Le schéma ci-dessous, tiré du site officiel de
L'ESMT (wébographie n°2), illustre l'organisation et la structure
de L'ESMT.
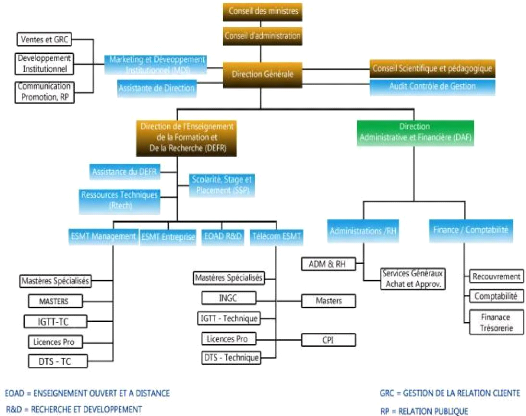
Figure 1: Organigramme de
l'ESMT

CHAPITRE II

CHAPITRE II : Présentation des outils
nécessaires II.1. Le proxy SQUID
II.1.1. Définition
Un serveur proxy aussi appelé serveur mandataire est
à l'origine une machine faisant fonction d'intermédiaire entre
les ordinateurs d'un réseau local et internet. La plupart du temps le
serveur proxy est utilisé pour le web, il s'agit alors d'un proxy HTTP.
Il nous permettra ainsi de gérer l'accès à internet aux
utilisateurs de notre réseau local en fonction des heures
d'accès, des ports de destination d'un service, d'IP sources, etc. Il
permet aussi de mettre en cache les sites les plus visités afin
d'accélérer le trafic. Comme serveur proxy, nous allons utiliser
le serveur SQUID qui est un logiciel libre distribué selon les termes de
la licence GNU GPL. Son rôle initial est de relayer des requêtes
HTTP entre un poste client de notre réseau local et un serveur web se
trouvant sur Internet. Il peut aussi assurer d'autres fonctions
essentielles.
II.1.2. Fonctionnement et
Rôles
II.1.2.1. Fonctionnement
Le principe de fonctionnement basique d'un serveur proxy est
assez simple : il s'agit d'un serveur "mandaté" par une application pour
effectuer une requête sur Internet à sa place. Ainsi, lorsqu'un
utilisateur se connecte à internet à l'aide d'une application
cliente configurée pour utiliser un serveur proxy, celle-ci va se
connecter en premier lieu au serveur proxy et lui donner sa requête. Le
serveur proxy va alors se connecter au serveur que l'application cliente
cherche à joindre et lui transmettre la requête. Le serveur va
ensuite donner sa réponse au proxy, qui va à son tour la
transmettre à l'application cliente. Les objets consultés par les
clients sur internet, sont stockés en cache disque par le serveur.
À partir du deuxième accès, la

lecture se fera en cache, au lieu d'être
réalisée sur le serveur d'origine. De ce fait il permet
d'accélérer nos connexions à l'internet en plaçant
en cache les documents les plus consultés.
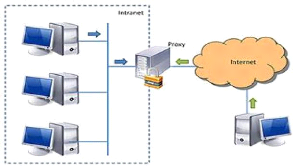
Figure 2: Principe de
fonctionnement
II.1.2.2. Role
Le serveur proxy SQUID peut assurer plusieurs rôles parmi
lesquels :
· Le role de cache : En jargon
informatique, une mémoire cache sert à conserver localement des
informations qui ont une certaine probabilité de servir à nouveau
à court terme. Un serveur proxy stocke provisoirement les pages web que
les utilisateurs vont chercher sur Internet. Si un internaute requiert une
information qui se trouve déjà dans le cache, il sera servi plus
rapidement.
· Le rôle d'enregistrement :
Comme tout serveur qui se respecte, un proxy génère un
fichier journal (log file). On y trouve la trace de toutes les requêtes
effectuées par tous les postes clients dépendant du serveur en
question.
· Le role de filtre : On peut
configurer un serveur proxy de telle sorte qu'il examine le contenu des paquets
qu'il reçoit pour le compte des clients, et qu'il refuse de transmettre
ceux qui ne répondent pas à certains critères.
· Le role de sécurité : En y
ajoutant certains logiciels de sécurité, le serveur proxy assure
ainsi des fonctions de sécurité pour le réseau local.

