|

0. Introduction générale
0.1. Contexte et motivation
L'évolution du monde est le fait conjugué des
certains événements dont le plus important est l'informatique,
qui représente une évolution majeur de la science et de la
technologie.
La science informatique nous a permis de perfectionner les
méthodes utilisées en automatisant autant de système de
correspondance, sur laquelle l'homme a toujours rêvé
d'améliorer son niveau de travail.
Aujourd'hui, l'informatique est présentée pour
intervenir à des insuffisances humaines. Elle inspire une manière
appropriée pour l'évolution meilleure dans la vie. Ce dernier est
aujourd'hui pratiqué par tous, aucun domaine ne lui est
épargné.
Toujours dans la même conception de l'évolution
technologique, la technologie web a connu une évolution qui aujourd'hui
a permis au diverses entreprises utilisant des technologies ou plate-forme
différentes (hétérogène) localiser
géographiquement distant, de communiquer et ses partager des
informations en temps réel.
0.2. Intérêt du sujet
Le thème de ce travail de fin d'étude est «
l'analyse d'intégration des technologies web service dans un
système distribué pour l'authentification et le suivi permanant
des étudiants ».
Un service Web est un programme informatique permettant la
communication et l'échange de données entre applications ou les
systèmes hétérogènes dans un environnement
distribué. Il s'agit donc d'un ensemble de fonctionnalités
exposées sur internet ou sur un réseau intranet par des
applications ou pour les applications sans intervention humaine, de
manière synchrone ou asynchrone.
Le développement des services web est devenu depuis
quelques années un enjeu primordial pour des entreprises. Il permet de
mettre à la disposition d'autres, des services spécifiques
à son domaine d'activité qu'ils soient gratuits ou payant pour
une meilleur qualité de services. Les services web offerts par Google
maps, par exemple, sont devenus depuis quelques années des standards
dans le domaine de la géolocalisation.
Partant des recherches et des analyses faites, cette
technologie des services web existe depuis un certain nombre d'années,
il est exploité dans le but d'assurer la communication entre les
systèmes hétérogènes dans un environnement
distribué. Mais, dans le cas cible c'est-à-dire le coin que nous
avons

II
opté pour, nous affirmons que ce dernière n'est
pas encore exploité pour répondre à un cas tel que nous le
traitons.
0.3. Problématique
Le système académique peut être vu comme
une structure organisée dont la gestion d'inscriptions pourrait
être le socle, dans le sens où pour fonctionner, une
université a besoin d'étudiants, ces derniers qu'il faut d'abord
inscrire après une étape importante des tests d'admission pour
des promotions de recrutement.
La dite démarche parait à première vue
logique et sans faille, mais seulement en analysant de plus près ce
processus, l'on constate certaines failles en amont du dit processus, une que
nous ciblerons plus exactement, pour ce faire analysons un peu le
scénario suivant :
? Dans le cas où l'étudiant venu pour
l'inscription serait issu d'une autre université, et que celui-ci
demanderais à être inscrit dans une promotion montante et c'est
légitime puisque dossiers à l'appui, il évoque les raisons
de son changement d'université ou transfert et bien-sûr son
dossier académique parle pour lui et atteste entre autre qu'il aurait
commencé un cursus précis dans son université de
provenance, cursus au bout duquel il aurait obtenu de bon résultat, et
qu'il est de ce fait en droit de s'inscrire en promotion montante partout
ailleurs.
? Evidemment, l'agent chargé des inscriptions face
à un dossier complet et à vue d'oeil authentique, n'aura nul
autres choix que celui d'enclencher pour cet étudiant le processus
d'inscription standard.
Seulement on s'interroge afin de savoir, qu'est-ce qui prouve
l'authenticité réelle du contenu de ce dossier ? Entre autre des
relevés des côtes. Car l'agent chargé de l'inscription
n'ayant pour seul moyen de vérification que ses yeux et
éventuellement d'autres moyens aussi subjectifs les uns que les autres,
ne peut guère juger de l'authenticité évidente du dossier.
On se rend donc compte qu'il se pose là un problème de manque
communication entre les établissements universitaires, car ceux-ci n'ont
aucun moyen probant, d'interagir entre eux et d'assurer par la même
occasion le suivi de leurs étudiants après leur
désinscription ou de leur désertion.
Ainsi, en sachant que les falsifications des documents en tous
genres sont de nos jours monnaies courantes dans notre pays, plus encore nous
craignons que l'on puisse dire que c'est un domaine fort rentable dans lequel
excellent les mafieux de notre pays et désireux de combler peu à
peu les failles de notre système universitaire, et pallier à ce
problème, il sied de s'interroger sur les questions suivantes :

III
? Quelle solution est la mieux adaptée afin de
résoudre ce problème de quasi non-interaction entre les
systèmes de nos universités ? ? Comment arriver à mettre
en oeuvre cette dite solution ?
0.4. Hypothèses
Connaissant le problème auquel nous faisons face, il
nous paraît opportun de donner quelques pistes des solutions
envisageables pour résoudre pour palier à ce dernier.
Ainsi, dans le cadre de ce travail, pour nous permettre
d'authentifier un étudiant et suivre son cursus, nous envisageons les
solutions suivantes :
i' La conception d'un système basé sur la
technologie des services web autour d'une base des données, où
chaque université pourra envoyer son palmarès chaque année
et celui-ci sera publier pour être visible à d'autres. Cette
solution nous paraît de loin la meilleure, car elle permet de faire
communiquer des environnements hétérogènes dans un
système distribué.
i' Le système développé sera accessible
via internet pour permettre la communication distante. Ainsi une
université pourra invoquer le service publié pour vérifier
l'authenticité du dossier d'un étudiant ou pour visualiser son
cursus.
0.5. Intérêt du sujet
La définition de l'objectif ou des objectifs est
l'aspect primordial pour tout projet. D'où l'intérêt que
porte ce travail de fin d'étude, est premièrement d'ordre
économique, aussi sur le plan sécuritaire dans le cadre
d'authentification et protection des document et social, car son
développement permet de résoudre le problème de manque de
communication entre les universités de notre pays, il facilitera le
contrôle d'authenticité des documents des étudiants, qui,
parfois sont produits d'une falsification par tiers individus malsains. Sur le
plan scientifique, développer ce sujet est une occasion pour nous de
comprendre et approfondir certains concepts technique et technologique que nous
avons appris tout au long de notre parcours académique et aussi
découvrir par des nouvelles façons de résoudre des
problèmes liés aux systèmes distribués, la
conception d'une architecture orientée service et son
implémentation en se servant des services web ; ce qui peut être
aussi une aide pour toute personne désirant comprendre certains concepts
développés dans ce travail.

iv
0.6. Choix des techniques et méthodes
utilisées
Les différentes techniques évoquées pour
l'élaboration de ce travail
sont :
a. La Technique documentaire : cette
technique, nous a permis de consulter les ouvrages, des articles ainsi que les
notes des cours en rapport avec notre étude surtout du domaine
informatique.
b. La Technique d'interview : cette
technique nous a permis de récolté les informations
nécessaire lié à l'élaboration de notre travail
d'une manière de bouche à l'oreille au sein des
différentes universités de la ville province de Kinshasa.
c. Le langage UML : est un langage graphique
destiné à la modélisation de systèmes et de
processus. UML nous a permis de modéliser le système à
mettre en place grâce à ses différents diagrammes.
0.7. Délimitation du travail
Vous l'aurez surement compris, notre sujet porte
principalement sur la «conception et le développement d'un
système distribué basé sur une architecture
orientée services, implémenté grâce au web
service». Pour mieux circonscrire notre propos, il est absolument
nécessaire de limiter notre étude dans le temps et dans l'espace.
Mais de quoi sera-t-il question dans cette étude ? Pour ce faire, il
importe dès lors d'en poser des limites à notre champ
d'action.
Dans l'espace, notre travail couvre uniquement les
universités tant publiques que privées de l'ensemble du
territoire national, et cela couvre la période de l'élaboration
de ce présent travail, donc l'année en cours.
0.8. Subdivision du travail
Excepté l'introduction et la conclusion
générale, pour des raisons d'organisation et de structuration,
nous avons trouvé bon de subdiviser notre travail en quatre chapitres
aussi essentiels les uns que les autres :
? Dans le chapitre premier, intitulé
Généralités sur les systèmes
distribués, nous exposons les différentes
architectures des systèmes distribués, leurs
spécificités leurs utilisations, leurs avantages ainsi que leurs
désavantages.
? Dans le chapitre deuxième, intitulé
Architecture Orientée Services, nous avons mis
en exergue, les concepts de SOA et ses caractéristiques, ses
technologies d'implémentation entre autre le service web.
? Dans le chapitre troisième, titré
Analyse et modélisation système, comme
l'indique clairement sa nomination, il va être question ici de faire une
analyse d'activités, des données et des flux d'informations
liées au cursus d'un étudiant et une conception par la
modélisation UML.

V
? Dans le quatrième et dernier chapitre, titré
Mise en oeuvre de l'Application, il va être
question d'enfin « prendre le taureau par les cornes », dans le sens
où il va sonner pour nous le temps, d'entamer la réalisation
concrète de
notre système de gestion des flux interuniversitaire.

1
Chapitre I. Généralités sur les
systèmes distribués
[2][11][12]
I.1. Introduction
Le mot distribué en termes tels que "système
distribué", "programmation distribuée" et "algorithme
distribué" désignait à l'origine des réseaux
informatiques où des ordinateurs individuels étaient physiquement
répartis dans une certaine zone géographique. Les termes sont de
nos jours utilisés dans un sens beaucoup plus large, se
référant même à des processus autonomes qui
s'exécutent sur le même ordinateur physique et interagissent les
uns avec les autres par la transmission de messages.
Bien qu'il n'y ait pas de définition unique d'un
système distribué, les propriétés de
définition suivantes sont couramment utilisées comme:
? Il existe plusieurs entités de calcul autonomes
(ordinateurs ou noeuds), dont chacune possède sa propre mémoire
locale.
? Les entités communiquent entre elles par transmission
de messages.
Un système distribué peut avoir un objectif
commun, tel que la résolution d'un gros problème de calcul;
l'utilisateur perçoit alors la collection de processeurs autonomes comme
une unité. Alternativement, chaque ordinateur peut avoir son propre
utilisateur avec des besoins individuels, et le but du système
distribué est de coordonner l'utilisation des ressources
partagées ou de fournir des services de communication aux
utilisateurs.
Les systèmes distribués sont désormais
monnaie courante, mais restent souvent difficiles domaine de recherche. Cela
s'explique en partie par les nombreuses facettes de ces systèmes et
difficulté inhérente à isoler ces facettes les unes des
autres. Dans ce chapitre, nous fournissons un bref aperçu des
systèmes distribués: ce qu'ils sont, leurs objectifs
généraux de conception et certains des types les plus
courants.
Définition des concepts 1.2.1. Système
d'information
Plusieurs définitions peuvent concourir afin de tenter
d'expliquer ce que veut dire le vocable « système d'information
» dans son ensemble.
De toutes ces définitions, nous retenons celle qui suit
: Le système d'information est le véhicule des entités de
l'organisation. Sa structure est constituée de l'ensemble des ressources
(les personnels, le matériel, les logiciels, les

2
procédures) organisées pour : collecter,
stocker, traiter et communiquer les informations. Le système
d'information coordonne, grâce à la structuration des
échanges, les activités de l'organisation et lui permet ainsi,
d'atteindre ses objectifs.
Un système d'information informatique est un
système composé de personnes et d'ordinateurs qui traite ou
interprète des informations. Le terme est également parfois
utilisé pour désigner simplement un système informatique
avec un logiciel installé.
Le Système d'information est une étude
académique des systèmes avec une référence
spécifique à l'information et aux réseaux
complémentaires de matériel et de logiciel que les personnes et
les organisations utilisent pour collecter, filtrer, traiter, créer et
également distribuer des données. L'accent est mis sur un
système d'information ayant une limite définitive, les
utilisateurs, les processeurs, le stockage, les entrées, les sorties et
les réseaux de communication précités.
1.2.1.1. Objectifs du système d'information
Un système d'information suit un certain nombre
d'objectifs :
? Recueil de l'information : pour
fonctionner, le système doit être alimenté. Les
informations proviennent de différentes sources, internes ou
externes.
? Mémorisation de l'information : Une
fois l'information saisie, il faut en assurer la pérennité, c'est
à dire garantir un stockage durable et fiable.
? Traitement de l'information : Pour
être exploitable, l'information subit des traitements. Là encore,
les traitements peuvent être manuels (c'est de moins en moins souvent le
cas) ou automatiques (réalisés par des ordinateurs).
? Diffusion de l'information : pour
être exploitée, l'information doit parvenir dans les meilleurs
délais à son destinataire. Les moyens de diffusion de
l'information sont multiples : support papier, forme orale et de plus en plus
souvent, utilisation de supports numériques qui garantissent une vitesse
de transmission optimale et la possibilité de toucher un maximum
d'interlocuteurs. Ceci est d'autant plus vrai à l'heure d'Internet et de
l'interconnexion des systèmes d'information.
1.2.1.2 Besoins d'un système d'information
Toute organisation (entreprise) a toujours des objectifs
à poursuivre ou des buts à atteindre. Alors que la mise en place
d'un système d'information informatisé nécessite bel et
bien des besoins, nous disons que le système d'information a comme
besoins :
? Echange des données entre application
hétérogènes manipulant des donnés au format divers
et propriétaire divers ;
·

3
. Interopérabilité des applications et des
plateformes ;
· . Gestion de la cohérence des données ;
· . Gestion des accès concurrents ;
· . Persistance ou la pérennisation des
données ;
· . Disponibilité des données ;
· . Sécurité des données.
Des nouveaux besoins peuvent encore se faire sentir du fait
que la distribution et l'accès à l'information sont des facteurs
fondamentaux du succès des entreprises voilà pourquoi
l'informatique est par nature distribué, évolutif et vairé
et doit pourvoir aux besoins de nouvelles architectures informatiques.
I.2.2. Système distribué
L'informatique distribuée est un domaine de
l'informatique qui étudie les systèmes distribués. Un
système distribué est un système dont les composants sont
situés sur différents ordinateurs en réseau, qui
communiquent et coordonnent leurs actions en se transmettant des messages. Les
composants interagissent les uns avec les autres afin d'atteindre un objectif
commun.
Dans le cadre de notre étude qui concerne la
distribution au niveau de la couche logiciel, nous définissons : Un
système distribué est une collection de processus autonomes
interconnectés qui échangent des informations via un
système de communication qui est le réseau, ces processus
s'exécutent sur un ensemble de machines sans mémoire
partagée, mais pourtant l'utilisateur voit comme une seule et unique
machine, et cela est dû au faite qu'il utilise un middleware, qui
s'occupe d'activer des composants et de coordonner leurs activités, ce
qui a pour conséquence qu'un utilisateur percevra le système
comme un seul et unique système intégré.
A ne pas confondre avec le système
décentralisé, qui est l'allocation de ressources, tant
matérielles que logicielles, à chaque poste de travail ou
emplacement de bureau. En revanche, le système centralisé existe
lorsque la majorité des fonctions sont exécutées ou
obtenues à partir d'un emplacement centralisé distant.
1.2.3. Système reparti
Un système reparti est un ensemble de machines
autonomes connectées par un réseau et équipées d'un
logiciel dédié à la coordination des activités du
système ainsi qu'au partage de ses ressources. Ce système permet
à plusieurs sites de se partager à un groupe de pages de
mémoire et il est applicable sur toute forme de donnée (pages,
variables, fichiers).

