Dédicace
A tous ceux qui ament la science et qui contribuent sans relache
à son evolution, nous dedions ce travail
II
Remerciement
A la Providence, pour sa grâce et ses bontés
infinies tout au long de ce parcours terrestre en générale et de
ma vie estudiantine en particulier.
A mon directeur le Chef des travaux Kanyinda Kayembe
Christopher, mes sentiments de profonde gratitude pour avoir accepté en
dépit de ses nombreuses occupations s'est consacré à nous
pour ce travail.
A tous les amis de ma promotion, notamment : Christian
Ngomeyang, Kabamba Adolph, Florent Tshianga, Luabeya Auguy, Kitanda Edmond,
Jochard Masengo, Deborah Nsingi, Jupsie Musau, Ange Balengo, Merveille Mvashi
et aussi Bernice Ashes, qui par leurs conseils et encouragements, j'ai pu
arriver à achever mon cycle de graduat.
Je ne serai pas ingrat envers mon encadreur,
l'ingénieur Jonathan Basikaba, qui, malgré ses multiples
occupations, s'est sacrifié corps et âme pour ce travail.
A mes amis et connaissances qui par leurs multiples
conseils m'ont aidé à opérer des choix judicieux pour ma
vie.
A vous tous qui de loin ou des près avez
participé à l'élaboration de ce modeste travail.
Que le Tout Puissant vous comble des
bénédictions
Daniel Kabamba K.
III
Liste des sigles et abréviations
API : Applicative Program Interface (interface de
programmation applicative)
ASP : Active Server Page
CERN : Centre Européen de Recherche Nucléaire
CGI : Common Gateway Interface
CIF : Contrainte d'Intégrité Fonctionnelle
CMS ou SGC : Content Management System (Système de
gestion des contenus)
CSS: Cascading Style Sheet
FTP: File Transfer Protocol
HTML: HyperText Markup Language
JSP: Java Server Page
LDPA: Lightweight Directory Access Protocol
MCD : Modèle Conceptuel des Données
MCT : Modèle Conceptuel de Traitement
MLD : Modèle Logique de Données
MLT : Modèle Logique de Traitement
MOD : Modèle Organisationnelle des Données
MOT : Modèle Organisationnelle de Traitement
MPD : Modèle Physique des données
MPT : Modèle Physique de Traitement
MVC : Modèle Vue Contrôleur
NTIC : Nouvelle Technologie de l'Information et de la
Communication
PHP: Personal Home Page
RSS: Rich Site Summary ou Really Simple Syndication
SGBD : Système de Gestion de Bases des
données
SQL: Structured Query Language
TM: Tache Manuelle
TR : Temps Réel
ULT : Unité Logique de traitement
URL: Uniform Resource Locator
WWW: World Wide Web
XML : Extensible Markup Language
iv
Liste des figures
Figure I.1 : Architecture d'une application web à deux
niveaux
Figure I.2 : Architecture d'une application web à trois
niveaux
Figure I.3 : présentation générale d'une
page web
Figure II.1 : architecture d'un CMS
Figure II.2 : Utilisation de Template et des feuilles de
styles (CSS)
Figure III.1 : représentation d'un objet
Figure III.2 : présentation des contraintes
d'intégrité fonctionnelle
Figure III.3 : présentation du MCD
Figure III.4 : formalisme du MCT
Figure III.5 : présentation du MCT
Figure III.6 : présentation du MOD
Figure III.7 : présentation du MOT
Figure III.8 : présentation du MLD Brut
Figure III.9 : présentation du MLD validé
Figure III.10 : présentation du MLT
Figure IV.1 : Authentification phpMyAdmin
Figure IV.2 : Création de la base des données
Figure IV.3 : Création des tableaux
Figure IV.4 : Présentation des relations entre
tables
Figure IV.5 : Présentation de la page d'accueil
Figure IV.6 : Présentation de l'interface
d'authentification et inscription
Figure IV.7 : interface de la page des membres
V
Liste des tableaux
Tableau III.1 : description des entités Tableau III.2 :
description des relations Tableau III.3 : Quantification des objets Tableau
III.4 : Quantification des propriétés Tableau III.5 : Calcul du
volume des objets Tableau III.6 : calcul du volume des relations Tableau III.7
: calcul du volume des tables Tableau III.8 : calcul du volume des index
1
0. INTRODUCTION GENERALE
0.1 Généralités
L'apparition de nouvelle technologie de l'information et de
communication (NTIC en sigle) modernise le monde à une vitesse
vertigineuse. Nous tendons donc vers un monde entièrement
électronique. Les méthodes de traitement et de gestion des
informations qui, jadis étaient considérées comme les plus
performantes, ne sont presque plus utilisés car leur efficacité
reste à désirer. Pour ce faire, Différents
établissements et institutions modifient leur environnement de travail
en vue de pouvoir évoluer avec ce monde dynamique.
Vers la fin du XXe siècle, le monde a connu
des avancées significatives dans la technologie. L'invention de
l'ordinateur, du téléphone, a facilité l'échange
d'informations, réduire les pertes en énergie, et accroitre le
rendement en temps. Actuellement, il n'est plus nécessaire de faire de
longs voyages pour participer à une conférence, ou s'exprimer
face à un grand public via la radio ou la télévision et
autre ; mais simplement avec un click, on peut atteindre le mode entier
grâce au web et à l'internet. Ce travail traite sur le web et
quelques technologies utilisées pour concevoir un forum interactif pour
les étudiants.
0.2 Problématique
Les années passent, les universités naissent et
les étudiants se font de plus en plus nombreux. Il y a bien longtemps,
on pouvait facilement réunir un échantillon d'étudiants
représentants des différentes universités pour un exercice
donné : soit une étude, soit un concours, soit autres choses. En
République Démocratique du Congo, les universitaires rencontrent
des difficultés de communications, le manque d'infrastructures ; des
difficultés à organiser des conférences et débats
participatifs. Vu toutes ces difficultés, nous nous sommes posés
des questions à savoir :
Pourquoi les étudiants sont restreints dans leurs
milieux éducatifs ? Comment les amener à exprimer leurs
idées et s'ouvrir au monde ? Comment les encourager dans leurs domaines
d'études ? Comment et pourquoi les amener à participer dans des
conférences scientifiques ? Est-il possible d'arriver à
réunir tous ces étudiants ? comment développer un forum
web dynamique et interactif ?
2
0.3 Hypothèses et intérêt du
sujet
Il est maintenant acquis qu'un site web, qu'il soit
déployé en intranet ou à l'Internet, doit pouvoir
être administré de manière interactive pour pouvoir
répondre à l'attente des internautes qui se résident plus
à la participation active sur la toile, c'est à dire qu'il doit
offrir une interface permettant à ses responsables et/ou aux
utilisateurs de définir de nouvelles pages, de nouvelles rubriques, de
mettre à jour et réorganiser les informations.
Nous pensons que les étudiants sont restreints de part
et d'autre dans leurs milieux universitaires par le manque de moyens de
communication. Pour amener les étudiants à s'exprimer
aisément et partager leur opinions et point de vue sur dans leurs
domaines respectifs, nous proposons quelques solutions : mettre en oeuvre une
plateforme web dans lequel ils pourront interagir, échanger et partager
des connaissances ; mettre l'étudiant au centre des activités.
Nous pensons pouvoir mettre en oeuvre cette plateforme à l'aide d'un CMS
(Content Management System), un outil du web qui permet de répondre aux
besoins de la publication en ligne et de gérer dynamiquement les
différentes fonctionnalités d'un site web.
0.4 Délimitation du sujet
Notre travaille traitera principalement sur la
révolution du web et ses différentes technologies, dont les
systèmes de gestions de contenus et leurs applications dans la
réalisation d'une plateforme web de forum interuniversitaire. Ce travail
couvrira une période allant de 2017 à 2018 qui est notre
dernière année du premier cycle universitaire.
0.5 Méthodes et techniques utilisées
Dans ce travail, nous avons fait recours à la
méthode MERISE : est une méthode d'analyse systématique
destinée à concevoir et à développer des
systèmes d'information avec l'approche de la séparation de
données et de traitement. Celle-ci nous a permis de concevoir une base
des données, le mode de fonctionnement et comprendre la façon
dont les informations seront fournies et traitées par le système
que nous allons implémenter.
A l'absence d'un système existant, nous avons
opté pour la technique d'interview. Elle nous a permis de communiquer
verbalement avec quelques étudiants, dans le but de connaitre leurs
préoccupations, et avoir leurs contributions, pour orienter notre
travail vers les besoins des universitaires.
3
0.6 Difficultés rencontrées
Au cours de mes recherches, j'ai rencontré plusieurs
difficultés... j'avoue que ce n'est pas du tout facile d'écrire
un Travail de fin de cycle, un ouvrage où toutes nos idées
liées au sujet que l'on veut traiter doivent être
rassemblées de manière cohérentes et harmonieuse.
Je commencerai par évoquer la difficulté
concernant le choix du sujet que j'ai eu à reformuler une fois
après avoir été jugé mal formulé par le
jury. Une autre difficulté liée à mon ordinateur qui,
avant la fin du second chapitre tomba en panne pendant plus d'un mois. Tant
d'autres difficultés ont survenu lors de mes recherches, l'accès
à l'internet, les difficultés liées à
l'électricité. Les plus grandes difficultés ont
été la conception du système et la réalisation
complète de mon travail, l'utilisation d'Un système de gestion
des contenus qui, pour moi a été un autre grand défi
à relever.
Je vais finir par une note optimiste, en essayent de me
convaincre que pour tout problème il y a une solution. Petit à
petit, à force du travail et de la persévérance, on peut
obtenir des bons résultats
0.7 Subdivision du travail
Hormis l'introduction et la conclusion générale,
ce travail est structuré
en quatre chapitres.
Chapitre 1 : Aperçu sur le web
Chapitre 2 : Notion sur les systèmes de gestion de
contenus
Chapitre 3 : Conception du nouveau système
Chapitre 4 : Mise en place et fonctionnement du logiciel
CHAPITRE I : APERÇU SUR LE WEB
I.1 Généralités sur le web
I.1.1 Historique
La culture numérique change notre vie, notre
façon de travailler, et même au soleil estival, certains restent
connectés... La faute à ces 3 consonnes sans doute les plus
utilisées de la planète : WWW ! A l'origine de cette
célébrité du « World Wide Web », un homme, Tim
Bernes-Lee, informaticien du CERN (Organisation européenne pour la
recherche nucléaire). En mars 1989, il rédige un projet. Son
idée est de pouvoir échanger et partager de l'information avec
ses collaborateurs. Le CERN rassemble en effet une communauté de
scientifiques venant d'universités réparties dans 80 pays du
monde. Leur besoin d'échanger de communiquer le plus facilement possible
est primordial.1
Il eut l'idée de créer un système
hypertexte partagé sur le réseau informatique. A la fin des
années 89, il présente ce projet au CERN. Il évoque
l'idée d'une toile où chacun pourrait naviguer de contenus en
contenus. Le principe est de pouvoir relier les postes informatiques des
scientifiques, via les réseaux informatiques, en un système
d'information puissant, mais surtout simple à faire fonctionner.
L'ingénieur système Robert Cailliaud, convaincu de
l'intérêt de ce projet, l'aide à mettre au point un
logiciel, « Enquire », pour naviguer en suivant les liens
hypertextes.
En 1990, pour faire fonctionner le système, Tim
Berners-Lee met au point le protocole HTTP (HyperText Transfer Protocol), ainsi
que le langage HTML (HyperText Markup Language). Ce protocole est d'abord
testé au CERN, sur l'ordinateur NeXT. Celui-ci est toujours au
Microcosme du CERN, avec une étiquette manuscrite indiquant en rouge:
« this machine is a server: do not power down!!! ».
Le 6 août 1991, Tim Berners-Lee donne officiellement vie
au World Wide Web via un message public adressé sur Usenet.
I.1.2 définition
Web (nom anglais signifiant «toile»), contraction
de World Wide Web (d'où l'acronyme www), le world wide
web, littéralement la toile d'araignée mondiale,
communément appelé Web, est un système hypertexte public
fonctionnant sur Internet. Le web permet de consulter, à l'aide d'un
logiciel appelé navigateur, des pages accessibles sur des sites web.
4
1
www.Histoire-cigref.org
I.1.3 Caractéristiques du web
Le web est un réseau maillé dont l'entité
de base est la page web et dont la structure repose sur la notion de liens. Ce
réseau permet à tout individu de lire, utiliser les informations
mises à disposition mais aussi, de produire et diffuser ses propres
informations: site internet, weblog, contribution à des sites
collaboratifs.2 Le web est un "système d'information
multimédia": une page web peut contenir du texte, des images, du son et
de la vidéo. Les pages sont liées entre elles au moyen de liens
hypertextes qui permettent de naviguer :
? A l'intérieur même d'une page
? Vers une page différente située sur le
même serveur (généralement sur le même site web)
? Vers une page qui se trouve sur n'importe quel autre serveur
connecté C'est l'hyper textualité qui fait toute la force et
l'intérêt du web.
I.1.4 Quelques protocoles utilisés dans le web
Un protocole est une méthode standard qui permet la
communication entre des processus, c'est-à-dire un ensemble des
règles et des procédures à respecter pour emmètre
et recevoir des données sur un réseau. Voici quelques-uns :
? HTTP (HyperText Transfert Protocol)
Le protocole de transfert hypertexte (HyperText Transfer
Protocol) est le principal canal de diffusion de données sur Internet,
principalement des fichiers HTML (mais également de tous types de
fichiers). Il dispose de nombreuses méthodes lui permettant
théoriquement d'accomplir de nombreuses actions sur le serveur. Ces
méthodes sont GET, POST, PUT, DELETE, HEAD, TRACE, OPTIONS et CONNECT.
Sa variante sécurisée est HTTPS, qui utilise les protocoles SSL
ou TLS pour chiffrer la communication ou vérifier l'identité du
site.