· L'authentification : SQUID permet
d'authentifier les clients avant qu'ils accèdent à la ressource
qu'ils demandent. Nous utiliserons un serveur LDAP pour authentifier nos
utilisateurs.
II.2. L'annuaire LDAP II.2.1.
Definition
Un annuaire est un recueil de données dont le but est
de pouvoir retrouver facilement des ressources (généralement des
personnes ou des organisations) à l'aide d'un nombre limité de
critères. Cette série d'articles s'intéresse tout
particulièrement à un type spécifique d'annuaires: les
annuaires électroniques. L'implémentation d'un annuaire
électronique peut être totalement différente d'un serveur
à un autre, c'est pourquoi il a été nécessaire de
définir une interface normalisée permettant d'accéder de
façon standard aux différents services de l'annuaire. C'est le
rôle du protocole LDAP (Lightweight Directory Access Protocol),
dont le rôle est uniquement de fournir un moyen unique (standard ouvert)
d'effectuer des requêtes sur un annuaire (compatible LDAP). LDAP est un
protocole basé sur TCP/IP qui permet de partager des bases de
données sur un réseau interne ou externe. Elles peuvent contenir
tout type d'informations, des informations sur les personnes, sur des
ressources. Dans notre cas, nous utilisons l'annuaire Open Source appelé
OpenLDAP qui est développé sous licence GNU GPL. Il nous est
possible de faire des recherches dans la base en employant plusieurs
critères et aussi de faire des modifications et suppressions. Mais
contrairement à un SGBD, un annuaire est prévu pour être
plus sollicité en lecture qu'en écriture. Cela signifie qu'un
annuaire est conçu pour être plus souvent consulté que mis
à jour. En effet, comme un annuaire est beaucoup plus lu que modifier,
il a été optimisé en lecture et ne possède pas les
mécanismes de transaction complexe que les SGBD possèdent pour
traiter de gros volumes de données.
II.2.2. Fonctions
Comme l'annuaire téléphonique, la
première fonction de l'annuaire LDAP est de retrouver facilement les
coordonnées d'une personne : son adresse électronique, son
adresse professionnelle, son téléphone professionnel en fonction
de différents critères de recherche.

De nombreuses applications nécessitant une
authentification sont aujourd'hui capables d'interroger un annuaire LDAP pour
vérifier l'identité d'un utilisateur gr~ce à un couple
login et mot de passe. C'est cette fonction qui va le plus nous
intéresser dans notre étude. Grâce à cet annuaire,
notre proxy SQUID va pouvoir authentifier ses utilisateurs.
II.2.3. Structure
Les données LDAP sont structurées dans une
arborescence hiérarchique qu'on peut comparer au système de
fichier Unix. Chaque noeud de l'arbre correspond à une entrée de
l'annuaire ou Directory Service Entry (DSE) et au sommet de cette arbre,
appelé Directory Information Tree (DIT), se trouve la racine ou suffixe.
Ce modèle est en fait repris de X500, mais contrairement à ce
dernier, conçu pour rendre un service d'annuaire mondial (ce que le DNS
fait par exemple pour les noms de machines de l'Internet), l'espace de nommage
d'un annuaire LDAP n'est pas inscrit dans un contexte global.
Les entrées correspondent à des objets abstraits
ou issus du monde réel, comme une personne, une imprimante, ou des
paramètres de configuration. Elles contiennent un certain nombre de
champs appelés attributs dans lesquelles sont stockées des
valeurs. Chaque serveur possède une entrée spéciale,
appelée root Directory Specific Entry (rootDSE) qui contient la
description de l'arbre et de son contenu.
Un objet est constitué d'un ensemble de paires
clés/valeurs appelées attributs permettant de définir de
façon unique les caractéristiques de l'objet à stocker.
Par analogie avec la terminologie objet on parle ainsi de classe d'objet pour
désigner la structure d'un objet, c'est-à-dire l'ensemble des
attributs qu'il doit comporter. De cette façon un objet est un ensemble
d'attributs avec des valeurs particulières.
LDAP utilise le format LDAP Data Interchange Format (LDIF)
qui permet de représenter les données LDAP sous format texte
standardisé, il est utilisé pour afficher ou modifier les
données de la base.
ou=profs
dc=esp, dc=sn
ou=etudiants
cn=sall
uid=100
cn=ouya uid=101
cn=djiby
uid=200
cn=fatou uid=201
Dc : domain component Ou : organizational units Cn : common
name
Uid : user identifier

