|
UNIVERSITÉ DE DSCHANG UNIVERSITY OF DSCHANG
********* *********
ÉCOLE DOCTORALE POSTGRADUATE SCHOOL
********* *********
FACULTÉ DES SCIENCES FACULTY OF SCIENCES
DSCHANG SCHOOL OF SCIENCES AND TECHNOLOGY
|
|
DÉPARTEMENT DE
MATHÉMATIQUES-INFORMATIQUE
DEPARTMENT OF MATHEMATICS AND
COMPUTER SCIENCE
|
|
|
Présenté et soutenu en accomplissement
de Master Option :
Matricule
Licencié
Sous
Chargé de Cours, Université
|
Mémoire
partiel, en vue de l'obtention du diplôme en
Informatique
Par
: CM04-10SCI1755 en Informatique
la direction de
de Dschang, Cameroun.
2016
|
|
|
REPUBLIQUE DU CAMEROUN
Pay-- Tramait -
Patrie
REPUBLIC OF CAtOON
Peace Work Faheerattif
UNIVERSTIt DE DSCHAI4G UNIVERSITY OF D NG
Sdrrdae Theariirass hi ancrienex
BP 96, Dschang (Cameroun) - i fEax 7) 233 45 H
Ri W _http://www.univ-dschang.org_ E-rwena_udsrectorat(a~
univ-dschang.org
|
|
FA CULTE DES SCIENCES
FACULTY OF SCIENCE
Département de Mathématiques
et
bairemnatique
Department ofMathernatir c and
Comprittr
Science
BE 67, Dschang (Ornerons)
TILfFax j237 233 45 17 35
--~ dept-MI.sciences,
univ-dschang.org
|
FICHE DE CERTIFICATION DE L'ORIGINALITÉ DU
TRAVAIL
Je soussigné ZEKENG NDADJI Milliam Maxime,
matricule CM04-IOSCI1755, atteste que le présent Mémoire est le
fruit de mes propres travaux effectués au Laboratoire d'Informatique
Fondamentale et Appliquée (LIFA) de l'Université de Dschang sous
la direction de Dr TCHOUPÉ TCHENDJI Maurice, Chargé de
cours à l'Université de Dschang.
Ce Mémoire est authentique et n'a pas
fait l'objet d'une présentation antérieure pour l'acquisition de
quelque grade universitaire que ce soit.
Fait à Dschang le 18 Juillet
2016
L'auteur L'encadreur

ZEKENG NDADJI Milliam Maxime TCHOUPÉ TCHENDJI
Maurice
(Chargé de cours, Directeur du
Mémoire)
Chef de département

TAYOU DJAMEGNI Clémentin
(Maitre de
conférences)
|
|
|
TCHOUPË TCHENDJI Maurice (Chargé de
cours)
|
|
TAYOU DJAMEGNI Clémentin (Maitre de
conférences)
|
|
|
Chef de département
|
|
|
|
TAYOU DJAMEGNI Clémentin (Maitre de
conférences)
|
|
KENGNE TCHENDJI Vianney (Chargé de
cours)
|
|
REPUBLIQUJE DU CAMEROUN
Puzx-- Pairie
REPcmuc OF CAMEROON
Pence
-- Work Ruherlaud
UMVERSTIt IIA.
UNIVERS= OF DSCELANG
Scitalat
Thesmausi&hairgeasis Ibi Confina
BP 96, Dschang (Cameroun) -- Ta /Fax (237) 233
4513 St
Wd.aitiL-http:
//www.univ-dschang.org_
E- _ udsrectorat@univ-dschang org
|
|
FACULTE DES SCIENCES
FACULTY OF
SCIENCE
Département de Iviadtimatiques
et
htfiarma€igne
Depatiment of Idathemaiks and Computer
Scie
ce
BP 67, Dschang (CamercIZI)
T"OJFax (237) 233 45 17
35
E-nom _ deot-MI. sciences (
univ-dschang.org
|
ATTESTATION OE CORRECTION OU MEMOIRE DE MASTER
(c)E
Monsieur ZEKENG 14DADJI Milliam Maxime
Nous attestons que le Mémoire de
Master de Monsieur ZEKENG NDADJI Milliam Maxime intitulé
«Réconciliation par consensus des mises à jour des
répliques partielles d'un document structuré »
a effectivement été corrigé, conformément aux
remarques et aux recommandations du Jury devant lequel, ledit Mémoire a
été soutenu le 12 Juillet 2016, au Département de
Mathématiques-Informatique de la Faculté des Sciences de
l'Université de Dschang.
En foi de quoi, la présente attestation lui
est délivrée pour servir et valoir ce que de
droit.
Fait à Dschang le 18 Juillet
2016
Président du Jury Rn . .. rteur, du
Tu
Dédicaces
i
À mon père NDADJI EMMANUEL et
à ma mère MAFFO ZEMTSOP MARIE.
ii
Remerciements
Alors que mon regard s'illumine et que je commence à
percevoir le bout de cet énorme tunnel que fut ce travail, je remarque
que tous les progrès réalisés et présentés
ici, reposent sur l'infinie bonté du Seigneur et sur les qualités
innombrables et incomparables de bien de personnes, tant physiques que morales.
Je ne trouverai certainement pas les formules justes pour vous exprimer toute
ma gratitude. Pour compenser, si cela est possible, je voudrais mentionner ici
vos noms et/ou prénoms ainsi que vos rôles respectifs dans
l'accomplissement de ce travail. Un merci chaleureux:
-- Au Dr. TCHOUPÉ TCHENDJI Maurice, mon encadreur,
parce que vous avez su avoir confiance en moi et qu'avec le laps de temps qui
nous était imparti, vous avez fait de moi un prototype
d'éditeur coopératif de documents structurés. Vous
êtes, sans conteste, mon idole;
-- À tous les membres du jury, pour l'immense honneur
que vous m'accordez en appréciant ce travail;
-- À tous les enseignants du département de
Mathématiques-Informatique de la Faculté des Sciences de
l'université de Dschang (en particulier, le Pr. TAYOU DJAMEGNI
Clémentin), pour tous vos enseignements et conseils judicieux;
-- Au Dr. FUTE TAGNE Elie, parce que vous avez su aller au
delà de votre fonction d'enseignant pour vous imposer comme un
véritable père pour moi;
-- Au Dr. KENGNE TCHENDJI Vianney, à M. SOH Mathurin,
au Dr. BOMGNI Alain Bertrand et à M. KUITCHE KAMELA Esaïe Durel,
vous m'avez fait prendre conscience des capacités et des
possibilités qui étaient à ma bourse en me proposant
régulièrement des challenges;
-- À mes parents, NDADJI Emmanuel et MAFFO ZEMTSOP
Marie, parce que vous vous êtes donné la peine d'assurer mon
éducation depuis ma naissance;
-- À mes frères et soeurs (Chanceline, Emanie,
Alex alias Tété, Arnold alias Nicky, Brice alias Toutou), pour
votre soutien inconditionnel;
-- À tous mes camarades de promotion de Master 2
Recherche, je ne vous changerai pour rien au monde parce qu'avec vous,
j'apprends à devenir un Homme meilleur. Merci pour vos relectures et vos
suggestions constructives;
-- À tous mes amis (Audrey, Jaurès, Blaise,
Brel, Armel, Lionel, Léonard, Osman, Rodrigue, Sidoine, Yannick,
Patrick, Doris, Fabrice, Jeanne, Ange...), vous avez tellement pensé
tout haut que j'allais y arriver au point que je commence à y
arriver;
-- À tous mes collègues des lycées
technique et classique de Dschang, pour votre dynamisme permanent qui a
été pour moi une source d'inspiration;
-- À tous les membres et amis de la communauté
Maths-Info Universe, pour votre confiance et la bonne humeur permanente dont
vous faites preuve;
-- À ZILE CHONGANG Virginie, pour tout et le reste;
-- Que tous ceux dont les noms ne figurent pas sur cette page
ne se sentent point lésés.
iii
Table des matières
Dédicaces i
Remerciements ii
Résumé vi
Abstract vii
Introduction 1
Le contexte du travail 1
Les documents structurés 1
L'édition coopérative des documents
structurés 2
La problématique étudiée 2
Le travail réalisé 3
Organisation du manuscrit 3
Chapitre 1 Notions d'édition
coopérative et de conflits 5
1.1 - Le travail coopératif 5
1.1.1 - Coopération vs Collaboration 6
1.1.1.1 - Le comportement des personnes 6
1.1.1.2 - L'organisation du travail 6
1.1.2 - Notion de Travail Coopératif Assisté par
Ordinateur (CSCW) 7
1.1.2.1 - Les caractéristiques des systèmes de CSCW
7
1.1.2.2 - Classification des systèmes de CSCW 8
1.1.2.3 - Les systèmes de CSCW comme systèmes
à flots de tâches . . . 9
1.2 - Un exemple de CSCW : L'édition coopérative
11
1.2.1 - Les types de documents électroniques 11
1.2.1.1 - Les documents non structurés 12
1.2.1.2 - Les documents structurés 12
1.2.2 - Les documents dans un système de workflow (BPMN)
14
1.2.3 - Édition coopérative et conflits 15
1.2.3.1 - Les techniques de détection des conflits 17
1.2.3.2 - La résolution des conflits 17
1.3 - Synthèse 18
Chapitre 2 L'édition coopérative
des documents structurés 19
2.1 - Documents structurés, conformité et
édition 19
2.1.1 - Représentation d'un document structuré
20
2.1.2 - Conformité d'un document structuré 21
2.1.2.1 - Notion d'AST (Abstract Syntax Tree) 21
2.1.2.2 - Notion d'automate d'arbre 22
2.1.3 - Une approche d'édition coopérative des
documents structurés 24
2.2 - Vues, projection et répliques partielles 26
2.2.1 - Les vues d'un document structuré 26
2.2.2 - Projection d'un document structuré 27
Table des matières iv
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
2.3 - Expansion des répliques partielles 27
2.3.1 - Le problème de la projection inverse 28
2.3.2 - Sérialisation d'un document structuré
29
2.3.3 - Représentation de l'expansion d'une
réplique partielle et exemple . . . 30
2.4 - Fusion des répliques partielles 31
2.4.1 - Produit synchrone des automates d'arbre 31
2.4.2 - Fusion des répliques partielles 32
2.5 - Synthèse 32
Chapitre 3 Fusion consensuelle des mises
à jour des répliques partielles 33
3.1 - Problématique de la réconciliation par
consensus 34
3.2 - Calcul du consensus 34
3.2.1 - Consensus entre plusieurs (deux) documents 35
3.2.2 - Construction de l'automate du consensus 36
3.2.3 - Illustration de l'algorithme de la fusion consensuelle
39
3.3 - Synthèse 43
Chapitre 4 Un prototype d'éditeur
coopératif désynchronisé (TinyCE v2) 45
4.1 - Architecture et fonctionnement de TinyCE v2 46
4.1.1 - Fertilisation croisée Haskell-Java 47
4.1.2 - Interaction client-serveur 52
4.2 - Le matériel de construction de TinyCE v2 52
4.3 - Mise en oeuvre d'un workflow d'édition sous TinyCE
v2 53
4.4 - Synthèse 54
Conclusion générale 58
La problématique étudiée et les choix
méthodologiques 58
Analyse critique des résultats obtenus 59
Quelques perspectives 60
Bibliographie 61
Annexe A Un autre exemple complet de fusion
consensuelle 65
Annexe W Quelques fonctions Haskell pour le
calcul des consensus 69
v
Table des figures
1.1 - Matrice 2 x2 de Johansen [Joh88] pour la
catégorisation des systèmes de CSCW. 9 1.2 - Matrice 3 x
3 de Grudin pour la catégorisation des systèmes de
CSCW [Sar05]. 10
1.3 - Un exemple de document structuré XML contraint par
une DTD. 13
1.4 - Un exemple de diagramme d'orchestration BPMN, illustrant
le processus de
sélection d'un étudiant dans une des
filières de la FS UDs. 16
2.1 - Représentation graphique d'un arbre et indexation de
ses éléments. 21
2.2 - Un AST et l'arbre de dérivation qu'il
détermine 22
2.3 - Illustration de la procédure de vérification
de la conformité d'un arbre à partir
d'un automate d'arbre 24
2.4 - Un diagramme d'orchestration
BPMN pour le processus d'édition coopérative
désynchronisée. 26
2.5 - Exemple de projections et de mises à jour
effectuées sur un document 27
2.6 - Exemple de projections inverses d'une réplique
partielle 28
2.7 - Linéarisation d'un arbre
(tma j
v1 ) : on a associé les symboles de Dyck
'(1' et
')1'
(resp. '(2' et
')2') au symbole grammatical A
(resp. B) 29
3.1 - Fusion consensuelle progressive de deux documents 36
3.2 - Exemple de workflow d'une édition avec conflit et
consensus correspondant. . 40
3.3 - Arbres consensuels générés à
partir de l'automate (sc). 43
4.1 - Le logo de TinyCE v2. 46
4.2 - L'architecture de TinyCE v2. 47
4.3 - Utilisation de TinyCE v2 en mode serveur (poste 1) :
création du work-
flow ExempleChapitre3 avec 3 acteurs (Maxim10
(propriétaire ayant une vue globale), Auteur1
(associé à la vue '1"1 =
{A,B}) et Auteur2 (associé à
la vue
'1"2 = {A,C}))
55
4.4 - Utilisation de TinyCE v2 par le co-auteur Auteur1 :
authentification et connexion
au workflow ExempleChapitre3 55
4.5 - Modèle
local et réplique partielle obtenus par le co-auteurAuteur1,
à partir du
modèle et du document initial du workflow
ExempleChapitre3. 56
4.6 - Édition de sa réplique
partielle par Auteur1, conformément au modèle local
reçu. 56 4.7 - Consensus obtenu après synchronisation des mises
à jour apportées sur leurs
répliques partielles respectives, par les co-auteurs
Auteur1 et Auteur2. 57
A.1 - AST et arbre de dérivation
généré à partir de l'automate consensuel
(sc). . . .
68
vi
Résumé
Le travail réalisé dans ce mémoire
s'inscrit dans le domaine du CSCW (Computer Supported Cooperative Work);
plus précisément, il contribue aux travaux sur
l'édition coopérative des documents et a pour but, la production
d'un algorithme de fusion des répliques partielles d'un document
structuré. En fait, dans un workflow d'édition coopérative
asynchrone d'un document structuré, chacun des co-auteurs reçoit
au cours des différentes phases du processus d'édition une copie
du document pour y insérer sa contribution. Pour des raisons de
confidentialité, cette copie peut n'être qu'une réplique
partielle ne contenant que les parties du document (global) qui sont d'un
intérêt avéré pour le coauteur
considéré. Remarquons que certaines parties peuvent être
d'un intérêt avéré pour plus d'un co-auteur; elles
seront par conséquent accessibles et éditables en concurrence.
Quand vient le moment de la synchronisation (à la fin d'une phase du
processus d'édition par exemple), il faut alors fusionner toutes les
contributions de tous les co-auteurs en un document unique. Du fait de
l'asynchronisme de l'édition et de l'existence potentielle des parties
offrant des accès concurrents, des conflits peuvent surgir et rendre les
répliques partielles non fusionnables dans leur entièreté
: on dit que ces répliques sont incohérentes ou en conflit. Nous
proposons dans ce mémoire une approche de fusion (basée sur le
modèle d'édition coopérative proposé dans [BTT08,
BTT07, TT09]) dite par consensus de telles répliques partielles à
l'aide des automates d'arbres. Plus précisément, à partir
des répliques partielles mises à jour, nous construisons un
automate d'arbre dit du consensus qui accepte et/ou engendre exactement les
préfixes maximums ne contenant pas de conflit des répliques
partielles fusionnées. Ces préfixes maximums constituent les
documents du consensus.
Mots clés : Documents
structurés, Workflow d'édition Coopérative, Fusion des
répliques partielles, Conflits, Consensus, Automates d'arbre, Produit
d'automates, Évaluation paresseuse, TinyCE v2.
vii
Abstract
The work presented in this master thesis belongs to CSCW
(Computer Supported Cooperative Work) research field; precisely, it is
a contribution to the cooperative editing of documents and its goal is, the
production of an algorithm that can merge partial replicas of a structured
document. In fact, in an asynchronous cooperative editing workflow of a
structured document, each of the co-authors receives in the different phases of
the process, a copy of the document in which he inserts his contribution.
Sometimes, to increase confidentiality and cooperation, this copy may only be a
partial replica containing just some parts of the (global) document which are
of demonstrated interest for the considered co-author. Note that some parts may
interest more than one co-author; those parts will therefore be accessible and
editable concurrently. When comes the synchronization time (at the end of a
phase of the process for example), a merging of all contributions of all
authors in a single document should be made. Due to the asynchronism of edition
and to the potential existence of the document parts offering concurrent
access, conflicts may arise when merging and make partial replicas unmergeable
in their entirety: those replicas are inconsistent or in conflict. We propose
in this master thesis, a merging approach (based on the cooperative edition
model presented in [BTT08, BTT07, TT09]) said by consensus of such partial
replicas using tree automata. Specifically, from the updated partial replicas,
we build a tree automaton that accepts and/or generates exactly the maximum
prefixes containing no conflict of partial replicas merged. These maximum
prefixes are the consensus documents.
Keywords : Structured documents, Worflow of
cooperative edition, Merging partial replicas, Conflict, Consensus, Tree
automata, Automata product, Lazy evaluation, TinyCE v2.
1
Introduction
Sommaire
Le contexte du travail 1
La problématique étudiée 2
Le travail réalisé 3
Organisation du manuscrit 3
Le contexte du travail
La coopération et la collaboration apparaissent de nos
jours comme des valeurs essentielles pour les entreprises, les
différentes instances municipales et gouvernementales, les
établissements de santé, les grandes institutions d'enseignement
et autres... Réunir plusieurs acteurs (spécialistes) autour d'un
objectif commun est donc devenu un véritable challenge [Gir14]. C'est
dans ce contexte que le Travail Coopératif Assisté par
Ordinateur (TCAO ou CSCW - Computer Supported Cooperative
Work - en anglais) a vu le jour et a évolué. Le domaine du
CSCW a favorisé la mise sur pied de nombreux logiciels (group-ware
ou systèmes de CSCW) et de plusieurs approches
scientifiques pour la résolution des problèmes causés par
le CSCW : ces problèmes sont liés essentiellement aux contraintes
d'espace (la situation géographique de chaque acteur) et de temps (le
mode de communication entre les acteurs). Les systèmes de CSCW
permettent de mettre en relation plusieurs acteurs répartis dans le
temps, l'espace et à travers les organisations afin que ces derniers
coordonnent leurs actions pour l'accomplissement d'une tâche
précise.
Un exemple très présent de CSCW est
l'édition coopérative des documents. En effet, on
rencontre de plus en plus le scénario des auteurs situés sur des
sites géographiquement éloignés qui se coordonnent pour
éditer de façon asynchrone un même document (c'est le cas
par exemple de plusieurs chercheurs rédigeant un même article de
recherche). D'autres cas de CSCW reposent parfois sur l'édition
coopérative des documents; puisque ceux ci (les documents) sont de plus
en plus utilisés pour l'échange des informations entre
applications. Les documents constituent de ce fait, une véritable aide
à la coordination.
Les documents électroniques peuvent être
répartis en trois groupes : les documents linéaires, les
documents semi-structurés et les documents
structurés [Bon98]. Nous nous intéressons ici aux
documents structurés.
Les documents structurés
Ce sont des documents qui présentent une structure
régulière définie par un modèle
générique appelé modèle de document : ce
sont généralement des grammaires (modèles
La problématique étudiée 2
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
grammaticaux). La structure régulière
et l'interopérabilité de tels documents en ont fait de
véritables outils d'échange entre applications
hétérogènes ou non. Les documents structurés
facilitent la coopération et la coordination des actions de plusieurs
personnes. Toutes ces caractéristiques couplées à la
puissance toujours croissante des réseaux de communication en terme de
débit et de sûreté, ont révolutionné la
façon d'éditer de tels documents. On est passé du
modèle classique, dans lequel un auteur édite son document en
local, à un modèle selon lequel plusieurs co-auteurs participent
à l'édition asynchrone d'un même document. On peut imaginer
plusieurs scénarios pour la réalisation de ce modèle
d'édition en ce qui concerne les documents structurés.
L'édition coopérative des documents
structurés
Le processus d'édition coopérative d'un document
structuré est enclenché par l'un des co-auteurs; en effet, il
crée sur le serveur central, un document initial conforme à un
modèle donné. Ensuite, ledit document est distribué
à tous les co-auteurs pour qu'ils y insèrent, sur leurs sites
respectifs (en local), leurs contributions (phase de distribution). Une fois
que tous les différents co-auteurs ont édité leurs copies
respectives (conformément à un modèle local) du document,
il faut fusionner toutes leurs contributions, pour obtenir un document global :
on parle de synchronisation. Le document global obtenu, pourra
éventuellement être redistribué pour la suite de
l'édition.
L'édition coopérative des documents
structurés est un problème d'actualité en raison de la
forte utilisation de ces derniers dans les systèmes informatiques
modernes. Une approche d'édition coopérative asynchrone des
documents structurés [BTT08, BTT07, TT09] consiste, pour des raisons de
confidentialité, à associer une"vue" à chaque co-auteur.
La vue d'un co-auteur donné indique ainsi, les parties du document
auxquelles ce dernier a accès. De ce fait, pour chaque co-auteur, le
document global est répliqué suivant sa vue (on dit qu'il est
projeté), et la copie présente sur chaque site est donc une
réplique partielle du document global. Quand arrive un point de
synchronisation, on réalise la projection inverse de chaque
réplique partielle, pour obtenir des documents conformes au
modèle global, puis on fusionne les documents ainsi obtenus en un
document global.
La fusion des documents est une problématique assez
ancienne qui a déjà été étudiée dans
plusieurs contextes : le contexte des documents structurés XML [Ask94,
CSGM, CSR+, LF02, Lin04, Man01], le contexte des bases de
données, le contexte des programmes informatiques [Men02]... En ce qui
concerne l'édition coopérative des documents structurés,
il existe une approche de fusion des répliques partielles basée
sur les automates d'arbres [BTT08, BTT07, TT09].
La problématique étudiée
Pendant la fusion des documents structurés, on
recherche un document global intégrant les mises à jour de tous
les co-auteurs. À ce niveau, il peut surgir deux problèmes :
L'ambiguïté : on peut trouver
plusieurs documents satisfaisant ce critère de recherche. Ce
problème est en général dû à un défaut
de conception du modèle de document et une bonne analyse pourrait
permettre d'y remédier.
Les conflits : les modifications
portées par les différents co-auteurs peuvent ne pas être
compatibles. Cet état de chose rend impossible l'obtention d'un document
global qui intègre les mises à jour de tous les co-auteurs. Pour
éviter (anticiper) ce problème, on pourrait contrôler
les éditions locales afin d'assurer la cohérence et ainsi,
la compatibilité des
L'organisation du manuscrit 3
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
répliques partielles. On pourrait aussi, à
posteriori, réconcilier les différentes répliques
partielles : c'est à dire remettre en cause certaines actions
d'édition pour rendre les répliques fusionnables.
Le problème que nous étudions dans ce
mémoire est celui de la réconciliation des répliques
partielles d'un document structuré; plus précisément nous
voulons proposer un algorithme capable de détecter et d'annuler les
actions d'édition menant aux conflits puis de fusionner les nouvelles
répliques obtenues.
Le travail réalisé
Un document en cours d'édition est
représenté par un arbre contenant, potentiellement au niveau des
feuilles, des noeuds ouverts ou bourgeons. Éditer un document, consiste
à développer (remplacer) un ou plusieurs de ses bourgeons par un
ou plusieurs sous-arbres conformément au modèle de document.
Fusionner consensuellement les mises à jour
t1 ···tn de n
répliques partielles d'un document t, consiste à
trouver un document tc, conforme au modèle de
document (appelé modèle global dans la suite), intégrant
tous les noeuds des ti non en conflit et dans lequel, tous les noeuds
en conflit sont remplacés par des bourgeons. L'algorithme de fusion
consensuelle présenté dans ce mémoire est une adaptation
de celui de fusion proposé dans [BTT08] qui ne gère pas les
conflits. Techniquement, la démarche permettant d'obtenir les documents
faisant partie du consensus est la suivante:
1. Pour chaque mise à jour tma
j
i d'une réplique partielle, nous associons un
automate d'arbre à états de sortie (i)
reconnaissant les arbres (conforme au modèle global) dont
tma j
i est une projection.
2. L'automate consensuel (sc) engendrant
les documents du consensus est obtenu en effectuant un produit synchrone
des automates (i) au moyen d'un opérateur
commutatif noté ØÙ : (sc) =
ØÙ i (i) que nous
définissons.
L'automate consensuel obtenu est celui qui produit les
documents du consensus : c'est à dire les préfixes maximaux sans
conflits de la fusion des documents issus des différentes expansions des
diverses répliques partielles mises à jour.
Nous avons aussi proposé une implémentation en
Haskell de notre algorithme, puis nous avons construit un prototype de
réconciliateur graphique en Java pour pouvoir réaliser nos
tests.
L'organisation du manuscrit
La suite de ce mémoire est structurée en quatre
chapitres et deux annexes organisés comme suit:
Chapitre 1 - Notions d'édition
coopérative et de conflits. Nous présentons ici la
notion de travail coopératif et les notions qui lui sont connexes
(groupware, workflow...). Nous nous focalisons ensuite sur la
notion d'édition coopérative des documents (les types de
documents édités, la détection des conflits, la
résolution des conflits) et sur le rôle et la circulation de
ceux-ci dans les procédures d'entreprise.
Chapitre 2 - L'édition coopérative des
documents structurés. Dans ce chapitre, nous présentons
une approche d'édition coopérative et les outils formels issus de
la littérature (grammaires algébriques, automates d'arbre...) que
nous utilisons pour la spécification et
L'organisation du manuscrit 4
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
la manipulation des documents structurés, puis nous
introduisons de façon plus formelle et en accord avec [BTT08, BTT07,
TT09] les définitions relatives aux notions de vues, de projection, de
projection inverse et de fusion des répliques partielles d'un document
structuré.
Chapitre 3 - Fusion consensuelle des
mises à jour des répliques partielles. Nous
présentons dans ce chapitre notre solution au problème de la
réconciliation des répliques partielles d'un document
structuré.
Chapitre 4 - Un prototype
d'éditeur coopératif désynchronisé. Dans
ce chapitre, nous présentons TinyCE v2 (a Tiny Cooperative
Editor version 2, prononcer"taï-ni-ci-i"), un prototype
expérimental d'éditeur coopératif
désynchronisé inspiré de TinyCE (prononcer
"tennesse") [TT10] et qui nous permet de mettre en oeuvre les algorithmes
présentés dans ce travail et d'en faire la
démonstration.
Conclusion générale. Nous
réalisons le bilan de notre travail et nous répertorions quelques
perspectives d'amélioration de ce dernier.
Annexe A - Un autre exemple complet
de fusion consensuelle. Dans cette annexe, nous illustrons notre
algorithme de fusion consensuelle en l'appliquant à un workflow
d'édition sans conflit et dont les répliques partielles mises
à jour ne sont pas forcément des documents clos.
Annexe B - Quelques fonctions Haskell
pour le calcul des consensus. Nous donnons le code Haskell des
algorithmes qui ont été présentés ainsi que
quelques commentaires nécessaires pour une bonne
compréhension.
5
Chapitre1
État de l'art sur l'édition
coopérative et
sur la notion de conflits
Sommaire
1.1 - Le travail coopératif 5
1.2 - Un exemple de CSCW : L'édition coopérative
11
1.3 - Synthèse 18
Le travail que nous menons dans ce mémoire s'inscrit
dans le domaine de recherche du CSCW (Computer Supported Cooperative Work)
ou TCAO (Travail Coopératif Assisté par Ordinateur) en
français. Nous considérons un système à flots de
tâches (worflow system) dont les acteurs, géographiquement
distants, coordonnent leurs activités par échange de documents
électroniques qu'ils éditent de façon
désynchronisée. Les systèmes logiciels chargés
d'assurer la coopération entre les différents acteurs doivent
présenter certaines caractéristiques afin de faire face aux
contraintes du CSCW. Dans ce chapitre nous présentons la notion de
travail coopératif (sect. 1.1) en faisant le parallèle avec le
CSCW (sect. 1.1.2) et les systèmes de CSCW.
Ensuite nous nous focalisons sur l'édition
coopérative (sect. 1.2); nous présentons les différents
types de documents électroniques manipulés et/ou
échangés par les applications (sect. 1.2.1) et introduisons la
notation BPMN (Business Process Modeling Notation) pour la
représentation de la circulation de ces documents dans les
systèmes à flots de tâches (sect. 1.2.2).
Ce chapitre s'achève par une revue de la
littérature (sect. 1.2.3) sur les techniques de détection et de
résolution des conflits issus des éditions asynchrones des
répliques (partielles) d'un document électronique.
1.1. Le travail coopératif
Le terme «collaboration» est de nos jours
très utilisé dans le jargon industriel et exprime la
participation de plusieurs acteurs à une entreprise commune [MGa08].
Pour les entreprises, les différentes instances municipales et
gouvernementales, les établissements de santé, les grandes
institutions d'enseignement et autres, la collaboration est devenue une
1.1. Le travail coopératif 6
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
valeur, un objectif à atteindre, une compétence
[Gir14]. Très souvent ce mot est confondu ou est utilisé pour
désigner la coopération. Toutefois, il existe une nette
différence entre les deux termes. Dans cette section, nous
établissons la différence entre les termes collaboration
et coopération puis nous introduisons la notion de
Travail Coopératif Assisté par Ordinateur (TCAO) en
présentant quelques concepts qui lui sont associés.
1.1.1. Coopération et collaboration, quelles
différences?
La coopération et la collaboration impliquent plusieurs
acteurs et un but commun. Cependant ces deux concepts diffèrent au
niveau du comportement des personnes et du mode d'organisation du travail.
1.1.1.1. Le comportement des personnes
La collaboration est définie dans [Gir14] comme
étant un processus par lequel deux ou plusieurs personnes ou
organisations s'associent pour réaliser un travail suivant des objectifs
communs. Theodore (Ted) Panitz [Pan99] ajoute que la collaboration est
une philosophie d'interaction et de style personnel de vie dans laquelle chaque
acteur est responsable de ses actions mais aussi de celles de ses pairs. La
collaboration repose donc sur les relations entre les acteurs, leur aptitude
à travailler ensemble pour atteindre un résultat commun. Tous les
collaborateurs ont un seul objectif, ce qui induit une co-responsabilité
(imputabilité).
La coopération par contre ne repose pas sur les
relations entre les acteurs, elle est une forme d'interaction réunissant
plusieurs personnes réalisant différentes tâches
complémentaires (objectifs individuels) dans le but d'obtenir un
résultat global [Pan99]. Dans ce mode de travail, les interactions entre
les acteurs sont minimes et les objectifs sont individuels pour chaque acteur
(individu ou équipe de collaborateurs).
1.1.1.2. L'organisation du travail
Sur le plan du travail, l'une des différences majeures
est la répartition des rôles aux acteurs. En effet, le travail
coopératif est très structuré et il résulte de la
subdivision d'une tâche en plusieurs actions; lesquelles sont
réparties entre les individus au départ et, ceux ci agissent de
manière autonome. Les interactions se limitent à l'organisation,
la coordination et le suivi de l'avancement (souvent sous la
responsabilité d'un individu chargé de s'assurer de la
performance individuelle de chacun). La responsabilité de chacun est
limitée à garantir la réalisation des actions qui lui
incombent : l'objectif global est atteint grâce à une
concaténation coordonnée des résultats individuels [Heu03,
SB92].
Le travail collaboratif est moins structuré. Les
acteurs forment un groupe dans lequel les interactions sont permanentes et
chacun peut concourir à l'action de tout autre membre du groupe afin
d'optimiser les performances globales. Il n'existe presque pas de
répartition des rôles entre les acteurs. Le mode collaboratif fait
donc appel à l'intelligence collective et met en avant le
caractère humain. C'est pourquoi il est le plus difficile à
mettre en oeuvre.
Exemple 1 Le cultivateur et son
champ
Un cultivateur dont la famille est nombreuse, veut
défricher l'un de ses champs. Il hésite entre deux approches
d'accomplissement de cette tâche:
1. Il pourrait réunir toute sa famille et se rendre
au champ. Ils travailleraient ainsi tout en s'amusant; les plus
expérimentés guidant ceux qui le sont moins. Avec un peu de
solidarité et de détermination, ils accompliraient cette
tâche dans les délais et, plus important encore, ils
économiseraient de l'argent. De plus, ils partageraient des moments
inoubliables et tous se satisferaient du fait que tout le champ soit
parfaitement défriché;
1.1. Le travail coopératif 7
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
2. Il pourrait aussi faire venir quelques professionnels.
Chacun défricherait une parcelle sous sa supervision et dans le cas
où un professionnel terminerait son travail, il lui donnerait son
salaire et ce dernier se satisferait de son rendement individuel puis
quitterait la plantation. Le champ serait ainsi parfaitement
défriché lorsque tous les professionnels auraient fini de
nettoyer leurs parcelles respectives. Cela pourrait lui coûter plus cher
mais les délais et la qualité seraient au rendez-vous.
Les deux approches ont le mérite de mener le
cultivateur à son but. Cependant, la première approche est
collaborative et sa réussite repose sur les liens entre les
différents membres de la famille. La seconde approche quant à
elle est coopérative et sa réussite est presque toujours
garantie.
1.1.2. Notion de Travail Coopératif Assisté
par Ordinateur (CSCW)
La collaboration et la coopération étant devenus
des objectifs importants pour les industriels [Gir14], l'essor des Technologies
de l'Information et de la Communication (TIC) a favorisé le
développement d'une nouvelle méthode de travail : il s'agit du
Travail Coopératif Assisté par Ordinateur (en anglais :
Computer Supported Cooperative Work, ou CSCW1 2 3). C'est
une méthode de travail qui met en relation des utilisateurs repartis
dans le temps, l'espace et à travers les organisations; ces personnes
devant alors collaborer pour répondre à un besoin donné
[Imi06]. Les applications du CSCW sont nombreuses et variées.
Exemple 2 Quelques applications du
CSCW [Imi06]
-- La conception et le développement d'un logiciel
par une équipe dont les membres sont disséminés
géographiquement;
-- L'écriture simultanée d'un article
scientifique ou de la documentation d'un produit par plusieurs chercheurs
(édition coopérative);
-- La participation à un séminaire, au
même instant, de plusieurs personnes situées à
différents endroits du globe terrestre;
-- L'accomplissement d'une tâche nécessitant
l'expertise de plusieurs personnes.
Les recherches dans le domaine du CSCW ont donné
naissance à de nombreux logiciels appelés systèmes de
CSCW ou groupware 4. Les systèmes de CSCW
communiquent à travers les réseaux pour atteindre leurs objectifs
(fournir des fonctionnalités afin de faciliter les échanges, la
coordination, la collaboration et la co-décision entre les acteurs du
CSCW) et ainsi braver les contraintes d'espace et de temps
auxquelles le CSCW est soumis.
1.1.2.1. Les caractéristiques des
systèmes de CSCW
La mise en place d'un système de CSCW nécessite
la prise en compte des contraintes auxquelles le CSCW est soumis. En
considérant par exemple les contraintes espace et temps, on peut se
poser les questions suivantes [TTTA12] :
-- où sont situés les différents acteurs
(sur le même site ou sur des sites différents)? -- comment
s'effectue la communication entre acteurs (synchrone, asynchrone)?
1. CSCW : c'est aussi le nom qu'on donne au domaine de
recherche qui se focalise sur le rôle des ordinateurs dans les travaux
coopératifs [SB92].
2. Le CSCW est très souvent assimilé à
tord au groupware. Les différences entre ces concepts
émanent principalement des différentes connotations des
expressions «groupe» et «travail
coopératif» [SB92] et aussi le fait que le groupware est
fortement lié au logiciel (software).
3. Nous utiliserons le sigle CSCW tout au long de ce
mémoire pour désigner le travail coopératif assisté
par ordinateur.
4. Nous utiliserons l'appellation systèmes de CSCW
dans la suite.
1.1. Le travail coopératif 8
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
On en déduit qu'un système de CSCW peut
être distribué (les objets partagés sont
répliqués sur les différents sites) ou non, synchrone
ou asynchrone...
Système distribué
Dans un contexte distribué, chaque site possède
des copies locales (répliques) des objets partagés et c'est donc
sur ces copies que sont portées les contributions locales. Pour obtenir
un état global, le système synchronise toutes les
répliques. Par conséquent, il est crucial de mettre en place une
procédure de contrôle de la concurrence et ce pour assurer la
convergence des copies vers un même état [Imi06].
Système non distribué
Dans un contexte non distribué, tous les acteurs
travaillent sur une unique copie de chaque objet partagé. Les
modifications sont donc réalisées au fur et à mesure, les
synchronisations se font à chaque sauvegarde et le système n'a
pas besoin de réaliser une opération finale de synchronisation
globale. Cet état de chose n'exclut cependant pas la présence
d'une procédure de contrôle de la concurrence étant
donné que plusieurs acteurs peuvent apporter leurs contributions au
même moment (accès concurrent à l'unique copie).
Système synchrone
Le CSCW est synchrone lorsque les mises à jour
apportées par un acteur sur les données partagées sont
immédiatement (en un intervalle de temps raisonnable) visibles par
l'ensemble des acteurs pouvant avoir accès à ces données.
Ces systèmes sont dits temps réel. Les éditeurs
collaboratifs temps réel (ou éditeurs WYSIWIS 5) tels
que Etherpad6 et Google Docs7 en sont
de parfaites illustrations.
Système asynchrone
Le mode de travail asynchrone permet aux acteurs de travailler
en même temps ou à des moments différents. Aussi, les
synchronisations sont faites en temps voulu par les acteurs. Les mises à
jour sont ainsi observées de manière différée. Ce
mode de fonctionnement peut être observé dans certains
systèmes de gestion de versions et dans certains outils de
synchronisation des fichiers [Imi06].
1.1.2.2. Classification des systèmes de CSCW
L'analyse des dimensions espace et temps ont permis à
plusieurs chercheurs de proposer des méthodes de classement des
systèmes de CSCW. La majorité de ces méthodes de
catégorisation sont des adaptations de la classification de Johansen
[Joh88] et sont par conséquent basées sur des matrices
espace/temps. On distingue entre autres les classifications de Johansen
[Joh88], de Grudin [Gru94], d'Andriessen [JHE03], de
Penichet et al. [PMG+07]...
La classification de Johansen
5. What You See Is What I See pouvant être traduit en
ce que vous voyez est ce que je vois.
6. Etherpad est un éditeur collaboratif temps réel
disponible à l'adresse
http://www.etherpad.org/.
7. L'une des fonctionnalités de Google Docs est la
possibilité de réaliser de l'édition temps réel et
à plusieurs,
https://docs.google.com/.
1.1. Le travail coopératif 9
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Johansen attribue les valeurs synchrone et
asynchrone (resp. distribué et non
distribué) à la dimension temps (resp. espace). Il obtient
ainsi une matrice 2 × 2 grâce à laquelle il peut
dire si un système de CSCW est synchrone et distribué, synchrone
et non distribué, asynchrone et distribué ou asynchrone et non
distribué (figure 1.1).
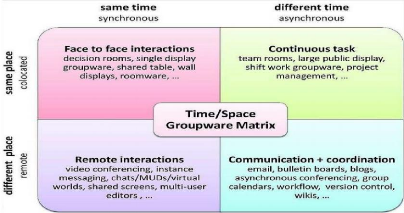
FIGURE 1.1 - Matrice 2 × 2 de Johansen [Joh88]
pour la catégorisation des systèmes de CSCW.
La classification de Grudin
Grudin [Gru94] s'appuyant sur les travaux de Johansen
a ajouté un caractère aux valeurs des dimensions espace et temps
pour construire un framework de catégorisation basé sur une
matrice 3 × 3 : ce caractère est la prévisibilité
des actions supportées [Sar05]. En effet, selon lui, dans un
contexte asynchrone (resp. distribué) les actions des acteurs peuvent
être prévisibles ou non. La matrice de Grudin (figure 1.2) permet
de ce fait de classer les systèmes de CSCW s'appliquant au même
endroit et au même instant, ceux s'appliquant à des
endroits différents prévisibles (connus) ou non, et ceux
s'appliquant à des instants différents
prévisibles ou non.
Les autres classifications
La classification d'Andriessen étend encore plus la
matrice de Johansen. Celle de Penichet et al. ajoute les
caractéristiques (partage de données, communication et
coordination) du CSCW aux dimensions espace et temps pour proposer une
classification encore plus précise et détaillée
[PMG+07].
Grâce à ces méthodes de
classification, il est possible de connaître quelques types de travaux
qu'on peut effectuer une fois qu'on a opéré un choix sur les
contraintes spatiales et sur les contraintes temporelles.
1.1.2.3. Les systèmes de CSCW comme
systèmes à flots de tâches (Workflows Systems)
Le workflow peut être défini comme une collection
de tâches organisées et réalisées soit par les
systèmes logiciels, soit par les humains ou par les deux dans le but
d'accomplir

