2016 contre la société Dyn (fournisseur de
système de noms de domaine) [9]. Nous pouvons aussi citer le malware
NyaDrop très similaire à celui de Mirai qui d'ailleurs a
été amélioré quelque temps après celui-ci.
- BASHLITE (également connu sous
le nom
de Gafgyt , Lizkebab , Qbot , Torlus et LizardStresser ) :
C'est un malware qui infecte
les systèmes Linux afin de lancer des attaques par
déni de service distribuées (DDoS). Il a
été utilisé pour lancer des attaques jusqu'à
400 Gbps. En 2016, il a été signalé qu'un million
d'appareils ont été infectés. Il se propage en utilisant
un dictionnaire intégré de noms d'utilisateur et de mots de passe
courants. Le logiciel malveillant se connecte à des adresses IP
aléatoires et tente de se connecter [10].
- Brickerbot : était
un logiciel malveillant qui tentait de détruire de
façon permanente les appareils non sécurisés de
l'Internet des objets. BrickerBot s'est connecté à des
appareils mal sécurisés et a exécuté des commandes
nuisibles pour les désactiver. Il a été
découvert pour la première fois par Radware (une entreprise
israélienne qui fournit des solutions de
cybersécurité) après avoir attaqué leur pot de
miel en avril 2017. Le 10 décembre 2017, BrickerBot a été
retiré. Selon Janit0r, l'auteur de BrickerBot, il a détruit plus
de dix millions d'appareils avant que celui-ci n'annonce le retrait de
BrickerBot le 10 décembre 2017 [11].
- Muhstik : Le botnet Muhstik existe
depuis mars 2018 et a une capacité d'auto-propagation de type ver pour
infecter les serveurs Linux et les appareils connectés. Muhstik a
utilisé plusieurs exploits de vulnérabilité pour infecter
différents services Linux, notamment WebLogic, WordPress et Drupal[12].
Le 28 avril 2019, une nouvelle variante du botnet Linux Muhstik a
été découverte qui exploite la dernière
vulnérabilité de serveur WebLogic pour s'installer sur des
systèmes vulnérables [13].
- Cache-cache ou Hide and Seek
: Découvert par le système de pots de miel de
BitDefender (entreprise qui fournit des solutions de
cybersécurité). Il a rassemblé plus de 90 000
appareils dans un vaste botnet en quelques jours [14]. Le malware
se propage via des informations d'identification SSH / Telnet à force
brute, ainsi que par d'anciens CVE. Il n'y a pas de serveur de commande et
de contrôle; à la place, il reçoit des mises à
jour à l'aide d'un réseau peer-to-peer personnalisé
créé à partir de périphériques
infectés [15].
La plupart de ces attaques utilisent des failles comme les
mots de passe simples, des configurations par défaut ou des services
réseaux non protégés ou mal protégés pour
infecter ces appareils.

Figure 6 : l'objet sert de
relais de diffusion d'une attaque.
Avec la figure ci-dessous, nous avons
voulu montrer que la prise de contrôle des appareils d'une maison peut
être une étape intermédiaire avant la véritable
cible. Il s'agit pour l'attaquant de prendre le contrôle du plus d'objets
connectés possible pour en faire des botnets et effectuer des attaques
sans que les utilisateurs de ces objets ne s'en rendent compte.
Avec les attaques énoncées plus haut, on peut se
rendre compte que les logiciels malveillants les plus répandues
destinées aux objets connectés les utilisent pour mener des
attaques de déni de services distribués de plus grande envergure
contre de gros sites ou de gros serveurs en ligne. Même s'il est tout
à fait possible pour un pirate informatique de se propager dans le
réseau domotique de sa victime et de lui voler des informations
personnelles ou juste de prendre le contrôle des autres objets
connectés du réseau. La cible finale n'est pas souvent l'appareil
connecté lui-même ou celui qui l'utilise à moins qu'il
s'agisse d'une attaque personnelle.
3. Quelques solutions de pare-feu des
objets connectés
3.1. IoT Sentinel
IoT Sentinel [16] est un système capable d'identifier
les types d'appareils connectés à un réseau et de
renforcer les mesures de sécurité pour chaque type d'appareil qui
possède des vulnérabilités de sécurité
potentielles. IoT Sentinel est basé sur la surveillance du comportement
de communication des appareils pendant le processus de configuration pour
générer des empreintes digitales spécifiques aux appareils
qui sont mappées aux types d'appareils à l'aide d'un
modèle de classification basé sur l'apprentissage automatique.
IoT Sentinel vise les réseaux domestiques et les
petits bureaux dans lesquels les objets sont connectés via une
passerelle qui offre des interfaces sans fil et filaire pour connecter des
appareils IP.
L'objectif d'IoT Sentinel est de restreindre la communication
avec le réseau local afin d'empêcher qu'un hacker se connecte
à un objet vulnérable afin d'exploiter ses faiblesses et pour
attaquer d'autres objets.
Afin d'arriver à ses objectif, IoT Sentinel :
? Identifie les caractéristiques d'un nouvel objet
connecté au réseau
? Répertorie les vulnérabilités de
l'objet grâce à ses caractéristiques
? Réduit la communication d'un objet nouvellement
connecté et/ou vulnérable
Pour chaque objet, ses vulnérabilités
potentielles peuvent être recensées en consultant de sources
extérieures. Le Common Vulnerabilities and
Exposures ou CVE est un
dictionnaire des informations publiques relatives aux
vulnérabilités de sécurité. Le dictionnaire est
maintenu par l'organisme MITRE, soutenu par le département de
la Sécurité intérieure des États-Unis [17]. En se
basant sur les vulnérabilités des objets qu'il identifie, IoT
Sentinel protège son réseau en limitant la communication de
l'objet vulnérable correspondant.

Figure 7 : Design d'un
système d'IoT Sentinel [16]
La figure ci-dessus tirée de
l'article [16] nous présente le design du système d'IoT
sentinel.
Elle nous montre clairement qu'IoT Sentinel a deux composants
majeurs :
- Passerelle de sécurité :
Sur la figure elle est en bleu et est constitué d'interfaces de
connexion sans fil et avec fil, des modules de création d'empreintes
digitale, de gestion des appareils Il agit comme un routeur de passerelle d'une
maison ou d'un petit bureau. Dans ce projet, les auteurs envisagent que la
passerelle de sécurité pourrait être déployé
en tant qu'équipement dédié, ou comme un module dans un
logiciel ou encore en tant que mise à jour dans un
« firmware » dans les points d'accès wifi qui ont
des ressources suffisantes. Cette passerelle gère et dresse un profil
de chaque objet du réseau et envoie ces informations appelées
empreintes digitales de l'objet au service de sécurité de l'IoT
pour une identification et une estimation des vulnérabilités de
chaque type d'objet du réseau. Basé sur les
vulnérabilités recueillies, le service de sécurité
de l'IoT retournera un niveau d'isolation que devra appliquer la passerelle de
sécurité sur l'objet.
- Service de sécurité des
objets connectés: Sous forme de nuage nommé IoT
Security Service sur la figure. Il est basé sur les empreintes digitales
de l'appareil fournies par la passerelle de sécurité, le
fournisseur de service de sécurité de l'IoT
(IoTSSP) utilise l'apprentissage par machine basé sur
des modèles de classification pour distinguer les objets suivant leurs
caractéristiques. C'est ainsi qu'on crée des profils pour chaque
objet. Pour chaque type d'objet dans les données d'entraînement,
l'IoTSSP effectue un recensement des vulnérabilités basé
sur l'interrogation des référentiels de la base de données
CVE pour les rapports de vulnérabilité liés au type de
périphérique. Lorsqu'une faille est
détectée, un niveau d'isolation est assigné nommé
«restricted ». Sinon on assigne un niveau appelé
« trusted ». Les objets inconnus se verront assigné
le niveau « strict ». Le fournisseur IoTSSP notifie
à la passerelle de sécurité le niveau d'isolation
assignée.
Pour gérer la vulnérabilité des objets,
il est possible de suivre plusieurs stratégies afin de minimiser le
risque :
- Isolation réseau : Il s'agit de
bloquer la communication d'un objet potentiellement corrompu avec d'autres
objets du réseau pour empêcher de possibles attaques. Dans ce cas,
la passerelle divise le réseau en deux sous réseaux
distincts : le réseau « trusted » et le
réseau « untrusted » où sont placés
les objets vulnérable ou corrompu qui sont strictement isolé des
autres objets.
- Filtrage de trafic : le but est
d'empêcher des personnes externes au réseau de communiquer avec
des objets vulnérables du réseau et exploiter leurs faiblesses ou
voler des données.
- Notifications à l'utilisateur : Dans
certains cas l'isolation du réseau et le filtrage du trafic ne sont pas
suffisants pour apporter une protection adéquate. Par exemple, si un
objet vulnérable est équipé d'une connexion cellulaire qui
ne peut pas être contrôlée par la passerelle de
sécurité, un autre objet compromis pourrait utiliser cette chaine
pour voler des données sensibles. La seule mesure efficace pour
sécuriser l'utilisateur du réseau est de retirer manuellement les
objets risqués.
Même si notre projet n'est pas une continuité du
projet IoT Sentinel, celui-ci nous a aidé à concevoir le
nôtre surtout en ce qui concerne l'identification des objets du
réseau. Nous nous sommes basés sur leur travail pour concevoir
l'algorithme qui permettait d'extraire les attributs dont notre futur
modèle avait besoin à l'aide des fichiers pcap dont nous
disposions mais aussi de concevoir l'algorithme d'apprentissage profond pour
l'identification des objets.
3.2. BPF
Le filtre de paquets de
Berkeley (BPF pour Berkeley Packet Filter) est une technologie
permettant entre autres d'analyser le trafic réseau et qui fournit une
interface brute aux couches de liaisons de données pour envoyer et
recevoir des paquets de couche de liaison bruts. Il est disponible sur la
plupart des systèmes d' exploitation de type
Unix. [18]
Il permet à l'utilisateur de filtrer les paquets
circulant dans le kernel tout en évitant de devoir les transférer
vers l'espace utilisateur. Toutefois, de par son côté minimaliste,
il possède peu d'instruction.
BPF permet à un processus de l'espace
utilisateur de fournir un programme de filtrage qui spécifie les
paquets qu'il souhaite recevoir. Par exemple,
un processus tcpdump peut souhaiter recevoir uniquement les
paquets qui initient une connexion TCP.
Les filtres comme ceux-ci fonctionnent en ayant des droits
administrateurs sur le système sur lequel nous travaillons car le kernel
est directement sollicité. Pour notre projet, avoir accès au
kernel et avoir des droits d'administrateurs est indispensable. De plus, il
serait très difficile pour nous de faire fonctionner un logiciel de
pare-feu propriétaire et qui a besoin de règles alors que nous
nous basons ici sur des modèles de prédiction. Nous avons
utilisé les syntaxes de filtre BPF pour filtrer le trafic reçu.
En fait même s'il n'est pas téléchargé ou
directement utilisé, certaines bibliothèques comme scapy
l'utilisent pour gérer les paquets dans le réseau.
3.3. Filter.tlk
Filter.tlk [19] est le fruit de recherches sur la protection
des objets connectés.
Sur la figure ci-dessous, Filter.tlk comprend trois
utilitaires différents pour aider à la création de filtres
BPF:
? une interface pour concevoir les conditions de
filtrage BPF, BPF design aid tool. BDAT est responsable de la
création de filtres BPF en tant que conditions définies à
partir des couches de transport et de réseau. BDAT a été
conçue comme une application Java autonome.
? un plugin Wireshark LUA pour automatiser le test des
filtres BPF avec les ensembles de données de paquets PCAP,
BPF testing tool. Le langage Lua a été utilisé
pour implémenter un écouteur Wireshark pour évaluer les
filtres et compter les paquets correspondant à la condition BPF cible
(acceptée) ou non (rejetée). Il applique un filtre ou un ensemble
de filtres sur un fichier pcap. En conséquence, nous obtenons des
informations pour chaque filtre appliqué sur le nombre de packages
analysés, acceptés et rejetés.
? un script pour compiler facilement les filtres BPF
et créer des règles iptables, IPTable rule
builder. IPTRB est un script bash qui utilise la commande dialog pour
fournir une interface utilisateur graphique intuitive et facile à
utiliser. Il peut transformer les filtres BPF non compilés en
règles IPTables complètes guidées par l'interface. La
règle peut être générée à des fins de
filtrage et / ou d'enregistrement de paquets nuisibles.

Figure 8 : Architecture de
filter.tlk [19]
Comme nous pouvons le déduire de la figure ci-dessus,
la conception d'une règle de pare-feu avec Filter.tlk comprend trois
étapes réalisées avec différents outils inclus dans
le package. Nous commençons par profiter du BDAT (outil d'aide à
la conception BPF) pour concevoir une condition de filtrage afin de
détecter un certain type de paquet. Ensuite Les filtres BPF peuvent
être testés avec différents ensembles de paquets (un
ensemble de paquets correspondant au format pcap et d'autres ne correspondant
pas au format pcap) à l'aide de l'outil de test BPF (BTT).Une fois les
règles BPF testées, elles peuvent être finalement
transformées en règles iptables à l'aide du script
IPTRB.
Enfin, ils ont utilisé Ansible (un outil
d'automatisation informatique) pour automatiser l'installation de Filter.tlk
sur toutes les plates-formes prises en charge.
Notre projet diffère de celui-ci dans le sens où
nous ne créons pas de règles iptables. Nous voulons simplifier le
travail du pare-feu. Les modèles d'apprentissage profond proposés
sont censés nous aider à détecter plus facilement le
trafic dont nous ne voulons pas et à décider plus rapidement
quel paquet est accepté et quel paquet est refusé.
L'inconvénient que nous avons trouvé à cet outil serait la
création de règles redondantes ou qui se ressemblent
énormément où l'un ferait en partie le travail d'une autre
règle.
4. Contexte et intérêt du
projet
Au Cameroun, les objets connectés sont plus en vogue
qu'on ne le croit. Les montres connectées grâce auxquelles on
reçoit nos messages et qui possèdent de ce fait nos informations
personnelles, les télévisions grâce auxquelles on peut
télécharger des jeux via sa console par exemple, les
écouteurs sans fil, les haut-parleurs Bluetooth, des caméras de
surveillance et même des brassards avec des capteurs de rythmes
cardiaques. Pour le moment cela concerne surtout des objets de divertissement
ou de simples gadgets mais il existe de plus en plus de start-up camerounaises
tel que ndoto [20] qui conçoit des compteurs intelligents par exemple,
d'ailleurs ENEO le concessionnaire du service public de
l'électricité au Cameroun a déjà installé
environ 4000 dans les ménages camerounais [21].
De ce fait, le Cameroun comme tous les autres pays du monde
n'est pas du tout épargné par les menaces qui planent sur les
objets connectés. D'après la carte des menaces de Kapersky, le
Cameroun est le pays 103ème pays le plus attaqué au
monde.