Figure 3: Exemple de
DIT

CHAPITRE III

Chapitre III : Mise en ° XIIE III.1. Mise
en place du proxy SQUID
III.1.1. Configuration matérielle et
logicielle
Avant d'installer et d'utiliser SQUID, il est
recommandé de bien choisir son matériel et le système
d'exploitation du serveur. Durant son lancement, SQUID a besoin de faire
beaucoup d'actions, notamment en rapport avec les caches, qui seront
consommateurs de CPU. Ainsi, le matériel minimum recommandé est
un Pentium III 550MHz, la RAM est un composant vital pour SQUID car il
réside en mémoire RAM et y stocke ses composants et les objets
les plus demandés par les clients. Lorsque le cache est activé,
il faut compter 10Mb de RAM par GIGA de données en cache. On doit alors
prévoir de l'espace disque suffisante pour le stockage des
données manipulées par SQUID notamment le cache disque, les logs
etc..
Il faut ainsi noter que le choix de la configuration
matérielle du serveur est important. Le choix d'une bonne carte
réseau est nécessaire parce qu'une carte réseau sous
dimensionnée par rapport au réseau sur lequel est branché
le Proxy provoquerait très rapidement un engorgement important et
ralentira les demandes des clients. Il est donc conseillé d'utiliser au
minimum une carte réseau 100Mbps. Il faut aussi bien vérifier
auparavant que la machine redémarre bien toute seule s'il y a coupure
d'électricité en vérifiant dans le BIOS si il y a une
option pour mettre en route la machine au rétablissement du courant, si
ce n'est pas le cas l'utilisation d'une telle machine est à
proscrire.
Concernant les systèmes d'exploitation, SQUID est
disponible sur beaucoup d'architectures et systèmes, en particulier les
différentes distributions Linux. Il est préférable
d'utiliser une version de Linux récente et stable. Dans notre
étude, nous installerons SQUID sur la dernière version de Ubuntu
actuellement disponible qui est la 10.04. Notre réseau local est le
192.168.2.0 et notre proxy va s'appeler firewall_esp.


III.1.2. Installation
III.1.2.1. Installation manuelle
Avant de commencer, il faut au préalable
télécharger la dernière version stable de SQUID. On peut
l'acquérir sur le site officiel de SQUID qui est
http://www.squid-cache.org.
La dernière version actuelle stable est la version 2.7.STABLE7. Une fois
le logiciel au format tar.gz (c'est à dire compressé sous ce
format) téléchargé, on pourra alors l'installer et on
suppose que le fichier décompressé sera placé dans le
répertoire /usr/local/src. On le décompresse via la
commande :
#tar -zxvf squid-2.7.STABLE7.tar.gz
--directory=/usr/local/src On doit obtenir ce répertoire :
/usr/local/src/squid-2.7.STABLE7.
Il convient maintenant de compiler SQUID. On se place dans le
répertoire de SQUID : #cd /usr/local/src/squid
On passe ensuite à la configuration des options de
compilation. Squid sera par défaut installé dans le
répertoire /usr/local/squid mais on peut utiliser un autre
répertoire via l'option --prefix. Si on souhaite avoir les messages
d'erreurs en français, on ajoute l'option --enable-err-language=French
mais on peut aussi faire cela au niveau de la configuration de SQUID. La
commande pour la compilation est alors :
#./configure --prefix=/usr/local/squid
--enable-errlanguage=French
Si tout c'est bien passé, il ne reste plus qu'à
compiler avec la commande : #make all
Puis procéder à l'installation avec la commande
:
#make install
Le fichier INSTALL situé dans la racine du
répertoire /usr/local/src/squid2.7.STABLE7 reprend en partie ce qui
vient d'être expliqué.
A la fin de l'installation, les répertoires suivants
seront créés :