1.1. Le travail coopératif 10
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
FIGURE 1.2 - Matrice 3 × 3 de Grudin pour la
catégorisation des systèmes de CSCW [Sar05].
un processus métier (ou processus
opérationnel ou procédure d'entreprise ou encore
business process en anglais) [GHS95]. L'objectif du Workflow est donc
celui de rationaliser, coordonner et contrôler des procédures
d'entreprise dans un environnement organisé, distribué et
informatisé. La WfMC8 (The Workflow Management
Coalition [WfM] définit une procédure d'entreprise comme une
procédure qui systématise l'organisation et la politique d'une
entreprise dans le but d'atteindre certains des objectifs de cette
entreprise.
Exemple 3 Quelques
procédures d'entreprise
-- Le processus d'inscription d'un étudiant dans une
faculté;
-- La conception d'un logiciel informatique;
-- Le suivi d'un dossier médical;
-- La procédure de prise de congés dans une
institution gouvernementale;
-- La procédure d'ouverture d'un compte dans une
agence bancaire;
-- L'organisation des secours en cas de catastrophe;
-- La procédure de réclamation de dommage
à une compagnie d'assurance.
Une procédure d'entreprise est donc une séquence
ordonnée de tâches (réalisées par les Hommes ou par
les programmes [GHS95, CG08], parfois même par les deux) répondant
à un schéma précis et qui mène à un
résultat déterminé. De ce fait, on peut considérer
une procédure d'entreprise comme un CSCW. Les Systèmes de Gestion
des Workflows (SGWf ou WfMS - Workflow Management Systems - en anglais), tout
comme les systèmes de CSCW, doivent fournir des fonctionnalités
afin de faciliter les échanges, la coordination, la collaboration et la
co-décision entre les acteurs humains ou non. Les systèmes de
CSCW sont donc des systèmes à flots de tâches. Toutefois,
ceux ci ne sont pas forcément des WfMS car les WfMS fournissent aussi
des outils pour la définition des processus, l'exé-cution de ces
définitions (par les moteurs de workflow) et l'administration
d'instances de processus [DG02].
8. La WfMC est une organisation internationale dont le but est
de développer des standards dans le domaine de Workflow en collaboration
avec les acteurs principaux du dit domaine.
1.2. Un exemple de CSCW : L'édition
coopérative 11
Mémoire - ZEKENG NDADJI
Milliam Maxime LIFA
1.2. Un exemple de CSCW : L'édition
coopérative
L'édition coopérative des documents est un
exemple très courant de CSCW. En effet, les documents
électroniques sont des outils incontournables pour la publication et
l'échange d'informations entre applications le plus souvent
hétérogènes et distantes. La forte évolution des
réseaux de communication en terme de débit et de
sûreté a aussi révolutionné la façon
d'éditer de tels documents. On est passé du modèle
classique d'un auteur éditant en local son document, à un
modèle dans lequel plusieurs auteurs situés sur des sites
géographiquement éloignés se coordonnent pour
éditer de façon asynchrone un même document. Les documents
échangés peuvent être considérés autant comme
des supports de communication et une aide à la coordination que
comme le produit de cette coopération. Cependant, dans un
contexte de travail coopératif, il est raisonnable de les
considérer comme des supports de communication et une aide à la
coordination car ils véhiculent des informations indispensables à
la coopération [TT09]. On peut donc imaginer une équipe
constituée par des acteurs, ayant chacun un domaine d'expertise propre,
qui coopèrent pour accomplir une tâche précise. Chaque
acteur peut opérer sur le document par le biais d'une interface lui
offrant des outils spécifiques liés à son domaine
d'expertise et à son rôle dans cette coopération. Ces
outils conçus au préalable imposeront des contraintes
d'édition aux acteurs en s'appuyant sur des modèles (grammaires)
préconçus. Avec de telles contraintes d'édition, la
cohérence entre les versions manipulées localement par chaque
acteur sera assurée. C'est dans ce sens que les documents serviront de
support à la coordination des différents acteurs.
Exemple 4 Un exemple d'édition
coopérative (partie 1/3)
Nous considérons ici le processus d'inscription
d'un nouvel étudiant à la faculté des sciences de
l'Université de Dschang (FS UDs) 9. C'est une
procédure d'entreprise dans laquelle, plusieurs acteurs et services
(l'étudiant, le CMS - Centre Médico-Social -, la
scolarité, les départements, la cellule informatique et la DAF -
Division Administrative et Financière -) se succèdent pour
éditer un même document: la fiche d'inscription ou fiche
personnelle de l'étudiant. Les différents acteurs ici ont des
domaines d'expertise différents (la santé, les finances, les
systèmes d'information...) et opèrent à partir des sites
(leurs bureaux) géographiquement éloignés. La fiche
d'inscription de l'étudiant est dans ce cas un support de coordination
(le service de la scolarité ne peut recevoir et enregistrer le dossier
d'un étudiant que si ce dernier a déjà été
reçu par le CMS), de communication et d'aide à la décision
(acceptation ou rejet de l'étudiant).
Après cette brève présentation du concept
d'édition coopérative, nous présentons les types de
documents manipulés et/ou échangés par les applications
puis nous introduisons la notation BPMN (Business Process Modeling Notation)
pour la représentation de la circulation des documents
électroniques dans les systèmes de workflow.
1.2.1. Les types de documents manipulés et/ou
échangés par les applications
Dans le processus d'édition et de publication des
documents, on peut se baser sur la structure (la nature et l'organisation de
l'information) de ces derniers pour les différencier. Selon les cas, on
distingue les documents linéaires, les documents
semi-structurés et
9. La description que nous faisons de cette procédure
est en partie le fruit de l'ajustement, pour des besoins d'illustration, d'une
enquête menée le 25 Mars 2015 auprès du service de la
scolarité de la FS UDs et de son chef de service Dr. Onabid.
Aussi, certaines analyses complémentaires proviennent de notre
connaissance de ce processus (nous avons à notre actif six
inscriptions/ré-inscriptions) et des témoignages de certains
étudiants.
1.2. Un exemple de CSCW : L'édition coopérative
12
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
les documents structurés [Bon98, KAA93]. Tout
au long de ce mémoire, nous utiliserons l'expression"documents non
structurés" pour désigner les documents linéaires et
les documents semi-structurés.
1.2.1.1. Les documents non structurés
Les documents linéaires sont ceux qui contiennent un
flux de données représentant à la fois le contenu du
document et sa présentation. Les fichiers DOC 10 (ou doc) par
exemple sont des documents linéaires contenant du texte, de la mise en
forme, des informations sur les états du fichier, des
scripts...[DOC15]
Les documents semi-structurés ou auto-descriptifs sont
libres de tout modèle de description de données mais leurs
structures présentent une certaine régularité [TT09]. Les
données contenues dans un document semi-structuré sont dites
semi-structurées car elles ne sont pas conformes à un
schéma prédéfini [Abi97]. De ce point de vue, en accord
avec [YS00], les documents semi-structurés sont ceux qui contiennent des
données semi-structurées. Comme exemples nous pouvons citer:
les fichiers BibTex, les documents HTML ou encore les documents
XML non contraints par une DTD (Document Type Definition) ou un XML
Schema.
1.2.1.2. Les documents structurés
Les documents structurés sont ceux qui
présentent une structure régulière définie par un
modèle générique appelé modèle
grammatical ou modèle de document (DTD, XML Schema...).
Ces modèles grammaticaux permettent la description de classes de
documents, de leurs composants, des relations hiérarchiques et de
voisinage que ces derniers entretiennent les uns avec les autres. Ils
permettent en plus, de décrire des informations d'ordre
sémantique associées aux composants [KAA93]. Les documents
structurés constituent une proportion importante des documents
manipulés et/ou échangés par des applications. C'est le
cas d'un bon nombre de documents XML qui sont très utilisés comme
fichiers de configuration et/ou fichiers d'échanges par des applications
telles que yEd Graph Editor11 ou encore Notepad++
12.
Contrairement aux documents linéaires dont le contenu
est généralement en binaire et uniquement exploitable par le
logiciel qui le produit en théorie 13, les documents
structurés contiennent du texte compréhensible, manipulable par
tout le monde et respectant les normes et les standards industriels
fixés par des organismes de standardisation (ISO [ISO], W3C [W3C], IEEE
[IEE]...). C'est ce qui favorise leur interopérabilité, justifie
leur large diffusion et leurs utilisations variées. Une fois de plus,
les documents XML 14 (stan-dard du W3C [BPSM+06])
illustrent parfaitement nos propos car ils peuvent servir de fichiers de
configuration, de format d'échange (COLLADA15 [COL] par
exemple)... Néanmoins, le stockage des documents sous forme textuelle
est un facteur dépréciant pour la
10. DOC est une extension de nom de fichier, utilisée
pour la documentation en format texte propriétaire, sur une large
variété de systèmes d'exploitations [DOC15].
11. yEd est un logiciel libre d'édition des graphes et
de différents diagrammes (Flowchart, UML, BPMN...). Il est disponible
sur le site
http://www.yWorks.com/.
12. L'éditeur de texte Notepad++ est disponible
à l'adresse
http://notepad-plus-plus.org/.
13. Les formats des documents linéaires sont en
majorité propriétaire et ne respectent pas forcément les
normes et standards fixés par les organismes spécialisés
(ISO - International Organization for Standardization - [ISO], W3C - World Wide
Web Consortium - [W3C], IEEE - Institute of Electrical and Electronics
Engineers - [IEE]...) ce qui limite leur interopérabilité.
14. XML est un métalangage qui permet de structurer
une très grande variété de contenus car son vocabulaire et
sa grammaire peuvent être redéfinis.
15. COLLADA signifie Collaborative Design Activity et a pour
but d'établir un format de fichier d'échange basé sur XML
pour les applications 3D interactives.
1.2. Un exemple de CSCW : L'édition coopérative
13
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
publication de ceux ci; En effet, de tels documents peuvent
être modifiés directement par un utilisateur utilisant des
applications non spécialisées (un éditeur de texte par
exemple), ce qui remet en cause leur intégrité [Bon98]. Le
travail réalisé dans ce mémoire ne s'inté-resse
qu'à l'édition coopérative des documents
structurés.
Exemple 5 Un exemple
d'édition coopérative (partie 2/3)
Une partie de la fiche personnelle de l'étudiant
sollicitant une inscription en FS UDs peut être considérée
comme un document structuré contenant entre autres les informations
suivantes: informations d'identification personnelle (noms, sexe,
nationalité, langue, adresse, numéro de CNI...), informations sur
sa santé, informations d'identification des parents ou tuteurs,
formation sollicitée (3 choix sont requis), profil scolaire
(diplômes obtenus, années d'obtention, mention...). La figure 1.3
présente une fiche personnelle d'un étudiant (document XML
réduit à quelques informations) conforme à une DTD
présentée sur la même illustration.