Figure 9 : classement des pays du
monde par détection d'activité de botnet [22]
Kaspersky fournit une carte des menaces
informatiques en temps réel. Sur le classement par pays ci-dessus vous
pouvez observer l'activité des botnets détectés dans le
mode les dernières semaines. Le Cameroun est 9ème
[22]. La détection de l'activité botnet montre les statistiques
des adresses IP identifiées des victimes d'attaques DDoS et des serveurs
C&C des botnet acquis avec le SSoS Intelligence System de Kaspersky.
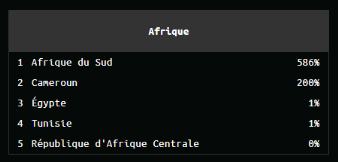
Figure 10 : Classement sur le
continent africain des activités de détection de botnet [22]
Et sur le classement du continent
africain, est 2ème toujours Selon Kaspersky.
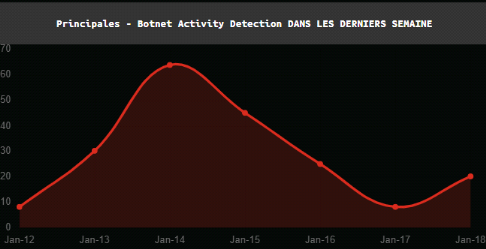
Figure 11 : Détection
d'activité de botnet au Cameroun du 12 janvier au 18 janvier [22]
Ceci est le volume des attaques de
botnet qu'a relevé Kaspersky du 12 janvier au 18 janvier 2021 au
Cameroun.
Le Cameroun reste donc une cible d'attaques de botnet à
travers le monde à ne pas négliger. D'ailleurs Kaspersky
décrit aussi le volume des intrusions détectées et
répertorié au Cameroun.

Figure 12 : Détection
d'intrusion au Cameroun du 11 Janvier au 17 Janvier[22]
Les intrusions cherchent à
exploiter à distances des applications, des services et des
systèmes d'exploitation vulnérables ou mal configurés via
un réseau pour réaliser l'exécution de code arbitraire et
effectuer des activités réseau non autorisées. Le Cameroun
a subi des dizaines de milliers d'intrusions en l'espace de 7 jours.
La carte des attaques de LookingGlass Threat Map [23]
présente aussi une vue des attaques en temps réel à partir
du moment où on se connecte donc il n'y a pas d'historique comme sur
Kaspersky. Au moment de la connexion un point d'infection est apparu sur le
Cameroun.

Figure 13 : Vue en temps
réel d'une infection du botnet Sality su MTN Cameroun [23]
Sality est un virus infectant des
fichiers. MTN Network Solutions Cameroun à Douala vers 08:15 subissait
une attaque de ce virus.
D'ailleurs vous pouvez observer sur les statistiques que le jour
où cette capture d'écran a été faite soit le 19
janvier, il représentait presque 90% des botnets détectés.
Les attaques vers le Cameroun étaient rares et très courtes,
juste quelques secondes. De plus, la plupart des entreprises attaquées
étaient des opérateurs de télécommunications et des
fournisseurs d'accès à internet.
Nous avons déjà démontré plus haut
que même si les objets connectés ne sont pas toujours des cibles,
bien qu'il soit possible de voler des données personnelles, de bloquer
les appareils ou alors d'espionner leurs utilisateurs, elles servent
d'appareils zombies qui permettent ensuite de s'attaquer à de plus gros
sites ou compagnies dans le monde afin de faire du chantage pour obtenir de
l'argent ou juste pour saboter une entreprise.
La véritable cible des attaques visant les objets
connectées et aussi la vraie bénéficiaire d'une issue
à ce problème n'est pas un pays ou un utilisateur en particulier
mais plutôt les infrastructures informatiques de grosses entreprises.
Les solutions présentées plus haut ont chacune
pour objectif de protéger les objets connectés. IoT Sentinel
utilise une base de données qui le renseigne sur le
« danger » que peut représenter un objet du
réseau pour ensuite l'isoler et empêcher toute attaque vers le
réseau IoT. BPF est un outil utilisé par les systèmes
d'exploitation qui est utilisé de manière implicite lors de la
construction de filtres. Et filter.tlk propose de filtrer les paquets et
concevoir des règles de pare-feu afin de protéger le
réseau ou un système.
Notre approche est différente. Nous ne voulons pas
créer des règles de pare-feu qu'il faudra gérer par la
suite. Ensuite se baser sur une base de données mise à jour est
une solution qui présenterait des limites au cas où un objet ne
présente pas de « mauvais profil » mais serait une
fois entré dans la zone « trusted » plus tard
victime d'une attaque et propagent un virus.
Nous proposons d'utiliser une passerelle IoT pour filtrer les
paquets vers et depuis les paquets du réseau interne. Ce type
d'équipement sert de pont entre les capteurs, objets connectés,
équipements réseaux et le Cloud. Il comprend souvent plusieurs
ports pour plusieurs protocoles différents et grâce à lui
on peut connecter divers appareils IoT. De ce fait, on dégage d'abord
l'une des premières limites lorsqu'on veut créer une solution
pour l'IoT, la diversité des objets et protocoles de communication
rencontrés.
Nous ne sommes pas liés à un objet en
particulier et nous devrons obtenir des données variées pour
proposées des modèles qui ne sont pas dépendant d'une
seule technologie, qui devra fonctionner sur ces passerelles. Ces passerelles
pourront ainsi protéger tout le réseau d'appareils dont elle
gère la communication grâce aux modèles d'apprentissage
profond proposés.
5. Problématique
Les utilisateurs s'équipent d'objets connectés
sans vraiment se rendre compte de la vulnérabilité de ces objets
face aux hackers. En effet, la plupart des consommateurs d'objets
connectés ne s'intéressent pas vraiment à la
sécurité de leurs objets connectés ou ne voient pas en
quoi c'est important. Ceci est dû entre autres au fait qu'ils ne
manipulent pas de système d'exploitation de l'objet c'est-à-dire
pouvoir par exemple mettre à jour le système et n'ont
accès qu'aux options proposé par l'objet.
Ces objets connectés qui ne possèdent souvent
aucun moyen de protection à part des clés de chiffrement faible
pour assurer la confidentialité et l'intégrité ou encore
des mots de passe faible, peuvent être utilisés :
- Pour se propager vers nos téléphones
portables et ordinateurs
- Rendre vos appareils inutilisables
- Comme botnet pour attaqués des gros sites internet
ou serveurs important afin de les rendre indisponible
- Vous espionner et voler des informations confidentielles
voire votre identité
De plus, très peu de fabricants de ces objets
conçoivent la sécurité de l'objet. Ce n'est souvent
qu'après des attaques ou la révélation de leur faille dans
les médias que ceux-ci s'y intéressent un peu plus et fournissent
des mises à jour ou alors vendent d'autres objets mis à jour. Il
se peut aussi qu'ils ne connaissent pas les vulnérabilités des
objets qu'ils conçoivent.
De nouveaux objets peuvent intégrer le réseau
à tout moment, est-ce un objet fiable ? Faut-il autoriser les
connexions avec l'extérieur ? Comment surveiller le trafic et
éviter les connexions malveillantes ? Comment protéger un
réseau d'objets connectés
Le réseau domotique est un réseau privé
mais connecté à internet qui lui est un réseau public et
les objets qui composent le réseau domotique sont peu
protégés face aux intrusions à cause de leur
capacité limitée.
Nous suggérons d'installer un équipement ou une
application sur une passerelle d'objets connectés à la
frontière entre le réseau privé et le réseau public
pour filtrer le trafic échangé et ne laisser passer que le trafic
autorisé pourrait protéger le réseau domotique des
intrusions. Il pourrait aussi empêcher qu'un hacker n'exploite les
failles d'un objet du réseau privé.
Ceci se fait déjà avec un pare-feu classique,
sauf qu'un pare-feu utilise des règles qui ont besoin d'être
ajouté manuellement par un administrateur qui doit aussi se charger de
les mettre à jour, gérer des anomalies comme deux règles
avec des actions filtrantes différentes qui correspondent à un
même paquet, accepter un trafic vers des services ou objets inexistants,
une règle qui n'est jamais utilisé ou encore ou encore des
règles redondantes[24].
La réalisation d'un logiciel complet qui viendrait
résoudre les problèmes d'anomalies des pare-feu classiques
demanderait la réalisation de plusieurs algorithmes presque pour chaque
anomalie ou tâche ce qui serait très long !
D'où notre approche de faire intervenir une
intelligence artificielle pour effectuer des opérations de filtrage de
manière automatique en détectant la nature du trafic et en
identifiant les objets concernés, pour diminuer le travail d'un pare-feu
en allégeant sa tache de filtre de paquets. L'avantage d'un
modèle par rapport à un logiciel qu'on programmait pour faire ce
travail est qu'il demande moins de programmation pour décrire en
détail les étapes de calcul nécessaire à
l'ordinateur ou encore à gérer moins de bug lors de ces calculs.
6. Objectif du projet
L'objectif principal de ce mémoire est le
suivant :
Protéger les objets vulnérables d'un
réseau domotique en mettant en oeuvre le filtrage du trafic au niveau de
la passerelle grâce à l'apprentissage automatique.
Nous proposons de protéger un réseau d'objets
connectés d'attaques très connus en créant des
modèles d'apprentissage automatique qui vont permettre de filtrer le
trafic réseau. Notre proposition serait, grâce à
l'intelligence artificielle, de nous servir d'algorithmes pour
reconnaître beaucoup plus facilement et surtout plus rapidement le trafic
malveillant spécifiques aux objets connectés et pouvoir ainsi
accepter ou rejeter un paquet. Tout en identifiant les objets du réseau
et reconnaître plus rapidement les objets piratés ou malveillants.
Nous allègerons le travail d'un pare-feu.
Pour cela nous pouvons définir plusieurs sous objectifs
qui sont :
? Pouvoir analyser un réseau d'objets connectés
à travers la passerelle pour identifier les différents types
d'objets
? Analyser le trafic et détecter les paquets
malveillants en se basant sur quelques attaques connues des objets
connectés
? Bloquer les connexions malveillantes
en se basant sur des prédictions faites par le modèle
CHAPITRE 2 :
MÉTHODOLOGIE
Introduction
Dans ce chapitre nous allons principalement aborder notre
méthodologie de travail pour atteindre les objectifs posés,
proposer des modèles et suggérer une solution de filtrage des
paquets. Nous allons présenter les concepts sur les algorithmes
d'apprentissage profond et d'empreinte digitale. Nous allons présenter
la méthodologie de créations des modèles de la collecte
des données jusqu'à la création des réseaux de
neurones. Enfin nous allons parler de l'implémentation d'un filtre qui
fonctionne avec le kernel et qui permet de filtrer des paquets.
1. Définition de concepts
clés
1.1. Algorithme d'apprentissage profond
L'apprentissage profond est un sous domaine d'intelligence
artificielle qui s'appuie sur un réseau de neurones artificiels. Il
permet globalement « d'apprendre à reconnaître,
d'identifier ou prédire ». La particularité
intéressante de l'intelligence artificielle est d'apprendre de ses
erreurs à peu près comme un être capable de penser
à beaucoup encourager les recherches dans le but de développer
cette discipline. Il est présent aujourd'hui dans plusieurs domaines
différents tels que la reconnaissance d'image, la traduction
automatique, la voiture autonome, le diagnostic médical, des
recommandations personnalisées dans nos e-commerces, les
modérateurs automatique, les chatbots, l'exploration spatiale et bien
évidement la sécurité informatique dans la
détection de malware [25].
Les réseaux de neurones artificiels sont
inspirés de l'architecture des réseaux de neurones humains.
C'est une combinaison de plusieurs neurones connectés sous la forme d'un
réseau. Ces neurones sont interconnectés pour traiter et
mémoriser des informations, comparer des problèmes ou situations
quelconque avec des situations (informations en entrée, erreurs, etc)
similaires passées, analyser les solutions et résoudre le
problème de la meilleure façon possible. La figure
ci-dessous nous montre un exemple basique d'un réseau neuronal. Un
réseau neuronal artificiel a une couche d'entrée, une ou
plusieurs couches cachées intermédiaires et une couche de sortie.
Sa forme la plus simple est le perceptron simple où on retrouve deux
couches. La couche d'entré et la couche de sortie.

Figure 14 : un réseau de
neurone avec trois couches
Tel que montré à la
figure ci-dessus chaque couche possède un ensemble de neurones
connectés aux neurones de la couche suivante excepté la couche de
sortie.
La figure ci-dessous nous montre les détails des liens
entre les neurones de la couche précédente et un neurone de la
couche suivante. Chaque lien connectant un neurone à un autre est
associé à un poids wi
représentant la force de la connexion.
La somme (poids wi multiplié par la valeur de
l'entrée précédente du lien xi)
ou fonction d'agrégation des liens de la couche précédente
est multipliée par la fonction d'activation du neurone de la couche
suivante ce qui donne une sortie représentative de l'activation du
neurone. La figure ci-dessous nous montre que chaque neurone d'une couche
effectue des calculs en fonction des sorties des couches
précédentes.