? FTP (File Transfert Protocol)
Protocole de transfert de fichier, il crée un flux de
données entre le serveur est le client qui peut être beaucoup plus
long que via HTTP (celui-ci fermant la connexion dès que le document est
envoyé). Il comprend bien plus de méthodes d'accès aux
données que HTTP, ce qui le rend bien plus utile pour le
5
2 http//
campus.hesge.ch/gen_internet/caractéristique
6
transfert de grand nombre de fichiers (vers ou depuis le
serveur). A la différence de la plupart des protocoles, FTP utiliser
deux connexion au lieu d'une seule : l'une pour envoyer les commandes vers le
serveur et en recevoir des informations, l'autre pour le transfert de
données.
I.2 Programmation web
Tout le monde a vécu l'explosion de la sphère
Internet en seulement quelques années. Au début confidentiel, le
Web est devenu un réseau utilisé par tous,
sociétés, particuliers, gouvernements. Les technologies ont
évolué tout aussi vite, la navigation est devenue plus
aisée, plus fluide ; Les pages se sont petit à petit remplies
d'effets et de fonctionnalités améliorant l'expérience de
l'utilisateur, les contenus des pages se sont mis à changer sans
intervention de l'internaute. Des pages statiques, où cohabitaient
simplement un texte et des images, nous sommes progressivement passés
aux pages alimentées par des bases de données, au design
élégant et conçues pour faciliter l'accès à
l'information. Puis l'avènement des applications Web qui a changé
la façon de voir le web.
I.2.1. Les langages web
Les applications web ont beaucoup évolué depuis
l'apparition des nouvelles technologies du WEB, les sites internet ne sont plus
que des simples pages statiques mais des pages qui sont vivantes et remplies
d'interactions.
Dans les années 90, après l'invention du web par
Tim Berners-Lee du CERN, les sites internet n'utilisaient que le des simples
pages avec des liens hypertextes grâce au HTML (HyperText Markup
Language) langage apparut à 1991 pour organiser le fond de la page et 5
ans après en 1996 il eut aussi apparition du CSS (Cascading Style Sheet)
pour gérer la forme, la présentation de la page, à la
même année la technologie flash était lancé elle qui
était devenu l'une des méthodes les plus populaire pour ajouter
des animations, des publicités ou des jeux vidéo, du streaming
... dans la page web. Après cela s'en est suivi une pluie de langage et
des technologies pour le web.
Aujourd'hui, les langages de programmation web se divisent en
deux catégories, ceux utilisés pour le développement
coté client (exécutable au niveau du navigateur de la machine de
l'internaute) dit langage front-end et ceux utilisés pour le
développement coté serveur dit langage back-end
? Le front-end
En programmation web, les langages du front-end
désignent l'ensemble de langage de programmation web s'exécutant
coté client. Actuellement pour réaliser le front-end d'une
application web, nous faisons généralement recours aux langages
suivant :
·
7
HTML qui est un langage de balisage et dont le rôle est de
donner la structure d'une la page web.
· CSS qui donne la forme de la page web.
· JavaScript : qui est le langage qui a apporté
le dynamisme de la page coté client, il peut aussi faire des allers
retours au serveur grâce à Ajax en actualisant juste une portion
de la page web.
Il existe un grand nombre de technologies qui permettent aux
développeurs front-end d'être productifs, de démarrer leurs
projets sur des bonnes bases et de respecter les bonnes manières de
développement et surtout permettre la réutilisation des codes.
Nous présentons ici quelques-unes de ces technologies :
· Booststrap : un Framework css
développé par twitter, il a été
créé pour développer des sites pour tout type
d'écrans que ce soit, un mobile, une tablette ou un ordinateur. En
utilisant au mieux ses classes CSS, nous avons la garanti d'avoir un site
responsive et d'autre style prêt à l'emploi qui jadis demandait
énormément du code CSS. Il existe aussi Materialize et beaucoup
d'autres framework css.
· Angular: c'est le Framework de Google
qui dans sa première version était basé sur JavaScript et
actuellement à la version 6 et se base sur typescript ;
il permet de créer des single-page App, se base sur le
principe de
composant. Il n'est pas le seul dans ce secteur nous pouvons
parler entre autre de VueJS, ReactJS...
· JQuerry : visiblement, une des
bibliothèques les plus utilisées qui se base sur le JavaScript,
il permet de simplifier l'écriture de JavaScript. Il suffit de la
télécharger et l'intégrer dans les scripts de votre site
web.
· Etc.
Tout ceci permet de développer le front-end d'une
application web et de soigner le font et la forme, c'est-à-dire ce qui
est visible dans le navigateur.
Le back-end
En programmation web, les langages du back-end
désignent l'ensemble de langage de programmation web s'exécutant
coté serveur ; c'est là où se développe la logique
métier de l'application. Pour réaliser le back-end d'une
application web, il existe énormément de langages à
disposition ; nous pouvons citer entre autre : PHP, NodeJS,
ASP.NET, Java, Ruby, Python.
Certains d'entre eux sont liés à un type
spécifique de système d'exploitation du
serveur. ASP.NET, par exemple, sont
des plates-formes de serveur uniquement destiné aux serveurs Windows.
Certains, comme PHP, peuvent
fonctionner sur tout système de plate-forme et
d'exploitation, mais il y a quelques différences mineures dans la mise
en oeuvre sur la base du serveur.
I.3. Application web I.3.1.
Définition
Une application web désigne un logiciel applicatif
hébergé sur un serveur et accessible via un navigateur web.
Contrairement à un logiciel traditionnel, l'utilisateur d'une
application web n'a pas besoin de l'installer sur son ordinateur. Il lui suffit
de se connecter à l'application à l'aide de son navigateur
favoris, la tendance actuelle est d'offrir une expérience utilisateur et
des fonctionnalités équivalentes aux logiciels directement
installés sur les ordinateurs.3
I.3.2 Avantages et désavantages ?
Avantages4
Nous pouvons donc résumer les principaux avantages
d'une application web de la manière suivante :
? Cout de développement réduit; ?
Accessibilité optimisée ;
? Gain de temps ;
? Meilleure gestion de la sécurité.
? Désavantage
Les applications web présentent un désavantage
majeur qui est la nécessité d'une connexion internet ou intranet
pour les utiliser. Un autre désavantage est l'incapacité
d'interroger tous les composants du terminal sur lequel elles tournent. Les
applications web sont limitées par la qualité de la connexion
web, et plus pour l'affichage des pages en haute définition sur les
terminaux, risquant d'amoindrir l'expérience utilisateur par un temps
d'affichage trop long.
I.3.3 Catégories des applications web
Les applications web ne sont pas conçues uniquement
pour les ordinateurs, mais pour tout navigateur internet d'ordinateur ou de
mobile. Il y en a plusieurs types. Leur classification peut se faire en
fonction de la façon dont le contenu de l'application est
présenté. Nous pouvons distinguer :
3
www.ideematic.com/application-web
8
4 Frederick Mpiana,
Séminaire Informatique, Université Révérend Kim
2018, page 11
Application web statique
La première chose à savoir sur ce type
d'application est qu'elle contienne peu d'informations et, en
général, son contenu n'évolue pas ou très peu.
Le développement d'applications web se fait
habituellement en HTML et CSS. Il peut, néanmoins y avoir des objets
animés tels que bannières, GIF, vidéos, etc.
La modification du contenu des applications statiques n'est pas
facile. Pour ce faire, vous devez télécharger le code HTML,
l'éditer, puis l'uploader de nouveau sur le serveur.
Application web dynamique.
Les applications web dynamiques sont plus complexes sur le
plan technique. Elles utilisent des bases de données pour charger des
informations, et le contenu est mis à jour à chaque fois que
l'utilisateur se connecte à l'application. Pour créer facilement
des applications web dynamique, nous pouvons utiliser des SGC (Système
de gestion des contenus).5
I.3.4. Architecture et fonctionnement d'une application
web
I. 3.4.1 Architecture d'une application web à
deux niveaux
L'architecture de base pour un site Web est une architecture
à 2 niveaux entre un client (le navigateur Web) et un serveur.
L'architecture s'appuie sur un poste central, qui envoie les données aux
machines clientes:
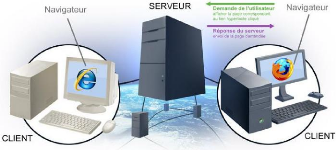
Figure I.1 Architecture d'une application web à deux
niveaux
? Le client émet une requête HTTP vers le serveur
sur lequel est stockée la page HTML.
? Le serveur accède alors à ce fichier et le
retourne au navigateur.
? Le navigateur interprète les balises HTML et affiche la
page en résultat.
9
5
Fr.yeeply.com/blog/6_types-des-applications-web
10
La connexion des applications client-serveur ouvre donc les
systèmes d'information vers l'extérieur.
Les technologies qui permettent d'obtenir un contenu
dynamique depuis le poste client s'inscrivent également dans une
architecture à 2 niveaux. Les programmes qui accèdent au serveur
sont appelés des programmes clients. Dans le cas des scripts JavaScript
ou des applets Java, les fonctionnalités supplémentaires
apportées au niveau de la page ne dépendent pas de traitement
opéré depuis le serveur ; c'est le navigateur qui
interprète les scripts et affiche les données correspondantes. Il
est donc nécessaire que votre navigateur accepte ces scripts. Il faut
que JavaScript soit activé (ce qui est le plus souvent le cas, mais pas
toujours pour des raisons de sécurité) et, pour les applets, vous
devez disposer de la Java Virtual Machine(JVM) qui va compiler le code Java
pour qu'il soit compréhensible par le navigateur.
Il existe de nombreux programmes légers et
extensibles, également appelés plugins, qui,
intégrés au navigateur, permettent d'enrichir ses
fonctionnalités.
I.3.4.2 Architecture d'une application web à
trois niveaux
Le développement de sites interactifs,
nécessitant de conserver des données sur les visiteurs,
d'accéder à de grandes masses d'information ou de modifier
régulièrement le contenu, repose aujourd'hui sur une architecture
à 3 niveaux (ou architecture trois-tiers) entre serveur de
données, serveur d'applications et client web.
Ce type d'architecture, plus complexe que le client-serveur,
permet l'accès aux bases de données stockées
elles-mêmes sur un serveur. Plus généralement, elle offre
la possibilité d'exécuter des programmes du côté
serveur. Les résultats sont prétraités avant leur envoi
final, vers le navigateur.
Les 3 niveaux s'articulent dès lors de la
manière suivante:
? Le premier niveau s'occupe de l'interface avec
l'utilisateur depuis le navigateur.
? Le second héberge le serveur web qui est
complété par le serveur d'application qui exécutent les
traitements demandés lors de l'appel HTTP d'une page. Le serveur HTTP,
aussi appelé middleware, est donc à la fois serveur et client.
Serveur vis-à-vis du navigateur et client par rapport au conteneur web
à qui il envoie une requête et dont il attend en retour le
résultat. Une fois reçus, le serveur HTTP le renvoie au
client.
11
? Le troisième niveau assure la gestion des
données au sein d'un SGBD (Système de Gestion de Bases de
Données) et répond aux requêtes du serveur HTTP.
Entre le serveur de données et le serveur
d'applications, il existe toute une panoplie de technologies, disponibles
suivant les serveurs. Les serveurs dynamiques sont capables de publier des
informations adaptées aux besoins des utilisateurs en disposant de
technologies comme la passerelle CGI, les API ou encore les servlets Java qui
vont permettre d'ajouter des extensions aux serveurs (contenant les
paramètres des requêtes) et de produire ainsi du contenu
dynamique.
Les technologies serveurs les plus récentes offrent
aujourd'hui la possibilité de composer des pages actives sur le serveur.
Le principal bénéfice de technologies telles PHP, les ASP ou les
JSP est de fournir au serveur HTTP des données issues de programmes
d'application mais directement intégrés au code HTML suite
à un traitement préalable (le plus souvent par un
interpréteur ou moteur particulier). Les pages actives côté
serveur s'inscrivent dans une architecture trois-tiers, mais peuvent être
perçues comme une couche supplémentaire de fonctionnalités
sur le serveur.
Dans la technologie la plus courante, l'application web
s'oriente autour d'un serveur web sur lequel est branché le logiciel
applicatif, le tout parfois accompagné d'un serveur de bases de
données. L'ensemble est appelé Serveur d'applications.
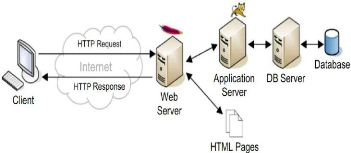
Figure I.2 Architecture d'une application web à trois
niveaux
Le code source du logiciel applicatif est placé
directement dans des pages web. Ces pages sont stockées par le serveur.
Lorsque le client demande une page, le serveur web va rechercher la page, puis
exécute les instructions qu'elle contient. Ces instructions peuvent
faire appel au serveur de base de données. Le serveur web transmet la
page avec le résultat de l'exécution au client.
12
La transmission des informations entre le client et le serveur
se fait selon le protocole http. Ce qui permet d'utiliser le même
logiciel client : un navigateur web. Ce qui rend l'application portable,
c'est-à-dire qu'elle ne dépend pas de plateforme (système
d'exploitation).