4
1.2.4. Système centralisé
Un système aussi appelée solution sur site
central (Mainframe) centralisé est un système dont les composants
sont localisés sur un site unique et il y a également la
centralisation de données, des traitements et de la présentation
historiquement sur systèmes propriétaires.
I.3. Objectifs d'un système distribué
La conception d'un système distribué vise des
objectifs divers, entre
autres :
? La séparation fonctionnelle : les ordinateurs ont des
configurations différentes (clients et serveurs, collection des
données et traitement des données).
? La distribution inhérente au système :
information créée et mise à jour par des personnes
différentes (pages web, etc.).
? L'équilibrage des charges
? Fiabilité : Sauvegarde des données
(réplication)
? L'économie : partage des ressources
I.4. Caractéristiques d'un système
distribué
Un système distribué peut avoir des
caractéristiques comme ci-après :
a. Interopérabilité
Dans un système distribué, il se pose un vrai
problème de coopération entre différents composants du
système. Ce problème peut être vu au niveau de la couche
« matérielle » (différents réseaux physiques et
plateforme matérielle), de la couche système d'exploitation
(divers OS utilisés (UNIX, Windows, Mac OS, Solaris)), de la couche
application (
l.NET pour Microsoft, Corba pour le
Consortium OMG, ...).
Actuellement, il existe deux approches principales de
standardisation pour masquer l'hétérogénéité
: les middlewares et les machines virtuelles.
b. Partage des ressources
Le partage des ressources est le facteur principal de
motivation pour construire les systèmes répartis. Des ressources
telles que des imprimantes, des dossiers, des pages Web ou des disques, de base
de données sont contrôlées par des serveurs du type
approprié. Par exemple, les serveurs Web contrôlent des pages Web
et d'autres ressources d'enchaînement. Des ressources sont
consultées par des clients - par exemple, les clients des serveurs web
s'appellent généralement les browsers (navigateurs).
c. 
5
Ouverture
Cette caractéristique fait mention de
l'extensibilité dans la mesure où des composants peuvent
être ajoutés, remplacés ou supprimés dans un
système distribué sans en affecter les autres. Et lorsque nous
parlons des composants, nous voyons les matériels (les
périphériques, mémoires, interfaces, etc.) et les
logiciels (protocoles, pilote, etc.).
L'ouverture nécessite que les interfaces logicielles
soient documentées et accessibles aux développeurs
d'applications.
d. Expansible
Nous disons qu'un système distribué est
expansible lorsque les modifications du système et des applications ne
sont pas nécessaires quant à l'augmentation de la taille de ce
système.
e. Performance
Dans ce cas, le système doit s'adapter à bien
fonctionner même quand le nombre d'utilisateurs ou de ressources
augmentent.
f. Transparence
La transparence cache aux utilisateurs l'architecture, la
distribution des ressources, le fonctionnement de l'application ou du
système distribué pour apparaître comme une application
unique cohérente.
La norme ISO (1995) définit différents niveaux
de transparences telle que la transparence d'accès, de localisation, de
concurrence, de réplication, de mobilité, de panne, de
performance, d'échelle.
· Transparence d'accès : il s'agit
d'utiliser les mêmes opérations pour l'accès aux ressources
distantes que locales ;
· Transparence à la localisation :
l'accès aux ressources indépendamment de leur emplacement doit
être inconnue à l'utilisateur ;
· Transparence à la concurrence : il
s'agit de cacher à l'utilisateur l'exécution possible de
plusieurs processus en parallèle avec l'utilisation des ressources
partagées en évitant des interférences ;
· Transparence à la réplication :
la possibilité de dupliquer certains éléments/ressources
(fichiers de base de données) pour augmenter la fiabilité et
améliorer les performances doit être cachée à
l'utilisateur ;
· Transparence de mobilité : il s'agit
de permettre la migration des ressources et des clients à
l'intérieur d'un système sans influencer le déroulement
des applications ;
· Transparence de panne : il s'agit de
permettre aux applications des utilisateurs d'achever leurs exécutions
malgré les pannes qui peuvent affecter les composants d'un
système (composants physiques ou logiques) ;

6

7
? Transparence à la modification de
l'échelle : il s'agit de la possibilité d'une extension
importante d'un système sans influence notable sur les performances des
applications.
? Transparence à la reconfiguration : il
s'agit de cacher à l'utilisateur la possibilité de reconfigurer
le système pour en augmenter les performances en fonction de la
charge.
g. Concurrence
Le problème de la concurrence permet l'accès
simultané à des ressources par plusieurs processus. Ce
problème se pose pour les systèmes distribués comme pour
les systèmes centralisés. En effet, il y a bien d'autres
ressources dont l'accès simultané n'est pas possible. Dans ce
cas, leur manipulation ne peut se faire que par un processus à la fois.
Le cas des ressources physiques telles que l'imprimante mais aussi des
ressources logiques telles que les fichiers, les tables des bases de
données, etc. Dans ce cas, les applications distribuées
(reparties) actuelles autorisent l'exécution de plusieurs services en
concurrence (cas de l'accès à une base de données). Chaque
demande est prise en compte par un processus simple appelé thread ; et
la gestion de la concurrence fait appel aux mécanismes de
synchronisation classiques.
I.5. Type d'architecture de systèmes
distribués
La recherche de classification n'est pas une tâche
facile, car les systèmes distribués sont complexes et
variés. Nous proposons dans cette partie une classification à
trois niveaux qui reflète la structuration en couche. Au premier niveau,
on repartie les systèmes distribués en considérant leurs
caractéristiques matérielles (couche matérielle). Au
second niveau, les systèmes distribués sont vus dans l'angle des
systèmes d'exploitation qui les supportent. Quant au troisième
niveau, il s'agit d'étudier les diverses approches de structuration
(architecture logiciel) des applications distribuées en terme de
composants (ou processus) et répartition des rôles.
? Architecture matérielle :
D'un point de vu abstrait, un ordinateur se compose de deux
types d'entités essentielles : les mémoires et les processeurs.
On peut envisager un système distribué physique comme une
collection des mémoires et des processeurs interconnectés de
telle sorte à pouvoir communiquer.
? Architecture logicielle : les systèmes
d'exploitation
Il existe une relation étroite entre les applications
distribuées et les systèmes d'exploitation. Dans un premier lieu,
la mise en oeuvre des applications distribuées dépend des
systèmes d'exploitation qui gèrent les différentes
plateformes matériels (c'est-à-dire les
services qu'ils offrent). Dans le second lieu, les systèmes
d'exploitation eux-mêmes peuvent être distribués.
? Architecture des applications
distribuées
Naturellement, les applications reparties ont plus
d'indépendance vis-à-vis de plateformes physiques et peuvent de
ce fait être organisées d'une multitude des façons.
L'Architecture client/serveur et se variantes constitue actuellement le
modèle le plus utilisé dans l'organisation des applications
distribuées. Cependant, d'autres modèles existent et leurs
utilisations augmente du jour au jour ; c'est le cas du modèle poste
à poste (processus pairs) et ses variantes. Il n'est pas rare dans les
applications distribuées que plusieurs modèles soient
combinés à la fois pour tirer profit des avantages des uns et
atténuer les inconvénients des autres.
I.6. Communication dans un système
distribué
Maintenant que nous connaissons les différentes
structures des
systèmes distribués, nous abordons les
différents mécanismes de communication
qui le régit.
Les technologies les plus utilisées aujourd'hui sont les
suivants :
? Les sockets
? Les communications synchrones : RPC (Remote Procedure Call)
ou
« message passing » des micronoyaux
? Le Java RMI (Remote Method Invocation)
? Les bus à objet distribués CORBA
Les sockets et le RPC ne permette pas de gérer
directement les différences de modèle de mémoire qui
peuvent exister entre deux machines différentes.
Les RMI sont spécifiques au langage JAVA. Cela impose
l'utilisation d'un seul langage(Java) sur l'ensemble des hôtes qui
désirent utiliser ce procédé. CORBA est indépendant
du langage utilisé et des machines d'exécution. Il peut donc
faire cohabiter des systèmes parfaitement
hétérogènes. Le « message passing » impose
d'implanter le même système d'exploitation sur les machines qui
utilisent cette technologie.
I.6.1. Le Socket
Un socket est défini comme l'extrémité
d'une voie de communication dans une paire de processus. Ce lien comporte donc
obligatoirement deux sockets.
Un socket est construit par la concaténation d'une
adresse IP et d'un numéro de port.

8
Les sockets sont utilisés dans bons nombre
d'applications structurées en « client/serveur ».
L'établissement d'une connexion entre deux processus se fait de la
manière suivante :
? Le serveur crée un socket et se positionne en
écoute de demande de connexion
? Un client fait une demande de connexion (création d'un
socket local)
? Le serveur accepte la connexion
? Le client et le serveur sont connectés par le tube
ainsi créé et peuvent lire ou écrire dans le socket
respectif. A partir de cet instant, chaque processus (ou thread) peut
être producteur ou consommateur de données.
Dans le cas où deux machines communiquent mais
possèdent des processeurs dont le modèle mémoire n'est pas
le même, il faut prévoir de convertir les données.
Une solution élégante est d'utiliser la couche
XDR (« Extended Data Représentation »). Cette technique permet
de travailler en environnement hétérogènes mais n'est pas
simple à mettre en oeuvre.
I.6.2. La communication synchrone
On attend par « communication » tout
procédé qui permet d'exécuter une section de code distant
de la même manière que si l'appel était local.
L'exécution se fait de façon séquentielle vis-à-vis
du programme.
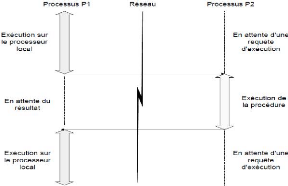
Figure I.1. Communication synchrone

9

10
I.6.3. RMI (Remote Method Invocator)
RMI permet, contrairement aux RPC, d'invoquer une
méthode distante en passant en paramètres des objets complets.
L'invocation des méthodes distantes passe par un système
d'assemblage et de dessablage pris en charge par les « stubs » et les
« squelettes ». Le « stub » est implanté coté
client et crée un paquet contenant le nom de la méthode à
appeler ainsi que les paramètres associés. Cette opération
est baptisée « assemblage ». Le squelette reçoit les
demandes venant des « stubs ». Il est chargé du
désassemble des paquets et appelle la méthode demandée par
le client. Enfin, il assemble la valeur de retour (ou éventuellement une
exception) et la transmet au client. Les « stubs » et les «
squelettes » sont des entités complètement transparentes
pour le programmeur JAVA. Lorsque les paramètres sont des objets locaux,
ils sont passés par copie. Cette opération se nomme «
sérialisation d'objet ». Si un objet distant est passé en
paramètre, le stub client passera la référence sur cet
objet. Cela permettra au serveur d'invoquer à son tour des
méthodes de l'objet distant. Pour qu'une méthode puisse
être invoquée en distance, celle-ci doit être
enregistrée dans un catalogue global nommée « RMI registry
».
La recherche d'un objet distant se fait la
concaténation du nom de l'hôte (ou l'adresse IP) et du nom de la
méthode cherchée :
« rmi://nom_hote/nom_methode ».
Cette méthode sous-entend que le programmeur connait
le ou les noms des machines qui exportent les objets. Les méthodes
inscrites dans les systèmes RMI peuvent être
déclarées « synchronized ». Cela permet de gérer
simplement l'accès concurrent de plusieurs threads sur une
méthode. Pour gérer le « stub » et le « squelette
», il faut utiliser le RMI compilé « RMIC ». Les RMI sont
une technologie JAVA vers JAVA, cela signifie qu'une application
distribuée reposant sur les RMI est forcément
développée avec le langage JAVA.
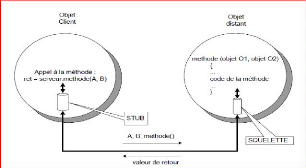
Figure I.2. Fonctionnement RMI
I.6.4. CORBA (Common Object Request Broker
Architecture)
CORBA est un « middleware » (couche logicielle
intermédiaire) orienté objets, qui a pour objectif
l'intégration d'application distribuées
hétérogènes à partir des technologies objet
indépendamment :
? Des moyens de communication réseaux ? Des langages de
programmation
? Des systèmes d'exploitation
Toutes les requetes à des objets distants passent par
un ORB (Object Request Brocker). L'ORB d'un client doit trouver l'objet distant
dans le système distribué ; il communique avec l'ORB serveur.
L'ORB est appelé « Bus logiciel ».
Comme pour les RMI, les objets s'inscrivent dans un catalogue
global au système. Pour pouvoir communiquer avec un objet distant, un
client doit au préalable trouver le nom de l'objet dans le catalogue.
Un système CORBA fonctionne de la façon suivante
:
Dès qu'un client a obtenu une référence
à un objet distant, toutes les invocations aux méthodes de cet
objet passent par l'ORB (via le stub client). Lorsque l'ORB du serveur
reçoit une requête, il appelle le squelette approprié ;
celui-ci invoque à son tour la méthode demandée. Des
valeurs de retour peuvent être renvoyées par ce même canal
de communication.
I.7. Avantages d'un système
distribué
· Partage de données : il existe
une disposition dans l'environnement permettant à l'utilisateur d'un
site d'accéder aux données résidant sur d'autres sites.
· Répartition géographique :
mettre à la disposition des usagers les moyens informatiques
locaux en même temps que ceux distant de leurs collègues.
· Disponibilité : si un site
tombe en panne dans un système distribué, les sites restants
peuvent continuer à fonctionner. Ainsi, une défaillance d'un site
n'implique pas nécessairement l'arrêt du système.
· Accélération des calculs :
Lorsqu'un calcul peut être décomposé à un
ensemble des sous calculs parallèle, le système distribué
permet la répartition de cette charge sur ses différents
sites.
· Adaptabilité à une
forte croissance des besoins informatiques d'une entreprise
· Flexibilité :
s Par nature modulaire (possibilité
d'évolution)
·

