4.2. Indexation des documents :
4.2.1. Méthode d'indexation :
On distingue ici deux méthodes d'indexation, l'indexation
automatique et l'indexation manuelle.
4.2.2. Données indexées :
Les critères d'indexation peuvent être multiples et
variés. On a retenu : - Le titre du document.
-Ses différents sous-titres (balises <H1>... .
<Hn>).
-Son en-tête (le <META>tag).
-Sa date de création et/ou modification. -Sa taille.
-Les URLs qu'il cite.
-Le texte des URLs qu'il cite.
-D'autres balises éventuelles.
5. Le robot de recherche :
On va essayer de donner un aperçu du fonctionnement des
robots utilisés par un grand nombre de moteurs de recherche.
5.1. Les différentes parties d'un robot :
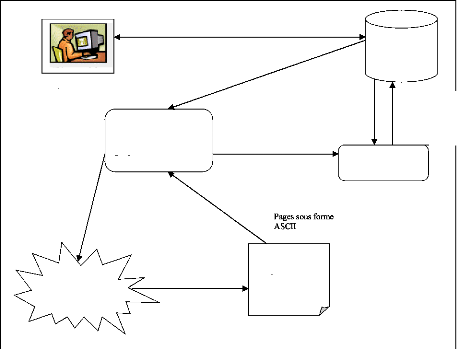
Requêtes de recherche
URLs à visiter
Module de récupération des pages
Bases de
données
Parser
Enregistrements ces URLs
Envoyer ces pages récupérées
Requêtes (HTTP ou autres)
Pages Web
Internet
Utilisateur
Indexation des pages selon algorithme ou robot
Figure 1.3. Les trois parties essentielles au bon
fonctionnement d'un robot.
5.1.1. Première partie :
Le module de récupération des pages il va
permettre, à partir d'une URL, de récupérer la page
correspondante. Cette partie fait intervenir d'importantes notions de
réseau tel que le fonctionnement client/serveur et le protocole HTTP.
5.1.2. Deuxième partie : (le parser)
Il est fortement dépendant des critères
d'indexation du robot, sur lesquels on reviendra. Le parseur sert à
extraire les informations des pages récupérés. Ce travail
est nécessaire car certaines parties de la page, notamment tous ce qui
concerne la mise en page, ne sont pas pertinentes pour le robot et
l'utilisateur.
De plus, il faut classer les informations selon les
critères d'indexations. Par exemple, le robot ne traite pas de la
même manière les liens de texte pur.
Il n' y a pas de règles d'implémentation
d'écriture d'un parseur, cela dépend fortement des
critères d'indexations. Cependant, là encore, des langages de
programmation tels que Java proposent des outils pour parser des pages HTML.
5.1.3. Troisième partie :( la base de
données)
Celle-ci stocke deux informations très importantes : d'une
part les URLs des pages, d'autre part un index des pages parsées. Cet
index permet d'associer des critères de recherche aux URLs. Lorsque
l'utilisateur émet une requête via un module de recherche, le
robot va interroger sa base de données et renvoyer les URLs qui lui
semblent pertinents. Il peut également, à l'image de Google,
renvoyer des morceaux de texte où sont présents les mots ou
expressions recherchés.
La complexité de la base de données
dépend du nombre d'informations différentes que le robot doit
stocker.
En effet, si on souhaite associer à chaque URL un (et
un seul) mot clé, la base sera très simple. En revanche, si on
souhaitons associer à chaque URL un grand nombre de mots clés,
pondérés en fonction de leur place dans le texte, ainsi que des
informations sur la popularité de la page ou le type de contenu (par
exemple .html .doc ...), l'indexation de la page sera autrement plus
compliquée.
Remarque importante :
On a essayé de présenter jusqu' a maintenant les
parties théoriques nécessaires à un robot de recherche .Il
faut cependant avoir à l'esprit que les grands moteurs de recherche
utilisant ce type d'outils traitent des volumes de données
considérables. Un ordinateur, aussi puissant soit-il, ne peut suffire
à réaliser tout ce travail. Il faut donc ajouter une couche de
complexité en répartissant le travail sur plusieurs machines,
elle-même utilisant plusieurs processus. Par exemple, google annonce
utilise plusieurs milliers de serveurs pour indexer les pages Web ainsi que
pour permettre aux utilisateurs d'effecteurs des recherches.
6. CONCLUSION :
Au cours de ce chapitre on a essayé de définir
et de donner une idée sur les fonctionnalités d'un moteur de
recherche. Suite à cette étude on cherchera à trouver des
solution pour le cas étudié, on commençons par la partie
conception qui sera détailler dans le chapitre suivant.
| 