Les applications web font souvent usage du mécanisme
des cookies : en réponse à une requête, le serveur envoie
une information de repérage au client (le cookie). Puis le client va lui
renvoyer cette information lors de la prochaine requête. Le
mécanisme est utilisé pour identifier le client et suivre les
manipulations
I.4. Présentation générale d'une
page web
Il convient de noter que la taille de la page web
dépend essentiellement de la définition de l'affichage. En vue
d'obtenir des pages plus attractives, il est nécessaire de respecter une
certaine ergonomie. Le terme Ergonomie désigne l'utilisation de
connaissances scientifiques dans le but d'améliorer son environnement de
travail. Elle est caractérisée par l'efficacité
(c'est-à-dire l'adoption des solutions appropriés d'utilisation
d'un produit) ; la sécurité (le choix des solutions
adéquats pour protéger l'utilisateur) et le confort d'utilisation
(c'est-à-dire faire en sorte que l'utilisateur se fatigue le moins
possible en lisant la page). Puisque les utilisateurs sont de profils
différents il faudra alors tenir compte des leurs attentes (tous les
utilisateurs n'ont pas les mêmes attentes) ; leurs habitudes ; leurs
âge ; les équipements (l'affichage du site dépend du
navigateur et de la résolution d'affichage) et leurs niveaux de
connaissances (tenir compte du fait que tous les utilisateurs du site ne sont
des experts en informatiques. L'ergonomie devra alors est conçu en
fonction de l'utilisateur le moins expérimenté).
Aussi faut-il savoir que la position des informations d'une
page web est d'une importance capitale. Ainsi les informations les plus
importantes doivent être situées au début de la page.
Généralement les pages web contiennent les
éléments ci-après :
? Un en-tête : il contient le
nom du site, un bandeau de navigation et une zone réservée
à la publicité ;
? Un logo : il est situé
généralement au coin supérieur gauche de la page. Un clic
sur ce logo nous amène à la page d'accueil. ;
? Une zone de navigation
(également appelés menu) : elle située
à gauche ou à droite de la page ;
? Le corps de la page : il contient
tous les informations utiles.
? Un pied de page : il contient un
lien vers un formulaire de contact, un plan d'accès, la date de la mise
à jour et autres
Ainsi voici comment peut se présenter un site web :
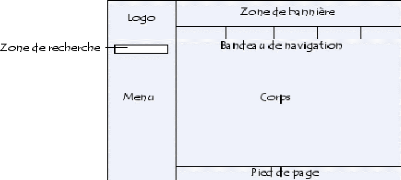
Figure I.3 présentation générale d'une page
web
I.5 Catégories des sites web6
En fonction des buts poursuivis, les sites web peuvent
être regroupés en catégories suivantes :
· Les sites personnels : ce
sont des sites réalisés par des particuliers. Ce genre des sites
n'a souvent pas d'objectif visé. Ils juste à titre de loisir, par
passion d'une discipline, d'un domaine, d'une star, etc.
· Les sites communautaires :
ce sont des sites réunissant les utilisateurs autour d'un
intérêt commun.
· Les sites intranet : ce sont
des sites mis au point au sein d'une entreprise ou organisation en vue de
permettre la communication entre différents services de l'entreprise
pour l'échange des informations.
· Les sites d'information :
leur but est de fournir des informations particulières à un type
précis d'internautes et dans des domaines bien précis.
· Les sites catalogues : leur
unique but est de présenter l'offre de l'entreprise ou de
l'organisation.
· Les sites vitrines : ce sont des
sites qui ont pour objectif la présentation de l'image de l'entreprise.
Attendez par-là la présentation des services offerts et les
produits vendus par cette dernière. Ils sont également
appelés sites plaquettes ou sites identités.
13
6
www.nooveo.fr/article-8-categories
14
? Les sites marchands : ce sont des
sites permettant la vente des produits en ligne. Le payement s'effectuant
également de la même manière (c'est-à-dire en
ligne).
? Les sites institutionnels : ce
sont des sites qui présentent une organisation. On y décrit
toutes les activités et on fournit toutes les organisations se
rapportant à ladite entreprise.
I.6. Le référencement
Le référencement désigne l'ensemble des
techniques permettant d'améliorer la visibilité d'un site web.
Parmi ces techniques nous pouvons citer :
? indexation : c'est
l'opération qui consiste à faire connaître le site
auprès des outils de recherche grâce aux formulaires qu'ils
possèdent ;
? positionnement : c'est
l'opération qui consiste à placer le site ou certaines
pages de ce dernier en première page de
résultat pour certains mots-clés ; ? classement
: c'est une opération qui a un but identique au
positionnement
mais lui concerne des expressions plus
élaborées.
Si l'on veut donner plus de référencement aux
pages du site ; il faudra avoir un contenu attrayant, bien choisir le titre,
avoir une adresse adaptée, un corps de texte lisible par les moteurs,
les balises Meta (ce sont des balises insérées au début
des documents HTML, mais qui ne s'affichent pas sur la page. Elles
décrivent exactement le contenu de la page), des liens biens
pensés et des attributs ALT pour déterminer le contenu des
images.
CHAPITRE II NOTION SUR LES SYSTÈMES DE
GESTION
DE CONTENUS (CMS)
L'idée qui préside dans ce concept est la
dissociation entre contenu et mise en forme : d'un côté, les
contenus (textes, images, multimédia) sont stockés sans mise en
forme, par exemple dans une base de données ; de l'autre la mise en
forme et la mise en ligne peuvent être adaptées à
volonté par le concepteur en fonction de l'utilisateur.
II.1. Définitions
? De l'anglais « Content Management System (CMS) »
est l'équivalent du français « Système de gestion de
contenus ». Un Système de gestion de contenus est un type
particulier de logiciel utilisé pour concevoir et mettre en ligne des
pages web.
? Un CMS (Content Management System) est un
ensemble de logiciel qui permet de construire et gérer un site dont les
pages sont construites dynamiquement, et de telle manière que la mise en
ligne de contenus sur le site ne requiert aucune compétence technique
particulière. En résumé, un CMS fournit toute une
chaîne de publication (en jargon : workflow) qui limite
l'investissement technique requis pour la création d'un site et son
suivi.7
Ces sont des outils récents qui permettent de
répondre aux besoins de la publication en ligne. Auparavant, le travail
sur un site web était marqué par l'usage obligatoire d'un
logiciel de construction de pages web; leur modification, leur envoi par
serveur FTP devaient être manuel. Le webmaster possédait seul la
compétence de réalisation du site et était un point de
passage obligé pour tout travail sur le site. Tout comme les blogs, et
les wikis, les CMS permettent de faciliter la publication en ligne. Ce type
d'outil permet la création, la validation et la publication de contenu,
sans avoir à écrire de code HTML ni utiliser d'outil de
développement spécifique. Leur principale caractéristique
est de séparer le contenu qui est stocké dans une base de
données, du contenant, autrement dit de la forme même du document.
C'est le contenu des champs de la base qui est créé ou
modifié par le rédacteur, et non pas la page elle-même. Les
sites deviennent dynamiques. Les CMS permettent d'obtenir une classification
thématique automatique de l'information, ainsi qu'une navigation assez
sophistiquée.
15
7
www.top-hebergement.net
16
Un comité de rédaction peut se créer pour
administrer le site directement, comme existe la possibilité de
préparer des articles qui seront ensuite publiés
ultérieurement.
II.2. Evolution
Les premiers sites web ont été
édités par des équipes de passionnés utilisant
majoritairement des éditeurs HTML (Dreamweaver, FrontPage, voire le bon
vieux Notepad, etc.) pour créer des sites dits « statiques
».
A cette époque héroïque ou le webmestre
était l'homme à tout faire du site, les fonctions de
création, ainsi que de maintenance, ont été souvent
confondues. Si la première catégorie de tâches est souvent
gratifiante et a permis à de nombreux individus de s'affirmer, la
seconde est vite apparue comme une tâche fastidieuse, sans réelle
valeur ajoutée, mais très chronophage et plaçant le
webmestre dans la délicate position de goulot d'étranglement de
la production du site ».
La gestion de pages « statiques » pose rapidement
de nombreux problèmes techniques dès que le site devient un plus
important :
· Tenue à jour des liens amont et avals des pages
délicates ;
· Obligation de ressaisir les contenus publiés
à plusieurs endroits par de fastidieuses opérations de
copier-coller, avec des risques d'erreur ;
· Outils de gestion de la qualité de l'information
(workflows, certificats de validité) peu efficaces voire inexistants
;
· Difficultés pour réorganiser le site, ou
pour faire évoluer son architecture ;
· Difficultés pour faire évoluer la forme du
site dans ses aspects graphiques ;
· Outils de base (éditeurs HTML) trop difficiles
à utiliser par des utilisateurs moyens ou novices, rendant illusoire la
délégation de la production des pages aux détenteurs
d'information.
Pour répondre à ces difficultés, deux
évolutions successives ont été développées
:
1. La première (chronologiquement) a consisté
à organiser les sites à travers des bases de données
reliées aux pages par des scripts (morceaux de programmes)
programmés en perl, en PHP, en ASP, etc. cette approche, toutefois,
manque souvent de souplesse et requiert de gros travaux de codage dès
que d'importantes modifications sont décidées.
2. La seconde, suite logique de la précédente,
a donné naissance à des logiciels permettant à des
utilisateurs novices de produire le contenu des pages à travers un
navigateur internet, le codage de ces contenus vers le site internet
étant entièrement automatisé. Ces logiciels, dont Vignette
fut le précurseur, ont donné naissance au concept de "content
management" (CM) pour le web.
Voyons à quel objet précis ces outils
répondent et quelles en sont les caractéristiques.
II.3. Principales fonctionnalités des CMS
II.3.1. Fonctionnalités liées à la
gestion de contenu
Ces fonctionnalités sont décrites de
manière très complète dans le livre blanc de la
société Smile8 et dans le mémoire de
Raphaël Produit9.
- Séparation fonds/forme : l'un des
principes clefs des CMS est d'établir une distinction entre le contenu,
géré par une base de données, et la forme
déterminée par des gabarits de présentation. De multiples
facteurs justifient cette séparation : ? Ces éléments
relèvent, en effet, de deux métiers différents : la mise
en page est élaborée par le webdesigner et le fond est fourni par
un utilisateur, appelé « auteur » l'un et l'autre doivent
pouvoir évoluer de manière indépendante ; on doit pouvoir
modifier le contenu sans se soucier de la forme et inversement.
? Cette séparation garantit
l'homogénéité du site malgré la diversité de
ses contenus.
? Enfin, le fait de séparer le contenu de la forme
permet de publier et d'exploiter ce dernier à travers différents
médias.
- La structure des articles ou la définition de
types d'articles : c'est la manière dont l'article est
décomposé. Lorsque l'article est découpé en champs
élémentaires comme le titre, le sous-titre, l'auteur, le corps du
texte, sa structuration est dite fonctionnelle. En opposition, la structuration
sémantique décompose l'article en « sous
éléments types », et est donc dépendante du sujet
traité. Une troisième approche consiste à concevoir la
structuration des articles sur la base de l'héritage8, qui permet
d'affiner progressivement les concepts. On prend un article
générique à partir duquel on va créer des
sous-types qui reprendront ses champs, en les complétant par des champs
qui leur seront spécifiques. La structuration permet de guider la saisie
des articles avec des formulaires adaptés, et d'assurer une
cohérence. En distinguant chaque composant de l'article, elle facilite
également la mise en forme lors de la restitution.
-L'organisation des contenus : elle va
déterminer la structure du site Le mode d'organisation le plus classique
est la structure hiérarchique arborescente, sorte de table des
matières. En raison de son manque de souplesse, on lui
préfère parfois d'autres solutions comme la publication
d'articles sous différentes rubriques, ou
8 BERTRAND Patrice, BADR Chentouf.
White paper : Content management, les solutions opensource version
1.6b. Paris : Smile, 2004. 51p.
17
9 PRODUIT Raphaël. Content
Management System (CMS) : étude des système de gestion dynamique
de contenu pour site web et développement d'une solution basée
sur la technologie J2EE. 2003
18
l'utilisation de mots-clefs et d'un moteur de recherche. En
associant des articles à différents thèmes, on obtient une
structure par ensembles.
- La Gestion des contributeurs : les CMS
permettent aux contributeurs premiers d'interagir directement en leur proposant
une interface pour la saisie et la modification des leurs articles. Il est donc
nécessaire de diviser le contenu et d'accorder aux auteurs des droits
limités à certaines actions telles que consulter, mettre à
jour, valider, publier... et à certaines parties du site.
- Workflow et chaîne de validation : Il
est nécessaire dans certains cas, notamment quand la contribution est
décentralisée et déléguée à
différents intervenants, de décomposer les étapes de la
réalisation d'un article, de sa création à sa publication.
La séparation des droits permet de mettre en place un workflow de
validation qui sert à garder un contrôle sur les publications. :
un contributeur écrit, un deuxième apporte des corrections, un
troisième valide le résultat... Avec les CMS le principe de
séparation des tâches devient transparent, le workflow est
automatisé et chacun est informé de la tâche qu'il doit
réaliser.
- Cycle de vie des articles : avec les CMS,
on peut programmer la mise en ligne automatique d'un contenu à une date
donnée, définir sa durée de vie et donc sa date limite de
visibilité au-delà de laquelle il sera transféré
dans une autre rubrique, par exemple celle des archives, ou devra être
mis à jour.
- Gestion des versions : elle permet de
conserver le même article dans ses différentes versions : le
brouillon, la version publiée, la version archivée.... Ce
contrôle des versions facilite le travail collaboratif puisque les
intervenants peuvent travailler à plusieurs sur le même article,
sans que les modifications des uns suppriment le travail des autres.
III.3.2. Fonctionnalités liées à la
publication
? Les gabarits de présentation : la
standardisation de la mise en forme du site est basée sur un dispositif
de templates. Ils définissent les informations affichées, leur
position dans la page et les attributs de mise en forme qui leur sont
appliqués. Il existe plusieurs techniques pour la mise en oeuvre de ces
templates :
? La plus simple consiste à insérer dans un fond
de page html des balises qui sont adressées au CMS. C'est à
partir de ces balises que le système déduira le contenu à
sélectionner et à insérer à la position voulue,
réalisera son insertion puis enverra la page.
? Les CMS basés sur le langage Java, utilise les pages
JPS. Les insertions de contenu sont définies soit par du code Java, soit
par des tags qui font référence à des objets Java. On
parle alors de « librairies de tags ».