11
Continuité de service pendant la maintenance
· L'informatique nomade : portable et point
d'accès mobile sur un réseau reparti aux frontières
floues(Internet).
I.8. Inconvénients d'un système
distribué
Dans un système où la communication s'effectue
via un réseau et entre entités différentes, des nombreux
problèmes peuvent naitre et créer d'énormes
dégâts, parmi lesquels :
? Le partage et distribution des données imposent des
mécanismes complexes (Synchronisation et sécurité)
? Problèmes inhérents aux communications
· Communication explicite si pas de mémoire
partagée
· Lenteur, saturation, perte de messages ? Logiciels de
gestion difficile à concevoir
· Peu d'expérience ou succès dans ce
domaine
· Complexité par la transparence ? Ne pas avoir
d'élément central
· Gestion du système totalement
décentralisé et distribué
· Nécessite la mise en place d'algorithmes plus ou
moins complexes
I.9. Architecture client - serveur
Le client server est avant tout un mode de dialogue entre
deux processus. Le premier appelé client demande l'exécution de
services au second appelé serveur. Le serveur accomplit les services et
envoi en retour des réponses. En général, un serveur est
capable de traiter les requêtes de plusieurs clients. Un serveur permet
donc de partager des ressources entre plusieurs clients qui s'adressant
à lui par des requêtes envoyées sous forme de messages.
En générale, les serveurs sont des ordinateurs
dédiés au logiciel serveur qu'ils abritent, et dotés de
capacités supérieures à celles des ordinateurs personnels
en termes de puissance de calcul, d'entrée-sorties et de connexions
réseaux. Les clients sont souvent des ordinateurs personnels ou des
appareils.
L'architecture client-serveur peut être
subdivisée en plusieurs types selon les niveaux :
· Architecture à 2 niveaux : Ce
type d'architecture (2-tier en anglais) caractérise les systèmes
client-serveur où le poste client demande une ressource au serveur qui
la fournit à partir de ses propres ressources.
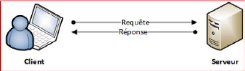

12
Figure I.3. : Architecture c/s à 2 niveaux
? Architecture à 3 niveaux : Dans
cette architecture (3-tier en anglais), existe un niveau supplémentaire
: Un client (l'ordinateur demandeur de ressources) équipé d'une
interface utilisateur (généralement un navigateur web)
chargé de la présentation. Un serveur d'application
(appelé middleware) qui fournit la ressource, mais en faisant appel
à un autre serveur. Un serveur de données qui fournit au serveur
d'application les données requises pour répondre au client.

Figure I.4. : Architecture c/s à 3 niveaux
? Architecture à N niveaux : On voit
que l'architecture 3 niveaux permet de spécialiser les serveurs dans une
tache précise : Avantage de flexibilité, de
sécurité et de performance. Potentiellement, l'architecture peut
être étendue sur un nombre de niveaux plus important : On parle
dans ce cas d'architecture à N niveaux (ou multi-tiers. Voici
schématisez cette architecture sur l'image ci-dessous.
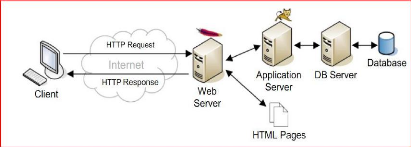
Figure I.5. : Architecture c/s à N-tiers.
A noter que le cadre des applications distribuées, la
communication entre le client et serveur est réalisé selon le
protocole TCP/IP qui est chargé du routage des données. De ce
fait, nous distinguons trois types de client :

13
? Le client léger : est une
application dont l'utilisateur ne se connecte explicitement qu'à la base
de données via l'unique serveur.
? Le client lourd : est une application
cliente graphique exécuté sur le système d'exploitation de
l'utilisateur possédant les capacités de traitement
évoluées donc il peut se connecter explicitement à tous
les serveurs dont il a besoin pour la requête qu'il veut formuler.
? Le client Riche : est l'assemblage du
client léger et client lourd dans lequel l'interface graphique est
décrite avec une grammaire basée sur la syntaxe XML.
En effet, nous venons de parcourir certaines notions qui
couvrent les systèmes distribués et ses différentes
architectures, parmi lesquelles, l'architecture au niveau de la couche
application a été notre point focal. Nous avons fini par
comprendre que dans les systèmes distribués, l'architecture
client-serveur est la plus rependue.

14
Chapitre II. Architecture orientée service
[1][3][6][11][15]
II.1. Introduction
L'informatique orientée services est un paradigme
informatique émergent qui utilise les services comme soubassement pour
soutenir le développement d'une composition rapide et peu coûteuse
d'applications distribuées. Les services sont des modules autonomes
déployés sur des plates-formes middleware standard qui peuvent
être décrits, publiés, localisés, orchestrés
et programmés à l'aide de technologies XML sur un réseau.
Tout morceau de code et tout composant d'application déployé sur
un système peuvent être transformés en un service
disponible sur le réseau. Les services reflètent une approche de
programmation «orientée services», basée sur
l'idée de décrire les ressources informatiques disponibles, par
exemple les programmes d'application et les composants du système
d'information, comme des services pouvant être fournis via une interface
standard et bien définie.
Les services exécutent des fonctions allant de la
réponse à de simples demandes à l'exécution de
processus métier nécessitant des relations d'égal à
égal entre les consommateurs et les fournisseurs de services. Les
services sont le plus souvent construits de manière indépendante
du contexte dans lequel ils sont utilisés. Cela signifie que le
fournisseur de services et les consommateurs sont faiblement couplés.
Les applications basées sur les services peuvent être
développées en découvrant, en appelant et en composant des
services disponibles sur le réseau plutôt qu'en créant de
nouvelles applications.
II.2. Définition
SOA, ou architecture orientée services,
définit un moyen de rendre les composants logiciels réutilisables
via des interfaces de service. Ces interfaces utilisent des normes de
communication communes de telle sorte qu'elles peuvent être rapidement
intégrées dans de nouvelles applications sans avoir à
effectuer une intégration profonde à chaque fois.
Chaque service d'une SOA incarne le code et les
intégrations de données nécessaires pour exécuter
un processus métier complet et discret (par exemple, vérifier le
crédit d'un client, calculer un paiement mensuel de prêt ou
traiter une demande de prêt hypothécaire). Les interfaces de
service fournissent un couplage lâche, ce qui signifie qu'elles peuvent
être appelées avec peu ou pas de connaissances sur la façon
dont l'intégration est mise en oeuvre en dessous. Les services sont
exposés à l'aide de protocoles réseau standard tels que
SOAP (protocole d'accès aux objets simples) / HTTP ou JSON / HTTP - pour
envoyer des

15

16
demandes de lecture ou de modification de données. Les
services sont publiés de manière à permettre aux
développeurs de les trouver rapidement et de les réutiliser pour
assembler de nouvelles applications.
L'objectif des processus métiers est de formaliser
l'exécution d'activités par des applications de manière
collaborative dans le but d'atteindre un objectif métier.
Formellement, un processus métier
peut être défini comme un enchaînement
d'activités. Dans un processus métier, on tient compte des
différents participants d'une opération, de leur rôle, de
l'objectif de cette opération et des moyens mis en oeuvre (messages,
documents). On peut agir sur ceux-ci en définissant des règles
métier, des règles de sécurité, des règles
de transactions. On peut ensuite lancer l'exécution du modèle
(automate à états finis) et vérifier le fonctionnement
théorique des différents processus. BPML est un standard
émergeant s'occupant de cela. Un processus métier est interne
à une entreprise et une seule. Il décrit les activités
nécessitant la collaboration de plusieurs entités
II.3. SOA et Service
Pour qu'une architecture orientée services soit
efficace, nous avons besoin d'une compréhension claire du terme
service.
Ces services peuvent être créés à
partir de zéro, mais sont souvent créés en exposant les
fonctions des anciens systèmes d'enregistrement en tant qu'interfaces de
service.
De cette manière, la SOA représente une
étape importante dans l'évolution du développement et de
l'intégration d'applications au cours des dernières
décennies. Avant l'émergence de la SOA à la fin des
années 1990, la connexion d'une application à des données
ou à des fonctionnalités hébergées dans un autre
système nécessitait une intégration point à point
complexe, une intégration que les développeurs devaient
recréer, en partie ou en totalité, pour chaque nouveau projet de
développement. L'exposition de ces fonctions via SOA élimine le
besoin de recréer l'intégration profonde à chaque fois.
Un service SOA est une unité
discrète des fonctionnalités qui peut être
accédée en distance, utilisée et mise à jour
indépendamment
Il existe deux rôles principaux dans l'architecture
orientée services:
? Fournisseur de services: le fournisseur de services est le
mainteneur du service et l'organisation qui met à disposition un ou
plusieurs services pour que d'autres puissent les utiliser. Pour annoncer des
services, le fournisseur peut les publier dans un registre, avec un contrat de
service qui spécifie la
nature du service, comment l'utiliser, les exigences du
service et les frais facturés.
+ Consommateur de service: le consommateur de service peut
localiser les métadonnées du service dans le registre et
développer les composants client requis pour lier et utiliser le
service.
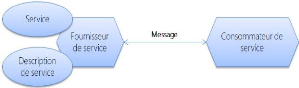
Figure II.1 Principaux rôles dans SOA
Le service est un composant clef de l'architecture
orientée services. Il consiste en une fonction ou fonctionnalité
bien définie. C'est aussi un composant autonome qui ne dépend
d'aucun contexte ou service externe. Il est divisé en opérations
qui constituent autant d'actions spécifiques que le service peut
réaliser. On peut faire un parallélisme entre opérations
et services d'une part, et méthodes et classes dans le mode
orienté objet d'autre part.
Un service est une entité de traitement qui respecte
les caractéristiques suivantes :
+ Large granularité (coarse-grained)
: les opérations proposées par un service encapsulent plusieurs
fonctions et opèrent sur un périmètre de données
large au contraire de la notion de composant technique.
+ Interface : un service peut
implémenter plusieurs interfaces, et aussi plusieurs services peuvent
implémenter une interface commune.
+ Localisable : avant d'appeler (bind,
invoke) un service, il faudra le trouver (find).
+ Instance unique : à la
différence des composants qui sont instanciés à la demande
et peuvent avoir plusieurs instances en même temps, un service est
unique. Il correspond au design pattern Singleton.
+ Couplage faible (loosely-coupled) : les
services sont connectés aux clients et aux autres services via des
standards. Ces standards assurent le découplage, c'est-à-dire la
réduction des dépendances. Ces standards sont des documents XML
comme dans les web services.
+ Synchrone ou
asynchrone.

17
II.4. Caractéristiques de la SOA
L'architecture orientée service peut avoir certaines des
caractéristiques
suivantes :
· . Connexion lâche - Les
services de SOA sont liés entre eux de manière lâche pour
former une connexion. Cela donne une présupposition au minimum
d'interdépendance entre chaque service. L'idée principale est de
réduire l'interdépendance au niveau où la
compatibilité est toujours maintenue.
· . L'interface de services normalisés
- Une exigence de base de la SOA est la nécessité de
normaliser les interfaces ainsi que les détails. Les détails
doivent inclure les données nécessaires, la manière dont
un service peut être utilisé et la manière dont les
règles doivent être appliquées.
· . Réutilisabilité -
Dans SOA, la réutilisabilité des services est également
possible le long de la chaîne de processus par d'autres parties et
à d'autres fins également.
· . Possibilité de trouver un service
- Une autre caractéristique est qu'un service doit être
facilement trouvé pour pouvoir l'utiliser. Pour tous les consommateurs,
des référentiels de services sont mis à disposition, et
ces référentiels comprennent l'interface et la méthode de
mise en oeuvre du service.
· . Autonomie du service - Chaque
service doit pouvoir fonctionner et fonctionner de manière
indépendante. Ce terme désigne les services autonomes et capables
de gérer seuls les ressources, la logique et l'environnement.
· . Capacité d'orchestration des services
- Il s'agit d'un processus dans lequel un service individuel est
combiné avec d'autres services de ce type pour aboutir à des
processus ou unités métier plus volumineux. Il s'agit d'une autre
caractéristique ou exigence de la SOA.
· . Apatridie des services - La
performance des services est basée sur le concept selon lequel un
service défini est rendu. Cela prend en compte la conservation des
données mais uniquement si l'exigence est spécifiée ou
demandée en particulier.
II.5. Principes directeurs d'une architecture
orientée
service
La section suivante présente les principes fondamentaux
qu'une architecture orientée services (SOA) doit exposer. Ils ne sont
pas présentés comme une vérité absolue, mais
plutôt comme un cadre de référence pour les discussions
liées à SOA.