Figure 15 : Connexion des
entrées d'une couche précédente vers un neurone de la
couche suivante
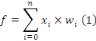
- f est la fonction
d'agrégation
- x est la valeur de la sortie d'un des neurones de la couche
précédente
- w est le poids synaptique d'un lien
Une fonction d'activation est une fonction mathématique
appliquée à un signal de sortie d'un neurone [25]. Il correspond
à un seuil d'activation qui une fois atteint entraine une réponse
du neurone. Il existe plusieurs fonctions d'activation. Par exemple la fonction
rampe ou identité f 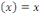 (2), la fonction logistique ou sigmoïde (2), la fonction logistique ou sigmoïde 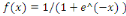 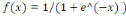 (3), la fonction relu ou unité de rectification
linéaire (3), la fonction relu ou unité de rectification
linéaire  (4)ou encore fonction tangente hyperbolique (4)ou encore fonction tangente hyperbolique   (5). (5).
Nous remarquons qu'il existe dans la plupart des cas un seuil
pour activer le neurone. Par exemple pour la fonction sigmoïde x elle se
trouve entre -1 et 1 ou encore celle de la fonction Relu où x doit
être supérieur à zéro.
Dans le cadre de notre projet deux types de réseau de
neurone nous ont intéressés, le perceptron multicouche et le
réseau récurrent LSTM.
Le perceptron multicouche (PMC en français ou MLP pour
MultiLayer perceptron) est un algorithme d'apprentissage dans lequel
l'information circule dans un seul sens et qui apprend une fonction en
s'entraînant à partir d'un jeu de donnée ou dataset avec
des attributs en entrées, plusieurs couches intermédiaires et des
classe/labels à prédire en sortie.
L'apprentissage du MLP se fait généralement par
rétro-propagation. Cela permet de trouver les poids minimisant une
fonction d'erreur globale. Elle permet de calculer le gradient de l'erreur pour
chaque neurone du réseau, de la dernière couche vers la
première.
Il y'a deux étapes principales dans la rétro
propagation. Nous avons en premier lieu la propagation
« avant » avec un ensemble d'opérations qui
permettent de calculer des valeurs d'activation des neurones de sorties. Nous
déterminons ainsi l'erreur d'apprentissage.
Ensuite la propagation « arrière »,
on circule des sorties vers les entrées. L'erreur d'apprentissage va
être distribuée aux neurones de couches cachées afin de
pouvoir ajuster plus tard les poids du réseau.
Le nouveau poids est égal à la somme de l'ancien
poids ajouté au produit du taux d'apprentissage, de l'erreur du neurone
actuel et de la sortie de la couche précédente.
Les phases de rétro-propagation sont
répétées autant de fois que le nombre
d'échantillons du jeu de données. Une fois terminé on
calcule la somme des erreurs d'apprentissage.
Les réseaux de neurones récurrents sont quant
à eux un type de réseau de neurones artificiel où les
liens entre les neurones forment un cycle direct ou encore où il existe
des liens récurrents [26]. Cela crée un état interne du
réseau qui permet d'avoir un comportement dynamique et une
mémoire. La spécificité d'un RNN est qu'ils ont une
«mémoire» qui capture des informations sur ce qui a
été calculé jusqu'à présent. Les
données sont récupérées au niveau de la couche
d'entrée. L'ensemble des neurones d'entrées doivent correspondre
aux attributs du jeu de données.
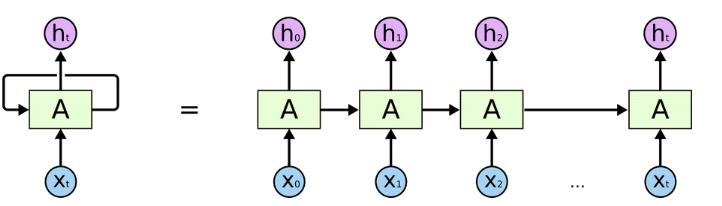
Figure 16 : Détail de
fonctionnement du réseau LSTM [26]
? Xt est l'entrée à un instant t
? Ht est la sortie à un instant t
? A est l'état caché à un instant t et
est calculé en fonction de l'état précédent
D'après la figure ci-dessus nous voyons que dans ce
type de réseau, chaque neurone peut utiliser sa mémoire interne
pour maintenir l'information concernant l'entrée
précédente. Cela signifie qu'en plus de pouvoir faire des
prédictions, ils peuvent apprendre les séquences d'un
problème et alors généré entièrement une
nouvelle séquence plausible du problème en question. Dans notre
cas par exemple, nous pourrions totalement générer de nouveaux
paquets plausibles ainsi que leurs classes. Cependant ce n'était pas le
but ici, nous voulions juste prédire la classe.
Le LSTM Les réseaux de mémoire à long
terme à court terme généralement appelés simplement
(LSTM : Long Short Term Memory) sont un type spécial de RNN. La cellule
LSTM est une adaptation de la couche récurrente qui permet aux signaux
plus anciens des couches profondes de se déplacer vers la cellule A du
présent.
L'apprentissage est une phase du développement d'un
réseau de neurones durant laquelle le comportement du réseau est
modifié jusqu'à l'obtention du résultat
désiré ou s'approchant de celui-ci !
Quelque soit le type de réseau, il existe plusieurs
types d'apprentissage :
? Apprentissage supervisé : Dans
ce type d'apprentissage, nous avons en entrées des données qui
sont associées à une étiquette ou une classe en sortie.
L'algorithme durant son entraînement va apprendre à
reconnaître ces données comme correspondant à ces
étiquettes particulières. Par la suite, il sera capable de
prédire une cible grâce à de nouvelles données
différentes de celles utilisées pendant l'entraînement.
? Apprentissage non supervisé :
Dans ce cas les données ne possèdent pas d'étiquettes.
l'algorithme pendant l'entraînement s'applique à trouver seul les
similarités et distinctions au sein de ces données et à
regrouper ensemble celles qui partagent des caractéristiques
communes.
? Apprentissage par renforcement : Elle
se base sur un cycle d'expérience / récompense et améliore
les performances à chaque itération. Donc lorsque
l'algorithme fait une bonne prédiction, il est récompensé
et ainsi encourager à en faire plus !
1.2. Empreinte digitale
L'empreinte digitale d'ordinateur ou empreinte
digitale de navigateur ; en anglais, device
fingerprint, machine
fingerprint ou browser fingerprint, est une
technique permettant de déterminer ou de distinguer de
manière anonyme un internaute ou un appareil afin de
surveiller ou observer son usage du web ou sa
localisation. Une empreinte digitale est
collectée sur un dispositif informatique distant pour effectuer une
identification, une reconnaissance ou une inspection.
C'est un système de traçage qui permet de
récolter des informations sur les activités
d'un appareil en ligne. De nos jours, il est
très utilisé sur des sites web pour identifier leurs
utilisateurs, construire des profils et proposer des publicités ou
réaliser des campagnes marketing très ciblées [27].
Une empreinte digitale est composée
d'une synthèse ou série d'informations, recueillie grâce
à un algorithme d'apprentissage profond, qui combinées forment
une signature unique pour l'appareil [28].
Les empreintes digitales rencontrent globalement deux
limites :
? Diversité : Deux appareils ne
doivent pas avoir la même empreinte mais en pratique un grand nombre
d'appareils ont souvent les mêmes données de configuration, et
donc possiblement la même empreinte.
? Stabilité : Les empreintes
digitales doivent restées les mêmes au fil du
temps cependant, la configuration d'un appareil peut changer.
Pour augmenter la stabilité nous pouvons réduire
le nombre de paramètres à ceux qui sont très peu
susceptibles de changer ; cependant, cela réduira la
diversité. Et une façon d'augmenter la diversité est de
récolter un plus grand nombre de paramètres de l'appareil ;
par contre, cela réduit la stabilité, car il y a alors un plus
grand nombre de paramètres qui peuvent changer au fil du temps.
On voit bien que l'amélioration de l'un a tendance
à avoir une incidence défavorable sur l'autre. Cependant dans le
cadre de notre projet dans lequel nous ne prévoyons qu'un tout petit
réseau où il y'a rarement des dizaines d'appareils identiques
comme des ordinateurs ou des imprimantes, il y'a donc moins de
diversité. De plus même s'il y aurait un problème de
stabilité, leur petit nombre dans le réseau fait en sorte que ce
ne soit pas un gros problème.
Il existe 3 façons de collecter les paramètres dont
nous avons besoin pour créer un jeu de données. [29].
La collecte passive se fait sans interrogation évidente
de l'appareil client, juste en surveillant ses communications. Une telle
collecte repose sur l'écoute des communications de l'appareil telles que
la configuration TCP/IP de l'appareil ou les paramètres de
la connexion sans fil.
La collecte active suppose que l'utilisateur accepte des
requêtes invasives c'est-à-dire qu'on collecte des informations
directement sur l'appareil en installant par exemple sur celui-ci un programme
exécutable chargé de faire ce travail et qui pourra avoir
accès à des informations qui ne sont disponible que de cette
façon comme l'adresse MAC.
Notre troisième classe de collecte, que nous appelons
la collecte d'empreinte digitale semi-passive, suppose qu'après que
celui qui veut générer l'empreinte aie initié une
connexion, il a par la suite la capacité d'interagir avec celui dont on
collecte l'empreinte sur cette connexion; par exemple un FAI (Fournisseurs
d'accès à internet) dans le milieu capable de modifier les
paquets en cours de route.
Les collectes passive et semi-passive ont pour avantages
qu'elles peuvent être effectuées alors que l'appareil en question
est derrière un NAT ou un firewall. Les collectes semi-passives et
actives peuvent se dérouler pendant une longue période de temps.
De plus, ces méthodes ne nécessitent pas la coopération
des appareils dont nous essayons de générer les empreintes.
Quelques outils de détection d'OS ou des paquets sont
scapy, Ethercap, Nmap, le pare-feu Netfilter grâce au kernel ou
encore dpkt.
Ces empreintes en plus d'identifier les objets sont surtout
très utiles pour identifier des appareils ou utilisateurs. Cela rendrait
la tâche Ceux qui tenteraient d'usurper l'identité d'un
utilisateur ou se faire passer pour un appareil du réseau.
L'implémentation de l'empreinte digitale par
apprentissage automatique est tout à fait possible et a
déjà été faite avec des projets tels que IoT
Sentinel. Les performances des algorithmes d'apprentissage dans la
prédiction ou l'identification ont fortement encouragé le
développement de projets dans ce sens.
2. Conception de la solution
2.1. Architecture de la solution
Pour pouvoir atteindre notre objectif, nous proposons une
solution qui devrait être déployé sur une passerelle ou
n'importe quel équipement qui servirait de passerelle aux objets
connectés tel qu'on peut le voir sur la figure ci-dessous. Cette
passerelle représente la frontière entre le réseau
privé que forment les objets connectés et le réseau
public.
Nous avons pris le réseau domotique comme notre
réseau de choix cependant, notre approche est devrait donner sur tous
les réseaux informatiques avec une portée de quelques dizaines de
mètres. Le travail que nous avons effectué ne fonctionne qu'avec
Linux car cela nous donne la possibilité d'accéder au kernel sans
droit spécial d'utilisation parce que ce n'est pas un système
propriétaire.

Figure 17 :
Architecture du réseau interne vers le réseau externe
La figure 17 nous présente plus
clairement le rôle de frontière joué par la passerelle.
Nous suggérons qu'il y aura un réseau interne où seront
connectés les objets à la passerelle qui servira de limite entre
2 réseaux et le réseau externe dont nous voulons surtout limiter
la communication avec le réseau d'objets connectés. C'est donc au
niveau de la passerelle, qu'il y aura toutes les opérations de
traitement et d'inspection des paquets. Elle s'occupera de surveiller les
paquets, les analyser et prendre des décisions. Tout le trafic du
réseau domotique vers internet devra passer par elle pour assurer une
bonne sécurité. Que ce soit le trafic venant du réseau
interne ou le trafic venant du réseau externe, tout doit être
inspecté.
Figure 18 : Architecture de la
solution
Pour prendre des décisions,
notre programme se base sur les résultats des modèles de
prédictions d'apprentissage profond et ensuite décide ce qu'il
faut faire d'un paquet ou pas comme nous le voyons sur la figure 18. Notre
modèle devrait faciliter le travail du pare-feu en prenant les
décisions de rejeter un paquet ou de l'accepter en fonction des
prédictions c'est-à-dire de la nature du paquet. Et permettre
à un administrateur de connaître les objets connectés de
son réseau toujours grâce aux modèles de d'apprentissage
profond.

Figure 19 : modèle
d'apprentissage profond pour prédire le trafic bénin ou
malicieux
Les figures 19 et 20 nous
présentent les étapes avant la prédiction. Tout d'abord il
nous faut collecter les données et extraire les attributs dont nous
avons besoin. Ensuite nous les pré traitons pour obtenir des
données compréhensibles par le modèle qui va pouvoir
prédire.
Figure 20 : Architecture du
modèle d'identification des objets grâce à l'apprentissage
profond
Ce sont les données
utilisées ainsi que l'objectif de prédiction qui
différencient les deux algorithmes. Ici nous ne visons pas à
protéger un objet en particulier. De ce fait, nous nous concentrons
plutôt sur les types d'attaques qui s'appuient sur les failles dont elles
sont victimes.
2.2. Les différentes fonctionnalités
Notre travail dans son ensemble devrais permettre de :
- Identifier un type d'objet : Chaque
objet dans le réseau devra être identifié afin qu'on puisse
connaître le type d'objet dont il s'agit.
- Déterminer la nature du trafic :
Cette fonctionnalité est importante car c'est à partir de la
nature du trafic surveillé qu'on déterminera si nous devons ou
pas rejeter un paquet.
- Bloquer les paquets malveillants : Cette
décision sera donc prise en fonction de la prédiction du
modèle
3. Outils utilisés
Pour concevoir les modèles proposées et notre
application, nous avons utilisés :
Tableau
1 : Les outils utilisés pour concevoir les modèles
|
Outils
|
Description
|
|
Python

|
Python est un langage de programmation
interprété et multiplateformes. Il est orienté objet. Nous
l'avons utilisé comme langage de script et de développement pour
la création de nos algorithmes et applications. Il est
particulièrement répandu dans le monde scientifique, et
possède de nombreuses bibliothèques optimisées
destinées au calcul numérique.
|
|
Anaconda

|
Anaconda est une distribution libre et
open source des langages de programmation Python et
R appliqué au développement d'applications
dédiées à la science des données et à
l'apprentissage automatique. C'est sur ce logiciel que nous avons
installé toutes les autres bibliothèques et outils qui nous ont
aidés à concevoir nos modèles d'apprentissage profond. Il
nous a permis de traiter une très grande quantité de
données mais aussi de les analyser et de faire des calculs
scientifiques. Il utilise beaucoup de ressources physiques.
|
|
Jupyter Notebook

|
Jupyter Notebook est une application Web open
source qui nous a permis de créer du code python, des équations,
des visualisations et du texte narratif. Grâce à lui nous avons pu
nettoyer et transformer les données, les visualiser et faire de
l'apprentissage automatique. Il est aussi possible de faire de la simulation
numérique, la modélisation statistique et bien plus encore.
|
|
Tensorflows

|
TensorFlow est un outil open source
d'apprentissage automatique de bout en bout dédiée au machine
learning développé par Google. Il est doté d'une interface
pour Python, Julia et R. Il nous a permis de développer des
réseaux de neurones après avoir fait le prétraitement des
données. En effet, elle propose un écosystème complet et
flexible d'outils, de bibliothèques et de ressources communautaires qui
nous a permis de développer des algorithmes de machine learning et
d'apprentissage profond, et de créer et de déployer facilement
des modèles utilisables dans une application.
|
|
Spyder

|
Spyder est un environnement de
développement scientifique gratuit et open source écrit en
Python, pour Python. Il intègre de nombreuses bibliothèques
d'usage scientifique : Matplotlib, NumPy, SciPy et IPython.
Cet environnement inclus dans Anaconda nous a permis de
créer et tester des applications python.
|
|
VirtualBox

|
VirtualBox [30] est un puissant logiciel libre
de virtualisation x86 et AMD64/Intel64 pour les entreprises et
les particuliers publié par Oracle. VirtualBox fonctionne sur les
hôtes Windows, Linux, Macintosh et Solaris.
Nous nous sommes servis de ce logiciel pour créer des
machines virtuelles afin de tester la capacité de filtre de paquet d'une
passerelle.
|
|
Ubuntu
|
Ubuntu [31] est un système d'exploitation basé
sur Debian GNU/Linux. Ubuntu est une
distribution GNU/Linux, c'est-à-dire un
regroupement de logiciels libres qui forment un tout
cohérent, modulable et adapté à l'utilisateur. Le
projet GNU a pour but de proposer un système
d'exploitation entièrement libre. Nous avons utilisé ce logiciel
sur les différentes machines virtuelles d'une part parce qu'il est
facile de créer un réseau et de manipuler des paquets et d'autre
part il permet d'avoir facilement accès au kernel pour filtrer des
paquets sans utiliser de logiciels propriétaire.
|
L'ordinateur utilisé pour réaliser ce projet
possède les caractéristiques suivantes :
- Modèle : Latitude E6520
- Type : PC à base x64
- Stockage : 500Go
- Système d'exploitation :
Microsoft Windows 10 Professionnel
- Ram : 8,00 Go
- Processeur : Intel(R)
Core™à i5-2540M CPU @2.60 GHz, 26010 MHz, 2 coeur(s), 4 processeurs
logiques
4. Conception des modèles
4.1. Conception des modèles d'apprentissage
profond
La création de nos modèles d'apprentissage
profond suit une succession d'étapes. Nous avons suivi les
étapes ci-après :
1- Acquisition de données :
l'algorithme se nourrissant des données en entrée, c'est une
étape importante.
2- Préparation et nettoyage des
données : les données recueillies doivent
être retouchées avant utilisation.
3- Création du modèle :
Nous créons les différentes couches avec le nombre de neurones
pour chaque couche et en spécifiant la fonction d'activation.
4- Évaluation : une fois
l'algorithme d'apprentissage automatique entraîné sur un premier
jeu de données, nous évaluerons sur un deuxième ensemble
de données qui sert de test afin de vérifier que le modèle
ne fasse pas de « sur apprentissage ».
5- Déploiement : le modèle
est déployé en production pour faire des prédictions, et
potentiellement utiliser les nouvelles données en entrée pour se
ré-entraîner et être amélioré.
Nous aborderons les trois premières étapes dans
ce chapitre et les deux autres dans le dernier chapitre.
4.1.1. Acquisition
du jeu de données
La première étape de conception de nos
modèles consiste en l'acquisition des jeux de données. Il nous
fallait obtenir les jeux de données des deux modèles
proposés. L'un pour identifier les objets du réseau et l'autre
pour déterminer la nature du trafic.
D'une part, nous avons commencé par obtenir un jeu de
données afin d'entraîner l'algorithme de réseau de
neurones détectant la nature du trafic d'objets connectés,
bénins ou malicieux.
Nous avons utilisé le jeu de données d'IoT-23.
IoT-23 est un nouvel ensemble de données sur le trafic réseau des
objets connectés. Il dispose de 20 captures de logiciels malveillants
exécutées sur des appareils connectés et de 3 captures
pour le trafic d'appareils connectés bénins.
Il a été publié pour la première
fois en janvier 2020, avec des captures allant de 2018 à 2019. Ce trafic
réseau a été capturé dans le laboratoire
Stratosphère, groupe AIC, FEL, Université CTU, de la
République tchèque [32]. Son objectif est de proposer un vaste
ensemble de données d'infections de logiciels malveillants réels
et étiquetés et de trafic bénin aux chercheurs pour
développer des algorithmes d'apprentissage automatique. Cet ensemble de
données et ses recherches sont financés par Avast Software
[33].
Cet ensemble de données possède deux types
d'ensembles de données: Il contient du trafic réseau mixte
(malveillant et bénin) et du trafic bénin uniquement. Les flux de
trafic bénins et malveillants ont des colonnes pour les
étiquettes de description du comportement du réseau. Ces
étiquettes sont attribuées suivant le processus suivant:
? Analyse : Le fichier pcap d'origine
est analysé manuellement. Les flux suspects sont détectés
et les libellés sont attribués dans un tableau de bord
d'analyse.
? Étiquetage : Un fichier
labels.csv est généré par l'analyste. Ce fichier
labels.csv contient un ensemble de règles utilisées par un script
python pour ajouter des étiquettes à chaque flux.
? Ajout des étiquettes : Le
script python lit les données de chaque flux dans le fichier conn.log
(jeu de données non étiqueté) et compare ces
données avec les règles trouvées dans le fichier
labels.csv. Le script compare chaque flux avec les données du fichier
csv et si les données de flux correspondent aux critères
d'étiquetage, l'étiquette correspondante est ajoutée.
Nous avons utilisé le jeu de données
étiquetés conn.log.labeled. Il s'agit du fichier
Zeek conn.log obtenu en exécutant l'analyseur de réseau Zeek sur
le fichier pcap d'origine.
Le trafic réseau capturé pour les
scénarios bénins a été obtenu en capturant le
trafic réseau de trois appareils connectés différents: une
lampe LED intelligente Philips HUE, un assistant personnel intelligent pour la
maison Amazon Echo et une serrure de porte intelligente Somfy. Il est important
de mentionner que ces trois objets connectés sont du matériel
réel et non simulé dans le laboratoire.

