|
REPUBLIQUE DU SENEGAL
***** * * ********
UNIVERSITE CHEIKH ANTA DIOP DE
DAKAR
ECOLE SUPERIEURE POLYTECHNIQUE
DEPARTEMENT GENIE INFORMATIQUE
Centre de Dakar

MEMOIRE DE FIN DE CYCLE
Pour l'obtention du :
DIPLOME D'INGENIEUR DE CONCEPTION (DIC) EN GENIE
INFORMATIQUE
Thème :
Etude de solutions libres de webmapping, et mise en
place d'une plateforme de cartographie dynamique
Lieu de
stage : Laboratoire de
Traitement de l'Information
Période
stage : 04 Février 2008 -
30 Juin 2008 
Présenté par : M. Issa
BALDE Sous la direction du professeur :
Claude LISHOU

 

Année Universitaire : 2007 -
2008
REPUBLIQUE DU SENEGAL
***** * * ********
UNIVERSITE CHEIKH ANTA DIOP DE
DAKAR
ECOLE SUPERIEURE POLYTECHNIQUE
DEPARTEMENT GENIE INFORMATIQUE
Centre de Dakar

MEMOIRE DE FIN DE CYCLE
Pour l'obtention du :
DIPLOME D'INGENIEUR DE CONCEPTION (DIC) EN GENIE
INFORMATIQUE
Thème :
Etude de solutions libres de webmapping, et mise en
place d'une plateforme de cartographie dynamique
Lieu de
stage : Laboratoire de
Traitement de l'Information
Période
stage : 04 Février 2008 -
30 Juin 2008 
Présenté par : M. Issa
BALDE Sous la direction du professeur :
Claude LISHOU




Année Universitaire : 2007 -
2008
DEDICACES
Je dédie ce mémoire :
A ma mère
A mon père
A mon père et tuteur feu Ismaïla
Baldé (Que la terre lui soit légère)
A ma famille pour tout son soutien
A tous mes camarades de classe, pour ces 3 années de
compagnonnage, je vous adore tous
A tous mes voisins de chambre (ceux de la
31A et de la 17A)
REMERCIEMENTS
Après avoir
rendu grâce à DIEU,
J'adresse mes remerciements les plus
chaleureux à :
· Mes parents que je ne remercierai jamais
assez,
· Pr. Claude LISHOU qui m'a
accueillit et encadrer durant toute la durée du stage
· M. Samuel
Ouya, Chef du département génie
informatique pour avoir souvent organisé des pré-soutenances qui
nous ont permis de rectifier nos erreurs et d'améliorer nos
présentations
· Mme Awa NIANG au labo
LTI
· M. Roger M. Faye au labo
LTI
· M. Salam Sawadogo au labo
LTI
· M. Mbaye DIOP chercheur au labo
LERG (Laboratoire d'Enseignement et de Recherche en Géomatique)
· M. Ahmat Bamba
Mbacké, (mention spéciale) pour sa disponibilité,
ses conseils, et son ouverture envers tous les étudiants
· M. Alex
Corenthin, enseignant au département
génie informatique pour les efforts fournis afin de nous placer en
position de stage
· M. Mamadou
NIANG, responsable pédagogique des
ingénieurs au département génie informatique
· Tout le corps professoral du département
génie informatique pour la qualité de leur enseignement
· Tous les membres du Labo LTI, pour avoir bien
accueilli et facilité mon intégration
Toutes les personnes qui de
prés ou de loin, ont contribué à la réalisation de
ce document.
1. TABLE DES MATIERES
Sigles et Abréviations
..................................................................................9
Glossaire 10
Table des figurs 11
Les tableaux 12
Table des
diagrammes.................................................................................13
Avant-propos 14
Introduction 15
1ere Partie : Présentation
générale et Choix de la méthode d'analyse et de
conception
· Chapitre
1 : Présentation générale
17
I. Présentation de la structure
d'accueil
17
II. Contexte du projet
17
1. Le projet TIC & Gouvernance locale
17
2. Problématiques et objectifs
18
· Chapitre
2 : Etat de l'art du Webmapping
20
I. Définition et présentation
des concepts de la cartographie en ligne
20
1. La cartographie
20
2. Le Webmapping ou cartographie dynamique sur
Internet
20
3. Principe de la cartographie sur Internet
20
II. Unités
cartographiques(I)
22
1. Point
22
2. Ligne ou segment de ligne
22
3. Surface ou zone
22
III. Nature des données
23
1. Les données
géométriques
23
a. Le mode raster
23
b. Le mode vecteur
23
2. Les données attributaires
23
IV. Affichage par couche
24
V. Les principales fonctionnalités
d'un SIG (I)
24
1. Abstraction :
25
2. Acquisition
25
3. Archivage
25
4. Analyse
25
5. Affichage
25
VI. Quelques solutions de Webmapping existants
25
1. Google Map
25
2. ArcGIS
26
· Chapitre
3 : Choix d'une méthode d'analyse
27
I. Définition des concepts
27
II. Pourquoi utiliser une
méthode ? (II)
28
III. Classification des méthodes
d'analyse et de conception
28
1. Les méthodes cartésiennes ou
fonctionnelles (II)
28
2. Les méthodes systémiques
(II)
28
3. Les méthodes objets
(II)
29
4. Approche orientée aspect
29
IV. Choix d'une méthode d'analyse et
de conception
31
1. Le Processus Unifié (UP)
31
a. Définition
31
b. Vie du processus unifié
32
c. Les Phases
34
2. La méthode RAD
35
V. Le langage UML
36
1. Pourquoi UML ?
36
2. Diagrammes structurels (les vues
statiques)
37
a. Les cas d'utilisation (uses cases)
37
b. Les diagrammes d'objets
38
c. Les diagrammes de classes
38
d. Les diagrammes de paquetages (ou
package)
38
e. Les diagrammes de composants et de
déploiement
38
3. Diagrammes comportementaux (les vues
dynamiques)
38
a. Les diagrammes de séquence
39
b. Les diagrammes de collaboration
39
c. Les diagrammes d'états-
transitions
39
d. Les diagrammes d'activités
39
2eme Partie : Analyse et Conception de la
plateforme
· Chapitre
4 : Analyse de la plateforme
41
I. Les acteurs du système
41
1. L'administrateur :
41
2. Responsable du site
41
3. Les utilisateurs membres
41
4. Les visiteurs
41
II. Interactions entre les acteurs et le
système
42
1. Diagrammes de cas d'utilisation
42
2. Scénarios textuels des cas
d'utilisation
45
3. Comportement des cas d'utilisation
47
4. Diagramme de classe d'analyse
49
· Chapitre
5 : Conception de la plateforme
51
I. Solution technique
51
1. Le portail d'accueil du SIG
51
2. Interface protégée
52
II. Fonctionnement du système
53
1. Etats des objets
53
2. Chronologie des interactions
55
3. Ebauche du diagramme de classe
57
3ere Partie : Mise en oeuvre de la
plateforme
· Chapitre
6 : Choix des outils à utiliser
60
I. Les Systèmes de Gestion de Bases
de données spatiaux
60
1. Présentation des
différences entre les cartouches spatiales
60
a. Model Objet
60
b. Système de Référence
Spatial
61
c. Prédicats
61
d. Opérateurs
61
e. Métadonnées
62
2. Présentation des
évaluations quantitatives des cartouches spatiales
62
a. Temps d'exécution
62
b. Critères de notations
63
3. Conclusion sur les SGBDR spatiaux
64
II. Les serveurs cartographiques
64
1. GéoServer
64
2. MapServer
65
a. Présentation de MapServer
65
b. Principes de fonctionnement
67
c. Fonctionnalités de MapServer
68
d. Points forts et points faibles de
MapServer
69
3. ArcIMS (I)
70
4. Conclusion sur les serveurs
cartographiques
71
III. Les serveurs web
71
1. Points forts et points faibles
71
2. Choix selon les besoins
72
a. Compétences faibles et exigences
modestes: IIS
72
b. Compétences fortes, tous types
d'exigences: Apache
72
c. Compétences moyennes et exigences
très fortes: Zeus
72
3. Autres informations pratiques
73
4. Conclusion sur les serveurs web
73
IV. Choix de la solution à
implémentée
74
· Chapitre
7 : Implémentation de la solution
75
I. Environnement de Travail
75
1. Environnement matériel
75
2. Environnement logiciel
75
II. Architectures de la plateforme
76
1. Architecture logiciel du
système
76
2. Architecture physique du
système
77
3. Architecture applicative de la
plateforme
77
4. Sécurité de la
plateforme
79
III. Présentation de
l'application
80
1. Zone privée
80
2. Interface publique
82
Conclusion générale
85
Réferences 86
Index 87
Annexes 88
SIGLES ET ABREVIATIONS
Le tableau ci-après représente la
traduction de quelques sigles et abréviations utilisés dans ce
document.
|
SIG
|
Système d'Information
Géographique
|
|
PFE
|
Projet de Fin
d'Etude
|
|
DUT
|
Diplôme Universitaire de
Technologie
|
|
BTS
|
Brevet de Technicien
Supérieure
|
|
DUES
|
Diplôme Universitaire
d'Etude Scientifique
|
|
API
|
Application Programming
Interface
|
|
PHP
|
Pre-HyperTexte-Processor
|
|
GPS
|
Global Positioning
System.
|
|
SGBD
|
Système de Gestion
de Bases de Données
|
|
CGI
|
Common Gateway
Interface
|
|
OGC
|
OpenGis
Consortium
|
|
ODBC
|
Open
DataBase Connectivity
|
|
XML
|
EXtensible Markup
Language
|
|
HTML
|
HyperText
Markup Language
|
|
SRS
|
Système de
References Spatiaux
|
|
UML
|
Unified Modelling
Language
|
|
AUF
|
Agence Universitaire de
la Francophonie
|
|
CNRS
|
Centre National de la
Recherche Scientifiques
|
|
IRD
|
Institut de Recherche pour
le Développement
|
|
JDK
|
Java Developpement
Kit
|
|
ESRI
|
Environmental Systems
Research Institute
|
|
UP
|
Unified Process
|
|
RAD
|
Rapid Application
Development
|
|
DBF
|
Data Base
File
|
|
SHP
|
SHaPe
|
|
SHX
|
SHape indeX
|
2. GLOSSAIRE
· Webmapping :
C'est la diffusion de carte via internet
·
Cartographie : C'est l'étude du tracé
de cartes
·
API : Application
Programming Interface. Il s'agit ici de l'ensemble des commandes
permettant d'accéder aux fonctionnalités du noyau
MapServer.
· CGI :
Un programme CGI est exécuté côté serveur. Il
permet l'échange de données entre le serveur et le navigateur.
Quand il reçoit une requête du poste client, le CGI
détermine (en fonction de l'extension) l'action à
effectuer.
· Open
Source : Possibilité de libre
redistribution, d'accès au code source, et de travaux
dérivés
·
Implémentation : Elle consiste à
réaliser le programme conformément aux critères
définis dans les phases d'analyse et de conception.
· Framework :
Infrastructure logicielle facilitant la conception et le
développement d'applications
· Layer : Il
s'agit d'un terme anglais signifiant « couche »
· Serveur :
C'est une machine ou un programme qui offre un service à un
client (source : Wikipédia)
·
Shapefile : "fichier de formes" est un
format de fichier issu du monde des Systèmes d'Informations
Géographiques (ou SIG).Initialement développé par ESRI
pour ses logiciels commerciaux, ce format est désormais devenu un
standard de facto, et largement utilisé par un grand nombre de logiciels
libres.
· Mapfile :
C'est un fichier texte d'extension .map qui contient toute la description de
l'image à générer par MapServer.
·
DBF :
extension de fichier qui contient les
données attributaires relatives aux objets contenus dans le
Shapefile.
· SHX :
extension de fichier qui stocke l'index de la géométrie.
· OGC : C'est
l'organisme référent en matière de normalisation des
informations géographiques. Association à but non lucratif, l'OGC
élabore des normes pour le traitement de l'information
géographique sur des plateformes informatiques ouvertes. Une de ses
spécifications est de faciliter l'interopérabilité des
systèmes afin de promouvoir le développement des SIG
libres.
· Extent :
L'extent correspond à l'étendue de la carte en coordonnées
géographique dans un système de projection
spécifique.
TABLE DES
FIGURES
Figure 1.1: Les modules du projet TIC &
Gouvernance Locale
18
Figure 2.1: Principe de cartographie sur
Internet
21
Figure 2.2: Procédé de
superposition de couches
24
Figure 2.3: la gamme de produit ArcGIS
26
Figure 3.1 : Illustration du caractère
itératif de UP
31
Figure 3.2 : Modèle représentant
les 4+1 vues de Kruchten
32
Figure 3.3 : Architecture bidirectionnelle du
PU
33
Figure 5.1 : Présentation du portail
LtiSig zone publique
52
Figure 5.2 : Présentation de
l'interface privée
53
Figure 6.1 : Représentation de la
note de chaque SGBD selon les critères choisis
63
Figure 6.2: Architecture de MapServer
67
Figure 6.3: Architecture de la solution
choisie
74
Figure 7.1 : Architecture applicative de la
plateforme
78
LES TABLEAUX
Tableau 4.1 : scénario textuel du cas
« Authentification »
45
Tableau 4.2 : scénario textuel du cas
« Navigation sur le portail »
46
Tableau 4.3 : scénario textuel du cas
« importer shapefile »
46
Tableau 5.1 : présentation des classes
de la phase conception
57
Tableau 5.2 : présentation des
attributs et opération des classes de la phase conception
58
Tableau 6.1 : Comparaison base de
données spatiaux : Version des SGBD
60
Tableau 6.2 : Comparaison base de
données spatiaux : Model objet
60
Tableau 6.3: Comparaison base de
données spatiaux : SRS
61
Tableau 6.4 : Comparaison base de
données spatiaux : Prédicats
61
Tableau 6.5: Comparaison base de
données spatiaux : Opérateurs
61
Tableau 6.6: Tables de
métadonnées définies par l'OGC
62
Tableau 6.7: Comparaison base de
données spatiaux : Gestion des métadonnées
62
Tableau 6.8 : Comparaison base de
données spatiaux : Temps d'exécution
62
Tableau 6.9: Comparaison base de données
spatiaux : Notations
63
Tableau 6.10 : Avantages et
inconvénients de GéoServer
65
Tableau 6.11: Extrait d'un Mapfile
66
Tableau 6.12: Points forts et points faibles
de MapServer
69
Tableau 6.13 : Points forts et points faibles des
serveurs web étudiés
71
Tableau 6.14 : Tableau donnant des
informations sur le Prix et la compatibilité pour les serveurs web
73
Tableau 7.1 : Caractéristiques des
équipements
75
Tableau 7.2: Les outils logiciels
utilisés
75
Tableau 7.3: Les librairies
utilisées
76
TABLE DES DIAGRAMMES
Diagramme 4.1 : Diagramme de cas d'utilisation
général
42
Diagramme 4.2 : Diagramme de cas d'utilisation
«Navigation sur le portail »
43
Diagramme 4.3 : Diagramme de cas d'utilisation
«Accès à la zone privée »
44
Diagramme 4.4 : Diagramme d'activité
«Authentification »
48
Diagramme 4.5 : Diagramme d'activité
«Accès à la zone privée »
48
Diagramme 4.6 : Diagramme d'activité
«importer shapefile »
49
Diagramme 4.7 : Diagramme de classe
d'analyse
50
Diagramme 5.1 : Diagramme
d'état-transition de l'objet utilisateur
53
Diagramme 5.2 : Diagramme d'état -
transition de l'objet couche
54
Diagramme 5.3 : Diagramme d'état -
transition de l'image générée
54
Diagramme 5.4 : Diagramme de séquence
de l'accès à la zone privée
55
Diagramme 5.5 : Diagramme de séquence
de l'importation des shapefile
56
Diagramme 5.6 : Diagramme de séquence
de navigation sur le portail
57
Diagramme 5.7 : Diagramme de classe de la
phase conception
58
Diagramme 7.1 : Diagramme de composants du
système
76
Diagramme 7.2 : Diagramme de
déploiement du système
77
AVANT- PROPOS
Le département génie informatique de
l'école supérieure polytechnique(ESP) de Dakar dispose d'un cycle
d'ingénieur de conception qui dure trois(3) ans. Cette formation est
accessible aux titulaires d'un DUT ou d'un BTS sélectionnés
sur dossier d'un DUES scientifique sélectionnés sur concours.
Ce cycle a pour objet de former des ingénieurs informaticiens dans le
domaine général de la gestion, de l'organisation et de la
production dans les entreprises.
Toutefois cette formation est bouclée par un stage d'au
moins cinq(5) mois durant lequel un PFE est soumis à
l'élève. Ce stage lui permettra, non seulement de mettre en
pratique ses connaissances, mais aussi d'intégrer le milieu
professionnelle.
A l'issue de ce stage un mémoire, expliquant clairement
le travail de réalisation du PFE, sera présenté et soutenu
devant un jury.
C'est dans ce contexte que nous avons été
accueillit au sein du Laboratoire de Traitement de l'Information (LTI).
INTRODUCTION
L'homme est culturellement initié aux
représentations symboliques, la cartographie en est une traduction. Elle
est la première étape de la création des Systèmes
d'Informations Géographiques.
L'essor des moyens de communication modernes tels que Internet
ont très vite servi de support à la diffusion cartographique.
L'arrivée à maturité de façon synchrone des SIG,
d'Internet et de l'élaboration d'une normalisation ont permis le
développement d'applications à fort potentiel.
Les formats image apparaissent à la fin des
années 70. Ce sont des formats d'images en mode matriciel. Mais il faut
attendre les années 90 pour voir apparaître des formats vectoriels
normalisés. Pour les représentations cartographiques cela
représente la base. Car le mode matriciel étant ancien, les
premières applications vont s'orienter sur ce mode vectoriel qui va
marquer profondément leur architecture.
L'élaboration de SIG performants et du Web sont
passés par de fortes structurations des données. Ces
données ainsi homogénéisées ont permis de concevoir
des systèmes qui analysent le contenu sans s'occuper de la forme. De
tels systèmes se sont ouverts au Web qui a connu les mêmes
structurations. Ceci a permis des représentations cartographiques sur le
Web. Certaines applications se limitent à un affichage d'information
spatialisé qui associées à la diffusion du Web introduit
un nouveau concept, le Webmapping1(*) qui est apparu au milieu des années 90. Le
Webmapping, ou diffusion de cartes via le réseau internet, est
un domaine en pleine expansion grâce au développement des
solutions Open Sources2(*).
C'est dans cette optique que, le Laboratoire de Traitement de
L'information, dans le cadre des projets d'appui à la
décentralisation au Sénégal, nous a confié le
projet de fin d'étude qui s'intitule
ainsi : « Etude de solutions libres de Webmapping,
et mise en place d'une plateforme de cartographie
dynamique ». Il s'agit donc pour nous de proposer une
solution libre de Webmapping, et ensuite de l'utiliser pour concevoir et mettre
en oeuvre une application pouvant importer et afficher des cartes
dynamiquement. La plateforme doit pouvoir gérer des données
cartographiques de formats vectoriels et rasters.
L'objectif premier du PFE est de se doter d'une plateforme
cartographique accessible via internet, permettant non seulement d'afficher des
cartes à la demande d'un utilisateur, mais aussi de positionner des
zones stratégiques en monde rurale sur celle-ci connaissant leurs
coordonnées géographiques. Ces zones sont réparties sous
forme de couches et il s'agit entre autres des écoles, des postes de
santé, des points d'eau, des institutions administratives.
L'application doit en outre offrir des outils de navigation
sur la carte. Ces outils sont entre autres le zoom, le déplacement,
affichage des informations d'une zone, affichage de la légende de la
carte.
Un autre objectif est de pouvoir représenter les
cadastres de certaines zones rurales découpés en parcelles
connaissant leurs limites géographiques.