18
+ Contrat de service standardisé:
spécifié par un ou plusieurs documents de description de
service.
+ Couplage lâche: les services sont
conçus comme des composants autonomes, maintiennent des relations qui
minimisent les dépendances avec d'autres services.
+ Abstraction: Un service est
complètement défini par des contrats de service et des documents
descriptifs. Ils cachent leur logique, qui est encapsulée dans leur
implémentation.
+ Réutilisabilité:
Conçus comme des composants, les services peuvent être
réutilisés plus efficacement, réduisant ainsi le temps de
développement et les coûts associés.
+ Autonomie: les services contrôlent la
logique qu'ils encapsulent et, du point de vue du consommateur de services, il
n'est pas nécessaire de connaître leur implémentation.
+ Découvrabilité: les services
sont définis par des documents de description qui constituent des
métadonnées supplémentaires grâce auxquelles ils
peuvent être efficacement découverts. La découverte de
services fournit un moyen efficace d'utiliser des ressources tierces.
+ Composabilité: En utilisant les
services comme éléments de base, des opérations
sophistiquées et complexes peuvent être mises en oeuvre.
L'orchestration et la chorégraphie des services fournissent un support
solide pour la composition de services et l'atteinte des objectifs
commerciaux.
II.6. Principaux objectifs de l'architecture
orientée services
On dénombre trois grands objectifs de l'architecture
orientée services, chacun axé sur une partie distincte du cycle
de vie applicatif.
+ Le premier vise à structurer sous forme de services
les procédures ou composants logiciels. Ces services sont conçus
pour être faiblement couplés aux applications : ils ne servent
qu'en cas de besoin. Ils sont prévus pour que les développeurs,
tenus de standardiser la création de leurs applications, les utilisent
facilement.
+ Le deuxième objectif est de fournir un
mécanisme de publication des services disponibles qui comprend la
fonctionnalité et les besoins d'entrée/sortie (E/S ou
I/O). Les services sont publiés de manière à faciliter
leur intégration aux applications.
+ Le troisième objectif de l'architecture SOA est de
contrôler l'utilisation de ces services pour éviter tout
problème de sécurité et de gouvernance. La
sécurité de cette SOA est surtout axée sur la
sécurité des composants individuels en son sein, sur les
procédures d'authentification et

19
d'identification en lien avec ces composants, et la
sécurisation des connexions entre les composants de l'architecture.
II.7. Avantages d'une architecture orientée
service
> Réutilisation des services: dans
SOA, les applications sont créées à partir de services
existants, ce qui permet de réutiliser les services pour créer de
nombreuses applications.
> Maintenance facile: les services
étant indépendants les uns des autres, ils peuvent être mis
à jour et modifiés facilement sans affecter les autres
services.
> Indépendant de la plateforme: SOA
permet de réaliser une application complexe en combinant des services
sélectionnés à partir de différentes sources,
indépendantes de la plateforme.
> Disponibilité: les installations
SOA sont facilement accessibles à tous sur demande.
> Fiabilité: les applications SOA
sont plus fiables car il est facile de déboguer de petits services
plutôt que des codes volumineux
> Évolutivité: les services
peuvent s'exécuter sur différents serveurs dans un environnement,
ce qui augmente l'évolutivité.
II.8. Désavantages d'une architecture
orientée service
> Frais généraux
élevés: une validation des paramètres
d'entrée des services est effectuée chaque fois que les services
interagissent, ce qui diminue les performances car cela augmente la charge et
le temps de réponse.
> Investissement élevé: un
investissement initial énorme est requis pour la SOA.
> Gestion de services complexes: lorsque
les services interagissent, ils échangent des messages aux tâches.
le nombre de messages peut aller en millions. Gérer un grand nombre de
messages devient une tâche fastidieuse
II.9. SOA et Service Web
L'architecture orientée services (SOA)
représente une nouvelle spirale évolutive dans le
développement d'applications logicielles et dans l'évaluation du
concept des systèmes d'information. SOA est basé sur des services
Web, appelés «entités de programme distribuées
granulées» qui coexistent indépendamment en interaction avec
d'autres programmes et services. Le service web est l'un des moyen actuel
auquel on peut faire recours pour implémenter une architecture
orienté service.

20
i' Selon la définition du W3C (World Wide Web
Consortium) :
Un Web service (ou service Web) est une application appelable
via Internet - par une autre application d'un autre site Internet - permettant
l'échange de données (de manière textuelle) afin que
l'application appelante puisse intégrer le résultat de
l'échange à ses propres analyses. Les requêtes et les
réponses sont soumises à des standards et normalisées
à chacun de leurs échanges.
i' Selon le Dico du net :
Une technologie permettant à des applications de
dialoguer à distance via Internet indépendamment des
plates-formes et des langages sur lesquels elles reposent.
i' Selon Wikipédia :
Un service Web est un programme informatique permettant la
communication et l'échange de données entre applications et
systèmes hétérogènes dans des environnements
distribués. Il s'agit donc d'un ensemble de fonctionnalités
exposées sur internet ou sur un intranet, par et pour des applications
ou machines, sans intervention humaine, et en temps réel.
II.9.1. Intérêts et caractéristiques
d'un service Web
a. Intérêts d'un service web
Les services Web (en anglais Web services) représentent
un mécanisme de communication entre applications distantes à
travers le réseau internet indépendant de tout langage de
programmation et de toute plate-forme d'exécution :
+ utilisant le protocole HTTP comme moyen de
transport. Ainsi, les communications s'effectuent sur un support universel,
maîtrisé et généralement non filtré par les
pare-feu ;
+ Employant une syntaxe basée sur la
notation XML pour décrire les appels de fonctions distantes et les
données échangées ;
+ Organisant les mécanismes d'appel et de
réponse.
Grâce aux services Web, les applications peuvent
être vues comme un ensemble de services métiers, structurés
et correctement décrits, dialoguant selon un standard international
plutôt qu'un ensemble d'objets et de méthodes
entremêlés. Le premier bénéfice de ce
découpage est la facilité de maintenance de l'application, ainsi
que l'interopérabilité permettant de modifier facilement un
composant (un service) pour le remplacer par un autre, éventuellement
développé par un tiers. Qui plus est, les services Web permettent
de réduire la complexité d'une application car le
développeur peut se focaliser sur un service, indépendamment du
reste de l'application.

21
Les services Web facilitent non seulement les échanges
entre les applications de l'entreprise mais surtout permettent une ouverture
vers les autres entreprises. Les premiers fournisseurs de services Web sont
ainsi les fournisseurs de services en ligne (météo, bourse,
planification d'itinéraire, pages jaunes, etc.), mettant à
disposition des développeurs des API (Application Programmable
Interface) payantes ou non, permettant d'intégrer leur service au sein
d'applications tierces.
b. Caractéristiques d'un service web
Un service Web possède les caractéristiques
suivantes :
+ Il est accessible via le réseau ;
+ Il dispose d'une interface publique (ensemble
d'opérations) décrite en XML
;
+ Ses descriptions (fonctionnalités, comment l'invoquer
et où le trouver ?) sont stockées dans un annuaire ;
+ Il communique en utilisant des messages XML, ces messages
sont transportés par des protocoles Internet (généralement
HTTP, mais rien n'empêche d'utiliser d'autres protocoles de transfert
tels : SMTP, FTP, BEEP...) ;
+ L'intégration d'application en implémentant
des services Web produit des systèmes faiblement couplés, le
demandeur du service ne connaît pas forcément le fournisseur.
+ Ce dernier peut disparaître sans perturber
l'application cliente qui trouvera un autre fournisseur en cherchant dans
l'annuaire.
II.9.2. Architecture d'un service Web
Les services Web reprennent la plupart des idées et des
principes du Web (HTTP, XML), et les appliquent à des interactions entre
machines. Comme pour le World Wide Web, les services Web communiquent via un
ensemble de technologies fondamentales qui partagent une architecture commune.
Ils ont été conçus pour être réalisés
sur de nombreux systèmes développés et
déployés de façon indépendante.
Les technologies utilisées par les services Web sont
HTTP, WSDL, REST, XML-RPC, SOAP et UDDI.
a. REST (REpresentational State Transfer)
REST est une architecture de services Web.
Élaborée en l'an 2000 par Roy Fiedling, l'un des créateurs
du protocole HTTP, du serveur Apache HTTPd et d'autres travaux fondamentaux,
REST est une manière de construire une application pour les
systèmes distribués comme le World Wide Web.
b. 
22
XML-RPC(eXtensible Markup Language Remote Procedure
Call)
XML-RPC est un protocole simple utilisant XML pour effectuer
des messages RPC. Les requêtes sont écrites en XML et
envoyées via HTTP POST. Les requêtes sont intégrées
dans le corps de la réponse HTTP. XML-RPC est indépendant de la
plate-forme, ce qui lui permet de communiquer avec diverses applications. Par
exemple, un client Java peut parler de XML-RPC à un Serveur Perl.
c. SOAP (Simple object Access Protocol)
SOAP est un protocole standard de communication. C'est
l'épine dorsale du système d'interopérabilité. SOAP
est un protocole décrit en XML et standardisé par le W3C. Il se
présente comme une enveloppe pouvant être signée et pouvant
contenir des données ou des pièces jointes. Il circule sur le
protocole HTTP et permet d'effectuer des appels de méthodes à
distance.
Les interactions entre services Web s'effectuent par le biais
d'envois de messages structurés au format XML. Le protocole SOAP fournit
le cadre permettant ces échanges. SOAP est originellement issu de
tentatives précédentes visant à standardiser l'appel de
procédures à distance, et en particulier de XML-RPC. Mais
`à la différence des technologies RPC, SOAP n'est pas
fondamentalement lié à la notion d'appel de procédure. En
effet, SOAP vise à faciliter l'échange de messages XML, sans se
limiter à des messages dont le contenu encode des paramètres
d'appel de procédure et sans favoriser des échanges
bidirectionnels de type requête-réponse comme c'est le cas des
protocoles RPC. Dans le jargon des services Web, SOAP permet d'encoder des
interactions orientées RPC mais aussi des interactions
orientées-document.
d. WSDL (Web Services Description Language)
WSDL est un langage de description standard. C'est
l'interface présentée aux utilisateurs. Il indique comment
utiliser le service Web et comment interagir avec lui. WSDL est basé sur
XML et permet de décrire de façon précise les
détails concernant le service Web tels que les protocoles, les ports
utilisés, les opérations pouvant être effectuées,
les formats des messages d'entrée et de sortie et les exceptions pouvant
être envoyées.
e. UDDI (Universal Description Discovery and
Integration)
UDDI est un annuaire de services. Il fournit l'infrastructure
de base pour la publication et la découverte des services Web. UDDI
permet aux fournisseurs de présenter leurs services Web aux clients.

23
Les informations qu'il contient peuvent être
séparées en trois types :
? les pages blanches qui incluent l'adresse, le contact et les
identifiants
relatifs au service Web ;
? les pages jaunes qui identifient les secteurs d'a?
Web ;
? les pages vertes qui donnent les informations techniques
II.9.3. Fonctionnement d'un service web
Le fonctionnement des services Web s'articule autour des
acteurs principaux illustrés par le schéma suivant :
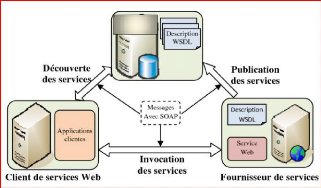
UDDI
Figure II.2 : fonctionnement du service web
? Fournisseur de services: le fournisseur de
services est le mainteneur du service et l'organisation qui met à
disposition un ou plusieurs services que d'autres peuvent utiliser. Pour
annoncer des services, le fournisseur peut les publier dans un registre, avec
un contrat de service qui spécifie la nature du service, comment
l'utiliser, les exigences du service et les frais facturés.
? Consommateur de service (client): le
consommateur de service peut localiser les métadonnées du service
dans le registre et développer les composants client requis pour lier et
utiliser le service.
? Courtier de services (UDDI) : Le courtier
de services, également connu sous le nom de registre de services, est
chargé de rendre l'interface de service Web et les informations
d'accès à l'implémentation accessibles à tout
demandeur de service potentiel. Celui qui implémente le courtier
décide de la portée du courtier. Les courtiers publics sont
disponibles sur Internet, tandis que les courtiers privés ne sont
accessibles qu'à un public limité, par exemple les utilisateurs
d'un intranet d'entreprise. En outre, certaines

24
décisions doivent être prises quant à la
quantité d'informations proposées. Certains courtiers se
spécialisent dans de nombreuses inscriptions. D'autres offrent un haut
niveau de confiance dans les services listés. Certains couvrent un large
éventail de services et d'autres se concentrent sur une industrie.
Certains courtiers cataloguent d'autres courtiers. Selon le modèle
commercial, les courtiers peuvent tenter de maximiser les demandes de
recherche, le nombre d'annonces ou l'exactitude des annonces. La
spécification UDDI (Universal Description, Discovery and Integration)
définit un moyen de publier et de découvrir des informations sur
les services Web.
II.9.4. Types de services Web
Les services Web peuvent être mis en oeuvre de
différentes manières. A ce jour, il existe deux types de services
Web largement utilisés, entre autres : les services Web SOAP et les
services web REST.
a. Web Services SOAP (Simple Object Access
Protocol)
Les services Web SOAP ont tous les avantages des services Web,
certains des avantages supplémentaires sont:
· Le document WSDL fournit le contrat et les
détails techniques des services Web pour les applications clientes sans
exposer les technologies d'implémentation sous-jacentes.
· SOAP utilise des données XML pour la charge
utile ainsi que pour le contrat, de sorte qu'il peut être facilement lu
par n'importe quelle technologie.
· Le protocole SOAP est universellement accepté,
c'est donc une approche standard de l'industrie avec de nombreuses
implémentations open source facilement disponibles.
Certains des inconvénients du protocole SOAP sont:
· Seul XML peut être utilisé, JSON et les
autres formats légers ne sont pas pris en charge.
· SOAP est basé sur le contrat, il existe donc un
couplage étroit entre les applications client et serveur.
· SOAP est lent car la charge utile est volumineuse pour
un message sous forme de chaîne simple, car il utilise le format XML.
· Chaque fois qu'il y a un changement dans le contrat
côté serveur, les classes de stub client doivent être
générées à nouveau.
· Ne peut pas être testé facilement dans le
navigateur

25
b. Services Web REST (Representational State
Transfer)
REST est l'acronyme de REpresentational State Transfer. REST
est un style architectural permettant de développer des applications
accessibles via le réseau. Le style architectural REST a
été mis en lumière par Roy Fielding dans sa thèse
de doctorat en 2000.
REST est une architecture client-serveur sans état
où les services Web sont des ressources et peuvent être
identifiés par leurs URI (Uniform Ressource Identifier). Les
applications clientes peuvent utiliser les méthodes HTTP GET, POST, PUT,
DELETE pour échanger avec les services Web Restful. REST ne
spécifie aucun protocole spécifique à utiliser, mais dans
presque tous les cas, il est utilisé via HTTP / HTTPS. Comparés
aux services Web SOAP, ils sont légers et ne respectent aucune norme.
Nous pouvons utiliser XML, JSON, texte ou tout autre type de données
pour la demande et la réponse.
Certains des avantages des services Web REST sont:
· La courbe d'apprentissage est facile car elle fonctionne
sur le protocole HTTP
· Prend en charge plusieurs technologies pour le transfert
de données telles que le texte, xml, json, image, etc.
· Aucun contrat défini entre le serveur et le
client, donc implémentation faiblement couplée.
· REST est un protocole léger
· Les méthodes REST peuvent être
testées facilement via le navigateur.
Toutefois, les services web REST présentent aussi
certains désavantages :
· Puisqu'il n'y a pas de contrat défini entre le
service et le client, il doit être communiqué par d'autres moyens
tels que la documentation ou les courriels.
· Comme cela fonctionne sur HTTP, il ne peut pas y avoir
d'appels asynchrones.
· Les sessions ne peuvent pas être maintenues.
II.9.5. Tableau comparatif de service web SOAP et REST
Service Web SOAP
|
Service Web REST
|
SOAP est un protocole standard de création de services
Web.
|
REST est un style architectural permettant de créer des
services Web.
|
SOAP est l'acronyme de Simple Object Access
|
REST est l'acronyme de REpresentational State
|
|