Figure
21 : Appareil Amazon echo[32]

Figure 22 : Dispositif de
verrouillage de porte Somfy[32]
Durant l'entraînement et le test,
nous n'avons utilisé que 05 captures. Nous avons utilisé 02
ensembles de données capturées comme trafic bénin et 03
autres ensembles de données capturés majoritairement comme trafic
malicieux.
Nous avons utilisé la lampe intelligente Philips HUE et
la serrure de porte intelligente Somfy pour l'entraînement et le test.
Sur chaque scénario malveillant, un échantillon
de malware spécifique dans un Raspberry Pi a été
exécuté et utilisait plusieurs protocoles et effectuait
différentes actions.
Le tableau ci-dessous montre le numéro de
scénario (ID), le nom de l'ensemble de données, la durée
en heure, le nombre de paquet, le nombre de flux d'ID Zeek dans le fichier
conn.log (obtenu en exécutant le framework d'analyse de réseau
Zeek sur le pcap d'origine file), la taille du fichier pcap d'origine et le nom
éventuel de l'échantillon de logiciel malveillant utilisé
pour infecter l'appareil ainsi que les protocoles utilisés et leurs
quantité.
Tableau
2 : Ensemble du jeu de donnée obtenu grâce à des
logiciels malveillants sur des objets connectés
|
#
|
Nom du Dataset
|
Durée
(heure)
|
Nombre de paquets
|
Nombre de flux d'ID Zeek
|
Taille pcap
|
Nom du logiciel malveillant
|
Protocole et quantité
|
|
1
|
CTU-IoT-Malware-Capture-34-1
|
34
|
233000
|
23140
|
121 MB
|
Mirai
|
http (12), dns(192), dhcp(2), irc (1641) et non reconnu
(21290)
|
|
19
|
CTU-IoT-Malware-Capture-3-1
|
36
|
496000
|
156104
|
56 MB
|
Muhstik
|
dns (1), dhcp(3), irc (6), ssh(5898) et non reconnu
(150195)
|
|
20
|
CTU-IoT-Malware-Capture-1-1
|
112
|
1686000
|
1008749
|
140 MB
|
Hide and Seek
|
http (32328), dns(1), dhcp(1) et non reconnu (1005507)
|
Ensuite pour les scénarios bénins La colonne
avec le nom du malware a été modifiée pour
spécifier le nom de l'appareil.
Tableau
3 : Ensemble du jeu de donnée du trafic normal et bénin
d'objets connectés
|
#
|
Nom du jeu de donnée
|
Durée (heure)
|
Nombre de paquets
|
Nombre de flux d'ID Zeek
|
Taille fichier pcap
|
Objet
|
Protocole et quantité
|
|
1
|
CTU-Honeypot-Capture-7-1(somfy-01)
|
1.4
|
8276
|
139
|
2.094KB
|
Somfy Door Lock
|
dns(54), dhcp(15), ssl(1) et non reconnu par zeek(60)
|
|
2
|
CTU-Honeypot-Capture-4-1
|
24
|
21000
|
461
|
4.594KB
|
Philips HUE
|
http(54), dns(191), dhcp(2) et non reconnu (205)
|
|
3
|
CTU-Honeypot-Capture-5-1
|
5.4
|
398000
|
1383
|
381 MB
|
Amazon Echo
|
http(157), dns(521), dhcp(156), ssl(86) et non reconnu
(454)
|
Le jeu de données contient également des
étiquettes pour décrire la relation entre les flux liés
à des activités malveillantes ou potentiellement malveillantes.
Ces étiquettes ont été créées dans le
laboratoire Stratosphère en tenant compte de l'analyse des captures de
logiciels malveillants.
Voici une brève explication sur les étiquettes
utilisées pour la détection de flux malveillants basée sur
l'analyse manuelle du réseau:
Attaque : cette étiquette indique
qu'il y a eu un certain type d'attaque du périphérique
infecté vers un autre hôte. Nous qualifions ici d'attaque tout
flux qui, en analysant sa charge utile et son comportement, tente de tirer
parti d'un service vulnérable. Par exemple, une force brute sur une
connexion telnet, une injection de commande dans l'en-tête d'une
requête GET, etc.
Bénin: cette étiquette indique
qu'aucune activité suspecte ou malveillante n'a été
trouvée dans les connexions.
C&C: cette étiquette indique que
le périphérique infecté était connecté
à un serveur C&C. Cette activité a été
détectée dans l'analyse de la capture de malware réseau
car les connexions au serveur suspect sont périodiques ou l'appareil
infecté télécharge des binaires à partir de
celui-ci ou des commandes IRC similaires ou décodées vont et
viennent.
DDoS: cette étiquette indique qu'une
attaque de déni de service distribué est en cours
d'exécution par le périphérique infecté. Ces flux
de trafic sont détectés dans le cadre d'une attaque DDoS en
raison de la quantité de flux dirigés vers la même adresse
IP.
Mirai: cette étiquette indique que les
connexions ont les caractéristiques d'un botnet Mirai. Cette
étiquette est ajoutée lorsque les flux ont des modèles
similaires à ceux des attaques Mirai connues les plus
courantes.
PartOfAHorizontalPortScan: cette
étiquette indique que les connexions sont utilisées pour
effectuer une analyse horizontale des ports afin de collecter des informations
afin de mener d'autres attaques. Pour mettre ces étiquettes, nous nous
appuyons sur le modèle dans lequel les connexions partageaient le
même port, un nombre similaire d'octets transmis et plusieurs adresses IP
de destination différentes.
Il y'a bien plus d'étiquettes dans le jeu de
données qu'à mis à disposition le laboratoire mais
celles-ci sont celles que nous avons retrouvées dans notre jeu de
données.
En ce qui concerne le modèle sur l'identification des
objets, un jeu de données a été obtenu en
téléchargeant un projet IoT SENTINEL sur la plateforme github. Il
s'agit d'un fichier contenant 27 tableaux Excel différents
représentant le jeu de données d'un type d'objet
différent. Tous ces objets sont simulés grâce à un
système prototype dans un laboratoire IoT[16].
Ce jeu de données a été obtenu en
implémentant le principe de l'empreinte digitale à partir d'une
machine Linux exécutant Kali Linux. Celle-ci émule une interface
Wifi sur un point d'accès, de même une interface Ethernet externe
est connectée au laptop pour émuler des ports Ethernet
typiquement présents dans les points d'accès. Le module de
capture de paquets était implémenté en utilisant
tcpdump sur les interfaces émulées.
Les paquets capturés et enregistrés
étaient envoyés au module chargé des de l'empreinte
digitale afin de collecter les attributs dont nous aurons besoin pour
l'identification des objets.