/usr/local/squid : répertoire de base de SQUID
/usr/local/squid/etc : répertoire contenant la
configuration de SQUID /usr/local/squid/bin : répertoire contenant les
binaires et les scripts /usr/local/squid/logs : répertoire contenant les
logs
III.1.2.2. Installation automatique
L'installation automatique de SQUID est relativement facile.
Il suffit juste de disposer d'une connexion internet, de se connecter en tant
que root sur le terminal de la machine et de taper la commande :
#apt-get install squid
De cette manière, c'est le système qui se
charge de télécharger tous les fichiers nécessaires c'est
à dire la dernière version stable disponible dans les
dépôts et éventuellement les dépendances s'il y en
a. L'installation automatique est ainsi recommandée car cette
dernière se charge d'acquérir à notre place tous les
fichiers nécessaires et aussi de les placer à l'endroit qu'il
faut. Le fichier de configuration de SQUID se trouvera dans le
répertoire /etc/squid et portera le nom de squid.conf. Les logs se
trouveront dans le répertoire /var/log/squid et le démon dans le
répertoire /etc/init.d/ sous le nom de squid.
III.1.3. Configuration
SQUID se configure via un unique fichier de configuration qui
/etc/squid/squid.conf. Celui-ci est chargé au lancement de SQUID qui
s'efforcera alors de refléter ce dernier. Chaque ligne du fichier est de
la forme suivante :
option paramètre [paramètre ...I
Les lignes débutant par un '#' sont des commentaires.
Les options non définies auront toujours une valeur par défaut.
Toutes les options de ce fichier sont dispersées dans plusieurs parties
distinctes. Nous détaillerons les options les plus intéressantes
de ces parties. Notons que le fichier de base fourni avec les sources est
très largement commenté et contient par défaut 4963
lignes. Pour plus de renseignement et des paramètres plus
poussés, il est donc préférable de consulter la
documentation officielle.