? Enfin, certains CMS utilisent les feuilles de style XSL,
basées sur le langage XML. Le contenu est sélectionné et
formaté par des tags XML. Puis ce contenu XML est transformé en
html grâce aux feuilles de style XSL. Cette technique plus complexe offre
l'avantage de pouvoir utiliser des bibliothèques de tags XML
standardisés ce qui facilite l'échange de contenu.
·
19
. La Sélection de contenu : les CMS
automatisent en partie la mise à jour du site en permettant de
sélectionner des articles selon des critères comme "les trois
dernier en date", "les articles rédigés par cet auteur".
· . Les moteurs de recherche : certains
CMS proposent des moteurs de recherche internes qui permettent aux utilisateurs
de retrouver facilement un document. Pour cela, ces outils procèdent
à une recherche "plein texte", sur tous les mots des textes qu'il aura
préalablement indexés, ou utilisent les
métadonnées. Néanmoins ces processus d'indexation et les
performances des moteurs restent à ce jour limités.
· . La personnalisation de la restitution :
cette fonction permet de différencier la restitution du contenu
en fonction des visiteurs. On distingue alors :
> La personnalisation souhaitée par le visiteur :
celui-ci configure l'agencement de l'information en fonction des
préférences qu'il déclare au système. Il s'agit en
principe, d'une personnalisation individuelle. L'internaute est reconnu soit
par une identification explicite, soit par un système de cookies.
> la personnalisation par habilitation est en
général une personnalisation de groupes définis par leur
profil : l'identification des internautes est nécessaire pour ces
profils.
· . La syndication, échanges de contenus
entres des sites : ce processus consiste à reprendre
l'information d'un site, sans avoir à le copier. Cet échange se
fait par envoi de contenu au format XML, qui permet au destinataire «
d'identifier sans ambiguïté, chaque champ d'information ».
Pour cela il faut un vocabulaire commun : le standard RSS - Rich Site Summary
-, au format XML permet aux sites de communiquer. Il donne le chemin pour
retrouver l'information : il n'y a pas transfert de contenu mais uniquement
transfert d'index.
· . Statistiques du site : la mesure de
la fréquentation des pages du site peut se faire de deux façon
:
> Elle peut être intégrée aux CMS, qui
relèvent l'audience au moment où ils sont sollicités pour
servir des pages. Dans ce cas on pourra utiliser cette fonction pour
paramétrer la restitution de pages : on mettra en avant les articles les
plus consultés.
> Elle peut être externe et utiliser des logiciels
d'analyse de fichiers log générés par les serveurs http
qui enregistrent toutes les URL qu'ils voient passer. Cette méthode
permet d'obtenir des informations beaucoup plus détaillées sur la
fréquentation des sites. Ces deux méthodes pourront être
combinées.
A ces fonctionnalités générales
s'ajoutent des fonctionnalités collaboratives comme la messagerie
électronique, les annuaires qui regroupent les coordonnées de
personnes ou définissent les droits des utilisateurs, les forums, et les
agendas partagés.
II.4 Structure et architecture d'un cms
II.4.1 Structure d'un cms10 4.1.1. Le
back-office
Il gère tout le cycle de vie d'une information : la
création du contenu, son stockage et le maintien en version, sa
structuration et son classement. Pour cela, il utilise :
- les outils de création de contenu :
les CMS proposent d'utiliser des outils d'édition
intégrés à un workflow, ou d'importer des données
issues du système d'information.
- un référentiel dans lequel toutes ces
données sont stockées ou pointées : elles y sont,
en général, décrites à l'aide de balises XML qui
fournissent des métadonnées (auteur, titre, date d'expiration).
Le référentiel contient également les gabarits des
documents qui seront utilisés pour l'assemblage des pages. Il s'appuie
généralement sur une base de données relationnelle.
Les métadonnées vont notamment servir à
créer automatiquement la page avec le bon gabarit, et placer en amont
les liens nécessaires dans les pages destinées à la
navigation
- l'outil de workflow : il offre des circuits
de validation de contenu plus ou moins hiérarchisés.
4.1.2. Le front office
Il permet de publier le contenu et de contrôler
l'accès à celui-ci. Il se présente sous la forme d'un site
frontal ou d'un portail : le portail est une plate-forme qui réunit, qui
agrège le contenu hétérogène, et présente
aux utilisateurs des pages composites, constituées de "pavés"
issus de différentes sources. Le portail gère également
l'identification unique du visiteur.
Lorsqu'une requête http arrive au serveur web, elle est
transmise au serveur d'application, qui assemble la page demandée. Ce
serveur peut être intégré ou non au CMS. Les pages
dynamiques sont créés à la volée, et parfois en
fonction de règles de personnalisation.
II.4.2 Architecture d'un cms
Les cms utilisent une architectures
MVC(modèle-vue-contrôleur) basé sur un Framework objet qui
exploite en masse le design pattern, les espaces de nommage, overrides des
templates, etc. Les codes des cms sont structurés et permettent des
développements complexes tout en respectant des normes et des
conventions professionnelles dans le monde de développeurs.
20
10 B. Anne-Camille, les
systèmes de gestion des contenus
21
Généralement, un cms fonctionne avec des
modules, des composants, des plugins et des templates.
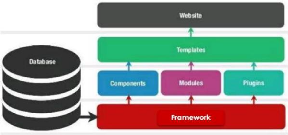
Figure II.1 : architecture d'un CMS
4.2.1 Utilisation d'une interface web classique
Les logiciels de gestion de contenu Web utilisent comme
interface un navigateur Web classique. Les navigateurs Web offrent l'avantage
de fonctionner dans tous les environnements et sur toutes les plateformes
informatiques. Ils ne nécessitent pas l'installation de logiciels
spécifiques. De plus, la convivialité des navigateurs permet une
prise en main rapide des outils de CMS. Aujourd'hui, Internet Explorer,
Mozilla, Opéra et Safari sont les navigateurs Web les plus couramment
utilisés.
4.2.2. Utilisation de gabarits et de feuilles de
styles
Un système de gestion de contenu utilise des gabarits
pour réaliser des pages dynamiques en HTML. Un gabarit permet de
réaliser une page modèle qui sera utilisée pour travailler
indépendamment sur le contenu ou la forme.
En règle générale, la présentation
du contenu (polices, couleurs, tailles...) fait appel à des feuilles de
styles qui permettent l'obtention d'une présentation rapide,
unifiée et automatique.
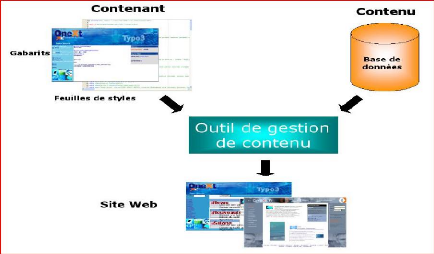
22
Figure II.2 : Utilisation des templates et des feuilles de styles
(CSS)
4.2.3 Utilisation d'une base des données
La base de données permet de stocker l'information (le
contenu) de façon structurée. Associées à des
méthodes de rangement de l'information (liens hypertextes, moteur de
recherche, tris), les données pourront ainsi être
gérées facilement et réutilisées à plusieurs
endroits du site, évitant les ressaisies et les erreurs.
4.2.4 Utilisation d'un mécanisme de gestion des
droits
La gestion des droits permet de répartir les
rôles de chaque utilisateur, qu'il soit rédacteur, validateur ou
administrateur sur le site.
Elle offre un contrôle du contenu et une garantie
supplémentaire de cohésion de l'ensemble du site. Elle permet
aussi de définir des profils de visiteurs et d'utilisateurs pour
lesquels la présentation du contenu sera différente.
II.5 Limites
En dépit de leurs qualités, les CMS affichent un
certain nombre de limites. Si l'on synthétise les récriminations
faites par leurs utilisateurs à leur encontre, on retrouve souvent le
manque de diversité (ils sont pour la plupart structurés sur
trois colonnes) comme, ce qui est paradoxal, une prise en main parfois
difficile des logiciels. Toutefois, on peut constater que la grande
majorité des critiques faites aux CMS sont dues à un manque de
compétences informatiques au sein de l'organisme qui choisit
d'administrer son site internet par ce type d'outil. Un certain jargon
technique doit, malgré tout être maitrisé : workflow
(« gestion de flux de
production » ou « chaine de production ») ou
templates ne sont, a priori, pas des termes du langage quotidien.
De plus, la mise en place d'un CMS requiert de définir
clairement quels sont les objectifs de communication que l'on veut assigner au
site internet, et d'identifier clairement les rôles dans la chaine de
responsabilité du site. Tout le monde ne peut s'improviser
rédacteur et l'on peut très bien délimiter les
accréditations, afin de limiter le nombre de personnes agissant
directement sur le site internet.
Le choix du CMS est lui aussi important et requiert une
étude préalable sérieuse des besoins réels de
l'organisme qui désire s'en servir. Sans cela, le choix du logiciel
risque de ne pas convenir, et nécessitera changements et retards de
publication préjudiciables
II.7 Quelques systèmes des gestions de
contenus11
Il existe plusieurs CMS à savoir :
+ Joomla ! : Un système de gestion de
contenu Web (sites internet et blogs) assez lourd mais du moins plutôt
simple à utiliser. Il requiert néanmoins des connaissances en
HTML et en PHP pour la mise en page et le système de gestion du contenu
du site.
+ Plone : CMS écrit en Python avec sa
propre base de données NoSQL ZODB. + Spip : SPIP est
notamment utilisé dans les milieux associatifs, administratifs et
éducatifs. Des gabarits (appelés squelettes)
tout faits existent et la
communauté d'aide est nombreuse et active.
+ Mambo : Ce SGC open source est polyvalent,
grâce aux modules qu'il propose. La hiérarchie des menus est
limitée à trois niveaux. Il a donné naissance à
Joomla! et ne semble plus actualisé, la dernière version est
d'avril 2013, le site n'est plus fonctionnel.
+ Drupal : Drupal est un SGC hybride et un
peu atypique. S'il est orienté communautés, ce n'est pas pour
autant un portail. Drupal permet de gérer une information comme un
noeud, ce noeud peut ensuite être attaché à un forum,
article, nouvelle, tutoriel, commentaire, livre collaboratif, etc. La forme
n'est pas figée à une architecture type. En contrepartie de cette
liberté, il faut passer un peu de temps pour se familiariser avec sa
logique particulière. Ce CMS est francisé mais pas
l'intégralité de ses modules.
+ Typo 3 : PHP/MySQL sous licence GNU GPL. Il
est basé sur le concept de pages et de blocs (une page contient un
ensemble de blocs). TYPO3 peut être multi-langue, multi site et
multi-utilisateur.
23
11
www.wikipedia.org/les_systemes_de_gestion_des_contenus
24
? WordPress : Sur une base de gestion de blog
(vocation historique), WordPress est à présent une solution
modulaire de gestion de contenu, multi-site et multilingue.
? Apache Lenya : Lenya est tout en XML
(contenus, utilisateurs, etc.), sans base de données, respectant les
standards W3C (XML, XSL, XHTML), 100 % Java, basé sur le framework ou
cadre d'applications Apache Cocoon.
? etc.
25
CHAPITRE III : CONCEPTION DU NOUVEAU SYSTÈME
III .1 Narration
L'internet abolit les frontières, il crée un
espace commun en facilitant la communication, les échanges, ...
Dans cette même optique, nous allons mettre en place une
plateforme web qui va permettre aux étudiants de partager des
connaissances, de poser des préoccupations et d'échanger des
ressources. Pour cela, ils doivent créer des comptes en précisant
leurs centres d'intérêt, domaines d'études, et
expériences. Dans la plateforme, l'étudiant sera capable de
créer des sujets, participer à la discussion, partager ou
bénéficier d'une ressource et enfin, fermer la discussion, voire
supprimer le sujet. L'administrateur crée des groupes et fait la mise
à jour des nouveaux utilisateurs.
Section I : CONCEPTION DU SYSTEME
D'INFORMATION
ORGANISATIONNEL (CSIO)
I.1 Etape conceptuelle
L'objectif est de représenter l'activité de
l'entreprise et de formaliser son "système d'information"
indépendamment de son organisation. Le compte rendu de cette
étude est matérialisé sous la forme de dessins
normalisés, de modèles complétés par un dossier
explicatif. Le but de ce chapitre est d'expliquer comment décrire
l'entreprise concernée en respectant les normes de chaque
modèle.
I.1.1 Modélisation Conceptuelle de Données
(MCD)
1.1.1 Définition et But de la modélisation
conceptuelle de données
Le modèle conceptuel des données est une
représentation statique du système d'information de l'entreprise
qui met en évidence sa sémantique. Il a pour but d'écrire
de façon formelle les données qui seront utilisées par le
système d'information. Il s'agit donc d'une représentation des
données, facilement compréhensible. Cet aspect recouvre les mots
qui décrivent le système ainsi que les liens existants entre ces
mots. Le formalisme adopté par la méthode Merise pour
réaliser cette description est basé sur les concepts «
entité-association ».
A. Définition des concepts
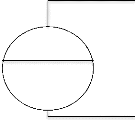
a. Entité
Une entité (ou objet) est une représentation
d'un élément matériel ou immatériel ayant une
existence propre et jouant un rôle dans le système que l'on
désire décrire. La figure ci-dessous nous montre la
représentation d'un objet.

Liste des propriétés ?
?
Libellé
Figure III.1 : représentation d'un objet
b. Occurrence
Une occurrence, c'est tout simplement une
« ligne » de valeurs. Dans une entité, une
occurrence correspond à l'ensemble des valeurs des
propriétés rattachées à un seul identifiant.