FIGURE 1.3 - Un exemple de document structuré XML
contraint par une DTD.
1.2. Un exemple de CSCW : L'édition coopérative
14
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
1.2.2. Les documents dans un système de workflow: La
notation BPMN
Les documents électroniques étant
considérés comme des supports de communication et d'aide à
la coordination, ils sont donc au centre de toute procédure
d'entreprise. Les documents circulent à travers le système, de
site en site, et sont édités au fur et à mesure par les
différents acteurs lorsque ceux ci réalisent leurs
activités. De tels systèmes sont appelés systèmes
à flots de tâches. Il existe plusieurs méthodes de
représentation des systèmes à flots de tâches : les
statecharts [TT09], des diagrammes d'activité UML
[LMLR08], les Réseaux de Pétri et/ou les
Réseaux de Pétri à Objets [CBBG07], la
notation BPMN [BPM]... La notation BPMN semble être la plus
appropriée pour la définition des workflows et des
procédures d'entreprise. C'est une notation graphique qui est
dédiée à la modélisation de telles
procédures; elle a comme objectif principal, la facilitation de la
communication entre les différents acteurs engagés dans le
développement et la maintenance des systèmes applicatifs
orientés sur les processus de l'entreprise.
La notation BPMN est un standard qui a été
développé par la Business Process Management Initiative (BPMI) et
qui est maintenu depuis 2005 par l'Object Management Group (OMG) 16
[BPM]. Le langage BPMN est très élaboré et directement
exploitable par des moteurs d'exécution des processus [WfM]. Cependant,
une toute petite fraction des fonctionnalités proposées par le
standard BPMN est exploitée par les professionnels de la
modélisation des procédures d'entreprise. Cet état des
choses illustre la déconnexion qui existe entre les efforts de
standardisation du Business Process Management (BPM) et les besoins
réels des professionnels de ce domaine [MPvdA12].
La représentation d'une procédure avec la
notation BPMN est basée sur trois éléments fondamentaux
[LMLR08] :
-- La tâche : C'est la plus petite unité
de décomposition hiérarchique d'une activité; une
tâche représente une action qui va être
réalisée par une personne ou une application. Il existe plusieurs
types de tâches (tâche de service, tâche d'envoi, tâche
utilisateur...) représentables avec la notation BPMN. Une tâche
est représentée par un rectangle aux coins arrondis.
-- Le branchement : Il représente la condition
de routage entre les flux en entrée et les flux en sortie. Pour mieux
définir le contrôle des flux, la notation BPMN fournit plusieurs
types de passerelles (exclusive, inclusive, parallèle...)
représentées par des losanges.
-- L'évènement : Il représente
un état particulier dans le processus (début,
intermédiaire, fin). Les évènements sont
représentés par des cercles.
La notation BPMN fournit en plus, des éléments
pour la représentation des données, des annotations, des
sous-processus, des participants... Il est aussi possible d'utiliser
différents types de diagrammes (orchestration, collaboration,
chorégraphie, conversation) pour représenter les
différentes perspectives d'un processus. Nous invitons le lecteur qui
désire en savoir plus, à consulter les spécifications
officielles [BPM] ou à suivre cette brève formation [INT] en
modélisation des processus avec la notation BPMN.
Exemple 6 Un exemple
d'édition coopérative (partie 3/3)
La figure 1.4 (page 16) est un diagramme d'orchestration
BPMN [INT] illustrant le processus de sélection d'un étudiant
désireux de s'inscrire dans l'une des filières de la FS UDs. En
fait, la sélection est réalisée par l'administration (la
scolarité et les trois départements représentants
16. Une branche de la BPMI et une autre de l'OMG ont
fusionné en 2005 pour former Business Modeling & Integration (BMI)
Domain Task Force (DTF).
1.2. Un exemple de CSCW : L'édition coopérative
15
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
les choix de l'étudiant). Suite à la
réception d'un dossier de candidature (évènement
déclencheur), le responsable de la scolarité (l'agent commis
à cet effet) l'enregistre puis envoie des copies de la fiche
d'inscription du candidat aux départements choisis par
l'étudiant. Chaque département étudie le dossier puis
décide de l'admissibilité du candidat (traitement en
parallèle), porte la mention correspondante sur la fiche d'inscription
de ce dernier, enregistre l'étudiant localement si ce n'est pas
déjà fait puis renvoie la fiche à la scolarité.
Lorsque la scolarité a reçu toutes les décisions des
différents départements, elle opère le choix final et met
à jour le dossier du candidat. Nous nous limitons à cette
description très incomplète pour des besoins
d'illustration.
Le diagramme de la figure 1.4 - page 16 -
(réalisé avec le logiciel Bizagi Modeler 17) illustre
quelques possibilités offertes par la notation BPMN. On y retrouve les
traitements séquentiels (représenté par la flèche),
les traitements parallèles encore appelés décomposition de
type 'et', les traitements alternatifs ou décomposition de type 'ou'. On
peut aussi remarquer la représentation des participants (la
scolarité et les départements) dans l'unité
organisationnelle qu'est l'administration de la FS UDs. L'utilisation des
annotations et autres artifacts font des diagrammes BPMN des outils
intuitifs et réellement exploitables par tous les acteurs intervenant
dans l'automatisation des procédures d'entreprise.
1.2.3. Conflits dans les systèmes d'édition
coopérative, méthodes de détection et approches de
résolution
Lorsque l'édition coopérative est
appliquée dans un environnement distribué asynchrone, on peut
envisager que chaque site possède des copies d'un même document.
Ces copies (qu'on appelle répliques ou réplicats en
accord avec [SS05]) peuvent être modifiées par les
différents co-auteurs. Il arrive un moment où on voudrait obtenir
un autre document de base intégrant les mises à jour
portées sur les différentes répliques : il faut alors
fusionner ces dernières. La fusion ou synchronisation des
répliques d'un document peut être définie de manière
informelle [TT09] comme une opération qui consiste à fusionner
les mises à jour effectuées de façon
désynchronisée sur ces répliques par rapport au document
de base afin d'obtenir une nouvelle copie du document de base qui
intègre éventuellement toutes les modifications des
différentes répliques dans le cas où elles sont non
conflictuelles, ou éventuellement des indications sur les sources de
conflits.
L'opération de fusion se déroule
généralement en deux phases [TT09] : la phase de
détection des mises à jour pendant laquelle on identifie
dans les différentes répliques, les endroits qui ont
été mis à jour depuis la dernière synchronisation,
et la phase de réconciliation dans laquelle on combine les
différentes mises à jour pour produire un nouveau document (sans
conflits). Il existe plusieurs techniques de fusion dans la littérature.
Nous pouvons citer les fusions two-way, three-way, textuelle,
sémantique, syntaxique et structurelle. Ces techniques
sont bien présentées et comparées dans [Men02]. Elles
diffèrent principalement par leurs capacités à
détecter et à résoudre les conflits.
L'un des problèmes majeurs posés par
l'opération de fusion est la gestion des conflits. Dans le cas de
l'édition coopérative des documents, les conflits
représentent les différentes parties pour lesquelles les
répliques divergent. Les sources des conflits sont en
général les mises à jour apportées à
différentes répliques par différents co-auteurs.
Toutefois, dans un contexte où l'édition n'est pas positive,
18 une seule mise à jour peut entraîner des conflits.
On distingue principalement les conflits d'ordre syntaxique,
sémantique ou structurel. Les
17. Bizagi Modeler est disponible à l'adresse
http://www.bizagi.com/.
18. Dans une édition positive basée sur une
réplication optimiste, les documents édités ne font que
croître: il n'y a pas d'effacement possible dès qu'une
synchronisation a été effectuée [SS05].
1.2. Un exemple de CSCW : L'édition coopérative
16
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
|
Administration de la Faculté des sciences de
l'université de Dschang
|
|
Département 3
|
Département 2
|
Département 1
|
Scolarité
|
|
|
|
I Ir Enregistrer le
1J~1 dossier
Reception L
d'un dossier
de
candidature
|
|
|
Traitement en parallèle par les départements.
|
|
·
|
|
|
|
Z.
Ô m
n
|
|
|
|
|
|
A
a n
[
m O
|
|
|
A
Y 2_ n
n
|
|
|
3 a
a n
m
|
|
|
|
|
3
3
|
4
|
|
rir une Vérifier
de la existence de la dé.
he fiche
'on
|
|
|
|
|
|
Vérifier
l'existence de la fiche
|
|
|
Vérifier
l'existence de la fiche
|
|
|
Si une copie de la fiche existe au département alors ily
a un doublon. On termine surune
erreur.
- 7/
|
|
|
0O 0 a
|
|
2 Q
o
o a
|
|
â 7.
|
|
â
|
|
|
n.
û9
|
|
|
6
|
r
|
.
6 Ç
4.
|
|
|
6
|
\
|
|
-
|
|
O
|
l l
|
|
O
|
|
|
\
|
|
Ô
|
|
d
L,
C
m m
|
|
ro
d
2. -
- C
m m
i
|
|
|
!.
-
m
|
~/
O
C i
|
|
Illll
|
|
|
|
|
|
|
|
|
|
Ille
. 2û O F
a n 3o o ro
|
|
|
Fin de la séquence parallèle et synchronisation
|
|
|
Y
|
|
r
Mettre a' ur le
dossier du
candidat 1
f Fin
|
FIGURE 1.4 - Un exemple de diagramme d'orchestration BPMN,
illustrant le processus de sélection d'un étudiant dans une des
filières de la FS UDs.
1.2. Un exemple de CSCW : L'édition coopérative
17
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
méthodes de détection des conflits sont
nombreuses dans la littérature. Nous présentons certaines dans
cette section ainsi que quelques approches de résolution des conflits.
Le lecteur intéressé est invité à consulter [Men02]
pour en savoir plus.
1.2.3.1. Les techniques de détection des conflits
Les matrices de fusion [SLMD96, Fea89, MD94]
Une piste intéressante pour la détection des
conflits lors de la fusion est l'analyse et la comparaison des mises à
jour qui ont été portées sur les différentes
répliques. On peut ainsi répertorier toutes les combinaisons des
opérations de mises à jour qui sont susceptibles
d'entraîner une inconsistance. Les combinaisons ainsi
détectées sont stockées dans une matrice de fusion ou
table de conflits. La détection des conflits se fait dans ce cas
par simple consultation des entrées de la matrice de fusion [SLMD96].
Une approche un peu plus générale [Fea89] basée sur les
matrices de fusion consiste à ne plus stocker dans ces dernières
les opérations mais plutôt les changements qu'elles induisent. De
cette façon, il est plus facile d'introduire de nouvelles
opérations sous la condition que celles ci n'occasionnent que des
changements déjà répertoriés dans la matrice de
fusion. On peut aussi stocker dans la matrice de fusion, à coté
des potentiels conflits, les actions à réaliser pour
résoudre les conflits [MD94]. Le problème principal posé
par les matrices de fusion est l'espace mémoire qu'elles occupent
lorsqu'il faut fusionner plus de deux répliques.
Les ensembles de conflit [WK97]
Les ensembles de conflit [WK97] peuvent être
utilisés à la place des matrices de fusion. Ils contiendront
ainsi les combinaisons d'opérations pouvant entraîner des
conflits. Ici, les opérations sont fortement liées à la
sémantique des éléments à fusionner. On construit
un ensemble de conflit pour chaque type de conflit susceptible
d'apparaître lors de la fusion. Il faut donc connaître ces types de
conflit à l'avance et, l'ensemble constitué de ces types est
statique vu qu'il ne varie pas tant que la sémantique des
éléments à fusionner est la même. Une même
opération peut intervenir dans plusieurs ensembles de conflit et deux
opérations appartenant au même ensemble de conflit sont
susceptibles de créer des conflits si on essaie de les fusionner.
1.2.3.2. La résolution des conflits
Après la détection des conflits, il faut pouvoir
les résoudre. Les approches de résolution dépendent
énormément du type de conflit qui a été
détecté. Ces approches de résolution peuvent être
complètement manuelles (appliquées par un Homme), interactives
(les correctifs sont appliqués avec l'accord d'un Homme) ou
complètement automatisées.
Certains conflits proviennent juste du fait que
l'opérateur de fusion soit non commutatif; l'ordre dans lequel
l'opération de fusion est appliquée aux répliques devient
alors crucial. La méthode de résolution est dans ce cas
plutôt simple car il suffit de trouver le bon ordre pour l'application de
l'opérateur de fusion [Men02].
Une autre stratégie de résolution des situations
de conflit consiste à calculer toutes les solutions valides et de les
proposer immédiatement aux co-auteurs pour que ces derniers
décident de la solution à appliquer. Bien entendu cette approche
dite d'explosion [WK97] peut être difficile à mettre en
oeuvre. En plus elle peut entraîner une explosion combinatoire (ensemble
de solutions valides très grand). Une autre façon (appelée
réconciliation [MD94]) de procéder serait de ne prendre
en compte aucune des mises à jour menant à un
1.3. Synthèse 18
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
conflit et, peut être de remplacer le noeud
correspondant au conflit par un noeud neutre dans le document global obtenu :
c'est cette approche que nous adoptons. De ce fait, les co-auteurs pourront
rééditer ou choisir une édition valide déjà
réalisée pour remplacer ces noeuds neutres. On pourrait
même envisager le calcul de l'ensemble des solutions valides grâce
à la stratégie d'explosion, et ainsi créer une
stratégie hybride (appelée consolidation [MD94]).
Les conflits peuvent être prévenus,
réduits ou même évités si on fixe les bonnes
pré-conditions à l'avance. Si on considère par exemple un
cas d'édition dans lequel chaque co-auteur est chargé de
rédiger une partie (un noeud) bien précise et distincte du
document, alors les conflits seront énormément réduits
voire inexistants. Dans un autre cas où plusieurs co-auteurs pourraient
éditer un même noeud, on peut définir une hiérarchie
entre ces co-auteurs et ainsi définir un ordre de priorité sur
les différentes contributions; la pré-condition stipulant qu'en
cas de conflit la contribution à retenir est celle qui a la plus haute
priorité, permet de résoudre certains conflits.
1.3. Synthèse
Dans ce chapitre nous avons présenté la notion
de travail coopératif et mis en exergue certaines de ses principales
caractéristiques. Nous avons présenté les
différentes caractéristiques des systèmes de CSCW. Nous
avons aussi établi en accord avec la littérature que la
coopération dans le cadre du CSCW peut avantageusement reposer sur
l'échange des documents électroniques. De ce fait, un même
document électronique peut être édité de
manière concurrente par plusieurs co-auteurs qui agissent sur ses
répliques. La mise à jour d'un document global s'obtient en
fusionnant les mises à jour portées sur les différentes
répliques. Cette opération peut être sujette à
plusieurs conflits; leur nombre peut être considérablement
réduit si des dispositions sont prises localement pour s'assurer, au
préalable, de ce que la réplique à envoyer pour la fusion
satisfait déjà à un certain nombre de
pré-conditions. Dans le chapitre suivant, nous allons présenter
une approche d'édition de documents structurés basée sur
le concept de "vue".
19
Chapitre2
L'édition coopérative des documents
structurés
Sommaire
2.1 - Documents structurés, conformité et
édition 19
2.2 - Vues, projection et répliques partielles 26
2.3 - Expansion des répliques partielles 27
2.4 - Fusion des répliques partielles 31
2.5 - Synthèse 32
Les documents structurés contiennent des informations
organisées suivant un modèle générique. Les
nombreux avantages de ces documents en ont fait d'importants outils
d'échange dans le monde informatique. Les applications
distribuées s'appuient sur eux pour permettre aux différents
acteurs de coopérer et de coordonner leurs actions. Ces documents sont
donc édités de manière asynchrone par plusieurs personnes
situées sur des sites géographiques potentiellement
éloignés. L'édition coopérative des documents
structurés nécessite que le procédé
d'édition soit défini à l'avance. BADOUEL Eric et
TCHOUPÉ TCHENDJI Maurice ont proposé une approche originale
d'édition coopérative des documents structurés dans
[BTT08, BTT07, TT09]. Étant donné que leur approche est la base
des travaux que nous menons, ce chapitre est majoritairement consacré
à la présentation de leurs travaux et il est organisé
comme suit : nous commençons par donner une représentation
formelle des documents structurés (sect. 2.1.1) et nous décrivons
l'approche de BADOUEL et TCHOUPÉ (que nous adoptons) pour
l'édition coopérative des documents structurés (sect.
2.1.3). Ensuite nous présentons les concepts utilisés pour
l'édition coopérative des documents suivant cette approche : les
notions de vue et de vue éditable (sect. 2.2.1), les
notions de projection et de réplique partielle (sect.
2.2.2), les notions d'expansion (sect. 2.3) et enfin de fusion
des mises à jour portées sur les répliques partielles
(sect. 2.4).
2.1. Documents structurés, conformité et
édition
Pour rappel, un document structuré est un document qui
présente une structure régulière définie par un
modèle générique. Il est usuel de représenter la
structure abstraite d'un
2.1. Documents structurés, conformité et
édition 20
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
document structuré par un arbre et son modèle
par une grammaire algébrique abstraite ; un document structuré
valide est alors un arbre de dérivation pour cette grammaire et on dit
que ce document est conforme à cette grammaire. Après avoir
défini formellement les grammaires algébriques abstraites, nous
représentons dans cette section les documents structurés valides
puis nous décrivons une démarche d'édition
coopérative de tels documents.
2.1.1. Représentation d'un document
structuré
Nous nous intéressons uniquement à la structure
des documents indépendamment de leurs contenus et des attributs qu'ils
peuvent contenir. De ce fait, un document est valide s'il est conforme à
une grammaire algébrique abstraite. Une telle grammaire définit
la structure de ses instances (les documents qui lui sont conformes) au moyen
des productions. Une production, généralement notée p
: X0 -+ X1...Xn est assimilable dans ce contexte à une
règle de structuration présentant comment le symbole X0
situé en partie gauche de la production se décompose en une
séquence d'autres symboles X1 ...Xn situés
dans sa partie droite. Plus formellement,
Définition 7 Une grammaire
algébrique abstraite est la donnée G = (S,P,A) d'un
ensemble fini S de symboles grammaticaux ou sortes qui correspondent aux
différentes catégories syntaxiques en jeu, d'un symbole
grammatical A E S particulier, appelé axiome, et d'un ensemble fini P c_
S x S* de productions. Une production P = (XP(0),XP(1)
···XP(n)) est notée P : XP(0) -+ XP(1)
···XP(n) et |P| désigne la longueur de la partie droite
de P.
L'annexe B contient la définition d'un type Haskell
[Has, HPHF99, GHC] pour les grammaires ainsi qu'un ensemble d'autres fonctions
implémentant les opérations définies dans ce
mémoire.
Exemple 8 Une grammaire algébrique
abstraite
Gexpl = (S,P,A) avec S = {A,B,C} et ayant les productions
suivantes :
P1 : A -+ C B P3 : B -+ C A P5 : C -+ A C
P2 : A -+ å P4 : B -+ B B P6 : C -+ C
C
P7 : C -+ å
est un exemple de grammaire algébrique. Signalons
qu'elle sera utilisée tout au long de ce manuscrit pour illustrer
certains de nos propos.
Un document structuré se présente sous la forme
d'un arbre dont les noeuds sont associés à des catégories
syntaxiques (symboles de la grammaire). Cette structure arborescente
reflète la structure hiérarchique du document. Pour certains
traitements sur les arbres (documents) il est nécessaire de
désigner précisément un noeud particulier. Plusieurs
techniques d'indexation existent parmi lesquelles celle dite de
numérotation dynamique par niveau (Dynamic Level Numbering - DLN - en
anglais) [BR04] basée sur des identificateurs à longueurs
variables inspirés de la classification décimale de
Dewey. Suivant ce système d'indexation, on peut définir
un arbre comme suit :
Définition 9 Un arbre dont les noeuds
sont étiquetés dans un alphabet S est
une fonction
t : N* -+ S
dont le domaine Dom(t) c_ N* est un
ensemble clos par préfixe tel que pour tout
u E Dom(t) l'ensemble {i E N | u · i E
Dom(t)} est un intervalle d'entiers [1,··· ,n] f1N non
vide (å E Dom(t)(racine)); l'entier n est l'arité du
noeud d'adresse u. t(w) est la valeur (étiquette) du noeud de t
d'adresse w. Un arbre tw, de racine le noeud d'adresse w E Dom(t) et
de domaine
2.1. Documents structurés, conformité et
édition 21
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Dom(tw) = {u | w.u E Dom(t)} et tw(u) =
t(w.u), est un sous-arbre de t si t1,··· ,tn sont des
arbres et a E S, on note t = a[t1,...,tn]
l'arbre t de domaine Dom(t) = {å} U {i · u | 1 < i <
n, u E Dom(ti)} avec t(å) = a et t(i · u) = ti(u).
L'arbre vide sera noté nil et next t =
[t1,··· ,tn] est la liste des sous-arbres de l'arbre
t = a[t1,...,tn].
La figure 2.1 est la représentation graphique de l'arbre
t définit sur l'alphabet {A,B,C}, dont une
linéarisation peut être donnée par t =
A[C[A[C[],B[C[],A[]]],C[]],B[C[C[],C[]],A[]]]. Les noeuds de t
sont identifiés suivant la technique de numérotation
dynamique par niveau.

FIGURE 2.1 - Représentation graphique d'un arbre et
indexation de ses éléments.
2.1.2. Conformité d'un document structuré
vis-à-vis de sa grammaire
Soient une grammaire algébrique G et un arbre t
(document) ; le document t est conforme à la grammaire G
(on note t ? G) si chacune des étapes de décomposition
hiérarchique de t obéit à une des productions de
G. On dit dans ce cas que t est un arbre de dérivation pour la
grammaire G. L'ensemble des arbres de dérivation pour la grammaire G en
utilisant le symbole X comme axiome est noté
Der(G,X) et est défini formellement comme suit :
Définition 10 L'ensemble
noté Der(G,X) des arbres de dérivation suivant la
grammaire G associés au symbole grammatical X est
constitué des arbres de la forme X[t1,··· ,tn]
pour lesquels il existe une production P = (XP(0),XP(1)
···XP(n)) telle que X = XP(0), |P| = n et ti E
Der(G,XP(i)) pour tout 1 < i < n.
2.1.2.1. Vérification de la conformité
d'un document : les AST
Dans un arbre de dérivation, les noeuds sont
étiquetés par des symboles grammaticaux. De la même
manière on peut définir les arbres de syntaxe abstraite (Abstract
Syntax Tree - AST -) qui sont des arbres dont les noeuds sont
étiquetés par des productions de la grammaire.
Définition 11 L'ensemble
noté AST(G,X) des arbres de syntaxe abstraite suivant la
grammaire G associés au symbole grammatical X est
constitué des arbres de la forme P[t1,···
,tn]
2.1. Documents structurés, conformité et
édition 22
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
oÙ P = (XP(0),XP(1)
···XP(n)) est une production telle que X = XP(0),
|P| = n et ti ? AST(G,XP(i)) pour tout 1 =
i = n.
Les AST peuvent être utilisés comme preuve de la
conformité d'un document. En effet, si pour un document t
donné on peut trouver un AST u équivalent, alors le
document en question est conforme à la grammaire. Ceci est garanti par
le fait que les AST ont des noeuds étiquetés par des productions
de la grammaire et que leur décomposition hiérarchique
obéit à ces productions par définition (définition
11). On dit dans ce cas que u détermine t et on note
u ` t ; la relation ` étant définie
formellement par P[u1,··· ,un] `
X[t1,··· ,tm] si X =
XP(0), n = m et ui `ti pour tout 1 =
i = n. Étant donné que chaque production de la
grammaire est caractérisée par la donnée conjointe de sa
partie gauche et de sa partie droite, il existe une correspondance bijective
entre l'ensemble des arbres de dérivation d'une grammaire et l'ensemble
de ses arbres de syntaxe abstraite. Le passage d'un AST à un arbre de
dérivation se fait juste par remplacement des productions dans l'AST par
leurs symboles en partie gauche. La figure 2.2 présente un AST et
l'arbre de dérivation équivalent sur la grammaire
Gexpl.