III.1.3.1. Configuration de la section
réseau
Cette section concerne toutes les configurations
réseau de SQUID ayant trait aux adresses IP et ports de communication.
Ces configurations réseau concernent les communications entre SQUID et
les serveurs distants, les clients et les caches distants.
http_port : définit le port
d'écoute de Squid pour les requêtes HTTP. Par défaut, le
port sera 3128. Pour plus de sécurité, nous changeons ce port par
défaut et nous prenons par exemple le port 8080.
http_port 8080
icp_port : définit le port
d'émission et d'écoute des requêtes ICP. Par défaut,
le port est 3130. Ceci nous permet de communiquer avec des proxy parents ou
voisins. La valeur 0 permet de ne pas utiliser ce service
visible_hostname : Nous indiquons ici le nom
de notre serveur proxy. Nous l'appelons firewall_esp
error_directory : Nous indiquins via cette
option le répertoire où se trouvent les messages d'erreurs
destinés à l'utilisateur. Par défaut, on a :
/usr/share/squid/errors/en et pour avoir ces messages en français, on
met le répertoire /usr/share/squid/errors/fr à la place. Les
messages d'erreurs qui apparaitront sur le navigateur du client seront ainsi en
français.
III.1.3.2. Configuration de la taille du
cache
cache_mem : correspond au cache
mémoire, la valeur dépend de votre système. Par
défaut SQUID utilise 8 Mo. Cette taille doit être la plus grande
possible afin d'améliorer les performances. Nous décidons
d'utiliser 100MB.
cache mem 100 MB _
maximum_object_size: permet de
spécifier la taille maximale des objets qui seront stockés dans
le cache. La taille par défaut est de 20480 KB.
minimum_object_size: permet de
spécifier la taille minimale des objets qui seront WintA iEQADMIKI I7
MIENISEU iéIIXWINiil lM %11FHIXLMJQIIIFD4Mj\ IaESIN ieE minimum pour les
objets.
ipcache_size: permet de
spécifier le nombre d'adresses IP qui seront enregistrées. Sa
valeur par défaut est de 1024
III.1.3.3. &KIPan /OP4s/EK1 facKatis/Oi/E4 8
'
Cache_dir Type RépertoireSource
MOctets Level1 Level2 : permet de définir un
cache. il est possible de définir
plusieurs fois cette option afin de multiplier le nombre de cache.
Détaillons les options de ce paramètre :
· Type : le type de stockage
qui sera utilisé par Squid pour écrire ses données. Ce
paramètre modifie le comportement de SQUID lors de l'écriture sur
le disque, ses accès au disque, sa répartition de données
sur l'espace qui lui est consacrée, etc.. Une liste des types
supportés est détaillée dans le fichier de configuration
de SQUID. Le type utilisé par défaut est ufs
· RépertoireSource : le
répertoire source de l'arborescence du cache. Le cache de SQUID se
présente sous forme d'une arborescence dans laquelle les objets sont
répartis
· MOctets : la taille en Mo
à réserver sur le disque pour ce cache ;
· Level1 : le nombre de
répertoire de niveau 1 dans l'arborescence du cache.
· Level2 : le nombre de
répertoire de niveau 2 dans l'arborescence du cache.
Par défaut, on a un cache de 100 MB se trouvant dans
le répertoire /var/spool/squid. On peut ajouter si on veut un autre
cache avec le répertoire de son choix avec la taille que l'on veut.
cache_dir ufs /var/spool/squid2 1000 16 256

access_log DirectoryPath/filename :
I'Hst le chemin vers le fichier de access.log qui contient tous les
accès au cache. Par défaut c'est le fichier
/var/log/squid/access.log
cache_log DirectoryPath/filename :
idem que pour access_log avec le fichier /var/log/squid/cache.log qui
contient toutes les informations des activités de SQUID.
cache_store_log DirectoryPath/filename
: idem que pour access_log avec le fichier /var/log/squid/store.log
qui contient toutes les entrées et sorties des objets dans le cache
Pour ces trois options précédentes, si on ne
souhaite pas avoir de log, on met le paramètre none à la place du
nom de fichier.
debug_options : c'est le niveau de debug.
Indiquer 9 pour avoir toutes les traces à la place de 1 utilisé
par défaut. Attention cela donne de gros fichiers.
III.1.3.4. Comportement avec les applications
externes
Cette section définit certains paramètres qui
modifieront le comportement de SQUID envers les applications qui lui sont
extérieurs comme les serveurs distant ou ses applications
déléguées.
ftp_user : permet de spécifier
quel sera le nom d'utilisateur envoyé à un serveur FTP par SQUID
lors d'une connexion en anonymous
ftp_list_width : permet de
définir la longueur maximale des noms de fichier dans une liste. Une
fois cette taille dépassée, le nom sera tronqué et des
points de suspensions ajoutés
ftp_passive on|off : permet de
spécifier le mode de connexion FTP utilisé
dns_children : le nombre de processus
de demande de DNS résidant en mémoire. Plus le serveur sera
sollicité, plus ce nombre devra être grand
dns_timeout : permet de
spécifier un timeout à partir duquel SQUID considèrera le
serveur DNS distant comme étant indisponible