Dans une relation, une occurrence correspond à l'ensemble des valeurs
des propriétés de la relation (représenté par les
clés de chaque entité liée) : on l'appelle alors une
occurrence de relation.12
c. Identifiant
L'identifiant est une propriété
particulière d'un objet telle qu'il n'existe pas deux occurrences de cet
objet pour lesquelles cette propriété pourrait prendre une
même valeur. Le modèle conceptuel des données propose de
souligner les identifiants (parfois de les faire précéder d'un
#).
d. Relation
Une association (appelée aussi parfois relation) est un
lien sémantique entre plusieurs entités.
? La dimension d'une association
La dimension d'une relation indique le nombre d'entités
participant à l'association. Les dimensions les plus courantes sont 2
(association binaire) et 3 (association ternaire) :
V' Une relation récursive
(ou réflexive) relie la même classe
d'entité ;
V' Une relation binaire
relie deux classes d'entité ; V' Une relation
ternaire relie trois classes d'entité ;
26
12
http://www.base-de-donnees.com/occurrence/
27
V' Une relation n'aire relie n entité.
Les relations sont représentées par des
hexagones (parfois des ellipses) dont l'intitulé décrit le type
de relation qui relie les entités (généralement un verbe
à l'infinitif). On peut éventuellement ajouter des
propriétés aux relations.
Une relation n'a pas d'existence propre et doit être
définie par les individus auxquels elle est rattachée.
? Une relation peut être porteuse des
propriétés
Les propriétés qui dépendent
fonctionnellement de plusieurs identifiants d'entités sont
portées par les associations entre ces entités. C'est une
dépendance fonctionnelle multi propriété au niveau de la
source.
Retenons : Les relations de type
père-fils ne sont plus porteuses des propriétés
B. Recensement et description des entités
a. Recensement des entités
L'analyse de règles de gestion nous a conduit à
ressortir les objets suivants :
V' Étudiant
V' Compte
V' Groupe
V' Publication
V' Commentaire
b. Description des entités
Tableau III.1 Description des entités
|
Objets
|
Propriétés
|
Code propriété
|
Taille
|
Type
|
Identifiant
|
|
Etudiant
|
Identifiant Etudiant
|
Idetud
|
5
|
AN
|
#
|
|
prenom Etudiant
|
Prenome
|
15
|
AN
|
|
|
Post-nom Etudiant
|
Postnom
|
15
|
AN
|
|
|
Sexe
|
sexe
|
1
|
AN
|
|
|
date de naissance
|
datenaiss
|
15
|
AN
|
|
|
lieu de naissance
|
lieunaiss
|
20
|
AN
|
|
|
Adresse
|
Adress
|
50
|
AN
|
|
|
telephone
|
tel
|
15
|
AN
|
|
|
E-mail
|
mail
|
30
|
AN
|
|
28
|
Groupe
|
Identifiant Groupe
|
Idgroup
|
5
|
AN
|
#
|
|
Nom Groupe
|
Nomgroup
|
15
|
AN
|
|
|
Compte
|
Identifiant compte
|
Idcompte
|
5
|
AN
|
#
|
|
pseudo
|
pseudo
|
15
|
AN
|
|
|
mot de passe
|
mdpass
|
10
|
AN
|
|
|
Publication
|
Identifiant publication
|
Idpub
|
5
|
AN
|
#
|
|
titre de la publication
|
Titrepub
|
20
|
AN
|
|
|
objet publié
|
Objpub
|
255
|
AN
|
|
|
Université
|
Identifiant de l'université
|
Iduniv
|
5
|
AN
|
#
|
|
Nom de l'université
|
Nomuniv
|
25
|
AN
|
|
|
Adresse
|
Adress
|
30
|
AN
|
|
|
Commentaire
|
Identifiant commentaire
|
Idcom
|
5
|
AN
|
#
|
|
Texte commentaire
|
Textecom
|
255
|
AN
|
|
C. Recensement et description des relations
a. Recensement des relations
L'analyse de règles de gestion nous a conduits à
ressortir les relations suivantes :
> Échanger
> Poster
> Créer
> Interagir
> Commenter
> Appartenir
b. Description des relations
Tableau III.2 Description des relations
|
Relation
|
Propriété
|
Dimension
|
Object associé
|
|
Echanger
|
Date
message
|
Unaire
|
Etudiant
|
|
Poster
|
Date
|
Binaire
|
Etudiant - Publication
|
|
Créer
|
Date
|
Binaire
|
Etudiant - Groupe
|
|
Appartenir
|
-
|
Binaire
|
Etudiant - université
|
|
Créer
|
-
|
Binaire
|
Etudiant - Compte
|
|
Commenter
|
Date
commentaire
|
Binaire
|
Etudiant - Publication
|
D. Présentation des contraintes de
cardinalités
La Contrainte de Cardinalité caractérise le lien
qui existe entre une
entité et la relation sur laquelle elle est
reliée.
> La borne minimale (généralement 0 ou 1)
décrit le nombre minimal des
occurrences d'un objet participant dans une relation ;
> La borne maximale (généralement 0 ou 1)
décrit le nombre maximal des
occurrences d'un objet participant dans une relation ;
> La cardinalité (1, n) signifie un ou plusieurs ;
> La cardinalité (1,1) signifie un et un seul ;
> La cardinalité (0,1) signifie zéro ou un ;
> La cardinalité (0, n) signifie zéro ou
plusieurs.
E. Présentation des contraintes
d'intégrité fonctionnelles (CIF)
D'une manière générale les contraintes
d'intégrités fonctionnelles sont, en dehors d'une
spécification par les cardinalités sur les pattes de la relation
concernée, représentées, selon que la relation soit
binaire ou n-aire, par les graphismes suivants :
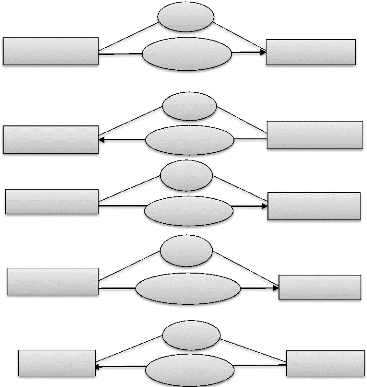
Etudiant
Etudiant
Etudiant
Etudiant
Etudiant
Appartenir
Créer
Poster
Créer
Créer
CIF
CIF
CIF
CIF
CIF
Groupe
Compte
Groupe
Université
Publication
29
Figure III.2 : présentation des contraintes
d'intégrité fonctionnelle
F. Présentation du modèle conceptuel des
données
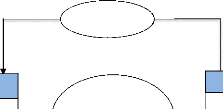
Interagir
1, n
1, n
#idetud Prenom Postnom Sexe Datnaiss Lieunaiss Adress Tel
email
1, n
1, n
Echanger
Date
message

interaction
Date
1, 1 1, n
Appartenir
1, n
Etudiant
1, n

Créer
1, 1
Groupe
#idgroupe
Nomgroup
Créer
1, n
1, n
Commenter
commentaire
Date
Université
#iduniv Nomuniv Adress
#idcompte Pseudo mdpass
Compte
1 ,1
Poster
1, 1
#idpub Titrepub objpub
Publication
1, n
Figure III.3 : présentation du MCD13
30
13 Jean Luc Baptiste, Merise Guide pratique,
édition eni, 174 pages
31
I.1.2 Modélisation Conceptuelle de Traitement
(MCT)
La modélisation conceptuelle de traitement
représente la dynamique du système d'information
c'est-à-dire les opérations sont réalisées en
fonction d'évènements sans faire référence aux
choix organisationnels ou des moyens d'exécution. Il a pour but de
décrire le processus de traitement sans tenir compte des moyens
utilisés et détermine le processus en tenant compte de
l'organisation de l'entreprise.
A. Définitions des concepts
? Evénement : c'est un
déclencheur ou stimulus d'opération provoquant un effet
? Opération : c'est l'ensemble
d'action déclencheur de résultats.
? Synchronisation : c'est une condition
d'exécution d'une opération et provoqué par
l'événement ;
? Processus : constitue un sous ensemble
d'activités de la société (domaine) dont les points
d'entrée et de sortie stables et indépendant du choix
d'organisation.
B. Formalisme
Evenement declencheur
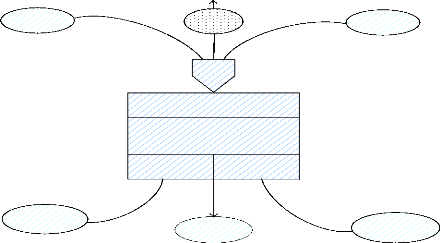
Synchronisation
Et/ou
Action interruptible
Action 1
Evenement
Evenement
Operation
Condition demission
Des résultat
Resultat 1
Resultat 2
Règle
demission 1
Regle
d'emission 2
Résultat
Figure III.4 : formalisme du MCT
C. Construction du modèle Conceptuel de
traitement
Accès
plateforme
ET
Posséder compte
1
Authentification
Vérification du pseudo et du
mot de passe
|
- Créer un groupe
- Poster une publication - Commenter une
publication
- Ecrire un message
|
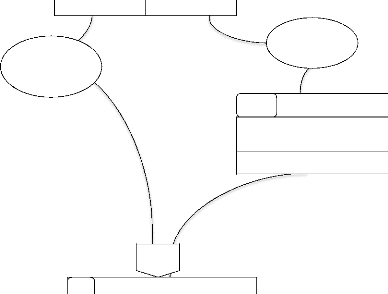
OK
KO
Accès autorisé
Nouvel utilisateu
Création compte
- S'inscrire
- Valider l'inscription
Toujours
2
OU
Interaction avec le système
3

A
32
Toujours
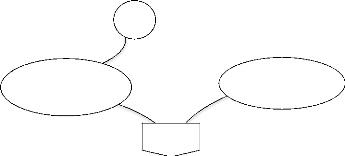
Opération effectuée
A
Et
Besoin de quitter
4
? Se déconnecter
3 Déconnexion
33
Figure III.5 : présentation du MCI
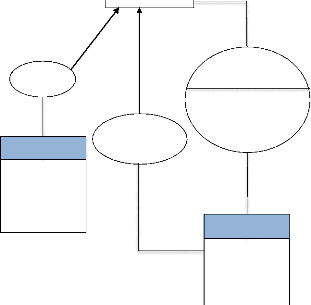
I.2 Etape organisationnelle
I.2.1 Modélisation organisationnelle des
données
Ce modèle d'organisation de données est
élaboré à partir du modèle conceptuel de
données, dont on ne conserve que les objets appelés à
être mémorisés informatiquement.
2.1.1 Règles de passage du MCD au MOD
Ce passage se fait de la manière suivante :
? la suppression des objets ou des propriétés
qui ne seront pas à modéliser informatiquement;
? la modification au besoin de certains
éléments, compte tenu du choix de mémorisation
informatique;
? la création évidente des nouveaux
éléments de substitution pour garder un lien avec les
supprimé.
2.2.2 Présentation du Modèle
Organisationnel de Données (MOD)
1, 1
1, n
Créer
Groupe
Echanger
Date
message
1, n
1, n
#idetud Prenom Postnom Sexe Datnaiss Lieunaiss Adress Tel
Email
Etudiant
1, n Interagir 1, n
1, 1 1, n
Appartenir
1, n
interaction Date
Université
#idgroupe Nomgroup
1, n
1, 1
#idcom Nomuniv Adress
Créer
Commenter
commentaire
1 ,1
Date
Poster
Compte
#idcompte Pseudo mdpass
1, n
Publication
1, 1
#idpub Titrepub objpub
34
Figure III.6 : présentation du MOD
35
2.2.3 Quantification de la multiplicité des
cardinalités
Par multiplicité de cardinalité, on sous-entend
un couple dont la cardinalité maximale est égale à N
c'est-à-dire le nombre d'occurrences maximum d'un objet participant aux
occurrences d'une relation donnée. Pour ce faire, on calcule la
cardinalité moyenne qui se base sur certaines variables statiques ainsi
que les occurrences des objets et relations.
La cardinalité moyenne est obtenue à partir de la
formule suivante :
Cm= [(Min+2Mo+Max)/4]*p
P=Mo/Max
? Cm : la cardinalité minimale
? Max : la cardinalité maximale
? Mo : la valeur modale
? Cm : la cardinalité moyenne
? P : Taux de participation.
Pour quantifier l'effectif des relations du type autre que
père fils on utilise la formule : N3=N1*cm2
Où N1 : Nombre d'occurrence de l'objet
source N3 : Nombre d'occurrence de la relation Cm2
: Cardinalité moyenne de l'objet cible.
La connaissance des effectifs des objets et des relations nous
permettra de calculer le volume approximatif du MOD global.