26
Protocol.
Transfer.
|
SOAP utilise WSDL pour exposer les méthodes prises en
charge et les détails techniques.
|
REST expose les méthodes via les URI, il n'y a pas de
détails techniques.
|
Les services Web SOAP et les programmes clients sont
liés au contrat WSDL
|
REST n'a aucun contrat défini entre le serveur et le
client
|
Les services Web et le client SOAP sont étroitement
liés au contrat.
|
Les services Web REST sont faiblement couplés.
|
La courbe d'apprentissage SOAP est difficile, nous oblige
à en apprendre davantage sur la génération WSDL, la
création de stubs clients, etc.
|
La courbe d'apprentissage REST est simple, les classes POJO
(Plain Old Java Object) peuvent être générées
facilement et fonctionnent sur des méthodes HTTP simples.
|
SOAP prend uniquement en charge le format de données
XML
|
REST prend en charge tous les types de données tels que
XML, JSON, image, etc.
|
Les services Web SOAP sont difficiles à maintenir, toute
modification du contrat WSDL nous oblige à créer à nouveau
des stubs client, puis à modifier le code client.
|
Les services Web REST sont faciles à maintenir par
rapport à SOAP, une nouvelle méthode peut être
ajoutée sans aucun changement côté client pour les
ressources existantes.
|
Les services Web SOAP peuvent être testés via
des programmes ou des logiciels tels que Soap UI.
|
REST peut être facilement testé via la commande
CURL, les navigateurs et les extensions telles que Chrome Postman.
|
|
Tableau II.1. Tableau comparatifs service web SOAP et
REST
II.10. SOA et micro services
La tension entre les deux visions, ensemble de principes et
mise en oeuvre logicielle spécifique, culmine avec l'arrivée de
deux phénomènes : la virtualisation et le Cloud computing.
Combinés, ils vont pousser les développeurs à concevoir
des applications à partir de composants fonctionnels plus petits. Les
micros services, une des tendances logicielles aiguës du moment, ont
été l'apogée de ce modèle de développement.
Plus il y a de composants, plus il faut d'interfaces et plus la conception
logicielle se complique : la tendance a mis au jour la complexité et les
défauts de performance de la plupart des mises en oeuvre SOA.
Finalement, les architectures logicielles à base de
micro services ne sont que des mises en oeuvre actualisées du
modèle SOA. Les composants logiciels sont conçus comme des
services à exposer via des API, comme l'exige la SOA. Un broker d'API
fait l'intermédiaire : il donne accès aux composants et garantit
l'observation des règles de sécurité et de gouvernance.
Par des techniques

27
logicielles, il assure la correspondance entre les
différents formats d'E/S des micros services et les applications qui les
utilisent.
Mais l'architecture SOA reste valable aujourd'hui comme au
premier jour. Ses principes nous ont amenés au cloud et prennent en
charge les techniques les plus avancées de développement de
logiciels cloud actuellement en usage.

28
Chapitre III. Conception et modélisation du
nouveau système [4][5][6][10]
III.1. Introduction
L'essence de ce chapitre réside dans le fait que ce
dernier va aider à réfléchir et présenter l'aspect
conceptuel de la construction d'une architecture orientée services
permettant aux Universités de transmettre des données requises au
ministère de l'ESU (Enseignement Supérieur et Universitaire), en
faisant interagir leurs programmes informatiques complètement
hétérogènes les uns des autres, et cela via un web service
que nous allons mettre en place.
Pour ce faire, on aura à modéliser les
opérations effectuées par les écoles, lesquelles sont
relatives à l'inscription ainsi qu'aux parcours scolaire de
l'élève, nous étudierons et prendrons donc en compte dans
notre analyse toutes les informations et entités logique ou physique,
à même de nous garantir une traçabilité plus clairs
du cursus de l'élève depuis son inscription. Ce chapitre est
reparti en deux sections dont la première s'intéresse à la
théorie du système à
réaliser et la seconde s'articule sur sa
modélisation tout en se basant sur
l'approche UML.
Section 1 : Théorie sur le système
à développer
III.1.I. Spécifications initiales du
logiciel
Le système que nous allons mettre en place est
basé sur une architecture orienté service. En effet, l'objectif
principal de ce système est d'assurer l'échange des informations
liées à l'authentification de l'étudiant et le suivi
permanant de son cursus, c'est-à-dire, la vérification de
l'authenticité de ses documents académique. Cet échange se
fera entre les Universités tout autour du Ministère de
l'Enseignement Supérieur et Universitaire (ESU) qui fournira à
ces dernières (universités) des services exploitables.
Ce système devra être en mesure de permettre aux
administrations de différentes universités, au moment de
l'inscription, de visualiser le parcours académique d'un étudiant
en cas d'une demande d'inscription spéciale en vue de s'assurer de la
véracité et de l'authenticité des informations contenues
dans son dossier académique. Et s'il s'agit d'un candidat au
recrutement, l'établissement pourra l'inscrire et l'identifier entant
qu'un nouvel étudiant dans son système et transmettre ses
coordonnées au Ministère de l'ESU.

29
III.1.2. Présentation des entités
(institutions) cible et leur rôle dans le système
Ce point a pour but principal de présenter les
différents rôles des systèmes qui interagissent dans le
cadre du système que nous allons mettre en place. Pour le système
que nous désirons mettre en place, il arrive souvent que les
entités participant à la communication, soient des
systèmes complémentaires et en même temps jouant des
rôles diamétralement opposés et distincts.
III.1.2.1. Ministère de l'ESU
La Direction des services académiques du
Secrétariat général du
Ministère de l'ESU a pour activités :
> Cartes Universitaires
> Entérinement et Homologation
> Bourses d'études
> Le contrôle de scolarité.
L'activité qui nous intéresse dans cette partie
est le contrôle de scolarité, elle
consistera à:
+ vérifier la régularité de l'admission de
l'étudiant sur base du diplôme d'Etat
ou d'un titre jugé équivalent par le
Ministère de l'Enseignement Primaire,
Secondaire et Technique (EPST) ;
+ vérifier la régularité de la
réussite de l'étudiant d'une promotion à une autre,
d'un cycle à un autre, sans dépassement des
sessions (4 sessions) autorisées
par année d'études ;
+ vérifier l'effectivité de l'exécution du
programme des cours, et s'assurer si les
cours reportés ont été dispensés;
III.1.2.2. Etablissement universitaire
L'Etablissement prendra toutes les dispositions pour remettre
à l'équipe de contrôle de scolarité du
Ministère de l'ESU la documentation ci-après pour la
réalisation de son travail, notamment :
+ les palmarès d'examens, grilles des points ou
procès-verbaux de délibérations des années
concernées ;
+ le dossier administratif de l'étudiant contenant le
diplôme d'Etat ou (la note à qui de droit délivré
par l'inspection Générale de l'EPST en cas de l'absence de la
photocopie du diplôme d'Etat) ou titre jugé équivalent ;
+ la fiche de la scolarité et autres pièces
exigées ;
+ la logistique de contrôle, notamment les fiches
d'Entérinement ou de l'Homologation des diplômes qui reprend les
Noms, post-noms des finalistes, saisie par ordre alphabétique, par
Faculté, par section ou option ;

30
+ pour les étudiants venus des autres Etablissements dans
le cadre de l'inscription spéciale, les documents académiques qui
confirment la réussite régulière.
III.1.3. Elaboration d'un concept de système
à développer
Il est vrai que bon nombre de systèmes existant de nos
jours sont pour la plupart le fruit d'un ensemble d'idées plutôt
vagues, sachant qu'on ne peut rien construire de d'efficace et de durable en
s'appuyant sur des bases imprécise, il va donc de soi que ces
idées aient besoin d'être étoffées afin d'avoir plus
de précision sur ce que l'on désir réaliser.
Pour ce faire, il sied de se poser une série de
question, dont les réponses apporteront plus de précision sur le
système à réaliser. En voici quelques-unes de ces fameuses
questions :
A qui le système est-il destiné
?
+ Le système sera destiné uniquement aux
universités où les échanges d'informations sont possibles,
car un étudiant peut quitter une université donnée pour
une autre, et non quitter une université pour un institut
supérieur et vice-versa;
+ Le système sera particulièrement
destiné au service administratif des universités publiques ou
privées agrées. Et au besoin, au service de contrôle de
scolarité de la direction des affaires académiques du
secrétariat général du Ministère de l'ESU.
Quels problèmes le système
résoudra-t-il ?
+ Il permettra d'avoir une visualisation en temps réel
des résultats académiques d'un étudiant à un temps
et un coût fortement réduit.
+ Il mettra fin aux vices que l'on constate dans les
procédures d'inscriptions spéciales dans nos universités,
qui donne la possibilité aux étudiant de se faire inscrire dans
des promotions montantes sans avoir les informations exactes les concernant.
+ Il va permettre d'atténuer les fraudes au niveau de
la falsification des documents, dans le sens où un document
falsifié et attestant des informations fictives, ne sera point
recevable.
Quelles seront les conditions d'utilisation du
système ?
+ Etre une université publique ou privée
agrée et disposer d'un code unique d'identification, qui permettra
d'associer le palmarès à son université;

31
+ Le système n'est utilisé que par des
universités qui vont intégrer le contrat de service fourni par le
web service dans leur système informatique et tout en
sachant que le champ d'utilisation est limité en fonction
des privilèges ;
+ La seule personne qui sera chargée d'administrer est
celui qui a tous les privilèges dans le système.
Pourquoi le système est-il attendu ?
+ Afin de gagner du temps aux administratifs des
universités, d'avoir des plus amples informations concernant le cursus
d'un étudiant.
+ Afin garantir la communication entre des systèmes
informatiques des universités.
+ Afin de permettre au ministère de l'ESU de
contrôler la scolarité des étudiants sans avoir à se
déplacer d'une université à une autre , suivre en
permanence leurs cursus et avoir une estimation plus ou moins exacte de
l'effectif des étudiants chaque année.
Où le système sera-il utilise
?
+ Le système sera utilisé dans un environnement
distribué qui regroupera certaines entités éducationnelles
(Universités) de la république.
III.1.4. Exigences du système à mettre
en place
Lors du développement d'un logiciel il y a toujours un
certain nombre d'exigences qu'il faut satisfaire entres autre :
V' Exigences fonctionnelles, c'est à dire une
application est créée tout d'abord pour répondre aux
besoins de l'entreprise.
V' Exigences techniques ce qui signifie qu'il ne suffit pas
seulement de créer une application mais également l'application
doit être performent c'est-à-dire réduire le temps de
réponses, assurer la disponibilité de l'application etc.
III.1.4.1. Spécifications
fonctionnelle
Une application est créée pour répondre
à un problème ou un besoin particulier c'est-à-dire
l'application doit faire un nombre des taches bien définie au
pare-avant. Pour notre cas le système que nous développons
effectue comme tâches :
> Identification des étudiants ;
> Description et publication des services dans l'annuaire
;

32
> Recherche des services publiés par les autres ;
> Echange des informations qui englobe les différents
processus liés à la publication des services et la recherche des
services publiés.
III.1.4.2. Spécifications techniques
Les spécifications techniques permettent de satisfaire
les besoins du client tout en commençant par la notion de performance,
ce qui implique le temps possible qu'un système prendra pour donner la
réponse à une demande ainsi que la disponibilité du
système. D'où nous serons obligés de faire un test de
performance à la fin du développement de l'application
Section 2 : Modélisation du système par
approche UML
Par définition, UML se définit comme un langage
de modélisation graphique et textuel destiné à comprendre
et décrire des besoins, spécifier et documenter des
systèmes, esquisser des architectures logicielles, concevoir des
solutions et communiquer des points de vue.
UML unifie à la fois les notations et les concepts
orientés objet. Il ne s'agit pas d'une simple notation, mais les
concepts transmis par un diagramme ont une sémantique précise et
sont porteurs de sens au même titre que les mots d'un langage. UML a une
dimension symbolique et ouvre une nouvelle voie d'échange de visions
systémiques précises. Ce langage est certes issu du
développement logiciel mais pourrait être appliqué à
toute science fondée sur la description d'un système.
Dans sa version 2.0, UML définit treize types de
diagrammes, divisés en trois catégories: Six types de diagrammes
représentent la structure d'application statique; trois
représentent des types généraux de comportement; et quatre
représentent différents aspects des interactions:
· :. Les diagrammes de structure incluent
:
> Diagramme de classe : Ce diagramme
représente la description statique du système en intégrant
dans chaque classe la partie dédiée aux données et celle
consacrée aux traitements. C'est le diagramme pivot de l'ensemble de la
modélisation d'un système.
> Diagramme d'objet - Le diagramme d'objet permet
la représentation d'instances des classes et des liens entre
instances.
> Diagramme de composants : Ce diagramme
représente les différents constituants du logiciel au niveau de
l'implémentation d'un système.