Ce document est subdivisé en trois grandes parties. La
première partie concerne la présentation générale
qui est elle-même constituée en trois chapitres dans lesquels nous
avons d'abord fait une présentation de la structure d'accueil, du
contexte du projet et des objectifs, ensuite le chapitre suivant évoque
l'état de l'art du webmapping où nous avons définit des
concepts de la cartographie sur internet, enfin le dernier chapitre de cette
partie à été consacré au choix d'une méthode
d'analyse et de conception. La seconde partie intitulée analyse et
conception évoque en deux chapitres l'étude fonctionnelle et
conceptuelle de l'ensemble des besoins des utilisateurs.
Dans la dernière partie consacrée à la
mise en oeuvre de la solution, nous distinguons deux chapitres. Le premier
chapitre est réservé au choix des outils à utiliser pour
réaliser la solution. Dans ce chapitre, nous avons mené des
études comparatives entre les différents outils susceptibles
d'être utilisé. Le tout dernier chapitre est consacré
à l'implémentation de la solution choisie.
CHAPITRE
1
Présentation
générale
I. Présentation de
la structure d'accueil
Dans cette partie nous allons présenter la structure au
sein de laquelle nous avons passé ces 5 mois de stage. Il s'agit en
l'occurrence du labo LTI3(*).
Créé en janvier 2004 le LTI est devenu l'un des
plus importants laboratoires de l'Ecole Supérieure Polytechnique,
unité de recherche, transversale sur les Sciences de
l'Ingénieur.
Les activités du LTI couvrent un large spectre
qui part de l'océanographie pour aboutir à des systèmes
complexes de transport, en passant par tous les composants de la chaîne
informatique : réseaux, systèmes répartis, calcul
numérique et calcul formel, logiciels de la recherche d'information et
d'aide à la décision, codage des langues nationales sur internet.
Le LTI se veut centre africain de référence et d'excellence
au coeur de la recherche et de ses applications. C'est dans cette optique
qu'ont été créées des collaborations avec les
grandes écoles de la sous région, unissant leur
compétence à celles du LTI.
Le laboratoire est également largement impliqué
dans les formations par la recherche, à travers le Mastère
Recherche SPI. Les chercheurs du LTI participent à de nombreux
programmes de recherche nationaux ou internationaux (AUF, CRDI, CNRS, etc...).
Ils sont les acteurs majeurs de l'activité scientifique internationale
par le biais de l'animation de comités éditoriaux de revues, de
l'organisation de très nombreuses conférences, l'accueil des
chercheurs étrangers etc. Enfin, le LTI entretient un tissu de relations
industrielles et des collaborations académiques avec des
universités ou des centres de recherche comme l'IRD à travers des
projets communs.
II. Contexte du
projet
1. Le projet TIC &
Gouvernance locale
Ce projet s'inscrit dans le contexte de la mise en oeuvre du
plan d'action du Sommet mondial sur la société de l'information
(SMSI). Ce plan met l'accent entre autres sur la nécessité d'un
partenariat public-privé pour permettre aux collectivités
africaines un accès généralisé aux technologies de
l'information et de la communication (TIC) pour stimuler leur
développement économique et sociale.
Le projet est une initiative conjointe d'Alcatel, du CRDI et
du FENU (Fonds d'équipement des Nations Unies). Il consiste à
conduire une expérience-pilote d'intégration d'applications et
services de TIC dans le processus de décentralisation et de gouvernance
locale au Sénégal. Il sera déployé dans huit
communautés rurales de deux départements (Kaffrine et
Kébémer), zones d'intervention du FENU, par une équipe
pluridisciplinaire de chercheurs du Laboratoire de traitement de l'information
de l'Ecole supérieure polytechnique de Dakar. Le projet pilote devra
fournir des enseignements de base pour une extension de l'expérience
dans l'espace et dans le temps. La figure ci-dessous donne les
différents modules ciblés par le projet.

Figure 1.1: Les
modules du projet TIC & Gouvernance Locale
2. Problématiques
et objectifs
Notre séjour au laboratoire de traitement de
l'information, a consisté à la mise en place du module
« Localisation cartographique
rurale ».
Il s'agissait donc pour nous de réaliser une plateforme
de cartographie dynamique accessible via internet à partir des outils du
monde libre.
Cette plateforme devra mettre à la disposition des
utilisateurs, le maximum de fonctionnalités offertes par un SIG
classique.
Il faut pouvoir positionner géographiquement des zones
stratégiques sur une carte. Il faudra égalent affiner la
navigation sur la carte en implémentant des outils de navigations tels
que le zoom +, le zoom - et le déplacement.
Il faudra aussi pouvoir afficher la légende de la
carte créée pour une meilleure lecture de l'image.
Lors qu'on sélectionne une zone, l'application devra
pouvoir afficher l'ensemble des informations concernant cette zone.
A travers cet outil cartographique, les projets d'appui
à la décentralisation au Sénégal ont pour but de
mettre à la disposition des communautés rurales une cartographie
complète des centres stratégiques tels que :
· Les écoles
· Les centres de santé
· Les postes de santé
· Les points d'eau
· Les institutions administratives
· ......
Par ailleurs un autre objectif peut être
distingué. Il s'agit de pouvoir visualiser le cadastre d'une zone
découpé en parcelles. Ce qui permettra bien sûre de pouvoir
localiser les champs dans un village, connaitre le propriétaire, la
surface et d'autres descriptions importantes.
CHAPITRE
2
Etat de l'art du Webmapping
I. Définition et présentation des
concepts de la cartographie en ligne
La cartographie en ligne répond à de
réels besoins de diffusion rapide de l'information et de mise à
jour à distance des données. Bien que le résultat
cartographique permette de faciliter la compréhension de l'espace
environnant, la mise en oeuvre de telles plateformes demande des
compétences transversales à la fois en informatique et en
géographie.
1. La cartographie
La cartographie désigne la réalisation et
l'étude des cartes. Elle mobilise un ensemble de techniques servant
à la production des cartes. La cartographie constitue un des moyens
privilégiés pour l'analyse et la communication en
géographie. Elle sert à mieux comprendre l'espace, les
territoires et les paysages. Elle est aussi utilisée dans des sciences
connexes, démographie, économie dans le but de proposer une
lecture spatialisée des phénomènes.
2. Le Webmapping ou cartographie dynamique sur
Internet
Ce terme générique défini à la
fois le processus de distribution de cartes via un réseau tel que
l'Internet ou l'Intranet et leur visualisation dans un navigateur. En d'autres
termes on peut l'appeler un SIG web.
Les données stockées et mises en relation dans
les SGBDR correspondent aux informations attributaires décrivant
l'espace donné, tandis que les objets géographiques tels que le
point, la ligne et le polygone sont des données
géométriques référencées dans un plan en x
par la longitude et en y par la latitude voire en z pour l'altitude.
Les données sont directement reliées à
une géométrie particulière dans un SIG grâce
à des connexions informatiques ODBC.
Dans une conception en ligne, la visualisation des cartes
passe par des programmes installés sur des serveurs cartographiques qui
communiquent par des protocoles prédéfinis. La
géométrie est gérée grâce à la
cartouche spatial du SGBDR.
3. Principe de la cartographie sur
Internet
La solution la plus répandue actuellement dans le
domaine de la mise en ligne de données cartographiques consiste à
créer à la volée une image correspondant à la
demande de l'utilisateur. Pour cela, il est le plus souvent fait appel à
un serveur cartographique.
C'est le protocole de communication TCP/IP qui permet à
des ordinateurs branchés en réseau d'échanger de
l'information via un navigateur web ou de transférer des fichiers via le
protocole ftp. L'architecture est de type client/serveur c'est-à-dire
qu'il existe une série d'ordinateurs dits clients connectés
à un serveur dédié qui lui-même communique vers
l'extérieur ou avec des serveurs particuliers par
l'intermédiaire de leur adresse IP. L'utilisateur sur sa machine locale
effectue des requêtes pour demander une carte spécifique ; le
serveur cartographique interprète cette requête et renvoie la
carte sous la forme d'une image matricielle (gif, jpg, png,...) ou vectorielle
(svg, flash). Le serveur cartographique est télécommandé
par des langages de script qui lui permettent de charger dynamiquement une
carte en réponse à la requête. L'ordinateur serveur peut
chercher cette information soit dans ses propres ressources, soit sur des
serveurs de données distants.
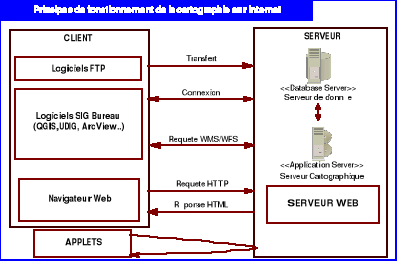
Figure 2.1:
Principe de cartographie sur Internet
La consultation de l'information requiert une installation
essentiellement côté serveur avec des logiciels tels que Apache ou
IIS (Internet Information Services) qui tournent en tâche de fond et
permettent aux serveurs de cartes d'accéder à l'Intranet et/ou
à l'Internet.
Il faut aussi rajouter des interpréteurs de scripts et
éventuellement une visionneuse pour afficher la carte sur le navigateur
du client. La visionneuse peut être un applet ou un servlet.
Dans le cas de l'applet, la visionneuse se
télécharge côté client à chaque utilisation,
dans le cas du servlet, elle s'exécute directement sur le serveur, la
différence se situe au niveau de la rapidité de chargement et de
la saturation potentielle des capacités du serveur.
Les requêtes sur un serveur cartographique peuvent
êtres exécutées par le navigateur ou par un programme
appelant. Les moteurs cartographiques sont des programmes dont le rôle
est de fabriquer à la volée, selon la demande de l'utilisateur
des fichiers images représentant des données géographiques
stockées sur le disque dur du serveur ou sur un autre serveur
relié. Au niveau du serveur de données, les SGBDR tels que
PostgreSQL ou MySQL, entre autres, peuvent être installés
directement sur le serveur contenant le serveur cartographique ou bien à
distance. Qu'importe le lieu, l'important est de pouvoir consulter et
éditer des données à distance.
II. Unités
cartographiques(I)
1.
Point
Le point est un élément sans dimension. Sa
localisation est donnée par ses coordonnées. Ce concept est
référencé à des étiquettes (constituant la
légende) qui permettent sa compréhension. Quoique sans dimension,
la notion de point soit relative à l'échelle à cause de
ce qu'elle peut représenter (hôpital ou ville). La notion de
distance entre deux points est souvent utilisée comme lien
topologique.
2. Ligne ou segment de
ligne
La ligne ou segment de ligne est un élément
à une dimension. Sa localisation est déterminée par les
coordonnées des deux extrémités du segment.
L'épaisseur du trait ou la forme du trait apporte une information
supplémentaire sur sa signification thématique. La notion de
distance est souvent utilisée pour caractériser une ligne.
3. Surface ou
zone
La surface ou zone est l'espace limité par une ligne
fermée ou un polygone. Du point de vue cartographique, c'est un
élément à deux dimensions. La localisation d'une surface
s'exprime par les coordonnées de son centre de gravité, d'une
référence interne ou des sommets du polygone qui forme ses
limites.
Un noeud est défini comme un sommet constituant
l'intersection de plus de deux segments tandis que la chaîne correspond
à la ligne brisée dont les deux extrémités sont des
éléments.
III. Nature des
données
1. Les données
géométriques
Décrivent les objets : leurs formes (ligne,
surface ou points), leur position par rapport à un système de
coordonnées ainsi que les relations spatiales entre ces
différents objets. Deux modes techniques permettent de mettre en oeuvre
cette information :
a. Le mode
raster
Nativement, un navigateur Web
connaissant le HTML peut
afficher une image numérique, encore appelée image BITMAP. Elle
se compose donc d'une matrice de pixels (abréviation de l'anglais
« Picture élément »), c'est-à-dire de
petits carrés noirs ou blancs ou de différents tons de gris ou de
couleur juxtaposés. Généralement les formats d'image les
plus utilisés sont le GIF, le JPEG et le PNG.
Le format GIF limite à 256 le nombre de couleurs
possibles mais restitue une image sans perte d'information. Il permet aussi de
gérer des effets de transparence. Le format JPEG ne connaît pas
cette limite et supporte des taux de compression plus élevés au
prix d'une certaine dégradation de l'image de base. Le format PNG, qui
est une émanation du consortium W3C, utilise un mode de
compression sans perte d'information qui est réputé d'une
efficacité excellente. Il a l'avantage de pouvoir traiter plusieurs
types d'images et d'être libre de tout droit. Cependant, il est encore
peu utilisé.
b. Le mode vecteur
Les fichiers vectoriels contiennent une description des
entités géographiques à représenter : points,
lignes, surfaces, formes géométriques élémentaires.
A ce jour, deux formats vectoriels se dégagent : le
SVG qui est un format ouvert et le SWF
dit aussi Flash qui est un format propriétaire. Que se
soit l'un ou l'autre des formats vectoriels, aucun n'est lu actuellement par un
navigateur Web sans l'adjonction d'un plug-in.
2. Les données attributaires
Ce sont des attributs mis en relation avec un objet ou une
localisation géographique, soit pour nous renseigner sur un objet
géographique, soit pour localiser des informations. Les données
attributaires regroupent différents types d'informations : nom, valeur
numérique, contenu thématique, etc.
IV. Affichage par couche
Un SIG affiche les informations concernant le monde par
superposition de couches thématiques pouvant être reliées
les unes aux autres par la géographie. Chaque couche contient des objets
de même type (routes, marchés, cours d'eau, limites de communes,
pistes, établissement, hôpitaux,...). Ce concept, à la fois
simple et puissant a prouvé son efficacité pour résoudre
de nombreux problèmes concrets.
Le schéma suivant montre, la création de l'image
de la carte finale par superposition de couches :
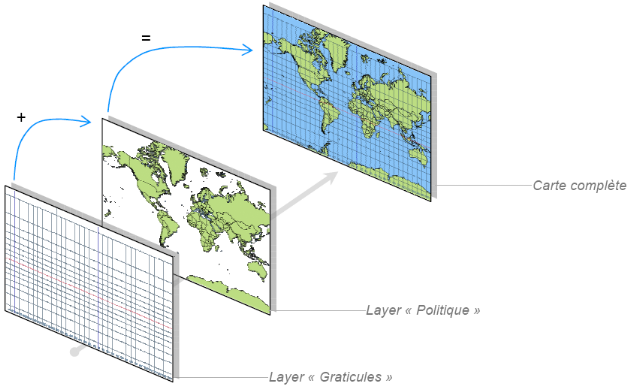
Figure 2.2:
Procédé de superposition de couches
V. Les principales fonctionnalités d'un
SIG (I)
Les SIG doivent être à la fois un outil de
gestion pour le technicien et un outil d'aide a la décision pour le
décideur. Il doit donc offrir les fonctions nécessaires à
ces deux objectifs, regroupées sous le terme des `5A':
1. Abstraction :
Elle vise à représenter le monde réel,
en organisant les données par composants géométriques et
par attributs descriptifs et en en établissant des relations entre les
objets.
2. Acquisition
L'acquisition revient à alimenter le SIG en
données par saisie des informations géographiques sous forme
numérique : la forme des objets géographiques et leurs
attributs et relations.
3.
Archivage
L'archivage revient à gérer la base de
données en transférant les données de l'espace de travail
vers l'espace d'archivage.
4.
Analyse
Elle permet de manipuler et d'interroger des données
géographiques afin de répondre aux requêtes des
utilisateurs.
5.
Affichage
Son but est de permettre à l'utilisateur
d'appréhender des phénomènes spatiaux dans la mesure
où la représentation graphique respecte les règles de la
cartographie.
VI. Quelques solutions de
Webmapping existants
Actuellement il existe une multitude de solutions de
Webmapping sur le marché. Nous allons parler entre autre de Google maps
et de ArcGIS.
1. Google
Map
Google Maps4(*) est un service gratuit de carte géographique et
de plan en ligne. Le service a été créé par Google.
Il s'agit d'une forme de géoportail. Lancé en 2004 aux
États-Unis et au Canada et en 2005 en Grande Bretagne (sous le nom de
Google Local), Google Maps a été lancé jeudi 27 avril
2006, simultanément en France, Allemagne, Espagne et Italie. Ce
service a ceci de particulier qu'il permet, à partir de l'échelle
d'un pays, de pouvoir zoomer jusqu'à l'échelle d'une rue. Deux
types de plan sont disponibles : un plan classique, avec nom des rues,
quartier, villes et un plan en image satellite, qui couvre aujourd'hui le monde
entier. Ce service n'est plus en version bêta depuis le 12 septembre
2007, et a été ajouté aux liens de la page d'accueil de
Google.
2. ArcGIS
Les récents développements de l'informatique
(généralisation d'Internet, avancées dans la technologie
des SGBD, programmation orientée objet, informatique nomade) et une
large adhésion au SIG ont fait évoluer ses perspectives et son
rôle.
En plus de l'environnement bureautique, les logiciels SIG
peuvent être centralisés sur des serveurs d'applications et des
serveurs Web pour fournir des fonctions SIG à un nombre infini
d'utilisateurs par l'intermédiaire de réseaux. Des ensembles
spécifiques de logique SIG peuvent être incorporés et
déployés dans des applications personnalisées. De
même, le SIG est de plus en plus déployé sur des
périphériques nomades pour des applications de terrain.
Dans
un environnement d'entreprise, les utilisateurs se connectent à des
serveurs SIG centraux par l'intermédiaire de SIG bureautiques
traditionnels, de navigateurs Web, d'applications spécialisées,
de matériels nomades et d'appareils numériques. Le concept de
plate-forme SIG progresse.
La gamme de produits ArcGIS5(*) a
été conçue pour s'adapter à ces besoins en
constante évolution et proposer une plateforme SIG complète et
évolutive, comme le montre le schéma ci-dessous.
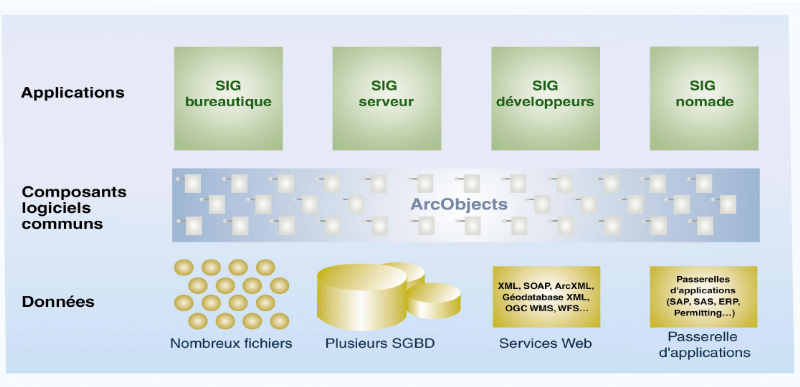
Figure 2.3: la
gamme de produit ArcGIS
CHAPITRE
3
Choix d'une méthode d'analyse
I. Définition des concepts
L'analyse permet de lister les
résultats attendus, en termes de fonctionnalités, de performance,
de robustesse, de maintenance, de sécurité,
d'extensibilité, etc. L'analyse répond donc à la question
« que faut-il faire ? » et a pour
but de se doter d'une vision claire et rigoureuse du problème
posé et du système à réaliser en déterminant
ses éléments et leurs interactions. Elle met l'accent sur une
investigation du problème et des exigences, plutôt que sur une
solution. A ce niveau d'abstraction, on doit capturer les besoins principaux
des utilisateurs en identifiant les éléments du domaine, ainsi
que les relations et interactions entre ces éléments : les
éléments du domaine sont liés au(x) métier(s) de
l'entreprise, ils sont indispensables à la mission du système,
ils gagnent à être réutilisés (ils
représentent un savoir-faire) (II).
La conception permet de décrire de
manière non ambiguë, le plus souvent en utilisant un langage de
modélisation, le fonctionnement futur du système, afin d'en
faciliter la réalisation. La conception menée à la suite
de la phase d'analyse répond donc à la question
« comment faut-il faire ce qu'il faut
faire ? ». Elle met l'accent sur une solution conceptuelle
qui satisfait aux exigences plutôt que sur une
implémentation6(*). Le processus de conception a ainsi pour but de figer
les choix techniques (outils, langages, frameworks7(*)). Il permet ainsi de
modéliser tous les rouages d'implémentation et de
détailler tous les éléments de modélisation issus
des niveaux supérieurs. Les modèles sont optimisés, car
destinés à être implémentés.