dns_nameservers : permet de
définir une liste d'adresse IP de serveur DNS qui remplacera celle lue
par défaut dans le fichier de configuration /etc/resolv.conf sous
Linux
authenticate_program : permet de
spécifier le chemin vers le programme chargé de
l'authentification des utilisateurs. En fonction du type d'authentification, un
chemin vers le fichier de profil peut être nécessaire en
deuxième option
authenticate_children : le nombre de
processus d'authentification à conserver en mémoire RAM.
III.1.3.5. I is !iP Ss 1PJ!!iQ!i
Cette section permet de configurer les différents
timeouts de SQUID
connect_timeout : le temps d'attente
d'une réponse du serveur distant avant de retourner une page d'erreur de
type "connection timeout" au client ;
request_timeout : le temps d'attente
de Squid entre deux requêtes HTTP avant de fermer la connexion ;
client_lifetime : le temps maximum
qu'un client a le droit de rester connecter à SQUID
pconn_timeout : le temps d'attente de
SQUID avant de fermer une connexion de type persistante ;
ident_timeout : le temps maximum
d'attente d'une authentification.
III.1.4. Contrôle des
accès
Il s'agit des options concernant les restrictions
d'accès aux ressources. Pour contrôler tout ce qui passe par votre
serveur proxy, vous pouvez utiliser ce que l'on appelle les ACL (Access Control
List). Les ACL sont des règles que le serveur applique. Cela permet par
exemple d'autoriser ou d'interdire certaines transactions. On peut autoriser ou
interdire en

fonction du domaine, du protocole, de l'adresse IP, du
numéro de port, d'un mot et aussi limiter ll1FFqs sur des plages
horaires. La syntaxe d'une ACL est la suivante :
acl aclname acltype string[string2]
http_access allow|deny aclname
aclname : peut être n'importe quel nom attribué par
l'utilisateur à un élément ACL acltype peut prendre comme
valeur :
· src (pour la source) : indication de l'adresse IP du
client sous la forme adresse/masque. On peut aussi donner une plage d'adresse
sous la forme aCrIMIA 3CIEXWECrIMIA 311n
· dst (pour la destination) : idem que pour src, mais on
vise l'adresse IP de l'ordinateur cible.
· srcdomain : Le domaine du client
· dstdomain : Le domaine de destination
· time : heure du jour et jour de la semaine
· url_regex : Une chaîne contenue dans l'URL
· urlpath_regex : Une chaîne comparée avec le
chemin de l'URL
· proto : Pour le protocole
· proxy_auth : Procédé externe
d'authentification d'un utilisateur
· maxconn : Nombre maximum de connexions pour une adresse
IP cliente
string[string2]: paramètres CIBlll$ 8z/
Exemple 1: Interdire
l'accès à un domaine : supposons que nous souhaitions
interdire l'accès à un domaine (par exemple le domaine
pas_beau.fr). On a donc
acl domaine_bloqué dstdomain pas_beau.fr http_access deny
domaine_bloqué
Exemple 2: interdire
l'accès aux pages contenant le mot jeu. acl bloqué_jeu
url_regex jeu
http_access deny bloqué_jeu