33
> Diagramme de déploiement : Ce diagramme
décrit l'architecture technique d'un système avec une vue
centrée sur la répartition des composants dans la configuration
d'exploitation.
> Diagramme de paquetage : Ce diagramme donne une
vue d'ensemble du système structuré en paquetage. Chaque
paquetage représente un ensemble homogène
d'éléments du système (classes, composants...).
> Diagramme de structure composite : Ce diagramme
permet de décrire la structure interne d'un ensemble complexe
composé par exemple de classes ou d'objets et de composants techniques.
Ce diagramme met aussi l'accent sur les liens entre les sous-ensembles qui
collaborent.
· :. Les diagrammes de comportement
incluent :
> Diagramme des cas d'utilisation : Ce diagramme
est destiné à représenter les besoins des utilisateurs par
rapport au système. Il constitue un des diagrammes les plus structurants
dans l'analyse d'un système.
> Diagramme d'état-transition : Ce
diagramme montre les différents états des objets en
réaction aux événements.
> Diagramme d'activités : Ce diagramme
donne une vision des enchaînements des activités propres à
une opération ou à un cas d'utilisation. Il permet aussi de
représenter les flots de contrôle et les flots de
données.
· :. Les diagrammes d'interaction, tous
dérivés du diagramme de comportement plus général,
incluent le diagramme de séquence, le diagramme de communication, le
diagramme de synchronisation (temps) et le diagramme de présentation des
interactions.
III.2.1. Présentation des diagrammes
utilisés
UML 2 décrit les concepts et le formalisme de ces
treize diagrammes mais ne propose pas de démarche de construction
couvrant l'analyse et la conception d'un système. Ce qui a pour
conséquence par exemple de ne pas disposer d'une vision d'interactions
entre les diagrammes.
? Processus « D'identification d'un
Etudiant»
Ce cas constitue l'aspect Gestion de notre système, en
raison du fait qu'il sera question ici, de modéliser le fonctionnement
classique d'un système de gestion inscription des étudiants, de
représenter graphiquement les interactions s'effectuant pendant le
processus d'inscription interne à une université et , ce qui
va

34
permettre entre autre de récupérer l'ensemble
des informations nécessaires afin de tracer le cursus complet suivi par
chaque étudiant. Ainsi c'est ces dites informations que l'on interrogera
au moment de l'authentification d'un candidat.
? Processus « D'authentification des flux
»
Ce cas constitue l'aspect « Web service » de notre
système, c'est même le vif de notre sujet, dans le sens où
il va falloir ici, modéliser le fonctionnement du système lors de
communication entre les systèmes des universités et celui du
Ministère de l'ESU dans une architecture orientée service,
interroger les données distant afin de pouvoir authentifier les flux
relatifs au candidat présent pour l'inscription spéciale. En
claire, il s'agit ici de simplement lancer une recherche dans le système
dans le système de l'ESU via un service web pour se renseigner sur la
provenance d'un candidat.
III.2.2.1. Diagramme des cas d'utilisation
(DCU)
Les cas d'utilisation constituent un moyen de recueillir et de
décrire les besoins et les activités des acteurs se rapportant au
système. Ils peuvent être aussi utilisés ensuite comme
moyen d'organisation du développement du logiciel.
Tout système peut être décrit par un
certain nombre de cas d'utilisation correspondant aux besoins exprimés
par l'ensemble des utilisateurs. À chaque utilisateur, vu comme acteur,
correspondra un certain nombre de cas d'utilisation du système.
L'ensemble de ces cas d'utilisation se représente sous
forme d'un diagramme.
o Présentation de Diagramme de cas
d'utilisation
uc
«Actor»
Université
Enregistrer
Etudiant
palmares
«include»
palmares
Consomer les
services
«include»
«include»
«include»
«include»
«include»
«include»
S'authentifier
consulter les
pamares
«include»
palmares
«include»
«include»
Rechercher
Créer et attribuer des
codes aux universités
Publier des
services
etudiant
Aministrateur

35
Elaborer
Figure III.1. Diagramme de cas d'utilisation
III.2.2.2. Diagramme de séquence (DSE)
valider
publier
L'objectif du diagramme de séquence
est de représenter les interactions entre objets en indiquant
la chronologie des échanges. Cette représentation peut se
réaliser par cas d'utilisation en considérant les
différents scénarios associés.
o Présentation de Diagramme de
séquence
sd Recherche d'un etudiant
Agent
Affichage des informations sur l'etudiant depuis le
palmares()
S'authentifier(user, pass)
Ouverture de la session()
Rechercher l'etudiant(noms, postnom, prenom)
:String
Systeme
Université
verification(user, pass)
Service
Web
Localiser le serveur()
Localiser le serveur()
Systeme
ESU
Traitement de la requete()

36
Figure III.2. Présentation du diagramme de
séquence
II.2.2.3. Diagramme d'activité(DA)
Les diagrammes d'activités permettent de mettre
l'accent sur les traitements. Ils sont donc particulièrement
adaptés à la modélisation du cheminement de flots de
contrôle et de flots de données. Ils permettent ainsi de
représenter graphiquement le comportement d'une méthode ou le
déroulement d'un cas d'utilisation.

37
o Présentation du diagramme
d'activités
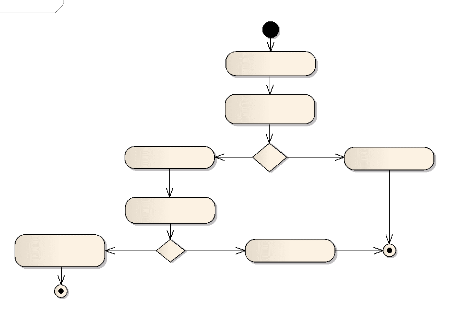
act Rechercher
Affichage des
informations provenant
des palmares
Fin
info trouvée
Lancement de la requete
de recherche
trouvé Non trouvé
Inv ocation du serv ice Serv ce introuv
able
pas d'info
Recherche du service
concerné
Information non trouvée
Rechercher
Fin
Figure III.3 Présentation du diagramme
d'activité
III.2.2.3. Diagramme de classes(DCL)
Le diagramme de classes est considéré comme le
plus important de la modélisation orientée objet, il est le seul
obligatoire lors d'une telle modélisation.
Alors que le diagramme de cas d'utilisation montre un
système du point de vue des acteurs, le diagramme de classes en montre
la structure interne. Il permet de fournir une représentation abstraite
des objets du système qui vont interagir ensemble pour réaliser
les cas d'utilisation. Il est important de noter qu'un même objet peut
très bien intervenir dans la réalisation de plusieurs cas
d'utilisation. Les cas d'utilisation ne réalisent donc pas une
partition1 des classes du diagramme de classes. Un diagramme de classes n'est
donc pas adapté (sauf cas particulier) pour détailler,
décomposer, ou illustrer la réalisation d'un cas d'utilisation
particulier.

38
o Présentation de Diagramme de Classes
class Diagramme
- idEtud: int
- matricule: string
- nomEtud: string - postnomEtud: string -
prenomEtud: string - sexe: char
- adresse: string
- lieuDeNais: string - dateDeNais:
string
+ Creer() : void + Modifier() :
void + Rechercher() : string +
Supprimer() : void + Afficher() :
void
Etudiant
- idUniv: int
- libUniv: String - adresse: string -
telephone: string - mailadress: string - siteweb:
string
Université
1..* 1..*
- idEtud: int
- idPromo: int
- anneeAcad: string
- pourcent: float
- mension: char
- matricule: string
+ Ajouter() : void +
Rechercher() : string + Modifier() :
void + Supprimer() : void +
Afficher() : void
Inscrire
1
comprendre
1..*
- idPromo: int
- libPromo: string
+ Créer() : void
+ Supprimer() : void
+ Modifier() : void
+ Rechercher() : string
- idFac: int
- libFac: String
Promotion
Faculté
1..*
1
Appartenir
contenir
1..*
1
- idOpt: int
- libOpt: string
+ Modier() : void
+ Rechercher() : string
+ Supprimer() : void
- idDepart: int
- libDepart: string
+ Creer() : void
Departement
Option
se trouver
1
1..*
Figure III.4. Diagramme de classe
III.2.2.4. Diagramme de déploiement
(DPL)
+ Creer() : void
+ Supprimer() : void +
Modifier() : void
+ Rechercher() : String
+ Creer() : void
+ Modifier() : void
+ Supprimer() : void +
Rechercher() : string
+ Creer() : void
+ Modifier() : void
+ Supprimer() : void +
Rechercher() : string
Le diagramme de déploiement permet de
représenter l'architecture physique supportant l'exploitation du
système. Cette architecture comprend des noeuds correspondant aux
supports physiques (serveurs, routeurs...) ainsi que la répartition des
artefacts logiciels (bibliothèques, exécutables...) sur ces
noeuds. C'est un véritable réseau constitué de noeuds et
de connexions entre ces noeuds qui modélise cette architecture.

39
o Présentation de Diagramme de
déploiement
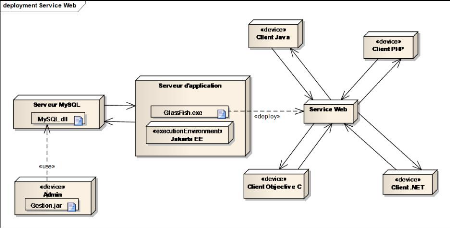
Figure III.5. Diagramme de déploiement
La conception et la modélisation constituent une phase
importante dans la réalisation d'un projet d'informatisation. Dans ce
chapitre nous venons de faire une analyse de la mise en oeuvre de notre
système, donc une étude de faisabilité, ce qui nous a
donné une idée claire sur ce qui sera l'implémentation de
notre système en se basant sur les différents diagrammes du
langage UML présentés dans ce chapitre.
Dans le chapitre qui va suivre, nous allons, grâce aux
analyses faites, mettre en oeuvre notre système, et comprendre son
fonctionnement.

40
Chapitre IV. Mise en oeuvre et fonctionnement de
l'application
IV.1. Introduction
IV.2. Présentation de la technologie
utilisée
Le système à réaliser est basé sur
une architecture orientée service qui sera déployé dans un
système distribué. Comme nous l'avons décrit dans le
chapitre deuxième de notre travail, le SOA n'est qu'un modèle de
conception dans lequel les applications sont conçues en termes de
services. Dans son implémentation, l'AOS ou SOA utilise les technologies
telles que : le service web ou les micros services. Le Service web est notre
choix pour implémenter notre système. De ce fait, nous avons
opté pour une architecture REST.
REST est utilisé dans le développement des
applications orientés ressources (ROA) ou orientées
données (DAO). Les applications respectant l'architecture REST sont
dites RESTful.
Les ressources utiliser dans REST sont Identifiées par
une URI (Uniform Resource Identifier), les méthodes permettant de
manipuler ces ressources sont les quatre méthodes HTTP : GET, POST, PUT,
DELETE et en fin la · représentation des ressources entre le
client et le serveur utilise les formats d'échanges (XML, JSON,
Text/plain, XHTML, CSV).
REST s'appuie sur le protocole HTTP pour effectuer des
opérations sur les objets. Ces opérations sont de bases CRUD
correspondant aux quatre principaux types de requêtes HTTP (GET, PUT,
POST, DELETE) :
? CREATE ? POST : La méthode POST
crée une nouvelle ressource sur le système.
? RETRIEVE ? GET : La méthode GET renvoie
une représentation de la ressource telle qu'elle est sur le
système.
? UPDATE ? PUT : la méthode PUT met
à jour de la ressource sur le système.
? DELETE ? DELETE : la méthode DELETE
Supprime la ressource identifiée par l'URI sur le serveur.
IV.3.Présentation des outils et environnements
de développement
IV.3.1. Le système de gestion de base de
données (SGBD) utilisé
Nous avons jeté notre dévolu sur MySQL dans sa
version 5.7, en utilisant un outil de conception graphique MySQL Workbench
6.3.

41
Ce SGBD va nous permettre de stocker et de restituer les
différentes informations publiées par les utilisateurs en cas
d'une recherche.
Figure IV.1. Interface d'accueil MySQL Workbench
6.3
IV.3.2. Le langage de programmation et environnement
utilisé o Au vu du langage de modélisation (UML)
utilisé pour la conception de notre système dans le chapitre
précédant, il nous semble bon de porter notre choix sur un
langage orienté objet. C'est pourquoi, nous allons utiliser le langage
Java dans son édition Standard (Java SE) avec pour environnement de
développement intégré(IDE) NetBeans 8.2, Jakarta EE pour
le Service web et son serveur GlassFish : qui est le serveur d'application
utilisé pour interprétation du script coté client et
coté serveur.

42
Figure IV.2. Accueil NetBeans 8.2
IV.3.3. Le Méthodes de programmations
utilisées
Etant donné que nous avons utilisé UML afin de
modéliser notre nouveau système, il faut savoir que choisir UML
pour la modélisation, est un fait implique certaines contraintes et
logique à appliquer au niveau de d'implémentation des classes
issues du diagramme de classe présenté plus haut, et ces
contraintes et logique sont essentiellement liés à la
méthode de programmation orientée objet, POO en sigle.
1. La Méthode objet
Cette méthode qui consiste à créer une
représentation informatique des éléments du monde
réel du monde auxquels on s'intéresse, sans forcément se
préoccuper de l'implémentation, ce qui signifie
indépendamment d'un langage de programmation.
Il s'agit donc d'identifier les objets présents dans le
système et d'isoler les données et les fonctions qu'ils
utilisent. En bref, c'est la description de ce qui est représenté
dans un diagramme de classe.
? Avantages de la POO
Choisir la méthode objet comme sa méthode de
programmation, présente un bon nombre d'avantage dont :
? La POO permet l'encapsulation : Le code constituant l'objet
est caché de l'utilisateur (l'utilisateur dont il est question ici c'est
celui qui se servira de vos objets afin d'animer le site ou l'application, et
non le visiteur qui demande la page depuis son navigateur, ou simplement
l'utilisateur de l'application).

43

44
Cela diminue le risque d'erreurs puisque l'utilisateur ne
pourra pas modifier le coeur même de votre code et évitera ainsi
beaucoup d'erreurs.
( Maintenance et évolutivité :
C'est-à-dire que la POO permet de concevoir une application dont les
différents constituants sont indépendants les uns des autres. De
ce fait, modifier un de ces constituants n'affectera pas les autres et
n'entraînera donc pas d'erreurs ou autres comportements erratiques, du
fait de la clarté du code vous retrouverez facilement les
éléments que vous souhaitez modifier.
( Possibilité de réutilisation :
L'indépendance de vos modules vous permet de les réutiliser dans
d'autres applications: module de news, galerie photo: ces
éléments sont présents sur une grande majorité de
sites, il est donc très intéressant de pouvoir les
réutiliser à chaque fois que ce sera nécessaire, sans
avoir à les réinventer!
·
· Inconvénients de
la POO
( La performance souffre parfois en utilisation
intensive du polymorphisme en temps d'exécution, patrons de conception
imbriqués et autres artifices POO.
( La redondance de code parfois imposée par
certaines contraintes et recommandations de l'OOP. Taille de la base de code
conséquente, résultat de l'accumulation des niveaux
d'abstraction.
( La sur-ingénierie ou Overengineering est un
piège qui guette les concepteurs (parfois expérimentés) et
qui peut causer des dégâts allant du retard jusqu'à
l'échec du projet.
( Exigence en savoir-faire en génie logiciel
pour les projets importants (architectes, ingénieurs, et
développeurs qualifiés en POO).
( Pas très pratique pour des petits projets ou
test de fonctionnalités non PPO. En somme, La réutilisation,
l'encapsulation, l'extensibilité et la maintenabilité ont parfois
des prix à payer : le temps et l'espace entre autre.
Il est important de notifier, qui l'existe des
méthodologies pouvant être combinées à la POO afin
d'accroître ces avantages en proposant une structuration bien
particulière et un niveau d'abstraction et d'organisation bien plus
élevé. Ces méthodologies sont connues sous le nom de
« designs patterns ».
2. Les Design patterns
Les designs patterns (en français patrons de
conception, Modèle de conception ou encore Motifs de conception)
représentent chacun un ensemble de bonnes pratiques de conception pour
un certain nombre de problème récurrents en programmation
orienté objet.
Ce concept de Designs patterns est issu des travaux de 4
chercheurs (Erich Gamma, Richard Helm, Ralph Johnson, et John Vlissides, groupe
de quatre chercheur connu sous le nom de « Gang of four » ou «
La bande des quatre »)
dans leur ouvrages intitulé « Design patterns :
Elements of Reusable Object-Oriented Software » édité en
1995 et proposant 23 motif de conception.
Il existe plusieurs types de patterns, mais dans le cadre de
notre implémentation, nous n'en avons utilisés que deux, à
savoir : le pattern singleton et le pattern DAO.
? Le Pattern Singleton
Le « singleton » [Gamma 95] est l'une des techniques
les plus utilisées en conception orientée objet. Il permet de
référencer l'instance d'une classe devant être unique par
construction. Certains objets techniques prennent en effet une
responsabilité particulière dans la gestion logique d'une
application.
C'est par exemple le cas d'objets comme le «
contrôleur des objets chargés en mémoire » ou le
« superviseur des vues », qui sont les seuls et uniques
représentants de leur classe. Ces objets sont le plus souvent
publiquement accessibles.
De tels cas de figure sont extrêmement fréquents
en conception objet, et le singleton est requis pour les concevoir.
Le singleton repose sur l'utilisation d'une opération
de classe, getInstance() :
Instance, chargée de rapporter à
l'appelant la référence de l'objet unique. De plus, le singleton
se charge automatiquement de construire l'objet lors du premier appel.
? Le Pattern DAO
Un objet d'accès aux données (en anglais Data
Access Object) est un patron de conception (en la langue de voltaire, un
modèle pour concevoir une solution) utilisé dans les
architectures logicielles objet. Ce modèle permet d'encapsuler la
façon dont un programme récupère les données d'un
système de stockage (fichier, BDD...).
Il fait donc abstraction de la façon dont les
données sont stockées au niveau des objets métier, Ainsi,
le changement du mode de stockage ne remet pas en cause le reste de
l'application. En effet, seules ces classes dites "techniques" seront à
modifier (et donc à ré-tester). Cette souplesse implique
cependant un coût additionnel, dû à une plus grande
complexité de mise en oeuvre.
IV.4. implémentation du système
IV.4.1. implémentation de la base des
données ? Script de création de la base des données
:
-- MySQL Workbench Forward Engineering
SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0;