Ainsi, l'analyse sert à la découverte et
à la compréhension et a pour but d'élaborer les
spécifications tandis que la conception sert à structurer et
à développer une solution (II).
II. Pourquoi utiliser une
méthode ? (II)
Les systèmes d'information ont beau gagné en
complexité, les temps de développement n'en sont pas pour autant
extensibles. Il faut, dès lors, privilégier l'approche
métier, associer utilisateurs et informaticiens, optimiser les
ressources et la technologie pour garantir délais et budget. Les
méthodes répondent à ces exigences et permettent la
construction d'applications fonctionnellement et techniquement conformes aux
attentes des divers intervenants du projet.
L'impératif est clair : plus vite, moins cher
et de meilleure qualité. Le succès d'un projet dépend
désormais de deux facteurs essentiels : l'implication des
utilisateurs et une méthode garantissant la réussite du projet
tout autant que la qualité de l'application.
Nous devons noter qu'avec les
progrès du génie logiciel plusieurs méthodes ont vues le
jour. Nous allons, dans le paragraphe suivant, les décrire et les
classifier.
III. Classification des
méthodes d'analyse et de conception
Les méthodes d'analyse et de conception peuvent
être divisées en quatre grandes familles :
1. Les méthodes
cartésiennes ou fonctionnelles (II)
Avec ces méthodes (SADT, SA-SD), le système
étudié est abordé par les fonctions qu'il doit assurer
plutôt que par les données qu'il doit gérer. Le processus
de conception est vu comme un développement linéaire. Il y'a
décomposition systématique du domaine étudié en
sous domaines, eux-mêmes décomposés en sous domaines
jusqu'à un niveau considéré élémentaire.
2. Les méthodes
systémiques (II)
Dans les méthodes systémiques (Merise,
REMORA8(*), etc.), le
système est abordé à travers l'organisation des
systèmes constituants l'entreprise. Elles aident donc à
construire un système en donnant une représentation de tous les
faits pertinents qui surviennent dans l'organisation en s'appuyant sur
plusieurs modèles à des niveaux d'abstraction différents
(conceptuel, organisationnel, logique, physique, etc.)
3. Les méthodes
objets (II)
L'approche objet permet d'appréhender un système
en centrant l'analyse sur les données et les traitements à la
fois. Les stratégies orientées objet considèrent que le
système étudié est un ensemble d'objet coopérant
pour réaliser les objectifs des utilisateurs. Les avantages qu'offre une
méthode de modélisation objet par rapport aux autres
méthodes sont la réduction de la « distance »
entre le langage de l'utilisateur et le langage conceptuel, le regroupement de
l'analyse des données et des traitements, la réutilisation des
composants mis en place.
4. Approche
orientée aspect
Bien qu'en étant encore à ses débuts, la
Programmation Orientée Aspect commence à se
faire connaître et séduit. C'est un principe novateur qui permet
de résoudre les problèmes de séparation des
préoccupations d'une application. Le code résultant devient plus
lisible, réutilisable et le remplacement de composants se fait
rapidement et à moindre coût du fait de la séparation des
préoccupations. Cette séparation se fait par la création
d'aspects contenant le code à greffer à l'application. Un
programme appelé « tisseur » greffe ensuite les aspects de
façon statique après la compilation, ou de façon dynamique
au moment de l'exécution.
Il existe déjà des tisseurs matures, comme
AspectJ pour Java, qui est parfaitement intégré
à Eclipse grâce au plug-in AJDT. La plateforme
.NET possède aussi des tisseurs très prometteurs, tels que
AspectDNG qui permet déjà une utilisation
professionnelle.
· Définition de quelques mots
-clés
Code cible ou code de base : Ensemble de
classes qui constituent une application ou une bibliothèque. Ces classes
n'ont pas connaissance des aspects (il n'y adonc aucune dépendance),
elles ne se "doutent" pas qu'elles vont constituer la cible d'un tissage.
Aspect : Il s'agit du code que l'on
souhaite tisser. Selon les tisseurs, un aspect peut être une simple
classe ou constituer un élément d'un langage
spécifique.
Zone de greffe : Ce sont les "endroits"
dans le code cible dans lesquels aura lieu le tissage.
Tissage : Processus qui consiste
à ajouter (tisser, greffer, injecter) le code des aspects sur les zones
de greffe du code cible.
Tisseur : Programme exécutable ou
framework dynamique qui procède au tissage. Le tisseur peut être
invoqué:
- statiquement avant la compilation du code cible (le tisseur
travaille sur le code source),
- statiquement pendant la compilation du code cible (le
tisseur intègre un compilateur du langage de programmation),
- statiquement après la compilation du code cible (le
tisseur travaille sur le code précompilé: bytecode),
- dynamiquement avant exécution du code (au moment de
la compilation Just-In-Time),
- dynamiquement pendant l'exécution du code (par la
technique d'interception d'invocation de méthode, utilisée
intensivement par les frameworks d'inversion de contrôle).
· Avantages et
inconvénients
Le couplage entre les modules gérant des aspects
techniques peut être réduit de façon très
importante, en utilisant ce principe, ce qui présente de nombreux
avantages :
Maintenance aisée : les modules techniques, sous
forme d'aspect, peuvent être maintenus plus facilement du fait de son
détachement de son utilisation,
Meilleure réutilisation : tout module peut
être réutilisé sans se préoccuper de son
environnement et indépendamment du métier ou du domaine
d'application. Chaque module implémentant une fonctionnalité
technique précise, on n'a pas besoin de se préoccuper des
évolutions futures : de nouvelles fonctionnalités pourront
être implémentées dans de nouveaux modules qui interagiront
avec le système au travers des aspects.
Gain de productivité : le programmeur ne se
préoccupe que de l'aspect de l'application qui le concerne, ce qui
simplifie son travail.
Amélioration de la qualité du code : la
simplification du code qu'entraine la programmation par aspect permet de le
rendre plus lisible et donc de meilleure qualité.
Par contre le tissage d'aspect qui n'est finalement que de la
génération automatique de code inséré à
certains points d'exécution du système développé,
produit un code qui peut être difficile à analyser (parce que
généré automatiquement) lors des phases de mise au point
des logiciels (débogages, test). Mais en fait cette difficulté
est du même ordre que celle apportée par toute
décomposition non linéaire (fonctionnelle ou objet par
exemple).
IV. Choix d'une
méthode d'analyse et de conception
Dans cette partie nous allons présenter deux
démarches d'analyses et de conceptions. Il s'agit de UP et de la
méthode RAD.
1. Le Processus
Unifié (UP)
a.
Définition
Le processus unifié est un processus de
développement logiciel itératif, centré sur
l'architecture, piloté par des cas d'utilisation et orienté vers
la diminution des risques.
C'est un patron de processus pouvant être adaptée
à une large classe de systèmes logiciels, à
différents domaines d'application, à différents types
d'entreprises, à différents niveaux de compétences et
à différentes tailles de l'entreprise.
ü UP est Itératif
L'itération est une répétition d'une
séquence d'instructions ou d'une partie de programme un nombre de fois
fixé à l'avance ou tant qu'une condition définie n'est pas
remplie, dans le but de reprendre un traitement sur des données
différentes.
Elle qualifie un traitement ou une procédure qui
exécute un groupe d'opérations de façon
répétitive jusqu'à ce qu'une condition bien définie
soit remplie.
Une itération prend en compte un certain nombre de cas
d'utilisation et traite en priorité les risques majeurs.
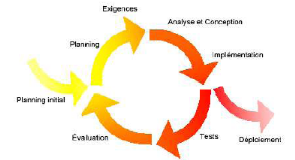
Figure 3.1 :
Illustration du caractère itératif de UP
ü UP est centré sur
l'architecture
Une architecture adaptée est la clé de
voûte du succès d'un développement. Elle décrit des
choix stratégiques qui déterminent en grande partie les
qualités du logiciel (adaptabilité, performances,
fiabilité...).
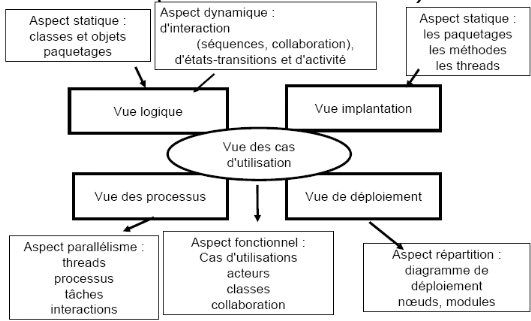
Figure 3.2 :
Modèle représentant les 4+1 vues de Kruchten
ü UP est piloté par les cas d'utilisation
d'UML
Le but principal d'un système informatique est de
satisfaire les besoins du client. Le processus de développement sera
donc accès sur l'utilisateur.
Les cas d'utilisation permettent d'illustrer ces besoins. Ils
détectent puis décrivent les besoins fonctionnels (du point de
vue de l'utilisateur), et leur ensemble constitue le modèle de cas
d'utilisation qui dicte les fonctionnalités complètes du
système.
b. Vie du processus
unifié
L'objectif d'un processus unifié est de maîtriser
la complexité des projets informatiques en diminuant les risques. UP est
un ensemble de principes génériques adapté en fonctions
des spécificités des projets.
UP répond aux préoccupations suivantes :
QUI participe au projet ?, QUOI, qu'est-ce
qui est produit durant le projet ?, COMMENT doit-il être
réalisé ?, QUAND est réalisé
chaque livrable ?
UP gère le processus de développement par deux
axes.
L'axe vertical représente les
principaux enchaînements d'activités, qui regroupent les
activités selon leur nature. Cette dimension rend compte l'aspect
statique du processus qui s'exprime en termes de composants, de processus,
d'activités, d'enchaînements, d'artefacts et de travailleurs.
L'axe horizontal représente le temps
et montre le déroulement du cycle de vie du processus; cette dimension
rend compte de l'aspect dynamique du processus qui s'exprime en terme de
cycles, de phases, d'itérations et de jalons.
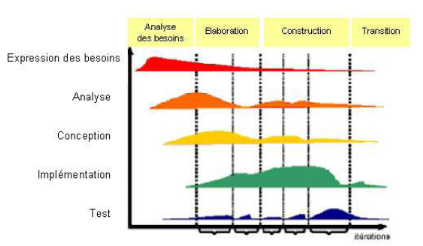
Figure 3.3 :
Architecture bidirectionnelle du PU
UP répète un certain nombre de fois une
série de cycle qui s'articule autours de 4 phases qui sont :
analyse des besoins, élaboration, construction, transition.
Pour mener efficacement un tel cycle, les développeurs
ont besoins de toutes les représentations du produit logiciel qui
sont : un modèle de cas d'utilisation, un modèle d'analyse
détaillant les cas d'utilisation et procéder à une
première répartition du comportement, un modèle de
conception ,finissant la structure statique du système sous forme de
sous-systèmes de classes et interfaces, un modèle
d'implémentation, intégrant les composants, un modèle de
déploiement ,définissant les noeuds physiques des ordinateurs, un
modèle de test, décrivant les cas de test vérifiant les
cas d'utilisation, et une représentation de l'architecture
c. Les
Phases
Pour bien mener un projet du début à la fin, UP
préconise les phases suivantes :
ü Expression des besoins
L'expression des besoins comme son nom l'indique, permet de
définir les différents besoins : inventorier les besoins
principaux et fournir une liste de leurs fonctions, recenser les
besoins fonctionnels (du point de vue de l'utilisateur) qui
conduisent à l'élaboration des modèles de cas
d'utilisation, appréhender les besoins non fonctionnels
(technique) et livrer une liste des exigences.
Le modèle de cas d'utilisation présente le
système du point de vue de l'utilisateur et représente sous forme
de cas d'utilisation et d'acteur, les besoins du client.
ü Analyse
L'objectif de l'analyse est d'accéder à une
compréhension des besoins et des exigences du client. Il s'agit de
livrer des spécifications pour permettre de choisir la conception de la
solution. Un modèle d'analyse livre une spécification
complète des besoins issus des cas d'utilisation et les structure sous
une forme qui facilite la compréhension (scénarios), la
préparation (définition de l'architecture), la modification et la
maintenance du futur système.
Il s'écrit dans le langage des développeurs et
peut être considéré comme une première
ébauche du modèle de conception.
ü Conception
La conception permet d'acquérir une
compréhension approfondie des contraintes liées au langage de
programmation, à l'utilisation des composants et au système
d'exploitation. Elle détermine les principales interfaces et les
transcrit à l'aide d'une notation commune. Elle constitue un point de
départ à l'implémentation :
- elle décompose le travail d'implémentation en
sous-système
- elle crée une abstraction transparente de
l'implémentation
ü Implémentation
L'implémentation est le résultat de la
conception pour implémenter le système sous formes de composants,
c'est-à-dire, de code source, de scripts, de binaires,
d'exécutables et d'autres éléments du même type. Les
objectifs principaux de l'implémentation sont de planifier les
intégrations des composants pour chaque itération, et de produire
les classes et les sous-systèmes sous formes de codes sources.
ü Tests
Les tests permettent de vérifier des résultats
de l'implémentation en testant la construction. Pour mener à bien
ces tests, il faut les planifier pour chaque itération, les
implémenter en créant des cas de tests, effectuer ces tests et
prendre en compte le résultat de chacun.
2. La méthode
RAD
Aujourd'hui, qualité et réactivité font
partie des objectifs généraux de beaucoup d'entreprises. Cela
entraîne un certain nombre de projets, qui tout en apportant satisfaction
aux utilisateurs, doivent être menés dans un délai court.
C'est à cela que répond la méthode RAD. RAD est une
méthode basée sur le partenariat. L'utilisateur s'affirme le vrai
maître de son application et, par sa participation active, il s'en
approprie la réalisation. Le RAD et le prototypage permettent de
réaliser en concevant, tout en testant ce que l'on réalise. La
méthode RAD propose de remplacer le cycle de vie classique par un autre
découpage temporel. Le déroulement est d'abord linéaire,
puis il suit le modèle de la spirale. Les étapes sont au nombre
de cinq :
ü La phase d'Initialisation
Cette phase permet de définir le
périmètre général du projet, de structurer le
travail par thèmes, de sélectionner les acteurs pertinents et
d'amorcer une dynamique de projet. Elle représente environ 6% du projet
en charge.
ü La phase Expression des besoins
Cette phase permet de spécifier les exigences
du système lors des entretiens avec les utilisateurs et de
définir la solution globale sur les plans stratégique,
fonctionnel, technologique et organisationnel. Cette phase représente
environ 9% du projet.
ü La phase de Conception
Cette phase permet de concevoir et de modéliser le
futur système avec le concours des utilisateurs pour l'affinage et la
validation des modèles. C'est aussi dans cette phase que nous validons
le premier niveau de prototype présentant l'ergonomie et la
cinématique générale de l'application. Cette phase
représente environ 23% du projet.
ü La phase de Construction
(développement itératif).
Durant cette phase, notre équipe développe
l'application module par module. L'utilisateur participe toujours activement
aux spécifications détaillées et à la validation
des prototypes. Plusieurs sessions itératives sont
nécessaires. Cette phase représente environ 50% du
projet.
ü La phase de mise en oeuvre
Des recettes partielles ayant été obtenues à
l'étape précédente, il s'agit dans cette phase
d'officialiser une livraison globale et de transférer le système
en exploitation et maintenance. Cette phase représente environ 12% du
projet.
V. Le langage
UML
La modélisation est incontournable pour permettre aux
différents acteurs de coopérer et de dialoguer efficacement.
Ainsi Il est donc important de connaître le langage et les techniques de
modélisation et de savoir quels modèles sont les plus
appropriés dans chaque situation. En effet, de la même
manière qu'il n'est pas judicieux d'utiliser tous les
éléments de la langue française pour écrire un
article, il n'est pas non plus obligatoire d'utiliser tous les concepts du
langage UML dans un projet.
Nous allons, dans les paragraphes suivants, présenter
l'intérêt d'utiliser UML dans la conception d'un SIG ainsi que
les différents diagrammes utilisés par ce langage.
1. Pourquoi
UML ?
Nombreuses sont les tentatives d'application des
méthodes de conception des systèmes d'information pour la mise en
oeuvre des systèmes d'information géographique. Les raisons les
plus significatives de leur inefficacité dans la conception des
systèmes d'information géographique sont entre autres les
suivantes.
Ces méthodes reposent sur deux approches distinctes,
privilégiant soit les données, soit les traitements. Or le
fonctionnement d'un système d'information géographique repose
justement sur une interdépendance étroite entre les
données et les traitements.
L'information géographique s'organise
hiérarchiquement et les traitements qui sont appliqués sont
souvent complexes et reposent aussi sur des processus d'agrégation de
l'information. Or les méthodes proposées par les systèmes
d'information d'entreprise ne prennent en compte que des traitements simples de
type flux ou échange de données.
L'utilisation des méthodes de conception des SI
présuppose que soient, au préalable, clairement identifiés
les besoins des applications et que l'on ait la maîtrise de leur
évolution. Or en matière d'analyse spatiale, de gestion et de
planification territoriale, les besoins s'identifient le plus souvent en
fonction des données dont on dispose, des résultats issus des
traitements réalisés, et de l'évolution des requêtes
adressées par les utilisateurs. Il est certain que la
modélisation UML ayant été élaborée pour
répondre aux besoins des systèmes d'information classiques n'est
donc pas conçue, a priori, pour répondre aux
spécificités des systèmes intégrant de
l'information géographique Ces derniers gérant à la fois
des données graphiques et des données non graphiques sont
considérés comme un cas particulier des SI.
Toutefois, il semble qu'a priori les principaux concepts
proposés par UML soient pertinents pour l'analyse et la conception des
systèmes de gestion et d'analyse des territoires. Cette approche peut
constituer un support intéressant en termes d'acquisition des
connaissances, de structuration de l'information géographique à
intégrer dans l'outil à concevoir, et de spécification des
fonctionnalités de l'outil.
2. Diagrammes structurels (les vues
statiques)
Ces diagrammes permettent de visualiser, spécifier,
construire et documenter l'aspect statique ou structurel du système
d'information. Il s'agit outre les diagrammes de cas d'utilisation, des
diagrammes de classes, d'objets, mais aussi de déploiement et de
composants
a. Les cas d'utilisation
(uses cases)
Les cas d'utilisation sont une technique de description du
système étudié privilégiant le point de vue de
l'utilisateur. Ils décrivent sous la forme d'actions et de
réactions, le comportement d'un système et servent, par
conséquent, à structurer les besoins des utilisateurs et les
objectifs correspondants du système.
La détermination et la compréhension
des besoins sont souvent difficiles car les intervenants sont noyés sous
de trop grandes quantités d'informations. Or, comment mener à
bien un projet si l'on ne sait pas où l'on va ?
Les uses cases ne doivent pas chercher l'exhaustivité,
mais clarifier, filtrer et organiser les besoins. Ils ne doivent donc en aucun
cas décrire des solutions d'implémentation. Leur but est
justement d'éviter de tomber dans la dérive d'une approche
fonctionnelle, où l'on liste une litanie de fonctions que le
système doit réaliser.
b. Les diagrammes
d'objets
Ce type de diagramme UML montre des objets (instances de
classes dans un état particulier) et des liens (relations
sémantiques) entre ces objets. Les diagrammes d'objets s'utilisent pour
montrer un contexte (avant ou après une interaction entre objets par
exemple). Il sert essentiellement en phase exploratoire, car il possède
un très haut niveau d'abstraction.
c. Les diagrammes de
classes
Les diagrammes de classes expriment de manière
générale la structure statique d'un système, en termes de
classes et de relations entre ces classes.