FIGURE 2.2 - Un AST et l'arbre de dérivation qu'il
détermine.
2.1.2.2. Vérification de la conformité d'un
document : les automates d'arbre
La conformité d'un arbre vis-à-vis d'une
grammaire peut être vérifiée grâce à un
auto-mate1 d'arbre descendant. En effet, quand on regarde les
productions d'une grammaire, on peut remarquer que chaque sorte est
associée à un ensemble de productions. On peut de ce point de
vue, considérer une grammaire comme une application
gram : symb ? [(prod, [symb])]
qui associe à chaque sorte une liste de couples
formés d'un nom de production et de la liste des sortes en partie droite
de cette production. Une telle observation suggère qu'une grammaire peut
être interprétée comme un automate d'arbre (descendant)
utilisable pour la reconnaissance ou pour la génération de ses
instances.
1. Les automates d'arbres sont des outils formels qui ont
plusieurs applications scientifiques. Le lecteur intéressé pourra
consulter [CDG+08] dans lequel il trouvera des définitions
formelles, des démonstrations et des applications possibles des
automates d'arbre.
2.1. Documents structurés, conformité et
édition 23
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Définition 12 Un automate d'arbre
(descendant) défini sur L est la donnée A =
(L,Q,R,F,q0) d'un ensemble L de symboles; ses
éléments sont les étiquettes des transitions de l'automate
A, d'un ensemble Q d'états, d'un état particulier q0 ? Q
appelé état initial, d'un ensemble F ? Q des
états finals et d'un ensemble fini R ? Q × L ×
Q* de transitions.
-- Un élément de R est noté q ?
(a,[q1,··· ,qn]) :
intuitivement, il s'agit de la liste des états
[q1,··· ,qn] accessibles à
partir d'un état q donné en franchissant une transition
-- Si q ? (a1,[q1
étiquetée a ;
1,··· ,q1
n1]),··· ,q ?
(ak,[qk 1,···
,qk nk]) désigne l'ensemble des transitions
associées à l'état q, on note next q =
[(a1,[q1 1,···
,q1 n1]),···
,(ak,[qk 1,···
,qk nk])] la liste formée des couples
(ai,[qi 1,···
,qi ni]). Dans le cas où q est un état terminal
(c-à-d. aucune transition n'est franchissable depuis l'état q),
next q = [];
-- Un état q ? Q appartient à F s'il
contient une transition de la forme q ? (a,[]).
On peut interpréter une grammaire G = (S,P,A)
comme un automate d'arbre (descendant) [CDG+08] A
= (L,Q,R,F,q0) en considérant que:
1. q0 = A;
2. L = P est le type des étiquettes des
transitions de l'automate A ; 3. Q = S est le type des
états et,
4. q ?
(a,[q1,··· ,qn])
est une transition de l'automate lorsque la paire
(a,[q1,··· ,qn])
apparaît dans la liste (gram q)2 ;
5. F = {N ? S, N ? E ? P},
c'est à dire l'ensemble des symboles possédant une E-production.
On notera AG l'automate d'arbre dérivé à partir
de G. Reconnaissance d'un arbre à partir de l'automate
d'arbre
Pour reconnaître un arbre à l'aide d'un automate
d'arbre, à partir d'un état initial, il suffit :
1. D'associer l'état initial à la racine de
l'arbre;
2. Si un noeud étiqueté X est
associé à l'état q, alors la transition q
? (p,[q1,··· ,qn]), n
= 0 avec p une X-production 3, est une
transition de l'automate. Si ce noeud possède n successeurs non
encore associés à des états, alors n > 0 et on
associe les états de q1 jusqu'à qn
à chacun de ces n successeurs;
3. L'arbre est reconnu si on a réussi à associer
un état à chacun des noeuds de l'arbre, et que les noeuds
feuilles sont tous associés à des états finals.
On note A ` t q le fait que l'automate
d'arbre A accepte l'arbre t à partir de l'état
initial q, et 2' (A,q) (langage d'arbre) l'ensemble des
arbres acceptés par l'automate A à partir de
l'état initial q. Ainsi, (A ` t I>q) ?
(t ? 2' (A,q)). Les arbres (documents) acceptés par
l'automate AG à partir d'un état q quelconque
sont conformes à la grammaire G; le procédé de
construction de l'automate AG et l'algorithme de reconnaissance nous
le garantissent.
2. Rappel : gram est l'application obtenue par
abstraction de G et a pour type : gram : symb ? [(prod,
[symb])].
3. Une production ayant X en partie gauche.
2.1. Documents structurés, conformité et
édition 24
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Exemple 13 L'automate d'arbre 91Gexpl =
(E,Q,R,q0) dérivé de la grammaire Gexpl est
défini par E = / 31= {P1,P2,··· ,P7},
Q = S = {A,B,C}, F = {A,C}, q0 = A et ses transitions sont les
suivantes :
A -+ (P1,[C,B]) B -+ (P3,[C,A]) C -+ (P5,[A,C])
A -+ (P2,[]) B -+ (P4,[B,B]) C -+ (P6,[C,C])
C -+ (P7,[])
La figure 2.3 illustre la procédure de
vérification de la conformité d'un arbre vis-à-vis de la
grammaire Gexpl grâce à l'automate 91Gexpl à
partir de l'état q0 = A. Au final, le dit arbre est conforme
(91Gexpl I- t L> A) car tous ses noeuds ont été
associés à des états de l'automate, et ses feuilles
associées à des états finals.

FIGURE 2.3 - Illustration de la procédure de
vérification de la conformité d'un arbre à partir d'un
automate d'arbre.
2.1.3. Une approche d'édition coopérative des
documents structurés
Les documents structurés, peuvent être
édités de manière coopérative par plusieurs
co-auteurs. On peut imaginer plusieurs approches pour réaliser une telle
édition. Nous décrivons ici l'approche qui est utilisée
dans ce mémoire.
Initialement, le document t à éditer
est dans un état précis (état initial) ; les
différents co-auteurs qui sont situés sur des sites
géographiques potentiellement éloignés, obtiennent une
copie (une réplique) du document qu'ils éditeront localement.
Pour des raisons de confidentialité (degré
d'accréditation) un co-auteur (i) donné n'aura pas
forcément accès à l'ensemble des symboles grammaticaux qui
apparaissent dans l'arbre ; seul un sous-ensemble d'entre eux, d'un type
donné, peut être jugé pertinent pour lui : c'est sa vue
(v). La réplique qu'il devra donc éditer localement
(sur son site) sera une partie du document initial : on parlera de
réplique partielle et elle est notée tv. La
réplique partielle sera obtenue par projection (x) du document
initial en fonction de la vue du dit co-auteur (tv = xv(t)).
Les co-auteurs éditeront alors de manière asynchrone les
répliques partielles ; et les documents locaux obtenus seront
appelés répliques partielles mises à jour
(tmaj
Vi ).
2.1. Documents structurés, conformité et
édition 25
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Nous nous intéressons uniquement à
l'édition positive; les documents édités ne feront que
grossir et le co-auteur ne pourra plus supprimer des parties du document une
fois qu'une synchronisation aura été effectuée. Pour,
à la fois, garantir cette propriété et pouvoir indiquer
à un co-auteur l'endroit où il doit contribuer, les documents en
cours d'édition seront représentés par des arbres
contenant des bourgeons ou noeuds ouverts qui indiquent, dans
un arbre, les seuls lieux où des éditions (mises à jour)
sont possibles. Les bourgeons sont typés; un bourgeon de sorte X
est un noeud feuille étiqueté X : il ne peut
être édité (étendu en un sous-arbre) qu'en utilisant
une X-production (production ayant
X en membre gauche). Ainsi donc, un document
structuré en cours d'édition et ayant la grammaire G =
(S,P,A) pour modèle est un arbre de dérivation pour la
grammaire étendue Gç = (S,P
uSç,A) obtenue de G en ajoutant à
l'ensemble P des productions et pour tout sorte X S, une
nouvelle E-production Xç : X --+ E ;
Sç = {Xç : X --+ E, X S}. Les
autres noeuds du document seront dit clos et le document sera clos
si tous ses noeuds sont clos (s'il ne possède aucun bourgeon).
Lorsqu'un point de synchronisation4 sera atteint,
on essayera de fusionner toutes les contributions tma
j
Vi des différents co-auteurs pour obtenir un
document global unique tf 5. Pour garantir que la fusion se fasse
toujours sans conflits on peut:
1. Contrôler les éditions locales; pour cela on
peut se servir d'une grammaire locale sur chaque site. Ces grammaires locales
sont obtenues à partir de la grammaire globale (du document) et suivant
les vues correspondantes. Un algorithme permettant d'obtenir de telles
grammaires est proposé dans [TTTAD14];
2. Considérer l'hypothèse selon laquelle une
catégorie syntaxique ne peut être éditée que par un
co-auteur précis (hypothèse d'édition disjointe)
: on évite ainsi les divergences et donc les conflits lors de la
synchronisation. Lever cette hypothèse et gérer les conflits est
l'objet principal du travail réalisé dans ce document (nous le
faisons dans le chapitre 3) mais nous considérons cette hypothèse
dans ce chapitre.
La figure 2.4 illustre grâce à un diagramme
d'orchestration BPMN, cette approche d'édition coopérative comme
procédure d'entreprise; sur le site 1 on réalise les
opérations de (re)distribution et de fusion du document (global)
conformément à un modèle G; sur les sites 2 et 3,
on édite des répliques partielles conformément aux
modèles G1 et G2 dérivés par projection
du modèle global de documents G.
Toutes les opérations de synchronisation et de
re-distribution peuvent être réalisées sur l'un des sites
dédié à cet effet (comme sur le site 1 de la figure 2.4).
Dans ce cas, le système est dit centralisé et le site de
synchronisation est appelé le serveur central. On peut
cependant envisager un système dans lequel les synchronisations se
feront en pair à pair et sur n'importe quel site d'édition; les
synchronisations n'impliqueront donc plus forcément les contributions de
tous les co-auteurs. Une telle approche s'adapte mieux aux procédures
d'entreprise et au fait que le document soit le support de coopération
dans ces procédures. Les idées maîtresses pour la mise sur
pied d'un éditeur coopératif en pair à pair sont, en ce
moment, élaborées et étudiées au Laboratoire
d'Informatique Fondamentale et Appliquée (LIFA) par TCHOUPÉ T.
Maurice et ses collaborateurs.
Dans les sections qui vont suivre, nous allons définir
formellement en accord avec [BTT08, BTT07, TT09] tous les concepts qui ont
été brièvement décrits ici.
4. Un point de synchronisation peut être défini
statiquement ou déclenché par un co-auteur dès que
certaines propriétés sont satisfaites.
5. Il peut arriver que l'édition doive être
poursuivie après la fusion (c'est le cas s'il existe encore des
bourgeons dans le document fusionné) : on doit redistribuer à
chacun des n co-auteurs une réplique (partielle) tVi
de tf telle que tVi =
ðVi(tf) pour la poursuite du processus
d'édition.

2.2. Vues, projection et répliques partielles 26
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
FIGURE 2.4 - Un diagramme d'orchestration BPMN pour le
processus d'édition coopérative désynchronisée.
2.2. Notion de vue, de projection et de réplique
partielle
La première étape dans le procédé
d'édition coopérative présenté à la section
2.1.3 est la définition et l'assignation d'une vue à chaque
co-auteur. Ensuite, il faut distribuer des copies du document global à
tous les co-auteurs. Ces copies sont obtenues par projection du document global
suivant les vues respectives de chaque co-auteur. Dans cette section, nous
présentons les notions de vue et de projection d'un document
structuré.
2.2.1. Les vues d'un document structuré
L'arbre de dérivation donnant la représentation
(globale) d'un document structuré édité de façon
coopérative, rend visible l'ensemble des symboles grammaticaux de la
grammaire ayant participé à sa construction. Comme
déjà mentionné à la section 2.1.3, pour des raisons
de confidentialité (degré d'accréditation), un co-auteur
manipulant un tel document n'aura pas accès nécessairement
à l'ensemble de tous ces symboles grammaticaux; seul un sous-ensemble
d'entre eux peut être jugé pertinent pour lui : c'est sa
vue. Une vue V est donc un sous-ensemble de symboles
grammaticaux (V ? S). Intuitivement, il s'agit des sortes visibles par
un co-auteur dans la représentation globale (arbre de dérivation)
du document considéré.
Les sortes visibles par un co-auteur donné ne sont pas
forcément éditables par ce dernier : elles peuvent juste
être consultables ou accessibles en lecture. En revanche, les
informations que ces sortes véhiculent peuvent guider le co-auteur dans
l'édition d'autres sortes pour lesquelles il a les droits de lecture et
d'écriture. Nous représentons par V (i)
edit le
sous-ensemble de symboles grammaticaux (V
(i)
edit ? Vi) visibles et éditables par le
co-auteur situé sur le site i (nous l'appelons vue
éditable du co-auteur situé sur le site i). Il est
évident que dans un contexte d'édition où
l'hypothèse d'édition disjointe est prise en compte, les vues
éditables des différents co-auteurs doivent être
mutuellement disjointes.
2.3. Expansion des répliques partielles
27
Mémoire - ZEKENG NDADJI
Milliam Maxime LIFA
2.2.2. Projection d'un document structuré
Une réplique partielle d'un document t suivant
une vue V, est une copie partielle de t obtenue en supprimant
dans t tous les noeuds étiquetés par des symboles
n'appartenant pas à V. Pratiquement, une réplique
partielle est obtenue via une opération de projection
notée ð. On note donc
ðV (t) = tV le fait que tV
soit une réplique partielle obtenue par projection de t
suivant la vue V. Pour une vue V donnée,
l'opération de projection efface des arbres de dérivation, les
noeuds étiquetés par des symboles invisibles (n'appartenant pas
à V) tout en conservant la structure de sous-arbre. Les
résultats sont des listes d'arbres qui pourront effectivement contenir
plusieurs éléments dans le cas où l'axiome est
invisible.
Les répliques partielles pourront être
éditées par les co-auteurs (ils pourront éditer les
bourgeons sur lesquels ils ont les droits de lecture et d'écriture);
notons tVi = tma j
Vi le fait que le document
tma j
Vi soit une mise à jour du document
tVi, c'est à dire que tma
j
Vi est obtenu
de tVi en remplaçant certains de ses
bourgeons par des arbres.
La figure 2.5 présente un document t conforme
à la grammaire Gexpl ainsi que deux répliques partielles
tv1 et tv2 obtenues respectivement par
projections à partir des vues V1 = {A,B} et
V2 = {A,C} et qui sont éditées respectivement
sur les sites 1 et 2; le coauteur 1 (resp. le co-auteur 2) ne peut
éditer que les bourgeons de type A (resp. C) (c'est
à dire queV(1)
edit = {A} et V edit (2) =
{C}); les documents mis à jour sont respectivement
tma j
v1
et tma j
v2 .
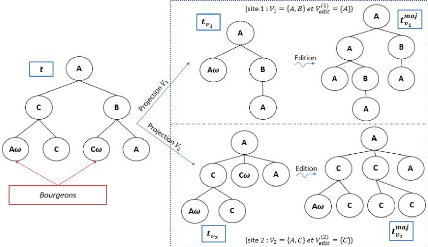
FIGURE 2.5 - Exemple de projections et de mises à jour
effectuées sur un document.
2.3. Notion de projection inverse ou d'expansion des
répliques partielles
Lorsque vient le moment de la synchronisation, il faut
fusionner les différentes mises à jour des différents
co-auteurs; ceci dans le but d'obtenir un document global conforme
2.3. Expansion des répliques partielles 28
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
à la grammaire globale. Sachant que les documents
à fusionner (répliques partielles mises à jour) ne sont
pas forcément conformes à de la grammaire globale6 ;
il faut au préalable, trouver des documents conformes au modèle
global et pour lesquels ces répliques partielles sont des projections.
La recherche de ces documents, connue comme étant le problème de
la projection inverse ou expansion, est l'objet de cette
section.
2.3.1. Le problème de la projection inverse
La projection inverse ou expansion d'une
réplique partielle mise à jour tma
'
Vi relativement
{ }
à une grammaire G = (S,P,A) donnée, c'est
l'ensemble Tma ' tma '
iS = iS ? G | ðVi(tma
'
iS ) = tma '
Vi
des documents conformes à G qui admettent
tma '
Vi comme réplique partielle suivant la vue
Vi. Ces documents peuvent être en nombre
infini; en effet si nous considérons la réplique partielle mise
à jour tma '
v1 obtenue en éditant sur le site 1 la
réplique partielle tv1 (tv1 étant obtenue par
projection du document t - conforme à la grammaire Gexpl
- suivant la vue V1 = {A,B}) (figure 2.5), on peut
trouver un nombre illimité de documents tma ' iS
qui sont ses projections inverses (il suffit d'itérer sur la
production C ? C C) comme l'illustre la figure 2.6.

FIGURE 2.6 - Exemple de projections inverses d'une
réplique partielle.
Le calcul des expansions des répliques partielles mises
à jour est primordial étant donné que ce sont les
documents de ces expansions qui seront fusionnés pour déterminer
les documents globaux intégrant toutes les mises à jour (dans le
cas où il n'y a pas de conflits) des différents co-auteurs.
L'expansion d'un document pouvant être infinie, il est souhaitable de ne
pas chercher à calculer tous les documents qui la constituent. Par
ailleurs, même si ces ensembles étaient finis, ce serait
très coûteux de les générer vu que ce n'est qu'une
infime proportion des documents qu'ils contiennent qui sera retenue à
l'issue de la fusion. L'idée proposée dans [BTT08, BTT07, TT09]
est donc d'implémenter les algorithmes d'expansion associés
à chaque vue sous la forme de co-routines qui construisent
6. Pour rappel, les répliques partielles ne sont pas
forcément conformes au modèle grammatical global mais
plutôt à des modèles grammaticaux locaux. Les
modèles locaux peuvent être obtenus en récrivant les
productions du modèle global; une solution (ne s'appliquant qu'à
une certaine classe de grammaire) basée sur ce raisonnement a
été proposé dans [TTTAD14].
2.3. Expansion des répliques partielles 29
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
de façon paresseuse7 une
représentation de leur espace de solution respectif; et par la suite, de
faire collaborer ces co-routines pour générer les documents
globaux recherchés. De ce fait, l'expansion d'une réplique
partielle sera représentée par un automate d'arbre qui sera
utilisé pour la génération de ses instances (les documents
de l'expansion).
2.3.2. Sérialisation d'un document
structuré
Pour des besoins de sérialisation, un arbre peut
être linéarisé sous la forme d'un mot de Dyck à
n lettres où n est la taille de l'alphabet
étiquetant les noeuds de l'arbre. Le langage de Dyck à n
lettres (Ón = {(i,)i |
1 i n}) c'est-à-dire le langage des parenthèses
bien formées sur n lettres, est donné par la
grammaire
(Dyck) -p (primeDyck)*
(primeDyck) -p (i (Dyck) )i 1 i
n
Un mot premier de Dyck code un arbre et un mot de Dyck une
suite d'arbres, c'est à dire une forêt. On associe une paire de
parenthèses à chaque symbole grammatical puis on effectue un
parcours en profondeur de l'arbre à sérialiser comme
illustré sur la figure 2.7 avec la réplique partielle mise
à jour tma j
v1 .