Le calcul de la multiplicité des cardinalités de
notre MOD global se fait de la manière suivante :

Interagir
Interaction
Date
Groupe
Max : 100
Mod : 90
Etudiant
Max : 10 000
Mod : 9 000
P=Mo/Max= 9000/10000 = 0,9 P=Mo/Max= 90/100 = 0,9
Cm1= [(Min+2*Mo+Max)/4]*p Cm2=
[(Min+2*Mo+Max)/4]*p
Cm1= [(1 + 2 * 9000 + 10 000)/4] * 0,9 Cm2= [(1 + 2 * 90 +
100)/4] * 0,9 = 64
= 100 808
N3=N1* Cm2= 10 000 * 64= 640 000
Etudiant
Publication


Commenter
Commentaire
date
Max : 5 000
Mod : 4 500
Max : 10 000
Mod : 9 000
P=Mo/Max= 9000/10000 = 0,9 P=Mo/Max= 4 500/5 000 = 0,9
Cm1= [(Min+2*Mo+Max)/4]*p Cm2= [(Min+2*Mo+Max)/4]*p
Cm1= [(1 + 2 * 9000 + 10 000)/4] * Cm2= [(1 + 2 * 4 500 + 5
000)/4] *
0,9 = 100 808 0,9 = 3 151
N3 = N1* Cm2 = 10 000 * 3151 = 31 510 000
Echanger
Message
date
Etudiant
Max : 10 000
Mod : 9 000
36
P=Mo/Max= 9000/10000 = 0,9
Cm1=Cm2 = [(Min+2*Mo+Max)/4]*p
|
= [(1 + 2 * 9000
|
+ 10 000)/4]
|
*
|
0,9
|
= 100 808
|
|
N3 = N1 * Cm2 = 10 000
|
* 100 808 =
|
1
|
008
|
000 000
|
2.2.4 Quantification des objets.
Tableau III.3 Quantification des objets
|
N°
|
Entité
|
Nombre d'occurrences
|
|
1
|
Etudiant
|
10000
|
|
2
|
Compte
|
10000
|
|
3
|
Groupe
|
5000
|
|
4
|
Publication
|
700
|
|
5
|
Université
|
100
|
|
Total
|
20900
|
37
2.2.5 Quantification des
propriétés
Tableau III.4 Quantification des propriétés
|
Object/Relation
|
Propriétés
|
Type
|
Taille
|
Taille totale
|
|
Etudiant
|
Identifiant Etudiant
|
AN
|
5
|
|
|
prénom Etudiant
|
AN
|
15
|
|
|
Post-nom Etudiant
|
AN
|
15
|
|
|
Sexe
|
AN
|
1
|
|
|
date de naissance
|
AN
|
15
|
166
|
|
lieu de naissance
|
AN
|
20
|
|
|
Adresse
|
AN
|
50
|
|
|
téléphone
|
AN
|
15
|
|
|
E-mail
|
AN
|
15
|
|
|
Groupe
|
Identifiant Groupe
|
AN
|
5
|
20
|
|
Nom Groupe
|
AN
|
15
|
|
|
Compte
|
Identifiant compte
|
AN
|
5
|
30
|
|
pseudo
|
AN
|
15
|
|
|
mot de passe
|
AN
|
10
|
|
|
Publication
|
Identifiant publication
|
AN
|
5
|
280
|
|
titre de la publication
|
AN
|
20
|
|
|
objet publié
|
AN
|
255
|
|
|
Université
|
Identifiant de l'université
|
AN
|
5
|
60
|
|
Nom de l'université
|
AN
|
25
|
|
|
adresse
|
AN
|
30
|
|
|
Commenter
|
Commentaire
|
AN
|
255
|
260
|
|
date
|
AN
|
15
|
|
|
Interagir
|
Interaction
|
AN
|
255
|
260
|
|
Date
|
AN
|
15
|
|
|
Echanger
|
Message
|
AN
|
255
|
260
|
|
Date
|
AN
|
15
|
|
2.2.6 Calcul du volume théorique du
MOD
Le volume du MOD modèle organisationnel de
données est l'espace qu'occupera la base de données sur un
support quelconque. Ce calcul nous permet d'envisager le choix sur les types de
supports que contiendront les données que nous allons enregistrer
(stocker) dans notre base de données. Il est exprimé en nombre de
caractères.
38
? Calcul du volume des objets : volume = effectif *
taille
Tableau III.5 calcul du volume des objets
|
Objet
|
Taille
|
Effectif
|
|
Volume
|
|
Etudiant
|
166
|
10 000
|
|
1 660 000
|
|
Compte
|
30
|
10 000
|
|
300 000
|
|
Publication
|
280
|
5 000
|
|
1 400 000
|
|
Université
|
60
|
700
|
|
42 000
|
|
Groupe
|
20
|
100
|
|
2 000
|
|
Volume total objet =
|
3 404 000
|
? Calcul du volume des relations : volume = effectif *
taille
Tableau III.6 Calcul du volume des relations
|
Objet
|
Taille
|
Effectif
|
Volume
|
|
Echanger
|
260
|
1 008 000 000
|
262 080 000 000
|
|
commenter
|
260
|
31 510 000
|
8 192 600 000
|
|
Interagir
|
260
|
640 000
|
166 400 000
|
|
Volume total relation =
|
270 439 000 000
|
2.2.7 Calcul du volume de la base de données ?
Calcul du volume des tables
On calcule le volume d'une table en multipliant l'effectif de
cette table par sa taille. D'où : N*Taille
Tableau III.7 Calcul du volume des tables
|
Objet
|
Taille (T)
|
Effectif (N)
|
|
Volume
|
|
Etudiant
|
166
|
10
|
000
|
1
|
660
|
000
|
|
Compte
|
30
|
10
|
000
|
|
300
|
000
|
|
Publication
|
280
|
5
|
000
|
1
|
400
|
000
|
39
|
Université
|
60
|
700
|
42 000
|
|
Groupe
|
20
|
100
|
2 000
|
|
Echanger
|
260
|
1 008 000 000
|
262 080 000 000
|
|
commenter
|
260
|
31 510 000
|
8 192 600 000
|
|
Interagir
|
260
|
640 000
|
166 400 000
|
|
Total volume tables =
|
270 442 404 000
|
? calcul du volume des index
Tableau III.8 Calcul du volume des index
|
Table
|
Index
|
Taille
|
Effectif
|
Volume
|
|
Etudiant
|
#idetud
|
5
|
10 000
|
100 000
|
|
#iduniv
|
5
|
|
|
|
Groupe
|
#idgroup
|
5
|
100
|
1 000
|
|
#idetud
|
5
|
|
|
|
Compte
|
#idcompte
|
5
|
10 000
|
100 000
|
|
#idetud
|
5
|
|
|
|
Publication
|
#idpub
|
5
|
5 000
|
50 000
|
|
#idetud
|
5
|
|
|
|
Université
|
#iduniv
|
5
|
700
|
3 500
|
|
Echanger
|
#idetud
|
5
|
1 008 000 000
|
5 040 000 000
|
|
commenter
|
#idetud
|
5
|
31 510 000
|
315 100 000
|
|
#idpub
|
5
|
|
|
|
interagir
|
#idpub
|
5
|
640 000
|
6 400 000
|
|
#idetud
|
5
|
|
|
|
Total volume des index =
|
5 361 754 500
|
? Calcul du volume de la base de
données
Le calcul du volume du MOD global nous a permis de calculer
l'espace approximative qu'occuperait notre base de données. Mais ici on
calcul l'espace réel ou exacte qu'occupera la base de données,
car à ce stade on connait déjà la liste exhaustive des
tables qui seront créer base de données relationnelle. Pour ce
faire, on utilise la formule suivante :
Volume de la base de données = (?volume tables +
?volume index)* coefficient de multiplication. Le coefficient varie entre 2,5
à 3.
500
40
|
D'où, le volume de la base de données : 270 442
|
404
|
000 + 5 361 754
|
|
= 2
|
775 804 158 500 octets = 2 775 804 158 500 / 1
|
048
|
576 = 2,64 Mo
|
I.2.2 Modélisation Organisationnel de Traitement
(MOT)
Le modèle organisationnel de traitement (MOT)
intégré les notions de temps et durées
(déroulement) de ressources, de lieu et de responsabilité (poste
de travail) et de nature de traitements (manuel ou automatique)
2.2.1 Formalisme
Le MOT dérive du MCT ajoutant les différentes
contraintes liées à
l'organisation dont nous avant :
+ Le déroulement de la tâche répondant
à la question « quand ? » ;
+ La nature de la tâche, répondant à la
question « qui ? » ;
+ Le poste de travail, répondant à la question
« où ? ».
2.2.2 Règles de passage du MCT au MOT
Les opérations définies dans les
différents processus du MCT découpes en procédures
fonctionnelle(PF) pour lesquelles on précise le déroulement de la
tâche, le poste de travail et la nature de la tache (manuel ou
automatisée) pour passage au MOI, il faudrait qu'on ajoute les
réponses aux questions « quand ? qui ? Et où ? »
+ Le déroulement de la tâche est la
réponse à la question quand ? on détermine le moment ou la
fréquence d'exécution de la tâche ;
+ Le poste de travail est la réponse à la
question où c'est l'endroit où sera exécutée la
tâche ;
+ La nature de tâche est la réponse relative
à la question qui ?
Elle implique aussi des réponses :
a) Si c'est l'homme, la tâche est manuelle (TM) ;
b) Si c'est la machine, la tâche est informatisée
temps réel (IR) il faut ajouter
aussi deux paramètre :
> Le modèle fonctionnement de la tâche
:
? La tâche peut être en mode unitaire (u).
C'est-à-dire exécutée une à une ;
? Elle peut-être en mode de traitement par lot (1)
c'est-à-dire exécutée en
bloc.
> Le délai de réponse : la
réponse peut-être immédiate (i) ou en différent
(d)
41
2.2.3. Présentation du Modèle
Organisationnel de Traitement
|
Période
|
Procédure fonctionnelle
|
Nature
|
|
Jour
Jour
Jour
|
Accès Posséder
plateforme compte
|
TR-I
TR-I
TR-I
|
|
|
ET
|
|
|
1
|
Authentification
|
|
|
Vérification du pseudo et du
mot de passe
|
|
|
OK
|
KO
|
|
|
|
|
Accès
|
Nouvel
utilisateur
|
|
autorisé
|
|
|
|
|
2
|
Création compte
|
|
- S'inscrire
- Valider l'inscription
|
|
Toujours
|
|
|
|
|
OU
|
|
|
3
|
Interaction avec
|
le système
|
|
|
- Créer un groupe
- Poster une
- Commenter
publication
- Ecrire un message
|
publication une
|
|
|
Toujours
|
|
|
|
A
|
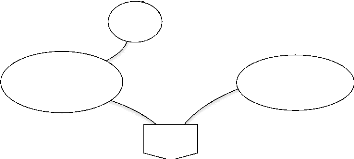
Opération effectuée
A
Et
Besoin de quitter
Quitter le Système
? Se déconnecter
4
3 Déconnexion
Jour
TR-I
42
Figure III.7 : présentation du MOT
Section II : CONCEPTION DU SYSTEME D'INFORMATION
INFORMATISE (CSII)
II.1 Etape logique
II.1.1 Modélisation Logique de Données
(MLD)
Comment ? Est la question posée à cette
étape pour déterminer les moyens et le ressources informatiques
en faisant à l'abstraction de leurs caractéristiques techniques
précises. Elle exprime la forme que doit prendre l'outil informatique
pour être adapté à l'utilisation, a son poste de travail et
celle ce fait indépendamment du langage de programmation et de
système de gestion de base de données.
43
A. Vocabulaire spécifique utilisé.
+ Les objets deviennent des tables
+ Les propriétés deviennent des attributs
+ Les identifiants deviennent des clés primaires
1.1.2 Règle de passage du MOD au MID
Brut.
Le passage du MOD global au MLD brut doit respecter les
règles suivantes :
> Les objets deviennent des entités dans le sens
mathématique du terme ; donc les lignes aux colonnes sur forme des
tables ;
> Les propriétés des objets deviennent les
attributs des tables ;
> Les identifiants des entités deviennent des
clés primaires ;
> Les relations dans le sens conceptuel ou
sémantique subissent plusieurs traitements selon le cas notamment :
? La relation du type Père et Fils disparait mais la
sémantique sera maintenue. Comme la table fils dépend de la table
Père, elle va recevoir la clé de son Père et cette
dernière sera migrée dans la table Fils comme clé
étrangère. Le fils va pointer le père ;
? Pour des relations du type autre que Père et fils,
cette relation devient une table et ses attributs seront la
concaténation de deux autres tables. Si la relation portait une
propriété, celle-ci demeurera dans la table comme attribut.
1.1.3 Présentation du modèle Logique des
données brutes
Etudiant
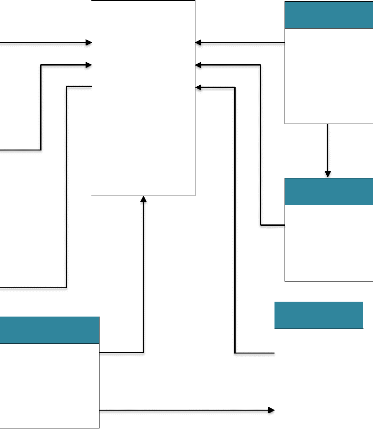
Commentaire Date
#idetud #idpub
Commenter
#idetud Prenom Postnom Sexe Datnaiss Lieunaiss Adress Tel
Email #iduniv
#idpub Titrepub Objpub date #idetud
Publication
Interaction Date #idetud #idgroup
#idgroup nomgroup #idetud
Interagir
Groupe
Echanger
Message Date #idetud
Compte
#idcompte Pseudo Mdpass #idetud
Université
#iduniv Nomuniv Adress
44
Figure III.8 : présentation du MLD Brut
1.1.4 Vérification et Normalisation.
Etant donné que le passage du MOD au MLD brut a permis
de crée des tables qui peuvent contenir de redondances,
l'opération de normalisation nous permet de pouvoir valider le MLD brut.
C'est ainsi que nous allons vérifier ces objets de manière que
ceux-ci aient des propriétés non répétitives. Cette
opération se fait en trois formes normales à respecter afin de
pouvoir valider notre MLD bruit.
45
? 1ère forme normale :
Une table est à la 1ère forme normale, si elle
possède une clé primaire et que ses attributs dépendent
directement de la clé primaire ;
? 2ème forme normale :
Une table est à la 2ème forme normale,
étant déjà à la 1ère forme normale, ses
attributs sont élémentaires c'est-à-dire non
décomposables ;
? 3ème forme normale :
Une table est à la 3ème forme normale, si
étant déjà à la 2ème forme normale, les
attributs qu'elle porte ont une dépendance fonctionnelle directe avec la
clé primaire, sans passer transitivement à un autre attribut.
Dès lors que les trois formes sont respectées,
les tables peuvent être déclarées normalisées et le
MLD sera validé.