Une classe permet de décrire un ensemble d'objets
(attributs et comportement), tandis qu'une relation ou association permet de
faire apparaître des liens entre ces objets.
d. Les diagrammes de
paquetages (ou package)
Les paquetages sont des éléments d'organisation
des modèles. Ils regroupent des éléments de
modélisation, selon des critères purement logiques. Ils
permettent d'
encapsuler des
éléments de modélisation et de structurer un
système en
catégories (
vue logique) et
sous-systèmes (
vue des composants). Ils
servent de « briques » de base dans la construction d'une
architecture.
e. Les diagrammes de
composants et de déploiement
Les diagrammes de composants permettent de décrire
l'architecture physique et statique d'une application en termes de modules :
fichiers sources, librairies, exécutables, etc. Ils montrent la mise en
oeuvre physique des modèles de la vue logique avec l'environnement de
développement.
Les diagrammes de déploiement montrent la disposition
physique des matériels qui composent le système et la
répartition des composants sur ces matériels. Les ressources
matérielles sont représentées sous forme de noeuds,
connectés entre eux à l'aide d'un support de communication.
3. Diagrammes comportementaux (les vues
dynamiques)
Ils modélisent les aspects dynamiques du
système, c'est à dire les différents
éléments qui sont susceptibles de subir des modifications. Parmi
eux on distingue, les diagrammes de séquence, de collaboration,
d'états - transitions et d'activités.
Ils représentent la dynamique du système,
à savoir, non seulement les interactions entre le système lui
même et les différents acteurs du système, mais aussi, la
façon dont les différents objets contenus dans le système
communiquent entre eux.
a. Les diagrammes de
séquence
Les diagrammes de séquences permettent de
représenter des
collaborations entre objets
selon un point de vue temporel, on y met l'accent sur la chronologie des envois
de messages. Les diagrammes de séquences peuvent servir à
illustrer un
cas d'utilisation
b. Les diagrammes de
collaboration
Les diagrammes de collaboration montrent des interactions
entre objets (instances de classes et acteurs). Ils permettent de
représenter le contexte d'une interaction, car on peut y préciser
les états des objets qui interagissent.
c. Les diagrammes
d'états- transitions
Ces diagrammes servent à représenter des
automates d'états finis, sous forme de graphes d'états,
reliés par des arcs orientés qui décrivent les
transitions. Ils permettent de décrire les changements d'états
d'un objet ou d'un composant, en réponse aux interactions avec d'autres
objets/composants ou avec des acteurs.
Un état se caractérise par sa durée et sa
stabilité, il représente une conjonction instantanée des
valeurs des attributs d'un objet.
Une transition représente le passage instantané
d'un état vers un autre. Une transition est déclenchée par
un événement. En d'autres termes : c'est l'arrivée d'un
événement qui conditionne la transition. Les transitions peuvent
aussi être automatiques, lorsqu'on ne spécifie pas
l'événement qui la déclenche. En plus de spécifier
un événement précis, il est aussi possible de conditionner
une transition, à l'aide de "gardes" : il s'agit d'expressions
booléennes, exprimées en langage naturel (et encadrées de
crochets).
d. Les diagrammes
d'activités
UML permet de représenter graphiquement le comportement
d'une méthode ou le déroulement d'un cas d'utilisation, à
l'aide de diagrammes d'activités (une variante des diagrammes
d'états-transitions). Une activité représente une
exécution d'un mécanisme, un déroulement d'étapes
séquentielles. Le passage d'une activité vers une autre est
matérialisé par une transition. Les transitions sont
déclenchées par la fin d'une activité et provoquent le
début immédiat d'une autre (elles sont automatiques).
En théorie, tous les mécanismes dynamiques
pourraient être décrits par un diagramme d'activités, mais
seuls les mécanismes complexes ou intéressants méritent
d'être représentés.
Conclusion : Le langage UML,
offre ainsi de nombreux avantages pour l'analyse et la conception d'un
système d'information géographique. Par conséquent, nous
combinerons UML au Processus Unifié pour mener à terme notre
système d'information.
CHAPITRE
4
Analyse de la plateforme
Dans ce chapitre, nous allons effectuer une analyse
complète de notre système afin d'effectuer un dimensionnement
correct des caractéristiques de notre produit. Il s'agit donc
d'effectuer une analyse fonctionnelle du système qui consiste à
distinguer les besoins fonctionnelles.
Il s'agit de l'ensemble des fonctionnalités qui
décrivent les services attendus. Dans cette partie, nous allons d'abord
décrire l'ensemble des acteurs qui interagissent avec notre
système, ensuite nous décrirons en détails l'ensemble des
interactions entre ces acteurs et le système à l'aide de
diagrammes de cas d'utilisation et enfin le comportement de ces cas
d'utilisation par des diagrammes d'activité.
I. Les acteurs du
système
Après avoir recensé l'ensemble des besoins, nous
avons distingué les différents acteurs suivants :
1. L'administrateur :
C'est le super-utilisateur qui gère le SIG. Il ajoute
des structures et crée un responsable de site pour chaque structure.
2. Responsable du
site
C'est le groupe de personne qui tous les droits sur
l'application concernant son espace c'est-à-dire seulement ce qui
concerne sa structure et qui est chargé de l'organisation de son site.
Il peut créer d'autres utilisateurs en leur attribuant des droits. C'est
lui qui met à jour et/ou valide toutes les mises à jour
effectuée. Il accède donc à toutes les interfaces de
l'application.
3. Les utilisateurs
membres
Il s'agit d'un groupe d'utilisateur qui est nommé par
l'administrateur et qui accède à l'interface
protégé avec des tâches réduites. Toutes les mises
à jour qu'ils effectuent sont d'abord validées par
l'administrateur avant d'être publiée.
4. Les
visiteurs
C'est le groupe qui accède uniquement à la zone
publique. Ils ne s'authentifient pas, et accède directement à
cette zone pour consultation (affichage d'une carte ou un plan, navigation,
recherches...). En d'autres termes ce sont les internautes.
II. Interactions entre les
acteurs et le système
Ces interactions seront décrites à l'aide de
diagrammes de cas d'utilisation. Si nécessaire certains cas
d'utilisation seront également décrits à l'aide d'un
scénario textuelle.
1. Diagrammes de cas
d'utilisation
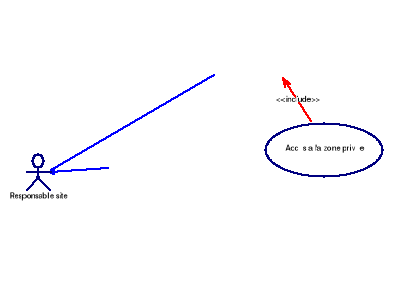
Diagramme 4.1 :
Diagramme de cas d'utilisation général
o Le cas d'utilisation « Navigation sur
le portail »
Ici, nous allons nous intéresser au cas
« navigation » car celui-ci permet d'effectuer toutes
les actions de la zone publique. Il faut noter que tous les acteurs peuvent
effectuer ce cas d'utilisation.
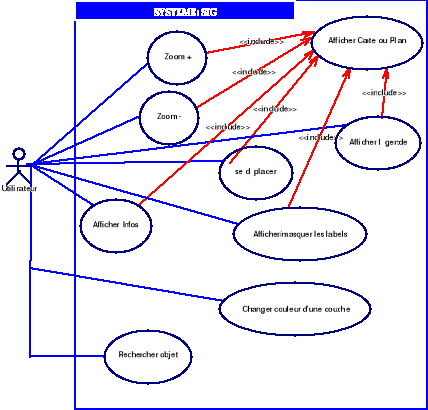
Diagramme 4.2 :
Diagramme de cas d'utilisation «Navigation sur le
portail »
Afficher Carte ou
Plan : il s'agit d'afficher une carte ou un plan
en choisissant les couches correspondantes.
Zoom (+/-) : Permet
d'agrandir/réduire les dimensions de la carte ou du plan sur la zone
cliquée.
Afficher légende :
Affiche la légende correspondante aux couches
sélectionnées.
Afficher infos : Permet
d'afficher les informations relatives à une zone à partir d'un
click sur la carte.
Tous ces trois derniers cas nécessitent l'affichage
d'une carte ou d'un plan.
Changer Couleur : Permet de
modifier la couleur de fond associée à une couche.
o Le cas d'utilisation « Accès
à la zone privée »
Ce cas décrit l'ensemble des fonctionnalités
disponibles dans la zone privée qui n'est accessible que par les
utilisateurs authentifiés.
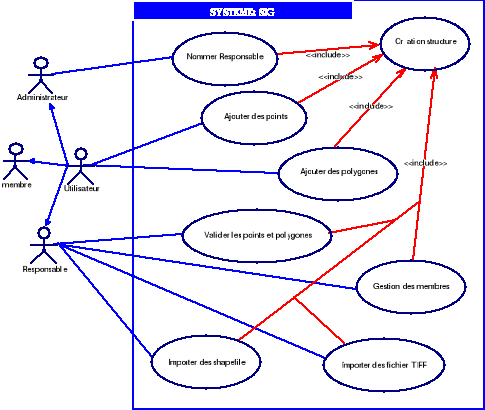
Diagramme 4.3 :
Diagramme de cas d'utilisation «Accès à la zone
privée »
Importer des shapefile : il
d'importer des fichiers shapes vers notre base de donnée spatiale.
Valider les points et
polygones : c'est la validation des points et des polygones
ajoutés par les membres avant d'être publié.
2. Scénarios
textuels des cas d'utilisation
Nous allons choisir ici de d écrire textuellement
les deux cas suivant : « Authentification »,
« Navigation » et « importation des
shapefile »
o Le cas
« Authentification »
Tableau 4.1 :
scénario textuel du cas
« Authentification »
|
Nom du cas
|
Authentification
|
|
Acteur
|
Les Utilisateurs sauf les visiteurs simples
|
|
Scénario
|
succès
|
|
Pré conditions
|
Utilisateur créé
Utilisateur appartient à la structure concernée
|
|
Actions
|
Le système présente le portail d'accueil
L'utilisateur sélectionne le menu paramétrage
Le système présente le formulaire
d'authentification
L'utilisateur saisie son login et son mot de passe
Le système vérifie et accepte l'identité de
l'utilisateur
Ensuite le système crée une session et enregistre
les paramètres de l'utilisateur dans celle-ci
Le système affiche la page admin correspondante au profil
de l'utilisateur
L'utilisateur accède ainsi à toutes les
fonctionnalités dont il a droit
|
|
Post condition
|
L'utilisateur est authentifié et est enregistré
dans la session courante
|
|
Variantes
|
L'utilisateur à oublier son compte
Le système lui redemande son login et mot de passe
|
o Le cas « Navigation sur le
portail »
Tableau 4.2 :
scénario textuel du cas « Navigation sur le
portail »
|
Nom du cas
|
Navigation sur le portail
|
|
Acteur
|
Tous les Utilisateurs
|
|
Scénario
|
succès
|
|
Pré conditions
|
Accès à internet ou à l'intranet
|
|
Actions
|
Le système le portail du site avec tous les outils de
navigation
L'utilisateur sélectionne une couche
Le système affiche la couche correspondante
L'utilisateur sélectionne l'outil zoom+ et click sur la
carte
Le système effectue le zoom avant à partir du point
de click
L'utilisateur sélectionne l'outil zoom-
Le système effectue le zoom arrière
L'utilisateur sélectionne l'outil déplacement
Le système effectue le déplacement du point
L'utilisateur demande d'afficher la légende
Le système affiche la légende correspondante aux
couches sélectionnées
L'utilisateur sélectionne l'outil info
Le système affiche les infos relatives à la zone
sélectionnée
L'utilisateur effectue la recherche sur un objet
Le système affiche tout le résultat de la
recherche
|
|
Post condition
|
Les couches sélectionnées sont affichées
Apres zoom l'emprise de la carte change
|
|
Variantes
|
L'utilisateur n'entre pas les bons critères de
recherche
Le système ne retourne aucun résultat
L'utilisateur tente de zoomer sans afficher au préalable
une carte
Le système lui affiche un message lui disant de
sélectionner et d'afficher d'abord une carte.
|
o Le cas « Importer
shapefile »
Tableau 4.3 :
scénario textuel du cas « importer
shapefile »
|
Nom du cas
|
Importer shapefile
|
|
Acteur
|
Seuls les responsables du site
|
|
Scénario
|
succès
|
|
Pré conditions
|
Responsable authentifié
|
|
Actions
|
L'utilisateur sélectionne le menu importer shapefile
Le système présente un formulaire d'importation
Le système demande à l'utilisateur de donner les
répertoires ou sont localisés les fichiers
L'utilisateur click sur parcourir et sélectionne les
chemins des répertoires
Le système récupère ces chemins
L'utilisateur click sur importer
Le système télécharge les fichiers de la
machine locale vers le server
Le système exécute la commande et crée le
contenu des shapes dans la base de donnée spatiale
Le système affiche un message signalant le succès
de l'importation
|
|
Post condition
|
Le système crée une nouvelle couche vecteur dans la
base de données spatiale
|
|
Variantes
|
L'utilisateur n'entre les bons types de fichier.
Le système envoie un message d'erreur
|
3. Comportement des cas
d'utilisation
Nous allons décrire ici le comportement de certains cas
d'utilisation à l'aide de diagrammes d'activités. Nous
décrivons ici les comportements des cas
« Authentification » et « Accès à
la zone privée » et « importation des
shapefile ».
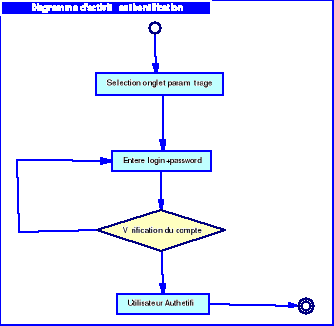
Diagramme 4.4 :
Diagramme d'activité
«Authentification »
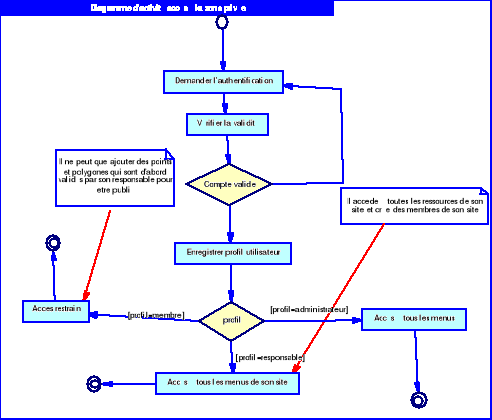
Diagramme 4.5 :
Diagramme d'activité «Accès à la zone
privée »
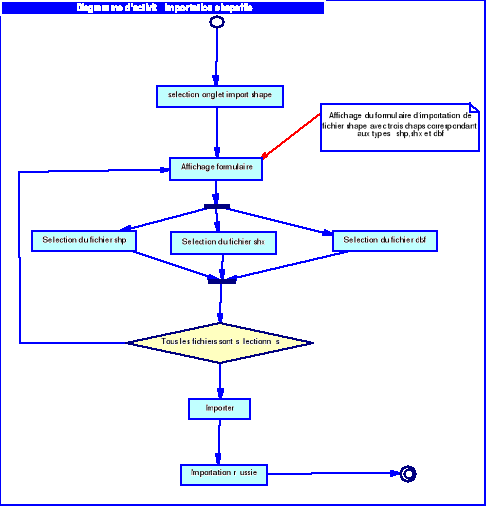
Diagramme 4.6 :
Diagramme d'activité «importer
shapefile »
4. Diagramme de classe
d'analyse
Apres avoir décrit l'ensemble des cas d'utilisation et
leurs comportements, nous aboutissons au diagramme de classe d'analyse
suivant :
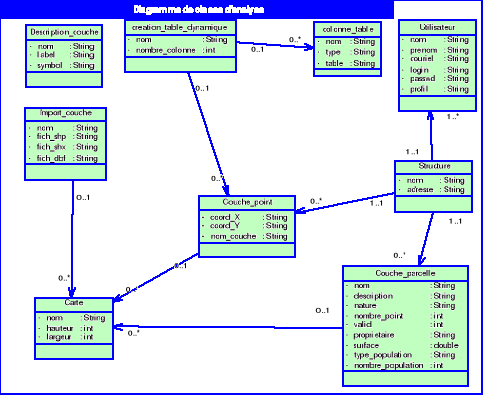
Diagramme 4.7 :
Diagramme de classe d'analyse
Après cette phase d'analyse qui nous a permis de bien
cerner le périmètre du système, nous allons passer dans le
prochain chapitre à la phase conception.
Conception de la
plateforme
CHAPITRE
5
Après la spécification et une analyse
complète des besoins, nous allons maintenant passer à la phase
conception. Cette phase détermine les principales interfaces et les
transcrit à l'aide d'une notation commune. Elle constitue un point de
départ à l'implémentation.
I. Solution
technique
Dans cette partie, nous allons présenter la solution
proposée pour l'ergonomie de la plateforme. Les études chapitre
précédent nous permettent de dégager deux interfaces
(zones) pour notre plateforme. Il s'agit de la zone publique accessible par
tous les visiteurs et de la zone privée qui n'est accessible que par les
utilisateurs authentifiés.
1. Le portail d'accueil du
SIG
Cette page est accessible par tous les visiteurs et
présente l'ensemble des outils de navigation. Le portail sera
organisé comme suit (avec des frames) :
Une bannière sera placée en haut de
l'écran. Dans celle-ci va figurer le logo du SIG et les mentions de
l'ensemble des outils libres qui ont permis de réaliser la plateforme.
A gauche de l'écran sera réservé à
la sélection des couches à afficher.
Au centre, nous aurons la zone d'affichage de la carte
générée à partir des couches qui ont
été sélectionnées ainsi que de la palette des
outils de navigation.
A droite nous aurons la partie consacrée à la
recherche.
Le schéma suivant donne un aperçu du portail
d'accueil LtiSig. (Voir page suivante).
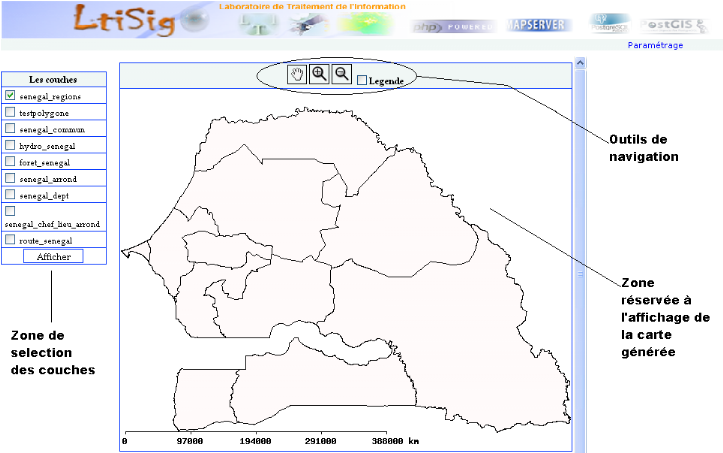
Figure 5.1 :
Présentation du portail LtiSig zone publique
2. Interface
protégée
Cette interface n'est accessible que par les utilisateurs
authentifiés. Chaque utilisateur voit l'écran son profil. Par
exemple le responsable du site pourra voire toutes les rubriques contrairement
au membre simple qui ne voit que l'ajout des points et des parcelles. Pour y
accéder il faut juste cliquer sur le lien paramétrage
situé au niveau du portail.
Pour le cas du responsable on a les rubriques
suivantes :
Importer shapefile : qui affiche
le formulaire d'importation des fichiers shapes.
Ajouter point : qui affiche le
formulaire d'ajout d'un point.
Ajouter parcelle : qui affiche le
formulaire de création d'une forme polygonale représentant une
parcelle.
Gestion des utilisateurs : qui
affiche l'interface de gestion des utilisateurs de son espace
Validation : qui affiche la
fenêtre de validation des informations ajoutées par le membre pour
que celles-ci puissent être vues par les visiteurs.