45
SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS,
FOREIGN_KEY_CHECKS=0;
SET
@OLD_SQL_MODE=@@SQL_MODE,
SQL_MODE='TRADITIONAL,ALLOW_INVALID_DATES';
-- Schema MonMemoire
CREATE SCHEMA IF NOT EXISTS `MonMemoire` DEFAULT CHARACTER SET
utf8 COLLATE utf8_general_ci ;
USE `MonMemoire` ;
-- Table `MonMemoire`.`Etudiant`
DROP TABLE IF EXISTS `MonMemoire`.`Etudiant` ;
CREATE TABLE IF NOT EXISTS `MonMemoire`.`Etudiant` (
`idEtud` INT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '',
`Matricule` VARCHAR(45) NOT NULL COMMENT '',
`nomEtud` VARCHAR(45) NULL COMMENT '',
`postnomEtud` VARCHAR(45) NULL COMMENT '',
`prenomEtud` VARCHAR(45) NULL COMMENT '',
`sexe` VARCHAR(45) NULL COMMENT '',
`adresse` VARCHAR(45) NULL COMMENT '',
`lieuDeNais` VARCHAR(45) NULL COMMENT '',
`dateNais` VARCHAR(45) NULL COMMENT '',
PRIMARY KEY (`idEtud`, `Matricule`) COMMENT '')
ENGINE = InnoDB;
-- Table `MonMemoire`.`Universite`
DROP TABLE IF EXISTS `MonMemoire`.`Universite` ; CREATE TABLE IF
NOT EXISTS `MonMemoire`.`Universite` ( `idUniversite` INT NOT NULL
AUTO_INCREMENT COMMENT '', `libUniv` VARCHAR(45) NULL COMMENT '', PRIMARY KEY
(`idUniversite`) COMMENT '') ENGINE = InnoDB;
-- Table `MonMemoire`.`Faculte`
DROP TABLE IF EXISTS `MonMemoire`.`Faculte` ;
CREATE TABLE IF NOT EXISTS `MonMemoire`.`Faculte` (
`idFaculté` INT NOT NULL AUTO_INCREMENT COMMENT '',
`ibFac` VARCHAR(45) NULL COMMENT '',
`idUniv` INT NOT NULL COMMENT '',
PRIMARY KEY (`idFaculté`) COMMENT '',
INDEX `fk_Faculté_Universite1_idx` (`idUniv` ASC) COMMENT
'')

46
ENGINE = InnoDB;
-- Table `MonMemoire`.`Departement`
DROP TABLE IF EXISTS `MonMemoire`.`Departement` ; CREATE TABLE
IF NOT EXISTS `MonMemoire`.`Departement` ( `idDepart` INT NOT NULL
AUTO_INCREMENT COMMENT '', `libDepart` VARCHAR(45) NULL COMMENT '',
`idFac` INT NOT NULL COMMENT '',
PRIMARY KEY (`idDepart`) COMMENT '',
INDEX `fk_Departement_Faculté1_idx` (`idFac` ASC) COMMENT
'') ENGINE = InnoDB;
-- Table `MonMemoire`.`Option`
DROP TABLE IF EXISTS `MonMemoire`.`Option` ;
CREATE TABLE IF NOT EXISTS `MonMemoire`.`Option` (
`idOption` INT NOT NULL AUTO_INCREMENT COMMENT '',
`libOpt` VARCHAR(45) NULL COMMENT '',
`idDepart` INT NOT NULL COMMENT '',
PRIMARY KEY (`idOption`) COMMENT '',
INDEX `fk_Option_Departement1_idx` (`idDepart` ASC) COMMENT
'')
ENGINE = InnoDB;
-- Table `MonMemoire`.`Promotion`
DROP TABLE IF EXISTS `MonMemoire`.`Promotion` ;
CREATE TABLE IF NOT EXISTS `MonMemoire`.`Promotion` ( `idPromo`
INT NOT NULL AUTO_INCREMENT COMMENT '', `libPromo` VARCHAR(45) NULL COMMENT
'',
`idOpt` INT NOT NULL COMMENT '',
PRIMARY KEY (`idPromo`) COMMENT '',
INDEX `fk_Promotion_Option1_idx` (`idOpt` ASC) COMMENT '') ENGINE
= InnoDB;
-- Table `MonMemoire`.`Appartenir`
DROP TABLE IF EXISTS `MonMemoire`.`Appartenir` ; CREATE TABLE IF
NOT EXISTS `MonMemoire`.`Appartenir` ( `idAppartenir` INT NOT NULL
AUTO_INCREMENT COMMENT '', `anneeAcad` VARCHAR(45) NOT NULL COMMENT '',
`pourcent` FLOAT NOT NULL COMMENT '', `mension` VARCHAR(45) NOT NULL COMMENT
'', `Session` VARCHAR(45) NULL COMMENT '',

47
`idEtud` INT UNSIGNED NOT NULL COMMENT '',
`Matricule` VARCHAR(45) NOT NULL COMMENT '',
`idPromo` INT NOT NULL COMMENT '',
PRIMARY KEY (`idAppartenir`) COMMENT '',
INDEX `fk_Appartenir_Etudiant_idx` (`idEtud` ASC, `Matricule`
ASC) COMMENT '',
INDEX `fk_Appartenir_Promotion1_idx` (`idPromo` ASC) COMMENT
'')
ENGINE = InnoDB;
SET SQL_MODE=@OLD_SQL_MODE;
SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS;
SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;
? Présentation du Schéma global de la
base des données
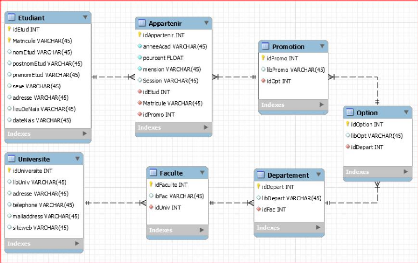
Figure IV.3. Schéma global de la base des
données
IV.4.2. Implémentation des services web
NetBeans prend en charge le développement rapide des
services Web RESTful, ces derniers étant très efficaces lorsqu'il
s'agit d'utiliser les Bases de Données. En plus de construire des
services Web RESTful, NetBeans prend également en charge les tests, le
développement d'applications clientes qui accèdent à des
services Web RESTful, et la génération de code pour invoquer des
services Web (à la fois RESTful et SOAP.)
Voici la liste des fonctionnalités RESTful fournies par
NetBeans:
? La création rapide de services Web RESTful des classes
et des modèles d'entités JPA.

48
? Génération de code rapide
pour appeler des services Web tels que Google Map, Yahoo Nouvelles Recherche,
et utilisation des composants Web services par glisser-déposer à
partir du gestionnaire de services Web dans la fenêtre Services.
? Génération de clients RESTful
Java pour les services enregistrés dans le gestionnaire de services
Web.
? Vue logique pour faciliter la navigation
des classes d'implémentation de services Web RESTful dans votre
projet.
Nous allons commencer par créer une application web
nommée GestionAuthentification et ensuite nous dans l'onglet services de
NetBeans pour ajouter une connexion à notre BD.
Figure IV.4. Création de la connexion à
la base de données
On fait ensuite un clic droit sur DataBase et on
sélectionne New connection (ou Nouvelle connexion). Cette action nous
conduira à l'interface suivante :
Figure IV.5. Choix du pilote de connexion
MySQL

49
On sélectionne comme Driver (pilote) MySQL (Connector/J
driver) et on clique sur le bouton Next.
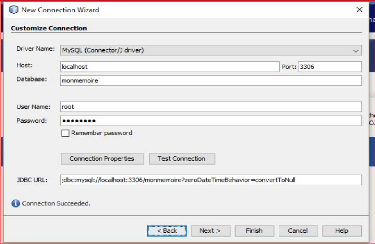
Figure IV.6. Personnalisation et de connexion MySQL
On entre ensuite le nom de la Base de Données, le nom
d'utilisateur ainsi que le mot de passe s'il y en a un et on clique sur Finish.
Vous pouvez aussi, avant de cliquer sur le bouton Finish, cliquer sur le bouton
Test Connection pour vérifier si les entrées sont exactes.
Figure IV.7. Aperçue de la nouvelle connexion
créée
Nous remarquons donc l'ajout dans NetBeans d'une connexion
vers notre Base de Données monmemoire. On rentre ensuite dans l'onglet
Projects de NetBeans pour ajouter à notre projet une source de
données. Pour ce faire, on se positionne sur le

50
projet et on y effectue un clic droit, on sélectionne
New (Nouveau) > Others (Autres) pour arriver à l'interface suivante
:
Figure IV.8. Création de pool de connexion JDBC pour
GlassFish
Dans Categories on sélectionne GlassFish et dans File
Types on sélectionne JDBC Connection Pool. En cliquant sur
Next nous arrivons à l'étape suivante :
Figure IV.9. Attribution du nom de pool de connexion
En premier, on nomme le pool de connexion et en second on
sélectionne la connexion définie pour la base des données
monmemoire que nous avions préalablement créé dans
NetBeans. On clique ensuite sur Next puis sur Finish dans l'interface qui suit
:
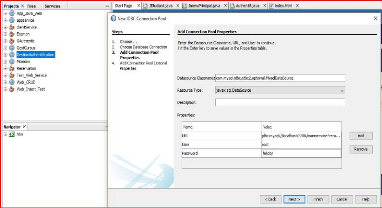

51
Figure IV.10. Fin de la création de notre pool
A ce stade notre pool de connexion cursusPool est
créé et il ne nous reste qu'à l'associer à une
ressource JDBC. Pour la ressource JDBC, on se positionne sur le projet, on
effectue un clic droit et on sélectionne New (Nouveau) > Others
(Autres) pour arriver à l'interface suivante :
Figure IV.11. Configuration de la ressource pour GlassFish
Cette fois ci dans le volet File Type on sélectionne
JDBC Resource. En cliquant sur Next nous avons l'interface
suivante dans laquelle on prendra soin de sélectionner comme pool de
connexion celui que nous avons créé préalablement
(GestAthentPool) et de nommer notre ressource JDBC
(jdbc/GestAuthent) :

52

53
Figure IV.12. Attachement du pool créé à
la ressource
Après avoir cliqué sur Finish, nous pouvons
commencer à créer notre service Web. Pour ajouter le service Web,
on se positionne sur le projet, on effectue un clic droit et on
sélectionne New > Others, mais
cette fois en sélectionnant web services dans
categorie et RESTful Web Services from Database dans
File Types.
Figure IV.13. Création des services web Restful
En cliquant sur Next, on prend soin de
sélectionner notre source de données «java :
app/jdbc/GestAuthent », on se retrouve devant la fenêtre qui va
suivre(figure IV.14.).
Nota : Pour des raisons de sécurité de notre
système et son bon fonctionnement, nous ne pouvons sélectionner
que des tables qui vont constituer l'objet de nos services qui seront
publiés et consommés par les clients.
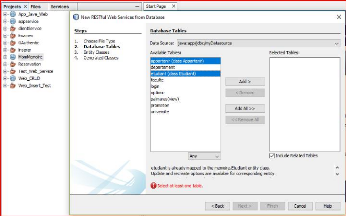
Figure IV.14. Création des classes entité pour le
WS
On clique sur le bouton Add», puis
sur Next pour nous retrouver sur l'interface suivante :
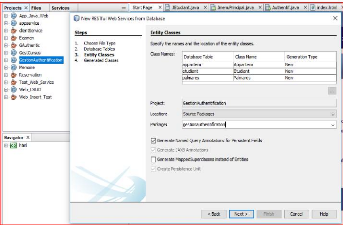
Figure IV.15. Finalisation de la création du service
web
Sur cette interface, nous pouvons voir nos classes
persistantes créées à partir des tables de notre base des
données. Apres avoir donné un nom à notre package, on
clique sur Next et puis Finish.
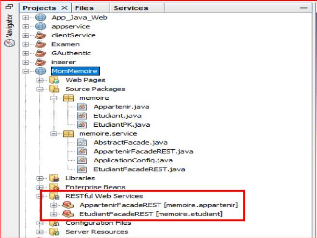

54
Figure IV.16. Présentation des services web
créés
Comme nous pouvons le constater sur figure IV.16. , nos
services web Restful viennent d'être s avec succès. Il n'attend
plus qu'à être déployer, ce que nous n'allons pas tarder
à faire, car c'est une étape qui va nous permettre d'effectuer
quelques tests.
IV.4.3. Déploiement du Service Web
Maintenant que nos services web sont créés, nous
allons passer au déploiement de notre application ou à sa
publication. Pour ce faire, il suffit de se positionner sur le noeud «
Restful Web services » et faire un clic droit puis sélectionner
Test Restful web services. Comme nos configurations sur les figures
précédentes étaient basées sur le serveur
GlassFish, notre application sera déployée sur ce denier.
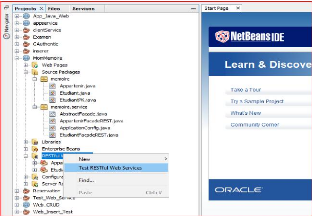
Figure IV.17. Test et déploiement des services Web
Restful