FIGURE 2.7 - Linéarisation d'un arbre (tma j
v1 ) : on a associé les symboles de Dyck '(1'
et ')1' (resp. '(2' et ')2') au symbole grammatical A (resp.
B).
On peut restreindre l'association des paires de
parenthèses à un sous-ensemble de symboles grammaticaux (une vue
- V par exemple -). La linéarisation des documents sera
partielle et ne représentera que les symboles visibles (ceux auxquels on
a adjoint une paire de parenthèse) dans le document : on parlera de la
trace visible du document en question. Ceci induit que des documents
(t1 et t2 par exemple) différents peuvent avoir la
même trace visible (t). Dans ce cas, leur trace visible commune
n'est rien d'autre que la linéarisation de leurs projections suivant la
vue considérée. On en déduit de ce fait que les documents
(t1 et t2) en question appartiennent à une même
expansion (celle de t).
7. L'évaluation paresseuse ou évaluation par
nécessité est une forme d'évaluation dans laquelle les
éléments sont calculés uniquement quand leurs
résultats sont nécessaires. Contrairement à
l'évaluation immédiate, cette technique permet de réaliser
des constructions à l'origine impossibles; comme la définition
d'une suite infinie...[Has, HPHF99, GHC]
2.3. Expansion des répliques partielles
30
Mémoire - ZEKENG NDADJI
Milliam Maxime LIFA
2.3.3. Représentation de l'expansion d'une
réplique partielle et
exemple
L'algorithme d'expansion va consister à associer un
automate d'arbre à une vue. Cet automate permet à la fois de
reconnaître tous les documents de l'expansion mais on peut aussi
l'utiliser pour générer (de façon paresseuse) ces
documents.
Comme pour la conformité, l'automate de l'expansion
sera construit à partir de la grammaire globale G. Cependant, la seule
propriété connue des documents de l'expansion que cet automate
devra générer est qu'ils ont tous la même trace visible
t (la réplique partielle). C'est pourquoi, l'état
initial de cet automate sera construit à partir de cette trace
visible.
Un exemple d'application
Dans cet exemple, nous construisons un automate d'arbre 91
permettant de reconnaître et/ou de générer tous les
documents (conformes à Gexpl) qui sont des expansions de la
réplique partielle mise à jour tma
'
v1 ; nous construisons donc 91 à
partir de v = {A,B} avec pour état initial
l'arbre tma '
v1 . Nous représentons des listes d'arbres
(forêts) par leurs linéa-risations. Dans l'écriture de ces
linéarisations, nous utilisons la parenthèse ouvrante '(' et
fermante ')' pour représenter les symboles de Dyck associés au
symbole visible A et le crochet ouvrant '[' et fermant ']' pour
représenter les symboles de Dyck associés au symbole visible
B. Chaque transition des automates associés aux
répliques partielles suivant la vue {A,B} est conforme
à l'un des schémas de transition suivants :
(A,w1) ->
(P1,[(C,u),(B,v)]) si w1
= u[v]
(A,w2) -> (P2,[]) si w2 =
å
(B,w3) ->
(P3,[(C,u),(A,v)]) si w3
= u(v) (B,w4) ->
(P4,[(B,u),(B,v)]) si w4
= [u][v] (C,w5) ->
(P5,[(A,u),(C,v)]) si w5
= (u)v (C,w6) ->
(P6,[(C,u),(C,v)]) si w6
= uv
(C,w7) -> (P7,[]) si w7 =
å
Ces schémas de règles sont obtenus à
partir des productions de la grammaire et les couples (X,wi)
sont des états dans lesquels X est un symbole grammatical et le
motif wi est une forêt codée dans le langage de Dyck. Le
premier schéma par exemple, stipule que les AST
générés à partir de l'état
(A,w1) sont ceux obtenus en utilisant la production
P1 pour créer un arbre de la forme
P1[t1,t2] ; t1 et t2 étant
générés respectivement à partir des états
(C,u) et (B,v) tel que w1 =
u[v]. Dans une telle décomposition (w1 =
u[v]), on peut déterminer u et v
à partir de w1 par pattern matching (filtrage
par motif) facilement et sans ambiguïté : on dit dans ce cas
que le motif w1 est déterministe. Les schémas de
transition dont les motifs sont non déterministes (le sixième
schéma par exemple - w6 = uv -) sont en
général responsables de la présence d'une infinité
de documents admettant la même trace visible.
Ayant associé les symboles de Dyck '(' et ')' (resp.
'[' et ']') au symbole grammatical A (resp. B), la
linéarisation de la réplique partielle mise à jour
tma '
v1 donne ((()[()])[()])
(figure 2.7). A
étant l'axiome de la grammaire et aussi un symbole visible
(appartenant à la vue), l'état initial de l'automate .91
est q0 = (A,(()[()])[()]). En ne considérant que
les états accessibles à partir de q0 et en appliquant
les schémas de règles présentés
précédemment, nous obtenons l'automate d'arbre suivant pour la
réplique tma '
v1 :
2.4. Fusion des répliques partielles 31
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
|
q0
|
->
|
(P1,[q1,q2])
|
|
avec
|
q1 = (C,(()[()])) et q2 =
(B,())
|
|
q1
|
->
|
(P5,[q3,q4])
|
|
avec
|
q3 = (A,()[()]) et q4 =
(C,å)
|
|
q1
|
->
|
(P6,[q4,q1]) |
|
(P6,[q1,q4])
|
|
|
|
q2
|
->
|
(P3,[q4,q5])
|
|
avec
|
q5 = (A,å)
|
|
q3
|
->
|
(P1,[q6,q2])
|
|
avec
|
q6 = (C,())
|
|
q4
|
->
|
(P6,[q4,q4]) |
|
(P7,[])
|
|
|
|
q5
|
->
|
(P2,[])
|
|
|
|
|
q6
|
->
|
(P5,[q5,q4])
|
|
|
|
|
q6
|
->
|
(P6,[q4,q6]) |
|
(P6,[q6,q4])
|
|
|
Il est aisé de vérifier que l'automate
présenté ci-dessus, accepte les arbres de la figure
2.6 qui sont des expansions de tmaj
v1 .
Génération des arbres à partir d'un
automate
Tout comme il est possible de générer des mots
du langage accepté par un automate classique (automate sur les
chaînes de caractères) à partir de ce dernier, il est
possible de générer des arbres à partir d'un automate
d'arbres. En effet, il suffit de partir de l'état initial vers les
états finals en se laissant guider par les transitions de l'automate. Il
existe tout de même le risque de tourner en rond (indéfiniment)
lorsque les transitions de l'automate décrivent un cycle ; on passe
alors plusieurs fois par un même état. Pour régler ce
problème, il suffit de fixer le nombre maximum d'utilisation d'un
état dans la génération. Sur ce principe, un
générateur (dont le code Haskell est donné dans l'an-nexe
B) a été proposé dans [BTT08, BTT07] ; ce dernier
énumère les arbres les plus simples acceptés par un
automate d'arbre, c'est à dire, les arbres tels que dans aucune branche,
un état de l'automate n'est utilisé plus d'une fois pour la
génération des noeuds de la branche. L'application de cette
fonction de génération à l'automate fournit l'AST
P1[P5[P1[P5[P2[],P7[]],P3[P7[],P2[]]],P7[]],P3[P7[],P2[]]]
correspondant au second arbre de la figure 2.6.
2.4. Fusion des répliques partielles mises à
jour
La dernière étape du procédé
d'édition coopérative présenté à la section
2.1.3 est la fusion des mises à jour portées par les co-auteurs
sur les différentes répliques partielles. Pour cela, on
synchronise les expansions des différentes répliques mises
à jour. Ces expansions étant représentées par des
automates d'arbre qui leur ont été associés, leur
synchronisation implique une synchronisation à base d'une
opération (produit synchrone) de ces automates. Dans cette section, nous
définissons le produit synchrone de plusieurs automates d'arbre puis
nous montrons comment ce produit peut être utilisé pour
réaliser la fusion des mises à jour portées sur les
répliques partielles.
2.4.1. Produit synchrone des automates d'arbre
Définition 14 Produit synchrone de k
automates
Soient (1) =
(E,Q(1),R(1),qo1)),.
., (k) =
(Ó,Q(k),R(k),qak))
k automates d'arbre. Le produit synchrone de cesi k
automates (1) ®··· ® (k) noté
®i (i), est l'automate
(sc) = (Ó,Q,R,q0) défini comme suit
:
Ses états sont les vecteurs d'états : Q
= Q(1) x ··· x
Q(k) ;
Son état initial est formé par le vecteur
des états initiaux des différents automates : q0 =
(q(1)
0 ,···,q(k)
0 );
2.5. Synthèse 32
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
-- Ses transitions sont données par :
~ ~
(q(1),...,q(k)) a ?
(q(1)
1 ,...,q(k) 1
),...,(q(1)
n ,...,q(k)
n ) ?
a
q(i) ?
(q(1i),...,qSii))
?i, 1 = i = k)
L'automate d'arbre produit permet de représenter
l'intersection des langages d'arbre acceptés par les automates
intervenants dans le calcul de ce produit ; il (l'automate produit) accepte
donc les arbres (documents) qui sont reconnus par tous les automates qui
permettent de le calculer. Plus formellement,
(?k )
i=191(i) ` t r
(q1,··· ,qk)) ?
(?i, 91(i) ` t r qi) donc 2'
(?k i=191(i),
(q1,··· ,qk)) = T2'
(91(i), qi
2.4.2. Fusion des répliques partielles
Le but de la fusion des mises à jour portées sur
les répliques partielles est celui de trouver un document tf
conforme à la grammaire globale qui intègre toutes les
contributions des différents co-auteurs. Pour chaque réplique
partielle, on sait déjà représenter, à l'aide d'un
automate, son expansion. Un arbre appartenant à l'expansion d'une
réplique partielle est conforme à la grammaire globale et admet
cette réplique comme trace visible (c'est à dire qu'il
intègre tous les noeuds de cette réplique). Pour atteindre
l'objectif de la fusion, il faut trouver des arbres qui appartiennent à
toutes les expansions des différentes répliques partielles
à fusionner : il faut donc calculer l'intersection de ces expansions.
Comme ces expansions sont représentées par des automates d'arbre,
leur intersection peut être représentée par un automate
d'arbre qui est le produit synchrone de ces automates. On peut donc en
déduire que, pour fusionner les mises à jour apportées
à k répliques partielles tV1,···
,tVk d'un document structuré t il faut :
1. Associer un automate d'arbre
(91(i)) à chaque réplique partielle
mise à jour (tma j
Vi , ? 1 =
i =k);
2. Calculer l'automate produit
91(SC) =
?i91(i) de ces automates;
3. Les documents reconnus par
91(SC) sont des documents globaux qui
intègrent toutes les mises à jour des différents
co-auteurs.
2.5. Synthèse
L'édition coopérative des documents
structurés peut être envisagée sous plusieurs angles. Nous
avons présenté dans ce chapitre le procédé qui
constitue la base de nos travaux (sect. 2.1.3). La mise en oeuvre de ce
procédé d'édition nécessite la définition et
la formalisation de certains outils et fonctions fondamentaux. C'est ainsi que
nous avons présenté, en accord avec [BTT08, BTT07, TT09], les
notions de vue et de vue éditable (sect. 2.2.1), de
projection et de réplique partielle (sect. 2.2.2),
d'expansion (sect. 2.3) et enfin de fusion des mises à
jour (sect. 2.4). Comme dans [BTT08, BTT07, TT09] ces notions ont
été présentées dans un contexte où les
documents à fusionner sont tous complets et où l'hypothèse
d'édition disjointe (une catégorie syntaxique ne peut être
éditée que par au plus un coauteur) est considérée.
Dans le chapitre 3 nous allons lever ces hypothèses et adapter les
différents algorithmes pour pouvoir adresser les nouveaux
problèmes qui surgiront.
33
Chapitre3
Fusion consensuelle des mises à jour
des répliques partielles
Sommaire
3.1 - Problématique de la réconciliation par
consensus 34
3.2 - Calcul du consensus 34
3.3 - Synthèse 43
La fusion des mises à jour portées sur les
répliques partielles d'un document structuré est
inévitable dans un processus d'édition coopérative
asynchrone. Dans notre approche d'édition coopérative, elle
consiste à trouver un document global qui intègre au mieux les
contributions de chaque co-auteur, sachant que chaque co-auteur a
édité sa réplique suivant un modèle grammatical
local (dérivé du modèle global); le modèle local
garantit la cohérence des mises à jour de la réplique
partielle vis-à-vis du modèle global 1 et assure ainsi
la faisabilité de la fusion. Pour différentes raisons, plusieurs
co-auteurs peuvent avoir le droit d'éditer un même noeud de
façon concurrente. Cette considération couplée à
l'asynchronisme de l'édition induit la possibilité que des mises
à jour soient incohérentes ou conflictuelles; il faut donc
pouvoir détecter ces conflits lors de la fusion et y remédier si
possible. L'algorithme de fusion proposé dans [BTT08, BTT07] ne permet
pas de remédier à de tels conflits. Nous proposons dans ce
chapitre une instrumentalisation de cet algorithme, afin de détecter et
éliminer (résoudre) les conflits lors de la fusion. Pour cela,
nous nous servons d'un automate d'arbre dit du consensus, construit en faisant
le produit synchrone des automates (à états de sortie)
associés aux différentes répliques partielles à
fusionner.
Ce chapitre est organisé comme suit : après
avoir présenté le problème de la fusion consensuelle
(sect. 3.1), nous définissons la notion d'automate d'arbre à
états de sortie, et ensuite, nous proposons un algorithme (algorithme 1)
pour la construction de l'automate du consensus (sect. 3.2).
1. Un modèle local garantit la cohérence des mises
à jour d'une réplique partielle ti
vis-à-vis du modèle global.
3.1. Problématique de la réconciliation par
consensus 34
Mémoire - ZEKENG NDADJI
Milliam Maxime LIFA
3.1. Problématique de la réconciliation
par consensus
Dans un processus d'édition coopérative
asynchrone d'un document, on peut permettre pour plusieurs raisons, à
différents co-auteurs d'éditer une même partie dudit
document ; on peut le faire, pour avoir différentes versions de ces
parties et ainsi, avoir la possibilité de choisir une version
satisfaisant, au mieux, les critères d'édition fixés
à l'avance. De ce fait, quand on atteint un point de synchronisation, on
peut se retrouver avec des répliques non fusionnables dans leur
entièreté car, contenant des mises à jour non compatibles
2 : il faut les réconcilier. On peut le faire en remettant en cause
(annulation) certaines actions des éditions locales afin de lever les
conflits et aboutir à une version globale cohérente dite de
consensus.
Les études portant sur la réconciliation des
versions d'un document reposent sur des heuristiques [Men02] dans la mesure
où il n'y a pas de solution générale à ce
problème. Rappelons que dans notre cas, étant donné que
toutes les actions d'édition sont réversibles 3 et
qu'il est facile de localiser les conflits lors de la tentative de fusion des
répliques partielles, nous disposons d'une méthode canonique pour
éliminer les conflits : nous remplaçons lors de la fusion tout
noeud (du document global) dont les répliques sont en conflit par un
bourgeon. On élague donc au niveau des noeuds où un conflit
apparaît, en remplaçant le sous arbre correspondant par un
bourgeon du type approprié, indiquant que cette partie du document n'est
pas encore éditée : les documents obtenus sont appelés les
consensus. Ce sont les préfixes maximaux sans conflits de la fusion des
documents issus des différentes expansions des diverses répliques
partielles mises à jour.
Le problème de la fusion consensuelle de n
répliques partielles dont le modèle global est donné
par une grammaire G = (S,P,A) peut donc
s'énoncer comme suit :
Problème de la fusion consensuelle :
Étant donné k vues
(Vi)1<i<k et k répliques
partielles (tma j
Vi )1<i<k, fusionner
consensuellement la famille (tma j
Vi )1<i<k consiste à
rechercher les plus grands documents tmaj S? G
satisfaisant :
bi E 1,...,n \I ]ti ? G, ti
ti= tmaj ðVi(ti) <
tNI
j
dans laquelle, la relation ti= permet de lier deux documents
non en conflit qui sont éventuellement des mises à jour l'un pour
l'autre.
3.2. Calcul du consensus
La solution que nous proposons au problème de la fusion
consensuelle découle d'une instrumentalisation de celle proposée
pour l'expansion dans [BTT08, BTT07, TT09] et décrite
précédemment (chap. 2 sect. 2.3). En effet, nous
définissons un opérateur binaire
commutatif noté pour synchroniser les automates d'arbre
A(i) construits pour réaliser
les
différentes expansions afin de générer l'automate d'arbre
de la fusion consensuelle. En notant A(sc) cet
automate, les documents du consensus sont les arbres du langage engendré
par l'automate A(sc) à partir d'un
état initial construit à partir du tuple formé des
états initiaux des automates A(i) : L
(A(sc), (qtmaj)) =
consensus{L (A(i), qtma
j)}. A(sc) est
Vi Vi
obtenu en procédant de la façon suivante :
2. C'est notamment le cas s'il existe au moins un noeud du
document global accessible par plus d'un coauteur et édité par au
moins deux d'entre eux en utilisant des productions différentes.
3. Rappel : Les actions d'édition effectuées
sur une réplique partielle peuvent être annulées tant
qu'elles n'ont pas encore été intégrées dans le
document global.
1. 3.2. Calcul du consensus 35
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Pour chaque vue v, construire l'automate
91(i) qui réalisera l'expansion de la
réplique
partielle tma j
Vi comme indiqué précédemment
(chap. 2 sect. 2.3.3) : (91(i), qtmaj) =
v
TS
j ;
2. Au moyen de l'opérateur ?Ù,
calculer l'automate générant le langage du consensus
91(sc) = ?Ùi
91(i) ;
3. Générer les documents acceptés par
91(sc) : ce sont ceux du consensus.
Avant de présenter l'algorithme du calcul du consensus,
précisons en utilisant les notions introduites
précédemment (chap. 2 section 2.1.1), les concepts de documents
en conflit et de consensus entre plusieurs documents.
3.2.1. Consensus entre plusieurs (deux) documents
Soient t1,t2 : N* ? A
deux arbres (documents) en conflit de domaines respectifs
Dom(t1) et Dom(t2) : si on appelle type
la fonction qui retourne le type 4 d'un noeud en se servant de
son étiquette, on dira que t1 et t2 n'admettent pas de
consensus, et on note t1 Yt2, si les types de leurs noeuds
racines sont différents. C'est dire (t1 Yt2)
? (type(t1(E)) =6 type(t2(E))). On
dira alors que t1 et t2 sont en conflit, et on note
t1 y t2, quand ils admettent un consensus mais ne sont pas
fusionnables dans leur entièreté. Intuitivement, deux documents
t1 et t2 (non réduits à des bourgeons) ne sont
pas entièrement fusionnables, s'il existe une adresse w ?
Dom(t1) n Dom(t2) telle que le type du
noeud n1 situé à l'adresse w dans t1
est différent de celui du noeud n2 situé à la
même adresse dans t2. Plus formellement, t1 y
t2 s'il existe une adresse w ? Dom(t1) n
Dom(t2) telle que t1(w) = t2(w) et
au moins un des noeuds n1i,1 = i = n
situés aux adresses w.i dans t1 a un type
différent de celui du noeud n2i (lorsqu'il existe)
situé à la même adresse dans t2. C'est à
dire
(t1 y t2 avec t1(E) =6
XW, t2(E) =6 XW) ?
(non (t1 Yt2)) et (?w.i ?
Dom(t1) nDom(t2), t1(w) =
t2(w), type(t1(w.i)) =6
type(t2(w.i)))
Si t1 et t2 sont en conflit, l'arbre consensuel
tc : N* ? A issu de t1
et t2 est tel que :
Le domaine de tc est l'union des
domaines des deux arbres auquel on soustrait les éléments
appartenant aux domaines des sous-arbres issus des noeuds en conflit (on
élague au niveau des noeuds en conflit).
Quand un noeud n1 de t1 est en conflit
avec un noeud n2 de t2, ils apparaissent dans l'arbre
consensuel tc sous la forme d'un (unique) bourgeon.
Ainsi, ?w ? Dom(tc) on a :
|
tc(w) =
|
{
|
t1(w) si t1(w) = t2(w)
t1(w) si t2(w) = XW
t2(w) si t1(w) = XW
t1(w) si w ?/ Dom(t2) et
?u, v ? N* tel que w = u.v, t2(u) =
XW
t2(w) si w ?/ Dom(t1) et
?u, v ? N* tel que w = u.v, t1(u) =
XW
XW si t1(w) =6 XW et
t2(w) =6 XW et t1(w) =6
t2(w)
|
La figure 3.1 (page 36) regroupe les étapes de la
fusion consensuelle de deux documents t1 et t2 en un document
tf. La fusion se fait par niveau hiérarchique du haut vers le
bas. Chaque étape illustre certaines des alternatives contenues dans la
formule ci-dessus ; les noeuds impliqués sont mis en évidence via
des couleurs. Au niveau 3 par exemple, nous illustrons le traitement de deux
noeuds en conflit (noeuds étiquetés C - en rouge -).
4. Rappel : on note XW l'étiquette
d'un bourgeon de type X ; et un noeud clos étiqueté
A est de type A.

3.2. Calcul du consensus 36
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
FIGURE 3.1 - Fusion consensuelle progressive de deux
documents.
3.2.2. Construction de l'automate du consensus
La prise en compte des documents avec des bourgeons
nécessite le réaménagement de certains modèles
utilisés. Par exemple, dans ce qui suit, nous manipulerons les
automates d'arbre avec états de sortie en lieu et place des
automates d'arbre introduits dans la définition 12. Intuitivement, un
état q d'un automate est qualifié d'état de
sortie s'il ne lui est associé qu'une unique transition q
? (Xe,[]) permettant de reconnaître un arbre
réduit à un bourgeon de type X ? L. Ainsi, un
automate d'arbre à états de sortie J1
est un quintuplet (L,Q,R,q0,exit) où L,Q,R,q0
désignent les mêmes objets que ceux introduits dans la
définition 12, et exit est un prédicat défini sur
les états (exit: Q ? Bool). Tout état q
de Q pour lequel exit q est Vrai est un
état de sortie.
Nous définissons un automate d'arbre à
états de sortie par le type Haskell suivant:
data Automata p q = Auto {exit::q -> Bool, next::q -> [(p,
[q])]}
dans lequel, le type générique (variable de
type) p est le type des productions qui étiquettent les transitions et q
est celui des états de l'automate. L'automate est défini ici au
moyen de deux sélecteurs : exit qui est un prédicat sur les
états ayant pour type Haskell
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
3.2. Calcul du consensus 37
exit :: Automata p q -> q -> Bool, permet de
déterminer si un état q d'un automate donné est un
état de sortie. La fonction next qui implémente la fonction de
transition, a pour type Haskell next :: Automata p q -> q -> [(p, [q])],
et retourne la liste des états accessibles à partir d'un
état q donné d'un automate.
Comme dans [BTT08, TT09, BTT07], nous représentons une
vue par un ensemble de prédicats sur les symboles de la grammaire. La
fonction gram2autoview [BTT08, TT09, BTT07] (dont le code est donné dans
l'annexe B) permet de construire un automate capable de reconnaître les
documents globaux qui sont des expansions d'une réplique partielle
suivant une vue donnée. Un état de l'automate
généré par gram2autoview, est de la forme (Tag symb, ts)
et permet de reconnaître (ou d'engendrer) l'ensemble des arbres de
dérivation ayant symb pour racine et ts pour projection suivant une vue
donnée. On dira qu'un tel état est de type symb. Le type Tag,
permet de distinguer les états de sortie (lorsque la donnée est
construite à l'aide de Open) des autres états (lorsqu'elle est
construite au moyen de Close). Ainsi, le type Tag est défini comme suit
:
data Tag x = Close x | Open x deriving (Eq,Show)
Dans la section 3.2.1 ci-dessus, nous avons dit que,
"lorsque les types des noeuds racines de deux arbres sont
différents, on dit qu'ils n'admettent pas de consensus". On peut,
à partir de cet extrait et de la définition des automates,
déduire que, "deux automates admettent un consensus (sont
consensuels) si et seulement si leurs états initiaux sont du même
type". En effet, si leurs états initiaux
q10 de la forme (Tag
symb1,ts1) et q20 de la forme
(Tag symb2,ts2) sont de même type, alors symb1
== symb2, et ces états permettent de générer des
arbres ayant comme racine un noeud de type "symb1". On a donc la
fonction haveConsensus suivante, qui permet de déterminer si deux
automates admettent un consensus à partir de deux états initiaux
donnés; cette fonction utilise la fonction untag permettant de
débarrasser un symbole de son "Tag" :
1 haveConsensus :: Eq symb => (Tag symb, t) -> (Tag symb,
t1) -> Bool
2 haveConsensus state1@(tagsymb1, ts1) state2@(tagsymb2, ts2)=
3 (untag tagsymb1) == (untag tagsymb2)
4
5 untag :: Tag x -> x
6 untag (Open x) = x
7 untag (Close x) =x
Dans cette même section (sect. 3.2.1), nous avons aussi
dit que, "quand deux noeuds sont en conflit, ils apparaissent dans l'arbre
consensuel sous la forme d'un (unique) bourgeon". Du point de vue de la
synchronisation d'automates, la notion de "noeuds en conflit" se traduit par la
notion "d'états en conflit" (qui est précisée ci-dessous)
et l'extrait précédent se traduit par "quand deux
états sont en conflit, ils apparaissent dans l'automate du consensus
sous la forme d'un (unique) état de sortie". Ainsi, si on
considère deux familles de transitions
1 1 1 1 1 nl n1 2 2 2 2 272
n2q
[(a1,[q1,···
qm1]),...,(an1,[e
,···,qm2])] et
q--
[(a[q···,qp1]),...,(an2,[ql
,···,qp2])]
associées aux états
q10 et q20 de
deux automates d'arbre auto1 et auto2, on dira que les
états q10 et
q20 (qui ne sont pas des états de sortie)
sont en conflit (et on note q10 y q20) s'il n'existe pas de
transition partant de chacun d'eux et portant la même étiquette,
c'est à dire qu'il n'existe aucune étiquette de transition
a3 telle que
(a3,[q31,...,q3n3])
appartient à
[(a11,[q11,···
,q1
m1]),...,(a1 n1,[qn1 1
,···
,qn1m2])] et
(a3,[q41,...,q4n4])
appartient à la famille [(a2
1,[q2
1,···,q2
p1]),...,(a2 n2,[qn2 1
,···
,qn2p2])].
Mémoire - ZEKENG NDADJI
Milliam Maxime LIFA
|
3.2. Calcul du consensus
|
|
38
|
|
1
|
autoconsens::(Eq a1, Eq a) =>(a -> a1) -> Automata a1
(Tag a, [t1])
|
|
|
|
2
|
-> Automata a1 (Tag a, [t]) -> Automata a1 ((Tag a, [t1]),
(Tag a,
|
[t]))
|
|
|
3
|
autoconsens symb2prod auto1 auto2 = Auto exit_ next_ where
|
|
|
|
4
|
exit_ (state1,state2) = case haveConsensus state1 state2 of
|
|
|
|
5
|
True -> (exit auto1 state1) && (exit auto2 state2)
|
|
|
|
6
|
False -> True
|
|
|
|
7
|
|
|
|
|
8
|
next_ (state1,state2) = case haveConsensus state1 state2 of
|
|
|
|
9
|
False -> []
|
|
|
|
10
|
True -> case (exit1,exit2) of
|
|
|
|
11
|
(False,False) -> case (isInConflicts state1 state2) of
|
|
|
|
12
|
True -> [(symb2prod(typeState state1),[])]
|
|
|
|
13
|
False -> [(a1,zip states1 states2) |
|
|
|
|
14
|
(a1,states1) <- next auto1 state1,
|
|
|
|
15
|
(a2,states2) <- next auto2 state2,
|
|
|
|
16
|
a1==a2, (length states1)==(length states2)]
|
|
|
|
17
|
|
|
|
|
18
|
(False,True) -> [(a, zip states1 (forwardSleepState
states1))
|
|
|
|
|
19
|
(a,states1) <- next auto1 state1]
|
|
|
|
20
|
|
|
|
|
21
|
(True,False) -> [(a, zip (forwardSleepState states2)
states2)
|
|
|
|
|
22
|
(a,states2) <- next auto2 state2]
|
|
|
|
23
|
|
|
|
|
24
|
(True,True) -> [(a1,[]) | (a1,[]) <- next auto1 state1,
|
|
|
|
25
|
(a2,[]) <- next auto2 state2, a1==a2]
|
|
|
|
26
|
|
|
|
|
27
|
where
|
|
|
|
28
|
exit1 = exit auto1 state1
|
|
|
|
29
|
exit2 = exit auto2 state2
|
|
|
|
30
|
forwardSleepState states = map (\state -> (Open (typeState
state),
|
[]))
|
states
|
|
31
|
typeState state@(tagsymb, ts1) = (untag tagsymb)
|
|
|
|
32
|
isInConflicts state1@(tagsymb1, ts1) state2@(tagsymb2, ts2) =
|
|
|
|
33
|
null [(a1,zip states1 states2) |
|
|
|
|
34
|
(a1,states1) <- next auto1 state1,
|
|
|
|
35
|
(a2,states2) <- next auto2 state2,
|
|
|
|
36
|
a1==a2, (length states1)==(length states2)]
|
|
|
algorithme 1 : algorithme de construction de
l'automate du consensus
L'automate synchronisé
consensuelJ1(sc) = ?Ù i
J1(i) dont le processus de construction (pour deux
automates) est décrit par l'algorithme 1 (écrit en Haskell [Has])
ci-dessus, est un automate à états de sortie. Il est obtenu en
considérant lors du calcul du produit synchrone des automates
J1(i) que:
1. un état q = (q1,---
,qk) est un état de sortie si :
a) les états composites qi
n'admettent pas de consensus (algorithme 1 lignes 4 et 6) ou
b) tous les états composites qi sont
des états de sortie (algorithme 1 ligne 5).
2. quand un automate J1(j) quelconque a
atteint un état de sortie5 (algorithme 1 lignes 18, 21 et
24), il ne contribue plus au comportement mais, ne s'oppose pas à la
5. Le noeud correspondant dans le document de la projection
inverse est un bourgeon et traduit le fait que l'auteur correspondant ne l'a
pas édité. Dans le cas où il serait partagé avec un
autre co-auteur l'ayant édité dans sa réplique, c'est
l'édition réalisée par ce dernier qui sera retenue lors de
la fusion.
3.2. Calcul du consensus 39
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
synchronisation des autres automates : on dit qu'il est
endormi. Un état endormi sera propagé convenablement
pour ne pas s'opposer à la synchronisation des autres automates
(algorithme 1 lignes 18 (second paramètre de la fonction zip) et 21);
pour cela, on se sert de la fonction forwardSleepState (algorithme 1 lignes 30
et 31) pour "fabriquer" des états endormis. En fait, forwardSleepState
prend une liste d'états en entrée et produit, en sortie, une
liste d'états de sortie dont les types sont ceux des états pris
en arguments.
Ainsi, pour k automates
.91(i) =
(Ó,Qi,Ri,q(i)
0 ,exiti) 1 < i < k, associés
à k répliques par-
tielles, l'automate synchronisé consensuel
.91(sc) =
®Ùi
.91(i) est construit comme suit (algorithme 1) :
1. Ses états sont des vecteurs d'états : Q
= Q1 x ··· x Qk ;
2. Son état initial est le vecteur formé des
états initiaux des différents automates :
(1) k
q0 = (q0
,···,q0 );
3. Ses transitions pour un état q =
(q(1),···
,q(k)) quelconque, sont données par :
a) Si les états composites de q sont non
consensuels, alors q n'admet aucune transition (algorithme 1 lignes 8
et 9) ;
b) Si les états composites de q admettent un
consensus, alors trois cas de figure se présentent :
i. Si aucun de ces états n'est de sortie et
qu'ils sont en conflit, alors q admet une
transition vers un état de sortie dont le type est le même que
celui de ces états composites (algorithme 1 lignes 11 et 12) ;
qu'ils ne sont pas en conflit, alors q
génère des arbres dont le noeud racine est
étiqueté par une production du type de ces états, et dont
les fils sont générés par des états qui sont des
couples formés à partir d'un état appartenant aux
états suivants de chacun de ces états composites (algorithme 1
lignes 13 à 16) ;
ii. Si certains de ces états sont des états de
sortie (ils sont endormis), alors q génère des arbres
dont le noeud racine est étiqueté par une production du type de
ces états et appartenant aux suivants des états qui ne sont pas
de sortie, et dont les fils sont générés par des
états qui sont de la forme ((Tag symb, ts), (Open symb, [])),
formés à partir d'états (de la forme (Tag symb, ts))
appartenant aux états suivants de l'état non de sortie
(algorithme 1 lignes 18 à 22) ;
iii. Si ces états sont tous des états de sortie
(q est un état de sortie), alors q admet une
transition vers un état de sortie de type, le type de ces états
(algorithme 1 lignes 24 et 25).
®Ùi est
donc une relaxation de la synchronisation d'automates que nous avons intro-
duite dans la définition 14 et 2'
(.91(sc),
(qtmaj)) = consensus(2'
(.91(i), qtmaj)). Il ne
reste plus
Vi Vi
qu'à appliquer notre générateur à
.91(sc) comme dans [BTT08] pour obtenir les
documents les plus simples qu'il accepte, c'est à dire ceux du
consensus.
3.2.3. Illustration de l'algorithme de la fusion
consensuelle
Nous illustrons l'algorithme de fusion consensuelle avec la
grammaire Gexpl de l'exemple 8. Nous associons des automates d'arbre
.91(1) et .91(2) respectivement aux
répliques par-
tielles mises à jour tma j
v1 et tma j
v2 (figure 3.2.c et 3.2.e), puis nous construisons
l'automate du
3.2. Calcul du consensus 40
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
consensus 91(sc) = 91(1)
0 91(2) par application de la démarche
décrite dans la section 3.2.2 et enfin nous présentons les
documents les plus simples du consensus (figure 3.3 page 43).