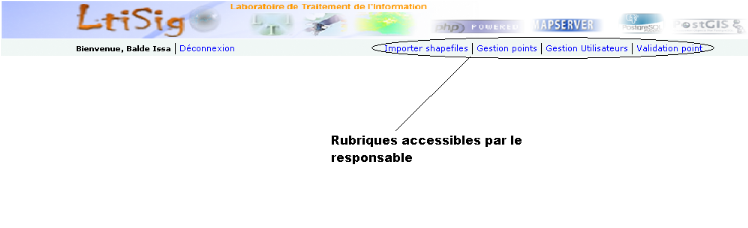
Figure 5.2 :
Présentation de l'interface privée
II. Fonctionnement du
système
Dans cette partie nous allons tenter d'appréhender le
fonctionnement global du system à l'aide de diagrammes
d'état-transition et des diagrammes de séquences qui nous
permettrons de voir la chronologie des interactions entre le système et
les acteurs.
1. Etats des
objets
Ici nous allons nous intéressé aux objets
susceptibles de passer d'un état à un autre. Ces changements
seront représentés par des diagrammes
d'état-transition.
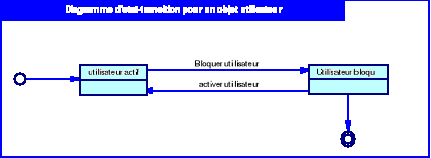
Diagramme 5.1 :
Diagramme d'état-transition de l'objet utilisateur
Pour éviter de supprimer un utilisateur lorsqu'il est
déjà créé, nous proposons de mettre l'état
de l'utilisateur à « bloque ». En ce moment il ne
pourra pas s'authentifié comme s'il à été
supprimé. Il suffira alors de débloquer son compte pour qu'il
retrouve son état initial.
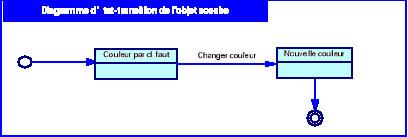
Diagramme 5.2 :
Diagramme d'état - transition de l'objet couche
L'application devra permettre à l'utilisateur de changer
les couleurs des couches.
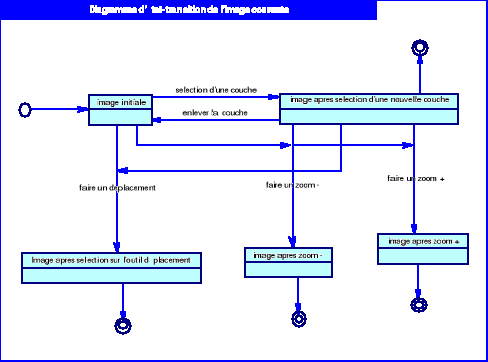
Diagramme 5.3 :
Diagramme d'état - transition de l'image
générée
Apres chaque requête de l'utilisateur l'image
générée change en fonction de la requête. En effet
si une nouvelle couche est sélectionnée, alors la nouvelle image
sera la superposition de la nouvelle couche et des couches
précédentes. Dans le cas d'un zoom, une nouvelle image est
générée avec une nouvelle emprise, la zone de click
devient plus grande et plus visible.
2. Chronologie des
interactions
Nous allons à présent, nous
intéressé de la chronologie des interactions entre les objets et
le système. Pour cela nous utiliserons des diagrammes de
séquences.
o Accès à la zone
privée : Ici l'utilisateur doit d'abord être
authentifié. Une fois l'utilisateur identifié, ses
paramètres personnels sont sauvegardés dans une session. Ceux-ci
seront actifs durant toute la durée de la session.
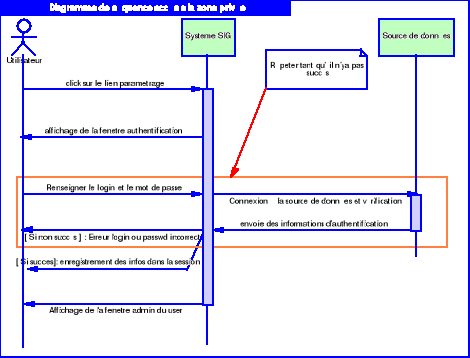
Diagramme 5.4 :
Diagramme de séquence de l'accès à la zone
privée
o Importation des shapefile :
Il s'agit ici de l'importation des données géographiques vers
notre base de données spatiale. Celle-ci se fait par le responsable du
site et repose essentiellement sur le téléchargement de trois
types de fichiers dont les extensions sont : shp, shx, et dbf.
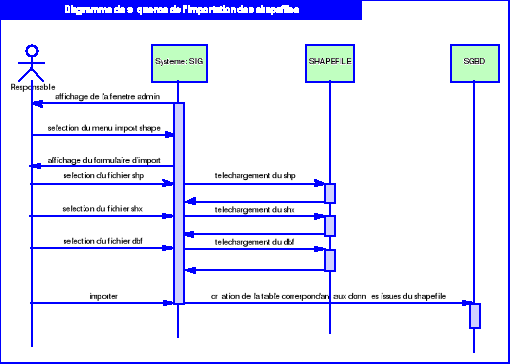
Diagramme 5.5 : Diagramme
de séquence de l'importation des shapefile
o Navigation sur le portail :
il s'agira ici de la chronologie de la navigation sur le portail.
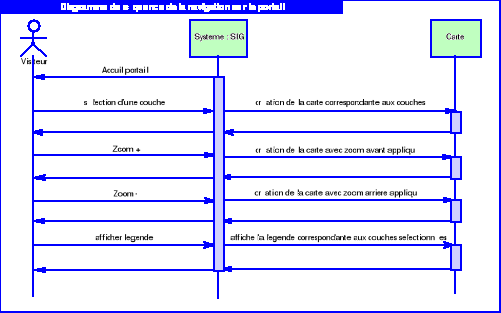
Diagramme 5.6 :
Diagramme de séquence de navigation sur le portail
3. Ebauche du diagramme de
classe
Après une étude approfondie du fonctionnement
global de notre système, nous aboutissons à une
représentation statique du système matérialisé par
le diagramme de classe de la page suivante.
Tableau 5.1 :
présentation des classes de la phase conception
|
Classe
|
Description
|
|
Utilisateur
|
Cette classe permet la gestion des utilisateurs
|
|
Description_couche
|
C'est une classe qui permet de manipuler les différentes
caractéristiques des couches. Elle renvoie les labels les couleurs... de
chaque couche
|
|
Structure
|
Permet la manipulation des structures. L'application appartient
au Labo lti et étant accessible via internet on peut vouloir
intégrer d'autres structures dans la plateforme sans avoir à la
déplacer
|
|
Import_couche
|
C'est une classe qui permet d'importer des fichiers shapes vers
notre BD et crée la table correspondante
|
|
Source_donnee
|
Permet de créer notre chaine de connexion à la BD
par exemple
|
|
Couche_point
|
Permet d'ajouter des points dans la plateforme via un
formulaire
|
|
Couche_parcelle
|
Permet d'ajouter des parcelles sous formes polygonales
|
|
carte
|
Toutes les fonctions permettant de créer et naviguer sur
la carte
|
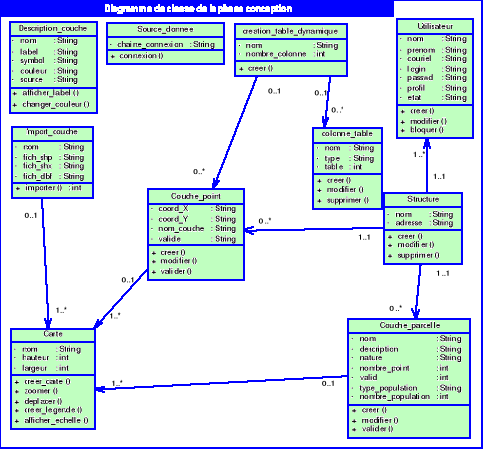
Diagramme 5.7 :
Diagramme de classe de la phase conception
Tableau 5.2 :
présentation des attributs et opération des classes de la phase
conception
|
Attributs
|
Description
|
Opérations
|
Description
|
|
Classe Structure
|
|
nom, adresse
|
Nom et adresse de la structure
|
Créer (), modifier (), supprimer ()
|
Opération de mise à jour
|
|
Classe Utilisateur
|
|
profil
|
Pour connaitre si l'utilisateur est administrateur ou responsable
ou membre
|
Bloquer ()
|
Permet de bloquer ou de rendre actif le compte d'un
utilisateur
|
|
etat
|
Si l'utilisateur est dans un état bloqué ou
actif
|
|
Classe Source_donnee
|
|
Chaine_connexion
|
Contient la valeur de la chaine de connexion à la source
de données
|
Connexion ()
|
Permet de se connecter à la source de donnée (BD) a
partir de la chaine donnée
|
|
Suite du tableau 5.2
|
|
Suite du tableau 5.2
|
|
Classe Import_couche
|
|
Nom
|
Nom de la couche
|
|
|
|
Fich_shp,fich_shx,fich_dbf
|
Les noms des fichiers shapes
|
Importer ()
|
Effectue l'importation des données shapes
|
|
Classe Description_couche
|
|
Nom
|
Nom de la couche
|
Afficher_label ()
|
Permet d'afficher le label associé à la couche
|
|
Label
|
Nom du champ à afficher
|
|
Symbol
|
Le symbole à afficher
|
Changer_couleur ()
|
Permet de changer la couleur de la couche
sélectionnée
|
|
Couleur
|
La couleur à attribuer a la couche
|
|
Source
|
La source de l'a couche
|
|
Classe Couche_point
|
|
Nom_couche, description
|
Nom et description du point
|
Créer (), modifier ()
|
Opérations de mise à jour
|
|
Nature
|
Par exemple : Ecole, hôpital...
|
|
Coord_X, coord_Y
|
Les coordonnées du point
|
Valider ()
|
Permet de valider un point ajouté par un membre
|
|
Valide
|
Détermine si le point est valide
|
|
Carte
|
|
Nom
|
Nom de la carte
|
|
|
|
Hauteur et largeur
|
La hauteur et la largeur de la carte
|
Créer ()
|
Génère l'image correspondant à la carte
|
|
Zoomer (), déplacer ()
|
Implémente les outils de navigations comme le zoom et le
déplacement
|
|
Créer_legende ()
|
Permet de créer la légende
|
|
Afficher_echelle ()
|
Affiche la barre d'échelle
|
NB : Il faut noter
que l'orsqu'une couche est importée une table, contenant toutes les
informations issues du fichier shape, est créée
dynamiquement.
L'or de l'implémentation des classes
nous avons ajouté pour chacune d'elles les méthodes accesseurs
qui sont des opérations publiques permettant d'affecter des valeurs aux
attributs et d'accéder aussi à ces valeurs.
Apres une bonne analyse, qui nous a permis
d'appréhender et d'organiser l'ensemble des besoins du système,
et une conception qui nous a permis de dégager des solutions techniques,
nous allons pouvoir nous intéressé aux outils dont nous aurons
besoin pour automatiser notre système.
CHAPITRE
6
Choix des outils à utiliser
I. Les Systèmes de Gestion de Bases de
données spatiaux
Dans cette partie, nous allons nous intéressé
à une étude comparative de trois système de gestion de
base de données qui intègrent des cartouches spatiaux. Il s'agit
notamment de MySQL9(*), Oracle10(*) et
PostgreSQL11(*).
Cette étude à été réalisée
par LINAGORA et CampToCamp12(*) pour le compte du
CNES13(*)
qui est le Centre National d'Etudes Spatiales.
Tableau 6.1 :
Comparaison base de données spatiaux : Version des
SGBD
|
SGBD
|
Version
|
|
MySQL
|
5.1 beta
|
|
PostgreSQL
|
8.1.4_postGIS 1.1.6
|
|
Oracle Spatial
|
Oracle-10gR2_spatial.ods
|
|
Oracle Locator
|
Oracle-10gR2_locator.ods
|
1. Présentation des
différences entre les cartouches spatiales
Les comparaisons seront effectuées par rapport aux
points suivant : Model Objet, Index Spatiaux, Système de
Référence Spatial(SRS), Prédicats, Opérateurs,
Autres fonctions, Métadonnées.
a. Model Objet
Il s'agit d'un model constitué essentiellement des
objets suivants : Point, Linestring, Polygon, GeomCollection,
MultiPoint, MultiLinestring, Multipolygon.
Tableau 6.2 :
Comparaison base de données spatiaux : Model
objet
|
MySQL
|
PostgreSQL
|
Oracle
|
|
- Point
- Linestring
- Polygon
- GeometryCollection
- MultiPoint
- MultiLineString
- MultiPolygon
- 2D (X-Y)
|
- Point
- Linestring
- Polygon
- GeometryCollection
- MultiPoint
- MultiLineString
- MultiPolygon
- CircularString
- CompoundCurve
- CurvePolygon
- MultiCurve
- 2D (X-Y)
- 3D (X-Y-Z)
- 3D (X-Y-M)
- 4D (X-Y-Z-M)
|
- Point
- Linestring
- Polygon
- GeometryCollection
- MultiPoint
- MultiLineString
- MultiPolygon
- Rectangle
- ArcLinestring
- ArcPolygon
- CompoundLinestring
- CompoundPolygon
- Circle
- 2D (X-Y)
- 3D (X-Y-Z)
- 3D (X-Y-M)
- 4D (X-Y-Z-M)
|
b. Système de Référence
Spatial
Il permet la gestion des systèmes de coordonnées,
le changement de systèmes et la prise en compte de coordonnées
géocentriques.
Tableau 6.3:
Comparaison base de données spatiaux : SRS
|
MySQL
|
PostgreSQL
|
Oracle
|
|
- Stockage SRID
- Pas de gestion des SRS
|
- Moteur de projection
PROJ4
- Définitions issues d'EPSG
(2670+ systèmes)
- Ajout de systèmes possible
- Pas de transformation
implicite (mêmes SRID pour les objets)
- Faible support des coordonnées géocentriques
|
- Package SRS: sdo_cs
- Schéma complet
décrivant les SRS
- Définitions issues
d'EPSG (codes EPSG +
codes Oracle)
- Gestion géocentrique
- Conversion d'unités
- Transformations complexes et implicites (filtres uniquement)
- Quelques restrictions
|
c. Prédicats
Des exemples de prédicats répondants aux
spécifications de l'OGC sont : Crosses, Touches, Within,
Disjoint.
Tableau 6.4 :
Comparaison base de données spatiaux :
Prédicats
|
MySQL
|
PostgreSQL
|
Oracle
|
|
- Uniquement sur les bbox
- Déclenchent l'utilisation des index spatiaux
|
- Tous implémentés
- Respect du nommage norme
- Ne déclenchent pas
l'utilisation des index
- Robustes
|
- Tous implémentés, ou prédicats
équivalents
- Non respect du nommage
- Déclenchent l'utilisation des index
|
d. Opérateurs
Voici une liste non exhaustive des opérateurs
répondant à la norme OGC. Il s'agit de
Union (mot réservé SQL...),
Intersection, Difference, Symmetric
Difference(SymDifference), Buffer,
ConvexHull.
Tableau 6.5:
Comparaison base de données spatiaux :
Opérateurs
|
MySQL
|
PostgreSQL
|
Oracle
|
|
- Pas de support
|
- Support de tous les opérateurs
- Respect du nommage OGC
|
- Support de tous les opérateurs
- Noms spécifiques
- Uniquement Oracle Spatial
|
e. Métadonnées
La norme OGC définie deux tables :
Tableau 6.6:
Tables de métadonnées définies par
l'OGC
|
Table
|
Description
|
|
spatial_ref_sys: qui stocke des
Systèmes de Référence Spatiaux
|
|
|
geometry_columns: qui stocke des tables
contenant des colonnes spatiales ainsi que les noms des colonnes
géométriques.
|
|
Tableau 6.7:
Comparaison base de données spatiaux : Gestion des
métadonnées
|
MySQL
|
PostgreSQL
|
Oracle
|
|
- Pas de gestion des
métadonnées
|
- Gestion des métadonnées
- Respect des règles de nommage
|
- Gestion des métadonnées
- Noms spécifiques: vue
USER_SDO_GEOM_
METADATA
- Schéma complet pour la gestion des SRS
|
2. Présentation des évaluations
quantitatives des cartouches spatiales
Dans cette partie nous présenterons l'évaluation
en termes de temps d'exécution et des critères de notations.
a. Temps d'exécution
Tableau 6.8 :
Comparaison base de données spatiaux : Temps
d'exécution
|
MySQL
|
PostgreSQL
|
Oracle
|
|
- Requête généralement les plus
rapides des 3
systèmes
- Jointures entre tables très rapides
- Temps prometteurs
|
- Jointures entre tables relativement lentes
- Buffer, ConvexHull prenant beaucoup de
temps
- Opérateurs performants
|
- Buffer, ConvexHull très performants
- Jointures entre tables très longues (plusieurs
dizaine de minutes)
- Union de gros polygones très longue (plusieurs
heures)
- Ordre des opérandes
important
|
b. Critères de notations
La notation est effectuée suivant les quatre
critères suivants : Conformité OGC, Fonctionnalités
principales, Autres fonctionnalités, Outillage. Le tableau ci-dessous
donne la moyenne associée à chaque système de gestion de
base de données pour chacun des critères.
Tableau 6.9:
Comparaison base de données spatiaux :
Notations
|
Critères
|
Note
|
|
MySQL
|
PostgreSQL
|
Oracle Spatial
|
Oracle Locator
|
|
Conformité Norme OGC
|
1.5
|
1.75
|
1.25
|
0.75
|
|
Portabilité
Niveau d'Implémentation
Respect des nommages
|
2
|
1
|
1
|
1
|
|
1
|
2
|
2
|
1
|
|
2
|
2
|
0
|
0
|
|
Fonctionnalités principales
|
0.5
|
1.5
|
2
|
1.67
|
|
Model Objet
Prédicats Spatiaux
Opérateurs
Gestion SRS
Index Spatiaux
Coordonnées Géocentriques
|
1
|
1
|
2
|
2
|
|
1
|
2
|
2
|
2
|
|
0
|
2
|
2
|
0
|
|
0
|
1
|
2
|
2
|
|
1
|
2
|
2
|
2
|
|
0
|
1
|
2
|
2
|
|
Autres fonctionnalités
|
0
|
0.5
|
2
|
0
|
|
Paquets SIG
Gestion Rasters
|
0
|
1
|
2
|
0
|
|
0
|
0
|
2
|
0
|
|
Outillage
|
1
|
2
|
1.5
|
1.5
|
|
Outils d'insertion
Outils de visualisation/Traitement
|
1
|
2
|
1
|
1
|
|
1
|
2
|
2
|
2
|
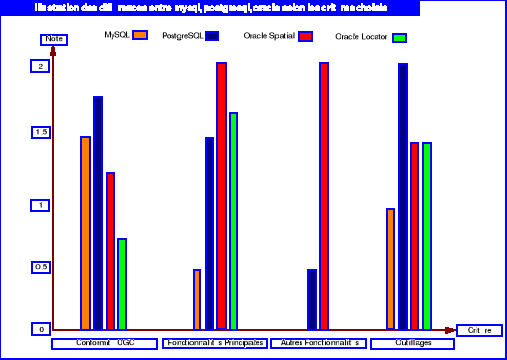
Figure
6.1 : Représentation de la note de chaque SGBD selon les
critères choisis
3. Conclusion sur les
SGBDR spatiaux
Si nous avions à effectuer une classification sur
l'ensemble des fonctionnalités offertes par les SGBDR
étudiés ci-dessus, Oracle Spatial viendrait en tête suivie
de PostgreSQL/PostGIS.
Cependant, nous portons notre choix sur le second du fait
qu'il n'est pas propriétaire donc libre et gratuit, et qui est quasiment
aussi performant que Oracle Locator qui est quand à lui un produit
propriétaire et non gratuit.
II. Les serveurs cartographiques
Le serveur cartographique est le guichet automatique auquel
l'utilisateur fait appel pour afficher des cartes sur son poste informatique,
il peut être contrôlé par des langages de script tels que
PHP, JavaScript, Python ou Perl qui lui
permettent de générer dynamiquement une carte en réponse
à une requête préparée par une interface
utilisateur14(*).