55
Etant donné que le test se fait en local, les services
web publiés seront visualisés via un navigateur web où ils
peuvent également être testés. Dans notre cas ici, nous le
ferons à l'aide de Google chrome, et nous y voilà :
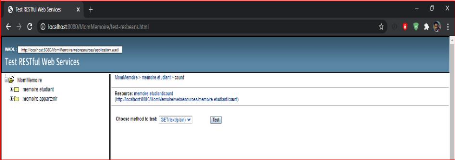
Figure IV.18. Présentation des services
publiés
Cette interface représente en tout ce que nous avons
appelé plus haut annuaire des services, il contient les
services publiés et leurs descriptions. Les services sont
déployés ou publiés grâce au protocole http comme
nous pouvons le voir dans la barre d'url de notre navigateur.
Remarque : Au début du corps de
notre page web se situe un label WADL qui signifie Web
Application Definition Language, il décrit les ressources
fournies par le service, comment les utiliser et les relations qui existent
entre elles. Dans notre test, il se presente comme suit :
http://!oca!host:8080/MomMemoire/webresources/app!ication.wad!
C'est l'équivalent du WSDL de services web
basé sur le protocole SOAP. En cliquant dessus, il nous présente
les descriptions suivantes :
Figure IV.19. Description de quelques services dans notre
wadl
Maintenant que nous avons fini l'implémentation et le
déploiement des services web, Analysons quelques codes
générés qui nous intéressent :
Pour chaque classe entité, l'IDE nous génère
une classe façade correspondante. Étudions la classe
EtudiantFacadeREST.java :
EtudiantFacadeREST.java
@Stateless
@Path("gestcurcis.etudiant")
public class EtudiantFacadeREST extends
AbstractFacade<Etudiant> {
@PersistenceContext(unitName = "GestCursusPU") private
EntityManager em;
private EtudiantPK getPrimaryKey(PathSegment pathSegment) {
gestcurcis.EtudiantPK key = new gestcurcis.EtudiantPK();
javax.ws.rs.core.MultivaluedMap<String, String> map =
pathSegment.getMatrixParameters();
java.util.List<String> idEtud = map.get("idEtud"); if
(idEtud != null && !idEtud.isEmpty()) {
key.setIdEtud(new java.lang.Integer(idEtud.get(0)));
}
java.util.List<String> matricule = map.get("matricule"); if
(matricule != null && !matricule.isEmpty()) {
key.setMatricule(matricule.get(0));
}
}

56
return key;

57
public EtudiantFacadeREST() { super(Etudiant.class);
}
@POST
@Override
@Consumes({MediaType.APPLICATION_XML,
MediaType.APPLICATION_JSON})
public void create(Etudiant entity) {
super.create(entity);
}
@PUT
@Path("{id}")
@Consumes({MediaType.APPLICATION_XML,
MediaType.APPLICATION_JSON}) public void edit(@PathParam("id") PathSegment id,
Etudiant entity) { super.edit(entity);
}
@DELETE
@Path("{id}")
public void remove(@PathParam("id") PathSegment id) {
gestcurcis.EtudiantPK key = getPrimaryKey(id);
super.remove(super.find(key));
}
@GET
@Path("{id}")
@Produces({MediaType.APPLICATION_XML,
MediaType.APPLICATION_JSON})
public Etudiant find(@PathParam("id") PathSegment id) {
gestcurcis.EtudiantPK key = getPrimaryKey(id);
return super.find(key);
}
@GET
@Override
@Produces({MediaType.APPLICATION_XML,
MediaType.APPLICATION_JSON})
public List<Etudiant> findAll() {
return super.findAll();
}

58
@GET
@Path("{from}/{to}")
@Produces({MediaType.APPLICATION_XML,
MediaType.APPLICATION_JSON})
public List<Etudiant> findRange(@PathParam("from") Integer
from,
@PathParam("to") Integer to) {
return super.findRange(new int[]{from, to});
}
@GET
@Path("count")
@Produces(MediaType.TEXT_PLAIN) public String countREST() {
return String.valueOf(super.count());
}
@Override
protected EntityManager getEntityManager() { return em;
}
}
? L'annotation @Stateless indique que la classe est une «
statelass session bean », en d'autre mot la classe est un servie. Comme
nous l'avons défini, un service n'a pas d'état, il referme des
fonctions, ...
? L'annotation @Path permet de définir l'URI dont la
classe va se servir pour les requêtes.
Comme on peut le remarquer, plusieurs méthodes de cette
classe sont annotées par les annotations : @POST, @PUT, @DELETE et @GET.
Ces méthodes seront automatiquement invoquées quand notre service
Web répondra à une requête HTTP. Notons par ailleurs que
plusieurs des méthodes sont aussi annotées par l'annotation
@Path, la raison est que certaines d'entre elles auront besoin de recevoir un
paramètre.
Sur la figure qui va suivre nous allons, nous allons voir une
portion de résultat de l'invocation du service etudiant par l'adresse
:
http://localhost:8080/MomMemoire/webresources/memoire.etudiant
Figure IV.20. Résultat de l'uri du service
étudiant
IV.5. Interfaces Homme Machine (IHM)
Nous allons ici présenter quelques interfaces de notre
application
selon une succession des étapes bien définies.
L'application est développée en langage Java, elle
servira du coté
fournisseur de services, et permettra de :
V' Visualiser les palmarès envoyés par des
universités,
V' Visualiser le parcours d'un étudiant en
faisant une recherche,
V' Créer des universités, et bien
d'autres.
V'
a. IHM d'Authentification de l'utilisateur
Comme dans toute application de gestion digne de ce nom, tout
commence par l'authentification, l'utilisateur nommé
Daniel s'authentifie avec son
mot de passe et se connecte à l'application. A noter que
selon le poste depuis
Figure IV.21. Interface d'authentification
59
lequel il se connecte, il sera redirigé vers
l'interface correspondant.
b. 
60
IHM Menu principal
L'interface présente est le menu principal de notre
application qui appelle directement une autre interface de visualisation des
palmarès.
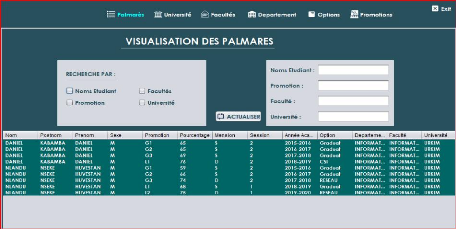
Figure IV.22. visualisation des palmarès
c. IHM Exemple de rechercher par le nom d'un
étudiant
Et nous y voilà, enfin un exemple de recherche dans le
palmarès. On peut obtenir le résultat en faisant une recherche
par les noms (nom ou post nom ou prénom) de l'étudiant.
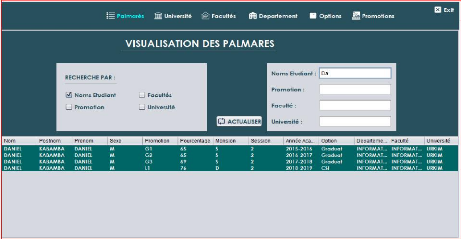
Figure IV.23. Visualisation d'une recherche par nom de
l'étudiant

61
Les interfaces homme machine présentées ci-haut
forment une application qui remplit certaines fonction dans le système
et représentent certaines actions d'un utilisateur. Il est donc possible
d'Enregistrer une université et lui attribuer un code unique pour ses
futures opérations dans le système entre autre : l'identification
des étudiants (enrésinement de ses étudiants), une
opération qui se fait une seule fois pour l'enregistrement, et
l'opération qui se fera régulièrement sera celle de
publier le palmarès.
Sur la dernière interface présentée, elle
représente le résultat d'une recherche d'un étudiant qui
existe déjà dans le système.

62
CONCLUSION GENERALE
La réalisation de ce travail a été
motivée par le désir et la volonté de comprendre les
différentes technologies qui montent en croissance dans le
développement des systèmes d'entreprise. Ainsi donc, il a
été question de réaliser un système
distribué basé sur une architecture orienté services
implémenté grâce aux services web.
L'objectif principal de ce mémoire était de
réaliser un système capable de permettre une communication entre
différentes universités, pour l'authentification des
étudiants. Par authentification, nous avons compris qu'il est
nécessaire de résoudre le problème de fraude et vice de
forme que connaissent les systèmes de nos universités, lorsqu'un
étudiant demande à changer d'université, demandant donc
une inscription spéciale dans son futur établissement où
il pourrait présenter des documents non authentiques.
Comme vous pouvez le voir, nous avons essayé de
parcourir la majorité des concepts de base qui régissent les
systèmes distribués, l'architecture orienté service, le
service web et nous avons fait un aperçu sur le langage de
modélisation UML, qui a été notre outils d'analyse par ses
différents digrammes présentés.
Pour conclure, nous envisageons dans l'avenir, l'objectif
à long terme serait celui d'étendre notre système jusqu'au
ministère de l'EPST pour permettre d'authentifier les étudiants
des classes de recrutement et surtout à des entreprises du pays pour
qu'elles obtiennent des vraies informations concernant le parcours
universitaire d'un demandeur d'emploi qui se présenteront à
elles.
Nous espérons avoir présenté un travail
scientifique de qualité pouvant aider la société ainsi que
plusieurs chercheurs, sans pour autant avoir la prétention de l'avoir
fait avec perfection car c'est une oeuvre humaine. Nous portons donc à
l'attention de l'ensemble des lecteurs de ce travail que nous recevrons
à coeur joie toutes formes des remarques et suggestions de leurs
parts.

63
BIBLIOGRAPHIE
I. Ouvrages
[1] Xavier Fournier-Morel, SOA, microservices et API
management
[2] Andrew S. Tanenbaim, Maartien Van Steen - Distributed
Systems: Principles and paradigms (Pearson, Second Edition, Amsterdam 2007)
[3] Michael P. Papazoglou- Web services: Principles and
Technology (Pearson, England 2008)
[4] Pascal Roques et Franck Vallée - UML 2 en action, de
l'analyse des besoins à la conception (Eyrolles, 4e Edition,
Paris, 2007)
[5] Joseph Gabay, David Gabay - UML 2 Analyse et Conception
(Dunod, Paris, 2008)
[6] Ian SOmmerville, Software Engineering 10th Edition (Pearson,
Edinburg gate, England 2016)
II. Notes de cours
[7] Kam's KANYNDA - Labo conception II (Université
Révérend Kim)
[8] Pierre KAFUNDA KATALAY, Base de données
Répartie (Université Révérend Kim), 2017-2018
[9] Pierre KAFUNDA KATALAY, Atelier Genie Logiciel
(Université Révérend Kim), 2017-2018
III. Webographie
[10]
www.OpenClassroom.com
[11] Encyclopédie Wikipedia
[12]
www.Commentcamarche.com
[13]
https://en.m.wikipedia.org/wiki/service_oriented_architecture
[14]
https://www.geeksforgeeks.org/service-oriented-architecture/
[15]
https://www.researchgate.net/figure/Fonctionnement-des-services-Web-selon-larchitecture-SOA_fig4_262913635

64
Table des matières
0. Introduction générale i
0.1. Généralités i
0.2. Etat de question i
0.3. Problématique ii
0.4. Hypothèses iii
0.5. Intérêt du sujet iii
0.6. Choix des techniques et langage utilisé
iv
0.7. Délimitation du travail iv
0.8. Subdivision du travail iv
Chapitre I. Notion sur les systèmes
distribués [2][11][12] 1
I.1. Introduction 1
I.2. Définition des concepts 1
1.2.1. Système d'information 1
I.2.2. Système distribué 3
1.2.3. Système reparti 3
1.2.4. Système centralisé 4
I.3. Objectifs d'un système distribue
4
I.4. Caractéristiques d'un système
distribué 4
a. Interopérabilité 4
b. Partage des ressources 4
c. Ouverture 5
d. Expansible 5
e. Performance 5
f. Transparence 5
h. Concurrence 6
I.5. Type d'architecture de systèmes distribues
6
I.6. Communication dans un système
distribué 7
I.6.1. Les Sockets 7
I.6.2. La communication synchrone 8
I.6.3. RMI (Remote Method Invocator) 9
I.6.4. CORBA (Common Object Request Broker Architecture)
10
I.7. Avantages d'un système distribué
10
I.8.

65
Inconvénients d'un système distribue
11
I.9. Architecture client - serveur 11
Chapitre II. Architecture orientée service
[1][3][6][11][15] 14
II.1. Introduction 14
II.2. Définition 14
II.3. SOA et Service 15
II.4. Caractéristiques de la SOA 17
II.5. Principes directeurs d'une architecture
orientée service 17
II.6. Principaux objectifs de l'architecture
orientée services 18
II.7. Avantages d'une architecture orientée
service 19
II.8. Désavantages d'une architecture
orientée service 19
II.9. SOA et Service Web 19
II.9.1. Intérêts et caractéristiques
d'un service Web 20
II.9.2. Architecture d'un service Web 21
II.9.3. Fonctionnement d'un service web 23
II.9.4. Types de services Web 24
II.9.5. Tableau comparatif de service web SOAP et REST
25
II.10. SOA et micro services 26
Chapitre III. Conception et modélisation du
nouveau système [4][5][6][10] 28
III.I. Introduction 28
Section 1 : Théorie sur le système à
développer 28
III.1.I. Spécifications initiales du logiciel
28
III.1.2. Présentation des entités
(institutions) cible et leur rôle dans le système 29
III.1.3. Elaboration d'un concept de système
à développer 30
III.1.4. Les exigences du système à mettre
en place 31
Section 2 : Modélisation du système par
approche UML 32
III.2.1. Présentation des diagrammes
utilisés 33
III.2.2.1. Diagramme des cas d'utilisation (DCU)
34
III.2.2.2. Diagramme de séquence (DSE)
35
II.2.2.3. Diagramme d'activité(DA) 36
III.2.2.3. Diagramme de classes(DCL) 37
III.2.2.4. Diagramme de déploiement (DPL)
38
Chapitre IV. Mise en oeuvre et fonctionnement de
l'application 40
IV.1.

66
Introduction 40
IV.2. Présentation de la technologie
utilisée 40
IV.3.Présentation des outils et environnements de
développement 40
IV.3.1. Le système de gestion de base de
données (SGBD) utilisé 40
IV.3.2. Le langage de programmation et environnement
utilisé 41
IV.4. implémentation du système
44
IV.4.1. implémentation de la base des
données 44
IV.4.2. Implémentation des services web
47
IV.4.3. Déploiement du Service Web 54
IV.5. Interfaces Homme Machine (IHM) 59
CONCLUSION GENERALE 62
BIBLIOGRAPHIE 63
Table des matières 64
| 