Figure 23 :
liste des objets connectés utilisés et de leurs
technologies de communications correspondantes [16]
La figure ci-dessus présente les
objets utilisés dans ce projet. Ainsi que les protocoles de
communications utilisés. Nous pouvons voir que le wifi domine largement
et que les autres technologies sont très peu utilisées.
Cependant nous avons aussi utilisé le jeu de
données fourni par le laboratoire stratosphère car le jeu de
données obtenu sur les objets de la figure 24 étaient
déjà nettoyés.
4.1.2.
Préparation et nettoyage des données
L'étape qui suit est de nettoyer les données
qu'on a téléchargées afin qu'elles puissent être
manipulables par l'algorithme.
En effet dans notre jeu de donnée, il y'a des valeurs
incomplètes, incohérentes, inexactes (contiennent des erreurs ou
des valeurs aberrantes) et des valeurs qui ne peuvent pas être
traités par l'algorithme car elles sont brutes et ne sont pas
compréhensible ou lisible pour celui-ci. Le prétraitement des
données permet d'améliorer la qualité des données
afin de favoriser l'extraction d'informations significatives à partir
des données.
Le prétraitement des données fait
référence à la technique de préparation (nettoyage
et organisation) des données brutes pour les adaptées à la
formation de modèles d'apprentissage profond. Ce processus aide à
nettoyer, formater et organiser les données brutes, les rendant ainsi
prêtes à l'emploi pour les modèles d'apprentissage
automatique.
Nous avons utilisés des bibliothèques Python
pour effectuer des tâches de prétraitement de données
spécifiques:
? NumPy : NumPy est le package
fondamental pour le calcul scientifique en Python. Par conséquent,
il est utilisé pour insérer tout type d'opération
mathématique dans le code
? Pandas : Pandas est une
bibliothèque Python open source pour la manipulation et l'analyse de
données. Nous l'avons utilisé pour importer et gérer
nos ensembles de données. Il intègre des structures de
données et des outils d'analyse de données hautes performances et
faciles à utiliser pour Python. Il nous a permis de manipuler nos
données, d'avoir une vue d'ensemble et de comprendre beaucoup plus
facilement nos données.
? Sklearn : Scikit-learn est
une bibliothèque libre Python destinée
à l'apprentissage automatique [34]. le
sklearn.preprocessing package, que nous avons beaucoup
utilisé, fournit plusieurs fonctions d'utilité communes et
classes de transformateurs pour changer les vecteurs de caractéristiques
bruts en une représentation qui convient mieux aux estimateurs en aval
[35]. Elle fait partie des bibliothèques majeures qui nous ont
aidés avec Pandas à faire le prétraitement des
données.
? Matplotlib : Matplotlib est une
bibliothèque du langage de programmation Python
complète pour créer des visualisations statiques, animées
et interactives en Python [36]. Elle peut être combinée avec
la bibliothèque python de calcul scientifique NumPy
[36].
Le jeu de données est dans le format texte pour le
premier modèle sur la détection de la nature du trafic. Avant
d'importer il faut spécifier que certaines valeurs manquantes dans mon
jeu de données sont spécifiées par le caractère ` -
'. Pour qu'il le remplace par un ` NaN '.
Nous avons séparé le jeu de données en
trois. Le jeu d'entraînement, le jeu de validation et le jeu de test.
L'ensemble du jeu d'entraînement de nos modèles
de machine learning représente 60% du jeu de donnée. Celui
de test pour mesurer la performance des modèles sur des données
non apprises représente 20% du jeu de données. La performance
d'un modèle sur l'ensemble de test correspond à une mesure de ce
modèle sur des données réelles, qui permettent
d'évaluer la capacité de généralisation du
modèle.
Un ensemble de validation pour s'assurer que notre
modèle ne se « sur ou sous entraine pas » et
effectuer des réglages des hyper paramètres du modèle.
Tout ceci pour que le modèle puisse faire une bonne
généralisation c'est-à-dire des prédictions justes
sur des données qu'il n'a jamais vues.
L'Overfitting (sur-apprentissage), et
l'Underfitting (sous-apprentissage) sont les causes
principales des mauvaises performances des modèles prédictifs
générés par les algorithmes d'intelligence
artificielle.
La notion d'overfitting désigne
le fait que le modèle choisi
est « habitué » aux données
d'entraînement. Le modèle prédictif produit par
l'algorithme de Machine Learning s'adapte très bien au jeu
d'entraînement. Par conséquent, le modèle
capturera tous les «aspects» et détails qui
caractérisent les données du jeu
d'entraînement. Dans ce sens, il capturera toutes les
fluctuations et variations aléatoires des données lors de
l'apprentissage. En d'autres termes, le modèle prédictif
capturera les corrélations généralisables beaucoup trop
bien.
A l'inverse,
l'underfitting désigne une situation où le
modèle n'est pas du tout assez complexe pour capturer le
phénomène dans son intégralité. Cela sous-entend
que le modèle prédictif généré lors de la
phase d'apprentissage, s'adapte mal aux données
d'entraînement. Autrement dit, le modèle prédictif
n'arrive même pas à capturer les corrélations du jeu
d'entraînement. Par conséquent,
le coût d'erreur en phase d'apprentissage reste
grand. Bien évidemment, le
modèle prédictif ne se généralise pas bien non
plus sur les données qu'il n'a pas encore vues. Finalement, le
modèle ne sera pas viable car les erreurs de prédictions seront
grandes.
Lorsqu'on veut généraliser un modèle,
nous avons besoin qu'il n'overfit pas et qu'il
n'underfit pas, qu'il soit pile entre les deux [37].
Les attributs utilisés dans le jeu de donnée
pour entraîner le modèle sont :
Tableau
4 : Attributs utilisés dans notre jeu de donnée
|
Attributs
|
Type
|
Utilité
|
|
Ts
|
Time
|
Horodatage de la mesure
|
|
Uid
|
String
|
Un identifiant unique de la session
|
|
id.orig_h
|
Adresse
|
Adresse IP du point de terminaison d'origine
|
|
id.orig_p
|
Port
|
Port TCP / UDP du point final d'origine
|
|
id.resp_h
|
Adresse
|
Adresse IP du point de terminaison répondant
|
|
id.resp_p
|
Port
|
Port TCP / UDP du point final en réponse
|
|
Proto
|
Transport-proto
|
Protocole de connexion de la couche de transport
|
|
Service
|
String
|
Protocole d'application détecté dynamiquement,
le cas échéant
|
|
orig_bytes
|
Count
|
Octets de charge utile de l'expéditeur; à partir
des numéros de séquence si TCP
|
|
resp_bytes
|
Count
|
Octets de charge utile du répondeur; à partir
des numéros de séquence si TCP
|
|
conn_state
|
Count
|
Code indiquant l'état de la session.
|
|
local_orig
|
Booléen
|
Indique si la session est lancée localement.
|
|
local_resp
|
Booléen
|
Indique si la session reçoit une réponse
localement.
|
|
missed_bytes
|
Count/Long
|
Nombre d'octets manquants dans les espaces de contenu
|
|
history
|
String
|
Drapeaux indiquant l'historique de la session.
|
|
orig_ip_bytes
|
Count
|
Nombre d'octets IP ORIG (via le champ d'en-tête IP
total_length)
|
|
resp_pkts
|
Count
|
Nombre de paquets RESP
|
|
resp_ip_bytes
|
Count
|
Nombre d'octets IP RESP (via le champ d'en-tête IP
total_length
|
|
label
|
String
|
L'étiquette
|
|
Duration
|
Interval
|
Durée de la session représentant le temps entre
le premier message et le dernier, en secondes.
|
|
orig_pkts
|
Count
|
Nombre de paquets ORIG
|
L'état des connexions peuvent prendre les valeurs
suivantes :
Tableau
5 : Valeurs possibles du champ conn_state
|
Etat
|
Description
|
|
S0
|
Tentative de connexion vue, pas de réponse
|
|
S1
|
Connexion établie, non terminé (0 octets )
|
|
SF
|
Établissement et terminaison normaux (> 0 octets)
|
|
REJ
|
Tentative de connexion rejetée
|
|
S2
|
Établi, ORIG tente de fermer, pas de réponse du
RESP.
|
|
S3
|
Établi, les tentatives de RESP se ferment, aucune
réponse d'ORIG
|
|
RSTO
|
Établi, ORIG abandonné (RST)
|
|
RSTR
|
Établi, RESP abandonné (RST)
|
|
RSTOS0
|
ORIG a envoyé SYN puis RST; pas de RESP SYN-ACK
|
|
RSTRH
|
RESP a envoyé SYN-ACK puis RST; pas de SYN ORIG
|
|
SH
|
ORIG a envoyé SYN puis FIN; pas de RESP SYN-ACK
(«semi-ouvert»)
|
|
SHR
|
RESP a envoyé SYN-ACK puis FIN; pas de SYN ORIG
|
|
OTH
|
Pas de SYN, pas fermé. Trafic médian. Connexion
partielle.
|
Et l'historique d'une session peut aussi avoir
différentes valeurs :
Tableau 6 : Valeurs possibles
du champ history
|
Lettre
|
Description
|
|
S
|
un SYN sans le bit ACK défini
|
|
H
|
un SYN-ACK («handshake»)
|
|
A
|
un ACK pur
|
|
D
|
paquet avec charge utile («data»)
|
|
F
|
paquet avec jeu de bits FIN
|
|
R
|
paquet avec jeu de bits RST
|
|
C
|
paquet avec une mauvaise somme de contrôle (checksum)
|
|
I
|
Paquet incohérent (SYN et RST)
|
Les 05 classes que nous avons obtenues après un
nettoyage manuel du jeu de donnée sont :
? Malicious Attack
? Malicious C&C
? Malicious DDoS
? Malicious PartOfAHorizontalPortScan
? Begnin
Les étapes que nous avons suivies pour obtenir un jeu
de donnée lisible sont :
- Modification des classes : Les classes
listées ci-dessus sont les étiquettes correspondantes à
chaque paquet dans le jeu de données. Cependant il nous a fallu les
nettoyer elles aussi car la différence entre certaines classes
n'étaient pas « pertinentes » pour notre projet.
D'abord nous avions 3 labels tunnel_parents, label et detailed-label qui
formaient une seule colonne. Le detailed-label concernait les détails du
label comme DDoS ou C&C par exemple. Et le tunnel_parents était soit
vide soit manquant raison pour laquelle nous ne l'avons pas trouvé
utile et donc supprimer. Les trois labels sont devenus une seule nommée
label qui mélangeait les détails du label et sa nature
(bénigne ou malicieuse). Ensuite nous avions 03 classes bénignes
différentes. Puisque l'important est de différencier la nature du
trafic, la différence entre les différentes classes comme
« Begnin, begnin, - Begnin - » ou encore
« Malicious PartOfAHorizontalPortScan, - Malicious
PartOfAHorizontalPortScan» par exemple, ne sont pas importantes
sachant que ce sont juste des espaces vides ou non mis. La dizaine de classes
qu'on avait au début s'est transformée en 05 classes.
- Remplacer les valeurs manquantes :
Nous les avons remplacées soit par None pour les
attributs catégoriques ou alors par -1 pour les
attributs numériques qui ont beaucoup trop de lignes vides. Lorsqu'il
y'a beaucoup de valeurs vides dans une colonne, il est souvent courant de le
supprimer ou de remplacer les valeurs vides par les valeurs proches, les plus
fréquentes ou encore par la moyenne. Nous, nous sommes allés
selon la logique qu'une valeur d'un champ d'un paquet IP est
significative. Par exemple, nous pouvons prendre la moyenne dans la
colonne ``protocole''. Sauf qu'on pourrait obtenir un chiffre comme 80 ou 99
qui correspondent à des protocoles bien définis. Donc pour
éviter de se retrouver avec 50 ou 100 lignes consécutives avec un
même protocole et induire l'algorithme en erreur dans ses
prédictions, nous avons préféré adopter la
stratégie d'une valeur par défaut -1 pour justement montrer qu'il
n'y a pas de valeur mais qu'il reste lisible par une machine.
- Encoder les valeurs
catégoriques : les valeurs catégoriques ne sont pas
compréhensibles par un algorithme d'apprentissage profond. Il faut donc
les transformer en valeurs numériques. Nous avons utilisé le
LabelEncoder(). C'est une étape à faire
après avoir rempli les espaces vides.
- Transformer les classes : Nous avions
une seule colonne Label qui représente les différentes classes
que l'on peut avoir. Mais nous voulons que chacune de ces classes devienne une
colonne. Nous utilisons l'encodage
« Dummy », pour que le nombre de
catégories soit égal au nombre de colonnes. Les variables
« Dummy » prenant la valeur 0 ou 1 pour
indiquer l'absence ou la présence d'une catégorie.
- Extraire les variables : Nous avons
d'une part les valeurs indépendantes qui sont les attributs et d'autres
part les valeurs dépendantes qui sont les classes de sorties à
prédire.
- Séparer le jeu de
données : Nous avons séparé le jeu de
données en jeu de d'entraînement, jeu de validation et jeu de
test. Le jeu d'entraînement est utilisé pour entraîner le
modèle tandis que le jeu de test sert à tester celui-ci et
prédire les classes. Dans notre cas, le jeu d'entraînement
représente 60%, le jeu de validation 20% et le jeu de test 20% du jeu
de données initial.
- Feature scaling : C'est la fin du
prétraitement. Il permet de standardiser (dans notre cas avec
StandardScaler()) ou normaliser les variables
indépendantes du jeu de données dans une plage de valeur
spécifique. Cette pratique est utile car dans notre jeu de
données, nous nous retrouvons avec des données qui ont de grandes
différences de valeurs. Une colonne où nous avons des valeurs
autour de 10000 et une autre colonne où nous avons des valeurs autour de
52 par exemple. La première colonne dominera sur la seconde et donnera
des résultats incorrects. Raison pour laquelle la standardisation est
importante pour l'algorithme.
Pour le second modèle suggéré, même
si la même logique n'a pas été forcément
appliquée, il s'agit généralement des mêmes
étapes pour pouvoir obtenir à la fin un jeu de données
lisible. Les 23 attributs nécessaires qu'on peut voir à la figure
25 doivent aussi être transformés en valeur numérique.
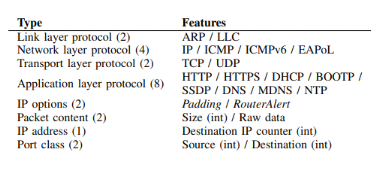
Figure 24 : description des 23
attributs utilisés pour former le modèle [16]
Contrairement au premier modèle où les
caractères ont été transformés en valeurs
numériques, ici la plupart des valeurs étaient binaires. Donc
dans le premier modèle nous avions une colonne
« history » ou « adresse » par exemple
avec différents valeurs possibles et ceux-ci étaient
transformés en valeurs numériques.
A l'inverse pour ce modèle, pas de transformation de
données catégorique en valeurs numériques. Les champs
prenaient pour la plupart des valeurs binaires en fonction de l'absence ou de
la présence de ce protocole. Des protocoles qui prenaient la valeur 1
lorsqu'ils étaient utilisés et 0 sinon. 16 des protocoles choisis
sont généralement utilisés durant la phase d'association
des appareils dans le wifi (entre l'objet et le point d'accès). Deux
attributs binaires représentent l'utilisation des entêtes IP
padding et router alert. La première adresse IP trouvée
démarre un compteur qui commence à 1 et celui-ci
s'incrémente au fur et à mesure que de nouvelles adresses sont
trouvées.
Les deux derniers attributs représentent les ports
sources et destinations utilisés :
? Si aucun port n'est utilisé, nous mettons 0
? Si un port connu dans la plage [0, 1023] est utilisé,
nous mettons 1
? Si c'est un port enregistré dans la plage [1024,
49151], nous mettons 2
? Si c'est un port dynamique, nous mettons 3
Les empreintes prennent en compte la dimension temporelle des
communications en les capturant et en les gardant dans leur ordre
séquentiel. Nous gardons les douze premiers paquets et on obtient un
vecteur d'attributs de dimension (12 paquets *23 attributs).
F0 = {f1,1, f2,1, . . . , f23,1, f1,2, f2,2, . . . , f22,et,
f23,i}
Nous avons créé un algorithme en python de
prétraitement des données pour effectuer ces tâches et
obtenir un fichier avec lequel le modèle peut identifier les objets.
4.1.3. Formation du
modèle d'apprentissage profond
Nous avons créé deux réseaux de neurones
différents pour la détection du trafic malveillant. Un
réseau multicouche profond et un réseau récurrent plus
spécifiquement un Long Short Term Memory (LSTM). Ils sont écrits
sur jupyter.
Nous avons ajouté des couches du réseau avec un
certain nombre de paramètres qui vont permettre de l'entraîner et
de créer un modèle.
D'abord nous instancions la classe
Sequential() grâce à laquelle nous créons
le modèle et nous ajoutons les couches LSTM, Dense et Dropout. Nous nous
servons de la méthode add() pour LSTM et
tf.keras.layers pour MLP pour ajouter de nouvelles couches.
Nous y ajoutons des paramètres comme le nombre de neurones de la couche,
Nous spécifions qu'on ajoutera plus de couches au modèle avec le
paramètre return_sequences (dans le cas du LSTM), la
fonction d'activation relu et sur la première couche
Nous ajoutons le nombre de pas de temps.
Après chaque nouvelle couche, nous ajoutons une couche
de suppression, au modèle LSTM. C'est une couche d'abandon qui permet
d'éviter le sur-ajustement qui est un phénomène dans
lequel un modèle d'apprentissage automatique fonctionne mieux sur les
données d'entraînement que sur les données de test. Nous
nous sommes servis de la méthode Dropout().
Pour rendre notre modèle plus robuste, nous ajoutons
une couche Dense() à la fin du modèle. Le
nombre de neurones dans la couche dense sera fixé à 6 car nous
voulons prédire 6 classes dans la sortie. Nous ajouterons aussi la
fonction d'activation softmax pour obtenir les sorties sous
formes de probabilités, c'est-à-dire que la somme des
résultats en sortie doit donner 1.
Le travail suivant consiste à compiler le réseau
de couches que nous venons de créer avant de pouvoir l'entraîner
sur les données d'entraînement. Nous utilisons l'erreur
quadratique moyenne comme fonction de perte afin de
réduire la perte et pour optimiser l'algorithme, nous utilisons
l'optimiseur adam et sgd. Nous ajoutons aussi la
précision comme métrique, la perte étant ajoutée
par défaut.
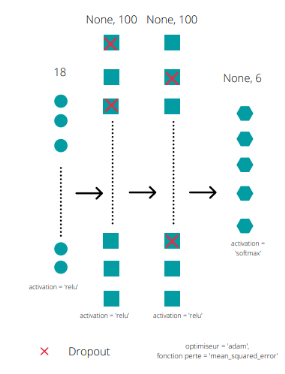
Figure 25 : Architecture
réseau LSTM
Notre réseau de neurones LSTM est
donc constitué de deux couches intermédiaires, de 18 neurones
à l'entrée et à 5 neurones à la couche de sortie.
Nous avons aussi ajouté deux couches dropout pour la
régularisation.
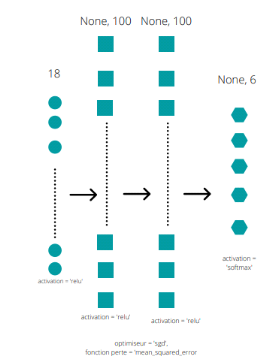
Figure 26 : Architecture
réseau MLP
Le réseau MLP est similaire mais sans couches de
régularisation.
Nous pouvons maintenant former le modèle que nous avons
défini. Nous utilisons la méthode fit() sur le modèle en
transmettant les données d'entraînement, le nombre
d' « epoch » et la taille de chaque batch. Nous
ajoutons aussi les données de validation qui nous permettra ainsi
d'obtenir la précision de validation et la perte de validation.
En ce qui concerne le second modèle, il s'agit
plutôt d'un algorithme écrit en python (sans jupyter). A chaque
objet type nous avons un classifieur. Donc une empreinte doit être
traitée par les différents classifieurs de type d'objets pour
trouver celui auquel il correspond. Donc à chaque fois qu'une nouvelle
empreinte d'un nouvel appareil est capturée, un nouveau classifieur est
entraîné sans modification aucune aux classifieurs existants. Ceci
évite un coût de réapprentissage. Cette approche permet la
découverte de nouveaux appareils et ne force aucune empreinte à
correspondre à une classe donnée.
NB : On parle de nouvelle empreinte lorsque celle-ci ne
correspond à aucun classifieur.
Toutefois une même empreinte peut correspondre à
différents types d'objets d'après les résultats du
classifieur. Une seconde étape consiste donc à calculer la
distance entre les différents types d'objets trouvés. Mais dans
notre travail nous n'avons pas pris en compte cette seconde étape et
nous avons plutôt pris la probabilité la plus
élevé !
4.2. Implémentation du modèle de
détection de trafic malveillant
Nous avons à ce niveau vérifié qu'on
pouvait bel et bien bloquer un paquet au niveau du kernel en fonction des
prédictions du modèle.
Pour ce faire, notre programme doit :
? Ouvrir une file d'attente
? se lier à une famille de réseau ( AF_PACKET
pour IPv4)
? fournir une fonction de rappel, qui sera automatiquement
appelée lors de la réception d'un paquet.
? Renvoyer un verdict avec le rappel en fonction des
prédictions
? Créer la file d'attente, en fournissant le
numéro de file d'attente qui doit correspondre aux --queue-num
grâce à iptables
? Lancez une boucle en attendant les événements.
Le programme devrait également fournir un moyen propre de quitter la
boucle
Nous nous sommes servis de Netfilter [38].
Netfilter fournit un mécanisme pour faire passer des paquets hors de la
pile pour la mise en file d'attente dans l'espace utilisateur, puis pour les
recevoir de nouveau dans le noyau avec un verdict spécifiant quoi faire
avec les paquets (comme ACCEPT ou DROP). Ces paquets peuvent
également être modifiés dans l'espace utilisateur avant
d'être réinjectés dans le noyau.
Un module de noyau appelé gestionnaire de
files d'attente peut s'inscrire auprès de Netfilter pour
effectuer les mécanismes de transmission de paquets vers et depuis
l'espace utilisateur.
Nfqueue est un petit wrapper autour de
libnetfilter_queue. NFQUEUE permet d'envoyer
des paquets pour des files d'attente séparées et
spécifiques. La file d'attente est identifiée par un id de 16
bits. Une fois nfqueue chargé, les paquets IP peuvent être
sélectionnés avec iptables et mis en file d'attente pour le
traitement de l'espace utilisateur via la cible QUEUE.
libnetfilter_queue est une bibliothèque de l'espace
utilisateur qui fournit un API aux paquets qui ont été
placés en file d'attente par le filtre de paquet du kernel. Il a
remplacé le vieux ip_queue / libipq. Il utilise nfqueue [39].
L'option --queue-num spécifie quelle file d'attente
utilisé et vers où envoyer les données. Si cette option
n'est pas placée, la file d'attente par défaut sera à 0.
Le chiffre de la file d'attente est un entier non signé de 16 bits, ce
qui veut dire qu'elle peut prendre n'importe quelle valeur comprise entre 0 et
65535.
Les cibles (les verdicts) les plus classiques sont :
? NF_ACCEPT: continuez la traversée normalement.
? NF_DROP: abandonnez le paquet; ne continuez pas la
traversée.
? NF_STOLEN: J'ai repris le paquet; ne continuez pas la
traversée.
? NF_QUEUE: mettez le paquet en file d'attente
(généralement pour la gestion de l'espace utilisateur).
? NF_REPEAT: rappelez, réinjecter le à la file
d'attente
Ces cibles permettent d'envoyer le paquet en espace
utilisateur pour qu'une application puisse effectuer sa propre analyse et
décider du verdict. Cependant avant toute chose nous devons rediriger le
trafic qui passe par la passerelle vers la file d'attente.
A moins de nous même programmer notre propre module qui
communique avec le kernel pour pouvoir mettre en place notre filtre, nous nous
sommes servis de celui-ci pour pouvoir émettre un verdict sur un paquet
en fonction du résultat de la prédiction. De cette façon,
nous accélérons le traitement des paquets dans la file d'attente
du pare-feu.
Conclusion
Au terme de ce chapitre, nous avons expliqué ce que c'est
qu'un réseau de neurone, nous avons manipulé de très
grandes quantités de données et appris à faire du
prétraitement qui s'est avéré être la tâche la
plus difficile et la plus chronophage lors de la création d'un
algorithme, nous avons créé nos propres réseau de neurone.
Il ne nous reste plus qu'à les entraîner et mesurer les
performances.
CHAPITRE 3 :
SIMULATIONS ET INTERPRÉTATION DES RÉSULTATS
Introduction
Dans le cadre de notre recherche, nous avons
suggéré quelques métriques que nous allions utiliser pour
évaluer les performances des modèles que nous proposons. Nous
avons entrainé et testé nos modèles en utilisant le jeu de
données déjà traité. Nous avons obtenu des
résultats que nous avons comparés entre elles pour décider
du meilleur choix. Enfin nous avons testé le filtre de paquets à
partir des prédictions du modèle.
1. Métriques d'évaluation
des modèles
Pour évaluer l'efficacité de nos algorithmes,
nous nous sommes servis de métriques d'évaluations. Ils sont
très importants pour nous guider dans la conception de nos
modèles. Ils nous aident à nous rendre compte de la performance
d'un modèle ou pas !
Pour obtenir les métriques que nous voulons, nous avons
eu besoin du :
- Vrai Positif (True Positive TP) :
nombre de classification positive correcte. Un vrai
positif est un résultat où le modèle
prédit correctement la
classe positive.
- Vrai Négatif (True Negative
TN): Nombre de classification négative correcte.
un vrai négatif est un résultat
où le modèle prédit correctement la
classe négative.
- Faux Positif (False Positive FP):
Nombre de classification positif incorrecte qui devrait être
négative. Un faux positif est un
résultat où le modèle prédit la
classe positive alors qu'elle est négative.
- Faux Négatif (False Negative
FN): Nombre de classification négatif incorrecte qui devrait
être positif. un faux négatif est un
résultat où le modèle prédit la
classe négative alors qu'elle est positive.
Ensuite, nous pouvons donc calculer le reste des
métriques.
La précision, c'est la capacité d'un
classifieur à ne pas étiqueter une instance positive qui est en
fait négative. Pour chaque classe, il est défini comme le
rapport des vrais positifs à la somme des vrais et des faux positifs.
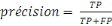 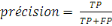 (6) (6)
Le rappel est défini comme le nombre de vrais positifs
sur le nombre de vrais positifs plus le nombre de faux négatifs.
C'est-à-dire qu'elle correspond au nombre de bonnes prédictions
ou d'éléments pertinents trouvés par rapport à
l'ensemble de ces éléments ou de bonnes prédictions au
total dans la base de données. Cela signifie que dans un jeu de
données où nous voulons prédire une classe par exemple,
plus on en obtient par rapport au nombre total de cette classe dans le jeu de
données, plus le rappel est élevé.
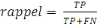 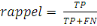 (7) (7)
Le score F1, également appelé score F
équilibré ou mesure F. Le score F1 peut être
interprété comme une moyenne pondérée ou harmonique
de la précision et du rappel, où un score F1 atteint sa meilleure
valeur à 1 et son pire score à 0. La contribution relative de la
précision et du rappel au score F1 est égale. La formule du
score F1 est:
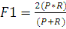 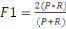 (8) (8)
Avec p mis pour précision et R mis pour rappel.
Dans le cas multi-classes et multi-étiquettes, il
s'agit de la moyenne du score F1 de chaque classe.
La matrice de confusion est une matrice qui montre
rapidement si un système de classification parvient à classifier
correctement.
Elle permet d'évaluer la qualité de la sortie
d'un classifieur sur l'ensemble de données. Les éléments
dans la diagonale représentent le nombre de points pour lesquels
l'étiquette prédite est égale. L'étiquette vraie,
tandis que les étiquettes hors diagonale sont celles qui sont mal
étiquetées par le classifieur. Donc plus les valeurs diagonales
de la matrice de confusion sont élevés, mieux
c'est, indiquant de nombreuses prédictions correctes.
Ensuite la perte correspond à la pénalité
pour une mauvaise prédiction. Autrement dit,
la perte est un nombre qui indique la
médiocrité de la prévision du modèle pour un
exemple donné. Si la prédiction du modèle est parfaite, la
perte est nulle. Sinon, la perte est supérieure à zéro.
Notre but est de trouver la perte la plus faible possible. Le calcul de la
perte dépend des fonctions de perte choisie. Dans notre cas nous avons
utilisé l'erreur quadratique moyenne qui est une mesure
caractérisant la « précision » d'un
estimateur. Elle mesure la moyenne des carrés entre les valeurs et
la valeur réelle [40].
Nous avons aussi pris compte du temps mis par chaque
algorithme pour fonctionner. Ce temps est très important pour
déterminer ses performances car il déterminera aussi le temps que
mettra un programme pour fonctionner et faire des prédictions.
2. Tests des modèles et
évaluation
2.1. Détection de trafic IoT malveillant
Nous avons entraîné et testé deux algorithmes
différents pour pouvoir choisir le plus efficace.
En ce qui concerne le modèle LSTM, ses performances
étaient faibles au début mais ont donné de bons
résultats par la suite en ajustant le réseau. Le modèle
avait du mal à se généraliser mais après avoir
réduit le nombre de neurones et le nombre de couches, il a fini par
donner de meilleurs résultats. La perte était
élevée lors des premiers tests de l'entraînement toutefois
elles ont aussi diminué. Une autre difficulté est le
modèle qui prenait aussi trop de temps à s'entraîner, au
moins 40 minutes pour un epoch et autour des 400 ms/étape et ça
pouvait largement dépasser ces chiffres. Les résultats du jeu de
validation nous ont permis de nous rendre compte que l'entraînement au
début n'était pas concluant et qu'il fallait changer les
paramètres du réseau de neurone.