Dans cette partie nous allons vous présenté
trois(3) serveurs cartographiques qui sont : GéoServer, MapServer
et ArcIMS.
1. GéoServer
GéoServer15(*) est un moteur cartographique Open Source
développé en environnement JAVA, et basé sur la librairie
GeoTools16(*).
GéoServer implémente de nombreuses spécifications Web
Service de l'OGC (WMS, WFS-T, WCS, SLD...), il est de plus application de
référence pour l'OGC pour le support de la norme WFS.
GéoServer permet de rapidement mettre en place un Web Service proposant
données vectorielles et/ou rasters.
GéoServer gère de nombreux formats de sortie
pour les données (PNG, SVG, KML, JPEG, PDF, GeoJSON...). De plus il est
aisé pour un utilisateur averti de rajouter son propre module de sortie
personnalisé pour des données vectorielles. C'est un outil de
représentation cartographique lourd. Dans le sens où il
nécessite l'installation d'un JDK 1.4 ou supérieur. Il dispose
d'une vitesse d'affichage correcte mais d'une finesse d'image
supérieure. Son interface est soigné et conviviale.
Tableau 6.10 :
Avantages et inconvénients de GéoServer
|
Avantages et inconvénients de
GéoServer
|
|
Avantages
|
- Structure homogène : GeoAPI, GeoTools, respect des
normes OGC
- Finesse de l'interface et des cartes
- Licence GPL
|
|
Inconvénients
|
- Lenteur par rapport à MapServer
- Nécessite l'installation d'un JDK 1.4 ou
supérieur
- Difficulté de trouver une bonne documentation
|
2. MapServer
Cette partie est entièrement consacrée à
tout ce qui tourne autour de MapServer
a. Présentation de MapServer
MapServer17(*) est un programme CGI18(*) qui s'exécute donc sur un serveur web. En
quelques mots, son rôle consiste à piocher dans des bases de
données et autres ressources afin de générer des images de
type matriciel, qui seront transmises à un client par
l'intermédiaire d'un serveur web.
La naissance de cet outil intervient dans un contexte
caractérisé par une forte demande de mutualisation et
d'accès à l'information. Il est disponible sur de nombreux OS :
Unix, Linux, MacOs X, Windows et s'appuie sur de nombreuses librairies libres,
telles que la Shapelib pour lire des shapefile, FreeType pour gérer du
texte dans les cartes, et Proj4 pour gérer les systèmes de
coordonnées et projections. Il existe enfin des API pour plusieurs
langages (PHP, Python, Java, Perl, C#).
L'usage "simple" de MapServer consiste à régler
quelques paramètres dans un fichier de configuration (le
mapfile), et cela suffit pour mettre en place un serveur WMS conforme
aux normes OGC.
Dix ans après sa création, MapServer est
aujourd'hui devenu une des alternatives les plus sérieuses aux logiciels
propriétaires spécialisés dans le webmapping. Son statut
de Logiciel Libre aidant, MapServer est en passe de devenir une solution de
webmapping de référence grâce à ses performances
remarquables et des fonctionnalités de plus en plus nombreuses.
ü MapServer en CGI ou avec
MapScript
MapServer peut être utilisé en CGI ou avec
MapScript. En CGI, Common Gateway Interface littéralement
« Interface passerelle commune », MapServer fonctionne comme un
exécutable retournant le contenu généré. CGI est le
standard industriel qui indique comment passer l'information du serveur HTTP au
programme et comment en récupérer le contenu
généré.
CGI permet de passer des paramètres au programme, de
telle manière qu'il en tienne compte pour générer les
données. Avec MapScript, MapServer est commandé par
phpmapscript ou javamapscript ou
perlmapscript....
Plus dur à mettre en oeuvre, il est aussi beaucoup plus
souple et permet d'obtenir précisément le résultat
attendu. MapScript est une API19(*) C qui s'interface avec PHP, Perl, C#, Java. Elle
permet d'utiliser les fonctions de MapServer à partir de ces scripts.
ü Le Mapfile
C'est l'élément essentiel, la pièce
maîtresse de l'agencement et de la sémiologie des couches. C'est
lui qui donne les instructions à MapServer. Il se compose d'objets
comportant eux même d'autres objets. Un mapfile20(*) est un fichier texte ASCII
structuré en plusieurs paragraphes qui définissent les
paramètres de la carte (cadre, échelle, légende et
couches). En pratique, il est appelé par un script et renvoie les
différentes couches (layers) sous la forme d'images. Celles-ci peuvent
provenir de différentes sources telles qu'une base de données
spatiale locale ou distante, un serveur distant grâce à une
requête GetMap, un fichier géométrique ou image dans le
disque dur local par son shapefile.
Tableau 6.11:
Extrait d'un Mapfile
|
MAP
// Ouverture du bloc map
EXTENT -17.5352 12.0287 -11.3558 16.9701
// définit la fenetre géographique de la carte
IMAGECOLOR 255 255 255
// Couleur d'arriere plan de l'image
IMAGETYPE png
// Type de l'image de sortie
SYMBOLSET "C:\wamp\www\ltisig\symbole\symbol.sym«
// Chemin du fichier des symboles
SIZE 600 480
// Dimensions de l'image
STATUS ON
// Activer le mapfile
UNITS METERS
// L'unité de la carte
NAME "ltisig«
// Nom du mapfile
OUTPUTFORMAT
NAME "png"
MIMETYPE "image/png"
DRIVER "GD/PNG"
EXTENSION "png"
IMAGEMODE "PC256"
TRANSPARENT FALSE
SUITE du tableau 6.11
|
|
END
LAYER
// Début d'un bloc Layer (couche)
CONNECTION "user=postgres dbname=ltisig
host=localhost« // Connexion à Postgres
CONNECTIONTYPE POSTGIS
// Type de connexion : POSTGIS
DATA "the_geom from senegal«
// Source de la donnée géographique
LABELITEM «nom«
// Nom de la colonne à afficher
NAME "senegal«
// Nom de la couche
STATUS ON
// Activer la couche
TYPE POLYGON
// Type de la donnée géographique
UNITS METERS
CLASS
// Debut d'un bloc class
NAME "Territoire«
// Nom de la classe
LABEL
.....
END
// Fin du bloc LAYER
.......
END
// Fin du bloc MAP
|
b. Principes de fonctionnement
Nous détaillons ici de manière
schématique le mécanisme d'une requête à un serveur
cartographique de type MapServer.
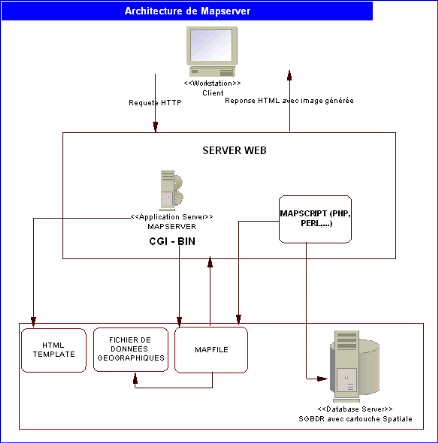
Figure 6.2:
Architecture de MapServer
c. Fonctionnalités de MapServer
L'arrivée de MapServer dans le monde des serveurs
cartographiques a joué un rôle important dans la diffusion de la
cartographie dynamique en ligne, non seulement du fait de ses performances et
de sa fiabilité reconnues, mais également par la diversité
de ses fonctionnalités. Son statut de logiciel libre (qui se traduit
entre autres par un code source ouvert) lui confère une certaine
richesse de ce point de vue grâce à une communauté active
d'utilisateurs/développeurs. En outre, MapServer s'appuie sur des
librairies qui s'enrichissent également en fonctionnalités avec
le temps. Nous recensons ici quelques caractéristiques importantes de
MapServer :
ü Une application multi
plateforme
Développé à la base sur des
systèmes d'exploitation libres, MapServer est aujourd'hui utilisable sur
un grand nombre de systèmes d'exploitation : Windows (95 à XP),
Linux, Mac OS X, BSD, Solaris.
ü Une compatibilité avec plusieurs
serveurs web
Une caractéristique fondamentale de MapServer est sa
compatibilité avec les différents types de serveurs web existant
actuellement. Il fonctionne aussi bien sur les serveurs libres que
propriétaires : Apache, Microsoft IIS/PWS, Netscape Enterprise, NCSA
Httpd.
ü Projection à la
volée
L'utilisation de la librairie PROJ.4 permet à MapServer
de projeter des couches à la volée depuis et vers toute
projection et système de coordonnées supportés par la
librairie (en raster et en vecteur). Un millier de projections sont ainsi
prédéfinies.
ü Une diversité de formats raster en
entrée
MapServer supporte directement une grande diversité de
formats aussi bien en raster qu'en vecteur. Il lit nativement les images au
format TIFF, EPPL, PNG, JPEG, GIF ainsi qu'une trentaine d'autres formats
à travers la librairie GDAL.
ü Une diversité de formats vectoriels en
entrée
MapServer peut lire de nombreux formats de données
vectorielles : Shapefile, DGN, UK .NTF, SDTS, etc. Cette caractéristique
lui fournit une interopérabilité avec la presque totalité
des solutions de SIG actuellement sur le marché.
ü Formats d'images en sortie
MapServer peut produire des images sous un grand nombre de
formats. On utilise principalement les sorties PNG, JPEG, PDF, GIF, BMP,
GeoTIFF, etc.
ü Connexion à des bases de données
spatiales
MapServer offre la possibilité de se connecter à
différents types de bases de données spatiales (libres comme
propriétaires) : PostgreSQL/PostGIS, ArcSDE, Oracle Spatial/Locator
etc.
ü Une compatibilité avec divers langages
de développement
Même si MapServer est à la base écrit en
C, celui-ci est compatible avec la plupart des langages et environnement de
script actuellement utilisés : PHP, Python, Perl, Rubis, Java et C#.
ü Une forte modularité
En plus de ces fonctionnalités de base, MapServer offre
une multitude de fonctionnalités annexes permettant entre autres :
l'affichage des légendes de la carte, l'affichage d'une carte de
référence, l'affichage d'une barre d'échelle, la mise
à disposition d'outils de contrôle et de navigation
(déplacement et zoom sur la carte), la possibilité de faire des
requêtes ...
Cette diversité de fonctions fait aujourd'hui de
MapServer un des logiciels de cartographie en ligne les plus complets et les
plus extensibles. Ceci est un des piliers de son succès grandissant.
d. Points forts et points faibles de
MapServer
Tableau 6.12:
Points forts et points faibles de MapServer
|
Points forts et points faibles de
MapServer
|
|
Points forts
|
- Le statut de MapServer comme solution libre
- Les performances de MapServer et sa stabilité
remarquable
- L'adaptabilité et la flexibilité
- Interopérabilité
- Nombreuses fonctionnalités
- Evolution rapide
|
|
Points faibles
|
- Forte nécessité en développements
- Qualité du rendu graphique
- Lourdeur de l'installation
|
Remarque : Il faut noter
que MapServer à lui tout seul « n'est rien ». Il
est « manipulé » à l'aide langages de script
tels que php, perl, java...
3. ArcIMS
(I)
Les principaux produits d'ESRI pour les serveurs SIG
sont :
ArcIMS : Serveur cartographique
Internet évolutif. Il est beaucoup utilisé pour publier des
cartes, des données et des métadonnées SIG à un
grand nombre d'utilisateurs sur le Web.
ArcSDE : Serveur de données
spatiales qui permet à une application cliente quelconque, de stocker,
gérer et utiliser des données spatiales dans un SGBD.
ArcGIS Server : Plate-forme
permettant de développer des services Web.
Par contre ArcIMS est le seul serveur qui permet le
Webmapping, la publication Web des SIG et qui prend en charge les applications
cartographiques Java et HTML nécessaire a notre application. Il s'agit
en réalité d'une offre double puisqu'elle comporte deux
technologies différentes :
Des traitements Serveur qui affichent des images
cartographiques générées par le serveur dans des pages
HTML classiques, éventuellement agrémentées de scripts
clients pour améliorer les capacités fonctionnelles de celles-ci
;
Une applet Java pour afficher et interroger (requêtes
spatiales, analyses thématiques ...) des données vectorielles au
format Shape File d'ArcView, transférées au poste client
dans un format compressé.
ArcIMS est par ailleurs intégrable avec des solutions
plus générales, et dispose d'un véritable gestionnaire de
publication, fort utile aux auteurs de sites.
Cette offre se distingue particulièrement par son
caractère « serveur centralisé de données
géographiques ». Il ne s'agit en effet pas simplement d'une offre
pour la consultation et l'interrogation des informations. Plusieurs
fonctionnalités originales sont en effet disponibles : extraction de
données vectorielles vers le poste afin de réaliser des
traitements locaux, croisement des données « classiques »
résidant sur le poste client ou sur un réseau local.
4. Conclusion sur les
serveurs cartographiques
GéoServer et MapServer offrent quasiment les
mêmes fonctionnalités et les mêmes performances. Certes
GéoServer offre un meilleur rendu, néanmoins il nécessite
l'installation du JDK avec une version supérieure à 1.4. Il est
également très difficile de trouver une bonne documentation pour
GéoServer. Notons que ArcIMS est propriétaire et distribué
sous licence payante. Par contre MapServer lui hérite d'une large
communauté qui évolue rapidement et qui peut s'interfacer avec
plusieurs langages de scripts comme php, perl, java, etc. C'est ce qui à
motivé notre choix pour MapServer.
III. Les serveurs web
L'univers des serveurs web est un petit monde clos,
arc-bouté autour de la domination sans partage de deux acteurs :
Microsoft IIS21(*) et
Apache22(*). Selon
l'enquête de Netcraft en septembre 2007, IIS
possédait environ 34,94% des parts de marché. A pareille date,
une autre enquête, réalisée par
SecuritySpace, n'accordait quant à elle qu'un maigre
20,47% des parts au serveur IIS par rapport à 73.28% pour Apache. Il
reste donc bien peu de place pour la concurrence. Cependant, du haut de ses
1,4 % du gâteau des serveurs, Zeus23(*) s'impose comme un outsider incontournable :
quelques uns des plus gros Intranets et des plus gros sites Web ont
opté pour lui. Un critère qui a conduit à le retenir dans
notre comparatif.
1. Points forts et points faibles
Dans le tableau suivant, chacun de ces trois serveurs Web est
passé au crible de quatre critères : coût, ergonomie,
performances et efficacité du support.
Tableau 6.13 :
Points forts et points faibles des serveurs web
étudiés
|
Points forts et points faibles de chaque
produit
|
|
Nom du produit
|
Apache
|
Microsoft IIS
|
Zeus
|
|
Points forts
|
- Gratuité
- Peu gourmand en ressources
matérielles
- Excellente stabilité
|
- Grande simplicité d'installation et d'utilisation
|
- Peu gourmand en ressources matérielles
- Excellente
stabilité
- Capacité à tenir de très gros pics
de fréquentation
- Interface native avec certaines bases de
données
|
|
Points faibles
|
- Installation et administration plus laborieuses (pas
d'interface graphique)
- Pas de support technique
|
- Coût du support technique
- Très gourmand en
ressources matérielles
|
- Coût de la licence (1700 €)
- Coût du
support technique
|
2. Choix selon les besoins
L'utilisation de Microsoft IIS se justifie en effet toujours
dans certains contextes, de même que celle de Zeus ou d'Apache. Les
portraits brossés ci-après permettront de se faire une
idée du profil de l'entreprise qui trouvera intérêt dans
l'un ou l'autre de ces serveurs web :
a. Compétences faibles et exigences modestes:
IIS
Le Serveur Web de Microsoft est très facile à
installer et relativement facile à administrer. Il dispose d'une
fonction de redémarrage automatique en cas de plantage. Et il est inclus
par défaut dans l'OS serveur de Microsoft. Mais si l'on souhaite confier
à IIS un gros site Web ou un gros Intranet, la facture hardware
monte beaucoup plus vite que celle d'Apache ou Zeus, de même que la
facture logicielle : la base de données Microsoft SQL devient
rapidement indispensable, et l'on sait son tarif conséquent.
On
réservera donc IIS aux entreprises qui disposent de compétences
informatiques moyennes, et dont les exigences en termes de performances vont de
modérées à moyennes.
b. Compétences fortes, tous types d'exigences:
Apache
Le Serveur Web le plus populaire est fort complexe à
paramétrer et à administrer : tout se passe sur un
écran noir, en mode ligne de commande. Aucun support technique
téléphonique n'est fourni puisqu'Apache n'a pas de distributeur
officiel.
Il faut donc assurer soi même son support en naviguant
sur les sites d'information consacrés à Apache, ou encore
souscrire à un contrat de support auprès d'une
société spécialisée. Cependant, Apache est gratuit,
il consomme des ressources matérielles très modestes, et il est
irréprochable en termes de fiabilité.
Apache est donc un très bon choix pour les entreprises
qui disposent de compétences informatiques fortes et plus
spécifiquement sous Unix et Linux. Notons qu'il sera parfois
intéressant d'acquérir ces compétences : les
linuxiens chevronnés se font de moins en moins rares sur le
marché, et Apache demande à charge
égale beaucoup moins de ressources matérielles qu'IIS, ce
qui rend son TCO (Cout Total de Possession) excellent pour les applications
lourdes.
c. Compétences moyennes et exigences
très fortes: Zeus
Zeus simplifie la tâche de l'administrateur.
L'installation démarre en mode ligne de commande, mais elle est
rapidement facilitée par des boites de dialogue judicieusement
conçues.
L'administration se fait à distance à travers un
navigateur Web : c'est un modèle d'ergonomie. Quant aux
performances de Zeus, elles sont équivalentes à celles d'Apache,
avec un avantage de taille : Zeus est capable de tenir le choc de
plusieurs milliers de requêtes par seconde. Une assurance contre le
plantage en cas de pic de fréquentation. Zeus est compatible en natif
avec une foule d'API qui lui permet de s'interfacer sans effort avec un grand
nombre de bases de données. Le seul défaut de Zeus : son
prix (1700 € pour la licence sans compter le support)24(*). Zeus sera le meilleur choix
pour les entreprises aux exigences très fortes aussi bien en nombre
de connexions simultanées qu'en termes de disponibilité.
3. Autres informations pratiques
Le tableau qui suit donne des informations
supplémentaires sur le prix et compatibilité de ces trois
serveurs web.
Tableau 6.14 :
Tableau donnant des informations sur le Prix et la compatibilité pour
les serveurs web
|
Informations pratiques
|
|
Nom du produit
|
Apache
|
Microsoft IIS
|
Zeus
|
|
Prix
|
0 €
|
inclus dans Windows 2000 serveur, lequel vaut 1300 €
|
1900 €
|
|
Compatibilité
|
Linux, Windows 98 à XP, de nombreux Unix,
MacOs X
|
Windows 2000 serveur
|
Linux, de nombreux Unix, MacOs X
|
4. Conclusion sur les
serveurs web
Cette étude, nous a permis de mettre en mettre en
évidence les trois serveurs web du marché les plus connus. En ce
qui nous concerne, nous avons porté notre choix sur apache du fait non
seulement de son statut libre et gratuit, mais aussi de sa vaste part de
marché.
IV. Choix de la solution à
implémentée
Après une étude comparative très
rigoureuse, nous avons pu choisir les outils qui répondent mieux
à nos besoins. Il s'agit du serveur cartographique
MapServer avec
PHP/MapScript, du célèbre serveur web
apache, et du SGBDR
PostgreSQL avec sa cartouche spatiale
PostGIS.
L'architecture de cette solution est représentée
par le schéma ci-dessous :

Figure 6.3:
Architecture de la solution choisie
Après avoir effectué notre choix pour les outils
dont nous avons besoin, nous allons passer dans le chapitre qui suit à
la phase implémentation.
CHAPITRE
7
Implémentation de la solution
I. Environnement de Travail
Nous avons effectué la totalité de notre stage
au sein du Laboratoire de Traitement de l'Information. Donc dans cette partie,
nous allons décrire les outils matériels et logiciels que nous
avons utilisés pour la réalisation de notre plateforme.