1.1.5 Présentation du MLD
validé
Etudiant
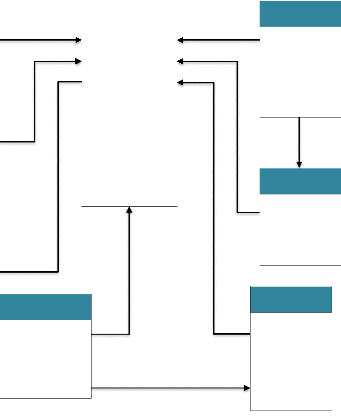
Commentaire Date
#idetud #idpub
Commenter
Figure III.9 : présentation du MLD validé
#idetud Prenom Postnom Sexe Datnaiss Lieunaiss Adress Tel
Email #iduniv
#idpub Titrepub Objpub date #idetud
Publicatio
Interaction Date #idetud #idgroup
#idgroup nomgroup #idetud
Interagir
Groupe
Echanger
Message Date #idetud
Compte
#idcompte Pseudo Mdpass #idetud
Université
#iduniv Nomuniv Adress
46
1.1.6 Schémas relationnels associé au MLD
validé.
? Table Etudiant : {[#idetud : int(5)] ; [Prenom
: varchar(15)] ; [Postnom : varchar(15)] ; [sexe : char(1)] ; [Datnaiss :
varchar(15)] ; [lieunaiss : varchar(20)] ; [Adress : varchar(30)] ; [tel :
varchar(15)] ; [Email : varchar(25)] ;[iduniv : int(5)]} ;
? Table Commenter : {[commentaire [:
varchar(255)] ; [Date : varchar(15)] ; [#idetud : int(5)] ; [#idpub : int(5)]}
;
? Table Publication : {[#idpub: int(5)] ;
[titrepub : varchar(20)] ; [objpub: varchar(255)] ; [Date :varchar(15)] ;
[#idetud : int(5)]} ;
? Table Université: {[#iduniv :
int(5)] ; [nomuniv : varchar(25)] ; [Adress : varchar(30)]} ;
47
? Table Groupe : {[#idgroup : intr(5)] ;
[Nomgroup : varchar(20)] ; [#idetud :
intr(5)]} ;
? Table compte : {[#idcompte : int(5)] ; [pseudo
: varchar(20)] ; [mdpass : varchar(12)] ; [idetud: int(5)]} ;
? Table Echanger: {[Message: varchar(255)] ;
[Date : varchar(15)] ; [idetud : int(5)]} ;
? Table Interagir : {[interaction: varchar(255)]
; [Date : varchar(15)] ; [#idetud : int(5)] ; [#idgroup : int(5)]} ;
II.1.2 Modélisation Logique de Traitement
(MLT)
Dans le modèle logique des traitements, nous
présentons les moyens que le concepteur va utiliser pour construire les
programmes informatiques traduisant les solutions adoptées afin de
répondre aux exigences définies au niveau organisationnel. En
d'autres termes il s'agit de décrire le modèle
précédent suivant un formalisme compréhensible.
1.2.1 Règle de passage du MOT au MLT
Ce passage concerne la réflexion et/ou l'imagination du
développeur de l'application, selon sa maîtrise et/ou sa
pensée dans laquelle il appliquera sur la conception de ses interfaces
graphiques. Cependant, nous allons éliminer à partir du MOT les
tâches qui ne seront pas informatisées et les tâches
restantes. Celles-ci détermineront l'unité logique de traitement
ou les événements fonctionnels disparaissent et cèdent la
place aux actions des utilisateurs, notamment : clic ou clique, saisir, etc.
Les tâches deviennent des unités logiques de traitement ; les
procédures fonctionnelles deviennent des procédures logiques ;
l'ensemble des procédures logiques constituent le MLT et les postes de
travail deviennent des sites.
1.2.2 Présentation du Modelé Logique de
Traitement
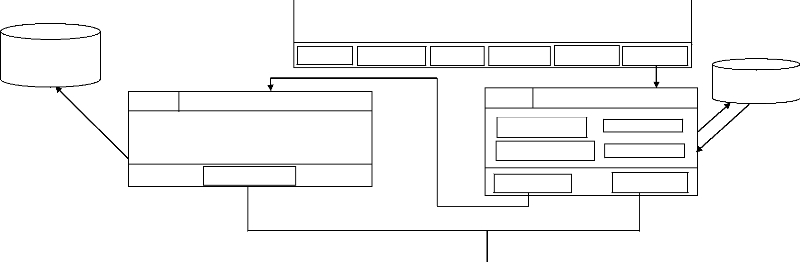
Groupes
Accueil
Membres
Connexion
A propos
Publications
ULT
Inscription
ULT 02
Connexion
+Affichage O3
-Ecrire
- Cliquer
Valider
S'inscrire
Connexion
Table étudiant
+Affichage -Cliquer
Table compte
User :
Password :
48
ULT 04
|
Compte
|
|
+Affichage -Ecrire -Cliquer
|
|
|
Notification
|
Messages
|
Amis
|
Réglages
|
Se déconnecter
|
|
Groupes
|
|
|
|
|
|
|
|
Figure III.10 Présentation du modèle logique de
traitement
49
1.2.3 Détail des Unités Logique des
Traitements (ULT) ? ULT01 : authentification
Pseudo :
Mot de passe :
Inscription
Connexion
Connexion
? ULT02 : Inscription
Inscription
Prénom ...
Post nom ...
Email ...
Téléphone ...
Mot de passe ...
Confirmer mot de passe ...
? UTL 03 : Page d'accueil
Page d'Accueil
|
Accueil | Publications | Groupes | Membres | Profile
|
50
1.2.4 Enchaînement des ULT
Les enchainements assurent les liaisons entre les
différents ULT d'un MLT. Ils représentent les origines des appels
de l'ULT (événements logiques) ; et les liaisons conditionnelles
vers d'autres ULT (résultats logiques).
L'enchainement prend en charge le transfert d'informations
éventuellement nécessaires entre les ULT. Cependant, il ne faut
pas confondre l'enchainement des différents traitements au sein d'une
ULT exprimé dans la logique fonctionnelle et l'enchainement entre des
ULT distinctes exprimés ici.
ULT 01 : Connexion
|
Bouton
|
Action
|
Résultat
|
|
Connexion Inscription
|
Clic
clic
|
Affichage Page de publications Affichage formulaire
d'inscription
|
ULT 02 : Inscription
|
Bouton
|
Action
|
Résultat
|
|
Inscription
|
Clic
|
Affichage Page de publications
|
ULT 03 : Page d'accueil :
|
Menus
|
Action
|
Résultat
|
|
Accueil Publications Groupes Membres Profile
|
Clic Clic Clic Clic Clic
|
Affichage activités des membres inscrits Affichage espace
de publications Affichage des groupes Affichage des membres Affichage du
compte
|

1.2.5 Présentation du dialogue
homme-machine
Observation
Message 1 :
Inscription validée
51
-Lancer le navigateur
Saisir l'adresse du site dans le navigateur
-Cliquer sur déconnexion
- Cliquer sur connexion
- S'authentifier ou s'inscrire
-Cliquer sur publication
-Rediger commentaire, cliquer sur poster
- Cliquer sur groupes
- Créer ou adhérer si groupes existent
-Fermer l'onglet dans le navigateur
Homme
Rechercher le site sur le serveur et afficher la page d'accueil
et les différents liens des pages
-Affichage du profile
-Attribution de rôle si nouveau utilisateur
Affichage des groupes ou valider l'adhésion
Affichage page d'authentification
Affichage commentaires
Quitter le système
Machine
52
III.2.2 Etape physique
2.2.1 Modélisation physique de
données
Le modèle physique de données consiste à
la prise en compte des contraintes techniques liées aux matériels
et aux logiciels de traitements choisir pour élaborer la solution
informatique. Ainsi le model physique de données apparait finalement
étant celle qui prend en compte les préoccupations et choix
techniques pour fournir les éléments nécessaires à
l'implantation de données et la mise en place des traitements.
2.2.2. Règle de passage du MID validé au
MPD
Le passage du modèle logique de données au
modèle physique de données respecte le formalisme d'accès
au système de gestion de base de données choisi pour la
réalisation de la base de données. Les tables du modèle
logique de la base de données deviennent des fichiers, les
propriétés deviennent les champs, les identifiants deviennent de
clés primaire (champ indexé sous doublons), les clés
indexes deviennent de clés secondaire
2.2.3 Présentation du MPD
Il n'existe pratiquement pas aujourd'hui une approche
normalisé pour la description et la présentation du niveau
physique de données. Ce niveau est étroitement lié au
choix technique informatique en rapport avec le système de gestion de
base de données. Cependant, quelques règles sont à
émettre selon l'orientation de choix technique effectué. Nous
pouvons dire que le MPD représente le résultat du MLD sous forme
des tables.
Table étudiant
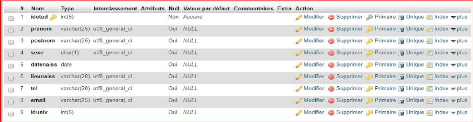
53
Table publication
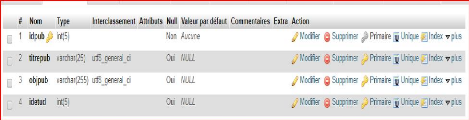
Table compte

Table commenter
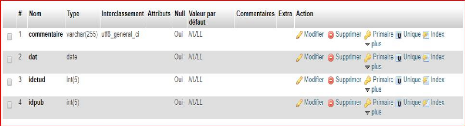
Table université
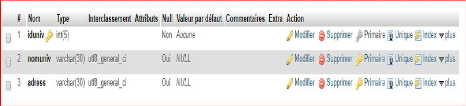
54
Table interagir

Table échanger
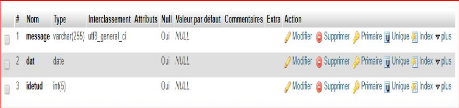
Table Etudiant
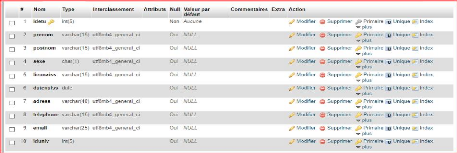
2.2.3. Modélisation Physique des
Traitements
Le modèle physique de traitement (MPT) constitue
l'ensemble de tous les programmes informatiques que nous allons exécuter
dans l'application. Cet ensemble des programmes devra être
structurés et organisés en une architecture technique de
programme selon un langage de programmation spécifique. Cette technique
matérialise la logique de traitement en fonction des possibilités
techniques et de moyens de programmation.
Le modèle organisationnel de traitement
spécifiait l'enchaînement de l'ensemble des tâches à
réaliser du point de vue de l'utilisateur ; le modèle logique de
traitement traduisait à son tour la logique informatique correspondant
à l'informatisation de toutes les tâches automatiques et
réelles décrites dans le
55
modèle organisationnel de traitement. Enfin, le
modèle physique de traitement nous permettra de décrire la
solution technique de construction du logiciel.
Il consiste en l'écriture du programme. Celui-ci peut
être généré dans le cadre d'un "atelier de
génie logiciel". La finalité de la méthode MERISE
est la production de "code" automatique à partir de la conception.
2.3.1. Passage du MIT au MPT
Le MPT s'élabore à partir du modèle logique
de traitement en faisant un regroupement de toutes unités logiques en
programmes. Il se présente ainsi sous forme d'une structure arborescente
des programmes à réaliser
Créer un sujet
Commentaire
Publications
Page d'accueil
Membres
Groupes
A propos Connexion
Créer groupe
Adhérer dans un groupe
Liste des membres
Authentification Inscription
Interagir
Profile
Messages
Notifications
Mes groupes Mes adhésions
Paramètres
2.3.2. Présentation du Modèle Physique de
Traitement (MPT)
56
Chapitre IV : MISE EN PLACE ET FONCTIONNEMENT
DU LOGICIEL
IV.1. Implémentation de la base de
données.
IV.1.1. Choix du système de gestion de base de
données.
Notre choix a été orienté vers le SGBD
MySQL qui est libre de droit, et facile à utiliser. La mise en place des
différentes tables sous MySQL est présentée par les
différentes requêtes SQL dont ces tables sont citées
précédemment, avec ses propriétés respectives.
MySQL dérive directement de SQL (Structured Query Language) qui est un
langage de requête vers les bases de données exploitant le
modèle relationnel.
IV.1.2. Création de la base de données
Cliquons premièrement sur le boutons démarrer en
suite lançons WampSever et cliquer sur phpMyAdmin. Nous voici à
la page d'authentification dans la plateforme WampServer pour la
création d'une base de données sous MySQL et nous
procéderons de la manier ci-après :
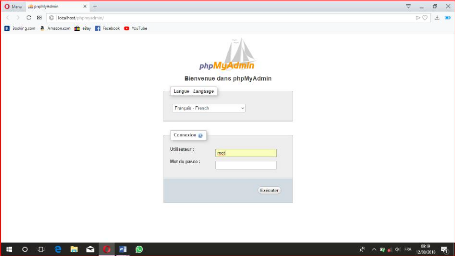
Figure IV.1 Authentification phpMyAdmin
? Sur cette écran, dans le champ nom d'utilisateur,
saisissons root et laissons le champ mot de passe vide, puis cliquons sur
exécuter. Nous aurons un affichage comme ci-après, cliquons sur
Bases de données, donnons-lui un nom et cliquons sur
créer :
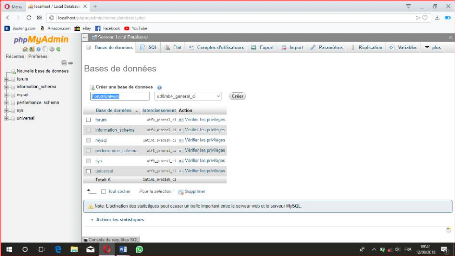
57
Figure IV.2 : Création de la base des données
? Notre base des données ainsi créée,
cliquons sur lui pour créer des tables, à l'exemple de la table
étudiant suivante, ensuite cliquons sur exécuter :
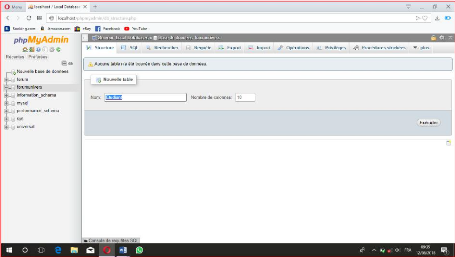
Figure IV.3 : Création de table
58
IV.1.3 Présentation des relations entre tables
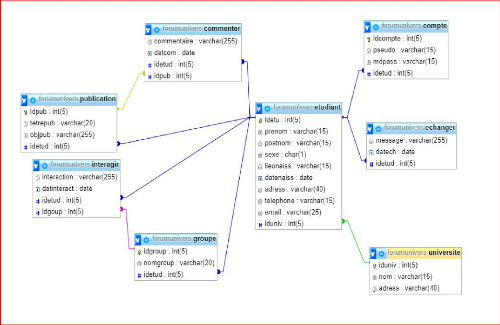
Figure IV.4 : présentation des relations entre les
tables
IV.2. CHOIX DU CMS
Notre choix a porté sur le CMS Joomla pour
réaliser notre application web car il se démarque principalement
par la convivialité de son interface d'administration.