FIGURE 3.2 - Exemple de workflow d'une édition avec
conflit et consensus correspondant.
Les schémas de transition pour la vue
{A,B}
Une liste d'arbres (forêt) est représentée
par la concaténation de leurs linéarisations. Nous utilisons la
parenthèse ouvrante '(' et fermante ')' pour représenter les
symboles de Dyck associés au symbole visible A et le crochet
ouvrant '[' et fermant ']' pour représenter ceux associés au
symbole visible B. Puisque les arbres manipulés peuvent
contenir des bourgeons, ils est nécessaire de pouvoir linéariser
ces derniers. Nous associons donc les symboles '(w' et
')w' (resp. '[w' et ']w') au bourgeon
Aw (resp. Bw) de type A (resp.
B). Chaque transition des automates associés aux
répliques partielles suivant la vue {A,B} est conforme
à l'un des schémas de règles suivants :
(A,w1) -+
(P1,[(C,u),(B,v)]) si w1
= u[v]
(A,w2) -+ (P2,[]) si w2 =
E
(A,w3) -+ (Aw,[]) si
w3 = (w )w
(B,w4) -+
(P3,[(C,u),(A,v)]) si w4
= u(v)
(B,w5) -+
(P4,[(B,u),(B,v)]) si w5
= [u][v]
(B,w6) -+ (Bw,[]) si
w6 = [w]w
(C,w7) -+
(P5,[(A,u),(C,v)]) si w7
= (u)v
(C,w8) -+
(P6,[(C,u),(C,v)]) si w8
= uv =6 E
(C,w9) -+ (Cw,[]) si
w9 = E
Ces schémas de règles [BTT08] sont obtenus
à partir des productions de la grammaire. Les états
(A,w3) avec w3 = (w )w,
(B,w6) avec w6 = [w]w et (C,w9)
avec w9 = E sont des états de sortie [BTT08]. La règle
(C,w9) -+ (Cw,[]) liée à la
production P7 stipule que l'AST
3.2. Calcul du consensus 41
généré à partir de l'état
(C,w9) est réduit à un bourgeon de type C
(C est le symbole situé en partie gauche de
P7).
Remarque 15 Nous ne représentons pas
tout l'ensemble des schémas de règles dans cet exemple; seul le
sous-ensemble utile pour la réconciliation des documents clos est
représenté car les documents à réconcilier ici sont
tous clos. L'ensemble des schémas de règles est totalement
représenté dans l'annexe A.
Construction de l'automate
A(1) associé à
tv1
Ayant associé les symboles de Dyck '(' et ')' (resp. '['
et ']') au symbole grammatical A (resp. B), la
linéarisation de la réplique partielle tmaj
.
v1 (fig. 3.2.c) donne (([[()()][()]])[()])
Comme A est l'axiome de la grammaire et qu'il est
visible, l'état initial de l'automate A(1) est
q10 = (A,([[()()][()]])[()]). En ne
considérant que les états accessibles à partir de
q10 et en appliquant les schémas de
règles présentés précédemment, nous obtenons
l'automate d'arbre suivant pour la réplique tma
j
v1 (fig. 3.2.c) :
|
q10
q11
q11
q12
q13
q14
q15
q16
q17
q18
q18
|
-+
-+
-+ -+ -+ -+ -+ -+ -+ -+ -+
|
(P1,[q11,q12])
(P5,[q13,q14])
(P6,[q1
4,q11]) |
(P3,[q14,q15])
(P1,[q14,q16])
(Cw,[])
(P2,[])
(P4,[q17,q12])
(P3,[q18,q15])
(P5,[q15,q14])
(P6,[q18,q14])
|
|
(P6,[q11,q14])
(P6,[q14,q18])
|
avec
avec
avec
avec
avec
avec
|
q11 = (C,([[()()][()]]))
et q12 =
(B,())
q13 = (A,[[()()][()]]) et
q14 =
(C,e)
q15 = (A,e)
q16 = (B,[()()][()])
q17 = (B,()())
q1 8= (C,())
|
L'état q14 =
(C,e) est le seul état de sortie de l'automate
A(1). Il est aisé de vérifier que le document
de la figure 3.2.f issu de la projection inverse de
tv1maj appartient au langage
accepté par l'automate A(1).
Construction de l'automate
A(2) associé à
tv2
En associant au symbole grammatical C (resp.
A) les symboles de Dyck '[' et ']' (resp. '(' et ')'), en associant
aussi au bourgeon Cw (resp. Aw) les
symboles de Dyck '[w' et ']w' (resp. '(w' et
')w'), les schémas des transitions des automates
associés aux répliques partielles suivant la vue {A,Cl
sont les suivants :
(A,w1) -+
(P1,[(C,u),(B,v)]) si w1
= [u]v
|
(A,w2) -+ (P2,[])
|
si w2 = e
|
(A,w3) -+ (Aw,[]) si
w3 = (w)w
(B,w4) -+
(P3,[(C,u),(A,v)]) si w4
= [u](v)
(B,w5) -+
(P4,[(B,u),(B,v)]) si w5
= uv =6 e
(B,w6) -+ (Bw,[]) si
w6 = e
(C,w7) -+
(P5,[(A,u),(C,v)]) si w7
= (u)[v]
(C,w8) -+
(P6,[(C,u),(C,v)]) si w8
= [u][v]
(C,w9) -+ (P7,[]) si w9 =
e
(C,w10) -+(Cw,[]) si
w10 = [w]w
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
3.2. Calcul du consensus 42
Le mot de Dyck ([([][]()[]())[]][[][]]()) est la
linéarisation de la réplique partielle
tma j
v2
(fig. 3.2.e). L'état q20
= hA,[([][]()[]())[]][[][]]()i est donc l'état initial de
l'automate 91(2) associé à cette
réplique. Ses transitions sont :
avec q21 =
hC,([][]()[]())[]i et q22 =
hB,[[][]]()i
avec q23 = hA,[][]()[]()i
et q24 = hC,åi avec
q25 = hC,[][]i et
q26 = hA,åi avec
q27 = hB,[]()[]()i
avec q28 =
hB,åi, q29 = hB,[]i,
q210 = hB,()[]()i,
q211 = hB,[]()i,
q212 =
hB,[]()[]i et q2 13 = hB,()i
q20
|
q21
q22
q23
q24
q25
q26
q27
q28
q29
|
-?
-? -? -? -? -? -? -?
-?
-?
|
(P1,[q2
1,q22])
(P5,[q23,q24])
(P3,[q25,q26])
(P1,[q24,q27])
(P7,[])
(P6,[q24,q24])
(P2,[])
(P4,[q28,q27])
|
(P4,[q29,q210])
|
(P4,[q2 11,q211]) |
(P4,[q212,q213])
|
(P4,[q27,q28])
(Bù,[])
(P4,[q2
8,q29]) |
(P4,[q29,q28])
|
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
q210
|
q211
q212
q213
q214
|
-?
-?
-?
-?
-?
|
(P4,[q28,q210])
(P4,[q214,q213])
(P3,[q2
4,q26])
(P4,[q28,q212])
(P4,[q2 11,q29])
(P4,[q28,q213])
(P4,[q2 8,q214])
(P4,[q214,q28])
|
|
(P4,[q213,q211])
|
(P4,[q210,q28])
| (P4,[q29,q2 14])
|
(P4,[q212,q28])
| (P4,[q2 13,q28])
| (P4,[q2 13,q29])
|
|
|
|
|
avec
|
q214 = hB,()[]i
|
L'état q28 est le seul
état de sortie de l'automate 91(2).
Construction de l'automate du consensus
91(sc)
Par application du produit synchrone de plusieurs automates
d'arbres décrit dans la section 3.2.2 aux automates
91(1) et 91(2), l'automate du consensus
91(sc) = 91(1) ?Ù
91(2) a pour état initial q0 =
(q10,q20).
91(1) possède une transition de
q10 vers
[q11,q12]
étiquetée P1. De même, 91(2)
possède une transition de q20 vers
[q21,q22]
étiquetée P1. On a donc dans
91(sc) une transition étiquetée
P1 permettant d'accéder aux états [q1 =
(q11,q21),q2
= (q12,q22)]
à partir de l'état initial q0 =
(q10,q20).
Suivant ce principe, on construit l'automate consensuel suivant :
|
q0
q1
q2
q3
q4
q5
q6
|
-? -? -? -? -? -?
-?
|
(P1,[q1,q2])
(P5,[q3,q4]) (P3,[q5,q6])
(P1,[q4,q7]) (P7,[])
(P6,[q8,q8])
(P2,[])
|
q0 =
(q10,q20)
avec q1 = (q1
1,q21) et q2 =
(q1 2,q22)
avec q3 =
(q13,q23) et
q4 =
(q14,q24)
avec q5 =
(q14,q25) et
q6 =
(q15,q26)
avec q7 =
(q16,q27)
avec q8 = (qs1,q24) et
qs1
hOpen C,[]i
|
=
|
3.3. Synthèse 43
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
|
q7 -+ (P4,[q9,q10]) |
(P4,[q11,q12]) |
(P4,[q13,q14]) |
(P4,[q15,q16]) |
(P4,[q17,q18])
|
avec q9 =
(q17,q28),
q10 =
(q12,q27),
q11 =
(q17,q29),
q12 =
(q12,q210),
q13 =
(q17,q211),
q14 =
(q12,q211),
q15 =
(q17,q212),
q16 =
(q12,q213),
q17 =
(q17,q27) et
q18 =
(q12,q28)
|
q8 -+ (P7,[])
q9 -+ (P3,[q19,q20]) avec
q19 = (q18,qs1) et q20 =
(q15,qs2),
qs2 = (Open A,[])
q13 -+ (P3,[q21,q6]) avec
q21 = (q1 8,q2
4)
q14 -+ (P3,[q4,q6])
q18 -+ (P3,[q22,q20]) avec
q22 = (q14,qs1)
q19 -+
(P5,[q20,q22]) |
(P6,[q19,q22]) |
(P6,[q22,q19])
q20 -+ (P2,[])
q10 -+
(Ba),[]), q11 -+
(Ba),[]), q12 -+
(Ba),[]), q15 -+
(Ba),[]), q16 -+
(Ba),[]),
q17 -+ (Ba),[]), q21
-+ (Ca),[]), q22 -+
(Ca),[])
Les états
{q10,q11,q12,q15,q16,q17,q21,q22}
sont les états de sortie de l'automate .(sc). Ce sont
des états dont les états composites sont soit en conflit (par
exemple q10 =
(q12,q7) et
q12 y q27), soit
sont tous des états de sortie (par exemple q22 =
(q14,qs1)).
L'utilisation de la fonction de génération des
AST (avec bourgeons) les plus simples d'un langage d'arbre à partir de
son automate [BTT08, BTT07, TT09] sur l'automate .(sc),
produit quatre AST dont les arbres de dérivations (les
consensus) sont schématisés sur la figure 3.3.

FIGURE 3.3 - Arbres consensuels générés
à partir de l'automate .(sc).
3.3. Synthèse
Nous avons présenté dans ce chapitre une
approche de réconciliation dite par consensus, des
répliques partielles d'un document soumis à un processus
d'édition coopérative asynchrone. L'approche proposée
s'appuie sur une relaxation du produit synchrone d'auto-mates d'arbre pour
construire un automate pouvant générer les documents du
consensus. Les algorithmes présentés ici ont été
implémentés en haskell [Has, GHC, HPHF99] et
expérimentés sur bien des exemples (dont celui
présenté à la section 3.2.3 et celui
présenté
3.3. Synthèse 44
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
dans l'annexe6 A) avec des résultats
probants. Nous nous investissons actuellement à la production des
preuves mathématiques (formelles) des différents algorithmes
proposés. Dans le chapitre suivant, nous présentons un prototype
d'éditeur, qui permettrait d'expé-rimenter, via une interface
graphique, les algorithmes proposés dans un environnement
véritablement distribué.
6. Nous présentons dans cette annexe un exemple
d'application de notre algorithme à un workflow d'édi-tion
coopérative sans conflit.
45
Chapitre4
Un prototype d'éditeur coopératif
désynchronisé (TinyCE v2)
Sommaire
4.1 - Architecture et fonctionnement de TinyCE v2 46
4.2 - Le matériel de construction de TinyCE v2 52
4.3 - Mise en oeuvre d'un workflow d'édition sous
TinyCE v2 53
4.4 - Synthèse 54
Les travaux que nous menons, visent essentiellement
l'automatisation des procédures d'entreprises et des travaux
coopératifs reposant sur l'édition coopérative des
documents structurés. Ainsi, notre dénouement ne saurait
être purement théorique; il doit aussi être technologique et
donc pratique. À cet effet, nous avons entrepris de construire un outil
de conception et de mise en oeuvre des CSCW basés sur l'édition
coopérative des documents structurés. Nous poursuivons ainsi un
objectif énoncé dans [TT09] et démarré avec le
prototype TinyCE1 (prononcer"tennesse") [TT10];
d'ailleurs l'outil que nous mettons en oeuvre se nomme TinyCE
v22 (que nous prononçons"taï-ni-ci-i version 2"
3) en hommage au prototype précédent. Un tel
outil se devant d'être fiable, robuste, efficace, extensible et
sécurisé, il est primordial de le concevoir minutieusement tout
en reposant sur des outils (langages, bibliothèques, API - Application
Programming Interface -, frameworks...) existants et présentant les
caractéristiques recherchées. Nous présentons donc dans ce
chapitre, les idées maîtresses pour la construction de TinyCE
v2.
TinyCE v2 est un éditeur permettant l'édition
graphique et coopérative de la structure abstraite (arbre de
dérivation) des documents structurés. Il s'utilise en
réseau suivant un modèle client-serveur. Son interface
utilisateur offre à l'usager des facilités pour l'édition
de ses vues suivant les grammaires qui lui sont associées,
l'édition et la validation d'une réplique partielle. Bien plus,
cette interface lui offre aussi des fonctionnalités lui permettant
d'expérimenter les concepts de projection, d'expansion et de fusion
consensuelle étudiés dans ce mémoire.
1. TinyCE pour "a Tiny Cooperative Editor" ou "a Tiny
Collaborative Editor" [TT09] (prononcer "tennesse").
2. TinyCE v2 signifie "a Tiny Cooperative Editor
version 2" (prononcer "taï-ni-ci-i version 2").
3. Nous avons choisi une nouvelle prononciation parce que
nous ne parvenions pas à nous adapter à l'ancienne; la nouvelle
prononciation est celle qui nous revenait à chaque fois qu'il fallait
évoquer TinyCE.

4.1. Architecture et fonctionnement de TinyCE v2 46
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
FIGURE 4.1 - Le logo de TinyCE v2.
Nous allons tout d'abord présenter l'architecture
générale et le fonctionnement de Ti-nyCE v2 (sect. 4.1); puis
nous présenterons les outils utilisés pour sa confection (sect.
4.2) et enfin nous déroulerons, à base de notre outil, un des
exemples de workflows d'édition manipulés dans ce mémoire
(sect. 4.3).
4.1. Architecture et fonctionnement de TinyCE v2
L'architecture de TinyCE v2 implémente, en langage
Java, le design pattern MVC (Model View Controller ou Modèle Vue
Contrôleur en français) qui est une référence
en matière de patron de conception (architectural). Dans cette
architecture, les vues affichent des résultats et
récupèrent des entrées (données et commandes)
qu'elles transmettent aux modèles à travers les contrôleurs
(qui les valident); les modèles réalisent les traitements
(parsing, stockage, communication...) puis notifient les vues pour
rafraîchissement. Sous TinyCE v2, le modèle, la vue et le
contrôleur sont organisés comme suit:
-- Le modèle est la pièce maîtresse
réalisant le plus gros du travail. Il repose sur trois
principaux éléments : des parseurs, un
communicateur et un "interpréteur Haskell" né
de la fertilisation croisée du langage purement orienté objet
Java et du langage purement fonctionnel Haskell (sect. 4.1.1);
· Les parseurs (Parsers) servent à
encoder/décoder les données pour qu'elles soient soit
sauvegardées à la XML, soit communiquées à une
autre entité (distante ou non) ou encore interprétées;
· Le communicateur (RemoteCommunicator) sert
d'interface de communication entre des entités distantes. C'est
grâce à cette entité que le modèle d'un client
quelconque pourra communiquer avec le modèle d'un serveur par
exemple;
· L'interpréteur Haskell (HaskellRunner)
permet d'exécuter des commandes Haskell. En effet, nous avons
réalisé une autre approche de la fertilisation croisée des
langages Java et Haskell [TT10]. Ainsi, TinyCE v2 est doté d'un moteur
(engine) écrit en Haskell réunissant toutes les
fonctions nécessaires pour la représentation des documents et la
fusion consensuelle de ceux-ci.
-- La vue donne une représentation graphique des
documents et des commandes dans le but de permettre une interaction conviviale
entre TinyCE v2 et ses utilisateurs. Elle dispose donc de parseurs pouvant
réaliser la correspondance entre les données reçues et les
données à afficher. Sous TinyCE v2, la vue présente les
mêmes fonctionnalités qu'on soit en mode client ou en mode serveur
(il n'existe qu'une seule vue). En effet, dans une édition
centralisée, le site serveur réalise les opérations de
synchronisation et de (re)distribution en plus des actions
réalisées par les clients (éditions...); mais dans une
version pair à pair, les opérations de synchronisation
4.1. Architecture et fonctionnement de TinyCE v2 47
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
et de (re)distribution peuvent être
réalisées sur n'importe quel site. Le mode client-serveur est
donc un cas particulier du mode pair à pair. TinyCE v2 est conçu
pour pouvoir supporter (dans le futur) des éditions en pair à
pair; ce qui explique nos choix. La vue est entièrement codée en
langage Java et se sert de quelques bibliothèques que nous
présenterons dans la suite de ce chapitre (sect. 4.2);
-- Le contrôleur quant à lui, est chargé
d'établir le pont entre la vue et le modèle. La figure 4.2 (page
47) résume l'architecture de TinyCE v2 ci-dessus
présentée.