1. Environnement matériel
Le tableau suivant décrit l'ensemble de
l'équipement matériel utilisé
Tableau 7.1 :
Caractéristiques des équipements
|
Equipement matériel
|
|
Nom de l'équipement
|
Caractéristiques
|
|
Ordinateur PC
|
- Marque : HP Compaq
- Processeur : Intel Pentium 4
- Vitesse Processeur : 3.05 Go
- Mémoire Ram : 256 Mo
- Disque dur : 80 Go
- Ecran : 17 pouce
|
2. Environnement logiciel
Les tableaux suivant décrivent l'ensemble des outils
logiciels et bibliothèques utilisés
Tableau 7.2:
Les outils logiciels utilisés
|
Equipement logiciel
|
|
Nom du logiciel
|
Description
|
|
Système d'exploitation
|
Débian sarge noyau linux 4.0
|
|
MapServer avec MapScript
|
Serveur cartographique version 5
|
|
PHP
|
PHP version 5 pour le pilotage du serveur cartographique
|
|
Apache
|
Serveur Web version 2
|
|
PostgreSQL/PostGIS
|
Serveur de Bases de données + cartouche spatial
Respectivement version 8 et 1.3.2
|
|
PgAdmin3
|
Utilitaire de gestion du SGBD PostgreSQL
|
|
Quanta plus
|
Editeur de texte pour PHP
|
Tableau 7.3:
Les librairies utilisées
|
Equipement logiciel
|
|
Nom de la librairie
|
Description
|
|
PROJ4
|
PROJ est un paquetage permettant de tirer profit des
systèmes de projection spatial, notamment des reprojections entre divers
systèmes (Lambert II étendu, Lambert III etc...)
|
|
GDAL
|
Ensemble qui permet la gestion des formats rasters
|
|
PDFLIB
|
Permet la génération de fichiers pdf a partir de
php
|
|
GD
|
Ensemble de fonction permettant la génération d'une
image
|
|
GEOS
|
Ce paquetage contient notamment une librairie qui permet
d'ajouter des fonctionnalités supplémentaires à PostGIS
notamment Within (), Intersects ()...
|
|
OGR
|
Ensemble qui permet la gestion des formats vecteurs
|
II. Architectures de la plateforme
Après une solide analyse et conception des besoins,
nous avons réalisé l'architecture logicielle et physique ainsi
que l'architecture applicative de notre système.
1. Architecture logiciel
du système
Nous allons représenter ici l'architecture logicielle
du système par un diagramme des composants.
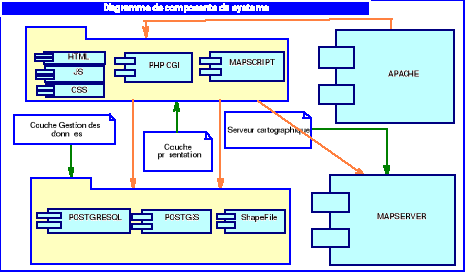
Diagramme 7.1 :
Diagramme de composants du système
2. Architecture physique
du système
Nous allons maintenant représenter l'architecture
physique des composants matériels qui supporte l'exécution du
système. Cette représentation se fera à l'aide d'un
diagramme de déploiement.
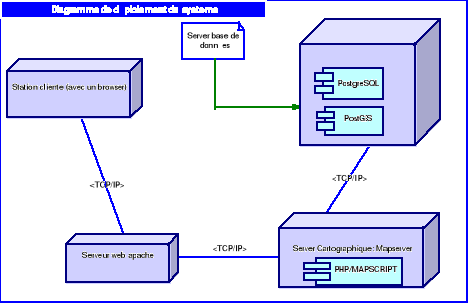
Diagramme 7.2 :
Diagramme de déploiement du système
3. Architecture
applicative de la plateforme
Le schéma de la page suivante représente
l'architecture applicative de la plateforme.

Figure 7.1 : Architecture applicative de la
plateforme
4. Sécurité
de la plateforme
La sécurité informatique est l'ensemble des
techniques qui assurent que les ressources du système d'information
(matérielles ou logicielles) d'une organisation sont utilisées
uniquement dans le cadre où il est prévu qu'elles le
soient25(*).
Nous distinguons au moins quatre services de
sécurité de base.
ü La
confidentialité : C'est l'assurance que les
données échangées ne seront
pas lues par un tiers qui n'en a pas le droit lors de leur
transmission ou lorsqu'elles sont stockées.
ü
L'intégrité : Elle garantit que les
données n'ont pas été altérées ou
détruites durant leur transmission.
ü L'authentification :
Elle est le processus de validation de l'identité de
l'émetteur et du récepteur. Elle est vue sous
deux aspects notamment
§ L'authenticité et l'accessibilité :
assurance de l'identité,
§ L'identification : signature, carte
électronique, clé.
ü La non
répudiation : Le but est que l'émetteur d'un
message ne puisse pas
nier l'avoir envoyé si la sécurité de
leurs clés n'a pas été compromise et le récepteur
l'avoir reçu.
Dans notre plateforme, nous avons implémenté un
service d'authentification par login et mot de passe. C'est un système
d'authentification qui sécurise l'accès à l'interface
protégé. Ainsi seuls les utilisateurs authentifiés sont
habilités à mettre à jour des informations privées.
Une fois l'utilisateur est reconnu par le système son
profil et les paramètres d'affichage sont chargés.
Cette démarche permet la protection et la
sécurité du SIG, en interdisant ainsi la modification des
données aux utilisateurs non autorisés.
III. Présentation
de l'application
Dans cette partie, nous allons présenter ce que nous
avons pu réaliser durant ces 5 mois de stage, sous forme de captures
d'écran.
1. Zone
privée
Nous présentons ici les écrans de la zone
protégée.
Après authentification on affiche la fenêtre
admin
Ecran paramétrages
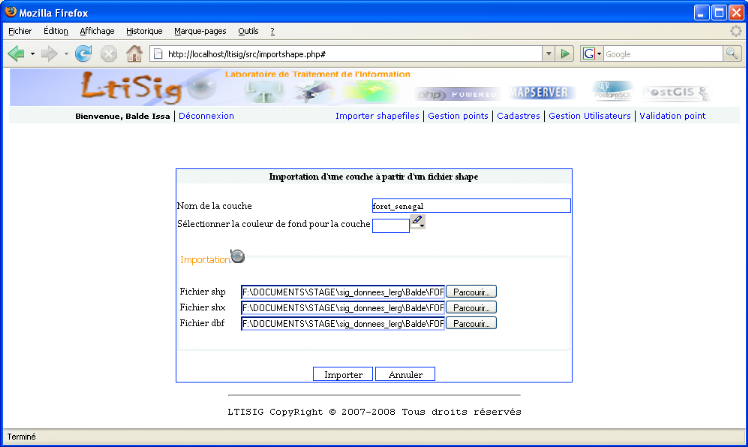
Ecran qui permet l'importation des
shapefiles
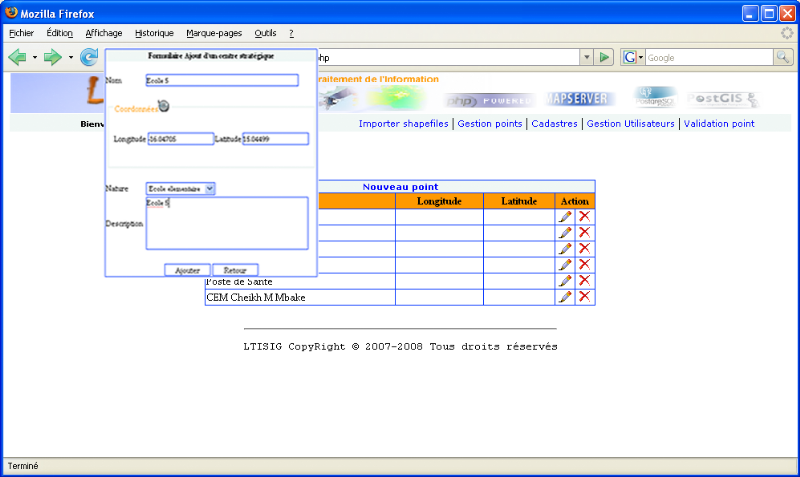
Ecran gestion des points
2. Interface
publique
Les écrans qui suivent représentent celles de la
zone publique. Il s'agit de l'affichage de cartes et de la navigation sur le
portail.
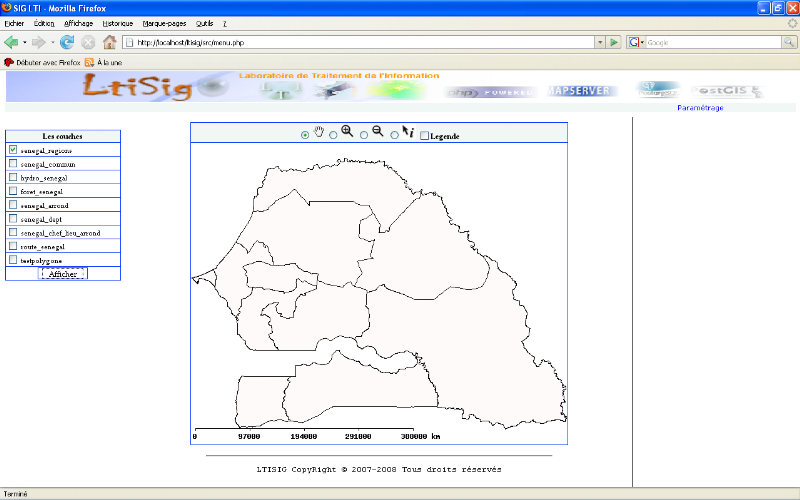
Ecran de navigation sur le portail
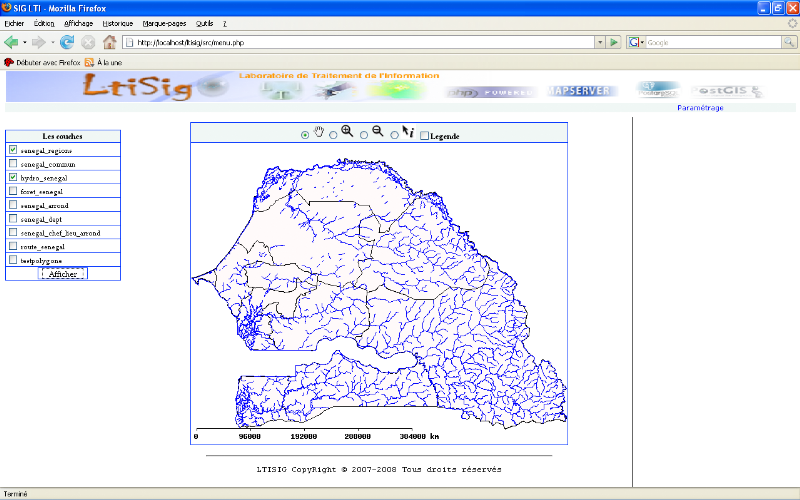
Carte créée après ajout de la
couche hydrographie
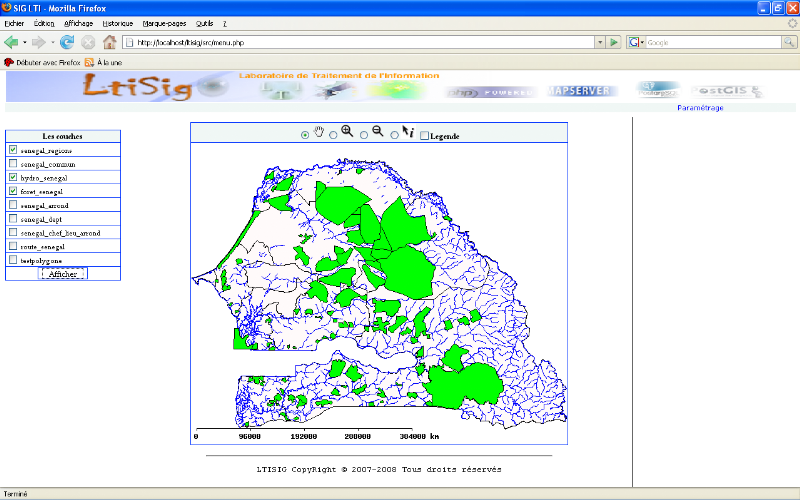
Carte créée après ajout de la
couche foret
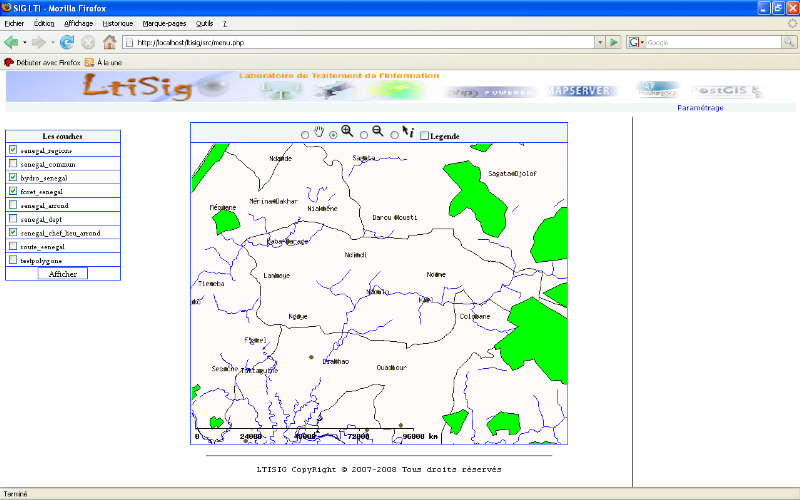
Affichage de la carte après Zoom sur la
région de Diourbel
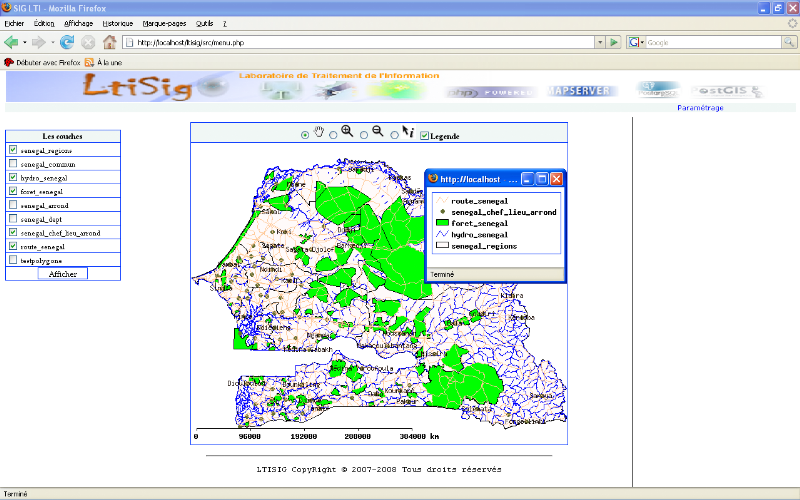
Affichage de la légende
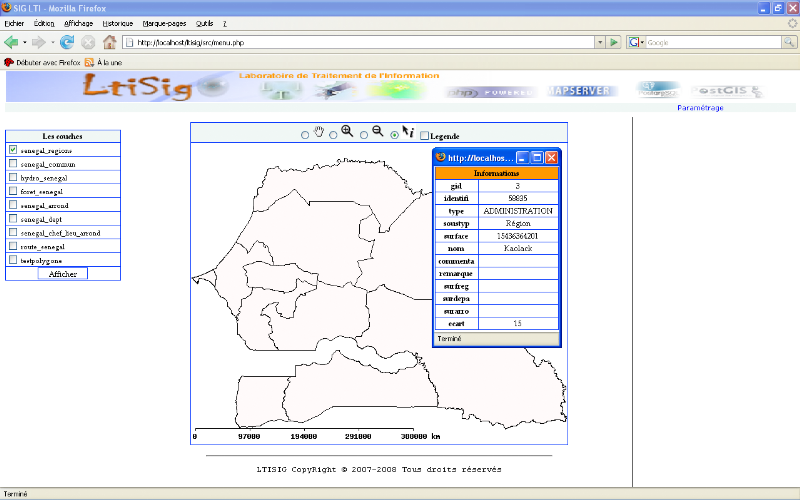
Affichage des informations d'une zone après click
sur celle-ci
CONCLUSION GENERALE
Les études que nous avons menées nous ont permis
de mettre en place une plateforme de cartographie dynamique accessible
à travers internet, conformément aux besoins des projets d'appui
à la décentralisation au Sénégal.
Ces études nous ont aussi permis de choisir des outils
informatiques Open Source. En effet, nous avons choisi le système
d'exploitation linux notamment la distribution debian. Nous avons
utilisé aussi MapServer, comme server cartographique, le langage de
programmation php/MapScript pour l'affichage dynamique des pages web et des
cartes, et apache comme server web. Comme server de base de données,
nous avons porté notre choix sur PostgreSQL muni de sa cartouche
spatiale PostGIS. Il faut noter que tous ces outils sont libres, gratuits et
téléchargeable sur internet.
Nous avons pu produire une application web évolutive
accessible via internet et qui peut offrir à ce stade presque les
mêmes services que les logiciels SIG bureautiques qui eux ne sont pas
accessibles via internet. L'application n'est pas encore à sa phase
finale, mais elle reste ouverte à toute évolution sachant que
tous les outils qu'elle utilise sont open source et donc son code source est
utilisable et modifiable à volonté.
Comme prévu nous n'avons pas pu réaliser la
gestion des formats rasters qui nous aurait permis d'afficher des cartes en
images satellites. Nous avons aussi prévu pour la suite de faire en
sorte que la plateforme puissent récupérer des données
géographiques à partir d'un format de fichier XML bien
définit.
Par ailleurs ces cinq mois passé au laboratoire de
traitement de l'information, nous ont été d'un apport
considérable. En effet c'est une expérience qui nous a permis de
découvrir un domaine nouveau en l'occurrence les systèmes
d'informations géographiques. Il faut surtout noter que c'est un domaine
en pleine expansion qui est assigné à un bel avenir. C'est pour
cela d'ailleurs que nous recommandons au responsable pédagogique du
département d'intégrer, dans le programme des ingénieurs
des modules de cours sur les SIG pour permettre aux étudiants
d'acquérir certaines bases avant d'aller en stage.
En annexe, nous avons joins un extrait de notre code source et
des classes des objets de bases de l'API Mapscript pour PHP ; nous avons
également joins toutes les options de l'importateur
shp2pgsql qui a permis l'importation des shapefile.
REFERENCES
· BIBLIOGRAPHIE
· (I) Sana Kanzari Mémoire DIC INFO
2007 (thème :
Elaboration d'un site web de cartographie dynamique pour
l'aide à la gestion de la région de
Matam).
· (II) Mohamadou Mbengue Mémoire DIC INFO
2006 (thème : Mise en place d'une plateforme de
conception de sondage, de test de connaissance et d'évaluation de stage
pour le Ministère des finances et de l'industrie de la France) promotion
2006.