Figure 27 : Evolution de la
précision de l'algorithme LSTM lors de l'entraînement avec le jeu
de validation et d'entraînement lors du premier entrainement avec 04
couches de 128 neurones chacun
Cette courbe présente
l'évolution de la précision du modèle après chaque
epoch pendant l'un des premiers entraînements. Nous obtenions presque
toujours les mêmes schémas. Elle était très
élevée au début autour de 90% ou 80% et descendait
drastiquement jusqu'à 40% ou moins avant de remonter et se maintenir
autour de 55% quelque soit le nombre d'epoch et le temps
d'entraînement.
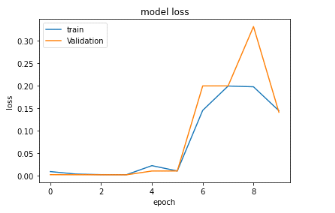
Figure 28 : Evolution de
la perte de l'algorithme LSTM lors de l'entraînement
avec le jeu de validation et celui d'entraînement lors du premier
entraînement avec 04 couches de 128 neurones chacun
Cette figure nous permet de visualiser
l'évolution des pertes après chaque epoch lors des premiers
entraînements. Celle-ci était faible durant les premiers epoch,
environ 0.1% mais ensuite augmentait tout aussi vite que descendait la
précisions et se maintenait autour des 14% ou 15% quelque soit le nombre
d'epoch.
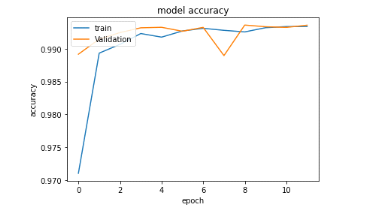
Figure 29 : Evolution de la
précision de l'algorithme LSTM lors de l'entraînement avec le jeu
de validation et d'entraînement lors du dernier entraînement avec
02 couches de 100 neurones chacun
Ensuite nous avons changé les
paramètres du réseau, réduit le nombre de couches et le
nombre de neurones. Nous avons aussi changé le nombre de classes
à prédire pour mélanger certaines classes que nous avons
jugé non pertinentes de séparer. La figure ci-dessus nous
démontre que cela a eu des effets positifs sur le modèle. Elle a
rapidement atteint les 99% de précision et le temps d'entraînement
de chaque epoch a diminué de quelques minutes.
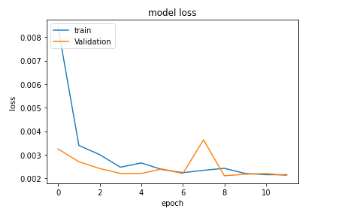
Figure 30 : Evolution de la
perte de l'algorithme LSTM lors de l'entraînement avec le jeu de
validation et d'entraînement lors du dernier entraînement avec 02
couches de 10101 neurones chacun
La perte quant à elle a énormément
diminué et même si celle du jeu de validation nous a prouvé
qu'on pouvait encore plus entraîner le modèle, le temps
d'entraînement global du modèle qui pouvait prendre un jour ou
deux nous a amenés à nous arrêter à ces
résultats.
A contrario, le modèle MLP était beaucoup plus
performant et donnait des résultats encourageants dès les
premiers entraînements. La précision dépassait souvent les
98% et la perte très faible était inférieure à 1%
pendant tous les entraînements même lorsqu'on changeait les
paramètres du réseau ou les fonctions de pertes et
d'optimisation. Le sur-ajustement n'est pas énorme. Le temps
d'entraînement ici était 10 fois plus rapide. Tout au plus 15
minutes par epoch.
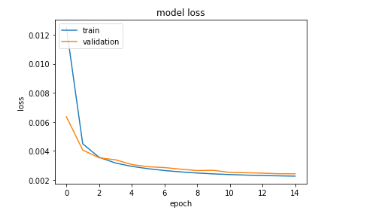
Figure 31 : Evolution de la
perte de l'algorithme lors de l'entraînement avec le jeu d'entrainement
et celui de validation
On observe sur la figure 31 que la
courbe de la perte du jeu de validation est légèrement au-dessus
à celle du jeu d'entraînement. La perte du jeu
d'entraînement diminuait à chaque epoch pour essayer de rattraper
la perte du jeu de validation qui était toujours plus faible.

Figure 32 : Evolution de la
précision de l'algorithme lors de l'entraînement avec le jeu
d'entraînement et le jeu de validation
Les modèles ont
été entraînés plusieurs fois avec des
paramètres différents (nombre de couches, nombres de neurones
dans chaque couche, fonction de perte, optimiseur, etc.) pour pouvoir obtenir
des résultats satisfaisants. Nous ne déduisons que le choix de
l'algorithme impacte énormément sur les résultats mais
aussi le choix des attributs en entrées, leur nombre et celui des
classes à prédire en sortie. Lors de l'entraînement, le
LSTM a été celui qui nous a donné le plus de
difficulté surtout qu'un entraînement de seulement 05 epoch
pouvait prendre une journée et parallèlement il était plus
facile d'essayer plusieurs changements sur le MLP au niveau des
paramètres car plus rapide.
Il faut savoir que nous avons entraîné le LSTM
avec moins de 9000 échantillons par epoch alors que pour le MLP,
c'était environ 25800 échantillons par epoch. Cela
démontre bien à quel point le LSTM était lent même
avec un nombre d'échantillons inférieur.
Une fois que les résultats de l'entraînement
nous satisfaisaient, nous enregistrions le modèle, faisions des
prédictions et évaluions les résultats afin de comparer ce
que le modèle prédit et les valeurs réelles.
Tableau
7 : Comparaison entre les résultats des modèles sur le jeu
de test
|
Précision
|
Perte
|
Temps
|
|
MLP
|
98.75%
|
0.37 %
|
9s
|
|
LSTM
|
99.40%
|
0.19%
|
743s
|
Avec les chiffres obtenus pour chacun le même nombre
d'échantillons, il apparaissait donc clairement que le LSTM était
le meilleur choix pour la prédiction par rapport aux performances de la
machine sur laquelle on travaillait. Cependant nous avons aussi pris en compte
le temps de prédiction de chaque modèle et même si le LSTM
donne de bons résultats, nous avons opté pour le MLP pour
prédire car plus rapide.
Toutefois, si on décide d'effectuer le travail de
prédiction dans le cloud avec des serveurs beaucoup plus performants
avant de renvoyer les résultats à la passerelle, on pourrait
utiliser le LSTM.
2.2. Identification du type d'objet
Pour le second modèle proposé à
entraîner, les résultats sur les 27 premiers appareils
entraînés semblent concluants, vous pouvez les retrouver en
annexe. La précision dépassait les 97% au moins pour chaque
appareil, ce qui était de bons résultats. Toutefois nous ne
disposions pas des fichiers pcap correspondant à ces appareils, nous
n'avions que des fichiers Excel déjà prétraités. Il
nous fallait générer nos propres fichiers Excel
prétraités pour entraîner et tester notre modèle.
Nous nous sommes servis des fichiers pcap dont nous disposions
sur le trafic bénin concernant la détection du trafic
malveillant. D'abord il s'agissait de trafic généré par
des appareils que le modèle nous supposions ne connaissait pas. Il
fallait le ré-entraîner et donc extraire les attributs dont le
modèle avait besoin.
Nous avons donc écrits un programme en python
d'extraction des paramètres dont nous avions besoin en se basant sur les
travaux déjà faits c'est-à-dire qu'on a
décidé de prendre les mêmes attributs, de leur donner des
valeurs 0 ou 1 et nous les avons extraits des fichiers pcap dont nous
disposions. Nous avons donc obtenu 03 fichiers csv différents (Edimax,
l'ampoule hue bridge et la serrure Somfy).
Nous avons créé trois fichiers Excel
différents correspondants aux trois types d'objets qui avaient
généré du trafic bénin.
Ensuite nous avons entrainé nos modèles et
réalisé les tests. Les trois figures ci-dessous vous montrent les
rapports de classifications des objets que nous avons testés !
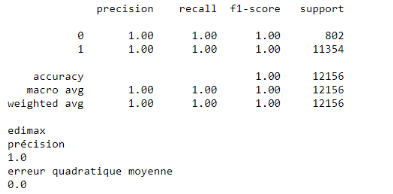
Figure 33 : Rapport de
classification de l'objet connecté Amazon echo

Figure
34 : Rapport de classification de l'ampoule hue bridge

Figure
35 : Rapport de classification de la serrure somfy
L'une des choses que nous pouvons
observer dans les trois figures ci-dessus est que le jeu de données est
déséquilibré. Ensuite ses performances pour la
précision, le score-f1 et le rappel sont déjà très
bons.