VI.2.1. Présentation de WordPress
Le CMS WordPress est un système de gestion de contenus
multimédia pour le Web, écrit dans le langage de programmation
PHP. Il nécessite un serveur web et une base de données MySQL.
Tous les éléments nécessaires au bon fonctionnement du
site (code source du moteur du site, fichiers de configuration, contenus textes
et médias) étant sur le serveur, que ce soit dans la base de
données ou dans l'espace de stockage des fichiers, son administration
s'effectue directement en ligne depuis un ordinateur ou un smartphone si
celui-ci est hébergé : seule une connexion Internet est
nécessaire.
WordPress est constitué de deux interfaces distinctes
:
·
59
Frontal (frontend) : partie visible
du site, par laquelle il est aussi possible de créer et gérer des
articles ainsi que les contenus de certaines extensions ;
· Administration (backend) :
partie réservée à la configuration globale, à la
structure des contenus, la gestion des utilisateurs, des extensions, etc.
IV.2.2. Les extensions
L'API (acronyme anglais pour «interface de
programmation» ou Application Programming Interface) Joomla constitue la
passerelle entre les créations des développeurs tiers et le noyau
de WordPress.
Ces extensions sont de trois types :
· Les composants : fonctions
évoluées possédant en général une interface
d'administration. Exemple : système de lettres d'information, de forum,
de boutique en ligne, de galeries multimédias, de sauvegarde, etc.
· Les modules : éléments
affichés dans le site autour du contenu central. Exemple : menus,
bannières, infos défilantes, date, etc.
· Les plug-ins : éléments
s'intégrant au noyau (core) de WordPress. Exemple :
système d'authentification, recherche dans les contenus, etc. Certaines
extensions sont constituées d'un composant, de modules et de plug-ins.
De base, WordPress intègre les fonctions pour gérer :
- Les contenus : éditeur, explorateur de
fichiers, bannière, contact, flux RSS, sondage, liens web ;
- Les utilisateurs et leurs droits :
consultation, rédaction, modification, publication, gestion,
administration ;
- L'aspect visuel : habillage du site, position
des éléments, affichage des contenus ;
- Les extensions : installation, publication,
accès, affichage, etc.
IV.2.3 Justification du choix de WordPress
Plusieurs raisons nous ont permis de choisir Joomla comme CMS
:
· Il est OpenSource ;
· Présence d'une communauté dynamique et
mondiale ;
· Site entièrement géré par une base
de données ;
· Gestion simple des utilisateurs avec des autorisations
d'administration spécifiques ;
· Prise en main facile et rapide par les utilisateurs
;
· Gestion du contenu divisé en section,
catégorie et article ;
· Édition du contenu via un éditeur
intégré de type Word ;
· Gestion efficace des archives pour stocker tous les
anciens articles... ;
· Multilinguisme ;
60
? Compatibilité avec la majorité des navigateurs
web et les sites développés par WordPress sont responsive,
c'est-à-dire capable de s'adapter à tout type d'cran
? Facilité d'inclure ses propres extensions ;
? Charte graphique personnalisable ;
? Très grande diversité d'extensions gratuites et
libres etc.
IV.2.4 Interface Homme-machine(IHM)
Une interface est le côté visuel d'une
application, c'est-à-dire l'ensemble des contrôles accessibles
à l'utilisateur et devant provoquer des actions programmées :
boutons de commande, barre de menu, cases à cocher, zones de texte et
listes modifiables, etc....
IV.2.5 Présentation des quelques interfaces
Après avoir cliqué sur l'icône de
l'application on aura comme affichage de la page d'accueil suivante :
Page d'accueil : elle affiche toutes les
activités du site, à savoir, les mises à jours des groupes
et des publications, voire des profiles
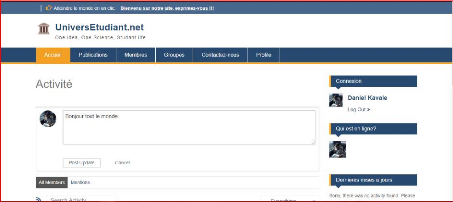
Figure IV.5 : interface de la page d'accueil
Page d'inscription et de connexion : si
l'utilisateur n'est pas authentifié et qu'il venait à cliquer sur
la page publication, le système lui demandera
de s'authentifier ou de s'inscrire.
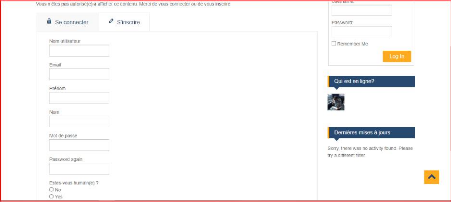
61
Figure IV.6 : présentation de l'interface
d'authentification et inscription Page Membres : ici nous
pouvons voir quelques mebres du sites
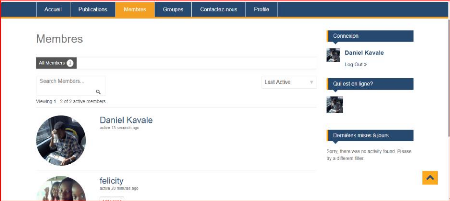
Figure IV.7 : interface de la page des membres
62
Conclusion générale
Au terme de notre étude portant sur la mise en
oeuvre d'une plateforme web de forum interuniversitaire, rendu possible
avec un système de gestion des contenus, nous avons pu réaliser
une application web permettant aux internautes de créer des comptes
utilisateur pour échanger des connaissances sous forme des publications
et commentaire, créer des groupes de discussions, échanger par
messages.
En effet, Le web et ses différentes technologies ont
été passés en revue tout au long de notre étude
enfin d'en ressortir les apports sur les sites web du point de vue tant
technologique que social, et d'en mettre en oeuvre grâce aux
systèmes de gestion de contenus (CMS).
A l'égard de ce qui précède nous
affirmons avec véracité que l'oeuvre abattue est humaine, nous
restons ouverts à toutes critiques, remarques, et suggestions provenant
de toute personne qui aura l'opportunité de la lire.
63
BIBLIOGRAPHIE
I. OUVRAGES
[1] Bazzoli Anne-Camille, Les systèmes de gestion
de contenu : l'offre logicielle, Edition enssib, 74 pages, Mars 2005
[2] BERTRAND Patrice, BADR Chentouf. White paper :
Content management, les solutions opensource version 1.6b.Paris : Smile,
2004. 51p.
[3] PRODUIT Raphaël. Content Management System (CMS)
: étude des systèmes de gestion dynamique de contenu pour site
web et développement d'une solution basée sur la technologie
J2EE. 2003
[4]Jean Luc Baptiste, Merise Guide pratique, édition
eni, 174 pages
II. NOTES DES COURS, THESES, TFE et TFC
[5] Frederick Mpiana, séminaire informatique,
université Révérend Kim 2018
[6] Mbikayi Jean Marcel, Cours des Méthode et analyse
informatique 2, université Révérend Kim 2018
[7] Gildas Ntoya, Mise en application du web 2.0 à
l'aide d'un système de gestion de contenus (cms), Université de
Kinshasa 2012
III. WEBOGRAPHIE
[8]
www.wikipedia.com
[9]
www.openClassroom.com
[10]
www.SupInfo.com
[11]
www.Histoire-cigref.org
[12]
www.ideematic.com/application-web
[13]
Fr.yeeply.com/blog/6_types-des-applications-web
[14]
www.nooveo.fr/article-8-categories
Table des matières
64
0. INTRODUCTION GENERALE 1
0.1 Généralités 1
0.2 Problématique 1
0.3 Hypothèse et intérêt du sujet 2
0.4 Délimitation du sujet 2
0.5 Méthodes et techniques utilisées 2
0.6 Difficultés rencontrées 3
0.7 Subdivision du travail 3
CHAPITRE I : APERÇU SUR LE WEB 4
I.1 Généralités sur le web 4
I.1.1 Historique 4
I.1.2 définition 4
I.1.3 Caractéristiques du web 5
I.1.4 Quelques protocoles utilisés dans le web 5
I.2 Programmation web 6
I.2.1Les langages web 6
I.3 Application web 8
I.3.1Définition 8
I.3.2 Avantages et désavantages 8
I.3.3 Catégories des applications web 8
I.3.4. Architecture et fonctionnement d'une application web
9
3.4.1 Architecture d'une application web à deux niveaux
9
3.4.2 Architecture d'une application web à trois
niveaux 10
I.4 Présentation générale d'une page web
12
I.5 Catégories des sites web 13
I.6. Le référencement 14
CHAPITRE II NOTION SUR LES SYSTÈMES DE GESTION DE
CONTENUS (CMS) 15
II.1. Définitions 15
II.2. Evolution 16
II.3. Principales fonctionnalités des CMS 17
II.3.1. Fonctionnalités liées à la
gestion de contenu 17
III.3.2. Fonctionnalités liées à la
publication 18
II.4 Structure et architecture d'un cms 20
4.1.1Le back-office 20
4.1.2 Le front office 20
65
II.4.2 Architecture d'un cms 20
4.2.1 Utilisation d'une interface web classique 21
4.2.2. Utilisation de gabarits et de feuilles de styles 21
4.2.3 Utilisation d'une base des données 22
4.2.4 Utilisation d'un mécanisme de gestion des droits
22
II.5 Limites 22
II.7 Quelques systèmes des gestions de contenus 23
CHAPITRE III : CONCEPTION DU NOUVEAU SYSTÈME 25
III .1 Narration 25
Section I : CONCEPTION DU SYSTEME D'INFORMATION
ORGANISATIONNEL (CSIO) 25
III.I.1 Etape conceptuelle 25
I.1.1 Modélisation Conceptuelle de Données (MCD)
25
1.1.1 Définition et But de la modélisation
conceptuelle de données 25
A. Définition des concepts 26
B. Recensement et description des entités 27
C. Recensement et description des relations 28
D. Présentation des contraintes de cardinalités
29
E. Présentation des contraintes
d'intégrité fonctionnelles (CIF) 29
F. Présentation du modèle conceptuel des
données 30
I.1.2 Modélisation Conceptuelle de Traitement (MCT)
31
A. Définitions des concepts 31
B. Formalisme 31
C. Construction du modèle Conceptuel de traitement
32
III.I.2 Etape organisationnelle 33
I.2.1 Modélisation organisationnelle des données
33
2.1.1 Règles de passage du MCD au MOD 33
2.2.2 Présentation du Modèle Organisationnel de
Données (MOD) 34
2.2.3 Quantification de la multiplicité des
cardinalités 35
2.2.4 Quantification des objets 36
2.2.5 Quantification des propriétés 37
2.2.6 Calcul du volume théorique du MOD 37
2.2.7 Calcul du volume de la base de données 38
I.2.2 Modélisation Organisationnel de Traitement (MOT)
40
2.2.1 Formalisme 40
2.2.2 Règles de passage du MCT au MOT 40
2.2.3 Présentation du Modèle Organisationnel de
Traitement 41
66
Section II : CONCEPTION DU SYSTEME D'INFORMATION INFORMATISE
(CSII) 42
III.II.1 Etape logique 42
II.1.1 Modélisation Logique de Données (MLD)
42
A. Vocabulaire spécifique utilisé 43
1.1.2 Règle de passage du MOD au MLD Brut 43
1.1.3 Présentation du modèle Logique des
données brutes 44
1.1.4 Vérification et Normalisation 44
1.1.5 Présentation du MLD validé 46
1.1.6 Schémas relationnels associé au MLD
validé 46
II.1.2 Modélisation Logique de Traitement (MLT) 47
1.2.1 Règle de passage du MOT au MLT 47
1.2.2 Présentation du Modelé Logique de
Traitement 48
1.2.3 Détail des Unités Logique des Traitements
(ULT) 49
1.2.4 Enchaînement des ULT 50
1.2.5 Présentation du dialogue homme-machine 51
III.II.2 Etape physique 52
II.2.1 Modélisation physique de données 52
2.1.1 Règle de passage du MLD validé au MPD
52
Chapitre IV : MISE EN PLACE ET FONCTIONNEMENT DU LOGICIEL
56
IV.1. Implémentation de la base de données.
56
IV.1.1. Choix du système de gestion de base de
données. 56
IV.1.2. Création de la base de données 56
IV.1.3 Présentation des relations entre tables 58
IV.2. CHOIX DU CMS 58
VI.2.1. Présentation de WordPress 58
IV.2.2. LES EXTENSIOINS 59
IV.2.3 Justification du choix de WordPress 59
IV.2.4 Interface Homme-machine(IHM) 60
IV.2.5 Présentation des quelques interfaces 60
Conclusion générale 62
BIBLIOGRAPHIE 63