Attention url_regex est sensible aux majuscules/minuscules.
Pour interdire JEU, il faut aussi ajouter JEU dans votre ACL. Il n'est pas
besoin de réécrire toute l'ACL. On peut ajouter JEU
derrière jeu en laissant un blanc comme séparation (cela
correspondant à l'opérateur logique OU).
Exemple 3: Interdire les
accès pendant les plages horaires 8h-12h et 14h-18h en semaine.
«S Sunday M Monday T Tuesday W Wednesday H Thursday F
Friday A Saturday»
acl matin time MTWH 08:00-12:00 acl soir time MTWH
14:00-18:00 http_access deny matin reseau_esp http_access deny soir
reseau_esp
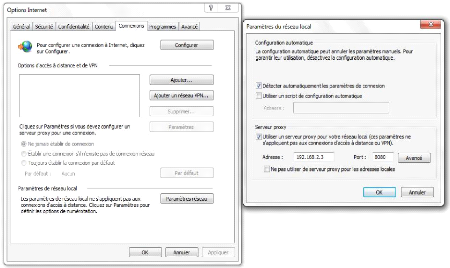
III.1.5. Configuration manuelle des clients et test
de fonctionnalité
Nous allons procéder à une configuration
manuelle des clients c'est-à-dire des utilisateurs de notre proxy. Pour
ce faire, il faut indiquer au navigateur du client de passer par notre proxy
pour pouvoir accéder à l'internet. Nous allons faire la
configuration sur les deux navigateurs les plus utilisés au monde qui
sont Mozilla Firefox et Internet Explorer
· Mozilla Firefox
1. Au niveau du menu navigateur, allez dans Outils =>
Options
2. Cliquez sur l'onglet Avancé
3. Sélectionner le sous-onglet
Réseau
4. Cliquer sur le bouton Paramètres
5. Et enfin sélectionner Configuration manuelle
du proxy puis remplir les champs en donnant l'adresse IP
De cette manière, nos clients sont configurés
pour passer par notre proxy avant de pouvoir accéder à internet.
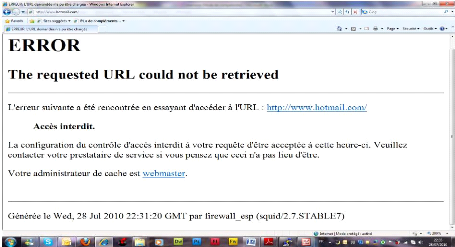
Mais par défaut, SQUID bloque toute les connexions vers internet et
l'image ci-dessous nous le démontre.
Pour que nos clients puissent bénéficier d'une
connexion à Internet, nous devons éditer le fichier squid.conf en
déclarant notre réseau local et permettre la connexion à
internet. On y ajoute ces lignes :
reseau_esp est le nom ACL et la ligne suivante est la
règle qui s'applique. 192.168.2.0 désigne l'adresse réseau
dont le masque correspond à 255.255.255.0. La ligne suivante autorise
l'accès à internet à l'acl du nom de reseau_ esp
c'est-à-dire la ligne précédente.
On quitte le fichier en enregistrant les modifications
apportées puis on redémarre le serveur via la commande :
Notre serveur est alors opérationnel pour notre
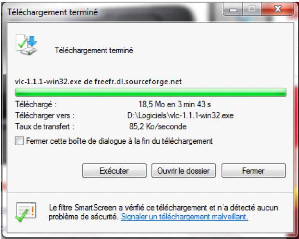
réseau local et joue bien son rôle. Pour en avoir la preuve, on
décide de télécharger deux fois de suite un même
fichier sur le même site et aussi on supprime complètement ce
fichier de notre disque dur avant de le retélécharger.
On remarque que le téléchargement du fichier de
18,5 Mo a duré pour la première fois 3min43s et que la vitesse de
téléchargement a été en moyenne de 85,2 Ko/s. Pour
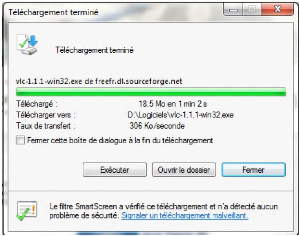
le second téléchargement, ce temps a beaucoup baissé et
est de 1min2s avec une augmentation de la vitesse moyenne de
téléchargement qui est pour cette fois ci de 306 Ko/s.
On en déduit alors que notre proxy fonctionne bien et
joue son rôle de cache car pour le second téléchargement le
temps a fortement diminué et la vitesse moyenne qui est de 306 Ko/s nous
montre que le téléchargement s'est effectué depuis notre
serveur proxy qui a mis en cache ce fichier lors du 1er
téléchargement.
Utiliser un proxy nécessite normalement qu'on configure
manuellement les navigateurs de tous nos utilisateurs de manière
à ce qu'ils interrogent toujours le proxy, quelle que soit la cible.
Cette tiche s'avère alors difficile si nous avons un très grand
nombre d'utilisateurs et aussi nos utilisateurs ont la main sur ce
paramétrage, et pourront probablement passer outre le proxy, s'ils le
décident, contournant par le fait toutes vos stratégies. Il
existe cependant un moyen d'éviter ceci en rendant le proxy transparent,
ce qui
veut dire que configurés ou non, les requêtes http
passeront quand même par le proxy. Pour arriver à ce
résultat, il faut réaliser deux opérations :