Figure 36 : Matrice de
confusion entre x_test et les prédictions
La figure 29 présente la matrice
de confusion entre les prédictions du modèle et les
véritables valeurs. Nous voyons que les modèles ont des
résultats excellents et permettent d'identifier les objets
entraînés et testés.
Les résultats obtenus avec le classifieur MLP sont bons
et nous n'avons pas eu à faire beaucoup de changement sur l'algorithme
lors de l'entraînement.
Toutefois ceci est peut être dû au fait que
c'était déjà un modèle entrainé que nous
avons pris et qu'il avait déjà testé au préalable
certains objets comme par exemple un nommé
« Edimax » (voir Annexe). Il se pourrait donc qu'on ait
fait que ré entraîné des modèles qui avaient
déjà été testé ! Donc je précise
que nous ne disposions pas de beaucoup d'informations sur les
caractéristiques des objets déjà
entraînés.
3. Implémentation du
modèle de détection de trafic malveillant
Pour s'assurer qu'il était possible de bloquer des
paquets entrants et sortants, il nous fallait simuler un réseau d'objets
connectés. Mais nous ne disposons pas des objets spécifiques qui
ont servi aux laboratoires pour enregistrer les fichiers pcap et encore moins
des logiciels qui ont permis d'extraire les attributs.
Nous nous sommes donc servis des paquets que nous avions
déjà afin de les rejouer sur deux machines virtuelles
créées sur VirtualBox sur un système Ubuntu afin de
simuler un réseau d'objets connectés.
Sur une machine virtuelle considérée comme la
passerelle, était installé le code permettant de charger les
paquets en file d'attente et d'émettre des verdicts. Nous
précisons qu'il faut avoir des droits administrateurs et avoir
accès au kernel via un gestionnaire, quelque chose de très
difficile avec Windows. Pour chaque paquet qu'il recevait, il émettait
son verdict en se basant sur les prédictions du modèle.
Un premier test a été de ne créer que
deux machines virtuelles. Une passerelle et une machine dans un réseau
privé. Le but était de simplement pouvoir observer la
fonctionnalité de filtre sur la passerelle.
Le rôle de l'autre machine virtuelle était
très simple : permettre de simuler un trafic d'objets
connectés en rejouant les paquets contenus dans les fichiers pcap dont
nous disposions. Il se contentait d'envoyer ces paquets à la machine
virtuelle passerelle.
Ci-dessus vous pouvez voir les deux figures qui
présentent la configuration des deux machines virtuelles.
L'adresse IP utilisée est le 10.42.0.0 avec le masque
255.255.255.0.
Figure 37 : Configuration des
interfaces du gateway

Figure
38 : Configuration des interfaces d'une autre machine sur le réseau
interne
Nous avons mis les deux machines
virtuelles dans un réseau interne pour qu'ils puissent
communiquer mais sans internet!
Ensuite nous nous sommes servis des prédictions de
l'algorithme et du fichier pcap correspondant pour émettre un statut
(trafic bénin ou pas) pour pouvoir bloquer ou accepter les paquets
joués.
La figure ci-dessous nous montre ce qu'on pouvait observer sur
les deux machines.
Figure 39 : envoie,
réception et détection des paquets malveillants
La figure ci-dessus nous montre les
paquets envoyés depuis une machine du réseau interne (la machine
sandra@sandra-virtualBox) et reçu sur la machine qui nous sert
de gateway (laroche@laroche-VirtualBox). En fonction des
prédictions, le paquet donc est refusé ou
accepté !
La passerelle est capable de refuser ou d'accepter un
paquet.
Un deuxième test a cette fois-ci consisté
à créer deux sous réseau. Un réseau privé
qui représente notre réseau domotique qu'on doit protéger,
un réseau public qui représente internet et notre passerelle qui
va filtrer le trafic, chacun représenté par une machine
virtuelle.
La passerelle est la limite entre ces deux réseaux.
Notre but est de filtrer les paquets d'un réseau vers un autre et donc
de constater sur une autre machine que les paquets ont bel et bien
été filtrés.
La configuration réseau est simple :
Tableau 8 : Configuration des
machines du réseau
|
Adresse
|
Réseau
|
Masque
|
Passerelle
|
|
Machine 1
|
10.42.1.2
|
Privé/interne
|
255.255.255.0
|
10.42.1.1
|
|
Machine 2
|
2.42.0.2
|
Public/internet
|
255.255.255.0
|
2.42.0.1
|
|
Machine 3
|
10.42.1.1
2.42.0.1
|
passerelle
|
255.255.255.0
|
/
|
Figure 40 : Configuration IP
des deux machines de 2 réseaux différents
Sur la figure ci-dessus, nous observons la
configuration de la machine externe machineun@machineun-VirtualBox
avec l'adresse 2.42.0.2 et celle de la machine interne
sandra@sandra-VirtualBox.
Ensuite nous avons configuré une machine comme
étant le routeur pour qu'il puisse effectuer le filtrage entre les deux
réseaux. Notre passerelle possède 2 cartes réseaux. Une
carte connectée au réseau interne et l'autre au réseau
externe. Nous avons configuré les deux cartes avec les adresses que vous
pouvez retrouver dans le tableau précédent. Dans les deux cas
nous avons des adresses statiques de classes A.
La figure ci-dessous montre notre configuration IP.
Ensuite nous avons configuré le routage sur notre
passerelle. Nous avons activé
« net.ipv4.ip_forward=1 » dans le fichier
/etc/sysctl.conf. Ensuite ajouter une règle de routage
« iptables -t nat -A POSTROUTING -o eth0 -j
MASQUERADE » pour activer le NAT sur l'interface
connecté au réseau externe eth0. Enfin nous avons
automatisé le montage de nos règles à l'activation de
notre interface eth0. A chaque fois que notre interface sera activée,
les règles iptables se réappliquerons. Nous enregistrons nos
règles iptables dans le fichier
/etc/iptables_rules.save. Ensuite dans le fichier
/etc/network/interfaces on ajoute la ligne
« post-up iptables-restore <
/etc/iptables_rules.save ». Et enfin nous avons
rechargé nos interfaces. Je précise que nous avons ajouté
notre passerelle comme route par défaut pour les 2 machines des 2
réseaux différents.
Nous pouvons observer sur les figures ci-dessus que de simples
ping d'un réseau à l'autre fonctionnent parfaitement.

Figure 41 : Ping entre les 2
machines de 2 réseaux différents
Ensuite il s'agissait de faire fonctionner le filtre
c'est-à-dire envoyer juste quelques paquets.
Nous avons envoyé un lot de 20 paquets sur lesquels
juste 10 était malveillants et regarder de l'autre côté
nos deux paquets bénins reçus.
Donc nous avons pris un fichier pcap et envoyé juste 20
paquets. Utiliser les prédictions et s'assurer que la passerelle filtre
correctement. Ici le trafic est généré depuis le
réseau interne.

Figure 42 : Envoi et
réception des paquets de part et d'autre du réseau
Sur la figure ci-dessus, La machine
sandra dans le réseau interne est l'émetteur. Il suffit
de regarder les détails du paquet envoyé au niveau des champs
src et dst. Et machineun est le destinataire des
paquets et renifle les paquets qu'il reçoit en ne filtrant et affichant
que ceux qui viennent de l'adresse 10.42.1.2. Nous l'avons fait pour
éviter d'afficher pleins de paquets de source divers,les paquets ARP,
les requêtes icmp, etc.
Nous pouvons observer que sur la machine
sandra-Virtual-Box, 20 paquets ont été envoyés et
de l'autre côté 9 paquets ont été
reçus ! C'est parce que la passerelle a bloqué les paquets
que le filtre a décidé comme étant malveillant.
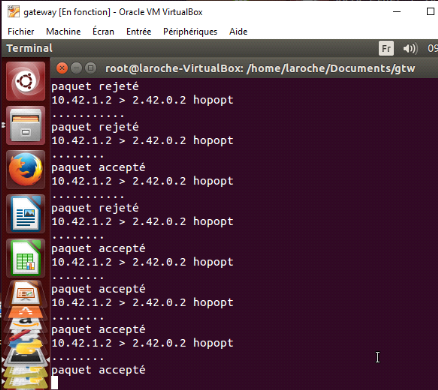
Figure 43 : Filtrage du
trafic
Cette figure nous montre les paquets
acceptés et rejetés par le filtre. Lorsqu'un paquet est
détecté comme étant malveillant, il est rejeté.
Nous avons aussi vérifié qu'on pouvait filtrer les
paquets provenant de l'extérieur.