FIGURE 4.2 - L'architecture de TinyCE v2.
4.1.1. Fertilisation croisée Haskell-Java
Tout comme TinyCE, TinyCE v2 est programmé en utilisant
deux langages de programmation : Haskell (pour le moteur) et Java (pour le
reste). L'utilisation de ce couple de langages permet de tirer le meilleur de
chacun d'entre eux. Nous exploitons Java pour la facilité qu'il offre
pour la mise en oeuvre des interfaces graphiques ainsi que pour tirer profit
des avantages offerts par les langages à objets (robustesse,
modularité...). Du langage Haskell nous tirons profit de son grand
pouvoir d'abstraction, de son mode d'évaluation (paresseuse), de la
modularité... Afin de faire coopérer en parfaite synergie ce
couple de langages, nous exploitons la possibilité d'appeler un code
exécutable à l'intérieur de programmes Java (la même
chose est possible à partir du langage Haskell). En effet, nous
démarrons un interpréteur Haskell (GHCi - the Glasgow Haskell
Compiler interactive -) à partir de Java, puis nous lui passons au
fur et à mesure les commandes à exécuter et nous
récupérons en sortie les éventuels résultats et/ou
erreurs. Nous présentons sommairement ci-dessous cette
démarche.
Implémentation du moteur Haskell
L'implémentation GHC [GHC] de Haskell n'est pas qu'un
compilateur. On peut donc y créer des fonctions (programmes) et les
faire exécuter (interpréter) en mode interactif
4.1. Architecture et fonctionnement de TinyCE v2 48
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
grâce à son module GHCi. Un programme Haskell
sous GHC est un fichier, bien conçu, d'extension.hs semblable
à celui ci-dessous enregistré par exemple dans un fichier
dénommé helloGHC.hs :
1 module HelloGHC where
2 sayHello name = "Bonjour "++name
Pour exécuter ce programme en mode interactif, il
suffit de charger le module avec la commande :load ou son raccourci :l puis
d'appeler la fonction sayHello de la manière suivante (où xxx est
l'argument de l'appel) :
1 :load "helloGHC.hs"
2 sayHello xxx
Exécution d'un code Haskell dans Java
Java permet de lancer un code exécutable (quelconque)
à partir d'un code java, et donc, de lancer l'interpréteur GHCi
de GHC. Pour exécuter un programme en Java on peut se servir de la
classe ILanguageRunner définie comme suit:
1 import
java.io.*;
2
3 public class ILanguageRunner{
4 protected Process process = null;
5 protected String language;
6 protected String command;
7 public ILanguageRunner(String language, String command){
8 this.language = language;
9 this.command = command;
10 }
11 public void startExecProcess() throws IOException{
12 ProcessBuilder processBuilder = new
ProcessBuilder(command);
13 process = processBuilder.start();
14 }
15 public void killExecProcess(){
16 if(process != null)
17 process.destroy();
18 }
19 public void setExecCode(String code) throws IOException
{
20 OutputStream stdin = process.getOutputStream();
21 OutputStreamWriter stdinWriter = new
OutputStreamWriter(stdin);
22 try{
23 stdinWriter.write(code);
24 }finally{
25 try{stdinWriter.close();}catch(IOException e){}
26 try{stdin.close();}catch(IOException e){}
27 }
28 }
29 public void getExecErrors() throws IOException{
30 InputStream stdout = process.getErrorStream();
31 InputStreamReader stdoutReader = new
InputStreamReader(stdout);
32 BufferedReader stdoutBuffer = new BufferedReader
(stdoutReader);
33 StringBuffer errorBuffer = null;
34 try{
35 String line = null;
36 while((line = stdoutBuffer.readLine()) != null){
4.1. Architecture et fonctionnement de TinyCE v2 49
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
37 if (errorBuffer == null)
38 errorBuffer = new StringBuffer();
39 errorBuffer.append(line);
40 }
41 }finally{
42 try{stdoutBuffer.close();}catch(IOException e){}
43 try{stdoutReader.close();}catch(IOException e){}
44 try{stdout.close();}catch(IOException e){}
45 }
46 if(errorBuffer != null)
47 throw new IOException(errorBuffer.toString());
48 }
49 public String getExecResult() throws IOException{
50 InputStream stdout = process.getInputStream();
51 InputStreamReader stdoutReader = new
InputStreamReader(stdout);
52 BufferedReader stdoutBuffer = new
BufferedReader(stdoutReader);
53 StringBuffer resultBuffer = null;
54 try{
55 String line = null;
56 while((line = stdoutBuffer.readLine()) != null){
57 if (resultBuffer == null)
58 resultBuffer = new StringBuffer();
59 resultBuffer.append(line);
60 }
61 }finally{
62 try{stdoutBuffer.close();}catch(IOException e){}
63 try{stdoutReader.close();}catch(IOException e){}
64 try{stdout.close();}catch(IOException e){}
65 }
66 if(resultBuffer != null)
67 return resultBuffer.toString();
68 return null;
69 }
70 public String getCommand(){
71 return command;
72 }
73 public void setCommand(String command){
74 this.command = command;
75 }
76 public String getLanguage(){
77 return language;
78 }
79 public void setLanguage(String language){
80 this.language = language;
81 }
82 public String executeCode(String code) throws
IOException{
83 startExecProcess();
84 setExecCode(code);
85 getExecErrors();
86 String result = getExecResult();
87 killExecProcess();
88 return result;
89 }
90 }
Dans cette classe,
4.1. Architecture et fonctionnement de TinyCE v2 50
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
-- les attributs process, language et command (lignes 2, 3 et
4) représentent respectivement le processus Java permettant de lancer
l'exécutable, le langage courant4 et le chemin d'accès
à l'exécutable;
-- la méthode startExecProcess (lignes 9 à 12)
construit le processus Java à partir de la commande courante. La
méthode killExecProcess (lignes 13 à 16) détruit le
processus lorsque celui-ci existe;
-- la méthode setExecCode (lignes 17 à 26)
permet d'écrire sur l'entrée standard de l'interpréteur le
code à exécuter (cela correspond au passage des arguments au
programme exécuté);
-- les méthodes getExecErrors (lignes 27 à 46)
et getExecResult (lignes 47 à 67) permettent respectivement de
récupérer les éventuelles erreurs survenues lors de
l'exécution du code définit par setExecCode (les erreurs sont
renvoyées sous forme d'exception Java) et de récupérer les
éventuels résultats de l'exécution dudit code;
-- enfin, la méthode executeCode (lignes 80 à
87) exécute un code quelconque. Elle démarre un processus,
définit le code, récupère les erreurs s'il y en a, sinon
elle récupère le résultat puis détruit le
processus.
Une utilisation de la classe ILanguageRunner ci-dessus, pour
l'exécution du code Haskell en mode interactif par GHCi peut se faire
à travers la classe HaskellRunner qui hérite de ILanguageRunner
et dont le code est donné ci-dessous :
1 import
java.io.IOException;
2
3 public final class HaskellRunner extends ILanguageRunner{
4 public HaskellRunner(){
5 super("Haskell", "ghci");
6 }
7 @Override
8 public String getExecResult() throws IOException{
9 String execResult = super.getExecResult(), tmpString;
10 if(execResult == null)
11 return null;
12 String[] tab = execResult.split("Prelude> ");
13 if(tab.length == 2)
14 tab = tab[1].split("\\*[a-zA-Z0-9_]{1,}>");
15 StringBuilder goodResult = new StringBuilder();
16 for(int i = 1; i < tab.length - 1; i++){
17 tmpString = tab[i].trim();
18 if(!tmpString.isEmpty()){
19 goodResult.append(tmpString);
20 goodResult.append("\n");
21 }
22 }
23 return goodResult.toString();
24 }
25 @Override
26 public void setCommand(String command){}
27 @Override
28 public void setLanguage(String language){}
29 }
4. Notons que ce code est taillé pour
l'exécution des interpréteurs interactifs de tous types et non
pas seulement pour l'exécution de GHCi.
4.1. Architecture et fonctionnement de TinyCE v2 51
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Dans cette classe, on a fixé le nom de la commande
à ghci (ceci implique que le chemin d'accès du répertoire
contenant le programme GHCi doit être inscrit dans la variable
d'environnement path) et celui du langage à Haskell (ces deux valeurs ne
peuvent plus être changées : les redéfinitions des
méthodes setCommand et setLanguage associées au fait que la
classe HaskellRunner ne puisse pas être dérivée5
nous le garantissent.). On a redéfini la méthode getExecResult
pour mieux formater le résultat en le débarrassant des
chaînes superflues ajoutées par GHCi.
On peut donc désormais, exécuter notre moteur
Haskell grâce au code suivant:
|
1
2
3
4
|
import
java.io.IOException;
public class HelloTinyCE {
public static void main(String[] args){
|
|
|
5
|
|
|
HaskellRunner runner = new HaskellRunner();
|
|
|
6
|
|
|
String nom = "\"Ange Frank et Chris Maxime\"";
|
|
|
7
|
|
|
String commande = ":load helloGHC.hs\nsayHello " + nom;
|
|
|
8
|
|
|
try{
|
|
|
9
|
|
|
String resultat = runner.executeCode(commande);
|
|
|
10
|
|
|
System.out.println("Le résultat de l'exécution est
: "
|
+
|
|
11
|
|
|
resultat);
|
|
|
12
|
|
|
}catch(IOException ex){
|
|
|
13
|
|
|
System.err.println("Des erreurs sont survenues lors de"
|
+
|
|
14
|
|
|
" l'exécution des commandes.");
|
|
|
15
|
|
|
}
|
|
|
16
|
|
}
|
|
|
|
17
|
}
|
|
|
|
L'exécution de ce code fournit le résultat
suivant:
1 Le résultat de l'exécution est : "Bonjour Ange
Frank et Chris Maxime"
Si on remplace le code de la ligne 7 par le code String
commande = " :load helloGHC.hs \nsayHello"; alors le résultat
obtenu est désormais le suivant:
1 Des erreurs sont survenues lors de l'exécution des
commandes.
C'est donc une version de la classe HaskellRunner qui joue le
rôle"d'interpréteur Haskell" au sein de TinyCE v2. Elle permet une
communication bidirectionnelle entre le modèle de TinyCE v2 (codé
en Java) et Haskell suivant un protocole basé sur du texte
(chaînes de caractères bien formées suivant un codage
à la XML) que nous avons mis en oeuvre. L'approche que nous employons
diffère nettement de celle présentée dans [TT10]. Les
principales différences entre ces approches sont quasiment les
mêmes qui animent les débats portant sur les langages
interprétés et les langages compilés; notre approche
étant assimilée aux langages interprétés et celle
de [TT10] étant assimilée aux langages compilés. En effet
pour que notre approche fonctionne, il faut toujours que le site sur lequel
TinyCE v2 s'exécute soit muni d'un interpréteur Haskell en plus
de la machine virtuelle Java. En plus, le code du moteur Haskell sera toujours
visible par les utilisateurs de Ti-nyCE v2 ce qui constitue un risque en
matière de sécurité. Néanmoins cette approche
présente l'avantage d'être portable (car il existe des
interpréteurs Haskell pour toutes les plateformes), d'offrir la
facilité de mise à jour du moteur Haskell et surtout la
possibilité d'exploiter toute la puissance qu'offre le langage Haskell.
De plus, sous TinyCE v2, le moteur Haskell n'est nécessaire que pour le
fonctionnement en mode serveur; c'est à dire
5. Ceci à cause de l'utilisation du modificateur
final.
4.2. Le matériel de construction de TinyCE v2 52
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
qu'il ne sert qu'à faire de la synchronisation et de la
(re)distribution. Même les parseurs ont tous été
écrits en Java. Ainsi, dans une utilisation purement centralisée
de TinyCE v2, seul le serveur aura besoin d'un interpréteur Haskell;
sachant que les routines de vérification de la conformité des
répliques partielles mises à jour vis à vis de leurs
modèles respectifs, peuvent être écrites ou
générées en Java (à partir du couple d'outils
(f)lex et yacc/bison6 ou encore grâce
à Xtext 7).
4.1.2. Interaction client-serveur
Durant les échanges entre plusieurs machines distantes
à travers TinyCE v2, les opérations de synchronisation et de
(re)distribution sont réalisées sur l'une des machines : c'est le
serveur. Les autres machines sont des postes clients et donc, ils ne servent
qu'à l'édi-tion des répliques partielles. Mais il n'y a
pas de TinyCE v2 Client et de TinyCE v2 Server; ces deux
entités sont intégrées dans TinyCE v2. N'importe quel site
peut donc être client puis serveur : cela dépend des
échanges effectués (via le communicateur). Cette faculté,
permet d'ouvrir le chemin au développement des échanges en pair
à pair.
Le communicateur est mis en oeuvre avec la technologie RMI
(Remote Method Invocation). Pour l'aspect sécurité, les
informations échangées sont cryptées, avec une clé
et un vecteur d'initialisation partagés, grâce à
l'algorithme AES (Advanced Encryption Standard) combiné au mode
d'opération CBC (Cipher Block Chaining). Les informations
reçues sont décryptées avec la même clé et le
même vecteur d'initialisation. Le mode de cryptographie est donc
symétrique, la clé et le vecteur d'initialisation étant
inscrits en dur dans le code source de TinyCE v2; ce qui constitue un risque de
sécurité (reverse engineering). Pour réduire la
taille de ce risque, TinyCE v2 crypte chaque workflow. Ainsi, chaque workflow
possède une clé et un vecteur d'initialisation partagés
par ses participants (sites) et permettant de sécuriser ce dernier; ces
outils de chiffrement sont renouvelés à chaque synchronisation.
Néanmoins cette stratégie n'est pas infaillible vu que les outils
de chiffrement des workflows sont eux mêmes cryptés avec les
outils de chiffrement généraux de TinyCE v2. Il serait donc
judicieux d'envisager d'autres moyens plus sûrs pour protéger les
informations circulant entre les utilisateurs de TinyCE v2. Le chiffrement des
clés partagées grâce à un algorithme de
cryptographie à clé publique (asymétrique) pourrait
être une bonne piste.
4.2. Le matériel de construction de TinyCE
v2
Comme nous l'avons déjà
révélé, TinyCE v2 est construit à partir de deux
langages: Java et Haskell. La version de Java qui a été
utilisée pour cette construction est Java 7 (avec le JDK -
Java Development Kit - 1.7); et la version de GHC est la plateforme
dénommée HaskellPlatform-2014.2.0.0. Pour les
communications en réseau nous avons utilisé l'API RMI.
Les sauvegardes et les analyses des fichiers XML ont
été réalisées avec l'API DOM (Document Object
Model) et le framework DOM4J (Document Object Model for Java).
Avec DOM4J, nous avons utilisé un parseur de type SAX (Simple API
for XML) et la technologie XPath (pour manipuler les données
XML).
6. L'outil yacc/bison est un produit GNU (GNU's Not UNIX) qui
permet la construction d'un analyseurs syntaxiques à partir des
grammaires. Combiné à l'outil (f)lex (qui permet la construction
d'analyseurs lexicaux), il peut permettre la construction d'un réel
compilateur.
7. Xtext est un framework de développement des
langages, utilisé comme plug-in pour l'IDE eclipse et permettant de
créer des DSL (Domain-Specific Language).
4.3. Mise en oeuvre d'un workflow d'édition sous TinyCE v2
53
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Les éléments des workflows (grammaires, vues,
documents, acteurs...) ont été sauvegardé sous le format
JSON (JavaScript Object Notation). Nous avons utilisé
la bibliothèque open source Gson, développée par
Google, pour sérialiser nos données dans leur
représentation JSON et pour désérialiser ces
données à partir de leur représentation JSON.
Les données stockées, tout comme celles
échangées, ont été cryptées puis
décryptées grâce à l'API JCE (Java
Cryptography Extension).
L'interface graphique a été complètement
développée grâce à l'API Swing. Pour la
représentation graphique des documents (sous forme d'arbres) avec Swing,
nous avons utilisé la version Java de la bibliothèque
mxGraph. Cette version est dénommée
JGraphX8. Nous avons de ce fait, réussi le pari
d'utiliser de bons outils gratuits et open source pour la plupart. De bons
outils qui nous ont conduit à la création d'un logiciel
disponible pour Windows et pour Linux (ce sont les
plateformes sur lesquelles nous avons réalisé nos tests).
4.3. Mise en oeuvre d'un workow d'édition sous
TinyCE v2
Pour cette présentation, nous disposons de deux postes
(un poste client-serveur (poste 1) et un poste client (poste 2)) pouvant
communiquer via une connexion réseau. L'utilisa-tion de TinyCE v2 pour
la mise en oeuvre d'un workflow d'édition, peut être la
suivante:
Sur le poste 1 (en mode serveur)
1. Authentification et création d'un nouveau
workflow d'édition : pour créer un nouveau workflow, on peut
se servir du menu'Fichier/Nouveau/Workflow' ou du bouton
'Créer un nouveau workflow' (dont l'icône porte le
symbole'+' sur un fond circulaire de couleur orange) de la barre d'outils.
Pour la création du workflow, on précise:
2. Le nom du workflow : il permet de
générer un identifiant pour ledit workflow;
3. Le serveur de synchronisation : il s'agit de
l'adresse du poste qui sera chargé des (re)distributions et des
synchronisations;
4. La grammaire : on saisit les productions de la
grammaire conformément au modèle9 accepté par
TinyCE v2, puis on choisit l'axiome de cette grammaire;
5. Les vues : il s'agit d'entrer les noms des
différentes vues et les symboles appartenant à ces vues;
6. Les différents acteurs/co-auteurs : on
précise pour chaque co-auteur, ses paramètres d'authentification
(login et mot de passe), son site d'édition (facultatif), la vue qui lui
est associée...
7. Le document initial : un document initial est
généré à partir de la grammaire; mais l'utilisateur
a la possibilité de proposer un autre document initial, qui sera
validé par TinyCE v2.
Pour enregistrer le workflow ainsi crée, il suffit de
cliquer sur le bouton'Terminer'. Il est utile de noter qu'un workflow
peut être crée à partir d'un modèle (template)
existant.
8. La bibliothèque mxGraph était
précédemment dénommée JGraph et ne proposait que la
représentation des graphes en Java avec Swing. À partir de la
version 6, les éditeurs ont proposé des versions de ladite
bibliothèque pour plusieurs autres langages (JavaScript,...). Le nom
mxGraph a donc été adopté pour désigner l'ensemble
de ces versions et JGraphX a été adopté pour
désigner JGraph 6 (la version Java de mxGraph).
9. Ce modèle est donné dans l'utilitaire d'aide
de TinyCE v2.
4.4. Synthèse 54
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Sur les postes 1 et 2 (en mode client)
1. Authentification : le co-auteur concerné,
fournit ses paramètres d'authentification;
2. Recherche des workflows d'édition : pour
cela, il faut se rendre dans l'onglet "workflows distants", puis
entrer l'adresse du serveur de synchronisation dans la zone de texte
prévue à cet effet et enfin cliquer sur le bouton"Actualiser"
(dont l'icône est une loupe).
3. Connexion au workflow : le co-auteur doit se
connecter au workflow, pour obtenir, par projection suivant sa vue, une copie
locale de ce dernier (copie locale de la grammaire et du document). Pour se
connecter à un workflow distant, il suffit de sélectionner ledit
workflow, puis de cliquer sur le bouton "Se connecter au workflow";
4. Édition en local du document: les
workflows locaux sont listés dans l'onglet "Workflows locaux".
Pour éditer en local le document d'un tel workflow, il suffit de
sélectionner ce dernier puis de cliquer sur le bouton "Éditer
ce workflow". TinyCE v2 dispose d'un éditeur permettant de modifier
les documents et de les sauvegarder;
5. Synchroniser: après l'édition de sa
réplique partielle, le co-auteur peut déclencher un processus de
synchronisation en cliquant sur le bouton "Synchroniser". Les autres
participants à ce workflow seront alors notifiés et
invités à envoyer leurs répliques pour compléter le
processus de synchronisation. Une fois que toutes les répliques
parviennent au serveur de synchronisation, TinyCE v2 réalise la fusion
consensuelle et propose, en mode interactif, le choix du consensus lorsqu'il y
en a plusieurs. Le document résultant est redistribué pour la
suite de l'édition.
Les captures d'écran suivantes (page 55), illustrent la
mise en oeuvre du workflow d'édition présenté au chapitre
3 (sect. ??), sous TinyCE v2 :
4.4. Synthèse
Nous avons présenté, dans ce chapitre, un
prototype d'éditeur coopératif asynchrone dénommé
TinyCE v2. Ce prototype a servi à réaliser nos
expérimentations; mais l'objectif de sa conception est bien plus grand.
C'est d'ailleurs ce qui explique tous nos choix (méthodologie et
outils). En effet, comme pour le logiciel TinyCE [TT10], nous avons choisi de
développer TinyCE v2 au moyen de deux langages, exploitant ainsi le
meilleur compromis entre ces derniers pour construire une application
possédant les qualités attendues et définies par le
génie logiciel. Le langage Java nous a principalement servi dans la
construction de l'IHM (Interface Homme Machine) et le langage Haskell nous a
servi dans le développement d'une grande partie du module métier
de TinyCE v2. L'extension des fonctionnalités de TinyCE v2 est
actuellement en cours; le but étant celui de fournir un réel
éditeur coopératif et un environnement de conception et
d'implantation des workflows basés sur l'édition
coopérative des documents structurés.

4.4. Synthèse 55
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
FIGURE 4.3 - Utilisation de TinyCE v2 en mode serveur (poste
1) : création du workflow ExempleChapitre3 avec 3 acteurs
(Maxim10 (propriétaire ayant une vue globale), Auteur1
(associé à la vue V1 = {A,B}) et
Auteur2 (associé à la vue V2 =
{A,C})).

FIGURE 4.4 - Utilisation de TinyCE v2 par le co-auteur Auteur1
: authentification et connexion au workflow ExempleChapitre3.
4.4. Synthèse 56
FIGURE 4.5 - Modèle local et réplique partielle
obtenus par le co-auteurAuteur1, à partir du modèle et
du document initial du workflow ExempleChapitre3.

Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
FIGURE 4.6 - Édition de sa réplique partielle
par Auteur1, conformément au modèle local
reçu.
4.4. Synthèse 57
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
FIGURE 4.7 - Consensus obtenu après synchronisation des
mises à jour apportées sur leurs répliques partielles
respectives, par les co-auteurs Auteur1 et Auteur2.
58
Conclusion générale
Sommaire
La problématique étudiée et les choix
méthodologiques 58
Analyse critique des résultats obtenus 59
Quelques perspectives 60
Le bilan que nous faisons de notre travail est organisé
comme suit : tout d'abord, nous rappelons la problématique
étudiée et les choix méthodologiques opérés
dans le développement de nos solutions. Ensuite, nous indiquons les
résultats obtenus et les limites de ceux-ci avant de proposer un
ensemble de pistes d'extension de ce travail.
La problématique étudiée et les
choix méthodologiques
Nous avons étudié le problème de la
réconciliation des répliques partielles d'un document
structuré soumis à un processus d'édition
coopérative asynchrone. En effet, dans un tel processus basé sur
les concepts de 'vues' [BTT08, BTT07, TT09], chaque co-auteur (site
d'édition) est associé à une'vue'; des répliques
partielles, obtenues par projection du document global suivant les
différentes vues, sont distribuées aux différents
co-auteurs; chaque co-auteur édite donc sa réplique partielle
conformément à un modèle local. Les répliques
partielles mises à jour sont ensuite synchronisées pour fournir
un document global mis à jour. Il peut arriver que plusieurs co-auteurs,
ayant tous accès à une partie précise du document,
l'éditent de manière concurrente; ce qui pourrait entraîner
des conflits lors de la synchronisation des répliques partielles mises
à jour. Il faut donc proposer un algorithme de synchronisation capable
de détecter les conflits et d'y remédier (en annulant les actions
d'édition les engendrant par exemple).
Nous avons considéré les mêmes
hypothèses et opéré les mêmes choix
méthodologiques que ceux opérés dans [BTT08, BTT07, TT09],
pour pouvoir apporter une solution (basée sur l'algorithme de fusion
proposé dans ces travaux) au problème de la réconciliation
des répliques partielles d'un document structuré. Ces
hypothèses ont été principalement: l'édition
positive et la séparation complète entre la structure logique du
document et ses présentations concrètes; et les choix
méthodologiques ont été : la modélisation des
documents comme des arbres de syntaxe abstraite pour une grammaire
algébrique, la considération d'une vue comme un sous-ensemble de
symboles grammaticaux et l'utilisa-tion du code Haskell pour l'écriture
de nos algorithmes. Ces considérations nous ont mené
Analyse critique des résultats obtenus 59
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
à des solutions algorithmiques là où on
ne pouvait espérer obtenir de solution dans le cas général
10.
Analyse critique des résultats obtenus
Sachant que nous avons modélisé les documents en
cours d'édition sous forme d'arbres contenant des bourgeons, et que nous
avons considéré qu'une réplique partielle (forêt)
d'un document t étiqueté par des symboles grammaticaux
S est obtenue par projection (ðV ) de t suivant
une vue V E S (sous-ensemble de symboles grammaticaux),
à cette étape du travail les résultats qu'on a pu obtenir
sont les suivants:
Réconciliation des mises à jour des
répliques partielles
Au problème de la réconciliation des vues
partielles d'un document structuré qui
s'énonce comme suit : étant donné k
vues (Vi)1<i<k et k
répliques partielles (tma j
Vi )1<i<k,
fusionner consensuellement la famille (tma j
Vi )1<i<k consiste à
rechercher les plus grands
documents tma j
S ? G satisfaisant:
/ ~
Vi E 1,...,n ?ti ? G,
ti = tma j
S , ðVi(ti) <
tma j
Vi
, nous avons proposé une solution. En effet, nous avons
proposé un algorithme construisant un automate d'arbre qui permet de
générer de tels documents.
TinyCE v2
Nous avons remodelé le projet TinyCE [TT10] pour
fournir un autre prototype d'édi-teur coopératif
désynchronisé tout aussi embryonnaire mais qui intègre la
gestion des conflits; bien plus, notre prototype peut être autant la base
du développement d'une plateforme expérimentale de conception et
de simulation d'applications de travail coopératif basées sur
l'échange de documents structurés, que la base d'un réel
éditeur coopératif (pair à pair ou non) de tels
documents.
Une communication liée à ce
travail
Le travail contenu dans ce mémoire a donné lieu
à une communication co-rédigée par TCHOUPÉ TCHENDJI
MAURICE et nous (ZEKENG NDADJI MILLIAM MAXIME). Ladite communication est
intitulée"Réconciliation par consensus des mises à
jour des répliques partielles d'un document structuré", elle
comporte treize pages et sera (au moment où nous
rédigeons ceci) présentée lors de la treizième
édition du Colloque Africain sur la Recherche en Informatique
(CARI'2016); le colloque se tiendra à Tunis
(Tunisie), du 11 au 14 octobre 2016.
Quelques critiques relatives, à la fois, à la
preuve formelle des algorithmes proposés et au modèle grammatical
choisit, peuvent être portées à ce travail:
Pas de preuves mathématiques de nos
algorithmes
Bien que les algorithmes proposés aient
été testé sur des exemples significatifs avec des
résultats positifs, la preuve de leur exactitude reste à
établir. Cette preuve pourra
10. Pour rappel, les études portant sur la
réconciliation des versions d'un document reposent sur des heuristiques
[Men02].
Quelques perspectives 60
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
certainement être établie; car nos algorithmes
reposent sur des objets mathématiques (non inventés dans ce
travail) dont les propriétés mathématiques ont
déjà été démontrées dans d'autres
travaux.
Grammaires généralisées
Dans des documents XML il est usuel de manipuler des noeuds
ayant un nombre non borné de successeurs; par exemple, pour
représenter une liste, en général non ordonnée,
d'éléments d'une même catégorie : employés
d'une entreprise, livres d'une bibliothèque, hôtels d'un
système de réservation... Il faudrait de ce point de vue utiliser
des grammaires algébriques généralisées dans
lesquelles les parties droites des productions sont des expressions
régulières : ce que nous n'avons pas fait. Toutefois, une piste
d'utilisation de telles grammaires, pouvant s'adapter à notre cas, est
donnée dans [TT09]; et maintenant que nous avons une meilleure
compréhension du sujet, il nous sera plus aisé de le faire.
Implémentation du système
coopératif
Les travaux que nous menons doivent pouvoir nous mener
à des outils facilitant la conception des systèmes
coopératifs basés sur l'édition des documents
structurés. Nous en sommes encore bien loin. Bien que notre prototype
soit l'ébauche d'une telle plateforme, nous l'utilisons pour
démontrer les algorithmes introduits dans ce travail. Néanmoins,
avec les différentes approches considérées (gestion des
conflits, fusion en pair à pair...) on peut espérer pouvoir
bientôt lui donner l'orientation qui est à son origine.
Quelques perspectives
Ce travail porte bien son qualificatif de mémoire
vu que, bien qu'il présente quelques résultats, il n'est que
l'ébauche d'un ensemble de travaux bien plus grands et bien plus
consistants, qui pourraient faire l'objet d'études dans un cadre bien
plus important (une thèse de doctorat par exemple). Nous listons ici,
quelques uns de ces possibles travaux:
Extension aux grammaires
généralisées
Étendre le travail aux grammaires algébriques
généralisées pour prendre en compte les DTD qu'on
rencontre usuellement dans la pratique.
Preuves mathématiques et
évaluation
Présenter les preuves mathématiques de la
validité des algorithmes proposés ainsi qu'une étude de
leur complexité.
TinyCE v2 sous forme de plug-in
On pourrait, outre un logiciel autonome, construire une
version de TinyCE v2 sous forme de plug-in (extension) pour des IDE (Integrated
Development Environment) tels que Eclipse 11 ou
NetBeans 12, permettant ainsi l'édition
coopérative efficace des documents structurés.
11. Eclipse est disponible à l'adresse
http://www.eclipse.org
12. NetBeans est disponible à l'adresse
http://www.netbeans.org
61
Bibliographie
[Abi97] S. Abiteboul. Querying semistructured data. In
proceedings of the Interna-
tional Conference on Database Theory, pages 1-18,
January 1997.
[Ask94] U. Asklund. Identifying conflicts during structural
merge. In proceedings of
Nordic Workshop on Programming Environment Research
(NWPER'94), Nordic Workshop on Programming Environment Research, Lund, Sweden,
pages 231-242, June 1994.
[Bon98] Stéphane Bonhomme. Transformation de documents
structurés, une combi-
naison des approches explicite et automatique. PhD
thesis, Université Joseph Fourier - Grenoble I, Décembre 1998.
[BPM] Business Process Modeling Notation (BPMN) 2.0 : (OMG 2011)
538 p. Dis-
ponible à l'adresse
http://www.omg.org/spec/BPMN/2.0.
[BPSM+06] Tim Bray, Jean Paoli, C. M.
Sperberg-McQueen, Eve Maler, François Yer-geau, and John Cowan. W3C
recommendation : Extensible markup language (xml) 1.1 (second edition), 2006.
http://www.w3.org/TR/2006/
REC-xml11-20060816/.
[BR04] Timo Böhme and Erhard Rahm. Supporting Efficient
Streaming and Inser-
tion of XML Data in RDBMS. In proceedings International
Workshop Data Integration over the Web (DIWeb), pages 70-81, 2004.
[BTT07] Eric Badouel and Maurice T. Tchoupé. Projection et
cohérence de vues dans
les grammaires algébriques. Electronic Journal of
ARIMA (African Revue in Informatics and Mathematics Applied), 8 :18-48,
2007.
[BTT08] Eric Badouel and Maurice T. Tchoupé. Merging
hierarchically structured
documents in workflow systems. In proceedings of the Ninth
Workshop on Coalgebraic Methods in Computer Science (CMCS 2008), Budapest.
Electronic Notes in Theoretical Computer Science, 203(5) :3-24, 2008.
[CBBG07] Mohamed Amine Chaâbane, Lotfi Bouzguenda, Rafik
Bouaziz, and Faiez
Gargouri. Spécification des processus workflows
évolutifs versionnés. Sche-dae, 2007.
prépublication numéro 11, (fascicule numéro 2, p.
21-29).
[CDG+08] H. Comon, M. Dauchet, R. Gilleron, D. Lugiez,
F. Jacquemard, C. Löding,
S. Tison, and M. Tommasi. Tree Automata Techniques and
Applications (TATA). Draft, Available at
http://www.grappa.univ-lille3.fr/tata/,
November 2008.
[CG08] V. Curcin and M. Ghanem. Scientific workflow systems - can
one size fit
all? In proceedings of the 2008 IEEE, CIBEC'08, 2008.
4.4. Synthèse 62
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
[COL] Collaborative Design Activity.
http://www.khronos.org/collada/.
[CSGM] Chawathe, Sudarshan, and Hector Garcia-Molina.
Meaningful change de-
tection in structured data. ACM SIGMOD International
Conference on Management of Data, ACM Press, pages 26-37.
[CSR+] Chawathe, Sudarshan, Anand Rajaraman, Hector
Garcia-Molina, and Jen-
nifer Widom. Change detection in hierarchical structured
information. ACM SIGMOD International Conference on Management of Data, ACM
Press, pages 493-504.
[DG02] Schahram Dustdar and Harald Gall. Towards a Software
Architecture
for Distributed and Mobile Collaborative Systems. In
proceedings of the 26 th Annual International Computer Software and
Applications Conference (COMPSAC'02 : IEEE Computer Society), 2002.
[DOC15] Doc (informatique), Juillet 2015. Disponible à
https://fr.wikipedia.
org/wiki/Doc_(informatique). Visité le 15 Janvier
2016.
[Fea89] Martin S. Feather. Detecting Interference when Merging
Specification Evo-
lutions. In Proceedings Fifth International Workshop
Software Specification and Design, pages 169-176, 1989.
[GHC] The Glasgow Haskell Compiler: GHC. Available at
http://www.haskell.
org/ghc/.
[GHS95] Diimitrios Georgakopoulos, Mark Hornick, and Amit
Sheth. An Overview of
Workflow Management: From Process Modeling to Workflow
Automation Infrastructure. Distributed and Parallel Databases, 3
:119-153, 1995.
[Gir14] Suzanne Girard. Coopération et collaboration au
travail, quelle est la
différence? Formation, Août 2014. disponible
à l'adresse
http://
conseilsrhcoaching.com/cooperer-et-collaborer-article/.
[Gru94] Jonathan Grudin. CSCW : History and Focus. IEEE
Computer, 27(5) :19-26,
1994.
[Has] Haskell : A purely functional language.
http://www.haskell.org/.
[Heu03] Jean Heutte. Apprentissage collaboratif : vers
l'intelligence collective...,
Septembre 2003. Bloc notes de Jean Heutte..., disponible
à l'adresse http: //
jean.heutte.free.fr/spip.php?article55.
[HPHF99] Paul Hudak, John Peterson, and Joseph H. Fasel. A
gentle introduction to
haskell 98, October 1999.
[IEE] Institute of Electrical and Electronics Engineers.
http://www.ieee.org/.
[Imi06] Abdessamad Imine. Conception Formelle
d'algorithmes de Réplication Opti-
miste Vers l'édition Collaborative dans les
Réseaux Pair-à-Pair. PhD thesis, Université Henri
Poincaré - Nancy 1, Décembre 2006.
[INT] Introduction au BPMN 2.0. Disponible à l'adresse
http:
//
introductionbpmn2.0.voila.net/co/IntroductionauBPMN2_0.html
visitée le 14 Mars 2015.
4.4. Synthèse 63
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
[ISO] International Organization for Standardization.
http://www.iso.org/.
[JHE03] Andriessen J. H. E. Working with Groupware. Understanding
and Evalua-
ting Collaboration Technology. Springer, 2003.
[Joh88] R. Johansen. Groupware : Computer support for business
teams. New York:
The Free Press, 1988.
[KAA93] Extase K. A. Akpotsui. Transformation de types dans
les systèmes d'édition de
documents structurés. PhD thesis, Institut
National Polytechnique de Grenoble - INPG, Octobre 1993.
[LF02] Robin La Fontaine. Merging xml files : A new approach
providing intelligent
merge of xml data sets. In proceedings of XML Europe, Berlin,
Germany, 2002.
[Lin04] Tancred Lindholm. A three-way merge for xml documents.
In proceedings of
the 2004 ACM Symposium on Document Engineering, pages
1-10, October 2004.
[LMLR08] Yuan Lin, Isabelle Mougenot, and Thérèse
Libourel Rouge. Un nouveau
langage de workflow pour les sciences expérimentales.
INFORSID'08 : Atelier ERTSI Evolution, Réutilisation et
Traçabilité des Systèmes d'Information, Fontainebleau,
France, pages 1-15, May 2008.
[Man01] Gerald W. Manger. A generic algorithm for merging
sgml/xml instances. In
proceedings of XML Europe, Berlin, Germany, 2001.
[MD94] Jonathan P. Munson and Prasun Dewan. A Flexible Object
Merging Fra-
mework. In Proceedings ACM Conference Computer Supported
Collaborative Work, pages 231-241, 1994.
[Men02] Tom Mens. A state-of-the-art survey on software merging.
IEEE Transactions
on Software Engineering, 28(5) :449-462, 2002.
[MGa08] Danièle Morvan, Françoise Gérardin,
and al. Le Robert de poche. La société
Dictionnaires Le Robert, 2008.
[MPvdA12] Wil M. P. van der Aalst. Business Process Management
: A Comprehensive Survey. ISRN Software Engineering (Hindawi Publishing
Corporation), 2013, September 2012.
[Pan99] Theodore (Ted) Panitz. Collaborative versus
cooperative learning : A com-
parison of the two concepts which will help us understand the
underlying nature of interactive learning. Educational Resources
Information Center (ERIC), December 1999. 13p.
[PMG+07] V.M.R. Penichet, I. Marin, J.A. Gallud, M.D.
Lozano, and R. Tesoriero. A
Classification Method for CSCW Systems. Electronic Notes
in Theoretical Computer Science, 168 :237-247, 2007.
[Sar05] Anita Sarma. A survey of collaborative tools in software
development. Tech-
nical report, Institute for Software Research; Donald Bren
School of Information and Computer Sciences; University of California, Irvine,
March 2005.
4.4. Synthèse 64
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
[SB92] Kjeld Schmidt and Liam Bannon. Taking CSCW seriously
supporting articu-
lation work. Kluwer Academic Publishers, Computer Supported
Cooperative Work (CSCW), 1 :7-40, July 1992.
[SLMD96] Patrick Steyaert, Carine Lucas, Kim Mens, and Theo
D'Hondt. Reuse
Contracts : Managing the Evolution of Reusable Assets. In
Proceedings OOPSLA'96 ACM SIGPLAN N otice, volume 31, pages 268-286,
1996.
[SS05] Yasushi Saito and Marc Shapiro. Optimistic replication.
ACM Computing
Surveys, 5(3) :1-44, 2005.
[TT9] Maurice T. Tchoupé. Une approche
grammaticale pour la fusion des réplicats
partiels d'un document
structuré: application à l'édition coopérative
asynchrone. Software Engineering. PhD thesis, Université de Rennes
1 (France), Université de Yaoundé 1 (Cameroun), Août
2009.
[TT10] Maurice Tchoupé T. Fertilisation croisée
d'un langage fonctionnel et d'un
langage objet : application à la
mise en oeuvre d'un prototype d'éditeur coopératif asynchrone.
CARI 2010 - YAMOUSSOUKRO, pages 541-549, 2010.
[TTTA12] Maurice T. Tchoupé and Marcellin T. Atemkeng.
Un modèle de documents
stable par projections pour la communication dans les
systèmes workflow hiérarchiques : Application à
l'édition coopérative asynchrone. ARIMA, 1, 2012.
[TTTAD14] Maurice T. Tchoupé, Marcellin T. Atemkeng,
and Rodrigue Djeumen. Un modèle de documents stable par projections pour
l'édition coopérative asynchrone. CARI 2014 Proceedings, 1
:325-332, 2014.
[W3C] The World Wide Web Consortium.
http://www.w3.org/.
[WfM] The Workflow Management Coalition. Disponible à
l'adresse
http://www.
wfmc.org/standards/docs/Glossary_French.PDF.
[WK97] Edwards W. Keith. Flexible Conflict Detection and
Management In Collabo-
rative Applications. In proceedings Symposium User
Interface Software and Technology, 1997.
[YS00] Jeonghee Yi and Neel Sundaresan. A classifier for
semi-structured docu-
ments. IBM Almaden Research Center, 2000.
65
AnnexeA
Un autre exemple complet de fusion
consensuelle
Dans cette annexe, nous illustrons notre algorithme de
réconciliation (chap. 3 sect. 3.2) sur le workflow d'édition
coopérative présenté comme exemple dans le chapitre 2
(figure 2.5 page 27). Pour rappel le document t conforme à la
grammaire Gexpl est projeté suivant les vues V1 =
{A,B} et V2 = {A,C} pour engendrer les
forêts (répliques partielles) tv1 et
tv2. Ces répliques partielles sont
éditées respectivement sur les sites 1 et 2 ; le coauteur 1
(resp. le co-auteur 2) ne peut éditer que les bourgeons de type A
(resp. C) (c'est à dire que V (1)
edit = {A} et Vedit(2) =
{C}) ; les documents mis à jour sont respectivement
tma j
v1 et
tma j
v2 . Nous allons donc fusionner
tma j
v1 et tma j
v2 grâce à notre algorithme. Le but
recherché ici est celui de montrer que notre algorithme prend en compte
les documents non clos (tma j
v2 )
et aussi qu'il peut s'appliquer lorsque la fusion n'engendre pas
de conflits.
Les schémas des règles de
transition
Rappelons que les schémas des transitions
(complétés pour prendre en compte les documents non clos) de
l'automate permettant de représenter les expansions des répliques
partielles suivant la vue V1 = {A,B} lorsqu'on
associe les symboles de Dyck '(' et ')' (resp. '[' et ']') au symbole visible
A (resp. B) et qu'on associe les symboles '(W' et
')W' (resp. '[W' et ']W') au bourgeon
AW (resp. BW) de type A (resp.
B), sont les suivants :
hA,w1i -?
(P1,[hC,ui,hB,vi]) si
w1 = u[v]
hA,w2i -?
(P1,[hC,ui,hB,w11i]) si
w2 = uw11 avec w11 = [W]W
hA,w3i -? (P2,[]) si w3 =
E
hA,w4i -? (AW,[]) si
w4 = (W )W
hB,w5i -?
(P3,[hC,ui,hA,vi]) si
w5 = u(v)
hB,w6i -?
(P3,[hC,ui,hA,w4i]) si
w6 = uw4
hB,w7i -?
(P4,[hB,ui,hB,vi]) si
w7 = [u][v]
hB,w8i -?
(P4,[hB,w11i,hB,vi]) si
w8 = w11[v]
hB,w9i -?
(P4,[hB,ui,hB,w11i]) si
w9 = [u]w11
hB,w10i -?
(P4,[hB,w11i,hB,w11i]) si
w10 = w11w11
hB,w11i -? (BW,[]) si
w11 = [W]W
hC,w12i -?
(P5,[hA,ui,hC,vi]) si
w12 = (u)v
hC,w13i -?
(P5,[hA,w4i,hC,vi]) si
w13 = w4v
hC,w14i -?
(P6,[hC,ui,hC,vi]) si
w14 = uv =6 E
hC,w15i -? (CW,[]) si
w15 = E
Les automates 91(1) et
91(2) 66
De même, en associant au symbole grammatical C
(resp. A) les symboles de Dyck '[' et ']' (resp. '(' et ')'), en
associant aussi au bourgeon CW (resp.
AW) les symboles de Dyck '[W' et ']W'
(resp. '(W' et ')W'), les schémas des transitions
(complets) des automates associés aux répliques partielles
suivant la vue V2 = {A,C} sont les suivants :
(A,w1) -+
(P1,[(C,u),(B,v)]) si w1
= [u]v
(A,w2) -+
(P1,[(C,w20),(B,v)]) si
w2 = w20v avec w20 = [W
]W
(A,w3) -+ (P2,[]) si w3 =
E
(A,w4) -+ (AW,[]) si
w4 = (W )W
(B,w5) -+
(P3,[(C,u),(A,v)]) si w5
= [u](v)
(B,w6) -+
(P3,[(C,w20),(A,v)]) si
w6 = w20(v)
(B,w7) -+
(P3,[(C,u),(A,w4)]) si w7
= [u]w4
(B,w8) -+
(P3,[(C,w20),(A,w4)]) si
w8 = w20w4
(B,w9) -+
(P4,[(B,u),(B,v)]) si w9
= uv =6E
(B,w10) -+ (BW,[]) si
w10 = E
(C,w11) -+
(P5,[(A,u),(C,v)]) si w11
= (u)[v]
(C,w12) -+
(P5,[(A,w4),(C,v)]) si
w12 = w4[v]
(C,w13) -+
(P5,[(A,u),(C,w20)]) si
w13 = (u)w20
(C,w14) -+
(P5,[(A,w4),(C,w20)]) si
w14 = w4w20
(C,w15) -+
(P6,[(C,u),(C,v)]) si w15
= [u][v]
(C,w16) -+
(P6,[(C,w20),(C,v)]) si
w16 = w20[v]
(C,w17) -+
(P6,[(C,u),(C,w20)]) si
w17 = [u]w20
(C,w18) -+
(P6,[(C,w20),(C,w20)]) si
w18 = w20w20
(C,w19) -+ (P7,[]) si w19 =
E
(C,w20) -+ (CW,[]) si
w20 = [W]W
Les automates 91(1)
et 91(2)
Construction de l'automate
91(1) associé à
tma j
v1
La trace visible des documents de l'expansion de
tma j
v1 est ((()[()])[()]); A étant
l'axiome de la grammaire et aussi un symbole visible (appartenant à la
vue), l'état initial de l'auto-mate 91(1) est
q10 = (A,(()[()])[()]). En ne
considérant que les états accessibles à partir de
q10 et en appliquant les schémas de
règles présentés précédemment, nous obtenons
l'automate d'arbre suivant pour la réplique tma
j
|
q10
q11
q11
q12
q13
q14
q15
q16
q16
|
-+ -+ -+ -+ -+ -+ -+ -+ -+
|
(P1,[q11,q12])
(P5,[q13,q14])
(P6,[q14,q11])
(P3,[q14,q15])
(P1,[q16,q12])
(CW,[]) (P2,[])
(P5,[q15,q14])
(P6,[q14,q16])
|
|
(P6,[q11,q14])
| (P6,[q1
6,q14])
|
avec
avec
avec
avec
|
v1 :
q11 = (C,(()[()])) et
q12 = (B,())
q13 = (A,()[()]) et
q14 = (C,E)
q1 5 = (A,E) q16
= (C,())
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
L'état q14 est le seul
état de sortie de cet automate.
L'automate consensuel Asc 67
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Construction de l'automate
A(2) associé
à tmaj
v2
Ayant associé au symbole grammatical C (resp.
A) les symboles de Dyck '[' et ']' (resp. '(' et ')'), la
linéarisation de la réplique partielle
tma j
v2 (fig. 2.5) donne le mot de
Dyck ([(ù
)ù[]][[][]]()). L'automate
A(2) associé à cette réplique
a donc pour état initial q20 =
hA,[(ù)ù[]][[][]]()i
et pour transitions :
|
q20
q21
q22
q22
q23
q24
q25
q26
q27
q28
q29
|
-?
-?
-?
-?
-? -? -? -? -? -? -?
|
(P1,[q2
1,q22])
(P5,[q23,q24])
(P3,[q25,q26])
(P4,[q27,q22])
(P4,[q22,q27])
(Aù,[]) (P7,[])
(P6,[q24,q24])
(P2,[]) (Bù,[])
(P4,[q27,q28])
|
(P4,[q27,q29])
|
|
|
(P4,[q28,q29])
(P4,[q28,q27])
(P4,[q29,q27])
|
|
|
avec
avec avec avec
|
q21 =
hC,(ù)ù[]i
et
q22 =
hB,[[][]]()i
q23 =
hA,(ù)ùi et
q24 = hC,åi
q25 = hC,[][]i et
q26 = hA,åi
q27 =
hB,åi, q28 =
hB,[[][]]i et
q29 =
hB,()i
|
Les états q23 et
q27 sont les seuls états de sortie de cet
automate.
L'automate consensuel Asc
En appliquant notre algorithme de calcul du produit synchrone
de plusieurs automates d'arbre aux automates A(1)
et A(2), on obtient l'automate du consensus
A(sc) = A(1)?Ù
A(2) ayant pour état initial
q0 =
(q10,q20) et
dont les transitions sont les suivantes :
|
q0
q1
q2
q3
q4
q5
q6
q7
q7
q8
q9
q10
q11
|
-? -? -? -?
-? -? -? -?
-? -? -? -? -?
|
(P1,[q1,q2])
(P5,[q3,q4]) (P3,[q5,q6])
(P1,[q7,q8])
(P7,[]) (P6,[q9,q9])
(P2,[]) (P5,[q10,q11])
(P6,[q11,q7]) |
(P3,[q11,q10]) (P7,[]) (P2,[])
(Cù,[])
|
(P6,[q7,q11])
|
avec avec avec avec
avec
avec
|
q0 = (q1
0,q2 0)
q1 = (q1
1,q21) et q2 =
(q1 2,q22)
q3 =
(q13,q23) et
q4 =
(q14,q24) q5
= (q14,q25)
et q6 = (q1
5,q26)
q7 =
(q16,qs1), qs1
=
hOpen C,[]i et q8 = (q1
2,qs2), qs2 = hOpen B,[]i
q9 = (qs1,q24)
q10 =
(q15,qs3), qs3
=
hOpen A,[]i et q11 =
(q14,qs1)
|
l'état q11 de A(sc) =
A(1) ?ÙA(2) est un
état de sortie ; en effet, les états qui le composent
(q14 et qs1) sont tous des
états de sortie. L'absence d'états de sortie dont les
états composites
L'automate consensuel Asc 68
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
soient en conflit est une preuve de l'absence des conflits
dans le workflow étudié ici. Notre générateur
fournit un seul arbre (figure A.1) à partir de l'automate
A(sc).

FIGURE A.1 - AST et arbre de dérivation
généré à partir de l'automate consensuel
A(sc).
69
AnnexeB
Quelques fonctions Haskell pour le
calcul des consensus
Dans cette annexe, nous décrivons quelques fonctions et
types Haskell permettant de représenter des documents structurés
et d'effectuer la fusion consensuelle de ces derniers. Afin de mieux
appréhender les notions présentées ici, une connaissance
du langage Haskell (que le lecteur ne trouvera pas ici) est requise. Nous
sommes persuadés que les références suivantes seront
d'excellents compagnons et/ou guides pour le lecteur désireux de
découvrir et/ou d'en apprendre plus sur l'univers de la programmation
fonctionnelle avec Haskell: [Has, GHC, HPHF99].
Représentation des grammaires et des
vues
Une grammaire est constituée d'un ensemble de symboles et
d'un ensemble de productions. Nous représentons une grammaire par le
type Gram suivant:
1 data Gram prod symb = Gram {prods::[prod],
2 symbols::[symb],
3 lhs::prod -> symb,
4 rhs::prod -> [symb]}
La fonction lhs (resp. rhs) prend en argument une grammaire G
et une production p de G puis retourne le symbole en partie gauche (
resp. la liste des symboles en partie
droite) de p. À partir de ce type, on peut construire la grammaire
Gexpl (chap 2 exemple 8) grâce au code Haskell suivant:
|
1
2
3
4
|
data Prod = P1 | P2 | P3 | P4 | P5
deriving (Eq, Show)
data Symb = A | B | C deriving (Eq,
|
| P6 |
Show)
|
P7 | Aomega
|
|
|
Bomega
|
|
|
Comega
|
|
5
|
gram :: Gram Prod Symb
|
|
|
|
|
|
|
|
|
|
6
|
gram = Gram lprod lsymb lhs_ rhs_
|
|
|
|
|
|
|
|
|
|
7
|
where
|
|
|
|
|
|
|
|
|
|
8
|
lprod = [P1, P2, P3, P4, P5,
|
P6, P7]
|
|
|
|
|
|
|
|
|
9
|
lsymb = [A, B, C]
|
|
|
|
|
|
|
|
|
|
10
|
lhs_ p = case p of
|
|
|
|
|
|
|
|
|
|
11
|
P1 -> A; P2 -> A; P3 ->
|
B; P4
|
-> B; P5
|
->
|
C;
|
P6
|
->
|
C;
|
P7 -> C
|
|
12
|
rhs_ p = case p of
|
|
|
|
|
|
|
|
|
|
13
|
P1 -> [C, B]; P2 -> [];
|
P3 ->
|
[C, A];
|
P4
|
->
|
[B,
|
B];
|
|
|
|
14
|
P5 -> [A, C]; P6 -> [C,
|
C]; P7
|
-> []
|
|
|
|
|
|
|
Représentation des documents ou arbres 70
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Les productions Aomega, Bomega et Comega ont été
introduites pour pouvoir désigner les bourgeons de types respectifs A, B
et C.
Comme dans [BTT08, TT09, BTT07], nous représentons une
vue par un ensemble de prédicats sur les symboles de la grammaire.
Ainsi, les vues V1 = {A,B} et V2 = {A,C},
définies sur la grammaire Gexpl, peuvent être
déclarées de la manière suivante :
1 viewAB :: Symb -> Bool
2 viewAB symb = case symb of
3 A->True
4 B->True
5 C -> False
6
7 viewAC :: Symb -> Bool
8 viewAC symb = case symb of
9 A->True
10 B -> False
11 C -> True
Représentation des documents ou arbres
Conformément à notre approche, un AST est soit
un bourgeon (BUD) soit un noeud (NODE) étiqueté par une
production et possédant plusieurs AST comme fils. Le type Haskell
correspondant est le suivant:
1 data AST a = BUD | NODE {node_label::a, unNODE::[AST a]}
deriving Eq
Dans la même lancée, un arbre de dérivation
dont les étiquettes des noeuds sont de type a peut être
représenté par le type Haskell suivant:
1 data BTree a = BTree {value::a, sons::Maybe [BTree a]} deriving
Eq
Un arbre de dérivation est donc un noeud
étiqueté par value possédant peut être (Maybe) des
fils (sous-arbres) rangés dans une liste (sons); lorsqu'il en
possède (sons est construite grâce au constructeur de
données Just), il est un noeud clos. Dans le cas contraire (sons est
construite plutôt grâce à Nothing), l'arbre est
réduit à un bourgeon. Nous pouvons par exemple coder les
états initiaux des automates (1) (replicatAB) et
(2) (replicatAC), de l'exemple du chapitre 3 (sect.
??), grâce au code Haskell suivant:
1 replicatAB = [BTree A (Just [BTree B (Just [BTree B (Just
[BTree A (Just []),
2 BTree A (Just [])]), BTree B (Just [BTree A (Just [])])])]),
3 BTree B (Just [BTree A (Just [])])]
4
5 replicatAC = [BTree C (Just [BTree A (Just [BTree C (Just
[]),BTree C (Just []),
6 BTree A (Just []), BTree C (Just []), BTree A (Just [])]),
BTree C
7 (Just [])]), BTree C (Just [BTree C (Just []), BTree C (Just
[])]),
8 BTree A (Just [])]
La fonction projection dont le code est le suivant, permet de
projeter un document quelconque suivant une vue donnée. Elle retourne
donc une forêt (liste d'arbres) représentant la réplique
partielle du dit document pour la vue considérée.
1 projection :: (symb -> Bool) -> BTree symb -> [BTree
symb]
2 projection view t@(BTree a Nothing) = if view a then [t] else
[]
3 projection view t@(BTree a (Just xs)) = if view a then [BTree a
(Just sons_)]
Génération des documents 71
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
4 else sons_
5 where
6 sons_ = concat (map (projection view) xs)
Calcul de l'automate associé à une
vue
Rappelons que, nous définissons un automate d'arbre
à états de sortie par le type Automata suivant:
1 data Automata p q = Auto {exit::q -> Bool, next::q ->
[(p, [q])]}
Le type générique p est le type des productions qui
étiquettent les transitions et q est le type des états de
l'automate.
L'adaptation de la fonction gram2autoview [BTT08, TT09, BTT07]
suivante, permet de construire un automate à états de sortie
capable de reconnaître les documents globaux qui sont des expansions
d'une réplique partielle suivant une vue donnée.
1 gram2autoview :: Eq t => Gram a t -> (t -> a) -> (t
-> Bool)
2 -> Automata a (Tag t, [BTree t])
3 gram2autoview gram symb2prod view = Auto exit next
4 where
5 exit (Open symb,[]) = True
6 exit _ = False
7
8 next (Open symb,_) = [(symb2prod symb,[])]
9 next (Close symb,ts) = [(p, zipWith trans (rhs gram p) tss)
|
10 p <- prods gram, symb == lhs gram p,
11 tss <- match_ view (rhs gram p) ts]
12
13 trans symb (Close ts) = (Close symb, ts)
14 trans symb (Open ts) = (Open symb, ts)
15
16 match_ :: (Eq symb)=> (symb ->
Bool)->[symb]->[BTree symb]->[[Tag [BTree symb]]]
17 match_ view [] ts = if null ts then [[]] else []
18 match_ view (symb:symbs) ts = [(ts1:tss)| (ts1,ts2) <-
matchone_ view symb ts,
19 tss <- match_ view symbs ts2]
20
21 matchone_ :: (Eq symb) => (symb -> Bool) -> symb
-> [BTree symb]
22 -> [(Tag [BTree symb],[BTree symb])]
23 matchone_ view symb ts =
24 if view symb
25 then if null ts then []
26 else case (head ts) of
27 (BTree symb' Nothing) -> if symb==symb'
28 then [(Open [], tail ts)]
29 else []
30 (BTree symb' (Just ts')) -> if symb==symb'
31 then [(Close ts', tail ts)]
32 else []
33 else [(Open [], ts)]++
34 [(Close (take n ts),drop n ts) | n <- [1..(length ts)]]
Génération des documents 72
Mémoire - ZEKENG NDADJI Milliam Maxime
LIFA
Génération des documents
Nous définissons notre générateur par la
fonction Haskell suivante qui prend un automate A et un état q
quelconque en paramètre et retourne la liste des AST les plus simples du
langage accepté par A à partir de q :
1 enum :: (Eq b) => Automata a b -> b -> [AST a]
2 enum auto init = enum_ [ ] init
3 where
4 enum path state | elem state path = []
5 | otherwise = (if((exit auto state) && (null (next
auto state)))
6 then [BUD]
7 else []) ++ [NODE elet list_tree |
8 (elet, states) <- next auto state,
9 list_tree <- dist (map (enum_ (state : path)) states)]
Le combinateur dist 1 fabrique un ensemble L2
de listes à partir d'un ensemble L1 de listes tel que
chaque liste de L2 contient un élément de chaque liste
de L1.
Grâce à toutes ces fonctions, il est donc
possible de calculer l'ensemble des préfixes maximums sans conflits les
plus simples issus de la fusion de plusieurs (deux) répliques
partielles. Dans cette optique, on peut se servir d'un code comme celui ci (ce
code est valide pour l'exemple présenté dans le chapitre 3 (sect.
??)) :
1 docconsensus = enum auto initstate where
2 initstate = ((Close A, replicatAB2), (Close A, replicatA))
3 autoview1 = gram2autoview gram symb2BudProd viewAB
4 autoview2 = gram2autoview gram symb2BudProd viewAC
5 auto = autoconsens symb2BudProd autoview1 autoview2
Dans ce code, initstate est l'état initial à
partir duquel la génération se fait. Il est, comme prévu,
un vecteur composé des états initiaux des automates qui sont
fusionnés. L'automate autoview1 (resp. autoview2) est l'automate
associé à la réplique partielle suivant la vue viewAB
(resp. viewAC). La fonction symb2BudProd permet de transformer un symbole en
une production étiquetant un bourgeon de type ce symbole. Son code, pour
cet exemple, est le suivant:
1 symb2BudProd symb = case symb of
2 A -> Aomega
3 B -> Bomega
4 C -> Comega
L'automate auto est le produit consensuel de autoview1 et
autoview2. Les documents consensuels les plus simples sont ainsi
énumérés par la fonction enum et l'ensemble
résultant est désigné par docconsensus.
1. dist est défini par pattern matching comme suit:
dist: : [[a]] ? [[a]]
dist [ ] = [[ ]]
dist (xs : xss) = [y : ys | y
f- xs, ys f- dist xss]