· Pascal Roques UML 2 par la
pratique 5eme Edition (EYROLLES)
· Eric Daspet, Cyril Pierre de Geyer PHP 5
avancé 4eme Edition (EYROLLES)
· WEBOGRAPHIE
Pour voir l'ensemble des classes de l'API mapscript
·
http://www.veremes.com/download/php-mapscript_class_diagram-4.6_int.pdf
Exemple d'utilisation de PHP/Mapscript
·
www.davidgis.fr/documentation/win32/html/apl.html
·
http://mapserver.gis.umn.edu/docs/howto/phpmapscript-byexample
Sites de téléchargement de fichiers Shape et
TIF
· http://www.maplibrary.org/
· http://www.reefbase.org/
Documentation de référence de mapscript
·
http://mapserver.gis.umn.edu/docs/reference/mapscript
Tutoriel d'installation de MapServer
·
http://mapserver.gis.umn.edu/docs/howto/phpmapscript-install
Sites de références pour PHP
· http://www.php.net
· www.manuelphp.com
Site de référence Postgis
· www.postgis.org
Documentation sur l'ensemble PHP/mapscript/postgis
·
http://www.davidgis.fr/documentation/win32/html/
Présentation de la méthode RAD
·
http://merckel.org/article.php3?id_article=32
INDEX
A
analyse ..6, 7, 10, 13, 16, 20, 27, 28, 29, 31, 34, 35, 37, 38,
40, 41, 49, 50, 51, 78, 83
Apache 21, 70, 73, 74, 75, 77, 78
C
cartographie 15, 20
G
GéoServer 66
I
IIS. 21, 70, 73, 74, 75
M
mapfile 67, 68
MapScript 67, 68, 76, 77, 78
MapServer 67
méthode 28
MySQL 22, 60, 61, 62, 63, 64
O
OGC 9, 10, 61, 62, 63, 64, 66, 67
Oracle 60, 61, 62, 63, 64, 65, 70
P
PHP 9, 67, 68, 71, 76, 77, 78, 85
PostgreSQL 22, 60, 61, 62, 63, 64, 65, 70, 76, 77, 78
R
rasters 15, 66
S
servlet 21, 22
SGBD 9, 26, 60, 77, 78
SGBDR 7, 20, 22, 65, 76
shapefile 67, 70
SIG 23
U
UML 33, 37
UP. 9, 31, 32, 33, 34
V
vecteurs 15
vectoriel 15, 23, 70
W
Webmapping 15, 16, 20
Z
Zeus 73, 74, 75
ANNEXES
Annexe A: Extraits du diagramme de
classes de l'API mapscript
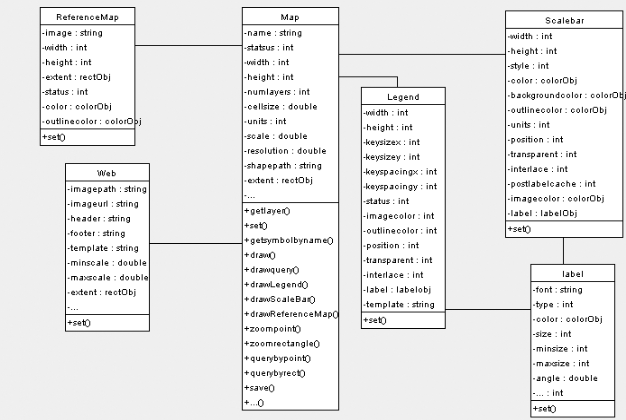
Les classes reliées à l'objet
map
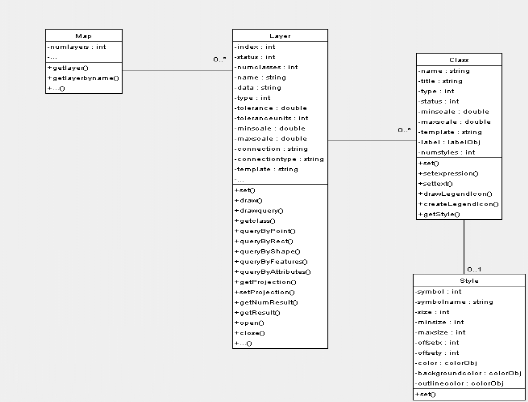
Les classes reliées à l'objet
« layer »
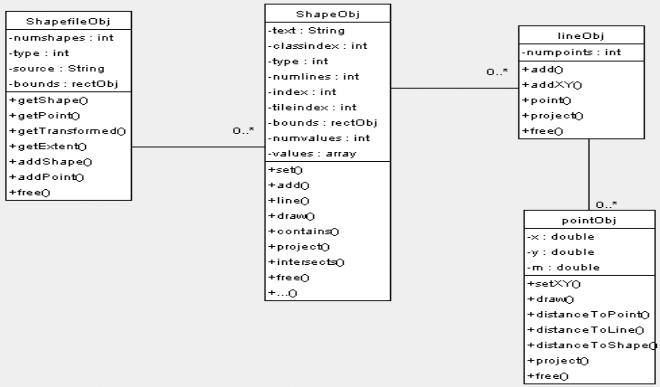
Les classes reliées à l'objet
shape
Annexe B : Extrait du code source de notre
application
Extrait 1 : Création et
affichage de la carte
|
/*************************************************************************************)
(**** CopyRight
ltisig Juin 2008 *************)
(**** Auteur: Issa BALDE
stagiaire DIC3 G.Info *************)
(************************************************************************************)*/
// on crée l'objet map
$map = ms_newMapObj($map_path . $map_file);
$map->setSymbolSet($symb_path);// definition du fichier des
symbole
$layer = ms_newLayerObj($map);
// Nom du layer
$layer->set( "name",$choix_couche);
// Affichage : oui par défaut
$layer->set("status",MS_DEFAULT);
// Type de connexion = PostGIS
$layer->set("connectiontype",MS_POSTGIS);
$layer->set("connection",
"user=".$user." dbname=".$db." host=".$hote);
$layer->set("labelitem",$label);// affichage des etiquettes ou labels
// Les METADATA
$layer->setMetaData("Description",$choix_couche);
$layer->setMetaData("Result_Fields","nom");
$layer->setMetaData("Layer",$choix_couche);
//On récupere les colones
géometriques
$MS_GEOM = pg_query($conn,
"SELECT f_geometry_column,type FROM
geometry_columns WHERE f_table_name
LIKE '".$choix_couche."'"
);
$colonne_geometrique = pg_result( $MS_GEOM,0,0 );
$type_geometrique = pg_result( $MS_GEOM,0,1 );
// La requete spatiale
$layer->set( "data",$colonne_geometrique." from
".$choix_couche);
switch ($type_geometrique)
{
case "POINT":
$layer->set("type",MS_LAYER_POINT);
$layer->set("status",MS_ON);
// Ajout de la class
$class = ms_newClassObj($layer);
$class->set("name",$choix_couche);
// Ajout du Label
$label = $class->label;
$label->set("size",MS_SMALL);
$label->color->setRGB("22","8","3");
// Ajout du style
$style = ms_newStyleObj($class);
// Précision sur la taille de
l'objet
$style->set("size",7);
$style->set("symbolname","circle");
if(isset($R)&&($R!='')){$style->color->setRGB($R,$G,$B);}else{$style->color->setRGB("255","0","0");}
break;
case "MULTIPOLYGON":
$layer->set("type",MS_LAYER_POLYGON);
$layer->set("status",MS_ON);
$class = ms_newClassObj($layer);
$class->set("name",$choix_couche);
// Ajout du Label
$label = $class->label;
// Précision sur l'affichage de la données de
type attributaire
// la couleur, la taille de la donnée ...
$label->set("size",MS_TINY);
$label->set("position",MS_CC);
$label->backgroundcolor->setRGB("0","255","0");
$label->color->setRGB("0","0","0");
$label->outlinecolor->setRGB("255","255","255");
$style = ms_newStyleObj($class);
$style->set("size",5);
if(isset($R)&&($R!='')){
$style->color->setRGB($R,$G,$B);
}else{$style->color->setRGB("255","250","250");}
$style->outlinecolor->setRGB("0","0","0");
break;
case "POLYGON":
$layer->set("type",MS_LAYER_POLYGON);
$layer->set("status",MS_ON);
$class = ms_newClassObj($layer);
$class->set("name",$choix_couche);
// Ajout du Label
$label = $class->label;
// Précision sur l'affichage de la données de
type attributaire
// la couleur, la taille de la donnée ...
$label->set("size",MS_TINY);
$label->set("position",MS_CC);
$label->backgroundcolor->setRGB("0","255","0");
$label->color->setRGB("255","0","0");
$label->outlinecolor->setRGB("255","255","255");
$style = ms_newStyleObj($class);
$style->set("size",5);
if(isset($R)&&($R!='')){$style->color->setRGB($R,$G,$B);}else{$style->color->setRGB("255","250","150");}
$style->outlinecolor->setRGB("80","80","255");
break;
default:
$layer->set("type",MS_LAYER_LINE );
$layer->set("status",MS_ON);
$class =
ms_newClassObj($layer);
$class->set("name",$choix_couche);
// Ajout du Label
$label =
$class->label;
// Ajout du style
$style =
ms_newStyleObj($class);
// Précision sur l'affichage
des données géométriques
// couleur de bourdure en code 128
0 0 pour RGB
$style->set("size",10);
if(isset($R)&&($R!='')){$style->outlinecolor->setRGB($R,$G,$B);}else{$style->outlinecolor->setRGB("128","0","0");}
break;
}
/*-----------------------------------------------------------
------- calcul de l'Extent pour chaque couche
----------
-------------------------------------------------------------*/
$Requete_Extent = "select
xmin(extent(".$colonne_geometrique.")),
ymin(extent(".$colonne_geometrique.")),
xmax(extent(".$colonne_geometrique.")),
ymax(extent(".$colonne_geometrique.")) from ".$choix_couche;
$Resultat_Extent = pg_query( $conn, $Requete_Extent);
while ( $Row_Extent = pg_fetch_object( $Resultat_Extent ))
{
$Xmin[] = $Row_Extent->xmin;
$Ymin[] = $Row_Extent->ymin;
$Xmax[] = $Row_Extent->xmax;
$Ymax[] = $Row_Extent->ymax;
}
}// fin du while
/*
--------------------------------------------------------------------------
--------- Calcul de l'Extent générale et des
dimensions de l'image -----
----------------------------------------------------------------------------
*/
$xmin= min($Xmin);
$ymin= min($Ymin);
$xmax= max($Xmax);
$ymax= max($Ymax);
$longueur_image = 600;
$longueur_extent = abs($xmax-$xmin);
$hauteur_extent = abs($ymax-$ymin);
$rapport_extent = $longueur_extent / $hauteur_extent;
$hauteur_image =$longueur_image / $rapport_extent;
$map->set("width", $longueur_image);
$map->set("height", $hauteur_image);
$map->backgroundcolor->setRGB("0","200","255");
/*------------------------------------------------------------------------------
------------------------------- ajout de la barre
d'echelle -----------------
--------------------------------------------------------------------------------*/
$map->scalebar->set("style", 1);
$map->scalebar->set("units", MS_KILOMETERS);
$map->scalebar->set("intervals",4);
$map->scalebar->set("transparent", MS_ON);
$map->scalebar->set("status", MS_EMBED);
$map->scalebar->set("width", 400);
$map->scalebar->color->setRGB(0,0,0);
// echelle
$scaleBar = $map->drawScaleBar();
/*------------------------------------------------------------------------------
------------------------------- ajout de la legende
-----------------
--------------------------------------------------------------------------------*/
$map->legend->set("status", MS_ON);
// legende
$legend = $map->drawLegend();
$url_legende=$legend->saveImage($img_path."legende_".session_id().".png");
/*----------------------------------------------------------------------------
------------ Construction de la carte de reference
---------------------------
-----------------------------------------------------------------------------*/
$map->reference->set("image",$img_path."miniMap.png");
$map->reference->set("width",150);
$map->reference->set("height",119);
$map->reference->set("status",MS_ON);
$map->reference->extent->setextent($xmin,$ymin,$xmax,$ymax);
$map->reference->color->setRGB(-1,-1,-1);
$map->reference->outlinecolor->setRGB(255,0,0);
$image_ref=$map->drawReferenceMap();
$url_ref=$image_ref->saveImage($img_path."miniMap.png");
/*-----------------------------------------------------------------
----------- Dessin et sauvaugarde de l'image
généré ----
------------------------------------------------------------------*/
$image = $map->draw();
$image->saveImage($img_path.$image_name);
|
Extrait 2 : Affichage de la fenêtre
d'informations
|
// Fonction javascript qui permet d'afficher une fenetre popup
avec les parametres nom (nom des champs) val (valeurs des champs)
<script langage= `JavaScript'>
function info(nom,val){
var url="info.php?nom="+nom+"&&val="+val+"";
var
prop="status=no,scrollbars=yes,toolbar=no,menubar=no,resizable=yes,location=no,width=200,height=80,top=235,left=690";
window.open(url,"info",prop);
</script>
$clkpoint->SetXY($_POST['img_x'], $_POST['img_y']);
$ProvExtents = explode(" ", $_POST['extent']);// On
récupere le nouvel extent
$dfMinX = doubleval($ProvExtents[0]);
$dfMinY = doubleval($ProvExtents[1]);
$dfMaxX = doubleval($ProvExtents[2]);
$dfMaxY = doubleval($ProvExtents[3]);
// tester si on a clické sur l'outils infos
if($_SESSION['outils']==2)
{
// création d'un nouvel objet point
$oClickGeo = ms_newPointObj();
$width = $map->width;
$height = $map->height;
// récupération des coordonnées du click
$x_clik=intval($_POST['img_x']);
$y_clik=intval($_POST['img_y']);
// conversion des coordonnées pixel en coordonées
géoréferencés avec notre fonction LtiSigPix2Geo()
$nClickGeoX = LtiSigPix2Geo($x_clik, 0, $width, $dfMinX,
$dfMaxX, 0);
$nClickGeoY = LtiSigPix2Geo($y_clik, 0, $height,$dfMinY,
$dfMaxY, 1);
$oClickGeo->setXY($nClickGeoX, $nClickGeoY);
@$layer->queryByPoint($oClickGeo, MS_MULTIPLE, -1); //
exécution de la requete
// on récupere le nombre de couches actives (layer)
$numcouches = $map->numlayers;
$nResults=0;
for($i = 0; $i < $numcouches; $i++){
$layer=$map->getLayer($i);
$nLayerResults = $layer->getNumResults();
if ($nLayerResults == 0)
continue; // Pas de résultats
$layer->open();
$champs = explode(" ",
$layer->getMetaData("RESULT_FIELDS"));// On récupère les
attributs de la couche explorée
//qui correspondent aux attributs indiqués dans
RESULT_FIELdS du fichier ltisig.map
for ($iRes=0; $iRes < $nLayerResults; $iRes++)
{
$oRes = $layer->getResult($iRes);
$oShape =
$layer->getShape($oRes->tileindex,$oRes->shapeindex);
// selectionner tous les champs
$i=0;
while ( list($key,$val) = each($oShape->values) )
{
$champs[$i++] = $key;
}
// recupération des noms de colonnes
$nom_champ=array();
$val_champ=array();
for ($iField=0; $iField < count($champs); $iField++)
{
$nom_champ[$iField]=$champs[$iField];
}
// Récupération de la valeur des champs
for($iField=0; $iField < sizeof($champs); $iField++)
{
$val_champ[$iField]=$oShape->values[$champs[$iField]];
}
// On converti les tableaux en chaines de caracteres pour les
envoyé sur la page info par popup
$_nom_champ=implode("|",$nom_champ);
$_val_champ=implode("|",$val_champ);
?>
<!-- Appel de la fenetre popup info avec du javascript -->
<script language="javascript">
info('<?php echo $_nom_champ;?>','<?php echo
$_val_champ;?>');
</script>
<?php $oShape->free();
}
$layer->close();
}
}// fin test outils infos
/*---------------------------------------------------------------------------------------*/
/*---------- Code de la page info.php
-----------------------------------*/
/*---------------------------------------------------------------------------------------*/
<body marginheight="1" leftmargin="1" rightmargin="1">
<?php
$nom=$_GET['nom'];
$val=$_GET['val'];
$_nom=explode("|",$nom);
$_val=explode("|",$val);
?>
<table align="center" cellspacing="0" border="1"
class="tableinfo">
<tr class="ligne"><td
colspan="2">Informations</td></tr>
<?php for($i=0;$i<count($_nom);$i++)
{?>
<tr align="center"><td><b><?php echo
$_nom[$i];?></b></td><td><?php echo
$_val[$i];?></td></tr>
<?php }?>
</table>
</body>
|
REMARQUE : Pour que ce type de
requête QueryByPoint () fonctionne pour une couche
donnée, il faut d'abor définir pour celle-ci un Template en
ajoutant dans cette couche le mot clé Template. Par exemple
$layer->set ("template","ttt_couche.html");
Cependant vous n'avez pas à créer ce fichier
html.
Annexe C: Les options de l'utilitaire
shp2pgsql (I)
Syntax: Sh2pgsql [options] [fich-shape] [nom-table]
[BD] | psql [BD]
Les options
|
-d
|
Supprime la table de la base de données avant la
création de la nouvelle table avec les données du fichier vecteur
(Shape).
|
|
-a
|
Ajoute les données du fichier vecteur dans la table de la
base de données. Notez qu'il faut utiliser cette option pour charger
plusieurs fichiers, qui doivent contenir les mêmes attributs et les
mêmes types de données.
|
|
-c
|
Crée une nouvelle table et la remplie avec le contenu du
fichier vecteur (Shape). C'est le mode par défaut.
|
|
-p
|
Produit uniquement le code de création des tables, sans
ajouter les données. Cela peut être utilisé lorsque vous
avez besoin de séparer complètement les étapes de
création de la table et de sont remplissage.
|
|
|
-D
|
Utilise le format d'export de PostgreSQL pour extraire les
données. Cette option peut être combiné avec -a, -c et -d.
C'est plus rapide pour charger des données que d'utiliser des
requêtes au format SQL de type "INSERT". Utilisez ceci pour l'insertion
d'une grande quantité de données.
|
|
|
-s <SRID>
|
Crée et remplie les tables géométriques avec
le SRID spécifié.
|
|
|
-k
|
Respecte la syntaxe (casse : majuscules/minuscules) des
identifiants (colonne, schéma et attributs). Notez que les attributs
dans des fichiers vecteurs sont en majuscules.
|
|
|
-i
|
Conversion de tous les entiers en entiers 32 bits standards.
|
|
|
-I
|
Crée un index GiST sur la colonne
géométrique.
|
|
|
-w
|
Retour au format WKT, utilisé avec les anciennes versions
(0.X) de PostGIS. Notez que cela introduira des dérives de
coordonnées et supprimera les valeurs M des fichiers vecteurs.
|
|
|
-W <encoding>
|
Spécifie l'encodage des données en entrée
(du fichier dbf). Lorsque cette option est utilisée, tous les attributs
du dbf sont convertis de l'encodage spécifié en UTF-8. La sortie
SQL résultante contiendra une commande SET CLIENT_ENCODING to UTF8, donc
le serveur principal sera capable de reconvertir de l'UTF-8 dans l'encodage
choisi dans configuration de la base de données.
|
|
Les options de l'importateur
shp2pgsql         ![]() ![]() ![]() ![]() ![]() ![]()  
* 1 Cartographie dynamique sur
internet
* 2 Possibilité de libre
redistribution, d'accès au code source, et de travaux
dérivés
* 3 http://www.lti-ucad.sn
* 4 http://maps.google.com
* 5 http://www.esrifrance.fr/
* 6
Implémentation : Elle consiste à
réaliser le programme conformément aux critères
définis dans les phases d'analyse et de conception.
* 7 Framework :
Infrastructure logicielle facilitant la conception et le
développement d'applications.
* 8
REMORA : Méthode qui met l'accent sur les
événements qui affectent l'état du système à
travers l'exécution d'opérations, sur leur ordonnancement dans le
temps, leur synchronisation et leurs dépendances causales.
* 9 http://www.mysql.com
* 10 http://www.oracle.com
* 11
http://www.postgresql.org
* 12
http://www.camptocamp.org
* 13 http://www.cnes.fr
* 14 http://mapemonde.mgm.fr
* 15 http://geoserver.org
* 16
http://www.geotools.org/
* 17
http://mapserver.gis.umn.edu/
* 18 Un programme CGI est
exécuté côté serveur. Il permet l'échange de
données entre le serveur et le navigateur. Quand il reçoit une
requête du poste client, le CGI détermine (en fonction de
l'extension) l'action à effectuer
* 19 Il s'agit ici de
l'ensemble des commandes permettant d'accéder aux fonctionnalités
du noyau MapServer
* 20 Un fichier d'extension
.map
* 21
http://www.microsoft.com/france
* 22 http://www.apache.org
* 23
http://www.zeus.com/products/zws
* 24 Site officiel de Zeus
http://www.zeus.com/products/zws
* 25
http://www.dicodunet.com
| 