Figure 44 : la machine interne
renifle les paquets qu'elle reçoit
La machine sandra est cette
fois-ci le destinataire et renifle les paquets. Le même nombre de paquets
ont été envoyés avec le même nombre de paquets
malveillants et bénins. Les résultats sont les mêmes que
ceux obtenus lorsque machineun était le destinataire.
Ceci prouve qu'il est effectivement possible de filtrer le
trafic venant de l'extérieur et celui venant de l'intérieur.
4. Discussions
Après le prétraitement des données,
l'entraînement des algorithmes est ce qui nous a pris le plus de temps
pour pouvoir arriver à des résultats satisfaisants. Une petite
modification du jeu de donnée ou encore une modification du nombre de
classes et tous les paramètres étaient à revoir. Nous
avons utilisé le jeu de données du laboratoire
stratosphère d'abord prévu pour la détection de trafic IoT
malveillant pour l'identification d'objets. Ensuite l'algorithme d'extraction
des attributs que nous avons conçus nous a permis d'obtenir un jeu de
données pré traité adéquat pour entraîner le
modèle.
Les deux réseaux de neurones suggérés
dans ce projet, LSTM et MLP, ont tous deux donné de bons
résultats avec des précisions dépassant les 95%.
Toutefois le LSTM a été beaucoup plus difficile à
entraîner. Le volume d'échantillons traités était
deux fois inférieur à celui du MLP à chaque epoch, mais le
temps d'entraînement était beaucoup plus élevé.
Cependant, la machine sur laquelle nous avons travaillé pourrait ne pas
avoir les ressources physiques nécessaires.
Cela nous amènerait à envisager deux cas pour
une passerelle IoT :
- Travailler avec une passerelle physique qui possède
déjà de bonnes capacités.
- Envoyer les données reçu sur la passerelle
dans le Cloud où les prédictions seront faites et les
renvoyés à la passerelle qui filtre
Les attaques sur lesquelles nous avons entraîné
nos modèles sont Mirai, Trojan, Gafgyt, Muhstik et Hide and seek. Les
deux modèles se sont révélés efficaces pour les
détecter. Nous avons choisi les plus couramment rencontrés mais
chaque année bien d'autres virus voient le jour et il faudrait
entraîner ces modèles, les optimiser et les mettre à
jour.
Le plus gros du travail d'identification des objets est la
création de l'algorithme d'extraction des attributs. Une fois fait nous
avons ré entraîné le modèle à
reconnaître les objets utilisés et obtenu grâce au
laboratoire Stratosphère. Les performances sont bonnes toutefois il
faudrait plus de données avec des objets différents pour pouvoir
l'entraîner. Les résultats d'IoT Sentinel étaient
déjà bons cependant sur certains objets nous avons obtenus de
meilleurs résultats. Les résultats des travaux sur IoT Sentinel
se trouvent à l'annexe.
Tableau 9 : Comparaison des
résultats entre le modèle d'IoT Sentinel et notre
modèle
|
Objets
|
Précision-Résultat d'IoT
Sentinel
|
Précision- Nos resultats
|
|
Aria
|
1
|
0.98
|
|
HomeMatchPlug
|
1
|
1
|
|
Withings
|
1
|
0.97
|
|
MAXGateway
|
1
|
0.95
|
|
HueBridge
|
1
|
1
|
|
HueSwitch
|
1
|
1
|
|
EdnetGateway
|
1
|
0.987
|
|
EdnetCam
|
0.95<p<1
|
0.93
|
|
EdimaxCam
|
0.95<p<1
|
0.938
|
|
Lightify
|
0.95<p<1
|
1
|
|
WeMoInsightSwitch
|
1
|
1
|
|
WemoLink
|
1
|
1
|
|
WemoSwitch
|
0.95<p<1
|
1
|
|
D-LinkHomehub
|
1
|
1
|
|
D-LinkDoorSensor
|
1
|
1
|
|
D-LinkDayCam
|
1
|
0.984
|
|
D-LinkCam
|
0.95<p<1
|
1
|
|
D-LinkSwitch
|
0.6
|
1
|
|
D-LinkWaterSensor
|
0.5<=1<0.6
|
1
|
|
D-LinkSiren
|
0.4 <=p<0.5
|
0.996
|
|
D-LinkSensor
|
0.4
|
1
|
|
TP-LinkPlugHS110
|
0.6 <p <0.8
|
1
|
|
TP-LinkPlugHS100
|
<0.6 et >0.5
|
0.95
|
|
EdimaxPlug1101W
|
0.6<p<0.7
|
0.97
|
|
EdimaxPlug2101W
|
0.5<p<0.6
|
0.96
|
|
SmarterCoffee
|
0.4<p<0.5
|
0.875
|
|
iKettle2
|
0.4
|
0.933
|
Nous avons montré qu'il était tout à fait
possible de filtrer les paquets si nous disposions d'un système libre de
droit et qui nous donnait accès au Kernel. Nous pouvons détecter
et filtrer le trafic malveillant allant vers et venant du réseau
interne.
Les tests que nous avons menés constituent une preuve
de concept préliminaire pour démontrer la pertinence de notre
approche. Les résultats des modèles proposés sont
prometteurs même si nous pensons qu'on pourrait les améliorer ou
optimiser les algorithmes. En effet contrairement à Filter.tlk, qui
crée des filtres BPF et crée des règles nous nous
détectons d'abord et filtrons par la suite. L'identification des objets
basés sur l'empreinte digitale permettrait à la passerelle de
connaître tous les objets de son réseau et d'en détecter de
nouveaux. Un appareil dont le comportement changerait impacterait aussi son
empreinte digitale. Il serait bon de décider d'une stratégie
à la suite de ce changement d'empreinte comme l'isolation de l'objet en
question afin de s'assurer qu'il ne contient pas de virus ou que son
comportement n'est pas malveillant avant de le réintégrer dans le
réseau. Ces deux fonctions réunies dans une passerelle IoT
permettraient de protéger un réseau d'objets connectés.
Conclusion
Dans ce chapitre, nous avons parlé des tests et des
résultats obtenus avec les différents modèles
proposés afin de suggérer une solution pour le filtrage d'un
réseau d'objets connectés. Nous avons créé des
modèles de détection d'attaques visant divers objets
connectés sans prendre dépendre d'un protocole de communication
en particulier et vérifier qu'un filtrage était possible sans
avoir besoin de créer des règles iptables. Une application de
notre approche pourrait être installée soir sur la passerelle
directement ou alors sur le Cloud et les paquets une fois analysés et
pré traité pourraient être envoyés vers le Cloud
pour effectuer des prédictions qu'on renverra vers la passerelle pour
qu'elle filtre les paquets dans la file d'attente.
CONCLUSION ET PERSPECTIVES
Dans ce travail, nous avons proposé des
modèles de détection et d'identification d'objets
spécifique aux objets connectés, en nous concentrant sur les
attaques les plus fréquentes dont ils sont victimes et ayant pour but de
protéger tout un réseau et non un objet particulier grâce
à la passerelle qui représente la limite entre le réseau
interne qu'on veut protéger et internet ,le réseau externe.
Même s'il est vrai que comparé au reste du monde, les
ménages camerounais sont moins connectés, les entreprises
camerounaises qui disposent de gros équipements réseaux sont
elles aussi de potentielles victimes de botnet quelque soit l'origine dans le
monde de ces attaques. Nous avons décidé de nous concentrer sur
la cause des attaques et non pas sur les cibles principales. Cette approche
permet d'alléger le travail d'un pare-feu, sans créer des
règles qu'il faudra gérer par la suite afin d'éviter des
anomalies, en s'occupant des paquets possiblement malveillant et en
protégeant les objets à l'intérieur du réseau
d'attaques qu'un simple pare-feu ne peut pas arrêter. Elle permet aussi
de protéger les objets au sein du réseau interne et la
confidentialité des données des utilisateurs.
Afin de suggérer ces modèles et la solution en
elle-même, nous nous sommes basés sur nos nombreuses lectures sur
les différents travaux sur les objets connectés et leur
sécurité qui avaient déjà été faits,
sur ce qu'est l'apprentissage profond, la création d'algorithme et de
réseau de neurone mais aussi la notion d'empreinte digitale. Nous avons
aussi beaucoup appris sur la création d'algorithmes, l'exploration et
l'exploitation de grosses quantités de données.
Ce projet nous a permis d'apprendre et de réaliser
des modèles d'intelligence artificielle et d'apprendre python, sur
lesquelles nous n'avions jamais réalisé de projet avant mais
aussi de mieux cerner les avantages et les limites de l'intelligence
artificielle par apprentissage supervisé et non supervisé.
Toutefois, notre travail a quelques limites. D'abord nous
avons travaillé sur 2 modèles différents qui n'ont aucun
impact l'un sur l'autre. Ensuite nous n'avons pas créé d'outils
ou de logiciels afin d'utiliser ces modèles et enfin cette approche
obligerait aussi une passerelle à avoir des ressources
nécessaires pour modéliser les attaques et les empreintes
digitales si ce traitement ne se fait pas sur le Cloud.
Nous pouvons suggérer plusieurs perspectives qui
pourraient améliorer ce travail:
? Nous pourrions nous servir de la passerelle pour
détecter les différentes faiblesses des objets du réseau
interne ou détecter des comportements anormaux.
? Concevoir un logiciel à part entière qui
pourrait être installé sur les passerelles connus des objets
connectés.
? Sensibiliser les utilisateurs à travers des messages
ou des notifications si possibles sur la passerelle pour leur indiquer les
dangers auxquels ils s'exposent lorsque plusieurs paquets malveillants sont
détectés.
? Faire en sorte que nos deux modèles détection
et identification puissent travaillés avec les résultats de
l'autre pour de meilleures performances
? Implémenté la division
du réseau en zone de confiance et zone de non confiance pour des
appareils suspects
ANNEXES 1
Tableau 8 : Tableau
récapitulatifs des protocoles possibles d'un réseau d'objets
connectés
|
Technologie
|
Topologie
|
Débit
|
Portée
|
Description et détails
|
|
GSM (GPRS/EDGE)
|
Cellulaire
|
35-170 Kbit/s (GPRS), 120-384 Kbit/s (EDGE)
|
Quelques dizaines à des centaines de
kilomètres
|
Fonctionnalités multimédia (SMS, MMS),
accès Internet et introduction de la carte SIM. Portée faible en
zone rurale
Possible abandon de la maintenance du réseau par les
opérateurs
Portée faible en zone rurale
Possible abandon de la maintenance du réseau par les
opérateurs
|
|
3G
|
Cellulaire
|
384 Kbit/s-2 Mbit/s (UMTS)
|
Quelques dizaines à des centaines de
kilomètres
|
Sécurité élevée, itinérance
internationale. Consommation élevée d'énergie, couverture
de réseau faible, coût élevé de licence de
spectre
Consommation élevée d'énergie, couverture
de réseau faible, coût élevé de licence de
spectre
|
|
4G
|
Cellulaire
|
600 Kbit/s-10 Mbit/s
|
Quelques dizaines à des centaines de
kilomètres
|
Très haut débit, haute disponibilité,
très bonne couverture géographique, gestion de la
mobilité.
Consommation en batterie grande, prix de l'abonnement
important
|
|
LTE-M
|
Cellulaire
|
3-10 Mbit/s
|
Des dizaines voire centaines de kilomètres
|
Apport de nouvelles fonctionnalités d'économie
d'énergie adaptées à une variété
d'applications IoT. Pas d'utilisation d'un modem spécifique. Gère
la mobilité des objets
En cours de déploiement, délai de livraison
d'une donnée à l'objet variable
|
|
SIgfox
|
Diffusion
|
10-1 000 bit/s
|
30-50 km (environnements ruraux), 3-10 km
(environnements urbains)
|
prix bas pour l'appareil et l'abonnement (~ 1 € / mois),
économie de la batterie (> 10 ans)
Dépendance à une technologie propriétaire,
utilisation d'un modem spécifique, ne gère pas la mobilité
des objets, délai de livraison d'une donnée à l'objet
très variable (jusqu'à plusieurs jours)
|
|
LoRaWAN
|
Diffusion
|
Bas
|
2-5 km (environnement urbain), 15 km (environnement
suburbain)
|
faible puissance, prix bas pour l'appareil et l'abonnement (~ 1
€ / mois) , économie de la batterie (> 10 ans)
Utilisation d'un modem spécifique, Itinérance en
cours de déploiement, ne gère pas la mobilité des
objets, délai de livraison d'une donnée à l'objet
très variable (jusqu'à plusieurs jours)
|
|
NBIoT
|
Celllaire
|
Bas
|
Quelques mètres à des dizaines de
mètres
|
Prix bas pour l'appareil et l'abonnement (~ 1 € / mois)
réduit, économie de la batterie (> 10 ans)
Utilisation d'un modem spécifique, ne gère pas la
mobilité des objets, délai de livraison d'une donnée
à l'objet variable
|
|
WiFi
|
Etoile
|
600 Mbit/s maximum, mais les vitesses habituelles sont
plus proches de 150 Mbit/s, en fonction de la fréquence de canal
utilisée et du nombre d'antennes
|
Jusqu'à plusieurs dizaines de mètres
|
qualité du signal assurée, connexion simple et
rapide à la passerelle
Non adapté aux objets uniquement alimentés par
batterie. Une passerelle WiFi mal configurée expose le réseau
à des failles de sécurité (man in the middle)
|
|
ZigBee
|
Mesh
|
250 Kbit/s
|
Une dizaine de mètres à maximum une centaine de
mètre
|
Technologie peu consommatrice en énergie et
s'intègre à bas coût dans les équipements
Achat d'appareils spécifiques car la technologie n'est
pas disponible dans les smartphones et ordinateurs
|
|
Z-Wave
|
Mesh
|
9,6 / 40 / 100 Kbit/s
|
Jusqu'à plusieurs mètres
|
Adapté aux objets alimentés par batterie et
communiquent à bas débit
Technologie adaptée à des besoins très
spécifiques. Achat d'appareils spécifiques
|
|
Bluetooth
|
Etoile
|
1 Mbit/s (Smart/BLE)
|
Jusqu'à plusieurs mètres voire des dizaines de
mètres
|
Quasiment intégré dans tous les appareils du
quotidien
Si la sécurité n'est pas bien configurée
alors l'objet s'expose à des failles de sécurités telles
que le bluejacking et le bluesnarfing
|
|
NFC
|
Etoile
|
100-420 Kbit/s
|
Environ 10 cm
|
Technologie facile à utiliser et à mettre en
place. Idéal pour échanger de courtes informations
Contrairement au Bluetooth, la technologie n'est pas encore
disponible dans les objets du quotidien tels que les smartphones
|
|
LiFi
|
Etoile
|
Haut
|
X
|
Technologie moins coûteuse qu'une technologie radio car
les ampoules LED peuvent être utilisées en tant que point
d'accès (passerelle). La lumière ne traverse pas les
murs contrairement aux technologies radio cela offre une meilleure
sécurité pour l'accès au réseau LiFi
Pas de communication sans lumière allumée.
Technologie unidirectionnelle et doit être
couplée avec une autre technologie (CPL, WiFi) ou être
utilisée si il n'est besoin uniquement de débit descendant
|
|
6lowPAN(IPv6 Low-power wireless Personel Area
Network)
|
X
|
X
|
x
|
C'est une technologie IP. Ce n'est pas un protocole de
communication tel que ZigBee ou Bluetooth mais plutôt un protocole de
réseau qui définit les mécanismes d'encapsulation et de
compression d'en-têtes. Elle peut être utilisée sur
différentes plateformes de communications telles que WiFi ou
Ethernet.
|
ANNEXES 2

Figure 45 : Partie 1
résultat du modèle d'identification des objets

Figure
46 : Partie 2 résultat du modèle d'identification des
objets
ANNEXES 3
Figure 47 : Résultats
des travaux d'IoT Sentinel
RÉFÉRENCES
[1]
https://safeatlast.co/blog/iot-statistics/#gref
consulté le
15/09/2020
[2]
peut
on sécuriser l'internet des objets du blogueur d'Olivier Ezratty
consulté le
15/09/2020
[3]
https://www.kaspersky.com/about/press-releases/2019_iot-under-fire-kaspersky-detects-more-than-100-million-attacks-on-smart-devices-in-h1-2019
consulté le
17/09/2020
[4] Pallavi Sethi and Smruti R.. Review Article «Internet
of Things: Architectures, Protocols, and Applications Sarangi Department of
Computer Science», IIT Delhi, New Delhi, India
[5] Mahmoud Elkhodr, Seyed Shahrestani and Hon Cheung .
«A MIDDLEWARE FOR THE INTERNET OF THINGS School of Computing, Engineering
and Mathematics», Western Sydney University, Sydney, Australia.
International Journal of Computer Networks & Communications (IJCNC) Vol.8,
No.2, March 2016 DOI : 10.5121/ijcnc.2016.8214 159
[6] « Internet des objets: architectures,
protocoles et applications » de Pallavi Sethi et Smruti R.
Sarangi publié sur Hindawi Journal of Electrical and Computer
Engineering Volume 2017, Article ID 9324035, 25 pages
https://doi.org/10.1155/2017/9324035
[7]Le projet AWASP 2018 voir sur :
https://owasp.org/www-pdf-archive/OWASP-IoT-Top-10-2018-final.pdf
consulté le 25/10/2020
[8] Shafiq Ul Rehman et Selvakumar Manickam.
« A Study of Smart Home Environment and it's Security Threats»,
Article in International Journal of Reliability Quality
and Safety Engineering · May 2016 DOI: 10.1142/S021853931640005.Voir
https://www.researchgate.net/publication/303089918
[9]
https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/
[10]
https://fullcirclemagazine.org/2016/09/04/bashlite-malware-turning-millions-of-linux-based-iot-devices-into-ddos-botnet/
consulté le 1/11/2020
[11]
https://www.cyberswachhtakendra.gov.in/alerts/BrickerBot_IoT_Malware.html
[12]
https://unit42.paloaltonetworks.com/muhstik-botnet-attacks-tomato-routers-to-harvest-new-iot-devices/
consulté le 16/11/2020
[13]
https://unit42.paloaltonetworks.com/muhstik-botnet-exploits-the-latest-weblogic-vulnerability-for-cryptomining-and-ddos-attacks/
consulté le 16/11/2020
[14]
https://labs.bitdefender.com/2018/09/hide-and-seek-iot-botnet-learns-new-tricks-uses-adb-over-internet-to-exploit-thousands-of-android-devices/
[15]
https://www.malwaretech.com/2019/01/tracking-the-hide-and-seek-bonet.html#:~:text=Hide%20and%20Seek%20(HNS)%20is,well%20as%20some%20old%20CVEs.
Consulté le 15/11/220
[16]Markus Miettinen, Ahmad-Reza Sadeghi, Samuel Marchal , N.
Asokan, Ibbad Hafeez, Sasu Tarkoma, «IOT SENTINEL: Automated Device-Type
Identification for Security Enforcement in IoT», page 1-5
[17]
https://cve.mitre.org/about/faqs.html
consulté
le 15/09/2020
[18]
https://connect.ed-diamond.com/MISC/MISC-064/BSD-Packet-Filter
consulté le 20/09/2020
[19] Bruno Cruz , Silvana Go'mez-Meire , David Ruano-Orda's ,
Helge Janicke, Iryna Yevseyeva , and Jose R. Me'ndez . «A Practical
Approach to Protect IoT Devices against Attacks and Compile Security Incident
Datasets.»
[20]
https://www.agenceecofin.com/telecom/3006-78021-la-start-up-camerounaise-ndoto-concoit-un-compteur-electrique-intelligent-permettant-de-reduire-la-fraude
consulté le 15/01/2021
[21]
https://www.investiraucameroun.com/entreprises/1006-12769-a-fin-avril-2019-l-electricien-camerounais-eneo-installe-environ-4000-compteurs-intelligents-dans-les-menages
consulté le 15/01/2021
[22]
https://cybermap.kaspersky.com/fr/stats#country=210&type=BAD&period=w
consulté le 19/01/2021
[23]
https://map.lookingglasscyber.com/
consulté le 19/01/2021
[24] Korosh Golnabi, Richard K. Min, Latifur Khan, Ehab
Al-Shaer, « Analysis of Firewall Policy Rules Using Data Mining
Techniques », Department of Computer Science The University of Texas
at Dallas Richardson, USA, School of Computer Science, Telecommunications and
Information Systems DePaul University Chicago, USA
[25]
https://www.infor.uva.es/~teodoro/neuro-intro.pdf
Ben Krose & Patrick van der Smagt, «An introduction
to neural network», Faculty of Mathematics Computer Science, Institute of
Robotics and System Dynamics, University of Amsterdam, German Aerospace
Research Establishment
[26]
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
consulté le 09/12/2020
[27]
https://effeuillage-la-revue.fr/portfolio-item/le-fingerprinting/
[28]Tadayoshi Kohno, CSE Department, UC San Diego & Andre
Broido CAIDA, UC San Diego & kc claffy CAIDA, UC San Diego, «Remote
physical device fingerprinting»
[29] Tadayoshi Kohno & Andre Broido & K.C. Claffy,
«Remote physical device fingerprinting»,
https://homes.cs.washington.edu/~yoshi/papers/PDF/KoBrCl2005PDF-Extended-lowres.pdf
consulté
le 14/11/2020
[30]
https://www.virtualbox.org/
consulté le 02/12/2020
[31]
https://cercll.wordpress.com/2012/09/23/ubuntu-cest-quoi/
consulté le 04/12/2020
[32]
https://mcfp.felk.cvut.cz/publicDatasets/IoTDatasets/
consulté le 10/09/2020
[33]
https://www.stratosphereips.org/datasets-iot23
Stratosphere Laboratory. A labeled dataset with malicious and benign IoT
network traffic. January 22th. Agustin Parmisano, Sebastian Garcia, Maria
Jose Erquiaga.
[34]
https://scikit-learn.org/
[35]
https://scikit-learn.org/stable/modules/preprocessing.html#preprocessing
consulté le 04/12/2020
[36]
https://matplotlib.org/
consulté le 03/12/2020
[37]
https://mrmint.fr/overfitting-et-underfitting-quand-vos-algorithmes-de-machine-learning-derapent
consulté le 04/12/2020
[38]
https://www.netfilter.org/documentation/HOWTO/netfilter-hacking-HOWTO-4.html
consulté le 04/12/2020
[39]
https://www.inetdoc.net/guides/iptables-tutorial/nfqueuetarget.html
Consulter le 5/12/2020
[40]
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_error.html
| 

